Область техники, к которой относится изобретение
Настоящее изобретение относится к способу и считываемому компьютером носителю для импорта и экспорта иерархически структурированных данных.
Предшествующий уровень техники
Приложения программного обеспечения для компьютеров позволяют пользователям создавать документы, содержащие данные, организованные в виде иерархической структуры, такие как электронные таблицы, календари, выписки банка, списки изделий, обзоры и т.д., для обмена с другими пользователями по компьютерным сетям, таким как Интернет. Например, пользователи могут создавать документы, используя программы расширяемого языка разметки (XML) для обмена иерархическими данными между компьютерными системами, в которых используются различные форматы. XML-документы имеют определяемые пользователем описательные теги, соединяющие содержащиеся в них данные, делая данные понимаемыми различными компьютерами. Данные могут импортироваться из документа для просмотра пользователем посредством простого синтаксического анализа носящих описание тегов. После просмотра данных пользователь затем может экспортировать данные в новый или отредактированный документ с иерархическим форматированием для пересылки другим пользователям.
Синтаксический анализ документа, однако, является медленным и сложным процессом, требующим несколько шагов. Некоторые современные синтаксические анализаторы, такие как простой программный интерфейс приложения для XML (Simple API для XML (SAX)(ППР)), представляют собой синтаксические анализаторы на основе событий, в которых теги XML считываются последовательно, один за раз. Однако пользователю необходимо поддерживать состояние и поиск по всему файлу для нахождения требуемых тегов XML. Другие синтаксические анализаторы, такие как объектная модель документа (ОМД), представляют собой синтаксические анализаторы на основе дерева, которые загружают весь XML-файл в память и которые позволяют осуществлять произвольный доступ, тем самым делая легким нахождение требуемых тегов XML, по сравнению с синтаксическими анализаторами на основе событий. Однако синтаксические анализаторы на основе дерева требуют навигации по "дереву" для нахождения требуемых тегов XML. Кроме того, такие синтаксические анализаторы требуют значительного количества времени и памяти, делая их непрактичными для синтаксического анализа больших XML-файлов.
Таким образом, в настоящее время не существует простых способов импорта данных из иерархического структурированного документа. То есть нет легких путей для селективного поиска в документе конкретного тега или раздела, содержащего данные, которые могут представлять интерес для пользователя, без необходимости просмотра всего документа синтаксическими анализаторами на основе событий, такими как ППР, или без необходимости навигации по дереву с одновременным использованием значительных временных ресурсов и ресурсов памяти с синтаксическими анализаторами на основе дерева, такими как ОМД.
Аналогично, хотя синтаксические анализаторы на основе дерева, такие как ОМД (которые хранят весь файл в памяти), могут экспортировать поддеревья или другие иерархические данные, такие синтаксические анализаторы ограничены значительным использованием временных ресурсов и ресурсов памяти, присущих таким синтаксическим анализаторам.
Поэтому в этой области техники существует потребность в способе и системе селективного импорта и экспорта содержимого иерархических структурированных документов. Именно в отношении этих и других соображений было выполнено настоящее изобретение.
Краткое изложение сущности изобретения
Настоящее изобретение обеспечивает способ и систему селективного импорта и экспорта данных в электронном документе. В одном варианте выполнения изобретения предусмотрен способ селективного импорта содержимого из электронного документа. Принимается электронный документ, имеющий данные, расположенные в виде иерархической файловой структуры. Иерархической файловой структурой может быть XML. Данные в электронном документе включают в себя содержимое, связанное с данными. Данные могут включать в себя XML-элементы, атрибуты, узлы и текст. Определяются конкретные данные из документа, подлежащие импортированию, и выполняется действие над определенными данными с целью импортирования связанного с ними содержимого. Действие может включать в себя синтаксический анализ документа в отношении определенных данных и извлечение порций содержимого, связанного с этими определенными данными.
В другом варианте выполнения изобретения предусмотрен способ экспорта данных из источника в компьютерной системе с целью создания электронного документа. Определенные (специфические) данные, принятые от источника в компьютерной системе, экспортируются с целью создания электронного документа. Созданный электронный документ может иметь иерархическую файловую структуру, такую как XML. Созданный документ может включать в себя XML-элементы, атрибуты и узлы. Источником может быть клиент или сервер в компьютерной системе. Данные могут быть экспортированы в поток данных, буфер памяти или файл.
Варианты выполнения настоящего изобретения также обеспечивают считываемый компьютером носитель для селективного импорта и экспорта данных в электронном документе. Дополнительные подробности, касающиеся различных аспектов настоящего изобретения, станут очевидны из подробного описания изобретения, которое следует ниже.
Краткое описание чертежей
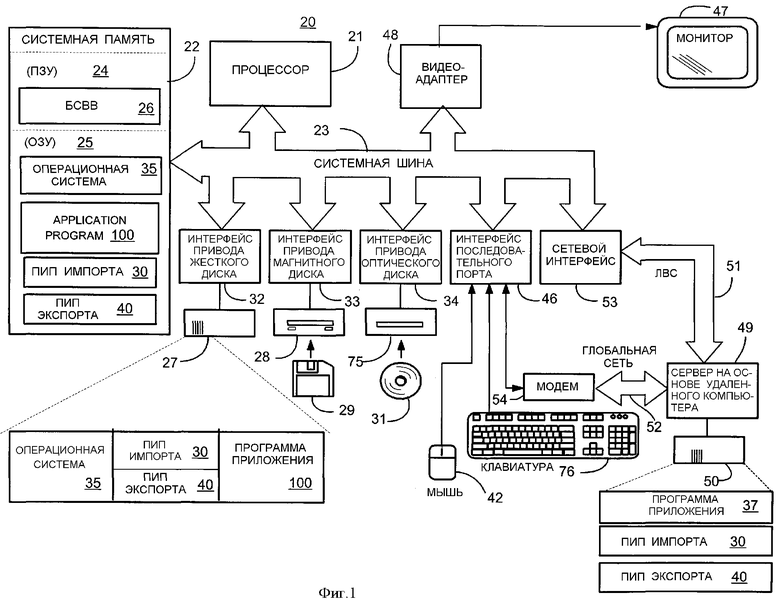
На фиг.1 представлена блок-схема компьютера и связанных с ним периферийных и сетевых устройств, которые обеспечивают иллюстративную операционную среду для настоящего изобретения.
На фиг.2 представлена блок-схема, изображающая иллюстративную архитектуру для импорта электронного документа в соответствии с вариантом выполнения настоящего изобретения.
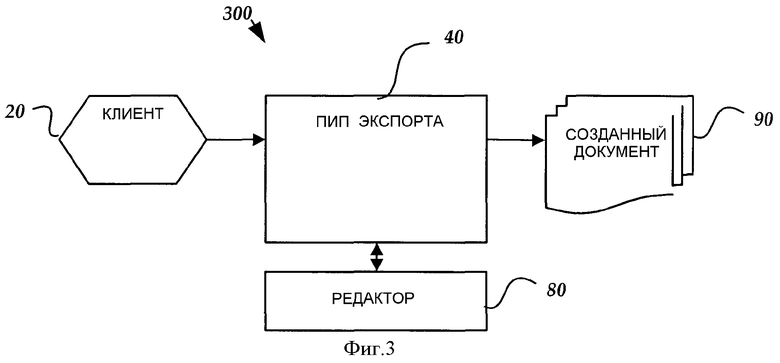
На фиг.3 представлена блок-схема, изображающая иллюстративную архитектуру для экспорта данных с целью создания электронного документа в соответствии с вариантом выполнения настоящего изобретения.
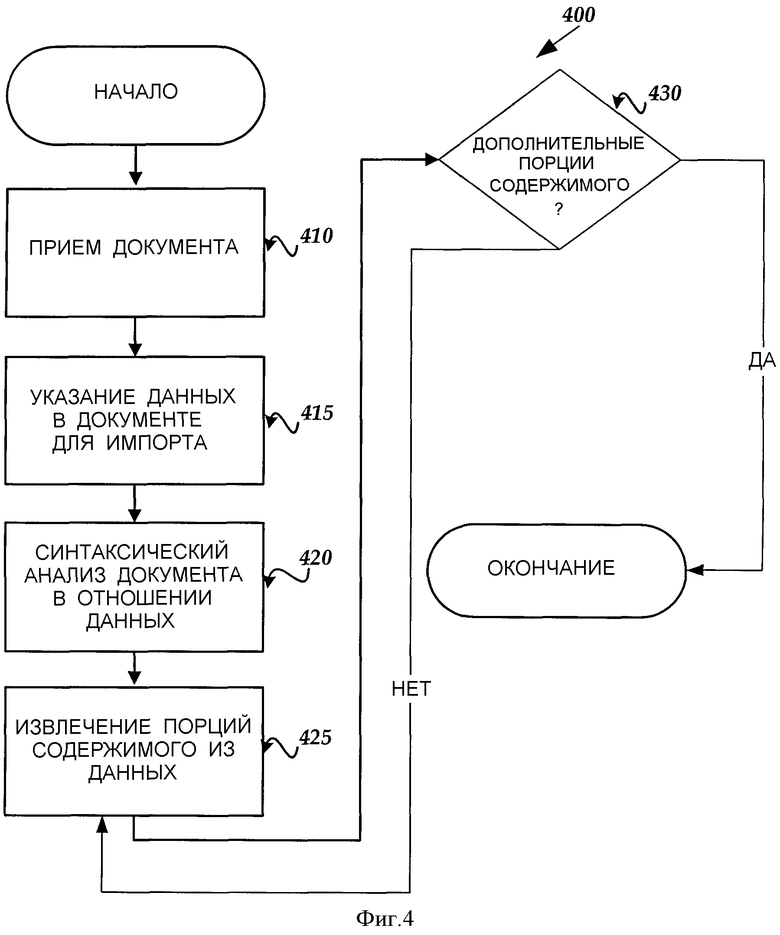
На фиг.4 представлена схема последовательности операций, изображающая шаги, выполняемые иллюстративной программой импорта электронного документа в соответствии с вариантом выполнения настоящего изобретения.
