Настоящее изобретение касается способа калибровки аудиоинтонации.
Оно также касается способа приобретения устных навыков в языке, изучаемого субъектом, и способа выполнения пения субъектом.
В общих чертах настоящее изобретение касается способа, в котором выдача аудиосигнала человеком видоизменяется путем изменения звуковой информации, которую он принимает, когда говорит.
Способ этого вида основывается на известном принципе, посредством которого голосовое обеспечение объекта, то есть звуки, которые он издает, подвергается главному преобразованию как функция слухового обеспечения, прилагаемого к тому же самому субъекту, то есть звуковой информации, которую он принимает.
Известно использование оборудования, в котором аудиосигнал, издаваемый субъектом, воспроизводится для слуховых органов субъекта после обработки в режиме реального времени и особенно в частной области преподавания и произнесения языков.
В частности, способ этого вида описывается в документе WO 92/14229.
Этот документ описывает устройство, в котором аудиосигналы, издаваемые субъектом, изменяются путем его обработки, чтобы учитывать характеристики изучаемого иностранного языка и гармоническое содержание языка. Измененный аудиосигнал затем предоставляется субъекту в режиме реального времени вибрирующим сигналом, в общем случае звуковым сигналом, для того чтобы изменить издаваемый субъектом аудиосигнал.
Однако в описанном выше документе аудиосигнал, издаваемый субъектом, обрабатывается заранее заданным образом как функция полосы частот изучаемого языка и, в частности, как функция огибающей этой полосы частот.
На практике схема обработки сигнала содержит многочастотный эквалайзер, который устанавливается заранее заданным образом как функция рассматриваемого иностранного языка и, конкретнее, полосы частот этого языка и формы этой полосы частот, то есть огибающей полосы частот. На практике эквалайзер составляется из множества последовательных фильтров, настроенных на разные частоты.
Таким образом, частотные параметры эквалайзера устанавливаются заранее заданным образом характеристиками изучаемого языка.
Подобным же образом указанный выше документ описывает вторую форму обработки, применяемую к аудиосигналу, издаваемому субъектом, в котором регулировочные параметры устанавливаются как функция звукового колебательного гармонического содержания от собранного произношения и параметров в зависимости от изучаемого языка.
В этом случае параметры многочастотного эквалайзера устанавливаются посредством разности между обработанным сигналом, поступающим от действительного звукового обеспечения субъекта, и заранее заданными характеристиками языка.
Таким образом, указанный выше документ описывает создание из первого сигнала, представляющего звук, издаваемый субъектом, второго сигнала, измененного в соответствии с первым сигналом заранее заданным образом и как функция полосы частот изучаемого языка и, в частности, как функция огибающей этого языка, и третьего сигнала, который получается из первого сигнала изменением его как функции действительного гармонического содержания произношения и характеристик языка.
Сигналы затем выборочно воспроизводятся субъекту.
Приведенный выше вид известной системы имеет недостаток в использовании установок заранее заданных параметров без учета типа аудиосигнала, издаваемого субъектом.
Задача настоящего изобретения состоит в улучшении существующих способов калибровки аудиоинтонации для того, чтобы упростить их использование и расширить их применения.
Для решения этой задачи настоящее изобретение обеспечивает способ калибровки аудиоинтонации, по которому аудиосигнал, издаваемый субъектом, воспроизводится для слуховых органов упомянутого субъекта после обработки в режиме реального времени.
Согласно предлагаемому изобретению вышеуказанный способ характеризуется тем, что содержит следующие шаги:
- получение модельного аудиосигнала, подлежащего имитации;
- спектральный анализ упомянутого модельного аудиосигнала;
- получение аудиосигнала, имитированного субъектом;
- спектральный анализ имитированного аудиосигнала;
- сравнение спектров модельного аудиосигнала и имитированного аудиосигнала;
- коррекция имитированного аудиосигнала как функции результата упомянутого сравнения; и
- воспроизведение скорректированного аудиосигнала слуховым органам субъекта.
Анализируя частотное содержание аудиосигнала, подлежащего имитации, и аудиосигнала, имитированного субъектом, настоящее изобретение преобразует интонацию человека изменением в режиме реального времени гармонического содержания его произношения и воспроизведением сигнала, который скорректирован на основе частотного анализа.
Таким образом, способ калибровки делает возможным увеличивать или уменьшать в режиме реального времени интенсивность различных частот, содержащихся в имитированном аудиосигнале, сравнением с предварительно записанным модельным аудиосигналом.
Этот вид способа калибровки позволяет субъекту воспроизводить очень точно любой тип голоса, работая на основе аудиосигнала, подлежащего имитации. В результате он находит применение не только в приобретении устных навыков в иностранном языке, в котором возможно имитировать последовательность слов или фраз, произнесенных выбранным носителем языка, но также в исполнении песни, караоке, в случае чего становится возможным воспроизводить интонации певца, когда исполняется песня.
В соответствии с предпочтительными признаками изобретения вышеуказанный способ калибровки аудиоинтонации также включает в себя следующие шаги:
- измерение динамического диапазона аудиосигнала, имитированного субъектом;
- измерение динамического диапазона корректированного аудиосигнала;
- сравнение динамического диапазона имитированного аудиосигнала и корректированного аудиосигнала; и
- коррекция динамического диапазона скорректированного аудиосигнала как функции результата упомянутого сравнения перед воспроизведением скорректированного аудиосигнала слуховым органам субъекта.
Таким образом возможно изменять полную огибающую скорректированного сигнала как функцию имитированного аудиосигнала, чтобы избежать ситуации, когда скорректированный сигнал, воспроизведенный субъекту, имеет динамический диапазон, который чересчур отличается от аудиосигнала, издаваемого субъектом.
Согласно предпочтительным признакам изобретения вышеуказанный способ калибровки далее включает в себя шаг сохранения спектрального анализа модельного аудиосигнала, подлежащего имитации.
Соответственно, возможно использовать спектральный анализ модельного аудиосигнала для воплощения способа калибровки аудиоинтонации, когда аудиосигнал, подлежащий имитации, повторяется субъектом после временной задержки.
Включение в способ калибровки аудиоинтонации шага выдачи модельного аудиосигнала, подлежащего имитации, к слуховым органам субъекта перед шагом получения аудиосигнала, имитированного субъектом, особенно практично, в частности, при приобретении устных навыков в языке.
То, что субъект прослушивает сигнал, подлежащий имитации, перед его имитацией, облегчает дальнейшее приобретение устных навыков в языке и улучшение интонации при произнесении слов или фраз на иностранном языке.
В первом применении вышеуказанного способа калибровки аудиоинтонации настоящее изобретение обеспечивает способ приобретения устных навыков в изучаемом языке, в котором аудиосигнал, выдаваемый субъектом, воспроизводится к слуховым органам субъекта после обработки в режиме реального времени. Этот способ приобретения использует способ калибровки аудиоинтонации согласно изобретению.
Альтернативно, во втором применении настоящее изобретение также обеспечивает способ исполнения песни субъектом, в котором аудиосигнал, выдаваемый субъектом, воспроизводится к слуховым органам субъекта в режиме реального времени. Этот способ исполнения песни также использует способ калибровки аудиоинтонации согласно изобретению.
Наконец, настоящее изобретение обеспечивает также фиксированные или передвижные средства хранения информации, содержащие части программного кода, пригодные для исполнения шагов способа калибровки аудиоинтонации, для способа согласно изобретению приобретения устных навыков в языке.
Остальные признаки и преимущества изобретения будут представлены в ходе последующего описания.
На приложенных чертежах, которые представлены посредством неограничивающего примера:
- фиг.1 является алгоритмом, показывающим способ калибровки аудиоинтонации согласно первому варианту осуществления изобретения;
- фиг.2а, 2b, 2с являются диаграммами, показывающими шаги способа калибровки аудиоинтонации, показанного на фиг.1 или 5;
- фиг.3 является алгоритмом, показывающим способ приобретения устных навыков в языке в соответствии с вариантом осуществления изобретения;
- фиг.4 является алгоритмом, показывающим шаг калибровки, воплощенный на фиг.3 и 6;
- фиг.5 является алгоритмом, показывающим способ калибровки аудиоинтонации согласно второму варианту осуществления изобретения;
- фиг.6 является алгоритмом, показывающим способ исполнения песни в соответствии с вариантом осуществления изобретения; и
- фиг.7 является блок-схемой, показывающей компьютер, приспособленный для воплощения изобретения.
Сначала со ссылкой на фиг.1 описывается способ калибровки аудиоинтонации в соответствии с первым вариантом осуществления.
В этом примере способ калибровки аудиоинтонации адаптируется для использования в способе приобретения устных навыков в языке.
Он основывается на том факте, что каждый язык использует одну или более спектральных полос с интенсивностями, которые специфичны для него. Таким образом, ухо каждого субъекта приучается воспринимать спектральные области, которые специфичны для его родного языка. Теперь голос воспроизводит только то, что слышит ухо, так что для субъекта трудно правильно произносить слова на иностранном языке, когда его ухо не приучено слышать области, специфичные для нового изучаемого языка.
Способ калибровки аудиоинтонации согласно изобретению поэтому переобучает ухо субъекта, заставляя субъекта в манере произношения слышать области, специфичные для изучаемого языка.
Этот способ содержит, прежде всего, шаг Е10 получения модельного аудиосигнала, подлежащего имитации.
В случае иностранного языка этот аудиосигнал может быть словом или набором слов, произнесенных носителем изучаемого языка.
Модель предпочтительно получается из компьютерного файла, в котором могут храниться различные модельные аудиосигналы.
Эти звуковые файлы F могут храниться на компьютерном жестком диске или любом ином носителе данных, таком как CD-ROM, карта памяти и т.п., или могут загружаться через сеть связи, такую как Интернет. Аудиосигнал, подлежащий имитации, анализируется затем на шаге Е11 спектрального анализа.
Интенсивность, специфичная для каждой из анализируемых частотных полос, измеряется на шаге Е11 анализа.
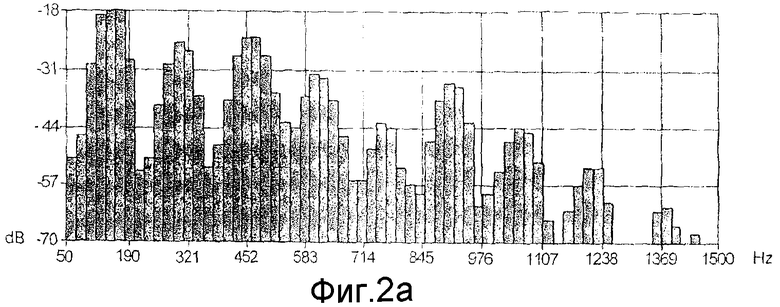
Результат спектрального анализа иллюстрируется в примере на фиг.2а. Шаг Е11 анализа выполняется поэтому по последовательности частотных полос в диапазоне звуковых частот от 30 до 10000 Гц.
Последовательность частотных полос соответствует подразделению частотного диапазона.
На практике частотный диапазон разделяется на по меньшей мере 50 частотных полос, а предпочтительно на по меньшей мере 160 частотных полос, чтобы получить достаточно тонкий анализ аудиосигнала.
Фиг.2а показывает этот вид подразделения по диапазону частот от 50 до 1500 Гц.
Таким образом, интенсивность в децибелах каждой частотной полосы, представленной в аудиосигнале, подлежащем имитации, может быть измерена.
В этом первом варианте осуществления результат спектрального анализа (т.е. анализа, показанного на фиг.2а в настоящем примере) сохраняется в файле на шаге Е12 сохранения.
Способ калибровки аудиоинтонации включает в себя также шаг Е13 получения аудиосигнала, имитированного субъектом S. На этом шаге Е13 получения имитированный аудиосигнал улавливается, к примеру, микрофоном из аудиосигнала, выдаваемого субъектом S.
В этом варианте осуществления динамический диапазон имитированного аудиосигнала сначала измеряется на шаге Е14 измерения.
Шаг Е14 измерения тем самым делает также возможным найти полную огибающую имитированного аудиосигнала.
Согласно изобретению шаг Е15 спектрального анализа применяется затем к имитированному аудиосигналу. Шаг Е15 спектрального анализа аналогичен ранее описанному для аудиосигнала, подлежащего имитации, и анализирует интенсивность аудиосигнала, собранного таким образом от субъекта S, по последовательности частотных полос.
