Область техники, к которой относится изобретение
Данное раскрытие относится к кодированию и декодированию данных.
Уровень техники
Описание "Уровня техники", представленное здесь, предназначено для общего представления контекста раскрытия. Работа названных в настоящее время авторов изобретения, в той степени, как она описана в этом разделе "Предшествующий уровень техники", так же, как и аспекты описания, которые, не могут быть квалифицированы, как предшествующий уровень техники во время подачи, ни в явном виде, ни скрыто не допущены, как предшествующий уровень техники, против настоящего раскрытия.
Существует несколько систем кодирования и декодирования видеоданных, в которых используется преобразование видеоданных в представление в области частоты, квантование коэффициентов в области частоты и затем применение определенной формы энтропийного кодирования для квантованных коэффициентов. Это позволяет достичь сжатия видеоданных. Соответствующая технология декодирования или разворачивания данных применяется для восстановления реконструированной версии оригинальных видеоданных.
Используемые в настоящее время видеокодеки (декодеры - кодеры), такие как используются в H.264/MPEG-4 Усовершенствованное видеокодирование (AVC) обеспечивают сжатие данных, в основном, только благодаря кодированию разности между последовательными видеокадрами. В таких кодеках используются регулярные массивы так называемых макроблоков, каждый из которых используется в качестве области сравнения с соответствующим макроблоком в предыдущем видеокадре, и область изображения в макроблоке затем кодируют в соответствии со степенью движения, определенной между соответствующими текущими и предыдущими макроблоками в последовательности видеоданных, или между соседними макроблоками в пределах одного кадра последовательности видеоданных.
Высокоэффективной кодирование видеоданных (HEVC), также известное как Н.265 или MPEG-H Часть 2, является предложенным преемником для H.264/MPEG-4 AVC. Для HEVC предполагается улучшение качества видеоизображения и удвоение степени сжатия данных по сравнению с Н.264, и обеспечение возможности масштабирования от 128×96 до 7680×4320 пикселей разрешения, что приблизительно эквивалентно скоростям передачи битов в диапазоне от 128 кбит/с до 800 Мбит/с.
В HEVC так называемая структура блока 4:2:0 предложена для оборудования потребителя, в которой объем данных, используемый в каждом канале цветности, составляет одну четверть канала яркости. Это связано с тем, что субъективно люди в большей степени чувствительны к вариациям яркости, чем к вариациям цвета, и, таким образом, возможно использовать большую степень сжатия и/или меньше информации в каналах цветности без субъективной потери качества.
HEVC заменяет макроблоки, определенные в существующих стандартах Н.264 и MPEG, более гибкой схемой на основе модулей кодирования (CU), которые представляют собой структуры переменного размера.
Следовательно, при кодировании данных изображения в видеокадрах, размеры CU можно выбирать в соответствии с кажущейся сложностью изображения или детектируемыми уровнями движения, вместо использования равномерно распределенных макроблоков. Следовательно, может быть достигнута гораздо большая степень сжатия в областях, в которых присутствует мало движения между кадрами, и с малыми вариациями в пределах кадра, в то время как лучшее качество изображения может быть сохранено в областях с большим движением между кадрами движения или с большей сложностью изображения.
Каждый CU содержит один или больше модулей прогнозирования (PU) с переменным размером блока, либо для прогнозирования внутри кадра, или для прогнозирования между кадрами, и один или больше модулей преобразования (TU), которые содержат коэффициенты для пространственного преобразования блоков и квантования.
Кроме того, блоки PU и TU предусмотрены для каждого из трех каналов; яркости (Y), который представляет яркость или канал яркости, и который можно рассматривать как канал серой шкалы, и два цветоразностных канала или канала цветности (chroma); Cb и Cr. Эти каналы обеспечивают цвет для изображения серой шкалы канала яркости. Термины Y, яркость и luma используются взаимозаменяемо в данном описании, и аналогично термины Cb и Cr цветности и chroma используются здесь взаимозаменяемо, соответственно, с учетом того, что термины цветность или chroma могут использоваться в общем смысле для "одного или обоих Cr и Cb", когда будет описываться один конкретный канал цветности, он будет обозначен термином Cb или Cr.
В общем случае PU рассматривается как независимый от канала за исключением того, что PU имеет часть яркости и часть цветности. В общем, это означает, что образцы, формирующие часть PU для каждого канала, представляют ту же область изображения, таким образом, что существует фиксированная взаимосвязь между PU, между тремя каналами. Например, для видеоизображения 4:2:0, PU 8×8 для яркости всегда имеет соответствующие PU 4×4 для цветности, при этом части цветности PU, представляющие те же области, что и часть яркости, но содержащие меньшее количество пикселей, благодаря свойствам подвыборки данных цветности 4:2:0 по сравнению с данными яркости в видеоизображении 4:2:0. Два канала цветности совместно используют информацию прогнозирования внутри кадра; и три канала совместно используют информацию прогнозирования между кадрами. Точно так же структуры TU также имеют фиксированную взаимосвязь между этими тремя каналами.
Однако для профессиональной широковещательной передачи и оборудования цифрового кино желательно иметь меньшую степень сжатия (или большее количество информации) в каналах цветности, и это может повлиять, на то, как работают современная и предложенная обработка HEVC.
Раскрытие изобретения
Настоящее раскрытие направлено на устранение или уменьшение проблем, возникающих при такой обработке.
Соответствующие аспекты и свойства настоящего раскрытия определены в приложенной формуле изобретения.
Следует понимать, что как представленное выше общее описание, так и следующее подробное описание изобретения являются примерными, но не являются ограничительными в отношении настоящей технологии.
Краткое описание чертежей
Более полная оценка раскрытия и множества его сопутствующих преимуществ будут легко достигнуты по мере их лучшего понимания, со ссылкой на следующее подробное описание изобретения, которое рассматривается совместно с приложенными чертежами, на которых:
на фиг. 1 схематично иллюстрируется система передачи и приема аудио/видео (A/V) данных, в которой используется сжатие и распаковка видеоданных;
на фиг. 2 схематично показана система отображения видео, в которой используется распаковка видеоданных;
на фиг. 3 схематично показана система накопителя аудио/видеоданных, используя сжатие и распаковку видеоданных;
на фиг. 4 схематично показана видеокамера, в которой используется сжатие видеоданных;
на фиг. 5 представлен общий обзор описания схемы устройства сжатия и распаковки видеоданных;
на фиг. 6 схематично показано генерирование прогнозируемых изображений;
на фиг. 7 схематично показан наибольший модуль кодирования (LCU);
на фиг. 8 схематично показан набор из четырех модулей кодирования (CU);
на фиг. 9 и 10 схематично представлены модули кодирования по фиг. 8, разделенные на меньшие модули кодирования;
на фиг. 11 схематично показан массив модулей прогнозирования (PU);
на фиг. 12 схематично показан массив модулей преобразования (TU);
на фиг. 13 схематично показано частично кодированное изображение;
на фиг. 14 схематично показан набор возможных направлений прогнозирования внутри кадра;
на фиг. 15 схематично показан набор режимов прогнозирования;
на фиг. 16 схематично показана диагональная развертка сверху вправо;
на фиг. 17 схематично показано устройство сжатия видеоданных;
на фиг. 18А и 18В схематично представлены возможные размеры блока;
на фиг. 19 схематично показано использование совместно размещенной информации из блоков цветности и яркости;
на фиг. 20 схематично показана ситуация, в которой совместно размещенная информация из одного канала цветности используется относительно другого канала цветности;
на фиг. 21 схематично показаны пиксели используемые для режима LM-ЦВЕТНОСТИ;
на фиг. 22 схематично показан набор направлений прогнозирования яркости;
на фиг. 23 схематично показаны направления для фиг. 22, в применении к горизонтальному прореженному каналу цветности;
на фиг. 24 схематично показаны направления для фиг. 22, отображенные на прямоугольную матрицу пикселей цветности;
на фиг. 25-28 схематично представлена интерполяция пикселя яркости и цветности;
на фиг. 29А и 29В схематично представлены таблицы параметров квантования для 4:2:0 и 4:2:2 соответственно;
на фиг. 30 и 31 схематично представлены таблицы изменения квантования;
на фиг. 32 схематично представлена компоновка для модификации углового шага;
на фиг. 33 схематично показано изменение угловых шагов;
на фиг. 34 и 35 схематично представлены структуры развертки;
на фиг. 36 схематично представлен выбор структуры развертки в соответствии с режимом прогнозирования;
на фиг. 37 схематично представлен выбор структуры развертки в соответствии с режим прогнозирования для прямоугольного блока цветности;
на фиг. 38 схематично представлена компоновка для выбора структуры развертки;
на фиг. 39 схематично представлена компоновка для выбора преобразования с разделением по частоте;
на фиг. 40 схематично представлен кодер САВАС;
на фиг. 41A-41D схематично представлено предложенное ранее выделение по-соседству; и
на фиг. 42А - 45 схематично представлено выделение переменной контекста в соответствии с вариантами осуществления раскрытия.
Осуществление изобретения
Рассматривая теперь чертежи, фиг. 1-4 предусмотрены для предоставления схематичной иллюстрации устройства или систем с использованием устройства сжатия и/или распаковки, которое описано ниже в связи с вариантами осуществления раскрытия.
Все из устройств сжатия и/или распаковки данных, которые будут описаны ниже, могут быть воплощены в виде аппаратных средств, в виде программного обеспечения, работающего в устройстве обработки данных общего назначения, таком как компьютер общего назначения, в виде программируемых аппаратных средств, таких как специализированная интегральная схема (ASIC) или программируемая пользователем вентильная матрица (FPGA) или как их комбинации. В случаях когда варианты осуществления воплощены в виде программных средств и/или встроенного программного обеспечения, следует понимать, что такие программное средство и/или встроенное программное обеспечение, и энергонезависимые носители для сохранения данных, на которых такие программное средство и/или встроенное программное обеспечение сохранены или по-другому предусмотрены, рассматриваются как варианты осуществления настоящего раскрытия.
На фиг. 1 схематично иллюстрируется система передачи и приема аудио/видеоданных, использующая сжатие и распаковку видеоданных.
Входной аудио/видеосигнал 10 подают в устройство 20 сжатия видеоданных, которое сжимает, по меньшей мере, видеокомпонент аудио/видеосигнала 10 для передачи по маршруту 30 передачи, такому как кабель, оптическое волокно, беспроводное соединение и т.п. Сжатый сигнал обрабатывается устройством 40 распаковки, для предоставления выходного аудио/видеосигнала 50. Для обратного пути, устройство 60 сжатия сжимает аудио/видеосигнал для передачи вдоль маршрута 30 передачи в устройство 70 распаковки.
Устройство 20 сжатия и устройство 70 распаковки поэтому могут формировать один узел соединения передачи. Устройство 40 распаковки и устройство 60 распаковки могут формировать другой узел соединения передачи. Конечно, в случаях когда соединение передачи является однонаправленным, только в одном из узлов могло бы потребоваться устройство сжатия, и в другом узле могло бы потребоваться только устройство для распаковки.
На фиг. 2 схематично иллюстрируется система отображения видеоизображения, в которой используется распаковка видеоданных. В частности, сжатый аудио/видеосигнал 100 обрабатывают в устройстве ПО распаковки для получения распакованного сигнала, который может отображаться на дисплее 120. Устройство ПО распаковки может быть воплощено как единая часть дисплея 120, например, может быть установлено в том же корпусе, что и устройство дисплея. В качестве альтернативы устройство 110 распаковки может быть предусмотрено как (например) так называемая телевизионная приставка (STB), следует отметить, что выражение "телевизионная приставка" не подразумевает требования того, чтобы приставка была установлена в какой-либо конкретной ориентации или положении относительно дисплея 120; это просто термин, используемый в данной области техники для обозначения устройства, которое может быть подключено к дисплею как периферийное устройство.
На фиг. 3 схематично иллюстрируется система сохранения аудио/видеоданных, в которой используются сжатие и распаковка видеоданных. Входной аудио/видеосигнал 130 поступает в устройство 140 сжатия, которое генерирует сжатый сигнал для сохранения устройством 150 сохранения, таким как устройство магнитного диска, устройство оптического диска, устройство на магнитной ленте, твердотельное устройство сохранения данных, такое как полупроводниковое запоминающее устройство или другое устройство сохранения. Для повторного воспроизведения сжатые данные считывают из устройства 150 сохранения и передают в устройство 160 распаковки для распаковки, для получения выходного аудио/видеосигнала 170.
Следует понимать, что сжатый или кодированный сигнал и носитель сохранения информации, на котором содержится такой сигнал, рассматриваются как варианты осуществления настоящего раскрытия.
На фиг. 4 схематично иллюстрируется видеокамера, в которой используется сжатие видеоданных. На фиг. 4 устройство изображения съемки 180, такое как датчик изображения на основе прибора с зарядовой связью (CCD) и соответствующие элементы управления и электронной схемы считывания, генерирует видеосигнал, который поступает в устройство 190 сжатия. Микрофон (или множество микрофонов) 200 генерируют аудиосигнал, который должен быть передан в устройство 190 сжатия. Устройство 190 сжатия генерирует сжатый аудио/видеосигнал 210, который должен быть сохранен и/или передан (в общем, обозначен как этап 220 на схеме).
Технологии, которые будут описаны ниже, относятся, в основном, к сжатию и распаковке видеоданных. Следует понимать, что множество существующих технологий могут использоваться для сжатия аудиоданных совместно с технологиями сжатия видеоданных, которые будут описаны для генерирования сжатого аудио/видеосигнала. Соответственно, отдельная дискуссия сжатия аудиоданных не будет предусмотрена. Следует также понимать, что скорость передачи данных, ассоциированных с видеоданными, в частности видеоданными качественной широковещательной передачи, обычно намного выше, чем скорость передачи данных, ассоциированных с аудиоданными (сжатыми или несжатыми). Следует поэтому понимать, что несжатые аудиоданные могут сопровождать сжатые видеоданные для формирования сжатого аудио/видеосигнала. Также, следует понимать, что, хотя настоящие примеры (показаны на фиг. 1-4) относятся к аудио/видеоданным, технологии, которые будут описаны ниже, могут найти использование в системе, которая просто работает (то есть сжимает, распаковывает, сохраняет, отображает и/или передает) с видеоданными. То есть в вариантах осуществления может применяться сжатие видеоданных без необходимости использовать любую ассоциированную обработку аудиоданных вообще.
На фиг. 5 схематично показан общий обзор устройства сжатия и распаковки видеоданных.
Контроллер 343 управляет общей работой устройства и, в частности, со ссылкой на режим сжатия, управляет процессом кодирования с проверкой (будет описан ниже), для выбора различных режимов работы, таких как размеры блоков CU, PU и TU.
Последовательные изображения входного видеосигнала 300 поступают в сумматор 310 и в блок 320 прогнозирования изображения. Блок 320 прогнозирования изображения будет описан ниже более подробно со ссылкой на фиг. 6. Сумматор 310 фактически выполняет операцию вычитания (отрицательное суммирование), состоящую в том, что он принимает входной видеосигнал 300 на входе "+" и вывод блока 320 прогнозирования изображения на входе таким образом, что прогнозируемое изображение вычитается из входного изображения. Результат представляет собой генерирование так называемого остаточного сигнала 330 изображения, представляющего разность между фактическим и прогнозируемым изображениями.
Одна из причин, по которой генерируется остаточный сигнал видеоизображения, состоит в следующем. Технологии кодирования данных, которые будут описаны, то есть технологии, которые применяются к сигналу остаточного изображения, проявляют тенденцию более эффективной работы, когда в изображении, предназначенном для кодирования, меньше "энергии". Здесь термин "эффективно" относится к генерированию малого количества кодированных данных; для конкретного уровня качества изображения желательно (и рассматривается как "эффективно"), генерировать так мало данных, насколько это практически возможно. Ссылка на "энергию" в остаточном изображении относится к количеству информации, содержащейся в остаточном изображении. Если прогнозируемое изображение было идентично реальному изображению, разность между ними двумя (то есть остаточное изображение) содержала бы нулевую информацию (ноль энергии), и была бы очень легко кодирована в кодированные данные с малым объемом. В общем, если добиться обоснованно хорошей работы процесса прогнозирования, можно ожидать, что данные остаточного изображения будут содержать меньше информации (меньше энергии), чем входное изображение, и так его будет проще кодировать с получением кодированных данных с малым объемом.
Данные 330 остаточного изображения подают в модуль 340 преобразования, который генерирует представление дискретного косинусного преобразования (DCT) данных остаточного изображения. Сама по себе технология DCT хорошо известна и не будет подробно описана здесь. Существуют, однако аспекты технологий, используемых в настоящем устройстве, которые будут более подробно описаны ниже, в частности, в отношении выбора разных блоков данных, в которых применяется операция DCT. Они будут описаны со ссылкой на фиг. 7-12, представленные ниже. В некоторых вариантах осуществления другое преобразование разделения частоты может избирательно использоваться вместо DCT в системе, известной как MDDT (направленное преобразование, зависимое от режима), которое будет описано ниже. Пока предполагается, что используется преобразование DCT.
Выход модуля 340 преобразования, который можно представить как набор коэффициентов DCT для каждого преобразованного блока данных изображения, подают в блок 350 квантования. Различные технологии квантования известны в области сжатия видеоданных, в диапазоне от простого умножения на коэффициент масштабирования квантования до применения сложных справочных таблиц под управлением параметра квантования. Общая цель является двойной. Во-первых, процесс квантования уменьшает количество возможных значений преобразованных данных. Во-вторых, процесс квантования позволяет увеличить вероятность того, что значения преобразованных данных равны нулю. Оба эти эффекта могут обеспечить более эффективную работу процесса энтропийного кодирования, который будет описан ниже, при генерировании малых объемов сжатых видеоданных.
Процесс развертки данных применяется модулем 360 развертки. Назначение процесса развертки состоит в том, чтобы изменить порядок квантованных преобразованных данных, так, чтобы собрать вместе как можно большее количество ненулевых квантованных преобразованных коэффициентов, и, конечно, потому, чтобы собрать вместе как можно больше коэффициентов со значением ноль. Эти свойства могут обеспечить так называемое неравномерное кодирование или аналогичные технологии, которые будут применены эффективно. Таким образом, процесс развертки подразумевает выбор коэффициентов из квантованных преобразованных данных, и, в частности, из блока коэффициентов, соответствующего блоку данных изображения, который был преобразован и квантован, в соответствии с "порядком развертки" таким образом, что (а), все коэффициенты выбирают один раз как часть развертки, и (b) развертка проявляет тенденцию предоставления требуемого изменения порядка. Один пример порядка развертки, которая может проявлять тенденцию получения полезных результатов, представляет собой так называемый порядок диагональной развертки сверху вправо. В некоторых вариантах осуществления может использоваться так называемая система MDC (развертка коэффициента зависимости от режима), таким образом, что структура развертки может изменяться от блока до блока. Такие компоновки будут более подробно описаны ниже. Теперь предполагается, что используется диагональная развертка сверху вправо.
Коэффициенты, полученные в результате развертки, затем передают в энтропийный кодер 370 (ЕЕ). И снова, могут использоваться различные типы энтропийного кодирования. Два примера представляют собой вариант так называемой системы CAB АС (адаптивное к контексту двоичное арифметическое кодирование) и варианты так называемой системы CAVLC (адаптивное к контексту кодирование переменной длины). В общем, САВАС рассматривается как обеспечивающее лучшую эффективность, и в некоторых исследованиях было показано, что оно обеспечивает уменьшение на 10-20% качества кодированных выходных данных при качестве изображения, сравнимом с CAVLC. Однако считается, что CAVLC представляет гораздо более низкий уровень сложности (в смысле его воплощения), чем САВАС. Следует отметить, что процесс развертки и процесс энтропийного кодирования представлены как отдельные процессы, но фактически могут быть скомбинированы или могут обрабатываться совместно. То есть считывание данных в энтропийный кодер может происходить в порядке развертки. Соответствующие обсуждения, применимые для соответствующих обратных процессов, будут описаны ниже. Следует отметить, что текущие документы HEVC, которые рассматривались во время подачи, больше не включают в себя возможности кодера коэффициента CAVLC.
Выход энтропийного кодера 370, вместе с дополнительными данными (упомянутыми выше и/или описанными ниже), например, определяющий подход, в соответствии с которым блок 320 прогнозирования, сгенерировавший изображение прогнозирования, обеспечивает сжатый выходной видеосигнал 380.
Однако обратный путь также обеспечивается, поскольку операция самого блока 320 прогнозирования зависит от распакованной версии сжатых выходных данных.
Причина такого свойства состоит в следующем. В качестве соответствующего этапа в процессе распаковки (будет описан ниже) генерируется распакованная версия остаточных данных. Такие распакованные остаточные данные должны быть добавлены к прогнозируемому изображению для генерирования выходного изображения (поскольку оригинальные остаточные данные представляли собой разность между входным изображением и прогнозируемым изображением). Для того чтобы такой процесс был сравнимым как между стороной сжатия, так и распакованной стороной, прогнозируемые изображения, генерируемые блоком 320 прогнозирования, должны быть одинаковыми в ходе процесса сжатия и во время процесса распаковки. Конечно, во время распаковки, устройство не имеет доступа к оригинальным входным изображениям, но только к распакованным изображениям. Поэтому при сжатии, устройство 320 прогнозирования основывает свое прогнозирование (по меньшей мере, для кодирования между изображениями) на распакованных версиях сжатых изображений.
Такой процесс энтропийного кодирования, выполняемый энтропийным кодером 370, рассматривается как кодирование "без потерь", то есть можно сказать, что его можно реверсировать для получения в точности тех же данных, которые были вначале поданы в энтропийный кодер 370. Таким образом, обратный путь может быть воплощен перед этапом энтропийного кодирования. Действительно, процесс развертки, выполняемый модулем 360 развертки, также рассматривается как выполняемый без потерь, но в настоящем варианте осуществления обратный путь 390 осуществляется с выхода квантователя 350 на вход взаимодополняющего обратного квантователя 420.
В общих чертах, энтропийный декодер 410, модуль 400 реверсной развертки, обратный квантователь 420 и модуль 430 обратного преобразования обеспечивают соответствующие инверсные функции энтропийного кодера 370, модуля 360 развертки, квантователя 350 и модуля 340 преобразования. От этого момента описание будет продолжено в отношении процесса сжатия; процесс распаковки входного сжатого видеосигнала будет описан ниже отдельно.
В процессе сжатия коэффициенты после развертки передают через обратный путь 390 из квантователя 350 в обратный квантователь 420, который выполняет обратную операцию модуля 360 развертки. Обратное квантование и процесс обратного преобразования выполняются модулями 420, 430 для генерирования сжатого-распакованного сигнала 440 остаточного изображения.
Сигнал 440 изображения добавляют в сумматор 450 к выходу блока 320 прогнозирования, для генерирования реконструированного выходного изображения 460. Это формирует входные данные для блока 320 прогнозирования изображения, как будет описано ниже.
Возвращаясь теперь к процессу, применяемому для распаковки принятого сжатого видеосигнала 470, сигнал подают в энтропийный декодер 410 и оттуда в цепочку модуля 400 обратной развертки, обратного квантователя 420 и модуля 430 обратного преобразования перед добавлением к выходу модуля 320 прогнозирования изображения через сумматор 450. В понятных терминах выход 460 сумматора 450 формирует выходной распакованный видеосигнал 480. На практике дополнительная фильтрация может применяться перед выводом сигнала.
Таким образом, устройство на фиг. 5 и 6 может действовать как устройство сжатия или устройство распаковки. Функции двух типов устройства накладываются в большой степени. Модуль 360 развертки и энтропийный кодер 370 не используется в режиме распаковки, и в операции блока 320 прогнозирования (который будет более подробно описан ниже), и другие модули следуют режиму и информации параметра, содержащимся в или по-другому ассоциированных с принятым сжатым потоком битов, вместо генерирования такой информации самостоятельно.
На фиг. 6 схематично иллюстрируется генерирование прогнозируемых изображений, и, в частности, операция блока 320 прогнозирования изображения.
Существуют два основных режима прогнозирования так называемое прогнозирование внутри изображения и так называемое прогнозирование между изображениями, или с компенсацией движения (МС).
Прогнозирование внутри изображения основывает прогнозирование содержания блока изображения данных в пределах одного изображения. Это соответствует, так называемому, кодированию I-кадра в других технологиях сжатия видеоданных. В отличие от кодирования I-кадра, в случае когда все изображение кодируют внутри изображения, в настоящих вариантах осуществления выбор между кодированием внутри изображения и между изображениями может быть выполнен на основе от блока к блоку, хотя в других вариантах осуществления раскрытия выбор все еще делают на основе от изображения к изображению.
Прогнозирование с компенсацией движения представляет собой пример прогнозирования изображения между изображениями, и в нем используется информация о движении, которая стремится определить источник в другом соседнем или расположенном рядом изображении, детали изображения, которые должны быть кодированы в текущем изображении. В соответствии с этим в идеальном примере, содержание блока данных изображения в прогнозируемом изображении может быть кодировано очень просто как опорное изображение (вектор движения), указывающий на соответствующий блок в том же или несколько отличающемся положении в расположенном рядом изображении.
Возвращаясь к фиг. 6, здесь показаны две компоновки прогнозирования изображения (соответствующие прогнозированию внутри и прогнозированию между изображениями), результаты которых выбирают с помощью мультиплексора 500 под управлением сигнала 510 режима, так, чтобы обеспечить блоки прогнозируемого изображения для передачи в сумматоры 310 и 450. Выбор делают в зависимости от того, какой выбор дает самую низкую "энергию" (которая, как описано выше, может рассматриваться как объем информации, требующей кодирования), и выбор передают в кодер в пределах кодированного выходного потока данных. Энергия изображения, в этом контексте, может быть детектирована, например, при выполнении пробного вычитания в области из двух версий прогнозируемого изображения из входного изображения, возведении в квадрат каждого значения пикселя изображения разности, суммировании возведенных в квадрат значений и идентификации, какая из этих двух версий приводит к повышению значения низкого среднеквадратичного изображения разности, относящегося к этой области изображения.
Фактическое прогнозирование в системе кодирования внутри изображения выполняется на основе блоков изображения, принятых как часть сигнала 460, то есть прогнозирование основано на кодированных - декодированных блоках изображения для того, чтобы точно такое же прогнозирование можно было выполнить в устройстве распаковки. Однако данные могут быть выведены из входного видеосигнала 300 с помощью селектора 520 режима внутри изображения, для управления операцией блока 530 прогнозирования изображения внутри изображения.
Для прогнозирования между изображениями блок 540 прогнозирования с компенсированным движение (МС) использует информацию о движении, такую как векторы движения, выведенные блоком 550 оценки движения из входного видеосигнала 300. Такие векторы движения применяют к обрабатываемой версии реконструированного изображения 460 с помощью блока 540 прогнозирования компенсированного движения, для генерирования блоков прогнозирования между изображениями.
Обработка, применяемая для сигнала 460, будет описана ниже. Вначале сигнал фильтруют с помощью модуля 560 фильтра, который будет описан более подробно ниже. Это улучшает применение фильтра "удаления блоков", для удаления или, по меньшей мере, проявления тенденции к уменьшению эффектов обработки на основе блока, выполняемой модулем 340 преобразования и при последующих операциях. Фильтр, адаптивный к выборке смещения (SAO) (более подробно описан ниже) также может использоваться. Кроме того, адаптивный контурный фильтр применяют, используя коэффициенты, выведенные при обработке реконструированного сигнала 460 и входного видеосигнала 300. Адаптивный контурный фильтр представляет собой фильтр такого типа, который, используя известные технологии, применяет адаптивные коэффициенты фильтра к данным, которые должны быть отфильтрованы. То есть коэффициенты фильтра могут изменяться в зависимости от различных факторов. Данные, определяющие, какие коэффициенты фильтра следует использовать, включены как часть кодированного выходного потока данных.
Адаптивная фильтрация представляет фильтрацию в контуре для восстановления изображения. LCU может быть отфильтрован, используя вплоть до 16 фильтров, с выбором фильтра и выводом статуса включено/выключено ALF в отношении каждого CU в пределах LCU. В настоящее время управление выполняется на уровне LCU, а не на уровне CU.
Отфильтрованный выход из модуля 560 фильтра фактически формирует выходной видеосигнал 480, когда устройство работает как устройство сжатия. Его также помещают в буфер в одном или больше хранилищ 570 изображения или кадра; сохранение последующих изображений является необходимым при обработке компенсированного прогнозирования движения, и, в частности, при генерировании векторов движения. Для сохранения в соответствии с требованиями к сохранению сохраненные изображения в хранилищах 570 изображения могут содержаться в сжатой форме и затем могут быть распакованы для использования при генерировании векторов движения. С этой конкретной целью может использоваться любая известная система сжатия/распаковки. Сохраненные изображения пропускают в фильтр 580 интерполяции, который генерирует более высокую версию разрешения сохраненных изображений; в этом примере промежуточные выборки (подвыборки) генерируют так, что разрешение интерполированного изображения выводят с помощью фильтра 580 интерполяции, которое составляет 4-кратное (в каждом измерении) значение, чем у канала яркости для схемы 4:2:0, является 8 кратным для канала яркости (в каждом измерении), чем у изображений, сохраняемых в хранилищах 570 изображении, для каналов цветности по схеме 4:2:0. Интерполированные изображения пропускают на вход блока 550 оценки движения и также блока 540 прогнозирования компенсированного движения.
В вариантах осуществления раскрытия предусмотрен дополнительный необязательный этап, который предназначен для умножения значения данных входного видеосигнала на коэффициент четыре, используя множитель 600 (эффективно просто сдвигающий данные на два бита), и применения соответствующей операции деления (сдвиг вправо на два бита) на выходе устройства, используя делитель или модуль 610 сдвига вправо. Таким образом, сдвиг влево и сдвиг вправо изменяют данные просто для внутренней операции устройства. Эта мера может обеспечить более высокую точность расчета внутри устройства, поскольку уменьшается эффект каких-либо ошибок, связанных с округлением данных.
Способ, в соответствии с которым данные разделяют для обработки сжатия, будет описан ниже. На основном уровне изображение, которое предназначено для сжатия, рассматривают как массив блоков из выборок. Для назначения настоящего описания наибольший такой рассматриваемый блок представляет собой так называемый наибольший модуль 700 кодирования (LCU), который представляет собой квадратный массив обычно из 64×64 выборок (размер LCU можно конфигурировать с помощью кодера, вплоть до максимального размера, такого как определено документами HEVC). Здесь описание относится к выборкам яркости. В зависимости от режима цветности, такого как 4:4:4, 4:2:2, 4:2:0 или 4:4:4:4 (данные GBR "плюс" данные ключа), существует разное количество соответствующих выборок цветности, соответствующих блоку яркости.
Ниже будут описаны три основных типа блоков: модули кодирования, модули прогнозирования и модули преобразования. В общих чертах, рекурсивное подразделение LCU позволяет вводить изображение, которое должно быть разделено, таким способом, что как размеры блока, так и параметры кодирования блока (такие как режимы прогнозирования или остаточного кодирования) могут быть установлены в соответствии с определенными характеристиками изображения, предназначенного для кодирования.
LCU может быть подразделен на так называемые модули кодирования (CU). Модули кодирования всегда являются квадратными и имеют размер от 8×8 выборок до полного размера LCU 700. Модули кодирования могут быть размещены в виде, своего рода, структуры дерева, таким образом, что первое подразделение может происходить, как показано на фиг. 8, при котором делят модули 710 кодирования из 32×32 выборок; и затем могут произойти последующие подразделения на избирательной основе, для того, чтобы подать некоторые модули кодирования 720 из 16×16 выборок (фиг. 9) и потенциально некоторые модули 730 кодирования размером 8×8 выборок (фиг. 10). В целом, этот процесс может обеспечить структуру дерева кодирования с адаптацией к содержанию из блоков CU, каждый из которых может быть настолько большим, как LCU, или настолько малым, как 8×8 выборок. Кодирование выходных видеоданных происходит на основе структуры модуля кодирования, то есть кодируют один LCU, и затем обработка переходит в следующий LCU, и так далее.
На фиг. 11 схематично иллюстрируется массив из модулей прогнозирования (PU). Модуль прогнозирования представляет собой основной модуль для переноса информации, относящейся к процессам прогнозирования изображения, или, другими словами, к дополнительным данным, добавленным к остаточным данным изображения после энтропийного кодирования, для формирования выходного видеосигнала из устройства по фиг. 5. В общем, модули прогнозирования не ограничены квадратной формой. Они могут принимать другие формы, в частности, прямоугольную форму, формируя половину одного из квадратных модулей кодирования (например, 8×8, CU могут иметь PU размером 8×4 или 4×8). Использование PU, которые совмещаются со свойством изображения, не является обязательной частью системы HEVC, но общая цель может состоять в том, чтобы обеспечить хороший кодер, который выравнивает границу соседних модулей прогнозирования так, чтобы они соответствовали (как можно более плотно) границе реальных объектов в изображении, так, чтобы разные параметры прогнозирования можно было применять для разных реальных объектов. Каждый модуль кодирования может содержать один или больше модулей прогнозирования.
На фиг. 12 схематично иллюстрируется массив из модулей преобразования (TU). Модуль преобразования представляет собой основной модуль процесса квантования и преобразования. Модули преобразования могут быть или могут не быть квадратными и могут иметь размер выборок от 4×4 до 32×32. Каждый модуль кодирования может содержать один или больше модулей преобразования. Акроним SDIP-P на фиг. 12 обозначает так называемое разделение прогнозирования внутри изображения на коротком расстоянии. При такой компоновке используются только одномерные преобразования, таким образом, что блок 4×N пропускают через N преобразований с входными данными, при этом преобразования основаны на ранее декодированных соседних блоках и ранее декодированных соседних строках в пределах текущего SDIP-P. SDIP-P в настоящее время не включен в HEVC, на время подачи настоящей заявки.
Как отмечено выше, кодирование происходит как один LCU, затем следующий LCU и так далее. В пределах LCU кодирование выполняется CU за CU. В пределах CU кодирование выполняют для одного TU, затем следующий TU и так далее.
Далее будет описан процесс прогнозирования внутри изображения. В общих чертах прогнозирование внутри изображения подразумевает генерирование прогнозирования текущим блоком (модулем прогнозирования) выборок из ранее кодированных и декодированных выборок того же изображения. На фиг. 13 схематично иллюстрируется частично кодированное изображение 800. Здесь изображение кодируют от верхнего левого к нижнему правому на основе LCU. Пример LCU, частично кодированного в результате обработки всего изображения, показан в блоке 810. Затененная область 820 выше и левее блока 810 уже была кодирована. При выполнении прогнозирования внутри изображения содержания блока 810 может использоваться любая затененная область 820, но не может использоваться незатененная область ниже нее. Следует, однако отметить, что для индивидуального TU в текущем LCU, иерархический порядок кодирования (CU за CU затем TU за TU), описанные выше, означают, что должны присутствовать ранее кодированные выборки в текущем LCU и доступные для кодирования этого TU, которые, например, расположены выше справа или ниже слева от TU.
Блок 810 представляет LCU; как описано выше, с целью обработки прогнозирования внутри изображения, он может быть подразделен на ряд меньших модулей прогнозирования и модулей преобразования. Пример текущего TU 830 показан в LCU 810.
Прогнозирование внутри изображения учитывает выборки, кодированные текущим рассматриваемым TU, такие как находящиеся выше и/или левее от текущего TU. Выборки - источники, по которым прогнозируют требуемые выборки, могут быть расположены в разных положениях или направлениях относительно текущего TU. Для принятия решения, какое направление является соответствующим для текущего модуля прогнозирования, селектор 520 режима примерного кодера может тестировать все комбинации доступных структур TU для каждого направления кандидата и выбирать направление PU и структуру TU с наилучшей эффективностью сжатия.
Изображение также может быть кодировано на основе "среза". В одном примере срез представляет собой горизонтально расположенную рядом друг с другом группу LCU. Но в более общих чертах, все остаточное изображение может формировать срез, или срез может представлять собой отдельный LCU, или срез может представлять собой ряд LCU, и так далее. Срезы могут обеспечить определенную устойчивость к ошибкам, поскольку их кодируют как независимые модули. Состояния кодера и декодера полностью сбрасывают на границе среза. Например, прогнозирование внутри изображения не выполняется за пределами границ среза; границы среза обрабатывают как границы изображения с этой целью.
На фиг. 14 схематично иллюстрируется набор возможных направлений прогнозирования (кандидаты). Полный набор из 34 направлений кандидатов является доступным для модуля прогнозирования из 8×8, 16×16 или 32×32 выборок. Особые случаи размера модуля прогнозирования с размером 4×4 и 64×64 выборки имеют уменьшенный набор направлений кандидатов, доступных для них (17 направлений кандидатов и 5 направлений кандидатов, соответственно). Направления определяют по горизонтальному и вертикальному смещениям относительно текущего положения блока, но их кодируют как "режимы" прогнозирования, набор, который показан на фиг. 15. Следует отметить, что так называемый режим DC представляет простое среднее арифметическое окружающих находящихся сверху и с левой стороны выборок.
На фиг. 16 схематично иллюстрируется так называемая диагональная развертка сверху вправо, которая представляет собой пример структуры развертки, которая может применяться модулем 360 развертки. На фиг. 16 показана структура для примерного блока коэффициентов 8×8 DCT, при этом коэффициент DC установлен в верхнем левом положении 840 блока, и с увеличением горизонтальной и вертикальной пространственных скоростей, представляемых коэффициентами, на увеличивающихся расстояниях вниз и вправо от верхнего - левого положения 840. Другие альтернативные порядки развертки могут использоваться вместо нее.
Вариации компоновок блока и структур CU, PU и TU будут описаны ниже. Они будут описаны в контексте устройства по фиг. 17, которое аналогично во многих отношениях тому, что представлено на описанных выше фиг. 5 и 6. Действительно, используется множество одинаковых номеров ссылочных позиций, и эти детали не будут описаны дополнительно.
Основная существенная разница между фиг. 5 и 6 относится к фильтру 560 (фиг. 6), который на фиг. 17 показан более подробно как содержащий фильтр 1000 удаления блочности и соответствующий блок 1030 принятия решения об ассоциированном кодировании, фильтр 1010 адаптивного смещения выборки (SAO) и ассоциированный генератор 1040 коэффициента, и фильтр 1020 адаптивного контура (ALF) и ассоциированный генератор 1050 коэффициента.
Фильтр 1000 удаления блочности пытается уменьшить искажение и улучшить визуальное качество и характеристики прогнозирования путем сглаживания резких углов, которые могут сформироваться между границами CU, PU и TU, когда используются технологии кодирования блока.
Фильтр 1010 SAO классифицирует реконструированные пиксели по разным категориям и затем пытается уменьшить искажение путем простого добавления смещения для каждой категории пикселей. Интенсивность пикселей и свойства кромки используются для классификации пикселя. Для дополнительного повышения эффективности кодирования, изображение может быть разделено на области для локализации параметров смещения.
ALF 1020 пытается восстановить сжатое изображение таким образом, чтобы разность между реконструированными кадрами и кадрами источника была сведена к минимуму. Коэффициенты ALF рассчитывают и передают на основе кадра). ALF затем может применяться для всего кадра или в локальных областях.
Как отмечено выше, в предложенных документах HEVC используют определенную схему выборок цветности, известную как схема 4:2:0. Схема 4:2:0 может использоваться для домашнего оборудования/бытового оборудования. Однако возможны некоторые другие схемы.
В частности так называемая схема 4:4:4 может быть пригодной для профессиональной, широковещательной передачи, мастеринга и цифровых кинофильмов, и, в принципе, может иметь наивысшее качество и скорость передачи данных.
Аналогично так называемая схема 4:2:2 может использоваться для профессиональной, широковещательной передачи, для мастеринга и цифровых кинофильмов с некоторой потерей точности воспроизведения.
Эти схемы и их соответствующие структуры блоков PU и TU описаны ниже.
Кроме того, другие схемы включают в себя монохромную схему 4:0:0.
В схеме 4:4:4 каждый из трех каналов Y, Cb и Cr имеет одинаковую скорость выборки. В принципе, поэтому в этой схеме присутствует вдвое больше данных цветности, чем данных яркости.
Следовательно, в HEVC, в этой схеме каждый из трех каналов Y, Cb и Cr мог бы иметь соответствующие блоки PU и TU, которые имеют одинаковый размер; например, блоки яркости 8×8 могли бы иметь соответствующие блоки цветности 8×8 для каждого из двух каналов цветности.
Следовательно, в этой схеме обычно используется непосредственная взаимосвязь 1:1 между размерами блока в каждом канале.
В схеме 4:2:2, для двух компонентов цветности получают выборку с половиной частоты выборки яркости (например, используя вертикальную или горизонтальную подвыборки, но с целью настоящего описания, предполагается горизонтальная подвыборка). Поэтому в принципе, в этой схеме присутствует такое же количество данных цветности, как и данных яркости, хотя данные цветности могли бы быть разделены между двумя каналами цветности.
Следовательно, при использовании HEVC, в этой схеме каналы Cb и Cr могут иметь разный размер блоков PU и TU по сравнению с каналом яркости; например, блок яркости 8×8 мог бы иметь соответствующие блоки цветности размером 4 в ширину × 8 в высоту для каждого канала цветности.
В частности поэтому в данной схеме блоки цветности могут не быть квадратными, даже притом, что они соответствуют квадратным блокам яркости.
В предложенной в настоящее время схеме HEVC 4:2:0, в двух компонентах цветности получают выборку для четверти частоты выборки яркости (например, используя вертикальную и горизонтальную подвыборки). Поэтому в принципе, в этой схеме присутствует только половина данных цветности, чем данных яркости, и данные цветности разделены между двумя каналами цветности.
Следовательно, в HEVC, в такой схеме снова каналы Cb и Cr имеют другой размер блоков PU и TU, чем в канале яркости. Например, блок яркости 8×8 может иметь соответствующие 4×4 блока цветности для каждого канала цветности.
Описанные выше схемы известны в уровне техники на уровне обсуждения как "отношение каналов", как в выражении "отношение каналов 4:2:0"; следует, однако понимать, что в представленном выше описании фактически это не всегда означает, что каналы Y, Cb и Cr сжимают или по-другому предоставляют с этим отношением. Следовательно, в то время как их называют отношением каналов, не следует понимать это буквально. Фактически, скорректированные отношения для схемы 4:2:0 представляет собой 4:1:1 (отношения для схемы 4:2:2 и схемы 4:4:4 фактически являются корректными).
Перед описанием конкретных компоновок со ссылкой на фиг. 18А и 18В, будет кратко представлена некоторая общая терминология.
Наибольший модуль кодирования (LCU) представляет собой корневое изображение объекта. Как правило, он охватывает область, эквивалентную 64×64 пикселям яркости. Его можно рекурсивно разделять для формирования иерархии дерева модулей кодирования (CU). В общих чертах, три канала (один канал яркости и два канала цветности) имеют одинаковую иерархию дерева CU. Однако после такого утверждения, в зависимости от отношения каналов, определенный CU яркости может содержать другое количество пикселей, чем соответствующие CU цветности.
CU в конце иерархии дерева, то есть CU наименьшего размера, получаемые в процессе рекурсивного разделения (которые могут называться CU листьев) затем разделяют на модули прогнозирования (PU). Три канала (канал яркости и два канала цветности) имеют одинаковую структуру PU за исключением случаев, когда соответствующие PU для канала цветности могли бы иметь слишком мало выборок, и в этом случае только один PU для этого канала является доступным. Это можно конфигурировать, но обычно минимальный размер PU внутри изображения составляет 4 выборки; минимальный размер PU между изображениями составляет 4 выборки яркости (или 2 выборки цветности для 4:2:0). Реконструкция минимального размера CU всегда является достаточно крупной для, по меньшей мере, одного PU для любого канала.
Листовые CU также разделяют на модули преобразования (TU). TU могут, и когда они слишком большие (например, больше 32×32 выборки), должны быть разделены на дополнительные TU. Накладывается предел, связанный в тем, что TU могут быть разделены до максимальной глубины дерева, сконфигурированного в настоящее время из 2 уровней, то есть может присутствовать не больше чем 16 TU для каждого CU. Иллюстративный наименьший допустимый размер TU составляет 4×4 выборки, и наибольший допустимый размер TU составляет 32×32 выборки. И снова, три канала имеют одинаковую структуру TU каждый раз, когда это возможно, но если TU не может быть разделен до определенной глубины для заданного канала, из-за ограничения по размеру, он остается с большим размером. Так называемая неквадратная компоновка преобразования квадрадерева (NSQT) является аналогичной, но способ разделения на четыре TU не обязательно должен представлять собой 2×2, но может 4×1 или 1×4.
Обращаясь к фиг. 18А и 18В, разные возможные размеры блоков сведены для блоков CU, PU и TU, при этом "Y" обозначает блоки яркости, и "С" обозначает в общем смысле представителя одного из блоков цветности, и цифры, относящиеся к пикселям. "Интер" относится к прогнозированию PU между изображениями (в отличие от прогнозирования PU внутри изображения). Во многих случаях показаны только размеры блока для блоков яркости. Соответствующие размеры ассоциированных блоков цветности соотносятся с размерами блока яркости в соответствии с отношениями канала. Таким образом, для 4:4:4 каналы цветности имеют такие же размеры блока, как и у блока яркости, показанного на фиг. 18A и 18B. Для 4:2:2 и 4:2:0, каждый из блоков цветности будет иметь меньшее количество пикселей, чем у соответствующего блока яркости, в соответствии с отношением каналов.
Компоновки, показанные на фиг. 18А и 18В, относятся к четырем возможным размерам CU: 64×64, 32×32, 16×16 и 8×8 пикселей яркости, соответственно. Каждый из этих CU имеет соответствующий вариант опций PU (показаны в столбце 1140) и опций TU (показаны в столбце 1150). Для возможных размеров CU, определенных выше, ряды и опции обозначены как 1100, 1110, 1120 и 1130 соответственно.
Следует отметить, что 64×64 в настоящее время является максимальным размером CU, но это ограничение будет меняться.
В каждом из рядов 1100…1130 показаны разные опции PU, применимые для этого размера CU. Опции TU, применимые для этих конфигураций PU, показаны с горизонтальным выравниванием с соответствующей опции (опций) PU.
Следует отметить, что в нескольких случаях предусмотрено множество опций PU. Как отмечено выше, цель устройства при выборе конфигурации PU состоит в том, чтобы соответствовать (как можно более тесно) границе реальных объектов в изображениях, так, что разные параметры прогнозирования могут применяться для разных реальных объектов.
Размеры и формы блока PU основаны на решении кодера, под управлением контроллера 343. Данный способ подразумевают проведение испытаний множества структур дерева TU для множества направлений, получение наилучшей "стоимости" на каждом уровне. Здесь стоимость может быть выражена как мера искажения, или шумы, или ошибки, или скорость передачи битов, получаемая из структуры каждого блока. Таким образом, кодер может попытаться выполнить две или больше (или даже все доступные) перестановки размеров блока и формы в пределах этих разрешенных трех подструктур дерева и иерархий, описанных выше, перед выбором одного из результатов испытаний, который получил самую низкую скорость передачи битов для определенной требуемой меры качества, или самое низкое искажение (или уровень ошибок или шумов, или комбинации этих мер) для требуемой скорости передачи битов, или комбинации этих мер.
Исходя из выбора конкретной конфигурации PU, различные уровни разделения могут применяться для генерирования соответствующих TU. Рассмотрим ряд 1100, в случае PU 64×64, этот размер блока слишком велик для использования в качестве TU и, таким образом, первый уровень разделения (с "уровня 0" (не разделен), до "уровня 1") является обязательным, в результате чего, получают массив из четырех TU яркости 32×32. Каждый из них может подвергаться дальнейшему разделению в иерархии дерева (с "уровня 1" до "уровня 2"), если требуется, при этом разделение выполняют перед преобразованием или квантованием, выполнявшимися этим TU. Максимальное количество уровней в дереве TU ограничено (например) документами HEVC.
Другие опции предусмотрены для размеров PU и форм, в случае пикселя CU яркости 64×64. Они ограничены использованием только с изображениями кодированными между изображениями и, в некоторых случаях с так называемой включенной опцией AMP. AMP относится к асимметричному разделению движения и позволяет асимметрично разделить PU.
Аналогично, в некоторых случаях предусмотрены опции для размеров и форм TU. Если разрешено NQST (неквадратное преобразование квадродерева, в принципе, позволяющее неквадратное TU), то разделение до уровня 1 и/или уровня 2 может быть выполнено, как показано, тогда как, если NQST не разрешено, размеры TU соответствуют структуре разделения соответствующего наибольшего TU для этого размера CU.
Аналогичные возможности предусмотрены для других размеров CU.
В дополнение к графическому изображению, показанному на фиг. 18А и 18В, цифровая часть той же информации представлена в следующей таблице, хотя представление на фиг. 18А и 18В, рассматривается как определяющее, "n/a" обозначает режим, который не разрешен. Горизонтальный размер пикселя указан первым. Если представлен третий чертеж, он относится к количеству случаев размера этого блока, как и в блоках (горизонтальный) × (вертикальный) × (количество случаев) блоков. N представляет собой целое число.


Варианты структуры блока 4:2:0, 4:2:2 и 4:4:4
Следует понимать, что обе схемы 4:2:0 и 4:4:4 имеют квадратные блоки PU для кодирования с прогнозированием внутри изображения. Кроме того, в настоящее время в схемах 4:2:0 разрешают использовать 4×4 пикселя для блоков PU & TU.
В вариантах осуществления настоящего раскрытия, далее предложено, чтобы для схемы 4:4:4 была разрешена рекурсия для блоков CU, вплоть до 4×4 пикселя, вместо 8×8 пикселей, поскольку, как отмечено выше, в режиме 4:4:4 блоки яркости и цветности будут иметь одинаковый размер (то есть не требуется делать подвыборку данных цветности), и таким образом, для CU 4×4, не требуется, чтобы PU или TU были меньше чем уже разрешенный минимум 4×4 пикселя.
Аналогично схеме 4:4:4 в варианте осуществления настоящего раскрытия каждый из каналов Y, Cr, Cb, или Y и двух каналов Cr, Cb вместе могли бы иметь соответствующие иерархии дерева CU. Флаг затем можно использовать для передачи сигнала, какая иерархия или компоновка иерархий должны использоваться. Такой подход мог бы также использоваться для схемы цветов RGB 4:4:4. Однако в качестве альтернативы иерархии дерева для цветности и яркости могут вместо этого быть независимыми.
В примере 8×8 CU в схеме 4:2:0 это приводит к четырем PU яркости 4×4 и одному PU цветности 4×4. Следовательно, в схеме 4:2:2, имеющей в два раза больше данных цветности, одна из опций в таком случае состоит в том, чтобы иметь два PU цветности 4×4, где (например) нижний блок цветности мог бы соответствовать по положению нижнему левому блоку яркости. Однако следует понимать, что использование одного неквадратного PU цветности размером 4×8 в этом случае могло больше соответствовать компоновкам формата цветности 4:2:0.
В схеме 4:2:0, в принципе, имеются некоторые неквадратные блоки TU, разрешенные для определенных классов кодирования с прогнозированием между изображениями, но не для кодирования с прогнозированием внутри изображения. Однако при кодировании с прогнозированием между изображениями, когда неквадратное преобразование квадродерева (NSQT) не разрешено (что принято по умолчанию в настоящее время значение для схемы 4:2:0), все TU будут квадратными. Следовательно, фактически схема 4:2:0 в настоящее время принудительно устанавливает квадратные TU. Например, TU яркости 16×16 для схемы 4:2:0 могут соответствовать соответствующим Cb & Cr 8×8 для TU цветности схемы 4:2:0.
Однако как отмечено выше, схема 4:2:2 может иметь неквадратный PU. Следовательно, в варианте осуществления настоящего раскрытия предложено разрешить неквадратные TU для схемы 4:2:2.
Например, в то время как TU яркости 16×16 для схемы 4:2:2 соответствует двум соответствующим Cb & Cr 8×8 TU цветности для схемы 4:2:2, в этом варианте осуществления они могут вместо этого соответствовать соответствующим Cb & Cr размером 8×16 для TU цветности для схемы 4:2:2.
Аналогично четыре TU яркости 4×4 для схемы 4:2:2 могли бы соответствовать двум соответствующим Cb+Cr размером 4×4 для TU для схемы 4:2:2, или в этом варианте осуществления вместо этого могли бы соответствовать соответствующим Cb & Cr размером 4×8 TU для схемы 4:2:2.
Использование неквадратных TU цветности и, следовательно, меньшего количества TU может быть более эффективными, поскольку они, вероятно, будут содержать меньше информации. Однако это может повлиять на процессы преобразования и развертки таких TU, как будет описано ниже.
Для схемы 4:4:4: возможно в вариантах осуществления раскрытия предотвратить разделение блоков яркости до (например) блоков 4×4, если происходит дополнительное разделение, чем у блоков цветности. Это может привести к более эффективному кодированию.
В конечном итоге для схемы 4:4:4 может быть предпочтительным иметь независимую от канала структуру TU и выбираемую на уровне последовательности, изображения, среза или на более тонком уровне.
Как отмечено выше, NSQT в настоящее время отключена в схеме 4:2:0 HEVC. Однако если для прогнозирования между изображениями NSQT будет включена, и будет разрешено разделение с асимметричным движением (AMP), это позволяет выполнять асимметричное разделение PU; таким образом, например, CU 16×16 может иметь PU 4×16 и PU 12x16. В этих обстоятельствах важно дополнительно рассмотреть структуру блока для каждой из схем 4:2:0 и 4:2:2.
Для схемы 4:2:0 в NSQT минимальная ширина/высота TU может быть ограничена 4 выборками яркости/цветности:
Следовательно, в неограничительном примере, структура PU размером 16×4/16×12 яркости имеет четыре TU 16×4 яркости и четыре TU 4×4 цветности, где TU яркости находятся в вертикальной компоновке блока 1×4, и TU цветности, находятся в компоновке блока 2×2.
В аналогичной компоновке, когда разделение было выполнено скорее вертикально, чем горизонтально, структура PU яркости 4×16/12×16 имеет четыре TU яркости 4×16 и четыре TU цветности 4×4, где TU яркости установлены в компоновке горизонтального блока 4×1, и TU цветности расположены в компоновке блока 2×2.
Для схемы 4:2:2, в NSQT, в качестве не ограничительного примера структура PU яркости 4×16/12×16 имеет четыре TU яркости 4×16 и четыре TU цветности 4×8, где TU яркости находится в горизонтальной компоновке блока размером 4×1; TU цветности находится в компоновке блока 2×2.
Однако следует понимать, что другую структуру можно рассмотреть для некоторых случаев. Следовательно, в варианте осуществления настоящего раскрытия, в NSQT, в качестве неограничительного примера, структура PU яркости 16×4/16×12 имеет четыре TU яркости 16×4 и четыре TU цветности 8×4, но теперь TU яркости и цветности расположены в компоновке вертикального блока 1×4, будучи выровненными с компоновкой PU (в отличие от компоновки в стиле 4:2:0 из четырех TU цветности 4×8, в компоновке блока 2×2).
Аналогично, PU 32×8 могут иметь четыре TU яркости 16×4 и четыре TU цветности 8×4, но теперь TU яркости и цветности расположены в компоновке блока 2×2.
Следовательно, в более общем случае для схемы 4:2:2, в NSQT размеры блока TU выбирают так, чтобы он совмещался с асимметричной компоновкой блока PU. Следовательно, NSQT с пользой обеспечивает возможность выравнивания границ TU с границами PU, что уменьшает высокочастотные артефакты, которые в противном случае могли бы возникнуть.
В общих чертах, варианты осуществления раскрытия могут относиться к способу кодирования видеоданных, устройству или программе, работающим в отношении изображений видеосигнала в формате 4:2:2. Изображение, предназначенное для кодирования, разделяют на модули кодирования, модули прогнозирования и модули преобразования, для кодирования, модуль кодирования представляет собой квадратный массив из выборок яркости и соответствующих выборок цветности, причем здесь используется один или больше модулей прогнозирования в модуле кодирования, и в модуле кодирования содержится один или больше модулей преобразования; в которых модуль прогнозирования представляет собой элементарный модуль прогнозирования так, что все выборки в пределах одного модуля прогнозирования будут спрогнозированы, используя общую технологию прогнозирования, и модуль преобразования представляет собой основной модуль преобразования и квантования.
Режим неквадратного преобразования (такой как режим NSQT) разрешают с тем, чтобы обеспечить возможность неквадратных модулей прогнозирования. В случае необходимости, обеспечивается возможность асимметричного разделения движения, с тем, чтобы разрешить асимметрию между двумя или больше модулями прогнозирования, соответствующими одному модулю кодирования.
Контроллер 343 управляет выбором размера блока модуля преобразования для выравнивания с компоновкой блока модуля прогнозирования, например, путем детектирования свойств изображения на участке изображения, соответствующем PU и выбора размеров блока TU в отношении этого PU, с тем, чтобы выровнять границы TU с кромками свойств изображения на участке изображения.
Описанные выше правила диктуют, какие комбинации размеров блока являются доступными. Кодер может только попробовать разные комбинации. Как описано выше, проверка может включать в себя две или больше, и вплоть до всех доступных опций. Проверочные процессы кодирования могут выполняться в соответствии с результатами измерений функции стоимости и результатом, выбранным в соответствии с оценкой функции стоимости.
Учитывая, что имеется три уровня вариаций, в соответствии с размером и формой CU, размером и формой PU, и размером и формой TU, это может привести к большому количеству взаимных замен, которые потребуется закодировать для проверки. Для уменьшения этих вариаций, система может выполнять кодирование для проверки, для размера CU, используя произвольно выбранную одну из конфигурации PU/TU, допустимую для каждого размера CU; затем, после выбора размера CU, могут быть выбраны размер и форма PU, используя кодирование для проверки разных опций PU, каждая с произвольно выбранной одной конфигурацией TU. Затем, после выбора CU и PU, система может попытаться проверить все допустимые конфигурации TU для выбора конечной конфигурации TU.
Другая возможность состоит в том, что некоторые кодеры могут использовать фиксированный выбор конфигурации блока, или могут обеспечить возможность ограниченного поднабора из набора комбинаций, описанных выше.
Прогнозирование внутри изображения
4:2:0 прогнозирование внутри изображения
Возвращаясь теперь к фиг. 22, для прогнозирования внутри изображения, HEVC разрешает угловое прогнозирование цветности.
В качестве введения, на фиг. 22 иллюстрируется 35 режимов прогнозирования, применимых для блоков яркости, 33 из которых устанавливают направления для опорных выборок, для текущих прогнозируемых положений ПО выборки. Остальные два режима представляют собой режим 0 (плоский) и режим 1 (dc).
В HEVC разрешено, чтобы цветность имела DC, вертикальный, горизонтальный, плоский, DM_CHROMA и LM_CHROMA режимы.
DM_CHROMA обозначает, что режим прогнозирования, который должен использоваться, представляет собой такой же, как и режим у PU яркости, расположенный в том же месте (то есть один из 35, показанных на фиг. 22).
LM_CHROMA (цветность в линейном режиме) обозначает, что совместно расположенные выборки яркости (с дополнительной выборкой, в соответствии с отношением каналов) используются для вывода прогнозируемых выборок цветности. В этом случае, если PU яркости, из которого мог бы быть выбран режим прогнозирования DM_CHROMA, выбрал режим DC, вертикальный, горизонтальный или плоский, эта запись в списке прогнозирования цветности будет заменена, используя режим 34. В режиме LM_CHROMA пиксели яркости, из которых прогнозируют пиксели цветности, масштабируют (и имеют приложенное смещение, если соответствует), в соответствии с линейной взаимозависимостью между яркостью и цветностью. Такая линейная взаимозависимость поступает из окружающих пикселей, и вывод может быть выполнен на основе от блока к блоку, при этом декодер заканчивает декодирование одного блока перед перемещением к следующему.
Известно, что в режимах 2-34 прогнозирования выборка углового диапазона составляет от 45 градусов до 225 градусов; то есть одну диагональную половину квадрата. Такой подход является полезным в случае схемы 4:2:0, в которой, как отмечено выше, используется только квадратный PU цветности для прогнозирования внутри изображения.
Варианты прогнозирования внутри изображения 4:2:2
Однако так же, как отмечено выше, схема 4:2:2 могла бы иметь прямоугольный (неквадратный) PU цветности, даже когда PU яркости является квадратным. Или действительно, может выполняться противоположное условие: прямоугольные PU яркости могут соответствовать квадратному PU цветности. Причина несоответствия состоит в том, что в 4:2:2, для цветности выполняют подвыборку в горизонтальном направлении (относительно яркости), но не в вертикальном. Таким образом, размер блока яркости и соответствующего блока цветности, как можно ожидать, будет разным. В соответствии с этим формат 4:2:2 представляет один пример (и существуют другие примеры, такие как 4:2:0) видеоформата, в котором выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности является отличным от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок образцов яркости имеет разное отношение аспектов с соответствующим блоком образцов цветности.
Следовательно, в варианте осуществления настоящего раскрытия, для PU цветности, имеющих разное соотношение размеров для соответствующего блока яркости, таблица отображения может потребоваться для направления. Предположим (например), соотношение размеров 1 к 2 для прямоугольных PU цветности, затем, например, режим 18 (в настоящее время под углом 135 градусов) может быть повторно отображен на 123 градуса. В качестве альтернативы выбор текущего режима 18 может быть повторно отображен на выбор текущего режима 22 для получения, в основном, того же эффекта.
Следовательно, в более общем случае для неквадратных PU, могут быть предусмотрены разное отображение между направлением опорной выборки, и выбранный режим прогнозирования внутри изображения может быть предусмотрен по сравнению с тем, который используется для квадратных PU.
Также в более общем случае любой из режимов, включая в себя ненаправленные режимы, также может быть повторно отображен на основе эмпирических данных.
Возможно, чтобы такое отображение приводило к соотношению "множество к одному", что делает спецификацию полного набора режимов избыточной для PU цветности 4:2:2. В этом случае, например, возможно, что только 17 режимов (соответствующих половине углового разрешения) являются необходимыми. В качестве альтернативы или в дополнение, эти режимы могут быть распределены неоднородно по углу.
Аналогично сглаживающий фильтр, используемый для опорной выборки, при прогнозировании пикселя в положении выборки, может использоваться по-разному; в схеме 4:2:0 он используется только для сглаживания пикселей яркости, но не пикселей цветности. Однако в схемах 4:2:2 и 4:4:4 этот фильтр также может использоваться для PU цветности. В схеме 4:2:2 снова фильтр может быть модифицирован в соответствии с разными отношениями размеров PU, например, когда он используется только для поднабора режимов, близких к горизонтальному. Примерный поднабор режимов предпочтительно представляет собой 2-18 и 34, или более предпочтительно 7-14. В 4:2:2 сглаживание может быть выполнено только для левого столбца опорных выборок, в вариантах осуществления раскрытия.
В общих чертах в вариантах осуществления, которые будут описаны, первое направление прогнозирования определено в отношении первой решетки первого соотношения размеров в отношении набора текущих выборок, которые должны быть спрогнозированы; и отображение направления применяется для направления прогнозирования, с тем, чтобы генерировать второе направление прогнозирования, определенное относительно второй решетки других отношений размеров. Первое направление прогнозирования может быть определено в отношении квадратного блока образцов яркости, включающих в себя текущую выборку яркости; и второе направление прогнозирования может быть выведено в отношении прямоугольного блока образцов цветности, включающих в себя текущий образец цветности.
Эти компоновки более подробно описаны ниже.
Варианты прогнозирования внутри изображения 4:4:4
В схеме 4:4:4 PU цветности и яркости имеют одинаковый размер, и, таким образом, режим прогнозирования внутри изображения для PU цветности может быть либо тем же, что и для расположенного в том же месте PU яркости (что позволяет сэкономить некоторое количество служебных сигналов в потоке битов, благодаря тому, что не требуется кодировать отдельный режим), или, в качестве альтернативы, он может быть выбран независимо.
В этом последнем случае поэтому в варианте осуществления настоящего раскрытия можно иметь 1, 2 или 3 разных режима прогнозирования для каждого из PU в CU;
В первом примере PU Y, Cb и Cr все могут использовать одинаковый режим прогнозирования внутри изображения.
Во втором примере Y PU может использовать один режим прогнозирования внутри изображения, и PU Cb и Cr оба используют другой независимо выбранный режим прогнозирования внутри изображения.
В третьем примере PU для Y, Cb и Cr каждый использует соответствующий независимо выбранный режим прогнозирования внутри изображения.
Следует понимать, что при наличии независимых режимов прогнозирования для каналов цветности (или каждого канала цветности) улучшается точность прогнозирования цвета. Но это происходит за счет дополнительной передачи служебных данных для передачи независимых режимов прогнозирования как часть данных кодирования.
Для устранения этого выбор количества режимов может быть обозначен в синтаксисе высокого уровня (например, в последовательности, в изображении или на уровне среза). В качестве альтернативы количество независимых режимов могло бы быть выведено из видеоформата; например, GBR мог бы иметь вплоть до 3, в то время как YCbCr мог быт быть ограничен 2.
В дополнение к независимому выбору режимов может быть разрешено, чтобы доступные режимы отличались от схемы 4:2:0 в схеме 4:4:4.
Например, поскольку PU яркости и цветности имеет одинаковый размер в 4:4:4, PU цветности могут получать пользу от доступа ко всем 35+LM_CHROMA + DM_CHROMA доступных направлений. Следовательно, для случая Y, Cb и Cr, каждый из которых имеет независимый режим прогнозирования, канал Cb мог бы иметь доступ к DM_CHROMA & LM_CHROMA, в то время как канал Cr мог бы иметь доступ к DM_CHROMA_Y, DM_CHROMA_Cb, LM_CHROMA_Y и LM_CHROMA_Cb, где эти каналы заменяют опорные значения для канала яркости со ссылками на каналы цветности Y или Cb.
В случае когда режимы прогнозирования яркости передают в виде сигналов, путем вывода списка из наиболее вероятных режимов и установки индекса для этого списка, тогда если режим (режимы) прогнозирования цветности будут независимыми, может потребоваться вывести независимые списки наиболее вероятных режимов для каждого канала.
В конечном итоге аналогично тому, что отмечено для представленного выше случая 4:2:2, в схеме 4:4:4 сглаживающий фильтр, используемый для опорной выборки при прогнозировании пикселя в положении выборки может использоваться для PU цветности аналогично PU яркости. В настоящее время, может применяться фильтр низкой частоты [1, 2, 1] для опорных выборок перед прогнозированием внутри изображения. Это используется только для TU яркости при использовании определенных режимов прогнозирования.
Один из режимов прогнозирования внутри изображения, доступных для TU цветности, состоит в том, чтобы основывать прогнозируемые выборки на, так называемых, выборках яркости. Такая компоновка схематично представлена на фиг. 19, на которой представлен массив из 1200 TU (из области изображения источника), представленный малыми квадратами в каналах Cb, Cr и Y, представляющими специальное выравнивание между свойствами изображения (схематично обозначенные квадратами 1200 с темнотой и светлой штриховкой) в каналах Cb и Y и в каналах Cr и Y. В этом примере предпочтительно заставить TU цветности основывать свои прогнозируемые выборки на выборках яркости, расположенных в том же месте. Однако свойства изображения не всегда соответствуют между тремя каналами. Фактически, определенные свойства могут появляться только в одном или двух из каналов, и обычно содержание изображения трех каналов может отличаться.
В вариантах осуществления раскрытия для TU Cr, LM_Chroma в случае необходимости могут быть размещены в расположенных в одном месте выборках из канала Cb (или, в других вариантах осуществления, может существовать другая зависимость, может быть выполнена по-другому). Такая компоновка схематично показана на фиг. 20. Здесь пространственно выровненные TU представлены между каналами Cr, Cb и Y. Дополнительный набор TU, помеченный как "источник", представляет собой схематическое представление цветного изображения, в том виде, как его можно видеть в целом. Свойства изображения (верхний левый треугольник и нижний правый треугольник), которые можно видеть в изображении источника, фактически не представляют изменения яркости, но только изменения цветности между двумя треугольными областями. В этом случае, основываясь на LM_Chroma для Cr выборок яркости можно получить плохое прогнозирование, но основывая его на выборках Cb, можно получить лучшее прогнозирование.
Решение, в соответствии с каким режимом использовать LM_Chroma, может быть принято контроллером 343 и/или контроллером 520 режима, на основе кодирования с проверкой разных опций (включая в себя опцию, основанную на LM_Chroma, для расположенных в одном месте выборок яркости или расположенных в одном месте выборок цветности), при этом решение, какой режим следует выбрать, принимается путем оценки функции стоимости, аналогично тому, как описано выше, в отношении разного кодирования с проверкой. Примеры функции стоимости представляют собой шум, искажение, частоту ошибок или скорость следования битов. Выбирают режим среди режимов, подвергаемых кодированию с проверкой, который позволяет получить самую низкую из любой одной или больше из этих функций стоимости.
На фиг. 21 схематично иллюстрируется способ, используемый для получения опорных выборок для прогнозирования внутри изображения в вариантах осуществления раскрытия. При рассмотрении фиг. 21 следует понимать, что кодирование выполняется в соответствии со структурой развертки, таким образом, что в общих чертах кодированные версии блоков выше и левее текущего блока, предназначенного для кодирования, доступны для процесса кодирования. Иногда используют выборки, расположенные ниже слева или выше справа, если они были ранее кодированы, как часть других уже кодированных TU в текущем LCU. Ссылка делается на фиг. 13, как, например, описано выше.
Затушеванная область 1210 представляет текущий TU, то есть TU, который в данный момент кодируют.
В схемах 4:2:0 и 4:2:2 столбец пикселей непосредственно слева от текущего TU не содержит расположенные в одном месте выборки яркости и цветности из-за горизонтальной подвыборки. Другими словами, это связано с тем, что форматы 4:2:0 и 4:2:2 имеют на половину меньше пикселей цветности, чем пикселей яркости (в горизонтальном направлении), таким образом, не каждое положение выборки яркости имеет расположенную в этом же месте выборку цветности. Поэтому хотя выборки яркости могут присутствовать в столбце пикселей непосредственно слева от TU, выборки цветности не присутствуют. Поэтому в вариантах осуществления раскрытия, столбец, расположенный на две выборки левее текущего TU, используется для обеспечения опорных выборок для LM_Chroma. Следует отметить, что ситуация отличается в схеме 4:4:4 тем, что столбец, расположенный непосредственно слева от текущего TU, действительно содержит расположенные в том же месте выборки яркости и цветности. Такой столбец поэтому должен использоваться для предоставления опорных выборок.
Опорные выборки используются следующим образом.
В режиме LM_Chroma прогнозируемые выборки цветности выводят из реконструированных выборок яркости, в соответствии с линейной взаимосвязью. Таким образом, в общих чертах, можно сказать, что прогнозируемые значения цветности в TU определяют из следующей формулы:
PC=а+bPL,
где PC представляет собой значение выборки цветности, PL представляет собой реконструированное значение выборки яркости в том же положении, и а, и b являются константами. Константы выводят для определенного блока, детектируя взаимосвязь между реконструированными выборками яркости и выборками цветности в ряду, который расположен непосредственно выше этого блока и в столбце, который расположен непосредственно левее этого блока, и эти положения представляют собой положения выборок, которые уже были кодированы (см. выше).
В вариантах осуществления раскрытия константы а и b выводят следующим образом:
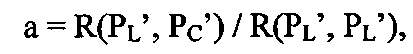
где R представляет собой линейную функцию регрессии (наименьшие квадраты), и PL′ и PC′ представляют собой выборки яркости и цветности, соответственно, из соседнего ряда и столбца, как описано выше, и:
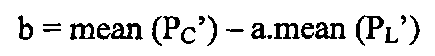
Для 4:4:4 значения PL′ и PC′ получают из столбца, расположенного непосредственно слева от текущего TU, и из ряда, расположенного непосредственно выше текущего TU. Для 4:2:2, значения PL′ и PC′ получают из ряда, непосредственно выше текущего TU и столбца в соседнем блоке, который расположен на два положения выборки от левой кромки текущего TU. Для 4:2:0 (для которого подвыборки выполняют вертикально и горизонтально) значения PL′ и PC′ в идеале можно было бы получить из ряда, который расположен на два ряда выше текущего TU, но фактически его получают из ряда в соседнем блоке, который находится в положении одной выборки выше текущего TU, и столбца в соседнем блоке, который находится в положении двух выборок от левой кромки текущего TU. Причина этого состоит в том, чтобы исключить необходимость поддержания дополнительных полных необработанных данных в запоминающем устройстве. В этом отношении, 4:2:2 и 4:2:0 обрабатывают с аналогичным подходом.
В соответствии с этим такие технологии применяются для способов кодирования видеоданных, имеющих режим прогнозирования цветности, в котором текущий блок выборок цветности, представляющих область изображения, кодируют путем вывода и кодирования взаимосвязи выборок цветности в отношении блока, расположенного в том же месте для выборок яркости (таких как реконструированные выборки яркости), представляющих ту же область изображения. Взаимосвязь (такую как линейная взаимосвязь) выводят путем сравнения расположенных в одном месте (по-другому выраженные как расположенные соответствующим образом) выборок яркости и цветности из соседних уже кодированных блоков. Выборки цветности выводят из выборок яркости в соответствии с взаимосвязью; и разность между прогнозируемыми выборками цветности и фактическими выборками цветности кодируют как остаточные данные.
Что касается первого разрешения выборки (такого как 4:4:4), в случае когда выборки цветности имеют такую же частоту выборки, как и у выборки яркости, выборки, находящиеся в том же месте, представляют собой выборки в положениях выборки, расположенных рядом с текущим блоком.
Что касается второго разрешения выборки (такого как 4:2:2 или 4:2:0), где выборки цветности имеют меньшую частоту выборки, чем у выборок яркости, ближайший столбец или ряд расположенных в том же месте выборок яркости и цветности от соседнего уже кодированного блока, используется для предоставления выборок, находящихся в том же месте. Или в случае когда второе разрешение выборок представляет собой разрешение выборки 4:2:0, выборки в соответствующих местах представляют собой ряд выборок, расположенных рядом с текущим блоком и ближайшим столбцом, или выборки яркости и цветности в соответствующем месте от соседних, уже кодированных блоков.
На фиг. 22 схематично иллюстрируется доступные углы прогнозирования для выборок яркости. Текущий пиксель, прогнозируют, как показано в центре схемы как пиксель 1220. Меньшие точки 1230 представляют соседние пиксели. Те, которые расположены в верхней или с левой сторон текущего пикселя, являются доступными как опорные выборки для генерирования прогнозирования, поскольку они были уже ранее кодированы. Другие пиксели в данный момент неизвестны (во время прогнозирования пикселя 1220) и будут сами спрогнозированы соответствующим образом.
Каждое пронумерованное направление прогнозирования указывает на опорные выборки 1230 из группы опорных выборок кандидатов верхней или левой кромок текущего блока, которые используются для генерирования текущего прогнозируемого пикселя. В случае блоков меньшего размера, когда направление прогнозирования указывает на места между опорными выборками, используется линейная интерполяция между соседними опорными выборками (с любой стороны положения выборки, на которое указывает направление, обозначенное текущим режимом прогнозирования).
Возвращаясь к прогнозированию внутри угла для выборок цветности, для схемы 4:2:0, меньшее количество направлений прогнозирования доступно из-за относительного недостатка выборок цветности. Однако если будет выбран режим DM_CHROMA, тогда текущий блок цветности будет использовать то же направление прогнозирования, что и расположенный в том же месте блок яркости. В свою очередь, это означает, что направления яркости для прогнозирования внутри изображения также доступны для цветности.
Однако для выборок цветности в 4:2:2, использование того же алгоритма прогнозирования и направления, что и для яркости, при выборе DM_CHROMA, можно рассматривать алогичным, при условии, что блоки цветности не имеют разное соотношение размеров с блоками яркости. Например, линия под углом 45° для квадратного массива яркости из выборок все еще должна отображаться на линии 45° для выборок цветности, хотя с массивом выборок прямоугольных размеров. Наложение прямоугольной сетки на квадратную сетку обозначает, что линия 45° затем фактически должна отображаться на линии 26,6°.
На фиг. 23 схематично иллюстрируются направления прогнозирования внутри кадров яркости, такие как применяются для пикселей цветности в 4:2:2, в отношении текущего пикселя, который прогнозирует 1220. Следует отметить, что существует на половину меньше пикселей по горизонтали, чем по вертикали, поскольку в схеме 4:2:2 частота горизонтальных выборок в канале цветности составляет половину по сравнению с каналом яркости.
На фиг. 24 схематично иллюстрируется преобразование или отображение пикселей цветности 4:2:2 на квадратную сетку, и затем, как такое преобразование изменяет направления прогнозирования.
Направления прогнозирования яркости показаны как пунктирные линии 1240. Пиксели 1250 цветности повторно отображают на квадратную сетку, предоставляя для прямоугольного массива половину ширины 1260 соответствующего массива яркости (как показано на фиг. 22). Направления прогнозирования, показанные на фиг. 23, были повторно отображены на прямоугольный массив. Как можно видеть, некоторые пары направлений (пара, представляющая собой направление яркости и направление цветности), либо накладывается, или находится в близкой взаимосвязи. Например, направление 2 в массиве яркости, по существу, накладывается на направление 6 в массиве цветности. Однако следует также отметить, что некоторые направления яркости, приблизительно их половина, не имеют соответствующего направления цветности. Пример представляет собой направление яркости номер 3. Кроме того, некоторые направления цветности (2-5) не имеют эквивалент в массиве яркости, и некоторые направления яркости (31-34) не имеют эквивалент в массиве цветности. Но, в общем, наложение, такое как показано на фиг. 24, демонстрирует, что было бы неуместно использовать тот же угол для обоих каналов яркости и цветности.
На фиг. 33 схематично иллюстрируется компоновка (которая может быть воплощена как часть функции контроллера 343) для модификации "углового шага", определяющего направления прогнозирования. На фиг. 33 угловой шаг подают в модификатор 1500, который, используя вспомогательные данные 1510, такие как справочная таблица, индексированная по входному угловому шагу, отображает входные угловые шаги на выходные угловые шаги, или данные, определяющие заданный алгоритм модификации или функцию, отображает направление, определенное входным угловым шагом на направление, определенное выходным угловым шагом.
Но перед подробным описанием операции на фиг. 33 будут представлены некоторые дополнительные предпосылки по выводу углов прогнозирования, и, в частности, "угловых шагов".
Как описано выше, в операции прогнозирования внутри изображения, выборки в пределах текущего блока могут быть спрогнозированы из одной или больше опорных выборок. Их выбирают из группы опорных выборов кандидатов, формирующих ряд, над текущим блоком 1560 и столбец слева от текущего блока. На фиг. 33 схематично иллюстрируется такой ряд 1520 и столбец 1530 опорных выборок кандидатов.
В среде опорных выборок кандидатов на фактическую выборку, которую требуется использовать для определенной операции прогнозирования, указывает направление прогнозирования. Это выражается как "угловой шаг". Для преобладающего вертикального направления прогнозирования (которое в данном контексте представляет собой направление, которое обращается к опорной выборке в ряду 1520), угловой шаг представляет собой смещение влево или вправо от положения 1540 выборки, которое смещается вертикально над положением 1550 текущей выборки, для которой выполняется прогнозирование. Для преобладающего горизонтального направления прогнозирования (которое в данном контексте представляет собой направление, которое обращается к опорной выборке в столбце 1530), угловой шаг представляет собой смещение выше или ниже углового положения 1570, которое смещается горизонтально влево от текущего положения 1550 выборки.
Поэтому следует понимать, что угловой шаг может быть равен нулю (в случае чисто горизонтального или чисто вертикального направления прогнозирования) или может представлять смещение в любом смысле (вверх/вниз/влево/вправо).
Фактически с целью расчетов вариантов осуществления раскрытия столбец 1530 и ряд 1520 можно рассматривать как линейный массив одиночного порядка, предоставляющий набор кандидатов опорных выборок, начинающийся снизу столбца 1530 и продолжающийся в правый конец ряда 1520. В вариантах осуществления раскрытия линейный массив фильтруют (с помощью фильтра, формирующего часть модуля 530 прогнозирования), с тем, чтобы применить операцию сглаживания или фильтрации низкой частоты вдоль линейного массива. Пример соответствующего сглаживающего фильтра представляет собой нормализованный фильтр 1-2-1, для которого можно сказать, что фильтр заменяет определенную выборку (только с целью действия в качестве опорной выборки) суммой ¼ выборки слева (в линейном массиве), ½ этой выборки и ¼ этой выборки справа (в линейном массиве). Сглаживающий фильтр можно применять для всего массива или для поднабора массивов (такого как выборки, происходящие из ряда или столбца)
Для вывода соответствующего угла прогнозирования для цветности, когда (а) выбирают DM_CHROMA и (b) режим DM_CHROMA, используемый в настоящее время, обозначает, что направление прогнозирования цветности должно представлять собой направление для совместно размещенного блока яркости, модификатор 1500 применяет следующую процедуру, для модификации значений углового шага. Следует отметить, что процедура относится к инверсии углового шага. Это значение можно использовать как удобное свойство для расчетов, выполняемых для генерирования прогнозирования, но оно представляет собой вариацию углового шага, который является существенным для настоящего описания.
(i) вывести угловой шаг для прогнозирования внутри изображения (и, в случае необходимости, его инверсию) в соответствии с направлением яркости
(ii) если направление яркости является, преимущественно, вертикальным (то есть например, режим с номерами от 18 до 34 включительно), тогда угловой шаг прогнозирования внутри изображения делят пополам (и его инверсию удваивают).
(iii) в противном случае, если направление яркости является, преимущественно, горизонтальным (то есть например, режим с номерами от 2 до 17 включительно) тогда угловой шаг прогнозирования внутри изображения удваивают (и его инверсию делят пополам).
Такие расчеты представляют пример применения с помощью модификатора 1500 заданного алгоритма, для модификации значений углового шага, для того, чтобы отобразить направление, выведенное в отношении сетки яркости положений выборки в направлении, применимом для 4:2:2 или другой сетки цветности в подвыборках для положений выборки. Аналогичный результат может быть получен с помощью модификатора 1500, который обращается, вместо этого, к справочной таблице, отображающей входные угловые шаги на выходные угловые шаги.
В соответствии с этим в этих вариантах осуществления направление прогнозирования определяет положение выборки относительно группы кандидатов опорных выборок, содержащих горизонтальный ряд и вертикальный столбец из выборок, соответственно, расположенных выше и слева от набора текущих выборок, предназначенных для прогнозирования. Модуль 530 прогнозирования воплощает операцию фильтрации, которая, как описано выше, упорядочивает группу кандидатов опорных выборок в виде линейного массива опорных выборок; и применяет сглаживающий фильтр для линейного массива опорных выборок в направлении вдоль линейного массива.
Процесс выполнения отображения может осуществляться, например, в отношении угловых шагов, в которых направление прогнозирования для текущей выборки определяют с помощью ассоциированного углового шага; угловой шаг для, преимущественно, вертикального направления прогнозирования представляет собой смещение вдоль горизонтального ряда положений выборки группы кандидатов опорных выборок относительно положения выборки в этом ряду, которое вертикально смещено от текущей выборки; угловой шаг для, в основном, горизонтального направления прогнозирования представляет собой смещение вдоль вертикального столбца положений выборки группы кандидатов опорных выборок, относительно положения выборки в этом столбце, которое горизонтально смещено от текущей выборки; и положение выборки вдоль горизонтального ряда или вертикального столбца, обозначенное смещением, предоставляет указатель на положение выборки, которую требуется использовать при прогнозировании текущей выборки.
В некоторых вариантах осуществления этап применения отображения по направлению может содержать подэтапы, на которых: применяют заданную функцию к угловому шагу, соответствующему первому направлению прогнозирования. Пример такой функции является таким, как описано выше, а именно:
выводят угловой шаг в соответствии с первым направлением прогнозирования; и
(i) если первое направление прогнозирования является, преимущественно, вертикальным, тогда уменьшают на половину соответствующий угловой шаг для генерирования углового шага для второго направления прогнозирования; или
(ii) если первое направление прогнозирования является, преимущественно, горизонтальным, тогда удваивают соответствующий угловой шаг для генерирования углового шага второго направления прогнозирования.
В вариантах осуществления раскрытия, если угловой шаг (такой как модифицированный шаг, как описано выведено выше) не является целым числом, угловой шаг используется для определения группы из двух или больше положений выборок в пределах группы кандидатов опорных выборок (например, двух выборок с каждой стороны положений, на которое указывает это направление) для интерполяции, для обеспечения прогнозирования текущей выборки.
В других вариантах осуществления раскрытия этап применения отображения по направлению содержит: используют первое направление прогнозирования для индексации справочной таблицы, таблица предоставляет соответствующие значения второго направления прогнозирования.
В соответствии с вариантами осуществления раскрытия этап детектирования первого направления прогнозирования может содержать: в случае операции кодирования, выбирают направление прогнозирования в соответствии с проверкой двух или больше кандидатов направлений прогнозирования; или, в случае операции декодирования, детектируют информацию, определяющую направление прогнозирования, ассоциированное с видеоданными, которые должны быть декодированы. Это представляет собой общий момент, по которому различают варианты осуществления систем кодирования и декодирования: в декодере определенные параметры предусмотрены в кодированных данных или ассоциированы с ними. В кодере такие параметры генерируют для передачи кодированных данных в декодер.
В вариантах осуществления раскрытия первое направление прогнозирования используется для прогнозирования выборок яркости из набора выборок; и второе направление прогнозирования, выведенное на этапе применения из первого направления прогнозирования, используют для прогнозирования выборок цветности для этого набора выборок.
Варианты осуществления раскрытия могут обеспечивать способ кодирования или декодирования видеоданных, в котором выборки яркости и первого, и второго компонентов цветности прогнозируют в соответствии с режим прогнозирования, ассоциированным с выборкой, которую требуется прогнозировать, содержит этап, на котором: прогнозируют выборки второго компонента цветности из выборок первого компонента цветности.
Варианты осуществления раскрытия могут обеспечивать способ кодирования или декодирования видеоданных, в котором наборы выборок прогнозируют из других соответствующих опорных выборок, в соответствии с направлением прогнозирования, которое ассоциировано с выборкой, предназначенной для прогнозирования, направление прогнозирования, определяющее положение выборки, относительно группы опорных выборок - кандидатов, расположенных относительно набора текущих выборок, которые предназначены для прогнозирования, содержит этапы, на которых:
упорядочивают группу кандидатов опорных выборок в виде линейного массива опорных выборок; и
применяют сглаживающий фильтр для поднабора линейного массива опорных выборок в направлении вдоль линейного массива.
Варианты осуществления раскрытия могут предоставлять способ кодирование или декодирования видеоданных, в котором выборки яркости и цветности изображения прогнозируют из других соответствующих опорных выборок, выведенных из того же изображения, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое отношение размеров, чем соответствующий блок выборок цветности, выборки цветности, представляющие первый и второй компоненты цветности;
способ, содержащий этапы, на которых:
выбирают режим прогнозирования, определяющий выбор одной или больше опорных выборок или значений для прогнозирования текущей выборки цветности первого компонента цветности; и
выбирают другой режим прогнозирования, определяющий другой выбор одной или больше опорных выборок или значений, для прогнозирования текущей выборки цветности второго компонента цветности, находящегося в том же месте, что и текущая выборка цветности первого компонента цветности.
Варианты осуществления раскрытия могут обеспечить способ кодирования или декодирования видеоданных, в котором выборки яркости и цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности будет отличаться от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности; способ содержит этап, на котором:
применяют другой соответствующий алгоритм прогнозирования для выборок яркости и цветности, в зависимости от различий отношений размеров.
На фиг. 33 показан пример такой технологии при использовании. Угловой шаг 1580 выводят в соответствии с сеткой яркости. (При этом возможно его также использовать в отношении прогнозирования выборки яркости, но достаточно для настоящего описания, чтобы его выводили в соответствии с сеткой яркости и процедурами. Другими словами, фактически он может не использоваться для прогнозирования яркости). Массив 4:2:2 выборок 1580 цветности показан, как с удвоенной шириной на той же сетке; но с использованием тех же точек направления 1590 прогнозирования для другой опорной выборки (другое смещение от расположенной вертикально выборки 1540) в этом случае. Поэтому угловой шаг модифицируют, в соответствии с процедурой, установленной выше, для получения модифицированного углового шага 1600, который указывает на правильную опорную выборку цветности, для представления того же направления прогнозирования в сетке цветности.
В соответствии с этим варианты осуществления настоящего раскрытия относятся к способам кодирования или декодирования видеоданных, устройству или программам, в которых прогнозируют выборки яркости и цветности из других соответствующих опорных выборок, в соответствии с направлением прогнозирования, ассоциированным с текущей выборкой, предназначенной для прогнозирования. В таких режимах как 4:2:2, выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, поэтому отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности. Вкратце, это означает, что блок выборок яркости имеет другое отношение размеров, чем соответствующий блок выборок цветности.
Модуль 530 прогнозирования внутри изображения, например, работает как детектор для детектирования первого направления прогнозирования, определенного в отношении первой сетки, с первым соотношением размеров относительно набора текущих выборок, предназначенных для прогнозирования; и в качестве модуля отображения направления, для применения отображения направления на направление прогнозирования, для генерирования второго направления прогнозирования, определенного в отношении второй сетки с другим соотношением размеров. В соответствии с этим модуль 530 прогнозирования представляет пример модуля отображения направления. Модуль 540 прогнозирования может предоставлять другой соответствующий пример.
В вариантах осуществления раскрытия первая сетка, используемая для детектирования первого направления прогнозирования, определена в отношении положений выборки одной из выборок яркости или цветности, и вторая сетка, используемая для детектирования второго направления прогнозирования, определена в отношении положений выборок других из выборок цветности или яркости. В конкретных примерах, описанных в настоящем описании, направление прогнозирования яркости может быть модифицировано для обеспечения направления прогнозирования цветности. Но может использоваться совершенно другой способ.
Данная технология, в частности, применима для прогнозирования внутри изображения, таким образом, что опорные выборки представляют собой выборки, выводимые из (например, реконструированные из сжатых данных, выведенных из) того же соответствующего изображения, что и выборки, предназначенные для прогнозирования.
По меньшей мере, в некоторых компоновках, первое направление прогнозирования определено в отношении квадратного блока выборок яркости, включающего в себя текущую выборку яркости; и второе направление прогнозирования определено в отношении прямоугольного блока выборок цветности, включающего в себя текущую выборку цветности.
При этом возможно обеспечить независимые режимы прогнозирования для двух компонентов цветности. В такой компоновке выборки цветности содержат выборки первого и второго компонентов цветности, и технология содержит: применяют описанный выше этап отображения направления в отношении первого компонента цветности (такого как Cb); и предоставляют другой режим прогнозирования в отношении второго компонента цветности (такого как Cr), что может (например) вовлекать прогнозирование второго компонента цветности из выборок первого компонента цветности.
Видеоданные могут иметь, например, формат 4:2:2.
В случае декодера или способа декодирования направления прогнозирования могут быть детектированы путем детектирования данных, определяющих направления прогнозирования в кодированных видеоданных.
В общих чертах варианты осуществления раскрытия могут предоставлять независимые режимы прогнозирования для компонентов цветности (например, для каждого из компонентов яркости и цветности по отдельности). Эти варианты осуществления относятся к способам видеокодирования, в которых выборки яркости и цветности изображения прогнозируют из других соответствующих опорных выборок, выведенных из того же изображения, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности будет отличаться от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое отношение размеров, чем соответствующий блок выборок цветности, и выборки цветности, представляющие первый и второй компоненты цветности.
Селектор 520 режима внутри изображения выбирает режим прогнозирования, определяющий выбор одной или больше опорных выборок для прогнозирования текущей выборки цветности первого компонента цветности (такого как Cb). Он также выбирает другой режим прогнозирования, определяющий другой выбор одной или больше опорных выборок для прогнозирования текущей выборки цветности второго компонента цветности (такого как Cr), расположенного в том же месте, что и текущая выборка цветности первого компонента цветности.
Фильтр опорной выборки в случае необходимости можно применять для горизонтальных выборок или вертикальных выборок (или для обеих). Как описано выше, фильтр может представлять собой нормализованный фильтр "1 2 1" с 3 выводами, в настоящее время применяемый для всех опорных выборок яркости за исключением нижней левой и верхней правой (выборки блока N×N собирают вместе, для формирования одного массив 1D с размером 2N+1, и затем в случае необходимости фильтруют). В вариантах осуществления раскрытия применяют только первые (левая кромка) или последние (верхняя кромка) N+1 выборок цветности для 4:2:2, но следует отметить, что нижняя левая, верхняя правая и верхняя левая затем не будут отрегулированы; или все выборки цветности (что касается яркости), для 4:2:2 и 4:4:4.
Варианты осуществления раскрытия также предоставляют способы кодирования или декодирования видеоданных, устройство или программы, для которых прогнозируют выборки яркости и первого, и второго компонентов цветности (например, из других соответствующих опорных выборок или значений), в соответствии с режимом прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, что подразумевает прогнозирование выборок второго компонента цветности из выборок первого компонента цветности. В некоторых вариантах осуществления режим прогнозирования, ассоциированный с выборкой, которая должна быть спрогнозирована, может обозначать направление прогнозирования, определяющее одну или больше из других соответствующих опорных выборок, из которых эта выборка должна быть спрогнозирована.
Варианты осуществления раскрытия также могут обеспечивать способы кодирования или декодирования видеоданных, устройство или программы, в которых выборки яркости и первого и второго компонента цветности прогнозируют из других соответствующих опорных выборок, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, используя фильтрацию опорных выборов.
Как описано со ссылкой на фиг. 19 и 20, возможно, чтобы разный режим прогнозирования содержал режим, в соответствии с которым выборки второго компонента цветности прогнозировали из выборок первого компонента цветности.
Следует отметить, что режимы 0 и 1 не являются режимами углового прогнозирования, и они не включены в эту процедуру. Эффект процедуры, показанной выше, состоит в том, чтобы отображать направления прогнозирования цветности на направления прогнозирования яркости на фиг. 24.
Для 4:2:0, когда выбирают любой из чисто горизонтального режима прогнозирования (режим 10 яркости) или чисто вертикального режима прогнозирования (режим 26 яркости), верхнюю или левую кромки прогнозируемого TU подвергают фильтрации только для канала яркости. Для горизонтального режима прогнозирования верхний ряд фильтруют в вертикальном направлении. Для вертикального режима прогнозирования фильтруют левый столбец в горизонтальном направлении.
Под фильтрацией столбца выборок в горизонтальном направлении можно понимать применение горизонтально ориентированного фильтра для каждой выборки по очереди столбцов выборок. Таким образом, для индивидуальной выборки ее значение будет модифицировано действием фильтра, на основе фильтруемого значения, генерируемого из текущего значения этой выборки и одной или больше других выборок в положениях выборки, смещенных от этой выборки в горизонтальном направлении (то есть одной или больше других выборок, расположенных слева и/или справа от рассматриваемой выборки).
Фильтрацию ряда выборок в вертикальном направлении можно понимать как применение вертикально-ориентированного фильтра к каждой выборке по очереди рядов выборок. Таким образом, для индивидуальной выборки ее значение будет модифицировано действием фильтра, на основе фильтруемого значения, генерируемого из текущего значения этой выборки и одной или больше других выборок в положениях выборки, смещенных от этой выборки в вертикальном направлении (то есть одной или больше других выборок, расположенных выше и/или ниже от рассматриваемой выборки).
Одно из назначений процесса фильтрации пикселя на кромке, описанного выше, состоит в том, чтобы уменьшить блок на основе эффектов кромки при прогнозировании, стремясь, таким образом, уменьшить энергию остаточных данных изображения.
В вариантах осуществления раскрытия соответствующий процесс фильтрации также предусмотрен для TU цветности в 4:4:4 и 4:2:2. Принимая во внимание горизонтальную подвыборку, одно из предложений состоит только в том, чтобы фильтровать только верхний ряд TU цветности в 4:2:2, но фильтровать как верхний ряд, так и левый столбец (соответственно, в соответствии с выбранным режимом) в 4:4:4. При этом считается соответствующим фильтровать только эти области, с тем, чтобы исключить фильтрацию слишком большого количества полезных деталей, которые (будучи отфильтрованными), приведут к увеличению энергии остаточных данных.
Для 4:2:0, когда выбирают режим DC, верхнюю и/или левую кромки прогнозируемого TU подвергают фильтрации только для канала яркости.
Фильтрация может быть выполнена таким образом, что в Режиме DC, фильтр выполняет операцию (1 × смежный за пределами выборки +3* кромка выборки)/4 усреднения для всех выборок на обеих кромках. Однако для верхнего левого участка функция фильтра представляет собой (2 × текущая выборка +1 × расположенная выше выборки +1 × левая выборка)/4.
Фильтр H/V представляет собой среднее между соседней внешней выборкой и выборкой кромки.
В вариантах осуществления раскрытия такой процесс фильтрации также предусмотрен для TU цветности в схемах 4:4:4 и 4:2:2. И снова, принимая во внимание горизонтальную подвыборку, в некоторых вариантах осуществления раскрытия, только верхний ряд выборок цветности фильтруют для схемы 4:2:2, но верхний ряд и левый столбец TU цветности фильтруют для схемы 4:4:4.
В соответствии с этим эта технология может применяться в отношении способа кодирования или декодирования видеоданных, устройства или программы, в которых выборки яркости и цветности в формате 4:4:4 или 4:2:2 прогнозируют по другим соответствующим выборкам, в соответствии с направлением прогнозирования, ассоциированным с блоками выборок, предназначенных для прогнозирования.
В вариантах осуществления технологии направление прогнозирования обнаруживают в отношении текущего блока, предназначенного для прогнозирования. Прогнозируемый блок выборок цветности генерируют в соответствии с другими выборками цветности, определенными направлением прогнозирования. Если обнаруживаемое направление прогнозирования будет, по существу, вертикальным (например, находится пределах ±n режимов утла от точно вертикального режима, где n равно (например) 2), левый столбец выборок фильтруют (например, в горизонтальном направлении) в блоке прогнозирования выборок цветности. Или, если обнаруживаемое направление прогнозирования является, по существу, горизонтальным (например, находится в пределах ±n режимов угла в точно горизонтальном режиме, где n равно (например) 2), верхний ряд выборок фильтруют (например, в вертикальном направлении) в прогнозируемом блоке выборок цветности. Затем разность между отфильтрованным прогнозированным блоком цветности и фактическим блоком цветности кодируют, например, как остаточные данные. В качестве альтернативы проверка может быть выполнена для точно вертикального или горизонтального режимов, вместо, по существу, горизонтального или вертикального режимов. Допуск ±n может применяться к одной из проверок (вертикальной или горизонтальной), но не для других.
Прогнозирование между изображениями
Следует отметить, что прогнозирование между изображениями в HEVC уже позволяет использовать прямоугольный PU, таким образом, что режимы 4:2:2 и 4:4:4 уже совместимы с PU для обработки прогнозирования между изображениями.
Каждый фрейм видеоизображения представляет собой дискретную выборку реальной сцены, и, в результате, каждый пиксель представляет собой пошаговую аппроксимацию градиента реального мира в цветах и яркости.
С учетом этого, при прогнозировании значения Y, Cb или Cr пикселя в новом видеокадре от значения предыдущего видеокадра, пиксели в этом предыдущем видеокадре интерполируют для формирования лучшей оценки оригинальных реальных градиентов, для обеспечения более точного выбора яркости или цвета для нового пикселя. Следовательно, векторы движения, используемые для указания между видеокадрами, не ограничиваются целочисленным разрешением пикселей. Скорее, они могут указывать на положение подпикселей в пределах интерполированного изображения.
4:2:0 прогнозирование между изображениями
Рассмотрим теперь фиг. 25 и 26, в схеме 4:2:0, как отмечено выше, обычно PU 1300 яркости 8×8 будет ассоциирован с PU 1310 цветности 4×4 Cb и Cr. Следовательно, для интерполяции данных пикселей яркости и цветности до одинаково эффективного разрешения, используют разные фильтры интерполяции.
Например, для PU яркости размером 8×8 для 4:2:0, интерполяция составляет ХА пикселя, и, таким образом, фильтр ×4 с 8 отводами применяют вначале горизонтально, и затем такой же фильтр ×4 с 8 отводами применяют вертикально, так что PU яркости эффективно растягивают в 4 раза в каждом направлении для формирования интерполированного массива 1320, как показано на фиг. 25. В то же время соответствующий PU цветности 4×4 для 4:2:0 представляет собой 1/8 пикселя, интерполированного для генерирования такого же возможного разрешения, и, таким образом, применяется фильтр ×8 с 4 отводами вначале горизонтально, и затем такой же фильтр ×8 с 4 отводами применяется вертикально, так, что PU цветности 4:2:0 эффективно растягивается 8 раз в каждом направлении для формирования массива 1330, как показано на фиг. 26.
Прогнозирование между изображениями 4:2:2
Аналогичная компоновка для 4:2:2 будет описана ниже со ссылкой на фиг. 27 и 28, на которых иллюстрируется PU 1350 яркости и пара соответствующих PU 1360 цветности.
Обращаясь к фиг. 28, как отмечено ранее, в схеме 4:2:2 PU 1360 цветности может быть неквадратным, и для случая PU яркости 8×8 для схемы 4:2:2 обычно применяется PU цветности с размерами 4 в ширину × на 8 в высоту для схемы 4:2:2 для каждого из каналов Cb и Cr. Следует отметить, что PU цветности вычерчены для назначения фиг. 28 как массив квадратной формы из неквадратных пикселей, но обычно следует отметить, что PU 1360 представляют собой массивы размером 4 (по горизонтали) ×8 (по вертикали) пикселей.
В то время как поэтому возможно использовать существующий фильтр яркости ×4 с 8 отводами вертикально для PU цветности, в варианте осуществления настоящего раскрытия предполагается, что существующего фильтра цветности ×8 с 4 отводами будет достаточно для вертикальной интерполяции, поскольку на практике интересуются только ровным расположением фракций интерполированного PU цветности.
Следовательно, на фиг. 27 показан PU 1350 яркости для 4:2:2 размером 8×8, интерполированный, как и прежде, с использованием фильтра ×4 с 8 отводами, и PU 1360 цветности 4:2:2 размером 4×8, интерполированный существующим фильтром цветности ×8 с 4 отводами в горизонтальном и вертикальном направлениях, но при этом только равномерные результаты фракции используются для формирования интерполированного изображения в вертикальном направлении.
Эти технологии применимы для способов кодирования или декодирования видеоданных, устройства или программ, в которых используется прогнозирование между изображениями, для кодирования входных видеоданных, в которых каждый компонент цветности имеет горизонтальное разрешение 1/М компонента яркости и вертикальное разрешение 1/N компонента яркости, где М и N представляют собой целые числа, равные 1 или больше. Например, для 4:2:2, М=2, N=1. Для 4:2:0, М=2, N=2.
Накопитель 570 кадра во время работы сохраняет одно или больше изображений, предшествующих текущему изображению.
Фильтр 580 интерполяции во время работы интерполирует версию с более высоким разрешением модулей прогнозирования сохраненных изображений так, что компонент яркости модуля интерполированного прогнозирования имеет горизонтальное разрешение Р раз соответствующей части сохраненного изображения, и вертикальное разрешение Q раз соответствующей части сохраненного изображения, где Р и Q представляют собой целые числа большие 1. В текущих примерах Р=Q=4, так что фильтр 580 интерполяции во время работы генерирует интерполированное изображение с разрешением 1/4 выборки.
Блок 550 оценки движения во время работы детектирует движение между изображениями между текущим изображением и одним или больше интерполированными сохраненными изображениями для генерирования векторов движения между модулем прогнозирования текущего изображения и появляется в одном или больше предыдущих изображений.
Модуль 540 прогнозирования со скомпенсированным движением во время работы генерирует прогнозирование со скомпенсированным движением модуля прогнозирования текущего изображения в отношении области интерполированного сохраненного изображения, на которую указывает соответствующий вектор движения.
Возвращаясь к описанию операции фильтра 580 интерполяции, варианты осуществления этого фильтра, во время работы, применяют фильтр интерполяции ×R по горизонтали и ×S по вертикали для компонентов цветности сохраненного изображения, для генерирования интерполированного модуля прогнозирования цветности, где R равно (U×М×Р), и S равно (V×N×Q), U и V представляют собой целые числа, равные 1 или больше; и для подвыборки интерполированного модуля прогнозирования цветности, таким образом, что его горизонтальное разрешение будет разделено с коэффициентом U, и его вертикальное разрешение будет разделено с коэффициентом V, в результате чего, получают блок из MP×NQ выборок.
Так, в случае 4:2:2, фильтр 580 интерполяции применяет интерполяцию ×8 в горизонтальном и вертикальном направлениях, но затем выполняет вертикальную подвыборку с коэффициентом 2, например, используя каждую 2-ую выборку в интерполированном выходе.
Эта технология поэтому позволяет использовать тот же (например, ×8) фильтр в отношении 4:2:0 и 4:2:2, но с дополнительным этапом подвыборки в случае, когда требуется обеспечить 4:2:2.
В вариантах осуществления раскрытия, как описано выше, модуль интерполированного прогнозирования цветности имеет высоту выборок в два раза большую, чем модуль прогнозирования в соответствии с форматом 4:2:0, интерполированный с использованием таких же фильтров интерполяции ×R и ×S.
Необходимость в обеспечении разных фильтров может быть исключена или устранена, используя эти технологии, и, в частности, путем использования одних и тех же горизонтальных ×R и вертикальных ×S фильтров интерполяции, в отношении входных видеоданных 4:2:0 и входных видеоданных 4:2:2.
Как описано выше, этап подвыборки модуля интерполированного прогнозирования цветности содержит: используют каждую V-ю выборку модуля интерполированного прогнозирования цветности в вертикальном направлении, и/или используют каждую U-ую выборку модуля интерполированного прогнозирования цветности в вертикальном направлении.
Варианты осуществления раскрытия могут вовлекать получение вектора движения яркости для модуля прогнозирования; и независимо выводят один или больше векторов движения цветности для этого модуля прогнозирования.
В вариантах осуществления раскрытия, по меньшей мере, один из R и S равен 2 или больше, и в вариантах осуществления раскрытия горизонтальный ×R и вертикальный ×S фильтры интерполяции также применяются для компонентов яркости сохраненного изображения.
Варианты прогнозирования между изображениями 4:4:4
Путем расширения тот же принцип использования только результатов выровненной фракции для существующего фильтра цветности ×8 с 4 выводами можно применять как вертикально, так и горизонтально для PU цветности 4:4:4 размером 8×8.
В дополнение к этим примерам фильтр цветности ×8 можно использовать для всей интерполяции, включающей в себя яркость.
Дополнительные варианты прогнозирования между изображениями
В одном варианте осуществления производного вектора движения (MV) один вектор получают для PU в срезе Р (и два вектора для PU в срезе В (где срез Р использует прогнозирование из предыдущего кадра, и срез В использует прогнозирование из предыдущего и следующего кадров, аналогично кадрам MPEG Р и В). Следует отметить, что в данном варианте осуществления в схеме 4:2:0 векторы являются общими для всех каналов, и, кроме того, данные цветности не требуется использовать для расчета векторов движения. Другими словами, во всех каналах используют вектор движения на основе данных яркости.
В варианте осуществления настоящего раскрытия в схеме 4:2:2 вектор цветности может быть выведен так, чтобы он был независимым от яркости (то есть один вектор для каналов Cb и Cr может быть выведен отдельно), и в схеме 4:4:4 векторы цветности могут быть дополнительно независимыми для каждого из каналов Cb и Cr.
Варианты осуществления раскрытия могут обеспечить способ кодирования или декодирования видеоданных, в котором выборки яркости и цветности изображения прогнозируют по другим соответствующим опорным выборкам, выведенным из того же изображения, в соответствии с режимом прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, представляющие первый и второй компоненты цветности; способ, содержащий: выбирают, по меньшей мере, для некоторых выборок, тот же режим прогнозирования для каждого из компонентов яркости и цветности, соответствующих области изображения.
Варианты осуществления раскрытия могут обеспечивать способ кодирования или декодирования видеоданных, в котором выборки яркости и цветности изображения прогнозируют по другим соответствующим опорным выборкам, выведенным из того же изображения, в соответствии с режимом прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, представляющие первый и второй компоненты цветности; способ, содержащий: выбирают, по меньшей мере, для некоторых выборок, разные соответствующие режимы прогнозирования для каждого из компонентов яркости и цветности, соответствующих области изображения.
В любом случае либо тот же режим прогнозирования или другие соответствующие режимы прогнозирования можно использовать для каждого из компонентов яркости и цветности, соответствующих области изображения, при этом выбор выполняют в соответствии с последовательностью изображения, для изображения или области изображения.
Для выбора схемы режима прогнозирования при операции кодирования варианты осуществления могут, например, выполнять первое кодирование с проверкой области изображения, используя тот же режим прогнозирования для компонентов цветности и яркости; выполнять второе кодирование с проверкой этой области изображения, используя другие соответствующие режимы прогнозирования для компонентов цветности и яркости; и выбирая либо тот же режим прогнозирования или разные соответствующие режимы прогнозирования для использования в отношении последовательности изображений, изображения или области изображения на основе данных, кодированных первым и вторым кодированиями с проверкой.
Обработка результатов проверки в вариантах осуществления раскрытия может подразумевать детектирование одного или больше заданных свойств данных, кодированных первым и вторым кодированием с проверкой; и выбора либо того же режима прогнозирования, или других соответствующих режимов прогнозирования для использования в отношении последовательности изображений, изображения или области изображения на основе детектируемых одного или больше свойств. Одно или больше свойств, например, могут содержать свойства, выбранные из набора, состоящего из: шумы изображения; искажение изображения; и количество данных изображения. Выбор может быть выполнен для индивидуальных цветоделеных срезов изображения или блоков изображения. Варианты осуществления раскрытия во время работы могут ассоциировать информацию с кодированным видеосигналом (например, как часть кодированного потока данных, как один или больше флагов данных в пределах потока данных), обозначающую: используется ли один и тот же режим прогнозирования или разные режимы прогнозирования; и в случае, когда используется один и тот же режим прогнозирования, идентификацию этого одного режима прогнозирования; или, в случае, когда используются разные соответствующие режимы прогнозирования, идентификацию этих разных соответствующих режимов прогнозирования, например, используя схему нумерации, описанную в этой заявке в отношении режимов прогнозирования.
Для вариантов осуществления, выполняющих операцию декодирования, способ может содержать: детектируют информацию, ассоциированную с видеоданными для декодирования, информация, определяющая, является ли тот же режим прогнозирования или разные режимы прогнозирования ассоциированными с видеоданными для декодирования. Если такая информация (например, флаг размером один бит в заданном положении относительно потока данных) обозначает, что используются один и тот же режим прогнозирования, декодер применяет информацию режима прогнозирования, определенную в отношении одного компонента (такого как яркость) для декодирования других компонентов (таких как цветность). В противном случае, декодер применяет индивидуально установленные режимы прогнозирования для каждого компонента.
В вариантах осуществления раскрытия, как описано, изображение формирует часть видеосигнала 4:2:2 или 4:4:4.
Преобразования
В HEVC большая часть изображений кодирована как векторы движения из ранее кодированных/декодированных кадров, при этом векторы движения сообщают декодеру, из каких мест в этих других декодируемых кадрах следует копировать хорошие аппроксимации текущего изображения. Результат представляет собой приблизительную версию текущего изображения. HEVC затем кодирует так называемый остаток, который представляют собой ошибку между аппроксимированной версией и прямым изображением. Этот остаток требует намного меньше информации, чем непосредственное установление фактического изображения. Однако все еще, в общем, является предпочтительным сжатие этой остаточной информации для дополнительного уменьшения общей скорости передачи битов.
Во многих способах кодирования, включая в себя HEVC, такие данные преобразуют в домен пространство - частота, используя целочисленное косинусное преобразование (ICT), и обычно некоторое сжатие выполняют затем путем сохранения данных с низкой пространственной частотой и отбрасывания данных с высокой пространственной частотой, в соответствии с требуемым уровнем сжатия.
Преобразования 4:2:0
Преобразования пространственной частоты, используемые в HEVC, обычно представляют собой преобразования, которые генерируют коэффициенты в степени 4 (например, 64 коэффициента частоты), поскольку это особенно удобно для общих способов квантования/сжатия. Квадратные TU в схеме 4:2:0 все имеют степени 4 и, следовательно, этого легко достичь.
Если обеспечиваются варианты опции NSQT, некоторые неквадратные преобразования доступны для неквадратных TU, таких как 4×16, но снова следует отметить, что в результате из них получают коэффициенты 64, то есть снова степень 4.
Варианты преобразования 4:2:2 и 4:4:4
Схема 4:2:2 может привести к неквадратным TU, которые не являются степенью 4; например, TU 4×8 имеют 32 пикселя, и 32 не является степенью 4.
В варианте осуществления настоящего раскрытия поэтому неквадратное преобразование для коэффициентов, не являющихся степенью 4, могут использоваться, подтверждая то, что модификации могут потребоваться для последующего процесса квантования.
В качестве альтернативы в варианте осуществления настоящего раскрытия неквадратные TU разделяют на квадратные блоки, имеющие площади в степени 4 для преобразования, и затем полученные в результате коэффициенты могут быть подвержены перемежению.
Например, для блоков 4×8 нечетные/четные вертикальные выборки могут быть разделены на два квадратных блока. В качестве альтернативы для блока 4×8 верхние 4×4 пикселей и нижние 4×4 пикселей могут формировать два квадратных блока. И снова, в качестве альтернативы, для блоков 4×8 вейвлет разложение Хаара можно использовать для формирования блока 4×4 нижней и верхней частоты.
Любые из этих опций могут быть сделаны доступными, и выбор конкретной альтернативы может быть передан в виде сигналов в декодер или может быть выведен декодером.
Другие режимы преобразования
В схеме 4:2:0 предложен флаг (так называемый ′qpprime_y_zero_transquant_bypass_flag′), позволяющий включать остаточные данные в поток битов без потерь (то есть без преобразования, квантования или дополнительной фильтрации). В схеме 4:2:0 флаг применяется для всех каналов.
В соответствии с этим такие варианты осуществления представляют способ кодирование или декодирования видеоданных, устройство или программу, в которых прогнозируют выборки яркости и цветности, и разность между выборками и соответствующими прогнозируемыми выборками кодируют, используя индикатор, выполненный с возможностью обозначения, должны ли быть включены данные контраста яркости в выходной поток битов без потерь; и для независимого обозначения, должны ли цветоразностные данные быть включены в поток битов без потерь.
В варианте осуществления настоящего раскрытия предложено, чтобы флаг для канала яркости был отделен от каналов цветности. Следовательно, для схемы 4:2:2, такие флаги должны быть предусмотрены отдельно для канала яркости и для каналов цветности, и для схемы 4:4:4, такие флаги должны быть предусмотрены либо отдельно для каналов яркости и цветности, или один флаг должен быть предусмотрен для каждого из трех каналов. Это распознает увеличенные скорости данных цветности, ассоциированные со схемами 4:2:2 и 4:4:4, и позволяет, например, использовать данные яркости без потерь вместе со сжатыми данными цветности.
Для кодирования с прогнозированием внутри изображения направленное преобразование, зависимое от режима (MDDT), позволяет заменить горизонтальный или вертикальный ICT (или оба ICT) для TU на целочисленное синусное преобразование, в зависимости от направления прогнозирования внутри изображения. В схеме 4:2:0 это не применяется для TU цветности. Однако в варианте осуществления настоящего раскрытия предложено применять его для TU цветности 4:2:2 и 4:4:4, следует отметить, что IST только в настоящее время определены для 4 измерений преобразования выборки (либо горизонтальные, или вертикальные), и поэтому в настоящее время не может применяться по вертикали для TU цветности 4×8. MDDT будет дополнительно описан ниже.
В способах кодирования видеоданных могут быть размещены различные варианты осуществления раскрытия так, что они будут обозначать, должны ли данные контраста яркости быть включены в выходной поток битов без потерь; и независимо от обозначения, должны ли быть данные цветоразности включены в поток битов без потерь, и кодировать или включать соответствующие данные в форме, определенной такими обозначениями.
Квантование
В схеме 4:2:0 расчет квантования является таким же для цветности, как и для яркости. Только параметры квантования (QP) отличаются.
QP для цветности рассчитывают из QP яркости следующим образом:

