ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение в целом имеет отношение к машинам поиска. Более подробно, изобретение имеет отношение к способам и системам улучшения ранжирования поиска с использованием информации о статье, такой как информация клиентской стороны.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Машины поиска полезны для определения местоположения определенной желаемой или релевантной статьи в большой совокупности статей. Известные машины поиска часто возвращают результаты на основе системы оценки или ранжирования. Например, известные машины поиска сортируют статьи результата поиска на основе содержимого статей, например, на основе количества появлений ключевого слова или конкретного слова или фразы в каждой статье.
Известные приложения клиентской стороны возвращают результаты на основе, например, определенных атрибутов статьи или данных хронологии. Например, существующие поисковые приложения клиентской стороны предоставляют результаты поиска, ранжированные по дате и времени, по тому, когда статья была сохранена последний раз, типу статьи или размеру статьи. Пользователь может ограничить поиск, вводя другие параметры, такие как время последнего редактирования, другие слова или фразы в статье или тип статьи. Атрибуты статьи и данные хронологии, используемые традиционными поисковыми приложениями клиентской стороны для ранжирования обнаруженных статей, ограничены.
Аспекты сортировки и ранжирования таких традиционных систем недостаточны. Нехватка возможности эффективного ранжирования часто приводит к огромному количеству результатов поиска и требует от пользователя больших когнитивных усилий в составлении (или переработке) полезных запросов поиска и дополнительных затрат времени. Существующие клиентские поисковые приложения практически не ранжируют статьи в соответствии со многими релевантными факторами или даже не оценивают эти факторы, которые могли бы служить для лучшего ограничения поиска желательных статей. Соответственно, существующие клиентские поисковые приложения могут быть затратными по времени и трудоемкими, обременительными в использовании, медленными и вообще неэффективными.
Таким образом, существует потребность в способах и системах для улучшения ранжирования поиска с использованием информации о статье, такой как информация на клиентской стороне. Например, существует потребность в клиентском поисковом приложении, которое ранжирует статьи, которые находятся в файловой структуре клиентского компьютера или к которым пользователь ранее обратился, на основе достаточных факторов, таким образом, чтобы наиболее релевантные статьи были выданы пользователю быстро и легко.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Варианты воплощения данного изобретения включают системы и способы, которые улучшают поиск. Один аспект одного варианта воплощения данного изобретения содержит сортировку и ранжирование результатов поиска на основе, по меньшей мере частично, данных поведения на клиентской стороне, связанных с ранжированными статьями. Это позволяет, например, машине поиска на клиентской стороне лучше оценивать, какие потенциальные результаты поиска будут представлять наибольший интерес для пользователя. Дальнейшие признаки и преимущества данного изобретения сформулированы ниже.
ПЕРЕЧЕНЬ ЧЕРТЕЖЕЙ
Фиг.1 - блок-схема системы в соответствии с одним вариантом воплощения данного изобретения;
Фиг.2 - подробное представление части системы, иллюстрированной на Фиг.1, в соответствии с одним вариантом воплощения данного изобретения;
Фиг.3 - схема последовательности операций способа в соответствии с одним вариантом воплощения данного изобретения;
Фиг.4 - схема последовательности операций одного варианта воплощения процедуры из состава способа, показанного на Фиг.3; и
Фиг.5 - схема последовательности операций одного варианта воплощения процедуры из состава процедуры, показанной на Фиг.4.
ПОДРОБНОЕ ОПИСАНИЕ
Данное изобретение содержит способы и системы для улучшения ранжирования результатов поиска с использованием информации о статье. В соответствии с данным изобретением могут быть созданы различные системы. Фиг.1 представляет собой блок-схему, показывающую иллюстративную систему, в которой могут функционировать иллюстративные варианты воплощения данного изобретения. Данное изобретение может функционировать и быть воплощено также и в других системах.
Система 100, показанная на Фиг.1, содержит несколько клиентских устройств 102a-n, пользователей 112a-n, сеть 106 и сервер 190. Показанная сеть 106 содержит Интернет. В других вариантах воплощения могут использоваться другие сети, такие как внутрикорпоративная сеть, локальная сеть (LAN) или глобальная сеть (WAN). Каждое из показанных клиентских устройств 102a-n содержит машиночитаемый носитель, такой как оперативное запоминающее устройство (ОЗУ) 108, соединенный с процессором 110. Процессор 110 выполняет набор машиновыполняемых команд программы, сохраненных в памяти 108. Такие процессоры могут содержать микропроцессор, специализированную интегральную микросхему и конечные автоматы. Такие процессоры содержат или взаимодействуют с носителями, например, машиночитаемыми носителями, которые хранят команды, которые при выполнении процессором предписывают процессору выполнять способы, описанные здесь.
Варианты воплощения машиночитаемых носителей включают в себя, но без ограничения, электронное, оптическое, магнитное или другое устройство памяти или передачи, которое может предоставить процессору машиночитаемые команды. Другие примеры подходящих носителей включают в себя, но без ограничения, гибкий диск, постоянное запоминающее устройство на компакт-диске (CD-ROM), магнитный диск, микросхему памяти, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), специализированную интегральную микросхему, конфигурированный процессор, все оптические носители, все магнитные ленты или другие магнитные носители или любой другой носитель, с которого процессор компьютера может читать команды. Кроме того, различные другие виды машиночитаемых носителей могут передавать или переносить команды на компьютер, в том числе маршрутизатор, частная сеть или сеть общего пользования или другое устройство передачи или канал, как проводной, так и беспроводной. Команды могут содержать код на любом языке программирования, в том числе, например, C, C++, C#, Visual Basic, HTML, Java и JavaScript.
Клиентские устройства 102a-n могут также содержать множество внешних или внутренних устройств, таких как мышь, постоянное запоминающее устройство на компакт-диске (CD-ROM), клавиатура, аппаратные средства распознавания речи, дисплей или другие устройства ввода или вывода. Примеры клиентских устройств 102a-n - персональные компьютеры, цифровые секретари, персональные цифровые секретари, сотовые телефоны, мобильные телефоны, смарт-фоны, пейджеры, цифровые планшеты, портативные компьютеры, переносные компьютеры, устройство на основе процессора и подобные типы систем и устройств. Вообще, клиентское устройство 102a-n может быть любым типом платформы на основе процессора, которая взаимодействует с одной или более прикладными программами. Клиентские устройства 102a-n, показанные на Фиг.1, содержат персональные компьютеры.
Память 108 содержит средство 140 мониторинга, клиентское приложение 170, клиентскую статью 171 и процессор 180 запросов. Статьи могут содержать документы, например, Web-страницы различных форматов, таких как формат языка гипертекстовой разметки (HTML), формат расширяемого языка разметки (XML), формат расширяемого языка гипертекстовой разметки (XHTML), файлы в формате переносимого документа (PDF) и файлы документов прикладных программ текстового процессора, базы данных, сообщения чата, сообщения электронной почты, аудио-, видео- или любую другую информацию любого типа, каким бы то ни было образом доступную в сети (такой как Интернет), на персональном компьютере или других вычислительных средствах или средствах хранения. Клиентская статья 171 содержит любую статью, связанную с устройством пользователя или клиента. В показанном варианте воплощения клиентское приложение 170 содержит приложение текстового процессора, а клиентская статья 171 содержит документ в формате, пригодном для использования с приложением текстового процессора.
Показанное средство 140 мониторинга определяет данные о поведении на стороне клиента, связанные с клиентским приложением 170. Данные о поведении на стороне клиента могут содержать, например, данные о вводе, данные о переписке, данные о хронологии статей и данные о ссылках, а также другие виды данных о поведении на стороне клиента. Каждый из этих типов данных будет обсуждаться более полно ниже. Средство 140 мониторинга отслеживает взаимодействия пользователя и взаимодействия клиентского компьютера со статьями на клиентском компьютере. В других вариантах воплощения средство 140 мониторинга отслеживает взаимодействия нескольких пользователей со статьями на клиентском компьютере, в ассоциированной сети или в другом месте. Как один пример, средство 140 мониторинга отслеживает клиентскую статью 171 и обнаруживает, что пользователь 112a вводит данные в клиентскую статью 171, используя клиентское приложение 170. Средство 140 мониторинга отслеживает и записывает количество времени, которое пользователь 112a проводит, вводя данные в статью. Средство 140 мониторинга отслеживает и записывает взаимодействия с несколькими статьями (не показаны здесь) на клиенте 102a. Сбор и использование данных о поведении на стороне клиента описаны далее ниже.
Средство 140 мониторинга согласно иллюстративному варианту воплощения хранит собранные данных о поведении на стороне клиента в хранилище 160 данных. Хранилище 160 данных в иллюстративном варианте воплощения содержит базу 164 данных с данными о поведении на стороне клиента. Согласно другим аспектам или вариантам воплощения данного изобретения хранилище 160 данных может содержать существующую ранее базу данных. Элементы хранения данных в хранилище 160 данных могут содержать любой из способов хранения данных или их комбинацию, в том числе без ограничения, массивы, хэш-таблицы, списки и пары. К другим подобным типам устройств хранения данных можно обратиться клиентским устройством 102. База 164 данных с данными о поведении клиента хранит данные, связанные с клиентским приложением 170, и данные о поведении на стороне клиента, такие как данные о печати, просмотре, прокрутке, движении мыши, переписке по электронной почте или другие виды данных о поведении на стороне клиента. Данные о поведении клиента могут быть объединены с другими данными в одной базе данных или могут быть сохранены в нескольких базах данных.
Процессор 180 запросов содержит программное обеспечение и аппаратные средства, которые дают возможность процессору 180 запросов принять либо явный запрос 114 поиска, введенный пользователем 112a, либо сгенерировать неявный запрос на основе данных о поведении на стороне клиента. Процессор 180 запросов затем форматирует неявный или явный запрос в сигнал 182 запроса, который может быть принят машиной 120 поиска.
Память 108 также содержит машину 120 поиска. Машина 120 поиска определяет местоположение релевантной информации в ответ на сигнал 182 запроса от процессора 180 запросов. Сигнал 182 запроса может соответствовать, например, сигналу явного запроса, сгенерированному на основе запроса поиска, введенного пользователем 112a, или сигналу неявного запроса, сгенерированному на основе сигналов события от средства 140 мониторинга. Машина 120 поиска отвечает на сигнал 182 запроса, возвращая набор релевантной информации, или результат 150 поиска, пользователю 112a.
Показанная машина 120 поиска содержит средство определения (определитель) 134 местоположения статьи, процессор 138 ранжирования и процессор 136 данных о поведении клиента. В показанном варианте воплощения каждый из этих элементов содержит машинный код, находящийся в памяти 108. Определитель 134 местоположения статьи идентифицирует набор релевантных статей в ответ на сигнал 182 запроса от процессора 180 запросов. Процессор 136 данных о поведении клиента извлекает из хранилища 160 данных или иначе определяет данные о поведении на стороне клиента, связанные со статьями в наборе релевантных статей, возвращенном определителем 134 местоположения статьи. Процессор 138 ранжирования ранжирует или оценивает каждую статью в наборе релевантных статей, идентифицированных определителем 134 местоположения статьи на основе релевантности сигналу 182 запроса в свете данных о поведении на стороне клиента, определенных процессором 136 поведения клиента. Следует отметить, что другие функции и характеристики определителя 134 местоположения статьи, процессора 138 ранжирования и процессора 138 данных о пользователе описаны далее ниже.
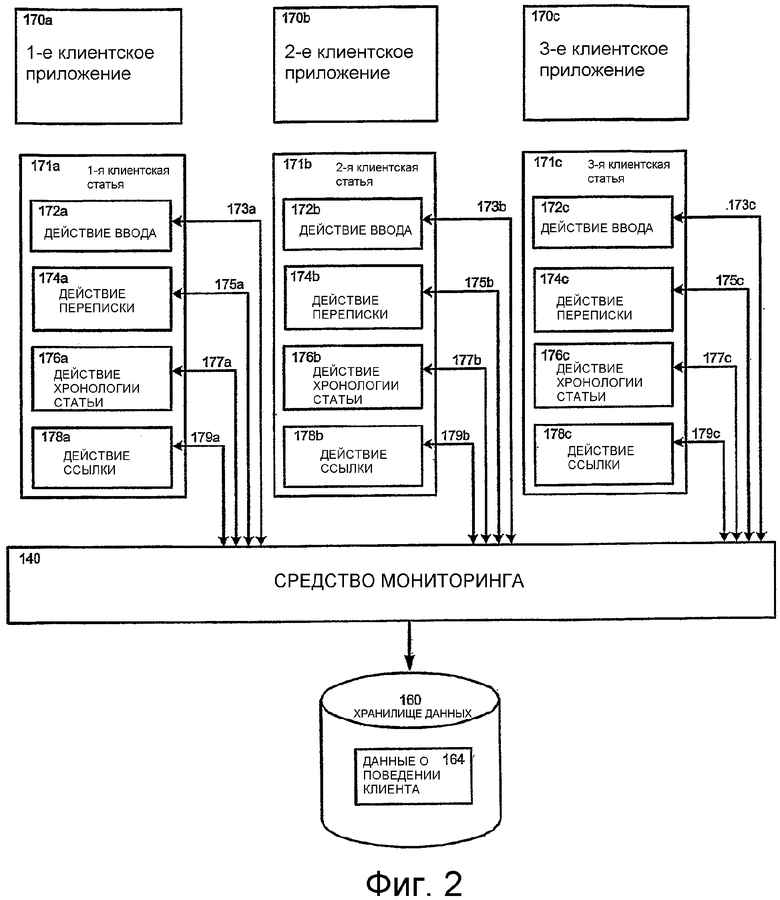
Фиг.2 показывает более подробное представление средства 140 мониторинга, показанного на Фиг.1. По мере того как клиент 102a или пользователь 112a взаимодействует с клиентскими статьями 171a-c, средство 140 мониторинга отслеживает такую поведенческую деятельность клиента и из этой поведенческой деятельности клиента создает данные о поведении на клиентской стороне, связанные с клиентскими статьями 171a-c. Поведенческая деятельность клиента, связанная с клиентскими статьями 171a-c, в соответствии с иллюстративным вариантом воплощения содержит одно или более действий 172a-c ввода, действий 174a-c переписки, действий 176a-c хронологии статьи и действий 178a-c ссылок. Эти четыре общих категории действий пользователя 112a и/или клиента 102a, связанных с клиентскими статьями, даются только в целях иллюстрации. Существуют другие не изображенные общие категории действий, в том числе, например, действие ассоциации, которое обсуждается далее ниже. На Фиг.2 клиентские статьи 171a-c изображены, чтобы проиллюстрировать, что средство 140 мониторинга может отслеживать множество статей, связанных с одним или более приложениями, и создавать данные о поведении на клиентской стороне, связанные с каждой статьей индивидуально. Типы данных, иллюстрированных на Фиг.2, предложены только как примеры типов данных о поведении на стороне клиента, связанных с клиентскими статьями 171a-c, связанными с клиентскими приложениями 170a-c. Другие типы данных о поведении на клиентской стороне, связанных с клиентскими статьями 171a-c, могут использоваться в пределах объема данного изобретения. Например, данные о поведении на клиентской стороне могут включать в себя данные относительно предпочтений клиента, например, информацию о том, каким образом пользователь 112a отреагировал на отдельный тип статьи в прошлом или какое количество деятельности на стороне клиента обычно связано со статьей отдельного типа. Например, пользователь 112a может демонстрировать предпочтение Web-страницам, выбирая Web-страницы из списка результатов поиска, содержащих как Web-страницы, так и документы обработки текстов, или проводя большинство поведения пользователя в отдельном типе статьи. Настоящее изобретение может использовать данные, отражающие предпочтения пользователя 112a, одни или в комбинации с другими факторами, чтобы определять оценку ранжирования для связанных статей.
Средство 140 мониторинга отслеживает действия пользователя 112a и/или клиента 102a и определяет соответствующие данные о поведении на стороне клиента. Соответствующие данные о поведении на стороне клиента могут содержать, например, данные 172a-c о действиях ввода, данные 174a-c о действиях переписки, данные 176a-c о действиях хронологии статьи или данные 178a-c о действиях ссылок. Более широко, данные о поведении на стороне клиента могут содержать любой тип деятельности клиента, которая может произойти в данном приложении. Данное приложение может иметь один или более способов действия ввода, каждый из которых может быть связан с данными о поведении на стороне клиента и может передать связанный вес ранжирования статье, над которой производится действие. В целях иллюстрирования только четыре общих категории данных о поведении на стороне клиента были изображены на Фиг.2. Однако данное изобретение не ограничено этими четырьмя общими категориями поведения на стороне клиента, изображенными на Фиг.2. Например, приложение программирования может иметь действие ввода по компилированию данных. Пользователь, работающий в приложении программирования, может периодически компилировать данные. Это действие могло бы указать на более высокое значение для компилируемых статей и является другим примером данных о поведении на стороне клиента, созданных и используемых данным изобретением. Данное изобретение может также назначать разные весовые коэффициенты разным типам действий, связанных с отдельным приложением.
Данные 172a-c о действиях ввода, изображенные на Фиг.2, могут содержать, например, данные о вводе данных, данные о движении мыши, данные о прокрутке, данные ввода распознавания речи, данные о копировании и вставке или любой другой вид данных ввода. Данные 174a-c о действиях переписки могут содержать, например, данные о печати, данные об ответах, данные об электронной почте, данные о пересылке или любой другой вид данных о переписке. Данные 176a-c о действиях хронологии статьи могут содержать, например, данные о времени последнего сохранения, данные о размере файла, данные об авторе или любой другой тип данных о хронологии статьи. Данные 178a-c о ссылках могут содержать, например, данные о закладках, данные о гиперссылках, данные о сносках, данные о перекрестных ссылках или любой другой тип данных о ссылках. Данные о действиях ассоциации, не изображенные на Фиг.2, могут содержать, например, информацию о том, что электронная почта связана с документом обработки текстов (через вложение) или что над двумя документами работают параллельно, как документ обработки текстов и презентация. Одни или более данных, содержащих соответствующие данные о поведении на клиентской стороне для клиентских статей 171a-c, потенциально могут быть пустым множеством.
После определения соответствующих данных о поведении на клиентской стороне для клиентских статей 171a-c средство 140 мониторинга обрабатывает данные о поведении на клиентской стороне, связанные с клиентскими статьями 171a-c, так, чтобы они были готовы к их приему базой 164 данных с данными о поведении клиента, расположенной в хранилище 160 данных. Средство 140 мониторинга затем передает данные в хранилище 160 данных для хранения. Данные о поведении на клиентской стороне передаются с идентификационной информацией для статьи, связанной с данными, и данные сохраняются в ассоциации с этой идентификационной информацией.
Средство 140 мониторинга определяет данные о поведении на клиентской стороне для статей нескольких пользователей и гарантирует, что данные о поведении на клиентской стороне, связанные со статьей, идентифицированы с этой конкретной статьей. Средство 140 мониторинга передает данные о поведении на клиентской стороне вместе с информацией идентификации, которая связывает данные с конкретной статьей, к которой они имеют отношение, в хранилище 160 данных для хранения таким способом, который сохраняет ассоциации между статьей и поведением клиента.
Как пример функционирования средства 140 мониторинга рассмотрим пользователя 112a, работающего со статьей, связанной с приложением обработки текстов, В этом примере статья представлена клиентской статьей 171a на Фиг.2 и приложение обработки текстов представлено клиентской статьей 171a. По мере того как пользователь 112a взаимодействует с клиентской статьей 171a (в этом примере статьей из приложения обработки текстов), данные о поведении клиента отслеживаются и принимаются средством 140 мониторинга.
В этом примере, если пользователь 112a вводит текст в клиентскую статью 171a, средство 140 мониторинга обнаруживает эту деятельность и принимает данные 173a о действиях ввода, содержащие, например, данные, указывающие, что ввел пользователь 112a и как долго пользователь 112a делал ввод. Если пользователь 112a затем сохраняет статью и посылает ее по электронной почте другу, средство 140 мониторинга обнаруживает эту деятельность и принимает дополнительные данные о поведении пользователя, содержащие, например, данные 177a о действиях хронологии статьи, содержащие, например, время и дату сохранения статьи и общее количество байтов данных в статье. Средство 140 мониторинга также создало данные 175a о действиях переписки, содержащие, например, тот факт, что статья была отправлена по электронной почте получателя, которому отправили статью, и любое описание, сопровождающее статью.
Средство 140 мониторинга затем конфигурирует данные о поведении на клиентской стороне, связанные с приложением обработки текстов, для их приема базой данных 164 с данными о поведении клиента, расположенной в хранилище 160 данных, таким способом, чтобы они остались связанными со статьей, к которой они имеют отношение.
Таким образом, в данном примере средство 140 мониторинга создает данные о поведении на клиентской стороне в ответ на ввод, сохранение и отправление по электронной почте, совершаемые пользователем 112a. Эти данные о поведении на клиентской стороне связаны с документом обработки текстов, который пользователь 112a использовал, когда произошли события, генерирующие данные о поведении на клиентской стороне. Эта ассоциация сохраняется в хранилище 160 данных таким образом, что если определитель 134 местоположения статьи определяет, что документ обработки текстов релевантен сигналу 182 запроса, процессор 136 данных о поведении клиента может отыскать данные о поведении на клиентской стороне, связанные с документом обработки текстов.
Данные о поведении на клиентской стороне, созданные средством 140 мониторинга, могут затем использоваться для оценки или ранжирования машиной 120 поиска. Например, статья, связанная с большим количеством деятельности по печати, редактированию, просмотру и прокрутке, потенциально получит более высокую оценку ранжирования, чем статья, с которой связана небольшая деятельность или не связана никакая деятельность по печати, редактированию, просмотру и прокрутке, потому что деятельность, вероятно, указывает на более высокий интерес пользователя 112a к статье, связанной с этой деятельностью. Текстовый документ, например, который был открыт, но никогда не был напечатан или отредактирован, с меньшей вероятностью был прочитан пользователем, чем текстовый документ, у которого имеется большая деятельность по редактированию и печати, связанная с ним.
Точно так же текстовый документ, с которым не связано никакой деятельности по вводу, с меньшей вероятностью редактировался пользователем, чем документ с большим количеством деятельности по вводу. Статья, которая с меньшей вероятностью редактировалась пользователем или была прочитана пользователем, с меньшей вероятностью будет важна для этого пользователя. Процессор 138 ранжирования может, таким образом, назначить более низкую оценку ранжирования статье с меньшим количеством пользовательской деятельности, связанной с ней.
Должно быть отмечено, что данное изобретение может содержать системы, имеющие архитектуру, отличающуюся от той, которая показана на Фиг.1 и 2. Система 100, показанная на Фиг.1, и подробное представление системы мониторинга, показанное на Фиг.2, являются лишь иллюстративными и использованы для разъяснения иллюстративных способов, которые показаны на Фиг.3-5.
Различные способы могут быть выполнены в соответствии с данным изобретением. Один иллюстративный способ в соответствии с данным изобретением содержит получение запроса поиска, определение релевантной статьи, связанной с запросом поиска, и определение оценки ранжирования для релевантной статьи на основе, по меньшей мере частично, данных о поведении на клиентской стороне, связанных с релевантной статьей.
Например, если пользователь 112a желает отыскать статьи, касающиеся совещания по продажам, которое пользователь 112a недавно посетил, пользователь 112a может ввести термины "совещание по продажам" в качестве запроса 114 поиска. Данное изобретение берет этот запрос 114 поиска, "совещание по продажам", и определяет местоположение документов, которые являются релевантными этому поиску. Они могут включать в себя, например, электронную почту, которая содержит эти слова в поле темы, текстовый документ, который содержит эти слова в теле документа, и электронную таблицу, которая содержит эти слова в заголовке. Не все статьи, определенные как релевантные запросу 114 поиска, будут обязательно представлять большой интерес для пользователя 112a. Данное изобретение отражает это, ранжируя релевантные статьи согласно различным действиям пользователя 112a, когда он работал с этой статьей. Например, если пользователь 112a прокручивал электронную таблицу, нажимал на ней мышью, вводил в нее текст, печатал ее и часто просматривал, вероятно, что пользователь 112a редактировал или готовил электронную таблицу или что она иным образом представляла непосредственный интерес для пользователя 112a. Если, с другой стороны, пользователь 112a почти не производил никакой деятельности с текстовым документом, более вероятно, что он не представлял непосредственного интереса для пользователя 112a. Таким образом, данное изобретение может отразить относительную важность электронной таблицы перед текстовым документом, ранжируя ее с более высокой оценкой ранжирования. Таким образом, когда результаты запроса 114 поиска выдаются пользователю 112a, электронная таблица может быть отображена способом, который акцентирует внимание на ней, а не на текстовом документе. Акцентирование внимания на электронной таблице поможет пользователю 112a выбрать ее из результатов поиска, таких как текстовый документ, которые менее интересны пользователю 112a.
Фиг.3-5 показывают различные аспекты иллюстративных способов в соответствии с данным изобретением. Фиг.3 показывает иллюстративный способ 200 в соответствии с данным изобретением. Этот иллюстративный способ предоставлен посредством примера, поскольку имеется множество путей выполнить способы в соответствии с данным изобретением. Способ 200, показанный на Фиг.3, может быть осуществлен или иным образом выполнен любой из различных систем. Способ 200 описан ниже как выполняемый системой 100, показанной на Фиг.1 и 2 в качестве примера, и различные элементы системы 100 упоминаются при разъяснении иллюстративных способов по Фиг.3-5. Показанный способ 200 обеспечивает улучшение поиска на стороне клиента, предоставляя ранжирование результатов поиска на основе данных о поведении клиента. Способы в соответствии с данным изобретением могут быть воплощены другими средствами, в том числе сетевым поиском, поиском на стороне сервера, комбинированным поиском и другими системами.
Каждый блок, показанный на Фиг.3-5, представляет один или более процессов, способов или процедур, выполняемых в иллюстративном способе 200. На Фиг.3 иллюстративный способ 200 начинается в блоке 202. В блоке 202 переменная n счетчика устанавливается в значение 1. Переменная n счетчика используется, чтобы регламентировать, сколько итераций способа 200 совершено для данного поиска. За блоком 202 следует блок 204, в котором предоставляется база данных с данными о поведении клиента. Это может быть достигнуто, например, путем создания такой базы данных с помощью средства мониторинга или путем установления взаимодействия с такой базой данных.
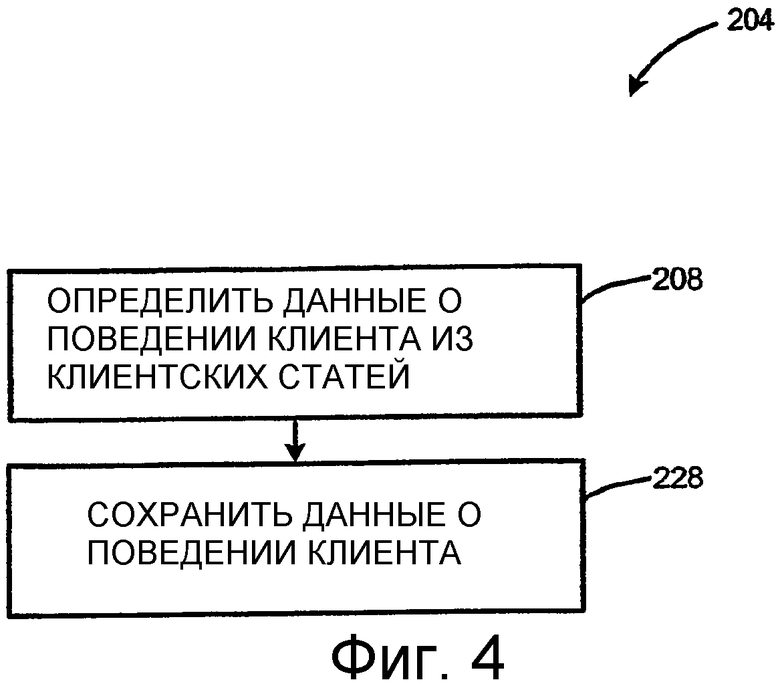
Фиг.4 является более подробным представлением блока 204 на Фиг.3 и иллюстрирует пример способа для предоставления базы данных с данными о поведении клиента. Способ, показанный на Фиг.4, начинается в блоке 208, в котором в соответствии с иллюстрированным примером данные о поведении на клиентской стороне, связанные со статьей, определены средством 140 мониторинга. Как показано на Фиг.2, эти данные о поведении на клиентской стороне могут содержать любое количество отдельных типов данных, в том числе, например, действие 172a-c ввода, действие 174a-c переписки, действие 176a-c хронологии статьи или действие 178a-c ссылки. Другие типы данных о поведении на клиентской стороне также могут быть получены в блоке 208 на Фиг.4. Как альтернатива данные о поведении клиента могут быть получены из ранее существующей базы данных.
За блоком 208 следует блок 224, в котором сохраняются данные о поведении на клиентской стороне, полученные в блоке 208. В соответствии с системой, иллюстрированной на Фиг.4, данные о поведении клиента от средства 140 мониторинга, полученные от клиентских статей 171a-c, отправляются в базу 164 данных с данными о поведении клиента в хранилище 160 данных и сохраняются там. Это обсуждается более подробно в отношении Фиг.2.
Фиг.5 является иллюстративным вариантом воплощения процесса, показанного в блоке 208 на Фиг.4. В блоке 208 на Фиг.4 данные о поведении клиента получены от клиентских статей 171a-c. Способ, показанный на Фиг.5, начинается с блока 210. Должно быть отмечено, что блоки на Фиг.5 предназначены, чтобы служить примерами типов данных о пользовательской деятельности, которые могут быть записаны в течение выполнения блока 208 на Фиг.4. Фиг.5 не дает всесторонний список всех возможных видов пользовательской поведенческой деятельности, которые могут быть получены от клиентского приложения или иным образом получены как часть всего процесса ранжирования, связанного с данным изобретением.
Фиг.5 начинается с блока 210, в котором определяются данные о деятельности по прокрутке, связанные со статьей. Данные о деятельности по прокрутке могут содержать, например, данные относительно количества прокруток на Web-странице или в текстовой статье, данные относительно местоположения в статье, в котором происходит деятельность по прокрутке, данные относительно времени, потраченного на прокрутку (по сравнению, например, со временем, в течение которого статья была активна), или другие данные относительно деятельности по прокрутке.
За блоком 210 следует блок 211, в котором определяются данные о печати, связанные со статьей. Данные о печати могут содержать, например, данные относительно того, когда статья или статьи были напечатаны, как часто статья или статьи выводились на печать, какие части статьи или статей были напечатаны, или любую другую информацию относительно печати статьи или статей.
За блоком 211 следует блок 212, в котором определяются данные о закладках, связанные со статьей. Информация о закладках может содержать, например, информацию о закладке унифицированного указателя информационного ресурса (URL) в Интернете, закладке в текстовой статье на другие части той же самой статьи или на отдельную статью, сколько закладок связано с отдельной статьей, текстовое содержание закладки, связанной со статьей, или любую другую информацию относительно закладок, связанных со статьей или статьей.
За блоком 212 следует блок 213, в котором определяются данные о бездействии, связанные со статьей. Данные о бездействии могут содержать, например, данные относительно того, сколько прошло времени с тех пор, как пользовательская деятельность с отдельной статьей прекратилась, активна ли отдельная статья или видима для пользователя, получает ли отдельная статья ввод от пользователя или другой программы, получают ли другие программы пользовательский ввод или деятельность, или любые другие данные относительно бездействия отдельной статьи.
За блоком 213 следует блок 214, в котором определяются данные об использовании прикладной компьютерной программы, связанные со статьей. Данные об использовании прикладной компьютерной программы могут содержать, например, данные относительно того, какие программы являются активными, какие программы являются видимыми пользователю, тип ввода, который отдельное приложение обрабатывает, или другие данные относительно данных прикладной компьютерной программы. Они могут также содержать количество раз, которое приложение использовалось, среднее время, которое пользователь проводит в течение сеанса. Эта информация может переместить вес ранжирования для статей, произведенных приложением.
За блоком 214 следует блок 215, в котором определяются данные о частоте доступа к статье, связанные со статьей. Данные о частоте доступа к статье могут содержать, например, данные относительно того, как часто обращались к отдельной статье, как часто к отдельной статье обращался отдельный пользователь, как часто к отдельной статье обращаются по сравнению с частотой использования других приложений, время между периодами доступа к статье, частоту доступа как функцию других переменных, таких как время дня, или любые другие данные относительно частоты доступа использования.
За блоком 215 следует блок 216, в котором определяются данные о времени доступа, связанные со статьей. Данные о времени доступа могут содержать, например, время дня, когда к отдельной статье осуществлялся доступ, продолжительность времени доступа, связанного с отдельной статьей, время, прошедшее с предыдущего доступа к статье, время доступа к статье относительно времени доступа или использования других приложений, время использования приложения или любую другую информацию относительно данных о времени доступа.
За блоком 216 следует блок 217, в котором определяются данные о способе взаимодействий клиента со второй статьей. Данные о способе взаимодействий клиента со второй статьей могут содержать, например, способ ввода, который пользователь 112a посылает второй статье, тип ввода, который пользователь посылает второй статье, тип вывода, который вторая статья генерирует для пользователя, или объем вывода, который генерирует вторая статья.
За блоком 217 следует блок 218, в котором определяются данные о количестве взаимодействий клиента со второй статьей. Данные о способе взаимодействий клиента со второй статьей могут содержать, например, объем ввода, который пользователь 112a посылает второй статье, тип ввода, который пользователь посылает второй статье, тип вывода, который вторая статья генерирует для пользователя, или объем вывода, который генерирует вторая статья.
За блоком 218 следует блок 219, в котором определяются данные о движении мыши. Данные о движении мыши могут содержать, например, количество движений мыши в отдельной статье, способ движения мыши в статье, вероятность того, что движение мыши, связанное с отдельной статьей, является намеренным или непреднамеренным, или любые другие данные относительно информации о движении мыши, связанной со статьей. Позиция мыши может также быть важна. Если мышь зависает над определенной областью в течение длительного периода времени после перемещения в нее, это может указывать область, представляющую интерес.
За блоком 219 следует блок 220, в котором определяются данные об ответах, связанные со статьей. Данные об ответах могут содержать, например, информацию о том, был ли отправлен ответ по электронной почте, через службу обмена мгновенными сообщениями или другую среду переписки в качестве реакции на статью, была ли статья получена как ответ на другую переписку, требует ли статья ответа, или любые другие данные об ответах, связанные со статьей.
За блоком 220 следует блок 221, в котором определяются данные о копировании, связанные со статьей. Данные о копировании могут содержать, например, информацию о том, были ли текст, графика или другой материал в статье скопированы, количество материалов в статье, которые были скопированы, содержит ли статья материал, который был скопирован из другого приложения, или любые другие данные копирования, связанные со статьей.
За блоком 221 следует блок 222, в котором определяются данные о пересылке, связанные со статьей. Данные о пересылке могут содержать, например, информацию о том, пересылалась ли статья, была ли отдельная статья получена как пересланное сообщение, или любую другую информацию о пересылке, связанную со статьей.
За блоком 222 следует блок 223, в котором определяются данные о местоположении, связанные со статьей. Данные о местоположении могут содержать, например, имя полного пути, указывающее на местоположение, где статья сохранена, или хронологию того, где документ был сохранен ранее. Например, если статья сохранена в "c:\documents\budgets\proposals\DecemberForecast.txt", то каждый из этих элементов может быть связан со статьей, даже если они явно не появляются в самой статье. Дополнительно, если статья перемещена из старого местоположения в новое местоположение, данные о местоположении, связанные со статьей, могут содержать информацию, касающуюся как имени пути, связанного со старым местоположением, так и имени пути, связанного с новым местоположением.
Способ 208, иллюстрированный на Фиг.5, заканчивается блоком 223. Каждый из блоков с 210 до 223 является необязательным и может не быть включен или может не содержать никаких данных для отдельной статьи. Также следует заметить, что определение данных о поведении на клиентской стороне предпочтительно продолжается постоянно, даже хотя показан только один цикл такого мониторинга на Фиг.5 в иллюстративных целях. Способ на Фиг.5 является процедурой, выполняемой в блоке 208 способа на Фиг.4.
Возвращаемся теперь к Фиг.4, она представляет процедуру способа по Фиг.3. За блоком 208 на Фиг.4 следует блок 224, в котором сохраняются данные о поведении на клиентской стороне. Данные о поведении на клиентской стороне могут быть сохранены, например, в хранилище 160 данных, в памяти 108 или на любом другом носителе данных, связанном с клиентом 102. Блок 224 является последним блоком, иллюстрированным в процедуре на Фиг.4.
Обращаемся теперь снова к Фиг.3, за блоком 204 следует блок 228, в котором сигнал 182 запроса принимается машиной 120 поиска. Сигнал 182 запроса может быть сгенерирован в ответ на запрос 114 поиска, явно введенный пользователем 112a, или через неявный запрос поиска, сгенерированный на основе контекстных ключей от средства 140 мониторинга. Например, если пользователь 112a работает в приложении обработки текста и вводит в статью фразу "повестка дня совещания по составлению бюджета", процессор 180 запроса может получить информацию относительно введенного текста от средства 140 мониторинга и сгенерировать неявный запрос, чтобы искать статьи, содержащие любой из терминов "повестка дня", "составление бюджета" или "совещание". Процессор 180 запроса может затем послать сигнал 182 запроса, отражающий этот неявный запрос поиска, машине 120 поиска.
За блоком 228 следует блок 230, в котором набор релевантных статей, релевантных сигналу 182 запроса, определяется определителем 134 местоположения статьи. В этом блоке определитель 134 местоположения статьи, расположенный в машине 120 поиска, определяет релевантную статью или множество релевантных статей из данных о статьях, расположенных в хранилище 160 данных или в памяти 108. Например, если запрос 114 поиска, введенный пользователем, является фразой "план совещания по бюджету", определитель 134 местоположения статьи определит, какие статьи в хранилище 160 данных или в памяти 108 релевантны условиям поиска. Этот набор может содержать, например, сообщения электронной почты, документы обработки текстов, сессии чата и электронные таблицы, которые содержит слова "бюджет", "совещание" и/или "план". Релевантные статьи, определенные в этом блоке, потенциально многочисленны по сравнению с результатом 150 поиска, который будет в конечном счете возвращен пользователю 112a после ранжирования, сортировки и показа релевантных статей. Релевантные статьи, определенные в этом блоке, могут быть отсортированы по релевантности с использованием традиционного способа без информации о поведении на клиентской стороне или могут быть отсортированы по времени.
За блоком 230 следует блок 232, в котором определяется общее количество T релевантных статей в наборе релевантных статей, возвращенных определителем 134 местоположения статьи. Предпочтительно, общее количество T релевантных статей отражает все статьи, определенные как релевантные поиску, хотя другие варианты воплощения могут использовать другое количество (например, максимум 100). Переменная T используется вместе со счетчиком n, чтобы определить, сколько итераций части показанного способа 200 нужно совершить.
За блоком 232 следует блок 234, в котором машина 120 поиска определяет релевантную статью с порядковым номером n из общего количества T релевантных статей, связанных с сигналом 182 запроса. В течение первой итерации способа 200 счетчик n равен 1, и, таким образом, машина 120 поиска определяет первую релевантную статью, связанную с сигналом 182 запроса. На последующих итерациях машина 120 поиска определяет последующий релевантный документ в общем количестве T релевантных статей. В дополнительных вариантах воплощения релевантные статьи, связанные с сигналом 182 запроса, могут уже быть отсортированы. Например, статьи могут быть отсортированы по мере релевантности, которая не включает данных о поведении клиента, или статьи могут быть отсортированы по времени.
За блоком 234 следует блок 236, в котором определяются данные о поведении на клиентской стороне, связанные со статьей с порядковым номером n. В этом блоке 236 в показанном варианте воплощения процессор 136 данных о поведении клиента, расположенный в машине 120 поиска, получает от определителя 134 местоположения статьи информацию, указывающую на статью с порядковым номером n, связанную с запросом. Процессор 136 данных о поведении клиента затем определяет данные о поведении на клиентской стороне из хранилища 160 данных, которые связаны со статьей с порядковым номером n, которая определена определителем 134 местоположения статьи как релевантная сигналу 182 запроса.
Например, если сигнал 182 запроса относится к запросу 114 поиска для фразы "план совещания по бюджету", то определитель 134 местоположения статьи определит местоположение всех статей, релевантных этому запросу, который может содержать, например, все статьи со словами "план совещания по бюджету" в тексте, заголовке, поле темы и т.д. Конкретная статья с порядковым номером n затем выбирается из всех релевантных статей, определенных как релевантные этому запросу. Статья с порядковым номером n в этом примере могла бы быть, например, электронной таблицей, названной "план совещания по бюджету". В соответствии с вариантом воплощения, иллюстрированным здесь, процессор 136 данных о поведении клиента тогда может извлечь из хранилища 160 данных все данные о поведении на клиентской стороне, связанные с электронной таблицей. Они могут содержать, например, информацию о количестве прокруток в электронной таблице, отправляли ли электронную таблицу по электронной почте, когда она была последний раз сохранена и сколько раз она была напечатана. Эти данные о поведении на клиентской стороне затем используются в блоке 238, чтобы помочь сформулировать оценку ранжирования для статьи.
В блоке 238, который следует за блоком 236, данные о поведении на клиентской стороне, связанные со статьей с порядковым номером n, предоставляются процессору 138 ранжирования. В этом блоке 238 данные о поведении на клиентской стороне, определенные процессором 136 данных о поведении клиента как связанные со статьей с порядковым номером n, релевантной сигналу 182 запроса, извлекаются из базы 164 данных с данными о поведении клиента в хранилище 160 данных. Данные о поведении на клиентской стороне, извлеченные из базы 164 данных с данными о поведении клиента, затем отправляются процессору 138 ранжирования. Таким образом, в этом блоке данные о поведении на клиентской стороне, связанные со статьей, которая определена как релевантная сигналу 182 запроса, извлекаются и отправляются процессору 138 ранжирования, в котором они могут использоваться, чтобы сгенерировать оценку ранжирования, как описано в блоке 240.
В других вариантах воплощения "оценка поведения клиента", отражающая относительную частоту и тип взаимодействий пользователя 112a и/или клиента 102a со статьей или типом статьи, например с Web-страницей или Web-страницами с отдельного сайта, предопределена и сохранена в хранилище 160 данных. В соответствии с аспектами вариантов воплощения, содержащих оценку поведения клиента, когда машина 120 поиска получает сигнал 182 запроса, оценка поведения клиента отправляется процессору 138 ранжирования вместо данных о поведении на клиентской стороне, связанных со статьей, или в дополнение к ним. Оценка поведения клиента может быть определена.
За блоком 238 следует блок 240, в котором определяется оценка ранжирования для статьи с порядковым номером n. В этом блоке 240 в показанном варианте воплощения процессор 138 ранжирования получает данные о поведении на клиентской стороне от процессора 136 данных о поведении клиента. Процессор 138 ранжирования также принимает сигнал 182 запроса. Процессор 138 ранжирования определяет оценку ранжирования на основе, по меньшей мере частично, данных о поведении на клиентской стороне, извлеченных из процессора 136 данных о поведении клиента, связанных со статьей с порядковым номером n. Это может быть достигнуто, например, с помощью алгоритма ранжирования, который взвешивает различные данные о поведении клиента и другие факторы ранжирования, связанные с сигналом 182 запроса, чтобы создать оценку ранжирования. Различные типы данных о поведении клиента могут иметь различные веса, и эти веса могут быть различными для различных приложений. В дополнение к данным о поведении клиента процессор 138 ранжирования может использовать традиционные способы для ранжирования статей в соответствии с терминами, содержащимися в статьях. Он может также использовать информацию, полученную от сервера в сети, например в случае Web-страниц, процессор 138 ранжирования может запросить от сервера значение PageRank для Web-страницы и дополнительно использовать это значение, чтобы вычислить оценку ранжирования. Оценка ранжирования может также зависеть от типа статьи. Оценка ранжирования может также зависеть от времени, такого как время дня или день недели. Например, пользователь может обычно работать над и интересоваться определенными типами статей в течение дня и интересоваться другими видами статей в течение вечера или на выходных.
Рассмотрим снова пример, в котором пользователь 112a желает отыскать статьи, касающиеся совещания по продажам, которое пользователь 112a недавно посетил. Пользователь 112a может ввести термины "совещание по продажам" в качестве запроса 114 поиска. Сигнал 182 запроса, соответствующий запросу 114 поиска "совещание по продажам", будет сгенерирован, и определитель 134 местоположения статьи определит местоположение статей, которые являются релевантными этому поиску. Они могут содержать электронную почту, содержащую слова "совещание по продажам" в поле темы, текстовый документ, содержащий слова "совещание по продажам" в теле текстового документа, и электронную таблицу, содержащую эти слова в заголовке. Как только релевантные статьи обнаружены, процессор 136 данных о поведении клиента определит, какие данные о поведении на клиентской стороне связаны с этой статьей.
Пользователь 112a провел определенные действия в отношении статьи, в том числе печатал ее, прокручивал электронную таблицу, нажимал на нее мышью, просматривал ее и вводил в нее текст. Судя по этой деятельности, вероятно, что пользователь 112a редактировал или готовил электронную таблицу, из чего она иным образом представляла непосредственный интерес для пользователя 112a. Процессор 138 ранжирования отражает относительную важность электронной таблицы перед другими статьями, которые определены как релевантные поиску и которые не были связаны с таким же количеством и типом данных о поведении на клиентской стороне, назначая ей более высокую оценку ранжирования, чем другим релевантным статьям. Когда результаты запроса 114 поиска выдаются пользователю 112a, электронная таблица может быть размещена выше в списке результатов поиска или иным образом отображена способом, который акцентирует внимание на ней, а не на текстовом документе. Это помогает пользователю 112a различить ее среди других статей, связанных с запросом, но представляющих меньший интерес для пользователя 112a.
Блок 242 следует за блоком 240. В блоке 242 определяется, равен ли текущий номер n статьи общему количеству T результатов поиска. Если n равно T, то способ переходит к блоку 244. Если n не равно T, то способ переходит к блоку 243. В блоке 243 переменная n увеличивается до следующего целого числа, и способ возвращается к блоку 234, чтобы повторить блоки 234-242. Может использоваться порог для количества статей, которые следует обработать, или для продолжительности обработки, чтобы было обработано меньше, чем T статей. Например, могут быть обработаны не более 1000 статей или обработке может быть разрешено занимать максимум 500 миллисекунд.
Например, на первом проходе способа 200 переменная n равна 1, и, таким образом, из набора релевантных статей выбирается первая релевантная статья. Если в наборе релевантных статей имеется 10 документов, тогда T равно 10. В блоке 242, поскольку 1 не равна 10, способ перейдет к блоку 243, где переменная n получит значение n+1, что сделает переменную n теперь равной 2. Этот процесс повторяется до тех пор, пока переменная n не будет равна 10. Когда переменная n равна 10, десятая (и последняя) статья будет выбрана из набора релевантных статей. Тогда в блоке 242, поскольку переменная n теперь равна T, способ 200 перейдет к блоку 244.
В блоке 244 релевантные статьи, обработанные в блоках 234-240, размещаются в порядке ранжирования в соответствии с оценкой ранжирования, связанной с каждой релевантной статьей из блока 240.
За блоком 244 следует блок 246, в котором релевантные статьи, размещенные в порядке ранжирования в блоке 244, отображаются пользователю 112a. Есть множество способов, которыми результаты могут быть отображены пользователю 112a, которые отразят порядок ранжирования из блока 244. Один возможный способ состоит в том, чтобы перечислить три лучшие статьи как гиперссылки и поместить в список одну гиперссылку на все остальные релевантные статьи, которую пользователь может выбрать, если желаемая статья не расположена среди этих трех гиперссылок.
За блоком 246 следует блок 248, в котором способ 200 завершается. В альтернативной версии способа 200 возможно использовать данные о поведении пользователя, чтобы оценить документы независимо от запроса. Например, PageRank, хотя и не используемый здесь, является примером способа, который может вычислить независимую от запроса оценку. Позже, когда запрос получен, способ 200 может объединить независимую от запроса оценку поведения пользователя с традиционными способами сопоставления. В одной версии статьи обрабатываются в порядке, определенном независимой от запроса оценкой поведения пользователя. Это позволяет системе экономить время обработки, потому что, возможно, нет необходимости обработать все статьи. В дополнение, обработка может быть разбита на фазы, в которых первая фаза производит начальную оценку, основанную на независимой от запроса оценке поведения пользователя, и вторая фаза делает более затратную обработку статей, которые были наиболее высоко ранжированы в первой фазе.
Одна или более оценок, сделанных на основе, по меньшей мере частично, данных о поведении на клиентской стороне, также могут быть показаны пользователю независимо от запроса поиска. Например, оценку или оценки для Web-страницы можно показать на инструментальной панели, когда пользователь просматривает сайт.
Данное изобретение не ограничено выдачей результатов на основе статей только на клиентской стороне или поиском статей только на клиентской стороне. В качестве примера дополнительные варианты воплощения данного изобретения могут содержать объединение результатов поиска в сети, такой как Интернет или локальная внутрикорпоративная сеть, с результатами поиска, полученными способом 200. В дополнение, данное изобретение может определять оценку ранжирования для статьи частично на основе данных о поведении на клиентской стороне и частично на основе оценок ранжирования Интернета. Кроме того, данное изобретение может использовать данные о поведении на клиентской стороне, одни или в комбинации с другими факторами, чтобы определять оценку ранжирования для статей, расположенных в сети, такой как Интернет или локальная внутрикорпоративная сеть. Данное изобретение может использовать данные о поведении на клиентской стороне, одни или в комбинации с другими факторами, чтобы определять оценку ранжирования для статей, расположенных на клиенте 102a, для статей, расположенных в сети 106, такой как Интернет или локальная внутрикорпоративная сеть, или любой другой статьи, сохраненной на любом носителе или в любом местоположении, доступном машине 120 поиска локально или по удаленному соединению.
Хотя вышеприведенное описание содержит много специфических подробностей, эти специфические подробности должны рассматриваться не как ограничения объема изобретения, а лишь как пояснения примером раскрытых вариантов воплощения. Специалисты в области техники предвидят много других возможных разновидностей, которые находятся в пределах объема изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ структурирования результатов поиска по текстам, содержащим информацию о научной и исследовательской деятельности | 2017 |
|
RU2656469C1 |
| СБОР ДАННЫХ О ПОЛЬЗОВАТЕЛЬСКОМ ПОВЕДЕНИИ ПРИ ВЕБ-ПОИСКЕ ДЛЯ ПОВЫШЕНИЯ РЕЛЕВАНТНОСТИ ВЕБ-ПОИСКА | 2007 |
|
RU2435212C2 |
| ПЕРСОНАЛИЗИРОВАННЫЙ РЕПОЗИТОРИЙ ОБЪЕКТОВ | 2016 |
|
RU2696225C1 |
| Система гарантированного возврата товаров в розничной сети продаж | 2018 |
|
RU2699068C1 |
| ВЫЯВЛЕНИЕ НАВИГАЦИОННЫХ РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2680757C2 |
| ОТНОСИТЕЛЬНЫЕ РЕЗУЛЬТАТЫ ПОИСКА НА ОСНОВЕ ПОЛЬЗОВАТЕЛЬСКОГО ВЗАИМОДЕЙСТВИЯ | 2006 |
|
RU2419860C2 |
| УСОВЕРШЕНСТВОВАННЫЕ СИСТЕМЫ И СПОСОБЫ РАНЖИРОВАНИЯ ДОКУМЕНТОВ НА ОСНОВАНИИ СТРУКТУРНО ВЗАИМОСВЯЗАННОЙ ИНФОРМАЦИИ | 2004 |
|
RU2367997C2 |
| ВЫЯВЛЕНИЕ НАВИГАЦИОННЫХ РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2730278C2 |
| СИСТЕМА, СПОСОБ И ИНТЕРФЕЙС ДЛЯ ОБЕСПЕЧЕНИЯ ПЕРСОНАЛИЗИРОВАННОГО ПОИСКА И ДОСТУПА К ИНФОРМАЦИИ | 2005 |
|
RU2419858C2 |
| НАСТРОЙКА ПОИСКА В РЕАЛЬНОМ ВРЕМЕНИ | 2014 |
|
RU2663478C2 |


Изобретение относится к системам и способам ранжирования поиска с использованием информации о статье. Техническим результатом является расширение поиска и улучшение его качества. Система для ранжирования поиска с использованием информации о статье содержит процессор для выполнения машиночитаемых программных команд, память для их хранения, клиентское приложение для обеспечения возможности поведенческой деятельности клиентской стороны, клиентскую статью, процессор запросов для приема запроса поиска, средство мониторинга для определения данных о поведении клиентской стороны, связанных с поведенческой деятельностью клиента, полученной статьей, машину поиска для определения того, что статья связана с запросом поиска, приема из хранилища данных упомянутой предопределенной оценки поведения клиента, связанной со статьей, размещения статьи среди результатов поиска по запросу поиска на основе, по меньшей мере частично, упомянутой предопределенной оценки поведения клиента, связанной со статьей, и выдачи статей, связанных с запросом поиска, в порядке ранжирования на основе, по меньшей мере частично, упомянутого размещения, и хранилище данных для связывания предопределенной оценки поведения клиента с клиентской статьей и хранения данных о поведении клиентской стороны, связанных с клиентской статьей. 5 н. и 42 з.п. ф-лы, 5 ил.
определяют данные о поведении на клиентской стороне, связанные со статьей,
предоставляют эти данные о поведении на клиентской стороне, связанные со статьей, процессору ранжирования,
вычисляют предопределенную оценку поведения клиента для статьи на основе, по меньшей мере частично, упомянутых данных о поведении на клиентской стороне, связанных со статьей,
сохраняют эту предопределенную оценку поведения клиента в хранилище данных, причем данная предопределенная оценка поведения клиента связывается со статьей в хранилище данных,
принимают запрос поиска,
определяют, что статья связана с запросом поиска,
принимают из хранилища данных упомянутую предопределенную оценку поведения клиента, связанную со статьей,
размещают статью среди результатов поиска по запросу поиска на основе, по меньшей мере частично, упомянутой предопределенной оценки поведения клиента, связанной со статьей, и
отображают, по меньшей мере, часть этих результатов поиска пользователю.
программный код для определения данных о поведении на клиентской стороне, связанных со статьей,
программный код для предоставления этих данных о поведении на клиентской стороне, связанных со статьей, процессору ранжирования,
программный код для вычисления предопределенной оценки поведения клиента для статьи на основе, по меньшей мере частично, упомянутых данных о поведении на клиентской стороне, связанных со статьей,
программный код для сохранения этой предопределенной оценки поведения клиента в хранилище данных, причем данная предопределенная оценка поведения клиента связывается со статьей в хранилище данных,
программный код для приема запроса поиска,
программный код для определения того, что статья связана с запросом поиска,
программный код для приема из хранилища данных упомянутой предопределенной оценки поведения клиента, связанной со статьей,
программный код для размещения статьи среди результатов поиска по запросу поиска на основе, по меньшей мере частично, упомянутой предопределенной оценки поведения клиента, связанной со статьей, и
программный код для отображения, по меньшей мере, части этих результатов поиска пользователю.
процессор для выполнения машиночитаемых программных команд, которые приспособлены для улучшения ранжирования поиска с использованием информации о статье,
память для хранения этих машиночитаемых программных команд,
клиентское приложение для обеспечения возможности поведенческой деятельности клиентской стороны,
клиентскую статью, которая может получать поведенческую деятельность клиентской стороны,
процессор запросов для приема запроса поиска,
средство мониторинга для определения данных о поведении клиентской стороны, связанных с поведенческой деятельностью клиента, полученной статьей, при этом средство мониторинга дополнительно сконфигурировано для предоставления данных о поведении клиентской стороны, связанных со статьей, процессору ранжирования,
процессор ранжирования для вычисления предопределенной оценки поведения клиента для статьи на основе, по меньшей мере частично, упомянутых данных о поведении клиентской стороны, связанных со статьей, причем процессор ранжирования дополнительно сконфигурирован для сохранения этой предопределенной оценки поведения клиента в хранилище данных,
машину поиска для определения того, что статья связана с запросом поиска, приема из хранилища данных упомянутой предопределенной оценки поведения клиента, связанной со статьей, размещения статьи среди результатов поиска по запросу поиска на основе, по меньшей мере частично, упомянутой предопределенной оценки поведения клиента, связанной со статьей, и выдачи статей, связанных с запросом поиска, в порядке ранжирования на основе, по меньшей мере частично, упомянутого размещения, и
хранилище данных для связывания предопределенной оценки поведения клиента с клиентской статьей и хранения данных о поведении клиентской стороны, связанных с клиентской статьей.
определяют данные о поведении на клиентской стороне, связанные со статьей,
предоставляют эти данные о поведении на клиентской стороне, связанные со статьей, процессору ранжирования,
вычисляют предопределенную оценку поведения клиента для статьи на основе, по меньшей мере частично, упомянутых данных о поведении на клиентской стороне, связанных со статьей,
сохраняют эту предопределенную оценку поведения клиента в хранилище данных, причем данная предопределенная оценка поведения клиента связывается со статьей в хранилище данных,
определяют набор релевантных статей, которые релевантны сигналу запроса, причем этот набор релевантных статей включает в себя упомянутую статью,
принимают из хранилища данных упомянутую предопределенную оценку поведения клиента, связанную со статьей,
размещают упомянутый набор релевантных статей по порядку на основе, по меньшей мере частично, упомянутой предопределенной оценки поведения клиента, связанной со статьей, и
отображают, по меньшей мере, часть упомянутого набора релевантных статей пользователю в упомянутом порядке.
определяют данные о поведении на клиентской стороне, связанные со статьей,
предоставляют эти данные о поведении на клиентской стороне, связанные со статьей, процессору ранжирования,
вычисляют предопределенную оценку поведения клиента для статьи на основе, по меньшей мере частично, упомянутых данных о поведении на клиентской стороне, связанных со статьей,
сохраняют эту предопределенную оценку поведения клиента в хранилище данных в клиентском устройстве, причем данная предопределенная оценка поведения клиента связывается со статьей в хранилище данных,
принимают запрос поиска,
определяют, что статья связана с запросом поиска,
принимают из хранилища данных упомянутую предопределенную оценку поведения клиента, связанную со статьей,
размещают статью среди результатов поиска по запросу поиска по порядку на основе, по меньшей мере частично, упомянутой предопределенной оценки поведения клиента, связанной со статьей, и
отображают, по меньшей мере, часть этих результатов поиска пользователю в упомянутом порядке.
| US 2003123443 А1, 03.07.2003 | |||
| СИСТЕМА ПОИСКА ИНФОРМАЦИИ В КОМПЬЮТЕРНОЙ СЕТИ | 1998 |
|
RU2138076C1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |

