Предшествующий уровень техники
Настоящее изобретение, в целом, относится к системам идентификации изображений. В частности, настоящее изобретение относится к способам и процедурам для повышения производительности и надежности систем идентификации изображений.
Системы идентификации изображений использовались ранее, в частности, как системы идентификации биометрических изображений. Один тип системы идентификации биометрических изображений представляет собой систему идентификации отпечатков пальцев. В системе идентификации отпечатков пальцев пользователь помещает подушечку пальца на сканирующую поверхность устройства считывания изображения отпечатка пальца. Каждый гребешковый вырост эпидермиса (кожного покрова) усеян потовыми железами, которые создают увлажнение, которое, в сочетании с маслянистыми выделениями и другими веществами, обычно присутствующими на подушечке пальца, позволяют сканировать изображение отпечатка пальца. (Настоящее изобретение можно также успешно применять к изображениям, генерируемым считывающими устройствами, которые не используют влагосодержание кожи для восприятия (захвата) изображения). Устройство считывания изображения отпечатка пальца создает сканированное изображение, воспринимая картину характеристик папиллярных выростов отпечатка пальца, присутствующих на подушечке пальца. Многие системы предусматривают сравнение изображения с базой данных других сохраненных изображений отпечатков пальцев или моделей изображения отпечатка пальца для проверки, аутентификации или некоторой другой формы анализа.
Реализация технологии идентификации отпечатков пальцев в защитных системах позволяет обеспечить их надежность и простоту применения. Эти преимущества проистекают из того факта, что технология не требует, чтобы пользователь системы хранил какой-либо фрагмент информации, например пароль, личный идентификационный номер, их комбинацию или какой-либо другой код. Также пользователь не обязан иметь карту, ключ или какое-либо другое физическое устройство для получения доступа к защищенной среде. Защитный ключ аутентификации отпечатка пальца, в отличие от защитного ключа аутентификации на основе информации или владения, почти невозможно потерять, украсть или забыть.
Развитию практических приложений системы безопасности, в которой используется технология идентификации изображения, препятствует отсутствие, в целом, повторяемости данных от одного сканированного изображения к другому. В частности, физические изменения, присутствующие в среде устройства считывания отпечатков пальцев, могут приводить к существенным несовпадениям между одним сканированным изображением отпечатка пальца и последующим сканированным изображением того же самого отпечатка пальца. Различия в температуре, величине давления, приложенного к сканирующей поверхности, влагосодержания пальца, а также влияние лекарств и различия в кровяном давлении могут способствовать существенным несовпадениям между сканированными изображениями. Эти несовпадающие результаты препятствуют развитию большинства приложений технологии идентификации отпечатков пальцев, поскольку несоответствующие данные приводят к неприемлемо высокому количеству ложных признаний (множественные идентификации, включающие в себя совпадения с посторонними лицами) и ложных отказов (отсутствие распознавания зарегистрированного пользователя) для приложений, где может требоваться осуществление мгновенных и неконтролируемых сравнений сканированных изображений отпечатка пальца с базой данных изображений отпечатков пальцев или моделей отпечатков пальцев. Другая проблема, связанная со многими системами идентификации изображений, состоит в малом объеме данных, собираемых обычной системой из каждого изображения. Например, большинство систем идентификации отпечатков пальцев являются подетальными, что обычно означает, что каталогизируются и доступны для анализа только мостики, островки и раздвоения. Идеальное сканирование изображения, осуществляемое подетальной системой, будет обычно собирать максимум, приблизительно, 50 полезных точек данных, и это количество может дополнительно снижаться за счет точек данных, которые могут не появляться в сканированном изображении в силу рассмотренных ранее помех в среде устройств считывания изображения. Различительная способность обычной системы подетальной идентификации не подходит для приложений, требующих мгновенных и точных сравнений, которые нужно делать между изображением, сканированным в режиме реального времени, и базой данных потенциально совпадающих изображений или моделей. Кроме того, системы, которые собирают только малое количество полезных точек данных, более восприимчивы к мошеннически созданным поддельным отпечаткам пальцев.
Еще одна проблема, связанная с системой идентификации усредненного изображения, состоит в том, что она обеспечивает неэффективную модель для осуществления сравнений между изображением, сканированным в режиме реального времени, и базой данных потенциально совпадающих изображений или моделей. Большинство систем сравнивают изображение, сканированное в режиме реального времени, или модель, построенную на основании этого сканирования, с каждым изображением или каждой моделью из базы данных изображений или моделей, по принципу «одно с одним», пока не будет обнаружена совпадающая пара. В зависимости от размера базы данных время, необходимое для отыскания совпадающей пары, может быть значительным.
В силу этих классических ограничений технологии идентификации изображений приложения идентификации изображений обычно ограничивались использованием в средах с низким уровнем защиты и/или контроля, в которых быстрая обработка не является приоритетной. Например, многие правоохранительные органы, которые в настоящее время используют системы идентификации отпечатков пальцев, действуют в рамках подетального совпадения. Подетальная система может быть пригодна в такой среде, где специалист по дактилоскопии имеет достаточно времени для того, чтобы контролировать систему и действовать как арбитр в случаях множественных совпадений с оперативной базой данных.
Подетальные системы и другие традиционные системы идентификации отпечатков пальцев непригодны для неконтролируемых приложений массового потребления, например банкоматов, которые содержат систему идентификации отпечатков пальцев и требуют от пользователя предоставить действительное сканированное изображение отпечатка пальца при использовании банковской карты для осуществления финансовой транзакции. Кроме того, традиционные системы не пригодны в качестве систем аутентификации, предназначенных для избирательного и мгновенного предоставления доступа к местам и устройствам, например компьютерам, компьютерным сетям, промышленным установкам, автомобилям и бытовым приборам, на основании получения авторизованного изображения. Экономичное и эффективное функционирование этих типов приложений зависит от уровня быстроты и точности анализа, который, по существу, не достижим для традиционной системы идентификации изображений отпечатков пальцев.
Другое преимущество, связанное с системой аутентификации, которая включает в себя идентификацию изображений, состоит в регулируемости системы, т.е. возможности регулировать уровень различения или критерии совпадения в зависимости от характера охраняемой среды и соответствующего требуемого уровня безопасности. Вследствие неповторяемости данных, ложных признаний совпадения и ложных отклонений совпадения диапазон и количество уровней, в которых можно регулировать традиционную систему идентификации изображений, весьма ограничены. Такая система может вообще не подлежать регулировке. Даже наивысший уровень различения в традиционной системе обеспечивает существенно ограниченную степень различения.
Сущность изобретения
Способы и процедуры для повышения производительности и надежности анализа изображения в системе идентификации изображении включают в себя ряд функций оценки изображений, предназначенных для быстрой обработки части имеющихся данных сканированного изображения и обеспечения обратной связи с пользователем системы в отношении качества и аутентичности изображения. Согласно одному варианту осуществления, если оценка изображения приводит к заключению о том, что сканированное изображение является мошенническим или имеет недостаточное качество, то обработка изображения прерывается.
Кроме того, настоящее изобретение предусматривает функции, предназначенные для создания моделей изображения на основании исходных данных изображения и для внесения таких моделей изображения в поисковую базу данных. Согласно одному варианту осуществления создание модели изображения предусматривает анализ данных изображения, принятых от устройства считывания изображения, и происходящих из них новых наборов данных и манипулирование ими. Модели изображения, зарегистрированные в поисковой базе данных, согласно одному варианту осуществления настоящего изобретения, можно получать из одной операции сканирования объекта или из двух или более операций сканирования того же объекта.
Настоящее изобретение также предусматривает функции сравнения одной модели изображения с другой. Согласно одному варианту осуществления, ряд алгоритмов сдвига и поворота применяют к, по меньшей мере, одной модели изображения, пока не идентифицируют позицию наилучшего сравнения двух моделей. Вычисляют оценку, выражающую соотношение между двумя моделями изображения, или долю элементов данных, являющихся общими для них. Согласно одному варианту осуществления уровень подобия, необходимый, чтобы две модели изображения можно было считать совпадающими, является регулируемым.
Наконец, настоящее изобретение предусматривает функции для осуществления быстрого определения, какая, если таковая имеется, из возможных тысяч (или более, т.е. миллионов и даже сотен миллионов) моделей изображения в поисковой базе данных проявляет нужный уровень подобия при сравнении с целевой моделью изображения. Согласно одному варианту осуществления, вместо того, чтобы конкретно сравнивать модели, задают набор индексных ключей базы данных, описывающих характеристики другой модели изображения, что позволяет производить общие, а не конкретные, сравнения. Согласно одному варианту осуществления, уровни различения могут быть регулируемыми.
Краткое описание чертежей
Фиг. 1 - блок-схема системы формирования изображения отпечатка пальца.
Фиг. 2 - блок-схема операций алгоритма, выполняемых в системе формирования изображения отпечатка пальца, отвечающей настоящему изобретению.
Фиг. 3 - наглядное представление иллюстративного набора параметров сканирования изображения.
Фиг. 4 - блок-схема набора процедурных компонентов, соответствующих операциям оценивания изображения, показанным на фиг. 2.
Фиг. 5 - иллюстрация первичного сканированного изображения.
Фиг. 6 - иллюстрация промежуточного изображения, полученного в соответствии с операциями предварительной обработки, показанным на фиг. 4.
Фиг. 7 - иллюстрация монохромного изображения, полученного в соответствии с операциями предварительной обработки, показанными на фиг. 4.
Фиг. 8А - иллюстрация монохромного изображения, полученного с источника в виде лавсановой пленки с использованием светодиодного источника света в устройстве считывания изображения.
Фиг. 8В - иллюстрация монохромного изображения, полученного с бумажного источника с использованием светодиодного источника света в устройстве считывания изображения.
Фиг. 9А - иллюстрация монохромного изображения, полученного с источника в виде лавсановой пленки с использованием инфракрасного источника света в устройстве считывания изображения.
Фиг. 9В - иллюстрация монохромного изображения, полученного с бумажного источника с использованием инфракрасного источника света в устройстве считывания изображения.
Фиг. 9С - иллюстрация монохромного изображения, полученного с источника в виде живого пальца с использованием инфракрасного источника света в устройстве считывания изображения.
Фиг. 10 - иллюстрация монохромного изображения после выполнения контурной трассировки в соответствии с операциями генерации таблицы крутизны, показанными на фиг. 4.
Фиг. 11 - иллюстрация монохромного изображения с наложением крутизны на основании таблицы крутизны, созданной в соответствии с операциями генерации таблицы крутизны, показанными на фиг. 4.
Фиг. 12 - иллюстрация гистограммы, созданной в соответствии с операциями генерации гистограммы, показанными на фиг. 4.
Фиг. 13 - иллюстрация гистограммы, перекрывающей первичное сканированное изображение, из которого получена гистограмма.
Фиг. 14 - иллюстрация ячейки гистограммы.
Фиг. 15 - блок-схема набора процедурных компонентов, соответствующих операциям создания модели, показанным на фиг. 2.
Фиг. 16 - блок-схема набора процедурных компонентов, соответствующих операциям предварительной обработки, показанным на фиг. 15.
Фиг. 17 - иллюстрация скорректированного первичного сканированного изображения.
Фиг. 18 - иллюстрация промежуточного изображения, полученного в соответствии с операциями предварительной обработки, показанными на фиг. 15.
Фиг. 19 - иллюстрация улучшенного изображения.
Фиг. 20 - иллюстрация монохромного изображения, полученного в соответствии с операциями предварительной обработки, показанными на фиг. 15.
Фиг. 21 - иллюстрация монохромного изображения после обнаружения и заливки иррегулярностей в изображении.
Фиг. 22 - иллюстрация залитого монохромного изображения.
Фиг. 23 - иллюстрация сглаженного и залитого монохромного изображения.
Фиг. 24 - наглядное представление альтернативного набора иллюстративных параметров сканирования изображения.
Фиг. 25 - иллюстрация монохромного изображения после выполнения контурной трассировки в соответствии с операциями генерации таблицы крутизны, показанными на фиг. 15.
Фиг. 26 - иллюстрация монохромного изображения с наложением крутизны на основании таблицы крутизны, созданной в соответствии с операциями генерации таблицы крутизны, показанными на фиг. 15.
Фиг. 27 - блок-схема набора процедурных компонентов, соответствующих операциям генерации каркаса, показанным на фиг. 15.
Фиг. 28 - иллюстрация монохромного изображения после первого удаления пикселей из папиллярных линий изображения.
Фиг. 29 - иллюстрация монохромного изображения с исчерпывающим представлением проходов удаления пикселей, произведенных в ходе утончения монохромного изображения до самых центральных пикселей папиллярных линий.
Фиг. 30 - иллюстрация фиг. 29, дополнительно включающая в себя наложение утоненного монохромного изображения, имеющего первичные линии каркаса.
Фиг. 31 - иллюстрация утоненного монохромного изображения с первичными линиями каркаса.
Фиг. 32 - иллюстрация утоненного монохромного изображения после удаления избыточных пикселей из первичных линий каркаса.
Фиг. 33 - иллюстрация соотношения между утоненным монохромным изображением после удаления избыточных пикселей и соответствующим монохромным изображением.
Фиг. 34 - иллюстрация утоненного монохромного изображения с удаленными избыточными пикселями, которое содержит представление данных из таблицы концевых точек.
Фиг. 35 - иллюстрация утоненного монохромного изображения с удаленными избыточными пикселями, которое содержит представление данных из таблицы центральных точек.
Фиг. 36 - иллюстрация очищенного набора линий каркаса.
Фиг. 37 - иллюстрация, демонстрирующая соотношение между очищенным набором линий каркаса и соответствующим монохромным изображением.
Фиг. 38 - иллюстрация, демонстрирующая соотношение между дополнительно очищенным набором линий каркаса, включающим в себя фиксированные концевые точки, и соответствующим монохромным изображением.
Фиг. 39 - иллюстрация, демонстрирующая соотношение между дополнительно очищенным набором линий каркаса, включающим в себя фиксированные и соединенные концевые точки, и соответствующим монохромным изображением.
Фиг. 40 - графическое представление элемента изображения, относящегося к раздвоению в отпечатке пальца.
Фиг. 41 - графическое представление элемента изображения, относящегося к мостику в отпечатке пальца.
Фиг. 42 - иллюстрация каркасного изображения отпечатка пальца, где оцененные мостики и раздвоения обведены кружками.
Фиг. 43 - иллюстрация каркасного изображения отпечатка пальца, где оцененные мостики и раздвоения обведены кружками и сегменты векторов трассированы.
Фиг. 44 - блок-схема набора процедурных компонентов, связанных с процессом сравнения изображений по принципу «одно с одним».
Фиг. 45 - блок-схема набора процедурных компонентов, связанных с процессом сравнения изображений по принципу «одно со многими» с помощью базы данных.
Фиг. 46 - блок-схема набора процедурных компонентов, связанных с другим процессом сравнения изображений по принципу «одно со многими» с помощью базы данных.
Подробное описание иллюстративных вариантов осуществления
Настоящее изобретение, в целом, относится к способом и процедурам для повышения производительности и надежности систем идентификации изображения. Принципы изобретения применимы в системах, предназначенных для работы с широким диапазоном типов изображений, в том числе, но не исключительно, изображениями автомобильных номерных знаков, графическими изображениями и текстовыми изображениями. Кроме того, настоящее изобретение предусматривает способы и процедуры, особенно пригодные для повышения производительности и надежности систем идентификации изображений отпечатков пальцев. Хотя в оставшейся части подробного описания настоящее изобретение будет рассмотрено в отношении систем идентификации изображений отпечатков пальцев, следует понимать, что принципы настоящего изобретения с тем же успехом применимы к другим типам систем идентификации изображений.
На фиг. 1 показана блок-схема системы 10 формирования изображения отпечатка пальца, в которой применимы способы и процедуры согласно настоящему изобретению. Система 10 формирования изображения содержит считывающий модуль 12, анализатор/обработчик 14 изображения и поисковую базу данных 16, которая дополнительно содержит выход 15. Считывающий модуль 12 может представлять собой любую из ряда известных систем, способных сканировать изображение отпечатка пальца и переносить данные, относящиеся к изображению, на анализатор изображений, например анализатор/обработчик 14 изображений.
Во многих случаях считывающий модуль 12 содержит оптическое устройство, содержащее отражающую поверхность, предназначенную для приема пальца, изображение которого нужно создать. Свет поступает в оптическое устройство от излучателя света, и оптическое изображение пальца отражается от оптического устройства в модуль формирования изображения, который принимает изображение и создает аналоговый сигнал изображения, соответствующий полученному оптическому сигналу. Во многих системах аналоговый сигнал поступает на традиционный аналого-цифровой преобразователь, который создает цифровое представление аналогового сигнала. Цифровой сигнал переформатируется в оцифрованное изображение, которое можно сохранять, и которым, в соответствии с вариантом осуществления настоящего изобретения, можно манипулировать. Наконец, оцифрованное изображение поступает от считывающего модуля на анализатор/обработчик 14 изображений. Конкретный вид анализатора/обработчика 14 изображений зависит от приложений, но в целом он анализирует принятые данные изображения для широкого круга целей и приложений.
Согласно варианту осуществления настоящего изобретения, как будет более подробно рассмотрено ниже, анализатор/обработчик 14 изображений создает модель изображения на основании конкретных особенностей и характеристик каждого изображения, принятого от считывающего модуля 12. Эти модели изображений являются более чем факсимиле связанных с ними изображений отпечатков пальцев и включают в себя уникальный диапазон элементов данных, которые обеспечивают аналитические возможности, составляющие часть настоящего изобретения.
Согласно одному варианту осуществления настоящего изобретения анализатор/обработчик 14 изображений сравнивает элементы данных одной модели изображения с элементами данных, по меньшей мере, одной другой модели изображения, хранящейся в поисковой базе данных 16. Модели изображения, содержащиеся в базе данных 16, соответствуют ранее полученным сканированным изображениям, тогда как сравниваемая модель изображения обычно соответствует сканируемому в данный момент изображению. Система 10 формирования изображения отпечатка пальца благодаря использованию этого процесса способна быстро и эффективно определять, подобна ли по существу модель изображения, соответствующая сканируемому в данный момент отпечатку пальца, какой-либо из моделей изображения, включенных в поисковую базу данных 16. Как будет более подробно рассмотрено ниже, для признания совпадения системе 10 требуется конкретный уровень подобия. Согласно одному варианту осуществления необходимый уровень подобия является регулируемым, и его можно регулировать в зависимости от характера среды, для обеспечения защиты которой предназначена система 10. Таким образом, система 10 формирования изображения отпечатка пальца обеспечивает эффективную и точную систему идентификации изображения отпечатка пальца, которую можно использовать, например, как меру защиты, чтобы определить, следует ли авторизовать человека, поместившего палец на считывающий модуль 12, для входа в комнату, для доступа к банковскому счету или для осуществления каких-либо других действий.
Согласно фиг. 1, поисковая база данных 16 включает в себя выход 15. Точный характер выхода 15 зависит от контекста применения системы 10 формирования изображений. Например, выход 15 может представлять собой указатель идентификации изображения, содержащегося в поисковой базе данных 16, которое по существу совпадает с изображением, отсканированным считывающим модулем 12. Это всего лишь один пример из многих возможных форм выхода 15.
На фиг. 2 показана блок-схема последовательности операций, производимых в системе 10, в частности в анализаторе/обработчике 14, в соответствии с вариантом осуществления настоящего изобретения. Процесс начинается, когда анализатор/обработчик 14 принимает данные изображения от считывающего модуля 12. Приняв данные изображения, анализатор/обработчик 14 изображений сначала выполняет ряд функций оценивания изображения, обозначенные блоком 18 на фиг. 2.
Подробности, относящиеся к оцениванию 18 изображения, будут рассмотрены более подробно со ссылкой на фиг. 4. В целом, оценивание 18 изображения предусматривает быструю обработку части доступных данных изображения, позволяющую гарантировать, что принятое изображение создано путем сканирования реального отпечатка пальца (в отличие от мошеннического отпечатка пальца) и имеет достаточное качество для обработки. Согласно одному варианту осуществления, если в результате процесса оценивания изображения оказывается, что сканированное изображение является мошенническим или имеет недостаточное качество, то обработка изображения останавливается или прерывается. В этом случае пользователю системы предоставляется обратная связь, относящаяся к идентифицированным несоответствиям, и он может продолжать обработку только после исправления несоответствий. В процессе оценивания 18 изображения обрабатывается лишь часть имеющихся данных изображения, что ускоряет обработку и обеспечивает обратную связь с пользователем системы, по существу, в режиме реального времени.
На этапе, следующим за оцениванием изображения, который обозначен блоком 20 на фиг. 2, создается модель изображения. Создание 20 модели описано более подробно ниже со ссылкой на фиг. 15. В целом, создание 20 модели предусматривает анализ данных изображения, принятых от считывающего модуля 12, и манипулирование ими. В силу возрастающей потребности в точности данные изображения, обрабатываемые в процессе создания 20 модели, являются полным набором данных изображения, в отличие от частичного набора, обрабатываемого в процессе оценивания 18 изображения. Хотя процедура создания и сборки модели изображения будет более подробно описана ниже, подчеркнем, что модель изображения является совокупностью данных, основанной на исходном изображении отпечатка, и не является факсимиле исходного изображения отпечатка.
После создания модели изображения согласно одному варианту осуществления настоящего изобретения модель изображения используется для одной из двух целей. Первая, как указано на фиг. 2, это регистрация 22 модели. Регистрация 22 модели - это процесс ввода модели в поисковую базу данных 16 и каталогизация в ней. Модели изображений, регистрируемые в базе данных 16, согласно одному варианту осуществления настоящего изобретения, можно получать либо из одного сканированного изображения отпечатка пальца, либо из двух или более сканированных изображений одного и того же отпечатка пальца. Когда для создания модели изображения используются два или более сканированных изображения, в модели изображения выявляются согласующиеся элементы модели, наблюдаемые от сканирования к сканированию. Несогласующиеся элементы модели, например расхождения в данных изображения, являющиеся результатом вышеупомянутых изменений среды считывающего модуля, исключаются.
Согласно одному варианту осуществления настоящего изобретения, когда в процессе регистрации 22 модели используются два или более сканированных изображения, палец удаляют из считывающего модуля 12 после каждой операции сканирования, а затем опять помещают на место перед следующей операцией сканирования. Согласно другому варианту осуществления, между операциями сканирования может пройти значительное время. Поскольку внешние факторы, как то давление пальца, влажность пальца и размещение пальца, могут изменяться от сканирования к сканированию, удаление пальца со считывающего модуля 12 между операциями сканирования повышает вероятность того, что несогласованности среды будут устранены, поскольку они не проявляются в каждой отдельной операции сканирования.
В соответствии с другим вариантом осуществления настоящего изобретения другая цель, для которой можно использовать модель изображения, это сравнение 24 моделей, обозначенное блоком 24 на фиг. 2. Сравнение 24 моделей более подробно описано ниже. В целом, сравнение 24 моделей - это процесс, который можно использовать для сравнения одной модели изображения с другой. Сравнение 24 моделей осуществляется путем применения ряда алгоритмов сдвига и поворота к, по меньшей мере, одной из моделей изображения, пока не будет найдена позиция, в которой две модели можно сравнивать наилучшим образом. Затем вычисляют оценку, выражающую соотношение или долю элементов данных, которые являются общими между двумя моделями изображения.
Согласно иллюстративному варианту осуществления настоящего изобретения, вместо сравнения 24 моделей или совместно с ним можно осуществлять поиск 26 в базе данных, что обозначено блоком 26 на фиг. 2. Поиск 26 в базе данных более подробно описан ниже. В целом, поиск 26 в базе данных предусматривает быстрое и эффективное определение, какая, если таковая существует, из, возможно, тысяч или даже миллионов моделей изображения в базе данных 16 проявляет требуемый уровень подобия при сравнении с целевой моделью изображения. Согласно одному варианту осуществления, целевая модель изображения - это модель изображения, связанная со сканируемым данный момент изображением. Вместо того, чтобы сравнивать модели изображений конкретно, задают набор ключей базы данных, которые описывают различные характеристики модели изображения, что позволяет производить общие, а не конкретные сравнения в процессе поиска 26 в базе данных. Нужный уровень подобия является регулируемым, и его можно выбирать на основании требуемой скорости обработки, требуемого уровня безопасности и других характеристик среды, для защиты которой предназначена система 10.
Подчеркнем, что почти все способы и процедуры, согласно настоящему изобретению, за исключением процедуры антиспуфинга (получения доступа путем обмена), рассмотренной ниже в этой заявке, не зависят от конкретного вида считывающего модуля 12 и могут быть настроены для работы с использованием любой технологии считывания. Однако в целях иллюстрации вариантов осуществления настоящего изобретения будет рассмотрен иллюстративный набор параметров сканирования изображения, соответствующих иллюстративному считывающему модулю 12. В частности, иллюстративные параметры будут соответствовать устройству считывания отпечатков пальцев SACcat™, предлагаемому и продаваемому фирмой Secured Access Control Technologies (работающей под названием BIO-key International), Иган, Миннесота.
На фиг. 3 наглядно представлены детали, относящиеся к иллюстративному набору параметров сканирования изображения. Иллюстративные параметры указаны в целом позицией 28 и не критичны для настоящего изобретения. Иллюстративный считывающий модуль 12, который выдает иллюстративные параметры 28, в данном примере включает в себя камеру, имеющую характеристическое (форматное) отношение 4 к 3, и обеспечивает 64 уровня серого, хотя ни одно из значений не критично для настоящего изобретения. Согласно фиг. 3, параметры 28 сканирования изображения включают в себя область 30 сканирования, которая больше области 32 обработки. Область 32 обработки является частью области 30 сканирования и единственной частью области 30 сканирования, которая обеспечивает данные, фактически воспринимаемые для анализа. В области 30 сканирования имеется 510 строк и 488 пикселей на строку. В целях упрощения объяснения настоящего изобретения предполагается, что считывающий модуль 12 не создает линейного искажения, обусловленного оптикой (предполагается плоское изображение).
На фиг. 4 представлена блок-схема набора процедурных компонентов, соответствующих операциям оценивания 18 изображения, показанным на фиг. 2. Подчеркнем, что основная цель оценивания 18 изображения состоит в том, чтобы гарантировать, что данные изображения, принятые анализатором/обработчиком 14 изображения от считывающего модуля 12, являются результатом сканирования не мошеннического отпечатка пальца и имеют достаточное качество для дальнейшей обработки изображения.
Согласно варианту осуществления настоящего изобретения, о чем было сказано выше, все функции оценивания 18 изображения выполняются с использованием части данных изображения, потенциально доступных для анализа. Согласно одному варианту осуществления, анализатор/процессор 14 принимает полный набор данных изображения от считывающего модуля 12, но использует для анализа при оценивании 18 изображения только каждую вторую строку и каждый второй пиксель информации. Иными словами, в ходе оценивания 18 изображения анализируется только четверть данных в области обработки 32. Цель обработки только части имеющихся данных состоит в ускорении обработки и, таким образом, в обеспечении обратной связи в отношении качества и аутентичности изображения, предоставляемой пользователю системы, по существу, в режиме реального времени. Получив обратную связь в режиме реального времени, пользователь системы может регулировать параметры (изменять давление, приложенное к сканирующей поверхности, создавать не мошеннический источник изображения, вытирать избыточную влагу с пальца и т.д.), пока не исправит всю негативную обратную связь, и результат сканирования изображения не приобретет достаточное качество для дальнейшей обработки изображения.
В частности, оценивание 18 изображения начинается с предварительной обработки 34 (см. фиг. 4). Когда анализатор/обработчик 14 получает данные изображения от считывающего модуля 12, они представляют собой первичный результат сканирования, который также именуют форматом шкалы уровней серого. Главной целью предварительной обработки 34 является уменьшение объема данных. В частности, целью является преобразование первичного сканированного изображения в монохромное изображение или двоичное изображение, что желательно для последующей обработки оценивания 18 изображения. Согласно одному варианту осуществления, предварительная обработка 34 применяется для преобразования первичного сканированного изображения в изображение, отдельные биты которого выражают белый или черный цвет.
В ходе предварительной обработки 34 от считывающего модуля 12 принимается первичное сканированное изображение, аналогичное первичному сканированному изображению 46 на фиг. 5, которое сначала преобразуется в промежуточное изображение, аналогичное промежуточному изображению 48 на фиг. 6. Согласно чертежам, промежуточное изображение 48 аналогично первичному сканированному изображению 46, но содержит улучшения основных особенностей. Для осуществления преобразования изображения, согласно варианту осуществления настоящего изобретения, каждый пиксель промежуточного изображения 48 создают путем усреднения массива n×n пикселей (где n больше 1), взятого из первичного сканированного изображения 46. Согласно одному варианту осуществления применяются массивы 3×3 пикселей. Пиксель (новое значение пикселя) в строке y и столбце x промежуточного изображения 48 задают следующим образом:
Уравнение 1
Задать новое значение пикселя равным нулю.
Цикл по значениям х1 от х-1 до х+1
Цикл по значениям y1 от y-1 до y+1
Прибавить к новому значению пикселя значение пикселя с координатами х1 и y1 в первичном сканированном изображении
Разделить новое значение пикселя на 9.
Сохранить новое значение пикселя в буфере промежуточного изображения в строке y и столбце х.
Следующий этап предварительной обработки 34, согласно одному варианту осуществления, состоит в преобразовании промежуточного изображения 48 (фиг. 6) в монохромное изображение 50, показанное на фиг. 7. Согласно варианту осуществления настоящего изобретения преобразование из промежуточного изображения 48 (фиг. 6) в монохромное изображение 50 (фиг. 7) осуществляется следующим образом. Каждый пиксель монохромного изображения создают, сравнивания среднее значение 5×5 для пикселя, взятого из промежуточного изображения 48, со средним значением 3×3 для того же местоположения пикселя. Следует указать, что, не выходя за пределы объема настоящего изобретения, можно использовать другие размеры пиксельных массивов. Пиксель (новое значение пикселя) в строке y и столбце х монохромного изображения задают следующим образом:
Уравнение 2.
Установить значение среднее_1 равным нулю.
Цикл по значениям х1 от х-2 до х+2
Цикл по значениям y1 от y-2 до y+2
Прибавить к значению среднее_1 значение пикселя с координатами х1 и y1 в улучшенном изображении
Разделить значение среднее_1 на 25 (5, умноженное на 5).
Установить значение среднее_2 равным нулю.
Цикл по значениям х1 от х-1 до х+1
Цикл по значениям y1 от y-1 до y+1
Прибавить к значению average_2 значение пикселя с координатами х1 и y1 в улучшенном изображении
Разделить значение среднее_2 на 9 (3, умноженное на 3)
Если значение среднее_2 больше значения среднее_1
То установить значение пикселя равным нулю
Иначе, установить значение пикселя равным 255.
Сохранить значение пикселя в строке y и столбце х монохромного изображения.
Согласно фиг. 4, другим процессом, входящим в оценивание 18 изображения, является антиспуфинг 36. Чтобы использовать описанные здесь методы антиспуфинга в системе 10 формирования изображения отпечатка пальца, в состав системы должен входить считывающий модуль 12, содержащий как инфракрасный источник света, так и светодиодный источник света для освещения оптического устройства. Конечно, с помощью других считывающих устройств можно реализовать другие технологии антиспуфинга. Антиспуфинг 36 - это способ обнаружения неживого пальца, например искусственного пальца, рисунка на бумаге или фотоизображения на лавсановой пленке. Антиспуфинг также обеспечивает защиту от предварительно записанных/воспроизведенных результатов сканирования, полученных вживую. Антиспуфинг, согласно одному варианту осуществления настоящего изобретения, предусматривает восприятие и сравнение двух последовательных изображений, причем первое изображение подсвечено сбоку инфракрасным источником света, а второе изображение подсвечено сзади светодиодным источником видимого света.
Процесс антиспуфинга начинается с того, что убеждаются, что светодиодный источник света для задней подсветки отключен. Затем включают источник инфракрасного света для боковой подсветки. Согласно одному варианту осуществления, это переключение источников света осуществляется на случайной основе, что не позволяет осуществлять сценарии спуфинговой атаки на основе предварительной записи/воспроизведения. Изображение с инфракрасной подсветкой воспринимается и, согласно одному варианту осуществления, подвергается предварительной обработке в соответствии с ранее описанной предварительной обработкой 34 для получения первого монохромного изображения. Монохромные изображения 58, 59 и 60, соответственно представленные на фиг. 9А, 9В и 9С, иллюстрируют изображения, полученные с использованием инфракрасного источника света для сканирования изображений, содержащихся, также соответственно, на источнике в виде лавсановой пленки, бумажном источнике и источнике в виде живого пальца.
Следующий этап процесса антиспуфинга состоит в отключении инфракрасного источника света и включении светодиодного источника света для задней подсветки с целью восприятия второго изображения, которое, согласно одному варианту осуществления, подвергается предварительной обработке и преобразованию во второе монохромное изображение. Монохромные изображения 52, 54 и 56, соответственно представленные на фиг. 8А, 8В и 8С, иллюстрируют изображения, полученные с использованием светодиодного источника света для задней подсветки для сканирования изображений, также соответственно, с источника в виде лавсановой пленки, с бумажного источника и источника в виде живого пальца.
На конечном этапе антиспуфинга инфракрасно-ориентированные монохромные изображения сравнивают со светодиодно-ориентированными изображениями и отмечают совпадающие значения пикселей. В целом, сканированные изображения живого пальца создают очень высокую корреляцию подобных значений по сравнению с изображениями, полученными с мошеннических источников изображения. Иллюстративно, изображения 56 и 62, по существу, одинаковы, тогда как главные особенности изображений 52 и 58 и изображения 54 и 60 включают в себя пиксели, имеющие значения, по существу, противоположные друг другу (т.е. особенность, которая является черной на одном изображении, не является черной в соответствующем сравнительном изображении). Согласно одному варианту осуществления настоящего изобретения, система 10 формирования изображения отпечатка пальца, получив результаты, указывающие, что было представлено неживое изображение, прекращает дальнейшую обработку, пока для сканирования не будет представлен живой палец.
Заметим, что, хотя способ антиспуфинга был описан в отношении сравнения монохромных сканированных изображений, процесс антиспуфинга с тем же успехом можно применять к первичному результату сканирования или другим конфигурациям изображения. Однако, поскольку монохромные изображения содержат ограниченный диапазон значений пикселей, они обеспечивают гладкую сравнительную модель, которая обычно дает чистый и точный результат.
Согласно фиг. 4, еще один компонент в процессе оценивания 18 изображения представляет собой генерацию 38 таблицы крутизны. Целью таблицы крутизны после ее генерации является не создание информации, непосредственно используемой для обеспечения обратной связи пользователю системы, а создание статистического инструмента, используемого как вспомогательное средство при последующей обработке оценивания 18 изображения. В частности, таблицу крутизны можно использовать для генерации 40 дополнительной гистограммы и можно использовать при определении 42 центра отпечатка.
Генерация 38 таблицы крутизны начинается с того, что монохромное изображение, созданное в ходе предварительной обработки 34, например монохромное изображение 50 (фиг. 7), подвергают разбиению с образованием массива сеток n×n пикселей (где n больше 1). Согласно одному варианту осуществления, применяется массив сеток 8×8 пикселей. Согласно этому варианту осуществления, и в соответствии с иллюстративными параметрами 28 сканирования (фиг. 3), массив сеток 8×8 пикселей состоит из 27 сеток в направлении х и 29 сеток в направлении y.
Для облегчения создания таблицы крутизны сначала создают первичную таблицу крутизны. Первичная таблица крутизны - это, иллюстративно, в соответствии с иллюстративными параметрами 28, двумерный массив 27×29, причем каждый элемент таблицы содержит три элемента:
1. Счетчик изменений координаты х.
2. Счетчик изменений координаты y.
3. Счетчик протестированных пикселей.
Таблицу первичных данных крутизны создают, производя контурную трассировку особенностей (признаков) в каждой сетке пикселей массива сеток пикселей, полученного при разбиении монохромного изображения 50. По мере прохождения трассы через пиксельные сетки три элемента, входящие в состав таблицы первичных данных крутизны, увеличиваются. Ниже приведена диаграмма, показывающая значения, подлежащие добавлению в таблицу первичных данных крутизны для возможных комбинаций восьми следующих пикселей (Р - текущий пиксель, N - следующий пиксель, * представляет обычный пиксель и служит заполнителем в целях отображения):
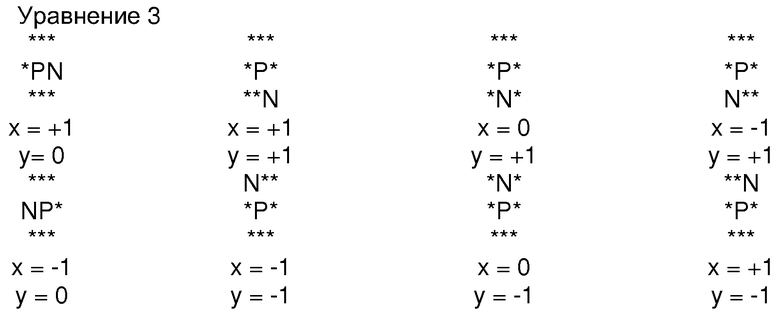
Изображение 64 на фиг. 10 является иллюстрацией монохромного изображения по завершении контурной трассировки.
По завершении контурной трассировки по всем пиксельным сеткам и по завершении создания таблицы первичных данных крутизны можно генерировать таблицу крутизны. Таблица крутизны - это двумерный массив и, согласно иллюстративным параметрам 28 (фиг. 3), имеет размер 27×29. Каждый элемент таблицы крутизны состоит из одного элемента, а именно крутизны папиллярной линии или папиллярных линий, проходящей(их) через каждую конкретную пиксельную сетку. Первоначально, все элементы в таблице крутизны установлены равными минус единице (неправильная крутизна). Крутизну для каждой пиксельной сетки вычисляют с использованием информации из таблицы первичных данных крутизны и, в частности, вычисляют следующим образом:
Уравнение 4
Установить счетчик координаты х равным нулю.
Установить счетчик координаты y равным нулю.
Установить значение счетчика пикселей равным нулю.
Цикл по значениям x1 от х-1 до х+1
Цикл по значениям y1 от y-1 до y+1
В координатах х1 и y1 первичной таблицы крутизны
Прибавить к счетчику пикселей счетчик протестированных пикселей.
Прибавить к счетчику координаты х изменения координаты х
Прибавить к счетчику координаты y изменения координаты y
В координатах х и y первичной таблицы крутизны
Прибавить к счетчику пикселей счетчик протестированных пикселей, затем разделить на 2.
Прибавить к счетчику координаты х изменения координаты х, затем разделить на 2.
Прибавить к счетчику координаты y изменения координаты y, затем разделить на 2.
Если счетчик пикселей больше 10
То вычислить крутизну с использованием тригонометрической функции арксинус.
Функция нахождения угла
Вход: дельта y и дельта х (предварительно вычисленные выше)
Установить квадрант равным 0
Если дельта y меньше 0
То прибавить 2 к квадранту
Если дельта х меньше 0
То прибавить 1 к квадранту
Гипотенуза = квадратный корень из ((дельта х в квадрате) + (дельта y в квадрате))
Угол = арксинус (дельта y, деленная на гипотенузу) умножить на количество градусов в радиане.
Если квадрант равен 1
То угол = 180 - угол
Иначе если квадрант равен 2
То угол = 360 - угол
Иначе если квадрант равен 3
То угол = 180 + угол
Поскольку крутизна имеет значения между 0 и 180, то угол преобразуется в крутизну следующим образом:
Если угол больше или равен 180
То крутизна равна угол минус 180
Иначе крутизна равна угол
Увеличить количество обработанных пикселей на единицу.
Изображение 66 на фиг. 11 является иллюстрацией монохромного изображения с наложением крутизны на основании полной таблицы крутизны.
Согласно фиг. 4, еще один компонент оценивания 18 изображения представляет собой генерацию 40 гистограммы. Полная гистограмма используется в системе 10 формирования изображения для определения качества данных сканированного изображения отпечатка пальца и пригодности данных изображения для последующей обработки.
Полная гистограмма представляет собой многомерный массив n×n (где n больше 1), например двумерный, и, согласно иллюстративным параметрам 28 (фиг. 3), массив 6×6. Каждая ячейка массива соответствует части данных изображения, подвергаемых анализу. Изображение 68 на фиг. 12 - это иллюстрация полной гистограммы, которая содержит ячейку 67, помимо других, непомеченных ячеек. Изображение 70 на фиг. 13 - это иллюстрация той же полной гистограммы, наложенной на первичное сканированное изображение, из которого иллюстративно получена гистограмма. Присваивая разные участки изображения разным ячейкам (интервалам) массива гистограммы, можно производить множественные отдельные определения качества для ограниченных объемов данных изображения, соответствующих каждой из различных ячеек гистограммы, вместо того, чтобы производить единичное определение качества для всего набора данных изображения. Согласно одному варианту осуществления настоящего изобретения, эти множественные определения качества можно использовать для избирательного исключения частей данных изображения, соответствующих ячейкам, которые демонстрируют низкие характеристики качества. Исключив ячейки низкого качества, можно произвести положительное или отрицательное системное определение относительно наличия или отсутствия достаточного количества ячеек данных приемлемого качества для последующей обработки.
Согласно варианту осуществления настоящего изобретения каждая ячейка гистограммы содержит список гистограммы. Список гистограммы в соответствии с вышеописанным иллюстративным считывающим модулем 12 представляет собой массив из 64 элементов (от нуля до 63). Каждому элементу присвоено значение пикселя (иллюстративный считывающий модуль 12 имеет 64 возможных значений пикселя), и он содержит счетчик количества пикселей данных изображения, имеющих присвоенное значение пикселя. Каждая ячейка гистограммы также иллюстративно содержит счетчик количества пикселей в ячейке, которые обработаны и классифицированы в списке гистограммы.
Следует понимать, что для некоторых технологий считывания могут требоваться гистограммы с другими конфигурациями для проведения точных определений качества. Например, некоторые технологии считывающего модуля 12 могут включать в себя более широкий или более узкий диапазон значений пикселя. Следует понимать, что гистограммы, подстроенные в соответствии с другими технологиями считывающего модуля 12, не выходят за пределы объема настоящего изобретения.
Ниже приведено более подробное описание функций, осуществляемых при генерации иллюстративного двухмерного 6×6 массива гистограммы на этапе генерации 40 гистограммы в составе оценивания 18 изображения:
Уравнение 5
Ширина окна определяется как количество пикселей на строку, деленное на 6 (включен каждый второй пиксель).
Высота окна определяется как количество строк, деленное на 6 (включена каждая вторая строка).
Цикл по значениям х от нуля до длины строки
Цикл по значениям y от нуля до количества строк
Значение пикселя равно содержимому первичного сканированного изображения в координатах х и y.
Координата х таблицы крутизны равна х, деленному на 8 (иллюстративный размер сетки таблицы крутизны).
Координата y таблицы крутизны равна y, деленному на 8 (иллюстративный размер сетки таблицы крутизны).
Если содержимое таблицы крутизны не равно -1
(Напомним: -1 представляет область, где нельзя вычислить крутизну.)
То
Координата х таблицы гистограммы равна х, деленному на ширину окна
Координата y таблицы гистограммы равна y, деленному на высоту окна.
Увеличить список гистограммы, при индексном значении пикселя, на единицу.
Согласно одному варианту осуществления генерации 40 гистограммы различают четыре уровня качества изображения:
1. Отличное.
2. Хорошее.
3. Удовлетворительное.
4. Плохое.
Кроме того, области, качество которых признано удовлетворительным или плохим, могут иметь два дополнительных атрибута: слишком темная или слишком светлая.
Конкретные детали, касающиеся типов элементов данных, записанных в полной гистограмме, и порядка интерпретации этих элементов данных для классификации качества изображения различаются в зависимости от нужных типов данных и считывающего модуля 12, используемого в системе 10 формирования изображения отпечатка пальца. Другими словами, классификацию качества можно настраивать в соответствии с нужным типом данных качества изображения и в соответствии с конкретным считывающим модулем 12.
Согласно одному варианту осуществления классификации качества данные, записанные в каждой ячейке гистограммы, включают в себя семь конкретных элементов данных. В интересах упрощения описания снабдим семь элементов данных метками A-G. Ячейка 72 гистограммы на фиг. 14 содержит элементы данных A-G, которые иллюстративно соответствуют следующей информации:
Уравнение 6
А. Выражает количество пикселей в списке гистограммы, соответствующих наиболее белым 25% из перечисленных значений пикселей.
В. Выражает количество пикселей в списке гистограммы, соответствующих наиболее белым 35% из перечисленных значений пикселей.
С. Максимальная высота между точками В и F (не используется в определении качества).
D. Среднее значение пикселя.
Е. Минимальная высота между точками В и F (не используется в определении качества).
F. Выражает количество пикселей в списке гистограммы, соответствующих наиболее черным 35% из перечисленных значений пикселей.
G. Выражает количество пикселей в списке гистограммы, соответствующих наиболее черным 25% из перечисленных значений пикселей.
Согласно одному варианту осуществления определения качества качество данных изображения определяют, сравнивая столбцы, связанные с точками A, B, F и G. В частности, качество данных изображения иллюстративно определяют следующим образом:

Согласно рассмотренному более подробно ниже, обратная связь в отношении установленного качества изображения предоставляется пользователю системы в соответствии со взаимодействием 44 обратной связи.
Согласно фиг. 4, определение 42 центра отпечатка - это еще один компонент, который может выходить в оценивание 18 изображения. Определение 42 центра отпечатка осуществляют, анализируя данные изображения с целью отыскания центра соответствующего изображения отпечатка. Один способ осуществления определения 42 центра отпечатка состоит в применении набора правил фильтрации к данным, содержащимся в таблице крутизны, сгенерированной в ходе генерации 38 таблицы крутизны. Определив центр отпечатка, производят дальнейшее определение в отношении того, следует ли произвести новое сканирование, когда палец пользователя системы повторно помещен на поверхность формирования изображения считывающего модуля 12. Обратная связь в отношении этого дополнительного определения предоставляется пользователю системы в соответствии со взаимодействием 44 обратной связи.
Согласно фиг. 4, взаимодействие 44 обратной связи является еще одним возможным способом оценивания 18 изображения. Как было отмечено выше, считывающий модуль 12 системы 10 формирования изображения отпечатка пальца (фиг. 1) способен воспринимать результат сканирования "вживую" отпечатка пальца. Согласно взаимодействию 44 обратной связи, когда анализатор/обработчик 14 изображений принимает данные изображения отпечатка пальца от считывающего модуля 12 и осуществляет функции оценивания 18 изображения относительно части этих данных, пользователю системы 10 предоставляются обратная связь, по существу, в режиме реального времени и инструкции в отношении того, что неадекватные характеристики данных сканированного изображения должны быть улучшены. Обратная связь и инструкции для исправления неадекватности данных изображения могут относиться к правильному расположению пальца пользователя на считывающем модуле 12 (определение 42 центра отпечатка). Альтернативно, они могут относиться к обнаружению живого пальца (антиспуфинг 36) или к характеристикам качества данных изображения (генерация 40 гистограммы). Согласно одному варианту осуществления настоящего изобретения, также может предоставляться обратная связь в отношении влагосодержания пальца пользователя системы.
По завершении оценивания 18 изображения следующий этап, указанный блоком 20 на фиг. 2, состоит в создании модели изображения. На фиг. 15 изображена блок-схема набора процедурных компонентов, которые, согласно варианту осуществления настоящего изобретения, составляют создание 20 модели. Для повышения точности создания 20 модели, по существу, все имеющиеся данные изображения, согласно одному варианту осуществления, все данные изображения, включенные в иллюстративную область 32 обработки (фиг. 3), поступают на анализатор/обработчик 14 изображения для обработки создания 20 модели. В этом состоит отличие от обработки части данных на этапе оценивания 18 изображения в целях скорости и экономии. Хотя некоторые из компонентов создания 20 модели аналогичны компонентам оценивания 18 изображения, ни один из наборов данных, сгенерированных на этапе оценивания 18 изображения, не используется на этапе создания 20 модели. Создание 20 модели, как и оценивание 18 изображения, начинается с установления данных первичного сканированного изображения и продолжается с этой точки.
Создание 20 модели, согласно фиг. 15, начинается с антиспуфинга 74. Антиспуфинг 74 - это необязательный этап, который осуществляется по существу таким же образом и в тех же целях, как описано выше в отношении антиспуфинга 36, процедурного компонента оценивания 18 изображения. Однако одно важное различие между антиспуфингом 74 и антиспуфингом 36 состоит в том, что антиспуфинг 74 осуществляется с использованием полного набора данных, тогда как антиспуфинг 36 осуществляется с использованием только части имеющихся данных. Целью антиспуфинга 74 является обеспечение дополнительной уверенности, что источник данных первичного сканированного изображения не является мошенническим. Согласно одному варианту осуществления, когда в результате антиспуфинга 74 выясняется, что источник первичных данных сканирования является мошенническим, то последующая обработка прекращается, пока системе 10 не будет представлен правильный источник изображения.
Антиспуфинг 74 можно осуществлять с использованием данных первичного сканированного изображения или альтернативного формата данных, созданного на этапе создания 20 модели. Например, антиспуфинг 74 можно осуществлять с использованием монохромных изображений, которые, как будет рассмотрено ниже, являются продуктом предварительной обработки 76. Другими словами, хотя антиспуфинг 74 проиллюстрирован на фиг. 15 как первый этап создания 20 модели, его можно осуществлять позднее в процессе создания 20 модели, или, поскольку антиспуфинг 74 является необязательным, этап вообще можно исключить.
Ранний этап в процессе создания 20 модели, обозначенный блоком 76 на фиг. 15, представляет собой предварительную обработку 76. Целью предварительной обработки 76 является создание монохромного изображения с отрегулированным характеристическим (форматным) отношением и со сглаженными и различимыми особенностями, пригодными для последующей обработки. Предварительная обработка 76 отличается от этапа предварительной обработки, описанного выше применительно к оцениванию 18 изображения. В частности, предварительную обработку 76 осуществляют с использованием полного, а не частичного, набора имеющихся данных изображения. Кроме того, предварительная обработка 76 включает в себя дополнительные этапы, предназначенные для устранения иррегулярностей и несогласованностей в окончательном монохромном изображении. Эти этапы, хотя и не необходимые для оценивания 18 изображения, оказываются полезными для последующей обработки в ходе обработки создания 20 модели.
На фиг. 16 показана блок-схема, иллюстрирующая основные процедурные компоненты предварительной обработки 76 в соответствии с вариантом осуществления настоящего изобретения. Начальный этап процесса, обозначенный блоком 90, состоит в генерации набора данных изображения, аналогичного данным первичного сканированного изображения, но с измененным форматным отношением. Согласно одному варианту осуществления, форматные отношение регулируют до конфигурации 1 к 1. Коррекция форматного отношения необходима для последующей обработки, которая предусматривает поворот изображения и соответствующих данных. По-видимому, создание 20 модели можно осуществлять без регулировки форматного отношения изображения, но регулировка полезна для процедур, выполняемых после создания 20 модели, например сравнения 24 моделей.
Согласно варианту осуществления настоящего изобретения форматное отношение первичного сканированного изображения изменяют путем построчного копирования первичного сканированного изображения и дублирования строк в надлежащие моменты времени и места, чтобы создавать скорректированное первичное сканированное изображение с нужным масштабом форматного отношения. Изображение 98 на фиг. 17 является иллюстрацией скорректированного первичного сканированного изображения, в котором форматное отношение первичного сканированного изображения отрегулировано равным 1 к 1.
Другой компонент предварительной обработки 76, обозначенный блоком 92 на фиг. 16, представляет собой преобразование скорректированного первичного результата сканирования (изображения 98 на фиг. 17) в монохромное изображение. Поскольку соответственно полученное монохромное изображение базируется на всех имеющихся данных изображения, связанных с изображением, имеющим измененное форматное отношение, маловероятно, что это монохромное изображение будет идентично изображению, сгенерированному в ходе оценивания 18 изображения. Кроме того, характеристики монохромного изображения, созданного на этапе создания 20 модели, которые будут рассмотрены ниже, в конце концов, изменяют и регулируют, чтобы подчеркнуть конкретные характеристики изображения. Это подчеркивание характеристик изображения полезно для создания 20 модели, но не является необходимым для оценивания 18 изображения.
Согласно варианту осуществления настоящего изобретения первый этап преобразования скорректированного первичного сканированного изображения в монохромное изображение состоит в создании промежуточного изображения. Целью создания промежуточного изображения является усреднение особенностей в скорректированном первичном сканированном изображении, которые, по большей части, являются слишком светлыми или слишком темными, возможно, вследствие влагосодержания пальца пользователя системы или характеристик подсветки. Усреднение этих особенностей создает результирующее изображение, которое обеспечивает генерацию более полного и согласованного (рамочного) каркаса, которая осуществляется на последующих этапах обработки. Согласно одному варианту осуществления для создания промежуточного изображения каждый пиксель выбирают путем усреднения пиксельного массива 5×5, взятого из скорректированного первичного сканированного изображения ("скорректированное" означает, что отрегулировано форматное отношение изображения). Пиксель (новое значение пикселя) в строке y и столбце х промежуточного изображения задают следующим образом:
Уравнение 8
Установить новое значение пикселя равным нулю.
Цикл по значению х1 от х-2 до х+2
Цикл по значению y1 от y-2 до y+2
Прибавить к новому значению пикселя значение пикселя с координатами х1 и y1 в скорректированном первичном сканированном изображении
Разделить новое значение пикселя на 25 и округлить до ближайшего целого значения.
Сохранить новое значение пикселя промежуточного изображения в строке y и столбце х.
Изображение 100 на фиг. 18 - это иллюстрация промежуточного изображения. Следует понимать, что, не выходя за рамки сущности настоящего изобретения, в ходе преобразования к формату промежуточного изображения можно применять пиксельные массивы других размеров.
Согласно одному варианту осуществления преобразования из формата скорректированного первичного сканированного изображения в формат монохромного изображения, после получения промежуточного изображения, к промежуточному изображению применяется алгоритм обнаружения краев для получения улучшенного изображения. Согласно одному варианту осуществления, алгоритм обнаружения краев применяется следующим образом:
Уравнение 9
Установить новое значение пикселя равным шестикратному значению пикселя в строке y и столбце х промежуточного изображения.
Вычесть из нового значения пикселя значение пикселя в строке y-1 и столбце х-1 промежуточного изображения.
Вычесть из нового значения пикселя значение пикселя в строке y-1 и столбце х+1 промежуточного изображения.
Вычесть из нового значения пикселя значение пикселя в строке y+1 и столбце х-1 промежуточного изображения.
Вычесть из нового значения пикселя значение пикселя в строке y+1 и столбце х+1 промежуточного изображения.
Если новое значение пикселя меньше нуля, то установить новое значение пикселя равным нулю.
Сохранить новое значение пикселя в строке y и столбце x улучшенного изображения.
Изображение 102 на фиг. 19 - это иллюстрация расширенного изображения после применения алгоритма обнаружения краев.
Окончательным этапом блока 92, входящего в состав предварительной обработки 76 (фиг. 16), является преобразование улучшенного изображения в формат монохромного изображения. Согласно одному иллюстративному варианту осуществления каждый пиксель монохромного изображения создают, определяя среднее значение пикселя большой области сетки и сравнивая это среднее со средним значением пикселя меньшей области сетки для того же местоположения пикселя. Для определения установления в этом месте соответствующего пикселя имеющим белый или черный уровень (т.е. для получения монохромного изображения) используют пороговое изменение разделения между средними значениями пикселя для большой и малой пиксельных сеток. Размеры пиксельных сеток и пороговые значения можно выбирать в соответствии с характеристиками используемого устройства считывания изображения. Согласно одному варианту осуществления, пиксель (новое значение пикселя) в строке y и столбце х монохромного изображения задают следующим образом:
Уравнение 10
Установить значение среднее_1 равным нулю.
Цикл по значению х1 от х-6 до х+6
Цикл по значению y1 от y-6 до y+6
Прибавить к значению среднее_1 значение пикселя с координатами х1 и y1 в изображении с обнаруженными краями
Разделить значение среднее_1 на 169 (13 в квадрате).
Установить значение среднее_2 равным нулю.
Цикл по значению х1 от х-1 до х+1
Цикл по значению y1 от y-1 до y+1
Прибавить к значению среднее_2 значение пикселя с координатами х1 и y1 в изображении с обнаруженными краями
Разделить среднее_2 на 9 (3 в квадрате).
Если значение среднее_2 больше, чем значение среднее_1 плюс 4
То установить значение пикселя равным нулю
Иначе, установить значение пикселя равным 255.
Сохранить значение пикселя в строке y и столбце х монохромного изображения.
Изображение 104 на фиг. 20 - это иллюстрация монохромного изображения, полученного соответствующим образом.
Еще один компонент предварительной обработки 76, указанный блоком 94 на фиг. 16, состоит в обнаружении и заливке иррегулярностей, в частности маленьких дырок в монохромном изображении. Обнаружение и заливка маленьких дырок в монохромном изображении необходима для того, чтобы в каркасном изображении, которое впоследствии будет получено из монохромного изображения в процессе создания 20 модели, не было пузырьков или пустот. Процесс обнаружения иррегулярностей осуществляется путем сканирования монохромного изображения, например изображения 104 на фиг. 20, до обнаружения необработанного пикселя со значением нуль. В этот момент обнаруженный пиксель помечается как обработанный и вызывается процедура рекурсивного спуска. Каждый пиксель с нулевым значением помечается как обработанный, и соответствующие координаты х и y сохраняются в таблице. Когда больше нельзя обнаружить пикселей с нулевым значением, вычисляется размер областей пикселей с нулевым значением (количество ячеек с координатами х и y в таблице). Иллюстративно, если размер области составляет 35 пикселей или меньше, то значение 35 пикселей выбирают на основании характеристик изображения, указанных в связи с фиг. 3, и, предполагая, что область имеет примерно круглую форму, область заливают с использованием значения 255 пикселя. Количество пикселей, необходимых, чтобы область можно было считать подлежащей заливке, можно регулировать в соответствии с конкретным считывающим модулем 12, не выходя за рамки сущности настоящего изобретения. После проверки всего монохромного изображения процесс блока 94 завершается.
Изображение 106 на фиг. 21 - это иллюстрация монохромного изображения, например изображения 104 на фиг. 20, после обнаружения иррегулярностей, которые в иллюстративных целях залиты пикселями, имеющими, по существу, белое значение. Согласно одному варианту осуществления настоящего изобретения, координаты центра областей белой заливки в изображении 106 на фиг. 21 и размер этих областей сохраняются в таблице и классифицируются как точечные элементы данных. Эти точечные элементы данных, иллюстративно именуемые микродеталями, классифицируемые по своему местоположению и соответствующему значению крутизны папиллярной линии, на которых они располагаются, являются точками данных изображения, которые являются уникальными для конкретного пользователя системы, и, совместно с другими точками элементов данных, могут каталогизироваться и использоваться для сравнения одного набора сканированных данных изображения с другим. Точечные микродетали малы (порядка одной тысячной дюйма в диаметре) и, вероятно, представляют местоположения потовых желез пользователя системы. Заметим, что количество точечных микродеталей, идентифицированных в результате сканирования изображения, существенно зависит от разрешающей способности конкретного считывающего модуля 12 и от состояния подушечки пальца (влажная, сухая, поврежденная и т.д.). Чем выше разрешающая способность считывающего модуля 12, тем больше точечных микродеталей можно идентифицировать.
Окончательный компонент предварительной обработки 76, обозначенный блоком 96 на фиг.16, состоит в сглаживании и заливке элементов изображения в монохромном изображении. Применительно к данным изображения отпечатка пальца элементы изображения в монохромном изображении обычно представляют собой элементы папиллярных линий отпечатка пальца. Процесс сглаживания и заливки предназначен для добавления и удаления пикселей на границе элементов папиллярных линий отпечатка пальца. Сглаживание границ вдоль элементов папиллярных линий оптимизирует качество получаемых в дальнейшем каркасных изображений, которые позднее выводятся из полного монохромного изображения в процессе создания 20 модели.
Входными данными процесса сглаживания и заливки 96, согласно одному варианту осуществления, является монохромное изображение, залитое в соответствии с блоком 94. Изображение 108 на фиг. 22 является иллюстрацией залитого монохромного изображения, в котором залитые пиксели уже не содержат, по существу, белое значение, как было в случае, изображенном на фиг. 21. На выходе процесса сглаживания и заливки 96 получают сглаженное монохромное изображение, подобное изображению 110 на фиг. 23. Для этого преобразования каждый пиксель залитого монохромного изображения используют как центр массива 3×3. Каждый из окружающих восьми пикселей используется для формирования индекса в таблице. Содержимое каждого элемента таблицы содержит два флага:
1. Ничего не делать
2. Установить центральный пиксель.
Ниже приведены индексы к таблице для тех значений, которые содержат флаг установки. Все остальные элементы таблицы содержат флаг «ничего не делать».



предварительная обработка 76, согласно варианту осуществления настоящего изобретения, также завершается.
Еще один процедурный компонент создания 20 модели, обозначенный блоком 78 на фиг. 15, представляет собой генерацию 78 таблицы крутизны. Генерация 78 таблицы крутизны, по существу, аналогична генерации 38 таблицы крутизны, описанной выше со ссылкой на фиг. 4 и оценивание 18 изображения. Основное различие между генерацией 78 таблицы крутизны и генерацией 38 таблицы крутизны состоит в том, что в процессе генерации 78 таблицы крутизны обрабатываются все имеющиеся данные изображения, а не часть имеющихся данных изображения. Кроме того, генерация 78 таблицы крутизны предусматривает обработку уникального монохромного изображения, сформированного в соответствии с процедурами предварительной обработки 76, а не ограниченного монохромного изображения, сформированного в соответствии с процедурами предварительной обработки 34.
В то время как генерация 38 таблицы крутизны в соответствии с иллюстративными параметрами 28 сканирования изображения, заданными со ссылкой на фиг. 3, предусматривала обработку иллюстративного массива пиксельных сеток 8×8 (сеток пикселей), имеющего 27 сеток в направлении х и 29 сеток в направлении y, генерация 78 таблицы крутизны предусматривает обработку более полного набора данных и, соответственно, другой конфигурации сеток. Кроме того, в ходе создания 20 модели иллюстративные параметры 28 могут изменяться в соответствии с настройками форматного отношения, произведенными в ходе предварительной обработки 76. Например, на фиг. 24 представлен альтернативный набор иллюстративных параметров 112 сканирования изображения, которые содержат область 114 сканирования и область 116 обработки. Альтернативные иллюстративные параметры 112 сканирования изображения аналогичны иллюстративным параметрам 28 сканирования, но область 116 обработки отражает иллюстративное изменение конфигурации размеров, которое может произойти при регулировке форматного отношения сканирования изображения в ходе предварительной обработки 76.
Поэтому, иллюстративно, в соответствии с иллюстративными параметрами 112 сканирования изображения, генерация 78 таблицы крутизны осуществляется путем разбиения изображения, соответствующего области 116 обработки с образованием иллюстративного массива сеток 10×10 пикселей. С учетом того, что нужно анализировать каждый пиксель и каждую строку, это дает 44 сетки в направлении х и 60 сеток в направлении y. Следует подчеркнуть, что точные значения, используемые в процессе генерации таблицы крутизны, зависят от характеристик используемого конкретного считывающего модуля 12. Анализ можно настраивать в соответствии с любым считывающим модулем 12.
Как объяснялось выше в отношении генерации 38 таблицы крутизны, в процессе генерации таблицы крутизны создается две таблицы: таблица первичных данных крутизны и таблица крутизны. В соответствии с иллюстративными параметрами 112 сканирования таблица первичных данных крутизны - это двумерный массив, состоящий из 44×60 ячеек, причем каждая ячейка в таблице первичных данных крутизны состоит из трех отдельных элементов:
1. Счетчик изменений координаты х.
2. Счетчик изменений координаты y.
3. Счетчик протестированных пикселей.
Таблицу первичных данных крутизны создают, производя контурную трассировку монохромного изображения, созданного в ходе предварительной обработки 76. По мере прохождения трассы через пиксельные сетки три элемента, входящие в состав таблицы первичных данных крутизны, увеличиваются. Ниже приведена диаграмма, демонстрирующая значения, подлежащие прибавлению для комбинаций восьми следующих пикселей (Р - это текущий пиксель, N - это следующий пиксель, * представляет обычный пиксель и является заполнителем для целей отображения):

