Настоящее изобретение относится к звуковому микшеру для микширования многодорожечных сигналов согласно указаниям пользователя. Оно относится к обработке аудиосигналов, в частности к задаче микширования многодорожечной записи согласно набору установленных пользователем критериев. Область применения изобретения дополнительно относится к способу микширования множества звуковых дорожек с образованием смешанного сигнала. Область применения изобретения также относится к компьютерной программе, предписывающей компьютеру осуществлять способ микширования множества звуковых дорожек.
Постоянно растущая доступность мультимедийного контента открывает перед пользователем новые возможности наслаждаться музыкой и взаимодействовать с музыкой. Эти возможности сопряжены с необходимостью разрабатывать инструменты, помогающие пользователю в такой деятельности.
С точки зрения извлечения информации эта задача была поставлена более десяти лет назад, что обусловило возникновение направления исследований, посвященных колебаниям, для извлечения музыкальной информации и многочисленных коммерческих применений.
Другой аспект, до сих пор не нашедший решения, это взаимодействие с контентом, доступным в многодорожечном формате. Многодорожечный формат может состоять из отдельных и выровненных по времени сигналов (также известных как одиночные дорожки (ST)) для каждого звукового объекта (SO) или групп объектов (стволов). Согласно одному определению стволы это отдельные компоненты микшированного сигнала, по отдельности сохраненные (обычно на диске или ленте) с целью использования для повторного микширования.
В традиционном процессе создания музыки множественные одиночные дорожки объединяются изощренным образом с образованием смешанного сигнала (MS), который затем доставляется конечному пользователю. Постоянное развитие цифровых аудиотехнологий, например разработка новых форматов аудиосигнала для параметрических аудиосигналов на объектной основе, позволяет значительно усилить взаимодействие с музыкой. Пользователь осуществляет доступ к многодорожечным записям и может активно управлять процессом микширования. Некоторые артисты начали выпускать стволы для некоторых своих песен, с тем чтобы слушатели могли свободно перемикшировать и повторно использовать музыку любым желаемым образом.
Музыкальное или звуковое произведение, выпущенное в многодорожечном формате, можно использовать различными способами. Пользователь может управлять параметрами микширования для разных дорожек, таким образом, выделяя выбранные дорожки и одновременно ослабляя другие дорожки. Одну или более дорожек можно приглушить, например, в целях караоке или подыгрывания. Звуковые эффекты, например эхо, реверберация, искажение, припев и т.д., можно применять к выбранным дорожкам, не оказывая влияния на другие дорожки. Одну или более дорожек можно извлечь из многодорожечного формата и использовать в другом музыкальном произведении или другой форме звукового произведения, например аудиокниге, лекции, подкасте и т.д. В нижеследующем описании рассмотрено применение раскрытых здесь принципов, в иллюстративной манере, например, к мастерингу записанного музыкального произведения. Однако следует понимать, что обработка любого записанного звука с применением микширования множества одиночных звуковых дорожек в равной степени подчиняется и охватывается раскрытыми здесь принципами.
Автоматическое микширование было и остается задачей ряда исследовательских проектов. В 2009 г. Perez-Gonzalez и др. описали способ автоматической коррекции многодорожечных сигналов (Е. Perez-Gonzalez and J. Reiss, "Automatic Equalization of Multi-Channel Audio Using Cross-Adaptive Methods", Proc. of the AES 127th Conv., 2009). Авторы представили способ автоматической настройки ослабления для каждого сигнала многодорожечного сигнала. Коэффициенты усиления определяются таким образом, чтобы громкость каждого сигнала была равна средней громкости всех сигналов. Другая статья тех же авторов называется "Automatic Gain and Fader Control for Live Mixing" и опубликована в Proc. of WASPAA, 2009.
Семантический HiFi - это название Европейского проекта IST-507913 (Н. Vinet et al., "Semantic HiFi Final Report", Final Report of IST-507913, 2006). Он, в основном, связан с извлечением, просмотром и совместным использованием мультимедийного контента. Это содержит просмотр и навигацию в базах данных, генерацию списков воспроизведения, внутридорожечную навигацию (с использованием структурного анализа наподобие идентификации строфы-припева) и совместное использование метаданных. Он также относится к взаимодействию/авторингу/редактированию: генерации смесей, включающих в себя синхронизацию (т.е. "конкатенацию" аудиосигналов, а не микширование многодорожечных сигналов), преобразование голоса, преобразование ритма, инструменты с голосовым управлением и эффекты.
Другой проект известен под названием "структурированный аудиосигнал" или MPEG 4. Структурированный аудиосигнал позволяет передавать аудиосигналы на низких битовых скоростях и перцептивно манипулировать акустическими данными и обращаться к ним с использованием символического и семантического описания сигналов (см. B.L. Vercoe and W.G. Gardner and E.D. Scheirer, "Structured Audio: Creation, Transmission, and Rendering of Parametric Sound Representations", Proc. of IEEE, vol. 86, pp. 922-940, 1998). Здесь представлено описание параметрического завершающего этапа создания звука для микширования множественных потоков и добавления звуковых эффектов. Параметрические описания определяют, как синтезируются звуки. Структурированный аудиосигнал относится к синтезированию аудиосигналов.
В международной патентной заявке, опубликованной под номером международной публикации WO 2010/111373 А1, раскрыты интерфейс и система с речевым управлением на контекстной основе. Система пользовательского интерфейса с речевым управлением включает в себя, по меньшей мере, один громкоговоритель для доставки аудиосигнала пользователю и, по меньшей мере, один микрофон для захвата речевых фрагментов пользователя. Устройство интерфейса сопрягается с громкоговорителем и микрофоном и обеспечивает множество аудиосигналов на громкоговоритель, чтобы их мог слышать пользователь. Схема управления оперативно соединена с устройством интерфейса и сконфигурирована для выбора, по меньшей мере, одного из множества аудиосигналов в качестве аудиосигнала переднего плана для доставки пользователю через громкоговоритель. Схема управления выполнена с возможностью распознавать речевые фрагменты пользователя и использовать распознанные речевые фрагменты для управления выбором аудиосигнала переднего плана.
В публикации патентной заявки США № US 2002/0087310 A1 раскрыты осуществляемый на компьютере способ и система для обработки речевого диалога с пользователем. Речевой ввод от пользователя содержит слова, относящиеся к множеству концепций. Речевой ввод пользователя содержит запрос услуги, подлежащей осуществлению. Распознавание речи речевого ввода пользователя используется для генерации распознанных слов. К распознанным словам применяется шаблон диалога. Шаблон диалога имеет узлы, которые связаны с заранее определенными концепциями. Узлы включают в себя различную информацию обработки запроса. Концептуальные области идентифицируются в шаблоне диалога на основании того, какие узлы связаны с концепциями, которые приближенно совпадают с концепциями распознанных слов. Запрос пользователя обрабатывается с использованием информации обработки запроса узлов, содержащихся в идентифицированных концептуальных областях.
В статье "Transient Detection of Audio Signals Based on an Adaptive Comb Filter in the Frequency Domain", авторами M. Kwong и R. Lefebvre представлен алгоритм переходного детектирования, пригодный для детектирования ритма в музыкальных сигналах. Во многих аудиосигналах низкоэнергичные переходы маскируются высокоэнергичными стационарными звуками. Эти замаскированные переходы, а также более высокая энергия и более видимые переходы, несут важную информацию о ритме и временном сегментировании музыкального сигнала. Предложенный алгоритм сегментирования использует синусоидальную модель, объединенную с адаптивным гребенчатым фильтром в частотной области для устранения стационарной компоненты звукового сигнала. После фильтрации, временная огибающая остаточного сигнала анализируется для определения местоположения переходных компонент. Результаты показывают, что предложенный алгоритм может точно детектировать наиболее низкоэнергичные переходы.
Микширование многодорожечной записи обычно является задачей авторинга, которая обычно выполняется экспертом, звукорежиссером. Современные разработки в области мультимедиа, например интерактивных форматов аудиосигнала, привели к созданию приложений, в которых многодорожечные записи требуется микшировать в автоматическом режиме или в полуавтоматическом режиме под руководством неспециалиста. Желательно, чтобы автоматически выводимый смешанный сигнал имел субъективное качество звучания, сравнимое со смешанным сигналом, генерируемым человеком-специалистом.
Раскрытые здесь принципы преследуют эту общую цель. Принципы относятся к обработке аудиосигналов, в частности к задаче микширования множественных дорожек согласно набору установленных пользователем критериев записи для (конечной) цели прослушивания. Звуковой микшер и способ микширования множества звуковых дорожек с образованием смешанного сигнала согласно раскрытым здесь принципам устанавливают связь между, по существу, эстетической идеей неспециалиста и результирующим смешанным сигналом.
По меньшей мере, одна из этих целей и/или возможных других целей достигается посредством звукового микшера по п. 1 или 16, способа микширования множества звуковых дорожек по п. 14 или 17 и компьютерной программы по п. 15 или 18.
Согласно раскрытым здесь принципам звуковой микшер для микширования множества звуковых дорожек с образованием смешанного сигнала содержит семантический интерпретатор команд, процессор звуковых дорожек и объединитель звуковых дорожек. Семантический интерпретатор команд сконфигурирован для приема команды семантического микширования и для выведения множества параметров микширования для множества звуковых дорожек из команды семантического микширования. Процессор звуковых дорожек сконфигурирован для обработки множества звуковых дорожек в соответствии с множеством параметров микширования. Объединитель звуковых дорожек сконфигурирован для объединения множества звуковых дорожек, обработанных процессором звуковых дорожек, в смешанный сигнал.
Способ микширования множества звуковых дорожек с образованием смешанного сигнала согласно раскрытым принципам содержит этапы, на которых: принимают команду семантического микширования; выводят множество параметров микширования для множества звуковых дорожек из команды семантического микширования; обрабатывают множество звуковых дорожек в соответствии с множеством параметров микширования; и объединяют множество звуковых дорожек, полученное в результате обработки множества звуковых дорожек, для формирования смешанного сигнала.
Компьютерная программа содержит или представляет инструкции, предписывающие компьютеру или процессору осуществлять способ микширования множества звуковых дорожек. Компьютерная программа может быть воплощена на машиночитаемом носителе, на котором хранится упомянутая компьютерная программа, для осуществления, при выполнении на компьютере, способа по п. 14.
Команда семантического микширования может базироваться на установленных пользователем критериях, которые обеспечивают семантическое описание желаемого результирующего смешанного сигнала. Согласно раскрытым здесь принципам семантический анализ аудиосигнала, психоакустика, обработка аудиосигналов могут быть включены друг с другом для автоматического выведения смешанного сигнала на основании семантических описаний. Этот процесс можно именовать "семантическим микшированием".
Семантическое микширование можно рассматривать как способ, который позволяет компьютеру микшировать многодорожечную запись согласно указанию, данному пользователем. Указание обычно дается в форме семантического описания. На основании этого семантического описания параметры микширования можно определять с учетом характеристик одиночной(ых) дорожки(ек) и человеческого слуха.
Звуковой микшер согласно раскрытым здесь принципам, таким образом, обычно содержит компьютер или процессор или взаимодействует с компьютером/процессором. Процессор звуковых дорожек и объединитель звуковых дорожек можно объединить в один блок.
Выведение множества параметров микширования из команды семантического микширования может предусматривать анализ смыслового значения команды семантического микширования или ее частей. Часть команды семантического микширования может представлять собой семантическое выражение, например слово или группу слов. Затем семантическое(ие) выражение(я) можно переводить в набор конкретных параметров микширования для множества звуковых дорожек. Таким образом, команда семантического микширования реализуется посредством конкретных параметров микширования, которые соответствуют смысловому значению команды семантического микширования. Действие перевода команды семантического микширования и/или составляющих ее семантических выражений может содержать, например, оценивание функции перевода или обращение к поисковой таблице. Параметры функции перевода или записей данных в поисковой таблице обычно являются заранее заданными и представляют совокупность экспертных знаний, например, опытных звукорежиссеров. Экспертные знания можно собирать в течение времени, например путем регистрации устных инструкций, которые артист или музыкальный продюсер дает своему звукорежиссеру, а также установок, осуществляемых звукорежиссером. Таким образом, функция перевода и/или поисковая таблица может совершенствоваться опытным звукорежиссером.
Согласно аспекту раскрытых здесь принципов семантический интерпретатор команд может содержать словарную базу данных для идентификации семантических выражений в команде семантического микширования. Посредством словарной базы данных, семантический интерпретатор команд может идентифицировать, например, синонимы. Дополнительно существует возможность отображать слово или группу слов, содержащее(ую)ся в команде семантического микширования, в конкретное значение. Например, слово для идентификации инструмента ("гитара") может отображаться в конкретный номер или идентификатор канала, на котором записан инструмент. Словарная база данных может дополнительно содержать элементы, идентифицирующие определенную часть музыкальной партии, например начало (например "вступление"), припев ("припев") или конец (например "кода" или "финал"). Словарную базу данных также можно использовать для распознавания и назначения семантически выраженных параметров или стилей микширования, например "громкий", "мягкий", "чистый", "приглушенный", "отдаленный", "близкий" и т.д.
Согласно варианту осуществления раскрытых здесь принципов звуковой микшер может дополнительно содержать блок идентификации звуковых дорожек для идентификации целевой звуковой дорожки из множества звуковых дорожек. Целевая звуковая дорожка может указываться в команде семантического микширования выражением идентификации звуковой дорожки. Блок идентификации звуковых дорожек может быть полезен, если множество звуковых дорожек нечетко помечены или идентифицированы в отношении того, какую партию или какой ствол они содержат. Например, звуковые дорожки можно просто пронумеровать как "дорожка 1", "дорожка 2", "дорожка N". Затем блок идентификации звуковых дорожек может анализировать каждую из множества звуковых дорожек для определения, что ни одна, одна или несколько звуковых дорожек выглядит совпадающими со звуковой дорожкой, идентифицированной выражением идентификации дорожки.
Блок идентификации звуковых дорожек может быть сконфигурирован для извлечения записи данных, которая соответствует выражению идентификации звуковой дорожки, из базы данных шаблонов звуковой дорожки, для осуществления анализа, по меньшей мере, одного из имени дорожки, идентификатора дорожки, тембра, ритмической структуры, диапазона частот, образца звучания и плотности гармоник, по меньшей мере, одной звуковой дорожки из множества звуковых дорожек, для сравнения результата анализа с записью данных для получения, по меньшей мере, одного показателя совпадения, и для определения целевой звуковой дорожки на основании, по меньшей мере, одного показателя совпадения между, по меньшей мере, одной звуковой дорожкой и записью данных. Задача, подлежащая осуществлению с помощью блока идентификации звуковых дорожек, состоит в идентификации целевой звуковой дорожки из множества звуковых дорожек. Целевая звуковая дорожка соответствует выражению идентификации звуковой дорожки, то есть, если выражением идентификации звуковой дорожки является "гитара", то, после успешной идентификации с помощью блока идентификации звуковых дорожек, целевая звуковая дорожка обычно должна содержать партию гитары музыкального произведения. База данных шаблонов звуковой дорожки может содержать запись данных, соответствующую инструменту "гитара", причем сама запись данных содержит значения и/или информацию, характерные для гитары. Например, запись данных может содержать частотную модель типичного звука гитары и/или модель фронтов-спадов типичного звука гитары. Запись данных также может содержать образец звучания гитары, который можно использовать для анализа подобия с помощью блока идентификации звуковых дорожек.
Согласно аспекту раскрытых здесь принципов звуковой микшер может дополнительно содержать блок идентификации временных отрезков для идентификации целевого временного отрезка во множестве звуковых дорожек, причем целевой временной отрезок указан в команде семантического микширования выражением идентификации временного отрезка. В случае когда пользователь желает микшировать первый отрезок аудиосигнала (например, музыкального произведения) иначе, чем второй отрезок того же аудиосигнала, звуковому микшеру обычно требуется знать, где начинаются и заканчиваются различные отрезки аудиосигнала, чтобы применять конкретные параметры микширования к этим отрезкам аудиосигнала.
Блок идентификации временных отрезков может быть сконфигурирован для структурирования множества звуковых дорожек во множество временных отрезков. В частности, музыкальные произведения часто имеют определенную структуру, определяемую музыкальными условностями, например форму песни с перемежающимися отрезками строфы и припева. Блок идентификации временных отрезков может использовать это знание, сначала определяя, согласуется ли аудиосигнал, представленный множеством звуковых дорожек, с определенной музыкальной структурой, и затем назначая временные отрезки аудиосигнала временным отрезкам музыкальной структуры. Для этого блок идентификации временных отрезков может содержать распознаватель шаблонов для распознавания повторяющихся и/или аналогичных шаблонов в аудиосигнале. Распознавание шаблона могут базироваться на анализе мелодии, гармоническом анализе и ритмическом анализе, и пр.
Блок идентификации временных отрезков может быть сконфигурирован для осуществления анализа множества звуковых дорожек для определения, по меньшей мере, одного момента времени, когда происходит изменение характерного свойства аудиосигнала, представленного множеством звуковых дорожек, и для использования, по меньшей мере, одного определенного момента времени в качестве, по меньшей мере, одной границы между двумя соседними временными отрезками.
Звуковой микшер может дополнительно содержать интерфейс метаданных для приема метаданных, относящихся к множеству звуковых дорожек, причем метаданные указывают, по меньшей мере, одно из имени дорожки, идентификатора дорожки, информации временной структуры, информации интенсивности, пространственных атрибутов звуковой дорожки или ее части, тембровых характеристик и ритмических характеристик. Метаданные могут генерироваться создателем множества звуковых дорожек и обеспечивать полезную информацию для звукового микшера или способа микширования множества звуковых дорожек. Доступность метаданных избавляет звуковой микшер или способ от необходимости осуществления углубленного анализа аудиосигнала для идентификации различных звуковых дорожек и/или временных отрезков. Интерфейс метаданных также можно использовать для сохранения результатов (инструментов, временной структуры, …) анализа для повторного использования в будущем. Таким образом, потенциально длительный анализ множества звуковых дорожек требуется осуществлять лишь однажды. Кроме того, любые имеющиеся вносимые поправки в автоматически определенные результаты анализа также могут сохраняться, что избавляет пользователя от необходимости снова и снова корректировать одни и те же места. Сохранив имеющиеся результаты анализа, пользователь может создавать различные смешанные варианты из одного и того же множества звуковых дорожек с использованием одних и тех же метаданных.
Согласно аспекту раскрытых здесь принципов звуковой микшер может дополнительно содержать командный интерфейс для приема команды семантического микширования в лингвистическом формате. Лингвистический формат позволяет пользователю выражать свои желания, касающиеся результата микширования, осуществляемого звуковым микшером, по существу, посредством нормального языка. Команда семантического микширования в лингвистическом формате может вводиться в звуковой микшер на разговорном языке с использованием микрофона или письменном языке с использованием, например, клавиатуры.
Согласно другому аспекту раскрытых здесь принципов звуковой микшер может дополнительно содержать иллюстративный интерфейс для приема иллюстративного смешанного сигнала и анализатор смешанного сигнала для анализа иллюстративного смешанного сигнала и для генерации команды семантического микширования на основании анализа иллюстративного смешанного сигнала. Используя иллюстративный смешанный сигнал, обеспеченный через иллюстративный интерфейс, анализатор смешанного сигнала может определять, какие признаки характеризуют иллюстративный смешанный сигнал. Например, анализатор смешанного сигнала может распознавать акцент на (сильно повторяющуюся) партию барабанов и партию басов при менее акцентированной мелодии. Эти выявленные признаки указывают на так называемый Dance-Mix, т.е. определенный стиль микширования. Эта информация может поступать от анализатора смешанного сигнала на семантический интерпретатор команд. На основании этой информации семантический интерпретатор команд может, например, увеличить громкость партии барабанов и партии басов относительно других партий. Семантический интерпретатор команд может даже заменить партию барабанов, например синтезированной партией барабанов, обычно используемой для желаемого стиля Dance-Mix.
Иллюстративный интерфейс может быть дополнительно сконфигурирован для приема множество иллюстративных звуковых дорожек, из которых был получен иллюстративный смешанный сигнал. Анализатор смешанного сигнала может быть сконфигурирован для сравнения иллюстративных звуковых дорожек с иллюстративным смешанным сигналом для определения параметров микширования, которые использовались для получения результирующего иллюстративного смешанного сигнала. Команда семантического микширования, вырабатываемая анализатором смешанного сигнала, может содержать описание, как были модифицированы иллюстративные звуковые дорожки до их микширования друг с другом для формирования иллюстративного смешанного сигнала. Например, команда семантического микширования может содержать выражение, например, "ударные значительно громче; вокальные партии умеренно мягче, более отдаленные, фильтрованы фильтром высоких частот". Затем семантический интерпретатор команд может вывести множество параметров микширования из этой команды семантического микширования.
Согласно другому аспекту раскрытых здесь принципов семантический интерпретатор команд может содержать перцептивный процессор для преобразования команды семантического микширования во множество параметров микширования согласно перцептивной модели свойств слухового восприятия смешанного сигнала. Перцептивная модель обычно реализует психоакустические правила, которые описывают, как следует выбирать определенные параметры микширования для достижения желаемого эффекта для слушателя. Например, для передачи впечатления расстояния, можно предусмотреть несколько действий обработки звука, например реверберацию, частотную фильтрацию и ослабление. Перцептивная модель, которая обычно основана на психоакустических сведениях, облегчает определение пригодных параметров микширования для реализации желаемого эффекта.
Согласно другому аспекту раскрытых здесь принципов семантический интерпретатор команд содержит процессор нечеткой логики для приема, по меньшей мере, одного нечеткого правила, выведенного из команды семантического микширования с помощью семантического интерпретатора команд, и для генерации множества параметров микширования на основании, по меньшей мере, одного нечеткого правила. Процессор нечеткой логики весьма пригоден для обработки команды семантического микширования в форме, по меньшей мере, одного нечеткого правила. По меньшей мере, одно нечеткое правило отображает входную величину процессора нечеткой логики в выходную величину процессора нечеткой логики в, по существу, семантической области, т.е. отображение величины первого семантического формата в величину второго семантического формата.
Процессор нечеткой логики может быть сконфигурирован для приема, по меньшей мере, двух конкурирующих нечетких правил, подготовленных семантическим интерпретатором команд, причем звуковой микшер дополнительно содержит случайный блок выбора для выбора одного конкурирующего нечеткого правила из, по меньшей мере, двух конкурирующих нечетких правил. Рандомизируя выбор нечеткого правила из двух или более конкурирующих нечетких правил, можно создавать иллюзию свободы творчества, поэтому смешанным сигналам, вырабатываемым звуковым микшером, не свойственно звучать, по существу, аналогично рассматриваемому стилю микширования, в противном случае звуковой микшер подчинялся бы более жесткой схеме по сравнению с нечеткими правилами.
В отношении способа микширования множества звуковых дорожек можно обращаться к словарной базе данных для идентификации семантических выражений в команде семантического микширования.
Способ может дополнительно или альтернативно содержать идентификацию целевой звуковой дорожки из множества звуковых дорожек, причем целевая звуковая дорожка указана в команде семантического микширования выражением идентификации звуковой дорожки. Для этого из базы данных шаблонов звуковой дорожки можно извлекать запись данных, которая соответствует выражению идентификации звуковой дорожки. Затем можно осуществлять анализ, по меньшей мере, одного из имени дорожки, идентификатора дорожки, тембра, ритмической структуры, диапазона частот, образца звучания и плотности гармоник, по меньшей мере, одной звуковой дорожки из множества звуковых дорожек. Результат анализа можно сравнивать с записью данных для получения, по меньшей мере, одного показателя совпадения. Затем целевую звуковую дорожку можно определять на основании, по меньшей мере, одного показателя совпадения между, по меньшей мере, одной звуковой дорожкой и записью данных.
Способ также может содержать действие для идентификации целевого временного отрезка во множестве звуковых дорожек, причем целевой временной отрезок указан в команде семантического микширования выражением идентификации временного отрезка. Действие для идентификации целевого временного отрезка может быть сконфигурировано для структурирования множества звуковых дорожек во множество временных отрезков. Идентификация временного отрезка может содержать осуществление анализа множества звуковых дорожек для определения, по меньшей мере, одного момента времени, когда происходит изменение характерного свойства аудиосигнала, представленного множеством звуковых дорожек, и использования, по меньшей мере, одного определенного момента времени в качестве, по меньшей мере, одной границы между двумя соседними временными отрезками.
Согласно другому аспекту раскрытых здесь принципов способ может дополнительно содержать прием метаданных, относящихся к множеству звуковых дорожек, на интерфейсе метаданных. Метаданные могут указывать, по меньшей мере, одного из имени дорожки, идентификатора дорожки, информации временной структуры, информации интенсивности, пространственных атрибутов звуковой дорожки или ее части, тембровых характеристик и ритмических характеристик.
Способ может дополнительно содержать прием команды семантического микширования в лингвистическом формате на командном интерфейсе соответствующего звукового микшера.
Согласно другому аспекту раскрытых здесь принципов способ может дополнительно содержать: прием иллюстративного смешанного сигнала на иллюстративном интерфейсе, анализ иллюстративного смешанного сигнала посредством анализатора смешанного сигнала и генерацию команды семантического микширования на основании анализа иллюстративного смешанного сигнала.
Действие выведения множества параметров микширования из команды семантического микширования может содержать: преобразование команды семантического микширования во множество параметров микширования согласно перцептивной модели свойств слухового восприятия смешанного сигнала.
Согласно аспекту раскрытых здесь принципов действие выведения множества параметров микширования может содержать: прием, по меньшей мере, одного нечеткого правила, выведенного из команды семантического микширования с помощью семантического интерпретатора команд, и генерацию множества параметров микширования на основании, по меньшей мере, одного нечеткого правила. Прием, по меньшей мере, одного нечеткого правила и генерация множества параметров микширования на основании, по меньшей мере, одного нечеткого правила могут осуществляться процессором нечеткой логики.
Способ может дополнительно содержать: прием, по меньшей мере, двух конкурирующих нечетких правил и случайный выбор одного конкурирующего нечеткого правила из, по меньшей мере, двух конкурирующих нечетких правил.
Раскрытые здесь принципы отличаются от вышеупомянутого уровня техники по следующим пунктам:
- способ, предложенный Пересом-Гонсалесом и др., не учитывает семантических описаний для управления обработкой;
- проект семантического HiFi не предусматривает обработку многодорожечных форматов. Он не предусматривает микширование сигналов согласно семантическим описаниям. Он не предусматривает перцептивные аспекты, необходимые для вычисления смешанного сигнала, который удовлетворяет семантическим описаниям;
- проект "структурированного аудиосигнала" относится к синтезированию аудиосигналов. Раскрытые здесь принципы (семантическое микширование), напротив, относятся к микшированию аудиосигналов.
Чтобы подытожить некоторые основные аспекты раскрытых здесь принципов, укажем, что микширование многодорожечной записи является задачей авторинга. Задачей семантического микширования является развитие решений микширования многодорожечной записи на основании семантический описаний. Оно объединяет в себе методы семантического анализа аудиосигнала, психоакустики и обработки аудиосигналов. Семантическое микширование применимо к различным областям, как то созданию музыки, SAOC (звуковому кодированию пространственных объектов), авторингу домашнего видео, виртуальной реальности и играм.
Семантическое микширование кратко можно описать следующими (частично необязательными) признаками:
- оно обеспечивает средство для взаимодействия с пользователем;
- семантическое микширование, по большей части, связано с перцептивным компонентом. Это может включать в себя также адаптацию к среде, систему воспроизведения и предпочтения пользователя;
- оно объединяет в себе семантическую часть и психоакустическую часть. Любая семантическая обработка нуждается в учете перцептивных аспектов. Оно сосредоточено на обработке аудиосигналов, а не на традиционных применениях семантического анализа (извлечении музыкальной информации, генерации списков воспроизведения). Оно ориентировано на новые способы взаимодействия с контентом;
- оно относится к обработке многодорожечных записей.
Раскрытые здесь принципы относятся, помимо прочего, к способу микширования многодорожечных сигналов согласно указаниям пользователя. Оно относится к обработке аудиосигналов, в частности к задаче микширования многодорожечной записи согласно набору установленных пользователем критериев. Установленные пользователем критерии обеспечивают семантическое описание результирующего смешанного сигнала. Раскрытые здесь принципы могут предусматривать анализ аудиосигнала, психоакустику и обработку аудиосигналов для автоматического выведения смешанного сигнала на основании семантического описания.
Вышеописанные признаки и другие признаки раскрытых здесь принципов явствуют из нижеследующего описания, которое приведено в порядке примера только со ссылкой на прилагаемые схематические чертежи, в которых:
фиг. 1 - упрощенная блок-схема звукового микшера;
фиг. 2 - иллюстративная временная структура музыкального произведения в структуре песни, часто применяемой в популярной музыке;
фиг. 3 - другая иллюстративная временная структура музыкального произведения в форме сонаты, известной в классической музыке;
фиг. 4 - иллюстративная конфигурация звуковых дорожек записи популярной музыки;
фиг. 5 - упрощенная блок-схема звукового микшера согласно раскрытым здесь принципам;
фиг. 6 - упрощенная блок-схема процессора нечеткой логики;
фиг. 7 - иллюстративная функция принадлежности для нечеткого множества;
фиг. 8 - упрощенная блок-схема звукового микшера, содержащего процессор нечеткой логики;
фиг. 9 - упрощенная блок-схема другой конфигурации звукового микшера согласно раскрытым здесь принципам;
фиг. 10 - команда семантического микширования и ее разложение согласно аспекту раскрытых здесь принципов;
фиг. 11 - другая команда семантического микширования и ее разложение согласно аспекту раскрытых здесь принципов;
фиг. 12 - упрощенная блок-схема дополнительной конфигурации звукового микшера согласно раскрытым здесь принципам;
фиг. 13 - упрощенная блок-схема конфигурации звукового микшера согласно раскрытым здесь принципам, содержащего блок идентификации звуковых дорожек;
фиг. 14 - упрощенная блок-схема конфигурации звукового микшера согласно раскрытым здесь принципам, содержащего блок идентификации временных отрезков;
фиг. 15 - упрощенная блок-схема конфигурации звукового микшера согласно раскрытым здесь принципам, содержащего интерфейс метаданных;
фиг. 16 - упрощенная блок-схема конфигурации звукового микшера согласно раскрытым здесь принципам, содержащего иллюстративный интерфейс для приема иллюстративных смешанных сигналов;
фиг. 17 - упрощенная блок-схема конфигурации звукового микшера согласно раскрытым здесь принципам, содержащего перцептивный процессор и перцептивную модель; и
фиг. 18 - упрощенная блок-схема операций способа микширования множества звуковых дорожек с образованием смешанного сигнала согласно раскрытым здесь принципам.
На Фиг. 1 показана упрощенная блок-схема звукового микшера. Звуковой микшер позволяет объединять множество одиночных дорожек ST с образованием смешанного сигнала MS. Для управления объединением одиночных дорожек ST каждая одиночная дорожка обычно подается на отдельный сигнальный процессор. Отдельный сигнальный процессор для одной одиночной дорожки может содержать, например, корректор EQ, регулятор панорамирования PAN, ревербератор REVERB, регулятор громкости VOL и, возможно, дополнительные звуковые эффекты. Основное назначение звукового микшера состоит в регулировке громкости каждой из множества одиночных звуковых дорожек ST, чтобы смешанный сигнал был хорошо сбалансированной суперпозицией аудиосигналов, обеспечиваемых множеством одиночных дорожек ST. Решение, какая конкретная настройка звуковых эффектов и уровней громкости одиночных дорожек ST образует хорошо сбалансированную суперпозицию, обычно принимает звукорежиссер. Множество отдельных сигнальных процессоров модифицирует множество сигналов звуковых дорожек. Затем модифицированные сигналы звуковых дорожек объединяются на объединителе Σ сигналов для создания смешанного сигнала MS.
На Фиг. 2 представлена временная структура типичной песни, принадлежащей жанру популярной музыки. Песня, используемая в качестве примера на фиг. 2, начинается со вступления (вступление), после которого следует отрезок строфы (строфа 1), припев (припев), второй отрезок строфы (строфа 2) с, по существу, такой же музыкой, но другой лирикой, повторение припева, проигрыш (проигрыш), еще одно повторение припева, и кода или финал (финал). Хотя существует большое количество вариаций этой основной схемы, большинство людей обычно может различать различные отрезки песни из жанра популярной музыки. Например, припев обычно повторяется в различных местах на протяжении песни с, по существу, одинаковой лирикой и мелодией, что позволяет слушателю легко распознавать его.
На Фиг. 3 показана временная структура музыкального произведения, написанного в форме сонаты. Форма сонаты используется большим количеством сочинителей классической музыки. Как говорит само название, форма сонаты широко используется в сонатах, обычно в их первых частях. Первые части многих симфоний также обычно выполнены в форме сонаты. Характерными отрезками формы сонаты являются экспозиция, развитие и реприза, в которых, в основном, один и тот же музыкальный материал представлен с различными модификациями, в частности в отношении аккордовой последовательности. В необязательном порядке, вступление и кода могут быть представлены в начале и конце музыкального произведения соответственно. Хотя для различения различных временных отрезков формы сонаты может потребоваться некоторый опыт, в целом, это не представляет трудности для слушателя.
Звукорежиссер может иметь намерение по-разному обрабатывать разные временные отрезки музыкального произведения. Причиной тому может быть желание добиться определенного художественного эффекта или сделать звучание смешанного сигнала MS более однородным за счет компенсации потенциальных изъянов, которые могут возникать при записи множества звуковых дорожек. Знание временной структуры музыкального произведения или, в общем случае, аудиозаписи (например, аудиокниги, лекции и т.д.) может помогать звукорежиссеру в отыскании начальных точек и конечных точек различных временных отрезков в записи.
На Фиг. 4 показана иллюстративная конфигурация звуковых дорожек записи песни в жанре популярной музыки. Существуют одиночные звуковые дорожки ST для следующих инструментов: соло-гитары, ритм-гитары, вокальной партии, фортепьяно и басовых инструментов. Ударная установка записана с использованием нескольких одиночных звуковых дорожек для различных частей ударной установки: подвесной тарелки, райд-тарелки, хай-хета, тамтамов, малого барабана и большого барабана. Использование нескольких звуковых дорожек ST для разных частей ударной установки позволяет звукорежиссер лучше балансировать партию барабанов, чем при использовании одиночной звуковой дорожки для всей ударной установки.
Имея множество одиночных звуковых дорожек, исполнитель и/или звукорежиссер может, при желании, мастеризовать музыкальное произведение. В частности, характер или "тональность" музыкального произведения может претерпевать значительные изменения за счет изменения параметров микширования, которые используются для множества звуковых дорожек ST. Предоставление потребителю множества звуковых дорожек ST для микширования дает потребителю большую степень свободы. Однако многим пользователям не хватает опыта для правильного выбора параметров микширования, в частности, вследствие сложных взаимосвязей и взаимодействий между параметрами микширования. Для достижения определенного эффекта который возникает на одиночной звуковой дорожке, может потребоваться регулировать параметры микширования нескольких или даже всех звуковых дорожек.
На Фиг. 5 показана упрощенная блок-схема звукового микшера согласно раскрытым здесь принципам, имеющего первую возможную конфигурацию.
Обычно пользователь (или слушатель) имеет определенное представление, как должен звучать смешанный сигнал, но не знает, как следует регулировать параметры микширования для достижения такого звучания.
Звуковой микшер согласно раскрытым здесь принципам устанавливает связь между семантическим выражением, которое описывает замысел или желание пользователя в краткой форме, и фактическими параметрами микширования, необходимыми для микширования множества одиночных звуковых дорожек ST в смешанный сигнал MS.
Приведем простой иллюстративный пример семантического описания, определяющего процесс микширования: "В ходе исполнения гитарного соло, выдвинуть гитару на передний план и слегка отодвинуть клавишные инструменты на задний план".
С этой целью обычно необходимо решить, по меньшей мере, некоторые из различных ниже перечисленных подзадач:
- захвата семантических описаний, данных пользователем с использованием надлежащего пользовательского интерфейса,
- перевода пользовательского ввода в машиночитаемую форму,
- осуществления семантического анализа музыкального аудиосигнала (например, идентификации дорожки гитары и дорожки клавишных инструментов, нахождения начала и конца гитарного соло),
- определения физических параметров микширования с учетом механизма человеческого слуха (например, определения коэффициента усиления, при котором воспринимаемая громкость гитары в смешанном сигнале выше, чем для любого другого инструмента, но не слишком высока; для клавишных инструментов, определения коэффициента усиления, задержки и коэффициента усиления сенд-дорожки для реверберационного эффекта для желаемого восприятия расстояния),
- выведения смешанного сигнала с использованием вычисленных физических параметров микширования. Параметры содержат коэффициенты усиления и задержки по времени для каждой комбинации одиночной звуковой дорожки ST и выходного канала. Кроме того, физические параметры микширования управляют процессорами цифровых звуковых эффектов (DAFx), например искусственной реверберации и обработки динамического диапазона.
Семантические описания могут указывать, например:
- воспринимаемые положение и громкость каждого звукового объекта SO в смешанном сигнале MS;
- параметры DAFx для каждой дорожки;
- характеристики для смешанного сигнала MS (например, величину реверберации, динамический диапазон).
В упрощенной блок-схеме на фиг. 5, где представлена возможная конфигурация звукового микшера согласно раскрытым здесь принципам, вышеупомянутые подзадачи выполняются модулями звукового микшера. Звуковой микшер содержит пользовательский интерфейс (UI) 20, интерпретатор 30 команд (CI), семантический анализатор 40 аудиосигнала (SAA), блок 50 назначения целевого описателя (DAU), перцептивный процессор 60 и сигнальный процессор 70.
Пользовательский интерфейс 20 обеспечивает средства для захвата ввода от пользователя звукового микшера. Существуют различные варианты реализации пользовательского ввода, проиллюстрированные множеством подмодулей, входящих в состав пользовательского интерфейса 20. Примерами являются:
- выбор одной из набора предустановок (подмодуль 22);
- набор n-мерных контроллеров, которые назначаются различным характеристикам одиночных дорожек и результирующего смешанного сигнала MS (подмодуль 21);
- ввод на естественном языке (подмодуль 24);
- ввод образца смешанного сигнала MS или образца многодорожечного сигнала совместно с соответствующим смешанным сигналом MS (подмодуль 23). Затем данный образец будет анализироваться для выведения семантического описания для смешанного сигнала MS. Режим работы звукового микшера под управлением такого рода пользовательского ввода в последующем описании будем именовать "микширование по образцу".
Интерпретатор 30 команд подключен к пользовательскому интерфейсу 20 и переводит ввод (человеко-читаемый или заданный образцами) в машиночитаемые команды. Эти команды обычно имеют ограниченный словарь и известную грамматику, которая обеспечивается и/или управляется подмодулем 31 грамматики и словаря.
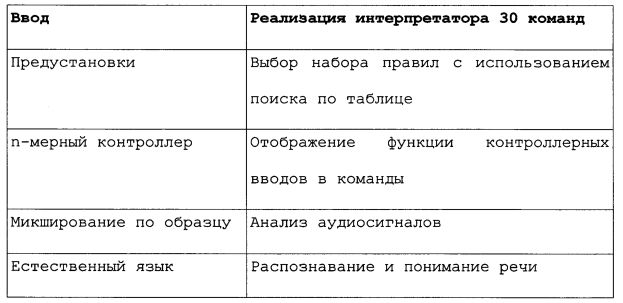
Примеры реализации интерпретатора 30 команд приведены в таблице 1 для разных конструкций пользовательского интерфейса.
Помимо пользовательского ввода, звуковой микшер также принимает в качестве входного сигнала данные 10, содержащие одиночные звуковые дорожки ST. В случае когда данные 10 соответствуют звуковым дорожкам музыкального произведения, данные 10 могут содержать контейнер 11 музыки и необязательный контейнер 1 метаданных 2. Данные 10 могут передаваться на звуковой микшер через подходящий интерфейс (не показана на фиг. 5).
Данные 10 поступают на семантический анализатор 40 аудиосигнала (SAA). Семантический анализатор 40 аудиосигнала обычно является автоматизированным процессом, который вычисляет набор метаданных для каждой из звуковых дорожек ST. Кроме того, можно вычислить метаданные, описывающие многодорожечный сигнал, т.е. множество звуковых дорожек (например, музыкальный жанр). Метаданные являются семантическими описателями, которые характеризуют аудиосигналы.
Семантический анализатор 40 аудиосигнала может содержать:
- идентификацию инструментов;
- структурный анализ (маркировка строфы, припева и других частей каждого сигнала);
- идентификацию стиля исполнения (соло, аккомпанемент, мелодическая, гармоническая и ритмическая энтропия);
- ритмический анализ (например, отслеживание ритма для синхронных с ритмом звуковыми эффектами);
- мелодический и гармонический анализ;
- характеризацию тембра (например, яркость, резкость, четкость);
- характеризацию сходств (в отношении тембра, стиля исполнения, формы) между одиночными звуковыми дорожками ST;
- музыкальный жанр.
Эти метаданные можно использовать для назначения надлежащей обработки сигнала, через параметры микширования, каждой из одиночных дорожек ST.
Семантический анализ аудиосигнала может осуществляться каждый раз, когда осуществляется процесс семантического микширования. В необязательном порядке, семантический анализ аудиосигнала может осуществляться однократно (в ходе создания/авторинга) и результирующие метаданные может сохраняться и передаваться совместно с мультимедийным материалом.
В необязательном порядке, семантический анализатор 4 0 аудиосигнала может действовать согласно пользовательским вводам, т.е. пользователь может помогать семантическому анализатору 40 аудиосигнала или может вводить метаданные, если он не удовлетворен одним или более из автоматически выводимых результатов семантического анализа аудиосигнала. Этот корректирующий пользовательский ввод может сохраняться семантическим анализатором аудиосигнала для учета в ходе будущих анализов, что позволяет семантическому анализатору 40 аудиосигнала адаптироваться к предпочтениям пользователя, т.е. семантический анализатор 40 аудиосигнала обучается с течением времени посредством пользовательских вводов.
Семантический анализатор 40 аудиосигнала может содержать первый подмодуль 41 для вычисления метаданных на основании аудиосигналов, содержащихся во множестве звуковых дорожек ST. Дополнительно или альтернативно, семантический анализатор 40 аудиосигнала может содержать второй подмодуль 42 для чтения метаданных, обеспечиваемых совместно с множеством звуковых дорожек ST.
К интерпретатору 30 команд и семантическому анализатору 40 аудиосигнала подключен блок 50 назначения целевого описателя (DAU). На основании команд от интерпретатора 30 команд и метаданных, полученных от семантического анализатора 40 аудиосигнала, блок 50 назначения целевого описателя выбирает части аудиосигнала (определяет дорожки и начальные и конечные моменты времени, которые соответствуют звуковым объектам, для которых существуют команды) и назначает им надлежащие перцептивные целевые описатели (PTD).
Перцептивный целевой описатель может описывать:
- воспринимаемую интенсивность (громкость) звукового объекта;
- пространственные атрибуты (азимутальный угол, высоту, расстояние, диффузность, ширину) звукового объекта;
- тембровые характеристики (например, яркость, четкость, резкость) звукового объекта;
- характеристики, связанные с цифровыми звуковыми эффектами (DAFx).
Если команды подаются с использованием лингвистических переменных, блок 50 назначения целевого описателя может использовать нечеткую логику для преобразования лингвистических переменных в четкие значения.
Выход блока 50 назначения целевого описателя, обеспечивающий перцептивный целевой описатель, подключен к входу перцептивного процессора (РР) 60. Перцептивный процессор 60 вычисляет физические параметры (параметры микширования) для микширования и дополнительной обработки сигнала (например, DAFx) при условии назначенного перцептивного целевого описателя. Это обычно весьма сложная задача, которая требует учета психоакустики 61 и экспертных знаний 62.
Это проиллюстрировано в следующем примере: для конкретного аудиосигнала, например дорожки гитары, описателю для воспринимаемого уровня присваивается значение "высокий". Простое решение состоит в увеличении коэффициента усиления гитары на определенную величину, например 6 дБ. Это простое решение может не всегда приводить к желаемому результату, поскольку восприятие громкости имеет весьма сложную зависимость от спектральных и временных характеристик обработанного аудиосигнала и смешанного сигнала MS.
Улучшенные результаты можно получить, задавая все уровни так, чтобы воспринимаемая слушателем громкость гитары в смешанном сигнале регулировалась, например, с использованием перцептивной модели громкости и частичной громкости. Частичная громкость - это громкость сигнала, представленного в виде смешанного звукового сигнала, где сигнал, представляющий интерес, частично замаскирован.
Помимо восприятия громкости, обычно необходимо рассматривать другие аспекты человеческого слуха и восприятия звука. Это - восприятие величины реверберации, локализация звука и восприятие пространственных атрибутов.
Психоакустическая часть важна для перевода семантического описания (например, "немного прибавить громкость") в физический параметр (например "повысить уровень на 4,5 дБ").
Один из выходов перцептивного процессора 60 подключен к входу сигнального процессора (SP) 70. Сигнальный процессор 70 может содержать модуль, регулирующий физические параметры 71 микширования, один или более цифровых звуковых эффектов 72 и модуль для форматирования 73. Сигнальный процессор 70 вычисляет смешанный сигнал MS на основании физических параметров для микширования и обработки сигнала.
В конвенционном документе "Automatic Music Production System Employing Probabilistic Expert Systems", Audio Engineering Society, представленном на 129-й конвенции, 2010 г. 4-7 ноября, за авторством R. Gang и др. предложено применять вероятностную графическую модель для внедрения профессиональных звукотехнических знаний и принятия решений на автоматическое создание на основании музыкальной информации, выделенной из аудиофайлов. Шаблону создания, представляемому в виде вероятностной графической модели, можно обучаться из эксплуатационных данных человека-звукотехника или его можно строить вручную из знания области техники. Перцептивный процессор 60 и/или семантический интерпретатор 30 команд могут реализовывать технические признаки, изложенные в этом конвенционном документе. Полное содержание вышеупомянутого конвенционного документа включено в данное описание в порядке ссылки.
Микширование многодорожечной записи содержит:
- регулировку уровней и позиций панорамирования для каждой одиночной дорожки (модуль для управления физическими параметрами 71 микширования);
- коррекцию (для одиночных дорожек ST и смешанного сигнала MS);
- обработку динамического диапазона (DRP) (для одиночных дорожек ST и смешанного сигнала MS);
- искусственную реверберацию;
- применение звуковых эффектов (DAFx 72).
Каждая из этих операций определяется физическими параметрами, вычисленными перцептивным процессором 60.
Форматирование 73, в необязательном порядке, требуется для соблюдения физических ограничений (например, применения автоматизированной регулировки коэффициента усиления) и преобразования формата (кодирование/декодирование аудиосигнала).
В следующем разделе подробно описана примерная реализация каждого из блоков обработки.
Пользовательский интерфейс 20 можно реализовать в виде набора предустановок. Каждая предустановка представляет "тип микширования" с набором характеристик. Эти характеристики могут задаваться как семантические выражения в форме "правил микширования" и описаны ниже в контексте описания интерпретатора 30 команд.
Тип микширования может быть, например, "Dance Mix", "Ambient Mix", "Rock Gitar Mix" и другие.
Эти названия дают описание целевого смешанного сигнала MS с высокой степенью сжатия, и все же пользователь может интерпретировать их (или их подмножество). Способность пользователя интерпретировать названия предустановок основана на соглашениях и широко используемых стилистических классификациях. Например, пользователь может связывать конкретный стиль исполнения и/или звук с именем определенного артиста.
В контексте интерпретатора 30 команд набор правил микширования назначается каждой из предустановок с использованием поисковой таблицы. Правила микширования представлены как логические умозаключения в форме операторов IF-THEN, как в нечеткой логике (J.M. Mendel, "Fuzzy Logic Systems for Engineering: A Tutorial", Proc. of IEEE, vol. 83, pp. 345-377, 1995), как показано здесь, где описатель звукового объекта <SOD> является антецедентом и описатель операции микширования <MOD> является консеквентом:
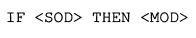
Операторы IF-THEN указывают:
- как звуковые объекты SO появляются в смешанном сигнале MS, выраженном в виде описателей операции микширования (MOD). MOD выбираются согласно характеристикам звуковых объектов, заданных описателями звукового объекта (SOD);
- характеристики смешанного сигнала MS, которые не зависят от конкретного описателя операции микширования MOD и указывают параметры операций для смешанного сигнала MS.
Описатель звукового объекта SOD можно представить как структуру (данных), например:
Описатели операции микширования MOD описывают уровень (т.е. громкость), позицию панорамирования, расстояние и другие характеристики звукового объекта SO, которые могут восприниматься в смешанном сигнале MS. Описатели операции микширования MOD, которые применяются к звуковому объекту SO, могут быть представлены посредством SO.MOD в структуре данных. Описатели операции микширования MOD также можно применять к смешанному сигналу MS. Эти описатели операции микширования MOD представлены посредством MT.MOD. Обычно эти описатели операции микширования MOD управляют обработкой сигнала, которая применяется ко всем аудиосигналам или к смешанному сигналу, например реверберацией или обработкой динамического диапазона DRP.
Описатель операции микширования MOD может состоять из перцептивного атрибута, и его значение назначается перцептивному атрибуту. Описатели операции микширования можно реализовать как лингвистические переменные.
Список перцептивных атрибутов может содержать следующие (помимо прочих):
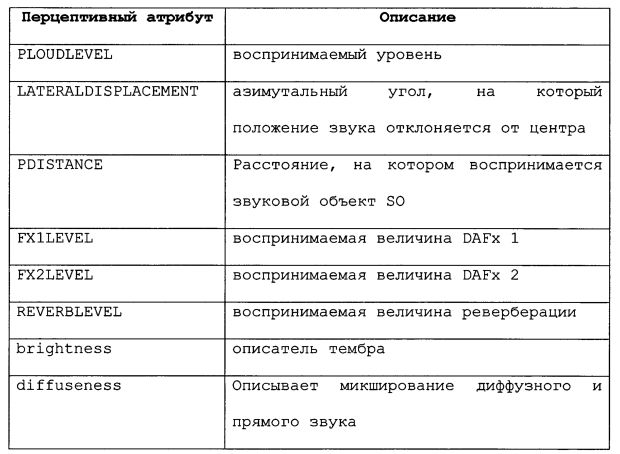
Перцептивные атрибуты могут быть лингвистическими переменными. Назначенные значения могут представлять собой одно из следующих: {"очень низкое", "низкое", "среднее", "высокое", "очень высокое"}.
Перцептивные атрибуты, которые не заданы описателем операции микширования MOD, устанавливаются на стандартные значения.
Правило микширование может выглядеть наподобие:
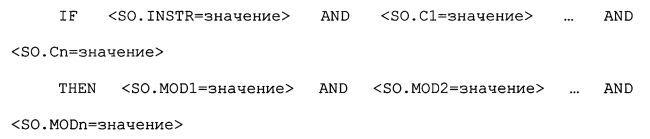
Следует отметить, что достаточно использовать конъюнкцию (т.е. "AND"), и дизъюнкцию (т.е. "OR") можно выразить отдельными правилами.
Иллюстративный набор правил: набор правил микширования для случая использования приведен здесь для примера Dance Mix:
Эти правила микширования заданы для инструментальных классов:

Следующие правила микширования задаются для характеристик независимо от инструментального класса:

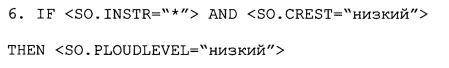
В необязательном порядке, правила микширования можно задавать для смешанного сигнала MS. Они не связаны с характеристиками звуковых объектов SO. Результирующее операции применяются ко всем звуковым объектам SO, если в IF-части правила микширования не указано никакого звукового объекта.

Кроме того, в IF-части правил, атрибуты также можно сравнивать с относительными значениями вместо абсолютных значений. Это означает, что атрибут одного звукового объекта SO можно сравнивать с тем же атрибутом всех остальных звуковых объектов SO с использованием операций наподобие "максимум" или "минимум", например

Следует отметить, что вышеперечисленные атрибуты и правила являются примерами и не призваны быть полным набором для конкретной предустановки микширования.
Согласно аспекту раскрытых здесь принципов можно осуществлять изменение набора правил. В частности, набор правил можно реализовать так, чтобы он содержал конкурирующие правила (правила с одним и тем же антецедентом, но разными консеквентами), одно из которых выбирается произвольно (случайно). Это вносит изменения в результаты и, таким образом, увеличивает удовлетворенность пользователя. Это также полезно в ситуациях, когда в процессе выработки набора правил не удается прийти к однородному набору правил.
Обратившись теперь к примерной реализации семантического анализатора 40 аудиосигнала, напомним, что семантический анализатор 40 аудиосигнала применяется для сбора информации о множестве звуковых дорожек ST и, возможно, многодорожечному сигналу, что может быть полезно для определения, какие параметры микширования следует применять к какому из множества звуковых дорожек ST. Семантический анализ аудиосигнала обрабатывает каждую звуковую дорожку ST из множества звуковых дорожек по отдельности и, дополнительно, представление многодорожечного сигнала МТ. Представление многодорожечного сигнала МТ можно получить, например, в форме смешанного сигнала, выведенного путем понижающего микширования всех звуковых дорожек ST с единичными коэффициентами усиления.
Результаты можно представить как массив структур (где каждый элемент массива содержит метаданные для одной звуковой дорожки ST) и дополнительную структуру, содержащую метаданные многодорожечного сигнала. Типами переменной элементов структуры могут быть строки (например, для названий инструментов), скалярные значения (например, для темпа, энтропии) или массивы (например, для начальных и конечных моментов времени для описания стилей исполнения), или специализированные структуры для нее самой (например, структуры для описания формы музыкального фрагмента).
Результат анализа может сопровождаться мерой достоверности, которая представляет степень надежности соответствующего результата.
Пример представления результата, полученного семантическим анализатором 40 аудиосигнала:

Семантический анализатор 40 аудиосигнала может быть полезен для стандартизации предоставленного многодорожечного аудиоматериала посредством назначение уникальных идентификаторов звуковым дорожкам ST и различным временным отрезкам музыкального произведения. В частности, многодорожечный аудиоматериал обычно не является заранее заданным форматом, подчиняющимся определенному соглашению. Другими словами, звуковой микшер не может исходить из того, что эта конкретная звуковая дорожка (например, "дорожка 1") всегда содержит определенный инструмент (например, "гитару"). Однако метаданные, созданные семантическим анализатором аудиосигнала, могут обеспечивать, по существу, стандартизованную информацию об организации и контенте многодорожечного сигнала, которые помогают другим модулям звукового микшера выполнять их соответствующие задачи. Стандартизация, осуществляемая семантическим анализатором аудиосигнала, полезна, поскольку она позволяет связывать команду микширования, обеспечиваемую интерпретатором 30 команд, с текущей ситуацией многодорожечного аудиосигнала. Таким образом, интерпретатор 30 команд и семантический анализатор 40 аудиосигнала "говорят на одном языке".
Блок 60 назначения целевого описателя DAU обрабатывает метаданные, обеспечиваемые семантическим анализатором 40 аудиосигнала, и правила микширования от интерпретатора 30 команд для назначения описателей операции микширования множеству звуковых дорожек ST или сегментам звуковых дорожек ST. Эти описатели, указывают, как каждый звуковой объект SO, доминирующий в соответствующем сегменте звуковой дорожки ST, воспринимается в целевом смешанном сигнале MS.
Предполагается, что в каждой звуковой дорожке ST в данный момент доминирует только один звуковой объект. На основании этого предположения, атрибуты, выведенные из семантического анализатора 40 аудиосигнала (которые вычисляются для каждой звуковой дорожки ST), обрабатываются как атрибуты для звукового объекта SO. Альтернативно, семантический анализатор аудиосигнала может выводить более чем одну структуру атрибутов для каждой звуковой дорожки ST, если звуковая дорожка ST содержит множественные звуковые объекты, в частности если несколько звуковых объектов SO располагаются последовательно друг за другом в звуковой дорожке ST, и это означает, что несколько звуковых объектов SO можно относительно легко отделить друг от друга. Другая возможность состоит в том, что первый звуковой объект SO1 присутствует, в основном, в левом канале стереосигнала, тогда как второй звуковой объект SO2 присутствует, в основном, в правом канале. Еще одна возможность состоит в том, что несколько звуковых объектов можно отделить друг от друга в частотной области посредством низкочастотных, высокочастотных и/или полосовых фильтров.
Нечеткую логику можно применять, если входные переменные являются четкими значениями, но набор правил формулируется с использованием нечетких атрибутов (например "низкий" или "высокий"). Например, степень изменения в игре инструмента можно выразить скалярным значением в диапазоне между 0 и 1. Кроме того, семантический анализатор 40 аудиосигнала может выводить метаданные совместно со значениями достоверности (например, вероятностями), описывающими степень достоверности, с которой были вычислены оцениваемые метаданные.
Нечеткая логика позволяет моделировать сложные задачи, нередко с внедрением экспертных знаний. При этом приходится использовать нечеткие множества, которые обеспечивают прямой механизм для преобразования точных значений в нечеткие описания и обратно.
Обзор обработки в случае реализации в виде системы нечеткой логики представлен в блок-схеме на фиг. 6 (Mendel, 1995). Система нечеткой логики содержит модуль 622 введения нечеткости, модуль 624 вывода, набор 626 правил и модуль 628 восстановления четкости. Модуль 622 введения нечеткости принимает набор четких вводов, например, от семантического анализатора 40 аудиосигнала. На основании четкого ввода модуль 622 введения нечеткости создает нечеткое входное множество, которое поступает на модуль 624 вывода. Модуль 624 вывода оценивает нечеткое входное множество посредством набора 626 правил, который также поступает на модуль 624 вывода. Набор 626 правил может обеспечиваться интерпретатором 30 команд. Модуль 624 вывода создает нечеткое выходное множество и подает его на модуль 628 восстановления четкости. На модуле 628 восстановления четкости нечеткое выходное множество переводится в четкие выходы, которые затем могут использоваться в качестве параметров микширования или промежуточных величин.
Обратившись теперь к более подробному рассмотрению введения нечеткости, назначение описателей операции микширования MOD одиночным звуковым дорожкам ST производится на основании критериев, описанных в IF-части набора правил, определенного интерпретатором 30 команд. Если соответствующие метаданные из семантического анализатора 40 аудиосигнала задаются как действительные числа или строки совместно со значением достоверности (например, в результате классификации инструментов), действительные числа переводятся в лингвистические переменные с использованием введения нечеткости. Нечеткие множества - это множества, элементы которых имеют степень принадлежности. Эта степень принадлежности может быть любым действительным числом в интервале [0, 1] (в отличие от классической теории множеств, где степень принадлежности принимает значения только 0 или 1).
Введение нечеткости осуществляется с использованием функций принадлежности для нечеткого множества, что в порядке примера показано на фиг. 7. При введении нечеткости, для каждой действительной входной переменной определяется соответствующее нечеткое множество (I.A. Zadeh, "Fuzzy Sets", Information and Control, vol. 8, pp. 338-353, 1965) и степень принадлежности. Например, если задано значение яркости 0.25, соответствующими нечеткими множествами являются "очень низкая" с принадлежностью 0.5 и "низкая" с принадлежностью 0.5.
На этапе или модуле 624 вывода, нечеткие множества для входных переменных отображаются в нечеткие множества для выходных переменных с использованием набора 626 правил. Результатом снова является набор лингвистических переменных (совместно с соответствующими достоверными степенями принадлежности) для перцептивных атрибутов.
На следующем этапе или модуле 628 восстановления четкости, результаты вывода преобразуются в четкие значения для выходных переменных с использованием их соответствующих нечетких множеств. Таким образом, переменные, перечисленные в вышеприведенной таблице перцептивных атрибутов, имеют дубликаты с четкими значениями.
В отношении перцептивного процессора 60, выходы интерпретатора 30 команд и блок 50 назначения целевого описателя определяют, как каждый из звуковых объектов SO должен появляться в смешанном сигнале MS. Пока что это указание задается посредством перцептивных значений.
Перцептивный процессор 60 переводит перцептивные значения в физические параметры микширования с учетом характеристик сигнала и механизмов человеческого слуха. В нижеследующих абзацах представлена обработка некоторых перцептивных значений, а именно уровней звука, коэффициентов панорамирования для данных азимутальных углов, уровней реверберации и задержек по времени, параметры DAFx, коррекция и обработка динамического диапазона.
Уровни звука для звуковых объектов SO можно вычислить с использованием перцептивной модели громкости, например модели, описанной Глазбергом в 2002 г.
Альтернативно, модель громкости, описанную Муром в 1996 г., можно использовать для вычисления громкости звукового сигнала в смешанных звуковых сигналах (B.C.J. Moore and B.R. Glasberg, "A Revision of Zwicker′s Loudness Model", Acustica - Acta Acustica, vol. 82, pp. 335-345, 1996).
Коэффициенты усиления для каждой звуковой дорожки ST вычисляются таким образом, чтобы воспринимаемая громкость звукового объекта SO на звуковой дорожке ST (или в смешанном сигнале MS) соответствовала семантическому описанию, выраженному описателем операции микширования MOD.
Коэффициенты панорамирования для данных азимутальных углов: восприятие азимутального положения звукового объекта SO определяется интерауральными разностями уровней (ILD) и интерауральными интервалами (ITD) при поступлении в каждое ухо (Lord Rayleigh, "On our Perception of Sound Direction", Philosophical Magazine, vol. 6, pp. 214-232, 1907). В контексте перцептивного процессора 60, задержки по времени и разности уровней определяются для каждого канала воспроизведения таким образом, чтобы обеспечить восприятие латерализации.
Уровни реверберации и задержки по времени: уровни для процессоров искусственной реверберации определяются таким образом, чтобы воспринимаемая величина реверберации соответствовала семантическим описаниям, данным пользователем. Уровни реверберации задаются для каждого звукового объекта по отдельности и/или для смешанного сигнала MS. Уровни реверберации можно регулировать для каждого звукового объекта по отдельности для обеспечения восприятия расстояния для конкретного звукового объекта SO. Восприятие расстояния дополнительно зависит от уровня, задержки по времени, кривой коррекции и азимутального положения.
Параметры DAFx: настройка параметров для цифровых звуковых эффектов зависит от конкретного процессора DAFx. Уровень DAFx-обработанного сигнала вычисляется с использованием модели громкости (например, Moore, 1996).
Коррекция: параметры для коррекции устанавливаются таким образом, чтобы обработанные сигналы соответствовали перцептивным атрибутам в отношении "яркости" звукового объекта или смешанного сигнала MS.
Обработка динамического диапазона: параметры для обработки динамического диапазона DRP устанавливаются в соответствии с перцептивными атрибутами для динамического диапазона.
На Фиг. 8 показана упрощенная блок-схема части звукового микшера, содержащего нечеткий процессор 37. Вход нечеткого процессора 37 подключен к семантическому анализатору 40 аудиосигнала и сконфигурирован для приема значений анализа дорожки через это соединение. Значения анализа дорожки могут быть либо четкими значениями, либо лингвистическими переменными. Нечеткий процессор 37 также имеет вход для приема правил или наборов правил от семантического интерпретатора 35 команд. Как объяснено выше, нечеткий процессор 37 использует правила для обработки значений анализа дорожки, для обеспечения четких параметров микширования, которые могут поступать на процессор 75 звуковых дорожек.
Правила создаются семантическим интерпретатором 35 команд на основании команды семантического микширования, обеспеченной пользователем.
Перцептивная модель 64 выдает параметры введения нечеткости и восстановления четкости на процессор 37 нечеткой логики. Параметры введения нечеткости и восстановления четкости определяют связь между численными значениями и соответствующими семантическими описаниями. Например, параметры введения нечеткости и восстановления четкости могут указывать диапазоны громкости для аудиосигналов, которые создают у слушателя ощущение мягкого, среднего или громкого звучания.
Кроме того, перцептивная модель 64 может указывать, какие параметры микширования нужно использовать для обеспечения определенного эффекта. Перцептивная модель 64 также может указывать соответствующие значения для этих параметров микширования. Эти указания могут поступать на семантический интерпретатор 35 команд в виде предписаний. Семантический интерпретатор 35 команд может следовать этим предписаниям при создании нечетких правил.
Звуковой микшер может содержать необязательный блок 38 случайного выбора нечеткого правила, который используется, когда семантический интерпретатор 35 команд создает два конкурирующих нечетких правила и только одно из них можно реализовать посредством процессора 37 нечеткой логики. Умеренная степень случайности может повышать удовлетворение пользователя, поскольку процесс микширования выглядит более естественным и "человеческим". В конце концов, звукорежиссер также может иногда действовать немного произвольно, что может восприниматься клиентом звукорежиссера как "творчество".
На Фиг. 9 показана упрощенная блок-схема возможной базовой конфигурации звукового микшера согласно раскрытым здесь принципам. Данные 10 обеспечиваются в форме множества одиночных звуковых дорожек ST. Звуковой микшер содержит семантический интерпретатор 35 команд, процессор 75 звуковых дорожек и объединитель 76 звуковых дорожек (AT СМВ).
Семантический интерпретатор 35 команд, по большей части, соответствует интерпретатору 30 команд, показанному на фиг. 5. Кроме того, семантический интерпретатор 35 команд может содержать некоторые функциональные возможности модуля 50 назначения целевого описателя и перцептивного процессора 60. Семантический интерпретатор 35 команд принимает команду семантического микширования в качестве входного сигнала и выводит один параметр микширования или множество параметров микширования из команды семантического микширования. Множество параметров микширования поступает на процессор 75 звуковых дорожек или, точнее, на отдельные процессоры АТР1, АТР2, АТР3, ATP N звуковой дорожки процессора 75 звуковых дорожек. Параметры микширования обычно имеют вид четких значений, которые нетрудно реализовать множеством отдельных процессоров звуковой дорожки АТР1-АТР N.
Множество отдельных процессоров звуковой дорожки АТР1-АТР N модифицируют аудиосигналы, обеспечиваемые соответствующими звуковыми дорожками ST1-ST N согласно параметрам микширования.
Модифицированные аудиосигналы объединяются объединителем 76 звуковых дорожек для получения смешанного сигнала MS.
В конфигурации, показанной на фиг. 9, семантический интерпретатор 35 команд способен назначать конкретный семантический контент в команде семантического микширования надлежащему параметру микширования для соответствующих отдельных процессоров звуковых дорожек АТР1-АТР N. Эта способность семантического интерпретатора 35 команд может базироваться на том факте, что множество одиночных звуковых дорожек ST1-ST N организовано согласно установленному стандарту, благодаря чему семантический интерпретатор 35 команд может знать, какая дорожка соответствует какому инструменту. На фиг. 11-14 представлены и описаны альтернативные конфигурации звукового микшера в соответствующих частях этого описания, которые способны выводить информацию об организации многодорожечной записи и/или временной структуры записанного музыкального произведения из самих данных.
Фиг. 10 иллюстрирует команду семантического микширования. Команда семантического микширования содержит лингвистическое выражение в форме предложения на английском языке. Конечно, можно использовать и другие языки. Предложение гласит: "в ходе исполнения гитарного соло, выдвинуть гитару на передний план". Семантический анализ этого предложения показывает, что предложение можно разложить на три части. Первая часть содержит выражение "в ходе исполнения гитарного соло" и может быть идентифицирована как выражение, указывающее целевой временной отрезок для команды семантического микширования. Вторая часть содержит выражение "гитара" и может быть идентифицирована как выражение, указывающее целевую дорожку. Третья часть содержит выражение "выдвинуть […] на передний план" и может быть идентифицирована как выражение, указывающее желаемую операцию микширования.
Фиг. 11 иллюстрирует расширенный пример команды семантического микширования. Расширенная команда микширования основана на командах семантического микширования из фиг. 10. Кроме того, добавлена вторая операция микширования для второй целевой дорожки, а именно "[…] слегка отодвинуть клавишные инструменты на задний план". Конъюнкция используется для указания отношения между первой операцией микширования/первой целевой дорожкой и второй операцией микширования/второй целевой дорожкой. В проиллюстрированном случае конъюнкция выражается словом "and", то есть первая операция микширования и вторая операция микширования осуществляются одновременно на их соответствующих целевых дорожках.
На Фиг. 12 показана упрощенная блок-схема части звукового микшера согласно другой возможной конфигурации. В частности, на фиг. 12 показано, как данные, обеспеченные множеством аудиосигналов ST1-ST N и стандартным смешанным ("многодорожечный") сигналом МТ, можно использовать для получения полезной информации о компоновке дорожек и/или временной структуре музыкального произведения. Если не указано обратное, ссылка на множество звуковых дорожек должна включать в себя ссылку на стандартный смешанный сигнал МТ.
Множество звуковых дорожек ST1-ST N поступает на семантический анализатор 40 аудиосигнала. Анализируя множество звуковых дорожек, можно получить информацию дорожек и информацию временной структуры, которая поступает на модуль 65 семантико-четкостного преобразования.
Команда семантического микширования содержит множество выражений, причем каждое выражение содержит указание целевого временного отрезка 26, целевой дорожки 27 и операции 28 микширования.
Модуль 65 семантико-четкостного преобразования приблизительно соответствует блоку 50 назначения целевого описателя, показанному на фиг. 5. Модуль 65 семантико-четкостного преобразования также принимает информацию из команды семантического микширования в качестве входного сигнала. На основании обеспеченных входов, модуль 65 семантико-четкостного преобразования создает один или более перцептивных целевых описателей PTD и соответствующие параметры микширования. Перцептивный целевой описатель PTD может содержать идентификаторы дорожки затронутых звуковых дорожек ST1-ST N, а также информацию временного отрезка в случае, если только временной отрезок затронутой(ых) звуковой(ых) дорожки(ек) подвержен команде микширования. Заметим, что параметры микширования могут быть либо четкими значениями, либо лингвистическими переменными, подлежащими разрешению на более поздней стадии.
Семантический анализатор 40 аудиосигнала может, в необязательном порядке, принимать указание 26 целевого временного отрезка и/или указание 27 целевой дорожки в качестве входного сигнала, чтобы семантический анализатор 40 аудиосигнала мог анализировать множество звуковых дорожек ST1-ST N с особым упором на предоставленные указания.
На Фиг. 13 показана упрощенная блок-схема другой возможной конфигурации звукового микшера согласно раскрытым здесь принципам. Эта конфигурация предусматривает блок 430 идентификации звуковых дорожек.
Базовая структура конфигурации, показанной на фиг. 13, по существу, такая же, как на фиг. 9; однако некоторые части для ясности опущены.
Поскольку не всегда очевидно, какая звуковая дорожка ST1-ST N содержит какой инструмент или вокальную партию, блок 430 идентификации звуковых дорожек можно использовать для определения этой информации. Блок 430 идентификации звуковых дорожек может входить в состав семантического анализатора 40 аудиосигнала.
Команда семантического микширования содержит идентификацию 27 целевой звуковой дорожки, что было упомянуто в связи с фиг. 12. Идентификация 27 целевой звуковой дорожки поступает в базу 432 данных шаблонов звуковой дорожки. База 432 данных шаблонов звуковой дорожки обеспечивает одну или более записей данных, которые соответствуют идентификации 27 целевой звуковой дорожки, и выводит ее (или их) на блок 432 идентификации звуковых дорожек. Запись данных может содержать информацию, например, об инструменте в форме значений измерения, образцов звука и т.д. Затем блок 430 идентификации звуковых дорожек может сравнивать информацию, содержащуюся в записи данных, с аудиосигналами каждой из множества звуковых дорожек ST1-ST N. Для этого блок идентификации звуковых дорожек может, например, осуществлять кросс-корреляцию образца звучания из записи данных с помощью короткого отрезка сигнала звуковой дорожки. Другим вариантом будет определение положения и величины обертонов сигнала звуковой дорожки и сравнение результата с соответствующими данными в записи данных. Еще один вариант предусматривает анализ и сравнение поведения "атака-затухание-стабильный участок-отпускание" сигнала звуковой дорожки.
Блок идентификации звуковых дорожек генерирует информацию идентификации дорожки, которая поступает на процессор 75 звуковых дорожек, что позволяет процессору 75 звуковых дорожек обрабатывать каждую одиночную звуковую дорожку ST1-ST N согласно указанию, например, названия инструмента в команде семантического микширования.
На Фиг. 14 показана упрощенная блок-схема другой возможной конфигурации звукового микшера, в которой блок 460 идентификации временных отрезков извлекает информацию временного отрезка из множества звуковых дорожек ST1-ST N. Блок 460 идентификации временных отрезков подключен к множеству звуковых дорожек ST1-ST N и сконфигурирован для анализа временной структуры музыкального произведения, которое представлено звуковыми дорожками ST1-ST N. В частности, блок 460 идентификации временных отрезков может искать аналогичные или, по существу, идентичные отрезки в музыкальном произведении. Если музыкальное произведение принадлежит жанру популярной музыки, эти аналогичные или, по существу, идентичные отрезки, скорее всего, являются припевом песни. Блок 460 идентификации временных отрезков также может отмеривать ритм или такт музыкального произведения для повышения точности идентификации временного отрезка.
Информация временного отрезка поступает на семантический интерпретатор 35 команд, который использует ее для перевода семантического выражения временного отрезка, используемого в команде семантического микширования, в четкие значения начального и конечного времени отрезка.
Анализ временной структуры музыкального произведения, осуществляемый блоком идентификации временных отрезков, может использовать один или более из способов, ранее предложенных различными исследователями. В их статье "Automatic Music Summarization Based on Music Structure Analysis", ICASSP 2005, Xi Shao et al., полное содержание которой включено в данное описание в порядке ссылки, предложен новый подход к аннотированию музыки на основании анализа музыкальной структуры. В частности, сначала из аудиосигнала выделяется вступление ноты для получения временного темпа песни. Анализ музыкальной структуры может осуществляться на основании этой информации темпа. После структурирования музыкального контента в различные области, например вступление (вступление), строфа, припев, окончание (финал), и т.д., можно создавать окончательную аннотацию музыки с припевом и музыкальными фразами, которые включены до или после выбранного припева для получения желаемой длины окончательной аннотации. Анализ музыкальной структуры различает между областями подобия на мелодической основе (строфами) и областями подобия на основе контента (припевом).
В "Chorus Detection with Combined Use of MFCC and Chroma Features and Image Processing Filters", Proc. of the 10th Int. Conference on Digital Audio Effects (DAFx-07), Bordeaux, France, September 10-15, 2007, автор Antti Eronen описывает вычислительно эффективный способ для выявления отрезка припева в популярной рок-музыке. Способ использует представление матрицы расстояний, которая получается суммированием двух отдельных матриц расстояния, вычисленных с использованием мел-частотного кепстрального коэффициента и признаков насыщенности тона. Полное содержание статьи Эронена включено в данное описание в порядке ссылки.
Марк Леви и др. являются авторами статьи "Extraction of High-Level Musical Structure from Audio Data and its Application to Thumbnail Generation", ICASSP 2006, содержание которой в полном объеме включено в данное описание в порядке ссылки. В статье предложен способ сегментирования музыкальной аудиозаписи с помощью иерархической модели тембров. Представлены новые факты, демонстрирующие, что сегментирование музыки можно переработать как кластеризацию признаков тембра, и описан новый алгоритм кластеризации.
В статье "A Chorus Section Detection Method for Musical Audio Signals and Its Application to a Music Listening Station", IEEE Transactions on Audio, Speech, and Language Processing, Vol. 14, No. 5, September 2006, автор Masataka Goto описывает способ получения списка повторяющихся отрезков припева ("хука") в компакт-дисковых записях популярной музыки. Прежде всего, 12-мерный вектор признака, именуемый вектором насыщенности, который устойчив к изменениям аккомпанемента, извлекается из каждого кадра входного сигнала, после чего вычисляется подобие между этими векторами. Отрезки, идентифицированные как повторяющиеся отрезки, заносятся в список и интегрируются. Способ даже позволяет обнаруживать модулированные отрезки припева за счет обеспечения перцептивно мотивированного акустического признака и подобия, которые позволяют обнаруживать повторяющийся отрезок припева даже после модуляции. Полное содержание статьи включено в данное описание в порядке ссылки.
Обзор затем известных способов автоматического структурного анализа музыки был скомпилирован Bee Suang Ong в его диссертации "Structural Analysis and Segmentation of Music Signals", Universitat Pompeu Barcelona, 2007, ISBN 978-84-691-1756-9, содержание которой в полном объеме включено в данное описание в порядке ссылки.
На Фиг. 15 показана упрощенная блок-схема дополнительно возможной конфигурации звукового микшера, в котором предусмотрен интерфейс 480 метаданных для использования метаданных 12, обеспечиваемых совместно с многодорожечным сигналом. Метаданные могут содержать информацию об организации звуковых дорожек или информацию временного отрезка, как объяснено со ссылкой на фиг. 12 и 13.
Метаданные 12, если присутствуют, избавляют звуковой микшер от необходимости определять информацию звуковых дорожек, информацию временного отрезка или другую полезную информацию из многодорожечного сигнала. Такое определение может быть сопряжено с вычислительно затратными задачами обработки данных, которые могут занимать сравнительно много времени. Кроме того, результаты определения, осуществляемого самим звуковым микшером, могут быть менее надежными, чем метаданные, создаваемые и предоставляемые источником многодорожечного аудиосигнала.
Интерфейс 480 метаданных сконфигурирован для выделения метаданных 12 из данных 12 многодорожечной записи. На выходной стороне, интерфейс 480 метаданных подключен к входу семантического интерпретатора 35 команд. В конфигурации, показанной на фиг. 15, семантический интерпретатор 35 команд сконфигурирован для использования метаданных 12, предоставляемых интерфейсом 480 метаданных в процессе выведения множества параметров микширования из команды семантического микширования.
На Фиг. 16 показана упрощенная блок-схема другой возможной конфигурации звукового микшера, в котором предусмотрены иллюстративный интерфейс 490 и иллюстративный анализатор 492 смешанного сигнала для генерации команды семантического микширования на основании иллюстративного смешанного сигнала.
Иллюстративный интерфейс 490 сконфигурирован для приема иллюстративного смешанного сигнала. Иллюстративный смешанный сигнал может, например, храниться в памяти или извлекаться по сети. Пользователь может выбирать иллюстративный смешанный сигнал из совокупности иллюстративных смешанных сигналов согласно своим предпочтениям, например, поскольку ему нравится, как был микширован конкретный смешанный сигнал. В целом, в качестве иллюстративного смешанного сигнала можно использовать любой аудиосигнал, но обычно предполагается, что результаты будут лучше, если иллюстративный смешанный сигнал имеет структуру и стиль, аналогичные многодорожечной записи. Например, он может быть полезен, если инструментовка иллюстративного смешанного сигнала, по существу, такая же, как инструментовка многодорожечного сигнала, подлежащего микшированию звуковым микшером.
Иллюстративный интерфейс 490 посылает иллюстративный смешанный сигнал на анализатор 492 смешанного сигнала. Анализатор 492 смешанного сигнала может быть сконфигурирован для идентификации инструментальных и вокальных партий в иллюстративном смешанном сигнале. Кроме того, анализатор 492 смешанного сигнала может определять относительные уровни громкости и/или частотные кривые идентифицированных инструментальных партий, идентифицированных вокальных партий, и/или иллюстративного смешанного сигнала в целом. Возможно также определение величины звукового эффекта, например реверберации. На основании определенных значений, анализатор 492 смешанного сигнала может устанавливать профиль иллюстративного смешанного сигнала и/или команду семантического микширования. Например, анализ, осуществляемый анализатором 492 смешанного сигнала, может выявлять, что дорожка барабанов и дорожка басов иллюстративного смешанного сигнала относительно выделены, тогда как другие дорожки мягче. Соответственно, команда семантического микширования может содержать выражение, указывающее, что дорожка барабанов и дорожка басов должна быть выделена на протяжении смешанного сигнала MS, вырабатываемого звуковым микшером.
Иллюстративный интерфейс 490 также может быть сконфигурирован для приема иллюстративных звуковых дорожек совместно с иллюстративным смешанным сигналом. Иллюстративные звуковые дорожки представлены на фиг. 16 пунктирным ромбоидом с надписью "иллюстративные ST". Иллюстративные звуковые дорожки поступают с иллюстративного интерфейса 490 на анализатор 492 смешанного сигнала. Иллюстративные звуковые дорожки соответствуют иллюстративному смешанному сигналу в том отношении, что иллюстративные звуковые дорожки использовались для генерации иллюстративного смешанного сигнала. При наличии иллюстративных звуковых дорожек, анализатор 492 смешанного сигнала может сравнивать иллюстративный смешанный сигнал с каждой из иллюстративных звуковых дорожек для определения, как был модифицирован определенный иллюстративный смешанный сигнал до микширования в иллюстративный смешанный сигнал. Таким образом, анализатор 492 смешанного сигнала может определять параметры микширования, связанные с дорожками в семантической форме или полусемантической форме.
На Фиг. 17 показана упрощенная блок-схема другой возможной конфигурации звукового микшера, в котором перцептивный процессор 63 и перцептивная модель 64 используются в процессе преобразования команды семантического микширования в параметры микширования. Перцептивный процессор 63 и перцептивная модель 64 представлены как части семантического интерпретатора 35 команд в конфигурации, показанной на фиг. 17. Как указано выше, перцептивный процессор 63 переводит перцептивные значения в физические параметры микширования с учетом характеристик сигнала и механизмов человеческого слуха. Параметры, описывающие механизмы человеческого слуха, обеспечиваются перцептивной моделью 64. Перцептивная модель 64 может быть организована как база данных или база знаний. Элементы базы данных могут содержать семантическое описание слухового явления и соответствующую реализацию в форме параметров для звуковых эффектов, громкости, относительной громкости, частотного состава и т.д. Слуховое явление можно описать такими выражениями, как "отдаленное", "близкое", "плоское", "полное", "яркое", "смещенное в сторону низких частот", "смещенное в сторону высоких частот", и т.д. Соответствующая реализация может содержать численные значения, которые указывают, как следует выбирать параметры микширования для одной или более из множества звуковых дорожек ST для достижения желаемого эффекта. Это отображение из семантического описания в соответствующие значения параметров микширования обычно основано на экспертных знаниях и психоакустике. Экспертные знания и психоакустика могут быть получены при проведении научных испытаний и исследований.
Конфигурации, показанные на фиг. 8 и 11-16, можно объединять друг с другом в любой комбинации. Например, объединив конфигурации, показанные на фиг. 12 и 13, можно обеспечить звуковой микшер, содержащий блок 430 идентификации звуковых дорожек и блок 460 идентификации временных отрезков.
На Фиг. 18 показана упрощенная блок-схема операций способа микширования множества аудиосигналов в смешанный сигнал. После начального этапа 102 способа принимается команда семантического микширования, как показано блоком 104. Команда семантического микширования может вводиться пользователем в текстовой форме с использованием клавиатуры, устно в виде речевой команды, посредством выбора из множества предустановок, путем регулировки одного или более параметров, в виде иллюстративного смешанного сигнала или другим образом.
В действии, представленном блоком 106, из команды семантического микширования выводят множество параметров микширования. Это действие может предусматривать использование экспертных знаний и психоакустики, чтобы параметры микширования приводили к нужному пользователю результату.
Множество звуковых дорожек обрабатывается согласно параметрам микширования в контексте действия, представленного блоком 108. Обработка множества звуковых дорожек может содержать настройку уровней громкости, позиций панорамирования, звуковых эффектов, частотную фильтрацию (коррекцию) и другие модификации.
В действии, представленном блоком 110, звуковые дорожки, полученные обработкой, объединяются для формирования смешанного сигнала, до окончания способа на блоке 112.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа могут выполняться аппаратным устройством (или с его использованием), например микропроцессором, программируемым компьютером или электронной схемой. В некоторых вариантах осуществления некоторые один или более из наиболее важных этапов способа могут выполняться таким устройством.
В зависимости от определенных требований реализации варианты осуществления изобретения можно реализовать программно или аппаратно. Реализация может осуществляться с использованием цифрового носителя данных, например флоппи-диска, DVD, Blue-Ray, CD, ПЗУ, ППЗУ, СППЗУ, ЭСППЗУ или флэш-памяти, где хранятся электронно-считываемые сигналы управления, которые кооперируются (или способны кооперироваться) с программируемой компьютерной системой для осуществления соответствующего способа. Таким образом, цифровой носитель данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно считываемые сигналы управления, которые способны кооперироваться с программируемой компьютерной системой, для осуществления одного из описанных здесь способов.
В общем случае варианты осуществления настоящего изобретения можно реализовать в виде компьютерного программного продукта с программным кодом, причем программный код предназначен для осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из описанных здесь способов, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа, отвечающего изобретению, предусматривает, таким образом, компьютерную программу, имеющую программный код для осуществления одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способов, отвечающих изобретению, предусматривает, таким образом, носитель данных (или цифровой носитель данных, или машиночитаемый носитель), на котором записана компьютерная программа для осуществления одного из описанных здесь способов. Носитель данных, цифровой носитель данных или записанный носитель обычно являются вещественными и/или постоянными.
Дополнительный вариант осуществления способа, отвечающего изобретению, предусматривает, таким образом, поток данных или последовательность сигналов, представляющий(ую) компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов может быть, например, сконфигурирован(а) для переноса через соединение для передачи данных, например, через интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированное для или выполненное с возможностью осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления содержит компьютер с установленной на нем компьютерной программой для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированное(ую) для переноса (например, электронного или оптического) компьютерной программы для осуществления одного из описанных здесь способов на приемник. Приемником может быть, например, компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система может, например, содержать файловый сервер для переноса компьютерной программы на приемник.
В некоторых вариантах осуществления программируемое логическое устройство (например, вентильную матрицу, программируемую пользователем) можно использовать для осуществления некоторых или всех функциональных возможностей из описанных здесь способов. В некоторых вариантах осуществления вентильная матрица, программируемая пользователем, может кооперироваться с микропроцессором для осуществления одного из описанных здесь способов. В общем случае, способы, предпочтительно, осуществляются любым аппаратным устройством.
Вышеописанные варианты осуществления призваны всего лишь иллюстрировать принципы настоящего изобретения. Следует понимать, что специалисты в данной области техники могут предложить различные модификации и вариации описанных здесь конфигураций и деталей. Таким образом, оно ограничено только объемом нижеследующей формулы изобретения, а не конкретными деталями, представленными посредством описания и объяснения данных вариантов осуществления.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПАРАМЕТРИЧЕСКОЕ СОВМЕСТНОЕ КОДИРОВАНИЕ АУДИОИСТОЧНИКОВ | 2006 |
|
RU2376654C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБОГАЩЕНИЯ АУДИОСИГНАЛА | 2003 |
|
RU2322654C2 |
| ПЕРЦЕПТИВНАЯ ОЦЕНКА ТЕМПА С МАСШТАБИРУЕМОЙ СЛОЖНОСТЬЮ | 2010 |
|
RU2507606C2 |
| УСТРОЙСТВО И СПОСОБ ГЕНЕРИРОВАНИЯ ВЫХОДНЫХ ЗВУКОВЫХ СИГНАЛОВ ПОСРЕДСТВОМ ИСПОЛЬЗОВАНИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННЫХ МЕТАДАННЫХ | 2009 |
|
RU2604342C2 |
| УСТРОЙСТВО И СПОСОБ ГЕНЕРИРОВАНИЯ ВЫХОДНЫХ ЗВУКОВЫХ СИГНАЛОВ ПОСРЕДСТВОМ ИСПОЛЬЗОВАНИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННЫХ МЕТАДАННЫХ | 2009 |
|
RU2510906C2 |
| МЕДИАСЕРВЕР С МАСШТАБИРУЕМОЙ СЦЕНОЙ ДЛЯ ГОЛОСОВЫХ СИГНАЛОВ | 2020 |
|
RU2807215C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ УЛУЧШЕННОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ | 2014 |
|
RU2660638C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОСУЩЕСТВЛЕНИЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ SAOC ОБЪЕМНОГО (3D) АУДИОКОНТЕНТА | 2014 |
|
RU2666239C2 |
| МИКШИРОВАНИЕ АУДИОПОТОКА С НОРМАЛИЗАЦИЕЙ ДИАЛОГОВОГО УРОВНЯ | 2011 |
|
RU2526746C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОНФИГУРАЦИИ И УПРАВЛЕНИЯ МИКШЕРА ДЛЯ АУДИОСИСТЕМЫ С ИСПОЛЬЗОВАНИЕМ БЕСПРОВОДНОЙ СИСТЕМЫ ДОК-СТАНЦИИ | 2012 |
|
RU2606243C2 |
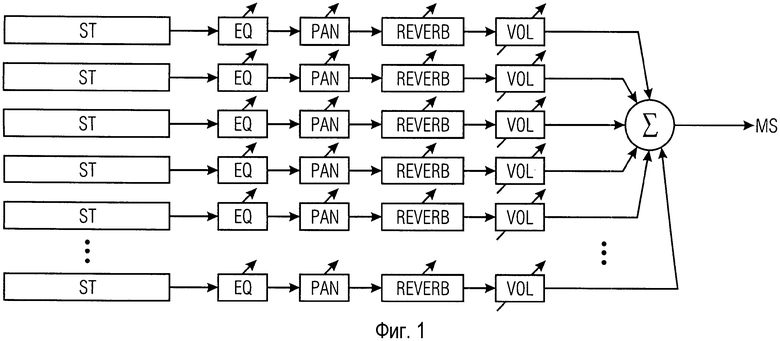


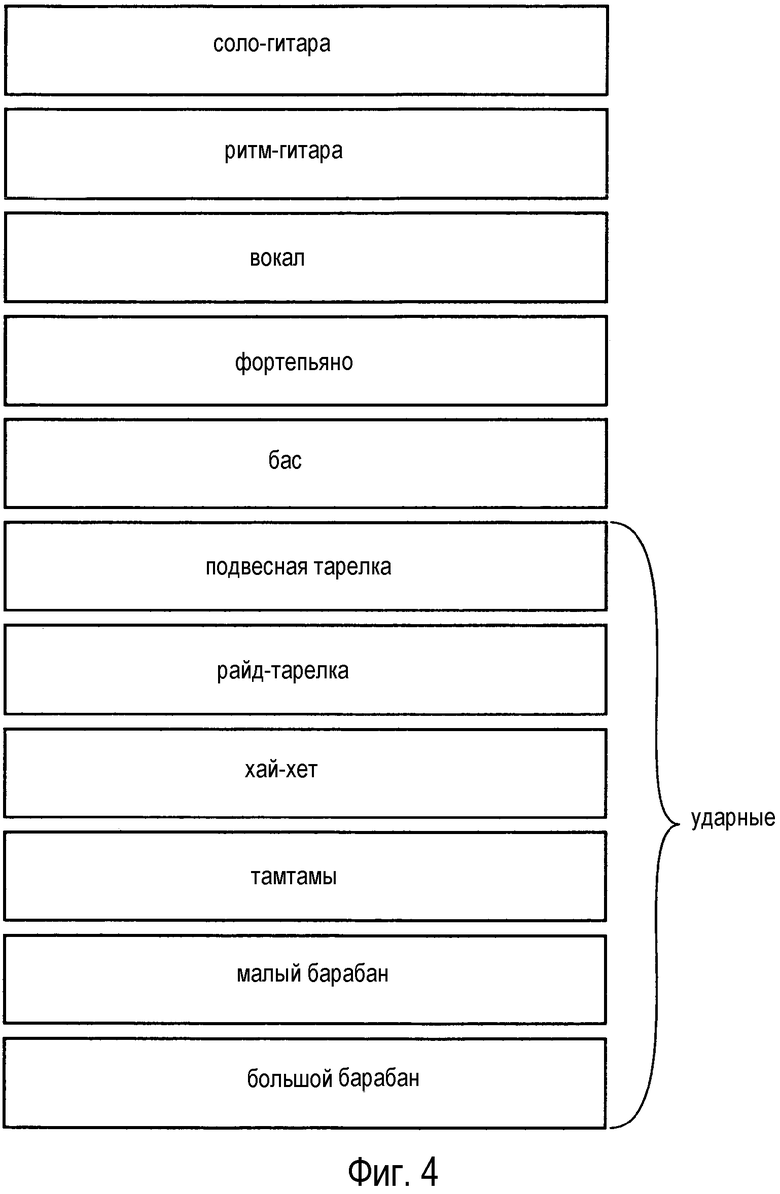
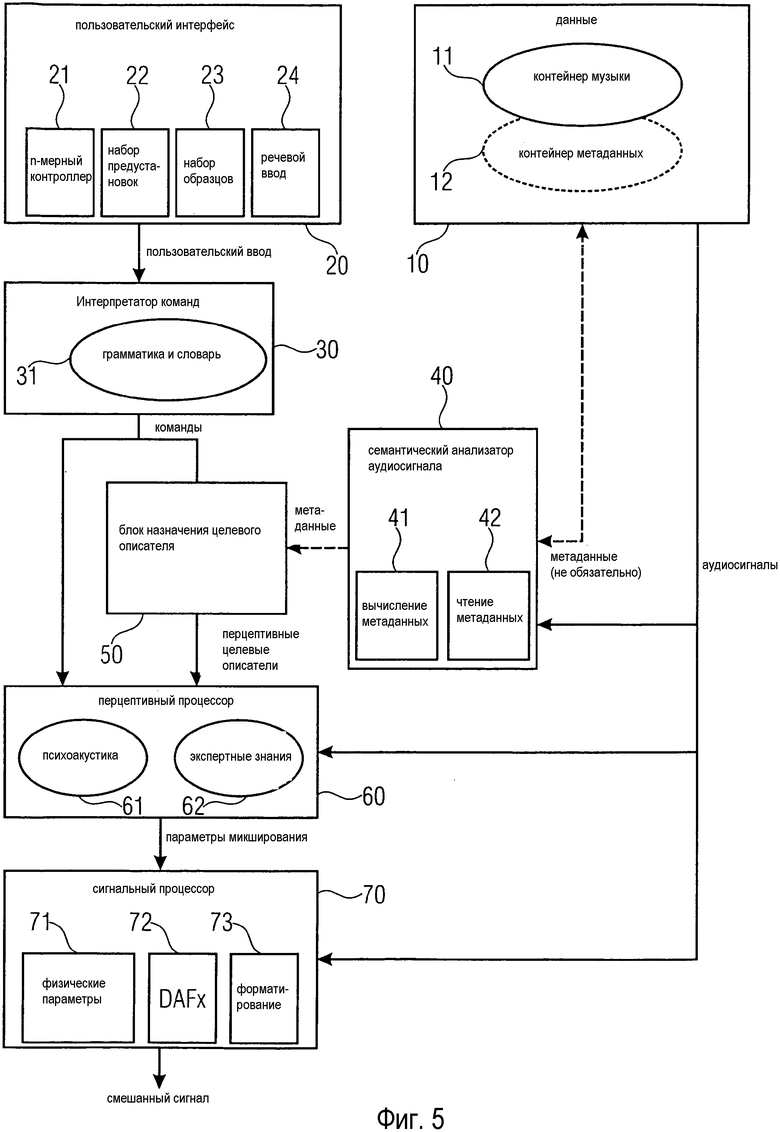
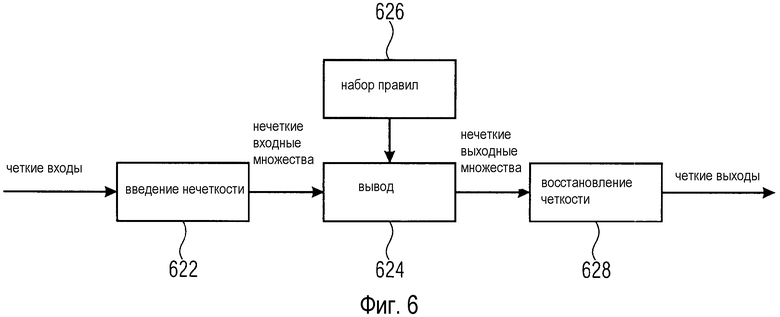
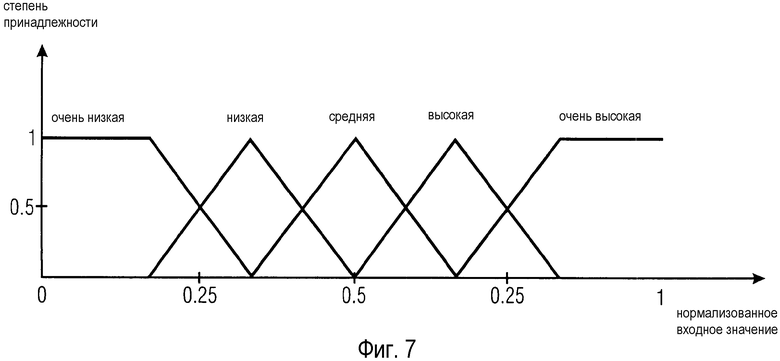
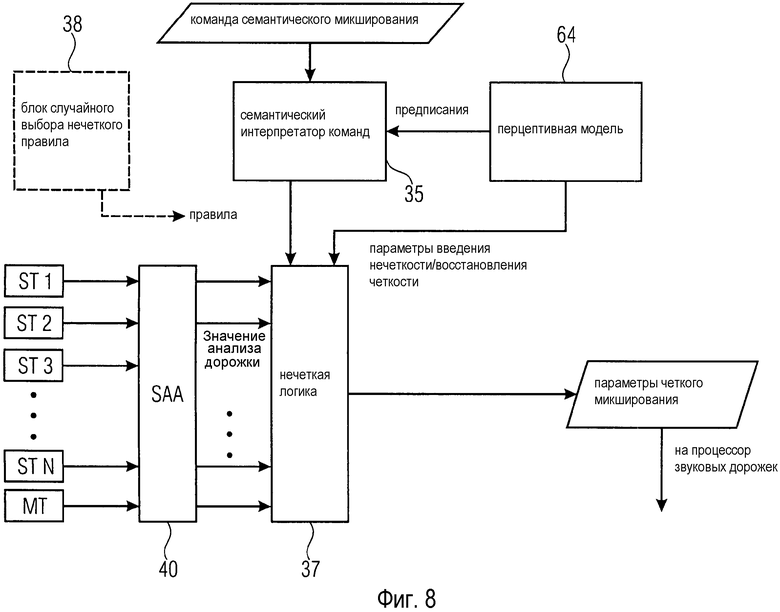
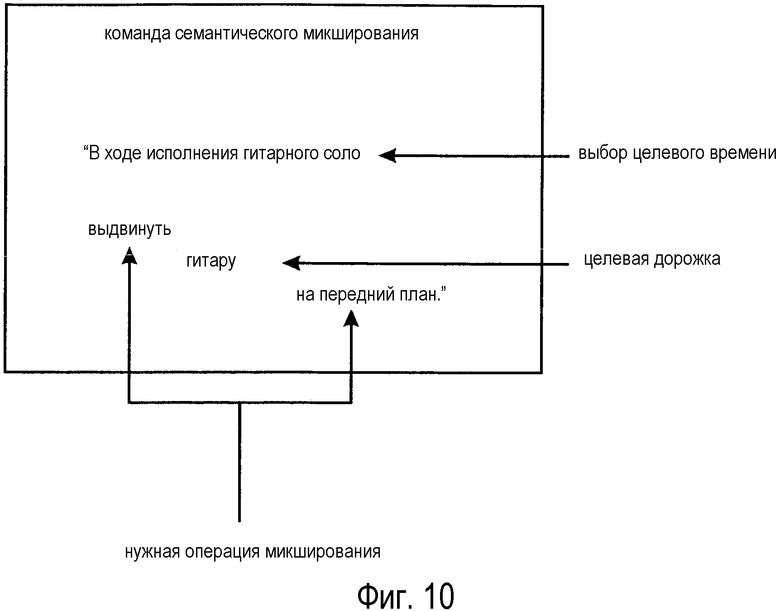
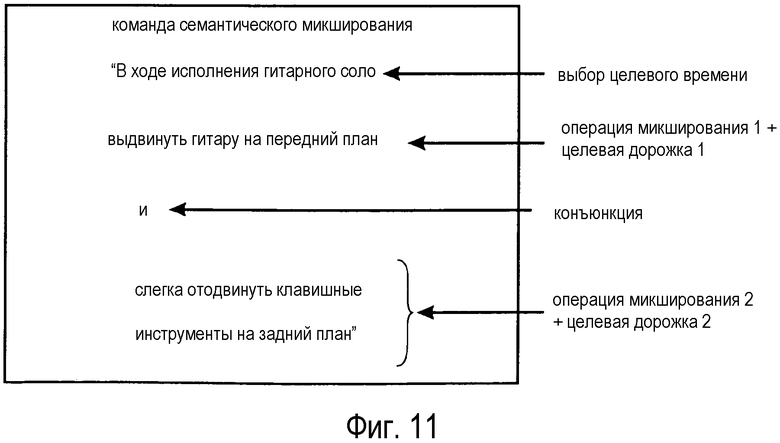
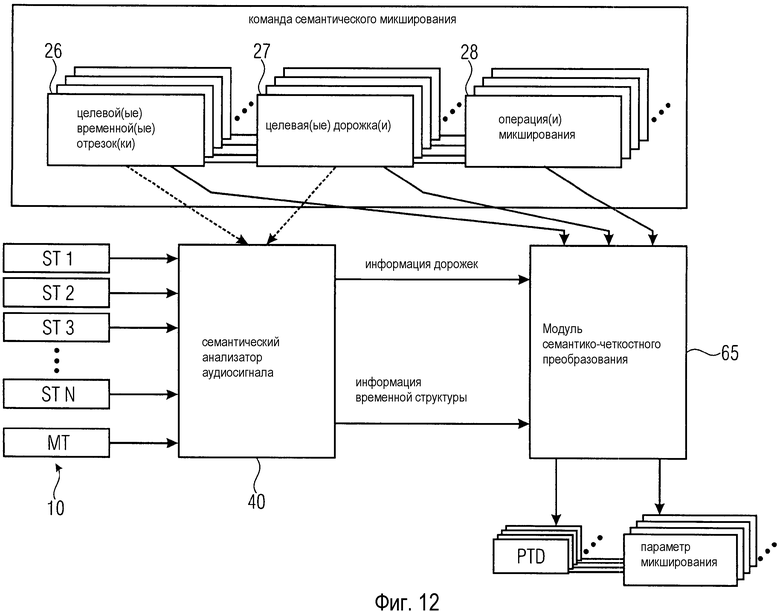
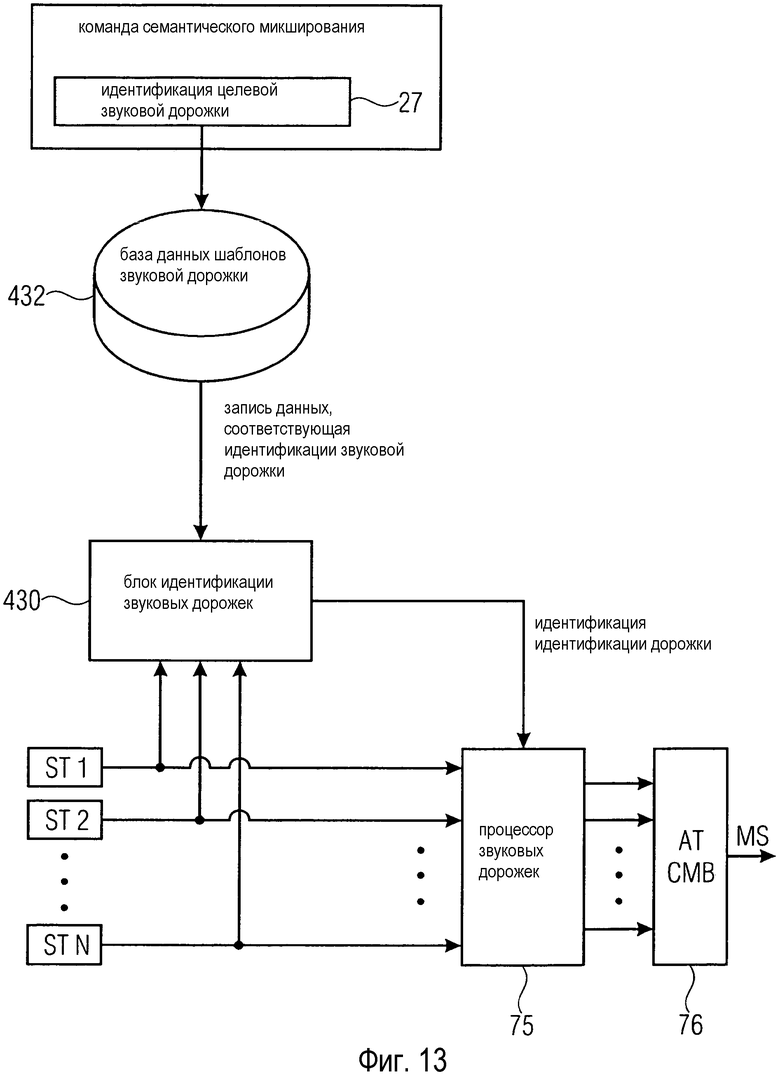
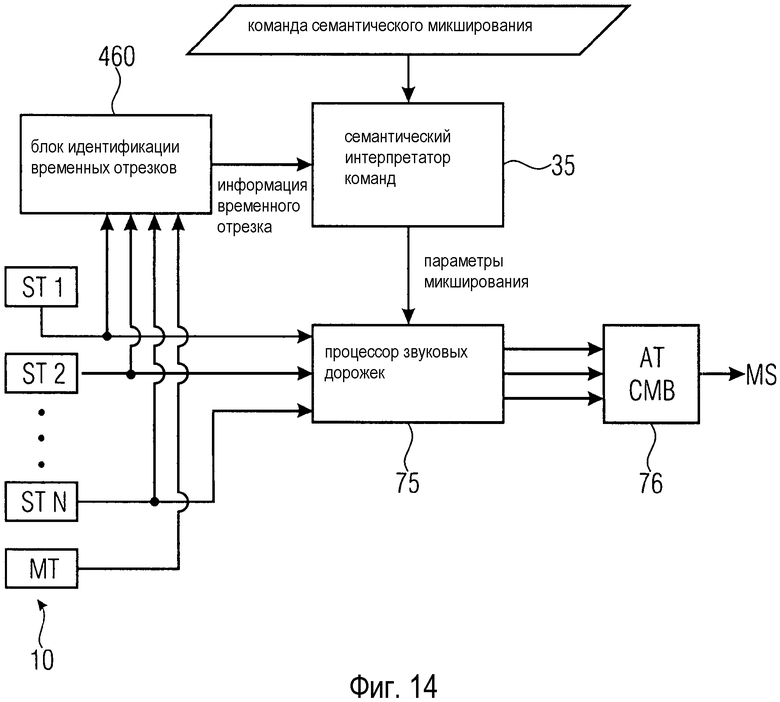
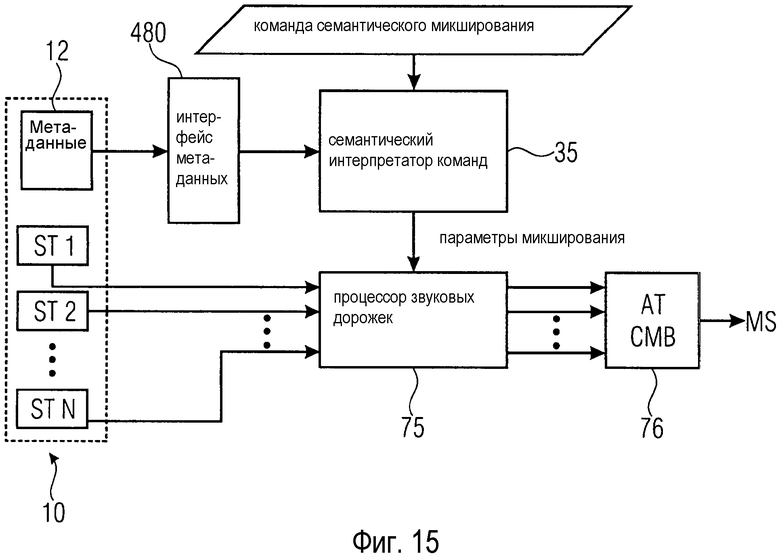
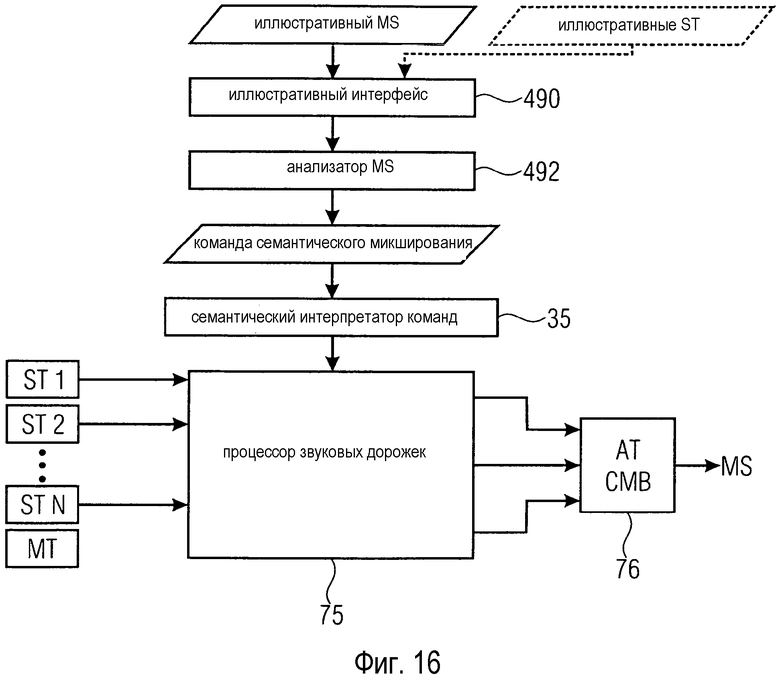
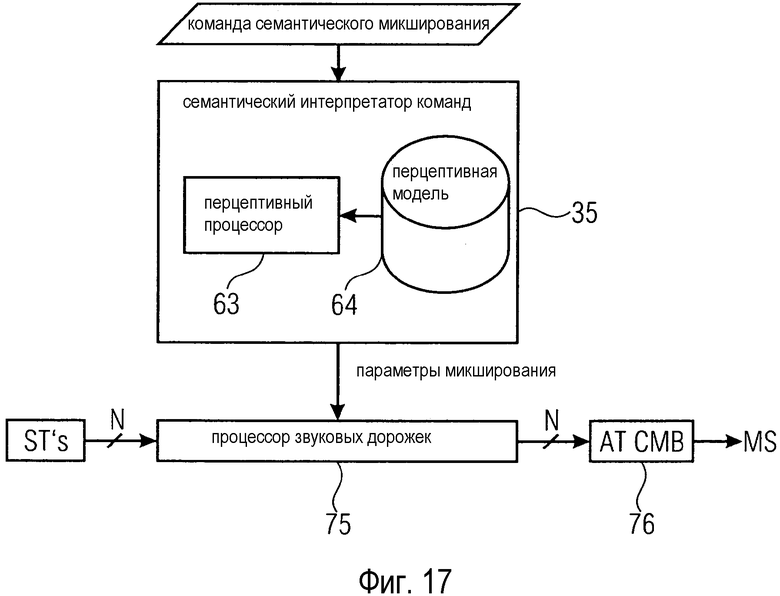
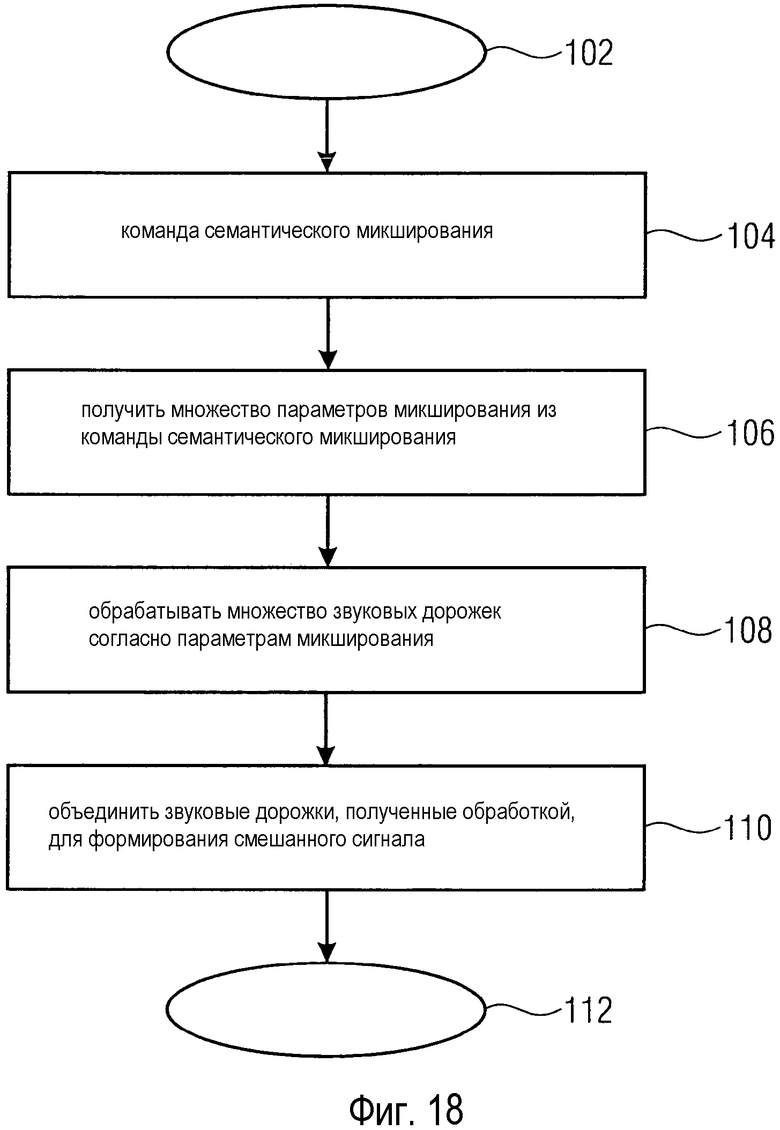
Изобретение относится к звуковому микшеру для микширования многодорожечных сигналов согласно указаниям пользователя. Технический результат заключается в обеспечении микширования множественных дорожек аудиозаписей согласно набору установленных пользователем критериев записи для конечной цели прослушивания. Технический результат достигается за счет того, что информация с дорожек аудиозаписей поступает на модуль семантико-четкостного преобразования, при этом модуль семантико-четкостного преобразования принимает информацию, выведенную из команды семантического микширования, причем модуль семантико-четкостного преобразования создает множество параметров микширования на основании информации дорожек и информации, выведенной из команды семантического микширования. 4 н. и 14 з.п. ф-лы, 18 ил., 1 табл.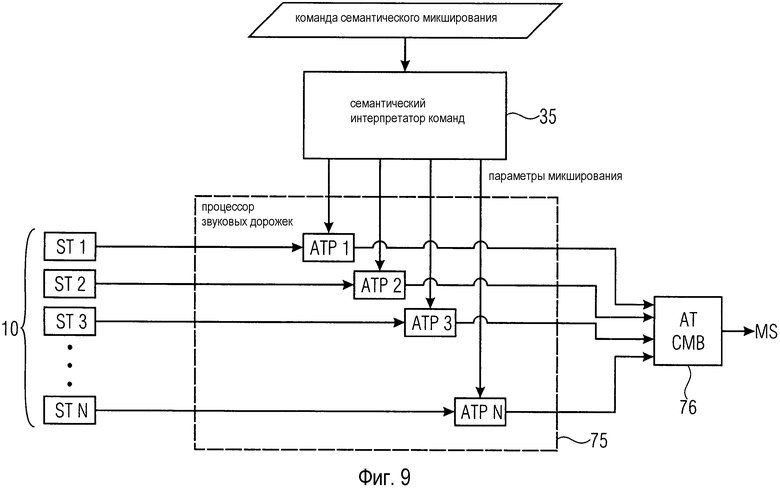
1. Звуковой микшер для микширования множества звуковых дорожек с образованием смешанного сигнала (MS), причем звуковой микшер содержит:
семантический анализатор (40) аудиосигнала, сконфигурированный для получения информации дорожек посредством анализа множества звуковых дорожек;
семантический интерпретатор (30; 35) команд для приема команды семантического микширования и для выведения множества параметров микширования для множества звуковых дорожек из команды семантического микширования, причем информация дорожек поступает на модуль (65) семантико-четкостного преобразования, при этом модуль (65) семантико-четкостного преобразования принимает информацию, выведенную из команды семантического микширования, причем модуль (65) семантико-четкостного преобразования создает множество параметров микширования на основании информации дорожек и информации, выведенной из команды семантического микширования,
процессор (70; 75) звуковых дорожек для обработки множества звуковых дорожек в соответствии с упомянутым множеством параметров микширования, и
объединитель (76) звуковых дорожек для объединения множества звуковых дорожек, обработанных процессором звуковых дорожек, в смешанный сигнал (MS).
2. Звуковой микшер по п. 1, в котором семантический интерпретатор (30; 35) команд содержит словарную базу (31) данных для идентификации семантических выражений в команде семантического микширования.
3. Звуковой микшер по п. 1, дополнительно содержащий блок (40; 430) идентификации звуковых дорожек для идентификации целевой звуковой дорожки из множества звуковых дорожек, причем целевая звуковая дорожка указана в команде семантического микширования выражением идентификации звуковой дорожки.
4. Звуковой микшер по п. 3, в котором блок (40; 430) идентификации звуковых дорожек сконфигурирован:
для извлечения записи данных, которая соответствует выражению идентификации звуковой дорожки, из базы (432) данных шаблонов звуковой дорожки, причем запись данных содержит информацию о соответствующем музыкальном инструменте в форме, по меньшей мере, одного из значения измерения и образца звучания,
для осуществления анализа, по меньшей мере, одного из тембра, ритмической структуры, диапазона частот, образца звучания и плотности гармоник, по меньшей мере, одной звуковой дорожки из множества звуковых дорожек,
для сравнения результата анализа с записью данных для получения, по меньшей мере, одного показателя совпадения, и
для определения целевой звуковой дорожки на основании, по меньшей мере, одного показателя совпадения между, по меньшей мере, одной звуковой дорожкой и записью данных.
5. Звуковой микшер по п. 1, дополнительно содержащий блок (40; 460) идентификации временных отрезков для идентификации целевого временного отрезка во множестве звуковых дорожек, причем целевой временной отрезок указан в команде семантического микширования выражением идентификации временного отрезка.
6. Звуковой микшер по п. 5, в котором блок (40; 460) идентификации временных отрезков сконфигурирован для структурирования множества звуковых дорожек во множество временных отрезков.
7. Звуковой микшер по п. 5, в котором блок (40; 460) идентификации временных отрезков сконфигурирован для осуществления анализа множества звуковых дорожек для определения, по меньшей мере, одного момента времени, когда происходит изменение характерного свойства аудиосигнала, представленного множеством звуковых дорожек, и для использования, по меньшей мере, одного определенного момента времени в качестве, по меньшей мере, одной границы между двумя соседними временными отрезками.
8. Звуковой микшер по п. 1, дополнительно содержащий интерфейс (42; 480) метаданных для приема метаданных (12) относительно множества звуковых дорожек, причем метаданные (12) указывают, по меньшей мере, одно из имени дорожки, идентификатора дорожки, информации временной структуры, информации интенсивности, пространственных атрибутов звуковой дорожки или ее части, тембровых характеристик и ритмических характеристик.
9. Звуковой микшер по п. 1, дополнительно содержащий командный интерфейс для приема команды семантического микширования в лингвистическом формате.
10. Звуковой микшер по п. 1, дополнительно содержащий:
иллюстративный интерфейс (23; 490) для приема другого смешанного сигнала в качестве иллюстративного смешанного сигнала согласно предпочтениям пользователя в отношении того, как был смикширован иллюстративный смешанный сигнал, и
анализатор (492) смешанного сигнала для анализа иллюстративного смешанного сигнала и для генерации команды семантического микширования на основании анализа иллюстративного смешанного сигнала.
11. Звуковой микшер по п. 1, в котором семантический интерпретатор (30; 35) команд содержит перцептивный процессор (63) для преобразования команды семантического микширования во множество параметров микширования согласно перцептивной модели (64) свойств слухового восприятия смешанного сигнала.
12. Звуковой микшер по п. 1, в котором семантический интерпретатор (30; 35) команд содержит процессор нечеткой логики для приема, по меньшей мере, одного нечеткого правила, выведенного из команды семантического микширования с помощью семантического интерпретатора команд, и для генерации множества параметров микширования на основании, по меньшей мере, одного нечеткого правила.
13. Звуковой микшер по п. 12, в котором процессор нечеткой логики сконфигурирован для приема, по меньшей мере, двух конкурирующих нечетких правил, подготовленных семантическим интерпретатором команд, причем звуковой микшер дополнительно содержит случайный блок выбора для выбора одного конкурирующего нечеткого правила из, по меньшей мере, двух конкурирующих нечетких правил.
14. Звуковой микшер по п. 1, в котором семантический интерпретатор (30; 35) команд содержит:
блок (50) назначения целевого описателя для выбора, по меньшей мере, одной части многодорожечного сигнала, содержащего множество звуковых дорожек, и назначения, по меньшей мере, одного надлежащего перцептивного целевого описателя (PTD), по меньшей мере, одной части многодорожечного сигнала на основании команды семантического микширования,
перцептивный процессор (60) для перевода перцептивных значений, заданных в, по меньшей мере, одном перцептивном целевом описателе (PTD), в параметры микширования с учетом характеристик сигнала и механизмов человеческого слуха.
15. Способ микширования множества звуковых дорожек с образованием смешанного сигнала, причем способ содержит этапы, на которых:
принимают команду семантического микширования,
получают информацию дорожек посредством анализа множества звуковых дорожек;
выводят множество параметров микширования для множества звуковых дорожек из команды семантического микширования, причем информация дорожек поступает на модуль (65) семантико-четкостного преобразования, при этом модуль (65) семантико-четкостного преобразования принимает информацию, выведенную из команды семантического микширования, причем модуль (65) семантико-четкостного преобразования создает множество параметров микширования на основании информации дорожек и информации, выведенной из команды семантического микширования,
обрабатывают множество звуковых дорожек в соответствии с упомянутым множеством параметров микширования, и
объединяют множество звуковых дорожек, полученное в результате обработки множества звуковых дорожек, для формирования смешанного сигнала.
16. Способ по п. 15, дополнительно содержащий этапы, на которых:
выбирают, по меньшей мере, одну часть многодорожечного сигнала, содержащего множество звуковых дорожек, и назначают, по меньшей мере, один надлежащий перцептивный целевой описатель (PTD), по меньшей мере, одной части на основании команды семантического микширования,
переводят перцептивные значения, заданные в, по меньшей мере, одном перцептивном целевом описателе (PTD), в параметры микширования с учетом характеристик сигнала и механизмов человеческого слуха.
17. Звуковой микшер для микширования множества звуковых дорожек с образованием смешанного сигнала (MS), причем звуковой микшер содержит:
семантический интерпретатор (30; 35) команд для приема команды семантического микширования и для выведения множества параметров микширования для множества звуковых дорожек из команды семантического микширования,
процессор (70; 75) звуковых дорожек для обработки множества звуковых дорожек в соответствии с множеством параметров микширования, и
объединитель (76) звуковых дорожек для объединения множества звуковых дорожек, обработанных процессором звуковых дорожек, в смешанный сигнал (MS), и
блок (40; 430) идентификации звуковых дорожек для идентификации целевой звуковой дорожки из множества звуковых дорожек, причем целевая звуковая дорожка указана в команде семантического микширования выражением идентификации звуковой дорожки, причем блок идентификации звуковых дорожек сконфигурирован для извлечения записи данных, которая соответствует выражению идентификации звуковой дорожки, из базы (432) данных шаблонов звуковой дорожки, причем запись данных содержит информацию о соответствующем музыкальном инструменте в форме, по меньшей мере, одного из значения измерения и образца звучания, для анализа звуковых дорожек, и для сравнения аудиосигналов звуковых дорожек с записью данных, для определения одной звуковой дорожки или нескольких звуковых дорожек, которые выглядят совпадающими с целевой звуковой дорожкой.
18. Способ микширования множества звуковых дорожек с образованием смешанного сигнала, причем способ содержит этапы, на которых:
принимают команду семантического микширования,
выводят множество параметров микширования для множества звуковых дорожек из команды семантического микширования, причем множество параметров микширования содержит параметр микширования для целевой звуковой дорожки,
идентифицируют целевую звуковую дорожку, указанную в команде семантического микширования выражением идентификации звуковой дорожки,
извлекают, из базы данных шаблонов звуковой дорожки, запись данных, которая соответствует выражению идентификации звуковой дорожки, причем запись данных содержит информацию о соответствующем музыкальном инструменте в форме, по меньшей мере, одного из значения измерения и образца звучания,
идентифицируют целевую звуковую дорожку из упомянутого множества звуковых дорожек посредством анализа аудиосигналов звуковых дорожек и сравнивают их с записью данных, для определения одной звуковой дорожки или нескольких звуковых дорожек, которые выглядят совпадающими с целевой звуковой дорожкой,
обрабатывают множество звуковых дорожек в соответствии с упомянутым множеством параметров микширования, и
объединяют множество звуковых дорожек, полученное в результате обработки множества звуковых дорожек, для формирования смешанного сигнала.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| EP 1995721 A1, 26.11.2008 | |||
| US 6931134 B1, 16.08.2005 | |||
| US 7308324 B2, 11.12.2007 | |||
| US 7778823 B2, 17.08.2010 | |||
| ПАРАМЕТРИЧЕСКОЕ СОВМЕСТНОЕ КОДИРОВАНИЕ АУДИОИСТОЧНИКОВ | 2006 |
|
RU2376654C2 |

