Изобретение предназначено для отыскания объектов местоположения, хранения, пребывания, рождения и т.п. по запросам, не содержащим точных названий, под которыми объекты значатся в инвентарных книгах, картотеках или каталогах и по которым работники хранилища находят эти объекты при помощи поисковых систем, содержащих адреса объектов.
Необходимость отыскания объектов по поисковым тематическим признакам возникает во всех сферах человеческой деятельности, в частности при поисках источников сведений (документов) по запросам с определенной тематикой (тематические запросы) при планировании и проведении научно-исследовательских работ, опытно-констукторских разработок, при анализе результатов этих видов деятельности, при написании заявок на изобретения при патентовании, в процессе экспертизы заявок на мирную новизну и т.д.
Число тематических запросов во всем мире ежегодно составляет десятки миллионов, по которым ведутся поиски объектов всех видов: документов, товаров, вещей, материалов, ископаемых организмов, людей, произведений искусства и т. п.
Тематические запросы имеют форму отдельных слов, групп слов или фраз (реже - текстов из нескольких предложений), которые задействуют неполные поисковые тематические признаки объектов.
Поскольку на любые объекты можно сделать поисковые тематизированные (т. е. подготовленные к тематическим поискам) описания, патентуемый способ в этой заявке будет описан на примере поисков тематических подборок документов. Однако в качестве поисковых тематических признаков объектов могут быть использованы не только знаковые признаки (буквы, цифры и т.п.), но и такие признаки, как вес тел, их цвет, твердость и т.п. (т.е. физико-химические и иные свойства) и по которым производится сортировка, выработка и иные подобные действия, эффективность которых может быть повышена при использовании патентуемого способа.
Неполные поисковые тематические признаки документов присущи, как правило, группам документов. Поэтому информационно-поисковые системы, предназначенные для удовлетворения тематических запросов, выдают обычно группы документов, называемые тематическими подборками документов. Такие системы можно назвать системами тематических поисков.
Системы тематических поисков включают в себя поисковые тематизированные описания документов с адресами хранения, которые составляют базы тематических поисков - предметы и систематические карточные или компьютерные каталоги библиотек, музеев, архивов, складов, выставок и т.п. В эмпирических компьютерных системах тематических поисков базы тематических поисков представляют собой поля ключевых слов, дескрипторов, форматов и т.п. Это предметная (в библиотечном понимании) или унитермная организация этих баз.
При помощи баз тематических поисков в системах тематических поисков по неполным поисковым тематическим признакам устанавливают адреса (места хранения или местоположения) документов в хранилище (шифры хранения, номера записей на машиночитаемых носителях документальных баз данных в системах тематических поисков, географические координаты и т.п.), по которым затем находят сами документы в фондах документов, документальных базах данных и т. п. Поэтому некоторые системы тематических поисков могут иметь также отдельную систему поиска документов по поисковым полным признакам - библиографическим данным. В носителе библиографического описания документа, так же как в поисковом тематизированном описании, указывается адрес хранения документа - его местоположение в фонде документов, документальной базе данных и т.п.
До недавнего времени теория многих оснований систем тематических поисков (философия, теория информации и классифицирования и т.п.) отсутствовала [1 - 3(26)]. Здесь в круглых скобах, заключенных в квадратные, дается общее число публикаций, найденных по данной тематике при помощи системы тематических поисков "Информотрон", включающей 2000 документов по теории и практике информотроники. Поэтому системы тематических поисков разрабатывались эмпирически и, как правило, эти системы тематических поисков не могут выдать то, что хотят пользователи. Это привело индустрию информационного обслуживания по тематическим запросам к кризису [4 - 6(15)].
Анализ результатов тематических поисков при помощи эмпирических систем тематических поисков, проведенный на основе поисковой информологии [7 - 9(13)], которая является основной патентуемого способа, показал, что причинами неудовлетворительной работы эмпирических систем тематического поиска являются, в частности, следующие.
1. Унитермная организация баз тематических поисков, позволяющая использовать в среднем сто лексикантов в каждой базе для представления в ней тысяч поисковых тематизированных описаний и значительно большего числа поисковым тематических предписаний, оперирующих миллионами информативных слоев - названий объектов, явлений, законов, наук и практик. Реальность этих цифр подтверждает, например, тот факт, что только химических соединений известно более одиннадцати миллионов.
2. Малолексикантность информационно-поисковых языков, которая вынуждает заменять естественные информативные слова документов и тематических запросов на, как правило, приблизительно соответствующие их смыслам лексиканты информационно-поискового языка данной базы тематического поиска, что является прямым искажением смыслов документов и запросов и приводит при автоматическом поиске к выдаче нерелевантных, неточных, несоответствующих теме запроса документов. Полученную автоматически информацию приходится в течение длительного времени визуально-ручным методом досортировывать и пополнять, используя диалоги, интерактивные процедуры и листание (броузинг), что значительно удлиняет процесс поиска и удорожает его.
В среднем каждый источник сведений представляется в базе тематических поисков тремя лексикантами, в то время как полное поисковое тематизированное описание должно, согласно принципу неопределенности, включать в среднем сто написанных и подразумеваемых информатичных слов-лексикантов.
Подразумеваемые слова - это те слова, которые логически (логонимически) следуют из написанных. Например, статье написаны слова "мозг", "сердце" и "печень"; слова "органы" и "анатомия" пишутся не всегда, но обязательно подразумеваются.
Таким образом, почти все документы представляются в упомянутых описаниях неполно и искаженно.
Доказательством того, что эмпирические поисковые тематизированные описания включает в среднем по три слова, является то, что на четырех- и более словные поисковые тематические предписания ни одна из более чем ста проведенных эмпирических систем тематических поисков не выдала автоматически тематическую подборку документов.
3. Низкая репрезентативность. Репрезентативность - число потенциальных тематических поисковых признаков в каждом поисковом тематизированном описании.
Число поисковых тематических признаков документов, которыми являются отдельные слова поискового тематизированного описания и их потенциальные комбинации (выборки), рассчитывается по формуле Кардано
X=2n-1,
где
n - число слов, которыми документ представляется в его поисковом тематизированном описании.
При n, равном 100, X приблизительно равно 1030, а при n, равном 3, X равно 101. Если принять, что 100 слов это все информативные слова документа и ими всеми документ представлен в его поисковом тематизированном описании, то это 100%-ная репрезентативность поисковых тематических признаков документа в базе тематических поисков, которая обеспечивает возможность поиска документа по любому из его 1030 одно-, двух-, ... и стословному поисковым тематическим признакам документа. Эти признаки являются потенциальными выборками 100 представленных в поисковом тематизированном описании слов. Выборки реализуются при поступлении соответствующих поисковых предписаний. Иными словами, данное стословное поисковое тематизированное описание документа позволяет отыскать документ по 1030 неодинаковым видам (тематикам) поисковых предписаний.
Если принять, что 100%-ная репрезентативность - это 1030 потенциальных поисковых тематических признаков стословного полного информологического описания, то 101 этих признаков трехсловных эмпирических писаний - это 10-25%-ная репрезентативность.
Столь ничтожный показатель репрезентативности эмпирических описаний является одной из причин неудовлетворительной работы унитермных систем тематических поисков и их сетей, их нерентабельности и т.п.
4. Использование слоев естественных языков в качестве поисковых тематических признаков документов, которое в последние годы стало чуть ли не единственным способом визуального решения проблемы релевантности тематических подборок документов [10 (7)], автоматически выдаваемых эмпирическими системами тематических поисков. Однако это не решило проблему при автоматических поисках.
Полисемия слоев естественных языков при автоматических поисках по-прежнему приводит к невысоким показателям релевантности и во многих случаях к несоответствию 100% документов в тематических подборках тематикам запросов, а синонимия слов является причиной локальной (для данной системы тематических поисков) неполноты тематических подборок документов. Локальная полнота - это все документы, имеющиеся в конкретной базе данных и включающие в текстах и подразумевающие информативные слова, указанные в тематике запроса.
При формировании по тематическим запросам поисковых предписаний работникам эмпирических систем тематических поисков приходится решать проблему полисемии, омонимии и синонимии столько же раз, сколько поступает тематических запросов, т.е. в масштабах мира - миллионы раз ежегодно. Решение этой проблемы в большей части случаев неудовлетворительное, т.к. большинство тех, кто формирует поисковые предписания, не являются профессионалами в естественной лингвистике и/или в тематике запросов. Поэтому для получения достаточно полной и релевантной тематической подборки документов по одной запросной тематике формируются десятки и больше поисковых предписаний и столько же раз ведется поиски практически во всех базах и файлах системы тематического поиска при визуальном контроле результатов поиска.
5. Использование фраз в роли лексикантов. Чтобы представить, насколько велики при этом искажения документов и запросов в базах тематических поисков, следует вообразить, например, "Капитанскую дочку" А.С.Пушкина переведенной на английский язык только при помощи ста фраз русско-английского фразового разговорника.
Поиск таким образом по одной тематике длиться в среднем около двух часов, хотя по одному поисковому предписанию ЭВМ может отыскиваться тематические подборки документов за десятки секунд.
Названные и другие причины являются основой глобального кризиса тематической информатики [4 - 6(15)], наносящего ежегодно во всех сферах человеческой деятельности в масштабах России ущерб на многие миллиарды рублей. Он проявляется в том, что 80% научных публикаций, патентных заявок, конструкторских разработок, а теперь и баз данных не содержит новых сведений и дублируют, как правило, не самое лучшее из известного [11, 12(15)]; многие учреждения и их подразделения дублируют друг друга, порождая неразбериху, около 50% ЭВМ бездействуют и лишь 5% компьютерного времени парка ЭВМ страны используется вообще. Из-за отсутствия до недавнего времени теории систем тематических поисков [1 - 3(26)] и под влиянием навязывающей пропаганды, обвиняющей невладельцев ЭВМ в некомпетентности и несовременности, ЭВМ приобретаются скорее для престижа, чем для тематических поисков; исчерпывающая информационная проработка планируемых, выполненных и предлагаемых к внедрению программ нередко стоит больше цены их воплощения в материалах, и т.д. Предлагаемый способ направлен на решение всех указанных и многих других проблем в области интелектуально-творческой деятельности и ее практического применения.
Общеизвестен способ поиска по библиографическим, реквизитным и другим полным запросам - полным поисковым признакам документов. Такой способ имеет следующие свойства, не позволяющие осуществлять поиски по тематическим запросам.
Библиографические системы поиска включают в себя полные описания поисковых библиографических признаков документов с адресами хранения. Эти описания составляют поисковую библиографическую базу данных библиографической системы поиска. Каждое описание относится только к одному документу и одному поисковому библиографическому признаку документа, и на один библиографический запрос выдается только один конкретный документ, если он есть в фонде или базе данных. Системы библиографических поисков могут выдавать конкретные документы, как правило, только по полным библиографическим описаниям.
При поступлении библиографического запроса при помощи поисковой библиографической базы данных (алфавитный авторско-заглавный картотечный или компьютерный каталог) устанавливают шифр хранения или номер записи в документальных базах данных. По установленному шифру хранения или номеру записи отыскивается или отображается на экране дисплея документ.
Наличие запрашиваемого документа в библиографической системе поиска определяется при помощи поисковой библиографической базы данных: если искомый документ есть в библиографической системе поиска, то в поисковой библиографической базе данных есть соответствующее описание и проблемы поиска нет. Библиографическая система поиска функционирует по принципу "Получаете то, что просили". Однако отношение числе библиографических и тематических запросов равно соответственно 1 к 1000.
Как упоминалось выше, библиографические поиски являются обязательным этапом работы и систем тематического поиска. Системы библиографических поисков старше систем тематических поисков. Поэтому по закону сохранения свойств (явлений, законов, морфологии) элементов и частей (старших форм материи) в образованных ими объектах (младших формах материи) и закону однонаправленности универсальности [7 - 9(13)] поиски по тематическим запросам при помощи систем тематических поисков должны обеспечивать также и библиографический поиск, а тематический поиск должен характеризоваться такой же определенностью, как и поиски при помощи библиографических систем поиска. Предлагаемый способ в значительной мере обеспечивает это.
Наиболее близким к заявленному является способ установления адреса объекта по поисковому тематическому признаку, заключающийся в том, что заранее составляют для каждого объекта данного хранилища ограниченный набор информативных слов и определяют адрес объекта, наносят элементы этого набора в форме адреса объекта в соответствующие поля носителя информации, приспособленного для снятия с помощью соответствующего считывающего средства, образуя тем самым в полях носителя информации тематические подборки адресов хранения объектов, при тематическом поиске составляют поисковый тематический запрос и наносят его в виде поискового тематического предписания на носитель информации, аналогичный носителю информации с полями адресов объектов, считывают поисковое тематическое предписание с носителя информации, сравнивают по заранее заданным критериям слова считываемого поискового тематического предписания с нанесенными на носитель информации названиями полей, считываемыми соответствующим считывающим средством, и определяют адрес объекта по результатам этих сравнений [13]. Недостатки этого прототипа указаны выше. Еще один недостаток: при увеличении числа полей (т.е. числа лексикантов информационно-поискового языка) экспоненциально увеличивается время поиска и уменьшается число документов, вводимых в систему.
Задача, следовательно, состоит в том, чтобы разработать такой способ представления максимального числа неискаженных поисковых тематических признаков в поисковых тематизированных описаниях документов, который на основе базы тематических поисков по тематикам запросов без изменения этих запросов обеспечивал бы выдачу тематических подборок документов с максимальной локальной полнотой и релевантностью, если только документы имеются в системе тематических поисков. Кроме того, желательно, чтобы этот способ уже на стадии формирования поисковых предписаний выявлял тематики, по которым данная система тематического поиска может выдать сведения автоматически, а также вероятность выдачи и объем тематической подборки документов.
Работникам библиографических систем поиска не придет в голову мысль изменить поступивший к ним библиографический запрос. Работники же системы тематического поиска из-за малолексикантности информационно-поисковых языков вынуждены изменять тематические запросы, ссылаясь, в частности, на то, что пользователи не умеют составить запрос, не знают, что хотят, и т.п. Первопричиной неидентичности поисковых предписаний и тематических запросов является несовершенство эмпирических систем тематического поиска и очень ограниченное число лексиконов в каждом информационно-поисковом языке. На основе предлагаемого способа при работе системы тематического поиска может быть воплощен "Получите то, что просили" (или до поиска: "В нашей системе тематического поиска интересующих Вас сведений нет или они автоматически недоступны").
Для решения поставленной задачи, т.е. для автоматического поиска максимально полных и точных тематических подборок документов (объектов), разработан способ установления адреса объекта по поисковому тематическому признаку, заключающийся в том, что заранее составляют для каждого объекта ограниченный набор информативных слоев и определяют адрес объекта, наносят элементы этого набора в форме адреса объекта в соответствующие поля носителя информации, приспособленного для считывания с помощью соответствующего считывающего средства, образуя тем самым в полях носителя информации тематические подборки адресов объектов, при тематическом поиске составляют поисковый тематический запрос и наносят его в виде поискового тематического предписания на носитель информации, аналогичный носителю информации с полями адресов объектов, считывают поисковое тематическое предписание с носителя информации, сравнивают слова считанного поискового тематического предписания с нанесенными на носители информации названиями полей, считываемыми соответствующими считывающим средством, и определяют адрес объекта по результатам этих сравнений, при этом, согласно настоящему изобретению, заранее составляют Универсальную Классификацию, основанную на морфолого-генезисных отношениях форм материи и ее атрибутов, названия которых используют в качестве словных поисковых тематических признаков искомых объектов, на базе Универсальной Классификации заранее формируют универсальный информационно-поисковый язык, в качестве которого используют классификанты Универсальной Классификации, присваивают каждому смыслу каждого классификанта Универсальной Классификации уникальный код, формируют массив десконов универсального информационно-поискового языка, для каждого объекта дополняют ограниченный набор информативных слоев до максимально полного набора характеризующих его информативных слоев, согласно которым сопоставляют данному объекту соответствующий ему участок Универсальной Классификации, объединяют выявленные для данного объекта и подразумеваемые для него соответствующим участком Универсальной Классификации информативные слова, кодируют их с помощью упомянутого массива десконов, после чего и наносят полученное тематизированное кодовое описание объекта с его адресом в качестве его поискового тематизированного описания на соответствующий носитель информации в виде цельной записи, а при упомянутом составлении поискового тематического представления кодируют все информативные слова его тематического запроса с помощью упомянутого массива десконов универсального информационно-проискового языка.