где таблица масштабирования определена, как можно видеть на фиг. 29А или 29В (для 4:2:0 и 4:2:2, соответственно), и "chroma_qp_index_offset" и "second_chroma_qp_index_offset" определены в устанавливаемом параметре изображении и могут быть одинаковыми или разными для Cr и Cb. Другими словами, значение в квадратных скобках определяет, в каждом случае "индекс" в таблице масштабирования (фиг. 29А и 29В), и таблица масштабирования затем передает пересмотренное значение Qp ("значение").
Следует отметить, что "chroma_qp_index_offset" и "second_chroma_qp_index_oriset" могут вместо этого называться cb_qp_offset и cr_qp_offset, соответственно.
Каналы цветности обычно содержат меньше информации, чем в канале яркости и, следовательно, имеют коэффициенты с меньшей магнитудой; это ограничение по цветности QP может предотвратить потерю каких-либо деталей цветности при значительных уровнях квантования.
Взаимосвязь знаменателя QP в 4:2:0 является логарифмической таким образом, что увеличение на 6 в QP эквивалентно удвоению знаменателя (размер этапа квантования описан в другом месте, в этом описании, хотя следует отметить, что он может быть дополнительно модифицирован с помощью матриц Q перед использованием). Следовательно, наибольшая разница в таблице масштабирования 51-39=12 представляет коэффициент 4-кратного изменения знаменателя.
Однако в варианте осуществления настоящего раскрытия, для схемы 4:2:2, которая потенциально содержит в два раза больше информации цветности, чем схема 4:2:0, максимальное значение QP цветности в таблице масштабирования может быть повышено до 45 (то есть имеющее знаменатель). Аналогично, для схемы 4:4:4, максимальное значение QP цветности в таблице масштабирования может быть повышено до 51 (то есть при том же знаменателе). В этом случае таблица масштабирования фактически является избыточной, но может поддерживаться просто для эффективности операций (то есть таким образом, что система работает со ссылкой на таблицу одинаково для каждой схемы). Следовательно, в более общем смысле, в варианте осуществления настоящего раскрытия, знаменатель QP цветности модифицируют в соответствии с количеством информации в схеме кодирования относительно схемы 4:2:0.
В соответствии с этим варианты осуществления раскрытия относятся к способу кодирования или декодирования видеоданных, работающих для квантования блоков, преобразованных по частоте компонентных видеоданных яркости и цветности в формате 4:4:4 или 4:2:2, в соответствии с выбранным параметром квантования, который определяет размер шага квантования. Ассоциацию параметра квантования (такого как, например, соответствующая таблица на фиг. 29А или 29В) определяют между параметрами квантования яркости и цветности, где ассоциация осуществляется таким образом, что максимальный размер шага квантования цветности меньше, чем максимальный размер шага квантования яркости для формата 4:2:2 (например, 45), но равен максимальному размеру шага квантования яркости для формата 4:4:4 (например, 51). Процесс квантования работает таким образом, что каждый компонент данных, преобразованных по частоте, делят на соответствующее значение, выводимое из соответствующего размера шага квантования, и результат округляют до целочисленного значения для генерирования соответствующего блока квантованных данных пространственной частоты.
Следует понимать, что этапы деления и округления представляют собой примеры, обозначающие обобщенный этап квантования, в соответствии с соответствующим размером шага квантования (или данными, выведенными из него, например, с помощью приложения Q матриц).
Варианты осуществления раскрытия включают в себя этап выбора параметра квантования или индекса (QP для яркости), для квантования пространственных коэффициентов частоты, при этом параметр квантования действует как опорный для соответствующего одного из набора размеров шага квантования, в соответствии с таблицами QP, применимыми для данных яркости. Процесс определения ассоциации параметра квантования может затем содержать: для компонентов цветности, ссылку на таблицу модифицируемых параметров квантования (такую как таблица на фиг. 29А или 29В), в соответствии с выбранным параметром квантования, что, в свою очередь, может вовлекать (i) для первого компонента цветности, добавляют первое смещение (такое как chroma_qp_index_offset) к параметру квантования и выбирают модифицированный индекс квантования, соответствующий входу в эту запись в таблице для индекса квантования, плюс первое смещение; и (ii) для второго компонента цветности, добавляют второе смещение (такое как second_chroma_qp_index_offset) к параметру квантования и выбирают модифицированный индекс квантования, соответствующий входу в эту запись в таблице для индекса квантования, плюс второе смещение; и обращаясь к соответствующему размеру шага квантования в наборе, в соответствии с параметром квантования для данных яркости и первому и второму модифицированным индексам квантования для первого и второго компонентов цветности. Другими словами, это представляет собой пример процесса, подразумевающего выбор параметра квантования для квантования пространственных коэффициентов частоты, при этом параметр квантования действует как ссылка на соответствующий один из набора размеров шага квантования; и в котором этап определения содержит: для компонентов цветности, ссылку на таблицу модифицированных параметров квантования, в соответствии с выбранным параметром квантования, этап ссылки, содержащий: для каждого компонента цветности, добавляют соответствующее смещение к параметру квантования и выбирают модифицированный параметр квантования, соответствующий входу в эту запись в таблице, для параметра квантования, плюс соответствующее смещение; и ссылку на соответствующий размер шага квантования в наборе, в соответствии с параметром квантования для данных яркости и для первого и второго модифицированных параметров квантования для первого и второго компонентов цветности.
Эти технологии являются особенно применимыми для компоновок, в которых последовательные значения размеров шага квантования в наборе соотносятся логарифмически, таким образом, что изменение параметра квантования m (где m представляет собой целое число) представляет изменение размера шага квантования на коэффициент р (где р представляет собой целое число большее 1). В настоящих вариантах осуществления m=6 и р=2.
В вариантах осуществления раскрытия, как описано выше, максимальный параметр квантования яркости равен 51; максимальный параметр квантования цветности равен 45 для формата 4:2:2; и максимальный параметр квантования цветности равен 51 для формата 4:4:4.
В вариантах осуществления раскрытия первое и второе значения смещения могут быть переданы в ассоциации с кодированными видеоданными.
В схеме 4:2:0 матрицы А преобразования, первоначально формируют (модулем преобразования 340) из истинно нормализованных N×N DCT и А′, используя:

где i и j обозначают положение в пределах матрицы. Такое масштабирование относительно нормализованной матрицы преобразования обеспечивает увеличение точности, исключает необходимость в дробных расчетах и увеличивает внутреннюю точность.
Игнорирование разности, связанной с округлением Aij, поскольку X умножают как на А, так и на AT (транспонирование матрицы А), полученные в результате коэффициенты отличаются от коэффициентов истинно нормализованных M×N (М=высота; Н=ширина) DCT на общий коэффициент масштабирования, равный:

Следует отметить, что общий коэффициент масштабирования может отличаться от этого примера. Также следует отметить, что умножение матрицы как на А, так и на AT, может быть выполнено различными способами, например, с использованием так называемого способа Баттерфляй. Существенным является тот факт, является ли выполняемая операция эквивалентной традиционному умножению матрицы, с учетом того, что она выполняется в определенном традиционном порядке операций.
Такой коэффициент масштабирования эквивалентен двоичной операции побитного сдвига влево на количество битов transformShift, поскольку в HEVC этот результат представляет степень 2:
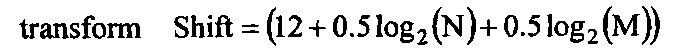
Для уменьшения требований в отношении внутренней точности битов, коэффициенты сдвигают вправо (используя положительное округление) дважды во время процесса преобразования:

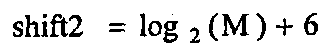
В результате, коэффициенты, по мере того как они выходят из процесса прямого преобразования и поступают в блок квантования, являются эффективно сдвинутыми влево на величину:

В 4:2:0, коэффициенты, разделенные частотой (например, DCT), генерируемые в результате преобразования частоты, больше на коэффициент  , чем можно было бы получить с нормализованным DCT.
, чем можно было бы получить с нормализованным DCT.
В некоторых вариантах осуществления раскрытия блоки являются либо квадратными, или прямоугольными с отношением размера 2:1. Поэтому для размера блока N×М, либо:
N=M, и в этом случае resultingShift представляет собой целое число и S=N=M=sqrt (NM); или
0,5N=2M или 2N=0,5M, и в этом случае resultingShift все еще представляет собой целое число и S=sqrt (NM)
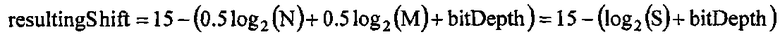
Эти коэффициенты впоследствии квантуют, где знаменатель квантования выводят в соответствии с параметром QP квантования.
Следует отметить, что resultingShift эквивалентен целому числу, таким образом, что общий коэффициент масштабирования представляет собой целое число в степени 2, общий сдвиг влево ′resultingShift′ в процессе преобразования также учитывают на этом этапе путем применения эквивалентного, но противоположного сдвига вправо, ′quantTransformRightShift′.
Такая операция сдвига битов возможна, поскольку resultingShift представляет собой целое число.
Также следует отметить, что соотношение знаменателя-QP (параметра квантования или индекса) следует кривой мощности по основанию 2, как упомянуто выше, в том, что увеличение QP на 6 имеет эффект удвоения знаменателя, в то время как увеличение QP на 3 имеет эффект увеличения знаменателя на коэффициент sqrt (2) (квадратный корень 2).
В связи с тем, что формат цветности равен 4:2:2, для TU существуют два отношения ширина: высота (N:M):
N=M (как указано выше), где S=N=M=sqrt (NM) (resultingShift представляет собой целое число),
0,5N=2M и 2N=0,5M (как указано выше), где S=sqrt (NM) (resultingShift представляет собой целое число),
N=2M, где S=sqrt (NM)
2M=N, где S=sqrt (NM)
4N=0,5M, где S=sqrt (NM)
В этих трех последних ситуациях resultingShift не является целым числом. Например, такой подход может применяться, в случае когда, по меньшей мере, некоторые из блоков выборок видеоданных содержат выборки M×N, где квадратный корень N/M не равен степени 2 целого числа. Такие размеры блока могут возникнуть в отношении выборок цветности, в некоторых из настоящих вариантов осуществления.
В соответствии с этим в таких случаях следующие технологии являются соответствующими, то есть в способах кодирования или декодирования видеоданных, устройстве или программах, работающих для генерирования блоков данных, квантованных по пространственной частоте, путем выполнения преобразования частоты для блоков выборок видеоданных, используя матрицу преобразования, содержащую массив целочисленных значений, каждое из которых масштабировано в отношении соответствующих значений нормализованной матрицы преобразования на величину, зависящую от размера матрицы преобразования, и для квантования данных пространственной частоты, в соответствии с выбранным размером шага квантования, имеющим этап преобразования частоты блока выборок видеоданных путем умножения матрицы блока на матрицу преобразования и транспонирования матрицы преобразования, для генерирования блока масштабирования коэффициентов пространственной частоты, каждый из которых больше на общий коэффициент масштабирования (например, resultingShift), чем коэффициенты пространственной частоты, которые могли бы быть получены из нормированного преобразования частоты этого блока выборок видеоданных.
Поэтому на этапе квантования соответствующая операция сдвига битов не может использоваться для отмены операции простым способом.
Для этого было предложено следующее решение:
На этапе квантователя применить сдвиг вправо:

где значение S′ выведено так, что

quantTransformRightShift представляет собой целое число
Разность между сдвигами на 1/2 эквивалентна умножению на корень из (2), то есть в этой точке коэффициенты в sqrt в (2) раза больше, чем они должны быть, что делает сдвиг бита сдвигом на целый бит.
Для процесса квантования применяют параметр квантования (QP+3), что означает, что знаменатель квантования эффективно увеличивается на коэффициент sqrt (2), устраняя, таким образом, коэффициент масштабирования sqrt (2) из предыдущего этапа.
В соответствии с этим эти этапы могут быть сведены вместе (в контексте способа кодирования или декодирования видеоданных (или соответствующего устройства или программы), которые работают для генерирования блоков квантованных данных, пространственной частоты, путем выполнения преобразования частоты по блокам выборок видеоданных, используя матрицу преобразования, содержащую массив целочисленных значений, каждый из которых масштабируют в отношении соответствующих значений нормализованной матрицы преобразования, и для квантования данных пространственной частоты в соответствии с выбранным размером этапа квантования, в котором используется преобразование частоты блока выборок видеоданных путем матричного умножения блока на матрицу преобразования и для генерирования блока масштабированных коэффициентов пространственной частоты, каждый из которых больше на общий коэффициент масштабирования, чем коэффициенты пространственной частоты, которые могли бы быть получены из нормированного частотного преобразования каждого блока выборок видеоданных) следующим образом: выбирают размер этапа квантования для квантования коэффициентов пространственной частоты; применяют сдвиг на n битов (например, quantTransformRightShift) для деления каждого из масштабированных коэффициентов пространственной частоты на коэффициент 2n, где n представляет собой целое число; и детектируют остаточный коэффициент масштабирования (например, resultingShift-quantTransformRightShifi), который представляет собой общий коэффициент масштабирования, разделенный на 2". Например, в ситуации, описанной выше, размер шага квантования затем должен в соответствии с остаточным коэффициентом масштабирования использоваться для генерирования модифицированного размера шага квантования; и каждый из масштабированных коэффициентов пространственной частоты в блоке делят на значение, зависящее от модифицированного размера шага квантования, и округляют результат до целочисленного значения для генерирования блока квантованных данных пространственной частоты. Как описано выше, модификация размера шага квантования может осуществляться просто путем добавления смещения к QP, для выбора другого размера шага квантования, когда QP отображают на таблицу размеров шага квантования.
Коэффициенты теперь имеют правильную магнитуду для оригинального QP.
Матрица преобразования может содержать массив целочисленных значений, каждое из которых масштабировано в отношении соответствующих значений нормализованной матрицы преобразования на величину, зависящую от размера матрицы преобразования.
Из этого следует, что требуемое значение для S′ всегда может быть выведено следующим образом:

В качестве альтернативного предложения S′ может быть выведено таким образом, что:

В этом случае  , и приложенный параметр квантования представляет собой (QP-3)
, и приложенный параметр квантования представляет собой (QP-3)
В любом в этих случаев (добавление 3 к QP или в вычитании 3 из QP) этап выбора размера шага квантования содержит выбор индекса квантования (например, QP), индекс квантования, определяющий соответствующий вход в таблицу размеров шага квантования, и этап модификации содержит изменение индекса квантования для выбора другого размера шага квантования, таким образом, что отношение разных размеров шага квантования к первоначально выбранному размеру шага квантования, по существу, равно остаточному коэффициенту масштабирования.
Все это работает особенно хорошо, когда как и в первом варианте осуществления, последовательные значения размеров шага квантования в таблице соотносятся логарифмически, таким образом, что изменение индекса квантования (например, QP) для m (где m представляет собой целое число) представляет изменение размера шага квантования на коэффициент р (где р представляет собой целое число больше 1). В настоящих вариантах осуществления m=6 и р=2, таким образом, что увеличение QP в 6 раз представляет удвоение применяемого размера шага квантования, и уменьшение в QP в 6 раз представляет уменьшение вдвое, полученного в результате размера шага квантования.
Как описано выше, модификация может осуществляться путем выбора индекса квантования (например, основания QP) в отношении выборок яркости; генерируя смещения индекса квантования, относительно индекса квантования, выбранного для выборок яркости, для выборок каждого или обоих компонентов цветности; изменения смещения индекса квантования, в соответствии с остаточным коэффициентом масштабирования; и передачи смещения индекса квантования в ассоциации с кодированными видеоданными. В вариантах осуществления HEVC смещение QP для двух каналов цветности передают в потоке битов. Эти этапы соответствуют системе, в которой смещение QP (за счет остаточного коэффициента масштабирования), равное ±3, может быть встроено в эти смещения, или для них может быть выполнено последовательное приращение/уменьшение, когда их используют для вывода QP цветности.
Следует отметить, что смещение QP не обязательно должно быть равным ±3, если используют блоки разных размеров; при этом ±3 просто представляет смещение, применимое для форм и соотношений размеров блока, описанных выше в отношении, например, видеоданных 4:2:2.
В некоторых вариантах осуществления n (величина сдвига битов, в том виде, как применяется) выбирают таким образом, что 2n будет больше чем или равно общему коэффициенту масштабирования. В других вариантах осуществления n выбирают таким образом, что 2n меньше чем или равно общему коэффициенту масштабирования. В вариантах осуществления раскрытия (используя любую из этих компоновок), сдвиг n бита может быть выбран таким, чтобы он был следующим ближайшим (в любом направлении) к общему коэффициенту масштабирования, таким образом, что остаточный коэффициент масштабирования представляет коэффициент, имеющий магнитуду меньше чем 2.
В других вариантах осуществления модификация размера шага квантования может быть выполнена просто путем умножения размера шага квантования на коэффициент, зависящий от остаточного коэффициента масштабирования. То есть модификация не обязательно должна включать в себя модификацию QP индекса.
Следует также отметить, что размер шага квантования, как описано, не обязательно представляет собой фактический размер шага квантования, на который делят преобразованную выборку. Размер шага квантования, выведенный таким образом, может быть дополнительно модифицирован. Например, в некоторых компоновках, размер шага квантования дополнительно модифицирован по соответствующим входам в матрицу по значениям (Qmatrix) таким образом, что разные конечные размеры шага квантования используются в разных положениях коэффициента в квантованном блоке коэффициентов.
Также известно, что в схеме 4:2:0, наибольший TU цветности составляет 16×16, тогда как для схемы 4:2:2 возможны TU 16×32, и для схемы 4:4:4 возможны TU цветности 32×32. Следовательно, в варианте осуществления настоящего раскрытия предложены матрицы квантования (Q матрицы) для TU цветности 32×32. Аналогично, Q матрицы должны быть определены для неквадратных TU, таких как TU 16×32, в одном варианте осуществления, который представляет собой подвыборку более крупной квадратной матрицы Q
Qmatrices могут быть определены по одному из следующих значений:
значения в сетке (как для Qmatrices размером 4×4 и 8×8);
пространственно интерполированные из меньших или более крупных матриц;
- в HEVC более крупные Qmatrices могут быть выведены из соответствующих групп коэффициентов меньшего размера опорных матриц, или меньшего размера матрицы могут быть выведены на основе подвыборки из более крупных матриц. Следует отметить, что такая интерполяция или подвыборка могут осуществляться в пределах соотношения канала - например, большая матрица для соотношения канала может быть интерполирована из меньшей матрицы для этого соотношения каналов.
относительно других Qmatrices (то есть значения разности или дельта);
- следовательно, необходимо передать только значения дельта.
Рассмотрим небольшой пример, только для иллюстрации, конкретная матрица для одного отношения канала может быть определена, такая как матрица 4×4 в соответствии со схемой 4:2:0
(а b)
(c d)
где а, b, с и d представляют собой соответствующие коэффициенты. Это действует как опорная матрица.
Варианты осуществления раскрытия могли бы затем определять набор значений разности для матрицы аналогичного размера в отношении другого соотношения канала:
(diff1 diff2)
(diif3 diff4)
таким образом, что для генерирования Qmatrix для другого соотношения каналов, матрица разностей представляет собой матрицу, добавленную к опорной матрице.
Вместо различий матрица мультипликативных коэффициентов может быть определена для другого соотношения каналов, таким образом, что либо (i), матрица мультипликативных коэффициентов представляет собой матрицу, умноженную на опорную матрицу, для генерирования Qmatrix для другого соотношения каналов, или (ii), каждый коэффициент в опорной матрице индивидуально умножают на соответствующий коэффициент для генерирования Qmatrix, для другого соотношения канала,
как функция другой Qmatrix;
- например, коэффициент масштабирования в отношении другой матрицы (таким образом, что каждый из а, b, с и d в представленном выше примере умножают на один и тот же коэффициент, или к ним добавляют одинаковую разность). Это уменьшает требования к данным для преобразования разности или данных коэффициента.
- следовательно, только коэффициенты функций необходимы для передачи (такие как коэффициент масштабирования),
как уравнение/функция (например, линейная кривая, состоящая из кусочков, экспонента, полином);
- следовательно, только коэффициенты уравнений необходимо передавать для вывода матрицы,
или любую комбинацию, указанную выше. Например, каждый из а, b, с и d фактически может быть определен по функции, которая может включать в себя зависимость от положений (i, j) коэффициента в матрице (i, j) может представлять собой, например, положение коэффициента, слева направо, после которого следует положение коэффициента сверху вниз матрицы. Пример представляет собой:

Следует отметить, что Q матрицы могут называться листами масштабирования в среде HEVC. В вариантах осуществления, в которых квантование применяют после процесса развертки, данные развертки могут представлять собой линейный поток последовательных выборок данных. В таких случаях концепция Qmatrix все еще применяется, но матрица (или список развертки) можно рассматривать как матрицу 1×N, таким образом, что порядок значений данных N в пределах матрицы 1×N соответствует порядку выборок, полученных при развертке, к которым требуется применять соответствующее значение Qmatrix. Другими словами, существует взаимозависимость 1:1 между порядком данных в данных, полученных при развертке, пространственной частотой, в соответствии со структурой развертки, и порядком данных в Qmatrix 1×N.
Следует отметить, что возможно, в некоторых вариантах осуществления, выполнить обход или пропуск этапа DCT (разделение по частоте), но при этом оставляют этап квантования.
Другая полезная информация включает в себя необязательный индикатор того, к какой матрице относятся данные значения, то есть предыдущий канал или первый (первичный) канал; например, матрица для Cr может представлять коэффициент масштабирования для матрицы для значений Y или для Cb, как обозначено.
В соответствии с вариантами осуществления раскрытие может предоставлять способ кодирования или декодирования видеоданных (и соответствующее устройство или компьютерную программу), работающие для генерирования блоков квантованных данных пространственной частоты (в случае необходимости) выполнения преобразования частоты для блоков выборок видеоданных и квантования видеоданных (таких как данные пространственной частоты) в соответствии с выбранным размером шага квантования и матрицей данных, модифицирующей размер шага квантования, для использования в разных соответствующих положениях блока в пределах упорядоченного блока выборок (такого как упорядоченный блок выборок преобразованных по частоте), способ работает в отношении, по меньшей мере, двух разных форматов подвыборки цветности.
Для, по меньшей мере, одного из форматов подвыборки цветности определяют одну или больше матриц квантования, в качестве одной или больше заданных модификаций в отношении одной или больше опорных матриц квантования, определенных для ссылки на один из форматов подвыборки цветности.
В вариантах осуществления раскрытия этап определения содержит: определяют одну или больше матриц квантования как матрицу значений, каждая из которых интерполирована из соответствующего множества значений опорной матрицы квантования. В других вариантах осуществления этап определения содержит: определяют одну или больше матриц квантования как матрицу значений, для каждой из которых выполняют подвыборку из значений опорной матрицы квантования. В вариантах осуществления раскрытия этап определения содержит: определяют одну или больше матриц квантования как матрицу разностей в отношении соответствующих значений опорной матрицы квантования.
В вариантах осуществления раскрытия этап определения содержит: определяют одну или больше матриц квантования как заданную функцию значений опорной матрицы квантования. В таких случаях заданная функция может представлять собой полиномиальную функцию.
В вариантах осуществления раскрытия предусматриваются одно или оба из следующих, например, как часть или в ассоциации с кодированными видеоданными: (i) опорные данные индикатора для обозначения в отношении кодированных видеоданных, опорной матрицы квантования; и (ii) данные индикатора модификации, для обозначения, в отношении значений кодированных данных, одной или больше заданных модификаций.
Такие технологии в особенности применимы в случае, когда два из форматов подвыборки цветности представляют собой форматы 4:4:4 и 4:2:2.
Количество матриц Q в HEVC 4:2:0 в настоящее время равно 6 для каждого размера преобразования: 3 для соответствующих каналов, и один набор для кодирования внутри и между изображениями. В случае схемы GBR 4:4:4 следует понимать, что либо один набор матриц квантования может использоваться для всех каналов, или могут использоваться три соответствующих набора матриц квантования.
В вариантах осуществления раскрытия, по меньшей мере, одна из матриц представляет собой матрицу 1×N. Это может представлять собой случай (как описано здесь), когда одна или больше из матриц, фактически, представляет собой список масштабирования и т.п., который представляет собой линейный упорядоченный массив коэффициентов 1×N.
Предложенные решения улучшают постепенное увеличение или постепенное уменьшение применяемого QP. Однако это может быть достигнуто множеством способов:
В HEVC смещения QP для двух каналов цветности передают в потоке битов ±3 может быть встроено в эти смещения, или для них может быть выполнено постепенное приращение/постепенное уменьшение, когда их используют для вывода QP цветности.
Как описано выше, в HEVC (QP яркости + смещение цветности) используют в качестве индекса для таблицы, для вывода QP цветности. Эта таблица может быть модифицирована соответствующим образом до ±3 (то есть постепенное увеличение/постепенное уменьшение значений оригинальной таблицы на 3)
После вывода QP цветности для каждого нормального процесса HEVC, результаты могут затем быть постепенно увеличены (или постепенно уменьшены) на 3.
В качестве альтернативы для модификации QP, коэффициент sqrt (2) или 1/sqrt (2) может использоваться для модификации коэффициентов квантования.
Для прямого/обратного квантования процессы деления/умножения реализованы при использовании (% QP 6) как индекс к таблице, чтобы получить коэффициент квантования или размер шага квантования, inverseQStep/scaledQStep. (Здесь, % QP 6 обозначает QP по модулю 6). Следует отметить, что, как описано выше, это, возможно, не представляет конечный размер шага квантования, который применяют к преобразованным данным; это может быть дополнительно модифицировано Qmatrices перед использованием.
Принятые по умолчанию таблицы HEVC имеют длину 6, которая охватывает октаву (удвоение) значений. Это просто представляет собой средство уменьшения требований к сохранению; таблицы расширяют для фактического использования, путем выбора входной записи в таблице, в соответствии с модулем QP (mod 6) и с последующим умножением или делением на соответствующую степень 2, в зависимости от разности (QP - QP модуль 6) заданного основного значения.
Такая компоновка может изменяться для обеспечения возможности смещения ±3 значения QP. Смещение может применяться в процессе поиска в таблице, или вместо этого, может выполняться процесс модуля, описанный выше, используя модифицированный QP. Предполагая, что смещение применяется при поиске в таблице, однако дополнительные входы в записи в таблице могут быть предусмотрены следующим образом:
Одна альтернатива состоит в том, чтобы расширить таблицы на 3 входа, где новые входы представляют собой следующее (для значений индекса 6-8).
Примерная таблица, показанная на фиг. 30, могла бы быть индексирована по [(QP % 6)+3] ("способ последовательного приращения QP"), где обозначение QP % 6 обозначает " QP модуль 6".
Пример таблицы, показанный на фиг. 31, может быть проиндексирован по [(QP % 6)-3] ("способ последовательного уменьшения QP"), который имеет дополнительные входы для значений индекса от -1 до -3:
Энтропийное кодирование
Основное энтропийное кодирование содержит: назначают кодовые слова для входных символов данных, где самые короткие доступные кодовые слова назначают для наиболее вероятных символов во входных данных. В среднем, результат представляет собой гораздо меньшее представление входных данных без потерь.
Такая основная схема может быть улучшена дополнительно путем распознавания того, что вероятность символа часто является условной в современных данных предшествующего уровня техники, и, следовательно, делает процесс назначения контекста адаптивным.
В такой схеме переменные контекста (CV) используют для определения выбора соответствующих моделей вероятности, и такие CV предусмотрены для схемы 4:2:0 в HEVC.
Для расширения энтропийного кодирования схемы 4:2:2, в которой, например, используется TU цветности размером 4×8, вместо TU 4×4, для TU яркости 8×8, в случае необходимости, переменные контекста могут быть предусмотрены путем простого вертикального повторения эквивалентных выборов CV.
Однако в варианте осуществления настоящего раскрытия выбор CV не повторяют для верхних - левых коэффициентов (то есть для коэффициентов с высокой энергией, DC и/или с низкой пространственной частотой) и вместо этого выводят новые CV. В этом случае, например, отображение может быть выведено из карты яркости. Такой подход также можно использовать для схемы 4:4:4.
Во время кодирования в схеме 4:2:0 выполняют так называемую зигзагообразную развертку через коэффициенты в порядке от высоких к низким частотам. Однако снова следует отметить, что TU цветности в схеме 4:2:2 могут не быть квадратными, и, таким образом, в варианте осуществления настоящего раскрытия разная развертка цветности предлагается с наклоненным углом развертки, чтобы сделать его в большей степени горизонтальным, или в более общем случае, чувствительным к соотношению размеров TU.
Аналогично, соседство для карты существенности выбора CV и системы c1/c2 для "более чем одного" и "более чем двух" выборов CV может быть адаптировано, соответственно.
Аналогично в варианте осуществления настоящего раскрытия последнее наименее значимое положение коэффициента (которое становится исходной точкой во время декодирования) также можно отрегулировать для схемы 4:4:4, с наименьшими значимыми положениями для TU цветности, которые кодируют по-разному из последнего значимого положения в расположенном в том же месте TU яркости.
Развертка коэффициента также может быть выполнена в режиме прогнозирования, в зависимости от определенных размеров TU. Следовательно, другой порядок развертки можно использовать для некоторых размеров TU, зависящих от режима прогнозирования внутри изображения.
В схеме 4:2:0 применяют только развертку коэффициента, зависящего от режима (MDCS), для TU яркости 4×4/8×8 и TU цветности 4×4, для прогнозирования внутри изображения. MDCS используются в зависимости от режима прогнозирования внутри изображения, под углами ±4 от рассматриваемых горизонтального и вертикального направлений.
В варианте осуществления настоящего раскрытия предложено, чтобы схема MDCS 4:2:2 применялась для TU цветности размером 4×8 и 8×4 для прогнозирования внутри изображения. Аналогично, предложено, чтобы в схеме MDCS 4:4:4 применялись TU от 8×8 до 4×4 цветности. MDCS для 4:2:2 также может быть выполнена только в горизонтальном или вертикальном направлениях, и чтобы диапазоны углов моли отличаться для цветности 4:4:4 по сравнению с яркостью 4:4:4, и по сравнению с цветностью 4:2:2, и по сравнению с яркостью 4:2:2, по сравнению с яркостью 4:2:0.
Контурные фильтры
Удаление блочности
Удаление блочности применяется для всех границ CU, PU и TU, и форма CU/PU/TU не учитывается при этом. Сила и размер фильтра зависят от локальной статистики, и удаление блочности имеет гранулярность пикселей яркости 8×8.
Следовательно, предполагается, что текущее удаление блочности, применяемое для схемы 4:2:0, также должно быть применимо для схем 4:2:2 и 4:4:4.
Смещение, адаптивное к выборке
При смещении, адаптивном к выборке (SAO), каждый канал является полностью независимым. SAO разделяет данные изображения для каждого канала, используя квадродерево, и полученные в результате блоки имеют, по меньшей мере, один LCU по размеру. Листовые блоки выравнивают с границами LCU, и каждый лист может работать в одном из трех режимов, как определяется кодером ("Смещение центральной полосы", "Смещение боковой полосы" или "Смещение кромки"). Каждый лист устанавливает категорию для своих пикселей, и кодер выводит значение смещения для каждой из этих 16 категорий путем сравнения входных данных SAO с данными источника. Эти значения смещения передают в декодер. Смещение для категории декодируемых пикселей добавляют к его значению для минимизации отклонения от источника.
Кроме того, SAO включают или отключают на уровне изображения; если оно будет включено для яркости, оно также может быть отдельно включено для каждого канала цветности. SAO поэтому будет применяться только для цветности, если оно применяется для яркости.
Следовательно, процесс в большой степени является прозрачным для лежащей в его основе блок-схеме, и при этом ожидается, что текущее SAO, применяемое для схемы 4:2:0 также должно быть применим для схем 4:2:2 и 4:4:4.
Адаптивная фильтрация контура
В схеме 4:2:0 адаптивная фильтрация контура (ALF) отключена по умолчанию. Однако в принципе (то есть если разрешено), ALF может применяться ко всему изображению для цветности.
При ALF выборки яркости могут быть отсортированы на одну из многих категорий, как определено документами HEVC; в каждой категории используется разный фильтр на основе Винера.
В отличие от этого выборки цветности 4:2:0 не разделяют на категории - здесь присутствует только один фильтр на основе Винера для Cb и один для Cr.
Следовательно, в варианте осуществления настоящего раскрытия с учетом увеличенной информации цветности в схемах 4:2:2 и 4:4:4 предложено, чтобы выборки цветности были разделены по категориям; например на К категорий для 4:2:2 и на J категорий для 4:4:4.
В то время как схема ALF 4:2:0 может быть отключена для яркости на основе каждого CU, используя флаг управления ALF (вплоть до уровня CU, установленного глубиной управления ALF), она может быть отключена для цветности на основе каждого изображения. Следует отметить, что в HEVC, такая глубина в настоящее время ограничена только уровнем LCU.
Следовательно, в варианте осуществления настоящего раскрытия в схемах 4:2:2 и 4:4:4 предусмотрены один или два флага управления ALF для цветности, определенные для канала.
Синтаксис
В HEVC синтаксис уже присутствует для обозначения схем 4:2:0, 4:2:2 или 4:4:4 и обозначает уровень последовательности. Однако в варианте осуществления настоящего раскрытия предложено также обозначать кодирование 4:4:4 GBR на этом уровне.
MDDT и MDCS
Использование направленного преобразования, зависящего от режима, и развертки коэффициента, зависящего от режима, будет описано ниже. Следует отметить, что оба такие подхода могут быть воплощены в одной и той же системе, или один из них может использоваться, а другой нет, или ни один из них может не использоваться.
MDCS будет описана вначале со ссылкой на фиг. 34-38.
Так называемая структура диагональной развертки сверху вправо была описана выше со ссылкой на фиг. 16. Структура развертки используется для вывода порядка, в соответствии с которым обрабатывают коэффициенты, разделенные по частоте, такие как коэффициенты DCT. Диагональная структура сверху вправо представляет собой один пример структур развертки, но другие структуры также доступны. Два дополнительных примера схематично показаны на фиг. 34 и 35, в этот раз, используя пример блока 4×4. Они представляют собой: структуру горизонтальной развертки (фиг. 34) и структуру вертикальной развертки (фиг. 35).
В MDCS структуру развертки выбирают из группы из двух или больше кандидатов структур развертки, в зависимости от используемого режима прогнозирования.
Существующие проблемы, в качестве примера, относятся к группе из трех кандидатов структур развертки, диагональная структура сверху вправо, горизонтальная структура и вертикальная структура. Но могут использоваться разные группы из двух или больше структур кандидатов.
Рассмотрим фиг. 36, на которой структура вертикальной развертки используется для режимов 6-14, которые представляют собой режимы, которые находятся в пределах горизонтального (преимущественно горизонтального) порогового угла (или количества режимов). Структура горизонтальной развертки используется для режимов 22-30, которые представляют собой режимы, которые находятся в пределах вертикального (преимущественно вертикального) порогового угла (или количества режимов). Диагональная развертка сверху вправо, упомянутая со ссылкой на фиг. 36 как практически "диагональная" развертка, используется для других режимов.
На фиг. 37 схематично иллюстрируется возможное отображение двух кандидатов структур развертки (вертикальной и горизонтальной) для направленных режимов прогнозирования, применимых для прямоугольных выборок цветности массива. Структура отличается от используемой (фиг. 36) для выборок яркости.
На фиг. 38 схематично иллюстрируется компоновка для выбора структуры развертки. Она может формировать часть функций, например, контроллера 343.
Селектор 1620 отвечает за режим прогнозирования для текущего блока и справочной таблицы 1630, которая отображает режим прогнозирования, для структуры развертки. Селектор 1620 выводит данные, обозначающие выбранную структуру развертки.
MDCS может быть разрешена для 4:2:2 и 4:4:4. Отображение структур развертки для режимов прогнозирования может быть таким же, как для 4:2:0, или может быть другим. Отношение каждого канала может иметь соответствующее отображение (и в этом случае селектор 1620 также может реагировать на соотношение каналов), или отображение может соответствовать отношениям между каналами. MDCS может применяться только к некоторым размерам блока, например, для размера блока не больше, чем пороговый размер блока. Например, максимальные размеры TU, в котором применяется MDCS, могут представлять собой:
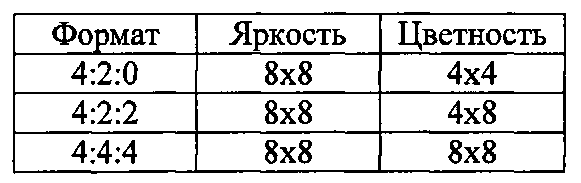
Для цветности MDCS может быть отключена, ограничена только TU 4×4 (яркости) или ограничена TU, используя только горизонтальную или вертикальную развертку. Воплощение свойства MDCS может меняться в зависимости от соотношения каналов.
Варианты осуществления раскрытия поэтому обеспечивают способ кодирования 4:2:2 или 4:4:4: видеоданных, в котором разности между прогнозируемыми и оригинальными выборками разделяют по частоте и кодируют, при этом способ содержит этапы, на которых прогнозируют выборки яркости и/или цветности изображения из других соответствующих опорных выборок, выведенных из того же изображения, в соответствии с режимом прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, режим прогнозирования выбирают для каждого из множества блоков выборок, из набора из двух или больше режимов прогнозирования -кандидатов; детектируют разность между выборками и соответствующими прогнозируемыми выборками; выполняют частотное разделение детектируемых разностей для блока выборок, используя преобразование разделения частоты для генерирования соответствующего набора коэффициентов с разделенной частотой; выбирают структуру развертки из набора из двух или больше кандидатов структур развертки, каждая структура развертки, определяющая порядок кодирования набора коэффициентов, разделенных по частоте, в зависимости от режима прогнозирования для этого блока выборок, используя отображение между структурой развертки и режимом прогнозирования, отображение между разными данными как между выборками цветности и яркости для, по меньшей мере, формата 4:4:4: (таким образом, другими словами, отображение будет разным для данных цветности 4:4:4 и данных яркости 4:4:4, и может быть разным или может не быть разным между данными яркости 4:2:2 и данными цветности 4:2:2); и кодирование разделенных по частоте данных разности в порядке разделенных по частоте коэффициентов, в соответствии с выбранной структурой развертки.
Отображение может быть разным для данных яркости 4:2:2 и цветности.
Отображение может быть разным для видеоданных 4:2:2 и 4:4:4.
В вариантах осуществления раскрытия размер текущего блока выборок яркости составлял 4×4 или 8×8 выборок. В качестве альтернативы варианты осуществления раскрытия содержат выбор размера текущего блока выборок из набора размеров кандидатов; и применение этапа выбора структуры развертки, если выбранный размер блока представлял собой один из заданного поднабора для набора размеров кандидатов. Таким образом, обработку отображения можно применять в отношении некоторых размеров блока, но не для других. Отображение может применяться (для 4:2:2) только в отношении выборок яркости.
В вариантах осуществления раскрытия набор структур - кандидатов развертки отличается для использования в отношении выборок яркости и цветности.
Этап выбора может быть выполнен с возможностью выбора горизонтальной структуры развертки в отношении набора преобладающе горизонтальных режимов прогнозирования, для выбора структуры вертикальной развертки в отношении набора преобладающе вертикальных режимов прогнозирования и для выбора диагональной структуры развертки в отношении других режимов прогнозирования.
Варианты осуществления раскрытия также направлены на способ декодирования видеоданных 4:2:2 или 4:4:4, в котором разность между прогнозированными и оригинальными выборами разделяют по частоте и кодируют, содержащий: прогнозируют выборки яркости и/или цветности изображения из других соответствующих опорных выборок, выведенных из того же изображения, в соответствии с режимом прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, режим прогнозирования выбирают для каждого из множества блоков выборок, из набора из двух или больше режимов - кандидатов прогнозирования; выбирают структуру развертки из набора из двух или больше структур - кандидатов развертки, причем каждая структура развертки, определяющая порядок кодирования набора коэффициентов, разделенных по частоте, в зависимости от режима прогнозирования для этого блока выборок, используя отображение между структурой развертки и режимом прогнозирования, отображение между ними является разным, как между выборками цветности и яркости, для, по меньшей мере, формата 4:4:4 (таким образом, что другими словами, отображение отличается для данных цветности 4:4:4 и данных яркости 4:4:4 яркости, и может отличаться или может не отличаться, как между данными яркости 4:2:2 и цветности 4:2:2); и декодируют разделенные по частоте данные разности, представляющие разделенную по частоте версию данных, обозначающую разность между выборками, предназначенными для декодирования, и соответствующими прогнозируемыми выборками, в порядке коэффициентов, разделенных по частоте, в соответствии с выбранной структурой развертки.
Что касается MDDT, на фиг. 39 схематично иллюстрируется компоновка для выбора преобразования с разделением по частоте, в соответствии с режимом прогнозирования. Компоновка может формировать часть функции модуля преобразования или контроллера.
Селектор 1700 принимает данные, определяющие текущий режим прогнозирования, и выбирает преобразование (из набора двух или больше кандидатов на преобразование), в зависимости от этого режима. Преобразование применяют с помощью механизма 1710 преобразования для преобразования выборки изображения в коэффициенты преобразования по частоте, на основе данных, обозначающих текущее преобразование, сохраненных в хранилище данных преобразования.
Примеры кандидата преобразований включают в себя дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST), преобразование Карунена-Лоэве; и преобразование, определенное соответствующими матрицами из рядов и столбцов для умножения матрицы на текущий блок выборок.
MDDT может быть разрешено, например, в отношении блоков цветности 4×4 в системе 4:4:4. Однако в вариантах осуществления раскрытия, MDDT разрешено в отношении данных 4:2:2.
В соответствии с этим варианты осуществления раскрытия могут обеспечить способ кодирования видеоданных 4:2:2 или 4:4:4, содержащий: выполняют прогнозирование выборок яркости и/или цветности изображения из других соответствующих опорных выборок, выведенных из того же изображения, в соответствии с режимом прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, режим прогнозирования выбирают для каждого множества блоков выборок из набора из двух или больше режимов - кандидатов прогнозирования; детектируют разности между выборками и соответствующими прогнозируемыми выборками; выбирают преобразование с разделением по частоте из двух или больше преобразований кандидатов разделений по частоте, в соответствии с режимом прогнозирования, ассоциированным с текущим блоком выборок, используя отображение между режимом преобразованием и прогнозирования, отображение между ними является разным, как между выборками цветности и яркости, для, по меньшей мере, формата 4:4:4 (таким образом, другими словами, отображение является разным для данных цветности 4:4:4 и яркости 4:4:4, и может быть или может не быть разным, как между данными яркости 4:2:2 и цветности 4:2:2); и кодируют детектированные разности с помощью разделения по частоте разности, используя выбранное преобразование с разделением по частоте.
Кандидаты преобразования могут содержать два или больше преобразований, выбранных из списка, состоящего из: дискретного косинусного преобразования; дискретного синусного преобразования; преобразования Карунена-Лоэве; и преобразований, определенных соответствующими матрицами из рядов и столбцов, для умножения матрицы на текущий блок выборок (таким образом, что, например, преобразование определяется TXTT, где Т представляет собой матрицу преобразования, верхний индекс Т обозначает транспонирование матрицы, и X обозначает блок выборок в матричной форме).
Как раньше, в вариантах осуществления раскрытия режим прогнозирования, ассоциированный с блоком выборок, которые должны быть прогнозированы, обозначает направление прогнозирования, определяющее одну или больше из других соответствующих опорных выборок, из которых каждая выборка для этого блока должна быть спрогнозирована, или может, например, обозначать режим прогнозирования dc.
В вариантах осуществления раскрытия отображение, предусмотренное между режимом прогнозирования и преобразованием с разделением по частоте, может быть разным между данными яркости и цветности для формата 4:2:2.
В вариантах осуществления раскрытия размер текущего блока выборок яркости представляет собой 4×4 выборок. В качестве альтернативы способ может содержать: выбирают размер текущего блока выборок из набора размеров кандидатов; и применяет этап выбора преобразования с частотным разделением, если выбранный размер блока является одним из заданного поднабора для набора размеров кандидатов, таким образом, что MDDT используется только для некоторых, но не для всех размеров блоков (например, TU).
В вариантах осуществления раскрытия этап кодирования детектированных разностей содержит: выбирают структуру развертки из набора из двух или больше кандидатов структур развертки, каждая структура развертки, определяющая порядок кодирования наборов коэффициентов, разделенных по частоте, в зависимости режима прогнозирования для этого блока выборок; и кодируют разделенные по частоте данные разности в порядке разделенных по частоте коэффициентов, в соответствии с выбранной структурой развертки. Другими словами, это представляет систему, в которой используется как MDCS, так и MDDT.
Флаг кодированного блока
Флаг кодированного блока (CBF) используется для обозначения (для TU яркости) содержит ли этот TU любые ненулевые коэффициенты. Он обеспечивает простой ответ типа да/нет, который позволяет процессу кодирования пропускать блоки, которые не содержат данные, предназначенные для кодирования.
В некоторых компоновках CBF используют для данных цветности, но они предусмотрены на каждом уровне разделения. Это связано с тем, что компоненты цветности часто имеют меньшее количество информации и, таким образом, может быть найден блок цветности, который содержит нулевые данные, на более высоком уровне разделения, чем уровень, на котором был найден соответствующий блок яркости, не содержащий данных.
В некоторых вариантах осуществления, однако цветность обрабатывают точно так же, как яркость, с целью распределения флагов CBF.
Кодирование САВАС и контекстное моделирование
На фиг. 40 схематично иллюстрируется операция энтропийного кодера САВАС.
Кодер САВАС работает в отношении двоичных данных, то есть данных, представленных только двумя символами 0 и 1. Кодер использует так называемый процесс контекстного моделирования, который выбирает "контекст" или вероятностную модель для последующих данных на основе ранее кодированных данных. Выбор контекста осуществляется детерминированным способом таким образом, что то же определение, на основе ранее декодированных данных, могло быть выполнено в декодере без необходимости добавления дополнительных данных (устанавливающих контекст), к кодированному потоку данных, передаваемому в декодер.
Как показано на фиг. 40, входные данные, которые должны быть кодированы, могут быть переданы в двоичный преобразователь 1900, если они не находятся уже в двоичной форме; если данные уже находятся в двоичной форме, выполняют обход преобразователя 1900 (с использованием переключателя 1910 на схеме). В настоящих вариантах выполнения преобразование в двоичную форму фактически осуществляется путем выражения квантованного DCT (или других разделенных по частоте) данных коэффициента, в виде последовательности двоичных "карт", которые будут дополнительно описаны ниже.
Двоичные данные могут затем обрабатываться по одному из двух путей обработки, "регулярного " пути и пути "обхода" (которые показаны схематично как отдельные пути, но которые* в вариантах осуществления раскрытия, описанных ниже, фактически могут быть воплощены на тех же этапах обработки, просто используя некоторые другие параметры). На обходном пути используется так называемый кодер 1920 обхода, который не обязательно использует контекстное моделирование в той же форме, что и нормальный путь. В некоторых примерах кодирования САВАС такой путь обхода может быть выбран, если существует потребность в особенно быстрой обработке партии данных, но в настоящих вариантах осуществления отмечены два свойства так называемых "обходных" данных: во-первых, обходные данные обрабатывают с помощью кодера (1950, 1960) САВАС, используя просто фиксированную контекстную модель, представляющую 50% вероятности; и во-вторых, обходные данные относятся к определенным категориям данных, один конкретный пример представляет собой данные знака коэффициента. В противном случае выбирают регулярный путь, используя схематичные переключатели 1930, 1940. Это улучшает обрабатываемые данные с помощью модуля 1950 моделирования контекста, после которого следует механизм 1960 кодирования.
Энтропийный кодер, показанный на фиг. 40, кодирует блок данных (то есть например, данные, соответствующие блоку коэффициентов, относящихся к блоку остаточного изображения), как одно значение, если блок сформирован полностью из данных со значением ноль. Для каждого блока, который не попадает в эту категорию, то есть для блока, который содержит, по меньшей мере, некоторые ненулевые данные, подготавливают "карту значимости". Карта значимости обозначает для каждого положения в блоке данных, предназначенном для кодирования, что соответствующий коэффициент в блоке не равен нулю. Данные карты значимости, находящиеся в двоичной форме, сами собой кодируются в соответствии с подходом САВАС. Использование карты значимости помогает при сжатии, поскольку данные не требуется кодировать для коэффициента с магнитудой, которую карта значимости обозначает как равную нулю. Кроме того, карта значимости может включать в себя специальный код для обозначения конечного ненулевого коэффициента в блоке, таким образом, что все из конечной высокой частоты/завершающих нулевых коэффициентов могут быть исключены из кодирования. После карты значимости следуют в кодированном потоке битов данные, определяющие значения ненулевых коэффициентов, установленных картой значимости.
Дополнительные уровни данных карты также подготавливают и кодируют, используя подход САВАС. Пример представляет карту, которая определяет в качестве двоичного значения (1 = да, 0 = нет), имеют ли данные коэффициента в положении на карте, где карта значимости была обозначена как фактически "ненулевая", значение "единица". Другая карта устанавливает, имеют ли данные коэффициента в положении карты, которое карта значимости обозначила как "ненулевое", фактически, значение равное "двум". Дополнительно карта обозначает, для тех положений карты, где карта значения обозначила, что данные коэффициента "не равны нулю", имеют ли данные значение, "большее чем два". Другая карта обозначает, снова для данных, идентифицированных как "ненулевые", знак значения данных (используя заданное двоичное обозначение, такое как 1 для +, 0 для - или, конечно, другой способ).
В вариантах осуществления раскрытия карта значимости и другие карты генерируют из квантованных коэффициентов DCT, например, с помощью модуля 360 развертки, и подвергают зигзагообразному процессу развертки (или процессу развертки, выбранному из описанных выше) до выполнения кодирования САВАС.
В общих чертах кодирование САВАС подразумевает прогнозирование контекста, или вероятностной модели, для следующего бита, предназначенного для кодирования, на основе других ранее кодированных данных. Если следующий бит является таким же, как бит, идентифицированный как "наиболее вероятно" с помощью вероятностной модели, тогда кодирование информации, такое как "следующий бит, согласуется с вероятностной моделью", может быть выполнено с большей эффективностью. Менее эффективно кодировать, что "следующий бит не согласуется с вероятностной моделью", поэтому вывод контекстных данных настолько важен для хорошей работы кодера. Термин "адаптивный" означает, что контексты модели или вероятностные модели адаптированы или изменяются во время кодирования, в попытке обеспечения хорошего соответствия со (все еще не кодированными) следующими данными.
Используя простую аналогию, в письменном английском языке, буква "U" встречается относительно редко. Но в положении буквы непосредственно после буквы "Q", она, действительно, следует очень часто. Так, вероятностная модель может устанавливать вероятность "U" как очень низкое значение, но если текущая буква представляет собой "Q", вероятностная модель для "U" в качестве следующей буквы может быть установлена как очень высокое значение вероятности.
Кодирование САВАС используют в настоящих компоновках для, по меньшей мере, карты значимости и карт, обозначающих, равны ли ненулевые значения единице или двум. Обработка обхода, которая в данных вариантах осуществления идентична кодированию САВАС, но учитывая тот факт, что вероятностная модель является фиксированной на равном (0.5:0.5) распределении вероятности единиц и нолей, используется для, по меньшей мере, данных знака, и карта обозначает, что значение >2. Для этих положений данных, обозначенных как >2, можно использовать отдельное так называемое кодирование данных сброса, для кодирования фактического значения данных. Это может включать в себя технологию кодирования Голомба-Райса.
Контекстное моделирование САВАС и процесс кодирования более подробно описаны в публикации WD4: Working Draft 4 of High-Efficiency Video Coding, JCTVC-F803_d5, Draft ISO/IEC 23008-HEVC; 201x(E) 2011-10-28.
Контекстные переменные сбрасывают в конце обработки среза.
Далее будет сделана ссылка на способ кодирования видеоданных, содержащий: прогнозируют блоки из выборок яркости и/или цветности изображения из других соответствующих опорных выборок или значений; детектируют разности между выборками в блоке и соответствующими прогнозированными выборами; выполняют разделение по частоте детектируемых разностей в отношении каждого блока для генерирования соответствующего массива разделенных по частоте коэффициентов, упорядоченных в соответствии с увеличенными пространственными частотами, представленными коэффициентами; и выполняют энтропийное кодирование разделенных по частоте коэффициентов, используя адаптивный к контексту арифметический код, который кодирует коэффициенты в отношении контекстных переменных, обозначающих вероятность коэффициента, имеющего определенное значение коэффициента; в котором этап энтропийного кодирования содержит: разделяют каждый массив на две или больше группы коэффициентов, группы представляют собой неквадратные подмассивы; и выбирают переменную контекста для кодирования коэффициента в соответствии с пространственными частотам, представленными этими коэффициентами и, в зависимости от значений коэффициентов в одной или больше расположенных рядом группах коэффициентов в этом массиве или в массиве, соответствующем соседнему блоку выборок.
Иногда это известно как выделение контекстной переменной по соседству, что позволяет устанавливать структуру выделения контекстной переменной для положения коэффициента на основе от подмассива к подмассиву (подмассив представляет собой часть блока коэффициентов) в соответствии с тем, присутствуют ли какие-либо ненулевые коэффициенты в соседних подмассивах. Структура развертки, выбранная для использования с частотно-разделенными данными, может быть соответствующей, таким образом, что этап энтропийного кодирования содержит кодирование коэффициентов массива в порядке, зависимом от структуре развертки, выбранной из набора из одной или больше структур - кандидата развертки. Каждый подмассив коэффициентов можно рассматривать как последовательный набор коэффициентов в порядке, определенном структурой развертки, применимой к этому массиву, где т представляет собой целочисленный коэффициент для количества коэффициентов в массиве. Например, т может быть равен 16.
На фиг. 41А - 41D схематично иллюстрируется ситуация для ранее предложенного выделения по-соседству.
В вариантах осуществления раскрытия этап выбора выделяет коэффициенты в группе для одного из установленных кандидатов в контекстных переменных таким образом, что в пределах каждой группы последовательные поднаборы коэффициентов, в порядке развертки, выделяют для соответствующих кандидатов контекстных переменных. В примерах, показанных на фиг. 42А - 43В, используется порядок вертикальной развертки, и выделение выполняют в этом порядке. На фиг. 44, используется горизонтальный порядок развертки, и выделение выполняют в этом порядке.
Как отмечено выше, этап выбора зависит от того, имеют ли расположенные рядом коэффициенты нулевое значение. Здесь могут присутствовать два кандидата контекстных переменных для каждой группы коэффициентов.
Возвращаясь теперь к фиг. 42А, 42В, 43А, 43В и 44, формат показанных чертежей является таким, что коэффициенты являются упорядоченными в пределах массива так, что горизонтальная пространственная частота повышается слева вправо в массиве и вертикальная пространственная частотах увеличивается сверху вниз массива.
Существуют две опции того, как работать с потерянными данными (например, данные на кромках изображения или среза, или данные, которые еще не были кодированы. В одной из опций (фиг. 42А), если группа коэффициентов рядом с текущей группой еще не была разделена по частоте, на этапе выбора назначают нулевые значения для этой группы, с целью выбора контекстной переменной для коэффициента в текущей группе. В другой опции (фиг. 42В), если первая группа коэффициентов рядом с текущей группой еще не была разделена по частоте, но вторая группа, соседняя с текущей группой была разделена по частоте, тогда при выборе назначают значения второй группы для первой группы с целью выбора контекстной переменной для коэффициента в текущей группе.
Обращаясь к фиг. 42А - 42В, если обе группы справа и снизу от текущей группы содержат данные ненулевых коэффициентов, то одну контекстную переменную выделяют, используя этап выбора для первых m коэффициентов текущей группы, в порядке развертки, и другую контекстную переменную для остающихся коэффициентов текущей группы. Если группа справа от текущей группы имеет ненулевые данные, но группа ниже текущей группы не имеет таких данных, тогда одну переменную контекста выделяют для этапа выбора для верхней половины текущей группы, и другую контекстную переменную для остальных коэффициентов текущей группы. Если группа ниже текущей группы имеет ненулевые данные, но группа справа от текущей группы не имеет такие данные, то одну контекстную переменную выделяют на этапе выбора для первых р коэффициентов текущей группы, в порядке развертки, и другую контекстную переменную для остающихся коэффициентов текущей группы. Если группа ниже текущей группы имеет ненулевые данные, но группа справа от текущей группы не имеет такие данные, тогда одну контекстную переменную выделяют путем выбора этапа для левой половины текущей группы, и другую контекстную переменную для остальных коэффициентов текущей группы. В представленных примерах m и р представляют собой целые числа, и m не равно р. В частности, в представленных примерах текущая группа содержит подмассив из 8×2 или 2×8 коэффициентов; и m=13, и р=6.
Показанный способ применим для блоков выборок, которые имеют размер, по меньшей мере, 8 выборок, по меньшей мере, в одном измерении. Пример составляет блок 8×8 или больше.
Эта технология применима, в случае когда, по меньшей мере, некоторые из блоков выборок (TU) являются квадратными, или, по меньшей мере, некоторые из блоков выборок (TU) являются неквадратными.
Рассмотрим теперь фиг. 45, варианты осуществления раскрытия также направлены на способ кодирования видеоданных, содержащий: прогнозируют блоки яркости и/или цветности выборок изображения из других соответствующих опорных выборок или значений; детектируют разности между выборками в блоке и в соответствующими прогнозируемыми выборками; выполняют разделение по частоте детектируемых разностей в отношении каждого блока, для того, чтобы генерировать соответствующий массив разделенных по частоте коэффициентов, упорядоченных в соответствии с пространственными частотами, представленными коэффициентами, причем один из коэффициентов представляет значение dc блока; и выполняют энтропийное кодирование разделенных по частоте коэффициентов, используя адаптивный к контексту арифметический код, который кодирует коэффициенты в отношении переменных контекста, обозначающих вероятность коэффициента, имеющую определенное значение коэффициента; в котором этап энтропийного кодирования содержит: выполняют разделение каждого массива на две или больше группы коэффициентов, причем группы являются неквадратными подмассивами; и генерируют выделение контекстных переменных для кодирования соответствующих коэффициентов, генерируемых в отношении неквадратного подмассива, в соответствии с пространственными частотами, представленными этим коэффициентом, путем повторения положения контекстных переменных выделений, применимых для квадратного подмассива, но без повторения положения выделения переменной контекста для коэффициента dc. Как показано на фиг. 45, структура выделения для подмассива 8×16 представляет собой структуру с повторяющимся значением, выведенную из структуры выделения подмассива 8×8, но выделение dc (верхний левый угол на чертеже) не повторяется по величине. Другими словами, переменная контекста, выделенная для коэффициента dc, не выделяется для любого другого коэффициента. Сигналы данных
Следует понимать, что сигналы данных, генерируемые вариантами устройства кодирования, описанного выше, и среда сохранения или передачи, переносящая такие сигналы, рассматриваются для представления в вариантах осуществления настоящего раскрытия.
В случае описания выше способов обработки, кодирования или декодирования, следует понимать, что устройство, выполненное с возможностью выполнения таких способов, также рассматривается как представляющее варианты осуществления раскрытия. Также следует понимать, что устройство сохранения, передачи, съемки и/или отображения видеоданных, в которое встроены такие технологии, рассматривается как представляющее вариант осуществления настоящего раскрытия.
В той мере как варианты осуществления раскрытия были описаны как воплощенные, по меньшей мере частично, с использованием управляемого программного устройства обработки данных, следует понимать, что энергонезависимый считываемый устройством носитель информации, на котором записано такое программное обеспечение, такой как оптический диск, магнитный диск, полупроводниковое запоминающее устройство и т.п., также рассматривается как вариант осуществления настоящего раскрытия.
Следует понимать, что множество модификаций и вариаций настоящего раскрытия возможно с учетом представленного выше описания. Поэтому следует понимать, что в пределах объема приложенной формулы изобретения, технология может быть выполнена на практике по-другому, чем, в частности, описано здесь.
Соответствующие варианты осуществления определены следующими пронумерованными пунктами:
(1) Способ кодирования или декодирования видеоданных, в котором выборки яркости и цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, подлежащей прогнозированию, при этом выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем выборки яркости, так, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности;
содержащий этапы, на которых:
обнаруживают первое направление прогнозирования, полученное в отношении сетки с первым соотношением размеров, в отношении набора текущих выборок, предназначенных для прогнозирования; и
применяют направления отображения к направлению прогнозирования, так, чтобы сгенерировать второе направление прогнозирования, определенное в отношении сетки выборок с другим соотношением размеров того же набора текущих выборок, подлежащих прогнозированию.
(2) Способ по (1), в котором первое направление прогнозирования определено в отношении одной из выборок яркости или цветности, а второе направление прогнозирование определено в отношении другой одной из выборок яркости или цветности.
(3) Способ по (1), в котором опорные выборки представляют собой выборки того же соответствующего изображения, что и выборки, подлежащие прогнозированию.
(4) Способ по любому из (1)-(3), в котором:
первое направление прогнозирования определено в отношении квадратного блока выборок яркости, включающего в себя текущую выборку яркости; а
второе направление прогнозирования определено в отношении прямоугольного блока выборок цветности, включающего в себя текущую выборку цветности.
(5) Способ по любому из (1)-(4), в котором выборки цветности содержат выборки первого и второго компонентов цветности, дополнительно содержащий этапы, на которых:
применяют этап отображения направления в отношении первого компонента цветности;
предоставляют другой режим прогнозирования в отношении второго компонента цветности.
(6) Способ по (5), содержащий этап, на котором:
предоставляют другие соответствующие режимы прогнозирования для каждого из компонентов яркости и цветности.
(7) Способ по (5) или (6), в котором различные режимы прогнозирования содержат режим, с помощью которого выполняют прогнозирование выборок второго компонента цветности из выборок первого компонента цветности.
(8) Способ по (6), в котором первый компонент цветности представляет собой компонент Cb, а второй компонент цветности представляет собой компонент Cr.
(9) Способ по любому из (1)-(8), содержащий этап фильтрации опорных выборок.
(10) Способ по любому из (1)-(9), содержащий этап предоставления выборок яркости и выборок цветности, в качестве видеосигнала в формате 4:2:2.
(11) Способ по любому из (1)-(10), в котором приложение отображения направления содержит следующие этапы, на которых:
(i) выводят угловой шаг для прогнозирования внутри изображения и его инверсию в соответствии с направлением яркости;
(ii) если направление яркости является преобладающе вертикальным, тогда при уменьшении наполовину углового шага для прогнозирования внутри изображения его уменьшают наполовину и увеличивают вдвое его инверсию; и
(iii) в противном случае если направление яркости является преобладающе горизонтальным, тогда удваивают угловой шаг для прогнозирования внутри изображения и уменьшают наполовину его инверсию.
(12) Способ кодирования или декодирования видеоданных, в котором яркость и первые, и вторые выборки компонента цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, способ, содержащий этап, на котором: прогнозируют выборки второго компонента цветности по выборкам первого компонента цветности.
(13) Способ кодирования или декодирования видеоданных, в котором яркость и первую и вторую выборки компонента цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, способ, содержащий этап фильтрации опорных выборок.
(14) Способ кодирования или декодирования видеоданных, в котором выборки яркости и цветности изображения прогнозируют по другим соответствующим опорным выборкам того же изображения, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличаются от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок из выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности, выборки цветности, представляющие первый и второй компоненты цветности;
содержащий этапы, на которых:
выбирают режим прогнозирования, определяющий выбор одной или больше опорных выборок для прогнозирования текущей выборки цветности первого компонента цветности; и
выбирают другой режим прогнозирования, определяющий другой выбор одной или больше опорных выборок, для прогнозирования текущей выборки цветности второго компонента цветности, расположенного в том же месте, что и текущая выборка цветности первого компонента цветности.
(15) Способ кодирования или декодирования видеоданных, в котором выборки яркости и цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается для отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности; способ, содержащий этап, на котором:
применяют другой соответствующий алгоритм прогнозирования для выборок яркости и цветности, в зависимости от разности соотношения размеров.
(16) Программное обеспечение, которое при его выполнении компьютером, обеспечивает выполнение компьютером способа в соответствии с любым из (1)-(16).
(17) Считываемый компьютером энергонезависимый носитель информации, на котором содержится программное обеспечение по (16).
(18) Сигнал данных, содержащий кодированные данные, генерируемые в соответствии со способом по любому из (1) - (15).
(19) Устройство кодирования или декодирования видеоданных, в котором выборки яркости и цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности;
содержащее:
устройство обнаружения, выполненное с возможностью обнаружения первого направления прогнозирования, определенного в отношении сетки из первого отношения размеров в отношении набора текущих выборок, предназначенных для прогнозирования;
блок отображения направления, выполненный с возможностью применения отображения направления к направлению прогнозирования, так, чтобы генерировать второе направление прогнозирования, определенное в отношении сетки выборок с другим соотношением размеров того же набора текущих выборок, предназначенных для прогнозирования.
(20) Устройство кодирования или декодирования видеоданных, в котором выборки яркости и цветности изображения прогнозируют по другим соответствующим опорным выборкам того же изображения, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности таким образом, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности, выборки цветности, представляющие первый и второй компоненты цветности;
содержащее:
селектор, выполненный с возможностью выбора режима прогнозирования, определяющий выбор одной или больше опорных выборок, для прогнозирования текущей выборки цветности первого компонента цветности; и выбора другого режима прогнозирования, определяющего другой выбор одной или больше опорных выборок, для прогнозирования текущей выборки цветности второго компонента цветности, расположенного в том же месте с текущей выборкой цветности первого компонента цветности.
(21) Устройство кодирования или декодирования видеоданных, в котором выборки яркости и выборки цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, выборки цветности, имеющие более низкую горизонтальную и/или вертикальную частоту выборки, чем у выборок яркости, таким образом, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности; содержащее:
модуль прогнозирования, выполненный с возможностью применения другого соответствующего алгоритма прогнозирования для выборок яркости и цветности, в зависимости от разности в отношении размера.
(22) Устройство кодирования или декодирования видеоданных, в котором выборки яркости и первого, и второго компонентов цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, устройство, содержащее модуль прогнозирования, выполненный с возможностью прогнозирования выборки второго компонента цветности по выборкам первого компонента цветности.
(23) Устройство кодирования или декодирования видеоданных, в котором выборки яркости и первого, и второго компонентов цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с выборкой, предназначенной для прогнозирования, устройство, содержащее фильтр, выполненный с возможностью фильтрации опорных выборок.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ДАННЫХ | 2013 |
|
RU2599935C2 |
| БЛОЧНОЕ АДАПТИВНОЕ КОДИРОВАНИЕ С ПРЕОБРАЗОВАНИЕМ ЦВЕТОВОГО ПРОСТРАНСТВА | 2015 |
|
RU2698760C2 |
| ЗАВИСИМЫЙ ОТ РЕЖИМА КОЭФФИЦИЕНТ СКАНИРОВАНИЯ И ПРЕОБРАЗОВАНИЕ НАПРАВЛЕНИЯ ДЛЯ РАЗНЫХ ФОРМАТОВ ДИСКРЕТИЗАЦИИ ЦВЕТА | 2013 |
|
RU2751080C2 |
| ЗАВИСИМЫЙ ОТ РЕЖИМА КОЭФФИЦИЕНТ СКАНИРОВАНИЯ И ПРЕОБРАЗОВАНИЕ НАПРАВЛЕНИЯ ДЛЯ РАЗНЫХ ФОРМАТОВ ДИСКРЕТИЗАЦИИ ЦВЕТА | 2013 |
|
RU2619888C2 |
| КОДИРОВАНИЕ ФЛАГОВ КОДИРОВАННЫХ БЛОКОВ | 2013 |
|
RU2627119C2 |
| ПАЛИТРОВОЕ ПРОГНОЗИРОВАНИЕ ПРИ КОДИРОВАНИИ ВИДЕО НА ОСНОВЕ ПАЛИТР | 2014 |
|
RU2641252C2 |
| СПОСОБ, УСТРОЙСТВО И СИСТЕМА ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ КАРТЫ ЗНАЧИМОСТИ ДЛЯ ОСТАТОЧНЫХ КОЭФФИЦИЕНТОВ ЕДИНИЦЫ ПРЕОБРАЗОВАНИЯ | 2013 |
|
RU2595936C2 |
| ГРУППИРОВАНИЕ БИНОВ ОБХОДА ПАЛИТР ДЛЯ ВИДЕОКОДИРОВАНИЯ | 2016 |
|
RU2706877C2 |
| СИСТЕМЫ И СПОСОБЫ ПРИМЕНЕНИЯ ФИЛЬТРОВ ДЕБЛОКИРОВАНИЯ К ВОССТАНОВЛЕННЫМ ВИДЕОДАННЫМ | 2019 |
|
RU2770650C1 |
| СИСТЕМЫ И СПОСОБЫ ПРИМЕНЕНИЯ ФИЛЬТРОВ ДЕБЛОКИРОВАНИЯ К ВОССТАНОВЛЕННЫМ ВИДЕОДАННЫМ | 2019 |
|
RU2768016C1 |



