ОБЛАСТЬ ТЕХНИКИ
Изобретение, в общем, имеет отношение к компьютерам и компьютерному программному обеспечению. В частности, это изобретение имеет отношение к механизмам поиска и взаимодействию пользователя со сформированным ими результирующим множеством.
УРОВЕНЬ ТЕХНИКИ
Механизмы поиска в общем случае являются компьютерными программами, которые используются для доступа к базам данных с информацией в ответ на запросы, представленные пользователями. Механизмы поиска обычно используются для доступа к широкому спектру баз данных и просеивания информации, чтобы найти релевантную информацию в ответ на запрос поиска.
Преобладающее применение механизмов поиска состоит в доступе к информации из сети Интернет. Например, механизм поиска часто используется для доступа к службам каталогов, чтобы идентифицировать документы, которые содержат информацию на конкретные темы. С помощью служб каталогов документы обычно классифицируются по темам, и адреса этих документов, а также их основные рефераты сохраняются в записях, доступных для поиска посредством механизма поиска.
Механизмы поиска также часто используются для доступа к службам индексирования, которые пытаются каталогизировать как можно больше документов из Интернета. Большинство служб индексирования обычно создают базы данных записей документов, читая документы в Интернете, каталогизируя важные термины и слова из них и следуя по любым ссылкам, предоставленным в каждом документе, чтобы определить местонахождение дополнительных документов.
По мере того как количество обнаруженных документов увеличивается, порядок, в котором эти документы представляются пользователю, также называемый "ранжированием" документов, становится более важным, поскольку пользователь обычно будет смотреть на документы, указанные вверху списка результатов поиска, перед тем, как смотреть на документы, указанные в результатах позднее.
Ранние механизмы поиска обычно полагались в общем случае на элементарные алгоритмы извлечения, которые ранжировали результаты запросов на основе таких факторов, как количество поисковых терминов, которые были найдены в каждом документе, количество появлений каждого поискового термина в каждом документе, близость поисковых терминов в каждом документе и/или местоположение поисковых терминов в каждом документе (например, давая больший вес поисковым терминам, находящимся наверху или в заглавии, или заголовке, или документе). Однако оказалось, что ранжирование результатов просто посредством размещения и частоты поисковых терминов часто приводит к плохим ранжированиям. Как один пример, некоторыми традиционными механизмами поиска авторы документов могут управлять через процесс, известный как "замусоривание", при котором поисковые термины вставляются в документы в их невидимых частях с единственной целью увеличить относительные ранги документов, выдаваемые механизмами поиска.
Чтобы учесть такие проблемы, некоторые традиционные механизмы поиска полагаются на дополнительную информацию для ранжирования результатов. Например, механизмы поиска для некоторых служб индексирования дают документам больший весовой коэффициент на основе того, перечислены ли документы также в соответствующих службах каталогов. Другие механизмы поиска используют "популярность ссылок" для ранжирования результатов, предоставляя более высокие ранги документам, на которые ссылаются другие документы.
Хотя описанные выше улучшения для традиционных механизмов поиска были до некоторой степени успешны при предоставлении пользователям более релевантных результатов поиска, продолжает существовать существенная потребность дальнейших усовершенствований в том, каким образом результаты поиска упорядочиваются и выдаются пользователям. В частности, предполагается, что дополнительный прирост в релевантности и удобстве использования результатов, выдаваемых механизмами поиска, может быть получен с использованием пользовательских взаимодействий с отдельными документами при упорядочении результатов поиска.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Изобретение обращается к этим и другим проблемам, относящимся к предшествующей области техники, обеспечивая множество программных продуктов и способов, которые полагаются на предшествующее пользовательское взаимодействие при ранжировании результатов поиска, выданных механизмом поиска. В соответствии с изобретением каждое множество записей в базе данных связано с параметром пользовательского взаимодействия, который используется при упорядочении записей, идентифицированных в результирующем множестве, сформированном в ответ на поисковый запрос. Однако характер действий, с помощью которых параметр пользовательского взаимодействия формируется, обновляется и используется при ранжировании результатов поиска, может различаться в разных приложениях.
Например, в соответствии с одним аспектом изобретения параметр пользовательского взаимодействия для заданной записи может быть выборочно обновлен в ответ на обнаружение периода времени, в течение которого пользователь осуществляет доступ к конкретной записи. Значение для механизма взаимодействия этого типа основано на предположении, что пользователь задерживается на отдельной записи дольше, если эта отдельная запись имеет релевантную информацию, уместную для отдельного поискового запроса.
В соответствии с другим аспектом изобретения параметр пользовательского взаимодействия для заданной записи может быть выборочно обновлен в ответ на обнаружение того, что период времени, в течение которого пользователь обращается к отдельной записи, превышает предопределенный релевантный период времени. Значение для механизма взаимодействия этого типа основано на предположении, что если пользователь задерживается на отдельной записи дольше, чем предопределенный релевантный период времени, это является хорошим признаком, что отдельная запись имеет релевантную информацию, уместную для отдельного запроса.
В соответствии с другим аспектом изобретения параметр пользовательского взаимодействия для заданной записи может быть выборочно обновлен в ответ на обнаружение того, что к записи с более низким рангом обращались в течение предопределенного релевантного периода времени. Значение для механизма взаимодействия этого типа основано на предположении, что запись, имеющая более высокий ранг, но не имевшая обращений, или запись, имеющая более высокий ранг и не имевшая обращений в течение предопределенного периода времени, является менее релевантной, чем запись, имевшая более поздние обращения, если к записи, имевшей более поздние обращения, осуществляли обращение в течение предопределенного периода времени.
Эти и другие преимущества и признаки, характеризующие изобретение, сформулированы в приложенной формуле изобретения и являются дополнительной частью этого документа. Однако для лучшего понимания изобретения и преимуществ и целей, достигаемых через его использование, будет дана ссылка на чертежи и сопроводительные описательные материалы, в которых описаны иллюстративные варианты воплощения изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 - блок-схема сетевой компьютерной системы, совместимой с изобретением.
