ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение относится к системам и средствам поиска информации, в частности реализация изобретения относится к системам поиска информации о научной и исследовательской деятельности, таких как статьи, диссертации, монографии и прочие публикации.
УРОВЕНЬ ТЕХНИКИ
Существует множество способов оптимизации процесса информационного поиска. Однако проблема больших временных затрат на поиск по статьям, диссертациям и прочим источникам научной и исследовательской информации, обусловленная их колоссальным объемом и отсутствием достаточной систематизации, остается актуальной.
Известен способ [RU 2409849 С2, G06F 17/30, 2006.01] поиска информации в политематических массивах неструктурированных текстов, заключающийся в том, что формируют базу терминов по определенной тематике, запрос и при поиске по запросу и нахождении каждого документа заносят в память компьютера его заголовок и адрес, пословно сравнивают заголовки с терминами из базы терминов по определенной тематике и заносят в память количество совпавших терминов для каждого документа и его адреса, проверяют наличие документов, для которых количество совпавших терминов равно нулю, и удаляют их заголовок и адрес из памяти компьютера, сортируют заголовки и адреса оставшихся документов по количеству совпавших терминов, осуществляют проверку выданного документа на соответствие первоначальному запросу, если выданный документ не соответствует первоначальному запросу, то всю информацию о нем удаляют и осуществляют выдачу на экран монитора следующего по критерию документа.
Известен способ [RU 2571406 C1, G06F 17/30, 2006.01] двухуровневого поиска информации в предварительно преобразованном структурированном массиве данных, заключающийся в том, что в структурированном исходном массиве данных формируют поисковый запрос. Идентифицируют массив данных, соответствующий запросу, семантическую часть, соответствующую запросу, и логическую конструкцию, содержащую семантическую часть. Демонстрируют идентифицированную логическую конструкцию. Выбирают идентифицированную логическую конструкцию и идентифицируют связанные с ней через связанные семантические части другие логические конструкции. Причем упомянутая идентификация осуществляется на основании сведений из карты связей компонентов. Идентифицируют логические конструкции, содержащие связанные семантические части, и демонстрируют логические конструкции, содержащие связанные семантические части, или демонстрируют отсутствие логических конструкций, содержащих связанные семантические части.
Известен способ [RU 2392660 С2, G06F 17/30, G06F 17/27, 2006.01] поиска информации в массиве текстов, заключающийся в том, что производится сравнение фраз по смыслу. При поступлении запроса его содержимое обрабатывают по предложениям, происходит попарное сопоставление предложений массива текстов и поискового запроса, по результатам которого вычисляют релевантность каждого документа массива текстов запросу на основе входящих в документы предложений. Индексирование массива текста происходит по отдельным предложениям. В предложениях вначале распознают точные значения слов и устанавливают семантические связи между ними, затем точные значения слов заменяют их разложением на элементарные значения, которые хранятся для каждого значения в тезаурусе, после чего для каждого предложения строят матрицу, содержащую связи между всеми парами объектов, входящих в предложение, затем составляют инвертированный индекс, где для каждого объекта, входящего в массив текста, указано в каких документах и в каких предложениях сколько раз он встречается.
В перечисленных выше способах не производится анализ смыслового содержания и систематизация текстов, по которым производится поиск. Это приводит к необходимости ручного перебора множества результатов поиска и, следовательно, большим временным затратам при осуществлении информационного поиска в некоторых случаях, в частности по текстам, содержащим информацию о научной и исследовательской деятельности.
Известны способы [RU 2335013 С2, G06F 17/30, 2006.01] для улучшения ранжирования поиска с использованием информации о статье, заключающиеся в том, что система для ранжирования поиска с использованием информации о статье содержит процессор для выполнения машиночитаемых программных команд, память для их хранения, клиентское приложение для обеспечения возможности поведенческой деятельности клиентской стороны, клиентскую статью, процессор запросов для приема запроса поиска, средство мониторинга для определения данных о поведении клиентской стороны, связанных с поведенческой деятельностью клиента, полученной статьей, машину поиска для определения того, что статья связана с запросом поиска, приема из хранилища данных упомянутой предопределенной оценки поведения клиента, связанной со статьей, размещения статьи среди результатов поиска по запросу поиска на основе, по меньшей мере частично, упомянутой предопределенной оценки поведения клиента, связанной со статьей, и выдачи статей, связанных с запросом поиска, в порядке ранжирования на основе, по меньшей мере частично, упомянутого размещения, и хранилище данных для связывания предопределенной оценки поведения клиента с клиентской статьей и хранения данных о поведении клиентской стороны, связанных с клиентской статьей. Недостатком этих способов является то, что для сортировки и ранжирования результатов поиска используются данные, собранные на клиентской стороне, которые могут отсутствовать в принципе или быть недоступными для некоторых поисковых систем.
Наиболее близким аналогом (прототипом) заявленного способа принят способ поиска и выборки информации с повышенной релевантностью, описанный в патенте [RU 2236699, C1 G06F 17/30], который включает формирование пользователем на своем рабочем месте по меньшей мере одного поискового запроса, передачу сформированного пользователем запроса в поисковую систему, обработку поисковой системой сформированных пользователем поисковых запросов путем выбора документов из баз данных, отличающийся тем, что поисковая система сортирует упомянутые выбранные документы по тематикам и формирует папки, каждая из которых содержит упомянутые документы, отсортированные по одной тематике, для каждого отсортированного документа выделяют признаки, характеризующие этот документ, внутри каждой папки поисковая система определяет рейтинг каждого признака, содержащегося в каждом отсортированном документе, после чего поисковая система определяет число совпадений признаков отдельных отсортированных документов одной папки с признаками других документов, содержащихся в других папках, определяет окончательный рейтинг каждого отсортированного документа с учетом числа совпадений признаков и с учетом весового коэффициента базы данных, после чего поисковая система снова сортирует упомянутые отсортированные документы с учетом окончательного рейтинга и направляет отсортированные в соответствии с окончательным рейтингом документы на рабочее место пользователя.
В прототипе для группировки документов используется тематической признак, а в рамках группы используется ранжирование по соответствию данным поискового запроса. Недостатком прототипа является то, что используемый тематический признак является единственным, что не отражает многие другие логические связи, которые могут быть между текстами в множестве искомых.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В настоящее время в ходе научной и исследовательской деятельности большое количество времени тратится на поиск и анализ информации, описывающей результаты проведенных исследований или других видов научной деятельности. Известные способы поиска в электронных библиографических и реферативных базах данных не решают в достаточной мере проблему фильтрации большого количества результатов поиска, поскольку фильтрация осуществляется, как правило, по формальным признакам и не охватывает смысловое содержание работ.
Для исследователей полезно знание о логических отношениях между работами, по которым производится поиск. Так, например, знание о том, что результаты научной деятельности, описанные в одной статье, опровергнуты в другой, могут сэкономить много времени, которое было бы потрачено на ложное направление исследований.
Техническим результатом является повышение информативности результатов поиска информации о научной и исследовательской деятельности, что позволяет сократить время, затрачиваемое на поиск и изучение его результатов.
Указанный технический результат достигается за счет того, что в способе структурирования результатов поиска по текстам, содержащих информацию о научной и исследовательской деятельности, производится лингвистический анализ текстов на естественном языке, содержащих информацию о научной и исследовательской деятельности, на основе результатов анализа производится построение структур, содержащих информацию о различных логических отношениях между проанализированными текстами, из построенных структур формируется база знаний (данных), которая используется при формировании результатов поиска для отображения логических отношений между результатами поиска, а также группировки некоторых результатов поиска.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
