Данное изобретение относится к хранению данных графов в В-дереве, которое существенно устраняет один или несколько недостатков существующего уровня техники.
Представлен способ и система для хранения комплексных данных графов. Данные графов могут отражать рабочий процесс бизнес-процесса. Бизнес-процесс может контролироваться машиной состояний. Данные рабочего процесса могут быть представлены тройкой, состоящей из стадий процесса (т.е. состояний машины состояний), задачи и исполнителя задачи. Данные тройки могут храниться в В-дереве.
В целях ускорения хранения и получения данных данные хранятся в виде троек, четверок, пятерок и т.д. в В-дереве. В-деревья являются структурами данных, допускающими операции над динамическими наборами данных. Такими операциями могут быть: поиск, поиск минимального и максимального значений, вставка, удаление, ссылки на родительскую или дочернюю директорию. Дерево может быть использовано в качестве словаря или приоритетной цепочки. Скорость операций в дереве пропорционально высоте. Данные читаются блоками из того же местоположения. Если узел дерева перемещается в оперативную память, то выделенный блок памяти перемещается, и операция выполняется очень быстро.
Дополнительные особенности и преимущества изобретения будут изложены в дальнейшем описании и частично будут очевидны из описания, или могут быть почерпнуты из практики изобретения. Преимущества изобретения будут реализованы и достигнуты посредством структуры, в частности указанной в письменном описании и формуле изобретения, а также прилагаемых чертежах.
Обычно данные хранятся в базах данных. Наиболее распространенными базами данных являются реляционные базы данных. Реляционная база данных представляет собой набор таблиц, состоящих из строк и столбцов. Все таблицы соединены (т.е. связаны) друг с другом посредством первичного ключа. Данные извлекаются из базы данных посредством, например, SQL-запросов, которые возвращают данные из одной или нескольких таблиц.
Один SQL-запрос может извлечь данные из нескольких таблиц с использованием оператора JOIN SQL, который соединяет таблицы, используя первичный ключ. Система реляционных баз данных является крайне сложной. Например, простой оператор SELECT для выбора данных может быть выполнен различными способами. Реляционная СУБД находит оптимальный способ выбора и извлечения данных. СУБД использует алгоритмы оптимизации для возвращения данных быстрейшим из возможных способов.
Однако в случае сотен тысяч или даже миллионов записей извлечение данных может быть довольно медленным. Данные могут быть сохранены и извлечены быстрее, если данные хранятся в виде троек, четверок или комбинаций произвольного числа элементов. Традиционные реляционные базы данных также могут работать с данными типа троек или четверок, однако, есть ряд недостатков этого подхода, такие как избыточность данных, что в свою очередь приводит к аномалиям и несогласованности данных. Обработка и поиск через тройки в обычных базах данных также является ресурсоемким процессом, который приводит к замедлению работы с реляционными базами данных.
Следовательно, существует потребность в данной области техники в системе и способе для эффективного хранения и поиска сложных данных графов.
Прилагаемые чертежи, которые включены для обеспечения дальнейшего понимания изобретения и составляют часть описания, иллюстрируют варианты осуществления изобретения и вместе с описанием служат для объяснения принципов изобретения.
На рисунках:
ФИГ. 1 иллюстрирует граф в соответствии с примерным вариантом;
ФИГ. 2 иллюстрирует базу данных со структурой В-дерева для хранения троек, в соответствии с примерным вариантом;
ФИГ. 3 иллюстрирует пример хранения предикатов с соответствующими атрибутами, в соответствии с примерным вариантом;
ФИГ. 4 иллюстрирует пример хранения предикатов с их атрибутами с помощью дополнительных ссылок;
ФИГ. 5 иллюстрирует пример В-дерева 5 порядка;
ФИГ. 6 иллюстрирует другой пример графа, который может быть записан в виде троек;
ФИГ. 7 иллюстрирует схему примерной компьютерной системы, которая может быть использована для реализации изобретения.
Ниже описаны способ и система для хранения сложных данных графов. Данные графов могут представлять рабочий процесс бизнес-процесса. Бизнес-процесс можно контролировать при помощи машины состояний. Далее данные рабочего процесса могут быть представлены тройкой (или, в более общем случае n-кортеж), представляющей стадии процесса (т.е. состояния машины состояний), задачу и ответственного за задачу. Условия взаимодействия между состояниями машины состояний могут служить в качестве предикатов тройки. Эти тройки хранятся в В-дереве. Рабочий процесс может иметь несколько задач и ответственных для каждого состояния процесса. Данные также могут быть представлены, например, в виде четверок, пятерок, и так далее.
Согласно примерному варианту для ускорения хранения и поиска данных рабочего процесса, данные могут храниться в виде троек, четверок, пятерок и т.д. в В-дереве. Деревья являются структурами данных, допускающими операции над динамическими наборами данных. Такими операциями могут быть: поиск, поиск минимального и максимального значений, вставка, удаление, ссылка на родительскую или дочернюю директорию. Дерево может быть использовано в качестве словаря или приоритетной цепочки.
Скорость операций в дереве пропорционально высоте. Сбалансированные деревья имеют минимальную высоту. Например, высота бинарного дерева с n узлами равна log n. В-деревья являются сбалансированными деревьями, а скорость операций внутри В-деревьев пропорциональна их высоте. В-деревья эффективно работают с дисковой памятью, поскольку минимизируют запросы Ввода/Вывода. Данные вычитываются в виде блоков из одной и той же локации.
Если узел дерева перемещается в оперативную память, то выделенный блок памяти перемещается, и операция выполняется очень быстро. Таким образом, нагрузка на сервер крайне мала, и время ожидания минимально. Поэтому использование В-дерева - выгодно для хранения сложных данных.
В соответствии с примерным вариантом тройки хранятся в хранилищах троек. Хранилище троек - это специальная база данных для хранения и извлечения троек. Тройка представляет собой сущность данных, состоящую из подлежащего-предиката-дополнения, например, "Джону-35 лет" или "Джон знает Хелен". Как и в реляционных базах данных, информация хранится в хранилищах троек и извлекается инструкцией запросов. В отличие от реляционных баз данных, хранилище троек оптимизировано для хранения и извлечения троек. В дополнение к запросам тройки могут быть импортированы/экспортированы при помощи Среды Описания Ресурса (RDF) и других форматов.
Хранилище троек может хранить миллиарды троек. Хранилища троек могут быть построены в виде проприетарных Систем Управления Базами Данных, или построены поверх существующих СУБД (например, СУБД на базе Язык Структурированных Запросов (SQL)). Базы данных на базе Аналитической Обработки в Реальном Времени (OLAP) используют хранилища троек интегрированные в существующие СУБД. Однако собственные (нативные) хранилища троек обладают преимуществами в производительности.
Сложность реализации хранилищ троек посредством SQL заключается в том, что реализация эффективных запросов RDF модели, основанной на графах, (например, сопоставление из SPARQL (языка запросов RDF, т.е. языка запросов для баз данных, предназначенного для извлечения и манипулирования данными, сохраненными в Среде Описания Ресурса) в SQL запросы) сложна. Семантическая Сеть имеет решение этого. Она включает в себя публикации на языках, специально предназначенных для данных: Среда Описания Ресурса (RDF), Язык Онтологии для Сети (OWL) и Расширяемый Язык Разметки (XML). HTML описывает документы и связи между ними. RDF, OWL и XML, напротив, могут описать произвольные вещи, такие как люди, встречи, автомобильные запчасти и т.д.
Онтологии являются столпами семантической сети, хотя они не имеют общепринятого определения. Словарь (семантической сети) можно рассматривать как специальную форму (как правило, легковесную) онтологий, или иногда просто как набор Унифицированных Идентификаторов Ресурса (URI), с (обычно неофициально) описанным смыслом.
Предполагается, что обычно онтологии сопровождаются некоторым документом на формальном языке онтологий, хотя некоторые онтологии не используют для этих целей стандартизированные форматы. В информатике и искусственном интеллекте языки онтологии являются формальными языками, используемыми для построения онтологий. Они позволяют кодировать знания о конкретных областях и часто включают в себя правила умозаключений, поддерживающих обработку этого знания. Языки онтологии, обычно, являются декларативными языками, почти всегда обобщенными структурированными языками, и, как правило, основаны либо на логике первого порядка или на описательной логике.
Данные технологии объединены для обеспечения описаний, которые дополняют или заменяют содержание веб-документов. Таким образом, содержание может выражать себя в виде описательных данных, хранящихся в веб-доступных базах данных, или в качестве разметки в документах, в частности, в Расширяемый HTML, XHTML, перемежаясь с XML, или исключительно в XML, с макетами или визуализацией подсказок, хранящихся отдельно. Машиночитаемые описания позволяют диспетчерам содержания добавлять смысл содержанию, т.е. описывать структуру доступного знания о содержании. Таким образом, аппарат может обрабатывать само знание вместо текста, с использованием процессов, схожих с человеческим дедуктивным мышлением и выводами, таким образом, получая более значимые результаты и помогая компьютерам выполнять автоматизированный сбор информации и исследования.
Среда Описания Ресурса (RDF) является семейством спецификаций, первоначально разработанных в виде модели данных метаданных. RDF стал использоваться в качестве общего метода концептуального описания или моделирования информации, который реализован в веб-ресурсах, при помощи различных форматов синтаксиса.
Модель данных RDF похожа на классические концептуальные подходы моделирования, таких как сущность-связь или диаграммы классов, так как она основана на идее создания утверждений о ресурсах (в частности веб-ресурсов) в виде выражения "подлежащее-предикат-дополнение". Эти выражения известны в терминологии RDF как тройки. Подлежащее обозначает ресурс, а предикат обозначает черты или аспекты ресурсов и выражает отношение между подлежащим и дополнением.
Например, один из способов представления понятия "Небо имеет цвет синий" в RDF: подлежащее - "небо", предикат - "имеет цвет" и дополнение - "синий". В классических обозначениях сущность-атрибут-значение в объектно-ориентированное моделировании можно записать как: объект - "небо", атрибут - "цвет" и значение - "синий". RDF представляет собой абстрактную модель с несколькими форматами сериализации (например, форматами файлов), и поэтому конкретный способ, которым кодируется ресурс или тройка, варьируется от формата к формату.
Данный механизм описания ресурсов является основным компонентом, предоставляемым активностью семантической сети, т.е. эволюционным этапом Всемирной сети, в котором автоматизированное программное обеспечение может хранить, обмениваться и использовать машиночитаемую информацию, распространяемую по всей сети, что в свою очередь, позволяет пользователям работать с информацией с большей эффективностью и определенностью. Простая модель данных RDF и возможность моделировать различные, абстрактные понятия также привели к ее увеличению использования в приложениях управления знаниями, не связанными с активностью семантической сети.
Коллекция RDF утверждений представляет собой маркированный ориентированный мультиграф. В силу этого, модель данных на базе RDF более органично подходит для определенных видов представления знаний, чем реляционная модель и другие онтологические модели. Однако на практике, RDF данные часто хранятся в реляционной базе данных или нативных представлениях, также называемых хранилищами троек или хранилищами четверок, если контекст (т.е. именованный граф) также хранится для каждой RDF тройки. Как показывают RDFS и OWL, на основе RDF могут быть построены дополнительные языки онтологий.
Используются два распространенных формата сериализации. Первый - XML-формат. Данный формат чаще всего называют просто RDF. Нотация 3 (или N3) - не XML сериализация RDF моделей, предназначенная для облегчения ручного написания, и в некоторых случаях, которым легче следовать. Поскольку он основан на табличной нотации, он делает основные тройки, закодированные в документе, более легкоразличимыми по сравнению с XML-сериализацией. N3 тесто связана с форматами Turtle (Кратким языком RDF троек) и N-Троек.
Нотация 3, или N3, как она более известна, является сокращенной XML сериализацией моделей Среды Описания Ресурсов, разработанной с учетом человеко-читаемостью. N3 более компактная и читабельная нотация, по сравнению с XML RDF нотацией.
N3 имеет ряд особенностей, которые выходят за рамки сериализации для RDF модели, таких как поддержка правил, основанных на RDF. Turtle является упрощенным строго RDF подмножеством N3.
Turtle (Краткий язык RDF троек) является упрощенным форматом для графов Среды Описания Ресурсов (RDF).
Пример Turtle:
©префикс rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@ префикс dc:<http://purl.org/dc/elements/l.l/>.
@ префикс ex:<http://example.org/stuff/1.0/>.
<http://www.w3.org/TR/rdf-syntax-grammar>
dc: заголовок "RDF/XML Спецификация синтаксиса (Откорректирована)";
ех: редактор [
ех: полное имя "Дейв Бэккетт";
ех: домашняя Страница<http://purl.org/net/dajobe/>
].
Примеры Turtle также верны для Нотации 3. Предметом RDF утверждения является либо Унифицированных Идентификаторов Ресурса (URI), либо пустой узел, оба из которых обозначают ресурсы. Ресурсы, обозначенные пустыми узлами, называются анонимными ресурсами. Они не являются непосредственно идентифицированными из RDF утверждения. Предикат - это URI, который также обозначает ресурс, отражающий связь. Дополнение - это URI, пустой узел или литеральная строчная константа в Юникоде.
В приложениях семантической сети (семантического веба) и в относительно популярных приложениях RDF, таких как RSS и FOAF (Друг Друга), ресурсы, как правило, представлены URI, которые сознательно обозначают, и могут быть использованы для доступа, актуальные данные во Всемирной Сети. Но, RDF, в целом, не ограничена описанием ресурсов основанных на Интернете. В действительности, URI, которые именуют ресурс, не должен быть де-ссылочным. Например, URI, который начинается с "http:" и используется как подлежащее RDF утверждения, не обязательно должен представлять собой ресурс, который доступен посредством HTTP, а также не должна представлять собой реальный, доступный посредством сети ресурс, такой URI может представлять абсолютно все. Тем не менее, существует общее соглашение, что простой URI (без символа #), который возвращает 300-уровневый закодированный ответ при использовании запроса HTTP GET, должен рассматриваться, как обозначающий доступный Интернет-ресурс.
Тройки (или четверки) могут представлять бизнес-объекты и правила, реализованные на любом языке программирования или языке выражений. Согласно примерному варианту осуществления для бизнес-процессов могут быть использованы специальные имена для правил переходов. Именами могут быть:
$свойство, которое идентифицирует объект;
$$сейчас, указывающую текущую дату и время, и
$$ТекущийПользователь, идентифицирующее текущего пользователя.
Бизнес-правила также могут быть сохранены в тройках. Тройки могут быть использованы для задач, сгенерированных машиной состояний. Условия связей между состояниями машины состояний могут служить в качестве предикатов троек. В управлении проектами задача является активностью, которую необходимо закончить за определенный период времени. Задача может быть назначена ответственному лицу. Задача имеет дату (время) начала и конца.
Задача является элементом, который используется для отслеживания пользовательской активности в отношении завершения определенных целей, определенных описанием задачи. Примером такой задачи является задача в MS Outlook. Другими примерами задач могут служить такие задачи, как исправление ошибок в компьютерном коде, генерирование отчетов, замена детали машины, перевозка грузов, написание исполняемого компьютерного модуля и т.д.
Например, необходимо исправить ошибку в компьютерном коде. Процесс выявляет ошибку и создает предмет/объект "ошибка". Объект обрабатывается в соответствии с рабочим процессом, который включает в себя стадии обработки объекта, представленные состоянием. Объект в рамках рабочего процесса представляет собой настраиваемую единицу, которая может переходить из одного состояния в другое, и может быть использована для отслеживания определенного бизнес-процесса. Переход объекта в рамках рабочего процесса может создавать задачи в необходимых шагах (состояниях) и может назначать их определенным пользователям.
Примерный рабочий процесс исправления ошибок в компьютерном коде работает следующим образом. Если обнаружена ошибка, корректору ошибок (разработчику) отдается распоряжение на исправление ошибки. После этого ошибка считается исправленной. Объект "ошибка" может иметь несколько состояний, таких как "ошибка обнаружена", "ошибка исправляется", "ошибка исправлена". Когда ошибка обнаружена, процесс обработки ошибки переходит в шаг "ошибка обнаружена". Процесс отдает распоряжение корректору ошибок (разработчику) исправить обнаруженную ошибку. Корректору ошибок генерируется задача "исправить ошибку".
После того как корректор ошибок (разработчик) откорректирует ошибку, корректор ошибок закрывает его задачу, и состояние объекта ошибка переходит в состояние "ошибка исправлена". Исполнитель задачи закрывает задачу по ее завершении. Таким образом, задача может иметь несколько параметров. Например, статус (открыта/закрыта), исполнитель задачи, дата генерирования, дата закрытия, название задачи и др.
Согласно примерному варианту параметры задач могут быть описаны тройками. Каждая задача имеет уникальный идентификатор задачи (т.е., например, число). Первая задача может иметь Идентификатор=001, вторая задача Идентификатор=002 и т.д. Стоит отметить, что идентификатор задачи может быть сгенерирован посредством хэширования названия задачи или даты создания. Статус задачи может быть описан как тройка: 001 статус открыта, 002 статус открыта.
В данном случае идентификатор задачи является подлежащим, статус является предикатом, а открыта дополнением. Например, "003 статус закрыт" указывает на то, что задача 003 была закрыта. "003 статус закрыт" указывает на то, что задача 003 была закрыта. Тройка "001 владелец Джон" указывает на то, что задача с Идентификатором=001 назначена Джону. Тройка "002 дата 12 дек" указывает на то, что задача с Идентификатором=002 была создана 12 декабря. Всякий раз, когда выполняется операция над задачей (например, открытие или закрытие задачи) в базу данных добавляются соответствующие тройки. Хранение троек в базе данных позволяет извлекать связанные с задачами данные для дальнейшего использования. Например, статус задачи и назначение могут быть получены путем запроса к базе данных.
Примерный запрос "?подлежащее статус открыт" вернет все подлежащие (идентификаторы задачи) со статусом открыт.В приведенном выше примере идентификаторы задач 001 и 002 будут возвращены в результате этого запроса. Стоит отметить, что запросы могут основываться на дополнениях, предикатах и подлежащих. Однако, хранение троек в базе данных
- неэффективно. Согласно примерному варианту тройки хранятся в В-деревьях или таблицах, которые подробно рассматриваются в настоящем документе.
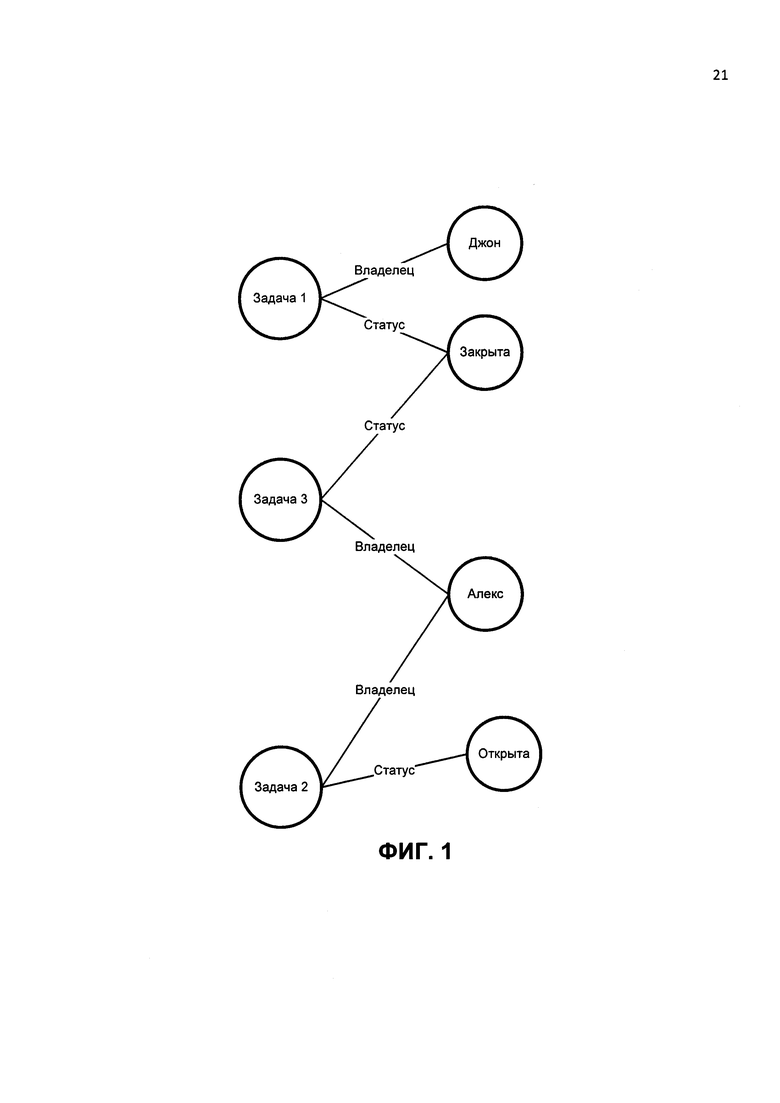
Согласно примерному варианту графы могут быть представлены тройками. ФИГ. 1 иллюстрирует примерный граф. Граф может быть описан тройками:
Задача 1 - владелец (исполнитель) Джон;
Задача 1 статус - закрыта;
Задача 2 - владелец (исполнитель) Алекс;
Задача 2 статус - открыта;
Задача 3 - владелец (исполнитель) Алекс;
Задача 3 статус - закрыта.
В данном примере "исполнитель" и "статус" являются предикатами (Р), Задача 1 и Задача 2 - подлежащими (S), а Джон и Алекс - дополнениями (D) троек.
Вышеуказанные тройки могут быть записаны следующим образом:
P1 S1 O1,
P1 S2 O2,
Р2 S1 O4,
Р2 S2 O3,
Р3 S1 O4,
Р3 S2 O2.
Тройки, записанные в вышеуказанной форме, представляют отношения между предикатами, дополнениями и подлежащими. Эти тройки могут быть записаны как функции предикатов:
S1(P1, O2),
S1(P2, O4),
S1(P3, O4),
S2 (P2, O3),
S2(P3, O2).
Тогда, если необходимо найти все задачи, назначенные Алексу, то необходимо просмотреть все тройки. Если количество троек превышает, например, тысячу, то поиск по всем тройкам становится очень медленным и требует огромных вычислительных ресурсов. Согласно примерному варианту для хранения представленных графами троек, четверок (где предикат зависит от трех атрибутов), пятерок (где предикат зависит от четырех атрибутов) и других используется В-дерево. Стоит отметить, что фактически графы не хранятся в В-дереве, а хранятся в В-дереве соответствующие тройки (четверки, пятерки и т.д.).
В описанном на ФИГ. 1 примере предикаты служат ребрами графа, а дополнения и подлежащее служат вершинами (узлами) графа. В описанном на ФИГ. 1 примере граф (G) представляет комбинацию двух наборов: вершин V (например, Задача 1, Джон, Алекс) и ребер Е (предикаты 1, 2, 3 и т.д.). Два набора скомбинированы на основе экземпляра (например, состояния рабочего процесса).
Каждое ребро е из множества Е инцидентно равно вершинам v', v″, связанными с этим ребром. Вершина v′ и ребро е являются совпадающими, а вершины v′ и v″ называются смежными. Если |V(G)|=n, |E(G)|=m, то граф G является (n,m) графом, где n - порядок графа (т.е. тройка, четверка, пятерка и т.д.), a m- размер графа.
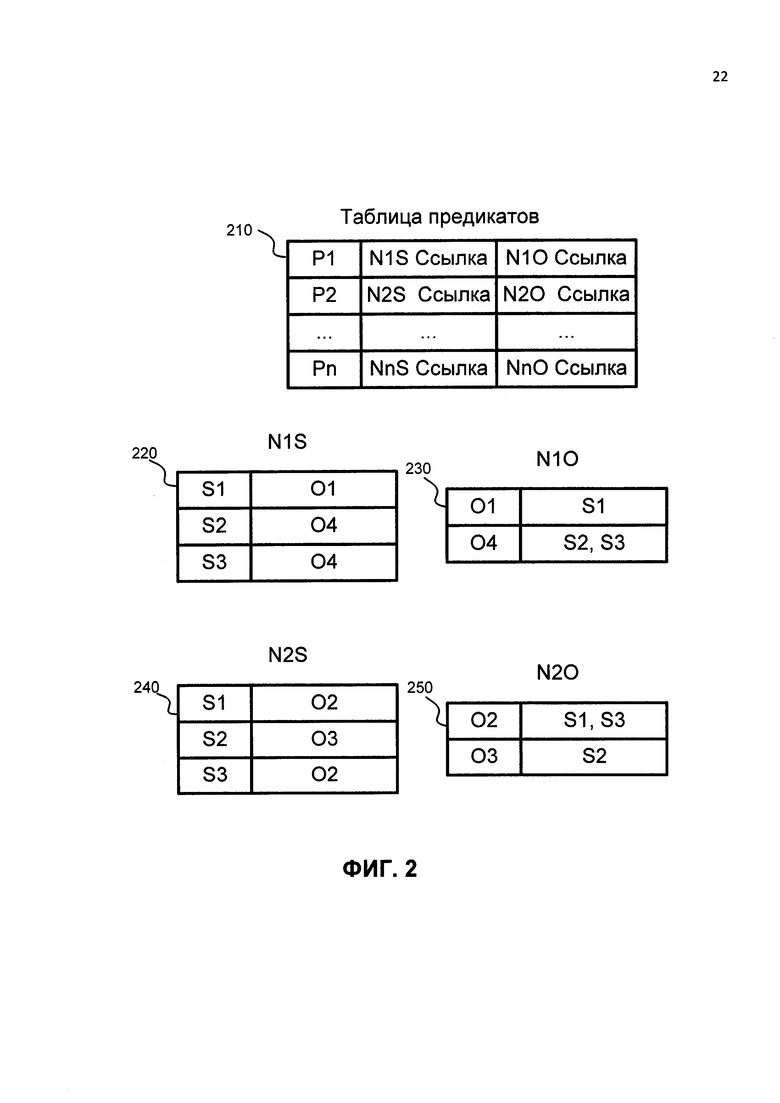
Согласно примерному варианту хранилище данных в форме В-дерева используется для того, чтобы сделать поиск более эффективным. В-дерево может быть реализовано в виде набора таблиц. На ФИГ. 2 показана база данных со структурой В-дерева для хранения троек, изображенных на ФИГ. 1. Согласно примерному варианту предикаты, дополнения и подлежащие хранятся в базе данных в хэшированном виде. Другими словами, значения задачи, статуса и владельца задачи могут быть захэшированы перед сохранением в таблицу. Хэширование позволяет ускорить процесс поиска путем сортировки значений хэшей в базе данных.
