Изобретение относится к вычислительной технике и может использоваться в качестве источника информации для слепых и слабовидящих людей, а также в качестве средства для обучения русскому языку.
Для людей, потерявших зрение или с отсутствием зрения, одной из важных проблем является задача самостоятельного получения информации, так как такие обычные источники информации, как книги, журналы и др. для них недоступны, специальная информация вообще отсутствует, а периодические источники информации из-за нерегулярного перевода становятся для них непериодическими.
Известное средство для получения незрячими информации в виде печатной продукции с использованием рельефно-точечной системы Брайля [1] обладает определенными недостатками. Такие книги занимают большой объем из-за рельефной печати, легко повреждаются при хранении и при чтении из-за механического контакта, кроме того, номенклатура их минимальна по сравнению с обычной печатной продукцией, не говоря уже об оперативности получения информации. Наконец, число незрячих, владеющих системой Брайля, имеет тенденцию к сокращению.
Другим известным средством для получения информации незрячими является так называемая "говорящая книга", представляющая собой магнитную ленту, на которую записаны тексты книг, журналов, газет и др. [2].
Достоинствами такого средства является то, что при восприятии речевой информации человек меньше устает, быстрее реагирует, при этом скорость обмена информацией существенно выше, чем при тактильном способе. При несомненных достоинствах этого устройства обмена информацией его отличает низкая оперативность, из-за чего слабо удовлетворяются индивидуальные запросы незрячего пользователя, особенно в области, связанной с профессиональной деятельностью, поскольку имеется только массовая, широко используемая продукция и отсутствует специальная информация, при этом не отслеживается новейшая и последняя информация.
Наиболее близким к изобретению является устройство, использующее персональный компьютер с оптико-механическим блоком чтения плоско-печатного текста и программируемым синтезатором речи [3].
Можно отметить довольно высокую натуральность и разборчивость синтезированной речи на уровне отдельных слов и значительное ухудшение этих показателей при синтезе слитной речи, когда возникают заметные паразитные звуковые эффекты. Кроме того, синтез осуществляется по строкам текста, а при таком подходе невозможно адекватно сформировать мелодический контур, поскольку он определяет интонацию фраз и синтагм, а строка прозаического текста содержит фрагменты одной или нескольких синтагм, т.е. синтезированная речь звучит "механически".
Независимо от качества иноязычные синтезаторы речи для чтения русскоязычных текстов непригодны. При синтезе речи на русском языке возникает много проблем, которые связаны со сложностью грамматики и фонетики русского языка, происходящего от кириллицы, и являются самыми сложными в мировой практике, так как требуют учета очень большого количества факторов, как ни в одном другом языке. Имевшие место до настоящего времени попытки создания таких устройств не решили данную задачу, так как эти устройства не удовлетворяли требованиям по качеству воспринимаемого сигнала, и все созданные варианты были отвергнуты потенциальными пользователями-слепыми.
Технической задачей изобретения является разработка компьютерного устройства для чтения плоскопечатного текста: осуществляющего считывание и звуковое воспроизведение печатного текста в реальном масштабе времени с высоким качеством синтезированной русской "славянской" речи за счет обеспечения ее натуральности и разборчивости фонемной, слоговой и словесной.
Поставленная задача решается в устройстве для чтения плоскопечатного текста, содержащем последовательно соединенные блок оптического ввода плоскопечатного текста и блок оптического распознавания текста, блок синтеза речи по орфографическому тексту, блок формирования аудиосигнала и оконечный блок, в котором согласно изобретению блок оптического ввода плоскопечатного текста выполнен в виде сканера, блок формирования аудиосигнала выполнен в виде звуковой платы, блок синтеза речи по орфографическому тексту выполнен в виде блока синтеза русской речи по орфографическому тексту, а также дополнительно введены блок унификации текстового файла, блок текстовой базы данных, тактильный дисплей, блок сопряжения тактильного дисплея с персональным компьютером и блок интерфейса, при этом выход блока оптического распознавания текста через последовательно соединенные блок унификации текстового файла и блок текстовой базы данных соединен с информационным входом блока синтеза речи по орфографическому тексту, а через блок сопряжения - с входом тактильного дисплея, выход блока синтеза русской речи по орфографическому тексту через звуковую плату соединен с оконечным аудиоблоком, управляющие входы блоков сопряжения тактильного дисплея и сканера, блок оптического распознавания текста, блок унификации текстового файла, блока синтеза русской речи по орфографическому тексту и блока текстовой базы данных соединены с соответствующими выходами блока интерфейса.
При этом блок унификации текстового файла может быть выполнен в виде последовательно соединенных блока распознавания многоколоночного текста, блока переформатирования текстового файла в одноколоночный, блока распознавания левых и правых границ текста, блока распознавания красных строк, блока выделения абзацев, блока исключения символов метаязыка, не входящих в допустимый алфавит, блока ликвидации переносов слов и блока переформатирования текстового файла.
Блок синтеза русской речи по орфографическому тексту может быть выполнен в виде блока компиляционного синтеза речи и содержащего последовательно соединенные блок выбора текущего абзаца, блок чтения текущего абзаца, блок предварительного синтаксического анализа абзаца, блок выделения слов в абзаце, селектор подслов на подмножествах алфавита метаязыка, блок распознавания слов на русском алфавите, первый блок ИЛИ, блок контекстной расшифровки сокращений слов, блок согласования, блок выделения фраз и синтагм, блок определения коммуникативного типа фраз и синтагм, блок определения логического ударения, блок фонетического транскрибирования текста, временной процессор, мелодический процессор, блок компиляции, блок формирования звукового файла и блок вывода звукового файла.
Блок предварительного синтаксического анализа абзаца может содержать последовательно соединенные селектор знаков пунктуации, коммутатор, блок вербализации знаков пунктуации и второй блок ИЛИ, при этом второй выход коммутатора через последовательно соединенные блок контекстного анализа пунктуационных знаков, блок устранения ненаходящих отражения в устной речи пунктуационных знаков, блок устранения графических пунктуационных фикций и блок вербализации знаков точки, запятой и тире в записи чисел подключен к второму входу второго блока ИЛИ, а управляющие вход коммутатора является управляющим входом блока предварительного синтаксического анализа.
Блок распознавания слов на русском алфавите содержит последовательно соединенные блок преобразования символьных кодов к одному регистру, селектор слов, включающих пунктуационные знаки, первый селектор слов-сокращений и третий блок ИЛИ, второй выход первого селектора слов-сокращений через последовательно соединенные четвертый блок ИЛИ, блок морфологического анализа, блок восстановления графемы "йо", селектор аббревиатур и блок расшифровки аббревиатур подключен к второму входу третьего блока ИЛИ, второй выход селектора аббревиатур через последовательно соединенные блок определения части речи и блок расстановки ударений подключен к третьему входу третьего блока ИЛИ, второй выход селектора слов, включающих пунктуационные знаки, через второй селектор слов-сокращений подключен к четвертому входу третьего блока ИЛИ, второй выход второго селектора слов-сокращений через блок исключения дефиса подключен к второму входу четвертого блока ИЛИ, третий выход селектора слов, включающих пунктуационные знаки, через блок исключения апострофа подключен к третьему входу четвертого блока ИЛИ, четвертый вход которого соединен с четвертым выходом селектора слов, содержащих пунктуационные знаки, выход третьего блока ИЛИ является выходом блока распознавания слов на русском алфавите.
Блок морфологического анализа содержит блоки памяти для префиксов, основ и флексий, реализованные в виде соответствующей базы данных, при этом блок морфологического анализа выполнен реализующим алгоритм решения соответствующего уравнения.
Блок расстановки ударений содержит последовательно соединенные селектор распознанных слов, блок определения ударного слога и пятый блок ИЛИ.
Блок трансляции слов метаязыка в слова на русском алфавите содержит последовательно соединенные селектор подмножеств алфавита метаязыка, шестой блок ИЛИ, блок вербализации арабской цифровой записи чисел и седьмой блок ИЛИ, второй выход селектора подмножеств алфавита метаязыка через последовательно соединенные селектор латинских цифр и блок преобразования латинской записи чисел в арабскую соединен с вторым входом шестого блока ИЛИ, второй выход блока преобразования латинской записи чисел в арабскую через последовательно соединенные восьмой блок ИЛИ и блок русификации слов латинского алфавита соединен с вторым входом седьмого блока ИЛИ, второй выход селектора латинских цифр соединен с вторым входом восьмого блока ИЛИ, третий вход которого соединен с третьим выходом селектора подмножеств алфавита метаязыка, четвертый выход которого через блок вербализации знаков алфавита метаязыка соединен с третьим входом седьмого блока ИЛИ, выход которого является выходом блока трансляции слов метаязыка в слова русского алфавита.
Блок выделения фаз и синтагм выполнен реализующим алгоритм выделения фраз путем разбиения абзаца на лексемы, отделенные символами {.?} и алгоритм выделения синтагм во фразах путем разбиения фразы на лексемы, отделенные символами {,:;-}.
Блок определения коммуникативного типа фраз и синтагм содержит последовательно соединенные селектор вопросительных фраз, блок определения синтагмы, содержащей вопрос, девятый блок ИЛИ и блок определения коммуникативного типа синтагм, второй выход селектора вопросительных фраз соединен со вторым входом девятого блока ИЛИ.
Блок определения коммуникативного типа синтагмы выполнен реализующим алгоритм определения следующих коммуникативных типов: завершенность, соответствующая синтагмам, завершающимся знакам { .:;}, первый и второй типы незавершенности, соответствующие синтагмам, завершающимся соответственно знаками {,-}, общий и частный вопросы для синтагм, завершающихся знаком {?} и соответственно не содержащих или содержащих вопросительное слово, а также синтагмы с акцентом, содержащие знак логического выделения на выделяемом слове.
Блок определения логического ударения содержит последовательно соединенные селектор логически выделенных слов и десятый блок ИЛИ, второй выход селектора логически выделенных слов через последовательно соединенные селектор слов, содержащих частный вопрос, и одиннадцатый блок ИЛИ подключен к второму входу десятого блока ИЛИ, второй выход селектора слов, содержащих частный вопрос, через селектор семантически значимых слов подключен к второму входу одиннадцатого блока ИЛИ, а второй выход селектора семантически значимых слов через блок определения последнего знаменательного слова синтагмы подключен к третьему входу одиннадцатого блока ИЛИ, выход десятого блока ИЛИ является выходом блока определения логического ударения.
Блок фонетического транскрибирования текста содержит последовательно соединенные блок устранения орфографических фикций, блок преобразования буквенной записи в фонетическую и блок формирования слитной речи.
Блок устранения орфографических фикций содержит последовательно соединенные блок устранения орфографических фикций в окончаниях слов, блок исключения непроизносимых согласных, блок замены сочетаний согласных эквивалентной буквенной записью и блок преобразования записи слов с твердым произношением "е".
Блок преобразования буквенной записи в фонетическую содержит последовательно соединенные селектор служебных слов, блок ликвидации ударений в служебных словах, блок ассимиляции служебных слов, двенадцатый блок ИЛИ, блок транскрибирования контекстов с мягким знаком, блок транскрибирования контекстов с твердым знаком, блок определения мягкости согласных перед маркированными гласными, блок транскрибирования йотированных гласных в начале синтагмы, блок транскрибирования йотированных гласных в позиции после гласной, блок транскрибирования непарных мягких согласных, блок определения звонкости-глухости согласных в сочетаниях согласных, блок оглушения шумных звонких согласных в конце синтагмы, блок ассимиляции твердых согласных перед мягкими, блок транскрибирования двойных согласных, селектор слабоударных слов, блок определения степени редукции гласных в словах с ударением, блок замены гласных первой степени редукции, тринадцатый блок ИЛИ и блок замены гласных второй степени редукции, второй выход селектора служебных слов через блок замены ударений в слабоударных словах соединен со вторым входом двенадцатого блока ИЛИ, а третий выход - с третьим входом двенадцатого блока ИЛИ, второй выход селектора слабоударных слов через блок определения степени редукции в слабоударных словах соединен со вторым входом тринадцатого блока ИЛИ.
Блок формирования слитной речи выполнен реализующим соответствующий алгоритм.
Блок определения степени редукции гласных выполнен реализующим алгоритм, в котором первая степень редукции, или вторая степень выделенности соответствует гласным в позициях первого предударного слога, в безударных позициях в конце синтагмы, в открытом конце слова, если следующее слово начинается с ударного слога и позиции после гласной, а вторая степень редукции, или первая степень выделенности - гласным во всех остальных безударных позициях, третья степень выделенности соответствует гласным в ударных позициях кроме последнего ударного слога синтагмы, гласному которого соответствует четвертая степень выделенности.
Блок замены гласных первой степени редукции выполнен реализующим алгоритм контекстной замены редуцированных безударных гласных первой степени редукции путем соответствующих подстановок.
Блок определения степени редукции гласных в слабоударных словах выполнен реализующим алгоритм редуцирования псевдоударного гласного в слабоударных словах до первой степени редукции.
Блок замены гласных второй степени редукции выполнен реализующим алгоритм контекстной замены редуцированных безударных гласных второй степени редукции путем соответствующих подстановок.
Временной процессор выполнен реализующим алгоритм, ставящий каждому символьному элементу фонетической записи в соответствие временной интервал, определяющий длительность соответствующего звука элемента компиляции, при этом гласные разбиты на три класса, отражающие различия в их фонетическом качестве.
Мелодический процессор содержит последовательно соединенные блок сегментирования синтагмы на слоговые фрагменты, блок определения класса слогового фрагмента и блок определения параметров закона изменения частоты основного тона для сегментов слогов.
Блок сегментирования синтагмы на слоговые фрагменты выполнен реализующим итерационный алгоритм решения соответствующих уравнений.
Блок определения класса слогового фрагмента выполнен реализующим соответствующий алгоритм, в котором слоговые фрагменты разделены на классы в зависимости от коммуникативного типа синтагмы, степени выделенности гласного слога и от совпадения слога с мелодическим центром синтагмы, совпадающим с логическим ударением синтагмы, при этом для завершенности и двух типов незавершенности выделены девять классов слогов: безударные слоги, ударные слоги со степенью выделенности гласного, равной трем, не совпадающие с мелодическим центром, последний ударный слог, не совпадающий с мелодическим центром, мелодический центр для синтагм с типом завершенности соответственно со степенью выделенности гласного n=4 и n=3, мелодический центр соответственно для синтагм с первым и вторым типами незавершенности и степенью выделенности гласного соответственно n= 3 и n= 4, для синтагм с коммуникативным типом "общий вопрос" выделены четыре класса слогов, соответственно безударные и ударные слоги - не мелодические центры с n=3, последний ударный слог - не мелодический центр, мелодический центр со степенями выделенности гласного соответственно n= 3 и n=4, а для синтагм с коммуникативным типом "частный вопрос" выделены два класса слогов - совпадающие и не совпадающие с мелодическим центром.
Блок определения параметров закона изменения частоты основного тона для сегментов слогов выполнен реализующим соответствующий алгоритм.
Блок компиляции содержит последовательно соединенные блок выделения контекста, шифратор кода элемента компиляции, блок акустико-сегментной базы синтеза, блок изменения временных и частотных характеристик элементов компиляции и блок композиции.
Блок акустико-сегментной базы синтеза выполнен в виде блока базы данных, акустико-сегментная база синтеза содержит базовые элементы компиляции в виде оцифрованных сегментов естественной речевой волны фонемной размерности - аллофонов, являющихся акустически и перцептивно различимыми контекстными реализациями фонем.
Шифратор кода элемента компиляции выполнен реализующим алгоритм формирования кода элемента компиляции.
Блок изменения временных и частотных характеристик элемента компиляции выполнен реализующим алгоритм соответствующего функционального преобразования.
Выполнение компьютерного устройства чтения плоскопечатного текста в виде последовательно соединенных блока оптического ввода плоскопечатного текста, выполненного в виде сканера, и блока оптического распознавания текста, блока компиляционного синтеза речи по орфографическому тексту, блока формирования аудиосигнала в виде звуковой платы, и оконечного сигнала, а также содержащим блок текстовой базы данных, тактильного дисплея, блока сопряжения тактильного дисплея с персональным компьютером и блока интерфейса и соответствующих связей между ними позволяет осуществлять считывание и звуковое воспроизведение с высоким качеством синтезированной речи текста, выполненного любым печатным шрифтом на русском языке.
Предложенное выполнение блока унификации текстового файла, блока синтеза русской речи по орфографическому тексту, блока предварительного синтаксического анализа абзаца, блока распознавания слов на русском алфавите, блока морфологического анализа, блока расстановки ударений, блока трансляции слов метаязыка в слова на русском алфавите, блока выделения фраз и синтагм, блока определения коммуникативного типа фраз и синтагм, блока определения коммуникативного типа синтагм, блока определения логического ударения, блока фонетического транскрибирования текста, блока устранения орфографических фикций, блока преобразования буквенной записи в фонетическую, блока формирования слитной речи, блока определения степени редукции гласных, блока замены гласных первой степени редукции, блока определения степени редукции гласных в слабоударных словах, блока замены гласных второй степени редукции, временного процессора, мелодического процессора, блока сегментирования синтагмы на слоговые фрагменты, блока определения класса слогового фрагмента, блока компиляции блока акустико-сегментной базы синтеза, шифратора кода элемента компиляции, а также блока изменения временных и частотных характеристик элемента компиляции позволяет повысить качество звукового воспроизведения синтезированной русской речи за счет обеспечения соответственно ее фонемной, слоговой и словесной разборчивости, а также ее натуральности.
На фиг. 1-14 приведены структурные электрические схемы следующих устройств и блоков: на фиг. 1 - компьютерного устройства для считывания плоскопечатного текста; на фиг. 2 - блока унификации текстового файла; на фиг. 3 - блока синтеза русской речи по орфографическому тексту; на фиг. 4 - блока предварительного синтаксического анализа абзаца; на фиг. 5 - блока распознавания слов на русском алфавите; на фиг. 6 - блока расстановки ударений; на фиг. 7 - блока трансляции слов метаязыка в слова на русском алфавите; на фиг. 8 - блока определения коммуникативного типа фраз и синтагм; на фиг. 9 - блока определения логического ударения; на фиг. 10 - блока фонетического транскрибирования текста; на фиг. 11 - блока устранения орфографических фикций; на фиг. 12 - блока преобразования буквенной записи в фонетическую; на фиг. 13 - блока мелодического процессора; на фиг. 14 - блока компиляции.
Устройство (фиг. 1) содержит блок 1 оптического ввода плоскопечатного текста, блок 2 оптического распознавания текста, блок 3 унификации текстового файла, блок 4 текстовой базы данных и блок 5 синтеза русской речи по орфографическому тексту, оконечный аудиоблок 6, блок 7 сопряжения, тактильный дисплей 8 и блок 9 интерфейса.
Блок 3 унификации текстового файла (фиг.2) содержит блок 10 распознавания многоколоночного текста, блок 11 переформатирования текстового файла в одноколоночный, блок 12 распознавания левых и правых границ текста, блок 13 распознавания красных строк, блок 14 выделения абзацев, блок 15 исключения символов метаязыка, не входящих в допустимый алфавит, блок 16 ликвидации переносов слов и блок 17 переформатирования текстового файла.
Блок 5 синтеза русской речи по орфографическому тексту (фиг.3) включает блок 18 выбора текущего абзаца, блок 19 чтения текущего абзаца, блок 20 предварительного синтаксического анализа абзаца, блок 21 выделения слов в абзаце, селектор 22 ъподслов на подмножествах алфавита метаязыка, блок 23 распознавания слов на русском алфавите, блок 24 трансляции слов метаязыка в слова на русском алфавите, первый блок ИЛИ 25, блок 26 контекстной расшифровки сокращений слов, блок 27 согласования, блок 28 выделения фраз и синтагм, блок 29 определения коммуникативного типа фраз и синтагм, блок 30 определения логического ударения в синтагмах, блок 31 фонетического транскрибирования текста, временной процессор 32, мелодический процессор 33, блок 34 компиляции, блок 35 формирования звукового файла и блок 36 вывода звукового файла.
Блок 20 предварительного синтаксического анализа абзаца (фиг.4) содержит селектор 37 знаков пунктуации, коммутатор 38, блок 39 вербализации знаков пунктуации, второй блок ИЛИ 40, блок 41 контекстного анализа пунктуационных знаков, блок 42 устранения пунктуационных фикций, селектор 43 пунктуационных знаков в записи чисел и блок 44 вербализации пунктуационных знаков в записи чисел.
Блок 23 распознавания слов на русском алфавите (фиг.5) включает блок 45 преобразования кодов прописных графем, селектор 46 слов, включающих пунктуационные знаки, первый селектор 47 словосокращений, третий блок ИЛИ 48, четвертый блок ИЛИ 49, блок 50 морфологического анализа, блок 51 восстановления графемы "йо", селектор 52 аббревиатур, блок 53 трансляции аббревиатур, блок 54 определения части речи, блок 55 расстановки ударений, второй селектор 56 слов-сокращений, блок 57 исключения дефиса и блок 58 исключения апострофа.
Блок 55 расстановки ударений (фиг.6) содержит селектор 59 распознанных слов, блок 60 определения ударного слога, пятый блок ИЛИ 61 и блок 62 определения ударного слога по эмпирическим правилам.
Блок 24 трансляции слов метаязыка в слова на русском алфавите (фиг.7) включает селектор 63 подмножеств алфавита метаязыка, шестой блок ИЛИ 64, блок 65 вербализации арабской цифровой записи чисел, седьмой блок ИЛИ 66, селектор 67 латинских цифр, блок 68 преобразования латинской записи чисел в арабскую, восьмой блок ИЛИ 69, блок 70 русификации слов латинского алфавита и блок 71 вербализации знаков алфавита метаязыка.
Блок 29 определения коммуникативного типа фраз и синтагм (фиг.8) содержит селектор 72 вопросительных фраз, блок 73 определения синтагмы, содержащей вопрос, девятый блок ИЛИ 74 и блок 75 определения коммуникативного типа синтагм.
Блок 30 определения логического ударения (фиг.9) включает селектор 76 логически выделенных слов, десятый блок ИЛИ 77, селектор 78 слов, содержащих частный вопрос, селектор 79 семантически значимых слов, блок 80 определения последнего знаменательного слова синтагмы, одиннадцатый блок ИЛИ 81 и блок 82 логического выделения.
Блок 31 фонетического транскрибирования текста (фиг.10) включает блок 83 устранения орфографических функций, блок 84 преобразования буквенной записи в фонетическую и блок 85 формирования слитной речи.
Блок 83 устранения орфографических фикций (фиг.11) включает блок 86 устранения орфографических фикций в окончаниях слов, блок 87 исключения непроизносимых согласных, блок 88 замены сочетаний согласных эквивалентной буквенной записью и блок 89 преобразования записи слов с твердым произношением "е".
Блок 84 преобразования буквенной записи в фонетическую (фиг.12) включает селектор 90 служебных слов, блок 91 ликвидации ударений в служебных словах, блок 92 ассимиляции служебных слов, двенадцатый блок ИЛИ 93, блок 94 замены ударений в слабоударных словах, блок 95 транскрибирования контекстов с мягким знаком, блок 96 транскрибирования контекстов с твердым знаком, блок 97 определения мягкости согласных перед маркированными гласными, блок 98 транскрибирования йотированных гласных в начале синтагмы, блок 99 транскрибирования йотированных гласных в позиции после гласной, блок 100 транскрибирования непарных мягких согласных, блок 101 определения звонкости-глухости согласных в сочетаниях согласных, блок 102 оглушения звонских согласных в конце синтагмы, блок 103 ассимиляции твердых согласных перед мягкими, блок 104 транскрибирования двойных согласных, селектор 105 слабоударных слов, блок 106 определения степени редукции гласных в словах с ударением, блок 107 замены гласных первой степени редукции, блок 108 определения степени редукции гласных в слабоударных словах, двенадцатый блок ИЛИ 109 и блок 110 замены гласных второй степени редукции.
Блок 33 мелодического процессора (фиг.13) содержит блок 111 сегментирования синтагмы на слоговые фрагменты, блок 112 определения класса слогового фрагмента и блок 113 определения параметров закона изменения частоты основного тона для сегментов слогов.
Блок компиляции 34 (фиг. 14) включает блок 114 выделения контекста, шифратор 115 кода элемента компиляции, блок 116 акустико-сегментной базы синтеза, блок 117 изменения временных и частотных характеристик элементов компиляции и блок композиции 118.
Устройство работает следующим образом.
По стартовому сигналу, поступающему с блока 9 интерфейса на блок 1 оптического ввода плоскопечатного текста,блок 1 начинает ввод графической информации, выполненной любым печатным шрифтом. В качестве блока оптического ввода плоскопечатного текста могут быть использованы серийно выпускаемые ручной или планшетный сканеры, например, сканеры фирмы Hewlett Packard, которые более автоматизированы и потому являются более удобны для незрячего пользователя. Для ввода книжного текста с помощью планшетного сканера необходима предварительная расшивка книги, все остальные операции по вводу осуществляются автоматически. Ручной сканер требует предварительной настройки зрячим оператором (в основном подбор яркости), имеет более узкую полосу захвата и более чувствителен к перекосу.
На выходе блока 1 появляется изображение вводимого текста в одном из графических форматов (обычно в TIFF-формате). По управляющему сигналу с блока 9 блок 2 оптического распознавания текста начинает распознавание графических символов алфавита для преобразования изображения текста в текстовый файл. Графический файл, как известно, представляет собой хранимую в оперативной или долговременной памяти матрицу изображения по элементам разрешения - пикселам. Для переносимости изображений, а также для их сжатия с целью экономии памяти используются различные стандартные форматы графических файлов - PCX, GIF,TIFF и др. Текстовый файл, как известно, представляет собой матрицу знакомест, где каждому знакоместу соответствует код некоего символа алфавита (пробел, буква, знак пунктуации, различные специальные символы).
Из разработанных систем оптического распознавания наиболее эффективны система CuneiForm фирмы Cognitive Technologies Ltd. и FineReader, разработка "Диалог-МИФИ".
Обе системы характеризуются высокой эффективностью распознавания (не более 1-3 ошибок на 1 страницы для типографского текста, текста, отпечатанного на лазерном или матричном 24-игольчатом принтерах, первого экз. машинописного текста (CuneiForm). Помимо того обеспечивает распознавание смешанных текстов (кириллица и латинский алфавит), а FineReader эффективно распознает и тексты низкого качества (например, ксерокопии, тексты, отпечатанные на 9-игольчатом матричном принтере). Блок 9 интерфейса обеспечивает интегрирование указанных систем оптического распознавания в заявленное устройство с учетом специфики незрячего пользователя.
С выхода блока 2 текстовый файл передается в блок 3 унификации текстового файла. Этот блок приводит полученный текстовый файл в соответствие с возможностями синтезатора речи, которые более ограниченны, чем возможности живого субъекта, читающего плоскопечатный текст.
Помимо знаков алфавита синтезируемого языка текст может включать различные символы метаязыка и нетекстовые вставки. Каждый текст имеет определенную графическую структуру (заголовки, разбивку на абзацы и т.д.), фрагментирующую текст на законченные в смысловом отношении фрагменты, причем приемы такой фрагментации достаточно разнообразны. Текст может иметь более или менее стандартное типографское оформление: выравнивание строк слева и справа, выделение абзацев красной строкой, отсутствие нетекстовых вставок. Однако при наличии нетекстовых вставок эта структура нарушается: может появиться несколько левых или правых границ. Машинописный текст, как правило, имеет нечеткое выравнивание по правой границе. Иногда абзацы не выделяются красной строкой и т. д. Графическая структура текста может оказаться нарушенной на выходе блока 2 оптического распознавания, если типографский текст набран немоноширинным шрифтом, может нарушиться выравнивание по правой границе текста (строки окажутся неравной длины), может оказаться сдвинутым начало строк, текст вообще может оказаться состоящим из нескольких колонок, из-за ошибок распознавания в текстовом файле могут проявиться символы, не входящие в допустимый алфавит.
Блок оптического распознавания позволяет выделять колонки текста, однако делается это вручную в интерактивном режиме, что неприемлемо для потенциального пользователя. В блоке 10 осуществляется автоматическая проверка наличия более одной колонки в тексте. Признаком многоколоночного текста является наличие пробелов в одних и тех же позициях строк. Будем рассматривать каждую строку как вектор, и преобразуем строки-вектора по следующему правилу: i-тая составляющая, соответствующая i-той позиции в строке, равна 0, если в этой позиции пробел, и 1, если в этой позиции символ, отличный от пробела. Векторное суммирование полученных векторов строк и сравнение составляющих результирующего вектора с порогом позволяет выделить в строке связные области, соответствующие колонкам текста, многоколоночный текстовый файл в блоке 11 переформатируется в одноколоночный.
Для того, чтобы выделить заголовки и абзацы текста, необходимо сначала проверить выровненность текста по левым и правым границам. Распознавание левых и правых границ текста осуществляется в блоке 12. Обозначим li - позицию в i-той строке, соответствующую первому отличному от пробела символу, и ri - позицию, соответствующую последнему, отличному от пробела и символа переноса строки символу. Пусть далее L - множество значений li, а R - множество значений ri для данного текста.
На множествах L и R определяются соответствующие распределения частотностей значений левых и правых границ строк в тексте, а также распределение правых границ строк, завершающихся знаком переноса, и правых границ строк, не завершающихся знаками конца фразы.
Правые границы текста распознаются по их коррелированности с границами строк, завершающихся переносами, или, если переносы слов в тексте отсутствуют, с границами "незавершенных" строк (строк, не завершающихся пунктуационными знаками, ставящимися в конце фраз). Для нечетких правых границ определяются их статистические характеристики (математическое ожидание и дисперсия). Левые границы определяются на подмножестве строк, следующих за вышеперечисленными.
Отступы красных строк определяются на подмножестве строк, начало которых не совпадает с выделенными левыми границами, по их коррелированности с началом фраз и с "неполнотой" предыдущей строки (т.е. в конце строки стоит пунктуационный знак конца фразы, а конец строки не доходит до правой границы текста или отклонение от нечеткой границы превышает толерантный интервал). По найденным значениям отступов красных строк и левых границ определяются начальные позиции для красных строк.
Красные строки (если они есть в тексте) распознаются в блоке 13 по соответствующей позиции начала строки и при условии, что начало строки соответствует началу фразы (для исключения случайных совпадений).
В блоке 14 выделяются абзацы. Обычно в тексте начало абзаца выделяется красной строкой, однако не всегда. Если в данном тексте красные строки не обнаружены, то конец абзаца определяется по признаку "неполноты" строки.
В блоке 15 проверяется наличие в тексте недопустимых символов, обнаруженные недопустимые символы заменяются пробелами.
В блоке 16 ликвидируются знаки переноса в словах (для уменьшения многозначности символа "-"), а блок 17 переформатирует текстовый файл в соответствии с принятым стандартом. Этому стандарту соответствует текст в одну колонку с выделением абзацев красными строками и с нечеткой правой границей. Если очередное слов не умещается на текущей строке, оно переносится на следующую, при этом правая граница не выравнивается за счет пробелов.
Основываясь на обычном житейском опыте, можно сказать, что человеку несвойственно однократное линейное чтение текстовой информации с начала и до конца. Люди обычно неоднократно возвращаются к ранее прочитанному для более адекватного понимания некоторых положений с учетом далее изложенного или просто для того, чтобы освежить в памяти кое-что из ранее прочитанного. Естественно, что каждый раз вводить и распознавать уже однажды прочитанный текст - пустая трата времени. Текстовый файл занимает объем памяти, на 2-3 порядка меньший, чем графический или звуковой файлы, поэтому есть смысл сохранять в долговременной памяти однажды полученный текстовый файл. 250 Мгб памяти на жестком диске позволяют хранить до 100 тыс. страниц текста (или примерно 100 страниц озвученного текста в виде звукового файла). Для того, чтобы можно было достаточно быстро отыскать нужный текстовый файл хранимые текстовые файлы необходимо организовать в некую базу данных (БД), которая становится уже предметом коллективного пользования. Конкретное построение БД будет изложено ниже.
В зависимости от управляющего сигнала на входе блока 4 на выход последнего поступает текущий текстовый файл, или файл, выбранный с помощью интерфейса БД. Этот файл с выхода блока 4 поступает на вход блока синтеза 5 и через блок 7 сопряжения - на вход тактильного дисплея 8. Блок синтеза 5 формирует на основе текстового файла звуковой файл в одном из звуковых форматов, последний преобразуется системой вывода звука типа Sound Blaster в аналоговый сигнал звуковой частоты. С линейного выхода этот сигнал поступает на оконечный аудиоблок 6, где преобразуется в требуемую для пользователя форму. В качестве оконечного аудиоблока могут использоваться пассивные или активные (с регулировкой громкости и тембра) акустические системы, преобразующие аналоговый сигнал в акустическую волну (речевой поток), и/или аналоговый магнитофон. В последнем случае параллельно звуковому выводу осуществляется магнитная запись речевого сигнала. Эта магнитная запись в дальнейшем может использоваться как обычная "говорящая книга". Синтезированная "говорящая книга" является побочным продуктом и естественно уступает по качеству "настоящей говорящей книге", являющейся чем-то вроде передачи "театр у микрофона". Однако она может быть оперативно получена с меньшими затратами (не требуется наличие квалифицированного диктора и студии звукозаписи, стоимость аренды которой достаточно высока). Кроме того, синтезированная и обычная "говорящая книга" имеют разное целевое назначение. Обычная "говорящая книга" удовлетворяет в основном эстетические запросы пользователя, а синтезированная - только информационные.
Тактильный дисплей дублирует речевой вывод, позволяя прочесть непонятные или просто плохо воспринимаемые на слух слова, кроме того, некоторые специфические графические средства текста, например таблицы, вообще плохо поддаются адекватной линейной вербализации.
В блоке синтеза 5 реализован компиляционный способ синтеза речи по орфографическому тексту, при этом в качестве базовых элементов компиляции выбраны сегменты фонемной размерности - аллофоны.
Поскольку при алфавитном письме базовыми элементами письменной речи являются буквы, которым в устной речи соответствуют элементы фонемной размерности, базовые элементы компиляции естественно выбрать той же размерности. При этом синтезатор речи, рассматриваемый как своего рода интеллектуальный решатель определенной задачи, получается прозрачным, или артикулирующим. Последнее означает, что такой решатель позволяет не только получить конечное решение, но и проследить весь путь его получения в привычной для данной предметной области форме. В данном случае это значит, что трансляция письменного речевого фрагмента на алфавит базовых элементов компиляции приводит к привычной для данной предметной области задаче фонетического транскрибирования текста, а фонетические значения, структурированные и формализованные с использованием технологий искусственного интеллекта, могут быть положены в основу базы знаний синтезатора.
В русском языке можно выделить 10 гласных и 37 согласных фонем. Сами по себе фонемы не исчерпывают всего многообразия звуков русской речи.
Артикуляция каждого звука, как гласного, так и согласного, состоит из трех фаз - начальной, когда активный орган речи их исходного положения движется по направлению к соответствующему пассивному (экскурсия), срединной, или выдержки, когда активный орган речи находится по отношению к пассивному органу в положении, необходимом для производства данного звука, и конечной, когда активный орган речи возвращается в исходное положение (рекурсия). В речевом потоке артикуляции разных звуков как бы накладываются друг на друга: рекурсия данного звука по времени совпадает с экскурсией следующего, а экскурсия - с рекурсией предыдущего.
Поэтому в слитном речевом потоке акустическая реализация конкретной фонемы будет зависеть от контекстного окружения. Эти контекстные реализации фонем - аллофоны - и выбраны в качестве базовых элементов компиляции. Общий объем акустико-сегментной базы синтеза при таком подходе составляет порядка 100 тыс. , что требует огромных трудозатрат на составление такого словаря. Необходимый набор можно сократить путем обобщения тождественных контекстных влияний. При удачном обобщении практически решается и проблема адекватной стыковки базовых элементов компиляции при синтезе речи. Задача поиска возможных обобщений и тем самым оптимального набора аллофонов может быть решена лишь с учетом знаний акустических рефлексов коартикуляционных процессов. Такой подход можно считать основанным на фонетических знаниях в том понимании, которое принято в исследованиях по искусственному интеллекту.
Для формирования аллофонной базы подобран специальный словарь, состоящий из слов, содержащих необходимые аллофоны в требуемых контекстах. Слова этого словаря произносятся диктором, записываются и вводятся в машину в цифровом виде. Затем с помощью пакета программ (например, Tool Kit) осуществляется вычленение акустических сегментов, соответствующих заданным аллофонам, и из этих сегментов формируется акустико-сегментная база синтеза.
Полученная акустико-сегментная база синтеза содержит 687 базовых элементов компиляции, в основном представляющих собой сегменты речевой волны фонемной размерности, хотя в некоторых случаях это соответствие нарушается. Для синтеза смычных и вибрантов используется более одного акустического сегмента, а для синтеза двухсимвольных последовательностей, например, заударных флексий, используется один акустический сегмент.
Гласные представлены шестью фонемами в сильной позиции (в ударном слоге): { а^,o^,y^,и^,ы^,э^} и восемью безударными, в том числе:
- первой степени редукции {а,у2,и,ы,о},
- второй степени редукции {ъ,ь,у1}.
В качестве левых контекстах выделены следующие:
- переднеязычный твердый {д,т,с,з,ц,дз,ш,ж,а^,а,ъ,э^,э},
- губной твердый {б,п,в,ф,л,у^,у1,у2,о^,о},
- переднеязычный носовой {н},
- губной носовой {м},
- вибрантный твердый {р},
- мягкий неносовой: все согласные, помещенные знаком мягкости ('), кроме {м',н'}, а также {и^,и,ь,ы^,ы},
- мягкий носовой переднеязычный {н'},
- мягкий носовой губной {м'},
- начало синтагмы (начальный).
В качестве правых выделены следующие классы контекстов:
- переднеязычный твердый {д,т,с,з,ц,дз,ш,ж,н,к,г,х,а^,а, ъ,э^,э,ы^,ы} кроме позиции согласных {к,г,х} перед {у^,у1,у2, о^,о},
- губной твердый { б,п,в,ф,л,м,у^,у1,у2,о^,о}, а также {к,г,х}, если за ними {у^,у1,у2,о^,о},
- вибрантный твердый {р},
- мягкий, т.е. все согласные, помеченные знаком мягкости, а также {и^,и, ь},
- конец синтагмы (конечный).
Согласные разделены на 7 классов:
1) звонкие и глухие смычные (твердые и мягкие) {б,д,г,п,т,к,б',д',г',п', т',к'},
2) твердые фрикативные (кроме [x]) {с,з,ш,ж,ц,ф,дз},
3) мягкие фрикативные (кроме [x']) {с',з'щ',ч'ф',ж',дж'}
4) носовые {м,н,м',н'},
5) плавные сонанты {л,h^,л',й'} и {в,в',x,x'},
6) вибранты {р,р'},
7) йот {j}.
Для классов 1) и 2) выделены только правые контексты, всего 4 класса:
- {у^,у,o^},
- конечный,
- для мягких звуков любой контекст, кроме конечного,
- все остальные контексты.
Для класса 3) выделены 2 класса левых контекстов:
- начальный,
- все остальные; и 2 класса правых контекстов:
- конечный,
- любой, кроме конечного, для мягких звуков.
Для носовых (класс 4) контексты не выделяются, т.е. реализация этих звуков не зависит от контекстного окружения.
Для класса 5) выделены 4 класса левых контекстов:
- {у^,у,o^},
- начальный,
- {и^,ы^,и,ы,ь,э^},
- все остальные,
и 4 класса правых контекстов:
- {у^,у,о^},
- конечный,
- любой, кроме конечного для мягких звуков,
- все остальные.
Для вибрант (класс 6) выделены левые, правые и связанные контексты, где под связанными контекстами понимаются случаи взаимозависимого существования левого и правого контекстов. Для данного класса - это условие одновременного наличия гласной слева и справа, т.е. интервокальная позиция. Для остальных случаев выделены 4 класса левых контекстов:
- {у^,у,о^,б,п,ф,в,л,м},
- начальный,
- {и^,ы^,и,ы,ь,э^} и все мягкие согласные,
- все остальные контексты;
и 4 класса правых контекстов:
- {у^,у,о^,б,п,ф,в,л,м},
- конечный,
- любой, кроме конечного, для [p'],
- все остальные контексты.
При формировании аллофонов для вибрант всегда, кроме случаев конечной позиции используются аллофоны для интервокальной позиции, объединяемые с контекстно обусловленными аллофонами, последние всегда приклеиваются со стороны согласного или начала. В случае окружения двух согласных склеиваются два одинаковых контекстно обусловленных аллофона и аллофон для интервокальной позиции вставляется между ними.
Для класса 7) выделены 4 класса левых контекстов, совпадающих с классами левых контекстов для вибрант, и 3 класса правых контекстов:
- конечный,
- гласные,
- согласные.
Блок синтеза 5 работает следующим образом. Озвучивание текстового файла осуществляется циклически - по завершении озвучивания очередного фрагмента начинается озвучивание следующего и т.д. Интерфейс предусматривает возможность возврата к прочитанному фрагменту и повторное его прочтение в выбранном режиме. Этот прием представляется вполне оправданным, поскольку текстовый файл может оказаться достаточно большим и нет смысла ожидать, пока он будет весь обработан от начала до конца. Фрагмент текста обрабатывается, преобразуется в звуковой файл, и пока этот звуковой файл выводится через систему ввода-вывода звука, происходит обработка следующего фрагмента. При этом сокращается время реакции (оно равно длительности обработки одного фрагмента, а не всего текста) и уменьшается объем выводимого звукового файла.
Минимальным однозначно выделяемым фрагментом, синтаксически независимым от соседних фрагментов, является абзац. В предлагаемом синтезаторе чтение осуществляется по абзацам, для этого в блоке 3 и осуществлялось распознавание и выделение абзацев.
В блоке 18 осуществляется выбор текущего абзаца для чтения. На информационный вход поступает озвучиваемый текстовый файл, а на первый управляющий вход от блока интерфейса поступает адрес абзаца, с которого начинается чтение. В дальнейшем адрес текущего абзаца поступает на второй управляющий вход с блока 35 вывода звукового файла (следующий абзац, возврат к предыдущему, повторный вывод и т.д.). Блок 19 осуществляет чтение текущего абзаца (перевод из долговременной памяти в оперативную, а в блоке 20 производится предварительный синтаксический анализ абзаца (предварительная обработка знаков пунктуации).
Блок 21 выделяет в абзаце слова - лексемы, отделенные пробелом или знаком переноса строки (переносы слов ликвидированы в блоке 3). Последовательность кодов, соответствующих Выделенному потоку слов абзаца, поступает в блок селектора 22. Селектор 22 разделяет слова, состоящие из кодов символов русского алфавита и кодов символов метаязыка (букв латинского алфавита, цифр, специальных знаков). Если слово состоит из кодов букв русского алфавита, то оно обрабатывается в блоке 23 распознавания слов на русском алфавите, где на основе морфологического анализа осуществляется распознавание слов русского языка, определение части речи и автоматическая расстановка ударений в словах, в противном случае слово обрабатывается в блоке 34, где оно транслируется в слова на русском алфавите. С выхода первого блока ИЛИ 25, объединяющего результаты этих двух ветвей обработки, поток кодов слов абзаца поступает на вход блока 36, где осуществляется контекстная расшифровка, не распознанных в блоке 23 сокращений слов. Правила контекстной расшифровки сокращений слов представляются в соответствующих пунктах базы знаний синтезатора.
В результате в блоке 26 устраняется неоднозначность использования точки - на выходе блока тока определяет только конец предложения. В блоке 27 осуществляется согласование словесных эквивалентов цифровой записи, полученных в блоке 24, и расшифровок слов-сокращений по родам, числам и падежам на основе анализа контекста.
В блоке 28 выделяются в абзаце фразы и синтагмы как последовательность лексем, разделенных знаками пунктуации. Путем анализа знаков пунктуации и слов фраз и ситагм в блоке 29 определяется коммуникативный тип последних, а в блоке 30 - логическое ударение. На основе информации об ударениях в словах и структурированных фонетических знаний о правилах перехода "буква-фонема" в словах с известным ударением в блоке 31 осуществляется автоматическое фонетическое транскрибирование текста абзаца. Временной процессор 32 и мелодический процессор 33 формируют параметры для управления просодией синтезированной речи: с помощью временного процессора 32 определяются требуемые длительности звуковых элементов, а с помощью мелодического процессора 33 - мелодический контур (аппроксимация закона изменения частоты основного тона).
В блоке компиляции 34 осуществляется собственно сборка речевого сообщения: фонетическая запись преобразуется в запись на языке алфавита элементов компиляции, необходимые элементы компиляции в виде оцифрованных сегментов естественной речевой волны извлекаются из базы данных, осуществляется их модификация в соответствии с параметрами, определенными в блоках 32 и 33, и сборка речевого сообщения путем композиции модифицированных фрагментов. Файл на выходе блока 34 представляет собой оцифрованный аудиосигнал.
В блоке 35 этот файл преобразуется в совместимый с используемой системой ввода-вывода звука формат (например, wav-, vjc- или snd-формат). В блоке 36 полученный звуковой файл передается для вывода через звуковую карту. На основе анализа прерываний от клавиатуры на втором выходе блока формируется управляющий сигнал для перехода к следующему абзацу, для повторного вывода текущего в том же режиме, для повторного формирования текущего в другом режиме или для возврата к предыдущему абзацу.
Пунктуация характеризуется тем, что располагает очень небольшим количеством средств. В этим связаны две особенности пунктуационных знаков: широта их значения и многозначность. Для снижения этой многозначности в блоке 20 осуществляется предварительный синтаксический анализ абзаца. Блок работает следующим образом.
Селектор 37 выделяет в абзаце коды знаков пунктуации, которые в зависимости от управляющего сигнала, поступающего на коммутатор 38, обрабатываются либо в блоке 39, либо в блоках 41,42,43,44.
В блоке 39 знаки пунктуации вербализуются. Этот режим пользователь выбирает в том случае, если хочет иметь полное представление о расстановке знаков препинания в исходном тексте абзаца, в том числе и о тех, которые не получают интонационного выражения в устной речи. Речевое сообщение в этом случае напоминает диктовку для машинистки.
В другом режиме синтаксис абзаца отражается только интонационными средствами.
Для уменьшения вышеупомянутой многозначности знаков пунктуации в блоке 41 эти знаки анализируются в контексте. Разделяются символы тире и дефиса (тире имеет пробелы слева и справа). Разделяются скобки как пунктуационный знак (наличие открывающей и закрывающей скобок, как в данном фрагменте) и скобка как графическое средство. Разделяются апостроф в функции кавычек (наличие пробела до или после апострофа) и апостроф, употребляемый в написании слов ("под'езд","а'натюрель"). Разделяются точка и многоточие, точка как пунктуационный знак и десятичная точка или запятая в записи десятичных дробей). В блоке 42 устраняются пунктуационные фикции, т.е. пунктуационные средства графической речи, которые не находят отражения в устной речи. Чисто графическим приемом является то, что после закрывающей скобки ставится знак препинания, которым должна завершаться часть фразы до скобок. В блоке 42 этот знак ставится перед открывающей скобкой, а сами скобки заменяются точками, если за закрывающей скобкой стоит знак завершения фразы, или запятыми, если пробел. Точкой заменяется и восклицательный знак и многоточие, если за ним следует новый абзац или слово с большой буквы (в противном случае - пробел). Заменяются пробелами знаки тире перед кавычками в начале абзаца (чисто графический прием, обозначающий диалог). Заменяются пробелами кавычки. При наличии нескольких пунктуационных знаков подряд (в результате вышеописанных преобразований или ошибок системы оптического распознавания) более слабые знаки поглощаются более сильными.
В блоке 43 пунктуационные знаки селектируются по признаку цифрового контекста. Если контекст цифровой (первый выход), пунктуационные знаки вербализуются в блоке 44, например:
5.6 - "5, точка 6,
5,6 - "5, запятая 6",
факс. 276-43-12 - "факс. 246, тире 43, тире 12".
Блок 23 распознавания слов на русском языке работает следующим образом. В блоке 45 коды анализируется коды символов, составляющих данное слово. Коды прописных символов преобразуются в коды строчных, а информация о наличии в слове кодов прописных букв запоминается. Далее в зависимости от наличия в составе слова пунктуационного знака и вида этого знака адрес слова передается на дальнейшую обработку. Если слово завершается точкой (первый выход селектора 46), обработка далее осуществляется в первом селекторе 47 слов-сокращений. Последний проверяет наличие данного слова в базе данных (в "списке") обычно используемых сокращений слов. Если слово там обнаружено, оно не обрабатывается в блоке 23 и поступает на его выход с первого выхода первого селектора 47 через третий блок ИЛИ 48.
Если слово не является словом-сокращением6 т. е. точка - знак конца предложения, то оно обрабатывается как обычное слово русского языка без всяких пунктуационных знаков (для последних четвертый выход селектора 46 - четвертый блок ИЛИ 49). Эта обработка осуществляется в блоке 50 морфологического анализа. Морфологический анализ осуществляется путем отсечения флексий и префиксов и выделения основы, заключающей лексическое значение слова.
Морфологический анализ эквивалентен решению уравнения
W = Хp•Х(1)•...Х(n-1)•Х(n),
где W - анализируемое слово,
Хp - префикс или пустое слово,
Х(1) ,...,Х(n-1) - одна или несколько основ (возможно, с соединительной гласной на конце),
Х(n) - флексия или пустое слов.
Уравнение решается следующим образом. В каждом цикле справа отсекается m символов, а оставшаяся слева часть слова рассматривается как потенциальная основа и осуществляется проверка наличия ее в базе данных основ. Если данная часть слова в базе данных не найдена, m увеличивается на единицу (начальное значение m=0), и цикл повторяется. Если ни в одном из циклов соответствующей основы не обнаружено, делается попытка выделить в начале слова один из префиксов списка, если это удается, префикс отсекается и процесс повторяется для оставшейся части слова. Если префикс выделить не удается, слово считается нераспознанным.
Если основа найдена в базе данных, то из базы данных выбирается множество флексий для данной основы, и отделенная справа часть слова сравнивается с ними. Если она совпадает с одной из флексий, слово считается распознанным, для данной словоформы из базы данных извлекается информация о части речи, грамматической форме и ударении (в русском языке в многоосновных словах ударение всегда определяется последней основой). Эта информация связывается с данной словоформой. Если же ни одна из флексий не совпадает с правой частью слова, а одна из них, включая флексию нулевой длины, является ее начальным вхождением, соответствующее слово слева, включая соединительную гласную, если она обнаружена отсекается, и процесс повторяется для оставшейся справа части. Таким образом распознаются слова без окончаний, флексивно изменяемые слова, слова, образованные с помощью префиксов, многоосновные слова.
В русском письме довольно часто используются не все буквы русского алфавита, в частности, вместо графемы "йо" часто употребляется графема "е", а вместо разделительного твердого знака иногда употребляется апостроф. Буква "йо" отсутствует во многих текстовых редакторах, в том числе и в редакторе ОСR CuneiForm. Для правильной фонетической транскрипции необходимо автоматическое восстановление там, где это требуется, графемы "йо". В базе данных содержатся оба варианта написания слов с "йо", и информация о наличии в слове "йо" вместе с другой грамматической информацией поступает на выход блока 50. По этой информации в блоке 51 нужная буква "е" заменяется на "йо".
В блоке 52 нераспознанные слова, ассоциированные с прописными буквами, воспринимаются как аббревиатуры. В блоке 53 аббревиатуры транскрибируются по следующим правилам:
- двухбуквенные аббревиатуры читаются "по буквам" (композиция из названий букв) с ударением на последней гласной (РФ - эрэ^ф, КА - каа^);
- трехбуквенные и четырехбуквенные аббревиатуры читаются "как слово" при отсутствии стечения двух и более согласных с ударением на первой прикрытой спереди согласной гласной, в остальных случаях - "по буквам" с ударением на последнем слоге. Например, ВОС - во^c, ЭМИ - эми^, НЛО - энэло^, НАТО - на^ то, ОПЕК - опе^к, ОДМО - одээмо^;
- все остальные читаются "как слово", если в аббревиатуре не более двух согласных подряд, или "по буквам" в противном случае, ударение падает на последнюю прикрытую справа согласной гласную (АСАЛМ - аса^лм, ЮНЕСКО - юне^ ско, ОБХСС - обэхаэсэ^с).
Если слово не воспринято как аббревиатура, то в блоке 54 на основании грамматической информации, ассоциированной со словом, определяется код части речи и в блоке 55 обозначается ударный слог.
Коды слов, содержащие символ дефиса, со второго выхода селектора 46 поступают на вход второго селектора 56. Последний аналогично первому селектору 47 распознает слова-сокращения, записанные через дефис (например, гр-н - граждани^н, ин-т - институ^т). Эти слова-сокращения в блоке 23 не обрабатываются. Если слово не является сокращением, то в блоке 57 дефис исключается, при этом используются следующие правила:
- в сложных словах, образованных с помощью части основы - "пол-", в сложных прилагательных (темно-синий) и в словах с частицами то-, -либо, -нибудь, кое-, таки-, -ка, -с, склеиваются две части слова, при этом если часть слова после дефиса начинается с йотированной гласной, то дефис заменяется твердым знаком (темно-синий - темносиний, пол-яблока - полъяблока);
- в остальных случаях дефис заменяется пробелом.
Далее слово поступает на четвертый блок ИЛИ 49 и обрабатывается по общим правилам.
В блоке 58 исключается знак апострофа, после чего слово обрабатывается по общим правилам. Последний встречается в словах иноязычного происхождения (а'ла, а'натюрель), задаваемых списком, в именах собственных ирландского, французского и иногда испанского происхождения после "о" и "д" (О'Хиггинс, д'Артаньян, д'Аламеда). В этих случаях разделяемые апострофом части слов склеиваются. В русских словах апостроф иногда пишут вместо разделительного твердого знака после приставок перед мягкими гласными, в этих случаях твердый знак восстанавливается.
Блок 56 расстановки ударений работает следующим образом.
На основании ассоциированной с данным словом информации в селекторе 59 разделяются распознанные и нераспознанные слова.
Для распознанных слов обозначается ударный слог, а для нераспознанных слов предпринимается попытка определить ударение с помощью некоторых эмпирических правил. Так, например, в русском языке существительные мужского рода, в именительном падеже, оканчивающиеся на "изм", во всех словоформах имеют ударение на этом слоге (эмпириокритици^зм, бихевиори^зм и т.д.), существительные мужского рода со второй основой "лог" имеют ударение на соединительной "о" (фило^логу, стомато^лога).
Блок 24 трансляции слов метаязыка в слова на русском алфавите работает следующим образом. В селекторе 63 разделяются слова, состоящие из различных символов различных подмножеств алфавита метаязыка.
Если слово состоит из арабских цифр, то обработка осуществляется по цепочке: первый выход селектора 63, шестой блок ИЛИ 64, блок 65. В последнем цифровая запись числа заменяется ее словесным эквивалентом. На втором выходе селектора 63 выделяются слова, состоящие из символов латинского алфавита, из которых на первом выходе селекторе 67 выделяются слова, состоящие из символов латинских цифр - {C,L,X,V,I}. В блоке 68 распознаются числа, записанные латинскими цифрами. Поскольку данные символы обозначают не только латинские цифры, но и могут встречаться в словах языков с латинской письменностью, в блоке 68 предпринимается попытка преобразовать последовательность этих символов в арабскую цифровую запись. Если сочетание этих символов не удовлетворяет правилам записи чисел латинскими цифрами, то последовательность символов рассматривается как обычное слово на латинском алфавите, передается на второй выход блока 68 и далее обрабатывается в блоке 70, как и слова, записанные латинскими буквами, но не содержащие символов, которыми обозначаются латинские цифры (второй выход блока 67).
Если же комбинация символов удовлетворяет правилам записи латинских цифр, число преобразуется в блоке 68 в арабскую запись и через шестой блок ИЛИ 64 поступает в блок 65, где вербализуется.
В блоке 70 слова, написанные латинскими буквами, транслируются на русский алфавит. Поскольку язык неизвестен, трансляция осуществляется по соответствующим правилам для слов латинского языка. Получается немного забавно, но понятно (windows - виндовс, "made in USA" - "мадэ ин уса").
Все остальные символы метаязыка { %,/,+,\ } вербализуются в блоке 71 (% - "процент", / - "дробь", + - "плюс", \ - "слэш" и т.д.).
Мелодический контур фразы зависит от ее коммуникативного типа. В русском языке выделяют следующие типы предложений: повествовательные, вопросительные, побудительные и восклицательные. Повествовательные предложения наиболее распространены в речи, нередко значительные отрывки произведений состоят из предложений только этого вида. Восклицательные предложения имеют эмоциональную окраску. Множество форм контуров основного тона отличается большим разнообразием, и значительная часть правил управления интонацией не только не формализована, но даже и неизвестна. Поскольку основное назначение предлагаемого комплекса состоит в передаче информации, число возможных форм речевого сообщения более ограничено, чем при речевом общении между людьми. Основным коммуникативным типом предложения при передаче информации является повествовательный тип, который, как отмечалось выше, вообще является основным типом в письменной речи. Поэтому в синтезаторе не воспроизводятся интонационные особенности, отражающие второстепенные оттенки преимущественно экспрессивного характера, а множество коммуникативных типов предложений сводится к двум: повествовательным и вопросительным, четко отражаемым в графической речи знаками пунктуации.
Соответственно выделяются шесть коммуникативных типов синтагм:
- завершенность (с возможным логическим ударением) для синтагм, ограниченных знаками {.:;},
- первый тип незавершенности для синтагм, ограниченных знаком запятой,
- второй тип незавершенности для синтагм, ограниченных знаком тире,
- общий вопрос для синтагм, ограниченных знаком вопроса и не содержащих вопросительного слова,
- частный вопрос для синтагм, ограниченных знаком вопроса и содержащих вопросительное слово, на которое падает логическое ударение,
- с логическим выделением выделением для синтагм, содержащих знак логического выделения.
Знак логического выделения может присутствовать в текстовом файле, если предварительно произведена ручная разметка текста, как это делается, например, в пособиях по художественному чтению.
Блок 29 определения коммуникативного типа фраз и синтагм работает следующим образом. В селекторе 72 выделяются вопросительные фразы. Если фраза завершается знаком [?], то управление передается блоку 73, где во фразе отыскиваются вопросительные слова. Если такое слово найдено, в конце синтагмы, его содержащей, ставится знак вопроса с признаком специального вопроса, слово маркируется, а в конце фразы, если эта синтагма не последняя, ставится точка. Девятый блок ИЛИ 74 объединяет обе ветви обработки. В блоке 75 по знакам препинания, разделяющим синтагмы, и наличию вопросительного слова или знака логического выделения в синтагме определяется коммуникативный тип синтагмы.
Блок 30 определения логического ударения работает следующим образом.
Логическое ударение, как уже отмечалось, не находит формального отражения в графической речи, а определяется семантикой текста. Известные методы машинного семантического анализа весьма далеки от совершенства и работают только в интерактивном режиме, поскольку понятие смысла является интуитивным и плохо формализуемым. Поэтому в синтезаторе используются упрощенные правила определения логического ударения.
Селектор 76 выделяет в синтагме слова со знаком логического выделения. Если такое слово обнаружено, то никаких дополнительных действий в блоке не осуществляется, если не обнаружено, то в селекторе 78 выделяются вопросительные слова, маркированные в блоке 73. Если такое слово найдено, в блоке 82 этому слову вместо простого знака ударения приписывается знак логического ударения. Если вопросительного слова не найдено, в блоке 79 проверяются случаи, когда семантически значимые слова определяются контекстом без полного семантического анализа предложения. Таковы, например, случаи, когда употребляются сравнительные частицы: "как бы", "как будто", "словно", "точно", "не то чтобы", или усилительная частица "это", а равно и "значит" в сочетании с инфинитивом. Знаменательное слово в следующем за ним словосочетании логически выделяется.
Если таких особых случаев не обнаружено, в блоке 80 определяется последнее знаменательное слово синтагмы, на которое и падает логическое ударение.
Блок 31 фонетического транскрибирования текста функционально решает следующие три задачи: устранение орфографических фикций (блок 83), преобразования буквенной записи в фонетическую (блок 84) и формирование слитной речи (блок 85).
Трансляция осуществляется путем операции подстановки Sb(W,X,Y), где вхождение Х в слово W заменяется на подслово Y.
В блоке 86 устранения орфографических фикций в окончаниях слов реализованы подстановки в соответствии с правилами пп.2,3 базы знаний: орфографические фикции в окончаниях родительного падежа единственного числа мужского и среднего рода на "-ого" и "-его" и мягкий знак на конце слов после шипящих в наречиях, существительных женского рода и инфинитиве.
В блоке 87 исключаются непроизносимые согласные.
В блоке 88 осуществляется транскрибирование случаев, когда фонема на письме обозначается сочетанием согласных.
В блоке 89 в словах с твердым произношением согласных перед "е" (в основном в словах иноязычного происхождения) "е" заменяется на "э".
Для преобразования кодов буквенных символов в коды символов фонем (блок 84) множество согласных букв S разобьем на следующие непересекающиеся классы:
S1 = {п,б,т,д,к,г,в,ф,с,з,р,м,н,л,х} - парные по твердости-мягкости;
S2 = {Ц,Ж,Ш} - непарные твердые;
S3 = {ч,щ} - непарные мягкие;
S4 = {й}.
Гласные буквы разделим на два непересекающихся класса:
G1 = {а,о,у,э,ы} - "твердые",
G2 = {я,е,ю,е,и} - "мягкие".
На множество фонем выделим следующие подмножества:
ф1 - твердые согласные;
ф2 - мягкие согласные;
ф3 = {а,о,у,э,ы,и} - гласные;
ф4 = {т,с,п,ф,к,ш,х,ц,т',c',п',ф',к',ч',щ'} - шумные глухие;
ф5 = {д,з,б,в,г,ж,h,z,д',з',б',в',г',j',ж'} - шумные звонкие;
ф6 = {т,д,с,з,н} - зубные твердые;
ф7 = {т',д',с',з',н'} - зубные мягкие;
ф8 = {к,г,х} - заднеязычные твердые;
ф9 = {к',г',х'} - заднеязычные мягкие,
и зададим соответствие по глухости-звонкости отображением
ϕ1 : ф4 --> ф5,
а соответствие по мягкости-твердости - отображениями
ϕ2 : ф6 --> ф7, ϕ3 : ф8 --> ф9.
Блок 84 преобразования буквенной записи в фонетическую работает следующим образом.
В селекторе 90 выделяются служебные и слабоударные слова, задаваемые "списками". Служебные слова в блоке 91 теряют ударение и в блоке 92 ассимилируются со знаменательным словом. При этом служебные слова-проклитики (предлоги) "приклеиваются" к следующему слову (если это слово начинается с "мягкой" гласной, то вместо пробела ставится "ъ"). Служебные слова-энклитики (частицы) "приклеиваются" к предыдущему слову. Слово, полученное в результате композиции, через одиннадцатый блок ИЛИ 93 поступает в блок 95 и далее транскрибируется по общим правилам.
В блоке 94 пометка ударения в слабоударных словах заменяется пометкой "слабое ударение". Все прочие слова без изменений через одиннадцатый блок ИЛИ 93 поступают на обработку в блок 95.
Контексты, содержащие код мягкого знака в блоке 95 транскрибируются с помощью последовательности операций контекстно-обусловленных подстановок:
- Sb(W,sь*,s'), s ∈ S1;
- Sb(W,s1ьs2,s1's2), s1∈ S1 ∪ S3, s2∈ S1;
- Sb(W,s2ьs,s2s), s2∈ S2, s ∈ S;
- Sb(W,sьg,s'й' (g)), s ∈ S1 ∪ S3, g ∈ G;
- Sb(W,sьg,sй' (g)), s ∈ S2, g ∈ G2;
где отображение α : G2 -> ф3 задано таблицей соответствия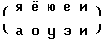
' - знак мягкости,
* - знак, разделяющий синтагмы.
Контексты, содержащие код твердого знака в блоке 91 транскрибируются путем подстановки
- Sb(W,sъg,s'й' α (g)), s ∈ S1\{д, т, с, з, н}, g∈G2.
Транскрибирование сочетаний "согласная-гласная" (СГ) осуществляется в блоке 96 путем подстановок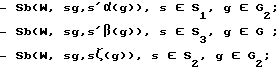
а отображения β и ζ заданы соответственно таблицами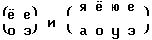
Транскрибирование гласных в начале синтагмы осуществляется в блоке 97 путем подстановки
- Sb(W, *g, й′α(g)), g ∈ G2\{и}.
Стечения "гласная-гласная" (ГГ) транскрибируются в блоке 98 путем подстановки
- Sb(W, gg2,gй′α(g2)), g ∈ G, g2∈ G2\{и}.
Мягкие согласные {ч,щ} при отсутствии знака мягкости транскрибируются в блоке 99 путем подстановки
-Sb(W,s,s'), s ∈ S3.
В блоке 100 учитывается свойственная современному русскому языку тенденция к озвончению шумных глухих согласных перед шумными звонкими и оглушению шумных звонких перед шумными глухими. Реализуется это путем подстановок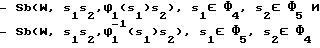
При сочетании более двух согласных два последних перехода осуществляются последовательно в несколько шагов.
В русском языке на месте звонких согласных на конце слова (синтагмы) произносятся соответствующие глухие. Это учитывается в блоке 101 путем соответствующих подстановок: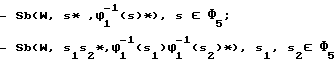 .
.
В блоке 102 транскрибируются двойные согласные в сочетании "твердый-мягкий" путем подстановки
-Sb(W,ss′,s′s′), s ∈ Φ1.
В блоке 103 учитывается тенденция к смягчению зубных твердых перед зубными мягкими и непарными мягкими и к смягчению заднеязычных твердых перед заднеязычными мягкими. Соответствующие подстановки: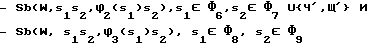 .
.
В блоке 104 транскрибируются двойные согласные путем подстановок:
Sb(W,ss,s:), s ∈ Φ1;
Sb(W,s's',s"), s′∈ Φ2.
В русском языке гласные фонемы, выделенные в подмножество ф3, могут произноситься только в ударном слоге. В безударных слогах в русском литературном языке гласные произносятся с той или иной степенью редукции, т.е. сокращения, произносятся менее явственно, и что особенно важно - в безударных слогах некоторые гласные не различаются, совпадая друг с другом.
Гласные по-разному редуцируются в обычных и слабоударных словах. Разделяются эти слова в селекторе 105 по результатам работы блока 94.
Ударный гласный - наиболее мощный по длительности и интенсивности (из ударных гласных выделяются гласные в последнем ударном слоге синтагмы как наиболее мощные среди ударных гласных).
Первая степень редукции на одну ступень ниже по длительности и интенсивности и соответствует позиции гласной в первом предударном слоге, безударным позициям в конце синтагмы, в открытом конце слова, если следующее слово начинается с ударного слога, и позиции после гласной.
Вторая ступень редукции еще ниже по длительности и интенсивности и соответствует всем остальным безударным позициям.
Эти правила определения степени редукции реализованы в блоке 106.
В слабоударных словах в блоке 108 псевдоударный гласный редуцируется до первой степени редукции, а все остальные гласные, если они есть, - по общему правилу.
Неразличимость некоторых гласных в безударных слогах учитывается в блоке 107, где редуцированные гласные первой степени редукции заменяются в соответствии со следующими правилами.
В позициях, соответствующих первой степени редукции, [a] и [o] произносятся как соответствующая редуцированная [и] в позиции после мягкого согласного, во всех остальных позициях - как редуцированный [a].
Гласная [э] первой степени редукции заменяется на [ы] или [и] в позициях соответственно после твердой и мягкой согласных.
В слабоударных словах псевдоударный гласный редуцированный до первой степени редукции, сохраняет качество.
В блоке 110 реализованы следующие правила замены редуцированных гласных второй степени редукции.
В позициях, соответствующих второй степени редукции, гласные [о,а,э] не различаются и заменяются на [ъ] в позиции после твердой согласной и на [ь] в позиции после мягкой согласной. В русском языке [ы] может быть только в позиции после твердой согласной, а [и] - после мягкой. Замена - по тому же правилу.
Произнесение звуков на границах слов различно в зависимости от того, выдерживаются между словами паузы, или слова образуют слитный речевой поток. Транскрибирование стыков слов для слитной речи осуществляется в блоке 85 в соответствии с произносительными нормами русского литературного языка. Произношение стечений звонких-глухих согласных в конце-начале слова в слитной речи аналогично произношению таких стечений на стыках морфологических частей слова, "и" в начале слова после твердой согласной в конце предыдущего слова заменяется на "ы".
В блоке временного процессора 32 определяются требуемые длительности элементов компиляции. Временной процессор 32 реализует следующий алгоритм.
Длительность гласных определяется степенью редукции и фонетическим качеством гласной. Разделим множество гласных звуков на три класса, отражающих различия в их фонетическом качестве: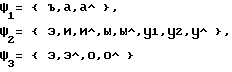 .
.
Для любой гласной в фонетической записи текста определим степень выделенности n. Первая, самая низкая степень выделенности (n=1), соответствует гласным второй степени редукции, вторая (n=2) - гласным первой степени редукции, третья (n=3) - ударным гласным за исключением последнего ударного слова в синтагме, этому случаю соответствует четвертая степень выделенности (n= 4). Тогда для ∀g∈Φi, i∈{1,2,3} длительность гласной в зависимости от степени ее выделенности определяется соотношением
τi(n) = τi,0+ (n-1+[n/4])/2
где [ ] - целая часть числа, а τi,0/ - фиксированная для i-го класса константа.
Для ударных гласных в реальной речи существует зависимость длительности от порядкового номера в синтагме содержащего их слова (q) и числа слогов (m) в этом слове. Для гласных со степенью выделенности 3 эта зависимость невелика и ею можно пренебречь, для гласных со степенью выделенности 4 эта зависимость существенна и аппроксимируется соотношением
τi′(4) = τi,1+ 0.74(τi(4)-τi,1)(m-1)(q-1),
где τi,1 - фиксированная для i-го класса длительность.
В позиции конца синтагмы гласные продлеваются независимо от степени их редукции и фонетического качества. Влияние согласных на длительность гласных учитывается лишь в наиболее ярких случаях, а именно, в позиции перед интервокальными вибрантами. В позиции перед интервокальными вибрантами и в конце синтагмы длительность любого гласного определяется дополнительными соотношениями, соответственно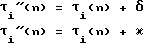
где δ - фиксированная для всех гласных величина,
κ - длительность инерционного хвоста.
При определении временных характеристик согласных учтены следующие факторы, позиции согласного относительно границ синтагмы и фонетического слова, интервокальная-неинтервокальная позиция, позиция в кластере (стечения согласных), простой-сложный состав базовых элементов компиляции, необходимых для звукового синтеза согласных.
Максимальную длительность согласные имеют в интервокальной позиции (в позиции между гласными). Эта длительность принимается за эталонную. Зависимость длительности согласных от сегментного окружения определена соотношением
τ = βiτ0, i∈{1,2,3,4}
где τ0 - эталонная длительность,
i=1 для позиции перед гласной (β1 = 0,8),
i=2 для позиции перед согласным (β2 = 0.6),
i= 3 для элементов компиляции, соответствующих фазе взрыва смычных согласных и вибрантам ( β3 = 1,0),
i=4 для долгих согласных ( β4 = 1,3).
Мелодический процессор 33 определяет закон временного изменения частоты основного тона в пределах синтагмы. Закон этот аппроксимируется кусочно-линейной зависимостью, при этом для каждого элемента компиляции определяются значения частоты основного тона для в качестве его начальной и конечной мелодических характеристик. Значения этих характеристик квантованы по шкале музыкальных тонов и формируются слева направо слоговыми циклами, т.е. в рамках последовательности sn g, где g гласный, sn, (n≥0) - последовательность из n согласных, предшествующих гласному.
Сегментирование синтагмы на слоговые фрагменты осуществляется в блоке 111. Это сегментирование эквивалентно итерационному решению уравнения
Сi = Sigi,1Ci+1, ∀g∈Ψg с начальными условиями С0 = С,
где gi,1 - первое вхождение любого символа гласной в фонетической записи g∈Ψg в слово Сi,
С - синтагма, рассматриваемая как слов на алфавите Ψ = Ψs∪Ψg,,
Ψg= Ψ1∪ Ψ2∪ Ψ3 - подмножество гласных,
Ψs - подмножество согласных, под i-ым слоговым фрагментом понимается композиция Sigi,1.
При определении мелодических характеристик элементов компиляции, входящих в текущий слог, учитываются следующие факторы: коммуникативный тип синтагмы, положение слога относительно мелодического центра контура (главноударного слога) - совпадение, слева, справа, положение слога относительно границ синтагмы, степень выделенности гласного в текущем слоге, степень выделенности гласного в предшествующем слоге, количество символьных элементов в слоге, тип символьного элемента (гласный-согласный) и его положение относительно начала слога (первый-непервый).
Принято, что вариации частоты основного тона составляют одну октаву относительно базового уровня Fб.
Для коммуникативных типов синтагмы - завершенность и два вида незавершенности - выделено семь классов слогов:,
К1 - безударные слоги (n≤2),
К2 - простые ударные слои (n=3),
К3 - последний ударный слог синтагмы, не являющийся мелодическим центром (n=4),
К4 - последний ударный слог синтагмы, являющийся мелодическим центром (n=4) для синтагмы с типом завершенности,
К5 - мелодический центр, не совпадающий с последним ударным слогом (n=3) для синтагмы с типом завершенности,
К6 - мелодический центр для синтагм с первым типом незавершенности (n= 4),
К7 - мелодический центр для синтагм с первым типом незавершенности (n= 3),
К8 - мелодический центр для синтагм с вторым типом незавершенности (n= 4),
К9 - мелодический центр для синтагм с вторым типом незавершенности (n= 3).
Для каждого класса слогов задана совокупность правил, с помощью которых определяются начальные и конечные мелодические характеристики символьных элементов слога.
Для класса К1 заданы 5 правил:
1) Fн = Fк = Fб для всех элементов слога.
2) Понижение на полтона для первого элемента слога, далее ΔF = 0.
3) Частота основного тона равномерно (в полутоновой шкале) понижается, Fк для последнего элемента слога ниже Fн первого элемента слога на пол-октавы, если текущий слог - первый из ударных слогов синтагмы, и на 3 полутона, если он - непервый.
4) Для согласных Fн = Fк = Fк предшествующего гласного, для гласного Fн = Fк предшествующего гласного, Fк на три полутона ниже Fб.
5) То же, что и 4), но для гласного Fк = Fб.
Для класса К2 заданы 5 правил:
1) Частота основного тона равномерно (в полутоновой шкале) повышается, Fк для последнего элемента слога выше Fн первого элемента слога на пол-октавы.
2) Аналогично правилу 1) для К1.
3) Частота основного тона равномерно (в полутоновой шкале) повышается, Fк для последнего элемента слога выше Fн первого элемента слога на пол-октавы, если текущий слог - первый из ударных слогов синтагмы, и на 3 полутона, если он - непервый.
4) Аналогично правилу 2) для К1.
5) Аналогично правилу 5) для К1.
Для класса К3 заданы 2 правила:
1) Аналогично правилу 4) для К1, но для гласных Fк на пол-октавы ниже Fб.
2) Аналогично правилу 1) для К1.
Для класса К4 заданы 2 правила:
1) Для согласных Fн = Fк = Fб,
Для гласного Fн = Fб, Fк на пол-октавы ниже Fб.
2) Частота основного тона равномерно (в полутоновой шкале) понижается, и для последнего элемента слога Fк на полоктавы ниже Fб.
Для класса К5 заданы 2 правила:
1) Для согласных
для первого Fн = Fк и на пол-октавы выше Fб,
далее Fн = Fк,
Для гласного Fн на пол-октавы выше Fб, Fк = Fб.
2) Для согласных Fн = Fк = Fк предшествующего гласного,
для гласного Fн = Fк предшествующего элемента, Fк = Fб.
Для классов Кh, h ≥ 6 заданы 2 правила:
1) Для первого элемента слога Fн = Fб, далее частота основного тона равномерно (в полутоновой шкале) повышается, и для последнего элемента слога Fк на сексту выше Fб.
2) Для первого элемента слога Fн = Fк предшествующего гласного, далее частота основного тона равномерно (в полутоновой шкале) повышается, суммарное повышение составляет сексту.
Применение вышеуказанных правил контекстно обусловлено. Зададим на множестве L слогов синтагмы отображение ξ : L --> R1, при этом ξ(l) = m, если l∈ Km, ξ(*)=0.
Тогда условия применения вышеуказанных правил могут быть заданы матрицей 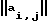 , где i = ξ(l) для слога - левого контекста, j - для правого, а значение элемента аi,j соответствует номеру правила.
, где i = ξ(l) для слога - левого контекста, j - для правого, а значение элемента аi,j соответствует номеру правила.
Для класса К1 :
а0,j = 1 для ∀j,
a2,6 = 3,
a8,j = 4, a9,j = 5 для ∀j,
ai,j = 2 всех остальных i и j.
Для класса К2:
а0,j = 1 для j ∈ {1,2,4,5} и а0,j = 2 для всех остальных j,
a1,j = 3 для j ∈ {1,2,4,5},
а9,j = 5 для ∀j,
аi,j = 4 всех остальных i и j.
Для класса К3:
а7,j = 2 для ∀j,
аi,j = 1 всех остальных i и j.
Для класса К4:
а0,j = 1 для ∀j,
аi,j = 2 всех остальных i и j.
Для класса К5:
а0,j = 1 для ∀j,
аi,j = 2 всех остальных i и j.
Для классов Кh, h ≥ 6:
а0,j = 1 для ∀j,
аi,j = 2 всех остальных i и j.
Для синтагм с коммуникативным типом "общий вопрос" выделим следующие классы слогов:
Q1 - безударные и простые ударные слоги (n≤3),
Q2 - последний ударный слог - не мелодический центр (n=4),
Q3 - мелодический центр (n=3),
Q4 - мелодический центр (n=4).
Для класса Q1 заданы 4 правила:
1) Для согласных Fн = Fк = Fб, для гласного Fн = Fк предшествующего элемента, а Fк на 1 полутон выше Fб.
2) Для первого элемента слога Fн = Fк предшествующего гласного, а Fк на один полутон ниже, для последующих элементов ΔF=0.
3) Для согласных действует правило 2), для гласного Fн = Fк предшествующего звука, Fк = Fб.
4) Аналогично правилу 3), но для гласного Fк на пол-октавы ниже Fб.
Соответственно элементы матрицы, обусловливающей применение этих правил, равны:
а0,j = 1 для ∀j,
а1,j = 2 для j ≤ 2 и а1,j = 1 для j ≥ 3,
а2,j = 2 для ∀j,
а3,j = 3 для ∀j,
a4,j = 4 для ∀j.
Для класса Q2 действует бесконтекстное правило, аналогичное правилу 1) для Q1, но Fк на пол-октавы ниже Fб.
Для классов Q3 и Q4 заданы 2 правила:
1) Если слог - первый в синтагме, то для первого элемента Fн = Fб, далее частота основного тона равномерно (в полутоновой шкале) повышается и для последнего элемента слога Fк на октаву выше Fб.
2) Если слог - не первый в синтагме, то действует правило, аналогичное 1), но для первого элемента Fн = Fк предшествующего гласного, а для последнего - Fк на октаву выше Fн первого элемента.
Для частного вопроса выделены два класса слогов Р1 - не мелодический центр и Р2 - мелодический центр.
Для класса Р1 заданы 5 правил:
1) Fн = Fк = Fб,
2) Аналогично правилу 1) для К2,
3) Аналогично правилу 2) для Q1,
4) Для первого элемента Fн = Fк предшествующего гласного, далее частота основного тона равномерно (в полутоновой шкале) понижается и для последнего элемента Fк на сексту ниже Fн первого элемента,
5) Для первого элемента Fн = Fк предшествующего гласного, Fк = Fб, для всех остальных Fн = Fк = Fб.
Правило 1) действует для слогов, находящихся левее мелодического центра, если следующий слог - также не мелодический центр, правило 2) - для слогов, непосредственно предшествующих мелодическому центру, правило 3) - для слогов правее мелодического центра (но не непосредственно за ним), правило 4) - для слога, следующего за мелодическим центром, если это - последний слог или последний ударный слог, правило 5) - для слога, следующего за мелодическим центром, если справа есть хотя бы один ударный слог.
Для класса Р2 заданы 2 правила:
1) Для первого слога синтагмы для согласных Fн = Fк = Fб, для гласного Fн на сексту выше Fб, а Fк на три полутона выше Fб.
2) Для прочих контекстов для согласных Fн = Fк = Fк, предшествующего элемента, для гласного Fн = Fк предшествующего элемента, а Fк на три полутона выше Fб.
Для согласных в конце синтагмы Fн = Fк = Fк предшествующего гласного.
Блок компиляции 34 работает следующим образом. В блоке 114 синтагмы обрабатываются слева направо, и для каждого текущего символа выделяются левый и правый контексты (предшествующий и последующий символы). В шифраторе 115 формируются коды элементов компиляции, соответствующих символам фонетической записи в соответствующем контексте. Код элемента компиляции представляет собой кортеж k1, k2, k3, k4>, где k1 - код текущего символьного элемента, k2 - код класса символьного элемента, k3 - код класса левого контекста и k4 - код класса правого контекста.
По этим кодам из блока 116 акустико-сегментной базы синтеза извлекаются соответствующие элементы синтеза в виде отрезков оцифрованной речевой волны. В блоке 117 эти последовательности отсчетов преобразуются в соответствии с определенными во временном процессоре 32 и мелодическом процессоре 33 временными и частотными параметрами элементов компиляции.
Для квазипериодических отрезков речевой волны изменение временных и частотных характеристик соответствующего элемента компиляции осуществляется путем функционального преобразования
ϕ(t) = Σϕi(t) _→ ϕ′(t) = Σϕj(t), i≤n0,j≤n
где ϕ(t) - сегмент естественной речевой волны, соответствующий текущему элементу компиляции;
ϕi(t) - ортогональная последовательность функций, совпадающих с ϕ(t) на интервале i-го квазипериода;
n0 - число квазипериодов в сегменте естественной речевой волны,
n=max(2,[τ(F(tк )+F(tн))/2] - требуемое число квазипериодов,
τ - определенная в блоке временного процессора требуемая длительность элемента компиляции;
F(tн) и F(tк) - соответственно определенные в блоке мелодического процессора начальное и конечное значения частоты основного тона.
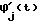 - результат функционального преобразования ϕi(t), где индекс i для ∀j определяется областью истинности предиката
- результат функционального преобразования ϕi(t), где индекс i для ∀j определяется областью истинности предиката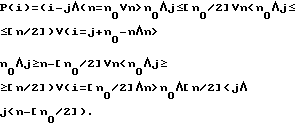
Функциональное преобразование  определено следующим образом
определено следующим образом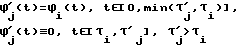
где 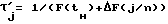 - требуемая длительность j-го квазипериода.
- требуемая длительность j-го квазипериода.
Для шумовых отрезков речевой волны частота основного тона, естественно не меняется (для шумового сигнала такой параметр вообще отсутствует), изменяется лишь длительность путем повторения или урезания базового элемента.
Как видно из вышеприведенных соотношений, при изменении длительности звука в первую очередь изменяется длительность фазы выдержки, а длительности фаз экскурсии и рекурсии по возможности сохраняются.
В блоке композиции 118 преобразованные последовательности отсчетов, соответствующие элементам компиляции записываются последовательно одна за другой в порядке, определяемом символьной фонетической записью.
В блоке 35 формируется звуковой файл выбранного формата, т.е. перед полученной последовательностью отсчетов формируется заголовок звукового файла.
Блок 36 осуществляется вывод звукового файла через звуковую плату.
При реализации текстовой базы данных реализован подход, аналогичный используемому в системе Xanadu. При таком подходе берутся соответствующие документы (книги, статьи и т.д.), переводятся в электронную форму без семантических изменений и пристыковываются друг к другу, образуя одну "большую книгу". Специализированные надстройки позволяют идентифицировать любую книгу в целом и каждую ее составляющую в отдельности. Для идентификации информации в БД используются такие надстройки как список названий статей в алфавитном порядке, список авторов в алфавитном порядке, иерархический индексный указатель для имеющейся информации в виде раздела "Содержание". Такой подход гарантирует исчерпывающий доступ, но утомителен при просмотре.
Для более быстрого получения информации, релевантной запросу, используется доступ к информации через механизм ключевых слов. Механизм фильтров обеспечивает селективность, при этом фильтры могут быть заданы через ключевые слова или фильтрация может быть выполнена с указанием атрибутов документов.
Интерфейс БД предусматривает диалог пользователя и ЭВМ на акустическом и тактильном уровнях. Сообщения компьютера (пункты меню и другие сообщения) дублируются речевым выходом через звуковую плату и отображаются на тактильном дисплее. Пользователь вводит информацию в ЭВМ через клавиатуру ПК в режиме "озвучивания клавиатуры" (при нажатии клавиши называется набранный символ), набранное сообщение озвучивается через синтезатор с подтверждением или неподтверждением ввода. Вводимой информацией могут являться названия статей, список ключевых слов, атрибуты фильтра (например, диапазон годов публикации - просмотреть все имеющиеся в базе публикации данного автора с такого-то по такой-то год), или составленный пользователем комментарий к документу (аннотация, предметная область, список ключевых слов и т.д.). Эта информация может как самостоятельно набираться пользователем, так и набираться зрячим оператором на индивидуальной карточке пользователя на гибком магнитном носителе. Пользователь лишь выбирает пункт меню: ввод с клавиатуры, ввод с флоппи-диска. На индивидуальной карточке также фиксируются все сеансы общения пользователя с системой, поэтому пользователь может получить быстрый доступ к информации, с которой работал ранее, но атрибуты которой забыл. С гибкого диска может также вводиться и заноситься в БД документ, кем-то ранее переведенный в электронную форму.
Блок интерфейса 9 предусматривает автоматический запуск всех блоков устройства в необходимой последовательности, по завершении каждого шага пользователю выдается речевое сообщение и запрашивается подтверждение на выполнение следующего шага (нажатие одной из двух клавиш воспринимается компьютером как ответ "да" или "нет"). По завершении работы с документом управление передается интерфейсу БД для того, чтобы пользователь мог связать с документом необходимую информацию.
Предлагаемое устройство позволяет незрячему или слабовидящему пользователю самостоятельно и независимо получать образование, как общее, так и профессиональное, самостоятельно и независимо осуществлять интеллектуальную и профессиональную деятельность с использованием аппаратно-программных комплексов, что позволяет решить социальную проблему профессиональной и социальной адаптации инвалидов в реальной социальной среде. При наличии предлагаемого устройства незрячий человек может составить себе информационную базу данных по своему выбору и использовать для этой цели любого вида литературу, предназначенную для зрячих пользователей, в том числе и уникальную, например, по истории музыки, сводам законов, истории, науки и т.д. Пользователь с помощью данного устройства может практически самостоятельно или при минимальном обращении к посторонним лицам получать интеллектуальное развитие, получить высшее образование и стать высококлассным профессионалом.
Данное устройство может быть также использовано для самостоятельного и независимого изучения и совершенствования русского языка с использованием живой и/или синтезированной русской речи непосредственно с печатного или другого вида носителя информации как зрячими, так и незрячими пользователями, а также инвалидами с нарушением опорно-двигательного аппарата.
Устройство может быть использовано для коллективного пользования в библиотеках для слепых, в школах для слепых на уроках и при проведении самостоятельного изучения материала.
Преимущества при использовании данного устройства для изучения языка очевидны. Кроме вышеуказанных особенностей и преимуществ пользователь одновременно воспринимает визуальное воспроизведение текста и синхронное ему речевое звучание текста. Одновременное использование двух анализаторов - слухового и зрительного, позволяет резко повысить восприятие любой информации на русском языке.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| СПОСОБ ОБМЕНА СООБЩЕНИЯМИ И УСТРОЙСТВА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2007 |
|
RU2324296C1 |
| СПОСОБ СИНТЕЗА РЕЧИ | 2009 |
|
RU2421827C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2011 |
|
RU2460154C1 |
| СПОСОБ КОМПИЛЯЦИОННОГО ФОНЕМНОГО СИНТЕЗА РУССКОЙ РЕЧИ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2005 |
|
RU2298234C2 |
| УСТРОЙСТВО СИНТЕЗА РЕЧИ | 2014 |
|
RU2606312C2 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1996 |
|
RU2101782C1 |
| Устройство для вывода речевой информации | 1975 |
|
SU607211A1 |
| СПОСОБ ПОДБОРА СЛОВ ДЛЯ СОЗДАНИЯ МНЕМОТЕХНИЧЕСКИХ СЛОВАРЕЙ | 2019 |
|
RU2722423C1 |
| Устройство для графического отображения синтезируемой устной речи | 1986 |
|
SU1411802A1 |
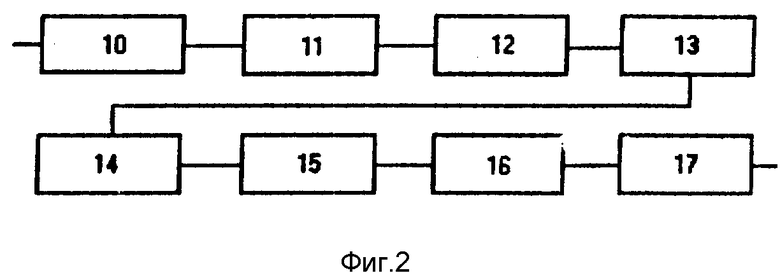
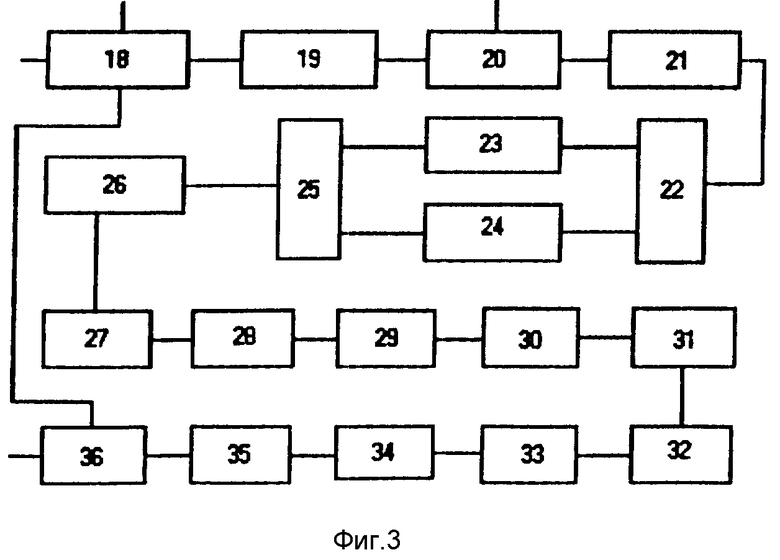
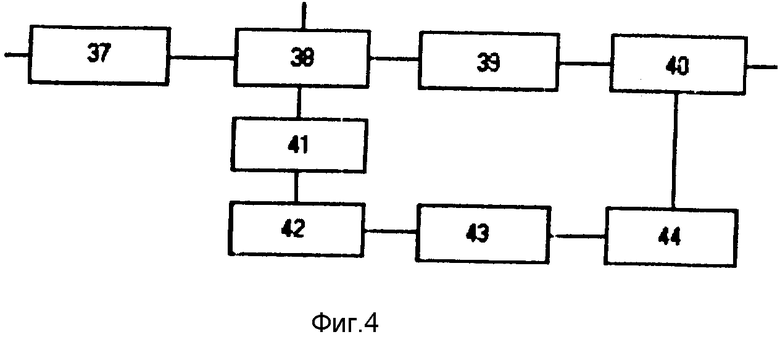
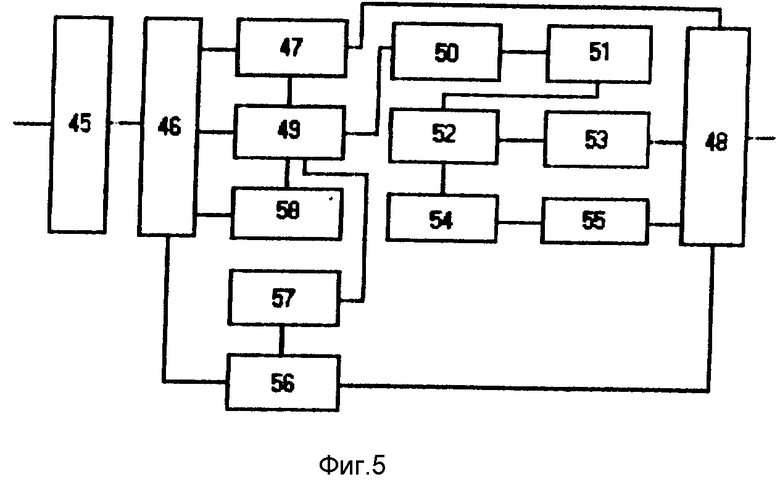
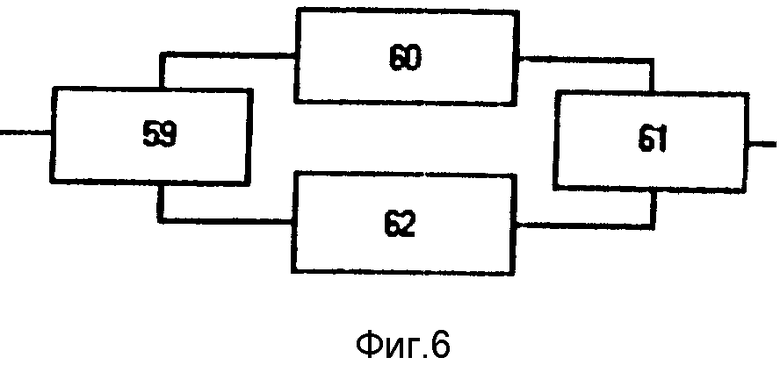
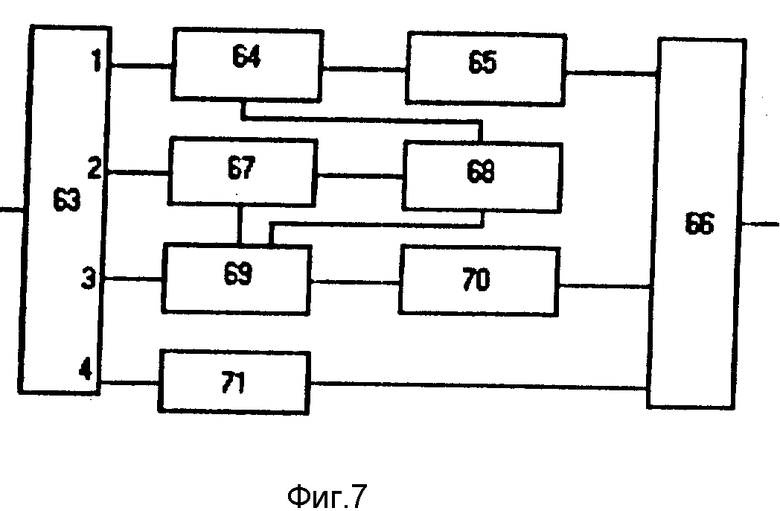
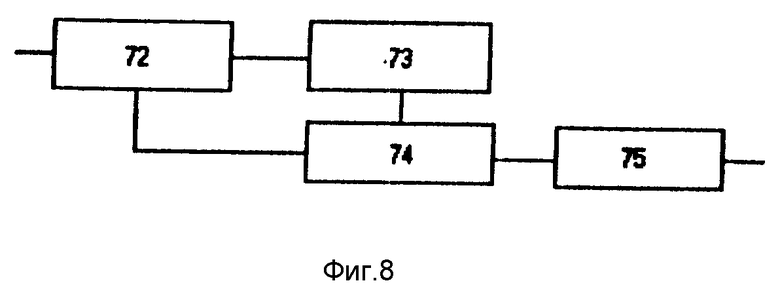
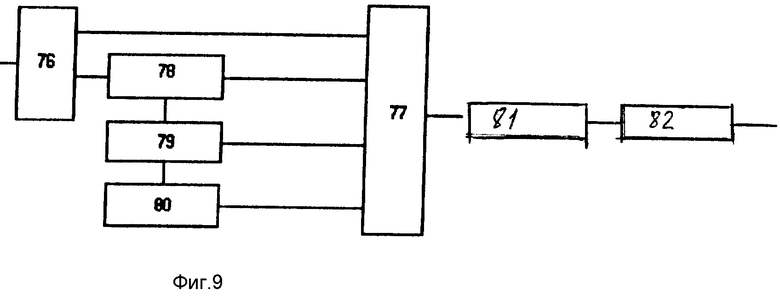
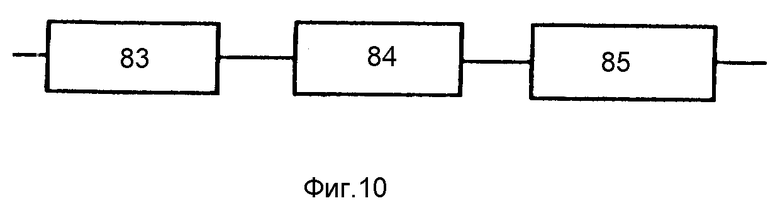

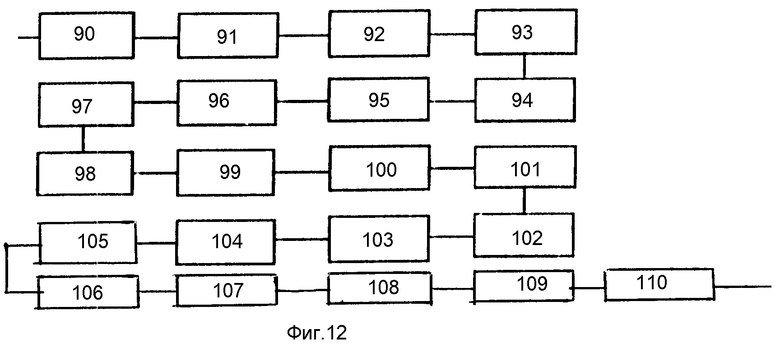
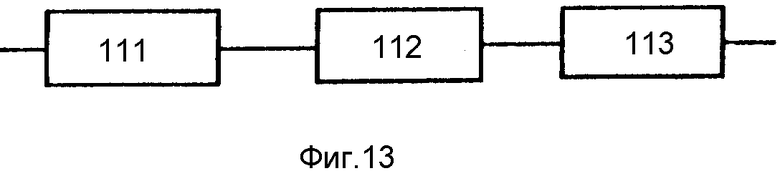

Изобретение относится к вычислительной технике. Его использование в качестве источника информации для слепых и средства обучения русскому языку позволяет обеспечить высокое качество синтеза русской речи при воспроизведении плоскопечатных текстов. Устройство содержит блок 1 оптического ввода плоскопечатного текста, блок 2 оптического распознавания текста, блок 5 синтеза речи по орфографическому тексту, блок формирования аудиосигнала (не показан) и оконечный аудиоблок 6. Технический результат достигается благодаря выполнению блока 1 в виде сканера, блока формирования аудиосигнала в виде звуковой платы, блока 5 в виде блока синтеза русской речи по орфографическому тексту, а кроме того, благодаря введению блока 3 унификации текстового файла, блока 4 текстовой базы данных, тактильного дисплея 8, блока 7 сопряжения тактильного дисплея с персональным компьютером и блока 9 интерфейса. 28 з.п. ф-лы, 14 ил.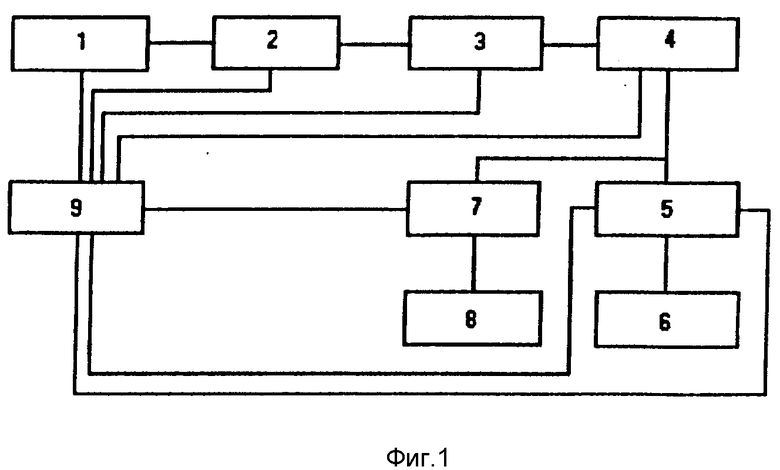
F : M _→ S,
где M - множество основ, определяющих лексическое значение слов русского языка;
S - множество классов флексий,
блок морфологического анализа выполнен реализующим алгоритм решения уравнения
W = Xp•X(1)•...•X(n-1)•X(n),
где W - анализируемое слово;
Xp - префикс или пустое слово;
X(1), . . ., X(n-1) - одна или несколько основ (возможно соединительной гласной на конце);
X(n) - флексия или пустое слово.
Sb(W,у,у2) - для гласной "у" в любом контексте;
Sb(W, s'g, s'и), g∈{o,a,э}, Sb(W, sэ, sы) - для контекстов типа "согласная-гласная" ("sg" или "s'g");
Sb(W, о, а) - для всех остальных контекстов.
Sb(W,у,у1) - для гласной "у" в любом контексте,
Sb(W,sg,sъ), g∈{o,a,э,ы} и Sb(W, s'g, s'ь), g∈{o,a,э,и} - для контекстов типа "согласная-гласная".
Ψ1 = {ъ,а,а∧};
Ψ2 = {ь,и,и∧,ы,ы∧,у1,у2,у∧};
Ψ3 = {э,э∧,o,o∧},
где ^ - знак ударения, длительности гласных в зависимости от степени выделенности n определены соотношением
τi(n) = τi,0+(n-1+[n/4])/2,i∈{1,2,3},
где i - индекс класса гласной;
[a] - целая часть,
τi,0 - фиксированная для каждого класса константа, длительности гласных в зависимости от номера, содержащего их слова в синтагме (q), и числа слогов в слове (m) определены для гласных четвертой степени выделенности дополнительным соотношением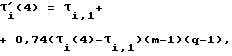
кроме того, длительность любого гласного в позиции перед интервокальными вибрантами и длительность гласных в конце синтагмы определены дополнительными соотношениями соответственно
где δ - фиксированная для всех гласных величина, ∂б - длительность итерционного хвоста, длительность согласных в зависимости от сегментного окружения и долготы согласного определена соотношением
τ = βiτ0, j∈(1,2,3,4} ,
где τ0 - эталонная длительность, соответствующая длительности в интервокальной позиции;
β1 = 0,8 для позиции после согласного перед гласным и β2 = 0,6 для позиции между согласными, при этом для элементов компиляции, соответствующих фазе взрыва смычных согласных и вибрантам β3= 1, β4 = 1,3 для долгих согласных.
C(i) = S(i)g(i,l)C(i+l), ∀g∈ψg,
с начальными условиями C(o) = C,
где g(i,l) - первое вхождение любого символьного элемента гласного g∈Ψg в слово C(i);
C - синтагма, рассматриваемая как слово на алфавите;
Ψ = Ψs∪ Ψg,Ψq= Ψ1∪ Ψ2∪ Ψ3 - подмножество гласных символьных элементов;
Ψs - подмножество согласных символьных элементов;
Под i-ым слоговым фрагментом понимается композиция S(i) g(i,l).
F(t) = Fн+(t-tн)/(tк-tн)ΔF,t∈[tн,tк];
ΔF = Fк-Fн,
где [tн, tк] - интервал длительности i-го сегмента, значения Fн и Fк квантованы по шкале музыкальных тонов, их значения определяются классом слога, положением слога относительно границ синтагмы (первый, непервый, последний), классами слогов - левого и правого контекстов, количеством сегментов в слоге, типом символьного элемента (гласный - согласный), его положением относительно начала слога (первый - непервый) и заданы таблично на допустимом подмножестве векторного произведения (K ∪ {*})⊗K⊗(K ∪{*}), где K - множество классов слогов, * - знак, разделяющий ситагмы, кроме того, для глухих щелевых и глухих аффрикант, для глухой смычки и взрыва в глухих смычных, для сегментов вокализации и паузы вибрант F(t) = const = Fmin, где Fmin - минимум частотного диапазона основного тона диктора, для звонких смычных линейное изменение частоты основного тона соответствует фазе смычки, а для фазы взрыва F(t)=Fmin.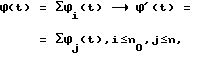
где ϕ(t) - сегмент естественной речевой волны, соответствующий текущему элементу компиляции ϕi(t) - ортогональная последовательность функций, совпадающих с ϕ(t) на интервале i-го квазипериода, no - число квазипериодов в сегменте естественной речевой волны, n = max(2,[τ(F(tк)+F(tн)/2] - требуемое число квазипериодов, τ - требуемая длительность элемента компиляции, F(tн) и F(tк) - соответственно заданные начальное и конечное значения частоты основного тона, при этом 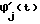 есть результат функционального преобразования ϕi(t), где индекс i для ∀j определяется областью истинности предиката
есть результат функционального преобразования ϕi(t), где индекс i для ∀j определяется областью истинности предиката
P(i)=(i=j^(n=novn>no^j≤[no/2]vn<no^j≤[n/2])v;
(i=j+no-n^n>no^j≥n-[no/2]vn<no^j≥[n/2])v;
(i=[no/2]^n>no^[n/2]<j^j<n-[no/2]),
а функциональное преобразование  определено следующим образом
определено следующим образом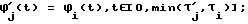
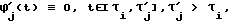
где 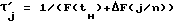 - требуемая длительность j-го квазипериода.
- требуемая длительность j-го квазипериода.
| Петров Ю.И | |||
| Обучение взрослых слепых письму и чтению по Брайлю | |||
| - М.: ВОС , 1988, стр.3-4 | |||
| BAUM Products GmbH, INKA, Version 1.0, Manual, March 1994 | |||
| Сорокин В.Н | |||
| Синтез речи | |||
| - М.: Наука, 1992 | |||
| US, патент, 4406626, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| US, патент, 5452380, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| JP, выложенна я заявка, 06-012011, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| JP, выложенная заявка, 06-1498 07, кл | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |

