Область технического применения
Настоящее изобретение относится к обнаружению звуковой активности, оценке фоновых шумов и классификации звуковых сигналов, где под звуком понимается полезный сигнал. Настоящее изобретение также относится к соответствующим детектору звуковой активности, эстиматору фонового шума и классификатору звуковых сигналов.
В частности, но не исключительно:
- обнаружение звуковой активности используется при выборе кадров для кодирования с использованием технологий, оптимизированных для неактивных кадров;
- классификатор звуковых сигналов используется для распознавания речевых сигналов различных классов и музыки, что позволяет осуществлять более эффективное кодирование звуковых сигналов, т.е. кодирование, оптимизированное для сигналов невокализованной речи и стабильной вокализованной речи, а также обобщенного кодирования других звуковых сигналов;
- предложен алгоритм, использующий несколько релевантных параметров и особенностей для улучшения выбора режима кодирования и более устойчивой оценки фонового шума;
- оценка тональности используется для улучшения производительности обнаружения звуковой активности в присутствии музыкальных сигналов, а также для лучшего распознавания невокализованных звуков и музыки. Например, оценка тональности может использоваться в сверхширокополосном кодеке для принятия решения о кодировании моделью кодека сигнала с частотой выше 7 кГц.
Предпосылки изобретения
В последнее время в различных областях применения, таких как конференц-связь, мультимедиа и беспроводная связь, возрастает потребность в эффективных цифровых узкополосных и широкополосных технологиях кодирования речевого сигнала с хорошим компромиссом между субъективным качеством и скоростью передачи битовых данных (битрейтом). До последнего времени диапазон частот телефонной связи, ограниченный 200-3400 Гц, в основном использовался для приложений, кодирующих речевой сигнал (дискретизация сигнала на частоте 8 кГц). Однако широкополосные речевые приложения, в сравнении с традиционным диапазоном частот телефонной связи, обеспечивают повышенную разборчивость и естественность передачи информации. В широкополосных средствах связи входной сигнал дискретизируется на частоте 16 кГц, а диапазон кодированных частот находится в пределах 50-7000 Гц. Установлено, что этот частотный диапазон является достаточным для обеспечения хорошего качества, давая впечатление общения практически лицом к лицу. Дальнейшее улучшение качества достигается при использовании так называемых сверхширокополосных технологий, где сигнал дискретизируется на частоте 32 кГц, а диапазон кодированных частот находится в пределах 50―15000 Гц. Поскольку практически вся энергия человеческой речи находится ниже 14000 Гц, для голосовых сигналов обеспечивается качество общения лицом к лицу. Данный частотный диапазон также обеспечивает значительное улучшение качества для аудиосигналов в целом, включая музыку (широкополосный частотный диапазон эквивалентен АМ-радиовещанию, сверхширокополосный - FM-радиовещанию). Более высокий частотный диапазон используется для аудиосигналов полного диапазона 20-20000 Гц (CD-качество с дискретизацией на частоте 44,1 кГц или 48 кГц).
Кодировщик звукового сигнала преобразует звуковой сигнал (голосовой или аудиосигнал) в цифровой поток, который передается через канал связи или хранится на информационном носителе. Звуковой сигнал оцифровывается, т.е. дискретизируется и кодируется, обычно 16 битами на каждое значение. Кодировщик звука представляет данные цифровые значения в виде минимального количества битов, при котором сохраняется хорошее субъективное качество. Декодер звука оперирует с переданным или сохраненным цифровым потоком, преобразуя его обратно в звуковой сигнал.
Технология кодирования Кодовое линейное предсказание (CELP) является одной из лучших среди предложенных ранее для достижения компромисса между субъективным качеством и скоростью передачи битовых данных. Данная технология лежит в основе нескольких стандартов кодирования речи как в беспроводных, так и проводных приложениях. При кодировании методом CELP дискретизированный речевой сигнал обрабатывается в виде последовательных блоков из L значений, обычно называемых кадрами, где L - заранее заданное число, соответствующее обычно 10-30 мс. Вычисляется фильтр с линейным предсказанием (ЛП) и передается каждый кадр. Кадр из L значений разбивается на меньшие блоки, называемые подкадрами. В каждом подкадре сигнал возбуждения обычно получается из двух компонент, компоненты прошлого возбуждения и прогрессивной компоненты, возбуждения с фиксированным словарем кодов. Компонента, полученная из прошлого возбуждения, часто называется адаптивным словарем кодов или возбуждением основного тона. Параметры, характеризующие сигнал возбуждения, кодируются и передаются в декодер, где реконструированный сигнал возбуждения используется в фильтре ЛП в качестве входного.
Использование кодирования речи с зависящей от источника переменной скоростью передачи битовых данных (VBR) существенно улучшает производительность системы. В зависящем от источника VBR-кодировании кодек использует модуль классификации сигналов, а для кодирования каждого речевого кадра на основе его сущности (например, вокализованной, невокализованной, промежуточной, фонового шума) используется оптимизированная модель кодирования. Кроме того, для каждого из классов могут использоваться различные скорости передачи битовых данных. Простейший способ зависящего от источника VBR-кодирования - обнаружение активности речи (VAD) и кодирование неактивных речевых кадров (фонового шума) с очень низкой скоростью передачи битовых данных. Кроме того, в отсутствие передачи данных (устойчивого фонового шума) возможно использование прерывистой передачи (DTX). Для генерирования фоновых шумовых характеристик декодер может использовать генерацию комфортного шума (CNG). Применение VAD/DTX/CNG приводит к значительному снижению средней скорости передачи битовых данных, а также, в приложениях с коммутацией пакетов, значительно снижает количество трассируемых пакетов. Алгоритмы VAD хорошо применимы к речевым сигналам, однако в случае музыкальных сигналов они могут привести к значительным трудностям. Фрагменты музыкальных сигналов могут быть классифицированы как невокализованные сигналы и соответственно кодироваться по оптимизированной для невокализованных сигналов модели, которая чрезвычайно отрицательно влияет на качество музыки. Кроме того, некоторые фрагменты устойчивых музыкальных сигналов могут быть классифицированы как устойчивый фоновый шум, что запустит модификацию фонового шума по алгоритму VAD и приведет к снижению производительности алгоритма. Поэтому было бы полезным расширение алгоритма VAD для лучшего распознавания музыкальных сигналов. В предыдущем раскрытии данный алгоритм носил название алгоритма выявления звуковой активности (SAD), где звук мог представлять из себя речь, музыку или любой другой полезный сигнал. В настоящем раскрытии также описан способ использования обнаружения тональности для улучшения производительности алгоритма SAD для случая музыкальных сигналов.
Другой подход к кодированию речевых и аудиосигналов заключается в концепции встраиваемого кодирования, также известной как многоуровневое кодирование. В многоуровневом кодировании сигнал кодируется на первом уровне с образованием первого цифрового потока. Затем расхождение между оригинальным сигналом и кодированным сигналом первого уровня кодируется, образуя второй цифровой поток. Кодируя различие между оригинальным сигналом и кодированным сигналом со всех предшествующих уровней, можно получать новые уровни. Для передачи цифровые потоки со всех уровней соединяются. Преимуществом многоуровневого кодирования является то, что части цифрового потока (соответствующие верхним уровням) могут быть потеряны в сети (например, в результате перегрузки), однако при этом сохраняется возможность декодирования сигнала в приемнике в зависимости от количества полученных уровней. Многоуровневое кодирование также пригодно для многоадресных приложений, где кодировщик генерирует цифровой поток от всех уровней, а сеть принимает решение об отсылке разных скоростей передачи битовых данных в разные конечные точки в зависимости от доступности скорости передачи битовых данных каждого из каналов связи.
Встраиваемое или многоуровневое кодирование также может быть применимо для улучшения качества существующих широко используемых кодеков, поддерживая функциональную совместимость с этими кодеками. Добавление новых уровней к базовому уровню кодека может привести к улучшению качества и даже увеличить частотный диапазон кодированного аудиосигнала. Примером является недавно стандартизированная рекомендация сектора электросвязи МСЭ G.729.1, где основной уровень функционально совместим с широко используемым широкополосным стандартом 8 кбит/с G.729, а верхние уровни генерируют скорости передачи битовых данных до 32 кбит/с (с широкополосным сигналом, начиная от 16 кбит/с). Текущие работы по стандартизации имеют целью добавление большего количества уровней для создания сверхширокополосного кодека (частотный диапазон 14 кГц) и стереорасширений. Другой пример - рекомендация сектора электросвязи МСЭ G.718 для кодирования широкополосных сигналов 8, 12, 16, 24 и 32 кбит/с. Данный кодек также расширен для кодирования сверхширокополосных и стереосигналов на более высоких скоростях передачи битовых данных.
Требования к встраиваемым кодекам обычно заключаются в хорошем качестве речевых и аудиосигналов. Поскольку речь может кодироваться на относительно невысоких скоростях передачи битовых данных с использованием приближения на основе модели, первый уровень (или первые два уровня) кодируется (кодируются) с использованием технологий, специфичных для кодирования речи, а сигнал рассогласования для верхних уровней кодируется с использованием обобщенных технологий кодирования аудиоинформации. Это обеспечивает хорошее качество речи на низких скоростях передачи битовых данных и хорошее качество аудио при повышении скоростей передачи битовых данных. В рекомендациях G.718 и G.729.1 первые два уровня основаны на технологии ACELP (алгебраическое кодовое линейное предсказание), пригодной для кодирования речевых сигналов. На верхних уровнях для кодирования сигнала рассогласования (разницы между исходным сигналом и выходным сигналом с первых двух уровней) используется кодирование на основе преобразования, пригодное для аудиосигналов. Для преобразования сигнала рассогласования в частотную область используется хорошо известное модифицированное дискретное косинусное преобразование (MDCT). На сверхширокополосных уровнях сигналы выше 7 кГц кодируются с использованием обобщенной модели кодирования или модели тонального кодирования. Для выбора наиболее подходящей модели кодирования также может быть использовано вышеупомянутое обнаружение тональности.
Краткое описание изобретения
Согласно первой особенности настоящего изобретения, изобретение предусматривает способ оценки тональности звукового сигнала, который включает в себя вычисление текущего остаточного спектра звукового сигнала; обнаружение пиков в текущем остаточном спектре; вычисление карты корреляции между текущим остаточным спектром и предыдущим остаточным спектром для каждого обнаруженного пика; вычисление на основе вычисленной карты корреляции долгосрочной карты корреляции, являющейся признаком тональности звукового сигнала.
Согласно второй особенности настоящего изобретения, изобретение предусматривает устройство для оценки тональности звукового сигнала, которое включает в себя средства вычисления текущего остаточного спектра звукового сигнала; средства обнаружения пиков в текущем остаточном спектре; средства вычисления карты корреляции между текущим остаточным спектром и предыдущим остаточным спектром для каждого обнаруженного пика; средства вычисления на основе вычисленной карты корреляции долгосрочной карты корреляции, являющейся признаком тональности звукового сигнала.
Согласно третьей особенности настоящего изобретения, изобретение предусматривает устройство для оценки тональности звукового сигнала, которое включает в себя вычислитель текущего остаточного спектра звукового сигнала; детектор пиков в текущем остаточном спектре; вычислитель карты корреляции между текущим остаточным спектром и предыдущим остаточным спектром для каждого обнаруженного пика; вычислитель на основе вычисленной карты корреляции долгосрочной карты корреляции, являющейся признаком тональности звукового сигнала.
Вышеперечисленные цели, преимущества и особенности настоящего изобретения станут яснее при ознакомлении с нижеследующим неограничивающим описанием иллюстративного варианта осуществления изобретения, данного исключительно в качестве примера с отсылкой к прилагаемым иллюстрациям.
Краткое описание графических материалов
Фиг.1 - блок-схема части примера системы звуковой связи, включающей обнаружение звуковой активности, модификацию оценки фонового шума и классификацию звуковых сигналов.
Фиг.2 - неограничивающая иллюстрация обработки методом окна в спектральном анализе.
Фиг.3 - неограничивающая графическая иллюстрация принципа вычисления спектрального дна.
Фиг.4 - неограничивающая иллюстрация вычисления карты спектральной корреляции в текущем кадре.
Фиг.5 - пример функциональной блок-схемы алгоритма классификации сигналов.
Фиг.6 - пример дерева решений для распознавания невокализованной речи.
Подробное описание изобретения
В неограничительном иллюстративном варианте осуществления настоящего изобретения обнаружение звуковой активности (SAD) осуществляется в системе звуковой связи для классификации кратковременных кадров сигналов звука или фонового шума/тишины. Обнаружение звуковой активности основано на частотно-зависимом отношении сигнал/шум (SNR) и использует оценку энергии фонового шума на критическую полосу. Принятие решения о модификации оценки фонового шума основывается на нескольких параметрах, включающих параметры, различающие фоновый шум/тишину и музыку, и предотвращающих таким образом модификацию оценки фонового шума на музыкальных сигналах.
SAD соответствует первому этапу классификации сигналов, используемому с целью распознавания неактивных кадров для оптимизированного кодирования неактивного сигнала. На втором этапе с целью оптимизированного кодирования невокализованного сигнала распознаются невокализованные речевые кадры. Также на втором этапе, во избежание классификации музыки как невокализованного сигнала, добавляется обнаружение музыки. На третьей стадии вокализованные сигналы распознаются через дальнейшее изучение параметров кадра.
Раскрытые здесь технологии могут употребляться как с узкополосными (УП) звуковыми сигналами, дискретизированными на частоте 8000 значений/с, так и с широкополосными (ШП) звуковыми сигналами, дискретизированными на частоте 16000 значений/с, или на любой другой частоте дискретизации. Кодировщик, используемый в неограничительном иллюстративном варианте осуществления настоящего изобретения, основан на кодеках AMR-WB (широкополосный речевой кодек AMR) [AMR Wideband Speech Codec: Transcoding Functions, 3GPP Technical Specification TS 26.190 (http://www.3gpp.org)] и VMR-WB (зависимый от источника многорежимный широкополосный речевой кодек с переменной скоростью передачи битовых данных) [Source-Controlled Variable-Rate Multimode Wideband Speech Codec (VMR-WB), Service Options 62 и 63 для Spread Spectrum Systems, 3GPP2 Technical Specification C.S0052-A v1.0, апрель 2005 г. (http://www.3gpp2.org)], которые используют внутреннее преобразование дискретизации для преобразования частоты дискретизации сигнала к 12800 значений/с (функционирует в частотном диапазоне 6,4 кГц). Таким образом, технология обнаружения звуковой активности является неограничительным иллюстративным вариантом осуществления изобретения, функционирующим после преобразования к 12,8 кГц как на узкополосных, так и на широкополосных сигналах.
На фиг.1 приведена блок-схема системы звуковой связи 100 согласно неограничительному иллюстративному варианту осуществления изобретения, который включает в себя обнаружение звуковой активности.
Система звуковой связи 100 (фиг.1) включает в себя препроцессор 101. Предварительная обработка в модуле 101 может осуществляться, как описано в нижеследующем примере (фильтрация верхних частот, передискретизация, предыскажения).
Перед преобразованием частоты входной звуковой сигнал подвергается фильтрации верхних частот. В данном неограничительном иллюстративном варианте осуществления изобретения частота среза фильтра верхних частот составляет 25 Гц для ШП и 100 Гц для УП. Фильтр верхних частот выступает в качестве меры предосторожности от низкочастотных составляющих. Например, может быть использована следующая функция преобразования:
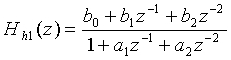
где для ШП: b 0=0,9930820, b 1 =-1,98616407, b 2=0,9930820, a 1=-1,9861162, a 2=0,9862119292; для УП: b 0=0,945976856, b 1=-1,891953712, b 2 =0,945976856, a 1=-1,889033079, a 2=0,894874345. Разумеется, фильтрация высоких частот может осуществляться и после редискретизации на 12,8 кГц.
В случае ШП, входной звуковой сигнал прореживается от 16 кГц до 12,8 кГц. Прореживание осуществляется при помощи повышающего дискретизатора, который осуществляет повышающую дискретизацию звукового сигнала на 4. Результирующий выходной сигнал затем фильтруется через фильтр низких КИХ (конечных импульсных характеристик) с частотой среза 6,4 кГц. Затем сигнал, подвергнутый фильтрации нижних частот, подвергается понижающей дискретизации на 5 при помощи подходящего понижающего дискретизатора. Задержка фильтрации на частоте дискретизации 16 кГц составляет 15 значений.
В случае УП, звуковой сигнал подвергается повышающей дискретизации от 8 кГц до 12,8 кГц. Для этой цели повышающий дискретизатор осуществляет повышающую дискретизацию звукового сигнала на 8. Результирующий звуковой сигнал фильтруется через фильтр низких КИХ с частотой среза 6,4 кГц. Затем понижающий дискретизатор осуществляет понижающую дискретизацию сигнала, подвергнутого фильтрации нижних частот, на 5. Задержка фильтрации на частоте дискретизации 8 кГц составляет 16 значений.
После преобразования дискретизации перед процессом кодирования звуковой сигнал подвергается предыскажению. В ходе предыскажения для введения предыскажений высоких частот используется фильтр верхних частот первого порядка, который образует предысказитель и использует, например, следующую функцию преобразования:
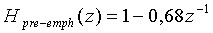 .
.
Предыскажение используется для того, чтобы улучшить производительность кодека на высоких частотах и перцепционное взвешивание в процессе минимизации рассогласования, используемой в кодировщике.
Как было описано выше, входной звуковой сигнал преобразуется к частоте дискретизации 12,8 кГц и подвергается предварительной обработке, пример которой также приведен выше. Однако раскрытая технология может таким же образом быть применена к сигналам с другими частотами дискретизации, например 8 кГц или 16 кГц, с другой предварительной обработкой или без предварительной обработки.
В неограничительном иллюстративном варианте осуществления настоящего изобретения кодировщик 109 (фиг.1), использующий обнаружение звуковой активности, функционирует на кадрах по 20 мс, содержащих 256 значений с частотой дискретизации 12,8 кГц. Кроме того, кодировщик 109 использует 10 мс предварительный вид следующего кадра для его анализа (фиг.2). Обнаружение звуковой активности следует той же структуре кадров.
Спектральный анализ согласно фиг.1 производится в анализаторе 102 спектра. В каждом кадре производится два анализа с использованием 20 мс окон с 50% перекрыванием. Принцип обработки методом окна проиллюстрирован на фиг.2. Энергия сигнала вычисляется для элементов разрешения по частоте и критических полос [J. D. Johnston, "Transform coding of audio signal using perceptual noise criteria," IEEE J. Select. Areas Commun., vol. 6, pp. 314-323, февраль 1988 г.].
Обнаружение звуковой активности (первый этап классификации сигнала) осуществляется в детекторе 103 звуковой активности с использованием оценок энергии шума, вычисленных в предыдущем кадре. Выводной сигнал детектора 103 звуковой активности представляет собой двоичную переменную, которая затем используется кодировщиком 109 и определяет кодирование текущего кадра как активного или неактивного.
Эстиматор 104 шума осуществляет нисходящую модификацию оценки шума (первый уровень оценки и модификации шума), т.е. если в критической полосе энергия кадра меньше, чем оценка энергии фонового шума, энергия оценки шума модифицируется в этой критической полосе.
В случае необходимости, к речевому сигналу прилагается шумоподавление посредством необязательного шумоподавителя 105, использующего, например, метод вычитания спектров. Пример такого шумоподавления описан в работе [M. Jelinek и R. Salami, "Noise Reduction Method for Wideband Speech Coding," in Proc. Eusipco, Vienna, Austria, сентябрь 2004 г.].
Анализ линейного предсказания (ЛП) и анализ основного тона с разомкнутой петлей осуществляются (обычно как часть алгоритма кодирования речи) ЛП-анализатором и следящим фильтром высоты тона 106. В данном неограничительном иллюстративном варианте осуществления изобретения параметры, полученные из ЛП-анализатора и следящего фильтра высоты тона 106, используются для принятия решения о модификации оценки шума в критических полосах, что производится в модуле 107. В качестве альтернативы, для принятия решения о модификации шума может использоваться детектор 103 звуковой активности. В качестве дополнительной альтернативы, функции, осуществляемые ЛП-анализатором и следящим фильтром высоты тона 106, могут являться составляющими алгоритма кодирования звука.
Перед модификацией оценок энергии шума в модуле 107 для предотвращения ложной модификации активных музыкальных сигналов осуществляется обнаружение музыки. Обнаружение музыки использует спектральные параметры, вычисленные анализатором 102 спектра.
В конечном итоге, оценки энергии шума модифицируются в модуле 107 (второй уровень оценки и модификации шума). Для принятия решения о модификации оценок энергии шума модуль 107 использует все доступные параметры, вычисленные в модулях 102-106.
В классификаторе 108 сигналов звуковой сигнал дополнительно классифицируется как невокализованный, устойчиво вокализованный или обобщенный. Для обеспечения принятия этого решения вычисляется несколько параметров. Режим кодирования звукового сигнала текущего кадра в классификаторе сигналов выбирается для наилучшего представления класса сигнала, который кодируется.
Кодировщик 109 сигнала осуществляет кодирование звукового сигнала на основе режима кодирования, который выбирается в классификаторе 108 сигналов. В других приложениях классификатором 108 сигналов может выступать автоматическая система распознавания речи.
Спектральный анализ
Спектральный анализ осуществляется спектральным анализатором 102 (фиг.1).
Для осуществления спектрального анализа и оценки энергии спектра используется преобразование Фурье. Спектральный анализ каждого кадра осуществляется дважды с использованием быстрого преобразование Фурье (БПФ) по 256 точкам с 50% перекрыванием (как показано на фиг.2). Окна анализа расположены таким образом, чтобы задействовать весь предварительный вид. Начало первого окна находится в начале текущего кадра кодировщика. Второе окно находится на 128 значений дальше. Для взвешивания входного звукового сигнала для спектрального анализа используется окно квадратных корней Хеннинга (которое эквивалентно окну синусов). Это окно особенно хорошо подходит для методов сложения с перекрытием (так, именно этот спектральный анализ используется в шумоподавлении, основанном на вычитании спектров и анализе/синтезе сложения с перекрытием). Окно квадратных корней Хеннинга задано следующим образом:
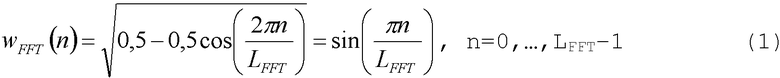
где L FFT=256 ― объем БПФ. Поскольку данное окно симметрично, вычисляется и сохраняется только половина окна (от 0 до L FFT/2).
Сигналы, обработанные методом окна, для обоих спектральных анализов (первого и второго спектрального анализа) получены с использованием следующих соотношений:
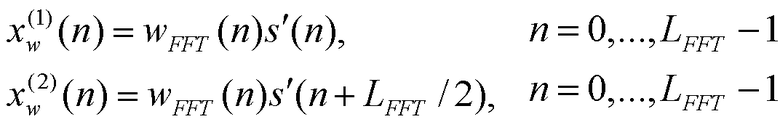
где s'(0) - первое значение в текущем кадре. В неограничивающем иллюстративном примере осуществления настоящего изобретения начало первого окна расположено в начале текущего кадра. Второе окно расположено 128 значениями дальше.
БПФ осуществляется на обоих сигналах, обработанных методом окна, давая для каждого кадра два набора спектральных параметров:
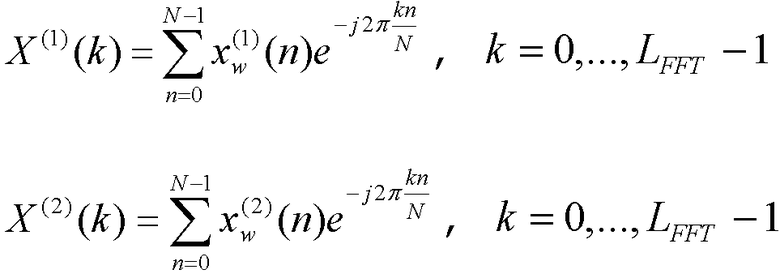
где N=L FFT.
БПФ дает вещественную и мнимую части спектра, обозначенные как X R (k), k=0-128, и X I (k), k=1-127. X R (0) соответствует спектру при 0 Гц (постоянная составляющая), X R (128) соответствует спектру при 6400 Гц. В этих точках спектр имеет только вещественные значения.
Спектр, полученный после анализа БПФ, разделяется на критические полосы с использованием интервалов, имеющих следующие верхние пределы [M. Jelinek и R. Salami, "Noise Reduction Method for Wideband Speech Coding," in Proc. Eusipco, Vienna, Austria, сентябрь 2004 г.] (20 полос в диапазоне частот 0-6400 Гц):
Критические полосы = {100,0, 200,0, 300,0, 400,0, 510,0, 630,0, 770,0, 920,0, 1080,0, 1270,0, 1480,0, 1720,0, 2000,0, 2320,0, 2700.0, 3150,0, 3700,0, 4400,0, 5300,0, 6350,0} Гц.
БПФ на 256 точках приводит к разрешающей способности по частоте 50 Гц (6400/128). Поэтому после пропуска постоянной составляющей спектра количество элементов разрешения по частоте для каждой критической полосы M CB={2, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4, 5, 6, 6, 8, 9, 11, 14, 18, 21} соответственно.
Средняя энергия в критической полосе вычисляется по следующему соотношению:
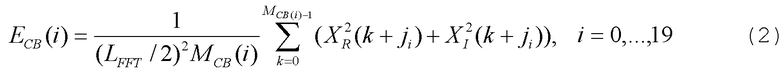
где XR(k) и XI(k) - соответственно, вещественная и мнимая части k элемента разрешения по частоте, а ji - индекс первого элемента разрешения по частоте в i критической полосе, который задан как j i={1, 3, 5, 7, 9, 11, 13, 16, 19, 22, 26, 30, 35, 41, 47, 55, 64, 75, 89, 107}.
Также спектральный анализатор 102 вычисляет нормированную энергию на элемент разрешения по частоте E BIN (k) в интервале 0-6400 Гц, используя для этого соотношение
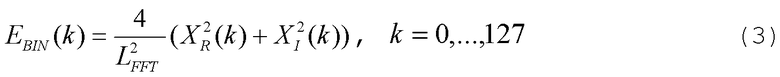
Кроме того, энергии спектра на элемент разрешения по частоте в обоих анализах объединяются, давая среднюю log-энергию спектра (в децибелах), т.е.
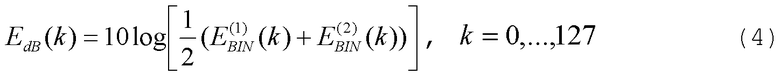
где верхние индексы (1) и (2) используются для указания первого и второго спектральных анализов соответственно.
В конечном итоге, анализатор 102 спектра вычисляет среднюю полную энергию для обоих, первого и второго, спектральных анализов в 20 мс кадре путем добавления средних энергий критических полос E CB. Таким образом, энергия спектра для определенного спектрального анализа вычисляется по следующему соотношению:
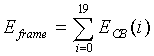
 (5)
(5)
а полная энергия кадра вычисляется как среднее энергий спектра для первого и второго спектральных анализов кадра:
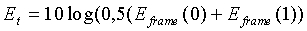 , дБ
, дБ
 (6)
(6)
Выводные параметры анализатора 102 спектра - средняя энергия на критическую полосу, энергия на элемент разрешения по частоте и полная энергия - используются в детекторе 103 звуковой активности. Средняя log-энергия спектра используется при обнаружении музыки.
В узкополосных вводных сигналах, дискретизированных на 8000 значений/с, после преобразования дискретизации в 12800 значений/с, содержимое на обоих концах спектра отсутствует, поэтому при вычислении релевантных параметров первая низкочастотная критическая полоса и три последние высокочастотные критические полосы не учитываются (учитываются только полосы i=1―16), что, однако, не оказывает влияния на уравнения (3) и (4).
Обнаружение звуковой активности (SAD)
Обнаружение звуковой активности осуществляется при помощи детектора 103 звуковой активности на основе отношения сигнал/шум (фиг.1).
Спектральный анализ, описанный выше, осуществляется анализатором 102 дважды для каждого кадра. Пусть 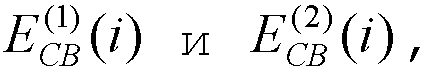 вычисленные по уравнению (2), обозначают информацию об энергии на критическую полосу в первом и втором спектральных анализах соответственно. Средняя энергия на критическую полосу для всего кадра и части предыдущего кадра вычисляется по следующему соотношению:
вычисленные по уравнению (2), обозначают информацию об энергии на критическую полосу в первом и втором спектральных анализах соответственно. Средняя энергия на критическую полосу для всего кадра и части предыдущего кадра вычисляется по следующему соотношению:
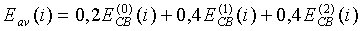

 (7)
(7)
где 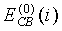 - информация об энергии на критическую полосу из второго спектрального анализа для предыдущего кадра. Тогда отношение сигнал/шум для каждой критической полосы вычисляется по следующему соотношению:
- информация об энергии на критическую полосу из второго спектрального анализа для предыдущего кадра. Тогда отношение сигнал/шум для каждой критической полосы вычисляется по следующему соотношению:
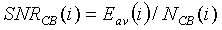 с ограничением
с ограничением 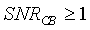 (8)
(8)
где 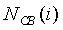 - оценка энергии шума на критическую полосу, как будет разъяснено ниже. Тогда среднее отношение сигнал/шум для каждого кадра вычисляется следующим образом:
- оценка энергии шума на критическую полосу, как будет разъяснено ниже. Тогда среднее отношение сигнал/шум для каждого кадра вычисляется следующим образом:
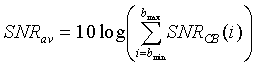
 (9)
(9)
где 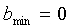 и
и 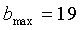 для широкополосных сигналов,
для широкополосных сигналов, 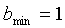 и
и 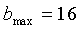 - для узкополосных сигналов.
- для узкополосных сигналов.
Звуковая активность обнаруживается путем сопоставления средних отношений сигнал/шум для каждого кадра с определенным порогом, являющимся функцией долгосрочного отношения сигнал/шум, которое задается следующим соотношением:
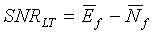
 (10)
(10)
где 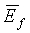 и
и 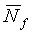 вычисляются по уравнениям (13) и (14) соответственно, как будет описано ниже. Исходное значение
вычисляются по уравнениям (13) и (14) соответственно, как будет описано ниже. Исходное значение 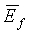 составляет 45 дБ.
составляет 45 дБ.
Порог является кусочно-линейной функцией долгосрочного отношения сигнал/шум. Используются две функции, одна из них описывает четкий речевой сигнал, а вторая - речевой сигнал, искаженный шумами.
Для широкополосных сигналов, если SNR LT<35 (речевой сигнал, искаженный шумами), пороговая величина равна
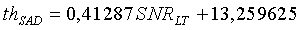
иначе (четкий речевой сигнал):
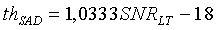
Для узкополосных сигналов, если SNR LT<20 (речевой сигнал, искаженный шумами), пороговая величина равна
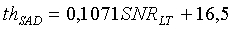
иначе (четкий речевой сигнал)
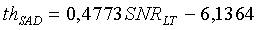
Кроме того, в алгоритм принятия решения об обнаружении звуковой активности (SAD) для предотвращения частых переключений в конце активного звукового периода добавлен гистерезис. Стратегия гистерезиса отличается для широкополосных и узкополосных сигналов и вступает в действие только в случае сигнала, искаженного шумами.
Для широкополосных сигналов стратегия гистерезиса применяется в тех случаях, когда кадр находится в "периоде затягивания", длительность которого изменяется в зависимости от долгосрочного отношения сигнал/шум:
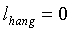 , если
, если 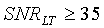
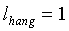 , если
, если 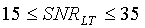
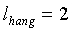 , если
, если 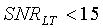
Период затягивания начинается в первом неактивном звуковом кадре после трех (3) последовательных активных звуковых кадров. Его назначение заключается в форсировании каждого неактивного кадра в течение периода затягивания как активного кадра. Принятие решения SAD будет разъяснено ниже.
Для узкополосных сигналов стратегия гистерезиса заключается в снижении порога принятия решения SAD
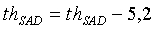 , если
, если 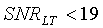
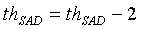 , если
, если 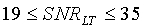
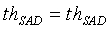 , если
, если 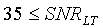
Таким образом, для сигналов, искаженных шумами с низким отношением сигнал/шум, пороговое значение становится ниже, отдавая предпочтение при принятии решения активным сигналам. Для узкополосных сигналов затягивание отсутствует.
В конечном итоге детектор 103 звуковой активности имеет два выходных сигнала - флаг SAD и локальный флаг SAD. Если обнаруживается активный сигнал, обоим флагам присваивается значение 1, иначе - 0. Кроме того, флагу SAD присваивается значение 1 в периоде затягивания. Решение SAD принимается путем сопоставления среднего отношения сигнал/шум для каждого кадра с порогом принятия решения SAD (например, при помощи компаратора):
 если
если 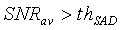
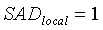
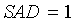
иначе
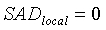
если в периоде затягивания
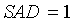
иначе
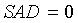
конец
конец.
Первый уровень оценки и модификации шума
Эстиматор 104 шума, показанный на фиг.1, вычисляет полную энергию шума, относительную энергию кадра, а также модифицирует долгосрочную среднюю энергию шума, долгосрочную среднюю энергию кадра, среднюю энергию на критическую полосу и коэффициент коррекции шума. Кроме того, эстиматор 104 шума осуществляет присвоение исходных значений и нисходящую модификацию энергии шума.
Полная энергия шума для каждого кадра вычисляется по следующему соотношению:
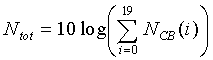
 (11)
(11)
где 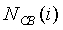 - оценка энергии шума на критическую полосу.
- оценка энергии шума на критическую полосу.
Относительная энергия кадра определяется по разности между энергией кадра в дБ и долгосрочной средней энергией. Относительная энергия кадра вычисляется по следующему соотношению:
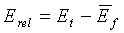
 (12)
(12)
где E t определяется из уравнения (6).
Долгосрочная средняя энергия шума или долгосрочная средняя энергия кадра модифицируется в каждом кадре. В случае активных кадров сигнала (флаг SAD=1), долгосрочная средняя энергия кадра модифицируется с использованием соотношения
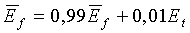 (13)
(13)
с начальным значением 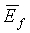 =45 дБ.
=45 дБ.
Для неактивных речевых кадров (флаг SAD=0) долгосрочная средняя энергия шума модифицируется следующим образом:
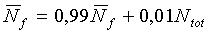 (14)
(14)
Начальное значение 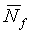 задается как эквивалентное
задается как эквивалентное 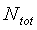 для первых четырех кадров. Кроме того, в первых четырех (4) кадрах величина
для первых четырех кадров. Кроме того, в первых четырех (4) кадрах величина 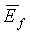 ограничена
ограничена 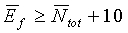 .
.
Энергия кадра на критическую полосу вычисляется для всего кадра путем усреднения энергий из первого и второго спектральных анализов кадра с использованием следующего соотношения:
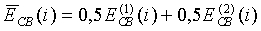 (15)
(15)
Энергии шума 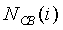 присваивается начальное значение 0,03.
присваивается начальное значение 0,03.
На этом этапе, по причине того, что энергия меньше, чем энергия фонового шума, для критических полос осуществляется только нисходящая модификация энергии шума. Вначале вычисляется промежуточная модифицированная энергия шума:
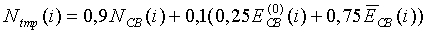 (18)
(18)
где 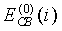 - энергия на критическую полосу, соответствующую второму спектральному анализу из предыдущего кадра.
- энергия на критическую полосу, соответствующую второму спектральному анализу из предыдущего кадра.
Тогда для i=0 до 19, если 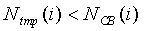 , тогда
, тогда 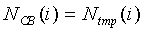 .
.
Второй уровень оценки и модификации шума осуществляется позднее путем приравнивания в случае, если кадр признан неактивным.
Второй уровень оценки и модификации шума
Модуль 107 параметрического обнаружения звуковой активности и оценки и модификации шума модифицирует оценки энергии шума на критическую полосу для использования в детекторе 103 звуковой активности в следующем кадре. Модификация осуществляется во время периодов неактивного сигнала. Однако осуществленное выше принятие решения SAD, основанное на отношении сигнал/шум на критическую полосу, для определения, модифицированы ли оценки энергии шума, не используется. На основе других параметров, более независимых, чем отношение сигнал/шум на критическую полосу, принимается другое решение. Параметры, используемые для модификации оценок энергии шума и имеющие низкую чувствительность к изменениям уровня шума: устойчивость основного тона, нестационарность сигнала, вокализованность и отношение между ЛП энергий остаточного рассогласования второго и шестнадцатого порядков. Принятие решения о модификации оценок энергии шума оптимизировано для речевых сигналов. Для улучшения обнаружения активных музыкальных сигналов используются другие параметры: спектральная разнородность, комплементарная нестационарность, характер шума и тональная устойчивость. Обнаружение музыки подробно описано в нижеследующем описании.
Причина, по которой принятие решения SAD не используется для модификации оценок энергии шума, заключается в необходимости придания оценке шума надежности по отношению к быстро изменяющимся уровням шума. Если для модификации оценок энергии шума используется принятие решения SAD, внезапное изменение уровня шума приведет к увеличению отношения сигнал/шум, даже для неактивных кадров сигнала, предотвращая модификацию оценок энергии шума, что, в свою очередь, будет поддерживать отношение сигнал/шум на высоком уровне в последующих кадрах и т.д. В результате этого модификация блокируется и для адаптации шума возникает необходимость в другой логике.
В неограничительном иллюстративном варианте осуществления настоящего изобретения для вычисления трех оценок основного тона с разомкнутой петлей на кадр, соответствующих первой половине кадра, второй половине кадра и предварительному виду (d 0, d 1 и d 2 соответственно), в анализаторе ЛП и следящем фильтре высоты тона 106 (фиг.1) осуществляется анализ основного тона с разомкнутой петлей на кадр. Данная процедура хорошо известна любому специалисту в данной области и в настоящем раскрытии подробно описана не будет (см., например, VMR-WB [Source-Controlled Variable-Rate Multimode Wideband Speech Codec (VMR-WB), Service Options 62 и 63 для Spread Spectrum Systems, 3GPP2 Technical Specification C.S0052-A v1.0, апрель 2005 г. (http://www.3gpp2.org)]). Модуль анализатора ЛП и следящего фильтра высоты тона 106 вычисляет счетчик устойчивости основного тона по соотношению
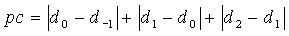 (19)
(19)
где 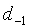 - запаздывание второй половины кадра для предыдущего кадра. При запаздываниях основного тона, превышающих 122, модуль анализатора ЛП и следящего фильтра высоты тона 106 устанавливает равенство d
2=d
1. Таким образом, для подобных запаздываний значение рс в уравнении (19) умножается на 3/2 для компенсации недостающего третьего члена уравнения. Устойчивость основного тона является истиной, если значение рс меньше 14. Кроме того, для кадров с низкой вокализованностью значение рс приравнивается 14 для обозначения неустойчивости основного тона. Более подробно:
- запаздывание второй половины кадра для предыдущего кадра. При запаздываниях основного тона, превышающих 122, модуль анализатора ЛП и следящего фильтра высоты тона 106 устанавливает равенство d
2=d
1. Таким образом, для подобных запаздываний значение рс в уравнении (19) умножается на 3/2 для компенсации недостающего третьего члена уравнения. Устойчивость основного тона является истиной, если значение рс меньше 14. Кроме того, для кадров с низкой вокализованностью значение рс приравнивается 14 для обозначения неустойчивости основного тона. Более подробно:
если 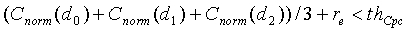 , тогда pc=14 (20),
, тогда pc=14 (20),
где 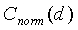 - нормированная грубая корреляция,
- нормированная грубая корреляция, 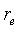 - необязательная поправка к нормированной корреляции, вводимая для компенсации снижения нормированной корреляции в присутствии фонового шума. Порог вокализованности
- необязательная поправка к нормированной корреляции, вводимая для компенсации снижения нормированной корреляции в присутствии фонового шума. Порог вокализованности 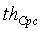 = 0,52 для ШП,
= 0,52 для ШП, 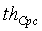 = 0,65 для УП. Поправочный коэффициент вычисляется по следующему соотношению:
= 0,65 для УП. Поправочный коэффициент вычисляется по следующему соотношению:
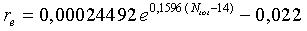
где 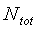 - полная энергия шума на кадр, вычисленная по уравнению (11).
- полная энергия шума на кадр, вычисленная по уравнению (11).
Нормированная грубая корреляция вычисляется на основе децимированного взвешенного звукового сигнала 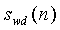 с использованием следующего соотношения:
с использованием следующего соотношения:
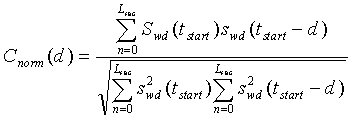
где пределы суммирования сами зависят от задержки. Взвешенный сигнал 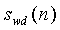 тот же, что и в анализе основного тона с разомкнутой петлей, и задается путем фильтрации предварительно обработанного в препроцессоре 101 входного звукового сигнала через взвешивающий фильтр в форме
тот же, что и в анализе основного тона с разомкнутой петлей, и задается путем фильтрации предварительно обработанного в препроцессоре 101 входного звукового сигнала через взвешивающий фильтр в форме 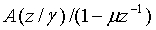 . Взвешенный сигнал
. Взвешенный сигнал 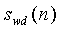 децимируется на 2, а пределы суммирования задаются следующим образом:
децимируется на 2, а пределы суммирования задаются следующим образом:
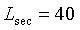 для
для 
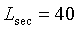 для
для 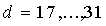
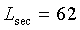 для
для 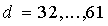
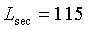 для
для 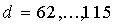
Эти отрезки гарантируют, что длина корреляционного вектора включает в себя, по меньшей мере, один период основного тона, что помогает получить надежное обнаружение основного тона с разомкнутой петлей. Моменты времени 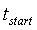 относятся к началу текущего кадра и задаются следующим образом:
относятся к началу текущего кадра и задаются следующим образом:
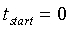 для первой половины кадра,
для первой половины кадра,
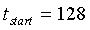 для второй половины кадра,
для второй половины кадра,
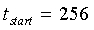 для предварительного вида
для предварительного вида
на частоте дискретизации 12,8 кГц.
Модуль 107 параметрического обнаружения звуковой активности и оценки и модификации шумов осуществляет оценку нестационарности сигнала на основе частного из отношения между энергией на критическую полосу и средней долгосрочной энергией на критическую полосу.
Средняя долгосрочная энергия на критическую полосу модифицируется согласно соотношению
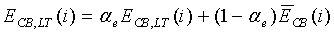 , для
, для 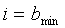 до
до 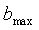 (21)
(21)
где 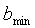 = 0,
= 0, 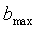 =19 для широкополосных сигналов,
=19 для широкополосных сигналов, 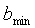 =1,
=1, 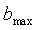 =16 для узкополосных сигналов,
=16 для узкополосных сигналов, 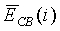 - энергия кадра на критическую полосу, определяемая по уравнению (15). Коэффициент модернизации
- энергия кадра на критическую полосу, определяемая по уравнению (15). Коэффициент модернизации 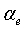 является линейной функцией полной энергии кадра, определяемой по уравнению (6), и задается следующим образом:
является линейной функцией полной энергии кадра, определяемой по уравнению (6), и задается следующим образом:
для широкополосных сигналов: 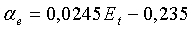 в пределах
в пределах 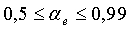 ;
;
для узкополосных сигналов: 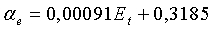 в пределах
в пределах 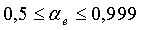 .
.
E t задается уравнением (6).
Нестационарность кадра задается частным от отношения между энергией кадра и средней долгосрочной энергией на критическую полосу. Подробнее:
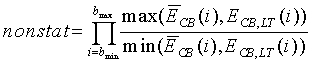 (22)
(22)
Затем модуль 107 параметрического обнаружения звуковой активности и оценки и модификации шумов вырабатывает коэффициент вокализованности для модификации шума, используя следующее соотношение:
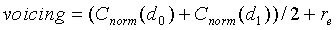 (23)
(23)
В конечном итоге, модуль 107 параметрического обнаружения звуковой активности и оценки и модификации шумов вычисляет отношение между ЛП остаточных энергий после анализов ЛП второго и шестнадцатого порядков по соотношению
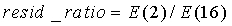 (24)
(24)
где E(2)и E(16) - ЛП остаточных энергии после ЛП анализов второго и шестнадцатого порядков соответственно, вычисленные в ЛП-анализаторе и следящем фильтре высоты тона 106 с использованием рекурсии Левинсона-Дарбина - процедуры, которая хорошо известна специалистам в данной области. Данное отношение отражает тот факт, что для представления огибающей спектра сигнала для речевого сигнала, как правило, необходимо ЛП более высокого порядка, чем для шума. Иными словами, для шума следует ожидать меньшей величины различия между E(2) и E(16), чем для активного речевого сигнала.
Принятие в модуле 107 параметрического обнаружения звуковой активности и оценки и модификации шумов решения о модификации осуществляется на основе переменной noise_update, которой присвоено начальное значение 6, уменьшаемое до 1, если обнаружен неактивный кадр, или увеличиваемое на 2, если обнаружен активный кадр. Переменная noise_update также ограничена значениями 0 и 6. Оценки энергии шума модифицируются только в случае, если noise_update=0.