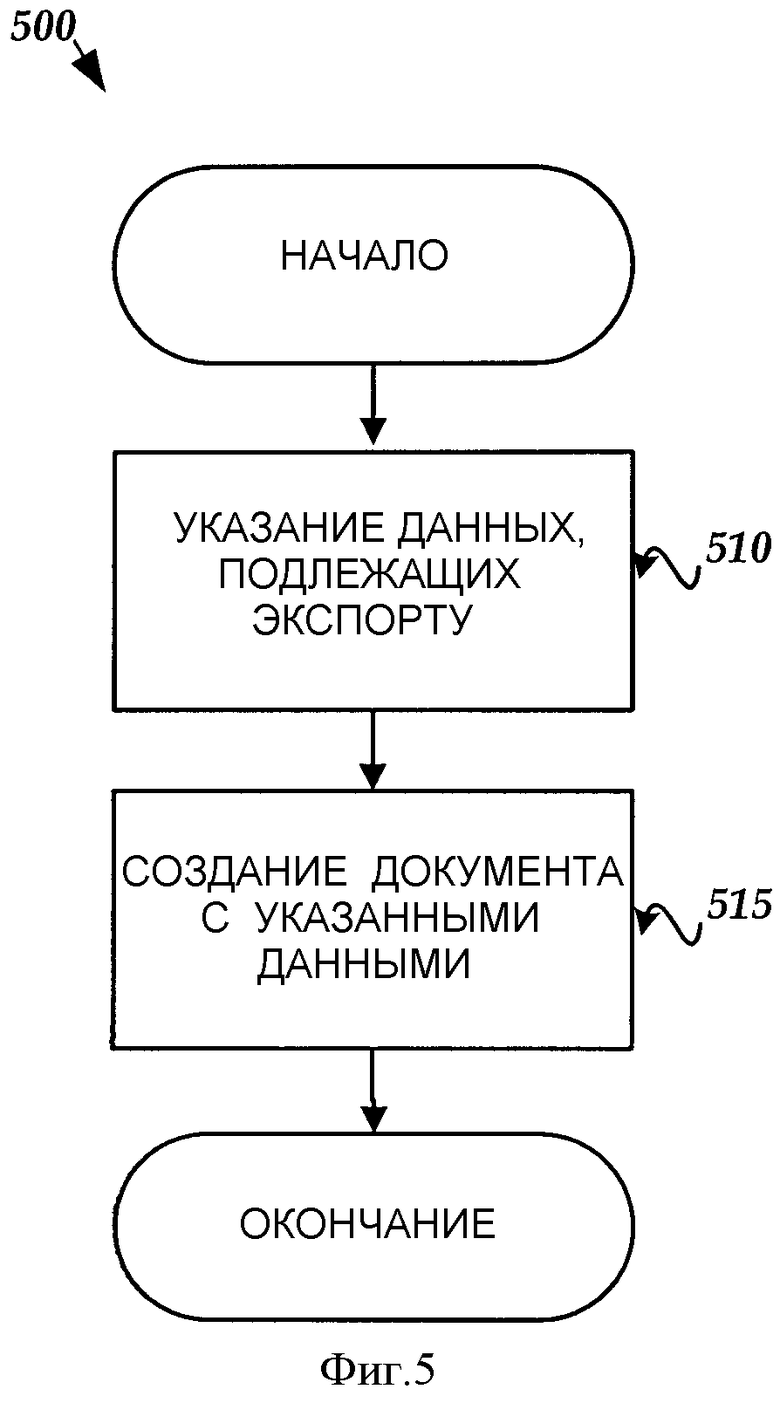
На фиг.5 представлена схема последовательности операций, изображающая шаги, выполняемые иллюстративной программой экспорта данных с целью создания электронного документа в соответствии с вариантом выполнения настоящего изобретения.
Подробное описание
Нижеследующее описание варианта выполнения настоящего изобретения выполнено с ссылкой на вышеописанные чертежи. Настоящее изобретение относится к способу и системе импорта и экспорта иерархически структурированных данных в электронном документе.
Операционная среда
Фиг.1 и последующее описание предназначены для предоставления краткого общего описания соответствующей вычислительной среды, в которой может быть осуществлено изобретение. Хотя изобретение будет описано в общем контексте программного интерфейса приложения, которое работает в операционной системе совместно с персональным компьютером, специалистам в этой области техники понятно, что изобретение также может быть осуществлено в комбинации с другими программными модулями. В общих чертах, программные модули включают в себя подпрограммы, программы, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Кроме того, специалистам в этой области техники понятно, что изобретение может быть осуществлено с другими конфигурациями компьютерных систем, включая в себя карманные устройства, мультипроцессорные системы, микропроцессорную или программируемую бытовую электронику, сотовые телефоны, миникомпьютеры, большие ЭВМ и т.д. Изобретение также может быть осуществлено в распределенных вычислительных средах, где задачи выполняются удаленными обрабатывающими устройствами, которые связаны через сеть передачи данных. В распределенной вычислительной среде программные модули могут находиться как на локальных, так и на удаленных запоминающих устройствах хранения.
Как показано на фиг.1, примерная система для осуществления изобретения включает в себя обычный персональный компьютер 20, включающий в себя обрабатывающий блок (процессор) 21, системную память 22 и системную шину 23, которая соединяет системную память с обрабатывающим блоком 21. Системная память 22 включает в себя постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25. Базовая система 26 ввода/вывода (БСВВ, BIOS), содержащая основные программы, которые способствуют пересылке информации между элементами в персональном компьютере 20, например, во время запуска, хранится в ПЗУ 24. Персональный компьютер 20 дополнительно включает в себя привод 27 жесткого диска, привод 28 магнитного диска, например, для считывания или записи на съемный диск 29 и привод 75 оптического диска, например, для считывания с компакт-диска 31 или для считывания или записи на другие оптические носители. Привод 27 жесткого диска, привод 28 магнитного диска и привод 75 оптического диска подсоединены к системной шине 23 при помощи интерфейса 32 привода жесткого диска, интерфейса 33 привода магнитного диска и интерфейса 34 привода оптического диска соответственно. Приводы и связанные с ними считываемые компьютером носители обеспечивают энергонезависимое запоминающее устройство для персонального компьютера 20. Хотя вышеприведенное описание считываемого компьютером носителя относится к жесткому диску, съемному магнитному диску и компакт-диску, специалистам в этой области техники должно быть понятно, что другие типы носителей, которые могут считываться компьютером, такие как магнитные кассеты, карты флэш-памяти, цифровые видеодиски, картриджи Бернулли и т.д., также могут быть использованы в примерной операционной среде.
Несколько программных модулей могут храниться на приводах и в ОЗУ 25, включая операционную систему 35, одну или несколько программ 37 приложения, таких как программа текстового процессора (или другой тип программы), программный интерфейс приложения (ПИП) 30 импорта, ПИП 40 экспорта и другие программные модули (не показаны).
Пользователь может вводить команды и информацию в персональный компьютер 20 при помощи клавиатуры 76 и указательного устройства, такого как мышь 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровой планшет, антенну спутниковой связи, сканер или т. п. Эти и другие устройства ввода часто подключаются к обрабатывающему блоку 21 через интерфейс 46 последовательного порта, который соединен с системной шиной, но могут быть подключены при помощи других интерфейсов, таких как игровой порт или универсальная последовательная шина (УПШ, USB). Монитор 47 или устройство отображения другого типа также подключается к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору персональный компьютер обычно включает в себя другие периферийные устройства вывода (не показаны), такие как громкоговорители или принтеры.
Персональный компьютер 20 может работать в сетевой среде, используя логические подключения к одному или нескольким удаленным компьютерам, таким как удаленный компьютер 49. Удаленным компьютером 49 может быть сервер, маршрутизатор, равноправное устройство или другой общий узел сети, и он обычно включает в себя многие или все из элементов, которые описаны в отношении персонального компьютера 20, хотя на фиг.1 было изображено только запоминающее устройство 50 хранения. Логические подключения, изображенные на фиг.1, включают в себя локальную вычислительную сеть (ЛВС) 51 и глобальную сеть (ГС) 52. Такие сетевые среды является обычным явлением в офисах, компьютерных сетях масштаба предприятия, интрасетях и Интернете.
При использовании в сетевой среде ЛВС персональный компьютер 20 подключается к ЛВС 51 через сетевой интерфейс 53. При использовании в сетевой среде ГС персональный компьютер 20 обычно включает в себя модем 54 или другое средство для установления связи по ГС 52, такой как Интернет. Модем 54, который может быть внутренним или внешним, подключается к системной шине 23 через интерфейс 46 последовательного порта. В сетевой среде программные модули, описанные в отношении персонального компьютера 20, или его частей, могут храниться на удаленных запоминающих устройствах хранения. Понятно, что показанные сетевые подключения являются примерными и могут быть использованы другие средства установления линии связи между компьютерами.
Работа
На фиг.2 представлена блок-схема, изображающая иллюстративную архитектуру 200 программного обеспечения для использования совместно с вариантом выполнения настоящего изобретения. Архитектура включает в себя программный интерфейс 30 приложения (ПИП, API) импорта для импорта содержимого из электронного документа, имеющего данные, расположенные в виде иерархической файловой структуры. В одном варианте выполнения электронным документом является XML-документ, состоящий из тегов, атрибутов и узлов (поддеревьев), связанных с различными видами содержимого. Только с целью примера, а не ограничения описанного здесь изобретения следующим является иллюстративный XML-файл, на основании которого может быть осуществлен ПИП 30:
Как показано на фиг.2, ПИП 30 импорта принимает электронный документ от клиентского компьютера 20, изображенного на фиг.1. В альтернативном варианте выполнения электронный документ также может быть принят от сервера, например сервера 49 на основе удаленного компьютера. ПИП 30 импорта поддерживает связь с синтаксическим анализатором 60 для выполнения синтаксического анализа электронного документа в отношении данных (т.е. элементов, атрибутов, узлов и текста), определяющих иерархическую структуру электронного документа и связанного с ними содержимого. ПИП 30 импорта управляет синтаксическим анализатором 60 с целью определения из документа конкретных данных, подлежащих синтаксическому анализу. В одном варианте выполнения синтаксическим анализатором 60 может быть синтаксический анализатор на основе событий, такой как OFFICE XML PARSER компании MICROSOFT CORPORATION, г. Редмонд, шт. Вашингтон, США. Синтаксическим анализатором 60 также может быть синтаксический анализатор на основе дерева, такой как синтаксический анализатор на объектной модели документа (ОМД, DOM). ПИП 30 выгоден по сравнению с непосредственным использованием синтаксических анализаторов на основе событий и на основе дерева, потому что пользователю разрешено определять (указывать) конкретные данные, которые он хочет, чтобы они были извлечены из документа. Как известно специалистам в этой области техники, синтаксические анализаторы на основе событий сканируют документы одну строку за раз и предоставляют последовательно одну порцию данных (такую как тег) за один раз, требуя, чтобы пользователь поддерживал состояние для нахождения требуемых данных. Синтаксические анализаторы на основе дерева загружают целиком документы в память, но пользователю все же необходимо производить навигацию по загруженным документам для нахождения требуемых данных. Вышеупомянутые преимущества будут подробно описаны ниже в отношении фиг.4.
ПИП 30 импорта также поддерживает связь с компонентом 50 обратного вызова. Компонент 50 обратного вызова сообщается с ПИП 30 импорта для определения дополнительных порций содержимого, подлежащих импорту из электронного документа после извлечения первых данных. Например, если элемент или узел в электронном документе связан более чем с одной порцией содержимого (такого как список имен), то ПИП 30 импорта извлекает первое имя и затем обращается к компоненту 50 обратного вызова для извлечения следующего имени до тех пор, пока все имена в списке не будут извлечены. Другими словами, для списка порций ПИП 30 импорта может передавать каждую порцию списка последовательно на компонент 50 обратного вызова, где клиент 20 ПИП 30 затем может сделать то, что он хочет с порцией. Клиент 20 также может использовать компонент 50 обратного вызова для обращения назад на ПИП 30 во время процесса импорта, чтобы внести изменение в отношение того, как обрабатывать остальные данные. В различных вариантах выполнения содержимым 70, импортируемым ПИП 30, может быть поток данных, буфер памяти или файл.
На фиг.3 показана блок-схема, иллюстрирующая иллюстративную архитектуру 300 программного обеспечения для использования совместно с вариантом выполнения настоящего изобретения. Архитектура включает в себя программный интерфейс 40 приложения (ПИП) экспорта для экспорта данных из источника с целью создания электронного документа 90. В одном варианте выполнения созданный документ 90 имеет иерархическую файловую структуру, такую как XML-документ. Как показано на фиг.3, ПИП 40 экспорта принимает данные от клиентского компьютера 20. В другом варианте выполнения данные могут быть приняты от сервера, такого как сервер 49 на основе удаленного компьютера. Подлежащие экспорту данные могут включать в себя текстовые строки или фиксированный список переменных из числа других данных.
ПИП 40 экспорта поддерживает связь с редактором 80 для приема данных, определенных посредством ПИП 40 экспорта для экспорта, и использования данных для записи элементов, узлов, атрибутов или текста в созданном электронном документе 90. ПИП 40 импорта управляет редактором 80 для определения конкретных данных, подлежащих экспорту. В одном варианте выполнения редактором 80 может быть компонент XML Exporter, такой как OFFICE XML EXPORTER компании MICROSOFT CORPORATION, г. Редмонд, шт. Вашингтон, США. ПИП 40 экспорта позволяет производить запись многочисленных блоков данных (таких как XML-содержимое) или всего файла в одном вызове ПИП. Это более выгодно, чем непосредственно получать доступ к редактору 80, так как редактор 80 позволяет производить запись только одного блока данных за раз. Следует понимать, что синтаксис для осуществления ПИП 40 экспорта может быть очень похож на ПИП 30 импорта. Таким образом, в варианте выполнения изобретения пользователь может использовать ПИП 40 экспорта и ПИП 30 импорта для записи и последующего считывания собственных данных пользователя, хотя пользователю нет необходимости использовать их обоих. Вышеупомянутые преимущества ПИП 40 экспорта ниже будут описаны в отношении фиг.5.
На фиг.4 представлена схема последовательности операций, изображающая иллюстративную последовательность 300 операций для селективного импорта содержимого из электронного документа, такого как XML-документ, в компьютерной системе в соответствии с вариантом выполнения изобретения. С целью описания фиг.4 описывается со ссылкой на фиг.1 и 2.
Последовательность 400 начинается на этапе 410, где ПИП 30 импорта принимает электронный документ от персонального компьютера 20 или сервера 49 на основе удаленного компьютера. На этапе 415 ПИП 30 импорта определяет данные в документе, подлежащие импорту. Пользователь может определить конкретные данные, подлежащие импорту, в программе 100 приложения (которой может быть текстовый процессор), которая, в свою очередь, передает эту информацию ПИП 30 импорта. Например, в приведенном выше иллюстративном XML-документе пользователь может быть заинтересован в содержимом элемента <Service>, содержимом узла <Subscription>, содержимом элемента <Currency> (например, типа Account Currency) и содержимом элемента <Amount> (например, влияние итогового баланса), но он не интересуется элементами и атрибутами <SOAP-ENV>, которые не передают никакой полезной информации пользователю. Посредством выбора конкретных узлов и элементов пользователь также выбирает все элементы, содержащиеся в них. Например, узел <Subscription> содержит узел <BalanceImpacts>, где <BalanceImpact> является списком элементов произвольной длины. Элемент <Services> также содержит произвольный список Service Names.
Последовательность 400 операций продолжается на этапе 420, где синтаксический анализатор 60 производит поиск данных в электронном документе (т.е. узлов и элементов), определенных посредством ПИП 30 импорта. На этапе 425 ПИП 30 импорта извлекает содержимое из данных в синтаксически анализируемом документе. Как кратко описано выше, в одном варианте выполнения синтаксическим анализатором 60 является синтаксический анализатор на основе событий, в котором каждый элемент в документе сканируется, и содержащееся в нем содержимое извлекается посредством ПИП 30 импорта. Например, синтаксический анализатор 60 сканирует (просматривает) документ в отношении элемента <Services>, ранее определенного пользователем, и ПИП 30 импорта извлекает текстовую строку "Some service" из атрибута "Name" элемента <Service>. Подобным образом сканируются все элементы до тех пор, пока все содержимое, связанное с определенными элементами, не будет извлечено из документа.
Последовательность 400 операций продолжается на этапе 430, где ПИП 30 импорта определяет, существуют ли дополнительные порции содержимого, содержащиеся в элементе, определенном для импорта. Если нет дополнительных порций содержимого, то последовательность 400 завершается. Клиент 20 затем может выбрать создание нового документа с извлеченным содержимым (например, используя ПИП 40 экспорта). Наоборот, если существуют дополнительные порции содержимого, содержащиеся в элементе, определенном для импорта, то последовательность операций возвращается на этап 425, где ПИП 30 извлекает следующую дополнительную порцию содержимого. Например, после того как ПИП 30 импорта извлечет строку "Some service" из атрибута "Name" элемента <Service>, ПИП 30 определяет, существуют ли какие-либо дополнительные элементы <Service>, содержащие атрибуты "Name", извлекает содержимое из каждого и передает его компоненту 50 обратного вызова для распечатки требуемой строки.
Последовательность операций, изображенная на фиг.4 для использования ПИП 30, может быть осуществлена в машинном коде, обрабатывающем XML-данные, как показано ниже в иллюстративных образцах кода.
Иллюстративное использование ПИП импорта:
MsoFImportXML(pistm, FMyCallback(), NULL, "o CancelResponse;o Services;(*o Service;a0 Name;c;p1;)c;o Subscriptions;(*o Subscription;a1 ID;o BalanceImpacts;p2;(*o BalanceImpact;a2 ImpactType;e3 Amount;c;p3;)c;c;)c;e4 Currency;e5 Amount;p4;f;", NULL, msoffixSOAP);
При иллюстративном использовании показанного выше ПИП 30 импорта клиент 20 передает в строке действий, которая определяет требуемое содержимое (например, один или несколько атрибутов "Name" элемента <Service>). Строка действий представляет собой последовательность индивидуальных действий, которые указывают содержимое для поиска или содержимое, ожидаемое в конкретной точке. В примере выше действие "o CancelResponse" означает переход на следующий открытый элемент <CancelResponse> в XML-документе, действие "a1 ID" означает копирование атрибута "ID" текущего элемента в запись #1 совокупности извлеченных строк, которые клиент может просмотреть во время его обратного вызова или после завершения ПИП импорта, действие "p2" означает вызов второго оператора выбора обратного вызова, и т. д. Строка действий также может содержать группы действий, которыми являются способы разметки последовательности действий, подлежащих обработке определенным образом. В примере выше группы действий указаны соответствующими действиями, заключенными в скобки, где группы действий, отмеченные звездочкой, означают, что совокупность указанных действий может повторяться ноль раз или более раз, образуя список. Другой пример группы действий (не показан выше в иллюстративном использовании) указывает совокупность действий или блоков содержимого, предполагаемых к появлению в данной точке в XML-документе.
Иллюстративная функция обратного вызова:
BOOL FmyCallback(void*pvClient, MSOHISD *phisd, MSOXPS *rgxps, int iState)
{switch(iState){
1: //Обработка списка <Services>
printf("<Service> Name attribute=%s\n", rgxps[0].wz);
beak;
2: //Обработка внешнего списка <Subscriptions>
printf("<Subscription> ID attribute=%s\n", rgxps[1].wz);
break;
3: /Обработка внутреннего вложенного списка <BalanceImpacts>
printf("<BalanceImpact> ImpactType attribute=%s\n", rgxps[2].wz);
printf("<Amount> element text=%s\n", rgxps[3].wz);
break;
4: //Обработка окончательных порций после вышеуказанных списков
printf("Final <Currency> element text=%s\n", rgxps[4].wz);
printf("Final <Amount> element text=%s\n", rgxps[5].wz);
break;
}
return TRUE;
}
Необходимо понимать, что ПИП 30 импорта также может быть использован без необходимости определения клиентом 20 функции обратного вызова, например, когда документ не содержит никаких списков или повторяющихся элементов. Например, если XML-файл содержал бы только один элемент <Service>, один узел <BalanceImpact> и один узел <Subscription>, то ПИП 30 импорта мог бы импортировать файл в виде одной строки кода, как показано ниже:
Таким образом, ПИП 30 импорта выгодно позволяет пользователю селективно импортировать содержимое из иерархического структурированного документа с единственной строкой кода и иерархического структурированного документа, содержащего списки с единственной строкой кода и оператором обратного вызова. Как кратко описано выше, ПИП 30 может импортировать содержимое в виде потока данных, буфера памяти или файла.
На фиг.5 представлена схема последовательности операций, изображающая иллюстративную последовательность 500 операций для селективного экспорта содержимого с целью создания электронного документа, такого как XML-файл, в компьютерной системе в соответствии с вариантом выполнения изобретения. С целью описания фиг.4 описывается с ссылкой на фиг.1 и 3.
Последовательность 500 операций начинается на этапе 510, где ПИП 40 экспорта определяет данные, подлежащие экспорту. Как кратко описано выше, данные могут включать в себя текстовые строки или фиксированный список переменных. Пользователь может определить (указать) конкретные данные, подлежащие экспорту, в программе 100 приложения (которой может быть текстовый процессор), которая, в свою очередь, передает эту информацию ПИП 40 экспорта. При определении данных, подлежащих экспорту, пользователь также определяет, как данные должны быть представлены в созданном документе. Например, пользователь может определить, чтобы текстовая строка "Services" была представлена в виде элемента, и "Name" - в виде атрибута элемента "Service". ПИП 40 экспорта посылает определенные (указанные) данные редактору 80, который создает документ, используя определенные данные на этапе 520.
Последовательность, изображенная на фиг.5, может быть осуществлена как вызов функции для создания приведенного выше иллюстративного XML-файла, используя иллюстративные образцы кода, показанные ниже.
Иллюстративное использование ПИП экспорта:
MsoFExportXML(pistm, "n o;o CancelResponse;o Services;e Service;a Name "Some service";c;o Subscriptions;o Subscription;a ID "Subscription ID";o BalanceImpacts;o BalanceImpact;a ImpactType "Type of impact";e Amount "Nonzero amount of impact";c;c;c;c;e Currency "Account Currency type";e Amount "Total balance impact";c;", msogrffexSOAP)
При иллюстративных использованиях ПИП экспорта, показанных выше, клиент 20 передает строку действий, отформатированную аналогичным образом, как и строки действий при иллюстративных использованиях ПИП 30 импорта. Здесь, строка действий представляет собой последовательность индивидуальных действий, указывающих содержимое для записи в XML-документ. В вышеприведенном примере действие "e Amount 'Total balance impact'" означает запись XML-элемента <Amount>, содержащего текст "Total balance impact" (Влияние итогового баланса), действие "c" означает запись закрывающего элемента, согласующегося с текущей областью действия и т.д. Иллюстративная строка кода выше может быть использована для создания всего XML-документа без списков. Созданный документ соответствует и может быть импортирован посредством образца кода импорта без списка (т.е. без функции обратного вызова), показанного выше при описании фиг.4.
MSOHEXS hexs;
MsoFInitExportXML(pistm, &hexs);
MsoFExportXMLContents(&hexs, "n o;o CanselResponse;o Services;");
while (FSomeItemsLeftInMyList(wzServiceName))// Заполнить wzServiceName текущей сервисной строкой.
MsoFExportXMLContents2(&hexs, "e Service ;a Name %0;", &wzServiceName);// запись: <Service Name="Some service">
MsoFExportXMLContents(&hexs, "c;");
// И т.д. для остальных тегов ...
MsoFFinishExportXML(&hexs);
Иллюстративные строки кода выше могут быть использованы для создания XML-файла со списками. Созданный файл соответствует и может быть импортирован примером кода импорта со списком (т.е. с функцией обратного вызова), показанным выше при описании фиг.4. Таким образом, ПИП 40 экспорта выгодно позволяет пользователю селективно экспортировать содержимое, включая одновременно многочисленные элементы и атрибуты, с целью создания иерархических структурированных документов с помощью единственной строки кода и иерархических структурированных документов, содержащих списки с помощью только нескольких строк кода.
Как описано выше, программный интерфейс приложения (ПИП) может быть реализован для импорта содержимого из иерархически структурированного документа, такого как XML-файл. ПИП работает совместно с синтаксическим анализатором для сканирования документа и извлечения содержимого из выбранных элементов, узлов, атрибутов и текста. ПИП также использует компоненту обратного вызова для обработки извлеченного содержимого (например, из списков). ПИП импорта позволяет извлекать спецификацию конкретных данных из документа. Это выгодно по сравнению с использованием синтаксических анализаторов на основе событий, которые последовательно предоставляют одну порцию данных за раз из документа, и синтаксических анализаторов на основе дерева, которые требовали выполнение навигации загруженного файла для непосредственного поиска требуемых данных.
ПИП также может быть осуществлен для экспорта данных с целью создания иерархически структурированного документа, такого как XML-файл. ПИП работает совместно с редактором для приема данных и экспорта данных в виде элементов, узлов, атрибутов и текста в иерархически структурированном документе. ПИП экспорта позволяет производить запись многочисленных блоков данных (таких как XML-содержимое) или всего файла в одном вызове ПИП. Это значительно выгоднее, чем использование редактора (такого как редактора XML), который позволяет производить запись только одного блока данных за один раз. Понятно, что ПИП 30 импорта и ПИП 40 экспорта могут быть осуществлены в виде управляемого или неуправляемого кода. Другие варианты выполнения изобретения очевидны специалистам в этой области техники из рассмотрения описания изобретения и практики описанного здесь изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНЕЧНЫЙ АВТОМАТ УНИФИЦИРОВАННОГО ОБМЕНА СООБЩЕНИЯМИ | 2008 |
|
RU2470364C2 |
| МОДУЛЬНЫЙ ФОРМАТ ДОКУМЕНТОВ | 2004 |
|
RU2368943C2 |
| МЕХАНИЗМ ДЛЯ ПОЛУЧЕНИЯ И ПРИМЕНЕНИЯ ОГРАНИЧЕНИЙ К ЛОГИЧЕСКИМ СТРУКТУРАМ В ИНТЕРАКТИВНОЙ СРЕДЕ | 2004 |
|
RU2367999C2 |
| МЕХАНИЗМ ДЛЯ ОБЕСПЕЧЕНИЯ РАСШИРЕННЫХ ФУНКЦИОНАЛЬНЫХ ВОЗМОЖНОСТЕЙ ДЛЯ ИНСТРУКЦИЙ КОМАНДНОЙ СТРОКИ | 2004 |
|
RU2395837C2 |
| СИСТЕМА И СПОСОБ ДЕКЛАРАТИВНОГО ОПРЕДЕЛЕНИЯ И ИСПОЛЬЗОВАНИЯ ПОДКЛАССОВ ВНУТРИ РАЗМЕТКИ | 2003 |
|
RU2347269C2 |
| РАСШИРЯЕМЫЙ XML-ФОРМАТ И ОБЪЕКТНАЯ МОДЕЛЬ ДЛЯ ДАННЫХ ЛОКАЛИЗАЦИИ | 2006 |
|
RU2419838C2 |
| ДЕЛЕГИРОВАННОЕ АДМИНИСТРИРОВАНИЕ РАЗМЕЩЕННЫХ РЕСУРСОВ | 2004 |
|
RU2360368C2 |
| СТРУКТУРА ДАННЫХ И СПОСОБЫ ПРЕОБРАЗОВАНИЯ ПОТОКА БИТОВ В ЭЛЕКТРОННЫЙ ДОКУМЕНТ И ФОРМИРОВАНИЯ ПОТОКА БИТОВ ИЗ ЭЛЕКТРОННОГО ДОКУМЕНТА НА ЕЕ ОСНОВЕ | 2002 |
|
RU2294012C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
| МЕХАНИЗМ ДЛЯ ПРЕДУСМОТРЕНИЯ ВЫВОДА УПРАВЛЯЕМОЙ ДАННЫМИ КОМАНДНОЙ СТРОКИ | 2004 |
|
RU2351976C2 |
Изобретение относится к вычислительной технике. Техническим результатом является обеспечение селективного импорта и экспорта данных в электронном документе. Программный интерфейс приложения (ПИП) импорта может быть реализован для импорта содержимого из иерархически структурированного документа, такого как XML-файл. ПИП импорта работает совместно с синтаксическим анализатором для просмотра документа и извлечения содержимого из выбранных элементов, узлов, атрибутов и текста. ПИП импорта также использует компонент обратного вызова для обработки извлеченного содержимого. ПИП экспорта также может быть осуществлен для экспорта данных с целью создания иерархически структурированного документа, такого как XML-файл. ПИП экспорта работает совместно с редактором для приема данных и экспорта данных в виде элементов, узлов, атрибутов и текста в иерархически структурированном документе. 2 н. и 18 з.п. ф-лы, 5 ил.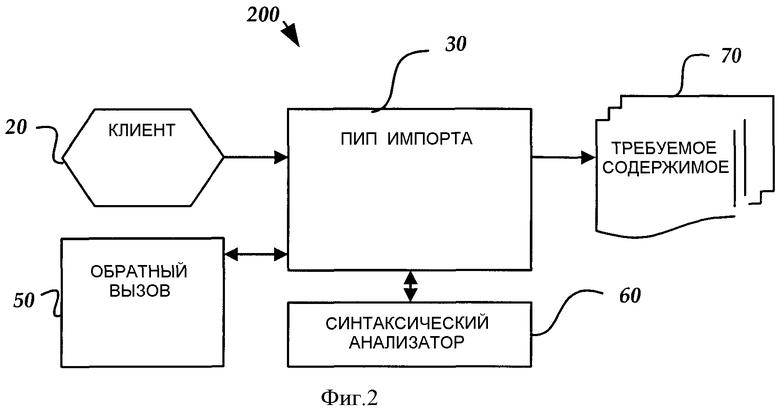
прием содержимого, содержащего данные, из источника данных;
указание посредством интерфейса прикладного программирования (API) экспорта данных, подлежащих экспорту для создания электронного документа;
экспорт данных через редактор, находящийся в связи с API экспорта, чтобы создать электронный документ;
прием электронного документа, имеющего данные и порции содержимого, ассоциированного с данными, причем данные расположены в виде иерархической файловой структуры;
указание посредством API импорта по меньшей мере одного блока данных в электронном документе, подлежащего импорту из электронного документа, причем упомянутый по меньшей мере один блок данных ассоциирован с по меньшей мере одной порцией содержимого в электронном документе;
выборочный синтаксический анализ электронного документа в отношении по меньшей мере одного блока данных посредством синтаксического анализатора, находящегося в связи с API импорта,
извлечение первой порции из содержимого, ассоциированного с упомянутым по меньшей мере одним блоком упомянутых данных, из электронного документа, таким образом позволяя импортировать описание указанных данных из электронного документа для отображения посредством устройства отображения,
после извлечения первой порции содержимого, ассоциированного с по меньшей мере одним блоком данных, из электронного документа, определение посредством компонента обратной связи, находящегося в связи с API импорта, имеются ли дополнительные порции содержимого, ассоциированного с упомянутым по меньшей мере одним блоком данных,
когда имеются дополнительные порции содержимого, ассоциированного с по меньшей мере одним блоком данных, извлечение следующей порции содержимого, ассоциированного с упомянутым по меньшей мере одним блоком данных, из электронного документа, и
отображение каждой порции извлеченного содержимого посредством устройства отображения для просмотра пользователем.
компонент экспорта для
приема в компоненте экспорта данных от компьютера-источника и
указания данных, подлежащих экспорту, для создания электронного документа, причем данные включают в себя строки текста или фиксированный список переменных,
компонент редактора для
приема в компоненте редактора указанных данных от компонента экспорта и экспорт этих данных для создания электронного документа, при этом экспорт данных содержит запись множества блоков данных в одном вызове интерфейса прикладного программирования (API),
компонент импорта для
приема электронного документа, имеющего данные и порции содержимого, ассоциированного с упомянутыми данными, причем упомянутые данные задают иерархическую файловую структуру;
указания подлежащих импорту из электронного документа по меньшей мере одного блока данных в электронном документе, ассоциированном по меньшей мере с одной порцией содержимого в электронном документе; и
извлечения порций содержимого, ассоциированного с упомянутым по меньшей мере одним блоком данных, из электронного документа,
после извлечения первой порции содержимого определение, имеются ли дополнительные порции содержимого, ассоциированного с упомянутым по меньшей мере одним блоком упомянутых данных,
если имеются дополнительные порции упомянутого содержимого, разрешают пользователю изменить, как должны быть обработаны дополнительные порции, и
обмена с компонентом синтаксического анализатора, и
компонент синтаксического анализатора для
выборочного синтаксического анализа электронного документа в отношении упомянутого по меньшей мере одного блока упомянутых данных, и
посылку по меньшей мере одного блока данных в компонент импорта для отображения посредством устройства отображения.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| JP 11096161 А, 09.04.1999 | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |

