ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к вычислительным
системам, а точнее к системам и способам обнаружения текстовых полей в электронных документах с использованием нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[0002] Обнаружение текстовых полей в электронных документах является фундаментальной задачей в обработке электронных документов. Традиционные подходы обнаружения полей могут включать использование большого количества настраиваемых вручную эвристик и поэтому могут требовать большого количества ручного труда.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] Вариант реализации настоящего изобретения описывает механизмы обнаружения текстовых полей в электронных документах с использованием нейронных сетей. Способ по раскрываемому изобретению включает извлечение из электронного документа множества признаков, где множество признаков включает множество символьных векторов, представляющих слова электронного документа; обработку символьных векторов с использованием нейронной сети; обнаружение обрабатывающим устройством множества текстовых полей в электронном документе, исходя из результата работы нейронной сети; и назначение обрабатывающим устройством каждого из текстовых полей одному из множества типов полей, исходя из результата работы нейронной сети.
[0004] Система по настоящему изобретению включает запоминающее устройство и обрабатывающее устройство, оперативно соединенное с запоминающим устройством; обрабатывающее устройство выполняет следующие операции: извлечение множества признаков из электронного документа, где множество признаков включает множество символьных векторов, представляющих слова электронного документа; обработку символьных векторов с использованием нейронной сети; обнаружение множества текстовых полей в электронном документе, исходя из результата работы нейронной сети; и назначение каждого из текстовых полей одному из множества типов полей, исходя из результата работы нейронной сети.
[0005] Энергонезависимый машиночитаемый накопитель данных по настоящему изобретению содержит инструкции, которые при обращении к ним обрабатывающего устройства приводят к выполнению операций обрабатывающим устройством, включая извлечение из электронного документа множества признаков, где множество признаков включает множество символьных векторов, представляющих слова электронного документа; обработку символьных векторов с использованием нейронной сети; обнаружение множества текстовых полей в электронном документе, исходя из результата работы нейронной сети; и назначение каждого из текстовых полей одному из множества типов полей, исходя из результата работы нейронной сети.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Изложение сущности изобретения будет лучше понятно из приведенного ниже подробного описания и приложенных чертежей различных вариантов осуществления изобретения. Однако не следует считать, что чертежи ограничивают сущность изобретения конкретными вариантами осуществления; они предназначены только для пояснения и улучшения понимания сущности изобретения.
[0007] Фиг. 1 представляет пример вычислительной системы, в которой может выполняться реализация данного изобретения;
[0008] Фиг. 2 представляет схему, иллюстрирующую пример нейронной сети в соответствии с некоторыми вариантами реализации настоящего изобретения;
[0009] Фиг. 3 представляет схему, иллюстрирующую пример механизма создания векторных представлений слов на уровне символов в соответствии с некоторыми вариантами реализации настоящего изобретения;
[0010] Фиг. 4 представляет схему, иллюстрирующую пример четвертого множества слоев нейронной сети на Фиг. 2 в соответствии с некоторыми вариантами реализации настоящего изобретения;
[0011] Фиг. 5 представляет схему, иллюстрирующую пример механизма вычисления карты признаков, содержащей признаки слов в соответствии с некоторыми вариантами реализации настоящего изобретения;
[0012] Фиг. 6 представляет блок-схему, иллюстрирующую способ
обнаружения текстовых полей в электронном документе в соответствии с некоторыми вариантами реализации настоящего изобретения;
[0013] Фиг. 7 представляет блок-схему, иллюстрирующую способ обнаружения текстовых полей с использованием нейронной сети в соответствии с некоторыми вариантами реализации настоящего изобретения; и
[0014] Фиг. 8 иллюстрирует блок-схему вычислительной системы в соответствии с некоторыми реализациями настоящего изобретения.
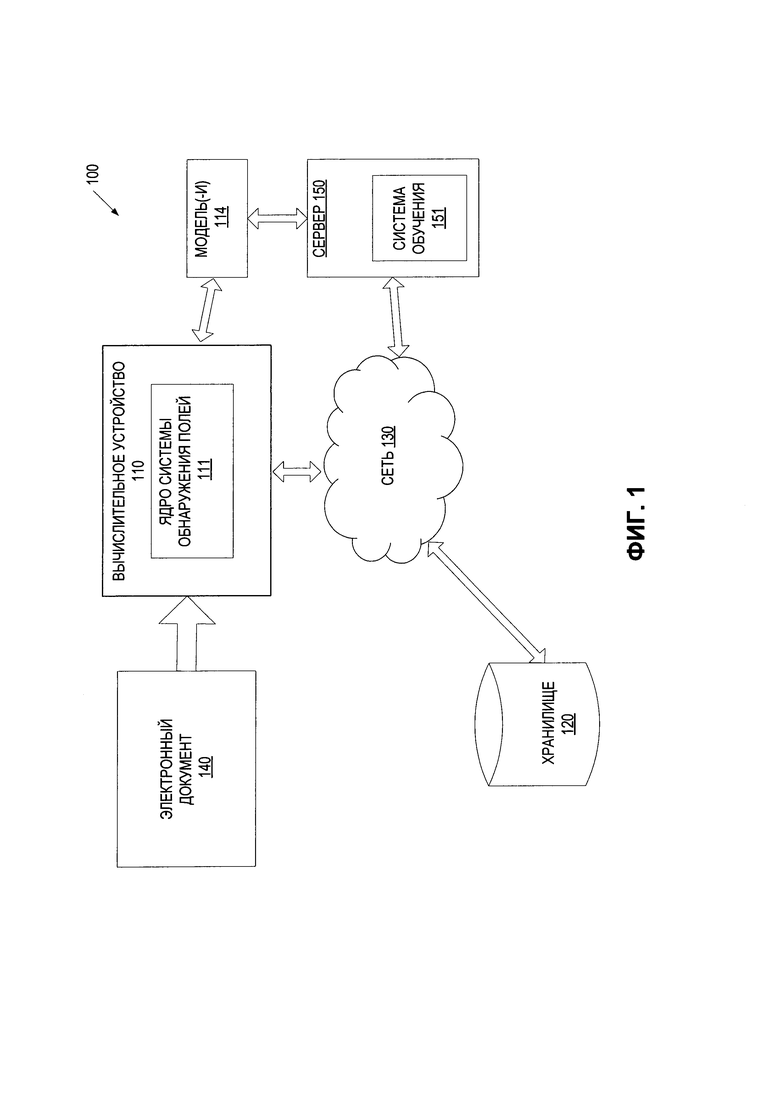
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0015] Описываются варианты реализации изобретения для обнаружения текстовых полей в электронных документах с использованием нейронных сетей. Одним из алгоритмов обнаружения полей и соответствующих им типов полей в электронных документах является эвристический подход. В случае эвристического подхода рассматривается большое количество (порядка сотен) электронных документов, например ресторанных счетов или квитанций, и накапливается статистика относительно того, какой текст (например, ключевые слова) используется рядом с определенным полем и где этот текст можно поместить относительно поля (например, справа, слева, выше, ниже). Например, эвристический подход отслеживает, какое слово или слова обычно расположены рядом с полем, указывающим общую сумму покупки, какое слово или слова находятся рядом с полем, указывающим на применимые налоги, какое слово или слова написаны рядом с полем, указывающим общую сумму оплаты по кредитной карте и т.д. На основе этих статистических данных при обработке нового счета можно определить, какие данные, обнаруженные в электронном документе, соответствуют определенному полю. Однако эвристический подход не всегда работает точно, потому что если по какой-то причине счет был распознан с ошибками, а именно в словосочетаниях «ОБЩИЙ НАЛОГ» и «ОБЩИЙ ПЛАТЕЖ» слова «налог» и «платеж» были распознаны плохо, то соответствующие значения могут не пройти классификацию.
[0016] Аспекты настоящего изобретения устраняют отмеченные выше и другие недостатки, предоставляя механизмы обнаружения текстовых полей в электронном документе с использованием нейронных сетей. Эти механизмы могут автоматически обнаруживать текстовые поля, имеющиеся в электронном документе, и связывать каждое из текстовых полей с типом поля. Под термином «текстовое поле» может подразумеваться поле данных в электронном документе, которое содержит текст. Под термином «тип поля» может подразумеваться тип содержимого, находящегося в текстовом поле. Например, типом поля может быть «имя», «наименование компании», «телефон», «факс», «адрес» и т.д.
[0017] Под термином «электронный документ» может подразумеваться файл, содержащий один или несколько элементов цифрового содержимого, которые могут быть переданы визуально для создания визуального представления электронного документа (например, на дисплее или на печатном носителе). В соответствии с различными реализациями настоящего изобретения электронный документ может быть представлен в виде файла любого подходящего формата, например, PDF, DOC, ODT и др.
[0018] Механизмы могут обучать нейронную сеть обнаруживать текстовые поля в электронных документах и классифицировать текстовые поля по заранее заданным классам. Каждый из заранее заданных классов может соответствовать типу поля. Нейронная сеть может содержать множество нейронов, связанных с получаемыми при обучении весами и состояниями. Эти нейроны могут быть организованы в слои. Нейронная сеть может быть обучена на обучающей выборке данных электронных документов, содержащих известные текстовые поля. Например, обучающая выборка данных может содержать примеры электронных документов, включающих в себя одно или более текстовых полей, в качестве исходных данных для обучения, и один или более идентификаторов типа поля, которые правильно соответствуют одному или более полям в качестве целевого результата. Нейронная сеть может построить наблюдаемый результат для каждых исходных данных для обучения. Наблюдаемый результат работы нейронной сети сравнивается с ожидаемым результатом работы, включенным в обучающую выборку данных, и ошибка распространяется назад, на предыдущие слои нейронной сети, в которых соответствующим образом регулируются параметры нейронной сети (веса и состояния нейронов). В ходе обучения нейронной сети параметры нейронной сети могут быть отрегулированы для оптимизации точности предсказания.
[0019] После обучения нейронная сеть может быть использована для автоматического обнаружения текстовых полей во входном электронном документе и выбора наиболее вероятного типа поля для каждого из этих текстовых полей. Использование нейронных сетей избавляет от необходимости ручной разметки текстовых полей и типов полей в электронных документах. Описанные здесь методы позволяют автоматически обнаруживать текстовые поля в электронных документах с использованием искусственного интеллекта. Использование описанных здесь механизмов обнаружения текстовых полей в электронном документе может повысить качество результатов обнаружения за счет выполнения обнаружения полей с использованием обученной нейронной сети, которая сохраняет информацию о пространственных параметрах, относящуюся к электронному документу. Эти механизмы могут с легкостью применяться к любым типам электронных документов. Кроме того, описанные здесь механизмы обнаружения могут обеспечить эффективное обнаружение текстовых полей и повысить скорость обработки вычислительного устройства.
[0020] Фиг. 1 представляет блок-схему примера вычислительной системы 100, в которой может выполняться реализация данного изобретения. Как показано на изображении, система 100 включает вычислительное устройство 110, хранилище 120 и сервер 150, подключенный к сети 130. Сеть 130 может быть общественной сетью (например, Интернет), частной сетью (например, локальная сеть (LAN) или распределенная сеть (WAN)), а также их комбинацией.
[0021] Вычислительное устройство 110 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, которое в состоянии использовать технологии, описанные в этом изобретении. В некоторых вариантах реализации изобретения вычислительное устройство 110 может быть и (или) включать одно или более вычислительных устройств 800 с Фиг. 8.
[0022] Электронный документ 140 может быть получен вычислительным устройством 110. Электронный документ 140 может содержать любой подходящий текст, например один или более символов, слов, предложений и т.д. Электронный документ 140 может относиться к любому подходящему типу, например «визитная карточка», «счет», «паспорт», «полис медицинского страхования», «опросный лист» и т.д. Тип электронного документа 140 в некоторых вариантах реализации изобретения может быть определен пользователем.
[0023] Электронный документ 140 может быть получен любым подходящим способом. Например, вычислительное устройство 110 может получить цифровую копию документа 140 путем сканирования документа или фотографирования документа. Кроме того, в тех вариантах реализации изобретения, где вычислительное устройство 110 представляет собой сервер, клиентское устройство, которое подключается к серверу по сети 130, может загружать цифровую копию документа 140 на сервер. В тех вариантах реализации изобретения, где вычислительное устройство 110 является клиентским устройством, соединенным с сервером по сети 130, клиентское устройство может загружать документ 140 с сервера.
[0024] Электронный документ 140 может быть использован для обучения набора моделей машинного обучения или может быть новым документом, для которого следует выполнить обнаружение и (или) классификацию полей. Соответственно, на предварительных этапах обработки электронный документ 140 можно подготовить для обучения набора моделей машинного обучения или для последующего распознавания. Например, в электронном документе 140 могут быть вручную или автоматически выбраны строки текста, могут быть отмечены символы, строки текста могут быть нормализованы, масштабированы и (или) бинаризованы. В некоторых вариантах реализации изобретения текст в электронном документе 140 может распознаваться с использованием любого подходящего метода оптического распознавания символов (OCR).
[0025] В одном из вариантов реализации изобретения вычислительное устройство 110 может содержать ядро системы обнаружения полей 111. Ядро системы обнаружения полей 111 может содержать инструкции, сохраненные на одном или более физических машиночитаемых носителях данных вычислительного устройства 110 и выполняемые на одном или более обрабатывающих устройствах вычислительного устройства 110. В одном из вариантов реализации изобретения ядро системы обнаружения полей 111 может использовать для обнаружения и (или) классификации текстовых полей набор обученных моделей машинного обучения 114. Модели машинного обучения 114 обучаются и используются для обнаружения и (или) классификации текстовых полей в исходном электронном документе. Ядро системы обнаружения полей 111 также может предварительно обрабатывать любые полученные электронные документы перед использованием этих электронных документов для обучения модели (моделей) машинного обучения 114 и (или) применения обученной модели (моделей) машинного обучения 114 к электронным документам. В некоторых вариантах реализации обученная модель (модели) машинного обучения 114 может быть частью ядра системы обнаружения полей 111 или может быть доступна для другой машины (например, сервера 150) через ядро системы обнаружения полей 111. На основе результатов работы обученной модели (моделей) распознавания полей 114 ядро системы обнаружения полей 111 может обнаруживать в электронном документе одно или более текстовых полей и может классифицировать каждое из текстовых полей, относя их к одному из множества классов, соответствующих заранее определенным типам полей.
[0026] Ядро системы обнаружения полей 111 может быть клиентским приложением или же сочетанием клиентского компонента и серверного компонента. В некоторых вариантах реализации изобретения ядро системы обнаружения полей 111 может быть запущено на исполнение на вычислительном устройстве клиента, например это могут быть планшетный компьютер, смартфон, ноутбук, фотокамера, видеокамера и т.д. В альтернативном варианте реализации клиентский компонент ядра системы обнаружения полей 111, исполняемый на клиентском вычислительном устройстве, может получать документ и передавать его на серверный компонент ядра системы обнаружения полей 111, исполняемый на серверном устройстве, который выполняет обнаружение и (или) классификацию полей. Серверный компонент ядра системы обнаружения полей 111 может затем возвращать результаты распознавания (например, определенный тип поля для обнаруженного текстового поля) в клиентский компонент ядра системы обнаружения полей 111, исполняемый на клиентском вычислительном устройстве, для сохранения или предоставления другому приложению. В других вариантах реализации изобретения ядро системы обнаружения полей 111 может исполняться на серверном устройстве в качестве интернет-приложения, доступ к которому обеспечивается через интерфейс браузера. Серверное устройство может быть представлено в виде одной или более вычислительных систем, например одним или более серверов, рабочих станций, больших ЭВМ (мейнфреймов), персональных компьютеров (ПК) и т.д.
[0027] Сервер 150 может быть и (или) включать стоечный сервер, маршрутизатор, персональный компьютер, карманный персональный компьютер, мобильный телефон, портативный компьютер, планшетный компьютер, фотокамеру, видеокамеру, нетбук, настольный компьютер, медиацентр или их сочетание. Сервер 150 может содержать обучающую систему 151. Обучающая система 151 может строить модель (модели) машинного обучения 114 для обнаружения полей. Модель (модели) машинного обучения 114, приведенная на Фиг. 1, может ссылаться на артефакт модели, созданный обучающей системой 151 с использованием обучающих данных, которые содержат обучающие входные данные и соответствующие целевые выходные данные (правильные ответы на соответствующие обучающие входные данные). Обучающая система 151 может находить в обучающих данных шаблоны, которые связывают обучающие входные данные с целевыми выходными данными (предсказанным ответом), и предоставлять модели машинного обучения 114, которые используют эти шаблоны. Как более подробно будет описано ниже, набор моделей машинного обучения 114 может быть составлен, например, из одного уровня линейных или нелинейных операций (например, машина опорных векторов [SVM]) или может представлять собой глубокую сеть, то есть модель машинного обучения, составленную из нескольких уровней нелинейных операций. Примерами глубоких сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети с одним или более скрытыми слоями и полносвязные нейронные сети. В некоторых вариантах реализации изобретения модель (модели) машинного обучения 114 может включать нейронную сеть, описанную применительно к Фиг. 2. [0028] Модель (модели) машинного обучения 114 может обучаться обнаружению полей в электронном документе 140 и определять наиболее вероятный тип поля для каждого из текстовых полей в электронном документе 140. Например, обучающая система 151 может создавать обучающие данные для обучения модели (моделей) машинного обучения 114. Эти обучающие данные могут содержать одни или более обучающих исходных данных и одни или более целевых выходных данных. Эти обучающие данные могут также содержать данные об отображении обучающих входных данных на целевые выходные данные. Обучающие входные данные могут содержать обучающую выборку документов, содержащих текст (также - «обучающие документы»). Каждый из обучающих документов может быть электронным документом, содержащим известные текстовые поля. Выходные данные обучения могут быть классами, представляющими типы полей, соответствующие известным текстовым полям. Например, первый обучающий документ в первой обучающей выборке может содержать первое известное текстовое поле (например, «Джон Смит»). Первый обучающий документ может быть первыми исходными данными обучения, которые можно использовать для обучения модели (моделей) машинного обучения 114. Первые целевые выходные данные, соответствующие первым обучающим входным данным, могут содержать класс, соответствующий типу поля для известного текстового поля (например, «имя»). В ходе обучения исходного классификатора обучающая система 151 может находить в обучающих данных шаблоны, которые можно использовать для отображения обучающих входных данных на целевые выходные данные. Эти шаблоны могут быть впоследствии использованы моделью (моделями) машинного обучения 114 для дальнейшего предсказания. Например, после получения исходных данных с неизвестными текстовыми полями, содержащих неизвестный текст (например, одно или более неизвестных слов), обученная модель (модели) машинного обучения 114 может предсказать тип поля, к которому относится каждое неизвестное текстовое поле, и может вывести предсказанный класс, определяющий тип поля, в качестве результата.
[0029] В некоторых вариантах реализации изобретения обучающая система 151 может обучать искусственную нейронную сеть, которая содержит множество нейронов, выполнению обнаружения полей в соответствии с настоящим изобретением. Каждый нейрон получает свои исходные данные от других нейронов или из внешнего источника и генерирует результат, применяя функцию активации к сумме взвешенных исходных данных и полученному при обучении значению состояния. Нейронная сеть может содержать множество нейронов, распределенных по слоям, включая входной слой, один или более скрытых слоев и выходной слой. Нейроны соседних слоев соединены взвешенными ребрами. Веса ребер определяются на этапе обучения сети на основе обучающей выборки данных, которая содержит множество электронных документов с известной классификацией. В иллюстративном примере все веса ребер инициализируются случайными значениями. Нейронная сеть активируется в ответ на любые исходные данные из набора данных для обучения. Наблюдаемый результат работы нейронной сети сравнивается с ожидаемым результатом работы, включенным в набор данных для обучения, и ошибка распространяется назад, на предыдущие слои нейронной сети, в которых соответственно регулируются веса. Этот процесс может повторяться, пока ошибка в результатах не будет удовлетворять заранее определенным условиям (например, станет ниже заранее определенного порогового значения). В некоторых вариантах реализации изобретения искусственная нейронная сеть может быть и (или) содержать нейронную сеть 200 с Фиг. 2.
[0030] После обучения модели (моделей) машинного обучения 114 набор модели (моделей) машинного обучения 114 может быть передан в ядро системы обнаружения текстовых полей 111 для анализа новых электронных документов с текстом. Например, ядро системы обнаружения текстовых полей 111 может вводить электронный документ 140 и (или) признаки электронного документа 140 в набор моделей машинного обучения 114 в качестве исходных данных. Ядро системы обнаружения полей 111 может получать один или более итоговых результатов от набора обученных моделей машинного обучения и может извлекать из итоговых результатов один или более типов полей для каждого текстового поля, обнаруженного в электронном документе 140. Предполагаемый тип поля может включать определенный тип поля, соответствующий типу обнаруженного поля (например, «имя», «адрес», «наименование компании», «логотип», «адрес электронной почты» и т.д.).
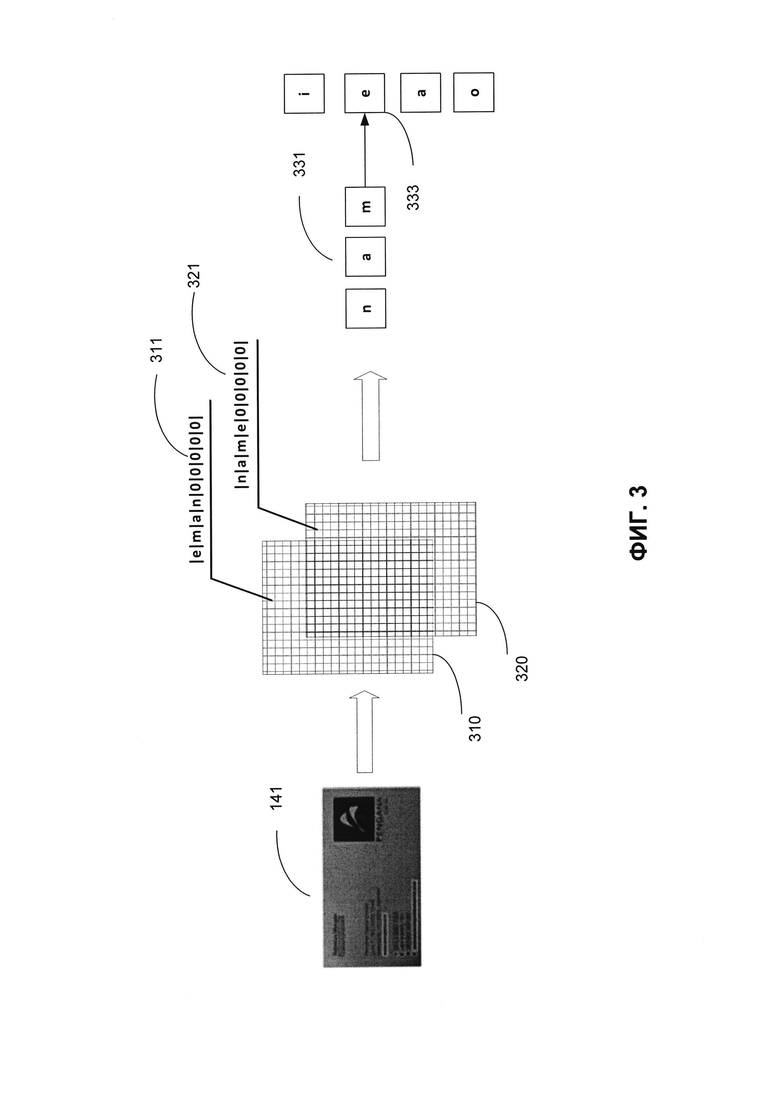
[0031] В некоторых вариантах реализации изобретения для создания признаков электронного документа 140, обрабатываемого моделью (моделями) машинного обучения 114, ядро системы обнаружения полей 111 может распознавать текст в электронном документе 140 (например, используя подходящие способы распознавания символов) и может разделить текст на множество слов. Ядро системы обнаружения полей 111 может извлекать из слов множество последовательностей символов. Каждая из последовательностей символов может содержать множество символов, содержащихся в словах. Например, ядро системы обнаружения полей 111 может преобразовывать слово во множество первых последовательностей символов, обрабатывая каждое слово в первом порядке (например, в прямом порядке). Ядро системы обнаружения полей 111 может также преобразовывать слова во множество вторых последовательностей символов, обрабатывая каждое слово во втором порядке (например, в обратном порядке). Каждая из первых последовательностей символов также может включать первое множество символов соответствующей второй последовательности символов в обратном порядке. Например, слов «name» может быть преобразовано в символьные последовательности «name» и «eman».
[0032] Исходя из последовательностей символов ядро системы обнаружения полей 111 может создавать множество векторов признаков. Каждый из векторов признаков может быть символьным представлением одного или более слов. В одном из вариантов реализации ядро системы обнаружения полей 111 может создавать одну или более таблиц, содержащих последовательности символов. Например, как показано на Фиг. 3, первые последовательности символов и вторые последовательности символов могут быть помещены в таблицу суффиксов 310 и таблицу префиксов 320 соответственно. Каждый столбец или строка таблицы может содержать последовательность символов и может рассматриваться как символьное представление слова. Например, строка 311 таблицы суффиксов 310 может содержать последовательность символов «eman», извлеченную из слова «name», и может рассматриваться как первое символьное представление слова «name». Строка 321 таблицы префиксов 320 может содержать последовательность символов «name», извлеченную из слова «name», и может рассматриваться как второе символьное представление слова «name». В некоторых вариантах реализации изобретения каждое символьное представление в таблицах может иметь определенную длину (то есть заранее определенную длину). Если длина последовательности символов меньше определенной длины, то к ней могут быть добавлены заранее определенные значения, чтобы создать символьное представление заранее определенной длины (например, добавлены нули в пустые строки или столбцы таблиц).
[0033] Согласно Фиг. 1 в некоторых вариантах реализации изобретения ядро системы обнаружения полей 111 может использовать модель (модели) машинного обучения 114 для генерации гипотез о пространственной информации текстовых полей в исходном документе 140 и (или) типах этих текстовых полей. Ядро системы обнаружения полей 111 может оценивать эти гипотезы для выбора наилучшего сочетания гипотез для всего электронного документа. Например, ядро системы обнаружения полей 111 может выбирать лучшие (то есть с наибольшей вероятностью правильные) гипотезы или сортировать множество гипотез путем оценки качества (то есть признака корректности гипотез).
[0034] Хранилище 120 представляет собой постоянную память, которая в состоянии сохранять электронные документы, а также структуры данных для выполнения распознавания символов в соответствии с настоящим изобретением. Хранилище 120 может располагаться на одном или более запоминающих устройствах, таких как основное запоминающее устройство, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то что хранилище изображено отдельно от вычислительного устройства 110, в одной из реализаций изобретения хранилище 120 может быть частью вычислительного устройства 110. В некоторых вариантах реализации хранилище 120 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище содержимого 120 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, например объектно-ориентированной базы данных, реляционной базы данных и т.д., которая может находиться на сервере или одной или более различных машинах, подключенных к нему через сеть 130. Хранилище 120 может хранить учебные данные в соответствии с настоящим изобретением.
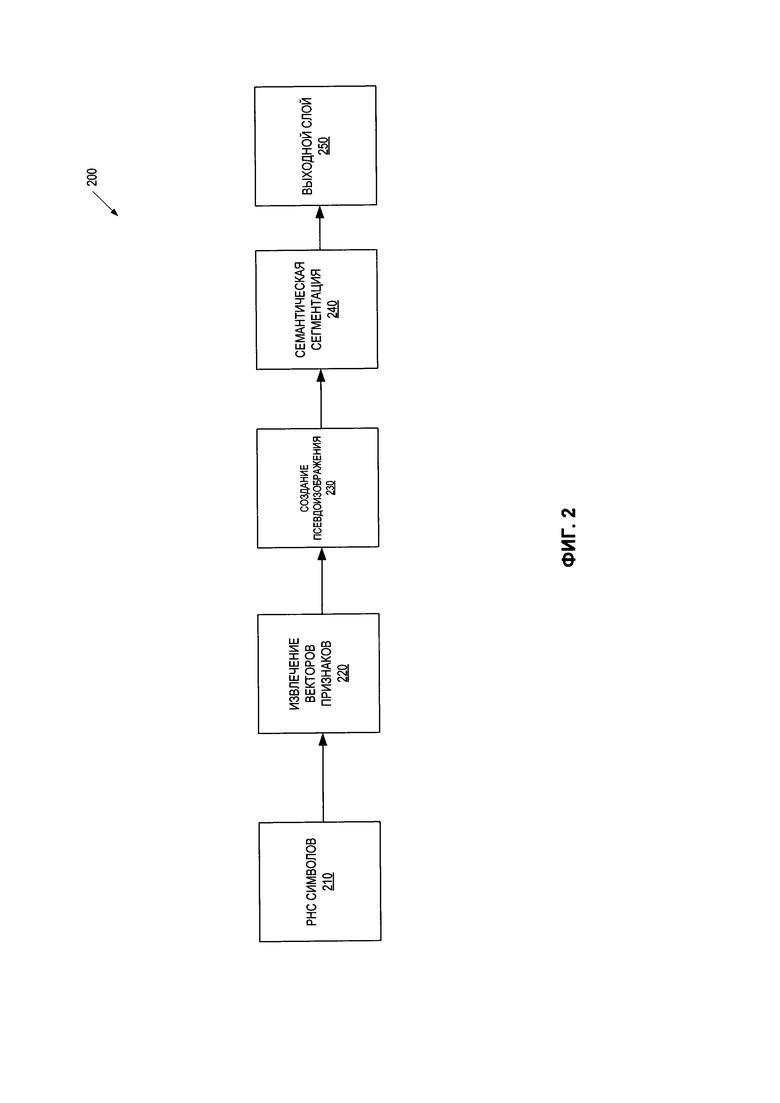
[0035] На Фиг. 2 представлена схема, иллюстрирующая пример 200 нейронной сети в соответствии с некоторыми вариантами реализации настоящего изобретения. Нейронная сеть 200 может содержать множество нейронов, связанных с получаемыми при обучении весами и состояниями. Эти нейроны могут быть организованы в слои. Как показано, нейронная сеть 200 может содержать первое множество слоев 210, второе множество слоев 220, третье множество слоев 230, четвертое множество слоев 240 и пятое множество слоев 250. Каждый из слоев 210, 220, 230, 240 и 250 может быть настроен для выполнения одной или более функций для обнаружения текстовых полей в соответствии с настоящим изобретением.
[0036] Первое множество слоев 210 нейронной сети 200 может содержать одну или более рекуррентных нейронных сетей. Рекуррентные нейронные сети (РНС) в состоянии поддерживать состояние сети, отражающее информацию об исходных данных, обрабатываемых сетью, таким образом позволяя сети использовать свое внутреннее состояние для обработки последующих исходных данных. Например, рекуррентная нейронная сеть может получать исходный вектор на входной слой рекуррентной нейронной сети. Скрытый слой рекуррентной нейронной сети обрабатывает исходный вектор. Выходной слой рекуррентной нейронной сети может создавать выходной вектор. Состояние сети может быть сохранено и использовано для обработки последующих исходных векторов с целью выполнения последующих оценок.
[0037] Первое множество слоев 210 нейронной сети 200 может обучаться созданию векторных представлений слов (также называются «векторами слов»). Например, первое множество слоев 210 может получать исходные данные, представляющие слово, и отображать это слово на вектор слова (то есть векторное представление слова). Термин «векторное представление слова», используемый в этом документе, может означать вектор действительных чисел или любое другое цифровое представление слова. Векторное представление слова можно получить, например, с помощью нейронной сети, реализующей математическое преобразование слов с помощью функций вложения, отображая слова на их цифровые представления. [0038] Исходные данные, полученные первым множеством слоев 210, могут включать признаки, извлеченные из исходного электронного документа. Признаки, извлеченные из электронного документа, могут включать, например, множество символьных представлений, отображающих слова из электронного документа. В одном из вариантов реализации исходные данные могут включать таблицу суффиксов 310 и таблицу префиксов 320, как описано применительно к Фиг. 1 и 3. Вектор слов может быть векторным представлением символов слова, извлеченным из символов слова. Например, первое множество слоев 210 нейронной сети 200 может быть обучено на основе прогнозирующей модели, которая может предсказывать следующий символ слова (например, символ 333, как показано на Фиг. 3) исходя из одного или более предыдущих символов слова (например, символов 331, как показано на Фиг. 3). Это предсказание может быть сделано исходя из параметров прогнозирующей модели, которая соответствует множеству векторных представлений слов. Например, первое множество слоев 210 может получать представления множества известных слов в качестве исходных данных. Затем первое множество слоев 210 может генерировать исходные данные для обучения и результаты обучения исходя из известных слов. В одном из вариантов реализации изобретения первое множество слоев 210 может преобразовывать каждое из известных слов в одну или более последовательностей символов. Каждая из последовательностей символов может содержать один или более символов, входящих в одно из известных слов. Первый слой 210 может использовать первое множество символов из последовательностей символов в качестве исходных данных для обучения и результатов обучения соответственно. Например, каждый символ из первого множества символов может соответствовать предыдущему символу в одном из известных слов (например, первому символу каждого из известных слов, первым трем символам каждого из известных слов и т.д.). Второе множество символов может соответствовать следующему символу, который следует за предыдущим символом. Для предсказания следующего символа может использоваться прогнозирующая модель (например, символа «е» в слове «name»), использующая в качестве базы один или более предыдущих символов слова (например, символы «nam» слова «name»). Предсказание может строиться на базе векторных представлений на уровне символов, назначенных символам. Каждое из векторных представлений слов на уровне символов может соответствовать вектору в непрерывном векторном пространстве. Схожие слова (то есть семантически схожие слова) отображаются в близко расположенные точки в непрерывном векторном пространстве. В ходе процесса обучения первое множество слоев 210 может найти векторные представления на уровне символов, которые могут оптимизировать вероятность правильного предсказания следующего символа исходя из предыдущих символов.
[0039] Второе множество слоев 220 нейронной сети 200 может создавать структуру данных, содержащую признаки слова (также - «первые признаки слова»). Эта структура данных в некоторых вариантах реализации изобретения может быть и (или) включать одну или более таблиц (также - «первые таблицы»). Каждый из первых признаков слова может относиться к одному или более словам электронного документа 140. В одном из вариантов реализации изобретения слова электронного документа могут вводиться в ячейки первой таблицы (таблиц). Также в столбцы или строки первых таблиц может вводиться один или более векторов признаков, соответствующих каждому слову. В некоторых вариантах реализации изобретения таблица признаков слов может включать определенное количество слов. Например, предельное количество слов может определяться заданным типом электронного документа.
[0040] Каждый из первых признаков слова может быть и (или) включать любое допустимое представление одного или более признаков одного из слов. Например, первые признаки слова могут включать векторные представления слов на уровне символов, полученные в первом множестве слоев 210. В другом примере первые признаки слова могут включать один или более векторов слов, связанных со словами из словаря векторов признаков слов. Словарь векторов признаков слов может содержать данные об известных словах и их соответствующих векторах слов (то есть векторных представлений слов, назначенных словам). Словарь векторов признаков слов может включать любые подходящие структуры данных, которые могут представлять связи между каждым из известных слов и их соответствующими векторами слов, например в виде таблицы. Словарь вложений может создаваться с использованием любой подходящей модели или сочетания моделей, которые могут создавать векторные представления слов, таких как word2vec, GloVec и т.д. В некоторых вариантах реализации изобретения словарь векторов признаков слов может содержать векторные представления ключевых слов, соответствующих типу электронного документа, и может быть словарем ключевых слов, содержащим ключевые слова, относящиеся к определенному типу электронных документов, и соответствующих ему векторных представлений слов. Например, ключевые слова, относящиеся к визитной карточке, могут включать «телефон», «факс», часто встречающиеся имена и (или) фамилии, названия широко известных компаний, слова, относящиеся к адресам, географическим названиям и др. Для различных типов электронных документов могут использоваться различные словари ключевых слов (например, «визитная карточка», «счет», «паспорт», «медицинский полис», «опросный лист» и др.).
[0041] В качестве еще одного примера первые признаки слов могут содержать информацию об одной или более частях электронных документов, содержащих эти слова. Каждая часть электронных документов может содержать одно или более слов (например, соответствующее слово, множество слов, которые считаются связанными друг с другом и др.). Каждая часть электронных документов может быть прямоугольной областью или иметь другую подходящую форму. В одном из вариантов реализации информация о частях электронных документов, содержащих слова, может включать пространственную информацию о частях изображения электронного документа. Пространственная информация о данной части электронного документа, содержащего слово, может включать одну или более координат, определяющих положение данной части электронного документа. В другом варианте реализации информация о частях электронных документов, содержащих слова, может включать информацию о пикселях для частей изображения электронного документа. Информация о пикселях для данной части электронного документа, содержащего слово, может включать, например, одну или более координат и (или) любую другую информацию о пикселе в данной части электронного документа (например, центральном пикселе или любом другом пикселе в части изображения).
[0042] В качестве еще одного примера первые признаки слов могут содержать информацию о форматировании текста слов (например, высоту и ширину символов, расстояние между символами и т.д.). В качестве еще одного примера первые признаки слов могут содержать информацию о близости и (или) схожести слов в электронном документе. В одном из вариантов реализации близость слов может быть представлена в виде графа соседства слов, который был построен исходя из данных о частях электронных документов, содержащих слова (например, проекций прямоугольных областей, содержащих слова, расстояния между прямоугольными областями и др.). В другом варианте реализации близость слов может быть определена с помощью множества прямоугольников слов, вершины которых соединены. Информация о схожести слов может быть получена исходя из степени схожести последовательностей символов (например, путем сравнения последовательностей символов, извлеченных из слов).
[0043] Третье множество слоев 230 нейронной сети 200 может создавать псевдоизображение на базе структуры данных, включающей первые признаки слов (например, одну или более первых таблиц). Псевдоизображение может представлять проекцию признаков слов, созданную вторым слоем 220. Псевдоизображение может быть искусственно созданным изображением определенного размера, например трехмерным массивом размера h×w×d, где первая размерность h и вторая размерность w являются пространственными размерностями, а третья размерность d представляет множество каналов псевдоизображения. Каждое из слов в первых таблицах может быть назначено пикселю псевдоизображения. Таким образом, каждый пиксельпсевдоизображения может соответствовать одному из слов. Признаки слов могут быть записаны во множество каналов псевдоизображения. Соответственно, каждый пиксель псевдоизображения может дополнительно содержать пространственную информацию о соответствующем слове (то есть, информацию пикселя соответствующего слова).
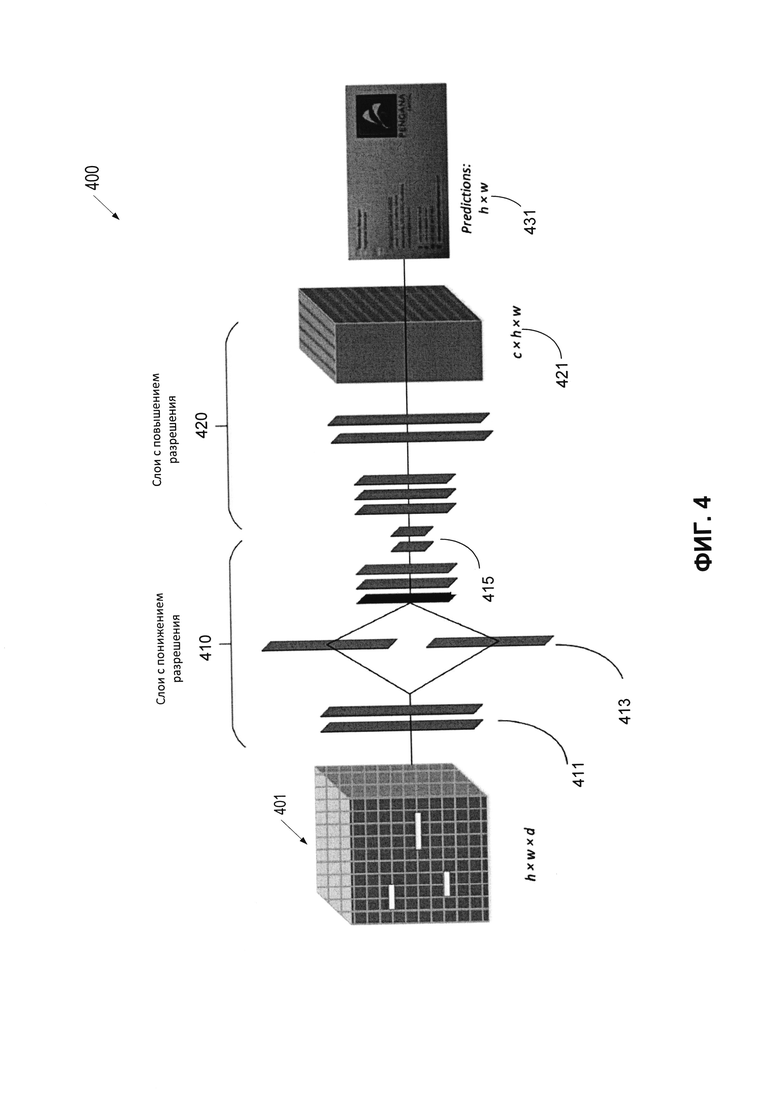
[0044] Четвертое множество слоев 240 нейронной сети 200 может извлечь один или более признаков, представляющих слова, из псевдоизображения (также - «второе множеством признаков слов»). Четвертое множество слоев 240 может быть и (или) содержать одну или более сверточных нейронных сетей, построенных на трансляционной инвариантности. Сверточные сети могут содержать один или более сверточных слоев, субдискретизирующих слоев и (или) любых других подходящих компонентов для извлечения признаков слов из псевдоизображения. Сверточный слой может извлекать признаки из изображения на входе, применяя один или более обучаемых фильтров уровня пикселей (также - «сверточные фильтры») к изображению на входе. Субдискретизирующий слой может выполнять подвыборку для получения карты признаков с пониженным разрешением, которая будет содержать наиболее релевантную информацию. Подвыборка может включать усреднение и (или) определение максимального значения групп пикселей. В некоторых вариантах реализации изобретения четвертое множество слоев 240 может содержать один или более слоев, как описано в связи с Фиг. 4.
[0045] В одном из вариантов реализации четвертое множество слоев 240 может выполнять семантическую сегментацию псевдоизображения для извлечения второго множества признаков слов. Например, четвертое множество слоев 240 может обрабатывать псевдоизображение для получения сжатого псевдоизображения. Это сжатое псевдоизображение может представлять одну или более карт первых признаков, содержащих информацию о типах полей, имеющихся в электронном документе, и их расположении друг относительно друга. Сжатое псевдоизображение может быть создано, например, путем обработки псевдоизображения с использованием одного или более слоев, выполняющих операции уменьшения разрешения (также - «слои с понижением разрешения»). Слои с понижением разрешения могут содержать, например, один или более сверточных слоев, субдискретизирующих слоев, объединяющих слоев и пр.
[0046] Четвертое множество слоев 240 может обрабатывать сжатое псевдоизображение, выдавая одну или более карт вторых признаков, содержащих второе множество признаков слов. Карты вторых признаков могут быть созданы путем выполнения транспонируемой свертки или одной или более других операций повышающей дискретизации над сжатым псевдоизображением. В некоторых вариантах реализации изобретения семантическая сегментация может выполняться путем выполнения одной или более операций, как описано применительно к Фиг. 4 ниже.
[0047] В некоторых вариантах реализации изобретения четвертое множество слоев 240 может создавать и выводить в качестве результата одну или более структур данных, включая второе множество признаков. Например, структуры данных могут содержать одну или более таблиц, содержащих второе множество признаков слов (также - «вторые таблицы»).
[0048] Пятый слой 250 может отнести каждое из слов к одному из множества
заранее определенных классов исходя из результата работы четвертого множества слоев 240. Каждый из заранее определенных классов может соответствовать одному из обнаруженных типов полей. Пятый слой 250 может выдавать результат работы нейронной сети 200, характеризующий результаты классификации. Например, результат работы нейронной сети 200 может содержать вектор, каждый элемент которого описывает степень связанности слова из исходного электронного документа с одним из заранее определенных классов (например, вероятность того, что слово относится к заранее определенному классу). В другом примере результат работы нейронной сети 200 может содержать один или более идентификаторов типов полей. Каждый из идентификаторов типов полей может идентифицировать тип поля, связанный с одним из слов. В некоторых вариантах реализации изобретения пятый слой 250 может быть «полносвязным» слоем, в котором каждый нейрон предыдущего слоя связан с каждым нейроном следующего слоя.
[0049] Фиг. 4 иллюстрирует пример архитектуры 400 четвертого множества слоев 240 нейронной сети 200 в соответствии с некоторыми вариантами реализации настоящего изобретения. Как показано на этом рисунке, четвертое множество слоев 240 может содержать один или более слоев с понижением разрешения 410 и слоев с повышением разрешения 420. Слои с понижением разрешения 410 могут дополнительно содержать один или более слоев свертки 411, слоев раздельной свертки 413, а также конкатенирующий слой 415.
[0050] Каждый из слоев свертки 411 и слоев раздельной свертки 413 может быть сверточным слоем, настроенным на извлечение признаков из исходного электронного документа путем применения одного или более фильтров уровня пикселей (также - «сверточные фильтры») к исходному изображению. Фильтр пиксельного уровня может быть представлен матрицей целых значений, производящей свертку по всей площади исходного электронного документа для вычисления скалярных произведений между значениями фильтра и исходного изображения в каждом пространственном положении, создавая таким образом карту признаков, представляющих собой отклики фильтра в каждом пространственном положении исходного электронного документа.
[0051] В некоторых вариантах реализации изобретения слои свертки 411 могут получать псевдоизображение 401 в качестве входных данных и извлекать один или более признаков из псевдоизображения 401 (например, псевдоизображения, описанного применительно к Фиг. 2 выше). Слои свертки 411 могут давать на выходе одну или более карт признаков, содержащих извлеченные признаки (также - «исходные карты признаков»). Каждый из слоев свертки 411 может выполнять одну или более операций свертки над псевдоизображением 401 для создания исходных карт признаков. Например, слой свертки 411 может применять один или более сверточных фильтров (также - «первые сверточные фильтры») к псевдоизображению 401. Применение каждого из этих сверточных фильтров к псевдоизображению 401 может привести к созданию исходных карт признаков. Каждый из первых сверточных фильтров может быть матрицей пикселей. Каждый из первых сверточных фильтров может иметь определенный размер, определяемый шириной, высотой и (или) глубиной. Ширина и высота матрицы могут быть меньше, чем ширина и высота псевдоизображения соответственно. Глубина матрицы в некоторых вариантах реализации изобретения может совпадать с глубиной псевдоизображения. Каждый из пикселей первых сверточных фильтров может иметь определенное значение. Первые сверточные фильтры могут быть обучаемыми. Например, количество первых сверточных фильтров, параметры каждого из первых сверточных фильтров (например, размер каждого из первых сверточных фильтров, значения элементов каждого из первых сверточных фильтров и др.) могут быть получены в ходе процесса обучения нейронной сети 200.
[0052] Применение данного сверточного фильтра к псевдоизображению может включать вычисление скалярного произведения данного сверточного фильтра и части псевдоизображения. Часть псевдоизображения может быть определена размером данного сверточного фильтра. Скалярное произведение данного сверточного фильтра и части псевдоизображения может соответствовать элементу исходной карты признаков. Слои перемежающейся свертки 411 могут создавать одну или более карт признаков путем свертки (то есть скольжения) данного сверточного фильтра по ширине и высоте псевдоизображения 401 и вычисления скалярных произведений элементов данного фильтра и псевдоизображения в каждом пространственном положении псевдоизображения. В некоторых вариантах реализации изобретения слои свертки 411 могут создавать множество исходных карт признаков путем применения каждого фильтра к псевдоизображению 401, как описано выше, и свертки (то есть скольжения) каждого из фильтров по ширине и высоте псевдоизображения 401.
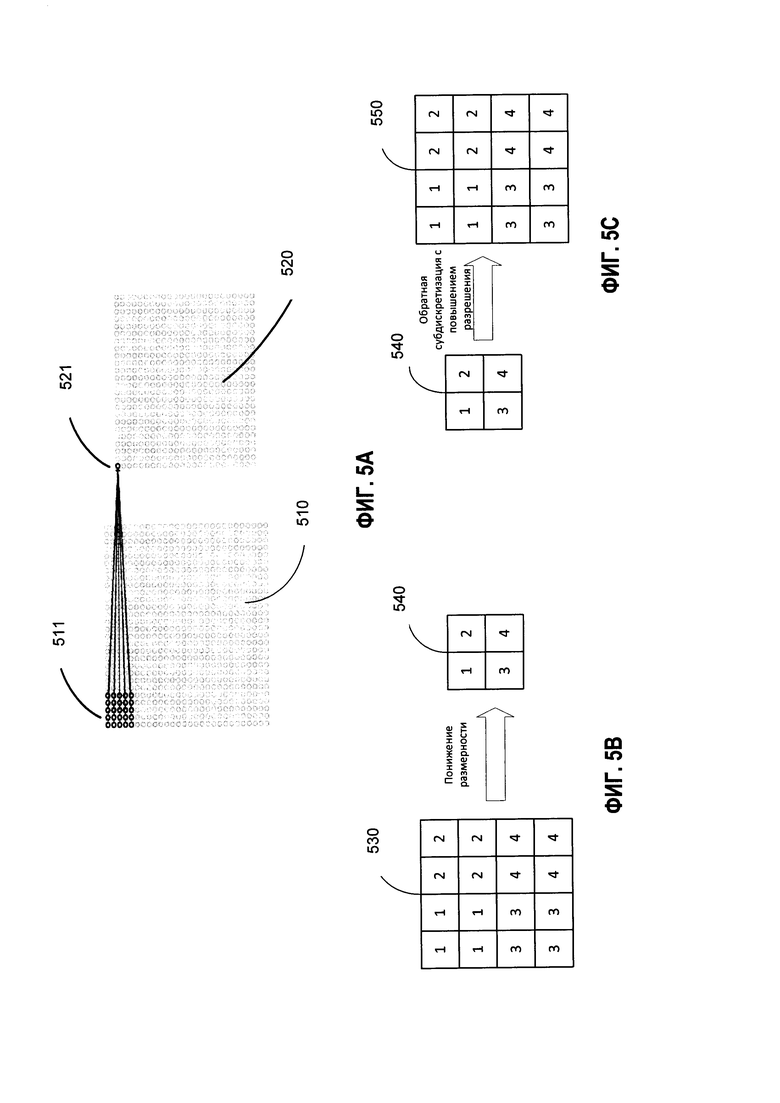
[0053] Например, как показано на Фиг. 5А, сверточный фильтр 511 может быть применен к части псевдоизображения 510. Точнее, например, значения фильтра 511 умножаются на значения пикселей части псевдоизображения, и все эти произведения складываются, давая в результате элемент 521 карты признаков 520. В некоторых вариантах реализации изобретения элемент 520 может быть одиночным числом. Карта признаков 520 может представлять отклики фильтра 511 в каждом пространственном положении псевдоизображения 510.
[0054] Согласно Фиг. 4, слой частной свертки 413 может выполнять одну или более операций свертки для каждой из исходных карт признаков. Каждая из операций свертки может включать применение сверточного фильтра (также - «второй сверточный фильтр») к одной из исходных карт признаков, созданных слоями свертки 411, свертку (то есть скольжение) второго сверточного фильтра по ширине и высоте первой карты признаков и вычисление скалярного произведения элементов второго сверточного фильтра и исходной карты признаков в каждом пространственном положении исходной карты признаков. В некоторых вариантах реализации изобретения операция свертки может включать свертку (то есть скольжение второго сверточного фильтра) по одной или более первым картам признаков в разных направлениях. Например, первая операция свертки и вторая операция свертки могут включать свертку второго сверточного фильтра в первом направлении (например, горизонтальном направлении) и втором направлении (например, вертикальном направлении) соответственно. Таким образом, слои раздельной свертки 413 могут отслеживать изменения в псевдоизображении 401, происходящие в разных направлениях.
[0055] В некоторых вариантах реализации изобретения слои уменьшающие размерность 410 могут дополнительно содержать один или более субдискретизирующих слоев (не показаны). Субдискретизирующий слой может выполнять подвыборку для получения карты признаков с пониженным разрешением, которая будет содержать наиболее релевантную информацию. Подвыборка может включать усреднение и (или) определение максимального значения группы пикселей. Субдискретизирующие слои могут размещаться между сверточными слоями 411 и (или) 413. Каждый из субдискретизирующих слоев может выполнять операцию подвыборки для своих входных данных для уменьшения пространственных размеров (то есть ширины и высоты) своих входных данных. Например, данный субдискретизирующий слой может получать в качестве исходных данных карту признаков, созданную сверточным слоем. Субдискретизирующий слой может выполнять с картой признаков математическую операцию для поиска наибольшего числа в части исходных данных. В некоторых вариантах реализации изобретения субдискретизирующий слой может применять фильтр к карте признаков с заранее определенным шагом для понижения дискретизации исходной карты признаков. Применение фильтра к карте признаков (например, путем скольжения фильтра по карте признаков) может создавать карту признаков с пониженной дискретизацией. Например, как показано на Фиг. 5В, карта признаков с пониженной дискретизацией 540 может быть получена из карты признаков 530.
[0056] В некоторых вариантах реализации изобретения слои уменьшающие размерность 410 могут дополнительно содержать один или более прореживающих слоев (не показаны). Прореживающий слой может случайным образом удалять информацию из карт признаков. Таким образом, прореживающие слои могут улучшать чрезмерно близкую аппроксимацию нейронной сети 200 и могут позволить избежать переобучения нейронной сети.
[0057] Как показано на Фиг. 4, слои с понижением разрешения 410 дополнительно содержат конкатенирующий слой 415, в котором объединяются несколько слоев. Конкатенирующий слой 415 может выдавать сжатое псевдоизображение, представляющее сочетание нескольких карт признаков, созданных слоями с понижением разрешения 410 (также - «первые карты признаков»).
[0058] Слои с повышением разрешения 420 могут содержать множество слоев, настроенных для обработки сжатого псевдоизображения с целью получения восстановленного псевдоизображения 421. Восстановленное псевдоизображение представляет собой сочетание множества вторых карт признаков. Каждая из первых карт признаков может иметь первый размер (например, первое разрешение). Каждая из вторых карт признаков может иметь второй размер (например, второе разрешение). Второй размер может быть больше, чем первый размер. В одном из вариантов реализации второй размер может определяться пространственными размерами исходного псевдоизображения (h×w). Например, сжатое псевдоизображение может представлять собой псевдоизображение с понижением разрешения на коэффициент ƒ Вторые карты изображений могут создаваться путем повышения разрешения сжатого псевдоизображения с коэффициентом ƒ В некоторых вариантах реализации изобретения слои с повышением разрешения 420 могут повышать разрешение сжатого псевдо изображения путем выполнения транспонирующей свертки сжатого псевдоизображения. Транспонирующая свертка может выполняться путем применения фильтра обратной свертки с определенным скольжением (например, скольжением ƒ). Например, как показано на Фиг. 5С, исходная карта признаков 540 размера 2×2 пикселя может быть подвергнута повышающей субдискретизации для получения карты признаков с повышенной дискретизацией 550 размером 4×4 пикселя. Согласно Фиг. 4 результат сегментации 431 может быть создан на основе реконструированного псевдоизображения. Результат сегментации 431 может представлять версию сегмента электронного документа 140, в котором слова, принадлежащие к одному и тому же текстовому полю, собраны в один кластер. В некоторых вариантах реализации изобретения результат сегментации 431 может быть получен из пятого слоя 250 нейронной сети 200 на Фиг. 2.
[0059] На Фиг. 6 и 7 приведены блок-схемы, иллюстрирующие способы 600 и 700 обнаружения текстовых полей с использованием модели машинного обучения в соответствии с некоторыми вариантами реализации настоящего изобретения. Каждый из способов 600 и 700 может выполняться логикой обработки, которая может включать аппаратные средства (например, электронные схемы, специализированную логику, программируемую логику, микрокоманды и т.д.), программное обеспечение (например, инструкции, выполняемые обрабатывающим устройством), встроенное программное обеспечение или комбинацию всех этих средств. В одном из вариантов реализации изобретения способы 600 и 700 могут выполняться обрабатывающим устройством (например, обрабатывающим устройством 802 на Фиг. 8) вычислительного устройства 110 и (или) сервера 150, как показано применительно к Фиг. 1.
[0060] Согласно Фиг. 6 способ 600 может начинаться с шага 610, в котором обрабатывающее устройство может извлекать множество признаков из исходного электронного документа. Исходный электронный документ может быть электронным документом 140, как описано со ссылкой на Фиг. 1. Признаки исходного электронного документа могут включать один или более векторов признаков, соответствующих словам. Каждый из векторов признаков может быть символьным представлением, соответствующим одному или более словам. Например, для создания векторов признаков обрабатывающее устройство может распознавать текст на изображении и может разделять этот текст на изображении на множество слов. Каждое из слов может быть связано с одной или более последовательностями символов. В одном из вариантов реализации обрабатывающее устройство может создавать множество первых последовательностей символов путем обработки каждого из слов в первом порядке (например, чтения слов в прямом порядке). Это обрабатывающее устройство также создает множество вторых последовательностей символов путем обработки каждого из слов во втором порядке (например, чтения слов в обратном порядке). Это обрабатывающее устройство также может создавать первую таблицу путем записи слов символ за символом в первую таблицу в первом порядке. Это обрабатывающее устройство также может создавать вторую таблицу путем записи слов символ за символом во вторую таблицу во втором порядке. Это обрабатывающее устройство также может создавать на основе последовательностей символов множество символьных представлений. Например, обрабатывающее устройство может создавать первое символьное представление, вставляя первый символ в первую таблицу. Обрабатывающее устройство может создавать второе символьное представление, вставляя второй символ во вторую таблицу.
[0061] На шаге 620 обрабатывающее устройство может обрабатывать
множество признаков, используя нейронную сеть. Нейронная сеть может быть обучена обнаружению текстовых полей в электронном документе и (или) определению типов полей для текстовых полей. Нейронная сеть может содержать множество слоев, как указано в связи с Фиг. 3 и 4 выше. В некоторых вариантах реализации изобретения признаки могут обрабатываться путем выполнения одной или более операций, описанных в связи с Фиг 7.
[0062] На шаге 630 обрабатывающее устройство может получать результат работы нейронной сети. Результат работы нейронной сети может включать результаты классификации, указывающие возможный тип поля в электронном документе, например вероятность того, что определенное слово в электронном документе относится к одному из множества заранее определенных классов. Каждый из заранее определенных классов соответствует предсказываемому типу поля.
[0063] На шаге 640 обрабатывающее устройство может обнаруживать множество текстовых полей в электронном документе, исходя из результатов работы нейронной сети. Например, обрабатывающее устройство может распределять слова электронного документа по кластерам исходя из их близости друг к другу и соответствующих им типов полей. В одном из вариантов реализации обрабатывающее устройство может распределять по кластерам одно или более соседних слов, которые относятся к одному полю, совместно (то есть, совместно распределять соседние слова «Джон» и «Смит», каждое из которых относится к типу поля «имя»). Электронные документы могут разделяться на поля данных, исходя из распределения слов по кластерам.
[0064] На шаге 650 обрабатывающее устройство может назначать каждое из множества текстовых полей одному из множества типов полей исходя из результатов работы нейронной сети. Например, обрабатывающее устройство может назначать тип поля, соответствующий заранее определенному классу, связанному со словами в текстовом поле, для каждого текстового поля.
[0065] На Фиг. 7 способ 700 может начинаться на шаге 710, где обрабатывающее устройство может создавать, используя первое множество слоев нейронной сети, первое множество векторов признаков, представляющих слова в электронном документе. Первое множество векторов признаков может создаваться на основе множества признаков, извлеченных из электронного документа (то есть признаков, извлеченных на шаге 610 на Фиг. 6). Например, первое множество слоев может извлекать множество векторных представлений слов, соответствующих словам из признаков электронного документа. Векторные представления слов могут содержать, например, одно или более векторных представлений слов на уровне символов, полученных в слоях 210 нейронной сети 200, как описано в связи с Фиг. 2 выше.
[0066] На шаге 720 обрабатывающее устройство может создавать, используя второе множество слоев нейронной сети, одну или более первых таблиц признаков слов исходя из первого множества векторов признаков и одного или более других признаков, представляющих слова электронного документа. Первые таблицы включают первое множество признаков слов, представляющих слова электронного документа. Каждый из первого множества признаков слов может быть одним из первого множества векторов признаков или других признаков, представляющих слова электронного документа. Один или более признаков, представляющих слова электронного документа, могут содержать второе множество векторов признаков, представляющих слова электронного документа. Второе множество векторов признаков может содержать, например, множество векторов слов из словаря векторов признаков слов, которые назначены словам электронного документа, множество векторов слов из словаря ключевых слов, ассоциированных со словами электронного документа и пр. Один или более признаков, представляющих слова, могут также включать признаки, представляющие пространственную информацию одной или более частей электронного документа, содержащих слова. Каждая из частей электронного документа может представлять собой прямоугольную область или другую подходящую часть электронного документа, которая содержит одно или более слов. Пространственная информация данной части электронного документа, содержащей одно или более слов, включает, например, одну или более пространственных координат, определяющих данную часть электронного документа, информацию о пикселях данной части электронного документа (например, одну или более пространственных координат центрального пикселя данной части электронного документа) и т.д. Первые таблицы включают первое множество признаков слов, представляющих слова электронного документа. В некоторых вариантах реализации изобретения каждая строка или столбец первых таблиц может содержать вектор или другое представление одного из первого множества признаков слов (например, одного из первого множества векторов признаков, одного из второго множества векторов признаков и пр.).
[0067] На шаге 730 обрабатывающее устройство может создавать, используя третье множество слоев нейронной сети, псевдоизображение на основе одной или более первых таблиц первых признаков слов. Псевдоизображение может быть трехмерным массивом, имеющим первое измерение, определяющее ширину псевдоизображения, второе измерение, определяющее высоту псевдоизображения, и третье измерение, определяющее множество каналов псевдоизображения. Каждый пиксель псевдоизображения может соответствовать одному из слов. Признаки слов могут быть записаны во множество каналов псевдоизображения.
[0068] На шаге 740 обрабатывающее устройство может обрабатывать, используя четвертое множество слоев нейронной сети, псевдоизображение, извлекая из него второе множество признаков слов, представляющее слова электронного документа. Например, четвертое множество слоев нейронной сети может выполнять семантическую сегментацию псевдоизображения для извлечения второго множества признаков слов. Более конкретно, например, четвертое множество слоев нейронной сети может выполнять над псевдоизображением одну или более операций уменьшающих размерность для получения сжатого псевдоизображения. Сжатое псевдоизображение может представлять собой комбинацию первого множества карт признаков, содержащих признаки, соответствующие словам. Четвертое множество слоев нейронной сети может затем выполнять над сжатым псевдоизображением одну или более операций увеличивающих размерность для получения восстановленного псевдоизображения. Восстановленное псевдоизображение может представлять собой комбинацию второго множества карт признаков, содержащих второе множество признаков, соответствующих словам. В некоторых вариантах реализации изобретения обрабатывающее устройство может также создавать одну или более вторых таблиц, содержащих второе множество признаков, представляющих слова.
[0069] На шаге 750 обрабатывающее устройство может создавать, используя пятый слой нейронной сети, результат работы нейронной сети. Пятый слой нейронной сети может быть полносвязным слоем нейронной сети. Результат работы нейронной сети может содержать информацию о предсказанном классе, который определяет предсказанный тип поля для каждого слова в электронном документе.
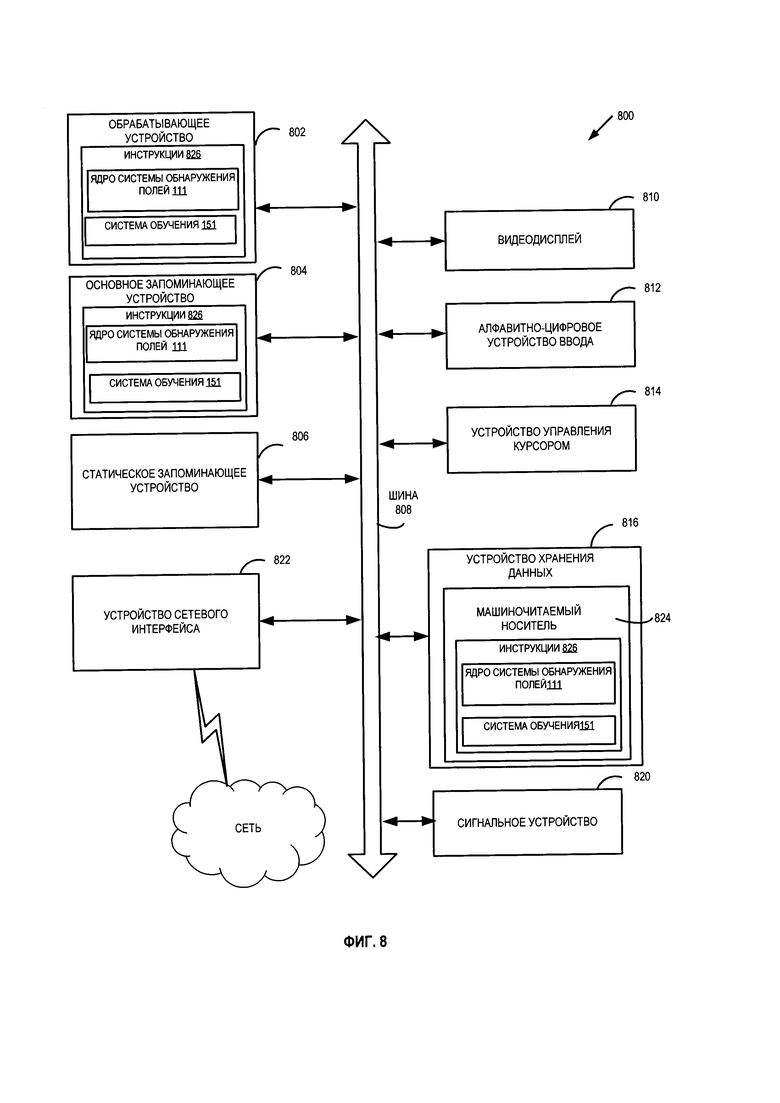
[0070] На Фиг. 8 приведен пример вычислительной системы 800, которая может выполнять один или более описанных здесь способов. Эта вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяет действия этого устройства. Кроме того, несмотря на то что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для реализации любого из описанных здесь способов или нескольких таких способов.
[0071] Пример вычислительной системы 800 включает устройство обработки 802, основное запоминающее устройство 804 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например синхронное DRAM (SDRAM)), статическую память 806 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство хранения данных 816, которые взаимодействуют друг с другом по шине 808.
[0072] Устройство обработки 802 представляет собой одно или более устройств обработки общего назначения, например микропроцессоров, центральных процессоров или аналогичных устройств. В частности, устройство обработки 802 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW), процессор, в котором реализованы другие наборы команд, или процессоры, в которых реализована комбинация наборов команд. Устройство обработки 802 также может представлять собой одно или более устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC, application specific integrated circuit), программируемая пользователем вентильная матрица (FPGA, field programmable gate array), процессор цифровых сигналов (DSP, digital signal processor), сетевой процессор и т.д. Обрабатывающее устройство 802 реализовано с возможностью выполнения инструкций 826 для реализации ядра системы обнаружения полей 111 и (или) обучающей системы 151 на Фиг. 1, а также выполнения операций и шагов, описанных в этом документе (то есть способов 600-700 на Фиг. 6-7).
[0073] Вычислительная система 800 может дополнительно включать устройство сетевого интерфейса 822. Вычислительная система 800 может также включать видеомонитор 810 (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (ЭЛТ)), устройство буквенно-цифрового ввода 812 (например, клавиатуру), устройство управления курсором 814 (например, мышь) и устройство для формирования сигналов 820 (например, громкоговоритель). В одном из иллюстративных примеров видеодисплей 810, устройство буквенно-цифрового ввода 812 и устройство управления курсором 814 могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0074] Устройство хранения данных 816 может содержать машиночитаемый носитель данных 824, в котором хранятся инструкции 826, реализующие одну или более из методик или функций, описанных в настоящем документе. Инструкции 826 могут также находиться полностью или по меньшей мере частично в основном запоминающем устройстве 804 и (или) в устройстве обработки 802 во время их выполнения вычислительной системой 800, основным запоминающим устройством 804 и обрабатывающим устройством 802, также содержащим машиночитаемый носитель информации. В некоторых вариантах осуществления изобретения инструкции 826 могут дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 822.
[0075] Несмотря на то что машиночитаемый носитель данных 824 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять одну или более методик, описанных в настоящем описании изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как содержащий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[0076] Несмотря на то что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться по крайней мере частично, одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[0077] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0078] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0079] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сформулирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0080] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если прямо не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «анализ» и т.п., относятся к действиям вычислительной системы или подобного электронного вычислительного устройства или к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах и памяти вычислительной системы в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[0081] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнито-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0082] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[0083] Варианты реализации настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) в целях выполнения процесса в соответствии с сущностью изобретения. Машиночитаемый носитель данных включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (то есть считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и пр.).
[0084] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанные в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя А; X включает в себя В; или X включает А и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «an», использованные в англоязычной версии этой заявки и в прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации» или «один вариант реализации» или «реализация» или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
[0085] Принимая во внимание множество вариантов и модификаций раскрываемого изобретения, которые, без сомнения, будут очевидны лицу со средним опытом в профессии после прочтения изложенного выше описания, следует понимать, что любой частный вариант осуществления изобретения, приведенный и описанный для иллюстрации, ни в коем случае не должен рассматриваться как ограничение. Таким образом, ссылки на подробности не должны рассматриваться как ограничение объема притязания, который содержит только признаки, рассматриваемые в качестве сущности изобретения.
Группа изобретений относится к области вычислительной техники и может быть использована для обнаружения текстовых полей в электронных документах с использованием нейронных сетей. Техническим результатом является повышение точности обнаружения текстовых полей. Способ содержит этапы, на которых извлекают из электронного документа множество признаков слов, где множество признаков включает множество символьных векторов, представляющих слова, имеющиеся на изображении; обрабатывают множество признаков слов с использованием нейронной сети, включающей множества слоев нейронной сети; обнаруживают процессорным устройством множество текстовых полей в электронном документе исходя из результата работы нейронной сети, на основании пространственной информации, указывающей на расположение указанных текстовых полей в электронном документе; и присваивают процессорным устройством каждое из текстовых полей одному из множества типов полей исходя из результата работы нейронной сети, с учетом отнесения на основании указанных признаков слов каждого из слов указанных текстовых полей к одному из заранее определенных классов, где каждый из заранее определенных классов соответствует одному из типов текстовых полей. 3 н. и 17 з.п. ф-лы, 8 ил.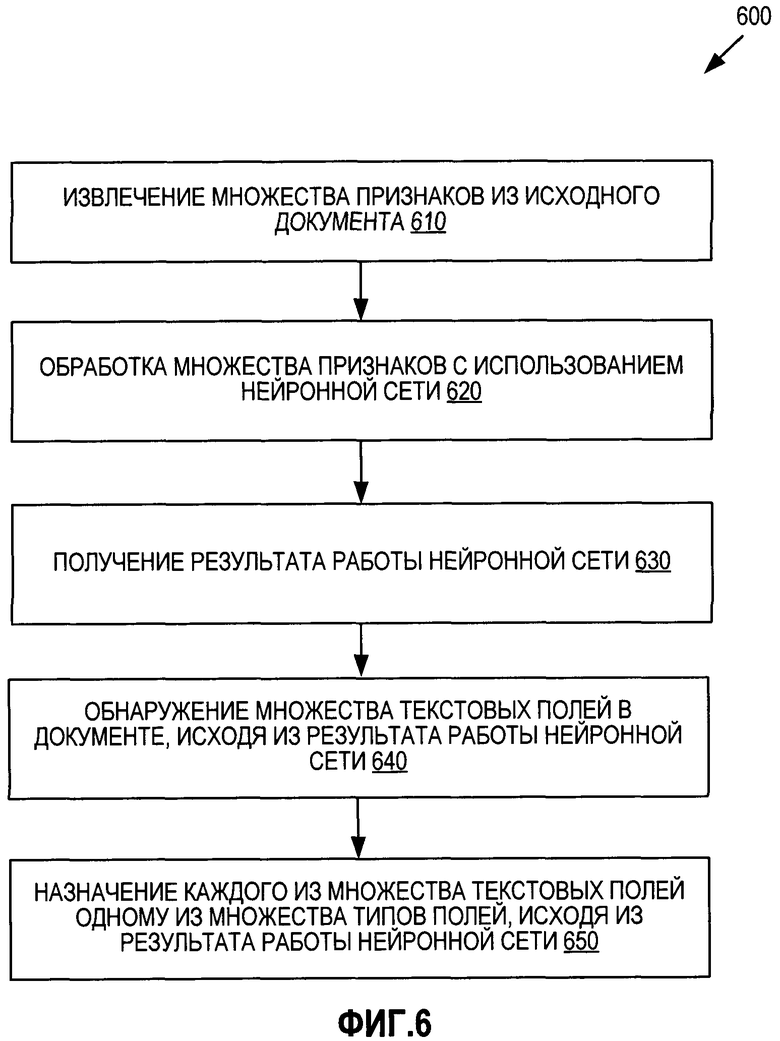
1. Способ анализа электронного документа, включающий:
извлечение из электронного документа множества признаков слов, где множество признаков включает множество символьных векторов, представляющих слова, имеющиеся на изображении;
обработку множества признаков слов с использованием нейронной сети, включающей множества слоев нейронной сети;
обнаружение процессорным устройством множества текстовых полей в электронном документе исходя из результата работы нейронной сети, на основании пространственной информации, указывающей на расположение указанных текстовых полей в электронном документе; и
присвоение процессорным устройством каждого из текстовых полей одному из множества типов полей исходя из результата работы нейронной сети, с учетом отнесения на основании указанных признаков слов каждого из слов указанных текстовых полей к одному из заранее определенных классов, где каждый из заранее определенных классов соответствует одному из типов текстовых полей.
2. Способ по п. 1, отличающийся тем, что извлечение множества признаков электронного документа включает:
распознавание текста на изображении электронного документа;
разделение распознанного текста на изображении на слова;
извлечение множества последовательностей символов из каждого слова;
и извлечение множества символьных векторов из множества последовательностей символов.
3. Способ по п. 2, отличающийся тем, что извлечение множества последовательностей символов из слов включает:
извлечение из каждого слова первого множества символов и второго множества символов, причем первое множество символов соответствует второму множеству символов в обратном порядке.
4. Способ по п. 1, отличающийся тем, что обработка множества признаков с использованием нейронной сети включает:
обработку первым множеством слоев нейронной сети множества последовательностей символов для извлечения первого множества векторов признаков, представляющих слова электронного документа.
5. Способ по п. 4, отличающийся тем, что первое множество векторов признаков содержит множество векторных представлений слов.
6. Способ по п. 4, отличающийся тем, что обработка множества признаков с использованием нейронной сети включает:
обработку вторым множеством слоев нейронной сети множества признаков, извлеченных из электронного документа, для построения по меньшей мере одной первой таблицы первого множества признаков слов исходя из первого множества векторов признаков и второго множества векторов признаков, представляющих слова электронного документа.
7. Способ по п. 6, отличающийся тем, что второе множество векторов признаков содержит по меньшей мере одно из:
множество векторов слов из словаря векторов признаков слов или множество векторов слов из словаря ключевых слов.
8. Способ по п. 6, отличающийся тем, что второе множество векторов признаков содержит пространственную информацию о множестве частей электронного документа, содержащих слова, где каждая из множества частей электронного документа соответствует одному из слов.
9. Способ по п. 6, отличающийся тем, что обработка множества признаков с использованием нейронной сети включает:
создание с использованием третьего множества слоев нейронной сети псевдоизображения на основе не менее одной первой таблицы первого множества признаков слов, где псевдоизображение содержит пространственную информацию, указывающую на расположение текстовых полей в электронном документе; и
обработку псевдоизображения с использованием четвертого множества слоев нейронной сети для извлечения из него второго множества признаков слов, представляющего слова электронного документа.
10. Способ по п. 9, отличающийся тем, что обработка псевдоизображения с использованием четвертого множества слоев нейронной сети включает выполнение семантической сегментации псевдоизображения.
11. Способ по п. 9, дополнительно содержащий создание по меньшей мере второй таблицы, содержащей второе множество признаков слов.
12. Способ по п. 8, отличающийся тем, что обработка множества признаков с использованием нейронной сети дополнительно включает:
отнесение пятым слоем нейронной сети каждого из слов к одному из заранее определенных классов исходя из второго множества признаков слов, где каждый из заранее определенных классов соответствует одному из типов полей.
13. Система анализа электронного документа, включающая:
по меньшей мере одно запоминающее устройство; и
по меньшей мере одно процессорное устройство, функционально связанное с запоминающим устройством и предназначенное для извлечения из электронного документа множества признаков слов, где множество признаков включает множество символьных векторов, представляющих слова электронного документа, и настроенное выполнять:
обработку множества признаков слов с использованием нейронной сети, включающей множества слоев нейронной сети;
обнаружение множества текстовых полей в электронном документе исходя из результата работы нейронной сети, на основании пространственной информации, указывающей на расположение указанных текстовых полей в электронном документе; и
присвоение каждого из текстовых полей одному из множества типов полей исходя из результата работы нейронной сети, с учетом отнесения на основании указанных признаков слов каждого из слов указанных текстовых полей к одному из заранее определенных классов, где каждый из заранее определенных классов соответствует одному из типов текстовых полей.
14. Система по п. 13, отличающаяся тем, что для обработки множества признаков с помощью нейронной сети процессорное устройство дополнительно выполняет следующие действия:
обработку первым множеством слоев нейронной сети множества последовательностей символов для извлечения первого множества векторов признаков, представляющих слова электронного документа.
15. Система по п. 14, отличающаяся тем, что для обработки множества признаков с помощью нейронной сети процессорное устройство дополнительно выполняет следующие действия:
обработку вторым множеством слоев нейронной сети множества признаков, извлеченных из электронного документа, для построения по меньшей мере одной первой таблицы первого множества признаков слов исходя из первого множества векторов признаков и второго множества векторов признаков, представляющих слова электронного документа.
16. Система по п. 15, отличающаяся тем, что для обработки множества признаков с помощью нейронной сети процессорное устройство дополнительно выполняет следующие действия:
создание с использованием третьего множества слоев нейронной сети псевдоизображения на основе не менее одной первой таблицы первого множества признаков слов, где псевдоизображение содержит пространственную информацию, указывающую на расположение текстовых полей в электронном документе; и
обработку псевдоизображения с использованием четвертого множества слоев нейронной сети для извлечения из него второго множества признаков слов, представляющего слова электронного документа.
17. Система по п. 16, отличающаяся тем, что для обработки псевдоизображения с помощью четвертого множества слоев нейронной сети процессорное устройство дополнительно выполняет семантическую сегментацию псевдоизображения с помощью четвертого множества слоев нейронной сети.
18. Система по п. 16, отличающаяся тем, что процессорное устройство дополнительно используется для создания по меньшей мере второй таблицы, содержащей второе множество признаков слов.
19. Система по п. 16, отличающаяся тем, что для обработки множества признаков с помощью нейронной сети процессорное устройство дополнительно выполняет следующие действия:
отнесение пятым слоем нейронной сети каждого из слов к одному из заранее определенных классов исходя из второго множества признаков слов, где каждый из заранее определенных классов соответствует одному из типов полей.
20. Постоянный машиночитаемый носитель данных, содержащий исполняемые инструкции, которые при их исполнении процессорным устройством побуждают его выполнять:
обработку множества признаков слов с использованием нейронной сети, включающей множества слоев нейронной сети;
обнаружение множества текстовых полей в электронном документе исходя из результата работы нейронной сети, на основании пространственной информации, указывающей на расположение указанных текстовых полей в электронном документе; и
присвоение каждого из текстовых полей одному из множества типов полей исходя из результата работы нейронной сети, с учетом отнесения на основании указанных признаков слов каждого из слов указанных текстовых полей к одному из заранее определенных классов, где каждый из заранее определенных классов соответствует одному из типов текстовых полей.
| CN 104899304 A, 09.09.2015 | |||
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| CN 107203511 A, 26.09.2017 | |||
| CN 106570170 A, 19.04.2017 | |||
| ДИФФЕРЕНЦИАЛЬНАЯ КЛАССИФИКАЦИЯ С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ НЕЙРОННЫХ СЕТЕЙ | 2017 |
|
RU2652461C1 |