Для того чтобы найти связи между вершинами графов поиск в базе данных выполняется с помощью предикатов. Таким образом, таблица ключей в базе данных является таблицей, содержащей связи между предикатами, подлежащими и дополнениями. Подлежащие в таблице ключей отсортированы. Таблица предикатов 210 содержит предикаты Р1…Pn, используемые для выбора подлежащих и дополнений.
Стоит отметить, что данный метод хранения данных не ограничен задачами в тройках. Данные четверок также могут храниться в таблице ключей. Ссылки N1S…NnS являются значениями в таблице предикатов и которые представляют собой ссылки на таблицы N1S…NnS (220 и 240 соответственно). Таблицы 220 и 240 представляют собой связи между подлежащим и дополнениями. Таблица предикатов 210 также содержит ссылки на таблицы N10…NnO (230 и 250 соответственно), которые также представляют собой связи между подлежащим и дополнениями. Для некоторых предикатов (т.е. для предикатов одного типа), например, для предиката Р1=владелец, создается свой собственный набор таблиц N1S…NnS, а для других типов предикатов, например, для Р2=имя, создается другой набор таблиц N10…NnO. Стоит отметить, что приведенный выше пример использует тройки, которые используют только два зависимых значения (атрибута). Любой узел графа может быть использован в качестве атрибута. В случаях, когда используется более двух связанных аргументов, например P1 (a1, а2, а3), то используется альтернативный метод для хранения. Также используется В-дерево.
Примером предиката с тремя атрибутами может служить утверждение:
"кружки цвет красный вчера " или " цвет(чашка, красный, вчера). Другими словами, " цвет" - это предикат, а "чашка" - подлежащее, "красный" - дополнение и "вчера" - обстоятельство (атрибуты) данного предиката. Примером предиката с четырьмя атрибутами может служить утверждение: Европа ("Франция", "Германия", "Испания", "Италия"). Все атрибуты: Франция, Германия, Испания и Италия являются странами. Основная связь - это то, что все они - страны в Европе. Таким образом, Европа является предикатом. Может использоваться предикат "записать", встроенный в язык программирования, например в Пролог. Данный предикат отвечает за передачу данных на экран компьютера. Такие предикаты не требуют специального описания в коде и могут быть легко использованы: записать ("Синоним храбрости - это")
Кавычки в данном утверждении используются для определения строки символов: "Синоним храбрости - это". Предикат "записать" может содержать название переменных. В данном случае кавычки не требуются.
Простой пример: записать (X),
где X - название переменной. Если величина X равна "дорогой", то предикат "записать" напечатает слово "дорогой".
Строка символов и переменная являются атрибутами предиката "записать". Атрибуты могут быть смешаны в произвольном порядке согласно синтаксическим правилам. Например: записать("Сегодня",Н,"-ый день",М,", ",Д,".").
Данный предикат напечатает "Сегодня 19-ый день Августа, Вторник.", если значения переменных Н, М, Д равны "19", "Августа" и "Вторник" соответственно.
В данном примере "записать " является предикатом, а:
"Сегодня"
Н
"-й день"
М
","Д
","
являются семью атрибутами данного предиката. Другими словами, предикат имеет седьмую степень.
Рассмотрим В-дерево, в котором необходимо сохранить следующие наборы:
первый набор Р1(а1, а2, а3);
второй набор Р1(а1);
третий набор Р1(а1, а4);
четвертый набор P1(S1, O4);
пятый набор Р1(а1, а5).
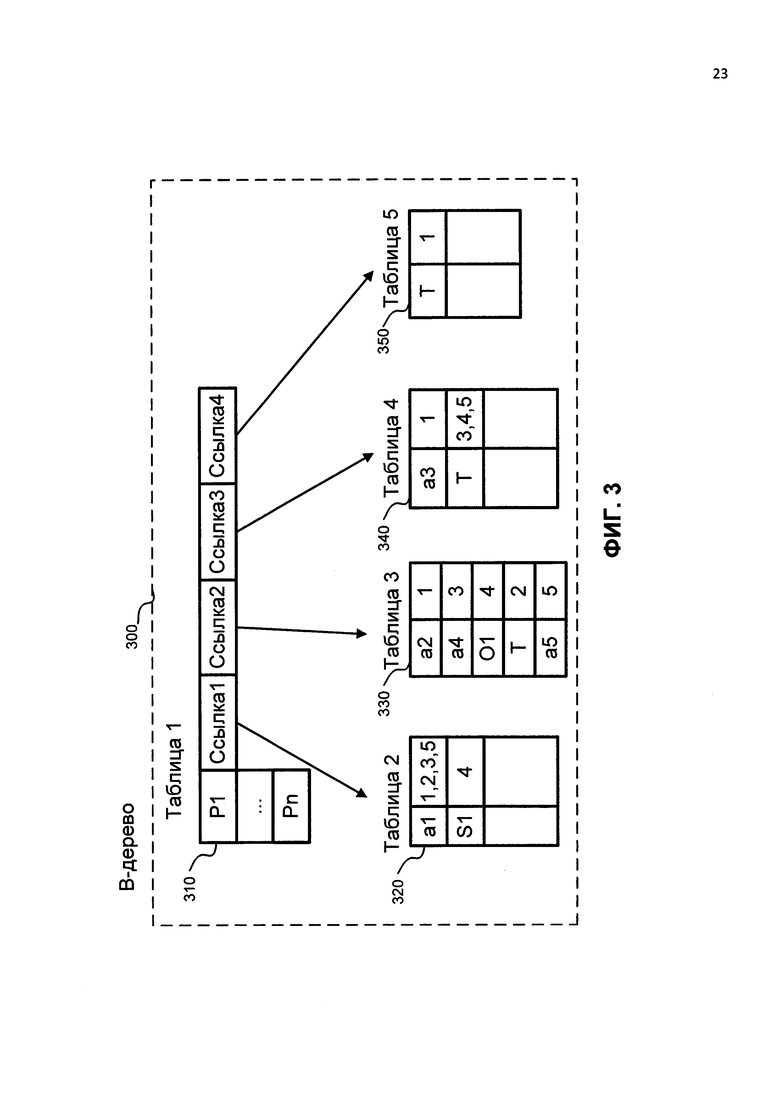
На ФИГ. 3 проиллюстрирован пример хранения предикатов с их атрибутами в В-дереве согласно примерному варианту. Таблица предикатов 310 содержит предикаты, отсортированные в определенном порядке. Таблица предикатов 310 также содержит ссылки на соответствующие сохраненные атрибуты для каждого из предикатов.
Запись предикатов и их соответствующих атрибутов в В-дерево 300 реализуется следующим образом: первый набор предиката Р1 имеет степень три (т.е. у предиката есть три атрибута). Следовательно, когда первый предикат записан в таблицу 310, таблица 310 содержит четыре ссылки на сохраненные атрибуты. Первая ссылка (Ссылка 1) ссылается на таблицу 320, содержащую все первые атрибуты (т.е. атрибуты, размещенные первыми во всех наборах). Вторая ссылка (Ссылка 2) указывает на таблицу 330, содержащую все вторые атрибуты всех наборов. Третья ссылка (Ссылка 3) указывает на таблицу 340, которая содержит все третьи атрибуты. Четвертая ссылка (Ссылка 4) является дополнительной ссылкой, которая указывает на таблицу 350, которая содержит терминатор.