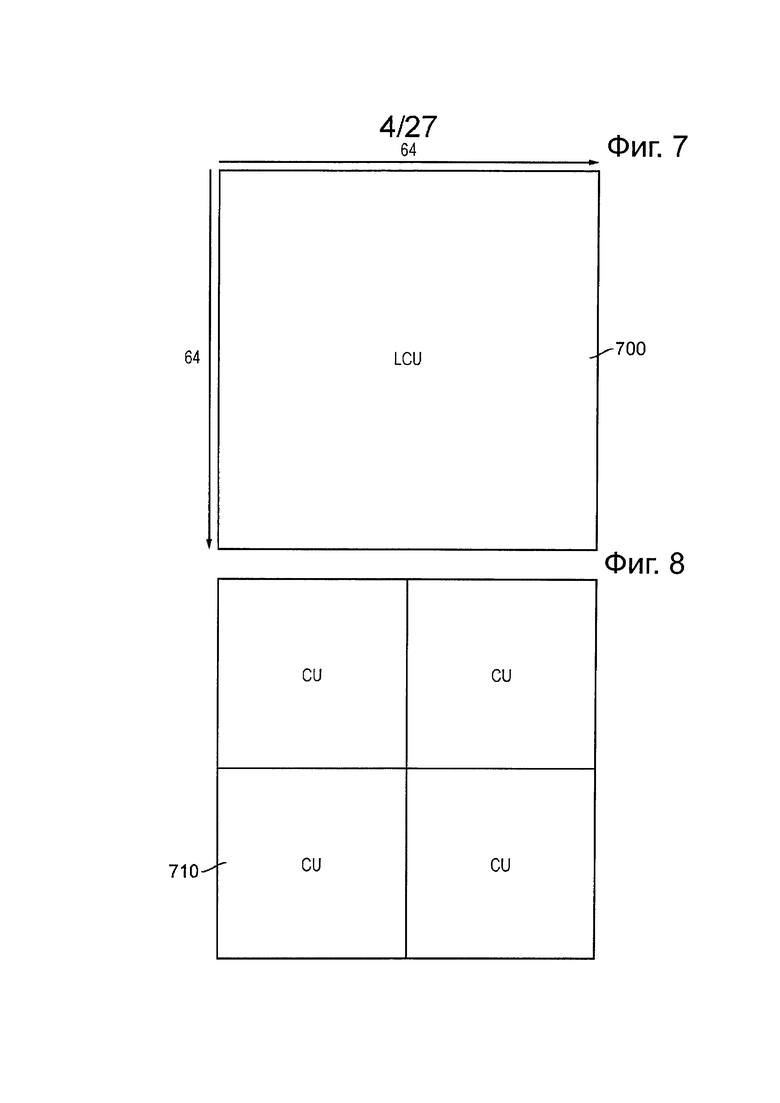
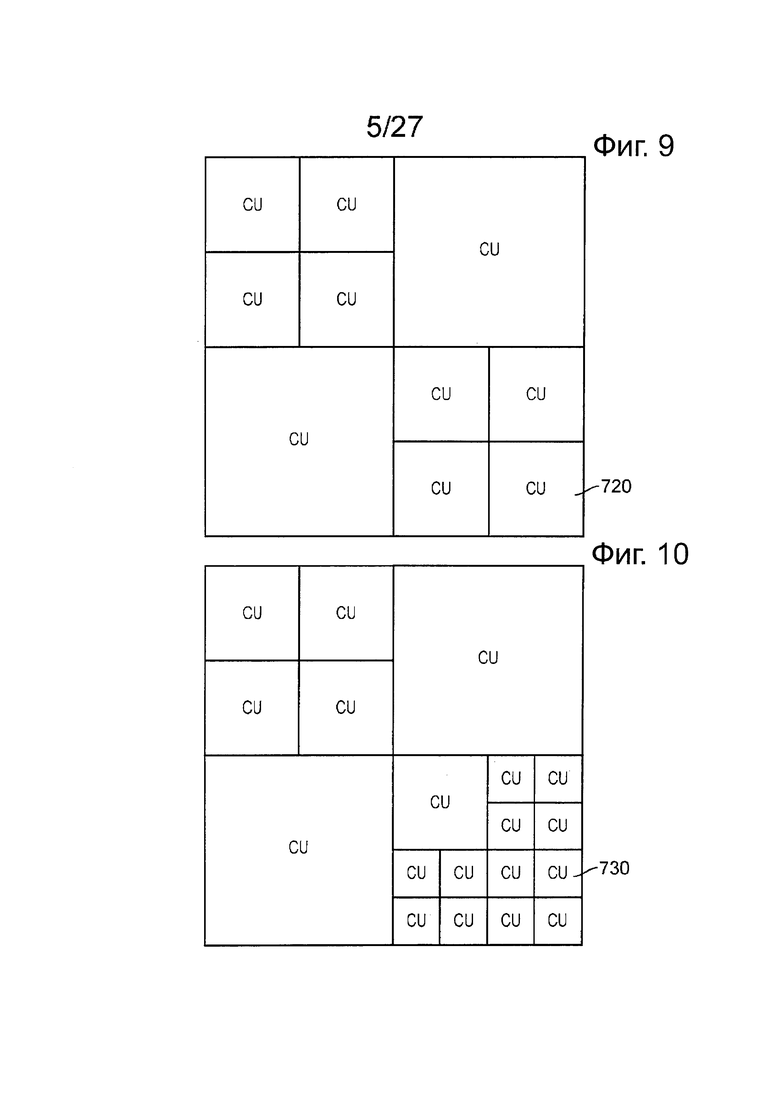
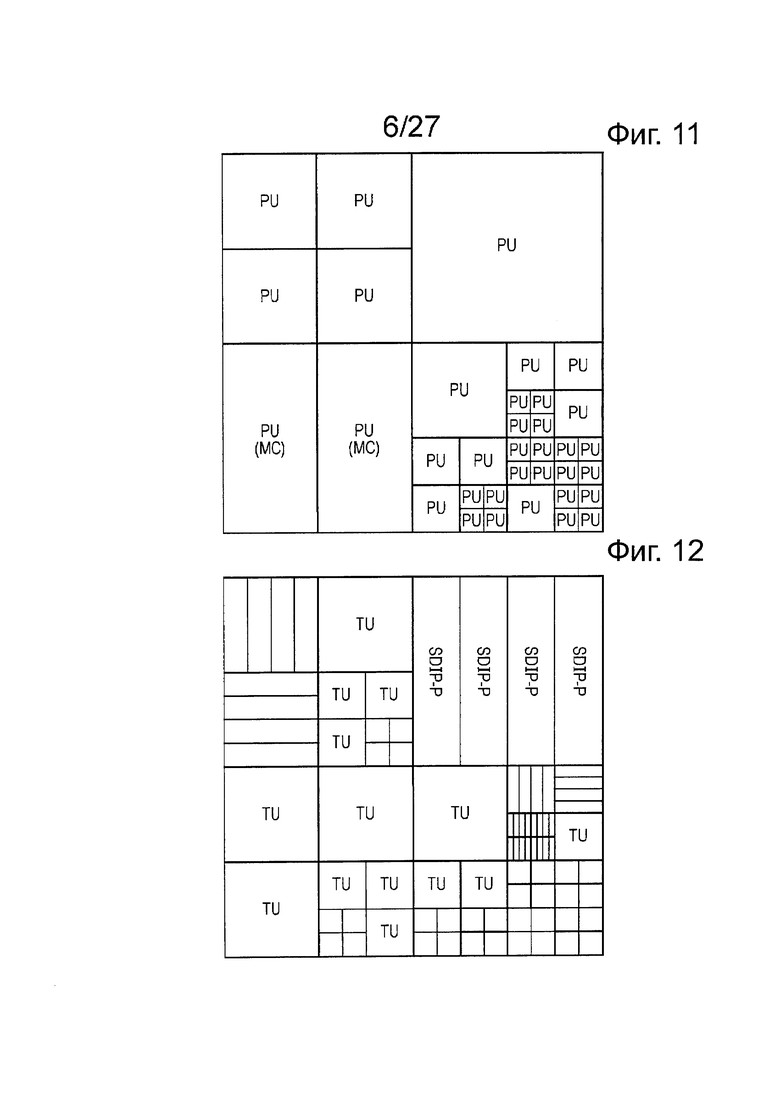


