Предпосылки создания изобретения
Область техники, к которой относится изобретение
Настоящее изобретение относится к синтезу речи. Изобретение относится, в частности, к способу и системе, которые позволяют на основе поступающих в реальном масштабе времени данных повышать разборчивость синтезированной речи в динамическом режиме.
Краткое изложение сущности изобретения
В последнее время были разработаны системы, назначение которых состоит в повышении разборчивости воспроизводимого в виде синтезированной речи звука и улучшения его восприятия слушателем в самых разнообразных окружающих условиях, например в салоне автомобиля, в кабине самолета, а также в жилых и офисных помещениях. Так, например, в результате последних разработок, направленных на улучшение характеристик, соответственно, качества воспроизведения звука автомобильными аудиосистемами, были созданы эквалайзеры, которые позволяют либо вручную, либо автоматически регулировать спектральный состав воспроизводимого аудиосистемой звука. В отличие от традиционных систем, в которых подобная регулировка осуществлялась слушателем вручную с помощью различных органов управления аудиосистемой, в более современных разработках предусмотрен выборочный контроль за условиями воспроизведения звука в окружающем пространстве, в котором находится слушатель. Подход, основанный на использовании эквалайзеров в аудиосистемах, обычно требует знания значительного объема информации об условиях, которые предположительно будут преобладать в окружающем пространстве, в котором будет эксплуатироваться аудиосистема. Тем самым подобный тип адаптации звука к условиям его воспроизведения ограничивается регулированием выходных параметров аудиосистемы и применительно к автомобилю обычно привязан к конкретной его марке и модели.
Помимо этого на протяжении уже многих лет в связи для управления воздушным движением и в военной связи используется фонетический алфавит, основанный при произнесении слова по буквам на их замене словами, начинающихся с этих же букв (т.е., например, в английском языке букве "а" соответствует слово "alpha", букве "b" соответствует слово "bravo", букве "с" соответствует слово "Charlie" и т.д.), и позволяющий исключить возможность неоднозначного толкования отдельно произносимых букв в сложных условиях связи. В основе подобного подхода, таким образом, также лежит теоретическое предположение, согласно которому при наличии шума в канале связи и/или фонового шума некоторые звуки по своей природе обладают большей разборчивостью по сравнению с другими.
В качестве еще одного примера повышения разборчивости речи можно назвать обработку сигналов в мобильных или сотовых телефонах для уменьшения различимых на слух искажений, возникающих при передаче сигнала по восходящим/нисходящим линиям связи или через базовую станцию. При этом следует отметить, что подобный подход направлен на устранение искажений, обусловленных шумом в канале связи (или шумом, возникающим при сверточном кодировании сигнала), и не позволяет учитывать фоновый (или аддитивный) шум, присутствующий в окружающем пространстве, в котором находится слушатель. Еще одним примером повышения разборчивости речи служит традиционная система подавления эхо-сигналов, которую обычно используют в конференц-связи.
Необходимо также отметить, что ни один из описанных выше методов улучшения воспроизведения звука не позволяет модифицировать синтезированную речь в динамическом режиме. Вместе с тем в настоящее время существует острая необходимость в разработке подобных методов динамической модификации синтезированной речи, поскольку синтез речи быстро приобретает популярность, учитывая прогресс, достигнутый в последнее время в улучшении выходных характеристик синтезаторов речи. Однако несмотря на все достигнутые в последнее время в этой области успехи по-прежнему не решенным остается целый ряд проблем, связанных с синтезом речи. Так, в частности, одна из таких проблем состоит в том, что уже при разработке всех обычных синтезаторов речи для установки их управляющих параметров на определенные значения необходимо заранее располагать информацией об условиях, которые предположительно будут преобладать в окружающем пространстве, в котором будет использоваться синтезатор речи. Очевидно, что подобный подход является абсолютно негибким и допускает возможность применения того или иного конкретного синтезатора речи в сравнительно ограниченном наборе окружающих условий, в которых возможна оптимальная работа синтезатора речи. Исходя из вышеизложенного, представляется целесообразным разработать способ и систему, которые позволяли бы модифицировать синтезированную речь на основе поступающих в реальном масштабе времени данных и тем самым улучшать ее разборчивость.
Эта и другие задачи решаются с помощью предлагаемого в изобретении способа модификации синтезированной речи. Этот способ заключается в том, что на основе вводимого текста и множества значений параметров динамического управления генерируют синтезированную речь. Далее на основе входного сигнала, характеризующего разборчивость речи воспринимающим ее слушателем, формируют поступающие в реальном масштабе времени данные. Затем в соответствии с предлагаемым в изобретении способом на основе этих поступающих в реальном масштабе времени данных модифицируют одно или несколько значений параметров динамического управления, в результате чего повышается разборчивость синтезированной речи. Модификация указанных значений параметров управления синтезатором речи в динамическом режиме, а не на стадии его разработки, обеспечивает высокий уровень адаптации, которого невозможно достичь при традиционных подходах.
В настоящем изобретении предлагается также способ модификации одного или нескольких параметров динамического управления синтезатором речи. Этот способ заключается в том, что получают поступающие в реальном масштабе времени данные и на основе этих поступающих в реальном масштабе времени данных определяют релевантные характеристики синтезированной речи. Такие релевантные характеристики синтезированной речи имеют соответствующие, относящиеся к ним параметры динамического управления. Затем в соответствии с предлагаемым в изобретении способом значения параметров динамического управления изменяют в соответствии с регулировочными значениями, внося таким путем необходимые изменения в релевантные характеристики синтезированной речи.
Еще одним объектом настоящего изобретения является система адаптации синтезатора речи, имеющая преобразующий текст в речь (ТВР) синтезатор, систему аудиоввода и устройство управления адаптацией. Указанный синтезатор генерирует синтезированную речь на основе вводимого текста и множества значений параметров динамического управления. Система аудиоввода формирует поступающие в реальном масштабе времени данные на основе фонового шума, присутствующего в окружающем пространстве, в котором воспроизводится синтезированная речь. Устройство управления адаптацией функционально связанно с этими синтезатором и системой аудиоввода. Такое устройство управления адаптацией на основе поступающих в реальном масштабе времени данных модифицирует одно или несколько значений параметров динамического управления, что обеспечивает уменьшение взаимных помех между фоновым шумом и синтезированной речью.
Следует отметить, что приведенное выше общее описание и последующее подробное описание изобретения носят исключительно иллюстративный характер и предназначены в первую очередь для пояснения общих принципов и концепций, лежащих в основе изобретения. Прилагаемые к описанию чертежи дополнительно служат для более наглядного пояснения предлагаемого в изобретении решения и в соответствии с этим являются составной частью настоящего описания. Эти чертежи, на которых представлены различные отличительные особенности изобретения и варианты его осуществления, наряду с описанием служат для пояснения лежащих в основе изобретения принципов и функциональных особенностей предлагаемой в нем системы.
Краткое описание чертежей
Различные отличительные особенности и преимущества настоящего изобретения более подробно рассмотрены в последующем описании и в формуле изобретения со ссылкой на прилагаемые к описанию чертежи, на которых показано:
на фиг.1 - схема предлагаемой в изобретении системы адаптации синтезатора речи,
на фиг.2 - блок-схема, иллюстрирующая процесс модификации синтезированной речи в соответствии с настоящим изобретением,
на фиг.3 - блок-схема, иллюстрирующая процесс формирования поступающих в реальном масштабе времени данных на основе входного сигнала согласно одному из вариантов осуществления настоящего изобретения,
на фиг.4 - блок-схема, иллюстрирующая процесс определения характеристик фонового шума и их представления в виде поступающих в реальном масштабе времени данных согласно одному из вариантов осуществления настоящего изобретения,
на фиг.5 - блок-схема, иллюстрирующая процесс модификации одного или нескольких значений параметров динамического управления согласно одному из вариантов осуществления настоящего изобретения, и
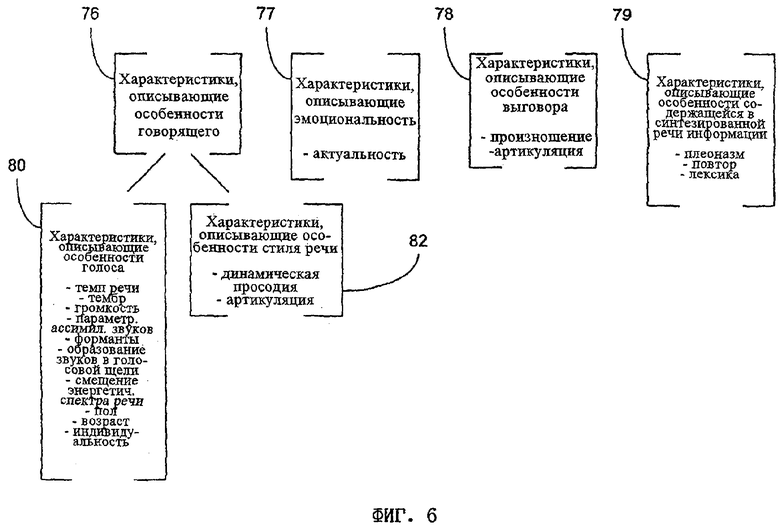
на фиг.6 - схема, на которой изображены релевантные характеристики и соответствующие им параметры динамического управления согласно одному из вариантов осуществления настоящего изобретения.
Подробное описание предпочтительных вариантов осуществления изобретения
На фиг.1 показана выполненная по предпочтительному варианту система 10 адаптации синтезатора речи. Обычно такая система 10 адаптации имеет преобразующий текст в речь (ТВР) синтезатор 12, который на основе вводимого текста 16 и множества значений 42 параметров динамического управления генерирует синтезированную речь 14. На основе фонового шума 22, присутствующего в некотором окружающем пространстве 24, в котором воспроизводится синтезированная речь 14, системой 18 аудиоввода формируются поступающие в реальном масштабе времени данные (ПРМВД) 20. С этими синтезатором 12 и системой 18 аудиоввода функционально связано устройство 26 управления адаптацией. Такое устройство 26 управления адаптацией на основе поступающих в реальном масштабе времени данных 20 модифицирует одно или несколько значений 42 параметров динамического управления, что обеспечивает уменьшение взаимных помех между фоновым шумом 22 и синтезированной речью 14. Для преобразования звуковых колебаний в электрические система 18 аудиоввода в предпочтительном варианте имеет преобразователь акустического сигнала в электрический, например микрофон.
Фоновый шум 22 может создаваться целым рядом различных источников, некоторые из которых в качестве примера показаны на чертеже. Подобные источники фонового шума, создающего помехи восприятию речи, воспроизводимой синтезатором, классифицируются по их типу и характеристикам. Так, например, некоторые источники шума, в частности сирена 28 полицейского автомобиля и пролетающий самолет (не показан), создают кратковременные шумовые помехи высокого уровня, обычно с быстро изменяющимися характеристиками. Другие источники шума, например работающие механизмы, установленные на производстве 30, и кондиционеры (не показаны), обычно создают длительный постоянный фоновый шум низкого уровня. Третьи источники шума, например радиоприемники 32 и различного рода бытовая аппаратура (не показана), часто создают непрерывные шумовые помехи, в частности в виде музыки или пения, характеристики которых аналогичны характеристикам синтезированной речи 14. Источником шумовых помех могут являться, кроме того, и присутствующие в окружающем пространстве 24 разговаривающие между собой люди 34, характеристики речи которых практически идентичны характеристикам синтезированной речи 14. Помимо этого преобладающие в окружающем пространстве 24 условия также могут влиять на характеристики воспроизведения синтезированной речи 14. При этом условия в окружающем пространстве 24, а тем самым и оказываемое ими влияние могут динамически изменяться во времени.
Следует отметить, что настоящее изобретение не ограничено показанной на чертеже в качестве примера системой 10 адаптации, в которой поступающие в реальном масштабе времени данные 20 формируются на основе фонового шума 22, присутствующего в окружающем пространстве 24, где воспроизводится синтезированная речь 14. Так, например, поступающие в реальном масштабе времени данные 20 могут также формироваться на основе информации, вводимой самим слушателем 36 через соответствующее устройство 19 ввода, как это более подробно описано ниже.
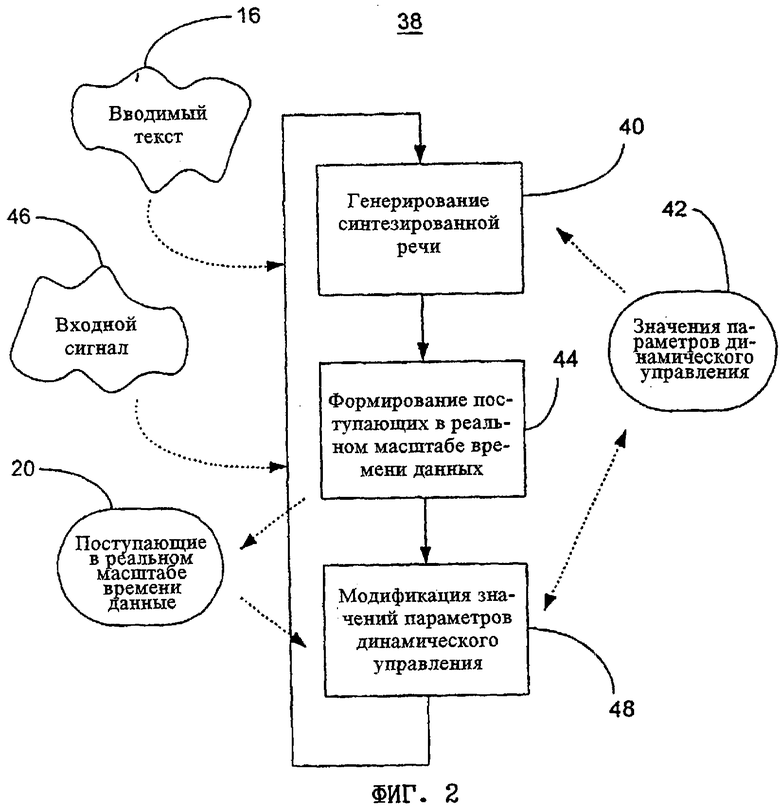
На фиг.2 показана блок-схема 38, иллюстрирующая процесс модификации синтезированной речи. В соответствии с этой блок-схемой на шаге 40 на основе вводимого текста 16 и множества значений 42 параметров динамического управления генерируется синтезированная речь. На шаге 44 на основе входного сигнала 46, характеризующего разборчивость речи воспринимающим ее слушателем, формируются поступающие в реальном масштабе времени данные 20. Как уже упоминалось выше, источником входного сигнала 46 может служить непосредственно фоновый шум в окружающем пространстве либо сам слушатель (или иной пользователь). Однако в любом случае входной сигнал 46 содержит данные, относящиеся к разборчивости речи, и в соответствии с этим является важным источником информации, используемой для адаптации речи в динамическом режиме. На шаге 48 на основе поступающих в реальном масштабе времени данных 20 модифицируется одно или несколько значений 42 параметров динамического управления, в результате чего повышается разборчивость синтезированной речи.