Согласно примерному варианту терминатор является постоянной величиной (числовой или текстовой). Терминатор используется для получения троек из В-дерева 300. Тройки идентифицируются внутри В-дерева посредством терминатора. Когда атрибуты считываются из В-дерева 300, поиск тройки продолжается до тех пор, пока не будет найден терминатор, соответствующий конкретной тройке.
Каждому набору атрибутов, наряду с соответствующим предикатом, присваивается идентификационный номер при записи в В-дерево 300. Следующий идентификационный номер увеличивается на единицу. Таким образом, наборы данных упорядочены согласно тому, когда они записаны в В-дерево 300. Таким образом, каждый набор (предикат, атрибуты и терминатор) обладает соответствующим уникальным идентификатором, также сохраненным в В-дереве 300.
Кроме того, каждый атрибут обладает идентификатором позиции, который идентифицирует позицию атрибута в наборе (т.е. первую, вторую, третью и т.д.). В примере на ФИГ. 3 первый набор содержит атрибут "a1" на первой позиции. Следовательно, атрибут "a1" записан в таблицу 320 с идентификатором "1", указывающим на то, что атрибут принадлежит первому набору.
Атрибут "а2" - второй в первом наборе. Таким образом, он записан в таблицу 330 с идентификатором "1." Атрибут "а3" - третий в первом наборе. Следовательно, он записан в таблицу 340 с идентификатором "1." Терминатор с идентификатором "1" записан в таблицу 350. Терминатор "1" указывает на то, что в первом наборе больше нет атрибутов.
Атрибут "a1" - первый во втором наборе. Следовательно, он записан в таблицу 320 с идентификатором "2", который указывает на то, что атрибут "a1" принадлежит второму набору. Второй набор содержит только один атрибут. Таким образом, терминатор с идентификатором "2" записан в таблицу 330.
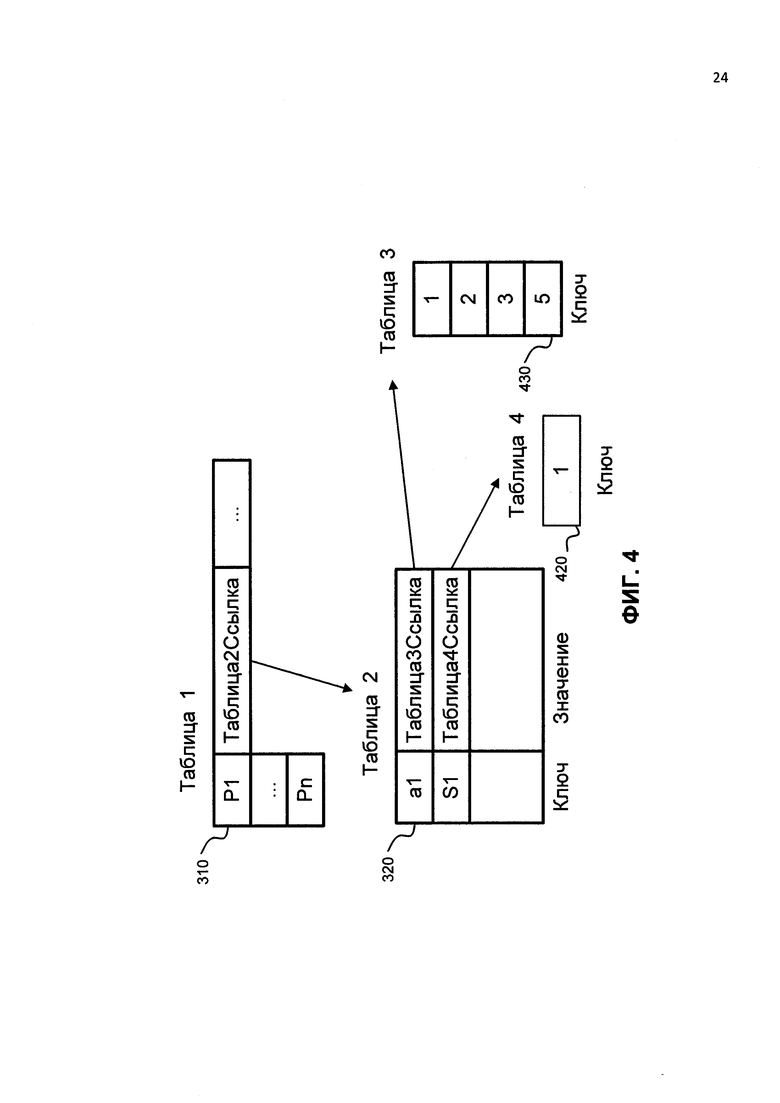
Для всех остальных наборов предикаты, атрибуты и терминаторы сохранены таким же образом. Стоит отметить, что таблицы 320 - 350 могут содержать ссылки на другие таблицы вместо фактических идентификаторов. Данный пример изображен на ФИГ. 4. Таблица 310 содержит ссылку (Таблица 2 Ссылка) на таблицу 320. Таблица 320 содержит ссылки (Таблица 3 Ссылка и Таблица 4 Ссылка), которые указывают на таблицы 420 и 430, содержащие идентификаторы.
Стоит отметить, что изображенные на ФИГ. 4 и ФИГ. 5 таблицы принадлежат В-дереву. Другими словами, таблицы служат ветвями В-дерева. Если необходимо получить определенный набор данных (предикат с атрибутами) из В-дерева, то предикат, атрибуты и терминатор ищутся на основе соответствующего идентификатора.
Например, если необходимо получить первый набор, то первый набор "Р1" ищется в таблице 310. Затем из таблиц 320, 330, 340 и 350 вычитываются соответствующие атрибуты. Атрибуты с идентификатором "1" ищутся в таблицах 320-350. Следовательно, атрибуты получаются в том порядке, в котором они располагаются в первоначальном наборе (т.е. первый атрибут размещается первым, второй - вторым и т.д.). Терминатор ищется для того, чтобы убедиться, что получены все атрибуты из набора.
При чтении набора из В-дерева может быть использован следующий подход (для троек, четверок, пятерок и т.д.):
В качестве примера рассмотрим случай, в котором нам необходимо найти набор Р1(а1, а4). Атрибут a1 - на первом месте, а атрибут а4 - на втором, поэтому поиск проводится в Таблице 2 (320) и Таблице 3 (330). Также необходимо провести поиск в Таблице 4 (340), куда записан терминатор, как описано выше.
Аргумент a1 вычитывается из Таблицы 320, и идентификатор a1 также вычитывается. Затем в Таблице 330 ищется аргумент а4, и также идентификаторы а4. Далее читается Таблица 340 ради идентификаторов терминатора.
Затем поиск выполняется для пересекающихся идентификаторов для a1, а4 и терминатора.
Получая первый идентификатор для ("1") для a1, который означает, что аргумент a1 принадлежит первому предикату, записанному в В-дерево.
Далее учитывая идентификаторы для аргумента а4 первый идентификатор - "3", который означает, что аргумент а4 расположен найден у третьего предиката в В-дереве (и, возможно, у следующих предикатов тоже). В таком случае набор идентификаторов для аргумента а4 становится главным для поиска пересекающихся идентификаторов. Набор идентификаторов для аргумента a1 становится зависимым набором идентификаторов, а набор идентификаторов для терминатора также является зависимым, и находится после идентификаторов a1.
Далее выполняется поиск равного "3" идентификатора аргумента a1. Далее необходимо найти идентификатор, равный трем "3", в наборе идентификаторов для терминаторов. Как он будет найден, это будет означать, что Р1(а1, а4) существует в В-дереве. Набор идентификаторов для терминаторов становится главным набором, и процесс поиска идентификаторов продолжается таким же способом.
Другой пример состоит в следующем:
Рассмотрим случай, когда необходимо найти все предикаты вида Р1(а1, ?). Здесь символ "?" означает, что мы ищем предикаты степени 2, где подлежащее - это аргумент a1, а дополнение - любой другой аргумент, т.е. а5, а0, а2 и т.д. Поскольку степень предиката - 2 (как и в предыдущем примере), нам нужно искать в таблицах 320, 330 и 340. Как и в предыдущем примере нам нужно прочитать набор идентификаторов для аргумента a1 и набор идентификаторов для терминаторов. Второй аргумент не известен, поэтому процесс поиска заключается в следующем:
Набор идентификаторов для a1 считывается из таблицы 320, а набор идентификаторов для терминаторов считывается из таблицы 340. Далее набор идентификаторов для первого аргумента (здесь - а2) считывается из таблицы 330, и определяются пересекающиеся идентификаторы, как обсуждалось ранее.
После того как определены все пересекающиеся идентификаторы, набор идентификаторов для следующего аргумента считывается из таблицы 330, и также определяются все пересечения.
Процесс продолжается до тех пор, пока из таблицы 330 не будут прочитаны все идентификаторы для всех аргументов и не будут сравнены с набором идентификаторов для аргумента a1 и терминаторов.
Поиск остальных предикатов осуществляется аналогичным образом.
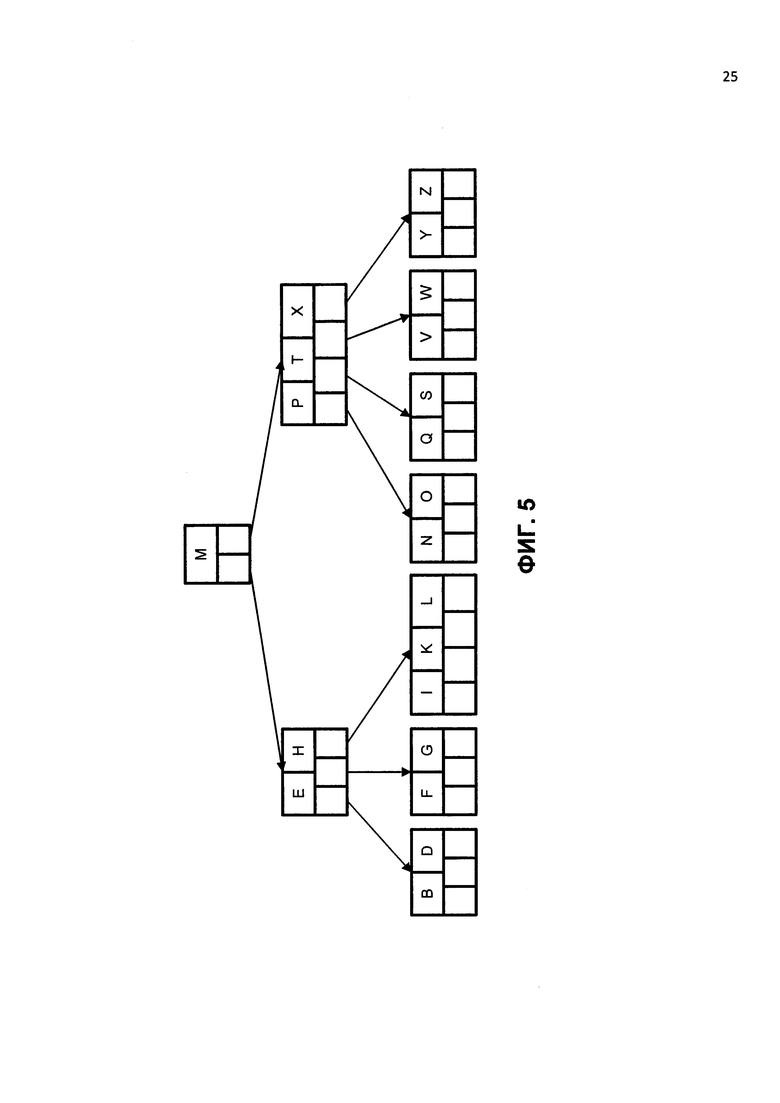
На ФИГ. 5 изображен пример В-дерева порядка 5. Это означает, что (за исключением корневого узла) все внутренние узлы имеют, по крайней мере, ceil(5/2)=ceil(2.5)=3 ребенка (и, следовательно, по крайней мере, 2 ключа). Конечно, максимальное количество детей, которые может иметь данный узел, равняется 5 (так что 4 - максимальное количество ключей). Согласно условию 4 (смотри ниже), каждый листовой узел должен содержать, по крайней мере, 2 ключа. На практике, В-деревья обычно имеют порядки много больше 5. В-дерево является древовидной структурой данных, содержащей отсортированные данные и обеспечивающей поиск, последовательный доступ, вставки и удаление в логарифмической шкале времени. В-дерево - это тип дерева с бинарным поиском, которое имеет более двух детей на узел.
В В-деревьях внутренние (не листья) узлы могут иметь переменное число дочерних узлов в пределах заранее определенного диапазона. Когда данные вставляются или удаляются из узла, количество дочерних узлов изменяется. В целях поддержания предварительно заданного диапазона внутренние узлы могут быть объединены или разделены. Поскольку допускается определенный диапазон дочерних узлов, то нет необходимости заново балансировать В-деревья так часто, как другие самобалансирующиеся поисковые деревья. Однако они могут занимать некое место, поскольку узлы заполнены не полностью. Для конкретной реализации нижняя и верхняя границы количества дочерних узлов, как правило, фиксированы. Например, в 2-3 В-дереве (часто просто называемом 2-3 деревом) каждый внутренний узел может иметь только 2 или 3 дочерних узла.
Каждый внутренний узел В-дерева содержит несколько ключей. На практике ключи занимают большую часть места в узле. Обычно, количество ключей выбирается в диапазоне от d до 2d. Коэффициент 2 гарантирует, что узлы могут быть разделены или объединены. Если внутренний узел имеет 2d ключей, то добавление ключа к данному узлу может быть достигнуто путем разделения 2d-ключевого узла на два d-ключевых узла и добавлением ключа в родительский узел. Каждый отделенный узел обладает минимальным необходимым количеством ключей. Аналогичным образом, если у внутреннего узла, и у его соседа есть ключи, то ключ может быть удален из внутреннего узла путем его объединения с соседним. Удаление ключа сделало бы у внутреннего узла d-1 ключей. Объединение соседей добавило бы d ключей плюс еще один ключ от родителя соседа. Результатом является заполненный узел с 2d ключами.
Количество ветвей (или дочерних узлов) из одного узла - на единицу больше чем количество ключей, сохраненных в узле. В 2-3 В-дереве внутренние узлы хранят либо один ключ (с двумя дочерними узлами), либо два ключа (с тремя дочерними узлами). В-дерево может быть описано параметрами (d+1) - (2d+l) или самым высоким порядком ветвления (2d+l).
В-дерево остается сбалансированным посредством требования того, что все листовые узлы должны располагаться на одной глубине. Глубина нарастает медленно с добавлением элементов в дерево, но увеличение общей глубины - крайне редко, и результатом является то, что все листовые узлы являются удаленными на один узел от корня.
В-деревья обладают существенными преимуществами по сравнению с альтернативными реализациями, когда время доступа к узлу значительно превышает время доступа внутри узлов, поскольку затраты на доступ к узлу могут быть амортизированы посредством множественных операций внутри узла. Это обычно происходит, когда узлы находятся во вторичных хранилищах, например на жестких дисках. Благодаря увеличению количества дочерних узлов в пределах каждого внутреннего узла, высота дерева уменьшается, и количество доступов к затратному узлу снижается. Кроме того, перебалансировка дерева требуется значительно реже.
Максимальное количество дочерних узлов зависит от данных, должны быть сохранены для каждого дочернего узла, а также от размера полного блока диска или от аналогичного размера на вторичном хранилище. В то время как 2-3 В-деревья легче объяснить, практически В-деревья, использующие вторичное хранилище, требуют большого количества дочерних узлов для повышения производительности.
В отличие от бинарного дерева каждый узел В-дерева может иметь переменное количество ключей и детей. Ключи хранятся в неубывающем порядке. Каждый ключ имеет связанного с ним ребенка, являющегося корнем поддерева, содержащего все узлы с ключами меньшими или равными этому ключу, но большими чем предыдущий ключ. У узла также есть дополнительный крайний ребенок, который является корнем поддерева, содержащего все ключи, которые больше любого ключа в узле.
Поскольку каждый узел стремится иметь максимальный коэффициент ветвления (максимальное количество детей), необходимо относительно пройти несколько узлов перед обнаружением нужного ключа. Если для доступа к каждому узлу требуется доступ к диску, то В-дерево минимизирует количество необходимых обращений к диску. Минимизирующий коэффициент обычно выбирается таким, чтобы общий размер каждого узла был кратным размеру блока нижележащего устройства хранения. Данный выбор упрощает и оптимизирует доступ к диску. Следовательно, В-дерево является идеальной структурой данных для ситуаций, когда все данные невозможно разместить на основном устройстве хранения, и доступ к вторичным устройствам хранения относительно дорогостоящ (или требует много времени).
Для n больше или равного единице, высота h n-ключа В-дерева T высоты h с минимальной степенью t большей или равной 2,
h<=log ((n+1)/2)
В худшем случае высота равна O(log n). Поскольку "ветвистость" В-дерева может быть относительно большой по сравнению с другими сбалансированными древовидными структурами, основание логарифма имеет тенденцию увеличиваться. Таким образом, количество узлов, посещенных в процессе поиска, как правило, меньше, чем требуется для других древовидных структур. Хотя это и не влияет на асимптотическую высоту в крайнем случае, В-деревья, как правило, имеют меньшую высоту, чем другие деревья с подобной асимптотической высотой.
В-дерево должно удовлетворять следующим условиям:
- каждый узел содержит хотя бы один ключ. Ключи в каждом узле упорядочены. Корневой узел содержит от 1 до 2t-l ключей. Любой другой узел содержит от t-1 до 2t-l ключей (листья не исключаются). Где t - параметр дерева, не меньший 2-ух (обычно находится в диапазоне от 50 до 2000).
- у листьев нет потомков. Любой другой узел, содержащий ключи К1,…Кn, содержит n+1 детей, где:
- ребенок и все его потомки содержат ключи из интервала (-бесконечность, К1)
- для 2 менее либо равных i менее либо равных n, i-й ребенок и все его потомки содержат ключи из интервала (Ki-1, Ki)
- (n+1)-й сын и все его потомки содержат ключи из интервала (Кn, бесконечность)
- все листья имеют ту же самую глубину.
Второе условие можно сформулировать иначе: каждый узел В-дерева (за исключением листьев) можно рассматривать как упорядоченный массив, состоящий из чередующихся ключей и ссылок на детей.
Согласно примерному варианту, если ключ содержится в корне, его легко найти. В противном случае определяется интервал и ищется соответствующий ребенок. Эти операции повторяются, пока процесс не достигнет листа.
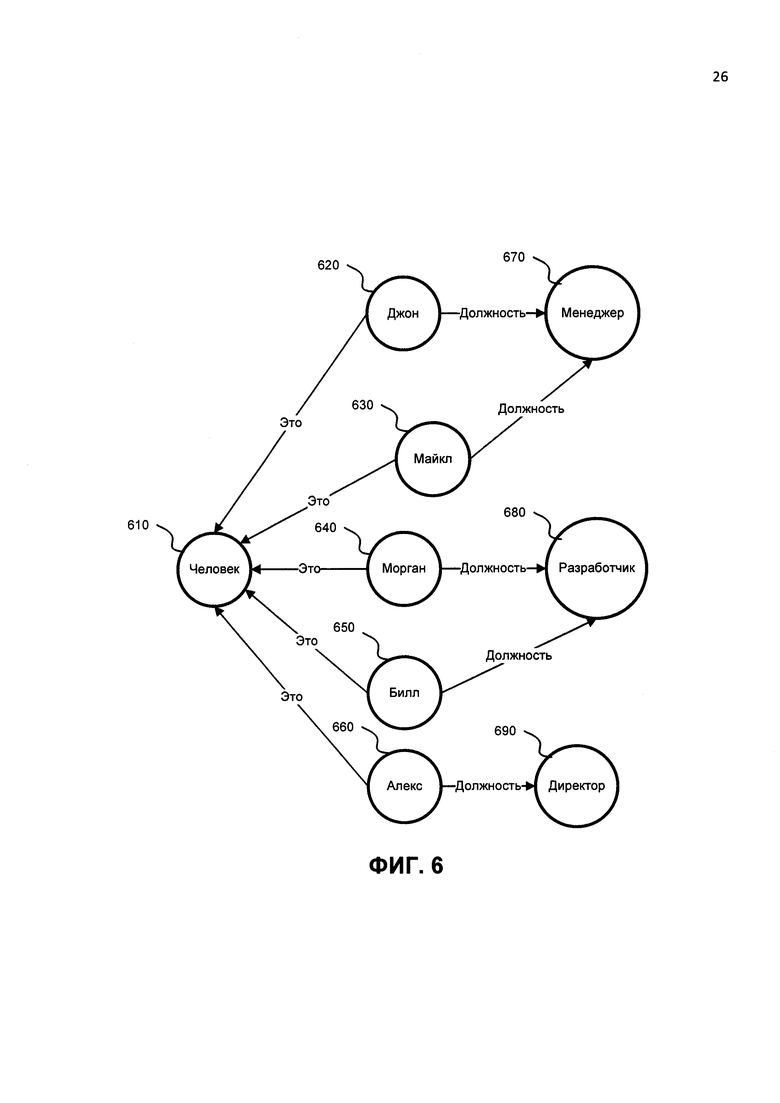
На ФИГ. 6 показан примерный граф, который может быть записан в виде троек. Примерный граф может быть записан в виде десяти троек:
Джон это человек (связь 620 с 610);
Майкл это человек (связь 630 и 610);
Морган это человек (связь 640 и 610);
Билл это человек (связь 650 и 610);
Алекс это человек (связь 660 и 610);
Джон должность менеджер (связь 620 и 670);
Майкл должность менеджер (связь 630 и 670);
Морган должность разработчик (связь 640 и 680);
Билл должность разработчик (связь 650 и 680);
Алекс должность директор (связь 660 и 690).
Те же самые тройки могут быть записаны в следующем виде:
Это (Джон, человек);
Это (Майкл, человек);
Это (Морган, человек);
Это (Билл, человек);
Это (Алекс, человек);
Должность (Джон, менеджер);
Должность (Майкл, менеджер);
Должность (Морган, разработчик);
Должность (Билл, разработчик);
Должность (Алекс, директор).
Со ссылкой на ФИГ. 7, типичная система для реализации изобретения включает в себя многоцелевое вычислительное устройство в виде компьютера 20 или сервера, включающего в себя процессор 21, системную память 22 и системную шину 23, которая связывает различные системные компоненты, включая системную память с процессором 21.
Системная шина 23 может быть любого из различных типов структур шин, включающих шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из множества архитектур шин. Системная память включает постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25. В ПЗУ 24 хранится базовая система ввода/вывода 26 (БИОС), состоящая из основных подпрограмм, которые помогают обмениваться информацией между элементами внутри компьютера 20, например, в момент запуска.
Компьютер 20 также может включать в себя накопитель 27 на жестком диске для чтения с и записи на жесткий диск, не показан, накопитель 28 на магнитных дисках для чтения с или записи на съемный магнитный диск 29, и накопитель 30 на оптическом диске для чтения с или записи на съемный оптический диск 31 такой, как компакт-диск, цифровой видео-диск и другие оптические средства. Накопитель 27 на жестком диске, накопитель 28 на магнитных дисках и накопитель 30 на оптических дисках соединены с системной шиной 23 посредством, соответственно, интерфейса 32 накопителя на жестком диске, интерфейса 33 накопителя на магнитных дисках и интерфейса 34 оптического накопителя. Накопители и их соответствующие читаемые компьютером средства обеспечивают энергонезависимое хранение читаемых компьютером инструкций, структур данных, программных модулей и других данных для компьютера 20.
Хотя описанная здесь типичная конфигурация использует жесткий диск, съемный магнитный диск 29 и съемный оптический диск 31, специалист примет во внимание, что в типичной операционной среде могут также быть использованы другие типы читаемых компьютером средств, которые могут хранить данные, которые доступны с помощью компьютера, такие как магнитные кассеты, карты флеш-памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Различные программные модули, включая операционную систему 35, могут быть сохранены на жестком диске, магнитном диске 29, оптическом диске 31, ПЗУ 24 или ОЗУ 25. Компьютер 20 включает в себя файловую систему 36, связанную с операционной системой 35 или включенную в нее, одно или более программное приложение 37, другие программные модули 38 и программные данные 39. Пользователь может вводить команды и информацию в компьютер 20 при помощи устройств ввода, таких как клавиатура 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, геймпад, спутниковую антенну, сканер или любое другое.
Эти и другие устройства ввода соединены с процессором 21 часто посредством интерфейса 46 последовательного порта, который связан с системной шиной, но могут быть соединены посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (УПШ). Монитор 47 или другой тип устройства визуального отображения также соединен с системной шиной 23 посредством интерфейса, например видеоадаптера 48. В дополнение к монитору 47, персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показано), такие как динамики и принтеры.
Компьютер 20 может работать в сетевом окружении посредством логических соединений к одному или нескольким удаленным компьютерам 49. Удаленный компьютер (или компьютеры) 49 может представлять собой другой компьютер, сервер, роутер, сетевой ПК, пиринговое устройство или другой узел единой сети, а также обычно включает в себя большинство или все элементы, описанные выше, в отношении компьютера 20, хотя показано только устройство хранения информации 50. Логические соединения включают в себя локальную сеть (ЛВС) 51 и глобальную компьютерную сеть (ГКС) 52. Такие сетевые окружения обычно распространены в учреждениях, корпоративных компьютерных сетях, Интранете и Интернете.
Компьютер 20, используемый в сетевом окружении ЛВС, соединяется с локальной сетью 51 посредством сетевого интерфейса или адаптера 53. Компьютер 20, используемый в сетевом окружении ГКС, обычно использует модем 54 или другие средства для установления связи с глобальной компьютерной сетью 52, такой как Интернет.
Модем 54, который может быть внутренним или внешним, соединен с системной шиной 23 посредством интерфейса 46 последовательного порта. В сетевом окружении программные модули или их части, описанные применительно к компьютеру 20, могут храниться на удаленном устройстве хранения информации. Надо принять во внимание, что показанные сетевые соединения являются типичными, и для установления коммуникационной связи между компьютерами могут быть использованы другие средства.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ ГРАФОВ | 2015 |
|
RU2708939C2 |
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ГЛОБАЛЬНОЙ ИДЕНТИФИКАЦИИ В КОЛЛЕКЦИИ ДОКУМЕНТОВ | 2015 |
|
RU2591175C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ, ИЗВЛЕКАЕМОЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2015 |
|
RU2605077C2 |
| СПОСОБ УСКОРЕНИЯ ОБРАБОТКИ МНОЖЕСТВЕННЫХ ЗАПРОСОВ ТИПА SELECT К RDF БАЗЕ ДАННЫХ С ПОМОЩЬЮ ГРАФИЧЕСКОГО ПРОЦЕССОРА | 2012 |
|
RU2490702C1 |
| СПОСОБ И СИСТЕМА ДЛЯ МАШИННОГО ИЗВЛЕЧЕНИЯ И ИНТЕРПРЕТАЦИИ ТЕКСТОВОЙ ИНФОРМАЦИИ | 2015 |
|
RU2592396C1 |
| ОПРЕДЕЛЕНИЕ СТЕПЕНЕЙ УВЕРЕННОСТИ, СВЯЗАННЫХ СО ЗНАЧЕНИЯМИ АТРИБУТОВ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ | 2016 |
|
RU2640297C2 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ, СОДЕРЖАЩИХ ТЕКСТ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2607976C1 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ (СУБД) | 2018 |
|
RU2704873C1 |
Изобретение относится к области хранения данных графов в В-дереве. Техническим результатом является эффективное хранение и поиск сложных данных графов. Раскрыт внедренный в компьютер способ для хранения данных графов, представляющих рабочий процесс бизнес-процесса, при этом способ содержит: генерирование рабочего процесса бизнес-процесса; генерирование графа, имеющего множество вершин и соединяющих ребер, при этом данные рабочего процесса хранятся в форме графов; генерирование данных графов, имеющих предикаты и аргументы, соответствующие вершинам; реализацию В-дерева в виде набора таблиц, содержащего таблицу предикатов и таблицы аргументов; сохранение предиката в таблице предикатов В-дерева; сохранение аргументов в отдельных таблицах В-дерева; сохранение связей между аргументами в таблице связей; генерирование ссылки на таблицу связей; генерирование ссылок на таблицы, содержащие аргументы; сохранение ссылки на таблицу связей В-дерева и ссылок на таблицы, содержащие аргументы, В-дерева в таблице предикатов В-дерева для указания связи между таблицей связей В-дерева и таблицами, содержащими аргументы В-дерева, где связи между предикатом и аргументами определяются ребрами графа, при этом поиск в В-дереве осуществляется через предикаты для нахождения связей между вершинами графов. 2 н. и 13 з.п. ф-лы, 7 ил.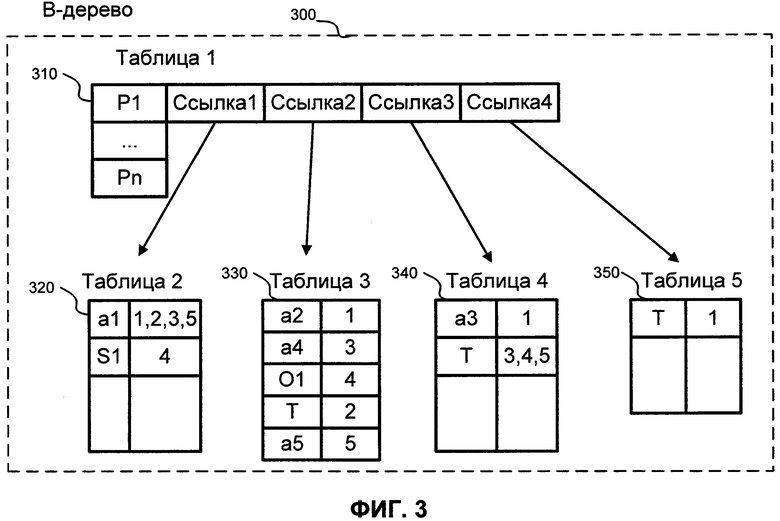
1. Внедренный в компьютер способ для хранения данных графов, представляющих рабочий процесс бизнес-процесса, при этом способ содержит:
генерирование рабочего процесса бизнес-процесса;
генерирование графа, имеющего множество вершин и соединяющих ребер, при этом данные рабочего процесса хранятся в форме графов;
генерирование данных графов, имеющих предикаты и аргументы, соответствующие вершинам;
реализацию В-дерева в виде набора таблиц, содержащего таблицу предикатов и таблицы аргументов;
сохранение предиката в таблице предикатов В-дерева;
сохранение аргументов в отдельных таблицах В-дерева;
сохранение связей между аргументами в таблице связей;
генерирование ссылки на таблицу связей;
генерирование ссылок на таблицы, содержащие аргументы;
сохранение ссылки на таблицу связей В-дерева и ссылок на таблицы, содержащие аргументы, В-дерева в таблице предикатов В-дерева для указания связи между таблицей связей В-дерева и таблицами, содержащими аргументы В-дерева,
где связи между предикатом и аргументами определяются ребрами графа,
при этом поиск в В-дереве осуществляется через предикаты для нахождения связей между вершинами графов.
2. Способ по п. 1, где предикат имеет произвольное количество соответствующих аргументов.
3. Способ по п. 1, содержащий сверх того присвоение уникального идентификатора предикату и соответствующим аргументам.
4. Способ по п. 3, содержащий сверх того сортировку предикатов в таблице предикатов на базе идентификаторов.
5. Способ по п. 1, содержащий сверх того генерирование значения терминатора и сохранение его в таблицу терминаторов в В-дереве.
6. Способ по п. 5, где значение терминатора указывает на конец аргументов, соответствующих определенному предикату.
7. Способ по п. 1, где таблицы, на которые ссылаются ссылки, хранящиеся в таблице предикатов, содержат ссылки на другие таблицы, содержащие аргументы и терминаторы.
8. Способ по п. 1, где предикаты хэшируются перед хранением в таблице предикатов.
9. Способ по п. 8, где предикаты сортируются посредством сортировки соответствующих хэш-значений.
10. Способ по п. 1, где аргументы хэшируются перед хранением в таблицах аргументов.
11. Способ по п. 10, где аргументы сортируются путем сортировки соответствующих хэш-значений.
12. Способ по п. 1, где поиск предикатов в В-дереве включает выявление пересечений атрибутов идентификаторов.
13. Способ по п. 1, где идентификаторы сортируются на основе порядка записи наборов идентификаторов в В-дерево.
14. Способ по п. 1, где В-дерево - это дерево бинарного поиска, которое имеет множество узлов.
15. Система для хранения данных графов, представляющая рабочий процесс бизнес-процесса, при этом система содержит:
процессор;
память, связанную с процессором;
программу компьютерной логики, сохраненную в памяти и исполняемую процессором, для реализации шагов, описанных в пункте 1.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 7089266 B2, 08.08.2006 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Автоматический огнетушитель | 0 |
|
SU92A1 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИОННЫХ ТЕКСТОВЫХ МАТЕРИАЛОВ | 2003 |
|
RU2242048C2 |