Изображение 118 на фиг. 25 является иллюстрацией монохромного изображения, полученного в соответствии с предварительной обработкой 76, по завершении контурной трассировки. После трассировки всего изображения и завершения создания таблицы первичных данных крутизны генерируется таблица крутизны. Иллюстративно, таблица крутизны - это также двумерный массив, состоящий из 44×60 ячеек. Каждая ячейка в таблице крутизны состоит из одного элемента, а именно крутизны папиллярной линии или папиллярных линий, проходящих через соответствующую сетку. Первоначально, все элементы в таблице крутизны установлены равными -1 (неверная крутизна). Крутизну для каждой пиксельной сетки вычисляют с использованием информации из таблицы первичных данных крутизны и делают это следующим образом:
Уравнение 13
Установить счетчик координаты х равным нулю.
Установить счетчик координаты y равным нулю.
Установить значение счетчика пикселей равным нулю.
Цикл по значениям x1 от х-1 до х+1
Цикл по значениям y1 от y-1 до y+1
В координатах х1 и y1 первичной таблицы крутизны
Прибавить к счетчику пикселей счетчик протестированных пикселей.
Прибавить к счетчику координаты х изменения координаты х
Прибавить к счетчику координаты y изменения координаты y
В координатах х и y первичной таблицы крутизны
Прибавить к счетчику пикселей счетчик протестированных пикселей, затем разделить на 2.
Прибавить к счетчику координаты х изменения координаты х, затем разделить на 2.
Прибавить к счетчику координаты y изменения координаты y, затем разделить на 2.
Если счетчик пикселей больше 10
То вычислить крутизну с использованием тригонометрической функции арксинус.
Функция нахождения угла
Вход: дельта y и дельта х (предварительно вычисленные выше)
Установить квадрант равным 0
Если дельта y меньше 0
То прибавить 2 к квадранту
Если дельта х меньше 0
То прибавить 1 к квадранту
Гипотенуза = квадратный корень из ((дельта х в квадрате) + (дельта y в квадрате))
Угол = арксинус (дельта y, деленная на гипотенузу) умножить на количество градусов в радиане.
Если квадрант равен 1
То угол = 180 - угол
Иначе если квадрант равен 2
То угол = 360 - угол
Иначе если квадрант равен 3
То угол = 180 + угол
Поскольку крутизна имеет значения между 0 и 180, то угол преобразуется в крутизну следующим образом:
Если угол больше или равен 180
То крутизна равна угол минус 180
Иначе крутизна равна угол
Увеличить количество обработанных пикселей на единицу.
Изображение 120 на фиг. 26 - это иллюстрация монохромного изображения, полученного в соответствии с предварительной обработкой 76 и с наложением крутизны, согласующимся с полной таблицей крутизны. Полная таблица крутизны используется при последующей обработке. В частности, она используется как вспомогательное средство при генерации 82 каркаса при расширении линий каркаса и при удалении ненужных линий каркаса.
В соответствии с блоком 80 на фиг. 15 и согласно варианту осуществления настоящего изобретения в процессе создания 20 модели можно генерировать гистограмму. Гистограмму, полученную в результате генерации 80 гистограммы, можно применять для определения качества изображения в разных фрагментах анализируемых данных изображения. Если определено, что часть сетки имеет недостаточное качество для перехода к дальнейшей обработке, то эту часть сетки можно независимо исключить из оставшейся части процесса создания 20 модели. Заметим, что, согласно настоящему изобретению, генерация 80 гистограммы может осуществляться на любом этапе процесса создания 20 модели.
Генерация 80 гистограммы осуществляется, по существу, таким же образом, как и генерация 40 гистограммы, описанная выше со ссылкой на фиг. 4, и оценивание 18 изображения. Основные различия между генерацией 80 гистограммы и генерацией 40 гистограммы состоят в том, что в ходе генерации 80 гистограммы обрабатываются все, а не часть имеющихся данных изображения, и в том, что значения таблицы крутизны, используемые в ходе генерации 80 гистограммы, представляют собой значения, сгенерированные в ходе генерации 78 таблицы крутизны, а не в ходе генерации 38 таблицы крутизны.
Важным компонентом создания 20 модели является генерация 82 каркаса, указанная блоком 82 на фиг. 15. Генерация 82 каркаса - это процесс утонения конкретного набора тонких линий, иллюстративно именуемых линиями каркаса, особенностей, - в частности, особенностей папиллярных линий отпечатка пальца, входящих в состав монохромного изображения, полученного в соответствии с предварительной обработкой 76. На фиг. 27 показана блок-схема, подробно иллюстрирующая процедурные компоненты генерации 82 каркаса согласно варианту осуществления настоящего изобретения.
Один из компонентов генерации 82 каркаса, указанный блоком 122 на фиг. 27, представляет собой обнаружение пикселей монохромного изображения, которые располагаются приблизительно по центру множества краев, в данном случае, приблизительно по центру папиллярных линий отпечатка пальца. Выявив центральные пиксели, создают утоненный вариант монохромного изображения, утоняя папиллярные линии к центральным пикселям, чтобы создать набор линий каркаса. Эффективный способ обнаружения пикселей, которые располагаются приблизительно по центру папиллярных линий, и, таким образом, утонения монохромного изображения до линий каркаса состоит в следующем (конечно, можно использовать и другие способы):
Уравнение 14
Задать значение тестового пикселя равным 255.
Задать значение сменного пикселя равным 254.
Повторять, пока никакие пиксели не заменены
КОММЕНТАРИЙ: обработка изображения по горизонтали
Цикл по значениям координаты y от нуля до количества строк.
Цикл по значениям координаты х от нуля до количества пикселей на строку.
Если пиксель с координатами х и y изображения имеет значение тестового пикселя
Если пиксель с координатами х+1 и y изображения имеет значение 255
Установить пиксель с координатами х+1 и y на значение сменного пикселя.
Цикл по значениям координаты х от количества пикселей на строку до нуля.
Если пиксель с координатами х и y изображения имеет значение тестового пикселя
Если пиксель с координатами х-1 и y изображения имеет значение 255
Установить пиксель с координатами х-1 и y на значение сменного пикселя.
КОММЕНТАРИЙ: обработка изображения по вертикали
Цикл по значениям координаты х от нуля до количества пикселей на строку.
Цикл по значениям координаты y от нуля до количества строк.
Если пиксель с координатами х и y изображения имеет значение тестового пикселя
Если пиксель с координатами х и y+1 имеет значение 255
Установить пиксель с координатами х и y+1 на сменное значение пикселя.
Цикл по значениям координаты y от количества строк до нуля.
Если пиксель с координатами х и y изображения имеет значение тестового пикселя
Если пиксель с координатами х и y-1 изображения имеет значение 255
Установить пиксель с координатами х и y-1 на значение сменного пикселя.
Уменьшить значение тестового пикселя на единицу.
Уменьшить значение сменного пикселя на единицу.
При этом центральные пиксели будут иметь наименьшие значения. Описанный ниже процесс позволяет выявить эти пиксели.
Очистить каркасное изображение.
КОММЕНТАРИЙ обработка изображения по горизонтали
Цикл по значениям координаты y от нуля до количества линий
Цикл по значениям координаты х от нуля до количества пикселей на строку.
Установить тестовый пиксель на значение с координатами х и y в изображении
Если тестовый пиксель не равен нулю
Пока пиксель в изображении с координатами х+1 и y меньше, чем тестовый пиксель
Установить тестовый пиксель на значение с координатами х+1 и y в изображении
Увеличить х на единицу.
Установить пиксель в каркасном изображении с координатами х-1 и y равным 255.
Если пиксель с координатами х и y в изображении равен тестовому пикселю
Установить пиксель в каркасном изображении с координатами х-1 и y равным 255.
Изображение 134 на фиг. 28 - это иллюстрация монохромного изображения после первого удаления пикселей из папиллярных линий изображения. Изображение 136 на фиг. 29 - это иллюстрация монохромного изображения с исчерпывающим представлением проходов удаления пикселей, осуществленных в ходе утонения монохромного изображения до центральных пикселей линии изображения. Изображение 138 на фиг. 30 - это иллюстрация фиг. 29, дополнительно содержащее наложение утоненного монохромного изображения, имеющего первичные линии каркаса. Наконец, изображение 140 на фиг. 31 является иллюстрацией утоненного монохромного изображения с первичными линиями каркаса.
Блок (этап) 122 (фиг. 27) процесса утонения предусматривает создание утоненного варианта монохромного изображения, который содержит линии каркаса, которые могут иметь, в некоторых местах, толщину более одного пикселя. Кроме того, утоненное изображение как целое может содержать пиксели, которые не принадлежат ни одной линии. Соответственно, еще один компонент генерации 82 каркаса, обозначенный блоком 124, представляет собой удаление 124 избыточных пикселей. Согласно одному варианту осуществления компонент 124 действует следующим образом: утоненную версию монохромного изображения сканируют, пока не обнаружат пиксель с ненулевым значением. Затем используют окружающие восемь пикселей для формирования индекса к таблице. Элемент таблицы содержит флаги, задающие операции, которые можно выполнять, а именно:
1. Удаление центрального пикселя.
2. Удаление центрального пикселя и задание нового пикселя (М).
3. Задание нового пикселя (N).
Ниже приведены индексы в таблице:




