УРОВЕНЬ ТЕХНИКИ
[0001] При написании кода во время разработки программных приложений разработчики обычно тратят значительное количество времени на "отладку" кода для поиска ошибок времени выполнения и других ошибок в исходном коде. При этом разработчики могут применять несколько подходов к повторению и локализации дефекта в исходном коде, таких как наблюдение за поведением программы на основе разных входных данных, вставка отладочного кода (например, чтобы печатать значения переменных для отслеживания ветвей исполнения, и т.д.), временное удаление частей кода, и т.д. Выискивание ошибок времени выполнения для выявления дефектов кода может отнимать значительную часть времени разработки приложений.
[0002] Многие типы отладочных приложений ("отладчиков") были разработаны для того, чтобы помочь разработчикам в процессе отладки кода. Эти инструменты предлагают разработчикам возможность выполнять трассировку, визуализировать и изменять исполнение машинного кода. Например, отладчики могут визуализировать исполнение представленных в коде инструкций, могут отражать значения переменных в коде в разное время в ходе исполнения кода, могут позволить разработчикам изменять пути исполнения кода и/или могут позволить разработчикам устанавливать "точки останова" и/или "точки наблюдения" в интересуемых элементах кода (которые, при достижении в ходе исполнения, приводят к приостановке исполнения кода), помимо прочего.
[0003] Перспективная форма отладочных приложений позволяет выполнять отладку "с переходом по времени", "обратную" или "хронологическую" отладку. При отладке "с переходом по времени" исполнение программы (например, исполняемых объектов, таких как потоки выполнения) записывается/трассируется посредством приложения трассировки в один или несколько файлов трассировки. Эти файл(ы) трассировки затем могут использоваться для воспроизведения исполнения программы позже, как для прямого, так и для обратного анализа. Например, отладчики "с переходом по времени" могут позволить разработчику устанавливать точки останова/наблюдения в прямом порядке (как обычные отладчики), а также точки останова/наблюдения в обратном порядке.
[0004] При записи файлов трассировки могут приниматься во внимание несколько факторов. Наиболее заметно то, что существует заложенный компромисс между надежностью записанных данных трассировки и издержками, возникающими при трассировке программы. Эти компромиссы проявляются в первую очередь в размере файла трассировки и влиянии на производительность исполнения трассируемой программы. Более того, поскольку трассировка может совершаться при поддержке со стороны аппаратного обеспечения (либо полностью с помощью программного обеспечения), могут также существовать конструктивные варианты аппаратного обеспечения и другие факторы затрат на аппаратное обеспечение.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] Варианты осуществления, описанные в данном документе, направлены на механизмы для создания записей трассировки "с переходом по времени" с точностью до бита с использованием поддержки со стороны аппаратного обеспечения при посредстве обрабатывающего устройства (процессора). Эти механизмы основаны на трассировке результатов исполнения на всем множестве блоков обработки с использованием, по меньшей мере, двух ярусов или уровней кэшей обрабатывающих устройств. В частности, эти механизмы могут модифицировать аппаратное обеспечение и/или микропрограмму обрабатывающего устройства таким образом, чтобы это помогало (i) обнаруживать входящий поток (т.е. кэш-промах) во внутренний или "нижнего уровня" кэш обрабатывающего устройства на основе действий со стороны трассируемого блока обработки и (ii) использовать внешний или "верхнего уровня" разделяемый кэш обрабатывающего устройства, чтобы определить, были ли уже зарегистрированы данные этого входящего потока от имени другого трассируемого блока обработки. Если эти данные уже были зарегистрированы, то входящий поток может быть зарегистрирован посредством ссылки на предшествующий элемент регистрации. Эти методы могут быть расширены до "N" уровней кэшей. Для записи файлов трассировки таким образом могут потребоваться лишь незначительные модификации обрабатывающего устройства и, по сравнению с прежними подходами к записи трассировки, это может уменьшить на несколько порядков как величину влияния на производительность записи трассировки, так и размер файла трассировки.
[0006] Варианты осуществления направлены на вычислительное устройство(а), которое включает в себя множество блоков обработки, множество кэшей уровня N и кэш уровня (N+i). Кэш уровня (N+i) соотнесен с двумя или более из множества кэшей уровня N и выполнен с возможностью работы в качестве резервного хранилища для множества кэшей уровня N. В этих вариантах осуществления вычислительное устройство(а) включает в себя управляющую логику, которая конфигурирует вычислительное устройство(а) для обнаружения входящего потока в первый кэш уровня N из множества кэшей уровня N, и при этом входящий поток содержит данные, хранящиеся в ячейке памяти. Управляющая логика также конфигурирует вычислительное устройство(а) для проверки кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки. Управляющая логика также конфигурирует вычислительное устройство(а), основываясь на этой проверке, для выполнения либо (i) вызова регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки (т.е. если данные для ячейки памяти были ранее зарегистрированы от имени второго блока обработки), либо (ii) вызова регистрации данных для ячейки памяти по значению от имени первого блока обработки (т.е. если данные для ячейки памяти ранее не регистрировались от имени второго блока обработки).
[0007] Варианты осуществления также направлены на способы для записи трассировки, основанные на записи входящего потока в кэш нижнего уровня посредством ссылки на предшествующие данные регистрации на основе сведений об одном или нескольких кэшах верхнего уровня. Эти способы реализуются на вычислительном устройстве, которое включает в себя (i) множество блоков обработки, (ii) множество кэшей уровня N и (iii) кэш уровня (N+i), который соотнесен с двумя или более из множества кэшей уровня N и который выполнен с возможностью работы в качестве резервного хранилища для множества кэшей уровня N. Способ включает в себя этап, на котором обнаруживают входящий поток в первый кэш уровня N из множества кэшей уровня N, причем входящий поток содержит данные, хранящиеся в ячейке памяти. Способ также включает в себя этап, на котором, на основе обнаружения входящего потока в первый кэш уровня N, проверяют кэш уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки. Способ также включает в себя этап, на котором, на основе этой проверки, выполняют либо (i) вызов регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки, если данные для ячейки памяти были ранее зарегистрированы от имени второго блока обработки, либо (ii) вызов регистрации данных для ячейки памяти по значению от имени первого блока обработки, если данные для ячейки памяти ранее не были зарегистрированы от имени второго блока обработки.
[0008] Варианты осуществления также могут быть воплощены в виде исполняемых компьютером инструкций (например, микропрограмма обрабатывающего устройства), хранящихся на аппаратном устройстве хранения, и которые могут исполняться для выполнения вышеуказанного способа.
[0009] Данный раздел "Сущность изобретения" приводится для того, чтобы в упрощенной форме представить подборку концепций, которые дополнительно описаны ниже в разделе "Подробное описание изобретения". Данный раздел "Сущность изобретения" не предназначен для выявления ключевых признаков или основных признаков заявленного изобретения, а также не предназначен для использования в качестве помощи при определении объема заявленного изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0010] Для того чтобы описать, каким образом могут быть получены вышеупомянутые и другие преимущества и признаки настоящего изобретения, более детальное описание настоящего изобретения, кратко описанного выше, будет предоставлено со ссылкой на его отдельные варианты осуществления, которые проиллюстрированы на прилагаемых чертежах. Подразумевая, что эти чертежи изображают только типичные варианты осуществления настоящего изобретения и, следовательно, не должны рассматриваться как ограничивающие его объем, настоящее изобретение будет описано и объяснено с дополнительной спецификой и детализацией посредством использования сопроводительных чертежей, на которых:
[0011] Фиг. 1 показывает иллюстративную вычислительную среду, которая облегчает запись с "точностью до бита" трассировок исполнения на всем множестве блоков обработки с использованием, по меньшей мере, двух ярусов или уровней кэшей обрабатывающего устройства, что включает в себя обнаружение входящего потока во внутренний или "нижнего уровня" кэш обрабатывающего устройства и использование внешнего или "верхнего уровня" разделяемого кэша обрабатывающего устройства, чтобы определить, можно ли зарегистрировать этот входящий поток посредством ссылки на ранее зарегистрированное значение;
[0012] Фиг. 2A показывает пример вычислительной среды, включающей в себя многоуровневые кэши;
[0013] Фиг. 2B показывает пример кэша;
[0014] Фиг. 3 показывает блок-схему последовательности операций иллюстративного способа для записи трассировки на основе записи входящего потока в кэш нижнего уровня, посредством ссылки на предшествующие данные регистрации, на основе сведений об одном или нескольких кэшах верхнего уровня;
[0015] Фиг. 4A показывает иллюстративный разделяемый кэш, который расширяет каждую из своих строк кэша одним или несколькими дополнительными учетными битами;
[0016] Фиг. 4B показывает пример разделяемого кэша, который включает в себя одну или несколько зарезервированных строк кэша для хранения учетных битов, применимых для обычных строк кэша; и
[0017] Фиг. 5 показывает пример множественно-ассоциативного отображения между системной памятью и кэшем.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0018] Варианты осуществления, описанные в данном документе, направлены на механизмы для создания записей трассировки "с переходом по времени" с точностью до бита с использованием поддержки со стороны аппаратного обеспечения при посредстве обрабатывающего устройства. Эти механизмы основаны на трассировке результатов исполнения на всем множестве блоков обработки с использованием, по меньшей мере, двух ярусов или уровней кэшей обрабатывающих устройств. В частности, эти механизмы могут модифицировать аппаратное обеспечение и/или микропрограмму обрабатывающего устройства таким образом, чтобы это помогало (i) обнаруживать входящий поток (т.е. кэш-промах) во внутренний или "нижнего уровня" кэш обрабатывающего устройства на основе действия со стороны трассируемого блока обработки и (ii) использовать внешний или "верхнего уровня" разделяемый кэш обрабатывающего устройства, чтобы определить, были ли уже зарегистрированы данные этого входящего потока от имени другого трассируемого блока обработки. Если эти данные уже были зарегистрированы, то входящий поток может быть зарегистрирован посредством ссылки на предшествующий элемент регистрации. Эти методы могут быть расширены до "N" ступеней кэшей. Для записи файлов трассировки таким образом могут потребоваться лишь незначительные модификации обрабатывающего устройства и, по сравнению с прежними подходами к записи трассировки, это может уменьшить на несколько порядков как величину влияния на производительность записи трассировки, так и размер файла трассировки.
[0019] Фиг. 1 показывает иллюстративную вычислительную среду 100, которая облегчает запись с "точностью до бита" трассировок исполнения на всем множестве блоков обработки с использованием, по меньшей мере, двух ярусов или уровней кэшей обрабатывающего устройства, что включает в себя обнаружение входящего потока во внутренний или "нижнего уровня" кэш обрабатывающего устройства и использование внешнего или "верхнего уровня" разделяемого кэша обрабатывающего устройства, чтобы определить, можно ли зарегистрировать этот входящий поток посредством ссылки на ранее зарегистрированное значение. Как изображено, варианты осуществления могут содержать или задействовать компьютерную систему 101, специализированную или общего назначения, которая включает в себя компьютерное аппаратное обеспечение, такое как, например, одно или несколько обрабатывающих устройств 102, системная память 103, одно или несколько хранилищ 104 данных и/или аппаратное обеспечение 105 ввода/вывода.
[0020] Варианты осуществления в пределах объема настоящего изобретения включают в себя физические и другие машиночитаемые носители для переноса или хранения исполняемых компьютером инструкций и/или структур данных. Такие машиночитаемые носители могут быть любыми пригодными носителями, к которым может получить доступ компьютерная система 101. Машиночитаемые носители, которые хранят исполняемые компьютером инструкции и/или структуры данных, представляют собой компьютерные устройства хранения. Машиночитаемые носители, которые переносят исполняемые компьютером инструкции и/или структуры данных, представляют собой средства передачи данных. Таким образом, для примера, но не ограничения, варианты осуществления настоящего изобретения могут содержать, по меньшей мере, два совершенно разных типа машиночитаемых носителей: компьютерные устройства хранения и средства передачи данных.
[0021] Компьютерные устройства хранения представляют собой физические устройства аппаратного обеспечения, которые хранят исполняемые компьютером инструкции и/или структуры данных. Компьютерные устройства хранения включают в себя различное компьютерное аппаратное обеспечение, такое как ОЗУ, ПЗУ, ЭСППЗУ, твердотельные накопители ("SSD"), флэш-память, память с изменением фазы ("PCM"), хранилище на оптических дисках, хранилище на магнитных дисках или другие магнитные устройства хранения, или любое другое устройство(а) аппаратного обеспечения, которое может использоваться для хранения программного кода в форме исполняемых компьютером инструкций или структур данных, и к которым может получить доступ и исполнить компьютерная система 101, чтобы реализовать раскрываемые функциональные возможности настоящего изобретения. Таким образом, например, компьютерные устройства хранения могут включать в себя изображенную системную память 103, изображенное хранилище 104 данных, которое может хранить исполняемые компьютером инструкции и/или структуры данных, или другое хранилище, такое так встроенное в обрабатывающее устройство хранилище, как будет обсуждаться ниже.
[0022] Средства передачи могут включать в себя сеть и/или каналы передачи данных, которые могут использоваться для переноса программного кода в форме исполняемых компьютером инструкций или структур данных, и к которым может получить доступ компьютерная система 101. "Сеть" определяется как один или несколько каналов передачи данных, которые обеспечивают возможность транспортировки электронных данных между компьютерными системами и/или модулями и/или другими электронными устройствами. Когда информация перемещается или предоставляется по сети или иному соединению связи (будь то проводное, беспроводное или комбинация проводного или беспроводного) в компьютерную систему, компьютерная система может рассматривать это соединение как средство передачи. Комбинации вышеперечисленного также должны быть включены в объем машиночитаемых носителей. Например, аппаратное обеспечение 105 ввода/вывода может содержать аппаратное обеспечение (например, модуль сетевого интерфейса (например, "NIC")), которое устанавливает соединение с сетью и/или каналом передачи данных, которые могут использоваться для переноса программного кода в форме исполняемых компьютером инструкций или структур данных.
[0023] Кроме того, при достижении различных компонентов компьютерной системы, программный код в форме исполняемых компьютером инструкций или структур данных может автоматически перемещаться от средств передачи на компьютерные устройства хранения (или наоборот). Например, исполняемые компьютером инструкции или структуры данных, принятые по сети или каналу передачи данных, могут быть помещены в буфер в ОЗУ внутри NIC (например, аппаратное обеспечение 105 ввода/вывода), а впоследствии перемещены в системную память 103 и/или менее энергозависимые компьютерные устройства хранения (например, хранилище 104 данных) в компьютерной системе 101. Таким образом, следует понимать, что компьютерные устройства хранения могут быть включены в состав компонентов компьютерной системы, которые тоже (или даже в первую очередь) задействуют средства передачи.
[0024] Исполняемые компьютером инструкции содержат, например, инструкции и данные, которые, при исполнении в обрабатывающем устройстве(ах) 102, заставляют компьютерную систему 101 выполнять определенную функцию или совокупность функций. Исполняемые компьютером инструкции могут быть представлены, например, двоичными данными, инструкциями в промежуточном формате, таком как язык ассемблера, или даже исходным кодом.
[0025] Специалистам в данной области техники будет понятно, что настоящее изобретение может быть реализовано на практике в сетевых вычислительных средах со многими типами конфигураций компьютерных систем, включающих в себя персональные компьютеры, настольные компьютеры, дорожные компьютеры, устройства обработки сообщений, переносные устройства, многопроцессорные системы, микропроцессорную или программируемую бытовую электронику, сетевые ПК, миникомпьютеры, большие многопользовательские компьютеры, подвижные телефоны, КПК, планшеты, устройства персонального вызова, маршрутизаторы, коммутаторы, и тому подобное. Настоящее изобретение также может быть реализовано на практике в средах распределенных систем, где задачи выполняют как локальные, так и удаленные компьютерные системы, которые связаны (посредством либо проводных каналов передачи данных, либо беспроводных каналов передачи данных, либо комбинации проводных и беспроводных каналов передачи данных) через сеть. Собственно, в среде распределенных систем компьютерная система может включать в себя множество составляющих компьютерных систем. В среде распределенных систем программные модули могут быть расположены как в локальных, так и в удаленных запоминающих устройствах.
[0026] Специалистам в данной области техники также будет понятно, что настоящее изобретение может быть реализовано на практике в среде облачных вычислений. Среды облачных вычислений могут быть распределенными, хотя это не обязательно. При распределении среды облачных вычислений могут быть распределены по всему миру в рамках организации и/или иметь компоненты, которыми владеют различные организации. В данном описании изобретения и последующей формуле изобретения "облачные вычисления" определяются как модель для предоставления по требованию сетевого доступа к разделяемому пулу настраиваемых вычислительных ресурсов (например, сетей, обслуживающих узлов, хранилищ, приложений и услуг). Определение "облачные вычисления" не ограничивается какими-либо другими многочисленными преимуществами, которые могут быть получены благодаря такой модели при правильном развертывании.
[0027] Модель облачных вычислений может складываться из различных характеристик, таких как самообслуживание по требованию, свободный доступ к сети, объединение ресурсов, способность к быстрой адаптации, измеримое обслуживание и так далее. Модель облачных вычислений также может принимать форму различных моделей обслуживания, таких как, например, Программное обеспечение как услуга ("SaaS"), Платформа как услуга ("PaaS") и Инфраструктура как услуга ("IaaS"). Модель облачных вычислений также может быть развернута с использованием разных моделей развертывания, таких как частное облако, коллективное облако, публичное облако, гибридное облако, и так далее.
[0028] Некоторые варианты осуществления, такие как среда облачных вычислений, могут содержать систему, которая включает в себя один или несколько узлов, каждый из которых способен обеспечивать функционирование одной или нескольких виртуальных машин. Во время работы виртуальные машины эмулируют действующую вычислительную систему, поддерживая операционную систему, а также, возможно, одно или несколько других приложений. В некоторых вариантах осуществления каждый узел включает в себя гипервизор (программу управления операционными системами), который эмулирует виртуальные ресурсы для виртуальных машин, используя физические ресурсы, которые представлены абстрагировано для виртуальных машин. Гипервизор также обеспечивает надлежащую изоляцию между виртуальными машинами. Таким образом, с точки зрения любой данной виртуальной машины, гипервизор создает иллюзию того, что виртуальная машина взаимодействует с физическим ресурсом, даже при том, что виртуальная машина взаимодействует лишь с внешним представлением (например, виртуальным ресурсом) физического ресурса. Примеры физических ресурсов включают в себя вычислительную мощность, память, дисковое пространство, пропускную способность сети, медиа-накопители, и так далее.
[0029] Как показано, хранилище 104 данных может хранить исполняемые компьютером инструкции и/или структуры данных, представляющие прикладные программы, такие как, например, трассировщик 104a, ядро 104b операционной системы и приложение 104c (например, приложение, которое является объектом трассировки для трассировщика 104a, и один или несколько файлов 104d трассировки). Когда эти программы исполняются (например, с использованием обрабатывающего устройства 102), системная память 103 может хранить соответствующие данные времени выполнения, такие как структуры данных времени выполнения, исполняемые компьютером инструкции, и т.д. Поэтому Фиг. 1 показывает системную память 103 как включающую в себя код 103a времени выполнения приложения и данные 103b времени выполнения приложения (например, которые соответствуют приложению 104c).
[0030] Трассировщик 104a может использоваться для записи с точностью до бита трассировки исполнения приложения, такого как приложение 104c, и сохранять данные трассировки в файле(ах) 104d трассировки. В некоторых вариантах осуществления трассировщик 104a является автономным приложением, тогда как в других вариантах осуществления трассировщик 104a интегрирован в другой компонент программного обеспечения, такой как ядро 104b операционной системы, гипервизор, облачная структура, и т.д. Хотя файл(ы) 104d трассировки изображен как хранящийся в хранилище 104 данных, файл(ы) 104d трассировки также может быть записан монопольно или временно в системной памяти 103 или в каком-то другом устройстве хранения. Как будет разъяснено позже, трассировщик 104a может быть совместим с некоторыми специфическими функциональными возможностями обрабатывающего устройства(ств) 102, которые обеспечивают возможность трассировки с использованием протокола когерентности кэша (CCP) обрабатывающего устройства.
[0031] Фиг. 1 включает в себя упрощенное представление внутренних аппаратных компонентов обрабатывающего устройства(устройств) 102. Как показано, каждое обрабатывающее устройство 102 включает в себя множество блоков 102a обработки. Каждый блок обработки может быть физическим (т.е. физическим ядром обрабатывающего устройства) и/или логическим (т.е. логическим ядром, представленным физическим ядром, которое поддерживает гиперпотоковую обработку, при которой на физическом ядре исполняется более одного потока выполнения приложения). Таким образом, например, даже при том, что обрабатывающее устройство 102 в некоторых вариантах осуществления может включать в себя только один физический блок обработки (ядро), оно может включать в себя два или более логических блоков 102a обработки, представленных этим одним физическим блоком обработки.
[0032] Каждый блок 102a обработки исполняет инструкции обрабатывающего устройства, которые задаются приложениями (например, трассировщиком 104a, операционным ядром 104b, приложением 104c, и т.д.), и такие инструкции выбираются из предварительно заданной архитектуры набора инструкций (ISA) обрабатывающего устройства. Конкретная ISA каждого обрабатывающего устройства 102 варьируется в зависимости от производителя обрабатывающего устройства и модели обрабатывающего устройства. Распространенные ISA включают в себя архитектуры IA-64 и IA-32 от компании INTEL, INC., архитектуру AMD64 от компании ADVANCED MICRO DEVICES, INC. и различные архитектуры Advanced RISC Machine ("ARM") от компании ARM HOLDINGS, PLC, хотя большое количество других ISA существуют и могут использоваться настоящим изобретением. Вообще, "инструкция" является наименьшей внешне видимой (т.е. внешней по отношению к обрабатывающему устройству) единицей кода, которая может исполняться обрабатывающим устройством.
[0033] Каждый блок 102a обработки получает инструкции обрабатывающего устройства из одного или нескольких кэша(ей) 102b обрабатывающего устройства и исполняет инструкции обрабатывающего устройства на основе данных в кэше(ах) 102b, на основе данных в регистрах 102d, и/или без входных данных. Вообще, каждый кэш 102b представляет собой оперативную память небольшого объема (т.е. небольшого по сравнению с обычным объемом системной памяти 103), которая хранит на обрабатывающем устройстве копии частей резервного хранилища, такого как системная память 103 и/или другой кэш в числе кэша(ей) 102b. Например, при исполнении кода 103a приложения один или несколько из кэша(ей) 102b вмещает части данных 103b времени выполнения приложения. Если блок(и) 102a обработки запрашивают данные, еще не сохраненные в конкретном кэше 102b, то происходит "кэш-промах", и эти данные извлекаются из системной памяти 103 или другого кэша, вероятно, "вытесняя" некоторые другие данные из этого кэша 102b.
[0034] Часто кэш(и) 102b обрабатывающего устройства разделяются на отдельные ярусы, уровни или ступени, такие как уровень 1 (L1), уровень 2 (L2), уровень 3 (L3) и т.д. В зависимости от реализации обрабатывающего устройства, ярусы могут быть частью самого обрабатывающего устройства 102 (например, L1 и L2) и/или могут быть отделены от обрабатывающего устройства 102 (например, L3). Таким образом, кэш(и) 102b на Фиг. 1 может содержать один из этих уровней (L1) или может содержать множество этих уровней (например, L1 и L2, и даже L3). Фиг. 2A показывает иллюстративную среду 200, демонстрируя многоуровневые кэши. На Фиг. 2A присутствуют два обрабатывающих устройства 201a и 201b (например, каждое из которых соответствует своему обрабатывающему устройству 102 на Фиг. 1) и системная память 202 (например, соответствующая системной памяти 103 на Фиг. 1). В иллюстративной среде 200 каждое обрабатывающее устройство 201 включает в себя четыре физических блока обработки (т.е. блоки A1-A4 для обрабатывающего устройства 201a и блоки B1-B4 для обрабатывающего устройства 210b).
[0035] Иллюстративная среда 200 также включает в себя трехуровневый кэш в каждом блоке 201 обработки. Среда 200 является лишь одним иллюстративным макетом, и она не накладывает ограничения на иерархические структуры кэша, в которых могут работать варианты осуществления в данном документе. В среде 200 на самом нижнем или самом внутреннем уровне каждый блок обработки соотнесен со своим собственным выделенным кэшем L1 (например, кэшем L1 "L1-A1" в обрабатывающем устройстве 201a для блока A1, кэшем L1 "L1-A2" в обрабатывающем устройстве 201a для блока A2 и т.д.). Продвигаясь на один уровень вверх, каждое обрабатывающее устройство 201 включает в себя два кэша L2 (например, кэш L2 "L2-A1" в обрабатывающем устройстве 201a, который служит резервным хранилищем для кэшей L1 L1-A1 и L1-A2, кэш L2 "L1-A2" в обрабатывающем устройстве 201a, который служит резервным хранилищем для кэшей L1 L1-A3 и L1-A4, и т.д.). Наконец, на самом верхнем или самом внешнем уровне каждый обрабатывающий блок 201 включает в себя один кэш L3 (например, кэш L3 "L3-A" в обрабатывающем устройстве 201a, который служит резервным хранилищем для кэшей L2 L2-A1 и L2-A2, и кэш L3 "L3-B" в обрабатывающем устройстве 201b, который служит резервным хранилищем для кэшей L2 L2-B1 и L2-B2). Как показано, системная память 202 служит резервным хранилищем для кэшей L3 L3-A и L3-B.
[0036] Как продемонстрировано на Фиг. 2A, при использовании нескольких уровней кэша блок(и) 102a обработки обычно взаимодействуют непосредственно с самым нижним уровнем (L1). В большинстве случаев данные перетекают между уровнями (например, при считывании кэш L3 взаимодействует с системной памятью 103 и подает данные в кэш L2, а кэш L2, в свою очередь, подает данные в кэш L1). Когда блок 102a обработки выполняет запись, кэши координируются, чтобы гарантировать, что в тех кэшах, которые имели подвергшиеся изменению данные, которые разделялись блоком(ами) 102a обработки, их больше нет. Эта координация выполняется с использованием CCP.
[0037] Таким образом, кэши в среде 200 могут рассматриваться как "разделяемые" кэши. Например, каждый кэш L2 и L3 обслуживает несколько блоков обработки в пределах данного обрабатывающего устройства 201 и, следовательно, разделяется этими блоками обработки. Кэши L1 в пределах данного обрабатывающего устройства 201, в совокупности, также могут считаться разделяемыми, даже если каждый из них соответствует одному блоку обработки, поскольку отдельные кэши L1 могут координироваться друг с другом (т.е. через CCP), чтобы гарантировать согласованность (т.е. для того, чтобы каждая кэшированная ячейка памяти последовательно просматривалась во всех кэшах L1). Кэши L2 в пределах каждого обрабатывающего устройства 201 аналогичным образом могут координироваться через CCP. Помимо этого, если обрабатывающее устройство 201 поддерживает гиперпотоковую обработку, каждый отдельный кэш L1 может просматриваться, будучи разделенным двумя или более логическими блоками обработки и, следовательно, являться "разделяемым" даже на отдельно взятой ступени.
[0038] Как правило, каждый кэш содержит множество "строк кэша". Каждая строка кэша хранит участок памяти из своего резервного хранилища (например, системной памяти 202 или кэша более высокого уровня). Например, Фиг. 2B показывает пример, по меньшей мере, части кэша 203, который включает в себя множество строк 206 кэша, каждая из которых содержит, по меньшей мере, адресную часть 204 и часть 205 значения. Адресная часть 204 каждой строки 206 кэша приспособлена для хранения адреса в системной памяти 202, которому соответствует эта строка кэша, а часть 205 значения первоначально хранит значение, принятое из системной памяти 202. Часть 205 значения может быть модифицирована блоками обработки, и впоследствии вытеснена обратно в резервное хранилище. Как обозначено многоточием, кэш 203 может включать в себя большое количество строк кэша. Например, современное 64-битное обрабатывающее устройство INTEL может вмещать отдельные кэши L1, содержащие 512 или более строк кэша. В таком кэше каждая строка кэша обычно может использоваться для хранения 64-байтового (512-битного) значения со ссылкой на адрес памяти, от 6-байтового (48-битного) до 8-байтового (64-битного). Как наглядно обозначено на Фиг. 2A, размеры кэша обычно увеличиваются с каждым уровнем (т.е. кэши L2 обычно больше, чем кэши L1, кэши L3 обычно больше, чем кэши L2 и т.д.).
[0039] Адрес, хранящийся в адресной части 204 каждой строки 206 кэша, может быть физическим адресом, таким как фактический адрес памяти в системной памяти 202. В качестве альтернативы, адрес, хранящийся в адресной части 204, может быть виртуальным адресом, который отображается на физический адрес для обеспечения абстракции (например, с использованием таблиц страниц, администрируемых операционной системой). Такие абстракции могут использоваться, например, чтобы способствовать изоляции памяти между разными процессами, исполняемыми на обрабатывающем устройстве(ах) 102, в том числе изоляции между процессами в пользовательском режиме и процессами в режиме ядра, соотнесенными с ядром 104b операционной системы. При использовании виртуальных адресов обрабатывающее устройство 102 может включать в себя буфер 102f быстрого преобразования адреса (TLB) (обычно это составная часть блока управления памятью (MMU)), который поддерживает недавно использованные отображения адресов памяти между физическими и виртуальными адресами.
[0040] Кэш(и) 102b могут включать в себя части кэша для кода и части кэша для данных. При исполнении кода 103a приложения часть(и) кода кэша(ей) 102b могут хранить, по меньшей мере, часть инструкций обрабатывающего устройства, хранящихся в коде 103a приложения, а часть(и) данных кэша(ей) 102b могут хранить, по меньшей мере, часть структур данных из данных 103b времени выполнения приложения. Помимо этого, кэши могут быть инклюзивными, эксклюзивными, или предусматривать как инклюзивное, так и эксклюзивное поведение. Например, в инклюзивном кэше уровень L3 будет хранить надмножество данных в уровнях L2 ниже него, а уровни L2 хранят надмножество уровней L1 ниже них. В эксклюзивных кэшах уровни могут быть непересекающимися, например, если в кэше L3 имеются данные, которые нужны кэшу L1, они могут обмениваться информацией, такой как данные, адрес, и тому подобное.
[0041] Возвращаясь к Фиг. 1, каждое обрабатывающее устройство 102 также включает в себя микропрограмму 102c, которая содержит управляющую логику (т.е. исполняемые инструкции), которая управляет работой обрабатывающего устройства 102, и которая обычно выполняет функцию интерпретатора между аппаратным обеспечением обрабатывающего устройства и ISA обрабатывающего устройства, раскрытой обрабатывающим устройством 102 для исполнения приложений. Микропрограмма 102 обычно на практике реализуется во встроенном в обрабатывающее устройство хранилище, таком как ПЗУ, ЭСППЗУ, и т.д.
[0042] Регистры 102d представляют собой аппаратные ячейки хранения, которые задаются на основе ISA обрабатывающего устройства(в) 102, и из которых осуществляется считывание и/или в которые осуществляется запись благодаря инструкциям обрабатывающего устройства. Например, регистры 102d обычно используются для хранения значений, извлеченных из кэша(ей) 102b для использования инструкциями, для хранения результатов исполнения инструкций и/или для хранения статуса или состояния, к примеру, некоторых побочных эффектов исполнения инструкций (например, признак изменения значения, достижение значением нуля, возникновение переноса, и т.д.), счетчика циклов обрабатывающего устройства, и т.д. Поэтому некоторые регистры 102d могут содержать "флаги", которые используются, чтобы сигнализировать о некотором изменении состояния, вызванном исполнением инструкций обрабатывающего устройства. В некоторых вариантах осуществления обрабатывающие устройства 102 также могут включать в себя управляющие регистры, которые используются для управления разными аспектами работы обрабатывающего устройства. Хотя на Фиг. 1 регистры 102d изображены в виде одного прямоугольника, следует понимать, что каждый блок 102a обработки обычно включает в себя один или несколько соответствующих наборов регистров 102d, которые являются специфическими для этого блока обработки.
[0043] В некоторых вариантах осуществления обрабатывающее устройство(а) 102 может включать в себя один или несколько буферов 102e. Как будет обсуждаться в данном документе ниже, буфер(ы) 102e может использоваться в качестве временной ячейки хранения для данных трассировки. Таким образом, например, обрабатывающее устройство(а) 102 может хранить части данных трассировки в буфере(ах) 102e, и сбрасывать эти данные в файл(ы) 104d трассировки в подходящее время, к примеру, когда доступны полоса пропускания шины памяти и/или свободные циклы обрабатывающего устройства.
[0044] Как упоминалось выше, обрабатывающие устройства работают с кэшем(ами) 102b в соответствии с одним или несколькими CCP. В целом, CCP задает, как поддерживается согласованность между данными среди множества различных кэшей 102b в то время, когда различные блоки 102a обработки считывают и записывают данные в различные кэши 102b, и как обеспечивается, чтобы различные блоки 102a обработки всегда считывали действительные данные из данной ячейки в кэше(ах) 102b. CCP связаны с моделью памяти, заданной ISA обрабатывающего устройства 102, и приспособлены к ней.
[0045] Примеры общих CCP включают в себя протокол MSI (т.е. Modified, Shared, and Invalid - Модифицированная, Разделяемая и Недействительная), протокол MESI (т.е. Modified, Exclusive, Shared, and Invalid - Модифицированная, Эксклюзивная, Разделяемая и Недействительная), и протокол MOESI (т.е. Modified, Owned, Exclusive, Shared, and Invalid - Модифицированная, Собственная, Эксклюзивная, Разделяемая и Недействительная). Каждый из этих протоколов определяет состояние для отдельных ячеек (например, строк) в кэше(ах) 102b. "Модифицированная" ячейка кэша содержит в себе данные, которые были модифицированы в кэше(ах) 102b и поэтому, вероятно, не согласованы с соответствующими данными в резервном хранилище (например, в системной памяти 103 или в другом кэше). Когда ячейка, имеющая состояние "модифицированная", вытесняется из кэша(ей) 102b, общие CCP требуют, чтобы кэш гарантировал, что его данные записаны обратно в резервное хранилище, или что другой кэш взял на себя эту ответственность. "Разделяемая" ячейка кэша содержит в себе данные, которые не модифицированы по сравнению с данными в резервном хранилище, находятся в состоянии только для чтения и разделяются блоком(ами) 102a обработки. Кэш(и) 102b могут вытеснить эти данные, не записывая их в резервное хранилище. "Недействительная" ячейка кэша не содержит в себе действительных данных и может считаться пустой и пригодной для сохранения данных в результате кэш-промаха. "Эксклюзивная" ячейка кэша содержит в себе данные, которые совпадают с резервным хранилищем, и используется только одним блоком 102a обработки. Она может быть изменена на состояние "разделяемая" в любое время (т.е. в ответ на запрос на считывание) или может быть изменена на состояние "модифицированная" при записи в нее. "Собственная" ячейка кэша разделяется двумя или более блоками 102a обработки, но один из блоков обработки имеет эксклюзивное право вносить в нее изменения. Когда такой блок обработки вносит изменения, он уведомляет другие блоки обработки, так как уведомляемым блокам обработки может потребоваться признание недействительности или обновление, в зависимости от реализации CCP.
[0046] Как упоминалось выше, варианты осуществления задействуют кэш(и) 102b обрабатывающего устройства 102, чтобы эффективно записывать с точностью до бита трассировку исполнения приложения 104c и/или ядра 104b операционной системы. Эти варианты осуществления строятся на том наблюдении со стороны автора настоящего изобретения, что обрабатывающее устройство 102 (включающее в себя кэш(и) 102b) формирует полу- или квазизамкнутую систему. Например, после загрузки части данных для обработки (т.е. данных кода и данных приложения времени выполнения) в кэш(и) 102b, обрабатывающее устройство 102 может работать само по себе, без какого-либо ввода данных, как полу- или квазизамкнутая система в течение коротких интервалов времени. В частности, как только кэш(и) 102b загружены данными, один или несколько блоков 102a обработки исполняют инструкции из части(ей) кода кэша(ей) 102b, используя данные времени выполнения, хранящиеся в части(ях) данных кэша(ей) 102b, и используя регистры 102d.
[0047] Когда блоку 102a обработки требуется некоторый входящий поток информации (например, потому что инструкция, которую он исполняет, будет исполнять или может исполнить, обращается к данным кода или к данным времени выполнения, которых еще нет в кэше(ах) 102b), происходит "кэш-промах", и эта информация заносится в кэш(и) 102b из системной памяти 103. Например, если кэш-промах данных происходит, когда исполняемая инструкция выполняет операцию в памяти по адресу памяти в пределах данных 103b времени выполнения приложения, данные из этого адреса памяти заносятся в одну из строк кэша части данных кэша(ей) 102b. Аналогично, если происходит кэш-промах кода, когда инструкция выполняет операцию в памяти по коду 103a приложения с адресом памяти, хранящемуся в системной памяти 103, код из этого адреса памяти заносится в одну из строк кэша части(ей) кода кэша(ей) 102b. Затем блок 102a обработки продолжает исполнение, используя новую информацию в кэше(ах) 102b, пока новая информация снова не будет занесена в кэш(и) 102b (например, вследствие другого кэш-промаха или некэшированного считывания).
[0048] Автор настоящего изобретения также заметил, что для записи представления с точностью до бита исполнения приложения трассировщик 104a может записывать достаточно данных, чтобы иметь возможность повторить входящий поток информации в кэш(и) 102b в тот момент, когда блоки обработки исполняют этот поток(и) выполнения приложения. Например, один подход к записи этих входящих потоков работает в расчете на один блок обработки и на самом внутреннем уровне кэша (например, L1). Этот подход может охватывать запись, для каждого трассируемого блока обработки, всех кэш-промахов и некэшированных считываний (т.е. считываний из аппаратных компонентов и некэшируемой памяти), соотнесенных с кэшем L1 этого блока обработки, а также времени в ходе исполнения, когда каждый фрагмент данных был занесен в кэш L1 этого блока обработки (например, используя количество исполненных инструкций или какой-нибудь другой счетчик). Если есть события, которые могут быть упорядочены по блокам обработки (например, доступы к разделяемой памяти), эти события могут регистрироваться в результирующих потоках данных (например, с помощью монотонно прирастающего числа (MIN) по всем потокам данных).
[0049] Однако, поскольку уровень кэша L1 может включать в себя несколько различных кэшей L1, каждый из которых соотнесен со своим физическим блоком обработки (например, как показано на Фиг. 2A), запись таким образом может записывать повторяющиеся данные и, следовательно, больше данных, чем это строго необходимо для трассировки "с полной достоверностью". Например, если несколько физических блоков обработки считывают из одной и той же ячейки памяти (что может быть частым явлением в многопоточных приложениях), этот подход может регистрировать кэш-промахи для одной и той же ячейки памяти и данных для каждого из нескольких физических блоков обработки. Существенно, что, как используется в данном документе, трассировкой "с полной достоверностью" является любая трассировка, которая вмещает достаточную информацию, чтобы обеспечить полное воспроизведение трассируемого объекта, даже если конкретная трассировка "с полной достоверностью" может фактически вмещать меньше данных, в которых заключена та же информация, чем может быть записано с использованием альтернативных методов трассировки.
[0050] Для того, чтобы дополнительно уменьшить размер файла трассировки, автор настоящего изобретения разработал усовершенствованные методы записи, которые задействуют один или несколько кэшей верхнего уровня, чтобы избежать записи, по меньшей мере, части этих повторяющихся данных. Вместо этого эти усовершенствованные методы могут производить регистрацию посредством ссылки на ранее зарегистрированные данные. В частности, варианты осуществления обнаруживают входящий поток (т.е. кэш-промах) во внутренний или "нижнего уровня" кэш обрабатывающего устройства (например, L1) на основе действий со стороны одного блока обработки, а затем используют один или несколько внешних или "верхнего уровня" разделяемых кэшей обрабатывающего устройства для регистрации этого входящего потока посредством ссылки на входящий поток, уже зарегистрированный от имени другого трассируемого блока обработки, когда это возможно.
[0051] Для понимания этих методов следует отметить, что в большинстве сред кэш верхнего уровня больше, чем кэши нижних уровней, расположенных ниже него, и часто является резервным хранилищем для нескольких кэшей нижнего уровня. Например, в иллюстративной среде на Фиг. 2A каждый кэш L2 является резервным хранилищем для двух кэшей L1, а каждый кэш L3 является резервным хранилищем для двух кэшей L2 (а следовательно, и для четырех кэшей L1). Таким образом, кэш верхнего уровня может хранить сведения о нескольких кэшах нижнего уровня (например, на Фиг. 2A кэш L2 L1-A1 может хранить сведения о кэшах L1 L1-A1 и L1-A2, кэш L2 L1-A2 может хранить сведения о кэшах L1 L1-A3 и L1-A4, и кэш L3 L3-A может хранить сведения о кэшах L2 L2-A1 и L2-A1, а также о кэшах L1 L1-A1, L1-A2, L1-A3 и L1-A4). Задействуя сведения об одном или нескольких верхних уровнях кэша, варианты осуществления в данном документе позволяют использовать множество возможностей для регистрации входящих потоков, вызванных одним блоком обработки, посредством ссылки на входящий поток, уже зарегистрированный от имени других блоков обработки.
[0052] В соответствии с этими вариантами осуществления, Фиг. 3 показывает пример способа 300 для записи трассировки на основе записи входящего потока в кэш нижнего уровня, посредством ссылки на предшествующие данные регистрации, на основе сведений об одном или нескольких кэшах верхнего уровня. Фиг. 3 далее описывается в контексте Фиг. 1 и 2.
[0053] В частности, способ на Фиг. 3 работает в таких средах, как обрабатывающее устройство 102 или 201a, которое включает в себя множество блоков обработки, множество кэшей уровня N, а также кэш уровня (N+i), который соотнесен с двумя или более из множества кэшей уровня N, и который выполнен с возможностью работы в качестве резервного хранилища для множества кэшей уровня N. В способе 300 (и в формуле изобретения) N и i являются положительными целыми числами, т.е. N≥1, так что N равно 1, 2, 3 и т.д.; и i≥1, так что i равно 1, 2, 3 и т.д. Например, в отношении обрабатывающего устройства 201a на Фиг. 2A, обрабатывающее устройство включает в себя множество блоков обработки: A1, A2 и т.д. Обрабатывающее устройство 201a также включает в себя множество кэшей уровня N: L1-A1, L1-A2 и т.д. (т.е. когда N равно 1). Обрабатывающее устройство 201a также включает в себя кэш уровня (N+i), который соотнесен с двумя или более из множества кэшей уровня N, и который выполнен с возможностью работы в качестве резервного хранилища для множества кэшей уровня N. Например, обрабатывающее устройство 201a включает в себя кэш уровня (N+i) L2-A1, который является резервным хранилищем для кэшей уровня N L1-A1 и L1-A2 (т.е. когда N равно 1, и i равно 1). В другом примере обрабатывающее устройство 201a включает в себя кэш уровня (N+i) L3-A, который является резервным хранилищем для кэшей уровня N L1-A1, L1-A2 и т.д. (т.е. когда N равно 1, а i равно 2). Обрабатывающее устройство 102/201a производит операции способа 300 на основе управляющей логики, такой как микропрограмма 102c и/или схемная логика.
[0054] Как показано, способ 300 включает в себя этап 301, на котором, во время исполнения на первом блоке обработки, обнаруживают входящий поток в кэш уровня N. В некоторых вариантах осуществления этап 301 содержит этап, на котором обнаруживают входящий поток в первый кэш уровня N из множества кэшей уровня N, причем входящий поток содержит данные, хранящиеся в ячейке памяти. Например, на основе действий со стороны блока A1 обработки, таких как запрашиваемый доступ к памяти в отношении системной памяти 202 (например, в результате нормального или упреждающего исполнения первого потока выполнения приложения 104c), может произойти кэш-промах в кэше L1-A1 (т.е. при N равном 1). Вследствие чего строка кэша L1-A1 получает входящий поток данных, в том числе актуальное значение запрашиваемой ячейки памяти. В зависимости от атрибутов кэша (например, какие существуют ступени верхнего уровня, является ли архитектура кэша инклюзивной или эксклюзивной, и т.д.) и текущего состояния кэша, входящий поток может поставляться из системной памяти 202 или из кэша верхнего уровня (например, L2-A1 и/или L3-A).
[0055] Способ 300 также включает в себя этап 302, на котором проверяют кэш уровня (N+i), чтобы определить, были ли уже зарегистрированы данные входящего потока на основе исполнения на втором блоке обработки. В некоторых вариантах осуществления этап 302 содержит этап, на котором, на основе обнаружения входящего потока в первый кэш уровня N, проверяют кэш уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки. Например, если i равно 1, так что кэш уровня (N+i) содержит кэш уровня (N+1), то обрабатывающее устройство 201 может проверять кэш L2, такой как L2-A1 (который обладает сведениями о кэше L1-A2 и блоке A2 обработки). Эта проверка может быть использована для определения, были ли ранее зарегистрированы данные для ячейки памяти от имени блока A2 обработки. Эти данные могут быть ранее зарегистрированы, например, на основе предшествующего исполнения второго потока выполнения приложения 104c в блоке A2 обработки, что вызвало кэш-промах в кэше L1-A2. В альтернативном примере, если i равно 2, так что кэш уровня (N+i) содержит кэш уровня (N+2), то обрабатывающее устройство 201 может проверять кэш L2, такой как кэш L3-A (который обладает сведениями обо всех других кэшах в обрабатывающем устройстве 201). Эта проверка может быть использована для определения, были ли ранее зарегистрированы данные для ячейки памяти от имени какого-либо из блоков A2-A4 обработки (например, на основе предшествующего исполнения одного или нескольких других потоков выполнения приложения 104c в одном или нескольких блоках A2-A4 обработки, что вызвало кэш-промах(и) в кэшах L1-A2, L1-A3 и/или L1-A4). Следует отметить, что в этом втором примере кэш L2 может быть пропущен при проверке.
[0056] Как показано, этап 302 может повторяться любое количество раз, при увеличении каждый раз значения i. Хотя i обычно увеличивается на 1 каждый раз, могут быть варианты осуществления, которые увеличивают его на положительное целое число, большее 1. Эффект от повторения этапа 302 заключается в том, что при увеличении i проверяется несколько кэшей верхнего уровня. Например, если i=1, то при первоначальном запуске этапа 302 обрабатывающее устройство 201 может проверить уровень кэша L2 (например, L2-A1 и/или L2-A2). Если в кэше L2 найдено недостаточно сведений о нужной ячейке памяти, то обрабатывающее устройство 201 может повторить этап 302 при i=2, тем самым проверяя уровень кэша L3 (например, L3-A). Это может быть продолжено для того количества уровней кэша, которое предоставляет вычислительная среда. Если i когда-либо увеличивается на значение больше 1, то один или несколько уровней кэша могут быть пропущены по ходу выполнения. Следует принимать во внимание, что может быть полезно проверить несколько уровней кэша в архитектурах, которые предоставляют эксклюзивные кэши или которые предоставляют кэши, которые демонстрируют гибридное инклюзивное/эксклюзивное поведение. Это связано с тем, что в этих архитектурах не может быть никакой гарантии, что внешний уровень кэша вмещает полное надмножество данных во внутреннем уровне(ях) кэша.
[0057] С учетом вышеизложенного понятно, что способ 300 может работать в таких средах, как обрабатывающее устройство 102 или 201a, при этом i равно 1, так что кэш уровня (N+i) содержит кэш уровня (N+1), и при этом обрабатывающее устройство также содержит кэш уровня (N+2), который выполнен с возможностью работы в качестве резервного хранилища для кэша уровня (N+1). В этих средах этап, на котором проверяют кэш уровня (N+1), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки (т.е. этап 302), может содержать этап, на котором определяют, что ни одна строка кэша в кэше уровня (N+1) не соответствует этой ячейке памяти. Кроме того, проверяют кэш уровня (N+2), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки.
[0058] Как показано, в зависимости от результата выполнения этапа 302, способ включает в себя этап 303, на котором, если данные уже были зарегистрированы, регистрируют входящий поток посредством ссылки; либо этап 304, на котором, если данные еще не были зарегистрированы, регистрируют входящий поток по значению.
[0059] В некоторых вариантах осуществления этап 303 содержит этап, на котором, если данные для ячейки памяти были ранее зарегистрированы от имени второго блока обработки, вызывают регистрацию данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки. Продолжая приведенные выше примеры, к примеру, если проверка кэша уровня (N+1) L2-A1 и/или проверка кэша уровня (N+2) L3-A приводит к определению того, что данные/ячейка памяти уже зарегистрированы от имени блока A2 обработки (на основе входящего потока в кэш L1-A2), то обрабатывающее устройство 201a может вызвать регистрацию входящего потока в кэш L1-A1 от имени блока A1 обработки посредством ссылки на элемент регистрации, произведенный для блока A2 обработки. Примеры того, как может быть совершена регистрация посредством ссылки, приведены ниже.
[0060] Обращаясь к альтернативному результату этапа 302, в некоторых вариантах осуществления этап 304 содержит этап, на котором, если данные для ячейки памяти ранее не были зарегистрированы от имени второго блока обработки, вызывают регистрацию данных для ячейки памяти по значению от имени первого блока обработки. Например, если проверка кэша уровня (N+1) L2-A1 и/или проверка кэша уровня (N+2) L3-A приводит к определению того, что данные/ячейка памяти еще не были зарегистрированы от имени другого блока обработки, то обрабатывающее устройство 201a может вызвать регистрацию входящего потока в кэш L1-A1 по значению от имени блока A1 обработки. Регистрация по значению может включать в себя, например, регистрацию адреса памяти и значения памяти в пакете данных для блока A1 обработки. Следует отметить, что регистрация по значению может включать в себя любое количество методов сжатия для уменьшения количества битов, необходимых для совершения фактической регистрации.
[0061] Как было описано применительно к Фиг. 1, обрабатывающее устройство(а) 102 может включать в себя буфер(ы) 102d, который может использоваться для временного хранения данных трассировки. Таким образом, в способе 300 "вызов" регистрации разных типов данных может подразумевать обрабатывающее устройство 102, сохраняющее такие данные в буфере(ах) 102d. В дополнение, или в качестве альтернативы, может предусматриваться обрабатывающее устройство 102, сообщающее такие данные трассировщику 104a, записывающее такие данные в файл(ы) 104d трассировки и/или уведомляющее трассировщик 104a о том, что данные доступны в буфере(ах) 102d. В некоторых вариантах осуществления буфер(ы) 102d может содержать одну или несколько зарезервированных частей кэша(ей) 102b. Таким образом, при использовании буферов 102d, на этапах 304/304 вызов регистрации данных для ячейки памяти, посредством ссылки либо по значению, от имени первого блока обработки, может содержать этап, на котором задерживают регистрацию на основе доступности ресурсов, таких как циклы обрабатывающего устройства, ячейки памяти, полоса пропускания шины и т.д. В вариантах осуществления, в которых буфер(ы) 102d содержит одну или несколько зарезервированных частей кэша(ей) 102b, отложенная регистрация может предусматривать признание недействительной строки кэша (в кэше уровня N и/или в кэше уровня (N+i)), а не ее вытеснение, чтобы оставить данные для ячейки памяти для целей отложенной регистрации.
[0062] Описание способа 300 относится к кэшам верхнего уровня, обладающим "сведениями" о кэшах нижнего уровня. Конкретная форма "сведений", которые хранит кэш верхнего уровня, о кэшах нижнего уровня может меняться, и далее последуют примеры.
[0063] В базовой форме эти "сведения" могут быть простым присутствием в кэше верхнего уровня строки кэша, которая соответствует строке(ам) кэша в кэше(ах) нижнего уровня (т.е. строкам кэша, соответствующим той же ячейке памяти и данным памяти). Как упоминалось выше, в инклюзивных кэшах верхний уровень(уровни) сохраняет надмножество данных в уровне(ях) ниже него. Например, предположим, что кэши на Фиг. 2A являются инклюзивными. В этом случае, когда действие блока A2 обработки вызывает импортирование ячейки из системной памяти 202 в кэш L1-A2, эта же ячейка памяти также кэшируется в кэши L2-A1 и L3-A. Если трассируется действие блока A2 обработки, варианты осуществления могут вызывать регистрацию ячейки памяти и ее значения от имени блока A2 обработки. Позже, если действие со стороны блока A1 обработки приводит к тому, что та же ячейка из системной памяти 202 импортируется в кэш L1-A1, и эта ячейка все еще хранит те же данные, они подаются из кэша L2-A1, поскольку кэш L2-A1 уже имеет эти данные. Предшествующие методы могут снова регистрировать эти данные для блока A1 обработки на основе того, что они являются входящим потоком в кэш L2-A1. Однако варианты осуществления в данном документе могут вместо этого распознавать, что ячейка памяти и ее значение уже присутствуют в кэше L2-A1, а значит уже присутствуют в кэше L1-A2. Поскольку блок A2 обработки регистрируется, варианты осуществления могут распознавать, что ячейка памяти и ее значение уже были бы зарегистрированы от имени блока A2 обработки, а следовательно, вызывать регистрацию этого нового действия блока A1 обработки, ссылаясь на данные регистрации, ранее записанные от имени блока A2 обработки.
[0064] Возможны также более тщательно продуманные формы «сведений» в кэше верхнего уровня. Например, варианты осуществления могут расширять строки кэша в одном или нескольких уровнях кэша дополнительными "учетными" битами (или битами регистрации), которые позволяют обрабатывающему устройству 102 идентифицировать, для каждой строки кэша, в которой реализованы учетные биты, была ли эта строка кэша зарегистрирована (возможно, с помощью идентификационной информации блока(ов) обработки, который зарегистрировал строку кэша). Для понимания этих концепций Фиг. 4A показывает иллюстративный разделяемый кэш 400a, подобный разделяемому кэшу 203 на Фиг. 2B, который расширяет каждую из своих строк 404 кэша одним или несколькими дополнительными учетными битами 401. Таким образом, каждая строка 404 кэша включает в себя учетный бит(ы) 401, обычные адресные биты 402 и биты 403 значения.
[0065] В качестве альтернативы, Фиг. 4B показывает пример разделяемого кэша 400b, который включает в себя обычные строки 405 кэша, которые хранят адреса 402 памяти и значения 403, а также одну или несколько зарезервированных строк 406 кэша для хранения учетных битов, которые применяются для обычных строк 405 кэша. Биты зарезервированной строки(строк) 406 кэша распределяются по разным группам учетных битов, каждая из которых соответствует одной отдельной из обычных строк 405 кэша.
[0066] В одной из вариаций примера на Фиг. 4B зарезервированная строка(и) 406 кэша может быть зарезервирована в качестве одного (или нескольких) входов в каждом индексе множественно-ассоциативного кэша (которые будут подробнее рассмотрены ниже). Например, во множественно-ассоциативном кэше с 8 входами один вход в множестве может быть зарезервирован для учетных битов, которые применяются к другим семи входам в множестве. Это может снизить сложность реализации зарезервированных строк кэша и ускорить доступ к зарезервированным строкам кэша, поскольку все входы в данном множестве обычно считываются параллельно большинством обрабатывающих устройств.
[0067] Независимо от того, как фактически хранятся учетные биты, учетный бит(ы) 401 каждой строки кэша может содержать один или нескольких битов, которые выполняют функцию флага (т.е. включено или выключено), используемого обрабатывающим устройством(ами) 102 для указания, было ли зарегистрировано текущее значение в строке кэша от имени блока обработки (или, в качестве альтернативы, потреблялось ли оно блоком обработки, который участвует в регистрации). Таким образом, проверка на этапе 302 может включать в себя этап, на котором используют этот флаг для определения, была ли строка кэша зарегистрирована блоком обработки, который участвует в регистрации.
[0068] В качестве альтернативы, учетные биты 401 каждой строки кэша могут содержать множество битов. Множество битов можно использовать несколькими способами. Используя один подход, упоминаемый в данном документе как "биты блоков", учетный бит(ы) 401 каждой строки кэша может включать в себя некоторое количество битов блоков, равное количеству блоков 102a обработки обрабатывающего устройства 102 (например, количеству логических блоков обработки, если обрабатывающее устройство 102 поддерживает гиперпотоковую обработку, или количеству физических блоков обработки, если гиперпотоковая обработка не поддерживается). Эти биты блоков могут использоваться обрабатывающим устройством 102, чтобы отслеживать, какие один или несколько конкретных блоков обработки зарегистрировали строку кэша (если таковые имеются). Таким образом, например, кэш, который разделяется двумя блоками 102a обработки, может соотносить два бита блоков с каждой строкой кэша.
[0069] В другом подходе к использованию множества учетных битов 401, упоминаемом в данном документе как "индексные биты", учетные биты 401 каждой строки кэша могут включать в себя некоторое количество индексных битов, достаточных для представления индекса для каждого из блоков 102a обработки обрабатывающего устройства 102 компьютерной системы 101, которые участвуют в регистрации, вместе с "зарезервированным" значением (например, -1). Например, если обрабатывающее устройство 102 включает в себя 128 блоков 102a обработки, эти блоки обработки могут идентифицироваться по значению индекса (например, 0-127), используя только семь индексных битов на каждую строку кэша. В некоторых вариантах осуществления одно значение индекса резервируется (например, "недействительный"), чтобы указывать, что никакое обрабатывающее устройство не зарегистрировало строку кэша. Соответственно, это будет означать, что семь индексных битов фактически смогут представлять 127 блоков 102a обработки плюс зарезервированное значение. Например, двоичные значения 0000000-1111110 могут соответствовать индексным ячейкам 0-126 (в десятичном исчислении), а двоичное значение 1111111 (например, -1 или 127 в десятичном исчислении, в зависимости от интерпретации), может соответствовать "недействительному", чтобы указывать, что никакое обрабатывающее устройство не зарегистрировало соответствующую строку кэша, хотя это обозначение может варьироваться, в зависимости от реализации. Таким образом, биты блоков могут использоваться обрабатывающим устройством 102 для указания, была ли зарегистрирована строка кэша (например, значение, отличное от -1), и как индекс для конкретного блока обработки, который зарегистрировал строку кэша (например, блок обработки, который последним потреблял ее). Этот второй подход к использованию множества учетных битов 401 имеет преимущество, заключающееся в поддержке большого числа блоков обработки при небольших издержках в кэше 102b, с недостатком, заключающимся в меньшей степени детализации по сравнению с первым подходом (т.е. только один блок обработки идентифицируется за один раз).
[0070] С учетом вышеизложенного понятно, что на этапе 302 проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки, может содержать этап, на котором определяют, имеет ли строка кэша в кэше уровня (N+i), которая соответствует ячейке памяти, один или несколько установленных учетных битов.
[0071] Другой механизм, который может использоваться для определения, была ли зарегистрирована строка кэша, заключается в том, чтобы задействовать множественно-ассоциативные кэши и блокировку входов. Поскольку кэш 102b обрабатывающего устройства, как правило, намного меньше системной памяти 103 (часто на порядки), значит обычно в системной памяти 103 намного больше ячеек памяти, чем строк в любом данном уровне кэша 102b. Поэтому некоторые обрабатывающие устройства задают механизмы для отображения множественных ячеек памяти системной памяти в строку(и) одного или нескольких уровней кэша. Как правило, обрабатывающие устройства применяют один из двух общих методов: прямое отображение и ассоциативное (или множественно-ассоциативное) отображение. При использовании прямого отображения разные ячейки памяти в системной памяти 103 отображаются только в одну строку в уровне кэша, так что каждая ячейка памяти может кэшироваться только в конкретную строку в этом уровне.
[0072] С другой стороны, при использовании множественно-ассоциативного отображения разные ячейки в системной памяти 103 могут кэшироваться в одну из множества строк в уровне кэша. Фиг. 5 показывает пример 500 множественно-ассоциативного отображения между системной памятью и кэшем. В этом случае строки 504 кэша уровня 502 кэша логически разделены на разные множества по две строки кэша в каждом, в том числе первое множество из двух строк 504a и 504b кэша (отождествленное с индексом 0), и второе множество из двух строк 504c и 504d кэша (отождествленное с индексом 1). Каждая строка кэша в множестве отождествляется со своим "входом", так что строка 504a кэша идентифицируется индексом 0, входом 0, строка 504b кэша идентифицируется индексом 0, входом 1, и так далее. Как изображено дополнительно, ячейки 503a, 503c, 503e и 503g памяти (индексы 0, 2, 4 и 6 памяти) отображаются в индекс 0. Соответственно, каждая из этих ячеек в системной памяти может кэшироваться в любую строку кэша в пределах множества с индексом 0 (т.е. строки 504a и 504b кэша). Конкретные шаблоны изображенных отображений предназначены только для иллюстративных и концептуальных целей и не должны интерпретироваться как единственный способ, которым индексы памяти могут отображаться в строки кэша.
[0073] Множественно-ассоциативные кэши, как правило, упоминаются как множественно-ассоциативные кэши с N входами, где N является количеством "входов" в каждом множестве. Таким образом, кэш 500 на Фиг. 5 может упоминаться как множественно-ассоциативный кэш с 2 входами. Обрабатывающие устройства обычно реализуют кэши с N входами, где N является степенью двух (например, 2, 4, 8, и т.д.), причем обычно значения N выбираются из 4 и 8 (хотя варианты осуществления в данном документе не ограничиваются никакими конкретными значениями N или подмножествами значений N). Примечательно, что множественно-ассоциативный кэш с 1 входом в целом эквивалентен кэшу с прямым отображением, поскольку каждое множество вмещает только одну строку кэша. Дополнительно, если N равно количеству строк в кэше, он упоминается как полностью ассоциативный кэш, поскольку он содержит единственное множество, вмещающее все строки в кэше. В полностью ассоциативных кэшах любая ячейка памяти может кэшироваться в любую строку в кэше.
[0074] Следует отметить, что Фиг. 5 представляет упрощенный вид системной памяти и кэшей, чтобы проиллюстрировать общие принципы. Например, хотя на Фиг. 5 отдельные ячейки памяти отображаются в строки кэша, следует понимать, что каждая строка в кэше может хранить данные, относящиеся к нескольким адресуемым ячейкам в системной памяти. Таким образом, на Фиг. 5, каждая ячейка (503a-503h) в системной памяти (501) может фактически представлять множество адресуемых ячеек памяти. Дополнительно, отображения могут быть между фактическими физическими адресами в системной памяти 501 и строками в кэше 502, или могут использовать промежуточный уровень виртуальных адресов.
[0075] Множественно-ассоциативные кэши могут использоваться для определения, была ли строка кэша зарегистрирована, посредством использования блокировки входа. Блокировка входа блокирует или резервирует один или несколько входов в кэше для какой-либо цели. В частности, варианты осуществления в данном документе задействуют блокировку входа, чтобы зарезервировать один или несколько входов для трассируемого блока обработки, так что заблокированные/зарезервированные входы используются исключительно для хранения кэш-промахов, относящихся к исполнению этого блока. Таким образом, возвращаясь к Фиг. 5, если "вход 0" был заблокирован для трассируемого блока обработки, то строки 504a и 504c кэша (т.е. индекс 0, вход 0 и индекс 1, вход 0) будут использоваться исключительно для кэш-промахов, относящихся к исполнению этого блока, а остальные строки кэша будут использоваться для всех других кэш-промахов. Таким образом, чтобы определить, была ли зарегистрирована конкретная строка кэша, обрабатывающему устройству 102 нужно только определить, является ли строка кэша, сохраненная в уровне кэша "N+1", составной частью входа, зарезервированного для трассируемого блока обработки.
[0076] С учетом вышеизложенного понятно, что на этапе 302 проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки, может содержать этап, на котором определяют, хранится ли строка кэша в кэше уровня (N+i), которая соответствует ячейке памяти, во входе, который соответствует зарегистрированному блоку обработки.
[0077] Как объяснялось выше, кэши работают согласно CCP, который задает, как поддерживается согласованность среди множества различных кэшей в то время, когда блоки обработки считывают и записывают данные в кэше, и как обеспечивается, чтобы блоки обработки всегда считывали действительные данные из данной ячейки в кэше. Таким образом, в отношении работы кэша, обрабатывающее устройство 102 поддерживает и хранит данные о состоянии CCP. Степень детализации, с которой разные обрабатывающие устройства и/или разные CCP отслеживают состояние когерентности кэша и делают эти данные когерентности кэша доступными для трассировщика 104a, может варьироваться. Например, на одной границе диапазона, некоторые обрабатывающие устройства/CCP отслеживают когерентность кэша для каждой строки кэша, а также для каждого блока обработки. Следовательно, эти обрабатывающие устройства/CCP могут отслеживать состояние каждой строки кэша, и как она связана с каждым блоком обработки. Это означает, что отдельная строка кэша может иметь информацию о своем состоянии, и как она связана с каждым блоком 102a обработки. Другие обрабатывающие устройства/CCP менее детализированы и отслеживают когерентность кэша только на уровне строки кэша (и не имеют информации по каждому блоку обработки). На другой границе диапазона производители обрабатывающих устройств могут выбирать для отслеживания когерентности кэша только уровень строки кэша, для эффективности, поскольку одновременно только одно обрабатывающее устройство может эксклюзивно владеть строкой (эксклюзивной, модифицированной, и т.д.). В качестве примера средней степени детализации, обрабатывающее устройство/CCP может отслеживать когерентность кэша для каждой строки кэша, а также индекс (например, 0, 1, 2, 3 для обрабатывающего устройства с четырьмя блоками обработки) для блока обработки, который имеет текущее состояние строки кэша.
[0078] Независимо от степени детализации, с которой данные состояния CCP поддерживаются в данном обрабатывающем устройстве, эти данные состояния CCP могут быть внесены в "сведения" о кэшированных данных, которыми обладает кэш уровня (N+i). В частности, данные состояния CCP, соотнесенные с данной строкой кэша в кэше уровня (N+i), могут использоваться для определения, была ли эта строка кэша зарегистрирована одним из блоков обработки. Например, если данные состояния CCP указывают, что конкретный блок обработки занял данную строку кэша в качестве "разделяемой", эти данные, в свою очередь, могут быть использованы для определения того, что блок обработки зарегистрировал считывание из строки кэша. Таким образом, следует понимать, что на этапе 302 проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки, может содержать этап, на котором определяют, имеет ли строка кэша в кэше уровня (N+i), соответствующая ячейке памяти, соотнесенные данные состояния CCP, которые можно использовать для определения того, что строка кэша была зарегистрирована.
[0079] На этапе 303 входящий поток данных может быть зарегистрирован посредством ссылки на ранее зарегистрированные данные (как правило, данные, зарегистрированные блоком обработки, отличным от того, который вызвал текущий входящий поток). Регистрация посредством ссылки может быть совершена с использованием одного или нескольких из множества различных способов (в том числе их комбинаций), некоторые из них описываются далее.
[0080] Первый способ производит регистрацию посредством ссылки на ранее зарегистрированный адрес памяти. Например, предположим, что блок A2 обработки на Фиг. 2A зарегистрировал данные, представляющие конкретный адрес памяти (т.е. в системной памяти 202), и конкретные данные, хранящиеся по этому адресу памяти. Позже, если этот конкретный адрес памяти/конкретные данные являются входящим потоком для блока A1 обработки, блок A1 обработки может сохранить элемент регистрации, который идентифицирует (i) конкретный адрес памяти и (ii) блок A2 обработки. При этом блок A1 обработки избегает повторной регистрации фактических данных, хранящихся по адресу памяти (которые могут быть значительного размера). Некоторые варианты этого первого способа могут также сохранять данные об упорядоченности, такие как MIN в последовательности, которое прирастает по всем потокам данных для блоков A1 и A2 обработки. Позже это MIN можно использовать для упорядочения этого входящего потока в исполнении блоком A1 обработки, в сопоставлении с одним или несколькими событиями в блоке A2 обработки (например, теми, которые тоже соотнесены с MIN из той же последовательности). Соответственно, на этапе 303, вызов регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки, может содержать этапы, на которых регистрируют адрес ячейки памяти или регистрируют адрес ячейки памяти и данные упорядочения, такие как MIN.
[0081] Второй способ производит регистрацию посредством ссылки на предыдущего владельца строки кэша, хранящей данные. Например, предположим, что блок A2 обработки на Фиг. 2A зарегистрировал первый входящий поток данных. Предположим также, что первый входящий поток вызвал кэширование данных в строке кэша в кэше уровня (N+i) (например, в кэше L2-A1), причем блок A2 обработки идентифицируется как владелец строки кэша. Позже, если блок A1 обработки вызывает второй входящий поток тех же данных, блок A1 обработки может стать владельцем этой строки кэша в кэше уровня (N+i). Блок A1 обработки может сохранить элемент регистрации, который идентифицирует предыдущего владельца строки кэша (т.е. блок A2 обработки), так что элемент регистрации блока A2 может быть использован позже для получения данных. Это означает, что регистрация посредством ссылки может подразумевать запись идентификационной информации строки кэша вместе с предыдущим владельцем строки кэша (например, потенциально избегая записи адресов памяти и значений памяти). Соответственно, на этапе 303, вызов регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки, может содержать этап, на котором регистрируют второй блок обработки в качестве предыдущего владельца строки кэша, соответствующей ячейке памяти.
[0082] Третий способ производит регистрацию посредством ссылки на данные CCP. Например, как уже упоминалось, CCP могут хранить состояние когерентности кэша по каждой строке кэша в то время, когда разные блоки обработки занимают ее для считывания и записи. Степень детализации этих данных может варьироваться в зависимости от реализации обрабатывающего устройства, но может, например, отслеживать состояние когерентности кэша для каждой строки кэша, и как она связана с каждым блоком обработки, отслеживать состояние когерентности кэша для каждой строки кэша вместе с индексом (например, 0, 1, 2, 3 и т.д.) для блока обработки, который владеет текущим состоянием строки кэша и т.д. Третий способ задействует доступные данные CCP для отслеживания того, какой блок(и) обработки ранее владели состоянием когерентности кэша для строки кэша, и это состояние когерентности кэша затем может использоваться для идентификации того, какой блок(и) обработки зарегистрировал значение строки кэша. Это означает, что регистрация посредством ссылки может подразумевать запись данных CCP для строки кэша (например, опять же потенциально избегая записи адресов памяти и значений памяти). Соответственно, на этапе 303, вызов регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки, может содержать этап, на котором регистрируют данные CCP с привязкой ко второму блоку обработки.
[0083] Четвертый способ производит регистрацию посредством ссылки на вход кэша. Как уже упоминалось, множественно-ассоциативные кэши могут использоваться для определения, была ли зарегистрирована строка кэша, благодаря использованию блокировки входов. Например, предположим, что блокировка входов используется для резервирования одного или нескольких входов для блока P2 обработки, и что P2 регистрирует первый входящий поток данных. Первый входящий поток также приводит к тому, что кэш уровня (N+i) (например, кэш L2-A1) сохраняет данные первого входящего потока в строке кэша, соотнесенной с этим входом. Когда другой блок обработки (например, P1) имеет второй входящий поток тех же данных, наличие этой строки кэша в кэше уровня (N+i) указывает, что P2 уже зарегистрировал данные. Варианты осуществления могут регистрировать ссылку на данные регистрации блока P2 на основе фиксирования входа, в котором хранится строка кэша, и опять же могут потенциально избегать регистрации адресов памяти и значений памяти. Этот вариант осуществления также может использоваться в сочетании с записью информации об упорядочении (например, MIN) для упорядочивания событий между P1 и P2. Соответственно, на этапе 303, вызов регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки, может содержать этап, на котором регистрируют ссылку на вход кэша или регистрируют ссылку на вход кэша и данные упорядочения.
[0084] В дополнение к регистрации входящего потока для первого блока обработки на основе предшествующего входящего потока со стороны второго блока обработки, варианты осуществления также включают в себя оптимизацию для уменьшения (и даже исключения) регистрации, когда есть несколько входящих потоков одних и тех же данных со стороны одного блока обработки. Например, обращаясь к Фиг. 2A, блок A1 обработки может вызвать кэш-промах в кэше уровня N (например, в кэше L1-A1) для конкретных данных в ячейке памяти. В ответ иерархическая структура кэша может импортировать эти данные в кэш L1-A1, и, возможно, также и в кэш уровня (N+i) (например, кэш L2-A1 и/или кэш L3-A). Помимо этого, входящий поток может быть зарегистрирован по значению для блока А1 обработки. Позже эти данные могут быть вытеснены из кэша L1-A1. В типичных средах кэширования это может привести к тому, что данные будут автоматически вытеснены также из кэша L2-A1 и/или кэша L3-A. Однако вместо того, чтобы вызывать вытеснение(я) в кэшах L2-A1 и/или L3-A, варианты осуществления могли бы вместо этого оставлять нужную строку(и) кэша в одном или нескольких из этих кэшей уровня (N+i). Соответственно, способ 300 может содержать этап, на котором вытесняют первую строку кэша в первом кэше уровня N, которая соответствует ячейке памяти, оставляя при этом вторую строку кэша в кэше уровня (N+i), которая соответствует ячейке памяти.
[0085] Позже, если блок A1 обработки вызывает последующий кэш-промах в кэше L1-A1 для тех же данных, оставленная строка(и) кэша в кэше уровня (N+i) (например, в кэшах L2-A1 и/или L3-A) может быть использована для определения того, что эти данные уже были зарегистрированы от имени блока A1 обработки. Таким образом, в некоторых вариантах осуществления этот последующий кэш-промах регистрируется с привязкой к предшествующему элементу регистрации со стороны блока A1 обработки. В других вариантах осуществления элемент регистрации может быть полностью опущен для этого последующего кэш-промаха, поскольку блок A1 обработки уже имеет данные в своей трассировке. Соответственно, способ 300 может содержать этап, на котором, на основе обнаружения последующего входящего потока в первый кэш уровня N, при этом последующий входящий поток также содержит данные, хранящиеся в ячейке памяти, вызывают регистрацию последующего входящего потока посредством ссылки на основе присутствия второй строки кэша. Помимо этого, или в качестве альтернативы, способ 300 может содержать этап, на котором (i) обнаруживают последующий входящий поток в первый кэш уровня N на основе исполнения дополнительного кода в первом блоке обработки, при этом последующий входящий поток также содержит данные, хранящиеся в ячейке памяти, и (ii) на основе, по меньшей мере, обнаружения последующего входящего потока в первый кэш уровня N, и на основе, по меньшей мере, присутствия второй строки кэша, определяют, что последующий входящий поток не должен регистрироваться.
[0086] Соответственно, варианты осуществления в данном документе создают записи трассировки "с переходом по времени" с точностью до бита на основе трассировки результатов исполнения на всем множестве блоков обработки с использованием, по меньшей мере, двух ярусов или уровней кэшей обрабатывающих устройств. Это может включать в себя модификации аппаратного обеспечения и/или микропрограммы обрабатывающего устройства, которые помогают (i) обнаруживать входящий поток (т.е. кэш-промах) во внутренний или "нижнего уровня" кэш обрабатывающего устройства на основе действия со стороны трассируемого блока обработки и (ii) использовать внешний или "верхнего уровня" разделяемый кэш обрабатывающего устройства, чтобы определить, были ли уже зарегистрированы данные этого входящего потока от имени другого трассируемого блока обработки. Если эти данные уже были зарегистрированы, то входящий поток может быть зарегистрирован посредством ссылки на предшествующий элемент регистрации. Эти методы могут быть расширены до "N" ступеней кэшей. Для записи файлов трассировки таким образом могут потребоваться лишь незначительные модификации обрабатывающего устройства и, по сравнению с прежними подходами к записи трассировки, это может уменьшить на несколько порядков как величину влияния на производительность записи трассировки, так и размер файла трассировки.
[0087] Настоящее изобретение может быть воплощено в других специфических формах без отступления от его сущности или существенных свойств. Описанные варианты осуществления должны рассматриваться во всех отношениях только как иллюстративные, а не ограничивающие. Следовательно, объем настоящего изобретения определяется прилагаемой формулой изобретения, а не предшествующим описанием. Все изменения, которые производятся в рамках смысла и диапазона эквивалентности формулы изобретения, должны восприниматься как входящие в ее объем.

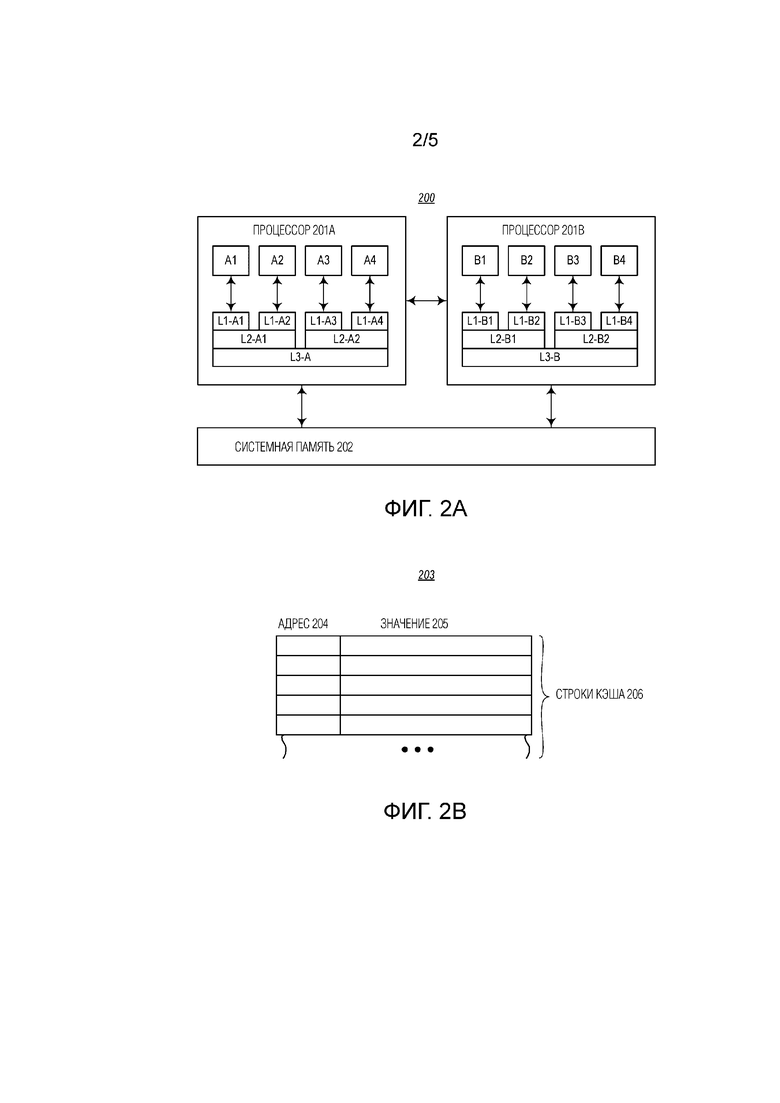


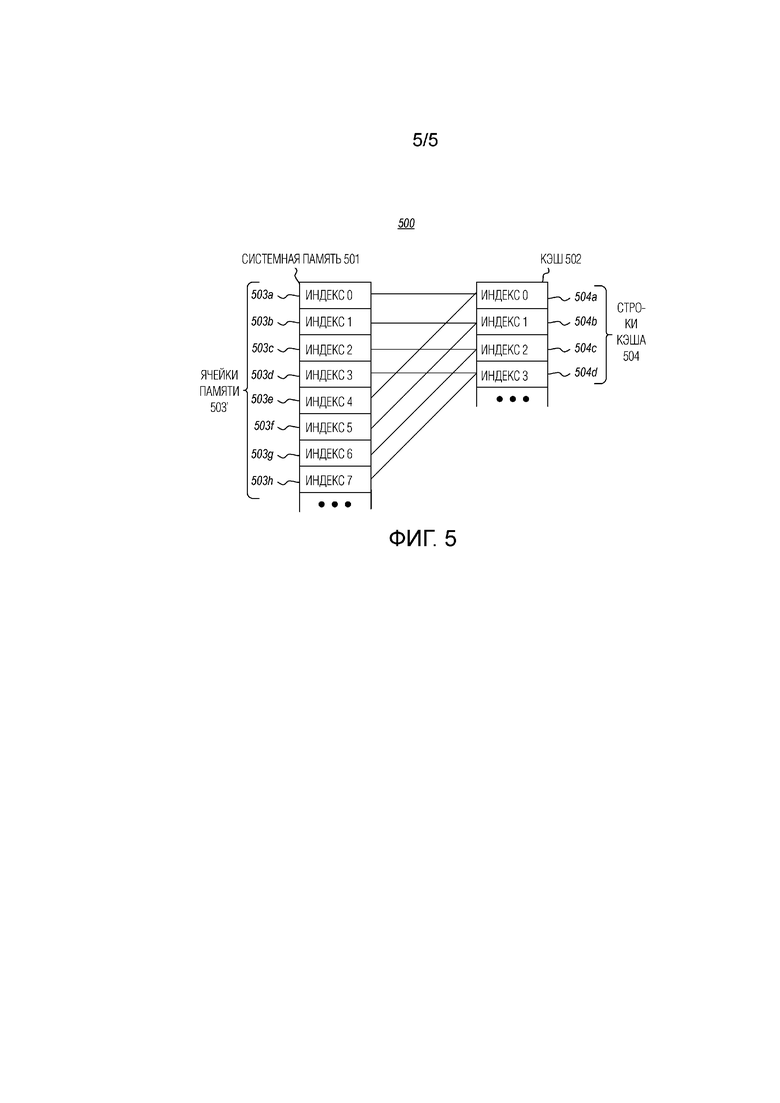
Изобретение относится к области вычислительной техники для отладки приложений в процессе их разработки. Технический результат заключается в повышении точности создания записей трассировки "с переходом по времени" с использованием поддержки со стороны аппаратного обеспечения. Технический результат достигается за счет обнаружения входящего потока в первый кэш уровня N из множества кэшей уровня N; и на основе обнаружения входящего потока в первый кэш уровня N, проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы упомянутые данные для ячейки памяти от имени второго блока обработки, и выполнение одного из следующего: если данные для ячейки памяти были ранее зарегистрированы от имени второго блока обработки, вызов регистрации этих данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки; или если данные для ячейки памяти ранее не регистрировались от имени второго блока обработки, вызов регистрации этих данных для ячейки памяти по значению от имени первого блока обработки. 3 н. и 17 з.п. ф-лы, 7 ил.
1. Вычислительное устройство, содержащее:
множество блоков обработки;
множество кэшей уровня N;
кэш уровня (N+i), который связан с двумя или более из множества кэшей уровня N и который сконфигурирован в качестве резервного хранилища для множества кэшей уровня N; и
управляющую логику, которая конфигурирует вычислительное устройство для выполнения, по меньшей мере, следующего:
обнаружение входящего потока в первый кэш уровня N из множества кэшей уровня N, при этом входящий поток содержит данные, хранящиеся в ячейке памяти; и
на основе обнаружения входящего потока в первый кэш уровня N, проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы упомянутые данные для ячейки памяти от имени второго блока обработки, и выполнение одного из следующего:
если данные для ячейки памяти были ранее зарегистрированы от имени второго блока обработки, вызов регистрации этих данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки; или
если данные для ячейки памяти ранее не регистрировались от имени второго блока обработки, вызов регистрации этих данных для ячейки памяти по значению от имени первого блока обработки.
2. Вычислительное устройство по п.1, в котором проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки, содержит одно или более из следующего:
определение того, имеет ли строка кэша в кэше уровня (N+i), которая соответствует упомянутой ячейке памяти, один или более установленных учетных битов;
определение того, хранится ли в кэше уровня (N+i) строка кэша, которая соответствует упомянутой ячейке памяти, во входе, который соответствует зарегистрированному блоку обработки; или
определение того, имеет ли строка кэша в кэше уровня (N+i), которая соответствует упомянутой ячейке памяти, связанные с ней данные состояния протокола когерентности кэша (CCP), которые можно использовать для определения того, что строка кэша была зарегистрирована.
3. Вычислительное устройство по п.1, при этом i равно 1, так что кэш уровня (N+i) содержит кэш уровня (N+1).
4. Вычислительное устройство по п.1, при этом i равно 2, так что кэш уровня (N+i) содержит кэш уровня (N+2).
5. Вычислительное устройство по п.1, при этом:
i равно 1, так что кэш уровня (N+i) содержит кэш уровня (N+1);
вычислительное устройство также содержит кэш уровня (N+2), который сконфигурирован в качестве резервного хранилища для кэша уровня (N+1); и
проверка кэша уровня (N+1), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки, содержит:
определение того, что ни одна строка кэша в кэше уровня (N+1) не соответствует упомянутой ячейке памяти; и
проверку кэша уровня (N+2), чтобы определить, были ли ранее зарегистрированы упомянутые данные для ячейки памяти от имени второго блока обработки.
6. Вычислительное устройство по п.1, в котором вызов регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки, содержит одно или более из следующего:
регистрация адреса упомянутой ячейки памяти;
регистрация адреса упомянутой ячейки памяти и данных упорядочения;
регистрация ссылки на вход кэша;
регистрация ссылки на вход кэша и данных упорядочения;
регистрация второго блока обработки в качестве предыдущего владельца строки кэша, соответствующей упомянутой ячейке памяти; или
регистрация данных протокола когерентности кэша (CCP) с привязкой ко второму блоку обработки.
7. Вычислительное устройство по п.1, в котором вызов регистрации данных для ячейки памяти от имени первого блока обработки содержит задержку регистрации на основе доступности одного или обоих из ресурсов процессора или памяти.
8. Вычислительное устройство по п.1, в котором задержка регистрации содержит обеспечение недействительности строки кэша, чтобы оставить упомянутые данные для ячейки памяти для целей отложенной регистрации.
9. Вычислительное устройство по п.1, в котором управляющая логика также конфигурирует вычислительное устройство для выполнения, по меньшей мере, следующего:
вытеснение первой строки кэша в первом кэше уровня N, которая соответствует упомянутой ячейке памяти, оставляя при этом вторую строку кэша в кэше уровня (N+i), которая соответствует этой ячейке памяти; и
на основе обнаружения последующего входящего потока в первый кэш уровня N, каковой последующий входящий поток также содержит упомянутые данные, хранящиеся в ячейке памяти, вызов регистрации этого последующего входящего потока посредством ссылки на основе присутствия второй строки кэша.
10. Вычислительное устройство по п.1, в котором управляющая логика также конфигурирует вычислительное устройство для выполнения, по меньшей мере, следующего:
вытеснение первой строки кэша в первом кэше уровня N, которая соответствует упомянутой ячейке памяти, оставляя при этом вторую строку кэша в кэше уровня (N+i), которая также соответствует этой ячейке памяти;
обнаружение последующего входящего потока в первый кэш уровня N на основе исполнения дополнительного кода в первом блоке обработки, причем этот последующий входящий поток также содержит упомянутые данные, хранящиеся в ячейке памяти; и
на основе, по меньшей мере, обнаружения последующего входящего потока в первый кэш уровня N и на основе, по меньшей мере, присутствия второй строки кэша, определение того, что упомянутый последующий входящий поток не должен регистрироваться.
11. Способ записи трассировки, основывающийся на записи входящего потока в кэш нижнего уровня посредством ссылки на предшествующие данные регистрации на основе сведений об одном или более кэшах верхнего уровня, причем способ реализуется на вычислительном устройстве, которое включает в себя (i) множество блоков обработки, (ii) множество кэшей уровня N и (iii) кэш уровня (N+i), который связан с двумя или более из множества кэшей уровня N и который сконфигурирован в качестве резервного хранилища для множества кэшей уровня N, при этом способ содержит этапы, на которых:
обнаруживают входящий поток в первый кэш уровня N из множества кэшей уровня N, причем входящий поток содержит данные, хранящиеся в ячейке памяти; и
на основе обнаружения входящего потока в первый кэш уровня N, проверяют кэш уровня (N+i), чтобы определить, были ли ранее зарегистрированы упомянутые данные для ячейки памяти от имени второго блока обработки, и выполняют одно из следующего:
если данные для ячейки памяти были ранее зарегистрированы от имени второго блока обработки, вызывают регистрацию этих данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки; или
если данные для ячейки памяти ранее не регистрировались от имени второго блока обработки, вызывают регистрацию этих данных для ячейки памяти по значению от имени первого блока обработки.
12. Способ по п.11, в котором проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки, содержит один или нескольких этапов, на которых:
определяют, имеет ли строка кэша в кэше уровня (N+i), которая соответствует упомянутой ячейке памяти, один или более установленных учетных битов;
определяют, хранится ли в кэше уровня (N+i) строка кэша, которая соответствует упомянутой ячейке памяти, во входе, который соответствует зарегистрированному блоку обработки; или
определяют, имеет ли строка кэша в кэше уровня (N+i), которая соответствует упомянутой ячейке памяти, связанные с ней данные состояния протокола когерентности кэша (CCP), которые можно использовать для определения того, что строка кэша была зарегистрирована.
13. Способ по п.11, в котором i равно 1, так что кэш уровня (N+i) содержит кэш уровня (N+1).
14. Способ по п.11, в котором i равно 2, так что кэш уровня (N+i) содержит кэш уровня (N+2).
15. Способ по п.11, в котором
i равно 1, так что кэш уровня (N+i) содержит кэш уровня (N+1);
вычислительное устройство также содержит кэш уровня (N+2), который сконфигурирован в качестве резервного хранилища для кэша уровня (N+1); и
проверка кэша уровня (N+1), чтобы определить, были ли ранее зарегистрированы данные для ячейки памяти от имени второго блока обработки, содержит этапы, на которых:
определяют, что ни одна строка кэша в кэше уровня (N+1) не соответствует упомянутой ячейке памяти; и
проверяют кэш уровня (N+2), чтобы определить, были ли ранее зарегистрированы упомянутые данные для ячейки памяти от имени второго блока обработки.
16. Способ по п.11, в котором вызов регистрации данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки, содержит одно или более из следующего:
регистрация адреса упомянутой ячейки памяти;
регистрация адреса упомянутой ячейки памяти и данных упорядочения;
регистрация ссылки на вход кэша;
регистрация ссылки на вход кэша и данных упорядочения;
регистрация второго блока обработки в качестве предыдущего владельца строки кэша, соответствующей упомянутой ячейке памяти; или
регистрация данных протокола когерентности кэша (CCP) с привязкой ко второму блоку обработки.
17. Способ по п.11, в котором вызов регистрации данных для ячейки памяти от имени первого блока обработки содержит задержку регистрации, включая обеспечение недействительности строки кэша, чтобы оставить упомянутые данные для ячейки памяти для целей отложенной регистрации.
18. Способ по п.11, дополнительно содержащий этапы, на которых:
вытесняют первую строку кэша в первом кэше уровня N, которая соответствует упомянутой ячейке памяти, оставляя при этом вторую строку кэша в кэше уровня (N+i), которая соответствует этой ячейке памяти; и
на основе обнаружения последующего входящего потока в первый кэш уровня N, каковой последующий входящий поток также содержит упомянутые данные, хранящиеся в ячейке памяти, вызывают регистрацию этого последующего входящего потока посредством ссылки на основе присутствия второй строки кэша.
19. Способ по п.11, дополнительно содержащий этапы, на которых:
вытесняют первую строку кэша в первом кэше уровня N, которая соответствует упомянутой ячейке памяти, оставляя при этом вторую строку кэша в кэше уровня (N+i), которая также соответствует этой ячейке памяти;
обнаруживают последующий входящий поток в первый кэш уровня N на основе исполнения дополнительного кода в первом блоке обработки, причем этот последующий входящий поток также содержит упомянутые данные, хранящиеся в ячейке памяти; и
на основе, по меньшей мере, обнаружения последующего входящего потока в первый кэш уровня N и на основе, по меньшей мере, присутствия второй строки кэша, определяют, что упомянутый последующий входящий поток не должен регистрироваться.
20. Машиночитаемый носитель, на котором хранятся машиноисполняемые инструкции, которые конфигурируют вычислительное устройство, которое включает в себя (i) множество блоков обработки, (ii) множество кэшей уровня N и (iii) кэш уровня (N+i), который связан с двумя или более из множества кэшей уровня N и который сконфигурирован в качестве резервного хранилища для множества кэшей уровня N, для выполнения, по меньшей мере, следующего:
обнаружение входящего потока в первый кэш уровня N из множества кэшей уровня N, причем входящий поток содержит данные, хранящиеся в ячейке памяти; и
на основе обнаружения входящего потока в первый кэш уровня N, проверка кэша уровня (N+i), чтобы определить, были ли ранее зарегистрированы упомянутые данные для ячейки памяти от имени второго блока обработки, и выполнение одного из следующего:
если данные для ячейки памяти были ранее зарегистрированы от имени второго блока обработки, вызов регистрации этих данных для ячейки памяти от имени первого блока обработки посредством ссылки на данные регистрации, которые ранее были зарегистрированы от имени второго блока обработки; или
если данные для ячейки памяти ранее не регистрировались от имени второго блока обработки, вызов регистрации этих данных для ячейки памяти по значению от имени первого блока обработки.
| US 9037911 B2, 19.05.2015 | |||
| US 9678150 B2, 13.06.2017 | |||
| US 20170052876 A1, 23.02.2017 | |||
| КЭШИРОВАНИЕ ГЕНЕРИРУЕМОГО ВО ВРЕМЯ ВЫПОЛНЕНИЯ КОДА | 2009 |
|
RU2520344C2 |
| US 20120066551 A1, 15.03.2012 | |||
| US 9300320 B2, 29.03.2016 | |||
| US 9361228 B2, 7.06.2016 | |||
| СХЕМА ОТЛАДКИ, СРАВНИВАЮЩАЯ РЕЖИМ ОБРАБОТКИ НАБОРА КОМАНД ПРОЦЕССОРА | 2007 |
|
RU2429525C2 |