Значение переменной noise_update модифицируется для каждого кадра следующим образом:
если 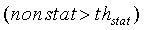 ИЛИ
ИЛИ 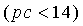 ИЛИ
ИЛИ 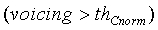 ИЛИ
ИЛИ 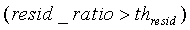
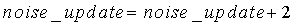
иначе
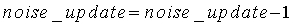 ,
,
где для широкополосных сигналов 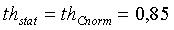 и
и 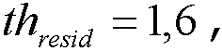 а для узкополосных сигналов
а для узкополосных сигналов 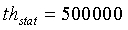 ,
, 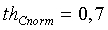 и
и 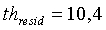 .
.
Иными словами, кадры признаются неактивными для модификации шума, когда
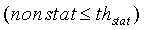 И
И 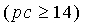 И
И 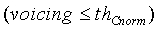 И
И 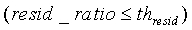 ,
,
а перед модификацией шума происходит затягивание протяженностью в 6 кадров.
Тогда, если noise_update=0, то
для 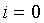 до 19
до 19 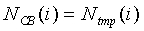 ,
,
где 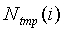 - промежуточно модифицированная энергия шума, уже вычисленная по уравнению (18).
- промежуточно модифицированная энергия шума, уже вычисленная по уравнению (18).
Улучшение обнаружения шума для музыкальных сигналов
Оценка шума, описанная выше, по причине оптимизации для обнаружения, главным образом, речевых сигналов, имеет ограничения для определенных музыкальных сигналов, таких как фортепианные концерты, инструментальная рок- и поп-музыка. Для улучшения обнаружения музыкальных сигналов в целом модуль 107 параметрического обнаружения звуковой активности и оценки и модификации шумов использует другие параметры или технологии в дополнение к существующим. Эти параметры и технологии включают в себя, как было указано выше, спектральную разнородность, комплементарную нестационарность, характер шума и тональную устойчивость, которые вычисляются вычислителем спектральной разнородности, вычислителем комплементарной нестационарности, вычислителем характера шума и эстиматором тональности соответственно, которые подробно описаны ниже.
Спектральная разнородность
Спектральная разнородность предоставляет информацию о существенных изменениях сигнала в частотной области. Изменения отслеживаются в критических полосах путем сопоставления энергий первого спектрального анализа текущего кадра и второго спектрального анализа за два кадра до него. Энергия в критической полосе первого спектрального анализа текущего кадра обозначается как 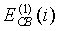 , а энергия в той же критической полосе, вычисленная за два кадра до текущего, как
, а энергия в той же критической полосе, вычисленная за два кадра до текущего, как 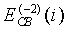 . Обе эти энергии имеют начальное значение 0,0001. Затем для всех критических полос выше 9 вычисляются максимумы и минимумы двух энергий:
. Обе эти энергии имеют начальное значение 0,0001. Затем для всех критических полос выше 9 вычисляются максимумы и минимумы двух энергий:
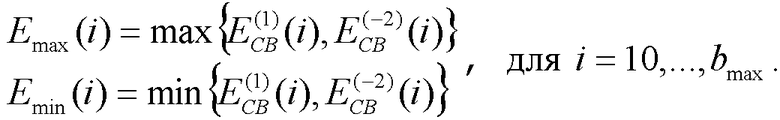
Затем в одной и той же критической полосе вычисляется отношение максимальной энергии к минимальной:
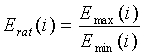 , для
, для 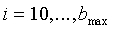 .
.
В конечном итоге, модуль 107 параметрического обнаружения звуковой активности и оценки и модификации шумов вычисляет параметр спектральной разнородности как нормированную взвешенную сумму отношений с весовым коэффициентом, являющимся максимальной энергией 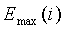 . Таким образом, параметр спектральной разнородности задается следующим соотношением:
. Таким образом, параметр спектральной разнородности задается следующим соотношением:
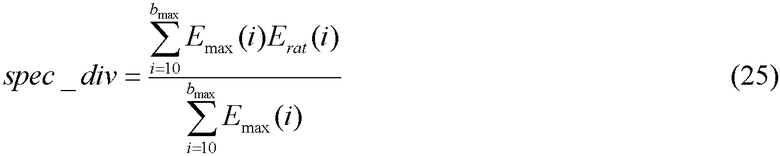
Параметр spec_div используется при принятии окончательного решения о музыкальной активности и модификации энергии шума. Кроме того, параметр spec_div используется в качестве вспомогательного для вычисления параметра комплементарной нестационарности, которое описано ниже.
Комплементарная нестационарность
Введение параметра комплементарной нестационарности обосновано тем фактом, что параметр нестационарности, определяемый по уравнению (22), отказывает в тех случаях, когда вслед за медленным уменьшением энергии в музыкальном сигнале происходит ее резкая атака. В этом случае средняя долгосрочная энергия на критическую полосу 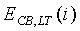 , определяемая по уравнению (21), медленно увеличивается в ходе атаки, в то время как энергия кадра на критическую полосу, определяемая по уравнению (15), медленно уменьшается. В некотором кадре после атаки эти две величины энергии встречаются, и параметр nonstat приобретает небольшое значение, указывающее на отсутствие активного сигнала, что приводит к ложной модификации шума, а затем и к принятию ложного решения SAD.
, определяемая по уравнению (21), медленно увеличивается в ходе атаки, в то время как энергия кадра на критическую полосу, определяемая по уравнению (15), медленно уменьшается. В некотором кадре после атаки эти две величины энергии встречаются, и параметр nonstat приобретает небольшое значение, указывающее на отсутствие активного сигнала, что приводит к ложной модификации шума, а затем и к принятию ложного решения SAD.
Для преодоления этой трудности вычисляется альтернативная средняя долгосрочная энергия на критическую полосу:
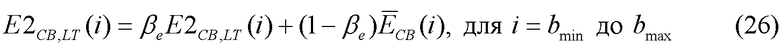
Переменной 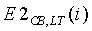 присваивается начальное значение 0,03 для всех i. Уравнение (26) имеет очень близкое сходство с уравнением (21) за одним исключением: коэффициент модификации
присваивается начальное значение 0,03 для всех i. Уравнение (26) имеет очень близкое сходство с уравнением (21) за одним исключением: коэффициент модификации 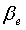 представлен как
представлен как
Если 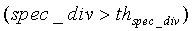
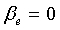
иначе
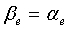
конец,
где 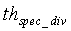 =5. При обнаружении энергетической атаки (spec_div>5) альтернативной средней долгосрочной энергии сразу же присваивается значение средней энергии кадра, т.е.
=5. При обнаружении энергетической атаки (spec_div>5) альтернативной средней долгосрочной энергии сразу же присваивается значение средней энергии кадра, т.е. 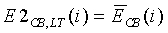 . Иначе, альтернативная средняя долгосрочная энергия модифицируется так же, как в случае обычной нестационарности, т.е. с использованием экспоненциального фильтра с коэффициентом модификации
. Иначе, альтернативная средняя долгосрочная энергия модифицируется так же, как в случае обычной нестационарности, т.е. с использованием экспоненциального фильтра с коэффициентом модификации 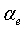 . Параметр комплементарной нестационарности вычисляется так же, как и параметр nonstat, но с использованием
. Параметр комплементарной нестационарности вычисляется так же, как и параметр nonstat, но с использованием 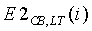 , т.е.
, т.е.
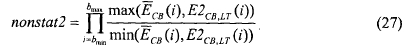
Параметр комплементарной нестационарности nonstat2 может отказать через несколько кадров после энергетической атаки, но не должен отказывать в проходах, характеризующихся медленно возрастающей энергией. Поскольку параметр nonstat хорошо работает во время энергетических атак и на нескольких кадрах после них, логическое разделение nonstat и nonstat2 решает проблему обнаружения неактивного сигнала на определенных музыкальных сигналах. Однако разделение применяется только в проходах, которые "вероятно активны". Правдоподобие вычисляется следующим образом:
если 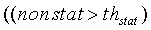 ИЛИ
ИЛИ 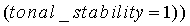
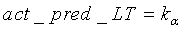
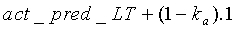
иначе
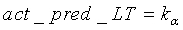
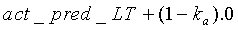
конец.
Коэффициенту 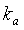 присваивается значение 0,99. Параметр act_pred_LT, приобретающий значения в интервале <0:1>, можно интрепретировать как предсказатель активности: если он близок к 1, сигнал с большой вероятностью активен, если близок к 0, сигнал с большой вероятностью не активен. Параметр act_pred_LT имеет исходное значение 1. При соблюдении вышеописанного условия tonal_stability - это двоичный параметр, используемый для обнаружения устойчивого тонального сигнала. Параметр tonal_stability описан ниже.
присваивается значение 0,99. Параметр act_pred_LT, приобретающий значения в интервале <0:1>, можно интрепретировать как предсказатель активности: если он близок к 1, сигнал с большой вероятностью активен, если близок к 0, сигнал с большой вероятностью не активен. Параметр act_pred_LT имеет исходное значение 1. При соблюдении вышеописанного условия tonal_stability - это двоичный параметр, используемый для обнаружения устойчивого тонального сигнала. Параметр tonal_stability описан ниже.
Параметр nonstat2 принимается во внимание (отдельно от nonstat) в модификации энергии, только если act_pred_LT превышает определенный порог, которому присвоено значение 0,8. Логика модификации энергии шума подробно разъясняется в конце данного раздела.
Характер шума
Характер шума представляет собой еще один параметр, используемый для обнаружения определенных музыкальных сигналов, напоминающих шум, таких как звуки тарелок и низкочастотных барабанов. Этот параметр определяется из следующего соотношения:
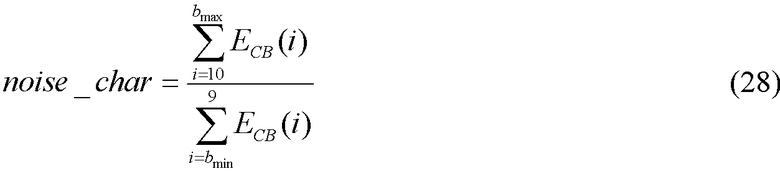
Параметр noise_char вычисляется только для кадров, спектральный состав которых содержит, по меньшей мере, минимальную энергию, что выполняется в том случае, когда значения числителя и знаменателя в уравнении (28) превышают 100. Значение параметра noise_char ограничено сверху 10, а его долгосрочное значение модифицируется при помощи следующего соотношения:
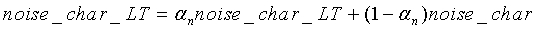 (29)
(29)
Начальное значение noise_char_LT=0, а αn присваивается значение 0,9. Параметр noise_char_LT используется в принятии решения о модификации энергии шума, которое разъяснено в конце данного раздела.
Тональная устойчивость
Тональная устойчивость является последним параметром, используемым для предотвращения ложной модификации оценок энергии шума. Также тональная устойчивость используется для предотвращения признания некоторых музыкальных сегментов невокализованными кадрами. Тональная устойчивость используется в дальнейшем во встроенном сверхширокополосном кодеке для принятия решения о выборе модели кодирования при кодировании сигнала с частотой более 7 кГц. Обнаружение тональной устойчивости использует тональную природу музыкальных сигналов. В типичном музыкальном сигнале присутствуют тона, которые сохраняют устойчивость в течение нескольких последовательных кадров. Для использования этой особенности необходимо отследить положения и формы интенсивных пиков в спектре, поскольку они могут соответствовать тонам. Обнаружение тональной устойчивости основано на анализе корреляций между спектральными пиками в текущем кадре и следующем кадре. Вводными данными является средний низкоэнергетический спектр, определяемый уравнением (4). Количество спектральных элементов разрешения обозначается как 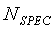 (элемент разрешения 0 - это постоянная составляющая,
(элемент разрешения 0 - это постоянная составляющая, 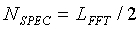 ). В настоящем раскрытии термин "спектр" относится к среднему низкоэнергетическому спектру, определяемому уравнением (4).
). В настоящем раскрытии термин "спектр" относится к среднему низкоэнергетическому спектру, определяемому уравнением (4).
Обнаружение тональной устойчивости осуществляется в три этапа. Для обнаружения тональной устойчивости используется вычислитель текущего остаточного спектра, детектор пиков в текущем остаточном спектре и вычислитель карты корреляции и долгосрочной карты корреляции, которые будут описаны ниже.
На первом этапе отыскиваются индексы локальных минимумов (например, при помощи устройства обнаружения спектральных минимумов) в цикле, описываемом нижеследующей формулой, и сохраняются в буфере i min, описываемом следующим образом:
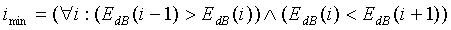 ,
, 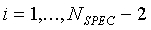 (30),
(30),
где символ 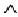 означает логическое И.
означает логическое И.
В уравнении (30) 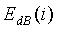 обозначает средний низкоэнергетический спектр, вычисляемый по уравнению (4). Первый индекс
обозначает средний низкоэнергетический спектр, вычисляемый по уравнению (4). Первый индекс 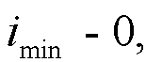 если
если 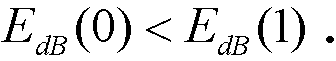 Соответственно, последний индекс
Соответственно, последний индекс 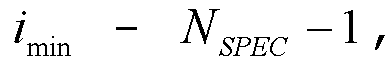 если
если 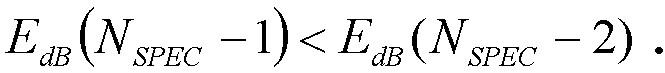 Обнаруженное количество минимумов обозначим как N
min.
Обнаруженное количество минимумов обозначим как N
min.
Второй этап заключается в вычислении спектрального дна (например, при помощи вычислителя спектрального дна) и его вычитании из спектра (например, при помощи подходящего вычитателя). Спектральное дно представляет собой кусочно-линейную функцию, которая проходит через обнаруженные локальные минимумы. Каждый линейный участок между двумя последовательными минимумами 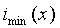 и
и 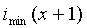 можно описать как
можно описать как

где k - наклон линии, 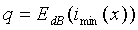 . Наклон k можно вычислить по следующему соотношению:
. Наклон k можно вычислить по следующему соотношению:
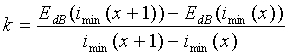 .
.
Таким образом, спектральное дно представляет собой логическую связь всех участков:
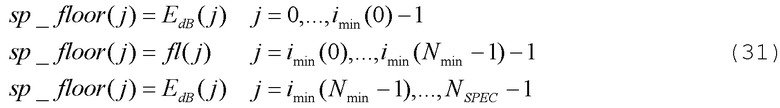
Начальные элементы разрешения до  и конечные элементы разрешения от
и конечные элементы разрешения от  спектрального дна устанавливаются в спектре сами. В конечном итоге, спектральное дно вычитается из спектра с использованием следующего соотношения:
спектрального дна устанавливаются в спектре сами. В конечном итоге, спектральное дно вычитается из спектра с использованием следующего соотношения:
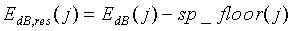 ,
, 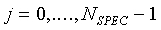 (32)
(32)
а результат называется остаточным спектром. Вычисление спектрального дна проиллюстрировано на фиг.3.
На третьем этапе из остаточного спектра текущего и предыдущего кадров вычисляется карта корреляции и долгосрочная карта корреляции, что также является кусочной операцией. Карта корреляции вычисляется пик за пиком до достижения минимума, разграничивающего пики. В данном раскрытии термин "пик" используется для обозначения участка, находящегося между двумя минимумами остаточного спектра 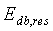 .
.
Обозначим остаточный спектр предыдущего кадра как 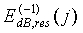 . Для каждого пика в текущем остаточном спектре вычисляется нормированная корреляция с формой, которая в предыдущем остаточном спектре соответствует положению этого пика. Если сигнал устойчив, пики от кадра к кадру не должны существенно перемещаться, а их положение и форма должны быть приблизительно одинаковыми. Таким образом, операция корреляции принимает во внимание все индексы (элементы разрешения) конкретного пика, которые определяются двумя последовательными минимумами. Нормированная корреляция вычисляется с использованием следующего соотношения:
. Для каждого пика в текущем остаточном спектре вычисляется нормированная корреляция с формой, которая в предыдущем остаточном спектре соответствует положению этого пика. Если сигнал устойчив, пики от кадра к кадру не должны существенно перемещаться, а их положение и форма должны быть приблизительно одинаковыми. Таким образом, операция корреляции принимает во внимание все индексы (элементы разрешения) конкретного пика, которые определяются двумя последовательными минимумами. Нормированная корреляция вычисляется с использованием следующего соотношения:
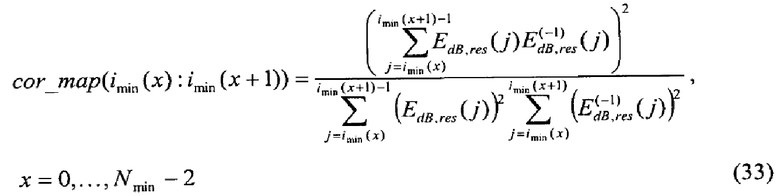
Головным элементам разрешения cor_map до 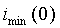 и завершающим элементам разрешения cor_map от
и завершающим элементам разрешения cor_map от 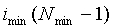 присваиваются нулевые значения. Карта корреляции показана на фиг.4.
присваиваются нулевые значения. Карта корреляции показана на фиг.4.
Карта корреляции текущего кадра используется для модификации ее долговременного значения, которое описывается следующим образом:
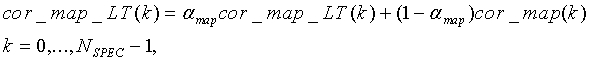 (34)
(34)
где 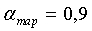 . Для всех k cor_map_LT присваиваются нулевые начальные значения.
. Для всех k cor_map_LT присваиваются нулевые начальные значения.
В конечном итоге все значения cor_map_LT суммируются (например, посредством сумматора)
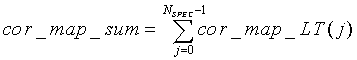 (35)
(35)
Если какое-либо значение cor_map_LT(j), j=0,…,N SPEC -1 превышает порог 0,95, флагу cor_srong (которое может рассматриваться как детектор) присваивается значение 1, иначе присваивается нулевое значение.
Принятие решения о тональной устойчивости вычисляется путем воздействия на cor_map_sum адаптивного порога thr_tonal. Порогу присваивается начальное значение 56, и он модифицируется в каждом кадре следующим образом:
если 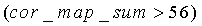
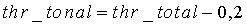
иначе
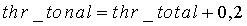
конец.
Адаптивный порог thr_tonal имеет верхний предел 60 и нижний предел 49. Таким образом, он понижается, когда корреляция относительно хорошо указывает на активный сегмент сигнала и увеличивается в противном случае. При понижении порога большее количество кадров с большей вероятностью классифицируется как активное, особенно в конце активных периодов. Поэтому адаптивный порог может рассматриваться как затягивание.
Параметру tonal_stability присваивается значение 1 всякий раз, когда cor_map_sum больше, чем thr_tonal, или когда флагу cor_strong присваивается значение 1. Подробнее:
если 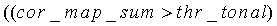 ИЛИ
ИЛИ 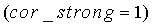
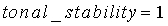
иначе
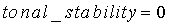
конец.
Использование параметров обнаружения музыки при модификации энергии шума
Все параметры обнаружения музыки включены в окончательное решение, принятие которого осуществляется в модуле 107 параметрического обнаружения звуковой активности и оценки и модификации шумов при модификации оценок энергии шума. Модификация оценок энергии шума происходит при условии нулевого значения noise_update, которому присваивается начальное значение 6, а модификация происходит в каждом кадре следующим образом:
если (nonstat>th stat) ИЛИ (pc<14) ИЛИ (voicing>th Cnorm) ИЛИ (resid_ratio>th resid) ИЛИ (tonal_stability=1) ИЛИ (noise_char_LT>0,3) ИЛИ ((act_pred_LT>0,8) и (nonstat2>th stat ))
noise_update=noise_update+2
иначе
noise_update=noise_update-1
конец.
Если комбинированное условие дает положительный результат, сигнал активен и параметр noise_update увеличивается. Иначе, сигнал неактивен и параметр уменьшается. При достижении нуля энергия шума модифицируется текущей энергией сигнала.
Кроме того, для модификации энергии шума в алгоритме классификации невокализованных звуковых сигналов также используется параметр tonal_stability. Параметр используется для улучшения надежности классификации невокализованных сигналов для музыки, как будет описано в следующем разделе.
Классификация звуковых сигналов (классификатор 108 звуковых сигналов)
Общая доктрина классификатора 108 звуковых сигналов (фиг.1) изображена на фиг.5. Подход может быть описан следующим образом. Классификация звуковых сигналов осуществляется в три стадии в логических модулях 501, 502 и 503, каждый из которых распознает конкретный класс сигналов. Детектор 501 активности сигнала (SAD) распознает активные и неактивные кадры сигнала. Данный детектор 501 активности сигнала является тем же самым, что и детектор 103 активности сигнала, обозначенный на фиг.1. Описание детектора активности сигнала было произведено в предшествующем описании.
Если детектор 501 активности сигнала обнаруживает неактивный кадр (сигнал фонового шума), цепь классификации завершается, и, если поддерживается прерывистая передача (DTX), модуль 541 кодирования, который может быть объединен с кодировщиком 109 (фиг.1), кодирует кадр с генерацией комфортного шума (CNG). В отсутствие поддержки DTX кадр продолжается в классификацию активных сигналов и чаще всего классифицируется как кадр невокализованной речи.
При обнаружении детектором 501 звуковой активности активного кадра сигнала этот кадр подвергается обработке во втором классификаторе 502, распознающем невокализованные речевые сигналы. Если классификатор 502 классифицирует кадр как невокализованный речевой сигнал, цепь классификации завершается, и модуль 542 кодирования, который может быть объединен с кодировщиком 109 (фиг.1), кодирует кадр при помощи способа кодирования, оптимизированного для невокализованных речевых сигналов.
В противном случае, кадр сигнала обрабатывается посредством "стабильно вокализованного" классификатора 503. Если кадр классифицируется классификатором 503 как стабильно вокализованный кадр, модуль 543 кодирования, который может быть объединен с кодировщиком 109 (фиг.1), кодирует кадр при помощи способа кодирования, оптимизированного для стабильно вокализованных и квазипериодических сигналов.
В противном случае, кадр с большой вероятностью содержит сегмент с нестационарным сигналом, таким как начало вокализованной речи или быстрое развитие вокализованной речи или музыкального сигнала. Кадры, как правило, требуют кодирующий модуль 544 общего назначения, который может быть объединен с кодировщиком 109 (фиг.1) для кодирования кадра с высокой скоростью передачи битовых данных с целью поддержки хорошего субъективного качества.
Далее раскрыта классификация кадров вокализованных и невокализованных сигналов. Описание детектора SAD 501 (или 103 на фиг.1), используемого для распознавания неактивных кадров, уже приводилось в предшествующем описании.
Невокализованные части речевого сигнала характеризуются отсутствием периодической компоненты и могут быть дополнительно разделены на неустойчивые кадры, в которых происходят быстрые изменения энергии и спектра, и устойчивые кадры, в которых эти характеристики относительно устойчивы. В неограничивающем иллюстративном варианте осуществления данного изобретения предлагается способ классификации невокализованных кадров с использованием следующих параметров:
- степени вокализованности, вычисляемой как усредненная нормированная корреляция 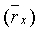 ;
;
- степени среднего наклона спектра 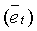 ;
;
- максимального кратковременного увеличения энергии на низком уровне (dE0), разработанного для эффективного обнаружения в сигнале взрывных звуков речи;
- тональной устойчивости (описанной в предшествующем описании) для установления отличия музыки от невокализованного сигнала; и
- относительной энергии кадра (E rel) для обнаружения чрезвычайно низкоэнергетических сигналов.
Степень вокализованности
Нормированная корреляция, используемая для определения степени вокализованности, вычисляется как часть анализа основных тонов с разомкнутой петлей в модуле ЛП-анализатора и следящего фильтра высоты тона 106 (фиг.1). Могут использоваться, например, кадры по 20 мс. Обычно модуль ЛП-анализатора и следящего фильтра высоты тона 106 выводит оценку основного тона с разомкнутой петлей каждые 10 мс (дважды на кадр). В данном случае, модуль ЛП-анализатора и следящего фильтра высоты тона 106 также используется для генерирования и вывода нормированных корреляционных критериев. Нормированные корреляции вычисляются на взвешенном сигнале и предыдущем взвешенном сигнале при задержке основного тона с разомкнутой петлей. Взвешенный речевой сигнал S w (n) вычисляется с использованием перцепционного взвешивающего фильтра. Например, может использоваться перцепционный взвешивающий фильтр с фиксированным знаменателем, пригодный для широкополосных сигналов. Примером функции преобразования для перцепционного взвешивающего фильтра может служить следующее соотношение:
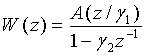 , где 0<γ2<γ1
<1,
, где 0<γ2<γ1
<1,
где A(z) - функция преобразования фильтра линейного предсказания (ЛП), вычисленная в модуле ЛП-анализатора и следящего фильтра высоты тона 106 и определяемая следующим соотношением:
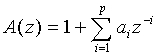
Подробности ЛП-анализа и анализа основных тонов с разомкнутой петлей в данном описании не приводятся, поскольку подразумевается, что они хорошо известны специалистам в данной области.
Критерий вокализованности задается средней корреляцией 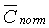 , которая определяется следующим образом:
, которая определяется следующим образом:
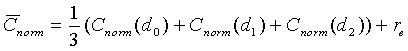 (36)
(36)
где C norm (d 0 ), C norm (d 1 ) и C norm (d 2 ) соответственно представляют нормированные корреляции первой половины текущего кадра, нормированные корреляции второй половины текущего кадра и нормированные корреляции предварительного вида (начала следующего кадра). Аргументами для корреляций являются вышеупомянутые запаздывания основного тона с разомкнутой петлей, вычисленные в модуле ЛП-анализатора и следящего фильтра высоты тона 106 (фиг.1). Например, можно использовать предварительный вид 10 мс. Для компенсации фонового шума (в присутствии фонового шума величина корреляции уменьшается) в среднюю корреляцию вводится поправочный коэффициент r e. Поправочный коэффициент вычисляется из следующего соотношения:
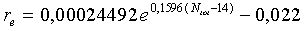 (37)
(37)
где N tot - полная энергия шума на кадр, вычисленная по уравнению (11).
Спектральный наклон
Параметр спектрального наклона содержит информацию о частотном распределении энергии. Спектральный наклон можно оценить в частотной области как отношение между энергией, сконцентрированной в низких частотах, и энергией, сконцентрированной в высоких частотах. Однако его также можно оценить, используя другие способы, как, например, отношение между первыми двумя коэффициентами автокорреляции сигнала.
Как описано выше, спектральный анализатор 102 (фиг.1) используется для осуществления двух спектральных анализов на каждый кадр. Энергия на высоких и низких частотах вычисляется в перцепционных критических полосах [M. Jelinek и R. Salami, "Noise Reduction Method for Wideband Speech Coding", in Proc. Eusipco, Vienna, Austria, сентябрь 2004 г.], повторенных в данном описании для удобства:
Критические полосы = {100,0, 200,0, 300,0, 400,0, 510,0, 630,0, 770,0, 920,0, 1080,0, 1270,0, 1480,0, 1720,0, 2000,0, 2320,0, 2700,0, 3150,0, 3700,0, 4400,0, 5300,0, 6350,0} Гц.
Энергия в высоких частотах вычисляется как среднее энергий двух последних критических полос по соотношению
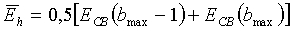 (39)
(39)
где энергии критических полос E CB (i) вычисляются по уравнению (2). Вычисления производятся дважды для каждого спектрального анализа.
Энергия в низких частотах вычисляется как среднее энергий десяти первых критических полос (для УП сигналов самая первая полоса исключается) по соотношению
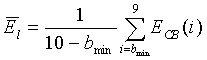
 (40)
(40)
Промежуточные критические полосы исключаются из вычислений для улучшения разграничения кадров с высокой концентрацией энергии в низких частотах (обычно вокализованных) и с высокой концентрацией энергии в высоких частотах (обычно невокализованных). В промежутке энергосодержание не является характеристическим для любого из классов и увеличивает неопределенность при принятии решения.
Однако энергия в низких частотах вычисляется иначе, чем для гармонических невокализованных сигналов с высоким энергосодержанием в низких частотах. Это происходит по причине того, что для улучшения вокализованного и невокализованного распознавания сегментов женской вокализованной речи можно воспользоваться гармонической структурой спектра. Подвергаемые воздействию сигналы либо имеют период основного тона короче 128, либо изначально не рассматриваются как невокализованные. Сигналы, изначально невокализованные, должны удовлетворять следующему критерию:
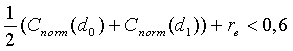 (41)
(41)
Таким образом, для сигналов, разграниченных по вышеприведенному критерию, энергия в низких частотах вычисляется для элементов разрешения, и только элементы разрешения по частоте, достаточно близкие к гармоникам, принимаются во внимание при суммировании. Точнее говоря, используется следующее соотношение:
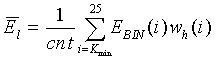 (42)
(42)
где K min - первый элемент разрешения (K min=1 для ШП, K min=3 для УП), E BIN (k) - энергии элементов разрешения, определяемые по уравнению (3), в первых 25 элементах разрешения по частоте (постоянная составляющая опущена). Эти 25 элементов разрешения соответствуют первым 10 критическим полосам. В вышеприведенном суммировании учитываются только члены, близкие к гармоникам основных тонов; w h (i) присваивается значение 1, если расстояние между ближайшими гармониками не превышает определенный частотный порог (например, 50 Гц), и нулевое значение - в противном случае; поэтому рассматриваются только элементы разрешения, находящиеся ближе 50 Гц к ближайшим гармоникам. Счетчик cnt равен количеству ненулевых членов суммирования. Тогда, если структура является гармонической на низких частотах, в суммирование будут включены только высокоэнергетические члены. С другой стороны, если структура гармонической не является, выбор членов будет случайным и сумма будет меньше. Таким образом, можно обнаружить только невокализованные звуковые сигналы с высоким энергосодержанием в низких частотах.
Спектральный наклон вычисляется по следующему соотношению:
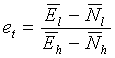 (43)
(43)
где 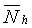 и
и 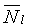 - усредненные энергии шума в двух (2) последних и 10 первых критических полосах (или 9 первых критических полосах для УП) соответственно, вычисленные так же, как
- усредненные энергии шума в двух (2) последних и 10 первых критических полосах (или 9 первых критических полосах для УП) соответственно, вычисленные так же, как 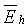 и
и 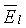 в уравнениях (39) и (40). Оценки энергий шума включаются в вычисление наклона для учета присутствия фонового шума. Для УП сигналов отсутствующие полосы компенсируются путем умножения
в уравнениях (39) и (40). Оценки энергий шума включаются в вычисление наклона для учета присутствия фонового шума. Для УП сигналов отсутствующие полосы компенсируются путем умножения 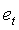 на 6. Вычисление спектрального наклона осуществляется дважды для каждого кадра для получения
на 6. Вычисление спектрального наклона осуществляется дважды для каждого кадра для получения 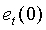 и
и 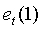 , соответствующих первому и второму спектральным анализам для каждого кадра. Средний спектральный наклон, используемый при классификации невокализованных кадров, вычисляется следующим образом:
, соответствующих первому и второму спектральным анализам для каждого кадра. Средний спектральный наклон, используемый при классификации невокализованных кадров, вычисляется следующим образом:
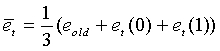 (44)
(44)
где 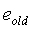 - наклон во второй половине предыдущего кадра.
- наклон во второй половине предыдущего кадра.
Максимальное кратковременное увеличение энергии на низком уровне
Максимальное кратковременное увеличение энергии на низком уровне dE0 оценивается для звукового сигнала s(n), где n=0 соответствует началу текущего кадра. Например, для кодирования используются 20 мс речевые кадры, каждый из которых разделен на 4 подкадра. Энергия сигнала оценивается дважды для каждого подкадра, т.е. 8 раз для каждого кадра, на основе кратковременных сегментов длиной 32 значения (на частоте дискретизации 12,8 кГц). Затем вычисляются кратковременные энергии последних 32 значений из предыдущего кадра. Кратковременные энергии вычисляются по следующему соотношению:
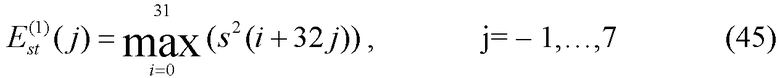
где j=-1 и j=0,…,7 соответствует концу предыдущего кадра и текущему кадру соответственно. Еще один набор 9 максимальных энергий вычисляется путем сдвига сигнальных индексов в уравнении (45) на 16 значений. То есть
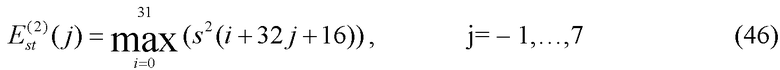
Для этих энергий, которые достаточно малы, т.е. удовлетворяют условию 10log(E st (j))<37, вычисляется отношение

для первого набора индексов, и то же самое вычисление повторяется для 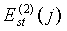 , давая два набора отношений rat
(1)
(j) и rat
(2)
(j). Единственный максимум в двух этих наборах отыскивается следующим образом:
, давая два набора отношений rat
(1)
(j) и rat
(2)
(j). Единственный максимум в двух этих наборах отыскивается следующим образом:
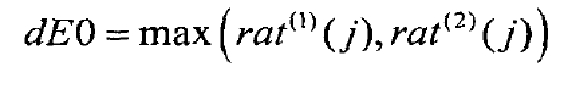 (48)
(48)
и является максимальным кратковременным увеличением энергии на низком уровне.
Степень равномерности спектра фонового шума
В данном примере неактивные кадры обычно кодируются в режиме кодирования, конструкция которого предназначена для невокализованной речи в отсутствие операции DTX. Однако в случае квазипериодического фонового шума, такого, как некоторые автомобильные шумы, более точной визуализации шума удается достичь путем обобщенного кодирования вместо использования ШП.
Для обнаружения фонового шума этого типа вычисляется и усредняется по времени степень неравномерности спектра фонового шума. Сначала для первой и четырех последних критических полос вычисляется средняя энергия шума:
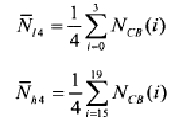
Затем с использованием нижеследующего соотношения вычисляется равномерность:
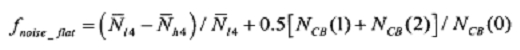
которая усредняется по времени с использованием следующего соотношения:
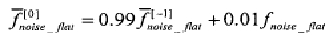
где 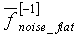 - усредненная степень равномерности предыдущего кадра, а
- усредненная степень равномерности предыдущего кадра, а 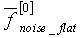 - модифицированное значение степени равномерности текущего кадра.
- модифицированное значение степени равномерности текущего кадра.
Классификация невокализованных сигналов
Классификация кадров невокализованных сигналов основана на параметрах, описанных выше: степени вокализованности , среднем наклоне спектра 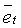 , максимальном кратковременном увеличении энергии на низком уровне dE0, а также степени равномерности спектра фонового шума
, максимальном кратковременном увеличении энергии на низком уровне dE0, а также степени равномерности спектра фонового шума 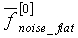 . Классификация дополнительно опирается на параметр тональной устойчивости и относительную энергию кадра, вычисляемые на стадии модификации энергии шума (модуль 107 на фиг.1). Относительная энергия кадра вычисляется с использованием следующего соотношения:
. Классификация дополнительно опирается на параметр тональной устойчивости и относительную энергию кадра, вычисляемые на стадии модификации энергии шума (модуль 107 на фиг.1). Относительная энергия кадра вычисляется с использованием следующего соотношения:

где 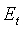 - полная энергия кадра (в дБ), вычисленная по уравнению (6),
- полная энергия кадра (в дБ), вычисленная по уравнению (6), 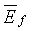 - долгосрочная средняя энергия кадра, модифицируемая в каждом активном кадре по соотношению:
- долгосрочная средняя энергия кадра, модифицируемая в каждом активном кадре по соотношению:
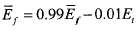
Модификация происходит только при условии установленного флага SAD (переменная SAD равна 1).
Правила классификации ШП сигналов как невокализованных подытожены ниже:
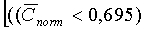 И
И 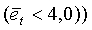 ИЛИ (
ИЛИ (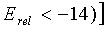 И [последний кадр НЕАКТИВНЫЙ ИЛИ НЕВОКАЛИЗОВАННЫЙ ИЛИ ((e
old<2,4) И
И [последний кадр НЕАКТИВНЫЙ ИЛИ НЕВОКАЛИЗОВАННЫЙ ИЛИ ((e
old<2,4) И
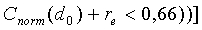 И
И
[dE0<250] И
[e t(1)<2,7] И
[(локальный флаг SAD=1) ИЛИ (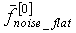 <1,45) ИЛИ (
<1,45) ИЛИ (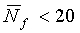 )] И
)] И
НЕ [(tonal_stability И (((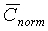 >0,52) И (
>0,52) И (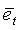 >0,5)) ИЛИ (
>0,5)) ИЛИ (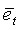 >0,85)) И (Erel>-14) И флаг SAD равен 1].
>0,85)) И (Erel>-14) И флаг SAD равен 1].
Первая строка условия относится к низкоэнергетическим сигналам и сигналам с низкой корреляцией, концентрирующим свою энергию в высоких частотах. Вторая строка покрывает вокализованные завершения, третья строка покрывает взрывные сегменты сигнала, четвертая строка относится к вокализованным вступлениям. Пятая строка обеспечивает равномерный спектр в случае неактивных кадров с шумами. Последняя строка распознает музыкальные сигналы, которые иначе могут быть отнесены к невокализованным сигналам.
Для УП сигналов условие классификации сигналов как невокализованных имеет следующую форму:
[локальный флаг SAD равен 0 ИЛИ (E rel<-25) ИЛИ
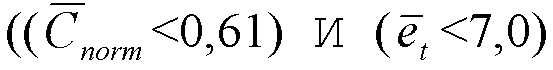 И (последний кадр НЕ АКТИВЕН ИЛИ НЕВОКАЛИЗОВАННЫЙ ИЛИ ((e
old<7,0) И (C
norm(d0)+re<0,52))))] И
И (последний кадр НЕ АКТИВЕН ИЛИ НЕВОКАЛИЗОВАННЫЙ ИЛИ ((e
old<7,0) И (C
norm(d0)+re<0,52))))] И
[dE0<250] И
[<390] И
НЕ [(tonal_stability И (((>0,52) И (>0,5)) ИЛИ (>0,75)) И (E
rel>-10) И флаг SAD равен 1].
Деревья решений для случаев ШП и УП сигналов показаны на фиг.6. Если комбинированные условия удовлетворяются, классификация завершается выбором режима кодирования невокализованных сигналов.
Классификация вокализованных сигналов
Если кадр не классифицирован как неактивный кадр или невокализованный кадр, осуществляется его проверка, если он является устойчивым вокализованным кадром. Правило принятия решения основано на нормированной корреляции каждого из подкадров (с ¼ разрешения подвыборки), во всех подкадрах производятся оценки среднего наклона спектра и основного тона с разомкнутой петлей (с ¼ разрешения подвыборки).
Процедура оценки основного тона с разомкнутой петлей осуществляется в модуле ЛП-анализатора и следящего фильтра высоты тона 106 (фиг.1). В уравнении (19) используются три оценки основного тона с разомкнутой петлей: d 0, d 1 и d 2, соответствующие первой половине кадра, второй половине кадра и предварительному виду. Для получения точной информации о высоте тона во всех четырех подкадрах вычисляется дробное уточнение высоты тона с ¼ разрешения выборки. Уточнение вычисляется на взвешенном звуковом сигнале S wd (n). В данном иллюстративном варианте осуществления изобретения взвешенный сигнал S wd (n) для уточнения оценки разомкнутого основного тона не децимируется. В начале каждого подкадра производится сокращенный корреляционный анализ (64 значения на частоте дискретизации 12,8 кГц) с разрешением в 1 значение в интервале (-7, +7) с использованием следующих задержек: d 0 - для первого и второго подкадра, d 1 - для третьего и четвертого подкадра. Затем корреляции интерполируются вокруг своих максимумов в дробных положениях d max-3/4, d max-1/2, d max-1/4, d max , d max+1/4, d max+1/2, d max+3/4. В качестве уточненной задержки основного тона выбирается величина, дающая максимальную корреляцию.
Обозначим уточненные задержки основного тона с разомкнутой петлей во всех четырех подкадрах как T(0), T(1), T(2) и T(3), а соответствующие нормированные корреляции - как C(0), C(1), C(2) и C(3). Тогда условие классификации вокализованного сигнала дается следующим образом:
[C(0)>0,605] И
[C(1)>0,605] И
[C(2)>0,605] И
[C(3)>0,605] И
[>4] И
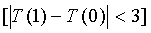 И
И
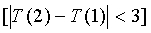 И
И
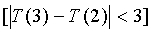
Условие указывает на то, что нормированная корреляция очень высока во всех подкадрах, оценки основного тона по всему кадру не расходятся, а энергия сконцентрирована в низких частотах. При соответствии этому условию классификация завершается выбором режима кодирования вокализованного сигнала, в противном случае сигнал кодируется в обобщенном режиме кодирования сигналов. Условие применимо к ШП и УП сигналам.
Оценка тональности в сверхширокополосном содержимом
При кодировании сверхширокополосных сигналов для звуковых сигналов с тональной структурой используется специфический режим кодирования. Частотный диапазон 7000-14000 Гц представляет наибольший интерес, однако он также может изменяться. Целью является обнаружение кадров, имеющих значительное тональное содержимое в интересующем диапазоне так, чтобы возможно было эффективное использование режима кодирования, специфического для тонов. Эта цель достигается при использовании описанного ранее в настоящем описании анализа тональной устойчивости. Однако в данном случае присутствуют некоторые отклонения, которые и описаны в этом разделе.
Во-первых, спектральное дно, вычитаемое из log-энергии спектра, вычисляется следующим образом. Спектр log-энергии фильтруется с использованием фильтра скользящего среднего (СС), или фильтра FIR, длина которого составляет L MA=15 значений. Отфильтрованный спектр описывается соотношением
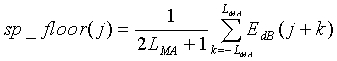
для j=L MA ,…,N SPEC -L MA -1.
Для сохранения вычислительной сложности операция фильтрации осуществляется только для j=L MA, а для остальных запаздываний она вычисляется как
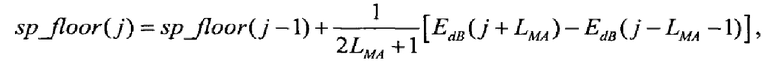
для j=L MA +1,…,N SPEC -L MA -1.
Для запаздываний 0,…,L MA-1 и N SPEC -L MA ,…,N SPEC -1 спектральное дно вычисляется при помощи экстраполяции. Более точно используется следующее соотношение:
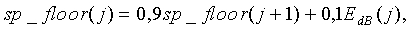 для
для 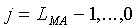 ,
,
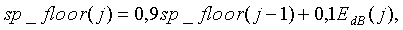 для
для 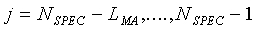 .
.
В первом из вышеприведенных уравнений процесс направлен по нисходящей от L MA-1 к 0.
Затем спектральное дно вычитается из log-энергии спектра так же, как в данном описании описано выше.
Остаточный спектр, обозначаемый как Eres,dB(j), затем сглаживается по трем значениям, как изложено ниже с использованием кратковременного фильтра скользящего среднего:
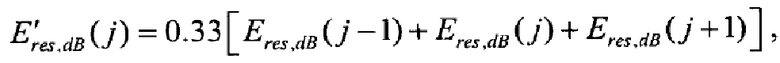
для j=1,…,N SPEC -1.
Поиск спектральных минимумов и их индексов, вычисление корреляционной карты и долгосрочной корреляционной карты осуществляются так же, как в способе, описанном в настоящем описании выше, с использованием сглаженного спектра E'res,dB(j).
Принятие решения о тональности сигнала в сверхширокополосном содержимом также осуществляется аналогично тому, как описано выше в настоящем описании, т.е. на основе адаптивного порога. Однако в данном случае используется другой фиксированный порог и шаг. Порогу thr_tonal присваивается начальное значение 130, которое модифицируется в каждом кадре следующим образом:
если (cor_map_sum>130)
thr_tonal=thr_tonal-1,0
иначе
thr_tonal=thr_tonal+1,0
конец.
Адаптивный порог thr_tonal имеет верхний предел 140 и нижний предел 120. Установка значения фиксированного порога производится с учетом частотного диапазона 7000-14000 Гц. Для другого диапазона необходима его корректировка. В качестве общего практического правила можно воспользоваться следующим взаимоотношением thr_tonal=N SPEC /2.
Последнее отличие от способа, описанного выше в настоящем описании, заключается в том, что обнаружение сильных тонов для сверхширокополосного содержимого не используется. Это мотивируется тем, что сильные тона перцепционно не подходят для цели кодирования тонального сигнала сверхширокополосного содержимого.
Хотя настоящее изобретение описано в вышеприведенном описании посредством неограничивающего иллюстративного варианта его осуществления, этот вариант осуществления может быть модифицирован каким угодно образом, оставаясь при этом в пределах прилагаемой формулы изобретения без отклонения от сути и содержания изобретения.