Изображение 142 на фиг. 32 - это иллюстрация утоненного варианта монохромного изображения после удаления избыточных пикселей. Изображение 144 на фиг.33 является иллюстрацией, демонстрирующей соотношение между утоненным вариантом монохромного изображения без избыточных пикселей и соответствующим монохромным изображением (папиллярные линии монохромного изображения в белом).
Согласно варианту осуществления настоящего изобретения, после создания утоненной версии монохромного изображения и удаления избыточных пикселей из линий каркаса осуществляется построение таблиц концевых точек и центральных точек, проиллюстрированное блоком 126 на фиг. 27. Для создания этих таблиц сканируют линии каркаса и заносят все концевые точки (те точки на линиях каркаса, которые касаются только одного другого пикселя) в таблицу концевых точек. По мере сканирования линий каркаса центральные точки (те пиксели, которые касаются более двух других пикселей) заносят в таблицу центральных точек. Изображение 148 на фиг. 35 - это иллюстрация утоненного монохромного изображения, которое включает в себя представление данных из таблицы центральных точек (белые точки представляют центральные точки).
Точки в таблицах концевых точек и центральных точек используются в дальнейшей обработке. Согласно одному варианту осуществления точки используются для идентификации уникальных элементов данных, например пиков, впадин и анти-папиллярных линий. Эти элементы данных можно идентифицировать и каталогизировать посредством данных, описывающих точное местоположение концевых точек или центральных точек, и значений крутизны, связанных с линиями, присоединенными к точкам. Ориентации этих элементов данных уникальны для отдельного пользователя системы, и их можно использовать для аутентификации или сопоставления одного набора данных изображения одного набора данных изображения с одним или более других наборов данных изображения.
После удаления избыточных пикселей из линий каркаса, содержащихся в утоненном монохромном изображении, выполняется следующий этап генерации 82 каркаса, обозначенный блоком 128 на фиг. 27, который состоит в создании очищенного набора линий каркаса путем отсечения избыточных ветвей. Как можно видеть в изображении 142 на фиг. 32, линии каркаса в утоненном монохромном изображении содержат много малых ветвей, отходящих от главных линий. В результате избирательного удаления этих ветвей остается очищенный набор линий каркаса, которые относительно гладки для последующего извлечения деталей и сегментов векторов.
Согласно одному варианту осуществления процесс удаления ветвей, обозначенный блоком 128, опирается на данные, взятые из таблиц концевых точек и крутизны, сгенерированых ранее в процессе создания 20 модели. Каждый элемент таблицы концевых точек используется для определения местоположения сегмента линии, который содержит концевую точку. Сегмент трассируют обратно от концевой точки вдоль соответствующего сегмента линии на протяжении семи пикселей или до обнаружения центральной точки. Если длина сегмента меньше пяти пикселей, его безусловно удаляют (пиксели "вычищаются" из изображения). Если сегмент оканчивается в центральной точке, то крутизну сегмента сравнивают с крутизной равноудаленных от него элементов изображения. Данные крутизны извлекают из таблицы крутизны. Если разность двух значений крутизны больше 25 градусов, то сегмент удаляют. Изображение 150 на фиг. 36 - это иллюстрация очищенного набора линий каркаса, которые получаются в результате удаления избыточных ветвей каркаса. Изображение 152 на фиг. 37 - это иллюстрация, демонстрирующая соотношение между очищенным набором линий каркаса и соответствующим монохромным изображением (папиллярные линии изображения выполнены в белом цвете).
После создания очищенного набора линий каркаса согласно одному варианту осуществления снова удаляют из изображения избыточные пиксели. Согласно одному варианту осуществления избыточные пиксели обнаруживают и удаляют таким же образом, как описано выше со ссылкой на Уравнение 15. Согласно одному варианту осуществления таблицу концевых точек и таблицу центральных точек повторно вычисляют либо до, но, иллюстративно, после повторного удаления избыточных пикселей.
Еще один процедурный компонент генерации 82 каркаса, обозначенный блоком 130 на фиг. 27, состоит в фиксации концевых точек. Как можно видеть в изображении 150 на фиг. 36, сегменты на конце линии в очищенном наборе линий каркаса могут скручиваться или демонстрировать угол крутизны, который не согласуется с равноудаленными элементами таблицы крутизны. Согласно одному варианту осуществления и в соответствии с блоком 130, для исправления этих недостатков, каждый элемент таблицы концевых точек используется для помощи в создании дополнительно очищенного набора линий каркаса. Соответственно, каждый элемент таблицы концевых точек используется для трассировки соответствующего сегмента линии обратно на семь пикселей или до достижения центральной точки. В случае достижения центральной точки сегмент восстанавливается. Если центральная точка не достигнута, то линию удаляют из каркасного изображения. После удаления линии из таблицы крутизны извлекают элемент таблицы крутизны для каждой концевой точки сегмента линии. Это значение крутизны используется для создания нового сегмента линии с использованием алгоритма рисования линии от концевой точки к концу монохромного изображения. Изображение 154 на фиг. 38 - это иллюстрация, демонстрирующая соотношение между дополнительно очищенным набором линий каркаса, содержащих фиксированные концевые точки, и соответствующим монохромным изображением (папиллярные линии изображения выполнены в белом цвете).
Согласно одному варианту осуществления, таблицы концевых точек и центральных точек повторно вычисляют после фиксации концевых точек в соответствии с блоком 130 и созданием дополнительно очищенного набора линий каркаса.
Еще один процедурный компонент генерации 82 каркаса, обозначенный блоком 132 на фиг. 27, состоит в соединении концевых точек. Элементы данных папиллярных линий отпечатков пальцев могут быть повреждены вследствие порезов от бумаги, волдырей, ожогов, морщинистости кожи, условиями сухости/влажности или в силу других проблем сканирования изображения, например, обусловленных влияниями окружающей среды в среде считывающего модуля 12. В соответствии с соединением 132 концевых точек пытаются соединить концевые точки, чтобы срастить зазоры в определенных папиллярных линиях.
Согласно одному варианту осуществления соединения 132 концевых точек, каждый элемент таблицы концевых точек сравнивают со всеми остальными элементами таблицы концевых точек. Если любые две точки находятся в пределах шести пикселей друг от друга, и крутизна соответствующих линий варьируется в пределах 25 градусов, то сегменты соединяются. Изображение 156 на фиг. 39 - это иллюстрация, демонстрирующая соотношение между дополнительно очищенным набором линий каркаса, содержащих фиксированные и соединенные концевые точки, и соответствующим монохромным изображением (папиллярные линии изображения выполнены в белом). Согласно одному варианту осуществления, таблицы концевых точек и центральных точек повторно вычисляют после соединения концевых точек. После соединения концевых точек в дополнительно очищенном наборе линий каркаса полное каркасное изображение, основанное на соответствующем монохромном изображении, в соответствии с генерацией 82 каркаса, будет завершено.
После преобразования монохромного изображения в полное каркасное изображение, согласно варианту осуществления настоящего изобретения, следующий компонент создания 20 модели, обозначенный блоком 84 на фиг.15, представляет собой анализ полного каркасного изображения с целью обнаружения раздвоений и мостиков, подлежащих каталогизации и включению в модель изображения, совместно с другими элементами данных. Согласно одному варианту осуществления, в отношении части 12 разрешения изображения и со ссылкой на фиг.40, общие элементы данных, относящиеся к раздвоению, таковы:
Уравнение 16
Подчеркнем, что точные значения, в частности значения, соответствующие счетчикам пикселей и счетчикам сегментов, можно изменять, не выходя за рамки настоящего изобретения. Такие изменения могут потребоваться в связи с другими технологиями считывающего модуля 12 (фиг.1). Конкретные значения, предусмотренные в настоящем описании применительно к иллюстративным вариантам осуществления, следует рассматривать только как иллюстративные значения.
Согласно одному варианту осуществления настоящего изобретения, обнаружение возможного раздвоения начинают с помощью таблицы центральных точек, созданной при генерации 82 каркаса. Каждый элемент таблицы центральных точек считается потенциальным раздвоением. Начиная с элемента центральной точки в таблице центральных точек, трассируют каждый сегмент, выходящий оттуда. По достижении длины в 17 пикселей соответствующие координаты х и y заносят в список и увеличивают счетчик сегментов ножки. Однако трассировка заканчивается при одном из следующих условий:
1. Достигнут счет 20 (иллюстративно 20) сегментов ножки.
2. Обнаружена концевая точка (из таблицы КТ).
3. Обнаружена центральная точка из таблицы центральных точек.
По завершении трассировки линий можно вычислить три угла для потенциальных раздвоений:
1. угол между сегментами 162 и 164 ножек.
2. угол между сегментами 164 и 168 ножек.
3. угол между сегментами 162 и 168 ножек.
Эти углы сортируют в порядке возрастания. Наименьший угол, между сегментами 162 и 164, сохраняют как угол разделения. Затем вычисляют угол 166 с использованием точки 167 в качестве начала координат 0,0. После идентификации сегментов ножек и вычисления соответствующих углов строят список раздвоений. Раздвоения иллюстративно задают посредством таблицы центральных точек.
Мостик считается частным случаем раздвоения. Согласно фиг. 41, где элементы, общие для фиг. 40 и 41, включают в себя идентичные ярлыки, иллюстративные общие элементы данных, относящиеся к мостику, и основанные на них предположения таковы:
Уравнение 17
Согласно одному варианту осуществления настоящего изобретения обнаружение возможного мостика начинают с использования таблицы концевых точек, созданной в ходе генерации 82 каркаса. Каждый элемент в таблице концевых точек считается потенциальным мостиком. Начиная с элемента таблицы концевых точек, трассируют соответствующий сегмент линии. По достижении длины в 17 (это значение может меняться) пикселей соответствующие координаты х и y заносят в список и увеличивают счетчик сегментов ножки. Трассировка прекращается при выполнении одного из следующих условий:
1. Достигнут счет 20 (иллюстративно 20) сегментов ножки.
2. Обнаружена концевая точка (из таблицы КТ).
3. Обнаружена центральная точка из таблицы центральных точек.
Согласно варианту осуществления настоящего изобретения мостики, подлежащие включению в модель изображения, должны удовлетворять определенным стандартам оценки. Соответственно, после трассировки сегмента вектора сегмент, проходящий из точки 170 в концевую точку 172, продолжают под тем же углом до 162/164. Если в процессе продолжения происходит пересечение с папиллярной линией изображения, то соответствующий мостик не сохраняют и не вводят в модель изображения. Кроме того, линию, перпендикулярную сегменту, проходящему от концевой точки 172 к точке 162/164, проводят в обоих направлениях на расстояние, иллюстративно, 20 (это значение может меняться) пикселей. Если ни одна из этих линий из 20 (это значение может меняться) пикселей не пересекает папиллярную линию изображения, то мостик не сохраняют. Затем сравнивают расстояния перпендикулярного прохождения, чтобы выяснить, является ли концевая точка 172 приблизительно средней точкой. Если нет, то мостик не сохраняют. На выходе этого процесса получают список оцененных мостиков, заданных посредством таблицы концевых точек. Угол 174 направления используют для помощи в задании мостиков и вычисляют с использованием точки 170 в качестве начала координат 0,0.
Чтобы мостики и раздвоения можно было включить в модель изображения, они должны быть не только обнаружены, но и удовлетворять определенным оценкам. Как было отмечено выше, мостики оценивают одновременно с обнаружением. Раздвоения же, в соответствии с блоком 86 на фиг. 15, чтобы быть включенными в модель изображения, должны удовлетворять нескольким оценкам помимо тех, которые применяются в процессе обнаружения раздвоения. Со ссылкой на фиг. 40, согласно одному варианту осуществления, ниже приведен список правил фильтрации, используемых для дальнейшего оценивания раздвоений с целью включения в модель изображения:
Уравнение 18
Изображение 176 на фиг. 42 - это иллюстрация изображения каркаса, в котором оцененные раздвоения и мостики обведены кружками. Концевые точки и центральные точки указаны белыми точками. Изображение 178 на фиг. 43 - это иллюстрация каркасного изображения, в котором те же оцененные раздвоения и мостики обведены кружками. В изображении 178 точки данных сегментов векторов (иллюстративных 20-пиксельных сегментов, проходящих от оцененных мостиков или раздвоений) трассированы и показаны в белом цвете. Точки данных сегментов векторов приблизительно намечают линии каркаса, которые связаны с оцененными раздвоениями и мостиками, и которые можно использовать для сравнения одной модели изображения с другой.
Конечный этап процесса создания 20 модели, обозначенный блоком 88 на фиг. 15, состоит в построении модели изображения на основании полного каркасного изображения и выведенных (полученных) из него элементов изображения. Полная модель изображения состоит из следующих элементов:

В каждой модели изображения раздвоения заданы пересечением сегментов папиллярных линий. Согласно фиг.40, в соответствии с одним вариантом осуществления настоящего изобретения, информация, относящаяся к раздвоению, записываемая в модели изображения, такова:

Мостики заданы окончанием сегмента папиллярной линии. Концевая точка должна быть приблизительно посередине между двумя сегментами папиллярной линии и, если она отстоит на конкретное количество пикселей, иллюстративно 10 или 20 (или какое-либо другое надлежащее значение), не должна касаться другого сегмента папиллярной линии. Согласно одному варианту осуществления, со ссылкой на фиг. 41, информация для мостика, записываемая в модели изображения, такова:

Согласно варианту осуществления настоящего изобретения, сегменты папиллярных линий, не используемые раздвоениями или мостиками, записывают в модель изображения следующим образом:

Согласно одному варианту осуществления, информацию в модели изображения можно сохранять в соответствии со следующим форматом хранения данных:

Опять же, подчеркнем, что точные значения, в частности значения, соответствующие счетчикам пикселей и счетчикам сегментов, можно изменять, не отклоняясь от настоящего изобретения. Такие изменения могут потребоваться в связи с другими технологиями считывающего модуля 12 (фиг.1). Представленные значения, явно или неявно указанные, являются лишь иллюстративными значениями.
Согласно блоку 24 на фиг.2 и в соответствии с вариантом осуществления настоящего изобретения, полную модель изображения можно использовать как основание для сравнения моделей. Сравнение 24 моделей - это процесс сравнения одной модели изображения с другой.
Сравнение моделей можно производить с использованием ряда алгоритмов сдвига и поворота для настройки, по меньшей мере, одной модели изображения с последующим вычислением количества совпадающих элементов данных. Элементы данных могут включать в себя, не исключительно, представления раздвоений, представления мостиков, сегменты векторов, связанные с представлениями раздвоений/мостиков, точечные микродетали и сегменты векторов, не включенные в представления раздвоений мостиков или не связанные с ними, и их комбинации. Когда в результате сдвигов и поворотов счетчик элементов данных достигает максимального значения или приближается к нему, две модели оказываются в точке максимального сравнения или приближаются к ней. Используя счетчики совпадающих элементов данных в точке максимального сравнения или вблизи нее, можно вычислить оценку, выражающую соотношение или процент совпадения.
Теория, лежащая в основе сравнения 24 моделей, утверждает, что при повороте и сдвиге одной модели количество совпадающих точек элементов данных будет увеличиваться или уменьшаться. Если построить график зависимости количества совпадающих точек от угла, получится колоколообразная кривая. Высшая точка этой кривой будет представлять точку наилучшего сравнения двух моделей.
Согласно одному варианту осуществления сравнения 24 моделей, процесс начинается с грубого сравнения каждого раздвоения и мостика в модели (модели А) со всеми раздвоениями и мостиками в другой модели (модели В). Грубое сравнение позволяет обнаруживать несовпадающие пары без значительных затрат времени. Грубое сравнение можно иллюстративно заменить более детальным сравнением. Согласно одному варианту осуществления, требования, предъявляемые к грубому сравнению, заданы следующим образом:
Уравнение 24
Согласно одному варианту осуществления на основании грубого сравнения генерируют таблицу возможных совпадений. Таблица возможных совпадений индексируется индексом раздвоения или мостика к модели А. Каждый элемент в таблице возможных совпадений состоит из:
Уравнение 25
Процесс сравнения в целом наилучшим образом описан простым примером кодирования. В частности, согласно одному варианту осуществления, кодирование задано следующим образом:
Уравнение 26
Генерировать таблицу возможных совпадений
Установить значение счетчика максимального совпадения равным нулю.
Установить угол поворота равным нулю.
Очистить главные значения сдвигов по х и y.
НАЧАЛО ЦИКЛА
Если угол поворота не равен нулю, то
Повернуть модель В на угол поворота. Это стандартная тригонометрическая функция.
Процесс сдвига на модели В (это описано ниже).
Отсчитывать раздвоения, мостики и сегменты, которые совпадают между моделью А и моделью В.
Если отсчет совпадений меньше максимального значения совпадений минус два, то
Выйти из цикла.
Если отсчет совпадений больше максимального отсчета совпадений
Установить максимальное значение совпадений равным максимальному значению.
Сохранить угол поворота.
Сохранить значения сдвига по х и y. Это выход вышеописанного процесса сдвига.
Увеличить угол поворота на один.
Если угол поворота меньше 30, то
Перейти к НАЧАЛО ЦИКЛА
Вышеозначенный цикл повторяется для углов от -1 до -30.
Скопировать рабочую таблицу возможных совпадений в таблицу возможных совпадений. Это будет использовано в процессе регистрации.
Используя сохраненные переменные угол поворота и значения сдвига по х и y, сдвинуть и повернуть всю модель В.
Отсчитывать раздвоения, мостики и сегменты, которые совпадают между моделью А и моделью В.
ОПИСАНИЕ ПРОЦЕССА СДВИГА
Задать макс. тест. х равным 90 (это значение может меняться) пикс.
Задать макс. тест. y равным 120 (это значение может меняться) пикс.
Очистить главные значения сдвига х и y.
Сделать рабочую копию таблицы возможных совпадений.
НАЧАЛО ЦИКЛА 1
Очистить счетчик сохраненных точек.
Очистить счетчик дельта х и дельта y.
Задать индекс модели А равным нулю.
НАЧАЛО ЦИКЛА 2
Задать возможный индекс равным нулю.
НАЧАЛО ЦИКЛА 3
Извлечь индекс модели В из таблицы возможных совпадений по индексу модели А и возможному индексу.
Вычислить расстояние между соответствующими раздвоениями или мостиками в модели А и модели В.
Если расстояние меньше макс. тест. х и макс. тест. y, то
Увеличить значение счетчика сохраненных точек.
Прибавить расстояние в направлении х к значению дельта х.
Прибавить расстояние в направлении y к значению дельта y.
Иначе
Удалить эту точку из рабочей копии таблицы возможных совпадений.
Увеличить возможный индекс на единицу.
Если возможный индекс меньше значения счетчика в таблицах возможных совпадений по индексу модели А.
Перейти к НАЧАЛО ЦИКЛА 3
Увеличить индекс модели А на единицу.
Если индекс модели А меньше счетчика раздвоений и мостиков в модели А, то
Перейти к НАЧАЛО ЦИКЛА 2
Если количество сохраненных точек равно нулю, то
Выйти из процедуры и возвратить нулевое значение (нет сравнения).
Прибавить значение дельта х, деленное на значение сохраненных точек, к значению главного х.
Прибавить значение дельта y, деленное на значение сохраненных точек, к значению главного y.
Отрегулировать все координаты х и y в модели В с использованием значений главных х и y.
Если макс. тест. х больше 20 (это значение может меняться) пикселей
Умножить макс. тест. х на 0.75.
Умножить макс. тест. y на 0.75.
Перейти к НАЧАЛО ЦИКЛА 1
Выйти из процедуры и возвратить значение счетчика сохраненных точек. (Помеченные и другие конкретно указанные значения могут быть зависимыми от приложения.)
// КОНЕЦ ПРИМЕРА КОДА
Результатом окончательного процесса сдвига и поворота является несколько счетчиков:
Уравнение 27
Для нижеследующего рассмотрения используются следующие определения:
Уравнение 28
Используя вышеуказанные значения счетчиков, можно вычислить процент совпадения (ниже приведен иллюстративный пример, основанный на одном образцовом считывающем устройстве... значения могут изменяться в зависимости от конкретной технологии считывания).

Альтернативно, с использованием вышеуказанных счетчиков, можно вычислить соотношение совпадения.

