Данное изобретение относится в целом к шрифтам, выравниванию текста и символов, а более конкретно к системе и способу автоматического измерения параметров международного шрифта (для текстов на разных языках).
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
"Они сказали: Давайте построим город и башню, с вершины которой можно достать до небес; и давайте сделаем наши имена известными прежде, чем мы будем рассеянны за границу по всем странам". Довольно скоро работа пошла полным ходом; "и они использовали кирпич вместо камней, и шлам (битум) вместо строительного раствора". Но Бог спутал их язык так, чтобы они не понимали речь друг друга, и таким образом рассеял их из того места во все страны, и они прекратили строить город". Книга Бытия 11:1-9. Со времен падения Вавилонской Башни поиск способов связи между различными языками и связанными с ними системами письменности был и остается сложной проблемой.
С началом всемирной глобализации задача решения этой сложной проблемы стала главной. Однако между нациями существуют сложные культурные различия, которые предотвращают создание полностью интегрированного глобального общества. В компьютерной промышленности эти различия вызывают проблемы с международной кооперацией из-за ограничений отображения данных и обмена данными на различных языках.
Одним из этапов решения этой сложной проблемы многонациональной вычислительной промышленностью стало создание в 1988 году Консорциума Уникода, который разработал глобальный стандарт идентификации символов. Задача консорциума состояла в том, чтобы разработать стандарт, который позволяет уникально идентифицировать символы для каждого языка. Консорциум разработал Стандарт Уникода, в настоящее время версии 2.1, который доступен из Addison-Wesley Developers Press 1997 (доступен по адресу http: // www.unicode.org).
К сожалению, способность печатать и отображать символы одного из многих языков является только маленьким шагом навстречу решению этой сложной международной проблемы. Проблемой одинаковой, а временами большей важности является форматирование документа, характеристики шрифтов и общие требования к тексту, которые делают текст удобочитаемым. Однако гарнитуры и написания шрифтов существующих языков различны, эклектичны и не подчиняются одинаковым правилам. Например, типичный английский шрифт, Times New Roman, вытекает из типографской формулы, которая основана на уникальном латинским шрифте, в котором высота строки типично устанавливается равной 120% от размера шрифта в пунктах. Терминология основывается на прямом шрифте. Концепция прямого шрифта (Roman) включают в себя базовую линию, высоту прописных букв, высоту надстрочного элемента, высоту подстрочного элемента и высоту строки.
Письменные языки не соблюдают те же самые правила для таких характеристик шрифта, как стандартная длина строки или гарнитура шрифта. Скорее, каждый язык и рукописный шрифт возникли на различных культурных базисах. Например, некоторые азиатские рукописные шрифты используют специальные знаки (глифы), которые развились из рисунков, а другие азиатские рукописные шрифты читаются справа налево и возникли из символов. Даже в пределах одного и того же языка рукописные и печатные шрифты не придерживаются предопределенной характерной формулы. Отыскание формулы для определения стандартных характеристик шрифта кажется невозможной задачей. Вместо того чтобы искать формулу, соответствующую всем языкам, художники-оформители (дизайнеры) полагаются на визуальное изменение длины строки, шрифта и высоты строки, изменяя каждый шрифт таким образом, чтобы исполнение было приятным глазу и отвечало требованиям удобочитаемости, известным художнику-оформителю.
В настоящее время не существует решения для определения характеристик шрифта, которые могут применяться ко всем известным шрифтам. Каждый шрифт возник из своей культуры и они имеют различные базисы и полностью различающиеся концепции. Даже если формула работает для конкретного шрифта и конкретного языка, в пределах каждого шрифта между многими характеристиками шрифта не существует линейного соотношения. Например, любые изменения в размере шрифта или длине строки в одном и том же шрифте требуют изменений в высоте строки, которую принимают во внимание для удобочитаемости. Художники-оформители обычно визуально изменяют длину строки, гарнитуру шрифта и высоту строки. Более длинные строки шрифта требуют большей высоты строки для удобочитаемости. Также, если размер шрифта связан с высотой строки, больший шрифт требует не той же самой высоты строки, как меньший шрифт.
Поскольку не существует линейных или других очевидных соотношений между высотой строки, длиной строки и изменением размера шрифта, многие компьютерные прикладные программы требуют ручных изменений. Дополнительно усложняет размещение текста (верстку) то, что художники-оформители не знают, на каком устройстве будет воспроизводиться шрифт из-за изобилия вычислительных машин для воспроизведения. Напечатанная страница, предназначенная для использования в качестве web-страницы, например, может быть воспроизведена на экране любого размера, оставляя неизвестными оптимальные для чтения значения размера длины строки, высоты строки и размера шрифта. Необходим способ для автоматического определения таких характеристик, которые в настоящее время требуют присутствия художника-оформителя. Необходимы автоматический способ и система, которая может вычислять параметры удобочитаемости, такие как высота строки, размер шрифта и длина строки, таким образом, чтобы текст мог быть воспроизведен на любом дисплее, на любом языке и шрифтом любого размера без ручной настройки.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Соответственно, система и способ автоматически определяют соответствующие характеристики шрифта для различных средств отображения и различных параметров удобочитаемости на любом языке. Один из вариантов осуществления предназначен для способа определения характеристик шрифта с помощью приема данных, которые включают в себя идентификатор шрифта и идентификатор языка, создания характерной строки текста на идентифицированном языке и идентифицированным шрифтом, измерения характеристик характерной строки текста и нормирования результатов измерения по множеству шрифтов и множеству языков. Более конкретно, измерение характеристик характерной строки текста может включать в себя измерение отношения количества черных пикселей к общему количеству пикселей в множестве рядов пикселей в характерной строке текста, идентификацию ряда с самым высоким отношением количества черных пикселей к общему количеству пикселей и использование идентифицированного ряда для определения характеристик шрифта в характерной строке текста по сравнению со множеством шрифтов и языков.
В одном из вариантов осуществления измерение характеристик характерной строки шрифта дополнительно включает в себя идентификацию высоты шрифта и в пределах высоты шрифта идентификацию первой части, которая включает в себя ряд с самым высоким отношением количества черных кластеров к общему количеству кластеров, причем первая часть включает в себя первый ряд пикселей и последний ряд пикселей, которые темнее, чем среднее значение ряда пикселей, идентификацию второй части, расположенной выше первой части, и идентификацию третьей части, расположенной ниже первой части. В обсуждении, которое следует далее, эти части упоминаются как размеры, связанные с термином "черная река", который является термином, используемым для идентификации напечатанных измеренных характеристик для определения среднего уровня серого по направлению перпендикуляра к направлению чтения. Средний уровень серого допускает сравнение множества шрифтов и языков.
В одном из вариантов осуществления для приема данных, которые включают в себя идентификатор шрифта и идентификатор языка, используется средство международного перевода, и принимаемые данные могут включать в себя текст на каком-нибудь языке. Идентификатор языка может включать в себя один или более языков, на который средство международного перевода переводит текст.
Другой вариант осуществления предназначен для способа размещения текста с использованием международного шрифта, в котором размещение текста относится к строке текста, которая воспроизводится шрифтом, размеры которого определяются в терминах кегельной (круглой) шпации, данный способ использует измеренные характеристики нормированной характерной строки международного текста, набранного предопределенным шрифтом, для определения оптимальных размера шрифта, высоты строки, количества колонок и длины строки. Характеристики нормированной характерной строки "международного" текста обеспечивают количество кластеров в одной фиксации взгляда и количество кластеров, приходящихся на кегельную шпацию.
Вариант осуществления, предназначенный для системы размещения международного текста, напечатанного одним из шрифтов, включает в себя входной фильтр структуры и размещения, сконфигурированный для считывания одного или более параметров текста, средство считывания показателей (метрик), присоединенное к структуре данных, причем средство считывания показателей сконфигурировано для приема одного или более параметров текста, и средство формирования параметров текста, присоединенное к средству считывания показателей. Средство формирования параметров текста включает в себя модуль, сконфигурированный для определения графической плотности шрифта, которая является средним уровнем серого в воспроизводимом тексте для данного шрифта на идентифицированном языке. Особенности (характеристики) шрифта, определяемые средством формирования параметров текста, включают в себя значения, представляющие количество кластеров, приходящихся на кегельную шпацию, насыщенность шрифта, ширину шрифта, ширину самой темной горизонтальной части шрифта и насыщенность самой темной горизонтальной части шрифта. Другая система согласно одному из вариантов осуществления включает в себя средство международного перевода, сконфигурированное в средстве размещения и подсоединенное к приложению прикладной программой. Средство международного перевода принимает данные от приложения и обеспечивает передачу приложению переведенного текста с соответствующими характеристиками размещения переведенного текста. В одном из вариантов осуществления средство международного перевода сконфигурировано для принятия одного или более идентификаторов языка и текста от приложения и обеспечения передачи переведенного текста и определения параметров, необходимых для входного фильтра структуры и размещения для создания одной или более структур данных, действующих со средством считывания показателей и средством формирования параметров текста. Средство международного перевода может быть внешним средством международного перевода, вызываемым из приложения. Приложение может быть сервером или клиентской машиной и отображать переведенный текст согласно идентификаторам языка с параметрами удобочитаемости, соответствующими любому дисплею, который вызывает приложение. Приложение может также быть прикладной программой Интернет, доступной для множества компьютеров, причем приложение принимает запросы на обеспечение передачи переведенного текста и передает переведенный текст, соответственно отформатированный для каждого дисплея каждого из множества компьютеров и на языке, который требует каждое множество компьютеров.
Дополнительные признаки и преимущества данного изобретения будут очевидны из следующего подробного описания показанных вариантов осуществления, которое выполнено со ссылкой к сопроводительным чертежам.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Хотя прилагаемая формула изобретения конкретно формулирует особенности настоящего изобретения, данное изобретение, вместе с его задачами и преимуществами, может быть лучше всего понято из последующего подробного описания, рассматриваемого вместе с сопроводительными чертежами, на которых:
Фиг. 1 - структурная схема, в общем виде иллюстрирующая примерную компьютерную систему, в которой осуществлено настоящее изобретение.
Фиг. 2 - структурная схема, иллюстрирующая примерный поток данных в пределах компьютерной системы в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 3 - более подробная структурная схема, иллюстрирующая поток данных, показанный на фиг. 2, в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 4 - последовательность операций, иллюстрирующая способ определения характеристик международного текста в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 5 - последовательность операций, иллюстрирующая более подробно способ определения характеристик международного текста в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 6 - последовательность операций, иллюстрирующая более подробно способ определения характеристик международного текста в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 7 показывает два изображения, представляющие графики и текст, являющиеся результатом применения способов в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 8 - последовательность операций, иллюстрирующая способ автоматического определения высоты строки и размера шрифта в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 9a иллюстрирует график, являющийся результатом выполнения способа определения характеристик шрифта в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 9b иллюстрирует другой график, являющийся результатом выполнения способа определения характеристик шрифта в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 10 - последовательность операций, иллюстрирующая способ определения размера шрифта в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 11 - график, иллюстрирующий кривую, соответствующую определению характеристик текста в зависимости от расстояния обозрения в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 12 - график, который иллюстрирует, как определяется область самого резкого фокусирования в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 13 - график, который иллюстрирует, как применяются тригонометрические функции для определения области самого резкого фокусирования в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 14 - последовательность операций, иллюстрирующая способ автоматического определения минимального и максимального размера шрифта в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 15 - структурная схема, иллюстрирующая поток данных, который используется для определения размера шрифта в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 16 - структурная схема, иллюстрирующая поток данных, который используется для определения характеристик текста в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 17 показывает пример одного и того же шрифта для различных языков, где показано изменение их ширины в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 18 - последовательность операций, иллюстрирующая способ автоматического масштабирования размера шрифта в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 19 - последовательность операций, иллюстрирующая способ настройки высоты строки, основанный на функции от количества кластеров в строке в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 20 - график, иллюстрирующий найденные опытным путем возможные значения высоты строки для заданного размера символа в пунктах в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 21 - последовательность операций, иллюстрирующая способ определения величины изменения заданной по умолчанию высоты строки в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 22 - структурная схема, иллюстрирующая поток данных в пределах средства считывания показателей в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 23 - график, иллюстрирующий определение длины строки в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 24 - структурная схема, иллюстрирующая поток данных при использовании средства международного перевода, расположенного в компьютерной системе, в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 25 - последовательность операций, иллюстрирующая способ использования средства перевода в комбинации с вариантами осуществления в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг. 26 - последовательность операций, иллюстрирующая способ использования средства перевода, расположенного в средстве размещения в соответствии с одним из вариантов осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Обращаясь к чертежам, на которых подобные ссылочные обозначения относятся к подобным элементам, изобретение иллюстрировано как воплощаемое в соответствующей вычислительной среде. Хотя это и не требуется, данное изобретение описано в общем контексте выполняемых компьютером команд, таких как модули программы, выполняемые персональным компьютером. В общем случае модули программы включают в себя подпрограммы, программы, задачи, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или воплощают определенные абстрактные типы данных. Кроме того, специалисты должны признать, что изобретение может использоваться при других конфигурациях компьютерной системы, которые включают в себя карманные компьютеры, многопроцессорные системы, программируемую или основанную на микропроцессорах бытовую электронику, сетевые ПК, миникомпьютеры, универсальные компьютеры и т.п. Изобретение может также использоваться в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, которые связаны через сеть связи. В распределенной вычислительной среде модули программы могут располагаться и в местных, и в удаленных запоминающих устройствах.
Фиг. 1 иллюстрирует пример соответствующей среды 100 вычислительной системы, в которой изобретение может быть осуществлено. Среда 100 вычислительной системы является только одним примером соответствующей вычислительной среды и не налагает никакого ограничения на формы использования или функционирование изобретения. Точно так же вычислительная среда 100 не должна интерпретироваться, как имеющая какую-либо зависимость или требования, относящиеся к одному или комбинации компонентов, иллюстрированных в типичной среде 100 обработки.
Изобретение работает с множеством других универсальных или специальных вычислительных системных сред или конфигураций. Примеры известных вычислительных систем, сред и/или конфигураций, которые могут использоваться с данным изобретением, включают в себя персональные компьютеры, серверы, карманные или портативные компьютеры, многопроцессорные системы, системы на основе микропроцессора, телеприставки, программируемые бытовые электронные устройства, сетевые ПК, миникомпьютеры, универсальные (большие) ЭВМ, распределенные вычислительные среды, которые включают в себя любую из вышеупомянутых систем или устройств, и т.п., но не ограничиваются ими.
Изобретение может быть описано в общем контексте выполняемых компьютером команд, таких как модули программы, выполняемые компьютером. В общем случае модули программы включают в себя подпрограммы, программы, задачи, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или воплощают определенные абстрактные типы данных. Изобретение может также применяться в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, которые связаны через сеть связи. В распределенной вычислительной среде модули программы могут располагаться и в местных, и в удаленных компьютерных носителях данных, которые включают в себя запоминающие устройства.
Обращаясь к фиг. 1, примерная система для осуществления изобретения включает в себя универсальное вычислительное устройство в виде компьютера 110. Компьютер 110 может включить в себя следующие компоненты: процессор 120, системную память 130 и системную шину 121, которая соединяет различные системные компоненты, которые включают в себя системную память, с процессором 120, но его состав не ограничен ими. Системная шина 121 может быть любой из нескольких видов шинных структур, которая включает в себя шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из разнообразия шинной архитектуры. Например, но не в качестве ограничения, такая архитектура включает в себя шину архитектуры, соответствующей промышленному стандарту (ISA), шину микроканальной архитектуры (MCA), шину расширенной стандартной архитектуры для промышленного применения (EISA), локальную шину Ассоциации по стандартам в области видеоэлектроники (VESA) и шину соединения периферийных устройств (PCI), также известную как шина расширения.
Компьютер 110 в типичном варианте включает в себя разнообразие считываемых компьютером носителей. Считываемые компьютером носители могут быть любыми доступными носителями, к которым может обратиться компьютер 110, и они включают в себя и энергозависимые, и энергонезависимые носители, сменные и несменные носители. Для примера, но не в качестве ограничения, считываемые компьютером носители могут содержать компьютерные носители данных и средства связи. Компьютерные носители данных включают в себя и энергозависимые и энергонезависимые, сменные и несменные носители, осуществленные любым способом или технологией для хранения информации, такой как считываемые компьютером команды, структуры данных, модули программы или другие данные. Компьютерные носители данных включают в себя: оперативную память, постоянное запоминающее устройство (ПЗУ), электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ), флэш-память или память, изготовленную с применением другой технологии, компакт-диски (CD-ROM), цифровые многофункциональные диски (DVD) или другие оптические дисковые запоминающие устройства, магнитные кассеты, магнитную ленту, магнитные дисковые запоминающие устройства или другие магнитные запоминающие устройства, или любой другой носитель, который может использоваться для хранения необходимой информации и к которому может обратиться компьютер 110, но не ограничены ими. Среда связи типично воплощает считываемые компьютером команды, структуры данных, модули программы или другие данные в модулируемый сигнал данных, такой как несущая или другой механизм транспортировки, и включают в себя любые средства доставки информации. Термин "модулированный сигнал данных" означает сигнал, который имеет одну или более из своих характеристик, которые устанавливаются или изменяются таким образом, чтобы кодировать информацию в сигнале. Для примера, а не в качестве ограничения, среда связи включает в себя проводные каналы связи, такие как проводные сети или прямое проводное подключение, и беспроводные каналы связи, такие как акустический, радиочастотный (РЧ), инфракрасный и другие беспроводные каналы связи. Считываемые компьютером носители должны также включать в себя комбинации любого из вышеупомянутых носителей.
Системная память 130 включает в себя компьютерные носители данных в форме энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ПЗУ) 131 и оперативная память (ОП) 132. Базовая система 133 ввода-вывода (BIOS), содержащая основные подпрограммы, которые помогают перемещать информацию между элементами в компьютере 110, например во время запуска, обычно хранится в ПЗУ 131. ОП 132 обычно содержит данные и/или модули программы, которые мгновенно доступны для обработки и/или в данный момент обрабатываются процессором 120. Для примера, а не в качестве ограничения, фиг. 1 показывает операционную систему 134, прикладные программы 135, другие модули 136 программы и данные 137 программы.
Компьютер 110 может также включать в себя другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных. Только для примера, фиг. 1 показывает накопитель 141 на жестком диске, который считывают информацию или который записывает информацию на несменный энергонезависимый магнитный носитель, накопитель на магнитном диске, который считывает информацию или записывает информацию на сменный энергонезависимый магнитный диск 152, и привод оптического диска, который считывает информацию или записывает информацию на сменный энергонезависимый оптический диск 156, такой как компакт-диск (CD ROM) или другой оптический носитель. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных, которые могут использоваться в типичной среде, включают в себя: кассеты с магнитной лентой, платы флэш-памяти, цифровые многофункциональные диски, цифровую видеоленту, полупроводниковую оперативную память, полупроводниковое ПЗУ и т.п., но не ограничены ими. Накопитель 141 на жестком диске типично подключается к системной шине 121 через средство сопряжения с несъемным запоминающим устройством, такое как средство 140 сопряжения, и накопитель 151 на магнитном диске и привод 155 оптического диска типично подключается к системной шине 121 через средство сопряжения со съемным запоминающим устройством, такое как средство 150 сопряжения (интерфейс).
Устройства и связанные с ними компьютерные носители данных, описанные выше и показанные на фиг. 1, обеспечивают хранение считываемых компьютером команд, структур данных, модулей программы и других данных для компьютера 110. На фиг. 1, например, жесткий диск 141 показан в качестве устройства хранения операционной системы 144, прикладных программ 145, других модулей 146 программы и данных 147 программ. Следует обратить внимание, что эти компоненты могут быть теми же самыми или могут отличаться от операционной системы 134, прикладных программ 135, других модулей 136 программы и данных 137 программы. Операционной системе 144, прикладным программам 145, другим модулям 146 программы и данным 147 программы присвоены различные обозначения для того, чтобы показать, что они, как минимум, являются различными копиями. Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода данных, такое как клавиатура 162 и устройство 161 позиционирования, обычно называемое "мышь", шаровой манипулятор ("трекболл") или сенсорная панель. Другие устройства ввода данных (не показаны) могут включать в себя микрофон, джойстик, игровую клавиатуру, спутниковую антенну, сканер или подобные им устройства. Эти и другие устройства ввода данных часто подключаются к процессору 120 через входное средство 160 сопряжения с пользователем (входной пользовательский интерфейс), которое подсоединено к системной шине, но может быть соединено с помощью другого интерфейса и шинных структур, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или другой тип устройства отображения также связан с системной шиной 121 через интерфейс (средство сопряжения), такой как видеоинтерфейс 190. В дополнение к монитору компьютеры могут также включать в себя другие периферийные устройства вывода, такие как громкоговорители 197 и принтер 196, которые могут быть связаны через средство 195 сопряжения с внешними устройствами вывода информации.
Компьютер 110 может работать в сетевой среде, используя логические подключения к одному или более удаленным компьютерам, таким как удаленный компьютер 180. Удаленный компьютер 180 может быть другим персональным компьютером, сервером, маршрутизатором, сетевым ПК, равноправным устройством сети или другим обычным сетевым узлом, и типично включает в себя многие или все элементы, описанные выше по отношению к персональному компьютеру 110, хотя только запоминающее устройство 181 показано на фиг. 1. Логические подключения, изображенные на фиг. 1, включают в себя локальную сеть (ЛС) 171 и глобальную сеть (ГС) 173, но могут также включать в себя другие сети. Такие сетевые среды являются обычными в офисах, компьютерных сетях в масштабах предприятия, корпоративных сетях (интранет) и Интернет.
При работе в среде с ЛС персональный компьютер 110 связан с ЛС 171 через сетевой интерфейс (средство сопряжения с сетью) или адаптер 170. При работе в среде глобальной сети компьютер 110 типично включает в себя модем 172 или другие средства установления связи с глобальной сетью 173, такой как Интернет. Модем 172, который может быть внутренним или внешним, может быть связан с системной шиной 121 через пользовательский входной интерфейс 160 или другой соответствующий механизм. В сетевой среде модули программы, изображенные относительно персонального компьютера 110 или его частей, могут храниться в удаленном запоминающем устройстве. Для примера, а не в качестве ограничения, фиг. 1 показывает, что удаленные прикладные программы 185 находятся в запоминающем устройстве 181. Следует признать, что показанные сетевые подключения приведены в качестве примера и могут использоваться другие средства установления связи между компьютерами.
В нижеследующем описании изобретение описано со ссылкой к действиям и символическим представлениям операций, которые выполняются одним или более компьютерами, если не обозначено иначе. Также понимается, что такие действия и операции, которые упоминаются время от времени как выполняемые компьютером, включают в себя обработку процессором компьютера электрических сигналов, представляющих данные в структурированной форме. Такая обработка преобразовывает данные или сохраняет их в ячейках системы памяти компьютера, которые реконфигурируют или иначе изменяют работу компьютера способом, хорошо понимаемым специалистами. Структуры данных, где хранятся данные, являются физическими ячейками памяти, которые имеют конкретные свойства, определяемые форматом данных. Однако, хотя изобретение описывается в указанном ранее контексте, он не должен являться ограничением, поскольку специалисты должны признать, что различные действия и операции, описанные далее, могут также быть осуществлены в аппаратных средствах.
В соответствии с одним важным аспектом изобретения, ссылка сделана к фиг. 2, которая представляет структурную схему клиентского программного обеспечения, такого как клиент Windows®, подходящего для воплощения вариантов осуществления настоящего изобретения. Структурная схема показывает прикладную программу 200, которая может быть любой прикладной программой, выполняющейся на компьютере 110, показанном на фиг. 1. Соответствующие прикладные программы включают в себя, например, Microsoft Word, Microsoft Publisher, QuarkXPress, Adobe InDesign и т.п. Показанная прикладная программа 200 включает в себя ведомость 210 свойств. Ведомость 210 свойств взаимодействует со средством 202 размещения, которое может находиться в компьютере 110 или может быть доступно через подключение клиент-сервер. Средство 202 размещения может быть приложением-клиентом, выполняющимся на компьютере 110, или может быть доступно через сетевое подключение. Ведомость 210 свойств, расположенная в прикладной программе 200, обеспечивает значения свойств для средства 202 размещения, которые принимаются во входной фильтр 230 структуры и размещения. Кроме входного фильтра 230 структуры и размещения средство 202 размещения также включает в себя средство 240 считывания показателей (метрик) и средство 250 формирования параметров текста. Структуры данных ведомости свойств включают в себя те элементы, которые требуются средству 202 размещения для обеспечения соответствующего размещения для визуализации шрифтов и текста для прикладной программы 200. Входной фильтр 230 структуры и размещения формирует элементы для ввода в средство 240 считывания показателей и обеспечивает передачу входных свойств к средству 240 считывания показателей. Средство 240 считывания показателей обрабатывает свойства и отправляет данные на средство 250 формирования параметров текста. Средство 250 формирования параметров текста принимает данные, которые включают в себя идентификаторы для гарнитуры шрифта и идентификаторы для языка, и выводит вычисленные данные, относящиеся к характеристикам текста, предназначенным для использования средством 240 считывания показателей.
Как описано более подробно ниже, средство 240 считывания показателей обрабатывает входные значения для обеспечения оптимальных типографских параметров настройки в пределах данных ограничений, имеющихся в вызывающих прикладных программах. Входные ограничения могут включать в себя ограничения среды и дизайнерские ограничения, но не ограничены ими. Ограничения среды могут включать в себя увеличение, размер экрана и разрешающую способность, оптическое увеличение для читателя и расстояние до читателя. Дизайнерские ограничения могут включить в себя требования к шрифту, требования к полям, требования к колонкам и требования к прямоугольнику размещения. С учетом этих ограничений средство 240 считывания показателей обеспечивает передачу параметров настройки, которые включают в себя параметры для окна, страницы и действующих размеров набора, размеров полей, оптимального количества колонок, оптимальных размеров колонки и поля переплета и оптимального размера шрифта и высоты строки. Передаваемые параметры настройки могут измеряться в пикселях или в пунктах согласно требованиям дизайна. Преимущественно, параметры настройки, выводимые из средства 240 считывания показателей, соответствуют известным языкам и шрифтам.
Обращаясь теперь к фиг. 3, структурная схема, показанная на фиг. 2, расширена в форме структурной схемы для иллюстрации потока информации в структуре данных. Фиг. 3 показывает ведомость 210 свойств, которая включает в себя такие элементы, как размер 312 страницы, поля 314 страницы, семейство 316 шрифтов, размер 318 шрифта, высота 320 строки, количество 322 колонок, ширина 334 колонки и размеры 326 страницы. Также ведомость 210 свойств включает в себя те значения, которые не могут быть изменены. Это те значения, которые настраиваются с помощью модуля 329, и те значения, которые не передаются входному фильтру 230 структуры и размещения. Более конкретно, входной фильтр 230 структуры и размещения включает в себя модуль 330 элементов и средство обнаружения 352 текстового потока. Модуль 330 элемента формирует данные в структуру данных. Показанная типичная структура данных включает в себя семейство 332 шрифта, язык 334, изменение 336 размера шрифта, изменение 338 высоты строки, поля 340 страницы, диапазон 342 изменения размера полей страницы и предпочтительное значение 344 количества колонок. Данные формируются в модуле 330 элементов и передаются как входные свойства средству 346 считывания показателей. В свою очередь, средство 352 обнаружения текстового потока обеспечивает передачу размера 354 окна к средству 240 считывания показателей. Альтернативно, средство 352 обнаружения текстового потока может быть связанным в сеть компонентом или системным компонентом в компьютере 110. В одном из вариантов осуществления средство 202 размещения взаимодействует с уровнем 360 взаимодействия со средой отображения. Уровень 360 взаимодействия со средой отображения обеспечивает передачу размера 362 среды отображения к средству 240 считывания показателей. Один пример размера 362 среды отображения включает в себя размер дисплея компьютера 110, показанного на фиг. 1.
Средство 240 считывания показателей воплощает варианты осуществления настоящего изобретения, как описано более подробно ниже. В одном из вариантов осуществления средство 240 считывания показателей взаимодействует с средством 250 формирования параметров текста и модулем 230 элементов. Модуль 230 элементов содержит входные свойства 346 для средства считывания показателей. Модуль 230 элементов подсоединен к средству 352 обнаружения текстового потока. В одном из вариантов осуществления модуль 230 элемента и средство 352 обнаружения текстового потока вместе формируют один компонент, который включает в себя структуру, расположенную в модуле 230 элемента, и размещение, расположенное в средстве 252 обнаружения текстового потока.
Средство 240 считывания показателей принимает входную информацию и обрабатывает ее для генерации параметров настройки, использующихся для размещения текста в вызывающей прикладной программе. Параметры настройки могут учитывать пользовательские параметры настройки для определения размеров или могут автоматически определять заданные по умолчанию размеры. Средство 250 формирования параметров текста является важной особенностью средства 202 размещения. Средство 250 формирования параметров текста, которое подает входную информацию средству 240 считывания показателей, которые добавляют специфические для языка данные, относящиеся к параметрам текста, принимает идентификатор семейства шрифта 364 и идентификатор языка 366. Выходная информация от средства 250 формирования параметров текста включает в себя измеренные значения, вычисленные в средстве 250 формирования параметров текста. Более конкретно, как объяснено более подробно ниже со ссылкой на фиг. 5, средство 250 формирования параметров текста измеряет соотношение черных и белых пикселей в каждом ряду пикселей в воспроизводимой строке шрифта и обеспечивает передачу этих результатов измерений, используя термины, которые идентифицируют характеристики характерной строки текста для данного шрифта и данного языка. Эти результаты 368 измерения параметров текста передаются средству 240 считывания показателей. Средство 240 считывания показателей использует уравнения и другие вычисления к результатам измерения и входным значениям свойств 346 для обеспечения выходных значений свойств 380, которые включают в себя размер 382 страницы, поля 384 страницы, семейство 386 шрифта, размер 388 шрифта, высоту 389 строки, расстояние 390 между колонками, ширину 392 изображения, ширину 394 колонок, количество 396 колонок и абзацный отступ 398. Эти свойства возвращаются к вызывающей прикладной программе 200.
Обращаясь к фиг. 4 в комбинации с фиг. 3, способ определения свойств размещения текста согласно одному из вариантов осуществления показан в виде последовательности операций. Способ относится к функциям, которые выполняются в средстве 240 считывания показателей и средстве 250 формирования параметров текста, показанных на фиг. 2 и 3. Более конкретно, на этапе 410 предусматривают прием данных о среде (оборудовании) для размещения международного текста. Как показано на фиг. 3, данные могут включать в себя элементы из одного или более модулей: ведомости 210 свойств, средства 252 обнаружения текстового потока и средства 250 формирования параметров текста. Данные о среде включают в себя данные, относящиеся к среде визуализации, такие как размер экрана, размер бумаги и т.п., а также определяемые пользователем или требуемые системой параметры, относящиеся к размерам полей, размеру шрифта, колонок, высоте строки, длине строки и языку. На этапе 420 обеспечивают обработку данных, используя измеренные характеристики нормированной характерной строки международного текста, напечатанного предопределенным шрифтом, и измеренные характеристики среды. Характеристики нормированной характерной строки международного текста измеряются в средстве 250 формирования параметров текста. Средство 240 считывания показателей может быть соединено со средством 250 формирования параметров текста или может вызвать средство 250 формирования параметров текста через интерфейс прикладной программы (ИПП, API). Характеристики среды измеряются в средстве 240 считывания показателей. После приема измеренных характеристик нормированной характерной строки международного текста средство 240 считывания показателей выполняет множество операций над принятыми вычисленными данными. Информация с выхода средства считывания показателей передается к вызывающей прикладной программе 200.
Работа средства 250 формирования параметров текста описана более подробно в виде последовательности операций на фиг. 5 и 6. Как показано, средство 250 формирования параметров текста принимает идентификатор 364 семейства шрифта и идентификатор 366 языка на этапе 510. На этапе 520 средство формирования параметров текста измеряет характеристики характерной строки шрифта на идентифицированном языке и для идентифицированного шрифта. Преимущественно, полученные результаты измерений дают возможность объективного определения размеров шрифта и высоты строки для любого заданного языка и шрифта для любого заданного размещения. На этапе 530 средство 250 формирования параметров текста нормирует измерения по множеству шрифтов и языков. Результаты измерений затем используются для определения соответствующих размеров.
Для целей этого раскрытия термин "размеры" включают в себя высоту строки, которая является расстоянием от опорной линии одной строки шрифта до опорной линии следующей строки, но не ограничивается ею. Опорная линия является видимой линией, на которой находятся символы в системе записи или с которой они "свисают". Для символов английского языка опорная линия является воображаемой линией, на которой находятся символы верхнего и нижнего регистра. Высота строчных букв (х - высота) (без выносных элементов) относится к стандартной высоте символов строчных букв, приблизительно эквивалентной высоте символа x нижнего регистра (строчной буквы х) для данного шрифта. Высота прописных букв относится к высоте прописных букв в строке шрифта, она не равна, но часто приравнивается к высоте надстрочного элемента. В некоторых шрифтах надстрочные элементы выше или короче, чем высота большинства заглавных букв. Надстрочный элемент - части строчных букв 1, t, f, b, d, h, k, которые находятся выше высоты строчных букв без выносных элементов. Подстрочный элемент относится к частям строчных букв g, j, p, q, y, которые находятся ниже опорной линии.
Кегельная шпация является единицей измерения, равной размеру шрифта. Таким образом, кегельная шпация является переменной единицей измерения, которая изменяется всякий раз, когда изменяется размер шрифта. Кегельная шпация для целей этого раскрытия является квадратом (кегельной площадкой) измеряемого шрифта. Например, если шрифт представлен шрифтом 12 пунктов, то кегельная шпация - 12 пунктов высотой и 12 пунктов шириной. Если шрифт представлен шрифтом 100 пунктов, то кегельная шпация - 100 пунктов высотой и 100 пунктов шириной. Поэтому кегельная шпация используется как нехарактерная единица измерения размера шрифта и она основана на том, как шрифт разработан, а не на его физических характеристиках. В результате некоторые рисунки шрифтов могут иметь типографскую краску, которые находятся вне кегельной шпации, например в тайском языке, а другие занимают значительно меньше места, чем кегельная шпация, например в корейском языке. "Кластер", для целей этого раскрытия относится к элементу воспроизведения анализируемого шрифта и текста. Более точно, кластер - напечатанное содержимое между точками, куда курсор может быть вставлен в строке электронного текста. Термин "кластер" является общим, потому что он определяется отсутствием пробелов в строке, а не нажатиями клавиши, символами или специальными знаками (глифами) и поэтому соответствует всем языкам. В латинских шрифтах кластер и символ могут быть эквивалентны.
Обращаясь теперь к фиг. 6, способ, представленный на фиг. 5, описан более подробно. Способы, описанные на фиг. 6, обеспечивают числовую характеристику уровня серого для любого вида текста, напечатанного любым шрифтом и на любом языке. Числовая характеристика основана на том, что читатель видит, когда шрифт размещается на странице, то есть на множестве темных строк, вдоль которых глаз следует в процессе чтения. Поскольку размер этих строк и пространство между ними изменяется при различных системах записи, типах шрифтов, языках и культурах, результаты измерений должны соответствовать любой системе записи на любом языке. Покрытое чернилами (типографской краской) место в строке текста в данной работе называется "черной рекой". Более точно, понятие "черная река" относится ко всему месту, занятому чернилами в одной строке текста для заданного шрифта и языка, которое включает в себя самые высокие и самые низкие точки, заполненные чернилами, в характерной строке шрифта.
Способы, которыми измеряется "черная река", описаны на фиг. 6. После приема идентификатора семейства шрифта и идентификатора языка, как показано на этапе 610, средство 250 формирования параметров текста измеряет отношение количества черных пикселей к общему количеству пикселей в множестве рядов пикселей в характерной строке шрифта. В одном из вариантов осуществления средство 250 формирования параметров текста измеряет отношение количества черных пикселей к общему количеству пикселей в каждом ряду пикселей в визуализируемой строке шрифта. После того как каждый ряд пикселей, который содержит черные пиксели, был измерен, ряд с самым высоким отношением количества черных пикселей к общему количеству пикселей приравнивается к черному цвету, как показано на этапе 620. Результаты измерений всех других рядов нормируются по отношению к этой черной точке. Нормирование допускает эквивалентные измерения параметров шрифтов с различной насыщенностью, так как черная точка шрифта может быть нормирована по всем шрифтам. Например, самая темная часть "черной реки", измеренная при 1/200 кегельной шпации, как полагают, является на 100 % черной, независимо от того, какую степень черноты она имеет в действительности. Все другие части "черной реки" измеряются для интенсивности серого, как значение между 0% (белый) и 100% (нормированный черный, или самая темная часть "реки"). Вычисляется среднее отношение, и затем отмечаются первый ряд пикселей и последней ряд пикселей, которые темнее, чем среднее значение.
На этапе 630 обеспечивают идентификацию высоты шрифта, используя измеренные отношения количества черных пикселей к общему количеству пикселей. На этапе 640 средство формирования параметров текста использует высоту шрифта и идентифицирует первую часть, которая в данной работе называется "канал", которая включает в себя ряд с самым высоким отношением количества черных пикселей к общему количеству пикселей, причем первая часть включает в себя первый ряд пикселей и последний ряд пикселей, которые темнее, чем среднее значение ряда пикселей. В латинских текстах "канал" приравнивают к высоте строчных букв без выносных элементов. В других шрифтах нет прямого эквивалента высоты строчных букв без выносных элементов. Поскольку каждый шрифт на каждом языке, визуализируемый в строке текста, будет иметь темную часть в строке текста, вместо высоты строчных букв без выносных элементов в вариантах осуществления используется термин "канал" и измерения, относящиеся к "каналу". Во многих описанных вариантах осуществления "канал" является важным измерением для определения соответствующей высоты строки и других параметров настройки для строки текста, напечатанной данным шрифтом. На этапе 650 средство 250 формирования параметров текста идентифицирует вторую часть, расположенную выше первой части. На этапе 660 средство 250 формирования параметров текста идентифицирует третью часть, расположенную ниже первой части. Вторая часть и третья часть в данной работе называются "предотмель" и "послеотмель" соответственно, а все вместе - "отмель". В большинстве шрифтов обычно существует "отмель" с обеих сторон идентифицированного "канала". "Отмель" является областью, где строка шрифта имеет чернила, но не каждый символ распространяется (выступает) в нее. В латинском шрифте существует "отмель", которая эквивалентна надстрочному элементу и подстрочному элементу. Язык с большим количеством знаков ударений типично имеет "отмель", которая включает в себя знаки ударений. Язык, который является существенно однородным, может идентифицироваться как имеющий "канал" с маленькой или отсутствующей "отмелью". Многие азиатские языки можно идентифицировать, как имеющие только "канал" и не имеющие "отмели". Эти языки имеют "реку" и "канал", которые имеют одинаковый размер.
На этапе 670 средство 250 формирования параметров текста создает график результатов измерений для осуществления идентификации точек выравнивания, пиков темноты и т.п.
После идентификации "канала" и "отмели" этап 680 обеспечивает определение среднего значения отношения количества черных пикселей к общему количеству пикселей в каждой части. Эти части описывают строку текста для конкретного шрифта, обеспечивая результаты трех измерений, которые включают в себя ширину "канала", ширину "предотмели" и ширину "послеотмели".
В одном из вариантов осуществления средство 250 формирования параметров текста возвращает средству 240 считывания показателей результаты измерений, которые включают в себя один или более из результатов измерений: отношение количества черных пикселей к общему количеству пикселей в самом темном ряду пикселей, среднее значение отношения количества черных пикселей к общему количеству пикселей во всей характерной строке шрифта, ширину "предотмели", отношение количества черных пикселей к общему количеству пикселей в "предотмели", ширину "канала", отношение количества черных пикселей к общему количеству пикселей в "канале", ширину "послеотмели" и отношение количества черных пикселей к общему количеству пикселей в "послеотмели". Когда слова на каком-то языке пишутся вертикально, например как в некоторых азиатских языках, те же самые измерения могут быть сделаны, измеряя колонки вертикального текста для языка с вертикальным написанием вместо измерения строки горизонтального текста для языков с горизонтальным написанием. Специалисты должны понять с помощью этого раскрытия, что принципы для определения характеристик языка с вертикальным написанием являются теми же самыми, так что, например, "канал" шрифта с вертикальным написанием будет на 90 градусов повернут для измерения по сравнению с "каналом" шрифта с горизонтальным написанием.
В других вариантах осуществления при необходимости средством 240 считывания показателей могут возвращаться дополнительные результаты измерений, такие как точки выравнивания при другой степени точности, чем деление на три части, или результаты измерений, которые соответствуют самым темным рядам, или пикам на любых созданных графиках.
Обращаясь к фиг. 7, показана фотография моделируемого текста с соответствующими графиками согласно одному из вариантов осуществления. Фотография 710 иллюстрирует латинский шрифт с засечками, показывая, что пики находятся в общем случае наверху заглавной буквы, на высоте строчной буквы без выносных элементов, на высоте перекладины строчной буквы "e", на опорной (базовой) линии и в подстрочном элементе. Для сравнения, фотография 720 иллюстрирует форму нелатинского шрифта с другими и более центрированными точками выравнивания.
Другими возвращаемыми результатами измерения могут быть результаты измерения относительно кегельной шпации. В средстве 250 формирования параметров текста и в средстве 240 считывания показателей кегельная шпация используется для определения и горизонтальных, и вертикальных размеров. Другим результатом измерения, который может возвращаться средством 250 формирования параметров текста, является количество кластеров на кегельную шпацию, которое может также быть результатом измерения, возвращаемым средству 240 считывания показателей. Количество кластеров, приходящееся на кегельную шпацию, эквивалентно отношению высоты шрифта к средней ширине кластера.
Другие результаты измерения, которые могут использоваться средством 240 считывания показателей, включают в себя ширину "черной реки" как вещественное число по отношению к кегельной шпации; ширину "предотмели" как вещественное число по отношению к кегельной шпации; ширину "послеотмели" как вещественное число по отношению к кегельной шпации; ширину "канала" как вещественное число по отношению к кегельной шпации; среднюю насыщенность "канала" и каждой из "отмелей" как вещественное число, такое что 0 = все белые и 1 = все черные после нормирования; среднее количество кластеров на кегельную шпацию; и общее количество кластеров в характерной строке текста. Значения ширины могут возвращаться к средству 240 считывания показателей как вещественное число по отношению к кегельной шпации, и значения насыщенности могут возвращаться к средству 240 считывания показателей как вещественное число по отношению к нормированной черной точке. В одном из вариантов осуществления общее количество кластеров предварительно запоминается в таблице языка или в средстве 240 считывания показателей, или в средстве 250 формирования параметров текста.
Фиг. 8 иллюстрирует примерный способ в виде последовательности операций, показывающей взаимодействие между средством 240 считывания показателей и действиями в средстве 250 формирования параметров текста. На этапе 810 пользователь маркирует документ в прикладной программе. Эта маркировка включает в себя индикацию языка и шрифта. Индикация может происходить через системный канал связи или через ввод информации пользователем. Индикацию, идентифицирующую язык и шрифт, передают на этапе 820 к средству 240 считывания показателей. В одном из вариантов осуществления средство 250 формирования параметров текста указывает объект шрифта и интерфейс прикладной программы (API), которые средство 240 считывания показателей может запросить для измерения. Если средство 240 считывания показателей подвергает обработке объект шрифта на этапе 822, то идентификаторы языка и шрифта передаются на средство 250 формирования параметров текста. В противном случае средство 240 считывания показателей оперирует с языком и шрифтом, не вызывая средство 250 формирования параметров текста. Например, если средство 240 считывания показателей имеет таблицу с необходимыми результатами измерений для этого шрифта и языка, то вызов средства 250 формирования параметров текста не нужен. Этап 828 обеспечивает, чтобы в средстве 250 формирования параметров текста идентификаторы языка и шрифта использовались или с помощью сравнения языка и шрифта с предопределенной таблицей для отыскания данных, относящихся к характеристикам шрифта, или с помощью отыскания характерной текстовой строки на языке. Если характерная текстовая строка найдена, то шрифт, или семейство шрифтов, применяется к языку для создания на этапе 829 характерной строки текста, которая может быть одной строкой текста или иметь другой подходящий для измерения формат. Этап 830 обеспечивает измерение средством формирования параметров текста "черной реки", "канала" и "отмели". Этап 832 обеспечивает, чтобы средство 250 формирования параметров текста затем нормировало черную точку и все связанные с ней значения в процентах. Этап 840 обеспечивает, чтобы средство 250 формирования параметров текста возвращало результаты измерения ширины и насыщенности, среднее количество кластеров на кегельную шпацию шрифта, общее количество кластеров в характерной строке шрифта и подобные результаты измерений, такие, как описано выше.
В одном из вариантов осуществления средство 250 формирования параметров текста измеряет ряды пикселей в характерной строке текста с интервалами в 1/200 кегельной шпации и записывает отношение количества черных пикселей к общему количеству пикселей в характерной строке текста в качестве среднего уровня серого. Результаты измерений могут быть записаны или как значение 0-255, или как два десятичных разряда процента. Этап 850 обеспечивает, чтобы после того как результаты измерений передают назад к средству 240 считывания показателей, средство 240 считывания показателей вычисляло размер шрифта и высоту строки. Этап 860 обеспечивает, чтобы пользователь видел страницу на любой поверхности обозрения со шрифтом, который имеет соответственно установленный размер и расположение. Обращаясь к фиг. 9a, график 900 иллюстрирует измеренный образец после того, как средство 250 формирования параметров текста вычислило результаты измерения, описанные на фиг. 8. График показывает результаты измерения шрифта Times New Roman, такие как нормированная версия графиков, показанных на фиг. 7. Показанные результаты измерения включают в себя средний уровень серого для каждого ряда пикселей, которые изменяются от 0 (черный цвет) до 255 (белый цвет). График 900 иллюстрирует нормированную версию, показывая уровень серого в процентах. Необработанные данные нормируются на графике 900 так, чтобы самая темная линия в шрифте рассматривалась как абсолютно черная или 100%, а самый светлый пиксель - 0%. Более конкретно, график 900 показывает высоту характерной строки текста по оси X 910 в пунктах и средний уровень серого для каждого ряда пикселей по оси Y 920 в процентах. Нормированные результаты измерений показывают сплошной линией 902, абсолютные результаты измерений "канала" и "отмели" показывают пунктирной линией 909, а среднее значение уровня серого показывают линией 906. Сравнение графика 710, показанного на фиг. 7, с графиком 900 показывает точки 930 и 940 выравнивания, а также показывает "канал", очерченный по высоте строчных букв без выносных элементов 940 и опорной линией 930 для данного шрифта и языка. Пересечение линии 906 с кривой 902 шрифта является точкой 24 данных, а следующее пересечение - точкой 71 данных. Полная высота шрифта - 91. Если кегельная шпация составляет 100%, то набор вещественных чисел по отношению к кегельной шпации будет: "предотмель" = 0,24; "канал" = 0,45; "послеотмель" = 0,20; и "черная река" = 0,91.
Фиг. 9b иллюстрирует график 990 с той же самой кривой 902 шрифта с пунктирной линией 950, показывающей среднее значение насыщенности для каждого из "отмели" и "канала". Средние значения насыщенности в процентах могут использоваться для определения значения высоты строки. Возвращенные значения могут включать в себя среднее значение насыщенности "предотмели" 0,099; среднее значение насыщенности "канала" 0,61; и среднее значение насыщенности "послеотмели" 0,038.
Результаты измерения от средства 250 формирования параметров текста возвращаются к средству 240 считывания показателей. Средство 240 считывания показателей использует результаты измерений для разнообразных целей.
Одной из функций средства 240 считывания показателей является определение заданного по умолчанию размера шрифта для удобочитаемого текста на любом языке. Заданные по умолчанию размеры шрифта предшествующего уровня техники используют жестко установленные числа в пунктах или пикселях, основанные на размерах шрифта Elite и шрифта Pica для пишущих машинок, такие как 12 шагов или 10 пунктов и 10 шагов или 12 пунктов. Средство 240 измерения показателей использует новый подход, определяя соответствующий размер для текста на любом заданном языке и для любого шрифта на основании характеристик чтения для определенных языка и культуры и характеристик физической визуализации шрифта, которые определяются с помощью средства 250 формирования параметров текста и факторами среды. Средство 240 считывания показателей может быть автоматическим и масштабируемым и может использовать вводимую зависимую от культуры информацию и настраиваемую пользователем входную информацию.
Более конкретно, средство 240 считывания показателей применяет способ согласно одному из вариантов осуществления, который определяет размер шрифта как функцию характеристик, связанных со средой отображения и характеристиками языка. Характеристики среды отображения включают в себя определение заданного по умолчанию расстояния от среды отображения, которое может быть изменено пользователем по мере необходимости.
Обращаясь к фиг. 10, последовательность операций иллюстрирует способ вычисления размера шрифта для заданного по умолчанию расстояния от дисплея. На этапе 1010 способ определяет минимальное и максимальное заданное по умолчанию расстояние от дисплея с использованием экспоненциального отношения минимального расстояния от любого дисплея. В одном из вариантов осуществления минимальное расстояние установлено как 12" и максимальное расстояние установлено приблизительно 27". Показательная кривая быстро стремится к большим расстояниям, когда дисплей становится больше. Функция ad2 + b = D является типичной показательной функцией, подходящей для определения заданного по умолчанию расстояния. В данной функции a представляет постоянный множитель для d2, и b представляет постоянное число, которое добавляют к ad2, так чтобы a+b=12, или минимальное расстояние, с которого читатель может рассматривать страницу со шрифтом. D и d - наблюдаемые точки на графике фактического расстояния чтения и размеров дисплея. Строчная буква d представляет диагональ поверхности дисплея в дюймах; и D представляет расстояние от поверхности дисплея в дюймах. В примере, если a и b были установлены а = 0,02353 и b = 11,97647, и данные точки преобразовывают, умножая на 72, то показательная кривая задается, как показано на графике на фиг. 11. Как показано, ось X представляет диагональ дисплея в общих единицах измерения, и ось Y 1102 является расстоянием от дисплея в общих единицах измерения. Хотя график на фиг. 11 показан в дюймах, если бы пример был преобразован в другие единицы измерения, то также необходимо было бы сделать подобное преобразование констант a и b.
После того как заданное по умолчанию расстояние до дисплея определено, это расстояние используется средством 240 считывания показателей для определения заданного по умолчанию размера шрифта для предопределенного шрифта. Более конкретно, этап 1020 обеспечивает использование тригонометрической функции фовеального (центрального) угла и плотности знака для определения размера шрифта для предопределенного шрифта, который является подходящим для считывания в какой-либо среде. В данной работе размер шрифта для предопределенного шрифта называется размером шрифта. Фовеальный угол используется для определения области самого резкого фокусирования на среде отображения. Чтобы определить эту область, функция использует двойной тангенс половины фовеального угла, умноженного на расстояние от обозреваемой поверхности. В дополнительном варианте осуществления фовеальный угол, который используется для определения расстояния, определяется с помощью введения информации об одном или больше определенном для читателя фовеальном угле или с помощью стандартного фовеального угла, равного приблизительно 0,75 градусов. Определенный для читателя фовеальный угол может отражать остроту зрения читателя. Например, определенный для читателя фовеальный угол может учитывать одно или больше из следующего: дегенерация желтого пятна, ухудшение зрения, остроту зрения, резко суженое поле зрения, болезни глаз, близорукость, дальнозоркость, дислексию и астигматизм. Чтобы продемонстрировать фовеальные углы, на фиг. 12 и 13 представлены диаграммы, которые показывают, как определяется область самого резкого фокусирования. Как показано, глаз 1202 видит обозреваемую поверхность 1204 с расстояния 1206 обозрения. Исследование способностей человеческого глаза указывает, что фовеальный угол 1208 в 0,75 градусов является максимальным углом самого резкого фокусирования глаза 1202. Демонстрация способа определения длины 1210 области самого резкого фокусирования показана на фиг. 13. Используя тригонометрические функции, длина 1210 может быть описана как двойной тангенс 1302 от половины фовеального угла 1304. Фовеальный угол человеческого глаза, основываясь на различных исследованиях, приблизительно равен 0,75°. Парафовеолярный угол равен 10-12°. В дополнение к диапазону зрения, в котором данные воспринимаются, но они находятся не на пике фокусирования, 12° является приблизительным диапазоном движения глаза до того, как непреднамеренное движение головы начинает помогать позиционированию глаза. В одном из вариантов осуществления считается, что оптимальной длиной строки является длина строки, равная приблизительно 16 фовеальных фиксаций взгляда. Количество кластеров является культурно-зависимым. Исследование длины строки в английском языке хорошо документировано и объективными исследованиями, и наблюдениями за развитием оформления книг. Исследования показывают, что для английского языка за одну фовеальную фиксацию взгляда мгновенно распознаются приблизительно 4 символа шрифта. Таким образом, один из вариантов осуществления использует оценку оптимальной длины строки в английском языке, равной 4 x 16 = 64 кластера в строке. Наблюдения показывает, что наборы символов, которые включают в себя больше информации в кластере, чем в английском языке, требуют меньшего количества кластеров в фиксации, чтобы ускорить понимание. Поскольку это не абсолютные отношения, один из вариантов осуществления использует таблицу, которая указывает для языков, расположенных один за другим, сколько кластеров будет в каждой фовеальной фиксации для данного языка. Таблица может быть составлена для языков или групп языков, которые включают в себя латинские, арабские, тайские, азиатские и индийские языки, но не ограничены ими. Такое объединение в группы сделано в соответствии с характеристиками систем записи. Любой отдельный язык может иметь другое или более оптимальное значение.
Возвращаясь к фиг. 10, на этапе 1020 обеспечивают использование плотности символов для определения размера шрифта. Плотность символов может определяться с помощью деления количества кластеров, приходящихся на кегельную шпацию, на количество кластеров в фиксации. Количество кластеров, приходящихся на фиксацию для шрифта конкретного языка, является константой, связанной с одним из множества языков, причем каждый из множества языков имеет константу, представляющую информационную плотность для чтения текста на данном языке. Количество кластеров на кегельную шпацию является описанием графической плотности. Поэтому плотность символов может быть описана как функция графической плотности и информационной плотности символа. В одном из вариантов осуществления графическая плотность и информационная плотность зависят от языка, что включает в себя характеристики чтения на данном языке в зависимости от количества информации в области самого резкого фокусирования, видимой читателю.
Согласно одному из вариантов осуществления средство 240 считывания показателей включает в себя или имеет доступ к лингвистической таблице количества кластеров, приходящихся на фовеальную фиксацию. Максимальное количество кластеров, распознаваемых за одну фовеальную фиксацию, может быть определено с помощью просмотра содержащихся в таблице языков или может быть введено пользователем, имеющим доступ к средству 240 считывания показателей. Каждый язык определяет, сколько кластеров вы можете видеть в 1/16 части парафовеолярного угла. Поэтому каждый язык имеет определяемое количество кластеров в парафовеолярном угле. Это значение может использоваться для определения длины строки, ширины колонки и т.п. В одном из вариантов осуществления предполагается, что количество кластеров, которое можно увидеть в строке, приблизительно равно десяти для каждого языка. Количество кластеров, определенное для данного языка, может быть умножено на число, которое представляет сравнение между алфавитами. Альтернативно, определяя количество кластеров в строке и деля это количество кластеров на константу, представляющую количество фиксаций взгляда человеческого глаза в этой строке текста, определяют количество кластеров на фовеальную фиксацию. Константа для одного или более языков может быть приблизительно равна 16. Количество кластеров, приходящихся на фиксацию, умножается на количество фовеальных фиксаций в парафовеолярной области, и это обеспечивает оптимальное количество кластеров, приходящихся на читаемую строку. Парафовеолярный угол является более широким углом, чем фовеальный угол, и в общем случае этот термин относится к углу, при котором глаз может видеть максимально фокусируемую область. В одном из вариантов осуществления парафовеолярный угол равен приблизительно 10 градусов. Как описано выше, фовеальный угол равен приблизительно 0,75 градусов и соотносится с двумя-четырьмя символами в области фовеальной фокусировки. Используя константу, равную 16 для количества фиксаций взгляда человеческого глаза в строке текста, и умножая ее на количество кластеров в фовеальной фиксации, количество кластеров в строке для каждого языка может быть определено, как показано в таблице.
Обращаясь к фиг. 14, способ определения плотности символа включает в себя на этапе 1410 определение количества кластеров в расчете на кегельную шпацию для шрифта. В примерном варианте осуществления количество кластеров, приходящихся на кегельную шпацию, получается из средства 250 формирования параметров текста. На этапе 1420 определяется отношение количества кластеров на кегельную шпацию в шрифте к количеству видимых кластеров в предопределенном фовеальном угле, в дальнейшем называемое количеством кластеров, приходящихся на фиксацию. Как описано выше, количество кластеров, приходящихся на фиксацию, может быть получено или может найдено из такого источника, как таблица, и оно различно для каждого шрифта каждого языка. На этапе 1430 обеспечивают умножение отношения количества кластеров, приходящихся на кегельную шпацию, к количеству кластеров, приходящихся на фиксацию, на ширину средства отображения в пунктах для получения оптимального размера в пунктах для семейства шрифтов при заданном расстоянии обозрения. На этапе 1440 обеспечивают дополнительное масштабирование полученного размера шрифта в соответствии с разметкой, вводимой пользователем или другим источником. На этапе 1450 обеспечивают определение минимального размера шрифта и максимального размера шрифта. Более подробно, в одном из вариантов осуществления минимальный размер шрифта основывается на максимальном количестве кластеров, которые пользователь может воспринимать в одной фовеальной фиксации. Максимальный размер шрифта основан на минимальном количестве кластеров, которые пользователь может воспринимать в одной фовеальной фиксации и все еще понять смысл из строки текста. В дополнительном варианте осуществления минимальный и максимальный размер шрифта может определяться на основе предопределенного процента от оптимального размера шрифта, например ±25% от значения количества кластеров, приходящихся на фиксацию (Cpf), указанного в таблице. Это переводится в минимальный размер шрифта, который равен 0,8, умноженному на оптимальный размер шрифта, и максимальный размер шрифта, который равен 1,33, умноженному на оптимальный размер шрифта. В другом альтернативном варианте осуществления минимальный размер шрифта может определяться с помощью средства визуализации, основываясь на разрешающей способности, с которой выводится информация, и на минимальном количестве пикселей, требуемых для успешной визуализации шрифта без нарушения целостности.
Обращаясь к фиг. 15, там показана система 1500 для настройки текста на определенном шрифте для оптимальной удобочитаемости на среде отображения. Система включает в себя клиентскую прикладную программу 200, которая включает в себя структуру данных, содержащую один или более текстовых параметров 1510. Система дополнительно включает в себя средство 240 считывания показателей, соединенное с клиентской прикладной программой 200, причем средство 240 считывания показателей сконфигурировано для принятия одного или больше параметров текста 1510. Средство 240 считывания показателей включает в себя модуль, сконфигурированный для определения плотности символов для шрифта 1520, и модуль, сконфигурированный для умножения значения плотности символов на значение размера области самого резкого фокусирования глаза для вычисления оптимального размера шрифта для удобочитаемости 1530. Показанный модуль 1520 определения плотности символов соединен через ИПП 1540 со средством 250 формирования параметров текста, предназначенным для определения количества кластеров, приходящихся на кегельную шпацию 1550 для шрифта. Плотность символов вычисляется с помощью деления количества кластеров, приходящихся на кегельную шпацию, на количество кластеров, приходящихся на фиксацию. В одном из вариантов осуществления средство 240 считывания показателей дополнительно включает в себя модуль, сконфигурированный для определения оптимальной ширины колонок через функцию определения оптимального размера шрифта, количества кластеров в фиксации для шрифта на определенном языке, количества кластеров, приходящихся на кегельную шпацию, и расстояния от средства отображения. Система 1500 дополнительно включает в себя устройство визуализации для среды 1560 отображения, причем среда отображения может быть напечатанной страницей, компьютерным экраном, личным цифровым помощником, голографическим изображением, доской объявлений, экраном кино, театра, вставкой в пару очков или подобным им.
Для примера, если язык является английским (количество кластеров в фиксации равно 4,0), и расстояние от монитора - 1368 пунктов (19 дюймов), и шрифт - Times New Roman (2,58 кластера на кегельную шпацию), то оптимальный размер шрифта для хорошей удобочитаемости задается с помощью 2 x тангенс от 0,006544 x 1368 x 2,58/4,0=11,5 пункта. Для другого шрифта, Linotype Palatino, который имеет только 2,33 кластера на кегельную шпацию, оптимальный размер шрифта задается с помощью 2 x тангенс от 0,006544 x 1368 x 2,33/4,0=10,4 пунктов.
Использование другого языка и формы шрифта привели бы к значительно отличающимся результатам. Например, шрифт Times New Roman для арабского языка. Культурологическое измерение количества кластеров в фиксации равно 4,4, а не 4,0, и количество кластеров на кегельную шпацию - 2,97. Поэтому оптимальный размер удобочитаемого шрифта в Times New Roman на арабском языке равен 2 x тангенс от 0,006544 x 1368 x 2,97/4,4=12,1 пунктов.
Хотя значение для количества кластеров на фиксацию должно определяться для каждой языковой группы, формула остается открытой для возможной настройки для резко суженого поля зрения, расстояния от обозреваемой поверхности и другого ухудшения зрения. Они будут воздействовать на входную информацию для формулы, чтобы изменить полученное значение по умолчанию. Некоторые из таких специальных настроек могут также быть автоматизированы, чтобы помочь приспособить текст к различным условиям обозрения, таким как множество колонок, маленькие устройства и большой экран, мониторы с высокой разрешающей способностью. В дополнительном варианте осуществления парафовеолярный угол, фовеальный угол и плотность символов могут изменятся в зависимости от вводимой пользователем информации, чтобы помочь физически неполноценным пользователям, пользователям, имеющим физические дефекты, или пользователям с более острым зрением. Более узкий парафовеолярный угол относится к пользователям с резко суженным полем зрения. Более широкий парафовеолярный угол относится к пользователям с острым периферийным зрением. Более узкий фовеальный угол относится к пользователям с ослаблением свойств желтого пятна.
Обращаясь к фиг. 16 в комбинации с фиг. 7 и 8, этап 850 на фиг. 8 обеспечивает вычисление размера шрифта и высоты строки. Как известно из предшествующего уровня техники, требования к высоте строки изменяются в зависимости от длины строки и для различных размеров шрифта. Даже для одного размера шрифта требования к высоте строки изменяются в зависимости от количества колонок на странице. Согласно представленным вариантам осуществления высота строки определяется с помощью различных способов, в зависимости от доступной информации. В одном из вариантов осуществления после того как размер шрифта определен, как описано выше, определяется высота строки для заданного размера шрифта. Эта высота строки может затем изменяться на основании количества кластеров в строке, длины строки и т.п.
Один из способов для вычисления высоты строки описан со ссылкой на фиг. 16. Как показано, средство 240 считывания показателей принимает от средства 250 формирования параметров текста множество результатов вычислений, касающихся уровня серого для заданного шрифта на заданном языке. Эти результаты вычислений включают в себя количество 1610 кластеров, приходящихся на кегельную шпацию, ширину 1620 "реки", насыщенность 1630 "реки", ширину "канала" 1640 и насыщенность "канала" 1650. В средстве 240 считывания показателей модуль 1660 определения коэффициента для оптимально читаемой высоты строки вычисляет высоту строки.
Более конкретно, один из вариантов осуществления направлен на вычисление высоты строки на основании отношения контраста между всей "рекой" и "каналом" для текста, напечатанного данным шрифтом с данной плотностью символов шрифта. Пять выходов от средства 250 формирования параметров текста, которые используются для определения высоты строки, 1610, 1620, 1630, 1640 и 1650, описаны более подробно. Первый является шириной "реки". Ширина "реки" (Rw) измеряется от самых верхних покрытых чернилами участков в шрифте до самых нижних покрытых чернилами участков в шрифте как коэффициент к размеру кегельной шпации. Ширина "реки" обычно не равна кегельной шпации, поскольку большинство латинских и азиатских шрифтов имеет значительно меньшую ширину "реки", чем размер кегельной шпации, а большинство арабских и тайских шрифтов имеет значительно большую ширину "реки", чем размер кегельной шпации. Например, обращаясь к фиг. 17, воспроизведение шрифта Tahoma 1710 английского языка показано рядом с шрифтом Tahoma 1720 арабского языка. Размер шрифта для кегельной шпации в Tahoma показан между линиями 1730 и 1740. Иллюстрация показывает, что шрифт Tahoma английского языка меньше, чем кегельная шпация, а шрифт Tahoma арабского языка, расположенный справа, значительно больше, чем кегельная шпация.
Возвращаясь к фиг. 16, нормированная насыщенность "реки" (Rd) 1620 относится к вычислениям в средстве 250 формирования параметров текста, которые нормированы к самому темному ряду пикселей в характерной строке измеренного текста, как описано выше на фиг. 8. Все значения насыщенности могут быть выражены относительно самого темного ряда пикселей. Насыщенность - среднее значение черного и представляет полное соотношение между пикселями в заданном промежутке текста.Rw x Ра обеспечивает полный уровень серого для "реки".
Уровень серого для "канала" вычисляется, используя ту же самую формулу, но основываясь на ширине "канала реки" (RCw) и насыщенности "канала реки" (RCd). Деля уровень серого для "канала" на полное значение уровня серого для "реки", обеспечивается коэффициент контрастности между "каналом" и остальной частью "реки".
Оптимально читаемая высота строки в модуле 1660 определения коэффициента определяется с помощью деления отношение уровня серого для "канала" к полному уровню серого на плотность символов шрифта (Cpm) для получения части размера шрифта, которую нужно добавить к размеру шрифта для определения высоты строки. Добавляя 1 к этому значению, система генерирует оптимальную высоту строки (LO) как коэффициент к размеру шрифта. Следующее уравнение суммирует действия в модуле определения коэффициента для получения оптимально читаемой высоты строки: (1 + ((RCW ×RCd) / (Rw x Rd) / Cpm)) × LΔ = LO.
В одном из вариантов осуществления высота строки умножается на масштаб разметки высоты строки (LΔ) прежде, чем определение оптимальной высота строки завершено.
В другом варианте осуществления результаты вычислений в средстве 250 формирования параметров текста включают в себя: Вh = ширине "предотмели"; Bd = насыщенности "предотмели"; Аh = ширине "послеотмели"; Ad = насыщенности "послеотмели"; RCw = ширине "канала"; RCd = насыщенности "канала"; Cpm = количеству кластеров в кегельной шпации; FS = заданному по умолчанию размеру шрифта, и следующее уравнение определяется в модуле 1660 определения коэффициента для оптимально читаемой высоты строки для того, чтобы вычислить высоту строки: FS / (((Bh × Bd) + (Аh × Ad) + (RCw x RCd)) × Cpm) = высота строки.
Другими словами, сумма размеров, умноженных на насыщенность для трех частей "реки", умноженная на количество кластеров в кегельной шпации, разделенная на размер шрифта, обеспечивает высоту строки. Таким образом, высота строки для шрифта Times New Roman размером в десять пунктов будет вычисляться следующим образом:
10 / (((0,24 × 0,09) + (0,45 × 0,6) + (0,22 × 0,04)) × 2,58) = 10 / (0,0216 + 0,27 × 0,0088) × 2,58 =10 / 0,775032 = 12,9.
Более простая версия того же самого способа использует следующую формулу: FS / (Rd ×Rw × Cpm) = L.
В других вариантах осуществления настройка типичной высоты строки, которая для английского текста используется равной 120 % от высоты шрифта, используется для обобщения высоты строки для других языков. Используя эти известные 120 %, другой способ определения высоты строки описан на фиг. 18. На этапе 1810 определяется заданная по умолчанию высота строки, вычисляя 120% от размера шрифта. На этапе 1820 заданная по умолчанию высота строки изменяется, применяя показательную функцию среднего значения ширины одного кластера в предопределенном шрифте. Более конкретно, данная функция может быть квадратным корнем суммы среднего значения ширины любого одного кластера в любом шрифте и квадрата фактической высоты шрифта. Фактическая высота и ширина любого кластера могут определяться в средстве 250 формирования параметров текста для любого международного шрифта. Один из вариантов осуществления использует следующее уравнение: 1,2 FS (Rw2 + (l/Cpm2))1/2, которое является показательной функцией, использующей FS в качестве размера заданного по умолчанию шрифта; 1,2 - вводимый пользователем или стандартный заданный по умолчанию коэффициент высоты строки;Rw - фактическая высота шрифта от его верхних точек, покрытых чернилами, до его низших точек, покрытых чернилами в кегельных шпациях; иCpm - количество кластеров в кегельной шпации.
Как пример, для заданного по умолчанию размера шрифта 10 пунктов высота строки вычисляется следующим образом: 10 × 1,2 × (0,912 + 1 / 2,582)1/2 = 12 × 0,9891 = 11,9.
Следовательно, оптимальная высота строки для шрифта Times New Roman в 10 пунктов будет рана 11,9 пунктами. Та же самая формула, однако, когда она применяется к шрифту Linotype Palatino в 10 пунктов, который имеет заполненную чернилами высоту 1,01 в кегельных шпациях и 2,33 в кластерах в кегельной шпации, привела бы к оптимальной высоте строки, равной 13,2 пунктов.
В другом варианте осуществления высота строки изменяется, если длина строки увеличивается. Обращаясь к фиг. 19, последовательность операций иллюстрирует такую настройку высоты строки, основанную на функции физической длины строки текста или количестве кластеров в строке. Этап 1910 обеспечивает определение требуемого количества кластеров в строке шрифта и оптимальной заданной по умолчанию длины строки в кластерах в строке шрифта. Этап 1920 обеспечивает масштабирование первоначального размера шрифта с помощью деления, используя требуемое количество кластеров на строку и оптимальную заданную по умолчанию длину строки в кластерах на строку. Как только высота строки определена в соответствии с размером шрифта, изменение размера шрифта изменит высоту строки. Если размер шрифта сделать больше, то определяемая высота строки не находится в линейных отношениях. В одном из вариантов осуществления изменение высоты строки при изменении размера шрифта может быть найдено, применяя показательную функцию. Показательная функция может включать в себя рассмотрение количества кластеров на кегельную шпацию. Первоначальный размер шрифта известен и высота строки для этого размера шрифта известна. Существует ограничение для увеличения размера шрифта. Высота строки не может быть меньше, чем сам шрифт. Поэтому, обращаясь к фиг. 20, график 2000 иллюстрирует найденные опытным путем возможные высоты строки для заданного размера шрифта в пунктах. Ось X 2002 представляет размер шрифта в пунктах; ось Y 2004 представляет длину строки в пунктах. Линия 2010 под углом в 45 градусов иллюстрирует высоту строки, которая равна размеру шрифта. При увеличении размера шрифта, размер высоты строки не увеличивается линейно. Вместо этого, при увеличении размера шрифта, требуемая высота строки уменьшается, как показано линией 2020. В одном из вариантов осуществления автоматический способ определения высоты строки использует показательную функцию. Данная функция использует переменное количество кластеров на кегельную шпацию. В частности, было обнаружено, что степенная функция может использоваться вместо использования в качестве показателя степени константы, изменяющейся между 1,02 и 1,07. Дополнительно, было обнаружено, что константа, которая может использоваться для всех шрифтов, равна 1,047. Эта константа приблизительно равна π/3. Другая переменная относится к совместимости "вниз". Если 20%-ая высота строки для шрифта высотой 30 пунктов применяется, то другой размер шрифта должен быть с ним связан и дать ту же самую высоту строки для того же самого размера шрифта, независимо от того, где способ начинается.
Обращаясь к фиг. 21, последовательность операций иллюстрирует способ определения размера шрифта. Этап 2110 обеспечивает определение соответствующей заданной по умолчанию спецификации высоты строки в отношении к предопределенной читаемой длине строки и размеру шрифта. Этап 2120 обеспечивает определение любых изменений значения размера шрифта, которые вызваны тем, что размер шрифта отличается от указанного значения по умолчанию. Как известно, больший шрифт требует меньшего коэффициента высоты строки от размера шрифта. Способы предшествующего уровня техники требуют, чтобы проектировщики выполняли настройку глазом. Если шрифт кажется плотным, то проектировщики добавляют межстрочный интервал. Если шрифт кажется свободным, то проектировщики уменьшают межстрочный интервал. Этап 2130 обеспечивает автоматическое определение новой высоты строки через определение разности между оптимальным заданным по умолчанию размером шрифта и реальным размером шрифта, и на этапе 2140 настраивают высоту строки с помощью константы, возведенной в степень разности между размерами шрифта. Уравнение: (1,047 (FSO - FSA) × (Lo/FSo - 1)) × FSA = LA представляет один из вариантов осуществления определения новой высоты строки согласно данному способу. В уравнении FSo представляет первоначальный заданный по умолчанию размер шрифта; FSA представляет новый размер шрифта; LO представляет первоначальную заданную по умолчанию высоту строки; и LА представляет новую высоту строки.
Для примера, чтобы найти новую высоту строки для шрифта Times New Roman с размером шрифта 14 пунктов, его значение по умолчанию может быть определено согласно способу, описанному выше для размера шрифта 10 пунктов и с высотой строки, равной 12,9 пунктов, и уравнение обеспечит следующие результаты: (1,047(10-14) × (12,9/10 - 1) +1) × 14 = ((1,047-4 × 0,29) + 1) × 14 = ((0,8321 × 0,29) + l) × 14 =1,2413 × 14 =17,38.
Диаграмма операций средства считывания показателей
Обращаясь к фиг. 22, последовательность операций показывает, как средство 240 считывания показателей обрабатывает входную информацию и как каждый вычисленный результат измерения совместно используется для определения других результатов измерения. Фиг. 22 показывает, как описанные выше варианты осуществления вписываются во всю систему средства 240 считывания показателей.
Этап 2202 представляет вводимое из таблицы языков или другого источника количество кластеров в фиксации. С этапа 2202 способ переходит к этапу 2204, который выводит количество кластеров в строке с наилучшей читаемостью. Эти вычисления могут выполняться в соответствии с таблицей.
Этап 2206 представляет ввод информации от компьютерной системы, которая обеспечивает значение размера среды отображения, например размер экрана по диагонали. Этап 2208 представляет вычисления для определения заданного по умолчанию расстояния от среды отображения. Один из способов определения заданного по умолчанию расстояние описан выше со ссылкой к фиг. 10. Этап 2210 обеспечивает ввод "масштаба шрифта", который может вводиться пользователем или посредством разметки страницы. Такая разметка может напоминать <Элемент масштаб шрифта = "1,2"> содержимое элемента. </Элемент>.
Каждый из этапов 2210, 2212, 2208 и 2202 обеспечивает ввод информации для вычисления оптимально читаемого размера шрифта. Этап 2214 представляет вычисление оптимально читаемого размера шрифта. Как описано выше, нахождение оптимального размера шрифта включает в себя сначала определение горизонтальной области на поверхности среды отображения в пределах предопределенного фовеального угла для предопределенного расстояния и определение размера шрифта согласно количеству кластеров, приходящихся на фиксацию, соответствующему заданному языку и шрифту. В одном из вариантов осуществления масштаб 2210 шрифта обеспечивает множитель для определения размера шрифта.
Этап 2214 обеспечивает входную информацию для этапа 2216, который обеспечивает определение минимального и максимального размера шрифта. В одном из вариантов осуществления минимальный и максимальный размер шрифта основан на 25%-ом отклонении от оптимального размера шрифта, или 0,8, умноженное на предопределенный размер шрифта для минимального размера шрифта, или 1,33, умноженное на предопределенный размер шрифта для максимального размера шрифта. В другом варианте осуществления максимальное количество кластеров, содержащихся в одной фовеальной фиксации, определяет минимальный размер шрифта и максимальный размер шрифта для заданного языка.
Этапы 2218, 2220, 2222, 2224 могут представлять выходную информацию от средства 250 формирования параметров текста, которое обеспечивает входную информацию для определения коэффициента 2228 высоты оптимально читаемой строки, как описано выше со ссылкой к фиг. 15. В одном из вариантов осуществления этап 2228 принимает входную информацию 2226 масштаба высоты строки из разметки или вводимой пользователем информации, такой как <Элемент масштаб высоты строки = "1,5"> содержание элемента. </Элемент>.
Этап 2230 обеспечивает определение минимального и максимального количества кластеров, приходящихся на строку. Определению минимального и максимального значений длины строки помогают возможные значения предпочтительного количества колонок, которые могут вводиться пользователем. В одном из вариантов осуществления предпочтительное количество колонок "низкое" обеспечивает оптимальную читаемую длину строки в кластерах для иммерсивного чтения. "Среднее", "высокое" и "максимальное" значения предпочтительного количества колонок обеспечивает прогрессивно более короткие строки с меньшим количеством кластеров. Предпочтительное количество колонок "одна" расширяет длину строки в кластерах вне стандартного иммерсивного чтения.
В одном из вариантов осуществления приращения однородны, в пределах от половины оптимального количества кластеров в строке до 1,167, умноженного на оптимальное количество кластеров в строке. Для определения минимальной длины строки в кластерах (Сm) и максимальной длины строки в кластерах (СM) применяют следующие уравнения:Сm = 0,5 × Cpl; СM = 1,167 × Cpl.
Минимальное и максимальное количество кластеров, приходящихся на строку 2232, наряду с количеством кластеров, приходящихся на наилучшим образом читаемой строке 2204, минимальным и максимальным читаемым размером шрифта 2216 и количеством кластеров на кегельную шпацию 2212 вводится на этап 2232, где определяются оптимальная, минимальная и максимальная ширина колонки.
Минимальная ширина колонки может быть определена, вычисляя минимальный размер шрифта и умножая минимальный размер шрифта на наименьшее количество кластеров, которое разрешено в строке. Следующие уравнения определяют оптимальную, минимальную и максимальную ширину колонки соответственно: CWo = FSo × Cpm × Cpl (количество кластеров, приходящихся на наилучшим образом читаемую строку); CWm = FSm × Cpm × Сm (минимальное количество кластеров, приходящихся на наилучшим образом читаемую строку) CWM = FSM × Cpm × CM (максимальное количество кластеров, приходящихся на наилучшим образом читаемую строку).
До определения оптимального, минимального и максимального количества 2242 колонок средство 240 считывания показателей сначала определяет потенциальную реальную ширину 2240 набора. Реальная область набора - область размещения, которая находится между полями страницы. Потенциальная реальная область набора - разность между размером окна и определяемыми пользователем установками значения полей. Поля вычисляются, основываясь на самом коротком размере (измерении) страницы. Поэтому сначала выполняется этап оценки для определения того, какой из вертикального размера или горизонтального размера страницы меньше. Значение размера полей, которые требуются в разметке, затем вычитаются из самого маленького размера. Результатом является реальная область набора. Входная информация для определения потенциальной реальной ширины набора включает в себя ширину окна (WW) 2234, высоту окна (WH) 2236 и пользовательские предпочтительные значения полей (MP) 2238. Таким образом, для определения ширины потенциальной реальной области набора (LWo) предпочтительное значение размеров полей в разметке (MP) вычитается из значения ширины окна (в пунктах) и умножается на самое короткое измерение окна: WW - (минимальное значение из (WW, WH) × MP × 2).
Размер потенциальной реальной области набора 2240 и оптимальная, минимальная и максимальная ширина колонки (CWo;CWm и CWM соответственно) 2232 обеспечивают входную информацию для определения оптимального, минимального и максимального количества колонок (CCo;CCm и ССм соответственно) 2242. В одном из вариантов осуществления для определения количества колонок уравнение позволяет вычислить количество колонок каждого из размеров, которые могут помещаться в потенциальной реальной ширине набора. Выходная информация обеспечивает диапазон минимального, максимального и оптимального количества колонок, которые будут помещаться на странице. Возможное количество колонок (CC) может вычисляться для минимальной, максимальной и оптимальной ширины колонки, деля потенциальную реальную ширину набора на ширину колонки. Следующие уравнения применяются для определения оптимального, минимального и максимального количества колонок: CCo = LWo × CWo; CCm = LWo × CWM; CCM = LWO × CWm.
Обращаясь к этапам 2244 и 2246, после того как количество колонок определено, средство 240 считывания показателей использует количество колонок и вводимое пользователем предпочтительное значение количества колонок для определения фактического количества выбранных колонок.
Вычисление фактического количества необходимо, потому что уравнения этапа 2242 не вырабатывает общее количество колонок. На этапе 2242 фактическое количество колонок, которое требуется, через предпочтительное количество колонок 2244 округляется до соответствующего целого количества колонок (CCA). В одном из вариантов осуществления этап 2246 является оценочным. Если предпочтительное количество колонок = "одна" ("0"), тоCCA будет автоматически равняться 1. Если предпочтительное количество колонок = "низкое" ("1"), тоCCA будет округляться доCCo.
Если предпочтительное количество колонок (CP) = "среднее | высокое" ("2 | 3"), то значениеCCA должно вычисляться.
Если предпочтительное количество колонок (CP) = "максимальное" ("4"), тоCCA будет округляться до ССм.
Вычисления для значений "среднее" и "высокое" будут одной третью и двумя третями между оптимальным значением и максимальным значением. ПоэтомуCCA может округляться до:
(( CCM - CC0) × 3 ) + CC0 (среднее)
((( CCM - CCo ) × 3 ) × 2 ) + CC0 (высокое)
Следующий псевдокод демонстрирует работу этапа 2246:
IF CP = 0
THEN CCA =1
ELSE CCA = ((( CCM - CCO ) / 3 ) × ( CP - 1 )) + CCO
Округление для общего количества колонок будет до большего значения, если требуемое количество колонок имеет дробную часть, превышающую 0,75, а иначе будет округляться до меньшего значения. Это значение 0,75 может быть изменено с помощью введения автором или пользователем другого значения.
Этап 2248 обеспечивает определение реальной ширины набора и принимает от этапа 2232 входную информацию оптимальной, минимальной и максимальной ширины колонки, от этапа 2240 - информацию потенциальной реальной ширины набора, от этапа 2244 - предпочтительные значения количества колонок и от этапа 2246 - количество колонок.
Поскольку фактическая реальная ширина набора (LWA) никогда не может быть больше, чем предварительно вычисленная потенциальная реальная ширина набора (LWo), то при вычислении сравнивают вычисленное значение с потенциальной шириной для проверки того, какая из них меньше. Меньшее значение является определяющим. Вычисление реальной ширины набора также имеет специальные случаи, базирующиеся на разметке пользователя для предпочтительного количества колонок. Если предпочтительное количество колонок = "одна", то этап 2248 обеспечивает на странице колонку такого большого размера, который будет помещаться в пределах параметров количества кластеров в строке 2204 и размера 2214 шрифта. Если предпочтительное количество колонок "низкое", то средство 240 считывания показателей пытается найти оптимальное значение опытным путем. Большее предпочтительное количество колонок может быть ограничено шириной доступного пространства. Следующий псевдокод демонстрирует определение реальной ширины набора.
IF CP = 0,
THEN минимальное значение из CWM или LWO = LWA
ELSE
IF CP=1,
THEN минимальное значение из (CCA x CWO) + (CWO × (CP - 1) × 0,075) или LW0 = LWA
ELSE LW0 = LWA
Количество 2246 колонок и реальная ширина набора 2248 вводятся к этапу 2250, который вычисляет фактическую ширину промежутка между колонками (CGA). Ширина промежутка между колонками может быть эквивалентна промежутку между колонками в свойствах разметки. Одно из различий состоит в том, что единица измерений для этапа 2250 может основываться на части колонки, но может немного повлиять на результат измерения колонки при распространении на множество колонок. С помощью следующего уравнения можно определить фактическую ширину расстояния между колонками(CGA): LWA × CCA × 0,075 = CGA.
Обращаясь к этапу 2252, когда фактическая ширина расстояния между колонками определена, может определяться фактическая ширина колонки (CWA), которая может быть равна свойству разметки "ширина колонки". Когда количество колонок, реальная ширина и расстояние между колонками известны, точный размер колонки может быть вычислен, используя следующее уравнение: (LWA × CCA) - ((CCA-1) × CGA) = CWA.
Обращаясь к этапу 2254, средство 240 считывания показателей вычисляет фактический размер шрифта (FSA), используя входную информацию от этапов 2252, 2212, 2214 и 2230. В одном из вариантов осуществления определение фактического размера шрифта выполняется с помощью вычисления рекомендованного размера шрифта(FSr) для размещения и последующего сравнения рекомендованного размера шрифта с минимальным размером шрифта и максимальным размером шрифта для обеспечения того, чтобы размер шрифта находился в пределах диапазона, который был вычислен ранее. Предыдущий процесс также является условным процессом, определяющим, является ли строка слишком длинной или слишком короткой для использования оптимального размера шрифта, из-за количества кластеров, которые появятся в строке. Только когда диапазон количества кластеров превышает оптимальное значение, изменяют размеры шрифта. Следующий псевдокод может выполнить вычисления для этапа 2254:.
IF: CWA > FSO × CM ÷ Cpm
THEN CWA - CM × Cpm
ELSE IF: CWA < FSO × Cm ÷ Cpm
THEN:CWA ÷ Cm × Cpm
ELSE: FSO = FSr
Проверка границ для завершения определения фактического размера шрифта (FSA) также является условным выражением:
IF: FSr > FSM
THEN: FSM
ELSE IF: FSr < FSm
THEN: FSm
ELSE: FSr = FSA
Обращаясь к этапу 2256, на нем вычисляется фактические количество кластеров на строку, используя значения, определенные на этапе 2254 и этапе 2252. Определение фактического количества кластеров, приходящихся на строку, выполняется до определения соответствующего значения высоты строки для конкретного шрифта. Следующее уравнение определяет количество кластеров на строку:CWA × FSA × Cpm.
Обращаясь к этапу 2258, средство 240 считывания показателей определяет фактическую высоту строки (LА) как коэффициент к размеру шрифта, который будет применен наилучшим образом к читаемому тексту для данной среды. Способ определения фактической высоты строки включает в себя по меньшей мере две настройки. Сначала средство 240 считывания показателей оптимизирует высоту строки для размера шрифта, еслиFSA≠FSО. Оптимизация обеспечивает, чтобы шрифты большего размера не приняли пропорционально такую же большую высоту строки, как меньшие шрифты. Затем средство 240 считывания показателей настраивает высоту строки для длины строки. Следующее уравнение выполняет оптимизацию и настройку: ((CA × (1,047 (FSO - FSA) × (Lo - 1))) × Cpl) + 1.
Следующая часть уравнения: (1,047 (FSO - FSA) × (LO - 1) настраивает размер шрифта. Остальная часть настраивает длину строки. Результатом является оптимальная высота строки для фактического размера шрифта для фактической ширины колонки.
Возвращаясь к фиг. 20, на фиг. 20 показана часть уравнения для размера шрифта. Фиг. 23 иллюстрирует график 2300 для настройки длины строки. Как показано, ось Y 2302 представляет размер шрифта, а ось Y 2304 представляет высоту строки. Выполняется настройка для линии 2320 (она та же самая, что и 2020) для строки, которую имеет половину длины, показанной линией 2323, и для линии 2330 для строки в 1,5 раза более длинной.
Возвращаясь к фиг. 22, на этапе 2260 обеспечивают вычисление фактического значения по умолчанию размера шрифта существенно тем же самым способом, как размер шрифта основного текста, но основываясь на установленном пользователем значении 0,75, умноженном на минимальное количество кластеров в строке (Cm), и реальной фактической ширине набора(LWA). Применяется следующее уравнение: HFSA =LWA × (0,75 × Cm) × Cpm.
В одном из вариантов осуществления размер шрифта заголовка фиксируется в верхней части диапазона для считывания выхода средства 240 считывания показателей.
Обращаясь к этапу 2262, заданная по умолчанию высота строки для размера шрифта заголовка (HLA) определяется согласно тому же самому уравнению, как для фактической высоты строки для размера шрифта основного текста 2258. Коэффициент генерируется на основании HFSA, а неFSA, и установленное пользователем значение 0,75 умножается на минимальное количество кластеров в строке(Cm) следующим образом:
(( 0,75 × Cm × ( 1,047(FSO - HFSA) × (L0 - 1))) × Cpl ) + 1 = HLA.
Высота строки нежестко основана на длине строки и размере шрифта и находится в промежутке между размером основного текста и размером заголовка для данного коэффициента размера шрифта. Таким образом, когда основной текст имеет высоту строки 1,16, умноженное на размер шрифта, высота строки для шрифта заголовка может быть только 1,05, умноженное на размер шрифта заголовка.
Обращаясь к этапу 2264, пункт средства считывания показателей определяется, используя входную информацию от фактического размера шрифта заголовка 2260 и фактического размера шрифта 2254. Пункт средства считывания показателей относится к двум типографски связанным пунктам: оптимальный читаемый размер шрифта для размещения и оптимальный размер шрифта верхнего уровня для заголовка в окне. В зависимости от них средство 240 считывания показателей строит график с помощью элементов приращения, каждый из которых определяется в месте пересечения как типографский пункт для данного семейства шрифта. Чтобы выполнять преобразование между "реальными" пунктами, равными 1/72'', и пунктами средства считывания показателей, могут быть созданы эквиваленты для верхней и нижней границ.
Значение пункта средства считывания показателей основано на сравнении заданного по умолчанию размера шрифта окна и фактического размера шрифта, который был вычислен. Значение по умолчанию - 12 пунктов. Поэтому при преобразовании к значениям средства 240 считывания показателей любая ссылка к шрифту 12 пункта интерпретируется как ссылка к FSA. Размеры ниже 12 пунктов интерпретируются с помощью коэффициента, который делитFSA на 12 частей. Следовательно:
Пункт средства считывания показателей =FSA × 12.
Однако значение пункта средства считывания показателей для шрифта выше 12 пунктов не обязательно равно значению пункта для размера шрифта, равному или ниже 12 пунктов. Значение пункта средства считывания показателей для размера шрифта выше 12 пунктов основано на делении промежутка между предварительно установленным оптимальным размером шрифта заголовка 48 пунктов (значение по умолчанию, поскольку оно является значением по умолчанию для размера шрифта текста Windows®) и размером основного текста в 12 пунктов. Поэтому для размера более 12 пунктов используется следующая формула:
Пункты средства считывания показателей = (HFSA -FSA) - 36.
Чтобы вычислить выходной размер для любого шрифта разметки (FSμ), используется следующая составная формула:
IF, FSμ ≤12,
THEN, FSμ × FSA ÷ 12
ELSE, ((FSμ - 12 ) × (( HFSA - FSA ) ÷ 36 )) + FSA
В результате этой операции любой размер шрифта разметки может интерпретироваться в соответствии со значением пункта средства считывания показателей, которое включает в себя заданные по умолчанию результаты измерения для размера шрифта, которые генерируются из таких стандартов, как стандарт иерархических (каскадных) стилевых таблиц (CSS), как "очень-очень маленький", "очень маленький", "маленький", "средний", "большой", "очень большой", "очень-очень большой", и значения по умолчанию для всех уровней заголовков равны от 1 до 7. Следует обратить внимание, что пункты средства считывания показателей применяются только к пунктам размера шрифта, а не к любому другому результату измерения в пунктах.
Обращаясь к этапу 2266, фактическое значение полей является блоком, который называется "поля", который может использоваться в комбинациях, которые настраивают значения некоторых других блоков (особенно размер колонки). Фактический размер полей (MA) определяется с помощью меньшего из реальной ширины набора (LWA) или высоты окна и предпочтительного значения полей (MP). Если высота окна меньше, чем реальная ширина набора, то фактическое значение полей определяется как высота окна, умноженная на предпочтительное значение полей. Однако, если реальная ширина набора меньше, чем высота окна, то средство считывания показателей вычисляют с помощью реальной ширины набора, разделенной на 1 минус предпочтительное значение полей. Следовательно, формула для полей(MA) является следующей:
IF, WH < LWA
THEN, WH × MP
ELSE, ((LWA ÷ ( 1 - 2MP )) - LWA) ÷ 2
Обращаясь к этапу 2268, фундаментальным инструментом для проектировщиков размещения в течение прошлых 500 лет была сетка. Но ее всегда рассматривали как статический инструмент, уместный только в одной публикации для заданного размера страницы. Allen Hurlburt в своей книге, выпущенной в 1977 г., Layout: The Design of the Printed Page (Watson-Guptill Publications, NY, NY 1977, 1989. Page 82.), приведенной для справки, утверждает:
Сетка проектировщика упорядочивает конкретное содержимое относительно точного места, которое оно будет занимать. Когда используется сетка, она дает возможность проектировщику создавать много различных размещений, содержащих разнообразие элементов в пределах структуры сетки. При использовании в разработки публикации, рекламной кампании или серии, она дает ощущение непрерывной последовательности, даже когда существуют значительные изменения в содержимом каждого отдельного модуля.
Хотя Hurlburt подчеркивает важность и необходимость хорошей сетки и в этой, и в своих более поздних публикациях, The Grid (1978) и The Design Concept (1981), он неоднократно подчеркивает, что статический характер сетки является именно тем, что делает ее полезной для использования проектировщиками. Однако проектировщики в электронном мире, в котором размер дисплея и его форма не известны заранее, были неспособны создать надежные сетки, если заранее не закреплять размер и форму дисплея.
Средство 240 считывания показателей выводит размер элемента сетки (Gu) 2268, который является динамическим и масштабируемым для широкого разнообразия размеров шрифтов и дисплеев. Входная информация для этапа 2268 включает в себя фактическую ширину колонки (CWA) 2252, фактический размер шрифта (FSA) 2254, количество кластеров в наилучшим образом читаемой строке(Cpl) и количество кластеров, приходящихся на кегельную шпацию(Cpm). Ширина каждого элемента сетки основана на определении оптимального количества кластеров на строку(Cpl), сбалансированного с помощью фактической ширины колонки (CWA). Уравнение делит Cpl на 6 и затем определяет, сколько элементов такой длины будет помещаться в Cwa при данном FSA. Дробные части распределяются равномерно по ширине целого элемента сетки. Следовательно:
GUA= CWA ÷ усеченное значение от ((6 x CWA × Cpm) ÷ ( FSA × Cpl)).
Сетка имеет одно измерение, основанное на его ширине. Если элемент сетки используется в качестве значения измерения высоты, он имеет то же самое значение в качестве значения ширины. В одном из вариантов осуществления размер элемента сетки может изменяться динамически, деля вертикальное пространство по-другому, чем горизонтальное пространство.
Обращаясь к этапу 2270, колонка имеет различные измерения при использовании по высоте и ширине. Таким образом при использовании в разметке ширина 1 колонки имеет другие размеры, чем высота 1 колонки. В одном из вариантов осуществления фактическая высота колонки делится без остатка на общее количество строк. Поэтому высота окна (WH), которая меньше полей, равна потенциальной реальной высоте набора (LHO). Усеченное значение от LHO, разделенное на длину строки (LА), умноженное на длину строки, равняется высоте колонки (Сн). Другими словами, WH - (2 × MA) (или другой коэффициент, если разметка указывает поля большего размера, чем 1MA) = LHO.
(Усеченное значение от (LHO / LА)) × LА = CH
Обращаясь к этапу 2272, фактическая высота страницы (PH) равна высоте колонки плюс верхнее и нижнее поля. Поэтому PH = CH + 2MA (или другой коэффициент, если разметка указывает поля большего размера, чем 1MA или вверху, или внизу).
Обращаясь к этапу 2274, фактическая ширина страницы (Pw) равна сумме ширины колонок, ширины расстояний между колонками и левого и правого полей. Поэтому Pw = (CWA × CCA) + (CGA × (CCA - 1)) + (2 × MA).
Таким образом, страница имеет различные размеры по высоте по сравнению с шириной, и они могут быть не равны размеру окна.
Обращаясь назад к фиг. 2 в комбинации с фиг. 22, способы, описанные выше для определения высоты строки, колонки и размера шрифта, допускают автоматическое определение оптимальных размеров для удобочитаемости на среде отображения при воспроизведении текста. В каждом случае соответствующее устройство для воплощения представленных способов может включать в себя компьютерные компоненты, такие как микропроцессор, для воплощения данных способов. Например, для целей определения оптимального размера шрифта такое устройство, как принтер или карманный компьютер, способный связываться с принтером или устройством отображения, может принимать ширину среды отображения и расстояние от среды отображения в качестве входной информации и обеспечивать в качестве выходной информации оптимальный размер и высоту строки для шрифта, или автоматически выводить информацию, используя определенные оптимальные размер шрифта и высоту строки. Устройство может также быть компьютером, переносным компьютером или микропроцессорным блоком, установленным в принтере и т.п. Информация с принтера или стройства может выводиться на среду отображения. Также среда отображения может быть напечатанной страницей, экраном, связанным беспроводным образом средством отображения, доской объявлений, изображением или любым средством воспроизведения шрифта. В некоторых вариантах осуществления ввод размеров среды отображения и расстояния от среды отображения может осуществляться по сети или в сетевой клиентской среде, через подключение к Интернет или подобные им.
Фиг. 22, описанная выше, иллюстрирует операции, которые происходят в средстве 202 размещения, показанном на фиг. 2. Обращаясь теперь к фиг. 24, один из вариантов осуществления направлен на использование средства 202 размещения вместе со средством международного перевода. Средство международного перевода в этом контексте включает в себя программы-преводчики, известные из предшествующего уровня техники, которые способны переводить текст на заданном языке и обеспечивают вывод текста на другом языке. Например, известны средства перевода, доступные по Интернет, которые соответствуют данным вариантам осуществления, которые переводят текст, расположенный в конкретном месте, указанном унифицированным указателем информационного ресурса (URL), на другой язык. Обращаясь к фиг. 24, там показана структурная схема, которая включает в себя средство 202 размещения и прикладную программу 200. Прикладная программа 200 могла быть любой прикладной программой, выполняющейся в компьютере 110, показанном на фиг. 1. Для данного варианта осуществления соответствующие прикладные программы включают в себя, например, Microsoft Word, Microsoft Publisher, QuarkXPress, Adobe InDesign, так же как другие прикладные программы, которые выполняются с помощью или через подключение к серверу, например вместе с браузером или прикладной программой почтового типа, такой как Microsoft Outlook® и т.п. Показанная прикладная программа 200 включает в себя ведомость 210 свойств и значения 220 свойств, хотя в одном из вариантов осуществления ведомость 210 свойств и значения 220 свойств могут быть доступными компонентами, так что прикладная программа 200 только связывается с другой прикладной программой, которая выдает содержимое компонентов ведомости 210 свойств и компонентов значения 220 свойств. Фиг. 24 дополнительно показывает внешнее средство 2460 международного перевода, соединенное с прикладной программой 200 через соединение 2470. Внешнее средство международного перевода показывают, как внешний компонент для тех вариантов осуществления, в которых прикладная программа 200 способна обращаться к средству перевода через Интернет или через серверное подключение к сетевому средству перевода, например по локальной сети. Альтернативно, внешнее средство международного перевода может быть внешним только для прикладной программы 200, например, доступным через центральную шину компьютерной системы. Обращаясь к фиг. 25 в комбинации с фиг. 24, в одном из вариантов осуществления внешнее средство международного перевода переводит текст, созданный или принятый в прикладной программе 200, этап 2510. Изменения свойств, которые происходят из-за внешнего средства 2460 международного перевода, передаются или к прикладной программе 200 для изменения элементов в ведомости 210 свойств или значения 220 свойств, или передаются непосредственно на средство 202 размещения, как показано на этапе 2520. Средство 202 размещения может иметь, но это не требуется для данного варианта осуществления, средство 2462 международного перевода. Если оно присутствует, то внешнее средство 2460 международного перевода может посылать и принимать данные от средства 2462 международного перевода, которые обеспечивает компоненты совместимости для осуществления хорошего взаимодействия между внешним средством 2460 международного перевода и средством размещения 202 (этап 2520). В одном из вариантов осуществления внешнее средство 2460 международного перевода обеспечивает передачу переведенного текста на языке и основного текста прикладной программе 200, которая затем посылает соответствующие данные через соединение 280 на средство размещения 202 (этап 2520). Средство размещения 202 затем обрабатывает данные, как описано выше, для обеспечения передачи параметров удобочитаемости прикладной программе 200 (этап 2530). Более конкретно, средство размещения 202, используя средство 240 считывания показателей и средство 250 формирования параметров текста, обрабатывает данные, принятые прикладной программой 200 и/или непосредственно от внешнего средства 2460 международного перевода, чтобы обеспечить передачу переведенного текста в удобочитаемом формате с колонками, высотой строки, размером шрифта и т.п., которые настроены для языка, на который переведен текст.
В альтернативном варианте осуществления, как показано на фиг. 26, прикладная программа 200 не взаимодействует с внешним средством международного перевода, но доставляет текстовые данные средству размещения 202 наряду с идентификаторами языка, указывающими язык, на котором доставляется текст, и один или более языков, на которые необходимо выводить текст (этап 2610). Средство 2462 международного перевода затем принимает идентификаторы языка и текст и обеспечивает передачу переведенного текста для определения параметров, необходимых для входного фильтра 230 размещения и структуры, чтобы создать структуры данных, которые обрабатываются с помощью средства 240 считывания показателей и средства 250 формирования параметров текста (этап 2620). Таким образом, в одном из вариантов осуществления прикладная программа 200 может выдавать данные на средство размещения на одном языке и принимать обратно данные, позволяющие прикладной программе 200 отображать текст на многочисленных языках, который отформатирован для данного дисплея для каждого требуемого языка и соответствует данным определенным языкам (этап 2630). Прикладная программа 200 может также выполняться на различных дисплеях, причем каждый дисплей имеет различный размер и каждый дисплей принимает тот же самый текст на различных языках, отформатированных для данного дисплея и данного языка. Таким образом, например, если прикладная программа 200 выполняется на сервере, который обслуживает клиентские машины в нескольких странах, то каждый дисплей в серверной группе принимает текст на соответствующем языке, имеющий размер и отформатированный соответственно для этого языка и для соответствующего дисплея. Для сервера, выполняющего почтовую или подобную программу, прикладная программа 200 может выполняться на каждой клиентской машине, например Microsoft Outlook®, или может выполняться на сервере, таком как Unix® сервер, и сервер может быть, например, сервером обменного типа. Сервер или клиентская машина, выполняющие прикладную программу 200, принимают текст на любом языке и могут быть сконфигурированы для взаимодействия со средством 202 размещения для автоматического перевода текста на любом принятом языке на местный язык или язык по выбору, который запрограммирован в средстве 2462 международного перевода, и вывода к прикладной программе 200 параметров, необходимых для такого форматирования переведенного текста, которое соответствует данному языку и данному дисплею (ям).
Все указанные ссылки, которые включают в себя любые патенты, патентные заявки и публикации, представлены в своей полноте для справки.
Ввиду многих возможных вариантов осуществления, к которым принципы этого изобретения могут применяться, следует признать, что описанный со ссылками на чертежи вариант осуществления является только иллюстративным и не должен использоваться в качестве ограничения объема изобретения. Например, специалисты должны признать, что элементы иллюстрированного варианта осуществления, воплощенные в программном обеспечении, могут быть осуществлены с помощью аппаратных средств, и наоборот, или что иллюстрированный вариант осуществления может изменяться в расположении и деталях, не отступая от объема изобретения. Поэтому описанное изобретение рассматривает все подобные варианты осуществления как находящиеся в объеме следующей формулы изобретения и эквивалентны ей.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОГО ИЗМЕРЕНИЯ ВЫСОТЫ СТРОКИ, РАЗМЕРА И ДРУГИХ ПАРАМЕТРОВ МЕЖДУНАРОДНОГО ШРИФТА | 2008 |
|
RU2464631C2 |
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОГО ИЗМЕРЕНИЯ ВЫСОТЫ СТРОКИ, РАЗМЕРА И ДРУГИХ ПАРАМЕТРОВ МЕЖДУНАРОДНОГО ШРИФТА | 2008 |
|
RU2451331C2 |
| ХОЛСТ С СЕТКОЙ | 2005 |
|
RU2376639C2 |
| СОВМЕЩЕНИЕ МАШИНОЧИТАЕМЫХ КОДОВ С ПИКСЕЛЯМИ ПЕЧАТАЮЩЕГО УСТРОЙСТВА | 1996 |
|
RU2198430C2 |
| РАЗДЕЛИТЕЛЬ ЧЕРНИЛ И ИНТЕРФЕЙС СООТВЕТСТВУЮЩЕЙ ПРИКЛАДНОЙ ПРОГРАММЫ | 2003 |
|
RU2358316C2 |
| МОДУЛЬНЫЙ ФОРМАТ ДОКУМЕНТОВ | 2004 |
|
RU2368943C2 |
| СПОСОБ ВЫБОРА ШРИФТА | 2003 |
|
RU2316814C2 |
| УСТРОЙСТВО ОБРАБОТКИ ИЗОБРАЖЕНИЙ, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ОБРАБОТКИ ИЗОБРАЖЕНИЙ | 2008 |
|
RU2437152C2 |
| СПОСОБ, СИСТЕМА И СЧИТЫВАЕМАЯ КОМПЬЮТЕРОМ СРЕДА ДЛЯ СОЗДАНИЯ И КОМПОНОВКИ ГРАФИКИ В ПРИКЛАДНОЙ ПРОГРАММЕ | 2005 |
|
RU2383929C2 |
| УСТРОЙСТВА И СПОСОБЫ, КОТОРЫЕ СТРОЯТ ИЕРАРХИЧЕСКИ УПОРЯДОЧЕННУЮ СТРУКТУРУ ДАННЫХ, СОДЕРЖАЩУЮ НЕПАРАМЕТРИЗОВАННЫЕ СИМВОЛЫ, ДЛЯ ПРЕОБРАЗОВАНИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ В ЭЛЕКТРОННЫЕ ДОКУМЕНТЫ | 2013 |
|
RU2625533C1 |
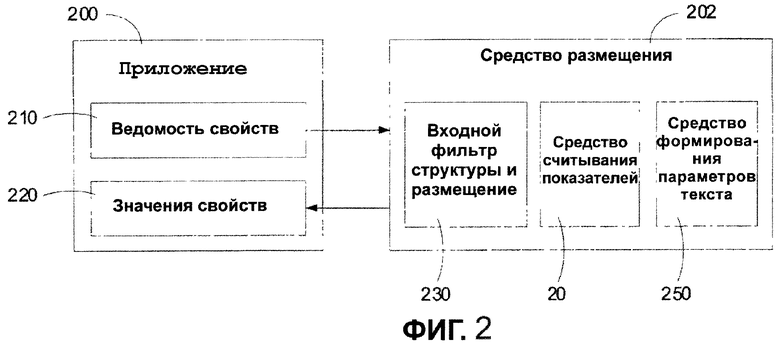
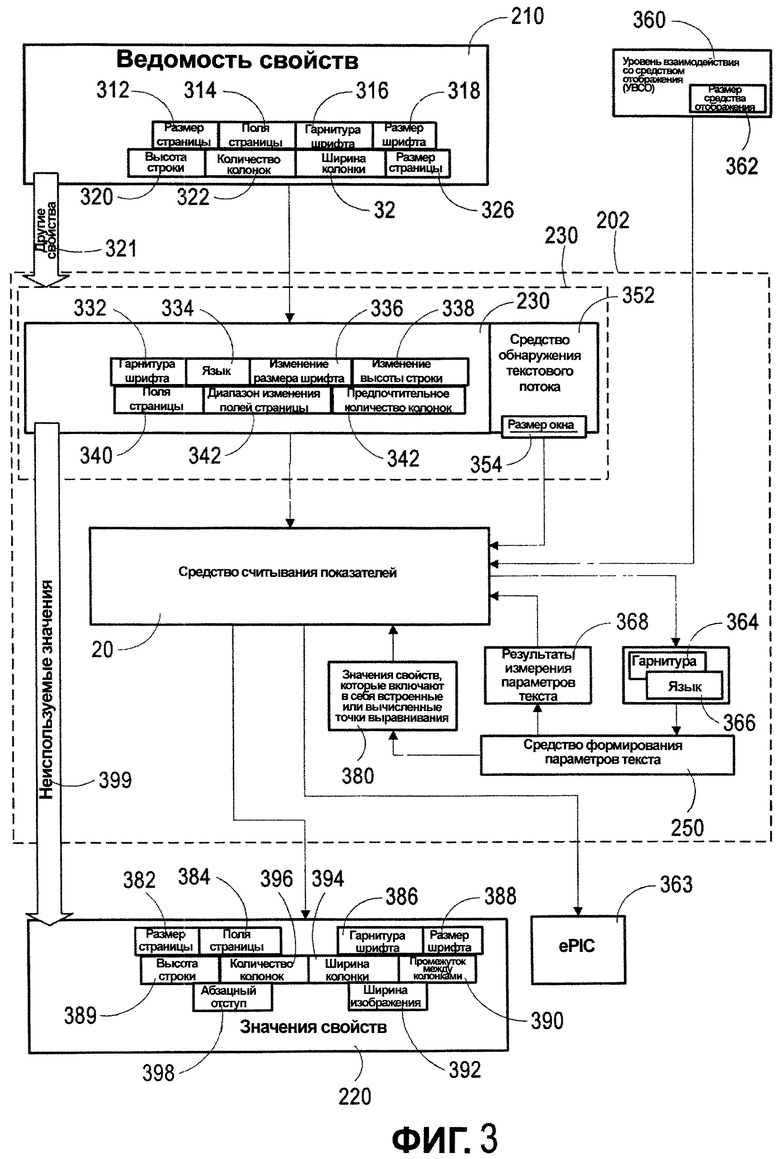
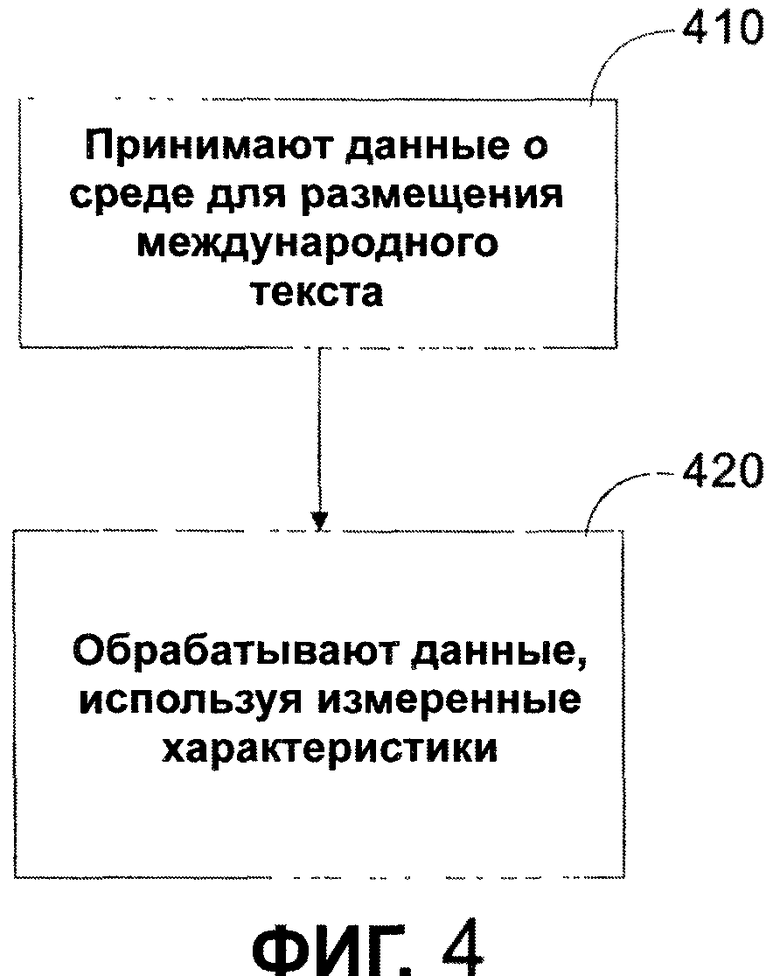
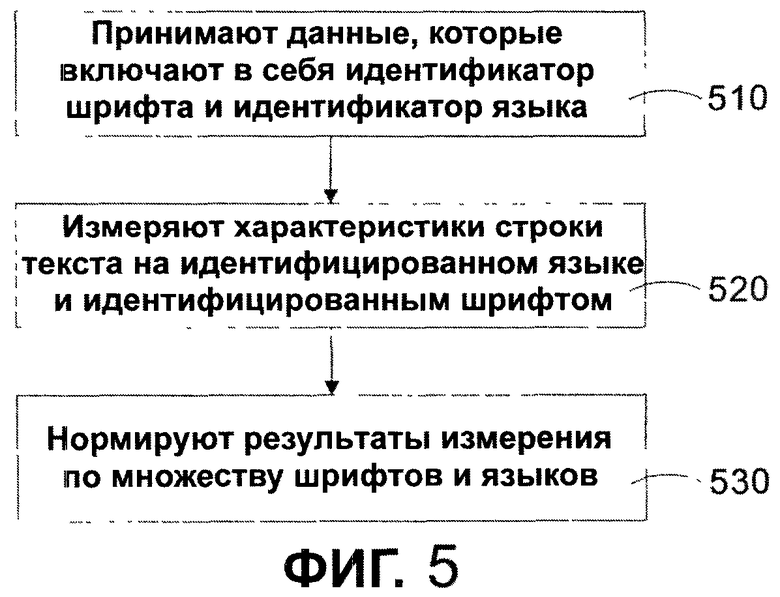
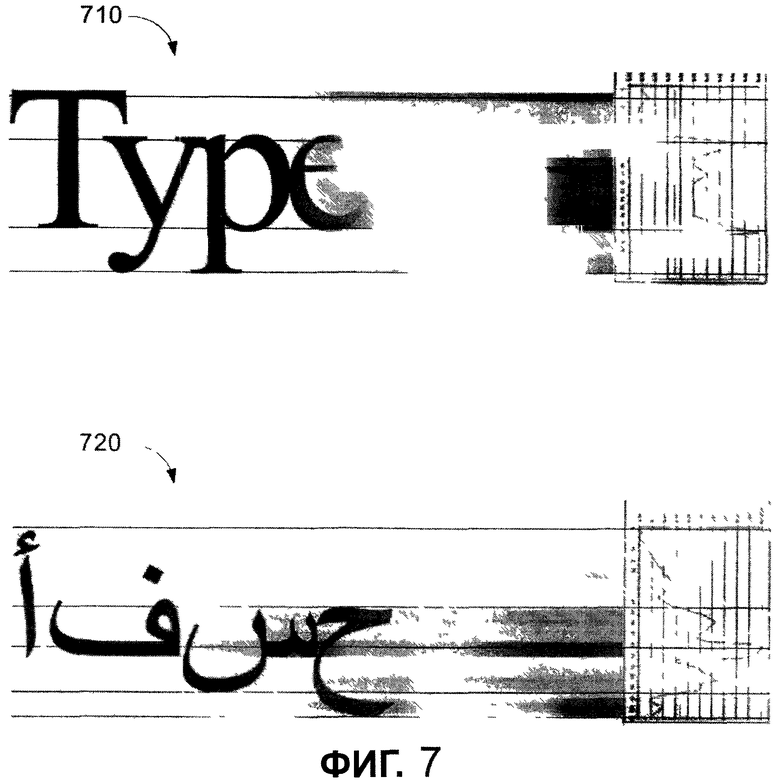
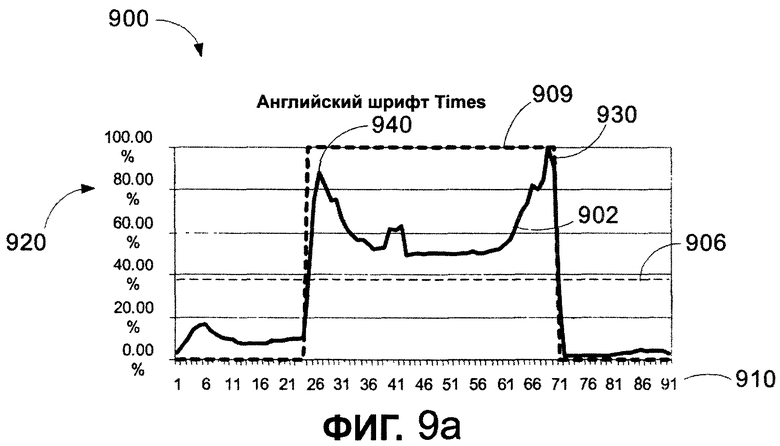
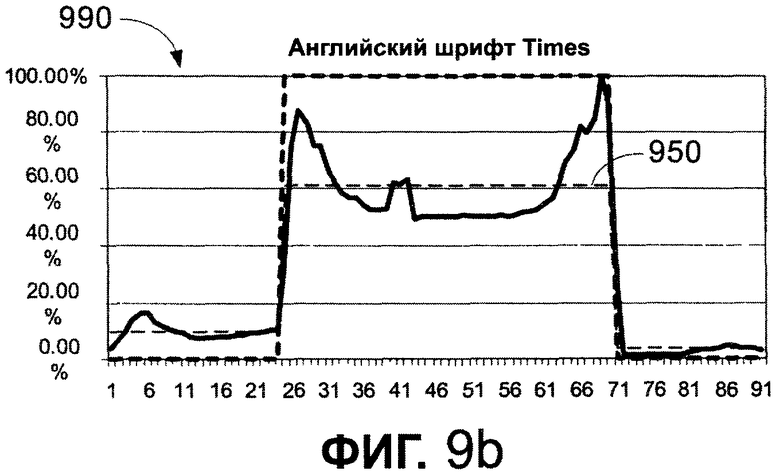
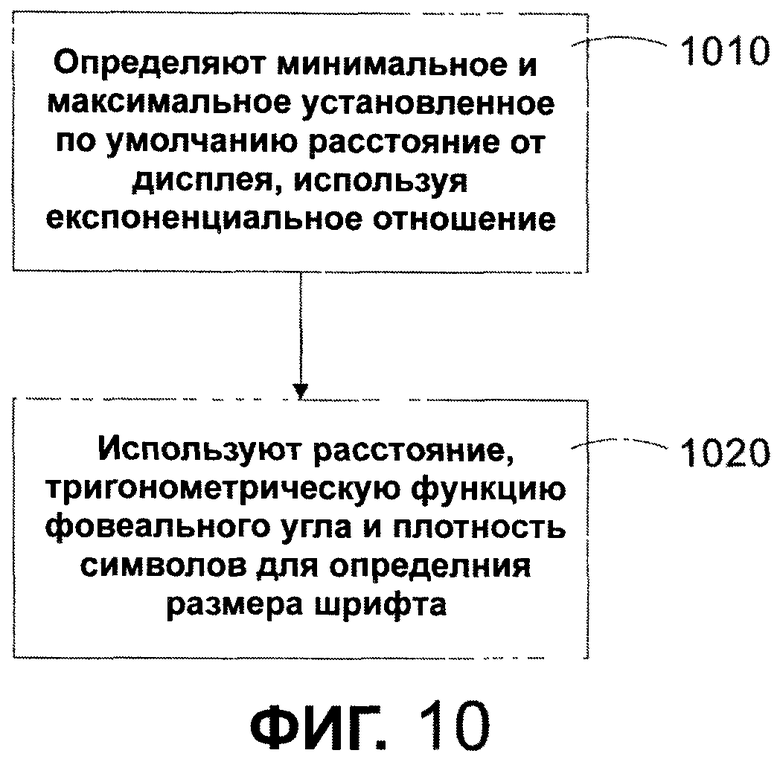
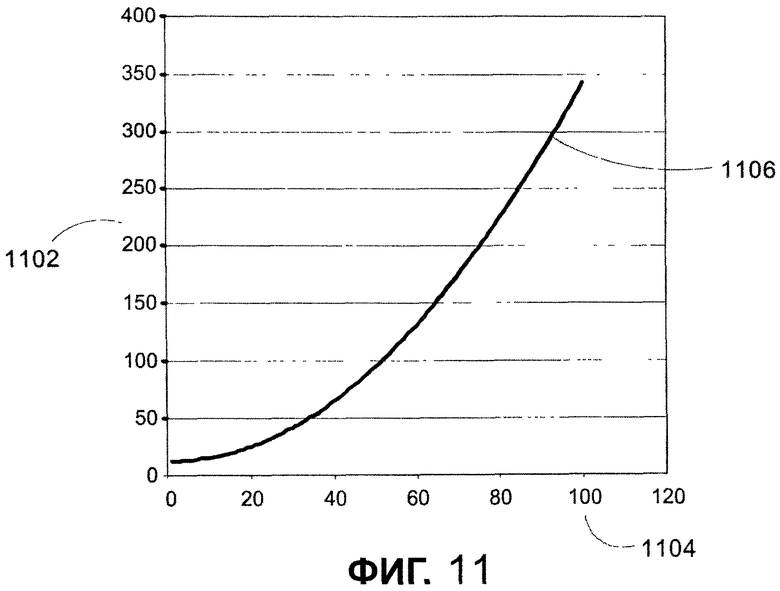
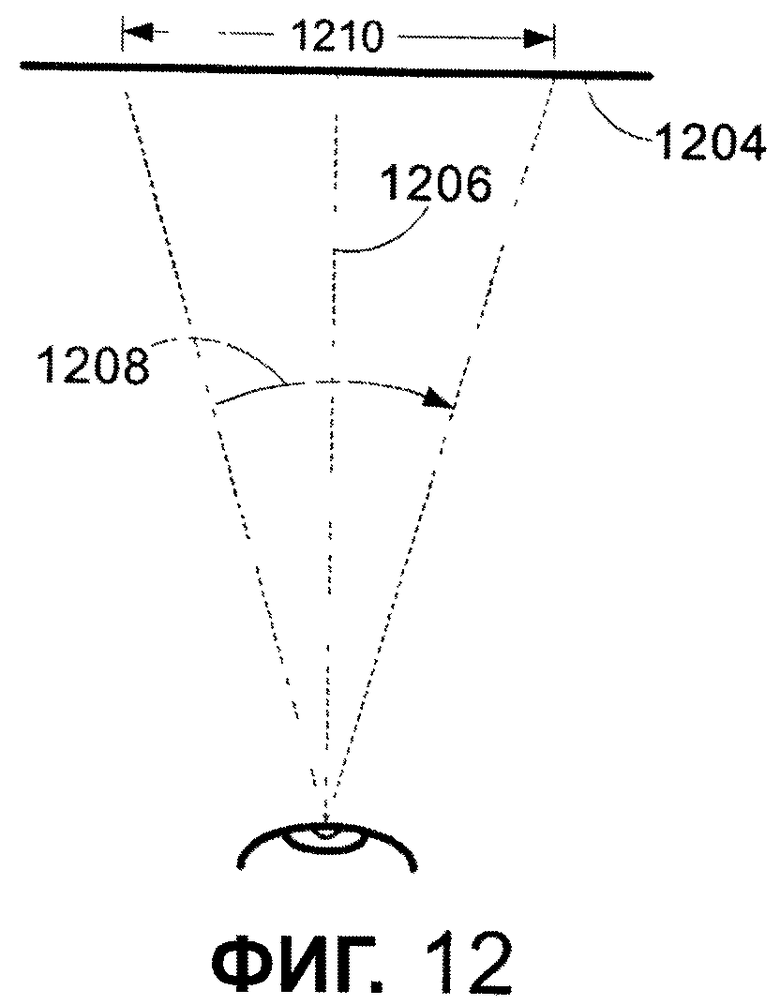
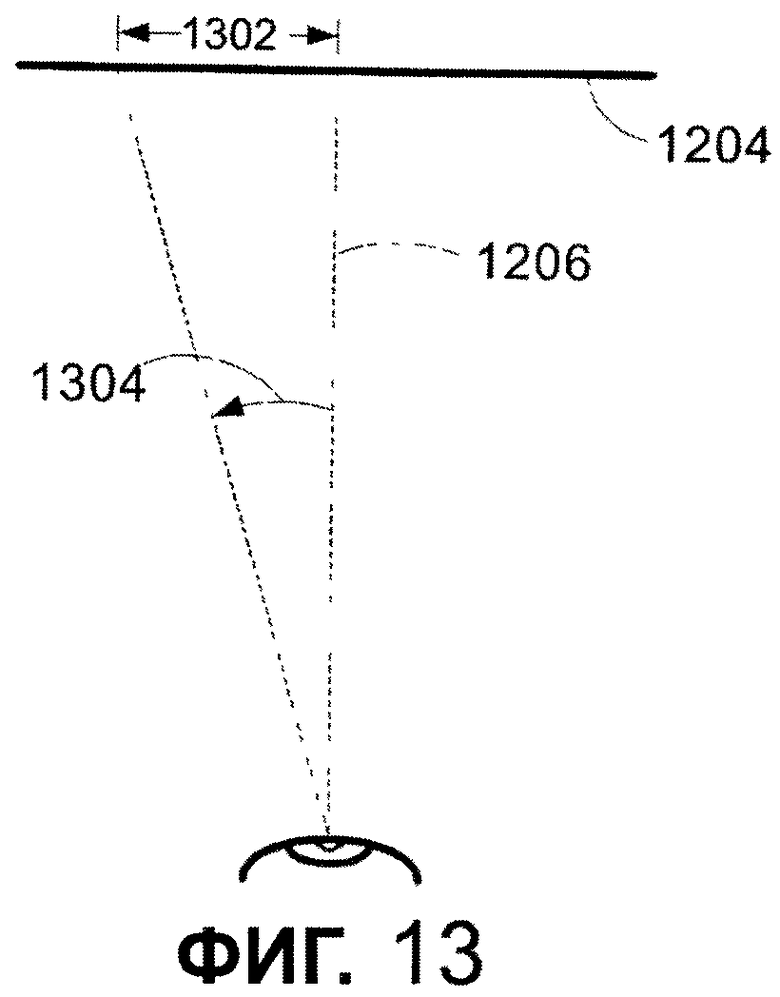
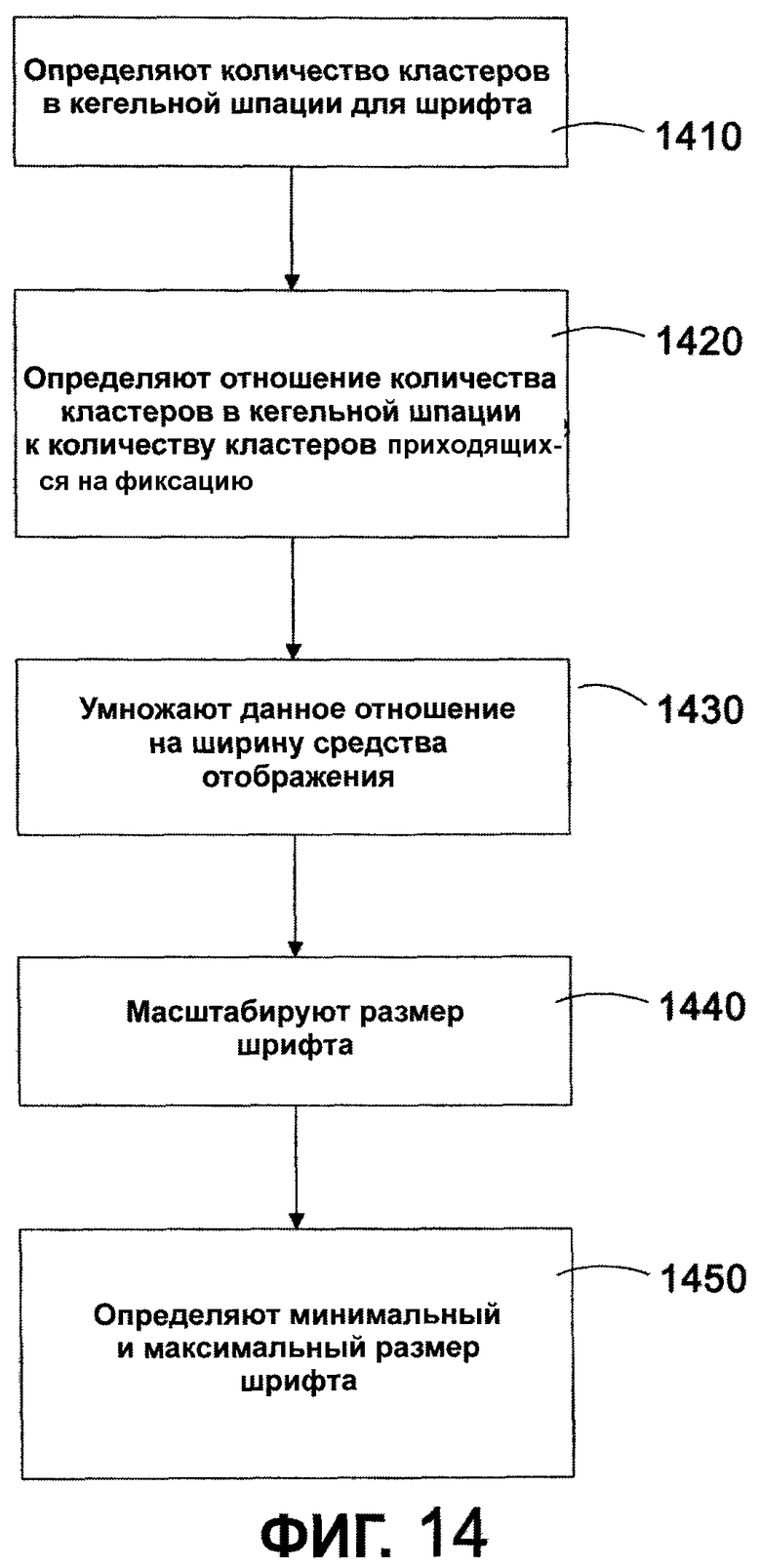
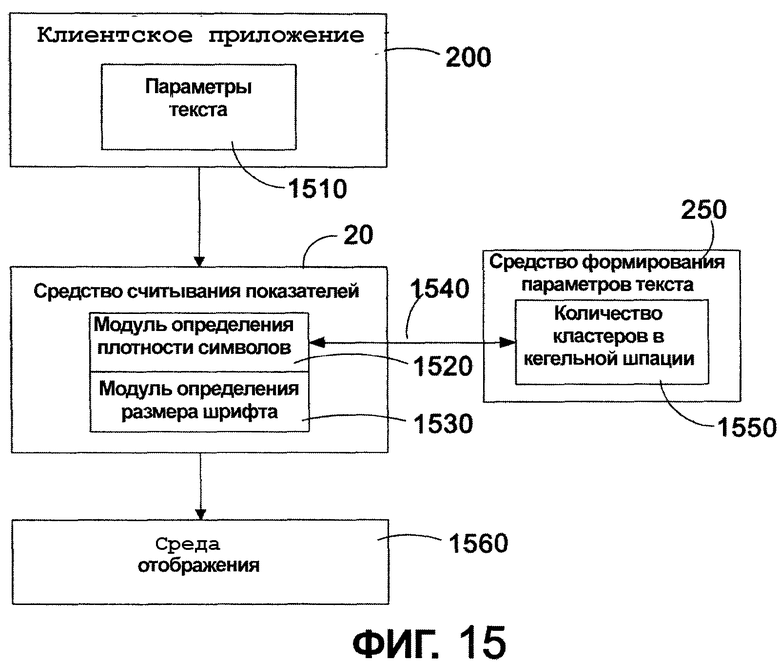
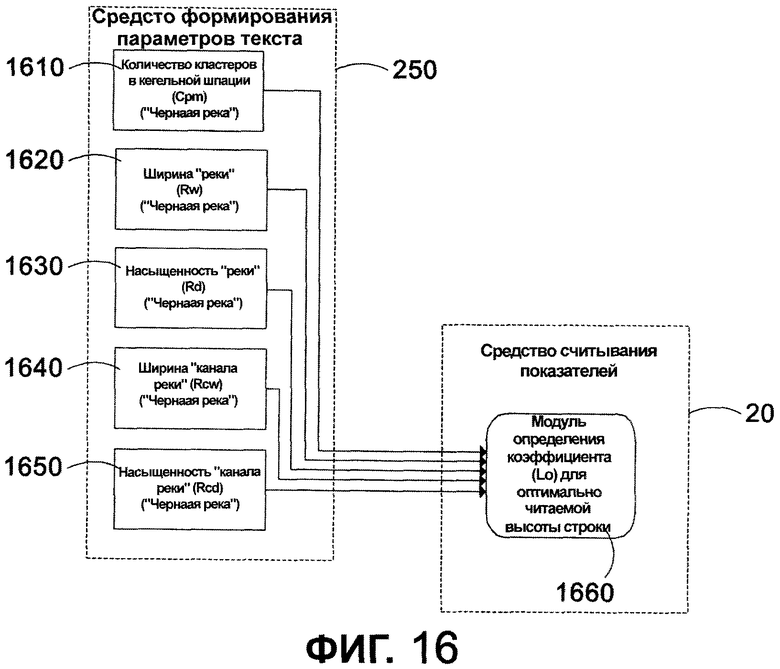

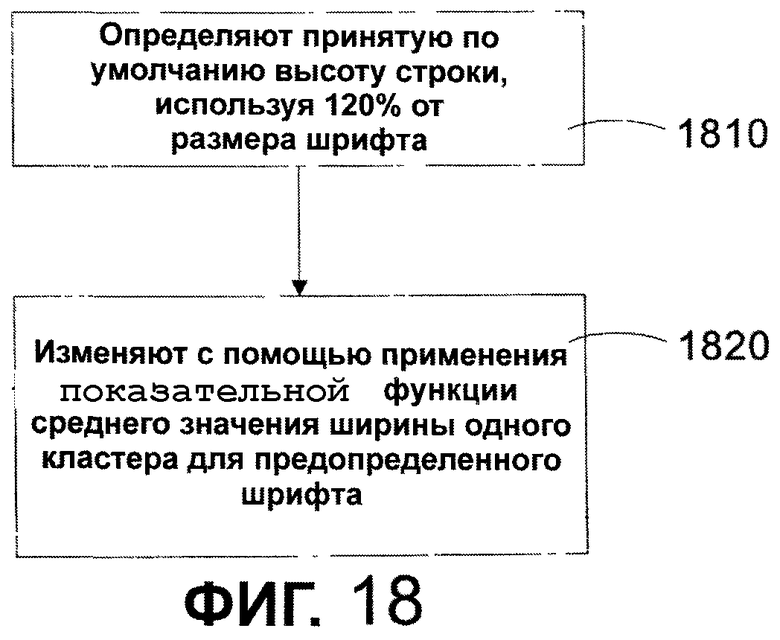
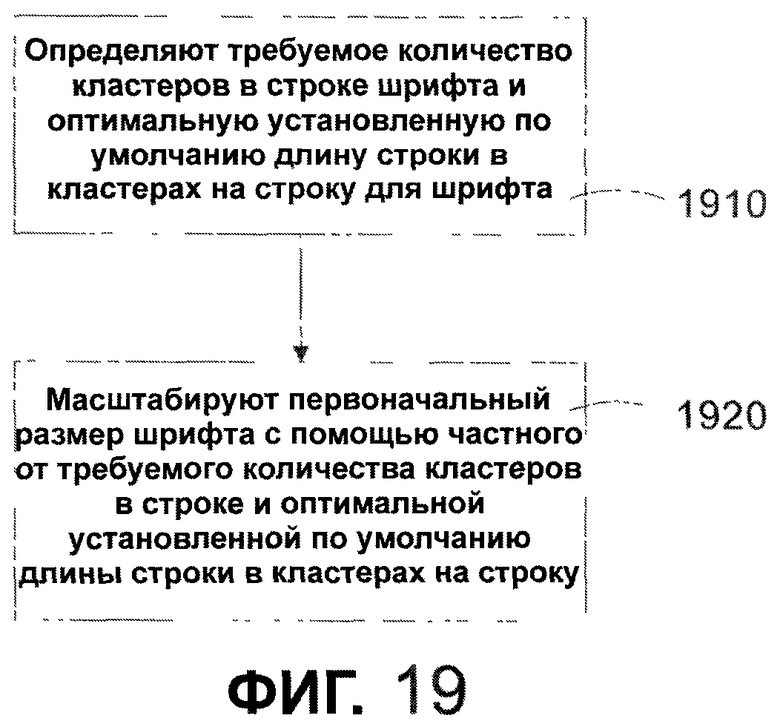
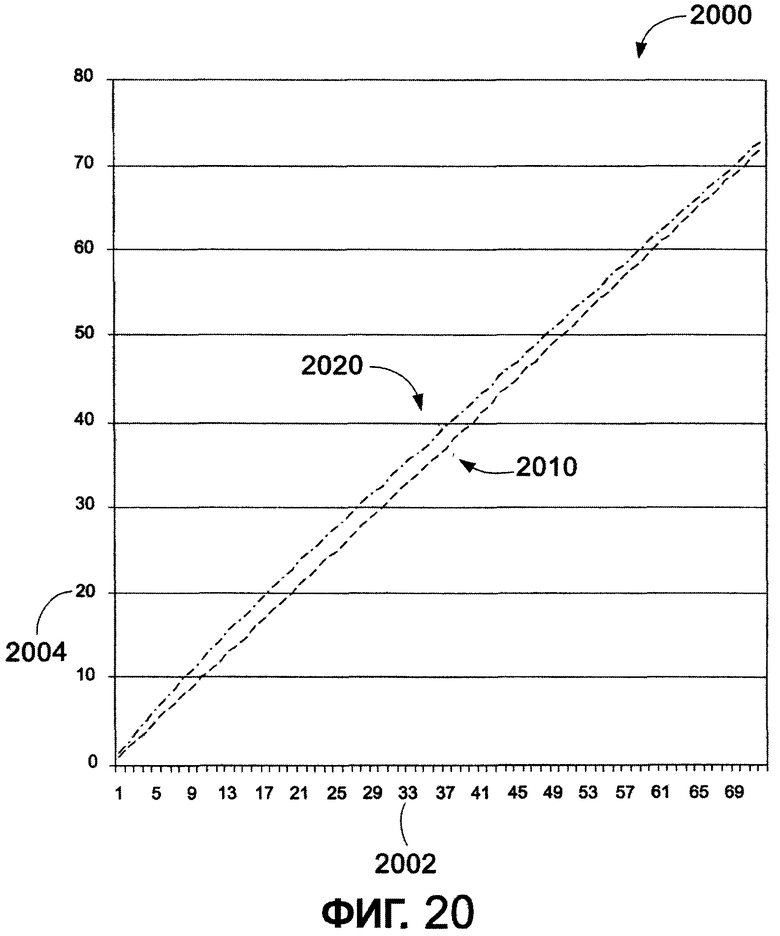
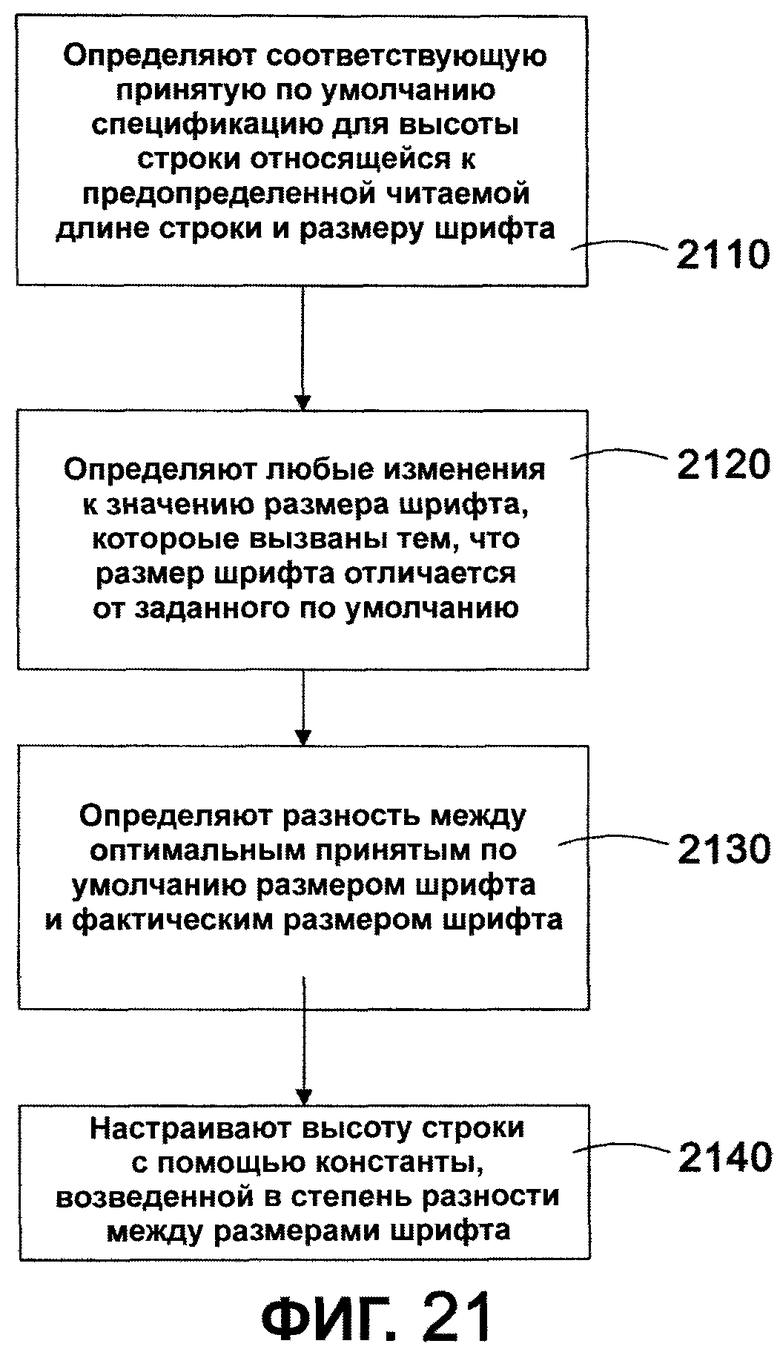
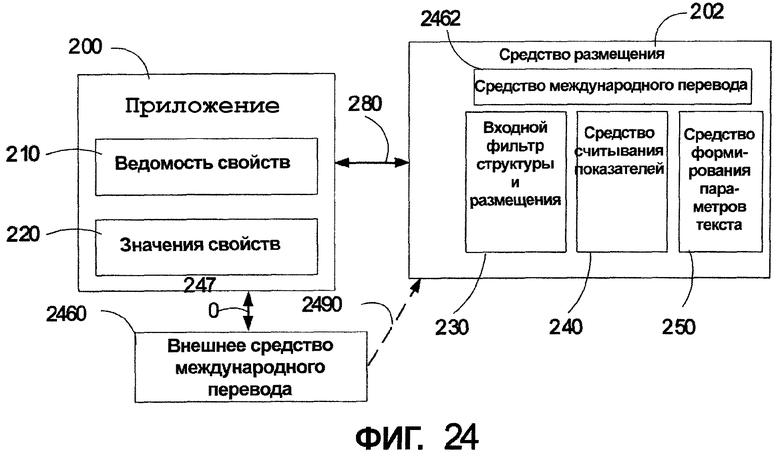
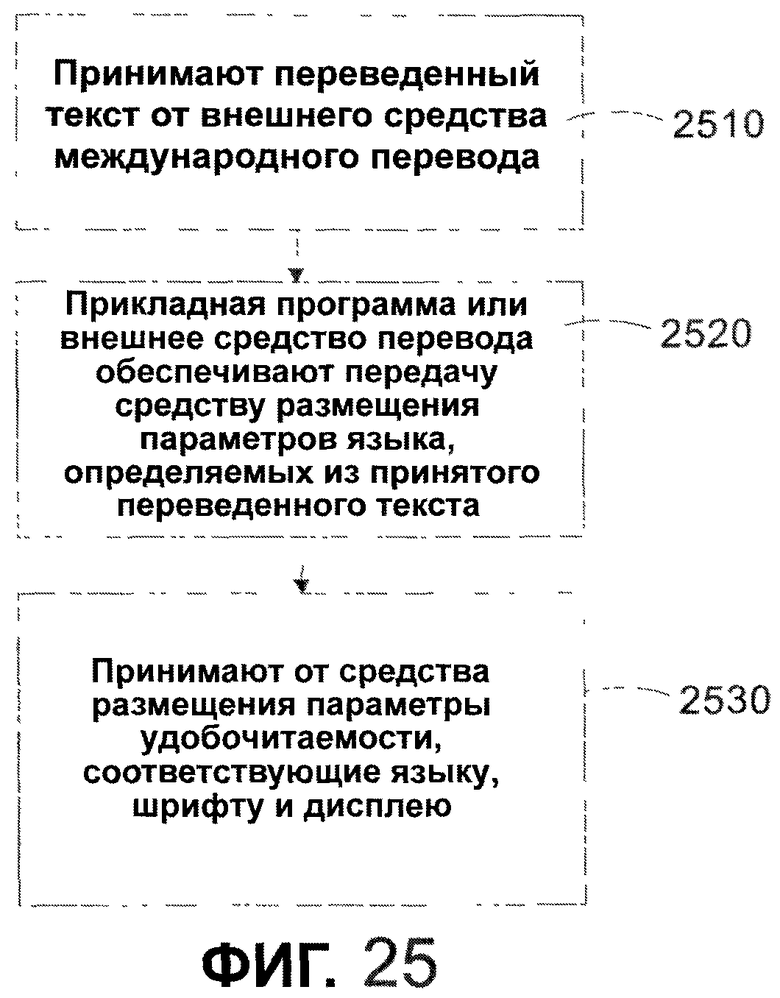
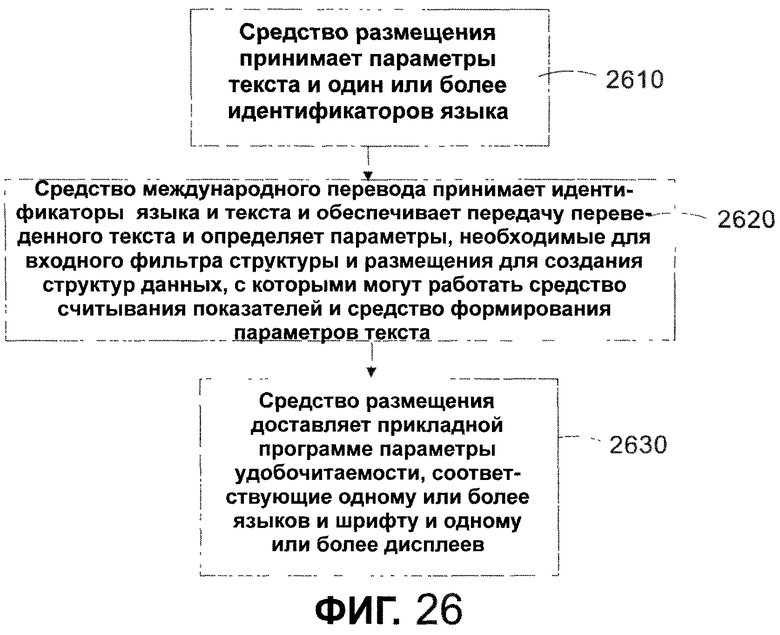
Изобретение относится к обработке текста. Технический результат заключается в автоматическом представлении текста, воспроизводимого на любом дисплее, на любом языке и шрифтом любого размера, в наиболее удобочитаемом виде. Определяют высоту строки текста посредством умножения параметра текста на показательную функцию средней ширины одного кластера шрифта. При этом параметром текста может быть заданная по умолчанию высота строки текста, среднее значение ширины одного символа, размер шрифта. 5 н. и 22 з.п. ф-лы, 27 ил., 1 табл.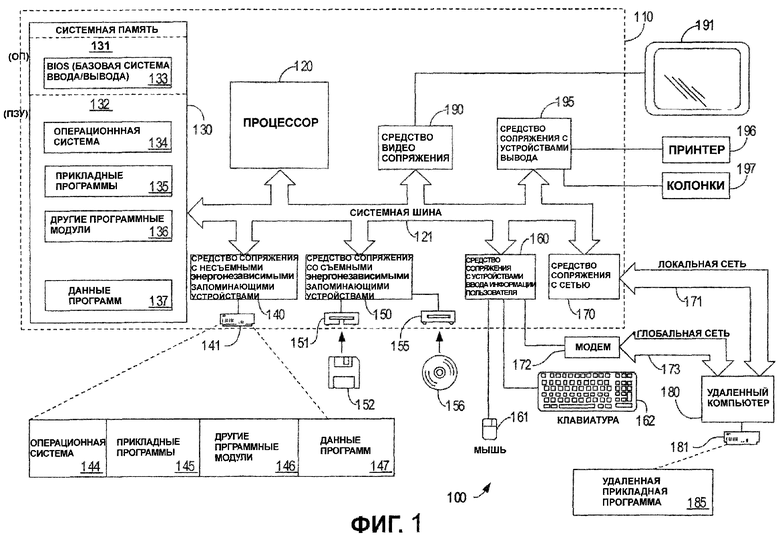
определяют средний уровень серого для типового образца текста для данного шрифта,
умножают средний уровень серого на количество кластеров в расчете на кегельную шпацию для данного шрифта, и определяют заданную по умолчанию высоту строки текста, умножая размер шрифта на обратное значение произведения среднего уровня серого и количества кластеров в расчете на кегельную шпацию.
| US 6256650 B1, 03.07.2001 | |||
| СПОСОБ ИЗГОТОВЛЕНИЯ МАКЕТА ИЗДАНИЯ | 1999 |
|
RU2172027C2 |
| US 5416898 A, 16.05.1995 | |||
| US 6075892 A, 13.06.2000 | |||
| US 5740456 A, 14.04.1998 | |||
| Устройство контроля цифро-аналоговых преобразователей | 1980 |
|
SU949801A1 |
| US 6320587 B1, 20.11.2001. | |||

