ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение в основном относится к кодированию и декодированию звуковых сигналов в системах связи. В частности, настоящее изобретение относится к способу модификации сигналов, особенно, но не исключительно, подходящему для кодирования с линейным предсказанием с кодовым возбуждением (CELP-кодирования).
ОБЗОР СОСТОЯНИЯ ТЕХНИКИ
Потребность в эффективных способах узкополосного и широкополосного цифрового кодирования речи с оптимальным соотношением качества по субъективной шкале оценки (субъективного качества) и скорости передачи информации в битах (битовой скорости) непрерывно возрастает в разных областях, например, в телеконференцсвязи, мультимедийной технике и беспроводной связи. До недавнего времени для кодирования речи использовали, главным образом, так называемую телефонную полосу частот, ограниченную диапазоном 200-3400 Гц. Однако применение широкой полосы частот для передачи речи обеспечивает большую разборчивость и естественность передаваемой речи, чем при использовании традиционной телефонной полосы частот. Как показали исследования, полоса частот, определяемая диапазоном 50-7000 Гц, достаточна, чтобы обеспечить такой уровень качества, который создает впечатление личного обмена информацией. Для обычных звуковых сигналов данная полоса частот обеспечивает приемлемое субъективное качество, но все же ниже уровня качества систем частотно-модулированного радиовещания (ЧМ-радиовещания) или компакт-диска (CD), которые используют частотные диапазоны, соответственно, 20-16000 Гц и 20-20000 Гц.
Речевой кодер преобразует речевой сигнал в двоичный поток, который передается по каналу связи или сохраняется на носителе информации. Речевой сигнал оцифровывается, затем дискретизируется и квантуется с использованием обычно 16 битов на отсчет. Речевой кодер выполняет функцию представления упомянутых цифровых отсчетов меньшим числом битов, но при этом обеспечивает высокое субъективное качество речи. Речевой декодер или синтезатор работает с переданным или сохраненным двоичным потоком и преобразует его обратно в звуковой сигнал.
CELP-кодирование является одним из лучших способов достижения компромисса между субъективным качеством и битовой скоростью. На данном способе кодирования основано несколько стандартов кодирования как для беспроводных, так и проводных линий связи. При CELP-кодировании дискретизированный речевой сигнал обрабатывается последовательно по блокам, состоящим из N отсчетов и обычно называемым кадрами, где N обозначает заданное число, обычно соответствующее 10-30 мс. С каждым кадром осуществляется вычисление и передача с использованием фильтра линейного предсказания (LP-фильтра). Вычисление LP-фильтра обычно требует упреждающего просмотра, т.е. 5-10-мс речевого сегмента из последующего кадра. Содержащий N отсчетов кадр делится на блоки меньшей протяженности, называемые подкадрами. Число подкадров обычно равно трем или четырем, чтобы получать в результате подкадры длительностью 4-10 мс. Возбуждающий сигнал в каждом подкадре обычно получают из двух компонентов: предшествующего возбуждения и нового возбуждения, определяемого по фиксированной кодовой книге. Компонент, сформированный из предшествующего возбуждения, часто называют возбуждением, определяемым по адаптивной кодовой книге, или возбуждением основным тоном. Параметры, характеризующие возбуждающий сигнал, кодируются и передаются в декодер, где реконструированный возбуждающий сигнал служит входным сигналом LP-фильтра.
При обычном CELP-кодировании долговременное предсказание для отображения предшествующего возбуждения в текущее возбуждение обычно выполняется на основе подкадров. Долговременное предсказание характеризуется параметром задержки и усилением основного тона, которые обычно вычисляются, кодируются и передаются в декодер для каждого подкадра. При низких битовых скоростях на данные параметры расходуется существенная доля располагаемого битового ресурса. Способы модификации сигналов (см. публикации [1-7])
[1] W.B. Kleijn, P. Kroon, and D. Nahumi, "The RCELP speech-coding algorithm", European Transactions on Telecommunications, Vol. 4, No. 5, pp. 573-582, 1994;
[2] W.B. Kleijn, R.P. Ramachandran, and P. Kroon, "Interpolation of the pitch-predictor parameters in analysis-by-synthesis speech coders", IEEE Transactions on Speech and Audio Processing, Vol. 2, No. 1, pp. 42-54, 1994;
[3] Y. Gao, A. Benyassine, J. Thyssen, H. Su, and E. Shlomot, "EX-CELP: A speech coding paradigm", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Salt Lake City, Utah, U.S.A., pp. 689-692, 7-11 May 2001;
[4] Патент США № 5704003, "RCELP-кодер" Lucent Technologies Inc., (W.B. Kleijn and D. Nahumi), от 19 сентября 1995 г.;
[5] Заявка на европатент № 0 602 826 A2, "Временной сдвиг для кодирования путем анализа через синтез", AT&T Corp., (B. Kleijn), от 1 декабря 1993 г.;
[6] Заявка на патент № WO 00/11653, "Речевой кодер с непрерывной деформацией времени, взаимосвязанной с долговременным предсказанием", Conexant Systems Inc., (Y. Gao), от 24 августа 1999 г.;
[7] Заявка на патент № WO 00/11654, "Речевой кодер, адаптивно принимающий обработку основного тона с непрерывной деформацией времени", Conexant Systems Inc., (H. Su and Y. Gao), от 24 августа 1999 г.
существенно повышают характеристики долговременного предсказания при низких битовых скоростях за счет корректировки подлежащего кодированию сигнала. Данный эффект достигается адаптацией эволюции периодов основного тона до согласования с задержкой долговременного предсказания, что позволяет передавать только один параметр задержки на кадр. Модификация сигнала основана на посылке, что разницу между модифицированным речевым сигналом и исходным речевым сигналом можно сделать неразличимой на слух. Выполняющие CELP-кодирование кодеры (CELP-кодеры), применяющие модификацию сигнала, часто называют обобщенными кодерами анализа через синтез или релаксационными CELP-кодерами (RCELP-кодерами).
Способы модификации сигнала предусматривают, что основной тон сигнала корректируется в соответствии с заданной кривой задержки. Затем, в результате выполнения долговременного предсказания предшествующий возбуждающий сигнал отображается на текущий подкадр с помощью упомянутой кривой задержки, а также регулировкой размаха параметром усиления. Кривую задержки получают непосредственным интерполированием по двум оценкам основного тона без обратной связи, где первую оценку получают в предшествующем кадре, а вторую оценку - в текущем кадре. Интерполирование дает величину задержки для каждого момента времени кадра. После получения кривой задержки основной тон в подкадре, подлежащем текущему кодированию, регулируется, чтобы следовать данной искусственной кривой, деформации времени, т.е. изменения шкалы времени сигнала.
При прерывистой деформации времени в соответствии с [1, 4 и 5] происходит сдвиг сегмента сигнала по времени без изменения протяженности сегмента. Прерывистая деформация времени нуждается в процедуре обработки результирующих перекрывающихся или пропущенных участков сигнала. При непрерывной деформации времени в соответствии с [2, 3, 6, 7] сегмент сигнала либо сжимается, либо растягивается. Данная операция выполняется с использованием непрерывной во времени аппроксимации сегмента сигнала и повторной его дискретизации на требуемой протяженности с неравными интервалами, определяемыми на основании кривой задержки. Для ослабления артефактов при выполнении указанных операций выдерживается небольшой допуск на изменение шкалы времени. Более того, для устранения результирующих искажений деформация времени обычно выполняется с использованием сигнала-остатка линейного предсказания или взвешенного речевого сигнала. Использование данных сигналов вместо речевого сигнала упрощает также обнаружение импульсов основного тона и участков пониженной мощности между данными импульсами и, следовательно, определение сегментов сигнала для деформации. Реальный модифицированный речевой сигнал формируется обратной фильтрацией.
По окончании модификации сигнала для текущего подкадра, кодирование может продолжаться любым традиционным методом, кроме того, что возбуждающий сигнал по адаптивной кодовой книге формируется с использованием заданной кривой задержки. По существу, можно использовать одинаковые способы модификации сигнала при узкополосном и широкополосном CELP-кодировании.
Способы модификации сигнала можно также применить в таких разнотипных способах кодирования речи, как интерполяционное кодирование аналогового сигнала и синусоидальное кодирование, например, в соответствии с публикацией [8].
[8] Патент США 6223151 "Способ и устройство для предварительной обработки речевых сигналов перед кодированием посредством основанных на преобразованиях речевых кодеров", Telefon Aktie Bolaget LM Ericsson, (W.B. Kleijn and T. Eroksson), от 10 февраля 1999 г.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к способу определения параметра задержки долговременного предсказания, характеризующего долговременное предсказание в методе, использующем модификацию сигнала для цифрового кодирования звукового сигнала, при этом способ содержит этапы, заключающиеся в том, что разбивают звуковой сигнал на ряд последовательных кадров, определяют местоположение признака звукового сигнала в предшествующем кадре, определяют местоположение соответствующего признака звукового сигнала в текущем кадре и определяют такой параметр задержки долговременного предсказания для текущего кадра, чтобы долговременное предсказание отображало признак сигнала предшествующего кадра в соответствующий признак сигнала текущего кадра.
Настоящее изобретение касается устройства для определения параметра задержки долговременного предсказания, характеризующего долговременное предсказание в методе, использующем модификацию сигнала для цифрового кодирования звукового сигнала, при этом устройство содержит блок разбивки звукового сигнала на ряд последовательных кадров, блок определения признака звукового сигнала в предшествующем кадре, блок определения соответствующего признака звукового сигнала в текущем кадре и блок вычисления параметра задержки долговременного предсказания для текущего кадра, при этом вычисление параметра задержки долговременного предсказания выполняется так, чтобы долговременное предсказание отображало признак сигнала предшествующего кадра на соответствующий признак сигнала текущего кадра.
В соответствии с настоящим изобретением предлагается способ модификации сигнала, предназначенный для применения в методе цифрового кодирования звукового сигнала, при этом способ содержит этапы, заключающиеся в том, что разбивают звуковой сигнал на ряд последовательных кадров, разбивают каждый кадр звукового сигнала на совокупность сегментов сигнала и деформируют шкалу времени, по меньшей мере, части сегментов сигнала кадра, при этом упомянутая деформация шкалы времени содержит операцию, заключающуюся в том, что деформированные по времени сегменты сигнала ограничивают границами кадра.
В соответствии с настоящим изобретением предлагается устройство для модификации сигнала, предназначенное для применения в методе цифрового кодирования звукового сигнала, содержащее первый блок разбивки звукового сигнала на ряд последовательных кадров, второй блок разбивки каждого кадра звукового сигнала на совокупность сегментов сигнала и средство деформирования шкалы времени сегмента сигнала, в которое подается, по меньшей мере, часть сегментов сигнала кадра, при этом упомянутое средство деформирования шкалы времени содержит блок ограничения деформированных по времени сегментов сигнала границами кадра.
Настоящее изобретение относится также к способу поиска импульсов основного тона в звуковом сигнале, содержащему этапы, заключающиеся в том, что разбивают звуковой сигнал на ряд последовательных кадров, разбивают каждый кадр на несколько подкадров, формируют сигнал-остаток фильтрацией звукового сигнала анализирующим фильтром линейного предсказания, определяют местоположение последнего импульса основного тона звукового сигнала предшествующего кадра из сигнала-остатка, выделяют образцовый импульс основного тона заданной протяженности вокруг местоположения последнего импульса основного тона предшествующего кадра с использованием сигнала-остатка и определяют местоположение импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
Настоящее изобретение касается также устройства для поиска импульсов основного тона в звуковом сигнале, содержащего блок разбивки звукового сигнала на ряд последовательных кадров, блок разбивки каждого кадра на несколько подкадров, анализирующий фильтр линейного предсказания для фильтрации звукового сигнала и, тем самым, формирования сигнала-остатка, блок определения последнего импульса основного тона звукового сигнала предшествующего кадра по сигналу-остатку, блок выделения образцового импульса основного тона заданной протяженности вокруг местоположения последнего импульса основного тона предшествующего кадра по сигналу-остатку и блок определения импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
В соответствии с настоящим изобретением предлагается также способ поиска импульсов основного тона в звуковом сигнале, содержащий этапы, заключающиеся в том, что разбивают звуковой сигнал на ряд последовательных кадров, разбивают каждый кадр на несколько подкадров, формируют взвешенный звуковой сигнал обработкой звукового сигнала взвешивающим фильтром, при этом взвешенный звуковой сигнал характеризует периодичность сигнала, определяют местоположение последнего импульса основного тона звукового сигнала предшествующего кадра из взвешенного звукового сигнала, выделяют образцовый импульс основного тона заданной протяженности вокруг местоположения последнего импульса основного тона предшествующего кадра с использованием взвешенного звукового сигнала и определяют местоположение импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
Также в соответствии с настоящим изобретением предлагается устройство для поиска импульсов основного тона в звуковом сигнале, содержащее блок разбивки звукового сигнала на ряд последовательных кадров, блок разбивки каждого кадра на несколько подкадров, взвешивающий фильтр для обработки звукового сигнала для формирования взвешенного звукового сигнала, при этом взвешенный звуковой сигнал характеризует периодичность сигнала, блок определения последнего импульса основного тона звукового сигнала предшествующего кадра по взвешенному звуковому сигналу, блок выделения образцового импульса основного тона заданной протяженности вокруг местоположения последнего импульса основного тона предшествующего кадра по взвешенному звуковому сигналу и блок определения импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
Кроме того, настоящее изобретение относится к способу поиска импульсов основного тона в звуковом сигнале, содержащему этапы, заключающиеся в том, что разбивают звуковой сигнал на ряд последовательных кадров, разбивают каждый кадр на несколько подкадров, формируют синтезированный взвешенный звуковой сигнал фильтрацией синтезированного речевого сигнала, сформированного в течение последнего подкадра предшествующего кадра звукового сигнала, взвешивающим фильтром, определяют местоположение последнего импульса основного тона звукового сигнала предшествующего кадра из синтезированного взвешенного звукового сигнала, выделяют образцовый импульс основного тона заданной протяженности вокруг местоположения последнего импульса основного тона предшествующего кадра с использованием синтезированного взвешенного звукового сигнала и определяют местоположение импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
Настоящее изобретение касается также устройства для поиска импульсов основного тона в звуковом сигнале, содержащего блок разбивки звукового сигнала на ряд последовательных кадров, блок разбивки каждого кадра на несколько подкадров, взвешивающий фильтр для фильтрации синтезированного речевого сигнала, сформированного в течение последнего подкадра предшествующего кадра звукового сигнала, и, тем самым, для формирования синтезированного взвешенного звукового сигнала, блок определения последнего импульса основного тона звукового сигнала предшествующего кадра по синтезированному взвешенному звуковому сигналу, блок выделения образцового импульса основного тона заданной протяженности вокруг местоположения последнего импульса основного тона предшествующего кадра по синтезированному взвешенному звуковому сигналу и блок определения импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
В соответствии с настоящим изобретением предлагается также способ формирования возбуждающего сигнала по адаптивной кодовой книге в процессе декодирования звукового сигнала, разбитого на последовательные кадры и предварительно кодированного методом, использующим модификацию сигнала для цифрового кодирования звукового сигнала, при этом способ содержит этапы, заключающиеся в том, что:
принимают для каждого кадра параметр задержки долговременного предсказания, характеризующий долговременное предсказание в методе цифрового кодирования звукового сигнала;
восстанавливают кривую задержки с использованием параметра задержки долговременного предсказания, принятого в течение текущего кадра, и параметра задержки долговременного предсказания, принятого в течение предшествующего кадра, при этом кривая задержки с долговременным предсказанием отображает признак сигнала предшествующего кадра на соответствующий признак сигнала текущего кадра;
формируют по адаптивной кодовой книге возбуждающий сигнал в адаптивной кодовой книге соответственно кривой задержки.
