Настоящее изобретение касается способа кодирования для кодирования описательного элемента экземпляра схемы типа XML, определяющей иерархическую структуру описательных элементов, причем указанная иерархическая структура содержит иерархические уровни, родительские описательные элементы и дочерние описательные элементы, при этом описательный элемент, который должен кодироваться, содержит информационное наполнение.
Изобретение также касается способа декодирования для декодирования фрагмента, содержащего информационное наполнение и последовательность данных идентификационной информации.
Изобретение также касается кодера, предназначенного для реализации указанного способа кодирования, декодера, предназначенного для реализации указанного способа декодирования, и системы передачи, содержащей такой кодер и/или такой декодер.
Изобретение также касается таблицы, предназначенной для использования в таком способе кодирования или декодирования, и сигнала, передающего кодированные описательные элементы, сформированные с использованием такого способа кодирования.
Изобретение может применяться для экземпляров типа XML схем типа XML. В частности, оно применимо для документов стандарта MPEG-7.
XML (расширяемый Маркировочный язык 1.0, от 6 октября 2000) - это рекомендация консорциума W3C (Консорциум глобальной гипертекстовой системы Интернет). XML-схема - эта также рекомендация консорциума W3C. XML-схема определяет иерархическую структуру описательных элементов (называемых элементом или атрибутом в рекомендации W3C). Экземпляр XML-схемы содержит описательные элементы, структурированные так, как определено в указанной XML-схеме.
Цель изобретения заключается в том, чтобы предложить способ кодирования и декодирования для передачи и хранения одного или более описательных элементов(та) документа XML-типа, который представляет экземпляр схемы XML-типа.
Способ кодирования согласно изобретению, как он описан в вводном абзаце, характеризуется тем, что он включает:
- использование по меньшей мере одной таблицы, выведенной (полученной) из указанной схемы, при этом указанная таблица содержит идентификационную информацию для однозначного идентифицирования каждого описательного элемента (элемента описания) в иерархическом уровне и структурную информацию для поиска любого дочернего описательного элемента от его родительского описательного элемента,
- просмотр находящегося в памяти иерархического представления указанного экземпляра от родительских описательных элементов к дочерним описательным элементам до тех пор, пока не будет достигнут описательный элемент, который должен кодироваться, и извлечение идентификационной информации для каждого просмотренного описательного элемента,
- кодирование указанного описательного элемента, который должен кодироваться, в виде фрагмента, содержащего указанное информационное наполнение и последовательность данных извлеченной идентификационной информации.
Когда описательный элемент определяется в схеме как элемент, возможно, имеющий множество вхождений (наличий), таблица дополнительно содержит информацию о вхождениях этого описательного элемента для указания на то, что указанный описательный элемент может иметь множество вхождений в экземпляре, и когда вхождение, имеющее заданный ранг, просматривается во время кодирования, то соответствующая извлеченная идентификационная информация индексируются этим рангом.
А способ декодирования согласно изобретению, как он описан в вводном абзаце, характеризуется тем, что он включает:
- использование по меньшей мере одной таблицы, полученной из схемы XML-типа, указанная схема определяет иерархическую структуру описательных элементов (элементов описания), содержащую иерархические уровни, родительские описательные элементы и дочерние описательные элементы, при этом таблица содержит идентификационную информацию для однозначного идентифицирования каждого описательного элемента в иерархическом уровне и структурную информацию для извлечения любого дочернего описательного элемента из его родительского описательного элемента,
- просмотр указанной последовательности данных идентификационной информации, пошагово друг за другом,
- на каждом шаге выполнение поиска в указанной таблице описательного элемента, к которому относится текущая идентификационная информация, и добавление этого описательного элемента к хранящемуся в памяти иерархическому представлению экземпляра указанной схемы, если он уже не содержится в этом хранящемся в памяти иерархическом представлении,
- добавление упомянутого информационного наполнения к описательному элементу из упомянутого иерархического представления, хранящегося в памяти, к которому (элементу) относится последняя идентификационная информации из упомянутой последовательности.
Когда описательный элемент определен в схеме как элемент, возможно, имеющий множество вхождений, тогда таблица дополнительно содержит для этого описательного элемента данные о вхождении (наличии) для указания на то, что описательный элемент может иметь множество вхождений в экземпляре, и когда упомянутая последовательность содержит индексированную идентификационную информацию, тогда этот индекс интерпретируется как ранг вхождения для относящегося к нему описательного элемента, причем один и тот же описательный элемент(ы) более низкого ранга(ов) добавляются к упомянутому иерархическому представлению, хранящемуся в памяти, если он(они) уже не содержатся в нем.
Согласно изобретению каждый описательный элемент (элемент описания) представляется независимым фрагментом в потоке, обеспечивающем, кроме произвольного доступа к элементам и атрибутам, также высокий уровень гибкости, что касается пошаговых переходов. Этот фрагментарный подход также учитывает фундаментальную гибкую и расширяемую природу MPEG-7 за счет использования схем для вычисления последовательности данных идентификационной информации, относящихся к заданному описательному элементу. Фрагментарный подход приводит к тому, что предложенный бинарный формат удовлетворяет следующим свойствам:
- произвольный доступ к элементам и атрибутам экземпляра;
- пошаговое неупорядоченное и изменяемое перемещение;
- компактность: кодируются только элементы и атрибуты, которые имеют информационное наполнение простейшего типа;
- легкая интеграция с усовершенствованным протоколом экземпляра;
- легкая интерпретация и частичная реализация бинарных описаний MPEG-7.
Другие достоинства изобретения выявляются при использовании промежуточного представления схемы. Действительно, таблица, которая непосредственно и однозначно создана из схемы, позволяет совместно использовать общую информацию о возможных действительных экземплярах между сервером и клиентом в форме, специально предназначенной для бинарного кодирования и декодирования этих экземпляров. Эта общая информация, объединяющая такую информацию как структура, тип и имя признака элементов и атрибутов, не нужна для пересылки клиенту, что приводит к эффективной схеме кодирования экземпляров. Это также дает возможность для бинарного формата достигнуть средства обеспечения полной расширяемости для дальнейших схем, определенных в рамках MPEG-7 или вне этих рамок.
