2420-159026RU/017
УСТРОЙСТВО ОБРАБОТКИ ИЗОБРАЖЕНИЙ, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ОБРАБОТКИ ИЗОБРАЖЕНИЙ
Область техники, к которой относится изобретение
Настоящее изобретение относится к методике преобразования сканированного изображения документа, выполненного на бумаге, в данные, позволяющие производить поиск в цифровой форме.
Уровень техники
Поскольку за последние годы широкое распространение получили сканеры и устройства хранения данных большой емкости, такие как, например, накопители на жестких дисках и т.п., то документы, которые были сохранены как документы, выполненные на бумаге, сканируют и сохраняют в виде цифровых документов. В этом случае данные об изображениях, полученные посредством сканирования документа, выполненного на бумаге, подвергают обработке по распознаванию символов для считывания текстовой информации, описанной в этом документе, и эту текстовую информацию сохраняют совместно с изображением. Пользователь может производить поиск в цифровых документах, ассоциативно связанных с текстовой информацией, с использованием ключевых слов поиска. Для быстрого поиска этим способом желаемого документа из большого количества сохраненных групп документов важно обеспечить возможность поиска по ключевым словам даже для сканированных изображений.
Например, в выложенном патенте Японии № 2000-322417 описана следующая методика. А именно, когда пользователь производит поиск цифрового документа, ассоциативно связанного с текстовой информацией, с использованием ключевых слов поиска, то фрагменты текста, которые описывают ключевые слова поиска, выделяют на этом изображении документа для того, чтобы пользователь мог их распознать. Поскольку фрагменты текста, соответствующие ключевым словам поиска, являются выделенными, то в том случае, если документ включает в себя множество фрагментов описания с идентичными ключевыми словами, пользователь может эффективно распознавать эти фрагменты описания посредством переключения изображений страниц.
С другой стороны, также существует способ, в котором результаты обработки по распознаванию символов внедряют в файл изображения в виде прозрачного текста (коды символов обозначены прозрачным цветом в качестве цвета визуализации) и этот файл изображения сохраняют в формате PDF (формат переносимого документа). При отображении файла в формате PDF, сгенерированного таким способом, на экране дисплея на изображениях символов в изображении документа формируют изображение прозрачного текста. Следовательно, при выполнении поиска по ключевым словам находят прозрачный текст, но пользователь не может видеть непосредственно сам прозрачный текст, и создается представление, что как будто бы было найдено изображение. Таким образом, изображение, которое позволяет производить поиск с использованием ключевых слов поиска, может быть визуально воспроизведено на основании файла описанного формата с использованием языка описания страниц, позволяющего визуализировать изображение и текст.
Для визуализации текста в цифровом документе с использованием языка описания страниц, такого как, например, формат PDF, формат SVG (формат масштабируемой векторной графики) и т.п., необходима информация о форме символа для каждого символа, то есть графическое представление (глиф) данных о шрифте. Однако, поскольку данные о шрифте обычно имеют большой объем, то обычной практикой является не сохранение данных о шрифте в цифровом документе, а только лишь обозначение типов шрифтов в цифровом документе. Таким образом, приложение может визуализировать текстовые данные с использованием шрифтов, установленных в персональном компьютере.
С другой стороны, часто желательно, чтобы данные о шрифте были сохранены в цифровом документе. Например, когда цифровой документ, сгенерированный приложением генерации документов, необходимо открыть другим персональным компьютером, то, если данные о шрифте, использованные в этом цифровом документе, не установлены в персональном компьютере, цифровой документ не может быть открыт в точном виде. Другими словами, если сами данные о шрифте сохранены в цифровом документе, то цифровой документ может быть точно воспроизведен даже в том случае, когда этот цифровой документ воспроизводит персональный компьютер или приложение, в которых не установлены указанные данные о шрифте.
В некоторых случаях желательно, чтобы данные о шрифте, используемые для визуализации символов в цифровом документе, были сохранены как обязательное условие, зависящее от используемых приложений. Например, что касается файлов, которые должны быть сохранены на долгосрочный период, шрифты, установленные по умолчанию, могут быть изменены вследствие изменений в операционной системе (ОС) по истечении длительного периода времени. Следовательно, данные о шрифте желательно сохранять в необходимом формате.
Некоторые форматы имеют обязательное условие сохранения данных о шрифте в цифровом документе. Например, в формате XPS (спецификация расширяемого языка гипертекстовой разметки (XML) для бумажных документов) при сохранении текстовых данных вместе с ними необходимо сохранять данные о шрифте.
Однако когда данные о шрифте сохранены в цифровом документе, объем самого цифрового документа увеличивается. Когда увеличивается объем файла, то передача цифрового документа через сеть занимает большое время, или же для сохранения документа требуется большой объем памяти запоминающего устройства.
Таким образом, в цифровом документе, имеющем такой формат файла, в котором визуализацию символов осуществляют с использованием данных о шрифте, сохраненных в цифровом документе, желательно не допускать увеличения объема файла. Увеличение объема файла желательно не допускать, в особенности в том случае, когда сканированное изображение, текстовые данные, полученные в результате распознавания символов, и данные о шрифте, используемые для визуализации текста, сохранены вместе в цифровом документе. Когда в цифровом документе необходимо сохранить данных о шрифте вследствие ограничений, присущих формату, системе и т.п., то увеличение объема файла часто быстро создает проблему.
Раскрытие изобретения
Согласно настоящему изобретению, вышеизложенные проблемы решают посредством предоставления устройства обработки изображений, содержащего:
блок распознавания символов, выполненный с возможностью выполнять обработку по распознаванию символов для множества изображений символов в изображении документа для получения кодов символов, соответствующих соответствующим изображениям символов; и
блок генерации, выполненный с возможностью генерировать цифровой документ, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных блоком распознавания символов, и данные о глифе, при этом данные о глифе используют в качестве общих данных для множества кодов символов при визуализации символов, соответствующих этому множеству кодов символов.
Дополнительные признаки настоящего изобретения станут очевидными из приведенного ниже описания вариантов осуществления изобретения, которые приведены в качестве примеров, со ссылкой на приложенные чертежи.
Краткое описание чертежей
На Фиг.1 изображена блок-схема, на которой показан пример устройства согласно первому варианту осуществления;
на Фиг.2 изображена схема последовательности этапов, на которой показан пример процедуры обработки для генерации цифрового документа согласно первому варианту осуществления;
на Фиг.3 изображена схема последовательности этапов, на которой показан пример процедуры обработки для поиска в цифровых документах и их просмотра согласно первому варианту осуществления;
на Фиг.4 изображена схема последовательности этапов, на которой показаны подробности процедуры обработки для генерации данных цифрового документа, выполняемой на этапе S208 Фиг.2;
на Фиг.5 изображена схема последовательности этапов, на которой показаны подробности процедуры обработки для визуализации страницы, выполняемой на этапе S306 Фиг.3;
на Фиг.6 показан пример цифрового документа, который генерируют согласно первому варианту осуществления;
на Фиг.7 показан пример изображения страницы, подлежащего обработке;
на Фиг.8 показан пример результата обработки по разделению области на сегменты;
на Фиг.9 показан пример генерируемых данных об областях;
на Фиг.10 показан пример обработки, выполняемой тогда, когда должны быть извлечены изображения символов после выполнения обработки по распознаванию символов;
на Фиг.11 показан пример данных о строке кодов символов, генерация которых осуществлена на основании результата распознавания символов;
на Фиг.12 показан пример таблицы строк кодов символов;
на Фиг.13 показан пример отображения страницы, на которой выделен результат поиска;
на Фиг.14A и Фиг.14Б показан пример отображения страницы, на которой результат поиска выделен посредством другого способа выделения информации на экране;
на Фиг.15 показан пример цифрового документа, который сгенерирован согласно второму варианту осуществления;
на Фиг.16 показан пример отображения страницы, на которой выделен результат поиска;
на Фиг.17 показан пример изображения страницы, подлежащего обработке; и
на Фиг.18 показан пример отображения страницы, на которой выделен результат поиска.
Осуществление изобретения
Теперь будет приведено подробное описание предпочтительных вариантов осуществления настоящего изобретения со ссылкой на чертежи. Следует отметить, что относительное расположение компонентов, численные выражения и численные значения, изложенные в этих вариантах осуществления, не ограничивают объем настоящего изобретения, если не сделано специальной оговорки.
Первый вариант осуществления
На Фиг.1 изображена блок-схема, на которой показан пример структуры устройства обработки изображений.
Устройство 100 обработки изображений представляет собой устройство для реализации этого варианта осуществления и выполняет преобразование данных об изображении документа в цифровой документ, позволяющий производить поиск. Устройство 100 обработки изображений содержит сканер 101, центральный процессор (ЦП) 102, запоминающее устройство 103, накопитель 104 на жестких дисках, сетевой интерфейс 105 и интерфейс 106 пользователя (ИП). Сканер 101 сканирует информацию на поверхности листа документа, выполненного на бумаге, и преобразовывает ее в данные об изображении документа. ЦП 102 представляет собой процессор, выполняющий компьютерные программы и т.п., необходимые для анализа данных об изображениях и для преобразования их в цифровой документ, позволяющий производить поиск. Запоминающее устройство 103 представляет собой запоминающую среду, в которой хранят программы и промежуточные данные обработки, и которая используется в качестве рабочей области для ЦП. Накопитель 104 на жестких дисках представляет собой запоминающую среду большой емкости, используемую для хранения компьютерных программ и данных, например, цифровых документов и т.п. Сетевой интерфейс 105 представляет собой интерфейс, необходимый для соединения с сетью 120, и его используют для передачи данных, таких как сканированное изображение, преобразованный цифровой документ, позволяющий производить поиск, и т.п., во внешнее устройство, и для приема данных из внешнего устройства. Интерфейс 106 пользователя представляет собой интерфейс, используемый для приема команд от пользователя, и содержит устройство ввода, включающее в себя клавиши ввода, сенсорную панель и т.п., и дисплей, например, жидкокристаллический дисплей или аналогичное устройство. Следует отметить, что структура устройства настоящего изобретения не ограничена этим конкретным вариантом структуры.
Устройство 110 обработки изображений может производить поиск в цифровых документах, сгенерированных устройством 100 обработки изображений, и их просмотр. ЦП 111 выполняет компьютерные программы, необходимые для выполнения обработки для поиска и просмотра цифровых документов. Запоминающее устройство 112 представляет собой запоминающую среду, используемую в качестве рабочей области при выполнении программ и для временного хранения данных. Накопитель 113 на жестких дисках представляет собой запоминающую среду большой емкости, используемую для хранения компьютерных программ и данных, например, цифровых документов и т.п. Сетевой интерфейс 114 представляет собой интерфейс, используемый для приема данных, таких как, например, цифровые документы и т.п., из внешнего устройства и для передачи данных во внешнее устройство. Интерфейс 115 пользователя представляет собой средство взаимодействия, используемое для приема команд от пользователя, и содержит устройство ввода, включающее в себя клавиши ввода, сенсорную панель и т.п., и дисплей, например, жидкокристаллический дисплей или аналогичное устройство.
Ниже приведено описание процедуры обработки согласно первому варианту осуществления со ссылкой на схемы последовательности этапов, показанные на Фиг.2 и Фиг.3.
На Фиг.2 изображена схема последовательности этапов, на которой показан пример процедуры обработки, выполняемой тогда, когда устройство 100 обработки изображений генерирует цифровой документ, позволяющий производить поиск на основании данных об изображениях, полученных, например, посредством сканирования документа, выполненного на бумаге, и производит передачу цифрового документа в устройство 110 обработки изображений.
На этапе S201 ЦП 102 определяет адресата передачи и способ передачи цифрового документа, который будет сгенерирован, в соответствии с действием команды пользователя. Пользователь выдает команды через интерфейс 106 пользователя. Способ передачи выбирают, например, из следующих вариантов: передача по электронной почте, передача файла с использованием протокола передачи файлов (протокола FTP) и т.п.
Когда пользователь устанавливает документ, выполненный на бумаге, и нажимает клавишу "пуск", то на этапе S202 ЦП 102 выполняет сканирование установленного документа, выполненного на бумаге, с использованием сканера 101 для генерации данных об изображении документа, и сохраняет данные об изображении документа в запоминающем устройстве. Когда документ, включающий в себя множество страниц, введен с использованием устройства автоматической подачи документов или аналогичного устройства, каждую страницу преобразовывают в данные об изображении одной страницы, и преобразованные данные об изображениях страниц сохраняют в запоминающем устройстве 103 в том порядке, в котором они введены.
На Фиг.7 показан пример изображения страницы. Изображение 701 страницы, показанное на Фиг.7, включает в себя строку 702 символов 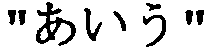 и строку 703 символов
и строку 703 символов  , и фотографию 704. Следует отметить, что для простоты фотография 704 проиллюстрирована просто в виде сплошного прямоугольника, но на практике она представляет собой обычное изображение. В примере, показанном на Фиг.7, изображение 701 страницы содержит только строки 702 и 703 символов и фотографию 704, но оно также может включать в себя область графической информации и т.п. В примере на Фиг.7 показаны строки 702 и 703 символов японского языка. Однако настоящее изобретение не ограничено японским языком. Например, также могут быть аналогичным образом обработаны строки символов, представляющих собой буквы алфавита (английского языка и т.п.). На Фиг.17 показан пример изображения 1701 документа, включающего в себя строки 1702 и 1703 алфавитных символов.
, и фотографию 704. Следует отметить, что для простоты фотография 704 проиллюстрирована просто в виде сплошного прямоугольника, но на практике она представляет собой обычное изображение. В примере, показанном на Фиг.7, изображение 701 страницы содержит только строки 702 и 703 символов и фотографию 704, но оно также может включать в себя область графической информации и т.п. В примере на Фиг.7 показаны строки 702 и 703 символов японского языка. Однако настоящее изобретение не ограничено японским языком. Например, также могут быть аналогичным образом обработаны строки символов, представляющих собой буквы алфавита (английского языка и т.п.). На Фиг.17 показан пример изображения 1701 документа, включающего в себя строки 1702 и 1703 алфавитных символов.
В качестве формата данных об изображении страницы, например, когда документ, выполненный на бумаге, представляет собой цветной документ, данные об изображении страницы обрабатывают как цветное изображение, в котором оттенки цвета выражены 8 битами для каждой из составляющих красного (R), зеленого (G) и синего (B) цветов. Когда документ, выполненный на бумаге, представляет собой черно-белый документ, то данные об изображении страницы обрабатывают как полутоновое изображение, в котором яркость выражена 8 битами, или как бинарное изображение, в котором черное и белое выражено 1 битом.
На этапе S203 ЦП 102 выбирает в качестве изображения, подлежащего обработке, те данные об изображении страницы, которые сохранены в запоминающем устройстве 103, но еще не обработаны. При наличии множества изображений страниц ЦП 102 выбирает в качестве изображения, подлежащего обработке, изображение одной страницы в соответствии с порядком ввода.
На этапе S204 ЦП 102 выполняет обработку по анализу областей для анализа изображения, подлежащего обработке, и для распознавания областей, имеющих различные свойства, таких как, например, область "текст", область "графика", область "фотография", область "таблица" и т.п., для генерации данных об областях, ассоциативно связанных с соответствующими распознанными областями, и сохраняет данные об областях в запоминающем устройстве 103. Следует отметить, что данные о каждой области включают в себя координаты левой верхней точки (значения координат x и y) прямоугольника, описанного вокруг этой области, значения количества элементов изображения, отображающих размер (ширину и высоту) описанного прямоугольника, и тип распознанной области. Предполагают, что обработку по анализу областей (которую также именуют обработкой по распознаванию областей, обработкой по различению областей, обработкой по выделению областей и т.п.) выполняют с использованием методик предшествующего уровня техники. Например, при использовании методики, раскрытой в патенте Японии № 6-68301, зона, в которой кластеры черных элементов изображения, имеющие аналогичные размеры, сцеплены по вертикали или по горизонтали, могут быть извлечены из двоичных данных об изображении документа в качестве области "текст".
В результате обработки по анализу областей для изображения 701 страницы, показанного на Фиг.7, распознаны область 801 "текст" и область 802 "фотография", показанные на Фиг.8. На Фиг.9 показан пример данных об области, полученных посредством обработки по анализу этой области. Когда обработке по анализу областей подвергают изображение, содержащее строки алфавитных символов (например, изображение 1701, показанное на Фиг.17), то получают результат анализа областей, аналогичный результату, показанному на Фиг.7.
На этапе S205 ЦП 102 применяет обработку по распознаванию символов к изображениям символов в области "текст", распознанной при обработке по анализу областей, для получения данных о строках кодов символов, и сохраняет полученные данные в запоминающем устройстве 103. Предполагают, что данные о каждой строке кодов символов включают в себя информацию о кодах символов в качестве результата распознавания для каждого изображения символа, включенного в область "текст", и информацию о прямоугольнике, описанном вокруг этого изображения символа (информацию о координатах левого верхнего угла и о ширине и высоте описанного прямоугольника).
Ниже приведено краткое описание примера обработки по распознаванию символов. Следует отметить, что при обработке для распознавания изображения символа как символа могут использоваться способы предшествующего уровня техники.
Когда изображение документа не является бинарным изображением, бинарное изображение в каждой области "текст" получают, например, посредством бинаризации изображения в области "текст". Генерируют гистограммы посредством подсчета количества черных элементов изображения для соответствующих вертикальных и горизонтальных строк в каждой бинаризованной области "текст". На основании вертикальной и горизонтальной гистограмм определяют направление, в котором появляются периодические гистограммы, как направление строки, и ту часть, в которой значения количества элементов изображения в гистограммах становятся равными или большими, чем заранее заданное пороговое значение, определяют как часть, образующую строку символов, получая, тем самым, изображения строк, имеющих форму полос. Гистограммы вычисляют для каждого изображения строки в направлении, перпендикулярном к направлению строки, и изображение каждого символа извлекают на основании результата, полученного посредством гистограмм. Этот извлеченный диапазон представляет собой информацию о прямоугольнике, описанном вокруг одного символа. В этом случае этап определения выполняют с использованием гистограмм, полученных посредством подсчета значений количества черных элементов изображения. В альтернативном варианте каждая область символа может быть определена с использованием оценки, указывающей, содержит ли каждая строка черные элементы изображения или нет.
Из изображения в прямоугольнике, описанном вокруг каждого изображения символа, извлекают краевые компоненты и т.п. для получения вектора признаков, и полученный вектор признаков сравнивают с зарегистрированными заранее векторами признаков в словаре распознавания символов, вычисляя, таким образом, подобия. Код типа буквы (тип символа), имеющий набольшее подобие, определяют как код символа, соответствующий изображению символа в прямоугольнике. Таким образом получают данные, полученные посредством присвоения кодов символов всем прямоугольникам, описанным вокруг символов, содержащихся в области "текст". Затем из кодов символов, полученных из каждой области "текст", формируют строку кодов символов.
Для областей символов английского алфавита также производят проверку наличия межсловного пробела между соседними символами. Например, производят проверку того, является ли расстояние между символами большим или нет, и производят проверку разрывности слова посредством выполнения сопоставления между строкой символов в результатах распознавания символов в изображениях символов и словарем слов. Следовательно, может быть произведена проверка того, существует ли межсловный пробел или нет. Если определено, что межсловный пробел существует, то в строку кодов символов вставляют код символа этого пробела.
На Фиг.10 и Фиг.11 показан пример результата обработки по распознаванию символов для области 801 "текст", показанной на Фиг.8. Из области 1000 "текст" на Фиг.10 извлечены строки 1001 и 1002 символов. Из строки 1001 символов извлечены три символа 1011, 1012 и 1013 и, соответственно, подвергнуты обработке по распознаванию символов. В результате, получены коды символов, соответствующие этим символам, следовательно, сгенерированы данные 1101 о строке кодов символов, показанные на Фиг.11. Аналогичным образом, три символа 1021, 1022 и 1023, извлеченные из строки 1002 символов, подвергнуты обработке по распознаванию символов, таким образом, сгенерированы данные 1102 о строке кодов символов, показанные на Фиг.11.
Следует отметить, что приведенное выше описание является примером, и что строка кодов символов может быть получена с использованием способов обработки, в которых используют иные известные способы распознавания символов. На Фиг.10 и Фиг.11 показан случай, в котором обработке по распознаванию символов подвернута область "текст" на японском языке. Однако настоящее изобретение не ограничено японским языком. Например, области "текст", содержащие другие языки (например, алфавит английского языка и подобные алфавиты), аналогичным образом подвергают обработке по распознаванию символов для получения кодов символов.
На этапе S206 ЦП 102 временно сохраняет данные об изображении страницы, подлежащие обработке, данные об областях и данные о строках кодов символов в запоминающем устройстве 103 или в накопителе 104 на жестких дисках как ассоциативно связанные друг с другом.
На этапе S207 ЦП 102 проверяет, остались ли еще какие-либо данные об изображениях, подлежащие обработке. Если все еще остаются еще какие-либо данные об изображениях, подлежащие обработке, то в последовательности этапов возвращаются к этапу S203 для выполнения обработки следующих данных об изображении страницы. В противном случае в последовательности этапов переходят вперед к выполнению этапа S208.
На этапе S208 ЦП 102 объединяет данные для всех страниц, сохраненные в запоминающем устройстве 103 или в накопителе 104 на жестких дисках, в порядке следования страниц для генерации цифрового документа, позволяющего производить поиск, который включает в себя множество страниц.
Данные цифрового документа, сгенерированного на этапе S208, могут содержать как информацию о визуализации, необходимую для вывода в цифровом виде изображения каждой страницы на экран дисплея или аналогичного устройства, или для печати изображения каждой страницы на принтере, так и информацию о содержимом, которая позволяет пользователю производить поиск с использованием поиска по ключевым словам. В качестве форматов данных, удовлетворяющих таким условиям, могут быть использованы форматы PDF, SVG и т.п. Однако в этом варианте осуществления предполагают, что в качестве формата генерируемого цифрового документа намечено внедрение данных о шрифте. В качестве формата, включающего в себя внедрение данных о шрифте в качестве обязательного условия, известен, например, формат XPS или аналогичный. Приведенное ниже описание изложено с учетом предположения о том, что спецификация формата описания страницы дана с использованием представления на расширяемом языке гипертекстовой разметки (XML). Однако настоящее изобретение не ограничено этим конкретным форматом.
На Фиг.6 показан пример описания страницы цифрового документа, сгенерированного на основании спецификации формата описания страницы, используемой в описании этого варианта осуществления, в том случае, когда введен документ, включающий в себя изображения страниц для двух страниц. В этом варианте осуществления в качестве примера формата описания страницы, описания объединены в едином файле, как показано на Фиг.6. Однако настоящее изобретение не ограничено этим вариантом. Например, может использоваться следующий формат (например, формат XPS). А именно, подготавливают независимый файл данных о шрифте и обращаются к нему из основного файла, и эти файлы объединяют в единый цифровой документ, например, посредством сжатия файлов архиватором в формате ZIP или аналогичным способом.
Ниже приведено описание примера процедуры обработки для генерации данных цифрового документа, выполняемой на этапе S208, со ссылкой на схему последовательности этапов, показанную на Фиг.4.
При выполнении этапа S401 ЦП 102 описывает тэг начала цифрового документа. В спецификации формата описания данных о странице из этого описания элемент <Document> представляет собой тэг начала цифрового документа. Следует отметить, что описание на языке XML внутри области, ограниченной элементом <Document> и элементом </Document>, обозначающим конец документа, соответствует данным описания, ассоциативно связанным с соответствующими страницами, содержащимися в этом документе. В примере, показанном на Фиг.6, номером 601 позиции обозначен тэг начала цифрового документа, а номером 612 позиции обозначен тэг его конца.
На этапе S402 ЦП 102 задает данные, ассоциативно связанные с первой страницей из неописанных страниц, и определяет их как данные, подлежащие обработке.
На этапе S403 ЦП 102 генерирует и описывает тэг, отображающий начало данных о странице, подлежащих обработке. В этом примере тэг элемента <Page> отображает начало данных о странице, и описание на языке XML в пределах области, ограниченной тэгом <Page> и тэгом </Page>, служащим в качестве тэга конца, соответствует данным о визуализации и данным об информационном содержимом на этой странице. Тэг <Page> описывает физический размер страницы с использованием атрибутов "Width" ("ширина") и "Height" ("высота"), которые указывают ширину элемента изображения и высоту страницы, и атрибута "Dpi" ("количество точек на дюйм"), указывающего разрешающую способность, а также описывает номер страницы с использованием атрибута "Number" ("номер"), указывающего номер страницы.
В примере описания, который показан на Фиг.6, тэг 602 начала элемента <Page> описывает, что ширина "Width" страницы равна "1680", высота "Height" равна "2376", разрешающая способность (количество точек на дюйм) "Dpi" равна "200", а номер страницы "Number" равен "1". Данные первой страницы описаны внутри области (элементы 603 - 606) до тэга 606 конца.
На этапе S404 ЦП 102 генерирует и описывает тэг, отображающий данные о визуализации тех изображений, из которых сформирована страница.
В спецификации формата описания данных о странице из этого описания предполагают, что один элемент <Image> представляет собой данные о визуализации одного изображения. Также предполагают, что содержимое данных об изображении описано в атрибуте "Data" ("данные"), и что положение визуализации этого изображения на странице описано с использованием информации о координатах, содержащейся в атрибутах "X", "Y", "Width" ("ширина"), и "Height" ("высота"). Если страница включает в себя множество изображений, то данные о соответствующих изображениях описаны во множестве строк "снизу вверх" в порядке их появления. Следует отметить, что атрибут "Data" ("данные") описывает содержимое данных об изображениях в сжатом формате данных об изображениях. В качестве способа сжатия используют сжатую строку кода в формате JPEG для цветного или полутонового изображения, или используют сжатую строку кода в формате MMR для бинарного (двухградационного) изображения.
Элемент 603 на Фиг.6 определяет, что сканированное изображение первой страницы документа следует визуализировать на полной странице. Элемент 603 на Фиг.6 описывает положение и размер изображения следующим образом: [X="0", Y="0", Width ("ширина") = "1680", Height ("высота") = "2376"]. К тому же, этот элемент описывает в качестве значения атрибута "Data" ("данные") строку символов, представляющую собой строку кода, сгенерированную посредством сжатия изображения в формате JPEG (для упрощения чертежа строка символов атрибута "Data" ("данные") на Фиг.6 частично опущена). Таким образом описывают элемент 603 <Image> ("изображение"). Следует отметить, что разрешающая способность сканированного изображения может быть изменена по мере необходимости перед сжатием сканированного изображения в формате JPEG и его сохранением (например, разрешающая способность изображения, отсканированного с разрешающей способностью 600 точек на дюйм, может быть изменена на разрешающую способность, равную 300 точкам на дюйм, и это изображение может быть сохранено).
На этапе S405 ЦП 102 генерирует описание, представляющее собой данные о визуализации тех символов, из которых сформирована страница.
В спецификации формата описания страницы из этого описания один элемент <Text> отображает данные о визуализации символов для одной строки. Данные об атрибутах, описанные в элементе <Text>, содержат следующие атрибуты: "Direction" ("направление"), "X", "Y", "Font" ("шрифт"), "Size" ("размер"), "Color" ("цвет"), "String" ("строка"), "CWidth" ("интервал между символами"), "CGlyphId" ("идентификатор глифа символа") и т.п. Следует отметить, что атрибут "Direction" ("направление") указывает, написана ли строка символов по вертикали или же по горизонтали. Атрибуты "X" и "Y" указывают координаты местоположения начала символа. Атрибут "Font" ("шрифт") указывает идентификатор данных о шрифте, необходимом для визуализации кода символа. Атрибут "Size" ("размер") указывает размер шрифта. Атрибут "Color" ("цвет") указывает цвет символов при визуализации с использованием набора из четырех значений, а именно, значения составляющей R (красного цвета), значения составляющей G (зеленого цвета), значения составляющей B (синего цвета), и значение альфа-канала, которое отображает прозрачность. Атрибут "String" ("строка") указывает содержимое строки символов (строки кодов символов). Атрибут "CWidth" указывает интервал между символами от каждого символа в "строке" ("String") до следующего символа. Атрибут "CGlyphId" ("идентификатор глифа символа") указывает идентификаторы данных о форме символов, то есть, глифов, используемых при визуализации соответствующих символов в "строке". Следует отметить следующее: когда атрибут "Direction" ("направление") не указан, то по умолчанию задано написание по горизонтали.
В качестве строки кодов символов, образующей каждый элемент <Text>, данные строк кодов символов, сгенерированные на этапе S205 на Фиг.2, дополнительно разделяют и используют в соответствии со строками символов, то есть с наборами символов, образующими цепочку по вертикали или по горизонтали.
В примере описания на Фиг.6, два элемента 604 и 605 <Text> ассоциативно связаны с описаниями визуализации символов на первой странице, то есть с описаниями, соответствующими данным 1102 и 1101 о строке кодов символов, показанным на Фиг.11. Например, в элементе 604 <Text>, соответствующем строке символов 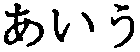 , написанной по горизонтали, которая содержит три символа из данных 1101, показанных на Фиг.11, указаны следующие атрибуты.
, написанной по горизонтали, которая содержит три символа из данных 1101, показанных на Фиг.11, указаны следующие атрибуты.
В атрибутах "X" и "Y" в качестве координат левого верхнего угла описанного прямоугольника для трех символов указаны значения X="236" и Y="272". В атрибуте "Direction" ("направление"), указано "Horizontal" ("по горизонтали"), что обозначает написание по горизонтали.
В атрибуте "Font" ("шрифт"), обозначающем тип шрифта, указано "Font01". В атрибуте "Size" ("размер"), обозначающем размер шрифта, указано "97" элементов изображения посредством проведения аналогии, исходя из высот символов в строке символов. В атрибуте "Color" ("цвет"), обозначающем цвет символов при визуализации, указано, что значение составляющий R = значению составляющий G = значению составляющий B=0 и что значение альфа-канала = 255 (то есть указан прозрачный цвет).
В атрибуте "String" ("строка"), обозначающем содержимое строки символов (строки кодов символов, соответствующих надлежащим символам), указаны значения "0х2422, 0х2424, 0х2426". В вышеупомянутом примере описаны коды символов, полученные при распознавании символов из строки символов на японском языке, показанной на Фиг.7. Однако при распознавании символов из строки символов на английском языке в изображении документа, показанном на Фиг.17, описаны коды символов алфавитов. В атрибуте, "CWidth", обозначающем интервал между символами для соответствующих символов, указаны разности координат между правым краем соседних символов и левым краем для первых двух символов, и значение, соответствующее ширине самого символа для последнего символа, а именно, "104, 96, 59".
В атрибуте "CGlyphId" ("идентификатор глифа символа"), обычно указывают идентификатор глифа, который соответствует данным о форме символа для каждого символа. Однако, поскольку в этом варианте осуществления форму символа визуализируют в виде прозрачного символа на сканированном изображении, то пользователь визуально не подтверждает ее независимо от формы символа. Следовательно, в этом варианте осуществления для уменьшения объема данных о форме символа (данных о шрифте) указывают идентичный идентификатор глифа даже для различных символов. Следовательно, в примере, показанном на Фиг.6, в атрибуте "CGlyphId" ("идентификатор глифа символа") описаны идентичные значения атрибутов, равные "0, 0, 0". Форма символа, указанная посредством этого идентификатора глифа, может являться простой формой (например, прямоугольником). Следует отметить, что ниже будет приведено описание подробностей формы глифа.
Следует отметить, что вышеупомянутые значения атрибутов приведены просто в качестве примеров и что они могут быть описаны с использованием других величин, имеющих тот же самый смысл. Например, атрибут "Size" ("размер"), указывающий размер шрифта, может быть описан с использованием таких величин, как, например, пункты (points) или аналогичные величины, вместо количества элементов изображения, на основании высоты элемента изображения и разрешающей способности изображения.
В приведенном выше примере в качестве опорной точки указывают координаты левого верхнего угла прямоугольника, описанного вокруг каждой строки символов, и размер шрифта указывают таким образом, чтобы он совпадал с высотой строки символов, для того, чтобы строка символов была визуализирована как наложенная почти в тех же самых местах, где расположены изображения символов на сканированном изображении. Однако настоящее изобретение не ограничено этим вариантом. В особенности, поскольку в этом варианте осуществления для каждого символа, подлежащего визуализации, указан прозрачный цвет, и пользователь не видит его, то отсутствует необходимость в наложении визуализируемой строки символов непосредственно поверх соответствующих изображений символов. Например, строка прозрачных символов может быть визуализирована в участках нижнего края соответствующих изображений символов. Например, если в примере элемента 604, показанного на Фиг.6, установлены значения X="236", Y="368" и размер "Size"="10", то строку прозрачных символов, имеющих малую высоту, визуализируют на нижних краях изображений символов. На этом этапе размер (высоту) визуализируемой строки прозрачных символов устанавливают равным заранее заданному размеру (например, равным 10), который является меньшим, чем размер изображений символов.
Визуализируемую строку прозрачных символов используют при проведении впоследствии поиска с использованием поиска по ключевым словам, и строку символов, которая совпадает с искомым ключевым словом, выделяют яркостью или цветом (например, ее отображают имеющей иной цвет). Поскольку строка прозрачных символов визуализирована в местоположении, почти соответствующем местоположению соответствующих изображений символов, то, несмотря на то, что поиск проводят с использованием строки прозрачных символов, у пользователя создается впечатление того, что как будто бы посредством поиска были найдены изображения символов. Следовательно, когда при проведении поиска для выделения символов на экране используют строку прозрачных символов, даже если она визуализирована на нижних краях соответствующих изображений символов, то в случае поиска соответствующие изображения символов выделяют на экране таким образом, что они как будто бы являются подчеркнутыми. Следовательно, не возникает никаких проблем. Местоположение визуализации строки прозрачных символов не ограничено нижним краем. Например, описание может быть выполнено таким образом, чтобы визуализируемая строка прозрачных символов была расположена в нижней или в верхней половине каждого изображения символа.
На этапе S406 ЦП 102 описывает тэг </Page>, указывающий конец страницы.
На этапе S407 ЦП 102 проверяет, осталась ли еще какая-либо страница, подлежащая описанию. Если осталась еще какая-либо страница, подлежащая описанию, то в последовательности этапов возвращаются к выполнению этапа S403, на котором в качестве изображения страницы, подлежащего обработке, берут следующую страницу. Если же не осталось страниц, подлежащих описанию, то в последовательности этапов переходят вперед к выполнению этапа S408.
В примере описания, который показан на Фиг.6, ЦП 102 выполняет этапы S404-S406 для изображения второй страницы, производя, таким образом, описание элементов 607-610.
На этапе S408 ЦП 102 описывает содержимое данных о шрифте, включающее в себя все глифы, используемые для визуализации строк символов в этом цифровом документе.
В спецификации формата описания данных о странице из этого описания данные о глифе, включенные в данные о шрифте, описывают как элемент <Glyph> ("глиф") внутри области, ограниченной элементами <Font> и </Font>. Элемент <Font> ("шрифт") включает в себя атрибут "ID" ("идентификатор"), указывающий тип этого шрифта. Элемент <Glyph> включает в себя атрибут "ID" ("идентификатор"), указывающий тип глифа, и атрибут "Path" ("путь"), указывающий глиф (форму символа), соответствующий этому идентификатору. Следует отметить, что атрибут "Path" ("путь") описан таким образом, что выражает глиф с использованием линейной или криволинейной функции в пределах визуализируемого единичного прямоугольника размером 1024×1024, в котором начало координат расположено в нижнем левом углу.
В примере описания, который показан на Фиг.6, в элементе 611 <Font> задан шрифт с идентификатором ="Font01", и в этом элементе задан один тип глифа с идентификатором глифа ="0". Атрибут "Path" ("путь") "M0,0 V-1024 H1024 V1024 f", указывающий форму символа, соответствующего этому глифу, описывает глиф, который выражает следующее: "Переместиться в начало координат (0, 0), визуализировать вертикальную строку длиной 1024 единицы, направленную вверх, визуализировать горизонтальную строку длиной 1024 единицы, направленную вправо, визуализировать вертикальную строку длиной 1024 единицы, направленную вниз, и закрасить область, ограниченную визуализированными строками, от текущей точки до исходной точки". То есть, этот атрибут имеет описание, которое выражает квадратный глиф, полученный посредством закрашивания прямоугольника размером 1024×1024.
Следует отметить следующее: описание элемента 611 <Font>, показанного на Фиг.6, приведено в качестве примера, могут быть определены другие простые формы символов, такие как, например, треугольник, круг, прямая линия и т.п., и в качестве формы символа может быть определен пробел (форма знака пробела).
На этапе S409 ЦП 102 описывает элемент </Document>, указывающий конец цифрового документа, завершая, таким образом, генерацию цифрового документа. Сгенерированный цифровой документ сохраняют в запоминающем устройстве 103 или в накопителе 104 на жестких дисках в устройстве 100 обработки изображений в виде файла. После запоминания файл может быть сжат с использованием известного способа сжатия текста.
И вновь со ссылкой на Фиг.2, на этапе S209 ЦП 102 производит передачу цифрового документа, сгенерированного при выполнении этапа S208, адресату передачи (например, в устройство 110 обработки изображений), определенному на этапе S201, способом передачи, определенным на этапе S201. При самой обработке для передачи данных используют способы предшествующего уровня техники, и ее описание здесь не приведено.
Устройство 110 обработки изображений, являющееся адресатом передачи, принимает переданный цифровой документ через сетевой интерфейс 114, и сохраняет его в накопителе 113 на жестких дисках. При обработке для приема данных используют способы предшествующего уровня техники, и их описание здесь не приведено.
Следует отметить, что для указания цифрового документа, сохраненного в накопителе на жестких дисках устройства, может использоваться произвольная идентификационная информация (имя файла и т.п.). Например, может быть назначена строка символов, связанная с временем приема. Кроме того, могут быть выбраны и автоматически назначены неперекрывающиеся числа, или же пользователь может указать такую информацию при генерации цифрового документа.
Ниже приведено описание примера процедуры обработки для поиска и просмотра цифровых документов со ссылкой на схему последовательности этапов, показанную на Фиг.3. Ниже в качестве примера проиллюстрирован случай, в котором поиск проводит устройство 110 обработки изображений. Однако настоящее изобретение не ограничено этим вариантом, и для проведения поиска может быть предназначено устройство 100 обработки изображений.
На этапе S301 пользователь вводит из интерфейса 115 пользователя искомое ключевое слово, которое может содержаться в тексте желательного цифрового документа, для того, чтобы произвести поиск строки символов этого цифрового документа в группе цифровых документов, сохраненных в устройстве 110 обработки изображений. Допустим, что длина введенной строки символов равна k.
На этапе S302 ЦП 111 проверяет, все ли файлы цифровых документов в накопителе 113 на жестких дисках устройства 110 обработки изображений включают в себя файлы тех цифровых документов, которые должны быть подвергнуты поисковой обработке. Если такие файлы цифровых документов включены, то ЦП 111 указывает из них один файл цифрового документа и распаковывает этот файл цифрового документа в том случае, если этот файл является сжатым. Затем в последовательности этапов переходят вперед к выполнению этапа S303. Если отсутствуют какие-либо цифровые документы, которые должны быть подвергнуты поисковой обработке, то в последовательности этапов переходят вперед к выполнению этапа S312, на котором пользователя уведомляют о том, что поисковая обработка для всех цифровых документов завершена.
На этапе S303 ЦП 111 выполняет подготовку к проведению поиска текстовых данных в цифровом документе, указанном на этапе S302. На этом этапе ЦП 111 размещает текст (коды символов) в документе в одну строку и инициализирует местоположение n начала поиска, то есть устанавливает n = 0.
Ниже приведено описание примера обработки, выполняемой на этапе S303. ЦП 111 анализирует данные цифрового документа с использованием синтаксического анализатора языка XML и производит сбор данных о строке кодов символов, описанной в атрибуте "String" ("строка"), тогда, когда появляется элемент <Text>. ЦП 111 добавляет набор кодов символов и указанное в описании местоположение значения этого кода символа в цифровом документе для каждого символа в таблицу строк кодов символов на основании строки кодов символов, описанной в этом атрибуте "String" ("строка"). Указанное в описании местоположение значения кода символа представляет собой количество символов, отсчитанное от головной части данных цифрового документа, для указания местоположения головной части строки символов, описывающей соответствующий код символа. На Фиг.12 показан пример таблицы строк кодов символов, сгенерированной на основании цифрового документа, показанного на Фиг.6. Например, три кода "0x2422", "0x2424" и "0x2426" символов, описанные в атрибуте "String" элемента 604 <Text> в цифровом документе, показанном на Фиг.6, соответственно описаны с положений 1093-го, 1100-го и 1107-го символов, отсчитанных от головной части этого цифрового документа. Аналогичным образом, для генерации таблицы строк кодов символов, показанной на Фиг.12, указанные в описании местоположения остальных шести кодов символов вычислены на основании элементов 605 и 609. На Фиг.12 номер (№) строки символов присваивают по очереди, начиная с нуля.
На этапе S304 ЦП 111 проверяет, совпадает ли каждый код символа в таблице строк кодов символов со строкой кодов символов искомого ключевого слова, используя в качестве исходной точки местоположение n начала поиска. Если обнаружена часть, совпадающая с искомым ключевым словом, то ЦП 111 задает переменную n в этот момент времени в качестве местоположения головной части совпадающей строки символов, и в последовательности этапов переходят вперед к выполнению этапа S305.
Если на этапе S304 определено, что совпадение не обнаружено, то в последовательности этапов переходят вперед к выполнению этапа S309, на котором проверяют, действительно ли все символы в таблице строк кодов символов подвергнуты поисковой обработке. Если определено, что поисковая обработка всех строк кодов символов, сохраненных в таблице строк кодов символов, завершена, то в последовательности этапов переходят вперед к выполнению этапа S311, на котором уведомляют о завершении поисковой обработки цифрового документа в качестве текущего документа, который должен быть подвергнут поисковой обработке. С другой стороны, если определено, что поисковая обработка всех строк символов еще не завершена, то в последовательности этапов переходят вперед к выполнению этапа S310, на котором значение переменной n увеличивают на 1. Затем в последовательности этапов возвращаются к выполнению этапа S304, на котором проверяют, совпадает ли строка кодов символов в следующем местоположении n начала поиска в таблице с искомым ключевым словом. Следует отметить следующее: предполагая, что общее количество кодов символов, сохраненных в таблице строк кодов символов равно N, если n<(N-k), то на этапе S309 определяют, что поисковая обработка всех строк кодов символов еще не завершена; а если n≥(N-k), то определяют, что поисковая обработка завершена.
Например, при поиске в таблице строк кодов символов, показанной на Фиг.12, той части, которая совпадает с искомым ключевым словом  , посредством просмотра строки кодов символов "0x242b" и "0x242d" этого искомого ключевого слова, начиная с головной части, этапы S304, S309 и S310 повторяют для извлечения n=3 в качестве номера строки символов из первой совпадающей строки символов.
, посредством просмотра строки кодов символов "0x242b" и "0x242d" этого искомого ключевого слова, начиная с головной части, этапы S304, S309 и S310 повторяют для извлечения n=3 в качестве номера строки символов из первой совпадающей строки символов.
На этапе S305 ЦП 111 указывает страницу цифрового документа, к которой относятся данные строки символов, соответствующие строке символов номер n.
Например, если при синтаксическом анализе данных цифрового документа определен элемент <Page>, описывающий элемент <Text>, то ЦП 111 может распознать номер страницы на основании атрибута "Number" ("номер"). Следовательно, ЦП 111 получает указанное в описании местоположение строки символов, соответствующее местоположению n, указанному на этапе S305, показанного на Фиг.12, и указывает страницу, к которой относится эта строка символов, посредством обнаружения элементов <Page>, между которыми существует указанное в описании местоположение. При синтаксическом анализе данных цифрового документа, выполняемом на этапе S303, когда ЦП 111 определяет элементы <Page>, описывающие соответствующие элементы <Text> и сохраняет их в таблице строк кодов символов, показанной на Фиг.12, он может легко определить номер страницы на основании номера строки символов. Следует отметить, что способ обнаружения совпадающей строки символов, выполняемый на этапе S304, и способ указания номера страницы, выполняемый на этапе S305, не ограничены вышеупомянутыми примерами.
На этапе S306 ЦП 111 визуализирует страницу, определенную при выполнении этапа S305, согласно описанию ее визуализации, и отображает эту страницу на интерфейсе 115 пользователя. На этом этапе при визуализации символа, для которого номер (№) строки символов находится в пределах интервала от n до n+k-1, ЦП 111 визуализирует эти символы с эффектом их выделения на экране для предоставления пользователю возможности легко распознать местоположение, соответствующее этому символу. Описание подробностей визуализации, которая дает эффект выделения участка, совпадающего с искомым ключевым словом, приведено ниже.
Ниже приведено описание обработки по визуализации страницы, выполняемой на этапе S306, со ссылкой на схему последовательности этапов, показанную на Фиг.5.
На этапе S501 ЦП 111 определяет размер изображения страницы, являющегося результатом визуализации, на основании значений атрибутов "Width" ("ширина") и "Height" ("высота") элемента <Page>, соответствующего заданному номеру страницы.
На этапе S502 ЦП 111 обеспечивает объем памяти запоминающего устройства, в котором может быть сохранена информация об элементах изображения страницы.
На этапе S503 ЦП 111 извлекает один из элементов, подлежащих обработке, из дочерних элементов элемента <Page> и определяет тип элемента, подлежащего обработке. Если определено, что элементом, подлежащим обработке, является элемент <Image> ("изображение"), то в последовательности этапов переходят вперед к выполнению этапа S504; а если определено, что элементом, подлежащим обработке, является элемент <Text> ("текст"), то в последовательности этапов переходят вперед к выполнению этапа S505. Если все дочерние элементы элемента <Page> уже были подвергнуты обработке, то в последовательности этапов переходят вперед к выполнению этапа S517.
На этапе S504 ЦП 111 извлекает сжатое изображение, описанное как значение атрибута "Data" ("данные") элемента <Image> ("изображение"). Кроме того, ЦП 111 масштабирует извлеченное изображение таким образом, чтобы вся визуализируемая прямоугольная область соответствовала по размеру изображению страницы, которое выражено атрибутами "X", "Y", "Width" ("ширина") и "Height" ("высота"), и перезаписывает это изображение в области памяти для хранения изображения страницы, обеспеченной на этапе S502. После этого в последовательности этапов возвращаются к выполнению этапа S503.
На этапе S505 ЦП 111 производит сбор данных о местоположении (X, Y) начала символа, об идентификаторе (F) шрифта символа, о размере (S) символа и о цвете (C) символа из соответствующих атрибутов, описанных в элементе <Text>, подлежащем обработке. ЦП 111 также производит сбор данных о количестве (N) символов, описанных в этом элементе <Text>.
На этапе S506 ЦП 111 обеспечивает объем памяти запоминающего устройства, необходимый для генерации изображения глифа. На этом этапе предполагают, что ЦП 111 обеспечивает объем памяти для хранения бинарного изображения размером 1024×1024 элемента изображения.
На этапе S507 ЦП 111 инициализирует показание i счетчика, указывающее интересующий символ, устанавливая его значение равным "1".
На этапе S508 ЦП 111 проверяет, выполняется ли условие i>N. Если i≤N, то в последовательности этапов переходят вперед к выполнению этапа S509; если же i>N, то ЦП 111 определяет, что обработка этого элемента <Text> завершена, и в последовательности этапов возвращаются к выполнению этапа S503.
На этапе S509 ЦП 111 производит сбор данных о коде (P) символа для i-го символа из атрибута "String" ("строка") элемента <Text> и об идентификаторе (Q) глифа i-го символа из атрибута "CGlyphId" ("идентификатор глифа символа").
На этапе S510, ЦП 111 ищет в цифровом документе описание элемента <Font> с идентификатором шрифта, равным (F), и производит сбор данных об атрибуте "Path" ("путь") из элемента <Glyph> дочерних элементов описания этого элемента <Font> с идентификатором глифа, равным (Q).
На этапе S511 ЦП 111 генерирует бинарное изображение глифа в области памяти для генерации изображения глифа, обеспеченной при выполнении этапа S506, в соответствии со значением атрибута "Path" ("путь"), полученным на этапе S510. Следует отметить, что бинарное изображение глифа представляет собой, например, изображение, в котором часть, подлежащая визуализации, выражена как "1", а часть, не подлежащая визуализации, выражена как "0". Следует отметить, что подлежащую визуализации часть, выраженную как "1", визуализируют позже прозрачным цветом.
На этапе S512 ЦП 111 масштабирует бинарное изображение глифа таким образом, чтобы оно имело вид прямоугольника, размер которого соответствует значению (S) атрибута "размер символа".
На этапе S513 ЦП 111 визуализирует бинарное изображение глифа, масштабированное на этапе S512, в прямоугольной области с привязкой к координатам (X, Y), хранящимся в области памяти для хранения изображения страницы. Значение элемента изображения для каждого элемента изображения при визуализации бинарного изображения, которое должно быть наложено на изображение страницы, определяется приведенным ниже уравнением. Предполагают, что значение каждого элемента изображения после визуализации глифа становится равным (r', g', b') относительно значения (r, g, b) элемента изображения страницы до визуализации глифа.
Значение элемента изображения, соответствующего значению элемента бинарного изображения глифа, равному "0", выражено следующим уравнением: (r', g', b') = (r, g, b).
Значение элемента изображения, соответствующего значению элемента бинарного изображения глифа, равному "1", выражено следующим уравнением: (r', g', b')=(F(r,Cr), F(g,Cg), F(b,Cb)), где F(r,Cr)=(r×A+Cr×(255-A))/255, F(g,Cg)=(g×A+Cg×(255-A))/255, и F(b,Cb)=(b×A+Cb×(255-A))/255. К тому же A представляет собой значение альфа-канала для цвета C символа, а Cr, Cg и Cb представляют собой значения составляющих R (красный), G (зеленый) и B (синий) цвета C символа. Когда в качестве значения альфа-канала указано значение "255", поскольку это бинарное изображение глифа является прозрачным, то (r', g', b')=(r, g, b) даже для того элемента изображения, который соответствует элементу бинарного изображения глифа, значение которого равно "1".
На этапе S514 ЦП 111 проверяет, например, с использованием таблицы строк кодов символов, показанной на Фиг.12, является ли интересующий i-ый символ тем символом, для которого его номер (№) строки символов находится в пределах интервала от n до n+k-1. В частности, поскольку указанные в описании местоположения начала соответствующих символов в интервале от n до n+k-1 могут быть обнаружены из таблицы строк кодов символов, то вышеупомянутую процедуру проверки выполняют на основании того, совпадает ли местоположение начала интересующего i-ого символа с одним из этих указанных в описании местоположений начала. Если интересующим i-ым символом является символ, для которого его номер строки символов находится в пределах интервала от n до n+k-1, то в последовательности этапов переходят вперед к выполнению этапа S515; в противном случае в последовательности этапов переходят вперед к выполнению этапа S516.
На этапе S515 ЦП 111 выполняет обработку по выделению информации на экране для указания того, что интересующий символ не выходит за пределы области, обнаруженной в качестве строки искомых символов. В частности, значения (r, g, b) элементов изображения в пределах прямоугольной области, которая соответствует той области, где была визуализирована строка символов и которая начинается с местоположения (X, Y) в области памяти для хранения изображения страницы, изменяют на значения (r', g', b') элементов изображения, которые определяются следующим выражением:
(r', g', b') = (G(r), G(g), G(b))
(для G(r)=255-r, G(g)=255-g, G(b)=255-b)
Следует отметить, что одним из примеров является обработка по выделению информации на экране, при которой выполняют инверсию цвета, и что могут быть использованы другие виды обработки по выделению информации на экране. Например, элементы изображения, которые соответствуют тем элементам бинарного изображения глифа, значения которых равны "0", могут оставаться неизменными, а значения (r, g, b) элементов изображения, которые соответствуют тем элементам бинарного изображения глифа, значения которых равны "1", могут быть изменены на указанные выше значения (r', g', b'). В альтернативном варианте, используя в качестве ширины прямоугольной области, подлежащей выделению, значение атрибута "CWidth" ("интервал между символами"), которое указывает ширину интервала между символами, вместо ширины бинарного изображения глифа, непрерывная строка искомых символов может быть заполнена без каких-либо пробелов. Когда обработку по выделению информации на экране выполняют с использованием интервала между символами, который имеют символы, пробел между символами также является заполненным, как показано на Фиг.16.
На этапе S516 ЦП 111 добавляет интервал между символами (значение атрибута "CWidth" ("интервал между символами")) для n-го символа к X и увеличивает значение n на 1 (n=n+1). Затем в последовательности этапов возвращаются к выполнению этапа S508.
На этапе S517 ЦП 111 передает результат визуализации для одной страницы, то есть содержимое области памяти для хранения изображения страницы, в котором визуализированы описания элементов <Image> и <Text> в элементе <Page>, в дисплейный буфер интерфейса 115 пользователя, отображая, таким образом, результат визуализации на дисплее.
Ниже приведено описание случая, в котором выполняют обработку согласно схеме последовательности этапов, показанной на Фиг.5, беря в качестве примера описание визуализации первой страницы цифрового документа, показанное на Фиг.6.
При выполнении этапа S501 ЦП 111 определяет, что размер изображения страницы равен 1680×2376 элементам изображения, на основании значений атрибутов "Width" ("ширина") = "1680" и "Height" ("высота") = "2376" из элемента <Page> первой страницы, показанного на Фиг.6.
При выполнении этапа S502 ЦП 111 обеспечивает объем памяти запоминающего устройства, равный 1680×2376×3 байтам, в том случае, когда, например, изображение страницы выражено 24-битовым представлением цвета в системе цветопередачи RGB (красный-зеленый-синий).
При выполнении этапа S504 ЦП 111 извлекает изображение из сжатого кода, описанного в значении атрибута "Data" ("данные") элемента 603 <Image>, который показан на Фиг.6, и перезаписывает это изображение во всей области памяти для хранения изображения страницы. Следует отметить, что ЦП 111 не применяет обработку по масштабированию, поскольку данные об изображении имеют размер, равный 1680×2376 элементам изображения, который является тем же самым, что и размер исходной страницы в этом примере.
При выполнении этапа S505 ЦП 111 производит сбор данных об X="236", об Y="272", о количестве N символов ="3", об идентификаторе шрифта символа = "Font01", о размере символов ="97" и о цвете "0, 0, 0, 255" символов из элемента 604 <Text>, показанного на Фиг.6.
При выполнении этапа S509 ЦП 111 сначала производит сбор данных о коде первого символа = 0x2422 и об идентификаторе глифа GlyphId = "0" из атрибута "String" ("строка") элемента <Text>.
Перед генерацией бинарного изображения глифа, выполняемой на этапе S511, выполняют этап S510, на котором ЦП 111 производит сбор данных об атрибуте "Path" ("путь") глифа с этим идентификатором на основании полученного идентификатора шрифта символа = "Font01". В примере из Фиг.6 ЦП 111 производит сбор данных об атрибуте "Path" ("путь") с идентификатором = "0" в элементе <Glyph> ("глиф"), содержащемся в элементе 611 <Font> ("шрифт"). На этапе S511 ЦП 111 генерирует изображение глифа на основании данных, полученных из атрибута "Path" с идентификатором = "0" из элемента <Glyph>. В частности, ЦП 111 генерирует изображение посредством заполнения единицами ("1") всей площади изображения глифа размером 1024×1024 элемента изображения в соответствии с описанием атрибута "Path".
Поскольку все значения "GlyphId" (идентификатора глифа) символов в элементах 604 и 605 <Text>, описанных в цифровом документе, показанном на Фиг.6, равны "0", то, следовательно, изображения глифа, сгенерированные на этапе S511 для всех символов, равны друг другу. Следовательно, ЦП 111 может временно сохранять изображение глифа, сгенерированное при выполнении этапа S511, в запоминающем устройстве, и может использовать временно сохраненное изображение глифа при визуализации другого символа.
На этапе S512 ЦП 111 масштабирует изображение символа глифа до изображения размером 97×97 элементов изображения на основании размера символа, равного "97".
На этапе S513 прямоугольная область размером 97×97 элементов изображения, начинающаяся с местоположения (X, Y)=(236, 272) в изображении страницы, служит в качестве области, визуализируемой посредством масштабированного изображения символа глифа. Поскольку в примере, показанном на Фиг.6, цвет символа = "0, 0, 0, 255 ", то есть, значение альфа-канала А=255, то всегда устанавливают (r', g', b')=(r, g, b) даже в том случае, когда значение соответствующего элемента изображения в бинарном изображении глифа равно "1". То есть значения элементов изображения в прямоугольной области в изображении страницы остаются неизменными до и после выполнения этапа S513.
На этапе S514 ЦП 111 на основании таблицы строк кодов символов проверяет, является ли первый символ в элементе 604 <Text>, показанном на Фиг.6, символом, соответствующим интервалу номеров строки символов от n до n+k-1.
В этом случае предполагают, что таблица строк кодов символов, показанная на Фиг.12, сгенерирована на основании, например, цифрового документа, показанного на Фиг.6, и что интервал номеров строк символов, определенный на этапе S304, показанной на Фиг.3, как совпадающий с ключевым словом, равен интервалу значений 3 и 4. Поскольку на этом этапе код первого символа в элементе 604 <Text>, показанном на Фиг.6, не находится в пределах интервала значений 3 и 4, то в последовательности этапов переходят вперед к выполнению этапа S516. Так как местоположение начала символа из описания кода первого символа в элементе 604 <Text> равно 1093, и оно не совпадает ни с одним из указанных в описании местоположений символов в интервале номеров строк символов 3 и 4 в таблице строк кодов символов, то может быть определено, что первый символ элемента 604 <Text> не является символом, соответствующим интервалу значений 3 и 4.
После этого при выполнении обработки первого символа в элементе 605 <Text>, показанном на Фиг.6, выполняют этап S514, на котором определяют, что первый символ совпадает с местоположением начала символов в интервале значений 3 и 4 в таблице строк кодов символов, и выполняют этап S515 обработки по визуализации выделения информации на экране.
Для этого символа на этапе S515 ЦП 111 изменяет значения (r, g, b) элементов изображения в области размером 92×92 элемента изображения, начинающейся с местоположения (236, 472) в области памяти для хранения изображения страницы, на значения (G(r), G(g), G(b)).
После того, как все элементы <Text> визуализированы описанным выше способом, получают изображение страницы, показанное на Фиг.13. Что касается областей, соответствующих символам в пределах интервала, который на этапе S304 определен как совпадающий с ключевым словом, то в каждом прямоугольнике инвертируют значения яркости, а в областях, соответствующих остальным символам, данные об изображении, визуализированные посредством элемента <Image> ("изображение"), остаются неизменными. Следует отметить, что в приведенном выше примере был объяснен случай, в котором документ составлен на японском языке. Ту же самую обработку также применяют для документа на английском языке. Например, когда процедуру обработки для генерации данных цифрового документа, показанную на Фиг.4, выполняют на основании изображения, показанного на Фиг.17, то генерируют данные цифрового документа, в котором элементы 604 и 605 цифрового документа, показанного на Фиг.6, описывают коды символов алфавита. При поиске в этих данных цифрового документа с использованием, например, строки символов "EF", выполняют обработку по визуализации, показанную на Фиг.5, и изображения в прямоугольных областях, соответствующих найденной строке символов, выделяют на экране, как показано на Фиг.18.
Таким образом, поскольку найденная строка символов выделена, то пользователь может легко определить местоположение искомого ключевого слова на странице просто посредством наблюдения изображения страницы, отображенного на дисплее на этапе S306.
На Фиг.14A и Фиг.14Б показан пример, указывающий, каким образом следует выводить на экран изображение страницы при применении выделения информации на экране, заданного другим способом. Описание визуализации страницы, показанное на Фиг.14A, описывает, что при описании данных атрибута элемента <Text> на этапе S405 на Фиг.4, прозрачный символ, размер которого (например, размер (Size) ="10") является меньшим, чем изображение каждого символа, должен быть визуализирован в местоположении, соответствующем нижней части (нижнему краю) соответствующего изображения символа. На основании такого описания визуализации страницы, когда на этапе S515 обработки по выделению информации на экране должна быть выделена прямоугольная область, размер которой равен интервалу между символами × размер символа для каждого символа, то генерируют изображение страницы, выделенное на экране таким образом, как показано на Фиг.14Б. Таким образом, пользователь может легко определить местоположение найденной строки символов на странице, поскольку найденная часть, которая является подчеркнутой, кажется выделенной. Следует отметить, что на чертежах Фиг.14A и Фиг.14Б показан пример изображения документа, содержащего строки символов японского языка, и такая же самая обработка может быть применена для изображения документа, содержащего строки символов английского языка (букв алфавита).
И вновь со ссылкой на Фиг.3, на этапе S307 ЦП 111 запрашивает пользователя выбрать один из следующих вариантов: следует ли завершить поиск и просмотреть результаты обработки, или же следует продолжить поиск другой искомой части. Если пользователь выбирает вариант "завершить поиск", то процедуру обработки, показанную на Фиг.3, завершают; а если он или она выбирает вариант "продолжить поиск", то в последовательности этапов переходят вперед к выполнению этапа S308.
На этапе S308 ЦП 111 устанавливает n=n+k, и в последовательности этапов возвращаются к выполнению этапа S304 для поиска следующей части, совпадающей с искомым ключевым словом.
Как описано выше, согласно первому варианту осуществления настоящего изобретения, после преобразования документа, выполненного на бумаге, в цифровой документ, этот цифровой документ содержит описание, необходимое для визуализации символов, извлеченных из страницы, прозрачным цветом в изображении страницы. Что касается этого цифрового документа, то пользователь может успешно производить поиск, подтверждая при этом те страницы, на каждой из которых выделена часть, совпадающая с искомым ключевым словом.
Этот цифровой документ включает в себя данные о шрифте с одной простой формой символов (например, прямоугольником) и описан таким образом, что обеспечивает визуализацию прозрачных символов различных типов символов в документе с использованием простой формы символов. То есть одну форму символов обычно используют для множества типов символов. Следовательно, объем файла (объем данных) цифрового документа может быть уменьшен даже в том случае, когда в этом цифровом документе необходимо сохранить данные о шрифте, используемом в цифровом документе.
Второй вариант осуществления
На чертеже Фиг.15 показан пример цифрового документа, сгенерированного согласно второму варианту осуществления. Как и в первом варианте осуществления, предполагают, что генерацию и передачу цифрового документа выполняет устройство 100 обработки изображений, а устройство 110 обработки изображений получает, просматривает и производит поиск в цифровом документе.
На Фиг.15 номерами 1501 и 1512 позиций обозначены описания, отображающие начало и конец цифрового документа. Номерами 1502 и 1506 позиций обозначены описания, отображающие начало и конец визуализации первой страницы. Номером 1503 позиции обозначено описание визуализации данных об изображении первой страницы. Номерами 1504 и 1505 позиций обозначены описания визуализации текста первой страницы. Номерами 1507 и 1510 позиций обозначены описания, отображающие начало и конец визуализации второй страницы. Номером 1508 позиции обозначено описание визуализации данных об изображении второй страницы. Номером 1509 позиции обозначен описание визуализации текста второй страницы. Номером 1511 позиции обозначено описание данных о шрифте, используемом в этом цифровом документе.
Поскольку описание процедуры обработки для генерации цифрового документа согласно второму варианту осуществления является почти таким же, как и описание этой процедуры обработки из первого варианта осуществления, изложенное с использованием Фиг.2 и Фиг.4, и описание процедуры обработки для поиска в цифровых документах и их просмотра является почти таким же, как и описание этой процедуры обработки из первого варианта осуществления, изложенное с использованием Фиг.3 и Фиг.5, то будет приведено объяснение отличий от первого варианта осуществления.
В элементах 1504, 1505 и 1509 <Text>, которые на Фиг.15 отображают визуализацию текста, не описан какой-либо атрибут "CGlyphId" ("идентификатор глифа символа"), который указывает идентификатор глифа каждого символа, и в них вместо идентификатора глифа использованы непосредственно сами коды символов, записанные в атрибуте "CString" данных 1511 о шрифте.
Данные атрибута "Path" ("путь") шести типов символов, заданные в данных 1511 о шрифте, определяют идентичную форму символа. Данные о шрифте, описанные таким образом, могут быть сжаты с высоким коэффициентом сжатия с использованием известной методики сжатия, например, методики, основанной на алгоритме Лемпеля-Зива 1977 г. (LZ77), или аналогичной методики.
Согласно второму варианту осуществления настоящего изобретения, после преобразования документа, выполненного на бумаге, в цифровой документ, этот цифровой документ содержит описание, необходимое для визуализации символов, извлеченных из страницы, прозрачным цветом в изображении страницы. Что касается этого цифрового документа, то пользователь может успешно производить поиск, подтверждая при этом те страницы, на каждой из которых выделена часть, совпадающая с искомым ключевым словом.
В этом цифровом документе сохранены данные о шрифте, сконфигурированные данными о форме символа одного и того же типа для соответствующих символов, описанных в документе. Поскольку данные о шрифте, сконфигурированные данными о форме символа одного и того же типа, могут быть сжаты с высоким коэффициентом сжатия обычным способом сжатия текста, то второй вариант осуществления также может уменьшить объем данных цифрового документа, сохраняя при этом данные о шрифте, используемом в цифровом документе. Поскольку во втором варианте осуществления форма символа, описанная глифом, также упрощена и сохранена, то объем данных непосредственно самих данных о форме символа также может быть уменьшен.
Третий вариант осуществления
Изложенные выше варианты осуществления обеспечивают генерацию цифрового документа, описывающего изображение полной страницы, полученное посредством применения сжатия в формате JPEG или аналогичного сжатия к сканированному изображению в элементе <Image> ("изображение"), и описывающего прозрачный текст в элементе <Text> ("текст"). Однако настоящее изобретение не ограничено таким конкретным документом.
Например, в элементе <Image> ("изображение") вместо описания изображения всего сканированного изображения, сжатого в формате JPEG, могут храниться бинарные изображения, сжатые в формате MMR, для соответствующих цветов области "текст" и области "графика", и изображение остальной области, сжатое в формате JPEG. В качестве способа анализа областей, включенных в изображение документа, и адаптивного применения обработки со сжатием, например, могут быть использованы способы, описанные в патенте Японии № 07-236062, в патенте Японии № 2002-077633 и т.п. Обработка для уменьшения объема данных о шрифте, используемых при визуализации прозрачного текста согласно настоящему изобретению, и такая обработка по сжатию изображения объединены, таким образом осуществляя генерацию цифрового изображения с более высоким коэффициентом сжатия.
Вместо изображения полной страницы могут быть сохранены только лишь частичные области, например, область "текст", область "графика", область "таблица", область "фотография" и т.п., вместе с данными об их местоположении.
Четвертый вариант осуществления
В изложенных выше вариантах осуществления часть, соответствующую результату поиска, выделяют на экране посредством инверсии цвета (r, g, b) изображения. Однако настоящее изобретение не ограничено использованием такого цвета. Например, может быть визуализирован заранее заданный полупрозрачный (например, значение альфа-канала равно 128) цвет (например, желтый), используемый для указания результата поиска. В альтернативном варианте цвет выделения может быть задан с использованием цвета (Cr, Cg, Cb) символов.
Пятый вариант осуществления
В изложенных выше вариантах осуществления при проведении поиска, поиск строки символов, совпадающей с ключевым словом, производят по очереди, начиная с головной части документа, и, как описано со ссылкой на чертежи Фиг.3 и Фиг.5, выделяют ту строку символов, которая найдена первой. Затем, если пользователь вводит команду "поиск следующего", то ищут следующую по очереди строку символов, совпадающую с ключевым словом, и результат поиска выделяют на экране. Таким образом, в изложенных выше вариантах осуществления поиск строки символов, совпадающей с искомым ключевым словом, производят по очереди, начиная с головной части, и результат поиска выделяют на экране при каждом совпадении с искомым ключевым словом. Однако настоящее изобретение не ограничено этим вариантом. Например, все строки символов, включенные в цифровой документ, могут быть сличены с искомым ключевым словом, при этом определяют все строки символов, совпадающие с ключевым словом, и все эти строки символов, совпадающие с ключевым словом, могут быть одновременно выделены на экране.
Другие варианты осуществления
Следует отметить, что цели настоящего изобретения также достигнуты посредством предоставления машиночитаемого носителя информации, на котором хранится программный код (компьютерная программа) программного обеспечения, реализующего функции вышеупомянутых вариантов осуществления для системы или устройства. К тому же, цели настоящего изобретения достигнуты тогда, когда компьютер (или центральный процессор (ЦП) или микропроцессорное устройство (МПУ)) системы или устройства считывает и выполняет программный код, хранящийся на носителе информации.
Компьютерная программа из настоящего изобретения побуждает устройство выполнить соответствующие этапы, описанные в вышеупомянутых схемах последовательности этапов. Другими словами, эта компьютерная программа представляет собой программу для того, чтобы компьютер функционировал в качестве соответствующих устройств обработки данных (соответствующих средств обработки), которые соответствуют соответствующим этапам из схем последовательности этапов. В этом случае сам программный код, считанный с машиночитаемого носителя информации, реализует функции вышеупомянутых вариантов осуществления, и носитель информации, на котором хранится этот программный код, является составной частью настоящего изобретения.
В качестве носителя информации для предоставления программного кода может быть использован, например, гибкий диск, накопитель на жестких дисках, оптический диск, магнитооптический диск, постоянное запоминающее устройство на компакт-диске (CD-ROM), компакт диск для однократной записи (CD-R), карта энергонезависимой памяти, постоянное запоминающее устройство (ПЗУ) и т.п.
Настоящее изобретение также включает в себя случай, в котором операционная система (ОС) или подобная система, работающая на компьютере, выполняет некоторые или все реальные способы на основании команд программного кода, посредством чего реализуют вышеупомянутые варианты осуществления.
В первом и втором вариантах осуществления, которые описаны выше, центральный процессор (ЦП) выполняет соответствующие этапы из схем последовательности этапов во взаимодействии с запоминающим устройством, накопителем на жестких дисках, дисплеем и т.п. Однако настоящее изобретение не ограничено вышеупомянутой конструкцией, и некоторые или все способы, выполняемые на соответствующих этапах, описанных с использованием схем последовательности этапов, могут быть сконфигурированы посредством специализированной электронной схемы вместо центрального процессора.
Согласно настоящему изобретению, цифровой документ генерируют посредством применения распознавания символов к изображениям символов в изображении документа и посредством визуализации результата распознавания символов в изображении документа прозрачным цветом. Таким образом, этот цифровой документ позволяет определить ту часть, которая соответствует искомому ключевому слову, в изображении документа после проведения поиска. Когда этот цифровой документ сгенерирован, то он включает в себя описание, необходимое для использования данных о шрифте с простой формой символов, которые являются общими для множества типов символов, в качестве данных о шрифте, используемых при визуализации результата распознавания символов. Следовательно, увеличение объема файла может быть сведено к минимуму даже в том случае, когда в цифровом документе должны быть сохранены данные о шрифте. К тому же, за счет визуализации с использованием простой формы символов может быть уменьшен объем самих данных о шрифте.
Объем файла также может быть уменьшен за счет использования идентичной формы символов в качестве данных о шрифте.
Несмотря на то, что настоящее изобретение было описано со ссылкой на варианты его осуществления, которые приведены в качестве примеров, следует понимать, что настоящее изобретение не ограничено раскрытыми вариантами его осуществления, которые приведены в качестве примеров. Следует предоставить самое широкое толкование объема приведенной ниже формулы изобретения для того, чтобы ею были охвачены все такие видоизменения и эквивалентные структуры и функции.
Настоящая заявка на изобретение притязает на приоритет заявки на патент Японии № 2007-172736, поданной 29 июня 2007, которая в полном объеме включена в настоящий документ посредством ссылки.
