Область техники, к которой относится изобретение
Настоящее изобретение относится к Web-серверам, в частности к поддержке множества языков в Web-серверах для встроенных систем.
Предшествующий уровень техники
Одна из основных ролей в Web-проектировании заключается в том, чтобы создавать Web-страницы так, чтобы они не зависели от типа броузеров, используемых терминалами клиента, то есть web-сраницы на Web-сервере должны выглядеть похожими, например, для программного обеспечения Netscape и Internet Explorer.
Для достижения этого Web-серверы, вообще говоря, имеют по одной странице на языке гипертекстовой разметки (HTML-странице) для каждого языка. Это делает участки HTML-файлов избыточными, то есть программы на макроязыке, HTML-форматирование, а также другие участки, не зависящие от языка, дублируются.
Указанная избыточная информация представляет собой избыточные затраты ресурсов памяти/запоминающего устройства, что является проблемой для встроенных систем, а также и других систем с ограниченными ресурсами.
Единственное известное решение заключается в том, чтобы иметь по одному набору HTML-страниц для каждого языка, поддерживаемого Web-сервером.
Проблема, связанная с известным вышеупомянутым решением, заключается в том, что, когда имеется набор HTML-файлов, переведенных на различные языки, участки контента (информационно-значимого содержимого) HTML-файлов становятся избыточными, то есть дублируются программы на макроязыке, HTML-форматирование и другие участки, не зависящие от языка. Указанное обстоятельство приводит к потребности в больших ресурсах памяти/запоминающего устройства, что является проблемой для встроенных систем и других систем с ограниченными ресурсами.
В будущем мобильные терминалы/устройства, вероятнее всего, будут содержать функциональные возможности Web-сервера. В таких малых устройствах емкость памяти ограничена вследствие как ограниченного размера, так и стоимости памяти. Следует отметить, что главным фактором, влияющим на потребность в ресурсах памяти, является контент (HTML-файлы, изображения и т.д.), предлагаемый Web-сервером, а не сама прикладная программа Web-сервера. Типичный объем памяти, требующийся для Web-сервера, предназначенного для встроенной системы, должен быть порядка 30 кбайт, в то время как объем контента, предлагаемого Web-сервером, может изменяться в широких пределах, от нескольких килобайт до нескольких сотен килобайт.
Таким образом, решение вышеупомянутых проблем, относящихся к излишним затратам ресурсов памяти/запоминающего устройства, будет даже более важным.
Многоязычные функциональные возможности, описанные в настоящем документе, помогут дополнительно снизить объем ресурсов памяти, требуемых для хранения элементов Web-сервера, относящихся к контенту.
Сущность изобретения
Задача настоящего изобретения заключается в том, чтобы обеспечить компоновку, решающую вышеописанную проблему. Признаки, определенные в независимых пунктах приложенной формулы изобретения, характеризуют указанный способ.
В частности, настоящее изобретение обеспечивает способ придания Web-серверам большей независимости от языка посредством просмотра HTML-файлов, соответствующих этим Web-срверам, на предмет уникальных текстовых фраз, зависящих от языка, и замены указанных фраз уникальными идентификаторами, оставляя неизменным контент, не зависящий от языка. Уникальные текстовые фразы, зависящие от языка, сохраняют в отдельных файлах текстовых фраз. Указанные файлы переводят на множество требуемых языков броузеров, что в результате дает по одному набору для каждого языка. При приеме запроса на файл Web-сервер просматривает файл на предмет уникальных идентификаторов, и при наличии таковых, извлекает соответствующие текстовые фразы из одного или большего числа файлов из набора файлов, переведенных на язык броузера, используемого запрашивающим терминалом. Затем Web-сервер предоставляет запрашивающему терминалу ответ, содержащий файл, в котором найденные уникальные идентификаторы заменены извлеченными текстовыми фразами.
Перечень фигур чертежей
Фиг.1 - иллюстрация процесса компиляции и объединения согласно настоящему изобретению,
фиг.2 - блок-схема алгоритма, показывающая передачу сигналов при запросе, выполняемом клиентом протокола передачи гипертекста (HTTP-клиента) на HTTP-сервер, поддерживающий многоязычные функциональные возможности согласно настоящему изобретению,
фиг.3 - многоязычные функциональные возможности на мобильном терминале, информационные ресурсы которого просматривают с помощью персонального компьютера (ПК), локально соединенного с этим терминалом,
фиг.4 - многоязычные функциональные возможности на мобильном терминале, информационные ресурсы которого просматривают с помощью (ПК), соединенного с этим терминалом через сеть Интернет и сеть GPRS (сеть с поддержкой общей службы пакетной радиопередачи).
Описание настоящего изобретения
Далее раскрывается общее описание настоящего изобретения, сопровождаемое двумя примерами вариантов воплощения того, как можно реализовать настоящее изобретение.
Фиг.1 схематично изображает основные концепции настоящего изобретения. Предложенное решение разделяет участки HTML-файла, зависящие от языка и независящие от языка, на Web-сервере на два отдельных файла. Когда к HTML-файлу осуществляют доступ, участки, зависящие от языка, и участки, не зависящие от языка, объединяют, результатом чего становится HTML-файл, содержащий форматирование и текст выбранного языка.
Для достижения указанной цели HTML-файл (на одном определенном языке) согласно настоящему изобретению должен быть подан в "языковый компилятор" прежде, чем он встраивается в файловую систему Web-сервера. Компилятор считывает HTML-файл и просматривает его на предмет текстовых фраз. Найденные текстовые фразы временно сохраняют в памяти для поиска идентичных текстовых фраз. Заметим, что текст и текстовые фразы в указанном контексте включают в себя все тексты и команды в файлах, зависящие от языка, такие как ссылки на графические объекты, мультимедийный контент, установки (например, набор символов) или обычный текст. Текстовые фразы, которые встретились ранее при поиске, удаляют для того, чтобы избежать двойного идентификатора для одной и той же фразы.
Затем для каждой фразы генерируют уникальный идентификатор фразы, и новый HTML-файл, в котором каждая текстовая фраза заменена соответствующим уникальным идентификатором (HTML-файл, не зависящий от языка), заменяет первоначальный файл. Одновременно текстовые фразы будут помещены в отдельный файл текстовых фраз.
Сгенерированный файл фраз посылают в средство перевода, которое переводит файл на требуемые языки (файлы фраз, зависящие от языка), что в результате дает по одному файлу на каждый язык.
Следовательно, HTML-страница, которая должна быть представлена на более чем одном языке, в дальнейшем будет иметь один HTML-файл с текстами, замененными уникальными идентификаторами, и некоторое количество файлов текстовых фраз (по одному для каждого языка), все из которых сохранены в файловой системе Web-сервера. Таким образом, содержимое, не зависящее от языка, не будет повторяться для каждого языка.
Когда Web-клиент запрашивает HTML-страницу, файловая система или Web-сервер должен просмотреть HTML-файл на предмет уникальных идентификаторов текстов. Когда уникальный идентификатор найден, его заменяют соответствующим текстом, взятым из файла текстовых фраз выбранного языка, то есть языка броузера, используемого Web-клиентом.
