Связанные заявки
В целом, настоящее изобретение может использоваться вместе с системами и способами, раскрытыми в следующих патентных заявках:
(a) заявка на патент США № 10/143 865, поданная 14 мая 2002, озаглавленная «Handwriting Layout Analysis of Freeform Digital Ink Input»;
(b) заявка на патент США № 10/143 864, поданная 14 мая 2002, озаглавленная «Classification Analysis of Freeform Digital Ink Input»;
(c) заявка на патент США № 10/143 804, поданная 14 мая 2002, озаглавленная «Classification Analysis of Freeform Digital Ink Input»; и
(d) заявка на патент США № 10/184 108, поданная 28 июня 2002, озаглавленная «Interfacing With Ink»
Каждая из этих ожидающих решения заявок на патент США полностью представлена для справки.
ОБЛАСТЬ ТЕХНИКИ
Аспекты настоящего изобретения относятся к системам, способам и считываемым компьютером носителям, которые облегчают связь между прикладной программой и электронными чернилами, которые включают в себя различные чернила и объекты разделения чернил. Некоторые примеры таких систем, способов и считываемых компьютером носителей предоставляют прикладной программе или коду клиента доступ к группировкам чернильных штрихов различной степени детализации для улучшения производительности прикладных программ, и предоставляют улучшенное взаимодействие этих программ и связанного с ними кода с цифровыми чернилами.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Типичные компьютерные системы, особенно компьютерные системы, использующие системы с графическим пользовательским интерфейсом (ГПИ, GUI), такие как Microsoft WINDOWS, оптимизированы для приема вводимой пользователем информации от одного или более дискретных устройств ввода данных, таких как клавиатура для ввода текста и устройство указания (например, мышь с одной или более кнопками) для управления интерфейсом пользователя. Повсеместно распространенный интерфейс клавиатуры и мыши обеспечивает быстрое создание и модификацию документов, электронных таблиц, полей баз данных, рисунков, фотографий и т.п. Однако, в некотором отношении, существует существенный недостаток в гибкости, которую обеспечивает интерфейс клавиатуры и мыши по сравнению с некомпьютерными (т.е. обычными) ручкой и бумагой. С помощью обычных ручки и бумаги пользователь может редактировать документ, записывать примечания на полях и рисовать изображения и другие фигуры и т.п. В некоторых случаях пользователь может предпочесть использовать ручку для пометок на документе, а не просматривать документ на компьютерном экране, из-за возможности свободно делать примечания вне ограничений интерфейса мыши и клавиатуры.
Некоторые компьютерные системы разрешают пользователям рисовать на экране. Например, приложение Microsoft READER позволяет пользователям добавлять электронные чернила (краску) (которые также упоминаются как «чернила» или «цифровые чернила») к документу. Система хранит эти чернила и обеспечивает их передачу пользователю, когда требуется. Другие приложения (например, приложения для рисования, такие как известные из предшествующего уровня техники, связанные с операционными системами Palm 3.x и 4.x и PocketPC) разрешают ввод и хранение рисунков. Также, различные приложения для рисования, такие как Corel Draw, и приложения для обработки и редактирования фотографий, такие как Photoshop, могут использоваться с изделиями для ввода информации с помощью пера, такими как планшетные изделия компании Wacom. Такие рисунки включают в себя другие свойства, связанные с чернильными штрихами, используемыми для создания рисунков. Например, ширина и цвет линии могут сохраняться вместе с чернилами. Одной из целей таких систем является воспроизведение (копирование) внешнего вида и восприятия физических чернил, которые наносят на лист бумаги.
Хотя известны компьютерные системы, которые воспринимают электронные чернила, в настоящее время их доступность и использование, по меньшей мере в некоторых отношениях, несколько ограничены. Чтобы дополнительно увеличивать их доступность и использование, прикладные программы должны включать в себя код, который дает возможность взаимодействия и сопряжения с электронными чернилами. Соответственно, интерфейс прикладного программирования («API»), который позволяет авторам кода легко, гибко и последовательно взаимодействовать и связываться с множеством различных группировок чернил, был бы очень полезен для тех, кто хочет написать код для прикладных программ, которые некоторым образом взаимодействуют с электронными чернилами.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Приложения, которые воплощают поверхности для рисования в свободном формате, где, например, пользователи могут вводить и взаимодействовать с электронными чернилами на странице, сталкиваются со сложной проблемой определения, в какой форме хранить и управлять штрихами, которые обеспечивает пользователь. Прямыми подходам для разработчика прикладных программ являются следующие: (1) обрабатывают каждый штрих отдельно или (2) совместно обрабатывают все штрихи на странице или в данном сеансе редактирования. Однако каждый из этих подходов имеет серьезные практические ограничения в легкости использования для конечного пользователя, а также в совместимости с существующим кодом компоновки документа. Идеальный подход для приложения, но подход, который обычно весьма трудно осуществить, состоит в том, чтобы обрабатывать штрихи в группах, содержащих слова, строки или абзацы. Этот подход имеет большие преимущества из-за легкости использования, совместимости, возможности улучшенного распознавания рукописного текста и многих других особенностей и т.д. Данное изобретение создает API (прикладной программный интерфейс), которые разработчики прикладных программ могут использовать для легкого достижения этих преимуществ без необходимости самим определять, как группировать штрихи, таким образом устраняя главную трудность данного подхода.
Аспекты настоящего изобретения относятся к системам и способам для обеспечения доступности информации для прикладной программы. Эти системы и способы могут включать в себя этапы: сохраняют множество чернильных штрихов; выдают или принимают запрос на разделение; в ответ на запрос на разделение выполняют группирование сохраненных чернильных штрихов в одну или более группировок штрихов, имеющих по меньшей мере первую заранее определенную степень детализации; и обеспечивают доступность прикладной программе информации, относящейся к одной или большему количеству группировок штрихов. Данная «информация», которая доступна прикладной программе, может включать в себя, например, по меньшей мере одну из одной или большего количества группировок штрихов; информацию, указывающую множество группировок штрихов, имеющих первую заранее определенную степень детализации; и сгенерированный машиной текст, который соответствует по меньшей мере одной из одной или большего количества группировок штрихов. Штрихи могут группироваться в различные группы с отличающейся степенью детализации, содержащие слова, строки, абзацы, предложения, рисунки и т.д. В процессе группирования также можно группировать штрихи в группировки больше чем одной отличающейся степени детализации, и он может повторяться после того, как набор чернильных штрихов изменяется, например, с помощью добавления, удаления, перемещения, изменения размеров или другого изменения одного или более штрихов. Код прикладной программы также может обеспечивать передачу анализатору информации о различных типах анализа во время работы описанных выше способов, например установки модуля распознавания, который будет использовать во время анализа, установки языка, который будет использоваться во время анализа, установки требуемой степени детализации, с которой штрихи будут анализироваться, установки ожидаемой высоты строки для строк текста, которые включают в себя чернильные штрихи, и т.п.
Дополнительные аспекты настоящего изобретения относятся к системам и способам поддержания связи между приложением и объектом разделения чернил, который хранит чернильные штрихи, которые будут разделены на группы. В некоторых примерах системы и способы включают в себя этапы: (a) выдают запрос на разделение к объекту разделения чернил, возможно, с помощью приложения; (b) в ответ на запрос на разделение вызывают метод разделения, который группирует сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере первую предопределенную степень детализации (например, слова, строки, абзацы, предложения, рисунки и т.д.); и (c) делают информацию, относящуюся к одной или большему количеству группировок штрихов, доступной приложению. Результаты метода разделения могут быть сохранены в объекте результата разделения чернил. В некоторых примерах объект результата разделения чернил может включать в себя (и позволять прикладной программе обращается к ним) первоначально разделенные чернильные штрихи и может допускать извлечение группировок штрихов с различными отличающимися степенями детализации. В дополнительных примерах изобретения способ разделения может использовать предопределенную или предварительно установленную характеристику языка, связанную с чернильными штрихами для обеспечения помощи в лучшем определении группировок чернильных штрихов. Другие дополнительные аспекты настоящего изобретения относятся к считываемым компьютером носителям, имеющим хранящиеся на них выполняемые компьютером команды для выполнения различных способов, в общем виде описанных выше. Дополнительные аспекты настоящего изобретения относятся к считываемым компьютером носителям, имеющим хранящиеся на них структуры данных для различных объектов разделения чернил, объектов «результат разделения чернил», объектов «модули разделения чернил» и объектов «модуль разделения чернил».
Эти и другие признаки и аспекты настоящего изобретения будут более очевидны после рассмотрения последующего подробного описания и чертежей.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Предшествующее описание сущности изобретения, так же как последующее подробное описание, будут лучше поняты при рассмотрении вместе с сопроводительными чертежами, которые приведены для примера, а не для ограничения по отношению к заявленному изобретению.
Фиг.1 показывает схематическое представление универсальной цифровой вычислительной среды, которая может использоваться для осуществления различных аспектов изобретения.
Фиг.2 показывает вид сверху вычислительной системы на основе светового пера, которая может использоваться в соответствии с различными аспектами настоящего изобретения.
Фиг.3 показывает общий обзор примера системы и/или способа анализа, который может использоваться вместе с примерами данного изобретения.
Фиг.4 показывает схему, в общем виде объясняющую поэтапную обработку анализа, который может использоваться вместе с примерами данного изобретения.
Фиг.5 иллюстрирует пример различных этапов анализа размещения, которые могут использоваться вместе с примерами данного изобретения.
Фиг.6A и 6B иллюстрируют примеры структур данных дерева анализа, которые могут быть получены, например, используя средство анализа размещения, которое выполняет этапы, показанные на фиг.5.
Фиг.7 показывает компоненты и особенности объекта InkDivider (разделения чернил), используемого в некоторых примерах настоящего изобретения.
Фиг.8 иллюстрирует компоненты и особенности объекта InkDivisionResult (результат разделения чернил), используемого в некоторых примерах настоящего изобретения.
Фиг.9 иллюстрирует компоненты и особенности объекта InkDivisionUnits (модули разделения чернил), используемого в некоторых примерах настоящего изобретения.
Фиг.10 иллюстрирует компоненты и особенности объекта InkDivisionUnit (модуль разделения чернил), используемого в некоторых примерах настоящего изобретения.
Фиг.11 иллюстрирует другой пример объекта InkDivider, используемого в некоторых примерах настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Последующее описание, для упрощения, разделено на подразделы. Подразделы включают в себя: термины; универсальный компьютер; общий уровень развития техники по отношению к анализу размещения чернил и классификационному анализу; объект разделения чернил и API; работа объекта разделения чернил и API; прикладные программные интерфейсы; альтернативный объект разделения чернил; и заключение.
I. ТЕРМИНЫ
«Чернила» - последовательность или набор из одного или более штрихов, возможно вместе со свойствами. Последовательность штрихов может включать в себя штрихи в упорядоченной форме. Последовательность можно упорядочить по времени ввода или по тому, где на странице появляются штрихи. Возможны также другие виды упорядочивания. Набор штрихов может включать в себя последовательности штрихов или неупорядоченные штрихи или любые их комбинации. Понятие «чернила» может быть расширено так, что оно будет включать в себя дополнительные свойства, способы, запускающие события и т.п.
Объект «чернила» - структура данных, хранящая один или более чернильных штрихов, вместе со свойствами, способами и/или событиями, или без них.
Штрих - последовательность или набор введенных точек. Например, при обработке последовательность точек может соединяться с помощью линий. Альтернативно штрих может быть представлен как точка и вектор в направлении следующей точки. Вкратце, штрих предназначен для охвата любого представления точек или сегментов, относящихся к чернилам, независимо от того, что лежит в основе представления точек и/или того, что соединяет точки. Точка - информация, определяющая местоположение в пространстве. Например, точки могут определяться относительно пространства ввода (например, точки на устройстве ввода графической информации), виртуального пространства чернил (координаты в пространстве, в котором вводимые чернила представлены или сохранены) и/или пространства отображения (точки или пиксели устройства отображения).
Обработка - процесс определения как графическая информация и/или чернила должны отображаться на экране, в печатном виде или при выводе в другом формате данных.
Сеанс рисования - период времени от момента, когда приложение начинает создавать или редактировать чернила, до того, как анализатор (например, объект разделения чернил) вызывают для анализа чернильных штрихов, и он возвращает проанализированный графический примитив чернил. Анализатор можно вызывать много раз в течение данного сеанса рисования, и штрихи можно добавлять, удалять или иным образом изменять между вызовами анализатора.
II. УНИВЕРСАЛЬНЫЙ КОМПЬЮТЕР
Фиг.1 иллюстрирует схематическое представление примера типовой универсальной цифровой вычислительной среды, которая может использоваться для воплощения различных аспектов настоящего изобретения. На фиг.1 компьютер 100 включает в себя процессор или процессорную систему 110, системную память 120 и системную шину 130, которая соединяет различные компоненты системы, которые включают в себя системную память процессора 110. Системная шина 130 может быть любым из нескольких типов шинных структур, которые включают в себя шину памяти или контроллер памяти, периферийную шину и локальную шину, использующих любую из разнообразия шинных архитектур. Системная память 120 включает в себя постоянное запоминающее устройство (ПЗУ) 140 и оперативную память (ОП) 150.
Базовая система ввода-вывода (BIOS) 160, содержащая основные подпрограммы, которые помогают перемещать информацию между элементами в пределах компьютера 100, например, во время запуска, хранится в ПЗУ 140. Компьютер 100 также включает в себя накопитель 170 на жестком диске для считывания и записи информации на жесткий диск (не показан), накопитель 180 на магнитных дисках для считывания или записи информации на сменный магнитный диск 190, и оптический дисковод 191 для считывания или записи информации на сменный оптический диск 192, например компакт-диск (CD-ROM), или другие оптические носители. Накопитель 170 на жестком диске, накопитель 180 на магнитных дисках и оптический дисковод 191 соединяются с системной шиной 130 с помощью интерфейса (средства сопряжения) 192 накопителя на жестком диске, интерфейса 193 накопителя на магнитных дисках и интерфейса 194 оптического дисковода, соответственно. Данные устройства и связанные с ними считываемые компьютером носители обеспечивают энергонезависимое хранение считываемых компьютером команд, структур данных, модулей программ и других данных для персонального компьютера 100. Специалисты должны признать, что другие типы считываемых компьютером носителей, которые могут хранить доступные компьютеру данные, например магнитные кассеты, платы флэш-памяти, цифровые видеодиски, картриджи Бернулли, оперативная память (ОП), постоянные запоминающие устройства (ПЗУ) и т.п., могут также использоваться в примерной рабочей среде.
На накопителе 170 на жестком диске, магнитном диске 190, оптическом диске 192, в ПЗУ 140 или в ОП 150 может храниться множество модулей программ, которые включают в себя операционную систему 195, одну или более прикладных программ 196, другие модули 197 программ и данные 198 программ. Пользователь может вводить команды и информацию в компьютер 100 с помощью устройств ввода данных, например клавиатуры 101, и устройства 102 позиционирования. Другие устройства ввода данных (не показаны) могут включать в себя микрофон, джойстик, игровую клавиатуру, спутниковую антенну, сканер или подобные им устройства. Эти и другие устройства ввода данных часто подключаются к процессору 110 через интерфейс 106 последовательного порта, который соединен с системной шиной 130, но может соединяться с помощью других интерфейсов, таких как параллельный порт, игровой порт или универсальную последовательную шину (USB). Дополнительно, эти устройства могут присоединяться непосредственно к системной шине 130 через соответствующий интерфейс (не показан). Монитор 107 или другой тип устройства отображения также соединен с системной шиной 130 через интерфейс, например видеоадаптер 108. В добавление к монитору 107 персональные компьютеры в типовом варианте включают в себя другие периферийные устройства вывода (не показаны), такие как динамики и принтеры. В качестве примера перьевое устройство 165 ввода графической информации (цифровой планшет) и соответствующее перо или пользовательское устройство 166 ввода данных обеспечивается для ввода в компьютер в цифровой форме вводимой от руки информации. Перьевое устройство 165 ввода графической информации может соединяться с процессором 110 через интерфейс 106 последовательного порта и системную шину 130, как показано на фиг. 1, или с помощью любого другого подходящего соединения. Кроме того, хотя устройство 165 ввода графической информации показано отдельно от монитора 107, используемая область ввода информации устройства 165 ввода графической информации может быть совмещена с областью отображения монитора 107. Дополнительно, устройство 165 ввода графической информации может быть интегрировано в монитор 107, или может существовать как отдельное устройство, расположенное сверху или иным образом прикрепленное к монитору 107.
Компьютер 100 может работать в сетевой среде, использующей логические подключения к одному или более удаленным компьютерам, например к удаленному компьютеру 109. Удаленный компьютер 109 может быть сервером, маршрутизатором, сетевым ПК, одноранговым маршрутизатором или другим обычным сетевым узлом, и типично включает в себя многие или все элементы, описанные выше по отношению к компьютеру 100, хотя только запоминающее устройство 111 с соответствующими прикладными программами 196 показано на фиг.1. Логические подключения, изображенные на фиг.1, включают в себя локальную сеть (ЛС) 112 и глобальную сеть (ГС) 113. Такие сетевые среды обычно используются в офисах, компьютерных сетях в масштабах предприятия, корпоративных сетях (интранет) и Интернет, используя проводные и беспроводные системы связи.
При работе в среде с ЛС компьютер 100 связан с местной сетью 112 через сетевой интерфейс или адаптер 114. При работе в среде с ГС персональный компьютер 100 в типовом случае включает в себя модем 115 или другие средства для установления связи с глобальной сетью 113, например с Интернет. Модем 115, который может быть внутренним или внешним, соединяют с системной шиной 130 через интерфейс 106 последовательного порта. В сетевой среде модули программ, изображенные как относящиеся к персональному компьютеру 100 или к его частям, могут храниться в удаленном запоминающем устройстве.
Следует признать, что показанные сетевые подключения являются примерными и что могут использоваться другие методы установления связи между компьютерами. Предполагается наличие любого из различных известных протоколов, таких как TCP/IP (протокол управления передачей/межсетевой протокол), Ethernet, FTP (протокол передачи файлов), HTTP (протокол передачи гипертекстовых файлов) и т.п., и система может использоваться в конфигурации клиент-сервер для того, чтобы дать возможность пользователю извлекать web-страницы из доступного через сеть сервера. Любой из различных существующих web-браузеров может использоваться для отображения и управления данными на web-страницах.
Фиг.2 показывает пример вычислительной системы 201 с перьевым вводом данных (вводом данных посредством пера (ручки) или карандаша), которая может использоваться вместе с различными аспектами настоящего изобретения. Компьютер на фиг.2 может включать в себя каждую или все особенности, подсистемы и функциональные возможности, показанные в системе на фиг.1. Вычислительная система 201 с перьевым вводом включает в себя большую поверхность 202 отображения, например дисплей с панелью оцифровывания, такой как жидкокристаллический (LCD) экран, на котором отображается множество окон 203. Используя перо 204, пользователь может выбирать, выделять и/или писать на оцифровывающей поверхности 202 отображения. Примеры подходящих оцифровывающих поверхностей отображения 202 включают в себя электромагнитные перьевые устройства ввода графической информации, такие как перьевые устройства ввода графической информации Mutoh или Wacom. Могут также использоваться другие типы перьевых устройств ввода графической информации, например оптические устройства ввода графической информации. Вычислительная система 201 с перьевым вводом интерпретирует действия, сделанные с использованием пера 204, для управления данными, ввода текста, создания рисунков и/или для выполнения обычных компьютерных прикладных задач, таких как электронные таблицы, программы обработки текстов и т.п.
Перо 204 может быть оборудовано одной или более кнопками или другими средствами для увеличения возможностей выбора. В одном из примеров перо 204 может быть реализовано как «карандаш» или «ручка», в котором один конец является элементом записи, и другой конец является стирающим элементом («ластиком»). При перемещении по дисплею в качестве ластика, ластик указывает части дисплея, которые будут стерты. Также могут использоваться другие типы устройств ввода данных, такие как мышь, шаровой манипулятор (трекбол) или подобные им. Дополнительно, собственный палец пользователя может быть пером 204 и может использоваться для выбора или указания части отображенного изображения на сенсорном или чувствительном к приближению дисплее. Следовательно, в данной работе термин «пользовательское устройство ввода данных» имеет широкое определение и охватывает много разновидностей известных устройств ввода данных, таких как перо 204. Область 205 показывает область обратной связи или область контакта, которая позволяет пользователю определять, где перо 204 контактирует с поверхностью 202 отображения.
Прикладной программный интерфейс и системы и способы в соответствии с примерами данного изобретения могут использоваться с вычислительными системами с перьевым вводом, которые принимают и обрабатывают электронные чернила и чернильные штрихи, подобно описанным выше вместе с фиг.2.
III. ОБЗОР ПРЕДШЕСТВУЮЩЕГО УРОВНЯ ТЕХНИКИ ДЛЯ АНАЛИЗА РАЗМЕЩЕНИЯ ЧЕРНИЛ И КЛАССИФИКАЦИОННОГО АНАЛИЗА
A. Обобщенное описание системы и способа полного анализа чернил
Чтобы помочь в понимании настоящего изобретения, полезно сделать обзор информации предшествующего уровня техники относительно «анализа размещения» чернил и классификационного анализа чернил (также называемого «анализ чернил»). Хотя любые подходящие системы и способы обработки данных могут использоваться без отрыва от данного изобретения, в некоторых примерах изобретения могут использоваться системы и способы анализа размещения, такие как описанные в заявке на патент США № 10/143 865, поданной 14 мая 2002, и в некоторых примерах изобретения могут использоваться системы и способы классификационного анализа, такие как описанные в заявке на патент США № 10/143 864, поданной 14 мая 2002. В общем случае анализ чернил может происходить любым подходящим способом без отрыва от данного изобретения.
Фиг.3 - схематическое представление, которое в общем виде иллюстрирует пример обобщенной системы и способа, в котором чернила могут анализироваться или разделяться в некоторых примерах данного изобретения. В примере на фиг.3 поступающие или вводимые чернильные штрихи 300 вначале подвергаются процедуре 302 анализа размещения, которая объединяет и анализирует вводимые чернильные штрихи 300 в связанные наборы штрихов, такие как слова, строки, абзацы (или блоки) и/или другие группировки 304. В общем случае способ или система 302 анализа размещения обнаруживают некоторую информацию, относящуюся к размеру и размещению чернильных штрихов 300 на странице, и группируют определенные штрихи, основываясь на размере, размещении и т.д. Пример такой системы или способа описан более подробно вместе с фиг.5, 6A и 6B.
После анализа 302 размещения данные могут вводиться в множество дополнительных средств анализа чернил. В примерной системе, показанной на фиг.3, данные затем вводятся в систему или средство 306 классификационного анализа. Данная система или средство 306 классификационного анализа определяет тип(ы) штрихов, включенные в конкретные вводимые данные (например, представляют ли конкретные штрихи или наборы штрихов блок-схемы, рисунки свободного формата, написанный от руки текст, музыку, математические знаки, диаграммы, графики и т.д.). В некоторых примерах изобретения при желании пользователь может «сообщать» системе о типе вводимых штрихов, например, выбирая «режим рисования», «текстовый режим» или подобные им, или назначая определенный тип штриха для одного или более штрихов (например, используя процедуру выбора и назначения с помощью блока или лассо).
Дополнительная обработка вводимых чернил может зависеть от типа штрихов, распознанного системой или средством 306 классификационного анализа (или определенного иным образом). Например, для штрихов или наборов штрихов, которые классифицированы как рукописный текст, таким образом классифицированные наборы штрихов можно послать системе 310 распознавания рукописного текста или другой соответствующей системе обработки. При необходимости или при желании, до введения в систему 310 распознавания рукописного текста или в другую систему обработки, данные о вводимых чернилах могут быть «нормализованы», используя алгоритм или систему 308 нормализации, для размещения данных вводимых чернил в оптимальной ориентации для анализа системой 310 распознавания рукописного текста или другой системой обработки (например, для поворота наклонных вводимых текстовых штрихов к горизонтальной опорной линии, в случае необходимости). Другие системы или способы 308 нормализации и/или системы или способы 310 распознавания рукописного текста (в случае необходимости и/или при желании) могут использоваться без отрыва от настоящего изобретения. Данные, которые выводят из системы или способа 310 распознавания рукописного текста, могут составлять или быть связаны со сгенерированным машиной текстом (например, строками, словами, абзацами и т.д.), который можно использовать любым обычным способом, например, в обычных системах обработки текстов (например, Microsoft WORD® или ему подобных), системах обработки почты, календарях, книгах для записи деловых встреч и т.д.
В качестве другого примера, как показано на фиг.3, если средство 306 классификационного анализа распознает вводимые штрихи или наборы штрихов как содержащие штрихи рисунков, то такие данные могут затем перемещаться к системе или способу 314 распознавания примечаний, которые могут использоваться, например, для распознавания текстовой информации на рисунке. Дальнейшая обработка может продолжаться любым подходящим образом. Например, при желании, рисунки могут быть «очищены», при этом рукописные примечания могут быть заменены сгенерированным машиной текстом, нарисованные от руки линии или фигуры (например, круги, треугольники, прямоугольники и т.д.) могут быть заменены сгенерированными машиной элементами и т.п. Также рисунки (или нарисованные от руки версии, или более поздние сгенерированные машиной версии) могут вводиться в любые соответствующие программы или системы без отрыва от данного изобретения.
Системы и способы 306 классификационного анализа, используемые в некоторых примерах изобретения, также могут распознавать другие специфические типы записей или рисунков без отрыва от данного изобретения. Например, система классификационного анализа может распознавать вводимые наборы штрихов, как содержащие музыкальные обозначения, математическую информацию (например, формулы, математические символы (+, -, =, %, x, sin, cos, tan и т.д.) и подобные им), таблицы, диаграммы, графики, блок-схемы, принципиальные схемы, рисунки, эскизы, каракули и т.д., без отрыва от данного изобретения. Такие наборы штрихов, если они присутствуют, могут посылаться к более специализированным системам распознавания и/или другим подходящим приложениям обработки без отрыва от настоящего изобретения.
Некоторые или все функциональные возможности, описанные вместе с описанием фиг.3, могут выполняться над вводимыми данными чернил после того, как пользователь полностью введет все чернила на электронную страницу или в документ (например, после команды пользователя, такой как команда «сохранить», «анализировать», «закрыть» или «распознать»). Однако из-за времени обработки, которое требуется компьютеру для выполнения типичного анализа размещения и анализа распознавания рукописного текста, пользователь может испытывать существенные задержки, если обработка проводится на этом очень редком, специализированном основании. Такие задержки при обработке могут быть достаточно долгими, так что пользователь будет разочарован ожиданием, пока компьютерная система завершит свой анализ перед переходом к последующим необходимым операциям (например, ввод большего количества чернил, переход к новой странице, печать, открытие нового документа или приложения и т.д.), особенно если электронный документ длинный или содержит большой объем чернил. Системы и способы согласно по меньшей мере некоторым примерам настоящего изобретения позволяют вычислительным системам с перьевым вводом выполнять различные анализы, такие как анализ 302 размещения, классификационный анализ 306, анализ 310 распознавания рукописного текста и т.д., поэтапно, в реальном масштабе времени, в то время как пользователи продолжают использовать вычислительные системы с перьевым вводом (например, вводить и/или изменять чернильные штрихи на странице). Кроме того, в некоторых примерах систем и способов согласно изобретению различные средства анализа работают в фоновом режиме, со «снимком» (копией) структуры данных прикладной программы, с целью минимизировать время, когда структура данных прикладной программы недоступна пользователю для ввода чернил (термин «структура данных прикладной программы», который используется в данном документе, означает структуру данных, используемую в связи с прикладной программой). Хотя любые подходящие поэтапные системы и способы анализа данных могут использоваться без отрыва от изобретения, примеры подходящих систем и способов описаны в заявке на патент США № 10/143 804, поданной 14 мая 2002.
B. Описание примерных систем и способов для анализа размещения и классификационного анализа
Фиг.4 иллюстрирует схематическое представление одного примера системы, которая пригодна для применения настоящего изобретения. Как показано, полная система 410 включает в себя прикладную систему или программу 420, которая включает в себя анализатор 422 или связана с ним. Полная система 410 может быть воплощена в вычислительной системе с перьевым вводом подобно той, которая показана на фиг.2. Пользователь 400 вводит чернильные штрихи в систему 410 (или чернильные штрихи загружаются, например, из памяти или из внешнего источника), и чернильные штрихи сохраняются прикладной программой 420, например, в структуре 402 данных прикладной программы (которую можно считать структурой 402 данных дерева документа, подобно показанным на фиг.6A и 6B). Для того чтобы пользователь 400 мог продолжать делать изменения в структуре 402 данных дерева документа в то время, когда анализатор 422 работает, анализатор 422 содержит структуру 404 данных зеркального дерева (точной копии). Изменения, сделанные в структуре 402 данных дерева документа (например, пользователем 400, анализатором 422, другим источником и т.д.), немедленно передают структуре 404 данных зеркального дерева так, чтобы структура 404 данных зеркального дерева полностью «отражала» содержимое структуры 402 данных дерева документа.
Структура 404 данных зеркального дерева используется для доставки вводимых данных двум средствам 406 и 408 анализа в анализаторе 422. В показанном на фиг.4 примере одним средством анализа является средство 406 анализа размещения (которое может проводить, например, анализ 302 размещения, как описано выше при обсуждении фиг.3), а другим - средство 408 распознавания (которое может проводить, например, анализ 310 распознавания рукописного текста и/или анализ 314 распознавания примечаний, как описано выше для фиг.3). Средства 406 и 408 принимают «снимки» (копии) 424 и 426, соответственно, структуры 404 данных зеркального дерева в качестве входных данных, и они оперируют с этими «снимками» 424 и 426 в фоновом режиме вместо того, чтобы работать непосредственно со структурой 402 данных дерева документа или структурой 404 данных зеркального дерева. Таким образом пользователь 400 может продолжать выполнять операции со структурой 402 данных дерева документа в прикладной программе 420 (например, добавлять чернила, удалять чернила, изменять чернила и т.д.), в то время как различные средства 406 и 408 анализа анализатора также работают, и пользователь 400 не испытывает существенных прерываний в работе (например, задержек обработки), когда средства 406 и 408 обрабатывают данные.
Для генерации «снимков» 424 и 426 в некоторых примерах существующие структуры данных снимка могут сравниваться со структурой 404 данных зеркального дерева. Отмечаются различия между ними, и минимальное количество операций выполняется для синхронизации снимков 424 или 426 со структурой 404 данных зеркального дерева. Таким образом, при создании снимка происходит минимальная перезапись данных (например, неизмененные данные от предыдущего снимка не перезаписываются), что также помогает ускорить работу анализатора 422.
Выходными данными средств 406 и 408 анализатора могут быть измененные или исправленные структуры данных. Например, если средство 406 анализа размещения является таким, которое показано на фиг.5, то выходная информация средства 406 анализа размещения может быть структурой данных, которая включает в себя отдельные чернильные штрихи, сгруппированные в связанные слова, строки, абзацы и т.п. Работа средства анализа размещения этого типа описана более подробно ниже. Точно так же, если средство 408 анализатора - система 310 распознавания рукописного текста, то выходная информация может включать в себя информацию или структуру данных, которая связывает чернильные штрихи со сгенерированным машиной текстом.
Когда средства 406 и 408 анализатора завершают свою работу с входными данными 424 и 426 снимков, соответственно, результирующую информацию можно послать назад прикладной программе 420, как обозначено стрелками 428 и 430, соответственно. Однако, как отмечено выше, пользователь 400 может изменить структуру 402 данных дерева документа в течение времени, когда средства 406 и 408 анализатора обрабатывают снимки 424 и 426. Поэтому, перед записью результатов работы средств анализа анализатора назад в структуру 402 данных дерева документа, анализатор 422 сравнивает структуру 402 данных дерева документа, существующую в настоящее время в прикладной программе 420 (которая включает в себя изменения пользователя), с исправленной структурой(ами) данных дерева документа, посланной средствами 406 и 408 анализатора, дополнительно используя структуру 404 данных зеркального дерева. Если пользователь 400 сделал изменения в структуре 402 данных дерева документа, которые не содержатся в исправленной структуре(ах) данных дерева документа, принятой от средств 406 и 408 анализатора (например, с помощью добавления, удаления, перемещения, изменения размеров или иного изменения одного или более штрихов), или если пользовательские изменения структуры 402 данных дерева документа приводят к спорам или конфликтам с изменениями структуры данных, сделанными средствами 406 и 408 анализатора (например, с помощью добавления, удаления или иного изменения штрихов), то структуру 402 данных дерева документа приложения исправляют, чтобы она включала в себя только те изменения, сделанные средствами анализа анализатора, которые не противоречат пользовательским изменениям (пользовательские изменения отменят сделанные анализатором изменения). Также только те части структуры 402 данных дерева документа, которые изменены по сравнению с существующей версией, изменяются или перезаписываются для уменьшения времени записи данных (и связанного с этим перерыва в работе, испытываемого пользователем 400). Таким образом, окончательная исправленная структура 402 данных дерева документа, присутствующая в прикладной программе 420, будет включать в себя все изменения, сделанные пользователем 400, и результаты предыдущих анализов средств анализатора в такой степени, в какой средство анализатора делает изменения, которые не противоречат или не отменяют пользовательские изменения.
Поскольку структура 402 данных дерева документа содержит совместно используемые данные, которые в конечном счете будут изменены пользователем 400 так же, как средствами 406 и 408 анализатора, пользователь 400 не может вводить новые данные в структуру 402 данных дерева документа, когда она перезаписывается для того, чтобы она включала в себя сделанные анализатором изменения. Если пользователь 400 пытается сделать это, то системы и способы согласно изобретению могут обрабатывать такие попытки любым подходящим способом. Например, новые штрихи или изменения могут игнорироваться, или они могут храниться во временной буферной памяти до тех пор, пока исправленная структура 402 данных дерева документа приложения не будет доступна для ввода данных. Однако из-за того, что структура 402 данных дерева документа в прикладной программе 420 согласно этому примеру изобретения в общем случае недоступна только в течение времени, когда система перезаписывает измененные части структуры 402 данных, недоступный период времени обычно весьма короток и часто не замечается пользователем.
Как только структура 402 данных дерева документа перезаписана или изменена (включая в себя изменения, сделанные пользователем и/или средством анализатора), структура 404 данных зеркального дерева модифицируется (обновляется) так, чтобы она отражала перезаписанную или измененную структуру 402 данных дерева документа, и средства 406 и 408 анализатора могли повторить их анализ (в случае необходимости). Преимущественно, в некоторых примерах, средства 406 и 408 анализатора будут работать только с теми частями структуры данных дерева документа, которые недавно изменились (и с любыми частями, которые затрагивают недавние изменения) для уменьшения времени обработки. С помощью поэтапного обновления операций средства анализатора в то самое время, когда пользователь вводит данные, анализатор 422 может вообще поддерживать ввод данных пользователя, таким образом минимизируя задержки при обработке, которые наблюдает пользователь.
Как упоминалось выше, в некоторых примерах изобретения время обработки может быть уменьшено, ограничивая обработку теми частями структуры данных, где произошли изменения (и всеми областями, которые затрагивают эти изменения). Если вводимая пользователем информация или предыдущие операции средства анализатора не затронули некоторые части структуры данных, то средству(ам) анализатора, возможно, не потребуется повторный анализ тех же самых частей (и, возможно, достижение тех же самых результатов). В качестве примера системы и способы согласно некоторым примерам могут повторно анализировать любую часть структуры данных, расположенную в заранее определенных пределах от изменения. Например, повторный анализ может включать в себя строку с любыми изменениями и любые одну или две строки, окружающие данное изменение, любые штрихи, расположенные в пределах круга с предварительно выбранным радиусом, окружающего данное изменение, любой блок текста (как описано более подробно ниже), который включает в себя данное изменение, или подобные им. Последующее описание более подробно объясняет примеры анализаторов, которые используют эти особенности.
C. Пример обработки, происходящей во время анализа
Данные, проанализированные или обработанные в системах и способах согласно примерам настоящего изобретения, могут принимать любую подходящую форму или структуру. Например, в одной из процедур, как показано на фиг.3, отдельные штрихи 300 из входных данных чернил объединены вместе в структуру данных в результате последовательности решений, сделанных средством 302 анализа размещения, которое группирует или связывает некоторые отдельные штрихи, основываясь на общем размещении чернил и статистике, полученной от ввода чернил. Средство 302 анализа размещения может обеспечить иерархическое группирование чернильных штрихов на странице, что позволяет выполнять глобальные статистические вычисления по группе(ам). Первые решения о группировании штрихов являются консервативными, основанными на локальных взаимоотношениях размещения, причем группы чернильных штрихов являются маленькими (например, маленькие группы, представляющие отдельные чернильные штрихи или относительно короткие комбинации штрихов). Более поздние решения о группировании штрихов могут быть более активными, из-за больших размеров статистических образцов, собранных из больших группировок чернильных штрихов (например, размеры штрихов по более длинной строке, относительное размещение штрихов, углы поворота строки и т.д.). Могут проводиться многочисленные проходы через вводимые данные чернил для того, чтобы дать возможность принятия все более и более активных решений в определении, объединить ли штрихи для формирования наборов штрихов, таких как слова, строки и/или блоки 304 из вводимых чернильных штрихов.
Фиг.5 в общем случае иллюстрирует этапы или средства анализа в одном из примеров средства анализатора, системы или способа 302 для анализа размещения чернил, которые полезны при создании и/или изменении структур данных, используемых в некоторых примерах данного изобретения. Из-за очень высокой степени свободы, которую обеспечивают пользователям при вводе цифровых чернил в системы и способы согласно некоторым примерам изобретения (например, пользователю разрешают писать где угодно на экране устройства ввода графической информации, в любой ориентации, в любое время, используя любой необходимый ему размер штрихов), когда начинается показанная на фиг.5 процедура 302 анализа размещения, может не быть никакой доступной предварительной информации, откуда определять правильное размещение, ориентацию или тип вводимых данных (например, являются ли поступающие вводимые данные 500 текстом, рисунком, математическими символами, музыкальными знаками, блок-схемами, диаграммами, графиками и т.д.). Элемент 502 на фиг.5 обеспечивает общее графическое изображение одного из типов возможных структур 500 вводимых данных в начале такой процедуры анализа размещения. Графическое изображение 502 показано более подробно в структуре данных дерева анализа на фиг.6A. В общем случае, когда начинается процедура 302 анализа размещения (например, даже когда пользователь, возможно, продолжает вводить чернильные штрихи в вычислительную систему с перьевым вводом), система обрабатывает каждый штрих S 600 на данной странице (или в данном документе) P 608 как отдельное слово W 602, каждое слово W 602 обрабатывается как отдельная строка L 604, и каждая строка L 604 обрабатывается как отдельный блок B 606 (или абзац). Средство 302 анализа размещения выполняет задачу соединения или объединения штрихов вместе для формирования наборов штрихов, содержащих правильные слова, строки и блоки связанных данных чернил. Хотя любое подходящее средство анализа размещения может использоваться вместе с данным изобретением, пример, показанный на фиг.5, описан более подробно ниже.
Хотя данное описание показанного средства анализа размещения 302 использует такие термины, как «слово», «строка» и «блок», эти термины используются в этой части описания для удобства ссылки на один или большее количество связанных штрихов или наборов штрихов. К тому времени, когда анализ 302 размещения первоначально происходит по меньшей мере в некоторых примерах изобретения, никакого окончательного определения не сделано относительно того, составляют ли отдельные штрихи или наборы штрихов надпись, рисунки, музыку и т.д. Также, хотя вышеупомянутое описание использует термин «страница», нет необходимости, чтобы данный электронный документ анализировался на основе постраничного анализа. Например, «блоки» или «абзацы» электронных документов могут объединять две или более страницы документа без отрыва от изобретения.
Средство 302 анализа размещения согласно данному примеру изобретения работает интенсивно, так что в течение каждого прохода (или операции каждого средства анализа), происходит операция слияния штрихов или строк, но разбиения не делают. Кроме того, средство 302 может использоваться с соответствующими проверками и допусками, так что не должно быть необходимости возвращаться и исправлять нежелательную операцию слияния.
В результате работы средства 302 анализа размещения отдельные штрихи 600 электронного документа могут быть объединены вместе в связанные наборы штрихов, которые включают в себя слова W, строки L и блоки B (или абзацы), соответственно. Фиг.6B показывает графическое изображение 506 возможной структуры выводимых данных 504 от средства 302 анализа размещения. Как очевидно из сравнения фиг.6A и 6B, вся страница (или документ) 608 содержит одинаковую штриховую информацию, но некоторые штрихи S 600 были объединены или связаны вместе, формируя слова W 610, и некоторые слова W 610 были объединены вместе, формируя строку L 612 в структуре данных на фиг.6B. Конечно, слово W 610 может содержать любое количество штрихов S 600, и аналогично строка L 612 может содержать любое количество слов W 610. Также, хотя это не показано в конкретном примере дерева анализа на фиг.6B, две или большее количество строк L 612 также можно объединить вместе для формирования блока B 614 (или абзаца).
В дополнение к помощи в определении структуры чернил в документе, различные узлы в дереве анализа (например, узлы 600, 610, 612 и т.д. на фиг.6B) могут использоваться для хранения пространственной информации, относящейся к различным уровням в дереве. Например, каждый узел 612 уровня строки может хранить строку возврата в предыдущее состояние/согласование для всех точек, которые составляют штрихи строки, «выпуклый каркас» для каждого штриха в строке, и/или любую другую необходимую информацию. Также структуры данных дерева анализа могут изменяться с помощью применения различных элементарных операций к штрихам, словам, строкам и блокам, которые содержатся в них. Подходящие операции могут включать в себя: добавление, удаление, объединение, разбиение и повторное определение родительского элемента. Более сложные операции могут быть составлены, используя эти элементарные операции. Поскольку эти операции выполняются с деревом структур данных, то статистическая информация, которая поддерживается на различных уровнях узлов, может автоматически модифицироваться, чтобы соответствовать новой структуре.
Фиг.5 обеспечивает обзор схемы одного примера подходящего средства 302 анализа размещения, полезного в некоторых примерах данного изобретения. В этом примере первый этап в процедуре 302 анализа размещения - этап 508 временного группирования строк, который в общем случае сравнивает особенности смежных по времени штрихов (т.е. последовательно записанных штрихов) и объединяет их как «строки», при соответствии. Различные факторы могут приниматься во внимание при определении, должно ли выполняться временное группирование строк из двух или большего количества смежных по времени штрихов, например размер штрихов, интервал между штрихами, угол наклона штрихов и т.д. Когда этап 508 временного группирования строк закончен, на следующем этапе в анализе 302, этапе 510 пространственного группирования блоков, сравнивают физически смежные временные группировки строк, сформированные на этапе 508, и объединяют временные группировки строк, которые расположены близко друг от друга, как пространственные блоки. Различные факторы могут приниматься во внимание при определении, должно ли выполняться пространственное группирование блока из смежных временных группировок строк, например размер штрихов, интервал между штрихами, угол наклона строки и т.д.
Строки, сгруппированные по времени появления (на этапе 508), могут быть дополнительно сгруппированы, если существует возможность, возможно учитывая их пространственные взаимное расположение или ориентацию в блоке, на этапе 512 пространственного группирования строк. Этот этап 512 пространственного группирования строк не должен рассматривать время появления одного штриха по сравнению с другим штрихом, хотя могут учитываться такие факторы в дополнение к пространственным соотношениям строк, как угол наклона строки, размер штрихов и т.д. Также результаты описанной выше процедуры 510 пространственного группирования блоков могут использоваться в качестве фактора при определении, должно ли выполняться пространственное группирование строк между двумя существующими временными (сгруппированными по времени появления) группировками строк.
Когда пространственное группирование строк закончено, процедура 302 анализа размещения согласно этому примеру может затем объединять отдельные штрихи в группировках строк в одну или более пространственных группировок 516 слов, в зависимости, например, от таких факторов, как интервал между штрихами, ориентация строк, размер штрихов и т.д. Результирующий выходной информацией 504 может быть структура 506 данных со штрихами, сгруппированными в слова, строки и блоки, как описано со ссылками на фиг.6B.
На фиг.5 также прерывистыми линиями показывают дополнительное средство или этап анализа, который может использоваться как часть анализа 302 размещения. Этот дополнительный этап называют этапом 514 «обнаружением списка». Часто, когда люди записывают список, они имеют тенденцию записывать (вертикальный) столбец чисел, букв или маркерных точек, а затем заполнять элементы списка (в горизонтальном направлении). В другое время люди записывают содержимое списка, а затем позднее добавляют вертикальный столбец чисел, букв или маркерных точек. Средство 514 обнаружения списка может обнаруживать эти конкретные обстоятельства (например, посредством просмотра ориентации и определения времени для временных группировок строк и т.д.), и оно объединяет штрихи чисел, букв или маркерных точек списка с соответствующим текстом элемента списка.
Различные этапы в этом приведенном в качестве примера средстве 302 анализа чернил (фиг.5) могут быть изменены по порядку следования или опущены без отрыва от изобретения. Например, при необходимости этап 512 пространственного группирования строк может происходить перед этапом 510 пространственного группирования блоков.
Выходные данные 504 от средства 302 анализа размещения могут использоваться любым подходящим образом, например средством 306 классификации, как показано на фиг.3, и оттуда данные могут быть направлены к другим соответствующим средствам обработки (например, к средству 314 распознавания примечаний, к средству 310 распознавания рукописного текста и т.д.). Средство 302 анализа размещения, или комбинация средства 302 анализа размещения и средства 306 классификации, могут формировать средство 406 анализатора, как показано при описании фиг.4.
Конечно, настоящее изобретение не ограничено работой со средством анализа размещения или каким-нибудь определенным типом средства анализа. Другие подходящие средства или процедуры для группирования или связывания отдельных штрихов в соответствующие структуры данных или любой другой требуемый анализ могут выполняться без отрыва от данного изобретения. Также, при желании, до обработки, пользователь может указать системе, что некоторые штрихи всегда должны группироваться вместе (например, рисуя линию или «лассо» вокруг, выделяя или иным образом выбирая вводимые штрихи данных, которые будут связаны вместе).
IV. ОБЪЕКТ РАЗДЕЛЕНИЯ ЧЕРНИЛ И API
A. Общее описание
В данном описании приводится подробное описание примеров анализаторов и прикладных программных интерфейсов согласно изобретению, которые включают в себя конкретный пример, а именно объект InkDivider (разделения чернил). Одно из назначений систем и способов согласно изобретению (например, объекта InkDivider) - взять совокупность чернильных штрихов, обеспеченных приложением, и разделить эти штрихи на проанализированные сущности указанной степени детализации (например, на слова, строки, предложения, абзацы, рисунки или подобные им). Без надлежащего анализа электронные чернила имеют тенденцию или становиться слишком гранулированным (детализированными) (т.е. имеют большое количество несгруппированных штрихов), или существует тенденция группировать их как единый объект «чернила», что делает трудным или невозможным выполнение необходимых перемещений, выбора, масштабирования и других операций, особенно с отдельными чернильными штрихами или маленькими группами чернильных штрихов. Системы и способы согласно изобретению, которые включают в себя, например, объект разделения чернил и API, показывают сообществу разработчиков технологию анализа и результаты, которые таким образом позволят авторам кода использовать преимущества и результаты средства анализа при написании кода для новых приложений.
В общем случае во время сеанса рисования чернильные штрихи некоторым образом добавляются и/или удаляются из совокупности чернильных штрихов, находящихся в приложении. Дополнительно, во время сеанса рисования существующие штрихи в пределах совокупности чернильных штрихов могут быть перемещены, изменены в размерах, частично стерты и/или иначе изменены.
Когда сеанс рисования заканчивается (а, возможно, через определенные этапы, во время проведения сеанса рисования), работающая прикладная программа вызывает анализатор (который, например, включает в себя объект InkDivider), который обрабатывает штрихи в наборы штрихов или группы различной степени детализации (по меньшей мере новые штрихи и/или измененные штрихи, и/или любые штрихи, которые затронуты новыми и/или измененными штрихами с предыдущего вызова анализатора). В общем случае при вызове анализатора прикладная программа доставляет чернильные штрихи анализатору и принимает назад некоторую информацию. В некоторых примерах возвращенная информация содержит обратный указатель, который идентифицирует исходные штрихи, которые были разделены. Системы и способы согласно некоторым примерам изобретения также могут обеспечивать метод (названный «ResultByType» (результат в зависимости от типа) в этом примере) для отыскания требуемой совокупности штрихов указанной степени детализации. Например, прикладная программа может запросить результаты разделения, чтобы получить модули различной степени детализации анализа, в зависимости от требуемого типа степени детализации (например, слова, строки, блоки, рисунки и т.д.). Результаты анализа также могут иметь информацию об опорной линии для исправления надписи, повернутой по отношению к горизонтальной опорной линии, перед подачей таких данных на средство распознавания рукописного текста, в случае необходимости и/или при желании. Это может быть достигнуто, например, созданием матрицы вращения, доступной для авторов кода.
Следует обратить внимание, что отдельные чернильные штрихи могут принадлежать многим совокупностям чернильных штрихов или группировкам с различной степенью детализации, например штрих может быть частью слова и частью абзаца.
Имея в виду этот краткий обзор и предшествующий уровень техники, ниже более подробно описаны различные особенности примеров объекта разделения чернил и API согласно изобретению. Хотя большая часть последующего обсуждения относится к конкретному объекту разделения чернил и связанным с ним объектам, свойствам и т.д., специалисты должны признать, что различные изменения могут быть сделаны в конкретном описанном ниже воплощении без отрыва от изобретения.
B. Объект разделения чернил (InkDivider)
Фиг.7 в общем виде иллюстрирует содержимое примерного объекта 700 InkDivider, полезного в некоторых примерах изобретения. В данном примере объект 700 InkDivider содержит два свойства 702, а именно свойство 704 «штрихи» (Strokes) и свойство 706 RecognizerContext (установки средства распознавания). Показанный объект 700 InkDivider также включает в себя один из методов 708, а именно метод 710 разделения.
Свойство 704 «штрихи» (Strokes) возвращает и/или устанавливает совокупность чернильных штрихов, которые будут подвергнуты методу 710 разделения (Divide). Штрихи в общем случае посылаются свойству 704 «штрихи» с помощью используемой прикладной программы, которая определяет в свойстве 704 «штрихи», какие штрихи добавить и/или удалить, и/или иначе изменить в совокупности штрихов. Это в общем виде показано на фиг.7 стрелкой 712, которая представляет входящие штрихи, посланные прикладной программой (или иначе посланные свойству 704 «штрихи» любым подходящим и/или желаемым способом). Штрихи также могут добавляться и/или удаляться из свойства 704 «штрихи» конечным пользователем любым подходящим образом, например, через операции вставки чернил, вклейки чернил, вырезания или удаления чернил и т.д. При желании, информация о штрихах, посланная свойству 704 «штрихи», может не включать в себя все особенности или свойства чернильных штрихов, например цвет. Вместо этого, при желании, достаточно послать только особенности или свойства чернильных штрихов, которые являются важными для анализа.
Данные ввода и вывода для свойства 704 «штрихи» (Strokes) могут принимать следующую форму:
[propputref]HRESULT Strokes([in]InkStrokes*Strokes);
[propget]HRESULT Strokes([out,retval]InkStrokes**Strokes).
Свойство 706 RecognizerContext возвращает и/или устанавливает средство распознавания, которое будет использоваться и/или будет связано с объектом 700 InkDivider. Это свойство 706 полезно по меньшей мере в некоторых примерах изобретения, потому что требуемая операция анализа может включать в себя распознавание рукописного текста, которое будет основано на языке, отличающемся от заданного по умолчанию языка системы, на которой выполняются программное обеспечение или прикладная программа. Например, вычислительная система с перьевым вводом может иметь английский язык в качестве заданного по умолчанию языка для операционной системы и/или клавиатуры. Однако, если пользователь компьютера владеет двумя языками или если другой пользователь использует компьютер, то в некоторых случаях пользователь может записать или сделать примечание на другом языке, чем английский язык. Если средство распознавания рукописного текста с заданным по умолчанию английским языком является единственным доступным в системе средством, то это может привести к ошибкам, когда средство распознавания пытается распознать неанглийский рукописный текст. Другие специализированные средства распознавания также могут устанавливаться с помощью кода приложения, например специализированное средство распознавания для распознавания музыкальных знаков, математических формул и символов, деталей рисунков и т.д. Предоставляя возможность авторам кода устанавливать и/или использовать различные средства распознавания рукописного текста (которые включают в себя средства распознавания для различных языков), окончательные результаты распознавания рукописного текста могут быть улучшены. Возможность авторов кода устанавливать необходимое средство распознавания рукописного текста показана на фиг.7 стрелкой 714. В некоторых примерах изобретения свойство 706 RecognizerContext может иметь по умолчанию «нулевое» (NULL) значение, которое в этих примерах означает, что заданный по умолчанию язык операционной системы компьютера будет использоваться в качестве языка распознавания рукописного текста, и/или средство распознавания, поставляемое операционной системой, будет использоваться в качестве средства распознавания до тех пор, пока свойство 706 RecognizerContext не изменено для определения другого средства распознавания. Заданное по умолчанию или «нулевое» значение языка может соответствовать значению по умолчанию идентификатора территории для «клавиатуры» во время начальной установки системы. Эта заданная по умолчанию или нулевая входная особенность показана на фиг.7 стрелкой 716, которая обозначена как «нулевое значение» (NULL).
Данные ввода и вывода для свойства 706 RecognizerContext могут иметь следующую форму:
[propputref]Recognizer([in]InkRecognizer*Recognizer);
[propget]Recognizer([out,reval]InkRecognizer**Recognizer).
При работе, по меньшей мере в некоторых примерах изобретения, анализатор будет делать первый проход при определении границ слов в рукописном тексте, основываясь на пространственных и временных метаданных, связанных со штрихами чернил. Это может включать в себя, например, этапы временного (по времени появления) группирования строк, пространственного группирования блоков и пространственного группирования строк, которые в общем виде описаны выше со ссылкой на фиг.5. Эти операции анализа могут проводиться относительно быстро, но в общем случае результаты не будут обладать совершенством и точностью, связанными со средством распознавания рукописного текста и связанной с ним моделью языка. Поэтому, по меньшей мере в некоторых примерах изобретения, средство распознавания рукописного текста используется для выполнения второго прохода по каждой рукописной «строке» текста и для точной идентификации разрывов между словами, используя словарь, связанный со средством распознавания рукописного текста, чтобы лучше идентифицировать границы слов. Средство распознавания также может преобразовывать рукописный текст в сгенерированный машиной текст (например, в формат, подходящий для программ обработки текстов, почты, электронных календарей и книг для записи деловых встреч и т.д.).
Фиг.7 также показывает метод 710 Divide «разделение», который составляет часть объекта 700 InkDivider в данном примере. Этот метод 710 разделяет, или анализирует, связанные штрихи (полученные от свойства 704 «штрихи» - см. стрелку 718), используя средство распознавания, установленное с помощью свойства 706 RecognizerContext (см. стрелку 720). Метод 710 «разделение» создает и возвращает объект 800 InkDivisionResult (результат разделения чернил), который содержит результаты разделения чернил (или анализа). Процесс создания и возвращения объекта 800 InkDivisionResult показан на фиг.7 стрелкой 722. Пример доступного формата выводимых данных метода 710 «разделение» показан ниже:
HRESULTDivide([out,retval]InkDivisionResult** divisionResults). По меньшей мере в некоторых примерах изобретения метод 710 «разделение» выполняют или вызывают синхронно, когда дополнительные чернила можно добавить, удалить или иначе изменить в документе в прикладной программе. В дополнительных примерах систем и способов согласно изобретению метод 710 «разделение» может работать в фоновом режиме со штрихами, обеспеченными через свойство 704 «штрихи», и он не возвращает объект 800 InkDivisionResult, пока вся операция анализа не закончена. Когда данный метод работает в фоновом режиме и не затрагивает дополнительно вводимые или изменяемые штрихи, во многих случаях использование метода 710 «разделение» (Divide) будет прозрачно или почти прозрачно для пользователя вычислительной системы с перьевым вводом и не будет вызывать существенной задержки обработки.
Каждый раз, когда вызывают метод 710 «разделение», может создаваться новый объект 800 InkDivisionResult, который фактически делает «снимок» (копию) структуры данных дерева анализа чернил (см. фиг.6B) во время вызова метода 710 «разделение». По меньшей мере в некоторых примерах изобретения прикладная программа отвечает за сравнение штрихов каждого объекта 800 InkDivisionResult (который обсуждается более подробно ниже) для определения, изменились ли результаты анализа между различными вызовами методами 710 «разделение».
Конечно, без отрыва от изобретения объект разделения чернил может включать в себя методы, свойства и/или другие элементы в дополнение, и/или вместо, и/или в комбинации с конкретными методами и свойствами, показанными на фиг.7. В качестве примера объект разделения чернил дополнительно может включать в себя свойство «высота строки» (альтернативно свойство «высота строки» может быть связано с другим объектом или обеспечено любым подходящим образом). Свойство «высота строки» позволяет автору кода при вводе установить ожидаемую высоту строки для строк текста. Таким образом, во время анализа система анализа размещения и/или система классификационного анализа (или другие системы в анализаторе) могут использовать эту информацию об ожидаемой высоте строки и лучше выполнить работу по дифференциации между строками текста и рисунками или диаграммами. Давая анализатору это указание высоты строки, можно более эффективно и рационально дифференцировать многочисленные строки (например, в ориентации абзаца) или одиночные линии рисунков (например, линии рисунков типично более высокие, чем одиночная строка рукописного текста).
Хотя нет необходимости в ограничении ожидаемого размера высоты строки рукописных строк, в некоторых примерах изобретения системы и способы принимают только ту ожидаемую высоту строк, которая находится в пределах определенного диапазона. Конечно, этот диапазон ожидаемой высоты строки может изменяться в широких пределах. В некоторых примерах изобретения ожидаемая высота строки должна изменяться в пределах от минимальной высоты 100 пикселей устройства ввода графической информации до максимальной высоты 50 000 пикселей устройства ввода графической информации, с заданной по умолчанию высотой 1200 пикселей. Если автор кода пытается устанавливать ожидаемую высоту строк вне этих диапазонов, то свойство «высота строк» может возвратить сообщение об ошибках. Альтернативно свойство «высота строк» может автоматически изменять вводимую высоту строки к соответствующему минимальному или максимальному значению высоты, не возвращая сообщение об ошибках (например, автоматически устанавливая значение высоты строки 50 000, если код прикладной программы пытается устанавливать значение 50 003). В качестве другой альтернативы предпринятая попытка установить значение высоты линии вне допустимого диапазона может привести просто к игнорированию значения (и к возвращению назад к предыдущему значению высоты строки или к значению по умолчанию).
В качестве выходной информации свойство «высота строки» сообщает прикладной программе предварительно установленное значение для свойства «высота строки», или оно возвращает значение по умолчанию, если предыдущее значение не было установлено.
В качестве примера входные и выходные данные для свойства «высота строки» согласно данному примеру изобретения могут принимать следующие формы:
HRESULT [propput] LineHeight([in]Long LineHeight);
HRESULT[propget]LineHeight([out,retval]Long*LineHeight).
C. Объект «результат разделения чернил» (InkDivisionResult)
Фиг.8 графически иллюстрирует объект 800 InkDivisionResult согласно некоторым примерам изобретения. Как отмечено выше, метод 710 «разделение» (Divide) объекта 700 InkDivider анализирует совокупность штрихов (полученных из свойства 704 «штрихи») (Strokes), основываясь на выбранном свойстве 706 RecognizerContext, и создает объект 800 InkDivisionResult. Объект 800 InkDivisionResult вводит структуру данных, полученную от операции разделения и/или анализа, которую можно рассматривать как «дерево анализа», показанное на фиг.6B, по меньшей мере в некоторых примерах изобретения. Результирующая структура данных, существующая в объекте 800 InkDivisionResult, может дополнительно использоваться, например, в последующих операциях ResultByType (описанных более подробно ниже) для отыскания наборов чернил с различными уровнями детализации для данной совокупности штрихов.
Как показано на фиг.8, данный пример объекта 800 InkDivisionResult имеет свойство 802, называемое «штрихи» 804 («Strokes»). Это свойство 804 «штрихи», когда его вызывают, возвращает ссылку к штрихам, которые первоначально использовались при создании объекта 800 InkDivisionResult. Объект 700 InkDivider внутренним образом формирует структуру данных, которая соответствует определенному набору штрихов в какой-то момент времени. Объект «чернила» (Ink), содержащий эти штрихи, однако не является статическим. Вместо этого новые штрихи можно добавлять (или по отдельности, или в большом количестве, например, через операцию вклеивания), а существующие штрихи можно удалять или перемещать, или иначе изменять в любое время (даже в то время, когда выполняется операция анализа). Поэтому свойство 804 «штрихи» в объекте 800 InkDivisionResult обеспечивает коду прикладной программы или коду клиента средство определения: (a) какие штрихи были подвержены разделению для создания конкретного объекта 800 InkDivisionResult, и (b) были ли затронуты или изменены эти штрихи с тех пор, как последний объект InkDivisionResult был получен (например, с последнего вызова метода 710 «разделение»). Данное свойство 804 «штрихи» также позволяет коду приложения или коду клиента сравнивать два объекта InkDivisionResult для определения, изменилось ли дерево анализа с одного вызова метода «разделение» до следующего.
Свойство 804 «штрихи» объекта 800 InkDivisionResult принимает, содержит и/или поддерживает список штрихов, используемых при создании объекта 800 InkDivisionResult. Это показано на фиг.8 входной стрелкой 806. Эти входные данные штрихов могут быть получены или введены, например, из свойства 704 «штрихи» объекта 700 InkDivider, или из любого другого подходящего источника. Возможность выводить данные, представляющие чернильные штрихи, которые используются при получении объекта 800 InkDivisionResult, показана на фиг.8 стрелкой 808 от свойства 804 «штрихи». Выходные данные 808 свойства 804 «штрихи» могут принимать следующую форму:
[propget]HRESULTStrokes([out,retval]InkStrokes**Strokes).
Поскольку объект 700 InkDivider инкапсулирует средство анализа, и объект 800 InkDivisionResult инкапсулирует структуру данных дерева анализа для определенной операции разделения чернил, можно освободить объект 700 InkDivider (например, для дальнейших операций), в то время как один или более объектов 800 InkDivisionResult продолжают существовать.
В качестве альтернативы вместо того, чтобы объект 800 InkDivisionResult включал в себя свойство 804 «штрихи», код клиента или код прикладной программы может кэшировать информацию штрихов внешним образом. Однако при вероятности создания многочисленных объектов 800 InkDivisionResult во время сеанса рисования может быть трудно и в вычислительном отношении дорого поддерживать пары: объект 800 InkDivisionResult - внешний набор данных чернильных штрихов. Поэтому, обеспечивая свойство 804 «штрихи», в качестве части объекта 800 InkDivisionResult уменьшают непроизводительные издержки для кода клиента или кода прикладной программы и помогают в эффективном использовании API разделения чернил.
Объект 800 InkDivisionResult согласно данному примеру дополнительно включает в себя метод 810, называемый ResultByType (результат в зависимости от типа) 812, как дополнительно показано на фиг.8. Этот метод 812 ResultByType, когда его вызывают, возвращает совокупность совокупностей штрихов (в Модулях (Units) разделения), которые следуют из данного DivisionType (типа разделения, например, слова, строки, абзацы, рисунки и т.д.). В качестве примера данный метод 812 возвращает вводимые штрихи, сгруппированные как слова, строки, абзацы, рисунки и т.д., в зависимости от того, требует ли код клиента или код приложения слова, строки, абзацы, рисунки и т.д. Этот метод 812 может вызваться много раз, при желании, для отыскания результатов разделения для различных отличающихся степеней детализации анализа. Например, один вызов может обеспечить слова в анализируемой совокупности штрихов, другой вызов может обеспечить строки, другой - абзацы и т.д.
Входная информация для метода 812 ResultByType включает в себя по меньшей мере требуемый InkDivisionType, который, как отмечено выше, в некоторых примерах может означать слова, строки, абзацы, рисунки и т.д. Эта входная информация показана на фиг.8 входной стрелкой 814. Выходная информация, которая включает в себя совокупность совокупностей штрихов для данного DivisionType (например, объекта InkDivisionUnits), представлена на фиг.8 выходной стрелкой 816. Эти данные могут иметь следующий формат:
HRESULTResultByType([in]InkDivisionTypedivisionType,
[out,retval]InkDivisionUnits*divisionUnits ).
В некоторых примерах изобретения, если никакой DivisionType (тип разделения) не определен (DivisionType=NULL), как представлено на фиг.8 стрелкой 818, то возвращенная совокупность объектов InkDivisionUnits, по меньшей мере в некоторых примерах изобретения, может включать в себя все степени детализации, идентифицированные анализатором. Поскольку некоторые степени детализации относятся к категории других степеней детализации (например, строка может содержать несколько слов), результирующая совокупность может содержать перекрывающиеся модули разделения. Конечно, любая подходящая заданная по умолчанию степень детализации (или даже отсутствие заданной по умолчанию степени детализации) может легко использоваться без отрыва от изобретения. Например, в некоторых версиях значением по умолчанию DivisionType может быть «слово» (WORD), до тех пор пока другая степень детализации не будет определена пользовательским кодом или кодом приложения.
Как показано на фиг.8, метод 812 ResultByType может принимать входную структуру данных от метода 710 «разделение» (Divide) объекта 700 InkDivider, как показано стрелкой 820. Конечно, без отрыва от изобретения объект 800 InkDivisionResult может включать в себя методы, свойства и/или другие элементы в дополнение, и/или вместо, и/или в комбинации с конкретными методами и свойствами, показанными на фиг.8.
D. Объект «модули разделения чернил» (InkDivisionUnits)
Фиг.9 иллюстрирует объект 900 InkDivisionUnits, полезный в некоторых примерах данного изобретения. Этот объект 900 - оболочка совокупностей для результатов операции анализа. Ожидается, что совокупность, по меньшей мере в некоторых примерах данного изобретения, типично будет содержать фактически все штрихи, первоначально заданные для объекта 700 InkDivider. Например, совокупность штрихов, которая была разделена на слова (Words), может быть представлена совокупностью объектов 900 InkDivisionUnits, которая содержит один объект 1000 InkDivisionUnit для каждого слова (см. также фиг.10, описанную более подробно ниже). Штрихи, которые получают из расширения отдельных объектов 1000 InkDivisionUnit в соответствующие им штрихи, как ожидается, будут соответствовать первоначальному набору штрихов, переданных объекту 700 InkDivider.
Как показано на фиг.9, объект 900 InkDivisionUnits данного примера содержит свойство 902, называемый «счетчик» (Count) 904. Свойство 904 «счетчик» обеспечивает счетчик (или количество) модулей разделения, присутствующих в данной совокупности штрихов, и делает эту информацию доступной API для использования в коде приложения или коде клиента. Например, свойство 904 «счетчик» (Count) может сообщить прикладной программе, что заданная совокупность штрихов содержит x слов и/или y строк, и/или z абзацев. Эти данные могут быть определены любым подходящим образом, например, просматривая структуру данных дерева анализа на фиг.6B для заданной совокупности штрихов, которая существует в объекте 800 InkDivisionResult. Выходная информация свойства 904 счетчика показана на фиг.9 стрелкой 906. Выходные данные могут быть структурированы следующим образом:
[propget] HRESULT Count([out,retval]Long** Count).
Объект 900 InkDivisionUnits данного примера дополнительно включает в себя метод 908, названный «элемент» 910 (Item). Метод 910 «элемент», когда его вызывают, возвращает конкретный объект 1000 InkDivisionUnit в совокупности штрихов, заданный индексным значением (Index) модуля в совокупности (например, «возвратить четвертое слово»). Выходная информация представлена на фиг.9 стрелкой 912. Выходные данные метода 910 «элемент» (Item) могут быть структурированы следующим образом:
HRESULTItem([in]Longindex,[out,retval]InkDivisionUnit*
divisionUnit).
Другое свойство 902, содержащееся в объекте 900 InkDivisionUnits данного примера, называют «_NewEnum» 914. Это свойство 914 возвращает или «IEnum Variant», или «IEnum UNKNOWN» интерфейс перечня для оцениваемой совокупности штрихов. Это свойство 914 может использоваться для отыскания любого отдельного объекта в оцениваемой совокупности чернильных штрихов, как показано на фиг.9 выходными стрелками 916 и 918, соответственно. Данные, оцененные с помощью метода 914 «_NewEnum», могут иметь следующий формат:
[propget]HRESULT_NewEnum([out,retval]IUnknown**_NewEnum).
Следует обратить внимание, что в этом примере изобретения (a) свойство 904 «счетчик» плюс метод 910 «элемент» и (b) свойство 914 «_NewEnum», которые описаны выше, являются двумя эффективно эквивалентными способами обращения к элементам совокупности чернильных штрихов, в зависимости от языка программирования и стиля кодирования, используемого кодом прикладной программы или клиентом. Комбинация метода 910 «элемент» и свойства 904 «счетчик» может использоваться в традиционном цикле «For», в то время как свойство 914 «_NewEnum» может использоваться в конструкции «For each», доступной в некоторых языках программирования.
Конечно, без отрыва от изобретения, объект 900 InkDivisionUnits может содержать свойства, методы и/или другие элементы в дополнение, и/или вместо, и/или в комбинации с конкретными свойствами и методами, описанными выше вместе с фиг.9.
E. Объект «модуль разделения чернил» (InkDivisionUnit)
Другой объект в API согласно некоторым примерам изобретения, как показано на фиг.10, называют объектом 1000 «InkDivisionUnit». Этот объект 1000 представляет отдельный элемент совокупности чернильных штрихов, полученных из операции анализа для степени детализации, определенной операцией «InkDivisionResult.ResultByType». Например, объект 1000 InkDivisionUnit может включать в себя отдельное слово проанализированной совокупности чернильных штрихов, когда указанная степень детализации анализа (или тип разделения) была «слово». Первое свойство 1002 в этом примерном объекте 1000 - свойство 1004 «штрихи» (Strokes). Свойство 1004 «штрихи» включает в себя штрихи, содержащиеся в модуле, который получен из разделения чернил (например, штрихи в слове или в строке, или в абзаце, в зависимости от выбранной степени детализации). Это свойство 1004 дает авторам кода облегченный доступ к штрихам, которые составляют результат каждой степени детализации операции анализа. Данные, которые выводятся с помощью данного свойства или которые доступны через данное свойство 1004 «штрихи» (как обозначено стрелкой вывода 1030), могут быть в следующем формате:
[propget]HRESULT Strokes([out,retval]InkStrokes**Strokes)
Свойство 1006 RecognizedString (распознанная строка) также содержится в этом примере объекта 1000 InkDivisionUnit, как показано на фиг.10. Выходной информацией этого свойства 1006, которая показана на фиг.10 стрелкой 1032, является сгенерированный машиной текст, полученный после операции распознавания рукописного текста (и/или указатель на местоположение в памяти данных для этого распознанного текста).
Этот пример объекта 1000 InkDivisionUnit дополнительно включает в себя свойство, называемое DivisionType 1008, как показано на фиг.10. Это свойство 1008 возвращает тип модуля разделения в объекте 1000 (например, слово, строка, предложение, абзац, рисунок и т.д.), как показано на фиг.10 выходной стрелкой 1034. Выходные данные для свойства 1008 DivisionType могут быть в следующем формате:
[propget]HRESULTdivisionType([out,retval]InkDivisionType** divisionType)
В некоторых примерах и/или применениях изобретения это свойство 1008 DivisionType может быть полезно, когда данная совокупность объектов 900 InkDivisionUnits содержит объекты 1000 InkDivisionUnit с различными InkDivisionTypes.
Другое свойство, существующее по меньшей мере в некоторых примерах объекта 1000 InkDivisionUnit - свойство 1010 RotationTransform (преобразование с помощью поворота). Данное свойство 1010 возвращает требуемую информацию матрицы преобразования, например, для поворота штрихов в объекте 1000 InkDivisionUnit к горизонтальному положению. Это может использоваться, например, для поворота чернильных штрихов в данном объекте 1000 на горизонтальную опорную линию перед посылкой их на средство распознавания. Выходные данные от этого свойства 1010 могут иметь следующий формат, по меньшей мере в некоторых примерах изобретения:
[propget]HRESULTRotationTransform([out,retval]InkTransform*RotationTransform
Доступность выходных данных от свойства 1010 RotationTransform показана на фиг.10 выходной стрелкой 1036.
Свойство 1010 RotationTransform, которое доступно по меньшей мере в некоторых примерах изобретения, может предоставить выгодную особенность, присутствующую в некоторых прикладных программах, при которой рукописный текст, который написан не горизонтально, может все равно точно анализироваться. В общем случае многие известные средства распознавания рукописного текста внутри себя не очень хорошо обрабатывают негоризонтальные письменные линии, и лучшие результаты распознавания в общем случае получаются только в тех случаях, когда опорная линия для рукописного текста является горизонтальной. Однако в некоторых системах анализатор автоматически вычисляет или определяет опорную линию и применяет вращательное преобразование при необходимости для получения данных, соответствующих горизонтальной линии, и таким образом улучшает возможность распознавания рукописного текста средства распознавания рукописного текста. Свойство 1010 RotationTransform позволяет коду клиента определять, была ли собранная рукописная информация горизонтальной. Таким образом, код клиента может использовать это свойство для «очистки» почерка конечного пользователя с помощью его выравнивания и/или для точного проведения линий или других форм вокруг рукописного текста пользователя.
В некоторых примерах изобретения возможно, что отдельные объекты 1000 InkDivisionUnit существуют в той же самой совокупности 900 InkDivisionUnits, но имеют различные свойства 1010 RotationTransform. Например, если пользователь сделал запись в круге и спросил обо всех этих словах, то совокупность 900 InkDivisionUnits содержала бы все слова, и каждый объект 1000 InkDivisionUnit имел различный угол опорной линии в свойстве 1010 RotationTransform.
Следует отметить, что свойство 1010 RotationTransform может быть важным не для всех объектов 1000 InkDivisionUnit. Например, это свойство 1010 может быть важно для InkDivisionUnit «слово» и InkDivisionUnit «строка», но оно не обязательно для «рисунка» или «абзаца». При желании для InkDivisionUnit DivisionType «абзац» анализатор без отрыва от изобретения может вычислять угол поворота абзаца, основываясь на отдельных составляющих его строках. Также, при желании, анализатор может вычислить угол поворота рисунка, по меньшей мере в некоторых случаях, из образцов, наблюдаемых в его штрихах. Поэтому, хотя свойство 1010 RotationTransform может присутствовать для всех InkDivisionTypes, это не является обязательным.
Объект 1000 InkDivisionUnit дополнительно включает в себя перечень 1020, вызываемый InkDivisionType 1022, как показано на фиг.10. Требуемый InkDivisionType может быть установлен клиентом или кодом прикладной программы по умолчанию, или любым другим подходящим образом. В его выходной информации (представленной выходной стрелкой 1038) перечень 1022 описывает тип InkDivisionUnits, требуемый от операции анализа. Эта информация может использоваться, например, операцией «InkDivisionResult.ResultByType». В качестве примера InkDivisionTypes для этого перечня 1020 может быть определен следующим образом:
InkDivisionType для слова=0
InkDivisionType для строки=1
InkDivisionType для абзаца=2
InkDivisionType для рисунка = 3.
Конечно, другие перечни могут использоваться без отрыва от изобретения. Например, перечень «сегмент» может использоваться, чтобы он соответствовал или слову, или символу, особенно для использования в системах, предназначенных для восточных языков. В качестве другого примера, если возможно для данной совокупности объектов InkDivisionUnits, чтобы она содержала объекты InkDivisionUnit различных типов InkDivisionType, тогда конкретные значения для записей в этом перечне могут изменяться, например, следующим образом:
Все InkDivisionTypes=0
InkDivisionType для слова=1
InkDivisionType для строки=2
InkDivisionType для абзаца=4
InkDivisionType для рисунка=8.
Таким образом InkDivisionType может стать битовым полем, и к отдельным типам может применяться операция логического сложения для определения комбинации InkDivisionType, которые требуются от операции ResultByType.
Конечно, без отрыва от изобретения объект 1000 InkDivisionUnit может включать в себя свойства, методы, перечни и/или другие элементы в дополнение, и/или вместо, и/или в комбинации с определенными свойствами и перечнями, показанными на фиг.10.
V. РАБОТА ОБЪЕКТА РАЗДЕЛЕНИЯ ЧЕРНИЛ И API
Производительность во время сеанса рисования
При использовании чернильные штрихи можно добавлять, удалять и/или иначе изменять в пределах свойства 704 «штрихи» объекта 700 InkDivider совокупности любым подходящим способом без отрыва от данного изобретения. Например, при желании, полностью новое свойство 704 «штрихи» может записываться и вставляться каждый раз, когда штрих добавляется, удаляется и/или иначе изменяется в существующем свойстве 704 «штрихи». Однако, если действовать таким образом, это, вероятно, может привести к недопустимым задержкам обработки, поскольку компьютер будет должен повторно анализировать все чернильные штрихи в свойстве 704 «штрихи» с начала каждый раз, когда штрих изменяется.
Соответственно, в некоторых примерах изобретения код клиента (или код прикладной программы), который использует объект 700 InkDivider, включает в себя способы для: (a) добавления отдельных чернильных штрихов, (b) добавления наборов чернильных штрихов (например, с помощью операции вклеивания), (c) удаления чернильных штрихов и (d) удаления наборов чернильных штрихов (например, с помощью операции вырезания) в/из объекта InkDivider совокупности свойств 704 «штрихи», вместо замены полной совокупности свойств 704 «штрихи» каждый раз, когда штрих добавляется, удаляется или иным образом изменяется. Используя способы, которые добавляют, удаляют и иначе изменяют только затронутые штрихи в свойстве 704 «штрихи» текущего объекта InkDivider, внутренняя структура данных дерева анализа может поэтапно модифицироваться. Например, когда штрих добавляют к предварительно проанализированной линии (возможно, для проведения пересекающей линии в букве «t»), если новый штрих передают объекту 700 InkDivider, используя метод «добавления» (например, через операцию «Ink Divider.Strokes.Add(newstroke)» (Разделитель чернил. Штрихи. Добавить (новый штрих)), тогда структура данных дерева анализа внутреннего анализатора может быть сделана недействительной в пределах предопределенного расстояния от местоположения нового штриха (ов), и таким образом разрешить повторный анализ штрихов только в ближайшей области от новых штрихов (также названных «грязными» штрихами или «грязными узлами»), т.е. от нового штриха, связанного с буквой «t» и другими близлежащими штрихами, в данном примере. В некоторых примерах этого поэтапного анализа штрихов анализируется не только фактически недавно добавленный чернильный штрих, но дополнительные чернильные штрихи рядом с новым штрихом также повторно анализируются, учитывая присутствие нового штриха. В некоторых примерах изобретения круговая область вокруг недавно добавленного, удаленного и/или иначе измененного штриха (ов) повторно анализируется (чтобы гарантировать, что недавно добавленные, удаленные или измененные штрихи рассматриваются в объединении с окружающими их штрихами и что окружающие штрихи рассматриваются в объединении с недавними изменениями).
Также в некоторых примерах системы и способы согласно изобретению выполняют настолько большой анализ, насколько это возможно, в фоновом режиме, не ожидая явного вызова метода «разделение» кодом клиента или кодом прикладной программы. Например, когда или устанавливают свойство 704 «штрихи» объекта InkDivider, или добавляют, или иначе изменяют штрихи в свойстве 704 «штрихи» объекта InkDivider, анализ происходит немедленно, в фоновом режиме на «снимке» структуры данных дерева анализа, как в общем случае обсуждалось выше при описании фиг.4. Поэтому, когда код клиента или код прикладной программы фактически вызывает метод «разделение» (например, в конце сеанса рисования), объект 700 InkDivider должен только (a) закончить анализ самых последних добавленных/удаленных/измененных штрихов (т.е. сосредоточиться на «грязных узлах», если они есть) и затем (b) создать и возвратить новый объект 800 InkDivisionResult.
B. Производительность при возвращении к сеансу рисования
Если ожидается, что пользовательские приложения будут входить и выходить из сеансов рисования множество раз и «передавать» объект «чернила» приложению, то объект 700 InkDivider могут вызывать для повторного анализа всех существующих данных с начала каждый раз, когда прикладная программа открывает содержащий чернила документ. Хотя это может быть приемлемо в некоторых ситуациях, производительность может пострадать, и это приведет к задержкам в обработке, особенно при открытии документов, которые содержат большое количество данных чернил.
По меньшей мере в некоторых примерах изобретения для улучшения производительности в таких ситуациях, когда существующие документы повторно открываются, могут быть полезны следующие варианты.
1. Сохранение теневых объектов
Когда прикладная программа выходит из сеанса рисования и передает данные чернил на отображение на экране, по меньшей мере в некоторых примерах изобретения может быть полезно создавать и поддерживать копии штрихов в совокупностях свойств 1004 «штрихи» каждого объекта 1000 InkDivisionUnit, вместо того, чтобы вырезать эти первоначальные штрихи из совокупности.
Приложения такого характера могут быть предназначены для постоянного поддержания теневых объектов «чернила» всех чернильных штрихов, которые требуют анализа, так же как объекта 700 InkDivider и его совокупности свойств 704 «штрихи» (штрихи, присоединенные к объекту разделения чернил). Когда вызывают метод «разделение» (Divide) (например, в конце сеанса рисования), приложение должно копировать, а не вырезать, объекты «чернила» из теневого объекта в их «родные» объекты приложений.
Если какие-либо чернила в объекте приложения редактируются не в сеансе рисования (например, выполняя другие операции, такие как масштабирование или вращение), то приложению в этом примере изобретения может потребоваться удалить и повторно добавить штрихи, соответствующие данному объекту приложения, к теневой совокупности. Например, если изменяют местоположение нарисованного объекта, который обеспечивается в программе обработки текстов, то теневой объект «чернила» должен быть изменен, чтобы отразить такое изменение местоположения.
При возвращении к сеансу рисования только новые штрихи должны добавляться или удаляться до того, как метод 710 «разделение» будет снова вызван. Это предоставляет возможность поэтапной обработки чернил между сеансами рисования.
В общем случае для поддержания поэтапного анализа требуется только один теневой объект «чернила», так как две физические копии данного объекта «чернила» существуют и должны быть синхронизированы. В случае прикладной программы обработки рисунков, которая берет результаты объекта 700 InkDivider и создают отдельные объекты «чернила» для каждого из объектов 1000 InkDivisionUnit (так, чтобы их можно отдельно активировать и редактировать, как элементы рисунка), для каждого объекта «чернила» требуется один теневой объект «чернила», который создает прикладная программа рисования, но всего существуют только две копии чернил.
Преимущество этого способа - увеличение производительности при переходе между сеансами рисования. Недостатками являются занимаемый объем памяти и накладные расходы на поддержание совокупности объектов «чернила» в синхронизации.
2. Сокращение с помощью эвристики
Другой возможностью улучшения производительности анализа при возвращении к сеансу рисования (после выхода из сеанса) является уменьшение набора данных о том, который из анализаторов должен работать. Например, можно применять эвристику, которая определяет, выиграет ли «переданный» объект «чернила» от повторного анализа. В качестве примерной иллюстрации приложение может ограничить повторный анализ только теми «переданными» объектами «чернила», которые пересекаются с новыми чернилами или расположены на некотором пространственном расстоянии от новых чернил. В некоторых случаях, в зависимости от сценария и/или воплощения, упорядоченность по Z-координате «переданных» объектов «чернила» также может быть фактором для повторного анализа.
Хотя такой подход первоначально может показаться более простым, чем подход с теневым объектом, обсуждаемым выше, необходимо принять предосторожность для того, чтобы гарантировать, что большинство, если не все, штрихов, имеющих отношение к InkDivisionUnits, которые InkDivider будет изменять, включены в сокращение с помощью эвристики. Невозможность сделать это может привести к несогласованностям в результатах анализа и, следовательно, повлияет на возможность рисования конечного пользователя.
Кроме того, сам внутренний анализатор находится действительно в лучшем положении, чтобы решать, какие штрихи он должен включать в себя, потому что он знает схему определения недействительности, которая будет использоваться для принятия решения о том, какие штрихи повторно анализировать. Одна из схем определения недействительности использует радиальное определение недействительности, но без отрыва от изобретения могут использоваться другие схемы.
VI. ПРИКЛАДНЫЕ ПРОГРАММНЫЕ ИНТЕРФЕЙСЫ
Можно использовать многочисленные прикладные программные интерфейсы («API») для «усиления» различных возможностей API чернил. Некоторые примеры включают в себя:
(a) События: в некоторых примерах изобретения завершение различных частей операции анализа (например, описанного выше метода 800 «разделение») может запускать различные события, например уведомлять код клиента о том, что по меньшей мере часть операции анализа закончена, что по меньшей мере некоторые результаты анализа являются доступными и/или что анализатор можно снова вызвать. Примеры таких событий включают в себя события «ParsingComplete» (анализ завершен) и «DivisionComplete» (разделение завершено). Событие «ParsingComplete», которое используется в некоторых примерах изобретения, сообщает прикладной программе о том, что вводимые чернильные штрихи были разделены на соответствующие им местоположения в структуре данных дерева анализа (например, так, как показано на фиг.6B). В это время в данном примере изобретения средство распознавания еще не обрабатывало данные чернильных штрихов, поэтому отдельные результаты по словам еще не доступны. С другой стороны, событие «DivisionComplete» может использоваться для сообщения прикладной программе о том, что все операции анализа и распознавания закончены. В описанном выше примере, когда событие DivisionComplete запущено, оно сообщает коду прикладной программы о том, что объект 800 InkDivisionResult является непосредственно доступным, и метод ResultByType может использоваться для отыскания объектов InkDivisionUnit для анализа с требуемой степенью детализации.
(b) Факты: факты могут (Factoids) использоваться для регулирования распознавания, например, с помощью сообщения анализатору об ожидаемой информации или образцах в чернилах, которые будут распознаваться. Например, факт может сообщить анализатору, что входящая строка находится в поле для почтового индекса. Анализатор может в таком случае искать знакомые образцы из пяти или девяти чисел. Дополнительно, анализатор может предпочтительно распознавать символы как цифры, когда входит в поле почтового индекса (например, предпочтительно распознавать штрих в форме буквы S как цифру «5», а не букву «S», и/или предпочтительно распознавать цифру «1», а не прописную букву «l» или заглавную букву «I»).
(c) Теневые объекты: объект 700 InkDivider, по меньшей мере в некоторых примерах, может обеспечить метод, который приведет к созданию внутреннего теневого объекта «чернила», к которому он относится, вместо внешне управляемого объекта «чернила». Конечно, InkDivider (или связанный с ним теневой объект менеджера чернил) также будет обеспечивать средства доступа к теневому объекту(ам) «чернила» и методы управления им.
(d) Сокращение с помощью эвристики: API анализатора также может быть расширен, по меньшей мере в некоторых примерах изобретения, чтобы он включал в себя «рекомендованные» механизмы сокращения набора данных, такие, что если бы требования разработчика приложения были удовлетворены, то разработчик не должен был бы волноваться о сокращении с помощью эвристики и вместо этого указывал бы анализатору, чтобы он сделал все от него зависящее.
(e) Замена анализатора: чтобы позволить третьим лицам использовать любое средство распознавания или анализатор, который они желают, API анализатора может включать в себя поддержку «замены» на новые средства распознавания и анализаторы, которые будут загружены пользователем. Эти альтернативные средства анализа, естественно, должны иметь свои собственные модели объектов, аналогичные описанному выше объекту RecognizerContext API.
VII. АЛЬТЕРНАТИВНЫЙ ОБЪЕКТ РАЗДЕЛЕНИЯ ЧЕРНИЛ
Фиг.7-10 показывают пример объекта разделения чернил и некоторых объектов, которые относятся к нему в соответствии с некоторыми примерами данного изобретения. Фиг.11 обеспечивает другой пример объекта 1100 InkDivider. Этот образец объекта 1100 может включать в себя различные свойства 1102, методы 1104, перечни 1106 и события 1108, каждый из которых описан более подробно ниже.
Свойство 1110 «чернила» (Ink) возвращает/устанавливает ссылку на объект «чернила» или штрихи, которые будут обработаны. Это свойство 1110 является родственным свойству 704 «штрихи», обсуждаемому выше. Свойство 1112 «чернила» возвращает совокупность объектов «чернила», сгенерированных методом 1120 «разделение» (который обсуждается более подробно ниже). Свойство 1114 DivisionGranularity (степень детализации при разделении) получает/устанавливает степень детализации, с помощью которой чернила в свойстве 1110 «чернила» анализируются методом 1120 «разделение». Хотя любое значение по умолчанию (или даже отсутствие значения по умолчанию) может использоваться без отрыва от данного изобретения, в некоторых примерах данного изобретения свойство 1114 DivisionGranularity будет по умолчанию равно степени детализации «слово». Свойство 1114 DivisionGranularity может быть установлено, используя перечень 1106 DivisionGranularity, который может включать в себя, например, перечни, представляющие «абзацы», «строки», «предложения», «слова», «рисунки» и т.д. Требуемое значение DivisionGranularity может быть установлено кодом клиента или кодом прикладной программы через значение по умолчанию или любым другим соответствующим образом.
Метод 1120 «разделение» выполняет операцию анализа чернил на чернильных штрихах, присутствующих в свойстве 1110 «чернила», основываясь на наборе свойств 1114 DivisionGranularity. Событие 1130 DivisionComplete будет запущено для сообщения прикладной программе, когда метод 1120 «разделение» завершит свою работу. Проанализированные результаты способа 1120 разделения записываются в свойства 1112 «чернила», и оттуда они могут быть доступны коду прикладной программы или коду клиента, как показано стрелкой 1132. Когда код клиента или код прикладной программы принимает событие 1130 DivisionComplete, он знает, что он может извлечь свойство 1112 «чернила» и извлечь результаты выполнения операции анализа.
В зависимости от конкретных воплощений, свойство 1112 «чернила» может быть или не быть доступным во время выполнения операции анализа (т.е. метода 1120 «разделение») и создания внутреннего дерева анализа, представляющего чернила.
Конечно, без отрыва от изобретения объект 1100 InkDivider может включать в себя свойства, методы, перечни, события и/или другие элементы в комбинации, и/или в дополнение, и/или вместо определенных свойств, методов, перечней и событий, показанных на фиг.11.
VIII. ЗАКЛЮЧЕНИЕ
Хотя данное изобретение было описано на основе различных конкретных примеров, эти конкретные примеры просто иллюстрируют изобретение, а не ограничивают его. Специалисты должны признать, например, что хотя различные конкретные названия используются для объектов, свойств, методов, перечней, событий и т.п. в данном описании, эти конкретные названия - просто примеры возможных названий, и они не должны рассматриваться как ограничение изобретения. Конечно, другие названия могут использоваться для объектов, свойств, методов, перечней, событий и т.п. без отрыва от данного изобретения. Дополнительно, конкретное выполнение объектов, свойств, методов, перечней, событий и т.д. может отличаться от описанных и показанных размещений без отрыва от данного изобретения.
Дополнительно, тот факт, что специфические признаки или функциональные возможности изобретения описаны вместе с конкретным примером, не подразумевает, что эти признаки или функциональные возможности ограничены использованием с этим конкретным примером изобретения или что каждый пример должен включать в себя этот специфический признак или функциональную возможность. Вместо этого, если иначе не определено, различные описанные выше признаки и функциональные возможности могут использоваться свободно в любом примере изобретения. Специалисты должны признать, что изменения и модификации могут быть сделаны в показанных версиях изобретения без отрыва от объема и формы изобретения, которое определено в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| АЛЬТЕРНАТИВЫ АНАЛИЗА В КОНТЕКСТНЫХ ДЕРЕВЬЯХ | 2005 |
|
RU2398276C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2358308C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2351982C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2352981C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2008 |
|
RU2485579C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2326435C2 |
| СПИСКИ АВТОМАТИЧЕСКОГО ЗАПОЛНЕНИЯ И РУКОПИСНЫЙ ВВОД | 2006 |
|
RU2412470C2 |
| ВВОД И ВОСПРОИЗВЕДЕНИЕ ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2365979C2 |
| СИСТЕМА И СПОСОБ ДЛЯ СОХРАНЕНИЯ ДОКУМЕНТА В ПОСЛЕДОВАТЕЛЬНОМ ДВОИЧНОМ ФОРМАТЕ | 2006 |
|
RU2406142C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
Изобретение относится к способам связи между прикладной программой и электронными чернилами. Изобретение позволяет упростить и повысить гибкость взаимодействия прикладных программ с множеством различных группировок чернил. Способы для поддержания связи между приложением и объектом разделения чернил (который хранит чернильные штрихи, которые будут разделены на группы), могут включать в себя этапы: (а) выдают запрос на разделение к объекту разделения чернил, возможно, с помощью приложения; (b) в ответ на запрос на разделение вызывают метод разделения, который группирует сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих первую заранее определенную степень детализации (например, слова, строки, абзацы, предложения, рисунки и т.д.); и (с) делают информацию, относящуюся к одной или большему количеству группировок штрихов, доступной приложению. Эта «информация», которая сделана доступной приложению, может включать в себя, например, существующие группировки штрихов, количество группировок штрихов, имеющих первую заранее определенную степень детализации, машинно-сгенерированный текст, соответствующий группировкам штрихов, или подобную информацию. 6 н. и 49 з.п. ф-лы, 12 ил.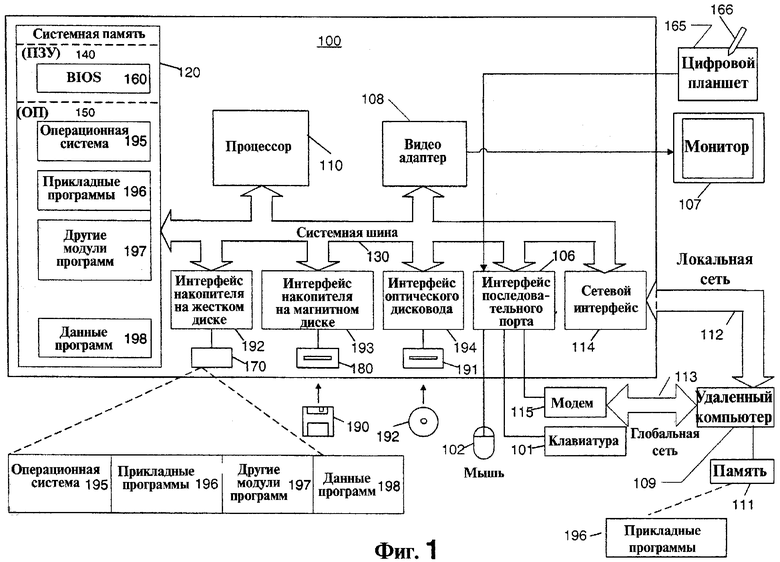
1. Способ обеспечения доступности информации прикладной программе, содержащий этапы:
сохраняют множество чернильных штрихов,
выдают запрос на разделение,
в ответ на запрос на разделение группируют сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере первую заранее определенную степень детализации, и
делают информацию, относящуюся к одной или более группировкам штрихов, доступной прикладной программе, причем информация, которая сделана доступной прикладной программе, включает в себя информацию, указывающую количество группировок штрихов, имеющих первую заранее определенную степень детализации.
2. Способ по п.1, в котором информация, которая сделана доступной прикладной программе, включает в себя по меньшей мере одну из одной или более группировок штрихов.
3. Способ по п.1, в котором информация, которая сделана доступной прикладной программе, включает в себя сгенерированный машиной текст, который соответствует по меньшей мере одной из одной или более группировок штрихов.
4. Способ по п.1, дополнительно содержащий этап:
информируют прикладную программу, когда процесс группирования закончен.
5. Способ по п.1, в котором по меньшей мере часть информации, которая относится к одной или более группировкам штрихов, которая сделана доступной прикладной программе, хранится в объекте результата разделения чернил.
6. Способ по п.1, в котором язык представляет собой по меньшей мере один из факторов, которые рассматривают при группировании сохраненных чернильных штрихов в одну или более группировок штрихов, имеющих первую заранее определенную степень детализации.
7. Способ по п.1, в котором первая заранее определенная степень детализации выбирается из группы, состоящей из: слова, строки, абзаца, предложения и рисунка.
8. Способ по п.1, в котором при группировании дополнительно группируют сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере вторую заранее определенную степень детализации.
9. Способ по п.1, дополнительно содержащий этап:
делают информацию, относящуюся к одной или более группировок штрихов, имеющих вторую заранее определенную степень детализации, доступной прикладной программе.
10. Способ по п.1, дополнительно содержащий этапы:
изменяют сохраненные чернильные штрихи для генерации модифицированного набора чернильных штрихов, выдают второй запрос на разделение, и
в ответ на второй запрос на разделение группируют модифицированный набор чернильных штрихов в одну или более группировок.
11. Считываемый компьютером носитель, имеющий выполняемые компьютером команды для выполнения способа обеспечения доступности информации прикладной программе, причем способ содержит этапы:
сохраняют множество чернильных штрихов,
принимают запрос на разделение,
в ответ на запрос на разделение, группируют сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере первую заранее определенную степень детализации, и
делают информацию, относящуюся к одной или более группировкам штрихов, доступной прикладной программе, причем информация, относящаяся к одной или более группировкам штрихов, включает в себя информацию, указывающую количество группировок штрихов, имеющих первую заранее определенную степень детализации.
12. Считываемый компьютером носитель по п.11, в котором информация, которая сделана доступной прикладной программе, включает в себя по меньшей мере одну из одной или более группировок штрихов.
13. Считываемый компьютером носитель по п.11, в котором информация, которая сделана доступной прикладной программе, включает в себя сгенерированный машиной текст, который соответствует по меньшей мере одной из одной или более группировок штрихов.
14. Считываемый компьютером носитель по п.11, в котором способ дополнительно включает в себя этап:
информируют приложение, когда процесс группирования закончен.
15. Считываемый компьютером носитель по п.11, в котором по меньшей мере часть информации, относящейся к одной или более группировкам штрихов, которая сделана доступной прикладной программе, хранится в объекте результата разделения чернил.
16. Считываемый компьютером носитель по п.11, в котором язык представляет собой по меньшей мере один из факторов, который рассматривают при группировании сохраненных чернильных штрихов в одну или более группировок штрихов, имеющих первую заранее определенную степень детализации.
17. Считываемый компьютером носитель по п.11, в котором первая заранее определенная степень детализации выбирается из группы, состоящей из: слова, строки, абзаца, предложения и рисунка.
18. Считываемый компьютером носитель по п.11, в котором при группировании дополнительно группируют сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере вторую заранее определенную степень детализации.
19. Считываемый компьютером носитель по п.11, в котором способ дополнительно включает в себя этап:
делают информацию, относящуюся к одной или более группировкам штрихов, имеющих вторую заранее определенную степень детализации, доступной прикладной программе.
20. Считываемый компьютером носитель по п.11, в котором способ дополнительно включает в себя этапы:
принимают модифицированный набор чернильных штрихов,
принимают второй запрос на разделение, и в ответ на второй запрос на разделение группируют модифицированный набор чернильных штрихов в одну или более группировок.
21. Способ связи между приложением и объектом разделения чернил, причем объект разделения чернил хранит чернильные штрихи, которые должны быть разделены на группы, причем способ содержит этапы:
выдают запрос на разделение к объекту разделения чернил,
в ответ на запрос на разделение вызывают метод разделения, который группирует сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере первую заранее определенную степень детализации, и
делают информацию, относящуюся к одной или более группировок штрихов, доступной приложению, причем информация, относящаяся к одной или более группировок штрихов, включает в себя информацию, указывающую количество группировок штрихов, имеющих первую заранее определенную степень детализации.
22. Способ по п.21, в котором информация, которая сделана доступной приложению, включает в себя по меньшей мере одну из одной или более группировок штрихов.
23. Способ по п.21, в котором информация, которая сделана доступной приложению, включает в себя сгенерированный машиной текст, который соответствует по меньшей мере одной из одной или более группировок штрихов.
24. Способ по п.21, дополнительно содержащий этап: информируют приложение, когда метод разделения закончен.
25. Способ по п.21, в котором по меньшей мере часть информации, относящейся к одной или более группировок штрихов, которая сделана доступной приложению, хранится в объекте результата разделения чернил.
26. Способ по п.21, в котором во время работы метода разделения язык является по меньшей мере одним из факторов, который рассматривают при группировании сохраненных чернильных штрихов в одну или более группировок штрихов, имеющих первую заранее определенную степень детализации.
27. Способ по п.21, в котором первую заранее определенную степень детализации выбирают из группы, состоящей из: слова, строки, абзаца, предложения и рисунка.
28. Способ по п.21, в котором во время работы метода разделения метод разделения дополнительно группирует сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере вторую заранее определенную степень детализации.
29. Способ по п.21, дополнительно содержащий этап: делают информацию, относящуюся к одной или более группировкам штрихов, имеющих вторую заранее определенную степень детализации, доступной приложению.
30. Способ по п.21, дополнительно содержащий этапы:
изменяют сохраненные чернильные штрихи для генерации модифицированного набора чернильных штрихов,
выдают второй запрос на разделение к объекту разделения чернил, и в ответ на второй запрос на разделение, вызывают метод разделения, который группирует модифицированный набор чернильных штрихов в одну или более группировок.
31. Считываемый компьютером носитель, имеющий выполняемые компьютером команды для выполнения способа связи между приложением и объектом разделения чернил, причем объект разделения чернил хранит чернильные штрихи, которые должны быть разделены на группы, данный способ содержит этапы:
выдают запрос на разделение к объекту разделения чернил,
в ответ на запрос на разделение вызывают метод разделения, который группирует сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере первую заранее определенную степень детализации, и
делают информацию, относящуюся к одной или более группировкам штрихов, доступной приложению, причем информация, относящаяся к одной или более группировкам штрихов, включает в себя информацию, указывающую количество группировок штрихов, имеющих первую заранее определенную степень детализации.
32. Считываемый компьютером носитель по п.31, в котором информация, которая сделана доступной приложению, включает в себя по меньшей мере одну из одной или более группировок штрихов.
33. Считываемый компьютером носитель по п.31, в котором информация, которая сделана доступной приложению, включает в себя сгенерированный машиной текст, который соответствует по меньшей мере одной из одной или более группировок штрихов.
34. Считываемый компьютером носитель по п.31, в котором способ связи дополнительно включает в себя этап:
информируют приложение, когда метод разделения закончен.
35. Считываемый компьютером носитель по п.31, в котором по меньшей мере часть информации, относящейся к одной или более группировок штрихов, которая сделана доступной приложению, хранится в объекте результата разделения чернил.
36. Считываемый компьютером носитель по п.31, в котором во время работы метода разделения язык является по меньшей мере одним из факторов, который рассматривают при группировании сохраненных чернильных штрихов в одну или более группировок штрихов, имеющих первую заранее определенную степень детализации.
37. Считываемый компьютером носитель по п.31, в котором первую заранее определенную степень детализации выбирают из группы, состоящей из: слова, строки, абзаца, предложения и рисунка.
38. Считываемый компьютером носитель по п.31, в котором во время работы метода разделения метод разделения дополнительно группирует сохраненные чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере вторую заранее определенную степень детализации.
39. Считываемый компьютером носитель по п.31, в котором способ связи дополнительно включает в себя этап:
делают информацию, относящуюся к одной или более группировкам штрихов, имеющих вторую заранее определенную степень детализации, доступной приложению.
40. Считываемый компьютером носитель по п.31, в котором способ связи дополнительно включает в себя этапы:
принимают изменения к сохраненным чернильным штрихам для генерации модифицированного набора чернильных штрихов,
выдают второй запрос на разделение объекту разделения чернил, и в ответ на второй запрос на разделение, вызывают метод разделения, который группирует модифицированный набор чернильных штрихов в одну или более группировок.
41. Считываемый компьютером носитель по п.31, дополнительно имеющий хранящуюся на нем структуру данных для объекта разделения чернил, содержащий:
первый набор данных, определяющий свойство штрихов для сохранения информации, относящейся к одному или более чернильным штрихам, и второй набор данных, определяющий метод разделения для группирования одного или более чернильных штрихов в одну или более группировок штрихов, имеющих по меньшей мере первую заранее определенную степень детализации, и
третий набор данных, определяющий пронумерованное значение, соответствующее типу разделения.
42. Считываемый компьютером носитель по п.41, в котором объект разделения чернил дополнительно включает в себя четвертый набор данных, определяющий свойство контекста средства распознавания для сохранения информации, относящейся к средству распознавания, которое используется при разделении одного или более чернильных штрихов.
43. Считываемый компьютером носитель по п.31, дополнительно имеющий хранящуюся на нем структуру данных для объекта результата разделения чернил, содержащий:
первый набор данных, определяющий свойство штрихов для сохранения информации, относящейся к одному или более чернильных штрихов, которые были подвергнуты методу разделения и были сгруппированы в одну или более группировок, имеющих по меньшей мере первую заранее определенную степень детализации,
второй набор данных, определяющий метод «результат в зависимости от типа» для разрешения извлечения группировок чернильных штрихов по меньшей мере первой заранее определенной степени детализации, и третий набор данных, определяющий пронумерованное значение, соответствующее типу разделения.
44. Считываемый компьютером носитель по п.43, в котором метод «результат в зависимости от типа» допускает извлечение группировок чернильных штрихов множества различных степеней детализации, которые включают в себя первую заранее определенную степень детализации.
45. Считываемый компьютером носитель по п.31, дополнительно имеющий хранящуюся на нем структуру данных для объекта «модуль разделения чернил», содержащий:
первый набор данных, определяющий свойство штрихов для сохранения информации, относящейся к одному или более чернильных штрихов, содержащихся в группировке из одного или более чернильных штрихов, второй набор данных, определяющий тип разделения для сохранения информации, относящейся к типу содержащихся в группировке чернильных штрихов, и
третий набор данных, определяющий пронумерованное значение, соответствующее типу разделения.
46. Считываемый компьютером носитель по п.45, в котором структура данных дополнительно включает в себя четвертый набор данных, определяющий или указывающий на сгенерированный машиной текст, соответствующий одному или более чернильных штрихов, содержащихся в свойстве штрихов.
47. Считываемый компьютером носитель по п.46, в котором структура данных дополнительно включает в себя пятый набор данных, определяющий угол поворота, необходимый для поворота одного или более штрихов, которые содержатся в свойстве штрихов, к углу, подходящему для введения в систему распознавания рукописного текста.
48. Считываемый компьютером носитель по п.45, в котором структура данных дополнительно включает в себя четвертый набор данных, определяющий угол поворота, необходимый для поворота одного или более штрихов, которые содержатся в свойстве штрихов, к углу, подходящему для введения в систему распознавания рукописного текста.
49. Считываемый компьютером носитель по п.31, дополнительно имеющий хранящуюся на нем структуру данных для объекта «модуль разделения чернил», содержащий:
первый набор данных, определяющий счетчик группировок штрихов, существующих в объекте «чернила», и
второй набор данных, определяющий метод «элемент», который извлекает конкретную группировку штрихов, заданную индексным значением для конкретной группировки штрихов.
50. Способ связи между анализатором и прикладной программой, содержащий этапы:
посылают данные, представляющие множество чернильных штрихов, от прикладной программы к анализатору,
передают анализатору информацию для анализа,
группируют чернильные штрихи в одну или более группировок штрихов, имеющих по меньшей мере первую заранее определенную степень детализации, и
делают информацию, относящуюся к одной или более группировкам штрихов, доступной прикладной программе, причем информация, относящаяся к одной или более группировкам штрихов, сделанная доступной прикладной программе, включает в себя информацию, относящуюся к количеству группировок.
51. Способ по п.50, в котором передача информации для анализа включает в себя этап:
устанавливают средство распознавания, используемое для данной группировки.
52. Способ по п.50, в котором передача информации для анализа включает в себя этап:
устанавливают язык, используемый для данной группировки.
53. Способ по п.50, в котором передача информации для анализа включает в себя этап:
устанавливают первую заранее определенную степень детализации.
54. Способ по п.50, в котором передача информации для анализа включает в себя этап:
устанавливают ожидаемую высоту строки для строк текста, которые включают в себя чернильные штрихи.
55. Считываемый компьютером носитель, который включает в себя сохраненные на нем выполняемые компьютером команды для выполнения способа по п.50.
| US 5517578 А, 14.05.1996 | |||
| RU 96102579 А, 20.05.1998 | |||
| US 5889523 А, 30.03.1999 | |||
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |

