Область техники
Изобретение относится к вычислительной технике, системам мультимедиа и может быть использовано для профессиональной постановки техники исполнения вокальных партий, правильного интонирования и ритмического изложения музыкальных композиций в устройствах караоке, а также для развития исполнительских способностей при обучении пению.
Предшествующий уровень техники
Известны способы оценки качества вокального исполнения музыкального произведения, основанные на компьютерной системе обучения вокальному исполнению музыкального произведения на базе визуализации на экране контура частоты основного тона (RU, № 2356105), (US, № 7271329).
Известные способы включают преобразование нотной записи музыкального произведения в первое графическое изображение в координатных осях «время-высота тона» и его визуализацию на экране, вокальное исполнение пользователем указанного музыкального произведения, его звуковую запись и цифровое преобразование записи. На преобразованной цифровой записи в течение каждого интервала времени, соответствующего звучанию отдельной ноты музыкального произведения, производят множество вычислений значения частоты основного тона вокального исполнения пользователем музыкального произведения, по полученным значениям строят в координатных осях «время-высота тона» второе графическое изображение вокального исполнения пользователем музыкального произведения. Сопоставляют первое и второе графические изображения и выявляют места несовпадения второго графического изображения с первым графическим изображением, по которым оценивают качество вокального исполнения пользователем музыкального произведения, по меньшей мере, в течение времени, соответствующего звучанию каждой отдельной ноты музыкального произведения.
Однако в известных способах мелодия отображается нотами (дискретными значениями с разрывами), а голос, как известно, может непрерывно переходить от ноты к ноте и сами ноты певец исполняет с индивидуальной интонацией. В этих способах отсутствует звуковая обратная связь, когда голос пользователя в реальном масштабе времени обработки сигнала («на лету») синтезируется с исправленной интонацией, что не позволяет пользователю корректировать свое пение на слух.
Известен способ, выполненный на базе караоке-устройства, позволяющий певцу-исполнителю по звуковому воспроизведению его скорректированного пения понять, как нужно изменить манеру пения (US, № 8027631).
В этом способе данные голосовой модели целевого исполнения сопоставляются с введенными голосовыми данными певца-исполнителя в направлении оси времени. Затем меняется высота тона певца-исполнителя так, чтобы она совпадала в соответствующем кадре голосовых данных модели целевого исполнения. При этом осуществляется временное масштабирование голосовых данных певца-исполнителя таким образом, чтобы длина участка голосовых данных певца-исполнителя совпадала с соответствующей длиной участка голосовых данных модели целевого исполнения, после чего осуществляется регенерация скорректированных голосовых данных певца-исполнителя и формируется соответствующий скорректированный звуковой сигнал из громкоговорителя.
Этот способ позволяет создать подробное графическое изображение целевого исполнения музыкального произведения на протяжении времени ее звучания в вокальном исполнении и осуществлять формирование и запись скорректированного аудиосигнала певца-исполнителя, что позволяет певцу исполнителю на слух осознать свое пение и осуществить некие изменения своей манеры исполнения музыкального произведения.
Однако способ не позволяет в динамике осуществлять анализ исполненного музыкального произведения и наблюдать исполнителю за успехами или неудачами, достигнутыми им в процессе работы над музыкальным произведением. Это обусловлено тем, что коррекция (увеличение или уменьшение) фрейма определенной длины голосовых данных певца-исполнителя осуществляется на ряде участков в соответствии с информацией разделителя, хранящейся в памяти, указывающие на предопределенные участки голосовых данных модели целевого исполнения в направлении оси времени, поэтому нет эффекта обратной акустической связи и певец-исполнитель может осознать свое пение только с опозданием. Так как в данном способе не оценивается контур частоты основного тона (ЧОТ) и не осуществляется его визуализация, то невозможно во время пения осуществлять коррекцию ритмических ошибок, потерю интонирования из-за нехватки воздуха и т.п.
Таким образом, в известном техническом решении по существу возможно только отображение мелодии, и отсутствует визуализация элементов, характеризующих манеру исполнения. В частности, не обеспечивается возможность отрабатывать певческие штрихи, такие как форшлаги, глиссандо, вибрато.
Наиболее близким к предлагаемому способу модификации голоса с визуальной и звуковой обратной связью является способ модификации голоса, реализованный на основе караоке (RU, № 2591640).
Известный способ позволяет реализовать два режима работы: корректировки входного голоса певца-исполнителя по нотам и корректировки голоса певца-исполнителя по эталонному исполнению, что позволяет обеспечить возможность точного исполнения заданной мелодии голосом певца-исполнителя караоке, а также корректировать голос певца-исполнителя караоке по эталонному исполнению песни и мелодии, позволяющих имитировать мастерство пения певца-профессионала. Обобщенная функциональная схема устройства модификации голоса, в которой осуществляется реализация известного способа по первому или второму вариантам показана на фигуре 1.
Общую синхронизацию работы устройства по этому способу осуществляет центральный процессор, а обработка голоса певца-исполнителя (сигнала из микрофона), модификация его и вывод в громкоговоритель выполняется в аудиопроцессоре (АП). Устройство, реализующее известный способ, может быть выполнено на современных вычислительных платформах, таких как персональные компьютеры, мобильные вычислительные системы, например, смартфоны. Как правило, данные вычислительные платформы имеют несколько вычислительных ядер, одно из которых выполняет функции аудиопроцессора.
В таблице параметров устройства представлены несколько наборов параметров для хранения, характеризующих песню - музыкальную композицию (мелодию и стихи), подготовленных заранее. Центральный процессор выбирает один желательный из наборов параметров в таблице параметров и конфигурирует аудиопроцессор этим выбранным набором параметров. Выходной аудиосигнал, который сформирован аудиопроцессором в соответствии с выбранным набором параметров и который представляет собой выходной голосовой сигнал, близкий к целевому певцу, поступает через устройство вывода аудиосигнала на громкоговоритель. Как в большинстве известных подходов, для манипуляции с частотой основного тона выбирается гармоническое моделирование, которое предполагает разложение сигнала на периодические компоненты нескольких частот и извлечение их параметров [J.Bonada, and X.Serra, "Synthesis of the singing voice by performance sampling and spectral models" IEEE Signal Processing Magazine, vol. 24, issue 2, pp. 67-79, March 2007; J.Laroche, Y.Stylianou and E.Moulines, “HNS: Speech modification based on a harmonic+noise model,” in IEEE ICASSP 1993 - IEEE International Conference on Acoustic, Speech, and Signal Processing, April 27-30, Minneapolis, USA, Proceedings, 1993. - pp. 550-553.]. Разделение речи на детерминированные и стохастические компоненты требуется для уменьшения слышимых артефактов.
Выбор набора параметров, характеризующий музыкальную композицию (мелодию и стихи), задается на панели управления в составе средства управления и выводится на экран. Караоке-аккомпанемент генерируется согласно предоставляемым последовательно по времени данным трека исполнения и последовательно по времени выбираются наборы параметров согласно данным трека управления, предоставляемым последовательно по времени синхронно с данными исполнения: текст песни, выводимый на экран монитора. Данные трека исполнения и трека управления генерируются центральным процессором.
Известный способ модификации голоса певца-исполнителя, поющего песню-караоке, осуществляется согласно следующим шагам:
Шаг 1. Инициализация устройства модификации голоса.
Шаг 2. Выбор параметров модификации голоса 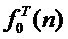 из таблицы параметров при помощи средства управления.
из таблицы параметров при помощи средства управления.
Шаг 3. Параллельно караоке-аккомпанементу вводится через устройство ввода аудиосигнала голос певца-исполнителя из микрофонного входа в аудиопроцессор.
Шаг 4. Выполняется в аудиопроцессоре параметрический анализ (математическая модель сигнала: гармоники плюс шум) данного фрейма сигнала для получения вектора параметров: мгновенные амплитуды 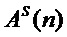 , частота основного тона (ЧОТ)
, частота основного тона (ЧОТ)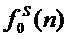 , мгновенные значения фаз
, мгновенные значения фаз 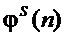 и шумовой составляющей сигнала
и шумовой составляющей сигнала 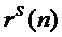 .
.
Шаг 5. Формирование выходного контура ЧОТ 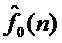 в соответствии с целевой мелодией в средстве формирования динамических параметров.
в соответствии с целевой мелодией в средстве формирования динамических параметров.
Шаг 6. Преобразование параметров фрейма сигнала в средстве формирования динамических параметров для получения вектора выходных параметров [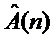 ,
,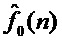 ,
,  ,
, 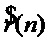 ] на основании параметров певца-исполнителя мгновенных амплитуд
] на основании параметров певца-исполнителя мгновенных амплитуд 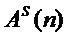 , значений фаз и шумовой составляющей .
, значений фаз и шумовой составляющей .
Шаг 7. Выполняется параметрический синтез в соответствии с данными параметрами в аудиопроцессоре, согласно которому формируется модифицированный фрейм сигнала выходного голоса певца-исполнителя.
Шаг 8. Далее в устройстве вывода аудиосигнала выходной фрейм сигнала голоса певца-исполнителя микшируется с музыкальным сопровождением, переданным в устройство вывода аудиосигнала центральным процессором из таблицы параметров, и выводится на громкоговоритель.
Шаг 9. Если музыкальная композиция не закончена, то процесс повторяется с ввода нового фрейма аудиосигнала входного голоса певца-исполнителя из микрофонного входа (переход на шаг 3).
Можно отметить, что работа осуществляется в реальном масштабе времени и центральный процессор осуществляет синхронизацию параллельной работы аудиопроцессора, устройства ввода аудиосигнала и устройства вывода аудиосигнала согласно принципу фреймовой обработки сигналов (Vanhoof, J., Rompaey, K., Bolsens, I., Goossens, G., Man, H.: High-Level Synthesis for Real-Time Digital Signal Processing. Springer US, Boston, MA (1993)).
Следует отметить, что в известном способе процесс формирования выходного контура частоты основного тона на экране монитора не отражается, а производится автоматическая корректировка входного голоса певца-исполнителя по нотам или корректировка голоса певца-исполнителя по эталонному исполнению.
Анализ данного способа модификации голоса показывает, что:
- способ не позволяет обучить певца профессиональной технике исполнения вокальных партий, правильного интонирования и ритмического изложения музыкальных композиций, а также не позволяет певцу-исполнителю моментально видеть отклонения от правильной интонации и свои ритмические ошибки. Он не может корректировать эти ошибки непосредственно в процессе пения, что не позволяет певцу-исполнителю вносить исправления в свое пение на слух;
- недостаточное временное разрешение в оценке мгновенной частоты основного тона обуславливает сглаживание контура ЧОТ, что не позволяет видеть в реальном времени режимы фонации, фрагменты хрипа, потери интонирования из-за нехватки воздуха и т.п.
Краткое раскрытие сущности изобретения
Решаемая изобретением задача - обеспечение обучения в реальном масштабе времени профессиональной постановки техники исполнения вокальных партий и ритмического изложения музыкальных композиций.
Технический результат, который получен при реализации способа модификации голоса, - повышение временного разрешения в оценке мгновенной частоты основного тона, уменьшение латентности обработки и модификации голоса певца-исполнителя.
В компьютерных и сетевых технологиях латентность - задержка или ожидание, которая увеличивает реальное время отклика по сравнению с ожидаемым. В заявленном техническом решении достигается латентность аудиосигнала не более 60 мс, что с учетом времени слухового восприятия человеком распространяемого звука позволит певцу-исполнителю избежать дискомфорта и нарушений пения, которые вызваны эхом, самостоятельно скорректировать свое исполнение и осуществить правильное интонирование; высокое временное разрешение и отображение контура частоты основного тона певца-исполнителя с задержкой не более 100 мс, без сглаживания дает певцу-исполнителю больше информации о звучании его голоса.
Для решения поставленной задачи с достижением указанного технического результата, как и в известном способе-аналоге модификации голоса (RU, № 2591640), параллельно и синхронно караоке-аккомпанементу вводится через устройство ввода аудиосигнала голос певца-исполнителя из микрофонного входа в аудиопроцессор для выполнения параметрического анализа (математическая модель сигнала: гармоники плюс шум) данного фрейма сигнала и получения вектора параметров: мгновенных амплитуд , частоту основного тона (ЧОТ) 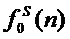 , мгновенные значения фаз и шумовую составляющую сигнала . Далее осуществляется получение выходного контура ЧОТ
, мгновенные значения фаз и шумовую составляющую сигнала . Далее осуществляется получение выходного контура ЧОТ 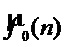 в соответствии с целевой мелодией , на основании которого и параметров певца-исполнителя - мгновенных амплитуд , значений фаз и шумовой составляющей - формируется вектор выходных параметров [
в соответствии с целевой мелодией , на основании которого и параметров певца-исполнителя - мгновенных амплитуд , значений фаз и шумовой составляющей - формируется вектор выходных параметров [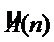 , , , ]. В соответствии с данными параметрами в аудиопроцессоре выполняется параметрический синтез, согласно которому формируется фрейм сигнала выходного голоса певца-исполнителя. Далее в устройстве вывода аудиосигнала фрейм сигнала выходного голоса певца-исполнителя микшируется с музыкальным сопровождением, переданным в устройство вывода аудиосигнала центральным процессором из таблицы параметров средства обеспечения, и выводится на громкоговоритель.
, , , ]. В соответствии с данными параметрами в аудиопроцессоре выполняется параметрический синтез, согласно которому формируется фрейм сигнала выходного голоса певца-исполнителя. Далее в устройстве вывода аудиосигнала фрейм сигнала выходного голоса певца-исполнителя микшируется с музыкальным сопровождением, переданным в устройство вывода аудиосигнала центральным процессором из таблицы параметров средства обеспечения, и выводится на громкоговоритель.
В отличие от ближайшего аналога, в заявленном способе модификации голоса с визуальной и звуковой обратной связью вводится временное масштабирование фрейма сигнала микрофона, согласованное с мгновенной ЧОТ данного фрейма, комплексно-модулированный банк фильтров анализа и синтеза соответственно для выделения гармонических компонент сигнала и интерполирования модифицированных гармонических параметров для формирования выходного сигнала, обратное временное масштабирование выходного сигнала в соответствии с выходным контуром ЧОТ 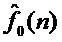 и суммирование со стохастической компонентой для получения модифицированного сигнала голоса певца-исполнителя и передача в громкоговоритель, а также вывод в реальном времени на экран монитора нот мелодии , контура мгновенной ЧОТ голоса певца-исполнителя и входного контура ЧОТ.
и суммирование со стохастической компонентой для получения модифицированного сигнала голоса певца-исполнителя и передача в громкоговоритель, а также вывод в реальном времени на экран монитора нот мелодии , контура мгновенной ЧОТ голоса певца-исполнителя и входного контура ЧОТ.
Возможны дополнительные варианты осуществления способа, в которых целесообразно, чтобы:
- время обработки с момента ввода сигнала голоса певца-исполнителя в микрофон устройства ввода аудиосигнала до вывода на громкоговоритель составляло не более 60 мс, а до вывода на экран монитора нот целевой мелодии, контура мгновенной частоты основного тона голоса певца-исполнителя, выходного контура частоты основного тона составляло не более 100 мс;
- синхронно с выводом на экран монитора нот целевой мелодии, контура мгновенной частоты основного тона голоса певца-исполнителя и выходного контура частоты основного тона выводили на экран строку текста исполняемого вокального произведения;
- для определения ЧОТ сигнала голоса певца-исполнителя, детерминированная часть модели которого представляет собой сумму периодических компонент с нестационарными параметрами - амплитудой, частотой и фазой, производят передискретизацию входного фрейма сигнала голоса певца-исполнителя для каждого кандидата периода ЧОТ, нормируют энергию каждого передискретизированного входного фрейма к 1, производят оценку мгновенных параметров синусоидальной модели, вычисляют функцию формирования кандидатов периода (ФФКП) частоты основного тона для соответствующего набора параметров - амплитуды, частоты и фазы, умножают вычисленное значение функции формирования кандидатов периода основного тона на взвешивающую функцию для ограничения низкочастотных кандидатов ЧОТ, определяют наилучший непрерывный контур частоты основного тона при помощи динамического программирования, максимизирующего сумму ФФКП на локальной последовательности кадров, в результате чего выбирают лучшего кандидата ЧОТ, который является начальной оценкой частотны основного тона, далее вычисляют уточненную оценку ЧОТ, используя мгновенные параметры синусоидальной модели, полученные для лучшего кандидата.
Достоинством предложенного способа модификации голоса с визуальной и звуковой обратной связью является обеспечение максимально точного попадания голоса певца-исполнителя в заданную мелодию за счет включения обучающего процесса в цикл настройки способа модификации голоса с использованием принципов визуальной/звуковой (биологической) обратной связи для тренировки певческих навыков, при этом певец-исполнитель слышит целевую ноту, сформированную аудиопроцессором в результате модификации его голоса, т.е. свой голос, а также на экране видит контуры мелодии, основного тона своего голоса и основного тона модифицированного голоса певца-исполнителя (своего измененного голоса), т.е. видит и слышит насколько точно он «попал» в мелодию. Так как процесс обработки и синтеза модифицированного голоса производится в реальном времени, то с учетом времени слухового восприятия человеком уровней звука певец-исполнитель в течение времени исполнения произведения может корректировать свое исполнение; высокое временное разрешение и отображение контура частоты основного тона певца-исполнителя без сглаживания дает певцу-исполнителю больше информации о звучании его голоса. При этом, в реальном времени видны режимы фонации, фрагменты хрипа, потеря интонирования из-за нехватки воздуха; певец-исполнитель видит на экране монитора контур частоты основного тона своего голоса на протяжении необходимого времени, что дает широкие возможности для анализа интонирования и исправления ошибок непосредственно в процессе пения; возможность визуализации в реальном времени элементов, характеризующих манеру исполнения, позволяет отрабатывать певческие штрихи, такие как форшлаги, глиссандо, вибрато.
Указанные преимущества, а также особенности настоящего изобретения поясняются с помощью варианта его выполнения со ссылками на фигуры.
Краткий перечень чертежей
Фиг. 1 изображает обобщенную функциональная схему устройства модификации голоса, реализующую способ ближайшего аналога (предшествующий уровень техники);
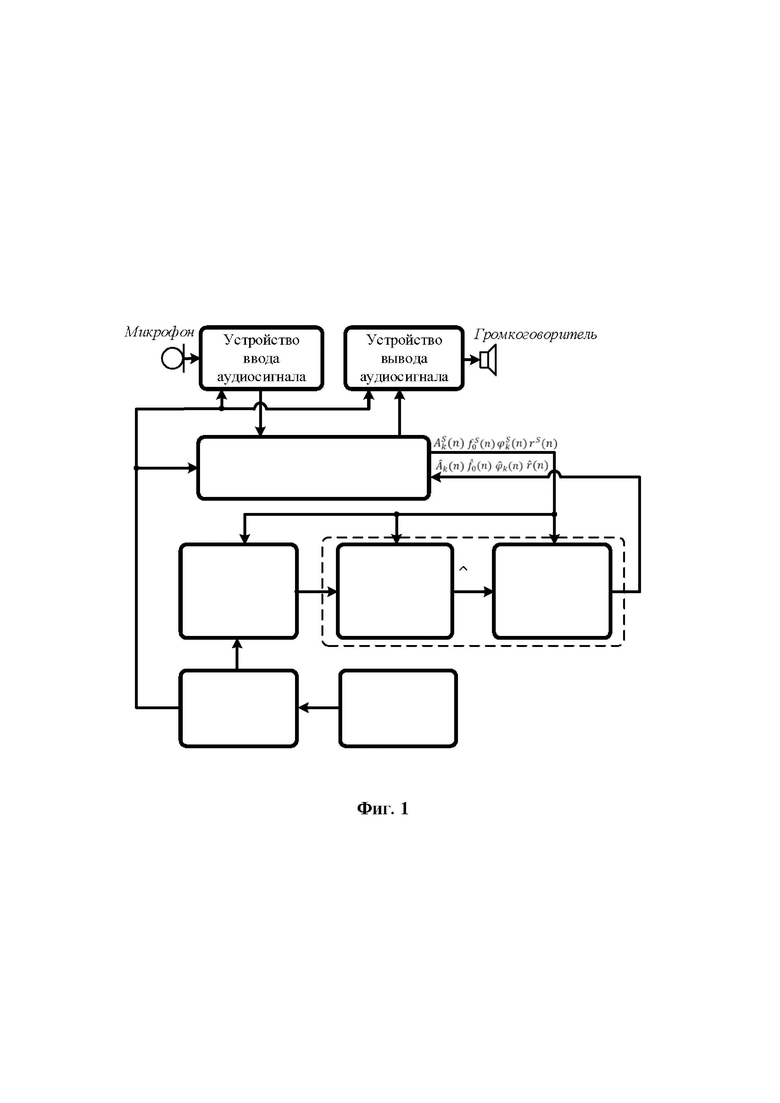
Фиг. 2 изображает обобщенную функциональную схему устройства модификации голоса, реализующую заявленный способ модификации голоса с визуальной и звуковой обратной связью;
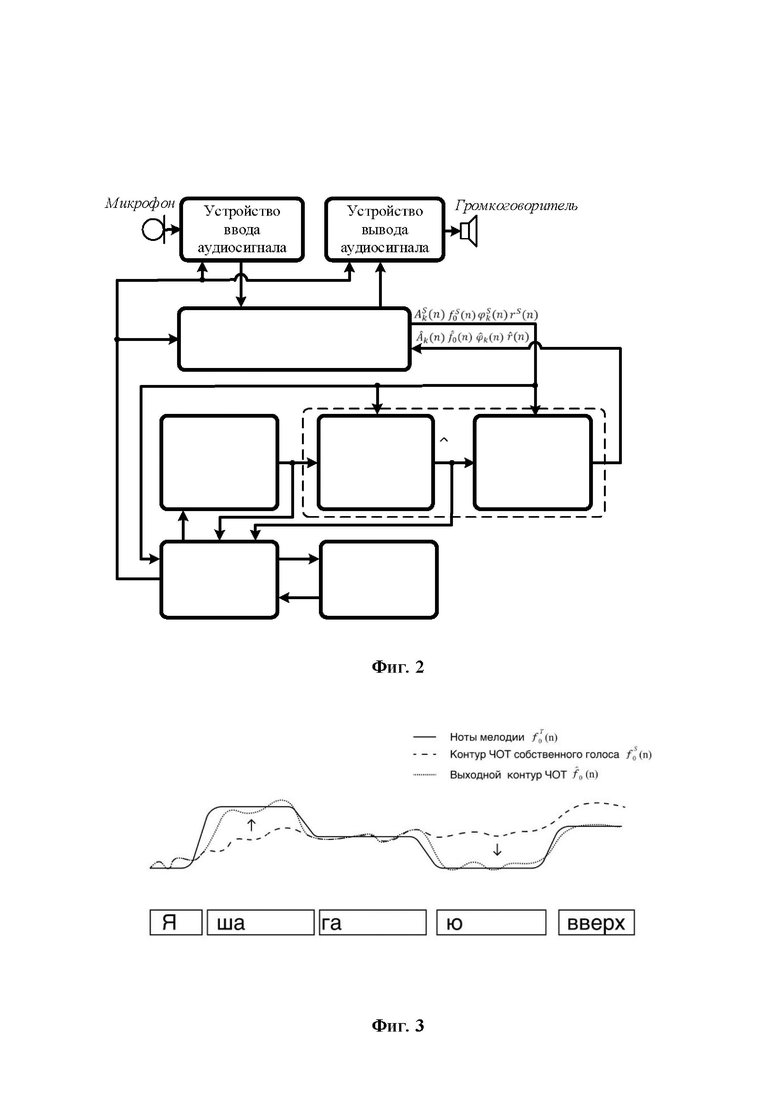
Фиг. 3 изображает наблюдаемые певцом-исполнителем на экране монитора ноты мелодии , контур мгновенной частоты основного тона собственного голоса и выходной контур частоты основного тона ;
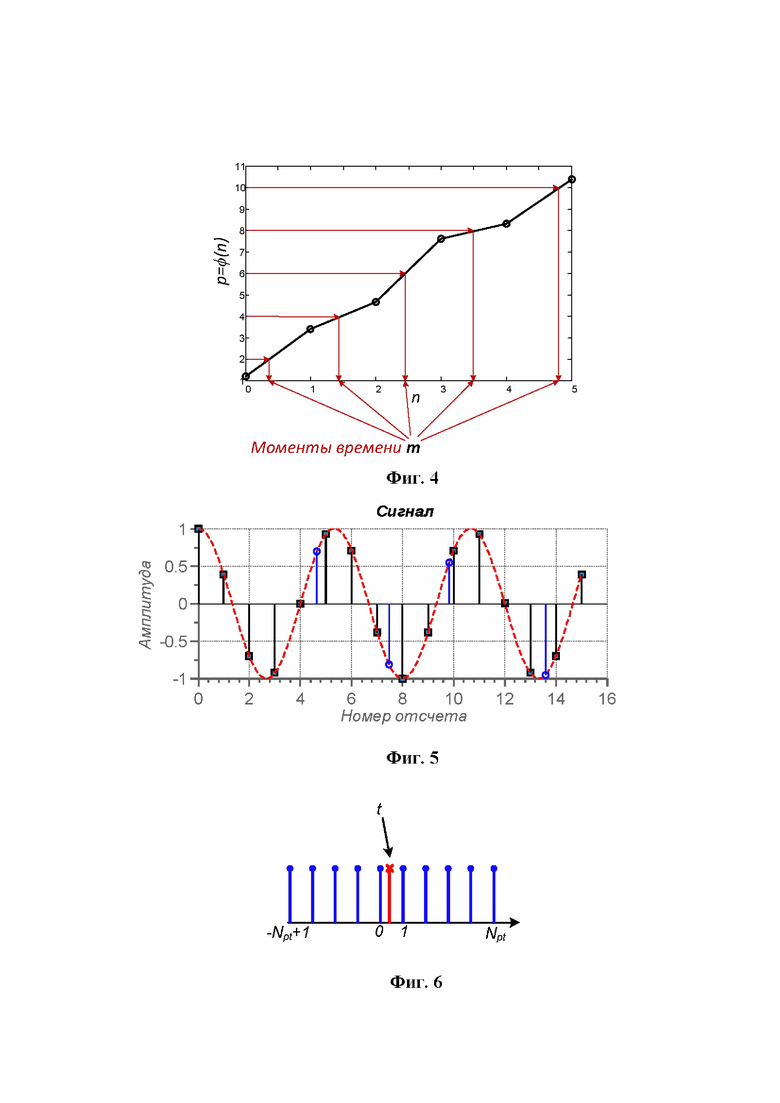
Фиг. 4 - иллюстрация расчета новых моментов времени для масштабирования сигнала;
Фиг. 5 иллюстрирует вычисление значений сигнала в произвольные моменты времени;
Фиг. 6 иллюстрирует интерполяцию сигнала функциями sinc со смещением от 0 до 1;
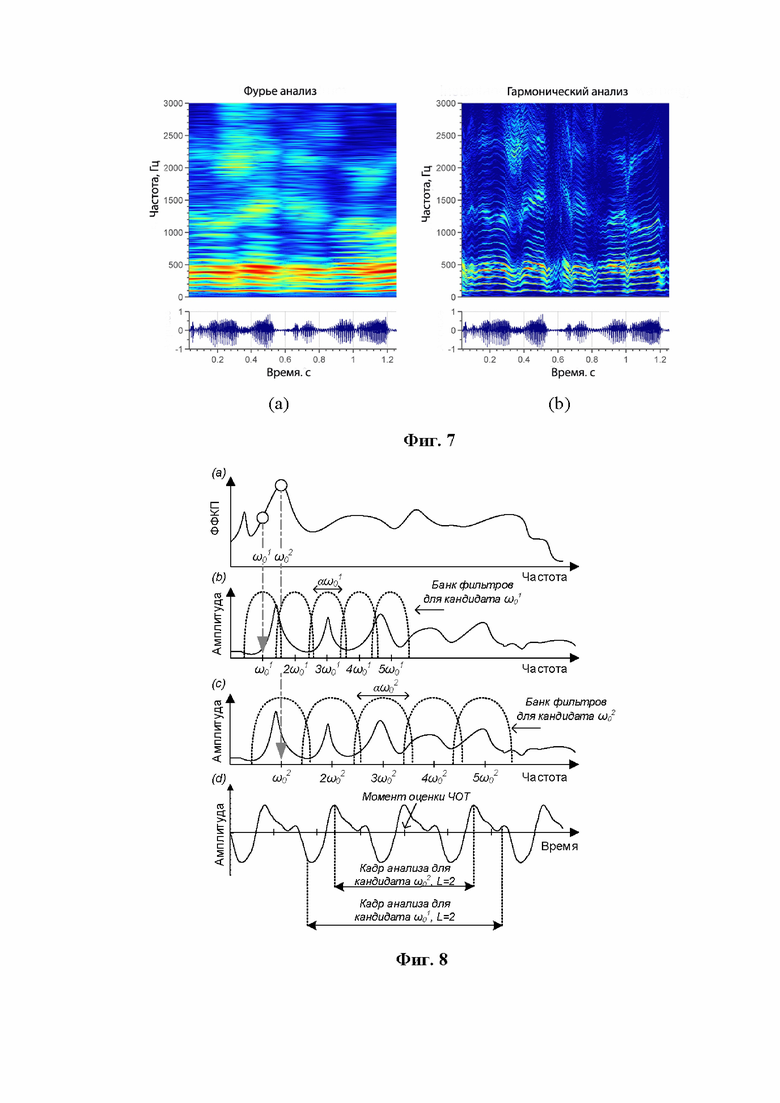
Фиг. 7 иллюстрирует спектрограммы входного сигнала для (а) Фурье анализа и (b) гармонического анализа (ЧОТ зависимого);
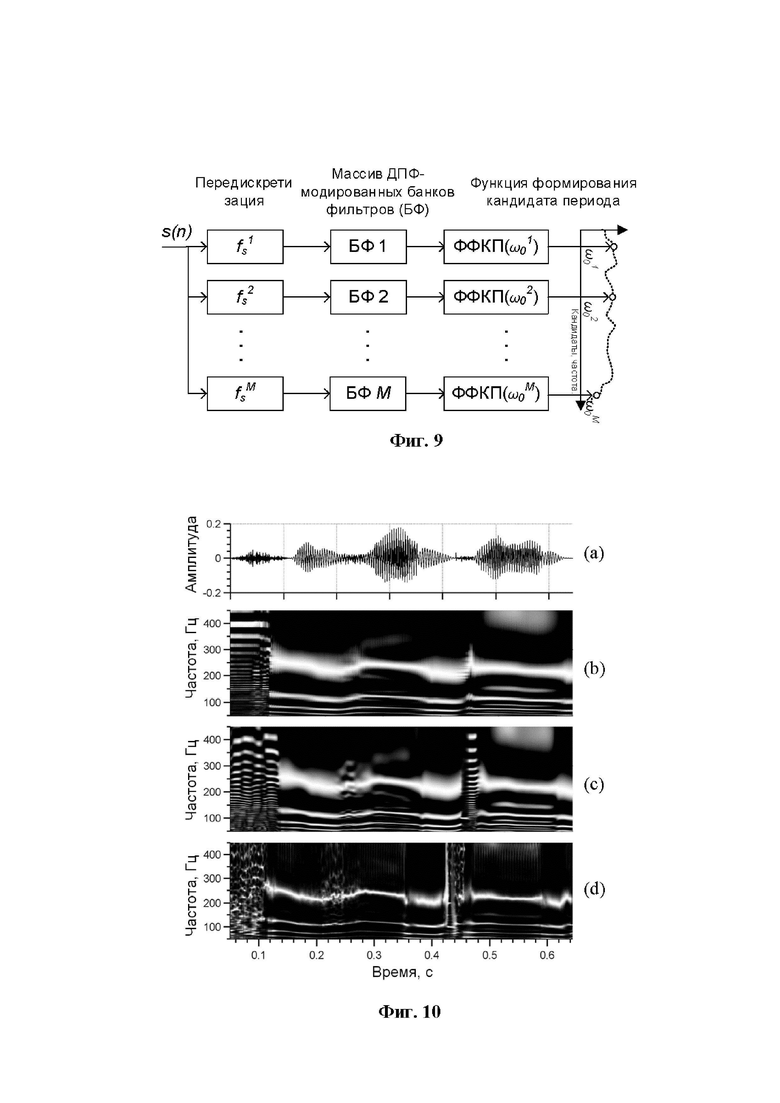
Фиг. 8 иллюстрирует масштабирование анализирующего банка фильтров для каждого кандидата ЧОТ, где (a) - функция формирования кандидата периода (ФФКП), (b) - амплитудный спектр и банк фильтров для кандидата 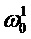 , (c) - амплитудный спектр и банк фильтров для кандидата
, (c) - амплитудный спектр и банк фильтров для кандидата 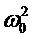 , (d) - исходный сигнал;
, (d) - исходный сигнал;
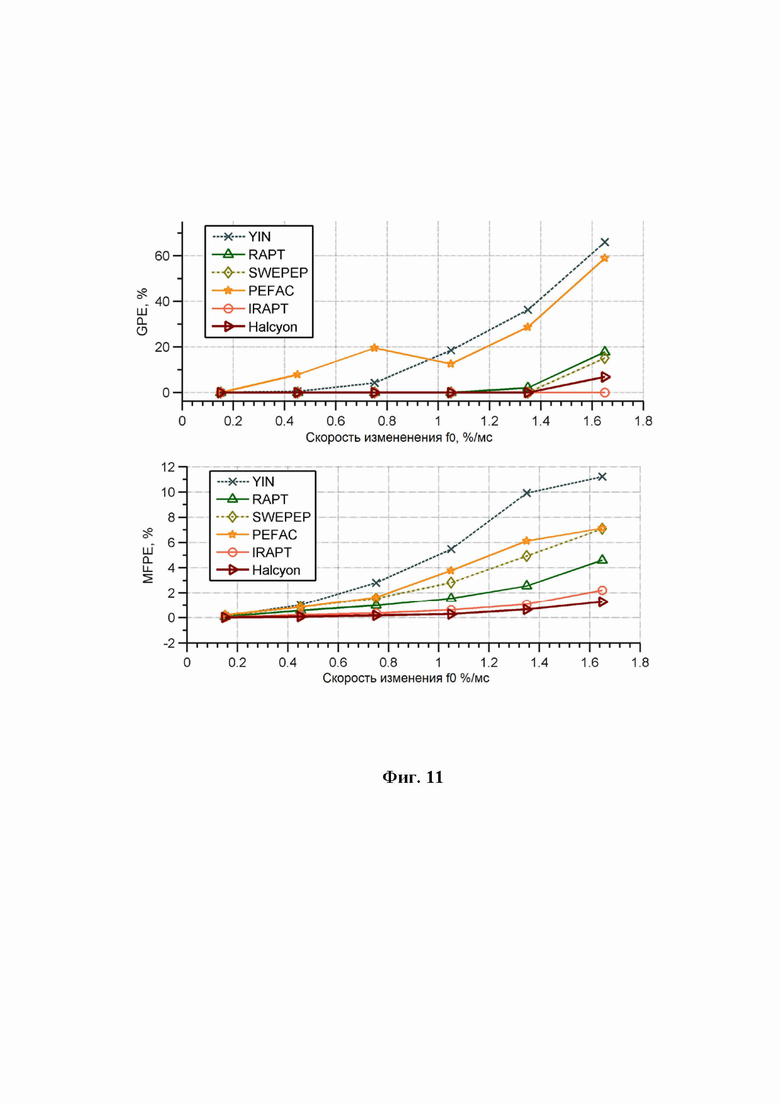
Фиг. 9 иллюстрирует многоскоростную схему вычисления ФФКП основного тона (М - количество кандидатов периода ЧОТ);
Фиг. 10 - иллюстрация формирования кандидатов периода ЧОТ, где (a) - исходный сигнал, (b) - ФФКП 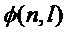
 , (c) - ФФКП, полученная на основе синусоидальной модели
, (c) - ФФКП, полученная на основе синусоидальной модели 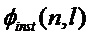 , (d) - предлагаемая ФФКП
, (d) - предлагаемая ФФКП 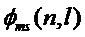 (
( );
);
Фиг. 11 - иллюстрация оценки временного разрешения алгоритмов выделения основного тона.
Подробное раскрытие изобретения
Заявленное новое устройство (фиг. 2) отличается от ранее известного (фиг. 1) тем, что в известное техническое решение введены связь выхода аудиопроцессора со входом центрального процессора для передачи контура ЧОТ текущего обрабатываемого фрейма сигнала микрофона s(n) певца-исполнителя в центральный процессор, а также связи выхода средства обеспечения (таблица параметров) и выхода блока формирования выходного контура ЧОТ средства формирования динамических параметров со входами центрального процессора, которые позволяют передавать в центральный процессор соответственно контур мелодии и выходной контур ЧОТ обработанного голоса певца-исполнителя. Выход центрального процессора связан со входом средства управления и монитора, что позволяет центральному процессору формировать изображение соответствующих контуров ЧОТ фрейм по фрейму обрабатываемого сигнала микрофона s(n) певца-исполнителя синхронно с текстом исполняемого произведения и выводить его на экран монитора. Это позволяет певцу-исполнителю на экране монитора видеть контуры мелодии, основного тона своего голоса и основного тона модифицированного голоса певца-исполнителя (своего измененного голоса), а также вывод модифицированного голоса певца-исполнителя в громкоговоритель дает возможность реализовать принципы визуальной/звуковой (биологической) обратной связи для тренировки певческих навыков: певец-исполнитель слышит в наушнике целевую ноту, сформированную аудиопроцессором в результате модификации его голоса, т.е. свой голос, а также видит и слышит насколько точно он «попал» в мелодию.
Для решения поставленной задачи - обеспечения обучения в реальном масштабе времени профессиональной постановки техники исполнения вокальных партий и ритмического изложения музыкальных композиций - в настоящем изобретении реализован принцип интерактивной обратной связи: и визуальной, и звуковой. Из голоса певца-исполнителя "на лету" (в реальном времени обработки сигнала) выделяется певческая интонация и графически на экране накладывается на мелодию композиции синхронно с воспроизводимым аккомпанементом (визуальная обратная связь), а также голос певца-исполнителя синтезируется с исправленной интонацией и выводится в громкоговоритель (звуковая обратная связь). Время задержки или латентность (задержка сигнала микрофона в аудиопроцессоре - время обработки и вывода в громкоговоритель синтезированного сигнала), с которой выводится певческая интонация на экране и звучит синтезированный голос в громкоговорителе, должно быть небольшим (не более 60 мс) для того, чтобы информация, выводимая на экран монитора (панели управления), и синтезированный сигнал в громкоговорителе соотносились с текущим моментом (текущим состоянием певца - исполняемым им фрагментом музыкальной композиции). Таким образом, с учетом времени слухового восприятия человеком уровней звука певец-исполнитель видит и слышит свои отклонения от правильной интонации, ритмические ошибки и в течение времени исполнения произведения может корректировать свое исполнение (фиг. 3).
Как показывают исследования, латентность не должна превышать 60 мс для звука и 100 мс для визуального отображения. Например, динамические диапазоны отдельных музыкальных и речевых сигналов, измеренные с помощью приборов, показания которых соответствуют слуховому восприятию уровня громкости (время интеграции 60 мс), составляют в среднем 60-70 дБ для симфонического оркестра, 35 дБ для эстрадной музыки, 20 дБ для джаз-оркестра, 47 дБ для хора, 35 дБ для солистов вокалистов, 25 дБ для речи диктора.
Для достижения указанного технического результата необходимо совершенствование методов гармонического анализа/синтеза, а также вести обработку в реальном времени: мгновенную гармоническую параметризацию, модификацию и синтез параметров голоса певца-исполнителя. Устройство (фиг. 2) для реализации заявленного способа работает на фреймах переменной длины, которая зависит от значения мгновенной ЧОТ со смещением примерно 5 мс. Длина фрейма анализа/синтеза пропорциональна целому числу периодов ЧОТ . Параметры базовой гармонической модели обновляются примерно каждые 5 мс. Частота дискретизации составляет 44,1 кГц.
Определение параметров входного сигнала певца-исполнителя выполняется в следующем порядке:
1) к входному сигналу применяется временное масштабирование, что подразумевает адаптивную передискретизацию сигнала с переменной частотой дискретизации, пропорциональной извлеченной мгновенной ЧОТ. Сигнал дискретизируется таким образом, чтобы на каждый период ЧОТ приходилось равное количество отсчетов 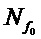 . Каждому входному отсчету речевого сигнала
. Каждому входному отсчету речевого сигнала 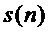 ставится в соответствие фаза периода основного тона
ставится в соответствие фаза периода основного тона 
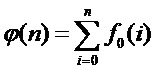 , где
, где 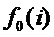 - нормализованная круговая частота основного тона в момент времени i. Новые моменты времени m, в которые необходимо перерасчитать входной сигнал, определяются как
- нормализованная круговая частота основного тона в момент времени i. Новые моменты времени m, в которые необходимо перерасчитать входной сигнал, определяются как 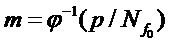 , где p - это индекс отсчета в масштабированной временной области. Обратная функция
, где p - это индекс отсчета в масштабированной временной области. Обратная функция 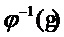 вычисляется при помощи линейной интерполяции ее известных значений для целых n, как показано на фиг. 4.
вычисляется при помощи линейной интерполяции ее известных значений для целых n, как показано на фиг. 4.
Вычисления значений сигнала в заданный момент времени выполняется по теореме Котельникова (см. фиг. 5, где пунктирная линия - непрерывный сигнал; квадратный маркер - сигнал дискретизированный с равным временным интервалом; круглый маркер - значения сигнала в моменты времени, не кратные интервалу дискретизации), согласно которой
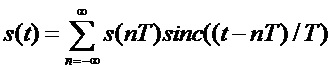 ,
,
где 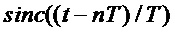 , T - интервал дискретизации,
, T - интервал дискретизации, 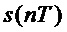 - значения сигнала в дискретные моменты времени
- значения сигнала в дискретные моменты времени 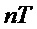 . Для простоты в дальнейшем примем
. Для простоты в дальнейшем примем 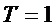 , а
, а 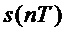 обозначим как
обозначим как 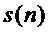 .
.
На практике из-за суммирования в бесконечных пределах выбирается конечное число точек сигнала 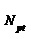 предшествующих моменту
предшествующих моменту  и последующих точек:
и последующих точек:
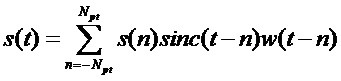 ,
,
где w(•) - оконная функция с центром симметрии в точке 0.
Для каждого выходного отсчета временные отметки пересчитываются таким образом, чтобы текущий момент всегда попадал в диапазон от 0 до 1, как показано на фиг. 6. Это позволяет использовать таблицу с заранее рассчитанными значениями функции sinc. Использование табличных значений дает возможность существенно сократить вычислительные затраты.
Временное масштабирование стабилизирует ЧОТ и уменьшает сглаживание в частотной области, вызванное модуляциями ЧОТ (на фиг. 7 показаны спектрограммы входного сигнала для Фурье анализа и для гармонического анализа (ЧОТ зависимого));
2) гармонические параметры выделяются из масштабируемого сигнала с использованием комплексно-модулированного банка фильтров. Так как масштабируемый сигнал имеет стабильный интервал дискретизации, окно анализа банка фильтров всегда содержит фиксированное количество периодов ЧОТ. Используя оценки амплитуды, мгновенной частоты и фазы каждой гармоники, оценивается спектральная огибающая;
3) далее, используя мгновенные значения ЧОТ, каждый сигнал субполосы банка фильтров классифицируется как периодический или стохастический. Решения для каждой гармоники объединены в вокализованные / невокализованные спектральные области;
4) голосовая часть сигнала синтезируется и вычитается из входного сигнала для получения остатка сигнала (стохастической компоненты ), который не изменяется при изменении высоты тона (ЧОТ).
Таким образом, определяется вектор параметров певца-исполнителя: мгновенные амплитуды , частота основного тона (ЧОТ) , мгновенные значения фаз и шумовая составляющая сигнала .
Модификация гармонических параметров и формирование выходного сигнала выполняются в следующем порядке:
1) гармонические параметры, определенные на этапе анализа, изменяются в соответствии с целевым ЧОТ (контуром нот мелодии), при этом сохраняется форма огибающей спектра гармоник входного сигнала. Новые фазы гармоник генерируются непрерывно, приближаясь к исходному относительному смещению относительно фазы гармоники ЧОТ. Из-за обработки в деформированной временной области, где фиксируются частоты гармоник, можно реализовать эффективную схему синтеза с антиалайзинговой фильтрацией на основе комплексно-модулированного банка фильтров синтеза, в котором каждый канал соответствует гармонической компоненте. Децимированные последовательности субканалов генерируются с использованием модифицированных гармонических параметров и интерполируются банком фильтров, что приводит к формированию выходного сигнала со стабильной ЧОТ;
2) для получения финального выходного сигнала выполняется обратное временное масштабирование выходного сигнала в соответствии с выходным контуром ЧОТ и суммирование со стохастической компонентой для получения модифицированного сигнала голоса певца-исполнителя и затем осуществляется его передача в громкоговоритель.
В случае формирования выходного контура ЧОТ по нотам из таблицы параметров считываются ноты мелодии выбранного музыкального произведения. Контур выходного тона формируется на основе нот мелодии с внесением наименьших искажений в обработанный сигнал. В первую очередь выполняется подбор октавы мелодии, наиболее близкой к голосу пользователя. Для этого частотный контур мелодии умножается и делится на коэффициенты 2 и 4, а затем сравнивается с ЧОТ входного сигнала голоса певца-исполнителя . После этого выполняется выравнивание контура ЧОТ входного сигнала голоса певца-исполнителя и мелодии по времени путем использования временного масштабирования на основе динамического программирования. За счет данной процедуры снижается уровень слышимых артефактов, вносимых в моменты переходов мелодии от ноты к ноте. Затем контур ЧОТ входного сигнала голоса певца-исполнителя притягивается к мелодии. Исходная форма контура ЧОТ входного сигнала голоса певца-исполнителя сохраняется на границах вокализованных сегментов для того, чтобы ослабить эффект "компьютерного акцента".
Таким образом, алгоритм способа модификации голоса с визуальной и звуковой обратной связью, соответствующий устройству (фиг. 2), выполняется в следующей последовательности шагов:
Шаг 1. Инициализация устройства модификации голоса.
Шаг 2. Выбор параметров модификации голоса из таблицы параметров средства обеспечения.
Шаг 3. Параллельно и синхронно аккомпанементу целевой мелодии вводится через устройство ввода аудиосигнала голос певца-исполнителя из микрофонного входа в аудиопроцессор.
Шаг. 4. Определение контура ЧОТ певца-исполнителя в аудиопроцессоре. В ближайшем аналоге определяли на шаге параметрического анализа, но согласно заявленному способу выполняется анализ ЧОТ зависимый, поэтому сначала находят ЧОТ, выполняют временное масштабирование и только затем переходят к параметрическому анализу.
Шаг 5. Временное масштабирование входного фрейма голоса певца-исполнителя в аудиопроцессоре.
Шаг 6. Выполнение в аудиопроцессоре ЧОТ зависимого параметрического анализа на основе комплексно-модулированного банка фильтров данного масштабированного фрейма сигнала для получения вектора параметров: мгновенных амплитуд , мгновенных значений фаз и шумовой составляющей сигнала .
Шаг 7. Формирование выходного контура ЧОТ в соответствии с целевой мелодией в средстве формирования динамических параметров.
Шаг 8. Преобразование параметров фрейма сигнала в средстве формирования динамических параметров для получения вектора выходных параметров [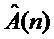 ,, , ] на основании параметров певца-исполнителя: мгновенных амплитуд , значений фаз .
,, , ] на основании параметров певца-исполнителя: мгновенных амплитуд , значений фаз .
Шаг 9. Выполнение параметрического синтеза модифицированной гармонической составляющей в соответствии с параметрами [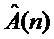 ,, ] в аудиопроцессоре.
,, ] в аудиопроцессоре.
Шаг 10. Обратное временное масштабирование модифицированной гармонической составляющей на основе комплексно-модулированного банка фильтров синтеза.
Шаг 11. Формирование модифицированного фрейма сигнала выходного голоса певца-исполнителя как сумма гармонической составляющей и шумовой составляющей .
Шаг 12. Далее в устройстве вывода аудиосигнала выходной фрейм сигнала голоса певца-исполнителя микшируется с музыкальным сопровождением, переданным в устройство вывода аудиосигнала центральным процессором из таблицы параметров, и выводится на громкоговоритель, а также центральный процессор выводит на экран монитора ноты мелодии , контур мгновенной частоты основного тона голоса певца-исполнителя и выходной контур частоты основного тона .
Шаг. 13. Если музыкальная композиция не закончена, то процесс повторяется с ввода нового фрейма аудиосигнала входного голоса певца-исполнителя из микрофонного входа (переход на шаг 3).
Время обработки с момента ввода аудиосигнала до вывода на экран монитора нот мелодии, контура мгновенной частоты основного тона голоса певца-исполнителя, выходного контура частоты основного тона и модифицированного голоса певца-исполнителя в громкоговоритель составляет не более 60 мс. Для удобства пользователя так же, как в караоке, на экране монитора может быть отражена плывущая строка текста исполняемого вокального произведения (фиг. 3).
Мелодии синхронизируются с корреспондентскими базами данных (контуры нот мелодии). Процедура оптимизации применяется к целевой мелодии, чтобы смягчить эффект «компьютерного акцента». Контуры исходного тона и голосовые / невокализованные решения анализируются, чтобы найти лучшие моменты для перехода между нотами. Система также может выполнять полифонический эффект, смешивая несколько выходов с различными контурами целевой частоты.
Обработка в реальном масштабе времени - необходимое условие достижения технического результата. Это предполагает двойную буферизацию входного сигнала певца-исполнителя: пока идет обработка текущего фрейма сигнала согласно обобщенной функциональной схеме (фиг. 2), следующий фрейм буферизируется. Таким образом, длина фрейма должна быть не менее 60 мс, что соответствует размеру буфера в отсчетах N=60/(период частоты дискретизации). Так, для частоты дискретизации 44,1 кГц размер буфера составит 2646 отсчетов входного сигнала певца-исполнителя. Реализация заявленного способа на мобильной платформе iPhone 5s показала возможность формирования модифицированного голоса певца исполнителя в реальном времени с временем латентности не более 60 мс: ввод-вывод сигнала певца исполнителя здесь занимает порядка 20 мс, еще примерно 40 мс затрачивается на обработку. Причем следует отметить, что операционная система iOS мобильной платформы iPhone 5s (многоядерная, подобная показанной на фиг. 2) применяет распараллеливание вычислительного процесса: параллельно могут выполняться два вычислительных процесса: 1) синтез гармонической составляющей и определение стохастической составляющей, 2) модификация гармонической составляющей, синтез модифицированной составляющей и обратное временное масштабирование. В реальном образце устройства, реализующего заявленный способ, латентность для звука составляла не более 60 мс, а для визуального отображения не более 100 мс.
Поскольку схема анализа сигнала певца-исполнителя зависима от мгновенной ЧОТ, то эффективность анализа определяется частотно-временным разрешением оценки ЧОТ. Алгоритм оценки ЧОТ основан на синусоидальной модели, которая представляет детерминированную часть сигнала в виде суммы периодических компонент с нестационарными параметрами:
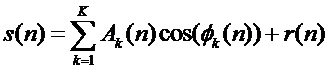 , (1)
, (1)
где 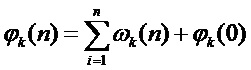 ,
, 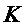 - количество периодических компонент,
- количество периодических компонент, 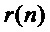 - шумовая компонента. Параметры данной модели (мгновенная амплитуда
- шумовая компонента. Параметры данной модели (мгновенная амплитуда 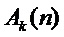 и частота
и частота 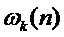 в рад/отсчет) используются в качестве начальных данных для оценки частоты основного тона. Для получения параметров модели сигнал
в рад/отсчет) используются в качестве начальных данных для оценки частоты основного тона. Для получения параметров модели сигнал 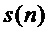 раскладывается на комплексные субполосные составляющие комплексно-модулированным банком фильтров, краткое описание которого приводится далее.
раскладывается на комплексные субполосные составляющие комплексно-модулированным банком фильтров, краткое описание которого приводится далее.
Равномерная сетка частот, соответствующая центральным частотам банка фильтров анализа, определяется как 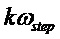 ,
, 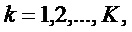
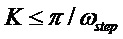 где
где 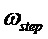 - шаг по частоте в рад/отсчет. Импульсная характеристика
- шаг по частоте в рад/отсчет. Импульсная характеристика 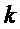 -го анализирующего фильтра определяется выражением:
-го анализирующего фильтра определяется выражением:
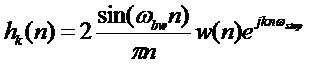 , (2)
, (2)
где 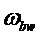 - половина ширины полосы пропускания фильтра,
- половина ширины полосы пропускания фильтра, 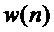 - четная оконная функция.
- четная оконная функция.
Выход каждого канала банка фильтров является аналитическим сигналом 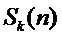 с ограниченной полосой, который можно представить как свертку входного сигнала
с ограниченной полосой, который можно представить как свертку входного сигнала 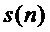 с импульсной характеристикой:
с импульсной характеристикой:
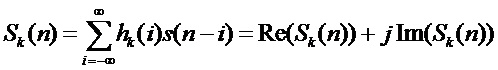 . (3)
. (3)
Мгновенные параметры субполосных компонент могут быть получены следующим образом:
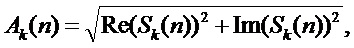 (4)
(4)
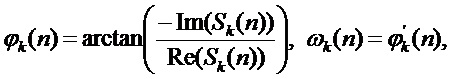 (5)
(5)
чтобы избежать точек разрывов, в выражении (5) применяется процедура развертывания фазы (phase unwrapping). Мгновенные параметры 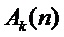 ,
, 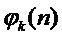 используются в качестве начальных данных для вычисления функции формирования кандидатов периода ЧОТ. Учитывая предположение, что вариация частоты основного тона пропорциональна её текущему значению, параметры анализирующего банка фильтров должны быть масштабированы для каждого кандидата периода следующим образом:
используются в качестве начальных данных для вычисления функции формирования кандидатов периода ЧОТ. Учитывая предположение, что вариация частоты основного тона пропорциональна её текущему значению, параметры анализирующего банка фильтров должны быть масштабированы для каждого кандидата периода следующим образом:
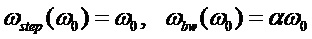 , (6)
, (6)
где 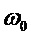 - частота кандидата в рад/отсчет,
- частота кандидата в рад/отсчет, 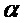 - допустимая относительная вариация тона. Длительность кадра анализа (
- допустимая относительная вариация тона. Длительность кадра анализа (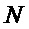 ) должна быть подобрана, чтобы включать целое число периодов основного тона:
) должна быть подобрана, чтобы включать целое число периодов основного тона:
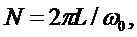 (7)
(7)
где 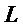 - число периодов в кадре анализа.
- число периодов в кадре анализа.
Изменение параметров банка фильтров для каждого кандидата периода в общем случае является вычислительно затратным процессом. Альтернативой данному подходу может служить применение банка фильтров с фиксированными параметрами, но к сигналу с измененяемой частотой дискретизации. В этом случае можно определить частоту дискретизации 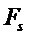 кратной частоте кандидата периода ЧОТ (
кратной частоте кандидата периода ЧОТ (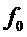 ):
):
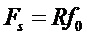 , (8)
, (8)
где - частота в Гц, 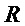 - целое число. Учитывая, что
- целое число. Учитывая, что 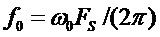 , выражение (7) принимает вид фиксированного по длительности кадра анализа для всех кандидатов на период:
, выражение (7) принимает вид фиксированного по длительности кадра анализа для всех кандидатов на период:
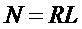 . (9)
. (9)
Параметр определяет число гармоник, которые оставляются в передискретизированной версии сигнала:
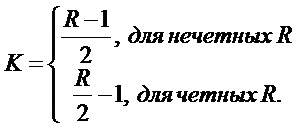 (10)
(10)
Данный подход иллюстрируется на фиг. 8.
Поскольку практическую значимость для определения ЧОТ имеют лишь несколько первых гармоник, для анализа можно использовать очень короткие по длительности кадры. Выражение (6), описывающее масштабирование параметров банка фильтров, принимает вид
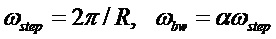 . (11)
. (11)
Параметры синусоидальной модели, необходимые для вычисления функции формирования кандидата периода (ФФКП), извлекаются из сигнала при помощи многоскоростной схемы (фиг. 9), на которой показаны: этап передискретизации в каналах в соответствии с выражением (11), массив комплексно-модулированных банков фильтров и этап определения функции формирования периода ЧОТ.
В качестве функции формирования кандидата периода основного тона (ФФКП), как правило, используются различные метрики, основанные на автокорреляционной функции, например, нормированная кросскорреляционная функция:
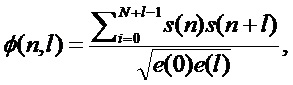 (12)
(12)
где 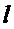 - задержка в отсчетах,
- задержка в отсчетах, 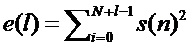 . Функция усредняет данные внутри кадра анализа и поэтому дает сглаженные значения. Чтобы улучшить временного разрешение, может использоваться нормированная кросскорреляционная функция на основе синусоидальной модели сигнала:
. Функция усредняет данные внутри кадра анализа и поэтому дает сглаженные значения. Чтобы улучшить временного разрешение, может использоваться нормированная кросскорреляционная функция на основе синусоидальной модели сигнала:
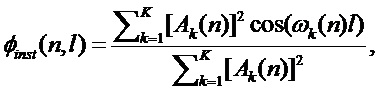 (13)
(13)
В данной функции предполагается, что ширина полос фильтров анализа уже, чем минимально допустимое значение частоты основного тона, вследствие чего каждая гармоника сигнала всегда попадает в отдельный канал.
Многоскоростная схема анализа (фиг. 9) подвержена явлению смешивания гармоник в каналах, которое возникает для высокочастотных кандидатов периода основного тона, когда обрабатываемый голос является низким. Вследствие этого появляются редкие единичные выбросы в высокочастотной области . Для того, чтобы уменьшить влияние эффекта смешивания гармоник, используют следующую ФФКП, которая использует мгновенные параметры, полученные для 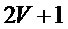 смежных отсчетов:
смежных отсчетов:
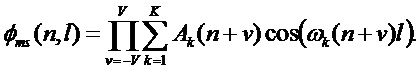 (14)
(14)
В каждом отдельном канале схемы на фиг. 9 выполняется вычисление (14), отвечающее за конкретное значение задержки 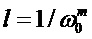 , где индекс
, где индекс 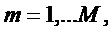 для чего в канал подается кадр сигнала, передискретизированный с коэффициентом
для чего в канал подается кадр сигнала, передискретизированный с коэффициентом 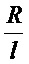 в соответствии с выражением (8). Уравновешивание значений для различных кандидатов выполняется путем нормализации к единичной энергии каждого передискретизированного кадра сигнала. Использование в выражении (14) амплитуд, не возведенных в квадрат, в отличие от выражения (13), позволяет сделать вклад амплитуд различных гармоник более сбалансированным. Как правило, эффект смешивания гармоник возникает на коротких временных периодах и может быть существенно уменьшен умножением нескольких термов вида
в соответствии с выражением (8). Уравновешивание значений для различных кандидатов выполняется путем нормализации к единичной энергии каждого передискретизированного кадра сигнала. Использование в выражении (14) амплитуд, не возведенных в квадрат, в отличие от выражения (13), позволяет сделать вклад амплитуд различных гармоник более сбалансированным. Как правило, эффект смешивания гармоник возникает на коротких временных периодах и может быть существенно уменьшен умножением нескольких термов вида 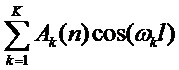 . На фиг. 10 показаны кандидаты периодов, сформированные функциями
. На фиг. 10 показаны кандидаты периодов, сформированные функциями 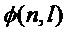 , и предлагаемой функцией для короткого речевого фрагмента, где (a) - исходный сигнал, (b) - ФФКП , (c) - ФФКП, полученная на основе синусоидальной модели, , (d) - предлагаемая ФФКП ().
, и предлагаемой функцией для короткого речевого фрагмента, где (a) - исходный сигнал, (b) - ФФКП , (c) - ФФКП, полученная на основе синусоидальной модели, , (d) - предлагаемая ФФКП ().
Очевидно, что функция имеет более высокое частотное и временное разрешение по сравнению с  и .
и .
Таким образом, алгоритм оценки частоты основного тона состоит из следующих шагов:
1) выполняют передискретизацию фрейма входного сигнала 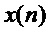 для каждого кандидата периода основного тона с частотой дискретизации согласно выражению (8);
для каждого кандидата периода основного тона с частотой дискретизации согласно выражению (8);
2) нормируют энергию каждого передискретизированного фрейма к 1;
3) оценивают мгновенные параметры синусоидальной модели согласно выражениям (1)-(5). Данный шаг повторяется для перекрывающихся кадров каждого фрейма. В качестве оконной функции можно использовать окно Хемминга;
4) вычисляют функцию формирования кандидатов периода частоты основного тона согласно выражению (14), используя соответствующий набор параметров;
5) умножают полученное значение функции формирования кандидатов периода основного тона на взвешивающую функцию для ограничения низкочастотных кандидатов периода: 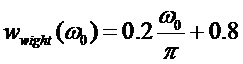 ;
;
6) определяют наилучший непрерывный контур частоты основного тона методом динамического программирования, максимизирующего сумму ФФКП на локальной последовательности кадров; в результате данного шага выбирается лучший кандидат 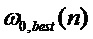 , который является грубой (начальной) оценкой частотны основного тона;
, который является грубой (начальной) оценкой частотны основного тона;
7) вычисляют уточненную оценку основного тона  , используя мгновенные параметры синусоидальной модели, полученные для лучшего кандидата:
, используя мгновенные параметры синусоидальной модели, полученные для лучшего кандидата:
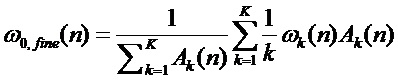 . (15)
. (15)
Вычислительная сложность алгоритма (число умножений, требуемое для оценки одного значения частоты основного тона) является невысокой, поскольку в основе реализации банка фильтров лежит быстрое преобразование Фурье. Ориентировочно вычислительная сложность О алгоритма оценивается как
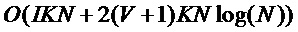 , (16)
, (16)
где 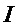 - порядок НЧ фильтра, используемого при децимации/интерполяции в процессе передискретизации, N - число отсчетов на анализируемом фрейме сигнала, K - количество гармоник ЧОТ, и V - число смежных фреймов сигнала.
- порядок НЧ фильтра, используемого при децимации/интерполяции в процессе передискретизации, N - число отсчетов на анализируемом фрейме сигнала, K - количество гармоник ЧОТ, и V - число смежных фреймов сигнала.
Для практической реализации алгоритма были использованы следующие значения параметров 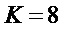 ,
, 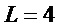 ,
, 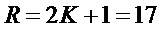 ,
, 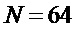 ,
, 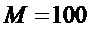 ,
, 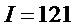 ,
, 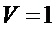 (L соответствует формуле (7), R - формуле (9), M - формуле (14) и фиг. 9, число каналов в банке фильтра). Аргумент функции О(•) показывает, как меняется вычислительная сложность в зависимости от параметров I, K, N, V. Диапазон поиска частоты основного тона 50-450 Гц. Данный диапазон разбит линейно в логарифмическом масштабе на 100 интервалов, каждый из которых соответствует одному кандидату периода частоты основного тона. Длительность передескритезированных кадров варьируется от 80 мс (самый низкочастотный кандидат) до 9 мс (самый высокочастотный кандидат).
(L соответствует формуле (7), R - формуле (9), M - формуле (14) и фиг. 9, число каналов в банке фильтра). Аргумент функции О(•) показывает, как меняется вычислительная сложность в зависимости от параметров I, K, N, V. Диапазон поиска частоты основного тона 50-450 Гц. Данный диапазон разбит линейно в логарифмическом масштабе на 100 интервалов, каждый из которых соответствует одному кандидату периода частоты основного тона. Длительность передескритезированных кадров варьируется от 80 мс (самый низкочастотный кандидат) до 9 мс (самый высокочастотный кандидат).
Оценщик ЧОТ «Halcyon», ранее опубликованный (E.Azarov, M. Vashkevich, A. Petrovsky. Intantaneous pitch estimation algorithm based on multirate sampling// ICASSP-2016, Shanghai, China, 2016), сравнивался с пятью известными и широко применяемыми алгоритмами RAPT, YIN , SWIPE, IRAPT, PEFAC. Сравнение выполнялось в терминах 1) процента грубых ошибок (gross pitch error - GPE) и 2) среднего значения мелких ошибок (mean fine pitch error - MFPE). GPE вычисляется как процент вокализованных фреймов с ошибкой в оценке основного тона, превышающей ± 20% от настоящего значения основного тона; при вычислении MFPE фреймы, содержащие грубые ошибки, не учитывались. Для оценки временного разрешения алгоритма и его устойчивости к быстрому изменению ЧОТ были синтезированы модельные сигналы с изменяющейся частотой основного тона в диапазоне от 100 до 350 Гц. Полученные экспериментальные результаты были разделены на 6 групп в зависимости от скорости изменения частоты основного тона, измеряемой в процентах изменения тона на миллисекунду (0-0.3, 0.3-0.6, 0.6-0.9, 0.9-1.2, 1.2-1.5, >1.5). Усреднённые значения ошибок показаны на фиг. 11.
Алгоритмы IRAPT и Halcyon показывают более высокую устойчивость к изменению частоты основного тона - процент грубых ошибок для них остается незначительным до значения 1,5 %/мс. График MFPE показывает, что алгоритм Halcyon превосходит все остальные алгоритмы по частотно/временному разрешению. Он и использовался при реализации заявленного способа.
Наиболее успешно заявленный способ модификации голоса с визуальной и звуковой обратной связью промышленно применим в обучающих интерактивных системах с возможностью обеспечения максимально точного попадания голоса певца-исполнителя в заданную мелодию при использовании принципов визуальной и звуковой (биологической) обратной связи для тренировки искусству и мастерству пения.
Изобретение относится к вычислительной технике, системам мультимедиа и может быть использовано для профессиональной постановки техники исполнения вокальных партий. Заявленный способ модификации голоса заключается в том, что сохраняют наборы параметров, каждый из которых характеризует ноты целевой мелодии. Вводят синхронно с музыкальным сопровождением нот целевой мелодии сигнал голоса певца-исполнителя. Производят обработку сигнала голоса певца-исполнителя, обеспечивающую создание модифицированного фрейма сигнала выходного голоса певца-исполнителя, нот целевой мелодии, контура мгновенной частоты основного тона голоса певца-исполнителя и выходного контура частоты основного тона. Микшируют модифицированный фрейм сигнала выходного голоса певца-исполнителя с музыкальным сопровождением целевой мелодии и выводят их на громкоговоритель, а также при помощи центрального процессора выводят на экран монитора ноты целевой мелодии, контур мгновенной частоты основного тона голоса певца-исполнителя и выходной контур частоты основного тона. Способ позволяет повысить временное разрешение в оценке мгновенной ЧОТ, уменьшить латентность обработки и модификации голоса певца-исполнителя. 2 н. и 3 з.п. ф-лы, 11 ил.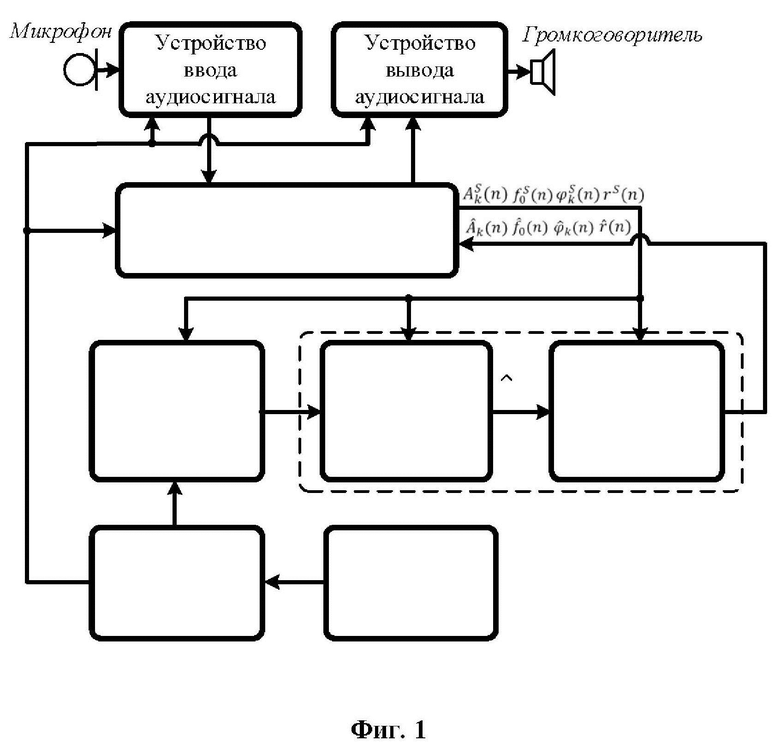
1. Способ модификации голоса певца-исполнителя с визуальной и звуковой обратной связью, заключающийся в том, что
обеспечивают наборы параметров, каждый из которых характеризует ноты целевой мелодии,
из числа указанных наборов параметров задают требуемый набор параметров для определенной целевой мелодии в виде нот целевой мелодии,
вводят синхронно с музыкальным сопровождением нот целевой мелодии сигнал голоса певца-исполнителя, имеющий соответствующий ему спектр частот,
производят обработку сигнала голоса певца-исполнителя, обеспечивающую создание модифицированного фрейма сигнала выходного голоса певца-исполнителя, нот целевой мелодии 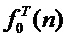 , контура мгновенной частоты основного тона голоса певца-исполнителя
, контура мгновенной частоты основного тона голоса певца-исполнителя 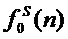 и выходного контура частоты основного тона
и выходного контура частоты основного тона 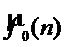 ,
,
микшируют указанный модифицированный фрейм с музыкальным сопровождением целевой мелодии и выводят их на громкоговоритель, а также выводят на экран монитора ноты целевой мелодии , контур мгновенной частоты основного тона голоса певца-исполнителя и выходной контур частоты основного тона ,
при этом время с момента ввода сигнала голоса певца-исполнителя до вывода на громкоговоритель модифицированного фрейма составляет не более 60 мс, а время до вывода на экран монитора нот целевой мелодии , контура мгновенной частоты основного тона голоса певца-исполнителя , выходного контура частоты основного тона составляет не более 100 мс.
2. Способ модификации голоса певца-исполнителя с визуальной и звуковой обратной связью, заключающийся в том, что
обеспечивают наборы параметров, каждый из которых характеризует ноты целевой мелодии,
из числа указанных наборов параметров задают требуемый набор параметров для определенной целевой мелодии в виде нот целевой мелодии,
вводят синхронно с музыкальным сопровождением нот целевой мелодии сигнал голоса певца-исполнителя, имеющий соответствующий ему спектр частот,
определяют контур частоты основного тона певца-исполнителя,
производят временное масштабирование входного фрейма сигнала голоса певца-исполнителя,
осуществляют зависимый от частоты основного тона параметрический анализ при помощи комплексно-модулированного банка фильтров анализа входного фрейма сигнала голоса певца-исполнителя для получения вектора параметров – мгновенных амплитуд 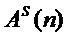 , мгновенных значений фаз
, мгновенных значений фаз 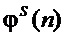 и шумовой составляющей
и шумовой составляющей 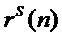 сигнала,
сигнала,
формируют выходной контур частоты основного тона в соответствии с целевой мелодией ,
преобразуют параметры входного фрейма сигнала голоса певца-исполнителя для получения вектора выходных параметров [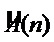 , ,
, ,  ,
, 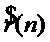 ], основанных на параметрах мгновенных амплитуд и соответствующих значений фаз сигнала голоса певца-исполнителя,
], основанных на параметрах мгновенных амплитуд и соответствующих значений фаз сигнала голоса певца-исполнителя,
осуществляют параметрический синтез модифицированной гармонической составляющей в соответствии с параметрами [, , ],
производят обратное временное масштабирование модифицированной гармонической составляющей при помощи комплексно-модулированного банка фильтров синтеза,
формируют модифицированный фрейм сигнала выходного голоса певца-исполнителя как сумму модифицированной гармонической составляющей и шумовой составляющей , и
микшируют модифицированный фрейм сигнала выходного голоса певца-исполнителя с музыкальным сопровождением целевой мелодии и выводят их на громкоговоритель, а также выводят на экран монитора ноты целевой мелодии , контур мгновенной частоты основного тона голоса певца-исполнителя и выходной контур частоты основного тона .
3. Способ по п. 2, отличающийся тем, что время обработки с момента ввода сигнала голоса певца-исполнителя до вывода на громкоговоритель составляет не более 60 мс, а до вывода на экран монитора нот целевой мелодии, контура мгновенной частоты основного тона голоса певца-исполнителя, выходного контура частоты основного тона составляет не более 100 мс.
4. Способ по п. 2, отличающийся тем, что синхронно с выводом на экран монитора нот целевой мелодии, контура мгновенной частоты основного тона голоса певца-исполнителя и выходного контура частоты основного тона выводят на экран строку текста исполняемого вокального произведения.
5. Способ по п. 2, отличающийся тем, что для определения частоты основного тона сигнала голоса певца-исполнителя, детерминированная часть модели которого представляет собой сумму периодических компонент с нестационарными параметрами – амплитудой, частотой и фазой, производят передискретизацию входного фрейма сигнала голоса певца-исполнителя для каждого кандидата периода частоты основного тона, нормируют энергию каждого передискретизированного входного фрейма к 1, производят оценку мгновенных параметров синусоидальной модели, вычисляют функцию формирования кандидатов периода частоты основного тона для соответствующего набора параметров – амплитуды, частоты и фазы, умножают вычисленное значение функции формирования кандидатов периода основного тона на взвешивающую функцию для ограничения низкочастотных кандидатов частоты основного тона, определяют наилучший непрерывный контур частоты основного тона при помощи динамического программирования, максимизирующего сумму функции формирования кандидатов периода на локальной последовательности кадров, выбирают лучшего кандидата частоты основного тона, который является начальной оценкой частоты основного тона, и далее вычисляют уточненную оценку частоты основного тона, используя мгновенные параметры синусоидальной модели, полученные для лучшего кандидата.
| СПОСОБ МОДИФИКАЦИИ ГОЛОСА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ (ВАРИАНТЫ) | 2015 |
|
RU2591640C1 |
| US 2005262989 A1, 01.12.2005 | |||
| EP 3905246 A1, 03.11.2021 | |||
| CN 110033670 A, 19.07.2019. | |||