Дополнительные особенности и достоинства изобретения станут более понятны из последующего подробного описания, которое характеризует и иллюстрирует предпочтительные варианты осуществления изобретения, в котором:
фиг.1 - схематичное представление системы передачи согласно изобретению;
фиг.2 - схема, описывающая этапы способа кодирования согласно изобретению;
фиг.3 - схема, описывающая этапы способа декодирования согласно изобретению;
фиг.4 - фрагмент, реализованный в сигнале, согласно изобретению;
фиг.5 - пример бинарного кодирования компактного ключа экземпляра;
фиг.6 - пример бинарного кодирования значения описательного элемента.
Ниже изобретение будет описано со ссылкой на экземпляры XML XML-схем. Но этим изобретение не ограничивается. Оно может применяться для любых экземпляров и схем, записанных на Маркировочном Языке того же типа.
Схема XML-типа определяет иерархическую структуру описательных элементов (либо элемента, либо атрибута в терминологии XML), содержащую родительские описательные элементы и дочерние описательные элементы. Экземпляром схемы XML-типа является документ XML-типа, содержащий описательные элементы, структурированные, как это определено в упомянутой схеме XML-типа. Некоторые из описательных элементов экземпляра имеют информационное наполнение. Другие представляют собой только структурные контейнеры.
Как показано на фиг.1, система передачи согласно изобретению содержит кодер BiM-C, расположенный на передающей стороне, и декодер BiM-D, расположенный на принимающей стороне. Кодер BiM-C и декодер BiM-D имеют доступ к XML-схеме XML-S (XML-схема либо имеется на месте, либо загружается).
Они также имеют доступ по меньшей мере к одной таблице EDT, называемой Таблицей описания элементов (ТОЭ), непосредственно и однозначно формируемой из XML-схемы. Таблица описания элементов, в первую очередь, предназначена для того, чтобы в ней содержалась вся информация, требующаяся для кодирования и декодирования любого экземпляра, который является действительным с точки зрения заданного определения схемы. Таблица описания элементов формируется один раз и является доступной для кодирования и декодирования экземпляра, который относится к этой схеме. Она не должна пересылаться клиенту.
Кодер просматривает иерархическое представление DM-C, хранящееся в памяти, экземпляра XML-C (DOM представление, как оно определено в спецификации W3C "Document Object Model (Модель документа объекта), спецификация уровня 1, версия 1.0, от 1 октября 1998", или любое другое хранящееся в памяти иерархическое представление экземпляра) и использует информацию, содержащуюся в Таблице описания элементов, для того чтобы сформировать один или более бинарных фрагментов BiM-F (БФ), причем каждый бинарный фрагмент относится к описательному элементу экземпляра.
Согласно изобретению описательные элементы, которые имеют информационное наполнение простейшего типа (например, предопределенный тип, простой тип, дескриптор с собственным бинарным представлением), кодируются в виде независимого фрагмента, состоящего из последовательности данных идентификационной информации (также называемой структурирующим ключом экземпляра) и информационного значения. Описательные элементы в XML иерархии, которые являются только структурными контейнерами (то есть не имеющие информационного значения), не передаются, а логически выводятся на стороне декодера из Таблицы описания элементов.
Бинарные фрагменты BiM-F передаются по сети передачи Интернет и принимаются декодером BiM-D (БД). Декодер использует Таблицу описания элементов для поиска:
- всех родительских структурных описательных элементов,
- сущности (элемент или атрибут) описательного элемента,
- имени описательного элемента,
- типа описательного элемента, чтобы декодировать информационное значение.
Декодер BiM-D обновляет (модифицирует) соответствующим образом хранящееся в памяти иерархическое представление DM-D. Затем из обновленного иерархического представления, хранящегося в памяти, формируется XML экземпляр XML-D.
Таблицу описания элементов можно представить как исчерпывающее определение возможных допустимых экземпляров, созданных единично и однозначно из схемы путем развития структур описания элементов и атрибутов. Действительно, XML-схема дает в основном два вида информации: с одной стороны, положение всех возможных элементов и атрибутов в XML иерархии экземпляра точно определяется с помощью определений (с именем или без имени) комплексного типа и описаний элементов, с другой стороны, тип их значения задается через использование предопределенных типов данных и определений простого типа. Для каждого элемента или атрибута, который точно определен в этой схеме и который может быть обнаружен в экземпляре, в Таблице описания элементов собираются их имя (например, имя тега для элемента), тип, сущность (элемент или атрибут) и ключ (называемый табличным структурирующим ключом), точно и однозначно определяющие его положение в иерархической XML структуре. Если схема определяет, как экземпляр должен "выглядеть", чтобы он удовлетворял требованиям по допустимости и функциональной совместимости, то Таблица описания элементов устанавливает, как экземпляр будет "выглядеть", исходя из структурного вида для цели кодирования.
Основа Таблицы описания элементов и ее использования в процессах кодирования и декодирования заключается в табличном структурирующем ключе, предназначенном для однозначного идентифицирования:
- типа и имени передаваемого описательного элемента;
- его положения в XML иерархии экземпляра.
Синтаксис этого структурирующего ключа представляет собой точечную запись, где точки обозначают уровни иерархии, и нумерация на каждом уровне выполняется путем "расширения" всех описаний элементов и атрибутов из схемы. Последняя цифра записи представляет собой идентификационную информацию, однозначно идентифицирующую описательный элемент на его иерархическом уровне. Предыдущие цифры являются указательной информацией, используемой для поиска дочернего описательного элемента от его родительского описательного элемента.
Когда описательный элемент определен в схеме, как имеющий или возможно имеющий множество вхождений, тогда информация о вхождении добавляется в конце точечной записи (в последующем описании информация о вхождении представляется с помощью скобок).