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДУЛЬНЫЙ ФОРМАТ ДОКУМЕНТОВ | 2004 |
|
RU2368943C2 |
| ТРЕХМЕРНЫЙ ТЕКСТ В ИГРОВОЙ МАШИНЕ | 2003 |
|
RU2344483C9 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНЫХ ТЕХНОЛОГИЙ НА ОСНОВЕ НЕЙРОСЕТЕЙ И КОМПЬЮТЕРНОГО ЗРЕНИЯ | 2020 |
|
RU2744769C1 |
| ВЫЯВЛЕНИЕ СНИМКОВ ЭКРАНА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2014 |
|
RU2595557C2 |
| УСТРОЙСТВО ОБРАБОТКИ ИЗОБРАЖЕНИЯ, СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЯ И НОСИТЕЛЬ ИНФОРМАЦИИ | 2011 |
|
RU2452126C1 |
| ДИСТАНЦИОННЫЙ ВВОД ИЗОБРАЖЕНИЯ С ЦЕНТРАЛИЗОВАННОЙ ОБРАБОТКОЙ И ХРАНЕНИЕМ | 1998 |
|
RU2231117C2 |
| СПОСОБ УПРАВЛЕНИЯ ДАННЫМИ В СФОРМИРОВАННОМ КОМПЬЮТЕРНОМ ДОКУМЕНТЕ И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ С ЗАПИСАННОЙ НА НЕМ ПРОГРАММОЙ | 2007 |
|
RU2379748C2 |
| УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЯ И СПОСОБ УПРАВЛЕНИЯ ДЛЯ НЕГО | 2005 |
|
RU2336558C1 |
| СПОСОБЫ И СИСТЕМЫ ОБРАБОТКИ ИЗОБРАЖЕНИЙ МАТЕМАТИЧЕСКИХ ВЫРАЖЕНИЙ | 2014 |
|
RU2596600C2 |
| АВТОМАТИЧЕСКАЯ ОПТИМИЗАЦИЯ РАСПОЛОЖЕНИЯ НОЖЕК СИМВОЛОВ ТЕКСТА | 2001 |
|
RU2258265C2 |
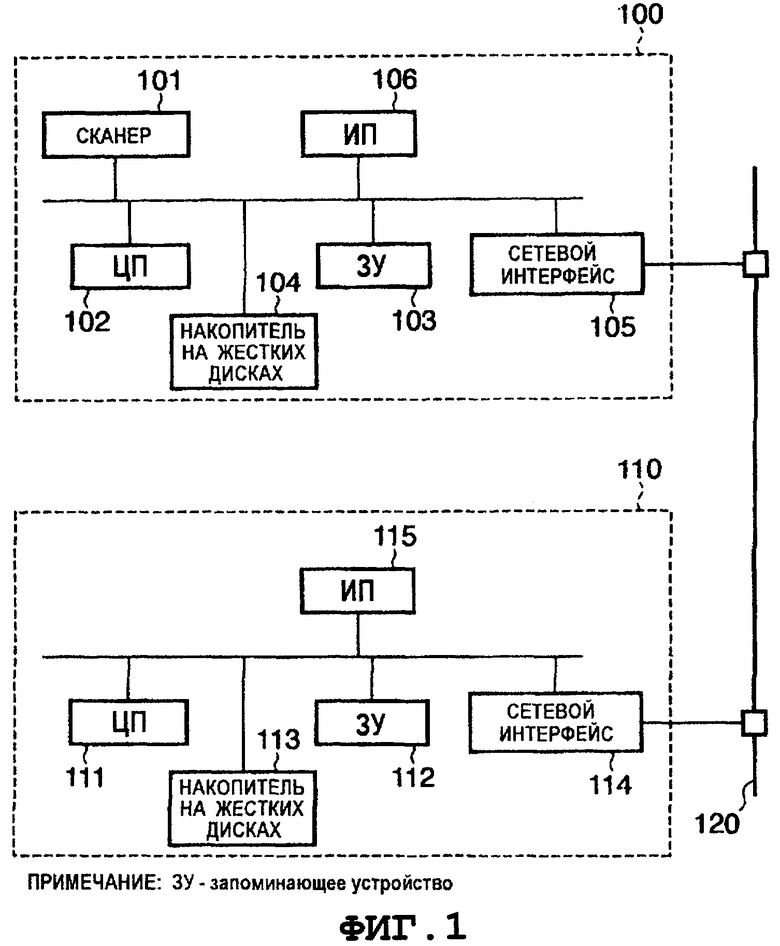
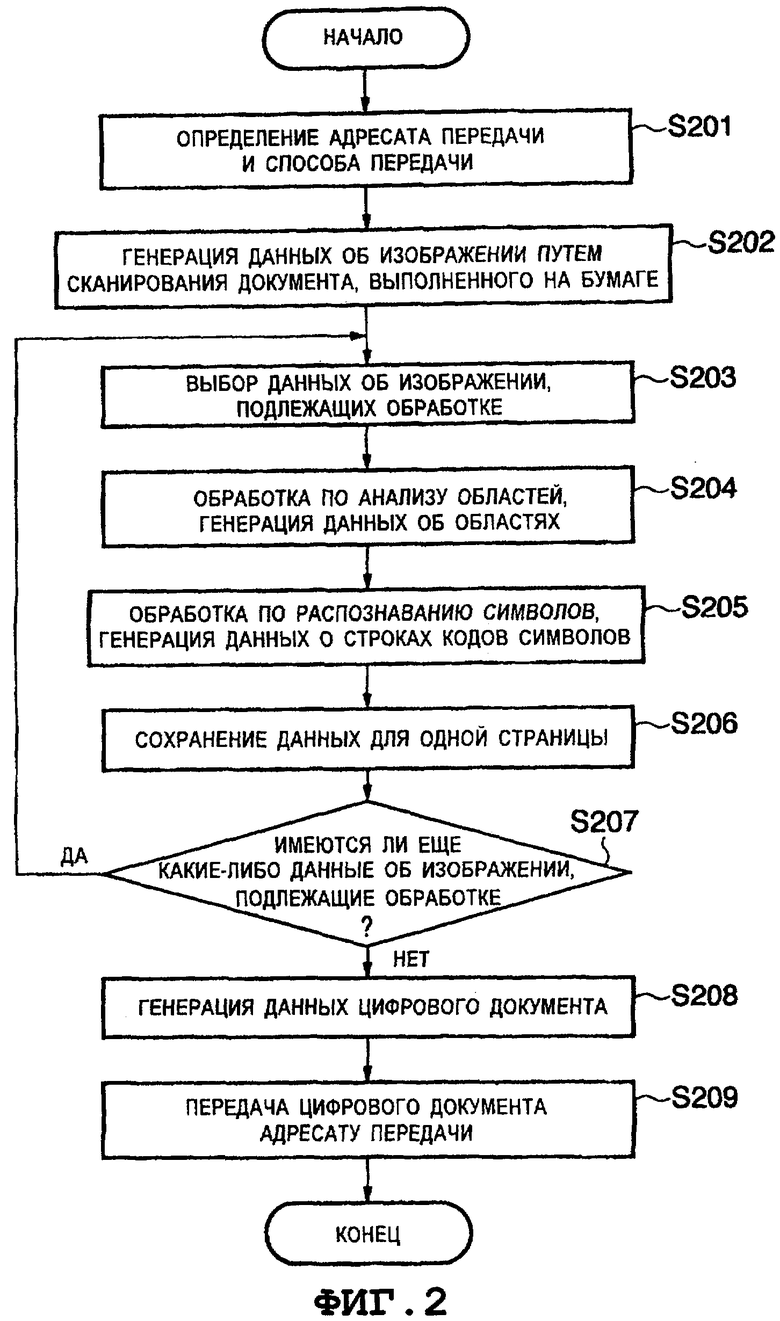

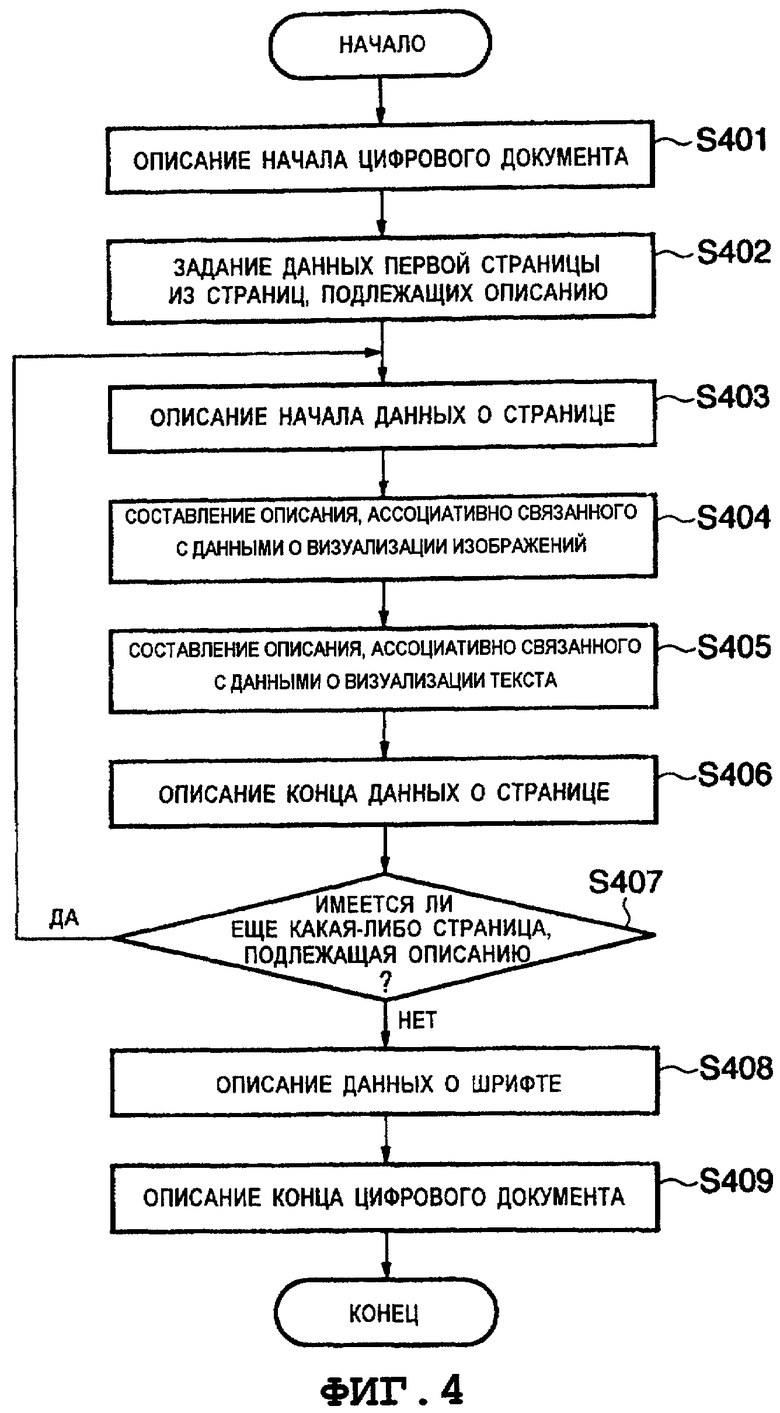
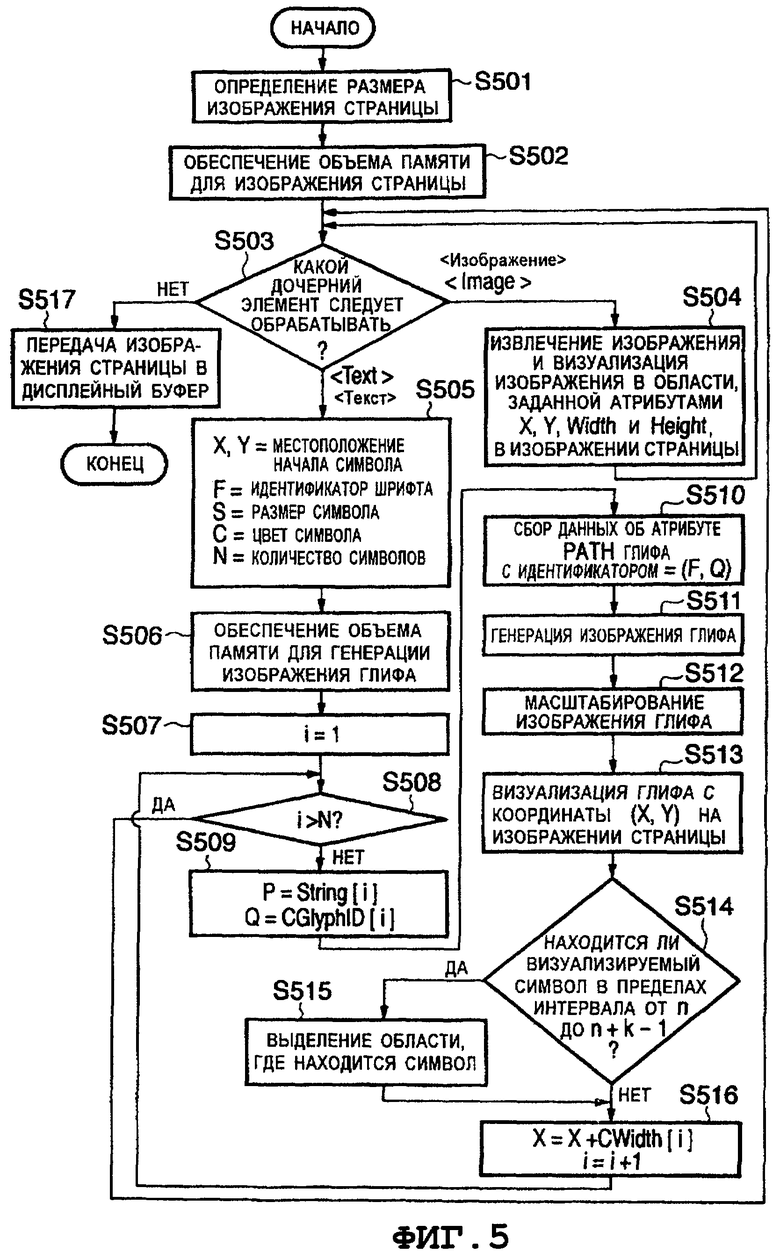
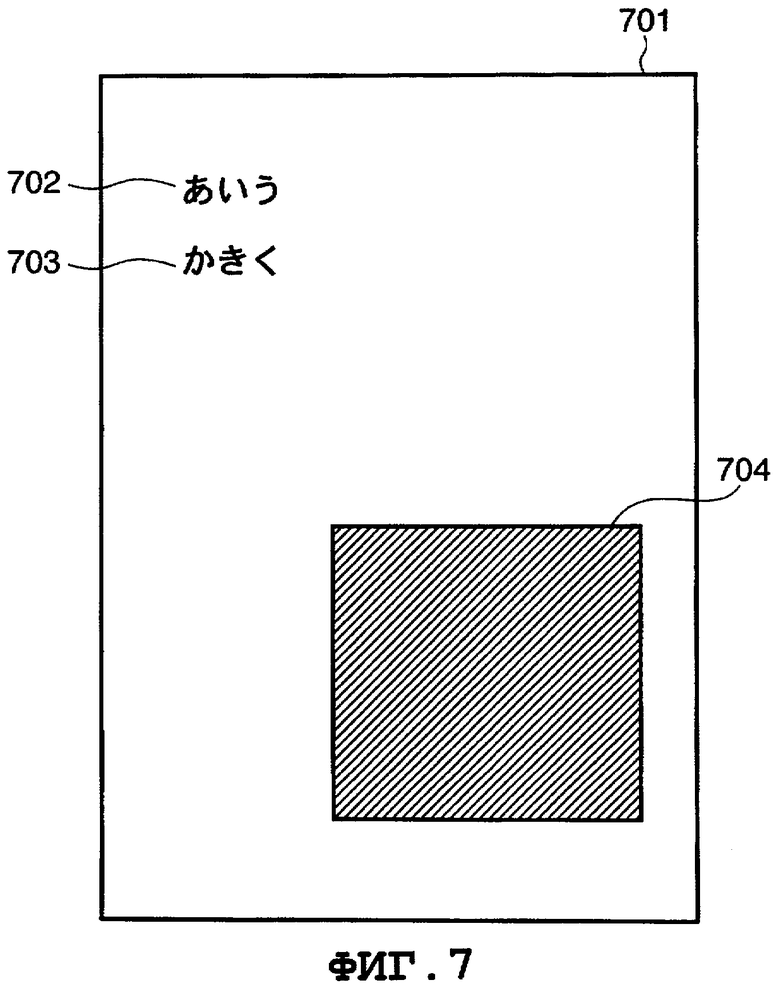
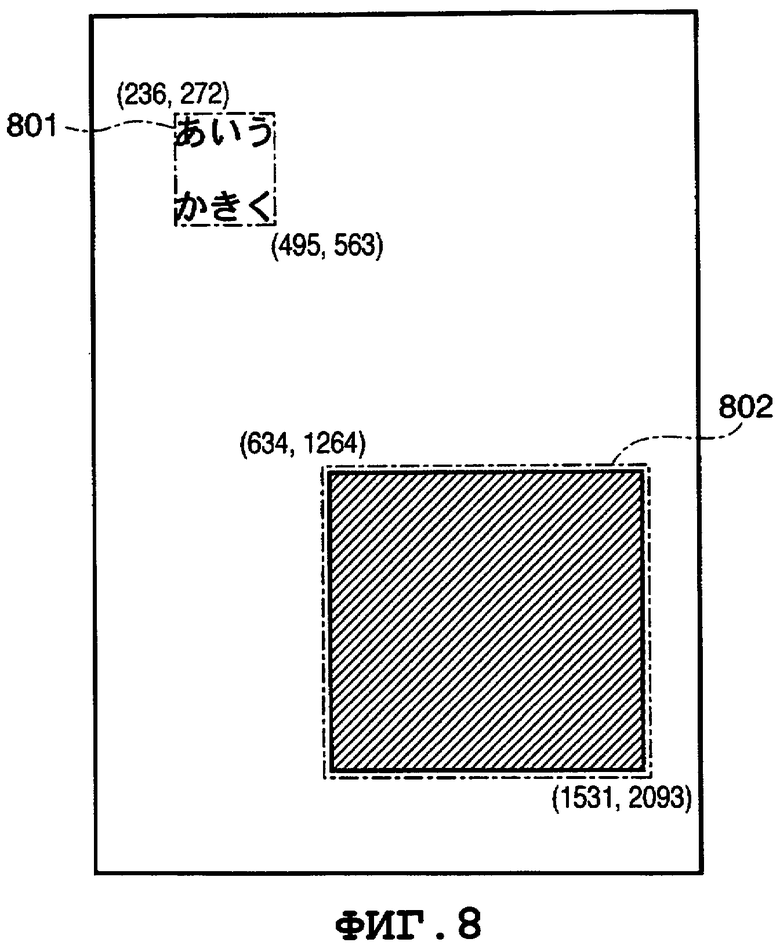
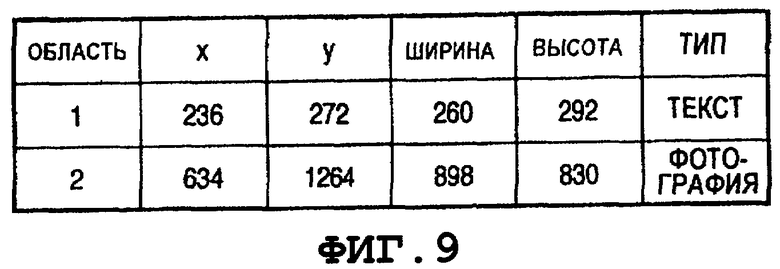
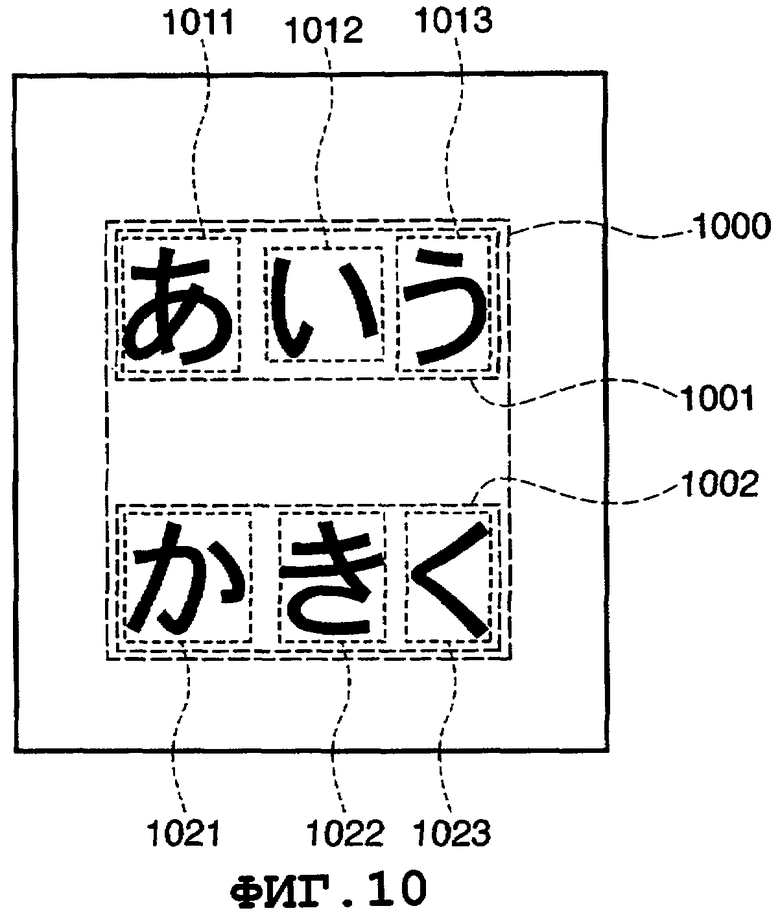
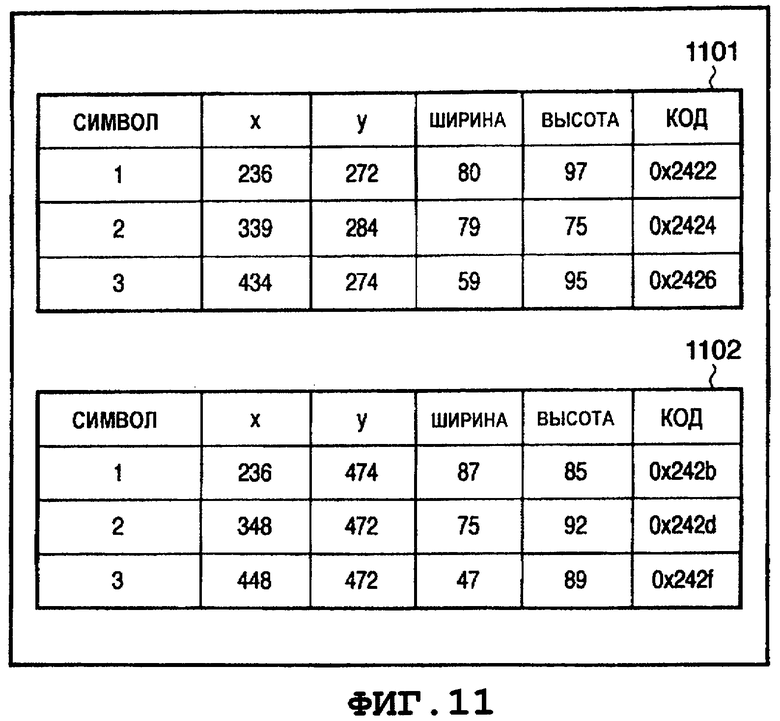

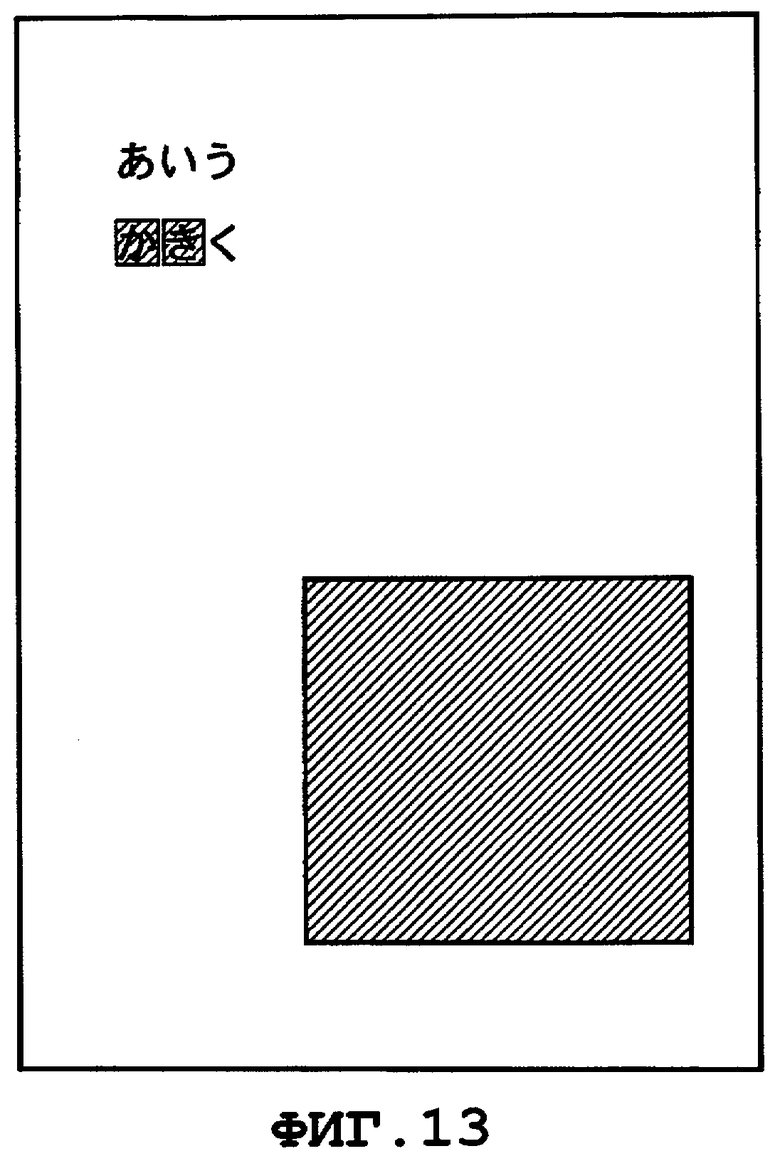

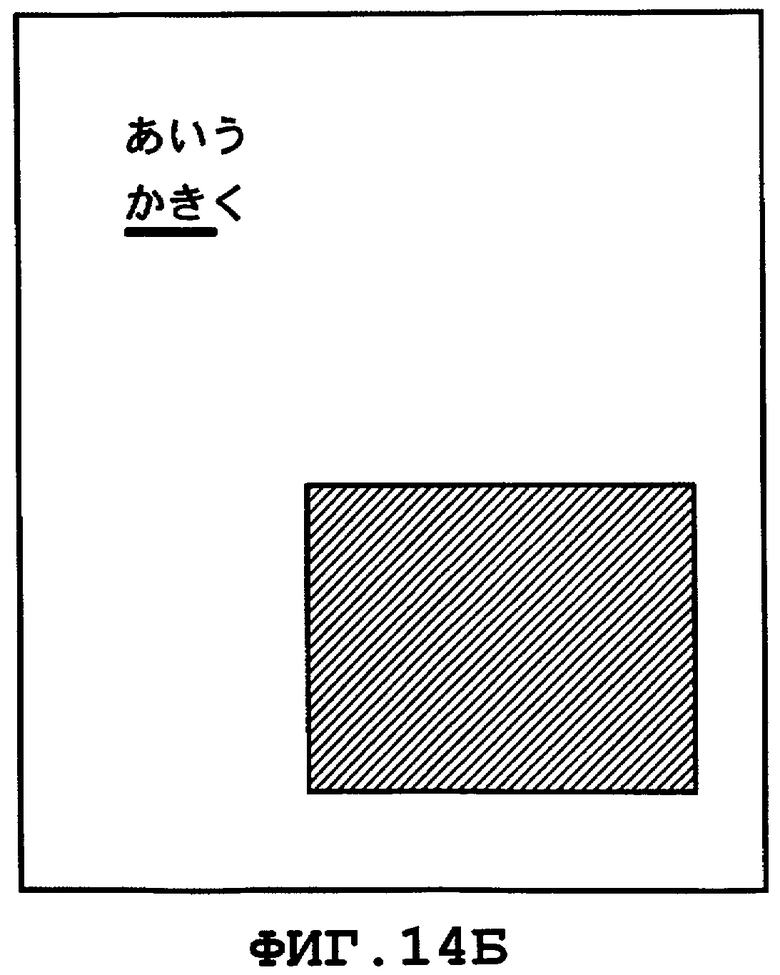

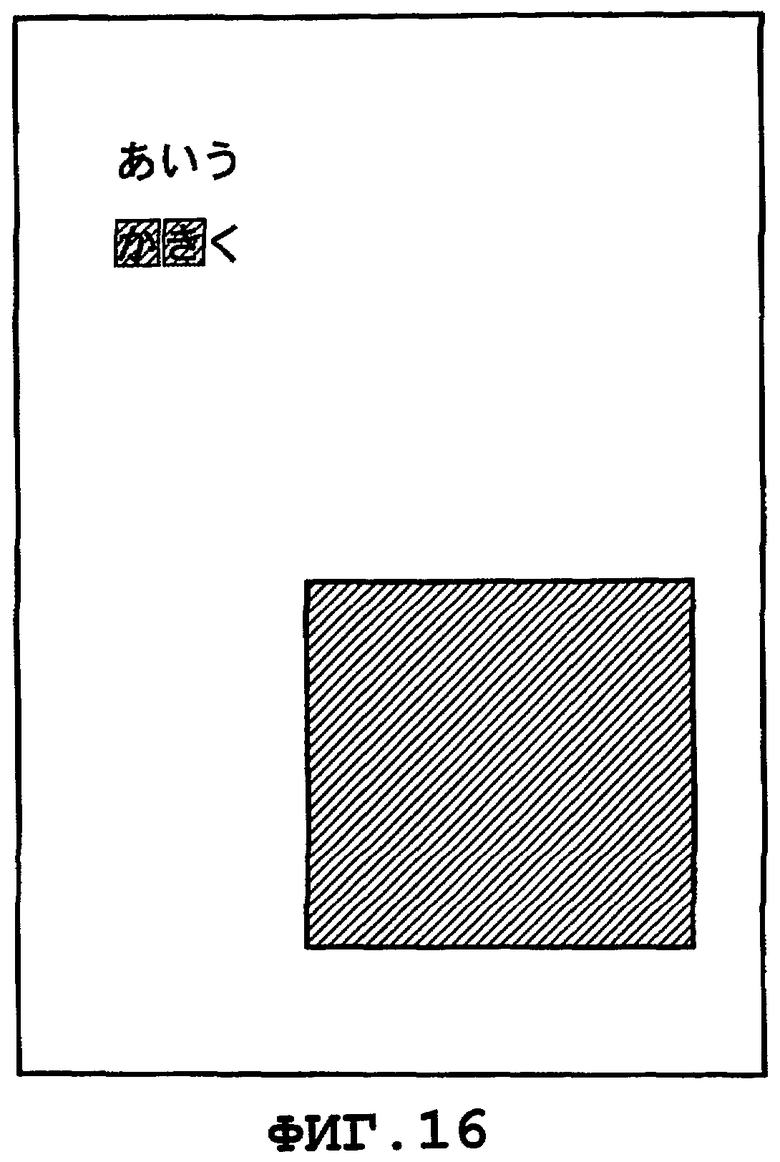
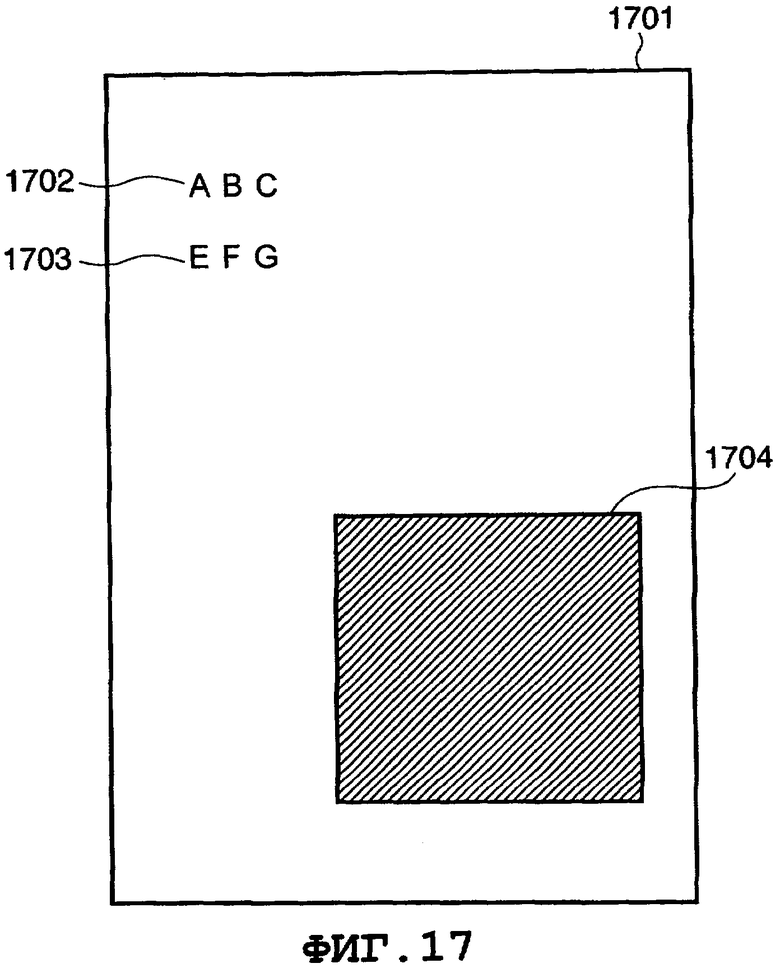
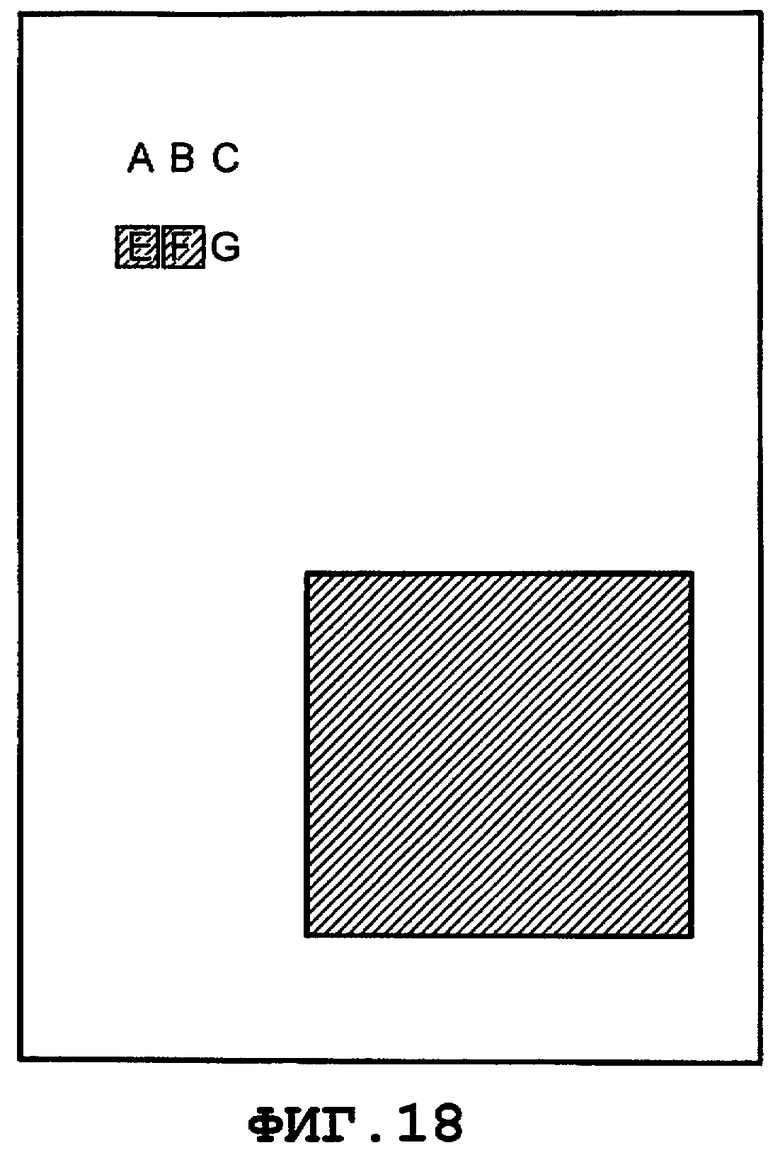
Изобретение относится к методике преобразования сканированного изображения документа, выполненного на бумаге, в данные, позволяющие производить поиск в цифровой форме. Технический результат заключается в оптимизации объема данных (размера файла) цифрового документа при обработке изображений. Устройство обработки изображений содержит блок распознавания символов, выполненный с возможностью выполнять обработку по распознаванию символов для множества изображений символов в изображении документа для получения кодов символов, соответствующих соответствующим изображениям символов, и блок генерации, выполненный с возможностью генерировать цифровой документ, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных упомянутым блоком распознавания символов, данные о глифе и описание, необходимое для визуализации данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа, при этом данные о глифе используют в качестве общих данных для множества кодов символов при визуализации символов, соответствующих этому множеству кодов символов. 6 н. и 11 з.п. ф-лы, 18 ил.
1. Устройство обработки изображений, содержащее:
блок распознавания символов, выполненный с возможностью выполнять обработку по распознаванию символов для множества изображений символов в изображении документа для получения кодов символов, соответствующих соответствующим изображениям символов;
и
блок генерации, выполненный с возможностью генерировать цифровой документ, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных упомянутым блоком распознавания символов, данные о глифе и описание, необходимое для визуализации данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа, при этом данные о глифе используют в качестве общих данных для множества кодов символов при визуализации символов, соответствующих этому множеству кодов символов.
2. Устройство по п.1, в котором данные о глифе указывают простую форму, причем простая форма представляет собой треугольную форму, форму круга или форму прямой линии.
3. Устройство по п.1, в котором данные о глифе указывают прямоугольную форму.
4. Устройство по п.1, в котором данные о глифе указывают форму символа пробела.
5. Устройство по п.1, в котором цифровой документ, сгенерированный упомянутым блоком генерации, включает в себя описание, необходимое для визуализации прозрачным цветом данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа.
6. Устройство по п.1, в котором цифровым документом является цифровой документ, описанный в формате XML.
7. Устройство по п.1, в котором цифровым документом является цифровой документ, описанный в формате XPS.
8. Устройство по п.1, дополнительно содержащее блок сжатия, выполненный с возможностью сжимать изображение документа,
при этом изображениями документов, сохраненными в цифровом документе, являются изображения документов, подвергнутые обработке по сжатию упомянутым блоком сжатия.
9. Устройство по п.8, в котором упомянутый блок сжатия анализирует области, включенные в изображение документа, и выполняет адаптивное сжатие этих областей.
10. Устройство по п.1, дополнительно содержащее блок поиска, выполненный с возможностью производить поиск в сгенерированном цифровом документе с использованием введенного ключевого слова и выделять часть, определенную на основании визуализированных данных о глифе, ассоциированных с кодами символов, которая совпадает с ключевым словом.
11. Устройство по п.10, в котором упомянутый блок поиска выделяет ту часть, которая совпадает с ключевым словом, посредством инверсии цвета этой части.
12. Устройство по п.10, в котором упомянутый блок поиска в качестве части, которая совпадает с ключевым словом, выделяет часть, соответствующую интервалу между символами × размер каждого символа, ассоциированного с кодами символов, которые совпадают с ключевым словом.
13. Устройство обработки изображений, содержащее:
блок распознавания символов, выполненный с возможностью выполнять обработку по распознаванию символов для множества изображений символов в изображении документа для получения кодов символов, соответствующих соответствующим изображениям символов;
и
блок генерации, выполненный с возможностью генерировать цифровой документ, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных упомянутым блоком распознавания символов, данные о глифе идентичной формы, которые следует использовать при визуализации символов, соответствующих этому множеству кодов символов, и описание, необходимое для визуализации данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа.
14. Способ обработки изображений, содержащий этапы, на которых:
управляют блоком распознавания символов для выполнения обработки по распознаванию символов для множества изображений символов в изображении документа, для получения кодов символов, соответствующих соответствующим изображениям символов;
и
управляют блоком генерации для генерации цифрового документа, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных на этапе управления блоком распознавания символов, данные о глифе и описание, необходимое для визуализации данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа, при этом данные о глифе используют в качестве общих данных для множества кодов символов при визуализации символов, соответствующих этому множеству кодов символов.
15. Способ обработки изображений, содержащий этапы, на которых:
управляют блоком распознавания символов для выполнения обработки по распознаванию символов для множества изображений символов в изображении документа, для получения кодов символов, соответствующих соответствующим изображениям символов;
и
управляют блоком генерации для генерации цифрового документа, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных на этапе управления блоком распознавания символов, данные о глифе идентичной формы, которые следует использовать при визуализации символов, соответствующих этому множеству кодов символов, и описание, необходимое для визуализации данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа.
16. Машиночитаемый носитель информации, на котором сохранена компьютерная программа, побуждающая компьютер выполнить этапы, на которых:
выполняют обработку по распознаванию символов для множества изображений символов в изображении документа для получения кодов символов, соответствующих соответствующим изображениям символов;
и
генерируют цифровой документ, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных на этапе выполнения обработки по распознаванию символов, данные о глифе и описание, необходимое для визуализации данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа, при этом данные о глифе используют в качестве общих данных для множества кодов символов при визуализации символов, соответствующих этому множеству кодов символов.
17. Машиночитаемый носитель информации, на котором сохранена компьютерная программа, побуждающая компьютер выполнять этапы
выполнения обработки по распознаванию символов для множества изображений символов в изображении документа для получения кодов символов, соответствующих соответствующим изображениям символов;
и
генерирования цифрового документа, причем этот цифровой документ включает в себя изображение документа, множество кодов символов, полученных на этапе выполнения обработки по распознаванию символов, данные о глифе идентичной формы, которые следует использовать при визуализации символов, соответствующих этому множеству кодов символов, и описание, необходимое для визуализации данных о глифе, соответствующих множеству кодов символов с меньшим размером, чем размеры изображений символов, в местоположениях, соответствующих нижним краям изображений символов в изображении документа.
| JP 2000322417 А, 24.11.2000 | |||
| JP 10162024 А, 19.06.1998 | |||
| СПОСОБ И СРЕДСТВО ДЛЯ МОБИЛЬНОГО ЗАХВАТА, ОБРАБОТКИ, ХРАНЕНИЯ И ПЕРЕДАЧИ ТЕКСТА И СМЕШАННОЙ ИНФОРМАЦИИ, СОДЕРЖАЩЕЙ ЗНАКИ И ИЗОБРАЖЕНИЯ | 2001 |
|
RU2287183C2 |
| JP 10289226 А, 27.10.1998. | |||