И далее, в соответствии с настоящим изобретением предлагается устройство для формирования возбуждающего сигнала по адаптивной кодовой книге в процессе декодирования звукового сигнала, разбитого на последовательные кадры и предварительно кодированного методом, использующим модификацию сигнала для цифрового кодирования звукового сигнала, при этом устройство содержит:
блок приема параметра задержки долговременного предсказания для каждого кадра, при этом параметр задержки долговременного предсказания характеризует долговременное предсказание в методе цифрового кодирования звукового сигнала;
блок вычисления кривой задержки по параметру задержки долговременного предсказания, принятому в течение текущего кадра, и параметру задержки долговременного предсказания, принятому в течение предшествующего кадра, при этом кривая задержки с долговременным предсказанием отображает признак сигнала предшествующего кадра на соответствующий признак сигнала текущего кадра; и
адаптивную кодовую книгу для формирования возбуждающего сигнала по адаптивной кодовой книге соответственно кривой задержки.
Вышеописанные и другие задачи, преимущества и признаки настоящего изобретения очевидны из следующего ниже неограничительного описания вариантов его осуществления, приведенных только в качестве примера, со ссылками на прилагаемые чертежи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 - пример исходного и модифицированного сигналов-остатков для одного кадра;
фиг.2 - функциональная блок-схема варианта осуществления способа модификации сигнала в соответствии с настоящим изобретением;
фиг.3 - принципиальная блок-схема примера системы речевой связи с описанием использования речевого кодера и декодера;
фиг.4 - принципиальная блок-схема варианта осуществления речевого кодера, который использует способ модификации сигнала;
фиг.5 - функциональная блок-схема варианта осуществления поиска импульса основного тона;
фиг.6 - пример определенного местоположения импульсов основного тона и соответствующего сегментирования на периоды основного тона для одного кадра;
фиг.7 - пример определения параметра задержки, когда число импульсов основного тона равно трем (c=3);
фиг.8 - пример интерполирования задержки (жирная линия) по речевому кадру в сравнении с линейной интерполяцией (тонкая линия);
фиг.9 - пример кривой задержки по десяти кадрам, выбранной в соответствии с интерполяцией задержки (жирная линия), изображенного на фиг.8, и линейной интерполяцией (тонкая линия), когда верное значение основного тона равно 52 отсчетам;
фиг.10 - функциональная блок-схема способа модификации сигнала, который предусматривает коррекцию речевого кадра по выбранной кривой задержки в соответствии с вариантом осуществления настоящего изобретения;
фиг.11 - пример коррекции контрольного сигнала 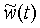 с использованием найденного оптимального сдвига δ и замены сегмента сигнала ws(k) интерполированными значениями, показанными серыми точками;
с использованием найденного оптимального сдвига δ и замены сегмента сигнала ws(k) интерполированными значениями, показанными серыми точками;
фиг.12 - функциональная блок-схема логики определения скорости передачи в соответствии с вариантом осуществления настоящего изобретения; и
фиг.13 - принципиальная блок-схема варианта осуществления речевого кодера, который использует кривую задержки, сформированную в соответствии с вариантом осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Хотя описания вариантов осуществления настоящего изобретения приведены ниже применительно к речевым сигналам и AMR-WB - стандарту компании 3GPP на кодек для широкополосной передачи речи по спецификации AMR (стандарт ITU-T G.722.2), следует иметь в виду, что принципы настоящего изобретения применимы также к звуковым сигналам других типов и другим речевым и аудиокодерам.
На фиг.1 приведен пример модифицированного сигнала-остатка 12 в границах одного кадра. Как видно из фиг.1, временной сдвиг в модифицированном сигнале остатке ограничен так, чтобы данный модифицированный сигнал-остаток был синхронизирован по времени с исходным немодифицированным сигналом-остатком 11 на границах кадра, которые соответствуют моментам времени tn-1 и tn. В данном случае n является индексом рассматриваемого кадра.
В частности, временным сдвигом косвенно управляет кривая задержки, применяемая для интерполирования параметра задержки по текущему кадру. Параметр и кривую задержки определяют с учетом ограничительных условий по временному совмещению на вышеупомянутых границах кадра. Когда применяют линейное интерполирование, чтобы обеспечить вынужденное временное совмещение, результирующие параметры задержки имеют тенденцию к колебанию в течение нескольких кадров. Данная особенность часто приводит к появлению заметных артефактов в модифицированном сигнале, основной тон которого повторяет синтезированную осциллирующую кривую задержки. Применение подходящего способа нелинейного интерполирования для получения параметра задержки существенно ослабляет упомянутые колебания.
Функциональная блок-схема наглядного варианта осуществления способа модификации сигнала в соответствии с настоящим изобретением представлена на фиг.2. Работа способа начинается с блока 101 "поиска периода основного тона" посредством определения местоположения отдельных импульсов основного тона и периодов основного тона. Для поиска, выполняемого в блоке 101, применяется интерполированная по кадру оценка основного тона в разомкнутом контуре. Найденные импульсы основного тона служат основой для разбивки кадра на такие сегменты периодов основного тона, каждый из которых содержит один импульс основного тона и ограничен границами кадра tn-1 и tn.
Функцией блока 103 "выбора кривой задержки" является определение параметра задержки для долговременного предсказания и формирование кривой задержки для интерполирования данного параметра задержки по кадру. Параметр и кривая задержки определяются с учетом ограничительных условий по временному совмещению на границах кадра tn-1 и tn. Параметр задержки, найденный в блоке 103, кодируется и передается в декодер, если разрешена модификация сигнала для текущего кадра.
Процедура модификации сигнала фактически выполняется в блоке 105 "модификация сигнала синхронно с основным тоном". В блоке 105 сначала формируется контрольный сигнал на основе кривой задержки, найденной в блоке 103, для последующего согласования отдельных сегментов периодов основного тона с данным целевым сигналом. Затем сегменты периодов основного тона сдвигаются поодиночке, чтобы максимально повысить значение их корреляции с упомянутым целевым сигналом. Во избежание усложнения процедуры не применяется непрерывная деформация шкалы времени в процессе поиска оптимального сдвига и осуществления сдвига сегментов.
Приведенный для примера вариант способа модификации сигнала в соответствии с настоящим изобретением обычно осуществим только при обработке исключительно вокализированных речевых кадров. Например, начальные нарастания вокализированного сигнала не модифицируют вследствие высокого риска появления артефактов. В исключительно вокализированных кадрах периоды основного тона обычно изменяются сравнительно медленно, и поэтому небольших сдвигов достаточно для адаптирования сигнала к модели с долговременным предсказанием. Благодаря выполнению лишь небольших, пуательных корректировок, вероятность формирования артефактов сводится к минимуму.
Способ модификации сигнала является мощным классификатором исключительно вокализированных сегментов и, следовательно, механизмом определения скорости передачи, необходимым для управляемого источником кодирования речевых сигналов. Каждый из блоков 101, 103 и 105, показанных на фиг.2, обеспечивает получение нескольких признаков периодичности сигнала и соответствия модификации сигнала текущему кадру. Упомянутые признаки анализируются в логических блоках 102, 104 и 106, чтобы определить надлежащий режим кодирования и битовую скорость для текущего кадра. В частности, данные логические блоки 102, 104 и 106 контролируют, обеспечивается ли положительный результат операциями, выполняемыми в блоках 101, 103 и 105.
Если в блоке 102 обнаруживается, что выполняемая в блоке 101 операция обеспечивает положительный результат, то процедура способа модификации сигнала продолжает выполняться в блоке 103. Если же блок 102 определяет безуспешность выполнения операции в блоке 101, то процедура модификации сигнала завершается, и для кодирования сохраняется неизмененный исходный речевой кадр (см. блок 108, соответствующий нормальному режиму (без модификации сигнала)).
Если в блоке 104 определяется, что выполняемая в блоке 103 операция успешна, то исполнение процедуры способа модификации сигнала продолжается в блоке 105. Если же, напротив, данный блок 104 определяет безуспешность операции, выполняемой в блоке 103, то процедура модификации сигнала завершается и для кодирования сохраняется неизмененный исходный речевой кадр (см. блок 108, соответствующий нормальному режиму (без модификации сигнала)).
Если в блоке 106 определяется, что выполняемая в блоке 105 операция успешна, то используют режим низкой битовой скорости с модификацией сигнала (см. блок 107). Напротив, если в данном блоке 106 определяется безуспешность операции, выполняемой в блоке 105, то процедура модификации сигнала завершается, и для кодирования сохраняется неизмененный исходный речевой кадр (см. блок 108, соответствующий нормальному режиму (без модификации сигнала)). Ниже в настоящем описании более подробно изложены операции, выполняемые в блоках 101-108.
На фиг.3 представлена принципиальная блок-схема примера системы речевой связи, иллюстрирующая использование речевого кодера и декодера. Изображенная на фиг.3 система речевой связи поддерживает передачу и воспроизведение речевого сигнала в канале 205 связи. Хотя канал 205 связи может содержать, например, проводную, оптическую линию связи или волоконную линию, обычно, по меньшей мере, часть данного канала составляет радиолиния. Радиолиния часто поддерживает одновременный обмен множеством параллельных речевых сообщений, требующий совместно используемого ресурса полосы частот, как, например, в сотовой телефонии. Хотя не показано, канал 205 связи можно заменить запоминающим устройством, которое записывает и сохраняет кодированный речевой сигнал для последующего воспроизведения.
На стороне передатчика микрофон 201 выдает аналоговый речевой сигнал 210, который подается в аналого-цифровой преобразователь (АЦП) 202. АЦП 202 предназначен для преобразования аналогового речевого сигнала 210 в цифровой речевой сигнал 211. Речевой кодер 203 кодирует цифровой речевой сигнал 211 и выдает набор кодовых параметров 212, которые закодированы в двоичном формате и подаются в канальный кодер 204. Канальный кодер 204 вносит избыточность в двоичное представление кодовых параметров перед их передачей в двоичном потоке 213 по каналу связи 205.
На стороне приемника вышеупомянутое избыточное двоичное представление кодовых параметров из принятого двоичного потока 214 поступает в канальный декодер 206, который обнаруживает и исправляет канальные ошибки, возникающие при передаче. Речевой декодер 207 преобразует двоичный поток 215, поступающий из канального декодера 206 с исправленными канальными ошибками, обратно в набор кодовых параметров для формирования синтезированного цифрового речевого сигнала 216. Синтезированный цифровой речевой сигнал 216, реконструированный речевым декодером 207, преобразуется в аналоговый речевой сигнал 217 цифроаналоговым преобразователем (ЦАП) 208 и воспроизводится акустическим блоком 209.
На фиг.4 представлена принципиальная блок-схема, изображающая операции, выполняемые вариантом осуществления речевого кодера 203 (фиг.3), содержащего в том числе встроенную функцию модификации сигнала. В настоящем описании представлен новый вариант осуществления функции модификации сигнала, представленной блоком 603 на фиг.4. Другие операции, выполняемые речевым кодером 203, широко известны специалистам в данной области техники и описаны, например, в публикации [10]
[10] 3GPP TS 26.190, "AMR Wideband Speech Codec: Transcoding Functions", 3GPP Technical Specification,
которая включена в настоящее описание посредством ссылки. В отсутствие других указаний выполнение операций кодирования и декодирования в приведенных вариантах осуществления и примерах настоящего изобретения будет соответствовать стандарту на кодек для широкополосной передачи речи по спецификации AMR (AMR-WB).
Как видно из фиг.4, речевой кодер 203 кодирует оцифрованный речевой сигнал с использованием одного или нескольких режимов кодирования. Если применяются несколько режимов кодирования, а функция модификации сигнала в одном из упомянутых режимов заблокирована, то работа в данном конкретном режиме будет соответствовать традиционным стандартам, известным специалистам в данной области техники.
Речевой сигнал дискретизируется с частотой 16 кГц, и каждый отсчет речевого сигнала оцифровывается, однако, данные операции на фиг.4 не показаны. Затем цифровой речевой сигнал разбивается на последовательные кадры заданной протяженности, а каждый из полученных таким образом кадров разбивается на заданное число последовательных подкадров. Далее цифровой речевой сигнал подвергается предварительной обработке в соответствии со стандартом AMR-WB. Данная предварительная обработка включает в себя фильтрацию верхних частот, фильтрацию предыскажений с использованием фильтра P(z)=1-0,68z-1 и субдискретизацию с частоты 16 кГц до 12,8 кГц. В последующих операциях, изображенных на фиг.4, предполагается, что входной речевой сигнал s(t) уже подвергнут предварительной обработке и субдискретизации до частоты взятия отсчетов 12,8 кГц.
Речевой кодер 203 содержит модуль анализа и квантования с линейным предсказанием (LP-модуль) 601, который, в зависимости от входного предварительно обработанного цифрового речевого сигнала s(t) 617, вычисляет и квантует параметры a0, a1, a2, ..., anA фильтра с линейным предсказанием (LP-фильтра) 1/A(z), где nA обозначает порядок фильтра, а A(z)=a0+a1z-1+a2z-2+...+anAz-nA. Двоичное представление 616 данных квантованных параметров LP-фильтра подается в мультиплексор 614 и затем мультиплексируется в двоичный поток 615. Неквантованные и квантованные параметры LP-фильтра можно интерполировать для получения соответствующих параметров LP-фильтра для каждого подкадра.
Речевой кодер 203 также содержит модуль 602 оценивания основного тона, чтобы вычислять оценки 619 основного тона без обратной связи для текущего кадра в зависимости от параметров 618 LP-фильтра, поступающих из LP-модуля 601 анализа и квантования. Упомянутые оценки 619 основного тона без обратной связи интерполируются по кадру для использования в модуле 603 модификации сигнала.
Операции, выполняемые в LP-модуле 601 анализа и квантования и модуле 602 оценивания основного тона, могут соответствовать спецификации вышеупомянутого стандарта AMR-WB.
Показанный на фиг.4 модуль 603 модификации сигнала выполняет операцию модификации сигнала до поиска в замкнутом контуре возбуждающего сигнала основного тона по адаптивной кодовой книге для коррекции речевого сигнала по найденной кривой задержки d(t). В приведенном варианте осуществления изобретения кривая задержки d(t) определяет задержку долговременного предсказания для каждого отсчета кадра. По своему построению кривая задержки полностью характеризуется по кадру t∈(tn-1, tn) параметром задержки 620 dn=d(tn) и его предшествующим значением dn-1=d(tn-1), которые равны значению кривой задержки на границах кадра. Определение параметра задержки 620 составляет часть операции модификации сигнала, и данный параметр кодируется и затем подается в мультиплексор 614, где мультиплексируется в двоичный поток 615.
Кривая задержки d(t), определяющая параметр задержки долговременного предсказания для каждого отсчета кадра, подается в адаптивную кодовую книгу 607. Адаптивная кодовая книга 607 формирует, соответственно кривой задержки df(t), возбуждающий сигнал ub(t) по адаптивной кодовой книге для текущего подкадра из возбуждающего сигнала u(t) с использованием кривой задержки d(t) по формуле ub(t)=u(t-d(t)). Следовательно, кривая задержки отображает прошлый отсчет возбуждающего сигнала u(t-d(t)) в текущий отсчет в возбуждающем сигнале ub(t) по адаптивной кодовой книге.
Кроме того, процедура модификации сигнала выдает модифицированный сигнал-остаток 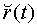 , используемый при формировании модифицированного целевого сигнала 621 для поиска в замкнутом контуре возбуждающего сигнала uc(t) по фиксированной кодовой книге. Модифицированный сигнал-остаток получают в модуле 603 модификации сигнала деформацией шкалы времени сегментов периодов основного тона сигнала-остатка долговременного предсказания и подают в модуль 604 для вычисления модифицированного целевого сигнала. Фильтрация посредством синтеза с линейным предсказанием модифицированного сигнала-остатка фильтром 1/A(z) обеспечивает формирование модулем 604 модифицированного речевого сигнала. Модифицированный целевой сигнал 621 поиска возбуждающего сигнала по фиксированной кодовой книге формируется в модуле 604 в соответствии со спецификацией стандарта AMR-WB, но с заменой исходного речевого сигнала его модифицированной версией.
, используемый при формировании модифицированного целевого сигнала 621 для поиска в замкнутом контуре возбуждающего сигнала uc(t) по фиксированной кодовой книге. Модифицированный сигнал-остаток получают в модуле 603 модификации сигнала деформацией шкалы времени сегментов периодов основного тона сигнала-остатка долговременного предсказания и подают в модуль 604 для вычисления модифицированного целевого сигнала. Фильтрация посредством синтеза с линейным предсказанием модифицированного сигнала-остатка фильтром 1/A(z) обеспечивает формирование модулем 604 модифицированного речевого сигнала. Модифицированный целевой сигнал 621 поиска возбуждающего сигнала по фиксированной кодовой книге формируется в модуле 604 в соответствии со спецификацией стандарта AMR-WB, но с заменой исходного речевого сигнала его модифицированной версией.
После получения возбуждающего сигнала ub(t) по адаптивной кодовой книге и модифицированного целевого сигнала 621 для текущего подкадра далее кодирование можно выполнять традиционным способом.
Назначение поиска в замкнутом контуре возбуждающего сигнала по фиксированной кодовой книге состоит в том, чтобы определить возбуждающий сигнал uc(t) по фиксированной кодовой книге для текущего подкадра. Чтобы схематически проиллюстрировать операцию поиска в замкнутом контуре по фиксированной кодовой книге, возбуждающий сигнал uc(t) по фиксированной кодовой книге усиливается усилителем 610. Аналогично, возбуждающий сигнал ub(t) по адаптивной кодовой книге усиливается усилителем 609. Усиленные возбуждающие сигналы ub(t) и uc(t), соответственно, по адаптивной кодовой книге и фиксированной кодовой книге суммируются в сумматоре 611 и составляют суммарный возбуждающий сигнал u(t). Суммарный возбуждающий сигнал u(t) обрабатывается синтезирующим фильтром 1/A(z) 612 с линейным предсказанием с получением на выходе последнего синтезированного речевого сигнала 625, который вычитается из модифицированного целевого сигнала 621 в сумматоре 605 с получением на выходе сумматора сигнала рассогласования 626. Модуль 606 весовой обработки и минимизации рассогласования предназначен для того, чтобы по сигналу рассогласования 626 вычислять традиционными способами параметры усиления усилителей 609 и 610 для каждого подкадра. Кроме того, модуль 606 весовой обработки и минимизации рассогласования вычисляет традиционными способами, по сигналу рассогласования 626, входной сигнал 627, подаваемый в фиксированную кодовую книгу 608. Квантованные параметры усиления 622 и 623 и параметры 624, характеризующие возбуждающий сигнал uc(t) по фиксированной кодовой книге, подаются в мультиплексор 614 и мультиплексируются в двоичный поток 615. Вышеописанная процедура выполняется идентично в обоих случаях как при задействованной, так и блокированной функции модификации сигнала.
Следует отметить, что, когда функция модификации сигнала заблокирована, адаптивная кодовая книга 607 назначения возбуждающего сигнала функционирует традиционным способом. В данном случае, в адаптивной кодовой книге 607 осуществляется поиск отдельного параметра задержки для каждого подкадра, чтобы уточнить оценки 619 основного тона, полученные без обратной связи. Данные параметры задержки кодируются, подаются в мультиплексор 614 и мультиплексируются в двоичный поток 615. Кроме того, целевой сигнал 621 для поиска по фиксированной кодовой книге формируется традиционным способом.
Речевой декодер, изображенный на фиг.13, функционирует традиционным способом, за исключением режима с разрешенной модификацией сигнала. Режимы работы с блокированной и разрешенной модификацией сигнала различаются, по существу, только способом формирования возбуждающего сигнала ub(t) по адаптивной кодовой книге. В обоих режимах работы декодер декодирует полученные в виде двоичного образа параметры. Обычно в состав принятых параметров входят параметры возбуждения, усиления, задержки и параметры долговременного предсказания (LP-параметры). Декодированные параметры возбуждения используются в модуле 701 для формирования возбуждающего сигнала uc(t) по фиксированной кодовой книге для каждого подкадра. Данный сигнал подается через усилитель 702 в сумматор 703. Аналогично, возбуждающий сигнал ub(t) по адаптивной кодовой книге для текущего подкадра подается в сумматор 703 через усилитель 704. В сумматоре 703 усиленные возбуждающие сигналы ub(t) и uc(t), соответственно, по адаптивной кодовой книге и фиксированной кодовой книге суммируются и тем самым составляют суммарный возбуждающий сигнал u(t) для текущего подкадра. Данный возбуждающий сигнал u(t) обрабатывается синтезирующим фильтром 1/A(z) 708 с линейным предсказанием, который использует LP-параметры, интерполированные модулем 707 для текущего подкадра, чтобы выдать синтезированный речевой сигнал 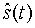 .
.
При разрешении модификации сигнала речевой декодер выделяет кривую задержки d(t) в модуле 705 с использованием принятого параметра задержки dn и ранее принятого значения dn-1 параметра задержки как в кодере. Данная кривая задержки d(t) определяет параметр задержки долговременного предсказания для каждого момента времени текущего кадра. Возбуждающий сигнал ub(t)=u(t-d(t)) по адаптивной кодовой книге формируется из предшествующего возбуждающего сигнала для текущего подкадра как в кодере с использованием кривой задержки d(t).
В остальной части описания следует подробное изложение процедуры 603 модификации сигнала, а также ее использования в составе механизма определения режима.
Поиск импульсов основного тона и сегментов периодов основного тона
Способ модификации сигнала работает в синхронизме с основным тоном и кадрами, осуществляя сдвиг каждого обнаруженного сегмента периода основного тона поодиночке, но с ограничением сдвига на границах кадра. При этом требуется средство для определения координат импульсов основного тона и соответствующих сегментов периодов основного тона для текущего кадра. В приведенном варианте осуществления способа модификации сигнала сегменты периодов основного тона определяются по обнаруженным импульсам основного тона, поиск которых выполняется в соответствии со схемой на фиг.5.
Поиск импульса основного тона может выполняться по сигналу-остатку r(t), взвешенному речевому сигналу w(t) и/или взвешенному синтезированному речевому сигналу 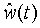 . Сигнал-остаток r(t) получают фильтрацией речевого сигнала s(t) LP-фильтром A(z), который интерполирован для подкадров. В приведенном варианте осуществления порядок LP-фильтра A(z) равен 16. Взвешенный речевой сигнал w(t) формируется обработкой речевого сигнала s(t) взвешивающим фильтром
. Сигнал-остаток r(t) получают фильтрацией речевого сигнала s(t) LP-фильтром A(z), который интерполирован для подкадров. В приведенном варианте осуществления порядок LP-фильтра A(z) равен 16. Взвешенный речевой сигнал w(t) формируется обработкой речевого сигнала s(t) взвешивающим фильтром
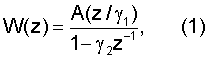
где коэффициенты γ1=0,92 и γ2=0,68. Взвешенный речевой сигнал w(t) часто используют в оценке основного тона без обратной связи (модуль 602), поскольку взвешивающий фильтр, определенный уравнением (1), ослабляет формантную структуру речевого сигнала s(t) и сохраняет периодичность также для сегментов синусоидального сигнала. Это облегчает поиск импульсов основного тона, поскольку возможная периодичность сигнала становится очевидной у взвешенных сигналов. Следует отметить, взвешенный речевой сигнал w(t) необходим также для предварительного просмотра, чтобы найти последний импульс основного тона в текущем кадре. Данную операцию можно выполнить с помощью взвешивающего фильтра по уравнению (1), созданного в последнем подкадре текущего кадра по участку предварительного просмотра.
Приведенная на фиг.5 процедура поиска импульсов основного тона начинает работать в блоке 301 с обнаружения координаты последнего импульса основного тона предшествующего кадра по сигналу-остатку r(t). Импульс основного тона обычно четко выделяется как максимальное абсолютное значение сигнала-остатка, подвергнутого фильтрации нижних частот, в периоде основного тона с протяженностью около p(tn-1). Чтобы облегчить определение координаты последнего импульса основного тона предшествующего кадра, фильтрацию нижних частот выполняют с использованием нормированной взвешивающей функции Хэмминга H5(z)=(0,08z-2+0,54z-1+1+0,54z+0,08z2)/2,24 протяженностью, равной пяти (5) отсчетам. Упомянутая найденная координата импульса основного тона обозначена T0. В приведенном варианте осуществления способа модификации сигнала по настоящему изобретению требуется всего лишь достаточно приближенная оценка координаты высокоэнергетического сегмента в границах периода основного тона вместо точного местоположения данного импульса основного тона.
После определения местоположения последнего импульса основного тона, T0, предшествующего кадра, в блоке 302, показанном на фиг.5, выделяется образцовый импульс основного тона с протяженностью, равной 2l+1 отсчетам, в области данной координаты, полученной грубой оценкой, например:
mn(k)=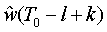 для k=0, 1, ..., 2l. (2)
для k=0, 1, ..., 2l. (2)
Данный образцовый импульс основного тона впоследствии служит для определения координат импульсов основного тона текущего кадра.
Для поиска импульса основного тона можно использовать синтезированный взвешенный речевой сигнал (или взвешенный речевой сигнал w(t)) вместо сигнала-остатка r(t). Данный подход облегчает поиск импульсов основного тона, поскольку во взвешенном речевом сигнале лучше сохранена периодическая структура сигнала. Синтезированный взвешенный речевой сигнал получают фильтрацией синтезированного речевого сигнала 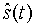 последнего подкадра предшествующего кадра взвешивающим фильтром W(z) по уравнению (1). Если образцовый импульс основного тона простирается за границу предшествующего синтезированного кадра, то вместо данного избыточного участка используют взвешенный речевой сигнал w(t) текущего кадра. Образцовый импульс основного тона характеризуется высокой степенью корреляции с импульсами основного тона взвешенного речевого сигнала w(t), если предшествующий синтезированный речевой кадр содержит уже выраженный период основного цикла. Таким образом, использование синтезированной речи при выделении образцового импульса обеспечивает дополнительную информацию для контроля за выполнением кодирования и выбором подходящего режима кодирования в текущем кадре, как будет подробнее изложено в последующей части описания.
последнего подкадра предшествующего кадра взвешивающим фильтром W(z) по уравнению (1). Если образцовый импульс основного тона простирается за границу предшествующего синтезированного кадра, то вместо данного избыточного участка используют взвешенный речевой сигнал w(t) текущего кадра. Образцовый импульс основного тона характеризуется высокой степенью корреляции с импульсами основного тона взвешенного речевого сигнала w(t), если предшествующий синтезированный речевой кадр содержит уже выраженный период основного цикла. Таким образом, использование синтезированной речи при выделении образцового импульса обеспечивает дополнительную информацию для контроля за выполнением кодирования и выбором подходящего режима кодирования в текущем кадре, как будет подробнее изложено в последующей части описания.
Выбор I=10 отсчетов обеспечивает хороший компромисс между сложностью и качеством при поиске импульса основного тона. Значение I можно также определять как величину, прямо пропорциональную оценке основного тона без обратной связи.
Если известно местоположение T0 последнего импульса предшествующего кадра, то можно предсказать, что первый импульс основного тона текущего кадра возникнет примерно в момент T0+p(T0). Здесь p(T) обозначает оценку основного тона без обратной связи, интерполированную для момента времени (местоположение) t. Данное предсказание выполняется в блоке 303.
В блоке 305 предсказанное местоположение импульса основного тона T0+p(T0) уточняется по формуле
T1=T0+p(T0)+arg max C(j), (3)
где выполняется корреляция взвешенного речевого сигнала w(t) в окрестности предсказанной координаты с образцовым импульсом:
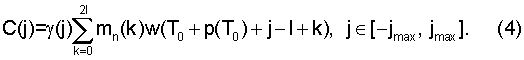
Следовательно, уточнением является аргумент j, ограниченный интервалом [-jmax, jmax], что максимально повышает взвешенное значение корреляции C(j) между образцовым импульсом и одним из вышеупомянутых сигналов, а именно, сигналом-остатком, взвешенным речевым сигналом или взвешенным синтезированным речевым сигналом. В соответствии с показанным примером предельное значение jmax прямо пропорционально оценке основного тона без обратной связи, min{20, 〈p(0)/4〉}, где оператор 〈·〉 означает округление до ближайшего целого числа. Взвешивающая функция
γ(j)=1-|j|/p(T0+p(T0)) (5)
в уравнении (4) действует предпочтительно для местоположения импульса, предсказанного с использованием оценки основного тона в разомкнутом контуре, поскольку γ(j) принимает максимальное значение, равное 1, при j=0. Делитель p(T0+p(T0)) в уравнении (5) является оценкой основного тона в разомкнутом контуре для предсказанного местоположения импульса основного тона.
Если найдено местоположение T1 первого импульса основного тона по уравнению (3), то можно предсказать момент времени T2=T1+p(T1) следующего импульса основного тона и затем уточнить вышеописанным способом. Описанный поиск импульса основного тона, содержащий этапы предсказания 303 и уточнения 305, повторяется до тех пор, пока процедура либо предсказания, либо уточнения обеспечит местоположение импульса основного тона за границами текущего кадра. Данные условия контролируются в логическом блоке 304 проверки предсказания местоположения следующего импульса основного тона (блок 303) и в логическом блоке 306 проверки уточнения этого местоположения импульса основного тона (блок 305). Следует отметить, что логический блок 304 прерывает поиск только в том случае, если предсказанное местоположение импульса настолько далеко заходит в последующий кадр, что этап уточнения не в состоянии вернуть его обратно в текущий кадр. Данная процедура выдает c местоположений импульсов основного тона, обозначаемых T1, T2,..., Tc, в границах текущего кадра.
В соответствии с показанным примером местоположение импульсов основного тона определяется с целочисленным разрешением, кроме последнего импульса основного тона в кадре, обозначенного Tc. Поскольку для определения подлежащего передаче параметра задержки необходимо точное расстояние между последними импульсами двух последовательных кадров, то местоположение последнего импульса определяется с использованием дробного разрешения 1/4 отсчета в уравнении (4) для j. Дробное разрешение обеспечивают сверхдискретизацией w(t) в области, окружающей последний предсказанный импульс основного тона перед вычислением значения корреляции по уравнению (4). В соответствии с показанным примером для сверхдискретизации используется синхронное интерполирование с обработкой взвешивающей функцией Хэмминга с протяженностью 33 отсчета. Дробное разрешение местоположения последнего импульса основного тона помогает поддерживать высокую эффективность долговременного предсказания, несмотря на ограничивающее условие временного синхронизма, установленное для конца кадра. Данное преимущество получают за счет дополнительной битовой скорости, необходимой для передачи с высокой точностью параметра задержки.
После сегментирования на периоды основного тона в текущем кадре определяют оптимальный сдвиг для каждого сегмента. Данную операцию выполняют с использованием взвешенного речевого сигнала w(t), как будет изложено в последующем описании. Для уменьшения искажения, вносимого деформацией шкалы времени, сдвиги отдельных сегментов периодов основного тона выполняются с использованием сигнала-остатка r(t) линейного предсказания. Поскольку сдвиг особенно сильно искажает сигнал около границ сегментов, данные границы необходимо располагать в пределах участков низкой мощности сигнала-остатка r(t). В приведенном примере границы сегментов расположены приблизительно посередине участка между двумя последовательными импульсами основного тона, но заключены внутри границ текущего кадра. Границы сегментов всегда выбирают внутри текущего кадра так, чтобы каждый сегмент содержал как раз один импульс основного тона. Поскольку сегменты, содержащие больше одного импульса основного тона, или "пустые" сегменты, не содержащие импульсов основного тона, затрудняют последующее, основанное на корреляции согласование с целевым сигналом, то необходимо исключить образование упомянутых сегментов при сегментировании на периоды основного тона. Выделенный сегмент с порядковым номером s, содержащий Is отсчетов, обозначен ws(k), где k=0, 1, ..., Is-1. Начальным моментом времени данного сегмента является момент ts, выбранный так, чтобы ws(0)=w(ts). Число сегментов в текущем кадре обозначено символом c.
Выбор границы сегмента между двумя последовательными импульсами основного тона Ts и Ts+1 внутри текущего кадра осуществляется с использованием следующей процедуры. Сначала вычисляется центральный момент времени между двумя импульсами по формуле Λ=〈(Ts+Ts+1)/2〉. Возможные местоположения границы сегмента находятся в области [Λ-εmax, Λ+εmax], где εmax соответствует пяти отсчетам. Энергия для каждого возможного местоположения границы вычисляется по формуле
Q(ε')=r2(Λ+ε'-1)+r2(Λ+ε'), ε'∈[-εmax, εmax]. (6)
Выбирается местоположение, дающее минимальную энергию, поскольку такой выбор обычно обеспечивает наименьшее искажение модифицированного речевого сигнала. Момент времени, для которого уравнение (6) дает минимальное значение, обозначается ε. Начальный момент времени нового сегмента выбирается по формуле ts=Λ+ε. Тем самым определяется также протяженность предшествующего сегмента, поскольку предшествующий сегмент заканчивается в момент времени Λ+ε-1.
На фиг.6 приведен пример сегментирования на периоды основного тона. Особо следует отметить первый и последний сегменты, соответственно, w1(k) и w4(k), выделенные так, чтобы в результате не было ни одного пустого сегмента и чтобы не были превышены границы кадра.
Определение параметра задержки
Основное преимущество модификации сигнала обычно заключается в том, что кодировать и передавать в декодер (не показан) требуется только один параметр задержки на кадр. Однако данный единственный параметр следует определять особенно тщательно. Параметр задержки не только определяет вместе со своим предшествующим значением эволюцию протяженности периода основного тона в течение кадра, но также оказывает воздействие на временной асинхронизм в результирующем модифицированном сигнале.
В соответствии со способами, описанными в публикациях [1, 4-7], на границах кадров не требуется обеспечивать временной синхронизм, и следовательно, подлежащий передаче параметр задержки можно определять просто с использованием оценки основного тона в разомкнутом контуре. Данный выбор обычно приводит к временному асинхронизму на границе кадра и преобразуется в накапливающийся временной сдвиг в последующем кадре, поскольку требуется сохранять непрерывность сигнала. Хотя человек не воспринимает на слух изменения шкалы времени синтезированного речевого сигнала, повышение степени временного асинхронизма усложняет задачи реализации кодера. Действительно, требуются буферные устройства для продолжительных сигналов, способные вмещать сигналы, у которых может быть растянута временная шкала, и управляющая логика должна быть реализована для ограничения накопленного сдвига в процессе кодирования. Кроме того, временной асинхронизм нескольких отсчетов, характерный для релаксационного CELP-кодирования (RCELP-кодирования), может вызвать рассогласование между LP-параметрами и модифицированным сигналом-остатком. Данное рассогласование может привести к формированию заметных артефактов в модифицированном речевом сигнале, который синтезируется LP-фильтрацией модифицированного сигнала-остатка.
Напротив, вариант осуществления способа модификации сигнала в соответствии с настоящим изобретением обеспечивает выдерживание временного синхронизма на границах кадров. Таким образом, сдвиг, происходящий на концах кадров, жестко ограничен, и каждый новый кадр начинается в момент времени, точно согласованный с исходным речевым кадром.
Чтобы обеспечить временной синхронизм на конце кадра, кривая задержки d(t) отображает с долговременным предсказанием последний импульс основного тона в конце предшествующего кадра синтезированного речевого сигнала в импульсы основного тона текущего кадра. Кривая задержки определяет параметр задержки долговременного предсказания, интерполированный по текущему n-ному кадру, для каждого отсчета от момента времени tn-1+1 до момента времени tn. В декодер передается только параметр задержки dn=d(tn) в конце кадра, а это означает, что кривая d(t) должна иметь форму, полностью определяемую переданными значениями. Параметр задержки долговременного предсказания следует выбирать так, чтобы результирующая кривая задержки выполняла отображение импульса. Данное отображение можно математически представить следующим образом: Пусть κc означает промежуточную временную переменную, а T0 и Tc являются местоположениями последних импульсов основного тона, соответственно, в предшествующем и текущем кадрах. Тогда параметр задержки dn следует выбрать так, чтобы, после псевдокодирования, показанного таблице 1, значение переменной κc было как можно ближе к T0 с целью сведения к минимуму погрешности |κc-T0|. Псевдокодирование начинается со значения κ0=Tc и повторяется c раз в обратном направлении итерационными корректировками вида κi:=κi-1-d(κi-1). Если после этого κc равняется T0, то долговременное предсказание можно использовать максимально эффективно без временного асинхронизма в конце кадра.
Цикл поиска оптимального параметра задержки
κ0:=Tc;
для i=1... c
κi:=κi-1-d(κi-1);
конец;
Пример операции цикла выбора задержки для случая, когда c=3, показан на фиг.7. Цикл начинается со значения κ0=Tc и содержит первую итерацию вида κ1=κ0-d(κ0) в обратном направлении. Итерации выполняются еще дважды по формулам κ2=κ1-d(κ1) и κ3=κ2-d(κ2). Затем окончательное значение κ3 сравнивают с T0 с точки зрения величины погрешности en=|κ3-T0|. Результирующая погрешность является функцией кривой задержки, которая корректируется по алгоритму выбора задержки, как показано далее в настоящем описании.
Способы модификации сигнала в соответствии с описаниями, приведенными в публикациях [1, 4, 6, 7], содержат операцию линейного интерполирования параметров задержки по кадру между dn-1 и dn. Однако, если в конце кадра требуется обеспечить временной синхронизм, то линейное интерполирование с высокой вероятностью приводит к колебаниям кривой задержки. Следовательно, периоды основного тона в модифицированном речевом сигнале периодически сжимаются и расширяются, что приводит к формированию заметных артефактов. Эволюция и амплитуда данных колебаний зависят от местоположения последнего импульса основного тона. Чем дальше последний импульс основного тона отстоит от конца кадра по сравнению с протяженностью периода основного тона, тем выше вероятность усиления колебаний. Поскольку обеспечение временного синхронизма в конце кадра является существенным требованием в варианте осуществления способа модификации сигнала в соответствии с настоящим изобретением, применение линейного интерполирования, описанного в известных способах, невозможно без снижения качества речевого сигнала. Вместо линейного интерполирования, в варианте осуществления способа модификации сигнала в соответствии с настоящим изобретением предлагается кусочно-линейная кривая задержки
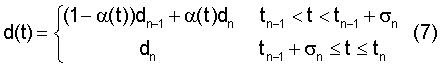
где α(t)=(t-tn-1)/σn. (8)
Использование данной кривой задержки обеспечивает существенное ослабление колебаний. В данных выражениях tn и tn-1 являются конечными моментами времени, соответственно, текущего и предшествующего кадров, а dn и dn-1 являются соответствующими значениями параметра задержки. Следует отметить, что tn-1+σn является моментом времени, после которого кривая задержки остается постоянной.
В приведенном примере параметр σn изменяется в зависимости от dn-1 в соответствии с выражением
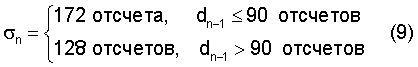
и протяженность N кадра равна 256 отсчетам. Чтобы исключить колебания, рекомендуется уменьшать значение σn, когда возрастает протяженность периода основного тона. С другой стороны, во избежание резких изменений кривой задержки d(t) в начале кадра, когда tn-1<t<tn-1+σn, параметр σn должен быть всегда, по меньшей мере, равен половине протяженности кадра. Быстрые изменения d(t) резко снижают качество модифицированного речевого сигнала.
Следует отметить, что, в зависимости от режима кодирования предшествующего кадра, dn-1 может быть либо значением задержки в конце кадра (при разрешенной модификации сигнала), либо значением задержки последнего подкадра (при блокированной модификации сигнала). Поскольку предыдущее значение dn-1 параметра задержки известно в декодере, кривая задержки однозначно определяется значением dn, и декодер может сформировать кривую задержки по уравнению (7).
Единственным параметром, который может изменяться в процессе поиска оптимальной кривой задержки, является dn, значение параметра задержки в конце кадра, ограниченного до протяженности [34, 231]. В общем случае не существует простого способа, который решал бы задачу оптимизации dn в явном виде. Вместо такого способа приходится тестировать несколько значений, чтобы найти наилучшее решение. Однако поиск является простым. Значение dn можно, во-первых, предсказать с помощью выражения
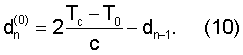
В варианте осуществления настоящего изобретения поиск выполняется за три ступени путем повышения разрешения и сведения подлежащего рассмотрению диапазона поиска в границы [34, 231] на каждой ступени. Параметры задержки, обеспечивающие наименьшую погрешность en=|κc-T0| при выполнении процедуры, представленной в таблице 1, на упомянутых трех ступенях обозначены, соответственно, 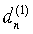 ,
, 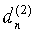 и dn=
и dn=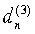 . На первой ступени поиск выполняется вблизи значения
. На первой ступени поиск выполняется вблизи значения 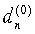 , предсказанного с помощью уравнения (10) с разрешением четыре отсчета в диапазоне [-11, +12], если <60, и в диапазоне [-15, +16] в ином случае. На второй ступени диапазон ограничивается до [-3, +3] и применяется целочисленное разрешение. На последней, третьей ступени рассматривается диапазон [-3/4, +3/4] с разрешением 1/4 отсчета при <92 1/2. При превышении данного значения, рассматривается диапазон [-1/2, +1/2] с разрешением 1/2 отсчета. На выходе данной третьей ступени получают оптимальный параметр задержки dn, который подлежит передаче в декодер. Данная процедура является компромиссным вариантом соотношения точности и сложности поиска. Естественно, специалисты в данной области техники легко смогут найти варианты осуществления поиска параметра задержки, при соблюдении требования к временному синхронизму, с использованием других средств без изменения сущности настоящего изобретения.
, предсказанного с помощью уравнения (10) с разрешением четыре отсчета в диапазоне [-11, +12], если <60, и в диапазоне [-15, +16] в ином случае. На второй ступени диапазон ограничивается до [-3, +3] и применяется целочисленное разрешение. На последней, третьей ступени рассматривается диапазон [-3/4, +3/4] с разрешением 1/4 отсчета при <92 1/2. При превышении данного значения, рассматривается диапазон [-1/2, +1/2] с разрешением 1/2 отсчета. На выходе данной третьей ступени получают оптимальный параметр задержки dn, который подлежит передаче в декодер. Данная процедура является компромиссным вариантом соотношения точности и сложности поиска. Естественно, специалисты в данной области техники легко смогут найти варианты осуществления поиска параметра задержки, при соблюдении требования к временному синхронизму, с использованием других средств без изменения сущности настоящего изобретения.
Параметр задержки dn∈[34, 231] можно кодировать с использованием девяти бит на кадр и разрешением 1/4 отсчета при dn<92 1/2 и 1/2 отсчета при dn>92 1/2.
На фиг.8 приведен пример интерполирования задержки, когда dn=50, dn-1=53, σn=172 и протяженность кадра N=256. Способ интерполирования, используемый в варианте осуществления способа модификации сигнала, представлен жирной линией, а линейное интерполирование в соответствии с известными способами представлено тонкой линией. Обе интерполированные кривые ведут себя приблизительно одинаково в цикле выбора задержки, показанном в таблице 1, однако, предлагаемое кусочно-линейное интерполирование дает меньшее абсолютное изменение |dn-1-dn|. Указанная особенность снижает вероятность колебаний кривой задержки d(t) и появления заметных артефактов в модифицированном речевом сигнале, основной тон которого будет повторять данную кривую задержки.
Чтобы дополнительно пояснить работу способа кусочно-линейного интерполирования, на фиг.9 приведен пример результирующей кривой задержки d(t) по десяти кадрам, изображенной жирной линией. Соответствующая кривая задержки d(t), полученная традиционным линейным интерполированием, изображена тонкой линией. Пример составлен с использованием искусственного речевого сигнала с постоянным параметром задержки, равным 52 отсчетам, на входе процедуры модификации сигнала. Параметр задержки d0=54 отсчета намеренно использовали в качестве исходного значения для первого кадра, чтобы продемонстрировать влияние типичных погрешностей оценки основного тона при кодировании речи. В данном случае, поиск параметров задержки dn при использовании как способа линейного интерполирования, так и предлагаемого здесь способа кусочно-линейного интерполирования выполнялся в соответствии с процедурой, приведенной в таблице 1. Все необходимые параметры выбирались в соответствии с приведенным для примера вариантом осуществления способа модификации сигнала по настоящему изобретению. Результирующие кривые задержки d(t) показывают, что кусочно-линейное интерполирование дает быстро сходящуюся кривую задержки d(t), а традиционное линейное интерполирование не в состоянии достигнуть верного значения за период времени протяженностью десять кадров. Такого рода продолжительные колебания кривой задержки d(t) часто являются причиной появления в модифицированном речевом сигнале заметных артефактов, снижающих общее качество восприятия.
Модификация сигнала
После определения параметра задержки dn и сегментирования на периоды основного тона, можно начинать исполнение непосредственно процедуры модификации сигнала. В варианте осуществления способа модификации сигнала речевой сигнал модифицируется сдвигом поодиночке отдельных сегментов периодов основного тона с целью корректировки их в соответствии с кривой задержки d(t). Сдвиг сегмента определяют операцией корреляции сегмента в области взвешенного речевого сигнала с целевым сигналом. Целевой сигнал формируется с использованием синтезированного взвешенного речевого сигнала предшествующего кадра и предшествующих, уже сдвинутых сегментов в текущем кадре. Фактический сдвиг выполняется на сигнале-остатке r(t).
Модификацию сигнала следует выполнять аккуратно, чтобы одновременно максимально повысить эффективность долговременного предсказания и сохранить воспринимаемое на слух качество модифицированного речевого сигнала. Кроме того, при модификации следует учитывать требование к временному синхронизму на границах кадра.
На фиг.10 представлена функциональная блок-схема наглядного варианта осуществления способа модификации сигнала. Модификация начинается выделением нового сегмента ws(k), содержащего Is отсчетов, из взвешенного речевого сигнала w(t) в блоке 401. Данный сегмент определяется протяженностью сегмента Is и начальным моментом времени ts, входящим в выражение для сегмента ws(k)=w(ts+k), где k=0, 1, ..., Is-1. Процедура сегментирования выполняется в соответствии с вышеприведенным описанием.
Если больше нельзя выбрать или выделить ни одного сегмента (блок 402), то операция модификации сигнала завершается (блок 403). В противном случае, операция модификации сигнала продолжается в блоке 404.
Для определения оптимального сдвига текущего сегмента ws(k), в блоке 405 формируется целевой сигнал . Для первого сегмента w1(k) в текущем кадре указанный целевой сигнал получают по рекуррентной формуле
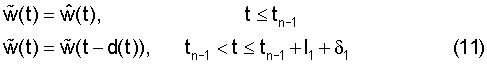
Здесь обозначает взвешенный синтезированный речевой сигнал, имеющийся в предшествующем кадре для ttn-1. Параметр δ1 представляет максимальный сдвиг, допустимый для первого сегмента протяженностью I1. Уравнение (11) можно интерпретировать как моделирование долговременного предсказания с использованием кривой задержки на таком участке сигнала, где потенциально может располагаться текущий сдвинутый сегмент. Вычисление целевого сигнала для последующих сегментов осуществляется с использованием такого же принципа и представлено ниже в данном разделе описания.
Процедура поиска оптимального сдвига текущего сегмента может начинаться после формирования целевого сигнала. Данная процедура основана на корреляции cs(δ'), вычисляемой в блоке 404 между сегментом ws(k), который начинается в момент времени ts, и целевым сигналом по формуле
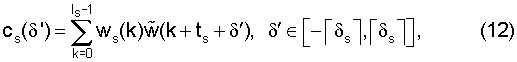
где δs определяет максимальный сдвиг, допустимый для текущего сегмента ws(k), а  обозначает округление в направлении плюс бесконечности. Вместо уравнения [12] можно использовать нормированную корреляцию, но с повышением сложности. В варианте осуществления для δs применяются следующие значения:
обозначает округление в направлении плюс бесконечности. Вместо уравнения [12] можно использовать нормированную корреляцию, но с повышением сложности. В варианте осуществления для δs применяются следующие значения:
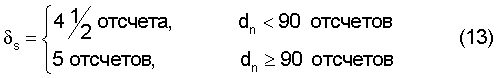
Как показано ниже в настоящем разделе, значение δs больше всего ограничено для первого и последнего сегментов в кадре.
Значение корреляции (12) выражается с целочисленным разрешением, при этом повышение точности улучшает характеристику долговременного предсказания. Во избежание усложнения процедуры не рекомендуется выполнять сверхдискретизацию непосредственно сигнала ws(k) или по уравнению (12). Вместо этого добиваются дробного разрешения путем рациональных вычислений при определении оптимального сдвига с использованием сверхдискретизированного значения корреляции cs(δ').
Сдвиг δ, максимизирующий значение корреляции cs(δ'), сначала находят с целочисленным разрешением в блоке 404. Тогда максимальное значение, найденное с дробным разрешением, должно быть в открытом интервале (δ-1, δ+1) и ограничено пределами [-δs, δs]. В блоке 406 выполняется сверхдискретизация значений корреляции cs(δ') в указанном интервале с разрешением 1/8 отсчета при использовании синхронного интерполирования с обработкой взвешивающей функцией Хэмминга с протяженностью, равной 65 отсчетам. Сдвиг δ, максимизирующий значение сверхдискретизированной корреляции, является в данном случае оптимальным сдвигом при дробном разрешении. После нахождения данного оптимального сдвига взвешенный речевой сегмент ws(k) пересчитывается с найденным дробным разрешением в блоке 407. А именно, уточняется новый момент начала сегмента по корректирующей формуле ts:=ts-δ+δI, где 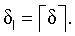 Затем, по сигналу-остатку r(t) в данной точке вычисляют остаточный сегмент rs(k), соответствующий взвешенному речевому сегменту ws(k) с дробным разрешением, также с использованием ранее описанного синхронного интерполирования (блок 407). Поскольку дробная составляющая оптимального сдвига входит в остаточный и взвешенный речевой сегменты, все последующие вычисления можно выполнять с округленным в большую сторону сдвигом
Затем, по сигналу-остатку r(t) в данной точке вычисляют остаточный сегмент rs(k), соответствующий взвешенному речевому сегменту ws(k) с дробным разрешением, также с использованием ранее описанного синхронного интерполирования (блок 407). Поскольку дробная составляющая оптимального сдвига входит в остаточный и взвешенный речевой сегменты, все последующие вычисления можно выполнять с округленным в большую сторону сдвигом
На фиг.11 показан пересчет сегмента ws(k) в блоке 407, показанном на фиг.10. В данном примере значение оптимального сдвига, которое находят с разрешением 1/8 отсчета максимальным повышением значения корреляции, равно δ=-13/8. Следовательно, целочисленная часть δI равна 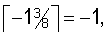 а дробная часть равна 3/8. Следовательно, момент начала сегмента корректируется по формуле ts=ts+3/8. На фиг.11 новые отсчеты ws(k) показаны серыми точками.
а дробная часть равна 3/8. Следовательно, момент начала сегмента корректируется по формуле ts=ts+3/8. На фиг.11 новые отсчеты ws(k) показаны серыми точками.
Если логический блок 106, описание которого приведено ниже, разрешает продолжать модификацию сигнала, то конечная задача заключается в том, чтобы скорректировать модифицированный сигнал-остаток копированием в него текущего сегмента rs(k) сигнала-остатка (блок 411):
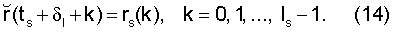
Поскольку сдвиги в последовательных сегментах взаимно независимы, то сегменты, устанавливаемые в , располагаются либо с перекрытием, либо с зазором между ними. Перекрывающиеся сегменты можно обработать простым взвешенным усреднением. Зазоры заполняются копированием соседних отсчетов из прилегающих сегментов. Поскольку число перекрывающихся или пропущенных отсчетов обычно невелико, а границы сегментов находятся в низкоэнергетических зонах сигнала-остатка, то воспринимаемые на слух артефакты обычно не формируются. Следует отметить, что непрерывная деформация шкалы времени сигнала, предложенная в публикациях [2], [6] и [7], не применяется, а модификация выполняется дискретно, сдвигом сегментов периодов основного тона для упрощения обработки.
Обработка последующих сегментов периодов основного тона осуществляется в соответствии с вышеописанной процедурой, за исключением того, что целевой сигнал формируется в блоке 405 иначе, чем для первого сегмента. Сначала отсчеты заменяются отсчетами модифицированного взвешенного речевого сигнала по формуле
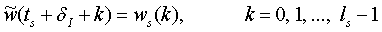 . (15)
. (15)
Данная процедура представлена на фиг.11. Затем отсчеты, следующие за скорректированным сегментом, также корректируются,
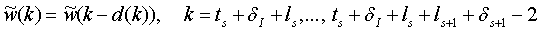 . (16)
. (16)
Коррекция целевого сигнала обеспечивает более высокую степень корреляции между последовательными сегментами периодов основного тона в речевом сигнале, модифицированном с учетом кривой задержки d(t), и следовательно, более точное долговременное предсказание. При обработке последнего сегмента кадра целевой сигнал корректировать не требуется.
Сдвиги первого и последнего сегментов кадра относятся к особым случаям, и потому нуждаются в особенно аккуратном исполнении. Перед сдвигом первого сегмента следует обеспечить, чтобы сигнал-остаток r(t) не содержал высокоэнергетических зон вблизи границы tn-1 кадра, поскольку сдвиг данного сегмента может привести к формированию артефактов. Поиск высокоэнергетической зоны выполняют вычислением квадрата сигнала-остатка r(t) по формуле
E0(k)=r2(k), k∈[tn-1-ς0, tn-1+ς0], (17)
где ς0=〈p(tn-1)/2〉.
Если максимум E0(k) определяется вблизи границы кадра в интервале [tn-1-2, tn-1+2], то допустимый сдвиг ограничен 1/4 отсчета. Если предполагаемый сдвиг |δ| первого сегмента меньше указанного предела, то процедура модификации сигнала в текущем кадре задействуется, но не затрагивает первый сегмент.
Последний сегмент кадра обрабатывается аналогичным образом. В соответствии с вышеприведенным описанием кривая задержки d(t) выбирается так, чтобы последний сегмент не требовалось сдвигать в принципе. Однако поскольку целевой сигнал многократно корректируется в процессе модификации сигнала с учетом значений корреляции между последовательными сегментами с использованием уравнений (16) и (17), то, вероятно, потребуется некоторый сдвиг последнего сегмента. В представленном варианте осуществления данный сдвиг всегда ограничен пределом менее чем 3/2 отсчета. Если в конце кадра существует высокоэнергетическая зона, то сдвиг не допускается. Данное условие проверяется с использованием квадратичного сигнала-остатка
E1(k)=r2(k), k∈[tn-ς1+1, tn+1], (18)
где ς1=p(tn).
Если максимум E1(k) достигается для значений k больше, чем или равных tn-4, то сдвиг последнего сегмента не допускается. Аналогично условию для первого сегмента, если предполагаемый сдвиг |δ|<1/4, то модификация настоящего кадра еще допустима, но не затрагивает последний сегмент.
Следует отметить, что в отличие от известных способов модификации сигнала сдвиг не переносится на следующий кадр, и каждый новый кадр начинается совершенно синхронно с исходным входным сигналом. Другое принципиальное отличие, в частности, от RCELP-кодирования, представленное в варианте осуществления способа модификации сигнала заключается в том, что, в соответствии с предлагаемым способом, полный речевой кадр обрабатывается до кодирования подкадров. Модификация по подкадрам позволяет формировать целевой сигнал для каждого подкадра с использованием ранее кодированного подкадра, что потенциально способствует повышению характеристик. Данный подход нельзя применить в представленном варианте осуществления способа модификации сигнала ввиду жесткого ограничения допустимого временного асинхронизма на конце кадра. Тем не менее, коррекция целевого сигнала с использованием уравнений (15) и (16) обеспечивает характеристики, по существу, эквивалентные характеристикам обработки по подкадрам, поскольку модификация разрешена только для плавно эволюционирующих вокализированных кадров.
Логика определения режима, встроенная в процедуру модификации сигнала
Представленный на фиг.2 вариант осуществления способа модификации сигнала в соответствии с настоящим изобретением включает в себя эффективный механизм классификации и определения режима. Каждая операция, выполняемая в блоках 101, 103 и 105, выдает несколько признаков, количественно выражающих достижимую эффективность долговременного предсказания в текущем кадре. Если любые из данных признаков выходят за допустимые пределы, то один из логических блоков 102, 104 или 106 завершает процедуру модификации сигнала. Тогда исходный сигнал сохраняется в неизменном виде.
Процедура поиска импульса основного тона, 101, выдает несколько признаков периодичности текущего кадра. Следовательно, логический блок 102 анализа данных признаков является важнейшим компонентом классифицирующей логики. Логический блок 102 сравнивает разности между найденными координатами импульсов основного тона и интерполированной оценкой в разомкнутом контуре основного тона с использованием условия
|Tk-Tk-1-p(Tk)|<0,2p(Tk), k=1, 2, ..., c, (19)
и прерывает процедуру модификации сигнала, если данное условие не выполняется.
Выбор кривой задержки d(t) в блоке 103 также дает дополнительную информацию об эволюции периодов основного тона и периодичности текущего речевого кадра. Данная информация анализируется в логическом блоке 104. После данного блока процедура модификации сигнала продолжается только в том случае, если выполняется условие |dn-dn-1|<0,2dn. Данное условие означает, что лишь небольшое изменение задержки допустимо, чтобы классифицировать текущий кадр как чисто вокализированный кадр. Кроме того, логический блок 104 оценивает результативность представленного в таблице 1 цикла выбора задержки посредством анализа разности |κc-T0| для выбранного значения dn параметра задержки. Если данная разность больше одного отсчета, то процедура модификации сигнала завершается.
Чтобы гарантировать высокое качество модифицированного речевого сигнала, целесообразно ограничивать сдвиги, выполняемые для последовательных сегментов периодов основного тона в блоке 105. Данное ограничение достигается в логическом блоке 106 проверкой на соответствие критерию
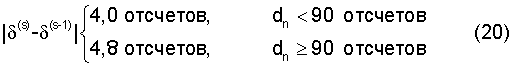
всех сегментов кадра. В данном случае δ(s) и δ(s-1) обозначают сдвиги, выполняемые для сегментов периодов основного тона с порядковыми номерами, соответственно, s и (s-1). Если имеет место выход за пороги, то процедура модификации сигнала завершается, и сохраняется исходный сигнал.
Если кадры, подвергающиеся модификации сигнала, кодируются с невысокой битовой скоростью, то необходимо сохранять подобную форму сегментов периодов основного тона по всему кадру. Данное условие позволяет точно моделировать сигнал посредством долговременного предсказания и, следовательно, кодировать с невысокой битовой скоростью без потери качества субъективного восприятия. Подобие последовательных сегментов можно легко выразить количественно с помощью нормированной корреляции
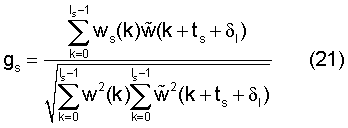 (21)
(21)
между текущим сегментом и целевым сигналом при оптимальном сдвиге после коррекции ws(k) в блоке 407, показанном на фиг.10. Нормированную корреляцию gs называют также усилением основного тона.
Сдвиг сегментов периодов основного тона в блоке 105 с целью максимального повышения значения их корреляции с целевым сигналом повышает степень периодичности и обеспечивает высокий коэффициент усиления предсказания основного тона, если в текущем кадре полезно выполнять модификацию сигнала. Процедура проверяется на положительный результат в логическом блоке 106 с использованием критерия
gs,84.
Если данное условие не выполняется для всех сегментов, то процедура модификации сигнала завершается (блок 409), и сохраняется исходный сигнал. Если данное условие выполняется (блок 106), то модификация сигнала продолжается в блоке 411. Усиление gs основного тона вычисляется в блоке 408 как корреляция сегмента ws(k), выданного блоком 407, с целевым сигналом , выданным блоком 405. Как правило, допустимый порог усиления для мужских голосов можно назначать немного ниже при одинаковой эффективности кодирования. Пороги усиления можно изменять в разных режимах работы кодера, чтобы регулировать коэффициент использования режима модификации сигнала и, следовательно, результирующую среднюю битовую скорость.
Логика определения режима для управляемого источником речевого кодека с переменной битовой скоростью
В данном разделе приведено описание использования процедуры модификации сигнала как составной части общего механизма определения битовой скорости в управляемом источником речевом кодеке с переменной битовой скоростью. Данная функция заложена в вариант осуществления способа модификации сигнала, так как обеспечивает нескольких признаков периодичности сигнала и предполагаемую эффективность кодирования с долговременным предсказанием в текущем кадре. К упомянутым признакам относятся эволюция периода основного тона, пригодность выбранной кривой задержки для описания данной эволюции и усиление предсказания основного тона, достижимое при использовании модификации сигнала. Если логические блоки 102, 104 и 106, показанные на фиг.2, разрешают модификацию сигнала, то долговременное предсказание может моделировать модифицированный речевой кадр и, тем самым, заметно облегчать его кодирование при низкой битовой скорости без снижения качества субъективного восприятия. В данном случае, преобладающий вклад в описание сигнала возбуждения вносит сигнал возбуждения по адаптивной кодовой книге, и, следовательно, можно снизить битовую скорость, выделенную сигналу возбуждения по фиксированной кодовой книге. Если логический блок 102, 104 или 106 блокирует функцию модификации сигнала, то кадр, вероятно, содержит нестационарный речевой сегмент, например, начальное нарастание вокализированного сигнала или быстро эволюционирующий вокализированный речевой сигнал. Данные кадры обычно требуют высокой битовой скорости, чтобы обеспечивать хорошее качество субъективного восприятия.
На фиг.12 представлена процедура модификации сигнала, 603, как составная часть логики, определяющей бутовую скорость и управляющей четырьмя режимами кодирования. В данном варианте осуществления набор режимов содержит специальные режимы для неактивных речевых кадров (блок 508), невокализированных речевых кадров (блок 507), стабильных вокализированных кадров (блок 506) и других видов кадров (блок 505). Следует отметить, что все данные режимы, кроме режима для стабильных вокализированных кадров (506), реализуются в соответствии со способами, широко известными специалистам в данной области техники.
Логика определения битовой скорости основана на классификации сигнала, выполняемой в три этапа в логических блоках 501, 502 и 504, причем функционирование блоков 501 и 502 широко известно специалистам в данной области техники.
Во-первых, блок 501 определения голосовой активности (VAD) выделяет активные и неактивные речевые кадры. Если речевой кадр определяется как неактивный, то речевой сигнал обрабатывается в режиме блока 508.
Если в блоке 501 определяется активный речевой кадр, то кадр передается во второй блок классификации 502, предназначенный принимать решения по вокализации. Если блок классификации 502 классифицирует текущий кадр как невокализированный речевой сигнал, то цепь классификации заканчивается, и речевой сигнал обрабатывается в режиме, представленном блоком 507. В ином случае речевой кадр пропускается через модуль 503 модификации сигнала.
Затем модуль модификации сигнала сам выдает решение, разрешить или блокировать модификацию сигнала для текущего кадра, в логический блок 504. Принятие данного решения практически является неотъемлемой составной частью процедуры, выполняемой в логических блоках 102, 104 и 106, согласно ранее приведенному описанию со ссылкой на фиг.2. Если модификация сигнала разрешена, то кадр считается стабильным вокализированным или чисто вокализированным речевым сегментом.
Если механизм определения битовой скорости выбирает режим 506, то разрешается режим модификации сигнала, и речевой кадр кодируется, как описано выше. Таблица 2 содержит информацию о распределении битов в варианте осуществления для режима 506. Поскольку кадры, подлежащие кодированию в данном режиме, характеризуются высокой периодичностью, то в данном случае высокое субъективное качество восприятия способна обеспечить битовая скорость существенно ниже той, которая необходима, например, для переходных кадров. Модификация сигнала позволяет также эффективно кодировать информацию о задержке с использованием всего девяти битов на 20-мс кадр и, тем самым, экономить значительную часть располагаемых битов для других параметров. Высокая эффективность долговременного предсказания позволяет использовать всего 13 битов на 5-мс подкадр для сигнала возбуждения по фиксированной кодовой книге без ущерба качеству субъективного восприятия речи. Фиксированная кодовая книга содержит одну дорожку с двумя импульсами, каждый из которых может быть в 64 позициях.
Распределение битов в вокализированном 6,2-кбит/с режиме для 20-мс кадра, содержащего четыре подкадра
Распределение битов в вокализированном 12,65-кбит/с режиме в соответствии с AMR-WB-стандартом
Другие режимы кодирования 505, 507 и 508 реализуются с использованием известных способов. Во всех данных режимах функция модификации сигнала блокируется. Таблица 3 содержит информацию о распределении битов в режиме 505, соответствующем AMR-WB-стандарту.
Технические условия [11] и [12], соответствующие AMR-WB-стандарту, прилагаются к настоящему описанию для справки о комфортном шуме и функциях блока определения голосовой активности (VAD), соответственно, в блоках 501 и 508.
[11] 3GPP TS 26.192, "AMR Wideband Speech Codec: Comfort Noise Aspects", 3GPP Technical Specification.
[12] 3GPP TS 26.193, "AMR Wideband Speech Codec: Voice Activity Detector (VAD)", 3GPP Technical Specification.
В общем в настоящем описании изложены сведения о синхронизированном с кадром способе модификации сигнала для чисто вокализированных речевых кадров, механизме классификации для определения подлежащих модификации кадров и применении данных способов в управляемом источником речевом CELP-кодеке с целью разрешения высококачественного кодирования при низкой битовой скорости.
Способ модификации сигнала содержит механизм классификации для определения подлежащих кодированию кадров. Данный способ отличается от известных способов модификации и предварительной обработки сигналов по принципу действия и характеристикам модифицированного сигнала. Функция классификации, заложенная в процедуре модификации сигнала, применяется как составная часть механизма определения битовой скорости в управляемом источником речевом CELP-кодеке.
Модификация сигнала выполняется синхронно основному тону и кадру, то есть с согласованием одного сегмента периода основного тона по времени в текущем кадре таким образом, чтобы начало последующего речевого кадра точно совмещалось по времени с исходным сигналом. Сегменты периодов основного тона ограничены границами кадра. Данная особенность предотвращает сдвиг по времени за границы кадра и, тем самым, упрощает осуществление кодера и снижает риск появления артефактов в модифицированном речевом сигнале. Поскольку временные сдвиги не накапливаются по последовательным кадрам, предлагаемый способ модификации сигнала не нуждается ни в буферах большой емкости для буферизации растянутых сигналов, ни в сложных логических схемах для контроля накопленного временного сдвига. При управляемом источником кодировании речи данный способ упрощает мультирежимную работу с переключением между режимами разрешения и блокирования модификации сигнала, поскольку каждый новый кадр начинается в момент времени, совмещенный с исходным сигналом.
Естественно, возможны различные модификации и изменения. Принимая во внимание приведенное выше подробное описание настоящего изобретения и прилагаемые чертежи, специалистам в данной области техники будут очевидны другие модификации и изменения. Должно быть также очевидно, что такие другие изменения могут быть осуществлены без отклонения от сущности и объема настоящего изобретения.
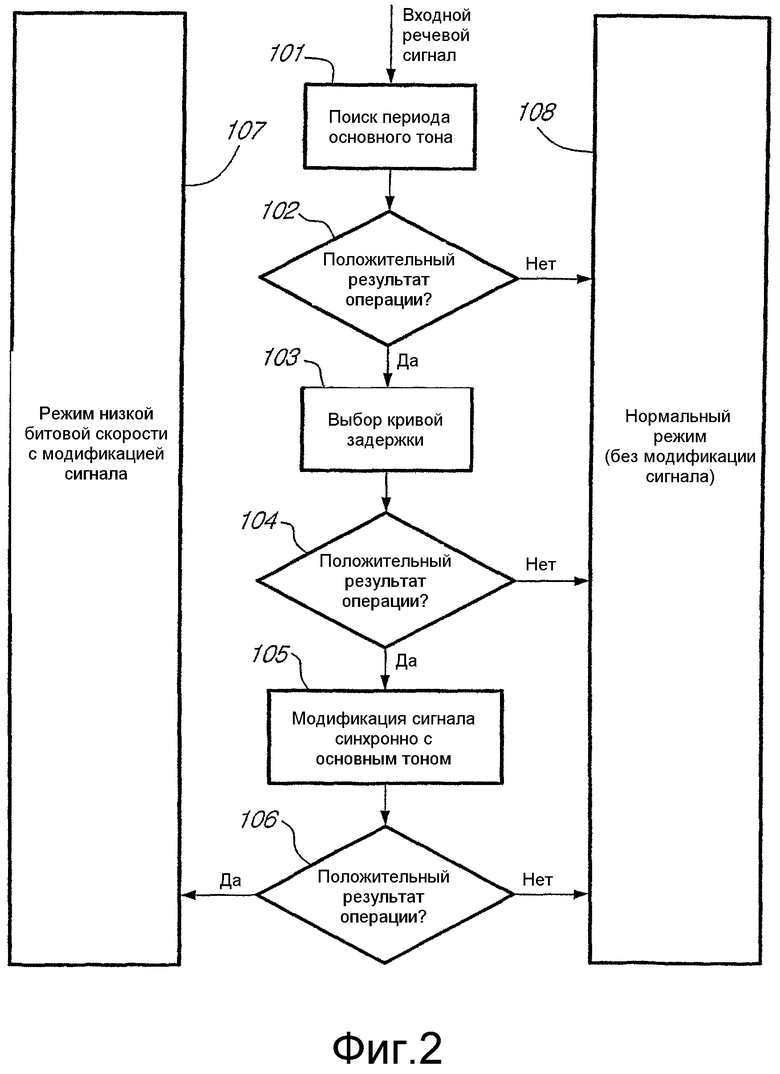
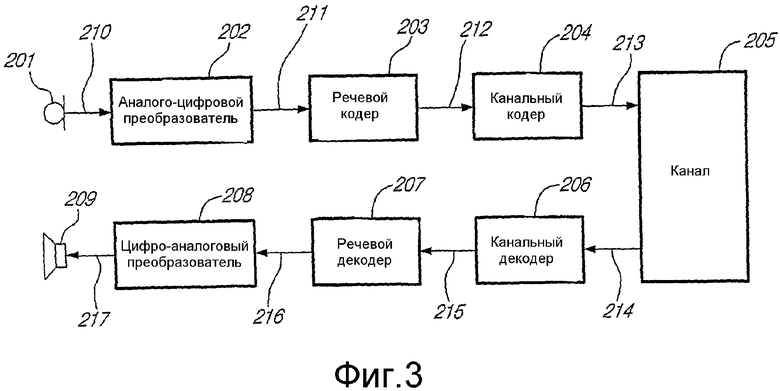
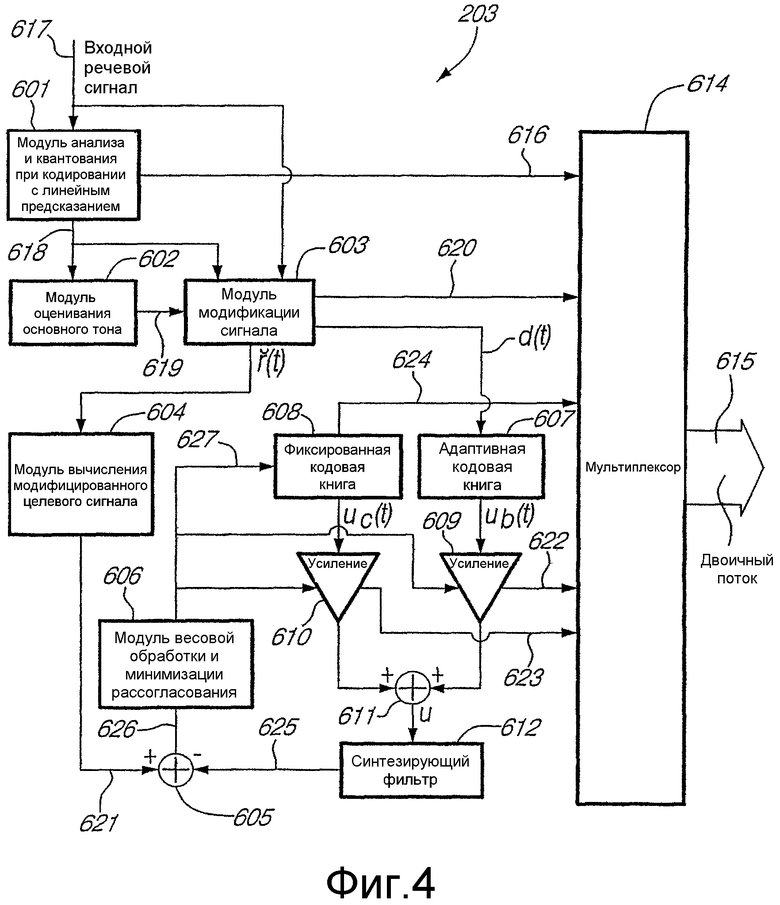
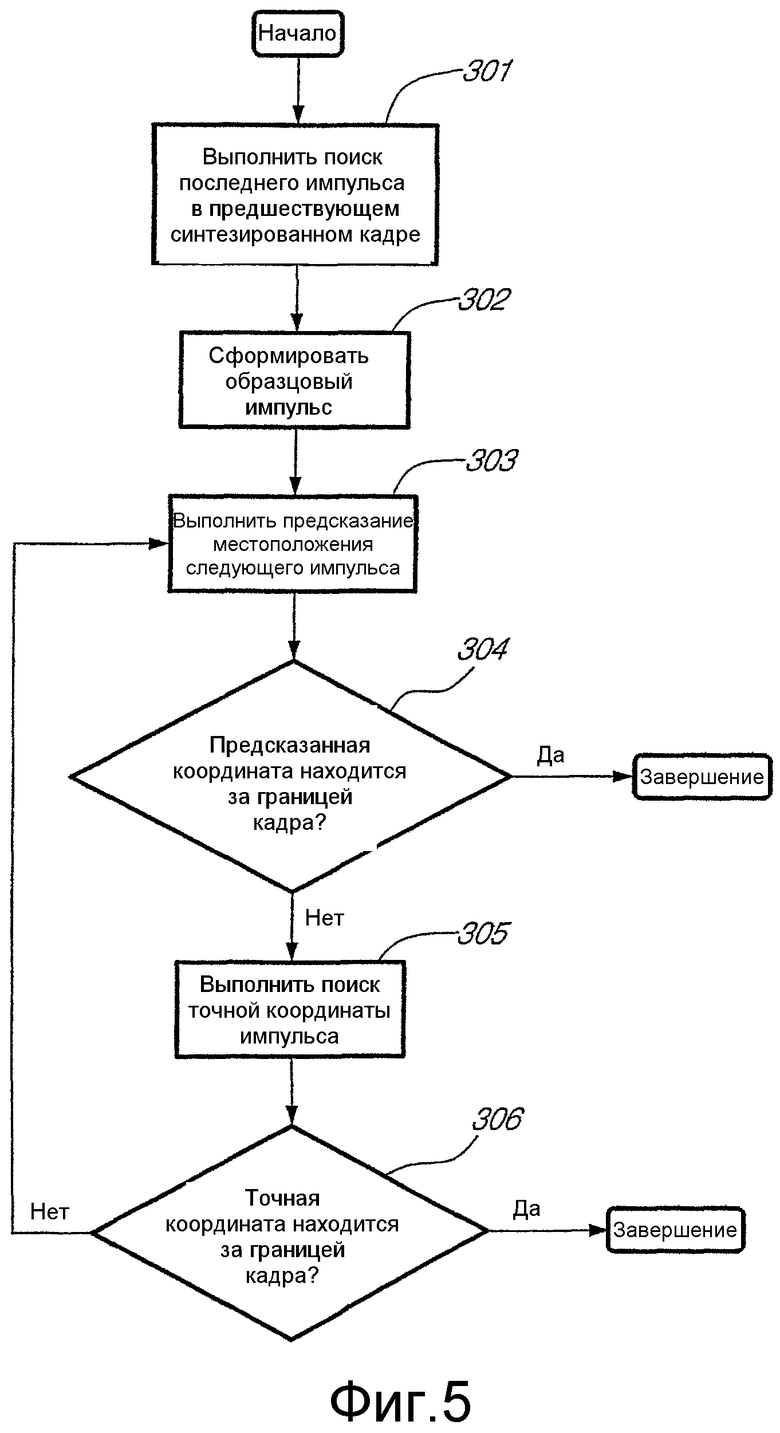
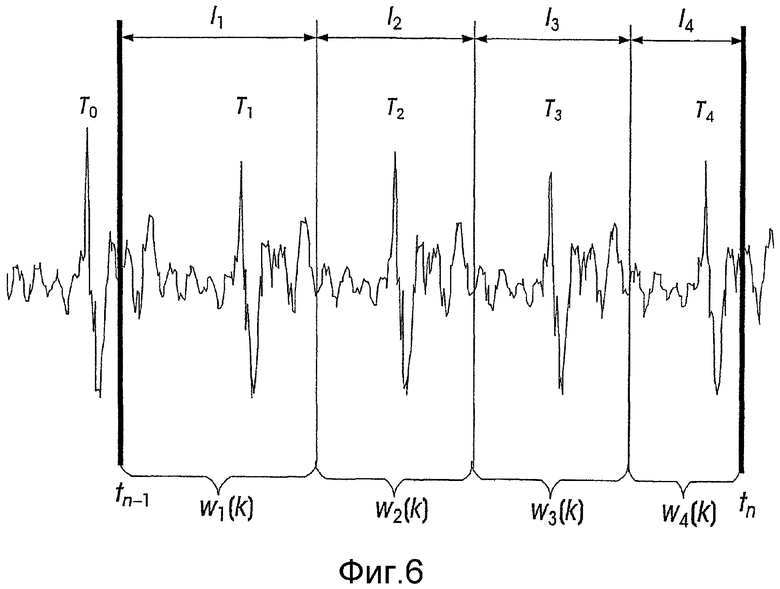
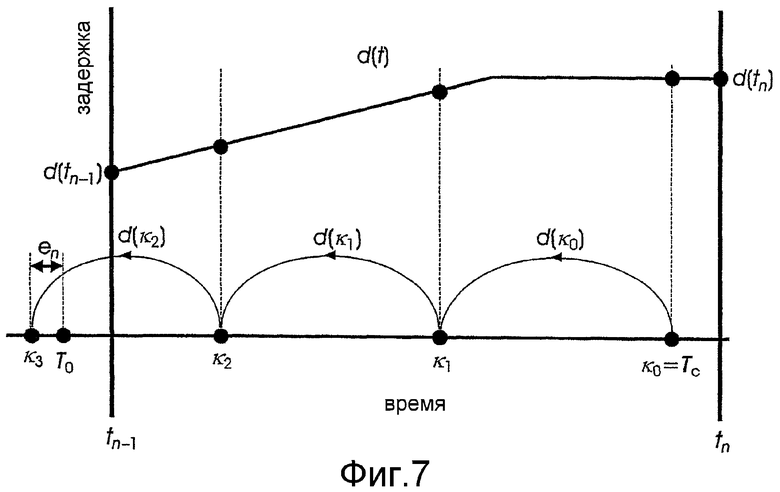
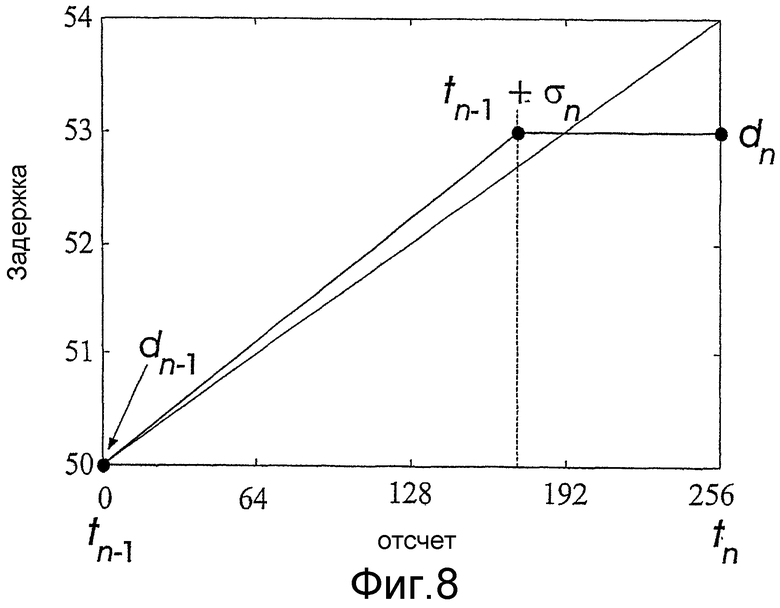
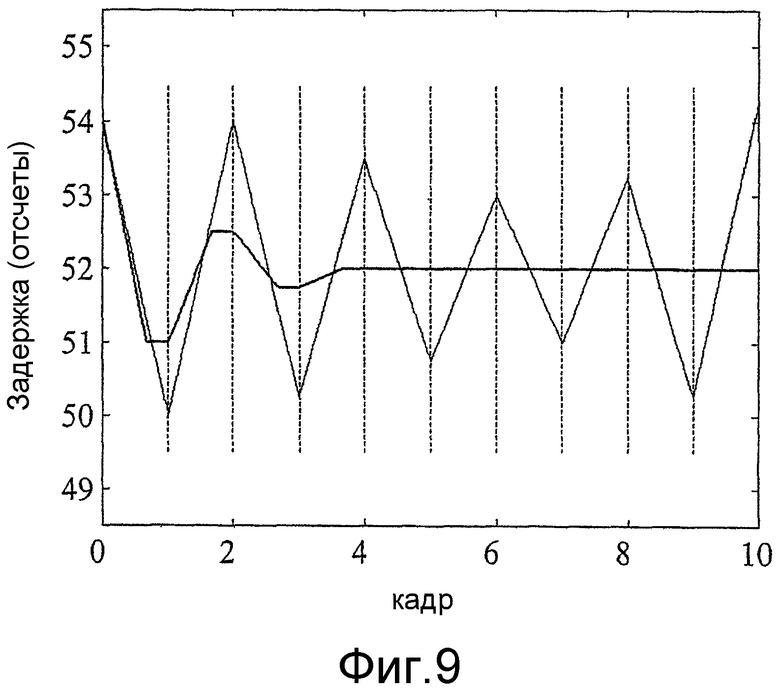
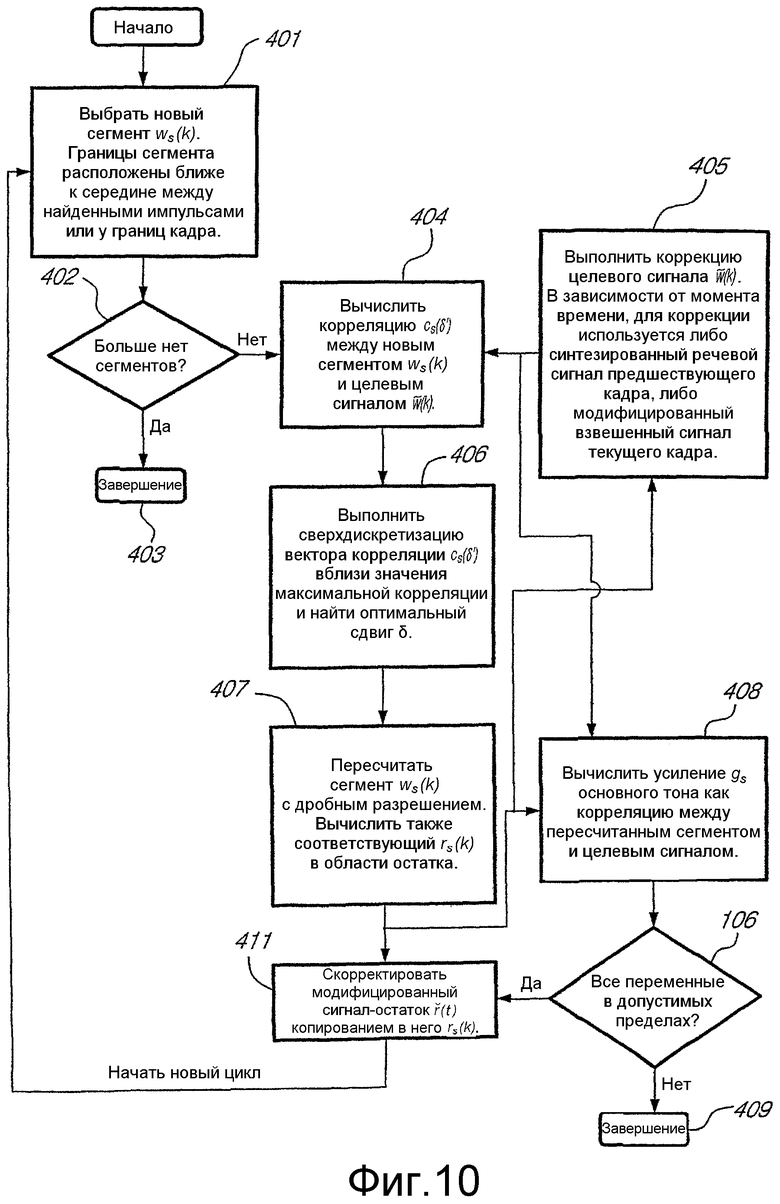
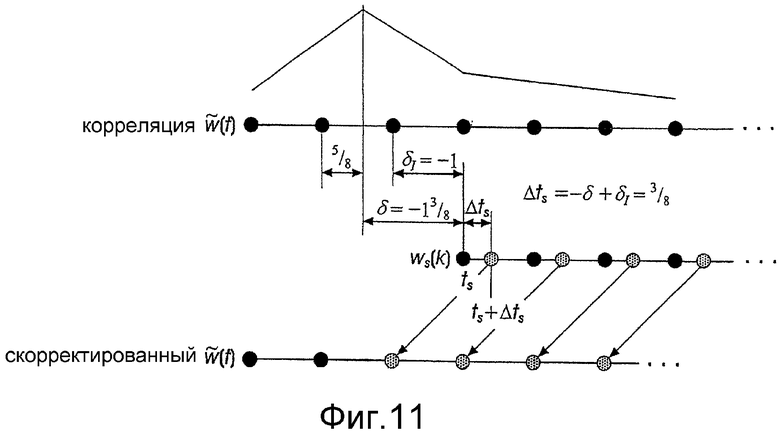
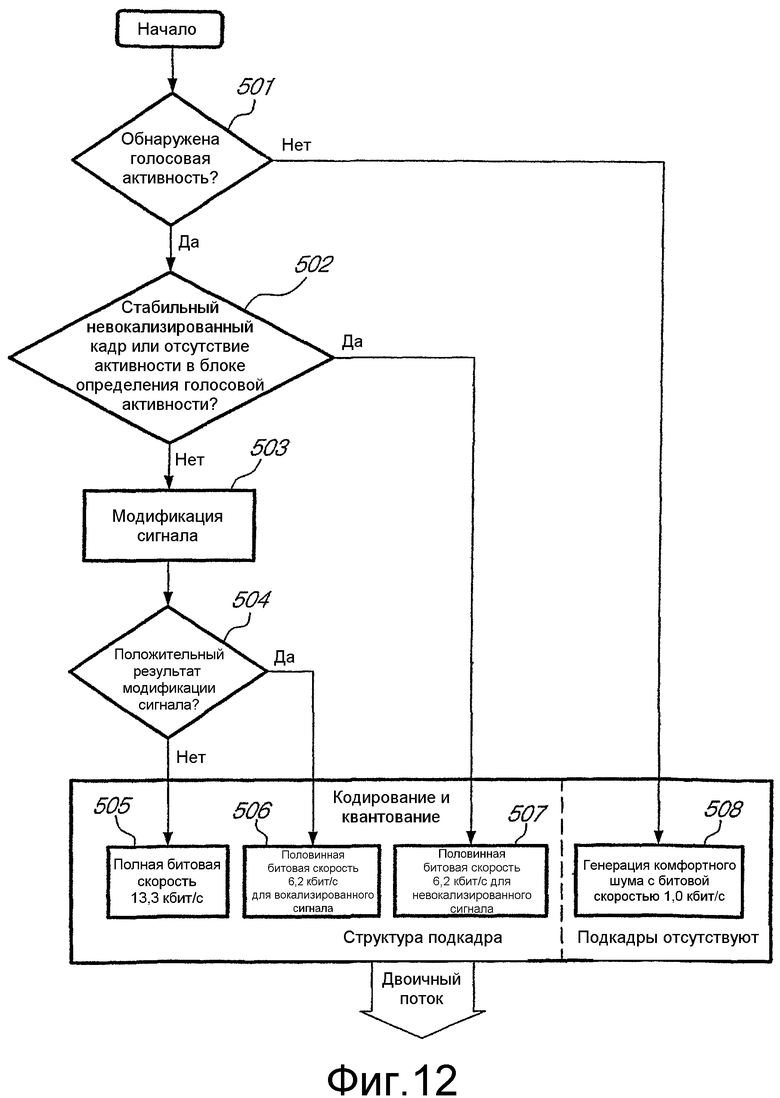
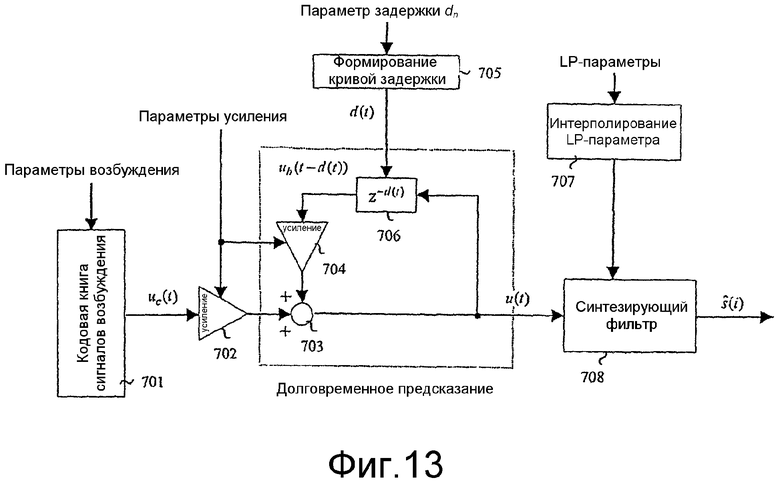
Изобретение относится к области кодирования. Технический результат заключается в обеспечении оптимального качества и скорости передачи звуковых сигналов. Сущность изобретения заключается в том, что речевой сигнал разбивают на последовательность кадров, формируют сигнал из речевого сигнала таким образом, чтобы импульсы основного тона могли быть идентифицированы из сформированного сигнала, определяют местоположение последнего импульса основного тона текущего кадра и местоположение последнего импульса основного тона предшествующего кадра со ссылкой на сформированный сигнал, определяют оптимальное значение параметра задержки таким образом, что кривая задержки основного тона, представляющая изменение задержки основного тона в текущем кадре, характеризуемом упомянутым оптимальным значением параметра задержки, обеспечивала наименьшую ошибку предсказания, когда кривая задержки основного тона используется для предсказания местоположения последнего импульса основного тона в предшествующем кадре. 5 н. и 50 з.п. ф-лы, 13 ил., 3 табл.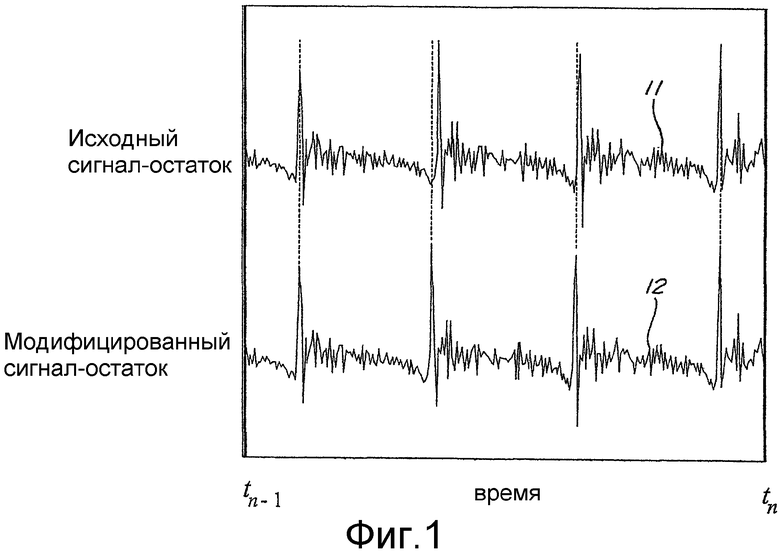
разбиение речевого сигнала на последовательность кадров,
формирование сигнала из речевого сигнала таким образом, чтобы импульсы основного тона могли быть идентифицированы из сформированного сигнала,
определение местоположения последнего импульса основного тона текущего кадра и местоположения последнего импульса основного тона предшествующего кадра со ссылкой на сформированный сигнал,
определение оптимального значения параметра задержки таким образом, что кривая задержки основного тона, представляющая изменение задержки основного тона в текущем кадре, характеризуемом упомянутым оптимальным значением параметра задержки, обеспечивает наименьшую ошибку предсказания, когда кривая задержки основного тона используется для предсказания местоположения последнего импульса основного тона в предшествующем кадре.
определение начального значения для параметра задержки, определение диапазона поиска параметра задержки относительно начального значения, причем диапазон поиска параметра задержки определяет диапазон значений параметра задержки, по которым должен проводиться поиск, для выбранных значений в пределах диапазона поиска параметра задержки,
формирование соответствующих кривых задержки основного тона, характеризующихся выбранными значениями и определяющих соответствующие ошибки предсказания, когда соответствующие кривые задержки основного тона используются для предсказания местоположения упомянутого последнего импульса основного тона предшествующего кадра, и
идентификацию выбранного значения параметра задержки, для которого соответствующая кривая задержки основного тона обеспечивает наименьшую величину ошибки предсказания.
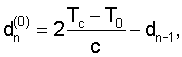
где Тс представляет местоположение последнего импульса основного тона в текущем кадре речевого сигнала;
Т0 представляет местоположение последнего импульса основного тона в предшествующем кадре речевого сигнала;
с представляет число импульсов основного тона в текущем кадре и
dn-1 представляет параметр задержки, определенный для упомянутого предшествующего кадра речевого сигнала, или параметр задержки, определенный для последнего подкадра упомянутого предшествующего кадра.
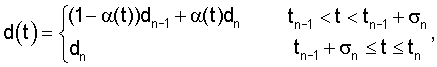
где α(t)=(t-tn-1)/σn;
tn и tn-1 - моменты, представляющие соответственно конец текущего кадра и конец предшествующего кадра речевого сигнала;
dn и dn-1 - значения параметра задержки, соответствующие tn и tn-1 соответственно, и
σn - постоянная.
формирование, по меньшей мере, одного из сигнала-остатка, взвешенного речевого сигнала и синтезированного взвешенного речевого сигнала,
выделение образцового импульса основного тона заданной длины относительно местоположения последнего импульса основного тона предшествующего кадра с использованием одного из остаточного сигнала, взвешенного речевого сигнала и синтезированного взвешенного речевого сигнала, и
определение местоположения импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
предсказание местоположения первого импульса основного тона текущего кадра с использованием местоположения предшествующего локализованного импульса основного тона и интерполированной оценки основного тона в разомкнутом контуре, определенной для момента времени, соответствующего местоположению предшествующего локализованного импульса основного тона, и
уточнение предсказанного местоположения упомянутого первого импульса основного тона текущего кадра путем максимизации взвешенной корреляции между образцовым импульсом и одним из сигнала-остатка, взвешенного речевого сигнала и синтезированного взвешенного речевого сигнала.
формирование взвешенного речевого сигнала путем обработки речевого сигнала посредством взвешивающего фильтра,
выбор сегмента взвешенных речевых выборок из взвешенного речевого сигнала,
формирование целевого сигнала,
определение корреляции выбранного сегмента взвешенных речевых выборок с целевым сигналом для нахождения максимального значения корреляции,
определение значения сдвига, соответствующего максимальному значению корреляции,
получение сегмента остатка, соответствующего выбранному сегменту взвешенных речевых выборок, причем сегмент остатка содержит выборки из сигнала-остатка линейного предсказания,
применение сдвига к сегменту остатка в соответствии с определенным значением сдвига для получения модифицированного сигнала-остатка.
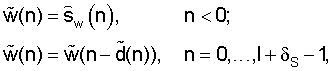
где 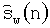 представляет взвешенный синтезированный речевой сигнал для предшествующего кадра,
представляет взвешенный синтезированный речевой сигнал для предшествующего кадра,
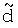 (n) представляет кривую задержки и
(n) представляет кривую задержки и
δS представляет максимальный сдвиг, допустимый для первого сегмента протяженностью l.
вычисление модифицированных значений выборок для выбранного сегмента взвешенных речевых выборок в соответствии с определенным значением сдвига для формирования сегмента модифицированных взвешенных значений выборок,
обновление целевого сигнала путем замены значений выборок целевого сигнала модифицированными взвешенными речевыми выборками.
определение, существует ли высокоэнергетичная зона в сигнале-остатке линейного предсказания вблизи границы кадра рядом с сегментом остатка, и
если найдено, что существует высокоэнергетичная зона вблизи
границы кадра, то ограничение сдвига, применяемого к сегменту остатка, до заданного значения.
разбиения речевого сигнала на последовательность кадров,
формирования сигнала из речевого сигнала таким образом, чтобы импульсы основного тона могли быть идентифицированы из сформированного сигнала,
определения местоположения последнего импульса основного тона текущего кадра и местоположения последнего импульса основного тона предшествующего кадра со ссылкой на сформированный сигнал,
определения оптимального значения параметра задержки таким образом, что кривая задержки основного тона, представляющая изменение задержки основного тона в текущем кадре, характеризуемом упомянутым оптимальным значением параметра задержки, обеспечивает минимизированную ошибку предсказания, когда кривая задержки основного тона используется для предсказания местоположения последнего импульса основного тона в предшествующем кадре.
выбора значений в пределах диапазона поиска параметра задержки, формирования соответствующих кривых задержки основного тона, характеризующихся выбранными значениями, и определения соответствующих ошибок предсказания, когда соответствующие кривые задержки основного тона используются для предсказания местоположения упомянутого последнего импульса основного тона предшествующего кадра, и
идентификации выбранного значения параметра задержки, для которого соответствующая кривая задержки основного тона обеспечивает наименьшую величину ошибки предсказания.
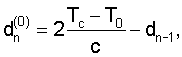
где Тc представляет местоположение последнего импульса основного тона в текущем кадре речевого сигнала;
Т0 представляет местоположение последнего импульса основного тона в предшествующем кадре речевого сигнала;
с представляет число импульсов основного тона в текущем кадре и
dn-1 представляет параметр задержки, определенный для упомянутого предшествующего кадра речевого сигнала, или параметр задержки, определенный для последнего подкадра упомянутого предшествующего кадра.
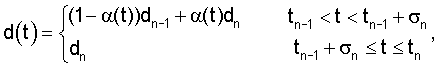
где α(t)=(t-tn-1)/σn
tn и tn-1 - моменты, представляющие соответственно конец текущего кадра и конец предшествующего кадра речевого сигнала,
dn и dn-1 - значения параметра задержки, соответствующие tn и tn-1 соответственно, и
σn - постоянная.
выделения образцового импульса основного тона заданной длины относительно местоположения последнего импульса основного тона предшествующего кадра с использованием одного из сигнала-остатка, взвешенного речевого сигнала и синтезированного взвешенного речевого сигнала, и
определения местоположения импульсов основного тона в текущем кадре с использованием образцового импульса основного тона.
уточнения предсказанного местоположения упомянутого первого импульса основного тона текущего кадра путем максимизации взвешенной корреляции между образцовым импульсом и одним из сигнала-остатка, взвешенного речевого сигнала и синтезированного взвешенного речевого сигнала.
формирования взвешенного речевого сигнала путем обработки речевого сигнала посредством взвешивающего фильтра,
выбора сегмента взвешенных речевых выборок из взвешенного речевого сигнала,
формирования целевого сигнала,
определения корреляции выбранного сегмента взвешенных речевых выборок с целевым сигналом для нахождения максимального значения корреляции,
определения значения сдвига, соответствующего максимальному значению корреляции,
получения сегмента остатка, соответствующего выбранному сегменту взвешенных речевых выборок, причем сегмент остатка содержит выборки из сигнала-остатка линейного предсказания, и
применения сдвига к сегменту остатка в соответствии с определенным значением сдвига для получения модифицированного сигнала-остатка.
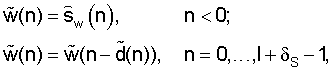
где обозначает взвешенный синтезированный речевой сигнал для предшествующего кадра,
(n) представляет кривую задержки и
δS представляет максимальный сдвиг, допустимый для первого сегмента протяженностью l.
обновления целевого сигнала путем замены значений выборок целевого сигнала модифицированными взвешенными речевыми выборками.
ограничения сдвига, применяемого к сегменту остатка, до заданного значения, если найдено, что существует высокоэнергетичная зона вблизи границы кадра.
| Устройство, сигнализирующее о присутствии в шахтах взрывчатой смеси | 1928 |
|
SU11653A1 |
| СПОСОБ КОДИРОВАНИЯ РЕЧЕВЫХ СИГНАЛОВ | 1993 |
|
RU2120700C1 |
| US 5974377 А, 26.10.1999 | |||
| US 2001023395 А1, 20.09.2001. | |||