Процесс формирования Таблицы описания элементов сопоставим с просмотром всех описаний элементов в схеме, чтобы достигнуть хранящегося в памяти иерархического представления наибольшего экземпляра (одного, реализующего все возможные элементы и атрибуты), соответствующего заданной схеме. Тем не менее, этот "наибольший" экземпляр является неограниченным, поскольку схема определяет самовстраивающиеся структуры, обычно используемые в MPEG-7. Следовательно, имеется явная необходимость в фиксировании самовключения в Таблицу описания элементов. Это делается путем точного определения, в случае самовключенного описательного элемента, табличного структурирующего ключа его предшествующего элемента в древовидной структуре, который имеет тот же самый комплексный тип. Следовательно, такой элемент не расширяется далее в Таблице описаний элементов. Табличный структурирующий ключ предшествующего элемента называется ключом самовключения. Он также используется для поиска дочернего описательного элемента от его родительского описательного элемента.
Указывающая информация вместе с ключом самовключения составляют структурную информацию, используемую для поиска любого дочернего описательного элемента от его родительского описательного элемента. Когда родительский описательный элемент является самовключенным описательным элементом, тогда его "дети" являются описательными элементами, у которых указывающая информация идентична самовключенному ключу указанного родительского описательного элемента. Когда "родитель" не является самовключенным описательным элементом, то его дочерние описательные элементы являются описательными элементами, указывающая информация которых идентична табличному структурирующему ключу указанного "родителя".
Таблица описания элементов позволяет установить единственную и однозначную нумерацию всех возможных экземпляров схемы. Теперь мы представим примеры схем и соответствующие Таблицы описания элементов.
ПРИМЕР 1
Схема 1:


Видно, что Таблица описания элементов как развитие описаний всех элементов схемы, может содержать наряду с другой информацией следующие имена элементов вместе с их соответствующими табличными структурирующими ключами:
ПРИМЕР 2
Схема 2:


Таблица описания элементов содержит наряду с другой информацией такую информацию как имя и ключ элементов, поле самовключения, когда уместно:

Подчеркнутые цифры табличного структурирующего ключа - это идентификационная информация. Не подчеркнутые цифры табличного структурирующего ключа и ключа самовключения - это структурная информация, используемая для поиска любого дочернего описательного элемента от его родительского описательного элемента.
Заметим, что скобки в табличном структурирующем ключе Элемента2 обозначают наличие множества элементов вхождения. Более того, Элемент2 и Элемент4 учитываются при нумерации, даже хотя они являются необязательными элементами. Заметим также, что Элемент1 появляется дважды в таблице, поскольку он может быть реализован в различных местах в древовидной структуре.
ПРИМЕР 3
Схема:



Подчеркнутые цифры табличного структурирующего ключа - это идентификационная информация. Не подчеркнутые цифры табличного структурирующего ключа и ключа самовключения - это структурная информация, используемая для поиска любого дочернего описательного элемента от его родительского описательного элемента.
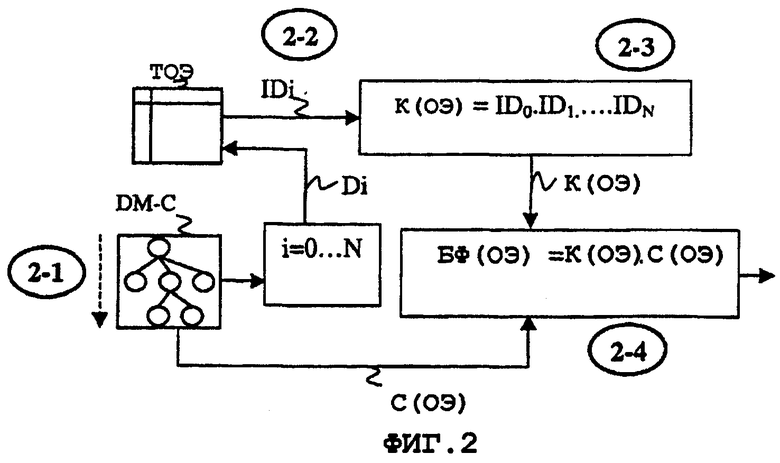
Ниже описан способ кодирования описательного элемента экземпляра схемы со ссылкой на фиг.2. Согласно фиг.2 для кодирования описательного элемента DE экземпляра XML-C схемы XML-S хранящееся в памяти иерархическое представление DM-C экземпляра XML-C просматривается от родительского к дочернему описательному элементу до достижения описательного элемента DE, который должен кодироваться (шаг 2-1). На каждом иерархическом уровне идентификационная информация IDi, относящаяся к просмотренному описательному элементу Di, извлекается из таблицы EDT, которая связана со схемой XML-S (шаг 2-2). Структурирующий ключ К(DE) экземпляра для описательного элемента DE формируется как последовательность (упорядоченный список значений) выведенной идентификационной информации IDi (шаг 2-3). В заключение фрагмент BiM-F(DE) формируется путем добавления информации С(DE) описательного элемента DE к последовательности выведенной идентификационной информации (шаг 2-4). Фрагмент преобразуется в бинарный формат для передачи.
Ниже дан пример такого процесса кодирования со ссылкой на вышеописанный ПРИМЕР 3.
ТАБЛИЦА-МАТРИЦА 1, приведенная ниже, дает пример экземпляра схемы, описанной в ПРИМЕРЕ 3. Слева приведен структурирующий ключ элемента экземпляра, а элемент определен в соответствующей строке таблицы-матрицы. Справа приведен структурирующий ключ атрибута экземпляра, а атрибут определен в соответствующей строке таблицы-матрицы. Эти структурирующие ключи экземпляра получены с помощью вышеописанного способа кодирования.
Теперь будет описано шаг за шагом в качестве иллюстрации кодирование описательного элемента <Медиа-Время единица времени="PT1N30F">, написанного жирным шрифтом в Таблице-матрице 1.