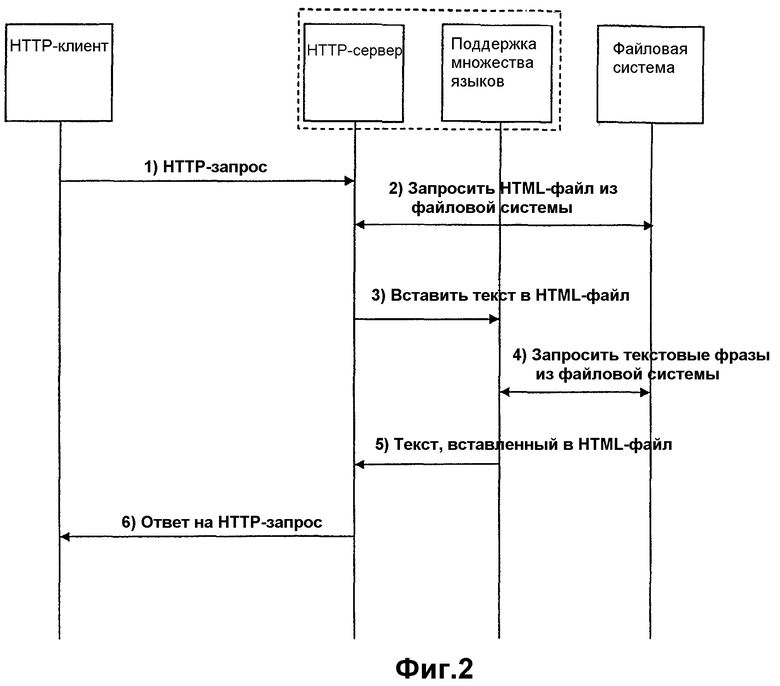
Фиг.2 изображает передачу сигналов, выполняемую тогда, когда HTTP-клиент (Web-броузер) запрашивает HTML-страницу из HTTP-сервера (Web-сервера), поддерживающего многоязычные функциональные возможности. Следующие этапы будут описываться со ссылкой на соответствующие номера позиций в блок-схеме алгоритма по фиг.2:
1. Web-клиент запрашивает HTML-страницу из Web-сервера, выдавая HTTP-запрос.
2. Web-сервер обрабатывает запрос и извлекает требуемую страницу из файловой системы.
3. Web-сервер запрашивает функцию поддержки множества языков просмотреть HTML-страницу на предмет идентификаторов текстов.
4. Функция поддержки множества языков запрашивает текстовые фразы из файловой системы и заменяет идентификаторы текстов, найденные в Web-странице.
5. HTML-файл, обновленный текстовыми фразами, возвращают на Web-сервер.
6. Запрошенный HTML-файл возвращают клиенту, запрашивающему упомянутую страницу.
В иллюстративных вариантах воплощения, описанных ниже, представлен Web-сервер, расположенный в мобильном терминале. Прототип мобильного терминала, содержащего функциональные возможности Web-сервера, был реализован, чтобы показать возможность иметь Web-сервер в таком небольшом устройстве.
Как упоминалось ранее, мобильные терминалы/устройства в будущем, вероятно, будут содержать функциональные возможности Web-сервера. Поэтому далее обсудим два иллюстративных варианта воплощения настоящего изобретения, в которых мобильный терминал служит в качестве Web-сервера.
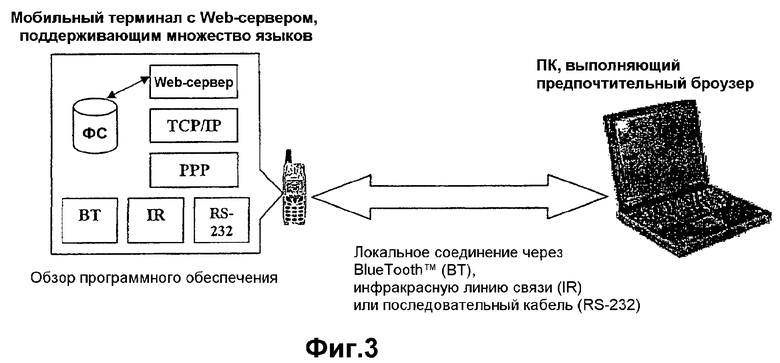
В первом примере, иллюстрируемом на фиг.3, мобильный терминал соединен с персональным компьютером, используя соединение по протоколу BlueTooth, инфракрасное (IR) соединение или соединение посредством последовательного кабеля.
Для установления соединения между компьютером и мобильным терминалом используется коммутируемая сеть связи.
HTML-файлы, не зависящие от языка, и файлы фраз, соответствующие конкретному языку, хранят в файловой системе (FS, ФС) терминала.
Когда броузер запрашивает одну из HTML-страниц, хранящихся в терминале, Web-сервер выполняет синтаксический анализ запрошенной HTML-страницы на предмет идентификаторов текстов и заменяет найденные идентификаторы текстов соответствующими текстовыми фразами, хранящимися в файле, соответствующем конкретному языку, перед тем как послать данные обратно в броузер.
Используемый файл фраз, соответствующий конкретному языку, зависит от того, для использования какого языка сконфигурирован Web-сервер.
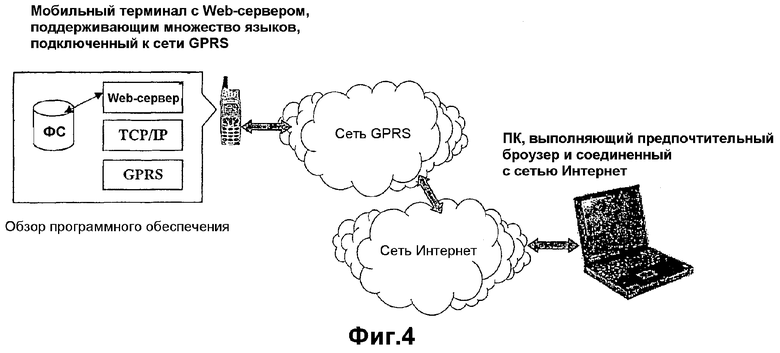
Как иллюстрируется на фиг.4, во втором примере того, как может использоваться настоящее изобретение, мобильный терминал соединен с сетью GPRS, имеющей доступ в сеть Интернет.
Компьютер, используемый для осуществления доступа к Web-серверу в мобильном терминале, имеет Интернет-соединение.
HTML-файлы, не зависящие от языка, и файлы фраз, соответствующие конкретному языку, хранятся в файловой системе (ФС) терминала.
Когда броузер запрашивает одну из HTML-страниц, хранящихся в терминале, Web-сервер выполняет синтаксический анализ запрошенной HTML-страницы на предмет идентификаторов текстов и заменяет найденные идентификаторы текстов соответствующими текстовыми фразами, хранящимися в файле, соответствующем конкретному языку, перед тем как послать данные обратно в броузер.
Используемый файл фраз, соответствующий конкретному языку, зависит от того, для использования какого языка сконфигурирован Web-сервер.
Очевидным преимуществом указанного решения по сравнению с известным решением является меньшее использование ресурсов памяти/запоминающего устройства. Причина этого заключается в том, что в дополнение к файлам текстовых фраз необходим только один набор HTML-страниц, общий для всех языков. Таким образом, никакие данные не повторяются, что приводит к отсутствию избыточной информации (HTML-форматирования, программ на макроязыке и других частей HTML-страницы, не зависящих от языка), в отличие от решения, в котором на каждый язык, поддерживаемый Web-сервером, приходится один набор HTML-страниц.
Улучшенная эксплуатация ресурсов памяти/запоминающего устройства в Web-серверах позволит реализовать функциональные возможности Web-сервера в небольших устройствах наподобие мобильных терминалов. Поскольку следующие поколения систем мобильной связи, наподобие GPRS и UMTS (универсальная система мобильных телекоммуникаций), обеспечивают "постоянную" доступность терминалов (благодаря технологии коммутации пакетов), для таких терминалов будет возможен просмотр их информационных ресурсов в режиме удаленного доступа, и в них потребуется реализация функциональных возможностей Web-сервера.
Настоящее изобретение также расширяет ограничения на количество Web-броузеров, совместимых с Web-сервером, поскольку эффективное использование ресурсов памяти/запоминающего устройства позволит представлять страницы на большем количестве языков.
Настоящее изобретение не ограничено традиционными Web-срверами, включающими в себя только файлы, скомпонованные в соответствии с HTML. Изобретение может также быть применимо в сочетании с другими файлами, родственными HTML, такими как файлы расширяемого языка разметки (XML), совместимые со стандартом WAP (протокол беспроводной связи с Интернет).
Изобретение относится к поддержке множества языков на Web-сервере для встроенных систем, содержащем исходные файлы, приспособленные для просмотра удаленными броузерами, находящимися на одном или более терминалах, имеющих прямое или опосредованное соединение с Web-сервером. Использование изобретения позволяет получить технический результат в виде сокращения объемов памяти, требуемых для хранения элементов Web-сервера, относящихся к контенту. Этот результат достигается благодаря тому, что в способе просматривают файлы на предмет уникальных текстовых фраз, зависящих от языка; генерируют один уникальный идентификатор для каждой уникальной текстовой фразы и заменяют каждую текстовую фразу соответствующим ей уникальным идентификатором в новых файлах, каждый из которых соответствует одному из исходных файлов; переводят текстовые фразы на требуемые языки и сохраняют переведенные текстовые фразы в файлах текстовых фраз; при приеме запроса на исходный файл просматривают соответствующий новый файл на предмет уникальных идентификаторов и извлекают соответствующие текстовые фразы из файлов, переведенных на язык броузера, используемого запрашивающим терминалом. 8 з.п. ф-лы, 4 ил.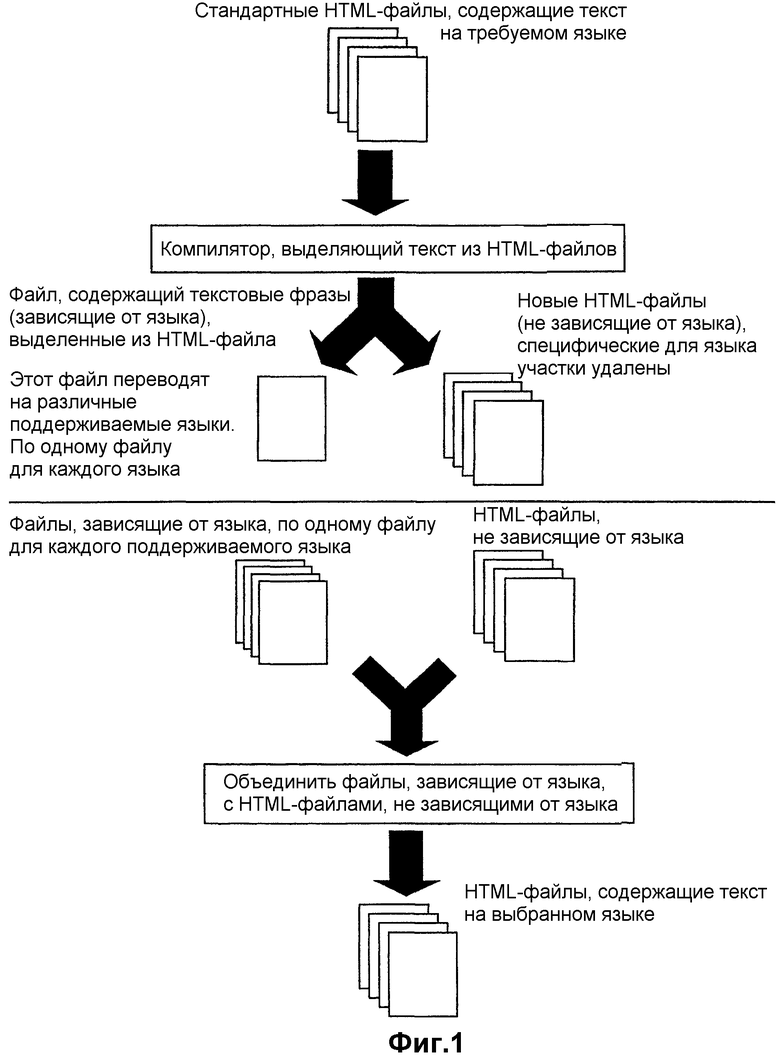
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| СПОСОБ ВЕЩАНИЯ ТЕЛЕПРОГРАММЫ С СИНХРОННЫМИ ПЕРЕВОДАМИ | 1995 |
|
RU2087079C1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| ЩИТОВОЙ ДЛЯ ВОДОЕМОВ ЗАТВОР | 1922 |
|
SU2000A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Состав для диффузионного упрочнения рабочих деталей штампов и прессформ | 1977 |
|
SU692909A1 |

