Область техники, к которой относится изобретение
Настоящее изобретение касается области логических схем обработки, микропроцессоров и связанной архитектуры набора команд, которые при исполнении процессором или другой логической схемой обработки осуществляют логические, математические или другие функциональные операции.
Уровень техники
Многопроцессорные системы становятся все более обычными системами. Приложения многопроцессорных систем включают в себя динамическое разбиение на области вплоть до настольных вычислений. Для того чтобы воспользоваться преимуществами многопроцессорных система исполняемый код может быть разделен на множество цепочек для исполнения различными обрабатывающими объектами. Каждая цепочка может быть исполнена параллельно другой. Более того, для увеличения использования обрабатывающего объекта может быть применен измененный порядок исполнения команд. При измененном порядке исполнения, команды могут быть исполнены тогда, когда станет доступен вход, нужный для таких команд. Таким образом, команда, которая появилась позже в последовательности кода может быть исполнена до команды, появившейся в последовательности кода раньше.
Краткое описание чертежей
Варианты осуществления изобретения показаны в качестве примера и не ограничены фиг. с приложенных чертежей:
фиг. 1А - вид, показывающий структурную схему примера вычислительной системы, выполненной с процессором, который может содержать блоки исполнения для исполнения команды, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 1В - вид, показывающий систему обработки данных, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 1С - вид, показывающий другие варианты осуществления системы обработки данных для выполнения операций сравнения текстовых строк;
фиг. 2 - вид, показывающий структурную схему микроархитектуры для процессора, которая может содержать логические схемы для выполнения команд, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 3А - вид, показывающий различные представления типа данных «упакованные данные» в мультимедийных регистрах, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 3В - вид, показывающий возможные форматы хранения данных в регистре, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 3С - вид, показывающий различные представления типа данных «упакованные данные» со знаком и без знака в мультимедийных регистрах, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 3D - вид, показывающий один вариант осуществления формата кодирования операций;
фиг. 3E - вид, показывающий другой возможный формат кодирования операций, содержащий сорок и более битов, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 3F - вид, показывающий еще один возможный формат кодирования операций, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 4A - вид, показывающий структурную схему, иллюстрирующую конвейер с исполнением команд по очереди и конвейер с измененным порядком исполнения/выдачи команд, со ступенью переименования регистров, в соответствии с вариантами осуществления изобретения;
фиг. 4В - вид, показывающий структурную схему, иллюстрирующую архитектуру ядра с исполнением команд по очереди и подлежащую вхождению в процессор логическую схему с измененным порядком исполнения/выдачи команд и логическую схему переименования регистров, в соответствии с вариантами осуществления изобретения;
фиг. 5А - вид, показывающий структурную схему процессора, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 5В - вид, показывающий структурную схему одного примера реализации ядра, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 6 - вид, показывающий структурную схему одной системы, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 7 - вид, показывающий структурную схему второй системы, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 8 - вид, показывающий структурную схему третьей системы, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 9 - вид, показывающий структурную схему системы-на-кристалле, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 10 - вид, показывающий процессор, содержащий центральный обрабатывающий блок и блок обработки графики, который может выполнить, по меньшей мере, одну команду, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 11 - вид, показывающий структурную схему, иллюстрирующую развитие IP-ядер, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 12 - вид, показывающий, как команда первого типа может быть эмулирована процессором другого типа, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 13 - вид, показывающий структурную схему, иллюстрирующую использование программного устройства преобразования команд для преобразования двоичных команд исходного набора команд в двоичные команды целевого набора команд, в соответствии с вариантами осуществления изобретения;
фиг. 14 - вид, показывающий структурную схему одной архитектуры набора команд процессора, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 15 - вид, более подробно показывающий структурную схему одной архитектуры набора команд процессора, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 16 - вид, показывающий структурную схему конвейера исполнения для процессора, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 17 - вид, показывающий структурную схему электронного устройства для использования процессора, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 18 - вид, показывающий пример системы для выгрузки и сортировки команд сохранения, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 19 - вид, показывающий ограничения, накладываемые на работу модуля поиска, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 20 - вид, показывающий пример работы модуля поиска с учетом ограничений, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 21А, 21В и 21C - вид, показывающий пример работы модуля поиска, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 22 - вид, показывающий пример работы модуля поиска по предсказанию или установке указателей поиска, в соответствии с вариантами осуществления настоящего изобретения;
фиг. 23 - вид, показывающий пример варианта осуществления способа поиска и упорядочивания команд сохранения, в соответствии с вариантами осуществления настоящего изобретения.
Подробное описание изобретения
Далее описана команда и логическая схема обработки, для сортировки и выгрузки команд сохранения в процессоре или со связью с процессором, виртуальным процессором, пакетом, компьютерной системой или другим устройством обработки. Такое устройство обработки может содержать процессор с измененным порядком исполнения команд. Более того, такое устройство обработки может содержать многопоточный процессор с измененным порядком исполнением команд. Кроме того, сортировка и выгрузка команд сохранения может быть выполнена из неупорядоченного буфера, такого как буфер команд сохранения. В последующем описании, для обеспечения более глубокого понимания вариантов осуществления настоящего изобретения изложено большое количество конкретных деталей, таких как логическая схема обработки, типы процессоров, микроархитектурные условия, события, механизмы реализации и подобное. Тем не менее, специалистам в рассматриваемой области следует понимать, что варианты осуществления изобретения могут быть реализованы без подобных конкретных деталей. Дополнительно, некоторые хорошо известные структуры, схемы и подобное не показаны подробно, чтобы не создавать ненужные помехи пониманию вариантов осуществления настоящего изобретения.
Хотя приведенные ниже варианты осуществления изобретения описаны со ссылкой на один процессор, другие варианты осуществления изобретения применимы к другим типам интегральных схем и логических устройств. Аналогичные технологии и идеи вариантов осуществления настоящего изобретения могут быть применены в других типах схем или полупроводниковых устройств, которые могут получить пользу от более высокой пропускной способности конвейера и улучшенной производительности. Идеи вариантов осуществления настоящего изобретения применимы в любом процессоре или машине, которые осуществляют манипуляции с данными. Тем не менее, варианты осуществления изобретения не ограничены процессорами или машинами, которые выполняют операции с 512-битовыми, 256-битовыми, 128-битовыми, 64-битовыми, 32-битовыми или 16-битовыми данными, и могут быть применены в любом процессоре и машине, в которых могут быть выполнены манипуляции с данными или управление данными. Кроме того, в последующем описании приведены примеры и с иллюстративными целями на приложенных чертежах показаны различные примеры. Тем не менее, эти примеры не должны рассматриваться как ограничения, так как они приведены как примеры вариантов осуществления настоящего изобретения, а не для предоставления исчерпывающего списка всех возможных реализаций вариантов осуществления настоящего изобретения.
Хотя в приведенных ниже примерах описана обработка команд и их распределение в случае блоков исполнения и логических схем, другие варианты осуществления настоящего изобретения могут быть реализованы с помощью данных или команд, которые сохранены на считываемом машиной, материальном носителе и которые, при их выполнении машиной, побуждают машину выполнять функции, согласующиеся, по меньшей мере, с одним вариантом осуществления изобретения. В одном варианте осуществления изобретения функции, связанные с вариантами осуществления настоящего изобретения, реализованы в исполнимых машиной командах. Команды могут быть использованы для того, чтобы побудить процессор общего назначения или процессор специального назначения, который может быть запрограммирован этими командами, выполнить этапы настоящего изобретения. Варианты осуществления настоящего изобретения могут быть предоставлены как компьютерный программный продукт или программное обеспечение, которое может содержать считываемой машиной или компьютером носитель, на котором сохранены команды, которые можно использовать для программирования компьютера (или другого электронного устройства) с целью выполнения одной или нескольких операций, соответствующих вариантам осуществления настоящего изобретения. Более того, этапы вариантов осуществления настоящего изобретения могут быть выполнены с помощью специальных аппаратных компонентов, которые содержат логическую схему фиксированного назначения для выполнения этих этапов, или с помощью любой комбинации программируемых компонентов компьютера и аппаратных компонентов фиксированного назначения.
Команды, используемые для программирования логической схемы для выполнения вариантов осуществления настоящего изобретения, могут храниться в памяти системы, такой как DRAM, кэш-память, флеш-память или другое запоминающее устройство. Более того, команды могут быть распределены по сети или распределены с помощью других считываемых компьютером носителей. Таким образом, считываемый машиной носитель может являться любым механизмом для хранения или передачи информации в форме, считываемой машиной (например, компьютером), такой как, помимо прочего, гибкие диски, оптические диски, компакт-диски (CD-ROM) постоянного запоминающего устройства и магнитооптические диски, постоянное запоминающее устройство (ROM), оперативное запоминающее устройство (RAM), стираемое программируемое постоянное запоминающее устройство (EPROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), магнитные или оптические карты, флеш-память или материальное, считываемое машиной запоминающее устройство, используемое при передаче информации по сети Интернет с помощью электрических, оптических, акустических или других форм распространяющихся сигналов (например, несущих волн, инфракрасных сигналов, цифровых сигналов и так далее). Соответственно, считываемый машиной носитель информации может содержать любой тип материального, считываемого компьютером носителя, подходящего для хранения или передачи электронных команд или информации в форме, считываемой машиной (например, компьютером).
Конструкция может проходить различные ступени от создания до моделирования и изготовления. Данные, представляющие конструкцию, могут представлять конструкцию различными способами. Во-первых, что может быть полезно при моделировании, аппаратное обеспечение может быть представлено с использованием языка описания аппаратного обеспечения или другого языка функционального описания. Кроме того, на некоторых ступенях процесса конструирования может быть изготовлена модель уровня схемы с логическими элементами и/или элементами-транзисторами. Более того, конструкции, на некоторой ступени, могут достичь уровня данных, представляющих физическое размещение различных устройств в модели аппаратного обеспечения. В случаях, когда используют некоторые технологии изготовления полупроводников, данные, представляющие модель аппаратного обеспечения, могут быть данными, определяющими наличие или отсутствие различных признаков на различных уровнях маски для масок, используемых для изготовления интегральной схемы. В любом представлении конструкции, данные могут быть сохранены в любой форме на считываемом машиной носителе. Память или магнитный или оптический накопитель, такой как диск, может быть считываемым машиной носителем для хранения информации, переданной с помощью оптической или электрической волны, модулированной или другим образом выработанной для передачи такой информации. Когда передают электрическую несущую волну, указывающую или несущую код или конструкцию, таким образом, что выполняют копирование, буферизацию или ретрансляцию электрического сигнала, может быть сделана новая копия. Таким образом, поставщик связи или поставщик доступа к сети может сохранять на материальном, считываемом машиной носителе, по меньшей мере, временно, изделие, такое как информация, закодированная в несущей волне и реализующая технологии вариантов осуществления настоящего изобретения.
В современных процессорах, для обработки и исполнения разного рода кода и команд может быть использовано большое количество разных блоков исполнения. Некоторые команды могут завершаться быстрее, а другие могут требовать для завершения некоторого количества тактовых циклов. Чем больше пропускная способность для команд, тем больше общая производительность процессора. Таким образом, предпочтительно, чтобы как можно большее количество команд исполнялось как можно быстрее. Тем не менее, могут присутствовать определенные команды, обладающие большей сложностью и требующие большего с точки зрения времени исполнения и ресурсов процессора, такие как команды с плавающей запятой, операции загрузки/сохранения, перемещения данных и так далее.
По мере использования большего количества компьютерных систем в интернет-приложениях, текстовых и мультимедийных приложениях, со временем была введена поддержка в виде дополнительного процессора. В одном варианте осуществления изобретения набор команд может быть связан с одной или несколькими архитектурами компьютера, содержащими типы данных, команды, архитектуру регистров, режимы адресации, архитектуру памяти, обработку прерываний и исключений и внешний ввод и вывод.
В одном варианте осуществления изобретения архитектура (ISA) набора команд может быть реализована одной или несколькими микроархитектурами, которые могут содержать логическую схему процессора и схемы, используемые для реализации одного или нескольких наборов команд. Соответственно, процессоры с различными микроархитектурами могут совместно использовать, по меньшей мере, часть общего набора команд. Например, процессоры Intel® Pentium 4, процессоры Intel® Core™ и процессоры компании Advanced Micro Devices, Inc., Саннивейл (Sunnyvale), Калифорния, реализуют практически идентичные версии набора х86 команд (с некоторыми расширениями, которые были добавлены в более новые версии), но обладают различными внутренними конструкциями. Аналогично, процессоры, разработанные другими компаниями-разработчиками процессоров, такими как ARM Holdings, Ltd., MIPS, или их лицензиаты или соразработчики, могут совместно использовать, по меньшей мере, часть общего набора команд, но могут обладать другими конструкциями. Например, одна и та же архитектура регистров из ISA может быть реализована различными путями в разных микроархитектурах, с использованием новых или хорошо известных технологий, в том числе специальных физических регистров, одного или нескольких динамических выделяемых физических регистров с использованием механизма переименования регистров (то есть, с использованием Таблицы (RAT) псевдонимов регистров, буфера (ROB) переупорядочивания и файла регистров выгрузки). В одном варианте осуществления изобретения регистры могут содержать один или несколько регистров, архитектур регистров, файлов регистров или других наборов регистров, которые могут как адресоваться, так и не адресоваться программистом.
Команда может подразумевать один или несколько форматов команд. В одном варианте осуществления изобретения формат команды может указывать различные поля (количество битов, расположение битов и так далее) для определения, помимо прочего, подлежащей выполнению операции и операндов, над которыми выполняют эту операцию. В еще одном варианте осуществления изобретения некоторые форматы команд могут быть дополнительно определены шаблонами команд (или подформатами). Например, шаблоны команды заданного формата команды могут быть определены так, что содержат разные подмножества полей формата команды и/или определены так, чтобы содержать заданное поле, интерпретируемое по-другому. В одном варианте осуществления изобретения команда может быть выражена с использованием некоторого формата команды (и, если определено, в одном из шаблонов команды для этого формата команды) и определяет или указывает операцию и операнды, над которыми будут выполнять эту операцию.
Научные, финансовые, автоматической векторизации общего назначения, RMS (распознавание, извлечение информации из данных и синтез) и визуальные и мультимедийные приложения (например, 2D/3D графика, обработка изображений, сжатие/распаковка видео, алгоритмы распознавания голоса и манипуляции звуком) могут требовать выполнения той же операции для большого количества элементов данных. В одном варианте осуществления изобретения тип команд (SIMD) с одним потоком команд и несколькими потоками данных представляет собой тип команд, который побуждает процессор выполнять операцию с множеством элементов данных. Технология SIMD может быть использована в процессорах, которые могут логически делить биты в регистре на некоторое количество элементов данных фиксированного размера или элементов данных переменного размера, каждый из которых представляет отдельное значение. Например, в одном варианте осуществления изобретения биты в 64-битовом регистре могут быть организованы как операнд-источник, содержащий четыре отдельных 16-битовых элемента данных, каждый из которых представляет отдельное 16-битовое значение. Этот тип данных может быть назван типом «упакованные» данные или типом «векторные» данные, и операнды этого типа данных могут называться операндами упакованных данных или векторными операндами. В одном варианте осуществления изобретения элемент упакованных данных или вектор может быть последовательностью элементов упакованных данных, сохраненной в одном регистре, и операнд упакованных данных или векторный операнд может быть операндом-источником или операндом-назначением SIMD команды (или «команды упакованных данных» или «векторной команды»). В одном варианте осуществления изобретения SIMD команда определяет одну векторную операцию, подлежащую выполнению для двух векторных операндов-источников с целью выработки векторного операнда-назначения (также называемого результирующим векторным операндом) такого же или другого размера, с таким же или другим количеством элементов данных и с таким же или другим порядком элементов данных.
Технология SIMD, такая, как использованная в процессорах Intel® Core™ с набором команд, содержащим команды x86, MMX™, потоковые SIMD расширения (SSE), SSE2, SSE3, SSE4.1 и SSE4.2, процессорах ARM, таких как семейство процессоров ARM Cortex®, набор команд которых содержит векторные команды (VFP) с плавающей запятой и/или команды NEON, и процессорах MIPS, таких как семейство процессоров Loongson, разработанные Институтом вычислительной технологии (ICT) китайской Академии наук, позволила значительно улучшить производительность приложений (Core™ и MMX™ являются зарегистрированными торговыми марками или торговыми марками компании Intel Corporation, Санта-Клара (Santa Clara), Калифорния).
В одном варианте осуществления изобретения регистры/данные назначения и источника могут быть общими терминами, представляющими источник и назначение соответствующих данных или операции. В некоторых вариантах осуществления изобретения они могут быть реализованы с помощью регистров, памяти или других областей хранения, обладающих названиями или функциями, отличающимися от упомянутых. Например, в одном варианте осуществления изобретения «DEST1» может быть регистром временного хранения или другой областью хранения, а «SRC1» и «SRC2» могут быть первым и вторым регистром-источником для хранения или другой областью хранения и так далее. В других вариантах осуществления изобретения две или несколько SRC и DEST областей хранения могут соответствовать разным элементам хранения данных в одной области хранения (например, SIMD регистр). В одном варианте осуществления изобретения один из регистров-источников также может выступать как регистр-назначение, например, благодаря обратной записи результата операции, выполненной с первыми и вторыми исходными данными, в один из двух регистров-источников, служащих в качестве регистров-назначений.
На фиг. 1А показана структурная схема примера вычислительной системы, выполненной с процессором, который может содержать блоки исполнения для исполнения команды, в соответствии с вариантами осуществления настоящего изобретения. Система 100 может содержать компонент, такой как процессор 102, для применения блоков исполнения, содержащих логическую схему для выполнения алгоритмов по обработке данных, в соответствии с настоящим изобретением, например, в соответствии с описанным в настоящем документе вариантом осуществления изобретения. Система 100 может быть представителем систем обработки, основанных на микропроцессорах PENTIUM® III, PENTIUM® 4, Xeon™, Itanium®, XScale™ и/или StrongARM™ компании Intel Corporation, Санта-Клара, Калифорния, хотя также могут быть использованы другие системы (в том числе PC с другими микропроцессорами, инженерные рабочие станции, телевизионные приставки и подобное). В одном варианте осуществления изобретения пример системы 100 может исполнять версию операционной системы WINDOWS™ компании Microsoft Corporation, Редмонд (Redmond), Вашингтон, хотя также могут быть использованы другие операционные системы (например, UNIX и Linux), встроенное программное обеспечение и/или графические интерфейсы пользователя. Таким образом, варианты осуществления настоящего изобретения не ограничены какой-либо конкретной комбинацией аппаратной схемы и программного обеспечения.
Варианты осуществления изобретения не ограничены компьютерными системами. Варианты осуществления настоящего изобретения могут быть использованы в других устройствах, таких как карманные устройства и встроенные приложения. Некоторыми примерами карманных устройств являются сотовые телефоны, устройства интернет-протокола, цифровые фотокамеры, персональные цифровые помощники (PDA) и карманные PC. Встроенными приложениями могут являться микроконтроллер, цифровой сигнальный процессор (DSP), система на микросхеме, сетевые компьютеры (NetPC), телевизионные приставки, сетевые концентраторы, коммутаторы глобальной вычислительной сети (WAN) или любая другая система, которая может выполнить одну или несколько команд в соответствии, по меньшей мере, в одним вариантом осуществления изобретения.
Компьютерная система 100 может содержать процессор 102, который может содержать один или несколько блоков 108 исполнения для выполнения алгоритма с целью исполнения, по меньшей мере, одной команды в соответствии с одним вариантом осуществления настоящего изобретения. Один вариант осуществления изобретения может быть описан в контексте однопроцессорной настольной или серверной системы, но другие варианты осуществления изобретения могут содержать многопроцессорную систему. Система 100 может быть примером «блочной» архитектуры системы. Система 100 может содержать процессор 102 для обработки сигналов данных. Процессор 102 может содержать микропроцессор (CISC) со сложным набором команд, микропроцессор (RISC) с сокращенным набором команд, микропроцессор (VLIW) с очень длинным командным словом, процессор, реализующий комбинации наборов команд, или любое другое процессорное устройство, такое как, например, цифровой сигнальный процессор. В одном варианте осуществления изобретения процессор 102 может быть связан с шиной 110 процессора, которая может передавать сигналы данных между процессором 102 и другими компонентами в системе 100. Элементы системы 100 могут выполнять обычные функции, хорошо известные специалистам в рассматриваемой области.
В одном варианте осуществления изобретения процессор 102 может содержать внутреннюю кэш-память 104 уровня 1 (L1). В зависимости от архитектуры, процессор 102 может содержать одну внутреннюю кэш-память или несколько уровней внутренней кэш-памяти. В другом варианте осуществления изобретения кэш-память может быть внешней по отношению к процессору 102. Другие варианты осуществления изобретения могут также содержать комбинацию как внутренних, так и внешних кэш-памятей, в зависимости от конкретной реализации и потребностей. Файл 106 регистров может хранить данные различных типов в различных регистрах, в том числе регистрах целых чисел, регистрах чисел с плавающей запятой, регистрах состояния и регистре указателей команд.
Блок 108 исполнения, содержащий логическую схему для выполнения операций с целыми числами и числами с плавающей запятой, также расположен в процессоре 102. Процессор 102 также может содержать ROM микрокода (ucode), в котором хранят микрокод для определенных макрокоманд. В одном варианте осуществления изобретения блок 108 исполнения может содержать логическую схему для обработки набора 109 команд для упакованных данных. Благодаря содержанию набора 109 команд для упакованных данных в наборе команд процессора 102 общего назначения, вместе с связанной схемой по исполнению команд, могут быть выполнены операции, используемые многими мультимедийными приложениями, с использованием упакованных данных в процессоре 102 общего назначения. Таким образом, многие мультимедийные приложения могут быть ускорены и исполнены более эффективно путем использования полной ширины шины данных процессора для выполнения операций с упакованными данными. Это может исключить потребность в переносе более мелких блоков данных по шине данных процессора с целью выполнения одной или нескольких операций с одним элементом данных за один раз.
Варианты осуществления блока 108 исполнения также могут быть использованы в микроконтроллерах, встроенных процессорах, графических устройствах, DSP и других типах логических схем. Система 100 может содержать память 120. Память 120 может быть реализована как динамическое оперативное запоминающее устройство (DRAM), статическое оперативное запоминающее устройство (SRAM), устройство флеш-памяти или другое устройство памяти. Память 120 может хранить команды и/или данные, представленные сигналами данных, которые могут быть исполнены процессором 102.
Микросхема 116 системной логики может быть связана с шиной 110 процессора и памятью 120. Микросхема 116 системной логики может содержать контроллер-концентратор (MCH) памяти. Процессор 102 может взаимодействовать с MCH 116 с помощью шины 110 процессора. MCH 116 может обеспечивать широкополосный путь 118 памяти к памяти 120 для хранения команд и данных и для хранения графических команд, данных и структур. MCH 116 может направлять сигналы данных между процессором 102, памятью 120 и другими компонентами в системе 100 и передавать сигналы данных между шиной 110 процессора, памятью 120 и вводом/выводом 122 системы. В некоторых вариантах осуществления изобретения микросхема 116 системной логики может предоставлять графический порт для связи с графическим контроллером 112. MCH 116 может быть соединен с памятью 120 с помощью интерфейса 118 памяти. Графическая карта 112 может быть связана с MCH 116 с помощью соединения 114 ускоренного графического порта (AGP).
Система 100 может использовать запатентованную шину 122 интерфейса концентратора для связи MCH 116 c контроллером-концентратором 130 (ICH) ввода-вывода. В одном варианте осуществления изобретения ICH 130 может обеспечивать прямые соединения с некоторыми устройствами ввода/вывода с помощью локальной шины ввода/вывода. Локальная шина ввода/вывода может содержать высокоскоростную шину ввода/вывода для соединения периферийных устройств с памятью 120, набором микросхем и процессором 102. Примерами могут являться контроллер звука, аппаратно реализованный программный концентратор 128 (флеш BIOS), устройство 126 беспроводной приемо-передачи, запоминающее устройство 124 для данных, существующий контроллер ввода/вывода, содержащий интерфейсы ввода данных пользователем и клавиатуры, последовательный порт расширения, такой как универсальная последовательная шина (USB) и сетевой контроллер 134. Запоминающее устройство 124 для данных может содержать накопитель на жестких дисках, накопитель на гибких дисках, устройство CD-ROM, устройство флеш-памяти или другое запоминающее устройство большой емкости.
В другом варианте осуществления системы, команда, соответствующая одному варианту осуществления изобретения, может быть использована с системой на микросхеме. Один вариант осуществления системы на микросхеме содержит процессор и память. Память для одной такой системы может содержать флеш-память. Флеш-память может быть расположена на том же кристалле, что и процессор и другие компоненты системы. Кроме того, в системе на микросхеме также могут быть расположены другие логические блоки, такие как контроллер памяти или графический контроллер.
На фиг. 1В показана система 140 обработки данных, в которой реализованы принципы вариантов осуществления настоящего изобретения. Специалисту в рассматриваемой области ясно, что описанные в настоящем документе варианты осуществления изобретения могут работать с альтернативными системами обработки, без выхода за границы объема патентования вариантов осуществления изобретения.
Компьютерная система 140 содержит обрабатывающее ядро 159 для выполнения, по меньшей мере, одной команды, в соответствии с одним вариантом осуществления изобретения. В одном варианте осуществления изобретения обрабатывающее ядро 159 представляет собой обрабатывающий блок с архитектурой любого типа, в том числе, помимо прочего, архитектурой типа CISC, RISC или VLIW. Обрабатывающее ядро 159 также может быть изготовлено с помощью одной или нескольких технологий обработки и может быть представлено на считываемом машиной носителе с достаточностью степенью детальности, может подходить для облегчения указанного изготовления.
Обрабатывающее ядро 159 содержит блок 142 исполнения, набор 145 файлов регистров и декодер 144. Обрабатывающее ядро 159 также может содержать дополнительную схему (не показана), которая может быть необязательной для понимания вариантов осуществления настоящего изобретения. Блок 142 исполнения может исполнять команды, принятые обрабатывающим ядром 159. Помимо выполнения типовых команд процессора, блок 142 исполнения может выполнять команды набора 143 команд для упакованных данных с целью выполнения операций над данными, представленными в форматах упакованных данных. Набор 143 команд для упакованных данных может содержать команды для выполнения вариантов осуществления изобретения и другие упакованные команды. Блок 142 исполнения может быть связан с файлом 145 регистров с помощью внутренней шины. Файл 145 регистров может представлять собой область хранения в обрабатывающем ядре 159 для хранения информации, в том числе данных. Как упомянуто выше, ясно, что область хранения может хранить упакованные данные, которые могут не быть критическими. Блок 142 исполнения может быть связан с декодером 144. Декодер 144 может декодировать команды, принятые обрабатывающим ядром 159, в сигналы управления и/или точки входа микрокода. В ответ на эти сигналы управления и/или точки входа микрокода, блок 142 исполнения выполняет соответствующие операции. В одном варианте осуществления изобретения декодер может интерпретировать код операции команды, который будет указывать, какую выполнять операцию с соответствующими данными, указанными в команде.
Обрабатывающее ядро 159 может быть связано с шиной 141 для обмена информацией с различными другими устройствами системы, которые могут содержать, помимо прочего, например, контроллер 146 синхронного динамического оперативного запоминающего устройства (SDRAM), контроллер 147 статичного оперативного запоминающего устройства (SRAM), интерфейс 148 пакетной флеш-памяти, контроллер 149 карты Международной ассоциации производителей карт памяти для персональных компьютеров (PCMCIA)/Сompact flash (CF), контроллер 150 жидкокристаллического дисплея (LCD), контроллер 151 прямого доступа (DMA) к памяти и интерфейс 152 альтернативного ведущего устройства шины. В одном варианте осуществления изобретения система 140 обработки данных также может содержать мост 154 ввода/вывода для связи с различными устройствами ввода/вывода с помощью шины 153 ввода/вывода. Такие устройства ввода/вывода могут содержать, помимо прочего, например, универсальное асинхронное устройство 155 (UART) приема/передачи, универсальную последовательную шину 156 (USB), UART 157 беспроводной технологии Bluetooth и интерфейс 158 расширения ввода/вывода.
Один вариант осуществления системы 140 обработки данных обеспечивает мобильную, сетевую и/или беспроводную связь и обрабатывающее ядро 159, которое может выполнять SIMD операции, в том числе операцию сравнения текстовых строк. Обрабатывающее ядро 159 может быть запрограммировано с помощью различных звуковых алгоритмов, видео алгоритмов, алгоритмов обработки изображений и алгоритмов связи, содержащих дискретные преобразования, такие как преобразование Уолша-Адамара, быстрое преобразование (FFT) Фурье, дискретное косинусное преобразование (DCT) и их соответствующие обратные преобразования; технологий сжатия/распаковки, такие как преобразование цветового пространства, оценка движения при кодировании видео или компенсация движения при декодировании видео; и функций (MODEM) модуляции/демодуляции, таких как импульсно-кодовая модуляция (PCT).
На фиг. 1С показаны другие варианты осуществления системы обработки данных, которая выполняет SIMD операции сравнения текстовых строк. В одном варианте осуществления изобретения система 160 обработки данных может содержать основной процессор 166, SIMD сопроцессор 161, кэш-память 167 и систему 168 ввода/вывода. Система 168 ввода/вывода может, при желании, быть связана с беспроводным интерфейсом 169. SIMD сопроцессор 161 может выполнять операции, содержащие команды, в соответствии с одним вариантом осуществления изобретения. В одном варианте осуществления изобретения обрабатывающее ядро 170 может быть изготовлено с помощью одной или нескольких технологий обработки и может быть представлено на считываемом машиной носителе с достаточностью степенью детальности, может подходить для облегчения изготовления всей или части системы 160 обработки данных, содержащей обрабатывающее ядро 170.
В одном варианте осуществления изобретения, SIMD сопроцессор 161 содержит блок 162 исполнения и набор файлов 164 регистров. Один вариант осуществления основного процессора 165 содержит декодер 165 для распознавания команд набора 163 команд, содержащего команды в соответствии с одним вариантом осуществления изобретения для исполнения блоком 162 исполнения. В других вариантах осуществления изобретения SIMD сопроцессор 161 также содержит, по меньшей мере, часть декодера 165 для декодирования команд набора 163 команд. Обрабатывающее ядро 170 также может содержать дополнительную схему (не показана), которая может быть необязательной для понимания вариантов осуществления настоящего изобретения.
При работе основной процессор 166 исполняет поток команд обработки данных, которые управляют операциями обработки данных общего типа, в том числе взаимодействиями с кэш-памятью 167 и системой 168 ввода/вывода. В поток команд обработки данных могут быть встроены команды SIMD сопроцессора. Декодер 165 основного процессора 166 распознает эти команды SIMD сопроцессора как команды такого типа, которые должны быть исполнены прикрепленным SIMD сопроцессором 161. Соответственно, основной процессор 166 направляет эти команды SIMD сопроцессора (или сигналы управления, представляющие команды SIMD сопроцессора) по шине 166 сопроцессора. Из шины 166 сопроцессора эти команды могут быть приняты любым прикрепленным SIMD сопроцессором. В этом случае SIMD сопроцессор 161 может принять и исполнить любую полученную и предназначенную для него команду SIMD сопроцессора.
Данные могут быть приняты с помощью беспроводного интерфейса 169 для обработки командами SIMD сопроцессора. В качестве одного примера, голосовая связь может быть принята в форме цифрового сигнала, который может быть обработан SIMD сопроцессором с помощью команд SIMD сопроцессора с целью восстановления образцов цифрового звука, представляющих голосовую связь. В качестве другого примера, сжатый звук и/или видео могут быть приняты в форме цифрового потока битов, который может быть обработан с помощью команд SIMD сопроцессора с целью восстановления образцов цифрового звука и/или видео кадров. В одном варианте осуществления обрабатывающего ядра 170 основной процессор 166 и SIMD сопроцессор 161 могут быть объединены в одно обрабатывающее ядро 170, содержащее блок 162 исполнения, набор файлов 164 регистров и декодер 165 для распознавания команд из набора 163 команд, содержащего команды в соответствии с одним вариантом осуществления изобретения.
На фиг. 2 показана структурная схема микроархитектуры процессора 200, который может содержать логические схемы для для исполнения команд, в соответствии с вариантами осуществления настоящего изобретения. В некоторых вариантах осуществления изобретения команда в соответствии с одним вариантом осуществления изобретения может быть реализована для работы с элементами данных, размер которых равен байту, слову, двойному слову, учетверенному слову и так далее, а также с такими типами данных, как целые одинарной и двойной точности и данные с плавающей запятой. В одном варианте осуществления изобретения входной блок 201 с исполнением команд по очереди может реализовывать часть процессора 200, которая может выбирать команды для исполнения и подготавливать команды для дальнейшего использования в конвейере процессора. Входной блок 201 может содержать несколько блоков. В одном варианте осуществления изобретения устройство 226 упреждающей выборки команд выбирает команды из памяти и подает команды на декодер 228 команд, который, в свою очередь, декодирует или интерпретирует команды. Например, в одном варианте осуществления изобретения декодер декодирует принятую команду в одну или несколько операций, называемых «микрокомандами» или «микрооперациями» (также называемые uop), которые может исполнять машина. В других вариантах осуществления изобретения декодер разбирает команду на код операции и соответствующие данные и поля управления, которые могут быть использованы микроархитектурой для выполнения операций в соответствии с одним вариантом осуществления изобретения. В одном варианте осуществления изобретения кэш-память 230 трассировки может собирать декодированные микрооперации в упорядоченные программой последовательности или трассы в очереди 234 микроопераций для исполнения. Когда кэш-память 230 трассировки сталкивается со сложной командой, ROM 232 микрокода предоставляет микрооперации, нужные для завершения операции.
Некоторые команды могут быть преобразованы в одну микрооперацию, тогда как другим нужно несколько микроопераций для завершения полной операции. В одном варианте осуществления изобретения, если нужно более четырех микроопераций для завершения команды, декодер 228 может обратиться к ROM 232 микрокода для выполнения команды. В одном варианте осуществления изобретения команда может быть декодирована в малое количество микроопераций для обработки в декодере 228 команд. В другом варианте осуществления изобретения команда может быть сохранена в ROM 232 микрокода, если для завершения операции нужно некоторое количество микроопераций. Кэш-память 230 трассировки обращается к точке входа программируемой логической матрицы (PLA) для определения корректного указателя микрокоманды с целью считывания из ROM 232 микрокода последовательности микрокода для завершения одной или нескольких команд в соответствии с одним вариантом осуществления изобретения. После того как ROM 232 микрокода завершает установку последовательности микроопераций для команды, входной блок 201 машины может возобновить выборку микроопераций из кэш-памяти 230 трассировки.
Механизм 203 исполнения с измененной очередью команд может подготовить команды для исполнения. Логическая схема исполнения с измененной очередью команд содержит некоторое количество буферов для сглаживания и переупорядочивания потока команд с целью оптимизации производительности, когда команды спускаются по конвейеру и при их планировании для исполнения. Логическая схема выделения выделяет буферы и ресурсы машины, которые нужны каждой микрооперации для исполнения. Логическая схема переименования регистров переименовывает логические регистры в записи в файле регистров. Устройство выделения также выделяет запись для каждой микрооперации в одной из двух очередях микроопераций, одна для операций с памятью и одна для операций без памяти, перед устройствами планирования команд: устройство планирования для памяти, быстрое устройство 202 планирования, медленное/общее устройство 204 планирования для плавающей запятой и простое устройство 206 планирования для плавающей запятой. Устройства 202, 204, 206 планирования для микроопераций определяют, когда микрооперация готова для исполнения на основе готовности зависимых входных операндов-источников и доступности ресурсов исполнения, которые нужны микрооперациям для завершения их операции. Быстрое устройство 202 планирования одного варианта осуществления изобретения может планировать в каждую половину основного такта цикла, а другие устройства планирования могут планировать только по тактам цикла основного процессора. Устройства планирования решают для портов отправления по планированию микроопераций для исполнения.
Файлы 208, 210 регистров могут быть расположены между устройствами 202, 204, 206 планирования и блоками 212, 214, 216, 218, 220, 222, 224 исполнения в узле 211 исполнения. Каждый из файлов 208, 210 регистров выполняет, соответственно, операции с целыми данными и с данными с плавающей запятой. Каждый из файлов 208, 210 регистров может содержать обходную сеть, по которой только завершенные результаты, которые еще не были записаны в файл регистров, могут обойти или быть направлены на новые зависимые микрооперации. Файл 208 регистров для целых данных и файл 210 регистров для данных с плавающей запятой могут обмениваться данными друг с другом. В одном варианте осуществления изобретения файл 208 регистров для целых данных может быть разделен на два отдельных файла регистров один файл регистров для младших тридцати двух битов данных, а второй файл регистров для старших тридцати двух битов данных. Файл 210 регистров для данных с плавающей запятой может содержать 128-битовые записи, так как команды с плавающей запятой обычно обладают операндами размером от 64 до 128 битов.
Узел 211 исполнения может содержать блоки 212, 214, 216, 218, 220, 222, 224 исполнения. Блоки 212, 214, 216, 218, 220, 222, 224 исполнения могут исполнять команды. Узел 211 исполнения может содержать файлы 208, 210 регистров, в которых хранятся значения операндов целых данных и данных с плавающей запятой, которые нужно исполнить микрокомандам. В одном варианте осуществления изобретения процессор 200 может содержать некоторое количество блоков исполнения: блок 212 (AGU) выработки адреса, AGU 214, быстрое ALU 216, быстрое ALU 218, медленное ALU 220, ALU 222 для данных с плавающей запятой, блок 224 перемещения для данных с плавающей запятой. В другом варианте осуществления изобретения блоки 222, 224 исполнения для данных с плавающей запятой В еще одном варианте осуществления изобретения ALU 222 для данных с плавающей запятой может содержать устройство деления 64-бита-на-64-бита для исполнения микроопераций деления, вычисления квадратного корня и остатка. В различных вариантах осуществления изобретения команды, подразумевающие значение с плавающей запятой, могут быть обработаны аппаратным обеспечением для данных с плавающей запятой. В одном варианте осуществления изобретения операции ALU могут быть переданы на высокоскоростные блоки 216, 218 исполнения ALU. Высокоскоростные ALU 216, 218 могут исполнять быстрые операции с эффективной задержкой в половину тактового цикла. В одном варианте осуществления изобретения наиболее сложные операции с целыми данными направляют в медленное ALU 220, так как медленное ALU 220 может содержать аппаратное обеспечение исполнения для целых данных для операций с длинной задержкой, таких как умножение, сдвиги, логические операции с флагами и обработка ветвлений. Операции загрузки/сохранения в памяти могут быть исполнены в AGU 212, 214. В одном варианте осуществления изобретения ALU 216, 218 для целых данных могут выполнять операции с целыми данными для 64-битовых операндов данных. В других вариантах осуществления изобретения ALU 216, 218, 220 могут быть реализованы для поддержки целого ряда битовых размеров данных, в том числе шестнадцати битовых, тридцати двух битовых, 128-битовых, 256-битовых и так далее. Аналогично, блоки 222, 224 для данных с плавающей запятой могут быть реализованы для поддержки ряда операндов с разными битовыми размерами. В одном варианте осуществления изобретения блоки 222, 224 для данных с плавающей запятой могут работать с 128-битовыми операндами упакованных данных в сочетании с SIMD и мультимедийными командами.
В одном варианте осуществления изобретения устройства 202, 204, 206 планирования микроопераций отправляют зависимые операции до завершения исполнения родительской загрузки. Так как микрооперации теоретически могут быть запланированы и исполнены в процессоре 200, то процессор 200 также может содержать логическую схему для обращения с промахами для памяти. Если загрузка данных не содержит данных в кэш-памяти, то могут присутствовать зависимые операции, обрабатываемые в конвейере, которые оставили устройство планирования с временно некорректными данными. Механизм повторного воспроизведения отслеживает и повторно исполняет команды, которые используют некорректные данные. Только для зависимых операций может понадобиться повторное воспроизведение, а независимым операциям могут позволить завершиться. Устройства планирования и механизм повторного воспроизведения одного варианта осуществления процессора также могут быть спроектированы для захвата последовательностей команд для операций сравнения текстовых строк.
Термином «регистры» могут называться встроенные в процессор ячейки хранения, которые могут быть использованы как часть команд для идентификации операндов. Другими словами, регистрами могут быть ячейки, которые можно использовать снаружи процессора (с точки зрения программиста). Тем не менее, в некоторых вариантах осуществления изобретения регистры могут быть не ограничены конкретным типом схемы. Предпочтительно, что регистр может сохранять данные, предоставлять данные и выполнять описанные в настоящем документе функции. Описанные в настоящем документе регистры могут быть реализованы схемой в процессоре, с использованием любого количества разных технологий, таких как специальные физические регистры, динамически выделяемые физические регистры с использованием переименования регистров, комбинации специальных и динамически выделяемых физических регистров и так далее. В одном варианте осуществления изобретения регистры целых данных хранят 32-битовые целые данные. Файл регистров одного варианта осуществления изобретения также содержит восемь мультимедийных SIMD регистров для упакованных данных. Для приведенного ниже описания, регистры можно понимать как регистры данных, спроектированные для содержания упакованных данных, такие как 64-битовые MMX™ регистры (также называемые в некоторых примерах «mm» регистрами) в микропроцессорах, поддерживающих технологию MMX компании Intel Corporation, Санта-Клара, Калифорния. Эти MMX регистры, доступные как в форме для целых данных, так и в форме для данных с плавающей запятой, могут работать с элементами упакованных данных, которые сопровождают SIMD и SSE команды. Аналогично, 128-битовые XMM регистр, относящиеся к технологии SSE2, SSE3, SSE4 и далее (в общем, называемые «SSEx»), могут содержать такие операнды с упакованными данными. В одном варианте осуществления изобретения, при сохранении упакованных данных и целых данных, регистрам не нужно различать эти два типа данных. В одном варианте осуществления изобретения целое значение и значение с плавающей запятой могут содержаться в одном файле регистров или в различных файлах регистров. Более того, в одном варианте осуществления изобретения данные с плавающей запятой и целые данные могут храниться в разных регистрах или в одинаковых регистрах.
В примерах, показанных на следующих фиг., может быть описано некоторое количество операндов данных. На фиг. 3А показаны различные представления типа данных «упакованные данные» в мультимедийных регистрах, в соответствии с вариантами осуществления настоящего изобретения. На фиг. 3А показаны типы данных для упакованного байта 310, упакованного слова 320 и упакованного двойного слова 330 для 128-битовых операндов. Формат 310 упакованного байта из этого примера может обладать длиной, равной 128 битам, и содержать шестнадцать байтовых элементов упакованных данных. Байт может быть определен, например, как восемь битов данных. Информация для каждого байтового элемента данных может быть сохранена в бите 7 - бите 0 для байта 0, в бите 15 - бите 8 для байта 1, в бите 23 - бите 16 для байта 2, … и, наконец, в бите 127 - бите 120 для байта 15. Таким образом, в регистре могут быть использованы все доступные биты. Эта компоновка хранения увеличивает эффективность хранения в процессоре. Также, с доступом к шестнадцати элементам данных, одна операция теперь может быть выполнена параллельно для шестнадцати элементов данных.
В общем, элемент данных может содержать отдельную часть данных, которая хранится в одном регистре или ячейке памяти с другими элементами данных той же длины. В последовательностях упакованных данных, относящихся к SSEx технологии, количество элементов данных, хранящихся в XMM регистре, может быть равно 128 битам, деленным на длину в битах отдельного элемента данных. Аналогично, в последовательностях упакованных данных, относящихся к MMX и SSE технологиям, количество элементов данных, хранящихся в MMX регистре, может быть равно 64 битам, деленным на длину в битах отдельного элемента данных. Хотя типы данных, показанные на фиг. 3А, могут обладать длиной 128 битов, варианты осуществления настоящего изобретения также могут работать с 64-битовыми операндами или операндами других размеров. Формат 320 упакованного слова из этого примера может обладать длиной, равной 128 битам, и содержать восемь элементов упакованных данных, размера равного слову. Каждое упакованное слово содержит шестнадцать битов информации. Формат 330 упакованного двойного слова из этого примера может обладать длиной, равной 128 битам, и содержать четыре элемента упакованных данных, размера равного двойному слову. Каждый элемент упакованных данных, размера равного двойному слову, содержит тридцать два бита информации. Упакованное четверное слово может обладать длиной, равной 128 битам, и содержать два элемента упакованных данных, размера равного четверному слову.
На фиг. 3В показаны возможные форматы хранения данных в регистре, в соответствии с вариантами осуществления настоящего изобретения. Каждые упакованные данные могут содержать более одного независимого элемента данных. Показано три формата упакованных данных; упакованные данные341 половинной точности, упакованные данные 342 одинарной точности, и упакованные данные 343 двойной точности. Один вариант осуществления упакованных данных 341 половинной точности, упакованных данных 342 одинарной точности и упакованных данных 343 двойной точности содержит элементы данных с фиксированной запятой. В другом варианте осуществления один или несколько из упакованных данных 341 половинной точности, упакованных данных 342 одинарной точности и упакованных данных 343 двойной точности могут содержать элементы данных с плавающей запятой. Один вариант осуществления упакованных данных 341 половинной точности может обладать длиной в 128 битов и содержать восемь 16-битовых элементов данных. Один вариант осуществления упакованных данных 342 одинарной точности может обладать длиной в 128 битов и содержать четыре 32-битовых элемента данных. Один вариант осуществления упакованных данных 343 двойной точности может обладать длиной в 128 битов и содержать два 64-битовых элемента данных. Ясно, что такие форматы данных могут быть дополнительно расширены на другие длины регистров, например, до 96 битов, 160 битов, 192 битов, 224 битов, 256 битов и более.
На фиг. 3С показаны различные представления типа данных «упакованные данные» со знаком и без знака в мультимедийных регистрах, в соответствии с вариантами осуществления настоящего изобретения. Упакованное байтовое представление 344 без знака показывает хранение упакованного байта без знака в SIMD регистре. Информация для каждого байтового элемента данных может быть сохранена в бите 7 - бите 0 для байта 0, в бите 15 - бите 8 для байта 1, в бите 23 - бите 16 для байта 2, … и, наконец, в бите 127 - бите 120 для байта 15. Таким образом, в регистре могут быть использованы все доступные биты. Эта компоновка хранения может увеличить эффективность хранения в процессоре. Также, с доступом к шестнадцати элементам данных, одна операция теперь может быть выполнена параллельным образом для шестнадцати элементов данных. Упакованное байтовое представление 345 со знаком показывает хранение упакованного байта со знаком. Заметим, что каждый восьмой бит каждого байтового элемента данных может быть указателем знака.
Упакованное представление 346 слов без знака показывает, как можно хранить слово семь - слово ноль в SIMD регистре. Упакованное представление 347 слов со знаком может быть аналогично упакованному представлению 346 слов без знака в регистре. Заметим, что каждый шестнадцатый бит каждого элемента данных слова может быть указателем знака. Упакованное представление 348 двойных слов без знака показывают, как хранят элементы данных из двойных слов. Упакованное представление 349 двойных слов со знаком может быть аналогично упакованному представлению 348 двойных слов без знака в регистре. Заметим, что обязательный бит знака может быть тридцать вторым битом каждого элемента данных из двойного слова.
На фиг. 3D показан один вариант осуществления кодирования операции (код операции). Более того, формат 360 может содержать операнд регистра/памяти, отсылающий к режимам, соответствующим типу формата кода операции, описанного в «Руководство для разработчиков программного обеспечения по IA-32 архитектуре Intel, том 2: Справка по набору команд», компания Intel Corporation, Санта-Клара, Калифорния, указанное руководство доступно на сайте intel.com/design/litcentr (www). В одном варианте осуществления изобретения любая команда может быть закодирована одним или несколькими полями из полей 361 и 362. Может быть идентифицировано до двух мест операндов на команду, в том числе до двух идентификаторов 364 и 365 операндов-источников. В одном варианте осуществления изобретения идентификатор 366 операнда-назначения может быть тем же, что и идентификатор 364 операнда-источника, при это в других вариантах осуществления изобретения они могут быть разными. В другом варианте осуществления изобретения идентификатор 366 операнда-назначения может быть тем же, что и идентификатор 365 операнда-источника, при это в других вариантах осуществления изобретения они могут быть разными. В одном варианте осуществления изобретения один из операндов-источников, идентифицированный идентификатором 364 и 365 операнда-источника, может быть переписан результатами операций сравнения текстовых строк, при этом в других вариантах осуществления изобретения идентификатор 364 соответствует элементу регистра источника, а идентификатор 365 соответствует элементу регистра назначения. В одном варианте осуществления изобретения идентификаторы 364 и 365 операнда могут идентифицировать 32-битовые или 64-битовые операнды-источники и операнды-назначения.
На фиг. 3E показан другой возможный формат 370 кодирования (код операции) операций, содержащий сорок или более битов, в соответствии с вариантами осуществления настоящего изобретения. Формат 370 кода операции соответствует формату 360 кода операции и содержит необязательный байт 378 префикса. Команда, соответствующая одному варианту осуществления изобретения, может быть закодирована одним или несколькими полями 378, 371 и 372. Идентификаторами 374 и 375 операндов-источников и байтом 378 префикса может быть идентифицировано до двух мест операндов на команду. В одном варианте осуществления изобретения байт 378 префикса может быть использован для идентификации 32-битовых или 64-битовых операндов-источников и операндов-назначений. В одном варианте осуществления изобретения идентификатор 376 операнда-назначения может быть тем же, что и идентификатор 374 операнда-источника, при это в других вариантах осуществления изобретения они могут быть разными. В другом варианте осуществления изобретения идентификатор 376 операнда-назначения может быть тем же, что и идентификатор 375 операнда-источника, при это в других вариантах осуществления изобретения они могут быть разными. В одном варианте осуществления изобретения команда работает с одним или несколькими операндами, идентифицированными идентификаторами 374 и 375 операндов, и один или несколько операндов, идентифицированных идентификаторами 374 и 375 операндов, могут быть переписаны результатами команды, при этом в других вариантах осуществления изобретения операнды, идентифицированные идентификаторами 374 и 375 операндов, могут быть записаны в другой элемент данных в другом регистре. Форматы 360 и 370 кода операции позволяют осуществлять адресацию регистр в регистр, память в регистр, регистр в память, регистр с помощью регистра, регистр с помощью непосредственного значения, регистр в память, которая определена в части полей 363 и 373 MOD и необязательными байтами масштабирование-индекс-основание и смещение.
На фиг. 3F показан еще один возможный формат кодирования (код операции) операций, в соответствии с вариантами осуществления настоящего изобретения. 64-битовые арифметические операции (SIMD) с одним потоком команд и несколькими потоками данных могут быть выполнены с помощью команды обработки (CDP) данных сопроцессором. Формат 380 кодирования операции (код операции) показывает одну такую CDP команду с полями 382 и 389 кода CDP операции. Тип CDP команды, для другого варианта осуществления изобретения, может быть закодирован с помощью одного или нескольких полей 383, 384, 387 и 388. Может быть идентифицировано до трех мест операндов на команду, в том числе до двух идентификаторов 385 и 390 операндов-источников и одного идентификатора 386 операнда-назначения. Один вариант осуществления сопроцессора может работать с восьми-битовыми, шестнадцати-битовыми, тридцати двух-битовыми и 64-битовыми значениями. В одном варианте осуществления изобретения команда может быть выполнена над целыми элементами данных. В некоторых вариантах осуществления изобретения команда может быть выполнена с условием, с использованием поля 381 условия. Для некоторых вариантов осуществления изобретения размеры исходных данных могут быть закодированы в поле 383. В некоторых вариантах осуществления изобретения, в SIMD полях может быть сделано определение нуля (Z), отрицательного (N), перемещения (C) и переполнения (V). Для некоторых команд, тип насыщения может быть закодирован в поле 384.
На фиг. 4A показана структурная схема, иллюстрирующая конвейер с исполнением команд по очереди и конвейер с измененным порядком исполнения/выдачи команд, со ступенью переименования регистров, в соответствии с вариантами осуществления изобретения. На фиг. 4В показана структурная схема, иллюстрирующая архитектуру ядра с исполнением команд по очереди и подлежащую вхождению в процессор логическую схему с измененным порядком исполнения/выдачи команд, логическую схему переименования регистров, в соответствии с вариантами осуществления изобретения. Прямоугольники, изображенные сплошными линиями на фиг. 4A, показывают конвейер с исполнением команд по очереди, а прямоугольники, изображенные пунктирными линиями, показывают конвейер с измененным порядком исполнения/выдачи команд и переименованием регистров. Аналогично, прямоугольники, изображенные сплошными линиями на фиг. 4В, показывают логическую схему архитектуры с исполнением команд по очереди, а прямоугольники, изображенные пунктирными линиями, показывает логическую схему переименования регистров и логическую схему с измененным порядком исполнения/выдачи команд.
На фиг. 4A конвейер 400 процессора может содержать ступень 402 выборки, ступень 404 декодирования длины, ступень 406 декодирования, ступень 408 выделения, ступень 410 переименования, ступень 412 планирования (также известна как отправление или выдача), ступень 414 чтения регистра/памяти, ступень 416 исполнения, ступень 418 повторной записи/записи в память, ступень 422 обработки исключений и ступень 424 фиксации.
На фиг. 4В стрелки показывают связи между двумя или несколькими блоками, а направление стрелок указывает направление потока данных между этими блоками. На фиг. 4B показано ядро 490 процессора, содержащее входной блок 430, связанный с блоком 450 механизма исполнения, при этом входной блок 1730 и блок 1750 механизма исполнения могут быть связаны с блоком 470 памяти.
Ядро 490 может быть вычислительным ядром (RISC) с сокращенным набором команд, вычислительным ядром (СISC) со сложным набором команд, ядром (VLIW) с очень длинным командным словом или ядром гибридного или альтернативного типа. В качестве еще одного варианта, ядро 490 может быть ядром специального назначения, таким как, например, сетевое ядро или ядро связи, ядро устройства сжатия, графическое ядро или подобное.
Входной блок 430 может содержать блок 432 предсказания ветвления, связанный с блоком 434 кэш-памяти команд. Блок 434 кэш-памяти команд может быть связан с буфером 436 ассоциативной трансляции (TLB) команд. TLB 436 может быть связан с блоком 438 выборки команд, который связан с блоком 440 декодирования. Блок 440 декодирования может декодировать команды и вырабатывать в качестве выхода одну или несколько микроопераций, точек входа микрокода, микрокоманд, других команд или других сигналов управления, которые могут быть декодированы, или другим образом могут отражать или могут быть получены из исходных команд. Декодер может быть реализован с использованием различных механизмов. Примерами подходящих механизмов являются, помимо прочего, таблицы соответствия, аппаратные реализации, программируемые логические матрицы (PLA), постоянные запоминающие устройства (ROM) с микрокодом и так далее. В одном варианте осуществления изобретения блок 434 кэш-памяти команд может быть дополнительно связан с блоком 476 кэш-памяти уровня 2 (L2) в блоке 470 памяти. Блок 440 декодирования может быть связан с блоком 452 переименования/выделения из блока 450 механизма исполнения.
Блок 450 механизма исполнения может содержать блок 452 переименования/выделения, связанный с блоком 454 выгрузки и набором из одного или нескольких блоков 456 планирования. Блоки 456 планирования представляют собой любое количество разных устройств планирования, в том числе резервирующие станции, центральное окно команд и так далее. Блоки 456 планирования могут быть связаны с блоками 458 файлов физических регистров. Каждый из блоков 458 файлов физических регистров представляет один или несколько файлов физических регистров, при этом различные файлы хранят данные одного или нескольких типов данных, таких как скалярные целые, скалярные с плавающей запятой, упакованные целые, упакованные с плавающей запятой, векторные целые, векторные с плавающей запятой и так далее, состояния (например, указатель команды, который является адресом следующей команды, подлежащей исполнению) и так далее. Блоки 458 файлов физических регистров могут быть перекрыты блоком 154 выгрузки для показа различных путей, которыми могут быть реализованы переименование регистров и измененный порядок исполнения команд (например, с использованием одного или нескольких буферов переупорядочивания и одного или нескольких файлов выгрузки регистров; с использованием одного или нескольких файлов будущего, одного или нескольких буферов истории и одного или нескольких файлов регистров выгрузки; с использованием карт регистров и пула регистров; и так далее.). В общем, архитектурные регистры могут быть видимы снаружи процессора или видимы с точки зрения программиста. Регистры могут быть не ограничены любым известным конкретным типом схемы. Различные типы регистров могут подходить, при условии, что они сохраняют и предоставляют данные, как описано в настоящем документе. Примеры подходящих регистров содержат, помимо прочего, специальные физические регистры, динамически выделяемые физические регистры с использованием переименования регистров и комбинации специальных и динамически выделяемых физических регистров и так далее. Блок 454 выгрузки и блоки 458 файлов физических регистров могут быть связаны с кластерами 460 исполнения. Кластеры 460 исполнения могут содержать набор из одного или нескольких блоков 462 исполнения и набор из одного или нескольких блоков 464 доступа к памяти. Блоки 462 исполнения могут осуществлять различные операции (например, сдвиги, сложение, вычитание, умножение) для различных типов данных (например, скалярных с плавающей запятой, упакованных целых, упакованных с плавающей запятой, векторных целых, векторных с плавающей запятой). Хотя некоторые варианты осуществления изобретения могут содержать некоторое количество блоков исполнения, выделенных для конкретных функций или наборов функций, другие варианты осуществления изобретения могут содержать только один блок исполнения или множество блоков исполнения, которые все выполняют все функции. Блоки 456 планирования, блоки 458 файла физических регистров и кластеры 460 исполнения показаны с возможностью наличия нескольких блоков, так как определенные варианты осуществления изобретения создают отдельные конвейеры для определенных типов данных/операций (например, конвейер скалярных целых, конвейер скалярных с плавающей запятой/упакованных целых/упакованных с плавающей запятой/векторных целых/векторных с плавающей запятой и/или конвейер доступа к памяти, каждый из которых обладает собственных блоком планирования, блоком файла физических регистров и/или кластером исполнения - и в случае отдельного конвейера доступа к памяти, могут быть реализованы определенные варианты осуществления изобретения, в которых только кластер исполнения этого конвейера содержит блоки 464 доступа к памяти). Также следует понимать, что, когда используют отдельные конвейеры, один или несколько этих конвейеров могут быть с измененным порядком исполнения/выдачи команд, а другие - с исполнением команд по очереди.
Набор блоков 464 доступа к памяти может быть связан с блоком 470 памяти, который может содержать блок 472 TLB данных, связанный с блоком 474 кэш-памяти данных, связанным с блоком 476 кэш-памяти уровня 2 (L2). В одном примере варианта осуществления изобретения блоки 464 доступа к памяти могут содержать блок загрузки, блок адреса хранения и блок хранения данных, каждый из которых может быть связан с блоком 472 TLB данных в блоке 470 памяти. Блок 476 кэш-памяти L2 может быть связан с одним или несколькими другими уровнями кэш-памяти и, в конечном счете, с основной памятью.
В качестве примера, архитектура ядра с измененным порядком исполнения/выдачи команд, с переименованием регистров, может реализовывать конвейер 400 следующим образом: 1) блок 438 выборки команд может выполнять ступени 402 и 404 выборки и декодирования длины; 2) блок 440 декодирования может выполнять ступень 406 декодирования; 3) блок 452 переименования/выделения может выполнять ступень 408 выделения и ступень 410 переименования; 4) блоки 456 планирования может выполнять ступень 412 планирования; 5) блоки 458 файлов физических регистров и блок 470 памяти могут выполнять ступень 414 считывания регистра/памяти; кластер 460 исполнения может выполнять ступень 416 исполнения; 6) блок 470 памяти и блоки 458 файлов физических регистров могут выполнять ступень 418 обратной записи/записи в память; 7) различные блоки могут участвовать в осуществлении ступени 422 обработки исключений; и 8) блок 454 выгрузки и блоки 458 файлов физических регистров могут выполнять ступень 424 фиксации.
Ядро 490 может поддерживать один или несколько наборов команд (например, набор х86 команд (с некоторыми расширениями, добавленными в более новых версиях); набор команд MIPS компании IPS Technologies, город Саннивейл (Sunnyvale), Калифорния; набор команд ARM (с необязательными дополнительными расширениями, такими как NEON) компании ARM Holdings, Саннивейл, Калифорния).
Ясно, что ядро может поддерживать многопоточность (исполнение двух или нескольких параллельных наборов операций или цепочек) разными способами. Поддержка многопоточности может быть выполнена, например, благодаря наличию многопоточности с квантованием времени, одновременной многопоточности (когда единственное физическое ядро предоставляет для каждой цепочки логическое ядро, которые физическое ядро выполняет одновременно) или их комбинаций. Такая комбинация может содержать, например, выборку с квантованием времени и декодирование и дальнейшую одновременную многопоточность, например, как в технологии Intel® Hyperthreading.
Хотя переименование регистров может быть описано в случае изменения порядка исполнения команд, следует понимать, что переименование регистров может быть использовано в архитектуре с исполнением команд по очереди. Хотя показанный вариант осуществления процессора также может содержать отдельные блоки 434/474 кэш-памяти команд и данных и совместно используемый блок 476 кэш-памяти L2, другие варианты осуществления изобретения могут содержать единственную внутреннюю кэш-память как для команд, так и для данных, такую как, например, внутренняя кэш-память уровня 1 (L1), или несколько уровней внутренней кэш-памяти. В некоторых вариантах осуществления изобретения система может содержать комбинацию внутренней кэш-памяти и внешней кэш-памяти, которая может являться внешней по отношению к ядру и/или процессору. В других вариантах осуществления изобретения, все кэш-памяти могут быть внешними для ядра и/или процессора.
На фиг. 5А показана структурная схема процессора 500, в соответствии с вариантами осуществления настоящего изобретения. В одном варианте осуществления изобретения процессор 500 может содержать многоядерный процессор. Процессор 500 может содержать системный агент 510, с возможностью обмена информацией, связанный с одним или несколькими ядрами 502. Более того, ядра 502 и системный агент 510 могут быть, с возможностью обмена информацией, связаны с одной или несколькими кэш-памятями 506. Ядра 502, системный агент 510 и кэш-памяти 506 могут быть связаны, с возможностью обмена информацией, с помощью одного или нескольких блоков 552 управления памятью. Более того, ядра 502, системный агент 510 и кэш-памяти 506 могут быть, с возможностью обмена информацией, связаны с графическим модулем 560 с помощью блоков 552 управления памятью.
Процессор 500 может содержать любой подходящий механизм для соединения ядер 502, системного агента 510 и кэш-памятей 506 и графического модуля 560. В одном варианте осуществления изобретения процессор 500 может содержать кольцеобразный блок 508 соединения, выполненный для соединения ядер 502, системного агента 510 и кэш-памятей 506 и графического модуля 560. В других вариантах осуществления изобретения процессор 500 может содержать любое количество хорошо известных технологий для соединения таких блоков. Кольцеобразный блок 508 соединения может использовать блоки 552 управления памятью для облегчения соединения.
Процессор 500 может содержать иерархию памяти, включающую в себя один или несколько уровней кэш-памяти в ядрах, один или несколько совместно используемых блоков кэш-памяти, таких как кэш-памяти 506, или внешнюю память (не показана), связанную с набором блоков 552 контроллеров интегрированной памяти. Кэш-памяти 506 могут содержать любую подходящую кэш-память. В одном варианте осуществления изобретения кэш-памяти 506 могут содержать одну или несколько кэш-памятей среднего уровня, такого как уровень 2 (L2), уровень 3 (L3), уровень 4 (L4), или другие уровни кэш-памяти, кэш-память (LLC) последнего уровня и/или их комбинации.
В различных вариантах осуществления изобретения одно или несколько ядер 502 способны поддерживать многопоточность. Системный агент 510 может содержать компоненты для координации и управления ядрами 502. Блок 510 системного агента может содержать, например, блок (PCU) управления питанием. PCU может являться или содержать логическую схему или компоненты, нужные для регулирования состояния электропитания ядер 502. Системный агент 510 может содержать механизм 512 отображения для приведения в действие одного или нескольких внешне подключенных дисплеев или графических модулей 560. Системный агент 510 содержать интерфейс 514 для шин связи для графики. В одном варианте осуществления изобретения интерфейс 514 может быть реализован с помощью PCI Express (PCIe). В другом варианте осуществления изобретения интерфейс 514 может быть реализован с помощью PCI Express Graphics (PEG). Системный агент 510 может содержать прямой мультимедийный интерфейс 516 (DMI). DMI 516 может обеспечивать каналы между различными мостами на материнской плате или другого участка компьютерной системы. Системный агент 510 может содержать PCIe мост 518 для обеспечения PCIe каналов к другим элементам вычислительной системы. PCIe мост 518 может быть реализован с использованием контроллера 520 памяти и логической схемы 522 когерентности.
Ядра 502 могут быть реализованы любым подходящим образом. Ядра 502 могут быть однородными или разнородными с точки зрения архитектуры и/или набора команд. В одном варианте осуществления изобретения некоторые ядра 502 могут быть ядрами с исполнением команд по очереди, а другие ядра могут быть ядрами с измененным порядком исполнения команд. В другом варианте осуществления изобретения два или несколько ядер 502 могут исполнять один и тот же набор команд, а другие могут исполнять только подмножество этого набора команд или другого набора команд.
Процессор 500 может содержать процессор общего назначения, такой как процессор Core™ i3, i5, i7, 2 Duo и Quad, Xeon™, Itanium™, XScale™ или StrongARM™, компания Intel Corporation, Санта-Клара, Калифорния. Процессор 500 может быть поставлен другой компанией, такой как ARM Holdings Ltd, MIPS, и так далее. Процессор 500 может быть процессором специального назначения, таким как, например, сетевой процессор или процессор связи, устройством сжатия, графический процессор, сопроцессор, встроенный процессор или подобный. Процессор 500 может быть реализован на одной или нескольких микросхемах. Процессор 500 может быть частью и/или может быть реализован на одной или нескольких подложках с использованием некоторого количества технологий обработки, таких как, например, BiCMOS, CMOS или NMOS.
В одном варианте осуществления изобретения одна заданная кэш-память 506 может быть совместно используемой многими ядрами из ядер 502. В другом варианте осуществления изобретения одна заданная кэш-память 506 может быть выделена для одного из ядер 502. Назначение кэш-памятей 506 ядрам 502 может быть выполнено контроллером кэш-памятей или другим подходящим механизмом. Одна заданная кэш-память 506 может быть использована совместно двумя или несколькими ядрами 502 путем реализации квантования времени для заданной кэш-памяти 506.
Графический модуль 560 может реализовывать подсистему обработки интегрированной графики. В одном варианте осуществления изобретения графический модуль 560 может содержать графический процессор. Более того, графический модуль 560 может содержать мультимедийный механизм 565. Мультимедийный механизм 565 может обеспечить мультимедийное кодирование и декодирование видео.
На фиг. 5В показана структурная схема одного примера реализации ядра 502, в соответствии с вариантами осуществления настоящего изобретения. Ядро 502 может содержать входной блок 570, с возможностью обмена информацией, связанный с механизмом 580 исполнения с измененным порядком команд. Ядро 502 может быть, с возможностью обмена информацией, связанным с другими участками процессора 500 с помощью иерархии 503 кэш-памяти.
Входной блок 570 может быть реализован любым подходящим способом, таким как полностью или частично с помощью входного блока 201, описанного выше. В одном варианте осуществления изобретения входной блок 570 может обмениваться информацией с другими участками процессора 500 с помощью иерархии 503 кэш-памяти. В еще одном варианте осуществления изобретения входной блок 570 может осуществлять выборку команд из участков процессора 500 и подготавливать команды для дальнейшего использования в конвейере процессора, при их прохождении к механизму 580 исполнения с измененным порядком команд.
Механизм 580 исполнения с измененным порядком команд может быть реализован любым подходящим способом, таким как полностью или частично с помощью механизма 203 с измененным порядком исполнения команд, описанный выше. Механизм 580 исполнения с измененным порядком команд может подготавливать к исполнению команды, принятые от входного блока 570. Механизм 580 исполнения с измененным порядком команд может содержать модуль 582 выделения. В одном варианте осуществления изобретения модуль 582 выделения может выделять ресурсы процессора 500 или другие ресурсы, такие как регистры или буферы, для исполнения заданной команды. Модуль 582 выделения может осуществлять выделения в устройствах планирования, таких как устройство планирования для памяти, быстрое устройство планирования или устройство планирования для данных с плавающей запятой. Такие устройства планирования могут быть представлены на фиг. 5В с помощью устройств 584 планирования ресурсов. Модуль 582 выделения может быть реализован полностью или частично с помощью логической схемы выделения, описанной при рассмотрении фиг. 2. Устройства 584 планирования ресурсов могут определять, когда команда готова для исполнения, что делают на основе готовности источников заданного ресурса и доступности ресурсов исполнения, которые нужны для исполнения команды. Устройства 584 планирования ресурсов могут быть реализованы, например, с помощью устройств 202, 204, 206 планирования, как описано выше. Устройства 584 планирования ресурсов могут планировать исполнение команд для одного или нескольких ресурсов. В одном варианте осуществления изобретения такие ресурсы могут быть внутренними для ядра 502, и они могут быть показаны, например, как ресурсы 586. В другом варианте осуществления изобретения такие ресурсы могут быть внешними для ядра 502 и к ним можно получить доступ, например, с помощью иерархии 503 кэш-памяти. Ресурсы могут содержать, например, память, кэш-памяти, файлы регистров или регистры. Ресурсы, внутренние по отношению к ядру 502, могут быть представлены как ресурсы 586 на фиг. 5В. При необходимости, значения, записанные в ресурсы 586 или считанные из ресурсов 586, могут быть скоординированы с другими участками процессора 500 с помощью иерархии 503 кэш-памяти. Когда командам назначены ресурсы, они могут быть расположены в буфере 588 переупорядочивания. Буфер 588 переупорядочивания может отслеживать команды при их исполнении и может по выбору переупорядочивать их исполнение на основе любых подходящих критериев процессора 500. В одном варианте осуществления изобретения буфер 588 переупорядочивания может идентифицировать команды или серии команд, которые могут быть исполнены независимо. Такие команды или серии команд могут быть исполнены параллельно другим таким командам. Параллельное исполнение в ядре 502 может быть выполнено любым подходящим количеством отдельных узлов исполнения или виртуальных процессоров. В одном варианте осуществления изобретения несколько виртуальных процессоров в заданном ядре 502 могут получить доступ к совместно используемым ресурсам - таким как память, регистры и кэш-памяти. В других вариантах осуществления изобретения множество обрабатывающих объектов из процессора 500 могут получить доступ к совместно используемым ресурсам.
Иерархия 503 кэш-памяти может быть реализована любым подходящим образом. Например, иерархия 503 кэш-памяти может содержать одну или несколько кэш-памятей низкого уровня или среднего уровня, таких как кэш-памяти 572, 574. В одном варианте осуществления изобретения иерархия 503 кэш-памяти может содержать LLC 595, с возможностью обмена информацией, связанную с кэш-памятями 572, 574. В других вариантах осуществления изобретения LLC 595 может быть реализована в модуле 590, доступ к которому можно получить для всех обрабатывающих объектов из процессора 500. В еще одном варианте осуществления изобретения модуль 590 может быть реализован в модуле, не содержащим ядра процессоров компании Intel, Inc. Модуль 590 может содержать участки или подсистемы процессора 500, которые необходимы для исполнения ядра 502, но которые могут не быть реализованы в ядре 502. Помимо LLC 595, модуль 590 может содержать, например, интерфейсы аппаратного обеспечения, устройства координации когерентности памяти, межпроцессорные соединения, конвейеры команд или контроллеры памяти. Доступ к RAM 599, возможный для процессора 500, может быть выполнен с помощью модуля 590 или, более конкретно, LLC 595. Более того, другие примеры ядра 502 могут аналогично получить доступ к модулю 590. Координация примеров ядра 502 может быть частично облегчена с помощью модуля 590.
На фиг. 6-8 могут быть показаны примеры систем, подходящих для расположения процессора 500, а на фиг. 9 можно проиллюстрировать пример системы (SoC) на микросхеме, которая может содержать одно или несколько ядер 502. Также могут подходить другие конструкции системы и реализации, известные в технике для лэптопов, настольных компьютеров, карманных компьютеров, персональных цифровых помощников, инженерных рабочих станций, серверов, сетевых устройств, сетевых концентраторов, коммутаторов, встроенных процессоров, цифровых сигнальных процессоров (DSP), графических устройств, устройств для видео игр, телевизионных приставок, микроконтроллеров, сотовых телефонов, переносных медиаплеееров, ручных устройств и различных других электронных устройств. В общем, могут подходить огромное количество разнообразных систем или электронных устройств, содержащих процессор и/или другую описанную здесь логическую схему исполнения.
На фиг. 6 показана структурная схема системы 600, в соответствии с вариантами осуществления изобретения. Система 600 может содержать один или несколько процессоров 610, 615, которые могут быть связаны с контроллером-концентратором 620 (GMCH) графики и памяти. Необязательная природа дополнительных процессоров 615 обозначена на фиг. 6 пунктирными линиями.
Каждый из процессоров 610, 615 может быть некоторой версией процессора 500. Тем не менее, следует заметить, что логическая схема интегрированной графики и блоки управления интегрированной памятью могут отсутствовать в процессорах 610, 615. На фиг. 6 показано, что GMCH 620 может быть связан с памятью 640, которая, например, может быть динамическим оперативным запоминающим устройством (DRAM). По меньшей мере, в одном варианте осуществления изобретения DRAM может быть связана с энергонезависимой кэш-памятью.
GMCH 620 может быть набором микросхем или частью набора микросхем. GMCH 620 может обмениваться информацией с процессорами 610, 615 и управлять взаимодействием процессоров 610, 615 и памяти 640. GMCH 620 также может действовать как интерфейс ускоренной шины между процессорами 610, 615 и другими элементами системы 600. В одном варианте осуществления изобретения GMCH 620 обменивается информацией с процессорами 610, 615 с помощью многоточечной шины, такой как системная шина 695 (FSB).
Более того, GMCH 620 может быть соединен с дисплеем 645 (таким как панель с плоским экраном). В одном варианте осуществления изобретения GMCH 620 может содержать устройство ускорения интегрированной графики. GMCH 620 может быть дополнительно связан с контроллером-концентратором 650 (ICH) ввода-вывода, который может быть использован для связи различных периферийных устройств с системой 600. Внешнее графическое устройство 660 может содержать или быть устройством дискретной графики, связанным с ICH 650 вдоль другого периферийного устройства 670.
В других вариантах осуществления изобретения в системе 600 также могут присутствовать дополнительные или другие процессоры. Например, дополнительные процессоры 610, 615 могут содержать дополнительные процессоры, которые могут быть такими же, как и процессор 610, дополнительные процессоры, которые могут быть неоднородными или асимметричными относительно процессора 610, устройства ускорения (такие как, например, графические устройства ускорения или цифровые сигнальные блоки (DSP) обработки), программируемые пользователем вентильные матрицы или любой другой процессор. Может присутствовать большое количество различий между физическими ресурсами 610, 615 с точки зрения разных мер, в том числе архитектурных характеристик, микроархитектурных характеристик, тепловых характеристик, характеристик потребления электроэнергии и подобных. Эти различия могут эффективно показывать себя как асимметрия и неоднородность в процессорах 610, 615. По меньшей мере, для одного варианта осуществления изобретения, различные процессоры 610, 615 могут располагаться в одном корпусе кристалла.
На фиг. 7 показана структурная схема второй системы 700, в соответствии с вариантами осуществления изобретения. Как показано на фиг. 7, многопроцессорная система 700 является системой соединений точка-точка и может содержать первый процессор 770 и второй процессор 780, связанные с помощью соединения 750 точка-точка. Каждый из процессоров 770 и 780 может быть некоторой версией процессора 500, как один или несколько процессоров 610, 615.
Хотя на фиг. 7 показаны только два процессора 770, 780, следует понимать, что объем настоящего изобретения этим не ограничен. В других вариантах осуществления изобретения один или несколько дополнительных процессоров могут присутствовать в заданном процессоре.
Процессоры 770 и 780 показаны содержащими соответственно блоки 772 и 782 контроллеров интегрированной памяти. Процессор 770 также может содержать, как часть своих блоков контроллеров шины, интерфейсы 776 и 778 точка-точка (Р-Р); аналогично, второй процессор 780 может содержать интерфейсы 786 и 788 Р-Р. Процессоры 770 и 780 могут обмениваться информацией с помощью интерфейса 750 точка-точка (Р-Р) с использованием интерфейсных схем 778, 788 Р-Р. Как показано на фиг. 7, IMC 772 и 782 могут связывать процессоры с соответствующими памятями, а именно памятью 732 и памятью 734, которые, в одном варианте осуществления изобретения, могут быть частями основной памяти, локально прикрепленными к соответствующим процессорам.
Каждый из процессоров 770, 780 может обмениваться информацией с набором 790 микросхем с помощью отдельных интерфейсов 752, 754 Р-Р с использованием интерфейсных схем 776, 794, 786, 798 точка-точка. В одном варианте осуществления изобретения набор 790 микросхем также может обмениваться информацией с высокопроизводительной графической схемой 738 с помощью высокопроизводительного графического интерфейса 739.
Совместно используемая кэш-память (не показана) может содержаться в каждом процессоре или снаружи обоих
процессоров, тем не менее, она связана с процессорами с помощью соединения Р-Р, так что информация локальной кэш-памяти любого процессора или обоих процессоров может быть сохранена в совместно используемой кэш-памяти, если процессор находится в режиме низкого энергопотребления.
Набор 790 микросхем может быть соединен с первой шиной 716 с помощью интерфейса 796. В одном варианте осуществления изобретения первая шина 716 может быть шиной соединения (PCI) периферийных компонентов или такой шиной, как шина PCI Express, или другой соединительной шиной ввода/вывода третьего поколения, хотя объем настоящего изобретения этим не ограничен.
Как показано на фиг. 7, различные устройства 714 ввода/вывода могут быть связаны с первой шиной 716 вместе с мостом 718 шин, который связывает первую шину 716 и вторую шину 720. В одном варианте осуществления изобретения вторая шина 720 может быть шиной (LPC) с малым числом контактов. Различные устройства могут быть связаны со второй шиной 720, в том числе, например, клавиатура и/или мышь 722, устройства 727 связи и блок 728 хранения, такой как дисковый привод или другие устройства хранения большой емкости, которые могут содержать команды/код и данные 730, в одном варианте осуществления изобретения. Далее, устройство 724 ввода/вывода звука может быть соединено со второй шиной 720. Заметим, что возможны другие архитектуры. Например, вместо архитектуры точка-точка с фиг. 7, система может реализовывать многоточечную шину или другую такую архитектуру.
На фиг. 8 показана структурная схема третьей системы 800 в соответствии с вариантами осуществления настоящего изобретения. Аналогичные элементы на фиг. 7 и 8 обозначены одинаковыми ссылочными позициями и некоторые аспекты с фиг. 7 опущены на фиг. 8 чтобы не мешать пониманию других аспектов фиг. 8.
На фиг. 8 показано, что процессоры 870, 880 могут содержать соответственно объединенные логические схемы 872 и 882 управления («СL») памятью и вводом/выводом. По меньшей мере, в одном варианте осуществления изобретения CL 872, 882 могут содержать блоки контроллера интегрированной памяти, такие как описаны выше при рассмотрении фиг. 5 и 7. Кроме того, CL 872, 882 также могут содержать логическую схему управления вводом/выводом. На фиг. 8 показано, что не только памяти 832, 834 могут быть связаны с CL 872, 882, но также устройства 814 ввода/вывода также могут быть связаны с логической схемой 872, 882 управления. Существующие устройства 815 ввода/вывода могут быть связаны с набором 890 микросхем.
На фиг. 9 показана структурная схема SoC 900, в соответствии с вариантами осуществления изобретения. Аналогичные элементы с фиг. 5 обозначены одинаковыми ссылочными позициями. Также прямоугольники, изображенные пунктирными линиями, могут представлять необязательные признаки для более совершенных SoC. Блоки 902 соединения могут быть связаны с: процессором 910 приложений, который может содержать набор из одного или нескольких ядер 902А-N и совместно используемые блоки 906 кэш-памяти; блоком 910 системного агента; блоками 916 контроллера шины; блоками 914 контроллера интегрированной памяти; набором или одним или несколькими медиа-процессорами 920, которые могут содержать логическую схему 908 интегрированной графики, процессор 924 изображений, для обеспечения функциональных возможностей фотокамеры и/или видеокамеры, звуковой процессор 926 для обеспечения аппаратного ускорения звука, и видео процессор 928 для обеспечения ускорения кодирования/декодирования видео; блоком 930 статического оперативного запоминающего устройства (SRAM); блоком 932 прямого доступа (DMA) к памяти; и блоком 940 отображения для связи с одним или несколькими внешними дисплеями.
На фиг. 10 показан процессор, содержащий центральный обрабатывающий блок (CPU) и блок (GPU) обработки графики, который может выполнить, по меньшей мере, одну команду, в соответствии с вариантами осуществления настоящего изобретения. В одном варианте осуществления изобретения команда для выполнения операций в соответствии, по меньшей мере, с одним вариантом осуществления изобретения, может быть выполнена CPU. В другом варианте осуществления изобретения команда может быть выполнена GPU. В еще одном варианте осуществления изобретения команда может быть выполнена с помощью комбинации операций, выполненных CPU и GPU. Например, в одном варианте осуществления изобретения, команда, соответствующая одному варианту осуществления изобретения, может быть принята и декодирована для исполнения в GPU. Тем не менее, одна или несколько операций в декодированной команде могут быть выполнены CPU, результат возвращен в GPU для окончательной выгрузки команды. Наоборот, в некоторых вариантах осуществления изобретения CPU может действовать как первичный процессор, а GPU как сопроцессор.
В некоторых вариантах осуществления изобретения команды, для которых полезны высоко параллельные производительные процессоры, могут быть выполнены в GPU, а команды, для которых полезны эффективные процессоры с глубокими конвейерными архитектурами, могут быть выполнены в CPU. Например, графические, научные приложения, финансовые приложения и другие параллельные рабочие нагрузки могут получать пользу от производительности GPU и исполняться соответственно, при этом более последовательные приложения, такие как ядро операционной системы или код приложения могут лучше подходить для CPU.
На фиг. 10 процессор 1000 содержит CPU 1005, GPU 1010, процессор 1015 изображений, видео процессор 1020, контроллер 1025 USB, контроллер 1030 UART, контроллер 1035 SPI/SDIO, устройство 1040 отображения, контроллер 1045 интерфейса памяти, контроллер 1050 MIPI, контроллер 1055 флеш-памяти, контроллер 1060 двойной скорости (DDR) передачи данных, механизм 1065 безопасности и контроллер 1070 I2S/I2C. Процессор с фиг. 10 может содержать другие логические схемы и схемы, в том числе большее количество CPU и GPU и других контроллеров интерфейсов периферийных устройств.
Один или несколько аспектов, по меньшей мере, одного варианта осуществления изобретения могут быть реализованы с помощью типовых данных, хранящихся на считываемом машиной носителе и представляющих различные логические операции в процессоре, которые при считывании машиной побуждают машину формировать логические операции для осуществления описанных здесь технологий. Такие представления, известные как «IP-ядра» могут храниться на материальном считываемом машиной носителе («ленте») и подаваться различным клиентам или производственным предприятиям для загрузки на производственные машины, которые фактически делают логические схемы или процессор. Например, IP-ядра, такие как ядра семейства процессоров Cortex™, разработанных компанией ARM Holdings, Ltd, и IP-ядра Loongson, разработанные Институтом вычислительной технологии (ICT) китайской Академии наук, могут быть лицензированы и проданы различным клиентам или лицензиатам, таким как компании Texas Instruments, Qualcomm, Apple или Samsung, и реализованы в процессорах, изготавливаемых этими клиентами или лицензиатами.
На фиг. 11 показана структурная схема, иллюстрирующая развитие IP-ядер, в соответствии с вариантами осуществления настоящего изобретения. Носитель 1100 информации может содержать программное обеспечение 1120 моделирования и/или аппаратную или программную модель 1110. В одном варианте осуществления изобретения данные, представляющие конструкцию IP-ядра, могут быть предоставлены на носитель 1100 с помощью памяти 1140 (например, накопитель на жестких дисках), проводного соединения 1150 (например, интернет) или беспроводного соединения 1160. Информация IP-ядра, выработанная инструментом моделирования и моделью, далее может быть передана на предприятие изготовления, где оно может быть изготовлено 3ей стороной с целью выполнения, по меньшей мере, одной команды, в соответствии, по меньшей мере, с одним вариантом осуществления изобретения.
В некоторых вариантах осуществления изобретения одна или несколько команд могут соответствовать первому типу или архитектуре (например, х86) и их могут транслировать или эмулировать на процессоре другого типа или архитектуры (например, ARM). Следовательно, команда, в соответствии с одним вариантом осуществления изобретения, может быть выполнена на любом процессоре или типе процессора, в том числе ARM, x86, MIPS, GPU или процессоре другого типа или архитектуры.
На фиг. 12 показано, как команда первого типа может быть эмулирована процессором другого типа, в соответствии с вариантами осуществления настоящего изобретения. На фиг. 12 программа 1205 содержит некоторые команды, которые могут выполнять такую же или по существу такую же функцию, что и команда, соответствующая одному варианту осуществления изобретения. Тем не менее, команды программы 1205 могут иметь тип и/или формат, который отличается или несовместим с процессором 1215, что означает, что команды типа команд из программы 1205 могут не исполняться исходно в процессоре 1215. Тем не менее, с помощью логической схемы 1210 эмуляции, команды программы 1205 могут быть транслированы в команды, которые могут быть исходно исполняться процессором 1215. В одном варианте осуществления изобретения логическая схема эмуляции может быть встроена в аппаратное обеспечение. В другом варианте осуществления изобретения логическая схема эмуляции может быть встроена в материальный, считываемый машиной носитель, содержащий программное обеспечение для трансляции команд типа команд программы 1205 в исходно исполнимые процессором 1205. В других вариантах осуществления изобретения логическая схема эмуляции может являться комбинацией аппаратного обеспечения с фиксированной функцией или программируемого аппаратного обеспечения и программы, хранящейся на материальном, считываемым машиной носителе. В одном варианте осуществления изобретения процессор содержит логическую схему эмуляции, при этом в других вариантах осуществления изобретения логическая схема эмуляции существует снаружи процессора и может быть предоставлена третьей стороной. В одном варианте осуществления изобретения процессор может загружать логическую схему эмуляции, встроенную в материальный, считываемый машиной носитель, содержащий программное обеспечение, путем исполнения микрокода или аппаратно реализованного программного обеспечения, содержащегося в процессоре или связанного с процессором.
На фиг. 13 показана структурная схема, иллюстрирующая использование программного устройства преобразования команд для преобразования двоичных команд исходного набора команд в двоичные команды целевого набора команд, в соответствии с вариантами осуществления изобретения. В показанном варианте осуществления изобретения устройство преобразования команд может являться программным устройством преобразования команд, хотя устройство преобразования команд может быть реализовано как программное обеспечение, аппаратное обеспечение, аппаратно реализованное программное обеспечение или различные комбинации перечисленного. На фиг. 13 показана программа на языке 1302 высокого уровня, которая может быть скомпилирована с использованием компилятора 1304 x86 с целью выработки двоичного кода 1306 х86, который может быть исходно исполнен процессором 1316, содержащим, по меньшей мере, одно ядро с набором х86 команд. Процессор 1316, содержащий, по меньшей мере, одно ядро с набором х86 команд, представляет собой любой процессор, который может осуществлять, по существу, те же функции, что и процессор компании Intel, содержащий, по меньшей мере, одно ядро с набором х86 команд, путем совместимого исполнения или другой обработки (1) существенной части набора команд ядра с набором Intel х86 команд или (2) версий объектного кода приложений или другого программного обеспечения, направленного на работу процессора Intel, содержащего, по меньшей мере, одно ядро с набором х86 команд, с целью достижения, по существу, того же результата, что и процессор Intel, содержащий, по меньшей мере, одно ядро с набором х86 команд. Компилятор 1304 x86 представляет собой компилятор, который может быть выполнен для выработки двоичного кода 1306 x86 (например, объектного кода), который может быть, с дополнительной компоновочной обработкой или без нее, исполнен процессором 1316, по меньшей мере, с одним ядром набора х86 команд. Аналогично, на фиг. 13 показано, что программа на языке 1302 высокого уровня может быть скомпилирована с использованием компилятора 1308 с альтернативным набором команд с целью выработки двоичного кода 1310 альтернативного набора команд, который может быть исходно исполнен процессором 1314, не содержащим, по меньшей мере, одно ядро с набором х86 команд (например, процессор с ядрами, которые исполняют набор команд MIPS компании MIPS Technologies, Саннивейл, Калифорния, и/или которые исполняют набор команд компании ARM Holdings, Саннивейл, Калифорния). Устройство 1312 преобразования команд может быть использовано для преобразования двоичного кода 1306 х86 в код, который может быть исходно исполнен процессором 1314 без ядра с набором х86 команд. Этот преобразованный код может не совпадать с кодом 1310 альтернативного набора команд; тем не менее, преобразованный код будет реализовывать общую операцию и будет состоять из команд альтернативного набора команд. Таким образом, устройство 1312 преобразования команд представляет собой программное обеспечение, аппаратно-реализованное программное обеспечение, аппаратное обеспечение или комбинации перечисленного, которое с помощью эмулирования, моделирования и любой другой обработки позволяет процессору или другому электронному устройству, не содержащему процессора или ядра с набором команд х86, исполнять двоичный код 1306 х86.
На фиг. 14 показана структурная схема одной архитектуры 1400 набора команд процессора, в соответствии с вариантами осуществления настоящего изобретения. Архитектура 1400 набора команд может содержать любое подходящее количество компонентов или любые типы компонентов.
Например, архитектура 1400 набора команд может содержать обрабатывающие объекты, такие как одно или несколько ядер 1406, 1407 и блок 1415 обработки графики. Ядра 1406, 1407 могут быть, с возможностью обмена информацией, связаны с оставшейся частью архитектуры 1400 набора команд с помощью любого подходящего механизма, такого как шина или кэш-память. В одном варианте осуществления изобретения ядра 1406, 1407 могут быть, с возможностью обмена информацией, связаны с управлением 1408 кэш-памятью L2, которое может содержать блок 1409 интерфейса шины и кэш-память 1410 L2. Ядра 1406, 1407 и блок 1415 обработки графики могут быть, с возможностью обмена информацией, связаны друг с другом и с оставшейся частью архитектуры 1400 набора команд с помощью соединения 1410. В одном варианте осуществления изобретения блок 1415 обработки графики также может использовать видеокодек 1420, определяющий способ, с помощью которого конкретные видео сигналы будут кодироваться и раскодироваться с целью подачи на выход.
Архитектура 1400 набора команд также может содержать любое количество или любые типы интерфейсов, контроллеров или других механизмов для сопряжения или обмена информацией с другими частями электронного устройства или системы. Такие механизмы могут облегчить взаимодействие, например, с периферийными устройствами, устройствами связи, другими процессорами или памятью. В примере с фиг. 14 архитектура 1400 набора команд может содержать видео интерфейс 1425 жидкокристаллического дисплея (LCD), интерфейс 1430 модуля (SIM) сопряжения абонента, интерфейс 1435 ROM загрузки, контроллер 1440 синхронного динамического оперативного запоминающего устройства (SDRAM), контроллер 1445 флеш-памяти и ведущий блок 1450 последовательного периферийного интерфейса (SPI). Видео интерфейс 1425 LCD может обеспечивать вывод видео сигналов, например, из GPU 1415 и, например, с помощью процессорного интерфейса 1490 (MIPI) производителей мобильных устройств или мультимедийного интерфейса 1495 (HDMI) высокой четкости на дисплей. Такой дисплей может содержать, например, LCD. SIM интерфейс 1430 может обеспечивать доступ с SIM карты или устройства на SIM карту или устройство. Контроллер 1440 SDRAM может обеспечивать доступ к памяти, такой как микросхема или модуль SDRAM. Контроллер 1445 флеш-памяти может обеспечивать доступ к памяти, такой как флеш-память или другие примеры RAM. Ведущий блок 1450 SPI может обеспечить доступ к модулям связи, таким как модуль 1470 Bluetooth, высокоскоростной 3G модем 1475, модуль 1480 глобальной системы позиционирования или беспроводной модуль 1485, реализующим стандарт связи, такой как 802.11.
На фиг. 15 более подробно показана структурная схема архитектуры 1500 команд процессора, реализующая одну архитектуру набора команд, в соответствии с вариантами осуществления настоящего изобретения. Архитектура 1500 команд может являться микроархитектурой. Архитектура 1500 команд может реализовывать один или несколько аспектов архитектуры 1400 набора команд. Более того, архитектура 1500 команд может иллюстрировать модули и механизмы для исполнения команд в процессоре.
Архитектура 1500 команд может содержать систему 1540 памяти, с возможностью обмена информации связанную с одним или несколькими объектами 1565 исполнения. Более того, архитектура 1500 команд может содержать блок интерфейса шины и кэш-памяти, такой как блок 1510, с возможностью обмена информации связанный с объектами 1565 исполнения и системой 1540 памяти. В одном варианте осуществления изобретения загрузка команд в объекты 1565 исполнения может быть выполнена с помощью одной или нескольких ступеней исполнения. Такие ступени могут содержать, например, ступень 1530 упреждающей выборки команды, ступень 1550 декодирования сдвоенных команд, ступень 1555 переименования регистров, ступень 1560 выдачи и ступень 1570 обратной записи.
В одном варианте осуществления изобретения система 1540 памяти может содержать указатель 1580 исполняемой команды. Указатель 1580 исполняемой команды может хранить значение, идентифицирующее самую старую, неотправленную команду в группе команд ступени 1560 выдачи с измененным порядком команд в цепочке, представленной многими нитями. Указатель 1580 исполняемой команды может быть вычислен в ходе ступени 1560 выдачи и передан на блоки загрузки. Команда может храниться в группе команд. Группа команд может быть в цепочке, представленной множеством нитей. Самая старая команда может соответствовать самому малом значению PO (программный порядок). PO может содержать уникальный номер команды. PO может быть использован для упорядочивания команд для обеспечения корректной семантики исполнения кода. РО может быть восстановлен с помощью таких механизмов, как оценка приращений к РО, закодированных в команде в отличие от абсолютного значения. Такой восстановленный РО может быть назван RPO. Хотя в настоящем документе могут ссылаться на РО, такой РО и RPO могут использовать взаимозаменяемо. Нить может содержать последовательность команд, которые зависят по данным друг от друга. Нить может быть организована двоичным транслятором во время компиляции. Аппаратное обеспечение, исполняющее нить, может исполнять команды заданной нити в порядке, который соответствует РО различных команд. Цепочка может содержать множество нитей, так что команды разных нитей могут зависеть друг от друга. РО заданной нити может быть РО самой старой команды в нити, которая еще не была отправлена на исполнение со ступени выдачи. Соответственно, при заданной цепочке из множества нитей и каждой нити, содержащей команды, упорядоченные с помощью РО, указатель 1580 исполняемой команды может хранить самое старое - проиллюстрированное самым малым числом - значение РО среди нитей цепочки на ступени 1560 выдачи с измененным порядком команд.
В другом варианте осуществления изобретения система 1540 памяти может содержать указатель 1582 выгрузки. Указатель 1582 выгрузки может хранить значение, идентифицирующее РО последней выгруженной команды. Указатель 1582 выгрузки может быть установлен, например, в блоке 454 выгрузки. Если еще не выгружено никаких команд, указатель 1582 выгрузки может содержать значение null.
Объекты 1565 исполнения могут содержать любое подходящее количество и типы механизмов, с помощью которых процессор может исполнять команды. В примере с фиг. 15, объекты 1565 исполнения могут содержать блоки 1566 умножения/ALU, ALU 1567, и блоки 1568 (FPU) для плавающей запятой. В одном варианте осуществления изобретения такие объекты могут использовать информацию, содержащуюся по заданному адресу 1569. Объекты 1565 исполнения вместе со ступенями 1530, 1550, 1555, 1560, 1570 могут образовывать блок исполнения.
Блок 1510 могут быть реализован любым подходящим образом. В одном варианте осуществления изобретения блок 1510 может выполнять управление кэш-памятью. В таком варианте осуществления изобретения, таким образом, блок 1510 может содержать кэш-память. Кэш-память 1525 может быть реализована, в другом варианте осуществления изобретения, как унифицированная кэш-память L2 любого подходящего размера, такого как ноль, 128 КБ, 256 КБ, 512 КБ, 1МБ или 2 МБ памяти. В другом, дополнительном, варианте осуществления изобретения кэш-память 1525 может быть реализована в памяти с корректировкой ошибок. В другом варианте осуществления изобретения блок 1510 может выполнять сопряжение шины с другими участками процессора или электронного устройства. В таком варианте осуществления изобретения, таким образом, блок 1510 может содержать блок 1520 интерфейса шины для обмена информацией по соединению, внутрипроцессорной шине, межпроцессорной шине или другой шине связи, порту или каналу. Блок 1520 интерфейса шины может обеспечить сопряжение с целью выполнения, например, выработки адресов памяти и ввода/вывода для передачи данных между объектами 1565 исполнения и участками системы, внешней по отношению к архитектуре 1500 команд.
Для дальнейшего облегчения своих функций, блок 1520 интерфейса шины может содержать блок 1511 распределения и управления прерываниями, выполненный для выработки прерываний и другого обмена информацией с другими участками процессора или электронного устройства. В одном варианте осуществления изобретения блок 1520 интерфейса шины может содержать блок 1512 управления отслеживанием, который работает с доступом к кэш-памяти и когерентностью для множества обрабатывающих ядер. В дополнительном варианте осуществления изобретения для обеспечения таких функциональных возможностей блок 1512 управления отслеживанием может содержать блок перемещений кэш-память-кэш-память, который выполнен для перемещения информации между различными кэш-памятями. В другом, дополнительном, варианте осуществления изобретения блок 1512 управления отслеживанием может содержать один или несколько фильтров 1514 отслеживания, которые отслеживают когерентность других кэш-памятей (не показаны), так что контроллеру кэш-памяти, такому как блок 1510, не нужно непосредственно выполнять такое отслеживание. Блок 1510 может содержать любое подходящее количество таймеров 1515 для синхронизации действий архитектуры 1500 команд. Также, блок 1510 может содержать АС порт 1516.
Система 1540 памяти может содержать любое подходящее количество и любые подходящие типы механизмов для хранения информации для нужд обработки в архитектуре 1500 команд. В одном варианте осуществления изобретения система 1540 памяти может содержать блок 1530 загрузки и сохранения для сохранения информации, касающейся команд, которые записывают в память или регистры, или считывают из памяти или регистров. В другом варианте осуществления изобретения система 1540 памяти может содержать буфер 1545 (TLB) ассоциативной трансляции команд, который обеспечивает соответствие значений физического адреса и виртуального адреса. В еще одном варианте осуществления изобретения блок 1520 интерфейса шины может содержать блок 1544 (MMU) управления памятью, выполненный для облегчения доступа к виртуальной памяти. В еще одном варианте осуществления изобретения система 1540 памяти может содержать устройство 1543 упреждающей выборки, выполненное для запроса команд из памяти до возникновения фактической необходимости в исполнении этих команд, что нужно для уменьшения задержки.
Работа архитектуры 1500 команд по исполнению команды может быть выполнена с помощью разных ступеней. Например, с использованием блока 1510, ступень 1530 упреждающей выборки команд может получить доступ к команде с помощью устройства 1543 упреждающей выборки. Восстановленные команды могут быть сохранены в кэш-памяти 1532 команд. Ступень 1530 упреждающей выборки может реализовывать вариант 1531 режима с быстрым циклом, когда исполняют серию команд, образующую настолько малый цикл, что команды помещаются в заданной кэш-памяти. В одном варианте осуществления изобретения такое исполнение может быть выполнено без необходимости получать доступ к дополнительным командам, например, кэш-памяти 1532 команд. Определение того, какие команды выбирать упреждающим образом, может быть выполнено, например, блоком 1535 предсказания ветвления, который может получить доступ к указаниям исполнения в общей истории 1536, указаниям целевых адресов 1537 или содержимого стека 1538 возвращения для определения того, какая из ветвлений 1557 кода будет исполнена далее. Такие ветвления возможно упреждающим образом выбрать в качестве результата. Ветвления 1557 могут быть выработаны с помощью других ступеней операции, как описано ниже. В ходе ступени 1530 упреждающей выборки команд на ступень декодирования сдвоенных команд могут предоставить команды, а также какие-либо предсказания о будущих командах.
В ходе ступени 1550 декодирования сдвоенных команд могут транслировать принятую команду в основанную на микрокоде команду, которая может быть исполнена. В ходе ступени 1550 декодирования сдвоенных команд могут одновременно декодировать две команды за тактовый цикл. Более того, в ходе ступени 1550 декодирования сдвоенных команд могут передать свои результаты на ступень 1555 переименования регистров. Кроме того, в ходе ступени 1550 декодирования сдвоенных команд могут определить любое результирующее ветвление из его декодирования и последующего исполнения микрокода. Такие результаты могут быть входом для ветвлений 1557.
В ходе ступени 1550 декодирования сдвоенных команд могут транслировать ссылки на виртуальные регистры или другие ресурсы в ссылки на физические регистры или ресурсы. Ступень 1550 декодирования сдвоенных команд может содержать указания такого отображения в пуле 1556 регистров. В ходе ступени 1550 декодирования сдвоенных команд могут изменять принятые команды и направлять результат на ступени 1560 выдачи.
В ходе ступени 1560 выдачи могут выдавать или отправлять команды на объекты 1565 исполнения. Такая выдачи может быть выполнена с измененным порядком команд. В одном варианте осуществления изобретения множество команд могут удерживаться на ступени 1560 выдачи до исполнения. Ступень 1560 выдачи может содержать очередь 1561 команд для содержания такого множества команд. Команды могут быть направлены в ходе ступени 1560 выдачи на конкретный обрабатывающий объект 1565 на основе любых приемлемых критериев, таких как доступность или пригодности ресурсов к исполнению заданной команды. В одном варианте осуществления изобретения ступень 1560 выдачи может так переупорядочить команды в очереди 1561 команд, что первая принятая команда может не быть первой исполненной командой. На основе упорядочивания очереди 1561 команд, на ветвления 1557 может быть предоставлена дополнительная информация ветвлений. В ходе ступени 1560 выдачи, команды могут пройти на объекты 1565 исполнения с целью исполнения.
После исполнения, в ходе ступени 1570 обратной записи данные могут быть записаны обратно в регистры, очереди или другие структуры архитектуры 1500 команд для передачи информации о завершении заданной команды. В зависимости от порядка команд, организованного на ступени 1560 выдачи, работа ступени 1570 обратной записи может позволить исполнить дополнительные команды. Производительность архитектуры 1500 команд можно отслеживать или налаживать в блоке 1575 регистрации.
На фиг. 16 показана структурная схема конвейера 1600 исполнения для процессора, в соответствии с вариантами осуществления настоящего изобретения. Конвейер 1600 исполнения может показывать работу, например, архитектуры 1500 команд с фиг. 15.
Конвейер 1600 исполнения может содержать любую подходящую комбинацию этапов и операций. В 1605 может быть выполнено предсказание ветвления, которое будет исполнено следующим. В одном варианте осуществления изобретения такие предсказания могут быть основаны на предыдущих исполнениях команды и их результатах. В 1610 команды, соответствующие предсказанному ветвлению исполнения, могут быть загружены в кэш-память команд. В 1615 одна или несколько таких команд в кэш-памяти команд могут быть выбраны для исполнения. В 1620 команды, которые были выбраны, могут быть декодированы в микрокод или более специфичный машинный язык. В одном варианте осуществления изобретения множество команд могут быть декодированы одновременно. В 1625 могут быть переприсвоены ссылки на регистры или другие ресурсы в декодированных командах. Например, ссылки на виртуальные регистры могут быть заменены ссылками на соответствующие физические регистры. В 1630 команды могут быть отправлены в очереди для исполнения. В 1640 команды могут быть исполнены. Такое исполнение может быть осуществлено любым подходящим образом. В 1650 команды могут быть выданы в подходящий объект исполнения. Способ, которым команду исполняют, может зависеть от конкретного объекта, исполняющего команду. Например, в 1655 ALU может выполнять арифметические функции. ALU может использовать один тактовый цикл для своей работы, а также два устройства сдвига. В одном варианте осуществления изобретения может быть использовано два ALU и, таким образом, в 1655 может быть исполнено две команды. В 1660 может быть выполнено определение результирующего ветвления. Программный счетчик может быть использован для обозначения назначения, в которое будет сделано ветвление. 1660 может быть исполнено за один тактовый цикл. В 1665 в одном или нескольких FPU может быть выполнена арифметика с плавающей запятой. Для исполнения операции с плавающей запятой может требоваться несколько тактовых циклов, например, от двух до десяти циклов. В 1670 могут быть выполнены операции умножения и деления. Такие операции могут быть выполнены за несколько тактовых циклов, например, за четыре тактовых цикла. В 1675 могут быть выполнены операции загрузки и сохранения для регистров или других участков конвейера 1600. Операции могут подразумевать загрузку и сохранение адресов. Такие операции могут быть выполнены за четыре тактовых цикла. В 1680 могут быть выполнены операции обратной записи, как нужно результирующим операциям из 1655-1675.
На фиг. 17 показана структурная схема электронного устройства 1700 для использования процессора 1710, в соответствии с вариантами осуществления настоящего изобретения. Электронное устройство 1700 может являться, например, ноутбуком, ультрабуком, компьютером, башенным сервером, стоечным сервером, компактным сервером, лэптопом, настольным компьютером, планшетным компьютером, мобильным устройством, телефоном, встроенным компьютером или любым другим подходящим электронным устройством.
Электронное устройство 1700 может содержать процессор 1710, с возможностью обмена информации связанный с любым подходящим количеством или любого подходящего типа компонентами, периферийными устройствами, модулями или устройствами. Такая связь может быть реализована любой подходящей шиной или интерфейсом, таким как I2C шина, шина (SMBus) управления системой, шина (LPC) с малым числом контактов, SPI, шина звука (HDA) высокой четкости, шина последовательного подключения (SATA) накопителей, шина USB (версии 1, 2, 3) или шина универсального асинхронного устройства (UART) приема/передачи.
Такими компонентами могут являться, например, дисплей 1724, сенсорный экран 1725, сенсорная панель 1730, блок 1745 стандарта (NFC) ближней радиосвязи, блок 1740 датчиков, тепловой датчик 1746, набор 1735 (EC) микросхем express, доверенный платформенный модуль 1738 (TPM), флеш-память/BIOS/аппаратно реализованное программное обеспечение 1722, цифровой сигнальный процессор 1760, привод 1720, такой как твердотельный накопитель (SSD) или накопитель (HDD) на жестких дисках, блок 1750 беспроводной локальной сети (WLAN), блок 1752 Bluetooth, блок 1756 беспроводной глобальной вычислительной сети (WWAN), блок глобальной системы (GPS) позиционирования, камера 1754, такая как USB 3.0 камера или блок 1715 памяти (LPDDR) пониженного энергопотребления и удвоенной скорости передачи данных, реализованный, например, в соответствии со стандартом LPDDR3.
Каждый из этих компонентов может быть реализован любым подходящим образом.
Более того, в различных вариантах осуществления изобретения, с использованием упомянутых выше компонентов, другие компоненты могут быть, с возможностью обмена информацией, связаны с процессором. Например, акселерометр 1741, датчик 1742 (ALS) внешней освещенности, компас 1743 и гироскоп 1744 могут быть, с возможностью обмена информацией, связаны с блоком 1740 датчиков. Тепловой датчик 1739, вентилятор 1737, клавиатура 1746 и сенсорная панель 1730 могут быть, с возможностью обмена информацией, связаны с EC 1735. Динамики 1763, наушники 1764 и микрофон 1765 могут быть, с возможностью обмена информацией, связаны с блоком 1764 звука, который, в свою очередь, может быть, с возможностью обмена информацией, связан с DSP 1760. Блок 1764 звука может содержать, например, аудиокодек и усилитель класса D. SIM карта 1757 может быть, с возможностью обмена информацией, связана блоком 1756 WWAN. Такие компоненты, как блок 1750 WLAN и блок 1752 Bluetooth, а также блок 1756 WWAN, могут быть реализованы в форм-факторе (NGFF) следующего поколения.
Варианты осуществления настоящего изобретения подразумевают команду и логическую схему для сортировки и выгрузки команд сохранения. В одном варианте осуществления изобретения сортировка и выгрузка могут быть выполнены из неупорядоченного буфера, такого как буфер команд сохранения. Команда и логическая схема могут быть выполнены со связью с процессором, виртуальным процессором, пакетом, компьютерной системой или другим устройством обработки. В одном варианте осуществления изобретения такое устройство обработки может содержать процессор с измененным порядком команд. В другом варианте осуществления изобретения такое устройство обработки может содержать многопоточный процессор с с измененным порядком команд. На фиг. 18 показан пример системы 1800 для выгрузки и сортировки команд сохранения, в соответствии с вариантами осуществления настоящего изобретения. Хотя определенные элементы могут быть показаны на фиг. 18 выполняющими описанные действия, любой подходящий участок системы 1800 может реализовывать описанные в настоящем документе функциональные возможности или действия.
Система 1800 может содержать многопоточный процессор 1808 с измененным порядком команд с любыми подходящими объектами для параллельного исполнения множества нитей. Команды одной цепочки могут быть сгруппированы в нити. В одном варианте осуществления изобретения многопоточный процессор 1808 с измененным порядком команд может исполнять команды каждой нити с учетом команд других нитей, так что команды выбираются, выдаются и исполняются не в программном порядке. Все команды, за исключением команд работы с памятью и допускающих прерывание команд, могут быть зафиксированы или выгружены не в программном порядке. Тем не менее, в одном варианте осуществления изобретения команды работы с памятью и допускающие прерывание команды могут быть зафиксированы или выгружены в порядке, относительном или как целое. Такая фиксация и выгрузка по порядку может быть результатом возможных ошибок зависимости данных. Исполнение по порядку может включать в себя исполнение в соответствии с последовательными значениями РО. Исполнение не по порядку может включать в себя исполнение, которое не обязательно следует последовательным значениям РО. Система 1800 может показывать элементы такого многопоточного процессора 1808 с измененным порядком команд, который может являться любым ядром процессора, логическим процессором, процессором или любым обрабатывающим объектом или элементом, таким как элементы, показанные на фиг. 1-17.
Система 1800 может содержать ступень 1560 выдачи для работы с потоком 1802 команд. Поток 1802 команд может содержать любое подходящее количество нитей 1804 или любые типы нитей 1804. Каждая нить 1804 может содержать серию команд, упорядоченных с помощью РО и зависящих друг от друга по данным. Более того, каждая нить 1804 может касаться других нитей, например, из-за операций разветвления или цикла. Команды в заданной нити могут быть исполнены в порядке относительно друг друга. Как описано выше, PO может содержать уникальный номер команды для упорядочивания команд с целью обеспечения корректной семантики исполнения кода. Нити могут быть обозначены с помощью ступени 1560 выдачи, двоичного транслятора или любого другого подходящего механизма.
Система 1800 может присвоить значения РО подмножеству команд. Значения РО могут быть присвоены тем командам, порядок которых должен быть восстановлен после выполнения обработки с измененным порядком команд и исполнения. Такие команды могут являться, например, командами работы с памятью или допускающими прерывание командами. Командами работы с памятью могут являться команды считывания или записи в память, кэш-память или регистры, такие как команды загрузки и команды сохранения. Допускающими прерывание командами могут являться команды, которые могут вызвать прерывания.
Процессор 1808 также может содержать ступень 1814 выделения для присвоения командам ресурсов обработки с целью их исполнения. Более того, ступень 1814 выделения может переименовывать ресурсы, используемые при исполнении, так как такое переименование может предоставить возможность параллельного исполнения нитей 1804, при этом команды из других нитей 1804 должны получать доступ к той же самой памяти или регистру, но фактически являются независимыми друг от друга. Кроме того, система 1800 может содержать ступень 1570 обратной записи для обработки выгрузки и фиксации уже исполненных команд.
В одном варианте осуществления изобретения система 1800 может содержать указатель 1806 (EIP) исполняемой команды. Указатель 1580 исполняемой команды может хранить значение, идентифицирующее самое старое значение программного порядка РО потока 1802 команд, которые еще не были исполнены. В еще одном варианте осуществления изобретения указатель 1580 исполняемой команды может хранить РО отдельной нити 1804, которая обладает самым старым значением РО среди нитей 1804. Так как нити могут быть исполнены параллельно друг с другом и с измененным порядком относительно друг друга, одна из нитей 1804 может содержать значение РО, которое гораздо меньше другого значения РО одной из нитей 1804. Такой результат может иметь место, например, если нить содержит команды, которые, в общем, обладают малым значением РО, или нить не исполнена, как многие ее команды.
Когда команды исполняют, их могут записывать в один или несколько буферов ступени 1570 обратной записи для выгрузки и фиксации. В одном варианте осуществления изобретения ступень 1570 обратной записи может содержать буфер 1810 команд сохранения для содержания команд сохранения до их фиксации. Когда команды сохранения исполнены и записаны в буфер 1810 команд сохранения, они могут быть расположены в порядке их исполнения. Соответственно, команды сохранения могут не быть упорядочены с точки зрения значений РО. Это показано в примерах с фиг. 18. Нижние записи буфера 1810 команд сохранения могут содержать самые старые записи (с точки зрения длительности нахождения в буфере 1810 команд сохранения), а верхние записи буфера 1810 команд сохранения могут быть самыми новыми записями буфера 1810 команд сохранения. Порядок записей в буфере 1810 команд сохранения не обязательно связан с РО таких записей.
Более того, команды могут быть расположены в порядке с точки зрения значений РО до их переупорядочивания для исполнения в соответствии с измененным порядком. Переупорядочивание может быть выполнено путем разбивания команд на разные нити 1804 и параллельного исполнения нитей 1804 с измененным порядком. Таким образом, исполнение команд для разных нитей 1804 может привести к исполнению команд с измененным порядком. Соответственно, когда команды исполняют и сохраняют в буфере 1810 команд сохранения, они могут появляться в измененном порядке.
После исполнения команд работы с памятью, им может потребоваться выгрузка или фиксация в порядке. Фиксация результирующих значений в архитектурном состоянии (таком как фактические регистры и системная память) процессора 1808 может потребовать отсутствия последующих ошибок зависимости данных для записанных значений. В противном случае могут появиться нарушения моделей непротиворечивости памяти, зависимостей управления, зависимостей названий и данных или исключений.
Более того, команды, даже при расположении в порядке, могут не быть расположены непрерывно. Например, появляющиеся последовательно команды могут не быть пронумерованы подряд идущими значениями РО. Промежутки в значениях РО между соседними командами могут быть вызваны, например, статическим присвоением командам значений РО. Команды фактически могут реализовывать динамические ветвления, которые может быть невозможно предсказать во время статического присвоения значений РО. Компилятор команд может не обладать точным видением последовательности команд программы. Не использованные пути могут быть не исполнены и в командах, которые были фактически исполнены, могут существовать промежутки в значениях РО. Более того, могут возникать циклы со статически неизвестным количеством повторений.
Таким образом, для выгрузки элементов буфера 1810 команд сохранения, его содержимое должно быть проанализировано, чтобы выгрузка могла быть выполнена в порядке. Такая выгрузка в порядке может быть сделана даже при продолжении исполнения, поступлении команд в измененном порядке и не подряд идущих значениях РО. Процессор 1808 может содержать модуль 1816 поиска для идентификации того, как в порядке выгружать элементы буфера 1810 команд сохранения. В одном варианте осуществления изобретения модуль 1816 поиска может идентифицировать диапазон значений РО, для которого модуль 1816 поиска может оценить элементы в буфере 1810 команд сохранения. В другом варианте осуществления изобретения модуль 1816 поиска может идентифицировать такой диапазон так, что элементы-кандидаты из буфера 1810 команд сохранения не являются причиной ошибок зависимости данных. В еще одном варианте осуществления изобретения модуль 1816 поиска может сортировать элементы-кандидаты и упорядочить их для корректной выгрузки в соответствии с PO.
Когда исполнена команда сохранения в буфере 1810 команд сохранения, и ее можно зафиксировать, ее можно называть старшей командой сохранения. Старшие команды сохранения могут быть записаны в очередь 1812 выгрузки команд сохранения, которая может быть реализована в соответствии со структурой данных «первым пришел - первым вышел». В одном варианте осуществления изобретения старшие команды сохранения могут быть классифицированы как обладающие RPO меньшим EIP 1806. Требуя это, SRQ 1812 может обеспечить, что все команды сохранения с меньшим значением RPO находятся в буфере 1810 команд сохранения. В другом варианте осуществления изобретения для обозначения команды сохранения как старшей команды сохранения, все команды сохранения с меньшим RPO также могут быть обозначены как старшие команды сохранения. Такое обозначение может гарантировать корректную последовательность для выгрузки команд сохранения. В еще одном варианте осуществления изобретения старшая команда сохранения может быть классифицирована как обладающая успешно транслированным линейным адресом и данными, доступными для выполнения команды сохранения. Благодаря этому, старшие команды сохранения могут избежать проблем с зависимостью данных.
В одном варианте осуществления изобретения модуль 1816 поиска может быть дополнительно ограничен размером буфера 1810 команд сохранения в поиске команд сохранения в буфере 1810 команд сохранения для выгрузки. Более конкретно, модуль 1816 поиска может быть ограничен количеством портов считывания буфера 1810 команд сохранения, обозначенным через N. Количество портов считывания ограничивает количество команд сохранения, которые могут быть параллельно записаны в SRQ 1812.
Также, в некоторых вариантах осуществления изобретения, участок буфера 1810 команд сохранения может быть уже зафиксирован и, таким образом, не требует сортировки, осуществляемой модулем 1816 поиска. Указатель (SCP) фиксации команд сохранения может определять РО последней зафиксированной команды сохранения.
В одном варианте осуществления изобретения модуль 1816 поиска может искать исполненные, но не зафиксированные команды сохранения в буфере 1810 команд сохранения. Более конкретно, модуль 1816 поиска может искать исполненные, но не зафиксированные команды сохранения, которые подходят для фиксации. Такие команды сохранения могут содержать команды с RPO, меньшим значения РО, которое хранится в EIP 1806. Более того, такие команды сохранения могут содержать команды с транслированным линейным адресом и данными, доступными для команды. Более того, поиск может быть выполнен последовательным образом относительно RPO, так что команда сохранения может быть найдена как старшая команда сохранения только если все предыдущие команды сохранения также являются старшими. Кроме того, модуль 1816 поиска может искать команды с целью оптимизации или увеличения эффективности считывания значений и их записи в SRQ 1812. Таким образом, такой поиск может включать в себя просмотр некоторого количества команд сохранения, ограниченного числом N, количеством портов считывания буфера 1810 команд сохранения. Когда найдены такие N или меньше кандидатов из команд сохранения, модуль 1816 поиска может отсортировать их и записать в SRQ 1812 для фиксации.
На фиг. 19 показаны ограничения, накладываемые на работу модуля 1816 поиска, в соответствии с вариантами осуществления настоящего изобретения. Буфер 1810 команд сохранения может содержать незафиксированные элементы, от самого старшего до самого младшего со значениями РО, равными [6, 1, 16, 7, 5, 8, 11, 8]. EIP 1806 может указывать значение PO, равное двенадцати. Более того, SCP 1808 может указывать значение PO, равное двум. Кроме того, количество портов считывания буфера 1810 команд сохранения может быть равно четырем. Более того, предположим, что все элементы, показанные на примере с фиг. 19, иначе подходят для фиксации с той точки зрения, что команда сохранения обладает адресом, который был линейно транслирован, и исполнение завершено.
С помощью простого поиска RPO < EIP, модуль 1816 поиска может определить, что в буфере 1810 команд сохранения присутствует кандидаты в количестве семи старших команд сохранения, что делают на основе того, что значение РО кандидатов меньше значения РО из EIP 1806, равного двенадцати. Тем не менее, семь кандидатов больше количества портов считывания для буфера 1810 команд сохранения.
На фиг. 20 показан пример работы модуля 1816 поиска, отражающий проблемы, возникшие в подходе, проиллюстрированном на фиг. 19, в соответствии с вариантами осуществления настоящего изобретения. Буфер 1810 команд сохранения может быть выполнен аналогично показанному на фиг. 19. EIP 1806 может по-прежнему содержать значение, равное двенадцати, буфер 1810 команд сохранения может содержать четыре порта считывания и SCP может по-прежнему обладать значением, равным двум.
Модуль 1816 поиска может содержать регулируемый указатель поиска, который может функционировать как переменный верхний предел для искомых значений РО. Указатель поиска может быть отрегулирован, если количество найденных результатов слишком велико или мало. Вместо поиска команд сохранения со значением РО, меньшим значения из EIP 1806, в одном варианте осуществления изобретения указатель поиска может быть определен как значение, которое всегда меньше или равно значению РО из EIP 1806. В другом варианте осуществления изобретения указатель поиска может быть определен как значение, меньшее значения РО из EIP 1806. В различных вариантах осуществления изобретения указатель поиска может быть переопределен на основе предыдущей попытки поиска кандидатов из команд сохранения в буфере 1810 команд сохранения.
EIP 1806 может обладать гарантирующим действием, что все команды сохранения со значениями РО, меньшими EIP, были уже рассмотрены на предмет выгрузки или выгружены. Путем выбора указателя поиска со значением, меньшим EIP 1806, модуль 1816 поиска может обеспечить, что в буфере 1810 команд сохранения отсутствуют команды сохранения со значением РО, большим EIP 1806. Такая команда сохранения может быть командой, которая еще не выгружена из-за измененного порядка исполнения, или командой, которая может все еще ждать отправки. Указатель поиска может обеспечить, что такая неготовая команда не рассматривается и, таким образом, не нарушить порядок команд сохранения.
Более того, модуль 1816 поиска может использовать SCP 1808 как нижний предел для диапазона поиска РО. Например, модуль 1816 поиска может определить, что начальный указатель поиска должен обладать значением РО, равным десяти. В ходе первой итерации модуль 1816 поиска может определить количество записей буфера 1810 команд сохранения, значения РО которых находятся между SCP 1808 и указателем поиска. В буфере 1810 команд сохранения может присутствовать пять таких записей, в предположении, что иначе каждая готова к фиксации. Пять таких записей больше четырех портов считывания в буфере 1810 команд сохранения. Таким образом, фиксация может быть неэффективной, если ее выполнять для пяти записей.
SCP 1808 может рассматривать как отслеживающее значение РО всех уже зафиксированных команд сохранения и, таким образом, SCP 1808 больше значений РО всех зафиксированных команд сохранения. Изначально указатель поиска может быть установлен равным значению, которое больше текущего SCP 1808 на некоторое эмпирическое значение дельта.
Далее модуль 1816 поиска может пересчитать указатель поиска для получения меньшего диапазона РО, чтобы лучше соответствовать количеству портов считывания буфера 1810 команд сохранения. Например, указатель поиска может быть установлен равным девяти. В ходе следующей итерации модуль 1816 поиска может определить, что четыре записи буфера 1810 команд сохранения обладают значениями РО, которые находятся между SCP 1808 и указателем поиска. Таким образом, четыре записи могут быть упорядочены и записаны в SRQ 1812.
На фиг. 21А, 21В и 21C показан пример работы модуля 1816 поиска, в соответствии с вариантами осуществления настоящего изобретения. На фиг. 21А, в (1) модуль 1816 поиска может предсказать значение для указателя поиска. В одном варианте осуществления изобретения указатель поиска может обладать значением, равным SCP 1808 плюс смещение или дельта. В ходе первой итерации дельта может обладать начальным значением, равным единице или любому другому подходящему значению по умолчанию. В различных вариантах осуществления изобретения указатель поиска могут поддерживать меньшим EIP 1806 и большим SCP 1808.
В (2) модуль 1816 поиска может выполнить поиск в буфере 1810 команд сохранения. Поиск может быть выполнен любым подходящим образом. В одном варианте осуществления изобретения поиск может быть выполнен как CAM поиск. Поиск направлен на определение того, сколько элементов буфера 1810 команд сохранения меньше указателя поиска. В еще одном варианте осуществления изобретения поиск также может определить, больше ли эти элементы SCP 1808. В еще одном варианте осуществления изобретения поиск может определить, готовы ли в противном случае элементы буфера 1810 команд сохранения для фиксации. Такие условия могут содержать, что линейный адрес заданной команды сохранения транслирован и что необходимые данные доступны.
В (3) могут быть возвращены результаты поиска. Если не было выполнено проверок на фиксацию, в одном варианте осуществления изобретения они могут быть выполнены при возвращении результатов из буфера 1810 команд сохранения.
В (4) модуль 1816 поиска может определить, превышает ли количество портов считывания буфера 1810 команд сохранения количество кандидатов из команд сохранения из буфера 1810 команд сохранения. Если превышает, то поиск может быть повторен с новым предсказанным указателем поиска, как показано на фиг. 21В. Если количество кандидатов из команд сохранения из буфера 1810 команд сохранения находится в пределах количества портов считывания буфера 1810 команд сохранения, могут быть выполнены операции с фиг. 21С.
На фиг. 21В в (1) может быть предсказан указатель поиска. Модуль 1816 поиска может снова предсказывать дельту или смещение относительно SCP 1808. В одном варианте осуществления изобретения предсказанная дельта может быть основана на количестве результатов, полученных в ходе предыдущего поиска. В другом варианте осуществления изобретения предсказанная дельта может быть основана на количестве портов считывания N буфера 1810 команд сохранения.
В (2) модуль 1816 поиска может выполнить CAM поиск в буфере 1810 команд сохранения с использованием обновленного указателя поиска. В (3) результаты могут быть возвращены, а в (4) может быть определено, сколько команд сохранения из буфера 1810 команд сохранения удовлетворяют условиям фиксации. Если количество команд сохранения из буфера 1810 команд сохранения, соответствующих поиску, превышает количество портов считывания буфера 1810 команд сохранения, могут быть повторены операции с фиг. 21В. В противном случае модуль 1816 поиска может выполнить операции с фиг. 21С.
На фиг. 21C в (1) модуль 1816 поиска может направить N или меньшее количество старших команд сохранения в сеть 2102 сортировки. Сеть 2102 сортировки может отсортировать в аппаратном обеспечении в соответствии со значением РО старшие команды сохранения. В (2) сеть 2102 сортировки может направить отсортированные старшие команды сохранения в SRQ 1812. В одном варианте осуществления изобретения в SRQ 1812 могут быть записаны только идентификаторы буфера 1810 команд сохранения старших команд сохранения. Старшие команды сохранения могут быть зафиксированы.
На фиг. 22 показан пример работы модуля 1816 поиска по предсказанию или установке указателей поиска, в соответствии с вариантами осуществления настоящего изобретения. В одном варианте осуществления изобретения для установки указателя поиска модуль 1816 поиска может использовать значение РО из EIP 1806. В другом варианте осуществления изобретения для установки указателя поиска модуль 1816 поиска может использовать значение РО для SCP 1808. В еще одном варианте осуществления изобретения для установки указателя поиска модуль 1816 поиска может использовать количество команд сохранения, найденных в ходе предыдущего поиска. Такое количество найденных команд сохранения может быть обозначено через M. Если ранее не было осуществлено поисков, то M может быть установлено равным нулю. В еще одном варианте осуществления изобретения для установки указателя поиска модуль 1816 поиска может использовать количество портов считывания буфера 1810 команд сохранения, которое может быть обозначено через N.
Модуль 1816 поиска может поддерживать ограничения, что указатель поиска должен быть меньше EIP 1806 и больше SCP 1808. В некоторых вариантах осуществления изобретения указатель поиска может быть установлен равным EIP 1806, если EIP 1806 и SCP 1808 отличаются меньше, чем на два значения.
В одном варианте осуществления изобретения модуль 1816 поиска может установить указатель поиска как меньшее значение из EIP 1806 и SCP 1808 плюс вычисленное значение дельта. Изначально, если не было выполнено поисков, значение дельта может быть установлено равным значению по умолчанию. Например, значение дельта может быть изначально установлено равным единице.
В другом варианте осуществления изобретения модуль 1816 поиска может установить значение дельта на основе M, количества команд сохранения, найденных в ходе предыдущего поиска. Таким образом, модуль 1816 поиска может итеративно отрегулировать значение дельта до тех пор, пока из буфера 1810 команд сохранения не будет выбрано более эффективное количество команд сохранения. В еще одном варианте осуществления изобретения модуль 1816 поиска может установить значение дельта на основе M и N, количества портов считывания, доступных в буфере 1810 команд сохранения.
В одном варианте осуществления изобретения модуль 1816 поиска может быть реализован с элементами, достаточными для выполнения математических вычислений. В таком варианте осуществления изобретения модуль 1816 поиска может использовать модель 2202 вычисления дельта. Модель 2202 вычисления дельта может определять, что текущая дельта должна быть равна предыдущей дельте, умноженной на M и деленной на N. Результаты, являющиеся дробным числом, могут быть округлены в большую или меньшую сторону до получения целых значений. Тем не менее, использование модели 2202 вычисления дельта может требовать элементов умножения и деления.
В другом варианте осуществления изобретения модуль 1816 поиска может быть реализован с устройствами сдвига и суммирующими устройствами, нужными для определения дельта. Такой вариант осуществления изобретения позволяет отказаться от необходимости использования элементов умножения и деления. Например, для определения значений дельта модуль 1816 поиска может использовать эвристическую модель 2204. Эвристическая модель 2204 может определять, что предыдущие значения дельта должны быть сдвинуты или побитно сложены. Например, если M было в диапазоне 0-1, то предыдущее значение дельта может быть сдвинуто влево на два бита, в результате дельта увеличится в четыре раза. Если M было в диапазоне двух, то предыдущее значение дельта может быть сдвинуто влево на один бит, в результате дельта увеличится в два раза. Если M было в диапазоне 3-4, то предыдущее значение дельта может быть сохранено. Если M было в диапазоне 5-8, то предыдущее значение дельта может быть сдвинуто вправо на один бит, в результате дельта уменьшится в два раза. Если M было в диапазоне 9-16, то предыдущее значение дельта может быть сдвинуто вправо на два бита, в результате дельта уменьшится в четыре раза. Если M было в диапазоне 17-32, то предыдущее значение дельта может быть сдвинуто вправо на три бита, в результате дельта уменьшится в восемь раз. Если M было в диапазоне 33-64, то предыдущее значение дельта может быть сдвинуто вправо на четыре бита, в результате дельта уменьшится в шестнадцать раз.
Параметры, определенные в эвристической модели 2204, могут быть определены эмпирически или могут быть основаны на размере буфера 1810 команд сохранения (пример размера - шестьдесят четыре записи) и количестве портов считывания буфера 1810 команд сохранения (пример размера - четыре порта). Для других размеров буфера команд сохранения могут быть использованы другие диапазоны. Таким образом, модуль 1816 поиска может изменить значения дельта пропорционально различию M и N.
Количество итераций поиска, осуществляемого модулем 1816 поиска, нужное для нахождения группы команд сохранения из буфера 1810 команд сохранения, удовлетворяющих условиям, может влиять на производительность. Большее количество итерация может быть нужно, если количество соответствующих команд сохранения в буфере 1810 команд сохранения, гораздо больше N. Более того, первая итерация, при которой получают менее N старших команд сохранения, может не воспользоваться всеми портами считывания буфера 1810 команд сохранения. Таким образом, в ходе поиска предсказание значений дельта может быть отрегулировано, как показано выше.
Если команды были выбраны строго по порядку, команды могут быть выгружены в порядке и, таким образом, отсутствует необходимость в модуле 1816 поиска. Тем не менее, такой подход может потребовать использования сроков, прикрепленных к командам, при их выборке и исполнении. Более того, это уничтожит достоинства обработки с измененным порядком, когда команды выбираются в соответствии с измененным порядком, добиваясь увеличения параллельности исполнения. Более того, разные нити выбираются процессором 1808 в соответствии с измененным порядком. Это противоречит любым требования по выборке команд в соответствии с порядком.
На фиг. 23 показан пример варианта осуществления способа 2300 по поиску и сортировке команд сохранения, в соответствии с вариантами осуществления настоящего изобретения. В одном варианте осуществления изобретения способ 2300 может быть выполнен многопоточным процессором с измененным порядком исполнением команд. Способ 2300 может начаться в любой подходящей точке и может исполняться в любом подходящем порядке. В одном варианте осуществления изобретения способ 2300 может начаться в 2305.
В 2305 упорядоченный поток команд, подлежащих исполнению, может быть разделен на множество нитей. Нити могут быть исполнены параллельно друг другу. Нити могут обладать зависимостями по данных в рамках заданной нити, но могут быть исполнены в соответствии с измененным порядком относительно друг друга. Более того, в рамках каждой нити, команды могут быть исполнены по порядку. Команды могут содержать указание РО для целей упорядочивания. Последовательно упорядоченные команды могут быть не пронумерованы подряд с точки зрения РО. В значениях РО последовательных команд могут существовать промежутки.
В 2310 могут быть выполнены этапы обработки. Такие этапы могут содержать, например, выборку, выдачу, отправление или исполнение команд в процессоре. Может быть выполнен цикл исполнения.
В 2315, так как каждая команда сохранения выделена, она может быть записана в буфер команд сохранения с N портами считывания. Буфер команд сохранения может содержать команды сохранения до тех пор, пока они не исполнены, выгружены и зафиксированы. Так как команды сохранения могут быть выбраны и исполнены в измененном порядке, они могут быть записаны в буфер команд сохранения в соответствии с измененным порядком и, таким образом, команды сохранения в буфере команд сохранения могут не быть упорядочены в соответствии с РО.
В 2320 могут быть определены значения РО для EIP и SCP. Значение EIP может соответствовать минимальному значению PO среди всех нитей для команд, которые еще не были отправлены на исполнение. Значение SCP может соответствовать значению РО последней выгруженной или зафиксированной команды сохранения.
В 2325 может быть определено начальное значение дельта, используемое для вычисления параметров поиска. Значением по умолчанию для дельты может быть единица.
В 2330 может быть определен указатель поиска, как верхний предел для поиска. В одном варианте осуществления изобретения указатель поиска может быть определен как минимум из EIP и SCP плюс значение дельта.
В 2335 в буфере команд сохранения могут выполнить поиск всех элементов с РО, меньшим указателя поиска и большим SCP. В 2340 результаты могут быть оценены с целью определения, удовлетворяют ли команды сохранения условиям фиксации. Такие критерии могут содержать, например, транслирован ли их линейный адрес и доступны ли данные для их работы. В 2345, результаты соответствия могут быть описаны как M разных команд сохранения.
В 2350 может быть определено, справедливо ли, что M меньше или равно N. Если да и если все M команды сохранения удовлетворяют критериям фиксации, способ 2300 может перейти к 2360. Если ответ нет, то способ 2300 возвращается к 2355.
В 2355 может быть отрегулировано значение дельта. В одном варианте осуществления изобретения значение дельта может быть отрегулировано на основе предыдущего значения дельта и M. В другом варианте осуществления изобретения значение дельта может быть отрегулировано на основе предыдущего значения дельта, M и N. Значение дельта может быть отрегулировано на основе, например, модели вычислений, в которой дельту умножают на M / N. В другом примере может быть использована эвристическая модель, в которой значение дельта сдвигают, в результате дельта увеличивается или уменьшается в соответствующее количество раз. Величина, на которую сдвигают дельту, может быть основана на определенных диапазонах значений M. В различных вариантах осуществления изобретения, таким образом, дельта может быть отрегулирована в соответствии с тем, насколько правильно или неправильно предыдущий поиск соответствует количеству доступных портов считывания буфера команд сохранения. Способ 2300 может вернуться к 2330.
В 2360 результаты могут быть отсортированы в аппаратном обеспечении в соответствии со значением РО. В 2365 результаты могут быть записаны или другим образом зафиксированы. В одном варианте осуществления изобретения в SRQ могут быть записаны идентификаторы буфера команд сохранения. В 2370, может быть определено, будет ли повторен способ 2300. Если да, то способ 2300 может возвратиться к 2305 или к любому другому подходящему элементу. Если нет, то способ 2300 может быть закончен.
Способ 2300 может быть запущен с помощью любого подходящего критерия. Более того, хотя способ 2300 описывает работу конкретных элементов, способ 2300 может быть выполнен с помощью любой подходящей комбинации элементов или любого типа элементов. Например, способ 2300 может быть реализован с помощью элементов, показанных на фиг. 1-22, или любой другой системы, выполненной для реализации способа 2300. Фактически, предпочтительная точка запуска способа 2300 и порядок элементов, составляющих способ 2300, могут зависеть от выбранной реализации. В некоторых вариантах осуществления изобретения некоторые элементы могут быть, при желании, опущены, преобразованы, повторены или объединены.
Варианты осуществления описанных в настоящем документе механизмов могут быть реализованы с помощью аппаратного обеспечения, аппаратно реализованного программного обеспечения, программного обеспечения или с помощью любой комбинации таких подходов к реализации. Варианты осуществления настоящего изобретения могут быть реализованы как компьютерные программы или программный код, исполняемый на программируемых системах, содержащих, по меньшей мере, один процессор, систему хранения (содержащую энергозависимую и энергонезависимую память и/или элементы хранения), по меньшей мере, одно устройство ввода и, по меньшей мере, одно устройство вывода.
Программный код может быть применен для ввода команд с целью выполнения описанных в настоящем документе функций и выработки выходной информации. Выходная информация может быть, известным образом, применена в одном или нескольких устройствах вывода. Для целей этой заявки, система обработки может содержать любую систему, которая содержит процессор, такой как, например, цифровой сигнальный процессор (DSP), микроконтроллер, специализированную интегральную схему (ASIC) или микропроцессор.
Программный код может быть реализован на процедурном или объектно-ориентированном языке программирования высокого уровня с целью связи с системой обработки. Программный код также, при желании, может быть реализован на ассемблере или машинном языке. Фактически, описанные в настоящем документе механизмы не ограничены каким-либо конкретным языком программирования. В любом случае язык может быть компилируемым или интерпретируемым языком.
Один или несколько аспектов, по меньшей мере, одного варианта осуществления изобретения могут быть реализованы с помощью типовых команд, хранящихся на считываемом машиной носителе и представляющих различные логические операции в процессоре, которые при считывании машиной побуждают машину формировать логические операции для осуществления описанных здесь технологий. Такие представления, известные как «IP-ядра» могут храниться на материальном считываемом машиной носителе и подаваться различным клиентам или производственным предприятиям для загрузки на производственные машины, которые фактически делают логические схемы или процессор.
Такой считываемый машиной носитель информации может содержать, без ограничения, долговременные, материальные конструкции из изделий или могут быть сформированы машиной или устройством, содержащим носитель информации, такой как жесткие диски, диск любого другого типа, в том числе гибкие диски, оптические диски, компакт-диски (CD-ROM) постоянных запоминающих устройств, перезаписываемые компакт-диски (CD-RW) и магнитооптические диски, полупроводниковые устройства, такие как постоянные запоминающие устройства (ROM), оперативные запоминающие устройства (RAM), такие как динамические оперативные запоминающие устройства (DRAM), статические оперативные запоминающие устройства (SRAM), стираемые программируемые постоянные запоминающие устройства (EPROM), флеш-памяти, электрически стираемые программируемые постоянные запоминающие устройства (EEPROM), магнитные или оптические карты или любой другой тип носителя, подходящий для хранения электронных команд.
Соответственно, варианты осуществления изобретения также могут содержать долговременный, материальный считываемый машиной носитель, содержащий команды или содержащий данные для проектирования, такие как язык (HDL) описания аппаратных средств, которые определяют структуры, схемы устройства, процессоры и/или системные признаки, описанные в настоящем документе. Такие варианты осуществления изобретения также могут называться программными продуктами.
В некоторых случаях, устройство преобразования команд может быть использовано для преобразования команды из исходного набора команд в целевой набор команд. Например, устройство преобразования команд может транслировать (например, с использованием статической двоичной трансляции, динамической двоичной трансляции, в том числе динамической компиляции), трансформировать, эмулировать или другим образом преобразовывать команду в одну или несколько других команд, подлежащих обработке ядром. Устройство преобразования команд может быть реализовано с помощью аппаратного обеспечения, аппаратнореализованного программного обеспечения, программного обеспечения или с помощью любой комбинации перечисленного. Устройство преобразования команд может быть расположено на процессоре, не на процессоре, или частично на процессоре и частично не на процессоре.
Таким образом, описаны технологии для осуществления одной или нескольких команд, в соответствии, по меньшей мере, с одним вариантом осуществления изобретения. Хотя описаны и показаны на приложенных чертежах определенные примеры вариантов осуществления изобретения, необходимо понимать, что такие варианты осуществления изобретения приведены только для иллюстрации и не ограничивают другие варианты осуществления изобретения и такие варианты осуществления изобретения не ограничены конкретными конструкциями и расположениями, показанными и описанными, так как при изучении этого изобретения специалистами в рассматриваемой области могут быть предложены различные другие модификации. В таких областях, как рассматриваемая, где имеет место быстрый рост и нелегко прогнозировать дальнейшие улучшения, описанные варианты осуществления изобретения могут быть легко модифицированы в плане расположения и деталей, чему способствуют технологические улучшения, что, однако не выходит за границы объема настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ДОСТУПА К ПАМЯТИ В КЛАСТЕРНОЙ МАШИНЕ ШИРОКОГО ИСПОЛНЕНИЯ | 2013 |
|
RU2662394C2 |
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ИДЕНТИФИКАЦИИ ИНСТРУКЦИЙ ДЛЯ УДАЛЕНИЯ В МНОГОПОТОЧНОМ ПРОЦЕССОРЕ С ИЗМЕНЕНИЕМ ПОСЛЕДОВАТЕЛЬНОСТИ | 2013 |
|
RU2644528C2 |
| ПРОЦЕССОРЫ, СПОСОБЫ, СИСТЕМЫ И КОМАНДЫ ДЛЯ СЛОЖЕНИЯ ТРЕХ ОПЕРАНДОВ-ИСТОЧНИКОВ С ПЛАВАЮЩЕЙ ЗАПЯТОЙ | 2014 |
|
RU2656730C2 |
| КОМАНДА И ЛОГИКА ДЛЯ ОБЕСПЕЧЕНИЯ ФУНКЦИОНАЛЬНЫХ ВОЗМОЖНОСТЕЙ ЦИКЛА ЗАЩИЩЕННОГО ХЕШИРОВАНИЯ С ШИФРОМ | 2014 |
|
RU2637463C2 |
| ПРОЦЕССОР, СПОСОБ, СИСТЕМА И ИЗДЕЛИЕ ДЛЯ ВЕКТОРНОГО ИНДЕКСИРОВАННОГО ДОСТУПА К ПАМЯТИ ПЛЮС АРИФМЕТИЧЕСКОЙ И/ИЛИ ЛОГИЧЕСКОЙ ОПЕРАЦИИ | 2014 |
|
RU2620930C1 |
| КОМАНДЫ ЗАГРУЗКИ/ПЕРЕМЕЩЕНИЯ И КОПИРОВАНИЯ ДЛЯ ПРОЦЕССОРА | 2002 |
|
RU2292581C2 |
| СИСТЕМЫ И СПОСОБЫ ПРОВЕРКИ АДРЕСА ВОЗВРАТА ПРОЦЕДУРЫ | 2014 |
|
RU2628163C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОГО ОБЪЕДИНЕНИЯ ДАННЫХ СО СДВИГОМ ВПРАВО | 2002 |
|
RU2273044C2 |
| СИСТЕМЫ И СПОСОБЫ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОГО ПЕРЕМЕЩЕНИЯ СТЕКА | 2014 |
|
RU2629442C2 |
| ИСПОЛЬЗОВАНИЕ СИСТЕМЫ ПЕРЕИМЕНОВАНИЯ РЕГИСТРА ДЛЯ ПЕРЕДАЧИ ПРОМЕЖУТОЧНЫХ РЕЗУЛЬТАТОВ МЕЖДУ СОСТАВНЫМИ КОМАНДАМИ И РАСШИРЕННОЙ КОМАНДОЙ | 2008 |
|
RU2431887C2 |
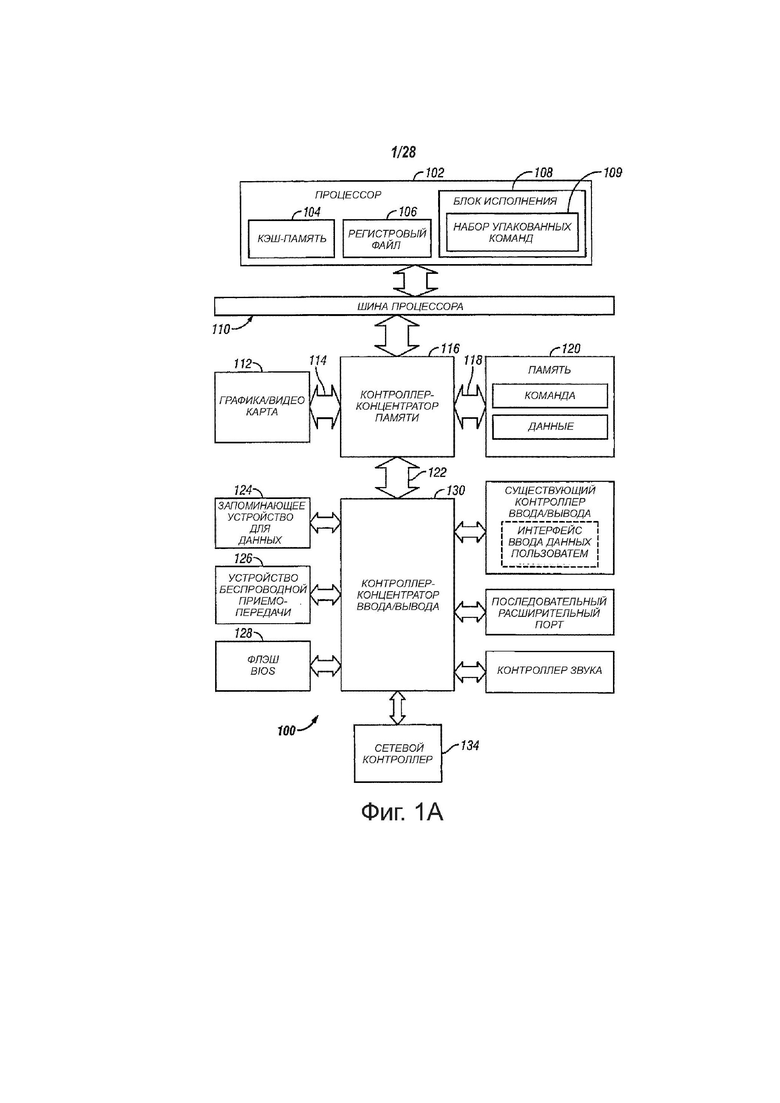

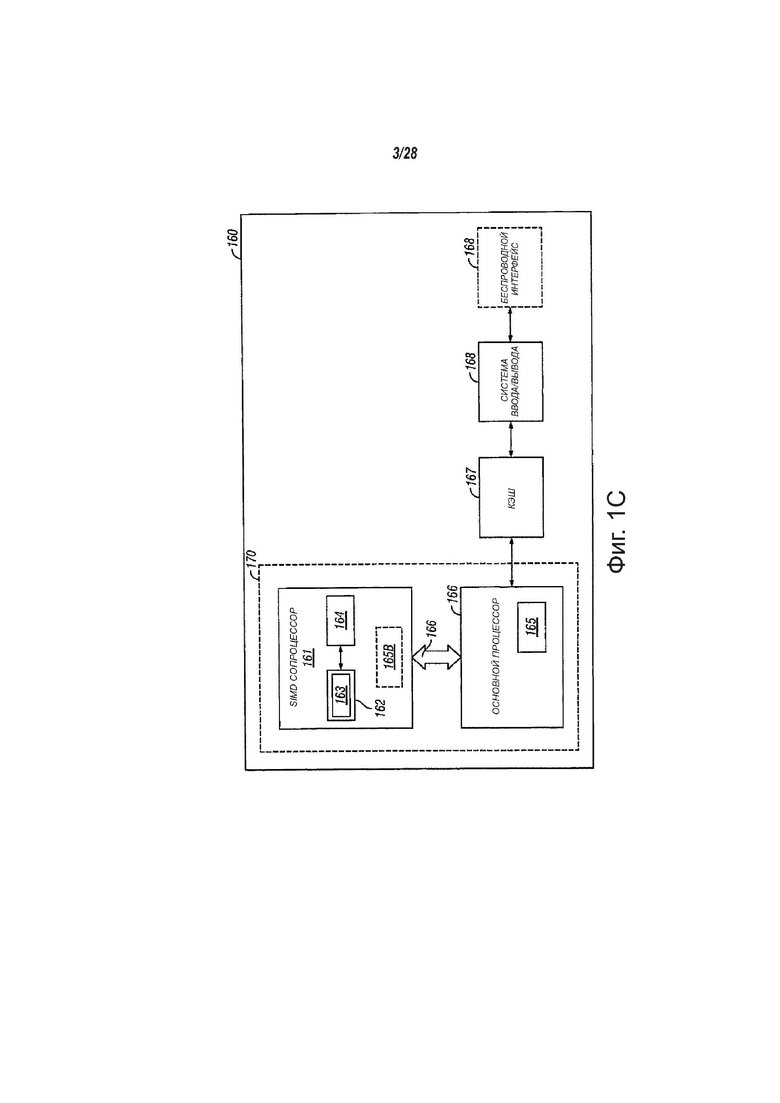
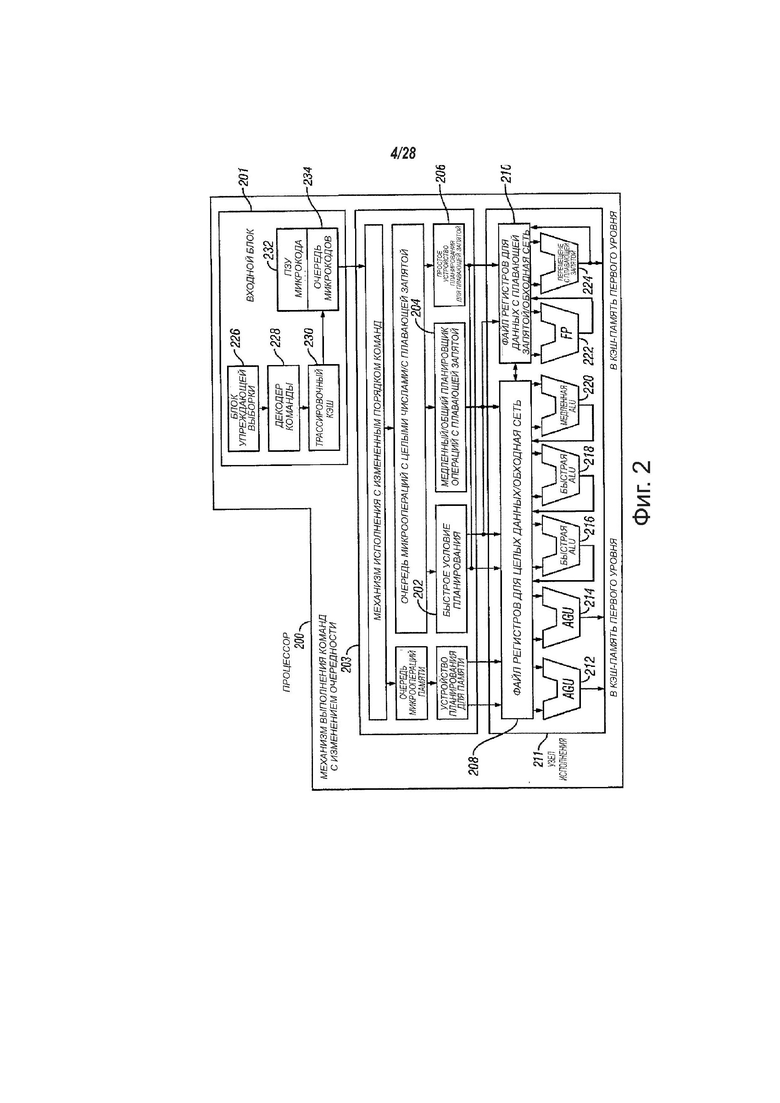
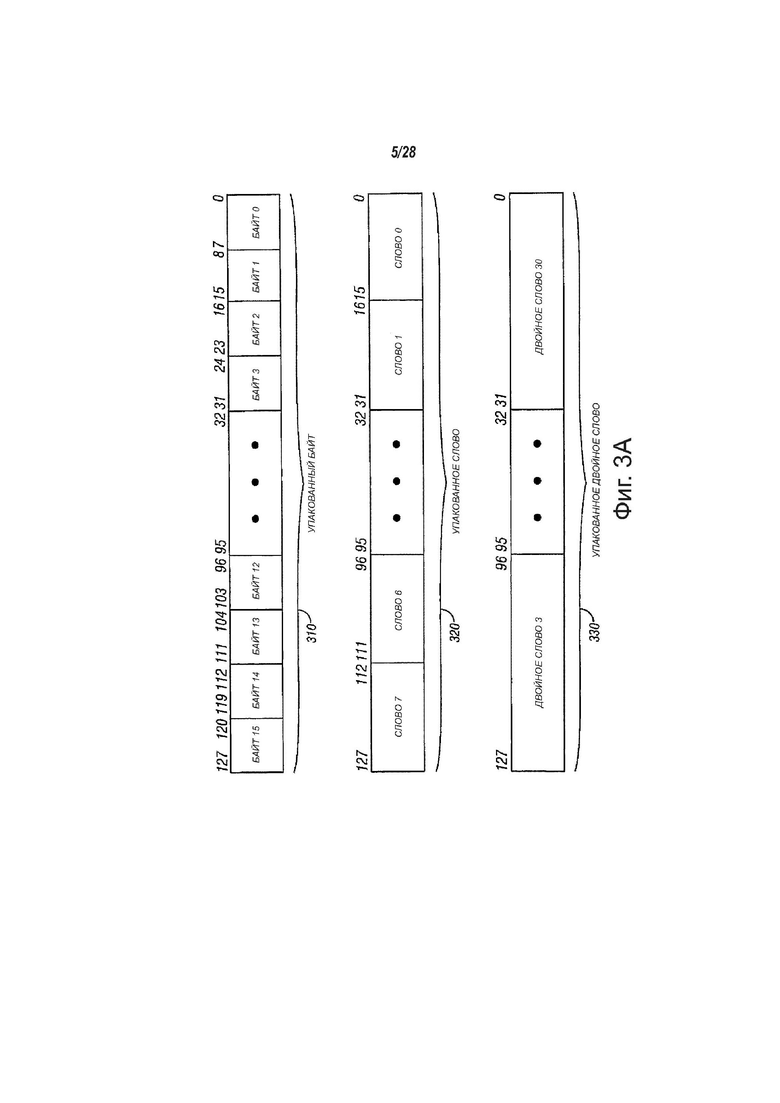
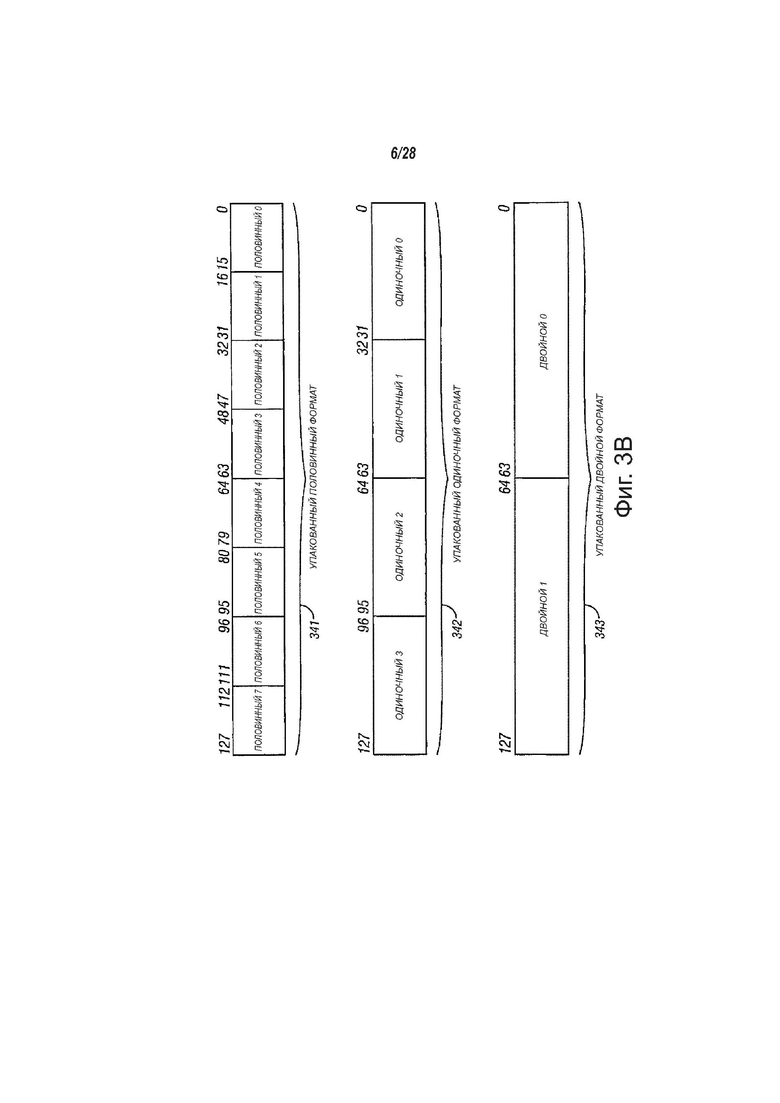

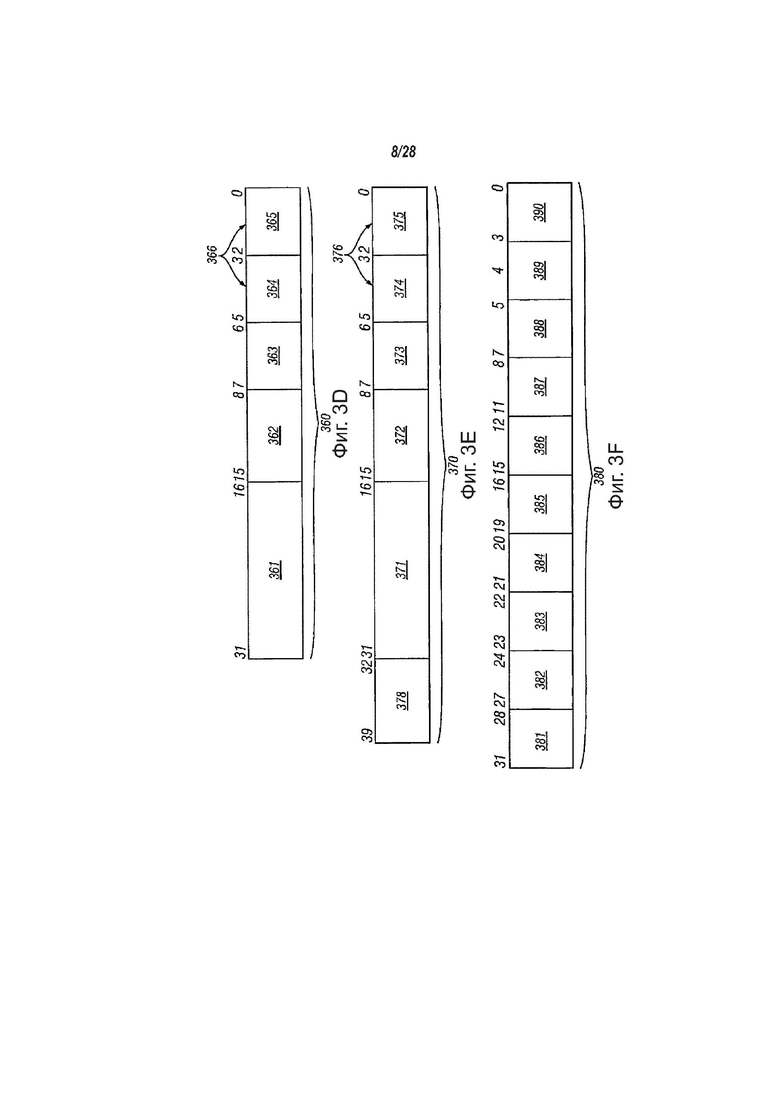
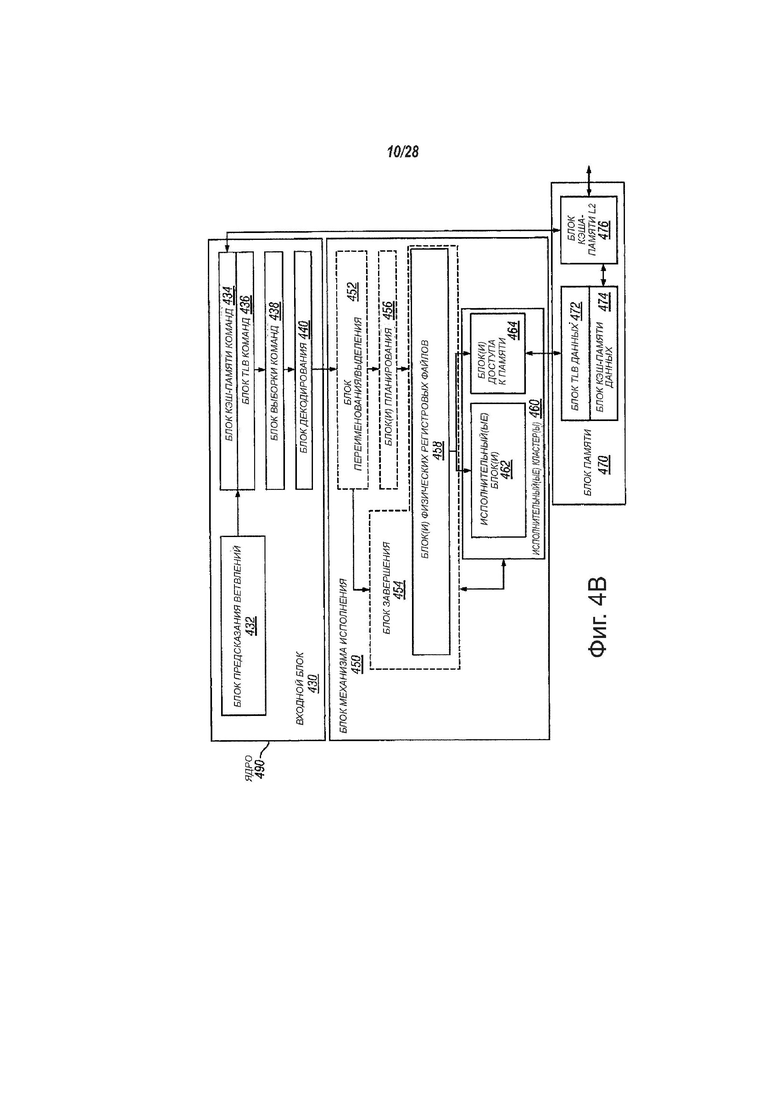
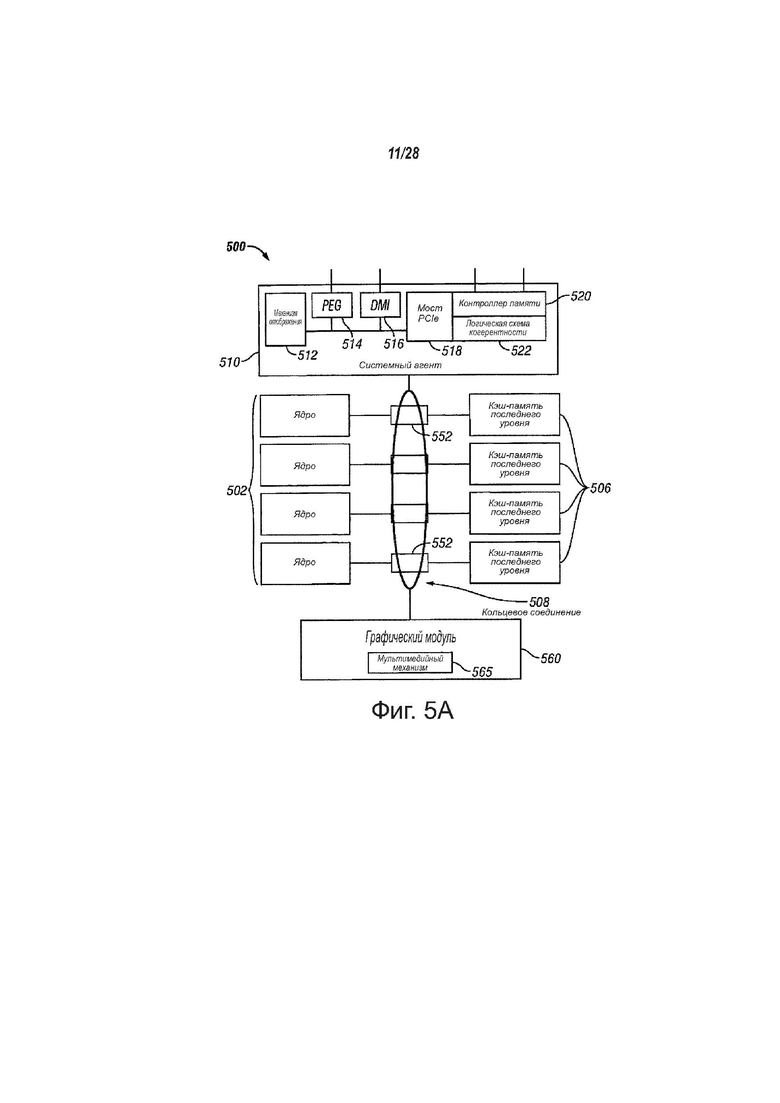
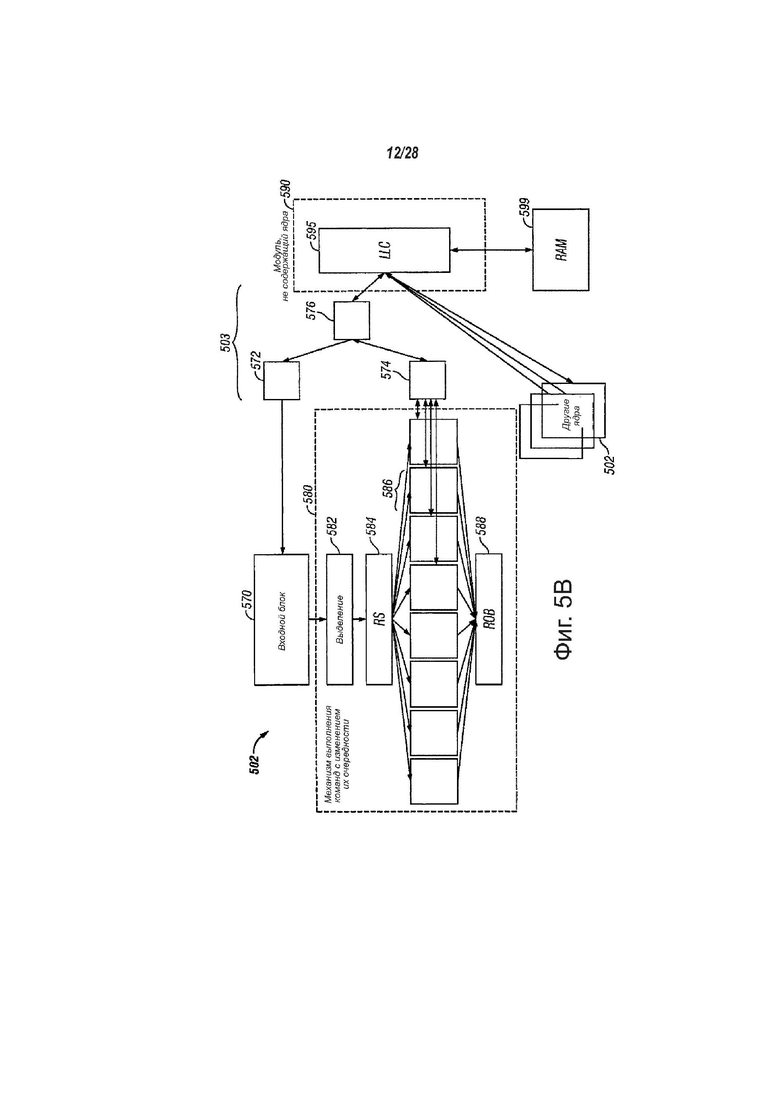
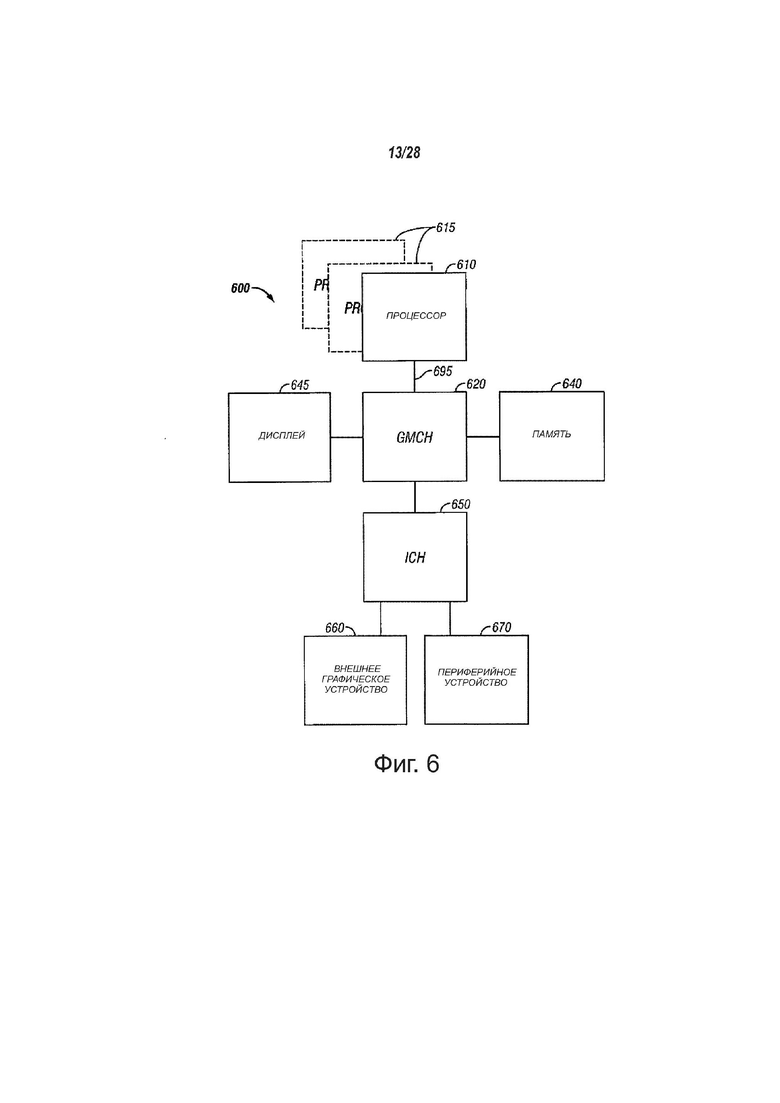

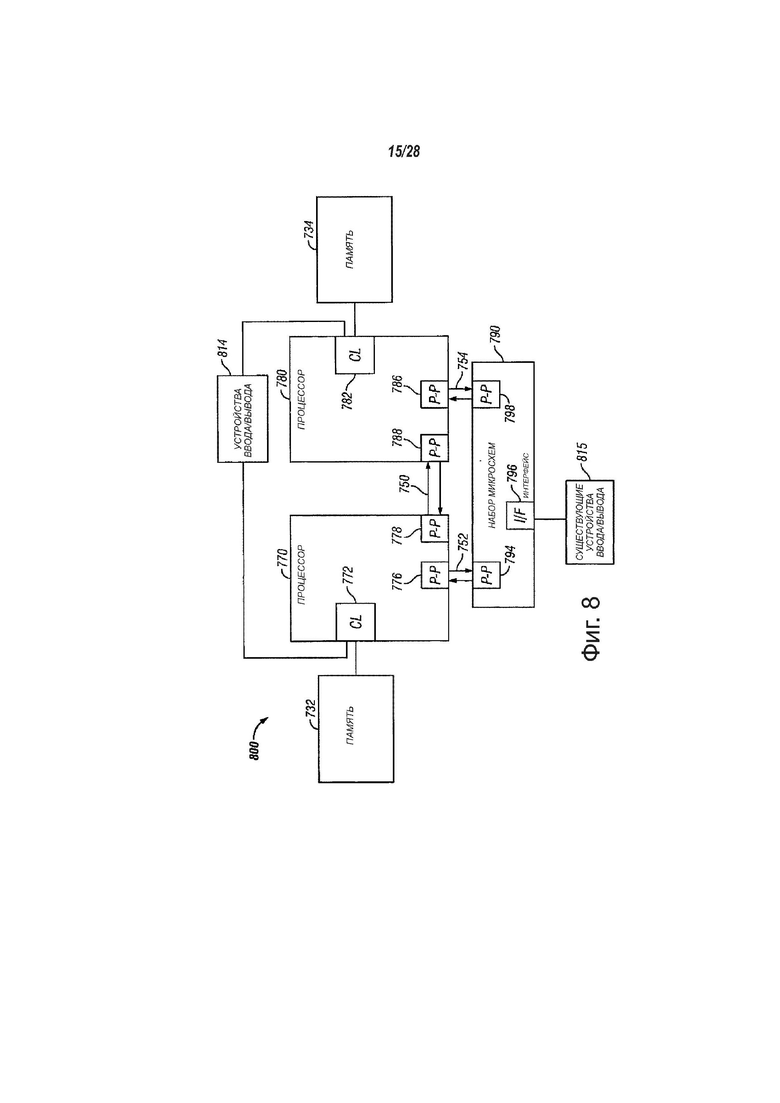
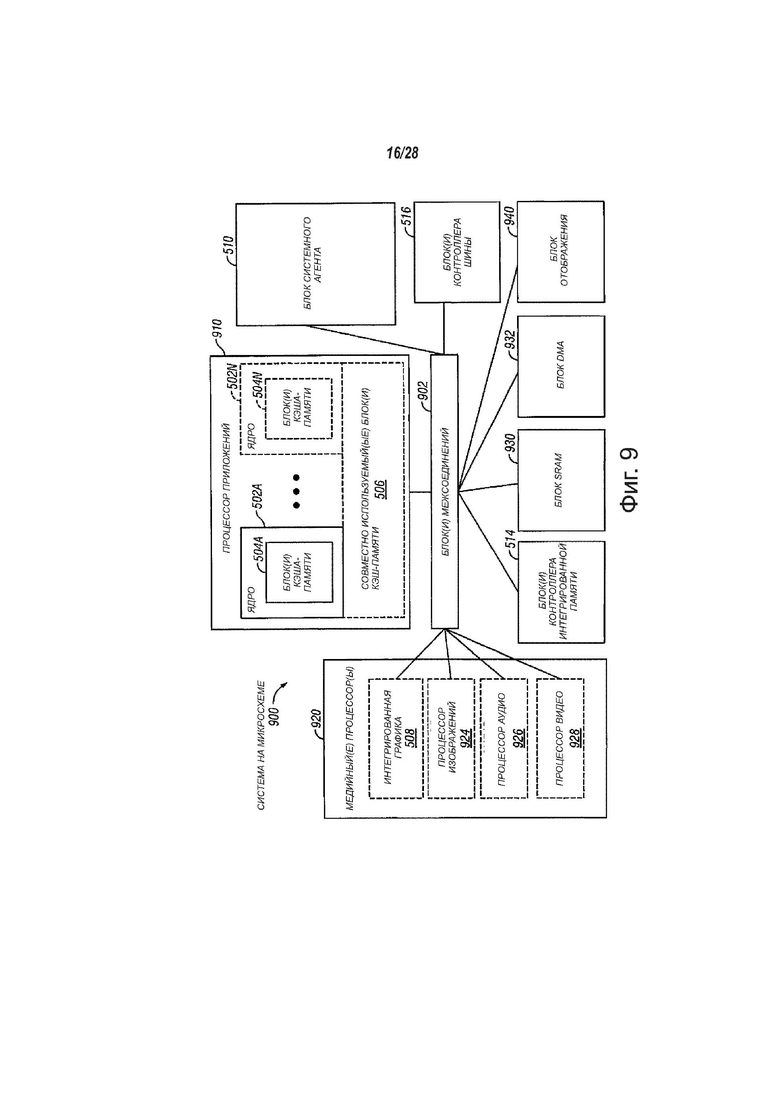
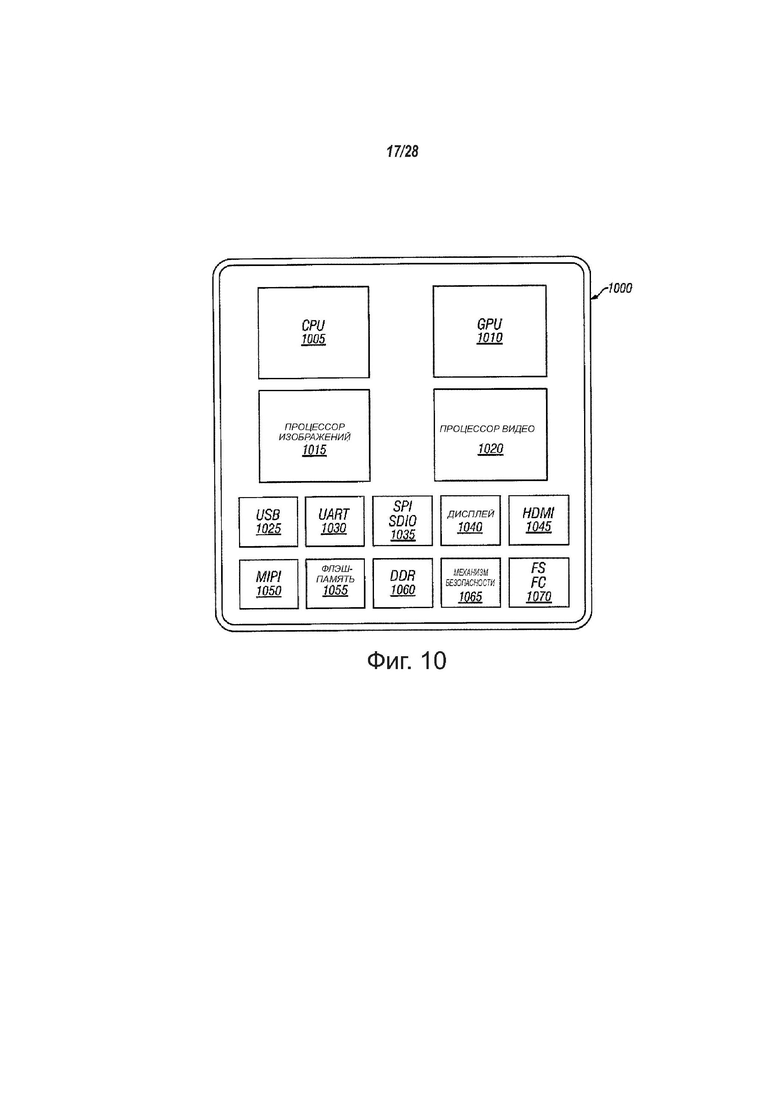
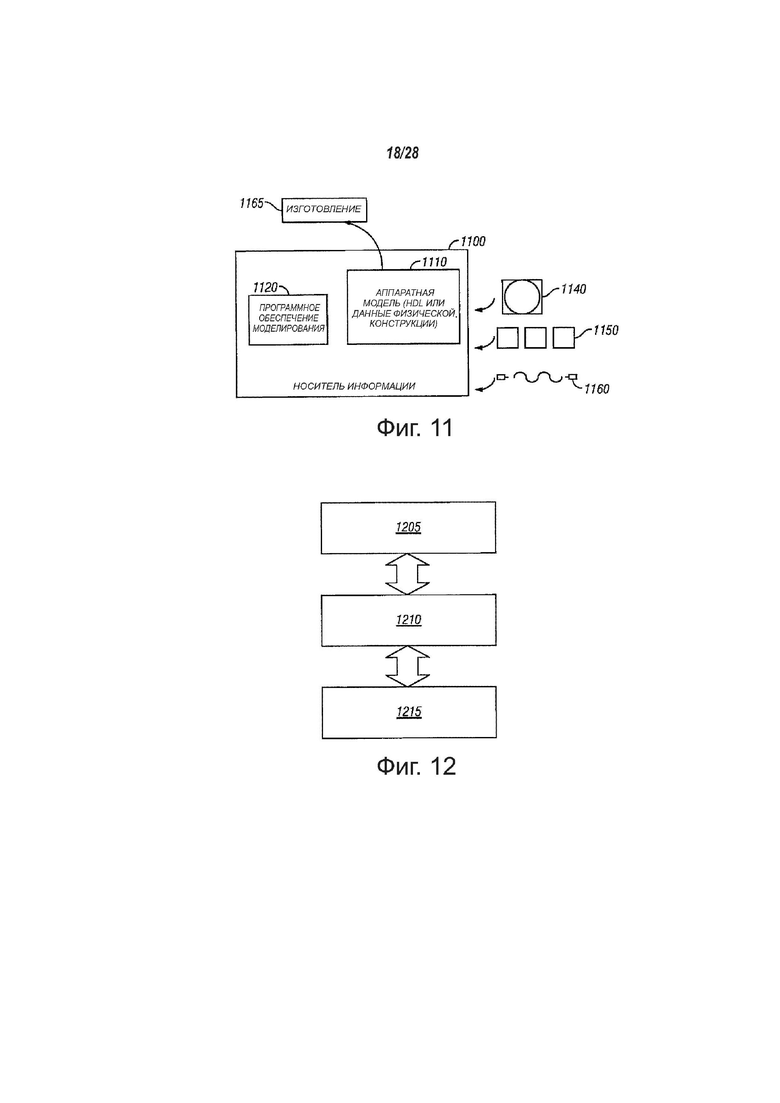
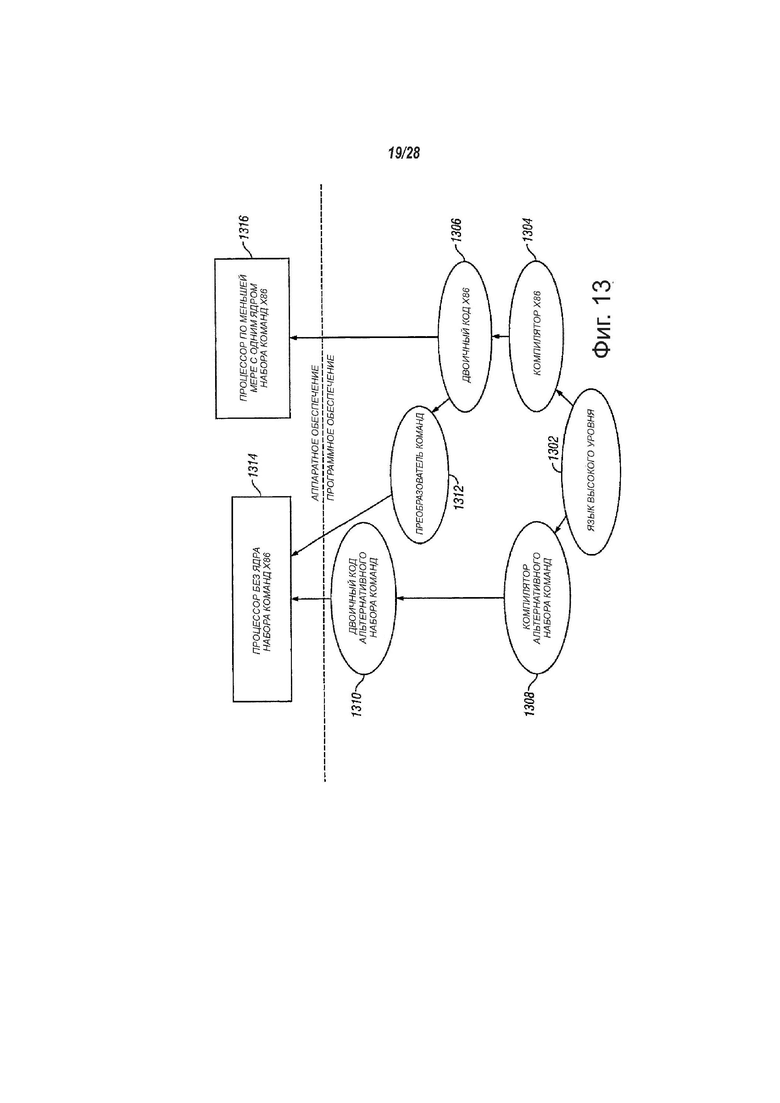

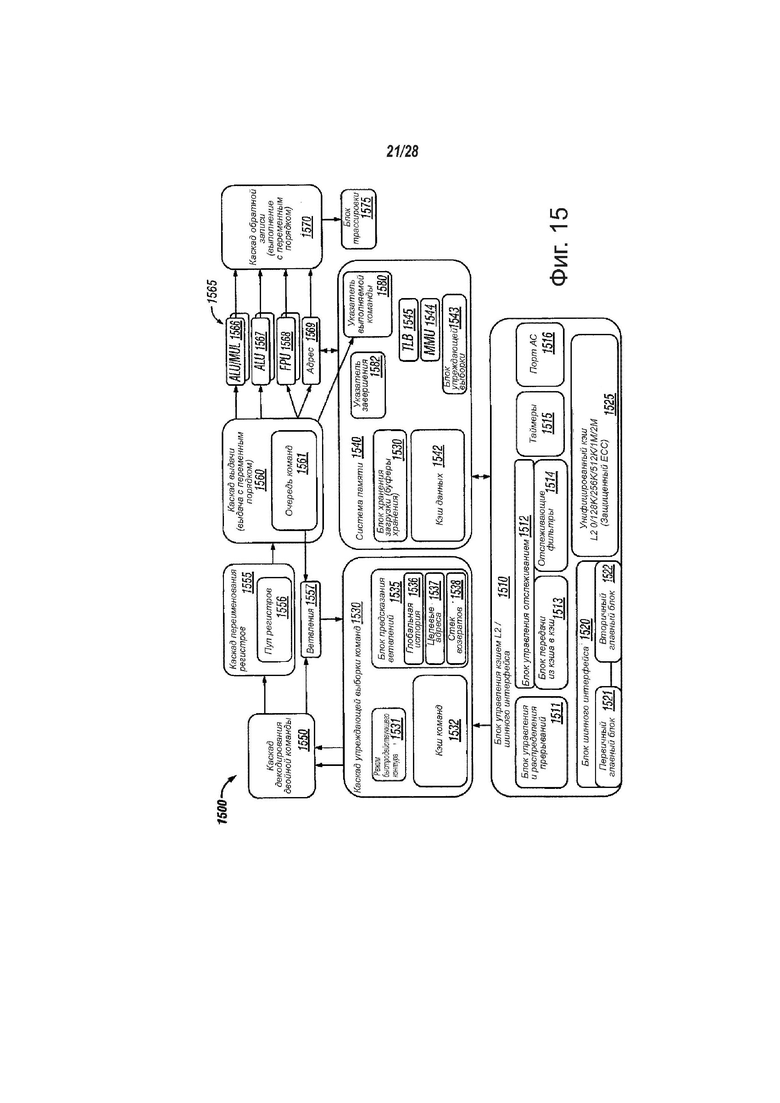

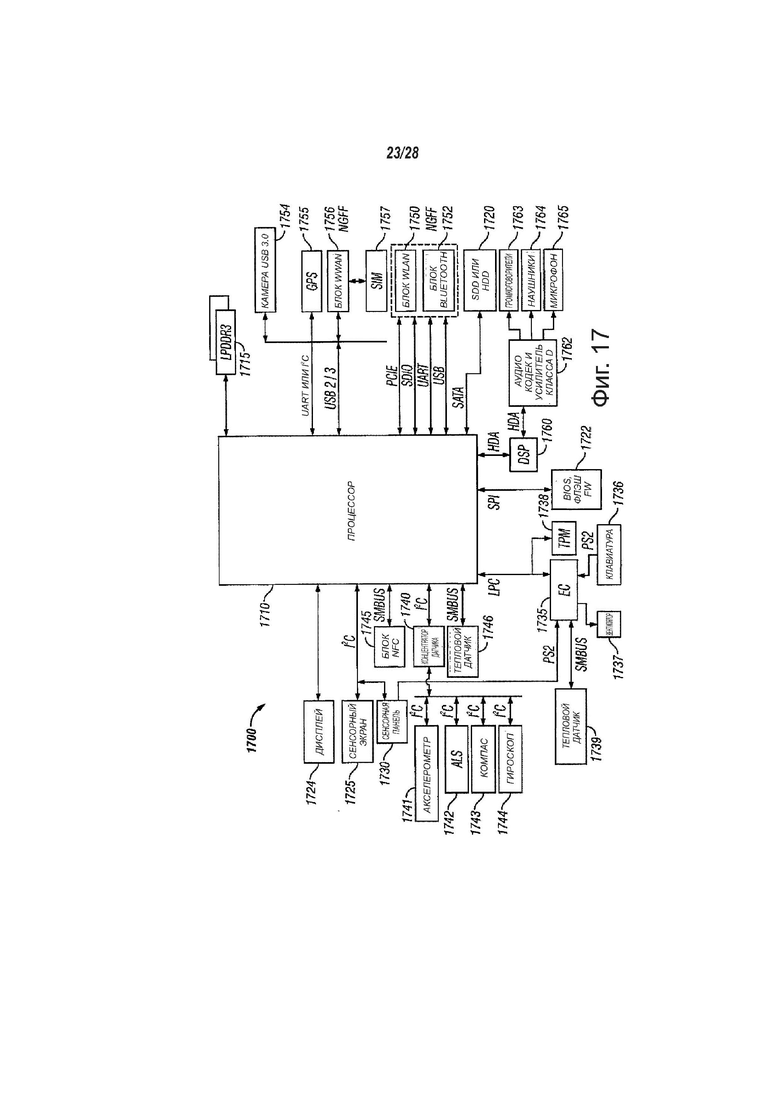

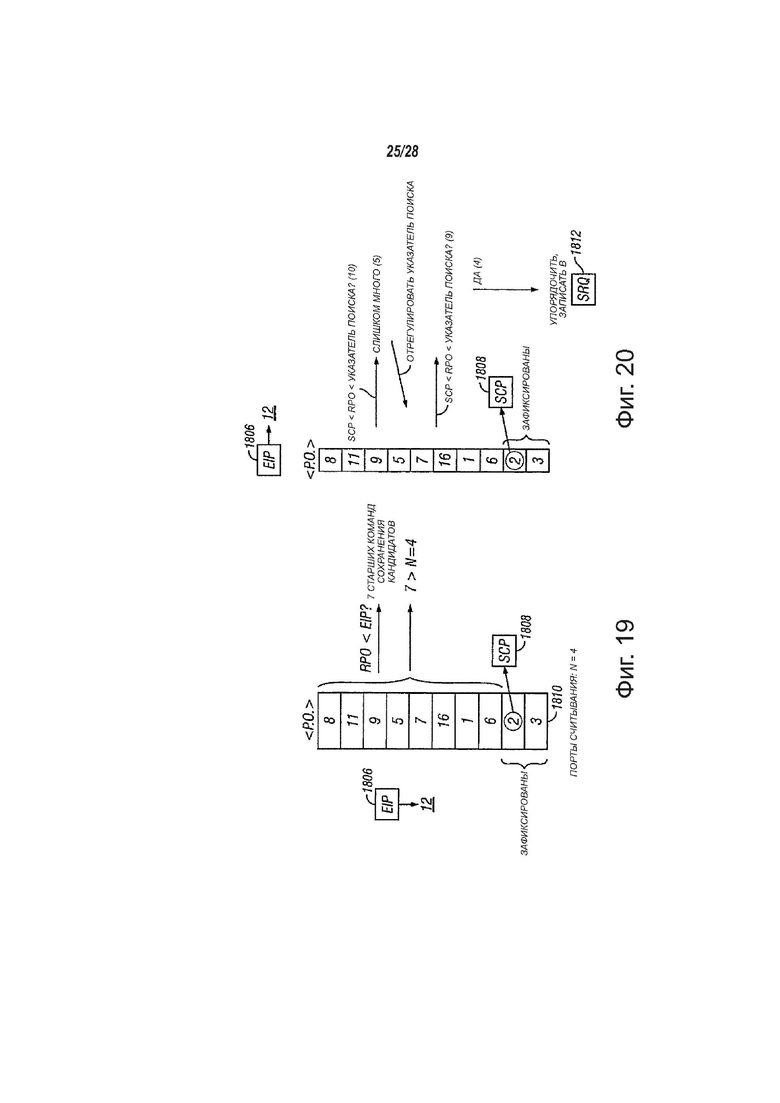
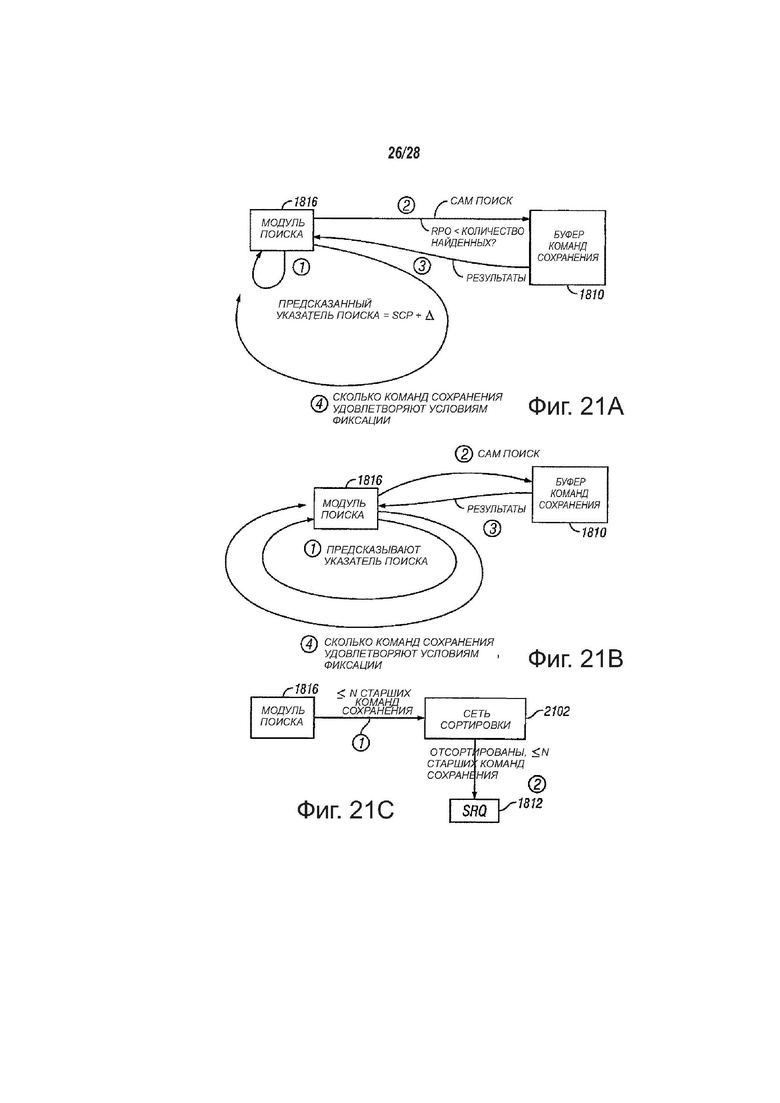

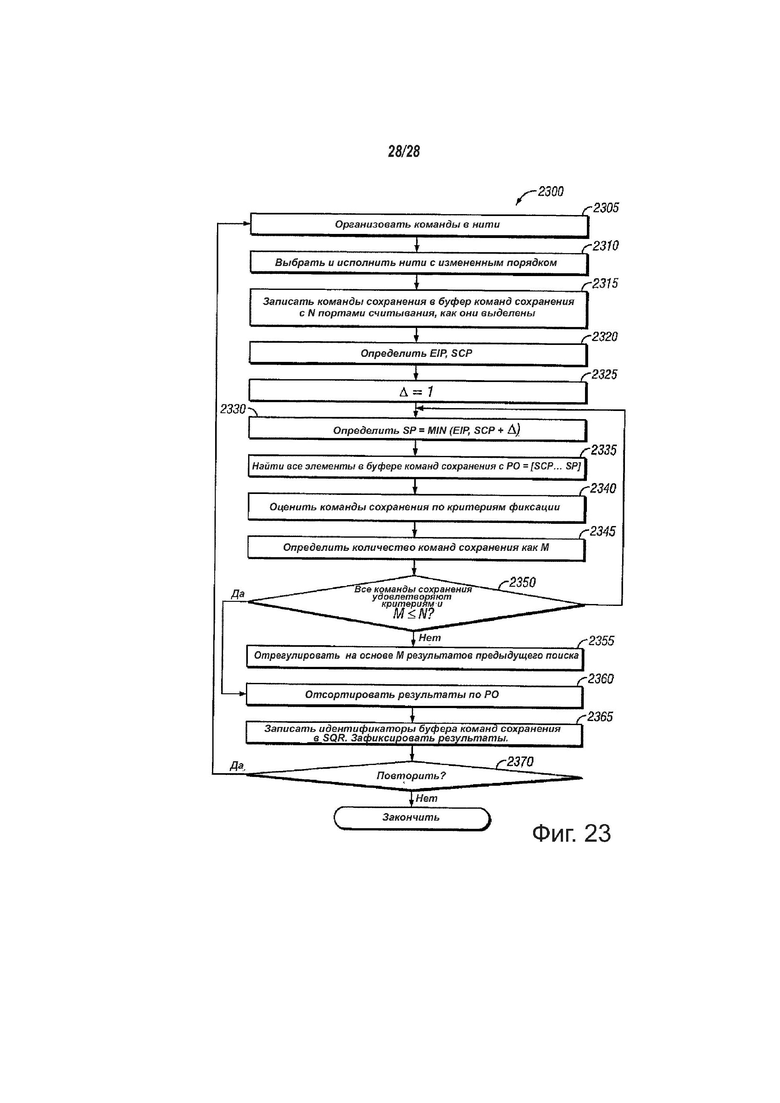
Группа изобретений относится к логическим схемам обработки и может быть использована для осуществления логических, математических функциональных операций. Техническим результатом является повышение пропускной способности и улучшение производительности. Процессор содержит логическую схему для исполнения потока команд с измененным порядком. Поток команд делят на множество нитей и их команды и команды в потоках упорядочивают в соответствии с программным порядком (PO). Процессор дополнительно содержит логическую схему для идентификации самой старой, неотправленной команды в потоке команд и записи ее соответствующего значения PO как указателя исполненной команды, для идентификации наиболее недавно зафиксированной команды сохранения в потоке команд и для записи ее соответствующего значения РО в качестве указателя фиксации команд сохранения указателя поиска со значением РО, меньшим указателя исполняемой команды, для идентификации первого набора команд сохранения в буфере команд сохранения со значениями РО, меньшими указателя поиска, и подходящих для фиксации, для оценки, больше ли первый набор команд сохранения количества портов считывания буфера команд сохранения, и для регулировки указателя поиска. 3 н. и 17 з.п. ф-лы, 34 ил.
1. Процессор, содержащий:
первую логическую схему для исполнения потока команд с измененным порядком, поток команд разделен на множество нитей, поток команд и его содержимое в каждой нити упорядочено в соответствии с программным порядком (PO);
вторую логическую схему для идентификации самой старой, неотправленной команды в потоке команд и для записи ее соответствующего значения РО в качестве указателя исполняемой команды;
третью логическую схему для идентификации наиболее недавно зафиксированной команды сохранения в потоке команд и для записи ее соответствующего значения РО в качестве указателя фиксации команд сохранения;
четвертую логическую схему для определения указателя поиска, значение РО которого меньше указателя исполняемой команды;
пятую логическую схему для идентификации первого набора команд сохранения в буфере команд сохранения, при этом каждая из этих команд сохранения обладает значением РО, которое меньше указателя поиска, и каждая из этих команд сохранения подходит для фиксации;
шестую логическую схему для оценки, больше ли первый набор команд сохранения количества портов считывания буфера команд сохранения; и
седьмую логическую схему для регулировки указателя поиска на основе оценки, больше ли первый набор команд сохранения количества портов считывания буфера команд сохранения.
2. Процессор по п. 1, дополнительно содержащий:
восьмую логическую схему для идентификации второго набора команд сохранения, в котором каждая команда сохранения обладает значением РО, меньшим указателя поиска после регулировки указателя поиска, выполненной седьмой логической схемой;
девятую логическую схему для оценки, больше ли второй набор команд сохранения количества портов считывания буфера команд сохранения; и
десятую логическую схему для фиксации второго набора команд сохранения на основе оценки, что размер второго набора команд сохранения меньше или равен количеству портов считывания буфера команд сохранения.
3. Процессор по п. 2, дополнительно содержащий одиннадцатую логическую схему для сортировки второго набора команд сохранения в соответствии со значением РО до фиксации второго набора команд сохранения.
4. Процессор по п. 2, дополнительно содержащий одиннадцатую логическую схему для записи идентификатора буфера команд сохранения для каждой команды сохранения из второго набора в очередь выгрузки команд сохранения с целью фиксации второго набора команд сохранения.
5. Процессор по п. 1, дополнительно содержащий восьмую логическую схему для регулировки указателя поиска на основе размера первого набора команд сохранения.
6. Процессор по п. 1, дополнительно содержащий восьмую логическую схему для регулировки указателя поиска на основе размера первого набора команд сохранения и количества портов считывания буфера команд сохранения.
7. Процессор по п. 1, дополнительно содержащий восьмую логическую схему для регулировки указателя поиска на основе предыдущей регулировки указателя поиска.
8. Способ для сортировки и выгрузки команд сохранения, включающий в себя, в процессоре следующее:
исполняют поток команд с измененным порядком, при этом поток команд разделен на множество нитей, поток команд и его содержимое в каждой нити упорядочено в соответствии с программным порядком (PO);
идентифицируют самую старую, неотправленную команду в потоке команд и записывают ее соответствующее значение РО в качестве указателя исполняемой команды;
идентифицируют наиболее недавно зафиксированную команду сохранения в потоке команд и записывают ее соответствующее значение РО в качестве указателя фиксации команд сохранения;
определяют указатель поиска, значение РО которого меньше указателя исполняемой команды;
идентифицируют первый набор команд сохранения в буфере команд сохранения, при этом каждая из этих команд сохранения обладает значением РО, которое меньше указателя поиска, и каждая из этих команд сохранения подходит для фиксации;
оценивают, больше ли первый набор команд сохранения количества портов считывания буфера команд сохранения; и
регулируют указатель поиска на основе оценки, больше ли первый набор команд сохранения количества портов считывания буфера команд сохранения.
9. Способ по п. 8, дополнительно включающий в себя следующее:
идентифицируют второй набор команд сохранения, в котором каждая команда сохранения обладает значением РО, меньшим указателя поиска после регулировки указателя поиска;
оценивают, больше ли второй набор команд сохранения количества портов считывания буфера команд сохранения; и
фиксируют второй набор команд сохранения на основе оценки, что размер второго набора команд сохранения меньше или равен количеству портов считывания буфера команд сохранения.
10. Способ по п. 9, дополнительно включающий в себя следующее: сортируют второй набор команд сохранения в соответствии со значением РО до фиксации второго набора команд сохранения.
11. Способ по п. 8, дополнительно включающий в себя следующее:
записывают идентификатор буфера команд сохранения для каждой команды сохранения из второго набора в очередь выгрузки команд сохранения с целью фиксации второго набора команд сохранения.
12. Способ по п. 8, дополнительно включающий в себя следующее: регулируют указатель поиска на основе размера первого набора команд сохранения.
13. Способ по п. 8, дополнительно включающий в себя следующее: регулируют указатель поиска на основе размера первого набора команд сохранения и количества портов считывания буфера команд сохранения.
14. Система для сортировки и выгрузки команд сохранения, содержащая:
первую логическую схему для исполнения потока команд с измененным порядком, поток команд разделен на множество нитей, поток команд и его содержимое в каждой нити упорядочено в соответствии с программным порядком (PO);
вторую логическую схему для идентификации самой старой, неотправленной команды в потоке команд и для записи ее соответствующего значения РО в качестве указателя исполняемой команды;
третью логическую схему для идентификации наиболее недавно зафиксированной команды сохранения в потоке команд и для записи ее соответствующего значения РО в качестве указателя фиксации команд сохранения;
четвертую логическую схему для определения указателя поиска, значение РО которого меньше указателя исполняемой команды;
пятую логическую схему для идентификации первого набора команд сохранения в буфере команд сохранения, при этом каждая из этих команд сохранения обладает значением РО, которое меньше указателя поиска, и каждая из этих команд сохранения подходит для фиксации;
шестую логическую схему для оценки, больше ли первый набор команд сохранения количества портов считывания буфера команд сохранения; и
седьмую логическую схему для регулировки указателя поиска на основе оценки, больше ли первый набор команд сохранения количества портов считывания буфера команд сохранения.
15. Система по п. 14, дополнительно содержащая:
восьмую логическую схему для идентификации второго набора команд сохранения, в котором каждая команда сохранения обладает значением РО, меньшим указателя поиска после регулировки указателя поиска, выполненной седьмой логической схемой;
девятую логическую схему для оценки, больше ли второй набор команд сохранения количества портов считывания буфера команд сохранения; и
десятую логическую схему для фиксации второго набора команд сохранения на основе оценки, что размер второго набора команд сохранения меньше или равен количеству портов считывания буфера команд сохранения.
16. Система по п. 15, дополнительно содержащая одиннадцатую логическую схему для сортировки второго набора команд сохранения в соответствии со значением РО до фиксации второго набора команд сохранения.
17. Система по п. 15, дополнительно содержащая одиннадцатую логическую схему для записи идентификатора буфера команд сохранения для каждой команды сохранения из второго набора в очередь выгрузки команд сохранения с целью фиксации второго набора команд сохранения.
18. Система по п. 14, дополнительно содержащая восьмую логическую схему для регулировки указателя поиска на основе размера первого набора команд сохранения.
19. Система по п. 14, дополнительно содержащая восьмую логическую схему для регулировки указателя поиска на основе размера первого набора команд сохранения и количества портов считывания буфера команд сохранения.
20. Система по п. 14, дополнительно содержащая восьмую логическую схему для регулировки указателя поиска на основе предыдущей регулировки указателя поиска.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СИСТЕМА ОБРАБОТКИ И СПОСОБ ЕЕ ФУНКЦИОНИРОВАНИЯ | 1994 |
|
RU2150738C1 |