Шаг 1-1: хранящееся в памяти иерархическое представление экземпляра просматривается от родительского описательного элемента к дочернему описательному элементу до тех пор, пока не достигнут описательный элемент, который должен кодироваться (здесь атрибут "Единица времени" элемента "Медиа-Время"); просмотренные описательные элементы следующие:

Шаг 1-2: соответствующая идентификационная информация (включая индекс, если имеется) выбирается из Таблицы 3:
Шаг 2: формируется последовательность из выбранной идентификационной информации: 0.3 [0].3 [1].2.2. Эта последовательность представляет собой структурирующий ключ экземпляра, относящийся к кодированному описательному элементу.
Другие структурирующие ключи экземпляра, приведенные в Таблице-матрице 1, могут быть получены таким же способом.
Структурирующий ключ экземпляра также может рассматриваться как реализация табличного структурирующего ключа. Действительно, элементы многократного вхождения фактически индексированы (приводя к образованию структурирующих ключей экземпляра, таких как 0.3[0], 0.3[1],...) и создаются циклы самовключения (приводя к образованию структурирующих ключей экземпляра, таких как 0.3[0].3[1].2.2, которые не появляются в таблице, но могут быть вычислены из нее). Структурирующий ключ экземпляра кодируется как идентификатор описательного элемента в бинарном фрагменте экземпляра.
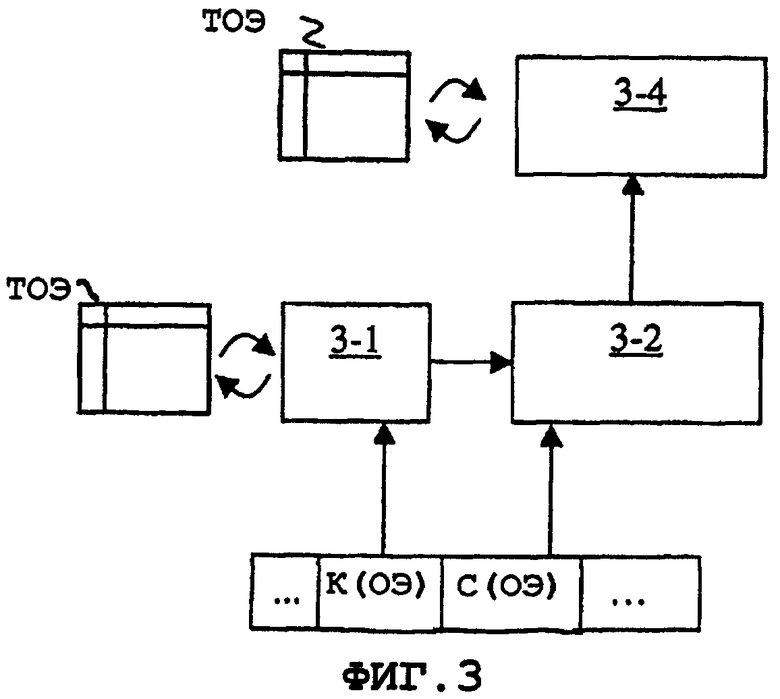
Ниже описан способ декодирования фрагмента со ссылкой на фиг.3. Согласно фиг.3 способ декодирования, соответствующий изобретению, включает:
- шаг 3-1: нахождение в таблице описательного элемента, относящегося к принятой последовательности данных идентификационной информации,
- шаг 3-2: декодирование принятого информационного наполнения (информации) упомянутого описательного элемента (найденного в таблице) в соответствии с простейшим типом,
- шаг 3-3: обновление хранящегося в памяти иерархического представления путем объединения упомянутого элемента с его информационным наполнением; добавления родительского описательного элемента, если они пропущены; и в случае множества вхождений добавление тех же описательных элементов более низкого ранга, если они пропущены.
На практике принятая последовательность данных идентификационной информации просматривается пошагово друг за другом, идентификационная информация за идентификационной информацией, и для обновления хранящегося в памяти иерархического представления применяется нижеприведенный алгоритм:
Алгоритм (1):
- шаг 4-1:
текущая лексема = первая идентификационная информация из последовательности;
текущий узел = корень хранящегося в памяти иерархического представления;
- шаг 4-2:
предыдущий описательный элемент = описательный элемент, соответствующий текущему узлу;
текущий описательный элемент = потомок предыдущего описательного элемента, имеющего текущую лексему в качестве идентификационной информации;
- шаг 4-3: текущий узел имеет дочерний узел, соответствующий текущему описательному элементу?
- шаг 4-4: если текущий узел имеет дочерний узел, соответствующий текущему описательному элементу, то переход на шаг 4-8:
- шаг 4-5: если текущий узел не имеет дочернего узла, соответствующего текущему описательному элементу, то создать такой дочерний узел;
- шаг 4-6: в случае множества вхождений создать "братский" узел(узлы) более низкого ранга, если они еще не существуют;
- шаг 4-7: если текущая лексема = последней идентификационной информации из принятой последовательности, то добавить информационное наполнение к узлу, созданному на шаге 4-5, и перейти на шаг 4-8;
- шаг 4-8:
текущая лексема = следующая идентификационная информация;
текущий узел = дочерний узел;
переход на шаг 4-2.
Например, на шаге 4-2 текущий описательный элемент может быть выведен с использованием нижеприведенного алгоритма, заданного в кодировке типа языка Си:
Алгоритм (2):
Пусть instance_key - упорядоченный список значений лексемы из первой идентификационной информации в принятой последовательности для текущей идентификации принятой последовательности.
Пусть edt_key - соответствующий табличный структурирующий ключ, как он найден в таблице.
Пусть prefix(key) - наибольший префикс (n первых лексем) key (ключа), который фактически существует в таблице.
Пусть suffix(key) - последние лексемы key, такие что key = prefix(key) + suffix(key).
Пусть self_cont(key) - ключ самовключения,
когда (prefix(instance_key)! = instance_key)
{
instance_key = self_cont(prefix(instance_key)) + suffix(intence_key);
}
edt_key = instance_key.
Применение шаг за шагом алгоритма (2) к последовательности 0.0.1.1.0 в вышеописанном ПРИМЕРЕ 2 дает:
instance_key = 0.0.1.1.0
prefix(instance_key) = 0.0.1
instance_key = self_cont(prefix(instance_key)) + suffix(intence_key) = 0.0+1.0=0.0.1.0
prefix(instance_key) = 0.0.1
instance_key = self_cont(prefix(instance_key)) + suffix(intence_key) = 0.0+0=0.0.0
Что приводит, наконец, к:
edt_key = 0.0.0,
что означает, что текущий описательный элемент - это Элемент 4.
В случае иерархий без самовключения соответствие между табличным структурирующим ключом и структурирующим ключом экземпляра прямое. Действительно, надо просто удалить индексы, найденные в структурирующем ключе экземпляра, чтобы вывести соответствующий табличный структурирующий код. В вышеописанном ПРИМЕРЕ 1 описательный элемент, представленный структурирующим ключом экземпляра, 0.1 [5], - это пятый Элемент 2, имеющийся в глобальном Элементе.
В предпочтительном варианте реализации изобретения табличный структурирующий ключ и структурирующий ключ экземпляра сжаты, как это будет описано далее. Эксперименты показали, что такое сжатие структурирующего ключа ведет к значительному выигрышу в размере ключа, хотя при этом предлагаются точно такие же функциональные возможности.
Получающиеся в результате ключи называются компактным ключом (сокращенно CSK). В наиболее простом случае (без самовлючения) CSK представляет собой номер записи структурирующего ключа в Таблице описаний элементов.
Сначала мы должны добавить ключ к текущему списку полей EDT путем нумерации записей в Таблице описаний элементов. В применении к вышеописанному ПРИМЕРУ 2 это приводит к следующему:

Алгоритм (3) используется для вычисления CSK в общем случае (с самовключенными структурами) из структурирующего ключа экземпляра:
Алгоритм (3):
Пусть instance_key - структурирующий ключ экземпляра заданного описательного элемента.
Пусть cs_key - соответствующий компактный структурирующий ключ.
Пусть prefix(key) - наибольший префикс (n первых лексем) key (ключа), который фактически существует в EDT (таблице).
Пусть suffix(key) - последние лексемы key (ключа), такие что key = prefix(key) + suffix(key).
Пусть self_cont(key) - ключ самовключения.
Пусть compact_form(key) - соответствующая компактная форма key в EDT.
когда (prefix(instance_key)! = instance_key)
{
cs_key = cs_key + compact_form(prefix(instance_key));
instance_key = self_cont(prefix(instance_key)) + suffix(intence_key);
}
cs_key = cs_key + compact_form(prefix(instance_key));
Пример: Мы хотим вычислить CSK, соответствующий следующему структурирующему ключу: 0.0.1.1.0.
Применяя шаг за шагом описанный выше алгоритм, получаем:
instance_key = 0.0.1.1.0
prefix(instance_key) = 0.0.1
cs_key = 3
instance_key = self_cont(prefix(instance_key))+suffix(intence_key) = 0.0.+1.0=0.0.1.0
prefix(instance_key) = 0.0.1
cs_key = 3.3
instance_key = self_cont(prefix(instance_key)) + suffix(intence_key) = 0.0.+0=0.0.0
Что приводит, наконец, к:
cs_key = 3.3.2
В вышеприведенном примере для простоты элемент не был элементом с множеством вхождений. Тем не менее, следует заметить, что каждая лексема структурирующего ключа экземпляра (соответственно CSK экземпляра) могла бы быть проиндексирована (соответственно, содержать несколько индексов).
Единственной целью формирования компактного структурирующего ключа является уменьшение размера потока. Поэтому, в первую очередь компактный структурирующий ключ экземпляра декодируется в его развернутую форму (структурирующий ключ экземпляра) с помощью декодера перед переходом к описанной выше фазе декодирования. Приведенный ниже алгоритм 4 восстанавливает структурирующий ключ экземпляра, соответствующий компактному ключу экземпляра:
Алгоритм (4):
Пусть resultNCKey - расширенная форма компактного ключа (результат применения этого алгоритма).
Пусть compact_key - компактный структурирующий ключ экземпляра заданного описательного элемента.
Пусть current_key - лексема компактного структурирующего ключа экземпляра compact_key.
Пусть compact_key[i] - i-я лексема compact_key.
Пусть size(compact_key) - число лексем compact_key.
Пусть diffCode(key1, key2) - подключ, полученный путем удаления общего префикса key1 и key2.
Пусть NCKey(CKey) - соответствующая расширенная форма компактного ключа Ckey.
Пусть self_cont(key) - самовключенный ключ для key.
Все индексы сначала удаляют из compact_key и помещают обратно (восстанавливают) в образованной форме compact_key на конце:
current_key = compact_key[0]
resultNCKey = NCKey(current_key)
for (i=1; i<size(compact_key); i++)
{
previous_key = current_key;
current_key = compact_key[i];
resultNCKey+ = "." + diffCode(NCKey(current_key),
self_cont(previous_key));
}
Пример: Мы хотим сформировать структурирующий ключ экземпляра, соответствующий следующему CSK 3.3.2.
Применение шаг за шагом описанного выше алгоритма приводит к следующему:
compact_key = 3.3.2
current_key = 3
resultNCKey = 0.0.1 (посмотрев в EDT)
(i=1)
previous_key = 3
current_key = 3
self_cont(previous_key) = 0.0
NCKey(current_key) = 0.0.1
diffCode(0.0.1, 0.0) = "1"
resultNCKey = resultNCKey+"." + "1"
⇒resultNCKey = 0.0.1.1
(i=2)
previous_key=3
current_key=2
self_cont(previous_key)=0.0
NCKey(current_key)=0.0.0
diffCode(0.0.0, 0.0)="0"
resultNCKey=resultNCKey+". "+"0"
⇒resultNCKey = 0.0.1.1.0
конец
Следовательно, 3.3.2 - это компактная форма структурирующего ключа экземпляра, 0.0.1.1.0.
Ниже описан пример бинарного синтаксиса. Фрагменты представляют собой часть файла, имеющего заголовок. Заголовок файла содержит, по меньшей мере, идентификатор схемы (определенный в стандарте MPEG идентификатор ID либо URL, как предлагается в M6142).
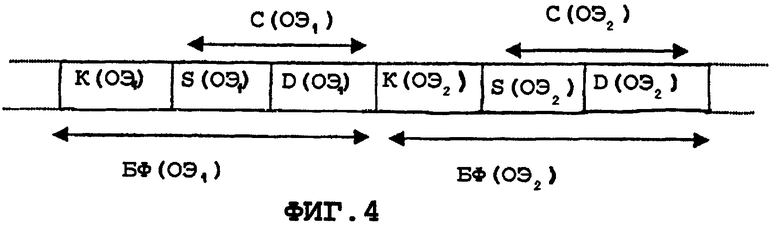
Каждый фрагмент состоит из компактного структурирующего ключа K(DEi) экземпляра (или структурирующего ключа экземпляра) и значения C(DEi) описательного элемента (также называемого информационным наполнением), как описано на фиг.4. Общая форма структурирующего ключа экземпляра следующая:
Key[ind](...)[ind]. Key[ind][ind](...)[ind]. (...), где каждая группа Key[ind][ind](...)[ind] называется лексемой. Лексемы структурирующего ключа экземпляра содержат в большинстве случаев один индекс. Лексемы компактного структурирующего ключа экземпляра могут содержать несколько индексов. Все ключи и индексы - целые значения, закодированные с использованием переменного числа байтов. Таким образом, весь структурирующий ключ закодирован с использованием переменного множества байтов, каждый из которых управляется 2 наиболее значимыми битами со следующей семантикой:
На фиг.4 также описан общий формат для кодирования значений описательного элемента. В соответствии с фиг.4 перед добавлением к бинарному файлу или потоку значения D(DEi) данных кодируется размер в байтах S(DEi) блока данных. Это выполняется для информирования декодера о размере кодируемых данных и для обеспечения легкого произвольного доступа к данным и быстрого интерпретирования потока. Поскольку определенные простейшие типы данных могут заключать в себе большое количество байтов (например, свободная аннотация текста или сценарии фильмов), предполагается для кодирования размера данных использовать переменное число байтов.
Следовательно, длина кодируется по умолчанию с использованием одного байта, причем наиболее значимый бит интерпретируется следующим образом:
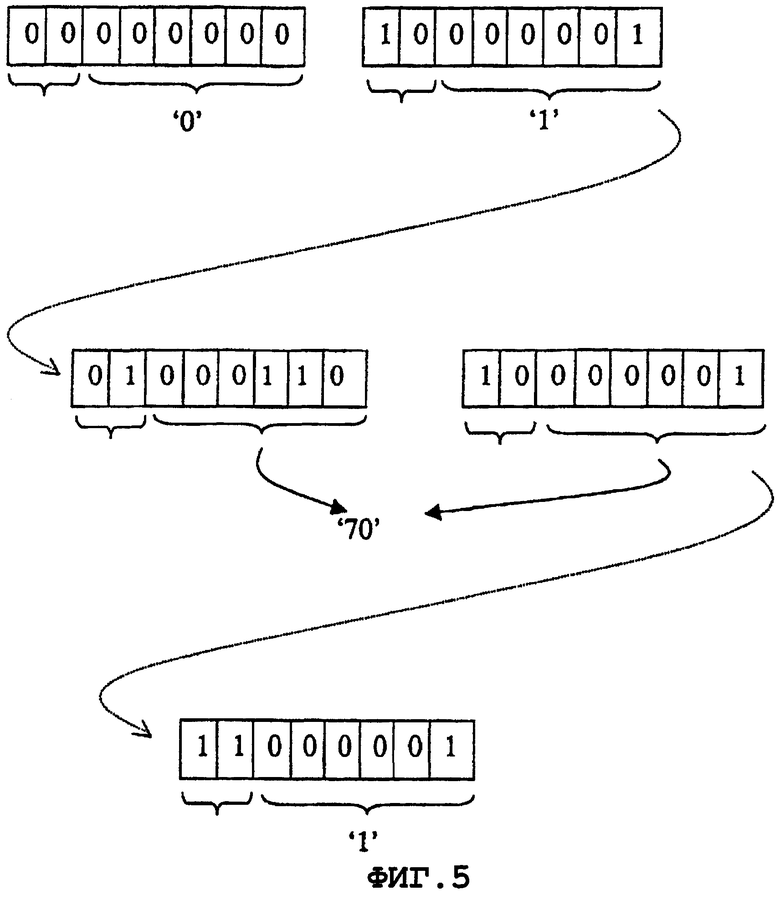
На фиг.5 показан пример бинарного кодирования для компактного ключа "0.1[70][1]". Пять байтов требуется для кодирования этого компактного ключа "0.1[70][1]". Каждый байт начинается с двух управляющих битов. Шесть менее значимых битов используются для кодирования значения. Управляющие биты первого байта - '00' (новый уровень). Биты значения - '000000', что является бинарным представлением первой идентификационной информации из последовательности ('0'). Управляющие биты второго байта - '10' (индексированные). Биты значения - '00001', что является бинарным представлением второй идентификационной информации из последовательности ('1'). Бинарное представление первого индекса '70'-'1000110', оно содержит более шести бит.
Поэтому кодирование выполняется на двух байтах: третьем и четвертом байтах. Управляющие биты третьего байта - '01' (продолжение). Биты значения - '000110' (менее значимые биты индекса, который должен кодироваться). Управляющие биты четвертого байта - '10' (индексирование). Биты значения - '000001' (наиболее значимые биты индекса, который должен кодироваться). И наконец, управляющие биты пятого байта - '11' (конец). А его биты значения - '000001' (бинарное значение индекса, который должен кодироваться).