Согласно одному варианту осуществления настоящего изобретения, в системе защиты на основе идентификации изображения уровень подобия, необходимый, чтобы объявить две модели изображения совпадающими, можно регулировать. Уровни подобия можно настраивать в зависимости от характера охраняемой среды. Строго настроенная система обеспечивает максимальную защиту, требуя высокого соотношения или процента совпадения, но может быть больше склонна к случайному отклонению совпадающей пары моделей изображения. Наоборот, свободно настроенная система требует более низкого соотношения или процента совпадения и, соответственно, обеспечивает более низкий уровень защиты. Однако свободно настроенная система более склонна к ошибочным определениям совпадения и менее склонна к отклонениям совпадения.
На фиг. 44 показана блок-схема, иллюстрирующая набор процедурных компонентов, связанных с процессом сравнения изображений «одно с одним», согласно варианту осуществления настоящего изобретения. Блок 180 обозначает первый иллюстративный этап процесса, а именно получение набора данных первого изображения на основании первого изображения и набора данных второго изображения на основании второго изображения. Наборы данных первого и второго изображений включают в себя совокупность элементов данных, которые иллюстративно, но не обязательно, связаны с изображениями отпечатков пальцев. Два набора данных являются модельными представлениями первого и второго изображений и иллюстративно создаются согласно описанному выше со ссылкой на другие фигуры, включенные в описание настоящего изобретения.
Блок 182 обозначает необязательное осуществление процесса грубого сравнения. Иллюстративно, первый и второй наборы элементов данных включают в себя совокупность типов элементов данных. Осуществление грубого сравнения, согласно описанному выше, экономизирует процесс сравнения за счет исключения тех элементов данных в одном из двух наборов, которые не попадают в заданный оценочный диапазон отклонения от элемента данных того же типа в другом из двух наборов.
Блок 184 обозначает сравнение элементов данных из набора данных первого изображения с элементами данных из набора данных второго изображения. Иллюстративно, согласно описанному выше, элементы данных включают в себя определяющие характеристики, имеющие числовую или математическую природу и облегчающие сравнение элементов данных. Например, согласно одному варианту осуществления, в процессе сравнения оценочный диапазон отклонения является выбираемым или заранее заданным. Оценочный диапазон отклонения выражает допустимое расхождение между определяющей характеристикой, по меньшей мере, одного элемента данных первого типа из набора данных первого изображения и соответствующей, по меньшей мере, одной определяющей характеристикой, по меньшей мере, одного элемента данных первого типа из набора данных второго изображения. Согласно одному варианту осуществления для определения одного типа элемента данных можно использовать множественные определяющие характеристики, каждая из которых имеет оценочный диапазон отклонения. Согласно одному варианту осуществления генерируют счетчик элементов данных из наборов данных первого и второго изображений, в которых величина отклонения между определяющими характеристиками (или характеристикой) находится в пределах оценочного диапазона отклонения. В сущности, этот счетчик представляет собой счетчик элементов данных в наборе данных первого изображения, которые приблизительно совпадают с элементами данных в наборе данных второго изображения.
Блок 186 обозначает проверку счетчика совпадающих элементов данных на предмет того, достигло ли значение счетчика максимального значения. Если было произведено только одно сравнение, значит, максимальное значение еще не достигнуто. В случаях, когда максимальное значение не достигнуто, что обозначено блоком 188, один из наборов данных первого или второго изображения и входящие в него элементы данных подвергаются перемещению (например, повороту, сдвигу или обоим). Затем процесс возвращается к блоку 184, где производится новое сравнение и генерируется новое значение счетчика.
Этапы сравнения, отсчета и перемещения иллюстративно повторяются для создания дополнительных подсчетов элементов данных в наборе данных первого изображения, которые приблизительно совпадают с элементами данных в наборе данных второго изображения. Когда, согласно описанному выше, значение счетчика достигает максимального значения, процесс продолжается.
Блок 190 обозначает сравнение значения счетчика с заранее определенным конечным значением. Согласно одному варианту осуществления, заранее определенное значение представляет выбранный уровень подобия, необходимый, чтобы считать первое и второе изображения совпадающими. Конечное значение можно регулировать в зависимости от желаемого уровня и полноты соответствующего приложения защиты. В соответствии с блоком 192, если значение счетчика превышает заранее определенное конечное значение, то указывается наличие совпадения. Как указано блоком 194, если значение счетчика меньше заранее определенного конечного значения, то указывается отсутствие совпадения. Согласно одному варианту осуществления, сравнение подсчетов можно производить на основании соотношения или процента, и можно сравнивать соотношения и проценты, а не подсчеты.
В соответствии с блоком 26 на фиг.2 и согласно иллюстративному варианту осуществления настоящего изобретения, поиск 26 в базе данных можно проводить вместо сравнения 24 моделей или совместно с ним. Поиск 26 в базе данных предусматривает быстрое и эффективное определение, проявляют ли, возможно, тысячи (или более, т.е. миллионы) моделей изображения, включенные в базу данных, нужный уровень подобия при сравнении с поданной, т.е. целевой, моделью изображения.
Согласно одному варианту осуществления настоящего изобретения, чтобы быстро идентифицировать отпечаток пальца из базы данных, содержащей тысячи (или миллионы или более) отпечатков, задают набор ключей базы данных. В силу многих факторов (палец слишком сухой, палец слишком влажный, положения пальца при помещении на сканер, искажения вследствие давления и т.д.) ключи имеют общий (приближенный), а не конкретный характер. Согласно варианту осуществления, эти общие ключи создают основу высокоскоростного общего индексирования.
Согласно одному варианту осуществления, набор ключей генерируют, используя некоторые из характеристик, связанных с элементами модели изображения раздвоений и мостиков (определенными выше со ссылкой на фиг. 40 и 41). Информация, используемая при генерации ключей для раздвоения, согласно фиг.40, состоит из следующих характеристик:
Уравнение 30
Мостик считается частным случаем раздвоения, и, согласно фиг.41, делаются следующие предположения:
Уравнение 31
Информация, используемая при генерации ключей для мостика, такова:
Уравнение 32
При сохранении моделей отпечатков в базе данных обновляются две таблицы. Первая таблица, KEY_1, представляет собой двухмерный массив. Первый индекс - это первый угол разделения, второй индекс - это второй угол разделения. Заметим, что первый угол разделения не может превышать 120 градусов и, согласно одному варианту осуществления, должен ограничиваться 115 градусами. Кроме того, второй угол разделения не может превышать 180 градусов. Угол направления может иметь любое значение от нуля до 359. Поэтому размер массива KEY_1 равен 116 (от 0 до 115) на 180 (от 9 до 179). Вторая таблица, KEY_2, содержит информацию ключей. KEY_2 - это одномерный массив с возможностью расширения.
Каждый элемент в KEY_1 содержит два элемента, счетчик и индекс к таблице KEY_2. Элемент - счетчик определяет количество раздвоений или мостиков, имеющих одинаковые углы разделения и направления. Элемент индекс определяет начальную точку для ключей, содержащихся в таблице KEY_2. Элемент таблицы KEY_2 состоит из следующих элементов:
Уравнение 33
Запись помечена как удаленная?
Согласно варианту осуществления настоящего изобретения, обновление таблиц, KEY_1 и KEY_2, наилучшим образом описано в нижеследующем примере кодирования:
Уравнение 34
раздвоениям и
мостикам в модели
НАЧАЛО ЦИКЛА 1
Извлечь из модели угол направления (DA).
Извлечь из модели первый угол разделения (SA1).
Извлечь из модели второй угол разделения (SA2).
Построить новый элемент для таблицы KEY_2.
Увеличить поле счетчика в таблице KEY_1[SA1][SA2] на единицу.
//Увеличить все остальные поля индекса ключа 2 в таблице KEY_1.
//При этом таблицу KEY_1 можно рассматривать как одномерный массив из 41760 (116 на 360) элементов.
Задать индекс обновления равным произведению SA1 на SA2.
НАЧАЛО ЦИКЛА 2
Увеличить индекс обновления (update index) на единицу.
Если индекс обновления меньше 41760
Увеличить KEY_1[update index].key_2_start_index.
Увеличить индекс обновления
Перейти к НАЧАЛО ЦИКЛА 2
//освободить место в таблице KEY_2, сдвинув все элементы, начиная с KEY_1[SA1][SA2]].key_2_start_index, на одну позицию вверх.
Задать индекс обновления равным количеству элементов, содержащихся в таблице KEY_2 минус один.
Задать индекс остановки равным значению, сохраненному в KEY_1[SA1][SA2].key_2_start_index.
НАЧАЛО ЦИКЛА 3
Если индекс обновления больше или равен индексу остановки
Скопировать элемент по индексу обновления в позицию по индексу обновления плюс один.
Уменьшить индекс обновления на единицу.
Перейти к НАЧАЛО ЦИКЛА 3
Сохранить новый ключ, сгенерированный выше, в таблице KEY_2 по индексу остановки.
Увеличить количество элементов, содержащихся в таблице KEY_2, на единицу.
//КОНЕЦ ПРИМЕРА КОДА
Таблицы KEY_1 и KEY_2 обеспечивают средство обнаружения всех раздвоений и мостиков, имеющих идентичные угловые характеристики. Таблица KEY_1 обеспечивает счетчик и индекс начала. Таблица KEY_2 обеспечивает данные ключей. Кроме того, заметим, что данные, сохраненные в таблице KEY_2, сгруппированы так, что все раздвоения и мостики, имеющие идентичные угловые характеристики, следуют один за другим.
Следующий этап после построения таблиц состоит в идентификации совпадающих моделей изображения. Те отпечатки, которые имеют большое количество раздвоений и мостиков, грубо совпадающих с элементом базы данных, скорее всего, получат высокую оценку при сравнении. Используя вышеописанные таблицы и некоторые правила фильтрации, создают таблицу возможных совпадений. Каждый элемент таблицы возможных совпадений содержит следующую информацию:
Уравнение 35
Эта таблица индексируется с использованием идентификационного номера модели и идентификационного номера пальца. Согласно одному варианту осуществления, таблицу создают следующим образом:
Уравнение 36
Очистить таблицу возможных совпадений.
Задать индекс модели равным нулю.
НАЧАЛО ЦИКЛА 1
Извлечь элемент модели.
//ОБРАБОТКА ДЛЯ РАЗДВОЕНИЙ
Если элемент является раздвоением
Извлечь из модели первый угол раздвоения.
Извлечь из модели второй угол раздвоения.
Извлечь из модели угол направления.
Извлечь из модели координату центральной точки.
Задать индекс начала 1 равным первому углу разделения минус отклонение (8 градусов).
Если индекс начала 1 меньше единицы
Задать индекс начала 1 равным 1.
Задать индекс остановки 1 равным первому углу разделения плюс отклонение (8 градусов).
Если индекс остановки 1 больше 116
Задать индекс остановки 1 равным 116.
Задать индекс начала 2 равным второму углу разделения минус отклонение (8 градусов).
Если индекс начала 2 меньше единицы
Задать индекс начала 2 равным 1.
Задать индекс начала 2 равным второму углу разделения плюс отклонение (8 градусов).
Задать индекс 1 равным индексу начала 1.
НАЧАЛО ЦИКЛА 2
Задать индекс 2 равным индексу начала 2.
НАЧАЛО ЦИКЛА 3
Задать счетчик цикла равным значению элемента счетчик в таблице KEY_1[index 1][index 2]
Если счетчик цикла не равен нулю
Задать индекс ключа 2 равным значению индекса в таблице KEY_1[index 1][index 2]
НАЧАЛО ЦИКЛА 4
Если заданные выше «правила грубого совпадения» выполнены
Использовать номера идентификации модели и пальца для формирования индекса к таблице возможных совпадений.
Увеличить счетчик совпадений и сохранить разность расстояний.
Увеличить индекс 2 ключа на единицу.
Уменьшить счетчик цикла
Если счетчик цикла больше нуля
Перейти к НАЧАЛО ЦИКЛА 4
Увеличить индекс 2
Если индекс 2 больше индекса 2 остановки
Перейти к НАЧАЛО ЦИКЛА 3
Увеличить индекс 1
Если индекс 1 больше индекса 1 остановки
Перейти к НАЧАЛО ЦИКЛА 2
//ОБРАБОТКА ДЛЯ МОСТИКОВ
Если элемент является мостиком
Извлечь из модели угол направления.
Извлечь из модели координаты центральной точки.
Задать индекс 1 начала равным направлению минус отклонение (20 градусов).
Если индекс 1 начала меньше нуля
Задать индекс 1 начала равным нулю.
Задать индекс 1 остановки равным направлению плюс отклонение (20 градусов).
Если индекс остановки 1 больше 359
Задать индекс остановки 1 равным 359.
Задать индекс 1 равным индексу 1 начала.
НАЧАЛО ЦИКЛА 5
Задать счетчик цикла равным значению элемента счетчик в таблице KEY_1[0][index 2]
Если счетчик цикла не равен нулю
Задать индекс ключа 2 равным значению индекса в таблице KEY_1[0][index 2]
НАЧАЛО ЦИКЛА 6
Если заданные выше «правила грубого совпадения» выполнены
Использовать номера идентификации модели и пальца для формирования индекса к таблице возможных совпадений.
Увеличить счетчик совпадений и сохранить разность расстояний.
Увеличить индекс ключа 2 на единицу.
Уменьшить счетчик цикла
Если счетчик цикла больше нуля
Перейти к НАЧАЛО ЦИКЛА 6
Увеличить индекс 1
Если индекс 1 больше индекса 1 остановки
Перейти к НАЧАЛО ЦИКЛА 5
Если индекс модели меньше суммарного количества элементов модели
Перейти к НАЧАЛО ЦИКЛА 1
//КОНЕЦ ПРИМЕРА КОДА
При этом таблица возможных совпадений содержит список всех моделей в базе данных, которые являются кандидатами для сравнения. Поле счетчика содержит значение счетчика грубо совпадающих раздвоений и мостиков. Список расстояний содержит упорядоченный список, элементы значения счетчика, расстояний от центральной точки модели до тех из элементов в базе данных. Некоторые из этих элементов неверны. Нижеприведенное правило фильтрации пытается удалить некоторые неверные значения. Чтобы удалить неверные элементы, список расстояний сначала сохраняют, с использованием расстояния х, в восходящем порядке (см. пример ниже). Затем этот список сканируют, ища самую длинную последовательность номеров, разность между которыми меньше 40. Затем индекс начала и конца этого списка используют для сортировки компонента y упорядоченных пар. Затем список сканируют, ища самую длинную последовательность номеров, разность между которыми меньше 40. Индекс начала и конца этого списка обеспечивает новый счетчик для замены старого счетчика.
Уравнение 37

В вышеописанном примере исходное значение счетчика равно 17. После первой сортировки и определения местоположения индекса индекс начала равен 4, и индекс конца равен 12 (представлен звездочкой). Вторая сортировка и определение местоположения индекса дает значение счетчика, равное 3.
После настройки всех счетчиков совпадений таблицу сортируют в нисходящем порядке по значению счетчика. Элементы на вершине списка (наивысшие значения счетчика) представляют те модели (из базы данных), которые следуют сравнивать с поданным результатом живого сканирования.
Параметры оценивания можно регулировать на нескольких уровнях в соответствии с характеристиками считывающего модуля 12 и уровнем общей защиты в отношении ложных совпадений против ложных отказов. Например, параметр расстояния таблицы совпадения можно расширить, чтобы рассматривать элементы, чье расстояние больше 60 против 40, что приведет к снижению уровня защиты, и, тем самым, снизить частоту ложных отказов ценой повышения частоты ложных признаний.
На фиг. 45 изображена блок-схема, иллюстрирующая набор процедурных компонентов, связанных с процессом сравнения изображений «одно со многими» или поиска в базе данных. Блок 196 обозначает первый иллюстративный этап процесса, а именно получение набора данных первого изображения на основании первого изображения и множественные наборы данных других изображений на основании совокупности других изображений. Наборы данных первого и других изображений включают в себя множественные элементы данных, которые иллюстративно, но не в обязательном порядке, связаны с изображениями отпечатков пальцев. Различные типы элемента данных, связанные с изображениями отпечатка пальца, описаны выше применительно к сравнениям «одного с одним», а также в других местах настоящего описания.
Наборы данных изображения, полученные из первого и других изображений, являются, иллюстративно, модельными представлениями соответствующих первого и других изображений. Наборы данных изображений иллюстративно генерируются, как описано выше со ссылкой на другие фигуры, включенные в описание настоящего изобретения.
Следующий этап, обозначенный блоком 198, состоит в создании директории, в которой последовательно перечислено, на основании, по меньшей мере, одной из измеренных характеристик (например, конкретных угла, длины и т.д.), реальное количество элементов данных конкретного типа (например, представлений раздвоения и/или представлений мостика и/или векторов, связанных и не связанных с ними, и/или точечных микродеталей и т.д.), которые присутствуют в совокупности других наборов данных изображения. Каждый элемент данных в директории иллюстративно перечислен с идентификатором, который выражает связь с конкретным набором данных изображения, в котором присутствуют элементы данных.
Блок 200 обозначает следующий этап процесса, на котором создают массив, который содержит двухэлементную ячейку для каждого из диапазона (или по существу всех) потенциальных конфигураций для того же одного типа элементов данных, которые перечислены в директории, созданной на этапе 198.
Блок 202 обозначает запись информации процесса в ячейки массива. Согласно одному варианту осуществления в одном элементе каждой двухэлементной ячейки записывают количественное значение, выражающее количество последовательных элементов данных в директории, которое демонстрирует характеристики, которые приблизительно аналогичны характеристикам одной из диапазона потенциальных конфигураций, которая соответствует конфигурации элемента данных, связанной с этой двухэлементной ячейкой. Иллюстративно, в другом элементе каждой двухэлементной ячейки записано значение индекса, соответствующее начальному элементу данных, с которого начинается количество последовательных элементов данных, перечисленных в директории. Другими словами, ячейки используются для записи местоположений в последовательной директории элементов данных, которые потенциально совпадают с элементом данных, связанным с местоположением данной ячейки.
Блок 204 обозначает следующий этап, на котором производят идентификацию двухэлементной ячейки массива, которая связана с конфигурацией элемента данных, характеристики которой приблизительно идентичны целевому элементу данных, элементу данных, взятому из набора данных первого изображения.
Блок 206 обозначает следующий этап, на котором целевой элемент данных сравнивают с группой последовательных элементов данных, перечисленных в директории, которые указаны двухэлементной ячейкой, связанной с этим целевым элементом данных. Как указано блоком 208, эта идентификация и сравнение целевых элементов данных с соответствующими последовательными элементами данных в директории повторяется для дополнительных целевых элементов данных.
Блок 210 указывает следующий этап. Этап содержит вычисление и указание количества элементов данных в каждом из совокупности наборов данных других изображений, которые приблизительно совпадают с элементами данных, иллюстративно, целевыми элементами данных, взятыми из набора данных первого изображения. При обнаружении совпадения целевых элементов данных с элементами данных в директории вышеупомянутые идентификаторы помогают узнать набор данных изображения, для которого следует увеличить счетчик.
В соответствии с блоком 212 аналогичные директории, массивы и счетчики могут быть сделаны для многочисленных типов элементов данных. Иллюстративно, этапы 198-210 осуществляют с использованием разнообразных типов элементов данных, и для каждого из наборов данных других изображений поддерживается единый счетчик прогонов.
Блок 214 обозначает следующий этап процесса. Этап содержит выбор из совокупности наборов данных других изображений заранее определенного количества наборов данных изображений, которые включают в себя наивысший счетчик или большинство элементов данных, которые приблизительно совпадают с целевыми элементами данных, взятыми из набора данных первого изображения.
Наконец, блок 216 обозначает осуществление более тщательного сравнения заранее определенного количества наборов данных изображения с набором данных первого изображения. Процесс более тщательного сравнения иллюстративно используется для различения между наборами данных изображения и, следовательно, изображениями, которые следует или не следует считать совпадающими. Согласно одному варианту осуществления процесс сравнения «одного с одним», описанный со ссылкой на фиг.44, используется в качестве процесса более тщательного сравнения.
На фиг. 46 показана блок-схема, иллюстрирующая набор процедурных компонентов, связанных с другим процессом сравнения изображений или поиска в базе данных в режиме «одно со многими», согласно другому варианту осуществления настоящего изобретения. Блок 218 обозначает первый иллюстративный этап процесса, а именно получение набора данных первого изображения на основании первого изображения и совокупности наборов данных других изображений на основании совокупности других изображений. Наборы данных первого и других изображений включают в себя совокупность элементов данных, которые иллюстративно, но не в обязательном порядке, связаны с изображениями отпечатка пальца. Другие типы элемента данных, связанные с изображениями отпечатка пальца, описаны выше в отношении сравнений «одного с одним», а также в других местах настоящего описания.
Наборы данных изображения, полученные для первого и других изображений, являются, иллюстративно, модельными представлениями соответствующих первого и других изображений. Наборы данных изображений, иллюстративно, генерируют, как описано выше со ссылкой на другие фигуры, включенные в описание настоящего изобретения.
Блок 220 обозначает этап процесса, содержащий создание файла данных В-дерева для каждого из совокупности типов элементов данных (например, представлений раздвоения, представлений мостика, векторов, связанных с представлениями вектора/мостика или независимых от них, точечных микродеталей и т.д.). Следует отметить, что файл данных В-дерева - это структура хранения данных, которая хорошо известна в области хранения данных и анализа данных. Иллюстративно, каждый файл данных В-дерева связан с отдельным типом элемента данных и содержит по существу все элементы данных, включенные в наборы данных других изображений (не набор данных первого/целевого изображения). Элементы данных из наборов данных других изображений, иллюстративно, перечисляют и каталогизируют в файлах данных В-дерева на основании правил нормализации данных. Каждый элемент данных, перечисленный в каждом файле данных В-дерева, сохраняют с идентификатором, который представляет связь с конкретным набором данных изображения, в котором присутствует каждый элемент данных. Согласно одному варианту осуществления каждый файл данных В-дерева отражает правила нормализации для соответствующего типа элемента данных, включая изменения относительного положения и/или поворота. Согласно другому варианту осуществления, каждый файл данных В-дерева отражает, по существу, все потенциальные родственные связи между элементами данных, сохраненными в файле данных, и совокупностью типов элементов данных.
Блок 222 обозначает сравнение, по меньшей мере, одного целевого элемента данных (элемента данных из набора данных первого изображения) с элементами данных в файлах данных В-дерева, имеющих элементы данных того же типа, что и сравниваемый целевой элемент данных. Другими словами, целевой элемент данных берут из набора данных первого изображения и последовательно сравнивают через соответствующее В-дерево (того же типа элементов данных). Цель состоит в поиске элементов данных в файлах данных В-дерева, которые приблизительно совпадают с целевым элементом данных.
Этапы процесса, обозначенные блоками 224, 226 и 228, по существу и соответственно, аналогичны блокам 210, 214 и 216, описанным со ссылкой на фиг.45. Например, в соответствии с блоком 224, при обнаружении, что целевые элементы данных совпадают с элементами данных, хранящимися в файле данных В-дерева, для каждого из множественных наборов данных других изображений генерируется счетчик включенных элементов данных, которые приблизительно совпадают с целевым элементом данных.
Блок 226 указывает следующий этап процесса. Этап содержит выбор из множественных наборов данных другого изображения заранее определенного количества наборов данных изображения, которые включают в себя наивысшее значение счетчика, или большинство элементов данных, которые приблизительно совпадают с целевыми элементами данных, взятыми из набора данных первого изображения. Наконец, блок 228 обозначает осуществление более тщательного сравнения заранее определенного количества наборов данных изображения с набором данных первого изображения. Процесс более тщательного сравнения иллюстративно используется для различения между наборами данных изображения, которые следует или не следует считать совпадающими. Согласно одному варианту осуществления в качестве процесса более тщательного сравнения используется процесс сравнения одного с одним, описанный со ссылкой на фиг. 44.
Хотя настоящее изобретение описано со ссылкой на иллюстративные варианты осуществления, специалисты в данной области могут предложить изменения, касающиеся формы и деталей, не выходя за рамки сущности и объема изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ВЕРИФИКАЦИИ И ИДЕНТИФИКАЦИИ ОТПЕЧАТКОВ ПАПИЛЛЯРНЫХ УЗОРОВ | 2006 |
|
RU2310910C1 |
| СПОСОБ И УСТРОЙСТВО ОБНАРУЖЕНИЯ ДЕФЕКТОВ НА ПОВЕРХНОСТИ ШИН | 2016 |
|
RU2657648C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ АНАЛИЗА ПОВЕРХНОСТИ ШИНЫ | 2016 |
|
RU2707723C2 |
| РАЗДЕЛЕНИЕ ИЗОБРАЖЕНИЙ НА ОБОСОБЛЕННЫЕ ЦВЕТОВЫЕ СЛОИ | 2021 |
|
RU2792722C1 |
| СПОСОБ, УСТРОЙСТВО И КОМПЬЮТЕРНЫЙ ПРОГРАММНЫЙ ПРОДУКТ ДЛЯ СОПОСТАВЛЕНИЯ ОТПЕЧАТКОВ ПАЛЬЦЕВ | 2007 |
|
RU2468429C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОГРАНИЧЕНИЙ УРОВНЯ БЛОКА В ЗАВИСИМОСТИ ОТ РЕЖИМА И РАЗМЕРА | 2019 |
|
RU2786022C1 |
| УРОВНИ ОГРАНИЧЕНИЯ ДЛЯ НЕЛИНЕЙНОГО АДАПТИВНОГО КОНТУРНОГО ФИЛЬТРА | 2020 |
|
RU2818228C2 |
| БЕСКОНТАКТНЫЙ ВВОД | 2013 |
|
RU2644520C2 |
| СПОСОБ ОБНАРУЖЕНИЯ ЧЕЛОВЕЧЕСКИХ ОБЪЕКТОВ В ВИДЕО (ВАРИАНТЫ) | 2013 |
|
RU2635066C2 |
| ОПТИЧЕСКАЯ СИСТЕМА ДЛЯ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ | 2016 |
|
RU2627926C1 |
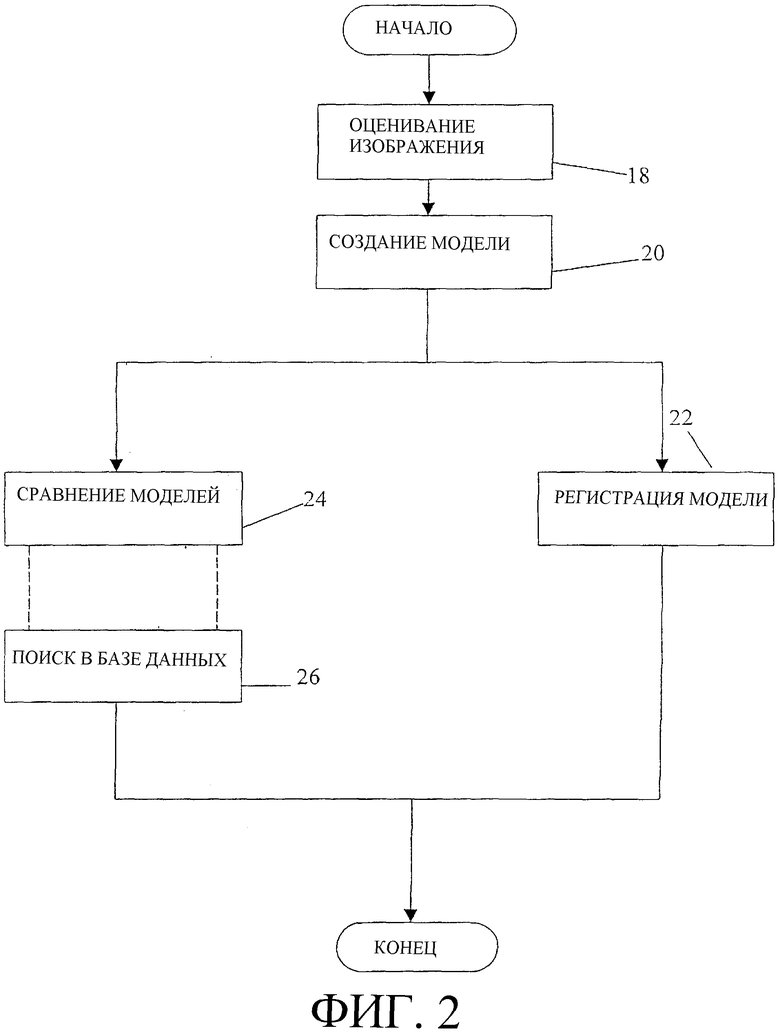

