Область техники, к которой относится изобретение
Варианты осуществления в соответствии с изобретением относятся к обработке аудиоданных на основе карты направленной громкости.
Уровень техники
С появлением перцептивных аудиокодеров возник значительный интерес к разработке алгоритмов, которые могут предсказывать качество аудиоданных для кодированных сигналов, не полагаясь на обширные субъективные тесты прослушивания для экономии времени и ресурсов. Широко распространены алгоритмы, выполняющие так называемую объективную оценку качества монауральных кодированных сигналов, такие как PEAQ [3] или POLQA [4]. Однако их рабочие характеристики для сигналов, кодированных с помощью методик пространственного аудио, по-прежнему считаются неудовлетворительными [5]. Кроме того, методики, не сохраняющие форму волны, такие как расширение полосы пропускания (BWE), также известны тем, что эти алгоритмы переоценивают потерю качества [6], поскольку многие функции, извлеченные для анализа, предполагают условия сохранения формы волны. Методики пространственного аудио и BWE в основном используются при кодировании аудиоданных с низкой битовой скоростью (около 32 Кбит/с на канал).
Предполагается, что пространственный аудиосодержимое более чем двух каналов может быть преобразовано посредством преобразования для прослушивания в бинауральное представление сигналов, поступающих в левое и правое ухо, с помощью наборов передаточных функций слухового аппарата (HRTF) и/или бинауральных импульсных характеристик помещения (BRIR) [5, 7]. Большинство предлагаемых расширений для бинауральной объективной оценки качества основаны на хорошо известных бинауральных слуховых ориентирах, связанных с восприятием человеком локализации аудиоданных и воспринимаемой шириной звукового источника, таких как интерауральные разности по уровню (ILD), интерауральные разности по времени (ITD) и интерауральная перекрестная корреляция (IACC) между сигналами, поступающими в левое и правое ухо [1, 5, 8, 9]. В контексте объективной оценки качества признаки извлекаются на основе этих пространственных ориентиров из эталонных и тестовых сигналов, а мера расстояния между ними используется в качестве индекса искажений. Рассмотрение этих пространственных ориентиров и связанных с ними воспринимаемых искажений позволило добиться значительного прогресса в контексте разработки алгоритма пространственного аудиокодирования [7]. Однако в случае использования прогнозирования общего качества пространственного аудиокодирования взаимодействие этих искажений ориентиров друг с другом и с монауральными/тембральными искажениями (особенно в случаях без сохранения формы волны) создает сложный сценарий [10] с изменчивыми результатами при использовании признаков для прогнозирования единой оценки качества, определяемой субъективными тестами качества, такими как MUSHRA [11]. Также были предложены другие альтернативные модели [2], в которых выходные данные бинауральной модели дополнительно обрабатываются посредством алгоритма кластеризации для определения количества участвующих источников в мгновенном слуховом образе, и, следовательно, также являются абстракцией классических моделей искажения слуховых ориентиров. Тем не менее, модель в [2] в основном ориентирована на перемещение источников в пространстве, и ее производительность также ограничена точностью и способностью отслеживания соответствующего алгоритма кластеризации. Количество добавленных функций, позволяющих использовать эту модель, также является значительным.
Системы объективного измерения качества аудиоданных также должны использовать как можно меньше взаимно независимых и наиболее релевантных извлеченных признаков сигнала, чтобы избежать риска чрезмерного обучения с учетом ограниченного количества экспериментальных данных для сопоставления искажений признаков с показателями качества, полученными в ходе тестов прослушивания [3].
Одна из наиболее заметных характеристик искажения, отмечаемых в тестах прослушивания для пространственно кодированных аудиосигналов на низких битовых скоростях, описана как коллапс стереофонического образа в сторону центрального положения и перекрестные помехи канала [12].
Таким образом, желательно разработать концепцию, которая обеспечивала бы улучшенный, эффективный и высокоточный анализ аудиоданных, аудиокодирование и аудиодекодирование.
Это достигается посредством предмета независимых пунктов формулы изобретения настоящей заявки.
Дополнительные варианты осуществления в соответствии с изобретением определены посредством предмета зависимых пунктов формулы изобретения настоящей заявки.
Раскрытие изобретения
Вариант осуществления в соответствии с настоящим изобретением относится к модулю анализа аудиоданных, например модулю анализа аудиосигнала. Модуль анализа аудиоданных выполнен с возможностью получения представления в спектральной области двух или более входных аудиосигналов. Таким образом, модуль анализа аудиоданных, например, выполнен с возможностью определения или получения представления в спектральной области. В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения представления в спектральной области посредством декомпозиции двух или более входных аудиосигналов на частотно-временные ячейки. Кроме того, модуль анализа аудиоданных выполнен с возможностью получения информации о направлении, ассоциированной со спектральными полосами представлений в спектральной области. Информация о направлении представляет собой, например, различные направления (или положения) звуковых компонентов, содержащихся в двух или более входных аудиосигналах. В соответствии с вариантом осуществления информация о направлении может рассматриваться как индекс панорамирования, который описывает, например, исходное местоположение в звуковом поле, созданном двумя или более входными аудиосигналами, при бинауральной обработке. Кроме того, модуль анализа аудиоданных выполнен с возможностью получения информации о громкости, ассоциированной с различными направлениями, в качестве результата анализа, причем вклады в информацию о громкости определяются в зависимости от информации о направлении. Другими словами, модуль анализа аудиоданных, например, выполнен с возможностью получения информации о громкости, ассоциированной с различными направлениями панорамирования или индексами панорамирования, или для множества разных оцененных диапазонов направления в качестве результата анализа. В соответствии с вариантом осуществления различные направления, например, направления панорамирования, индексы панорамирования и/или диапазоны направления могут быть получены из информации о направлении. Информация о громкости содержит, например, карту направленной громкости или информацию об уровне или информацию об энергии. Вклады в информацию о громкости являются, например, вкладами спектральных полос представлений в спектральной области в информацию о громкости. В соответствии с вариантом осуществления вклады в информацию о громкости являются вкладами в значения информации о громкости, ассоциированной с различными направлениями.
Этот вариант осуществления основан на идее о том, что выгодно определять информацию о громкости в зависимости от информации о направлении, полученной из двух или более входных аудиосигналов. Это позволяет получить информацию о громкости других источников в стереофоническом звуковом сочетании, реализованном двумя или более аудиосигналами. Таким образом, с помощью модуля анализа аудиоданных восприятие двух или более аудиосигналов может быть проанализировано очень эффективно посредством получения информации о громкости, ассоциированной с различными направлениями, в качестве результата анализа. В соответствии с вариантом осуществления информация о громкости может содержать или представлять собой карту направленной громкости, которая дает, например, информацию о громкости объединения двух или более сигналов по различным направлениям или информацию о громкости по меньшей мере одного общего временного сигнала двух или более входных аудиосигналов, усредненных по всем частотным полосам ERB (эквивалентной прямоугольной полосы пропускания).
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения множества взвешенных представлений (например, «направленных сигналов») в спектральной области (например, в частотно-временной области) на основе представлений в спектральной области (например, в частотно-временной области) двух или более входных аудиосигналов. Значения одного или более представлений в спектральной области взвешиваются в зависимости от различных направлений (например, направления панорамирования) (например, представлены весовыми коэффициентами) звуковых компонентов (например, спектральных интервалов или спектральных полос) (например, мелодических тонов инструментов или певца) в двух или более входных аудиосигналах, чтобы получить множество взвешенных представлений в спектральной области (например, «направленных сигналов»). Модуль анализа аудиоданных выполнен с возможностью получения информации о громкости (например, значений громкости для множества различных направлений; например, «карты направленной громкости»), ассоциированной с различными направлениями (например, направлениями панорамирования), на основе взвешенных представлений в спектральной области (например, «направленных сигналов») в качестве результата анализа.
Это означает, например, что модуль анализа аудиоданных анализирует, в каком направлении из различных направлений звуковых компонентов значения одного или более представлений в спектральной области влияют на информацию о громкости. Каждый спектральный интервал, например, ассоциирован с некоторым направлением, в котором информация о громкости, ассоциированная с некоторым направлением, может быть определена модулем анализа аудиоданных на основе более чем одного спектрального интервала, ассоциированного с этим направлением. Взвешивание может быть выполнено для каждого элемента разрешения или каждой спектральной полосы одного или более представлений в спектральной области. В соответствии с вариантом осуществления значения частотного интервала или группы частот обрабатываются с помощью оконной функции посредством взвешивания в одном из различных направлений. Например, они взвешиваются в направлении, с которым они ассоциированы, и/или в соседних направлениях. Например, направление ассоциировано с направлением, в котором частотный интервал или группа частот влияет на информацию о громкости. Значения, отклоняющиеся от того направления, например, взвешиваются менее значительно. Таким образом, множество взвешенных представлений в спектральной области может обеспечить показатель относительно спектральных интервалов или спектральных полос, влияющих на информацию о громкости в различных направлениях. В соответствии с вариантом осуществления множество взвешенных представлений в спектральной области может представлять собой по меньшей мере частично вклады в информацию о громкости.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью анализа (например, преобразования) двух или более входных аудиосигналов в область кратковременного преобразования Фурье (STFT) (например, с использованием окна Ханна) для получения двух или более преобразованных аудиосигналов. Два или более преобразованных аудиосигнала могут представлять собой представления в спектральной области (например, в частотно-временной области) двух или более входных аудиосигналов.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью группировки спектральных интервалов двух или более преобразованных аудиосигналов в спектральные полосы двух или более преобразованных аудиосигналов (например, таким образом, что ширина частотной полосы групп или спектральных полос увеличивается с увеличением частоты) (например, на основе частотной селективности передней части ушного лабиринта человека). Кроме того, модуль анализа аудиоданных выполнен с возможностью взвешивания спектральных полос (например, спектральных интервалов в спектральных полосах) с использованием различных весовых коэффициентов на основе модели внешнего уха и среднего уха для получения одного или более представлений в спектральной области двух или более входных аудиосигналов. С помощью специальной группировки спектральных интервалов в спектральные полосы и с помощью взвешивания спектральных полос два или более входных аудиосигнала подготавливаются таким образом, что восприятие громкости двух или более входных аудиосигналов пользователем, слышащим упомянутые сигналы, может быть очень точно и эффективно оценено или определено модулем анализа аудиоданных с точки зрения определения информации о громкости. Посредством этого преобразованные аудиосигналы, соответственно представления в спектральной области двух или более входных аудиосигналов, адаптируются к человеческому уху для повышения содержательности информации о громкости, полученной модулем анализа аудиоданных.
В соответствии с вариантом осуществления два или более входных аудиосигнала ассоциированы с различными направлениями или различными положениями громкоговорителей (например, L (левый), R (правый)). Различные направления или различные положения громкоговорителей могут представлять собой различные каналы для стерео и/или многоканальной аудиосцены. Два или более входных аудиосигнала можно отличить друг от друга индексами, которые могут, например, быть представлены буквами алфавита (например, L (левый), R (правый), M (средний)) или, например, положительным целым числом, указывающим номер канала из двух или более входных аудиосигналов. Таким образом, индексы могут указывать различные направления или положения громкоговорителей, с которыми ассоциированы два или более входных аудиосигнала (например, они указывают положение в пространстве прослушивания, из которой исходят входные сигналы). В соответствии с вариантом осуществления различные направления (далее, например, первые различные направления) двух или более входных аудиосигналов не относятся к различным направлениям (далее, например, вторым различным направлениях), с которыми ассоциирована информация о громкости, полученная модулем анализа аудиоданных. Таким образом, направление из первых различных направлений может представлять канал сигнала двух или более входных аудиосигналов, и направление из вторых различных направлений может представлять направление звукового компонента сигнала двух или более входных аудиосигналов. Вторые различные направления могут быть размещены между первыми направлениями. Дополнительно или в качестве альтернативы вторые различные направления могут быть размещены за пределами первых направлений и/или в первых направлениях.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью определения зависящего от направления взвешивания (например, на основе направлений панорамирования) для каждого спектрального интервала (например, а также для каждого временного шага/кадра) и для множества заданных направлений (желаемых направлений панорамирования). Заданные направления представляют собой, например, равноудаленные направления, которые могут быть ассоциированы с заданными направлениями/индексами панорамирования. В качестве альтернативы заданные направления, например, определяются с использованием информации о направлении, ассоциированной со спектральными полосами представлений в спектральной области, полученных модулем анализа аудиоданных. В соответствии с вариантом осуществления информация о направлении может содержать заданные направления. Зависящее от направления взвешивание, например, применяется модулем анализа аудиоданных к одному или более представлениям в спектральной области двух или более входных аудиосигналов. С помощью зависящего от направления взвешивания значение спектрального интервала, например, ассоциируется с одним или более направлениями из множества заданных направлений. Это зависящее от направления взвешивание, например, основано на идее, что каждый спектральный интервал представлений в спектральной области двух или более входных аудиосигналов вносит вклад в информацию о громкости в одном или более различных направлениях из множества заданных направлений. Каждый спектральный интервал, например, вносит вклад прежде всего в одном направлении и лишь немного в соседних направлениях, посредством чего выгодно взвешивать значение спектрального интервала по-разному для различных направлений.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью определения зависящего от направления взвешивания с использованием гауссовой функции, в результате чего зависящее от направления взвешивание уменьшается с увеличением отклонения между соответствующими извлеченными значениями направлений (например, ассоциированными с рассматриваемым частотно-временным интервалом) и соответствующими значениями заданного направления. Соответствующие извлеченные значения направлений могут представлять направления звуковых компонентов в двух или более входных аудиосигналах. Интервал для соответствующих извлеченных значений направлений может находиться между направлением полностью налево и направлением полностью направо, причем направления налево и направо рассматриваются относительно пользователя, воспринимающего два или более входных аудиосигналов (например, обращенного к громкоговорителям). В соответствии с вариантом осуществления модуль анализа аудиоданных может определить каждое извлеченное значение направления как значение заданного направления или равноудаленные значения направлений как значения заданного направления. Таким образом, например, один или более спектральных интервалов, соответствующих извлеченному направлению, взвешиваются в заданных направлениях, граничащих с этим извлеченным направлением, в соответствии с гауссовой функцией менее значительно, чем в заданном направлении, соответствующем извлеченному значению направления. Чем больше расстояние заданного направления от извлеченного направлению, тем больше уменьшается взвешивание спектральных интервалов или спектральных полос, в результате чего, например, спектральный интервал почти не имеет влияния или не имеет никакого влияния на восприятие громкости в местоположении, удаленном от соответствующего извлеченного направления.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью определения значения индекса панорамирования как извлеченных значений направлений. Значения индекса панорамирования, например, уникальным образом укажут направление частотно-временных компонентов (т.е. спектральных интервалов) источников в стереомикшированном сигнале, созданном двумя или более входными аудиосигналами.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью определения извлеченных значений направлений в зависимости от значений в спектральной области входных аудиосигналов (например, значений представлений в спектральной области входных аудиосигналов). Извлеченные значения направлений, например, определяются на основе оценки амплитудного панорамирования компонентов сигнала (например, в частотно-временных интервалах) между входными аудиосигналами или на основе соотношения между амплитудами соответствующих значений в спектральной области входных аудиосигналов. В соответствии с вариантом осуществления извлеченные значения направлений определяют меру сходства между значениями в спектральной области входных аудиосигналов.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения зависящего от направления взвешивания 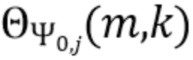 , ассоциированного с заданным направлением (например, представленным индексом
, ассоциированного с заданным направлением (например, представленным индексом 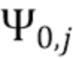 ), временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенный индексом спектрального интервала k, в соответствии с
), временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенный индексом спектрального интервала k, в соответствии с 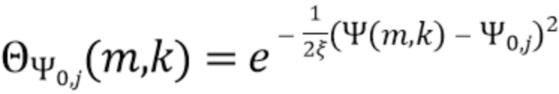 , где
, где 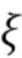 - заданное значение (которое контролирует, например, ширину гауссова окна).
- заданное значение (которое контролирует, например, ширину гауссова окна). 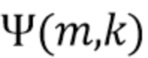 обозначает извлеченные значения направлений, ассоциированные со временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, и - значение направления, которое обозначает (или ассоциировано) заданное направление (например, имеющее индекс направления j). Зависящее от направления взвешивание основано на идее, что спектральные значения, или спектральные интервалы, или спектральные полосы с извлеченным значением направления (например, индексом панорамирования), равным
обозначает извлеченные значения направлений, ассоциированные со временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, и - значение направления, которое обозначает (или ассоциировано) заданное направление (например, имеющее индекс направления j). Зависящее от направления взвешивание основано на идее, что спектральные значения, или спектральные интервалы, или спектральные полосы с извлеченным значением направления (например, индексом панорамирования), равным 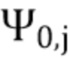 (например, равным заданному направлению), пропускаются без модификации зависящим от направления взвешиванием, а спектральные значения, или спектральные интервалы, или спектральные полосы с извлеченным значением направления (например, индексом панорамирования), отклоняющимся от , взвешиваются. В соответствии с вариантом осуществления спектральные значения, или спектральные интервалы, или спектральные полосы с извлеченным значением направления около взвешиваются и пропускаются, а остальная часть значений отбрасывается (например, далее не обрабатывается).
(например, равным заданному направлению), пропускаются без модификации зависящим от направления взвешиванием, а спектральные значения, или спектральные интервалы, или спектральные полосы с извлеченным значением направления (например, индексом панорамирования), отклоняющимся от , взвешиваются. В соответствии с вариантом осуществления спектральные значения, или спектральные интервалы, или спектральные полосы с извлеченным значением направления около взвешиваются и пропускаются, а остальная часть значений отбрасывается (например, далее не обрабатывается).
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью применения зависящего от направления взвешивания к одному или более представлениям в спектральной области двух или более входных аудиосигналов, чтобы получить взвешенные представления в спектральной области (например, «направленные сигналы»). Таким образом, взвешенные представления в спектральной области содержат, например, спектральные интервалы (т.е. частотно-временные компоненты) одного или более представлений в спектральной области двух или более входных аудиосигналов, которые соответствуют одному или более заданным направлениям, например, в пределах значения допуска (например, также спектральные интервалы, ассоциированные с различными заданными направлениями, граничащими с выбранным заданным направлением). В соответствии с вариантом осуществления для каждого заданного направления взвешенное представление в спектральной области может быть реализовано зависящим от направления взвешиванием (например, взвешенное представление в спектральной области может содержать зависящие от направления взвешенные спектральные значения, спектральные интервалы или спектральные полосы, ассоциированные с заданным направлением, и/или ассоциированные с направлением вблизи заданного направления по времени). В качестве альтернативы для каждого представления в спектральной области (например, двух или более входных аудиосигналов) получается одно взвешенное представление в спектральной области, которое представляет, например, соответствующее представление в спектральной области, нагруженное для всех заданных направлений.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения взвешенных представлений в спектральной области таким образом, что компоненты сигнала, имеющие ассоциированное первое заданное направление (например, первое направление панорамирования), усиливаются по сравнению с компонентами сигнала, имеющими ассоциированные другие направления (которые отличаются от первого заданного направления, и которые, например, ослабляются в соответствии с гауссовой функцией) в первом взвешенном представлении в спектральной области, а также таким образом, что компоненты сигнала, имеющие ассоциированное второе заданное направление (которое отличается от первого заданного направления) (например, второе направление панорамирования), усиливаются по сравнению с компонентами сигнала, имеющими ассоциированные другие направления (которые отличаются от второго заданного направления, и которые, например, ослабляются в соответствии с гауссовой функцией) во втором взвешенном представлении в спектральной области. Таким образом, например, для каждого заданного направления может быть определено взвешенное представление в спектральной области для каждого сигнала из двух или более входных аудиосигналов.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения взвешенных представлений в спектральной области 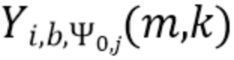 , ассоциированных с входным аудиосигналом или объединением входных аудиосигналов, обозначенных индексом i, спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом
, ассоциированных с входным аудиосигналом или объединением входных аудиосигналов, обозначенных индексом i, спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом 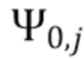 , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, в соответствии с
, временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, в соответствии с  , где
, где 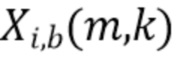 обозначает представление в спектральной области, ассоциированное с входным аудиосигналом или объединением входных аудиосигналов, обозначенных индексом i (например, i=L, или i=R, или i=DM; где L=left (левый), R=right (правый) и DM=downmix (микшированный с понижением)), спектральной полосой, обозначенной индексом b, временем (или временным кадром) обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, и обозначает зависящее от направления взвешивание (например, функцию взвешивания, такую как гауссова функция), ассоциированное с направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k. Таким образом, взвешенные представления в спектральной области могут быть определены, например, посредством взвешивания представления в спектральной области, ассоциированного с входным аудиосигналом или объединением входных аудиосигналов, с помощью зависящего от направления взвешивания.
обозначает представление в спектральной области, ассоциированное с входным аудиосигналом или объединением входных аудиосигналов, обозначенных индексом i (например, i=L, или i=R, или i=DM; где L=left (левый), R=right (правый) и DM=downmix (микшированный с понижением)), спектральной полосой, обозначенной индексом b, временем (или временным кадром) обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, и обозначает зависящее от направления взвешивание (например, функцию взвешивания, такую как гауссова функция), ассоциированное с направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k. Таким образом, взвешенные представления в спектральной области могут быть определены, например, посредством взвешивания представления в спектральной области, ассоциированного с входным аудиосигналом или объединением входных аудиосигналов, с помощью зависящего от направления взвешивания.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью определения среднего значения по множеству значений громкости полос (например, ассоциированных с различными частотными полосами, но с одним и тем же направлением, например, ассоциированным с заданным направлением и/или направлениями вблизи заданного направления), чтобы получить значение объединенной громкости (например, ассоциированное с определённым направлением или направлением панорамирования, т.е. с заданным направлением). Значение объединенной громкости может представлять информацию о громкости, полученную модулем анализа аудиоданных в качестве результата анализа. В качестве альтернативы информация о громкости, полученная модулем анализа аудиоданных в качестве результата анализа, может содержать значение объединенной громкости. Таким образом информация о громкости может содержать значения объединенной громкости, ассоциированные с разными заданными направлениями, из которых может быть получена карта направленной громкости.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения значений громкости полос для множества спектральных полос (например, ERB-полос) на основе взвешенного объединенного представления в спектральной области, представляющего множество входных аудиосигналов (например, объединение двух или более входных аудиосигналов) (причем, например, взвешенное объединенное спектральное представление может объединять взвешенные представления в спектральной области, ассоциированные с входными аудиосигналами). Дополнительно модуль анализа аудиоданных выполнен с возможностью получения в качестве результата анализа множества значений объединенной громкости (охватывающего множество спектральных полос; например, в виде одной скалярной величины) на основе полученных значений громкости частотных полос для множества различных направлений (или направлений панорамирования). Таким образом, например, модуль анализа аудиоданных выполнен с возможностью усреднения по всем значениям громкости частотных полос, ассоциированным с одним и тем же направлением, чтобы получить значение объединенной громкости, ассоциированное с этим направлением (что приводит, например, к множеству значений объединенной громкости). Модуль анализа аудиоданных, например, выполнен с возможностью получения значения объединенной громкости для каждого заданного направления.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью вычисления среднего значения квадратов спектральных значений взвешенного объединенного представления в спектральной области по спектральным значениям частотной полосы (или по спектральным интервалам частотной полосы) и применения возведения в степень с показателем между 0 и 1/2 (и предпочтительно меньшим или равный 1/3 или ¼) к среднему значению квадратов спектральных значений, чтобы определить значения громкости частотных полос (ассоциированные с соответствующей частотной полосой).
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения значений громкости частотных полос 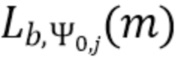 , ассоциированных со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, в соответствии с
, ассоциированных со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, в соответствии с 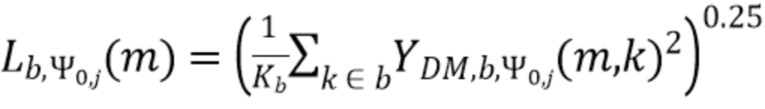 . Коэффициент Kb обозначает количество спектральных интервалов в частотной полосе, имеющей индекс частотной полосы b. Переменная k является бегущей переменной и обозначает спектральные интервалы в частотной полосе, имеющей индекс частотной полосы b, где b обозначает спектральную полосу.
. Коэффициент Kb обозначает количество спектральных интервалов в частотной полосе, имеющей индекс частотной полосы b. Переменная k является бегущей переменной и обозначает спектральные интервалы в частотной полосе, имеющей индекс частотной полосы b, где b обозначает спектральную полосу. 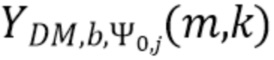 обозначает взвешенное объединенное представление в спектральной области, ассоциированное со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k.
обозначает взвешенное объединенное представление в спектральной области, ассоциированное со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения множества значений объединенной громкости L(m, ), ассоциированного с направлением, обозначенным индексом , и временем (или временным кадром), обозначенным временным индексом m, в соответствии с 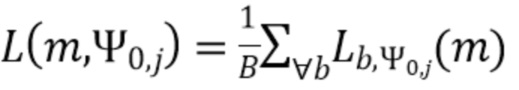 , Коэффициент B обозначает общее количество спектральных полос b, и обозначает значения громкости частотных полос, ассоциированные со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , и временем (или временным кадром), обозначенным временным индексом m.
, Коэффициент B обозначает общее количество спектральных полос b, и обозначает значения громкости частотных полос, ассоциированные со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , и временем (или временным кадром), обозначенным временным индексом m.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью распределения вкладов громкости в интервалы гистограммы, ассоциированные с различными направлениями (например, вторыми различными направлениями, как описано выше; например, заданными направлениями) в зависимости от информации о направлении, чтобы получить результат анализа. Вклады громкости, например, представлены множеством значений объединенной громкости или множеством значений громкости частотных полос. Таким образом, например, результат анализа содержит карту направленной громкости, определенную интервалами гистограммы. Каждый интервал гистограммы, например, ассоциирован с одним из заданных направлений.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения информации о громкости, ассоциированной со спектральными интервалами, на основе представлений в спектральной области (например, для получения объединенной громкости для каждой частотно-временной (T/F) ячейки). Модуль анализа аудиоданных выполнен с возможностью добавления вклада громкости в один или более интервалов гистограммы на основе информации о громкости, ассоциированной с определённым спектральным интервалом. Вклад громкости, ассоциированный с определённым спектральным интервалом, например, добавляется к различным интервалам гистограммы с различным взвешиванием (например, в зависимости от направления, соответствующего интервалу гистограммы). Выбор, в какой один или более интервалов гистограммы делается (т.е. добавляется) вклад громкости, основан на определении информации о направлении (т.е. извлеченного значения направления) для определённого спектрального интервала. В соответствии с вариантом осуществления каждый интервал гистограммы может представлять ячейку времени/направления. Таким образом интервал гистограммы, например, ассоциирован с громкостью объединенных двух или более входных аудиосигналов в некотором временном кадре и направлении. Для определения информации о направлении для определённого спектрального интервала, например, анализируется информация об уровне для соответствующих спектральных интервалов представлений в спектральной области двух или более входных аудиосигналов.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью добавления вкладов громкости в множество интервалов гистограммы на основе информации о громкости, ассоциированной с определённым спектральным интервалом, таким образом, что наибольший вклад (например, основной вклад) добавляется к интервалу гистограммы, ассоциированному с направлением, которое соответствует информации о направлении, ассоциированной с определённым спектральным интервалом (т.е. извлеченному значению направления), и таким образом, что сокращенные вклады (например, сравнительно меньшие, чем наибольший вклад или основной вклад) добавляются к одному или более интервалам гистограммы, ассоциированным с дополнительными направлениями (например, по соседству с направлением, которое соответствует информации о направлении, ассоциированной с определённым спектральным интервалом). Как описано выше, каждый интервал гистограммы может представлять ячейку времени/направления. В соответствии с вариантом осуществления множество интервалов гистограммы может определять карту направленной громкости, причем карта направленной громкости определяет, например, громкость для различных направлений по времени для объединения двух или более входных аудиосигналов.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения информации о направлении на основе аудиосодержимого из двух или более входных аудиосигналов. Информация о направлении содержит, например, направления компонентов или источников в аудиосодержимом из двух или более входных аудиосигналов. Другими словами, информация о направлении может содержать направления панорамирования или индексы панорамирования источников в стереомикшированном сигнале из двух или более входных аудиосигналов.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения информации о направлении на основе анализа амплитудного панорамирования аудиосодержимого. Дополнительно или в качестве альтернативы модуль анализа аудиоданных выполнен с возможностью получения информации о направлении на основе анализа фазового соотношения, и/или временной задержки, и/или корреляции между аудиосодержимым двух или более входных аудиосигналов. Дополнительно или в качестве альтернативы модуль анализа аудиоданных выполнен с возможностью получения информации о направлении на основе идентификации расширенных (например, декоррелированных и/или панорамированных) источников. Анализ амплитудного панорамирования аудиосодержимого может содержать анализ корреляции уровней между соответствующими спектральными интервалами представлений в спектральной области двух или более входных аудиосигналов (например, соответствующие спектральные интервалы с одинаковым уровнем могут быть ассоциированы с направлением посередине двух громкоговорителей, каждый из которых передает один из двух входных аудиосигналов). Аналогичным образом, может быть выполнен анализ фазового соотношения, и/или временной задержки, и/или корреляции между аудиосодержимым. Таким образом, например, фазовое соотношение, и/или временная задержка, и/или корреляция между аудиосодержимым анализируется для соответствующих спектральных интервалов представлений в спектральной области двух или более входных аудиосигналов. Дополнительно или в качестве альтернативы, кроме сравнений уровня/разности во времени между каналами существует дополнительный (например, третий) способ для оценки информации о направлении. Этот способ состоит в сопоставлении спектральной информации входящего аудиоданных с заранее измеренными «шаблонными спектральными откликами/фильтрами» функций моделирования восприятия аудиоданных (HRF) в различных направлениях.
Например: в некоторой частотно-временной ячейке огибающая спектра входящего сигнала на 35 градусов от левого и правого каналов может близко совпадать с формой линейных фильтров для левого и правого ушей, измеренных под углом 35 градусов. Затем алгоритм оптимизации или процедура сопоставления с образцом присвоит направление прихода аудиоданных, составляющее 35°. Более подробную информацию можно найти здесь: https://iem.kug.ac.at/fileadmin/media/iem/projects/2011/baumgartner_robert.pdf (см., например, главу 2). Этот способ имеет преимущество, позволяющее оценить входящее направление вертикально поднятых источников аудиоданных (в сагиттальной плоскости) в дополнение к горизонтальным источникам. Этот способ основан, например, на сравнениях спектральных уровней.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью расширения информации о громкости в множестве направлений (например, вне направления, обозначенного информацией о направлении) в соответствии с правилом расширения (например, гауссовым правилом расширения или ограниченным, дискретным правилом расширения). Это означает, например, что информация о громкости, соответствующая некоторому спектральному интервалу, ассоциированному с некоторой информацией о направлении, может также вносить вклад в соседние направления (некоторого направления спектрального интервала) в соответствии с правилом расширения. В соответствии с вариантом осуществления правило расширения может содержать зависящее от направления взвешивание или соответствовать ему, причем зависящее от направления взвешивание в этом случае, например, определяет по-разному нагруженные вклады информации о громкости некоторого спектрального интервала в множество направлений.
Вариант осуществления в соответствии с настоящим изобретением относится к модулю оценки сходства аудиоданных, который выполнен с возможностью получения первой информации о громкости (например, карты направленной громкости; например, одного или более значений объединенной громкости), ассоциированной с различными направлениями (например, панорамирования), на основе первого множества из двух или более входных аудиосигналов. Модуль оценки сходства аудиоданных выполнен с возможностью сравнения первой информации о громкости со второй (например, соответствующей) информацией о громкости (например, эталонной информацией о громкости, эталонной картой направленной громкости и/или эталонным значением объединенной громкости), ассоциированной с различными направлениями (например, панорамирования), и с множеством из двух или более эталонных аудиосигналов, чтобы получить информацию о сходстве (например, «выходную переменную модели» (MOV); например, одну скалярную величину), описывающую сходство между первым множеством из двух или более входных аудиосигналов и множеством из двух или более эталонных аудиосигналов (или представляющую, например, качество первого множества из двух или более входных аудиосигналов при сравнении с множеством из двух или более эталонных аудиосигналов).
Этот вариант осуществления основан на идее, что сравнение информации о направленной громкости (например, первой информации о громкости) двух или более входных аудиосигналов с информацией о направленной громкости (например, второй информацией о громкости) двух или более эталонных аудиосигналов является эффективным и улучшает точность показателя качества аудиоданных (например, информации о сходстве). Использование информации о громкости, ассоциированной с различными направлениями, особенно имеет преимущество в отношении стереомикшированных или многоканальных микшированных сигналов, поскольку различные направления могут быть ассоциированы, например, с направлениями (т.е. направлениями панорамирования, индексами панорамирования) источников (т.е. звуковые компонентов) в микшированных сигналах. Таким образом, может быть эффективно измерено ухудшение качества обработанной комбинации двух или более входных аудиосигналов. Другое преимущество состоит в том, что не сохраняющая форму сигнала обработка аудиоданных, такая как расширение частотной полосы (BWE), оказывает лишь минимальное влияние или не влияет на информацию о сходстве, поскольку информация о громкости для стереофонического образа или многоканального образа, например, определяется в области кратковременного преобразования Фурье (STFT). Кроме того, информация о сходстве на основе информации о громкости может быть легко дополнена информацией о монауральном/тембральном сходстве, чтобы улучшить перцептивное предсказание для двух или более входных аудиосигналов. Таким образом, используется только одна информация о сходстве, дополнительная к монауральным дескрипторам качества, что может сократить количество независимых и релевантных признаков сигнала, используемых системой объективного измерения качества аудиоданных, в отношении известных системы, использующих только монауральные дескрипторы качества. Использование меньшего количества признаков для одной и той же производительности снижает риск чрезмерного обучения и указывает на их более высокую перцептивную значимость.
В соответствии с вариантом осуществления модуль оценки сходства аудиоданных выполнен с возможностью получения первой информации о громкости (например, карты направленной громкости), причем первая информация о громкости (например, вектор, содержащий значения объединенной громкости для множества заданных направлений) содержит множество значений объединенной громкости, ассоциированных с первым множеством из двух или более входных аудиосигналов и ассоциированных с соответствующими заданными направлениями, причем значения объединенной громкости первой информации о громкости описывают громкость компонентов сигнала первого множества из двух или более входных аудиосигналов, ассоциированных с соответствующими заданными направлениями (причем, например, каждое значение объединенной громкости ассоциировано с отдельным направлением). Таким образом, например, каждое значение объединенной громкости может быть представлено векторным определением, например, изменением громкости во времени для некоторого направления. Это означает, например, что одно значение объединенной громкости может содержать одно или более значений громкости, ассоциированных с последовательными временными кадрами. Заданные направления могут быть представлены направлениями/индексами панорамирования компонентов сигнала первого множества из двух или более входных аудиосигналов. Таким образом, например, заданные направления могут быть заданы посредством методик амплитудного панорамирования, используемых для установления положения направленных сигналов в стереофоническом или многоканальном микшировании, представленном первым множеством из двух или более входных аудиосигналов.
В соответствии с вариантом осуществления модуль оценки сходства аудиоданных выполнен с возможностью получения первой информации о громкости (например, карты направленной громкости), причем первая информация о громкости ассоциирована с комбинациями множества взвешенных представлений в спектральной области (например, каждого аудиосигнала) первого множества из двух или более входных аудиосигналов, ассоциированных с соответствующими заданными направлениями (например, каждое значение объединенной громкости и/или взвешенное представление в спектральной области ассоциировано с отдельным заданным направлением). Это означает, например, что для каждого входного аудиосигнала вычисляется по меньшей мере одно взвешенное представление в спектральной области, и что затем объединяются все взвешенные представления в спектральной области, ассоциированные с одним и тем же заданным направлением. Таким образом, первая информация о громкости представляет, например, значения громкости, ассоциированные с несколькими спектральными интервалами, ассоциированными с одним и тем же заданным направлением. По меньшей мере некоторые из нескольких спектральных интервалов, например, взвешиваются иначе, чем другие интервалы из нескольких спектральных интервалов.
В соответствии с вариантом осуществления модуль оценки сходства аудиоданных выполнен с возможностью определения разности между второй информацией о громкости и первой информацией о громкости, чтобы получить разностную информацию о громкости. В соответствии с вариантом осуществления разностная информация о громкости может представлять информацию о сходстве, или информация о сходстве может быть определена на основе разностной информации о громкости. Разностная информация о громкости, например, рассматривается как мера расстояния между второй информацией о громкости и первой информацией о громкости. Таким образом, разностная информация о громкости может рассматриваться как расстояние направленной громкости (например, DirLoudDist). С помощью этого признака качество двух или более входных аудиосигналов, ассоциированных с первой информацией о громкости, может быть определено очень эффективно.
В соответствии с вариантом осуществления модуль оценки сходства аудиоданных выполнен с возможностью определения значения (например, одной скалярной величины), которое определяет величину различия по множеству направлений (и факультативно также по времени, например, по множеству кадров). Модуль оценки сходства аудиоданных, например, выполнен с возможностью определения средней величины разностной информации о громкости по всем направлениям (например, направлениям панорамирования) и по времени как значения, которое определяет величину различия. Тем самым определяется, например, единственное число, называемое выходной переменной модели (MOV), причем MOV определяет сходство первого множества из двух или более входных аудиосигналов относительно множества из двух или более эталонных аудиосигналов.
В соответствии с вариантом осуществления модуль оценки сходства аудиоданных выполнен с возможностью получения первой информации о громкости и/или второй информации о громкости (например, как карты направленной громкости) с использованием модуля анализа аудиоданных в соответствии с одним из вариантов осуществления, описанных в настоящем документе.
В соответствии с вариантом осуществления модуль оценки сходства аудиоданных выполнен с возможностью получения компонента направления (например, информации о направлении), используемого для получения информации о громкости, ассоциированной с различными направлениями (например, одной или более карт направленной громкости), с использованием метаданных, представляющих информацию о положении громкоговорителей, ассоциированных с входными аудиосигналами. Различные направления не обязательно ассоциированы с компонентом направления. В соответствии с вариантом осуществления компонент направления ассоциирован с двумя или более входными аудиосигналами. Таким образом, компонент направления может представлять идентификатор громкоговорителя или идентификатор канала, выделенный, например, различным направлениям или положениям громкоговорителя. Наоборот, различные направления, с которыми ассоциирована информация о громкости, могут представлять направления или положения звуковых компонентов в аудиосцене, реализованной двумя или более входными аудиосигналами. В качестве альтернативы различные направления могут представлять равномерно распределенные направления или положения в интервале положений (например, [-1; 1], где -1 представляет сигналы, панорамированные полностью налево, и +1 представляет сигналы, панорамированные полностью направо), в котором может разворачиваться аудиосцена, реализованная двумя или более входными аудиосигналами. В соответствии с вариантом осуществления различные направления могут быть ассоциированы с описанными здесь заданными направлениями. Компонент направления, например, ассоциирован с граничными точками интервала положений.
Вариант осуществления в соответствии с настоящим изобретением относится к аудиокодеру для кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Аудиокодер выполнен с возможностью обеспечения одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе одного или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала) или одного или более полученных из них сигналов (например, центрального сигнала, или микшированного с понижением сигнала и бокового сигнала, или сигнала разности). Дополнительно аудиокодер выполнен с возможностью адаптации параметров кодирования (например, для обеспечения одного или более кодированных аудиосигналов; например, параметров квантования) в зависимости от одной или более карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, направлением панорамирования) одного или более подлежащих кодированию сигналов (например, в зависимости от вкладов отдельных карт направленной громкости одного или более сигналов, подлежащих квантованию, в общую карту направленной громкости, например, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов))
Аудиосодержимое, содержащее один входной аудиосигнал, может быть ассоциировано с монауральной аудиосценой, аудиосодержимое, содержащее два входных аудиосигнала, может быть ассоциировано со стереофонической аудиосценой, и аудиосодержимое, содержащее три или более входных аудиосигнала, может быть ассоциировано с многоканальной аудиосценой. В соответствии с вариантом осуществления аудиокодер обеспечивает для каждого входного аудиосигнала отдельный кодированный аудиосигнал в качестве выходного сигнала или обеспечивает один объединенный выходной сигнал, содержащий два или более кодированных аудиосигнала из двух или более входных аудиосигналов.
Карты направленной громкости (т.е. DirLoudMap), от которых зависит адаптация параметров кодирования, могут быть разными для различного аудиосодержимого. Таким образом, для монауральной аудиосцены карта направленной громкости, например, содержит отклоняющиеся от нуля значения громкости только для одного направления (на основе единственного входного аудиосигнала), и, например, содержит равные нулю значения громкости для других направлений. Для стереофонической аудиосцены карта направленной громкости представляет, например, информацию о громкости, ассоциированную с обоими входными аудиосигналами, причем различные направления, например, ассоциированы с положениями или направлениями звуковых компонентов двух входных аудиосигналов. В случае трех или более входных аудиосигналов адаптация параметров кодирования зависит, например, от трех или более карт направленной громкости, причем каждая карта направленной громкости соответствует информации о громкости, ассоциированной с двумя из трех входных аудиосигналов (например, первая карта DirLoudMap может соответствовать первому и второму входным аудиосигналам; вторая карта DirLoudMap может соответствовать первому и третьему входным аудиосигналам; и третья карта DirLoudMap может соответствовать второму и третьему входным аудиосигналам). Как описано в отношении стереофонической аудиосцена, различные направления для карт направленной громкости в случае многоканальной аудиосцены, например, ассоциированы с положениями или направлениями звуковых компонентов нескольких входных аудиосигналов.
Варианты осуществления этого аудиокодера основаны на идее, что зависимость адаптации параметров кодирования от одной или более карт направленной громкости является эффективной и улучшает точность кодирования. Параметры кодирования, например, адаптируются в зависимости от разности карты направленной громкости, ассоциированной с одним или более входными аудиосигналами, и картой направленной громкости, ассоциированной с одним или более эталонными аудиосигналами. В соответствии с вариантом осуществления общие карты направленной громкости объединения всех входных аудиосигналов и объединения всех эталонных аудиосигналов сравниваются, или в качестве альтернативы карты направленной громкости отдельных или парных сигналов сравниваются с общей картой направленной громкости всех входных аудиосигналов (например, могут быть определены более чем одна разность). Разность между картами DirLoudMap может представлять качественную меру для кодирования. Таким образом, параметры кодирования, например, адаптируются таким образом, чтобы разность была минимизирована, чтобы гарантировать высококачественное кодирование аудиосодержимого, или параметры кодирования адаптируются таким образом, что кодируются только те сигналы аудиосодержимого, которые соответствуют разности при определенном пороговом значении, чтобы сократить сложность кодирования. В качестве альтернативы параметры кодирования, например, адаптируются в зависимости от отношения (например, вкладов) карт DirLoudMap отдельных сигналов или карт DirLoudMap пар сигналов в общую карту DirLoudMap (например, DirLoudMap, ассоциированную с объединением всех входных аудиосигналов). Аналогично разности это отношение может указывать сходство между отдельными сигналами или парами сигналов аудиосодержимого, или между отдельными сигналами и объединением всех сигналов аудиосодержимого, или парами сигналов и объединением всех сигналов аудиосодержимого, что приводит к высококачественному кодированию и/или сокращению сложности кодирования.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью адаптации распределения битов между одним или более сигналами и/или параметрами, подлежащими кодированию (или, например, между двумя или более сигналами и/или параметрами, подлежащими кодированию) (например, между разностным сигналом и микшированным с понижением сигналом, или между сигналом левого канала и сигналом правого канала, или между двумя или более сигналами, обеспеченными совместным кодированием нескольких сигналов, или между сигналом и параметрами, обеспеченными совместным кодированием нескольких сигналов) в зависимости от вкладов отдельных карт направленной громкости одного или более сигналов и/или параметров, подлежащих кодированию, в общую карту направленной громкости. Адаптация распределения битов, например, рассматривается как адаптация параметров кодирования аудиокодером. Распределение битов также может рассматриваться как распределение битовой скорости. Распределение битов, например, адаптируется посредством управления точностью квантования одного или более входных аудиосигналов аудиокодера. В соответствии с вариантом осуществления высокий вклад может указывать большое значение соответствующего входного аудиосигнала или пары входных аудиосигналов для высококачественного восприятия аудиосцены, создаваемой аудиосодержимым. Таким образом, например, аудиокодер может быть выполнен с возможностью обеспечения большого количества битов для сигналов с высоким вкладом и обеспечения лишь небольшого количества битов или отсутствия обеспечения битов для сигналов с низким вкладом. Таким образом, может быть достигнуто эффективное и высококачественное кодирование.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью запрещения кодирования определённого одного из подлежащих кодированию сигналов (например, разностного сигнала), когда вклады отдельной карты направленной громкости определённого одного из подлежащих кодированию сигналов (например, разностного сигнала) в общую карту направленной громкости ниже (например, заданного) порогового значения. Например, кодирование запрещается, если среднее отношение или отношение в направлении максимального относительного вклада ниже порогового значения. В качестве альтернативы или дополнительно вклады карт направленной громкости пар сигналов (например, отдельных карт направленной громкости пар сигналов (например, в качестве пары сигналов может рассматриваться комбинация двух сигналов; например, в качестве пары сигналов может рассматриваться комбинация сигналов, ассоциированных с различными каналами, и/или разностными сигналами, и/или микшированными с понижением сигналами)) в общую карту направленной громкости могут использоваться кодером, чтобы запретить кодирование определённого одного из сигналов (например, для трех подлежащих кодированию сигналов: как описано выше, три карты направленной громкости пар сигналов могут быть проанализированы относительно общей карты направленной громкости; таким образом, кодер может быть выполнен с возможностью определения пары сигналов с наиболее высоким вкладом в общую карту направленной громкости и кодирования только этих двух сигналов, и запрещать кодирование для оставшегося сигнала). Запрещение кодирования сигнала, например, рассматривается как адаптация параметров кодирования. Таким образом, не требуется кодировать сигналы, не очень релевантные для восприятия аудиосодержимого слушателем, и это приводит к очень эффективному кодированию. В соответствии с вариантом осуществления пороговое значение может быть установлено меньшим или равным 5%, 10%, 15%, 20% или 50% от информации о громкости общей карты направленной громкости.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью адаптации точности квантования одного или более подлежащих кодированию сигналов (например, между разностным сигналом и микшированным с понижением сигналом) в зависимости от вкладов отдельных карт направленной громкости (соответствующего) одного или более подлежащих кодированию сигналов в общую карту направленной громкости. В качестве альтернативы или дополнительно, аналогично описанному выше запрещению, вклады карт направленной громкости пар сигналов в общую карту направленной громкости могут использоваться кодером, чтобы адаптировать точность квантования одного или более подлежащих кодированию сигналов. Адаптация точности квантования может рассматриваться в качестве примера для адаптации параметров кодирования аудиокодером.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью квантования представления в спектральной области одного или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала; например, один или более входных аудиосигналов соответствуют множеству различных каналов; таким образом аудиокодер принимает, например, многоканальный вход) или одного или более полученных из них сигналов (например, центрального сигнала, или микшированного с понижением сигнала и бокового сигнала, или сигнала разности) с использованием одного или более параметров квантования (например, масштабных коэффициентов или параметров, описывающих, какая точность квантования или какой шаг квантования к каким спектральным интервалам или частотным полосам одного или более подлежащих квантованию сигналов следует применять) (причем параметры квантования описывают, например, распределение битов различным подлежащим квантованию сигналам и/или различным частотным полосам), чтобы получить одно или более квантованных представления в спектральной области. Аудиокодер выполнен с возможностью регулировки одного или более параметров квантования (например, чтобы адаптировать распределение битов между одним или более подлежащими кодированию сигналами) в зависимости от одной или более карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, направлением панорамирования) одного или более подлежащих квантованию сигналов, чтобы адаптировать обеспечение одного или более кодированных аудиосигналов (например, в зависимости от вкладов отдельных карт направленной громкости одного или более сигналов, подлежащих квантованию, в общую карту направленной громкости, например, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов)). Дополнительно аудиокодер выполнен с возможностью кодирования одного или более квантованных представлений в спектральной области, чтобы получить один или более кодированных аудиосигналов.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью регулировки одного или более параметров квантования в зависимости от вкладов отдельных карт направленной громкости одного или более подлежащих квантованию сигналов в общую карту направленной громкости.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью определения общей карты направленной громкости на основе входных аудиосигналов, причем общая карта направленной громкости представляет информацию о громкости, ассоциированную с различными направлениями (например, звуковых компонентов; например, с направлениями панорамирования) аудиосцены, представленной (или подлежащей представлению, например, после рендеринга на стороне декодера) посредством входных аудиосигналов (возможно, в сочетании со знаниями или вспомогательной информацией относительно положений громкоговорителей и/или знаниями или вспомогательной информацией, описывающей положения звуковых объектов). Общая карта направленной громкости представляет, например, информацию о громкости, ассоциированную со всеми (например, с объединением) входными аудиосигналами.
В соответствии с вариантом осуществления один или более подлежащих квантованию сигналов ассоциированы (например, фиксированным, не зависящем от сигналов методом) с различными направлениями (например, первыми различными направлениями) или ассоциированы с различными громкоговорителями (например, в различных заданных положениях громкоговорителей) или ассоциированы с различными звуковыми объектами (например, со звуковыми объектами, подлежащими рендерингу в различных положениях, например, в соответствии с информацией о рендеринге объектов; например, с индексом панорамирования).
В соответствии с вариантом осуществления подлежащие квантованию сигналы содержат компоненты (например, центральный сигнал и боковой сигнал стереофонического центрального/бокового кодирования) совместного многосигнального кодирования двух или более входных аудиосигналов.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью оценки вклада разностного сигнала совместного многосигнального кодирования в общую карту направленной громкости и регулировки одного или более параметров квантования в зависимости от этого. Оценочный вклад, например, представлен вкладом карты направленной громкости разностного сигнала в общую карту направленной громкости.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью адаптации распределение битов между одним или более сигналами и/или параметрами, подлежащими отдельному кодированию для различных спектральных интервалов или отдельному кодированию для различных частотных полос. Дополнительно или в качестве альтернативы аудиокодер выполнен с возможностью адаптации точности квантования одного или более подлежащих отдельному кодированию сигналов для различных спектральных интервалов или отдельному кодированию для различных частотных полос. С помощью адаптации точности квантования аудиокодер, например, также выполнен с возможностью адаптации распределения битов. Таким образом, аудиокодер, например, выполнен с возможностью адаптации распределения битов между одним или более аудиосигналами аудиосодержимого, подлежащего кодированию аудиокодером. Дополнительно или в качестве альтернативы адаптируется распределение битов между подлежащими кодированию параметрами. Адаптация распределения битов может быть выполнена аудиокодером отдельно для различных спектральных интервалов или отдельно для различных частотных полос. В соответствии с вариантом осуществления также возможно, что адаптируется распределение битов между сигналами и параметрами. Другими словами, каждый сигнал из одного или более подлежащих кодированию аудиокодером сигналов может содержать отдельное распределение битов для различных спектральных интервалов и/или различных частотных полос (например, соответствующего сигнала), и это отдельное распределение битов для каждого одного или более подлежащих кодированию сигналов может быть адаптировано аудиокодером.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью адаптации распределения битов между одним или более сигналами и/или параметрами, подлежащими кодированию (например, отдельно для каждого спектрального интервала или для каждой частотной полосы) в зависимости от оценки пространственного маскирования между двумя или более подлежащими кодированию сигналами. Кроме того, аудиокодер выполнен с возможностью оценки пространственного маскирования на основе карт направленной громкости, ассоциированных с двумя или более подлежащими кодированию сигналами. Это основано, например, на идее, что карты направленной громкости разложены в пространстве и/или во времени. Таким образом, например, тратится лишь немного битов или биты не тратятся для сигналов в маске, и больше битов (например, больше, чем для сигналов в маске) тратится для кодирования релевантных сигналов или компонентов сигналов (например, сигналов или компонентов сигналов, не маскированных другими сигналами или компонентами). В соответствии с вариантом осуществления пространственное маскирование зависит, например, от уровня, ассоциированного со спектральными интервалами и/или частотными полосами двух или более подлежащих кодированию сигналов, на пространственном расстоянии между спектральными интервалами и/или частотными полосами, и/или на временном расстоянии между спектральными интервалами и/или частотными полосами). Карты направленной громкости могут непосредственно обеспечивать информацию о громкости для отдельных спектральных интервалов и/или частотных полос для отдельных сигналов или объединения сигналов (например, пар сигналов), что приводит к эффективному анализу пространственного маскирования кодером.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью оценки эффекта маскирования вклада громкости, ассоциированного с первым направлением первого подлежащего кодированию сигнала, на вклад громкости, ассоциированный со вторым направлением (которое отличается от первого направления) второго подлежащего кодированию сигнала (в котором, например, эффект маскирования сокращается с увеличением разности углов). Эффект маскирования определяет, например, уместность пространственного маскирования. Это означает, например, что для вкладов громкости, ассоциированных с эффектом маскирования, который ниже порогового значения, тратится больше битов, чем для сигналов (например, пространственно маскированных сигналов), ассоциированных с эффектом маскирования, который выше порогового значения. В соответствии с вариантом осуществления пороговое значение может быть определено как 20%, 50%, 60%, 70% или 75% маскирование от полного маскирования. Это означает, например, что эффект маскирования соседних спектральных интервалов или частотных полос оценивается в зависимости от информации о громкости карт направленной громкости.
В соответствии с вариантом осуществления аудиокодер содержит модуль анализа аудиоданных в соответствии с одним из описанных в настоящем документе вариантов осуществления, причем информация о громкости (например, «карта направленной громкости»), ассоциированная с различными направлениями, формирует карту направленной громкости.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью адаптации шума, вносимого кодером (например, шума квантования), в зависимости от одной или более карт направленной громкости. Таким образом, например, одна или более карт направленной громкости одного или более подлежащих кодированию сигналов могут быть сравнены кодером с одной или более картами направленной громкости одного или более опорных сигналов. На основе этого сравнения аудиокодер, например, выполнен с возможностью оценки разности, указывающей на внесенный шум. Шум может быть адаптирован посредством адаптации квантования, выполняемой аудиокодером.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью использования отклонения между картой направленной громкости, которая ассоциирована с определённым не кодированным входным аудиосигналом (или с определённой некодированной входной парой аудиосигналов), и картой направленной громкости, достижимой посредством кодированной версии определённого входного аудиосигнала (или определённой входной пары аудиосигналов), в качестве критерия (например, целевого критерия) для адаптации формирования определённого кодированного аудиосигнала (или определённой кодированной пары аудиосигналов). Следующие примеры описаны только для одного определённого не кодированного входного аудиосигнала, но ясно, что они также применимы для определённой не кодированной входной пары аудиосигналов. Карта направленной громкости, ассоциированная с определённым не кодированным входным аудиосигналом, может быть ассоциирована с эталонной картой направленной громкости или может представлять эталонную карту направленной громкости. Таким образом, отклонение между эталонной картой направленной громкости и картой направленной громкости кодированной версии определённого входного аудиосигнала может указывать на шум, вносимый кодером. Для сокращения шума аудиокодер может быть выполнен с возможностью адаптации параметров кодирования для уменьшения отклонения, чтобы обеспечить высокое качество кодированного аудиосигнал. Это, например, реализуется с помощью контура обратной связи, каждый раз управляющего отклонением. Таким образом, параметры кодирования адаптируются, пока отклонение не станет ниже заданного порогового значения. В соответствии с вариантом осуществления пороговое значение может быть определено как 5%, 10%, 15%, 20% или 25% отклонения. В качестве альтернативы адаптация посредством кодера выполняется с использованием нейронной сети (например, осуществляющей контур с упреждением). С помощью нейронной сети карта направленной громкости для кодированной версии определённого входного аудиосигнала может быть оценена без непосредственного определения ее аудиокодером или модулем анализа аудиоданных. Таким образом, может быть реализовано очень быстрое аудиокодирование высокой точности.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью активации и деактивации инструмента совместного кодирования (который, например, совместно кодирует два или более из входных аудиосигналов или полученных из них сигналов) (например, чтобы принять решение о включении/выключении M/S (центральный/боковой сигнал)) в зависимости от одной или более карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений одного или более подлежащих кодированию сигналов. Чтобы активировать или деактивировать инструмент совместного кодирования, аудиокодер может быть выполнен с возможностью определения вклада карты направленной громкости каждого сигнала или каждой пары возможных сигналов в общую карту направленной громкости общей сцены. В соответствии с вариантом осуществления вклад выше порогового значения (например, вклад, составляющий по меньшей мере 10%, или по меньшей мере 20%, или по меньшей мере 30%, или по меньшей мере 50%, указывает, разумно ли применять совместное кодирование входных аудиосигналов. Например, пороговое значение может быть сравнительно низким для этого варианта использования (например, ниже, чем в других вариантах использования), чтобы прежде всего отфильтровать несоответствующие пары. На основе карт направленной громкости аудиокодер может проверить, приведет ли совместное кодирование сигналов к более эффективному кодированию и/или кодированию с высоким разрешением.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью определения одного или более параметров инструмента совместного кодирования (который, например, совместно кодирует два или более из входных аудиосигналов или полученных из них сигналов) в зависимости от одной или более карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений одного или более подлежащих кодированию сигналов (например, чтобы управлять сглаживанием зависящих от частоты коэффициентов предсказания; например, чтобы установить параметры инструмента совместного кодирования с «интенсивным стерео»). Одна или более карт информации о направленной громкости содержат, например, информацию о громкости в заданных направлениях и временных кадрах. Таким образом, например, аудиокодер выполнен с возможностью определения одного или более параметров для текущего временного кадра на основе информации о громкости предыдущих временных кадров. На основе карт направленной громкости эффекты маскирования могут быть проанализированы очень эффективно и могут быть указаны посредством одного или более параметров, посредством чего зависящие от частоты коэффициенты предсказания могут быть определены на основе одного или более параметров таким образом, что предсказанные значения отсчетов близки к первоначальным значениям отсчетов (ассоциированным с подлежащим кодированию сигналом). Таким образом, для кодера возможно определить зависящие от частоты коэффициенты предсказания, представляющие приближение порогового значения маскирования, а не подлежащего кодированию сигнала. Кроме того, карты направленной громкости, например, основаны на психоакустической модели, посредством чего определение зависящих от частоты коэффициентов предсказания на основе одного или более параметров дополнительно улучшается и может привести к очень точному предсказанию. В качестве альтернативы параметры инструмента совместного кодирования определяют, например, какой сигнал или пара сигналов должны быть кодированы совместно аудиокодером. Аудиокодер, например, выполнен с возможностью обоснования определения одного или более параметров на вкладах каждой карты направленной громкости, ассоциированной с подлежащим кодированию сигналом или парой сигналов, в общую карту направленной громкости. Таким образом, например, один или более параметров указывают отдельные сигналы и/или пары сигналов с наиболее высоким вкладом или вкладом, равным или выше порогового значения (см., например, определение порогового значения выше). На основе одного или более параметров аудиокодер, например, выполнен с возможностью совместного кодирования сигналов, указанных посредством одного или более параметров. В качестве альтернативы, например, пары сигналов, имеющие высокую близость/сходство в соответствующей карте направленной громкости, могут быть указаны посредством одного или более параметров инструмента совместного кодирования. Выбранные пары сигналов, например, совместно представлены посредством понижающего микширования. Таким образом количество битов, необходимых для кодирования, минимизируется или сокращается, поскольку микшированный с понижением сигнал или разностный сигнал подлежащих совместному кодированию сигналов очень малы.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью определения или оценки влияния вариации одного или более управляющих параметров, которые управляют обеспечением одного или более кодированных аудиосигналов, на карту направленной громкости одного или более кодированных сигналов и регулировки одного или более управляющих параметров в зависимости от определения или оценки влияния. Влияние управляющих параметров на карту направленной громкости одного или более кодированных сигналов может содержать меру для индуцируемого шума (например, управляющие параметры относительно положения квантования могут регулироваться) посредством кодирования аудиокодера, меры для искажений аудиоданных и/или меры для падения качества восприятия слушателя. В соответствии с вариантом осуществления управляющие параметры могут быть представлены параметрами кодирования, или параметры кодирования могут содержать управляющие параметры.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью получения компонента направления (например, информации о направлении), используемого для получения одной или более карт направленной громкости с использованием метаданных, представляющих информацию о положении громкоговорителей, ассоциированных с входными аудиосигналами (эта концепция также может использоваться в других аудиокодерах). Компонент направления, например, представлен в настоящем документе описанными первыми различными направлениями, которые, например, ассоциированы с различными каналами или громкоговорителями, ассоциированными с входными аудиосигналами. В соответствии с вариантом осуществления на основе компонента направления полученная одна или более карт направленной громкости могут быть ассоциированы с входным аудиосигналом и/или парой сигналов из входных аудиосигналов с одинаковым компонентом направления. Таким образом, например, карта направленной громкости может иметь индекс L, и входной аудиосигнал может иметь индекс L, где L указывает левый канал или сигнал для левого громкоговорителя. В качестве альтернативы компонент направления может быть представлен вектором, таким как (1, 3), который указывает комбинацию входных аудиосигналов первого канала и третьего канала. Таким образом, карта направленной громкости с индексом (1, 3) может быть ассоциирована с парой сигналов. В соответствии с вариантом осуществления каждый канал может быть ассоциирован с отдельным громкоговорителем.
Вариант осуществления в соответствии с настоящим изобретением относится к аудиокодеру для кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Аудиокодер выполнен с возможностью обеспечения одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе двух или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала) или на основе двух или более полученных из них сигналов с использованием совместного кодирования двух или более подлежащих совместному кодированию сигналов (например, с использованием центрального сигнала, или микшированного с понижением сигнала и бокового сигнала, или сигнала разности). Дополнительно аудиокодер выполнен с возможностью выбора подлежащих совместному кодированию сигналов из множества возможных сигналов или из множества пар возможных сигналов (например, из двух или более входных аудиосигналов или из двух или более полученных из них сигналов) в зависимости от карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, направлением панорамирования) возможных сигналов или пар возможных сигналов (например, в зависимости от вкладов отдельных карт направленной громкости возможных сигналов в общую карту направленной громкости, например, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов), или в зависимости от вкладов карт направленной громкости пар возможных сигналов в общую карту направленной громкости (например, ассоциированную со всеми входными аудиосигналами)).
В соответствии с вариантом осуществления аудиокодер может быть выполнен с возможностью активации и деактивации совместного кодирования. Таким образом, например, если аудиосодержимое содержит только один входной аудиосигнал, то совместное кодирование деактивируется, и оно активируется, только если аудиосодержимое содержит два или более входных аудиосигнала. Таким образом, с помощью аудиокодера возможно кодировать монауральное аудиосодержимое, стереофоническое аудиосодержимое и/или аудиосодержимое, содержащее три или более входных аудиосигнала (т.е. многоканальное аудиосодержимое). В соответствии с вариантом осуществления аудиокодер обеспечивает каждому входному аудиосигналу отдельный кодированный аудиосигнал в качестве выходного сигнала (например, подходящий для аудиосодержимого, содержащего только один единственный входной аудиосигнал), или обеспечивает один объединенный выходной сигнал (например, кодированные совместно сигналы), содержащий два или более кодированных аудиосигналов из двух или более входных аудиосигналов.
Варианты осуществления этого аудиокодера основаны на идее, что обоснование совместного кодирования на картах направленной громкости является эффективным и улучшает точность кодирования. Использование карт направленной громкости имеет преимущество, поскольку они могут указывать на восприятие аудиосодержимого слушателем и тем самым улучшать качество аудиоданных кодированного аудиосодержимого, особенно в контексте с совместным кодированием. Например, возможно оптимизировать выбор пар сигналов, подлежащих совместному кодированию, анализируя карты направленной громкости. Анализ карт направленной громкости дает, например, информацию о сигналах или парах сигналов, которыми можно пренебречь (например, сигналы, которые имеют лишь малое влияние на восприятие слушателя), что приводит к небольшому количеству битов, необходимых для кодированного аудиокодером аудиосодержимого (например, содержащего два или более кодированных сигнала). Это означает, например, что сигналами с низким вкладом их соответствующей карты направленной громкости в общую карту направленной громкости можно пренебречь. В качестве альтернативы анализ может указывать сигналы, которые имеют высокое сходство (например, сигналы со сходными картами направленной громкости), посредством чего, например, посредством совместного кодирования могут быть получены оптимизированные разностные сигналы.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью выбора подлежащих совместному кодированию сигналов из множества возможных сигналов или из множества пар возможных сигналов в зависимости от вкладов отдельных карт направленной громкости возможных сигналов в общую карту направленной громкости или в зависимости от вкладов карт направленной громкости пар возможных сигналов в общую карту направленной громкости (например, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов)) (или ассоциированную с общей (аудио)сценой, например, представленной входными аудиосигналами). Общая карта направленной громкости представляет, например, информацию о громкости, ассоциированную с различными направлениями (например, звуковых компонентов) аудиосцены, представленной (или подлежащей представлению, например, после рендеринга на стороне декодера) посредством входных аудиосигналов (возможно, в сочетании со знаниями или вспомогательной информацией относительно положений громкоговорителей и/или знаниями или вспомогательной информацией, описывающей положения звуковых объектов).
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью определения вклада пар возможных сигналов в общую карту направленной громкости. Дополнительно аудиокодер выполнен с возможностью выбора одной или более пар возможных сигналов, имеющих наиболее высокий вклад в общую карту направленной громкости, для совместного кодирования, или аудиокодер выполнен с возможностью выбора одной или более пар возможных сигналов, вклад которых в общую карту направленной громкости больше заданного порогового значения (например, вклад составляет по меньшей мере 60%, 70%, 80% или 90%), для совместного кодирования. Что касается наиболее высокого вклада, возможно, что только одна пара возможных сигналов имеет наиболее высокий вклад, но также возможно, что более одной пары возможных сигналов имеют одинаковый вклад, который представляет собой наиболее высокий вклад, или более одной пары возможных сигналов имеют сходные вклады с малыми отклонениями от наиболее высокого вклада. Таким образом, аудиокодер, например, выполнен с возможностью выбора более одного сигнала или пары сигналов для совместного кодирования. С помощью признаков, описанных в этом варианте осуществления, возможно найти релевантные пары сигналов для улучшенного совместного кодирования и отказаться от сигналов или пар сигналов, которые сильно не влияют на восприятие кодированного аудиосодержимого слушателем.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью определения отдельных карт направленной громкости двух или более возможных сигналов (например, карт направленной громкости, ассоциированных с парами сигналов). Дополнительно аудиокодер выполнен с возможностью сравнения отдельных карт направленной громкости двух или более возможных сигналов и выбора двух или более из возможных сигналов для совместного кодирования в зависимости от результата сравнения (например, таким образом, что возможные сигналы (например, пары сигналов, тройки сигналов, четверки сигналов и т.д.), отдельные карты громкости которых содержат максимальное сходство или сходство, которое выше порогового значения сходства, выбираются для совместного кодирования). Таким образом, например, тратится лишь немного битов или биты не тратятся для разностного сигнала (например, бокового канала относительно центрального канала) на поддержание высокого качества кодированного аудиосодержимого.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью определения общей карты направленной громкости с использованием понижающего микширования входных аудиосигналов и/или использования бинаурализации входных аудиосигналов. Понижающее микширование или бинаурализация учитывают, например, направления (например, ассоциации с каналами или громкоговорителем для соответствующих входных аудиосигналов). Общая карта направленной громкости может быть ассоциирована с информацией о громкости, соответствующей аудиосцене, созданной всеми входными аудиосигналами.
Вариант осуществления в соответствии с настоящим изобретением относится к аудиокодеру для кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Аудиокодер выполнен с возможностью обеспечения одного или более кодированных (например, квантованных и кодированных затем без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе двух или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала) или на основе двух или более полученных из них сигналов. Дополнительно аудиокодер выполнен с возможностью определения общей карты направленной громкости (например, целевой карты направленной громкости сцены) на основе входных аудиосигналов и/или определения одной или более отдельных карт направленной громкости, ассоциированных с отдельными входными аудиосигналами (или ассоциированных с двумя или более входными аудиосигналами, такими как пары сигналов). Кроме того, аудиокодер выполнен с возможностью кодирования общей карты направленной громкости и/или одной или более отдельных карт направленной громкости в качестве вспомогательной информации.
Таким образом, например, если аудиосодержимое содержит только один входной аудиосигнал, аудиокодер выполнен с возможностью кодирования только этого сигнала вместе с соответствующей отдельной картой направленной громкости. Если аудиосодержимое содержит два или более входных аудиосигнала, аудиокодер, например, выполнен с возможностью кодирования всех или по меньшей мере некоторых (например, одного отдельного сигнала и одной пары сигналов из трех входных аудиосигналов) сигналов отдельно вместе с соответствующей картой направленной громкости (например, с отдельными картами направленной громкости отдельных кодированных сигналов и/или с картами направленной громкости, соответствующими парам сигналов или другим комбинациям из более чем двух сигналов, и/или с общими картами направленной громкости, ассоциированными со всеми входными аудиосигналами). В соответствии с вариантом осуществления аудиокодер выполнен с возможностью кодирования всех или по меньшей мере некоторых сигналов, что дает в результате один кодированный аудиосигнал, например, вместе с общей картой направленной громкости в качестве выходных данных (например, один объединенный выходной сигнал (например, совместно кодированные сигналы), содержащий, например, два или более кодированных аудиосигнала из двух или более входных аудиосигналов). Таким образом, с помощью аудиокодера возможно кодировать монауральное аудиосодержимое, стереофоническое аудиосодержимое и/или аудиосодержимое, содержащее три или более входных аудиосигнала (т.е. многоканальное аудиосодержимое).
Варианты осуществления этого аудиокодера основаны на идее, что имеется преимущество в определении и кодировании одной или более карт направленной громкости, поскольку они могут указывать восприятие аудиосодержимого слушателем и тем самым улучшить качество аудиоданных кодированного аудиосодержимого. В соответствии с вариантом осуществления одна или более карт направленной громкости могут использоваться кодером для улучшения кодирования, например, посредством адаптации параметров кодирования на основе одной или более карт направленной громкости. Таким образом, кодирование одной или более карт направленной громкости имеет особое преимущество, поскольку они могут представлять информацию относительно влияния кодирования. С помощью одной или более карт направленной громкости в качестве вспомогательной информации в кодированном аудиосодержимом, обеспеченной аудиокодером, может быть достигнуто очень точное декодирование, поскольку аудиодекодером обеспечена информация относительно кодирования (например, в потоке данных).
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью определения общей карты направленной громкости на основе входных аудиосигналов, причем общая карта направленной громкости представляет информацию о громкости, ассоциированную с различными направлениями (например, звуковых компонентов) аудиосцены, представленной (или подлежащей представлению, например, после рендеринга на стороне декодера) посредством входных аудиосигналов (возможно, в сочетании со знаниями или вспомогательной информацией относительно положений громкоговорителей и/или знаниями или вспомогательной информацией, описывающей положения звуковых объектов). Различные направления аудиосцены представляют собой, например, описанные в настоящем документе вторые различные направления.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью кодирования общей карты направленной громкости в виде множества (например, скалярных) значений, ассоциированных с различными направлениями (и предпочтительно с множеством частотных интервалов или частотных полос). Если общая карта направленной громкости кодирована в виде множества значений, значение, ассоциированное с некоторым направлением, может содержать информацию о громкости множества частотных интервалов или частотных полос. В качестве альтернативы аудиокодер выполнен с возможностью кодирования общей карты направленной громкости с использованием значения центрального положения (например, с описанием угла или индекса панорамирования, в котором наблюдается максимум общей карты направленной громкости для определённого частотного интервала или частотной полосы) и информации о градиенте (например, одна или более скалярных величин, описывающих градиенты значений общей карты направленной громкости в угловом направлении или в направлении индекса панорамирования). Кодирование общей карты направленной громкости с использованием значения центрального положения и информации о градиенте может быть выполнено для различных определённых частотных интервалов или частотных полос. Таким образом, например, общая карта направленной громкости может содержать информацию о значении центрального положения и информацию о градиенте более чем для одного частотного интервала или частотной полосы. В качестве альтернативы аудиокодер выполнен с возможностью кодирования общей карты направленной громкости в виде полиномиального представления, или аудиокодер выполнен с возможностью кодирования общей карты направленной громкости в виде сплайнового представления. Кодирование общей карты направленной громкости в виде полиномиального представления или сплайнового представления является экономичным кодированием. Хотя эти признаки описаны относительно общей карты направленной громкости, это кодирование также может выполняться для отдельных карт направленной громкости (например, отдельных сигналов, пар сигналов и/или групп из трех или более сигналов). Таким образом, с помощью этих признаков карты направленной громкости кодируются очень эффективно, и обеспечивается информация, на которой основано кодирование.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью кодирования (а также, например, передачи или вставки в кодированное звуковое представление) одного (например, только одного) микшированного с понижением сигнала, полученного на основе множества входных аудиосигналов и общей карты направленной громкости. В качестве альтернативы аудиокодер выполнен с возможностью кодирования (а также, например, передачи или вставки в кодированное звуковое представление) множества сигналов (например, входных аудиосигналов или полученных из них сигналов) и кодирования (а также, например, передачи или вставки в кодированное звуковое представление) отдельных карт направленной громкости множества сигналов, которые кодируются (например, карт направленной громкости отдельных сигналов, и/или пар сигналов, и/или групп из трех или более сигналов). В качестве альтернативы аудиокодер выполнен с возможностью кодирования (а также, например, передачи или вставки в кодированное звуковое представление) общей карты направленной громкости, множества сигналов (например, входных аудиосигналов или полученных из них сигналов) и параметров, описывающих (например, соответствующие) вклады сигналов, которые кодируются в общей карте направленной громкости. В соответствии с вариантом осуществления параметры, описывающие вклады, могут быть представлены скалярными величинами. Таким образом, возможно посредством аудиодекодера, принимающего кодированное звуковое представление (например, аудиосодержимое или поток данных, содержащий кодированные сигналы, общую карту направленной громкости и параметры) воссоздать отдельные карты направленной громкости сигналов на основе общей карты направленной громкости и параметров, описывающих вклады сигналов.
Вариант осуществления в соответствии с настоящим изобретением относится к аудиодекодеру для декодирования кодированного аудиосодержимого. Аудиодекодер выполнен с возможностью приема кодированного представления одного или более аудиосигналов и обеспечения декодированного представления одного или более аудиосигналов (например, с использованием декодирования, подобного AAC, или с использованием декодирования подвергнутых энтропийному кодированию спектральных значений). Кроме того, аудиодекодер выполнен с возможностью приема кодированной информации о картах направленной громкости и декодирования кодированной информации о карте направленной громкости, получения одной или более (например, декодированных) карт направленной громкости. Дополнительно аудиодекодер выполнен с возможностью воссоздания аудиосцены с использованием декодированного представления одного или более аудиосигналов и с использованием одной или более карт направленной громкости. Аудиосодержимое может содержать кодированное представление одного или более аудиосигналов и кодированную информацию о картах направленной громкости. Кодированная информация о картах направленной громкости может содержать карты направленной громкости отдельных сигналов, пар сигналов и/или групп из трех или более сигналов.
Вариант осуществления этого аудиодекодера основан на идее, что определение и декодирование одной или более карт направленной громкости имеет преимущество, поскольку они могут указывать восприятие аудиосодержимого слушателем и тем самым улучшить качество аудиоданных декодированного аудиосодержимого. Аудиодекодер, например, выполнен с возможностью определения высококачественного сигнала предсказания на основе одной или более карт направленной громкости, посредством чего может быть улучшено разностное декодирование (или совместное декодирование). В соответствии с вариантом осуществления карты направленной громкости определяют информацию о громкости для различных направлений в аудиосцене по времени. Информация о громкости для некоторого направления в определенный момент времени или в некотором временном кадре может содержать информацию о громкости различных аудиосигналов или одного аудиосигнала, например, в различных частотных интервалах или частотных полосах. Таким образом, например, обеспечение декодированного представления одного или более аудиосигналов аудиодекодером может быть улучшено, например, посредством адаптации декодирования кодированного представления одного или более аудиосигналов на основе декодированных карт направленной громкости. Таким образом, воссозданная аудиосцена оптимизируется, поскольку декодированное представление одного или более аудиосигналов может достигнуть минимального отклонения от первоначального аудиосигнала на основе анализа одной или более карт направленной громкости, что дает в результате высококачественную аудиосцену. В соответствии с вариантом осуществления аудиодекодер может быть выполнен с возможностью использования одной или более карт направленной громкости для адаптации параметров декодирования, чтобы обеспечить эффективное декодированное представление одного или более аудиосигналов с высокой точностью.
В соответствии с вариантом осуществления аудиодекодер выполнен с возможностью получения выходных сигналов таким образом, что одна или более карт направленной громкости, ассоциированных с выходными сигналами, приблизительно равны или равны одной или более целевым картам направленной громкости. Одна или более целевых карт направленной громкости основаны на одной или более декодированных картах направленной громкости или равны одной или более декодированным картам направленной громкости. Аудиодекодер, например, выполнен с возможностью использования подходящего масштабирования или объединения одного или более декодированных аудиосигналов для получения выходных сигналов. Целевые карты направленной громкости, например, рассматриваются как эталонные карты направленной громкости. В соответствии с вариантом осуществления целевые карты направленной громкости могут представлять информацию о громкости одного или более аудиосигналов перед кодированием и декодированием аудиосигналов. В качестве альтернативы целевые карты направленной громкости могут представлять информацию о громкости, ассоциированную с кодированным представлением одного или более аудиосигналов (например, одну или более декодированных карт направленной громкости). Аудиодекодер принимает, например, параметры кодирования, используемые для кодирования, чтобы обеспечить кодированное аудиосодержимое. Аудиодекодер, например, выполнен с возможностью определения параметров декодирования на основе параметров кодирования для масштабирования одной или более декодированных карт направленной громкости, чтобы определить одну или более целевых карт направленной громкости. Также возможно, что аудиодекодер содержит модуль анализа аудиоданных, который выполнен с возможностью определения целевых карт направленной громкости на основе декодированных карт направленной громкости и одного или более декодированных аудиосигналов, причем, например, декодированные карты направленной громкости масштабируются на основе одного или более декодированных аудиосигналов. Поскольку одна или более целевых карт направленной громкости могут быть ассоциированы с оптимальной или оптимизированной аудиосценой, реализованной аудиосигналами, полезно минимизировать отклонение между одной или более картами направленной громкости, ассоциированными с выходными сигналами, и одной или более целевыми картами направленной громкости. В соответствии с вариантом осуществления это отклонение может быть минимизировано аудиодекодером посредством адаптации параметров декодирования или адаптации параметров относительно воссоздания аудиосцены. Таким образом, с помощью этого признака осуществляется управление качеством выходных сигналов, например, посредством контура обратной связи, анализирующего одну или более карт направленной громкости, ассоциированных с выходными сигналами. Аудиодекодер, например, выполнен с возможностью определения одной или более карт направленной громкости выходных сигналов (например, аудиодекодер содержит описанный в настоящем документе модуль анализа аудиоданных для определения карт направленной громкости). Таким образом, аудиодекодер обеспечивает выходные сигналы, которые ассоциированы с картами направленной громкости, которые приблизительно равны или равны целевым картам направленной громкости.
В соответствии с вариантом осуществления аудиодекодер выполнен с возможностью приема одного (например, только одного) кодированного микшированного с понижением сигнала (например, полученного на основе множества входных аудиосигналов) и общей карты направленной громкости; или множества кодированных аудиосигналов (например, входных аудиосигналов кодера или полученных из них сигналов) и отдельных карт направленной громкости множества кодированных сигналов; или общей карты направленной громкости, множества кодированных аудиосигналов (например, входных аудиосигналов, принятых аудиокодером, или полученных из них сигналов) и параметров, описывающих (например, соответствующие) вклады кодированных аудиосигналов в общую карту направленной громкости. Аудиодекодер выполнен с возможностью обеспечения на основе этого выходных сигналов.
Вариант осуществления в соответствии с настоящим изобретением относится к преобразователю формата для преобразования формата аудиосодержимого, который представляет аудиосцену (например, пространственную аудиосцену), из первого формата во второй формат. Первый формат может содержать, например, первое количество каналов или входных аудиосигналов и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную к первому количеству каналов или входных аудиосигналов, и причем второй формат может содержать, например, второе количество каналов или выходных аудиосигналов, которое могут отличаться от первого количества каналов или входных аудиосигналов, и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную ко второму количеству каналов или выходных аудиосигналов. Кроме того, преобразователь формата выполнен с возможностью обеспечения представления аудиосодержимого во втором формате на основе представления аудиосодержимого в первом формате. Дополнительно преобразователь формата выполнен с возможностью регулировки сложности преобразования формата (например, посредством пропуска одного или более входных аудиосигналов первого формата, вклад которых в карту направленной громкости ниже порогового значения, в процессе преобразования формата) в зависимости от вкладов входных аудиосигналов первого формата (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости аудиосцены (причем общая карта направленной громкости, например, может быть описана вспомогательной информацией первого формата, принятой преобразователем формата). Таким образом, например, вклады отдельных карт направленной громкости, ассоциированных с отдельными входными аудиосигналами, в общую карту направленной громкости аудиосцены анализируются для регулировки сложности преобразования формата. В качестве альтернативы эта регулировка может выполняться преобразователем формата в зависимости от вкладов карт направленной громкости, соответствующих комбинациям входных аудиосигналов (например, пар сигналов, центрального сигнала, бокового сигнала, микшированного с понижением сигнала, разностного сигнала, сигнала разности и/или групп из трех или более сигналов) в общую карту направленной громкости аудиосцены.
Варианты осуществления преобразователя формата основаны на идее, что преобразование формата аудиосодержимого на основе одной или более карт направленной громкости имеет преимущество, поскольку они могут указывать восприятие аудиосодержимого слушателем, и тем самым реализуется высокое качество аудиосодержимого во втором формате, и сокращается сложность преобразования формата в зависимости от карт направленной громкости. С помощью вкладов возможно получить информацию о сигналах, релевантных для высококачественного восприятия аудиоданных аудиосодержимого с преобразованным форматом. Таким образом, аудиосодержимое во втором формате, например, содержит меньше сигналов (например, только релевантные сигналы в соответствии с картами направленной громкости), чем аудиосодержимое в первом формате, при почти одинаковом качестве аудиоданных.
В соответствии с вариантом осуществления преобразователь формата выполнен с возможностью приема информации о картах направленной громкости и получения на основе этого общей карты направленной громкости (например, декодированной аудиосцены; например, аудиосодержимого в первом формате) и/или одной или более карт направленной громкости. Информация о картах направленной громкости (т.е. одной или более картах направленной громкости, ассоциированных с отдельными сигналами аудиосодержимого, или ассоциированных с парами сигналов или объединением трех или более сигналов аудиосодержимого) может представлять аудиосодержимое в первом формате, может являться частью аудиосодержимого в первом формате, или может быть определена преобразователем формата на основе аудиосодержимого в первом формате (например, описанным в настоящем документе модулем анализа аудиоданных; например, преобразователь формата содержит модуль анализа аудиоданных). В соответствии с вариантом осуществления преобразователь формата также выполнен с возможностью определения информации о картах направленной громкости аудиосодержимого во втором формате. Таким образом, например, карты направленной громкости до и после преобразования формата могут быть сравнены, чтобы сократить воспринимаемое ухудшение качества вследствие преобразования формата. Это, например, реализуется посредством минимизации отклонения между картой направленной громкости до и после преобразования формата.
В соответствии с вариантом осуществления преобразователь формата выполнен с возможностью получения общей карты направленной громкости (например, декодированной аудиосцены) из одной или более (например, декодированных) карт направленной громкости (например, ассоциированных с сигналами в первом формате).
В соответствии с вариантом осуществления преобразователь формата выполнен с возможностью вычисления или оценки вклада определённого входного аудиосигнала (например, сигнала в первом формате) в общую карту направленной громкости аудиосцены. Преобразователь формата выполнен с возможностью принятия решения, следует ли рассматривать определённый входной аудиосигнал при преобразовании формата, в зависимости от вычисления или оценки вклада (например, посредством сравнения вычисленного или оцененного вклада с заданным абсолютным или относительным пороговым значением). Если вклад, например, равен или выше абсолютного или относительного порогового значения, соответствующий сигнал может рассматриваться как релевантный, и, таким образом, преобразователь формата может быть выполнен с возможностью принятия решения рассмотреть этот сигнал. Это можно рассматривать как регулировку сложности с помощью преобразователя формата, поскольку не все сигналы в первом формате обязательно преобразовываются во второй формат. Заданное пороговое значение может представлять вклад по меньшей мере 2%, или по меньшей мере 5%, или по меньшей мере 10%, или по меньшей мере 20%, или по меньшей мере 30%. Например, это означает исключение неслышимых и/или не релевантных каналов (или почти неслышимых и/или не релевантных каналов), т.е. пороговое значение должно быть ниже (например, при сравнении с другими вариантами использования), например, 5%, 10%, 20%, 30%.
Вариант осуществления в соответствии с настоящим изобретением относится к аудиодекодеру для декодирования кодированного аудиосодержимого. Аудиодекодер выполнен с возможностью приема кодированного представления одного или более аудиосигналов и обеспечения декодированного представления одного или более аудиосигналов (например, с использованием декодирования, подобного AAC, или с использованием декодирования подвергнутых энтропийному кодированию спектральных значений). Кроме того, аудиодекодер выполнен с возможностью воссоздания аудиосцены с использованием декодированного представления одного или более аудиосигналов и регулировки сложности декодирования в зависимости от вкладов кодированных сигналов (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости декодированной аудиосцены.
Варианты осуществления этого аудиодекодера основаны на идее, что регулировка сложности декодирования на основе одной или более карт направленной громкости имеет преимущество, поскольку они могут указывать восприятие аудиосодержимого слушателем и тем самым одновременно реализовать сокращение сложности декодирования и улучшение качества аудиоданных декодера аудиосодержимого. Таким образом, например, аудиодекодер выполнен с возможностью принятия решения на основе вкладов, какие кодированные сигналы аудиосодержимого должны декодироваться и использоваться для воссоздания аудиосцены аудиодекодером. Это означает, например, что кодированное представление одного или более аудиосигналов содержит меньше аудиосигналов (например, только релевантные аудиосигналы в соответствии с картами направленной громкости), чем декодированное представление одного или более аудиосигналов, при почти одинаковом качестве аудиоданных.
В соответствии с вариантом осуществления аудиодекодер выполнен с возможностью приема кодированной информации о картах направленной громкости и декодирования кодированной информации о картах направленной громкости, получения общей карты направленной громкости (например, декодированной аудиосцены или, например, как целевой карты направленной громкости декодированной аудиосцены) и/или одной или более (декодированных) карт направленной громкости. В соответствии с вариантом осуществления преобразователь формата выполнен с возможностью определения или приема информации о картах направленной громкости кодированного аудиосодержимого (например, принятого) и декодированного аудиосодержимого (например, определенного). Таким образом, например, карты направленной громкости до и после декодирования могут быть сравнены, чтобы сократить воспринимаемое ухудшение качества вследствие декодирования и/или предыдущего кодирования (например, выполняемого описанным в настоящем документе аудиокодером). Это, например, реализуется посредством минимизации отклонения между картой направленной громкости до и после преобразования формата.
В соответствии с вариантом осуществления аудиодекодер выполнен с возможностью получения общей карты направленной громкости (например, декодированной аудиосцены или, например, как целевой карты направленной громкости декодированной аудиосцены) из одной или более (например, декодированных) карт направленной громкости.
В соответствии с вариантом осуществления аудиодекодер выполнен с возможностью вычисления или оценки вклада определённого кодированного сигнала в общую карту направленной громкости декодированной аудиосцены. В качестве альтернативы аудиодекодер выполнен с возможностью вычисления вклада определённого кодированного сигнала в общую карту направленной громкости кодированной аудиосцены. Аудиодекодер выполнен с возможностью принятия решения, следует ли декодировать определённый кодированный сигнал, в зависимости от вычисления или оценки вклада (например, посредством сравнения вычисленного или оцененного вклада с заданным абсолютным или относительным пороговым значением). Заданное пороговое значение может представлять вклад по меньшей мере 60%, 70%, 80% или 90%. Для сохранения хорошего качества пороговые значения должны быть ниже для случаев, в которых вычислительная мощность очень ограничена (например, для мобильного устройства), для этого диапазона могут подойти, например, 10%, 20%, 40%, 60%. Другими словами, в некоторых предпочтительных вариантах осуществления заданное пороговое значение должно представлять вклад по меньшей мере 5%, или по меньшей мере 10%, или по меньшей мере 20%, или по меньшей мере 40% или по меньшей мере 60%.
Вариант осуществления в соответствии с настоящим изобретение относится к модулю рендеринга (например, к модулю бинаурального рендеринга, или к модулю рендеринга в виде звуковой панели, или к модулю рендеринга в виде громкоговорителя) для преобразования аудиосодержимого для прослушивания. В соответствии с вариантом осуществления модуль рендеринга для распределения аудиосодержимого, представленного с использованием первого количества входных аудиоканалов и вспомогательной информации, описывающей желаемые пространственные характеристики, такие как размещение звуковых объектов или соотношения между аудиоканалами, в представление, содержащее определённое количество каналов, которое независимо от первого количества входных аудиоканалов (например, больше первого количества входных аудиоканалов или меньше первого количества входных аудиоканалов). Модуль рендеринга выполнен с возможностью воссоздания аудиосцены на основе одного или более входных аудиосигналов (или, например, на основе двух или более входных аудиосигналов). Кроме того, модуль рендеринга выполнен с возможностью регулировки сложности рендеринга (например, посредством пропуска одного или более входных аудиосигналов, вклад которых в карту направленной громкости ниже порогового значения, в процессе рендеринга) в зависимости от вкладов входных аудиосигналов (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости преобразованной для прослушивания аудиосцены. Общая карта направленной громкости, например, может быть описана посредством вспомогательной информации, принятой модулем рендеринга.
В соответствии с вариантом осуществления модуль рендеринга выполнен с возможностью получения (например, приема или самостоятельного определения) информации о картах направленной громкости и получения на основе этого общей карты направленной громкости (например, декодированной аудиосцены) и/или одной или более карт направленной громкости.
В соответствии с вариантом осуществления модуль рендеринга выполнен с возможностью получения общей карты направленной громкости (например, декодированной аудиосцены) из одной или более (или двух или более) (например, декодированных или самостоятельно полученных) карт направленной громкости.
В соответствии с вариантом осуществления модуль рендеринга выполнен с возможностью вычисления или оценки вклада определённого входного аудиосигнала в общую карту направленной громкости аудиосцены. Кроме того, модуль рендеринга выполнен с возможностью принятия решения, следует ли рассматривать определённый входной аудиосигнал при рендеринге, в зависимости от вычисления или оценки вклада (например, посредством сравнения вычисленного или оцененного вклада с заданным абсолютным или относительным пороговым значением)
Вариант осуществления в соответствии с настоящим изобретением относится к способу анализа аудиосигнала. Способ содержит получение множества взвешенных в спектральной области (например, в частотно-временной области) представлений (например, «направленных сигналов») на основе одного или более представлений в спектральной области (например, в частотно-временной области) двух или более входных аудиосигналов. Значения одного или более представлений в спектральной области взвешиваются в зависимости от различных направлений (например, направлений панорамирования) (например, представленных весовыми коэффициентами) звуковых компонентов (например, спектральных интервалов или спектральных полос) (например, мелодических тонов инструментов или певца) в двух или более входных аудиосигналах, чтобы получить множество взвешенных представлений в спектральной области (например, «направленных сигналов»). Дополнительно способ содержит получение информации о громкости (например, одну или более «карт направленной громкости»), ассоциированной с различными направлениями (например, направлениями панорамирования), на основе множества взвешенных представлений в спектральной области (например, «направленных сигналов») в качестве результата анализа.
Вариант осуществления в соответствии с настоящим изобретением относится к способу оценки сходства аудиосигналов. Способ содержит получение первой информации о громкости (например, карты направленной громкости; например, значений объединенной громкости), ассоциированной с различными направлениями (например, панорамирования), на основе первого множества из двух или более входных аудиосигналов. Дополнительно способ содержит сравнение первой информации о громкости со второй (например, соответствующей) информацией о громкости (например, эталонной информацией о громкости; например, эталонной картой направленной громкости; например, эталонными значениями объединенной громкости), ассоциированной с различными направлениями панорамирования, и с множеством из двух или более эталонных аудиосигналов, чтобы получить информацию о сходстве (например, «выходную переменную модели» (MOV)), описывающую сходство между первым множеством из двух или более входных аудиосигналов и множеством из двух или более эталонных аудиосигналов (или представляющую, например, качество первого множества из двух или более входных аудиосигналов при сравнении с множеством из двух или более эталонных аудиосигналов).
Вариант осуществления в соответствии с настоящим изобретением относится к способу кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Способ содержит обеспечение одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе одного или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала) или одного или более полученных из них сигналов (например, центрального сигнала, или микшированного с понижением сигнала и бокового сигнала, или сигнала разности). Кроме того, способ содержит адаптацию формирования одного или более кодированных аудиосигналов в зависимости от одной или более карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, направлений панорамирования) одного или более подлежащих кодированию сигналов. Адаптация формирования одного или более кодированных аудиосигналов, например, выполняется в зависимости от вкладов отдельных карт направленной громкости (например, ассоциированных с отдельным сигналом, парой сигналов или группой из трех или более сигналов) одного или более подлежащих квантованию сигналов в общую карту направленной громкости, например, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов)).
Вариант осуществления в соответствии с настоящим изобретением относится к способу кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Способ содержит обеспечение одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе двух или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала) или на основе двух или более полученных из них сигналов с использованием совместного кодирования двух или более подлежащих совместному кодированию сигналов (например, с использованием центрального сигнала, или микшированного с понижением сигнала и бокового сигнала, или сигнала разности). Кроме того, способ содержит выбор подлежащих совместному кодированию сигналов из множества возможных сигналов или из множества пар возможных сигналов (например, из двух или более входных аудиосигналов или из двух или более полученных из них сигналов) в зависимости от карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, направлений панорамирования) возможных сигналов или пар возможных сигналов. В соответствии с вариантом осуществления подлежащие совместному кодированию сигналы выбираются в зависимости от вкладов отдельных карт направленной громкости возможных сигналов в общую карту направленной громкости, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов), или в зависимости от вкладов карт направленной громкости пар возможных сигналов в общую карту направленной громкости.
Вариант осуществления в соответствии с настоящим изобретением относится к способу кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Способ содержит обеспечение одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе двух или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала) или на основе двух или более полученных из них сигналов. Кроме того, способ содержит определение общей карты направленной громкости (например, целевой карты направленной громкости сцены) на основе входных аудиосигналов и/или определение одной или более отдельных карт направленной громкости, ассоциированных с отдельными входными аудиосигналами (и/или определение одной или более карт направленной громкости, ассоциированных с парами входных аудиосигналов). Дополнительно способ содержит кодирование общей карты направленной громкости и/или одной или более отдельных карт направленной громкости в качестве вспомогательной информации.
Вариант осуществления в соответствии с настоящим изобретением относится к способу декодирования кодированного аудиосодержимого. Способ содержит прием кодированного представления одного или более аудиосигналов и обеспечение декодированного представления одного или более аудиосигналов (например, с использованием декодирования, подобного AAC, или с использованием декодирования подвергнутых энтропийному кодированию спектральных значений). Кроме того, способ содержит прием кодированной информации о картах направленной громкости и декодирование кодированной информации о картах направленной громкости, чтобы получить одну или более (например, декодированных) карт направленной громкости. Дополнительно способ содержит воссоздание аудиосцены с использованием декодированного представления одного или более аудиосигналов и с использованием одной или более карт направленной громкости.
Вариант осуществления в соответствии с настоящим изобретением относится к способу преобразования формата аудиосодержимого, который представляет аудиосцену (например, пространственную аудиосцену), из первого формата во второй формат. Первый формат может содержать, например, первое количество каналов или входных аудиосигналов и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную к первому количеству каналов или входных аудиосигналов, и причем второй формат может содержать, например, второе количество каналов или выходных аудиосигналов, которое могут отличаться от первого количества каналов или входных аудиосигналов, и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную ко второму количеству каналов или выходных аудиосигналов. Способ содержит обеспечение представления аудиосодержимого во втором формате на основе представления аудиосодержимого в первом формате и регулировку сложности преобразования формата (например, посредством пропуска одного или более входных аудиосигналов первого формата, вклад которых в карту направленной громкости ниже порогового значения, в процессе преобразования формата) в зависимости от вкладов входных аудиосигналов первого формата (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов, и т.д.) в общую карту направленной громкости аудиосцены. Общая карта направленной громкости, например, может быть описана посредством вспомогательной информации аудиосодержимого в первом формате, принятого преобразователем формата.
Вариант осуществления в соответствии с настоящим изобретением относится к способу, который содержит прием кодированного представления одного или более аудиосигналов и обеспечение декодированного представления одного или более аудиосигналов (например, с использованием декодирования, подобного AAC, или с использованием декодирования подвергнутых энтропийному кодированию спектральных значений). Способ содержит восстановление аудиосцены с использованием декодированного представления одного или более аудиосигналов. Кроме того, способ содержит регулировку сложности декодирования в зависимости от вкладов кодированных сигналов (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости декодированной аудиосцены.
Вариант осуществления в соответствии с настоящим изобретением относится к способу рендеринга аудиосодержимого. В соответствии с вариантом осуществления настоящее изобретение относится к способу повышающего микширования аудиосодержимого, представленного с использованием первого количества входных аудиоканалов и вспомогательной информации, описывающей желаемые пространственные характеристики, такие как размещение звуковых объектов или соотношения между аудиоканалами, в представление, содержащее каналы, количество которых больше, чем первое количество входных аудиоканалов. Способ содержит воссоздание аудиосцены на основе одного или более входных аудиосигналов (или на основе двух или более входных аудиосигналов). Кроме того, способ содержит регулировку сложности рендеринга (например, посредством пропуска одного или более входных аудиосигналов, вклад которых в карту направленной громкости ниже порогового значения, в процессе рендеринга) в зависимости от вкладов входных аудиосигналов (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости преобразованной для прослушивания аудиосцены. Общая карта направленной громкости, например, может быть описана посредством вспомогательной информации, принятой модулем рендеринга.
Вариант осуществления в соответствии с настоящим изобретением относится к компьютерной программе, имеющей программный код для выполнения описанного в настоящем документе способа при его исполнении на компьютере.
Вариант осуществления в соответствии с настоящим изобретением относится к кодированному представлению аудиоданных (например, аудиопотоку или потоку данных), содержащему кодированное представление одного или более аудиосигналов и кодированную информацию о картах направленной громкости.
Описанные выше способы основаны на тех же самых соображениях, как описанные выше модуль анализа аудиоданных, модуль оценки сходства аудиоданных, аудиокодер, аудиодекодер, преобразователь формата и/или модуль рендеринга. Между тем способы могут быть дополнены всеми признаками и функциональными возможностями, которые также описаны в отношении модуля анализа аудиоданных, модуля оценки сходства аудиоданных, аудиокодера, аудиодекодера, преобразователя формата и/или модуля рендеринга.
Краткое описание чертежей
Чертежи не обязательно должны соблюдать масштаб, вместо этого акцент обычно делается на иллюстрации принципов изобретения. В следующем описании различные варианты осуществления изобретения описаны со ссылкой на следующие чертежи.
Фиг. 1 показывает блок-схему модуля анализа аудиоданных в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 2 показывает подробную блок-схему модуля анализа аудиоданных в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 3a показывает блок-схему модуля анализа аудиоданных, использующего первый подход индекса панорамирования, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 3b показывает блок-схему модуля анализа аудиоданных, использующего второй подход индекса панорамирования, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 4a показывает блок-схему модуля анализа аудиоданных, использующего первый подход гистограммы, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 4b показывает блок-схему модуля анализа аудиоданных, использующего второй подход гистограммы, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 5 показывает схемы представлений в спектральной области, подлежащих анализу модулем анализа аудиоданных, и результаты направленного анализа, вычисления громкости для каждого частотного интервала и вычисления громкости для каждого направления модулем анализа аудиоданных в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 6 показывает схематические гистограммы двух сигналов для направленного анализа модулем анализа аудиоданных в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 7a показывает матрицы с одним отличным от нуля масштабным коэффициентом для каждой частотно-временной ячейки, ассоциированной с направлением, для масштабирования, выполняемого модулем анализа аудиоданных, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 7b показывает матрицы с несколькими отличными от нуля масштабными коэффициентами для каждой частотно-временной ячейки, ассоциированной с направлением, для масштабирования, выполняемого модулем анализа аудиоданных, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 7c показывает схематическое изображение печатной платы с первой проводящей дорожкой, второй проводящей дорожкой после обработки в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 8 показывает блок-схема модуля оценки сходства аудиоданных в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 9 показывает блок-схему модуля оценки сходства аудиоданных для анализа стереосигнала в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 10a показывает цветной график эталонной карты направленной громкости, которая может использоваться модулем оценки сходства аудиоданных, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 10b показывает цветной график карты направленной громкости, подлежащей анализу модулем оценки сходства аудиоданных, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 10c показывает цветной график карты направленной громкости разности, определенную модулем оценки сходства аудиоданных, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 11 показывает блок-схему аудиокодера в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 12 показывает блок-схему аудиокодера, выполненного с возможностью адаптации параметров квантования, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 13 показывает блок-схему аудиокодера, выполненного с возможностью выбора подлежащих кодированию сигналов, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 14 показывает схематичный чертеж, иллюстрирующий определение вкладов отдельных карт направленной громкости возможных сигналов в общую карту направленной громкости, выполняемое аудиокодером, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 15 показывает блок-схему аудиокодера, выполненную с возможностью кодирования информации о направленной громкости в качестве вспомогательной информации, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 16 показывает блок-схему аудиодекодера в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 17 показывает блок-схему аудиодекодера, выполненного с возможностью адаптации параметров декодирования, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 18 показывает блок-схему преобразователя формата в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 19 показывает блок-схему аудиодекодера, выполненного с возможностью регулировки сложности декодирования, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 20 показывает блок-схему модуля рендеринга в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 21 показывает блок-схему способа анализа аудиосигнала в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 22 показывает блок-схему способа оценки сходства аудиосигналов в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 23 показывает блок-схему способа кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 24 показывает блок-схему способа совместного кодирования аудиосигналов в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 25 показывает блок-схему способа кодирования одной или более карт направленной громкости в качестве вспомогательной информации в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 26 показывает блок-схему способа декодирования кодированного аудиосодержимого в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 27 показывает блок-схему способа преобразования формата аудиосодержимого, который представляет аудиосцену, из первого формата во второй формат в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 28 показывает блок-схему способа декодирования кодированного аудиосодержимого и регулировки сложности декодирования в соответствии с вариантом осуществления настоящего изобретения; и
Фиг. 29 показывает блок-схему способа рендеринга аудиосодержимого в соответствии с вариантом осуществления настоящего изобретения.
Осуществление изобретения
Одинаковые или эквивалентные элементы представляют собой элементы с одинаковой или эквивалентной функциональностью. В нижеследующем описании они обозначены равными или эквивалентными ссылочными позициями, даже если они встречаются на разных чертежах.
В следующем описании изложено множество подробностей, чтобы обеспечить более полное объяснение вариантов осуществления настоящего изобретения. Однако специалистам в данной области техники будет очевидно, что варианты осуществления настоящего изобретения могут быть реализованы на практике без этих конкретных подробностей. В других случаях хорошо известные конструкции и устройства показаны в виде блок-схемы, а не подробно, чтобы не затруднять понимание вариантов осуществления настоящего изобретения. Кроме того, признаки разных описанных ниже вариантов осуществления могут сочетаться друг с другом, если специально не указано иное.
На фиг. 1 показана блок-схема модуля 100 анализа аудиоданных, который выполнен с возможностью получения представления 1101 в спектральной области первого входного аудиосигнала, например, XL,b(m, k), и представления 1102 в спектральной области второго входного аудиосигнала, например, XR,b(m, k). Таким образом, например, модуль 100 анализа аудиоданных принимает представления 1101, 1102 в спектральной области в качестве входной информации 110, подлежащей анализу. Это означает, например, что первый входной аудиосигнал и второй входной аудиосигнал преобразовываются в представления 1101, 1102 в спектральной области внешним прибором или устройством и затем обеспечиваются модулю 100 анализа аудиоданных. В качестве альтернативы представления 1101, 1102 в спектральной области могут быть определены модулем 100 анализа аудиоданных, как будет описано в отношении фиг. 2. В соответствии с вариантом осуществления представления 110 в спектральной области могут быть представлены как 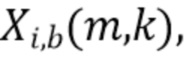 , например, для i={L; R; DM} или для i
, например, для i={L; R; DM} или для i 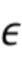 [1; I].
[1; I].
В соответствии с вариантом осуществления представления 1101, 1102 в спектральной области подаются в модуль 120 определения информации о направлении для получения информации 122 о направлении, например, 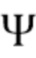 (m, k), ассоциированной со спектральными полосами (например, спектральными интервалами k во временном кадре m) представлений 1101, 1102 в спектральной области. Информация 122 о направлении представляет, например, различные направления звуковых компонентов, содержащихся в двух или более входных аудиосигналах. Таким образом, информация 122 о направлении может иметь отношение к направлению, с которого слушатель услышит компонент, содержащийся в двух входных аудиосигналах. В соответствии с вариантом осуществления информация о направлении может представлять индексы панорамирования. Таким образом, например, информация 122 о направлении содержит первое направление, указывающее певца в помещении для прослушивания, и дополнительные направления, соответствующие различным музыкальным инструментам частотной полосы в аудиосцене. Информация 122 о направлении, например, определяется модулем 100 анализа аудиоданных посредством анализа отношений уровней между представлениями 1101, 1102 в спектральной области для всех частотных интервалов или групп частот (например, для всех спектральных интервалов k или спектральных полос b). Примеры для модуля 120 определения информации о направленности описаны относительно фиг. 5-7b.
(m, k), ассоциированной со спектральными полосами (например, спектральными интервалами k во временном кадре m) представлений 1101, 1102 в спектральной области. Информация 122 о направлении представляет, например, различные направления звуковых компонентов, содержащихся в двух или более входных аудиосигналах. Таким образом, информация 122 о направлении может иметь отношение к направлению, с которого слушатель услышит компонент, содержащийся в двух входных аудиосигналах. В соответствии с вариантом осуществления информация о направлении может представлять индексы панорамирования. Таким образом, например, информация 122 о направлении содержит первое направление, указывающее певца в помещении для прослушивания, и дополнительные направления, соответствующие различным музыкальным инструментам частотной полосы в аудиосцене. Информация 122 о направлении, например, определяется модулем 100 анализа аудиоданных посредством анализа отношений уровней между представлениями 1101, 1102 в спектральной области для всех частотных интервалов или групп частот (например, для всех спектральных интервалов k или спектральных полос b). Примеры для модуля 120 определения информации о направленности описаны относительно фиг. 5-7b.
В соответствии с вариантом осуществления модуль 100 анализа аудиоданных выполнен с возможностью получения информации 122 о направлении на основе анализа амплитудного панорамирования аудиосодержимого; и/или на основе анализа фазового соотношения, и/или временной задержки, и/или корреляции между аудиосодержимым двух или более входных аудиосигналов; и/или на основе идентификации расширенных (например, декоррелированных и/или панорамированных) источников. Аудиосодержимое может содержать входные аудиосигналы и/или представления 110 в спектральной области входных аудиосигналов.
На основе информации 122 о направлении и представлений 1101, 1102 в спектральной области модуль 100 анализа аудиоданных выполнен с возможностью определения вкладов 132 (например, 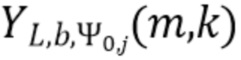 и
и 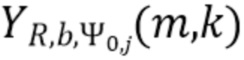 ) в информацию 142 о громкости. В соответствии с вариантом осуществления первые вклады 1321, ассоциированные с представлением 1101 в спектральной области первого входного аудиосигнала, определяются блоком 130 определения вкладов в зависимости от информации 122 о направлении, и вторые вклады 1322, ассоциированные с представлением 1102 в спектральной области второго входного аудиосигнала, определяются блоком 130 определения вкладов в зависимости от информации 122 о направлении. В соответствии с вариантом осуществления информация 122 о направлении содержит различные направления (например, извлеченные значения направлений (m, k)). Вклады 132 содержат, например, информацию о громкости для заданных направлений в зависимости от информации 122 о направлении. В соответствии с вариантом осуществления вклады 132 определяют информацию об уровне спектральных полос, направление которых (m, k) (соответствующее информации 122 о направлении) равняется заданным направлениям , и/или масштабированную информацию об уровне спектральных полос, направление которых (m, k) граничит с заданным направлением .
) в информацию 142 о громкости. В соответствии с вариантом осуществления первые вклады 1321, ассоциированные с представлением 1101 в спектральной области первого входного аудиосигнала, определяются блоком 130 определения вкладов в зависимости от информации 122 о направлении, и вторые вклады 1322, ассоциированные с представлением 1102 в спектральной области второго входного аудиосигнала, определяются блоком 130 определения вкладов в зависимости от информации 122 о направлении. В соответствии с вариантом осуществления информация 122 о направлении содержит различные направления (например, извлеченные значения направлений (m, k)). Вклады 132 содержат, например, информацию о громкости для заданных направлений в зависимости от информации 122 о направлении. В соответствии с вариантом осуществления вклады 132 определяют информацию об уровне спектральных полос, направление которых (m, k) (соответствующее информации 122 о направлении) равняется заданным направлениям , и/или масштабированную информацию об уровне спектральных полос, направление которых (m, k) граничит с заданным направлением .
В соответствии с вариантом осуществления извлеченные значения направлений 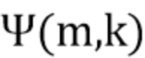 определяются в зависимости от значений в спектральной области (например,
определяются в зависимости от значений в спектральной области (например, 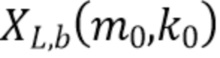 как
как 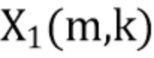 и
и  как
как 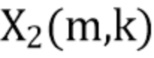 в обозначении [13]) входных аудиосигналов.
в обозначении [13]) входных аудиосигналов.
Чтобы получить информацию 142 о громкости (например, L(m, ) для множества различных оценочных диапазонов направлений (j [1; J] для J заданных направлений)), ассоциированных с различными направлениями (например, заданными направлениями) как результат анализа посредством модуля 100 анализа аудиоданных, модуль 100 анализа аудиоданных выполнен с возможностью объединения вкладов 1321 (например, ), соответствующих представлению 1101 в спектральной области первого входного аудиосигнала, и вкладов 1322 (например, ), соответствующих представлению 1102 в спектральной области второго входного аудиосигнала, чтобы принять объединенный сигнал как информацию 142 о громкости, например, двух или более каналов (например, первый канал ассоциирован с первым входным аудиосигналом и представлен индексом L, и второй канал ассоциирован со вторым входным аудиосигналом и представлен индексом R). Тес самым получается информация 142 о громкости, которая определяет громкость с течением времени и для каждого из различных направлений . Это выполняется, например, посредством блока 140 определения информации о громкости.
На фиг. 2 показан модуль 100 анализа аудиоданных, который может содержать признаки и/или функциональные возможности, как описано в отношении модуля 100 анализа аудиоданных на фиг. 1. В соответствии с вариантом осуществления модуль 100 анализа аудиоданных принимает первый входной аудиосигнал хL 1121 и второй входной аудиосигнал xR 1122. Индекс L ассоциирован с левой стороной, и индекс R ассоциирован с правой стороной. Индексы могут быть ассоциированы с громкоговорителем (например, с установлением положения громкоговорителей). В соответствии с вариантом осуществления индексы могут быть представлены номерами, указывающими канал, ассоциированный с входным аудиосигналом.
В соответствии с вариантом осуществления первый входной аудиосигнал 1121 и/или второй входной аудиосигнал 1122 может представлять сигнал во временной области, который может быть преобразован модулем 114 преобразования из временной области в спектральную область, чтобы получить представление 110 в спектральной области из соответствующего входного аудиосигнала. Другими словами, модуль 114 преобразования из временной области в спектральную область может выполнить декомпозицию двух или более входных аудиосигналов 1121, 1122 (например, xL, xR, xi) в область кратковременного преобразования Фурье (STFT), чтобы получить два или более преобразованных аудиосигнала 1151, 1152 (например, X’L, X’R, X’i). Если первый входной аудиосигнал 1121 и/или второй входной аудиосигнал 1122 представляет собой представление 110 в спектральной области, модуль 114 преобразования из временной области в спектральную область может быть опущен.
Факультативно входные аудиосигналы 112 или преобразованные аудиосигналы 115 обрабатываются модулем 116 преобразования с использованием модели уха для получения представления 110 в спектральной области из соответствующего входного аудиосигнала 1121 и 1122. Спектральные интервалы обрабатываемого сигнала, например, 112 или 115, группируются в спектральные полосы, например, на основе модели для восприятия спектральных полос человеческим ухом, и затем спектральные полосы могут быть взвешены на основе модели внешнего уха и/или среднего уха. Таким образом, посредством модуля 116 обработки с использованием модели уха может быть определено оптимизированное представление 110 в спектральной области входных аудиосигналов 112.
В соответствии с вариантом осуществления представление 1101 в спектральной области первого входного аудиосигнала 1121, например XL,b(m, k), ассоциировано с информацией об уровне первого входного аудиосигнала 1121 (например, обозначенного индексом L) и различных спектральных полосах (например, обозначенных индексом b). Для каждой спектральной полосы b представление 1101 в спектральной области представляет, например, информацию об уровне для временных кадров m и для всех спектральных интервалов k соответствующей спектральной полосы b.
В соответствии с вариантом осуществления представление 1102 в спектральной области второго входного аудиосигнала 1122, например XR,b(m, k), ассоциировано с информацией об уровне второго входного аудиосигнала 1122 (например, обозначенного индексом R) и различных спектральных полосах (например, обозначенных индексом b). Для каждой спектральной полосы b представление 1102 в спектральной области представляет, например, информацию об уровне для временных кадров m и для всех спектральных интервалов k соответствующей спектральной полосы b.
На основе представления 1101 в спектральной области первого входного аудиосигнала 112 и представления 1102 в спектральной области второго входного аудиосигнала определение информации 120 о направлении может быть выполнено модулем 100 анализа аудиоданных. С помощью модуля 124 анализа направления может быть определена информация 125 о направлении панорамирования, например, (m, k). Информация 125 о направлении панорамирования представляет, например, индексы панорамирования, соответствующие компонентам сигнала (например, компонентам первого входного аудиосигнала 1121 и второго входного аудиосигнала 1122, панорамированным в некотором направлении). В соответствии с вариантом осуществления входные аудиосигналы 112 ассоциированы с разными указанными направлениями, например, посредством индекса L для левой стороны и индекса R для правой стороны. Индекс панорамирования определяет, например, направление между двумя или более входными аудиосигналами 112 или направление в направлении входного аудиосигнала 112. Таким образом, например, в случае двухканального сигнала, как показано на фиг. 2, информация 125 о направлении панорамирования может содержать индексы панорамирования, соответствующие компонентам сигнала, панорамированным полностью в левую сторону или в правую сторону, или в каком-либо промежуточном направлении.
В соответствии с вариантом осуществления на основе информации 125 о направлении панорамирования модуль 100 анализа аудиоданных выполнен с возможностью выполнения определения 126 масштабного коэффициента, чтобы определить зависящее от направления взвешивание 127, например, для j [1; i]. Зависящее от направления взвешивание 127 определяет, например, масштабный коэффициент в зависимости от направлений (m, k), извлеченный из информации 125 о направлении панорамирования. Зависящее от направления взвешивание 127 определяется для множества заданных направлений . В соответствии с вариантом осуществления зависящее от направления взвешивание 127 определяет функции для каждого заданного направления. Функции зависят, например, от направлений (m, k), извлеченных из информации 125 о направлении панорамирования. Масштабный коэффициент зависит, например, от расстояния между направлениями (m, k), извлеченных из информации 125 о направлении панорамирования, и заданным направлением . Масштабные коэффициенты, т.е. зависящее от направления взвешивание 127, могут быть определены для каждого спектрального интервала и/или для каждого временного шага/временного кадра.
В соответствии с вариантом осуществления зависящее от направления взвешивание 127 использует гауссову функцию, в результате чего зависящее от направления взвешивание уменьшается с увеличением отклонения между соответствующими извлеченными значениями направлений (m, k) и соответствующими заданными значениями направлений .
В соответствии с вариантом осуществления модуль 100 анализа аудиоданных выполнен с возможностью получения зависящего от направления взвешивания 127 , ассоциированного с заданным направлением (например, представленным индексом ), временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, в соответствии с , где - заданное значение (которое управляет, например, шириной гауссова окна); где обозначает извлеченные значения направлений, ассоциированные со временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k; и где - (например, заданное) значение направления, которое обозначает (или которое ассоциировано) заданное направление (например, имеющее индекс направления j).
В соответствии с вариантом осуществления модуль 100 анализа аудиоданных выполнен с возможностью определения, информации о направлении, содержащей информацию 125 о направлении панорамирования и/или зависящее от направления взвешивание 127, посредством использования модуля 120 определения информации о направлении. Эта информация о направлении, например, получается на основе аудиосодержимого двух или более входных аудиосигналов 112.
В соответствии с вариантом осуществления модуль 100 анализа аудиоданных содержит модуль 134 масштабирования и/или модуль 136 объединения для определения 130 вкладов. С помощью модуля 134 масштабирования зависящее от направления взвешивание 127 применяется к одному или более представлениям 110 в спектральной области двух или более входных аудиосигналов 112, чтобы получить взвешенные представления 135 в спектральной области (например, 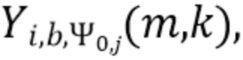 для разных
для разных 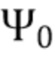 (j [1; J] или j = {L; R; DM})). Другими словами, представление 1101 в спектральной области первого входного аудиосигнала и представление 1102 в спектральной области второго входного аудиосигнала взвешиваются для каждого заданного направления индивидуально. Таким образом, например, взвешенное представление 1351 в спектральной области, например,
(j [1; J] или j = {L; R; DM})). Другими словами, представление 1101 в спектральной области первого входного аудиосигнала и представление 1102 в спектральной области второго входного аудиосигнала взвешиваются для каждого заданного направления индивидуально. Таким образом, например, взвешенное представление 1351 в спектральной области, например,  первого входного аудиосигнала может содержать только компоненты сигнала первого входного аудиосигнала 112, соответствующего заданному направлению
первого входного аудиосигнала может содержать только компоненты сигнала первого входного аудиосигнала 112, соответствующего заданному направлению 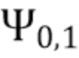 , или дополнительно взвешенные (например, уменьшенные) компоненты сигнала первого входного аудиосигнала 1121, ассоциированные с соседними заданными направлениями. Таким образом значения одного или более представлений 110 в спектральной области (например, ) взвешиваются в зависимости от различных направлений (например, направлений панорамирования ) (например, представленных весовыми коэффициентами ) звуковых компонентов.
, или дополнительно взвешенные (например, уменьшенные) компоненты сигнала первого входного аудиосигнала 1121, ассоциированные с соседними заданными направлениями. Таким образом значения одного или более представлений 110 в спектральной области (например, ) взвешиваются в зависимости от различных направлений (например, направлений панорамирования ) (например, представленных весовыми коэффициентами ) звуковых компонентов.
В соответствии с вариантом осуществления модуль 126 определения масштабного коэффициента выполнен с возможностью определения зависящего от направления взвешивание 127, в результате чего для каждых заданных компонентов сигнала направления, извлеченные значения направлений (m, k) которых отклоняются от заданного направления , взвешиваются таким образом, чтобы они имели меньшее влияние, чем компоненты сигнала, извлеченные значения направлений (m, k) которых равны заданному направлению . Другими словами, в зависящем от направления взвешивании 127 для первого заданного направления компоненты сигнала , ассоциированные с первым заданным направлением , усиливаются по отношению к компонентам сигнала, ассоциированным с другими направлениями, в первом взвешенном представлении в спектральной области , соответствующем первому заданному направлению .
В соответствии с вариантом осуществления модуль 100 анализа аудиоданных выполнен с возможностью получения взвешенных представлений 135 в спектральной области , ассоциированных с входным аудиосигналом (например, 1101 для i=1 или 1102 для i=2) или объединением входных аудиосигналов (например, с объединением двух входных аудиосигналов 1101 и 1102 для i=1,2), обозначенных индексом i, спектральной полосой, обозначенной индексом b, (например, заданным) направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k, в соответствии с 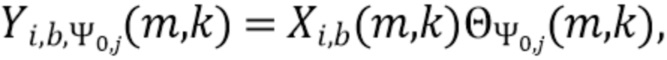 где обозначает представление 110 в спектральной области, ассоциированное с входным аудиосигналом 112 или объединением входных аудиосигналов 112, обозначенным индексом i (например, i=L, или i=R, или i=DM, или i представлен номером, указывающим канал), спектральной полосой, обозначенной индексом b, временем (или временным кадром), обозначенным временным индексом m. и спектральным интервалом, обозначенным индексом спектрального интервала k; и где обозначает зависящее от направления взвешивание 127, ассоциированное с (например, заданным) направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k.
где обозначает представление 110 в спектральной области, ассоциированное с входным аудиосигналом 112 или объединением входных аудиосигналов 112, обозначенным индексом i (например, i=L, или i=R, или i=DM, или i представлен номером, указывающим канал), спектральной полосой, обозначенной индексом b, временем (или временным кадром), обозначенным временным индексом m. и спектральным интервалом, обозначенным индексом спектрального интервала k; и где обозначает зависящее от направления взвешивание 127, ассоциированное с (например, заданным) направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k.
Дополнительные или альтернативные функциональные возможности модуля 134 масштабирования описаны в отношении фиг. 6-7b.
В соответствии с вариантом осуществления взвешенные представления 1351 в спектральной области первого входного аудиосигнала и взвешенные представления 1352 в спектральной области второго входного аудиосигнала объединяются модулем 136 объединения, чтобы получить взвешенное объединенное представление 137 в спектральной области 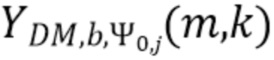 . Таким образом, с помощью модуля 136 объединения взвешенные представления 135 в спектральной области всех каналов (в случае фиг. 2 первого входного аудиосигнала 1121 и второго входного аудиосигнала 1122) соответствующие заданному направлению , объединяются в один сигнал. Это выполняется, например, для всех заданных направлений (для j [1; i]). В соответствии с вариантом осуществления взвешенное объединенное представление 137 в спектральной области ассоциировано с разными частотными полосами b.
. Таким образом, с помощью модуля 136 объединения взвешенные представления 135 в спектральной области всех каналов (в случае фиг. 2 первого входного аудиосигнала 1121 и второго входного аудиосигнала 1122) соответствующие заданному направлению , объединяются в один сигнал. Это выполняется, например, для всех заданных направлений (для j [1; i]). В соответствии с вариантом осуществления взвешенное объединенное представление 137 в спектральной области ассоциировано с разными частотными полосами b.
На основе взвешенного объединенного представления 137 в спектральной области выполняется определение 140 информации о громкости, чтобы получить в качестве результата анализа информацию 142 о громкости. В соответствии с вариантом осуществления определение 140 информации о громкости содержит определение 144 громкости в частотных полосах и определение 146 громкости по всем частотным полосам. В соответствии с вариантом осуществления определение 144 громкости в частотных полосах выполнено с возможностью определения значений 145 громкости частотных полос для каждой спектральной полосы b на основе взвешенных объединенных представлений 137 в спектральной области. Другими словами, определение 144 громкости в частотных полосах определяет громкость в каждой спектральной полосе в зависимости от заданных направлений . Таким образом, полученные значения 145 громкости частотных полос больше не зависят от отдельных спектральных интервалов k.
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью вычисления среднего значения квадратов спектральных значений взвешенных объединенных представлений 137 в спектральной области (например, ) по спектральным значениям частотной полосы (или по спектральным интервалам (k) частотной полосы (b)), и применять возведение в степень с показателем между 0 и 1/2 (и предпочтительно меньше чем 1/3 или ¼) к среднему значению квадратов спектральных значений, чтобы определить значения 145 громкости частотных полос (например, ) (например, ассоциированных с соответствующей частотной полосой (b)).
В соответствии с вариантом осуществления модуль анализа аудиоданных выполнен с возможностью получения значений 145 громкости частотных полос , ассоциированных со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, в соответствии с 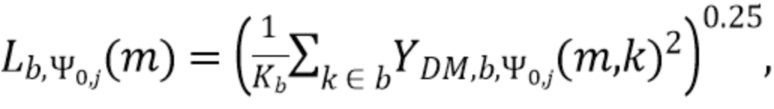 где Kb обозначает количество спектральных интервалов в частотной полосе, имеющей индекс частотной полосы b; где k - бегущая переменная и обозначает спектральные интервалы в частотной полосе, имеющей индекс частотной полосы b; где b обозначает спектральную полосу; и где обозначает взвешенное объединенное представление 137 в спектральной области, ассоциированное со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k.
где Kb обозначает количество спектральных интервалов в частотной полосе, имеющей индекс частотной полосы b; где k - бегущая переменная и обозначает спектральные интервалы в частотной полосе, имеющей индекс частотной полосы b; где b обозначает спектральную полосу; и где обозначает взвешенное объединенное представление 137 в спектральной области, ассоциированное со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , временем (или временным кадром), обозначенным временным индексом m, и спектральным интервалом, обозначенным индексом спектрального интервала k.
При определении 146 информации о громкости по всем частотным полосам значения 145 громкости частотных полос, например, усредняются по всем спектральным полосам, чтобы обеспечить информацию 142 о громкости, зависящую от заданного направления и по меньшей мере одного временного кадра m. В соответствии с вариантом осуществления информация 142 о громкости может представлять общую громкость, вызванную входными аудиосигналами 112 в различных направлениях в помещении для прослушивания. В соответствии с вариантом осуществления информация 142 о громкости может быть ассоциирована со значениями объединенной громкости, ассоциированным с различными определёнными или заданными направлениями .
Модуль анализа аудиоданных по одному из пунктов 1-17, в котором модуль анализа аудиоданных выполнен с возможностью получения множества значений объединенной громкости L(m, ), ассоциированных с направлением, обозначенным индексом , и временем (или временным кадром), обозначенным временным индексом m, в соответствии с 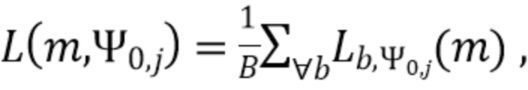 где B обозначает общее количество спектральных полос b, и где обозначает значения 145 громкости частотных полос, ассоциированных со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , и временем [или временным кадром], обозначенным временным индексом m.
где B обозначает общее количество спектральных полос b, и где обозначает значения 145 громкости частотных полос, ассоциированных со спектральной полосой, обозначенной индексом b, направлением, обозначенным индексом , и временем [или временным кадром], обозначенным временным индексом m.
На фиг. 1 и фиг. 2 модуль 100 анализа аудиоданных выполнен с возможностью анализа представления 110 в спектральной области двух входных аудиосигналов, но модуль 100 анализа аудиоданных также выполнен с возможностью анализа более чем двух представлений 110 в спектральной области.
На фиг. 3a-4b показаны различные реализации модуля 100 анализа аудиоданных. Модуль анализа аудиоданных, показанный на фиг. 1-4b, не ограничен признаками и функциональными возможностями, показанными для одной реализации, но также может содержать признаки и функциональные возможности других реализаций модуля анализа аудиоданных, показанного на различных фиг. 1-4b.
На фиг. 3a и фиг. 3b показаны два разных подхода для определения информации 142 громкости на основе определения индекса панорамирования посредством модуля 100 анализа аудиоданных.
Модуль 100 анализа аудиоданных, показанный на фиг. 3a, является аналогичным или эквивалентным модулю 100 анализа аудиоданных, показанному на фиг. 2. Два или более входных сигнала 112 преобразовываются в частотно-временные сигналы 110 посредством частотно-временной декомпозиции 113. В соответствии с вариантом осуществления частотно-временная декомпозиция 113 может содержать преобразование из временной области в спектральную область и/или обработку с использованием модели уха.
На основе частотно-временных сигналов выполняется определение 120 информации о направлении. Определение 120 информации о направлении содержит, например, направленный анализ 124 и определение 126 оконных функций. В блоке 130 определения вкладов направленные сигналы 132 получаются, например, посредством разделения частотно-временных сигналов 110 на направленные сигналы посредством применения зависящих от направления оконных функций 127 к частотно-временным сигналам 110. На основе направленных сигналов 132 выполняется вычисление 140 громкости для получения информации 142 о громкости в качестве результата анализа. Информация 142 о громкости может содержать карту направленной громкости.
Модуль 100 анализа аудиоданных на фиг. 3b отличается от модуля 100 анализа аудиоданных на фиг. 3a вычислением 140 громкости. В соответствии с фиг. 3b вычисление 140 громкости выполняется до вычисления направленных сигналов частотно-временных сигналов 110. Таким образом, например, в соответствии с фиг. 3b значения 141 громкости частотных полос вычисляются непосредственно на основе частотно-временных сигналов 110. Посредством применения зависящей от направления оконной функции 127 к значениям 141 громкости частотных полос 141 может быть получена информация 142 о направленной громкости в качестве результата анализа.
Фиг. 4a и фиг. 4b показывают модуль 100 анализа аудиоданных который в соответствии с вариантом осуществления выполнен с возможностью определения информации 142 о громкости с использованием подхода с помощью гистограммы. В соответствии с вариантом осуществления модуль 100 анализа аудиоданных выполнен с возможностью использования частотно-временной декомпозиции 113, чтобы определить частотно-временные сигналы 110 на основе двух или более входных сигналов 112.
В соответствии с вариантом осуществления на основе частотно-временных сигналов 110 вычисление 140 громкости выполняется для получения значения 145 объединенной громкости для каждой частотно-временной ячейки. Значение 145 объединенной громкости не ассоциировано ни с какой информацией о направлении. Значение объединенной громкости, например, ассоциировано с громкостью, получаемой в результате наложения входных сигналов 112 на частотно-временную ячейку.
Кроме того, модуль 100 анализа аудиоданных выполнен с возможностью выполнения анализа 124 направления частотно-временных сигналов 110, чтобы получить информацию 122 о направлении. В соответствии с фиг. 4a информация 122 о направлении содержит один или более векторов направления со значениями отношений, указывающими частотно-временные ячейки с одинаковым отношением уровня между двумя или более входными сигналами 112. Этот анализ 124 направления, например, выполняется, как описано в отношении фиг. 5 или фиг. 6.
Модуль 100 анализа аудиоданных на фиг. 4b отличается от модуля 100 анализа аудиоданных, показанного на фиг. 4a, в том, что после анализа 124 направления факультативно выполняется направленное размытие 126 значений 1221 направлений. С помощью направленного размытия 126 также частотно-временные ячейки, ассоциированные с направлениями, соседствующими с заданным направлением, могут быть ассоциированы с заданным направлением, в котором полученная информация 1222 о направлении может дополнительно содержать для этих частотно-временных ячеек масштабный коэффициент, чтобы минимизировать влияние в заданном направлении.
На фиг. 4a и фиг. 4b модуль 100 анализа аудиоданных выполнен с возможностью накопления 146 объединенных значений 145 громкости в интервалах гистограммы направления на основе информации 122 о направлении, ассоциированной с частотно-временными ячейками.
Более подробная информация об модуле 100 анализа аудиоданных в фиг. 3a и фиг. 3b описана далее в главе «Обобщенные этапы для вычисления карты направленной громкости» и в главе «Варианты осуществления различных форм вычисления карт громкости с использованием обобщенных критериальных функций».
На фиг. 5 показано представление 1101 в спектральной области первого входного аудиосигнала и представление 1102 в спектральной области второго входного аудиосигнала, подлежащих анализу посредством описанного здесь модуля анализа аудиоданных. Анализ 124 направления представлений 110 в спектральной области дает в результате информацию 122 о направлении. В соответствии с вариантом осуществления информация 122 о направлении представляет вектор направления со значениями отношения между представлением 1101 в спектральной области первого входного аудиосигнала и представлением 1102 в спектральной области второго входного аудиосигнала. Таким образом, например, частотные ячейки, например, частотно-временные ячейки представлений 110 в спектральной области с одинаковым отношением уровня ассоциируются с одним и тем же направлением 125.
В соответствии с вариантом осуществления вычисление 140 громкости дает в результате значения 145 объединенной громкости, например, для каждой частотно-временной ячейки. Значения 145 объединенной громкости, например, ассоциируются с объединением первого входного аудиосигнала и второго входного аудиосигнала (например, объединением двух или более входных аудиосигналов).
На основе информации 122 о направлении и значений 145 объединенной громкости значения 145 объединенной громкости могут быть накоплены 146 в интервалах гистограммы, зависящих от направления и времени. Таким образом, например, суммируются все значения 145 объединенной громкости, ассоциированные с некоторым направлением. В соответствии с информацией 122 о направлении направления ассоциируются с частотно-временными ячейками. С помощью накопления 146 в результате получается гистограмма направленной громкости, которая может представлять информацию 142 о громкости как результат анализа описанного здесь модуля анализа аудиоданных.
Также возможно, что частотно-временные ячейки, соответствующие одному и тому же направлению и/или соседним направлениям в другом или соседнем временном кадре (например, в предыдущем или последующем временном кадре), могут быть ассоциированы с направлением на текущем временном этапе или временном кадре. Это означает, например, что информация 122 о направлении содержит информацию о направлении для каждой частотной ячейки (или частотного интервала) в зависимости от вовремя. Таким образом, например, информация 122 о направлении получается для нескольких временных кадров или для всех временных кадров.
Более подробная информация о подходе с использованием гистограммы, показанном на фиг. 5, будет описана в главе «Варианты осуществления различных форм вычисления карт громкости с использованием обобщенных критериальных функций», вариант 2.
На фиг. 6 показано определение 130 вкладов на основе информации о направлении панорамирования, выполняемое описанным здесь модулем анализа аудиоданных. На фиг. 6a показано представление в спектральной области первого входного аудиосигнала, и на фиг. 6b показано представление в спектральной области второго входного аудиосигнала. В соответствии с фиг. 6a1- 6a3.1 и фиг. 6b1-6b3.1 спектральные интервалы или спектральные полосы, соответствующие одному и тому же направлению панорамирования, выбираются для вычисления информации о громкости в этом направлении панорамирования. Фиг. 6a3.2 и фиг. 6b3.2 показывают альтернативный процесс, в котором рассматриваются не только частотные интервалы или частотные полосы, соответствующие направлению панорамирования, но также и другие частотные интервалы или группы частот, которые взвешиваются или масштабируются для меньшего влияния. Более подробная информация относительно фиг. 6 описана в главе «Восстановление направленных сигналов с помощью функции оконной обработки/выбора, полученной из индекса панорамирования».
В соответствии с вариантом осуществления информация 122 о направлении может содержать масштабные коэффициенты, ассоциированные с направлением 121 и частотно-временными ячейками 123, как показано на фиг. 7a и/или фиг. 7b. В соответствии с вариантом осуществления на фиг. 7a и фиг. 7b частотно-временные ячейки 123 показаны только для одного временного этапа или временного кадра. Фиг. 7a показывает масштабные коэффициенты, в которых рассматриваются только частотно-временные ячейки 123, которые вносят вклад в некотором (например, заданном) направлении 121, как например описано в отношении фиг. 6a1- 6a3.1 и фиг. 6b1-6b3.1. В качестве альтернативы на фиг. 7b также рассматриваются соседние направления, но они масштабируются, чтобы уменьшить влияние соответствующей частотно-временной ячейки 123 в соседних направлениях. В соответствии с фиг. 7b частотно-временная ячейка 123 масштабируется таким образом, что ее влияние будет уменьшаться по мере увеличения отклонения от ассоциированного направления. Вместо этого на фиг. 6a3.2 и фиг. 6b3.2 все частотно-временные ячейки, соответствующие другому направлению панорамирования, масштабируются одинаково. Возможны различные вычисления или взвешивания. В зависимости от масштабирования может быть улучшена точность результата анализа модуля анализа аудиоданных.
На фиг. 8 показан вариант осуществления модуля 200 оценки сходства аудиоданных. Модуль 200 оценки сходства аудиоданных выполнен с возможностью получения первой информации 1421 о громкости (например, L1(m, )) и второй информации 1422 о громкости (например, L2(m, )). Первая информация 1421 о громкости ассоциирована с различными направлениями (например, с заданными направлениями панорамирования ) на основе первого множества из двух или более входных аудиосигналов 112a (например, xL, xR или xi для i ϵ [1;n]), и вторая информация 1422 о громкости ассоциирована с различными направлениями на основе второго множества из двух или более входных аудиосигналов, которые могут быть представлены множеством эталонных аудиосигналов 112b (например, x2,R, x2,L, x2,i для i ϵ [1;n]). Первое множество входных аудиосигналов 112a и множество эталонных аудиосигналов 112b могут содержать n аудиосигналов, где n представляет целое число больше или равное 2. Каждый аудиосигнал первого множества входных аудиосигналов 112a и множества эталонных аудиосигналов 112b может быть ассоциировано с разными громкоговорителями, помещенными в разные положения в пространстве прослушивания. Первая информация 1421 о громкости и вторая информация 1422 о громкости могут представлять распределение громкости в пространстве прослушивания (например, в положениях громкоговорителей или между ними). В соответствии с вариантом осуществления первая информация 1421 о громкости и вторая информация 1422 о громкости содержат значения громкости для дискретных положений или направлений в пространстве прослушивания. Различные направления могут быть ассоциированы с направлениями панорамирования аудиосигналов, выделенными для одного множества аудиосигналов 112a или 112b в зависимости от того, какое множество соответствует информации о громкости, подлежащей вычислению.
Первая информация 1421 о громкости и вторая информация 1422 о громкости могут быть определены посредством определения 100 информации о громкости, которое может быть выполнено модулем 200 оценки сходства аудиоданных. В соответствии с вариантом осуществления определение 100 информации о громкости может быть выполнено модулем анализа аудиоданных. Таким образом, например, модуль 200 оценки сходства аудиоданных может содержать модуль анализа аудиоданных или принимать первую информацию 1421 о громкости и/или вторую информацию 1422 о громкости от внешнего модуля анализа аудиоданных. В соответствии с вариантом осуществления модуль анализа аудиоданных может содержать признаки и/или функциональные возможности, как описано в отношении модуля анализа аудиоданных на фиг. 1-4b. В качестве альтернативы только первая информация 1421 о громкости определяется посредством определения 100 информации о громкости, а вторая информация 1422 о громкости принимается или получается модулем 200 оценки сходства аудиоданных из банка данных с эталонной информацией о громкости. В соответствии с вариантом осуществления банк данных может содержать эталонные карты информации о громкости для различных настроек громкоговорителей и/или конфигураций громкоговорителей, и/или различные множества эталонных аудиосигналов 112b.
В соответствии с вариантом осуществления множество эталонных аудиосигналов 112b может представлять идеальное множество аудиосигналов для оптимизированного восприятия аудиоданных слушателем в пространстве прослушивания.
В соответствии с вариантом осуществления первая информация 1421 о громкости (например, вектор, содержащий элементы от L1(m, ) до L1(m,  )) и/или вторая информация 1422 о громкости (например, вектор, содержащий элементы от L2(m, ) до L2(m, )), могут содержать множество значений объединенной громкости, ассоциированных с соответствующими входными аудиосигналами (например, входными аудиосигналами, соответствующими первому множеству входных аудиосигналов 112a, или эталонными аудиосигналами, соответствующими множеству эталонных аудиосигналов 112b (и ассоциированными с соответствующими заданными направлениями)). Соответствующие заданные направления могут представлять индексы панорамирования. Поскольку каждый входной аудиосигнал, например, ассоциирован с громкоговорителем, соответствующие заданные направления могут восприниматься как равномерно распределенные положения между соответствующими громкоговорителями (например, между соседними громкоговорителями и/или другими парами громкоговорителей). Другими словами, модуль 200 оценки сходства аудиоданных выполнен с возможностью получения компонента направления (например, описанного здесь первого направления), используемого для получения информации 1421 и/или 1422 о громкости с другими направлениями (например, описанным здесь вторым направлением) с использованием метаданных, представляющих информацию о положении громкоговорителей, ассоциированных с входными аудиосигналами. Значения объединенной громкости первой информации 1421 о громкости и/или второй информации 1422 о громкости описывают громкость компонентов сигнала соответствующего множества входных аудиосигналов 112a и 112b, ассоциированных с соответствующими заданными направлениями. Первая информация 1421 о громкости и/или вторая информация 1422 о громкости ассоциированы с комбинациями множества взвешенных представлений в спектральной области, ассоциированных с соответствующим заданным направлением.
)) и/или вторая информация 1422 о громкости (например, вектор, содержащий элементы от L2(m, ) до L2(m, )), могут содержать множество значений объединенной громкости, ассоциированных с соответствующими входными аудиосигналами (например, входными аудиосигналами, соответствующими первому множеству входных аудиосигналов 112a, или эталонными аудиосигналами, соответствующими множеству эталонных аудиосигналов 112b (и ассоциированными с соответствующими заданными направлениями)). Соответствующие заданные направления могут представлять индексы панорамирования. Поскольку каждый входной аудиосигнал, например, ассоциирован с громкоговорителем, соответствующие заданные направления могут восприниматься как равномерно распределенные положения между соответствующими громкоговорителями (например, между соседними громкоговорителями и/или другими парами громкоговорителей). Другими словами, модуль 200 оценки сходства аудиоданных выполнен с возможностью получения компонента направления (например, описанного здесь первого направления), используемого для получения информации 1421 и/или 1422 о громкости с другими направлениями (например, описанным здесь вторым направлением) с использованием метаданных, представляющих информацию о положении громкоговорителей, ассоциированных с входными аудиосигналами. Значения объединенной громкости первой информации 1421 о громкости и/или второй информации 1422 о громкости описывают громкость компонентов сигнала соответствующего множества входных аудиосигналов 112a и 112b, ассоциированных с соответствующими заданными направлениями. Первая информация 1421 о громкости и/или вторая информация 1422 о громкости ассоциированы с комбинациями множества взвешенных представлений в спектральной области, ассоциированных с соответствующим заданным направлением.
Модуль 200 оценки сходства аудиоданных выполнен с возможностью сравнения первой информации 1421 о громкости со второй информацией 1422 о громкости, чтобы получить информацию 210 о сходстве, описывающую сходство между первым множеством из двух или более входных аудиосигналов 112a и множеством из двух или более эталонных аудиосигналов 112b. Это может быть выполнено блоком 220 сравнения информации о громкости. Информация 210 о сходстве может указывать качество первого множества входных аудиосигналов 112a. Чтобы дополнительно улучшить предсказание восприятия первого множества входных аудиосигналов 112a на основе информации 210 о сходстве, можно рассматривать только подмножество частотных полос в первой информации 1421 о громкости и/или во второй информации 1422 о громкости. В соответствии с вариантом осуществления первая информация 1421 о громкости и/или вторая информация 1422 о громкости определяются только для частотных полос с частотами 1,5 кГц и выше. Таким образом, подвергнутая сравнению информация 1421 и 1422 о громкости может быть оптимизирована на основе чувствительности слуховой системы человека. Таким образом, блок 220 сравнения информации о громкости выполнен с возможностью сравнения информации 1421 и 1422 о громкости, которая содержит только значения громкости релевантных частотных полос. Релевантные частотные полосы могут быть ассоциированы с частотными полосами, соответствующими чувствительности (например, человеческого уха) выше заданного порогового значения для заданных разностей уровней.
Чтобы получить информацию 210 о сходстве, например, вычисляется разность между второй информацией 1422 о громкости и первой информацией 1421 о громкости.
Эта разность может представлять разностную информацию о громкости и уже может определять информацию 210 о сходстве. В качестве альтернативы разностная информация о громкости дополнительно обрабатывается для получения информации 210 о сходстве. В соответствии с вариантом осуществления блок 220 оценки сходства аудиоданных выполнен с возможностью определения значения, которое определяет величину разности по множеству направлений. Это значение может представлять собой одну скалярную величину, представляющую информацию 210 о сходстве. Для получения скалярной величины блок 220 сравнения информации о громкости может быть выполнен с возможностью вычисления разности для участков или полной продолжительности первого множества входных аудиосигналов 112a и/или множества эталонных аудиосигналов 112b и затем усреднения полученной разностной информации о громкости по всем направлениям панорамирования (например, по различным направлениям, с которыми ассоциирована первая информация 1421 о громкости и/или вторая информация 1422 о громкости) и по времени для получения одного числа, называемого выходной переменной модели (MOV).
На фиг. 9 показан вариант осуществления модуля 200 оценки сходства аудиоданных для вычисления информации 210 о сходстве на основе эталонного входного стереосигнала 112b (REF) и стереосигнала 112a, подлежащего анализу (например, в данном случае тестируемого сигнала (SUT)). В соответствии с вариантом осуществления модуль 200 оценки сходства аудиоданных может содержать признаки и/или функциональные возможности, как описано в отношении модуля оценки сходства аудиоданных на фиг. 8. Два стереосигнала 112a и 112b могут быть обработаны посредством периферийной модели 116 уха для получения представлений 110a и 110b в спектральной области входных стереосигналов 112a и 112b.
В соответствии с вариантом осуществления на следующем этапе звуковые компоненты стереосигналов 112a и 112b могут быть проанализированы на предмет их информации о направлении. Различные направления 125 панорамирования могут быть заданы и могут быть объединены с шириной 128 окна для получения зависящего от направления взвешивания 1271-1277. На основе зависящего от направления взвешивания 127 и представления 110a и/или 110b в спектральной области соответствующего входного стереосигнала 112a и/или 112b может быть выполнена направленная декомпозиция 130 индекса панорамирования, чтобы получить вклады 132a и/или 132b. В соответствии с вариантом осуществления вклады 132a и/или 132b затем обрабатываются, например, посредством вычисления 144 громкости, чтобы получить громкость 145a и/или 145b для каждой частотной полосы и направления панорамирования. В соответствии с вариантом осуществления выполняется частотное усреднение 146 с учетом ERB (эквивалентной прямоугольной полосы пропускания) сигналов 145b и/или 145a громкости, чтобы получить карты 142a и/или 142b направленной громкости для сравнения 220 информации о громкости. Сравнение 220 информации о громкости, например, выполнено с возможностью вычисления меры расстояния на основе двух карт 142a и 142b направленной громкости. Мера расстояния может представлять карту направленной громкости, содержащую разности между двумя картами 142a и 142b направленной громкости. В соответствии с вариантом осуществления одно число, называемое выходной переменной модели MOV, может быть получено в качестве информации 210 о сходстве посредством усреднения меры расстояния по всем направлениям панорамирования и времени.
Фиг. 10c показывает меру расстояния, как описано на фиг. 9, или информацию о сходстве, как описано на фиг. 8, представленные картой 210 направленной громкости, показывающей различия громкости между картой 142b направленной громкости, показанный на фиг. 10a, и картой 142a направленной громкости, показанной на фиг. 10b. Карты направленной громкости, показанные на фиг. 10a-10c, представляют, например, значения громкости с течением временем и по направлениям панорамирования. Карта направленной громкости, показанная на фиг. 10a, может представлять значения громкости, соответствующие входному сигналу с эталонным значением. Эта карта направленной громкости может быть вычислена, как описано на фиг. 9, или посредством модуля анализа аудиоданных, как описано на фиг. 1- 4b, или в качестве альтернативы может быть взята из базы данных. Карта направленной громкости, показанная на фиг. 10b, соответствует, например, тестируемому стереосигналу, и может представлять информацию о громкости, определенную модулем анализа аудиоданных, как разъяснено на фиг. 1-4b и фиг. 8 или 9.
На фиг. 11 показан аудиокодер 300 для кодирования 310 входного аудиосодержимого 112, содержащего один или более входных аудиосигналов (например, xi). Входной аудиосодержимое 112 содержит предпочтительно множество входных аудиосигналов, таких как стереосигналы или многоканальные сигналы. Аудиокодер 300 выполнен с возможностью обеспечения одного или более кодированных аудиосигналов 320 на основе одного или более входных аудиосигналов 112 или на основе одного или более сигналов 110, полученных из одного или более входных аудиосигналов 112 посредством факультативной обработки 330. Таким образом, либо один или более входных аудиосигналов 112, либо один или более сигналов 110, полученных из них, кодируются 310 аудиокодером 300. Обработка 330 может содержать центральную/боковую обработку, обработку понижающего микширования или разности, преобразование из временной области в спектральную область и/или обработку с использованием модели уха. Кодирование 310 содержит, например, квантование и затем кодирование без потерь.
Аудиокодер 300 выполнен с возможностью адаптировать 340 параметры кодирования в зависимости от одной или более карт 142 направленной громкости (например, Li(m, ) для множества различных ), которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, заданных направлений или направлений одного или более сигналов 112, подлежащих кодированию). В соответствии с вариантом осуществления параметры кодирования содержат параметры квантования и/или другие параметры кодирования, такие как распределение битов и/или параметры, относящиеся к запрещению/разрешению кодирования 310.
В соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью выполнения определения 100 информации о громкости для получения карты 142 направленной громкости на основе входного аудиосигнала 112 или на основе обработанного входного аудиосигнала 110. Таким образом, например, аудиокодер 300 может содержать модуль 100 анализа аудиоданных, как описано в отношении фиг. 1- 4b. В качестве альтернативы аудиокодер 300 может принимать карту 142 направленной громкости от внешнего модуля анализа аудиоданных, выполняющего определение 100 информации о громкости. В соответствии с вариантом осуществления аудиокодер 300 может получать более чем одну карту 142 направленной громкости, относящуюся к входным аудиосигналам 112 и/или к обработанным входным аудиосигналам 110.
В соответствии с вариантом осуществления аудиокодер 300 может принимать только один входной аудиосигнал 112. В этом случае карта 142 направленной громкости содержит, например, значения громкости только для одного направления. В соответствии с вариантом осуществления карта 142 направленной громкости может содержать значения громкости, равные нулю для направлений, отличающихся от направления, ассоциированного с входным аудиосигналом 112. В случае только одного входного аудиосигнала 112 аудиокодер 300 может принимать решение на основе карты 142 направленной громкости, должна ли быть выполнена адаптация 340 параметров кодирования. Таким образом, например, адаптация 340 параметров кодирования может содержать установку параметров кодирования к стандартным параметрам кодирования для моносигналов.
Если аудиокодер 300 принимает стереосигнал или многоканальный сигнал в качестве входного аудиосигнала 112, карта 142 направленной громкости может содержать значения громкости для различных направлений (например, отличных от нуля). В случае входного стереосигнала аудиокодер 300 получает, например, одну карту 142 направленной громкости, ассоциированную с двумя входными аудиосигналами 112. В случае многоканального входного аудиосигнала 112 аудиокодер 300 получает, например, одну или более карт 142 направленной громкости на основе входных аудиосигналов 112. Если многоканальный сигнал 112 кодируется аудиокодером 300, то, например, общая карта 142 направленной громкости на основе всех сигналов каналов и/или карт направленной громкости и/или одна или более карт 142 направленной громкости на основе пар сигналов многоканального входного аудиосигнала 112 могут быть получены посредством определения 100 информации о громкости. Таким образом, например, аудиокодер 300 может выполнен с возможностью выполнения адаптации 340 параметров кодирования в зависимости от вкладов отдельных карт 142 направленной громкости, например, пар сигналов, центрального сигнала, бокового сигнала, микшированного с понижением сигнала, сигнала разности и/или групп из трех или более сигналов в общую карту 142 направленной громкости, например, ассоциированную с несколькими входными аудиосигналами, например, ассоциированную со всеми сигналами многоканального входного аудиосигнала 112 или обработанного многоканального входного аудиосигнала 110.
Определение 100 информации о громкости, как описано в отношении фиг. 11, является иллюстративным и может быть выполнено идентичным или аналогичным образом всеми последующими аудиокодерами или декодерами.
На фиг. 12 показан вариант осуществления аудиокодера 300, который может содержать признаки и/или функциональные возможности, как описано в отношении аудиокодера на фиг. 11. В соответствии с вариантом осуществления кодирование 310 может содержать квантование посредством модуля 312 квантования и кодирование посредством блока 314 кодирования, например, энтропийное кодирование. Таким образом, например, адаптация параметров 340 кодирования может содержать адаптацию параметров 342 квантования и адаптацию параметров 344 кодирования. Аудиокодер 300 выполнен с возможностью кодирования 310 входного аудиосодержимого 112, содержащего, например, два или более входных аудиосигнала, для обеспечения кодированного аудиосодержимого 320, содержащего, например, кодированные два или более входных аудиосигнала. Это кодирование 310 зависит, например, от карты 142 направленной громкости или множества карт 142 направленной громкости (например, Li(m, )), которые представляют собой входной аудиосодержимое 112 и/или кодированную версию 320 входного аудиосодержимого 112, или которые основаны на них.
В соответствии с вариантом осуществления входной аудиосодержимое 112 может быть непосредственно кодирован 310 или факультативно обработан 330 ранее. Как уже описано выше, аудиокодер 300 может быть кодирован для определения представления в спектральной области 110 одного или более входных аудиосигналов входного аудиосодержимого 112 посредством обработки 330. В качестве альтернативы обработка 330 может содержать дальнейшие этапы обработки для получения одного или более сигналов входного аудиосодержимого 112, которые могут подвергаться преобразованию из временной области в спектральную область для получения представления 110 в спектральной области. В соответствии с вариантом осуществления сигналы, полученные посредством обработки 330, могут содержать, например, центральный сигнал или микшированный с понижением сигнал и боковой сигнал или сигнал разности.
В соответствии с вариантом осуществления сигналы входного аудиосодержимого 112 или представления 110 в спектральной области могут подвергаться квантованию посредством модуля 312 квантования. Модуль 312 квантования использует, например, один или более параметров квантования для получения одного или более квантованных представлений 313 в спектральной области. Эти один или более квантованных представлений 313 в спектральной области могут быть кодированы блоком 314 кодирования для получения одного или более кодированных аудиосигналов кодированного аудиосодержимого 320.
Для оптимизации кодирование 310 посредством аудиокодера 300 аудиокодер 300 может быть выполнен с возможностью адаптации 342 параметров квантования. Параметры квантования, например, содержат масштабные коэффициенты или параметры, описывающие, какую точность квантования или какие этапы квантования к каким спектральным интервалам частотных полос одного или более сигналов, подлежащих квантованию, следует применять. В соответствии с вариантом осуществления параметры квантования описывают, например, распределение битов различным сигналам, подлежащим квантованию, и/или различным частотным полосам. Адаптация 342 параметров квантования может пониматься как адаптация точности квантования и/или адаптация шума, вносимого кодером 300, и/или как адаптация распределения битов между одним или более сигналами 112/110 и/или параметрами, подлежащими кодированию аудиокодером 300. Другими словами, аудиокодер 300 выполнен с возможностью регулировки одного или более параметров квантования, чтобы адаптировать распределение битов для адаптации точности квантования и/или адаптации шума. Дополнительно параметры квантования и/или параметры кодирования могут быть кодированы 310 аудиокодером.
В соответствии с вариантом осуществления адаптация 340 кодирования параметров, такая как адаптация 342 параметров квантования и адаптация 344 параметров кодирования, может выполняться в зависимости от одной или более карт 142 направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений, направлений панорамирования, одного или более сигналов 112/110, подлежащих квантованию. Точнее говоря, адаптация 340 может быть выполнена в зависимости от вкладов отдельных карт 142 направленной громкости одного или более сигналов, подлежащих кодированию, в общую карту 142 направленной громкости. Это может быть выполнено, как описано в отношении фиг. 11. Таким образом, например, адаптация распределения битов, адаптация точности квантования и/или адаптация шума могут выполняться в зависимости от вкладов отдельных карт направленной громкости одного или более сигналов 112/110, подлежащих кодированию, в общую карту направленной громкости. Это выполняется, например, посредством регулировки одного или более параметров квантования посредством адаптации 342.
В соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью определения общей карты направленной громкости на основе входных аудиосигналов 112 или представления 110 в спектральной области, в результате чего общая карта направленной громкости представляет информацию о громкости, ассоциированную с различными направлениями, например, звуковых компонентов аудиосцены, представленной входным аудиосодержимым 112. В качестве альтернативы общая карта направленной громкости может представлять информацию о громкости, ассоциированную с различными направлениями аудиосцены, которая будет представлена, например, после рендеринга на стороне декодера. В соответствии с вариантом осуществления различные направления могут быть получены посредством определения 100 информации о громкости, возможно в сочетании со знаниями или вспомогательной информацией относительно положений громкоговорителей и/или знаниями или вспомогательной информацией, описывающей положения звуковых объектов. Эти знания или вспомогательная информация могут быть получены на основе одного или более сигналов 112/110, подлежащих квантованию, поскольку эти сигналы 112/110, например, ассоциированы фиксированным, не зависящим от сигнала образом с различными направлениями или с разными громкоговорителями, или с разными звуковыми объектами. Например, сигнал ассоциирован с некоторым каналом, который может быть интерпретирован как направление из различных направлений (например, описанных здесь первых направлений). В соответствии с вариантом осуществления звуковые объекты одного или более сигналов панорамируются в различных направлениях или преобразовываются для прослушивания в различных направлениях, которые могут быть получены посредством определения 100 информации о громкости как информация о рендеринге объекта. Эти знания или вспомогательная информация могут быть получены посредством определения 100 информации о громкости для групп из двух или более входных аудиосигналов входного аудиосодержимого 112 или представления 110 в спектральной области.
В соответствии с вариантом осуществления сигналы 112/110, подлежащие квантованию, могут содержать компоненты, например, центральный сигнал и боковой сигнал стереофонического центрального/бокового кодирования, совместного многосигнального кодирования двух или более входных аудиосигналов 112. Таким образом, аудиокодер 300 выполнен с возможностью оценки вышеупомянутых вкладов карт 142 направленной громкости одного или более разностных сигналов совместного многосигнального кодирования в общую карту 142 направленной громкости и регулировки одного или более параметров 340 кодирования в зависимости них.
В соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью адаптации распределения битов между одним или более сигналами 112/110 и/или параметрами, подлежащими кодированию, и/или адаптации точности квантования одного или более сигналов 112/110, подлежащих кодированию, и/или адаптации шума, вносимого кодером 300, индивидуально для разных спектральных интервалов или индивидуально для разных частотных полос. Это означает, например, что адаптация 342 параметров квантования выполняется таким образом, что кодирование 310 улучшается для индивидуальных спектральных интервалов или индивидуальных разных частотных полос.
В соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью адаптации распределения битов между одним или более сигналами 112/110 и/или параметрами, подлежащими кодированию, в зависимости от оценки пространственного маскирования между двумя или более подлежащими кодированию сигналами. Аудиокодер, например, выполнен с возможностью оценки пространственного маскирования на основе карт 142 направленной громкости, ассоциированных с двумя или более сигналами 112/110, подлежащими кодированию. Дополнительно или в качестве альтернативы аудиокодер выполнен с возможностью оценки пространственного маскирования или эффекта маскирования вклада громкости, ассоциированного с первым направлением первого сигнала, подлежащего кодированию, на вклад громкости, ассоциированный со вторым направлением, которое отличается от первого направления, второго сигнала, подлежащего кодированию. В соответствии с вариантом осуществления вклад громкости, ассоциированный с первым направлением, может представлять, например, информацию о громкости звукового объекта или звукового компонента сигналов входного аудиосодержимого, и вклад громкости, ассоциированный со вторым направлением, может представлять, например, информацию о громкости, ассоциированную с другим звуковым объектом или звуковым компонентом сигналов входного аудиосодержимого. В зависимости от информации о громкости вклада громкости, ассоциированного с первым направлением, и вклада громкости, ассоциированного со вторым направлением, и в зависимости от расстояния между первым направлением и вторым направлением может быть оценен эффект маскирования или пространственного маскирования. В соответствии с вариантом осуществления эффект маскирования уменьшается с увеличением разности углов между первым направлением и вторым направлением. Аналогичным образом, может быть оценено временное маскирование.
В соответствии с вариантом осуществления адаптация 342 параметров квантования может быть выполнена аудиокодером 300, чтобы адаптировать шум, вносимый кодером 300, на основе карты направленной громкости, достижимой с помощью кодированной версии 320 входного аудиосодержимого 112. Таким образом аудиокодер 300, например, выполнен с возможностью использования отклонения между картой 142 направленной громкости, которая ассоциирована с определённым не кодированным входным аудиосигналом 112/110 (или двумя или более входными аудиосигналами), и картой направленной громкости, достижимой с помощью кодированной версии 320 определённого входного аудиосигнала 112/110 (или двух или более входных аудиосигналов), в качестве критерия адаптации формирования определённого кодированного аудиосигнала или аудиосигналов кодированного аудиосодержимого 320. Это отклонение может представлять качество кодирования 310 кодера 300. Тем самым кодер 300 может быть выполнен с возможностью адаптации 340 параметров кодирования таким образом, что отклонение находится ниже определенного порогового значения. Таким образом, реализован контур 322 обратной связи для улучшения кодирования 310 аудиокодером 300 на основе карт 142 направленной громкости кодированного аудиосодержимого 320 и карт 142 направленной громкости не кодированного входного аудиосодержимого 112 или не кодированных представлений 110 в спектральной области. В соответствии с вариантом осуществления в контуре 322 обратной связи кодированный аудиосодержимое 320 декодируется для выполнения определения 100 информации о громкости на основе декодированных аудиосигналов. В качестве альтернативы также возможно, что карты 142 направленной громкости кодированного аудиосодержимого 320 осуществляются посредством упреждения, реализованного нейронной сетью (например, предсказываются).
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью регулировки одного или более параметров квантования посредством адаптации 342, чтобы адаптировать обеспечение одного или более кодированных аудиосигналов кодированного аудиосодержимого 320.
В соответствии с вариантом осуществления адаптация 340 параметров кодирования может выполняться, чтобы запретить или разрешить кодирование 310 и/или активировать и деактивировать инструмент совместного кодирования инструмент, который, например, используется блоком 314 кодирования. Например, это выполняется посредством адаптации 344 параметров кодирования. В соответствии с вариантом осуществления адаптация 344 параметров кодирования может зависеть от тех же самых критериев, как и адаптация 342 параметров квантования. Таким образом, в соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью запрещения кодирования 310 определённого одного из подлежащих кодированию сигналов, например, разностного сигнала, когда вклады отдельной карты 142 направленной громкости определённого одного из подлежащих кодированию сигналов (или, например, когда вклады карты 142 направленной громкости пары подлежащих кодированию сигналов или группы из трех или более подлежащих кодированию сигналов) в общую карту направленной громкости находятся ниже порогового значения. Таким образом, аудиокодер 300 выполнен с возможностью эффективного кодирования 310 только релевантной информации.
В соответствии с вариантом осуществления инструмент совместного кодирования блока 314 кодирования, например, выполнен с возможностью совместного кодирования двух или более из входных аудиосигналов 112 или полученных из них сигналов 110, например, чтобы принять решение о включении/выключении M/S (центральный/боковой сигнал). Адаптация 344 параметров кодирования может быть выполнена таким образом, что инструмент совместного кодирования активируется или деактивируется в зависимости от одной или более карт 142 направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений одного или более сигналов 112/110, подлежащих кодированию. В качестве альтернативы или дополнительно аудиокодер 300 может быть выполнен с возможностью определения одного или более параметров инструмента совместного кодирования как параметров кодирования в зависимости от одной или более карт 142 направленной громкости. Таким образом, с помощью адаптации 344 параметров кодирования, например, можно управлять сглаживанием зависимых от частоты коэффициентов предсказания, например, чтобы установить параметры инструмента совместного кодирования с «интенсивным стерео».
В соответствии с вариантом осуществления параметры квантования и/или параметры кодирования могут рассматриваться как управляющие параметры, которые могут управлять обеспечением одного или более кодированных аудиосигналов 320. Таким образом, аудиокодер 300 выполнен с возможностью определения или оценки влияния вариации одного или более управляющих параметров на карту 142 направленной громкости одного или более кодированных сигналов 320 и регулировки одного или более управляющих параметров в зависимости от определения или оценки влияния. Это может быть реализовано посредством контура 322 обратной связи и/или упреждения, как описано выше.
На фиг. 13 показан аудиокодер 300 для кодирования 310 входного аудиосодержимого 112, содержащего один или более входных аудиосигналов 1121, 1122. Предпочтительно, как показано на фиг. 13, входное аудиосодержимое 112 содержит множество входных аудиосигналов, например, два или более входных аудиосигнала 1121, 1122. В соответствии с вариантом осуществления входное аудиосодержимое 112 может содержать сигналы во временной области или сигналы в спектральной области. В некоторых случаях сигналы входного аудиосодержимого 112 могут быть обработаны 330 аудиокодером 300, чтобы определить возможные сигналы, например, первый возможный сигнал 1101 и/или второй возможный сигнал 1102. Обработка 330 может содержать, например, преобразованием из временной области в спектральную область, если входные аудиосигналы 112 являются сигналами во временной области.
Аудиокодер 300 выполнен с возможностью выбора 350 сигналов, подлежащих совместному кодированию 310, из множества возможных сигналов 110 или из множества пар возможных сигналов 110 в зависимости от карт 142 направленной громкости. Карты 142 направленной громкости представляют информацию о громкости, ассоциированную с множеством различных направлений, например, направления панорамирования, возможные сигналы 110 или пары возможных сигналов 110, и/или заданные направления.
В соответствии с вариантом осуществления карты 142 направленной громкости могут быть вычислены посредством определения 100 информации о громкости согласно настоящему описанию. Таким образом, определение 100 информации о громкости может быть реализовано, как описано в отношении аудиокодера 300, описанного на фиг. 11 или фиг. 12. Карты 142 направленной громкости основаны на возможных сигналах 110, причем возможные сигналы представляют входные аудиосигналы входного аудиосодержимого 112, если аудиокодером 300 не применяется обработка 330.
Если входное аудиосодержимое 112 содержит только один входной аудиосигнал, этот сигнал выбирается посредством выбора 350 как подлежащего кодированию аудиокодером 300, например, с использованием энтропийного кодирования, чтобы обеспечить один кодированный аудиосигнал в качестве кодированного аудиосодержимого 320. В этом случае, например, аудиокодер выполнен с возможностью запрещения совместного кодирования 310 и переключения на кодирование только одного сигнала.
Если входное аудиосодержимое 112 содержит два входных аудиосигнала 1121 и 1122, которые могут быть описаны как X1 и X2, оба сигнала 1121 и 1122 выбираются 350 аудиокодером 300 для совместного кодирования 310, чтобы обеспечить один или более кодированных сигналов в кодированном аудиосодержимом 320. Таким образом, кодированное аудиосодержимое 320 факультативно содержит центральный сигнал и боковой сигнал, или микшированный с понижением сигнал и сигнал разности, или только один из этих четырех сигналов.
Если входное аудиосодержимое 112 содержит три или более входных аудиосигнала, выбор 350 сигнала основан на картах 142 направленной громкости возможных сигналов 110. В соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью использования выбора 350 сигнала, чтобы выбрать одну пару сигналов из множества возможных сигналов 110, для которой в соответствии с картой 142 направленной громкости могут быть реализованы эффективное аудиокодирование и высококачественный выходной аудиосигнал. В качестве альтернативы или дополнительно также возможно, что выбор 350 сигнала выбирает три или более сигнала из возможных сигналов 110, подлежащих совместному кодированию 310. В качестве альтернативы или дополнительно возможно, что аудиокодер 300 использует выбор 350 сигнала, чтобы выбрать более чем одну пару сигналов или группу сигналов для совместного кодирования 310. Выбор 350 сигналов 352, подлежащих кодированию, может зависеть от вкладов отдельных карт 142 направленной громкости объединения двух или более сигналов в общую карту направленной громкости. В соответствии с вариантом осуществления общая карта направленной громкости ассоциирована с несколькими выбранными входными аудиосигналами или с каждым сигналом входного аудиосодержимого 112. То, каким образом этот выбор 350 сигнала может быть выполнен аудиокодером 300, в качестве примера описано на фиг. 14 для входного аудиосодержимого 112, содержащего три входных аудиосигнала.
Таким образом, аудиокодер 300 выполнен с возможностью обеспечения одного или более кодированных, например, квантованных и затем кодированных без потерь аудиосигналов, например, кодированных представлений в спектральной области на основе двух или более входных аудиосигналов 1121, 1122 или на основе двух или более полученных из них сигналов 1101, 1102 с использованием совместного кодирования 310 двух или более сигналов 352, подлежащих совместному кодированию.
В соответствии с вариантом осуществления аудиокодер 300, например, выполнен с возможностью определения отдельных карт 142 направленной громкости двух или более возможных сигналов и сравнения отдельных карт 142 направленной громкости двух или более возможных сигналов. Дополнительно аудиокодер, например, выполнен с возможностью выбора двух или более из возможных сигналов для совместного кодирования в зависимости от результата сравнения, например, таким образом, что для совместного кодирования выбираются возможные сигналы, отдельные карты громкости которых содержат максимальное сходство или сходство, которое выше порогового значения сходства. Посредством этого оптимизированного выбора может быть реализовано очень эффективное кодирование, поскольку высокое сходство подлежащих совместному кодированию сигналов может привести к кодированию с использованием только небольшого количества битов. Это означает, например, что микшированный с понижением сигнал или разностный сигнал выбранной пары возможных сигналов могут быть эффективно совместно кодированы.
На фиг. 14 показан вариант осуществления выбора 350 сигнала, который может быть выполнен любым описанным здесь аудиокодером 300, каким как аудиокодер 300 на фиг. 13. Аудиокодер может быть выполнен с возможностью использования выбора 350 сигнала, как показано на фиг. 14, или применения описанного выбора 350 сигнала более чем к трем входным аудиосигналам, для выбора сигналов, подлежащих совместному кодированию, из множества возможных сигналов или из множества пар возможных сигналов в зависимости от вкладов отдельных карт направленной громкости возможных сигналов в общую карту 142b направленной громкости или в зависимости от вкладов карт 142a1-142a3 направленной громкости пар возможных сигналов в общую карту 142b направленной громкости, как показано на фиг. 14.
В соответствии с фиг. 14 для каждой возможной пары сигналов карта 142a1-142a3 направленной громкости, например, получается посредством выбора 350 сигнала, и общая карта 142b направленной громкости, ассоциированная со всеми тремя сигналами входного аудиосодержимого, получается посредством блока 350 выбора сигнала. Карты 142 направленной громкости, например, карты 142a1-142a3 направленной громкости пар сигналов и общая карта 142b направленной громкости могут быть приняты от модуля анализа аудиоданных или могут быть определены аудиокодером и выданы блоку 350 выбора сигнала. В соответствии с вариантом осуществления общая карта 142b направленной громкости может представлять общую аудиосцену, например, представленную входным аудиосодержимым, например, перед обработкой аудиокодером. В соответствии с вариантом осуществления общая карта 142b направленной громкости представляет информацию о громкости, ассоциированную с различными направлениями, например, звуковых компонентов представленной или подлежащей представлению аудиосцены, например, после рендеринга на стороне декодера посредством входных аудиосигналов 1121-1123. Общая карта направленной громкости, например, представлена как DirLoudMap(1, 2, 3). В соответствии с вариантом осуществления общая карта 142b направленной громкости определяется аудиокодером с использованием понижающего микширования входных аудиосигналов 1121-1123 или с использование бинаурализации входных аудиосигналов 1121-1123.
На фиг. 14 показан выбор 350 сигнала для трех каналов CH1-CH3 соответственно, ассоциированных с первым входным аудиосигналом 1121, вторым входным аудиосигналом 1122 или третьим входным аудиосигналом 1123. Первая карта 142a1 направленной громкости, например, DirLoudMap (1, 2), основана на первом входном аудиосигнале 1121 и втором входном аудиосигнале 1122, вторая карта 142a2 направленной громкости, например, DirLoudMap (2, 3), основана на втором входном аудиосигнале 1122 и третьем входном аудиосигнале 1123, и третья карта 142a3 направленной громкости, например, DirLoudMap (1, 3), основана на первом входном аудиосигнале 1121 и третьем входном аудиосигнале 1123.
В соответствии с вариантом осуществления каждая карта 142 направленной громкости представляет информацию о громкости, ассоциированную с различными направлениями. Различные направления обозначены на фиг. 14 линией между L и R, где L ассоциировано с панорамированием звуковых компонентов в левую сторону, и где R ассоциировано с панорамированием звуковых компонентов в правую сторону. Таким образом, различные направления содержат левую сторону и правую сторону и направления или углы между левой и правой стороной. Карты 142 направленной громкости, показанные на фиг. 14, представлены как диаграммы, но в качестве альтернативы также возможно, что карты 142 направленной громкости могут быть представлены гистограммами направленной громкости, как показано на фиг. 5, или матрицей, как показано на фиг. 10a-10c. Ясно, что только информация, ассоциированная с картами 142 направленной громкости, является релевантной для выбора 350 сигнала, и что графическое представление предназначено только для улучшения понимания.
В соответствии с вариантом осуществления выбор 350 сигнала выполняется таким образом, что определяется вклад пар возможных сигналов в общую карту 142b направленной громкости. Отношение между общей картой 142b направленной громкости и картами 142a1-142a3 направленной громкости пар возможных сигналов может быть описано формулой
DirLoudMap (1,2,3) = a*DirLoudMap (1,2,3) + b*DirLoudMap (2,3) + c*DirLoudMap (1,3).
Вклад, определяемый аудиокодером посредством использования выбора сигнала, может быть представлен коэффициентами a, b и c.
В соответствии с вариантом осуществления аудиокодер выполнен с возможностью выбора для совместного кодирования одной или более пар возможных сигналов 1121-1123, имеющих наиболее высокий вклад в общую карту 142b направленной громкости. Это означает, например, что посредством выбора 350 сигнала выбирается пара возможных сигналов, которая ассоциирована с наиболее высоким коэффициентом из коэффициентов a, b и c.
В качестве альтернативы аудиокодер выполнен с возможностью выбора для совместного кодирования одной или более пар возможных сигналов 1121-1123, имеющих вклад в общую карту 142b направленной громкости, который больше заданного порогового значения. Это означает, например, что выбрано заданное пороговое значение, и что каждый коэффициент a, b, c сравнивается с заданным пороговым значением для выбора каждой пары сигналов, ассоциированной с коэффициентом, который больше заданного порогового значения.
В соответствии с вариантом осуществления вклады могут находиться в диапазоне от 0% до 100%, что означает, например, для коэффициентов a, b и c диапазон от 0 до 1. Вклад 100%, например, ассоциирован с картой 142a направленной громкости, которая точно равна общей карте 142b направленной громкости. В соответствии с вариантом осуществления заданное пороговое значение зависит от того, сколько входных аудиосигналов включено во входное аудиосодержимое. В соответствии с вариантом осуществления заданное пороговое значение может быть определено как вклад по меньшей мере 35%, или по меньшей мере 50%, или по меньшей мере 60%, или по меньшей мере 75%.
В соответствии с вариантом осуществления заданное пороговое значение зависит от того, сколько сигналов должно быть выбрано посредством выбора 350 сигнала для совместного кодирования. Например, если должны быть выбраны по меньшей мере две пары сигналов, то могут быть выбраны две пары сигналов, которые ассоциированы с картами 142a направленной громкости, имеющими наиболее высокий вклад в общую карту 142b направленной громкости. Это означает, например, что выбирается 350 пара сигналов с наиболее высоким вкладом и со вторым наиболее высоким вкладом.
Выгодно основывать выбор подлежащих кодированию сигналов аудиокодером на картах 142 направленной громкости, поскольку сравнение карт направленной громкости может указывать качество восприятия кодированных аудиосигналов слушателем. В соответствии с вариантом осуществления выбор 350 сигнала выполняется аудиокодером таким образом, что выбирается пара сигналов или пары сигналов, для которых их карта 142a направленной громкости является наиболее сходной с общей картой 142b направленной громкости. Это может привести к сходному восприятию выбранной пары и пар возможных сигналов по сравнению с восприятием всех входных аудиосигналов. Таким образом, качество кодированного аудиосодержимого может быть улучшено.
На фиг. 15 показан вариант осуществления аудиокодера 300 для кодирования 310 входного аудиосодержимого 112, содержащего один или более входных аудиосигналов. Предпочтительно два или более входных аудиосигналов кодируются 310 аудиокодером 300. Аудиокодер 300 выполнен с возможностью обеспечения одного или более кодированных аудиосигналов 320 на основе двух или более входных аудиосигналов 112 или на основе двух или более полученных из них сигналов 110. Сигнал 110 может быть получен из входного аудиосигнала 112 посредством факультативной обработки 330. В соответствии с вариантом осуществления факультативная обработка 330 может содержать признаки и/или функциональные возможности, как описано в отношении других описанных здесь аудиокодеров 300. С помощью кодирования 310 подлежащие кодированию сообщения, например, квантуются и затем кодируются без потерь.
Аудиокодер 300 выполнен с возможностью определения 100 общей карты направленной громкости на основе входных аудиосигналов 112 и/или определения 100 одной или более отдельных карт 142 направленной громкости, ассоциированных с отдельными входными аудиосигналами 112. Общая карта направленной громкости может быть представлена как L(m,Ψ0,j), и отдельные карты направленной громкости могут быть представлены как Li(m,Ψ0,j). В соответствии с вариантом осуществления общая карта направленной громкости может представлять целевую карту направленной громкости сцены. Другими словами, общая карта направленной громкости может быть ассоциирована с желаемой картой направленной громкости для объединения кодированных аудиосигналов. Дополнительно или в качестве альтернативы возможно, что аудиокодером 300 могут быть определены 100 карты направленной громкости Li(m,Ψ0,j) пар сигналов или групп из трех или более сигналов.
Аудиокодер 300 выполнен с возможностью кодирования 310 общей карты 142 направленной громкости и/или одной или более отдельных карт 142 направленной громкости и/или одной или более карт направленной громкости пар сигналов или групп из трех или более входных аудиосигналов 112 в качестве вспомогательной информация. Таким образом, кодированное аудиосодержимое 320 содержит кодированные аудиосигналы и кодированные карты направленной громкости. В соответствии с вариантом осуществления кодирование 310 может зависеть от одной или более карт 142 направленной громкости, посредством чего выгодно также кодировать эти карты 142 направленной громкости, чтобы обеспечить возможность высококачественного декодирования кодированного аудиосодержимого 320. С помощью карт 142 направленной громкости в качестве кодированной вспомогательной информации первоначально намеченная характеристика качества (например, подлежащая достижению посредством кодирования 310 и/или с помощью аудиодекодера) обеспечивается кодированным аудиосодержимым 320.
В соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью определения 100 общей карты направленной громкости L(m,Ψ0,j) на основе входных аудиосигналов 112, в результате чего общая карта направленной громкости представляет информацию о громкости, ассоциированную с различными направлениями, например, звуковых компонентов аудиосцены, представленной входными аудиосигналами 112. В качестве альтернативы общая карта направленной громкости L(m,Ψ0,j) представляет информацию о громкости, ассоциированную с различными направлениями, например, звуковых компонентов аудиосцены, которая будет представлена, например, после рендеринга на стороне декодера входными аудиосигналами. Определение 100 информации о громкости может быть выполнено аудиокодером 300 факультативно в сочетании со знаниями или вспомогательной информацией относительно положений громкоговорителей и/или знаниями или вспомогательной информацией, описывающей положения звуковых объектов во входных аудиосигналах 112.
В соответствии с вариантом осуществления определение 100 информации о громкости может быть реализовано, как описано с помощью других описанных здесь аудиокодеров 300.
Аудиокодер 300, например, выполнен с возможностью кодирования 310 общей карты направленной громкости L(m,Ψ0,j) в форме множества значений, например, скалярных величин, ассоциированных с различными направлениями. В соответствии с вариантом осуществления значения дополнительно ассоциированы с множеством частотных интервалов частотных полос. Каждое значение или значения в дискретных направлениях общей карты направленной громкости могут быть кодированы. Это означает, например, что каждое значение цветовой матрицы, как показано на фиг. 10a-10c, или значения различных интервалов гистограммы, как показано на фиг. 5, или значения кривой карты направленной громкости, как показано на фиг. 14, кодируются для дискретных направлений.
В качестве альтернативы аудиокодер 300, например, выполнен с возможностью кодирования общей карты направленной громкости L(m,Ψ0,j) с использованием значения центрального положения и информации о градиенте. Значение центрального положения описывает, например, угол или направление, в котором расположен максимум общей карты направленной громкости для данной частотной полосы или частотного интервала, или для множества частотных интервалов или частотных полос. Информация о градиенте представляет, например, одну или более скалярных величин, описывающих градиенты значений общей карты направленной громкости в угловом направлении. Скалярные величины информации о градиенте являются, например, значениями общей карты направленной громкости для направлений, граничащих со значением центрального положения. Значение центрального положения может представлять скалярную величину информации о громкости и/или скалярную величину направления, соответствующего значению громкости.
В качестве альтернативы аудиокодер, например, выполнен с возможностью кодирования общей карты направленной громкости L(m,Ψ0,j) в виде полиномиального представления или в виде сплайнового представления.
В соответствии с вариантом осуществления описанные выше возможности кодирования 310 для общей карты направленной громкости L(m,Ψ0,j) также могут быть применены для отдельных карт направленной громкости Li(m,Ψ0,j) и/или для карт направленной громкости, ассоциированных с парами сигналов или группами из трех или более сигналов.
В соответствии с вариантом осуществления аудиокодер 300 выполнен с возможностью кодирования одного микшированного с понижением сигнала, полученного на основе множества входных аудиосигналов 112 и общей карты направленной громкости L(m,Ψ0,j). Факультативно также вклад карты направленной громкости, ассоциированной с микшированным с понижением сигналом, например, кодируется с общей картой направленной громкости в качестве вспомогательной информации.
В качестве альтернативы аудиокодер 300, например, выполнен с возможностью кодирования 310 множества сигналов, например, входных аудиосигналов 112 или полученных из них сигналов 110 и кодирования 310 отдельных карт громкости Li(m,Ψ0,j) множества кодируемых 310 сигналов 112/110 (например, отдельных сигналов, пар сигналов или групп из трех или более сигналов). Кодированное множество сигналов и кодированные отдельные карты направленной громкости, например, передаются в кодированное звуковое представление 320 или вставляются в кодированное звуковое представление 320.
В соответствии с альтернативным вариантом осуществления аудиокодер 300 выполнен с возможностью кодирования 310 общей карты направленной громкости L(m,Ψ0,j), множества сигналов, например, входных аудиосигналов 112 или полученных из них сигналов 110 и параметров, описывающих вклады, например, относительные вклады сигналов, которые кодируются с общей картой направленной громкости. В соответствии с вариантом осуществления параметры могут быть представлены параметрами a, b и c, как описано на фиг. 14. Таким образом, например, аудиокодер 300 выполнен с возможностью кодирования 310 всей информации, на которой основано кодирование 310, чтобы обеспечить, например, информацию для высококачественного декодирования обеспеченного кодированного аудиосодержимого 320.
В соответствии с вариантом осуществления аудиокодер может содержать или объединять отдельные признаки и/или функциональные возможности, как описано в отношении одного или более аудиокодеров 300, описанных на фиг. 11-15.
На фиг. 16 показан вариант осуществления аудиодекодера 400 для декодирования 410 кодированного аудиосодержимого 420. Кодированное аудиосодержимое 420 может содержать кодированные представления 422 одного или более аудиосигналов и кодированную информацию 424 о картах направленной громкости.
Аудиодекодер 400 выполнен с возможностью приема кодированного представления 422 одного или более аудиосигналов и обеспечения декодированного представления 412 одного или более аудиосигналов. Кроме того, аудиодекодер 400 выполнен с возможностью приема кодированной информации 424 о картах направленной громкости и декодирования 410 кодированной информации 424 о картах направленной громкости для получения одной или более декодированных карт 414 направленной громкости. Декодированные карты 414 направленной громкости могут содержать признаки и/или функциональные возможности, как описано в отношении вышеописанных карт 142 направленной громкости.
В соответствии с вариантом осуществления декодирование 410 может выполняться аудиодекодером 400 с использованием декодирования, подобного AAC, или с использованием декодирования подвергнутых энтропийному кодированию спектральных значений, или с использованием декодирования подвергнутых энтропийному кодированию значений громкости.
Аудиодекодер 400 выполнен с возможностью воссоздания 430 аудиосцены с использованием декодированного представления 412 одного или более аудиосигналов и с использованием одной или более карт 414 направленной громкости. На основе воссоздания 430 аудиодекодером 400 может быть определено декодированное аудиосодержимое 432, такое как многоканальное представление.
В соответствии с вариантом осуществления карта 414 направленной громкости может представлять целевую карту направленной громкости, подлежащую достижению посредством декодированного аудиосодержимого 432. Таким образом, с помощью карты 414 направленной громкости воссоздание аудиосцены 430 может быть оптимизировано и привести к высококачественному восприятию слушателем декодированного аудиосодержимого 432. Это основано на идее, что карта 414 направленной громкости может указывать на желаемое восприятие для слушателя.
На фиг. 17 показан кодер 400, показанный на фиг. 16, с факультативным признаком адаптации 440 параметров декодирования. В соответствии с вариантом осуществления декодированное аудиосодержимое может содержать выходные сигналы 432, которые представляют, например, сигналы во временной области или сигналы в спектральной области. Аудиодекодер 400, например, выполнен с возможностью получения выходных сигналов 432 таким образом, что одна или более карт направленной громкости, ассоциированных с выходными сигналами 432, приблизительно равны или равны одной или более целевым картам направленной громкости. Одна или более целевых карт направленной громкости основаны на одной или более декодированных картах 414 направленной громкости, или равны одной или более декодированным картам 414 направленной громкости. В некоторых случаях аудиодекодер 400 выполнен с возможностью использования подходящего масштабирования или объединения одной или более декодированных карт 414 направленной громкости, чтобы определить целевую карту или карты направленной громкости.
В соответствии с вариантом осуществления одна или более карт направленной громкости, ассоциированных с выходными сигналами 432, могут быть определены аудиодекодером 400. Аудиодекодер 400 содержит, например, модуль анализа аудиоданных для определения одной или более карт направленной громкости, ассоциированных с выходными сигналами 432, или выполнен с возможностью приема от внешнего модуля 100 анализа аудиоданных одной или более карт направленной громкости, ассоциированных с выходными сигналами 432.
В соответствии с вариантом осуществления аудиодекодер 400 выполнен с возможностью сравнения одной или более карт направленной громкости, ассоциированных с выходными сигналами 432, и декодированных карт 414 направленной громкости; или сравнения одной или более карт направленной громкости, ассоциированных с выходными сигналами 432, с картой направленной громкости, полученной из декодированной карты 414 направленной громкости, и адаптации 440 параметров декодирования или воссоздания 430 на основе этого сравнения. В соответствии с вариантом осуществления аудиодекодер 400 выполнен с возможностью адаптации 440 параметров декодирования или адаптации воссоздания 430 таким образом, что отклонение между одной или более картами направленной громкости, ассоциированными с выходными сигналами 432, и одной или более целевыми картами направленной громкости ниже заданного порогового значения. Это может представлять собой контур обратной связи, посредством чего декодирование 410 и/или воссоздание 430 адаптированы таким образом, что одна или более карт направленной громкости, ассоциированных с выходными сигналами 432, приближаются к одной или более целевым картам направленной громкости по меньшей мере на 75%, или по меньшей мере на 80%, или по меньшей мере на 85%, или по меньшей мере на 90%, или по меньшей мере на 95%.
В соответствии с вариантом осуществления аудиодекодер 400 выполнен с возможностью приема кодированного микшированного с понижением сигнала как кодированного представления 422 одного или более аудиосигналов и общей карты направленной громкости как кодированной информации 424 о картах направленной громкости. Кодированный микшированный с понижением сигнал, например, получается на основе множества входных аудиосигналов. В качестве альтернативы аудиодекодер 400 выполнен с возможностью приема множества кодированных аудиосигналов как кодированного представления 422 одного или более аудиосигналов и отдельных карт направленной громкости множества кодированных сигналов как кодированной информации 424 о картах направленной громкости. Кодированный аудиосигнал представляет собой, например, входные аудиосигналы, кодированные кодером, или сигналы, полученные из входных аудиосигналов, кодированных кодером. В качестве альтернативы аудиодекодер 400 выполнен с возможностью приема общей карты направленной громкости как кодированной информации 424 о картах направленной громкости, множества кодированных аудиосигналов как кодированного представления 422 одного или более аудиосигналов, и дополнительно параметров, описывающих вклады кодированных аудиосигналов в общую карту направленной громкости. Таким образом кодированное аудиосодержимое 420 может дополнительно содержать параметры, и аудиодекодер 400 может быть выполнен с возможностью использования этих параметров, чтобы улучшить адаптацию 440 параметров декодирования и/или улучшить воссоздание 430 аудиосцены.
Аудиодекодер 400 выполнен с возможностью обеспечения выходных сигналов 432 на основе одного из ранее упомянутого кодированного аудиосодержимого 420.
На фиг. 18 показан вариант осуществления преобразователя 500 формата для преобразования 510 формата аудиосодержимого 520, которое представляет аудиосцену. Преобразователь 500 формата принимает, например, аудиосодержимое 520 в первом формате и преобразует 510 аудиосодержимое 520 в аудиосодержимое 530 во втором формате. Другими словами, преобразователь 500 формата выполнен с возможностью обеспечения представления 530 аудиосодержимого во втором формате на основе представления 520 аудиосодержимого в первом формате. В соответствии с вариантом осуществления аудиосодержимое 520 и/или аудиосодержимое 530 могут представлять пространственную аудиосцену.
Первый формат, например, может содержать первое количество каналов или входных аудиосигналов и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную к первому количеству каналов или входных аудиосигналов. Второй формат, например, может содержать второе количество каналов или выходных аудиосигналов, которое может отличаться от первого количества каналов или входных аудиосигналов, и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную ко второму количеству каналов или выходных аудиосигналов. Аудиосодержимое 520 в первом формате содержит, например, один или более аудиосигналов, один или более микшированных с понижением сигналов, один или более разностных сигналов, один или более центральных сигналов, один или более боковых сигналов и/или один или более других сигналов.
Преобразователь 500 формата выполнен с возможностью регулировки 540 сложности преобразования 510 формата в зависимости от вкладов входных аудиосигналов первого формата в общую карту 142 направленной громкости аудиосцены. Аудиосодержимое 520 содержит, например, входные аудиосигналы первого формата. Вклады могут непосредственно представлять собой вклады входных аудиосигналов первого формата в общую карту 142 направленной громкости аудиосцены, или могут представлять собой вклады отдельных карт направленной громкости входных аудиосигналов первого формата в общую карту 142 направленной громкости, или могут представлять собой вклады карт направленной громкости пар входных аудиосигналов первого формата в общую карту 142 направленной громкости. В соответствии с вариантом осуществления вклады могут быть вычислены преобразователем 500 формата, как описано на фиг. 13 или фиг. 14. В соответствии с вариантом осуществления общая карта 142 направленной громкости, например, может быть описана с помощью вспомогательной информации первого формата, принятой преобразователем 500 формата. В качестве альтернативы преобразователь 500 формата выполнен с возможностью определения общей карты 142 направленной громкости на основе входных аудиосигналов аудиосодержимого 520. В некоторых случаях преобразователь 500 формата содержит модуль анализа аудиоданных, как описано в отношении фиг. 1-4b, для вычисления общей карты 142 направленной громкости, или преобразователь 500 формата выполнен с возможностью приема общей карты 142 направленной громкости от внешнего модуля анализа аудиоданных, как описано в отношении фиг. 1-4b.
Аудиосодержимое 520 в первом формате может содержать информацию о картах направленной громкости входных аудиосигналов в первом формате. На основе информации о картах направленной громкости преобразователь 500 формата, например, выполнен с возможностью получения общей карты 142 направленной громкости и/или одной или более карт направленной громкости. Одна или более карт направленной громкости могут представлять собой карты направленной громкости каждого входного аудиосигналы в первом формате и/или карты направленной громкости групп или пар сигналов в первом формате. Преобразователь 500 формата, например, выполнен с возможностью получения общей карты 142 направленной громкости из одной или более карт направленной громкости или информации о картах направленной громкости.
Регулировка 540 сложности, например, выполняется таким образом, чтобы проверять, возможен ли пропуск одного или более входных аудиосигналов первого формата, вклад которых в карту направленной громкости ниже порогового значения. Другими словами, преобразователь 500 формата, например, выполнен с возможностью вычисления или оценки вклада определённого входного аудиосигнала в общую карту 142 направленной громкости аудиосцены и принятия решения, следует ли рассмотреть определённый входной аудиосигнал в преобразование 510 формата, в зависимости от вычисления или оценки вклада. Вычисленный или оцененный вклад, например, сравнивается преобразователем 500 формата с заданным абсолютным или относительным пороговым значением.
Вклады входных аудиосигналов первого формата в общую карту 142 направленной громкости могут указывать на релевантность соответствующего входного аудиосигнала для качества восприятия аудиосодержимого 530 во втором формате. Таким образом, например, только аудиосигналы в первом формате с высокой релевантностью подвергаются преобразованию 510 формата. Это может дать в результате высококачественное аудиосодержимое 530 во втором формате.
На фиг. 19 показан аудиодекодер 400 для декодирования 410 кодированного аудиосодержимого 420. Аудиодекодер 400 выполнен с возможностью приема кодированного представления 420 одного или более аудиосигналов и обеспечения декодированного представления 412 одного или более аудиосигналов. Декодирование 410 использует, например, декодирование, подобное AAC, или декодирование подвергнутых энтропийному кодированию спектральных значений. Аудиодекодер 400 выполнен с возможностью воссоздания 430 аудиосцены с использованием декодированного представления 412 одного или более аудиосигналов. Аудиодекодер 400 выполнен с возможностью регулировки 440 сложности декодирования в зависимости от вкладов кодированных сигналов в общую карту 142 направленной громкости декодированной аудиосцены 434.
Регулировка 440 сложности декодирования может быть выполнена аудиодекодером 400 аналогично регулировке 540 сложности преобразователя 500 формата на фиг. 18.
В соответствии с вариантом осуществления аудиодекодер 400 выполнен с возможностью приема кодированной информации о картах направленной громкости, например, извлеченной из кодированного аудиосодержимого 420. Кодированная информация о картах направленной громкости может быть декодирована 410 аудиодекодером 400, чтобы определить декодированную информацию 414 о направленной громкости. На основе декодированной информации 414 о направленной громкости может быть получена общая карта направленной громкости одного или более аудиосигналов кодированного аудиосодержимого 420 и/или одна или более отдельных карт направленной громкости одного или более аудиосигналов кодированного аудиосодержимого 420. Общая карта направленной громкости одного или более аудиосигналов кодированного аудиосодержимого 420, например, получаются из одной или более отдельных карт направленной громкости.
Общая карта 142 направленной громкости декодированной аудиосцены 434 может быть вычислена посредством определения 100 карты направленной громкости, которое может быть факультативно выполнено аудиодекодером 400. В соответствии с вариантом осуществления аудиодекодер 400 содержит модуль анализа аудиоданных, как описано в отношении фиг. 1-4b, для выполнения определения 100 карты направленной громкости, или аудиодекодер 400 может передать декодированную аудиосцену 434 внешнему модулю анализа аудиоданных и принять от внешнего модуля анализа аудиоданных общую карту 142 направленной громкости декодированной аудиосцены 434.
В соответствии с вариантом осуществления аудиодекодер 400 выполнен с возможностью вычисления или оценки вклада определённого кодированного сигнала в общую карту 142 направленной громкости декодированной аудиосцены и принятия решения, следует ли декодировать 410 определённый кодированный сигнал, в зависимости от вычисления или оценки вклада. Таким образом, например, общая карта направленной громкости одного или более аудиосигналов кодированного аудиосодержимого 420 может быть сравнена с общей картой направленной громкости декодированной аудиосцены 434. Определение вкладов может быть выполнено, как описано выше (например, как описано относительно фиг. 13 или фиг. 14), или аналогичным образом.
В качестве альтернативы аудиодекодер 400 выполнен с возможностью вычисления или оценки вклада определённого кодированного сигнала в декодированную общую карту 414 направленной громкости кодированной аудиосцены и принятия решения, следует ли декодировать 410 определённый кодированный сигнал, в зависимости от вычисления или оценки вклада.
Регулировка 440 сложности, например, выполняется таким образом, чтобы проверять, возможен ли пропуск одного или более кодированных представлений одного или более входных аудиосигналов, вклад которых в карту направленной громкости ниже порогового значения.
Дополнительно или в качестве альтернативы регулировка 440 сложности декодирования может быть выполнена с возможностью адаптации параметров декодирования на основе вкладов.
Дополнительно или в качестве альтернативы регулировка 440 сложности декодирования может быть выполнена с возможностью сравнения декодированных карт 414 направленной громкости с общей картой направленной громкости декодированной аудиосцены 434 (например, общая карта направленной громкости декодированной аудиосцены 434 является целевой картой направленной громкости) для адаптации параметров декодирования.
На фиг. 20 показан вариант осуществления модуля 600 рендеринга (преобразования для прослушивания). Модуль 600 рендеринга представляет собой, например, модуль бинаурального рендеринга, или модуль рендеринга в виде звуковую панели, или модуль рендеринга в виде громкоговорителя. С помощью модуля 600 рендеринга аудиосодержимое 620 подвергается рендерингу для получения преобразованного для прослушивания аудиосодержимого 630. Аудиосодержимое 620 может содержать один или более входных аудиосигналов 622. Модуль 600 рендеринга использует, например, один или более входных аудиосигналов 622 для воссоздания 640 аудиосцены. Предпочтительно воссоздание 640, выполняемое модулем 600 рендеринга, основано на двух или более входных аудиосигналах 622. В соответствии с вариантом осуществления входной аудиосигнал 622 может содержать один или более аудиосигналов, один или более микшированных с понижением сигналов, один или более разностных сигналов, другие аудиосигналы и/или дополнительную информацию.
В соответствии с вариантом осуществления для воссоздания 640 аудиосцены модуль 600 рендеринга выполнен с возможностью анализа одного или более входных аудиосигналов 622, чтобы оптимизировать рендеринг для получения требуемой аудиосцены. Таким образом, например, модуль 600 рендеринга выполнен с возможностью модификации пространственного размещения звуковых объектов аудиосодержимого 620. Это означает, например, что модуль 600 рендеринга может воссоздать 640 новую аудиосцену. Новая аудиосцена содержит, например, перестроенные звуковые объекты по сравнению с первоначальной аудиосценой аудиосодержимого 620. Это означает, например, что гитарист, и/или певец, и/или другие звуковые объекты помещаются в новую аудиосцену в других пространственных местоположениях по сравнению с первоначальной аудиосценой.
Дополнительно или в качестве альтернативы модулем 600 рендеринга преобразовываются для прослушивания количество аудиоканалов или соотношение между аудиоканалами. Таким образом, например, модуль 600 рендеринга может преобразовать аудиосодержимое 620, содержащий многоканальный сигнал, например, в двухканальный сигнал. Например, это желательно, если для представления аудиосодержимого 620 доступны только два громкоговорителя.
В соответствии с вариантом осуществления рендеринг выполняется модулем 600 рендеринга таким образом, что новая аудиосцена проявляет линь незначительные отклонения относительно первоначальной аудиосцены.
Модуль 600 рендеринга выполнен с возможностью регулировки 650 сложности рендеринга в зависимости от вкладов входных аудиосигналов 622 в общую карту 142 направленной громкости преобразованной для прослушивания аудиосцены 642. В соответствии с вариантом осуществления преобразованная для прослушивания аудиосцена 642 может представлять собой новую аудиосцену, описанную выше. В соответствии с вариантом осуществления аудиосодержимое 620 может содержать общую карту 142 направленной громкости как вспомогательную информацию. Эта общая карта 142 направленной громкости, принятая как вспомогательная информация модулем 600 рендеринга, может указывать на требуемую аудиосцену для преобразованного для прослушивания аудиосодержимого 630. В качестве альтернативы определение 100 карты направленной громкости может определять общую карту 142 направленной громкости на основе преобразованной для прослушивания аудиосцены, принятой от блока 640 воссоздания. В соответствии с вариантом осуществления модуль 600 рендеринга может содержать определение 100 карты направленной громкости или принимать общую карту 142 направленной громкости внешнего определения 100 карты направленной громкости. В соответствии с вариантом осуществления определение 100 карты направленной громкости может быть выполнено модулем анализа аудиоданных, как описано выше.
В соответствии с вариантом осуществления регулировка 650 сложности рендеринга, например, выполняется посредством пропуска одного или более входных аудиосигналов 622. Входные аудиосигналы 622, подлежащие пропуску, например, являются сигналами, вклад которых в карту 142 направленной громкости ниже порогового значения. Таким образом, модулем 600 рендеринга преобразуются для прослушивания только релевантные входные аудиосигналы.
В соответствии с вариантом осуществления модуль 600 рендеринга выполнен с возможностью вычисления или оценки вклада определённого входного аудиосигнала 622 в общую карту 142 направленной громкости аудиосцены, например, преобразованной для прослушивания аудиосцены 642. Кроме того, модуль 600 рендеринга выполнен с возможностью принятия решения, следует ли рассматривать определённый входной аудиосигнал при рендеринге, в зависимости от вычисления или оценки вклада. Таким образом, например, вычисленный или оцененный вклад сравнивается с заданным абсолютным или относительным пороговым значением.
На фиг. 21 показан способ 1000 анализа аудиосигнала. Способ содержит получение 1100 множества взвешенных в спектральной области (например, в частотно-временно области) представлений ( для различных (j [1; J]); «направленных сигналов») на основе одного или более представлений (например, для i = {L; R}; или 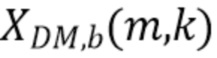 ) в спектральной области (например, в частотно-временной области) двух или более входных аудиосигналов (xL, xR, xi). Значения одного или более представлений в спектральной области (например) взвешиваются 1200 в зависимости от различных направлений (например, направления панорамирования) (например, представленных весовыми коэффициентами) звуковых компонентов (например, спектральных интервалов или спектральных полос) (например, мелодических тонов инструментов или певца) в двух или более входных аудиосигналах, чтобы получить множество взвешенных представлений в спектральной области ( для разных (j [1; J]); «направленных сигналов»). Кроме того, способ содержит получение 1300 информации о громкости (например, L(m, ) для множества различных ; например, «карты направленной громкости»), ассоциированной с разными направлениями (например, направлением панорамирования) на основе множества взвешенных представлений в спектральной области ( для различных (j [1; J]); «направленных сигналов») в качестве результата анализа.
) в спектральной области (например, в частотно-временной области) двух или более входных аудиосигналов (xL, xR, xi). Значения одного или более представлений в спектральной области (например) взвешиваются 1200 в зависимости от различных направлений (например, направления панорамирования) (например, представленных весовыми коэффициентами) звуковых компонентов (например, спектральных интервалов или спектральных полос) (например, мелодических тонов инструментов или певца) в двух или более входных аудиосигналах, чтобы получить множество взвешенных представлений в спектральной области ( для разных (j [1; J]); «направленных сигналов»). Кроме того, способ содержит получение 1300 информации о громкости (например, L(m, ) для множества различных ; например, «карты направленной громкости»), ассоциированной с разными направлениями (например, направлением панорамирования) на основе множества взвешенных представлений в спектральной области ( для различных (j [1; J]); «направленных сигналов») в качестве результата анализа.
На фиг. 22 показан способ 2000 оценки сходства аудиосигналов. Способ содержит получение 2100 первой информации о громкости (L1(m, ); карты направленной громкости; значения объединенной громкости), ассоциированной с различным направлениями (например, панорамирования) (например) , на основе первого множества из двух или более входных аудиосигналов (xR, xL, xi) и сравнение 2200 первой информация о громкости (L1(m, )) со второй (например, соответствующей) информацией о громкости (L2(m, )); эталонной информацией о громкости; эталонной картой направленной громкости; эталонным значением объединенной громкости), ассоциированной с различными направлениями панорамирования (например) и с множеством из двух или более эталонных аудиосигналов (x2,R, x2,L, x2,i), для получения 2300 информации о сходстве (например, «выходной переменной модели» (MOV)) описывающей сходство между первым множеством из двух или более входных аудиосигналов (xR, xL, xi) и множеством из двух или более эталонных аудиосигналов (x2,R, x2,L, x2,i) (или представляющей качество первого множества из двух или более входных аудиосигналов при сравнении с множеством из двух или более эталонных аудиосигналов).
На фиг. 23 показан способ 3000 кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Способ содержит обеспечение 3100 одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе одного или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала), или одного или более полученных из них сигналов (например, центрального сигнала, или микшированного с понижением сигнала и бокового сигнала, или сигнала разности). Дополнительно способ 3000 содержит адаптацию 3200 обеспечения одного или более кодированных аудиосигналов в зависимости от одной или более карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, направлением панорамирования) одного или более подлежащих кодированию сигналов (например, в зависимости от вкладов отдельных карт направленной громкости одного или более сигналов, подлежащих квантованию, в общую карту направленной громкости, например, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов)).
На фиг. 24 показан способ 4000 кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Способ содержит обеспечение 4100 одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе двух или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала), или на основе двух или более полученных из них сигналов с использованием совместного кодирования двух или более подлежащих совместному кодированию сигналов (например, с использованием центрального сигнала или микшированного с понижением сигнала и бокового сигнала или сигнала разности). Кроме того, способ 4000 содержит выбор 4200 сигналов, подлежащих совместному кодированию, из множества возможных сигналов или из множества пар возможных сигналов (например, из двух или более входных аудиосигналов или из двух или более полученных из них сигналов) в зависимости от карт направленной громкости, которые представляют информацию о громкости, ассоциированную с множеством различных направлений (например, направлением панорамирования) возможных сигналов или пар возможных сигналов (например, в зависимости от вкладов отдельных карт направленной громкости возможных сигналов в общую карту направленной громкости, например, ассоциированную с несколькими входными аудиосигналами (например, с каждым сигналом из одного или более входных аудиосигналов), или в зависимости от вкладов карт направленной громкости пар возможных сигналов в общую карту направленной громкости).
На фиг. 25 показан способ 5000 кодирования входного аудиосодержимого, содержащего один или более входных аудиосигналов (предпочтительно множество входных аудиосигналов). Способ содержит обеспечение 5100 одного или более кодированных (например, квантованных и затем кодированных без потерь) аудиосигналов (например, кодированных представлений в спектральной области) на основе двух или более входных аудиосигналов (например, сигнала левого канала и сигнала правого канала), или на основе двух или более полученных из них сигналов. Дополнительно способ 5000 содержит определение 5200 общей карты направленной громкости (например, целевой карты направленной громкости сцены) на основе входных аудиосигналов и/или определение одного или более отдельных карт направленной громкости, ассоциированных с отдельными входными аудиосигналами, и кодирование 5300 общей карты направленной громкости и/или одной или более отдельных карт направленной громкости в качестве вспомогательной информации.
На фиг. 26 показан способ 6000 декодирования кодированного аудиосодержимого, содержащий прием 6100 кодированного представления одного или более аудиосигналов и обеспечение 6200 декодированного представления одного или более аудиосигналов (например, с использованием декодирования, подобного AAC, или с использованием декодирования подвергнутых энтропийному кодированию спектральных значений). Способ 6000 содержит прием 6300 кодированной информации о картах направленной громкости и декодирование 6400 кодированной информации о картах направленной громкости, чтобы получить 6500 одну или более (декодированных) карт направленной громкости. Дополнительно способ 6000 содержит восстановление 6600 аудиосцены с использованием декодированного представления одного или более аудиосигналов и с использованием одной или более карт направленной громкости.
На фиг. 27 показан способ 7000 преобразования 7100 формат аудиосодержимого, который представляет аудиосцену (например, пространственную аудиосцену), из первого формата во второй формат (причем первый формат, например, может содержать первое количество каналов или входных аудиосигналов и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную к первому количеству каналов или входных аудиосигналов, и причем второй формат, например, может содержать второе количество каналов или выходных аудиосигналов, которое могут отличаться от первого количества каналов или входных аудиосигналов, и вспомогательную информацию или пространственную вспомогательную информацию, адаптированную ко второму количеству каналов или выходных аудиосигналов). Способ 7000 содержит обеспечение представления аудиосодержимого во втором формате на основе представления аудиосодержимого в первом формате и регулировку 7200 сложности преобразования формата (например, посредством пропуска одного или более входных аудиосигналов первого формата, вклад которых в карту направленной громкости ниже порогового значения, в процессе преобразования формата) в зависимости от вкладов входных аудиосигналов первого формата (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости аудиосцены (причем общая карта направленной громкости, например, может быть описана вспомогательной информацией первого формата, принятой преобразователем формата).
На фиг. 28 показан способ 8000 декодирования кодированного аудиосодержимого, содержащий прием 8100 кодированного представления одного или более аудиосигналов и обеспечение 8200 декодированного представления одного или более аудиосигналов (например, с использованием декодирования, подобного AAC, или с использованием декодирования подвергнутых энтропийному кодированию спектральных значений). Способ 8000 содержит восстановление 8300 аудиосцены с использованием декодированного представления одного или более аудиосигналов. Дополнительно способ 8000 содержит регулировку 8400 сложности декодирования в зависимости от вкладов кодированных сигналов (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости декодированной аудиосцены.
На фиг. 29 показан способ 9000 рендеринга аудиосодержимого (например, для повышающего микширования аудиосодержимого, представленного с использованием первого количества входных аудиоканалов и вспомогательной информации, описывающей желаемые пространственные характеристики, такие как размещение звуковых объектов или соотношение между аудиоканалами, в представление, содержащее количество каналов, которое больше, чем первое количество входных аудиоканалов), содержащий восстановление 9100 аудиосцены на основе одного или более входных аудиосигналов (или на основе двух или более входных аудиосигналов). Способ 9000 содержит регулировку 9200 сложности рендеринга (например, посредством пропуска одного или более входных аудиосигналов, вклады которых в карту направленной громкости ниже порогового значения, в процессе рендеринга) в зависимости от вкладов входных аудиосигналов (например, одного или более аудиосигналов, одного или более микшированных с понижением сигналов, одного или более разностных сигналов и т.д.) в общую карту направленной громкости преобразованной для прослушивания аудиосцены (причем общая карта направленной громкости, например, может быть описана вспомогательной информацией, принятой модулем рендеринга).
Замечания
Далее будут описаны различные варианты осуществления изобретения и аспекты в главе «Объективная оценка качества пространственного звучания с использованием карт направленной громкости», в главе «Использование направленной громкости для аудиокодирования и объективного измерения качества», в главе «Направленная громкость для аудиокодирования», в главе «Общие этапы для вычисления карты направленной громкости (DirLoudMap)», в главе «Пример: Восстановление направленных сигналов с помощью функции оконной обработки/выбора, полученной из индекса панорамирования» и в главе «Варианты осуществления различных форм вычисления карт громкости с использованием обобщенных оценочных функций».
Кроме того, дополнительные варианты осуществления будут определены приложенной формулой изобретения.
Следует отметить, что любые варианты осуществления, определенные в формуле изобретения, могут быть дополнены любыми из деталей (признаков и функциональных возможностей), описанных в вышеупомянутых главах.
Кроме того, варианты осуществления, описанные в вышеупомянутых главах, могут использоваться отдельно, а также могут быть дополнены любым из признаков в другой главе или любым признаком, включенным в формулу изобретения.
Кроме того, следует отметить, что отдельные аспекты, описанные в настоящем документе, могут использоваться по отдельности или в сочетании. Таким образом, детали могут быть добавлены к каждому из упомянутых отдельных аспектов без добавления деталей к другому из упомянутых аспектов.
Также следует отметить, что настоящее раскрытие описывает, явно или неявно, признаки, используемые в аудиокодере (устройстве для обеспечения кодированного представления входного аудиосигнала) и в аудиодекодере (устройстве для обеспечения декодированного представления аудиосигнала на основе кодированного представления). Таким образом, любой из описанных здесь признаков может использоваться в контексте аудиокодера и в контексте аудиодекодера.
Кроме того, любые раскрытые в настоящем документе признаки и функциональные возможности, относящиеся к способу, также могут использоваться в устройстве (выполненном с возможностью реализации таких функциональных возможностей). Кроме того, любые признаки и функциональные возможности, раскрытые в настоящем документе в отношении устройства, также могут использоваться в соответствующем способе. Другими словами, способы, раскрытые в настоящем документе, могут быть дополнены любыми из признаков и функциональных возможностей, описанных в отношении устройств.
Кроме того, любые из признаков и функциональных возможностей, описанных в настоящем документе, могут быть реализована в аппаратном или программном обеспечении или с использованием комбинации аппаратного и программного обеспечения, как будет описано в разделе “Альтернативы реализации”.
Альтернативы реализации
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, в котором блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока, или элемента или признака соответствующего устройства. Некоторые или все этапы способа могут быть исполнены посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления один или более из наиболее важных этапов способа могут исполняться таким устройством.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может быть выполнена с использованием цифрового запоминающего носителя, например, дискеты, цифрового универсального диска (DVD), диска Blu-Ray, компакт-диска (CD), постоянного запоминающего устройства (ROM), программируемого постоянного запоминающего устройства (PROM), стираемого программируемого постоянного запоминающего устройства (EPROM), электрически стираемого программируемого постоянного запоминающего устройства (EEPROM) и флэш-памяти, имеющего сохраненные на нем считываемые электронным образом сигналы, которые взаимодействуют (или способны к взаимодействию) с программируемой компьютерной системой, в результате чего выполняется соответствующий способ. Таким образом, цифровой носитель информации может являться машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных, имеющий считываемые электронным образом управляющие сигналы, которые способны к взаимодействию с программируемой компьютерной системой, в результате чего выполняется один из описанных здесь способов.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, программный код способен функционировать для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в настоящем документе способов, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления способа изобретения, таким образом, представляет собой компьютерную программу, имеющую программный код для выполнения одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способов изобретения, таким образом, представляет собой носитель данных (или цифровой запоминающий носитель или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровой запоминающий носитель или носитель с записанными данными обычно являются материальными и/или непереходными.
Дополнительный вариант осуществления способа изобретения, таким образом, представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов, например, могут быть выполнены с возможностью передачи через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, выполненную с возможностью переноса (например, в электронном или оптическом виде) компьютерной программы для выполнения одного из способов, описанных в настоящем документе, к приемнику. Приемник, например, может являться компьютером, мобильным устройством, запоминающим устройством и т.п. Устройство или система, например, могут содержать файловый сервер для переноса компьютерной программы к приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторой или всей функциональности способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Обычно способы предпочтительно выполняются любым аппаратным устройством.
Устройство, описанное в настоящем документе, может быть реализовано с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Устройство, описанное в настоящем документе, или любые компоненты устройства, описанного в настоящем документе, могут быть реализованы по меньшей мере частично в аппаратном и/или программном обеспечении.
Способы, описанные в настоящем документе, могут быть выполнены с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в настоящем документе, или любые компоненты устройства, описанного в настоящем документе, могут быть выполнены по меньшей мере частично аппаратным и/или программным обеспечением.
Описанные выше варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Подразумевается, что модификации и вариации размещений и подробностей, описанных в настоящем документе, будут очевидны для других специалистов в данной области техники. Таким образом, подразумевается, что изобретение ограничено только объемом последующей патентной формулы изобретения, а не конкретными подробностями, представленными посредством описания и разъяснения представленных в настоящем документе вариантов осуществления.
Объективная оценка качества пространственного звучания с использованием карт направленной громкости
2. Реферат
В этой работе вводится признак, например, извлеченный из стереофонических/бинауральных аудиосигналов, служащий для измерения воспринимаемого ухудшения качества в обработанных пространственных аудиосценах. Эта функция может быть основана на упрощенной модели, предполагающей стереомикширование, созданное направленными сигналами, расположенными с использованием методики панорамирования уровня амплитуды. Мы вычисляем, например, соответствующую громкость в стереофоническом образе для каждого направленного сигнала в области кратковременного преобразования Фурье (STFT), чтобы сравнить эталонный сигнал и ухудшенную версию и получить меру искажения, направленную на описание показателей воспринимаемого ухудшения, полученных в тестах прослушивания.
Эта мера была протестирована на обширной базе данных тестов прослушивания со стереосигналами, обработанными перцептивными аудиокодеками существующего уровня техники с использованием методов, не сохраняющих форму волны, таких как расширение полосы и совместное стереокодирование, известных тем, что они вызывают затруднения для существующих предикторов качества [1], [2]. Результаты показывают, что полученная мера искажения может быть включена в качестве дополнения к существующим автоматизированным алгоритмам оценки качества восприятия для улучшения прогнозирования пространственно кодированных аудиосигналов.
Ключевые слова - пространственное звучание, объективная оценка качества, PEAQ, индекс панорамирования.
1. Введение
Мы предлагаем простой признак, направленный на описание ухудшения воспринимаемого звукового стереофонического образа, например, на основе изменения громкости в областях, которые имеют общий индекс панорамирования [13]. Например, это частотно-временные области бинаурального сигнала, которые имеют одинаковое соотношение уровней интенсивности между левым и правым каналами, и поэтому соответствуют определённому воспринимаемому направлению в горизонтальной плоскости звукового образа.
Использование измерений направленной громкости в контексте анализа аудиосцены для рендеринга аудиоданных сложных виртуальных сред также предложено в [14], тогда как текущая работа сосредоточена на общей объективной оценке качества пространственного аудиокодирования.
Воспринимаемое искажение стереофонического образа может быть отражено в виде изменений на карте направленной громкости определённой степени детализации, соответствующей количеству значений индексов панорамирования, которые должны быть оценены в качестве параметра.
2. Способ
В соответствии с вариантом осуществления эталонный сигнал (REF) и тестируемый сигнал (SUT) обрабатываются параллельно, чтобы извлечь признаки, которые направлены на описание - при сравнении - ухудшения качества воспринимаемого аудиоданных, вызванного операциями, выполняемыми для получения сигнала SUT.
Оба бинауральных сигнала могут быть сначала обработаны блоком периферийной модели уха. Каждый входной сигнал, например, подвергается декомпозиции в область преобразования STFT с использованием окна Ханна с размером блока  отсчета и наложением
отсчета и наложением  , задающими временное разрешение 21 мс при частоте дискретизации FS=48 кГц. Частотные интервалы преобразованного сигнала затем, например, группируются для учета частотной селективности передней части ушного лабиринта человека по шкале ERB [15] в общей сложности в
, задающими временное разрешение 21 мс при частоте дискретизации FS=48 кГц. Частотные интервалы преобразованного сигнала затем, например, группируются для учета частотной селективности передней части ушного лабиринта человека по шкале ERB [15] в общей сложности в 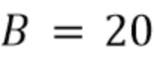 подмножествах частотных интервалов или частотных полосах. Затем каждая частотная полоса может быть взвешена посредством значения, полученного из объединенной линейной передаточной функции, которая моделирует внешнее и среднее ухо, как описано в [3].
подмножествах частотных интервалов или частотных полосах. Затем каждая частотная полоса может быть взвешена посредством значения, полученного из объединенной линейной передаточной функции, которая моделирует внешнее и среднее ухо, как описано в [3].
Затем периферийная модель выдает сигналы 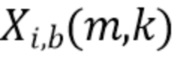 в каждом временном кадре
в каждом временном кадре  и частотном интервале
и частотном интервале  , и для каждого канала
, и для каждого канала 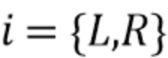 и каждой группы частот
и каждой группы частот 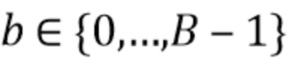 с разной шириной
с разной шириной  , выраженной в частотных интервалах.
, выраженной в частотных интервалах.
2.1. Вычисление направленной громкости (например, выполняемое описанным в настоящем документе модулем анализа аудиоданных и/или модулем оценки сходства аудиоданных)
В соответствии с вариантом осуществления вычисление направленной громкости может быть выполнено для различных направлений таким образом, что, например, определённое направление панорамирования  может интерпретироваться как
может интерпретироваться как  , где j ϵ [1; J]. Следующая концепция основана на методе, представленном в [13], в котором мера сходства между левым и правым каналами бинаурального сигнала в области преобразования STFT может быть использована для извлечения частотно-временных областей, занятых каждым источником в стереофонической записи, на основе их обозначенных коэффициентов панорамирования в процессе микширования.
, где j ϵ [1; J]. Следующая концепция основана на методе, представленном в [13], в котором мера сходства между левым и правым каналами бинаурального сигнала в области преобразования STFT может быть использована для извлечения частотно-временных областей, занятых каждым источником в стереофонической записи, на основе их обозначенных коэффициентов панорамирования в процессе микширования.
С учетом выходного сигнала периферийной модели частотно-временная (T/F) ячейка 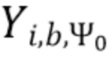 может быть восстановлена из входного сигнала, соответствующего определённому направлению панорамирования , посредством умножения входного сигнала на оконную функцию
может быть восстановлена из входного сигнала, соответствующего определённому направлению панорамирования , посредством умножения входного сигнала на оконную функцию 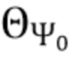 :
:
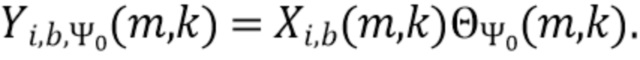 (1)
(1)
Восстановленный сигнал будет иметь частотно-временные компоненты входного сигнала, которые соответствуют направлению панорамирования в пределах значения допуска. Функция оконной обработки может быть определена как гауссово окно, центрированное в требуемом направлении панорамирования:
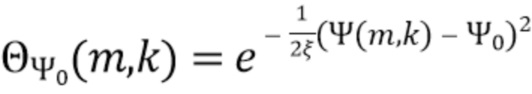 (2)
(2)
где 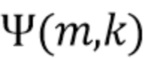 - индекс панорамирования, вычисляемый в [13] с определенной поддержкой
- индекс панорамирования, вычисляемый в [13] с определенной поддержкой 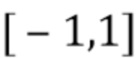 соответствующих сигналов, панорамированных полностью влево или вправо, соответственно. Действительно, может содержать частотные интервалы, значения которых в левом и правом каналах приведут к тому, что функция будет иметь значение или вблизи него. Все другие компоненты могут быть ослаблены в соответствии с гауссовой функцией. Значение представляет ширину окна и, таким образом, упомянутую окрестность для каждого направления панорамирования. Значение =0,006 было выбрано, например, для отношения сигнал/помеха (SIR) в -60 дБ [13]. Факультативно множество из 22 равномерно расположенных направлений панорамирования в пределах выбирается эмпирически для значений . Для каждого восстановленного сигнала вычисление громкости [16] в каждой частотной полосе ERB и в зависимости от направления панорамирования выражается, например, следующим образом:
соответствующих сигналов, панорамированных полностью влево или вправо, соответственно. Действительно, может содержать частотные интервалы, значения которых в левом и правом каналах приведут к тому, что функция будет иметь значение или вблизи него. Все другие компоненты могут быть ослаблены в соответствии с гауссовой функцией. Значение представляет ширину окна и, таким образом, упомянутую окрестность для каждого направления панорамирования. Значение =0,006 было выбрано, например, для отношения сигнал/помеха (SIR) в -60 дБ [13]. Факультативно множество из 22 равномерно расположенных направлений панорамирования в пределах выбирается эмпирически для значений . Для каждого восстановленного сигнала вычисление громкости [16] в каждой частотной полосе ERB и в зависимости от направления панорамирования выражается, например, следующим образом:
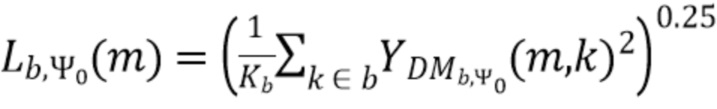 (3)
(3)
где  - суммарный сигнал каналов . Затем громкость усредняется, например, по всем частотным полосам ERB, чтобы обеспечить карту направленной громкости, определенную в области панорамирования
- суммарный сигнал каналов . Затем громкость усредняется, например, по всем частотным полосам ERB, чтобы обеспечить карту направленной громкости, определенную в области панорамирования 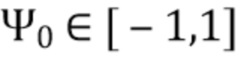 по временному кадру :
по временному кадру :
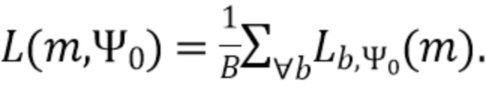 (4)
(4)
Для дальнейшего уточнения уравнение 4 может быть вычислено только с учетом подмножества полос ERB, соответствующих частотным областям 1,5 кГц и выше, чтобы приспособиться к чувствительности слуховой системы человека до разностей уровней в этой области, согласно теории дуплекса [17]. В соответствии с вариантом осуществления используются полосы 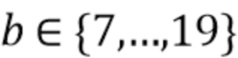 , соответствующие частотам от 1,34 кГц до
, соответствующие частотам от 1,34 кГц до  .
.
В качестве шага, например, карты направленной громкости на время эталонного сигнала и сигнала SUT вычитаются, и затем абсолютное значение разности усредняется по всем направлениям панорамирования и времени для получения одного числа, следуя терминологии в [3] называемого выходной переменной модели (MOV). Ожидается, что это число, эффективно выражающее искажение между картами направленной громкости эталонного и тестируемого сигналов, будет предсказывать ассоциированное субъективное ухудшение качества, о котором сообщается в тестах прослушивания.
На фиг. 9 показана блок-схема для предложенного вычисления MOV (выходного значения модели). На фиг. 10a-10c показан пример применения концепции карты направленной громкости к паре из эталонного (REF) и ухудшенного (SUT) сигналов и абсолютное значение их разности (DIFF). На фиг. 10a к 10c показан пример записи соло скрипки с продолжительностью 5 секунд, панорамированной влево. Более ясные области на картах представляют, например, более громкое содержание. Ухудшенный сигнал (SUT) представляет временной коллапс направления панорамирования акустического события от левой стороны к центру между моментами времени 2 и 2,5 секунды, и снова между 3 и 3,5 секунды.
3. Описание эксперимента
Чтобы проверить и подтвердить полезность предложенного значения MOV, был проведен регрессионный эксперимент, аналогичный описанному в [18], в котором значения MOV были рассчитаны для пар эталонного и тестируемого сигналов в базе данных и сравнены с их соответствующими субъективными оценками качества из теста прослушивания. Эффективность прогнозирования системы, использующей это значение MOV, оценивается с точки зрения корреляции с субъективными данными ( ), оценки абсолютной погрешности (
), оценки абсолютной погрешности ( ) и количества выбросов (
) и количества выбросов (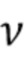 ), как описано в [3].
), как описано в [3].
База данных, используемая для эксперимента, соответствует части теста верификации унифицированного кодирования речи и аудиоданных (USAC), множество 2 [19], который содержит стереосигналы, кодированные на битовых скоростях в пределах от 16 до 24 Кбит/с с использованием инструментов совместного стерео [12] и расширения частотной полосы наряду с их качественной оценкой по шкале MUSHRA. Речевые элементы были исключены, поскольку предложенное значение MOV, как ожидается, не будет описывать основную причину искажения речевых сигналов. В общей сложности 88 элементов (например, средняя длина 8 секунд) остались в базе данных для эксперимента.
Для учета возможных монофонических/тембральных искажений в базе данных результаты реализации стандартного PEAQ (расширенная версия), называемого объективной оценкой разности (ODG), и POLQA, называемого средней оценкой мнения (MOS), были приняты в качестве дополнительных значений MOV, дополняющих искажение направленной громкости (DirLoudDist; например, DLD), описанных в предыдущем разделе. Все значения MOV могут быть нормализованы и адаптированы, чтобы выдать оценку 0 для указания наилучшего качества и 1 для наихудшего возможного качества. Результаты теста прослушивания были соответствующим образом масштабированы.
Одна случайная часть доступного содержимого базы данных (60%, 53 элемента) была зарезервирована для обучения регрессионной модели с использованием многомерных адаптивных регрессионных сплайнов (MARS) [8], отображающих значения MOV на субъективные оценки элементов. Остальная часть (35 пунктов) была использована для тестирования эффективности обученной регрессионной модели. Чтобы исключить влияние процедуры обучения из общего анализа эффективности значений MOV, цикл обучения/тестирования был проведен, например, 500 раз со случайными элементами обучения/тестирования, и средние значения для , и были рассмотрены в качестве показателей эффективности.
4. Результаты и обсуждение
Таблица 1: Средние значения производительности для 500 циклов обучения/подтверждения (например, тестирования) регрессионной модели с разными множествами значений MOV. CHOI представляет 3 бинауральных значения MOV, как вычислено в [20], EITDD соответствует высокочастотной огибающей значения MOV искажения ITD, как вычислено в [1]. SEO соответствует 4 бинауральным значениям MOV из [1], включая EITDD. DirLoudDist является предложенным значением MOV. Число в круглых скобках представляет общее количество используемых значений MOV (факультативно).
Таблица 1 показывает средние значения производительности (корреляция, оценка абсолютной погрешности, количество выбросов) для эксперимента, описанного в разделе 3. В дополнение к предложенному значению MOV также для сравнения были протестированы способы для объективной оценки пространственно кодированных аудиосигналов, предложенные в [20] и [1]. Обе сравниваемые реализации используют классические интерауральные искажения ориентиров, упомянутые во введении: искажение IACC (IACCD), искажение ILD (ILDD) и ITDD.
Как упомянуто, базовые рабочие характеристики заданы посредством ODG и MOS, которые отдельно достигают R=0,66, но представляют объединенный показатель R=0,77, как показано в таблице 1. Это подтверждает, что признаки являются комплементарными в оценке монофонических искажений.
С учетом работы Choi et. al. [20] добавление трех бинауральных искажений (CHOI в таблице 1) к двум монофоническим показателям качества (составляющим до пяти совместных значений MOV) не обеспечивает дальнейшего улучшения системы с точки зрения производительности прогнозирования для используемого набора данных.
В [1] были внесены некоторые дополнительные факультативные уточнения модели для упомянутых признаков с точки зрения локализации в боковой плоскости и возможности обнаружения искажений ориентиров. Кроме того, например, было включено новое значение MOV, которое учитывает высокочастотные искажения огибающей интерауральной разности во времени (EITDD) [21]. Набор из этих четырех бинауральных значений MOV (помеченных как SEO в таблице 1) плюс два монауральных дескриптора (всего шесть значений MOV) значительно повышает производительность системы для текущего набора данных.
Учитывая вклад в улучшение EITDD, возможно предположить, что частотно-временные энергетические огибающие, используемые в совместных стереофонических методах [12], представляют собой важный аспект общего восприятия качества.
Однако представленное значение MOV на основе искажений карты направленной громкости (DirLoudDist) еще лучше коррелирует с воспринимаемым ухудшением качества, чем EITDD и даже достигает сходных рабочих показателей как комбинации всех бинауральных значений MOV [1] при использовании одного дополнительного значение MOV для двух монауральных дескрипторов качества вместо четырех. Использование меньшего количества признаков для одной и той же производительности снижает риск чрезмерного обучения и указывает на их более высокую перцептивную значимость.
Максимальная средняя корреляция с субъективными оценками для базы данных 0,88 показывает, что еще имеются возможности для улучшения.
В соответствии с вариантом осуществления предложенный признак основан на описанной здесь модели, которая предполагает упрощенное описание стереосигналов, в котором звуковые объекты локализуются только в боковой плоскости с помощью ILDS, что обычно имеет место в аудиосодержимом студийного производства [13]. Для искажений ITD, обычно присутствующих при кодировании записей с несколькими микрофонами или более естественных звуков, модель должна быть либо расширена, либо дополнена подходящей мерой искажения ITD.
5. Выводы и направления дальнейших исследований
В соответствии с вариантом осуществления была введена метрика искажения, описывающая изменения в представлении аудиосцены на основе громкости событий, соответствующих определённому направлению панорамирования. Значительное увеличение производительности по отношению к только монауральному прогнозированию качества показывает эффективность предложенного метода. Этот подход также предлагает возможную альтернативу или дополнение при измерении качества для пространственного аудиокодирования с низкой битовой скоростью, когда установленные измерения искажений, основанные на классических бинауральных ориентирах, не работают удовлетворительно, возможно, вследствие не сохраняющего форму сигнала характера обработки аудиоданных, участвующего в обработке.
Измерения рабочих характеристик показывают, что до сих пор существуют сферы для улучшения до более полной модели, которая также включает в себя искажения аудиоданных на основе эффектов, не связанных с разностями уровней каналов. Дальнейшие исследования также включают в себя изучение того, каким образом модель может описать временную нестабильность/модуляцию в стереофоническом образе, как сообщается в [12], в отличие от статических искажений.
Литература
[1] Jeong-Hun Seo, Sang Bae Chon, Keong-Mo Sung, and Inyong Choi, “Perceptual objective quality evaluation method for high quality multichannel audio codecs,” J. Audio Eng. Soc, vol. 61, no. 7/8, pp. 535-545, 2013.
[2] M. Scha¨fer, M. Bahram, and P. Vary, “An extension of the PEAQ measure by a binaural hearing model,” in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, May 2013, pp. 8164- 8168.
[3] ITU-R Rec. BS.1387, Method for objective measurements of perceived audio quality, ITU-T Rec. BS.1387, Geneva, Switzerland, 2001.
[4] ITU-T Rec. P.863, “Perceptual objective listening quality assessment,” Tech. Rep., International Telecommunication Union, Geneva, Switzerland, 2014.
[5] Sven Ka¨mpf, Judith Liebetrau, Sebastian Schneider, and Thomas Sporer, “Standardization of PEAQ-MC: Extension of ITU-R BS.1387-1 to Multichannel Audio,” in Audio Engineering Society Conference: 40th International Conference: Spatial Audio: Sense the Sound of Space, Oct 2010.
[6] K Ulovec and M Smutny, “Perceived audio quality analysis in digital audio broadcasting plus system based on PEAQ,” Radioengineering, vol. 27, pp. 342-352, Apr. 2018.
[7] C. Faller and F. Baumgarte, “Binaural cue coding-Part II: Schemes and applications,” IEEE Transactions on Speech and Audio Processing, vol. 11, no. 6, pp. 520- 531, Nov 2003.
[8] Jan-Hendrik Fleßner, Rainer Huber, and Stephan D. Ewert, “Assessment and prediction of binaural aspects of audio quality,” J. Audio Eng. Soc, vol. 65, no. 11, pp. 929-942, 2017.
[9] Marko Takanen and Gae¨tan Lorho, “A binaural auditory model for the evaluation of reproduced stereo- phonic sound,” in Audio Engineering Society Conference: 45th International Conference: Applications of Time-Frequency Processing in Audio, Mar 2012.
[10] Robert Conetta, Tim Brookes, Francis Rumsey, Slawomir Zielinski, Martin Dewhirst, Philip Jackson, Søren Bech, David Meares, and Sunish George, “Spatial audio quality perception (part 2): A linear regression model,” J. Audio Eng. Soc, vol. 62, no. 12, pp. 847-860, 2015.
[11] ITU-R Rec. BS.1534-3, “Method for the subjective assessment of intermediate quality levels of coding systems,” Tech. Rep., International Telecommunication Union, Geneva, Switzerland, Oct. 2015.
[12] Frank Baumgarte and Christof Faller, “Why binaural cue coding is better than intensity stereo coding,” in Audio Engineering Society Convention 112, Apr 2002.
[13] C. Avendano, “Frequency-domain source identification and manipulation in stereo mixes for enhancement, suppression and re-panning applications,” in 2003 IEEE Workshop on Applications of Signal Processing to Au- dio and Acoustics, Oct 2003, pp. 55-58.
[14] Nicolas Tsingos, Emmanuel Gallo, and George Drettakis, “Perceptual audio rendering of complex virtual environments,” in ACM SIGGRAPH 2004 Papers, New York, NY, USA, 2004, SIGGRAPH ’04, pp. 249-258, ACM.
[15] B.C.J. Moore and B.R. Glasberg, “A revision of Zwicker’s loudness model,” Acustica United with Acta Acustica:the Journal of the European Acoustics Associ- ation, vol. 82, no. 2, pp. 335-345, 1996.
[16] E. Zwicker, “U¨ber psychologische und methodische Grundlagen der Lautheit [On the psychological and methodological bases of loudness],” Acustica, vol. 8, pp. 237-258, 1958.
[17] Ewan A. Macpherson and John C. Middlebrooks, “Listener weighting of cues for lateral angle: The duplex theory of sound localization revisited,” The Journal of the Acoustical Society of America, vol. 111, no. 5, pp. 2219-2236, 2002.
[18] Pablo Delgado, Ju¨rgen Herre, Armin Taghipour, and Nadja Schinkel-Bielefeld, “Energy aware modeling of interchannel level difference distortion impact on spatial audio perception,” in Audio Engineering Society Conference: 2018 AES International Conference on Spatial Reproduction - Aesthetics and Science, Jul 2018.
[19] ISO/IEC JTC1/SC29/WG11, “USAC verification test report N12232,” Tech. Rep., International Organisation for Standardisation, 2011.
[20] Inyong Choi, Barbara G. Shinn-Cunningham, Sang Bae Chon, and Koeng-Mo Sung, “Objective measurement of perceived auditory quality in multichannel audio compression coding systems,” J. Audio Eng. Soc, vol. 56, no. 1/2, pp. 3-17, 2008
[21] E R Hafter and Raymond Dye, “Detection of interaural differences of time in trains of high-frequency clicks as a function of interclick interval and number,” The Journal of the Acoustical Society of America, vol. 73, pp. 644- 51, 03 1983.
Использование направленной громкости для аудиокодирования и объективного измерения качества
Дополнительное описание см. в главе «Объективная оценка качества пространственного звучания с использованием карт направленной громкости».
Описание: (например, описание фиг. 9)
Представлен признак, извлеченный, например, из стереофонических/бинауральных аудиосигналов в пространственной (стерео) аудиосцене. Признак основан, например, на упрощенной модели стереомикширования, которая извлекает направления панорамирования событий в стереофоническом образе. Может быть вычислена ассоциированная громкость в стереофоническом образе для каждого направления панорамирования в области кратковременного преобразования Фурье (STFT). Признак факультативно вычисляется для эталонного и кодированного сигнала и затем сравнивается для получения меры искажения с целью описать оценку воспринимаемого ухудшения, сообщаемую в тесте прослушивания. Результаты показывают улучшенную устойчивость по отношению к низкой битовой скорости, не сохраняющим форму волны параметрическим методам, таким как совместное стерео и расширение полосы пропускания, по сравнению с существующими методами. Результаты показывают улучшенную устойчивость к низким битовым скоростям, не сохраняющим форму волны параметрическим методам, таким как совместное стерео и расширение полосы пропускания, по сравнению с существующими методами. Это может быть объединено в стандартизированных системах объективного измерения оценки качества, таких как PEAQ или POLQA (PEAQ - объективные измерения воспринимаемого качества аудиоданных; POLQA - анализ воспринимаемого объективного качества прослушивания).
Терминология:
- Сигнал: например, стереофонический сигнал, представляющий объекты, понижающие микширования, разности и т.д.
- Карта направленной громкости (DirLoudMap): например, полученная из каждого сигнала. Представляет, например, громкость в частотно-временной (T/F) области, ассоциированную с каждым направлением панорамирования в аудиосцене. Она может быть получена из более чем двух сигналов посредством использования бинаурального рендеринга (HRTF (передаточная функция слухового аппарата) / BRIR (бинауральная импульсная характеристика помещения)).
Применения (варианты осуществления):
1. Автоматическая оценка качества (вариант осуществления 1):
- Как описано в главе «Объективная оценка качества пространственного звучания с использованием карт направленной громкости»
2. Распределение битов на основе направленной громкости (вариант осуществления 2) в аудиокодере, на основе отношения (вклада) карт DirLoudMap отдельных сигналов в общей карте DirLoudMap.
- факультативная вариация 1 (независимые стереопары): аудиосигналы как громкоговорители или объекты.
- факультативная вариация 2 (понижающее микширование/разностные пары): вклад карты DirLoudMap микшированного с понижением сигнала и разностной карты DirLoudMap в общую карту DirLoudMap. "Величина вклада" в аудиосцене для критериев распределения битов.
1. Аудиокодер, выполняющий совместное кодирование двух или более каналов, например, полученных в результате в каждом одном или более сигналах понижающего микширования и разностных сигналах, в которых вклад каждого разностного сигнала в общую карту направленной громкости определяется, например, из фиксированного правила декодирования (например, MS-Stereo) или посредством оценки процесса обратного совместного кодирования из параметров совместного кодирования (например, вращения в MCT). На основе вклада разностного сигнала в общую карту DirLoudMap адаптируется распределение битовой скорости между сигналом понижающего микширования и разностным сигналом, например, посредством управления точностью квантования сигналов или с помощью непосредственного отбрасывания разностных сигналов, вклад которых ниже порогового значения. Возможные критерии «вклада», например, представляют собой среднее отношение или отношение в максимальном относительном вкладе направления.
- Проблема: комбинация и оценка вклада отдельной карты DirLoudMap в полученную в результате/общую карту громкости.
3. (вариант осуществления 3) На стороне декодера направленная громкость может помочь декодеру принять следующее обоснованное решение.
- Сложность масштабирования/преобразования формата: каждый аудиосигнал может быть включен или исключен в процессе декодирования на основе его вклада в общую карту DirLoudMap (переданного как отдельный параметр или оцененного на основе других параметров) и тем самым изменить сложность рендеринга для разных применений/преобразования формата. Это позволяет выполнять декодирование с уменьшенной сложностью, когда доступны только ограниченные ресурсы (т.е. многоканальный сигнал, преобразуется для прослушивания на мобильном устройстве).
- Поскольку полученная в результате карта DirLoudMap может зависеть от настройки целевого воспроизведения, это гарантирует, что будут воспроизведены наиболее важные/существенные сигналы для отдельного сценария, таким образом, имеется преимущество перед не пространственными подходами, такими как простой уровень приоритета сигнала/объекта.
4. Для принятия решения о совместном кодировании (вариант осуществления 4) (например, описание фиг. 14)
- Определить вклад карты направленной громкости каждого сигнала или каждой пары возможных сигналов во вклад карты DirLoudMap общей сцены.
1. факультативная вариация 1) Выбрать пару сигналов с наиболее высоким вкладом в общую карту громкости
2. факультативная вариация 2) Выбрать пару сигналов, причем сигналы имеют высокую близость/сходство в своей соответствующей карте DirLoudMap => может быть совместно представлен посредством понижающего микширования
- Поскольку возможно каскадное совместное кодирование сигналов, карта DirLoudMap, например, микшированного с понижением сигнала не обязательно соответствуют точечному источнику от одного направления (например, одному громкоговорителю), следовательно вклад в карту DirLoudMap, например, оценивается на основе параметров совместного кодирования.
- Карта DirLoudMap общей сцены может быть вычислена через некоторое понижающее микширование или бинаурализацию, которые учитывают направления сигналов.
5. Параметрический аудиокодек (вариант осуществления 5) на основе направленной громкости
- передает, например, карту направленной громкости сцены --> передается как вспомогательная информация в параметрической форме
1. «стиль PCM» = квантованные значения по направлениям
2. центральное положение + линейные градиенты для левой/правой стороны
3. полиномиальное или сплайновое представление
- передает, например, один сигнал, или меньше сигналов, или эффективную передачу,
1. факультативная модификация 1) передает параметризованную целевую карту DirLoudMap сцены+1 канал с понижающим микшированием
2. факультативная модификация 2) передает несколько сигналов, каждый с ассоциированной картой DirLoudMap
3. факультативная модификация 3) передает общую целевую карту DirLoudMap и несколько сигналов плюс параметрический относительный вклад в общую карту DirLoudMap
- синтезирует, например, полную аудиосцену на основе переданного сигнала, на основе карты направленной громкости сцены.
Направленная громкость для аудиокодирования
Введение и определения
DirLoudMap=Карта направленной громкости
Вариант осуществления для вычисления карты DirLoudMap:
a) выполнить частотно-временную декомпозицию (+ группировку в критические частотные полосы (CB)) (например, с помощью набора фильтров, преобразованием STFT, ...)
b) выполнить функцию анализа направления для каждой частотно-временной ячейки
c) ввести/накопить результат пункта b) в гистограмме карты DirLoudMap факультативно (при необходимости применения):
d) обобщить выходные данные по критическим частотным полосам (CB), чтобы обеспечить широкополосную карту DirLoudMap
Вариант осуществления уровня карты DirLoudMap/функции анализа направления:
- Уровень 1 (факультативный): Направления вклада в карты в соответствии с пространственным положением воспроизведения сигналов (каналов/объектов) - (без знания об используемом содержании сигнала). Использует функцию анализа направления, учитывающую только направление воспроизведения канала/объекта +/- направление воспроизведения окна расширения L1 канала/объекта +/- окно расширения (может быть широкополосным, т.е. одинаковым для всех частот),
- Уровень 2 (факультативный): Направления вклада в карты в соответствии с пространственным положением воспроизведения сигналов (каналов/объектов) плюс *динамическая* функция содержания сигналов каналов/объектов (функция анализа направления) разных уровней сложности.
Позволяет идентифицировать
факультативно L2a): панорамированные фантомные источники (-> индекс панорамирования) [уровень], или факультативно L2b) задержка уровень+время панорамированные фантомные источники [уровень и время], или факультативно L2c) расширенные (декоррелированные) панорамированные фантомные (еще более усовершенствованные) источники
Применения для перцептивного аудиокодирования
Вариант осуществления A) маскирование каждого канала/объекта - нет инструментов совместного кодирования -> цель: управление шумом квантования кодера (таким образом, что первоначальная и кодированная/декодированная карта DirLoudMap отклоняются менее определенного порогового значения, т.е. целевого критерия в области карт DirLoudMap),
Вариант осуществления B) маскирование каждого канала/объекта - инструменты совместного кодирования (например, M/S+предсказание, MCT)
-> цель: управление шумом квантования кодера в обработанных инструментом сигналах (например, M или сигнал вращаемой «суммы»), чтобы соответствовать целевому критерию в области карт DirLoudMap
Пример для B)
1) вычислить общую карту DirLoudMap на основе всех сигналов
2) применить инструменты совместного кодирования
3) определить вклад обработанных инструментом сигналов (например, «сумма» и «разность») к карте DirLoudMap с учетом функции декодирования (например, панорамирование посредством вращения/предсказания)
4) управлять квантованием посредством
a) учета влияния шума квантования на карту DirLoudMap
b) учета нулевых значений квантования частей сигнала в карте DirLoudMap
Вариант осуществления C) Управление применением (например, вкл/выкл MS) и/или параметрами (например, коэффициентом предсказания) инструментов совместного кодирования
цель: управление параметрами кодера/декодера инструментов совместного кодирования для соответствия целевому критерию в области карт DirLoudMap
Примеры для C)
- управлять принятием решения вкл/выкл M/S на основе карты DirLoudMap
- управлять сглаживанием зависящих от частоты коэффициентов предсказания на основе влияния изменения параметров на карту DirLoudMap
(для более дешевого дифференциального кодирования параметров)
(= управление компромиссом между вспомогательной информацией и точностью предсказания)
Вариант осуществления D) определить параметры (вкл/выкл, ILD, ...) инструментов *параметрического* совместного кодирования (например, интенсивности стерео)
-> цель: Управление параметром инструмента параметрического совместного кодирования для соответствия целевому критерию в области карт DirLoudMap
Вариант осуществления E) Параметрическая система кодера/декодера, передающая карту DirLoudMap как вспомогательную информацию (а не традиционные пространственные ориентиры, например, ILD, ITD/IPD, ICC, ...)
-> Кодер определяет параметры на основе анализа карты DirLoudMap, формирует микшированный с понижением сигнал(ы) и параметры (битового потока), например, общую карту DirLoudMap+вклад каждого сигнала в карту DirLoudMap
-> Декодер синтезирует переданную карту DirLoudMap подходящими средствами
Вариант осуществления F) Снижение сложности декодера/модуля рендеринга/преобразователя формата
Определить вклад каждого сигнала в общую карту DirLoudMap (возможно, на основе переданной вспомогательной информации), чтобы определить «важность» каждого сигнала. В применениях с ограниченной вычислительной способностью пропускать декодирование/рендеринг сигналов, вклад которых в карту DirLoudMap ниже порогового значения.
Общие этапы для вычисления карты направленной громкости (DirLoudMap)
Это, например, действительно для любой реализации: (например, описание фиг. 3a и/или фиг. 4a)
a) Выполнить частотно-временную декомпозицию нескольких входных аудиосигналов.
- факультативно: группировка спектральных компонентов в частотные полосы обработки относительно частотного разрешения слуховой системы человека (HAS)
- факультативно: взвешивание в соответствии с чувствительностью HAS в различных частотных областях (например, передаточная функция внешнего/среднего уха)
-> результат: частотно-временные ячейки (например, представления в спектральной области, спектральные полосы, спектральные интервалы, …)
Для (FOR) нескольких (например, каждых) частотных полос (контуров):
b) Вычислить, например, направленную аналитическую функцию на частотно-временных ячейках нескольких входных аудиоканалов-> результат: направление d (например, направление или направление панорамирования ).
c) Вычислить, например, громкость на частотно-временных ячейках нескольких входных аудиоканалов
-> результат: громкость L
- Вычисление громкости может представлять собой просто энергию, или - конкретнее - энергию (или по модели Цвикера: альфа=0,25-0,27)
d.a) например, ввести/накопить вклад l в карту DirLoudMap под направлением d
- Факультативно: расширение (индекс панорамирования: оконная обработка) l распределений между смежными направлениями
конец для (END FOR)
факультативно (при необходимо для применения): вычислить широкополосную карту DirLoudMap
d.b) обобщить карту DirLoudMap по нескольким (избегать: по всем) частотным полосам, чтобы обеспечить широкополосную карту DirLoudMap, указывающую «активность» аудиоданных в зависимости от направления/пространства
Пример: Восстановление направленных сигналов с помощью функции оконной обработки/выбора, полученной из индекса панорамирования (описание фиг. 6)
Сигналы левого (см. фиг. 6a; красный цвет) и правого (см. фиг. 6b; синий цвет) каналов, например, показаны на фиг. 6a и фиг. 6b. Полосы могут представлять собой интервалы DFT (дискретного преобразования Фурье) целого спектра, критические частотные полосы (группы частотных интервалов), или интервалы DFT в пределах критической частотной полосы и т.д.
Критериальная функция произвольным образом определена как: 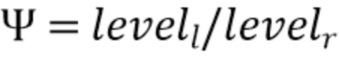 .
.
Критерий, например, представляет собой «направление панорамирования в соответствии с уровнем». Например, уровень каждого или более интервалов FFT.
a) Из критериальной функции мы можем извлечь оконную функцию/функцию взвешивания, которая выбирает соответствующие частотные интервалы/спектральные группы/компоненты и восстанавливает направленные сигналы. Таким образом, входной спектр (например, L и R) будет умножен на различные оконные функции  (одна оконная функция на каждое направление панорамирования )
(одна оконная функция на каждое направление панорамирования )
b) Из оценочной функции мы получаем различные направления, ассоциированные с различными значениям (т.е. отношениями уровней между L и R)
Для восстановления сигналов с использованием способа a)
Пример 1) Центральное направления панорамирования,  (содержит полосы, только имеющие соотношение
(содержит полосы, только имеющие соотношение  . Это направленный сигнал (см. фиг. 6a1 и фиг. 6b1).
. Это направленный сигнал (см. фиг. 6a1 и фиг. 6b1).
Пример 2) Направление панорамирования немного смещено влево, 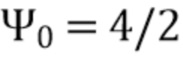 (содержит только полосы, которые имеют соотношение
(содержит только полосы, которые имеют соотношение 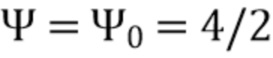 . Это направленный сигнал (см. фиг. 6a2 и рис. 6b2).
. Это направленный сигнал (см. фиг. 6a2 и рис. 6b2).
Пример 3) Направление панорамирования немного смещено вправо, 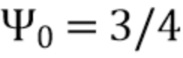 (содержит только полосы, которые имеют соотношение
(содержит только полосы, которые имеют соотношение 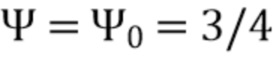 , это направленный сигнал (см. фиг. 6a3.1 и фиг. 6b3.1).
, это направленный сигнал (см. фиг. 6a3.1 и фиг. 6b3.1).
Критериальная функция может быть произвольным образом определена как уровень каждого интервала DFT, энергия для группы интервалов DFT (критическая частотная полоса) 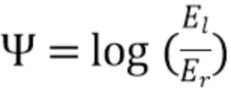 или громкость для каждой критической частотной полосы
или громкость для каждой критической частотной полосы 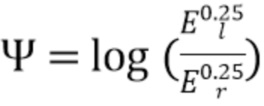 . Для разных применений возможны различные критерии.
. Для разных применений возможны различные критерии.
Взвешивание (факультативно)
Примечание: не следует путать с взвешиванием с помощью передаточной функции внешнего/среднего уха (периферийная модель), которая взвешивает, например, критические полосы.
Взвешивание: факультативно вместо точного значения используется допустимый диапазон и вес менее важных значений, которые отклоняются от т.е. “извлечь все полосы, которые удовлетворяют соотношению 4/3 и передать их с весовым коэффициентом 1, находящиеся вблизи значения взвесить с коэффициентом меньше 1 -> для этого может использоваться гауссова функция. В упомянутых выше примерах направленные сигналы имели бы больше интервалов, взвешенных не со значением 1, а с меньшими значениями.
Мотивация: взвешивание дает возможность «более гладкого» перехода между различными направленными сигналами, разделение является не настолько резким, поскольку имеется некоторая «утечка» среди различных направленных сигналов.
Например 3), это может выглядеть, как показано на фиг. 6a3.2 и фиг. 6b3.2.
Варианты осуществления различных форм вычисления карт громкости с использованием обобщенных оценочных функций
Факультативный вариант 1: подход с использованием индекса панорамирования (см. фиг. 3a и фиг. 3b):
Для (всех) различных может быть собрана карта «значений» для этой функции во времени. Так называемая «карта направленной громкости» может быть построена в соответствии с одним из следующих примеров.
- Пример 1) с использованием критериальной функции «направления панорамирования в соответствии с уровнем отдельных интервалов FFT» 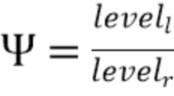 , таким образом, направленные сигналы, например, состоят из отдельных интервалов DFT. Затем, например, с использованием вычисления энергии в каждой критической полосе (группе интервалов DFT) для каждого направленного сигнала, и затем подъема этих энергий для каждой критической полосы с экспонентой 0,25 или подобной. -> аналогично главе «Объективная оценка качества пространственного звучания с использованием карт направленной громкости».
, таким образом, направленные сигналы, например, состоят из отдельных интервалов DFT. Затем, например, с использованием вычисления энергии в каждой критической полосе (группе интервалов DFT) для каждого направленного сигнала, и затем подъема этих энергий для каждой критической полосы с экспонентой 0,25 или подобной. -> аналогично главе «Объективная оценка качества пространственного звучания с использованием карт направленной громкости».
- Пример 2) Вместо оконной обработки амплитудного спектра можно выполнять оконную обработку спектра громкости. Направленные сигналы будут находиться уже в области громкости.
- Пример 3) с использованием непосредственно критериальной функции «направления панорамирования в соответствии с громкостью каждой критической полосы» 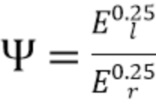 . Тогда направленные сигналы будут состоять из участков целых критических полос, которые подчиняются значениям, заданным посредством .
. Тогда направленные сигналы будут состоять из участков целых критических полос, которые подчиняются значениям, заданным посредством .
Например, для 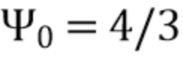 направленный сигнал может представлять собой:
направленный сигнал может представлять собой:
Y= 1*critical_band_1+0,2*critical_band_2+0,001*critical_band_3.
и различные комбинации применяются для других направлений/направленных сигналов панорамирования. Следует отметить, что в случае использования взвешивания разные направления панорамирования могут содержать одни и те же критические полосы, но скорее всего с разными значениями весового коэффициента. Если взвешивание не применяется, направленные сигналы являются взаимоисключающими.
Факультативный вариант 2: подход с использованием гистограммы (см. фиг. 4b):
Это более общее описание общей направленной громкости. Оно не обязательно использует индекс панорамирования (т.е. не нужно восстанавливать «направленные сигналы» посредством оконной обработки спектра для вычисления громкости). Частотный спектр общей громкости «распределен» в соответствии с «проанализированным направлением» в соответствующей частотной области. Анализ направления может быть основан на разности уровней, временной разности или иметь другую форму.
Для каждого временного кадра (см. фиг. 5):
Разрешение гистограммы 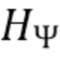 будет задано, например, величиной значений, заданных множеству . Например, это величина интервалов, доступных для группировки случаев
будет задано, например, величиной значений, заданных множеству . Например, это величина интервалов, доступных для группировки случаев  при оценке во временном кадре. Например, значения накапливаются и сглаживаются по времени, возможно с «коэффициентом забывания»
при оценке во временном кадре. Например, значения накапливаются и сглаживаются по времени, возможно с «коэффициентом забывания» 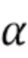 :
:
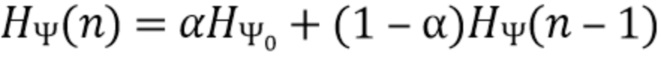
Где n - индекс временного кадра.
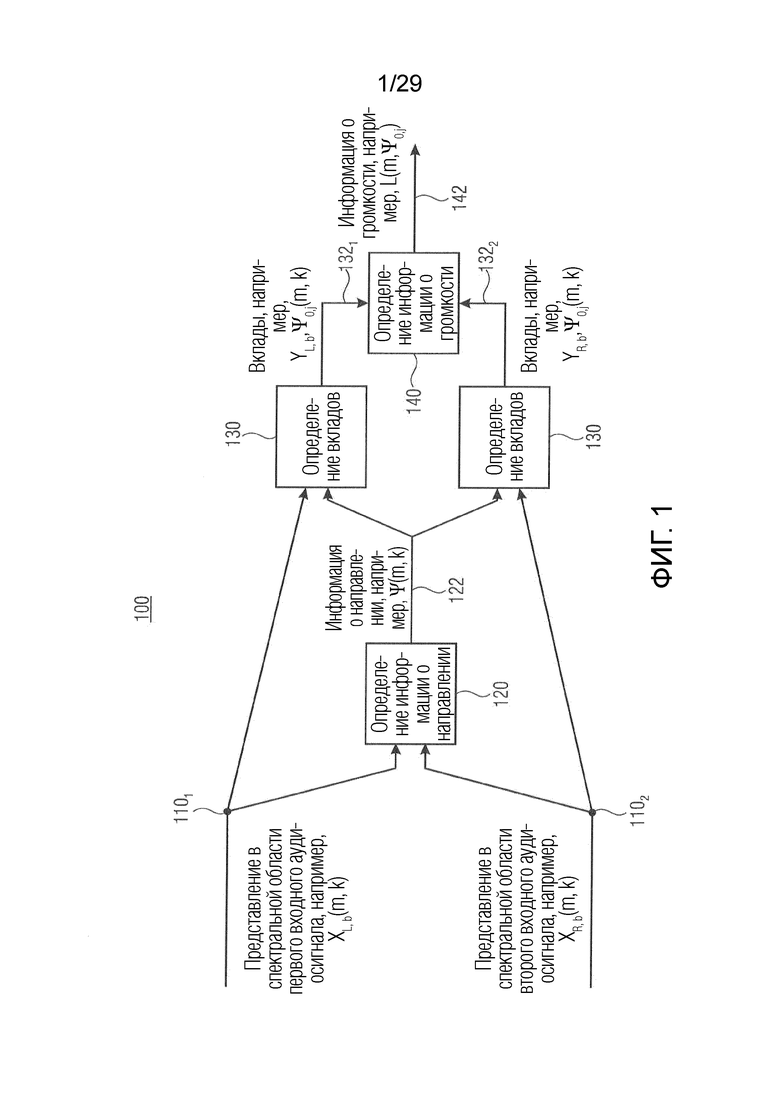
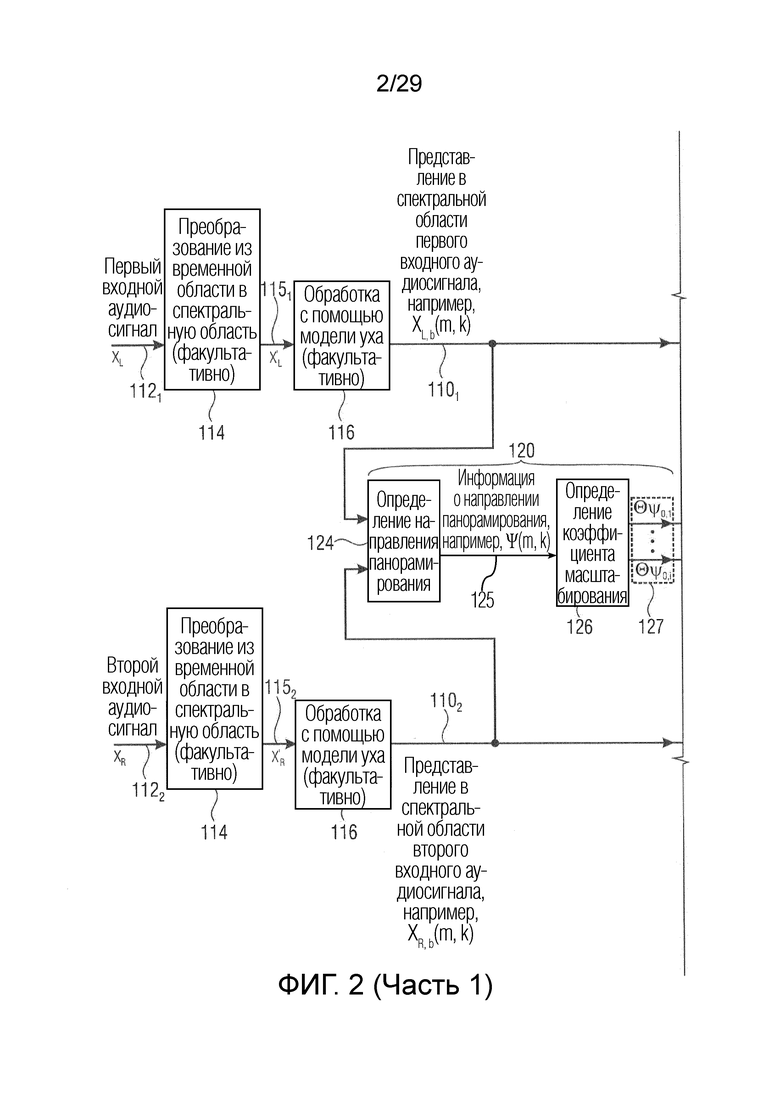
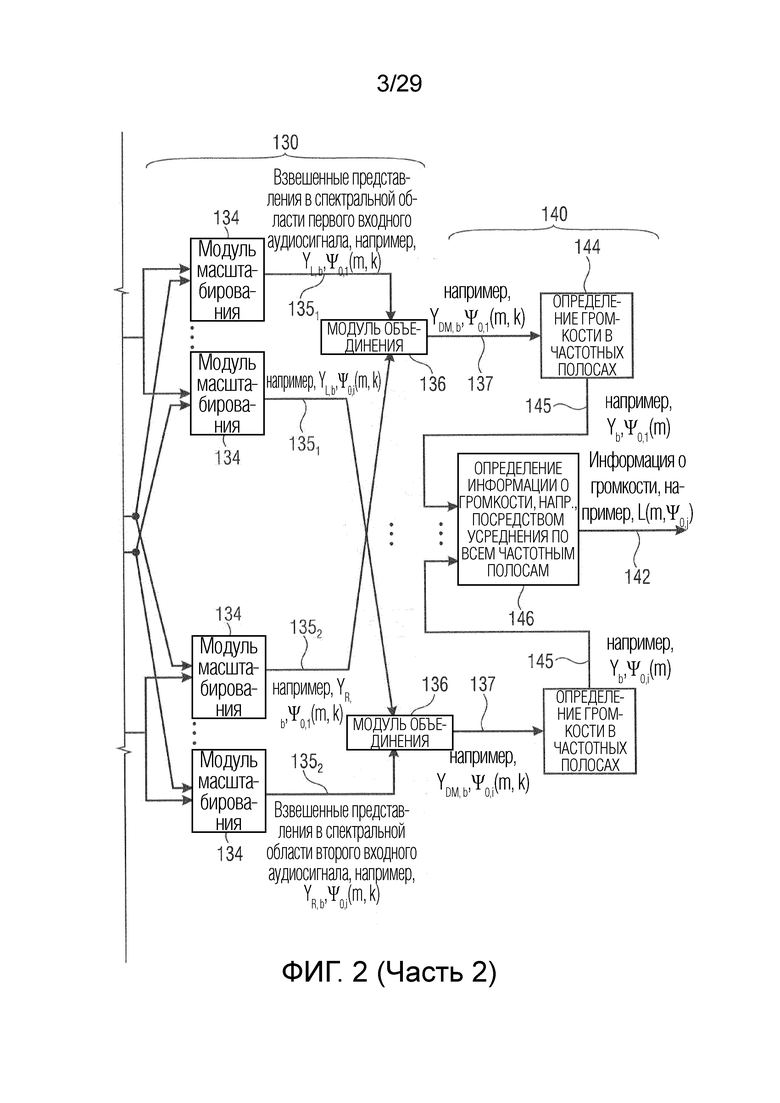
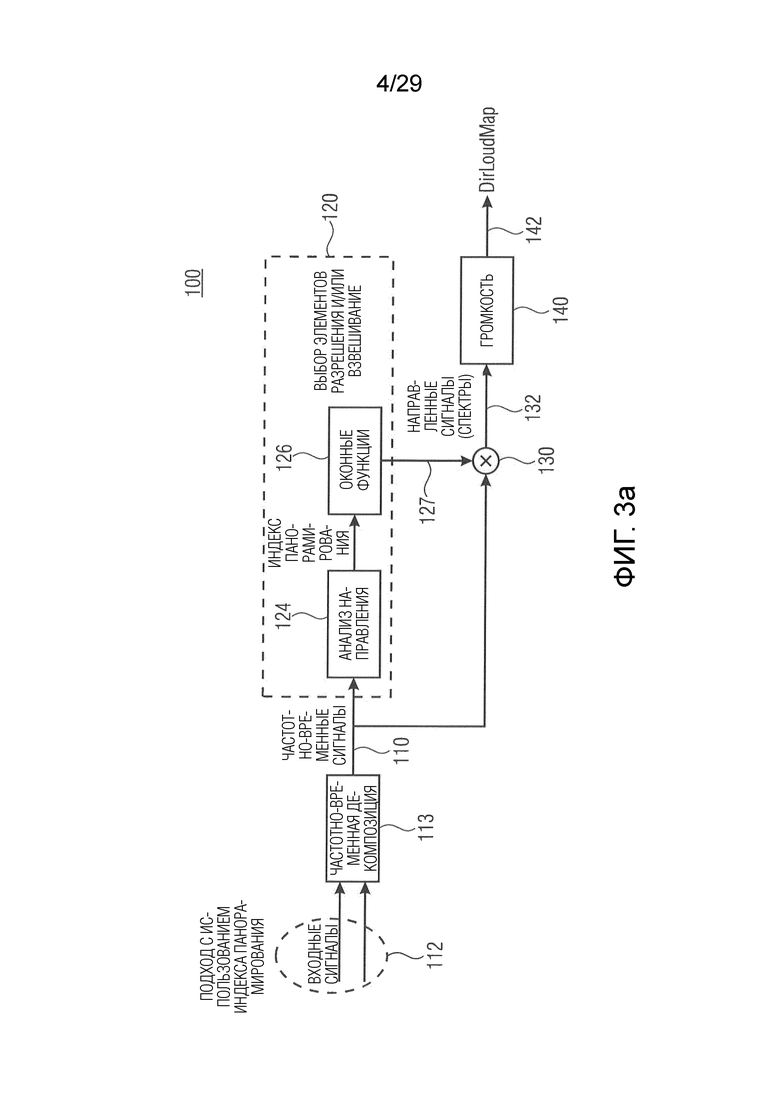
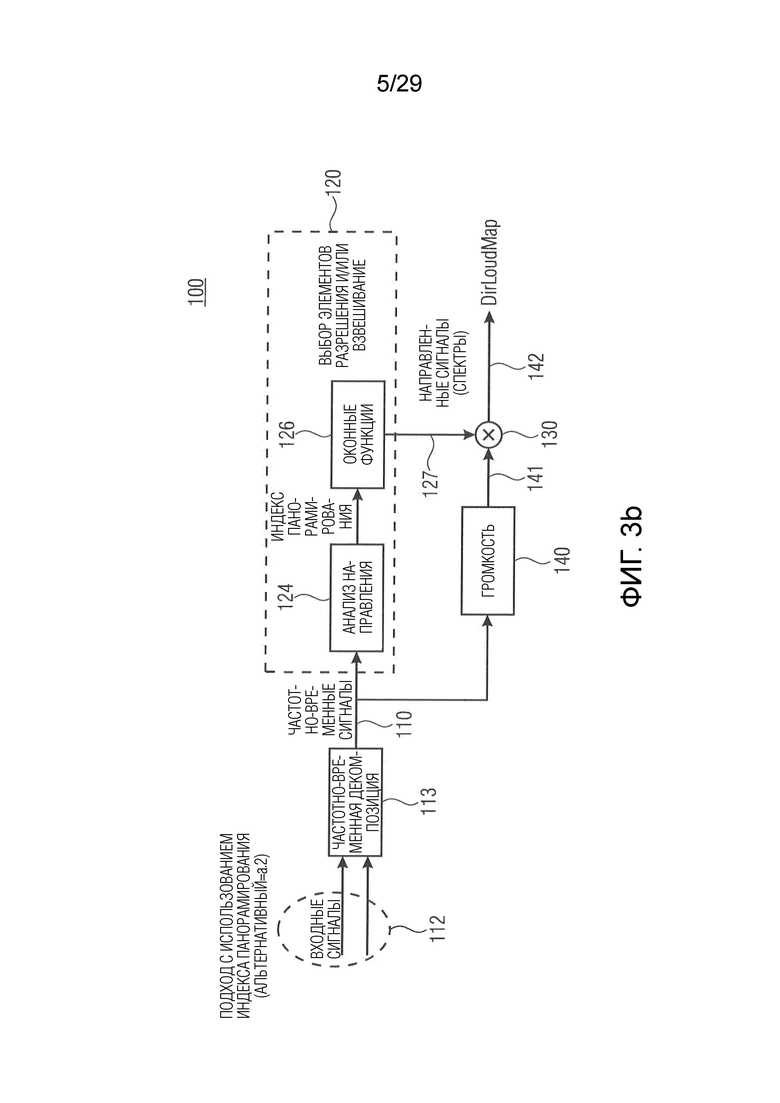
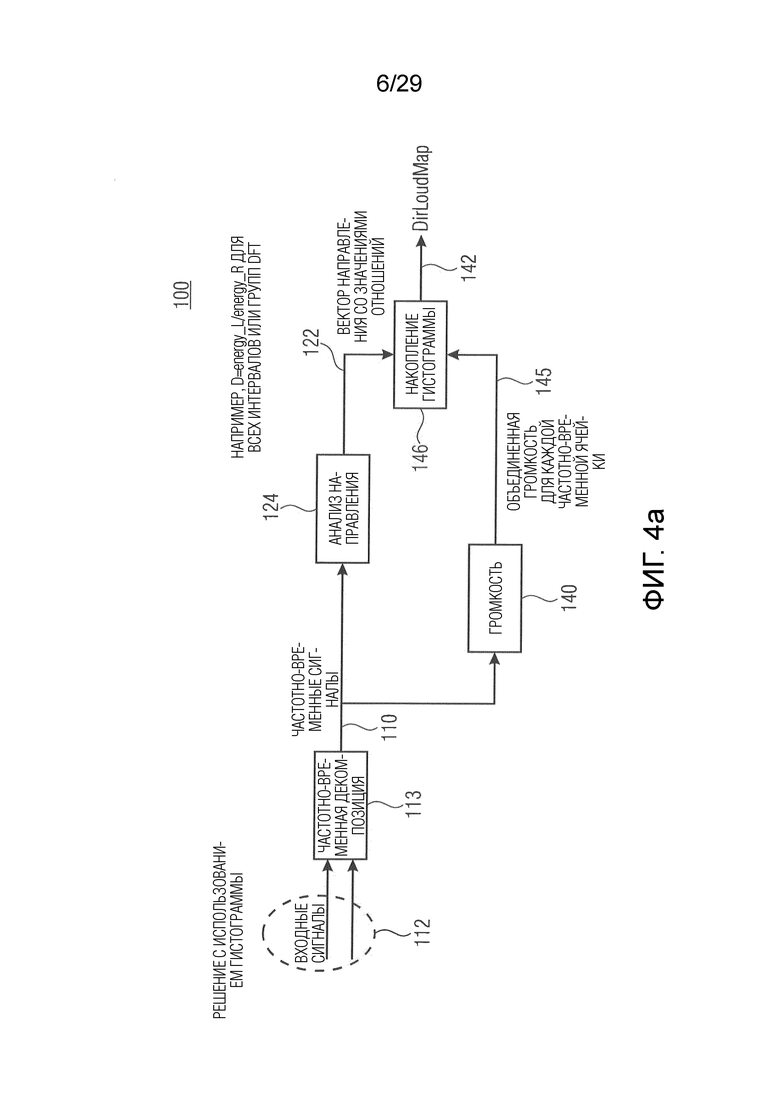

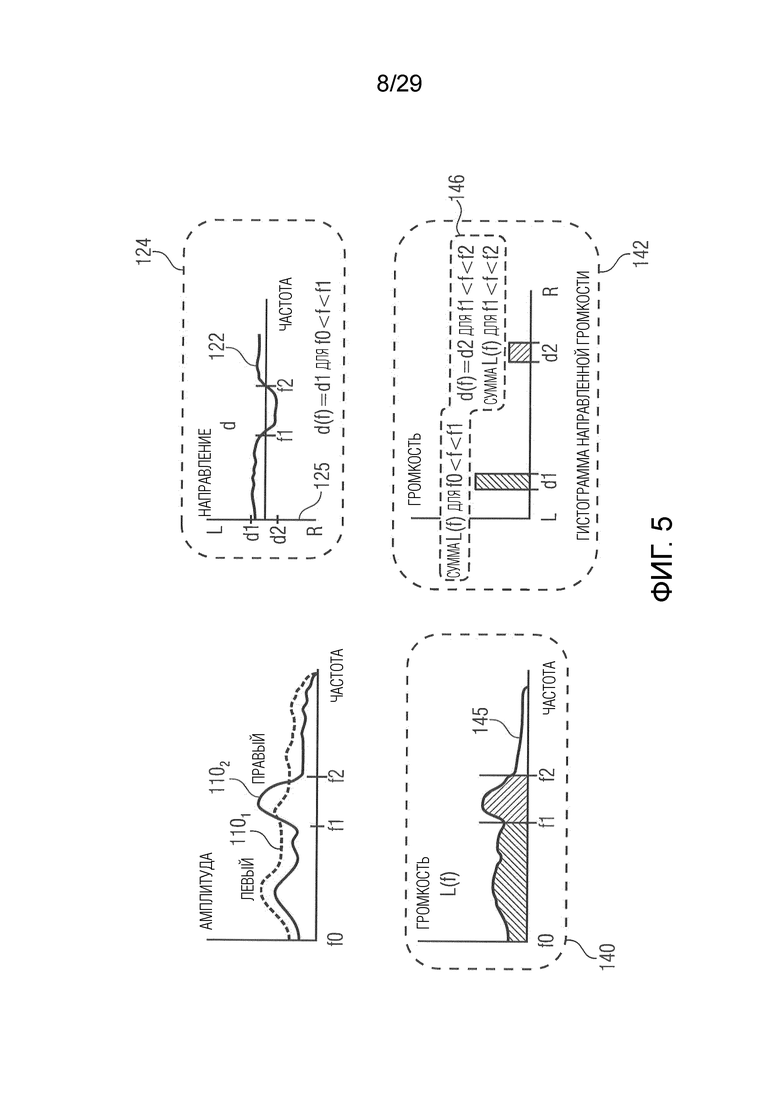

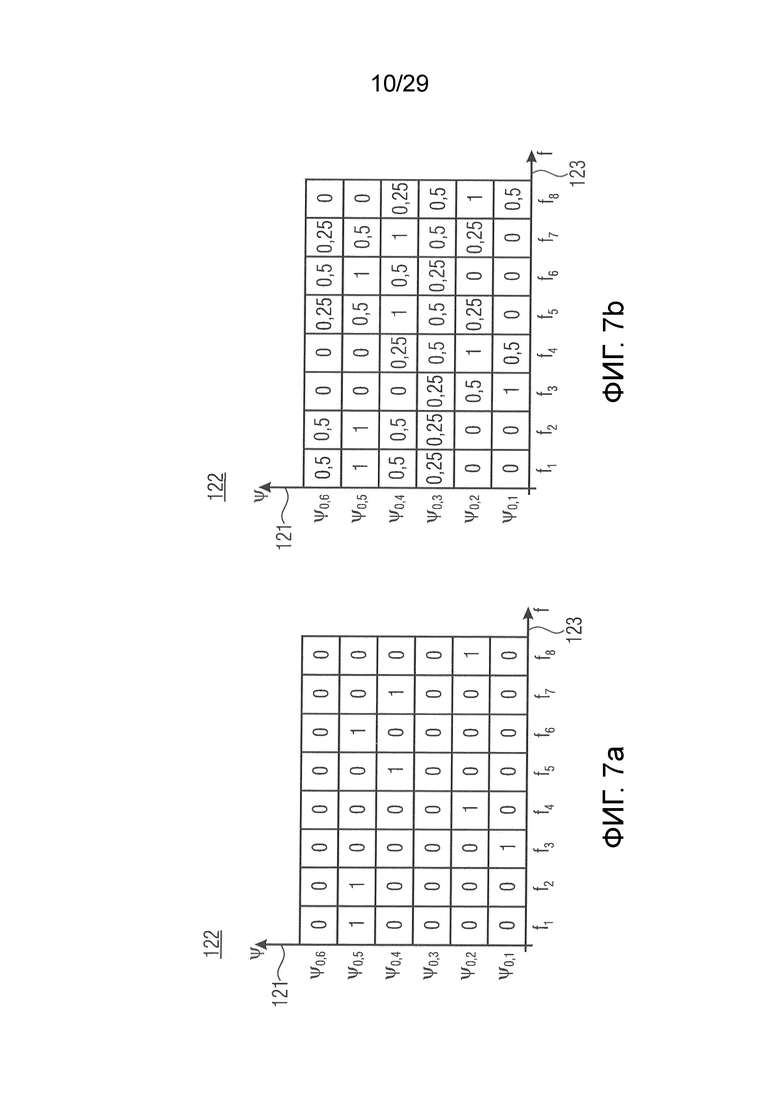
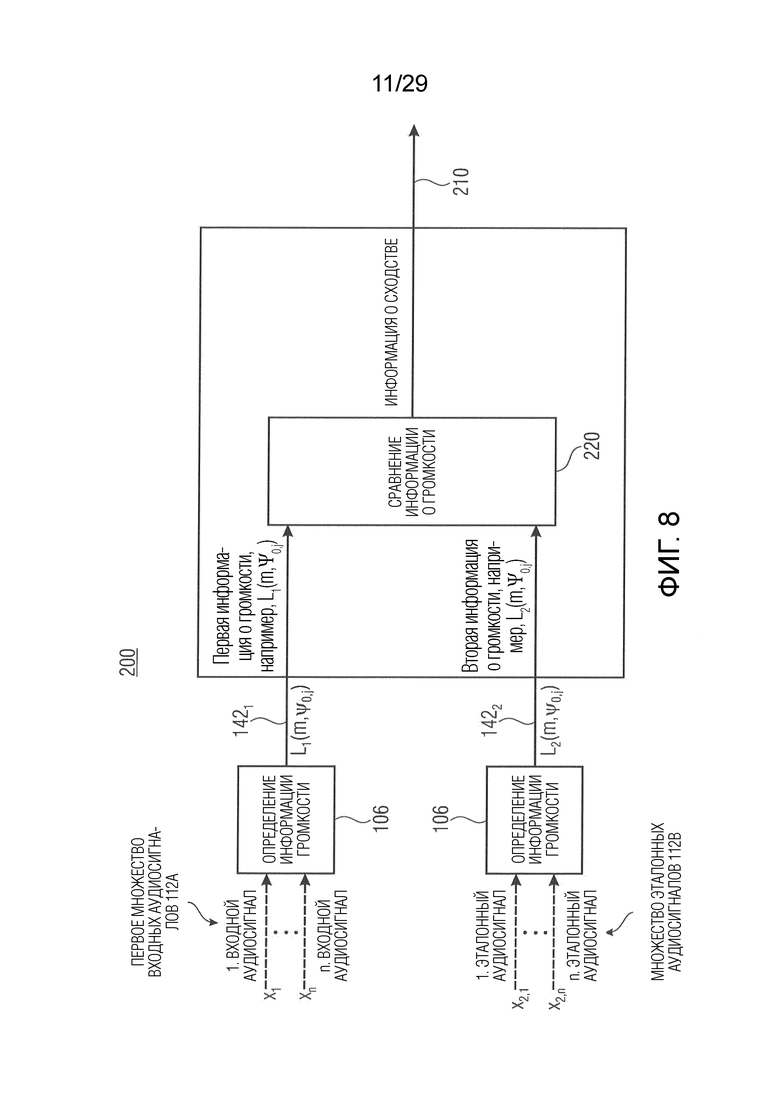
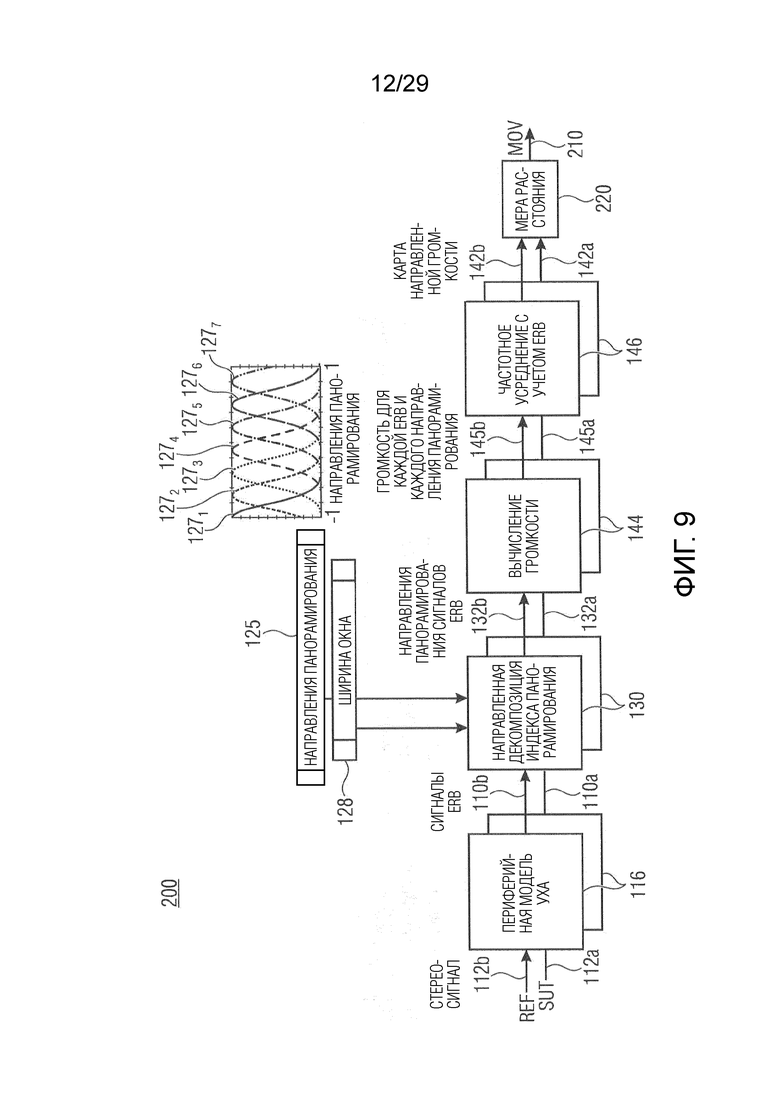
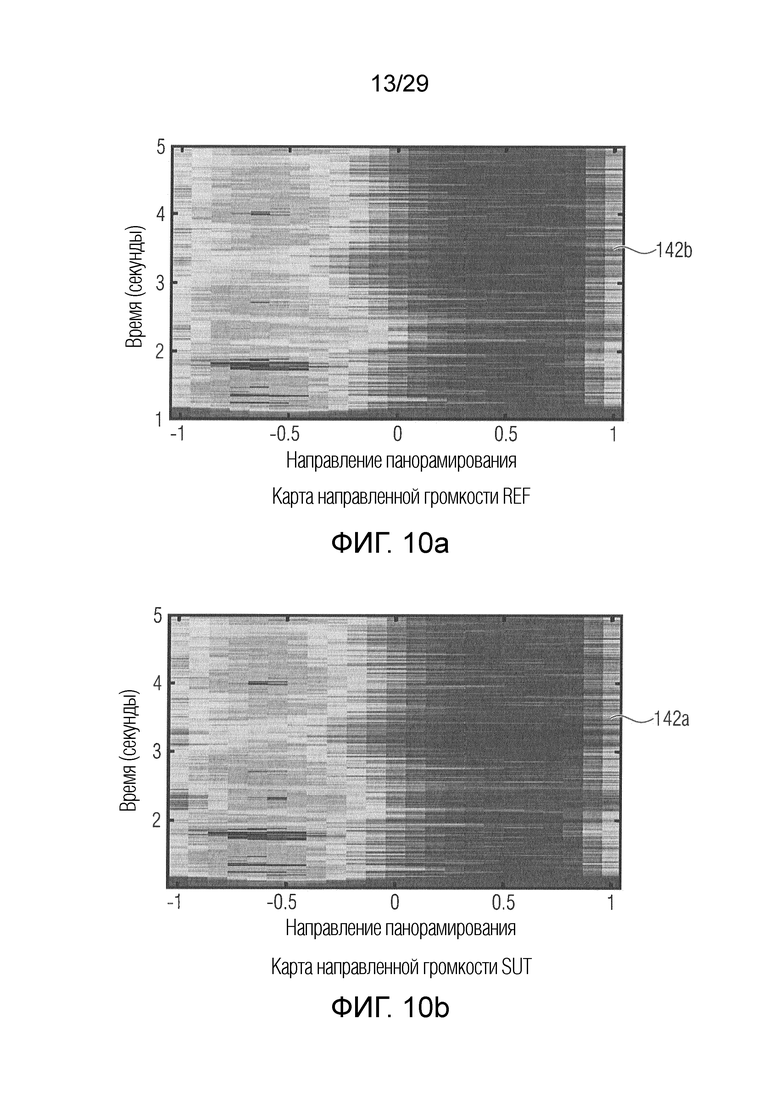

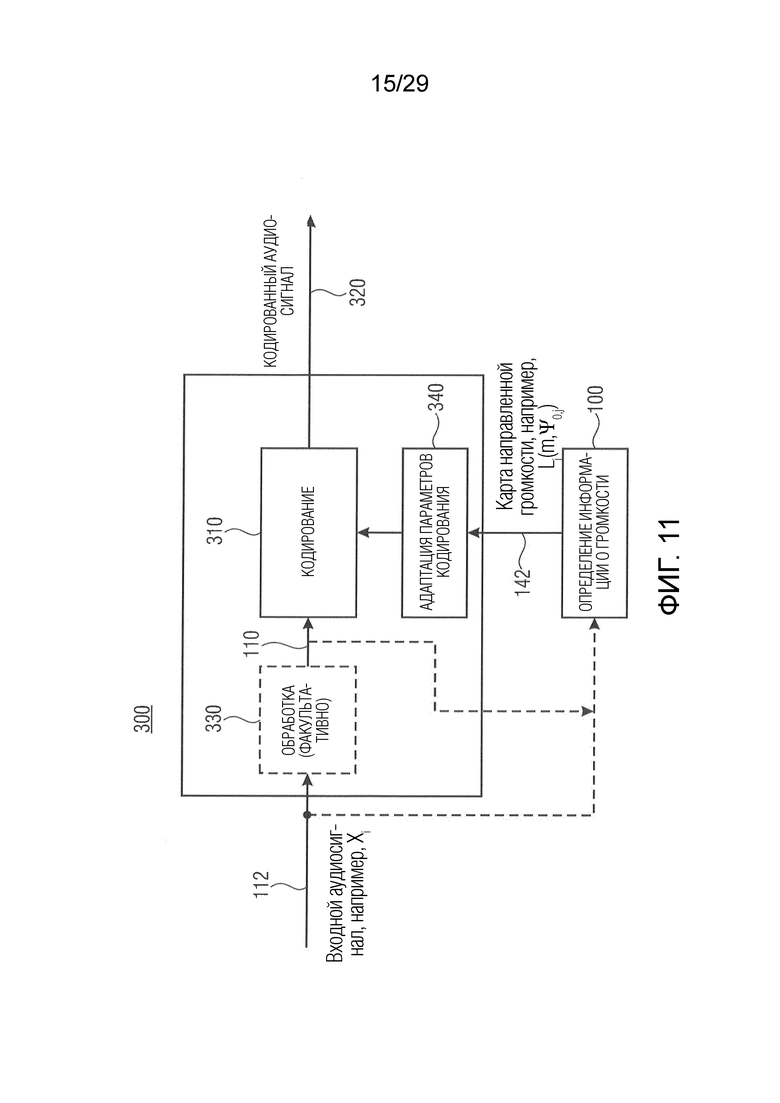
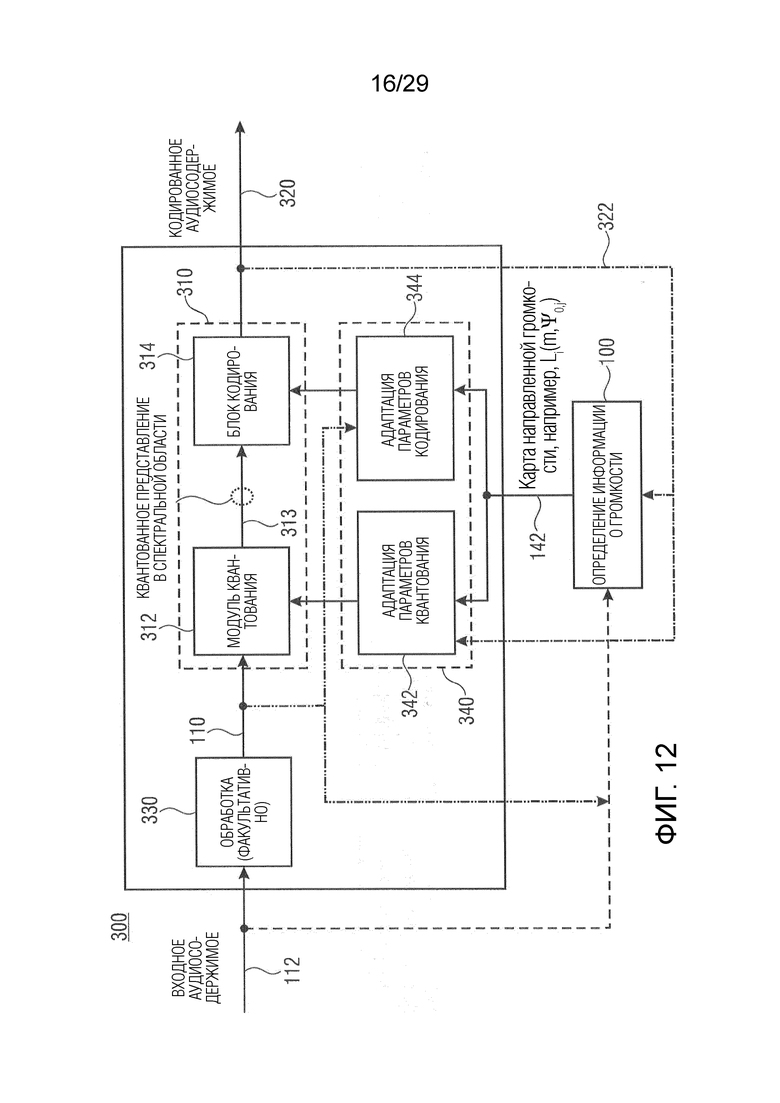
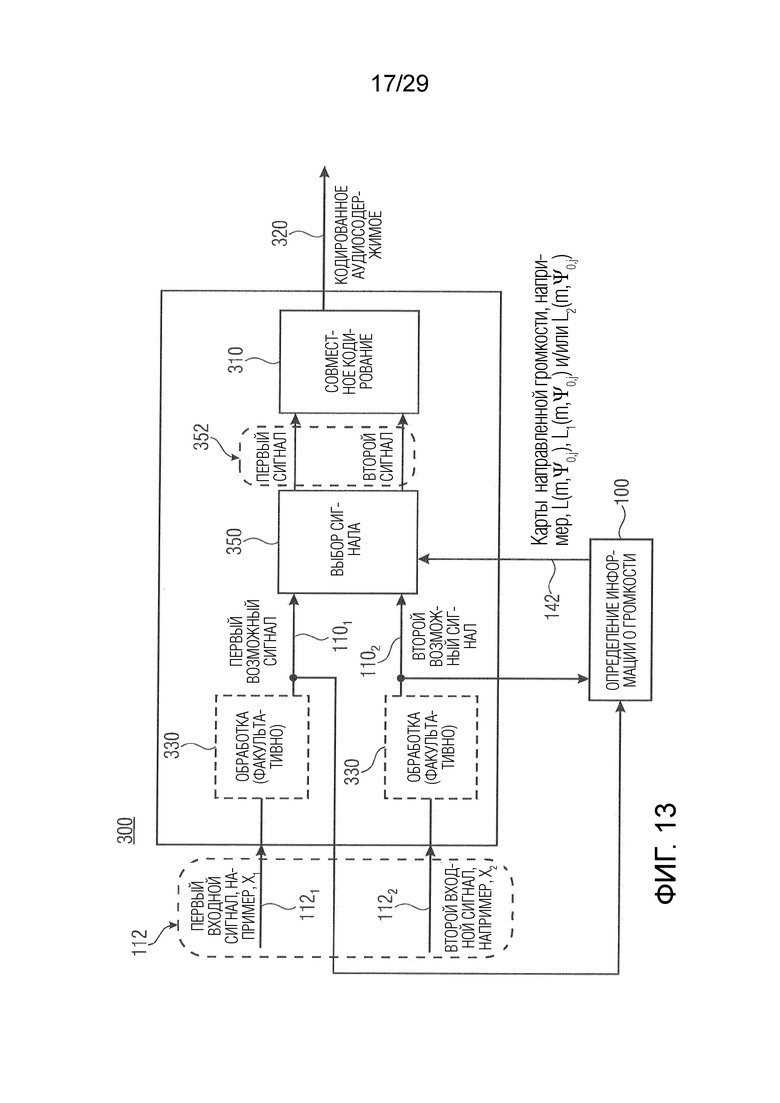
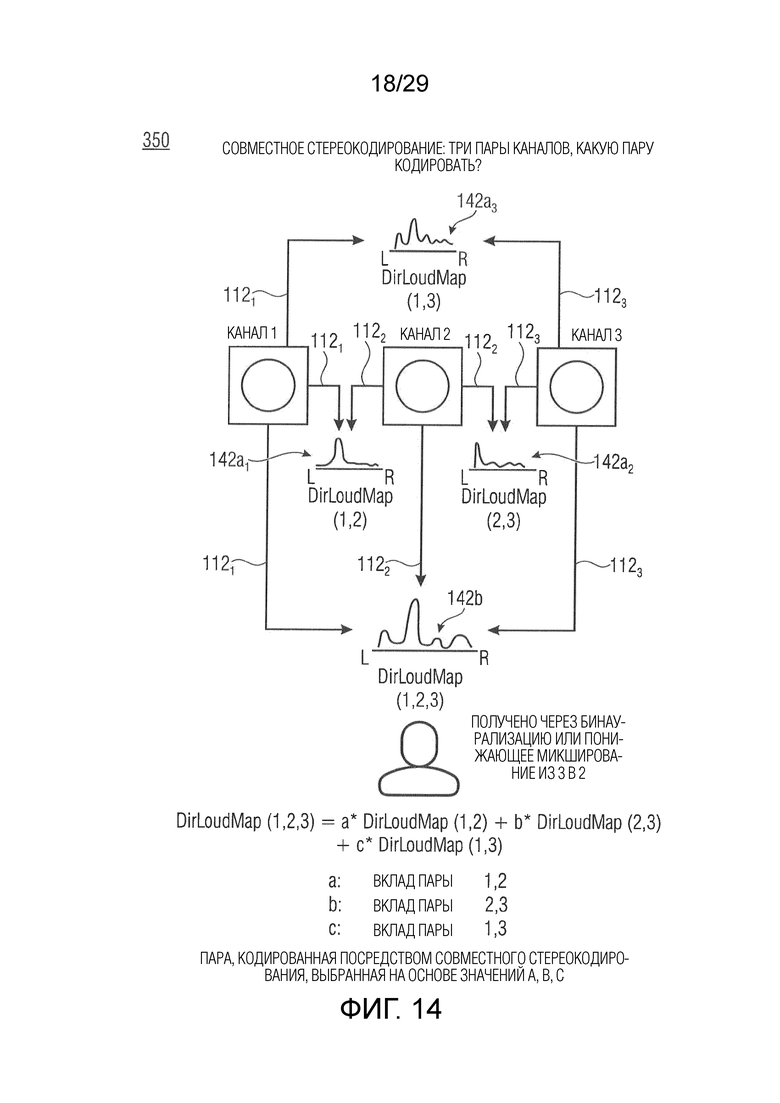

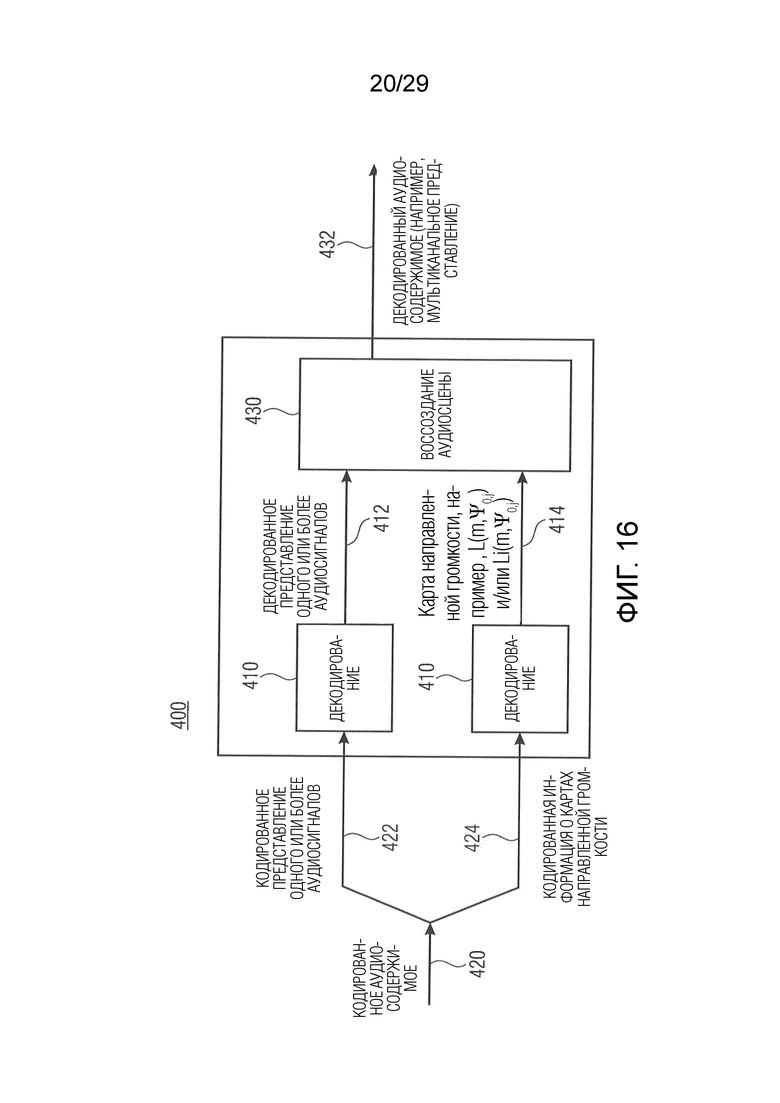
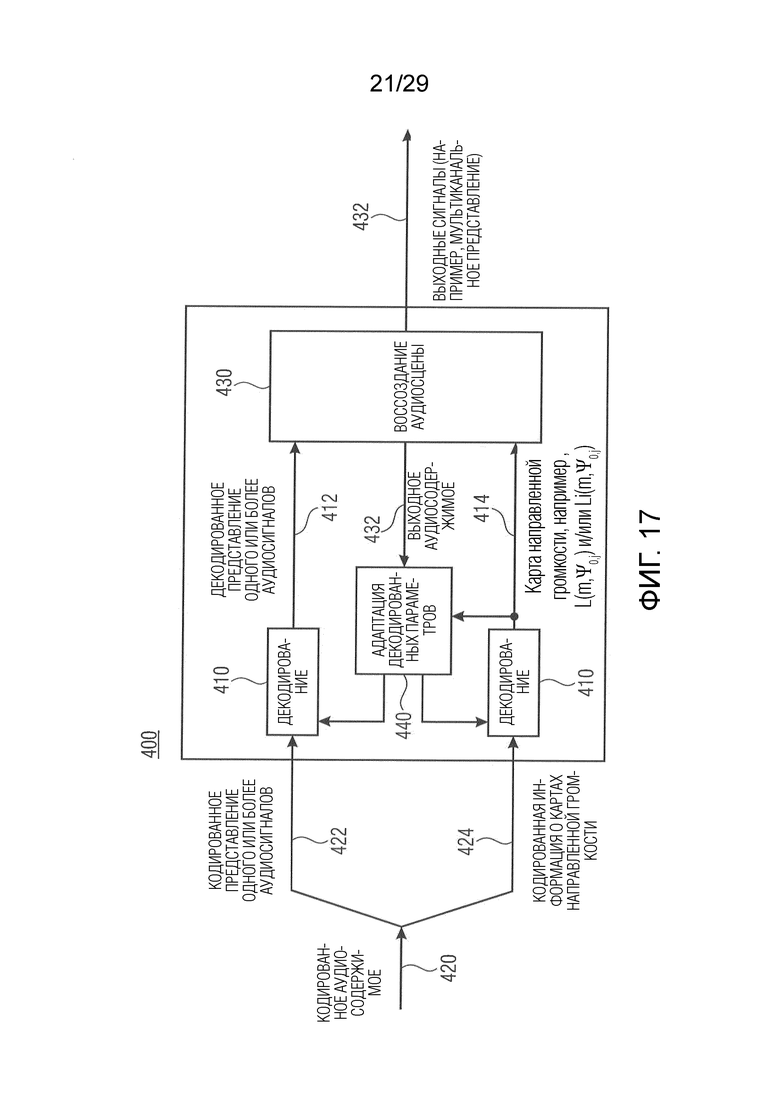
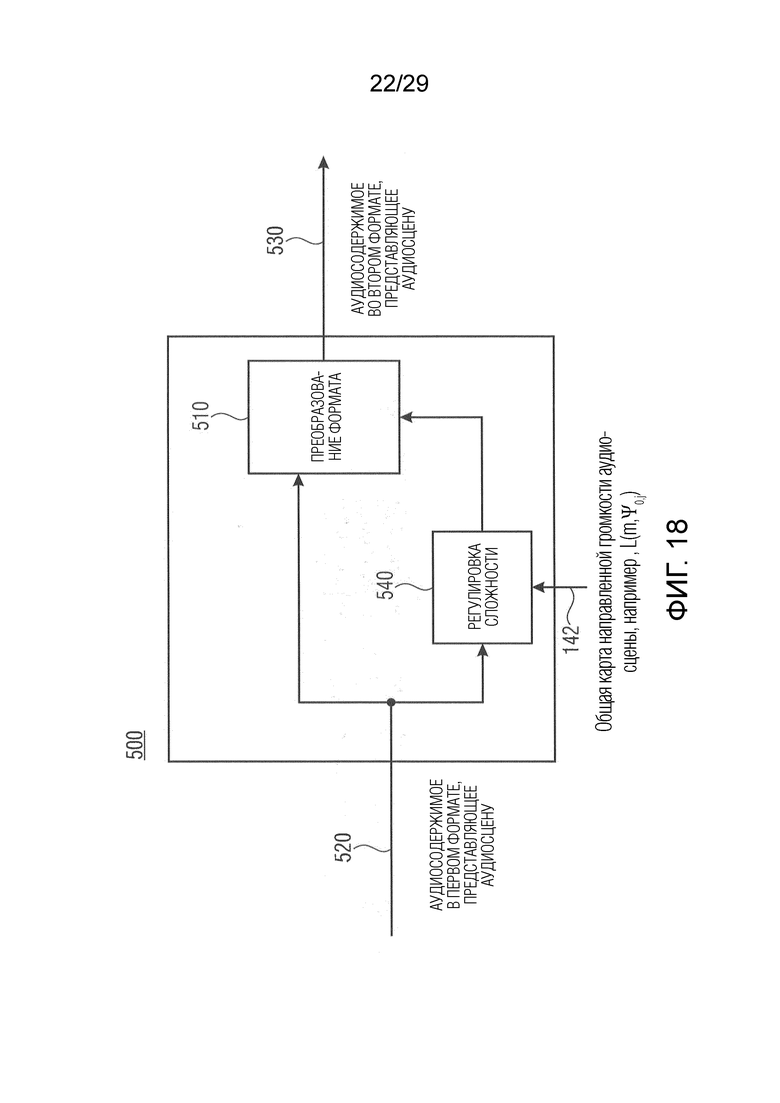
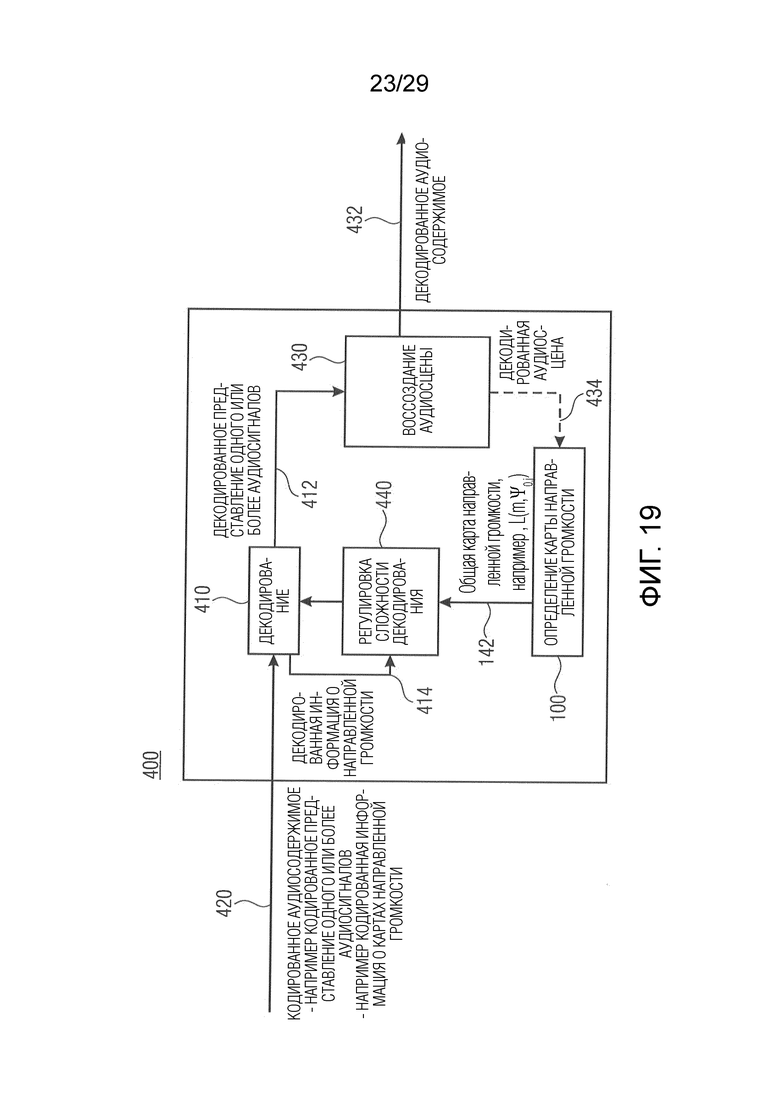
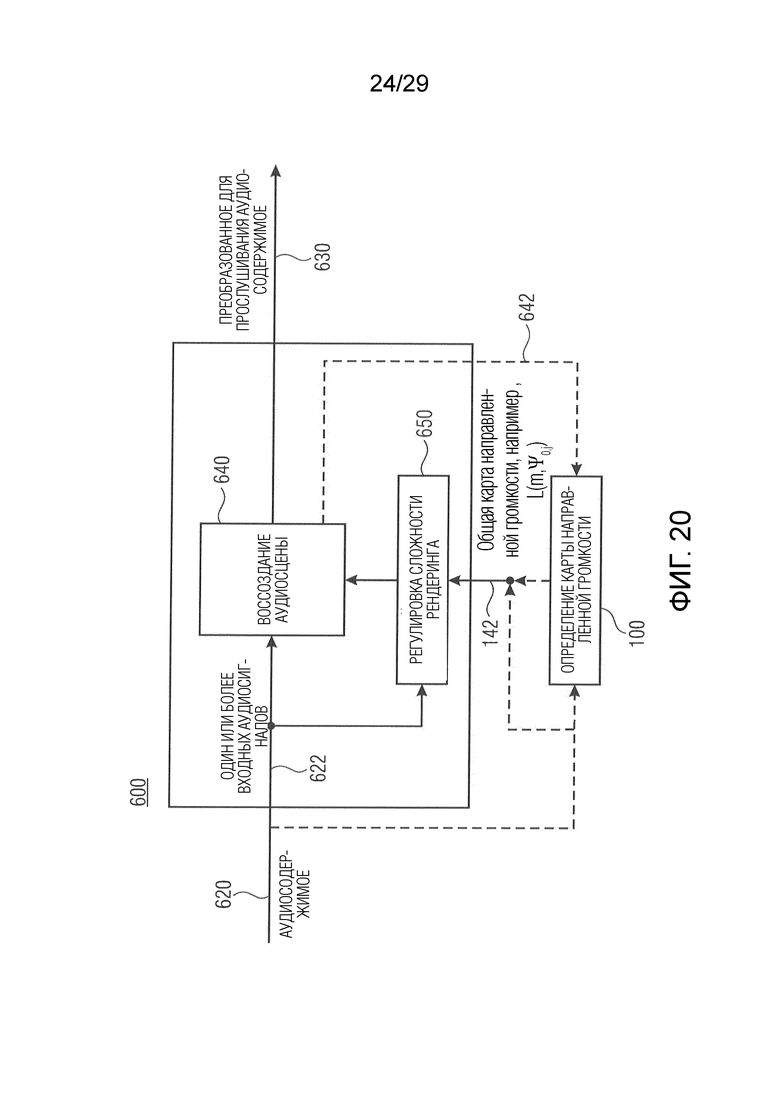
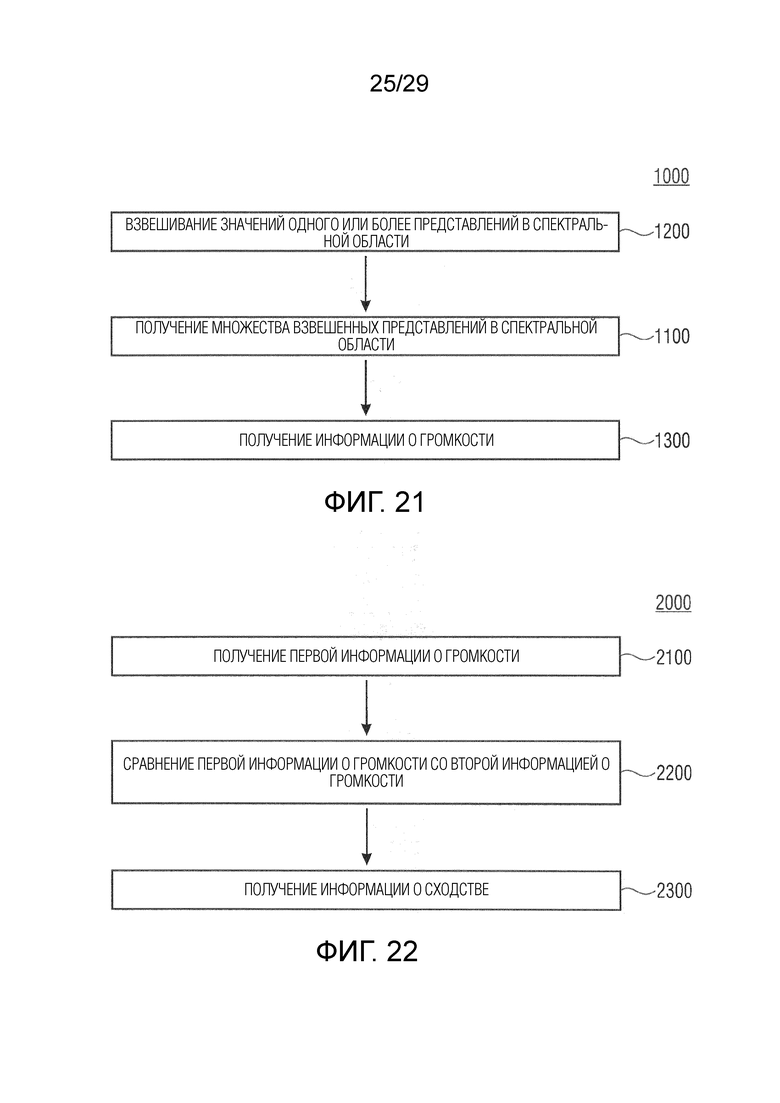
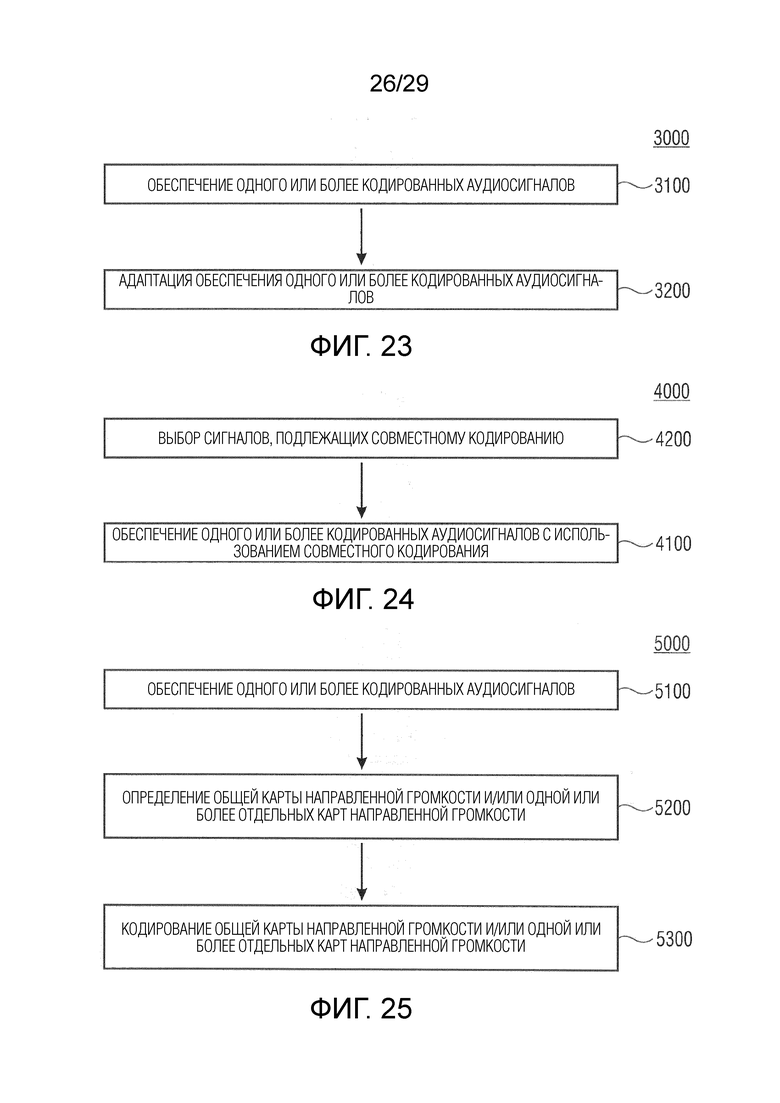
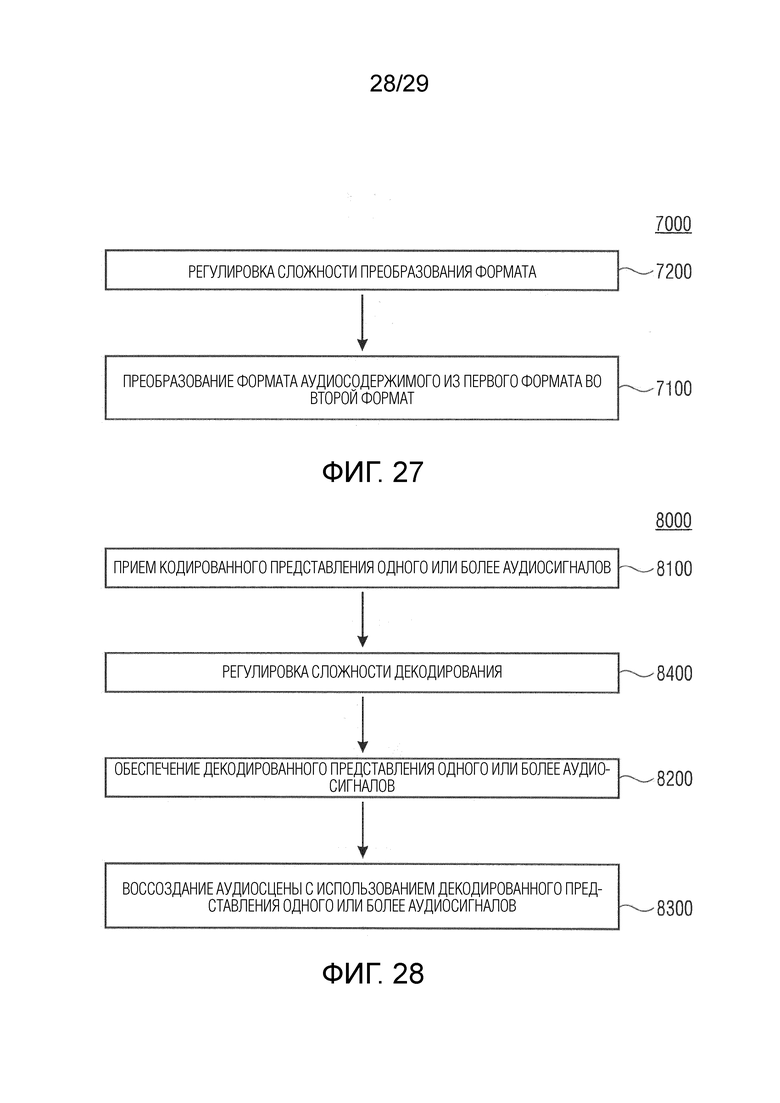
Изобретение относится к области вычислительной техники для обработки аудиоданных на основе карты направленной громкости. Технический результат заключается в повышении точности обработки аудиоданных. Технический результат достигается за счет регулирования сложности рендеринга в зависимости от вкладов входных аудиосигналов в общую карту направленной громкости из преобразованной для прослушивания аудиосцены. 7 н. и 9 з.п. ф-лы, 34 ил., 1 табл.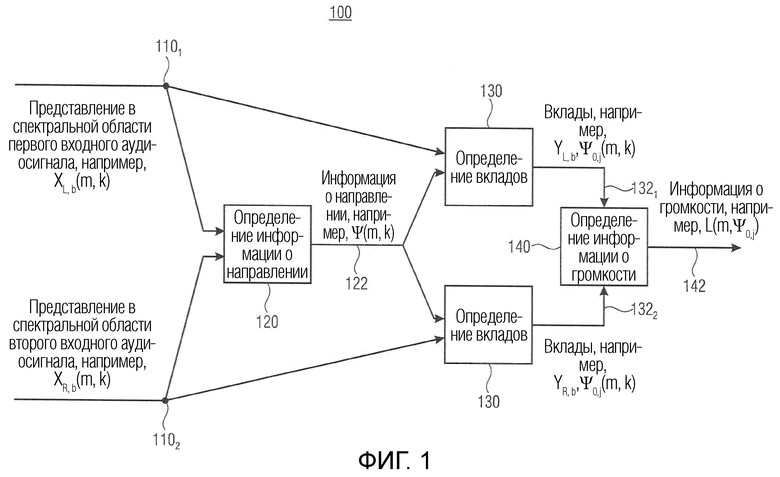
1. Преобразователь (500) формата для преобразования (510) формата аудиосодержимого (520), который представляет аудиосцену, из первого формата во второй формат,
причем преобразователь (500) формата выполнен с возможностью обеспечения представления (530) аудиосодержимого во втором формате на основе представления аудиосодержимого в первом формате;
причем преобразователь (500) формата выполнен с возможностью регулирования (540) сложности преобразования формата в зависимости от вкладов входных аудиосигналов (112, 1121, 1122, 1123, 112a, 112b) первого формата в общую карту направленной громкости аудиосцены.
2. Преобразователь (500) формата по п. 1,
причем преобразователь (500) формата выполнен с возможностью приёма информации о картах направленной громкости и получения на ее основе общей карты направленной громкости и/или одной или более карт направленной громкости.
3. Преобразователь (500) формата по п. 2,
причем преобразователь (500) формата выполнен с возможностью получения общей карты направленной громкости из одной или более карт направленной громкости.
4. Преобразователь (500) формата по п. 1,
причем преобразователь формата (500) выполнен с возможностью вычисления или оценки вклада определённого входного аудиосигнала в общую карту направленной громкости аудиосцены; и
причем преобразователь (500) формата выполнен с возможностью принятия решения, следует ли учитывать определённый входной аудиосигнал при преобразовании формата, в зависимости от вычисления или оценки вклада.
5. Аудиодекодер (400) для декодирования (410) кодированного аудиосодержимого (420),
причем аудиодекодер (400) выполнен с возможностью приёма кодированного представления (420) одного или более аудиосигналов и обеспечения декодированного представления (432) одного или более аудиосигналов;
причем аудиодекодер (400) выполнен с возможностью воссоздания (430) аудиосцены с использованием декодированного представления (432) одного или более аудиосигналов;
причем аудиодекодер (400) выполнен с возможностью регулирования (440) сложности декодирования в зависимости от вкладов кодированных сигналов в общую карту направленной громкости декодированной аудиосцены.
6. Аудиодекодер (400) по п. 5,
причем аудиодекодер (400) выполнен с возможностью приёма кодированной информации (424) о картах направленной громкости и декодирования кодированной информации (424) о картах направленной громкости для получения общей карты направленной громкости и/или одной или более карт направленной громкости.
7. Аудиодекодер (400) по п. 6,
причем аудиодекодер (400) выполнен с возможностью получения общей карты направленной громкости из одной или более карт направленной громкости.
8. Аудиодекодер (400) по п. 5,
причем аудиодекодер (400) выполнен с возможностью вычисления или оценки вклада определённого кодированного сигнала в общую карту направленной громкости декодированной аудиосцены; и
причем аудиодекодер (400) выполнен с возможностью принятия решения, следует ли декодировать определённый кодированный сигнал, в зависимости от вычисления или оценки вклада.
9. Модуль (600) рендеринга для выполнения рендеринга аудиосодержимого,
причем модуль (600) рендеринга выполнен с возможностью воссоздания (640) аудиосцены на основе одного или более входных аудиосигналов (112, 1121, 1122, 1123, 112a, 112b);
причем модуль (600) рендеринга выполнен с возможностью регулирования (650) сложности рендеринга в зависимости от вкладов входных аудиосигналов (112, 1121, 1122, 1123, 112a, 112b) в общую карту (142) направленной громкости из преобразованной для прослушивания аудиосцены (642).
10. Модуль (600) рендеринга по п. 9,
причем модуль (600) рендеринга выполнен с возможностью получения информации о карте (142) направленной громкости и получения на ее основе общей карты направленной громкости и/или одной или более карт направленной громкости.
11. Модуль (600) рендеринга по п. 10,
причем модуль (600) рендеринга выполнен с возможностью получения общей карты направленной громкости из одной или более карт направленной громкости.
12. Модуль (600) рендеринга по п. 9,
причем модуль (600) рендеринга выполнен с возможностью вычисления или оценки вклада определённого входного аудиосигнала в общую карту направленной громкости аудиосцены; и
причем модуль (600) рендеринга выполнен с возможностью принятия решения, следует ли рассматривать определённый входной аудиосигнал при рендеринге, в зависимости от вычисления или оценки вклада.
13. Способ (7000) преобразования (7100) формата аудиосодержимого, который представляет аудиосцену, из первого формата во второй формат,
причем способ содержит этап, на котором обеспечивают представление аудиосодержимого во втором формате на основе представления аудиосодержимого в первом формате;
причем способ содержит этап, на котором регулируют (7200) сложность преобразования формата в зависимости от вкладов входных аудиосигналов первого формата в общую карту направленной громкости аудиосцены.
14. Способ (8000) декодирования кодированного аудиосодержимого,
причем способ содержит этапы, на которых принимают (8100) кодированное представление одного или более аудиосигналов и обеспечивают (8200) декодированное представление одного или более аудиосигналов;
причем способ содержит этап, на котором воссоздают (8300) аудиосцену с использованием декодированного представления одного или более аудиосигналов;
причем способ содержит этап, на котором регулируют (8400) сложность декодирования в зависимости от вкладов кодированных сигналов в общую карту направленной громкости декодированной аудиосцены.
15. Способ (9000) рендеринга аудиосодержимого,
причем способ содержит этап, на котором воссоздают (9100) аудиосцену на основе одного или более входных аудиосигналов;
причем способ содержит этап, на котором регулируют (9200) сложность рендеринга в зависимости от вкладов входных аудиосигналов в общую карту направленной громкости преобразованной для прослушивания аудиосцены.
16. Машиночитаемый носитель, на котором сохранена компьютерная программа, имеющая программный код для выполнения способа по п. 13, или 14, или 15 при его выполнении на компьютере.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗВУКОВОГО СИГНАЛА | 2008 |
|
RU2439720C1 |