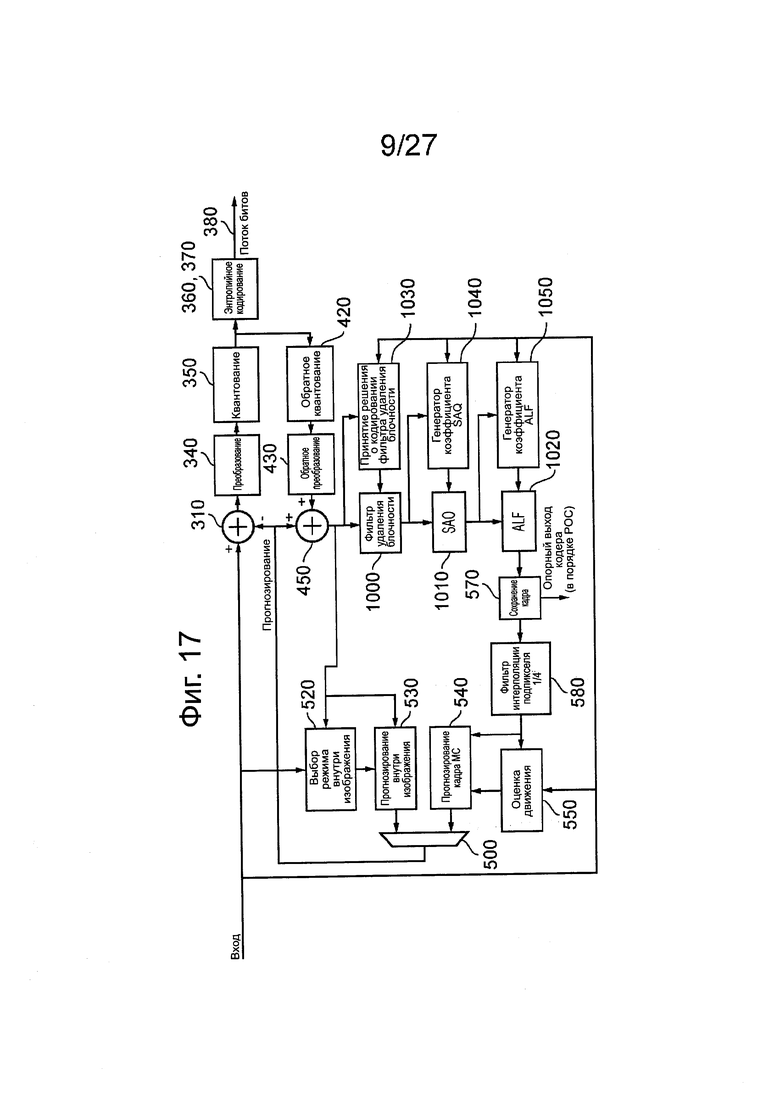



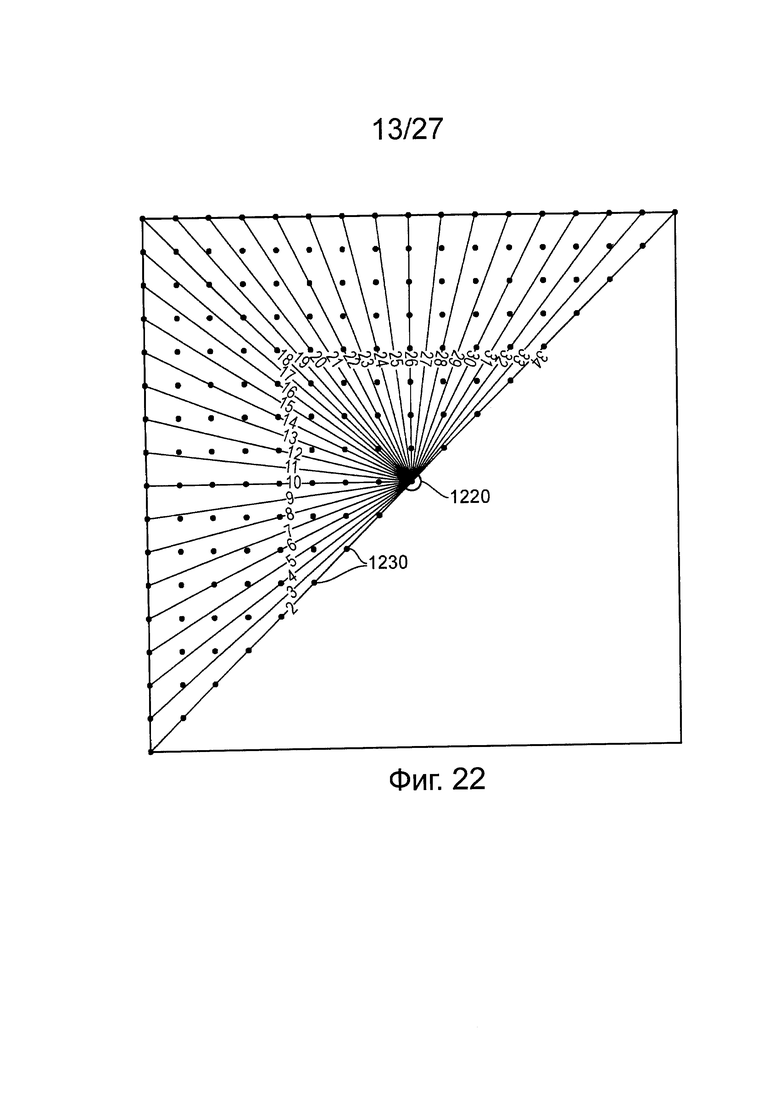



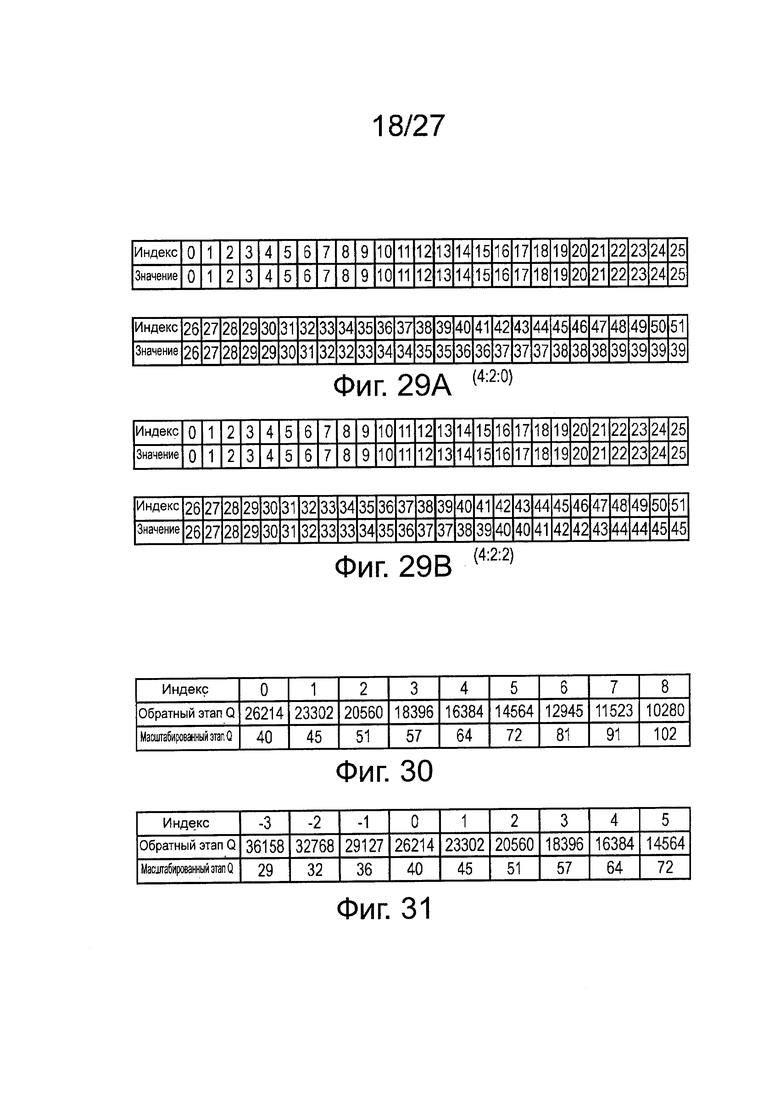
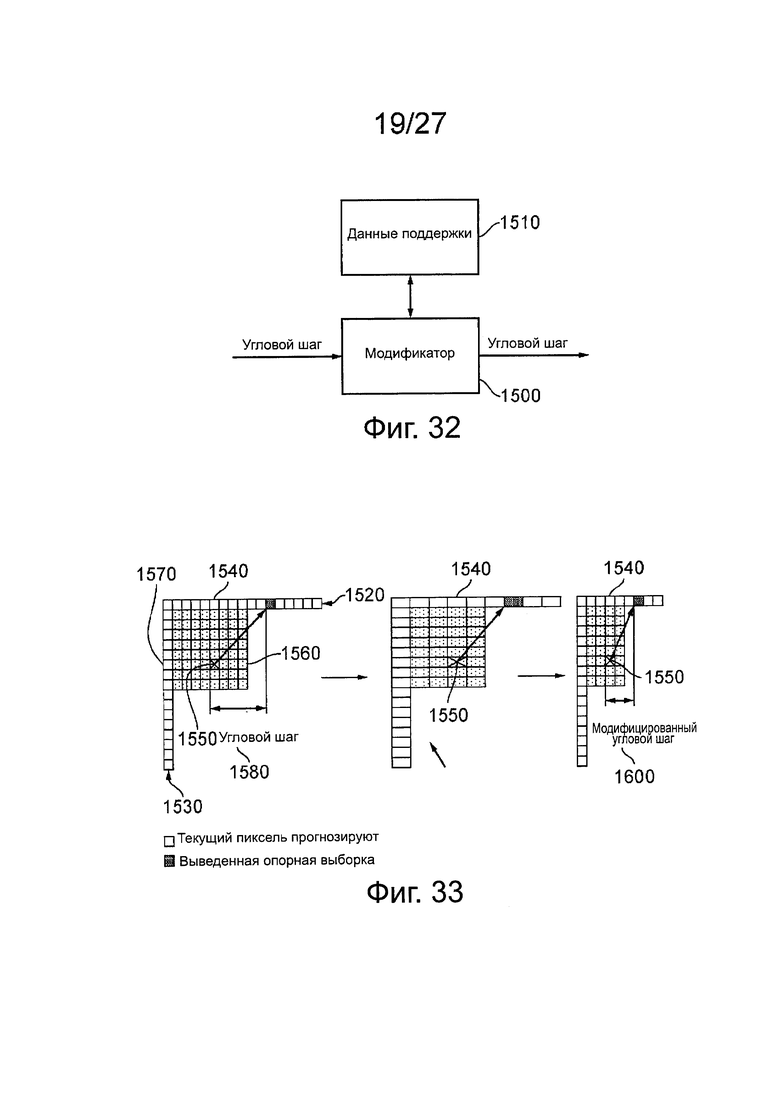

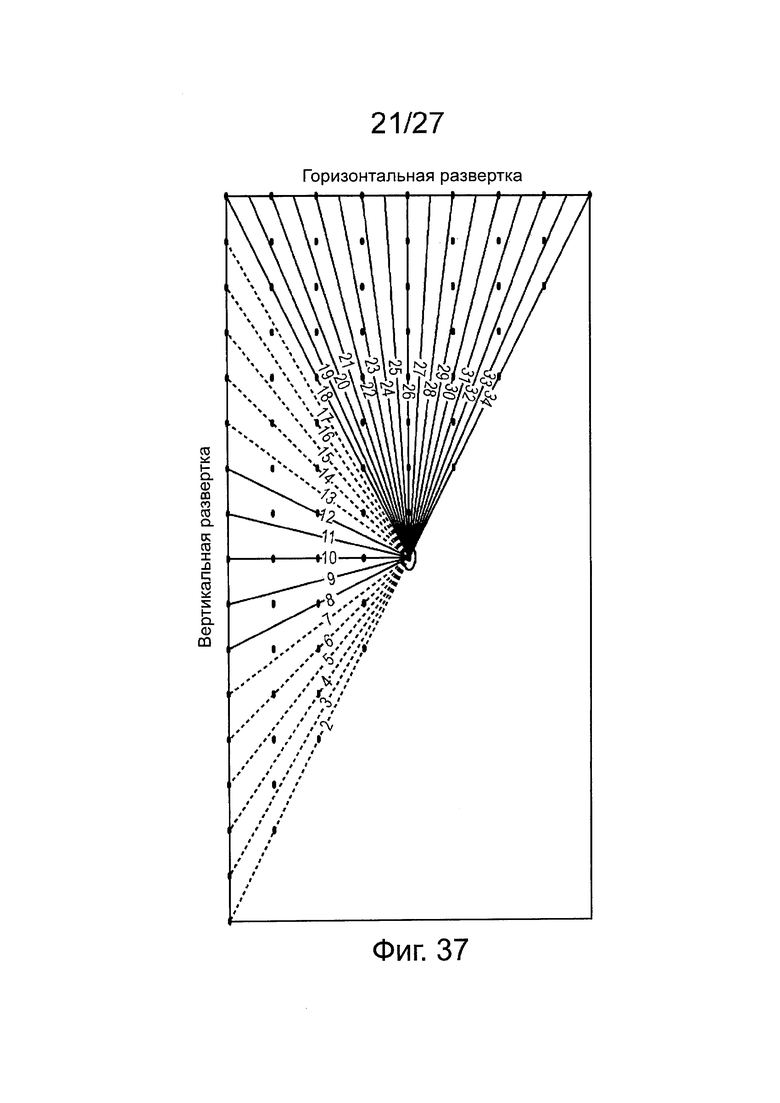
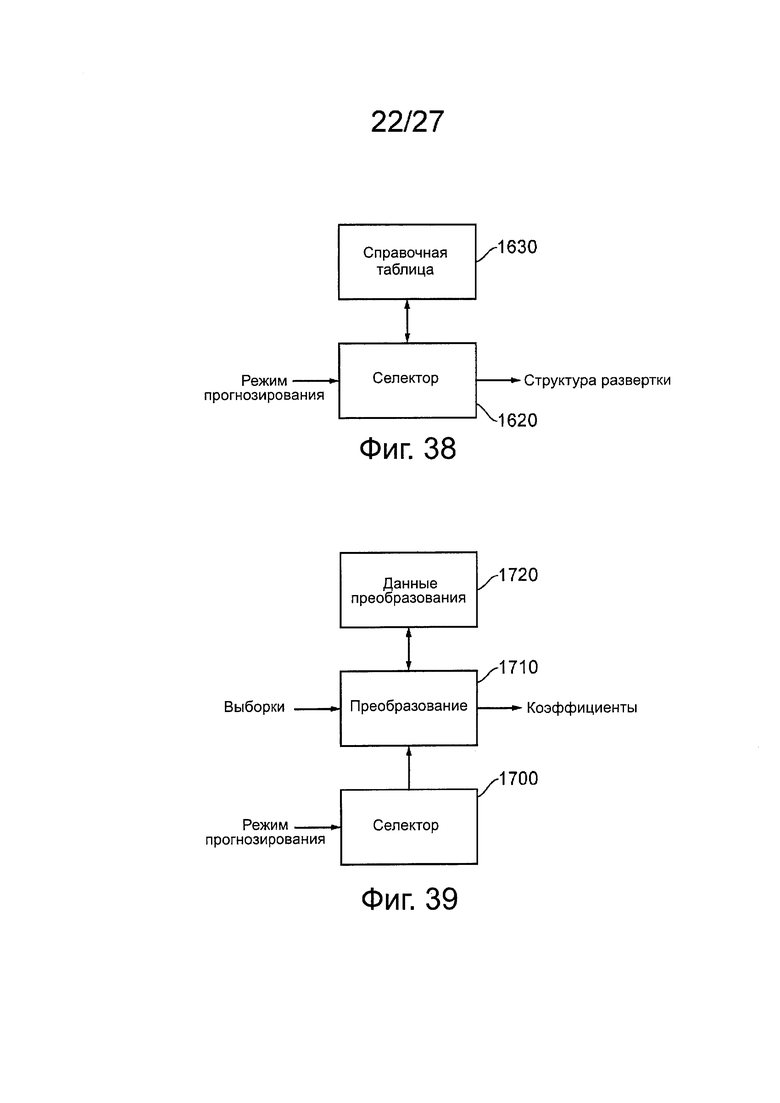




Изобретение относится к области кодирования декодирования данных. Технический результат - обеспечение меньшей степени сжатия в каналах цветности. Способ декодирования видео, в котором выборки яркости и цветности прогнозируют по другим соответствующим опорным выборкам в соответствии с направлением прогнозирования, ассоциированным с текущей выборкой, подлежащей прогнозированию, при этом выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем выборки яркости, так, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности; содержит этапы, на которых: обнаруживают первое направление прогнозирования, определенное в отношении первой сетки с первым соотношением размеров, в отношении набора текущих выборок, подлежащих прогнозированию; и применяют отображение направления к направлению прогнозирования для генерирования второго направления прогнозирования, определенного в отношении второй сетки с другим соотношением размеров. 6 н. и 27 з.п. ф-лы, 45 ил.
1. Способ декодирования видео, в котором выборки яркости и цветности прогнозируют по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с текущей выборкой, подлежащей прогнозированию, при этом выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем выборки яркости, так, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности;
содержащий этапы, на которых:
обнаруживают первое направление прогнозирования, определенное в отношении первой сетки с первым соотношением размеров, в отношении набора текущих выборок, подлежащих прогнозированию; и
применяют отображение направления к направлению прогнозирования для генерирования второго направления прогнозирования, определенного в отношении второй сетки с другим соотношением размеров.
2. Способ по п. 1, в котором первая сетка, используемая для обнаружения первого направления прогнозирования, определена в отношении положений выборки одной из выборок яркости или цветности, и вторая сетка, используемая для обнаружения второго направления прогнозирования, определена в отношении положений выборок другой из выборок цветности или яркости.
3. Способ по п. 1, в котором направление прогнозирования представляет собой направление прогнозирования внутри изображения, а опорные выборки представляют собой выборки, выведенные из того же соответствующего изображения, что и выборки, подлежащие прогнозированию.
4. Способ по любому из пп. 1-3, в котором:
первое направление прогнозирования определено в отношении квадратного блока выборок яркости, включающего в себя текущую выборку яркости; а
второе направление прогнозирования определено в отношении прямоугольного блока выборок цветности, включающего в себя текущую выборку цветности.
5. Способ по п. 1, в котором выборки цветности содержат выборки первого и второго компонентов цветности, дополнительно содержащий этапы, на которых:
применяют этап отображения направления в отношении первого компонента цветности; и
предоставляют другой режим прогнозирования в отношении второго компонента цветности.
6. Способ по п. 5, содержащий этап, на котором:
обеспечивают другие соответствующие режимы прогнозирования для каждого из компонентов цветности и яркости.
7. Способ по п. 5, в котором другой режим прогнозирования содержит режим, в котором выборки второго компонента цветности прогнозируют по выборкам первого компонента цветности.
8. Способ по п. 5, в котором первый компонент цветности представляет собой компонент Cb, а второй компонент цветности представляет собой компонент Cr.
9. Способ по п. 5, содержащий этап предоставления выборок яркости и выборок цветности в качестве видеосигнала формата 4:2:2.
10. Способ по п. 5, в котором направление прогнозирования определяет положение выборки относительно группы кандидатов опорных выборок, содержащих горизонтальный ряд и вертикальный столбец из выборок, соответственно, расположенных выше и слева от набора текущих выборок, подлежащих прогнозированию.
11. Способ по п. 10, содержащий этапы, на которых:
упорядочивают группы кандидатов опорных выборок в виде линейного массива опорных выборок; и
применяют сглаживающий фильтр для опорных выборок линейного массива в направлении вдоль линейного массива.
12. Способ по п. 10, в котором:
направление прогнозирования для текущей выборки определяют с помощью ассоциированного углового шага; при этом
угловой шаг для, преимущественно, вертикального направления прогнозирования представляет собой смещение вдоль горизонтального ряда положений выборки группы кандидатов опорных выборок относительно положения выборки в указанном ряду, которое вертикально смещено от текущей выборки;
угловой шаг для, в основном, горизонтального направления прогнозирования представляет собой смещение вдоль вертикального столбца положений выборки группы кандидатов опорных выборок относительно положения выборки в указанном столбце, горизонтально смещенного от текущей выборки; а
положение выборки вдоль горизонтального ряда или вертикального столбца, обозначенное смещением, обеспечивает указатель на положение выборки, используемой при прогнозировании текущей выборки.
13. Способ по п. 12, в котором этап применения отображения по направлению содержит подэтап, на котором: применяют заданную функцию к угловому шагу, соответствующему первому направлению прогнозирования.
14. Способ по п. 13, в котором этап применения отображения по направлению содержит этапы, на которых:
выводят угловой шаг в соответствии с первым направлением прогнозирования; и
если первое направление прогнозирования является, преимущественно, вертикальным, уменьшают наполовину соответствующий угловой шаг для генерирования углового шага для второго направления прогнозирования; или
если первое направление прогнозирования является, преимущественно, горизонтальным, тогда удваивают соответствующий угловой шаг для генерирования углового шага второго направления прогнозирования.
15. Способ по п. 14, в котором, если угловой шаг не является целым числом, угловой шаг используется для определения группы из двух или более положений выборок в пределах группы кандидатов опорных выборок для интерполяции для обеспечения прогнозирования текущей выборки.
16. Способ по п. 1, в котором этап применения отображения по направлению содержит подэтап, на котором: используют первое направление прогнозирования для индексации справочной таблицы, причем таблица выполнена с возможностью обеспечения соответствующих значений второго направления прогнозирования.
17. Способ по п. 1, в котором этап обнаружения первого направления прогнозирования содержит подэтап, на котором обнаруживают информацию, определяющую направление прогнозирования, ассоциированное с видеоданными, подлежащими декодированию.
18. Способ по п. 1, в котором:
первое направление прогнозирования используют для прогнозирования выборок яркости из набора выборок; а
второе направление прогнозирования, выведенное на этапе применения из первого направления прогнозирования, используют для прогнозирования выборок цветности для указанного набора выборок.
19. Способ кодирования видеоданных, в котором прогнозируют выборки яркости и цветности по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с текущей выборкой, подлежащей прогнозированию, при этом выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем выборки яркости, так, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое соотношение размеров, чем соответствующий блок выборок цветности; причем способ содержит этапы, на которых:
обнаруживают первое направление прогнозирования, определенного в отношении первой сетки с первым соотношением размеров, в отношении набора текущих выборок, подлежащих прогнозированию; и
применяют отображение направления к направлению прогнозирования для генерирования второго направления прогнозирования, определенное в отношении второй сетки с другим соотношением размеров.
20. Способ по п. 19, в котором этап обнаружения первого направления прогнозирования содержит подэтап, на котором выбирают направление прогнозирования в соответствии с проверкой двух или более кандидатов направлений прогнозирования.
21. Способ по п. 19, в котором первая сетка, используемая для обнаружения первого направления прогнозирования, определена в отношении положений выборки одной из выборок яркости или цветности, и вторая сетка, используемая для обнаружения второго направления прогнозирования, определена в отношении положений выборок другой из выборок цветности или яркости.
22. Способ по п. 19 или 21, в котором:
первое направление прогнозирования определено в отношении квадратного блока выборок яркости, включающего в себя текущую выборку яркости; а
второе направление прогнозирования определено в отношении прямоугольного блока выборок цветности, включающего в себя текущую выборку цветности.
23. Способ по п. 19, в котором выборки цветности содержат выборки первого и второго компонентов цветности, дополнительно содержащий этапы, на которых:
применяют этап отображения направления в отношении первого компонента цветности;
предоставляют другой режим прогнозирования в отношении второго компонента цветности; и
предоставляют выборки яркости и выборки цветности в качестве видеосигнала формата 4:2:2.
24. Машиночитаемый энергонезависимый носитель информации, хранящий программное обеспечение, вызывающее при его исполнении компьютером выполнение компьютером способа по любому из пп. 1-23.
25. Устройство декодирования видеоданных, характеризующееся тем, что выполнено с возможностью прогнозирования выборок яркости и цветности изображения из других соответствующих опорных выборок, в соответствии с направлением прогнозирования, ассоциированным с текущей выборкой, подлежащей прогнозированию, причем выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем выборки яркости, так, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое отношение размеров, чем соответствующий блок выборок цветности; при этом
устройство содержит:
устройство обнаружения, выполненное с возможностью обнаружения первого направления прогнозирования, определенного относительно первой сетки с первым соотношением размеров относительно набора текущих выборок, подлежащих прогнозированию; и
модуль отображения направления, выполненный с возможностью применения отображения направления на направление прогнозирования, для генерирования второго направления прогнозирования, определенного в отношении второй сетки с другим соотношением размеров.
26. Устройство по п. 25, в котором первая сетка, используемая для обнаружения первого направления прогнозирования, определена в отношении положений выборки одной из выборок яркости или цветности, и вторая сетка, используемая для обнаружения второго направления прогнозирования, определена в отношении положений выборок другой из выборок цветности или яркости.
27. Устройство по п. 25 или 26, в котором:
первое направление прогнозирования определено в отношении квадратного блока выборок яркости, включающего в себя текущую выборку яркости; а
второе направление прогнозирования определено в отношении прямоугольного блока выборок цветности, включающего в себя текущую выборку цветности.
28. Устройство по п. 25, в котором выборки цветности содержат выборки первого и второго компонентов цветности, а модуль отображения направления дополнительно выполнен с возможностью:
осуществления отображения направления в отношении первого компонента цветности;
предоставления другого режима прогнозирования в отношении второго компонента цветности; и
предоставления выборки яркости и выборки цветности в качестве видеосигнала формата 4:2:2.
29. Устройство кодирования видеоданных, характеризующееся тем, что выполнено с возможностью прогнозирования выборки яркости и цветности по другим соответствующим опорным выборкам, в соответствии с направлением прогнозирования, ассоциированным с текущей выборкой, подлежащей прогнозированию, при этом выборки цветности имеют более низкую горизонтальную и/или вертикальную частоту выборки, чем выборки яркости, так, что отношение горизонтального разрешения яркости к горизонтальному разрешению цветности отличается от отношения вертикального разрешения яркости к вертикальному разрешению цветности так, что блок выборок яркости имеет другое отношение размеров, чем соответствующий блок выборок цветности; при этом
устройство содержит:
устройство обнаружения, выполненное с возможностью обнаружения первого направления прогнозирования, определенного относительно первой сетки с первым соотношением размеров относительно набора текущих выборок, подлежащих прогнозированию; и
модуль отображения направления, выполненный с возможностью применения отображения направления на направление прогнозирования, для генерирования второго направления прогнозирования, определенного в отношении второй сетки с другим соотношением размеров.
30. Устройство по п. 29, в котором первая сетка, используемая для обнаружения первого направления прогнозирования, определена в отношении положений выборки одной из выборок яркости или цветности, и вторая сетка, используемая для обнаружения второго направления прогнозирования, определена в отношении положений выборок другой из выборок цветности или яркости.
31. Устройство по п. 29 или 30, в котором:
первое направление прогнозирования определено в отношении квадратного блока выборок яркости, включающего в себя текущую выборку яркости; а
второе направление прогнозирования определено в отношении прямоугольного блока выборок цветности, включающего в себя текущую выборку цветности.
32. Устройство по п. 29, в котором выборки цветности содержат выборки первого и второго компонентов цветности, а модуль отображения направления дополнительно выполнен с возможностью:
осуществления отображения направления в отношении первого компонента цветности;
предоставления другого режима прогнозирования в отношении второго компонента цветности; и
предоставления выборки яркости и выборки цветности в качестве видеосигнала формата 4:2:2.
33. Устройство хранения, передачи, съемки или отображения видеоизображений, содержащее устройство по любому из пп. 25-32.
| EP 1909508 A1, 09.04.2008 | |||
| Способ наружной аортальной контрпульсации | 1987 |
|
SU1509045A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |