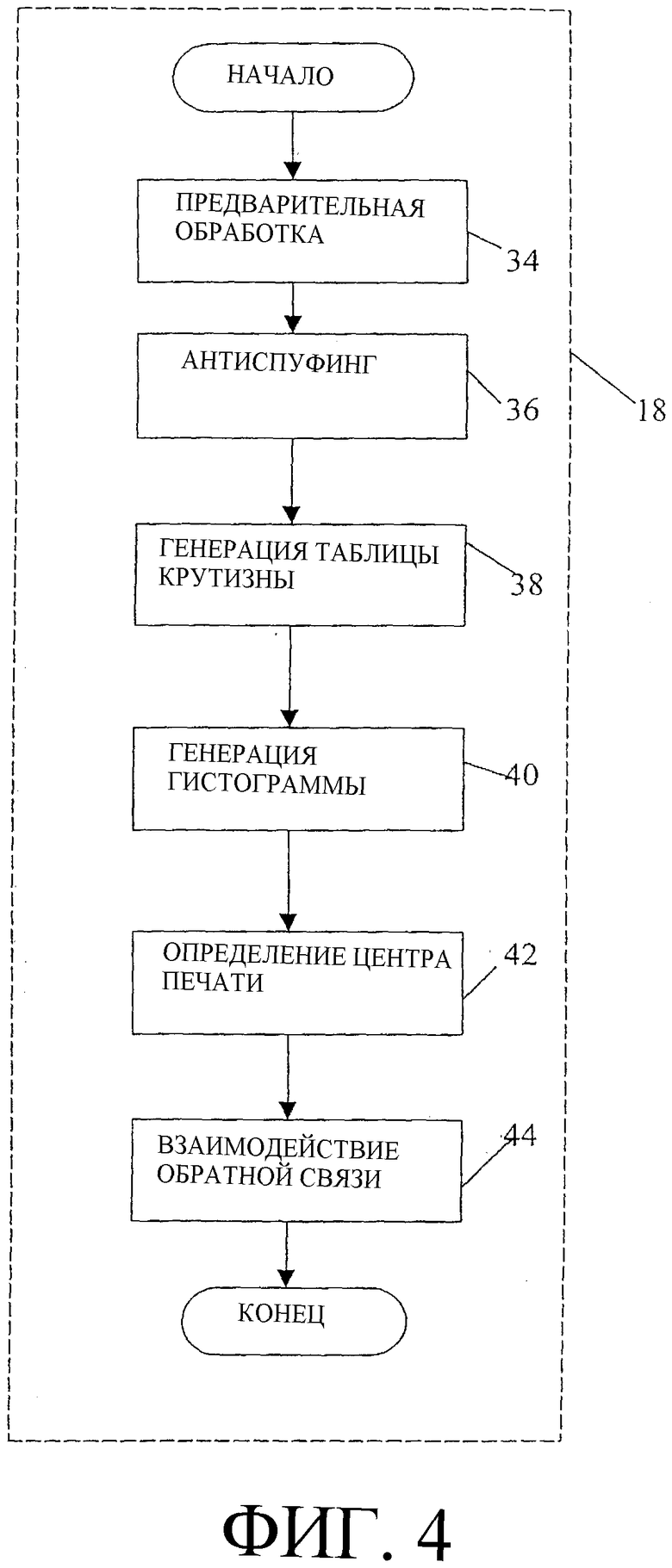
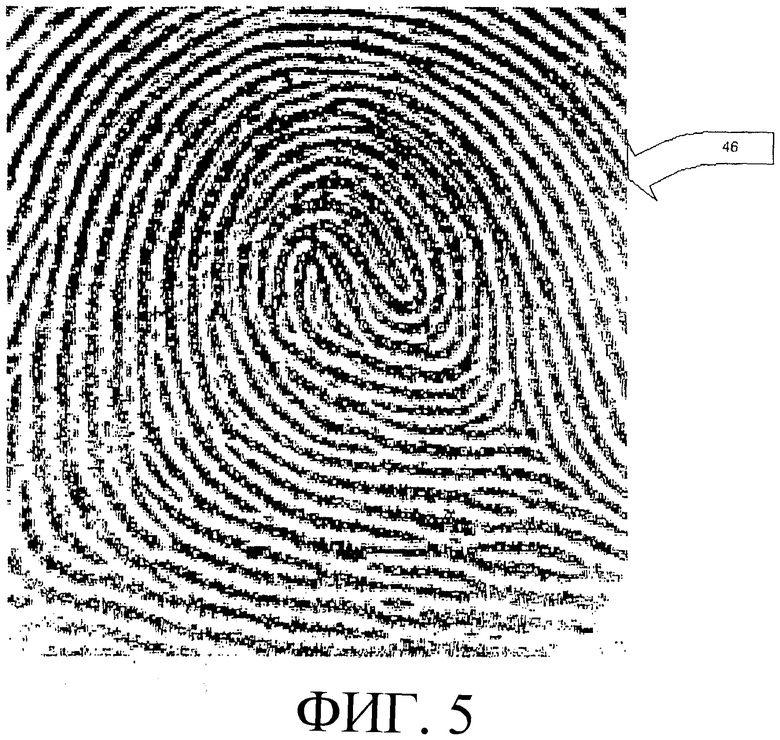

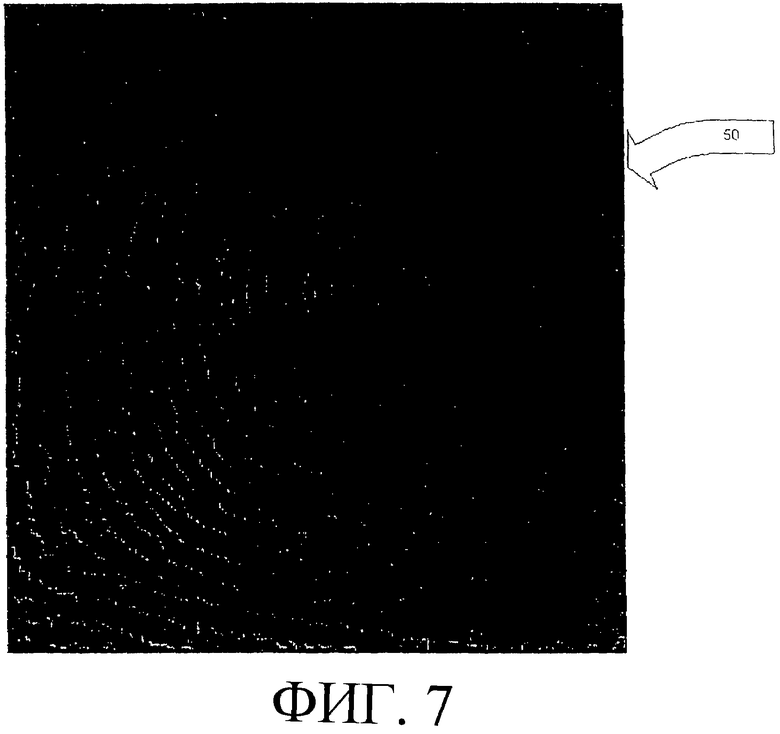

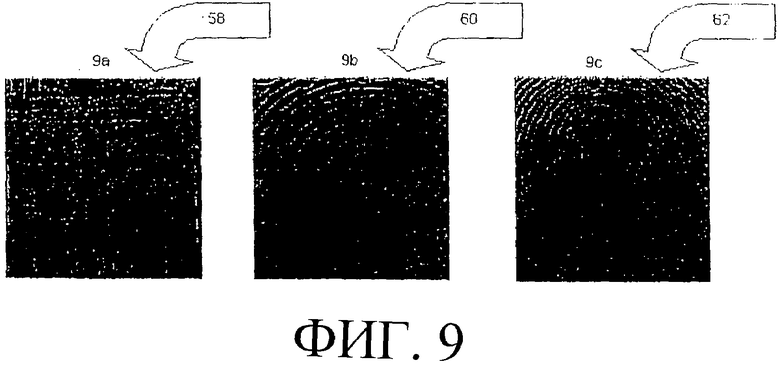





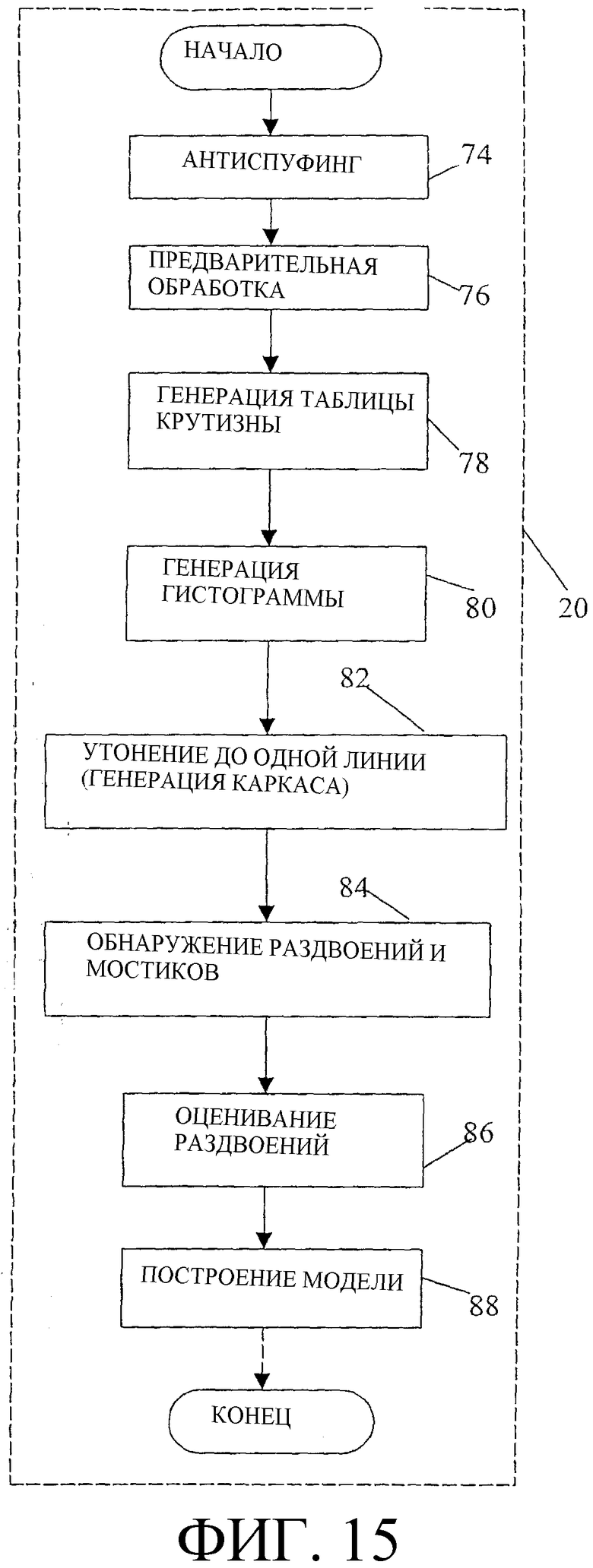
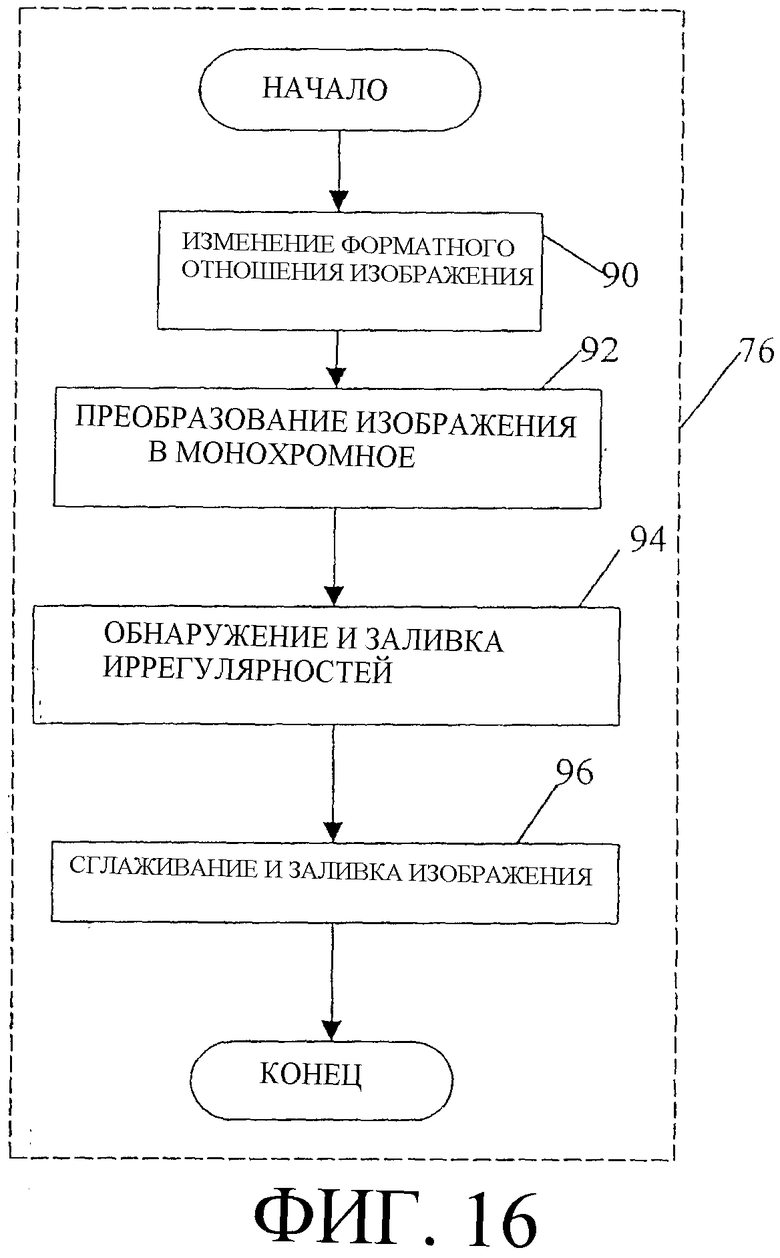