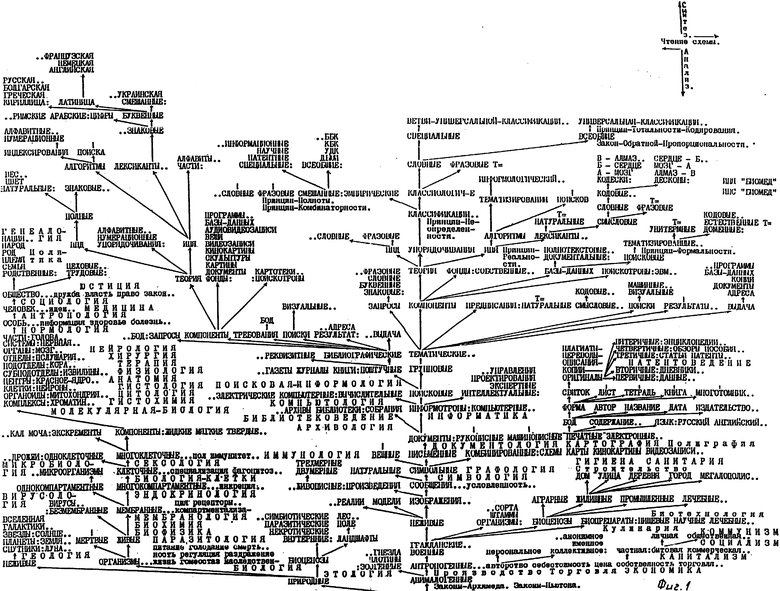
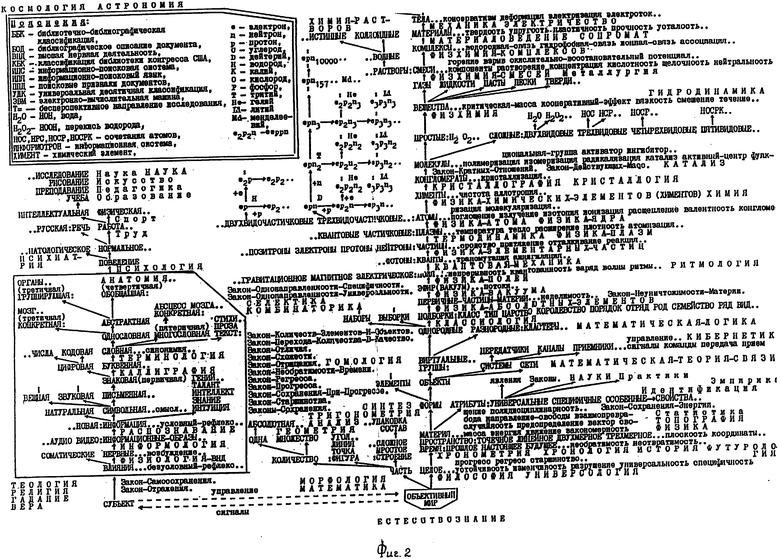
На фиг. 1 и 2 приведена схема универсальной классификации, используемой в предлагаемом способе.
Изобретение будет подробно описано на примере тематического поиска документов.
Способ установления адреса объекта по поисковому тематическому признаку согласно данному изобретению состоит из следующих операций:
- заранее составляют Универсальную Классификацию информативных слов, основанную на морфолого-генезисных отношениях всех форм материи и ее атрибутов, доказанных современной теорией и практикой и используемых в качестве словных поисковых тематических признаков искомых объектов;
- заранее формируют универсальный информационно-поисковый язык, в качестве лексикантов которого используют классификанты Универсальной Классификации;
- при превращении классификанта в лексикант присваивают каждому смыслу каждого классификанта Универсальной Классификации уникальный код;
- формируют массив десконов универсального информационно-поискового языка;
- для каждого объекта данного хранилища заранее составляют поисковое тематизированное описание из максимального числа информативных слов и адреса объекта, при этом выявляют характеризующие этот объект информативные слова, согласно которым сопоставляют данному объекту соответствующий ему участок Универсальной Классификации;
- объединяют выявленные для данного объекта и подразумеваемые для него соответствующим участком Универсальной Классификации информативные слова;
- кодируют эти слова с помощью упомянутого массива десконов;
- наносят полученное полное тематизированное кодовое описание каждого объекта с его адресом в качестве его кодового поискового тематизированного описания на соответствующий носитель информации в виде цельной записи;
- при поиске объекта составляют поисковое тематическое предписание путем кодирования всех информативных слов тематического запроса с помощью упомянутого массива десконов универсального информационно-поискового языка;
- наносят полученное кодовое поисковое тематическое предписание на носитель информации, аналогичный носителю информации с поисковым тематизированным описанием;
- считывают поисковое тематическое предписание с носителя информации;
- сравнивают лексиканты считанного поискового тематического предписания с лексикантами нанесенных на носитель информации поисковых тематизированных описаний, считываемых соответствующим считывающим средством;
- определяют адрес объекта по результатам этих сравнений.
Универсальная Классификация представлена на фиг. 1 и 2. Она основана на тех морфолого-генезисных отношениях, которые присущи всем формам материи и ее атрибутам и которые известны современной науке, т.е. доказаны современной теорией и подтверждены практикой. Универсальная Классификация создана на базе учения об универсальном классифицировании - классификатики [7 - 9 (13)], которое максимально объективно.
На фиг. 1 и 2 стрелки указывают направление прогресса (эволюции, развития) форм материи и ее атрибутов. В этих же направлениях уменьшаются фундаментальность, универсальность и старшинство и увеличиваются специфичность и сложность объектов, явлений, законов, наук и практик.
Чтение схемы Универсальной Классификации по направлению стрелок позволяет проследить генезис форм материи и ее атрибутов. Анализ схемы в обратном направлении раскрывает сущность регресса (деградации, революции) всех форм материи и ее атрибутов.
Ступень (начало) схемы ОБЪЕКТИВНЫЙ МИР заключена в рамку, как включающая в себя самую обобщающую и единственную категорию, которой можно охватить все денотации всех форм материи и ее атрибутов.
Часть ветви классификации, идущей от ступеньки "Субъект", также взята в рамку, чтобы выделить объекты, явления, законы, науки и практики, связанные с теорией субъективной информации (информологией) и пониманием информации только как нейро-физиологического процесса (явления), которая несвойственна неживым формам материи; неживые системы функционируют на основе сигналов. Сигналы являются основой информации.
Названия объектов (материальных образований) напечатаны на фиг. 1 и 2 большими буквами без пробелов между ними (ОБЪЕКТИВНЫЙ МИР), явления - строчными буквами (движение), законы - в виде слов, начинающихся с большой буквы и соединяемых дефисом, и после них ставится точка (Закон-Неуничтожимости-Материи. ), науки - большими буквами в разрядку (МОРФОЛОГИЯ) и практики - словами в разрядку с первой большой буквой (Металлургия).
Черточка над серединой слова или сбоку означает, что далее (вверх или вбок) идет ветвь, идентичная ветви рядом стоящего слова.
Двоеточие означает перечисление классификантов, которое осуществляется вверх, влево или вправо (по направлению стрелок).
Две точки по горизонтали или вертикали свидетельствуют, что соответственно перечень классификантов не закончен или они пропущены, как в ветви АТОМЫ.
Три точки по горизонтали означают, что в число явлений объектов данной ступени входят все явления всех нижележащих (старших) объектов.
Универсальная Классификация является универсальной организацией предметов знаний или моделью Единого Знания, вобравшей интеллект современной науки.
На базе Универсальной Классификации формируют универсальный информационно-поисковый язык. Словными частями лексикантов, т.е. "словами" этого языка являются классификанты Универсальной Классификации, - те слова, которые входят в соответствующие уровни этой классификации (см. фиг. 1 и 2). При этом каждому смыслу каждого естественного слова присваивается уникальный код. Например, у слова "ключ" имеются такие смыслы: ключ воды, ключ для шифрования, ключ для открывания замков. Поэтому каждому из этих смыслов присваивается свой ключ: А, Б, В соответственно. Тогда синонимы каждого смысла получат тот же код, - скажем, "родник" и "ручей" будут иметь тот же код А, что и "ключ воды". Каждое естественное слово в паре со своим смысловым кодом образует лексикант - дескон (дескриптор-код) вида "Ключ-А", "Родник-А", "Ключ-В", "Отмычка-В" и т.п. Все десконы в алфавитном порядке образуют массив универсального информационно-поискового языка, используемый в дальнейшем для составления поисковых тематизированных описаний и тематических предписаний. Здесь же можно отметить, что обратные лексиканты, т.е. "А-Ключ", "Б-Ключ", "А-Ручей" и т.д. называются кодесками (код-дескриптор) и составляют другое множество лексикантов информационно-поискового языка, которое применяют, в частности, для создания алфавитного списка (массива) десконов. Информативные слова новых знаний становятся новыми классификантами, классификанты - кодесками, а кодески - десконами.
Затем для каждого документа данного хранилища выявляется максимальное число информативных слов этого документа. Это принцип тотальности тематизирования, который обусловлен концепцией неопределенности, связанной с тем, что разработчики систем тематического поиска не могут заранее предвидеть, по каким поисковым тематическим признакам будут вестись поиски документов. По этим информативным словам определяется тот участок Универсальной Классификации, которому соответствует этот документ. Фактически речь идет о выделении классификационного домена документа.
Информационно-поисковый язык для документов данного уровня Универсальной Классификации (предметно ориентированный информационно-поисковый язык) должен быть полным, чтобы обеспечить релевантность результатов поиска запросу (принцип полноты предметно ориентированного информационно-поискового языка). Это значит, что в число лексических единиц (лексикантов) информационно-поискового языка данной предметно ориентированной системы тематического поиска должны войти не только слова, специфичные для данной области знаний, которая охватывается конкретной документальной базой данных, но и вся терминология всех более старших, т.е. расположенных слева и ниже на Универсальной Классификации (см. чертеж) по сравнению с данной областью знаний, для которой разрабатывается предметно ориентированный информационно-поисковый язык и система тематического поиска. Принцип полноты предметно ориентированного информационно-поискового языка обусловлен законами сохранения элементов при прогрессе и однонаправленности универсальности. На практике полнота предметно ориентированного информационно-поискового языка обеспечивает возможность введения в систему тематического поиска тех документов с новыми знаниями, которые все более глубоко раскрывают сущность данной области знаний; при этом такой информационно-поисковый язык, поисковые тематизированные описания документов и базы тематических поисков не переделываются и могут быть полезны сколь угодно долго. =Далее с помощью Универсальной Классификации определяют все те слова, которые не встречаются в данном документе, но подразумеваются исходя из выявленного участка Универсальной Классификации (как в вышеприведенном примере слова "органы" и "анатомия" для слов "сердце", "мозг", "печень").
Все выявленные в документе и подразумеваемые слова объединяют и кодируют с помощью вышеописанного заранее составленного массива десконов. При этом кодируют именно смыслы слов, о которых можно сказать, что одно слово может иметь несколько смыслов (вышеприведенный пример со словом "ключ"), а может и один смысл выражаться несколькими словами (вода, влага, жидкость, напиток).
При создании информационно-поискового языка только из слов документов, использованных в процессе формирования их поисковых тематизированных описаний, принцип полноты выдерживается путем создания свободных кодов, которые присваиваются новым дескрипторам (смыслам слов), выявляемым в процессе формирования поисковых тематизированных описаний. Это также позволяет развивать информационно-поисковый язык и базу тематических поисков без переделки.
Но наиболее безграничные и эффективные возможности будут иметь системы тематических поисков, при создании которых будут использоваться полные Универсальная Классификация и универсальный информационно-поисковый язык при доменной организации баз тематических поисков: эти системы без изменений могут становиться универсальными после введения в них соответствующих документов. Универсальность позволяет избегать образования множества специальных систем тематических поисков.
Представление документов в поисковых тематизированных описаниях кодами именно смыслов слов, диктуемых контекстом, наиболее полно отражает смысл данного документа, и поиски по кодам смыслов слов дают затем автоматически максимально полную и релевантную тематическую подборку документов. Полученный набор кодов и является кодовым поисковым тематизированным описанием документа.
Это кодовое поисковое тематизированное описание наносят на соответствующий носитель информации, допускающий возможность считывания с помощью какого-либо считывающего устройства или по меньшей мере возможность механической сортировки. При этом данное описание с адресом данного документа наносят в виде цельной записи.
При необходимости найти какой-либо документ (какие-либо документы) по определенным тематическим признакам в данной системе тематических поисков пользователи составляют тематические запросы, которые с помощью того же самого массива десконов кодируют и превращают тем самым в кодовые поисковые тематические предписания точно так же, как это рассмотрено выше для кодовых поисковых тематизированных описаний документов. Если все информативные слова тематического запроса могут быть трансформированы в кодовое поисковое предписание без изменения смыслов его слов и соответствующие лексиканты имеют числа использования, то всегда будет иметься определенная вероятность результативного поиска.
Полученное кодовое поисковое тематическое предписание наносят на такой же носитель информации, как и описанный выше для кодовых поисковых тематизированных описаний документов.
Далее считывают этот носитель с кодовым поисковым тематическим предписанием с помощью того же считывающего устройства, для которого пригоден такой носитель информации.
Считанное кодовое предписание сравнивают с кодовыми описаниями имеющихся в базе данных для документов этого хранилища, что можно осуществить, например, с помощью ЭВМ. Важно отметить, что при этом просматривается вся база тематических поисков, а не какая-то ее часть, как это имеет место в базах, организованных по унитермному, а не по доменному принципу. В результате за один просмотр пользователю выдается полная тематическая подборка адресов документов, имеющихся в конкретной базе данных, по интересующему его вопросу. Время получения полной тематической подборки адресов документов равняется времени, в течение которого считывающее устройство сравнивает поисковое предписание со всеми описаниями данной базы тематических поисков. При помощи базы библиографических поисков и других устройств по найденным адресам система тематических поисков выдает тематическую подборку документов или их копий или изображений на экране.
На этапе составления поисковых тематизированных описаний документов можно специально отмечать каждый случай использования того или иного дескона. В результате при составлении кодового поискового тематического предписания еще до его считывания с носителя информации и даже до его нанесения на этот носитель можно сделать вывод о наличии в конкретной базе данных интересующих пользователя документов, поскольку отсутствие какого-либо дескона (равенство нулю количества его появлений или использований в перечне десконов конкретной базы данных) из числа содержащихся в поисковом тематическом предписании делает бесполезным проведение автоматического поиска в этой конкретной базе данных. Если же число использований какого-либо дескона, код которого включен в поисковое тематическое предписание, отлично от нуля для конкретной базы данных, то это число характеризует определенную вероятность получения адресов документов с помощью данной системы тематического поиска по данному поисковому тематическому предписанию, а также максимально возможное количество этих адресов. Эта вероятность тем выше, чем короче предписание и чем больше числа использования его десконов.
Рассмотренный способ обеспечивает достижение следующих технических результатов:
1. Повышается информативность крупных систем тематических поисков на много порядков - с 1010 для эмпирических систем тематического поиска до 10100 и выше для информологических систем (за счет соблюдения принципа тотальности тематизирования и следующей из этого максимальной полноты поисковых тематизированных описаний документов или репрезентативности).
2. Увеличение в сотни раз полноты и в десятки раз релевантности отыскиваемых тематических подборок документов, поскольку проблема полисемии, омонимии и синонимии устраняется на этапе создания информационно-поискового языка, а также вследствие соблюдения принципа тотальности тематизирования.
3. Осуществление тематического поиска в автоматическом режиме работы ЭВМ и однократность поиска по одной запросной тематике за счет совокупности принципов при создании информационно-поискового языка и поисковых тематизированных описаний документов.
4. Упрощение машинного языка за счет доменной организации баз тематических поисков, сокращение времени поиска по одной тематике за счет бездиалоговости и автоматичности поиска и поэтому удешевление поиска тематических подборок документов.
5. Унифицирование лексики поисковых тематических баз данных за счет использования готовых полных Универсальной Классификации и универсальностью информационно-поискового языка, что позволяет создавать сети систем тематических поисков без дополнительных затрат на разработку языков-трансляторов, необходимых, когда у каждой базы тематических поисков свой информационно-поисковый язык.
6. Увеличение числа видов и типов ЭВМ, используемый в качестве компьютерной основы системы тематического поиска за счет упрощения машинного языка поисков при доменной организации баз тематических поисков.
7. Бездиалоговость (однократность, автоматичность) позволяет в процессе просмотра машиной всех баз тематических поисков (за один раз) получить тематические подборки документов по многим запросным тематикам за счет использования компьютеров с параллельными процессорами. Параллельность поисков еще больше ускоряет и удешевляет их себестоимость.
8. Доменная организация баз тематических поисков позволяет с пользой задействовать всю емкость носителя, что недостижимо при унитермной организации баз тематических поисков, когда по разным причинам "гуляет" свободной примерно половина емкости носителя.
9. При доменной организации баз тематических поисков практически не будет дублирования адресов, которые записываются по одному разу и которые при унитермной организации баз тематических поисков записываются столько раз, сколько ключевых слов данного документа представляются в соответствующих полях носителя.
10. При формировании универсального информационно-поискового языка за счет кодирования смыслов естественных слов решается один раз проблема полисемии, омонимии и синонимии, которая при помощи информационно-поисковых языков с естественными словами в роли лексикантов решается при каждом превращении тематических запросов в поисковые тематические предписания - десятки миллионов раз ежегодно в масштабе мира.
11. В рамках одной системы тематических поисков с доменной организацией баз тематических поисков достаточно будет иметь одну документальную базу, одну Универсальную Классификацию, один универсальный информационно-поисковый язык и одну базу тематических поисков, в то время как эмпирические системы тематических поисков, как правило, имеют десятки и больше документальных баз, классификаций, информационно-поисковых языков и баз тематических поисков (файлов).
12. За счет в среднем стокодовых поисковых тематизированных описаний документов возникает возможность вести тематические поиски по поисковым предписаниям (тематическим запросам) теоретически от однолексикантного до столексикантного (в среднем до десятилексикантного) поисковых тематических предписаний, изменять в этих пределах числа лексикантов в предписаниях, во много раз точнее, автоматически управлять объемом тематических подборок документов и характером содержащихся в них сведений: чем больше лексикантов в предписании, тем меньше объем и более специфичные сведения в тематических подборках документов, и наоборот. Унитермные базы тематических поисков позволяют достичь регулирования в пределах от одного в среднем только до трехлексикантных поисковых тематических предписаний, из-за чего тематические подборки документов, как правило, очень большие, включают в себя много неиспользуемой информации (информационный шум) и требуют визуально-ручной диалоговой или интерактивной или броузинговой (автоматизированной) досортировки и пополнения, на что уходят часы, а то и дни и недели работы.
13. Информологические системы тематических поисков могут служит сколь угодно долго.
14. В процессе тематизирования проставляют числа использования лексикантов универсального информационно-поискового языка, что делает этот язык реальным, т. е. пригодным для тематических поисков только в данной системе тематических поисков. Реальность готового универсального информационно-поискового языка позволяет до поиска по числам использования лексикантов, коды которых вошли в поисковое тематическое предписание, рассчитать и заранее знать вероятность получения и максимально возможный объем будущей тематической подборки документов, управлять этим объемом до поиска, изменяя числа кодов в предписании. Эти знания позволяют, не проводя поисков, выбрать ту систему тематических поисков в сети типа "Интернет", которая с большей вероятностью выдаст необходимую тематическую подборку документов. Иными словами, реальность информационно-поисковых языков позволяет вести поиски оптимальных систем тематических поисков, например, при помощи компьютерной базы информационно-поисковых языков в объединенных в сеть системах тематических поисков. Точнее, создается возможность предварить поиск тематической подборки документов поиском оптимальной системы тематических поисков.
15. Цельность записи поискового тематизированного описания позволяет делать его сколь угодно большим, а доменную базу тематических поисков - на бесконечном числе носителей.
Рассмотренный способ реализован в нескольких системах тематического поиска, в частности в системе "Биомед" [7 - 9 (13)], которая на базе 15000 рефератов теоретически способна выдать тематические подборки документов примерно по 1012 тематикам (показатель информативности). Данная система реализована на картах с краевой перфорацией, имеющих 17 полей. В среднем описание включает 12 лексикантов. В каждом поле имеется 141 бесшумный код. Информационно-поисковый язык системы тематического поиска "Биомед" включает в себя только реальные лексические единицы 10000 лексикантов, использованные при составлении поисковых тематизированных описаний документов, и имеет около 5 млн. свободных кодов. Общее число потенциальных тематических подборок составляет 317 - 1 ≈ 1012. Локальная полнота по нескольким тысячам осуществленных поисков в среднем равна 30 %, релевантность - 50 %. Тематические подборки документов делаются только по реальным тематическим запросам.
Для сравнения, реальная информативность всех систематических карточек Российской Государственной Библиотеки равна числу подборок библиографических карточек, что составляет примерно 1010. Полнота и релевантность тематических подборок документов, выдаваемых эмпирическими системами тематических поисков, в среднем равны соответственно 1 % и 5 %. Из 1010 готовых тематических подборок карточек этой библиотеки лишь несколько процентов релевантны реальным запросам так же, как готовые тематические подборки адресов хранения в компьютерных базах тематических поисков с унитермной организацией.
Приведенный иллюстративный пример реализации способа по настоящему изобретению для поиска документов ни в коей мере не является ограничивающим, т. к. данный способ пригоден для поисков любых объектов, адреса которых известны. Объем патентных притязаний определяется только прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ информационного поиска лингвистических моделей выражения деловых отношений в документах архивного фонда | 2017 |
|
RU2656982C1 |
| Способ структурирования результатов поиска по текстам, содержащим информацию о научной и исследовательской деятельности | 2017 |
|
RU2656469C1 |
| СИСТЕМА АНАЛИТИЧЕСКОГО ВЫЯВЛЕНИЯ ПРОБЛЕМНЫХ ВОПРОСОВ В НОРМАХ ПРАВОВОГО РЕГУЛИРОВАНИЯ | 2011 |
|
RU2479017C1 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В ПОЛИТЕМАТИЧЕСКИХ МАССИВАХ НЕСТРУКТУРИРОВАННЫХ ТЕКСТОВ | 2008 |
|
RU2409849C2 |
| Гибридная автоматическая система управления доступом пользователей к информационным ресурсам в публичных компьютерных сетях | 2018 |
|
RU2697925C1 |
| Система автоматического определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта | 2023 |
|
RU2823436C1 |
| СПОСОБ ФОРМИРОВАНИЯ И РЕГУЛЯРНОЙ ДОСТАВКИ ПОЛЬЗОВАТЕЛЯМ ИНФОРМАЦИОННЫХ ИЗДАНИЙ И СИСТЕМА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 1999 |
|
RU2177638C2 |
| ИНФОРМАЦИОННАЯ СИСТЕМА | 2008 |
|
RU2368008C1 |
| Способ использования системы определения тематики документов для целей информационной безопасности | 2018 |
|
RU2701990C1 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
Изобретение относится к способу установления адреса объекта по поисковому тематическому признаку. Его использование при создании новых и модернизации существующих систем тематических поисков и баз данных позволяет резко повысить репрезентативность тематических поисков. Способ заключается в том, что заранее составляют для каждого объекта ограниченный набор информативных слов и определяют адрес объекта, наносят элементы этого набора в форме адреса объекта в соответствующие поля носителя информации, приспособленного для считывания с помощью соответствующего считывающего средства, при тематическом поиске составляют поисковый тематический запрос и наносят его в виде поискового тематического предписания на носитель информации, аналогичный носителю информации с полями адресов объектов, считывают поисковое тематическое предписание с носителя информации, сравнивают слова считанного поискового тематического предписания с нанесенными на носители информации названиями полей, считываемыми соответствующим считывающим средством, и определяют адрес объекта по результатам этих сравнений. Технический результат достигается благодаря тому, что заранее составляют Универсальную Классификацию, на базе которой заранее формируют универсальный информационно-поисковый язык, в качестве лексикантов которого используют классификанты Универсальной Классификации, присваивают каждому смыслу каждого классификанта Универсальной Классификации уникальный код, формируют массив десконов универсального информационно-поискового языка, для каждого объекта дополняют ограниченный набор информативных слов до максимально полного набора характеризующих его информативных слов, согласно которым сопоставляют данному объекту соответствующий ему участок Универсальной Классификации, объединяют выявленные для данного объекта и подразумеваемые для него соответствующим участком Универсальной Классификации информативные слова, кодируют их с помощью массива десконов, после чего и наносят полученное тематизированное кодовое описание объекта с адресом в качестве его поискового тематизированного описания на соответствующий носитель информации в виде цельной записи, а при составлений поискового тематического предписания кодируют все информативные слова тематического запроса с помощью массива десконов универсального информационно-поискового языка. 2 з.п.флы, 2 ил.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Grolier E | |||
| Conference summary | |||
| - Tools for knowledge organization and human interface | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Frankfurt/Main: INDEKS Verlag, p.248-251, 1991 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Hirshheim R., Klain H.K | |||
| Paradigmig influence on information system development methodologies: evolution and conceptual advances | |||
| - Adv.in Computers | |||
| Нивелир для отсчетов без перемещения наблюдателя при нивелировании из средины | 1921 |
|
SU34A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Ford N | |||
| Knowledge-based information retrieval | |||
| - J.Amer.Soc | |||
| inform.Sci (USA), v.42, N1, p.72-74, 1991 | |||
| Очаг для массовой варки пищи, выпечки хлеба и кипячения воды | 1921 |
|
SU4A1 |
| Feldman T | |||
| CD-ROM | |||
| Blueprint Publishing Ltd | |||
| (UK), 130 p., 1987 | |||
| Кипятильник для воды | 1921 |
|
SU5A1 |
| Нестеров А.В | |||
| Библиотечно-информационные барьеры в системе управления библиотекой | |||
| - Управление научной библиотекой в условиях НТР.-Новосибирск: ГПНТБ СО АН СССР, 1992, с.153-162 | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Young J.B | |||
| Crisis in cataloging revisited: the year's work in subject analysis, 1990 | |||
| - Library resources and techn | |||
| Serv | |||
| (USA), v.35, N 3, p.265-282, 1991 | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Шпаков А.А | |||
| Некоторые основания аналитической археологии | |||
| Теоретические проблемы исторического исследования.-Киев: Музейное объединение, 1992, с.65-81 | |||
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| Shpackov A.A | |||
| The nature and boundaries of information science(s).-J.Amer.Soc.Inform.Sci | |||
| (USA), v.43, N 10, p.678-681, 1992 | |||
| Разборный с внутренней печью кипятильник | 1922 |
|
SU9A1 |
| Шпаков А.А | |||
| Личная картотека учебного на картах с краевой перфорацией (на примере картотеки по некоторым вопросам биологии) | |||
| Научно-техническая информация.-М.: ВИНИТИ, сер.1, 1977, N 3, с.10-12 | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Sang E.J.K.A connectionist view on knowledge representation.-Language and cognition | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Циркуль-угломер | 1920 |
|
SU1991A1 |
| Universiteitsdrukkerij Groningen, 2-nd ed., p.255-264, 1992 | |||
| Походная разборная печь для варки пищи и печения хлеба | 1920 |
|
SU11A1 |
| Смык А.А | |||
| Новая концепция информационного обслуживания | |||
| Первая конференция Восток-Запад по научной, технической и деловой информации | |||
| Доклады.-М.: МЦНТИ, 1990, с.181-185 | |||
| Способ гальванического снятия позолоты с серебряных изделий без заметного изменения их формы | 1923 |
|
SU12A1 |
| Tullett B.B | |||
| Bibliographic relationships: an empirical stuby of the LC machine readable records | |||
| - Library recources and technical services | |||
| ALCTS: USA, v.36, N 2, p.162-188, 1992 | |||
| Насос | 1917 |
|
SU13A1 |
| Василевич А.Ф | |||
| Руководство по проведению поиска в базах данных МЦНТИ.-М.: МЦНТИ, 1987, с.103. | |||