Фиг.2 - блок-схема иллюстративной аппаратной и программной среды для сетевой компьютерной системы, показанной на фиг.1.
Фиг.3 - блок-схема операций, которые происходят во время взаимодействия с механизмом поиска в компьютерной системе, показанной на фиг.2.
Фиг.4 - блок-схема последовательности операций, иллюстрирующая процесс выполнения программы основной подпрограммы для браузера, показанного на фиг.2, для серверной реализации настоящего изобретения.
Фиг.5 - блок-схема, иллюстрирующая процесс выполнения программы основной подпрограммы для механизма поиска, показанного на фиг.2, для серверной реализации настоящего изобретения.
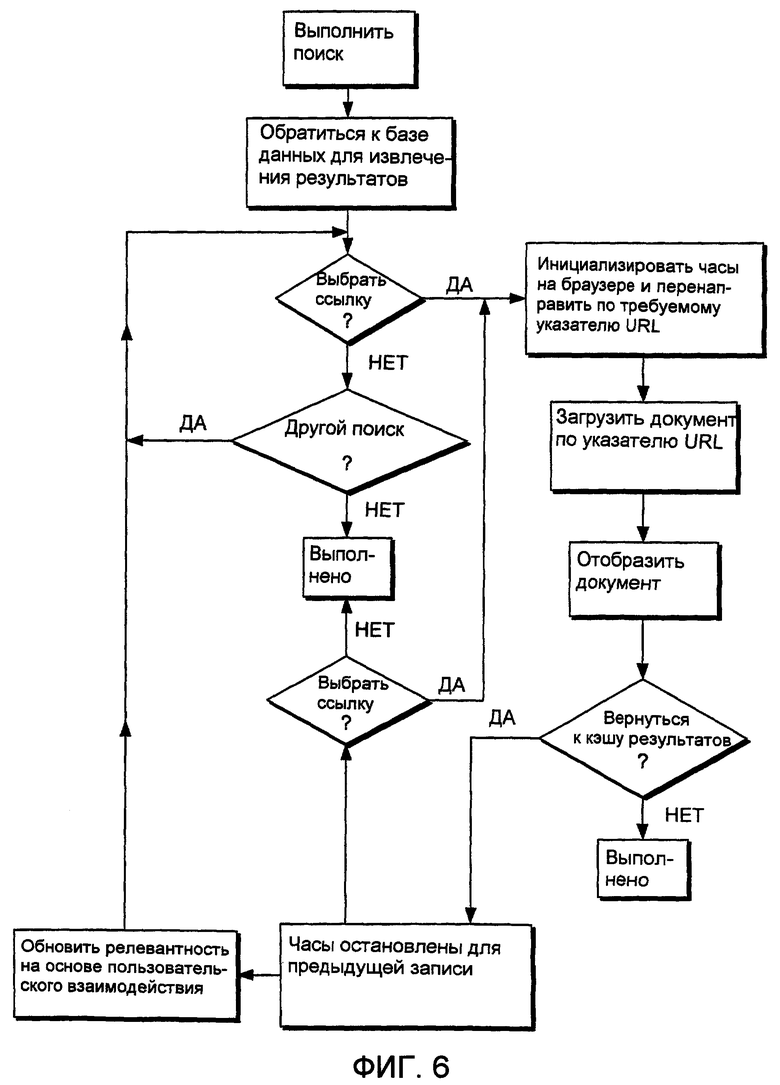
Фиг.6 - блок-схема последовательности операций, иллюстрирующая процесс выполнения программы основной подпрограммы для браузера, показанного на фиг.2, для реализации настоящего изобретения в браузере.
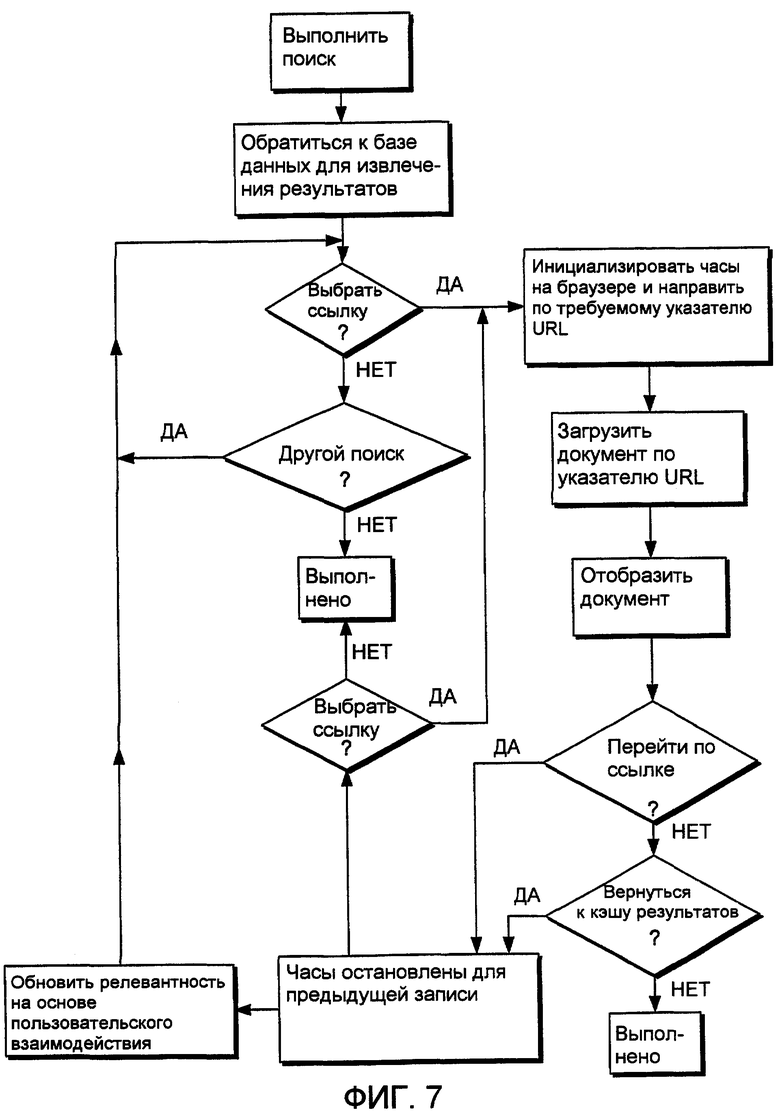
Фиг.7 - блок-схема последовательности операций, иллюстрирующая процесс выполнения программы основной подпрограммы для браузера, показанного на фиг.2, для реализации настоящего изобретения в браузере, имеющей пользовательское взаимодействие с переходом по ссылкам.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Аппаратная и программная среда
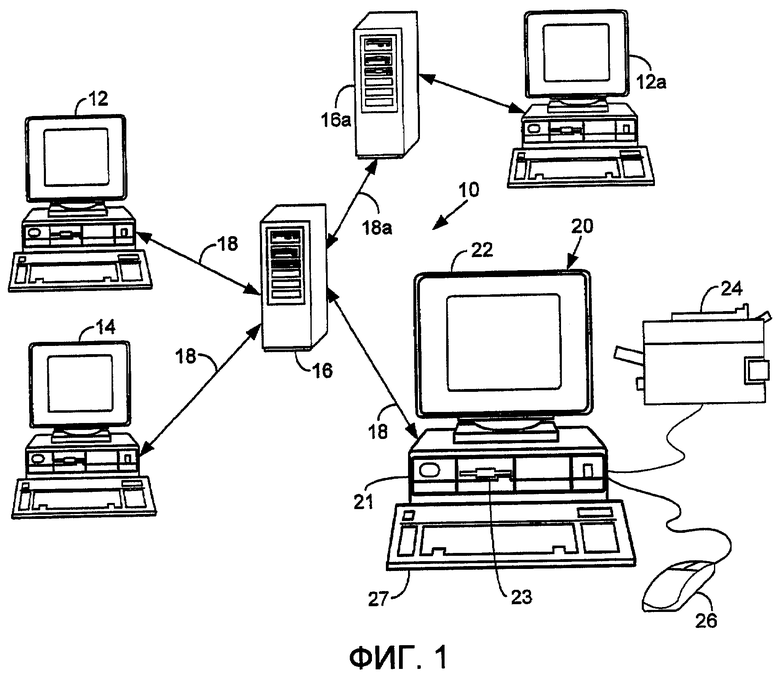
Обратимся к чертежам, на которых аналогичные ссылочные позиции обозначают аналогичные части всюду на нескольких чертежах. Фиг.1 иллюстрирует компьютерную систему 10, совместимую с изобретением. Компьютерная система 10 проиллюстрирована как сетевая компьютерная система, которая определяет многопользовательскую компьютерную среду и которая включает в себя один или более клиентских компьютеров 12, 14 и 20 (например, настольные или персональные компьютеры, рабочие станции и т.д.), соединенных с сервером 16 (например, сервером на основе персонального компьютера, мини-компьютером, компьютером средней производительности, универсальной вычислительной машиной и т.д.) через сеть 18. Также проиллюстрирован дополнительный сервер 16a, соединенный с сервером 16 по сети 18a и к которому присоединен клиентский компьютер 12a. Сети 18 и 18a могут представлять собой практически любой тип сетевой взаимосвязи, включающей в себя, но не ограниченной этим, локальные, глобальные, беспроводные сети и сети общего пользования (например, Интернет). Кроме того, любое количество компьютеров и других устройств может быть соединено через сети 18, 18a, например дополнительные клиентские компьютеры и/или серверы.
Клиентский компьютер 20, который может быть аналогичным компьютерам 12, 12a и 14, обычно включает в себя центральный обрабатывающий блок 21; некоторое количество периферийных компонентов, таких как, среди прочего, компьютерный дисплей 22; запоминающее устройство 23; принтер 24; и различные устройства ввода (например, мышь 26 и клавиатура 27). Серверные компьютеры 16, 16a могут быть сконфигурированы аналогичным образом, хотя обычно с большей производительностью и емкостью запоминающего устройства, как известно в данной области техники.
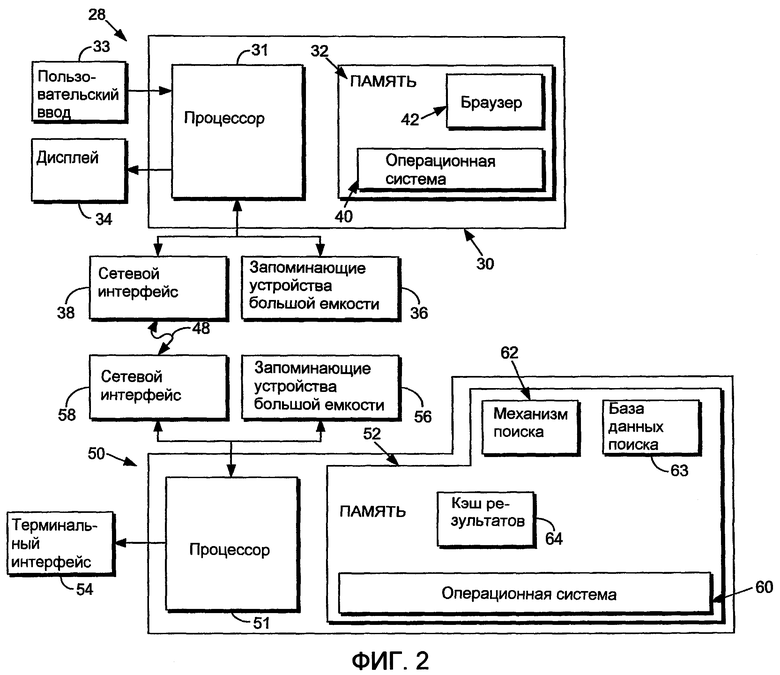
Фиг.2 другим образом показывает иллюстративную аппаратную и программную среду для сетевой компьютерной системы 10, включающую в себя устройство 28, которое включает в себя клиентское устройство 30, соединенное с серверным устройством 50 через сеть 48. В целях изобретения клиентское устройство 30 может представлять собой фактически любой тип компьютера, компьютерной системы или другого программируемого электронного устройства, которое может работать как клиент, в том числе настольный компьютер, портативный компьютер, встроенный контроллер и т.д. Аналогичным образом серверное устройство 50 может представлять собой практически любой тип многопользовательской или главной компьютерной системы. Каждое из устройств 28, 30 и 50 может в дальнейшем также называться "компьютером" или "компьютерной системой", хотя следует понимать, что термин "устройство" может также включать в себя другие подходящие программируемые электронные устройства, совместимые с изобретением.
Компьютер 30 обычно включает в себя, по меньшей мере, один процессор 31, соединенный с памятью 32, и компьютер 50 аналогичным образом включает в себя, по меньшей мере, один процессор 51, соединенный с памятью 52. Каждый процессор 31, 51 может представлять собой один или более процессоров (например, микропроцессоров), и каждая память 32, 52 может представлять собой оперативное запоминающее устройство (ОЗУ; RAM), содержащее основную память соответствующего компьютера 30, 50, а также любые дополнительные уровни памяти, например устройства кэш-памяти, устройства энергонезависимой или резервной памяти (например, устройства программируемой или флэш-памяти), постоянные запоминающие устройства и т.д. Кроме того, можно полагать, что каждая память 32, 52 включает в себя устройство хранения, физически расположенное в каком-либо другом месте в соответствующем компьютере 30, 50, например, любую кэш-память или любую емкость запоминающего устройства, используемую как виртуальная память, такую как в запоминающем устройстве большой емкости или на другом компьютере, соединенном с соответствующим компьютером 30, 50 через внешнюю сеть.
Каждый компьютер 30, 50 также обычно принимает множество входов и выходов для внешнего обмена информацией. Для интерфейса с пользователем или оператором компьютер 30 обычно включает в себя одно или более пользовательских устройств 33 ввода данных (например, среди прочего, клавиатуру, мышь, шаровой манипулятор, джойстик, сенсорную панель и/или микрофон) и дисплей 34 (например, среди прочего, монитор на электронно-лучевой трубке, жидкокристаллический дисплей и/или динамик). Аналогичным образом пользовательский интерфейс с компьютером 50 обычно обрабатывается через терминал, соединенный с терминальным интерфейсом 54.
Для дополнительной памяти каждый компьютер 30, 50 может также включать в себя одно или более запоминающих устройств 36, 56 большой емкости, например, среди прочего, накопитель на дискетах или других съемных дисках, накопитель на жестких дисках, устройство памяти с прямым доступом (DASD), накопитель на оптических дисках (например, накопитель на компакт-дисках (CD), накопитель на цифровых универсальных дисках (DVD) и т.д.) и/или накопитель на магнитной ленте. Кроме того, каждый компьютер 30, 50 может включать в себя интерфейс с одной или более сетями через сетевой интерфейс 38, 58 (например, среди прочего, с локальной сетью, глобальной сетью, беспроводной сетью и/или Интернетом), чтобы дать возможность обмена информацией с другими компьютерами, присоединенными к сети.
Компьютер 30 работает под управлением операционной системы 40 и исполняет или иным образом полагается на различные компьютерные приложения, компоненты, программы, объекты, модули, структуры данных и т.д. (например, браузер 42).
Аналогичным образом компьютер 50 работает под управлением операционной системы 60 и исполняет или иным образом полагается на различные компьютерные приложения, компоненты, программы, объекты, модули, структуры данных и т.д. (например, механизм 62 поиска, базу 63 данных поиска, кэш 64 результатов, таблицу 68 обработки выбранных ссылок и таблицу 69 обработки поискового запроса). Кроме того, различные приложения, компоненты, программы, объекты, модули и т.д. также могут исполняться на одном или более процессорах в другом компьютере, соединенном с любым из компьютеров 30, 50, например, в распределенной вычислительной среде или вычислительной среде клиент-сервер.
В общем случае подпрограммы, исполняемые для реализации вариантов воплощения изобретения, реализованы ли они как часть операционной системы или отдельное приложение, компонент, программа, объект, модуль или последовательность команд, будут называться здесь "компьютерными программами" или просто "программами". Компьютерные программы обычно содержат одну или более команд, которые находятся в разное время в различных устройствах памяти в компьютере и которые при их считывании и исполнении одним или более процессорами в компьютере заставляют этот компьютер выполнять этапы, необходимые для исполнения этапов или элементов, воплощающих различные аспекты изобретения. Кроме того, хотя изобретение описывалось и в дальнейшем будет описываться в контексте полностью функционирующих компьютеров и компьютерных систем, специалисты в данной области техники должны понимать, что различные варианты воплощения изобретения могут распространяться как программный продукт в различных видах и что изобретение одинаково применяется независимо от конкретного типа носителя сигнала, используемого для фактического выполнения распространения. Примеры носителей сигнала включают в себя, но без ограничения, записываемые носители, такие как, среди прочего, энергозависимые и энергонезависимые устройства памяти, дискеты и другие съемные диски, накопители на жестких дисках, магнитные ленты, оптические диски (например, компакт-диски, предназначенные только для чтения (CD-ROM), цифровые универсальные диски (DVD) и т.д.), и передающие носители, такие как цифровые и аналоговые линии связи.
Кроме того, различные программы, описанные в дальнейшем, могут быть идентифицированы на основе применения, для которого они реализованы в заданном варианте воплощения изобретения. Однако следует понимать, что любая конкретная система наименований программ используется лишь для удобства, и, таким образом, изобретение не должно быть ограничено использованием исключительно в каком-либо отдельном применении, идентифицированном и/или подразумеваемом такой системой наименований.
Специалисты в данной области техники должны понимать, что иллюстративные среды, показанные на фиг.1 и 2, не подразумевают ограничения настоящего изобретения. Действительно, специалисты в области техники должны понимать, что могут использоваться другие альтернативные аппаратные и/или программные среды без отступления от объема изобретения.
Упорядочение результатов поиска на основе
пользовательских взаимодействий
Проиллюстрированные здесь варианты воплощения в общем случае работают посредством улучшения формирования и упорядочения результатов поиска от механизма поиска в ответ на пользовательское взаимодействие с записями, содержащими результаты поиска. Кроме того, в проиллюстрированном варианте воплощения база данных, к которой обращается механизм поиска, является характерной для базы сети Интернет, используемой вместе с алгоритмом индексирования и хранящей множество записей, отражающих язык гипертекстовой разметки (совместимые с форматом HTML документы, сохраненные в сети, такой как Интернет и/или частная сеть). Как должно быть легко понятно специалисту в данной области техники, каждая запись в базе данных включает в себя, по меньшей мере, адрес соответствующего документа, хранящегося в сети, обычно в виде унифицированного указателя ресурса (URL).
Хотя проиллюстрированные реализации сосредоточены на описанном выше применении в сети Интернет, будет понятно, что описанные здесь методики могут использоваться вместе с улучшением извлечения данных из базы данных любого типа. Поэтому изобретение не ограничено обсуждаемой здесь конкретной реализацией на основе формата HTML.
Проиллюстрированная реализация полагается на "параметр пользовательского взаимодействия", который привязан к каждой записи в информации базы данных, имеющей отношение к взаимодействию одного или более пользователей с записью. Параметр пользовательского взаимодействия, привязанный к каждой записи, включает в себя один или более весовых коэффициентов, используемых для обеспечения ранга для записи относительно других записей, найденных в ответ на поисковый запрос.
Например, относительные весовые коэффициенты записей в результирующем множестве могут являться единственным основанием для ранжирования и упорядочивания элементов результирующего множества. Или пользовательское взаимодействие может быть еще одним компонентом, используемым при упорядочении результатов поиска. В частности, первичным способом упорядочения результатов поиска является релевантность восприятия каждой записи в смысле степени, в которой каждая запись соответствует поисковому запросу. Для этой операции первичного упорядочения может быть использовано любое количество параметров механизма поиска, например количество совпадающих поисковых терминов, близость поисковых терминов, размещение поисковых терминов, частота появления каждого поискового термина и т.д. Пользовательское взаимодействие используется как дополнительный или вторичный параметр упорядочения, чтобы помогать в упорядочении записей, имеющих сходные релевантности.
Кроме того, следует понимать, что дополнительные параметры также могут использоваться вместе с пользовательским взаимодействием, чтобы помогать в упорядочении записей в результирующем множестве. Например, также могут использоваться другие традиционные параметры, такие как популярность ссылок, присутствие в соответствующем списке каталога и т.д.
Здесь представлены две иллюстративные реализации параметра пользовательского взаимодействия: реализация на стороне сервера и реализация на стороне пользователя.
Реализация на стороне сервера
Для реализации на стороне сервера механизм поиска или веб-сервер могут включать в себя функциональные возможности отслеживания, совместимые с изобретением, для общей поддержки двух первичных операций для использования в выполнении упорядочения результатов поиска на основе пользовательского взаимодействия. Одной операцией является инициирование поискового запроса для выдачи результирующего множества, которое идентифицирует одну или более записей из базы данных, которые соответствуют поисковому запросу. Второй операцией является пользовательское взаимодействие с записями в результирующем множестве, используемое для отслеживания пользовательских взаимодействий с такими записями с целью формирования базы данных информации пользовательских взаимодействий для использования при упорядочении будущих результирующих множеств.
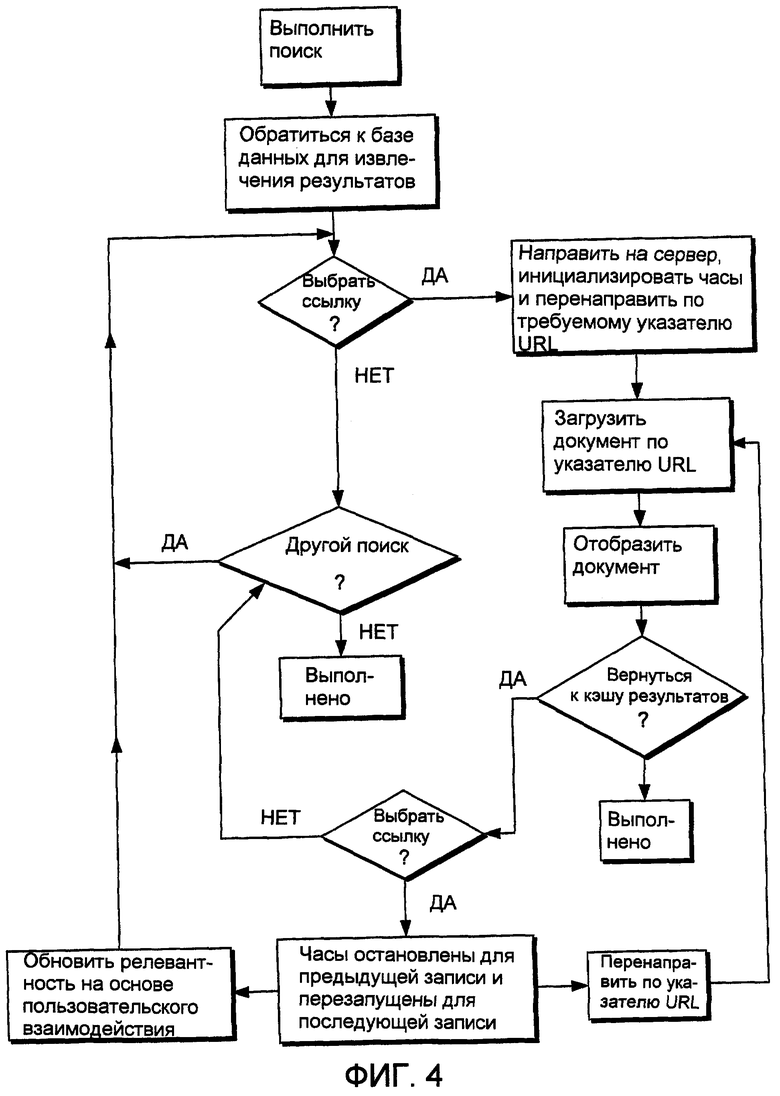
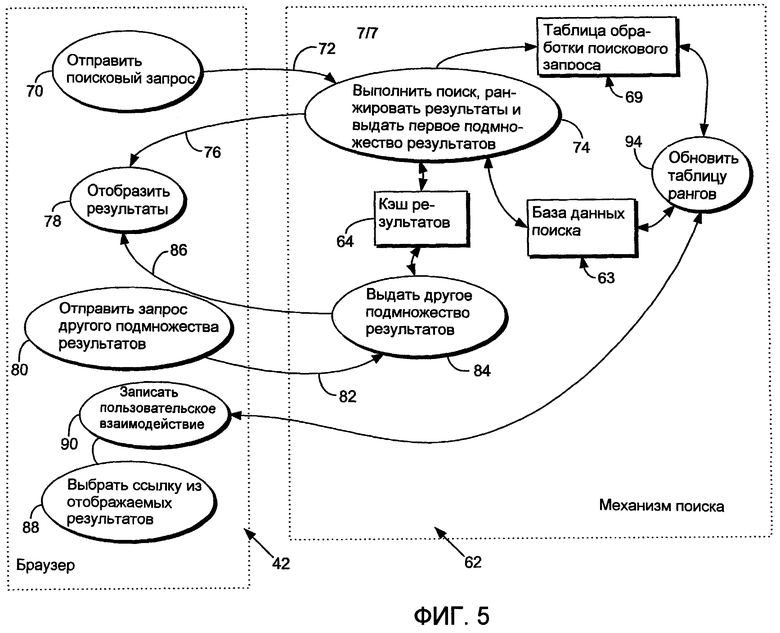
Фиг.3 иллюстрирует общие операции, обрабатываемые механизмом 62 поиска в ответ на запросы от пользовательского рабочего браузера 42. Как проиллюстрировано на этапе 70, например, пользователь может инициализировать и отправить поисковый запрос 72 механизму 62 поиска. В ответ на поисковый запрос механизм 62 поиска выполняет поиск, ранжирует результаты и возвращает первое подмножество результатов пользователю, как представлено ссылочной позицией 76. Подмножество результатов отображается пользователю в браузере 42, как представлено на этапе 78, и включает в себя гипертекстовые ссылки, указывающие на сервер для механизма 62 поиска, с тем чтобы механизм поиска мог обнаружить пользовательский выбор конкретной ссылки в подмножестве результатов. Сервер автоматически перенаправляет пользователя на требуемый результирующий документ.
Кэш 64 результатов обычно используется для хранения подмножеств результатов, выданных в ответ на поисковый запрос, с тем чтобы не нужно было делать повторный запрос к базе данных поиска всякий раз, когда пользователь желает посмотреть другие результаты из результирующего множества. В проиллюстрированной реализации механизм поиска создает гипертекстовые документы, представляющие подмножества результатов, например, каждый гипертекстовый документ содержит гипертекстовые ссылки на подмножество записей, идентифицированных в ответ на поисковый запрос.
После перенаправления на конкретную ссылку механизм поиска инициализирует часы или в качестве альтернативы ставит временную метку на ссылку, чтобы привязать стартовое время для пользовательского взаимодействия с конкретным документом, и затем определяет числовой ранг ссылки, к которой произведено обращение (например, результат поиска с номером 4 из 25 релевантных документов). Механизм 62 поиска продолжает отсчет часов для ссылки до тех пор, пока пользователь не выберет альтернативную ссылку. После выбора альтернативной гипертекстовой ссылки из результирующего множества сервер вычисляет разность времени между перенаправлением на предыдущую ссылку и перенаправлением на последующую ссылку, чтобы определить, по существу, продолжительность времени, в течение которого просматривалась запись. Затем часы инициализируются для последующей результирующей ссылки с целью получения данных времени доступа для последующей ссылки, и сохраняется ранг последующей ссылки. Это продолжается до тех пор, пока не завершится взаимодействие с кэшем результатов.
Сервер вычисляет и назначает весовые коэффициенты данным параметров пользовательских взаимодействий, привязанным к каждой записи, чтобы помогать в упорядочении последующих результатов поиска. Сервер назначает весовой коэффициент релевантности для каждой записи, обращение к которой осуществлялось дольше предопределенного времени (например, пяти минут). Далее каждая запись, которая имеет более высокий номер ранга, чем "релевантная запись, к которой осуществлено обращение" (то есть запись, время обращения к которой превысило предопределенные критерии времени) и к которой либо не было осуществлено обращение, либо осуществлено обращение и не выполнены предопределенные критерии времени релевантности, может быть понижена в ранге или иным образом получит параметр с нерелевантным весовым коэффициентом. Эти параметры сохраняются в базе 63 данных поиска. Однако следует понимать, что альтернативно данные параметра пользовательского взаимодействия, сохраненные в базе данных поиска, могут сохраняться в отдельной структуре данных.
Механизм 62 поиска периодически обновляет информацию пользовательских взаимодействий, сохраненную в базе 63 данных поиска. Как следствие, с течением времени, ожидается, что будет разработано, чтобы база 63 данных поиска предоставляла более полезные показания для документов, обращение к которым осуществлялось дольше всего и которые, по-видимому, являются наиболее релевантными, представленные записями в базе данных поиска.
Реализация на стороне пользователя
Параметр пользовательского взаимодействия аналогично может быть реализован через пользовательское приложение, такое как пользовательский браузер. Компьютерная программа 90 на пользовательском браузере может использоваться для отслеживания пользовательских взаимодействий с записями с помощью компьютерной программы, обеспечивающей периодические уведомления механизму поиска. Эта программа может находиться на компьютере пользователя или может быть встроена в браузер, например, как его дополнительный модуль или адаптация, или загружена на компьютер пользователя.
В этой реализации пользователь может инициализировать и отправлять поисковый запрос 72 механизму 62 поиска. В ответ на поисковый запрос механизм 62 поиска выполняет поиск, ранжирует результаты и возвращает первое подмножество результатов пользователю, как представлено ссылочной позицией 76. Подмножество результатов отображается пользователю в браузере 42, как представлено на этапе 78, и содержит гипертекстовые ссылки на релевантные документы. После выбора конкретной ссылки браузер 42 пользователя инициализирует внутреннее устройство отсчета времени или часы и определяет числовой ранг ссылки, к которой осуществлено обращение (например, результат поиска с номером 4 из 25 релевантных документов). Когда пользователь уходит с этой ссылки, например, щелкая мышью по значку "назад", по другой ссылке, возвращаясь на домашнюю страницу (щелкая мышью по значку «домой») или закрывая браузер, браузер останавливает часы и сохраняет продолжительность времени, в течение которого осуществлялось обращение к записи. Это продолжается до тех пор, пока не завершится взаимодействие с кэшем 64 результатов. Таким образом, браузер сохраняет данные пользовательских взаимодействий для каждой записи, к которой осуществлялось обращение в кэше результатов. Данные взаимодействия состоят из продолжительности времени, в течение которого осуществлялось обращение к записи, и ранга одного или более документов в кэше результатов, к которым осуществлялось обращение.
Если пользователь щелкает мышью по ссылке в документе, к которому осуществляется обращение, браузер инициализирует внутреннее устройство отсчета времени. Когда пользователь уходит с этой ссылки или по истечении некоторого времени после этого, определяется продолжительность времени, в течение которого осуществлялось обращение к этой вторичной записи, и браузер загружает на сервер информацию идентификации вторичной записи и продолжительности времени. Сервер определяет, соответствует ли вторичная запись результату в кэше 64 результатов. Если это так, продолжительность времени, в течение которого осуществлялось обращение к этой вторичной записи, сравнивается с предопределенным релевантным периодом времени взаимодействия. И для этой вторичной записи создается набор данных взаимодействия, чтобы увеличить или уменьшить ее весовой коэффициент релевантности после последующих поисковых запросов.
Периодически, например, в конце взаимодействия пользователя с кэшем результата браузер уведомляет сервер о данных взаимодействий. Сервер оценивает и назначает весовые коэффициенты данным параметров пользовательских взаимодействий, привязанным к каждой записи, чтобы помогать в упорядочении последующих результатов поиска. Сервер назначает весовой коэффициент релевантности для каждой записи, обращение к которой осуществлялось дольше предопределенного времени (например, пяти минут). Далее, каждая запись, которая имеет более высокий номер ранга, чем "релевантная запись, к которой осуществлено обращение" (то есть запись, время обращения к которой превысило предопределенные критерии времени) и к которой либо не было осуществлено обращение, либо было осуществлено обращение и не выполнены предопределенные критерии времени релевантности, может быть понижена в ранге или иным образом получит параметр с нерелевантным весовым коэффициентом. Эти параметры сохраняются в базе 63 данных поиска. Однако следует понимать, что альтернативно данные параметра пользовательского взаимодействия, сохраненные в базе данных поиска, могут сохраняться в отдельной структуре данных.
Механизм 62 поиска периодически обновляет информацию пользовательских взаимодействий, сохраненную в базе 63 данных поиска. Как следствие, в течение времени ожидается, что будет разработано, чтобы база 63 данных поиска предоставляла более полезные показания для документов, представленных записями в базе данных поиска, обращение к которым осуществлялось дольше всего и которые, по-видимому, являются наиболее релевантными.
В описанных вариантах воплощения могут быть сделаны различные изменения, совместимые с изобретением. Описанные здесь методики механизма поиска также могут использоваться локально для заданного пользователя или группы отдельных пользователей, а не полагаться на предыдущие взаимодействия, совершенные всеми пользователями механизма поиска. Кроме того, механизм поиска может быть реализован во внутренней сети, тем самым предоставляя возможность, например, группе сотрудников, имеющих связанные рабочие функции, быть единственными пользователями, для которых отслеживаются данные пользовательских взаимодействий. Альтернативно также могут быть использованы другие способы выбора релевантного множества пользователей для получения от них релевантной информации пользовательских взаимодействий.
Специалисту в данной области техники должны быть понятны другие модификации. Поэтому изобретение заключено в приложенной далее формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ И ПОИСКОВАЯ СИСТЕМА ПРЕДОСТАВЛЕНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ НА МНОЖЕСТВО КЛИЕНТСКИХ УСТРОЙСТВ | 2015 |
|
RU2632423C2 |
| СПОСОБ И СЕРВЕР ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2718216C2 |
| Способ и сервер для определения обучающего набора для обучения алгоритма машинного обучения (MLA) | 2020 |
|
RU2817726C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ВЫБОРА ЗНАЧИМЫХ ЭЛЕМЕНТОВ СТРАНИЦЫ С НЕЯВНЫМ УКАЗАНИЕМ КООРДИНАТ ДЛЯ ИДЕНТИФИКАЦИИ И ПРОСМОТРА РЕЛЕВАНТНОЙ ИНФОРМАЦИИ | 2015 |
|
RU2708790C2 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
| СИСТЕМА ДЛЯ ПОЛУЧЕНИЯ ИНФОРМАЦИИ ИЗ ИНТЕРНЕТА (ВАРИАНТЫ) И СИСТЕМА ПОДАЧИ ИНФОРМАЦИИ НА КЛИЕНТСКОЕ УСТРОЙСТВО (ВАРИАНТЫ) | 2013 |
|
RU2583737C2 |
Изобретение относится к области механизмов поиска и взаимодействия пользователя со сформированным ими результирующим множеством. Техническим результатом является повышение эффективности доступа к базе данных на основе пользовательского взаимодействия. Способ основывается на пользовательском взаимодействии при упорядочении результатов поиска, возвращенных механизмом поиска. Каждое множество записей в базе данных привязано к параметру пользовательского взаимодействия, который привязан к продолжительности времени, в течение которого пользователь осуществляет обращение к данной записи результата поиска. При условии, что продолжительность времени, в течение которого пользователь осуществляет обращение к записи, больше предопределенного релевантного периода времени, параметру пользовательского взаимодействия присваивается весовой коэффициент для увеличения релевантности этой записи относительно записей, к которым не осуществлялись обращения в течение релевантного периода времени, используемого при упорядочении записей, идентифицированных в результирующем множестве, сформированном в ответ на поисковый запрос. 2 н. и 10 з.п. ф-лы, 7 ил.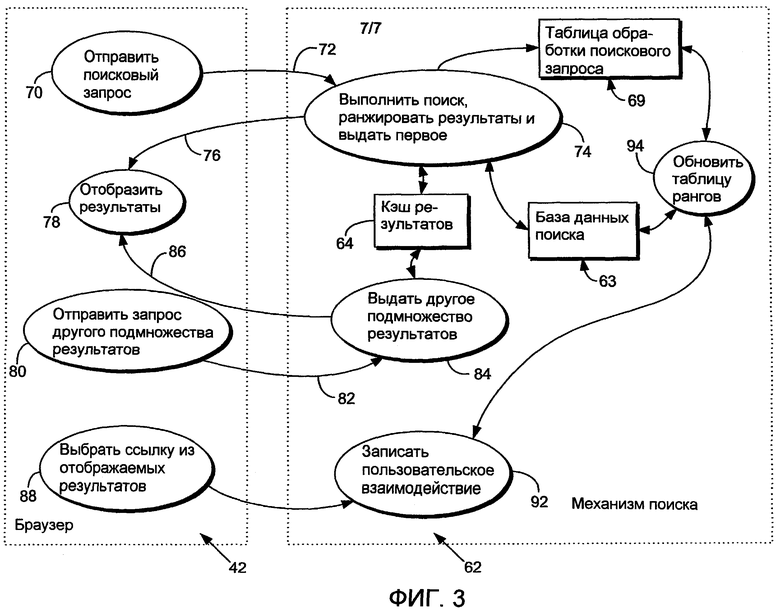
1. Способ доступа к базе данных, причем способ содержит этапы, на которых:
(a) в ответ на первый поисковый запрос формируют первое результирующее множество, идентифицирующее одну или более записей;
(b) обеспечивают первое результирующее множество пользователю;
(c) в ответ на обращение пользователя к записи первого результирующего множества инициализируют часы для измерения продолжительности доступа записи пользователем;
(d) для каждой из одной или более идентифицированных записей создают параметр пользовательского взаимодействия, ассоциированный с ней, в зависимости от продолжительности времени, в течение которого запись была доступна для пользователя, и номер документа, ассоциированный с упорядочиванием документа в списке результатов поиска;
(e) определяют, что по меньшей мере одна запись была первоначально доступна за менее, чем пороговый промежуток времени, и поскольку, по меньшей мере, одна запись была не доступна за пороговый промежуток времени, понижают параметр времени, ассоциированный с, по меньшей мере, одной записью; и
(f) упорядочивают идентификации записей во втором результирующем множестве, которое содержит, по меньшей мере, одну из записей, идентифицированных в первом результирующем множестве с использованием параметра пользовательского взаимодействия, ассоциированного с по меньшей мере одной идентифицированной записью в первом результирующем множестве.
2. Способ по п.1, дополнительно содержащий этап, на котором: (f) выборочно обновляют параметр пользовательского взаимодействия, ассоциированный с первой записью, в ответ на определение, что продолжительность времени, в течение которого пользователь осуществлял обращение к первой записи, превышает период времени релевантности.
3. Способ по п.1, дополнительно содержащий этап, на котором увеличивают параметр пользовательского взаимодействия, ассоциированный с первой записью, в ответ на продолжительность времени первой записи получают доступ, превышающий предопределенный период времени релевантности.
4. Способ по п.1, дополнительно содержащий этап, на котором обнаруживают ранг одной или более записей первого результирующего множества и увеличивают параметр пользовательского взаимодействия, ассоциированный с первой записью, в ответ на то, что продолжительность времени, в течение которого осуществлялось обращение к первой записи, превышает предопределенный период времени релевантности относительно параметра пользовательского взаимодействия записей, имеющих более высокий ранг, которые не удовлетворяли периоду времени релевантности.
5. Способ по п.4, в котором период времени релевантности не был удовлетворен, поскольку к записи не осуществлялись обращения.
6. Способ по п.1, в котором этап инициализации часов для измерения продолжительности обращения пользователя достигается посредством сервера, имеющего механизм поиска.
7. Способ по п.6, в котором формирование первого результирующего множества включает в себя формирование множества гипертекстовых ссылок, каждая из которых выполнена с возможностью обращаться к серверу для формирования уведомления о том, что к привязанной к ней записи обратился пользователь, и инициализации часов для привязанной записи.
8. Способ по п.1, в котором этап инициализации часов для измерения продолжительности обращения пользователя достигается браузером для пользователя.
9. Способ по п.8, в котором браузер содержит часы и средство для обнаружения ухода пользователя с первой записи, причем браузер измеряет продолжительность времени обращения пользователя к первой записи до инициирования клавиши перехода назад.
10. Способ по п.9, в котором браузер дополнительно содержит память для поддержания данных продолжительности времени для первой записи, и в котором этап инициализации часов для измерения продолжительности доступа пользователя дополнительно содержит этап, на котором механизму поиска периодически предоставляют уведомление о данных продолжительности времени.
11. Способ по п.1, в котором этап инициализации часов реализован пользовательским приложением.
12. Машиночитаемый носитель, имеющий машиноисполняемые инструкции, при исполнении которых осуществляется способ по любому из пп.1-11.
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6873982 B1, 29.03.2005 | |||
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |