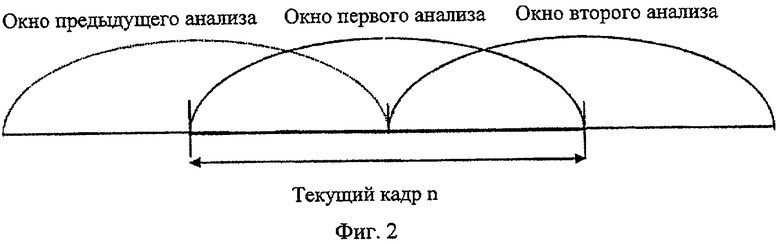
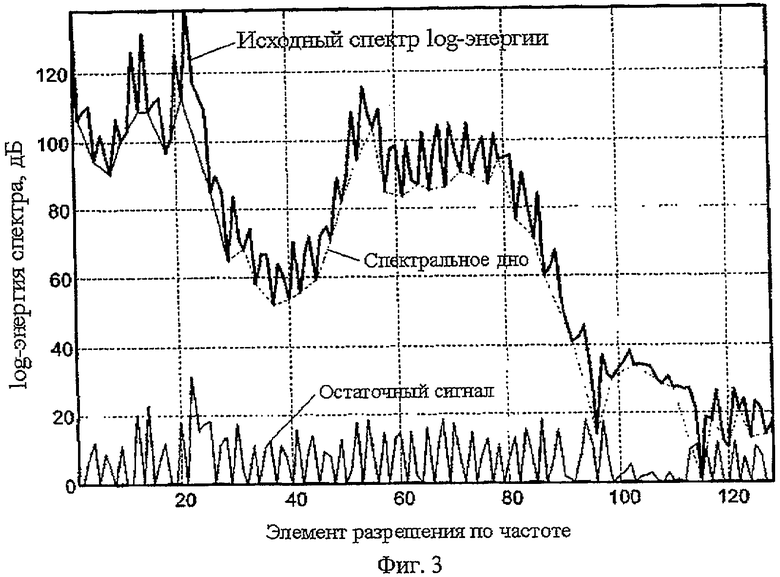
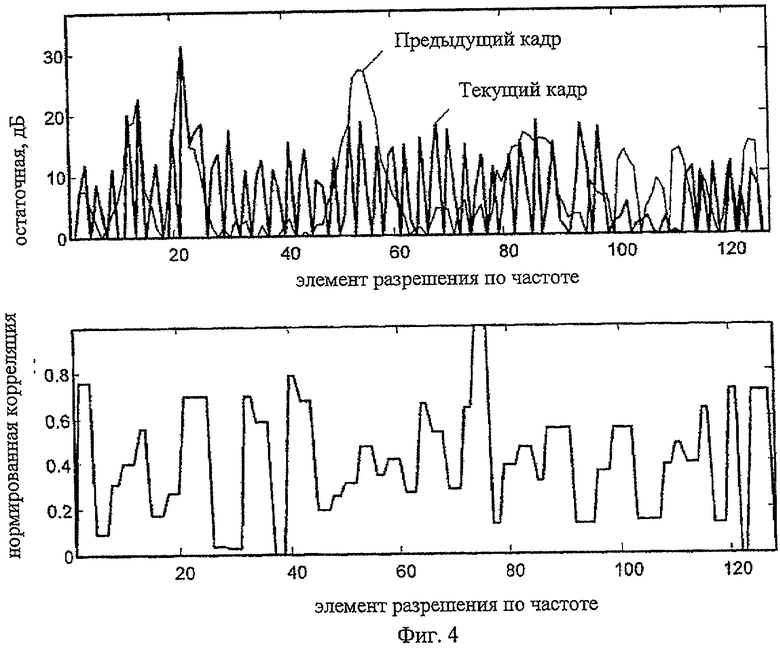
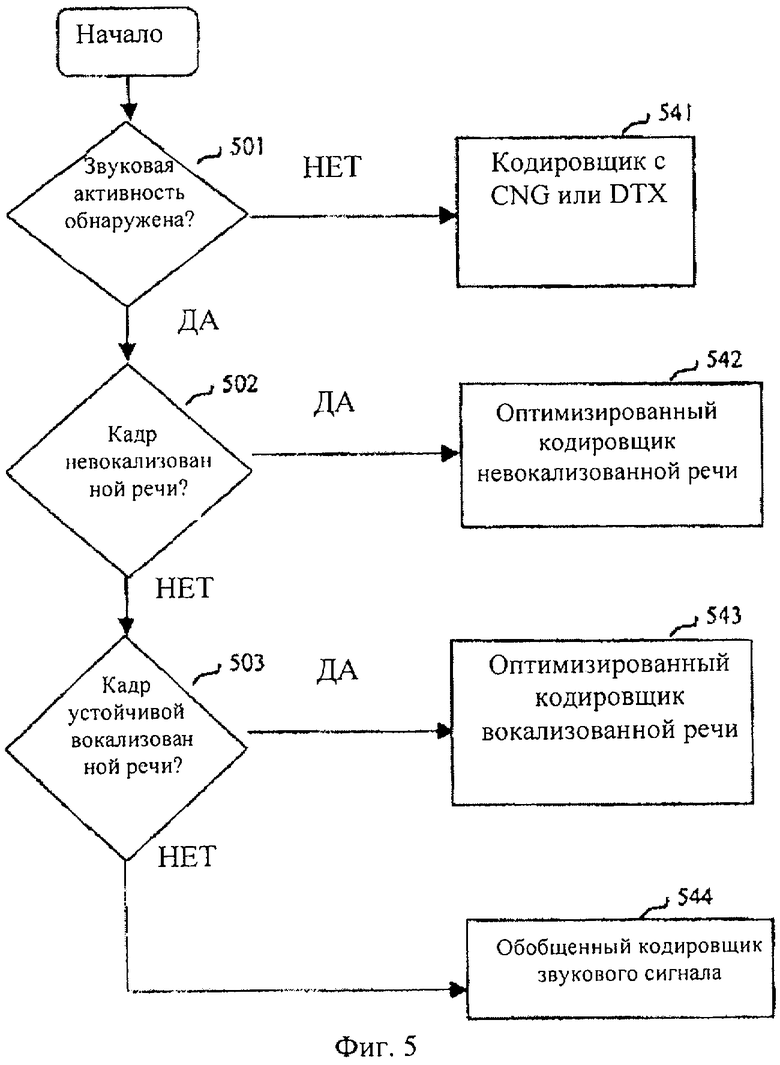
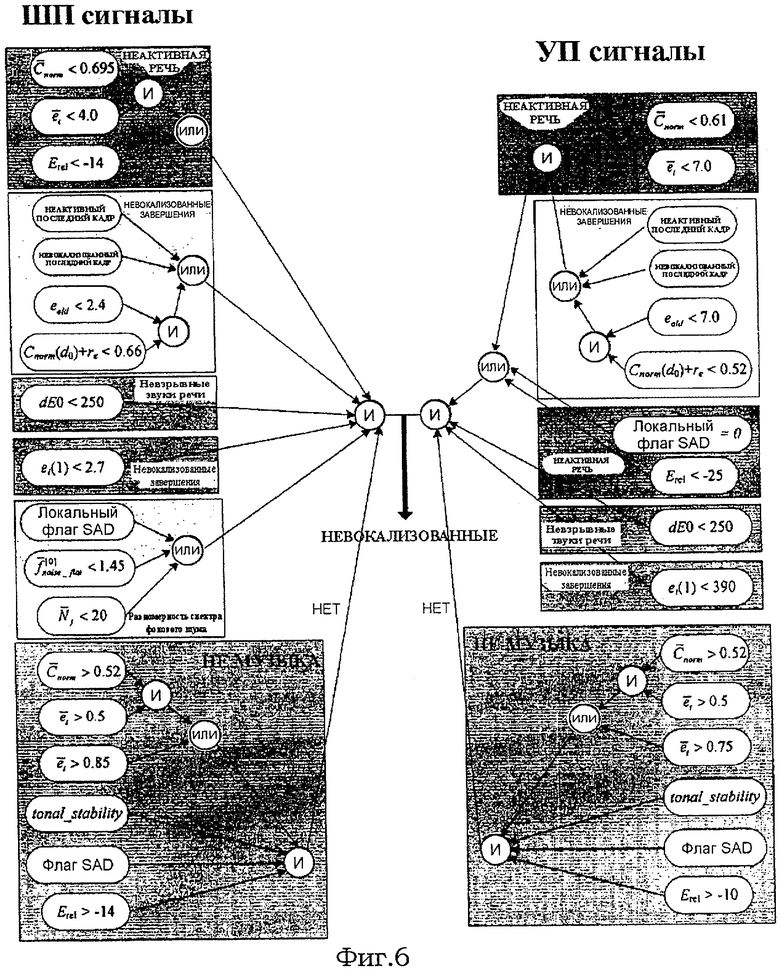
Настоящее изобретение относится к обнаружению звуковой активности, оценке фоновых шумов и классификации звуковых сигналов, где под звуком понимается полезный сигнал. Техническим результатом является улучшение производительности обнаружения звуковой активности в присутствии музыкальных сигналов, а также улучшение распознавания невокализованных звуков и музыки. Указанный результат достигается тем, что в способе оценки тональности звукового сигнала выполняют вычисление текущего остаточного спектра звукового сигнала, обнаружение пиков в текущем остаточном спектре, вычисление карты корреляции между текущим остаточным спектром и предыдущим остаточным спектром для каждого обнаруженного пика, вычисление долгосрочной карты корреляции на основе вычисленной карты корреляции. При этом долгосрочная карта корреляции характеризует тональность звукового сигнала. 12 н. и 54 з.п. ф-лы, 6 ил.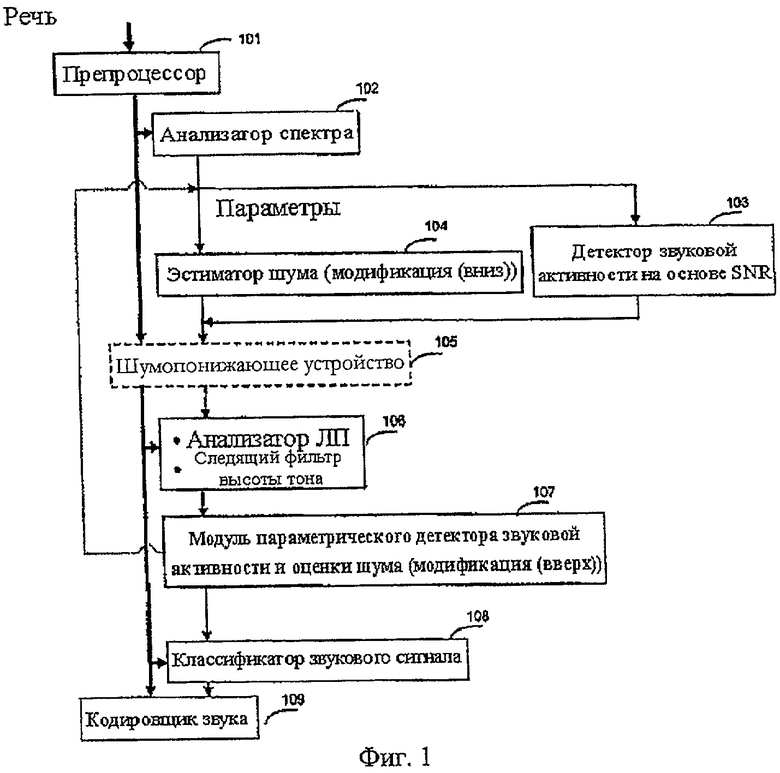
1. Способ оценки тональности звукового сигнала, который включает:
вычисление текущего остаточного спектра звукового сигнала;
обнаружение пиков в текущем остаточном спектре;
вычисление карты корреляции между текущим остаточным спектром и предыдущим остаточным спектром для каждого обнаруженного пика;
вычисление долгосрочной карты корреляции на основе вычисленной карты корреляции, причем долгосрочная карта корреляции характеризует тональность звукового сигнала.
2. Способ по п.1, отличающийся тем, что вычисление спектра текущего сигнала включает:
поиск минимумов в спектре звукового сигнала в текущем кадре;
оценку спектрального дна путем соединения минимумов друг с другом;
вычитание оценки спектрального дна из спектра звукового сигнала в текущем кадре для получения текущего остаточного спектра.
3. Способ по п.1, отличающийся тем, что обнаружение пиков в текущем остаточном спектре включает определение положения максимума между каждой парой из двух последовательных минимумов.
4. Способ по п.1, отличающийся тем, что вычисление карты корреляции включает:
вычисление для каждого пика, обнаруженного в текущем остаточном спектре, величины нормированной корреляции с предыдущим остаточным спектром по элементам разрешения по частоте между двумя последовательными минимумами в текущем остаточном спектре, которые ограничивают пик; и
присвоение каждому обнаруженному пику оценки, соответствующей значению нормированной корреляции; и
присвоение величины нормированной корреляции пика по элементам разрешения по частоте между двумя последовательными минимумами, ограничивающими пик, для каждого обнаруженного пика, чтобы сформировать карту корреляции.
5. Способ по п.1, отличающийся тем, что вычисление долгосрочной карты корреляции включает:
фильтрацию карты корреляции через однополюсный фильтр на элементе разрешения по частоте на основе элементов разрешения по частоте;
суммирование отфильтрованной карты корреляции по элементам разрешения по частоте с тем, чтобы получить суммарную долгосрочную карту корреляции.
6. Способ по п.1, отличающийся тем, что дополнительно включает обнаружение в звуковом сигнале сильных тонов.
7. Способ по п.6, отличающийся тем, что обнаружение сильных тонов в звуковом сигнале включает поиск по карте корреляции элементов разрешения по частоте, имеющих величину, которая превышает заданный фиксированный порог.
8. Способ по п.6, отличающийся тем, что обнаружение сильных тонов в звуковом сигнале включает сопоставление суммарной долгосрочной карты корреляции с адаптивным порогом, характеризующим звуковую активность в звуковом сигнале.
9. Способ по п.1, отличающийся тем, что дополнительно включает проверку присутствия сильных тонов.
10. Способ обнаружения звуковой активности в звуковом сигнале, где звуковой сигнал классифицируют как неактивный звуковой сигнал или активный звуковой сигнал в соответствии с обнаруженной в звуковом сигнале звуковой активностью, который включает:
оценку параметра, связанного с тональностью звукового сигнала, применяемую для того, чтобы отличить музыкальный сигнал от сигнала фонового шума;
причем оценку тональности производят по одному из пп.1-9.
11. Способ по п.10, отличающийся тем, что дополнительно включает предотвращение модификации оценок энергии шума в случае обнаружения тонального звукового сигнала.
12. Способ по п.10, отличающийся тем, что обнаружение звуковой активности в звуковом сигнале дополнительно включает обнаружение звуковой активности на основе отношения сигнал/шум (SNR).
13. Способ по п.12, отличающийся тем, что обнаружение звуковой активности на основе отношения сигнал/шум (SNR) включает обнаружение звукового сигнала на основе частотно-зависимого отношения сигнал/шум (SNR).
14. Способ по п.12, отличающийся тем, что обнаружение звуковой активности на основе отношения сигнал/шум (SNR) включает сопоставление среднего отношения сигнал/шум (SNRav) с порогом, вычисленным как функция долгосрочного отношения сигнал/шум (SNRLT).
15. Способ по п.14, отличающийся тем, что обнаружение звуковой активности в звуковом сигнале на основе отношения сигнал/шум (SNR) дополнительно включает оценку энергии шума, произведенную в предыдущем кадре при вычислении SNR.
16. Способ по п.15, отличающийся тем, что обнаружение звуковой активности на основе отношения сигнал/шум (SNR) дополнительно включает модификацию оценок шума для следующего кадра.
17. Способ по п.16, отличающийся тем, что модификация оценок энергии шума для следующего кадра включает принятие решения о модификации, основанного, по меньшей мере, на одном из следующих показателей: устойчивости основного тона, вокализованности, параметра нестационарности звукового сигнала и отношения между линейными предсказаниями остаточных энергий погрешности второго и шестнадцатого порядка.
18. Способ по п.14, отличающийся тем, что включает классификацию звукового сигнала как неактивного звукового сигнала или активного звукового сигнала и включает обнаружение неактивного звукового сигнала в случае, если среднее отношение сигнал/шум (SNRav) не превышает вычисленный порог.
19. Способ по п.14, отличающийся тем, что включает классификацию звукового сигнала как неактивного звукового сигнала или активного звукового сигнала и включает обнаружение активного звукового сигнала в случае, если среднее отношение сигнал/шум (SNRav) превышает вычисленный порог.
20. Способ по п.10, отличающийся тем, что оценка параметра, связанного с тональностью звукового сигнала, предотвращает модификацию оценок энергии шума в случае обнаружения музыкального сигнала.
21. Способ по п.10, отличающийся тем, что дополнительно включает вычисление параметров комплементарной нестационарности и характера шума для установления отличия музыкального сигнала от сигнала фонового шума и предотвращения модификации оценок энергии шума на музыкальном сигнале.
22. Способ по п.21, отличающийся тем, что вычисление параметра комплементарной нестационарности включает вычисление параметра, подобного параметру обычной нестационарности, со сбросом долгосрочной энергии в случае обнаружения спектральной атаки.
23. Способ по п.22, отличающийся тем, что сброс долгосрочной энергии включает приравнивание долгосрочной энергии к энергии текущего кадра.
24. Способ по п.22, отличающийся тем, что обнаружение спектральной атаки и сброс долгосрочной энергии включает вычисление параметра спектральной разнородности.
25. Способ по п.24, отличающийся тем, что вычисление параметра спектральной разнородности включает:
вычисление отношения энергии звукового сигнала в текущем кадре к энергии звукового сигнала в предыдущем кадре для диапазонов частот, превышающих заданное число; и
вычисление спектральной разнородности как взвешенной суммы вычисленного отношения по всем диапазонам частот, превышающим заданное число.
26. Способ по п.22, отличающийся тем, что вычисление параметра комплементарной нестационарности дополнительно включает вычисление параметра предсказания активности, характеризующего активность звукового сигнала.
27. Способ по п.26, отличающийся тем, что вычисление параметра предсказания активности включает:
вычисление долгосрочного значения двоичного выбора, полученного из оценки параметра, связанного с тональностью звукового сигнала, и обычного параметра нестационарности.
28. Способ по п.21, отличающийся тем, что модификация оценок энергии шума предотвращается в случае, если параметр предсказания активности превышает первый заданный фиксированный порог, и параметр комплементарной нестационарности превышает второй заданный фиксированный порог.
29. Способ по п.21, отличающийся тем, что вычисление параметра характера шума включает:
разделение набора диапазонов частот на первую группу, содержащую определенное количество первых диапазонов частот, и вторую группу, содержащую остальные диапазоны частот;
вычисление первого значения энергии для первой группы диапазонов частот и второго значения энергии - для второй группы диапазонов частот;
вычисление отношения первого значения энергии ко второму с тем, чтобы получить параметр характера шума;
вычисление долгосрочного значения параметра характера шума на основе вычисленного параметра характера шума.
30. Способ по п.29, отличающийся тем, что модификация оценок энергии шума предотвращается в случае, если значение параметра характера шума не превышает заданный фиксированный порог.
31. Способ классификации звукового сигнала для оптимизации кодирования звукового сигнала с использованием классификации звукового сигнала, который включает:
обнаружение звуковой активности в звуковом сигнале;
классификацию звукового сигнала как активного звукового сигнала или неактивного звукового сигнала, в соответствии со звуковой активностью, обнаруженной в звуковом сигнале;
в случае если звуковой сигнал классифицирован как активный звуковой сигнал, дальнейшую классификацию активного звукового сигнала как невокализованного речевого сигнала или речевого сигнала, не являющегося невокализованным;
причем классификация активного звукового сигнала как невокализованного речевого сигнала включает оценку тональности звукового сигнала для предотвращения классификации музыкальных сигналов как невокализованных речевых сигналов, причем оценку тональности выполняют по одному из пп.1-9.
32. Способ по п.31, отличающийся тем, что дополнительно включает кодирование звукового сигнала в соответствии с классификацией звукового сигнала.
33. Способ по п.32, отличающийся тем, что кодирование звукового сигнала в соответствии с классификацией звукового сигнала включает кодирование неактивных звуковых сигналов с генерацией комфортного шума.
34. Способ по п.31, отличающийся тем, что классификация активного звукового сигнала как невокализованного речевого сигнала включает вычисление правила принятия решения на основе, по меньшей мере, одного из параметров: степени вокализованности, степени среднего наклона спектра, максимального кратковременного увеличения энергии на низком уровне, тональной устойчивости и относительной энергии кадра.
35. Способ по п.31, отличающийся тем, что дополнительно включает классификацию речевого сигнала, не являющегося невокализованным, как устойчивого речевого сигнала или сигнала другого типа, отличающегося от устойчивого вокализованного речевого сигнала.
36. Способ по п.35, отличающийся тем, что классификация речевого сигнала, не являющегося невокализованным, как устойчивого вокализованного речевого сигнала включает вычисление правила принятия решения на основе, по меньшей мере, одной из оценок звукового сигнала: нормированной корреляции, среднего спектрального наклона и основного тона с разомкнутой петлей.
37. Способ кодирования верхнего диапазона звукового сигнала с использованием классификации звукового сигнала, который включает:
классификацию звукового сигнала как тонального звукового сигнала или нетонального звукового сигнала;
причем классификация звукового сигнала как тонального звукового сигнала содержит оценку тональности звукового сигнала по одному из пп.1-9.
38. Способ по п.37, отличающийся тем, что оценка параметра, связанного с тональностью звукового сигнала по одному из пп.1-9, дополнительно включает применение альтернативного способа для вычисления спектрального дна.
39. Способ по п.38, отличающийся тем, что применение альтернативного способа для вычисления спектрального дна включает фильтрацию log-энергии спектра звукового сигнала в текущем кадре с использованием фильтра скользящего среднего.
40. Способ по п.37, отличающийся тем, что оценка тональности звукового сигнала по одному из пп.1-9 дополнительно включает сглаживание остаточного спектра посредством кратковременного фильтра скользящего среднего.
41. Способ по п.37, отличающийся тем, что дополнительно включает кодирование верхнего диапазона звукового сигнала в соответствии с классификацией указанного звукового сигнала.
42. Способ по п.41, отличающийся тем, что кодирование верхнего диапазона звукового сигнала в соответствии с классификацией указанного звукового сигнала включает кодирование тональных звуковых сигналов с использованием модели, оптимизированной для этих сигналов.
43. Способ по п.37, отличающийся тем, что верхний диапазон звукового сигнала включает диапазон частот выше 7 КГц.
44. Устройство для оценки тональности звукового сигнала, включающее:
средства для вычисления текущего остаточного спектра звукового сигнала;
средства для обнаружения пиков в текущем остаточном спектре;
средства для вычисления карты корреляции между текущим остаточным спектром и предыдущим остаточным спектром для каждого обнаруженного пика; и
средства для вычисления долгосрочной карты корреляции на основе вычисленной карты корреляции, причем долгосрочная карта корреляции характеризует тональность звукового сигнала.
45. Устройство для оценки тональности звукового сигнала, включающее:
вычислитель текущего остаточного спектра звукового сигнала;
детектор пиков в текущем остаточном спектре;
вычислитель карты корреляции между текущим остаточным спектром и предыдущим остаточным спектром для каждого обнаруженного пика;
вычислитель долгосрочной карты корреляции на основе вычисленной карты корреляции, причем долгосрочная карта корреляции характеризует тональность звукового сигнала.
46. Устройство по п.45, отличающееся тем, что вычислитель текущего остаточного спектра включает:
устройство обнаружения минимумов в спектре звукового сигнала в текущем кадре;
устройство оценки спектрального дна, которое соединяет минимумы друг с другом; и
вычитатель оценки спектрального дна из спектра с тем, чтобы получить текущий остаточный спектр.
47. Устройство по п.45, отличающееся тем, что вычислитель долгосрочной карты корреляции включает:
фильтр для фильтрации карты корреляции на основе элементов разрешения по частоте;
сумматор для суммирования отфильтрованной карты корреляции на элементах разрешения по частоте с тем, чтобы получить суммарную долгосрочную карту корреляции.
48. Устройство по п.45, отличающееся тем, что дополнительно включает детектор сильных тонов в звуковом сигнале.
49. Устройство для обнаружения звуковой активности в звуковом сигнале, где звуковой сигнал классифицируют как неактивный звуковой сигнал или активный звуковой сигнал в соответствии с обнаруженной звуковой активностью, которое включает:
средства для оценки параметра, связанного с тональностью звукового сигнала, которые применяют для установления отличия музыкального сигнала от сигнала фонового шума;
причем средства оценки параметра тональности включают устройство по п.44.
50. Устройство для обнаружения звуковой активности в звуковом сигнале, где звуковой сигнал классифицируют как неактивный звуковой сигнал или активный звуковой сигнал в соответствии с обнаруженной звуковой активностью, которое включает:
эстиматор тональности звукового сигнала, применяемый для установления отличия музыкального сигнала от сигнала фонового шума;
причем эстиматор тональности включает устройство по одному из пп.45-48.
51. Устройство по п.50, отличающееся тем, что дополнительно включает детектор звуковой активности на основе отношения сигнал/шум (SNR).
52. Устройство по п.51, отличающееся тем, что детектор звуковой активности на основе отношения сигнал/шум (SNR) включает компаратор среднего отношения сигнал/шум (SNRav) с порогом, являющимся функцией долгосрочного отношения сигнал/шум (SNRTL).
53. Устройство по п.50, отличающееся тем, что дополнительно включает эстиматор для модификации оценок энергии шума при вычислении отношения сигнал/шум (SNR) в детекторе звуковой активности на основе отношения сигнал/шум (SNR).
54. Устройство по п.50, отличающееся тем, что дополнительно включает вычислитель параметра комплементарной нестационарности и вычислитель характера шума звукового сигнала для установления отличия музыкального сигнала от сигнала фонового шума и предотвращения модификации оценок энергии шума.
55. Устройство по п.50, отличающееся тем, что дополнительно включает вычислитель спектрального параметра, применяемого для обнаружения в звуковом сигнале изменений спектра и спектральных атак.
56. Устройство для классификации звукового сигнала с целью оптимизации кодирования звукового сигнала с использованием классификации звукового сигнала, которое включает:
средства для обнаружения звуковой активности в звуковом сигнале;
средства для классификации звукового сигнала как активного звукового сигнала или неактивного звукового сигнала в соответствии с обнаруженной в звуковом сигнале звуковой активностью;
в случае если звуковой сигнал классифицирован как активный звуковой сигнал, средства для дальнейшей классификации активного звукового сигнала как невокализованного речевого сигнала или речевого сигнала, не являющегося невокализованным;
причем средства для дальнейшей классификации звукового сигнала как невокализованного речевого сигнала содержат средства для оценки параметра, связанного с тональностью звукового сигнала, для предотвращения классификации музыкальных сигналов как невокализованных речевых сигналов, где средства для оценки параметра, связанного с тональностью звукового сигнала, включают устройство по одному из пп.45-48.
57. Устройство для классификации звукового сигнала с целью оптимизации кодирования звукового сигнала с использованием классификации звукового сигнала, которое включает:
детектор звуковой активности в звуковом сигнале;
первый классификатор звукового сигнала для классификации звукового сигнала как активного звукового сигнала или неактивного звукового сигнала в соответствии с обнаруженной в звуковом сигнале звуковой активностью;
второй классификатор звукового сигнала, соединенный с первым классификатором звукового сигнала, для классификации активного звукового сигнала как невокализованного речевого сигнала или речевого сигнала, не являющегося невокализованным,
где детектор звуковой активности включает эстиматор тональности для измерения тональности звукового сигнала для оценки тональности звукового сигнала с целью предотвращения классификации музыкальных сигналов как невокализованных речевых сигналов, который включает устройство по одному из пп.45-48.
58. Устройство по п.57, отличающееся тем, что дополнительно включает кодировщик звука для кодирования звукового сигнала в соответствии с классификацией звукового сигнала.
59. Устройство по п.58, отличающееся тем, что кодировщик звука включает кодировщик шума для кодирования неактивных звуковых сигналов.
60. Устройство по п.58, отличающееся тем, что кодировщик звука включает оптимизированный кодер невокализованной речи.
61. Устройство по п.58, отличающееся тем, что кодировщик звука включает оптимизированный кодер вокализованной речи для кодирования устойчивых вокализованных сигналов.
62. Устройство по п.58, отличающееся тем, что кодировщик звука включает обобщенный кодер звукового сигнала для кодирования быстро развивающихся вокализованных сигналов.
63. Устройство для кодирования верхнего диапазона звукового сигнала с использованием классификации звукового сигнала, которое включает:
средства для классификации звукового сигнала как тонального звукового сигнала или нетонального звукового сигнала;
средства для кодирования верхнего диапазона классифицированного звукового сигнала,
где средства для классификации звукового сигнала как тонального включают устройство для оценки тональности звукового сигнала по одному из пп.45-48.
64. Устройство для кодирования верхнего диапазона звукового сигнала с использованием классификации звукового сигнала, которое включает:
классификатор звукового сигнала для классификации звукового сигнала как тонального звукового сигнала или нетонального звукового сигнала;
кодировщик звука для кодирования верхнего диапазона классифицированного звукового сигнала,
где классификатор звукового сигнала включает устройство для оценки тональности звукового сигнала по одному из пп.45-48.
65. Устройство по п.64, отличающееся тем, что дополнительно включает фильтр скользящего среднего для вычисления спектрального дна, полученного из звукового сигнала, где спектральное дно применяют для оценки тональности звукового сигнала.
66. Устройство по п.64, отличающееся тем, что дополнительно включает кратковременный фильтр скользящего среднего для сглаживания остаточного спектра звукового сигнала, где остаточный спектр применяют для оценки тональности звукового сигнала.
| СПОСОБ МАНИПУЛИРОВАНИЯ ОБРАБАТЫВАЕМЫМИ ЗАГОТОВКАМИ ИЗДЕЛИЙ ТИПА БОЛТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1995 |
|
RU2073592C1 |
| DE 10134471 А1, 13.02.2003 | |||
| US 2005256705 А1, 17.11.2005 | |||
| JP 2007025290 А, 01.02.2007 | |||
| ПРИБОР ДЛЯ РЕГИСТРАЦИИ ФИЛЬТРАЦИОННЫХ ПОТЕРЬ ПРИ ПОСТОЯННОМ УРОВНЕ ВОДЫ В ВОДОЕМЕ | 1972 |
|
SU424016A1 |
| US 5712953 А, 27.01.1998 | |||
| US 2004181393 А1, 16.09.2004 | |||
| ОБНАРУЖЕНИЕ АКТИВНОСТИ СЛОЖНОГО СИГНАЛА ДЛЯ УСОВЕРШЕНСТВОВАННОЙ КЛАССИФИКАЦИИ РЕЧИ/ШУМА В АУДИОСИГНАЛЕ | 1999 |
|
RU2251750C2 |

