Уровень техники
Рынок программного обеспечения в последние годы становился все более интернациональным. Повсеместные прикладные программы ("программные приложения"), такие как текстовые процессы, электронные таблицы, электронная почта и т.п., сегодня доступны в различных странах. Предоставление доступности программных приложений в различных странах зачастую накладывает необходимость создания программных приложений с соответствующими пользовательскими интерфейсами и другим читаемым человеком текстом, таким как сообщения об ошибках, представляемыми на различных местных естественных языках (в отличие от компьютерных языков). Создание таких адаптированных к языку (локализованных) программных приложений необходимо для того, чтобы увеличить долю рынка и рыночную стоимость таких приложений. Включение местного языка касается главным образом пользовательского интерфейса программных приложений, такого как командный интерфейс, меню, сообщения, информация состояния, пометки, результаты вычислений и т.п. Потребность в программных приложениях на различных местных языках определяется за счет множества факторов, среди которых содержится возрастающее число стран с различными языками, в которых компьютеры все в большей степени используются как часть повседневного бизнеса и жизни, возрастающее число нетехнических областей, использующих программные приложения, имеющие пользовательские интерфейсы, которые требуют взаимодействия на естественном языке, такие как офисные программные приложения, например, текстовый процессор, в отличие от взаимодействия с техническими символами, т.е. взаимодействия с помощью учетных или математических символов, и потребность пользователей взаимодействовать с программными приложениями на местном языке. Общим термином в данной области техники, используемым для того, чтобы идентифицировать процесс создания программных приложений на различных местных языках, является "локализация".
Помимо читаемого человеком текста, видимые человеком графические компоненты, такие как значки, цвета и формы, и слышимые человеком звуки также могут потребовать локализации, чтобы разрешать культурную восприимчивость и контекст. Например, в некоторых азиатских культурах красный представляет счастье и преуспевание, тогда как в большинстве западных культур красный представляет опасность или предупреждение. Поэтому, если символ или фон диалогового окна в графическом пользовательском интерфейсе (GUI) отображается красным, это может иметь различные и сбивающие с толку подтексты для пользователей из различных культур. Следовательно, процесс локализации выходит за рамки простого перевода текста на другой язык и также включает в себя локализацию других символов, цветов и звуков.
Потребность в локализованных (адаптированных к языку) программных приложениях создает некоторые проблемы в ходе разработки и сопровождения программных приложений. Разработка и сопровождение локализованных программных приложений требует соответствующих средств разработки и сред разработки для обработки и локализации различных читаемых человеком и видимых человеком программных компонентов. Дополнительно, локализация программных приложений может быть выполнена несколькими организациями, каждая из которых содержит несколько подразделений, и каждое подразделение выполняет различную часть процесса локализации. Один из основных недостатков доступных в данный момент сред разработки и организаций - это ограничиваемая расширяемость и гибкость моделей данных, используемых средствами и средами разработки. Например, некоторые данные, используемые средствами и средами разработки, имеют двоичный формат, что в лучшем случае затрудняет чтение, редактирование, совместное использование и обработку данных.
Требуется формат данных, чтобы предоставить согласованность, расширяемость и гибкость для различных организаций и средств разработки. Дополнительно, требуются стандартные функциональные способы и способы интерфейсов данных для осуществления доступа и обработки этих данных.
Сущность изобретения
Данный раздел описания предусмотрен для того, чтобы в упрощенной форме представить набор идей, которые дополнительно описываются ниже в подробном описании. Этот раздел не предназначен для того, чтобы идентифицировать ключевые или важнейшие признаки заявляемого предмета изобретения, а также не предназначен для того, чтобы использоваться в качестве помощи при определении области применения заявляемого предмета изобретения.
Описываются способы, системы и машиночитаемые носители, включающие в себя машиночитаемые компоненты, для локализации (адаптации к языку) данных, включенных в прикладные программы. Машиночитаемые компоненты содержат элементы данных, задаваемые посредством схемы программных данных; элемент данных репозитория свойств для сохранения множества свойств данных об элементах данных; и элемент данных собственных комментариев, содержащий информацию о локализации данных, включенных в прикладные программы, и владельце с разрешением создавать, осуществлять доступ и обрабатывать элемент данных собственных комментариев.
Также описываются способы, системы и машиночитаемые носители, включающие в себя набор машиночитаемых компонентов, для локализации данных, включенных в прикладные программы. Набор (коллекция) машиночитаемых компонентов содержит элементы данных, заданные посредством схемы программных данных; элемент данных репозитория свойств для сохранения множества свойств данных об элементах данных; линейный список элементов данных локализации, используемых для разделения набора машиночитаемых компонентов на несколько поднаборов (подколлекций), отдельной обработки элементов данных в нескольких поднаборах и слияния нескольких поднаборов обратно в один набор машиночитаемых компонентов; и элемент данных собственных комментариев, содержащий информацию о локализации данных, включенных в прикладные программы, и владельце с разрешением создавать, получать доступ и обрабатывать элемент данных собственных комментариев.
Дополнительно описываются способы, системы и машиночитаемые носители, включающие в себя набор (коллекцию) программных объектов, сохраненных на них, для локализации прикладных программ. Набор программных объектов содержит данные и команды, включенные в каждый программный объект; объект элемента локализации, содержащий данные локализации и по меньшей мере одно из объекта списка элементов локализации, включающего в себя список других объектов элементов локализации; по меньшей мере один объект комментариев, содержит информацию о локализации прикладных программ; объект строковых данных для сохранения компьютерной текстовой информации; и объект двоичных данных для сохранения двоичной информации; при этом каждый программный объект соответствует структуре данных, заданной посредством схемы программных данных, и при этом каждый программный объект используется для того, чтобы осуществлять доступ и обрабатывать (манипулировать) данные, сохраненные в соответствующей структуре данных, заданной посредством схемы программных данных.
Описание чертежей
Вышеозначенные аспекты и многие из сопутствующих преимуществ изобретения должны стать более легко воспринимаемыми, а также более понятными посредством ссылки на последующее подробное описание, рассматриваемое вместе с прилагаемыми чертежами, на которых:
Фиг.1 - это графическая схема примерного процесса локализации;
Фиг.2 - это графическая схема, иллюстрирующая примерный поток данных локализации;
Фиг.3 - это графическая схема, иллюстрирующая еще один примерный поток данных локализации;
Фиг.4 - это графическая схема, иллюстрирующая примерные операции разделения и слияния файлов для файла XML-данных;
Фиг.5A - это графическая схема примерного контейнера свойств;
Фиг.5B - это графическая схема примерного булева XML-элемента;
Фиг.5C - это графическая схема примерного целочисленного XML-элемента;
Фиг.5D - это графическая схема примерного строкового XML-элемента;
Фиг.5E - это графическая схема примерного XML-строкового XML-элемента;
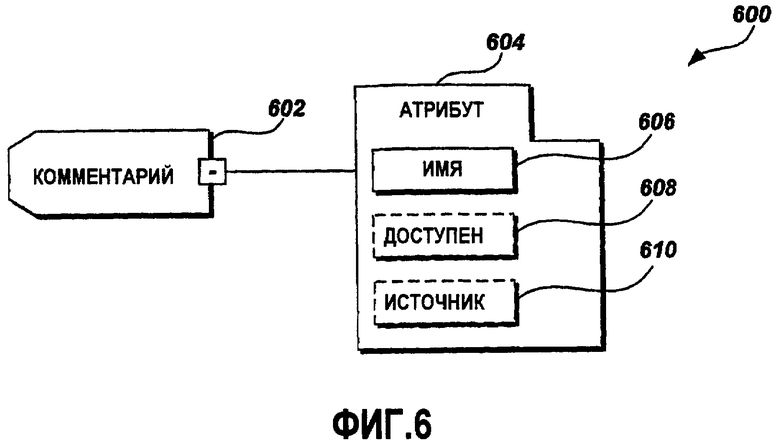
Фиг.6 - это графическая схема примерного формата данных комментариев с атрибутом источника;
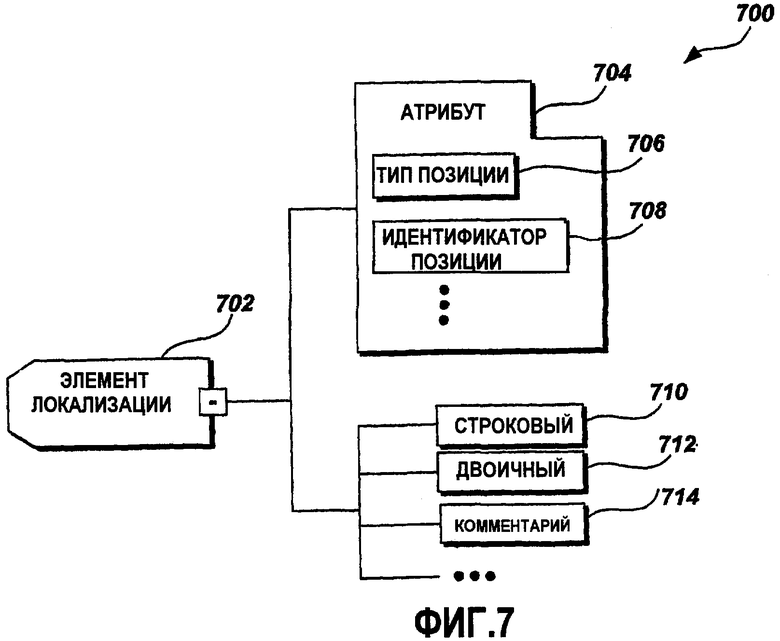
Фиг.7 - это блок-схема примерного формата данных элемента локализации с комментариями;
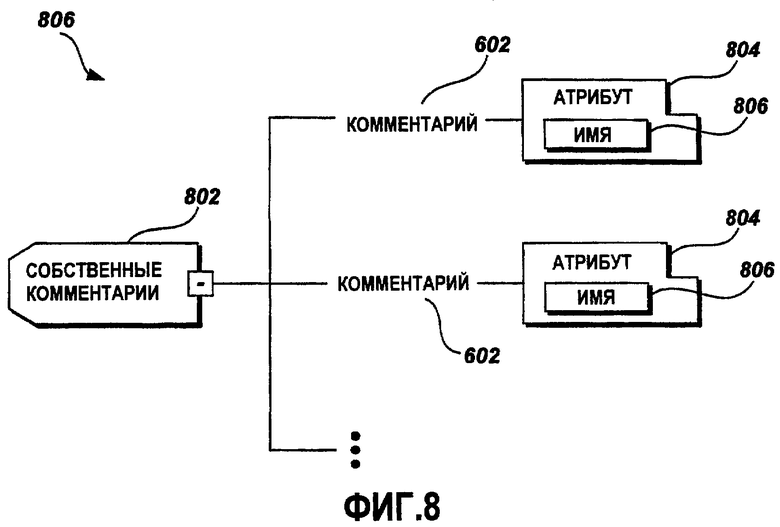
Фиг.8 - это графическая схема примерного формата данных собственных комментариев;
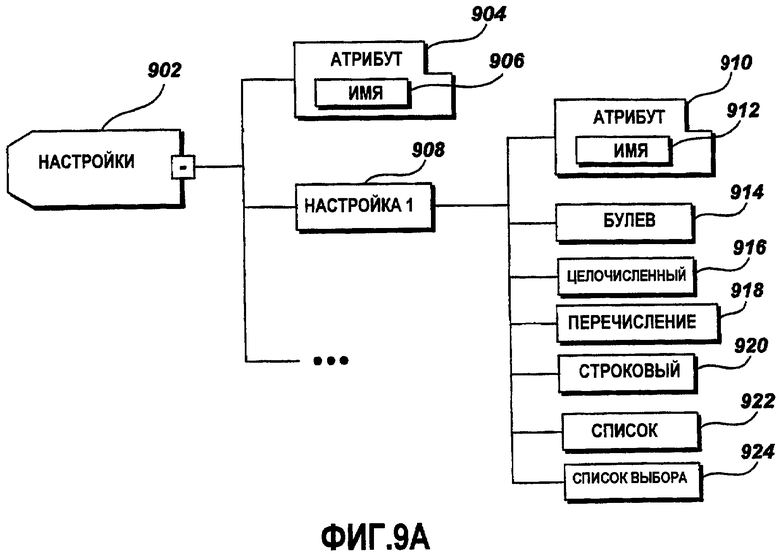
Фиг.9A - это графическая схема примерного формата данных настроек;
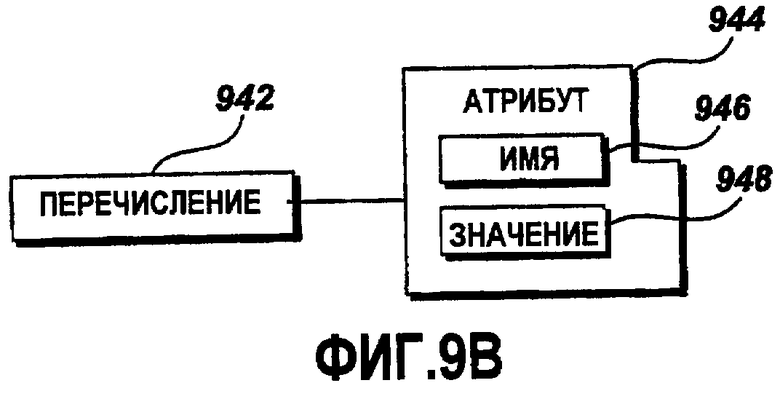
Фиг.9B - это графическая схема примерного элемента перечисления;
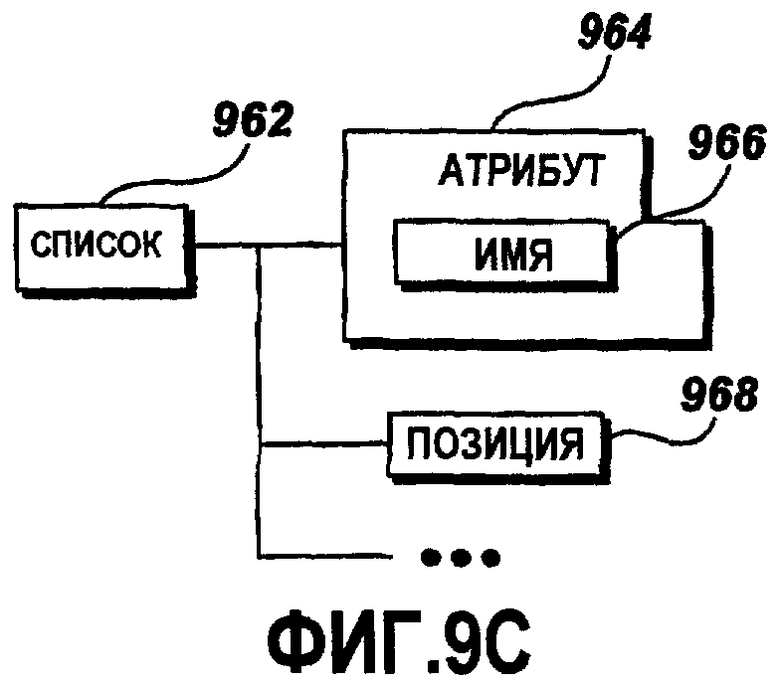
Фиг.9C - это графическая схема примерного элемента списка;
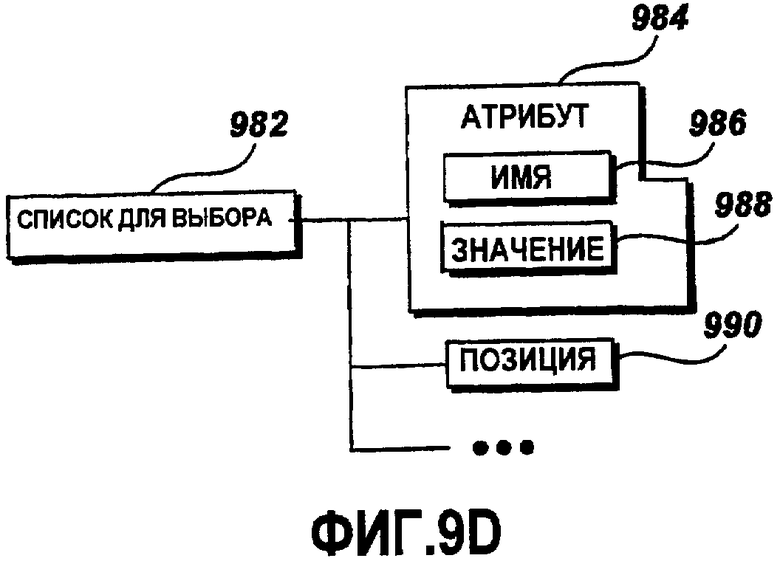
Фиг.9D - это графическая схема примерного элемента списка выбора;
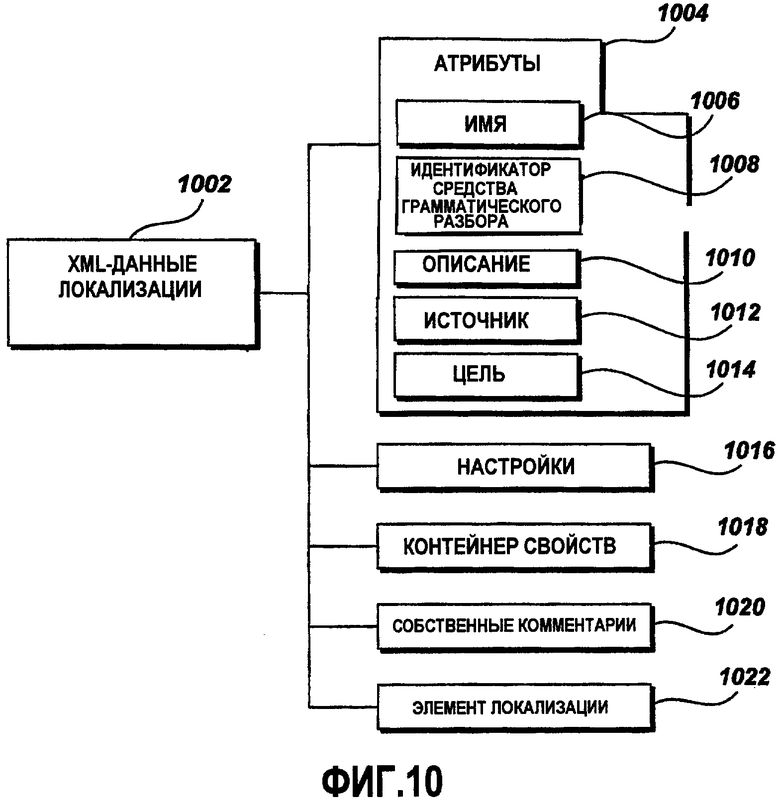
Фиг.10 - это графическая схема примерного формата XML-данных локализации;
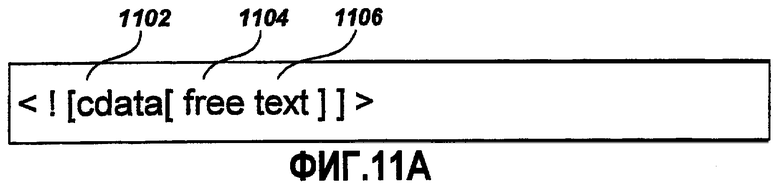
Фиг.11A - это примерная графическая схема текстовых данных, содержащихся в XML-элементе CDATA;
Фиг.11B - это примерная графическая схема текстовых данных, включающих в себя символ скобок, содержащийся в XML-элементе CDATA;
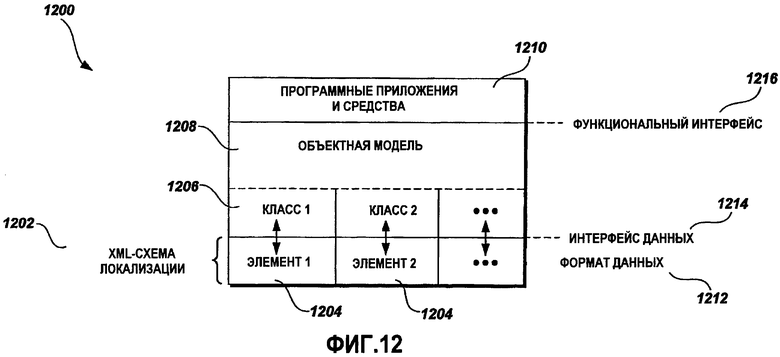
Фиг.12 - это блок-схема примерных взаимосвязей схемы локализации и соответствующей объектной модели;
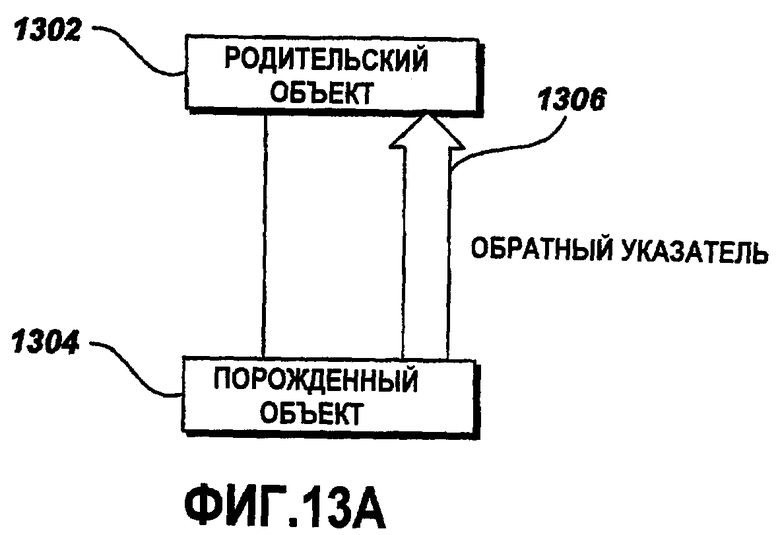
Фиг.13A - это блок-схема примерных родительских и дочерних объектов с обратным указателем;
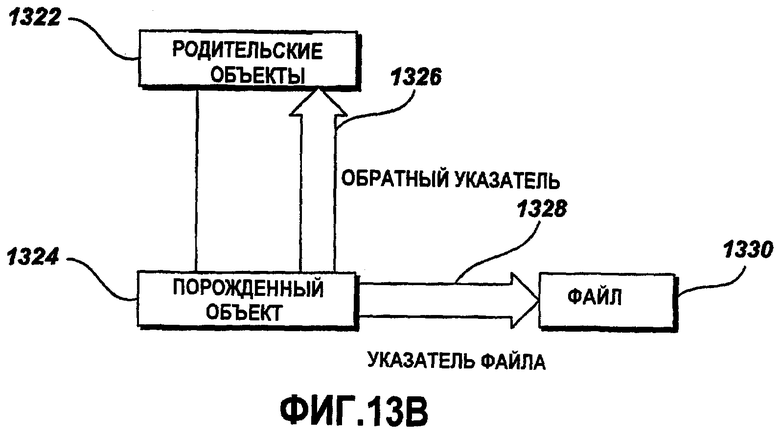
Фиг.13B - это блок-схема примерных родительских и дочерних объектов с обратным указателем и указателем файла;
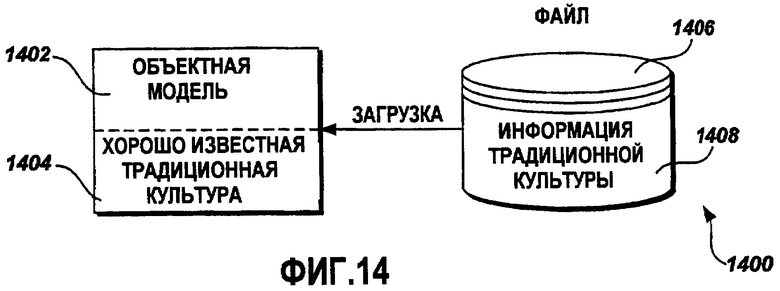
Фиг.14 - это графическая схема примерной объектной модели с внешней информацией традиционной культуры;
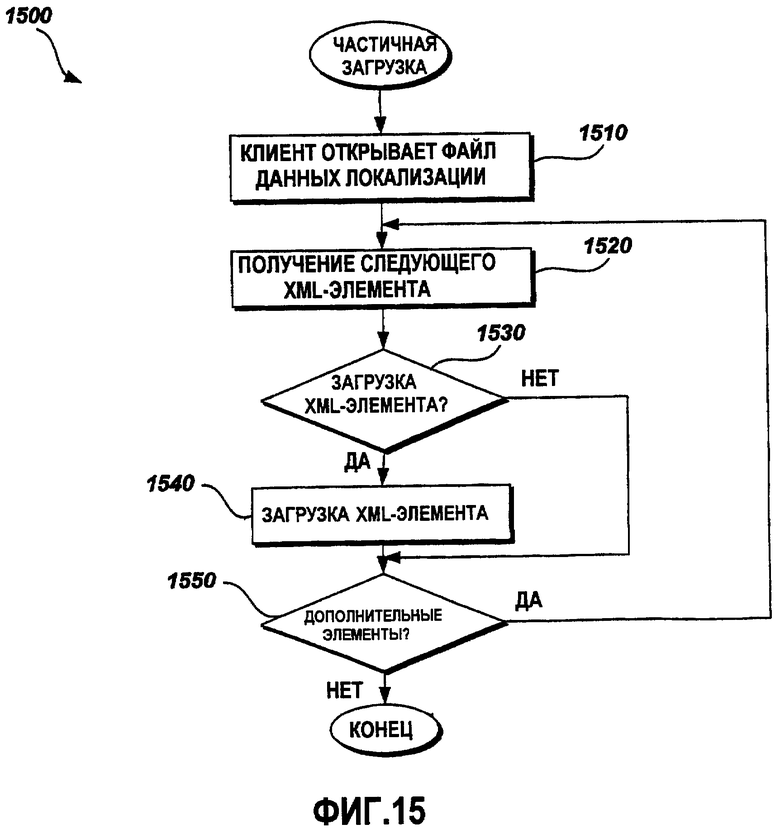
Фиг.15 - это функциональная блок-схема последовательности операций примерного способа частичной загрузки данных;
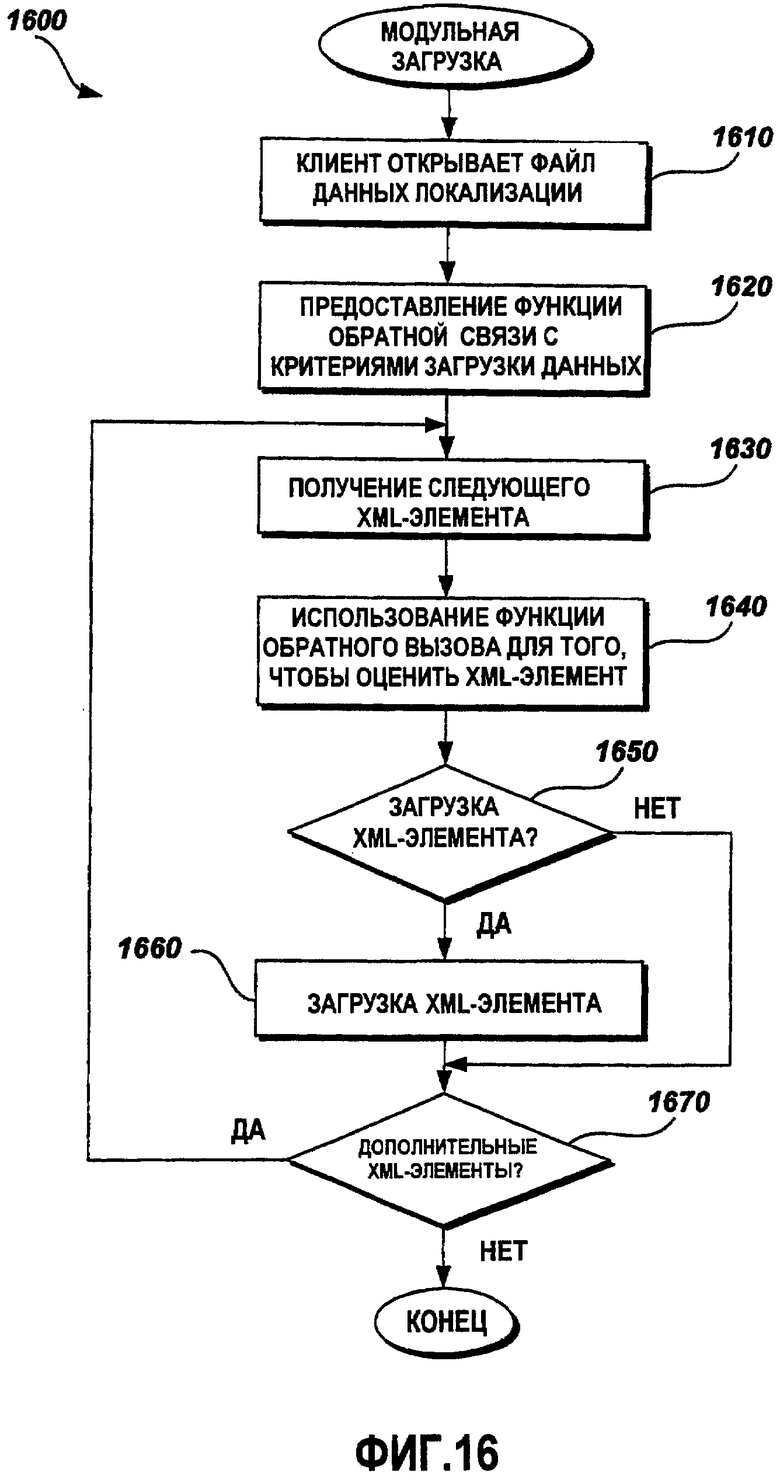
Фиг.16 - это функциональная блок-схема последовательности операций примерного способа модульной загрузки данных с функцией обратного вызова;
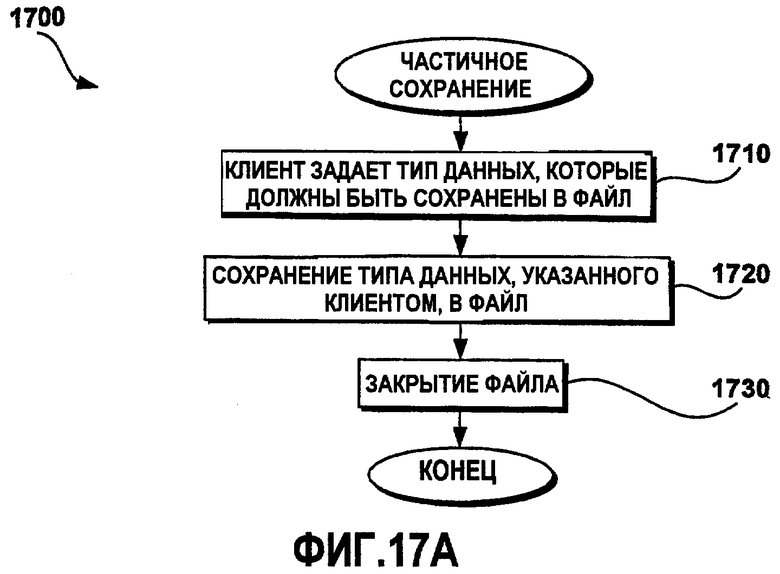
Фиг.17A - это функциональная блок-схема последовательности операций примерного способа частичного сохранения данных;
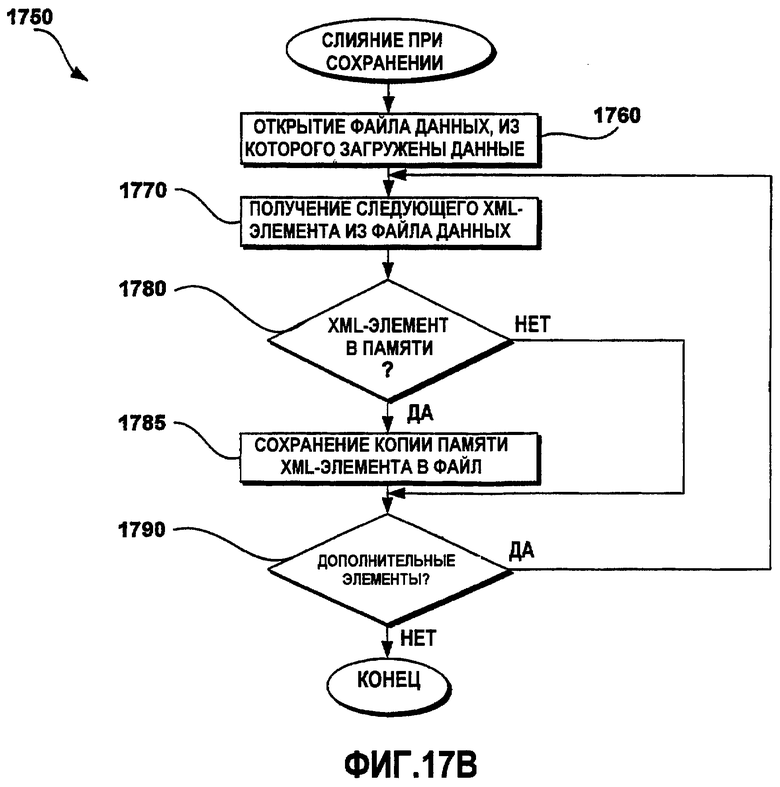
Фиг.17B - это функциональная блок-схема последовательности операций примерного способа слияния при сохранении данных;
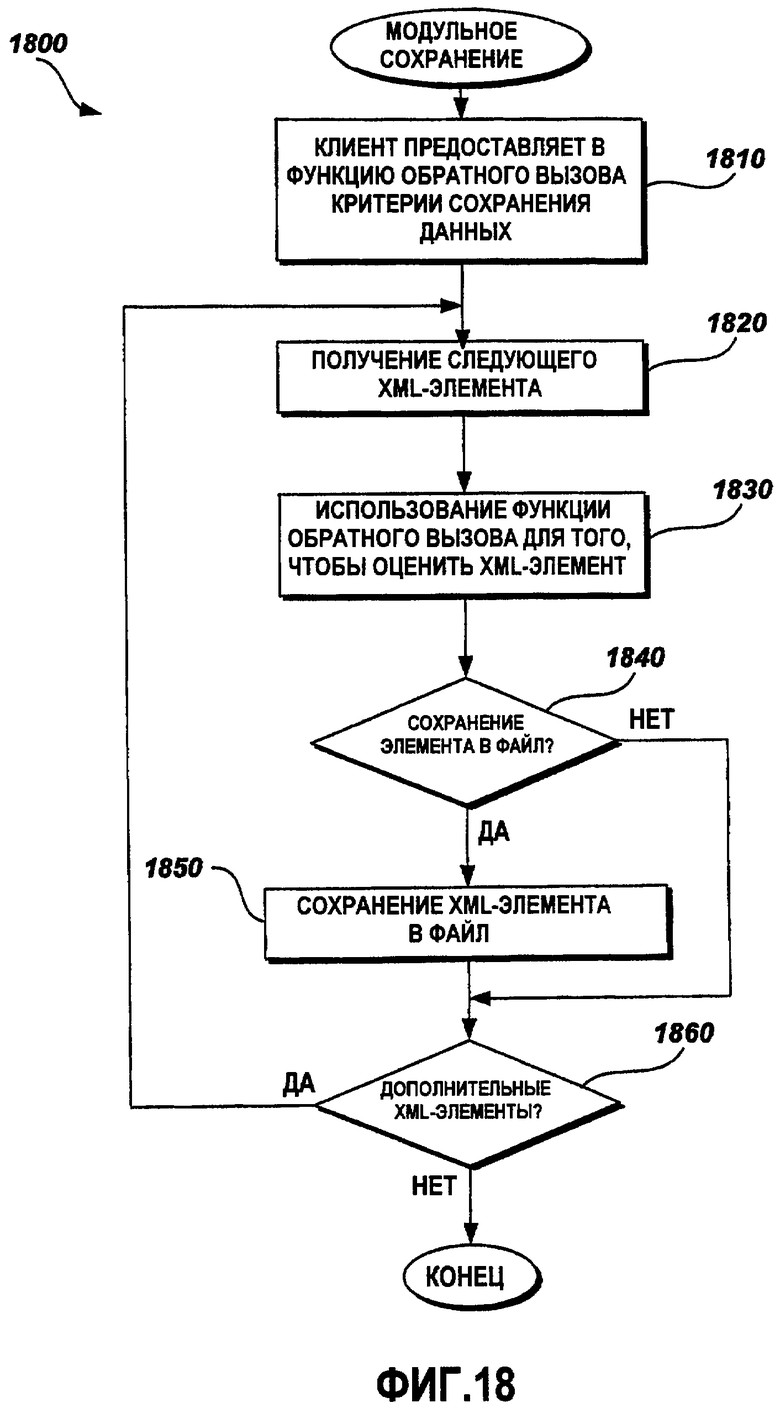
Фиг.18 - это функциональная блок-схема последовательности операций примерного способа модульного сохранения данных;
Фиг.19 - это графическая схема примерной объектной модели локализации;
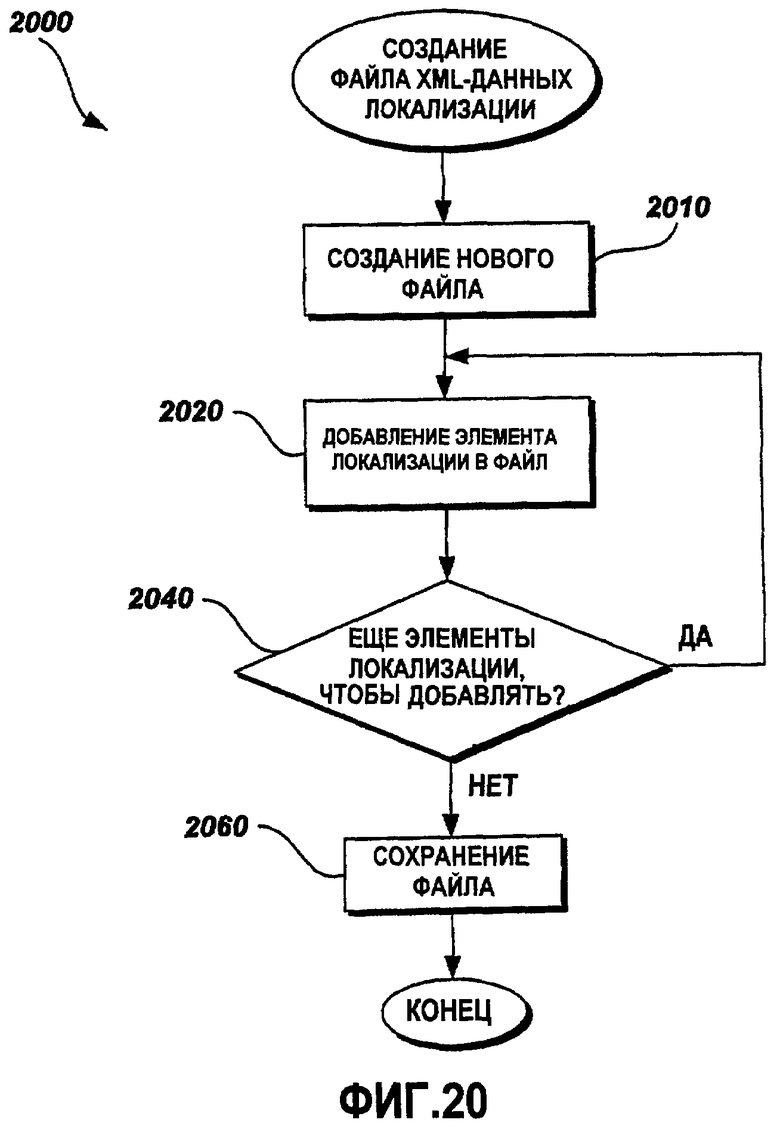
Фиг.20 - это функциональная блок-схема последовательности операций примерного способа создания и предоставления файла данных локализации;
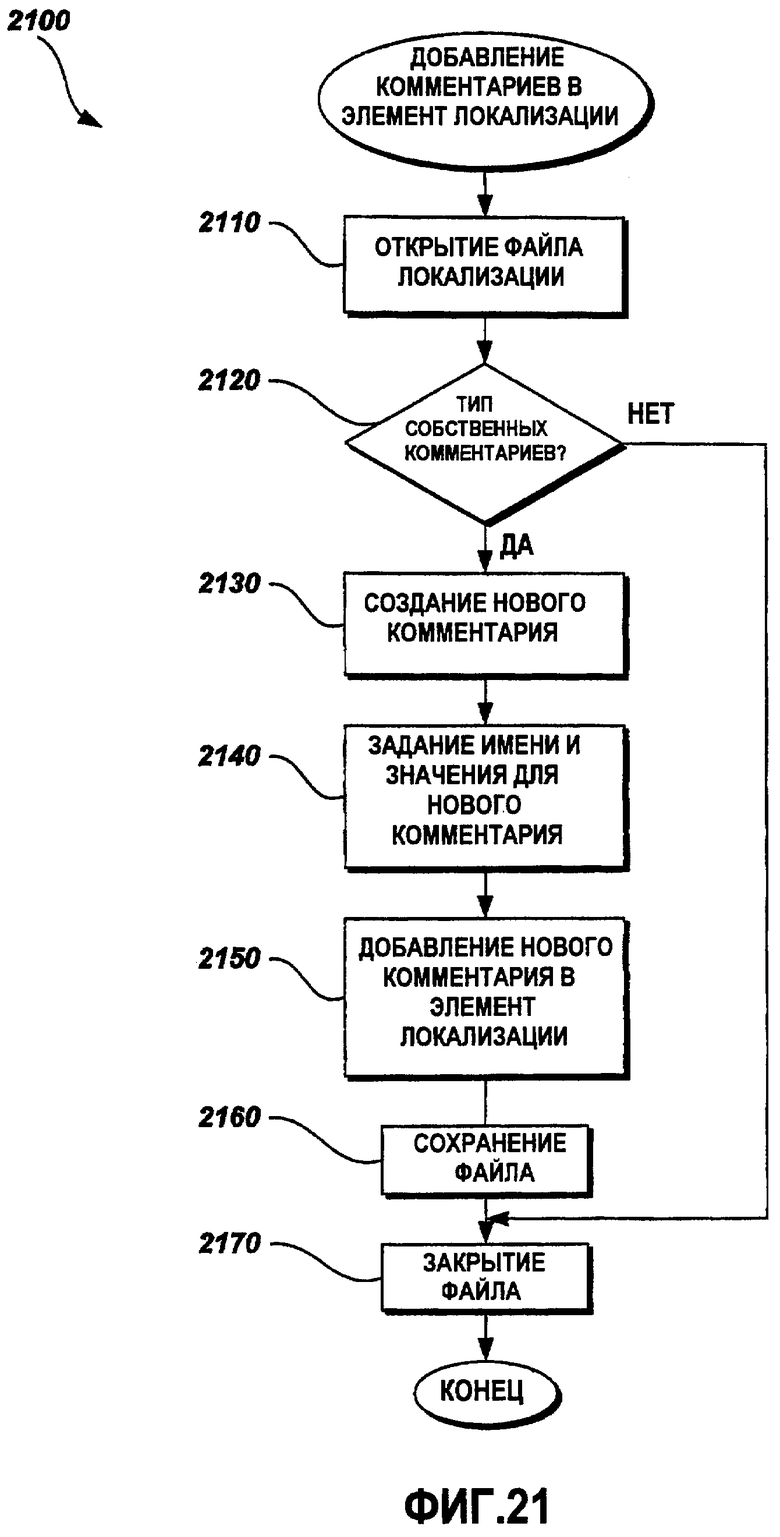
Фиг.21 - это функциональная блок-схема последовательности операций примерного способа добавления комментариев в элемент локализации; и
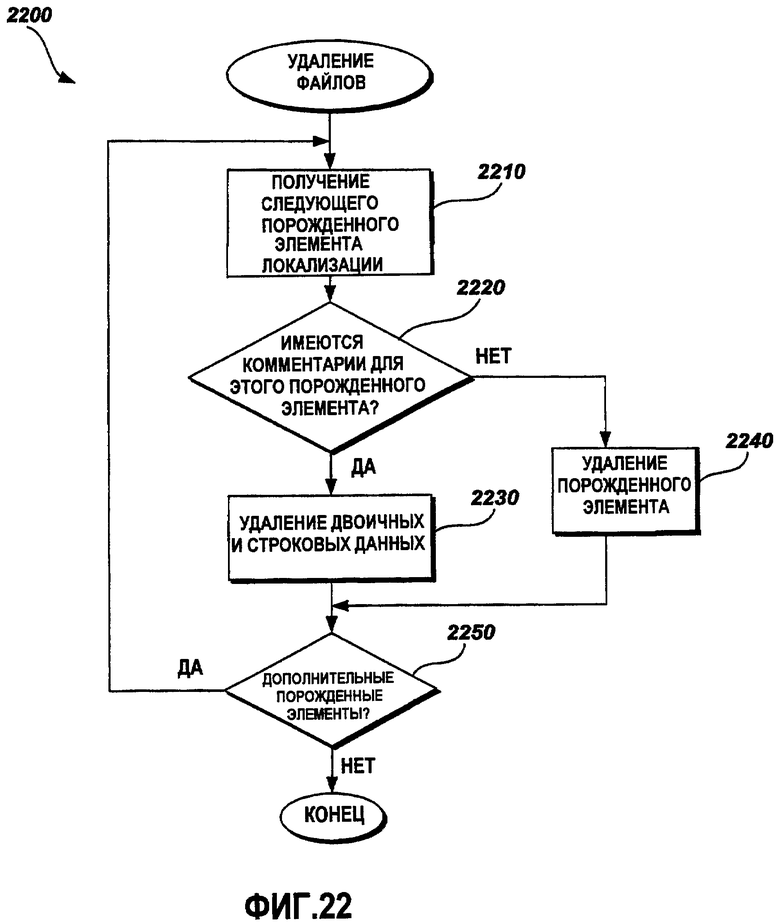
Фиг.22 - это функциональная блок-схема последовательности операций примерного способа удаления файлов.
Подробное описание изобретения
Описываются система и способ задания стандартных и расширяемых данных локализации и объектной модели для осуществления доступа и обработки этих данных. Хотя эта система и способ идеально подходят для применения в процессе локализации, система и способ могут найти применения в других программных средах, где вовлечены несколько средств разработки и организаций, которые совместно используют одни и те же базовые данные. Таким образом, следует понимать, что настоящее изобретение не должно рассматриваться как ограниченное в применении примерных вариантов осуществления, описанных в данном документе, и эти примерные варианты осуществления не должны рассматриваться как ограничивающие.
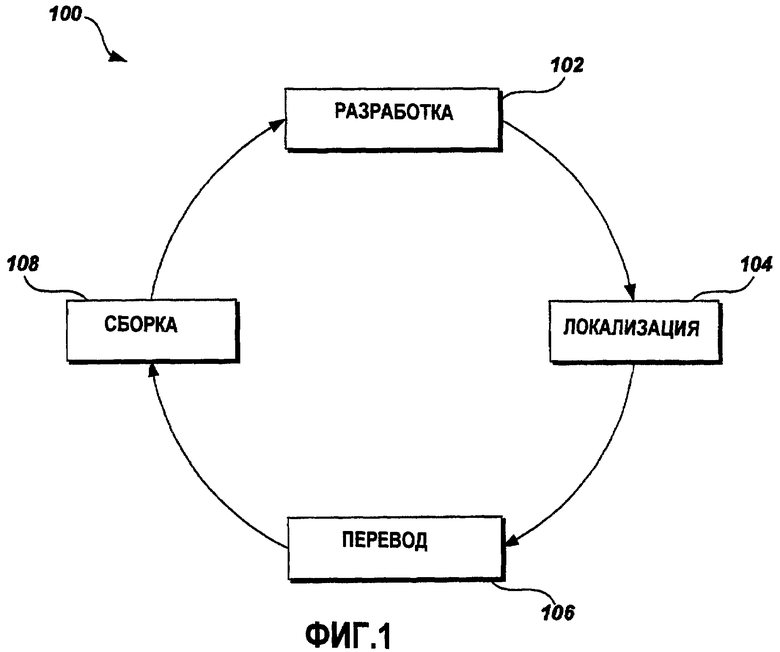
Фиг.1 - это графическая схема примерного процесса 100 локализации. Примерный процесс локализации содержит рабочий цикл, включающий в себя несколько отдельных стадий. Стадии включают в себя стадию 102 разработки, стадию 104 локализации, стадию 106 перевода и стадию 108 сборки. Специалисты в данной области техники должны признавать, что стадии рабочего цикла могут включать в себя большее или меньшее число стадий, чем описано в этом примерном варианте осуществления. Например, некоторые из стадий могут быть объединены так, чтобы создать меньшее число стадий, или дополнительно разбиты так, чтобы создать большее число стадий. На стадии 102 разработки специалисты по разработке прикладной программы ("программного приложения") разрабатывают программный код и пользовательский интерфейс (UI). UI может включать в себя текстовые, визуальные и звуковые компоненты. Например, специалисты по разработке пишут и компилируют код для программного приложения. Код может быть написан на любом из нескольких доступных языков программирования, таких как C, C++, C# и т.п., и включать в себя файлы исходного кода, файлы заголовков и файлы ресурсов. Файлы ресурсов, в общем, содержат визуальные и другие UI-элементы, такие как битовые карты. Специалисты по разработке также могут включать комментарии в некоторые из этих файлов, например в файлы ресурсов. Комментарии включают в себя примечания к коду или UI-элементам, а также команды к программным средствам, таким как различные программные компиляторы, средства администрирования и средства сборки, используемые в ходе разработки локализованных программных приложений. Специалисты по разработке передают наборы (коллекции) файлов, включающие в себя компилированный код и файлы ресурсов, на стадию 104 локализации, на которой специалисты по локализации продолжают процесс локализации. Специалисты по локализации добавляют дополнительные комментарии в файлы, которые применимы ко всем целевым языкам и культурам. Далее файлы передаются на стадию 106 перевода, где выполняется перевод файлов прикладных программ для каждого конкретного языка. В завершение, файлы передаются на стадию 108 сборки, где файлы компонуются так, чтобы сформировать исполняемые файлы прикладной программы для каждого из нескольких языков.
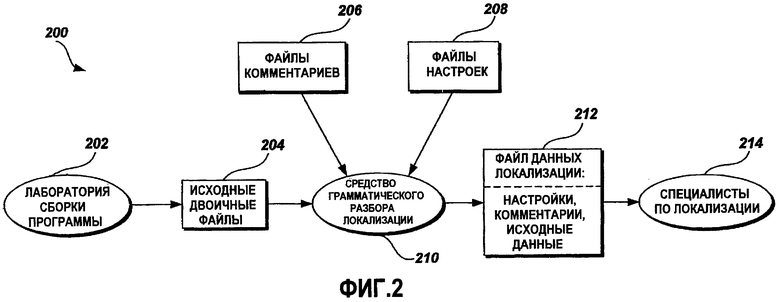
Фиг.2 - это графическая схема, иллюстрирующая примерный поток 200 данных локализации из стадии 102 разработки в стадию 104 локализации. Средство 210 грамматического разбора локализации используется для того, чтобы объединить несколько файлов, включающих в себя исходные двоичные файлы 204, файлы 206 комментариев и файлы 208 настроек (параметров), и сформировать выходной файл 212 данных локализации. Исходные двоичные файлы 204 поступают от специалистов по разработке и лаборатории 202 сборки программы. Файл 212 локализации - это файл, который передается специалистам 214 по локализации на стадии 104 локализации. В одном примерном варианте осуществления файл 212 данных локализации содержит настройки из файлов 208 настроек, комментарии из файлов 206 комментариев и исходные двоичные данные из исходных двоичных файлов 204. Исходные двоичные файлы 204, предоставляемые от лаборатории 202 построения программы, включают в себя двоичные данные, получающиеся в результате построения (сборки) исходных файлов прикладной программы на первоначальном языке, например на английском.
Комментарии, встроенные в файлы 206 комментариев, исходные двоичные файлы 204 и файлы 208 настроек снабжаются тегами, чтобы указать владельца и источник комментариев. Например, комментарии, исходящие от специалистов по разработке, могут быть снабжены тегом "DEV", чтобы указать источник комментариев, указываемый посредством этого тега. Различные программные средства, используемые в процессе локализации, такие как средство извлечения комментариев, позволяют добавлять комментарии также в файлы прикладных программ. Например, средство извлечения комментариев может снабжать тегами комментарии, принадлежащие средству извлечения комментариев, как "RCCX". Средство извлечения комментариев может не формировать выходной файл, если нет комментариев во входном файле, с которым работает средство извлечения комментариев. Комментарии являются чувствительными к регистру, т.е. буквы верхнего регистра и нижнего регистра задают различные слова, или комментарии не являются чувствительными к регистру. Комментарии также могут быть включены или отключены. Например, средство администрирования локализации может снабжать комментарии тегом "LCI" и может быть использовано для того, чтобы отключить другие комментарии DEV и RCCX. Средство сборки (построения) прикладной программы владеет одним или более из конкретных типов комментариев, идентифицированных посредством конкретного тега, такого как DEV и RCCX, причем эти типы обрабатывает средство сборки. В одном примерном варианте осуществления режим работы средств, например, средства сборки программ, управляется посредством параметров, заданных в конфигурационном файле.
Два различных типа файлов содержат и притязают на владение одним или более из одинаковых типов комментариев, как задано посредством тега комментариев. Притязание на владение одним или более из одинаковых типов комментариев посредством нескольких файлов создает конфликт. Конфликт владения может быть разрешен, например, посредством назначения владения самому новому файлу либо конфликт может быть разрешен на основе заранее назначенного свойства владения для файлов. Таким образом, файл с более высоким приоритетом должен иметь большее притязание на комментарии типа, подвергающегося конфликту владения. Другие типы разрешения конфликтов также могут быть использованы. Таким образом, эти примеры должны истолковываться как примерные, а не как ограничивающие.
Когда несколько файлов, содержащих различные типы комментариев, сливаются, могут быть выданы сообщения предупреждения или об ошибке, если возникают конфликты владения. Если в ходе операции слияния комментариев преднамеренные изменения встречаются, выдаются информационные сообщения, указывающие это. Например, информационное сообщение может быть выдано, когда комментарий игнорируется, поскольку доступна более новая версия файла, владеющего комментарием. Если комментарий не может быть отключен, формируется сообщение предупреждения. Аналогично, если комментарий не принадлежит файлу, либо средство отключено, выдается сообщение предупреждения. В одном примерном варианте осуществления владение типами комментариев переназначается от текущего владельца к новому владельцу. Например, владение комментарием типа DEV передается от средства грамматического разбора средству сборки. В одном примерном варианте осуществления каждый владелец имеет список владения типов комментариев, которыми владеет владелец. Если новый тип комментария не в списке владения владельца назначается владельцу, владелец сохраняет владение и выдает сообщение предупреждения. В одном примерном варианте осуществления, если два файла притязают на владение одним комментарием, выдается сообщение об ошибке. Данный конфликт владения может быть разрешен на более поздней стадии, такой как стадия 108 сборки процесса локализации. В одном примерном варианте осуществления ресурс, который не содержит тип комментария, которым владеет файл ресурса, рассматривается как имеющий пустой и включенный комментарий и обрабатывается таким образом в ходе операции слияния комментариев.
Как описано выше, в ходе процесса локализации комментарии добавляются в исходный код программы и в файлы локализации, чтобы предоставить информацию и команды для последующих этапов в процессе локализации. Комментарии помогают локализаторам программы повышать качество и снижать стоимость локализации. Преимущество предоставления комментариев включает в себя совместное использование информации, помощь в создании псевдо-сборок и проверку достоверности перевода. В одном примерном варианте осуществления совместное использование информации включает в себя предоставление стандартных команд локализуемости о строковых ресурсах, что уменьшает ошибки, создаваемые вследствие некорректной локализации этих строковых ресурсов. Строковые ресурсы включают в себя текстовые сообщения, такие как предупреждения, представляемые пользователю программы. Псевдо-сборки - это временные тестовые сборки программы (т.е. компиляция программного кода), используемые тестовыми группами для того, чтобы находить ошибки локализуемости на ранних стадиях цикла разработки продукта, планировать тестирование реальных локализованных сборок и уменьшать общую стоимость локализованной сборки. Достоверность перевода проверяется посредством использования команд и комментариев локализуемости. Достоверность перевода проверяется посредством сопоставления переводов, предоставленных локализаторами, с набором ограничений для локализации. Набор ограничений содержит сопоставление информации, такой как слова и фразы, между первоначальным языком программы и целевым языком, для которого локализуется программа.
В одном примерном варианте осуществления используется средство извлечения комментариев. Как указано выше, средство извлечения комментариев - это средство локализации, которое выполняется для файлов, которые включают в себя комментарии, чтобы извлекать и записывать эти комментарии в выходной файл, такой как файл данных локализации. В другом примерном варианте осуществления каждое средство, используемое в процессе локализации, может формировать комментарии и помечать тегами эти комментарии, чтобы идентифицировать средство в качестве источника комментариев. Средство может формировать комментарии с исходным тегом, который указывает другой источник. Например, средство извлечения комментариев может формировать комментарий DEV. В этом случае конфликт может возникнуть между двумя комментариями с одним тегом, но из различных источников. В одном варианте осуществления модель переопределения комментариев используется для того, чтобы отключать конфликтующие комментарии. Отключенный комментарий игнорируется в ходе обработки.
Фиг.3 - это графическая схема, иллюстрирующая другой примерный поток 104 данных локализации из стадии 104 локализации и стадии 106 перевода до стадии 108 сборки. В этом примере средство 312 сборки локализации обрабатывает данные, содержащиеся в исходном двоичном файле 204, файле 212 данных локализации и файле 310 локализованного языка, чтобы формировать выходной целевой двоичный файл 314. Как описано выше относительно Фиг.2, файл 212 данных локализации включает в себя настройки, комментарии и исходные данные, объединенные из данных в других файлах. Файл 310 локализованного языка включает в себя настройки, комментарии, исходные данные и данные перевода, добавленные специалистами 214 по локализации. Средство 312 сборки локализации использует исходные двоичные файлы 204, файл 212 данных локализации и файл 310 локализованного языка в качестве входных файлов и формирует целевой двоичный файл 314 на целевом языке. Создание целевого двоичного файла 314 - это конечный локализованный прикладной программный продукт, и он является основной целью процесса локализации.
Средства и процессы, описанные выше, зависят от общего и согласованного формата данных, на основе которого средства могут объединять и обрабатывать данные стандартизированным способом. В одном примерном варианте осуществления схема расширяемого языка разметки (XML) локализации используется для задания согласованных форматов данных для использования посредством различных средств локализации и связанных файлов, описанных выше. XML-схема локализации предоставляет расширяемый XML-формат, который дает возможность различным группам и организациям разрабатывать программные средства для того, чтобы обрабатывать конкретные задачи. XML-схема локализации также предоставляет возможность разработки средств и данных, которые могут быть совместно использованы несколькими организациями, тем самым обеспечивая сотрудничество между группами. Например, средство 210 синтаксического разбора локализации, средство 312 сборки локализации и средство администрирования локализации могут применять и совместно использовать одинаковые форматы данных для различных данных в процессе локализации. В одном примерном варианте осуществления XML-схема локализации также может быть расширяемой. Расширяемость XML-схемы локализации позволяет другим сторонам разрабатывать новые средства с новыми признаками без изменения формата данных.