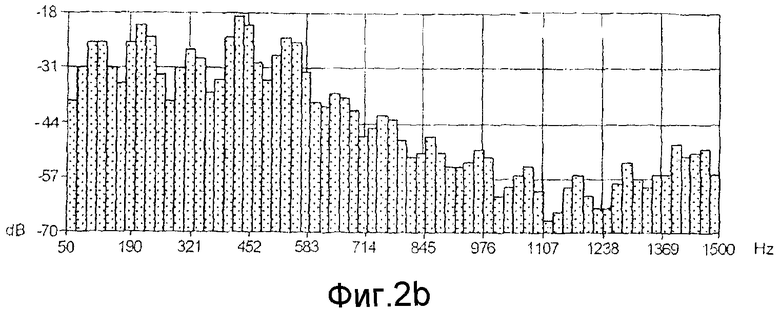
Как показано на фиг.2b, это обеспечивает спектр, позволяющий найти интенсивность сигнала в каждой частотной полосе по диапазону частот от 30 до 10000 Гц.
Фиг.2b показывает один пример этого спектра по диапазону частот от 50 до 1500 Гц.
Подразделение на частотные полосы идентично использованному на шаге Е11 спектрального анализа аудиосигнала, подлежащего имитации.
Спектры модельного аудиосигнала и имитированного аудиосигнала сравниваются затем на шаге Е16 сравнения.
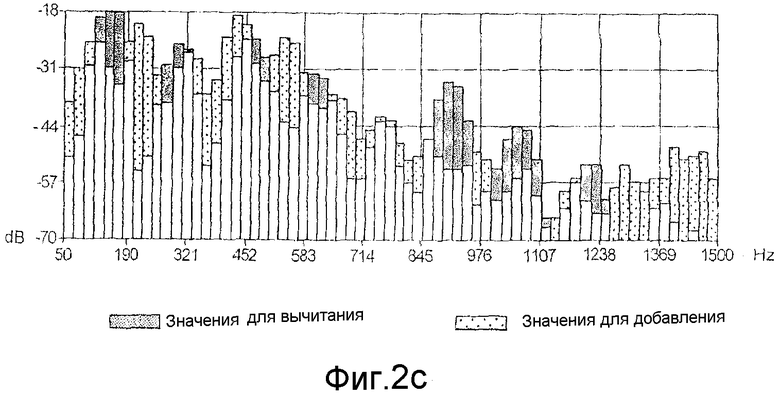
Результат этого сравнения, как показано на фиг.2с, используется на шаге Е17 вычисления, чтобы вычислить спектральные изменения, которые нужно сделать в имитированном аудиосигнале.
Как ясно показано на фиг.2с, и полоса за полосой, каждая частотная полоса имитированного аудиосигнала сравнивается с каждой частотной полосой аудиосигнала, подлежащего имитации, и корректируется так, чтобы значения интенсивности имитированного аудиосигнала соответствовали значениям интенсивности модели, подлежащей имитации.
На практике коррекция, подлежащая добавлению к уровню каждой частотной полосы или вычитанию из каждой частотной полосы, выводится из этого шага вычисления.
Поэтому шаг вычисления определяет увеличения и снижения, подлежащие применению в каждой частотной полосе в отношении модельного аудиосигнала.
Результат вычисления используется для коррекции имитированного аудиосигнала на шаге Е18. На практике параметры динамического многополосного эквалайзера устанавливаются, чтобы частотные области имитированного аудиосигнала были равны частотным областям полученного модельного аудиосигнала.
Параметры устанавливаются посредством автоматической регулировки усиления в каждой частотной полосе.
В этом предпочтительном варианте осуществления динамический диапазон скорректированного аудиосигнала после шага Е18 коррекции измеряется, чтобы сравнить на шаге Е19 сравнения динамический диапазон имитированного сигнала и динамический диапазон скорректированного аудиосигнала.
Шаг Е20 вычисления определяет изменение динамического диапазона, подлежащее применению к сигналу. Результат этого вычисления используется для коррекции на шаге Е21 коррекции динамического диапазона скорректированного аудиосигнала.
На практике результат вычисления, полученный на шаге Е20 вычисления, используется для установки параметров усилителя с регулируемым усилением, приспособленного для регулировки динамического диапазона сигнала.
Параметры устанавливаются общей автоматической регулировкой усиления.
Способ калибровки затем включает в себя шаг Е22 выдачи, который воспроизводит скорректированный аудиосигнал к слуховым органам субъекта S.
Эта выдача выполняется традиционно посредством усилителя, выход которого соединяется с наушниками.
Усилитель позволяет субъекту S выборочно прослушивать либо имитированный аудиосигнал, к которому применена описанная ранее обработка, или модельный аудиосигнал, полученный на шаге Е10 получения.
Шаг выдачи модельного аудиосигнала, подлежащего имитации, к слуховым органам субъекта S поэтому предпочтительно выполняется перед шагом Е13 получения имитированного аудиосигнала, выданного субъектом S.
Шаг Е23 изменения предпочтительно приспосабливается для изменения модельного аудиосигнала, подлежащего имитации, как функции от параметров, представляющих изучаемый язык.
На практике аудиосигнал, подлежащий имитации, проходит через заранее установленный многополосный графический эквалайзер, т.е. эквалайзер, параметры которого заранее устанавливаются как функция от выбранного языка, чтобы выделять частотные области, специфичные для этого языка.
Таким образом, субъект S более ясно постигает частотные области, в которых его уши обычно относительно чувствительны.
Чтобы дополнительно облегчить работу и, в частности, повторение аудиосигнала, подлежащего имитации субъектом S, если аудиосигнал является текстом, способ предпочтительно включает в себя шаг Е24 отображения текста, например, на экране, связанном с компьютером.
Способ приобретения устных навыков в изучаемом языке с помощью способа калибровки аудиоинтонации, показанного на фиг.1, описывается далее со ссылкой на фиг.3.
Этот способ приобретения устных навыков в языке тем самым улучшает произношение субъекта S, когда он говорит на выбранном языке.