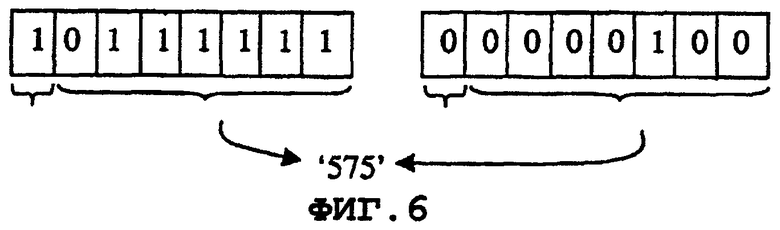
Фиг.6 дает пример бинарного кодирования размера данных, 575 (бинарное представление: 10 00111111). Первый байт состоит из 7 менее значимых битов значения длины с добавлением управляющего бита, определяющего, что требуется другой байт. Второй байт содержит оставшиеся биты с управляющим битом "конец".
Как уже упоминалось, основное достоинство предложенной схемы кодирования заключается в том, что кодируются только атрибуты и элементы, которые содержат значение простейшего типа, а элементы, которые являются только структурными контейнерами (например, с комплексным типом), пропускаются. Это позволяет обеспечить условие, что эта структура может быть логически выведена на стороне декодера с использованием Таблицы описания элементов.
Пример:
Рассмотрим следующий фрагмент экземпляра (найденного в центральной экспериментальной тестовой серии):
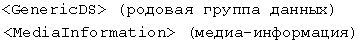

(URL - унифицированный указатель ресурсов)

В этом случае только MediaURL может быть кодировано (как строка), используя структурирующий ключ, который позволяет декодеру восстановить всю структуру по Таблице описания элементов. Другие элементы-контейнеры могут не передаваться.
В общем случае должны кодироваться все элементы, которые имеют простейший тип (т.е. для которых возможно выполнение бинарного представления стандартным путем, что обеспечивает интероперабельность).
Примерами таких простейших типов являются типы, предопределенные XML-схемой (например, строка, допуск,...), а также базовые специальные типы MPEG-7 (например, unsignedInt1 (беззнаковое целое 1), unsignedInt2 (беззнаковое целое 2),..., MediaTime (Среда-Время), Матрица,...).
Простейшие типы также включают расширенные типы, которые могут включать комплексные типы в следующих случаях:
- нет необходимости в том, чтобы осуществлять прямой доступ к включенным элементам в пределах структуры комплексного типа;
- уже существует эффективное бинарное представление.
Эти критерии определенно выполняются в случае, когда дескрипторы определены с помощью видео- и аудиогруппы MPEG-7. Действительно, компактное бинарное представление уже определено, и его следует использовать. Более того, нет необходимости (большую часть времени) в доступе к отдельным частям дескрипторов (они создают смысл как целое).
Эффективность (в смысле уплотнения информации) будет повышаться с увеличением числа простейших типов (которые кодируются оптимальным путем), но таким образом происходит усложнение декодера, который, предполагается, должен включать способы декодирования для всех стандартных простейших типов.
Нижеприведенная ТАБЛИЦА-МАТРИЦА 2 представляет пример компактного структурирующего ключа экземпляра для экземпляра, уже используемого в ТАБЛИЦЕ-МАТРИЦЕ 1. Компактный структурирующий ключ экземпляра, относящийся к описательному элементу <Медиа-Время Единица времени = 'PT1N30F'>, - 7[0].7[1].6. Бинарное представление этого компактного структурирующего ключа экземпляра - '10-00011100-000000 10-000111 00-000001 11-000110'. Длина информационного наполнения кодируется 1 байтом: 0-0000111. И значение PT1N30F преобразуется из знаков строки (последовательности) в байты, используя обычное кодирование знаков.
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДУЛЬНЫЙ ФОРМАТ ДОКУМЕНТОВ | 2004 |
|
RU2368943C2 |
| ДЕЛЕГИРОВАННОЕ АДМИНИСТРИРОВАНИЕ РАЗМЕЩЕННЫХ РЕСУРСОВ | 2004 |
|
RU2360368C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ ДАННЫХ ГРАФОВ | 2012 |
|
RU2605387C2 |
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ (СУБД) | 2018 |
|
RU2704873C1 |
| СПОСОБ ПОДГОТОВКИ ДОКУМЕНТОВ НА ЯЗЫКАХ РАЗМЕТКИ ПРИ РЕАЛИЗАЦИИ ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА ДЛЯ РАБОТЫ С ДАННЫМИ ИНФОРМАЦИОННОЙ СИСТЕМЫ | 2015 |
|
RU2613026C1 |
| МЕХАНИЗМЫ ОБНАРУЖИВАЕМОСТИ И ПЕРЕЧИСЛЕНИЯ В ИЕРАРХИЧЕСКИ ЗАЩИЩЕННОЙ СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2408070C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРЕОБРАЗОВАНИЯ ИЕРАРХИЧЕСКОЙ СТРУКТУРЫ ДАННЫХ НА ОСНОВЕ СХЕМЫ В ПЛОСКУЮ СТРУКТУРУ ДАННЫХ | 2004 |
|
RU2378690C2 |
| СИСТЕМА И СПОСОБ ВЗАИМНОГО ПРЕОБРАЗОВАНИЯ ПРОГРАММНЫХ ОБЪЕКТОВ И ДОКУМЕНТОВ НА БАЗЕ ЭЛЕМЕНТОВ СТРУКТУРИРОВАННОГО ЯЗЫКА | 2001 |
|
RU2287181C2 |
| ПРОГРАММИРУЕМОСТЬ ДЛЯ ХРАНИЛИЩА XML ДАННЫХ ДЛЯ ДОКУМЕНТОВ | 2006 |
|
RU2417420C2 |
Изобретение касается способа кодирования и декодирования, используемого для передачи и хранения описательных элементов документа XML-подобной схемы. Сущность способа состоит в использовании по меньшей мере одной таблицы, полученной из XML-схемы, причем таблица содержит идентификационную информацию для однозначного идентифицирования каждого описательного элемента на иерархическом уровне и структурную информацию, просмотр хранящегося в памяти иерархического представления экземпляра от родительского описательного элемента к дочерним описательным элементам до достижения кодируемого описательного элемента, и извлечение идентификационной информации каждого просмотренного описательного элемента, кодирование указанного описательного элемента в виде фрагмента, содержащего упомянутое информационное наполнение и последовательность извлеченной идентификационной информации. Технический результат - обеспечение эффективной схемы кодирования экземпляров и возможности расширения бинарного формата для последующих схем, определенных в рамках MPEG-7. 7 н. 2 з.п. ф-лы, 6 ил., 6 табл.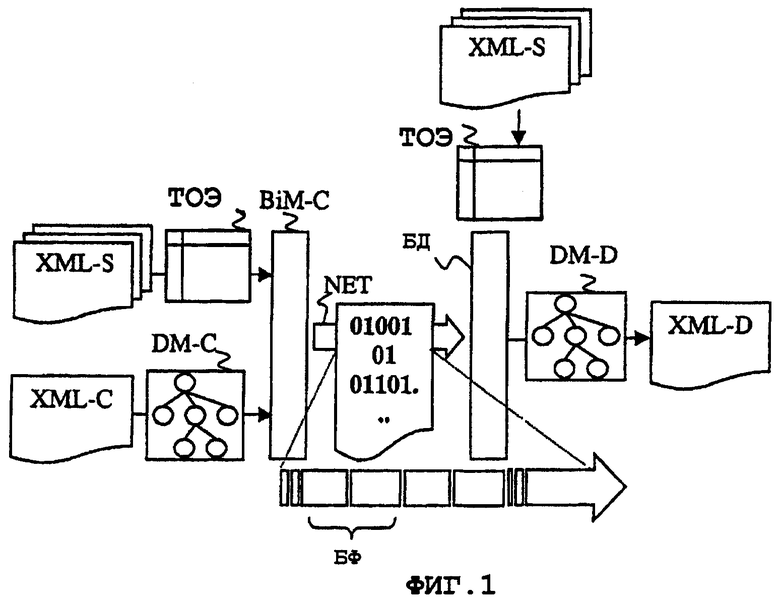
формируют по меньшей мере одну таблицу описания элементов из упомянутой XML-подобной схемы, определяющей иерархическую структуру описательных элементов, при этом таблица описания элементов содержит идентификационную информацию для однозначного идентифицирования каждого описательного элемента в каждом иерархическом уровне и структурную информацию для отыскания любого дочернего описательного элемента из его родительского описательного элемента,
просматривают хранящееся в памяти иерархическое представление упомянутого экземпляра от родительских описательных элементов к дочерним описательным элементам до достижения описательного элемента, который должен кодироваться, и извлекают из таблицы описания элементов на каждом иерархическом уровне идентификационную информацию каждого просмотренного описательного элемента,
формируют для каждого описательного элемента последовательность извлеченной идентификационной информации, состоящую из извлеченной идентификационной информации для этого описательного элемента на каждом иерархическом уровне,
кодируют упомянутый описательный элемент, который должен кодироваться, в виде фрагмента, причем упомянутый фрагмент формируется посредством добавления упомянутого информационного наполнения к последовательности извлеченной идентификационной информации.
формируют по меньшей мере одну таблицу описания элементов из XML-подобной схемы, при этом упомянутая XML-подобная схема определяет иерархическую структуру описательных элементов, содержащую иерархические уровни, родительские описательные элементы и дочерние описательные элементы, причем таблица описания элементов содержит идентификационную информацию для однозначного идентифицирования каждого описательного элемента на каждом иерархическом уровне и структурную информацию для отыскания любого дочернего описательного элемента из его родительского описательного элемента,
просматривают идентификационную информацию за идентификационной информацией в упомянутой последовательности идентификационной информации,
на каждом этапе просмотра осуществляют в таблице описания элементов поиск описательного элемента, относящегося к текущей идентификационной информации, и добавляют этот описательный элемент к хранящемуся в памяти иерархическому представлению экземпляра XML-подобной схемы, если он уже к этому времени не содержится в упомянутом хранящемся в памяти иерархическом представлении,
добавляют информационное наполнение к описательному элементу упомянутого хранящегося в памяти иерархического представления, который относится к последней идентификационной информации упомянутой последовательности идентификационной информации, так, чтобы сформировать экземпляр XML-подобной схемы.
память для хранения по меньшей мере одной таблицы описания элементов, полученной из XML-подобной схемы, определяющей иерархическую структуру описательных элементов, причем эта таблица описания элементов содержит идентификационную информацию для однозначного идентифицирования каждого описательного элемента на каждом иерархическом уровне и структурную информацию для отыскания любого дочернего описательного элемента из его родительского описательного элемента,
средство для просмотра упомянутого экземпляра от родительских описательных элементов к дочерним описательным элементам до достижения описательного элемента, который должен кодироваться, и извлечения из таблицы описания элементов на каждом иерархическом уровне идентификационной информации для каждого просмотренного описательного элемента, и
средство для формирования для каждого описательного элемента последовательности извлеченной идентификационной информации, состоящей из извлеченной идентификационной информации для описательного элемента на каждом иерархическом уровне,
средство для кодирования упомянутого описательного элемента, который должен кодироваться, в виде фрагмента, причем упомянутый фрагмент формируется посредством добавления упомянутого информационного наполнения к последовательности извлеченной идентификационной информации.
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| Зубчатая передача для преобразования движения | 1980 |
|
SU896284A1 |
| УСТРОЙСТВО ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ В ПАМЯТИ | 1996 |
|
RU2101762C1 |
| US 5590317 A, 31.12.1996. | |||