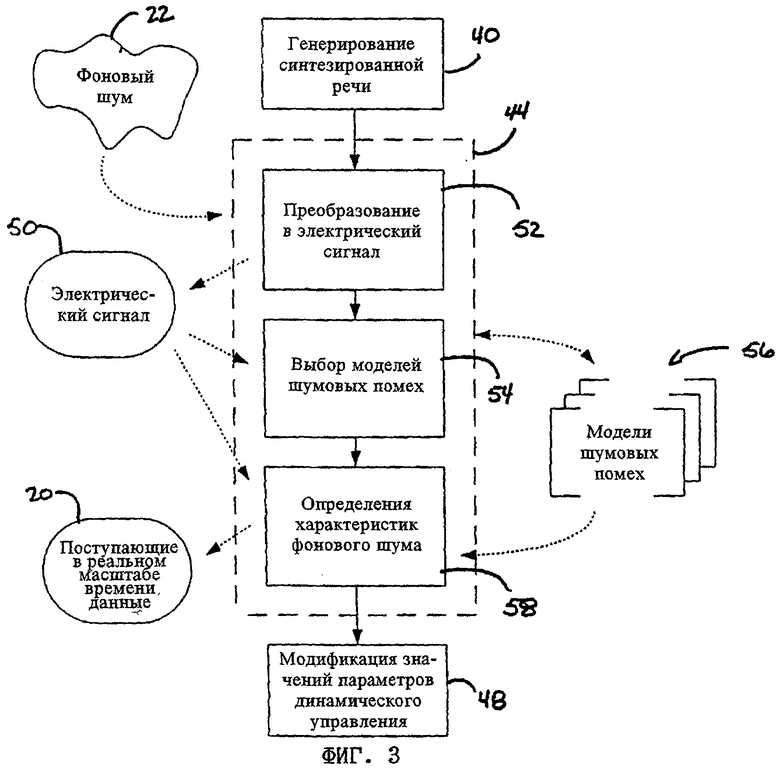
Как уже указывалось выше, в одном из вариантов осуществления настоящего изобретения поступающие в реальном масштабе времени данные 20 формируются на основе фонового шума, присутствующего в окружающем пространстве, в котором воспроизводится синтезированная речь. В соответствии с этим на фиг.3 проиллюстрирован предпочтительный процесс формирования поступающих в реальном масштабе времени данных 20 на шаге 44. Согласно показанной на этом чертеже блок-схеме на шаге 52 фоновый шум 22 преобразуется в электрический сигнал 50. Затем на шаге 54 из соответствующей базы данных, в которой хранятся модели шумовых помех (не показана), выбирается одна или несколько моделей 56 шумовых помех. После этого на шаге 58 на основе электрического сигнала 50 и моделей 56 шумовых помех можно определить характеристики фонового шума и представить их в виде поступающих в реальном масштабе времени данных 20.
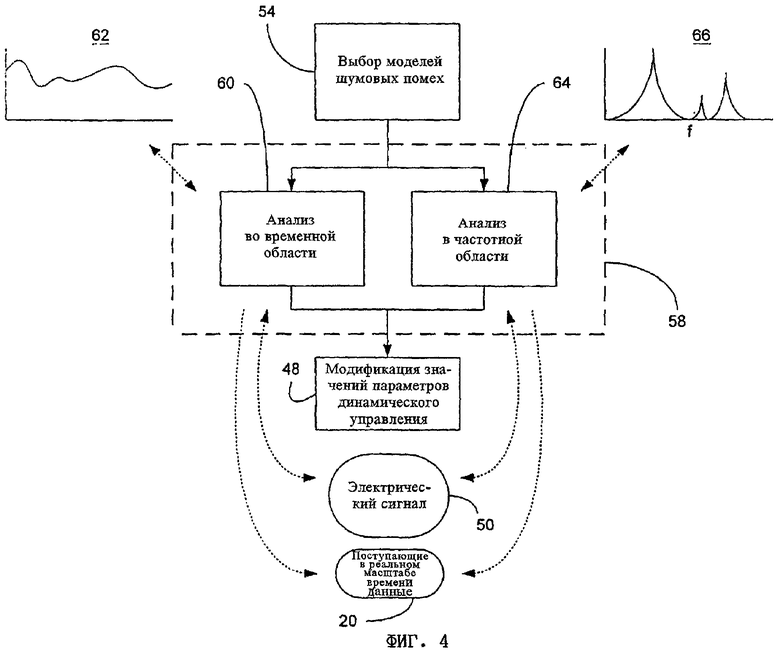
На фиг.4 показана блок-схема, иллюстрирующая предпочтительный процесс определения характеристик фонового шума на шаге 58. Согласно показанной на этом чертеже блок-схеме сначала на шаге 60 электрический сигнал 50 для определения его временных характеристик подвергается анализу во временной области. Полученные в результате этого анализа данные 62 об изменении электрического сигнала во времени содержат значительную часть информации, которая используется при выполнении рассмотренных в настоящем описании операций. Аналогичным образом на шаге 64 электрический сигнал 50 подвергается анализу в частотной области с получением данных 66 о его частотных характеристиках. При этом следует отметить, что порядок выполнения операций на шагах 60 и 64 не имеет существенного значения и не влияет на конечный результат.
Необходимо также отметить, что на шаге 58, на котором определяются характеристики фонового шума, предусмотрено выявление типа различного рода шумовых помех, присутствующих в фоновом шуме. В качестве примера подобных шумовых помех, присутствующих в фоновом шуме, можно назвать, но не ограничиваясь только ими, помехи высокого уровня, помехи низкого уровня, кратковременные помехи, длительные помехи, изменяющиеся помехи и постоянные помехи. На шаге 58, на котором определяются характеристики фонового шума, могут быть также предусмотрены операции по выявлению потенциальных источников фонового шума, по выявлению речи в фоновом шуме и по определению местонахождения всех таких источников фонового шума.
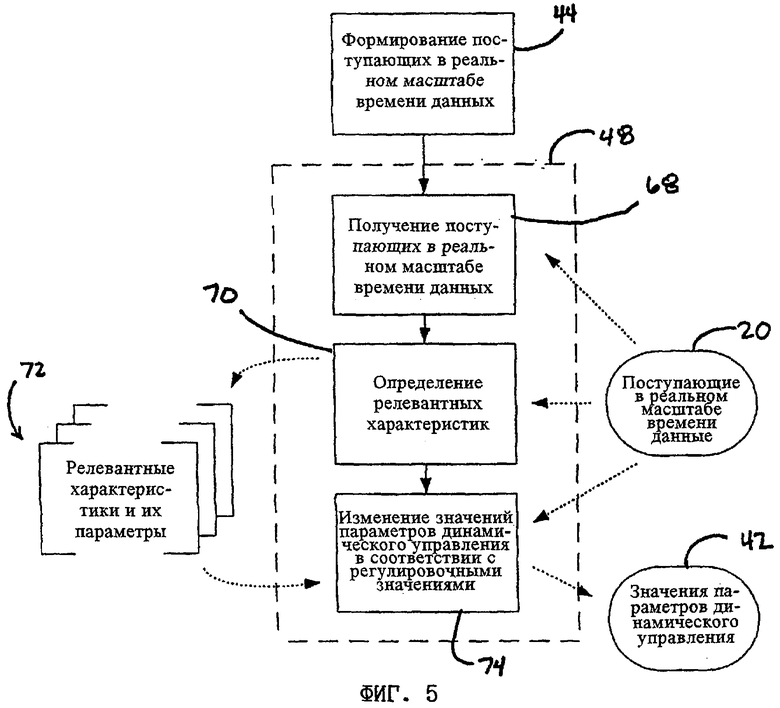
На фиг.5 показана блок-схема, на примере которой более подробно поясняется предпочтительный процесс модификации значений 42 параметров динамического управления. Согласно показанной на этом чертеже блок-схеме после получения на шаге 68 поступающих в реальном масштабе времени данных 20 затем на их основе на следующем шаге 70 определяются релевантные характеристики 72 синтезированной речи. Такие релевантные характеристики 72 синтезированной речи имеют соответствующие, относящиеся к ним параметры динамического управления. Далее на шаге 74 значения параметров динамического управления изменяются в соответствии с регулировочными значениями, в результате чего в релевантные характеристики 72 синтезированной речи также вносятся необходимые изменения.
На фиг.6 более подробно показаны возможные релевантные характеристики 72 синтезированной речи, описанные выше. Обычно такие релевантные характеристики 72 можно подразделить на характеристики 76, описывающие особенности говорящего, на характеристики 77, описывающие эмоциональность, на характеристики 78, описывающие особенности выговора, и на характеристики 79, описывающие особенности содержащейся в синтезированной речи информации. Характеристики 76, описывающие особенности говорящего, в свою очередь можно подразделить на характеристики 80, описывающие особенности голоса, и на характеристики 82, описывающие особенности стиля речи. К числу параметров, от которых зависят характеристики 80, описывающие особенности голоса, относятся, но ограничиваясь только ими, темп речи, тембр (основная частота), громкость, параметрическая ассимиляция звуков, форманты (частота формант и ширина полосы частот формант), образование звуков в голосовой щели, смещение энергетического спектра речи, пол, возраст и индивидуальность. К числу параметров, от которых зависят характеристики 82, описывающие особенности стиля речи, относятся, но ограничиваясь только ими, динамическая просодия (ритм, ударение и интонация) и артикуляция. Так, в частности, внятность речи можно повысить за счет четкого произношения конечных согласных и т.д., что позволяет потенциально улучшить разборчивость синтезированной речи.
Для привлечения внимания слушателя можно также использовать параметры, относящиеся к характеристикам 77, описывающим эмоциональность, такие как актуальность воспроизводимого в виде синтезированной речи сообщения. К числу характеристик 78, описывающих особенности выговора, можно отнести произношение и артикуляцию (форманты и т.д.). Очевидно, что к характеристикам 79, описывающим особенности содержащейся в синтезированной речи информации, относятся такие параметры, как плеоназм, повтор и лексика. Так, например, наличие или отсутствие плеоназма в речи определяется использованием слов- и фраз-синонимов (например, в английском языке для воспроизведения речевого сообщения с указанием текущего времени суток в 5 часов дня может использоваться фраза "five pm" либо фраза "five o'clock in the afternoon" ("пять часов пополудни")). Повтор предполагает избирательное повторение определенных частей сообщения, воспроизводимого с помощью синтезированной речи, с целью сделать более четкий акцент на содержащейся в нем важной информации. Помимо этого использование ограниченной лексики и ограниченного синтаксиса, обеспечивающее упрощение языка, также может способствовать повышению разборчивости речи.
В отношении показанной на фиг.1 системы следует также отметить, что для создания эффекта изменения пространственного местоположения источника синтезированной речи 14 в сочетании с системой 84 аудиовывода может использоваться полифоническая обработка звука, основанная на поступающих в реальном масштабе времени данных 20.
Из приведенного выше описания для специалиста в данной области техники очевидно, что предлагаемое в изобретении решение допускает возможность его практической реализации разнообразными путями. В соответствии с этим настоящее изобретение не ограничено конкретными вариантами его осуществления, на примере которых оно рассмотрено выше, а предполагает возможность внесения в них различных, очевидных для специалиста изменений и модификаций на основе описания изобретения, формулы изобретения и прилагаемых к описанию чертежей.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЛЯ ВОСПРОИЗВЕДЕНИЯ РЕЧИ, ВЫПОЛНЕННОЕ С ВОЗМОЖНОСТЬЮ МАСКИРОВКИ ВОСПРОИЗВОДИМОЙ РЕЧИ В ЗОНЕ МАСКИРОВАННОЙ РЕЧИ | 2016 |
|
RU2666675C1 |
| Синтезатор речи Кама-01 | 1990 |
|
SU1714642A1 |
| УСТРОЙСТВО ДЛЯ ИЗМЕРЕНИЯ ПОМЕХОУСТОЙЧИВОСТИ ВОСПРИЯТИЯ РЕЧИ ЧЕЛОВЕКОМ | 1998 |
|
RU2148391C1 |
| СИСТЕМА АДАПТИВНОЙ ФИЛЬТРАЦИИ АУДИОСИГНАЛОВ ДЛЯ УЛУЧШЕНИЯ РАЗБОРЧИВОСТИ РЕЧИ ПРИ НАЛИЧИИ ШУМА | 1996 |
|
RU2163032C2 |
| ПОВЫШЕНИЕ РАЗБОРЧИВОСТИ РЕЧИ В ЗВУКОЗАПИСИ РАЗВЛЕКАТЕЛЬНЫХ ПРОГРАММ | 2008 |
|
RU2440627C2 |
| Способ повышения разборчивости речи | 2016 |
|
RU2676022C1 |
| СПОСОБ ДОВРАЧЕБНОЙ ОЦЕНКИ КАЧЕСТВА РАСПОЗНАВАНИЯ РЕЧИ, СКРИНИНГОВОЙ АУДИОМЕТРИИ И ПРОГРАММНО-АППАРАТНЫЙ КОМПЛЕКС, ЕГО РЕАЛИЗУЮЩИЙ | 2020 |
|
RU2743049C1 |
| СПОСОБ АДАПТИВНОЙ ФИЛЬТРАЦИИ РЕЧЕВЫХ СИГНАЛОВ В СЛУХОВЫХ АППАРАТАХ | 1996 |
|
RU2111732C1 |
| СПОСОБ ИЗМЕРЕНИЯ РАЗБОРЧИВОСТИ РЕЧИ ПРИ РАЗЛИЧНЫХ ОТНОШЕНИЯХ СИГНАЛ/ШУМ | 2024 |
|
RU2819132C1 |
| Синтезатор речи | 1973 |
|
SU1084870A1 |
Изобретение относится, в частности, к способу и системе адаптации синтезатора речи с помощью поступающих в реальном масштабе времени данных. При осуществлении способа и системы динамической модификации синтезированной речи на основе вводимого текста и множества значений параметров динамического управления генерируют синтезированную речь. Далее на основе входного сигнала, характеризующего разборчивость речи воспринимающим ее слушателем, формируют поступающие в реальном масштабе времени данные, на основе которых модифицируют одно или несколько значений параметров динамического управления. Технический результат - повышение разборчивости синтезированной речи. 3 н. и 27 з.п. ф-лы, 6 ил.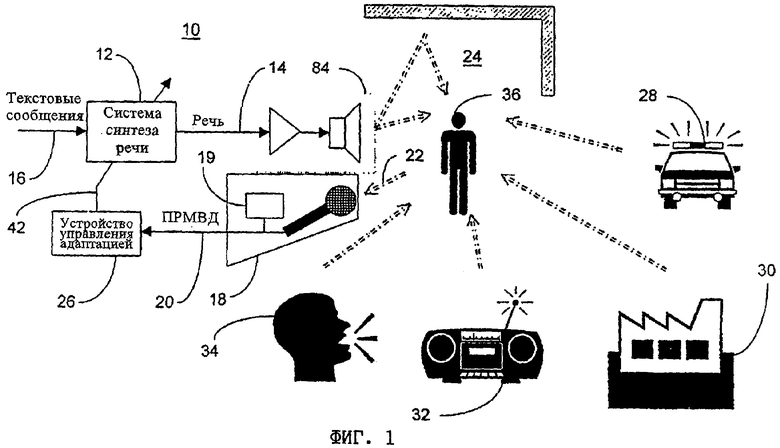
| US 6035273 А, 07.03.2000 | |||
| ПРОСТРАНСТВЕННАЯ ЗВУКОВОСПРОИЗВОДЯЩАЯ СИСТЕМА | 1996 |
|
RU2106074C1 |
| US 5434883 А, 18.01.1995 | |||
| СПОСОБ ПОЛУЧЕНИЯ АРОМАТИЧЕСКИХ а-СУЛЬФОНОКСИМОВ | 0 |
|
SU332079A1 |
| Устройство синтезирования речи | 1983 |
|
SU1100740A1 |