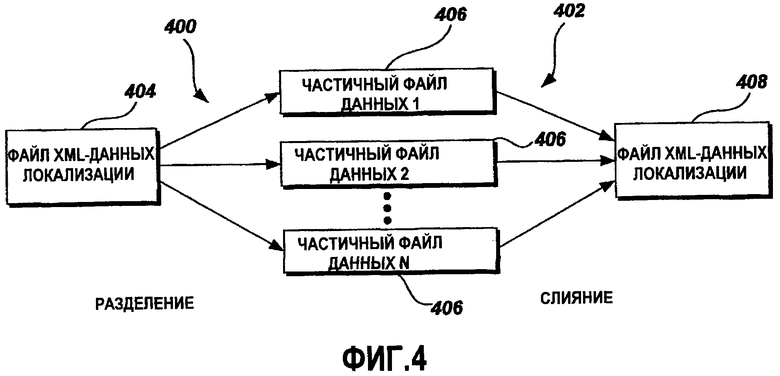
Фиг.4 - это графическая схема, иллюстрирующая примерные операции 400 и 402 разделения и слияния файлов (отличные от операции слияния комментариев), соответственно, для файла 404 XML-данных локализации на основе расширяемой XML-схемы локализации. В этом примерном варианте осуществления файл 404 XML-данных локализации разделяется на множество частичных файлов 406 данных с помощью операции 400 разделения файлов. Частичные файлы 406 данных могут быть использованы параллельно несколькими организациями или посредством программного средства параллельной обработки, обрабатывающего каждый частичный файл 406 данных независимо от других частичных файлов 406 данных. Например, каждая одна из множества третьих сторон, разрабатывающих файлы данных для нескольких программных средств, соответственно, может использовать один частичный файл данных, который относится к программному средству, разрабатываемому каждой одной из множества третьих сторон. В качестве другого примера, несколько организаций, переводящих одно программное приложение на несколько языков, могут использовать соответствующий частичный файл 406 данных, созданный посредством операции 400 разделения, для того чтобы создать переведенную версию ресурсов прикладной программы. Когда множество организаций завершают обработку частичных файлов 406 данных, частичные файлы 406 данных сливаются в один файл 408 XML-данных локализации с помощью операции 402 слияния файлов.
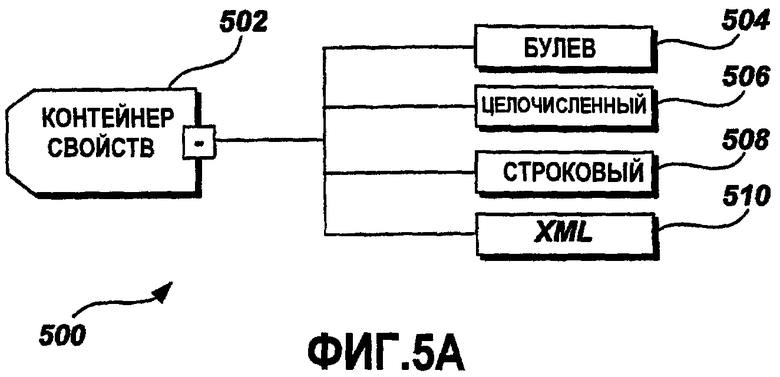
Файл 404 XML-данных локализации включает в себя XML-элементы, которые задают информацию локализации. Один из элементов, включенных в файл 404 XML-данных локализации, - это контейнер свойств. Фиг.5A-5E иллюстрируют примерные варианты осуществления контейнера свойств и соответствующих XML-элементов. Фиг.5A - это графическая схема примерной структуры 500 данных контейнера свойств. Контейнер 502 свойств - это контейнер данных для хранения любого числа свойств. В одном примерном варианте осуществления каждый комплексный тип данных ассоциативно связан, по меньшей мере, с одним комплектом свойств. Комплексный тип данных - это тип данных, который содержит другие типы данных. Например, XML-элемент, который содержит другие XML-элементы, является комплексным (сложным) типом данных. В одном примерном варианте осуществления уникальное имя, заданное с помощью атрибута Name (Имя), и значение присваиваются свойству. Значение должно иметь тип данных, поддерживаемый XML-схемой локализации. Каждый комплексный тип данных, заданный в XML-схеме локализации, включает в себя элемент контейнера свойств, чтобы сохранять любой объем данных, требуемых пользователем XML-схемы локализации. Примерный контейнер 502 свойств, проиллюстрированный на Фиг.5A, включает в себя булев тип 504 данных, целочисленный тип 506 данных, строковый тип 508 данных и XML-тип 510 данных.
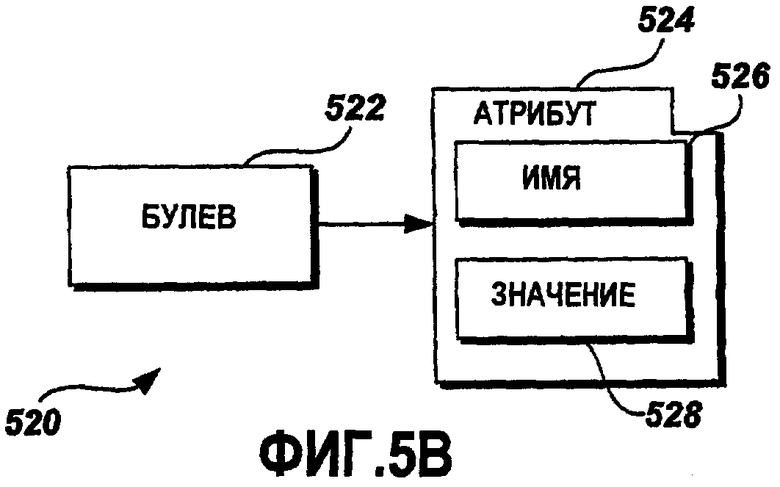
Фиг.5B - это графическая схема примерного булева XML-элемента 522. Булев XML-элемент 522 включает в себя список 524 атрибутов. Атрибуты типа данных в XML используются для того, чтобы представлять информацию о типе данных, такую как имя и значение типа данных. Один из атрибутов, включенных в список 524 атрибутов, - это Name 526. В одном варианте осуществления атрибут 526 Name - это буквенно-цифровая строка. Value (Значение) 528 - это другой атрибут булева XML-элемента 522. Value 528 представляет логическое значение булева XML-элемента 522. Логические значения включают в себя два значения логических состояний TRUE (ИСТИНА) и FALSE (ЛОЖЬ), как известно в данной области техники.
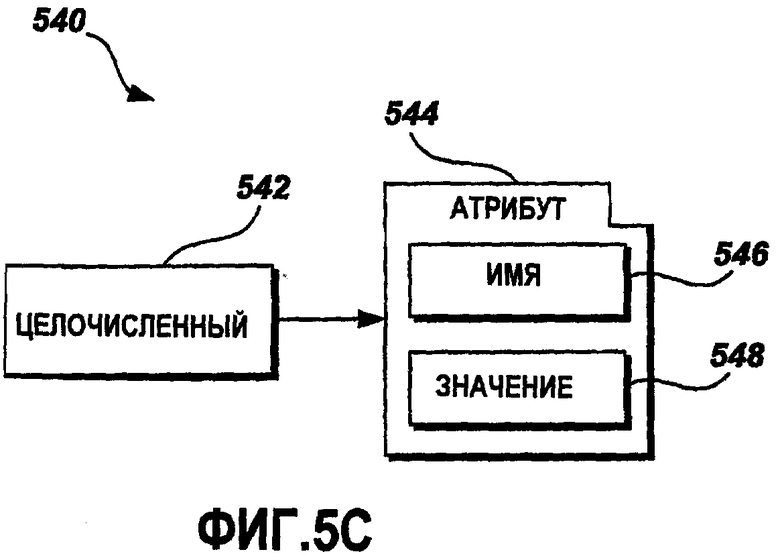
Фиг.5C - это графическая схема примерного целочисленного XML-элемента 542. Целочисленный XML-элемент 542 включает в себя список 544 атрибутов. Один из атрибутов, включенных в список 544 атрибутов, - это Name 546. В одном варианте осуществления атрибут 546 Name - это буквенно-цифровая строка. Value 548 - это другой атрибут целочисленного XML-элемента 542. Value 548 представляет целочисленное значение целочисленного XML-элемента 542.
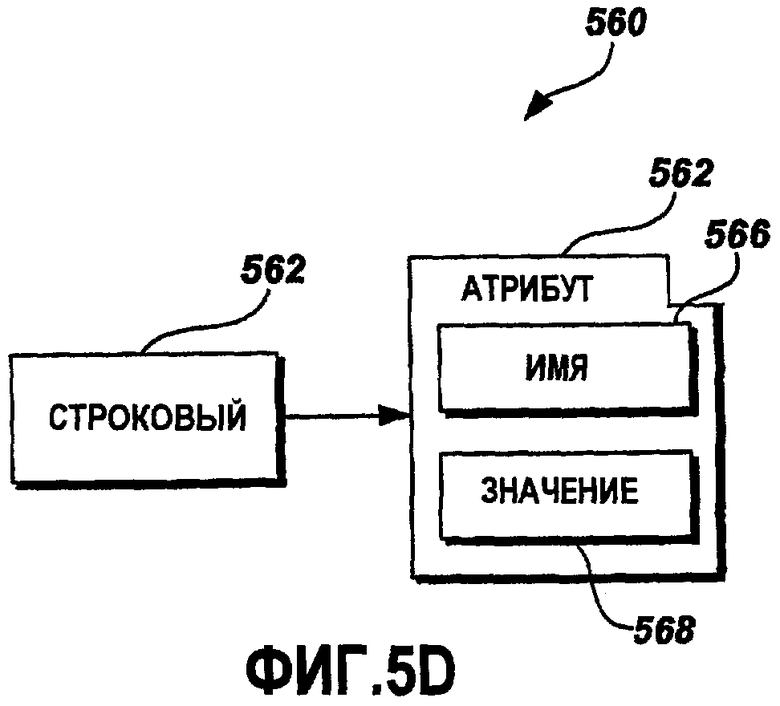
Фиг.5D - это графическая схема примерного строкового XML-элемента 562. Строковый XML-элемент 562 включает в себя список 564 атрибутов. Один из атрибутов, включенных в список 564 атрибутов, - это Name 566. В одном варианте осуществления атрибут 566 Name - это буквенно-цифровая строка. Value 568 - это другой атрибут строкового XML-элемента 562. Value 568 включает в себя строку символов, включающую в себя буквенно-цифровые, а также другие символы, представляемые посредством строкового XML-элемента 562.
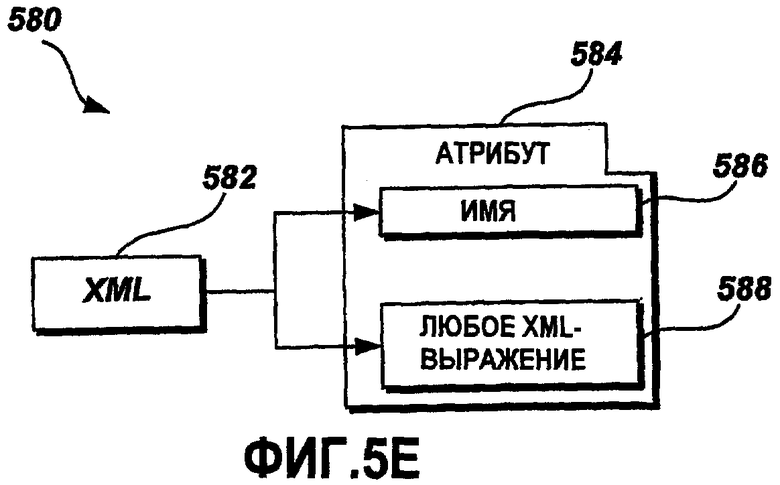
Фиг.5E - это графическая схема примерного XML-строкового XML-элемента 582. XML-строковый XML-элемент 582 представляет любое допустимое XML-предложение. XML-элемент 582 включает в себя список 584 атрибутов. Список 584 атрибутов включает в себя атрибут 586 Name. В одном примерном варианте осуществления атрибут 586 Name - это буквенно-цифровая строка. Список 584 атрибутов также включает в себя атрибут 588 Any XML Statement (Любое XML-предложение), содержащий любое допустимое XML-предложение.
Специалисты в данной области техники должны признавать, что возможны другие варианты элемента 502 контейнера свойств. Например, элемент 502 контейнера свойств может включать в себя тип элемента данных, такого как элемент Any (Любой) (не показан на вышеописанных чертежах), при этом элемент Any включает в себя атрибут имени, атрибут типа и атрибут значения. В этом примерном варианте осуществления атрибут типа задает то, как должен быть интерпретирован атрибут значения. Например, тип может равняться Unsigned_integer, а значение может равняться 15.
Фиг.6 - это графическая схема примерного формата 600 данных комментариев с атрибутом источника. В одном примерном варианте осуществления элемент 602 комментариев включает в себя текст естественного языка, предоставляющий информацию о процессе локализации для людей-операторов, а также заранее заданные текстовые строки, предоставляемые в качестве команд людям-операторам и программным средствам, которые обрабатывают файлы 206 комментариев и файлы 408 XML-данных локализации. Элемент 602 комментариев, проиллюстрированный на Фиг.6, включает в себя список 604 атрибутов. В одном примерном варианте осуществления список 604 атрибутов содержит атрибут 606 Name, атрибут 608 Enabled (Включено) и атрибут 610 SRC (для "источника"). Атрибут 606 Name используется для того, чтобы ссылаться на комментарий по имени. Атрибут 608 Enabled выступает в качестве индикатора, чтобы указывать то, включен или отключен комментарий 602. Атрибут 610 SRC указывает источник комментария, т.е. атрибут 610 SRC - это тег для идентификации владельца и источника комментария. Как описано выше со ссылкой на Фиг.2, различные типы комментариев принадлежат различным владельцам. Владелец комментария может включать команды и другую информацию о процессе локализации, которая относится к зоне ответственности владельца комментария. Например, разработчик программного обеспечения может предоставлять общую информацию и команды в форме комментариев. Комментарии, сделанные посредством конкретного владельца, снабжаются тегами, чтобы идентифицировать владельца комментария. В одном примерном варианте осуществления комментарии, сделанные каждым владельцем, могут обрабатываться только владельцем, которому принадлежат комментарии. В другом примерном варианте осуществления владение комментарием может быть перенесено от одного владельца к другому. Например, комментарию, помеченному DEV (т.е. разработчик, как описано выше), может быть разрешено принадлежать средству извлечения комментариев, которое обычно владеет только комментариями, тегированными как RCCX. В примерном варианте осуществления имена комментариев и комментарии могут быть чувствительны к регистру. Комментарии также могут быть включены или отключены. Как описано выше, отключенный комментарий игнорируется в ходе обработки.
Фиг.7 - это блок-схема примерного формата 700 данных элемента локализации с комментариями. В одном примерном варианте осуществления элемент 702 локализации включает в себя атрибуты 704. Атрибуты 704 содержат itemType (Тип элемента) 706 и itemID (Идентификатор элемента) 708. Элемент 702 локализации дополнительно включает в себя строковый элемент 710, двоичный элемент 712 и комментарии 714. Элемент 702 локализации - это любая часть или ресурс в локализуемой программе, который может быть переведен или иным образом адаптирован к местной культуре и языку. Например, текстовое сообщение или значок - это элемент 702 локализации. ItemType 706 - это атрибут, который обозначает тип элемента 702 локализации. Например, itemType 706 может указывать то, что конкретный элемент 702 локализации - это текстовое сообщение или цвет. ItemID 708 используется в качестве идентификатора элемента 702 локализации. Элемент 702 локализации необязательно может включать в себя строку 710, двоичные данные 712 и комментарии 714, в зависимости от itemType 706. Например, если itemType 706 указывает то, что элемент 702 локализации - это текстовая строка, элемент 702 локализации может включать в себя другой элемент, такой как элемент свойства (не показан на чертеже), задающий шрифт по умолчанию, который должен быть использован при локализации. В одном примерном варианте осуществления несколько типов строк 710 и двоичных данных 712 включены в элемент 702 локализации. Например, строки и двоичные данные для исходного языка, целевого языка и других эталонных языков могут быть включены в элемент 702 локализации. Эталонный язык может быть использован для того, чтобы предоставлять дополнительную информацию для перевода элемента 702 локализации с исходного языка на целевой язык. В одном примерном варианте осуществления родительский элемент 702 локализации включает в себя нуль или более других дочерних элементов 702 локализации (не показаны), совместно составляющих иерархическую структуру элементов 702 локализации. Дочерние элементы 702 локализации включают в родительский элемент 702 локализации посредством указателей или эквивалентных программных методик.
Фиг.8 - это графическая схема примерного формата 806 данных собственных комментариев. Проиллюстрированный примерный элемент 802 собственных комментариев включает в себя множество элементов 602 комментариев, каждый из которых содержит атрибут 804. Атрибут 804 включает в себя атрибут 806 имени.
Фиг.9A-9D иллюстрируют примерные варианты осуществления элемента 902 настроек и соответствующих XML-элементов. Фиг.9A - это графическая схема примерного формата данных настроек. Элемент 902 настроек включает в себя атрибут 904, содержащий имя 906. Элемент 902 настроек дополнительно содержит множество элементов настроек 908. Примерная настройка 1 содержит атрибут 910. Атрибут 910 включает в себя имя 912 настройки 1. Примерная настройка 1 дополнительно включает в себя булев элемент 914, целочисленный элемент 916, элемент 918 перечисления, строковый элемент 920, элемент 922 списка и элемент 924 списка выбора. Каждый из элементов настройки 908 дополнительно поясняется ниже. Элемент 902 настроек указывает текущие настройки файла данных локализации.
Фиг.9B - это графическая схема примерного элемента 942 перечислений. Примерный элемент 942 перечислений включает в себя атрибут 944, содержащий имя 946 и значение 948. Атрибут 946 имени идентифицирует элемент 942 перечисления по имени. Атрибут 948 значения включает в себя значение перечисления, представленное посредством перечисления 942.
Фиг.9C - это графическая схема примерного элемента 962 списка. Примерный элемент 962 списка включает в себя атрибут 964, содержащий имя 966 и множество элементов 968 позиции. Атрибут 966 имени идентифицирует элемент 962 списка по имени. Каждый из элементов 968 позиции представляет одну запись списка 962 и может включать в себя множество атрибутов (не показаны на этом чертеже), такие как идентификатор позиции, порядковый номер, имя исходного файла и т.п. Дополнительно, позиция 968 может включать в себя другие элементы (не показанные на этом чертеже), такие как строковый элемент, двоичный элемент, элемент комментариев и т.п.
Фиг.9D - это графическая схема примерного элемента 982 списка выбора. Примерный элемент 982 списка выбора включает в себя атрибут 984, содержащий имя 986 и атрибут 988 значения. Примерный элемент 982 списка выбора дополнительно включает в себя множество элементов 990 позиции. Атрибут 986 имени идентифицирует элемент 982 списка выбора по имени. Каждый из элементов 990 позиции представляет одну запись списка 982 выбора и может включать в себя множество атрибутов (не показаны на этом чертеже), такие как идентификатор позиции, порядковый номер, имя исходного файла и т.п. Дополнительно, позиция 990 может включать в себя другие элементы (не показанные на этом чертеже), такие как строковый элемент, двоичный элемент, элемент комментариев и т.п.
Специалисты в данной области техники должны признавать, что другие варианты элементов данных возможны. Например, элемент данных может включать в себя тип элемента данных, такого как элемент Any (не показан на вышеописанных чертежах), при этом элемент Any включает в себя атрибут имени, атрибут типа и атрибут значения. В этом примерном варианте осуществления атрибут типа задает то, как должен быть интерпретирован атрибут значения. Например, тип может равняться Unsigned_integer, а значение может равняться 15.
Фиг.10 - это графическая схема примерного формата 1002 XML-данных локализации. Формат XML-данных локализации используется для того, чтобы задавать общий формат данных локализации, используемых в процессе локализации. Примерный элемент 1002 XML-данных локализации включает в себя атрибуты 1004 и необязательные элементы, такие как настройки 1016, контейнер 1018 свойств, собственные комментарии 1020 и элемент 1022 локализации, описанные выше. Атрибуты 1004 включают в себя атрибут 1006 имени и другие необязательные атрибуты Parser ID (Идентификатор средства грамматического разбора) 1010, Description (Описание) 1012, Source (Источник) 1012 и Target (Назначение) 1014. Как описано выше относительно Фиг.7, элемент 1022 локализации может включать в себя нуль или более других дочерних элементов 1022 локализации (не показаны), совместно составляющих иерархическую структуру элементов 702 локализации.
Фиг.11A - это примерная графическая схема текстовых данных, содержащихся в XML-элементе 1102 CDATA. XML-элемент 1102 CDATA используется для того, чтобы представлять свободный текст 1104 в файлах данных локализации, аналогичный строке, широко известной в данной области техники. Свободный текст 1104, включенный в XML-элемент 1102 CDATA, разделяется с помощью закрывающих двойных скобок 1106 сразу после окончания последнего символа свободного текста 1104. Т.е. закрывающие двойные скобки 1106 вставляются в конец свободного текста 1104 без каких-либо пробельных символов, таких как пробел, табуляция и т.п., между последним символом свободного текста 1104 и закрывающими двойными скобками 1106. Фиг.11B - это примерная графическая схема текстовых данных, включающих в себя символ 1110 квадратной скобки, содержащейся в XML-элементе 1102a CDATA. Если свободный текст 1104a включает в себя символ 1110 квадратных скобок "]", пределы свободного текста 1104a не могут быть определены однозначно. Когда значение символа неоднозначное, т.е. когда символ может быть интерпретирован несколькими способами, символ выхода может быть использован для того, чтобы ограничивать интерпретацию символа. Символ выхода может быть использован помимо других методик для того, чтобы разрешать неоднозначность символа. В одном примерном варианте осуществления разрешение неоднозначности квадратных скобок "]" включает в себя вставку пробельного символа 1108, такого как символ пробела или табуляции, до символа 1110 квадратных скобок, чтобы идентифицировать квадратную скобку 1110 как часть свободного текста 1104a, но не часть закрывающихся двойных скобок 1106a. В других примерных вариантах осуществления другие специальные символы могут быть использованы аналогично.
Фиг.12 - это блок-схема примерных взаимосвязей 1200 XML-схемы 1202 локализации и соответствующей объектной модели 1208. Объектная модель 1208 содержит ряд классов 1206, причем каждый класс 1206 указывает конструкцию программного объекта в объектной модели. Специалистам в данной области техники понятно, что классы - это абстрактные объекты, которые используются для того, чтобы задавать программные объекты в объектно-ориентированных вычислительных языках, таких как C++ (C-plus-plus), C# (C-Sharp) и Java. Более того, специалисты в данной области техники должны признавать, что программный объект создается в памяти компьютера посредством создания экземпляра класса, т.е. посредством выделения памяти для того, чтобы создавать физический объект в памяти на основе формата, указанного посредством соответствующего класса. Объектная модель 1208 задает один класс 1206 в основном для каждого элемента 1204 в XML-схеме 1202 локализации. С помощью объектной модели 1208 XML-схема локализации реализуется в программных приложениях и средствах 1210. Как описано выше, элементы 1204 задают формат 1212 данных локализации. Интерфейс 1214 данных для указания форматов данных локализации, исходно заданных посредством элементов 1204, указывается посредством классов 1206 в объектной модели 1208. Программные приложения и средства 1210 используют интерфейс 1214 данных для того, чтобы корректно осуществлять доступ и обрабатывать данные локализации с помощью корректных форматов для каждого фрагмента данных. Программные приложения и средства 1210 также используют функциональный интерфейс 1216 для того, чтобы осуществлять доступ и обрабатывать данные локализации, чтобы конфигурировать и выполнять задачи локализации.
Фиг.13A - это блок-схема примерных родительских и дочерних объектов с обратным указателем. Родительский объект 1302 - это программный объект, экземпляр которого создан из первого класса. Дочерний объект 1304 - это программный объект, экземпляр которого создан из второго класса, который порожден из первого класса во время конструирования первого и второго классов. Специалисты в данной области техники должны признавать, что в объектно-ориентированных языках программирования, таких как C++, C# и Java, второй класс может быть извлечен (т.е. задан из) из первого класса. Второй класс, как предполагается, наследует членов, включенных в первом классе. Члены класса включают в себя функции, переменные, указатели и другие классы. Второй класс может определять дополнительных новых членов, не определенных в первом классе. Взаимосвязь получения членов первого класса посредством второго класса известна в данной области техники как наследование. Наследование - это процесс, который, как правило, осуществляется во время конструирования, а не во время выполнения (т.е. в ходе выполнения программного обеспечения) в ходе разработки программы. Другое свойство объектно-ориентированных языков, которое хорошо известно специалистам в данной области техники, известно как включение, также известное как агрегирование. Когда первый класс является членом второго класса, говорят, что первый класс содержится во втором классе. Включение - это взаимосвязь между объектами, которая отличается от наследования. Взаимосвязь включения между двумя объектами может быть создана или удалена во время выполнения посредством переназначения указателей. В данной области техники принято использовать термин "родительский" для того, чтобы представлять первый класс, и термин "порожденный", чтобы представлять второй класс, в отношениях наследования и включения. Соответственно, терминология родительский/порожденный (дочерний) будет использоваться в нижеприведенном описании. В примере, проиллюстрированном на Фиг.13A, порожденный (дочерний) объект 1304 в объектной модели 1208 (Фиг.12) включает в себя обратный указатель 1306, указывающий на соответствующий родительский объект 1302. Обратный указатель 1306 повышает производительность системы за счет предоставления прямой связи между родительским объектом 1302 и порожденным объектом 1304, посредством которой взаимосвязи объектов прослеживаются в объектной модели 1208. Все объекты поддерживают ссылку на соответствующие родительские объекты с помощью обратного указателя 1306. Обратный указатель 1306 задается посредством родительского объекта 1302, когда взаимосвязи устанавливаются между родительским объектом 1302 и порожденным объектом 1304. Когда взаимосвязи между родительским объектом 1302 и порожденным объектом 1304 прерываются, порожденный объект 1302 задается так, чтобы указывать на другой родительский объект.
Фиг.13B - это блок-схема примерных родительских и порожденных (дочерних) объектов с обратным указателем и указателем файла. Как описано выше, родительский объект 1322 задает обратный указатель 1326, когда взаимосвязи устанавливаются между родительским объектом 1322 и порожденным объектом 1324.
Когда взаимосвязи между родительским объектом 1322 и порожденным объектом 1324 прекращаются, порожденный объект 1322 задается так, чтобы указывать на другой родительский объект. Когда порожденный объект 1324 - это объект ресурса, указатель 1328 на файл используется посредством порожденного объекта 1324 для того, чтобы указывать на файл ресурса. Ресурс, как известно специалистам в данной области техники, - это, в общем случае, объект графических данных, представляющий графический компонент, такой как значок, меню или растр. Данные ресурса содержатся в файле 1330 ресурса, который создается из написанных спецификаций ресурсов с помощью компилятора ресурсов.
Фиг.14 - это графическая схема примерной объектной модели 1402 с внешней информацией традиционной культуры. Объектная модель 1402 по умолчанию включает в себя хорошо известные традиционные культуры 1404. Для локализации к языкам и культурам, не включенным в объектную модель 1402 по умолчанию, объектная модель 1402 дополняется информацией 1408 традиционной культуры из внешнего файла 1406. В одном примерном варианте осуществления внешний файл 1406 присутствует в локальной системе. В другом примерном варианте осуществления внешний файл 1406 размещается в удаленной системе. В одном примерном варианте осуществления информация 1406 традиционной культуры обновляется вручную. В другом примерном варианте осуществления информация 1406 традиционной культуры может быть записана в файл 1406 посредством прикладной программы локализации.
Фиг.15 - это функциональная блок-схема последовательности операций примерного способа 1500 частичной загрузки данных. На этапе 1510 клиентская прикладная программа открывает файл данных локализации. Как описано выше, файл данных локализации включает в себя данные локализации, используемые в процессе локализации посредством прикладных программных средств, также известных как клиентские прикладные программы. В одном варианте осуществления файл данных локализации содержит XML-элементы. Специалисты в данной области техники должны признавать, что другие способы и форматы могут быть использованы для того, чтобы представлять данные для прикладных программ, а следовательно, описания в данном документе о примерных XML-элементах должны рассматриваться как примерные, а не ограничивающие. Клиентская прикладная программа имеет внутреннюю логику для определения того, какие XML-элементы загружать в память для обработки. Например, клиентская прикладная программа, которая обрабатывает только текстовую информацию для локализации, должна загружать только связанную с текстом информацию, такую как шрифт и размер текстовых символов. На этапе 1520 следующий XML-элемент получается из файла данных локализации для загрузки в память и обработки. Далее, на этапе 1530 клиентская прикладная программа определяет то, должен ли быть загружен текущий XML-элемент. Если текущий XML-элемент выбран для загрузки, то на этапе 1540 текущий XML-элемент загружается, и способ 1500 переходит к этапу 1550. Если текущий XML-элемент не выбран для загрузки, то способ 1500 переходит к этапу 1550, на котором способ 1500 определяет то, есть ли еще XML-элементы, доступные в файле данных локализации. Если дополнительные XML-элементы доступны в файле данных локализации, способ 1500 переходит обратно к этапу 1520, чтобы получить следующий XML-элемент. Если дополнительные XML-элементы не доступны в файле локализации, способ 1500 завершается. В одном примерном варианте осуществления клиентская прикладная программа выбирает общий тип данных, который должен быть загружен, и другие общие типы данных, которые не должны быть загружены. Например, клиент, который обрабатывает текст, задает флаг для загрузки только строковых данных, но не двоичных данных. В этом случае выбор данных выполняется на макроуровне, различающем типы данных для загрузки на основе общих типов выбираемых данных.
Фиг.16 - это функциональная блок-схема последовательности операций примерного способа 1600 модульной загрузки данных с функцией обратного вызова. В одном варианте осуществления клиентская прикладная программа задает данные, которые должны быть загружены, на точном модульном уровне, включающем в себя все типы данных, такие как строковые данные и двоичные данные. Модульная загрузка данных выполняется на точном уровне в рамках всех типов данных, в отличие от частичной загрузки данных, описанной выше относительно Фиг.15, которая работает на макроуровне типов данных. При модульной загрузке клиентская прикладная программа выбирает конкретные критерии, согласно которым загружается каждый элемент данных. В одном примерном варианте осуществления клиентская прикладная программа предоставляет функцию обратного вызова в функциональный интерфейс объектной модели 1208, посредством которой объекты, которые извлекают данные локализации из файла данных локализации, определяют то, следует ли загружать каждый элемент данных. Функция обратного вызова использует критерии для выбора данных, задаваемые посредством клиентской прикладной программы. На этапе 1610 клиентская прикладная программа открывает файл данных локализации. Способ 1600 переходит к этапу 1620, на котором функция обратного вызова предоставляется посредством клиентской прикладной программы в объект из объектной модели 1208, осуществляющей доступ к файлу данных локализации. На этапе 1630 получается элемент XML-данных. Объект использует функцию обратного вызова, предоставляемую посредством клиентской прикладной программы, для того чтобы оценить элемент XML-данных для загрузки. На этапе 1650 способ 1600 определяет на основе результатов из функции обратного вызова то, следует ли загрузить текущий элемент XML-данных. Если текущий элемент XML-данных выбран для загрузки, способ 1600 переходит к этапу 1660, на котором элемент XML-данных загружается в память, и способ переходит к этапу 1670. Если текущий элемент XML-данных не выбран для загрузки, способ 1600 переходит к этапу 1670. На этапе 1670 способ 1600 определяет то, есть ли дополнительные доступные элементы XML-данных в файле данных локализации. Если дополнительные элементы XML-данных доступны, способ 1600 переходит обратно к этапу 1630, чтобы получить следующий элемент XML-данных. В противном случае способ 1600 завершается.
Фиг.17A - это функциональная блок-схема последовательности операций примерного способа 1700 частичного сохранения данных. Способ 1700 частичного сохранения дополняет способ 1500 частичной загрузки. Клиентской прикладной программе, которая имеет данные локализации в памяти, готовые для сохранения в файле данных, может быть необходимо сохранять только часть данных. Способ 1700 частичного сохранения дает возможность клиентской прикладной программе задавать то, какие данные должны быть сохранены в файле данных. Например, клиентской прикладной программе может быть необходимо сохранять только строковые данные. Клиентская прикладная программа может указывать, что только часть строковых данных должна быть сохранена в файл данных. На этапе 1710 клиентская прикладная программа задает тип данных, которые должны быть сохранены в файл данных. На этапе 1720 данные типа, заданного посредством клиентской прикладной программы, сохраняются в файл данных. На этапе 1730 файл данных закрывается, и способ 1700 завершается.
Фиг.17B - это функциональная блок-схема последовательности операций примерного способа 1750 слияния при сохранении данных. Будь то частичная или модульная загрузка данных, описанная выше, клиентская прикладная программа имеет только часть данных, загруженных в память. Если данные в памяти клиентской прикладной программы сохраняются как есть, все данные, не загруженные изначально в память, теряются и не записываются в выходной файл данных. Чтобы предотвратить потерю данных, способ 1750 объединяет данные в памяти клиентской прикладной программы с данными из файла данных, которые не загружены изначально в память клиентской прикладной программы. Чтобы сохранить модификации, выполненные посредством клиентской прикладной программы с загруженными данными, копия памяти данных, общая и для файла данных, и для памяти клиентской прикладной программы, сохраняется. На этапе 1760 исходный файл данных, из которого данные локализации загружены посредством клиентской прикладной программы, открывается. На этапе 1770 из файла данных получают следующий доступный XML-элемент. На этапе 1780 способ 1750 определяет то, существует ли текущий XML-элемент, полученный из файла данных, также в памяти клиентской прикладной программы. Если текущий XML-элемент существует в памяти, копия памяти XML-элемента сохраняется в файле данных на этапе 1785. Далее способ 1750 переходит к этапу 1790. На этапе 1780, если текущий XML-элемент не существует в памяти, текущий XML-элемент, не загруженный первоначально, остается немодифицированным и, следовательно, не должен быть сохранен в файле данных снова. В этом случае способ 1750 переходит к этапу 1790. На этапе 1790 способ 1750 определяет то, есть ли дополнительные XML-элементы, оставшиеся в файле данных. Если есть оставшиеся дополнительные элементы XML-данных, способ 1750 переходит обратно к этапу 1770, чтобы получить следующий элемент XML-данных. В противном случае способ 1750 завершается.
Фиг.18 - это функциональная блок-схема последовательности операций примерного способа 1800 модульного сохранения данных. Способ 1800 модульного сохранения дополняет способ 1600 модульной загрузки. Аналогично способу 1600 модульной загрузки, способ 1800 модульного сохранения указывает то, должен ли каждый элемент данных быть сохранен или нет. В одном варианте осуществления клиентская прикладная программа задает данные, которые должны быть сохранены, на точном модульном уровне, включающем в себя все типы данных, такие как строковые данные и двоичные данные. Модульное сохранение данных выполняется на мелкомодульном уровне в рамках всех типов данных, в отличие от частичного сохранения данных, описанного выше относительно Фиг.17A, которое работает на макроуровне типов данных. При модульном сохранении клиентская прикладная программа выбирает конкретные критерии, согласно которым сохраняется каждый элемент данных. В одном примерном варианте осуществления клиентская прикладная программа предоставляет функцию обратного вызова в функциональный интерфейс объектной модели 1208, посредством которой объекты, которые сохраняют данные локализации в файл данных локализации, определяют то, следует ли загружать каждый элемент данных. Функция обратного вызова использует критерии для выбора данных, задаваемые посредством клиентской прикладной программы. Способ 1800 переходит к этапу 1810, на котором функция обратного вызова предоставляется посредством клиентской прикладной программы в объект из объектной модели 1208, осуществляющей доступ к файлу данных локализации. На этапе 1820 элемент XML-данных получают из памяти клиентской прикладной программы. На этапе 1830 объект использует функцию обратного вызова, предоставляемую посредством клиентской прикладной программы, для того чтобы оценить элемент XML-данных для сохранения. На этапе 1840 способ 1800 определяет на основе результатов из функции обратного вызова то, следует ли сохранить текущий элемент XML-данных. Если текущий элемент XML-данных выбран для сохранения, способ 1800 переходит к этапу 1850, на котором элемент XML-данных сохраняется в файл данных, и способ переходит к этапу 1860. Если текущий элемент XML-данных не выбран для сохранения, способ 1800 переходит к этапу 1860. На этапе 1860 способ 1800 определяет то, есть ли дополнительные доступные элементы XML-данных в памяти. Если дополнительные элементы XML-данных доступны, способ 1800 переходит обратно к этапу 1820, чтобы получить следующий элемент XML-данных. В противном случае способ 1800 завершается.
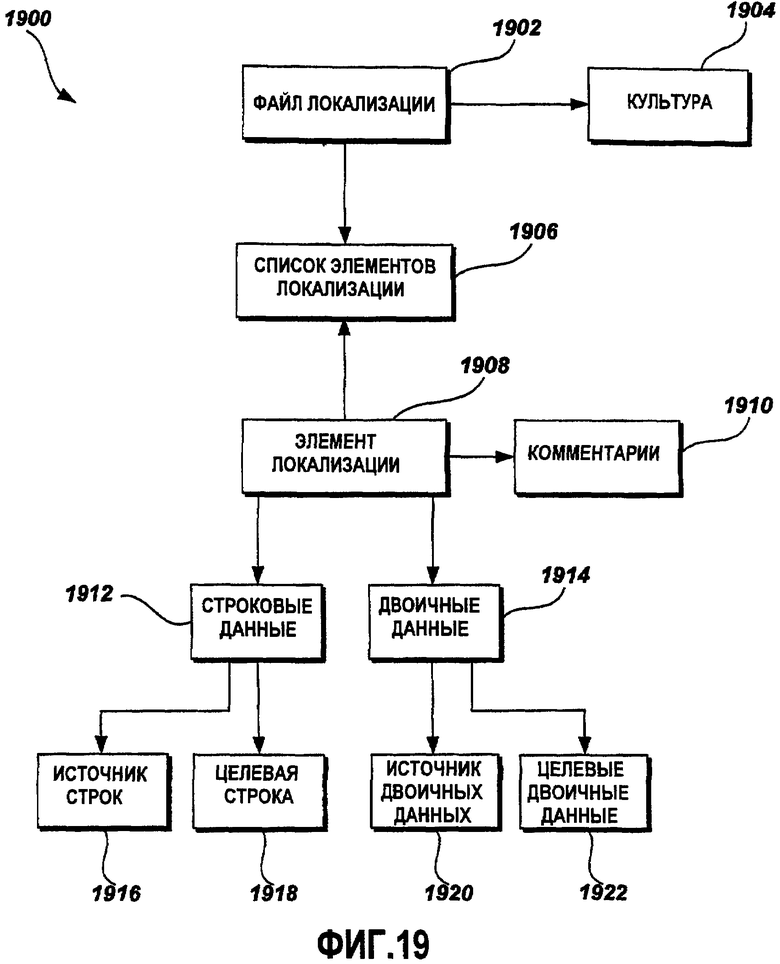
ФИГ.19 - это графическая схема примерной объектной модели 1900 локализации. Как указано выше, специалисты в данной области техники должны признавать, что объектная модель - это абстрактное представление взаимосвязей различных типов объектов, или классов (абстрактное представление объектов), в программной системе. Объектная модель может быть использована для того, чтобы представлять взаимосвязи наследования, а также взаимосвязи включения между объектами. Объектная модель 1900 предоставляет спецификацию по типам объектов и взаимосвязям, которые разрешают базовые функции ввода-вывода относительно данных в файлах данных локализации, создаваемых на основе XML-схемы 1202 локализации. Как описано выше, специалисты в данной области техники должны признавать, что объектная модель 1900 может применяться к другим типам схем данных, и пояснение примерной XML-схемы локализации не должно рассматриваться как ограничивающее изобретение. Объектная модель 1900 предоставляет разделение и слияние файлов данных локализации. Дополнительно, объектная модель 1900 предоставляет возможность добавления информации об источнике и описания комментариев. Объектная модель 1900 дополнительно предоставляет возможность включения эталонных переводов, чтобы предоставить помощью в процессе локализации. Как описано выше относительно Фиг. 12, объектная модель 1900 близко соответствует XML-схеме 1202 локализации. Т.е. каждый класс в объектной модели 1900 соответствует одному элементу в XML-схеме 1202 локализации. Соответственно, файл 1902 локализации - это класс, который представляет файл данных локализации на основе XML-схемы 1202 локализации. Класс 1902 файла локализации включает в себя класс 1904 культуры и класс 1906 списка элементов локализации. Класс 1906 списка элементов локализации 1906 включается в класс 1908 элементов локализации. В одном варианте осуществления класс 1906 списка элементов локализации является линейным списком, в отличие от иерархической структуры, дающей возможность простого разделения файла 404 данных локализации на частичные файлы 406 данных и слияния частичных файлов 406 данных обратно в файл 408 данных локализации. Класс 1908 элементов локализации - это центральный класс в объектной модели 1900, с которым связано большинство других классов в объектной модели 1900. В одном варианте осуществления класс 1908 элементов локализации включает в себя родительский ресурс, файл локализации, идентификатор ресурса, список элементов локализации (описан ниже) для порожденных элементов локализации, класс строковых данных (описан ниже), класс двоичных данных (описан ниже) и список комментариев (описан ниже).
Класс 1908 элементов локализации дополнительно включает в себя класс 1910 комментариев. В одном варианте осуществления класс 1910 комментариев - это часть класса списка комментариев. Класс 1908 элементов локализации также включает в себя класс 1912 строковых данных и класс 1914 двоичных данных. Класс 1912 строковых данных включает в себя класс 1916 источников строк и класс 1918 целевых строк. Класс 1916 источников строк предоставляет необработанную строку и другие свойства строки. Класс 1918 целевых строк включает в себя информацию локализации для строки. Класс 1914 двоичных данных включает в себя класс 1920 источников двоичных данных и целевых двоичных данных 1922. Класс 1920 источников двоичных данных предоставляет массив необработанных двоичных битов и других двоичных свойств. Класс 1922 целевых двоичных данных предоставляет информацию состояния двоичных данных. В другом варианте осуществления объектная модель 1900 может включать в себя другие классы, такие как класс информации отображения и класс идентификаторов ресурсов, включенные в класс 1908 элементов локализации. В примерном варианте осуществления класс 1912 строковых данных и класс 1914 двоичных данных включают в себя класс эталонных строк и класс эталонных двоичных данных (не показаны). Эталонный класс предоставляет информацию об эталонном языке, который может быть использован для того, чтобы предоставлять дополнительную информацию для перевода строковых и двоичных данных с исходного языка на целевой язык.
Фиг.20 - это функциональная блок-схема последовательности операций примерного способа 2000 создания и предоставления файла данных локализации. На этапе 2010 создается новый файл данных локализации. На этапе 2020 элемент локализации добавляется в файл данных локализации. На этапе 2040 способ определяет, остались ли еще элементы локализации, которые должны быть добавлены в файл данных локализации. Если дополнительные элементы локализации остались, способ 2000 переходит к этапу 2020, на котором элемент локализации добавляется в файл данных локализации. В противном случае способ 2000 переходит к этапу 2060, на котором файл данных локализации сохраняется.
Фиг.21 - это функциональная блок-схема последовательности операций примерного способа 2100 добавления комментариев в элемент локализации. Способ 2100 требует входной информации от клиентской прикладной программы для того, чтобы идентифицировать элемент локализации, в который должен быть добавлен комментарий. Как описано выше, команды для локализации могут быть осуществлены в комментариях, которые ассоциативно связаны с элементами локализации. На этапе 2110 файл данных локализации открывается. На этапе 2120 способ 2100 проверяет права на владение комментариями клиентской прикладной программы, которая пытается добавить комментарии в элемент локализации. Если клиентская прикладная программа не владеет типом комментария, добавленным в элемент локализации, способ 2100 переходит к этапу 2170, на котором файл данных локализации закрывается. Если клиентская прикладная программа владеет типом комментария, способ 2100 переходит к этапу 2130, на котором создается новый комментарий. На этапе 2140 атрибуты имени и значения комментария задаются равными требуемым значениям. На этапе 2150 комментарий добавляется в элемент локализации. Способ 2100 переходит к этапу 2160, на котором файл сохраняется. На этапе 2170 файл закрывается, и способ 2100 завершается.
Фиг.22 - это функциональная блок-схема последовательности операций примерного способа 2200 удаления файлов. Все данные, которые не должны быть сохранены в файл данных локализации, удаляются из памяти клиентской прикладной программы до сохранения данных. В одном варианте осуществления способ 2200 удаляет все элементы локализации, которые не содержат комментариев. Двоичная информация и строки удаляются из всех остальных элементов локализации. В одном варианте осуществления используется рекурсивный способ, который включает в себя порожденный элемент локализации в качестве ввода. Рекурсивный способ удаляет всю двоичную и строковую информацию из порожденного элемента локализации. Возвращаемое значение FALSE из вызова в рекурсивный способ подразумевает то, что порожденный элемент локализации, предоставленный в качестве ввода в рекурсивный способ, и все потомки порожденного элемента локализации не имеют комментариев, и порожденный элемент локализации и все потомки порожденного элемента локализации удаляются. На этапе 2210 осуществляется доступ к порожденному элементу локализации. На этапе 2220 способ 2200 определяет то, включает ли порожденный элемент комментарии. Если порожденный элемент имеет комментарии, способ 2200 переходит к этапу 2230, на котором отбрасываются двоичные и строковые данные порожденного элемента локализации. Если порожденный элемент не имеет комментариев, то порожденный элемент удаляется на этапе 2240. На этапе 2230 способ 2200 переходит к этапу 2250. На этапе 2240 способ 2200 переходит к этапу 2250, на котором определяется то, остались ли еще порожденные элементы локализации. Если дополнительные порожденные элементы локализации остались, способ 2200 переходит к этапу 2210, на котором осуществляется доступ к следующему порожденному элементу локализации для оценки. В противном случае способ 2200 завершается.
Хотя проиллюстрирован и описан в данный момент предпочитаемый вариант осуществления изобретения, специалистам в данной области техники следует принимать во внимание, что различные изменения могут выполняться в нем без отступления от сущности и области применения изобретения. Например, хотя системы и способы, описанные выше, направлены на данные локализации с помощью XML-схемы, другие спецификации форматов данных могут быть использованы. Таким образом, изобретение не должно рассматриваться как ограниченное примерными вариантами осуществления, описанными выше.
| название | год | авторы | номер документа |
|---|---|---|---|
| ХРАНИЛИЩЕ ДАННЫХ ДЛЯ ДОКУМЕНТОВ ПРОГРАММНОГО ПРИЛОЖЕНИЯ | 2006 |
|
RU2398274C2 |
| УПРАВЛЯЕМАЯ СРЕДА ВЫПОЛНЕНИЯ ДЛЯ ОРГАНИЗАЦИИ ВЗАИМОДЕЙСТВИЯ МЕЖДУ ПРОГРАММНЫМИ ПРИЛОЖЕНИЯМИ | 2007 |
|
RU2459238C2 |
| ПРОГРАММИРУЕМАЯ ОБЪЕКТНАЯ МОДЕЛЬ ДЛЯ ПОДДЕРЖКИ БИБЛИОТЕКИ ПРОСТРАНСТВ ИМЕН ИЛИ СХЕМ В ПРОГРАММНОМ ПРИЛОЖЕНИИ | 2004 |
|
RU2371759C2 |
| ПРОГРАММИРУЕМОСТЬ ДЛЯ ХРАНИЛИЩА XML ДАННЫХ ДЛЯ ДОКУМЕНТОВ | 2006 |
|
RU2417420C2 |
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
| ФОРМАТЫ ФАЙЛОВ, СПОСОБЫ И КОМПЬЮТЕРНЫЕ ПРОГРАММНЫЕ ПРОДУКТЫ ДЛЯ ПРЕДСТАВЛЕНИЯ ПРЕЗЕНТАЦИЙ | 2005 |
|
RU2400816C2 |
| МЕХАНИЗМ ДЛЯ ПРЕДУСМОТРЕНИЯ ВЫВОДА УПРАВЛЯЕМОЙ ДАННЫМИ КОМАНДНОЙ СТРОКИ | 2004 |
|
RU2351976C2 |
| СИСТЕМА И СПОСОБ ДЕКЛАРАТИВНОГО ОПРЕДЕЛЕНИЯ И ИСПОЛЬЗОВАНИЯ ПОДКЛАССОВ ВНУТРИ РАЗМЕТКИ | 2003 |
|
RU2347269C2 |
| МЕТОД ПОСТРОЕНИЯ КОРПУСА ТЕКСТОВ НА ОСНОВЕ ИНТЕРНЕТ-ФОРУМОВ | 2013 |
|
RU2565473C2 |

Изобретение относится к способам и устройствам для локализации данных, включенных в прикладные программы. Технический результат заключается в упрощении локализации программ на естественных языках. Машиночитаемые компоненты содержат элементы данных, задаваемые посредством схемы программных данных; элемент данных репозитория свойств для сохранения множества свойств данных об элементах данных; и элемент данных собственных комментариев, содержащий информацию о локализации данных, включенных в прикладные программы, и владельце с разрешением создавать, осуществлять доступ и обрабатывать элемент данных собственных комментариев. 3 н. и 17 з.п. ф-лы, 22 ил.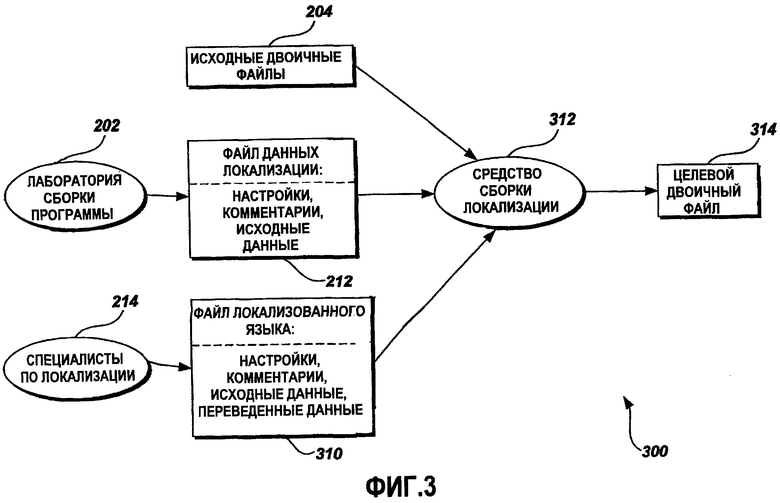
1. Машиночитаемый носитель, имеющий машиночитаемые инструкции, которые при выполнении их компьютером выполняют способ локализации данных, включенных в программы программного обеспечения, при этом способ содержит этапы:
определение элементов данных локализации, используя схему программных данных, причем по меньшей мере один элемент данных локализации из упомянутых элементов данных локализации включает в себя элемент данных репозитория свойств для сохранения множества свойств данных об этих элементах данных локализации;
определение элемента данных собственных комментариев, используя формат данных собственных комментариев в упомянутой схеме программных данных, при этом элемент данных собственных комментариев используется для генерирования комментариев для упомянутого по меньшей мере одного элемента данных локализации, причем комментарии содержат информацию о локализации данных, включенных в упомянутые программы программного обеспечения, при этом элемент данных собственных комментариев содержит информацию о владельце элемента данных собственных комментариев с разрешением создавать, осуществлять доступ и манипулировать элементом данных собственных комментариев, при этом элемент данных собственных комментариев включает в себя множество элементов комментария, причем каждый элемент комментария содержит по меньшей мере атрибут имени, используемый для ссылки на этот элемент комментария, и атрибут разрешения, указывающий, разрешен или запрещен упомянутый элемент комментария, и при этом, когда более чем один владелец, каждый имеющий список владения типов элементов данных комментария, требуют владения некоторым элементом, получающийся конфликт владения разрешается;
обработку по меньшей мере одного исходного файла из данных, включенных в программы программного обеспечения, и по меньшей мере одного элемента данных локализации, используя комментарии, сгенерированные для упомянутого по меньшей мере одного элемента данных локализации, чтобы получить по меньшей мере один локализованный файл.
2. Машиночитаемый носитель по п.1, в котором схема программных данных является схемой расширяемого языка разметки (XML).
3. Машиночитаемый носитель по п.1, в котором по меньшей мере два из элементов данных образуют иерархию с родительским элементом данных из упомянутых по меньшей мере двух элементов данных, размещенным выше в иерархии, чем по меньшей мере один порожденный элемент данных родительского элемента данных.
4. Машиночитаемый носитель по п.1, в котором элемент данных собственных комментариев содержит команды, связанные с локализацией данных, включенных в программы программного обеспечения для по меньшей мере одного средства локализации программного обеспечения.
5. Машиночитаемый носитель по п.1, в котором элемент данных собственных комментариев включает в себя описание элемента данных собственных комментариев и информацию об источнике элемента данных собственных комментариев.
6. Машиночитаемый носитель по п.1, в котором комментарии для упомянутого по меньшей мере одного элемента данных локализации генерируются программой программного обеспечения или пользователем этой программы программного обеспечения, причем способ дополнительно содержит верификацию, что программа программного обеспечения является владельцем элемента данных собственных комментариев.
7. Машиночитаемый носитель, хранящий множество машиночитаемых инструкций, которые при выполнении компьютером выполняют способ локализации данных, включенных в программы программного обеспечения, при этом множество машиночитаемых инструкций содержит:
инструкции для разделения линейного списка элементов данных локализации, которые задают информацию локализации в файле локализованных данных, на множество частичных файлов данных, и после того как элементы данных в каждом из множества частичных файлов данных обработаны по отдельности, для слияния упомянутых частичных файлов данных обратно в единый файл данных локализации, при этом элементы данных локализации задаются с использованием схемы данных программного обеспечения, и при этом по меньшей мере один элемент данных локализации из элементов данных локализации включает в себя элемент данных репозитория свойств для сохранения множества свойств данных об этом элементе данных локализации;
инструкции для генерирования комментариев для упомянутого по меньшей мере одного элемента данных локализации из элементов данных локализации, используя элемент данных собственных комментариев, определенный с использованием схемы программных данных, и содержащих информацию о локализации данных, включенных в упомянутые программы программного обеспечения, и информацию о владельце элемента данных собственных комментариев с разрешением создавать, осуществлять доступ и манипулировать элементом данных собственных комментариев, при этом элемент данных собственных комментариев включает в себя множество элементов комментария, причем каждый элемент комментария содержит по меньшей мере атрибут имени, используемый для ссылки на этот элемент комментария, и атрибут разрешения, указывающий, разрешен или запрещен упомянутый элемент комментария, и при этом попытка добавить новый комментарий к по меньшей мере одному элементу данных локализации приводит к созданию нового комментария только когда верифицировано, что этот новый комментарий добавляется владельцем, владеющим типом нового комментария;
инструкции для обработки по меньшей мере одного исходного файла из данных, включенных в программы программного обеспечения, и упомянутого по меньшей мере одного элемента данных локализации, используя комментарии, сгенерированные для упомянутого по меньшей мере одного элемента данных локализации, чтобы получить по меньшей мере один локализованный файл.
8. Машиночитаемый носитель по п.7, в котором схема программных данных является схемой расширяемого языка разметки (XML).
9. Машиночитаемый носитель по п.7, в котором по меньшей мере два из элементов данных локализации образуют иерархию с родительским элементом данных, размещенным выше в иерархии, чем по меньшей мере один порожденный элемент данных.
10. Машиночитаемый носитель по п.7, в котором элемент данных собственных комментариев содержит команды, связанные с локализацией данных, включенных в программы программного обеспечения для по меньшей мере одного из программного средства локализации и оператора-человека.
11. Машиночитаемый носитель по п.7, в котором элемент данных собственных комментариев включает в себя описание элемента данных собственных комментариев и информацию об источнике элемента данных собственных комментариев.
12. Машиночитаемый носитель по п.7, в котором каждый элемент комментария из множества элементов комментария дополнительно содержит атрибут значения, соответствующий атрибуту имени.
13. Машиночитаемый носитель по п.7, содержащий инструкции для генерирования комментариев для по меньшей мере одного исходного файла, используя элемент данных собственных комментариев, содержащий информацию комментария о локализации данных, включенных в упомянутые программы программного обеспечения, и информацию о владельце элемента данных собственных комментариев с разрешением создавать, осуществлять доступ и манипулировать элементом данных собственных комментариев, при этом элемент данных собственных комментариев включает в себя множество элементов комментария, каждый содержащий по меньшей мере атрибут имени.
14. Машиночитаемый носитель, имеющий набор программных объектов, сохраненных в нем, для выполнения, при исполнении их процессором, способа локализации программ программного обеспечения, при этом способ содержит:
обработку по меньшей мере одного исходного файла из программ программного обеспечения и по меньшей мере одного программного объекта из множества программных объектов, созданных с использованием соответствующего класса, в объектной модели для данных локализации, используя информацию комментария, сгенерированную для упомянутого по меньшей мере одного программного объекта, чтобы сформировать по меньшей мере один локализованный файл, причем упомянутый один программный объект содержит:
данные и инструкции; и
объект файла данных локализации, содержащий список объектов элементов локализации, причем каждый объект элементов локализации, созданный с использованием класса элементов локализации в объектной модели, содержит:
объект комментариев, созданный с использованием класса комментариев в упомянутой объектной модели и содержащий информацию комментария о локализации программ программного обеспечения, при этом объект комментариев включает в себя по меньшей мере атрибут имени, используемый для ссылки на объект комментария, и атрибут разрешения, указывающий, разрешен или запрещен упомянутый объект комментария;
объект строковых данных, созданный с использованием класса строковых данных в объектной модели, для сохранения компьютерной текстовой информации; и
объект двоичных данных, созданный с использованием класса двоичных данных в объектной модели, для сохранения двоичной информации;
при этом каждый класс в объектной модели соответствует структуре данных, заданной посредством схемы программных данных, и при этом каждый программный объект используется для того, чтобы осуществлять доступ и манипулировать данными, сохраненными в соответствующей структуре данных, заданной посредством схемы программных данных.
15. Машиночитаемый носитель по п.14, в котором каждый из программных объектов содержит программный класс на объектно-ориентированном компьютерном языке.
16. Машиночитаемый носитель по п.14, в котором схема программных данных является схемой расширяемого языка разметки (XML).
17. Машиночитаемый носитель по п.14, в котором по меньшей мере один из программных объектов сохраняет заранее выбранные данные в соответствующей структуре данных, и при этом упомянутые заранее выбранные данные заранее выбираются по меньшей мере одной программой программного обеспечения из упомянутых программ программного обеспечения.
18. Машиночитаемый носитель по п.14, в котором по меньшей мере два из программных объектов связаны друг с другом как родительский и порожденный объекты, при этом по меньшей мере один порожденный объект содержит объект, включенный в родительский объект или получен из родительского объекта.
19. Машиночитаемый носитель по п.18, в котором упомянутый по меньшей мере один порожденный объект включает в себя обратный указатель на родительский объект.
20. Машиночитаемый носитель по п.14, в котором класс строковых данных содержит:
класс источников строк, содержащий по меньшей мере одну необработанную строку и множество свойств строк, и
класс целевых строк, содержащий информацию локализации для упомянутой по меньшей мере необработанной одной строки, и причем класс двоичных данных содержит:
класс источников двоичных данных, содержащий множество необработанных двоичных байтов и множество двоичных свойств, и класс целевых двоичных данных, содержащий информацию состояния двоичных данных.
| US 5960198, 28.09.1999 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| EP 1302867 A2, 16.04.2003 | |||
| RU 2004105880 A, 10.08.2005. | |||