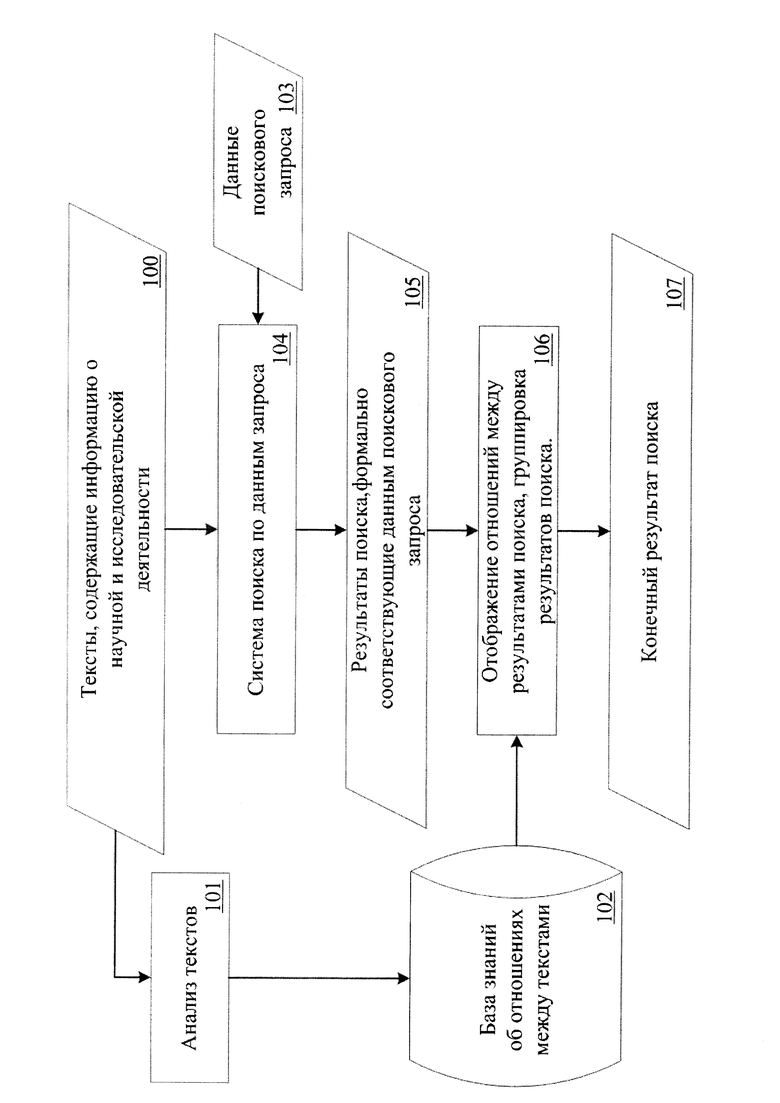
Фиг. 1 - блок-схема системы информационного поиска, в которой применен описанный способ структурирования результатов поиска по текстам, содержащим информацию о научной и исследовательской деятельности.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Способ структурирования результатов поиска по текстам, содержащим информацию о научной и исследовательской деятельности, реализуется следующим образом.
Согласно Фиг. 1, на первом этапе производится лингвистический анализ 101 текстов, содержащих информацию о научной и исследовательской деятельности 100, по которым реализуется поиск. Производится определение явных и косвенных ссылок между текстами, а также характера этих ссылок методами обработки естественного языка и методами обработки формальных грамматик. Далее производится сопоставление полученной информации об обнаруженных ссылках и их характере, на основании чего выявляются логические отношения между текстами. Типы выявляемых логических отношений и условия их выявления описаны ниже. Далее, информация о выявленных логических отношениях и их относительной значимости сохраняется в базу знаний (данных) 102.
Первый этап является подготовительным и может, также, выполняться при добавлении новых текстов в множество тех, по которым производится поиск.
Под структурированием результатов поиска понимается формирование и отображение различных отношений (связей) между результатами поиска и/или особый порядок вывода результатов поиска, показывающие отношения (связи) между результатами поиска.
Под построением структур, описывающих различные отношения между текстами, понимается создание множества объектов, идентифицирующих тексты, и множества связей различных типов между этими объектами.
Под текстами, содержащими информацию о научной и исследовательской деятельности, понимаются, в частности, статьи в электронных и бумажных периодических изданиях, статьи в сборниках статей, авторефераты диссертаций, тексты диссертаций, монографии и другие тексты на электронных и бумажных носителях, описывающие исследования, разработки и/или открытия в различных областях знаний.
Под логическими отношениями между текстами, логическими отношениями между результатами поиска понимаются логические связи между текстами, основанные на отношениях развития, сравнения текстов, опровержения, подтверждения, использования одного текста в другом, отношения текста к научной школе, к организации, сообществу или группе, к одному географическому признаку, отношении близкой характеристики текста.
Отношение развития. Отношение развития устанавливается между текстами в том случае, когда идеи, модели, методы, алгоритмы, механизмы, конструкции, решения, описания явлений, организмов, иные результаты или их характеристики, содержащиеся в тексте или множестве текстов, развиваются в другом тексте или множестве текстов. Например, один текст (статья 1) может содержать в себе описание алгоритма сортировки, который получил развитие (улучшение производительности или снижение затрат памяти) в другом тексте (статья 2). В этом случае между статья 2 и статья 1 устанавливается логическое отношение развития.
Отношение сравнения. Отношение сравнения устанавливается в том случае, когда идеи, модели, методы, алгоритмы, механизмы, конструкции, решения, описания явлений, организмов, иные результаты или их характеристики, содержащиеся в тексте или множестве текстов, сравниваются с теми, которые описаны в другом тексте или множестве текстов. Например, один текст (статья 1) может содержать в себе сравнение производительности разработанного метода с другим методом, описанным в другой работе (статья 2). В этом случае между статья 1 и статья 2 устанавливается отношение сравнения.
Отношение опровержения. Отношение опровержения устанавливается в том случае, когда идеи, модели, методы, алгоритмы, механизмы, конструкции, решения, описания явлений, организмов, иные результаты или их характеристики, содержащиеся в тексте или множестве текстов, опровергаются, или их корректность и/или достоверность подвергается сомнению в другом тексте или множестве текстов. Например, один текст (статья 1) может содержать в себе опровержение и/или отрицание результатов, полученных в другой работе (статья 2). В частности, опровержение полученных характеристик явлений, свойств объектов или иных результатов. В этом случае между статья 1 и статья 2 устанавливается отношение опровержения. Отношение опровержение является частным случаем отношения сравнения.
Отношение подтверждения. Отношение подтверждения устанавливается в том случае, когда идеи, модели, методы, алгоритмы, механизмы, конструкции, решения, описания явлений, организмов, иные результаты или их характеристики, содержащиеся в тексте или множестве текстов, подтверждаются или согласуются с явлениями или характеристиками, описанными в другом тексте или множестве текстов. Например, один текст (статья 1) может содержать в себе подтверждение результатов, полученных в другой работе (статья 2). В частности, подтверждение полученных гипотез, характеристик явлений, свойств объектов или иных результатов. В этом случае между статья 1 и статья 2 устанавливается отношение подтверждения.
Отношение использования. Отношение использования устанавливается в том случае, когда идеи, модели, методы, алгоритмы, механизмы, конструкции, решения, описания явлений, организмов, иные результаты или их характеристики, содержащиеся в тексте или множестве текстов, используются в другом тексте или множестве текстов. Например, один текст (диссертация 1) может содержать в себе информацию об использовании результатов, полученных в другом тексте (диссертация 2), в частности использование методов, подходов, моделей. В этом случае между диссертация 1 и диссертация 2 устанавливается отношение использования.
Отношение к одной научной школе. Отношение к одной научной школе устанавливается при определении принадлежности нескольких текстов к одной научной школе, научной идее или развитию (продолжению) идей определенной научной школы, ученому и/или группе ученых, научному руководителю, автору и/или группе авторов. Для этого используются заранее подготовленные списки ученых, исследователей или списки отдельных работ, относящихся к определенной научной школе. Например, один текст (диссертация 1) определен как относящийся к определенной научной школе. Если другой текст (диссертация 2) может быть определен как относящийся к той же научной школе, что и диссертация 1, то между диссертация 1 и диссертация 2 устанавливается отношение одной научной школы.
Отношение одного географического признака. Отношение одного географического признака устанавливается при определении принадлежности нескольких текстов к одному географическому признаку, в частности места его публикации, места проведения исследования. Например, один текст (статья 1) может быть классифицирован как опубликованный в определенном городе. Если другой текст (статья 2) может быть классифицирован как относящийся к тому же городу, что и статья 1, то между статья 1 и статья 2 устанавливается отношение одного географического признака.
Отношение к одной организации или группе лиц. Отношение к одной организации или группе лиц устанавливается при определении принадлежности нескольких текстов к одной организации или группе лиц, которым тексты соответствуют по одному или нескольким формальным признакам. Например, один текст (монография 1) может быть классифицирован как относящийся к определенной организации, в частности к ВУЗу, НИИ, ОКБ, лаборатории или иной форме организованной деятельности. Если другой текст (монография 2) может быть классифицирован как относящийся к той же организации, что и текст 1, то между монография 1 и монография 2 устанавливается отношение одной организации.
Отношение близкой характеристики текста. Под характеристикой текста понимается одна из логических или формальных характеристик текста, содержащего информацию о научной или исследовательской деятельности, в частности «объект исследования», «предмет исследования», «метод исследования», «результат исследования», «тема», «научная новизна», «цель», «задача», «гипотеза», «проблема», «теоретические основы», «методологические основы», «теоретическая значимость», «практическая значимость», «положение исследования», «вывод», и другие структурные единицы текстов. Отношение близкой характеристики устанавливается при обнаружении у двух или более текстов одинаковой или близкой характеристики текста. При этом близость характеристик может быть установлена с использованием онтологических баз знаний, содержащих в себе иерархию терминов естественного языка, позволяющих определять близкие по смыслу термины, а также словарей синонимов. Например, если один текст (диссертация 1) содержит одинаковый или схожий с другим текстом (диссертация 2) объект исследования, то между диссертация 1 и диссертация 2 устанавливается отношение близкого объекта исследования.
Описываемый способ структурирования результатов поиска позволяет использовать и комбинировать одно или несколько логических отношений между текстами.
На втором этапе производится обработка поискового запроса с целью отображения логических отношений между результатами поиска и/или группирования результатов поиска по логическим отношениям.
Для этого при поступлении в систему данных нового поискового запроса 103 (см. Фиг. 1) производится поиск документов, формально соответствующих данным поискового запроса. Реализация и интеграция изобретения в систему информационного поиска не зависит от конкретной реализации системы поиска по данным запроса 104. Важно, чтобы применяемая поисковая система в результате обработки поискового запроса выдавала набор текстов и/или ссылок на тексты, которые формально соответствуют данным поискового запроса (например, в силу частоты встречаемости терминов поискового запроса). В качестве примера такой поисковой системы можно привести Sphinx разработки компании Sphinx Technologies Inc.
Далее, для каждого из результатов поиска, формально соответствующих данным поискового запроса 105, производится выборка информации из базы знаний об отношениях между текстами 102, сохраненная в нее на первом этапе.
Если между текстами, входящими в результаты поиска 105, обнаружено одно или несколько отношений, то они могут быть отображены в конечном результате поиска 107 (в зависимости от фильтров поискового запроса). Таким образом реализуется отображение отношений между результатами поиска 106. При этом, в зависимости от фильтров поискового запроса, возможно включение в результаты поиска элементов, которые не соответствуют поисковому запросу (с отметкой таких результатов как нерелевантные). Это может быть полезно для отображения целостной структурированной картины научных трудов в области поиска.
Далее, в зависимости от фильтров поискового запроса или уточняющих запросов, которые могут быть получены после отображения конечного результата поиска, производится группировка результатов по одному или нескольким логическим отношениям. Для этого выбираются все результаты поиска, имеющие одинаковые логические отношения, и выводятся как группа (множество) результатов поиска. Так, например, может быть удобной группировка результатов поиска по отношению близкой характеристики текста «предмет исследования», что позволяет быстро определить тексты с одним предметом исследования.
Важно отметить, что возможна реализация способа структурирования результатов поиска по текстам, содержащим информацию о научной и исследовательской деятельности, когда формирование результатов поиска, формально соответствующих данным поискового запроса 105, может выполняться параллельно с 106.
Отображение описанных логических отношений между текстами, а также группировка результатов поиска решает задачу структурирования результатов поиска. Результаты поиска представляются в логически определенной зависимости и последовательности, содержат дополнительную информацию о связях между ними, что позволяет определять и/или выделять наиболее значимые и релевантные результаты поиска и не тратить время на изучение менее подходящих текстов, таким образом сокращая суммарное время на поиск нужной информации.
При этом описанный способ может применяться и для структурирования данных, являющихся результатами очень «широких» поисковых запросов, например, по запросу «иммунология». В этом случае использование метода позволяет получить систематизированную «карту» исследований в определенной области.
Представленное выше описание реализации заявленного способа не ограничивает множество возможных реализаций изобретения. Объем представленного изобретения ограничен только формулой изобретения и ее эквивалентами.
Изобретение относится к системам и средствам поиска информации. Технический результат заключается в повышении информативности результатов поиска информации. Технический результат достигается за счет представления результатов поиска в логически определенной зависимости и последовательности, позволяющей определять и выделять наиболее значимые результаты поиска. Для этого производится лингвистический анализ текстов, определение логических отношений между текстами, формирование базы знаний о логических отношениях между ними. Полученная база знаний используется при обработке и отображении результатов поиска, соответствующих данным поискового запроса. 2 з.п. ф-лы, 1 ил.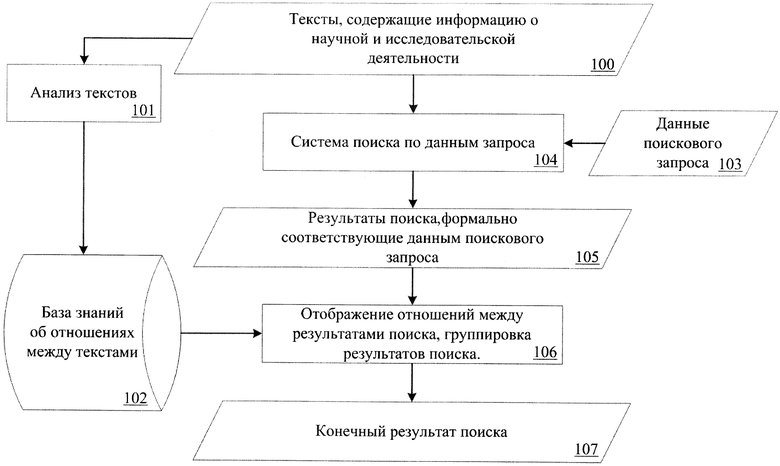
1. Способ структурирования результатов поиска по текстам, содержащим информацию о научной и исследовательской деятельности, заключающийся в том, что производят лингвистический анализ текстов, содержащих информацию о научной и исследовательской деятельности, определяют одно или несколько логических отношений между текстами, такие как отношение развития, определяемое, если один текст содержит развитие идей, гипотез, моделей, подходов, методов, алгоритмов, механизмов, конструкций, результатов исследования, решений, описаний явлений, организмов, содержащихся в другом тексте; отношение сравнения, определяемое, если один текст содержит сравнение идей, гипотез, моделей, подходов, методов, алгоритмов, механизмов, конструкций, решений, результатов исследования, описаний явлений, организмов, содержащихся в другом тексте; отношение опровержения, определяемое, если один текст содержит опровержение или подвергает сомнению корректность или достоверность идей, гипотез, моделей, подходов, методов, алгоритмов, механизмов, конструкций, результатов исследования, решений, описаний явлений, организмов, содержащихся в другом тексте; отношение подтверждения, определяемое, если один текст содержит подтверждение идей, гипотез, моделей, подходов, методов, алгоритмов, механизмов, конструкций, результатов исследования, решений, результатов, описаний явлений, организмов, содержащихся в другом тексте; отношение использования, определяемое, если в одном тексте используются идеи, гипотезы, модели, подходы, методы, алгоритмы, механизмы, конструкции, результаты исследования, решения, описания явлений, организмов, описанные в другом тексте; отношение к одной научной школе, определяемое, если два текста или более относятся к одной научной школе; отношение одного географического признака, определяемое, если два текста или более относятся к одному географическому признаку; отношение к одной организации или группе лиц, определяемое, если два текста или более относятся к одной организации или группе лиц; отношение близкой характеристики текста, определяемое, если тексты обладают близкими логическими характеристиками; производят построение структур, описывающих логические отношения между проанализированными текстами, применяют построенные структуры полностью или частично при формировании результатов поиска для отображения логических отношений между результатами поиска, группировки результатов поиска в зависимости от заданных критериев поиска.
2. Способ по п. 1, в котором в результаты поиска добавляют элементы, не релевантные с точки зрения данных запроса, но состоящие с релевантными элементами в логических отношениях, определяемых настройками или фильтрами поиска.
3. Способ по п. 1, в котором отношение близкой характеристики текста определяется если тексты обладают одной или более близкими характеристиками «объект исследования», «предмет исследования», «метод исследования», «результат исследования», «тема», «научная новизна», «цель», «задача», «гипотеза», «проблема», «теоретические основы», «методологические основы», «теоретическая значимость», «практическая значимость», «положение исследования», «вывод».
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |
| СПОСОБ ПРОВЕДЕНИЯ ПОИСКА (ВАРИАНТЫ), СЕРВЕР И ЭЛЕКТРОННОЕ УСТРОЙСТВО | 2014 |
|
RU2610279C2 |
| РАНЖИРАТОР РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2608886C2 |
| СПОСОБ ПРЕДСТАВЛЕНИЯ РЕЗУЛЬТАТОВ ПОИСКА В СООТВЕТСТВИИ С ПОИСКОВЫМ ЗАПРОСОМ В СЕТИ ИНТЕРНЕТ | 2014 |
|
RU2598789C2 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |