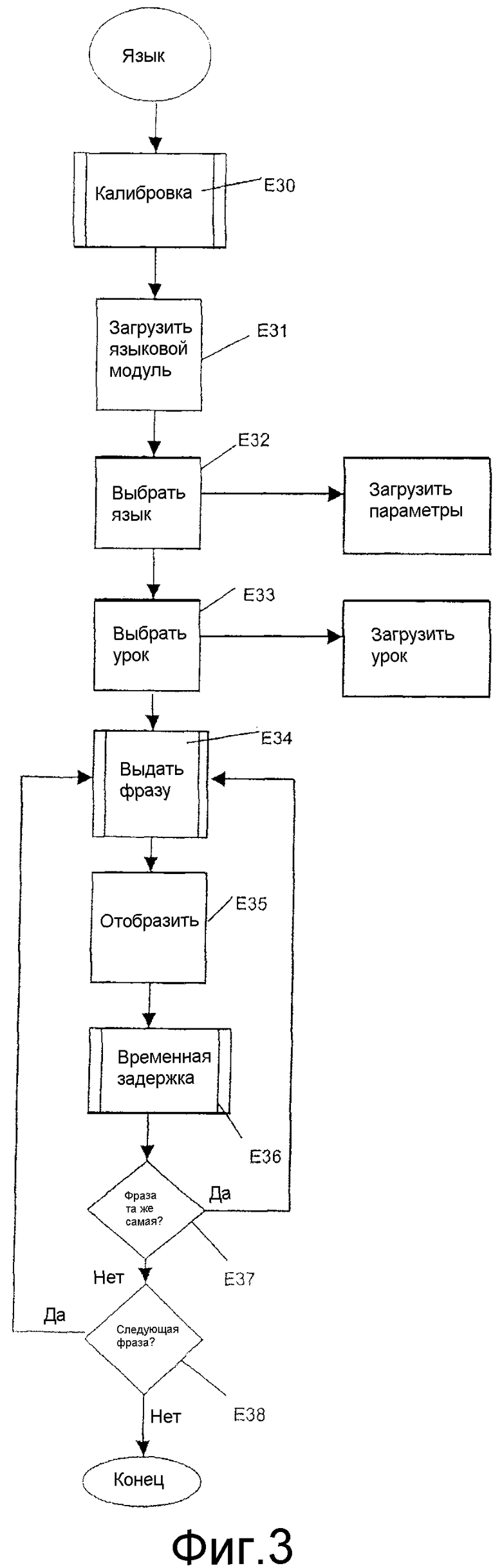
Способ приобретения, показанный на фиг.3, включает в себя, прежде всего, шаг Е30 калибровки.
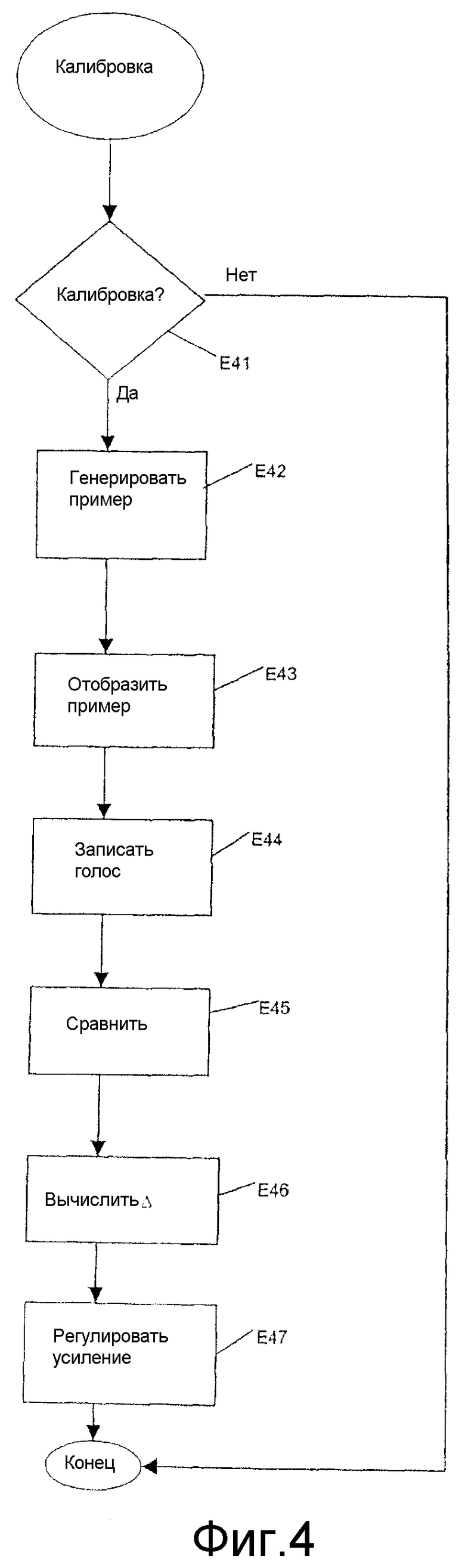
Этот шаг калибровки показан на фиг.4.
В своей общей основе этот шаг калибровки автоматически регулирует входной уровень компьютерной звуковой карты перед тем, как она начинает использоваться в сравнении уровня фразы, которую произносит субъект S, с заранее записанным примером.
Эта калибровка позволяет учащемуся работать автономно на способе приобретения устных навыков, предотвращая при этом слишком низкий или слишком высокий входные уровни, что могло бы помешать правильному функционированию способа.
С этой целью данный шаг калибровки включает в себя шаг Е41 проверки, во время которого субъект может принять решение, выполнять ли калибровку или нет. В частности, если компьютер и связанная с ним звуковая карта только что использовались тем же самым учащимся, шаг калибровки можно опустить.
Если калибровка выполняется, шаг Е42 генерирования примера генерирует опорный аудиосигнал.
Шаг Е43 отображения отображает текст, соответствующий аудиосигналу, генерируемому на шаге Е42 генерирования.
Субъект затем повторяет аудиосигнальный пример и его голос записывается на шаге Е44 записи.
Сравнение полной интенсивности аудиосигнального примера и аудиосигнала, выданного субъектом, на шаге Е45 сравнения позволяет вычислять разность уровней интенсивности между этими двумя аудиосигналами на шаге Е46 вычисления.
Входное усиление компьютерной звуковой карты регулируется затем на шаге Е47 регулировки.
Возвращаясь к фиг.3, когда шаг калибровки выполнен, шаг Е31 загрузки загружает программное обеспечение, содержащее код способа приобретения устных навыков в языке.
В этом варианте осуществления одно и то же программное обеспечение может использоваться для разных языков.
Разумеется, для разных иностранных языков можно использовать отдельное программное обеспечение.
В этом варианте осуществления требуемый язык выбирается на шаге Е32 выбора.
Шаг Е32 выбора загружает в компьютер все параметры, связанные с интересующим языком.
В частности, эти параметры включают в себя один или более частотных спектров, специфичных для изучаемого языка.
Конкретный урок можно выбрать на втором шаге Е33 выбора.
Может быть множество уроков для каждого языка, причем каждый урок содержит конкретное число заранее записанных слов или фраз.
Уроки могут ранжироваться в зависимости от уровня языковой трудности или в зависимости от различных фонем, над которыми надо поработать и которые специфичны для каждого языка.
На практике параметры и урок загружаются традиционным образом в оперативно запоминающее устройство (ОЗУ) (RAM) компьютера.
Способ приобретения далее включает в себя шаг Е34 выдачи фразы или слова, подлежащих повторению.
Этот шаг выдачи фразы соответствует шагу Е10 получения и шагу Е23 спектрального изменения, показанным на фиг.1.
На шаге Е34 выдачи активный вход усилителя является записью, хранящейся в звуковом файле F.
Таким образом, шаг Е34 позволяет субъекту S слышать аудиосигнал, подлежащий имитации, соответствующий слову или фразе текста, читаемого носителем изучаемого языка.
Шаг Е11 анализа и шаг Е12 сохранения спектрального анализа, показанные на фиг. 1, выполняются в одно и то же время.
Для облегчения запоминания субъектом термина, подлежащего повторению, шаг Е35 отображения, соответствующий шагу Е24 отображения, показанному на фиг.1, выполняется в то же самое время, что и шаг Е34 выдачи фразы.
Способ приобретения далее включает в себя шаг Е36 временной задержки, на котором выполняются все шаги Е13-Е22, показанные на фиг.1.
Соответственно, в течение этой временной задержки субъект повторяет аудиосигнал, подлежащий имитации, который корректируется, как описано ранее, и воспроизводится для слуха субъекта в режиме реального времени, так что субъект непроизвольно и спонтанно изменяет свое собственное произношение.
Длительность этого шага Е36 временной задержки практически соответствует длительности аудиосигнала, подлежащего имитации, плюс несколько секунд, чтобы дать возможность субъекту повторить слово или фразу.
Эта временная задержка может регулироваться, к примеру, субъектом, если ему требуется меньше времени или больше времени, чтобы повторить разные слова или фразы.
Продвижение по уроку, т.е. по последовательности слов, подлежащих повторению, и повторенных слов может быть автоматическим или ручным.
В данном варианте осуществления шаг Е37 проверки спрашивает субъекта, желает ли он работать снова над той же самой фразой или тем же самым словом.
Если да, шаг Е34 выдачи, шаг Е35 отображения и шаг Е36 временной задержки выполняются на том же самом аудиосигнале.
Если нет, второй шаг Е38 проверки спрашивает субъекта, желает ли он работать снова над следующими фразой или словом.
Если да, шаг Е34 выдачи, шаг Е35 отображения и шаг Е36 временной задержки также выполняются на следующих заранее записанных слове или фразе в текущем уроке.
В противном случае урок останавливается.
Таким образом, группы фраз или слов могут повторяться циклически, причем учащийся способен делать больше или меньше работы над конкретными частями урока.
После нескольких сеансов уши субъекта приспосабливаются воспринимать язык, и ощущение новых частотных областей, которые подаются к его уху, становится постоянным. Произношение субъекта затем также постоянно изменяется.
Аналогичный способ, позволяющий субъекту исполнять песню, описывается теперь со ссылкой на фиг.5 и 6.
В этом применении способ калибровки аудиоинтонации изменяет интонацию субъекта, чтобы приспособить его манеру пения оптимально к манере заранее записанного певца.
Он поэтому позволяет субъекту петь в манере этого певца и может использоваться, например, в системе караоке.
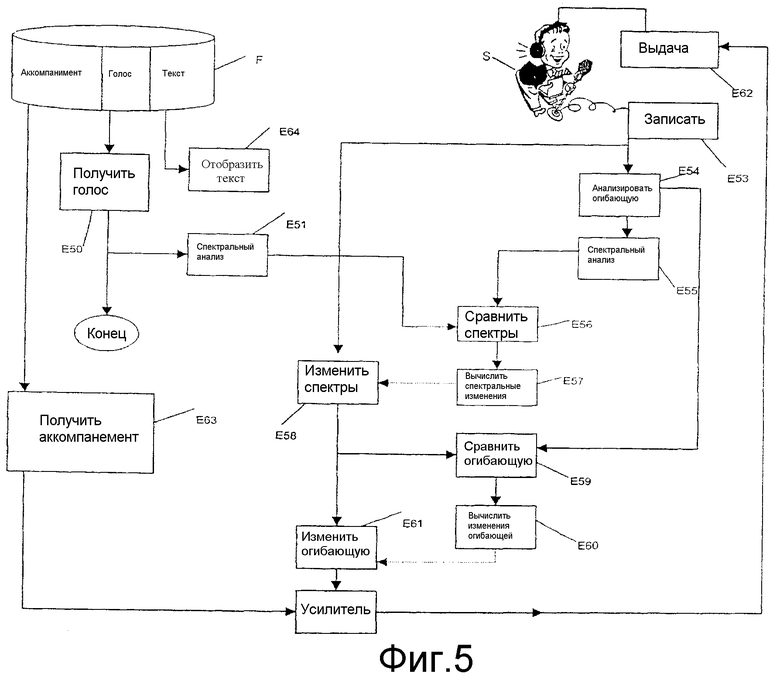
Способ калибровки аудиоинтонации в соответствии с изобретением описывается сначала со ссылкой на фиг.5 и аналогично использованному для фиг.1 способу приобретения устных навыков в языке.
В настоящем применении звуковой файл F приспосабливается для хранения одной или более песен. На практике для каждой песни имеется три звуковых файла, один из которых содержит голос артиста, другой - связанный с песней аккомпанемент, а третий - текст песни.
Как и ранее, этот звуковой файл может сохраняться на жестком диске компьютера или любом другом носителе данных (CD-ROM, карта памяти и т.п.). Его можно также получить загрузкой из сети связи, такой как Интернет.
В отличие от способа калибровки аудиоинтонации, показанного на фиг.1 (на которой шаг Е10 получения модели и шаг Е11 спектрального анализа модели, с одной стороны, и шаг Е13 записи и шаг Е15 спектрального анализа имитированного аудиосигнала, с другой стороны, выполняются альтернативно, вследствие чего требуется шаг Е12 сохранения спектрального анализа аудиосигнала, подлежащего имитации, для последующего сравнения), здесь шаг Е50 получения аудиосигнала, подлежащего имитации, соответствующего голосу певца, выполняется одновременно с шагом Е53 записи аудиосигнала, имитированного субъектом S.
Как и ранее, шаги Е51 и Е55 спектрального анализа применяются к аудиосигналу, подлежащему имитации, и к имитированному аудиосигналу соответственно, и результат подается на вход компаратора для выполнения шага Е56 сравнения спектров.
За шагом Е56 сравнения следует шаг Е57 вычисления для вычисления изменений, которые нужно сделать в имитированном аудиосигнале как функции записанной модели.
Эти шаги сравнения и вычисления аналогичны описанным со ссылкой на фиг.2а, 2b, 2с.
Для получения тщательного спектрального анализа частотный диапазон предпочтительно разделяется на по меньшей мере 160 частотных полос.
Изменения, вычисленные таким образом, применяются посредством автоматической регулировки усиления в каждой полосе, чтобы изменять аудиосигнал на шаге Е58 коррекции.
Как и ранее, коррекция может быть применена динамическим регулируемым графическим эквалайзером для регулировки имитированного аудиосигнала, одна частотная полоса за другой, как можно ближе к полученной модели.
Перед воспроизведением скорректированного сигнала субъекту, как и ранее, выполняется шаг Е61 изменения огибающей.
На практике шаг Е54 анализа динамического диапазона аудиосигнала, записанного на шаге Е53 записи, обеспечивает полную интенсивность сигнала. Шаг Е59 сравнения сравнивает динамический диапазон записанного аудиосигнала с динамическим диапазоном аудиосигнала, скорректированного на шаге Е58 коррекции.
Шаг Е60 вычисления вычисляет изменения, которые нужно сделать в скорректированном аудиосигнале. Эти изменения применяются полной автоматической регулировкой усиления для изменения скорректированного аудиосигнала на шаге Е61 изменения. Это изменение огибающей выполняется посредством усилителя с регулируемым усилением.
Аудиосигнал, скорректированный таким образом, воспроизводится субъекту с помощью усилителя на шаге Е62 выдачи.
Соответственно, в этом способе калибровки аудиоинтонации усилитель принимает одновременно в качестве входного сигнала скорректированный аудиосигнал и сигнал аккомпанемента, полученный из звукового файла F на шаге Е63 получения.
Субъект поэтому слышит одновременно аккомпанемент и свой голос как скорректированный ранее описанной обработкой.
Для облегчения исполнения песни шаг Е64 отображения отображает текст одновременно с проигрыванием песни.
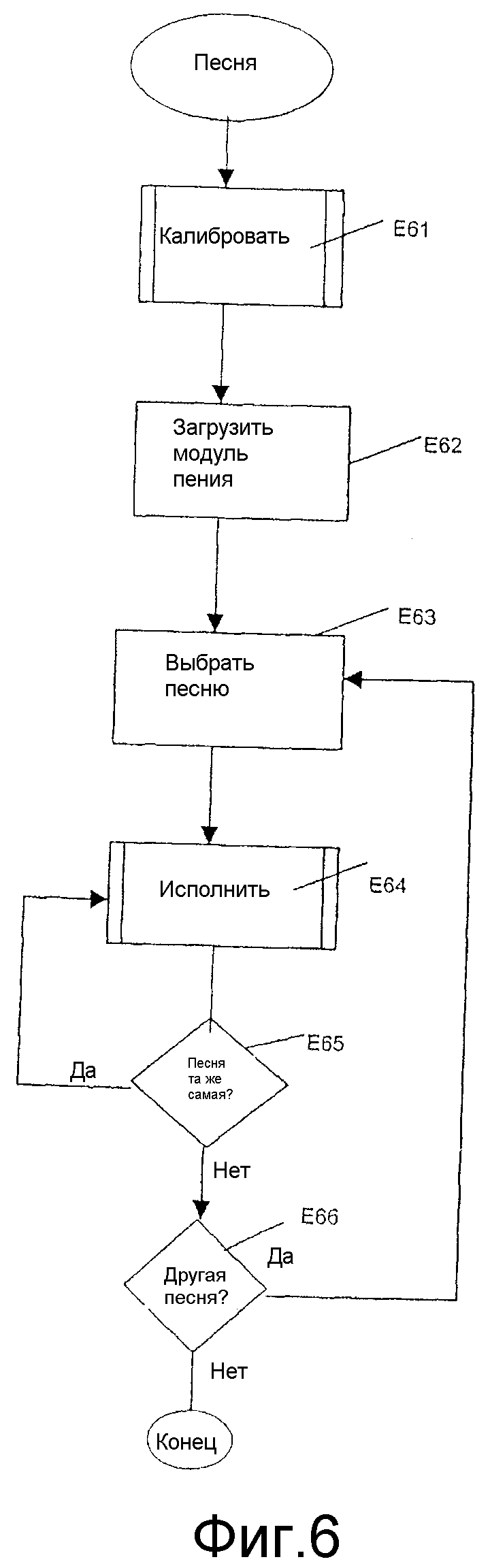
На практике и как показано на фиг.6 этот способ калибровки аудиоинтонации может использоваться в более сложных системах для исполнения песни субъектом в стиле караоке.
В этом способе исполнения песни шаг Е61 калибровки может выполняться перед исполнением песни.
Этот шаг калибровки соответствует шагу калибровки, описанному со ссылкой на фиг.4, и регулирует входное усиление компьютерной звуковой карты.
Шаг Е62 загрузки приспосабливается для загрузки программного обеспечения, содержащего код способа исполнения песни.
Шаг Е63 выбора на практике позволяет субъекту выбирать песню из тех, которые хранятся в звуковом файле F.
Шаг Е64 исполнения песни выполняется затем, как описано ранее со ссылкой на фиг.5.
Во время проигрывания песни файл, содержащий только аккомпанемент, подается субъекту S через усилитель и наушники.
Одновременно текст песни отображается на экране компьютера на шаге Е64 отображения. Модельный файл, содержащий голос, считывается одновременно и в точной синхронизации с файлом, содержащим аккомпанемент. Субъект также поет одновременно с аккомпанементом, чтобы спектральный анализ двух аудиосигналов мог выполняться одновременно для применения подходящих изменений в режиме реального времени к имитированному аудиосигналу.
Чтобы облегчить одновременность в интерпретации песни, может быть обеспечена помощь путем выдачи сигнала метронома и, возможно, курсора, показывающего на текст песни, для указания того, какую часть текста нужно петь.
Восприятие звука, который он издает как измененный в режиме реального времени, заставляет субъекта изменять звук, который он издает, неосознанно и тоже в режиме реального времени.
Поэтому его заставляют петь в манере заранее записанного певца.
Когда песня заканчивается, шаг Е65 проверки позволяет субъекту выбрать для исполнения ту же самую песню вновь.
Если да, шаг Е64 исполнения повторяется на том же самом содержании звукового файла.
Если нет, второй шаг Е66 проверки позволяет субъекту выбрать другую песню.
Если субъект предпочитает выбрать другую песню, шаг Е63 выбора повторяется для выбора одной из заранее записанных песен в звуковом файле.
Шаг Е64 исполнения выполняется затем для новой песни.
Способ исполнения песни заканчивается, когда никакая другая песня не выбирается после шага Е66 проверки.
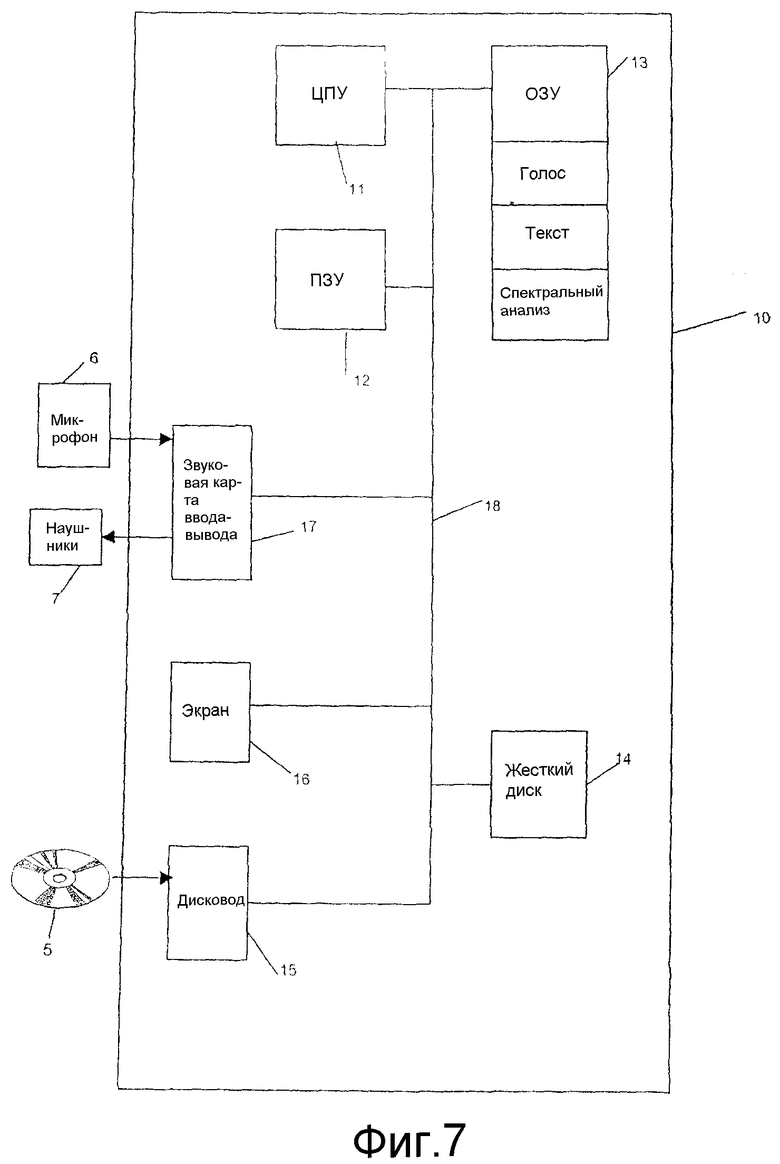
Способ калибровки аудиоинтонации, использованный для исполнения песни или приобретения устных навыков в изучаемом языке, может быть воплощен на компьютере, как показано на фиг.7.
Все из примененных этим способом средств встраиваются в микропроцессор (CPU) 11, а постоянно запоминающее устройство (ПЗУ) (ROM) 12 приспосабливается для хранения программы калибровки аудиоинтонации и программы для исполнения песни или приобретения устных навыков в языке.
Оперативно запоминающее устройство (ОЗУ) (RAM) 13 приспосабливается для хранения в регистрах значений, измененных в ходе выполнения этих программ.
На практике ОЗУ содержит регистры, приспособленные для сохранения звуковых файлов F и результатов спектрального анализа.
Микропроцессор 11 интегрируется в компьютер, который может соединяться с сетью связи через интерфейс связи.
Компьютер далее включает в себя средство для сохранения документов, такое как жесткий диск 14, или приспосабливается для совместной работы со съемным средством сохранения документов, таким как диск 5, посредством дисковода 15 (для гибкого диска, компакт-диска или компьютерной карты).
Фиксированное или съемное средство хранения может поэтому содержать код способа калибровки аудиоинтонации и код способа приобретения устных навыков в языке или способа исполнения песни.
Код этих способов может сохраняться на жестком диске компьютера 10, например, а звуковые файлы, используемые в различных применениях, могут сохраняться по отдельности на дисках 5, приспособленных для совместной работы с дисководом 15.
Альтернативно программа для воплощения изобретения может храниться в постоянно запоминающем устройстве 12.
Компьютер 10 также имеет экран 16, обеспечивающий интерфейс с субъектом S, в частности, для отображения субъекту текста, подлежащего повторению или пению.
Звуковая карта 17 также предусматривается и приспосабливается для совместной работы с микрофоном 6 и наушниками 7, чтобы выдавать аудиосигнал или принимать аудиосигнал, издаваемый субъектом.
Центральный процессорный блок 11 затем выполняет команды, относящиеся к воплощению изобретения. По включению программы и способы, относящиеся к изобретению и хранящиеся в памяти, к примеру, в постоянно запоминающем устройстве 12, переносятся в оперативно запоминающее устройство 13, которое затем содержит исполняемые коды изобретения и переменные, необходимые для воплощения изобретения.
Шина 18 связи обеспечивает связь между разными подсистемами, которые являются частью компьютера 10 или подключены к нему.
Представление шины 18 не ограничивает изобретение, и, в частности, микропроцессор 11 может посылать команды к любой подсистеме либо непосредственно, либо через другую подсистему.
Благодаря изобретению способ калибровки аудиоинтонации может быть воплощен на персональном компьютере и может использоваться субъектом S без необходимости внешнего вмешательства.
В частности, при приобретении устных навыков в языке субъект S может работать над своей интонацией с помощью различных заранее записанных звуковых файлов без необходимости в присутствии наставника.
Разумеется, многие модификации могут быть сделаны в ранее описанных вариантах осуществления без отхода от объема изобретения.
Изобретение относится к способу калибровки аудиоинтонации, в котором аудиосигнал, изданный субъектом (S), возвращается после обработки в режиме реального времени к слуховым органам упомянутого субъекта (S). Предлагаемый способ содержит следующие шаги: получение (Е10) модели аудиосигнала, подлежащего имитации; спектральный анализ (Е11) вышеупомянутой модели аудиосигнала; получение (Е13) аудиосигнала, имитированного субъектом (S); спектральный анализ (Е15) имитированного аудиосигнала; сравнение (Е16) спектров модели аудиосигнала и имитированного аудиосигнала; коррекция (Е18) имитированного аудиосигнала согласно результату упомянутого сравнения; и возвращение (Е22) скорректированного аудиосигнала к слуховым органам субъекта (S). Изобретение можно использовать, в частности, для устной практики в языке или исполнения песни. Техническим результатом изобретения является повышение качества калибровки аудиоинтонации. 6 н. и 9 з.п. ф-лы, 7 ил.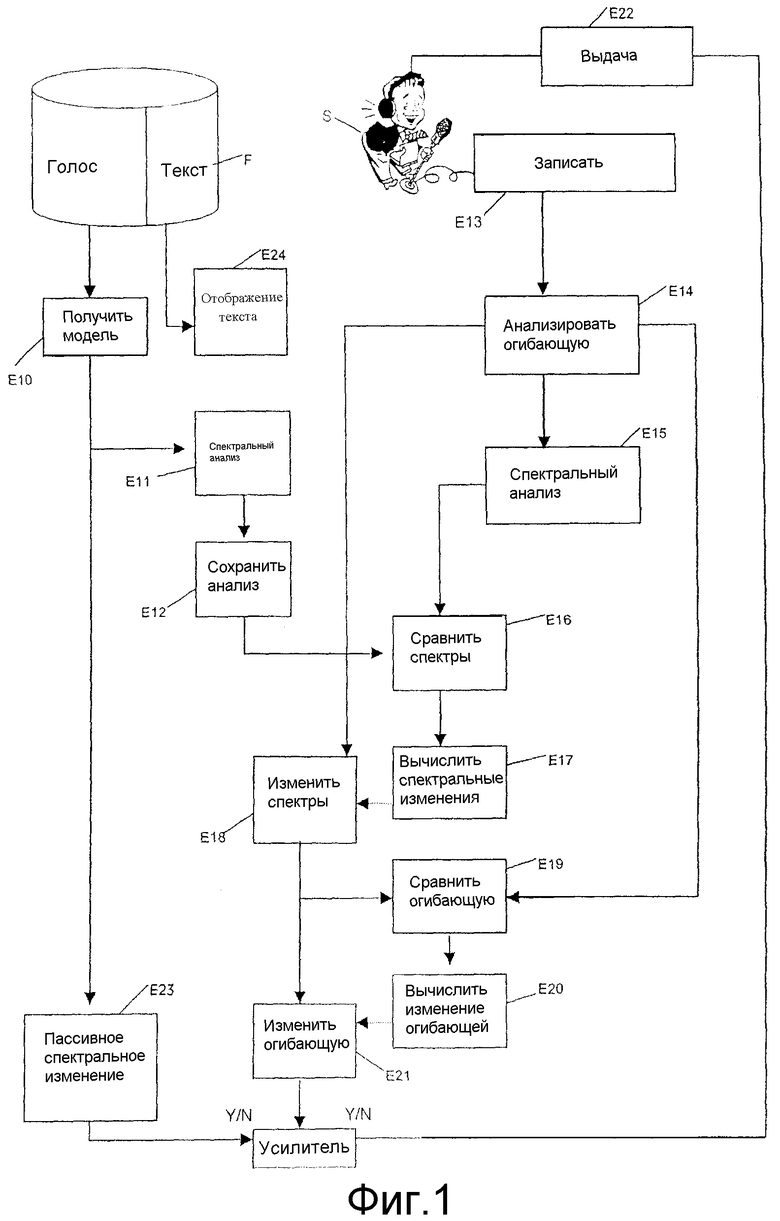
получение (Е10, Е50) модельного аудиосигнала, подлежащего имитации;
спектральный анализ (E11, E51) упомянутого модельного сигнала;
получение (Е13, Е53) аудиосигнала, имитированного субъектом (S);
спектральный анализ (Е15, Е55) имитированного аудиосигнала;
сравнение (Е16, Е56) спектров модельного аудиосигнала и имитированного аудиосигнала;
коррекция (Е18, Е58) имитированного аудиосигнала как функция результата упомянутого сравнения; и
воспроизведение (Е22, Е62) к слуховым органам субъекта (S) скорректированного аудиосигнала.
измерение (Е14, Е24) динамического диапазона аудиосигнала, имитированного субъектом (S);
измерение (E18, E28) динамического диапазона скорректированного аудиосигнала;
сравнение (Е19, Е59) динамического диапазона имитированного аудиосигнала и скорректированного аудиосигнала;
коррекция (Е21, Е61) динамического диапазона скорректированного аудиосигнала как функция результата упомянутого сравнения перед воспроизведением скорректированного аудиосигнала к слуховым органам субъекта (S).
| Автоматический огнетушитель | 0 |
|
SU92A1 |
| ЕР 1139318 А, 04.10.2001 | |||
| Способ получения нанокапсул сухого экстракта эвкалипта в гуаровой камеди | 2018 |
|
RU2674660C1 |
| СПОСОБ ТРАНСФОРМАЦИИ ВЕРБАЛЬНОЙ АУДИОИНФОРМАЦИИ НА УРОВЕНЬ ПОДПОРОГОВОГО ВОСПРИЯТИЯ ПРИ ПСИХОФИЗИОЛОГИЧЕСКОМ ВОЗДЕЙСТВИИ | 1998 |
|
RU2124371C1 |

