Область техники, к которой относится изобретение
Настоящее изобретение относится к технике кодирования и декодирования данных.
Описание уровня техники
Описание «уровня техники» приведено здесь с целью создания общего представления о контексте заявки. Работы авторов настоящей заявки в той степени, в какой они описаны в этом разделе, характеризующем известный уровень техники, равно как и аспекты настоящей заявки, которые не могут быть квалифицированы в качестве «уровня техники» на момент подачи заявки, ни явно, ни неявно не противопоставляются настоящему изобретению в качестве известных.
Известны несколько систем кодирования и декодирования видеоданных, использующих преобразование видеоданных в представление в частотной области, квантование коэффициентов частотной области (коэффициентов разложения на частотные составляющие) и затем применение какого-либо способа энтропийного кодирования к квантованным коэффициентам. Это может обеспечить сжатие видеоданных. Соответствующая технология декодирования или расширения данных применяется для восстановления реконструированной версии исходных видеоданных.
Современные видео кодеки (кодеры-декодеры), такие как применяемые в стандарте усовершенствованного видео кодирования H.264/MPEG-4 Advanced Video Coding (AVC) обеспечивают сжатие данных главным образом путем кодирования только разностей между последовательными видео кадрами. Эти кодеки используют регулярную матрицу так называемых макроблоков, каждый из которых используется в качестве области сравнения с соответствующим макроблоком в предыдущем видео кадре, а область изображения в пределах макроблока затем кодируют в соответствии со степенью движения, обнаруженного между соответствующими текущим и предыдущим макроблоками в видео последовательности или между соседствующими макроблоками в одном кадре видео последовательности.
Алгоритм высокоэффективного видео кодирования (High Efficiency Video Coding (HEVC)), известный также как Н.265 или MPEG-H Part 2, предлагается в качестве развития стандарта H.264/MPEG-4 AVC. Целью алгоритма HEVC является повышение качества изображения и удвоение коэффициента сжатия данных по сравнению со стандартом Н.264, а также масштабируемость от разрешения 128×96 пикселей к разрешению 7680×4320 пикселей, что грубо эквивалентно скоростям передачи данных в пределах от 128 кбит/с до 800 Мбит/с.
Согласно алгоритму HEVC для бытовой аппаратуры предложена так называемая блочная структура (профиль) 4:2:0, в которой объем данных, используемый для каждого канала цветности, составляет одну четверть объема данных яркостного канала. Это обусловлено тем, что субъективно люди более чувствительны к вариациям яркости, чем к вариациям цвета, так что можно использовать более сильное сжатие и/или передачу меньшего объема информации в каналах цветности без субъективно воспринимаемой потери качества.
Алгоритм HEVC заменяет макроблоки, применяемые в существующих стандартах Н.264 и MPEG, более гибкой схемой на основе единиц кодирования (coding unit (CU)), представляющих собой структуры переменного размера.
Следовательно, при кодировании данных изображения в видео кадрах можно выбирать размеры единиц CU в зависимости от кажущейся сложности изображения или измеренных уровней движения вместо того, чтобы использовать равномерно распределенные макроблоки. Это позволяет добиться значительно более высокой степени сжатия в областях, где имеет место небольшое движение между кадрами и незначительные вариации внутри кадра, и в то же время сохранить более высокое качество изображения в областях со значительным движением между кадрами или большой сложностью изображения.
Каждая единица CU содержит одну или более единиц прогнозирования (prediction unit (PU)) типа внутрикадрового или межкадрового прогнозирования для блоков переменного размера и одну или более единиц преобразования (transform unit (TU)), содержащих коэффициенты для преобразования и квантования пространственных блоков.
Более того, блоки единиц PU и TU предусмотрены для каждого из трех каналов; канала luma (Y), представляющего собой канал светимости или канал яркости, его можно также считать полутоновым или черно-белым каналом, и двух цветоразностных (chroma) каналов или каналов цветности; Cb и Cr. Эти каналы несут информацию о цвете для полутонового или черно-белого изображения, передаваемого яркостным каналом. Термины «Y, luminance и luma», т.е. яркость, канал яркости, в настоящей заявке используются взаимозаменяемо, и аналогично термины «Cb и Cr, chrominance и chroma», т.е. «цветоразностный, цветность, канал цветности» используются взаимозаменяемо, где это больше подходит, отметим, что термины «chrominance» или «chroma» могут быть использованы обобщенно для обозначения «один из или оба канала Cr и Cb», а в случае обсуждения конкретного цветоразностного канала, он будет идентифицирован термином Cb или Cr.
В общем случае единицы PU считаются независимыми от канала, за исключением того, что единица PU имеет яркостную составляющую и составляющую цветности. В общем случае это означает, что отсчеты, формирующие часть единицы PU для каждого канала, представляют одну и ту же область изображения, так что имеет место фиксированное соотношение между единицами PU для указанных трех каналов. Например, для видео в формате 4:2:0 единица PU размером 8×8 для яркостного канала всегда имеет соответствующую ей единицу PU размером 4×4 для цветоразностного канала, причем цветоразностные составляющие единицы PU представляют ту же самую область, что и яркостная составляющая, но содержат меньшее число пикселей вследствие субдискретизированной природы цветоразностных данных в формате 4:2:0 по сравнению с яркостными данными для видео в формате 4:2:0. Два цветоразностных канала совместно используют информацию внутрикадрового прогнозирования; а все три канала совместно используют информацию межкадрового прогнозирования. Аналогично, в структуре единицы TU также имеет место фиксированное соотношение между указанными тремя каналами.
Однако для профессионального вещательного оборудования и аппаратуры для цифрового кинематографа желательно иметь меньшую степень сжатия (или больший объем информации) в цветоразностных каналах, что может оказать нежелательное воздействие на работу современного и предполагаемых алгоритмов HEVC.
Раскрытие изобретения
Целью настоящего изобретения является рассмотрение или уменьшение значимости проблем, возникающих вследствие такой обработки данных.
Соответствующие аспекты или признаки настоящего изобретения определены в прилагаемой Формуле изобретения.
Следует понимать, что и предшествующее общее описание, и последующее подробное описание являются всего лишь примерами и никак не ограничивают предлагаемую технологию.
Краткое описание чертежей
Более полное представление о настоящем изобретении и множестве его преимуществ может быть легко получено и стать более понятным из последующего подробного описания, рассматриваемого в сочетании с прилагаемыми чертежами, на которых:
фиг. 1 схематично иллюстрирует систему передачи и приема аудио/видео (A/V) данных с использованием сжатия и расширения видеоданных;
фиг. 2 схематично иллюстрирует систему отображения видео, использующую расширение видеоданных;
фиг. 3 схематично иллюстрирует систему хранения аудио/видео данных с использованием сжатия и расширения видеоданных;
фиг. 4 схематично иллюстрирует видеокамеру, использующую сжатие видеоданных;
фиг. 5 представляет упрощенную общую схему устройства для сжатия и расширения видеоданных;
фиг. 6 схематично иллюстрирует генерирование изображений прогнозирования;
фиг. 7 схематично иллюстрирует наибольшую единицу кодирования (LCU);
фиг. 8 схематично иллюстрирует группу из четырех единиц кодирования (CU);
фиг. 9 и 10 схематично иллюстрируют разбиение единиц кодирования, показанных на фиг. 8, на меньшие единицы кодирования;
фиг. 11 схематично иллюстрирует матрицу единиц прогнозирования (PU);
фиг. 12 схематично иллюстрирует матрицу единиц преобразования (TU);
фиг. 13 схематично иллюстрирует частично кодированное изображение;
фиг. 14 схематично иллюстрирует набор возможных направлений внутрикадрового прогнозирования;
фиг. 15 схематично иллюстрирует группу режимов прогнозирования;
фиг. 16 схематично иллюстрирует диагональное сканирование вверх - вправо;
фиг. 17 схематично иллюстрирует устройство сжатия видеоданных;
фиг. 18а и 18b схематично иллюстрируют возможные размеры блоков;
фиг. 19 схематично иллюстрирует использование совмещенной информации от цветоразностных и яркостных блоков;
фиг. 20 схематично иллюстрирует ситуацию, когда совмещенную информацию из одного цветоразностного канала используют в отношении другого цветоразностного канала;
фиг. 21 схематично иллюстрирует пиксели, используемые для режима LM-CHROMA mode;
фиг. 22 схематично иллюстрирует набор направлений прогнозирования яркостного канала;
фиг. 23 схематично иллюстрирует направления, показанные на фиг. 22, применительно к горизонтально разреженному цветоразностному каналу;
фиг. 24 схематично иллюстрирует отображение направлений, показанных на фиг. 22, на прямоугольную матрицу пикселей цветоразностных каналов;
фиг. 25-28 схематично иллюстрируют интерполяцию пикселей яркостного и цветоразностных каналов;
фиг. 29а и 29b схематично иллюстрируют таблицы параметров квантования для форматов (профилей) 4:2:0 и 4:2:2 соответственно;
фиг. 30 и 31 схематично иллюстрируют таблицы вариаций квантования;
фиг. 32 схематично иллюстрирует схему для модификации углового шага;
фиг. 33 схематично иллюстрирует модификацию угловых шагов;
фиг. 34 и 35 иллюстрируют схемы сканирования;
фиг. 36 схематично иллюстрирует выбор схемы сканирования в соответствии с режимом прогнозирования;
фиг. 37 схематично иллюстрирует выбор схемы сканирования в соответствии с режимом прогнозирования для прямоугольного цветоразностного блока;
фиг. 38 схематично иллюстрирует устройство для выбора схемы сканирования;
фиг. 39 схематично иллюстрирует устройство для выбора преобразования с разложением на частотные составляющие;
фиг. 40 схематично иллюстрирует устройство для кодирования в стандарте САВАС;
фиг. 41А - 41D схематично иллюстрируют предложенное ранее назначение по соседству; и
фиг. 42А - 45 схематично иллюстрируют контекстно-переменное назначение согласно вариантам настоящего изобретения.
Описание вариантов
На фиг. 1-4 приведены схематичные иллюстрации устройств или систем, использующих устройства для сжатия и/или расширения данных, рассматриваемые ниже в связи с вариантами настоящего изобретения.
Все, что относится к устройству сжатия и/или расширения данных, которое будет рассмотрено ниже, может быть реализовано в аппаратуре, в программном обеспечении, исполняемом в устройстве обработки данных общего назначения, таком как компьютер общего назначения, в программируемой аппаратуре, такой как специализированная интегральная схема (application specific integrated circuit (ASIC)) или программируемая пользователем вентильная матрица (field programmable gate array (FPGA)), либо посредством сочетания этих компонентов. Когда варианты реализованы посредством загружаемого программного обеспечения и/или встроенного программного обеспечения, следует понимать, что такое загружаемое и/или встроенное программное обеспечение, а также энергонезависимые носители записи, на которых хранится или другим способом распространяется это загружаемое и/или встроенное программное обеспечение, считаются вариантами настоящего изобретения.
Фиг. 1 схематично иллюстрирует систему передачи и приема аудио/видео данных с использованием сжатия и расширения видеоданных.
Входной аудио/видео сигнал 10 поступает в устройство 20 сжатия видеоданных, осуществляющее сжатие по меньшей мере видео составляющей аудио/видео сигнала 10 для передачи по линии 30 передачи данных, такой как кабельная линия, оптоволоконная линия, беспроводная линия передачи или аналогичная линия. Сжатый сигнал обрабатывает устройство 40 расширения данных для получения выходного аудио/видео сигнала 50. В обратном направлении устройство 60 сжатия данных осуществляет сжатие аудио/видео сигнала для передачи по линии 30 передачи данных в устройство 70 расширения данных.
Указанные устройство 20 сжатия данных и устройство 70 расширения данных могут, таким образом, образовать один узел линии связи. Указанные устройство 40 расширения данных и устройство 60 расширения данных могут образовать другой узел линии связи. Безусловно, в случаях, когда линия связи является однонаправленной, только одному из узлов будет нужно устройство сжатия данных и только одному другому узлу потребуется устройство расширения данных.
Фиг. 2 схематично иллюстрирует систему отображения видео, использующую расширение видеоданных. В частности, сжатый аудио/видео сигнал 100 обрабатывают в устройстве 110 расширения данных для получения расширенного сигнала, который может быть представлен на экране устройства 120 отображения. Указанное устройство 110 расширения данных может быть реализовано в виде интегральной части устройства 120 отображения, например, может быть выполнено в одном общем корпусе с устройством отображения. В альтернативном варианте, такое устройство 110 расширения данных может быть выполнено в виде (например) так называемой приставки (set top box (STB)), отметим что выражение "set-top" («верхний», «устанавливаемый сверху») совсем не означает требования, чтобы приставка располагалась в какой-либо конкретной ориентации или позиции относительно устройства 120 отображения; это просто термин, используемый в технике для обозначения устройства, соединяемого с дисплеем в качестве периферийного устройства.
Фиг. 3 схематично иллюстрирует систему хранения аудио/видео данных, использующую сжатие и расширение видео данных. Входной аудио/видео сигнал 130 поступает в устройство 140 сжатия данных, генерирующее сжатый сигнал для сохранения в запоминающем устройстве 150, таком как магнитный дисковод, оптический дисковод, магнитофон, твердотельное запоминающее устройство, например, полупроводниковое запоминающее устройство, или другое запоминающее устройство. Для воспроизведения сжатые данные считывают из запоминающего устройства 150 и передают в устройство 160 расширения данных для осуществления расширения данных с целью получения выходного аудио/видео сигнала 170.
Следует понимать, что сжатый или кодированный сигнал и носитель записи, сохраняющий этот сигнал, считаются вариантами настоящего изобретения.
Фиг. 4 схематично иллюстрирует видеокамеру, использующую сжатие видеоданных. На фиг. 4 устройство 180 считывания изображения, такое как формирователь сигналов изображения на основе приборов с зарядовой связью (ПЗС) (charge coupled device (CCD)) с соответствующей электронной схемой управления и считывания информации генерирует видеосигнал, передаваемый в устройство 190 сжатия данных. Микрофон (или множество микрофонов) 200 генерирует аудио сигнал для передачи в устройство 190 сжатия данных. Это устройство 190 сжатия данных генерирует сжатый аудио/видео сигнал 210 для сохранения и/или передачи (на схеме показано обобщенно в виде модуля 220).
Технология, рассматриваемая ниже, относится главным образом к сжатию и расширению видеоданных. Следует понимать, что в сочетании с предлагаемой здесь технологией сжатия видеоданных могут быть использованы много самых разнообразных способов сжатия аудиоданных для генерации сжатого аудио/видео сигнала. Соответственно, способы сжатия аудиоданных отдельно обсуждаться не будут. Следует также понимать, что скорости передачи данных, ассоциированные с видеоданными, и в частности качественными видеоданными для систем вещания, в общем случае намного выше скоростей передачи данных, ассоциированных с аудиоданными (будь то сжатыми или несжатыми). Поэтому должно быть понятно, что несжатые аудиоданные могут сопровождать сжатые видеоданные, образуя сжатый аудио/видео сигнал. Должно быть также понятно, что хотя представленные примеры (показанные на фиг. 1-4) относятся к аудио/видео данным, рассматриваемые ниже способы могут быть применены в системе, имеющей дело (иными словами, сжимающей, расширяющей, сохраняющей, представляющей на дисплее и/или передающей) только видеоданные. Иными словами, рассматриваемые варианты могут быть применены к сжатию видеоданных без обязательных манипуляций с аудиоданными вовсе.
Фиг. 5 представляет упрощенную общую схему устройства для сжатия и расширения видеоданных.
Контроллер 343 управляет всеми операциями устройства и, в частности, применительно к режиму сжатия данных управляет процедурой пробного кодирования (будет рассмотрена ниже) с целью выбора различных режимов работы (размеров блоков единиц CU, единиц PU и единиц TU).
Последовательные изображения из состава входного видеосигнала 300 поступают в сумматор 310 и в модуль 320 прогнозирования изображения. Этот модуль 320 прогнозирования изображения ниже будет рассмотрен более подробно со ссылками на фиг. 6. Сумматор 310 на самом деле выполняет вычитание (отрицательное суммирование), т.е. принимает входной видеосигнал 300 на свой вход "+" и выходной сигнал модуля 320 прогнозирования изображения на свой вход так, что происходит вычитание прогнозируемого изображения из входного изображения. В результате происходит генерация так называемого сигнала 330 остаточного изображения, представляющего разность между реальным и прогнозируемым изображениями.
Одна из причин, почему генерируют сигнал остаточного изображения, состоит в следующем. Способы кодирования данных, которые будут рассмотрены далее, иными словами способы, которые будут применены к сигналу остаточного изображения, работают тем более эффективно, чем меньше «энергии» содержит изображение, подлежащее кодированию. Здесь термин «эффективно» означает генерацию небольшого объема кодированных данных; для конкретного уровня качества изображения желательно (и считается «эффективным») генерировать настолько мало данных, насколько это практически возможно. Ссылка на «энергию» в остаточном изображении относится к количеству информации, содержащемуся в остаточном изображении. Если прогнозируемое изображение оказалось идентично реальному изображению, разность между этими двумя изображениями (иными словами, остаточное изображение) будет содержать нулевую информацию (нулевую энергию) и его будет очень легко кодировать с генерацией очень небольшого количества кодированных данных. В общем случае, если удаться добиться разумно хорошей работы процедуры прогнозирования, ожидается, что данные остаточного изображения будут содержать меньше информации (меньше энергии), чем входное изображение, и потому будет легче кодировать его с преобразованием в небольшой объем кодированных данных.
Данные 330 остаточного изображения поступают в преобразовательный 340 модуль, осуществляющий дискретное косинусное преобразование (discrete cosine transform (DCT)) этих данных остаточного изображения. Способ такого преобразования DCT сам по себе хорошо известен и потому не будет здесь описан подробно. Однако способы, используемые в предлагаемом устройстве, содержат ряд аспектов, которые будут более подробно описаны ниже. В частности, это относится к выбору различных блоков данных, к которым применяется преобразование DCT. Эти вопросы будут рассмотрены ниже со ссылками на фиг. 7-12. В некоторых вариантах могут быть избирательно использованы различные способы преобразования с разложением на частотные составляющие (frequency-separation transform) вместо преобразования DCT, в системе известной под названием «зависящее от режима направленное преобразование» (MDDT (Mode Dependent Directional Transform)), которая будет рассмотрена ниже. Сейчас будет предполагаться, что используется преобразование DCT.
Выходные данные преобразовательного модуля 340, представляющие собой набор коэффициентов преобразования DCT для каждого преобразованного блока данных изображения, поступают в модуль 350 квантования. В области сжатия видеоданных известны разнообразные способы квантования в диапазоне от просто умножения на масштабный коэффициент квантования до применения сложных преобразовательных таблиц под управлением параметра квантования. Квантование имеет двоякую основную цель. Во-первых, процедура квантования уменьшает число возможных значений преобразованных данных. Во-вторых, процедура квантования может повысить вероятность того, что величины преобразованных данных окажутся равными нулю. Оба эти фактора могут повысить эффективность работы процедуры энтропийного кодирования, которая будет рассмотрена выше, с точки зрения генерации сжатых видеоданных небольшого объема.
Модуль 360 сканирования применяет процедуру сканирования данных. Целью процедуры сканирования является переупорядочение квантованных преобразованных данных, чтобы собрать вместе как можно большее число ненулевых квантованных коэффициентов преобразования, и, безусловно, собрать также вместе как можно большее число нулевых квантованных коэффициентов преобразования. Такой подход может позволить эффективно применить так называемое кодирование длин серий или аналогичные способы. Таким образом, процедура сканирования содержит выбор коэффициентов из совокупности квантованных преобразованных данных и, в частности, из блока коэффициентов, соответствующего блоку данных изображения, которые были преобразованы и квантованы, в соответствии с «порядком сканирования» или схемой сканирования таким образом, чтобы (а) все коэффициенты были выбраны по одному разу как часть процедуры сканирования, и (b) сканирование позволило бы реализовать желаемое переупорядочение. Одним из примеров порядка сканирования, который способен дать полезные результаты, является так называемый диагональный порядок сканирования вверх - вправо. В некоторых вариантах может быть использована так называемая система «зависящего от режима сканирования коэффициентов» (MDCS (Mode Dependent Coefficient Scanning)), так что схема сканирования может изменяться от блока к блоку. Такая конфигурация будет рассмотрена более подробно ниже. В настоящий момент предполагается, что используется схема диагонального сканирования вверх - вправо.
После сканирования коэффициенты передают в модуль 370 энтропийного кодирования (ЕЕ). Здесь также могут быть использованы разнообразные виды энтропийного кодирования. Два примера представляют варианты так называемой системы САВАС (контекстно-адаптивное двоичное арифметическое кодирование (Context Adaptive Binary Arithmetic Coding)) и варианты так называемой системы CAVLC (контекстно-адаптивное кодирование в коде переменной длины (Context Adaptive Variable-Length Coding)). В общем случае считается, что система САВАС обладает большей эффективностью, и некоторые исследования показали, что можно добиться уменьшения объема кодированных выходных данных на 10-20% при сопоставимом качестве изображения по сравнению с системой CAVLC. Однако считается, что система CAVLC имеет намного более низкий уровень сложности (с точки зрения реализации), чем система САВАС. Отметим, что процедура сканирования и процедура энтропийного кодирования показаны как раздельные процедуры, однако на деле их можно объединить или осуществлять совместно. Иными словами, считывание данных в модуле энтропийного кодирования может происходить в порядке сканирования. Подобные же соображения применимы также к соответствующим обратным процедурам, которые будут рассмотрены ниже. Отметим, что текущие документы по алгоритму HEVC, рассматриваемые на момент подачи настоящей заявки, уже не содержат возможности применения модуля кодирования коэффициентов для системы CAVLC.
Выходные данные модуля 370 энтропийного кодирования вместе с дополнительными данными (упомянутыми выше и/или рассматриваемыми ниже), например, определяющими способ, каким модуль 320 прогнозирования генерирует прогнозируемое изображение, составляют сжатый выходной видеосигнал 380.
Однако имеется также обратный путь, поскольку работа самого модуля 320 прогнозирования зависит от расширенной версии сжатых выходных данных.
Это происходит по следующей причине. На подходящей стадии процедуры расширения данных (будет рассмотрена ниже) генерируют расширенную версию остаточных данных. Эти расширенные остаточные данные необходимо суммировать с прогнозируемым изображением для генерации выходного изображения (поскольку исходные остаточные данные представляли собой разность между входным изображением и прогнозируемым изображением). Для того чтобы процесс был сопоставим между стороной сжатия данных стороной расширения данных, прогнозируемые изображения, генерируемые модулем 320 прогнозирования, должны быть одинаковыми и во время сжатия данных, и во время расширения данных. Безусловно, на этапе расширения данных устройство не имеет доступа к исходным входным изображениям, ему доступны только расширенные изображения. Поэтому на стадии сжатия данных модуль 320 прогнозирования основывает свой прогноз (по меньшей мере для межкадрового кодирования) на расширенных версиях сжатых изображений.
Процедура энтропийного кодирования, выполняемая модулем 370 энтропийного кодирования, считается кодированием «без потерь», иными словами, она может быть обращена для получения точно тех же данных, какие первоначально поступили в модуль 370 энтропийного кодирования. Таким образом, обратный путь может быть реализован прежде стадии энтропийного кодирования. Действительно, процедура сканирования, выполняемая модулем 360 сканирования, также считается сканированием без потерь, однако в рассматриваемом варианте обратный путь 390 проходит от выхода модуля 350 квантования к входу комплементарного ему модуля 420 обратного квантования.
В общем случае, модуль 410 энтропийного декодирования, модуль 400 обратного сканирования, модуль 420 обратного квантования и модуль 430 обратного преобразования выполняют соответствующие обратные функции для модуля 370 энтропийного кодирования, модуля 360 сканирования, модуля 350 квантования и преобразовательного модуля 340. Далее будет продолжено обсуждение процедуры сжатия данных; процедура расширения входного сжатого видеосигнала будет отдельно рассмотрена ниже.
В процессе сжатия данных сканированные коэффициенты передают по обратному пути 390 от модуля 350 квантования в модуль 420 обратного квантования, осуществляющий операцию, обратную операции, выполняемой модулем 350 квантования. Модули 420 и 430 выполняют процедуры обратного квантования и обратного преобразования для генерации сжатого-расширенного сигнала 440 остаточного изображения.
Сигнал 440 изображения суммируют, в сумматоре 450, с выходным сигналом модуля 320 прогнозирования для генерирования реконструированного выходного изображения 460. Оно составляет один из входных сигналов для модуля 320 прогнозирования изображения, как будет описано ниже.
Обратимся теперь к процедуре, применяемой для расширения принятого сжатого видеосигнала 470, этот сигнал поступает в модуль 410 энтропийного декодирования и из этого модуля в цепочку, составленную из модуля 400 обратного сканирования, модуля 420 обратного квантования и модуля 430 обратного преобразования, перед суммированием с выходным сигналом модуля 320 прогнозирования изображения в сумматоре 450. Прямо говоря, выходной сигнал 460 сумматора 450 образует выходной расширенный видеосигнал 480. На практике, перед тем как передать этот сигнал на выход может быть применена дополнительная фильтрация.
Таким образом, устройства, показанные на фиг. 5 и 6, могут действовать как устройство сжатия данных или как устройства расширения данных. Функции этих двух типов устройств очень сильно перекрываются. Модуль 360 сканирования и модуль 370 энтропийного кодирования не используются в режиме расширения данных, а работа модуля 320 прогнозирования (который будет подробно рассмотрен ниже) и других модулей зависит от информации о режиме и параметрах, содержащейся в или иным образом ассоциированной с принимаемым сжатым потоком битов данных, но не генерируемой самими модулями.
Фиг. 6 схематично иллюстрирует генерацию прогнозируемых изображений и, в частности, работу модуля 320 прогнозирования изображения.
Имеются два основных режима прогнозирования: так называемое внутрикадровое прогнозирование и так называемое межкадровое прогнозирование или прогнозирование с компенсацией движения (motion-compensated (МС)).
Внутрикадровое прогнозирование основано на прогнозировании содержания блока изображения с использованием данных из состава самого этого изображения. Это соответствует так называемому кодированию информационных кадров или I-кадров (I-frame) в других технологиях сжатия видеоданных. В отличие от кодирования I-кадров, при котором внутрикадровому кодированию подвергают все изображение, в рассматриваемых вариантах выбор между внутрикадровым и межкадровым кодированием может быть сделан для каждого блока отдельно, хотя в других вариантах выбор по-прежнему осуществляется для каждого кадра отдельно.
Прогнозирование с компенсацией движения представляет собой пример межкадрового прогнозирования и использует информацию движения, чтобы попытаться определить источник в другом, соседнем или близлежащем изображении, подробностей изображения, подлежащих кодированию в текущем изображении. Соответственно в идеальном случае содержание блока данных изображения в прогнозируемом изображении может быть закодировано очень просто посредством ссылки (вектора движения), указывающей на соответствующий блок в той же самой или в слегка отличной позиции в соседнем изображении.
На фиг. 6 показаны две схемы прогнозирования изображения (соответствующие внутрикадровому и межкадровому прогнозированию), результаты работы которых выбирает мультиплексор 500, управляемый сигналом 510 режима, чтобы передать блоки прогнозируемого изображения в сумматоры 310 и 450. Выбор осуществляется в зависимости от того, какой из вариантов дает наименьшую «энергию» (которую, как обсуждалось выше, можно рассматривать как информационное содержание, требующее кодирования), об этом выборе сообщают модулю кодирования в составе кодированного выходного потока битов данных. Энергию изображения в этом контексте можно определить, например, посредством пробного вычитания участка двух версий прогнозируемого изображения из входного изображения, возведения в квадрат величины каждого пикселя в разностном изображении, суммирования этих квадратов величин и идентификации, какая из двух версий дает наименьшую среднеквадратическую величину для разностного изображения на рассматриваемом участке изображения.
Реальное прогнозирование в системе внутрикадрового кодирования осуществляется на основе блоков изображения, принимаемых как часть сигнала 460, иными словами прогнозирование основано на кодированных-декодированных блоках изображения, чтобы точно такое же прогнозирование можно было выполнить в устройстве расширения данных. Однако селектор 520 внутрикадрового режима может выделить данные для управления модулем 530 внутрикадрового прогнозирования изображения из входного видеосигнала 300.
Для межкадрового прогнозирования модуль 540 прогнозирования с компенсацией движения (МС) использует информацию движения, такую как векторы движения, полученные модулем 550 оценки движения из входного видеосигнала 300. Эти векторы движения применяют к обработанной версии реконструированного изображения 460 посредством модуля 540 прогнозирования с компенсацией движения для генерации блоков в режиме межкадрового прогнозирования.
Далее будет рассмотрена процедура обработки, применяемая к сигналу 460. Сначала сигнал фильтруют посредством фильтрующего модуля 560, который будет подробно рассмотрен ниже. Такая фильтрация содержит применение «деблокирующего» фильтра для устранения или по меньшей мере попыток устранения эффектов поблочной обработки, осуществляемой преобразовательным модулем 340, и последующих операций. Может быть применен также нелинейный фильтр с адаптивными сдвигами в зависимости от отсчетов (sample adaptive offsetting (SAO)) (будет дополнительно рассмотрен ниже). Кроме того, применяется адаптивный контурный фильтр с использованием коэффициентов, полученных посредством обработки реконструированного сигнала 460 и входного видеосигнала 300. Адаптивный контурный фильтр представляет собой тип фильтра, который, используя известные способы, применяет коэффициенты адаптивной фильтрации к данным, подлежащим фильтрации. Иными словами, коэффициенты фильтрации могут изменяться в зависимости от различных факторов. Данные, определяющие, какие именно коэффициенты фильтрации использовать, входят составной частью в кодированный выходной поток битов данных.
Адаптивная фильтрация представляет собой фильтрацию в контуре для восстановления изображения. Единицу LCU можно фильтровать с использованием до 16 фильтров, причем выбор фильтра и состояние включено/выключено адаптивного контурного фильтра (ALF) определяют для каждой единицы CU в составе единицы LCU. Сегодня управление осуществляется на уровне единиц LCU, а не на уровне единиц CU.
Фильтрованные выходные данные от фильтрующего модуля 560 на деле составляют выходной видеосигнал 480, когда устройство работает в качестве устройства сжатия данных. Эти данные подвергают также буферизации в одном или нескольких запоминающих устройств 570 для изображений или кадров; сохранение последовательных изображений является требованием прогнозирования с компенсацией движения и, в частности, генерации векторов движения. Для экономии места в запоминающих устройствах изображения, сохраняемые в этих запоминающих устройствах 570, можно держать в сжатом виде и затем расширять для использования при генерации векторов движения. Для этой конкретной цели можно использовать любую известную систему сжатия/расширения данных. Сохраняемые изображения передают в интерполяционный фильтр 580, который генерирует обладающую повышенным разрешением версию сохраняемых изображений; в этом примере промежуточные отсчеты (суб-отсчеты) генерируют таким образом, чтобы разрешение интерполированного изображения на выходе интерполяционного фильтра 580 в 4 раза (по каждой координате) превосходило разрешение изображений, хранящихся в запоминающих устройствах 570, для яркостного канала в формате (профиле) 4:2:0 и в 8 раз (по каждой координате) превосходило разрешение изображений, хранящихся в запоминающих устройствах 570, для цветоразностных каналов в формате (профиле) 4:2:0. Интерполированные изображения передают в качестве входных данных в модуль 550 оценки движения и также в модуль 540 прогнозирования с компенсацией движения.
В вариантах настоящего изобретения в качестве опции предложен дополнительный этап процедуры, состоящий в умножении величин данных входного видеосигнала на коэффициент 4 с использованием умножителя 600 (эффективно - просто сдвиг величин данных влево на два бита) и затем применении соответствующей операции деления (сдвиг вправо на два бита) на выходе устройства с использованием делителя или регистра сдвига вправо 610. Таким образом, операции сдвига влево и сдвига вправо изменяют данные только для внутренних операций устройства. Эта мера позволяет добиться более высокой точности вычислений внутри устройства в качестве эффекта от уменьшения ошибок округления данных.
Сейчас будет рассмотрен способ секционирования изображения для сжимающей обработки. На базовом уровне изображение, подлежащее сжатию, рассматривают в виде матрицы блоков, составленных из отсчетов. Для целей настоящего обсуждения наибольший такой блок для рассмотрения представляет собой так называемую наибольшую единицу кодирования (LCU) 700, которая является квадратной матрицей, содержащей обычно 64×64 отсчетов (размер единицы LCU является конфигурируемым посредством модуля кодирования, вплоть до максимального размера, определенного в документах стандарта HEVC). Здесь обсуждение относится к отсчетам яркости. В зависимости от цветоразностного формата (профиля), такого как 4:4:4, 4:2:2, 4:2:0 или 4:4:4:4 (цветностная информация (GBR) плюс ключевые данные), будет иметь место различное число цветоразностных отсчетов, соответствующих яркостному блоку.
Будут рассмотрены три основных вида блоков: единицы кодирования, единицы прогнозирования и единицы преобразования. В общем случае рекурсивное разбиение единиц LCU позволяет секционировать входное изображение таким образом, что и размеры блоков, и параметры кодирования блоков (такие как режимы прогнозирования или кодирования остатка) могут быть заданы в соответствии с конкретными характеристиками изображения, подлежащего кодированию.
Единица LCU может быть разбита на так называемые единиц кодирования (CU). Единицы кодирования всегда являются квадратными и имеют размер в пределах от 8×8 отсчетов до полного размера единицы LCU 700. Единицы кодирования могут быть организованы в структуре типа дерева, так что первое разбиение может иметь место, как показано на фиг. 8, давая единицы 710 кодирования размером 32×32 отсчетов; последующие разбиения могут иметь место на избирательной основе для получения некоторого количества единиц 720 кодирования размером 16×16 отсчетов (фиг. 9) и потенциально некоторого количества единиц 730 кодирования размером 8×8 отсчетов (фиг. 10). В целом, эта процедура может создать контентно-адаптивную древовидную структуру кодирования блоков CU, каждый из которых может быть таким большим, как единица LCU, или таким маленьким, как 8×8 отсчетов. Кодирование выходных видеоданных происходит на основе такой структуры единиц кодирования, иными словами, сначала кодируют одну единицу LCU, а затем процедура переходит к кодированию следующей единицы LCU и т.д.
Фиг. 11 схематично иллюстрирует матрицу единиц прогнозирования (PU). Единица прогнозирования представляет собой базовую единицу для передачи информации, относящейся к процедуре прогнозирования изображения, или другими словами, дополнительные данные, добавляемые к подвергнутым энтропийному кодированию данным остаточного изображения для формирования выходного видеосигнала от устройства, показанного на фиг. 5. В общем случае, форма единиц прогнозирования не ограничена квадратной формой. Они могут иметь и другую форму, в частности, форму прямоугольника, составляющего половину одной квадратной единицы кодирования (например, единицы CU размером 8×8 могут иметь в составе единицы PU размером 8×4 или 4×8). Использование единиц PU, совмещенных с характерными элементами изображения, не является обязательной составляющей системы HEVC, но общей целью должно быть дать возможность хорошему модулю кодирования выравнивать границы соседствующих единиц прогнозирования для совмещения (настолько близко, насколько это возможно) с границами реальных объектов на картинке, чтобы к разным реальным объектам можно было применить различные параметры прогнозирования. Каждая единица кодирования может содержать одну или несколько единиц прогнозирования.
На фиг. 12 схематично показана матрица единиц преобразования (TU). Единица преобразования представляет собой базовую единицу для процедуры преобразования и квантования. Единица преобразования может быть или не быть квадратной формы и может иметь размер от 4×4 до 32×32 отсчетов. Каждая единица кодирования может содержать одну или несколько единиц преобразования. Сокращение SDIP-P на фиг. 12 обозначает так называемое разбиение для внутрикадрового прогнозирования на небольшом расстоянии (short distance intra-prediction partition). В такой конфигурации используются только одномерные преобразования, так что блок размером 4×N проходит через N преобразований, где входные данные для этих преобразований основаны на ранее декодированных соседствующих блоках и ранее декодированных соседствующих строках в текущей структуре. По состоянию на сегодня структура SDIP-P не входит в стандарт HEVC на момент подачи настоящей заявки.
Как указано выше в процессе кодирования сначала кодируют одну единицу LCU, затем следующую единицу LCU и т.д. В пределах единицы LCU кодируют одну единицу CU за другой единицей CU. В пределах единицы CU сначала кодируют одну единицу TU, затем следующую единицу TU и т.д.
Теперь будет рассмотрена процедура внутрикадрового прогнозирования. В общем случае внутрикадровое прогнозирование содержит генерацию прогноза для текущего блока (единицы прогнозирования) отсчетов на основе ранее кодированных и декодированных отсчетов в пределах того же самого изображения. Фиг. 13 схематично иллюстрирует частично кодированное изображение 800. Здесь изображение кодируют в направлении сверху слева вниз вправо на основе единиц LCU. Примером единицы LCU, кодированной частично в процессе обработки целого изображения, является блок 810. Заштрихованная область 820 сверху и слева от блока 810 уже закодирована. При внутрикадровом прогнозировании содержания блока 810 можно использовать любой участок заштрихованной области 820, но нельзя воспользоваться незаштрихованной областью снизу. Отметим однако, что для индивидуальной единицы TU в пределах текущей единицы LCU иерархический порядок кодирования (единица CU за единицей CU, затем единица TU за единицей TU), обсуждавшийся выше, означает, что в текущей единице LCU могут быть уже закодированные отсчеты, доступные для кодирования единицы TU и располагающиеся, например, сверху справа или снизу слева от этой единицы TU.
Блок 810 представляет единицу LCU; как обсуждалось выше, для целей внутрикадрового прогнозирования он может быть разбит на несколько меньших единиц прогнозирования и единиц преобразования. В качестве примера показана текущая единица TU 830 в пределах единицы LCU 810.
Процедура внутрикадрового прогнозирования учитывает отсчеты, кодированные прежде, чем приступить к рассмотрению текущей единицы TU, такие, как отсчеты, расположенные сверху и/или слева относительно текущей единицы TU. Исходные отсчеты, относительно которых осуществляется прогнозирование требуемых отсчетов, могут быть расположены в различных позициях или направлениях относительно текущей единицы TU. Для принятия решения, какое направление (режим прогнозирования) из совокупности режимов-кандидатов прогнозирования подходит для текущей единицы прогнозирования, селектор 520 режимов в составе рассматриваемого в качестве примера модуля кодирования может проверить все сочетания имеющихся структур единиц TU для каждого направления кандидата и выбрать направление единиц PU и структуру единиц TU, обеспечивающие наилучшую эффективность сжатия данных.
Кадр может быть также кодировано на основе «срезов». В одном из примеров срез представляет собой группу единиц LCU, соседствующих одна с другой по горизонтали. Но в более общем случае все остаточное изображение может представлять собой срез, либо срез может быть одной единицей LCU, либо срез может являться строкой единиц LCU и т.д. Срезы могут давать некую устойчивость против ошибок, поскольку их кодируют как независимые единицы. Состояние модулей кодирования и модулей декодирования полностью возвращаются к исходному состоянию на границе среза. Например, внутрикадровое прогнозирование не осуществляется через границы срезов; границы срезов в этом случае рассматриваются как границы изображения.
Фиг. 14 схематично иллюстрирует набор возможных (кандидатов) направлений прогнозирования. Для единицы прогнозирования размером 8×8, 16×16 или 32×32 отсчетов доступен полный набор из 34 направлений-кандидатов. В специальных случаях для единицы прогнозирования размером 4×4 и 64×64 отсчетов доступен уменьшенный набор направлений-кандидатов (17 направлений-кандидатов и 5 направлений-кандидатов, соответственно). Эти направления определяют посредством горизонтального и вертикального смещения относительно позиции текущего блока, но кодируют в качестве «режимов» прогнозирования, набор которых показан на фиг. 15. Отметим, что так называемый режим DC представляет собой простое арифметическое среднее окружающих отсчетов сверху и слева.
Фиг. 16 схематично иллюстрирует так называемое диагональное сканирование вверх - вправо, являющееся примером схемы сканирования, которая может быть применена модулем 360 сканирования. На фиг. 16 показана схема для примера блока из 8×8 коэффициентов преобразования DCT, где коэффициент постоянной составляющей (DC) расположен в верхней левой позиции 840 блока, а возрастающие горизонтальные и вертикальные пространственные частоты представлены коэффициентами, располагающимися на увеличивающихся расстояниях вниз и вправо от верхней левой позиции 840. Вместо этой схемы могут быть использованы другие, альтернативные порядки сканирования.
Ниже будут рассмотрены вариации структур единиц CU, PU и TU. Обсуждение будет проходить в контексте устройства, показанного на фиг. 17. Это устройство во многих отношениях аналогично устройствам, показанным на фиг. 5 и 6, обсуждавшихся выше. Действительно, здесь использовано много таких же цифровых позиционных обозначений, а соответствующие узлы дополнительно обсуждаться не будут.
Главное существенное отличие от фиг. 5 и 6 состоит в фильтре 560 (фиг. 6), который на фиг. 17 показан более подробно, а именно в составе фильтра 1000 удаления блочности и соответствующего кодирующего решающего блока 1030, нелинейного фильтра 1010 с адаптивными сдвигами в зависимости от отсчетов (sample adaptive offsetting (SAO)) и ассоциированного с ним генератора 1040 коэффициентов, а также адаптивного контурного фильтра (adaptive loop filter (ALF)) 1020 и ассоциированного с ним генератора 1050 коэффициентов.
Фильтр 1000 удаления блочности пытается уменьшить искажения и улучшить визуальное качество и характеристики прогнозирования путем сглаживания резких кромок, которые могут образоваться между границами единиц CU, PU и TU при использовании способов блочного кодирования.
Фильтр SAO 1010 классифицирует реконструированные пиксели по различным категориям и затем пытается уменьшить искажения путем простого добавления своей величины сдвига для каждой категории пикселей. Для классификации пикселей используются интенсивность пикселя и свойства кромки. Чтобы еще больше повысить эффективность кодирования, изображение может быть разбито на области для локализации параметров сдвига.
Фильтр ALF 1020 пытается восстановить сжатое изображение таким образом, чтобы минимизировать разницу между реконструированным и исходным кадрами. Коэффициенты фильтра ALF вычисляют и передают на покадровой основе. Фильтр ALF может быть применен ко всему кадру или к локальным областям кадра.
Как отмечено выше, предлагаемые документы стандарта HEVC используют конкретную схему (профиль) дискретизации цветоразностных данных, известную как схема 4:2:0. Эта схема 4:2:0 может быть использована для бытовой/потребительской аппаратуры. Однако возможны также некоторые другие схемы.
В частности, так называемая схема 4:4:4 была бы подходящей для профессионального вещания, эталонов и цифрового кинематографа, и, принципе, должна иметь наивысшее качество и скорость передачи данных.
Аналогично, так называемая схема (профиль) 4:2:2 могла бы быть использована в профессиональном вещании, для эталонов и цифрового кинематографа с некоторой потерей точности.
Эти схемы и соответствующие им возможные структуры блоков PU и TU будут рассмотрены ниже.
Возможны также другие схемы (профили), к которым относится, в том числе, черно-белая схема 4:0:0.
В схеме 4:4:4 каждый из трех каналов Y, Cb и Cr имеет одну и ту же частоту дискретизации. Поэтому, в такой схеме, в принципе, объем цветоразностных данных будет вдвое больше объема яркостных данных.
Следовательно, в стандарте HEVC, в такой схеме каждый из трех каналов Y, Cb и Cr будет иметь соответствующие блоки PU и TU одинакового размера; например яркостный блок размером 8×8 будет иметь соответствующие цветоразностные блоки размером 8×8 в каждом из двух цветоразностных каналов.
Следовательно, в этой схеме должно быть в общем случае прямое соотношение 1:1 между размерами блоков в каждом канале.
В схеме (профиле) 4:2:2 отсчеты двух цветоразностных составляющих выполняются с частотой дискретизации, составляющей половину частоты дискретизации яркостной составляющей (например, с использованием субдискретизации по вертикали или по горизонтали, но для целей настоящего описания предполагается, что выполняется субдискретизация по горизонтали). Поэтому в принципе, в этой схеме должно быть столько же цветоразностных данных, сколько имеется разностных данных, хотя цветоразностные данные будет распределены между двумя цветоразностными каналами.
Следовательно, в стандарте HEVC при использовании такой схемы каналы Cb и Cr будут иметь размеры блоков PU и TU, отличающиеся от размеров соответствующих блоков в яркостном канале; например, яркостному блоку размером 8×8 могут соответствующие цветоразностные блоки размером 4 ширина × 8 высота для каждого цветоразностного канала.
Примечательным в такой схеме является тот факт, что цветоразностные блоки могут быть неквадратными, даже хотя они соответствуют квадратным яркостным блокам.
В предлагаемой сегодня в стандарте HEVC схеме (профиле) 4:2:0 отсчеты двух цветоразностных составляющих выполняются с частотой дискретизации в четыре раза меньше частоты дискретизации яркостной составляющей (например, с использованием субдискретизации по вертикали и по горизонтали). В принципе, в такой схеме объем цветоразностных данных составляет половину объема яркостных данных, причем эти цветоразностные данные распределены между двумя цветоразностными каналами.
Следовательно, в стандарте HEVC в такой схеме снова в каналах Cb и Cr размеры блоков PU и TU отличаются от соответствующих размеров блоков в яркостном канале. Например, блок размером 8×8 яркостного канала будет иметь соответствующие цветоразностные блоки размером 4×4 в каждом цветоразностном канале.
Описанные выше схемы в разговорной речи известны как «пропорции каналов», как «пропорция каналов 4:2:0»; однако из приведенного выше описания должно быть понятно, что на деле это не всегда означает, что каналы Y, Cb и Cr сжимают или иначе формируют в такой пропорции. Следовательно, хотя это обозначение называется «пропорция каналов», его не следует понимать буквально. На самом деле правильная пропорция для схемы 4:2:0 выглядит 4:1:1 (пропорции для схемы 4:2:2 и схемы 4:4:4 на самом деле правильные).
Перед обсуждением конкретных схем со ссылками на фиг. 18а и 18b, будет дана общая сводка или обзор некоторой терминологии.
Наибольшая единица кодирования (Largest Coding Unit (LCU)) является основным, «корневым» объектом изображения. Обычно она занимает площадь, эквивалентную 64×64 яркостных пикселей. Такую единицу рекурсивно разбивают на части для образования «древовидной» иерархии единиц кодирования (Coding Unit (CU)). В общем случае все три канала (один канал яркости и два цветоразностных канала) имеют одинаковую древовидную иерархию единиц CU. При этом, однако, в зависимости от пропорции каналов конкретная яркостная единица CU может содержать число пикселей, отличное от соответствующих цветоразностных единиц CU.
Единицы CU на конце иерархического дерева, иными словами наименьшие единицы CU, полученные в результате рекурсивного разбиения (их можно назвать единицы-листья CU) затем разбивают на единицы прогнозирования (PU). Указанные три канала (канал яркости и два цветоразностных канала) имеют одинаковую структуру единиц PU за исключением случая, когда соответствующая единица PU для цветоразностного канала должна содержать слишком мало отсчетов, - в этом случае имеется только одна единица PU для этого канала. Это конфигурируемо, но в общем случае минимальный размер внутрикадровой единицы PU равен 4 отсчетам; минимальный размер межкадровой единицы PU равен 4 яркостным отсчетам (или 2 цветоразностным отсчетам для схемы 4:2:0). Порог ограничения минимального размера единицы CU всегда достаточно велик для обеспечения по меньшей мере по одной единицы PU для любого канала.
Единицы-листья CU также разбивают на единицы преобразования (Transform Unit (TU)). Эти единицы TU могут быть - и, когда они слишком велики (например, более 32×32 отсчетов), должны быть разбиты на единицы TU. Ограничение такого разбиения состоит в том, что единицы TU можно разбивать до максимальной глубины дерева, на сегодня конфигурируемой в виде 2 уровней, т.е. может быть не более 16 единиц 16 TU для каждой единицы CU. В качестве иллюстрации наименьший допустимый размер единицы TU равен 4×4 отсчетов и наибольший допустимый размер единицы TU равен 32×32 отсчетов. Снова эти три канала имеют одинаковую структуру единиц TU, где это возможно, но если единицу TU невозможно разбить до конкретной глубины для рассматриваемого канала вследствие размерных ограничений, она остается большего размера. Так называемая неквадратная структура преобразования с деревом четверок (non-square quad-tree transform arrangement (NSQT)) является аналогичной, но для разбиения на четыре, единица TU не должна иметь размер 2×2, но может иметь размер 4×1 или 1×4.
На фиг. 18а и 18b суммированы различные возможные размеры блоков для единиц CU, PU и TU, причем 'Y' обозначает яркостные блоки и 'С' является в общем смысле представителем одного из цветоразностных блоков. Термин 'Inter' обозначает единицы PU для межкадрового прогнозирования (в противоположность единицам PU внутрикадрового прогнозирования). Во многих случаях показан только размер яркостных блоков. Соответствующие размеры ассоциированных цветоразностных блоков связаны с размерами яркостных блоков согласно пропорциям каналов. Таким образом, для схемы 4:4:4 цветоразностные каналы имеют такой же размер блоков, как яркостные блоки, показанные на фиг. 18а и 18b. Для схем 4:2:2 и 4:2:0 цветоразностные блоки будут каждый иметь меньше пикселей, чем соответствующий блок яркости, в соответствии с пропорцией каналов.
Схема, показанная на фиг. 18а и 18b рассматривает четыре возможных размера единицы CU: 64×64, 32×32, 16×16 и 8×8 яркостных пикселей соответственно. Каждая из этих единиц CU имеет соответствующую строку опций единиц PU (показаны в столбце 1140) и опций единиц TU (показаны в столбце 1150). Для возможных размеров единиц CU, определенных выше, строки опций обозначены как 1100, 1110, 1120 и 1130 соответственно.
Отметим, что на сегодня размер 64×64 является максимальным размером единиц CU, но это ограничение может быть изменено.
В каждой строке 1100…1130 показаны различные опции единиц PU применимые к соответствующему размеру единицы CU. Опции единиц TU, применимые к этим конфигурациям единиц PU, показаны совмещенными по горизонтали с соответствующими опциями единиц PU.
Отметим, что в некоторых случаях предложены несколько опций единиц PU. Как обсуждается выше, целью выбора конфигурации единиц PU устройством является совмещение (настолько близко, насколько это возможно) границ реальных объектов на изображении, чтобы можно было к разным объектам применить различные параметры прогнозирования.
Решение о размерах и формах блоков и о единицах PU принимает модуль кодирования под управлением контроллера 343. Современный способ содержит выполнение пробных оценок нескольких древовидных структур единиц TU для многих направлений и получение наилучшей «стоимости» на каждом уровне. Здесь стоимость может быть выражена в виде меры искажений, или шумов, или погрешностей, или скоростей передачи битов данных, являющихся результатом применения каждой структуры блоков. Таким образом, модуль кодирования может попробовать два или более (или даже все доступные) сочетания размеров и форм блоков из совокупности вариантов, разрешенных в соответствии с древовидными структурами и иерархиями, обсуждавшимися выше, прежде чем выбрать один из этих опробованных вариантов, обеспечивающий самую низкую скорость передачи битов данных для некоторого требуемого показателя качества, или самые низкие искажения (или погрешности, или шумы, или сочетание этих показателей качества) для требуемой скорости передачи битов данных, либо сочетание перечисленных критериев.
После выбора конкретной конфигурации единиц PU можно применить различные уровни разбиения для генерации соответствующих единиц TU. Если обратиться к строке 1100, для случая размера 64×64 единицы PU, этот размер блоков слишком велик для использования в качестве единицы TU, так что первый уровень разбиения (от «уровня 0» (нет разбиения) к «уровню 1») является обязательным, что приводит к матрице из четырех яркостных единиц TU размером 32×32 каждая. Каждая из этих единиц может быть подвергнута дальнейшему разбиению в иерархическом дереве (от «уровня 1» к «уровню 2»), если потребуется, так что такое разбиение осуществляется прежде преобразования или квантования такой единицы TU. Максимальное число уровней в дереве единиц TU ограничено (например) в документах стандарта HEVC.
Другие опции предусмотрены для размеров и форм единиц PU для случая яркостной единицы CU размером 64×64 пикселей. Использование этих опций ограничено только изображениями с внутрикадровым кодированием и, в некоторых случаях, с активной опцией так называемого режима AMP. Аббревиатура AMP обозначает асимметричное секционирование движения (Asymmetric Motion Partitioning) и позволяет секционировать единицы PU асимметрично.
Аналогично, в некоторых случаях предусмотрены опции для размеров и форм единиц TU. Если NQST (неквадратная древовидная структура преобразования с разбиением на четыре (non-square quad-tree transform), в основном разрешающая неквадратные единицы TU) активизирована, тогда разбиение на уровне 1 и/или уровне 2 можно осуществлять, как показано, а если преобразование NQST не активизировано, тогда размеры единиц TU соответствуют схеме разбиения соответствующей наибольшей единицы TU для этого размера единицы CU.
Аналогичные опции предусмотрены для других размеров единиц CU.
В дополнение к графическому представлению, показанному на фиг. 18а и 18b, числовая часть этой же информации предложена в следующей таблице, хотя представление на фиг. 18а и 18b считается вполне достаточным. Аббревиатура "n/а" означает, что соответствующий режим не разрешен. Сначала указан горизонтальный размер в пикселях. Если приведена третья цифра, она относится к числу блоков такого размера - (горизонтальный размер) × (вертикальный размер) × (число блоков). Здесь N - целое число.
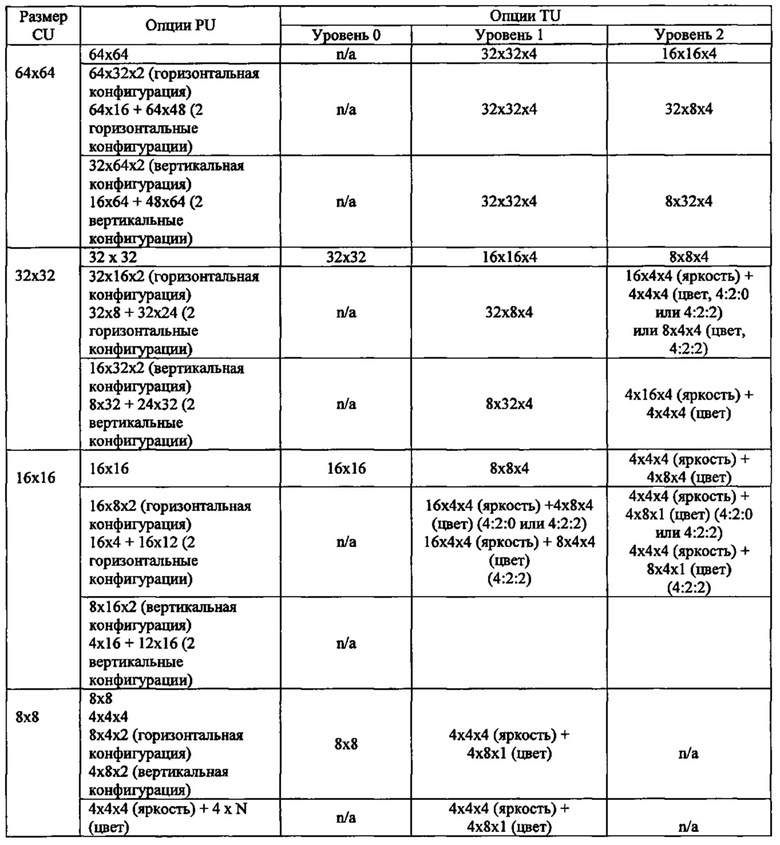
Варианты 4:2:0,4:2:2 и 4:4:4 структур блоков
Следует понимать, что обе схемы (профили) - 4:2:0 и 4:4:4, имеют квадратные блоки PU для внутрикадрового кодирования. Более того, современная схема 4:2:0 допускает блоки PU и TU размером 4×4 пикселей.
В вариантах настоящего изобретения предлагается, что для схемы 4:4:4 рекурсия блоков CU допускается в сторону уменьшения до размера 4×4 пикселей, а не до размера 8×8 пикселей, поскольку, как отмечено выше, в формате 4:4:4 яркостные и цветоразностные блоки будут иметь одинаковый размер (т.е. цветоразностные блоки субдискретизации не подвергаются), и поэтому для единицы CU размером 4×4 нет необходимости делать единицы PU или TU меньше, чем уже разрешенный минимум 4×4 пикселей.
Аналогично, в схеме 4:4:4 в одном из вариантов настоящего изобретения каждый из каналов Y, Cr, Cb или канал Y и два канала Cr, Cb вместе могут иметь соответствующие «древовидные» иерархические системы единиц CU. Может быть использован флаг, чтобы отметить, какую именно иерархию или совокупность иерархий следует использовать. Такой подход может быть также использован для схемы 4:4:4 в цветовом пространстве RGB. Однако, в альтернативном варианте «древовидные» иерархии для цветоразностных и яркостных каналов могут быть независимыми.
В примере с единицами CU размером 8×8 в схеме 4:2:0 это приводит к четырем яркостным единицам PU размером 4×4 каждая и одной цветоразностной единице PU размером 4×4. Следовательно, в схеме 4:2:2, имеющей вдвое больший объем цветоразностных данных, одна из опций в этом случае состоит в том, чтобы иметь две единицы PU размером 4×4, где (например) нижний цветоразностный блок будет соответствовать по положению нижнему левому яркостному блоку. Однако было признано, что использование одной неквадратной цветоразностной единицы PU размером 4×8 было бы лучше согласовано со схемами для цветоразностного формата 4:2:0.
В схеме 4:2:0 такие же, в принципе, неквадратные блоки TU допустимы для некоторых классов кодирования с межкадровым прогнозированием, но не для кодирования с внутрикадровым прогнозированием. Однако при кодировании с межкадровым прогнозированием, когда неквадратные преобразования NSQT выключены (что сегодня действует «по умолчанию» для схемы 4:2:0), все единицы TU являются квадратными. Следовательно, схема 4:2:0 на сегодня фактически принудительно применяет квадратные единицы TU. Например, яркостная единица TU размером 16×16 для схемы 4:2.0 будет соответствовать цветоразностным единицам TU размером 8×8 для каналов Cb & Cr в схеме 4:2:0.
Однако, как было отмечено ранее, схема (профиль) 4:2:2 может иметь неквадратные единицы PU. Следовательно, в одном из вариантов настоящего изобретения предлагается разрешить применение неквадратных единиц TU для схемы 4:2:2.
Например, хотя яркостная единица TU размером 16×16 в схеме 4:2:2 может соответствовать двум цветоразностным единицам TU для каналов Cb & Cr размером 8×8 в схеме 4:2:2, в рассматриваемом варианте она может вместо этого соответствовать цветоразностным единицам TU для каналов Cb & Cr размером 8×16 в схеме 4:2:2.
Аналогично, четыре яркостные TU размером 4×4 в схеме 4:2:2 могут соответствовать двум цветоразностным TU размером 4×4 для каналов Cb+Cr в схеме 4:2:2, или в этом варианте они могут вместо этого соответствовать цветоразностным TU размером 4×8 для каналов Cb & Cr в схеме 4:2:2.
Имея неквадратные цветоразностные единицы TU и, вследствие этого меньшее число единиц TU в целом, можно действовать более эффективно, поскольку они, вероятно, содержат меньше информации. Однако это может оказать нежелательное воздействие на процедуры преобразования и сканирования таких единиц TU, как это будет пояснено позднее.
Для схемы 4:4:4, можно в некоторых вариантах настоящего изобретения предотвратить разбиение яркостных блоков до уровня (например) блоков размером 4×4, если это уровень дальнейшего разбиения, которому подвергаются цветоразностные блоки. Это может позволять осуществлять более эффективное кодирование.
Наконец, для схемы 4:4:4 может быть предпочтительным иметь независимую от каналов структуру единиц TU, выбираемую на уровне последовательности, кадра, среза или более мелком уровне.
Как отмечено выше, сегодня в схеме 4:2:0 стандарта HEVC преобразование NSQT не активизировано. Однако если для межкадрового прогнозирования активизировать преобразование NSQT и разрешить асимметричное секционирование движения (AMP), это позволит асимметрично секционировать единицы PU; например, единица CU размером 16×16 может иметь единицу PU размером 4×16 и единицу PU размером 12×16. В таких обстоятельствах важно дополнительно рассмотреть структуру блоков для схем 4:2:0 и 4:2:2.
Для схемы 4:2:0 в преобразовании NSQT минимальная ширина/высота единицы TU может быть ограничена до 4 яркостных/цветоразностных отсчетов:
Следовательно, в неограничивающем примере структура яркостной единицы PU размером 16×4/16×12 имеет четыре яркостных единицы TU размером 16×4 и четыре цветоразностных единицы TU размером 4×4, причем яркостные единицы TU имеют вертикальное расположение блоков 1×4, а цветоразностные единицы TU имеют расположение блоков 2×2.
В аналогичной структуре, где секционирование было вертикальным, а не горизонтальным, структура яркостной единицы PU размером 4×16/12×16 имеет четыре яркостных единицы TU размером 4×16 и четыре цветоразностных единицы TU размером 4×4, причем яркостные единицы TU имеют горизонтальное расположение блоков 4×1, а цветоразностные единицы TU имеют расположение блоков 2×2.
Для схемы 4:2:2 в преобразовании NSQT в качестве неограничивающего примера структура яркостной единицы PU размером 4×16/12×16 имеет четыре яркостных единицы TU размером 4×16 и четыре цветоразностных единицы TU размером 4×8, причем яркостные единицы TU имеют горизонтальное расположение блоков 4×1, а цветоразностные единицы TU имеют расположение блоков 2×2.
Однако было определено, что в некоторых случаях можно рассматривать другую структуру. Следовательно, в одном из вариантов настоящего изобретения в преобразовании NSQT в качестве неограничивающего примера структура яркостной единицы PU размером 16×4/16×12 имеет четыре яркостных единицы TU размером 16×4 и четыре цветоразностных единицы TU размером 8×4, но сейчас яркостные и цветоразностные единицы TU имеют вертикальное расположение блоков 1×4 и совмещены с топологией единицы PU (в отличие от расположения для схемы 4:2:0, имеющего четыре цветоразностные единицы TU размером 4×8 с расположением блоков 2×2).
Аналогично единица PU размером 32×8 может иметь четыре яркостных единицы TU размером 16×4 и четыре цветоразностных единицы TU размером 8×4, но теперь яркостные и цветоразностные единицы имеют расположение блоков 2×2.
Следовательно, в более общем виде, для схемы 4:2:2 в преобразовании NSQT размеры блоков TU выбирают таким образом, чтобы совместить их с асимметричной топологией блока PU. Таким образом, преобразование NSQT с пользой позволяет границам единиц TU совместиться с границами единиц PU, что уменьшает высокочастотные артефакты, которые могли бы возникнуть в противном случае.
В общем случае, варианты настоящего изобретения могут относиться к способу кодирования видеоданных, устройству и программе, которые работают с изображениями в формате 4:2:2 видеосигнала. Изображение, подлежащее кодированию, разбивают на единицы кодирования, единицы прогнозирования и единицы преобразования, при этом единица кодирования представляет собой квадратную матрицу яркостных отсчетов и соответствующих цветоразностных отсчетов, в состав единицы кодирования входят одна или несколько единиц прогнозирования, а также одна или несколько единиц преобразования; где единица прогнозирования представляет собой элементарную ячейку (единицу) прогнозирования, так что прогнозирование всех отсчетов в составе одной единицы прогнозирования осуществляется с использованием общего способа прогнозирования, а единица преобразования представляет собой базовую ячейку (единицу) преобразования и квантования.
Режим неквадратного преобразования (такой как режим преобразования NSQT) активизируют, чтобы можно было работать с неквадратными единицами прогнозирования. В качестве опции активизируют асимметричное секционирование движения, что позволяет использовать асимметрию между двумя или более единицами прогнозирования, соответствующими одной единице кодирования.
Контроллер 343 управляет выбором размеров блоков единиц преобразования для совмещения их с топологией блоков единиц прогнозирования посредством, например, выявления характерных признаков изображения на участке изображения, соответствующем единице PU, и выбором размеров блоков единиц TU в составе этой единицы PU таким образом, чтобы совместить границы единиц TU с краями характерных элементов изображения на этом участке изображения.
Рассмотренные выше правила диктуют, какие сочетания размеров блоков являются возможными. Модуль кодирования может попробовать различные сочетания. Как указано выше, число пробных кодирований может составлять два или более - вплоть до опробования всех возможных вариантов. Пробные кодирования можно осуществлять с использованием целевой функции в качестве меры успешности результата и затем выбирать результат на основе оценки величины целевой функции.
Наличие трех уровней вариаций, а именно - согласно размерам и форме единиц CU, согласно размерам и форме единиц PU и согласно размерам и форме единиц TU, может привести к большому числу перестановок сочетаний, которые нужно подвергнуть пробному кодировании. Для уменьшения числа вариаций система может выполнить пробное кодирование для какого-то размера единиц CU с использованием произвольно выбранной одной конфигурации единиц PU/TU, разрешенной для каждого размера единиц CU; затем, уже имея выбранный размер единиц CU, размер и форму единиц PU можно выбрать, осуществляя пробное кодирование для разных вариантов единиц PU, причем с использованием какой-либо одной произвольно выбранной конфигурации единиц TU для каждого варианта. Затем, уже имея выбранные единицу CU и единицу PU, система может опробовать все применимые конфигурации единиц TU, чтобы выбрать окончательную конфигурацию единиц TU.
Другая возможность заключается в том, что некоторые модули кодирования могут использовать фиксированный выбор конфигурации блоков или могут разрешить применять только ограниченное подмножество сочетаний из той совокупности, которая была рассмотрена выше.
Внутрикадровое прогнозирование
Внутрикадровое прогнозирование в схеме 4:2:0
Как показано на фиг. 22, для внутрикадрового прогнозирования стандарт HEVC допускает «угловое» прогнозирование цветоразностных данных.
В качестве введения, фиг. 22 иллюстрирует 35 режимов прогнозирования, применимых к яркостным блокам. Из этих режимов 33 задают направление на опорные отсчеты от позиции 110 текущего прогнозируемого отсчета. Остальные два режима, это режим 0 (плоскость - planar) и режим 1 (постоянная составляющая - dc). Режим прогнозирования для каждого блока выбирают из этих режимов-кандидатов.
Стандарт HEVC разрешает для цветоразностных данных следующие режимы DC, Vertical, Horizontal, Planar, DM_CHROMA and LM_CHROMA.
Режим DM_CHROMA означает, что использовать следует такой же режим прогнозирования, как и для расположенной в этом же месте яркостной единицы PU (т.е. один из 35 режимов, показанных на фиг. 22).
Режим LM_CHROMA (линейный режим для цветоразностных данных) означает, что расположенные в этих же точках яркостные отсчеты (субдискретизированные в соответствии с пропорциями каналов) используются для получения прогнозируемых цветоразностных отсчетов. В этом случае, если яркостная единица PU, от которой должен быть взят режим DM_CHROMA прогнозирования, выбрала DC, Vertical, Horizontal или Planar, соответствующую запись в списке прогнозирования цветоразностных данных заменяют с использованием режима 34. В режиме LM_CHROMA яркостные пиксели, на основе которых прогнозируют цветоразностные пиксели, масштабированы (и имеют сдвиг, примененный к ним, если нужно) в соответствии с линейным соотношением между яркостными и цветоразностными данными. Это линейное соотношение определяют с использованием окружающих пикселей и производные пиксели вычисляют блок за блоком, так что декодер завершает декодирование одного блока прежде, чем перейти к следующему блоку.
Примечательно, что в режимах прогнозирования 2-34 отсчеты выполняют в диапазоне углов от 45 градусов до 225 градусов, иными словами, в одной диагональной половине квадрата. Это полезно в случае схемы 4:2:0, которая, как отмечено выше, использует только квадратные цветоразностные единицы PU для внутрикадрового прогнозирования.
Варианты внутрикадрового прогнозирования для схемы 4:2:2
Однако, также согласно отмеченному выше, схема 4:2:2 может иметь прямоугольные (неквадратные) цветоразностные единицы PU, даже когда яркостные единицы PU являются квадратными. Или же, действительно, может быть верно противоположное: прямоугольная яркостная единица PU может соответствовать квадратной цветоразностной единице PU. Причина такого расхождения состоит в том, что в схеме (профиле) 4:2:2 цветоразностные данные субдискретизируют по горизонтали (относительно яркостных данных), но не по вертикали. Поэтому можно ожидать, что коэффициенты формы яркостного блока и соответствующего ему цветоразностного блока окажутся разными. Соответственно, формат 4:2:2 представляет один из примеров (а есть еще и другие примеры, такие как 4:2:0) видео формата, в котором цветоразностные отсчеты имеют меньшую горизонтальную и/или вертикальную частоту дискретизации, чем яркостные отсчеты, вследствие чего отношение разрешения яркостных данных (яркостного разрешения) по горизонтали к разрешению цветоразностных данных (цветоразностному разрешению) по горизонтали отличается от отношения яркостного разрешения по вертикали к цветоразностному разрешению по вертикали, так что блок яркостных отсчетов имеет коэффициент формы, отличный от коэффициента формы соответствующего блока цветоразностных отсчетов.
Следовательно, в одном из вариантов настоящего изобретения для цветоразностных единиц PU, имеющих коэффициент формы, отличный от соответствующего яркостного блока, может потребоваться таблица отображения направления. Предположим (например) коэффициент формы 1:2 для прямоугольных цветоразностных единиц PU, тогда, например, режим 18 (на текущий момент - под углом 135 градусов) может быть переотображен на угол 123 градуса. В альтернативном варианте выбор текущего режима 18 может быть переотображен на выбор текущего режима 22 с тем же, по существу, эффектом.
Таким образом, в более общем смысле, для неквадратных единиц PU можно получить отображение между направлением на опорный отсчет и выбранным режимом внутрикадрового прогнозирования, отличное от отображения в случае квадратных единиц PU.
Еще более обобщенно, любой из режимов, включая ненаправленные режимы, может быть также переотображен на основе эмпирических данных.
Имеется возможность, что такое отображение приведет к соотношению «несколько к одному», что делает полный набор режимов избыточным для цветоразностных единиц PU в схеме 4:2:2. В этом случае, например, может быть необходимо только 17 режимов (соответствующих половинному угловому разрешению). В качестве альтернативы или в дополнение к указанному, эти режимы могут быть распределены по углу неравномерно.
Аналогично, сглаживающий фильтр, применяемый к опорному отсчету при прогнозировании пикселя, находящегося в позиции отсчета, может быть использован по-разному; в схеме 4:2:0 этот фильтр используется для сглаживания яркостных пикселей, но не цветоразностных пикселей. Однако в схемах 4:2:2 и 4:4:4 этот фильтр может быть использован также для цветоразностных единиц PU. В схеме 4:2:2 этот фильтр снова может быть модифицирован в ответ на различные коэффициенты формы для единиц PU, например, может быть использован только для подмножества почти горизонтальных режимов. Примером такого подмножества режимов является подмножество 2-18 и 34, или еще более предпочтительно подмножество 7-14. В схеме 4:2:2 в некоторых вариантах настоящего изобретения может быть выполнено сглаживание только левого столбца опорных отсчетов.
Более обобщенно, в вариантах, которые будут описаны позднее, первое направление прогнозирования определяют относительно первой сетки для первого коэффициента формы применительно к набору текущих отсчетов, подлежащему прогнозированию; и применяют алгоритм отображения направления к этому направлению прогнозирования с целью генерации второго направления прогнозирования, определяемого относительно второй сетки с другим коэффициентом формы. Первое направление прогнозирования может быть определено относительно квадратного блока яркостных отсчетов, куда входит текущий яркостный отсчет; а второе направление прогнозирования может быть определено относительно прямоугольного блока цветоразностных отсчетов, содержащего текущий цветоразностный отсчет.
Эти конфигурации будут позднее рассмотрены более подробно.
Варианты внутрикадрового прогнозирования для схемы 4:4:4
В схеме 4:4:4 цветоразностные и яркостные единицы PU имеют одинаковые размеры, так что режим внутрикадрового прогнозирования для цветоразностной единицы PU может быть либо таким же, как для яркостной единицы PU, расположенной в том же месте (тем самым удается сберечь некоторые издержки в потоке битов данных, за счет того, что не нужно кодировать отдельный режим), либо, в качестве альтернативы, этот режим можно выбирать независимо.
В последнем случае, поэтому, в одном из вариантов настоящего изобретения можно иметь 1, 2 или 3 различных режимов прогнозирования для каждой из единиц PU в составе единицы CU;
В первом примере, единицы PU в каналах Y, Cb и Cr могут все использовать один и тот же режим внутрикадрового прогнозирования.
Во втором примере, единицы PU в канале Y могут использовать один режим внутрикадрового прогнозирования, единицы PU в обоих каналах Cb и Cr могут использовать другой, независимо выбранный режим внутрикадрового прогнозирования.
В третьем примере, единицы PU в каждом из каналов Y, Cb и Cr используют свой для соответствующего канала, независимо выбранный режим внутрикадрового прогнозирования.
Следует понимать, что применение независимых режимов прогнозирования для цветоразностных каналов (или для каждого цветоразностного канала) повысит точность прогнозирования цвета. Но это достигается ценой дополнительных издержек при передаче данных, поскольку необходимо сообщать об этих независимых режимах прогнозирования в составе кодированных данных.
Для исключения таких издержек, выбор числа режимов можно указывать в составе синтаксиса высокого уровня (например, на уровне последовательности, кадра или среза). В качестве альтернативы, число независимых режимов может быть выведено из видео формата; например, формат GBR может иметь до 3 независимых режимов, тогда как число режимов в формате YCbCr может быть ограничено до 2.
В дополнение к возможности независимого выбора режимов в схеме (профиле) 4:4:4 сами доступные режимы могут отличаться от схемы 4:2:0.
Например, поскольку яркостные и цветоразностные единицы PU в схеме 4:4:4 имеют одинаковые размеры, цветоразностные PU могут выиграть от доступа ко всем - 35+LM_CHROMA+DM_CHROMA, возможным направлениям. Поскольку в этом случае каждый из каналов Y, Cb и Cr имеет независимые режимы прогнозирования, тогда канал Cb может иметь доступ к режимам DM_CHROMA & LM_CHROMA, тогда как канал Cr может иметь доступ к режимам DM_CHROMA_Y, DM_CHROMA_Cb, LM_CHROMA_Y и LM_CHROMA_Cb, где соответствующие литеры заменяют ссылки на яркостный канал ссылками на цветоразностные каналы Y или Cb.
Когда о режимах прогнозирования яркостных пикселей сообщают путем формирования списка наиболее вероятных режимов и передачи индекса к этому списку, тогда если режим(ы) прогнозирования цветоразностных каналов являются независимыми, может потребоваться сформировать независимый список наиболее вероятных режимов для каждого канала.
Наконец, способом, аналогичным способу, рассмотренному применительно к случаю схемы 4:2:2 выше, в случае схемы 4:4:4 сглаживающий фильтр, применяемый к опорному отсчету при прогнозировании пикселя в позиции этого отсчета, может быть использован для цветоразностных единиц PU аналогично яркостным единицам PU. Сегодня, к опорным отсчетам перед выполнением внутрикадрового прогнозирования может быть применен фильтр нижних частот [1, 2, 1]. Это применяется только для яркостных единиц TU при использовании некоторых режимов прогнозирования.
Один из режимов внутрикадрового прогнозирования, доступных для применения к цветоразностным единицам TU, состоит в определении прогнозируемых отсчетов на основе расположенных в том же месте яркостных отсчетов. Такой подход схематично иллюстрирует фиг. 19, где изображена матрица единиц TU 1200 (из области исходного изображения), представленных небольшими квадратиками, в каналах Cb, Cr и Y, показывая специальное совмещение между характерными элементами изображения (схематично представлены в виде темных и светлых заштрихованных квадратов 1200) в каналах Cb и Y, а также в каналах Cr и Y. В этом примере можно получить выигрыш, если формировать прогнозируемые отсчеты цветоразностных единиц TU на основе расположенных в этих же позициях яркостных отсчетов. Однако характерные элементы изображения не всегда соответствуют одни другим между этими тремя каналами. На деле, некоторые характерные элементы могут появляться только в одном или двух каналов, а в, общем, контент изображения в трех каналах может отличаться.
В некоторых вариантах настоящего изобретения для единиц TU в канале Cr данные в режиме LM_Chroma могут, в качестве опций, быть основаны на расположенных в этих же позициях отсчетах из канала Cb (или, в других вариантах, зависимость может быть иной). Такая конфигурация схематично показана на фиг. 20. Здесь изображены единицы TU, пространственно совмещенные между каналами Cr, Cb и Y. Еще один набор единиц TU, помеченный как «исходные», является схематичным представлением цветного изображения, рассматриваемого как единое целое. Характерные элементы (треугольник верху слева и треугольник внизу справа), видимые на исходном изображении, на деле представляют не изменения яркости, а только изменения цветности между двумя треугольными областями. В этом случае базирование режима LM_Chroma для канала Cr на яркостных отсчетах даст плохое прогнозирование, но базирование на отсчетах канала Cb может дать улучшенный результат прогнозирования.
Решение, какой из режимов LM_Chroma mode использовать, может быть принято контроллером 343 и/или селектором 520 режимов на основе пробного кодирования разных опций (включая опцию базирования LM_Chroma на расположенных в этом же месте яркостных отсчетах или расположенных в этом же месте цветоразностных отсчетов), причем решение, какой режим выбрать, принимается на основе вычисления целевой функции, аналогично описанному выше для других пробных кодирований. Примерами целевых функций являются уровни шумов, искажений, частоты потока ошибок или скорости передачи битов данных. Из совокупности результатов пробного кодирования выбирают режим, который дает наименьшее значение какой-либо одной или нескольких из этих целевых функций.
Фиг. 21 схематично иллюстрирует способ получения опорных отсчетов для внутрикадрового прогнозирования в некоторых вариантах настоящего изобретения. Изучая фиг. 21, следует помнить, что кодирование осуществляется в соответствии со схемой сканирования, так что в общем случае в процессе кодирования доступны для использования кодированные версии блоков, расположенных сверху и слева от кодируемого в настоящий момент текущего блока. Иногда используются отсчеты из областей снизу слева или сверху справа, если они были ранее закодированы в составе уже кодированных единиц TU в пределах текущей единицы LCU. Ссылки здесь сделаны на описанный выше фиг. 13, например.
Заштрихованная область 1210 представляет текущую единицу TU, иными словами, единицу TU, кодируемую в текущий момент.
В схемах 4:2:0 и 4:2:2 столбец пикселей, расположенный непосредственно слева от текущей единицы TU, не содержит расположенных в одном месте (сорасположенных) яркостных и цветоразностных отсчетов из-за горизонтальной субдискретизации. Другими словами, это обусловлено тем, что в каждом из форматов 4:2:0 и 4:2:2 число цветоразностных пикселей вдвое меньше числа яркостных пикселей (в горизонтальном направлении), так что не для каждой позиции яркостного отсчета имеется расположенный в этой же позиции цветоразностный отсчет. Поэтому, хотя в столбце непосредственно слева от единицы TU могут присутствовать яркостные отсчеты, цветоразностных отсчетов в нем нет. Вследствие этого, в вариантах настоящего изобретения столбец, расположенный на два отсчета левее текущей единицы TU, используется для получения опорных отсчетов для режима LM_Chroma. Отметим, что в схеме 4:4:4 ситуация отличается тем, что столбец, находящийся непосредственно слева от текущей единицы TU действительно содержит сорасположенные яркостные и цветоразностные отсчеты. Этот столбец можно, поэтому, использовать для получения опорных отсчетов.
Эти опорные отсчеты используются следующим образом.
В режиме LM_Chroma прогнозируемые цветоразностные отсчеты получают из реконструированных яркостных отсчетов с использованием линейного соотношения. Поэтому, обобщенно можно сказать, что прогнозируемые цветоразностные величины в единице TU получают по формуле:
PC=a+bPL
где PC - величина цветоразностного отсчета, PL - реконструированная величина яркостного отсчета в позиции рассматриваемого отсчета и а и b - константы. Эти константы получают для конкретного блока путем определения соотношения между реконструированными яркостными отсчетами и цветоразностными отсчетами в строке непосредственно над блоком и в столбце непосредственно слева от блока - это позиции уже закодированных отсчетов (см. выше).
В вариантах настоящего изобретения константы а и b определяют следующим образом:
a=R(PL',PC')/R(PL',PL')
где R - представляет линейную (наименьшие квадраты) функцию регрессии, a PL' и PC' - яркостные и цветоразностные отсчеты соответственно из соседних строки и столбца, как обсуждается выше, и:
b=mean(PC')-a.mean(PL')
Для схемы 4:4:4, величины PL' и PC' берут из столбца, расположенного непосредственно слева от текущей единицы TU, и строки, расположенной непосредственно сверху над текущей единицей TU. Для схемы 4:2:2 величины PL' и PC' берут из строки, расположенной непосредственно сверху над текущей единицей TU, и столбца в соседнем блоке, находящегося на две позиции отсчетов влево от левого края текущей единицы TU. Для схемы 4:2:0 (которая является субдискретизированной по вертикали и по горизонтали) величины PL' и PC' было бы идеально брать из строки, находящейся на две строки выше над текущей единицей TU, но на деле их берут из строки в соседнем блоке, расположенной на одну позицию отсчетов над текущей единицей TU, и столбца в соседнем блоке, расположенного на две позиции отсчетов слева от левого края текущей единицы TU. Причиной этого является стремление избежать сохранения дополнительной полной строки данных в памяти. В этом отношении схемы 4:2:2 и 4:2:0 обрабатывают одинаково.
Соответственно эти алгоритмы применимы к способам видео кодирования, имеющим режим прогнозирования цветоразностных данных, в котором текущий блок цветоразностных отсчетов, представляющий область изображения, кодируют путем вывода и кодирования соотношения между цветоразностными отсчетами и сорасположенным блоком яркостных отсчетов (таких как реконструированные яркостные отсчеты), представляющим ту же самую область изображения. Это соотношение (такое как линейное соотношение) получают (выводят) путем сравнения сорасположенных (иначе именуемых «соответственно расположенными») яркостных и цветоразностных отсчетов с уже кодированными блоками. Цветоразностные отсчеты получают из яркостных отсчетов в соответствии с найденным соотношением и кодируют разность между прогнозируемыми цветоразностными отсчетами и реальными цветоразностными отсчетами в качестве остаточных данных.
Применительно к первому разрешению дискретизации (такому, как 4:4:4), когда цветоразностные отсчеты имеют такую же частоту дискретизации, как яркостные отсчеты, сорасположенные отсчеты - это отсчеты, расположенные в тех же позициях в блоке, соседствующем с текущим блоком.
Применительно ко второму разрешению дискретизации (такому, как 4:2:2 или 4:2:0), когда частота дискретизации цветоразностных отсчетов ниже частоты яркостных отсчетов, для получения сорасположенных отсчетов используют ближайший столбец или строку сорасположенных яркостных и цветоразностных отсчетов из соседнего уже кодированного блока. Либо, когда вторым разрешением дискретизации является разрешение дискретизации схемы 4:2:0, сорасположенные отсчеты представляют собой строку отсчетов рядом с текущим блоком и ближайший столбец или строку соответственно расположенных яркостных и цветоразностных отсчетов из соседних уже кодированных блоков.
Фиг. 22 схематично иллюстрирует набор направлений (углов) прогнозирования яркостных отсчетов. Текущий, прогнозируемый в настоящий момент пиксель показан в центре диаграммы, как пиксель 1200. Меньшие точки 1230 представляют соседние пиксели. Пиксели, расположенные сверху или слева от текущего пикселя могут быть использованы в качестве опорных отсчетов для выполнения прогнозирования, поскольку они были ранее кодированы. Другие пиксели в текущий момент (в момент прогнозирования пикселя 1220) неизвестны и сами будут в должное время подвергнуты прогнозированию.
Каждое пронумерованное направление прогнозирования указывает на опорные отсчеты 1230 из группы опорных отсчетов-кандидатов на верхнем и левом краях текущего блока, используемых для генерации текущего прогнозируемого пикселя. В случае блоков меньшего размера, когда направления прогнозирования указывают на места между опорными отсчетами, применяют линейную интерполяцию между соседними опорными отсчетами (с обеих сторон от позиции, куда указывает направление, обозначенное текущим режимом прогнозирования).
Если обратиться теперь к внутриугловому прогнозированию, для цветоразностных отсчетов, для схемы (профиля) 4:2:0 доступно меньшее число направлений прогнозирования вследствие относительной разреженности цветоразностных отсчетов. Однако, если выбрать режим DM_CHROMA, текущий цветоразностный блок будет использовать те же самые направления прогнозирования, как и сорасположенный с ним яркостный блок. В свою очередь, это означает, что «яркостные» направления для внутрикадрового прогнозирования доступны также для цветоразностных данных.
Однако для цветоразностных отсчетов в схеме 4:2:2 можно считать противоречащим интуитивным соображениям использованием того же самого алгоритма и направления прогнозирования, как и для яркости, когда выбран режим DM_CHROMA, ибо цветоразностные блоки имеют коэффициент формы, отличный от яркостных блоков. Например, линия 45° для квадратной матрицы яркостных отсчетов должна по-прежнему отображаться в линию 45° для цветоразностных отсчетов, хотя эти отсчеты образуют прямоугольную матрицу. Наложение прямоугольной сетки на квадратную сетку показывает, что линия 45° фактически отображается в линию 26.6°.
Согласно вариантам настоящего изобретения может быть определено, что все области какого-либо изображения или все области каждого изображения используют один и тот же режим прогнозирования (например, по меньшей мере для цветоразностных отсчетов), такой как режим DM_CHROMA mode.
Фиг. 23 схематично иллюстрирует направления внутрикадрового прогнозирования для яркостных данных, применяемые к цветоразностным пикселям в схеме 4:2:2, относительно текущего пикселя 1220, подлежащего прогнозированию. Отметим, что число пикселей в горизонтальном направлении вдвое меньше, чем в вертикальном направлении, поскольку схема 4:2:2 имеет вдвое меньшую частоту дискретизации в горизонтальном направлении для цветоразностного канала по сравнению с яркостным каналом.
Фиг. 24 схематично иллюстрирует преобразование или отображение цветоразностных пикселей в схеме 4:2:2 на квадратную сетку и затем показывает, как это преобразование изменяет направления прогнозирования.
Направления прогнозирования яркости показаны штриховыми линиями 1240. Цветоразностные пиксели 1250 переотображены на квадратную сетку, что дало прямоугольную матрицу шириной вдвое меньше ширины 1260 соответствующей яркостной матрицы (так, как это показано на фиг. 22). Направления прогнозирования, показанные на фиг. 23, были переотображены на прямоугольную матрицу. Можно видеть, что для некоторых пар направлений (пара содержит яркостное направление и цветоразностное направление) имеет место либо наложение, либо тесная связь. Например, направление 2 яркостной матрицы по существу накладывается на направление 6 в цветоразностной матрице. Однако следует также отметить, что для некоторых яркостных направлений, примерно половины от общего числа этих направлений, нет соответствующих цветоразностных направлений. Примером может служить яркостное направление под номером 3. Кроме того, для некоторых цветоразностных направлений (2-5) нет эквивалента в яркостной матрице, а некоторые яркостные направления (31-34) не имеют эквивалента в цветоразностной матрице. Но в общем случае, наложение, как это видно на фиг. 24, демонстрирует, что было бы неправильно использовать один и тот же угол для обоих - яркостного и цветоразностного - каналов.
Фиг. 33 схематично иллюстрирует конфигурацию (которая может быть реализована как часть функции контроллера 343) для модификации «угловых шагов», определяющих направление прогнозирования. На фиг. 33 угловой шаг вводят в модификатор 1500, который, используя вспомогательные данные 1510, такие как преобразовательная таблица, индексированная угловым шагом, выполняет отображение входных угловых шагов в выходные угловые шаги, или, используя данные, описывающие заданный алгоритм или функцию модификации, отображает направление, определяемое входным угловым шагом, в направление, определяемое выходным угловым шагом.
Но прежде подробного обсуждения работы схемы, показанной на фиг. 33, будут приведены некоторые дополнительные «фоновые» данные относительно определения углов прогнозирования и, в частности, «угловых шагов».
Как обсуждается выше, в режиме внутрикадрового прогнозирования отсчеты в пределах текущего блока можно прогнозировать на основе одного или нескольких опорных отсчетов. Эти отсчеты выбирают из группы опорных отсчетов-кандидатов, образующих строку над текущим блоком 1560 и столбец слева от этого текущего блока. На фиг. 33 схематично показаны такие строка 1520 и столбец 1530 опорных отсчетов-кандидатов.
В совокупности опорных отсчетов-кандидатов реальный отсчет для использования в конкретной операции прогнозирования указан направлением прогнозирования. Это направление выражено посредством «углового шага». Для преимущественно вертикального направления прогнозирования (в рассматриваемом контексте это направление, указывающее опорный отсчет в строке 1520) угловой шаг представляет собой сдвиг влево или вправо от позиции 1540 отсчета, смещенного по вертикали вверх от позиции 1550 текущего прогнозируемого отсчета. Для преимущественно горизонтального направления прогнозирования (в рассматриваемом контексте это направление, указывающее опорный отсчет в столбце 1530) угловой шаг представляет собой сдвиг вверх или вниз от позиции 1570 отсчета, смещенного по горизонтали влево от позиции 1550 текущего прогнозируемого отсчета.
Поэтому должно быть понятно, что угловой шаг может быть нулевым (в случае чисто горизонтального или чисто вертикального направления прогнозирования) или может представлять смещение в другую сторону (вверх/вниз/влево/вправо).
На деле, для целей вычислений в рамках вариантов настоящего изобретения столбец 1530 и строку 1520 можно рассматривать в качестве одного упорядоченного линейного массива, содержащего множество опорных отсчетов-кандидатов, начиная от нижнего конца столбца 1530 и продвигаясь к правому концу строки 1520. Согласно вариантам настоящего изобретения этот линейный массив фильтруют (посредством фильтра, составляющего часть модуля 530 прогнозирования) с целью применения к линейному массиву сглаживающей фильтрации или фильтрации нижних частот. Примером подходящего сглаживающего фильтра является нормализованный фильтр 1-2-1, иными словами, этот фильтр заменяет конкретный отсчет (только для целей использования в качестве опорного отсчета) суммой 1А отсчета, расположенного слева (в линейном массиве), Vi самого рассматриваемого конкретного отсчета и 1А отсчета, расположенного справа (в линейном массиве). Сглаживающий фильтр может быть применен ко всему массиву или к подмножеству его элементов (такому, как отсчеты, «происходящие» из строки или из столбца).
Для определения подходящего угла прогнозирования для цветоразностных данных, когда ситуация, характеризующаяся (а) выбран режим DM_CHROMA и (b) режим DM_CHROMA используется в текущий момент, указывает, что в качестве направлений прогнозирования для цветоразностных данных следует использовать соответствующие направления для сорасположенного яркостного блока, модификатор 1500 применяет следующую процедуру с целью модификации величин углового шага. Отметим, что эта процедура имеет дело с обратной величиной углового шага. Эта величина может быть использована в качестве удобного компонента вычислений, выполняемых для генерации прогноза, но она является вариантом углового шага, важным для настоящего обсуждения.
(i) определение величины углового шага при внутрикадровом прогнозировании (и, в качестве опции, обратной величины шага) в соответствии с яркостным направлением
(ii) если яркостное направление является преимущественно вертикальным (иными словами, например, режимы с номерами с 18 по 34 включительно), тогда угловой шаг при внутрикадровом прогнозировании делят пополам (а обратную величину для этого шага удваивают).
(iii) в противном случае, если яркостное направление является преимущественно горизонтальным (иными словами, например, режимы с номерами с 2 по 17 включительно), тогда угловой шаг при внутрикадровом прогнозировании удваивают (а обратную величину для этого шага делят пополам).
Эти вычисления представляют пример применения модификатором 1500 заданного алгоритма для модификации величин углового шага с целью отобразить направление, полученное относительно яркостной сетки позиций отсчетов, на направление, применимое к схеме (профилю) 4:2:2, или другой субдискретизированной цветоразностной сетки позиций отсчетов. Аналогичный результат можно получить, если модификатор 1500 вместо этого будет обращаться к преобразовательной таблице, отображающей входные величины углового шага на выходные величины углового шага.
Соответственно, в этих вариантах направление прогнозирования определяет позицию отсчета относительно группы опорных отсчетов-кандидатов, содержащей горизонтальную строку и вертикальный столбец отсчетов, расположенные соответственно сверху и слева от совокупности текущих отсчетов, подлежащих прогнозированию. Модуль 530 прогнозирования осуществляет операцию фильтрации, которая, как обсуждается выше, упорядочивает группу опорных отсчетов-кандидатов в виде линейного массива опорных отсчетов; и применяет сглаживающий фильтр к опорным отсчетам в составе этого линейного массива в направлении вдоль линейного массива.
Процедура отображения может быть выполнена, например, относительно угловых шагов, когда направление прогнозирования для текущего отсчета определено с соответствующим угловым шагом; угловой шаг для преимущественно вертикального направления прогнозирования представляет собой сдвиг вдоль горизонтальной строки позиций отсчетов в группе опорных отсчетов-кандидатов относительно позиции отсчета в строке, смещенной по вертикали относительно текущего отсчета; угловой шаг для преимущественно горизонтального направления прогнозирования представляет собой сдвиг вдоль вертикального столбца позиций отсчетов в группе опорных отсчетов-кандидатов относительно позиции отсчета в столбце, смещенном по горизонтали относительно текущего отсчета; и позиция отсчета в горизонтальной строке или в вертикальном столбце, указываемая сдвигом, создает указатель на позицию отсчета, который должен быть использован для прогнозирования текущего отсчета.
В некоторых вариантах этап выполнения отображения направления может содержать применение заданной функции к угловому шагу, соответствующему первому направлению прогнозирования. Пример такой функции описан выше, а именно:
определение углового шага согласно первому направлению прогнозирования; и
(i) если первое направление прогнозирование преимущественно вертикальное, тогда уменьшение соответствующего углового шага вдвое для генерации углового шага для второго направления прогнозирования; или
(ii) если первое направление прогнозирование преимущественно горизонтальное, тогда увеличение соответствующего углового шага вдвое для генерации углового шага для второго направления прогнозирования.
В вариантах настоящего изобретения, если величина углового шага (такого, как описанный выше модифицированный шаг) не является целочисленной, этот угловой шаг используют для определения группы из двух или более позиций отсчетов в пределах совокупности опорных отсчетов-кандидатов (например, два отсчета с каждой стороны от позиции, на которую указывает рассматриваемое направление) с целью интерполяции для определения прогноза величины текущего отсчета.
В других вариантах настоящего изобретения этап отображения направления содержит использование первого направления прогнозирования в качестве индекса к преобразовательной таблице, которая содержит соответствующие величины для второго направления прогнозирования.
Согласно вариантам настоящего изобретения этап определения первого направления прогнозирования может содержать: в случае операции кодирования, выбор направления прогнозирования по результатам проб двух или более направлений-кандидатов прогнозирования; или в случае операции декодирования, выделение информации, определяющей направление прогнозирования, ассоциированное с видеоданными, подлежащими декодированию. Это главный момент, различающий варианты систем кодирования и декодирования: в декодер некоторые параметры поступают в составе кодированных данных или ассоциированы с ними. В модуле кодирования такие параметры генерируют для передачи вместе с кодированными данными в декодер.
В некоторых вариантах настоящего изобретения первое направление прогнозирования используют для прогнозирования яркостных отсчетов из множества отсчетов; а второе направление прогнозирования, получаемое посредством применения шага из первого направления, используют для прогнозирования цветоразностных отсчетов из множества отсчетов.
Варианты настоящего изобретения могут предоставить способ видео кодирования или декодирования, согласно которому яркостную и первую и вторую цветоразностные составляющие прогнозируют в соответствии с режимом прогнозирования, ассоциированным с отсчетом, подлежащим прогнозированию, этот способ содержит прогнозирование отсчетов второй цветоразностной составляющей на основе первой цветоразностной составляющей.
Варианты настоящего изобретения могут предложить способ видео кодирования или декодирования, согласно которому множества отсчетов прогнозируют на основе других опорных отсчетов в соответствии с направлением прогнозирования, ассоциированным с отсчетом, подлежащим прогнозированию, это направление прогнозирования определяет позицию отсчета относительно группы опорных отсчетов-кандидатов, расположенных рядом с множеством текущих отсчетов, подлежащих прогнозированию, этот способ содержит этапы, на которых:
упорядочивают группы опорных отсчетов-кандидатов в виде линейного массива опорных отсчетов; и
применяют сглаживающие фильтры к подмножеству линейного массива опорных отсчетов в направлении вдоль линейного массива.
Варианты настоящего изобретения могут предложить способ видео кодирования или декодирования, согласно которому яркостные и цветоразностные отсчеты из состава изображения прогнозируют на основе других соответствующих опорных отсчетов, полученных из этого же самого изображения согласно направлению прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, цветоразностные отсчеты, имеют более низкую частоту дискретизации по горизонтали и/или по вертикали, чем яркостные отсчеты, вследствие чего отношение яркостного разрешения по горизонтали к цветоразностному разрешению по горизонтали отличается от отношения яркостного разрешения по вертикали к цветоразностному разрешению по вертикали, так что блок яркостных отсчетов имеет коэффициент формы, отличный от коэффициента формы соответствующего блока цветоразностных отсчетов, где цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие;
способ содержит этапы, на которых:
выбирают режим прогнозирования, определяющего выбор одного или более опорных отсчетов или величин для прогнозирования текущего цветоразностного отсчета для первой цветоразностной составляющей; и
выбирают другой режим прогнозирования, определяющий другой, отличный выбор одного или более опорных отсчетов или величин для прогнозирования текущего цветоразностного отсчета для второй цветоразностной составляющей, сорасположенного с текущим цветоразностным отсчетом для первой цветоразностной составляющей.
Варианты настоящего изобретения могут предложить способ видео кодирования или декодирования, согласно которому яркостные и цветоразностные отсчеты из состава изображения прогнозируют на основе других соответствующих опорных отсчетов согласно направлению прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, цветоразностные отсчеты, имеют более низкую частоту дискретизации по горизонтали и/или по вертикали, чем яркостные отсчеты, вследствие чего отношение яркостного разрешения по горизонтали к цветоразностному разрешению по горизонтали отличается от отношения яркостного разрешения по вертикали к цветоразностному разрешению по вертикали, так что блок яркостных отсчетов имеет коэффициент формы, отличный от коэффициента формы соответствующего блока цветоразностных отсчетов; способ, содержащий этап, на котором:
применяют различные соответствующие алгоритмы прогнозирования к яркостным и цветоразностным отсчетам в зависимости от разницы коэффициентов формы.
Фиг. 33 показывает пример использования этого способа. Угловой шаг 1580 получают в соответствии с яркостной сеткой. (Имеется возможность также использовать этот шаг для прогнозирования яркостных отсчетов, однако для нашего обсуждения вполне достаточно, что этот шаг определяют в соответствии с яркостной сеткой и процедурами. Иными словами, на деле его можно не использовать для прогнозирования яркостных данных.) Показанная матрица отсчетов 1580 по схеме 4:2:2 имеет удвоенную ширину на той же самой сетке; но использование того же самого направления 1590 прогнозирования в этом случае указывает на другой опорный отсчет (другой сдвиг от вертикально расположенного отсчета 1540). Поэтому угловой шаг модифицируют согласно процедуре, указанной выше, для получения модифицированного углового шага 1600, указывающего на правильный цветоразностный опорный отсчет для представления того же самого направления прогнозирования в цветоразностной сетке.
Соответственно эти варианты настоящего изобретения относятся к способам видео кодирования или декодирования, устройствам или программам, согласно которым яркостные и цветоразностные отсчеты прогнозируют на основе других соответствующих опорных отсчетов согласно направлению прогнозирования, ассоциированному с текущим отсчетом, подлежащим прогнозированию. В режимах, таких как схема 4:2:2, цветоразностные отсчеты имеют более низкую частоту дискретизации по горизонтали и/или по вертикали, чем яркостные отсчеты, вследствие чего отношение яркостного разрешения по горизонтали к цветоразностному разрешению по горизонтали отличается от отношения яркостного разрешения по вертикали к цветоразностному разрешению по вертикали. Вкратце, это означает, что блок яркостных отсчетов имеет коэффициент формы, отличный от коэффициента формы соответствующего блока цветоразностных отсчетов.
Модуль 530 внутрикадрового прогнозирования, например, работает в качестве устройства обнаружения для выявления первого направления прогнозирования, определенного относительно первой сетки с первым коэффициентом формы для множества текущих отсчетов, подлежащих прогнозированию; и в качестве модуля отображения направления применительно к направлению прогнозирования для генерирования второго направления прогнозирования, определенного относительно второй сетки с другим коэффициентом формы. Соответственно, этот модуль 530 прогнозирования представляет пример модуля отображения направления. Модуль 540 прогнозирования может представлять другой соответствующий пример.
Согласно вариантам настоящего изобретения первая сетка, используемая для обнаружения первого направления прогнозирования, определена в соответствии с позициями отсчетов одного - яркостного или цветоразностного, вида, а вторая сетка, используемая для обнаружения второго направления прогнозирования, определена в соответствии с позициями отсчетов другого - цветоразностного или яркостного вида. В конкретных примерах, обсуждаемых в настоящем описании, направление прогнозирования яркостных отсчетов может быть модифицировано для получения направления прогнозирования цветоразностных отсчетов. Однако возможен и другой путь.
Предлагаемая технология, в частности, применима к внутрикадровому прогнозированию, так что опорные отсчеты представляют собой отсчеты, полученные из (например, реконструированы из сжатых данных, сформированных на основе) того же самого изображения, к которому относятся отсчеты, подлежащие прогнозированию.
По меньшей мере в некоторых схемах первое направление прогнозирования определено относительно квадратного блока яркостных отсчетов, содержащего текущий яркостный отсчет, а второе направление прогнозирования определено относительно прямоугольного блока цветоразностных отсчетов, содержащего текущий цветоразностный отсчет.
Можно также предложить независимые режимы прогнозирования для двух цветоразностных составляющих. В такой схеме совокупность цветоразностных отсчетов содержит отсчеты первой и второй цветоразностных составляющих, а способ содержит применение отображения направления, обсуждавшегося выше, к первой цветоразностной составляющей (такой как Cb); и применение другого режима прогнозирования ко второй цветоразностной составляющей (такой как Cr), что может (например) содержать прогнозирование второй цветоразностной составляющей на основе отсчетов первой цветоразностной составляющей.
Видеоданные могут быть в формате 4:2:2, например.
В случае декодера или способа декодирования направления прогнозирования могут быть обнаружены путем выявления данных, определяющих направления прогнозирования, в составе кодированных видеоданных.
Обобщенно, варианты настоящего изобретения могут предложить независимые режимы прогнозирования для цветоразностных составляющих (например, для каждой из яркостной и цветоразностных составляющих по отдельности). Эти варианты относятся к способам видео кодирования, согласно которым яркостные и цветоразностные отсчеты для изображения прогнозируют на основе соответствующих опорных отсчетов, полученных из этого же самого изображения в соответствии с направлением прогнозирования, ассоциированным с отсчетом, подлежащим прогнозированию, цветоразностные отсчеты, имеют более низкую частоту дискретизации по горизонтали и/или по вертикали, чем яркостные отсчеты, вследствие чего отношение яркостного разрешения по горизонтали к цветоразностному разрешению по горизонтали отличается от отношения яркостного разрешения по вертикали к цветоразностному разрешению по вертикали, так что блок яркостных отсчетов имеет коэффициент формы, отличный от коэффициента формы соответствующего блока цветоразностных отсчетов, а эти цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие.
Селектор 520 режима внутрикадрового прогнозирования выбирает режим прогнозирования, определяющий выбор одного или более опорных отсчетов для прогнозирования текущего цветоразностного отсчета для первой цветоразностной составляющей (такой как Cb). Он выбирает также другой режим прогнозирования, определяющий другой выбор одного или более опорных отсчетов для прогнозирования текущего цветоразностного отсчета для второй цветоразностной составляющей (такой как Cr), сорасположенного с текущим цветоразностным отсчетом для первой цветоразностной составляющей.
К горизонтальным отсчетам или вертикальным отсчетам (или и тем, и другим) может быть в качестве опции применен фильтр опорных отсчетов. Как обсуждается выше, этот фильтр может представлять собой нормализованный фильтр "1 2 1" с тремя отводами, сегодня применяемый ко всем опорным яркостным отсчетам за исключением нижнего левого и верхнего правого (отсчеты блока N×N собирают вместе для получения одного одномерного (1D) массива размером 2N+1 и затем фильтруют, в качестве опции). В вариантах настоящего изобретения этот фильтр применяется только к первым (левый край) или последним (верхний край) N+1 цветоразностным отсчетам для схемы 4:2:2, но отметим, что при этом нижний левый, верхний правый и верхний левый отсчеты изменяться не будут; либо ко всем цветоразностным отсчетам (как для яркостных отсчетов) для схем 4:2:2 и 4:4:4.
Варианты настоящего изобретения могут также предложить способы видео кодирования или декодирования, устройства или программы, согласно которым отсчеты яркостной и первой и второй цветоразностных составляющих прогнозируют (например, на основе других соответствующих опорных отсчетов или величин) в соответствии с режимом прогнозирования, ассоциированным с отсчетом, подлежащим декодированию, и в том числе прогнозируют отсчеты второй цветоразностной составляющей на основе отсчетов первой цветоразностной составляющей. В некоторых вариантах режим прогнозирования, ассоциированный с отсчетом, подлежащим прогнозированию, может указывать направление прогнозирования, определяющее один или несколько соответствующих опорных отсчетов, на основе которых должно быть произведено прогнозирование рассматриваемого отсчета.
Варианты настоящего изобретения могут также предложить способы видео кодирования или декодирования, устройства или программы, согласно которым отсчеты яркостной и первой и второй цветоразностных составляющих прогнозируют на основе других соответствующих опорных отсчетов в соответствии с режимом прогнозирования, ассоциированным с отсчетом, подлежащим декодированию, и в том числе применяют фильтрацию опорных отсчетов.
Как обсуждалось со ссылками на фиг. 19 и 20, есть возможность того, что другой, отличный режим прогнозирования представляет собой режим, согласно которому отсчеты второй цветоразностной составляющей прогнозируют на основе отсчетов первой цветоразностной составляющей.
Отметим, что режимы 0 и 1 не являются режимами углового прогнозирования и потому не входят в рассматриваемую процедуру. Эта процедура предназначена для отображения направлений прогнозирования цветоразностных отсчетов на направления прогнозирования яркостных отсчетов, показанные на фиг. 24.
Для схемы 4:2:0, когда выбран либо чисто горизонтальный режим прогнозирования (яркостный режим 10), либо чисто вертикальный режим прогнозирования (яркостный режим 26), верхний или левый края прогнозируемой единицы TU подвергают фильтрации только для яркостного канала. Для горизонтального режима прогнозирования верхнюю строку фильтруют в вертикальном направлении. Для вертикального режима прогнозирования левый столбец фильтруют в горизонтальном направлении.
Фильтрацию столбца отсчетов в горизонтальном направлении можно понимать, как применение горизонтально ориентированного фильтра к каждому отсчету по очереди в столбце отсчетов. Что касается каждого индивидуального отсчета, его величина будет модифицирована в результате воздействия фильтра на основе фильтрованной величины, генерируемой в функции текущей величины этого отсчета, и одного или нескольких других отсчетов, расположенных в позициях, смещенных от рассматриваемого отсчета в горизонтальном направлении (иными словами, одного или нескольких других отсчетов, расположенных слева и/или справа от рассматриваемого отсчета).
Фильтрацию столбца отсчетов в вертикальном направлении можно понимать, как применение вертикально ориентированного фильтра к каждому отсчету по очереди в строке отсчетов. Что касается каждого индивидуального отсчета, его величина будет модифицирована в результате воздействия фильтра на основе фильтрованной величины, генерируемой в функции текущей величины этого отсчета, и одного или нескольких других отсчетов, расположенных в позициях, смещенных от рассматриваемого отсчета в вертикальном направлении (иными словами, одного или нескольких других отсчетов, расположенных сверху и/или снизу от рассматриваемого отсчета).
Одной из целей описанной выше фильтрации пикселей, расположенных на краю, является уменьшение краевых эффектов блоков в процессе прогнозирования и тем самым уменьшение энергии, которую содержат данные остаточного изображения.
В вариантах настоящего изобретения предложена также соответствующая процедура фильтрации для цветоразностных единиц TU в схемах (профилях) 4:4:4 и 4:2:2. С учетом горизонтальной субдискретизации одно из предложений состоит в фильтрации только верхней строки в цветоразностной единице TU в схеме 4:2:2, но при этом фильтрации и верхней строки, и левого столбца (как подходит, в соответствии с выбранным режимом) в схеме 4:4:4. Считается целесообразным фильтровать только эти области, чтобы избежать удаления слишком большого числа полезных подробностей в результате фильтрации, что (удаление подробностей в результате фильтрации) привело бы к увеличению энергии в остаточных данных.
Для схемы (профиля) 4:2:0, когда выбран режим DC (DC Mode), верхний и/или левый края прогнозируемой единицы TU подвергают фильтрации только для яркостного канала.
Фильтрация может быть такой, что в режиме DC фильтр выполняет операцию усреднения по формуле (1×соседний внешний отсчет+3*краевой отсчет)/4 для всех отсчетов на обоих краях. Одна для верхнего левого угла функция фильтрации имеет вид (2×текущий отсчет+1×верхний отсчет+1×левый отсчет)/4.
Фильтр H/V представляет усреднение между соседним внешним отсчетом и краевым отсчетом.
В вариантах настоящего изобретения такая фильтрация применяется также для цветоразностных единиц TU в схемах 4:4:4 и 4:2:2. Снова, с учетом горизонтальной субдискретизации, в некоторых вариантах настоящего изобретения фильтруют только верхнюю строку цветоразностных отсчетов для схемы 4:2:2, но при этом фильтруют и верхнюю строку, и левый столбец цветоразностной единицы TU для схемы 4:4:4.
Следовательно, эта технология может быть применена в способе, устройстве или программе видео кодирования или декодирования, согласно которым яркостные и цветоразностные отсчеты в формате 4:4:4 или в формате 4:2:2 прогнозируют на основе других соответствующих отсчетов согласно направлению прогнозирования, ассоциированному с блоками отсчетов, подлежащими прогнозированию.
В вариантах рассматриваемой технологии направление прогнозирования определяют относительно текущего блока, подлежащего прогнозированию. Прогнозируемый блок цветоразностных отсчетов генерируют в соответствии с другими цветоразностными отсчетами, заданными направлением прогнозирования. Если найденное направление прогнозирования является по существу вертикальным (например, находится в пределах +/-n угловых режимов от точно вертикального режима, где n равно (например) 2), фильтруют левый столбец отсчетов (например, в горизонтальном направлении) в прогнозируемом блоке цветоразностных отсчетов. Либо, если найденное направление прогнозирования является по существу горизонтальным (например, находится в пределах +/-n угловых режимов от точно горизонтального режима, где n равно (например) 2), фильтруют верхнюю строку отсчетов (например, в вертикальном направлении) в прогнозируемом блоке цветоразностных отсчетов. Затем кодируют разность между фильтрованным прогнозируемым цветоразностным блоком и реальным цветоразностным блоком, в качестве, например, остаточных данных. В качестве альтернативы тест может быть выполнен для точно вертикального или горизонтального режима, а не для по существу вертикального или горизонтального режима. Допуск +/-n может быть применен к одному из тестов (вертикальному или горизонтальному), но не к другому.
Межкадровое прогнозирование
Следует отметить, что межкадровое прогнозирование в стандарте HEVC уже допускает прямоугольные единицы PU, так что режимы 4:2:2 и 4:4:4 уже совместимы с внутрикадровым прогнозированием единиц PU.
Каждый кадр видео изображения представляет собой дискретный «отсчет» (снимок) реальной сцены, и в результате каждый пиксель является ступенчатой аппроксимацией существующего в реальном мире градиента цвета и яркости.
С учетом этого, при прогнозировании величины Y, Cb или Cr для пикселя в новом видео кадре на основе величины из предыдущего видео кадра пиксели из этого предыдущего видео кадра интерполируют для получения лучшей оценки исходных градиентов, существующих в реальном мире, что должно позволить осуществить более точный выбор величины яркости или цвета для нового пикселя. Следовательно, векторы движения, используемые для указания точки между видео кадрами, не ограничиваются целочисленным разрешением пикселей. Скорее они могут указывать на субпиксельную позицию в интерполированном изображении.
Межкадровое прогнозирование в схеме 4:2:0
Как показано на фиг. 25 и 26, в схеме 4:2:0 в соответствии с отмеченным выше типовая яркостная единица PU 1300 размером 8×8 будет ассоциирована с цветоразностными единицами PU 1310 размером 4×4 для Cb и Cr. Следовательно, для интерполяции данных яркостных и цветоразностных пикселей до достижения того же самого эффективного разрешения используются другие интерполяционные фильтры.
Например, для яркостной единицы PU размером 8×8 в схеме 4:2:0 интерполяция осуществляется до 1А пикселя, так что сначала применяется фильтр 8-отводов ×4 горизонтально, а затем такой же самый фильтр 8-отводов ×4 применяется вертикально, так что яркостная единица PU эффективно растягивается в четыре раза в каждом направлении для образования интерполированной матрицы 1320, как показано на фиг. 25. В то же время, соответствующую цветоразностную единицу PU размером 4×4 для схемы 4:2:0 интерполируют до 1/8 пикселя для генерации того же конечного разрешения, так что сначала фильтр 4-отвода ×8 применяется горизонтально, а затем такой же фильтр 4-отвода ×8 применяется вертикально, так что цветоразностные единицы PU для схемы 4:2:0 эффективно растягиваются в 8 раз в каждом направлении для образования матрицы 1330, как показано на фиг. 26.
Межкадровое прогнозирование в схеме 4:2:2
Аналогичная конфигурация для схемы (профиля) 4:2:2 будет теперь рассмотрена со ссылками на фиг. 27 и 28, иллюстрирующие яркостную единицу PU 1350 и пару соответствующих цветоразностных единиц PU 1360.
На фиг. 28 показано, как было отмечено раньше, что в схеме 4:2:2 цветоразностная единица PU 1360 может быть неквадратной и что для случая яркостной единицы PU размером 8×8 в схеме 4:2:2 типичный размер цветоразностной единицы PU в этой схеме 4:2:2 будет 4 ширина × 8 высота для каждого из каналов Cb и Cr. Заметим, что цветоразностная единица PU изображена на фиг. 28 в виде квадратной матрицы из неквадратных матриц пикселей, но в общем случае отмечены, что единицы PU 1360 представляют собой массивы пикселей размером 4 (горизонталь) × 8 (вертикаль).
Хотя может оказаться возможным использовать, поэтому, существующий яркостный фильтр 8-отводов ×4 по вертикали для цветоразностной единицы PU, в одном из вариантов настоящего изобретения было признано, что существующего цветоразностного фильтра 4-отвода ×8 было бы достаточно для вертикальной интерполяции, поскольку на практике пользователь заинтересован получить одинаково дробные позиции в интерполированной цветоразностной единице PU.
Здесь на фиг. 27 показано, что яркостную единицу PU 1350 размером 8×8 в схеме 4:2:2 интерполируют, как и раньше, в фильтре 8-отводов ×4, а цветоразностную единицу PU 1360 размером 4×8 в схеме 4:2:2 интерполируют в существующем цветоразностном фильтре 4-отвода ×8 в горизонтальном и в вертикальном направлениях, но только одинаково дробные результаты используются для формирования интерполированного изображения в вертикальном направлении.
Эти технологии применимы к способам, устройствам или программам для видео кодирования или декодирования, использующим межкадровое прогнозирование для кодирования входных видеоданных, в составе которых каждая цветоразностная составляющая имеет горизонтальное разрешение 1/М от горизонтального разрешения яркостной составляющей и вертикальное разрешение 1/N от вертикального разрешения яркостной составляющей, где М и N - целые числа, равные 1 или более. Например, для схемы 4:2:2, М=2, N=1. Для схемы 4:2:0, М=2, N=2.
Запоминающее устройство 570 кадров сохраняет одно или несколько изображений, предшествующих текущему изображению.
Интерполяционный фильтр 580 осуществляет интерполяцию обладающей более высоким разрешением версии единиц прогнозирования в составе сохраняемых изображений таким образом, чтобы яркостная составляющая интерполированной единицы прогнозирования имела горизонтальное разрешение в Р раз выше, чем соответствующий участок сохраненного изображения, и вертикальное разрешение в Q раз выше, чем соответствующий участок сохраненного изображения, здесь Р и Q - целые числа больше 1. В рассматриваемых примерах Р=Q-4, так что интерполяционный фильтр 580 генерирует интерполированное изображение с разрешением ¼ отсчета.
Модуль 550 оценки движения определяет межкадровое движение между текущим изображением и одним или несколькими интерполированными сохраняемыми изображениями для генерации векторов движения между единицей прогнозирования в составе текущего изображения и областями одного или нескольких предшествующих изображений.
Модуль 540 прогнозирования с компенсацией движения генерирует прогноз с компенсацией движения для единицы прогнозирования в составе текущего изображения относительно области интерполированного сохраняемого изображения, на которую указывает соответствующий вектор движения.
Возвращаясь к обсуждению работы интерполяционного фильтра 580, варианты этого фильтра применяют интерполяционную фильтрацию с коэффициентом ×R по горизонтали и коэффициентом ×S по вертикали к цветоразностным составляющим сохраняемого изображения для генерации интерполированной цветоразностной единицы прогнозирования, где R равно (U×М×Р) и S равно (V×N×Q), U и V - целые числа, равные 1 или более; и для субдискретизации этой интерполированной цветоразностной единицы прогнозирования, так что ее горизонтальное разрешение оказывается разделено на коэффициент U, а вертикальное разрешение оказывается разделено на коэффициент V, что дает в результате блок размером MP×NQ отсчетов.
Таким образом, в случае профиля 4:2:2, интерполяционный фильтр 580 применяет интерполяцию ×8 и в горизонтальном, и вертикальном направлениях, но затем осуществляет субдискретизацию по вертикали с коэффициентом 2, например, путем использования каждого 2-го отсчета в интерполированном выходном изображении.
Этот способ позволяет, таким образом, использовать одинаковый (например, ×8) фильтр и для схемы 4:2:0, и для схемы 4:2:2, но в случае схемы 4:2:2 тогда применяется, где нужно, дополнительный этап субдискретизации.
В вариантах настоящего изобретения, как обсуждалось выше, интерполированная цветоразностная единица прогнозирования имеет высоту (в отсчетах) вдвое больше, чем единица прогнозирования в формате 4:2:0, интерполированная с использованием таких же интерполяционных фильтров типа ×R и ×S.
Необходимость в создании разных фильтров можно исключить или уменьшить при использовании этих способов, и в частности, при использовании одинаковых интерполяционных фильтров типа ×R по горизонтали и ×S по вертикали и применительно к входным видеоданным в формате 4:2:0, и применительно к входным видеоданным в формате 4:2:2.
Как обсуждается выше, этап субдискретизации интерполированной цветоразностной единицы прогнозирования содержит использование каждого V-го отсчета из состава этой интерполированной цветоразностной единицы прогнозирования в вертикальном направлении и/или использование каждого U-го отсчета рассматриваемой интерполированной цветоразностной единицы прогнозирования в вертикальном направлении.
Варианты настоящего изобретения могут содержать получение яркостного вектора движения для единицы прогнозирования; и независимое определение одного или нескольких цветоразностных векторов движения для этой же единицы прогнозирования.
В вариантах настоящего изобретения по меньшей мере один из коэффициентов R и S равен 2 или более, и кроме того в вариантах настоящего изобретения интерполяционные фильтра типа ×R по горизонтали и ×S по вертикали применяются также к яркостным составляющим сохраняемого изображения.
Варианты межкадрового прогнозирования в схеме 4:4:4
Расширяя, такие же принципы использования только одинаково дробных результатов для существующего цветоразностного фильтра типа 4-отвода ×8 могут быть применимы и по вертикали, и по горизонтали к цветоразностным единицам PU размером 8×8 в схеме 4:4:4.
Кроме того, в этих примерах цветоразностный фильтр типа ×8 может быть использован для всех интерполяций, включая яркостные.
Другие варианты межкадрового прогнозирования
В одном из вариантов реализации способа определения вектора движения (MV) генерируют один вектор для единицы PU в Р-срезе и два вектора для единицы PU в В-срезе (здесь Р-срез осуществляет прогнозирование на основе предшествующего кадра, а В-срез осуществляет прогнозирование на основе предшествующего и последующего кадров, аналогично кадрам P и B в стандарте MPEG). Примечательно, что в этом варианте реализации для схемы 4:2:0 эти векторы являются общими для всех каналов, и более того, нет необходимости использовать цветоразностные данные для вычисления векторов движения. Другими словами, все каналы используют вектор движения, полученный на основе яркостных данных.
В вариантах настоящего изобретения в схеме 4:2:2 цветоразностный вектор может быть получен независимо от яркостного вектора (т.е. один общий вектор для каналов Cb и Cr может быть получен отдельно), а в схеме 4:4:4 цветоразностные векторы могут быть также независимы для каждого из каналов Cb и Cr.
Варианты настоящего изобретения могут предлагать способ видео кодирования или декодирования, в котором яркостные и цветоразностные отсчеты изображения прогнозируют на основе других соответствующих опорных отсчетов, полученных из того же самого изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, так что цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие; этот способ содержит этап, на котором выбирают, по меньшей мере для некоторых отсчетов, одного и того же режима прогнозирования для каждой из яркостной и цветоразностных составляющих, соответствующих рассматриваемой области изображения.
Варианты настоящего изобретения могут предлагать способ видео кодирования или декодирования, в котором яркостные и цветоразностные отсчеты изображения прогнозируют на основе других соответствующих опорных отсчетов, полученных из того же самого изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, так что цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие; этот способ содержит этап, на котором выбирают, по меньшей мере для некоторых отсчетов, разных режимов прогнозирования для каждой из яркостной и цветоразностных составляющих, соответствующих рассматриваемой области изображения.
В любом случае, для каждой из яркостной и цветоразностных составляющих, соответствующих рассматриваемой области изображения, может быть выбран один и тот же режим прогнозирования или разные режимы прогнозирования, причем выбор осуществляется согласно последовательности изображений, отдельному изображению или области изображения.
Для выбора схемы режимов прогнозирования при выполнении операции кодирования варианты настоящего изобретения могут, например, осуществлять первое пробное кодирование области изображения с использованием одного и того же режима прогнозирования для яркостной и цветоразностных составляющих; осуществлять второе пробное кодирование с использованием разных режимов прогнозирования для яркостной и цветоразностных составляющих; и выбирать для использования одинаковый режим прогнозирования или разные режимы прогнозирования согласно последовательности изображений, отдельному изображению или области изображения на основе данных, кодированных посредством первого и второго пробных кодирований.
Обработка результатов проб может, в вариантах настоящего изобретения, содержать определение одного или более заданных свойств данных, кодированных посредством первого и второго пробных кодирований; и выбор либо одинакового режима прогнозирования, либо разных режимов прогнозирования для использования применительно к последовательности изображений, отдельному изображению или области изображения на основе найденных одного или нескольких свойств. В совокупность указанных одного или нескольких слов могут входить, например, свойства, выбранные из группы, содержащей: шумы на изображении; искажения изображения; и объем данных изображения. Выбор может быть сделан для отдельных срезов изображения или блоков изображения. Варианты настоящего изобретения ассоциируют с кодированным видеосигналом (например, в виде части кодированного потока данных в виде одного или нескольких флагов данных в составе потока данных) информацию, указывающую: используются ли одинаковые режимы прогнозирования или разные режимы прогнозирования, идентификацию этих разных режимов прогнозирования, например, с использованием схемы нумерации, обсуждавшейся в настоящей заявке применительно к режимам прогнозирования.
В вариантах, осуществляющих декодирование, предлагаемый способ может содержать: обнаружение информации, ассоциированной с видеоданными для декодирования и указывающей, ассоциирован ли с этими видеоданными для декодирования один и тот же режим прогнозирования или разные режимы прогнозирования. Если такая информация (например, однобитовый флаг в заданной позиции в потоке данных) указывает, что использованы одинаковые режимы прогнозирования, декодер применяет информацию о режиме прогнозирования, найденную для одной составляющей (такой как яркостная составляющая), к декодированию других составляющих, таких как цветоразностные составляющие). В противном случае, декодер применяет индивидуально заданные режимы прогнозирования к каждой составляющей.
В вариантах настоящего изобретения, как обсуждается выше, рассматриваемое изображение составляет часть видеосигнала в формате 4:2:2 или 4:4:4.
Преобразования
В стандарте HEVC большинство изображений кодируют в виде векторов движения от ранее кодированных/декодированных кадров, так что эти векторы движения сообщают декодеру, откуда из состава этих других декодированных кадров можно скопировать хорошие аппроксимации для текущего изображения. Результатом является аппроксимированная версия текущего изображения. Затем стандарт HEVC кодирует так называемый остаток, представляющий собой погрешность между аппроксимированной версией и правильным изображением. Объем остатка намного меньше объема информации, который требуется для непосредственной спецификации реального изображения. Однако в общем случае по-прежнему предпочтительно сжать эту остаточную информацию, чтобы еще больше уменьшить общую скорость передачи данных.
Во многих способах кодирования, включая стандарт HEVC, такие данные преобразуют в область пространственных частот с использованием целочисленного косинусного преобразования (integer cosine transform (ICT)), и при этом обычно некоторая степень сжатия достигается за счет сохранения данных низких пространственных частот и отбрасывания данных более высоких пространственных частот в соответствии с желаемой степенью сжатия.
Преобразования в схеме 4:2:0
Преобразования в область пространственных частот, используемые в стандарте HEVC, обычно генерируют коэффициенты в количестве, равном степени 4 (например, 64 частотных коэффициента), поскольку это особенно подходит для общеупотребительных способов квантования/сжатия. Квадратные единицы TU в схеме 4:2:0 все соответствуют степени 4, вследствие чего все это легко достигается.
Если активизированы опции преобразования NSQT, для неквадратных единиц TU, таких как 4×16, доступны некоторые неквадратные преобразования, но снова примечательно то, что они приводят к 64 коэффициентам, т.е. опять к степени 4.
Варианты преобразования для схем 4:2:2 и 4:4:4
Схема (профиль) 4:2:2 может привести к неквадратным единицам TU, не соответствующим степеням 4; например, TU размером 4×8 содержит 32 пикселя, а 32 не является степенью 4.
В одном из вариантов настоящего изобретения могут быть, поэтому, использованы неквадратные преобразования для неравного степени 4 числа коэффициентов, признавая при этом, что могут потребоваться некоторые модификации последующей процедуры квантования.
В качестве альтернативы в одном из вариантов настоящего изобретения неквадратные единицы TU разбивают на квадратные блоки, площадь которых соответствует степени 4, для преобразования, после чего можно выполнить перемежение полученных в результате коэффициентов.
Например, для блоков размером 4×8 нечетные/четные отсчеты по вертикали могут быть разбиты на два квадратных блока. В качестве альтернативы, для блоков размером 4×8 верхние 4×4 пикселей и нижние 4×4 пикселей могут образовать два квадратных блока. В качестве еще одной альтернативы, для блоков размером 4×8 может быть применено вейвлетное разложение Хаара для получения низкочастотного и высокочастотного блоков размером 4×4 каждый.
Может быть сделана доступной любая из этих опций, а о выборе конкретной альтернативы может быть сообщено декодеру, либо он сам может определить подходящую альтернативу.
Другие режимы преобразования
В схеме (профиле) 4:2:0 предлагается флаг (так называемый 'qpprime_y_zero_transquant_bypass_flag'), позволяющий вставить остаточные данные в поток битов данных без потерь (т.е. без преобразования, квантования или дополнительной фильтрации). В схеме 4:2:0 этот флаг применяется ко всем каналам.
Соответственно, такие варианты представляют способ, устройство или программу видео кодирования или декодирования, согласно которым прогнозируют яркостные и цветоразностные отсчеты и кодируют разность между отсчетами и соответствующими им прогнозируемыми отсчетами, используя индикатор, конфигурированный для указания, должны ли яркостные разностные данные быть вставлены в выходной поток битов данных без потерь; и для независимого указания, должны ли цветностные разностные данные быть вставлены в выходной поток битов данных без потерь.
В одном из вариантов настоящего изобретения предлагается, чтобы флаг для яркостного канала был отдельным от флагов для цветоразностных каналов. Следовательно, для схемы 4:2:2 такие флаги следует генерировать по отдельности для яркостного канала и для цветоразностных каналов, а для схемы 4:4:4 такие флаги следует генерировать либо по отдельности для яркостного и цветоразностных каналов, либо генерировать один флаг для каждого из трех каналов. Это учитывает увеличенные скорости передачи цветоразностных данных, ассоциированные со схемами 4:2:2 и 4:4:4, и позволяет, например, применять яркостные данные без потерь вместе со сжатыми цветоразностными данными.
Для кодирования в режиме внутрикадрового прогнозирования зависящее от режима направленное преобразование (MDDT) позволяет преобразование ICT по вертикали или по горизонтали (или оба преобразования ICT) для единицы TU заменить целочисленным синус-преобразованием Фурье (Integer Sine Transform) в зависимости от направления внутрикадрового прогнозирования. В схеме 4:2:0 это неприменимо к цветоразностным единицам TU. Однако в одном из вариантов настоящего изобретения предлагается применить это к цветоразностным единицам TU в схемах 4:2:2 и 4:4:4, помня, что преобразование IST на сегодня определено только для размера преобразования, равного 4 отсчетам (по горизонтали или по вертикали), и потому не может быть, по состоянию на сегодня, применено по вертикали к цветоразностной единице TU размером 4×8. Преобразование MDDT будет дополнительно обсуждаться ниже.
Применительно к способам видео кодирования различные варианты настоящего изобретения могут быть построены таким образом, чтобы указывать, следует ли вставить яркостные разностные данные в выходной поток битов данных без потерь; и независимо от этого для указания, следует ли вставить цветностные разностные данные в выходной поток битов данных без потерь, и для кодирования или введения соответствующих данных в форме, определяемой такими указаниями.
Квантование
В схеме 4:2:0 вычисления квантования для цветоразностных составляющих являются такими же, как для яркостной составляющей. Отличаются только параметры квантования (QP).
Параметры QP для цветоразностных составляющих вычисляют на основе параметров QP для яркостной составляющей следующим образом:
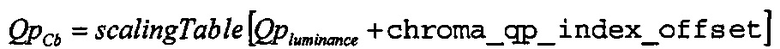
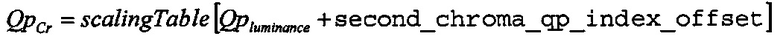
здесь таблица масштабирования (scaling table) определена, как показано на фиг. 29а или 29b (для схем 4:2:0 и 4:2:2 соответственно), a "chroma_qp_index_offset" и "second_chroma_qp_index_offset" определены в наборе параметров изображения и могут быть одинаковыми или разными для составляющих каналов Cr и Cb. Другими словами, величина в квадратных скобках определяет в каждом случае «индекс» в таблицу масштабирования (фиг. 29а и b), а таблица масштабирования в ответ выдает пересмотренную величину Qp ("величина").
Отметим, что параметры "chroma_qp_index_offset" и "second_chroma_qp_index_offset" могут вместо этого быть обозначены как cb_qp_offset и cr_qp_offset соответственно.
Цветоразностные каналы обычно содержат меньше информации, чем канал яркости, и вследствие этого имеют коэффициенты меньшей величины; это ограничение для цветоразностных параметров QP может предотвратить потери всех подробностей цветоразностной составляющей при высоких уровнях квантования.
Соотношение между QP и делителем в схеме 4:2:0 является логарифмическим, так что увеличение параметра QP на 6 эквивалентно удвоению делителя (размер шага квантования обсуждается в настоящем описании в другом месте, хотя и с указанием, что этот параметр может быть дополнительно модифицирован посредством матрицы Qmatrices перед использованием). Следовательно, наибольшая разница в таблице масштабирования, равная 51-39=12, представляет изменение делителя с коэффициентом 4.
Однако, в одном из вариантов настоящего изобретения, для схемы 4:2:2, потенциально содержащей вдвое больше цветоразностной информации, чем схема 4:2:0 максимальная величина параметра QP для цветоразностных данных (цветоразностного параметра) в таблице масштабирования может быть увеличена до 45 (т.е. уменьшение делителя вдвое). Аналогично, для схемы 4:4:4 максимальная величина цветоразностного параметра QP в таблице масштабирования может быть увеличена до 51 (т.е. тот же самый делитель). В этом случае таблица масштабирования является по существу избыточной, но может быть сохранена просто для повышения эффективности работы (т.е. система будет работать со ссылками на таблицу одинаковым образом для каждой схемы). Следовательно, более обобщенно, в одном из вариантов настоящего изобретения делитель цветоразностного параметра QP модифицируют в соответствии с объемом информации в схеме кодирования относительно схемы 4:2:0.
Соответственно, варианты настоящего изобретения применимы к способу видео кодирования или декодирования, осуществляющему квантование блоков преобразованных в частотную область видеоданных яркостной и цветоразностных составляющих в формате 4:4:4 или 4:2:2 согласно выбранному параметру квантования, определяющему размер шага квантования. Между яркостными и цветоразностными параметрами квантования определено ассоциирование (такое, как, например, подходящая таблица на фиг. 29а или 29b), причем это ассоциирование таково, что максимальный размер шага квантования для цветоразностной составляющей меньше максимального размера шага квантования для яркостной составляющей для формата 4:2:2 format (например, 45), но равен максимальному размеру шагу квантования для формата 4:4:4 (например, 51). Процедура квантования состоит в том, что каждую составляющую данных, преобразованных в частотную область, делят на соответствующую величину, полученную из соответствующего размера шага квантования, а результат деления округляют до целого числа для генерации соответствующих блоков квантованных пространственных частотных данных.
Должно быть понятно, что этапы деления и округления является показательными примерами общего этапа квантования согласно соответствующему размеру шага квантования (или данным, полученным на основе этого шага, например, путем применения матриц Qmatrices).
Варианты настоящего изобретения содержат этап выбора параметра квантования или индекса (QP для яркостной составляющей) для квантования коэффициентов разложения на пространственные частотные составляющие, этот параметр квантования действует в качестве ссылки на один из группы размеров шага квантования согласно таблицам QP, применимым к яркостным данным. Процедура определения ассоциирования шага квантования может тогда содержать: для цветоразностных составляющих, обращение к таблице модифицированных параметров квантования (такой как таблица на фиг. 29а или 29b) в соответствии с выбранным параметром квантования, который в свою очередь может содержать (i) для первой цветоразностной составляющей, добавление первого сдвига (такого как chroma_qp_index_offset) к параметру квантования и выбор модифицированного индекса квантования согласно входному значению по таблице для суммы индекса квантования с первым сдвигом; и (ii) для второй цветоразностной составляющей, добавление второго сдвига (такого как second_chroma_qp_index_offset) к параметру квантования и выбор модифицированного индекса квантования согласно входному значению по таблице для суммы индекса квантования со вторым сдвигом; и обращение к соответствующему размеру шага квантования в группе согласно параметру квантования для яркостных данных и первому и второму модифицированным индексам квантования для первой и второй цветоразностных составляющих. Если смотреть под другим углом зрения, это пример процедуры, содержащей выбор параметра квантования для коэффициентов разложения на пространственные частотные составляющие, так что этот параметр квантования действует в качестве ссылки на один из группы размеров шага квантования; и этап определения содержит: для цветоразностных составляющих обращение к таблице модифицированных параметров квантования согласно выбранному параметру квантования, этап обращения содержит: для каждой цветоразностной составляющей добавление соответствующего сдвига к параметру квантования и выбор модифицированного индекса квантования согласно входному значению по таблице для суммы индекса квантования с соответствующим сдвигом; и обращение к соответствующему размеру шага квантования в группе согласно параметру квантования для яркостных данных и первому и второму модифицированным индексам квантования для первой и второй цветоразностных составляющих.
Эти способы особенно применимы к системам, где последовательные величины размеров шага квантования в группе связаны логарифмически, так что изменение параметра m квантования (где m - целое число) представляет изменение размера шага квантования с коэффициентом параметра (где р - целое число больше 1). В рассматриваемых здесь вариантах m=6 и р=2.
В вариантах настоящего изобретения, как обсуждается выше, максимальная величина яркостного параметра квантования равна 51, а максимальная величина цветоразностного параметра квантования равна 45 для формата 4:2:2; и максимальная величина цветоразностного параметра квантования равна 51 для формата 4:4:4.
В вариантах настоящего изобретения первый и второй сдвиги можно сообщить вместе с кодированными видеоданными.
В формате 4:2:0 матрицы А преобразования первоначально создают (посредством преобразовательного модуля 340) из матрицы А' истинно нормированного преобразования DCT размера N×N с использованием:
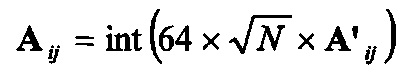
где i и j обозначают позицию в матрице. Это масштабирование относительно нормированной матрицы преобразования предоставляет увеличение точности, избегает необходимости дробных вычислений и увеличивает собственную точность.
Если игнорировать различия из-за округления элементов Aij, поскольку X умножают и на А, и на AT (транспонированная матрица А) получаемые коэффициенты отличаются от элементов истинно нормированного преобразования DCT размера M×N (М=высота; N=ширина) общим масштабным коэффициентом:

Отметим, что общий масштабный коэффициент в этом примере может быть другим. Отметим также, что умножение матрицы и на А, и на AT можно осуществлять различными способами, например, так называемым способом бабочки (Butterfly method). Важно здесь, выполняется ли эта операция эквивалентно традиционному умножению матриц, а не выполняется ли она в конкретном традиционном порядке действий.
Этот масштабный коэффициент эквивалентен двоичной операции побитового сдвига влево на число битов, равное transformShift, поскольку в стандарте HEVC это приводит к умножению на степень 2:

Для ослабления требований к внутренней битовой точности коэффициенты сдвигают вправо дважды в ходе процедуры преобразования:
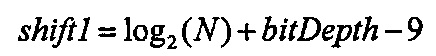

В результате эти коэффициенты при выходе из процесса прямого преобразования и входе в модуль квантования оказываются эффективно сдвинуты влево на:

В формате 4:2:0 коэффициент разложения на частотные составляющие (например, DCT), генерируемые в результате преобразования в частотную область (частотного преобразования), оказываются с коэффициентом (2resultingShift) больше коэффициентов, которые бы дало нормированное преобразование DCT.
В некоторых вариантах настоящего изобретения блоки являются либо квадратными, либо прямоугольными с коэффициентом формы 2:1. Поэтому при размере блока N×М, либо:
N=М, в каком случае параметр resultingShift является целым числом S=N=М=sqrt(NM); либо
0.5N=2М или 2N=0.5М, в каком случае параметр resultingShift по-прежнему is является целым числом и S=sqrt(NM)

Эти коэффициенты затем квантуют, причем делитель при квантовании определяется в соответствии с параметром квантования QP.
Отметим, что параметр resultingShift эквивалентен целому числу, так что общий масштабный коэффициент равен целой степени 2, параметр 'resultingShift' общего сдвига влево в процессе преобразования также учитывают на этом этапе путем применения равного по величине, но противоположного по направлению сдвига вправо, 'quantTransformRightShift'.
Такая операция сдвига битов возможна потому, что параметр resultingShift является целым числом.
Отметим также, что соотношение между делителем и параметром QP (параметр квантования или индекс) следует кривой степенной функции с основанием 2, как отмечено выше, так что увеличение параметра QP на 6 вызывает удвоение делителя, тогда как увеличение параметра QP на 3 приводит к увеличению делителя с коэффициентом sqrt(2) (корень квадратный из 2).
Для цветоразностных составляющих в формате 4:2:2 есть больше возможных отношений ширина : высота (N:M) для единиц TU:
N=М (как раньше), где S=N=М=sqrt(NM) (параметр resultingShift является целым числом)
0.5N=2М и 2N=0.5М (как и раньше), где S=sqrt(NM) (параметр resultingShift является целым числом)
N=2М, где S=sqrt(NM)
2М=N, где S=sqrt(NM)
4N=0.5М, где S=sqrt(NM)
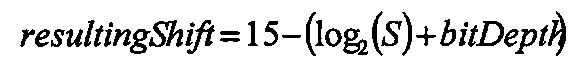
В трех последних случаях параметр resultingShift не является целым числом. Например, это может применяться, когда некоторые блоки отсчетов видеоданных содержат M×N отсчетов, причем корень квадратный из величины N/M не равен целочисленной степени 2. Такие размеры блоков могут иметь место для цветоразностных отсчетов в некоторых из представленных здесь вариантов.
Соответственно, в таких случаях применимы следующие способы, а именно в таких способах, устройствах или программах для видео кодирования или декодирования, генерирующих блоки квантованных данных разложения на пространственные частотные составляющие посредством частотного преобразования блоков отсчетов видеоданных с использованием матрицы преобразования, содержащей массив целочисленных величин, каждая из которых масштабирована относительно соответствующих величин нормированной матрицы преобразования на величину, зависящую от размера матрицы преобразования, и для квантования данных разложения на пространственные частотные составляющие в соответствии с выбранным размером шага квантования, имеющих этап частотного преобразования блока отсчетов видеоданных посредством матричного умножения этого блока на матрицу преобразования и на транспонированную матрицу преобразования с целью генерации блока масштабированных коэффициентов разложения на пространственные частотные составляющие, каждый из которых больше с общим масштабным коэффициентом (например, resultingShift), чем пространственные частотные коэффициенты, которые были бы получены в результате нормированного разложения на частотные составляющие этого блока отсчетов видеоданных.
Поэтому на этапе квантования подходящая операция побитового сдвига не может быть использована для устранения эффекта этой операции достаточно простым способом.
Предлагаемое решение состоит в следующем:
На этапе квантования применяют сдвиг вправо:
 ,
,
где величину S' получают так, что


Разница в ½ между сдвигами эквивалентна умножению на sqrt(2), т.е. в этот момент коэффициенты оказываются в sqrt(2) раз больше, чем они были бы в случае побитового сдвига на целое число битов.
Для процедуры квантования применение параметра квантования величиной (QP+3) означает, что квантующий делитель эффективно увеличивается с коэффициентом sqrt(2), компенсируя тем самым масштабный коэффициент sqrt(2), примененный на предыдущем этапе.
Соответственно, эти этапы (в контексте способа видео кодирования или декодирования (или соответствующего устройства или программы), генерирующих блоки квантованных данных разложения на пространственные частотные составляющие посредством частотного преобразования блоков отсчетов видеоданных с использованием матрицы преобразования, содержащей массив целочисленных величин, каждая из которых масштабирована относительно соответствующих величин нормированной матрицы преобразования на величину, зависящую от размера матрицы преобразования, и для квантования данных разложения на пространственные частотные составляющие в соответствии с выбранным размером шага квантования, содержат частотное преобразование блока отсчетов видеоданных посредством матричного умножения этого блока на матрицу преобразования и на транспонированную матрицу преобразования с целью генерации блока масштабированных коэффициентов разложения на пространственные частотные составляющие, каждый из которых больше с общим масштабным коэффициентом, чем коэффициенты разложения на пространственные частотные составляющие, которые были бы получены в результате нормированного разложения на частотные составляющие этого блока отсчетов видеоданных) можно суммировать следующим образом: выбор размера шага квантования для квантования коэффициентов разложения на пространственные частотные составляющие; применение n-битового сдвига (например, quantTransformRightShift) для деления каждого из масштабированных коэффициентов разложения на пространственные частотные составляющие на коэффициент 2n, где n - целое число; и определение остаточного масштабного коэффициента (например, resultingShift-quantTransformRightShift), представляющего собой результат деления общего масштабного коэффициента на 2n. Например, в обсуждавшейся выше ситуации размер шага квантования изменен в соответствии с остаточным масштабным коэффициентом для генерации модифицированного размера шага квантования; и каждый из масштабированных коэффициентов разложения на пространственные частотные составляющие в блоке разделен на величину, зависящую от модифицированного размера шага квантования, а результат деления округлен до целочисленной величины, для генерации блока квантованных данных разложения на пространственные частотные составляющие. Как обсуждалось выше, модификация размера шага квантования может быть произведена просто путем добавления сдвига к параметру QP, чтобы выбрать другой размер шага квантования, когда этот параметр QP отображают в таблицу размеров шага квантования.
Теперь коэффициенты имеют правильную величину для исходного параметра QP.
Матрица преобразования может содержать массив целочисленных величин, каждая из которых масштабирована относительно соответствующей величины в нормированной матрице преобразования на величину, зависящую от размера матрицы преобразования.
Отсюда вытекает, что требуемая величина S' всегда может быть получена следующим образом:
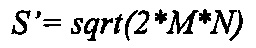
В качестве альтернативного предложения, величина S' может быть получена так, что:
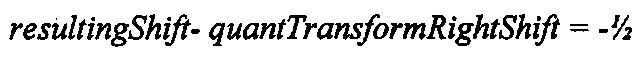
В этом случае,  , а примененный параметр квантования равен (QP-3)
, а примененный параметр квантования равен (QP-3)
В любом из этих случаев (добавление 3 к параметру QP или вычитание 3 из параметра QP), этап выбора размера шага квантования содержит выбор индекса квантования (например, QP), индекс квантования определяет соответствующий вход в таблицу размеров шага квантования, а этап модификации содержит изменение индекса квантования с целью выбора другого размера шага квантования, так что отношение нового размера шага квантования к первоначально выбранному размеру шага квантования по существу равно остаточному масштабному коэффициенту.
Это работает особенно хорошо там, где, как в рассматриваемых вариантах, последовательные величины размеров шага квантования в таблице связаны логарифмически, так что изменение индекса квантования (например, QP), равного m (где m - целое число) представляет изменение размера шага квантования с коэффициентом р (где р - целое число больше 1). В рассматриваемых вариантах m=6 и р=2, так что увеличение параметра QP на 6 представляет удвоение применяемого размера шага квантования, а уменьшение параметра QP на 6 представляет уменьшение результирующего размера шага квантования вдвое.
Как обсуждается выше, модификация может быть произведена путем выбора индекса квантования (например, базового параметра QP) применительно к яркостным отсчетам; генерации сдвига индекса квантования, относительно индекса квантования, выбранного для яркостных отсчетов, для отсчетов каждой или обеих цветоразностных составляющих; изменения сдвига индекса квантования в соответствии с остаточным масштабным коэффициентом; и передача этого сдвига индекса квантования в ассоциации с кодированными видеоданными. В вариантах стандарта HEVC, сдвиги параметра QP для двух цветоразностных каналов передают в составе потока битов данных. Эти этапы соответствуют системе, в которой сдвиг параметра QP (для учета остаточного масштабного коэффициента) величиной +/-3 может быть введен в эти сдвиги, либо сдвиги могут быть увеличены/уменьшены при использовании для получения параметра QP для цветоразностных составляющих.
Отметим, что сдвиг параметра QP не обязан быть равным +/-3, если применяются блоки другой формы; просто +/-3 представляет сдвиг, применимый к формам блоков и коэффициентам формы, обсуждавшихся выше для видео в формате 4:2:2, например.
В некоторых вариантах параметр n (применяемую величину сдвига битов) выбирают таким образом, чтобы величина 2" была больше или равна общему масштабному коэффициенту. В вариантах настоящего изобретения параметр n выбирают таким образом, чтобы величина 2n была меньше или равна общему масштабному коэффициенту. В вариантах настоящего изобретения, использующих какую-либо из этих схем, сдвиг n битов может быть выбран равным следующей ближайшей величине (в любом направлении) относительно общего масштабного коэффициента, так что величина остаточного масштабного коэффициента меньше 2.
В других вариантах модификация размера шага квантования может быть произведена путем умножения размера шага квантования на коэффициент, зависящий от остаточного масштабного коэффициента. Иными словами, в модификацию не входит модификация индекса QP.
Отметим также, что размер шага квантования в том виде, как он обсуждался выше, не обязательно является реальным размером шага квантования, на который делят преобразованный отсчет. Размер шага квантования, полученный таким способом, может быть дополнительно модифицирован. Например, в некоторых системах размер шага квантования дополнительно модифицируют посредством соответствующих входов в матрицу величин (Qmatrix), так что разные конечные размеры шагов квантования используют в разных позициях коэффициентов в квантованном блоке коэффициентов.
Также примечательно, что в схеме 4:2:0 наибольший размер цветоразностной единицы TU равен 16×16, тогда как в схеме 4:2:2 возможны единицы TU размером 16×32, а для схемы 4:4:4 возможны цветоразностные единицы TU размером 32×32. Вследствие этого, в одном из вариантов настоящего изобретения предложены матрицы квантования (Qmatrices) для цветоразностных единиц TU размером 32×32. Аналогично, следует определить матрицы Qmatrices для неквадратных единиц TU, таких как единицы TU размером 16×32, в одном из вариантов такая матрица может быть результатом субдискретизации квадратной матрицы Q большего размера
Матрицы Qmatrices могут быть определены одним из следующих способов:
посредством величин сетки (как для матриц Qmatrices размером 4×4 и 8×8);
путем пространственной интерполяции от матриц меньшего или большего размера;
- в стандарте HEVC матрицы Qmatrices большего размера могут быть получены из соответствующих групп коэффициентов опорных матриц меньшего размера, либо матрицы меньшего размера могут быть получены посредством субдискретизации матриц большего размера. Отметим, что такая интерполяция или субдискретизация может быть выполнена в рамках одного значения пропорции каналов - например, матрица большего размера для некоторого значения пропорции каналов может быть интерполирована из матрицы меньшего размера для того же самого значения пропорции каналов.
относительно других матриц Qmatrices (т.е. разностные величины или «дельты»);
- в таком случае нужно передавать только «дельты».
В качестве небольшого примера, только для целей иллюстрации, конкретная матрица для одного значения пропорции каналов может быть определена в виде матрицы размером 4×4 для схемы 4:2:0
(a b)
(c d)
здесь a, b, с и d - соответствующие коэффициенты. Она служит опорной матрицей.
Варианты настоящего изобретения могут тогда определить множество разностных величин для матрицы такого же размера, но применительно к другому значению пропорции каналов:
(diff1 diff2)
(diif3 diff4)
таким образом, для генерирования матрицы Qmatrix для другого значения пропорции каналов выполняют матричное суммирование матрицы разностей с опорной матрицей.
Вместо матрицы разностей для другого значения пропорции каналов может быть определена матрица множителей, так что либо (i) выполняют матричное умножение матрицы множителей на опорную матрицу для генерирования матрицы Qmatrix для другого значения пропорции каналов, либо (ii) каждый коэффициент опорной матрицы индивидуально умножают на соответствующий множитель для генерирования матрицы Qmatrix для другого значения пропорции каналов.
в качестве функции другой матрицы Qmatrix;
- например, пропорция масштабирования относительно другой матрицы (так что каждый из элементов а, b, с и d в приведенном выше примере умножают на один и тот же коэффициент, либо добавляют к каждому из указанных элементов одну и ту же разность). Это уменьшает объем данных, необходимый для передачи разностных данных или данных коэффициентов.
- следовательно, необходимо передавать только коэффициенты функций (такие, как пропорция масштабирования),
в качестве уравнения/функции (например, кусочно-линейная кривая, экспонента, полином);
- следовательно, для получения матрицы нужно передавать только коэффициенты этого уравнения,
или какое-либо сочетание перечисленных выше способов. Например, каждый из коэффициентов а, b, с и d может быть на деле определен посредством функции, которая может содержать зависимость от позиции (i, j) этого коэффициента в матрице. Пара индексов (i, j) может представлять, например, позицию коэффициента слева направо и затем позицию коэффициента сверху вниз в матрице. В качестве примера:
коэффициентi, j=3i+2j
Отметим, что матрицы Qmatrices могут быть в среде стандарта HEVC обозначены как «списки масштабирования» (Scaling List). В вариантах, в которых квантование применяется после сканирования, сканированные данные могут представлять собой линейный поток последовательных отсчетов данных. В таких случаях концепция матрицы Qmatrix применима по-прежнему, но эту матрицу (или список масштабирования) можно считать матрицей размером 1×N, так что порядок N величин данных в матрице размером 1×N соответствует порядку сканированных отсчетов, к которым следует применить соответствующую величину из матрицы Qmatrix. Другими словами, имеет место соотношение 1:1 между порядком данных в последовательности сканированных данных, пространственной частотой, соответствующей схеме сканирования, и порядком данных в матрице Qmatrix размером 1×N.
Отметим, что в некоторых вариантах реализации можно обойти или исключить этап преобразования DCT (разложение на частотные составляющие), но сохранить этап квантования.
Другая полезная информация содержит применяемый в качестве опции индикатор того, к какой другой матрице относятся рассматриваемые величины, т.е. предыдущего канала или первого (первичного) канала. Например, матрица для составляющей Cr может быть масштабным коэффициентом для матрицы составляющей Y или для составляющей Cb, как указано.
Соответственно варианты настоящего изобретения могут предлагать способ (и соответствующее устройство или компьютерную программу) для видео кодирования или декодирования, генерирующие блоки квантованных данных разложения на пространственные частотные составляющие посредством (в качестве опции) частотного преобразования блоков отсчетов видеоданных и квантования видеоданных (таких как данные разложения на пространственные частотные составляющие) в соответствии с выбранным размером шага квантования и матрицей данных, модифицирующей размер шага квантования для использования в разных позициях в упорядоченном блоке отсчетов (таком как упорядоченный блок отсчетов, подвергнутых разложению на частотные составляющие), способ оперирует по меньшей мере с двумя разными форматами субдискретизации цветоразностной составляющей.
По меньшей мере для одного из форматов субдискретизации цветоразностной составляющей одна или более матриц квантования определены в качестве одной или более заданных модификаций относительно одной или более опорных матриц квантования, определенных для опорного формата субдискретизации цветоразностной составляющей.
В вариантах настоящего изобретения, этап определения содержит определение одной или более матриц квантования в качестве матрицы величин, каждая из которых интерполирована от соответствующих нескольких величин опорной матрицы квантования. В других вариантах этап определения содержит определение одной или нескольких матриц квантования в качестве матрицы величин, каждая из которых получена посредством субдискретизации из величин опорной матрицы квантования.
В вариантах настоящего изобретения, этап определения содержит определение одной или более матриц квантования в качестве матрицы разностей относительно соответствующих величин опорной матрицы квантования.
В вариантах настоящего изобретения, этап определения содержит определение одной или более матриц квантования в качестве заданной функции величин опорной матрицы квантования. В таких случаях эта заданная функция может быть полиномиальной функцией.
В вариантах настоящего изобретения, формируют данные одного или обоих следующих видов, например, как часть кодированных видеоданных или в ассоциации с ними: (i) данные индикатора опоры для указания, в отношении кодированных видеоданных, опорной матрицы квантования; и (ii) данные индикатора модификации для указания, в отношении величин кодированных данных, одной или более заданных модификаций.
Эти способы особенно применимы для двух форматов - 4:4:4 и 4:2:2, субдискретизации цветоразностных составляющих.
Число матриц Q Matrices в стандарте HEVC для схемы (профиля) 4:2:0 в настоящий момент равно 6 для каждого размера преобразования: 3 для соответствующих каналов и одна группа для внутрикадрового прогнозирования и межкадрового прогнозирования. В случае схемы 4:4:4 GBR следует понимать, что либо одна группа матриц квантования может быть использована для всех каналов, либо могут быть использованы три соответствующие группы матриц квантования.
В вариантах настоящего изобретения, по меньшей мере одна из матриц является матрицей размером 1×N. Это будет в случае, когда (как рассмотрено выше), одна или несколько матриц является на деле списком(ами) сканирования или другим подобным объектом и при этом представляет собой линейный упорядоченный массив коэффициентов размером 1×N.
Предлагаемые решения содержат дискретное увеличение или уменьшения применяемого параметра QP. Однако это может быть достигнуто несколькими способами:
В стандарте HEVC, сдвиги параметров QP для двух цветоразностных каналов передают в потоке битов данных. В эти сдвиги может быть уже введена величина +/-3, либо соответствующее увеличение/уменьшение может быть внесено при использовании сдвигов для получения цветоразностного параметра QP.
Как обсуждается выше, в стандарте HEVC, величина (QP яркостного канала + сдвиг для цветоразностного канала) используется в качестве индекса к таблице для определения цветоразностного параметра QP. Эта таблица может быть модифицирована для внесения в нее величины +/-3 (т.е. путем дискретного увеличения/уменьшения величин в исходной таблице на 3)
После определения цветоразностного параметра QP, как в обычной процедуре стандарта HEVC, результаты могут быть увеличены (или уменьшены) на 3.
В качестве альтернативы для модификации параметра QP можно использовать множитель sqrt(2) или 1/sqrt(2) для модификации коэффициентов квантования.
Для прямого/обратного квантования процедуры деления/умножения реализованы с использованием параметра (QP % 6) в качестве индекса к таблице для получения коэффициента квантования или размера шага квантования, inverseQStep/scaledQStep.(Здесь, QP % 6 обозначает QP по модулю 6). Отметим, что, как обсуждается выше, это может и не представлять конечный размер шага квантования, применяемый к преобразованным данным; это может быть дополнительно модифицировано посредством матрицы Qmatrices перед использованием.
Таблицы по умолчанию в стандарте HEVC имеют длину 6, охватывая диапазон октавы (удвоение) величин. Это просто средство уменьшения потребности в объеме памяти; таблицы расширяют для реального использования путем выбора входа в таблицу в соответствии с модулем QP (mod 6) и затем умножения или деления на подходящую степень 2, в зависимости от разности (QP - QP modulus 6) относительно заданной базовой величины.
Такая конфигурация может изменяться, чтобы можно было внести сдвиг +/-3 в величину параметра QP. Этот сдвиг можно применить в процессе просмотра таблицы, либо, вместо этого, операция взятия по модулю, обсуждавшаяся выше, может быть выполнена с использованием модифицированного параметра QP. Однако в предположении, что сдвиг применяется в преобразовательной таблице, дополнительные входы в таблицу могут быть созданы следующим образом:
Одна из альтернатив состоит в расширении таблиц на 3 входа, где новые входы являются следующими (для величин индексов 6-8).
Пример таблицы, показанный на фиг. 30, будет индексирован посредством [(QP % 6)+3] ("способ увеличения параметра QP"), где обозначение QP % 6 означает "QP по модулю 6".
Пример таблицы, показанный на фиг. 31, будет индексирован посредством [(QP % 6)-3] ("способ уменьшения параметра QP"), и имеет дополнительные входы для величин индексов от -1 до -3:
Энтропийное кодирование
Базовый принцип энтропийного кодирования содержит назначение кодовых слов символам входных данных, так что самые короткие кодовые слова назначают наиболее вероятным символам входных данных. В среднем, результатом является кодирование без потерь, но при этом удается намного уменьшить объем представления входных данных.
Этот базовый подход можно усовершенствовать, если признать, что вероятность появления символов часто является условной и зависит от ранее принятых данных, и соответственно сделать процесс назначения кодовых слов контекстно-адаптивным.
При таком подходе используют контекстные переменные (context variable (CV)) для определения выбора соответствующих вероятностных моделей, причем такие переменные CV предложены для схемы 4:2:0 в стандарте HEVC.
Для расширения энтропийного кодирования на схему 4:2:2, которая, например, будет использовать цветоразностные единицы TU размером 4×8 вместо единиц TU размером 4×4 для яркостной единицы TU размером 8×8, тогда, в качестве опции, контекстные переменные могут быть созданы для простого вертикального повторения выбора эквивалентных переменных CV.
Однако, в одном из вариантов настоящего изобретения, выбор переменных CV не повторяется для верхних левых коэффициентов (т.е. коэффициентов с большой энергией, коэффициентов DC и/или коэффициентов для низких пространственных частот), а вместо этого получают новые переменные CV. В этом случае, например, может быть определено отображение для яркостной «карты». Такой подход может быть также использован для схемы 4:4:4.
В процессе кодирования по схеме 4:2:0 осуществляется так называемое зигзагообразное сканирование коэффициентов по порядку от высоких частот к низким. Однако здесь снова следует отметить, что цветоразностные единицы TU в схеме 4:2:2 могут быть неквадратными, и потому в одном из вариантов настоящего изобретения предложена другая схема сканирования, в которой угол сканирования может быть изменен, чтобы сделать его более горизонтальным или более вертикальным в соответствии с коэффициентом формы единицы TU.
Аналогично, принцип соседства для выбора переменных CV по карте значимости и система c1/c2 для выбора больше-одной или больше-двух переменных CV могут быть адаптированы соответствующим образом.
Аналогично, в одном из вариантов настоящего изобретения самая младшая позиция коэффициента (которая становится стартовой точкой при декодировании) может быть также приспособлена к схеме 4:4:4, так что самые младшие позиции для цветоразностных единиц TU кодируют отлично от самой младшей позиции в сорасположенной яркостной единице.
Сканирование коэффициентов также может быть сделано зависимым от режима прогнозирования для некоторых размеров единиц TU. Следовательно, для некоторых размеров единиц TU может быть применен другой порядок сканирования в зависимости от режима внутрикадрового прогнозирования.
В схеме (профиле) 4:2:0 зависимое от режима сканирование коэффициентов (mode dependent coefficient scanning (MDCS)) применяется только для яркостных единиц TU размером 4×4/8×8 и для цветоразностных единиц TU размером 4×4 при внутрикадровом прогнозировании. Здесь будет рассмотрено сканирование MDCS в зависимости от режима внутрикадрового прогнозирования с углами +/-4 от горизонтали и от вертикали.
В одном из вариантов настоящего изобретения предлагается в схеме 4:2:2 применять сканирование MDCS к цветоразностным единицам TU размером 4×8 и 8×4 для внутрикадрового прогнозирования. Аналогично, предлагается в схеме 4:4:4 применять сканирование MDCS к цветоразностным единицам TU размером 8×8 и 4×4. Сканирование MDCS для схемы 4:2:2 может быть произведено только в горизонтальном или вертикальном направлении, так что диапазон углов может быть разным для цветоразностной схемы 4:4:4 в сравнении с яркостной схемой 4:4:4 в сравнении с цветоразностной схемой 4:2:2 в сравнении с яркостной схемой 4:2:2 в сравнении с яркостной схемой 4:2:0.
Внутриконтурные фильтры
Удаление блочности
Удаление блочности применяется ко всем границам единиц CU, PU и TU, причем форма этих единиц CU/PU/TU в расчет не принимается. «Мощность» и размеры фильтра зависят от локальной статистики, а операция удаления блочности имеет «зернистость» 8×8 яркостных пикселей.
Следовательно, совершенно понятно, что удаление блочности, используемое сегодня в схеме 4:2:0, должно быть также применимо в схемах 4:2:2 и 4:4:4.
Нелинейный фильтр с адаптивными сдвигами в зависимости от отсчетов В нелинейном фильтре с адаптивными сдвигами в зависимости от отсчетов (sample adaptive offsetting (SAO)) каждый канал является полностью независимым. Фильтр SAO «расщепляет» данные изображения для каждого канала с использованием дерева четверок, а размер полученных в результате блоков равен по меньшей мере одной единице LCU. Блоки самого низкого ранга («листья» дерева) совмещены с границами единиц LCU, а каждый «лист» может работать в одном из трех режимов, как это определяет модуль кодирования («Сдвиг центральной полосы» ("Central band offset"), «Сдвиг боковой полосы» ("Side band offset") или «Сдвиг края» ("Edge offset")). Каждый «лист» классифицирует свои пиксели по категориям, а модуль кодирования определяет величину сдвига для каждой из 16 категорий путем сравнения входных данных фильтра SAO с исходными данными. Эти сдвиги передают декодеру. К величине каждого декодируемого пикселя добавляют величину сдвига для категории, к которой относится этот пиксель, чтобы минимизировать отклонение от исходных данных.
Кроме того, фильтрацию SAO активизируют или выключают на уровне кадров; если она активизирована для яркостной составляющей, она может быть также активизирована отдельно для каждого цветоразностного канала. Таким образом, фильтрация SAO будет применена к цветоразностным составляющим, только если она применена к яркостной составляющей.
Следовательно, процедура оказывается в большой степени прозрачной для лежащей в ее основе схемы блоков, и при этом считается, что современная процедура фильтрации SAO, применяемая к схеме 4:2:0, будет также применима к схемам 4:2:2 и 4:4:4.
Адаптивная контурная фильтрация
В схеме 4:2:0 адаптивная контурная фильтрация (adaptive loop filtering (ALF)) отключена по умолчанию. Однако в принципе (т.е. если ее разрешить) такая фильтрация ALF может быть применена ко всему кадру для цветоразностной составляющей.
В системе фильтрации ALF яркостные отсчеты могут быть рассортированы на несколько категорий, как это определено документами стандарта HEVC; каждая категория использует свой, отличный от других фильтр Винера.
Напротив, в схеме 4:2:0 цветоразностные отсчеты не разбивают по категориям - поэтому применяется только один фильтр Винера для составляющей Cb и один фильтр Винера для составляющей Cr.
Следовательно, в одном из вариантов настоящего изобретения, в свете увеличенного объема цветоразностной информации в схемах 4:2:2 и 4:4:4 предлагается разбивать цветоразностные отсчеты на категории; например, К категорий для схемы 4:2:2 и J категорий для схемы 4:4:4.
Тогда как в схеме 4:2:0 фильтрация ALF может быть для яркостной составляющей отключена для каждой единицы CU отдельно с использованием флага управления ALF (вплоть до уровня CU, заданного глубиной управления фильтрацией ALF), для цветоразностной составляющей такую фильтрацию можно отключить только для кадра в целом. Отметим, что на сегодня в стандарте HEVC эта глубина управления ограничена только уровнем единиц LCU.
Следовательно, в одном из вариантов настоящего изобретения в схемах 4:2:2 и 4:4:4 используются один или два специфичных для каналов флага управления фильтрацией ALF для цветоразностной составляющей.
Синтаксис
В стандарте HEVC синтаксис уже присутствует для индикации схем 4:2:0, 4:2:2 или 4:4:4 и действует на уровне последовательности. Однако в одном из вариантов настоящего изобретения предлагается также указывать на этом уровне кодирование GBR для схемы 4:4:4.
Зависимые от режима преобразование (MDDT) и сканирование (MDCS)
Теперь будет рассмотрено использование зависимого от режима направленного преобразования и зависимого от режима сканирования коэффициентов. Отметим, что оба вида операций могут быть реализованы в одной и той же системе, либо одна из операций может быть использована, а другая нет, либо не используются ни одна операция.
Сначала будет описано сканирование MDCS со ссылками на фиг. 34-38.
Выше со ссылками на фиг. 16 была рассмотрена схема так называемого диагонального сканирования вверх - вправо. Схема сканирования используется для определения порядка, в котором происходит обработка коэффициентов разложения по частотам, таких как коэффициенты преобразования DCT. Схема диагонального сканирования вверх - вправо является только один из примеров схем сканирования, но возможны и доступны и другие схемы сканирования. На фиг. 34 и 35 схематично показаны два других примера с использованием блока размером 4×4. Это схема горизонтального сканирования (фиг. 34) и схема вертикального сканирования (фиг. 35).
При сканировании MDCS схему сканирования выбирают из группы двух или более схем-кандидатов сканирования в зависимости от используемого режима прогнозирования.
Настоящий пример рассматривает группу из трех схем-кандидатов сканирования, а именно диагональной схемы сканирования вверх - вправо, горизонтальной схемы сканирования и вертикальной схемы сканирования. Но может быть использована и другая группа из двух или более схем-кандидатов.
Как показано на фиг. 36, вертикальная схема сканирования используется для режимов 6-14, которые находятся в пределах порогового угла (или номеров режимов) для горизонтального (преимущественно горизонтального) направления. Горизонтальная схема сканирования используется для режимов 22-30, которые находятся в пределах порогового угла (или номеров режимов) для вертикального (преимущественно вертикального) направления. Диагональное сканирование вверх - вправо, обозначенное на фиг. 36 просто как «диагональное», используется для других режимов.
Фиг. 37 схематично иллюстрирует возможное отображение двух схем-кандидатов сканирования (вертикальной и горизонтальной) на режимы направленного прогнозирования, применимые к прямоугольной матрице цветоразностных отсчетов. Эта схема отличается от схемы, используемой (фиг. 36) для яркостных отсчетов.
Фиг. 38 схематично иллюстрирует устройство для выбора схемы сканирования. Оно может составлять часть функциональных узлов контроллера 343, например.
Селектор 1620 реагирует на режим прогнозирования для текущего блока и управляет преобразовательной таблицей 1630, отображающей режим прогнозирования на схему сканирования. Этот селектор 1620 передает на выход данные, указывающие выбранную схему сканирования.
Сканирование MDCS может быть активизировано для схем 4:2:2 и 4:4:4. Отображение схем сканирования в режимы прогнозирования может быть таким же, как для схемы 4:2:0, или может отличаться. Каждое значение пропорции каналов может иметь соответствующее отображение (в таком случае селектор 1620 учитывает также пропорцию каналов), либо отображение может быть согласовано для диапазона значений пропорций каналов. Сканирование MDCS может быть применено только к некоторым размерам блоков, например, к блокам, размер которых не больше порогового размера блока. Например, максимальные размеры единиц TU, к которым применимо сканирование MDCS, могут быть:

Для цветоразностной составляющей сканирование MDCS может быть отключено и ограничиваться только единицами TU размером 4×4 (яркостными) или единицами TU, использующими только горизонтальное или вертикальное сканирование. Реализация сканирования MDCS может изменяться в соответствии с пропорцией каналов.
Варианты настоящего изобретения, таким образом, предлагают способ кодирования видеоданных по схеме, согласно которой разности между прогнозируемыми и исходными отсчетами разлагают на частотные составляющие и кодируют, способ содержит: прогнозирование яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих опорных отсчетов, полученных из того же самого изображения, согласно режиму прогнозирования, ассоциированному с отсчетами, подлежащими прогнозированию, режим прогнозирования выбирают, для каждого из нескольких блоков отсчетов, из группы двух или более режимов прогнозирования-кандидатов; определяют разности между отсчетами и соответствующими прогнозируемыми отсчетами; разложение найденных разностей для блока отсчетов на частотные составляющие с использования преобразования, разлагающего на частотные составляющие, для генерирования соответствующего множества коэффициентов разложения; выбор схемы сканирования из группы двух или более схем-кандидатов сканирования, так что каждая схема сканирования определяет порядок кодирования множества коэффициентов разложения на частотные составляющие, в зависимости от режима прогнозирования для блока отсчетов с использованием отображения, осуществляемого (например, контроллером 343) между схемой сканирования и режимом прогнозирования, это отображение различно для отсчетов разных видов, как для цветоразностных и для яркостных отсчетов, по меньшей мере для формата 4:4:4 (иными словами, это отображение различно для цветоразностных данных в формате 4:4:4 и для яркостных данных в формате 4:4:4 и может или не может быть различным как между яркостными данными в формате 4:2:2 и цветоразностными данными в формате 4:2:2); и кодирование разложенных на частотные составляющие разностных данных в порядке коэффициентов разложения согласно выбранной схеме сканирования.
Отображение может быть различным для яркостных и для цветоразностных данных в формате 4:2:2.
Отображение может быть различным для видеоданных в формате 4:2:2 и в формате 4:4:4.
В вариантах настоящего изобретения размер текущего блока яркостных отсчетов составляет 4×4 или 8×8 отсчетов. В качестве альтернативы варианты настоящего изобретения содержат выбор размера текущего блока отсчетов из группы размеров-кандидатов; и применение этапа выбора схемы сканирования, если выбранный размер блока является одним из заданной подгруппы из группы размеров-кандидатов. Таким образом, процесс отображения может быть применен только к некоторым размерам блоков, но не к другим. Отображение может быть применено (для формата 4:2:2) только в отношении яркостных отсчетов.
В вариантах настоящего изобретения группа схем-кандидатов сканирования отличается для использования в отношении яркостных и цветоразностных отсчетов.
Этап выбора может быть конфигурирован для выбора горизонтальной схемы сканирования в отношении группы преимущественно горизонтальных режимов прогнозирования, для выбора вертикальной схемы сканирования в отношении группы преимущественно вертикальных режимов прогнозирования и для выбора диагональной схемы сканирования в отношении других режимов прогнозирования.
Варианты настоящего изобретения предлагают также способ декодирования видеоданных в формате 4:2:2 или 4:4:4, в которых разности между прогнозируемыми и исходными отсчетами разложены на частотные составляющие и закодированы, этот способ содержит этапы, на которых: прогнозируют яркостные и/или цветоразностные отсчеты изображения на основе других соответствующих опорных отсчетов, полученных из того же самого изображения, согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим декодированию, режим прогнозирования выбирают для каждого из множества блоков отсчетов, из группы двух или более режимов-кандидатов прогнозирования; выбор схемы сканирования из группы двух или более схем-кандидатов сканирования, каждая схема сканирования определяет порядок кодирования множества коэффициентов разложения на частотные составляющие, в зависимости от режима прогнозирования для этого блока отсчетов с использованием отображения между схемой сканирования и режимом прогнозирования, причем это отображение различно для отсчетов разных видов, как для цветоразностных и для яркостных отсчетов, по меньшей мере для формата 4:4:4 (иными словами, это отображение различно для цветоразностных данных в формате 4:4:4 и для яркостных данных в формате 4:4:4 и может или не может быть различным как между яркостными данными в формате 4:2:2 и цветоразностными данными в формате 4:2:2); и декодирование разложенных на частотные составляющие разностных данных, представляющих разложенную на частотные составляющие версию данных, указывающих разности между отсчетами, подлежащими декодированию, и соответствующими прогнозируемыми отсчетами, в порядке коэффициентов разложения согласно выбранной схеме сканирования.
Относительно преобразования MDDT, фиг. 39 схематично иллюстрирует устройство для выбора преобразования для разложения на частотные составляющие согласно режиму прогнозирования. Это устройство составлять часть функциональных узлов преобразовательного модуля или контроллера.
Селектор 1700 принимает данные, определяющие текущий режим прогнозирования, и выбирает преобразование (из группы двух или более преобразований-кандидатов) в зависимости от этого режима. Это преобразование осуществляет преобразовательный модуль 1710, трансформирующий отсчеты изображения в коэффициенты разложения на частотные составляющие на основе данных, указывающих требуемое преобразование и хранящихся в запоминающем устройстве данных преобразования.
К примерам преобразований-кандидатов относятся дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST), преобразование Карунена-Лоэва и преобразования, определяемые соответствующими матрицами из строк и столбцов для матричного умножения на текущий блок отсчетов.
Преобразование MDDT может быть активизировано, например, в отношении цветоразностных блоков размером 4×4 в системе 4:4:4. Однако в вариантах настоящего изобретения преобразование MDDT активизировано в отношении данных 4:2:2.
Варианты настоящего изобретения могут предложить способ кодирования видеоданных в формате 4:2:2 или 4:4:4, содержащий: прогнозирование яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих опорных отсчетов, полученных из того же самого изображения, согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим декодированию, режим прогнозирования выбирают для каждого из нескольких блоков отсчетов, из группы двух или более режимов-кандидатов прогнозирования; определение разностей между отсчетами и соответствующими прогнозируемыми отсчетами; выбор преобразования для разложения на частотные составляющие из двух или более преобразований-кандидатов для разложения на частотные составляющие согласно режиму прогнозирования, ассоциированному с текущим блоком отсчетов, с использованием отображения (осуществляемого, например, контроллером 343) между преобразованием и режимом прогнозирования, причем это отображение различно для отсчетов разных видов, как для цветоразностных и для яркостных отсчетов, по меньшей мере для формата 4:4:4 (иными словами, это отображение различно для цветоразностных данных в формате 4:4:4 и для яркостных данных в формате 4:4:4 и может или не может быть различным как между яркостными данными в формате 4:2:2 и цветоразностными данными в формате 4:2:2); и кодирование найденных разностей посредством разложения этих разностей на частотные составляющие с использованием выбранного преобразования для разложения на частотные составляющие.
Совокупность преобразований кандидатов может содержать два или более преобразования, выбранных из списка, куда входят: дискретное косинусное преобразование; дискретное синусное преобразование; преобразование Карунена-Лоэва и преобразования, определяемые соответствующими матрицами из строк и столбцов для матричного умножения на текущий блок отсчетов (так что, например, преобразование определено формулой ТХТТ, где Т - матрица преобразования, надстрочный индекс Т обозначает транспонирование матрицы и X обозначает блок отсчетов, представленный в форме матрицы).
Как и раньше, в вариантах настоящего изобретения режим прогнозирования, ассоциированный с блоком отсчетов, подлежащих прогнозированию, указывает направление прогнозирования, определяющее один или несколько соответствующих опорных отсчетов, на основе которых следует прогнозировать каждый отсчет рассматриваемого блока, или может указывать, например, режим dc прогнозирования.
В вариантах настоящего изобретения отображение, осуществляемое между режимом прогнозирования и преобразованием для разложения на частотные составляющие, может быть различным между яркостными данными и цветоразностными данными в формате 4:2:2.
В вариантах настоящего изобретения размер текущего блока яркостных отсчетов равен 4×4 отсчетов. В качестве альтернативы способ может содержать выбор размера текущего блока отсчетов из группы размеров-кандидатов; и применение этапа выбора преобразования для разложения на частотные составляющие, если выбранный размер блока относится к заданной подгруппе из группы размеров-кандидатов, так что преобразование MDDT используется только для некоторых, но не для всех размеров блоков (например, единиц TU).
В вариантах настоящего изобретения этап кодирования найденных разностей содержит выбор схемы сканирования из группы двух или более схем-кандидатов сканирования, так что каждая схема сканирования определяет порядок кодирования множества коэффициентов разложения на частотные составляющие в зависимости от режима прогнозирования для рассматриваемого блока отсчетов; и кодирование разложенных на частотные составляющие разностных данных в порядке коэффициентов разложения на частотные составляющие согласно выбранной схеме сканирования. Другими словами, это представляет систему, использующую и сканирование MDCS и преобразование MDDT.
Флаг кодированного блока
Флаг кодированного блока (coded block flag (CBF)) используется для индикации -для яркостной единицы TU, - содержит ли эта единица TU какие-либо ненулевые коэффициенты. Флаг дает простой ответ «да/нет», что позволяет процедуре кодирования пропускать блоки, не имеющие данных, подлежащих кодированию.
В некоторых системах флаги CBF используются для цветоразностных данных, но формируются на каждом уровне разбиения. Это делается потому, что цветоразностные составляющие часто содержат меньший объем информации, вследствие чего может оказаться, что цветоразностный блок содержит нулевые данные, уже на более высоком уровне разбиения, чем тот уровень, на котором обнаружено, что соответствующий яркостями блок не содержит данных.
В некоторых вариантах, однако, цветоразностную составляющую обрабатывают для назначения флагов CBF точно так же, как яркостную составляющую.
Кодирование в стандарте САВАС и контекстное моделирование
Фиг. 40 схематично иллюстрирует работу модуля энтропийного кодирования в стандарте САВАС.
Модуль кодирования в стандарте САВАС оперирует с двоичными данными, иными словами, с данными, представленными только двумя символами - 0 и 1. Этот модуль кодирования использует процедуру так называемого контекстного моделирования, которая выбирает «контекст» или вероятностную модуль для последующих данных на основе ранее кодированных данных. Выбор контекста осуществляется на детерминистской основе, чтобы такое же определение на основе ранее декодированных данных можно было выполнить в декодере, не требуя добавления никаких дополнительных данных (специфицирующих контекст) к кодированному потоку битов данных, направляемому в декодер.
Как показано на фиг. 40, входные данные, подлежащие кодированию, могут быть направлены в двоичный преобразователь 1900, если они уже не находятся в двоичной форме; если данные уже находятся в двоичной форме, эти данные направляют в обход преобразователя 1900 (через показанный на схеме переключатель 1910). В рассматриваемых вариантах преобразование в двоичную форму реально осуществляется путем выражения квантованного коэффициента DCT (или другого преобразования с разложением на частотные составляющие) в виде ряда двоичных «карт», которые будут дополнительно описаны ниже.
Двоичные данные можно обрабатывать в одном из двух процессорных трактов - «регулярном» и «обходном» (которые показаны на схеме как отдельные тракты, но на деле, в вариантах настоящего изобретения, обсуждаемых ниже, могут быть реализованы в одних и тех же процессорных каскадах с использованием только слегка разных параметров). Обходной тракт применяет так называемый обходной модуль 1920 кодирования, который не обязательно использует контекстное моделирование в таком же виде, как регулярный тракт. В некоторых примерах кодирования по стандарту САВАС этот обходной тракт может быть выбран, если есть необходимость особенно быстрой обработки пакета данных, но в рассматриваемых вариантах отмечены два признака так называемых «обходных» данных: во-первых, обходные данные обрабатывает модуль кодирования в стандарте САВАС (1950, 1960), просто используя фиксированную контекстную модель, представляющую вероятность 50%; и во-вторых, обходные данные относятся к некоторым категориям данных, одним конкретным примером которых являются данные знака коэффициентов. В противном случае переключатели 1930, 1940 выбирают регулярный тракт. В него направляют данные, обрабатываемые модулем 1950 моделирования контекста, после которого расположен модуль 1960 кодирования.
Модуль энтропийного кодирования, показанный на фиг. 40, кодирует блок данных (иными словами, например, данные, соответствующие блоку коэффициентов, относящихся к блоку остаточного изображения) в виде одной величины, если блок полностью состоит из нулевых данных. Для каждого блока, не попадающего в эту категорию, иными словами, для блока, содержащего по меньшей мере некоторые ненулевые данные, формируют «карту значимости». Эта карта значимости указывает для каждой позиции в блоке данных, подлежащем кодированию, является ли соответствующий коэффициент в блоке ненулевым. Эта карта значимости, будучи в двоичной форме, сама кодируется с применением стандарта САВАС. Применение карт значимости помогает сжатию, поскольку не нужно кодировать данные для коэффициента, величина которого в карте значимости указана как нулевая. Кроме того, карта значимости может иметь в составе специальный код для индикации последнего ненулевого коэффициента в блоке, так что все последние высокочастотные/замыкающие нулевые коэффициенты могут быть исключены из кодирования. За картой значимости в кодированном потоке битов данных следуют данные, определяющие величины ненулевых коэффициентов, указанных картой значимости.
Также готовят и кодируют в стандарте САВАС данные карт других уровней. Например, карту, которая определяет - в виде двоичной величины (1 = да, 0 = нет), имеют ли данные коэффициентов в позиции, где карта значимости указывает «ненулевую величину», реально значение «единица». Другая карта определяет, имеют ли данные коэффициентов в позиции, где карта значимости указывает «ненулевую величину», реально значение «два». Еще одна карта определяет, имеют ли данные коэффициентов в позиции, где карта значимости указывает «ненулевую величину», реально значение «больше двух». Следующая карта указывает, снова для данных, идентифицированных как «ненулевые», знак величины этих данных (с использованием заданной двоичной нотации, такой как «1» для «+» и «0» для «-», или же, безусловно, как-нибудь иначе).
В вариантах настоящего изобретения карту значимости и другие карты генерируют на основе квантованных коэффициентов преобразования DCT, например, посредством модуля 360 сканирования, и подвергают зигзагообразному сканированию (или сканированию, выбранному из рассмотренных выше видов сканирования) прежде кодирования согласно стандарту САВАС.
Говоря обобщенно, процедура кодирования по стандарту САВАС содержит прогнозирование контекста или вероятностной модели для следующего бита, подлежащего кодированию, на основе других, ранее кодированных данных. Если следующий бит является таким же, как бит, идентифицированный вероятностной моделью в качестве «наиболее вероятного», тогда кодирование информации о том, что «следующий бит согласуется с вероятностной моделью», может быть произведено с очень большой эффективностью. Менее эффективно кодировать информацию, что «следующий бит не согласуется с вероятностной моделью», вследствие чего получение контекстных данных играет важную роль для обеспечения хорошей работы модуля кодирования. Термин «адаптивный» означает, что контекст или вероятностные модели адаптируются или изменяются в процессе кодирования в попытках добиться хорошего согласования со следующими (еще не кодированными) данными.
Используя простую аналогию, в письменном английском языке буква "U" употребляется относительно редко, но после буквы "Q" она ставится реально очень часто. Поэтому вероятностная модель может задавать очень маленькую вероятность буквы появления буквы "U", но если текущей буквой является "Q", тогда вероятностная модель может, для буквы "U" в качестве следующей буквы, задать очень высокую вероятность.
Кодирование в стандарте САВАС применяется, в предлагаемых системах, по меньшей мере для карты значимости и карт, указывающих, равны ли ненулевые величины единице или двум. Обходная обработка - которая в этих вариантах идентична кодированию в стандарте САВАС, но на деле здесь вероятностная модель фиксирована на уровне равного (0.5:0.5) распределения вероятностей 1 и 0, применяется по меньшей мере для данных знака и для карты, указывающей, являются ли соответствующие величины >2. Для позиций данных, идентифицированных как >2, может быть использовано отдельное, так называемое escape-кодирование, чтобы кодировать реальную величину данных. Сюда может входить способ кодирования Голомба-Райса.
Контекстное моделирование и кодирование в стандарте САВАС описано более подробно в документе (рабочем проекте) WD4: Working Draft 4 of High-Efficiency Video Coding, JCTVC-F803_d5, Draft КОЛЕС 23008-HEVC; 201x(E) 2011-10-28.
В конце обработки среза производится сброс (возврат в исходное состояние) контекстных переменных.
Теперь будут сделаны ссылки на способ кодирования видеоданных, содержащий: прогнозирование блоков яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих опорных отсчетов или величин; определение разностей между отсчетами в блоке и соответствующими прогнозируемыми отсчетами; разложение найденных разностей на частотные составляющие для генерации соответствующего массива коэффициентов разложения на частотные составляющие, упорядоченных согласно повышению пространственных частот, представленных коэффициентами; и энтропийное кодирование коэффициентов разложения на частотные составляющие с использованием контекстно-адаптивного арифметического кода, осуществляющего кодирование коэффициентов в соответствии с контекстными переменными, указывающих вероятность коэффициента конкретной величины; при этом этап энтропийного кодирования содержит: секционирование каждого массива на две или болеет группы коэффициентов, так что эти группы являются неквадратными подматрицами; и выбор контекстной переменной для кодирования коэффициента в соответствии с пространственными частотами, представленными этим коэффициентом, и в зависимости от величин коэффициентов одной или нескольких близлежащих группах коэффициентов в этом же массиве или в массиве, соответствующем соседствующему блоку отсчетов.
Такой подход иногда называют назначением контекстных переменных по соседству, что позволяет схему назначения контекстной переменной для позиции коэффициента задавать от одной подматрицы к другой (здесь подматрица представляет собой часть блока коэффициентов) в зависимости от того, имеются ли ненулевые коэффициенты в соседствующих подматрицах. Выбор схемы сканирования данных, полученных в результате разложения на частотные составляющие, может быть соответствующим, так что этап энтропийного кодирования содержит кодирование коэффициентов массива в порядке, зависящем от схемы сканирования, выбранной из набора одной или нескольких схем-кандидатов сканирования. Каждую подматрицу коэффициентов можно рассматривать как последовательный набор из n коэффициентов в порядке, определяемом схемой сканирования, применимой к указанному массиву, где n - целочисленный сомножитель числа коэффициентов в массиве. Например, n может быть равно 16.
Фиг. 41А - 41D схематично иллюстрируют ситуацию ранее предложенного назначения по соседству.
В вариантах настоящего изобретения на этапе выбора назначают коэффициенты в группе для одной из набора контекстных переменных-кандидатов таким образом, что в пределах каждой группы последовательные подмножества коэффициентов, в порядке сканирования, назначают соответствующим контекстным переменным-кандидатам. В примерах, показанных на фиг. 42А - 43В, использован вертикальный порядок сканирования, так что назначения выполнены в этом порядке. На фиг. 44 применен горизонтальный порядок сканирования, так что назначения выполнены в этом порядке.
Как указано выше, этап выбора зависит от того, имеют ли соседствующие коэффициенты нулевую величину. Здесь могут по две контекстные переменные-кандидаты для каждой группы коэффициентов.
На фиг. 42А, 42В, 43А, 43В и 44, формат чертежей показан таким, что коэффициенты в массиве упорядочены таким образом, что пространственная частота по горизонтали увеличивается в массиве слева направо, а пространстве частота по вертикали увеличивается в массиве верху вниз.
Есть два варианта действий применительно к потерянным данным (например, данным на краях кадра или среза или данным, которые еще не были кодированы). В одном варианте (фиг. 42А), если группа коэффициентов рядом с текущей группой еще не была разложена на частотные составляющие, этап выбора присваивает этой группе нулевые величины для целей выбора контекстной переменной для коэффициента в текущей группе. В другом варианте (фиг. 42В), если первая группа коэффициентов рядом с текущей группой еще не была разложена на частотные составляющие, а вторая группа коэффициентов рядом с текущей группой уже была разложена на частотные составляющие, тогда этап выбора присваивает первой группе величины второй группы для целей выбора контекстной переменной для коэффициента в текущей группе.
Как показано на фиг. 42А и 42В, если обе группы - справа и ниже текущей группы, содержат ненулевые данные коэффициентов, тогда на этапе выбора назначают одну контекстную переменную для первых m коэффициентов текущей группы в порядке сканирования и другую контекстную переменную назначают для остальных коэффициентов текущей группы. Если группа справа от текущей группы содержит ненулевые данные, а группа ниже текущей группы ненулевых данных не содержит, тогда одну контекстную переменную на этапе выбора назначают верхней половине текущей группы, а другую контекстную переменную назначают остальным коэффициентам текущей группы. Если группа ниже текущей группы содержит ненулевые данные, а группа справа от текущей группы ненулевых данных не содержит, тогда одну контекстную переменную на этапе выбора назначают первым р коэффициентам текущей группы в порядке сканирования, а другую контекстную переменную назначают остальным коэффициентам текущей группы. Если группа ниже текущей группы содержит ненулевые данные, а группа справа от текущей группы ненулевых данных не содержит, тогда одну контекстную переменную на этапе выбора назначают левой половине текущей группы, а другую контекстную переменную назначают остальным коэффициентам текущей группы. В показанных примерах тир являются целыми числами, причем m не равно р. В частности, в показанных примерах текущая группа содержит подматрицу коэффициентов размером 8×2 или 2×8; а также m=13 и р=6.
Описанный способ применим к блокам отсчетов, по меньшей мере один из размеров которых составляет по меньшей мере 8 отсчетов. Например, блок размером 8×8 или больше.
Этот способ применим, когда по меньшей мере некоторые из блоков отсчетов (единиц TU) являются квадратными, или по меньшей мере некоторые из блоков отсчетов (единиц TU) являются неквадратными.
Как показано на фиг. 45, варианты настоящего изобретения также предлагают способ кодирования видеоданных, содержащий: прогнозирование блоков яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих опорных отсчетов или величин; определение разностей между отсчетами в блоке и соответствующими прогнозируемыми отсчетами; разложение найденных разностей на частотные составляющие для генерации соответствующего массива коэффициентов разложения на частотные составляющие, упорядоченных согласно пространственным частотам, представленным этими коэффициентами, один из коэффициентов представляет постоянную составляющую (dc) для блока; и энтропийное кодирование коэффициентов разложения на частотные составляющие с использованием контекстно-адаптивного арифметического кода, осуществляющего кодирование коэффициентов в соответствии с контекстными переменными, указывающих вероятность коэффициента конкретной величины; при этом этап энтропийного кодирования содержит: секционирование каждого массива на две или более группы коэффициентов, так что эти группы являются неквадратными подматрицами; и генерацию назначения контекстных переменных для кодирования коэффициентов, формируемых для неквадратной подматрицы согласно пространственным частотам, представленным соответствующим коэффициентом, путем повторения позиций назначения контекстных переменных, применительно к квадратной подматрице, но без повторения позиции назначения контекстной переменной для коэффициента dc. Как показано на фиг. 45, схема назначения для подматрицы размером 8×16 представляет собой схему с повторением величин, полученных из схемы назначения для подматрицы размером 8×8, но назначение для коэффициента dc (верхний левый угол на чертеже) не повторяется. Другими словами, контекстную переменную, назначенную для коэффициента dc, не назначают никакому другому коэффициенту.
Сигналы данных
Следует понимать, что сигналы данных, генерируемые вариантами устройства кодирования, обсуждавшимися выше, и носители для хранения и передачи таких сигналов, считаются представителями вариантов настоящего изобретения.
Применительно к способам обработки, кодирования или декодирования, обсуждавшимся выше, должно быть понятно, что устройства, конфигурированные для реализации таких способов, также считаются представителями вариантов настоящего изобретения. Следует также понимать, что устройства для хранения, передачи, считывания и представления на дисплее видео, использующие указанные способы, считаются представителями вариантов настоящего изобретения.
В той степени, в какой варианты настоящего изобретения были описаны, как реализованные, по меньшей мере частично, посредством устройства обработки данных, управляемого с использованием программного обеспечения, должно быть понятно, что энергонезависимый машиночитаемый носитель записи, на котором записано такое программное обеспечение, - оптический диск, магнитный диск, полупроводниковое запоминающее устройство или другой подходящий носитель, также считается представителем вариантов настоящего изобретения.
Следует понимать, что в свете вышеизложенного возможны многочисленные модификации и вариации настоящего изобретения. Поэтому должно быть понятно, что в пределах объема прилагаемой Формулы изобретения конкретная технология может быть на практике реализована отлично от того, что описано выше.
Соответствующие признаки настоящего изобретения определены следующими нумерованными статьями:
(1) Способ кодирования видеоданных, содержащий этапы, на которых:
прогнозируют блоки яркостных и/или цветоразностные отсчеты изображения на основе других соответствующих отсчетов или величин;
определяют разности между отсчетами в блоке и соответствующими прогнозируемыми отсчетами;
раскладывают найденные разности на частотные составляющие применительно к каждому блоку для генерирования соответствующего массива коэффициентов разложения на частотные составляющие, упорядоченного согласно увеличению пространственных частот, представленных коэффициентами; и
осуществляют энтропийное кодирование коэффициентов разложения на частотные составляющие с использованием контекстно-адаптивного арифметического кода, осуществляющего кодирование коэффициентов с использованием контекстных переменных, указывающих вероятность того, что какой-либо коэффициент имеет конкретную величину; при этом
этап энтропийного кодирования содержит подэтапы, на которых:
осуществляют секционирование каждого массива на две или более группы коэффициентов, при этом указанные группы представляют собой неквадратные подматрицы; и
выбирают контекстную переменную для кодирования коэффициента в соответствии с пространственными частотами, представленными указанным коэффициентом, и в зависимости от величин коэффициентов в одной или более близлежащих групп коэффициентов в рассматриваемом массиве или в массиве, соответствующем соседствующему блоку коэффициентов.
(2) Способ по (1), в котором этап энтропийного кодирования содержит подэтап, на котором осуществляют кодирование коэффициентов массива в порядке, зависящем от схемы сканирования, выбранной из группы одной или более схем-кандидатов сканирования.
(3) Способ по (2), в котором каждая группа коэффициентов в массиве содержит последовательное множество из n коэффициентов в порядке, определяемом схемой сканирования, применимой к этому массиву, где n - целочисленный сомножитель числа коэффициентов в массиве.
(4) Способ по (3), в котором n равно 16.
(5) Способ по любому из (1)-(4), в котором на этапе выбора назначают коэффициенты в группе для одной из набора контекстных переменных-кандидатов, так что, в пределах каждой группы, последовательное подмножество коэффициентов в порядке сканирования назначено соответствующим контекстным переменным-кандидатам.
(6) Способ по любому из (1)-(5), в котором этап выбора зависит от того, имеют ли близлежащие коэффициенты нулевую величину.
(7) Способ по (6), в котором для каждой группы коэффициентов имеется две контекстные переменные-кандидаты.
(8) Способ по (6) или (7), в котором:
коэффициенты упорядочены в массиве так, что горизонтальная пространственная частота увеличивается в направлении слева направо в массиве, а вертикальная пространственная частота увеличивается сверху вниз в этом массиве; при этом
если обе группы - справа и снизу от текущей группы, содержат ненулевые данные коэффициентов, тогда на этапе выбора одну контекстную переменную назначают первым m коэффициентам текущей группы в порядке сканирования, а другую контекстную переменную назначают оставшимся коэффициентам в текущей группе; причем
если группа справа от текущей группы содержит ненулевые данные, а группа снизу от текущей группы ненулевых данных не содержит, тогда на этапе выбора одну контекстную переменную назначают верхней половине текущей группы, а другую контекстную переменную назначают оставшимся коэффициентам в текущей группе; при этом
если группа снизу от текущей группы содержит ненулевые данные, а группа справа от текущей группы ненулевых данных не содержит, тогда на этапе выбора одну контекстную переменную назначают первым р коэффициентам текущей группы в порядке сканирования, а другую контекстную переменную назначают оставшимся коэффициентам в текущей группе; и
если группа снизу от текущей группы содержит ненулевые данные, а группа справа от текущей группы ненулевых данных не содержит, тогда на этапе выбора одну контекстную переменную назначают левой половине текущей группы, а другую контекстную переменную назначают оставшимся коэффициентам в текущей группе; причем
m и р представляют собой целые числа, a m не равно р.
(9) Способ по (8), в котором текущая группа содержит подматрицу коэффициентов размером 8×2 или 2×8; а также m=13 и р=6.
(10) Способ по любому из (6)-(9), в котором, если группа коэффициентов рядом с текущей группой еще не была разложена на частотные составляющие, тогда на этапе выбора присваивают указанной соседней группе нулевые величины с целью выбора контекстной переменной для коэффициентов в текущей группе.
(11) Способ по любому из (6)-(9), в котором, если первая группа коэффициентов рядом с текущей группой еще не разложена на частотные составляющие, а вторая группа, соседствующая с текущей группой, уже разложена на частотные составляющие, тогда на этапе выбора присваивают первой группе величины второй группы с целью выбора контекстной переменной для коэффициентов в текущей группе.
(12) Способ по любому из (1)-(11), в котором блоки отсчетов имеют размер по меньшей мере 8 отсчетов по меньшей мере в одном направлении.
(13) Способ по любому из (1)-(12), в котором по меньшей мере некоторые из блоков отсчетов являются квадратными.
(14) Способ по любому из (1)-(13), в котором по меньшей мере некоторые из блоков отсчетов являются неквадратными.
(15) Способ кодирования видеоданных, содержащий этапы, на которых: прогнозируют блоки яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих отсчетов или величин;
определяют разности между отсчетами в блоке и соответствующими прогнозируемыми отсчетами;
раскладывают найденные разности на частотные составляющие применительно к каждому блоку для генерирования соответствующего массива коэффициентов разложения на частотные составляющие, упорядоченного согласно пространственным частотам, представленным коэффициентами, один из коэффициентов представляет постоянную составляющую (dc) для блока; и
осуществляют энтропийное кодирование коэффициентов разложения на частотные составляющие с применением контекстно-адаптивного арифметического кода, осуществляющего кодирование коэффициентов с использованием контекстных переменных, указывающих вероятность того, что какой-либо коэффициент имеет конкретную величину; при этом
этап энтропийного кодирования содержит подэтапы, на которых:
осуществляют секционирование каждого массива на две или более группы коэффициентов, причем указанные группы представляют собой неквадратные подматрицы; и
генерируют назначения контекстных переменных для кодирования коэффициентов, формируемых для неквадратной подматрицы согласно пространственным частотам, представленным соответствующим коэффициентом, посредством повторения позиций назначения контекстных переменных, применительно к квадратной подматрице, но без повторения позиции назначения контекстной переменной для коэффициента dc.
(16) Способ по (15), в котором, применительно к неквадратному блоку, контекстную переменную, назначенную коэффициенту dc, не назначают никакому другому коэффициенту.
(17) Компьютерное программное обеспечение, при выполнении которого компьютер осуществляет способ по любому из (1)-(16).
(18) Машиночитаемый энергонезависимый носитель записи, на котором хранится программное обеспечение по (17).
(19) Сигнал данных, содержащий кодированные данные, генерируемые в соответствии со способом по любому из (1)-(16).
(20) Устройство кодирования видеоданных, содержащее:
модуль прогнозирования для прогнозирования блоков яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих отсчетов или величин;
устройство определения для определения разностей между отсчетами в блоке и соответствующими прогнозируемыми отсчетами;
преобразовательный модуль для разложения найденных разностей на частотные составляющие применительно к каждому блоку для генерирования соответствующего массива коэффициентов разложения на частотные составляющие, упорядоченного согласно увеличению пространственных частот, представленных коэффициентами; и
модуль энтропийного кодирования для осуществления энтропийного кодирования коэффициентов разложения на частотные составляющие с использованием контекстно-адаптивного арифметического кода, осуществляющего кодирование коэффициентов с использованием контекстных переменных, указывающих вероятность того, что какой-либо коэффициент имеет конкретную величину;
при этом:
модуль энтропийного кодирования выполнен с возможностью осуществления секционирования каждого массива на две или более группы коэффициентов, причем указанные группы представляют собой неквадратные подматрицы, и для выбора контекстной переменной для кодирования коэффициента в соответствии с пространственными частотами, представленными этим коэффициентом, и в зависимости от величин коэффициентов в одной или нескольких близлежащих групп коэффициентов в рассматриваемом массиве или в массиве, соответствующем соседствующему блоку коэффициентов.
(21) Устройство кодирования видеоданных, содержащее:
модуль прогнозирования для прогнозирования блоков яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих отсчетов или величин;
устройство определения для определения разностей между отсчетами в блоке и соответствующими прогнозируемыми отсчетами;
преобразовательный модуль для разложения найденных разностей на частотные составляющие применительно к каждому блоку для генерирования соответствующего массива коэффициентов разложения на частотные составляющие, упорядоченного согласно пространственным частотам, представленным коэффициентами, при этом один из коэффициентов представляет постоянную составляющую (dc) для блока; и
модуль энтропийного кодирования для осуществления энтропийного кодирования коэффициентов разложения на частотные составляющие с применением контекстно-адаптивного арифметического кода, осуществляющего кодирование коэффициентов с использованием контекстных переменных, указывающих вероятность того, что какой либо коэффициент имеет конкретную величину; при этом
модуль энтропийного кодирования конфигурирован для секционирования каждого массива на две или более группы коэффициентов, причем указанные группы представляют собой неквадратные подматрицы, и для генерирования назначения контекстных переменных для кодирования коэффициентов, формируемых для неквадратной подматрицы согласно пространственным частотам, представленным соответствующим коэффициентом, путем повторения позиций назначения контекстных переменных, применительно к квадратной подматрице, но без повторения позиции назначения контекстной переменной для коэффициента dc.
(22) Устройство хранения, передачи, съемки или представления на устройстве отображения видео, содержащее устройство по (21) или (22).
Другие соответствующие варианты определены в следующих пронумерованных статьях:
(1) Способ видео кодирования или декодирования, в котором яркостные и цветоразностные отсчеты изображения прогнозируют на основе других соответствующих отсчетов, полученных из того же самого изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, при этом цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие; причем
способ содержит этапы, на которых:
выбирают по меньшей мере для некоторых отсчетов, один и тот же режим прогнозирования для яркостных и цветоразностных, составляющих, соответствующих области изображения.
(2) Способ видео кодирования или декодирования, в котором яркостные и цветоразностные отсчеты изображения прогнозируют на основе других соответствующих отсчетов, полученных из того же самого изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие; при этом
способ содержит этап, на котором:
осуществляют выбор, по меньшей мере для некоторых отсчетов, разных режимов прогнозирования для каждой - яркостной и цветоразностных, составляющих, соответствующих области изображения.
(3) Способ по (1)-(2), содержащий этап на котором:
осуществляют выбор либо одного и того же режима прогнозирования, либо разных соответствующих режимов прогнозирования для каждой - яркостной и цветоразностных, составляющих, соответствующих области изображения, так что этот выбор осуществляется в соответствии с последовательностью изображений, изображением или областью изображения.
(4) Способ по (3), содержащий, для осуществления кодирования, этапы, на которых:
осуществляют первое пробное кодирование области изображения с использованием одного и того же режима прогнозирования для яркостной и цветоразностных составляющих;
осуществляют второе пробное кодирование той же самой области изображения с использованием разных соответствующих режимов прогнозирования для яркостной и цветоразностных составляющих; и
осуществляют выбор либо одного и того же режима прогнозирования, либо разных соответствующих режимов прогнозирования применительно к последовательности изображений, изображению или области изображения на основе данных, кодированных посредством первого и второго пробных кодирований.
(5) Способ по (4), содержащий этап, на котором:
определяют одного или более заданных свойств данных, кодированных посредством первого и второго пробных кодирований; и
осуществляют выбор либо одного и того же режима прогнозирования, либо разных соответствующих режимов прогнозирования применительно к последовательности изображений, изображению или области изображения на основе найденных одного или более свойств.
(6) Способ по (5), в котором совокупность указанных одного или более свойств содержит свойства, выбранные из набора, куда входят:
шумы изображения;
искажения изображения; и
качество данных изображения.
(7) Способ по любому из (4)-(6), в котором выбор осуществляется для индивидуальных срезов изображения или блоков изображения.
(8) Способ по любому из (4)-(7), содержащий этапы, на которых:
ассоциируют информацию с кодированным видеосигналом, указывающую:
используется ли один и тот же режим прогнозирования или разные режимы прогнозирования; и
в случае, когда используется один и тот же режим прогнозирования, идентифицируют указанный единственный режим прогнозирования; или
в случае, когда используется разные соответствующие режимы прогнозирования, идентифицируют указанные разные соответствующие режимы прогнозирования.
(9) Способ по любому из (1)-(3), который для выполнения операции декодирования содержит этапы, на которых:
определяют информацию, ассоциированную с видеоданными для декодирования, при этом указанная информация указывает, ассоциирован ли с видеоданными для декодирования один и тот же режим прогнозирования или разные режимы прогнозирования.
(10) Способ по любому из (1)-(9), в котором изображение составляет часть видеосигнала в формате 4:2:2 или 4:4:4.
(11) Компьютерное программное обеспечение, при выполнении которого компьютер осуществляет способ по любому из (1)-(10).
(12) Машиночитаемый энергонезависимый носитель записи, на котором хранится программное обеспечение по (11).
(13) Сигнал данных, содержащий кодированные данные, генерируемые в соответствии со способом по любому из (1)-(10).
(14) Устройство кодирования или декодирования видеоданных, в котором яркостные и/или цветоразностные отсчетов изображения прогнозируют на основе других соответствующих отсчетов или величин, полученных из того же самого изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие;
устройство содержит контроллер, конфигурированный для выбора, по меньшей мере для некоторых отсчетов, одного и того режима прогнозирования для каждой -яркостной и цветоразностных составляющих, соответствующих области изображения.
(15) Устройство кодирования или декодирования видеоданных, в котором яркостные и/или цветоразностные отсчеты изображения прогнозируют на основе других соответствующих отсчетов или величин, полученных из того же самого изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, цветоразностные отсчеты представляют первую и вторую цветоразностные составляющие;
устройство содержит контроллер, конфигурированный для выбора, по меньшей мере для некоторых отсчетов, разных соответствующих режимов прогнозирования для каждой - яркостной и цветоразностных составляющих, соответствующих области изображения.
(16) Устройство по (14) или (15), в котором контроллер конфигурирован для выбора либо одного и того же режима прогнозирования, либо разных соответствующих режимов прогнозирования для каждой - яркостной и цветоразностных составляющих, соответствующих области изображения, согласно последовательности изображений, изображению или области изображения.
(17) Устройство для хранения, передачи, съемки или представления на устройстве отображения видео, содержащее устройство по любому из (14)-(16).

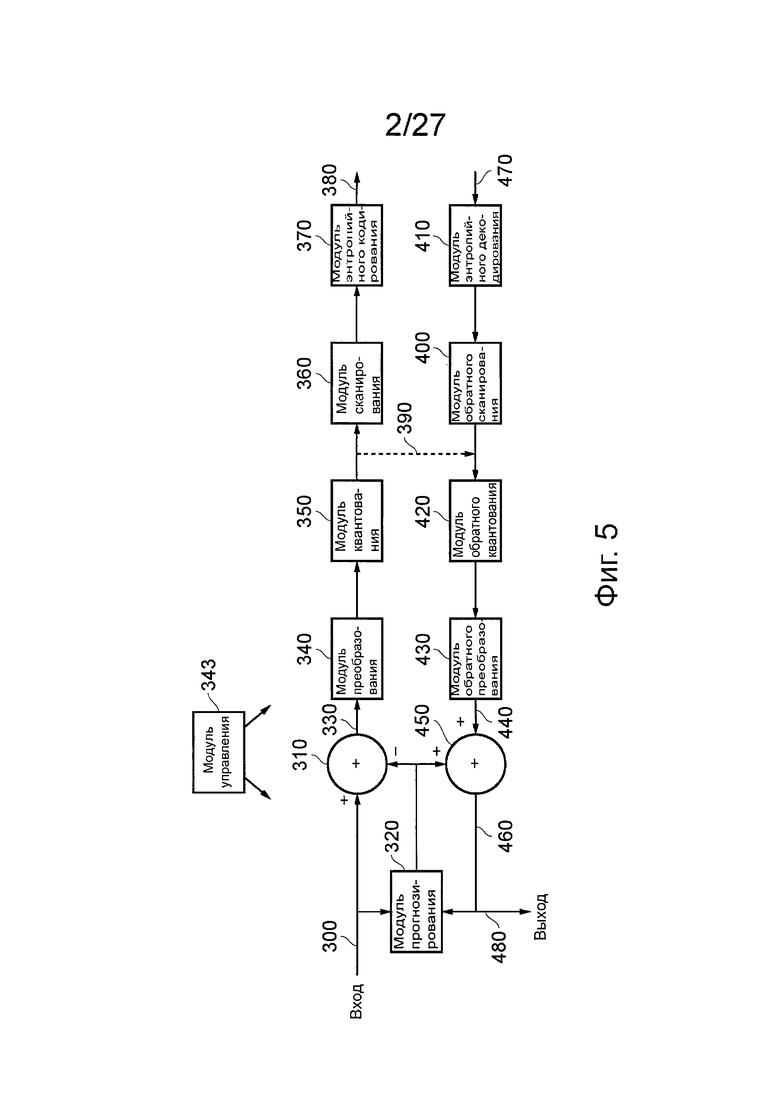

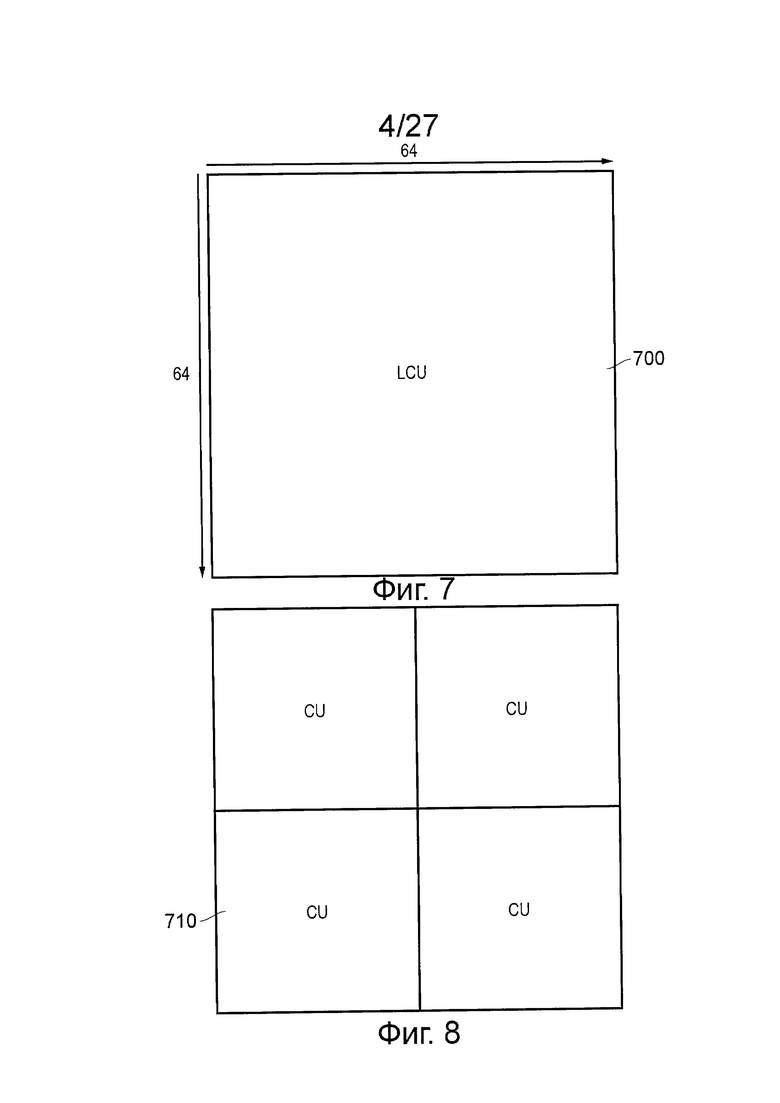

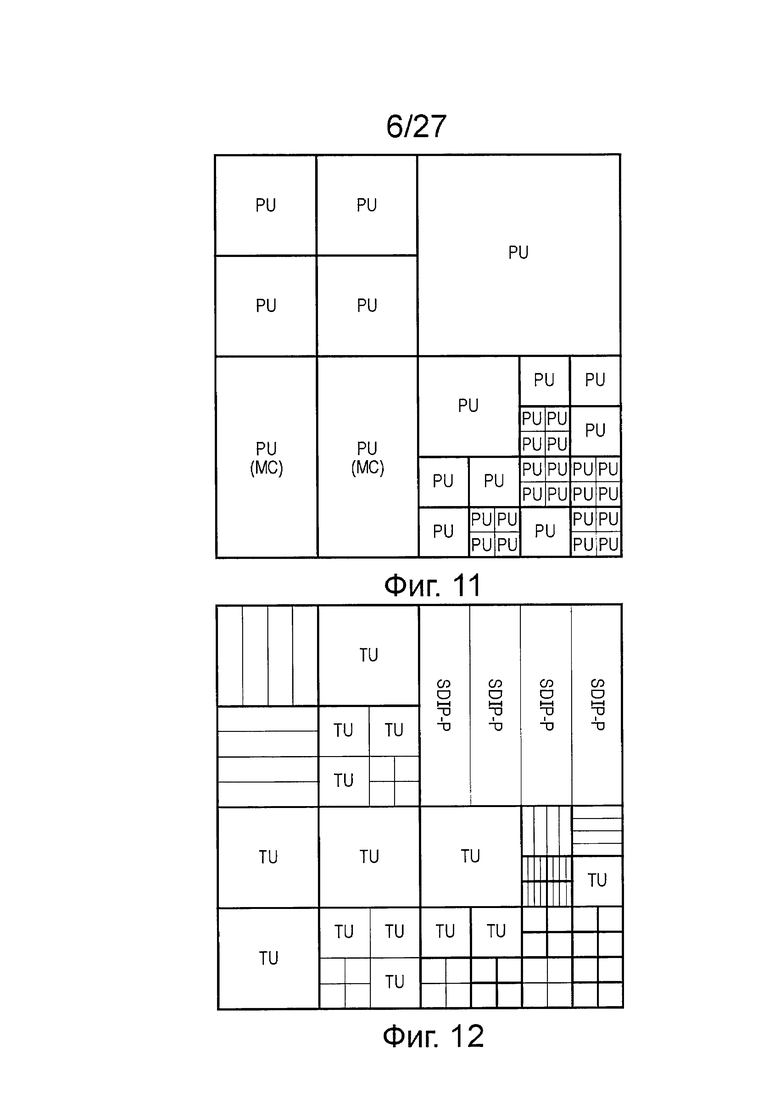




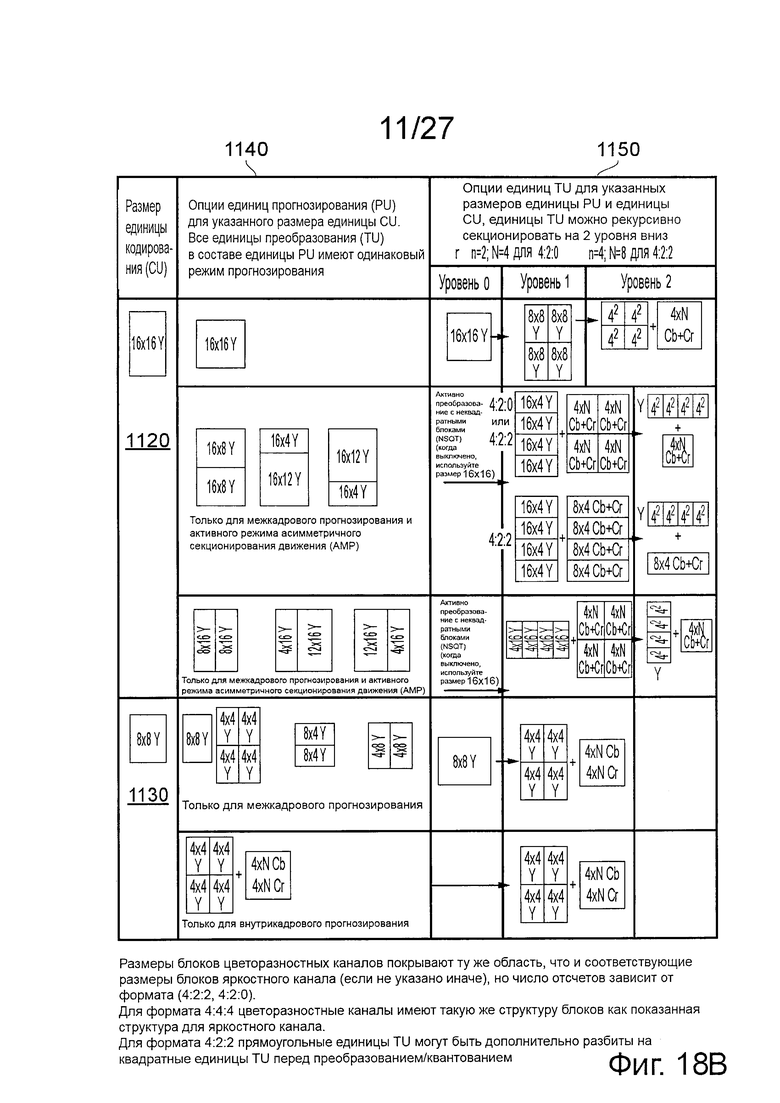


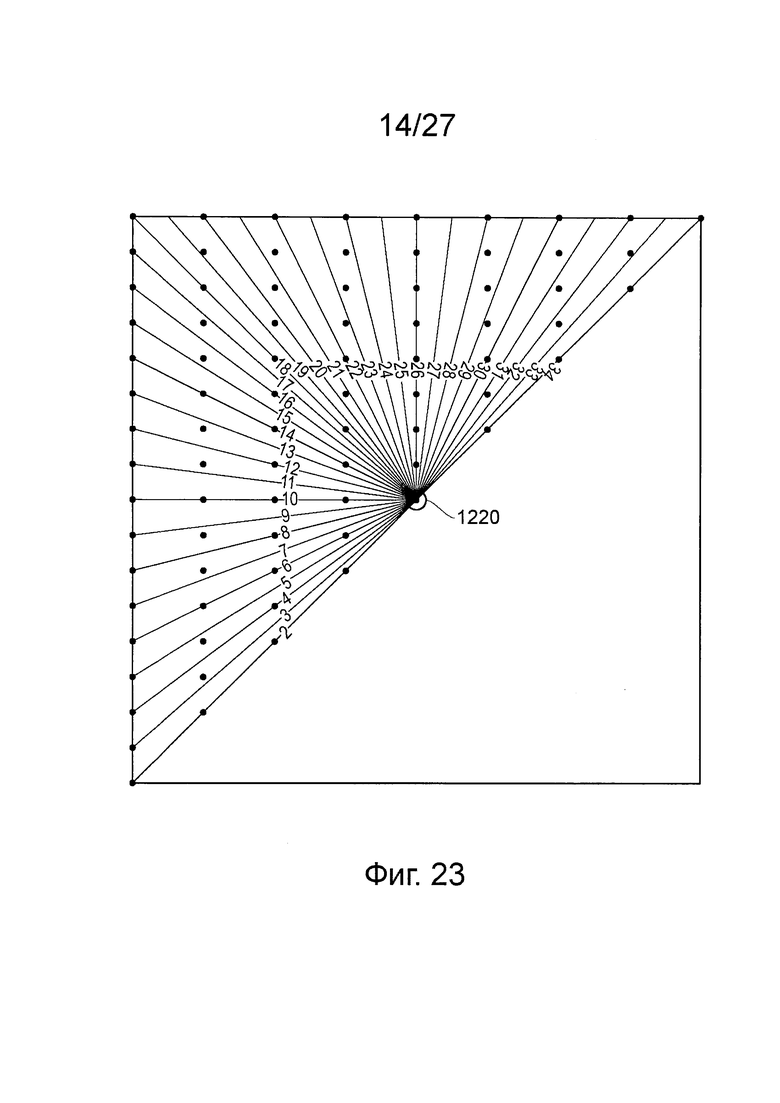



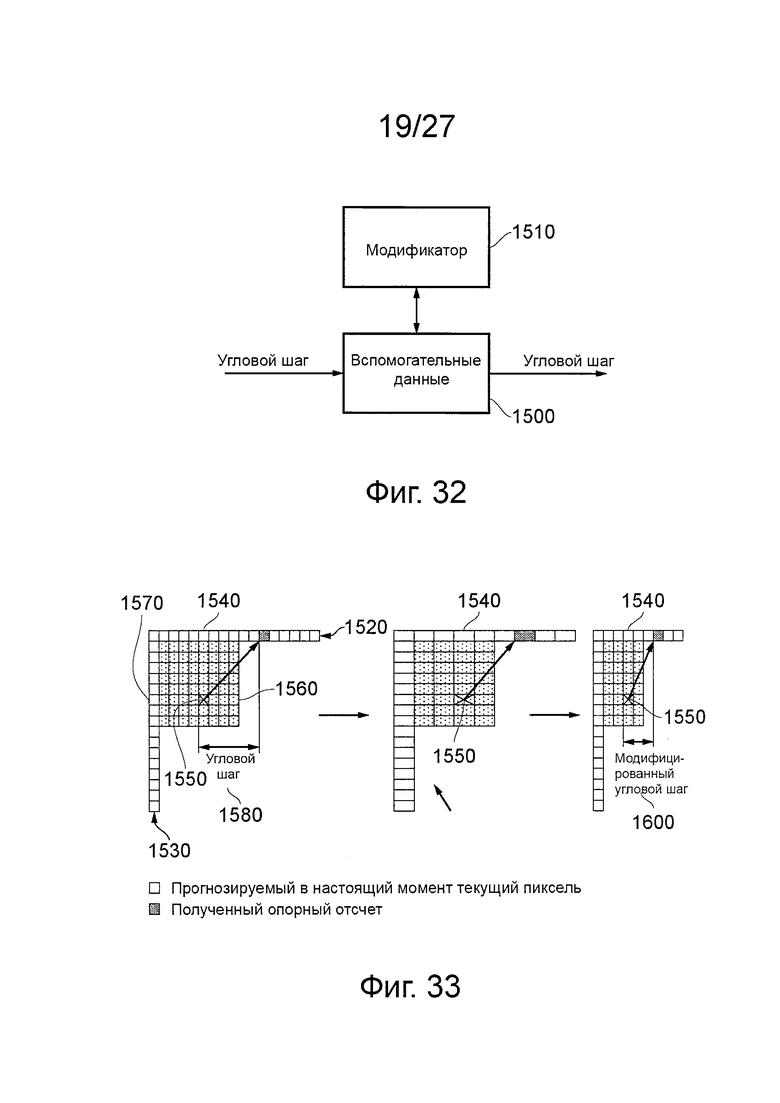







Изобретение относится к кодированию и декодированию данных. Техническим результатом является повышение качества изображения при кодировании и декодировании данных. Способ содержит этапы, на которых: прогнозируют яркостные и/или цветоразностные отсчеты изображения на основе других соответствующих опорных отсчетов, полученных из этого же изображения согласно режиму прогнозирования; определяют разности между отсчетами и соответствующими прогнозируемыми отсчетами; разлагают на частотные составляющие обнаруженные разности для блока отсчетов; выбирают схемы сканирования из группы двух или более схем-кандидатов сканирования; на этапе выбора выбирают схему горизонтального сканирования применительно к группе преимущественно вертикальных режимов прогнозирования, выбирают схему вертикального сканирования применительно к группе преимущественно горизонтальных режимов прогнозирования и выбирают схему диагонального сканирования применительно к другим режимам прогнозирования и кодируют разложенные на частотные составляющие разностные данные в порядке коэффициентов разложения на частотные составляющие согласно выбранной схеме сканирования. 6 н. и 7 з.п. ф-лы, 52 ил.
1. Устройство декодирования видеоданных, в котором разности между прогнозируемыми и исходными отсчетами разложены на частотные составляющие, с использованием преобразования для разложения на частотные составляющие, и кодированы, содержащее:
модуль прогнозирования для прогнозирования яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих опорных отсчетов, полученных из этого же изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, при этом указанный режим прогнозирования выбран для каждого из множества блоков отсчетов из группы из одного или более режимов-кандидатов прогнозирования;
селектор для выбора схемы сканирования из группы двух или более схем-кандидатов сканирования, при этом каждая схема сканирования выполнена с возможностью определения порядка кодирования множества коэффициентов разложения на частотные составляющие в зависимости от режима прогнозирования для рассматриваемого блока отсчетов с использованием отображения между схемами сканирования и режимами прогнозирования, причем указанное отображение различно для цветоразностных отсчетов и яркостных отсчетов, причем блок яркостных отсчетов имеет коэффициенты формы, отличающиеся от коэффициентов формы блока цветоразностных отсчетов, и отображение между схемами сканирования и режимами прогнозирования установлено различным в соответствии с отличием коэффициента формы; при этом
селектор выполнен с возможностью выбора схемы горизонтального сканирования применительно к группе преимущественно вертикальных режимов прогнозирования, выбора схемы вертикального сканирования применительно к группе преимущественно горизонтальных режимов прогнозирования и выбора схемы диагонального сканирования применительно к другим режимам прогнозирования; и
декодер для декодирования разложенных на частотные составляющие разностных данных, представляющих разложенную на частотные составляющие версию данных, указывающих разности между отсчетами, подлежащими декодированию, и соответствующими прогнозируемыми отсчетами, в порядке следования коэффициентов разложения на частотные составляющие согласно выбранной схеме сканирования.
2. Устройство кодирования видеоданных, в котором разности между прогнозируемыми и исходными отсчетами разлагают на частотные составляющие, с использованием преобразования для разложения на частотные составляющие, и кодируют, содержащее:
модуль прогнозирования, выполненный с возможностью прогнозирования яркостных и/или цветоразностных отсчетов изображения на основе других соответствующих опорных отсчетов, полученных из этого же изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, при этом указанный режим прогнозирования выбран для каждого из множества блоков отсчетов из группы из одного или более режимов-кандидатов прогнозирования;
детектор, выполненный с возможностью определения разностей между отсчетами и соответствующими прогнозируемыми отсчетами;
преобразовательный модуль, выполненный с возможностью разложения на частотные составляющие обнаруженных разностей для блока отсчетов с использованием преобразования для разложения на частотные составляющие для генерирования соответствующего множества коэффициентов разложения на частотные составляющие;
селектор, выполненный с возможностью выбора схемы сканирования из группы двух или более схем-кандидатов сканирования, причем каждая схема сканирования выполнена с возможностью определения порядка кодирования множества коэффициентов разложения на частотные составляющие в зависимости от режима прогнозирования для рассматриваемого блока отсчетов, причем блок яркостных отсчетов имеет коэффициенты формы, отличающиеся от коэффициентов формы блока цветоразностных отсчетов, и отображение между схемами сканирования и режимами прогнозирования установлено различным в соответствии с отличием коэффициента формы; при этом
селектор выполнен с возможностью выбора схемы горизонтального сканирования применительно к группе преимущественно вертикальных режимов прогнозирования, выбора схемы вертикального сканирования применительно к группе преимущественно горизонтальных режимов прогнозирования и выбора схемы диагонального сканирования применительно к другим режимам прогнозирования; и
модуль кодирования, выполненный с возможностью кодирования разложенных на частотные составляющие разностных данных в порядке коэффициентов разложения на частотные составляющие согласно выбранной схеме сканирования.
3. Способ кодирования видеоданных, в котором разности между прогнозируемыми и исходными отсчетами разлагают на частотные составляющие и кодируют, содержащий этапы, на которых:
прогнозируют яркостные и/или цветоразностные отсчеты изображения на основе других соответствующих опорных отсчетов, полученных из этого же изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, при этом указанный режим прогнозирования выбран для каждого из множества блоков отсчетов из группы из одного или более режимов-кандидатов прогнозирования;
определяют разности между отсчетами и соответствующими прогнозируемыми отсчетами;
разлагают на частотные составляющие обнаруженные разности для блока отсчетов с использованием преобразования для разложения на частотные составляющие для генерирования соответствующего множества коэффициентов разложения на частотные составляющие;
выбирают схемы сканирования из группы двух или более схем-кандидатов сканирования, при этом каждая схема сканирования определяет порядок кодирования множества коэффициентов разложения на частотные составляющие в зависимости от режима прогнозирования для рассматриваемого блока отсчетов с использованием отображения между схемой сканирования и режимом прогнозирования, причем блок яркостных отсчетов имеет коэффициенты формы, отличающиеся от коэффициентов формы блока цветоразностных отсчетов, и отображение между схемами сканирования и режимами прогнозирования установлено различным в соответствии с отличием коэффициента формы, при этом указанное отображение различно для цветоразностных и яркостных отсчетов; и
на этапе выбора выбирают схему горизонтального сканирования применительно к группе преимущественно вертикальных режимов прогнозирования, выбирают схему вертикального сканирования применительно к группе преимущественно горизонтальных режимов прогнозирования и выбирают схему диагонального сканирования применительно к другим режимам прогнозирования; и
кодируют разложенные на частотные составляющие разностные данные в порядке коэффициентов разложения на частотные составляющие согласно выбранной схеме сканирования.
4. Способ по п. 3, в котором режим прогнозирования, ассоциированный с блоком отсчетов, подлежащим прогнозированию, указывает направление прогнозирования, определяющее один или более других соответствующих опорных отсчетов, на основе которых прогнозируют каждый отсчет указанного блока.
5. Способ по п. 3 или 4, содержащий этап, на котором осуществляют отображение между режимом прогнозирования и схемой сканирования.
6. Способ по п. 5, в котором видеоданные представляют собой видеоданные в формате 4:2:2 и/или в формате 4:4:4 и отображение различается между яркостными данными в формате 4:2:2 и цветоразностными данными в формате 4:2:2.
7. Способ по п. 5, в котором видеоданные представляют собой видеоданные в формате 4:2:2 и/или в формате 4:4:4 и отображение различается между данными в формате 4:2:2 и данными в формате 4:4:4.
8. Способ по п. 3, в котором размер текущего блока яркостных отсчетов составляет 4×4 или 8×8 отсчетов.
9. Способ по п. 3, содержащий этапы, на которых:
выбирают размер текущего блока отсчетов из группы размеров-кандидатов;
применяют этап выбора схемы сканирования, когда выбранный размер блока является одним из размеров из состава заданного подмножества группы размеров-кандидатов.
10. Способ по п. 3, в котором группа схем-кандидатов сканирования различается для использования применительно к яркостным и к цветоразностным отсчетам.
11. Способ декодирования видеоданных, в которых разности между прогнозируемыми и исходными отсчетами разложены на частотные составляющие, с использованием преобразования для разложения на частотные составляющие, и кодированы, содержащий этапы, на которых:
прогнозируют яркостные и/или цветоразностные отсчеты изображения на основе других соответствующих опорных отсчетов, полученных из этого же изображения согласно режиму прогнозирования, ассоциированному с отсчетом, подлежащим прогнозированию, при этом указанный режим прогнозирования выбран для каждого из множества блоков отсчетов из группы из одного или более режимов-кандидатов прогнозирования;
выбирают схему сканирования из группы двух или более схем-кандидатов сканирования, при этом каждая схема сканирования выполнена с возможностью определения порядка кодирования множества коэффициентов разложения на частотные составляющие в зависимости от режима прогнозирования для рассматриваемого блока отсчетов с использованием отображения между схемой сканирования и режимом прогнозирования, причем блок яркостных отсчетов имеет коэффициенты формы, отличающиеся от коэффициентов формы блока цветоразностных отсчетов, и отображение между схемами сканирования и режимами прогнозирования установлено различным в соответствии с отличием коэффициента формы, такое отображение различно между цветоразностными и яркостными отсчетами; при этом
на этапе выбора выбирают схему горизонтального сканирования применительно к группе преимущественно вертикальных режимов прогнозирования, выбирают схему вертикального сканирования применительно к группе преимущественно горизонтальных режимов прогнозирования и выбирают схему диагонального сканирования применительно к другим режимам прогнозирования; и
декодируют разложенные на частотные составляющие разностные данные, представляющие разложенную на частотные составляющие версию данных, указывающих разности между отсчетами, подлежащими декодированию, и соответствующими прогнозируемыми отсчетами, в порядке следования коэффициентов разложения на частотные составляющие согласно выбранной схеме сканирования.
12. Машиночитаемый энергонезависимый носитель записи, хранящий компьютерное программное обеспечение, при выполнении которого компьютер осуществляет способ согласно любому из пп. 3-11.
13. Устройство хранения, передачи, съемки или представления на устройстве отображения видео, содержащее устройство по п. 1 или 2.
| YUNFEI ZHENG et al, ";CE11: Mode Dependent Coefficient Scanning";, Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SG29/WG11, 4 | |||
| Прибор для очистки паром от сажи дымогарных трубок в паровозных котлах | 1913 |
|
SU95A1 |
| Прибор для промывания газов | 1922 |
|
SU20A1 |
| US20110090955 A1, 21.04.2011 | |||
| WO2007046644 A1, 26.04.2007 | |||
| RU2447612 C2, 10.04.2012. | |||