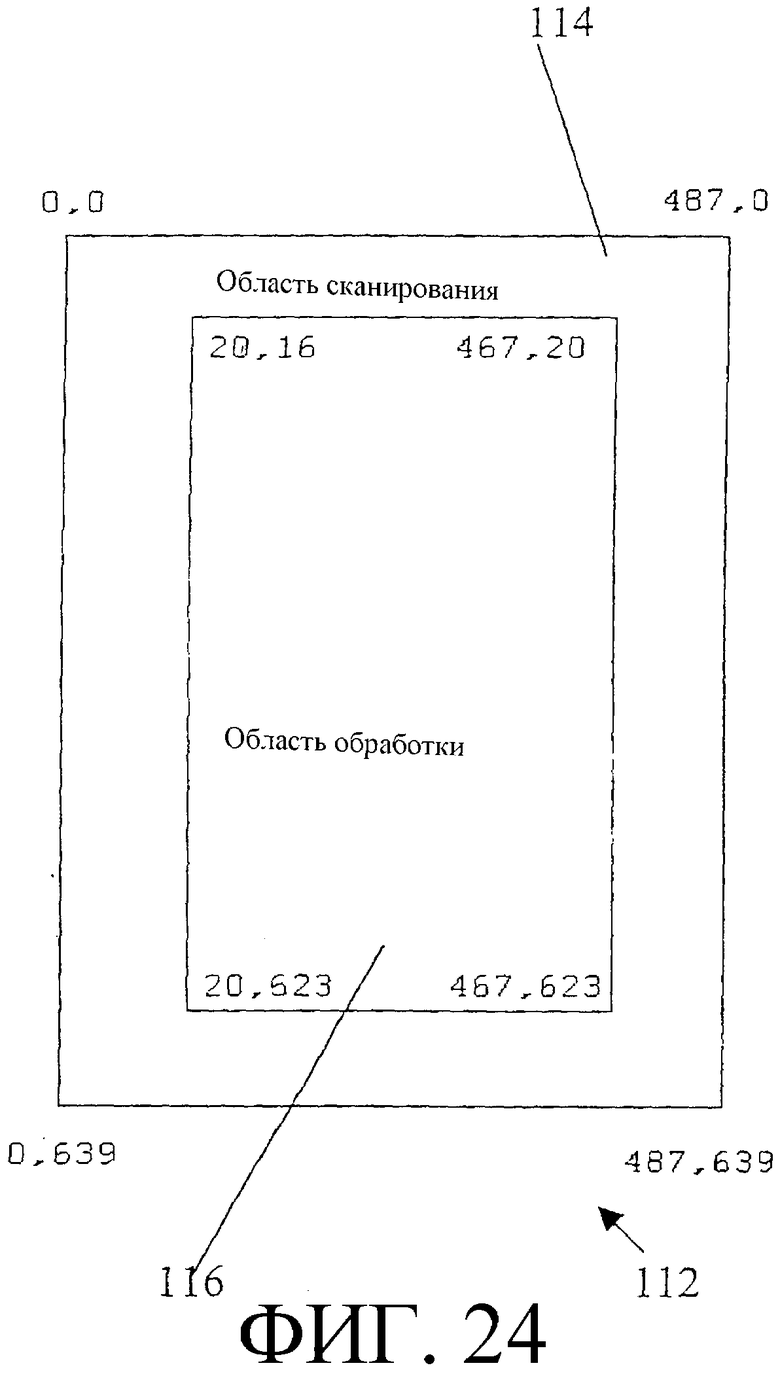


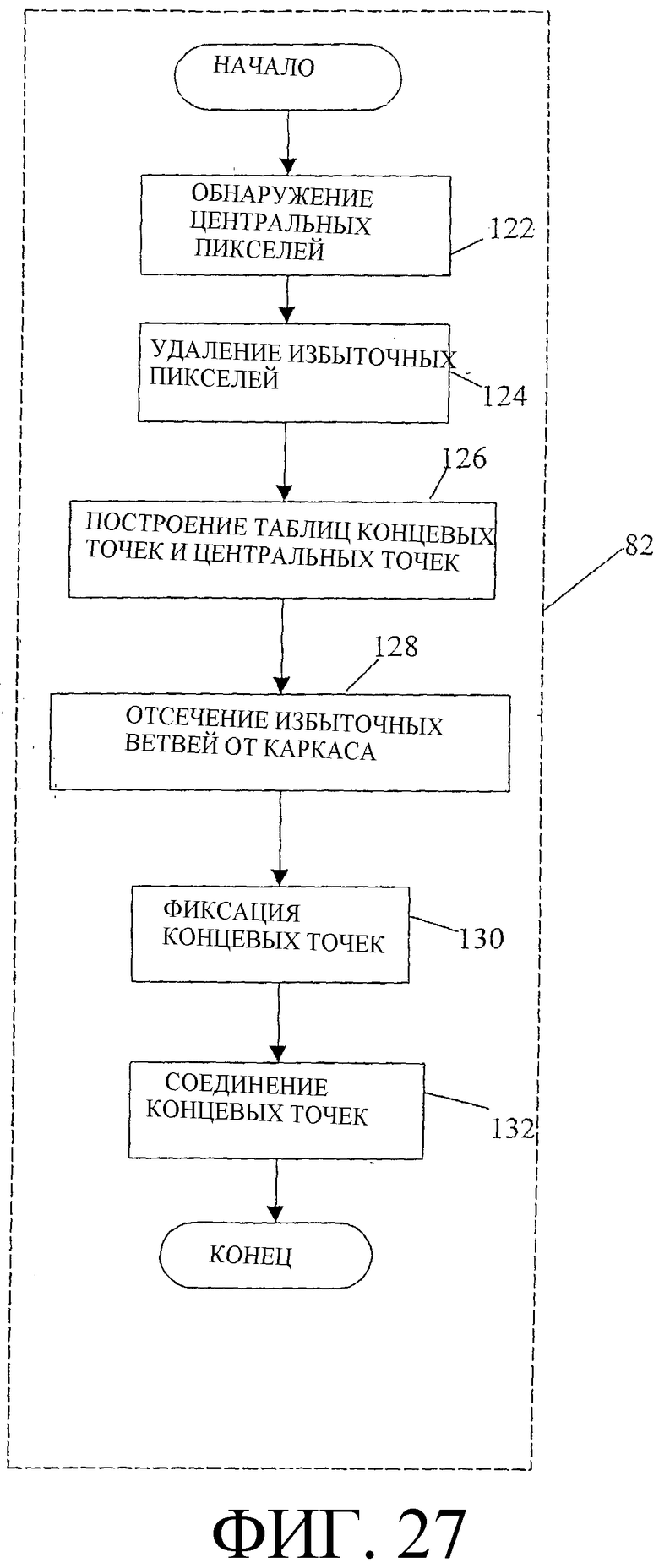












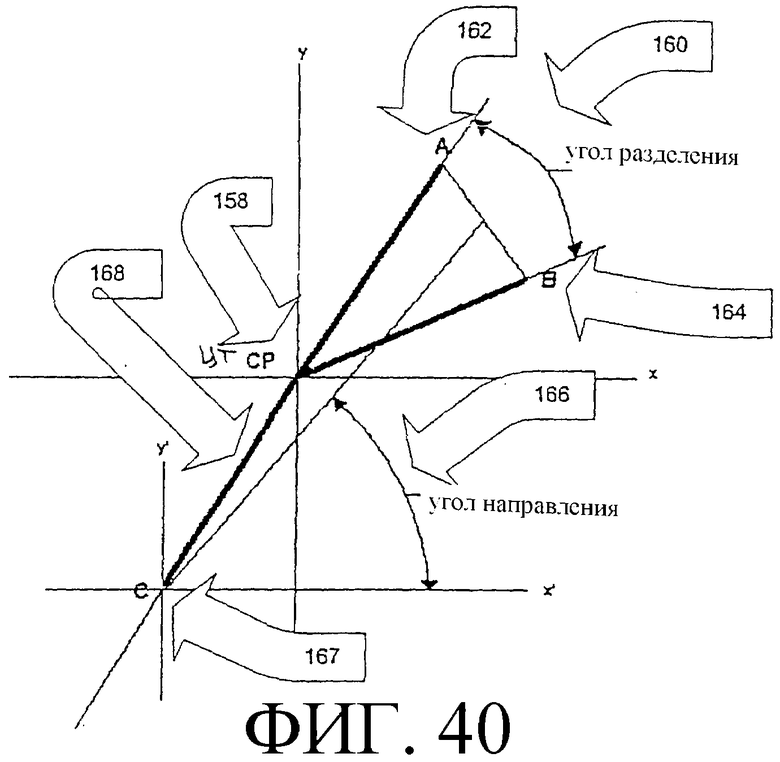

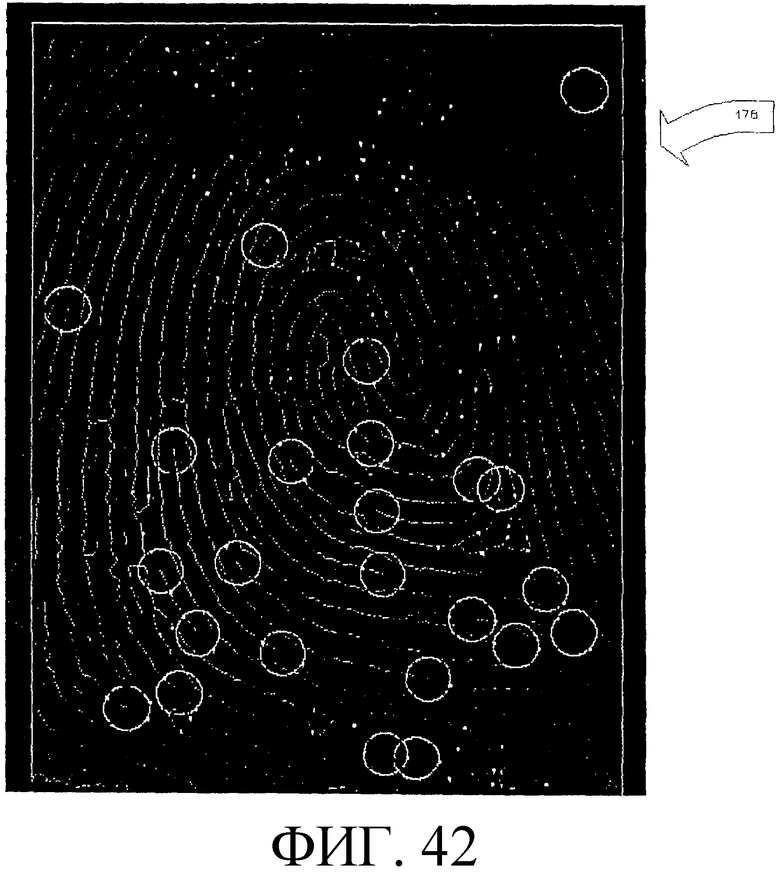


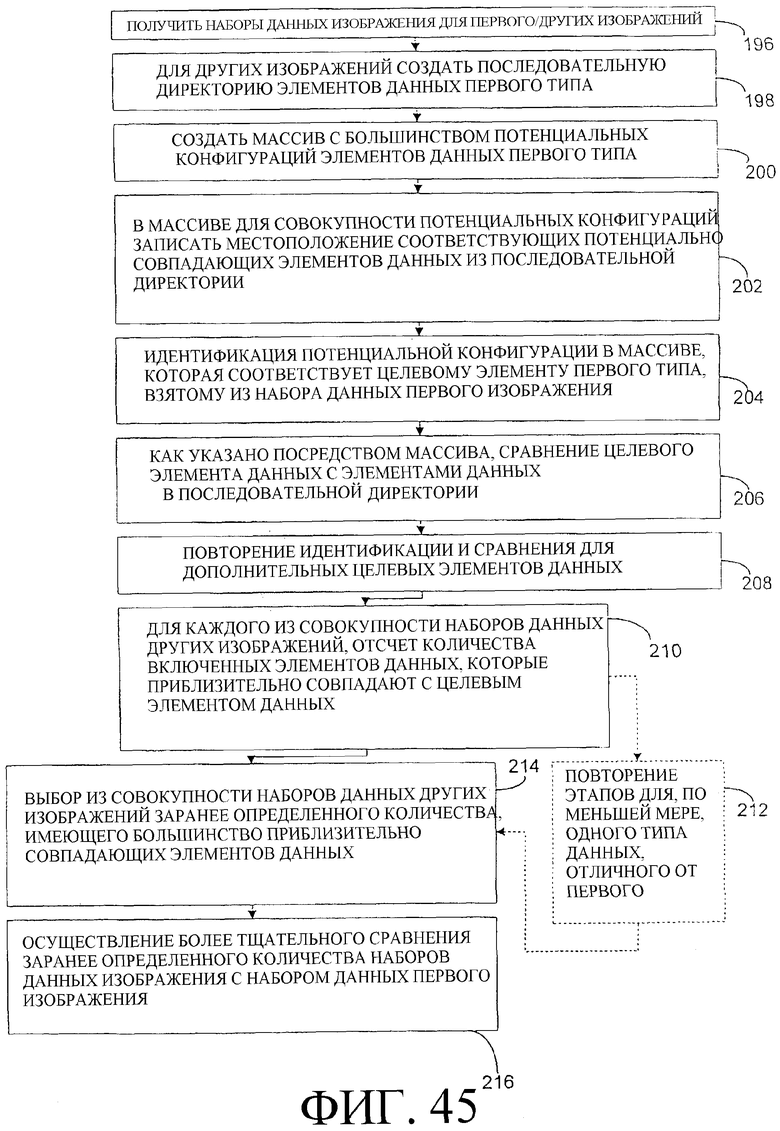
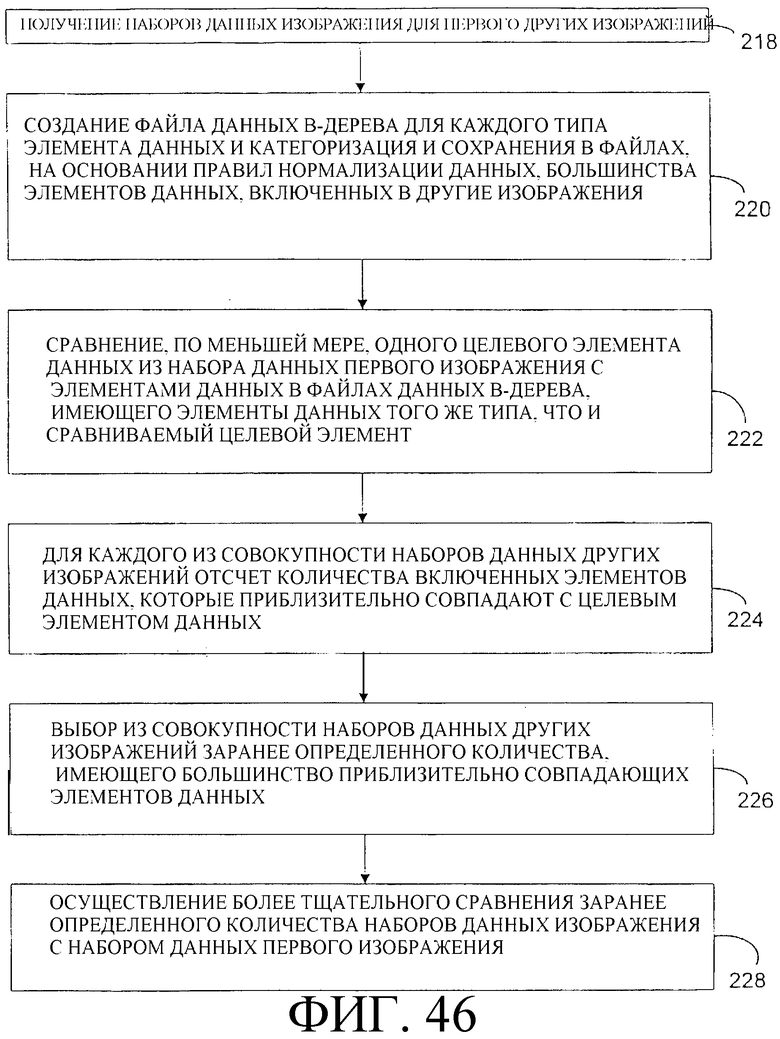
Настоящее изобретение относится к системам идентификации изображений, направлено на повышение производительности и надежности анализа изображения в системе идентификации изображения и включает в себя ряд функций оценивания изображения, предназначенных для быстрой обработки части имеющихся данных изображения и для обеспечения обратной связи пользователю системы в отношении качества и аутентичности изображения. Техническим результатом является увеличение скорости и улучшение качества идентификации изображений. Настоящее изобретение предусматривает функции, предназначенные для создания моделей изображения на основании исходных данных изображения и для занесения таких моделей изображения в поисковую базу данных, а также функции сравнения одной модели изображения с другой и функции для осуществления быстрого определения, какая, если она имеется, из моделей изображения в поисковой базе данных проявляет требуемый уровень подобия, при сравнении с целевой моделью изображения. 3 н. и 9 з.п. ф-лы, 49 ил, 2 табл.
предварительно определяют конкретное значение счетчика в зависимости от цели сравнения набора данных первого изображения с набором данных второго изображения, которое выражает выбранный уровень подобия, необходимый для того, чтобы наборы данных первого и второго изображений рассматривались совпадающими, и обеспечивают указание наличия совпадения, когда значение счетчика, соответствующее точке максимального сравнения, больше или равно конкретному значению счетчика.
вычисляют оценку, которая выражает процент элементов данных в наборе данных первого изображения, приблизительно совпадающих с элементами данных в наборе данных второго изображения в точке максимального сравнения.
предварительно определяют конкретную оценку на основании цели сравнения набора данных первого изображения с набором данных второго изображения, которая выражает выбранный уровень подобия, необходимый для того, чтобы наборы данных первого и второго изображений рассматривались совпадающими, и обеспечивают указание наличия совпадения, когда оценка, связанная с точкой максимального сравнения, больше или равна конкретной оценке.
вычисляют вероятность значения соотношения, которая выражает соотношение совпадения между множественными элементами данных в наборе данных первого изображения и множественными элементами данных в наборе данных второго изображения в точке максимального сравнения.
предварительно определяют конкретную вероятность значения соотношения на основании цели сравнения первого изображения со вторым изображением, которая выражает выбранный уровень подобия, необходимый для того, чтобы первое и второе изображения рассматривались совпадающими, и обеспечивают указание наличия совпадения, когда вероятность значения соотношения, связанная с точкой максимального сравнения, больше или равна упомянутой конкретной вероятности значения соотношения.
повторяют этапы идентификации и сравнения для, по меньшей мере, одного дополнительного целевого элемента данных, используют идентификаторы, связанные с элементами данных, перечисленными в директории, для вычисления и указания количества элементов данных в каждом из множественных наборов данных других изображений, которые приблизительно совпадают с элементами данных, взятыми из набора данных первого изображения, выбирают из множественных наборов данных других изображений заранее определенное количество наборов данных изображений, в которых большинство элементов данных приблизительно совпадают с элементами данных, взятыми из набора данных первого изображения, и
осуществляют более тщательное сравнение заранее определенного количества наборов данных изображения с набором данных первого изображения.
повторяют этапы идентификации и сравнения для, по меньшей мере, одного дополнительного целевого элемента данных, используют идентификаторы, связанные с элементами данных, перечисленными в директории, для вычисления и указания количества элементов данных в каждом из множественных наборов данных других изображений, которые приблизительно совпадают с элементами данных, взятыми из набора данных первого изображения,
повторяют предыдущие этапы, подставляя, по меньшей мере, один другой тип элементов данных вместо первого типа элементов данных, выбирают из множественных наборов данных других изображений заранее определенное количество наборов данных изображений, в которых большинство элементов данных приблизительно совпадают с элементами данных, взятыми из набора данных первого изображения, и осуществляют более тщательное сравнение заранее определенного количества наборов данных изображения с набором данных первого изображения.
сохраняют каждый элемент данных в файлах данных В-дерева с идентификатором, выражающим связь с конкретным набором данных изображения, в котором присутствует элемент данных, и сравнивают, по меньшей мере, один целевой элемент данных из набора данных первого изображения с элементами данных в файле данных В-дерева, имеющем элементы данных того же типа, что и сравниваемый целевой элемент данных.
| «A Real-time Matching System for Large Fingerprint Databases» Nalini K | |||
| Rama etc | |||
| MSU East Lansing, MI 488 | |||
| IEEE me | |||
| NEW YORK | |||
| US | |||
| Способ использования делительного аппарата ровничных (чесальных) машин, предназначенных для мериносовой шерсти, с целью переработки на них грубых шерстей | 1921 |
|
SU18A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| СИСТЕМА УПРАВЛЕНИЯ БЕЗОПАСНЫМ ДОСТУПОМ | 1993 |
|
RU2121162C1 |
| СПОСОБ КЛАССИФИКАЦИИ ОРИЕНТИРОВАННЫХ ОТПЕЧАТКОВ ПАЛЬЦЕВ | 1995 |
|
RU2103738C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ЛИЧНОСТИ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1995 |
|
RU2093890C1 |
| RU 2071114 C1, 27.12.1996 | |||
| ДАКТИЛОСКОПИЧЕСКАЯ СИСТЕМА ИДЕНТИФИКАЦИИ ИЗОБРАЖЕНИЯ | 1996 |
|
RU2154301C2 |
| ЭЛЕКТРОННАЯ КОНТРОЛИРУЮЩАЯ СИСТЕМА/СЕТЬ | 1995 |
|
RU2158444C2 |

