Описание
Область техники, к которой относится изобретение
Настоящее изобретение в целом относится к кодированию изображения и более конкретно к кодированию блоков видеокадров.
Уровень техники
Цифровое изображение, такое как видеоизображение, телевизионное изображение, неподвижное изображение или изображение, сгенерированное с помощью видеомагнитофона или компьютера, состоит из пикселей, расположенных в горизонтальных и вертикальных линиях. Число пикселей в одном изображении обычно равно десяткам тысяч. Каждый пиксель обычно содержит информацию яркости и цветности. Без сжатия количество информации, передаваемой из кодера изображения в декодер изображения, является настолько огромным, что оно делает передачу изображения в реальном времени невозможным. Чтобы уменьшить количество передаваемой информации, разработан ряд разных способов сжатия, таких как стандарты JPEG, MPEG и Н.263. В типичном видеокодере кадр исходной видеопоследовательности разделяют на прямоугольные области или блоки, которые кодируют во внутреннем режиме (режим I) или в промежуточном режиме (режим Р). Блоки кодируют независимо с использованием некоторого вида кодирования с преобразованием, такого как кодирование DCT, ДКП (дискретное косинусное преобразование). Однако простое кодирование на основе блоков только уменьшает корреляцию между пикселями в конкретном блоке без учета межблочной корреляции пикселей и оно по-прежнему создает высокие скорости бит для передачи. Современные стандарты кодирования цифровых изображений также используют определенные способы, которые уменьшают корреляцию величин пикселей между блоками.
Обычно блоки, закодированные в режиме Р, прогнозируют из одного из ранее закодированных и переданных кадров. Информацию прогнозирования блока представляют с помощью двумерного (2D) вектора движения. Для блоков, закодированных в режиме I, прогнозируемый блок формируют с использованием пространственного прогнозирования из уже закодированных соседних блоков в одном и том же кадре. Ошибку прогнозирования, например разность между кодируемым блоком и прогнозируемым блоком, представляют как множество взвешенных базовых функций некоторого дискретного преобразования. Преобразование обычно выполняют на основе блока 8х8 или 4х4. Весовые коэффициенты - коэффициенты преобразования затем квантуют. Квантование вносит потерю информации и, следовательно, квантованные коэффициенты имеют более низкую точность, чем оригиналы.
Квантованные коэффициенты преобразования вместе с векторами движения и некоторой управляющей информацией образуют полное представление закодированной последовательности и их называют синтаксическими элементами. Перед передачей из кодера в декодер все синтаксические элементы кодируют с учетом энтропии таким образом, чтобы дополнительно уменьшить число бит, необходимых для их представления.
В декодере блок в текущем кадре получают сначала с помощью составления его прогноза таким же способом, как в кодере, и с помощью добавления к прогнозу ошибки сжатого прогноза. Ошибку сжатого прогноза находят с помощью взвешивания базовых функций преобразования с использованием квантованных коэффициентов. Разность между восстановленным кадром и исходным кадром называют ошибкой восстановления.
Коэффициентом сжатия, т.е. отношением числа бит, использованных, чтобы представить исходную и сжатую последовательности, обе в случае блоков I и Р, управляют с помощью регулирования величины параметра квантования, который используют, чтобы квантовать коэффициенты преобразования. Коэффициент сжатия также зависит от использованного способа кодирования энтропии.
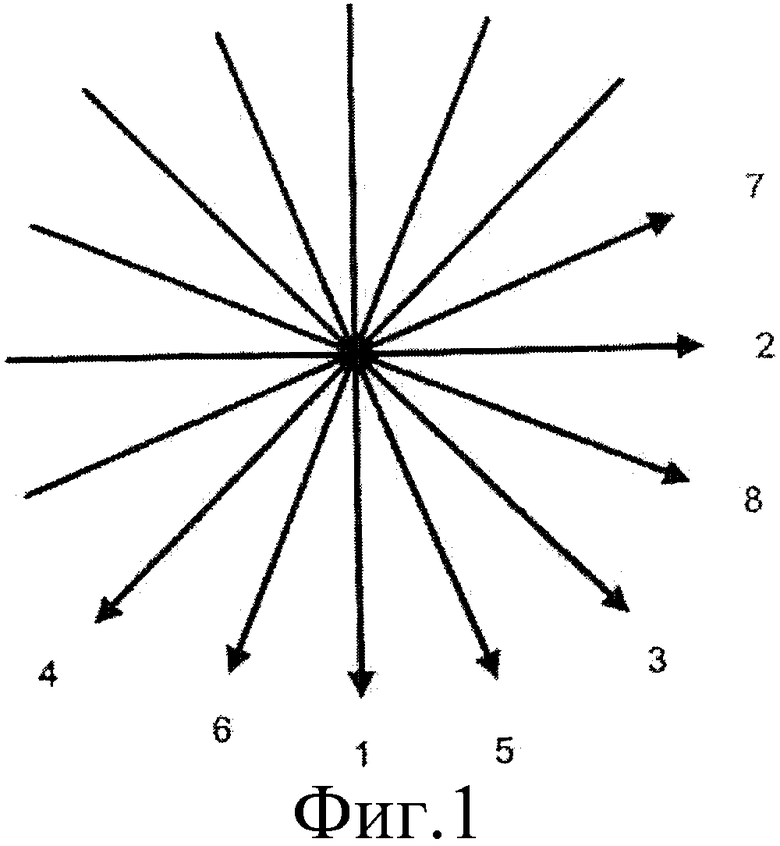
Пример пространственного прогнозирования, использованного в рабочем проекте номер 2 (WD2, РП2) кодера JVT описан следующим образом. Для того чтобы выполнить пространственное прогнозирование, кодер IVT предлагает 9 режимов для прогнозирования блоков 4х4, включая прогнозирование DC (режим 0) и режимы 8-ми направлений, отмеченные с 1 по 7, как изображено на фиг.1. Процесс прогнозирования проиллюстрирован на фиг.2. Как изображено на фиг.2, пиксели от а до р должны быть закодированы, а пиксели от A до Q из соседних блоков, которые уже закодированы, используют для прогнозирования. Если, например, выбран режим 1, тогда пиксели а, е, i и m прогнозируют с помощью установки их равными пикселю А, а пиксели b, f, j и n прогнозируют с помощью установки их равными пикселю В и т. д. Аналогично, если выбран режим 2, пиксели а, b, c и d прогнозируют с помощью установки их равными пикселю I, а пиксели e, f, g и h прогнозируют с помощью установки их равными пикселю J и т. д. Следовательно, режим 1 является прогнозирующим режимом в вертикальном направлении, а режим 2 является прогнозирующим режимом в горизонтальном направлении. Эти режимы описаны в документе VCEG-N54, опубликованном сектором стандартизации телекоммуникаций экспертной группы по кодированию видеоизображений (VCEG) ITU в сентябре 2001 г., и в документе JVT-B118r2, опубликованном совместной группой по видеоизображениям ISO/IEC MPEG и ITU-T VCEG в марте 2002 г.
Режим 0: прогнозирование DC
Обычно все выборки прогнозируют с помощью (A+B+C+D+I+J+K+L+4)>>3. Если четыре из выборок находятся вне изображения, среднее из остальных четырех используют для прогнозирования. Если все восемь выборок находятся вне изображения, прогнозирование для всех выборок в блоке равно 128. Следовательно, блок всегда может быть спрогнозирован в этом режиме.
Режим 1: вертикальное прогнозирование
Если A,B,C,D находятся внутри изображения, тогда
- a,e,i,m предсказывают с помощью А,
- b,f,j,n предсказывают с помощью B,
- c,g,k,o предсказывают с помощью C,
- d,h,l,p предсказывают с помощью D.
Режим 2: горизонтальное прогнозирование
Если E,F,G,H находятся внутри изображения, тогда
- a,b,c,d предсказывают с помощью E,
- e,f,g,h предсказывают с помощью F,
- i,j,k,l предсказывают с помощью G,
- m,n,o,p предсказывают с помощью H.
Режим 3: диагональное прогнозирование вниз/вправо
Этот режим используют только, если все A, B, C, D, I, J, K, L, Q находятся внутри изображения. Это является "диагональным" прогнозированием.
- m прогнозируют с помощью (J+2K+L+2)>>2
- i,n прогнозируют с помощью (I+2J+K+2)>>2
- e,j,o прогнозируют с помощью (Q+2I+J+2)>>2
- a,f,k,p прогнозируют с помощью (A+2Q+I+2)>>2
- b,g,l прогнозируют с помощью (Q+2A+B+2)>>2
- c,h прогнозируют с помощью (A+2B+D+2)>>2
- d прогнозируют с помощью (B+2C+D+2)>>2
Режим 4: диагональное прогнозирование вниз/влево
Этот режим используют только, если все A, B, C, D, I, J, K, L, Q находятся внутри изображения. Это является "диагональным" прогнозированием.
- а прогнозируют с помощью (A+2B+C+I+2J+K+4)>>3
- b,e прогнозируют с помощью (A+2B+C+I+2J+K+4)>>3
- c,f,i прогнозируют с помощью (C+2D+E+R+2L+M+4)>>3
- d,g,j,m прогнозируют с помощью (D+2E+F+L+2M+N+4)>>3
- h,k,n прогнозируют с помощью (E+2F+G+M+2N+O+4)>>3
- l,o прогнозируют с помощью (F+2G+H+N+2O+P+4)>>3
- p прогнозируют с помощью (G+H+O+P+2)>>3
Режим 5: вертикальное-левое прогнозирование
Этот режим используют только, если все A, B, C, D, I, J, K, L, Q находятся внутри изображения. Это является "диагональным" прогнозированием.
- a, j прогнозируют с помощью (Q+A+1)>>1
- b,k прогнозируют с помощью (A+B+1)>>1
- c,l прогнозируют с помощью (B+C+1)>>1
- d прогнозируют с помощью (C+D+1)>>1
- e,n прогнозируют с помощью (I+2Q+A+2)>>2
- f,o прогнозируют с помощью (Q+2A+B+2)>>2
- g,p прогнозируют с помощью (A+2B+C+2)>>2
- h прогнозируют с помощью (B+2C+D+2)>>2
- i прогнозируют с помощью (Q+2I+J+2)>>2
- m прогнозируют с помощью (I+2J+K+2)>>2
Режим 6: вертикальное-правое прогнозирование
Этот режим используют только, если все A, B, C, D, I, J, K, L, Q находятся внутри изображения. Это является "диагональным" прогнозированием.
- a прогнозируют с помощью (2A+2B+J+2K+L+4)>>3
- b,i прогнозируют с помощью (B+C+1)>>1
- c,j прогнозируют с помощью (C+D+1)>>1
- d,k прогнозируют с помощью (D+E+1)>>1
- l прогнозируют с помощью (E+F+1)>>1
- e прогнозируют с помощью (A+2B+C+K+2L+M+4)>>3
- f,m прогнозируют с помощью (B+2C+D+2)>>2
- g,n прогнозируют с помощью (C+2D+E+2)>>2
- h,o прогнозируют с помощью (D+2E+F+2)>>2
- p прогнозируют с помощью (E+2F+G+2)>>2
Режим 7: горизонтальное прогнозирование вверх
Этот режим используют только, если все A, B, C, D, I, J, K, L, Q находятся внутри изображения. Это является "диагональным" прогнозированием.
- a прогнозируют с помощью (B+2C+D+2I+2J+4)>>3
- b прогнозируют с помощью (C+2D+E+I+2J+K+4)>>3
- c,e прогнозируют с помощью (D+2E+F+2J+2K+4)>>3
- d,f прогнозируют с помощью (E+2F+G+J+2K+2L+4)>>3
- g,i прогнозируют с помощью (F+2G+H+2K+2L+4)>>3
- h,j прогнозируют с помощью (G+3H++K+3L+4)>>3
- l,n прогнозируют с помощью (L+2M+N+2)>>3
- k,m прогнозируют с помощью (G+H+L+M+2)>>2
- o прогнозируют с помощью (M+N+1)>>1
- p прогнозируют с помощью (M+2N+O+2)>>2
Режим 8: горизонтальное прогнозирование вниз
Этот режим используют только, если все A, B, C, D, I, J, K, L, Q находятся внутри изображения. Это является "диагональным" прогнозированием.
- a,g прогнозируют с помощью (Q+I+1)>>1
- b,h прогнозируют с помощью (I+2Q+A+2)>>2
- c прогнозируют с помощью (Q+2A+B+2)>>2
- d прогнозируют с помощью (A+2B+C+2)>>2
- e,k прогнозируют с помощью (I+J+1)>>1
- f,l прогнозируют с помощью (Q+2I+J+2)>>2
- i,o прогнозируют с помощью (J+K+1)>>1
- j,p прогнозируют с помощью (I+2J+K+2)>>2
- m прогнозируют с помощью (K+L+1)>>1
- n прогнозируют с помощью (J+2K+L+2)>>2
Поскольку каждый блок должен иметь режим прогнозирования, назначаемый и передаваемый в декодер, это потребовало бы значительного числа бит, если закодирован непосредственно. Для того чтобы уменьшить количество передаваемой информации, может быть использована корреляция режимов прогнозирования соседних блоков. Например, заявка на патент, принадлежащая Ватери и др. (WO 01/54416 А1 "Способ кодирования изображений и кодер изображений", далее упоминаемая как Ватери), раскрывает способ кодирования на основе блоков, в котором используют информацию направленности изображения в блоках, чтобы классифицировать множество режимов пространственного прогнозирования. Этот режим пространственного прогнозирования блока определяют с помощью информации направленности, по меньшей мере, соседнего блока.
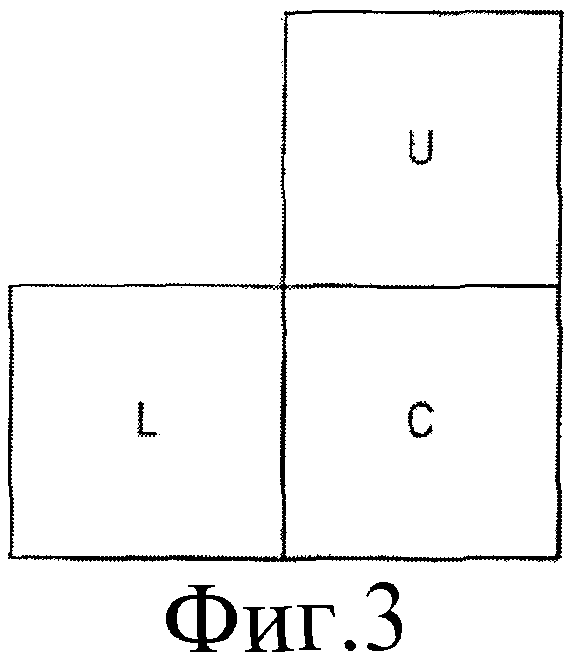
В кодере JVT, когда режимы прогнозирования соседних уже закодированных блоков U и L известны, дано упорядочение наиболее вероятного режима прогнозирования, следующего наиболее вероятного режима прогнозирования и т. д. для блока С (фиг.3). Упорядочение режимов задают для каждой комбинации режимов прогнозирования U и L. Эта упорядоченность может быть задана как список режимов прогнозирования для блока С, упорядоченных от наиболее вероятного до наименее вероятного режима. Упорядоченный список, использованный в РП2 кодера JVT, как раскрыто в VCEG-N54, приведен ниже:
В настоящем описании приведен пример режимов прогнозирования для блока C, как задано в РП2 кодера JVT, когда режим прогнозирования как для U, так и для L равен 2. Последовательность (2,8,7,1,0,6,4,3,5) указывает, что режим 2 является также наиболее вероятным режимом для блока С. Режим 8 является следующим наиболее вероятным режимом и т.д. В декодер будет передана информация, указывающая, что n-ый наиболее вероятный режим будет использован для блока С. Упорядочение режимов для блока С может быть также задано с помощью перечисления ранга для каждого режима: чем выше ранг, тем менее вероятным является способ прогнозирования. Для приведенного выше примера список рангов будет равен (5,4,1,8,7,9,6,3,2). Когда режимы (0,1,2,3,4,5,6,7,8) связаны со списком рангов (5,4,1,8,7,9,6,3,2), можно сказать, что режим 0 имеет ранг 5, режим 1 имеет ранг 4 и т. д.
Для более эффективного кодирования информация внутреннего прогнозирования двух блоков 4х4 может быть закодирована в одном кодовом слове.
Вышеупомянутый способ имеет один главный недостаток - требуется память, необходимая для хранения упорядочения режимов прогнозирования для блока С, при условии данных режимов прогнозирования блоков U и L. В РП2 кодера JVT, поскольку для прогнозирования используют 9 режимов, имеется 9х9 возможных комбинаций режимов для блоков U и L. Для каждой комбинации должно быть задано упорядочение 9 возможных режимов. Это значит, что требуется 9х9х9 байт (в настоящем описании заявитель допускает, что одно число требует один байт), чтобы задать упорядочение режимов прогнозирования. Кроме того, больше памяти может требоваться, чтобы задать специальные случаи, например, если один или оба блока U и L недоступны.
Следовательно, выгодно и желательно предоставить способ и устройство, предназначенные для кодирования цифрового изображения, в которых требования памяти уменьшены, в то время как потеря в эффективности кодирования является минимальной.
Сущность изобретения
Предложены способ и устройство, предназначенные для кодирования цифрового изображения с использованием блочного прогнозирования внутреннего режима. Получают список режимов прогнозирования для каждой комбинации режимов прогнозирования соседних блоков. Режимы, назначенные для каждой комбинации режимов прогнозирования, могут быть разделены на две группы. Первая группа включает в себя m (где m меньше чем общее число n имеющихся режимов) наиболее вероятных режимов прогнозирования, а вторая группа включает в себя остальные режимы. Режимы в первой группе упорядочивают в соответствии с их вероятностью. Эта упорядоченность может быть задана как список режимов, упорядоченных от наиболее вероятного до наименее вероятного режима. Режимы, принадлежащие ко второй группе, могут быть упорядочены некоторым заданным способом, который может быть задан в зависимости от информации, уже имеющейся в декодере. Информацию относительно того, принадлежит ли режим, выбранный для данного блока, к первой группе или ко второй группе, посылают в декодер. Если он принадлежит к первой группе, передают информацию, указывающую, что i-ый наиболее вероятный режим будет использован для блока С при условии данной комбинации режимов для блоков U и L. Если режим принадлежит ко второй группе, передают информацию, указывающую, что должен быть использован j-ый режим этой группы.
Настоящее изобретение станет понятным после прочтения описания, взятого совместно с фиг. с 4а по 8.
Краткое описание чертежей
Фиг.1 представляет схематическое представление, иллюстрирующее 8 направленных режимов, которые используют как режимы пространственного прогнозирования.
Фиг.2 представляет схематическое представление, иллюстрирующее пиксели, которые используют для прогнозирования текущего блока 4х4 пикселей.
Фиг.3 представляет схематическое представление, иллюстрирующее два соседних блока, используемых для прогнозирования текущего блока.
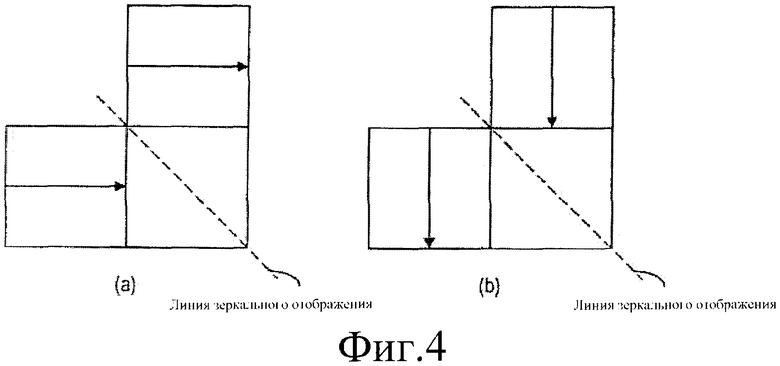
Фиг.4а представляет схематическое представление, иллюстрирующее режим пространственного прогнозирования двух соседних блоков, использованных для прогнозирования текущего блока.
Фиг.4b представляет схематическое представление, иллюстрирующее режим пространственного прогнозирования двух соседних блоков, имеющих зеркально отображенную зависимость с блоками фиг.4а.
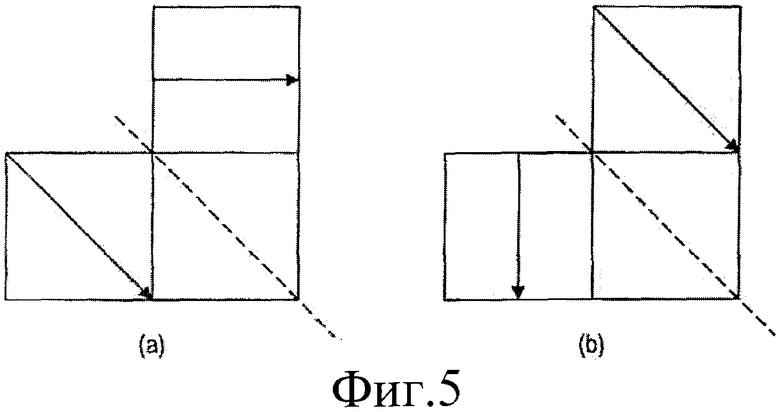
Фиг.5а представляет схематическое представление, иллюстрирующее другой режим пространственного прогнозирования.
Фиг.5b представляет схематическое представление, иллюстрирующее зеркально отображенную пару режима.
Фиг.6 представляет блок-схему, иллюстрирующую способ пространственного прогнозирования.
Фиг.7 представляет блок-схему, иллюстрирующую систему передачи блока цифрового изображения, предназначенную для реализации способа в соответствии с вариантом осуществления настоящего изобретения.
Фиг.8 представляет блок-схему, иллюстрирующую портативное устройство видеотелекоммуникаций, реализующее способ в соответствии с вариантом осуществления настоящего изобретения.
Наилучший способ для выполнения изобретения
Вариант осуществления настоящего изобретения использует то свойство, что можно получить упорядоченный список режимов прогнозирования для одной комбинации режимов прогнозирования соседних блоков как функцию режимов прогнозирования другой комбинации. С целью иллюстрации режимы прогнозирования двух соседних блоков U и L, как изображено на фиг.3, используют для того, чтобы логически выводить прогнозирование текущего блока С. Следует заметить, что комбинация режимов прогнозирования на фиг.4а может быть получена с помощью обращения режимов прогнозирования относительно диагонали, как изображено на фиг.4b. Таким образом, n-ый наиболее вероятный режим прогнозирования для блока С, когда используют комбинацию режимов на фиг.4а, должен быть тем же самым, что и "обращенный относительно диагонали" n-ый наиболее вероятный режим прогнозирования для комбинации режимов на фиг. 4b. Следовательно, если соседние блоки U и L имеют режимы "вертикальный" и "вертикальный", режим прогнозирования текущего блока, наиболее вероятно, является "вертикальным" (фиг.4b). Следовательно, когда эти блоки "обращены" или зеркально отображены относительно диагонали ("вниз/вправо"), известно, что из "горизонтального" и "горизонтального" должен быть получен "горизонтальный" для текущего блока (фиг.4а). Аналогично, если соседние блоки U и L являются блоками режимов 2 и 3, как изображено на фиг. 5а, тогда обращенные блоки U и L будут блоками режимов 3 и 1, как изображено на фиг.5b.
Для того чтобы дополнительно проиллюстрировать этот пример, заявитель определяет функцию f, которая отображает направление прогнозирования i в j, j=f(i). Каждому режиму i прогнозирования назначают режим j прогнозирования, полученный с помощью зеркального отображения его относительно диагональной линии, проходящей из верхнего левого угла блока в нижний правый угол блока. Для режимов прогнозирования на фиг. 1 результирующее назначение резюмировано в таблице II.
Когда функция определена, как указано выше, упорядоченный список режимов прогнозирования для комбинации режимов (k,l) может быть определен на основании упорядоченного списка для комбинации (i,j) таким образом, что i=f(l) и j=f(k), т.е., если режим p прогнозирования является n-ым наиболее вероятным режимом для комбинации (i,j), n-ый режим для комбинации (k,l) равен f(p). В качестве примера заявитель рассматривает комбинацию режимов (1,1), которой назначен упорядоченный список режимов для блока С: (1,6,2,5,3,0,4,8,7). Было бы возможно получить упорядоченный список режимов прогнозирования для комбинации (2,2) из этого упорядоченного списка с помощью отображения с использованием функции f: (2,7,1,8,3,0,4,6,5). Аналогично упорядоченный список режимов прогнозирования для комбинации (2,3) равен (2,0,8,1,3,7,5,4,6), а упорядоченный список режимов f(2,3)=(3,1) равен f(2,0,8,1,3,7,5,4,6)=(1,0,5,2,3,6,8,4,7). Следует заметить, что упорядоченный список режимов прогнозирования для (k,l), по существу, может быть симметричным списку для (i,j). Следовательно, функция f отображения может быть описана как функция зеркального отображения.
Первичной задачей настоящего изобретения является уменьшить размер таблицы, задающей режим прогнозирования как функцию режимов прогнозирования уже закодированных соседних блоков (например, таблица 1). Эта таблица получена во время процесса обучения. Чтобы получить упорядоченный список режимов прогнозирования для комбинации режимов (i,j) для некоторого большого числа блоков С, для которых соседние блоки имеют эту комбинацию, подсчитывают число, когда выбран каждый режим прогнозирования в соответствии с данным критерием выбора (например, наименьшая ошибка прогнозирования). Это число определяет ранг режима прогнозирования в списке режимов прогнозирования, назначенных комбинации (i,j), чем более часто выбирают режим, тем выше ранг, который он имеет в списке режимов прогнозирования.
Когда во время процесса обучения используют описанное отображение режимов прогнозирования, результирующая таблица, задающая режимы прогнозирования, будет меньше. Если упорядоченный список для комбинации (k,l) может быть получен из упорядоченного списка для комбинации (i,l), должен быть запомнен только упорядоченный список для комбинации (i,j). Во время обучения отображение может быть представлено следующим образом. Частоту появления каждого режима прогнозирования для комбинаций (k,l) и (i,j), таких что i=f(l) и j=f(k), подсчитывают совместно, т. е., если режим p прогнозирования был выбран для комбинации (k,l), также считают, что режим f(p) прогнозирования был выбран для комбинации (i,j). Также, когда режим p прогнозирования был выбран для комбинации (i,j), считают, что режим f(s) прогнозирования был выбран для комбинации (k,l).
Уменьшенная таблица в соответствии с настоящим изобретением изображена в таблице III.
В таблице III для некоторых комбинаций (U,L) не дан упорядоченный список режимов прогнозирования. Упорядоченные списки для этих комбинаций могут быть "восстановлены" с помощью отображения соответствующих элементов, которые оставлены в таблице прогнозирования, когда эти "восстановленные" элементы необходимы для прогнозирования текущего блока. Следовательно, обычно, поскольку элемент в таблице прогнозирования может быть получен или восстановлен из другого элемента в таблице прогнозирования посредством отображения, первый элемент может быть исключен. Иначе говоря, в таблице прогнозирования, содержащей первую группу элементов и вторую группу элементов, причем каждый элемент из второй группы элементов может быть восстановлен из соответствующего элемента первой группы с помощью функции отображения, вторая группа элементов может быть исключена.
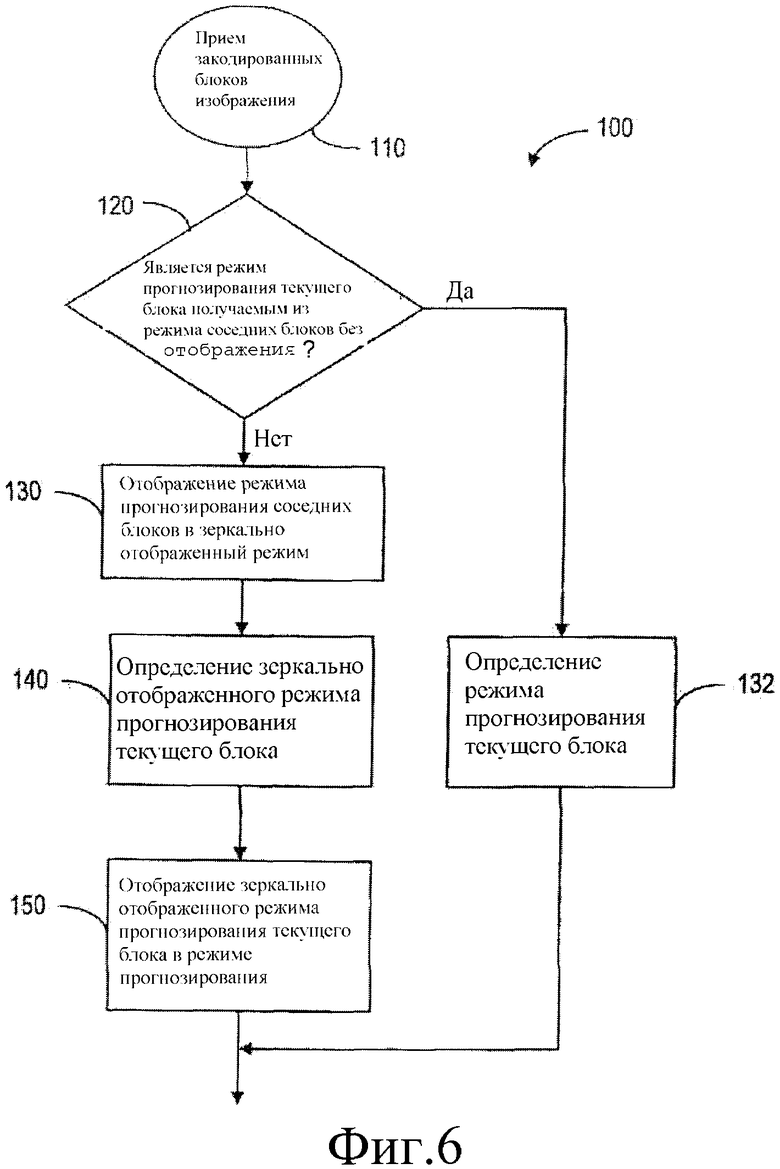
Фиг.6 представляет блок-схему, иллюстрирующую этап декодирования, когда используют симметрию в таблице прогнозирования. Как изображено, способ 100 содержит этап 110, на котором принимают множество блоков изображения. Когда текущий блок обработан, на этапе 120 определяют, может ли быть получен режим прогнозирования текущего блока из режима прогнозирования соседних блоков без отображения. Если это справедливо, тогда режим пространственного прогнозирования текущего блока определяют на основании режима прогнозирования соседних блоков на этапе 132. Иначе обеспечивают дополнительный режим прогнозирования соседних блоков на этапе 130 и определяют дополнительный режим прогнозирования текущего блока на основании дополнительного режима прогнозирования соседних блоков на этапе 140. На этапе 150 дополнительный режим прогнозирования текущего блока отображают в режим прогнозирования текущего блока.
В качестве альтернативы возможно назначение одной и той же метки разным режимам прогнозирования (группируя их вместе) блоков U и L перед их использованием для задания режима прогнозирования для блока С. Например, в случае кодера JVT режимы 1,5 и 6, могут быть сгруппированы вместе и отмечены как 1, а режимы 2,7 и 8, могут быть сгруппированы вместе и отмечены как 2. Как видно из фиг.1, направления режимов 7 и 8 находятся близко к направлению режима 2, а направления режимов 5 и 6 находятся близко к направлению режима 1. После этой группировки каждый из блоков U и L может иметь один из 5 режимов, отмеченных как 0,1,2,3 и 4. Следовательно, вместо 9х9 возможных комбинаций режимов прогнозирования U и L имеется только 5х5 таких комбинаций. Таким образом, память, необходимая для того, чтобы задать упорядочение режимов прогнозирования для блока С при условии данных режимов прогнозирования блоков U и L, будет 5х5х9 байт вместо 9х9х9 байт (допуская, что 1 байт памяти необходим для того, чтобы хранить 1 цифру). Кроме того, если используют функцию f отображения для "обращения" упорядоченного списка, таблица прогнозирования может быть дополнительно упрощена.
Пример таблицы, задающей режим прогнозирования как функцию упорядочения, передаваемую в виде сигнала в битовом потоке, когда оба этих способа используют совместно, представлен в таблице IV.
Кроме того, также возможно ограничить число режимов прогнозирования для блока С при условии данных режимов прогнозирования блоков U и L. В случае кодера JVT по-прежнему было бы 9х9 возможных комбинаций режимов прогнозирования U и L. Но каждой из этих комбинаций было бы назначено только m режимов, где m меньше чем 9. Таким образом, число возможных режимов прогнозирования уменьшают до (9х9xm)<(9х9х9). Аналогично, если используют функцию f отображения для "обращения" упорядоченных списков, таблица прогнозирования может быть дополнительно упрощена.
Эти способы могут быть использованы совместно или отдельно.
Основанное на пространственном прогнозировании внутреннее кодирование в соответствии с настоящим изобретением может быть легко встроено в цифровую систему передачи блоков изображения, как изображено на фиг.7. Допуская, что кадр должен быть закодирован во внутреннем формате с использованием некоторого вида внутреннего прогнозирования, кодирование кадра происходит следующим образом. Блоки кодируемого кадра направляют последовательно в кодер 50 системы видеопередачи, представленной на фиг.7. Блоки кадра принимают из источника цифрового изображения, например камеры или видеомагнитофона (не изображены), на входе 27 системы передачи изображения. В способе, известном сам по себе, блоки, принятые из источника цифрового изображения, содержат величины пикселей изображения. Кадр может быть временно запомнен в памяти кадров (не изображена) или в качестве альтернативы, кодер принимает входные данные непосредственно блок за блоком.
Блоки последовательно направляют в блок 35 выбора способа прогнозирования, который определяет, могут ли величины пикселей текущего кодируемого блока быть спрогнозированы на основании ранее закодированных внутренним способом блоков в том же самом кадре или сегменте. Для того чтобы сделать это, блок 35 выбора способа прогнозирования принимает входные данные из буфера кадров кодера 33, который содержит запись ранее закодированных, а затем декодированных и восстановленных внутренних блоков. Таким образом, блок выбора способа прогнозирования может определить, может ли прогнозирование текущего блока быть выполнено на основании ранее декодированных и восстановленных блоков. Кроме того, если имеются соответствующие декодированные блоки, блок 35 выбора способа прогнозирования может выбрать наиболее подходящий способ прогнозирования величин пикселей текущего блока, если может быть выбран более чем один такой способ. Следует понять, что в определенных случаях прогнозирование текущего блока является невозможным, поскольку подходящие блоки для использования в прогнозировании отсутствуют в буфере 33 кадров. В ситуации, когда имеется более чем один способ прогнозирования, информацию о выбранном способе прогнозирования подают в мультиплексор 13 для дальнейшей передачи в декодер. Также следует заметить, что в некоторых способах прогнозирования определенные параметры, необходимые для того, чтобы выполнить прогнозирование, передают в декодер. Конечно, это зависит от точной принятой реализации и никоим образом не ограничивает приложение внутреннего кодирования, основанного на прогнозировании в соответствии с настоящим изобретением.
Величины пикселей текущего блока прогнозируют в блоке 34 внутреннего прогнозирования. Блок 34 внутреннего прогнозирования принимает входные данные, относящиеся к выбранному способу прогнозирования, из блока 35 выбора способа прогнозирования и информацию, относящуюся к блокам, имеющимся для использования в прогнозировании, из буфера 33 кадров. На основании этой информации блок 34 внутреннего прогнозирования составляет прогноз для текущего блока. Спрогнозированные величины пикселей для текущего блока посылают в дифференциальный сумматор 28, который создает блок ошибки прогнозирования с помощью взятия разности между величинами пикселей спрогнозированного текущего блока и фактическими величинами пикселей текущего блока, принятого из входа 27. Затем информацию об ошибке для спрогнозированного блока кодируют в блоке кодирования ошибки прогнозирования в эффективном виде для передачи, например, с использованием дискретного косинусного преобразования (ДКП). Закодированный блок ошибки прогнозирования посылают в мультиплексор 13 для дальнейшей передачи в декодер. Кодер системы передачи цифрового изображения также включает в себя функциональные средства декодирования. Закодированную ошибку прогнозирования текущего блока декодируют в блоке 30 декодирования ошибки прогнозирования, а затем суммируют в сумматоре 31 со спрогнозированными величинами пикселей для текущего блока. Таким образом получают закодированный вариант текущего блока. Закодированный текущий блок затем направляют в буфер 33 кадров.
В настоящем описании также предполагают, что приемник принимает блоки, которые образуют кадр цифрового изображения, только по одному из каналов передачи.
В приемнике 60 демультиплексор принимает блоки демультиплексированной закодированной ошибки прогнозирования и информацию прогнозирования, переданную из кодера 50. В зависимости от рассматриваемого способа прогнозирования информация прогнозирования может включать в себя параметры, используемые в процессе прогнозирования. Следует понимать, что в случае, когда используют только один способ прогнозирования, информация, относящаяся к способу прогнозирования, использованному для кодирования блоков, является необязательной, хотя она по-прежнему может быть необходима, чтобы передавать параметры, используемые в процессе прогнозирования. На фиг.7 пунктирные линии используются, чтобы представлять необязательную передачу и прием информации о способе прогнозирования и/или параметров прогнозирования. Допуская, что может быть использован более чем один способ прогнозирования, информацию, относящуюся к выбору способа прогнозирования для текущего декодируемого блока, подают в блок 41 внутреннего прогнозирования. Блок 41 внутреннего прогнозирования исследует содержимое буфера 39 кадров, чтобы определить, существуют ли ранее закодированные блоки, предназначенные для использования в прогнозировании величин пикселей текущего блока. Если такие блоки изображения существуют, блок 41 внутреннего прогнозирования прогнозирует содержимое текущего блока с использованием способа прогнозирования, указанного с помощью принятой информации о способе прогнозирования, и, возможно, с помощью параметров, связанных с прогнозированием, принятых из кодера. Информацию об ошибке прогнозирования, связанную с текущим блоком, принимают с помощью блока 36 декодирования ошибки прогнозирования, который декодирует блок ошибки прогнозирования с использованием подходящего способа. Например, если информация об ошибке прогнозирования была декодирована с использованием дискретного косинусного преобразования, блок декодирования ошибки прогнозирования выполняет обратное ДКП, чтобы извлечь информацию об ошибке. Информацию об ошибке прогнозирования затем суммируют с прогнозом для текущего блока изображения в сумматоре 37 и выходные данные сумматора подают в буфер 39 кадров. Кроме того, так как каждый блок декодирован, его направляют на выход декодера 40, например, для отображения на некотором виде средства отображения. В качестве альтернативы кадр изображения может быть отображен только после того, как декодирован весь кадр и накоплен в буфере 39 кадров.
Следует заметить, что блок 34 внутреннего прогнозирования составляет прогноз текущего блока на основании ранее закодированных, а затем декодированных и восстановленных внутренних блоков, как предоставленных с помощью буфера 33 кадров. В частности, прогнозирование текущего блока определяют из режимов пространственного прогнозирования ранее восстановленных внутренних блоков с использованием таблицы прогнозирования, как изображено в таблице III или таблице IV (не изображены на фиг. 7). Однако, когда упорядоченный список для режимов (i,j) прогнозирования ранее восстановленных внутренних блоков пропущен в таблице прогнозирования, блок 32 преобразования может быть использован для отображения режимов пространственного прогнозирования ранее восстановленных блоков в дополнительные или зеркально отображенные режимы (k,l) пространственного прогнозирования. В этот момент блок 34 внутреннего прогнозирования может определить дополнительный или зеркально отображенный режим f(p) для текущего блока. Опять блок 32 отображения используют для получения режима p прогнозирования текущего блока с помощью отображения дополнительного режима f(p) прогнозирования. Таким же образом блок 38 отображения используют для отображения, когда необходимо.
Алгоритм отображения, который используют для выполнения отображения (i,j) в (k,l) и отображения f(p) в p, может быть закодирован в программе 69 программного обеспечения, которая содержит доступные для выполнения машиной этапы или псевдокоды, предназначенные для выполнения способа в соответствии с настоящим изобретением. Преимущественно программу программного обеспечения хранят на запоминающем носителе. Например, программу программного обеспечения хранят в устройстве памяти, находящемся в CPU, ЦП 70, или в отдельном устройстве 68 памяти, как изображено на фиг.8. Фиг.8 представляет упрощенную принципиальную схему подвижного терминала 90, предназначенного для использования в качестве портативного устройства видеотелекоммуникаций, осуществляющего способ отображения режима прогнозирования настоящего изобретения. Подвижный терминал 90 содержит, по меньшей мере, модуль 76 отображения, предназначенный для отображения изображений, устройство 72 захвата изображений и аудиомодуль 74 для захвата аудиоинформации из аудиоустройства 82 ввода и воспроизведения аудиоинформации на аудиоустройстве 80 воспроизведения. Преимущественно подвижный терминал 90 дополнительно содержит клавиатуру 70, предназначенную для ввода данных и команд, радиочастотный компонент 64, предназначенный для связи с мобильной телекоммуникационной сетью, и устройство 70 обработки сигналов/данных, предназначенное для управления работой телекоммуникационного устройства. Предпочтительно система (50, 60) передачи блока цифрового изображения реализована в процессоре 70.
В соответствии с дополнительным вариантом осуществления настоящего изобретения требования к памяти могли бы быть ограничены при получении эффективности кодирования.
Заявитель заметил, что для каждой комбинации режимов для блоков U и L имеется только несколько режимов для блока С, которые имеют высокую вероятность появления. Вероятность остальных режимов является значительно меньшей. Кроме того, вероятности появления этих остальных режимов являются одинаковыми и, следовательно, их упорядоченность в упорядоченном множестве режимов не имеет сильного влияния на эффективность кодирования.
Режимы, назначенные каждой комбинации режимов прогнозирования U и L, могут быть разделены на две группы. Первая группа включает в себя m (где m меньше чем общее число n имеющихся режимов) наиболее вероятных режимов прогнозирования, а вторая группа включает в себя остальные режимы. Режимы в первой группе упорядочены в соответствии с их вероятностью. Как описано выше, эта упорядоченность может быть задана как список режимов, упорядоченных от наиболее вероятного до наименее вероятного режима. Эти режимы, принадлежащие ко второй группе, могут быть упорядочены некоторым заданным способом, который может быть задан в зависимости от информации, уже доступной для декодера. Например, режим прогнозирования, который отмечен с использованием меньшего числа, может предшествовать режиму, который отмечен с помощью большего числа.
Иначе говоря, режимы прогнозирования расположены в упорядоченном множестве S. Упорядоченное множество режимов R, назначенных комбинаций режимов прогнозирования для U и L, создают с помощью объединения двух упорядоченных множеств режимов T={t1,t2,...,tk} и V={v1,v2,...,vl}:
R={t1,t2,...,tk, v1,v2,...,vl}.
Режимы в первом упорядоченном множестве Т упорядочены в соответствии с их ожидаемой вероятностью появления для комбинации режимов соседних блоков U и L. Чем более часто ожидается появление режима, тем меньше бит должно быть использовано, чтобы передавать сигнал о нем. Второе упорядоченное множество режимов V создано с помощью удаления элементов первого множества Т из множества S и сохранения упорядоченности остальных элементов. Например, если прогнозирование i предшествует режиму j прогнозирования в упорядоченном множестве S, прогнозирование i должно предшествовать режиму j прогнозирования в множестве V.
В качестве отдельного примера заявитель рассматривает режимы, имеющиеся в кодере JVT, и допускает, что для каждой комбинации режимов для блоков U и L только наиболее вероятный режим назначен в первую группу. Остальные 8 режимов перечислены в возрастающей последовательности их номеров. Чтобы дополнительно проиллюстрировать этот отдельный пример, заявитель рассматривает комбинацию режимов (1,1), которой назначен режим 1 как наиболее вероятный режим. Режим 1 составляет первое упорядоченное множество S, т. е. V={0,2,3,4,5,6,7,8}. В данном примере упорядоченное множество S создано с помощью перечисления девяти режимов прогнозирования в возрастающей последовательности номеров, т. е. S={0,1,2,3,4,5,6,7,8}.
Информацию относительно того, принадлежит ли режим, выбранный для данного блока, к первой группе или ко второй группе, посылают в декодер. Если он принадлежит к первой группе, передают информацию, указывающую, что i-ый наиболее вероятный режим будет использован для блока С при условии данной комбинации режимов для блоков U и L. В этом отдельном примере, если декодер принимает информацию о том, что выбрана первая группа, никакая дополнительная информация не требуется, поскольку только один режим принадлежит к этой группе. Если режим принадлежит ко второй группе, передают информацию, указывающую, что должен быть использован j-ый режим этой группы. В этом отдельном примере, если принята информация, что должен быть выбран первый режим, должен быть выбран режим 0.
Альтернативные варианты осуществления:
1. Правила, в соответствии с которыми упорядочивают режимы в множестве S, могут отличаться.
2. Способ, которым задают элементы первого множества T, зависит от режимов прогнозирования соседних блоков U и L. Элементы этого множества могут быть заданы, например, как таблица, хранимая в памяти как кодера, так и декодера, или они могут быть логически выведены из самих режимов U и L.
3. Передача сигнала в декодер относительно того, какой режим выбран, может быть выполнена многочисленными способами, например:
- может быть передана информация о ранге режима прогнозирования в упорядоченном множестве R;
- за информацией относительно того, какое множество - T или V выбрано, следует ранг режима в выбранном множестве.
Предпочтительная реализация для режимов прогнозирования, заданных в кодере JVT, описана следующим образом.
Одна и та же метка может быть назначена разным режимам прогнозирования блоков U и L перед использованием их для задания режима прогнозирования для блока С. Диагональные режимы 3, 5 и 8 сгруппированы вместе и обозначены как 3, а диагональные режимы 4, 6 и 7 сгруппированы вместе и обозначены как 4. После этой группировки каждый из блоков U и L может иметь один из пяти режимов, обозначенных как 0, 1, 2, 3 и 4. Следовательно, вместо 9х9 возможных комбинаций режимов прогнозирования U и L имеется только 5х5 таких комбинаций.
Упорядоченное множество S создано с помощью перечисления девяти режимов прогнозирования в возрастающей последовательности их номеров, т. е. S={0,1,2,3,4,5,6,7,8}. Для каждой комбинации режимов прогнозирования для U и L назначен только один наиболее вероятный режим, т. е. упорядоченное множество Т для каждой комбинации состоит только из одного элемента. Назначение дано в таблице V.
Первую информацию относительно того, использован ли наиболее вероятный режим, посылают в декодер. Эта информация закодирована совместно для двух блоков 4х4, как дано в таблице ниже.
Х обозначает, что должен быть использован наиболее вероятный режим. Для блоков, для которых не использован наиболее вероятный режим m, передают номер кода от 0 до 7, указывающий, какой из остальных режимов должен быть использован. Поскольку остальные режимы упорядочены в соответствии с их номерами, режим с меньшим номером предшествует режиму с более высоким номером, когда номер q кода принимают, использованный режим прогнозирования равен:
q, если q<m;
q+1, в противном случае.
Номер q кода посылают как кодовое слово из 3-х бит, которое является двоичным представлением соответствующего номера кода.
Сохранения в памяти для способа в соответствии с настоящим изобретением исходят из того факта, что декодер для каждой комбинации режимов блоков U и L должен запомнить, самое большее, упорядоченные множества S и T, пока S является одинаковым для всей комбинации режимов для блоков U и L.
В итоге настоящее изобретение предлагает способы, устройства и системы, предназначенные для кодирования в битовый поток и декодирования из битового потока информации изображения, содержащей множество блоков изображения, с использованием множества режимов пространственного прогнозирования для внутреннего режима прогнозирования блока. Режим пространственного прогнозирования текущего блока (С) может быть определен на основании множества полученных режимов прогнозирования, полученных из режимов пространственного прогнозирования множества соседних блоков (U, L) текущего блока (С). Множество из n полученных режимов прогнозирования группируют в первую группу из m первых режимов прогнозирования с m<n и вторую группу вторых режимов прогнозирования. Первые режимы прогнозирования имеют более высокую вероятность появления, чем вторые режимы прогнозирования. В то время как первые режимы прогнозирования упорядочивают в соответствии с вероятностью их появления, вторые режимы прогнозирования располагают заданным образом, известным декодеру. Следовательно, упорядоченное множество подают в устройство декодирования таким образом, чтобы дать возможность устройству декодирования определить последовательность вторых режимов декодирования на основании поданного упорядоченного множества. Упорядоченное множество связано с одной или несколькими группами режимов пространственного прогнозирования соседних блоков (U, L) текущего блока. Кроме того, битовый поток может включать в себя закодированную информацию, указывающую, какой из первых режимов прогнозирования имеет наивысшую вероятность появления, когда полученный режим прогнозирования с наивысшей вероятностью появления выбран для использования в кодировании текущего блока (С). Настоящее изобретение также предлагает компьютерную программу, имеющую псевдокоды, предназначенные для использования в группировке множества полученных режимов прогнозирования в первую и вторую группы и в упорядочении первых режимов прогнозирования в соответствии с вероятностью появления среди первых режимов прогнозирования.
Несмотря на то, что изобретение описано относительно предпочтительного варианта его осуществления, специалистам в данной области техники будет понятно, что могут быть сделаны вышеупомянутые и другие изменения, пропуски и отклонения изобретения по форме и деталям, не выходя за рамки объема этого изобретения.

Изобретение относится к кодированию изобретений и более конкретно к кодированию блоков видеокадров. Предложены способ и устройство, предназначенные для кодирования цифрового изображения с использованием прогнозирования блока во внутреннем режиме, причем список режимов прогнозирования получают для каждой комбинации режимов прогнозирования соседних блоков. Режимы, назначенные для каждой комбинации режимов прогнозирования, могут быть разделены на две группы. Первая группа имеет m наиболее вероятных режимов прогнозирования, а вторая группа имеет n-m режимов прогнозирования, при этом n является общим числом имеющихся режимов прогнозирования. Режимы в первой группе упорядочивают в соответствии с их вероятностью. Эта упорядоченность может быть задана как список режимов, упорядоченных от наиболее вероятного до наименее вероятного режима. Режимы, принадлежащие ко второй группе, могут быть упорядочены некоторым заданным способом, который может быть задан в зависимости от информации, уже имеющейся в декодере. Технический результат - сокращение объема памяти при минимальной потере эффективности кодирования. 6 н. и 23 з.п. ф-лы, 6 табл., 8 ил.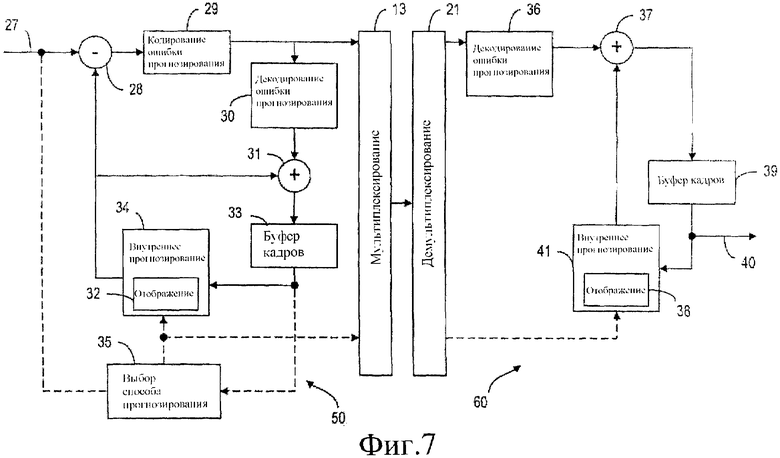
разделяют режимы прогнозирования для каждой комбинации режимов прогнозирования в первую группу и вторую группу, причем первая группа режимов прогнозирования имеет m режимов прогнозирования, а вторая группа режимов прогнозирования имеет (n-m) режимов прогнозирования, при этом n является общим числом имеющихся режимов прогнозирования и m меньше n, и, кроме того, первая группа режимов прогнозирования имеет более высокую вероятность появления, чем вторая группа режимов прогнозирования, и
кодируют в битовый поток информацию, указывающую, принадлежит ли режим пространственного прогнозирования текущего блока к упомянутой первой группе или к упомянутой второй группе.
кодируют в битовый поток информацию, указывающую, какой из первой группы режимов прогнозирования имеет наивысшую вероятность появления, когда полученная комбинация режимов прогнозирования с наивысшей вероятностью появления выбрана для использования в кодировании текущего блока.
удаляют целые числа, соответствующие первой группе режимов прогнозирования, из упорядоченного множества режимов прогнозирования для предоставления модифицированного упорядоченного множества режимов прогнозирования таким образом, чтобы дать возможность устройству декодирования определить последовательность второй группы режимов прогнозирования на основании модифицированного упорядоченного множества режимов прогнозирования.
обеспечивают устройство декодирования информацией, указывающей i-й режим среди второй группы режимов прогнозирования, если выбранный режим комбинации режимов прогнозирования находится во второй группе.
отображают полученные комбинации режимов пространственного прогнозирования соседних блоков для предоставления дополнительной комбинации режимов прогнозирования соседних блоков, когда необходимо, с помощью
определения дополнительного режима прогнозирования текущего блока на основании дополнительной комбинации режимов прогнозирования соседних блоков и с помощью
отображения дополнительного режима прогнозирования текущего блока для получения режима пространственного прогнозирования текущего блока.
отображение дополнительного режима прогнозирования упомянутого блока выполняют с помощью функции зеркального отображения.
средство, предназначенное для разделения режимов прогнозирования каждой комбинации режимов прогнозирования в первую группу и вторую группу, причем первая группа имеет m режимов прогнозирования, а вторая группа имеет (n-m) режимов прогнозирования, при этом n является общим числом имеющихся режимов прогнозирования и m меньше n, и, кроме того, первая группа режимов прогнозирования имеет более высокую вероятность появления, чем вторая группы режимов прогнозирования, и вторая группа режимов прогнозирования упорядочена заданным образом, известным устройству декодирования.
средство, предназначенное для кодирования в битовый поток информации, указывающей, принадлежит ли режим пространственного прогнозирования текущего блока к упомянутой первой группе или к упомянутой второй группе.
средство, реагирующее на упомянутую первую группу, предназначенное для упорядочения первой группы режимов прогнозирования в соответствии с вероятностью появления среди первой группы режимов прогнозирования для предоставления упорядоченного множества режимов прогнозирования.
средство, предназначенное для обеспечения устройства декодирования информацией, указывающей режимы прогнозирования в упорядоченном множестве режимов прогнозирования, которое имеет наивысшую вероятность появления.
средство, выполненное с возможностью предоставления дополнительного режима прогнозирования соседних блоков, когда необходимо, на основании режимов пространственного прогнозирования соседних блоков так, что дополнительный режим прогнозирования текущего блока может быть определен на основании дополнительного режима прогнозирования соседних блоков, и
средство, реагирующее на дополнительный режим прогнозирования текущего блока, предназначенное для обеспечения режима пространственного прогнозирования текущего блока на основании отображения дополнительного режима прогнозирования текущего блока.
разделяют режимы прогнозирования каждой комбинации режимов прогнозирования в первую группу и вторую группу, причем первая группа имеет m режимов прогнозирования, а вторая группа имеет (n-m) режимов прогнозирования, при этом n является общим числом имеющихся режимов прогнозирования и m меньше n, и, кроме того, первая группа режимов прогнозирования имеет более высокую вероятность появления, чем вторая группа режимов прогнозирования, и при этом информацию, указывающую, принадлежит ли режим пространственного прогнозирования текущего блока к упомянутой первой группе или упомянутой второй группе, кодируют в битовый поток, и
декодируют из битового потока информацию, указывающую, принадлежит ли режим пространственного прогнозирования текущего блока к упомянутой первой группе или упомянутой второй группе, таким образом, чтобы дать возможность устройству декодирования определить режим пространственного прогнозирования текущего блока на основании декодированной информации.
режимы прогнозирования каждой комбинации режимов прогнозирования разделены в первую группу и вторую группу, причем первая группа имеет m режимов прогнозирования, а вторая группа имеет (n-m) режимов прогнозирования, при этом n является общим числом имеющихся режимов прогнозирования и m меньше n, и, кроме того, первая группа режимов прогнозирования имеет более высокую вероятность появления, чем вторая группа режимов прогнозирования, отличающийся тем, что содержит
средство, реагирующее на декодированную информацию, предназначенное для определения, принадлежит ли режим пространственного прогнозирования текущего блока к упомянутой первой группе или упомянутой второй группе, и
средство, предназначенное для выбора режима пространственного прогнозирования на основании упомянутого определения.
средство, предназначенное для запоминания информации, указывающей на упомянутый заданный образ.
средство, предназначенное для разделения режимов прогнозирования каждой комбинации режимов прогнозирования в первую группу и вторую группу, причем первая группа имеет m режимов прогнозирования, а вторая группа имеет (n-m) режимов прогнозирования, при этом n является общим числом имеющихся режимов прогнозирования и m меньше n, и, кроме того, первая группа режимов прогнозирования имеет более высокую вероятность появления, чем вторая группа режимов прогнозирования,
средство, предназначенное для кодирования в битовый поток информации групп, указывающей, принадлежит ли режим пространственного прогнозирования текущего блока к упомянутой первой группе или к упомянутой второй группе, и
средство, предназначенное для декодирования из битового потока упомянутой информации групп таким образом, чтобы дать возможность устройству декодирования определить режим пространственного прогнозирования текущего блока на основании упомянутой декодированной информации.
средство, реагирующее на упомянутую первую группу, предназначенное для упорядочения первой группы режимов прогнозирования в соответствии с вероятностью появления среди первой группы режимов прогнозирования.
средство, реагирующее на упомянутую вторую группу, предназначенное для расположения второй группы режимов прогнозирования заданным образом, известным устройству декодирования.
псевдокод, предназначенный для использования в разделении режимов прогнозирования в каждой комбинации режимов прогнозирования в первую группу и вторую группу, причем первая группа имеет m режимов прогнозирования, а вторая группа имеет (n-m) режимов прогнозирования, при этом n является общим числом имеющихся режимов прогнозирования и m меньше n, и, кроме того, первая группа режимов прогнозирования имеет более высокую вероятность появления, чем вторая группа режимов прогнозирования,
псевдокод, предназначенный для использования в упорядочении первой группы режимов прогнозирования в соответствии с вероятностью появления среди первых режимов прогнозирования.
Приоритет по пунктам:
| СПОСОБЫ И УСТРОЙСТВА КОДИРОВАНИЯ ИЗОБРАЖЕНИЙ И НОСИТЕЛИ ИНФОРМАЦИИ ДЛЯ ЗАПИСИ ИЗОБРАЖЕНИЙ | 1994 |
|
RU2123769C1 |
| Дорожная спиртовая кухня | 1918 |
|
SU98A1 |
| US 5774593 А, 30.06.1998 | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Уплотнительная смазка для резьбовых соединений | 1977 |
|
SU687111A1 |

