Область техники, к которой относится изобретение
Настоящее изобретение относится к способу цифрового кодирования звукового сигнала, в частности, но не исключительно, речевого сигнала, в целях передачи и/или синтеза этого звукового сигнала. Более конкретно, настоящее изобретение относится к надежному кодированию и декодированию звуковых сигналов, чтобы сохранить хорошие характеристики в случае стертого кадра или кадров, например, из-за ошибок канала в беспроводных системах или из-за потерянных пакетов в приложениях передачи голоса по пакетной сети.
Предпосылки изобретения
Потребность в эффективных методах узкополосного и широкополосного кодирования речи с хорошим компромиссом между субъективным качеством и битовой скоростью растет в разных областях применения, таких, как телеконференцсвязь, мультимедиа и беспроводная связь. До недавнего времени в приложениях речевого кодирования использовалась в основном полоса частот телефонии, ограниченная диапазоном 200-3400 Гц. Однако широкополосные речевые приложения обеспечивают большую разборчивость и естественность в передачах по сравнению с обычной телефонной полосой. Было найдено, что полоса частот в интервале 50-7000 Гц достаточна для получения хорошего качества, давая впечатление непосредственного общения. Для обычных аудиосигналов эта полоса частот дает приемлемое субъективное качество, но оно все же ниже, чем качество FM-радио или CD, которые работают в диапазоне 20-16000 Гц и 20-20000 Гц соответственно.
Речевой кодер преобразует речевой сигнал в цифровой битовый поток, который передается по каналу связи или сохраняет на носителе для хранения данных. Речевой сигнал оцифровывается, то есть дискретизируется и квантуется обычно 16 битами на выборку. Речевой кодер выполняет роль представления этих цифровых выборок меньшим числом битов при сохранении хорошего субъективного качества речи. Речевой декодер, или синтезатор воздействует на переданный или сохраненный битовый поток и снова преобразует его в звуковой сигнал.
Линейное предсказание с кодовым возбуждением (CELP) является одним из лучших существующих методов достижения хорошего компромисса между субъективным качеством и битовой скоростью. Этот метод кодирования является основой нескольких стандартов речевого кодирования в приложениях как беспроводных, так и проводных линий связи. В CELP-кодировании дискретизированный речевой сигнал обрабатывается в последовательных блоках из L выборок, обычно называемых кадрами, где L есть заданное число, типично соответствующее 10-30 мс речевого сигнала. Фильтр линейного предсказания (LP) вычисляется и передается каждый кадр. Вычисление LP-фильтра обычно требует предварительного просмотра 5-15 миллисекундного речевого сегмента из последующего кадра. Кадр из L выборок разделяется на меньшие блоки, называемые подкадрами. Обычно число подкадров равно трем или четырем, что дает 4-10 миллисекундные подкадры. В каждом подкадре сигнал возбуждения обычно получают из двух компонентов: предшествующего возбуждения и обновленного возбуждения фиксированной кодовой книги. Компонент, образованный из предшествующего возбуждения, часто упоминается как адаптивная кодовая книга или возбуждение основного тона. Параметры, характеризующие сигнал возбуждения, кодируются и передаются на декодер, где реконструированный сигнал возбуждения используется как входной для LP-фильтра.
Поскольку основным применением речевого кодирования с низкой скоростью передачи битов являются беспроводные системы мобильной связи и сети пакетной передачи голоса, то повышение надежности речевых кодеков в случае стирания кадров имеет большое значение. В беспроводных сотовых системах энергия принимаемого сигнала часто может обнаруживать сильное затухание, что приводит к высокой частоте появления ошибочных битов, и это становится более явным на границах сот. В этом случае канальный декодер не способен исправить ошибки в принятом кадре и, как следствие, устройство обнаружения ошибок, обычно использующееся после канального декодера, объявит этот кадр как стертый. В приложениях передачи голоса в пакетной сети речевой сигнал объединяется в пакеты, причем обычно каждый пакет соответствует 20-40 мс звукового сигнала. В системах связи с коммутацией пакетов может произойти отбрасывание пакета в маршрутизаторе, если число пакетов станет очень большим, или пакет может дойти до приемного устройства с большим запаздыванием, и он будет объявлен как потерянный, если его запаздывание превысит длину буфера колебаний задержки на стороне приемного устройства. В этих системах кодек подвергается действию стирания кадров частотой типично от 3 до 5%. Кроме того, применение широкополосного речевого кодирования является большим достоинством этих систем, которое позволит им конкурировать с традиционной PSTN (коммутируемая телефонная сеть общего пользования), в которой исторически используются узкополосные речевые сигналы.
Адаптивная кодовая книга, или предсказатель основного тона, в CELP участвует в сохранении высокого качества речи при низкой скорости передачи битов. Однако, поскольку содержание адаптивной кодовой книги основано на сигнале от предшествующих кадров, это делает модель кодека чувствительной к потере кадра. В случае стертых или потерянных кадров содержимое адаптивной кодовой книги на декодере будет отличаться от его содержимого на кодере. Таким образом, после того как потерянный кадр замаскирован и получены последующие хорошие кадры, синтезированный сигнал в принятых хороших кадрах отличается от планировавшегося синтезированного сигнала, так как вклад адаптивной кодовой книги изменился. Влияние потерянного кадра зависит от природы речевого сегмента, в котором произошло стирание. Если стирание происходит в стационарном сегменте сигнала, то может быть осуществлена эффективная маскировка стирания кадра, и влияние на последующие хорошие кадры может быть сведено к минимуму. С другой стороны, если стирание происходит в начале речи или при переходе, эффект от стирания может распространиться на несколько кадров. Например, если потеряно начало голосового сегмента, то первый период основного тона в содержимом адаптивной кодовой книги будет пропущен. Это будет иметь сильное влияние на предсказатель основного тона в последующих хороших кадрах, что приведет к большему времени, прежде чем синтезированный сигнал сойдется к намеченному на кодере.
Суть изобретения
В частности, в соответствии с первым аспектом настоящего изобретения приложен способ маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и восстановления декодера после стирания кадров, причем способ включает в кодере: определение параметров маскировки/восстановления, в том числе по меньшей мере фазовой информации, относящейся к кадрам кодированного звукового сигнала; передачу на декодер параметров маскировки/восстановления, определенных в кодере, и в декодере: проведение маскировки стирания кадра в ответ на принятые параметры маскировки/восстановления, причем маскировка стирания кадра включает повторную синхронизацию кадров с замаскированным стиранием с соответствующими кадрами кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в фазовую информацию.
В соответствии со вторым аспектом настоящего изобретения предложено устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство включает в кодере: средство для определения параметров маскировки/восстановления, включая по меньшей мере фазовую информацию, относящуюся к кадрам кодированного звукового сигнала; средство для передачи на декодер параметров маскировки/восстановления, определенных в кодере; и в декодере: средство проведения маскировки стирания кадра в ответ на полученные параметры маскировки/восстановления, причем средство для проведения маскировки стирания кадра содержит средство повторной синхронизации кадров с замаскированным стиранием с соответствующими кадрами кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в фазовую информацию.
В соответствии с третьим аспектом настоящего изобретения предложено устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство содержит в кодере: генератор параметров маскировки/восстановления, включая по меньшей мере фазовую информацию, относящуюся к кадрам кодированного звукового сигнала; канал связи для передачи декодеру параметров маскировки/восстановления, определенных в кодере; и в декодере: модуль маскировки стирания кадров, на который подаются полученные параметры маскировки/восстановления и который содержит синхронизатор, который в ответ на полученную фазовую информацию проводит повторную синхронизацию кадров с замаскированным стиранием с соответствующими кадрами кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в фазовую информацию.
В соответствии с четвертым аспектом настоящего изобретения предложен способ маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем способ включает в декодере: оценку фазовой информации для каждого кадра кодированного звукового сигнала, который был стерт при передаче от кодера к декодеру; и проведение маскировки стирания кадра в ответ на оцененную фазовую информацию, причем маскировка стирания кадра включает повторную синхронизацию, в ответ на оцененную фазовую информацию, каждого кадра с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в оцененную фазовую информацию.
В соответствии с пятым аспектом настоящего изобретения предложено устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство содержит: средство для оценки на декодере фазовой информации о каждом кадре кодированного звукового сигнала, который был стерт при передаче от кодера к декодеру; и средство для проведения маскировки стирания кадра в ответ на оценку фазовой информации, причем средство для проведения маскировки стирания кадра содержит средство повторной синхронизации, в ответ на оцененную фазовую информацию, каждого кадра с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в оцененную фазовую информацию.
В соответствии с шестым аспектом настоящего изобретения предложено устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство содержит на декодере: модуль оценки фазовой информации о каждом кадре кодированного сигнала, который был стерт при передаче от кодера к декодеру; и модуль маскировки стирания, на который подается оценка фазовой информации и который содержит синхронизатор, который в ответ на оцененную фазовую информацию повторно синхронизирует каждый кадр с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в оцененную фазовую информацию.
Вышеупомянутые и другие цели, преимущества и отличительные признаки настоящего изобретения станут более понятны при прочтении следующего неограничивающего описания иллюстративных вариантов реализации, данных исключительно для примера, с обращением к приложенным чертежам.
Краткое описание чертежей
На приложенных чертежах:
фиг.1 является принципиальной блок-схемой системы речевой связи, показывающей пример применения устройств речевого кодирования и декодирования;
фиг.2 является принципиальной блок-схемой примера устройства CELP-кодирования;
фиг.3 является принципиальной блок-схемой примера устройства CELP-кодирования;
фиг.4 является принципиальной блок-схемой вложенного кодера на основе ядра G.729 (G.729 означает рекомендацию ITU-T G.729);
фиг.5 является принципиальной блок-схемой вложенного декодера на основе ядра G.729;
фиг.6 является упрощенной блок-схемой устройства CELP-кодирования по фиг.2, в котором модуль поиска основного тона с обратной связью, модуль расчета отклика при отсутствии входного сигнала, модуль генерирования импульсной характеристики, модуль поиска обновленного возбуждения и модуль обновления памяти были сгруппированы в один модуль поиска основного тона замкнутого контура и обновленной кодовой книги;
фиг.7 является расширением блок-схемы по фиг.4, в которую были добавлены модули, связанные с параметрами улучшения маскировки/восстановления;
фиг.8 является схематическим представлением, показывающим пример конечного автомата классификации кадров для маскировки стирания;
фиг.9 является блок-схемой, показывающей процедуру маскировки периодической части возбуждения согласно неограничительному иллюстративному варианту осуществления настоящего изобретения;
фиг.10 является блок-схемой, показывающей процедуру синхронизации периодической части возбуждения согласно неограничительному иллюстративному варианту осуществления настоящего изобретения;
фиг.11 показывает типичные примеры сигнала возбуждения с и без процедуры синхронизации;
фиг.12 показывает примеры реконструированного речевого сигнала с использованием сигналов возбуждения, показанных на фиг.11 и
фиг.13 является блок-схемой, иллюстрирующей случай, когда потерян начальный кадр.
Подробное описание
Хотя иллюстративный вариант осуществления настоящего изобретения будет описан в дальнейшем описании в отношении речевого сигнала, следует иметь в виду, что идеи настоящего изобретения применимы равным образом к сигналам другого типа, в частности, но не исключительно, к другим типам звуковых сигналов.
Фиг.1 иллюстрирует систему 100 речевой связи, показывая применение речевого кодирования и декодирования в иллюстративном контексте настоящего изобретения. Система 100 речевой связи на фиг.1 поддерживает передачу речевого сигнала по каналу 101 связи. Хотя он может содержать, например, проводную, оптическую связь или волоконную связь, обычно канал 101 связи содержит, по меньшей мере в части, радиочастотную связь. Такая радиочастотная связь часто поддерживает множество одновременных речевых передач, что требует совместно используемых ресурсов частотной полосы, как можно найти в системах сотовой телефонии. Хотя это не показано, канал 101 связи может быть заменен запоминающим устройством в варианте осуществления систем 100 с одним устройством, для записи и хранения кодированного речевого сигнала для последующего воспроизведения.
В системе 100 речевой связи по фиг.1 микрофон 102 производит аналоговый речевой сигнал 103, который подается на аналого-цифровой преобразователь (АЦП) 104 для его преобразования в цифровой речевой сигнал 105. Кодер 106 речи кодирует цифровой речевой сигнал 105 с получением набора параметров 107 кодирования сигнала, которые закодированы в двоичной форме и подаются на канальный кодер 108. Факультативный канальный кодер 108 добавляет избыточность в двоичное представление параметров 107 кодирования сигнала до передачи их по каналу 101 связи.
В приемном устройстве канальный декодер 109 использует указанную избыточную информацию в полученном битовом потоке 111, чтобы обнаружить и исправить ошибки канала, которые произошли при передаче. Затем декодер речи 110 преобразует битовый поток 112, полученный от канального декодера 109, снова в набор параметров кодирования сигнала и создает из восстановленных параметров кодирования сигнала синтезированный цифровой речевой сигнал 113. Синтезированный цифровой речевой сигнал 113, реконструированный в речевом декодере 110, преобразуется в аналоговую форму 114 посредством цифроаналогового преобразователя (ЦАП) 115 и воспроизводится через блок 116 громкоговорителя.
Неограничительный иллюстративный вариант осуществления эффективного способа маскировки стирания кадра, раскрываемого в настоящем описании, может применяться с любым из узкополосного или широкополосного кодека на основе линейного предсказания. Равным образом, этот иллюстративный вариант осуществления описан в отношении вложенного кодека на основе рекомендации G.729, стандартизованной Международным союзом телекоммуникаций (ITU) [ITU-T рекомендация G.729 "Кодирование речи на 8 кбит/с с применением сопряженно-структурного линейного предсказания с возбуждением алгебраического кода (CS-ACELP)", Женева, 1996].
Вложенный кодек на основе G.729 был стандартизован комитетом ITU-T в 2006 и известен как рекомендация G.729.1 [рекомендация ITU-T G.729.1 "Вложенный кодер G.729 с переменной скоростью передачи битов: Широкополосный битовый поток кодера, масштабируемый на интервале 8-32 кбит/с, способный взаимодействовать с G.729", Женева, 2006]. Методы, описанные в настоящем подробном описании, были реализованы в рекомендации ITU-T G.729.1.
Здесь следует понимать, что иллюстративный вариант осуществления способа эффективной маскировки стирания кадра может применяться для других типов кодеков. Например, иллюстративный вариант осуществления способа эффективной маскировки стирания кадров, представленный в настоящем описании, используется в алгоритме-кандидате для стандартизации комитетом ITU-T вложенного кодека с переменной скоростью передачи битов. В алгоритме-кандидате базовый уровень основан на методе широкополосного кодирования, сходном с AMR-WB (рекомендация ITU-T G.722.2).
В следующих разделах сначала будет дан обзор CELP и вложенных кодера и декодера на основе G.729. Затем будет описан иллюстративный вариант осуществления нового подхода к улучшению надежности кодека.
Обзор кодера ACELP
Дискретизированный речевой сигнал кодируется поблочно кодирующим устройством 200 по фиг.2, которое разбито на одиннадцать модулей, пронумерованных позициями с 201 по 211.
Таким образом, входной речевой сигнал 212 обрабатывается поблочно, т.е. в вышеупомянутых блоках длиной L выборок, называемых кадрами.
Согласно фиг.2 дискретизированный входной речевой сигнал 212 подается на факультативный модуль 201 предварительной обработки. Модуль 201 предварительной обработки может состоять из фильтра верхних частот с частотой отсечки 200 Гц для узкополосных сигналов и частотой отсечки 50 Гц для широкополосных сигналов.
Предварительно обработанный сигнал обозначается s(n), n=0, 1, 2,...,L-1, где L есть длина кадра, равная типично 20 мс (160 выборок при частоте дискретизации 8 кГц).
Сигнал s(n) используется для проведения LP-анализа в модуле 204. LP-анализ является методом, хорошо известным специалистам в данной области. В данной иллюстративной реализации используется автокорреляционный подход. В автокорреляционном подходе сигнал s(n) сначала обрабатывается методом окна, используя обычно окно Хэмминга, имеющее длину порядка 30-40 мс. Автокорреляции рассчитываются из сигнала, обработанного методом окна, для расчета коэффициентов LP-фильтра aj (где j=1,...,p и p есть порядок LP, типично равный 10 в узкополосном кодировании и 16 в широкополосном кодировании) применяется рекурсия Левинсона-Дурбина. Параметры aj являются коэффициентами передаточной функции A(z) LP-фильтра, которая задается следующим соотношением:
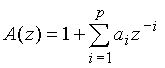
Считается, что LP-анализ для других целей хорошо известен специалистам, и соответственно он не будет описываться подробнее в настоящем описании.
Модуль 204 также проводит квантование и интерполяцию коэффициентов LP-фильтра. Коэффициенты LP-фильтра сначала трансформируются в другую эквивалентную область, более подходящую для целей квантования и интерполяции. Области линейных спектральных пар (LSP) и спектральных пар иммитанса (ISP) являются двумя областями, в которых можно эффективно провести квантование и интерполяцию. При узкополосном кодировании 10 коэффициентов LP-фильтра aj могут быть квантованы примерно 18-30 битами, используя расщепленное или многостадийное квантование или их комбинацию. Целью интерполяции является дать возможность обновить коэффициенты LP-фильтра каждого подкадра, одновременно передавая их один раз на каждый кадр, что улучшает характеристики кодера без повышения скорости передачи битов. Считается, что квантование и интерполяция коэффициентов LP-фильтра в других отношениях хорошо известны специалистам и, соответственно, не будут описываться подробнее в настоящем описании.
В следующем абзаце будут описаны остальные операции кодирования, проводимые на основе подкадров. В данной иллюстративной реализации 20-миллисекундный входной кадр делится на 4 подкадра длиной 5 мс (40 выборок на частоте дискретизации 8 кГц). В дальнейшем описании фильтр A(z) означает неквантованный интерполированный LP-фильтр подкадра, а фильтр В(z) означает квантованный интерполированный LP-фильтр подкадра. Фильтр В(z) подает каждый подкадр на мультиплексор 213 для передачи через канал связи (не показан).
В кодерах, действующих по принципу анализа через синтез, оптимальные параметры основного тона и обновления ищутся путем минимизации среднеквадратичной ошибки между входным речевым сигналом 212 и синтезированным речевым сигналом в перцептивно взвешенной области. Взвешенный сигнал sw(n) рассчитывается в перцептивном взвешивающем фильтре 205 в ответ на сигнал s(n). Пример передаточной функции для перцептивного взвешивающего фильтра 205 дается следующим соотношением:
W(z)=A(z/γ1)/A(z/γ2),
где 0<γ2<γ1≤1.
Чтобы упростить анализ основного тона, сначала в модуле 206 поиска основного тона в разомкнутом контуре из взвешенного речевого сигнала sw(n) оценивается запаздывание TOL основного тона разомкнутого контура. Затем анализ основного тона замкнутого контура, который проводится в модуле 207 поиска основного тона замкнутого контура на основе подкадров, ограничивается окрестностью запаздывания T0L основного тона разомкнутого контура, что значительно уменьшает сложность поиска LTP-параметров (параметров долгосрочного предсказания) T (запаздывание основного тона) и b (усиление основного тона). Анализ основного тона разомкнутого контура обычно проводится в модуле 206 один раз каждые 10 мс (два подкадра), используя методы, хорошо известные специалистам.
Сначала рассчитывается целевой вектор x для LTP-анализа (долговременное предсказание). Это обычно проводится вычитанием отклика s0 нулевого входа взвешенного синтезирующего фильтра W(z)/В(z) из взвешенного речевого сигнала sw(n). Этот отклик s0 нулевого входа рассчитывается устройством 208 расчета отклика нулевого входа в ответ на квантованный интерполированный LP-фильтр A(z) из модуля 204 LP-анализа, квантования и интерполяции и на начальные состояния взвешенного синтезирующего фильтра W(z)/В(z)), сохраненные в модуле 211 обновления памяти в ответ на LP-фильтры A(z) и В(z) и вектор возбуждения u. Эта операция хорошо известна специалистам и, соответственно, в настоящем описании не будет описываться более подробно.
N-мерный вектор импульсной характеристики h взвешенного синтезирующего фильтра W(z)/В(z) рассчитывается в генераторе 209 импульсной характеристики с использованием коэффициентов LP-фильтра A(z) и В(z) из модуля 204. Опять же эта операция хорошо известна специалистам и, соответственно, в настоящем описании не будет описываться более подробно.
Параметры b и T основного тона замкнутого контура (или кодовой книги основного тона) рассчитываются в модуле 207 поиска основного тона замкнутого контура, который в качестве входных параметров использует целевой вектор x, вектор импульсной характеристики h и запаздывание TOL основного тона замкнутого контура.
Поиск основного тона состоит в нахождении наилучшего запаздывания T и усиления b основного тона, которые минимизируют среднеквадратичную взвешенную ошибку предсказания основного тона, например,
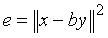
между целевым вектором x и масштабированной фильтрованной версией предшествующего возбуждения.
В частности, в настоящей иллюстративной реализации поиск основного тона (кодовой книги основного тона или адаптивной кодовой книги) состоит из трех (3) стадий.
На первой стадии запаздывание TOL основного тона разомкнутого контура оценивается в модуле 206 поиска основного тона разомкнутого контура в ответ на взвешенный речевой сигнал sw(n). Как указывалось выше в описании, этот анализ основного тона разомкнутого контура обычно осуществляется один раз каждые 10 мс (два подкадра), используя методы, хорошо известные специалистам.
На второй стадии в модуле 207 поиска основного тона замкнутого контура отыскивается критерий C поиска для целочисленных запаздываний основного тона в окрестности оценки запаздывания TOL основного тона разомкнутого контура (обычно ±5), что существенно упрощает процедуру поиска. Пример критерия C поиска задается формулой:
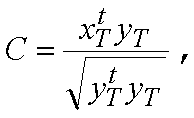
где t означает транспонирование вектора.
После того как на второй стадии найдено оптимальное целочисленное запаздывание основного тона, на третьей стадии поиска (модуль 207) проверяются, с помощью критерия C поиска, дробные части в окрестности этого оптимального целочисленного запаздывания основного тона. Например, в рекомендации ITU-T G.729 используется разрешение субдискретизации 1/3.
Индекс T кодовой книги основного тона кодируется и передается на мультиплексор 213 для передачи через канал связи (не показан). Усиление b основного тона квантуется и передается на мультиплексор 213.
После того как параметры b и T основного тона, или LTP-параметры (параметры долгосрочного предсказания) определены, следующим этапом является поиск оптимального обновленного возбуждения с помощью модуля 210 поиска обновленного возбуждения, показанного на фиг.2. Сначала обновляется целевой вектор x, вычитая вклад от LTP:
x'=x-byT,
где b есть усиление основного тона, а yT означает фильтрованный вектор кодовой книги основного тона (свертка предшествующего возбуждения при запаздывании T с импульсной характеристикой h).
Процедура поиска обновленного возбуждения в CELP проводится в обновленной кодовой книге, чтобы найти кодовый вектор ck оптимального возбуждения и усиление g, которые минимизируют среднеквадратичную ошибку E между целевым вектором x' и масштабированной фильтрованной версией кодового вектора ck, например:
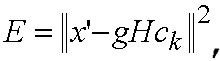
где H есть нижняя треугольная матрица свертки, выводимая из вектора импульсной характеристики h. Индекс k обновленной кодовой книги, соответствующий найденному оптимальному кодовому вектору ck, и усиление g подаются на мультиплексор 213 для передачи через канал связи.
В иллюстративной реализации используемая обновленная кодовая книга представляет собой динамическую кодовую книгу, содержащую алгебраическую кодовую книгу, за которой следует адаптивный предфильтр F(z), который усиливает особые спектральные компоненты, чтобы улучшить качество синтезированной речи, в соответствии с патентом US 5444816, выданным Adoul и др. 22 августа 1995. В данной иллюстративной реализации поиск обновленной кодовой книги проводится в модуле 210 с помощью алгебраической кодовой книги, как описано в патентах US 5444816 (Adoul и др.) от 22 августа 1995; 5699482, выдан Adoul и др. 17 декабря 1997; 5754976, выдан Adoul и др. 19 мая 1998, и 5701392 (Adoul и др.) от 23 декабря 1997.
Обзор декодеров ACELP
Речевой декодер 300 по фиг.3 показывает различные этапы, проводимые между входом 322 цифровых данных (входной битовый поток в демультиплексор 317) и выходным дискретизированным речевым сигналом sout.
Демультиплексор 317 выделяет параметры модели синтеза из двоичной информации (входной битовый поток 322), полученной из канала цифрового ввода. Параметрами, выделенными из каждого полученного двоичного кадра, являются:
- квантованные, интерполированные LP-коэффициенты В(z), называемые также параметрами краткосрочного предсказания (STP), формируемыми один раз на кадр;
- параметры T и b долгосрочного предсказания (LTP) (для каждого подкадра) и
- индекс k и усиление g обновленной кодовой книги (для каждого подкадра).
Как будет объяснено ниже, текущий речевой сигнал синтезируется на основе этих параметров.
Обновленная кодовая книга 318 в ответ на индекс k получает обновленный кодовый вектор ck, который масштабируется декодированным усилением g через усилитель 324. В иллюстративной реализации обновленная кодовая книга, какая описана в вышеупомянутых патентах US 5444816; 5699482, 5754976 и 5701392, используется для получения обновленного кодового вектора сk.
Масштабированный кодовый вектор основного тона bvT получается при использовании запаздывания T основного тона в кодовой книге 301 основного тона для получения кодового вектора основного тона. Затем кодовый вектор vT основного тона умножается на усиление b основного тона усилителем 326 для получения масштабированного кодового вектора bvT основного тона.
Сигнал u возбуждения вычисляется сумматором 320 как
u=gck+bvT.
Содержимое кодовой книги 301 основного тона обновляется при использовании прошлых значений сигнала u возбуждения, хранившихся в памяти 303, чтобы сохранить синхронность между кодером 200 и декодером 300.
Синтезированный сигнал s' рассчитывается фильтрацией сигнала u возбуждения через синтезирующий LP-фильтр 306, который имеет форму 1/В(z), где В(z) есть квантованный интерполированный LP-фильтр текущего подкадра. Как можно видеть на фиг.3, квантованные интерполированные LP-коэффициенты В(z) на линии 325 подаются из демультиплексора 317 на синтезирующий LP-фильтр 306, чтобы соответственно настроить параметры синтезирующего LP-фильтра 306.
Вектор s' фильтруется через постпроцессор 307, чтобы получить выходной дискретизированный речевой сигнал sout. Пост-обработка состоит типично в краткосрочной выходной фильтрации, долгосрочной выходной фильтрации и масштабировании усиления. Она может также состоять из фильтра верхних частот для удаления нежелательных низких частот. В других отношениях выходная фильтрация хорошо известна специалистам.
Обзор вложенного кодирования на основе G.729
Кодек G.729 основан на принципе объясненного выше алгебраического CELP-кодирования (ACELP). Распределение битов в кодеке G.729 на 8 кбит/с приведено в таблице 1.
Рекомендация ITU-T G.729 работает на кадрах длиной 10 мс (80 выборок при частоте дискретизации 8 кГц). LP-параметры квантуются и передаются по одному на кадр. Кадр G.729 делится на подкадры длиной 5 мс. Запаздывание основного тона (или индекс адаптивной кодовой книги) квантуется 8 битами в первом подкадре и 5 битами во втором подкадре (относительно запаздывания первого подкадра). Усиления основного тона и алгебраической кодовой книги квантуются вместе, используя 7 бит на подкадр. Для представления возбуждения обновленной или фиксированной кодовой книги используется 17-битовая алгебраическая кодовая книга.
Вложенный кодек построен на основе кодека с ядром G.729. Вложенное кодирование, или многоуровневое кодирование, состоит из базового уровня и дополнительных уровней для повышения качества или увеличения кодированной ширины полосы. Битовый поток, соответствующий верхним уровнем, может при необходимости быть отброшен сетью (в случае перегрузки или в ситуации групповой передачи, когда некоторые соединения имеют пониженную доступную скорость передачи битов). Декодер может восстановить сигнал на основе уровней, которые он принимает.
В данной иллюстративной реализации базовый уровень L1 состоит из G.729 на 8 кбит/с. Второй уровень L2 состоит из 4 кбит/с для улучшения качества для узкой полосы (при скорости передачи битов R2=L1+L2=12 кбит/с). Десять (10) верхних уровней, каждый на 2 кбит/с, используются для получения широкополосного кодированного сигнала. Десять уровней с L3 по L12 соответствуют скоростям передачи битов 14, 16,… и 32 кбит/с. Таким образом, вложенный кодер работает как широкополосный кодер для скоростей передачи битов 14 кбит/с и выше.
Например, кодер использует кодирование с предсказанием (CELP) в двух первых уровнях (G.729, модифицированный добавлением второй алгебраической кодовой книги) и затем квантует в частотной области ошибку кодирования первых уровней. Чтобы отобразить сигнал на частотную область, применяется MDCT (Модифицированное дискретное косинусное преобразование). MDCT-коэффициенты квантуются, используя масштабируемое алгебраическое векторное квантование. Чтобы расширить аудиополосу, для высоких частот применяется параметрическое кодирование.
Кодер работает с 20 миллисекундными кадрами и требует 5 мс задержки для окна LP-анализа. MDCT с 50%-ным перекрытием требует дополнительных 20 мс упреждения, которое может быть применено к любому из кодера или декодера. Например, MDCT-упреждение используется на стороне декодера, что, как будет объяснено ниже, приводит к улучшенной маскировке стирания кадров. Кодер формирует вывод на 32 кбит/с, что переводится в кадры длиной 20 мс, содержащие 640 бит каждый. Биты в каждом кадре упорядочены во вложенных уровнях. Уровень 1 имеет 160 бит, представляющих 20 мс стандарта G.729 на 8 кбит/с (что соответствует двум кадрам G.729). Уровень 2 содержит 80 бит, представляя дополнительные 4 кбит/с. Затем каждый дополнительный уровень (уровни 3-12) добавляют 2 кбит/с и так до 32 кбит/с.
Блок-схема примера вложенного кодера показана на фиг.4.
Исходный широкополосный сигнал x (401), дискретизированный на 16 кГц, сначала в модуле 402 разделяется на две полосы: 0-4000 Гц и 4000-8000 Гц. В примере по фиг.4 расщепление полосы реализуется с применением блока фильтров QMF (квадратурный зеркальный фильтр) с 64 коэффициентами. Эта операция хорошо известна специалистам. После расщепления полосы получают два сигнала: один, покрывающий частотную полосу 0-4000 Гц (нижняя полоса), и другой, покрывающий полосу 4000-8000 (верхняя полоса). Сигналы в каждой из этих двух полос субдискретизируются коэффициентом 2 в модуле 402. Это дает 2 сигнала на частоте дискретизации 8 кГц: xLF для нижней полосы (403) и xHF для верхней полосы (404).
Сигнал xLF из нижней полосы подается в модифицированную версию 405 кодера G.729а. Эта модифицированная версия 405 сначала производит стандартный G.729 битовый поток на 8 кбит/с, который образует биты для уровня 1. Отметим, что кодер работает на кадрах длиной 20 мс, таким образом, биты уровня 1 соответствуют двум G.729 кадрам.
Затем кодер G.729 405 модифицируется, чтобы включить вторую обновленную алгебраическую кодовую книгу для усиления сигнала нижней полосы. Эта вторая кодовая книга идентична обновленной кодовой книге в G.729 и требует 17 бит на 5-мс подкадр для кодирования импульсов кодовой книги (68 бит на кадр длиной 20 мс). Усиления второй алгебраической кодовой книги квантуются по отношению к усилению первой кодовой книги, используя 3 бита в первом и третьем подкадрах и 2 бита во втором и четвертом подкадрах (10 бит на кадр). Два бита используются, чтобы послать классификационную информацию для улучшения маскировки на декодере. Это дает 68+10+2=80 бит для слоя 2. Целевой сигнал, используемый для этой обновленной кодовой книги второй стадии, получается вычитанием вклада от обновленной кодовой книги G.729 во взвешенную речевую область.
Синтезированный сигнал 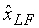 модифицированного кодера G.729а 405 получается суммированием возбуждения стандартного G.729 (добавление масштабированного обновленного и адаптивного кодовых векторов) и обновленного возбуждения дополнительной обновленной кодовой книги и пропусканием этого усиленного возбуждения через обычный синтезирующий фильтр G.729. Это тот синтезированный сигнал, который сформирует декодер, если он получит только уровень 1 и уровень 2 из потока битов. Отметим, что содержание адаптивной кодовой книги (или кодовой книги основного тона) обновляется, используя только G.729 возбуждение.
модифицированного кодера G.729а 405 получается суммированием возбуждения стандартного G.729 (добавление масштабированного обновленного и адаптивного кодовых векторов) и обновленного возбуждения дополнительной обновленной кодовой книги и пропусканием этого усиленного возбуждения через обычный синтезирующий фильтр G.729. Это тот синтезированный сигнал, который сформирует декодер, если он получит только уровень 1 и уровень 2 из потока битов. Отметим, что содержание адаптивной кодовой книги (или кодовой книги основного тона) обновляется, используя только G.729 возбуждение.
Уровень 3 расширяет полосу частот с узкополосного до широкополосного качества. Это делается, применяя параметрическое кодирование (модуль 407) к высокочастотному компоненту xHF. Для этого уровня вычисляются и передаются только огибающая спектра и огибающая промежутка времени xHF. Расширение полосы частот требует 33 бит. Оставшиеся 7 бит в этом уровне используются для передачи фазовой информации (положение голосового импульса) для улучшения маскировки стирания кадра в декодере по настоящему изобретению. Это будет пояснено более подробно в дальнейшем описании.
Затем, как следует из фиг.4, ошибка кодирования из сумматора 406 (xLF-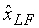 ) вместе с высокочастотным сигналом xHF отображаются на частотную область в модуле 408. Для этого частотно-временного отображения используется MDCT с 50% перекрытием. Это может быть осуществлено, используя два MDCT, по одному на каждую полосу. Сначала, до MDCT, сигнал верхней полосы может быть спектрально свернут оператором (-1)n, так что коэффициенты MDCT обоих преобразований могут быть в целях квантования объединены в один вектор. Затем коэффициенты MDCT квантуются в модуле 409, используя масштабируемое алгебраическое векторное квантование аналогично квантованию коэффициентов FFT (быстрое преобразование Фурье) в аудиокодере 3GPP AMR-WB+ (3GPP TS 26.290). Конечно, могут применяться и другие формы квантования. Полная скорость передачи битов для этого спектрального квантования составляет 18 кбит/с, что в сумме равняется 360 битов на кадр длиной 20 мс. После квантования соответствующие биты упорядочивают по уровням шагами по 2 кбит/с в модуле 410 для формирования уровней 4-12. Таким образом, каждый уровень 2 кбит/с содержит 40 бит на кадр длиной 20-мс. В одном иллюстративном варианте осуществления 5 битов могут быть зарезервированы в уровне 4 для передачи энергетической информации для улучшения декодером маскировки и сходимости в случае стирания кадров.
) вместе с высокочастотным сигналом xHF отображаются на частотную область в модуле 408. Для этого частотно-временного отображения используется MDCT с 50% перекрытием. Это может быть осуществлено, используя два MDCT, по одному на каждую полосу. Сначала, до MDCT, сигнал верхней полосы может быть спектрально свернут оператором (-1)n, так что коэффициенты MDCT обоих преобразований могут быть в целях квантования объединены в один вектор. Затем коэффициенты MDCT квантуются в модуле 409, используя масштабируемое алгебраическое векторное квантование аналогично квантованию коэффициентов FFT (быстрое преобразование Фурье) в аудиокодере 3GPP AMR-WB+ (3GPP TS 26.290). Конечно, могут применяться и другие формы квантования. Полная скорость передачи битов для этого спектрального квантования составляет 18 кбит/с, что в сумме равняется 360 битов на кадр длиной 20 мс. После квантования соответствующие биты упорядочивают по уровням шагами по 2 кбит/с в модуле 410 для формирования уровней 4-12. Таким образом, каждый уровень 2 кбит/с содержит 40 бит на кадр длиной 20-мс. В одном иллюстративном варианте осуществления 5 битов могут быть зарезервированы в уровне 4 для передачи энергетической информации для улучшения декодером маскировки и сходимости в случае стирания кадров.
Расширения алгоритма по сравнению с базовым кодером G.729 могут быть резюмированы следующим образом: 1) обновленная кодовая книга G.729 повторяется второй раз (уровень 2); 2) применяется параметрическое кодирование, чтобы расширить полосу частот, причем рассчитываются и квантуются только огибающая спектра и огибающая во временной области (информация усиления) (уровень 3); 3) MDCT рассчитывается каждые 20 мс, и его спектральные коэффициенты квантуются 8-мерными блоками, используя масштабируемое алгебраическое VQ (Векторное Квантование); и 4) используется процедура упорядочения битов по уровням для форматирования потока 18 кбит/с из алгебраического VQ в уровни 2 кбит/с каждый (уровни 4-12). В одном варианте осуществления 14-битовая информация маскировки и сходимости может быть передана на уровень 2 (2 бит), уровень 3 (7 бит) и уровень 4 (5 бит).
Фиг.5 является блок-схемой одного примера вложенного декодера 500. В каждом кадре длиной 20 мс декодер 500 может принимать любую поддерживаемую скорость передачи битов, от 8 кбит/с до 32 кбит/с. Это означает, что работа декодера обусловлена числом битов, или уровней, принимаемых в каждом кадре. На фиг.5 предполагается, что декодером были приняты по меньшей мере уровни 1, 2, 3 и 4. Случаи с меньшими скоростями передачи битов будут описаны ниже.
В декодере по фиг.5 принятый битовый поток 501 сначала разделяется на битовые уровни, как сформировано кодером (модуль 502). Уровни 1 и 2 образуют входные данные в модифицированный G.729 декодер 503, который формирует синтезированный сигнал для нижней полосы (0-4000 Гц, дискретизированный при 8 кГц). Напомним, что уровень 2 содержит в основном биты для второй обновленной кодовой книги с той же структурой, что и обновленная кодовая книга G.729.
Затем биты из уровня 3 образуют входные данные для параметрического декодера 506. Биты уровня 3 дают параметрическое описание диапазона верхней полосы частот (4000-8000 Гц, дискретизация 8 кГц). В частности, биты уровня 3 описывают высокочастотную огибающую спектра кадра длиной 20 мс, вместе с огибающей во временной области (или информацией усиления). Результатом параметрического декодирования является параметрическая аппроксимация высокочастотного сигнала, обозначенного  на фиг.5.
на фиг.5.
Затем биты из уровня 4 и выше образуют входные данные для обратного квантователя 504 (Q-1). Выходом обратного квантователя 504 является набор квантованных спектральных коэффициентов. Эти квантованные коэффициенты образуют входные данные для модуля 505 обратного преобразования (T-1), в частности, обратного MDCT с 50%-ным перекрытием. Выходом обратного MDCT является сигнал 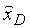 . Этот сигнал
. Этот сигнал 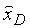 может рассматриваться как квантованная ошибка кодирования модифицированного кодера G.729 в нижней полосе, вместе с квантованной верхней полосой частот, если какие-либо биты распределены в верхнюю полосу в данном кадре. Модуль 505 обратного преобразования (T-1) реализован как два обратных MDCT, в этом случае будет состоять из двух компонентов:
может рассматриваться как квантованная ошибка кодирования модифицированного кодера G.729 в нижней полосе, вместе с квантованной верхней полосой частот, если какие-либо биты распределены в верхнюю полосу в данном кадре. Модуль 505 обратного преобразования (T-1) реализован как два обратных MDCT, в этом случае будет состоять из двух компонентов: 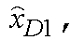 представляющего низкочастотный компонент, и
представляющего низкочастотный компонент, и 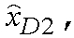 представляющего высокочастотный компонент.
представляющего высокочастотный компонент.
Компонент 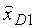 , образующий квантованную ошибку кодирования модифицированного кодера G.729, комбинируется затем с в сумматоре 507 с образованием низкочастотного синтеза
, образующий квантованную ошибку кодирования модифицированного кодера G.729, комбинируется затем с в сумматоре 507 с образованием низкочастотного синтеза  Точно так же компонент образующий квантованную верхнюю полосу частот, объединяется с параметрической аппроксимацией верхней полосы в сумматоре 508 с образованием высокочастотного синтеза
Точно так же компонент образующий квантованную верхнюю полосу частот, объединяется с параметрической аппроксимацией верхней полосы в сумматоре 508 с образованием высокочастотного синтеза  Сигналы
Сигналы 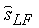 и
и 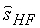 обрабатываются в блоке 509 синтезирующих QMF-фильтров с образованием итогового синтезированного сигнала
обрабатываются в блоке 509 синтезирующих QMF-фильтров с образованием итогового синтезированного сигнала  на частоте дискретизации 16 кГц.
на частоте дискретизации 16 кГц.
В случае, когда уровни 4 и выше не приняты, равен нулю и выходы сумматоров 507 и 508 равны их входам, а именно и 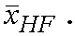 Если приняты только уровни 1 и 2, то декодер должен использовать только модифицированный декодер G.729, чтобы получить сигнал . Высокочастотный компонент будет нулевым, а сигнал, дискретизированный с увеличенной частотой 16 кГц (при необходимости), будет иметь содержимое только в нижней полосе. Если получен только уровень 1, то декодер должен использовать только декодер G.729 для получения сигнала .
Если приняты только уровни 1 и 2, то декодер должен использовать только модифицированный декодер G.729, чтобы получить сигнал . Высокочастотный компонент будет нулевым, а сигнал, дискретизированный с увеличенной частотой 16 кГц (при необходимости), будет иметь содержимое только в нижней полосе. Если получен только уровень 1, то декодер должен использовать только декодер G.729 для получения сигнала .
Надежная маскировка стирания кадра
Стирание кадров имеет большое влияние на качество синтезированной речи в цифровых системах речевой связи, особенно при работе в беспроводных средах и пакетно-коммутируемых сетях. В беспроводных сотовых системах энергия принятого сигнала часто может проявлять существенное постепенное затухание, что приводит к высокой частоте появления ошибочных битов, это становится более явным на границах сот. В этом случае канальный декодер не способен исправить ошибки в полученном кадре, и, как следствие, устройство обнаружения ошибок, обычно используемое после канального декодера, объявит этот кадр стертым. В приложениях передачи голоса по пакетной сети, таких, как передача голоса по IP-протоколу (VoIP), речевой сигнал объединяется в пакеты, причем обычно в каждый пакет помещается кадр длиной 20 мс. В пакетно-коммутируемых сетях может происходить отбрасывание пакета в маршрутизаторе, если число пакетов станет слишком большим, или пакет может прийти к приемному устройству с большой задержкой и должен быть объявлен как потерянный, если его задержка будет больше длины буфера колебаний задержки на стороне приемного устройства. В этих системах частоты стирания кадров в кодеке могут типично составлять от 3 до 5%.
Проблема обработки стирания кадра (FER) имеет в основном две стороны. Во-первых, когда приходит индикатор стертого кадра, пропущенный кадр должен быть генерирован с использованием информации, посланной в предыдущем кадре, и посредством оценки эволюции сигнала в потерянном кадре. Успех оценки зависит не только от стратегии маскировки, но также от места в речевом сигнале, где произошло стирание. Во-вторых, должен обеспечиваться плавный переход, когда восстанавливается нормальная работа, т.е. когда после блока стертых кадров (одного или более) приходит первый хороший кадр. Это является нетривиальной задачей, так как истинный синтез и оценка синтеза могут развиваться по-разному. Когда приходит первый хороший кадр, декодер с этого времени десинхронизирован с кодером. Основная причина этого в том, что кодеры с низкой скоростью передачи битов основаны на предсказании основного тона, и в течение стертых кадров память предсказателя основного тона (или адаптивная кодовая книга) уже не та, что память в кодере. Проблема усиливается, когда стерто много последовательных кадров. Что касается маскировки, трудность нормального процесса восстановления данных зависит от типа сигнала, например, речевого сигнала, в котором произошло стирание.
Отрицательный эффект от стирания кадров можно существенно уменьшить благодаря адаптации маскировки и восстановления нормальной обработки (дальнейшее восстановление) к типу речевого сигнала, в котором произошло стирание. Для этого необходимо классифицировать каждый кадр речи. Эта классификация может быть сделана в кодере и передана. Альтернативно, она может быть рассчитана в декодере.
Для наилучшей маскировки и восстановления имеется небольшое число критических характеристик речевого сигнала, которые нужно внимательно контролировать. Этими критическими характеристиками являются энергия или амплитуда сигнала, степень периодичности, огибающая спектра и период основного тона. В случае восстановления вокализованной речи дальнейшего улучшения можно достичь регулировкой фазы. За счет небольшого увеличения скорости передачи битов могут быть квантованы несколько дополнительных параметров и переданы для лучшего контроля. Если не имеется дополнительной полосы частот, параметры можно оценить в декодере. Регулированием этих параметров можно существенно улучшить маскировку стирания кадров и восстановление, особенно путем улучшения сходимости декодированного сигнала к реальному сигналу в кодере и смягчения эффекта рассогласования между кодером и декодером, когда восстанавливается нормальная обработка.
Эти идеи были раскрыты в патентной PCT-заявке [1]. В соответствии с неограничительным иллюстративным вариантом осуществления настоящего изобретения маскировка и сходимость дополнительно улучшаются путем лучшей синхронизации голосового импульса в кодовой книге основного тона (или адаптивной кодовой книги), как будет обсуждено ниже. Это можно осуществить с или без принятой фазовой информации, соответствующей, например, положению импульса основного тона или голосового импульса.
В иллюстративном варианте осуществления настоящего изобретения раскрываются способы эффективной маскировки стирания кадра и способы улучшения сходимости в декодере в кадрах, следующих за стертым кадром.
Методы маскировки стирания кадров, согласно иллюстративному варианту осуществления, были применены к описанному выше вложенному кодеку на основе G.729. В дальнейшем описании этот кодек будет служить примером структуры для реализации способов маскировки FER.
Фиг.6 дает упрощенную блок-схему уровней 1 и 2 вложенного кодера 600, основанного на модели CELP-кодера по фиг.2. В этой упрощенной блок-схеме модуль 207 поиска основного тона замкнутого контура, вычислитель 208 отклика нулевого входа, вычислитель 209 импульсной характеристики, модуль 210 поиска обновленного возбуждения и модуль 211 обновления памяти сгруппированы в модули 602 поиска основного тона замкнутого контура и обновленной кодовой книги. Кроме того, поиск кодовой книги второй стадии на уровне 2 также включен в модули 602. Это группирование сделано для упрощения введения модулей, относящихся к иллюстративному варианту осуществления настоящего изобретения.
Фиг.7 является расширением блок-схемы по фиг.6, в которую были добавлены модули, относящиеся к неограничительному иллюстративному варианту осуществления настоящего изобретения. В этих добавленных модулях 702-707 рассчитываются, квантуются и передаются дополнительные параметры с целью улучшить маскировку FER, сходимость и восстановление декодера после стертых кадров. В этом иллюстративном варианте осуществления указанные параметры маскировки/восстановления включают информацию о классе сигнала, энергии и фазе (например, оценку положения последнего голосового импульса в предшествующем кадре или кадрах).
В дальнейшем описании будут подробно объяснены расчет и квантование этих дополнительных параметров маскировки/восстановления, и они станут более понятны при обращении к фиг.7. Из этих параметров более подробно будет обсуждена классификация сигнала. В следующих разделах будет пояснена эффективная FER-маскировка с применением этих дополнительных параметров маскировки/восстановления для улучшения сходимости.
Классификация сигналов для FER-маскировки и восстановления
Основная идея использования классификации речи для реконструкции сигнала в присутствии стертых кадров состоит в том, что стратегия идеальной маскировки различна для квазистационарных речевых сегментов и для речевых сегментов с быстро меняющимися характеристиками. Тогда как наилучшая обработка стертых кадров в нестационарных речевых сегментах может быть определена как быстрая сходимость параметров кодирования речи к характеристикам шума окружающей среды, в случае квазистационарного сигнала параметры кодирования речи существенно не изменяются и могут оставаться практически неизменными в продолжение нескольких соседних стертых кадров, пока не затухнут. Также оптимальный способ восстановления сигнала, следующего за блоком стертых кадров, меняется в зависимости от классификации речевого сигнала.
Речевые сигналы можно грубо подразделить на вокализованные, невокализованные и паузы.
Вокализованная речь содержит некоторое количество периодических компонентов и может быть подразделена далее на следующие категории: начало вокализации, вокализованные сегменты, вокализованные переходы и конец вокализации. Начало вокализации начало определяется как начало сегмента вокализованной речи после паузы или невокализованного сегмента. В продолжении вокализованных сегментов параметры речевого сигнала (огибающая спектра, период основного тона, отношение периодических и непериодических компонентов, энергия) медленно меняются от кадра к кадру. Вокализованный переход характеризуется быстрыми изменениями вокализованной речи, такими, как переход между гласными звуками. Конец вокализации отличается постепенным уменьшением энергии и силы голоса в конце вокализованных сегментов.
Невокализованные части сигнала характеризуются отсутствием периодического компонента и могут быть подразделены далее на нестабильные кадры, где энергия и спектр быстро меняются, и стабильные кадры, характеристики которых остаются относительно стабильными.
Остальные кадры классифицируются как молчание. Кадры молчания содержат все кадры без активной речи, т.е. также кадры только шума, если присутствует фоновый шум.
Не все из вышеупомянутых классов должны обрабатываться отдельно. Таким образом, для целей методов маскировки ошибок некоторые классы сигналов группируются вместе.
Классификация в кодере
Когда в битовом потоке доступна полоса частот, чтобы включить классификационную информацию, классификация может быть проведена в кодере. Это имеет несколько преимуществ. Одним из них является то, что часто в речевых кодерах имеется упреждение. Упреждение позволяет оценить эволюцию сигнала в следующем кадре, и, следовательно, классификация может быть сделана с учетом будущего поведения сигнала. Вообще говоря, чем длиннее упреждение, тем лучше может быть классификация. Следующим преимуществом является уменьшение сложности, так как большинство обработок сигнала, требуемых для маскировки стирания кадра, все равно необходимы для речевого кодирования. Наконец, преимуществом является также работа с исходным сигналом, а не с синтезированным сигналом.
Классификация кадра проводится, имея в виду стратегию маскировки и восстановления. Другими словами, любой кадр классифицируется таким образом, чтобы маскировка могла быть оптимальной, если отсутствует следующий кадр, или чтобы восстановление могло быть оптимальным, если потерян предыдущий кадр. Некоторые из классов, использующихся в FER-обработке, не нужно передавать, так как они могут быть однозначно выведены в декодере. В настоящем иллюстративном варианте осуществления используется пять (5) разных классов, которые определены следующим образом:
- Класс НЕВОКАЛИЗОВАННЫЙ содержит все кадры невокализованной речи и все кадры без активной речи. Кадр конца вокализации также может быть классифицирован как НЕВОКАЛИЗОВАННЫЙ, если его конец стремится быть невокализованным, и маскировка, предназначенная для невокализованных кадров, может использоваться для следующего кадра в случае, если он потерян.
- Класс НЕВОКАЛИЗОВАННЫЙ ПЕРЕХОД содержит невокализованные кадры с возможным началом вокализации в конце. Однако начало еще слишком короткое или не развито в достаточной степени, чтобы использовать маскировку, предназначенную для вокализованных кадров. Класс НЕВОКАЛИЗОВАННЫЙ ПЕРЕХОД может следовать только за кадром, классифицированным как НЕВОКАЛИЗОВАННЫЙ или НЕВОКАЛИЗОВАННЫЙ ПЕРЕХОД.
- Класс ВОКАЛИЗОВАННЫЙ ПЕРЕХОД содержит вокализованные кадры с относительно слабыми характеристиками вокализации. Это типично вокализованные кадры с быстро меняющимися характеристиками (переходы между гласными) или концы вокализации, длящиеся целый кадр. Класс ВОКАЛИЗОВАННЫЙ ПЕРЕХОД может идти только за кадром, классифицированным как ВОКАЛИЗОВАННЫЙ ПЕРЕХОД, ВОКАЛИЗОВАННЫЙ или НАЧАЛО.
- Класс ВОКАЛИЗОВАННЫЙ содержит вокализованные кадры со стабильными характеристиками. Этот класс может следовать только за кадром, классифицированным как ВОКАЛИЗОВАННЫЙ ПЕРЕХОД, ВОКАЛИЗОВАННЫЙ или НАЧАЛО.
- Класс НАЧАЛО содержит все вокализованные кадры со стабильными характеристиками, идущие за кадром, классифицированным как НЕВОКАЛИЗОВАННЫЙ или НЕВОКАЛИЗОВАННЫЙ ПЕРЕХОД. Кадры, классифицированные как НАЧАЛО, соответствуют кадрам вокализованного начала, когда начало уже достаточно хорошо развито для использования маскировки, предназначенной для потерянных вокализованных кадров. Методы маскировки, используемые для стертого кадра, следующего за классом НАЧАЛО, являются теми же, что и для кадра, следующего за классом ВОКАЛИЗОВАННЫЙ. Разница заключается в стратегии восстановления. Если потерян кадр класса НАЧАЛО (т.е. ВОКАЛИЗОВАННЫЙ хороший кадр приходит после стирания, но последний хороший кадр до стирания был НЕВОКАЛИЗОВАННЫМ), может использоваться особый метод для искусственного восстановления потерянного начала. Этот сценарий можно видеть на фиг.6. Методы искусственного восстановления начала будут описаны более подробно в дальнейшем описании. С другой стороны, если хороший кадр НАЧАЛО приходит после стирания, а последний хороший кадр до стирания был НЕВОКАЛИЗОВАННЫМ, эта особая обработка не требуется, так как начало не было потеряно (не находилось в потерянном кадре).
Диаграмма состояния классификации показана на фиг.8. Если доступная полоса частот достаточна, классификация проводится в кодере и передается с использованием 2 бит. Как можно видеть на фиг.8, НЕВОКАЛИЗОВАННЫЙ ПЕРЕХОД 804 и ВОКАЛИЗОВАННЫЙ ПЕРЕХОД 806 могут быть объединены в группу, так как они могут быть однозначно дифференцированы в декодере (кадры НЕВОКАЛИЗОВАННОГО ПЕРЕХОДА 804 могут идти только за НЕВОКАЛИЗОВАННЫМИ кадрами 802 или кадрами НЕВОКАЛИЗОВАННОГО ПЕРЕХОДА 804, кадры ВОКАЛИЗОВАННОГО ПЕРЕХОДА 806 могут идти только за НАЧАЛОМ 810, ВОКАЛИЗОВАННЫМИ кадрами 808 или кадрами ВОКАЛИЗОВАННОГО ПЕРЕХОДА 806). В этом иллюстративном варианте осуществления классификация проводится в кодере и квантуется 2 битами, которые передаются на уровне 2. Таким образом, если принят по меньшей мере уровень 2, то для улучшения маскировки используется классификационная информация декодера. Если получен только базовый уровень 1, то классификация проводится в декодере.
Для классификации в кодере используются следующие параметры: нормированная корреляция rx, мера et спектрального смещения, отношение сигнал-шум snr, счетчик pc стабильности основного тона, относительная энергия кадра для сигнала в конце текущего кадра, Es, и счетчик zc пересечения.
Вычисление этих параметров, которые используются для классификации сигнала, поясняются ниже.
Нормированная корреляция rx рассчитывается как часть модуля 206 поиска основного тона разомкнутого контура, показанного на фиг.7. Этот модуль 206 обычно дает на выходе оценку основного тона разомкнутого контура каждые 10 мс (дважды на кадр). Здесь он используется также для выдачи оценок нормированной корреляции. Эти нормированные корреляции вычисляются на текущем взвешенном речевом сигнале sw(n) и прошлом взвешенном речевом сигнале при запаздывании основного тона разомкнутого контура. Средняя корреляция 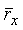 определяется как:
определяется как:
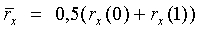
где rx(0), rx(1) означают соответственно нормированную корреляцию первой половины кадра и второй половины кадра. Нормированная корреляция rx(k) вычисляется следующим образом:

Корреляции rx(k) рассчитываются, используя взвешенный речевой сигнал sw(n) (как "x"). Моменты tk относятся к началу текущей половины кадра и равны 0 и 80 выборкам, соответственно. Величина Tk есть запаздывание основного тона в полукадре, которое максимизирует взаимную корреляцию 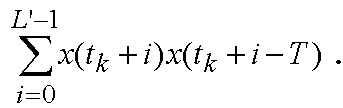 Длина расчета автокорреляции L' равна 80 выборкам. В другом варианте осуществления, чтобы определить величину Tk в полукадре, рассчитывается взаимная корреляция
Длина расчета автокорреляции L' равна 80 выборкам. В другом варианте осуществления, чтобы определить величину Tk в полукадре, рассчитывается взаимная корреляция 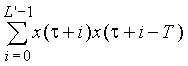 и находятся значения τ, соответствующие максимуму в трех зонах задержки 20-39, 40-79, 80-143. Затем Tk устанавливается на значение τ, которое максимизирует нормированную корреляцию в уравнении (2).
и находятся значения τ, соответствующие максимуму в трех зонах задержки 20-39, 40-79, 80-143. Затем Tk устанавливается на значение τ, которое максимизирует нормированную корреляцию в уравнении (2).
Параметр et спектрального наклона содержит информацию о частотном распределении энергии. В настоящем иллюстративном варианте осуществления спектральный наклон оценивается в модуле 703 как нормированные первые коэффициенты автокорреляции речевого сигнала (первый коэффициент отражения, полученный при LP-анализе).
Так как LP-анализ проводится дважды на кадр (один раз на каждый G.729 кадр длиной 10 мс), спектральный наклон рассчитывается как среднее первого коэффициента отражения от обоих LP-анализов. То есть
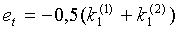
где k1 (j) есть первый коэффициент отражения из LP-анализа в полукадре j.
Величина snr отношения сигнал-шум (SNR) использует то, что у обычного кодера с согласованием формы сигнала SNR намного выше для вокализованных звуков. Оценка параметра snr должна проводиться в кодере в конце цикла подкадра, она рассчитывается для целого кадра в модуле 704 расчета SNR, используя соотношение:
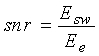
где Esw есть энергия речевого сигнала s(n) текущего кадра, а Ee есть энергия ошибки между речевым сигналом и синтезированным сигналом текущего кадра.
Счетчик pc стабильности основного тона определяет изменение периода основного тона. Он рассчитывается в модуле 705 классификации сигнала в ответ на оценки основного тона разомкнутого контура следующим образом:
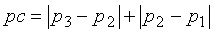
Значения p1, p2 и p3 соответствуют запаздыванию основного тона замкнутого контура из трех последних подкадров.
Относительная энергия кадра Es вычисляется модулем 705 как разность между энергией текущего кадра в дБ и ее долгосрочным средним:
где энергия кадра Ef как энергия обработанного методом окна входного сигнала (в дБ):
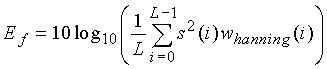
где L=160 есть длина кадра и 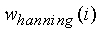 есть окно Хэннинга длиной L. Усредненная за длительный период энергия обновляется на кадрах активной речи, используя следующее соотношение:
есть окно Хэннинга длиной L. Усредненная за длительный период энергия обновляется на кадрах активной речи, используя следующее соотношение:
Последним параметром является параметр zc пересечений нуля, рассчитываемый на одном кадре речевого сигнала модулем 702 расчета пересечений нуля. В данном иллюстративном варианте осуществления счетчик zc пересечений нуля подсчитывает, сколько раз знак сигнала изменится с положительного на отрицательный в течение этого интервала.
Чтобы сделать классификацию более надежной, классификация параметров рассматривается в модуле 705 классификации сигнала вместе с формированием оценочной функции fm. Для этого классификационные параметры сначала масштабируются между 0 и 1, так что величина каждого параметра, типичного для невокализованного сигнала, переносится в 0, а величина каждого параметра, типичного для вокализованного сигнала, переносится в 1. Между ними используется линейная функция. Рассмотрим параметр px, его маштабированная версия получается с использованием:
и ограничена интервалом от 0 до 1 (за исключением относительной энергии, которая ограничена интервалом от 0,5 до 1). Коэффициенты функции kp и cp были найдены экспериментально для каждого из параметров, так что искажение сигнала из-за методов маскировки и восстановления, применяемых в присутствии FER, минимально. Значения, использованные в данной иллюстративной реализации, сведены в таблицу 2.
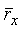
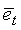
Оценочная функция была определена как:
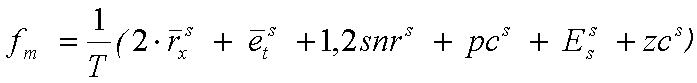
где надстрочный индекс s указывает на масштабированную версию параметров.
Затем оценочную функцию увеличивают в 1,05 раза, если масштабированная относительная энергия Es s равна 0,5, и увеличивают в 1,25 раз, если Es s больше 0,75. Далее, оценочную функцию также умножают на коэффициент fE, выведенный на основе конечного автомата, которая проверяет разность между мгновенным изменением относительной энергии и долгосрочным изменением относительной энергии. Это добавлено для улучшения классификации сигнала в присутствии фонового шума.
Параметр изменения относительной энергии Evar обновляется как:
Evar=0,05(Es-Eprev)+0,95Evar
где Eprev есть значение Es из предыдущего кадра.
Если (|Es-Eprev|<(|Evar|+6)) И (classold=НЕВОКАЛИЗОВАННЫЙ), то fE=0,8
иначе
если ((Es-Eprev)>(Evar+3)) И (classold=НЕВОКАЛИЗОВАННЫЙ или ПЕРЕХОД), то fE=1,1
иначе
если ((Es-Eprev)<(Evar-5)) И (classold=ВОКАЛИЗОВАННЫЙ или НАЧАЛО), то fE=0,6.
где classold есть класс предыдущего кадра.
Затем проводится классификация, используя оценочную функцию fm и следуя правилам, сведенным в таблицу 3.
ВОКАЛИЗОВАННЫЙ
ВОКАЛИЗОВАННЫЙ ПЕРЕХОД
НЕВОКАЛИЗОВАННЫЙ
Если в кодере имеется обнаружение голосовой активности (VAD), для классификации может использоваться флаг VAD, так как он напрямую указывает, что дальнейшая классификация не требуется, если его значение указывает на неактивную речь (т.е. кадр напрямую классифицируется как НЕВОКАЛИЗОВАННЫЙ). В данном иллюстративном варианте осуществления кадр напрямую классифицируется как НЕВОКАЛИЗОВАННЫЙ, если относительная энергия меньше 10 дБ.
Классификация в декодере
Если приложение не позволяет передавать информацию о классе (нет возможности передать дополнительные биты), классификация все же может быть проведена в декодере. В данном иллюстративном варианте осуществления биты классификации передаются на уровне 2, таким образом, классификация проводится в декодере также для случая, когда принимается только базовый уровень 1.
Для классификации в декодере используются следующие параметры: нормированная корреляция rx, показатель et спектрального наклона, счетчик pc стабильности основного тона, относительная энергия кадра сигнала в конце текущего кадра, Es, и счетчик zc пересечений нуля.
Расчет этих параметров, которые используются для классификации сигнала, поясняется ниже.
Нормированная корреляция rx вычисляется в конце кадра из синтезированного сигнала. Используется запаздывание основного тона последнего подкадра.
Нормированная корреляция rx рассчитывается синхронно с основным тоном следующим образом:
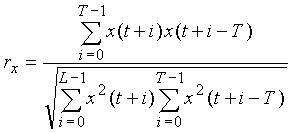
где T есть запаздывание основного тона последнего подкадра, t=L-T, и L есть размер кадра. Если запаздывание основного тона последнего подкадра больше, чем 3N/2 (N есть размер подкадра), то T устанавливается на среднее запаздывание основного тона двух последних подкадров.
Корреляция rx вычисляется с использованием синтезированного речевого сигнала sout(n). Для запаздываний основного тона меньше, чем размер подкадра (40 выборок), нормированная корреляция рассчитывается дважды в моменты t=L-T и t=L-2T, и rx дается как среднее этих двух вычислений.
Параметр et спектрального наклона содержит информацию о частотном распределении энергии. В настоящем иллюстративном варианте осуществления спектральный наклон в декодере оценивается как первый нормированный коэффициент автокорреляции синтезированного сигнала. Он вычисляется по трем последним подкадрам как:
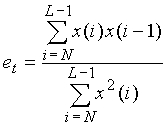
где x(n)=sout(n) есть синтезированный сигнал, N есть размер подкадра и L есть размер кадра (в данном иллюстративном варианте осуществления N=40 и L=160).
Счетчик pc стабильности основного тона определяет величину изменения периода основного тона. Он рассчитывается в декодере следующим образом:
Значения p0, p1, p2 и p3 соответствуют задержке основного тона замкнутого контура из 4 подкадров.
Относительная энергия Es кадра вычисляется как разность между энергией текущего кадра (в дБ) и его усредненной за длительный период энергией:

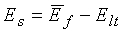
где энергия Ef кадра есть энергия синтезированного сигнала (в дБ), рассчитываемая синхронно с основным тоном в конце кадра как:
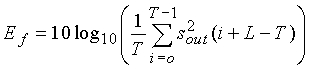
где L=160 есть длина кадра и T есть среднее запаздывание основного тона последних двух подкадров. Если T меньше размера подкадра, то T устанавливается на 2T (энергия, вычисленная с использованием двух периодов основного тона для коротких запаздываний основного тона).
Энергия, усредненная за длительный период, обновляется на кадрах активной речи, используя следующее соотношение:
Последним параметром является параметр zc пересечений нуля, рассчитываемый на одном кадре синтезированного сигнала. В данном иллюстративном варианте осуществления счетчик zc пересечений нуля подсчитывает, сколько раз знак сигнала изменится с положительного на отрицательный за этот интервал.
Чтобы сделать классификацию более надежной, параметры классификации рассматриваются вместе, образуя оценочную функцию fm. Для этого классификационные параметры сначала масштабируют линейной функцией. Рассмотрим параметр px, его масштабированная версия получается с использованием:
Масштабированный параметр когерентности основного тона ограничен интервалом от 0 до 1, масштабированный нормированный корреляционный параметр удваивается, если он положительный. Коэффициенты kp и cp функции были найдены экспериментально для каждого из параметров, так чтобы искажение сигнала из-за методов маскировки и восстановления, используемых в присутствии FER, было минимальным. Значения, использованные в данной иллюстративной реализации, сведены в таблицу 4.
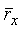
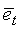
Оценочная функция была определена как:
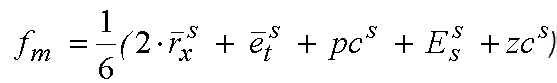
где надстрочный индекс s указывает на масштабированную версию параметров.
Затем проводится классификация, используя оценочную функцию fm и следуя правилам, суммированным в таблице 5.
ВОКАЛИЗОВАННЫЙ
ВОКАЛИЗОВАННЫЙ ПЕРЕХОД
ИСКУССТВЕННОЕ НАЧАЛО
НЕВОКАЛИЗОВАННЫЙ
Речевые параметры для FER-обработки
Имеется несколько параметров, которые внимательно контролируются, чтобы избежать раздражающих артефактов, когда происходит FER. Если может быть передано немного лишних битов, то эти параметры могут быть оценены в кодере, квантованы и переданы. Или же некоторые из них могут быть оценены в декодере. Эти параметры могут включать классификацию сигнала, энергетическую информацию, фазовую информацию и голосовую информацию.
Важность регулирования энергии проявляется главным образом, когда восстанавливается нормальная работа после блока стертых кадров. Так как большинство речевых кодеров используют предсказание, правильная энергия не может быть должным образом оценена в декодере. В сегментах вокализованной речи некорректная энергия может оставаться для нескольких последовательных кадров, что очень раздражает, особенно когда эта некорректная энергия увеличивается.
Энергия контролируется не только для вокализованной речи из-за долгосрочного предсказания (предсказания основного тона), она контролируется также для невокализованной речи. Причиной этого здесь является предсказание квантователя обновленного усиления, часто используемое в кодерах типа CELP. Неверная энергия в продолжении невокализованных сегментов может вызвать мешающую высокочастотную флуктуацию.
Регулировка фазы также является частью обсуждения. Например, посылается фазовая информация, относящаяся к положению голосового импульса. В патентной PCT-заявке [1] фазовая информация передается как положение первого голосового импульса в кадре и используется для реконструкции потерянных вокализованных начал. Кроме того, фазовая информация используется для повторной синхронизации содержимого адаптивной кодовой книги. Это улучшает сходимость декодера в замаскированном кадре и следующих кадрах и существенно улучшает качество речи. Процедура повторной синхронизации адаптивной кодовой книги (или предшествующего возбуждения) может быть проведена несколькими способами в зависимости от принятой фазовой информации (принята или нет) и от доступной задержки в декодере.
Энергетическая информация
Энергетическая информация может оцениваться и передаваться либо в области LP остатка, либо в области речевого сигнала. Передача информации в области остатка имеет тот недостаток, что не учитывается влияние синтезирующего LP-фильтра. Это может быть особенно ненадежным в случае восстановления речи после нескольких потерянных вокализованных кадров (когда FER случается во время сегмента вокализованной речи). Когда FER приходит после вокализованого кадра, при маскировке типично используется возбуждение последнего хорошего кадра с некоторой стратегией ослабления. Когда новый синтезирующий LP-фильтр поступает с первым хорошим кадром после стирания, может иметься рассогласование между энергией возбуждения и усилением синтезирующего LP-фильтра. Новый синтезирующий фильтр может давать синтезированный сигнал, энергия которого сильно отличается от энергии последнего синтезированного стертого кадра, а также от энергии исходного сигнала. По этой причине энергия рассчитывается и квантуется в зоне сигнала.
Энергия Eg рассчитывается и квантуется в модуле 706 оценки и квантования энергии по фиг.7. В данном неограничительном иллюстративном варианте осуществления используется 5-битовый однородный квантователь в диапазоне от 0 дБ до 96 дБ с шагом 3,1 дБ. Индекс квантования определяется целой частью от
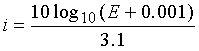
причем индекс ограничен интервалом 0≤i≤31.
E есть максимальная энергия выборки для кадров, классифицированных как ВОКАЛИЗОВАННЫЙ или НАЧАЛО, или средняя энергия на выборку для других кадров. Для классов ВОКАЛИЗОВАННЫЙ или НАЧАЛО максимальная энергия выборки рассчитывается синхронно с основным тоном в конце кадра следующим образом:
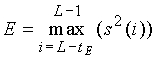
где L есть длина кадра, а сигнал s(i) означает речевой сигнал. Если запаздывание основного тона больше, чем размер подкадра (в данном иллюстративном варианте осуществления 40 выборок), tE равно округленному запаздыванию основного тона замкнутого контура в последнем подкадре. Если запаздывание основного тона короче 40 выборок, то tE устанавливается на удвоенную округленную задержку основного тона замкнутого контура последнего подкадра.
Для других классов E есть средняя энергия на выборку для второй половины текущего кадра, т.е. tE устанавливается равным L/2, а E рассчитывается как:
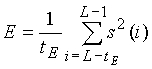
В данном иллюстративном варианте осуществления для расчета энергетической информации используется локальный синтезированный сигнал в кодере.
В данном иллюстративном варианте осуществления энергетическая информация передается на уровне 4. Таким образом, если уровень 4 принимается, эту информацию можно использовать для улучшения маскировки стирания кадра. В противном случае энергия оценивается на стороне декодера.
Информация о регулировке фазы
Регулировка фазы применяется по тем же причинам, какие описаны в предыдущем разделе, при восстановлении после потерянного сегмента вокализованной речи. После блока стертых кадров память декодера становится десинхронизированной с памятью кодера. Чтобы повторно синхронизиовать декодер, может быть передана некоторая фазовая информация. Как неограничивающий пример, в качестве фазовой информации могут быть посланы положение и знак последнего голосового импульса в предыдущем кадре. Затем, как будет описано позднее, эта фазовая информация используется для восстановления после потерянных вокализованных начал. Равным образом, как будет описано позднее, эта информация используется также для повторной синхронизации сигнала возбуждения стертых кадров, чтобы улучшить сходимость в правильно принятых последовательных кадрах (уменьшить распространяющуюся ошибку).
Фазовая информация может соответствовать либо первому голосовому импульсу в кадре, либо последнему голосовому импульсу в предыдущем кадре. Выбор будет зависеть от того, имеется ли в декодере дополнительная задержка или нет. В данном иллюстративном варианте осуществления в декодере имеется задержка в один кадр для операции наложения и суммирования в восстановлении MDCT. Таким образом, если стерт единственный кадр, параметры будущего кадра доступны (так как имеется дополнительная задержка кадра). В этом случае положение и знак максимального импульса в конце стертого кадра доступны из будущего кадра. Следовательно, возбуждение основного тона может быть замаскировано тем, что последний максимальный импульс выравнивается с положением, принятым в будущем кадре. Это будет обсуждаться более подробно ниже.
У декодера может не иметься дополнительной задержки. В этом случае фазовая информация не используется, когда маскируется стертый кадр. Однако в хорошем кадре, принятом за стертым кадром, фазовая информация используется для проведения синхронизации голосового импульса в памяти адаптивной кодовой книги. Это улучшит характеристики уменьшения распространения ошибки.
Пусть T0 будет округленной задержкой основного тона замкнутого контура для последнего подкадра. Поиск максимального импульса проводится на LP-остатке низкочастотной фильтрации. Остаток низкочастотной фильтрации определяется как:
Модуль 707 поиска и квантования голосового импульса ищет положение последнего голосового импульса τ среди T0 последних выборок остатка низкочастотной фильтрации в кадре путем поиска выборки с максимальной абсолютной амплитудой (τ есть положение относительно конца кадра).
Положение последнего голосового импульса кодируется, используя 6 бит, следующим образом. Точность, используемая для кодирования положения первого голосового импульса, зависит от значения T0 основного тона замкнутого контура для последнего подкадра. Это возможно, так как это значение известно и кодеру, и декодеру и не подвержено распространению ошибки после потери одного или нескольких кадров. Если T0 меньше 64, положение последнего голосового импульса относительно конца кадра кодируется напрямую с точностью в одну выборку. Когда 64≤T0<128, положение последнего голосового импульса относительно конца кадра кодируется с точностью в две выборки, используя простое целочисленное деление, т.е. τ/2. Когда T0≥128, положение последнего голосового импульса относительно конца кадра кодируется с точностью в четыре выборки с последующим делением τ на 2. Обратная процедура выполняется в декодере. Если T0<64, полученное квантованное положение используется как есть. Если 64≤T0<128, полученное квантованное положение умножается на 2 и увеличивается на 1. Если T0≥128, полученное квантованное положение умножается на 4 и увеличивается на 2 (увеличение на 2 приводит к однородно распределенной ошибке квантования).
Знак максимальной абсолютной амплитуды импульса также квантуется. Это дает всего 7 бит для фазовой информации. Знак используется для повторной синхронизации фазы, так как в форме голосового импульса часто содержится два широких импульса с противоположными знаками. Игнорирование знака может привести к малому сдвигу в положении и ухудшить проведение процедуры повторной синхронизации.
Следует отметить, что могут применяться эффективные способы квантования фазовой информации. Например, может квантоваться последнее положение импульса в предыдущем кадре относительно положения, оцененного из запаздывания основного тона первого подкадра в текущем кадре (это положение можно легко оценить из первого импульса в кадре, задержанного на запаздывание основного тона).
В случае, когда доступно больше битов, может кодироваться форма голосового импульса. В этом случае положение первого голосового импульса может быть определено корреляционным анализом между остаточным сигналом и формами возможных импульсов, знаками (положительный или отрицательный) и положениями. Форма импульса может также быть взята из кодовой книги форм импульсов, известной и кодеру, и декодеру, этот способ известен специалистам как векторное квантование. Затем форма, знак и амплитуда первого голосового импульса кодируются и передаются на декодер.
Обработка стертых кадров
Методы FER-маскировки в данном иллюстративном варианте осуществления демонстрируются на кодеках типа ACELP. Однако они легко могут быть применены к любым речевым кодекам, где синтезированный сигнал создается фильтрацией сигнала возбуждения через синтезирующий LP-фильтр. Стратегия маскировки может быть суммирована как сходимость энергии сигнала и огибающей спектра к оцененным параметрам фонового шума. Периодичность сигнала сходится к нулю. Скорость сходимости зависит от параметров класса полученного последним хорошего кадра и числа последовательных стертых кадров и регулируется коэффициентом ослабления α. Коэффициент α зависит, кроме того, от стабильности LP-фильтра для НЕВОКАЛИЗОВАННЫХ кадров. Вообще говоря, сходимость является медленной, если последний хороший полученный кадр находится в стабильном сегменте, и быстрой, если кадр находится в переходном сегменте. Значения α суммированы в таблице 6.
хороший кадр
ИСКУССТВЕННОЕ НАЧАЛО
В таблице 6 есть среднее усиление основного тона на кадр, задаваемое как
=0,1gp (0)+0,2gp (1)+0,3gp (2)+0,4gp (3)
где gp (i) есть усиление основного тона в подкадре i.
Величина β определяется как
 с ограничением 0,85<β<0,98
с ограничением 0,85<β<0,98
Значение θ есть коэффициент стабильности, рассчитываемый из показателя расстояния между соседними LP-фильтрами. Здесь коэффициент θ относится к LSP-показателю (линейная спектральная пара) расстояния и ограничен условием 0≤θ≤1, причем более высокие значения θ соответствуют более стабильным сигналам. Это приводит к уменьшению флуктуаций энергии и огибающей спектра, когда изолированное стирание кадра происходит внутри стабильного невокализованного сегмента. В данном иллюстративном варианте осуществления коэффициент стабильности θ задается как:
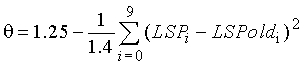 с ограничением 0≤θ≤1
с ограничением 0≤θ≤1
где LSPi есть LSP текущего кадра и LSPoldi означают LSP прошлых кадров. Отметим, что LSP расположены в области изменения косинуса (от -1 до 1).
В случае, если классификационная информации о будущем кадре недоступна, считается, что класс будет тем же, что и в последнем хорошем принятом кадре. Если информация о классе доступна в будущем кадре, класс потерянного кадра оценивается на основе класса в будущем кадре и класса последнего хорошего кадра. В данном иллюстративном варианте осуществления класс будущего кадра может быть доступен, если принимается уровень 2 будущего кадра (скорость передачи битов будущего кадра выше 8 кбит/с и не потеряна). Если кодер работает на максимальной скорости передачи битов 12 кбит/с, то дополнительная задержка кадра на декодере, используемая для MDCT при наложении с добавлением, не требуется, и разработчик может выбрать более низкую задержку в декодере. В этом случае маскировка будет проводиться только на прошлой информации. Это будет называться как режим декодера с низкой задержкой.
Пусть classold означает класс последнего хорошего кадра, classnew означает класс будущего кадра, и classlost есть класс потерянного кадра, который нужно оценить.
Сначала classlost приравнивается к classold. Если будущий кадр доступен, то его информация о классе декодируется в classnew. Затем значение classlost обновляется следующим образом:
- Если classnew является ВОКАЛИЗОВАННЫМ и classold есть НАЧАЛО, то classlost устанавливается на ВОКАЛИЗОВАННЫЙ.
- Если classnew является ВОКАЛИЗОВАННЫМ и класс кадра перед последним хорошим кадром есть НАЧАЛО или ВОКАЛИЗОВАННЫЙ, то classlost устанавливается на ВОКАЛИЗОВАННЫЙ.
- Если classnew НЕВОКАЛИЗОВАННЫЙ, а classold ВОКАЛИЗОВАННЫЙ, то classlost устанавливается на НЕВОКАЛИЗОВАННЫЙ ПЕРЕХОД.
- Если classnew ВОКАЛИЗОВАННЫЙ или НАЧАЛО и classold НЕВОКАЛИЗОВАННЫЙ, то classlost устанавливается на SIN НАЧАЛО (начало восстановления).
Построение периодической части возбуждения
Для маскировки стертых кадров, класс которых установлен на НЕВОКАЛИЗОВАННЫЙ или НЕВОКАЛИЗОВАННЫЙ ПЕРЕХОД, периодическая часть сигнала возбуждения не генерируется. Для других классов периодическая часть сигнала возбуждения строится следующим образом.
Сначала многократно копируется последний период основного тона предыдущего кадра. Если это случай первого стертого кадра за хорошим кадром, этот период основного тона сначала подвергается низкочастотной фильтрации. Используемый фильтр является простым 3-отводным линейным фазовым КИХ-фильтром (фильтр с конечной импульсной характеристикой) с коэффициентами фильтра, равными 0,18, 0,64 и 0,18.
Период основного тона Tc, используемый для выбора последнего периода основного тона и, следовательно, используемый при маскировке, определяется так, чтобы можно было избежать или уменьшить число кратных или дольных основных тонов. При определении периода основного тона Tc используется следующая логика:
если (T3<1,8Ts) И (T3>0,6Ts)) ИЛИ (Tcnt>30), то Tc=T3, иначе Tc=Ts.
Здесь T3 есть округленный период основного тона 4-го подкадра последнего хорошего принятого кадра и Ts есть округленный предсказанный период основного тона 4-го подкадра последнего хорошего стабильного вокализованного кадра с когерентными оценками основного тона. Стабильный вокализованный кадр определен здесь как ВОКАЛИЗОВАННЫЙ кадр, которому предшествует кадр вокализованного типа (ВОКАЛИЗОВАННЫЙ ПЕРЕХОД, ВОКАЛИЗОВАННЫЙ, НАЧАЛО). Когерентность основного тона устанавливается в данном варианте реализации проверкой, являются ли оценки основного тона замкнутого контура достаточно близкими, т.е. находятся ли соотношения между основным тоном последнего подкадра, основным тоном второго подкадра и основным тоном последнего подкадра предыдущего кадра в интервале (0,7, 1,4). Альтернативно, если потеряно несколько кадров, T3 является округленной оценкой периода основного тона 4-го подкадра последнего замаскированного кадра.
Это определение периода основного тона Tc означает, что если основной тон в конце последнего хорошего кадра и основной тон последнего стабильного кадра близки друг к другу, используется основной тон последнего хорошего кадра. В противном случае этот основной тон считается ненадежным, и вместо него используется основной тон последнего стабильного кадра, чтобы избежать влияния неверных оценок основного тона у вокализованных начал. Однако эта логика имеет смысл, только если последний стабильный сегмент находится не слишком далеко в прошлом. Поэтому определен счетчик Tcnt, который ограничивает радиус действия последнего стабильного сегмента. Если Tcnt больше или равен 30, т.е. если имеется по меньшей мере 30 кадров с последнего обновления Ts, основной тон последнего хорошего кадра используется систематически. Tcnt повторно устанавливается на 0 каждый раз, когда обнаруживается стабильный сегмент, и Ts обновляется. Затем период Tс удерживается постоянным в продолжении маскировки для всего стертого блока.
Для стертых кадров, следующих за правильно принятым кадром, не являющимся НЕВОКАЛИЗОВАННЫМ, буфер возбуждения обновляется только этой периодической частью возбуждения. Это обновление будет использоваться для построения возбуждения кодовой книги основного тона в следующем кадре.
Описанная выше процедура может привести к сдвигу положения голосового импульса, так как период основного тона, использованный для построения возбуждения, может отличаться от истинного периода основного тона в кодере. Это вызовет десинхронизацию буфера адаптивной кодовой книги (или буфера предшествующего возбуждения) и буфера фактического возбуждения. Таким образом, в случае, когда после стертого кадра принят хороший кадр, возбуждение основного тона (или возбуждение адаптивной кодовой книги) будет содержать ошибку, которая может сохраниться на нескольких кадрах и повлиять на поведение правильно принятых кадров.
Фиг.9 является блок-схемой, показывающей процедуру маскировки 900 периодической части возбуждения, описанную в иллюстративном варианте осуществления, а фиг.10 является блок-схемой, показывающей процедуру синхронизации 1000 периодической части возбуждения.
Чтобы преодолеть эту проблему и улучшить сходимость на декодере, раскрывается способ повторной синхронизации (900 на фиг.9), который подбирает положение последнего голосового импульса в замаскированном кадре, чтобы синхронизировать его с фактическим положением голосового импульса. В первом варианте реализации эта процедура повторной синхронизации может быть проведена на основе фазовой информации, относящейся к истинному положению последнего голосового импульса в замаскированном кадре, которая передается в будущий кадр. Во втором варианте реализации положение последнего голосового импульса оценивается в декодере, когда информация из будущего кадра недоступна.
Как описано выше, возбуждение основного тона всего потерянного кадра строится путем повторения последнего периода основного тона Tc предыдущего кадра (операция 906 на фиг.9), где Tc определен выше. Для первого стертого кадра (обнаруженного в операции 902 на фиг.9) период основного тона сначала подвергается низкочастотной фильтрации (операция 904 на фиг.9), используя фильтр с коэффициентами 0,18, 0,64 и 0,18. Это делается следующим образом:
u(n)=u(n-Tc), n=Tc,...,L+N-1
где u(n) есть сигнал возбуждения, L есть размер кадра и N - размер подкадра. Если это не первый стертый кадр, замаскированное возбуждение строится просто как:
Следует отметить, что замаскированное возбуждение рассчитывается также для дополнительного подкадра, чтобы облегчить повторную синхронизацию, как будет показано ниже.
Когда замаскированное возбуждение найдено, процедура повторной синхронизации проводится следующим образом. Если будущий кадр доступен (операция 908 на фиг.9) и содержит информацию о голосовом импульсе, то эта информация декодируется (операция 910 на фиг.9). Как описано выше, эта информация содержит положение абсолютно максимального импульса из конца кадра и его знак. Обозначим это декодированное положение как P0, тогда фактическое положение абсолютно максимального импульса задается как:
Plast=L-P0
Затем на основе возбуждения, прошедшего через низкочастотную фильтрацию, определяется положение максимального импульса в замаскированном возбуждении с начала кадра с таким же знаком, как знак декодированной информации (операция 912 на фигуре 9). То есть если декодированное положение максимального импульса положительно, то определяется максимальный положительный импульс в замаскированном возбуждении от начала кадра, иначе определяется отрицательный максимальный импульс. Обозначим первый максимальный импульс в замаскированном возбуждении T(0). Положения других максимальных импульсов определяются как (операция 914 на фиг.9):
где Np есть число импульсов (включая первый импульс в будущем кадре).
Ошибка в положении последнего скрытого импульса в кадре находится путем поиска импульса T(i), ближайшего к фактическому импульсу Plast (операция 916 на фиг.9). Если ошибка определяется как:
Te=Plast-T(k), где k - индекс импульса, ближайшего к Plast,
если Te=0, то повторная синхронизация не требуется (операция 918 на фиг.9). Если значение Te положительно (T(k)<Plast), то нужно ввести Te выборок (операция 1002 на фиг.10). Если Te отрицательно (T(k)>Plast), то нужно удалить Te выборок (операция 1002 на фиг.10). Далее, повторная синхронизация проводится, только если Te<N и Te<Np·Tdiff, где N есть размер подкадра, а Tdiff есть абсолютная разность между Tc и запаздыванием основного тона первого подкадра в будущем кадре (операция 918 на фиг.9).
Выборки, которые нужно добавить или удалить, распределяются по периодам основного тона в кадре. Определяются зоны с минимальной энергией в разных периодах основного тона, и в этих зонах проводится удаление или вставка выборок. Число импульсов основного тона в кадре есть Np при соответствующих положениях T(i), i=0,…,Np-1. Число зон минимальной энергии есть Np-1. Зоны с минимальной энергией определяются вычислением, используя скользящее окно с 5 выборками (операция 1002 на фиг.10). Положение минимальной энергии задается в середине окна, в котором энергия находится в минимуме (операция 1004 на фиг.10). Поиск проводится между двумя импульсами основного тона в положении T(i) и T(i+1) и ограничен интервалом от T(i)+Tc/4 до T(i+1)-Tc/4.
Обозначим положения минимума, определенные, как описано выше, как Tmin(i), i=0,…,Nmin-1, где Nmin= Np-1 есть число зон с минимальной энергией. Удаление или вставка выборок проводится в окрестности Tmin(i). Выборки, которые нужно добавить или удалить, распределяют по разным периодам основного тона, как будет описано далее.
Если Nmin=1, то имеется всего одна зона минимальной энергии, и все импульсы Te вставляются или удаляются при Tmin(0).
При Nmin>1 для определения числа выборок, которые нужно добавить или удалить в каждом периоде основного тона, используется простой алгоритм, причем меньше выборок добавляется/удаляется в начале и больше к концу кадра (операция 1006 на фиг.10). В данном иллюстративном варианте осуществления для значений Te полного числа импульсов, которые нужно удалить/добавить, и числа Nmin зон с минимальной энергией, число R(i) (i=0,…,Nmin-1) удаляемых/добавляемых выборок на один период основного тона находится с использованием следующего рекурсивного соотношения (операция 1006 на фиг.10):

где 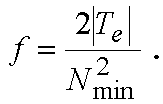
Следует отметить, что на каждом этапе проверяется условие R(i)<R(i-1), и если оно выполняется, то значения R(i) и R(i-1) меняются местами.
Значения R(i) соответствуют периодам основного тона, начиная с начала кадра. R(O) соответствует Tmin(0), R(1) соответствует Tmin(1),..., R(Nmin-1) соответствует Tmin(Nmin-1). Так как значения R(i) расположены в порядке возрастания, то больше выборок добавляется/удаляется к периодам в конце кадра.
Как пример для вычисления R(i), для Te=11 или -11 Nmin=4 (должно быть добавлено/удалено 11 выборок и 4 периода основного тона в кадре), найдены следующие значения R(i):
f=2*11/16=1,375
R(0)=round(f/2)=1
R(1)=round(2f-1)=2
R(2)=round(4,5f-1-2)=3
R(3)=round(8f-1-2-3)=5
Таким образом, 1 выборка добавляется/удаляется в окрестности положения минимальной энергии Tmin(0), 2 выборки добавляются/удаляются в окрестности положения минимальной энергии Tmin(1), 3 выборки добавляются/удаляются в окрестности положения минимальной энергии Tmin(2), и 5 выборок добавляются/удаляются в окрестности положения минимальной энергии Tmin(3) (операция 1008 на фиг.10).
Удаление выборок делается просто. Добавление выборок (операция 1008 на фиг.10) в данном иллюстративном варианте осуществления проводится путем копирования последних R(i) выборок после деления на 20 и изменения знака. В приведенном выше примере, когда нужно вставить 5 выборок в положение Tmin(3), делается следующее:
При использовании описанной выше процедуры последний максимальный импульс в замаскированном возбуждении принудительно выравнивается с фактическим положением максимального импульса в конце кадра, который передается в будущий кадр (операция 920 на фиг.9 и операция 1010 на фиг.10).
Если фазовая информация импульса недоступна, но будущий кадр доступен, значение основного тона будущего кадра может быть интерполировано прошлым значением основного тона, чтобы найти оценки запаздывания основного тона на подкадр. Если будущий кадр недоступен, значение основного тона пропущенного кадра может быть оценено и затем интерполировано прошлым значением основного тона, чтобы найти оценки запаздывания основного тона на подкадр. Затем рассчитывается полное запаздывание всех периодов основного тона в скрытом кадре как для запаздывания последнего основного тона, используемого в маскировке, так и для оценок запаздывания основного тона на подкадр. Разность между этими двумя полными запаздываниями определяется как оценка разности между последним замаскированным максимальным импульсом в кадре и оцененным импульсом. Затем импульсы могут быть повторно синхронизированы, как описано выше (операция 920 на фиг.9 и операция 1010 на фиг.10).
Если декодер не имеет дополнительной задержки, фазовая информация импульса, находящаяся в будущем кадре, может использоваться в первом полученном хорошем кадре для повторной синхронизации памяти адаптивной кодовой книги (предшествующее возбуждение) и выравнивания последнего максимального голосового импульса с положением, переданным в текущем кадре до построения возбуждения текущего кадра. В этом случае синхронизация будет делаться точно так, как описано выше, но в памяти возбуждения, а не в текущем возбуждении. В этом случае построение текущего возбуждения начнется с синхронизованной памяти.
Если не имеется дополнительной задержки, можно также передать положение первого максимального импульса текущего кадра, а не положение последнего максимального голосового импульса последнего кадра. Если это так, синхронизация также достигается в памяти возбуждения до построения текущего возбуждения. При такой конфигурации реальное положение абсолютно максимального импульса в памяти возбуждения определяется как
Plast=L+P0-Tnew,
где Tnew есть первый период основного тона нового кадра, а P0 есть декодированное положение первого максимального голосового импульса текущего кадра.
Так как последний импульс возбуждения предыдущего кадра используется для построения периодической части, его усиление приблизительно правильно в начале замаскированного кадра и может быть установлено на 1 (операция 922 на фиг.9). Затем усиление линейно уменьшается по всему кадру на основе последовательных выборок, чтобы достичь значения α в конце кадра (операция 924 на фиг.9).
Значение α (операция 922 на фиг.9) соответствует значениям в таблице 6, которые учитывают эволюцию энергии вокализованных сегментов. Эту эволюцию можно до некоторой степени экстраполировать, используя значения усиления возбуждения основного тона каждого подкадра последнего хорошего кадра. Вообще, если эти усиления больше 1, энергия сигнала повышается, если они меньше 1, энергия уменьшается. Таким образом, α приравнивается значение 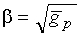 , как описано выше. Значение β ограничено интервалом от 0,98 до 0,85, чтобы избежать большого повышения или уменьшения энергии.
, как описано выше. Значение β ограничено интервалом от 0,98 до 0,85, чтобы избежать большого повышения или уменьшения энергии.
Для стертых кадров, следующих за правильно полученным кадром, не являющимся НЕВОКАЛИЗОВАННЫМ, буфер возбуждения обновляется только периодической частью возбуждения (после повторной синхронизации и масштабирования усиления). Это обновление будет применяться для построения возбуждения кодовой книги основного тона в следующем кадре (операция 926 на фиг.9).
Фиг.11 показывает типичные примеры сигнала возбуждения с процедурой синхронизации и без нее. Исходный сигнал возбуждения без стирания кадра показан на фиг.11b. На фиг.11c показан замаскированный сигнал возбуждения, когда кадр, показанный на фиг.11a, стерт, без использования процедуры синхронизации. Четко видно, что последний голосовой импульс в замаскированном кадре не выровнен с истинным положением импульса, показанным на фиг.11b. Кроме того, можно видеть, что эффект маскировки стирания кадра сохраняется в следующих кадрах, которые не стерты. Фиг.11d показывает замаскированный сигнал возбуждения, когда использовалась процедура синхронизации в соответствии с вышеописанным иллюстративным вариантом осуществления изобретения. Четко видно, что последний голосовой импульс в замаскированном кадре должным образом выровнен с истинным положением импульса, показанным на фиг.11b. Далее, можно видеть, что влияние маскировки стирания кадра на следующие правильно полученные кадры менее проблематично, чем в случае фиг.11c. Это наблюдение подтверждается на фиг.11e и 11f. Фиг.11e показывает ошибку между исходным возбуждением и замаскированным возбуждением без синхронизации. Фиг.11f показывает ошибку между исходным возбуждением и замаскированным возбуждением, когда применяется процедура синхронизации.
На фиг.12 показаны примеры реконструированного речевого сигнала с использованием сигналов возбуждения, показанных на фиг.11. Восстановленный сигнал без стирания кадра показан на фиг.12b. Фиг.12c показывает реконструированный речевой сигнал, когда кадр, показанный на фиг.12a, стерт, без использования процедуры синхронизации. Фиг.12d показывает реконструированный речевой сигнал, когда кадр, показанный на фиг.12a, стерт, с использованием процедуры синхронизации, как описано в приведенном выше иллюстративном варианте осуществления настоящего изобретения. Фиг.12e показывает соотношение сигнал-шум (SNR) на подкадр между исходным сигналом и сигналом по фиг.12c. Из фиг.12e можно видеть, что SNR остается очень низким, даже когда приняты хорошие кадры (он остается ниже 0 дБ для двух следующих хороших кадров и остается ниже 8 дБ до 7-го хорошего кадра). Фиг.12f показывает соотношение сигнал-шум (SNR) на подкадре между исходным сигналом и сигналом по фиг.12d. Из фиг.12d можно видеть, что сигнал быстро сходится к истинному восстановленному сигналу. SNR быстро поднимается выше 10 дБ после двух хороших кадров.
Построение случайной части возбуждения
Обновленная (непериодическая) часть сигнала возбуждения генерируется случайным образом. Она может генерироваться как случайный шум или используя обновленную книгу CELP-кодов со случайным образом генерированным индексами векторов. В настоящем иллюстративном варианте осуществления был использован простой генератор случайных чисел с приблизительно равномерным распределением. До установки обновленного усиления случайное генерированное обновление масштабируется до некоторого эталонного значения, здесь привязанного к единичной энергии на выборку.
В начале стертого блока инициализируется обновленное усиление gs, используя усиления обновленного возбуждения каждого подкадра последнего хорошего кадра:
где g(0), g(1), g(2) и g(3) есть фиксированная кодовая книга или обновленные усиления четырех (4) подкадров последнего правильно принятого кадра. Стратегия ослабления стохастической части возбуждения несколько отличается от ослабления возбуждения основного тона. Причина этого в том, что возбуждение основного тона (и, следовательно, периодичность возбуждения) сходится к 0, когда случайное возбуждение сходится к энергии возбуждения генерирования комфортного шума (CNG). Ослабление обновленного усиления проводится как

где gs 1 есть обновленное усиление в начале следующего кадра, gs 0 есть обновленное усиление в начале текущего кадра, gn есть усиление возбуждения, используемое при генерации комфортного шума, и α определено в таблице 5. Аналогично ослаблению периодического возбуждения, усиление ослабляется также линейно по всему кадру на основе последовательных выборок, начиная с gs 0 и доходя до значения gs 1, которое было бы достигнуто в начале следующего кадра.
Наконец, если принятый последний хороший (правильно принятый или нестертый) кадр отличается от НЕВОКАЛИЗОВАННОГО, обновленное возбуждение фильтруется через линейный фазовый КИХ-фильтр верхних частот с коэффициентами -0,0125, -0,109, 0,7813, -0,109, -0,0125. Чтобы уменьшить количество шумовых компонентов в продолжении вокализованных сегментов, эти коэффициенты фильтра умножаются на адаптивный коэффициент, равный (0,75-0,25rv), где rv есть фактор вокализации, лежащий в диапазоне от -1 до 1. Затем случайная часть возбуждения добавляется к адаптивному возбуждению, чтобы образовать полный сигнал возбуждения.
Если последний хороший кадр является НЕВОКАЛИЗОВАННЫМ, используется только обновленное возбуждение, и оно ослабляется далее умножением на коэффициент 0,8. В этом случае буфер прошлого возбуждения обновляется обновленным возбуждением, так как периодической части возбуждения не имеется.
Маскировка, синтез и обновление огибающей спектра
Чтобы синтезировать декодированную речь, должны быть получены параметры LP-фильтра.
В случае, если будущий кадр недоступен, огибающая спектра постепенно сдвигается к оценке огибающей шума окружающей среды. Здесь используется LSF-представление LP-параметров:
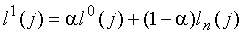 , j=0,..., p-1
, j=0,..., p-1
В уравнении (33) l1(j) есть величина j-го LSF текущего кадра, f0(j) есть значение j-го LSF предыдущего кадра, fn(j) есть значение j-го LSF оцененной огибающей комфортного шума, и p есть порядок LP-фильтра (отметим, что LSF находятся в частотной области). Альтернативно, параметры LSF стертого кадра могут быть просто приравнены параметрам из последнего кадра (l1(j)=l0(j)).
Синтезированная речь получается путем фильтрации сигнала возбуждения через синтезирующий LP-фильтр. Коэффициенты фильтра рассчитываются из LSF-представления и интерполируются для каждого подкадра (четыре (4) раза на кадр), как и при нормальной работе кодера.
В случае, когда будущий кадр доступен, параметры LP-фильтра на подкадр получаются интерполяцией значений LSP в будущем и предыдущем кадрах. Для нахождения интерполированных параметров могут быть использованы несколько способов. В одном способе параметры LSP для всего кадра находятся из соотношения:
где LSP(1) означают оценки LSP стертого кадра, LSF(0) есть LSP в прошлом кадре и LSP(2) есть LSP в будущем кадре.
В качестве неограничивающего примера: параметры LSP передаются дважды на кадр длиной 20 мс (в середине второго и четвертого подкадров). Таким образом, LSP(0) расположен симметрично относительно четвертого подкадра прошлого кадра, а LSP(2) расположен симметрично относительно второго подкадра будущего кадра. Таким образом, интерполированные LSP параметры могут быть найдены для каждого подкадра в стертом кадре как:
где i есть индекс подкадра. Параметры LSP лежат в области изменения косинуса (от -1 до 1).
Так как и квантователь обновленного усиления, и LSF-квантователь используют предсказание, их память не будет обновлена после того, как возобновится нормальная работа. Чтобы уменьшить этот эффект, в конце каждого стертого кадра память квантователей оценивается и обновляется.
Восстановление нормальной работы после стирания
Проблема восстановления после блока стертых кадров вызвана в основном строгим предсказанием, использующимся практически во всех современных кодерах речи. В частности, в речевых кодерах типа CELP их высокое отношение сигнал-шум для вокализованной речи достигается благодаря тому, что они используют прошедший сигнал возбуждения для кодирования возбуждения текущего кадра (долгосрочное предсказание или предсказание основного тона). Также большинство квантователей (LP-квантователи, квантователи усиления и т.д.) пользуются предсказанием.
Искусственное построение начала
Наиболее сложная ситуация, связанная с использованием долгосрочного прогноза в CELP-кодерах, возникает, когда потеряно вокализованное начало. Потерянное начало означает, что вокализованная речь началась где-то в стертом блоке. В этом случае последний хороший принятый кадр был невокализованным, и поэтому в буфере возбуждения не было найдено периодического возбуждения. Однако первый хороший кадр за стертым блоком является вокализованным, буфер возбуждения в кодере является сильно периодическим, и адаптивное возбуждение было кодировано с использованием этого периодического предшествующего возбуждения. Так как эта периодическая часть возбуждения полностью пропущена в декодере, может потребоваться несколько кадров для восстановления от этой потери.
Если потерян кадр НАЧАЛО (т.е. после стирания поступает ВОКАЛИЗОВАННЫЙ хороший кадр, но последний хороший кадр до стирания был НЕВОКАЛИЗОВАННЫМ, как показано на фиг.13), применяется особый метод для искусственного восстановления потерянного начала и для запуска синтеза речи. В данном иллюстративном варианте осуществления положение последнего голосового импульса в замаскированном кадре может быть доступным из будущего кадра (будущий кадр не потерян, и фазовая информация, относящаяся к предыдущему кадру, принимается в будущем кадре). В этом случае маскировка стертого кадра проводится, как обычно. Однако последний голосовой импульс стертого кадра восстанавливается искусственно на основе информации о положении и знаке, доступной из будущего кадра. Эта информация содержит расстояние максимального импульса от конца кадра и его знак. Таким образом, последний голосовой импульс в стертом кадре создается искусственно как импульс низкочастотной фильтрации. В данном иллюстративном варианте осуществления, если знак импульса положительный, используемый низкочастотный фильтр является простым линейным фазовым КИХ-фильтром с импульсной характеристикой hlow={-0,0125, 0,109, 0,7813, 0,109, -0,0125}. Если знак импульса отрицательный, используемый низкочастотный фильтр является линейным фазовым КИХ-фильтром с импульсной характеристикой hlow={0,0125, -0,109, -0,7813, -0,109, 0,0125}.
Рассматриваемый период основного тона является последним подкадром замаскированного кадра. Импульс низкочастотной фильтрации реализуется, помещая импульсную характеристику низкочастотного фильтра в память буфера адаптивного возбуждения (первоначально инициализированного как ноль). Голосовой импульс низкочастотной фильтрации (импульсная характеристика низкочастотного фильтра) будет находиться в центре декодированного положения Plast (переданного в битовом потоке будущего кадра). При декодировании следующего хорошего кадра возобновляется нормальное CELP-декодирование. Помещение голосового импульса низкочастотной фильтрации в надлежащее место в конце замаскированного кадра значительно улучшает свойства последующих хороших кадров и ускоряет сходимость декодера к реальным состояниям декодера.
Энергия периодической части искусственного начального возбуждения масштабируется затем путем усиления, соответствующего квантованной и переданной энергии для маскировки FER, и делением на усиление синтезирующего LP-фильтра. Усиление синтезирующего LP-фильтра вычисляется как:
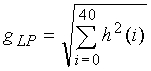
где h(i) есть импульсная характеристика синтезирующего LP-фильтра. Наконец, усиление искусственного начала уменьшают, умножая периодическую часть на 0,96.
LP-фильтр для выходного синтеза речи не интерполируется в случае искусственного построения начала. Вместо этого принятые LP-параметры используются для синтеза целого кадра.
Регулирование энергии
Одной задачей восстановления после блока стертых кадров является надлежащее регулирование энергии синтезированного речевого сигнала. Регулирование синтезированной энергии необходимо, так как в современных речевых кодерах обычно применяется строгое предсказание. Регулирование энергии проводится также, когда блок стертых кадров возникает во время вокализованного сегмента. Когда стирание кадра приходит после вокализованного кадра, при маскировке типично применяется возбуждение последнего хорошего кадра с некоторой стратегией ослабления. Когда новый LP-фильтр поступает с первым хорошим кадром после стирания, может быть рассогласование между энергией возбуждения и усилением нового синтезирующего LP-фильтра. Новый синтезирующий фильтр может формировать синтезированный сигнал с энергией, сильно отличающейся от энергии последнего синтезированного стертого кадра, а также от энергии исходного сигнала.
Регулирование энергии в течение первого хорошего кадра за стертым кадром может быть резюмировано следующим образом. Синтезированный сигнал масштабируется, так что его энергия в начале первого хорошего кадра становится близкой энергии синтезированного речевого сигнала в конце последнего стертого кадра и к концу кадра сходится к переданной энергии, чтобы предотвратить слишком сильное повышение энергии.
Регулирование энергии проводится в области синтезированного речевого сигнала. Даже если энергия регулируется в речевой области, сигнал возбуждения должен масштабироваться, так как он служит памятью долгосрочного предсказания для следующих кадров. Затем опять проводится синтез, чтобы сгладить переходы. Пусть g0 означает усиление, используемое для масштабирования первой выборки в текущем кадре, и усиление g1, используемое в конце кадра. Тогда сигнал возбуждения масштабируется следующим образом:
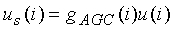 i=0,…,L-1
i=0,…,L-1
где us(i) есть масштабированное возбуждение, u(i) есть возбуждение до масштабирования, L означает длину кадра и gAGC(i) есть усиление, начинающееся от g0 и экспоненциально сходящееся к g1:
 i=0,…,L-1
i=0,…,L-1
с инициализацией 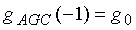 , где gAGC есть коэффициент ослабления, установленный в данной реализации на 0,98. Эта величина была найдена экспериментально как компромиссная, с одной стороны, дающая плавный переход от предыдущего (стертого) кадра, а с другой стороны, как можно лучше приближающая последний период основного тона текущего кадра к корректному (переданному) значению. Это делается, так как переданное значение энергии оценивается синхронно с основным тоном в конце кадра. Усиления g0 и g1 определены как:
, где gAGC есть коэффициент ослабления, установленный в данной реализации на 0,98. Эта величина была найдена экспериментально как компромиссная, с одной стороны, дающая плавный переход от предыдущего (стертого) кадра, а с другой стороны, как можно лучше приближающая последний период основного тона текущего кадра к корректному (переданному) значению. Это делается, так как переданное значение энергии оценивается синхронно с основным тоном в конце кадра. Усиления g0 и g1 определены как:
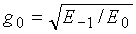
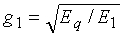
где E-1 есть энергия, рассчитанная в конце предыдущего (стертого) кадра, E0 есть энергия в начале текущего (восстановленного) кадра, E1 есть энергия в конце текущего кадра и Eq есть квантованная переданная энергетическая информация в конце текущего кадра, рассчитанная в кодера из уравнений (20,21). E-1 и E1 вычисляются сходным образом, с тем исключением, что они вычисляются на синтезированном речевом сигнале s'. E-1 рассчитывается синхронно с основным тоном при использовании маскированного периода основного тона Tс, и E1 использует последний подкадр округленного основного тона T3. E0 вычисляется сходным образом, используя округленное значение основного тона T0 первого подкадра, причем уравнения (20,21) изменяются следующим образом:
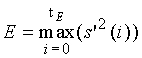
для кадров ВОКАЛИЗОВАННЫЙ и НАЧАЛЬНЫЙ. Если основной тон короче, чем 64 выборки, tE равно округленному запаздыванию основного тона или удвоенному этому значению. Для других кадров
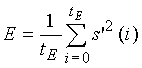
при tE, равном половине длины кадра. Усиления g0 и g1 ограничены, кроме того, максимальным допустимым значением, чтобы избежать большой энергии. В настоящей иллюстративной реализации это значение было принято равным 1,2.
Проведение маскировки стирания кадра и восстановление декодера включает, когда усиление LP-фильтра первого нестертого кадра, принятого после стирания кадра, выше, чем усиление LP-фильтра последнего кадра, стертого при указанном стирании кадра, настройку энергии сигнала возбуждения LP-фильтра, сформированного в декодере при приеме первого нестертого кадра, к усилению LP-фильтра указанного принятого первого нестертого кадра, используя следующее соотношение:
Если Eq не может быть передано, Eq приравнивается к E1.
Однако если стирание произошло в продолжении сегмента вокализованной речи (т.е. последний хороший кадр до стирания и первый хороший кадр после стирания классифицируются как ВОКАЛИЗОВАННЫЙ ПЕРЕХОД, ВОКАЛИЗОВАННЫЙ или НАЧАЛО), должны предприниматься дальнейшие меры предосторожности из-за упоминавшегося ранее возможного рассогласования между энергией сигнала возбуждения энергии и усилением LP-фильтра. Особо опасная ситуация возникает, когда усиление LP-фильтра первого нестертого кадра, принятого вслед за стиранием кадра, выше, чем усиление LP-фильтра последнего кадра, стертого при этом стирании кадра. В этом частном случае энергия сигнала возбуждения LP-фильтра, формируемого в декодере при приеме первого нестертого кадра, настраивается на усиление LP-фильтра первого принятого нестертого кадра, используя следующее соотношение:
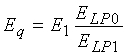
где ELP0 есть энергия импульсной характеристики LP-фильтра для последнего хорошего кадра до стирания, а ELP1 есть энергия LP-фильтра первого хорошего кадра после стирания. В этой реализации используются LP-фильтры последних подкадров кадра. Наконец, в этом случае значение Eq ограничено величиной E-1 (стирание вокализованного сегмента происходит без передачи информации о Eq).
Следующие исключения, все связанные с переходами в речевой сигнал, дополнительно перезаписывают вычисление g0. Если в текущем кадре используется искусственное начало, g0 приравнивается 0,5g1, чтобы заставить начальную энергию увеличиваться постепенно.
В случае, когда первый хороший кадр после стирания классифицирован как НАЧАЛО, не допускается, чтобы усиление g0 было выше g1. Эта мера предосторожности используется, чтобы предотвратить усиление вокализованного начала (в конце кадра) из-за положительной корректировки усиления в начале кадра (который, вероятно, все еще является по меньшей мере частично невокализованным).
Наконец, при переходе от вокализованного к невокализованному (т.е. этот последний хороший кадр классифицируется как ВОКАЛИЗОВАННЫЙ ПЕРЕХОД, ВОКАЛИЗОВАННЫЙ или НАЧАЛО, а текущий кадр классифицируется как НЕВОКАЛИЗОВАННЫЙ) или при переходе от периода неактивной речи к периоду активной речи (причем последний принятый хороший кадр кодируется как комфортный шум и текущий кадр кодируется как активная речь), g0 присваивается значение g1.
В случае стирания вокализованного сегмента проблема ошибочной энергии может проявиться также в кадрах, следующих за первым хорошим кадром после стирания. Это может случиться, даже если энергия первого хорошего кадра была настроена, как описано выше. Чтобы смягчить эту проблему, контроль энергии может продолжаться до конца вокализованного сегмента.
Применение описанной маскировки во вложенном кодеке с широкополосным базовым уровнем
Как указано выше, вышеописанный иллюстративный вариант осуществления настоящего изобретения использовался также в подходящем алгоритме для стандартизации комитетом ITU-T вложенного кодека с переменной скоростью передачи битов. В подходящем алгоритме базовый уровень основан на методе широкополосного кодирования, аналогичном AMR-WB (рекомендация ITU-T G.722.2). Базовый уровень работает на 8 кбит/с и кодирует полосу частот до 6400 Гц с внутренней частотой дискретизации 12,8 кГц (как и AMR-WB). Используется второй CELP-уровень с 4 кбит/с, повышающий скорость передачи битов до 12 кбит/с. Затем используется MDCT, чтобы получить верхние уровни со скоростью от 16 до 32 кбит/с.
Маскировка подобно способу, описанному выше, с небольшой разницей, в основном из-за другой частоты дискретизации базового уровня. Кадр имеет размер 256 выборок на частоте дискретизации 12,8 кГц, размер подкадра 64 выборки.
Фазовая информация кодируется 8 битами, причем знак кодируется 1 битом, и положение кодируется 7 битами следующим образом.
Точность, используемая для кодирования положения первого голосового импульса, зависит от значения T0 основного тона замкнутого контура для первого подкадра в будущем кадре. Когда T0 меньше 128, положение последнего голосового импульса относительно конца кадра кодируется напрямую с точностью в одну выборку. Когда T0≥128, положение последнего голосового импульса относительно конца кадра кодируется с точностью в две выборки, используя простое целочисленное деление, т.е. τ/2. Обратная процедура выполняется декодером. Если T0<128, полученное квантованное положение используется, как есть. Если T0≥128, полученное квантованное положение умножается на 2 и увеличивается на 1.
Параметры маскировки/восстановления заключаются в 8-битовой фазовой информации, 2-битовой классификационной информации и 6-битовой энергетической информации. Эти параметры передаются в третьем уровне со скоростью 16 кбит/с.
Хотя настоящее изобретение было описано в предшествующем описании в связи с неограничительным иллюстративным вариантом его осуществления, этот вариант осуществления при желании может быть изменен в рамках приложенной формулы, не выходя за сущность и объем заявленного изобретения.
Ссылки
[1] Milan Jelinek, Philippe Goumay. PCT-заявка на патент WO 03102921 A1, "Способ и устройство для эффективной маскировки стирания кадра в речевых кодеках на основе линейного предсказания".
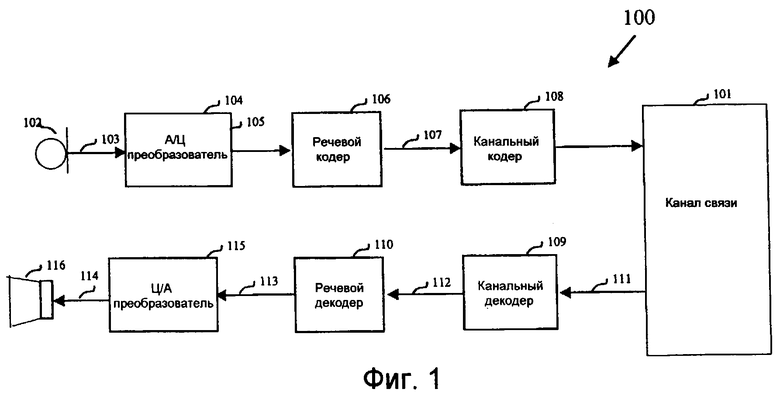
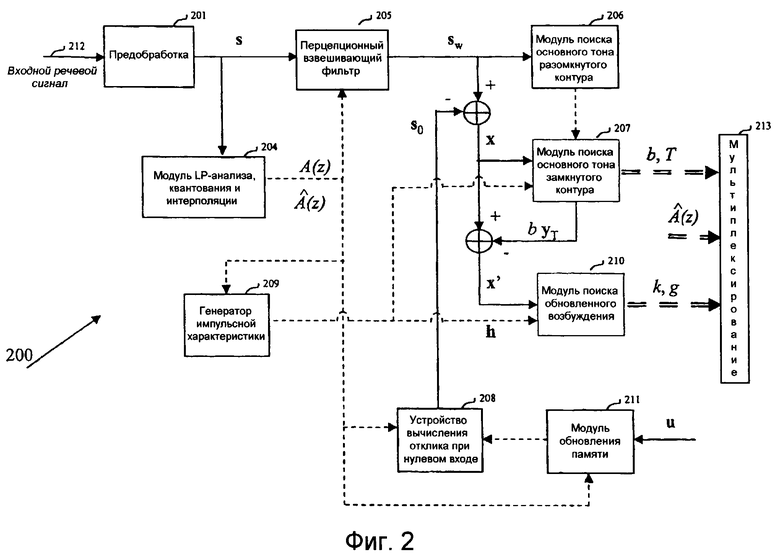
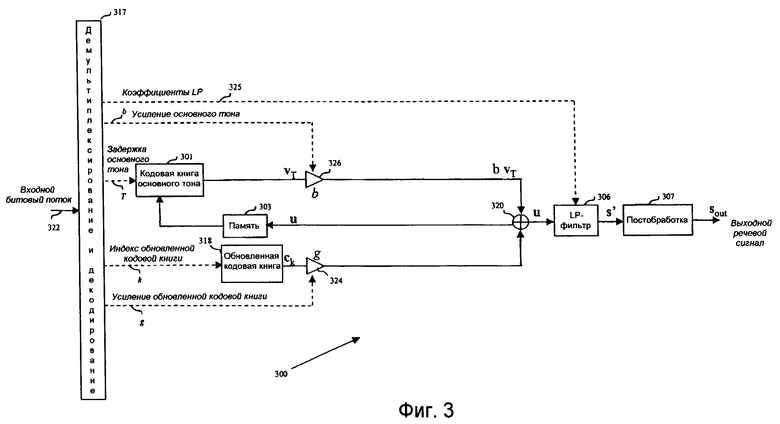
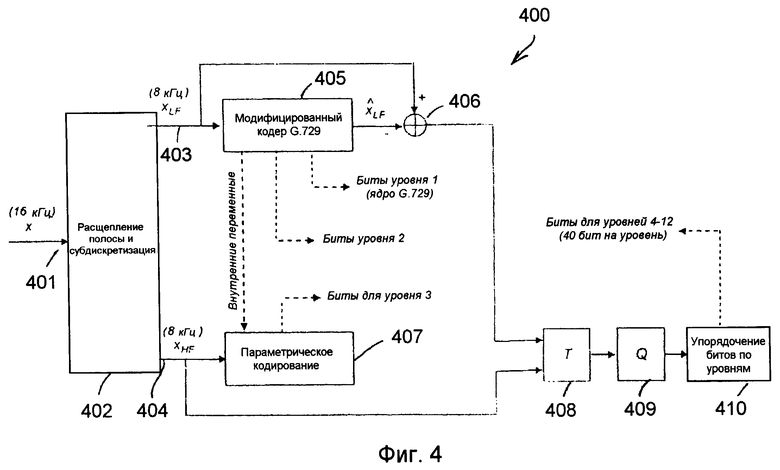
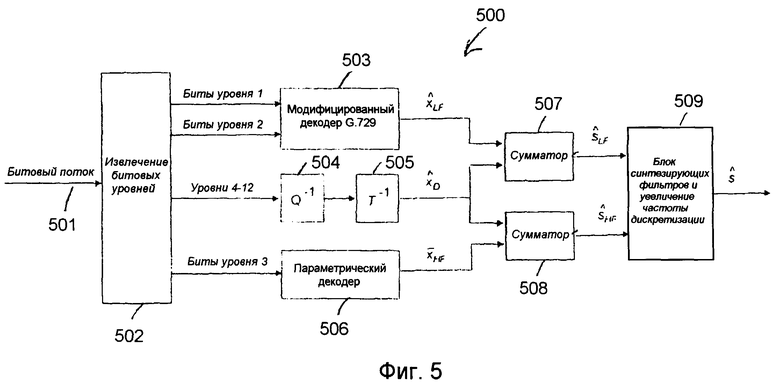
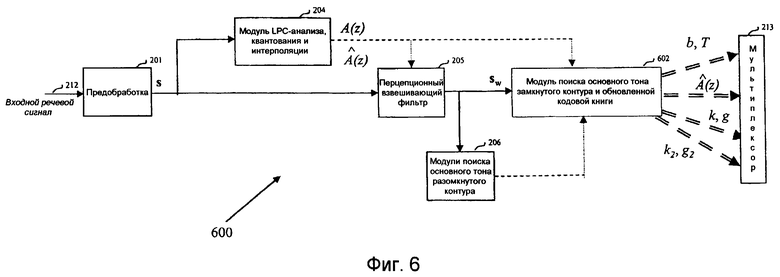
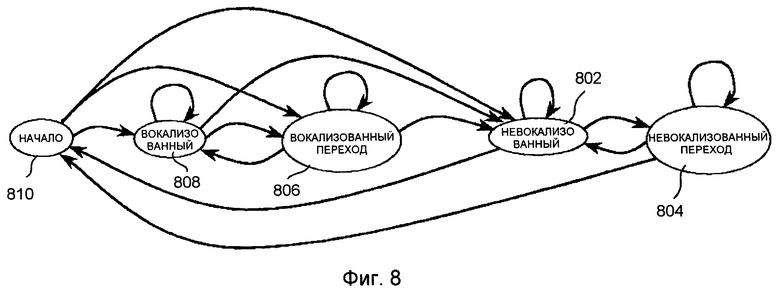
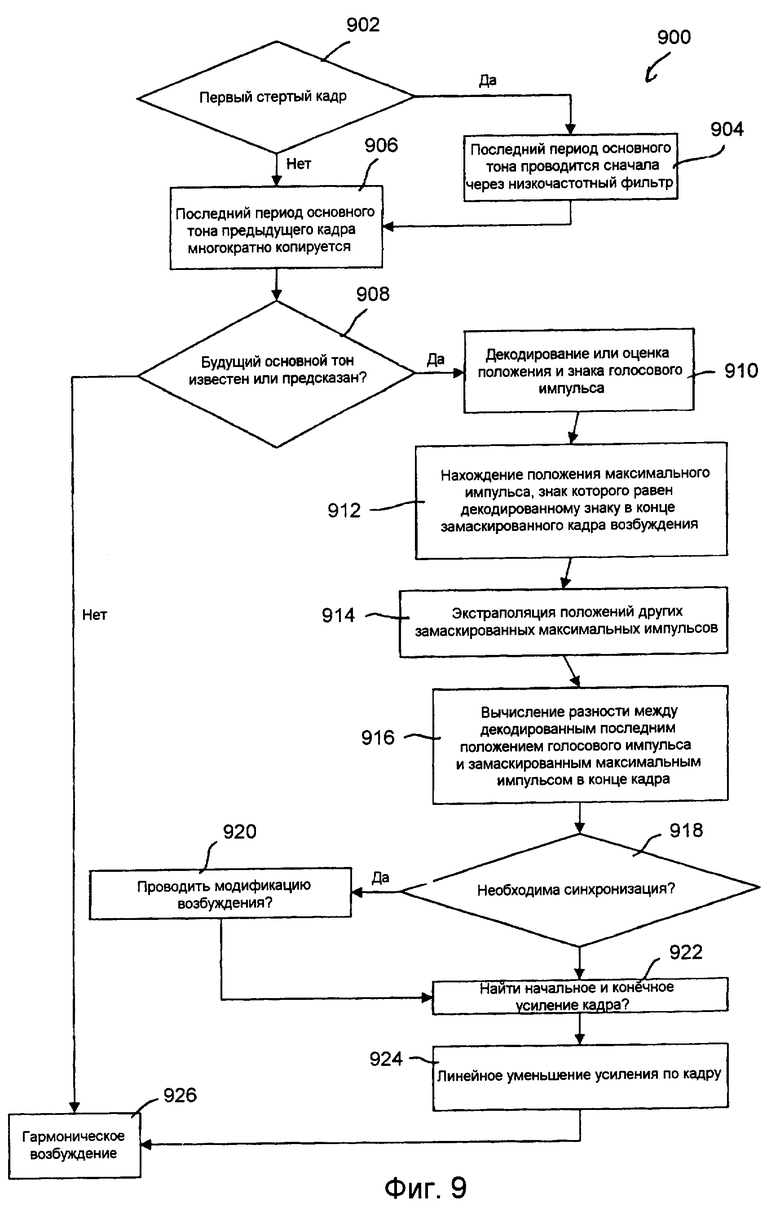
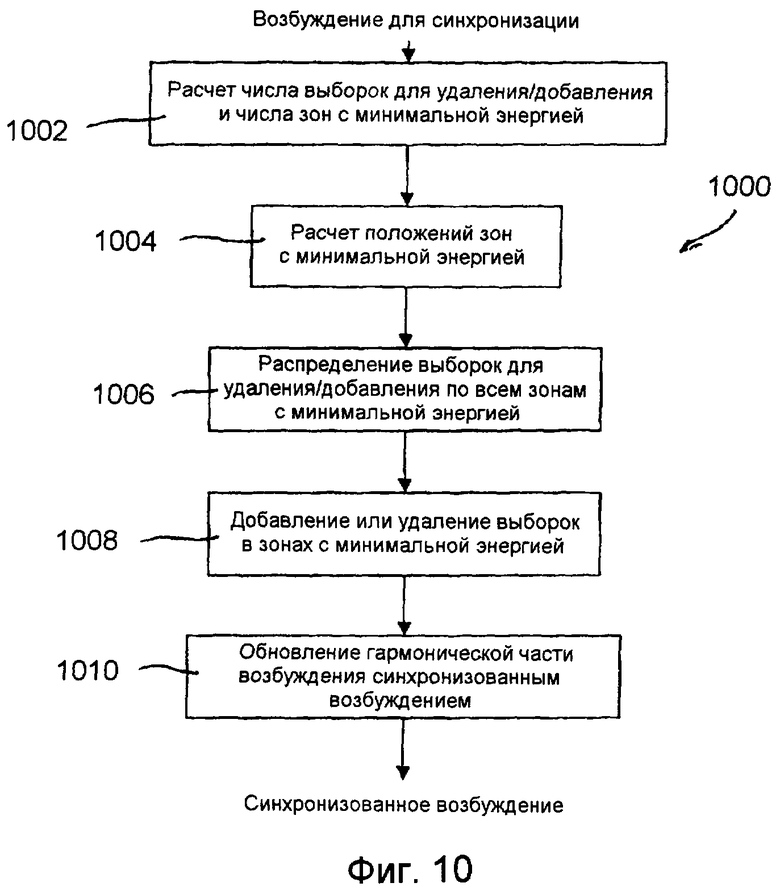
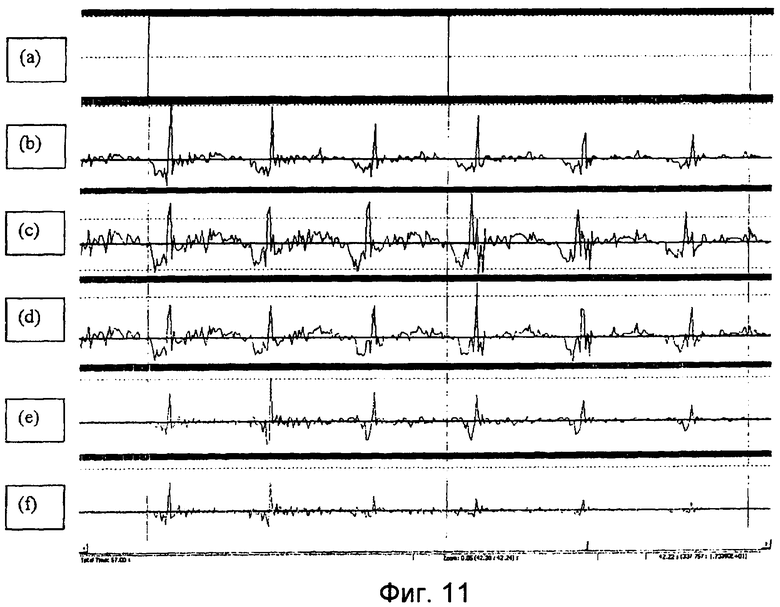
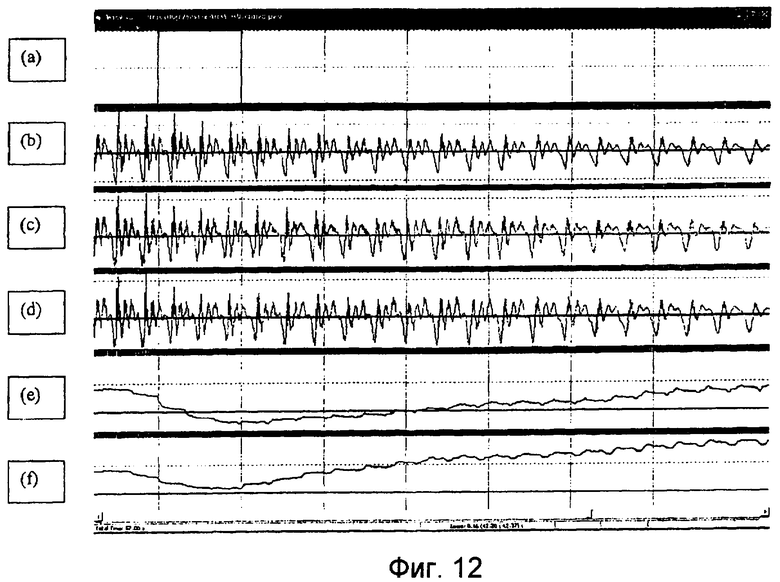

Изобретение относится к способу цифрового кодирования звукового сигнала. Способ и устройство для маскировки стирания кадров, вызванного стиранием кадров закодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров включают в кодере: определение параметров маскировки/восстановления, включая, по меньшей мере, фазовую информацию, относящуюся к кадрам кодированного звукового сигнала. Параметры маскировки/восстановления, определенные в кодере, передаются на декодер, в котором в ответ на принятые параметры маскировки/восстановления проводится маскировка стирания кадра. Маскировка стирания кадра включает повторную синхронизацию, в ответ на полученную фазовую информацию, кадров с замаскированным стиранием с соответствующими кадрами звукового сигнала, кодированного кодером. Когда параметры маскировки/восстановления на декодер не передаются, в декодере оценивается фазовая информация каждого кадра кодированного звукового сигнала, который был стерт при передаче от кодера к декодеру. Аналогично, маскировка стирания кадра проводится в декодере в ответ на оцененную фазовую информацию, причем маскировка стирания кадра включает повторную синхронизацию, в ответ на оцененную фазовую информацию, каждого кадра с замаскированным стиранием с соответствующим кадром звукового сигнала, кодированного в кодере. Технический результат - обеспечение надежного кодирования и декодирования звуковых сигналов. 6 н. и 68 з.п ф-лы, 13 ил., 6 табл.
1. Способ маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и восстановления декодера после стирания кадров, причем способ содержит
в кодере:
определение параметров маскировки/восстановления, включая, по меньшей мере, фазовую информацию, относящуюся к кадрам кодированного звукового сигнала;
передачу на декодер параметров маскировки/восстановления, определенных в кодере; и
в декодере:
проведение маскировки стирания кадра в ответ на принятые параметры маскировки/восстановления, причем маскировка стирания кадра включает повторную синхронизацию кадров с замаскированным стиранием с соответствующими кадрами кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в фазовую информацию.
2. Способ по п.1, в котором определение параметров маскировки/восстановления включает в качестве фазовой информации определение положения голосового импульса в каждом кадре кодированного звукового сигнала.
3. Способ по п.1, в котором определение параметров маскировки/восстановления включает в качестве фазовой информации определение положения и знака последнего голосового импульса в каждом кадре кодированного звукового сигнала.
4. Способ по п.2, дополнительно содержащий квантование положения голосового импульса до передачи положения голосового импульса на декодер.
5. Способ по п.3, дополнительно содержащий квантование положения и знака последнего голосового импульса до передачи положения и знака последнего голосового импульса на декодер.
6. Способ по п.4, дополнительно содержащий кодирование квантованного положения голосового импульса в будущем кадре кодированного звукового сигнала.
7. Способ по п.2, в котором определение положения голосового импульса включает:
измерение голосового импульса как импульса с максимальной амплитудой в заданном периоде основного тона каждого кадра кодированного звукового сигнала и
определение положения импульса с максимальной амплитудой.
8. Способ по п.7, дополнительно содержащий определение в качестве фазовой информации знака голосового импульса путем измерения знака импульса с максимальной амплитудой.
9. Способ по п.3, в котором определение положения последнего голосового импульса включает:
измерение последнего голосового импульса как импульса с максимальной амплитудой в каждом кадре кодированного звукового сигнала и
определение положения импульса с максимальной амплитудой.
10. Способ по п.9, в котором определение знака голосового импульса включает измерение знака импульса с максимальной амплитудой.
11. Способ по п.10, в котором повторная синхронизация кадра с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала включает:
декодирование положения и знака последнего голосового импульса указанного соответствующего кадра кодированного звукового сигнала;
определение, в кадре с замаскированным стиранием, положения импульса с максимальной амплитудой, имеющего знак, как у последнего голосового импульса соответствующего кадра кодированного звукового сигнала, ближайшего к положению указанного последнего голосового импульса указанного соответствующего кадра указанного кодированного звукового сигнала; и
выравнивание положения импульса с максимальной амплитудой в кадре с замаскированным стиранием с положением последнего голосового импульса соответствующего кадра кодированного звукового сигнала.
12. Способ по п.7, в котором повторная синхронизация кадра с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала включает:
декодирование положения голосового импульса указанного соответствующего кадра кодированного звукового сигнала;
определение, в кадре с замаскированным стиранием, положения импульса с максимальной амплитудой, ближайшего к положению указанного голосового импульса указанного соответствующего кадра указанного кодированного звукового сигнала; и
выравнивание положения импульса с максимальной амплитудой в кадре с замаскированным стиранием с положением голосового импульса соответствующего кадра кодированного звукового сигнала.
13. Способ по п.12, в котором выравнивание положение импульса с максимальной амплитудой в кадре с замаскированным стиранием с положением голосового импульса в соответствующем кадре кодированного звукового сигнала включает:
определение смещения между положением импульса с максимальной амплитудой в кадре с замаскированным стиранием и положением голосового импульса в соответствующем кадре кодированного звукового сигнала и
вставку/удаление в кадре с замаскированным стиранием ряда выборок, соответствующих определенному смещению.
14. Способ по п.13, в котором вставка/удаление ряда выборок включает:
определение, по меньшей мере, одной зоны минимальной энергии в кадре с замаскированным стиранием и
распределение ряда выборок для вставки/удаления в окрестности, по меньшей мере, одной зоны минимальной энергии.
15. Способ по п.14, в котором распределение ряда выборок для вставки/удаления в окрестности, по меньшей мере, одной зоны минимальной энергии включает распределение этого ряда выборок в окрестности, по меньшей мере, одной зоны минимальной энергии, используя следующее соотношение:
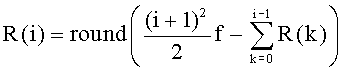 для i=0, …, Nmin-1, и k=0, …, i-1 и Nmin>1,
для i=0, …, Nmin-1, и k=0, …, i-1 и Nmin>1,
где 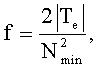 Nmin есть число областей с минимальной энергией и Те есть смещение между положением импульса с максимальной амплитудой в кадре с замаскированным стиранием и положением голосового импульса в соответствующем кадре кодированного звукового сигнала.
Nmin есть число областей с минимальной энергией и Те есть смещение между положением импульса с максимальной амплитудой в кадре с замаскированным стиранием и положением голосового импульса в соответствующем кадре кодированного звукового сигнала.
16. Способ по п.15, в котором R(i) расположены в порядке возрастания, так что выборки в основном добавляются/удаляются в конце кадра с замаскированным стиранием.
17. Способ по п.1, в котором проведение маскировки стирания кадра в ответ на полученные параметры маскировки/восстановления включает для вокализованных стертых кадров:
формирование периодической части сигнала возбуждения в кадре с замаскированным стиранием в ответ на принятые параметры маскировки/восстановления и
формирование стохастической части обновленного сигнала возбуждения путем генерирования случайным образом непериодического обновленного сигнала.
18. Способ по п.1, в котором проведение маскировки стирания кадра в ответ на принятые параметры маскировки/восстановления включает для невокализованных стертых кадров формирование стохастической части обновленного сигнала возбуждения путем генерирования случайным образом непериодического обновленного сигнала.
19. Способ по п.1, в котором параметры маскировки/восстановления дополнительно включают, кроме того, классификацию сигнала.
20. Способ по п.19, в котором классификация сигнала включает классификацию последовательных кадров кодированного звукового сигнала как «невокализованный», «невокализованный переход», «вокализованный переход», «вокализованный» или «начало».
21. Способ по п.20, в котором классификация потерянного кадра оценивается на основе классификации будущего кадра и последнего принятого хорошего кадра.
22. Способ по п.21, в котором потерянный кадр относится к классу «вокализованный», если будущий кадр является вокализованным, и последний принятый хороший кадр является «началом».
23. Способ по п.22, в котором потерянный кадр относится к классу «невокализованный переход», если будущий кадр является «невокализованным», а последний принятый хороший кадр является «вокализованным».
24. Способ по п.1, в котором:
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскировки/восстановления включает определение фазовой информации и классификацию сигналов последовательных кадров кодированного звукового сигнала;
проведение маскировки стирания кадра в ответ на параметры маскировки/восстановления, включает, когда потерян начальный кадр (на что указывает наличие вокализованного кадра, следующего за стиранием кадра, и невокализованного кадра до стирания кадра), искусственное восстановление потерянного начального кадра; и
повторную синхронизацию в ответ на фазовую информацию потерянного начального кадра с замаскированным стиранием с соответствующим начальным кадром кодированного звукового сигнала.
25. Способ по п.24, в котором искусственное восстановление потерянного кадра "начало" включает искусственное восстановление последнего голосового импульса в потерянном кадре "начало" как импульса, подвергнутого низкочастотной фильтрации.
26. Способ по п.24, дополнительно содержащий изменение масштаба восстановленного потерянного начального кадра путем умножения на коэффициент усиления.
27. Способ по п.1, содержащий, когда фазовой информации в момент маскировки стертого кадра не имеется, обновление содержимого адаптивной кодовой книги декодера фазовой информацией, если она доступна до декодирования следующего принятого нестертого кадра.
28. Способ по п.1, в котором:
определение параметров маскировки/восстановления включает в качестве фазовой информации определение положения голосового импульса в каждом кадре кодированного звукового сигнала; и
обновление адаптивной кодовой книги включает повторную синхронизацию голосового импульса в адаптивной кодовой книге.
29. Способ по п.1, в котором первый фазоуказующий признак кадра с замаскированным стиранием включает положение импульса с максимальной амплитудой, а второй фазоуказующий признак закодированного звукового сигнала включает положение голосового сигнала.
30. Способ маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и восстановления декодера после стирания кадров, причем способ включает
в декодере:
оценку фазовой информации каждого кадра кодированного звукового сигнала, который был стерт при передаче от кодера к декодеру; и
проведение маскировки стирания кадра в ответ на оцененную фазовую информацию, причем маскировка стирания кадра включает повторную синхронизацию каждого кадра с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра закодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в оцененную фазовую информацию.
31. Способ по п.30, в котором оценка фазовой информации включает оценку положения последнего голосового импульса каждого кадра кодированного звукового сигнала, который был стерт.
32. Способ по п.31, в котором оценка положения последнего голосового импульса каждого кадра кодированного звукового сигнала, который был стерт, включает:
оценку голосового импульса из прошлого значения основного тона и
интерполяцию оцененного голосового импульса с прошлым значением основного тона, чтобы определить оценку запаздывания основного тона.
33. Способ по п.32, в котором повторная синхронизация кадра с замаскированным стиранием и соответствующего кадра кодированного звукового сигнала включает:
определение импульса с максимальной амплитудой в кадре с замаскированным стиранием и
выравнивание импульса с максимальной амплитудой в кадре с замаскированным стиранием с оцененным голосовым импульсом.
34. Способ по п.33, в котором выравнивание импульса с максимальной амплитудой в кадре с замаскированным стиранием с оцененным голосовым импульсом включает:
вычисление периодов основного тона в кадре с замаскированным стиранием;
определение смещения между оцененными запаздываниями основного тона и периодами основного тона в кадре с замаскированным стиранием и
вставку/удаление ряда выборок, соответствующих определенному смещению в кадре с замаскированным стиранием.
35. Способ по п.34, причем вставка/удаление ряда выборок включает:
определение, по меньшей мере, одной зоны минимальной энергии в кадре с замаскированным стиранием и
распределение ряда выборок для вставки/удаления в окрестности по меньшей мере одной зоны минимальной энергии.
36. Способ по п.35, в котором распределение ряда выборок для вставки/удаления в окрестности, по меньшей мере, одной зоны минимальной энергии включает распределение ряда выборок вокруг по меньшей мере одной зоны минимальной энергии, используя следующее соотношение:
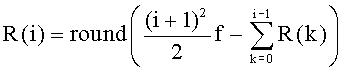 для i=0, …, Nmin-1, и k=0, …, i-1 и Nmin>1,
для i=0, …, Nmin-1, и k=0, …, i-1 и Nmin>1,
где  Nmin есть число областей с минимальной энергией и Te есть смещение между запаздываниями основного тона и периодами основного тона в кадре с замаскированным стиранием.
Nmin есть число областей с минимальной энергией и Te есть смещение между запаздываниями основного тона и периодами основного тона в кадре с замаскированным стиранием.
37. Способ по п.36, в котором R(i) упорядочены в порядке возрастания, так что выборки в основном добавляются/удаляются в конце кадра с замаскированным стиранием.
38. Способ по п.30, включающий уменьшение усиления каждого кадра с замаскированным стиранием линейно от начала к концу кадра с замаскированным стиранием.
39. Способ по п.38, в котором усиление каждого кадра с замаскированным стиранием уменьшается до достижения значения α, где α есть коэффициент регулирования скорости сходимости восстановления декодера после стирания кадра.
40. Способ по п.39, в котором коэффициент α зависит от стабильности LP-фильтра для невокализованных кадров.
41. Способ по п.40, в котором коэффициент α учитывает, кроме того, эволюцию энергии вокализованных сегментов.
42. Способ по п.30, в котором первый фазоуказующий признак каждого кадра с замаскированным стиранием включает положение импульса с максимальной амплитудой, а второй фазоуказующий признак закодированного звукового сигнала включает положение голосового сигнала.
43. Устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство содержит
в кодере:
средство для определения параметров маскировки/восстановления, включая, по меньшей мере, фазовую информацию, относящуюся к кадрам кодированного звукового сигнала;
средство для передачи на декодер параметров маскировки/восстановления, определенных в кодере; и
в декодере:
средство для проведения маскировки стирания кадров в ответ на полученные параметры маскировки/восстановления, причем средство для проведения маскировки стирания кадра содержит средство повторной синхронизации кадров с замаскированным стиранием с соответствующими кадрами кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующих кадров кодированного звукового сигнала, причем указанный второй фазоуказающий признак включен в фазовую информацию.
44. Устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство содержит
в кодере:
генератор параметров маскировки/восстановления, в том числе, по меньшей мере, фазовой информации, относящейся к кадрам кодированного звукового сигнала;
канал связи для передачи на декодер параметров маскировки/восстановления, определенных в кодере; и
в декодере:
модуль маскировки стирания кадра, на который подаются параметры маскировки/восстановления и который содержит синхронизатор, реагирующий на полученную фазовую информацию повторной синхронизацией кадра с замаскированным стиранием и соответствующих кадров кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующих кадров кодированного звукового сигнала, причем указанный второй фазоуказающий признак включен в фазовую информацию.
45. Устройство по п.44, в котором генератор параметров маскировки/восстановления генерирует в качестве фазовой информации положение голосового импульса в каждом кадре кодированного звукового сигнала.
46. Устройство по п.44, причем генератор параметров маскировки/восстановления генерирует в качестве фазовой информации положение и знак последнего голосового импульса в каждом кадре кодированного звукового сигнала.
47. Устройство по п.45, дополнительно содержащее квантователь для квантования положения голосового импульса до передачи положения голосового импульса на декодер по каналу связи.
48. Устройство по п.46, дополнительно содержащее квантователь для квантования положения и знака последнего голосового импульса до передачи положения и знака последнего голосового импульса на декодер по каналу связи.
49. Устройство по п.47, дополнительно содержащее кодер квантованного положения голосового импульса в будущем кадре кодированного звукового сигнала.
50. Устройство по п.45, в котором в качестве положения голосового импульса генератор определяет положение импульса с максимальной амплитудой в каждом кадре кодированного звукового сигнала.
51. Устройство по п.46, в котором в качестве положения и знака последнего голосового импульса генератор определяет положение и знак импульса с максимальной амплитудой в каждом кадре кодированного звукового сигнала.
52. Устройство по п.50, в котором в качестве фазовой информации генератор определяет знак голосового импульса как знак импульса с максимальной амплитудой.
53. Устройство по п.50, в котором синхронизатор
определяет в каждом кадре с замаскированным стиранием положение импульса с максимальной амплитудой, ближайшее к положению голосового импульса в соответствующем кадре кодированного звукового сигнала;
определяет смещение между положением импульса с максимальной амплитудой в каждом кадре с замаскированным стиранием и положением голосового импульса в соответствующем кадре кодированного звукового сигнала и
вводит/удаляет ряд выборок, соответствующих определенному смещению в каждом кадре с замаскированным стиранием, чтобы выровнять положение импульса с максимальной амплитудой в кадре с замаскированным стиранием с положением голосового импульса в соответствующем кадре кодированного звукового сигнала.
54. Устройство по п.46, в котором синхронизатор
определяет в каждом кадре с замаскированным стиранием положение импульса с максимальной амплитудой, имеющего такой же знак, как и знак последнего голосового импульса, ближайшее к положению последнего голосового импульса в соответствующем кадре кодированного звукового сигнала;
определяет смещение между положением импульса с максимальной амплитудой в каждом кадре с замаскированным стиранием и положением последнего голосового импульса в соответствующем кадре кодированного звукового сигнала и
вводит/удаляет ряд выборок, соответствующих определенному смещению в каждом кадре с замаскированным стиранием, чтобы выровнять положение импульса с максимальной амплитудой в кадре с замаскированным стиранием с положением последнего голосового импульса в соответствующем кадре кодированного звукового сигнала.
55. Устройство по п.53, в котором синхронизатор, кроме того,
определяет, по меньшей мере, одну зону минимальной энергии в каждом кадре с замаскированным стиранием путем использования скользящего окна и
распределяет ряд выборок для вставки/удаления в окрестности по меньшей мере одной зоны минимальной энергии.
56. Устройство по п.55, в котором синхронизатор использует следующее соотношение для распределения ряда выборок для вставки/удаления вокруг по меньшей мере одной зоны минимальной энергии:
для i=0, …, Nmin-1, и k=0, …, 1-1 и Nmin>1,
где Nmin есть число областей с минимальной энергией и Те есть смещение между положением импульса с максимальной амплитудой в кадре с замаскированным стиранием и положением голосового импульса в соответствующем кадре кодированного звукового сигнала.
57. Устройство по п.56, в котором R(i) упорядочены в порядке возрастания, так что выборки добавляются/удаляются в основном в конце кадра с замаскированным стиранием.
58. Устройство по п.44, в котором модуль маскировки стирания кадра, на который подаются полученные параметры маскировки/восстановления, содержит для вокализованных стертых кадров
генератор периодической части сигнала возбуждения в каждом кадре с замаскированным стиранием в ответ на полученные параметры маскировки/восстановления и
стохастический генератор непериодической обновленной части сигнала возбуждения.
59. Устройство по п.44, в котором модуль маскировки стирания кадра, на который подаются полученные параметры маскировки/восстановления, содержит для невокализованных стертых кадров стохастический генератор непериодической обновленной части сигнала возбуждения.
60. Устройство по п.44, в котором, когда фазовая информация в момент маскировки стертого кадра не имеется, декодер обновляет содержимое адаптивной кодовой книги декодера фазовой информацией, если она доступна, до декодирования следующего принятого нестертого кадра.
61. Устройство по п.60, в котором
генератор параметров маскировки/восстановления определяет в качестве фазовой информации положение голосового импульса в каждом кадре кодированного звукового сигнала и
декодер для обновления адаптивной кодовой книги повторно синхронизирует голосовой импульс в адаптивной кодовой книге.
62. Устройство по п.44, в котором первый фазоуказующий признак кадра с замаскированным стиранием включает положение импульса с максимальной амплитудой, а второй фазоуказующий признак закодированного звукового сигнала включает положение голосового сигнала.
63. Устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство содержит:
средство для оценки в декодере фазовой информации для каждого кадра кодированного звукового сигнала, который был стерт при передаче от кодера к декодеру; и
средство для проведения маскировки стирания кадра в ответ на оцененную фазовую информацию, причем средство для проведения маскировки стирания кадра содержит средство повторной синхронизации каждого кадра с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказующий признак включен в оцененную фазовую информацию.
64. Устройство для маскировки стирания кадров, вызванного стиранием кадров кодированного звукового сигнала при передаче от кодера к декодеру, и для восстановления декодера после стирания кадров, причем устройство содержит:
на стороне декодера блок оценки фазовой информации каждого кадра кодированного сигнала, который был стерт при передаче от кодера к декодеру; и
модуль маскировки стирания, на который подается оценка фазовой информации и который содержит синхронизатор, который в ответ на оцененную фазовую информацию повторно синхронизирует каждый кадр с замаскированным стиранием с соответствующим кадром кодированного звукового сигнала путем выравнивания первого фазоуказующего признака каждого кадра с замаскированным стиранием со вторым фазоуказующим признаком соответствующего кадра кодированного звукового сигнала, причем указанный второй фазоуказающий признак включен в оцененную фазовую информацию.
65. Устройство по п.64, в котором блок оценки фазовой информации оценивает, из прошлых значений основного тона, положение и знак последнего голосового импульса в каждом кадре кодированного звукового сигнала и интерполирует оцененный голосовой импульс прошлыми значениями основного тона, чтобы определить оцененные запаздывания основного тона.
66. Устройство по п.65, в котором синхронизатор определяет импульс с максимальной амплитудой и период основного тона в каждом кадре с замаскированным стиранием;
определяет смещение между периодами основного тона в каждом кадре с замаскированным стиранием и оцененными запаздываниями основного тона в соответствующем кадре кодированного звукового сигнала и
вводит/удаляет ряд выборок, соответствующих определенному смещению в каждом кадре с замаскированным стиранием, чтобы выровнять положение импульса с максимальной амплитудой в кадре с замаскированным стиранием с оцененным положением последнего голосового импульса.
67. Устройство по п.66, в котором синхронизатор, кроме того,
определяет, по меньшей мер, одну зону минимальной энергии, используя скользящее окно, и
распределяет число выборок вокруг, по меньшей мере, одной зоны минимальной энергии.
68. Устройство по п.67, в котором синхронизатор использует следующее соотношение для распределения числа выборок вокруг по меньшей мере одной зоны минимальной энергии:
для i=0, …, Nmin-1, и k=0, …, i-1 и Nmin>1,
где Nmin есть число областей с минимальной энергией и Те есть смещение между запаздываниями основного тона и периодами основного тона в кадре с замаскированным стиранием.
69. Устройство по п.68, в котором R(i) упорядочены в порядке возрастания, так что выборки добавляются/удаляются в основном в конце кадра с замаскированным стиранием.
70. Устройство по п.65, дополнительно содержащее аттенюатор для ослабления по линейному закону усиления каждого кадра с замаскированным стиранием от начала до конца кадра с замаскированным стиранием.
71. Устройство по п.70, в котором аттенюатор ослабляет усиление каждого кадра с замаскированным стиранием до α, где α есть коэффициент регулирования скорости сходимости восстановления декодера после стирания кадров.
72. Устройство по п.71, в котором коэффициент α зависит от стабильности LP-фильтра для невокализованных кадров.
73. Способ по п.72, в котором коэффициент α учитывает, кроме того, эволюцию энергии вокализованных сегментов.
74. Устройство по п.64, в котором первый фазоуказующий признак каждого кадра с замаскированным стиранием включает положение импульса с максимальной амплитудой, а второй фазоуказующий признак кодированного звукового сигнала включает положение голосового сигнала.
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Состав для обезвоживания и обессоливания нефти | 1978 |
|
SU747883A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| RU 2000102555 А, 10.01.2002 | |||
| US 5732389 A, 24.03.1998. | |||

