ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к устройству вычисления подобия и к программе вычисления подобия, которые сравнивают группы технических документов и судят об их подобии.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
В обычных патентных картах патентные документы используют для сравнения содержания документов по одинаковой или по аналогичной научно-исследовательской тематике на предмет технологии, посредством чего, как полагают, могут быть выявлены общие тенденции и распределения. Исследуя патентную карту, руководитель может анализировать элементы, являющиеся существенными для управленческих решений, например тенденции развития рынка, тенденции развития технологии, тенденции развития предприятий, выходящих на рынок, и предприятий-конкурентов, перспективы на будущее и т.п.
Когда в патентной карте необходимо выполнить крупномасштабное сравнение группы А технических документов, относящихся к компании A, и группы B технических документов, относящихся к компании B, то ранее производили мелкомасштабные сравнения между отдельными техническими документами, связанными с группой А технических документов, и отдельными техническими документами, связанными с группой B технических документов, и из этих результатов получали результаты крупномасштабных сравнений между группами технических документов.
На Фиг.19 показана ситуация, имеющая место при сравнениях из известного уровня техники, включающих в себя отдельные мелкомасштабные сравнения между техническими документами, принадлежащими к группе A технических документов, и техническими документами, принадлежащими к группе B технических документов.
Как показано на Фиг.19, при сравнении технологии, описанной в группе B технических документов, для ее сравнения с технологией, описанной в группе А технических документов, обычно выполняют мелкомасштабные сравнения для всех комбинаций технических документов (публикаций патентов, технических отчетов и т.п.), содержащихся в группе А технических документов, и технических документов (публикаций патентов, технических отчетов и т.п.), содержащихся в группе B технических документов, результаты количественно определяли как подобия и сравнения численных значений для двух групп технических документов ранее выполняли путем вычисления среднего значения и дисперсии (см., например, документ "Руководство по патентной карте" Патентного ведомства Японии от 4 августа 2002 г. ("Patent Map Guidance", Japan Patent Office, August 4 2002), размещенный в сети Интернет по адресу http://www5.ipdl.jpo.go.jp/pmgsl/pmgsl/pmgs).
В выложенной патентной публикации Японии № 2000-348015 описано устройство определения ценности интеллектуальной собственности, способ определения ценности интеллектуальной собственности и т.п. для количественного определения ценности интеллектуальной собственности, связанной с изобретениями и т.п., при подаче заявки на изобретение или после регистрации. Это устройство определения ценности интеллектуальной собственности содержит средство ввода данных о прибыли от внедрения, предназначенное для ввода данных, относящихся к прибыли от внедрения; средство ввода данных о текущем значении нормы прибавочной стоимости, предназначенное для ввода данных, относящихся к текущему значению нормы прибавочной стоимости за каждый год; средство вычисления значения текущей стоимости, предназначенное для вычисления текущего значения ежегодной компенсации за каждый год путем умножения прибыли от внедрения на данные, связанные с текущим значением нормы прибавочной стоимости за каждый год, которые введены при помощи средства ввода данных; средство вычисления ценности интеллектуальной собственности, предназначенное для вычисления ценности интеллектуальной собственности за каждый год путем добавления текущих значений ежегодной компенсации, вычисленных средством вычисления значения текущей стоимости; и средство вывода, предназначенное для вывода значения ценности интеллектуальной собственности, вычисленного средством вычисления ценности интеллектуальной собственности.
В этом и в иных подобных устройствах определения ценности интеллектуальной собственности предпринята попытка выяснения стоимости активов в форме патентов, имеющихся на текущий момент времени, из-за снижения стоимости активов в форме зарегистрированных патентов и связанных с ними продаж и прибыли. В этих изобретениях при определении ценности каждого патента предполагают, что для вычисления стоимости актива в форме интеллектуальной собственности, для которого не была предусмотрена конкретная лицензия, может быть осуществлено ранжирование и ввод значения ценности, определенного самой компанией, и значений ценности, определенных другими компаниями, и что может быть произведена оценка вклада каждого из них.
В выложенной патентной публикации Японии № 2001-76042 приведено описание системы, способа и носителей записи для оценки оцениваемых объектов, которые могут изменяться с течением времени, на основании первых данных, имеющих заданный интервал обновления, и вторых данных, интервал обновления которых является более коротким, чем интервал обновления для первых данных. Эта система содержит (a) средство создания первой модели оценки в соответствии с вводом первых данных в качестве образца; (b) средство применения первых данных в качестве образца в первой модели оценки и вычисления первого результата оценки; (c) средство создания второй модели оценки в соответствии с вводом вторых данных в качестве образца и первым результатом оценки; (d) средство применения первых данных в первой модели оценки в соответствии с вводом первых данных в качестве образца и вычисления второго результата оценки; и (e) средство применения вторых данных в качестве образца и второго результата оценки во второй модели оценки и вычисления результата оценки в качестве оценки. Таким образом, производят оценку оцениваемых объектов, подлежащих оценке, которые могут изменяться с течением времени.
В этой системе считают возможным вычислять в надлежащие моменты времени оценки работы предприятия за последнее время за счет применения данных о предприятии для оценки в двух моделях оценки, которыми являются статическая модель, в которой оценки работы предприятия вычисляют с использованием данных о ранжировании, значений вероятности банкротства и т.п., вычисленных из первых данных со сравнительно длительными интервалами обновления, например из данных о финансовом положении, полученных из балансовых отчетов и отчетов о прибылях и убытках, обновляемых ежегодно или ежеквартально, и динамическая модель, в которой оценки работы предприятия вычисляют динамически, на основании ввода вторых данных со сравнительно короткими интервалами обновления, которыми являются, например, ежедневно изменяющиеся курсы акций, процентные ставки и курсы обмена валют, с прогнозами, основанными на таких изменениях.
Кроме того, в выложенных патентных публикациях Японии № 8-287081, № 2001-337992, № 10-74205, № 8-278982, № 11-73415 и № 2001-331527 описаны устройства поиска подобных друг другу документов, системы поиска подобия и т.п., которые при поиске документов или текста с содержанием, подобным содержанию определенных документов или текста, обеспечивают возможность точного поиска подобных друг другу документов с высокой степенью подобия между документами и текстом и с высокой надежностью.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Однако в патентной карте, описанной в "Руководстве по патентной карте" Патентного ведомства Японии от 4 августа 2002 г. ("Patent Map Guidance", Japan Patent Office, August 4 2002), и в изобретениях, описанных в выложенных патентных публикациях Японии № 8-287081, № 2001-337992, № 10-74205, № 8-278982, № 11-73415 и № 2001-331527, даже при наличии запроса на крупномасштабное сравнение содержания, изложенного в технических документах, например, между группой А технических документов, относящихся к компании A, и группой B технических документов, относящихся к компании B, в известном уровне техники выполняли мелкомасштабные сравнения между каждым из технических документов, принадлежащих к группе А технических документов и к группе B технических документов, а результат крупномасштабного сравнения этих двух групп технических документов получали из множества результатов вычислений, поэтому возникала проблема, заключающаяся в низкой эффективности этого процесса.
Кроме того, в случае патентной карты, описанной в "Руководстве по патентной карте" Патентного ведомства Японии от 4 августа 2002 г. ("Patent Map Guidance", Japan Patent Office, August 4 2002), при технических сравнениях считают возможным определять общие тенденции и распределения для содержания по каждой из одинаковых или аналогичных научно-исследовательских тематик. Однако поскольку невозможно вычислить относительные оценки для каждой технологии по всем предприятиям, используя все технические документы всех предприятий в качестве генеральной совокупности, то полученные количественные или качественные результаты не обеспечивают способ оценки стоимости нематериальных активов, и поэтому существует проблема, заключающаяся в том, что не может быть вычислен показатель, определяющий ценность технологии, для его использования при принятии решений относительно стратегии применения патентов в рамках предприятия, направленных на получение оценок доверительного управления имуществом и капиталовложениями.
Кроме того, при использовании способа вычислений, содержащего усреднение таких мелкомасштабных подобий, например, в случае, показанном на Фиг.19, когда группа А технических документов и группа B технических документов являются совершенно различными, вычисленное подобие равно 0. Кроме того, среднее значение подобия, вычисленное для всех комбинаций, также равно 0, поэтому кажется, что не возникает никакой проблемы.
Однако даже в том случае, когда первая группа технических документов и вторая группа технических документов являются в точности одинаковыми, при определении мелкомасштабных подобий между техническим документом A1, содержащимся в первой группе технических документов, и техническими документами B1, B2, B3, B4, содержащимися во второй группе технических документов, когда два технических документа являются в точности одинаковыми (например, A1=B1), то вычисленное значение подобия между A1 и B1 равно единице, но в других случаях значение подобия обычно не равно единице. Кроме того, среднее значение подобия, определенное для всех комбинаций иных документов, чем документ A1, например для A2, A3, A4 и т.п., является средним значением единицы и числовых значений, меньших, чем единица, поэтому возникает проблема, заключающаяся в том, что вычисленное значение подобия никогда не равно единице.
Кроме того, при вычислении подобия для большого объема технических документов, например, в тех случаях, когда общее количество технических документов составляет несколько десятков тысяч или более, необходимо вычислять подобия для всех комбинаций технических документов, поэтому для вычисления подобий необходим огромный объем вычислений, требуется большое время вычислений и существует дополнительная проблема, заключающаяся в том, что не может быть осуществлено быстрое отображение результата вычисления подобия.
К тому же, если при вычислении подобия согласно известному уровню техники используется способ, в котором исследуемый объект и совокупность технических документов подразделены по ключевым словам, то вычисляют отношения количества технических документов, содержащих каждое из ключевых слов, к общему количеству технических документов и производят усреднение вычисленных отношений для всех ключевых слов для вычислений подобий, если же не выполняют умножение на весовой коэффициент на основании важности ключевого слова, то существует проблема, заключающаяся в том, что может возникнуть несоответствие между вычисленными подобиями и фактически воспринимаемыми подобиями.
При использовании для вычисления подобия таких ключевых слов с весовыми коэффициентами оператор может присвоить весовые коэффициенты для всех ключевых слов для создания тезауруса, и подобия могут быть вычислены на основании этих весовых коэффициентов. Это теоретически возможно, но в действительности присвоение весовых коэффициентов каждому из огромного количества ключевых слов является весьма затруднительным (граничащим с невозможностью), и такая задача не позволяет осуществлять ее автоматизированную обработку. Кроме того, подобия вычисляют для каждого отдельного технического документа, поэтому отсутствует какое-либо решение проблемы выполнения мелкомасштабных сравнений технических документов.
Кроме того, в случае патентной карты, описанной в "Руководстве по патентной карте" Патентного ведомства Японии от 4 августа 2002 г. ("Patent Map Guidance", Japan Patent Office, August 4 2002), стоимость программного обеспечения для содействия созданию патентных карт составляет приблизительно от 150000 до 500000 японских иен, и для обеспечения функционирования такого программного обеспечения требуются технические навыки и знания высокого уровня не только по компьютерам, но также и по считыванию формул изобретения и чертежей патентов и т.п. И когда организация, производящая обзор патентов, запрашивается о выполнении таких задач, то затраты обычно составляют от 300000 японских иен и выше по каждому делу и время, требуемое для создания патентной карты, равно приблизительно одному месяцу или более.
Следовательно, ожидается, что использование патентных карт будет ограниченным при их использовании коммерческими предприятиями с ограниченным капиталом и с ограниченными бюджетами на развитие или в том случае, когда существует необходимость в своевременности подачи заявок на патенты.
Кроме того, в устройствах оценки интеллектуальной собственности и т.п. из известного уровня техники существовала проблема, заключающаяся в сложности сбора информации, начиная с прошлой информации и заканчивая самой последней информацией, в широкой области техники для выполнения анализа тенденций развития техники среди конкурирующих компаний и в сложности проведения исследований тенденций развития техники и т.п. для выяснения уровней развития технологии перед началом исследований и разработок продукции.
Поскольку за последние годы возросла доля стоимости нематериальных активов в стоимости предприятия, то стоимость нематериальных активов оказывает очень сильное воздействие на стоимость предприятий.
Следовательно, существует тенденция использования трастовыми компаниями, связанными с доверительным управлением собственностью, инвесторами, связанными с капиталовложениями, и предприятиями, связанными с изменениями стратегии применения патентов, которые увеличивают прибыль, созданную интеллектуальной собственностью, нематериальных активов в качестве показателя.
Однако на известном уровне техники отсутствовал какой-либо надлежащий показатель для сравнения нематериальных активов, держателем которых является предприятие, с использованием общих технических документов, на которые ссылаются при принятии инвестиционных решений.
В частности, в области корпоративного управления, когда жизнеспособность предприятия находится под угрозой, существенно важным является наличие показателя, доступного для использования при исследовании стратегий применения патентов, который характеризует, в том числе, достаточно ли ценной является область техники для обеспечения гарантии фондов развития предприятия на ранней стадии нового выхода на рынок или в начало разработки новой продукции, следует ли подать заявку на патент, следует ли подать запрос на экспертизу, вероятность получения прав на технологию, являются ли переговоры по предоставлению лицензии предпочтительными с точки зрения рентабельности и т.п.
Следовательно, с учетом вышеизложенной ситуации, существующей в известном уровне техники, задачей этого изобретения является создание устройства вычисления подобия, программы вычисления подобия и способа вычисления подобия, которые предоставляют возможность сравнения групп технических документов в широкой области, не ограниченной публикациями патентов или подобными документами, между различными предприятиями и вычисления надлежащего подобия, соответствующего человеческому восприятию, и тем самым вычисления показателя, дающего возможность производить количественные и качественные оценки, а также оценки относительной стоимости нематериальных активов.
Другой задачей этого изобретения является создание устройства вычисления подобия, программы вычисления подобия и способа вычисления подобия, которые обеспечивают вычисление результатов сравнения для крупномасштабного подобия между первой группой технических документов и второй группой технических документов, не требуя больших объемов вычислений в течение длительных промежутков времени, с небольшой вероятностью того, что вычисленные значения подобия могут изменяться вследствие произвольного решения, принятого анализатором, который вычисляет подобие таким образом, что оно равно 0 только в том случае, когда первая группа технических документов и вторая группа технических документов являются совершенно различными, и который вычисляет подобие таким образом, что оно равно единице только в том случае, когда первая группа технических документов и вторая группа технических документов являются в точности одинаковыми.
Еще одной задачей этого изобретения является создание устройства вычисления подобия, программы вычисления подобия и способа вычисления подобия, которые могут выполнять вычисления подобия за сравнительно короткое время вычислений даже в том случае, когда общее количество технических документов, подлежащих сравнению, составляет несколько десятков тысяч или более.
Еще одной задачей этого изобретения является создание устройства вычисления подобия, программы вычисления подобия и способа вычисления подобия, которые способны производить крупномасштабное сравнение групп технических документов.
Еще одной задачей этого изобретения является создание устройства вычисления подобия, программы вычисления подобия и способа вычисления подобия, с которыми могут легко работать даже инвесторы и предприниматели общего профиля, которым нужно исследовать стоимость предприятия, выраженную через нематериальные активы.
Для решения вышеупомянутых проблем в этом изобретении предложено устройство вычисления подобия, вычисляющее показатель, по которому судят о техническом подобии между первой группой технических документов и второй группой технических документов, которые содержат патентные документы, технические отчеты или иные технические документы, отличающие тем, что содержит средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения; средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов Международной патентной классификации (МПК); средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации; средство вычисления подобия, предназначенное для вычисления в качестве подобия отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученному в результате кластерного анализа; и средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы произведений значения первой поправки, которая принимает значение, соответствующее количеству технических документов, содержащихся в каждом смешанном кластере, и значения второй поправки, которая принимает значение, соответствующее состоянию смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов в каждом смешанном кластере, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных количеству технических документов в каждом кластере в степени α (где 0<α), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления количества технических документов в каждом кластере в степени α (где 0<α) на нормировочный коэффициент, например на среднее значение количества технических документов во всех кластерах, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ) на нормировочный коэффициент, для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Настоящее изобретение также может отличаться тем, что нормировочный коэффициент равен максимальному значению вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ).
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит:
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных отношению коэффициента N/M состава и коэффициента n/m смешения в степени ζ (где 0<ζ), для коэффициента N/M состава, равного отношению количества N технических документов, содержащихся во второй группе технических документов, к количеству M технических документов, содержащихся в первой группе технических документов, и для коэффициента n/m смешения, равного отношению количества n технических документов из второй группы технических документов к количеству m технических документов из первой группы технических документов, которые содержатся в каждом смешанном кластере, полученном в результате кластерного анализа, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и для вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем установления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Также для обеспечения решения вышеупомянутых проблем настоящее изобретение содержит:
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и для вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления разности значений математического ожидания на количество технических документов в каждом смешанном кластере, и установления результата деления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и последующего деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Согласно настоящему изобретению устройство вычисления подобия, вычисляющее показатель, по которому судят о техническом подобии между первой группой технических документов и второй группой технических документов, каждая из которых содержит патентные документы, технические отчеты или иные технические документы, содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления в качестве подобия отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученных в результате кластерного анализа; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Следовательно, показатель, указывающий подобие технического содержания, описанного в группах технических документов, может быть легко вычислен на основании отношения общего количества проанализированных кластеров к количеству смешанных кластеров.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы произведения значения первой поправки, которая принимает значение, соответствующее количеству технических документов, содержащихся в каждом смешанном кластере, и значения второй поправки, которая принимает значение, соответствующее состоянию смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов в каждом смешанном кластере, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, может быть выполнено введение поправки, которая вследствие существования поправочного члена 1 обеспечивает больший весовой коэффициент для смешанного кластера в соответствии с количеством содержащихся в нем технических документов и вследствие существования поправочного члена 2 обеспечивает такой весовой коэффициент кластера, чтобы он являлся более важным по мере того, как состав технических документов, содержащихся в смешанном кластере, является более близким к заданному значению, для увеличения значения подобия таким образом, чтобы в результат вычисления подобия могла быть введена поправка для обеспечения его соответствия человеческому восприятию.
Следовательно, путем вычисления подобия с использованием поправочного члена 1 и поправочного члена 2 в подобие может быть введена поправка, увеличивающая вклад смешанных кластеров с большим количеством технических документов и уменьшающая значение подобия за счет введения поправки в том случае, когда состояние смешения технических документов является неустойчивым.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных количеству технических документов в каждом кластере в степени α (где 0<α), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, подобие может быть вычислено таким образом, что кластер приобретает большую важность тогда, когда в кластере имеется большее количество технических документов.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию деления количества технических документов в каждом кластере в степени α (где 0<α) на нормировочный коэффициент, например на общее количество кластеров, для вычисления подобия.
Следовательно, можно обеспечить, чтобы 0 ≤подобие ≤1.
В качестве нормировочного коэффициента используют среднее значение количества технических документов во всех кластерах, поэтому количество технических документов может быть вычислено с использованием в качестве опорной величины среднего значения количества технических документов во всех кластерах.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Другими словами, обеспечена функция, выполняющая вычисление с величиной (количество комбинаций выборки m технических документов из группы A и n технических документов из группы B)/(количество комбинаций выборки m+n технических документов из смешанной группы, состоящей из группы A и группы B), помещенной в числитель в средстве вычисления подобия. Следовательно, может быть введена поправка, обеспечивающая малое значение подобия для большого отклонения и большое значение подобия для малого отклонения, соответствующая (искусственному) отклонению в количестве технических документов из группы A и группы B, содержащихся в каждом смешанном кластере. Предусмотрен нормировочный коэффициент, равный максимальному значению вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), поэтому может быть гарантировано, что вычисленное значение подобия находится в следующем интервале: 0≤подобие≤1.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных отношению коэффициента N/M состава и коэффициента n/m смешения в степени ζ (где 0<ζ), для коэффициента N/M состава, представляющего собой отношение количества N технических документов, содержащихся во второй группе технических документов, к количеству M технических документов, содержащихся в первой группе технических документов, и для коэффициента n/m смешения, представляющего собой отношение количества n технических документов из второй группы технических документов к количеству m технических документов из первой группы технических документов, которые содержатся в каждом смешанном кластере, полученном в результате кластерного анализа, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, подобие может быть вычислено таким образом, чтобы оно имело более высокое значение (приближающееся к единице) по мере того, как коэффициент состава, равный отношению количества технических документов в группе A и в группе B, становится равным коэффициенту смешения технических документов в каждом кластере.
Путем задания экспоненты ζ для отношения коэффициента состава и коэффициента смешения большей, чем единица (ζ>1), может быть предотвращено сильное влияние смешанных кластеров с малым значением отношения коэффициента, равного отношению количества технических документов в группах A и B, и коэффициента смешения технических документов в каждом кластере, на результат вычисления подобия.
А путем задания экспоненты ζ, равной единице (ζ=1), может быть реализовано такое подобие, что оно просто увеличивается или уменьшается в соответствии с отношением коэффициента состава, равного отношению количества технических документов в группах A и B, и коэффициента смешения технических документов в каждом кластере.
А путем задания экспоненты числителя таким образом, что 0<ζ<1, влияние результата вычисления подобия может быть уменьшено в том случае, когда отношение коэффициента состава, равного отношению количества технических документов в группах A и B, и коэффициента смешения технических документов в каждом кластере является большим.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем установления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, введение поправки может быть выполнено таким образом, чтобы вызвать чувствительную реакцию результата вычисления подобия на разность значений математического ожидания в соответствии с заданным значением параметра ξ.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления разности значений математического ожидания на количество технических документов в каждом смешанном кластере, и установления результата деления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ) и последующего деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, введение поправки может быть выполнено таким образом, чтобы вызвать чувствительную реакцию результата вычисления подобия на разность значений математического ожидания в соответствии с заданным значением параметра ξ.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На Фиг.1 показана общая конфигурация системы вычисления подобия из этого изобретения;
на Фиг.2 показана блок-схема устройства вычисления подобия из этого изобретения;
на Фиг.3 показана конфигурация технических документов, содержащихся в группе А технических документов и в группе B технических документов;
на Фиг.4 изображена схема последовательности операций, на которой показана обработка данных для визуального отображения подобия;
на Фиг.5 показан пример выводимого на дисплей содержимого экрана для ввода данных, предназначенного для вычисления подобия;
на Фиг.6 показан пример выводимого на дисплей содержимого экрана, обеспечивающего визуальное отображение подобия, для уведомления пользователя о вычисленных подобиях;
на Фиг.7 показана конфигурация каждого кластера после кластерного анализа группы технических документов с использованием устройства вычисления подобия из этого изобретения;
на Фиг.8 изображена схема последовательности операций, на которой показана обработка данных для вычисления подобия;
на Фиг.9 приведена таблица, в которой показаны заданные условия, использованные при вычислениях подобия;
на Фиг.10 показана ситуация, имеющая место в том случае, когда в смешанном кластере 1 содержится множество технических документов;
на Фиг.11 приведена таблица, в которой показаны примеры результатов вычисления подобия для случая использования поправочного члена 1 (1);
на Фиг.12 приведена таблица, в которой показаны примеры результатов вычисления подобия для случая использования поправочного члена 2 (1);
на Фиг.13 приведена таблица, в которой показаны примеры результатов вычисления подобия для случая использования обоих поправочных членов: поправочного члена 1 (1) и поправочного члена 2 (1);
на Фиг.14 приведена таблица, в которой показаны примеры результатов вычисления подобия для случая использования поправочного члена 2 (2);
на Фиг.15 приведена таблица, в которой показаны примеры результатов вычисления подобия для случая использования двух поправочных членов: поправочного члена 1 (1) и поправочного члена 2 (2);
на Фиг.16 приведена таблица, в которой показаны примеры результатов вычисления разностей значений математического ожидания при подстановке условий 1-4 в уравнение (31);
на Фиг.17 приведена таблица, в которой показаны примеры результатов вычисления подобия для тех случаев, когда произведена подстановка условий 1-4 в уравнение (32) при ξ=10;
на Фиг.18 приведена таблица, в которой показаны примеры результатов вычисления подобия для того случая, когда использованы два поправочных члена: поправочный член 1 (1) и поправочный член 2 (3);
на Фиг.19 показана ситуация, имеющая место в известном уровне техники, при которой выполняют мелкомасштабные сравнения отдельных технических документов, содержащихся в группе A технических документов, и технических документов, содержащихся в группе B технических документов.
НАИЛУЧШИЙ ВАРИАНТ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
На Фиг.1 показана общая конфигурация системы вычисления подобия из этого изобретения.
Как указано на чертеже, система вычисления подобия, соответствующая изобретению, снабжена устройством 30 вычисления подобия, которое считывает технические документы, необходимые для вычислений подобия, из базы 20 данных, содержащей технические документы, через сеть 10 связи, вычисляет подобия и осуществляет их визуальное отображение на дисплее, и базой 20 данных, содержащей технические документы, в которой записаны технические документы, в том числе технические отчеты различных компаний, а также публикации патентов, публикации полезных моделей и иных патентных документов, полученных через сеть 10 связи.
Сеть 10 связи представляет собой сеть Интернет или иную сеть связи; устройство 30 вычисления подобия может получать информацию, связанную с патентными документами и иными техническими документами, из базы 20 данных, содержащей технические документы, через сеть 10 связи.
Устройство 30 вычисления подобия получает информацию, связанную с техническими документами, подлежащими сравнению, а также введенные пользователем условия сравнения документов, считывает технические документы, необходимые для вычисления подобия, из базы 20 данных, содержащей технические документы, через сеть 10 связи, и может вычислять подобия и отображать их на дисплее.
На Фиг.2 показана блок-схема устройства вычисления подобия, соответствующего изобретению.
Как показано на чертеже, узел приема/передачи информации устройства 30 вычисления подобия снабжен средством 365 передачи/приема (которое также может содержать функции средства ввода групп технических документов, средства ввода технической информации или средства вывода), которое может осуществлять обмен информацией с базой 20 данных, содержащей технические документы, или с другим устройством связи через сеть 364 связи, например через линии связи общего пользования, через сеть связи и т.п.
Средство 365 передачи/приема может осуществлять сбор технических документов, необходимых для вычисления подобия, из базы 20 данных, содержащей технические документы, через сеть 10 связи.
Устройство 30 вычисления подобия также снабжено находящимся в нем средством 370 ввода (которое также может содержать функции средства ввода технической информации), например клавиатурой, манипулятором типа "мышь" или аналогичным устройством, предназначенным для ввода пользователем информации, связанной с группами технических документов, подлежащими сравнению, и условий сравнения документов.
Устройство 30 вычисления подобия также содержит интерфейс 371 ввода (который может содержать функции средства ввода технической информации), предназначенный для считывания различной информации, введенной при помощи средства 370 ввода, и для передачи информации в средство 380 обработки информации, описание которого приведено ниже, и для вывода команд отображения на жидкокристаллический дисплей или аналогичное устройство на основании команд, поступивших из средства 380 обработки информации; средство 372 визуального отображения (которое также может содержать функции средства вывода), предназначенное для вывода на экран изображений, текста и иной информации; и интерфейс 373 средства визуального отображения (который может содержать функции средства вывода), предназначенный для вывода сигналов изображения для их вывода на экран средства 372 визуального отображения на основании команды, выданной средством 380 обработки информации. Средство 370 ввода не ограничено клавиатурой или манипулятором типа "мышь", но может, например, содержать планшет или иное устройство ввода данных.
Устройство 30 вычисления подобия снабжено устройством 378 для установки носителя записи, в которое может быть вставлен сменный носитель 377 записи, и интерфейсом 379 носителя записи (который может содержать функции средства ввода групп технических документов, средства ввода технической информации или средства вывода), который записывает информацию различных типов на носитель 377 записи и считывает с него информацию. Носитель записи 377 представляет собой вставляемый сменный носитель записи для магнитной записи, оптической записи или иной записи, типичными примерами которого являются платы памяти и иные полупроводниковые приборы, носители на магнитооптических дисках, магнитные диски и т.п.
Кроме того, устройство 30 вычисления подобия снабжено средством 380 обработки информации, которое осуществляет управление всем устройством 30 вычисления подобия, и запоминающим устройством 381, которое, в свою очередь, содержит постоянное запоминающее устройство (ПЗУ), в котором запомнены программы, выполняемые средством 380 обработки информации, и различные постоянные, и оперативное запоминающее устройство (ОЗУ), которое является средством записи, служащим в качестве рабочей области при выполнении обработки информации средством 380 обработки информации.
Средство 380 обработки информации (средство кластерного анализа или средство вычисления подобия) может обеспечивать реализацию функции получения информации, связанной с группами технических документов, подлежащих сравнению, и введенных пользователем условий сравнения технических документов, функции сбора технических документов, необходимых для вычисления подобия, из базы 20 данных, содержащей технические документы, и функции вычисления подобия между техническими документами на основании программы вычисления подобия и программы обработки данных для вычисления подобия, запомненных в средстве 384 хранения информации. Имеются функции визуального отображения результатов вычисления подобия на средстве 372 визуального отображения.
Средство 380 обработки информации (средство кластерного анализа) может обеспечивать реализацию функции разделения и записи текста, содержащего слова (одиночные слова, сложные слова, существительные, глаголы, предлоги, прилагательные, наречия, частицы и т.п.), содержащиеся в формулах изобретений, в подробных описаниях изобретений, в кратких пояснениях чертежей, в рефератах и т.п., входящих в состав документов; функции механического извлечения одного символа, двух символов и т.п. для поиска в технических документах; и функции выполнения кластерного анализа найденных технических документов по каждой технической информации.
Средство 380 обработки информации (средство кластерного анализа) может обеспечивать реализацию функции выполнения кластерного анализа с использованием объектов, содержащихся в элементах библиографического описания и т.п. (индекса МПК или иной классификации, даты подачи заявки, номера заявки, имен заявителей, авторов изобретения, был ли подан запрос на экспертизу, имеются ли изменения, имеется ли внутренний приоритет, была ли произведена подача заявки в других странах, имелись ли причины для отклонения заявки, даты регистрации, регистрационного номера и т.п.).
Средство 380 обработки информации (средство вычисления подобия) может обеспечивать реализацию функции вычисления отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученному из результатов кластерного анализа, для вычисления подобия между группами технических документов.
Вместо выполнения средством 380 обработки информации всего объема этой обработки, задачи настоящего изобретения могут быть достигнуты за счет распределения выполнения между множеством устройств обработки.
Кроме того, устройство 30 вычисления подобия снабжено накопителем на жестких дисках или иным средством 384 записи, способным осуществлять запись различных постоянных, относящихся к обработке, выполняемой устройством 30 вычисления подобия, информации об атрибутах, используемой при соединении с устройствами связи по сети для обеспечения связи с ними, унифицированных указателей информационного ресурса (URL), информации о межсетевых шлюзах, о системе доменных имен (DNS) и иной информации, связанной с соединением, информации, связанной с управлением предприятием, информации, связанной с патентами, патентными документами, техническими отчетами, ключевыми словами, технической информацией и иной информации; интерфейс 385 средства записи (который может содержать функции средства ввода групп технических документов, средства ввода технической информации или средства вывода), который считывает информацию, записанную в средстве 384 записи, и записывает информацию в средство записи 384; и средство 390, представляющее собой календарь/часы, которое отсчитывает время.
Различные периферийные схемы, в состав которых входит средство 380 обработки информации, интерфейс 373 средства визуального отображения, запоминающее устройство 381, интерфейс 385 средства записи, календарь/часы 390 и т.п., находящиеся в устройстве 30 вычисления подобия, соединены шиной 399, и в средстве 380 обработки информации могут быть реализованы функции управления различными периферийными схемами на основании выполняемой программы.
Средство 365 передачи/приема, интерфейс 379 носителя записи, интерфейс 385 средства записи и иные средства ввода технической информации могут обеспечивать ввод первой группы технических документов и второй группы технических документов, подлежащих сравнению.
Средство 365 передачи/приема, средство 370 ввода, интерфейс 371 ввода, интерфейс 379 носителя записи, интерфейс 385 средства записи и иные средства ввода технической информации могут обеспечивать ввод ключевых слов, индекса МПК и иной технической информации.
Средство 365 передачи/приема, интерфейс 373 средства визуального отображения, интерфейс 385 средства записи, интерфейс 379 носителя записи, интерфейс принтера и иные средства ввода технической информации могут осуществлять вывод подобий, вычисленных средством вычисления подобия, в средство записи, в средство визуального отображения или в средство связи.
Рассмотрены случаи, в которых показанная на Фиг.1 база 20 данных записана в средстве 384 записи, предоставлена в виде постоянного запоминающего устройства на компакт-диске (CD-ROM), перезаписываемого компакт-диска (CD-RW), универсального цифрового диска (DVD), магнитооптического диска (МО) или иного носителя 377 записи и получена из других устройств связи через сеть 364 связи.
Кроме того, вышеописанное устройство 30 вычисления подобия может быть реализовано с использованием персонального компьютера, рабочей станции или компьютера различных иных типов. Кроме того, возможен вариант его реализации путем подключения компьютеров к сети и использования распределительных функций.
Подобие между техническими документами, вычисленное устройством вычисления подобия или программой вычисления подобия, соответствующей настоящему изобретению, представляет собой числовое значение, вычисленное посредством крупномасштабных сравнений на основании заданных ключевых слов, индекса МПК и т.п. между первой группой технических документов (группой А технических документов) и отличной от нее второй группой технических документов (группой B технических документов); это числовое значение используется в качестве показателя для указания той степени, в которой группы технических документов являются родственными с технической точки зрения.
Предполагается, что первая группа технических документов (группа А технических документов) и вторая группа технических документов (группа B технических документов) являются собраниями технических документов, каждое из которых имеет некоторые конкретные атрибуты.
В настоящем изобретении может быть легко выполнено сравнение технических документов путем вычисления числового значения в качестве показателя для качественной оценки степени подобия между техническим содержанием, описанным в первой группе технических документов (в группе А технических документов), состоящей из публикаций патентов, поданных компанией A, или из технических отчетов, выпущенных компанией A, и техническим содержанием, описанным во второй группе технических документов (в группе B технических документов), состоящей из публикаций патентов, поданных компанией B, или из технических отчетов, выпущенных компанией B.
В варианте осуществления изобретения, объяснение которого приведено ниже, подобие определено как имеющее большее значение для больших степеней подобия между техническим содержанием, описанным в первой группе технических документов (в группе А технических документов) и во второй группе технических документов (в группе B технических документов).
В настоящем изобретении вычисления выполняются таким образом, что 0 ≤ подобие ≤ 1, поэтому существует возможность непосредственного сравнения вычисленного подобия между первой группой технических документов (группой А технических документов) и второй группой технических документов (группой B технических документов) и вычисленного подобия между третьей группой технических документов (группой C) технических документов и четвертой группой технических документов (группой D технических документов) даже в том случае, когда при вычислении подобия заданы различные условия. Однако интервал значений, которые могут принимать подобия, не ограничен этим интервалом.
На Фиг.3 показана конфигурация технических документов, содержащихся в группе А технических документов и в группе B технических документов.
Как показано на чертеже, группа А технических документов содержит M технических документов A1, A2, A3,..., AM, а группа B технических документов содержит N технических документов B1, B2, B3,..., BN.
На Фиг.4 изображена схема последовательности операций, на которой показана обработка данных для визуального отображения подобия.
Как показано на чертеже, когда пользователь намеревается произвести сравнение групп технических документов и исследовать степень подобия технического содержания, то выполняется операция S10 "ввод команды вычисления подобия" (ниже эта операция обозначена аббревиатурой "S10", и подобным же образом обозначены остальные операции), пользователь приводит в действие клавиатуру, манипулятор типа "мышь" или иное средство 370 ввода, имеющееся в устройстве 30 вычисления подобия, для ввода команды вычисления подобия, вызывая выполнение дальнейшей последовательности обработки.
При операции S100 "считывание/отображение содержимого экрана для ввода данных" устройство 30 вычисления подобия на основании команды вычисления подобия считывает из средства 384 записи информацию, подлежащую визуальному отображению в качестве содержимого экрана для ввода данных, для различных условий, относящихся к вычислениям подобия, и отображает содержимое экрана для ввода данных с условиями, необходимыми для вычисления подобия, на средстве 372 визуального отображения, на основании информации, подлежащей визуальному отображению.
На Фиг.5 показан пример выводимого на дисплей содержимого экрана для ввода данных, предназначенного для вычисления подобия.
Как показано на чертеже, содержимое экрана для ввода данных отображает на экране дисплея информацию, указывающую условия извлечения для первой группы технических документов и для второй группы технических документов, подлежащих сравнению, и информацию, относящуюся к описанию ключевых слов, к индексу МПК и к иной технической информации. На основании этого содержимого экрана, выведенного на дисплей, пользователь может вводить различные элементы данных.
В участке, предназначенном для ввода условий для кластерного анализа, могут быть введены публикации патентов, технические отчеты и иные документы для обработки. Также могут быть введены установочные параметры, указывающие участки для обработки, а именно весь текст, только формула изобретения и т.п., и различные условия для обработки, например, критерии для кластерного анализа, в том числе индекс МПК, ключевые слова и т.п. Кроме того, в качестве условий для извлечения групп документов отображены пункты для ввода периода дат подачи заявок для публикаций патентов, описания отраслей промышленности, наименования предприятий и имена частных лиц, которые являются источниками документов и т.п. На основании содержимого экрана для ввода данных, показанного на Фиг.5, пользователь может легко вводить условия для вычислений подобия и выбирать желательные условия вычисления из множества заранее заданных условий вычисления.
На Фиг.5 предусмотрен участок для ввода способа введения поправки для введения поправки в соотношение смешанных кластеров в соответствии с тем, для чего предназначено вычисление подобия.
Например, в качестве поправочного члена 1 пользователь может ввести условие введения поправки для введения поправки в подобие на основании значения, определенного в соответствии с количеством технических документов, содержащихся в каждом смешанном кластере.
А в качестве поправочного члена 2 пользователь может ввести условие введения поправки для введения поправки в значение подобия на основании значения, определенного в соответствии со степенью смешивания технических документов из первой группы технических документов и технических документов из второй группы технических документов, содержащихся в каждом смешанном кластере.
В настоящем изобретении в качестве способа введения поправки в соответствии со степенью смешивания с техническими документами может быть выбран способ введения поправки в соответствии с "вероятностью наличия конкретного количества технических документов". В этом способе введения поправки для каждого смешанного кластера вычисляется сумма значений поправки, пропорциональных вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов в степени γ (где 0<γ), и результат деления этой суммы на общее количество кластеров используется в качестве поправки для подобия.
В настоящем изобретении может быть выбран способ введения поправки в соответствии с "коэффициентом смешения технических документов". В этом способе введения поправки для каждого смешанного кластера вычисляется сумма значений поправки, пропорциональных отношению коэффициента состава и коэффициента смешения в степени ζ (где 0<ζ), для коэффициента N/M состава, равного количеству M технических документов, содержащихся в первой группе технических документов, и количества N технических документов, содержащихся во второй группе технических документов, и для коэффициента n/m смешения, равного отношению количества m технических документов из первой группы технических документов к количеству n технических документов из второй группы технических документов, содержащихся в каждом смешанном кластере, полученном в результате кластерного анализа; для введения поправки в подобие эта сумма делится на общее количество кластеров.
В настоящем изобретении способ введения поправки может быть выбран в соответствии с "разностью значений математического ожидания для технических документов". В этом способе введения поправки вероятность того, что в группе технических документов, объединяющей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, умножается на количество технических документов, содержащихся в каждом смешанном кластере, полученном в результате кластерного анализа, для вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, и вычисляется разность между этим значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, в качестве разности значений математического ожидания; для каждого смешанного кластера сумму значений поправки из этой разности значений поправки, имеющих отрицательные значения, берется в качестве экспоненты для произвольной постоянной ξ (где 1<ξ), и результат делится на количество всех кластеров для введения поправки в подобие.
При операции S12 "ввод условий вычисления подобия", показанной на Фиг.4, пользователь на основании указаний, отображенных на средстве визуального отображения, вводит при помощи средства 370 данные о типах технических документов, подлежащих сравнению: патентные документы, технические отчеты, информационные бюллетени компании, технических статьи и иные типы технических документов, а также группы технических документов для их сравнения, индекс МПК или ключевые слова, используемые в качестве условия для поиска технических документов в группах технических документов, для которых выполнен кластерный анализ, и информацию о введении поправки в соответствии с тем, для чего предназначено вычисление подобия.
При операции S102 "сбор технических документов" средство 380 обработки информации определяет базу данных, в которой будет производиться поиск, на основании типа технических документов (например, патентные документы), введенного пользователем, и выводит в указанную базу данных информацию для сбора данных о группах технических документов на основании введенного пользователем описания групп технических документов (например, группы А технических документов, относящихся к компании A, и группы B технических документов, относящихся к компании B).
При операции S130 "считывание технических документов" база 20 данных, содержащая технические документы, считывает найденные технические документы из базы данных на основании данных о типе технических документов, о группе технических документов и т.п., полученных из средства 30 вычисления подобия, и передает эти документы в устройство 30 вычисления подобия.
При операции S104 "обработка данных для вычисления подобия" устройство 30 вычисления подобия выбирает из групп технических документов, полученных из базы 20 данных (например, из группы А технических документов, относящихся к компании A, и группы B технических документов, относящихся к компании B), те технические документы, которые имеют указанный пользователем индекс МПК и содержат указанные пользователем ключевые слова, и выполняют кластеризацию.
Смешанный кластер определен как кластер, в котором, в результате кластерного анализа, смешаны технические документы, принадлежащие к группе А технических документов, и технические документы, принадлежащие к группе B технических документов. В настоящем изобретении подобие вычисляется на основании доли существующих смешанных кластеров среди всех кластеров.
В зависимости от назначения, для которого должно быть использовано подобие, введение поправки может быть выполнено в соответствии с количеством технических документов, содержащихся в каждом смешанном кластере, с вероятностью смешения, с коэффициентом смешения или в соответствии с комбинацией этих параметров.
При операции S106 "обработка данных для визуального отображения подобия" устройство 30 вычисления подобия отображает вычисленное подобие на средстве 372 визуального отображения для уведомления пользователя. При операции S106 вместо визуального отображения подобия на средстве 372 визуального отображения вычисленное подобие может быть выведено и передано в другое устройство связи через средство 365 передачи/приема и сеть 10 связи, или может быть выведено и записано в средстве 384 записи через интерфейс 385 средства записи, или может быть выведено и записано на носителе 377 записи через интерфейс 379 носителя записи. Кроме того, вычисленное подобие может быть выведено в средство печати через интерфейс принтера для его печати (на чертежах не показано).
На Фиг.6 показан пример экранного изображении для отображения подобия, для уведомления пользователя о подобиях, вычисленных устройством 30 вычисления подобия.
Как показано на чертеже, на экранном изображении для отображения подобия отображается введенная пользователем информация для указания и поиска групп технических документов, а также критерии, используемые при кластерном анализе ключевых слов, индексов МПК и иной технической информации, и введенная информация о способах введения поправок и т.п. для подтверждения.
Кроме того, в качестве поправочного члена 3 пользователь может, например, ввести в экранное изображение для отображения подобия условия введения поправки для каждого кластера, чтобы выполнить произвольное умножение на весовой коэффициент, при этом при выполнении кластерного анализа особое внимание обращено на заданные классификационные индексы патентов и ключевые слова. В показанном примере в качестве числового значения для поправочного члена 3 задано числовое значение, равное "1,000".
В экранном изображении для отображения подобия также предусмотрены участки для отображения результатов вычисления подобия, ползунков для непрерывного (бесступенчатого) изменения условий вычисления подобия, например параметров α, γ, ζ, ξ и т.п., для введения поправки в подобие, и содержания проанализированных кластеров, используемого при подтверждении поправочных членов для каждого кластера.
Пользователь может легко изменять условия вычисления подобия, просматривая вычисленные подобия. Когда пользователь приводит в действие ползунок, то средство 380 обработки информации принимает решение о завершении действия ползунка на основании времени, измеренного календарем/часами 390. Затем обработка, выполняемая средством 380 обработки информации, ответвляется к операции S104, при которой снова вычисляется подобие, и на экранном изображении для отображения подобия отображаются результаты вычисления подобия.
Как показано на Фиг.4, обработку данных для вычисления подобия завершают операцией S14 "конец", операцией S108 "конец" и операцией S140 "конец".
При вычислении "подобия" для использования при крупномасштабных сравнениях первой группы технических документов (группы A) и второй группы технических документов (группы B), кластерный анализ технических документов в этом изобретении содержит классификацию технических документов с использованием ключевых слов, индексов МПК и т.п.
Когда при создании этого изобретения была предпринята попытка получить панорамное представление двух групп технических документов для их сравнения, то вычисления были чрезвычайно сложными в том случае, когда эти две группы технических документов были отдельными. Однако полагали, что вычисления упростились бы в том случае, если бы эти две группы были бы "смешаны" и упорядочены и, следовательно, была проявлена находчивость, заключающаяся в "смешении" этих двух групп. И, как и ожидалось, оказалось, что эта ситуация хорошо подходит для вычислений подобия. После смешения этих двух групп технических документов по выполнении классификации посредством кластерного анализа появлялись кластеры (смешанные кластеры), содержащие составные элементы (технические документы) из обеих групп технических документов, и было установлено, что доля смешанных кластеров относительно количества всех кластеров являлась близкой к подобию с точки зрения нашего собственного обычного восприятия.
Сначала, как описано выше, смешивают технические документы из первой группы технических документов и из второй группы технических документов для получения одной группы.
Группу смешанных технических документов подвергают анализу, разделяя ее на малые наборы (именуемые кластерами) технических документов каким-либо способом классификации. Предположим, что некоторый кластер содержит m технических документов, принадлежащих к первой группе технических документов, и n технических документов, принадлежащих ко второй группе технических документов.
Термин "кластерный анализ" здесь определен как "деление на наборы" технических документов на основании индексов МПК или согласно тому, содержит ли технический документ заданное ключевое слово.
На Фиг.7 показана конфигурация отдельных кластеров после кластерного анализа группы технических документов с использованием устройства вычисления подобия согласно изобретению.
Например, как показано на Фиг.7, когда в качестве технических документов, классифицированных по индексу МПК "G06F 17/30", существуют "патентный документ A1" в первой группе технических документов и "патентный документ B1" во второй группе технических документов, то кластер индекса МПК "G06F 17/30" содержит элементы "патентный документ A1" и "патентный документ B1".
Кроме того, когда в качестве технических документов, содержащих выражение "обработка текста" в качестве ключевого слова, существует "технический документ A2" в первой группе технических документов и существуют "технический документ B2" и "технический документ B3" во второй группе технических документов, то кластер для ключевого слова "обработка текста" содержит следующие элементы: "технический документ A2", "технический документ B2" и "технический документ B3".
В зависимости от атрибутов отдельных технических документов в группе технических документов имеется два следующих подхода к способам кластерного анализа.
1. В случае наличия атрибутов, для которых имеются внешние критерии (которым дано определение "атрибут типа 1"), кластеры могут быть сконфигурированы с использованием этих атрибутов. Например, для технических документов, которыми являются публикации патентов или подобные документы, однозначно определены следующие атрибуты: дата подачи заявки, индекс МПК и иные атрибуты.
2. Когда атрибуты определены через внутренние связи (которым дано определение "атрибут типа 2"), кластеры должны быть сформированы путем многомерного анализа (кластерного анализа) или иным средством. Например, вследствие сложности применения внешнего критерия к рефератам, к формулам изобретений или к иным текстовым компонентам в технических документах, которыми являются публикации патентов, мелкомасштабное подобие между документами определяют по отдельности, и кластеры формируют с использованием результатов многомерного анализа на основании таких определений. За счет использования способа "частота встречаемости терминов, обратная частоте встречаемости документов" (TFIDF) или иных способов, обычно используемых для вычисления мелкомасштабных подобий между документами, может быть предотвращено произвольное вмешательство анализатора.
Средство 380 обработки информации или иное средство кластерного анализа производит поиск технических документов, содержащих техническую информацию, введенную при помощи средства ввода технической информации, для технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, и выполняет кластерный анализ найденных технических документов для каждой технической информации.
В вариантах осуществления изобретения смешанный кластер определен следующим образом.
В кластере "индекс G06F 17/30" МПК, показанном на Фиг.7, смешаны следующие документы: "патентный документ A1", принадлежащий к группе А технических документов, и "патентный документ B1", принадлежащий к группе B технических документов. Кластер, в котором смешан технический документ, принадлежащий к группе А технических документов, и технический документ, принадлежащий к группе B технических документов, именуют смешанным кластером.
В вариантах осуществления изобретения, несмешанный кластер определен следующим образом.
Рассматривая пример, показанный на Фиг.7, в качестве технического документа, имеющего индекс "B01" классификации МПК, существует "патентный документ A3" из группы А технических документов; но когда в группе B технических документов не существует никаких технических документов, имеющих индекс "B01" классификации МПК, то кластер "B01" содержит только лишь элемент "патентный документ A3".
Как показано на Фиг.7, когда в группе А технических документов не существуют технические документы, содержащие в качестве ключевого слова, например, выражение "неорганические соединения", но такой технический документ существует как "технический документ B1" в группе B технических документов, то кластер для ключевого слова "неорганические соединения" содержит только лишь элемент "технический документ B1".
Таким образом, определение "несмешанный кластер" дано тому кластеру, в котором не смешаны технические документы, принадлежащие к группе А технических документов и технические документы, принадлежащие к группе B технических документов.
На Фиг.8 изображена схема последовательности операций, на которой показана обработка данных для вычисления подобия.
Когда в последовательности операций обработки, выполняемых средством 380 обработки информации, переходят далее к операции S104, показанной на Фиг.4, то в последовательности операций обработки, выполняемых средством 380 обработки информации, происходит ответвление к операции S200, и выполняют операцию S200 обработки и дальнейшие операции.
При операции S200 "смешение группы А технических документов и группы B технических документов" средство 380 обработки информации, входящее в состав устройства 30 вычисления подобия, смешивает группы технических документов, полученные из базы данных при операции S102 "сбор технических документов" (например, первую группу технических документов, относящихся к компании A, и вторую группу технических документов, относящихся к компании B), и выполняет обработку для получения одной группы технических документов.
При операции S202 "обработка данных для кластерного анализа" средство 380 обработки информации выполняет обработку данных для кластерного анализа на основании ключевых слов, индексов МПК или иной технической информации. Затем выполняют операцию S204 "определение формулы для поправочного члена 1", при которой после ввода пользователем команды введения в подобие поправки в соответствии с количеством технических документов, содержащихся в каждом смешанном кластере, средство 380 обработки информации на основании этой команды выполняет обработку, производя выбор формулы для поправочного члена. Здесь обработку выполняют таким образом, чтобы произвести подстановку заданной формулы в поправочный член 1 в соответствии с содержанием поправки.
Поправочный член 1 представляет собой поправочный член, используемый для введения в подобие поправки путем умножения на такой весовой коэффициент, что чем большее количество технических документов содержится в смешанном кластере, то тем более важным считают имеющийся кластер и тем более высоким становится подобие.
Когда в подобие не вводят поправку в соответствии с количеством технических документов, содержащихся в смешанном кластере, то производят подстановку поправочного члена 1, равного единице (=1) (представляющего собой постоянную).
Когда при операции S206 "определение формулы для поправочного члена 2" пользователем введена команда введения в подобие поправки в соответствии с состоянием смешения группы А технических документов и группы B технических документов в каждом смешанном кластере, то средство 380 обработки информации выполняет обработку, производя выбор формулы для поправочного члена на основании этой команды. Здесь обработку выполняют таким образом, чтобы произвести подстановку заданной формулы для поправочного члена 2 в соответствии с содержанием поправки.
Поправочный член 2 представляет собой поправочный член для введения в подобие поправки путем умножения на такой весовой коэффициент, что чем более близкой к заданному значению является доля технических документов, содержавшихся в смешанном кластере, то тем более важным считают существующий кластер и тем более высоким становится подобие.
Когда в подобие не вводят поправку в соответствии с состоянием смешения технических документов, содержащихся в смешанном кластере, то производят подстановку поправочного члена 2, равного единице (=1) (представляющего собой постоянную).
Когда при операции S208 "определение значения поправочного члена 3" пользователем введена команда введения в подобие поправки путем умножения на произвольный весовой коэффициент, сосредотачивающий внимание на заданных классификационных индексах патентов и ключевых словах при кластерном анализе, то средство 380 обработки информации на основании этой команды производит выбор формулы для поправочного члена. Здесь обработку выполняют таким образом, чтобы произвести подстановку в поправочный член 3 заданного значения в соответствии с содержанием поправки. Когда отсутствует какая-либо особая необходимость в сосредоточении внимания на заданных классификационных индексах патентов или на ключевых словах при кластерном анализе, то производят подстановку поправочного члена 3, равного единице (=1) (представляющего собой постоянную).
При операции S210 "вычисление подобия" средство 380 обработки информации перемножает каждый из поправочных членов, которыми являются поправочный член 1, поправочный член 2 и поправочный член 3, для каждого смешанного кластера друг с другом и вычисляет сумму. Для дальнейшей нормировки результата это значение делят на общее количество кластеров, вычисляя подобие.
При операции S212 "конец" подпрограмму обработки данных для вычисления подобия завершают и в последовательности выполняемых операций возвращаются к исходной последовательности операций обработки.
На Фиг.9 показаны заданные условия, использованные при вычислениях подобия.
На Фиг.9 приведена таблица, в которой показано количество технических документов, имеющихся в первой группе технических документов и во второй группе технических документов, подлежащих сравнению, и в каждом из кластеров 1-4, для того случая, когда технические документы из этих двух групп в результате анализа распределены по четырем кластерам. Значения "ожидаемого подобия", приведенные в правом столбце таблицы, указывают ожидаемые значения вычисленного подобия для каждого из условий 1-4, полученные в результате слушаний, проведенных множеством специалистов, оценивших подобия технических документов. Как указано на чертеже в графе "допустимое отклонение", область допустимых отклонений, которые, как полагают, являются возможными для ожидаемых значений подобия, равна приблизительно ±0,050.
Следовательно, если при вычислении подобий с использованием устройства вычисления подобия из этого изобретения подобие вычислено в пределах допустимых отклонений, указанных на Фиг.9, то результат указывает, что выполняется оптимальное сравнение технических документов.
Базовый тип 1: Пример сравнения подобия (базового типа 1) без учета поправочных членов
Ниже проиллюстрирован пример вычисления базового значения подобия (базового типа 1) без использования поправочных членов. В этом примере вычисления подобия (базового типа 1) используют способ извлечения смешанных кластеров для вычисления подобия технических документов.
Полагают, что степень подобия технического содержания первой группы технических документов техническому содержанию второй группы технических документов (величина значения подобия) является пропорциональной "количеству смешанных кластеров".
Например, для того чтобы установить значение подобия в интервале значений 0≤ подобие ≤1, "количество смешанных кластеров" делят на "общее количество кластеров", которое представляет собой "сумму количества смешанных кластеров и количества несмешанных кластеров", и получают приведенное ниже уравнение (1) для вычисления подобия между группами технических документов.
Способ вычисления подобия, в котором учитывают смешанные кластеры, определен как способ извлечения смешанных кластеров. Наиболее основным подходом является показанное ниже уравнение (1). В приведенном ниже уравнении (1) показан пример вычисления в качестве подобия отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученному в результате кластерного анализа (это отношение ниже именуют коэффициентом смешанных кластеров). Следовательно, способы вычисления отношения количества смешанных кластеров к общему количеству кластеров не ограничены приведенным ниже уравнением (1).
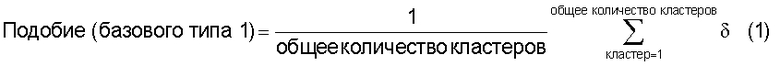
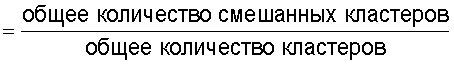
Здесь δ=1 для смешанного кластера и = 0 для несмешанного кластера.
Как объяснено выше, значение подобия представляет собой числовое значение, указывающее степень подобия между техническим содержанием, описанным в первой группе технических документов, и техническим содержанием, описанным во второй группе технических документов.
Количество смешанных кластеров представляет собой числовое значение, указывающее количество кластеров, в которых смешаны технические документы, принадлежащие к первой группе технических документов, и технические документы, принадлежащие ко второй группе технических документов.
Общее количество кластеров представляет собой числовое значение, указывающее общее количество кластеров, в которых существуют технические документы из первой группы технических документов или технические документы из второй группы технических документов.
Ниже приведено объяснение результатов вычислений, выполняемых с использованием формулы вычисления подобия (базового типа 1).
Если в результате кластерного анализа первой группы технических документов и второй группы технических документов, производимого с использованием заданных ключевых слов, индексов МПК или подобных параметров, получено общее количество кластеров, равное 10, и количество смешанных кластеров, равное 3, то вычисленное значение подобия (базового типа 1) равно 3/10=0,3.
Если общее количество кластеров равно 4, а количество смешанных кластеров равно 2, то вычисленное значение подобия (базового типа 1) равно 2/4=0,5.
Путем выполнения кластерного анализа с использованием ключевых слов, индексов МПК или подобных параметров технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, и вычисления в качестве подобия отношения количества смешанных кластеров к общему количеству кластеров может быть вычислено значение, представляющее собой основную долю подобия между этими двумя группами технических документов.
Кроме того, при вычислении подобия значение подобия, вычисленного путем деления количества смешанных кластеров на общее количество кластеров, может быть установлено таким образом, чтобы оно находилось в интервале значений 0≤ подобие ≤1.
Ниже приведено объяснение полезных результатов настоящего изобретения при использовании подобий (базового типа 1).
Путем использования ключевых слов, индексов МПК и т.п., содержащихся в первой группе технических документов и во второй группе технических документов, для выполнения кластерного анализа, и путем вычисления подобия на основании отношения количества смешанных кластеров к общему количеству проанализированных кластеров можно вычислить простыми средствами показатель, указывающий степень технического подобия между двумя группами технических документов. Было установлено, что вычисленное таким способом подобие между двумя группами технических документов, хорошо согласуется со степенью подобия, рассмотренной авторами изобретения с точки зрения здравого смысла.
В настоящем изобретении значения вычисленных подобий вычисляют таким образом, чтобы они находились в интервале значений 0≤ подобие ≤1, чтобы можно было вычислить показатель, являющийся постоянным вне зависимости от общего количества кластеров или от количества смешанных кластеров и вне зависимости от количества технических документов, содержащихся в группах технических документов.
Кроме того, можно непосредственно сравнить подобие, характеризующее сравнение первой группы технических документов и второй группы технических документов при наличии большего количества условий, с подобием, характеризующим сравнение первой группы технических документов с третьей группой технических документов.
Базовый тип 2: Пример сравнения подобия (базового типа 2) с учетом поправочных членов.
Ниже проиллюстрирован пример вычисления базового значения подобия (базового типа 2) с использованием поправочных членов. В этом примере вычисления подобия (базовый тип 2) к описанному выше примеру вычисления подобия (базового типа 1) добавлены поправочные члены 1-3.
Когда для вычисления подобия используют вышеупомянутое уравнение (1), то имеется преимущество, заключающееся в том, что значение подобия, пропорциональное количеству смешанных кластеров, может быть вычислено чрезвычайно быстро с использованием простой формулы.
Например, в простейшем случае вышеупомянутого уравнения (1) кластеры, содержащие большое количество технических документов, и кластеры, содержащие небольшое количество технических документов, вносят равные вклады. Из этого понятно, что уравнение (1) имеет недостаток, заключающийся в том, что не учитывается количество технических документов в отдельных кластерах. Следовательно, в уравнении (1) вычисляется одинаковое значение подобия вне зависимости от того, содержится ли в смешанном кластере большое количество технических документов или же в нем содержится только лишь два технических документа, и поэтому может возникнуть проблема, заключающаяся в том, что вычисленный результат будет отличаться от степени подобия, предполагаемой с точки зрения здравого смысла.
В дополнение к количеству технических документов, содержащихся в смешанном кластере, могут существовать случаи, в которых в вычисленное значение подобия должна вводиться поправка в соответствии с состоянием смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов, содержащихся в каждом смешанном кластере (количественное соотношение технических документов из первой группы технических документов и технических документов из второй группы технических документов) или путем применения умножения на произвольный весовой коэффициент в том случае, когда необходимо сосредоточить внимание на конкретных классификационных индексах патентов или ключевых словах.
На Фиг.10 показана ситуация, имеющая место в том случае, когда в смешанном кластере 1 содержится множество технических документов.
В примере по Фиг.10 в кластере 1 (смешанный кластер) содержится большое количество технических документов, поэтому считается, что кластер является важным, и его вклад может быть сделан наибольшим при вычислении подобия.
Другие кластеры (например, кластер 2, кластер 3, кластер 4 и т.п.) содержат меньшее количество технических документов, и, следовательно, считается, что они не являются важными, и поэтому желательно, чтобы вклады от этих кластеров были значительно меньшими, чем вклад от кластера 1.
Например, в ситуации, показанной в примере по Фиг.10, имеют место случаи, в которых влияние кластера 2, кластера 3 и кластера 4 следует уменьшить по сравнению с влиянием кластера 1. Если существование кластеров, содержащих небольшое количество технических документов, не игнорируется, то вычисленное значение подобия уменьшается до 0,5.
Следовательно, как показано в приведенном ниже уравнении (2), величина δ в уравнении (1) (где δ=1 в том случае, когда кластером является смешанный кластер, а в остальных случаях δ=0) умножается на поправочные члены. Необходим надлежащий нормировочный коэффициент для гарантии того, что в результате введения этой поправки интервал значений подобия не выходит за пределы интервала 0 ≤ подобие ≤ 1.
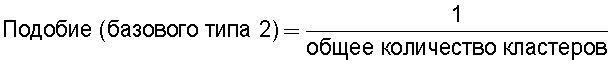
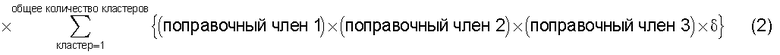
Здесь δ=1 для смешанного кластера и = 0 для несмешанного кластера.
Поправочный член 1 в уравнении (2) предназначен для вычисления подобия в соответствии с количеством технических документов, содержащихся в смешанном кластере. Этот поправочный член 1 используется для коррекции подобия с усиливающими весовыми коэффициентами, обеспечивающими следующее: чем большее количество технических документов содержится в смешанном кластере, тем более важным становится кластер и тем более высоким является подобие.
И наоборот, поправочный член 1 может вводиться в подобие поправки с ослабляющими весовыми коэффициентами, обеспечивающими следующее: чем меньшее количество технических документов содержится в смешанном кластере, тем менее важным является кластер, поэтому подобие становится меньшим.
Для поправочного члена 1 может использоваться иная формула вычисления значения первой поправки, которая принимает различные значения в соответствии с количеством технических документов, содержащихся в каждом смешанном кластере.
Поправочный член 2 в уравнении (2) используется для вычисления подобия в соответствии с состоянием смешения технических документов A и технических документов B в смешанном кластере (долями технических документов A и технических документов B).
Поправочный член 2 вводится в подобие поправки с усиливающими весовыми коэффициентами, обеспечивающими следующее: чем более близким является количество технических документов, содержащихся в смешанном кластере, к заданному количеству, тем более важным становится кластер и тем более высоким является подобие.
Поправочный член 2 также дает возможность вычисления значения второй поправки, которая может принимать значения в соответствии с состоянием смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов, содержащихся в каждом смешанном кластере.
Как указано в уравнении (2), для вычисления подобия вычисляется сумма поправочного члена 1, поправочного члена 2 или поправочного члена 3 для всех смешанных кластеров, и эта сумма делится на общее количество кластеров.
Термин "состояния смешения" технических документов, используемый при вычислении поправочного члена 2, означает следующее.
Этот поправочный член учитывает состояние смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов, содержащихся в определенном смешанном кластере. Когда технические документы обоих типов являются хорошо смешанными, то есть когда отсутствует какое-либо отклонение к любому из этих типов технических документов, то считается, что кластер является важным, и присваивается большой весовой коэффициент; а в том случае, когда технические документы не являются хорошо смешанными, то есть когда имеется отклонение к большему количеству технических документов из одной из групп технических документов, то считается, что кластер не является важным, и присваивается меньший весовой коэффициент.
Другими словами, поправочному члену присваивается больший весовой коэффициент в том случае, когда количество технических документов из первой группы технических документов и количество технических документов из второй группы технических документов, содержащихся в смешанном кластере, является близким к значению математического ожидания при случайной выборке документов из первой группы технических документов и из второй группы технических документов, а в том случае, когда это количество является далеким от значения математического ожидания, то ему присваивается меньший весовой коэффициент.
Поправочный член 3 используется для вычисления подобия с присвоенным произвольным весовым коэффициентом при учете конкретных классификационных индексов патентов или ключевых слов. Этот отдельный член создает пользователь, сравнивающий группы технических документов, и поэтому здесь подставлена постоянная "1", а дополнительные подробности не рассмотрены.
Прикладная задача типа 1: Пример вычисления поправочного члена 1 (1)



Пример вычисления подобия (уравнение (4)) с учетом поправочного члена 1 (1) имеет следующий вид.

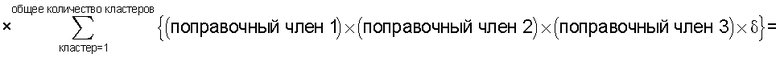
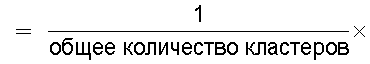


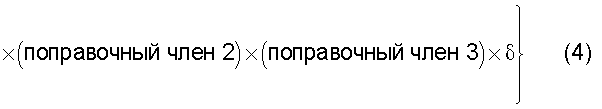
В поправочном члене 1 (1) для введения такой поправки, чтобы подобие имело большое значение в соответствии с количеством технических документов, содержащихся в смешанном кластере, в числитель вводится "количество технических документов в кластере" в степени α (где 0<α). А для обеспечения того, чтобы вычисленное значение подобия находилось в интервале 0 ≤ подобие ≤ 1, в знаменатель в формуле для поправочного члена 1 (1) вводится нормировочный коэффициент.
При вычислении поправочного члена 1 (1) в уравнении (4) в качестве нормировочного коэффициента это уравнение содержит среднее значение количества технических документов во всех кластерах, чтобы значение подобия не стало больше единицы даже при наличии большого количества технических документов в кластере, значение которого находится в числителе, и для обеспечения критерия, по которому судят о количестве технических документов. Нормировочный коэффициент также может быть получен путем вычисления суммы значений количества технических документов во всех кластерах в степени α и деления этой суммы на общее количество кластеров. Достаточно, чтобы этот нормировочный коэффициент обеспечивал следующее условие: 0 ≤ подобие ≤ 1, и этот коэффициент не ограничен формулой уравнения (4).
Кроме того, для предотвращения существенного воздействия смешанных кластеров, содержащих небольшое количество технических документов, на результат вычисления подобия значение экспоненты α в числителе устанавливается большим, чем единица (α>1).
Для увеличения или уменьшения значения подобия в соответствии с количеством технических документов в кластерах значение α устанавливается равным единице.
Для вычисления подобия в соответствии с количеством технических документов, содержащихся в кластерах, и уменьшения влияния воздействия при вычислении подобия, обусловленного существованием кластеров, содержащих большое количество технических документов, достаточно установить значение α в интервале 0<α<1.
Ниже приведено объяснение эффекта, обусловленного числителем и знаменателем формулы для "прикладной задачи типа 1: поправочный член 1 (1)".
Как объяснено в уравнении (4), в числителе поправочного члена 1 (1) находится значение "количества технических документов в кластерах", поэтому может быть вычислено подобие, пропорциональное количеству технических документов в кластерах.
Кроме того, в знаменателе поправочного члена 1 (1) имеется "нормировочный коэффициент", поэтому может быть обеспечено следующее условие: 0≤ подобие ≤1. В качестве нормировочного коэффициента в поправочном члене 1 (1) использовано среднее значение количества технических документов во всех кластерах, поэтому может быть вычислено относительное количество технических документов с привязкой к среднему значению количества технических документов во всех кластерах.
Кроме того, путем задания значения экспоненты в числителе, большего, чем единица (α>1), может быть предотвращено сильное влияние на результат вычисления подобия смешанных кластеров, содержащих небольшое количество технических документов. Путем задания значения экспоненты в числителе, равного единице (α=1), можно увеличивать или уменьшать значение подобия в соответствии с количеством технических документов в кластерах (простое сравнение количества). Путем задания значения экспоненты в числителе в интервале 0<α<1 может быть уменьшено влияние на результат вычисления подобия тех существующих кластеров, которые содержат большое количество технических документов.
Ниже приведен пример вычислений для случая подстановки условий из Фиг.9 в формулу (в уравнение (4)) для "прикладной задачи типа 1: поправочный член 1 (1)". Результаты вычислений представлены в таблице (Фиг.11), в которой описан пример результата вычисления подобия с использованием поправочного члена 1 (1) (результата вычислений при подстановке условий 1-4 в поправочный член 1 (1)).
Ниже представлены результаты пробных вычислений значений подобия, в которых в качестве условий для сравнения групп технических документов заданы условия 1-4 для того случая, когда учитывается только поправочный член 1 (1), а другие поправочные члены отсутствуют (то есть когда поправочный член 2 = 1, поправочный член 3 = 1), и выполняется простое сравнение количества технических документов, содержащихся в каждом смешанном кластере (то есть когда α=1).
Приведенное ниже уравнение (5) использовано для объяснения результатов вычислений для примера 4-1 вычислений (при подстановке условия 1 в уравнение (4)).
В случае условия 1 количество технических документов, содержащихся в каждом смешанном кластере (в этом варианте осуществления ими являются кластер 1 и кластер 2) равно трем. Следовательно, ожидается, что влияние поправки для подобия, обусловленной количеством технических документов, содержащихся в кластерах, будет малым.
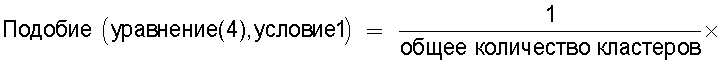

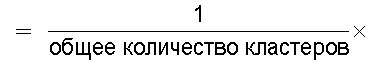


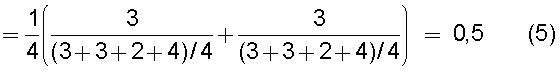
Значение подобия (при подстановке условия 1 в уравнение (4)), равное 0,5, которое вычислено с использованием уравнения (5), согласуется с результатом вычисления подобия, полученным с использованием уравнения (1); и когда также введен поправочный член 1 (1), то, по оценкам авторов изобретения, не происходит какого-либо существенного отклонения от подобия с точки зрения здравого смысла. Кроме того, значения количества технических документов в кластерах равны соответственно 3, 3, 2 и 4, поэтому все они вносят приблизительно одинаковый вклад; вычисленное значение подобия, равное 0,5, не сильно отклоняется от подобия, оцененного с точки зрения здравого смысла (равного приблизительно 0,30), и требования являются, по существу, выполненными.
Приведенное ниже уравнение (6) использовано для объяснения результатов вычислений для примера 4-2 вычислений (при подстановке условия 2 в уравнение (4)).
Количество технических документов, содержащихся в кластере 1 для условия 2, значительно больше, чем количество технических документов, содержащихся в кластерах с кластера 2 по кластер 4, поэтому ясно, что при вычислении подобия влияние количества технических документов, содержащихся в кластере 1, должно быть усилено при вычислении подобия для того, чтобы получить большее значение.
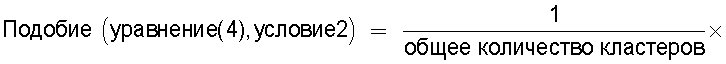

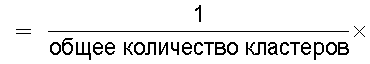


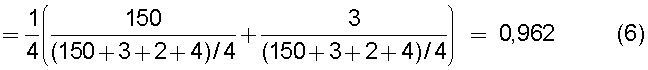
В значение подобия (при подстановке условия 2 в уравнение (4)), равное 0,962, которое вычислено с использованием уравнения (6), введена поправка, изменившая значение подобия от 0,5 (подобие, вычисленное при подстановке условия 1 в уравнение (4)) до значения подобия, равного 0,962 (подобие, вычисленное при подстановке условия 2 в уравнение (4)), причем это увеличение обусловлено наличием большого количества технических документов, содержащихся в кластере 1.
Ниже приведено объяснение полезных результатов уравнения (6) (при подстановке условия 2 в уравнение (4)).
Путем обработки данных для вычисления уравнения (6), когда количество технических документов, содержащихся в кластере, больше, чем количество технических документов, содержащихся в других кластерах, может быть обеспечено воздействие количества технических документов на результат вычисления подобия. Поскольку при вычислении подобия кластер 1 отображает, по существу, весь тренд, то это может рассматриваться как свойства кластера 1, определяющие подобие.
Было установлено, что этот результат вычисления подобия, по существу, согласуется со степенью подобия, оцененной с точки зрения здравого смысла.
Приведенное ниже уравнение (7) использовано для объяснения результатов вычислений для примера 4-3 вычислений (при подстановке условия 3 в уравнение (4)).
В случае условия 3 сумма значений количества технических документов, содержащихся в кластерах, та же, что и в случае условия 2, но количество технических документов, содержащихся в одиночном кластере 1, не является чрезвычайно большим, и, следовательно, желательно, чтобы при вычислении подобия влияние количества технических документов, содержащихся в кластере 1, не было бы столь же большим, как в случае условия 2.
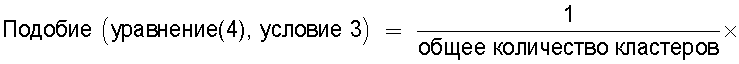
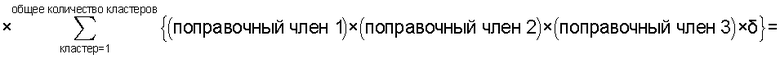


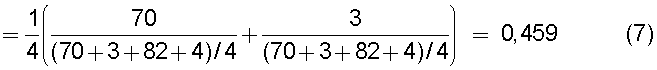
Значение подобия, вычисленное с использованием уравнения (7) (при подстановке условия 3 в уравнение (4)), равное 0,459, представляет собой значение с такой введенной поправкой, что количество технических документов, содержащихся в кластере 1, которое несколько меньше, чем количество технических документов, содержащихся в другом кластере 3, почти не вносит вклад в поправку для подобия.
Ниже приведено объяснение влияния результата вычисления уравнения (7) (при подстановке условия 3 в уравнение (4)).
Даже при большом количестве технических документов в кластере, если оно не сильно отличается от количества технических документов в другом кластере, путем выполнения обработки данных для вычисления поправочного члена 1 (1) можно предотвратить сильное влияние этого количества технических документов на результат вычисления подобия.
Результат вычисления подобия, полученный с использованием уравнения (7), дополнительно действует для сильного увеличения влияния кластера 1 и кластера 3, поэтому отсутствует заметное отклонение от подобия, оцененного с точки зрения здравого смысла (которое равно приблизительно 0,20), и получено, по существу, желаемое значение.
Приведенное ниже уравнение (8) использовано для объяснения результатов вычислений для примера 4-4 вычислений (при подстановке условия 4 в уравнение (4)).
В случае условия 4 сумма количества технических документов, содержащихся в кластерах, та же, что и для условия 3, но в этом случае доли технических документов первой группы и технических документов второй группы, содержащихся в кластере 1 и в кластере 2, являются в высокой степени неравными. Следовательно, желательно, чтобы вычисленное значение подобия не было большим, несмотря на большое количество технических документов, содержащихся в каждом смешанном кластере.

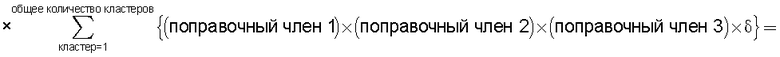



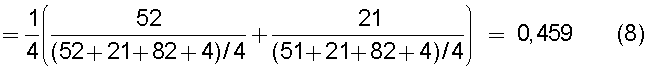
Значение подобия, вычисленное с использованием уравнения (8) (при подстановке условия 4 в уравнение (4)), равное 0,459, представляет собой значение с поправкой, введенной таким образом, что количество технических документов, содержащихся в кластере 1 и в кластере 2, которое является несколько меньшим, чем количество технических документов в другом кластере 3, почти не вносит вклад в поправку для подобия.
Ниже приведено объяснение влияния результата вычисления уравнения (8) (при подстановке условия 4 в уравнение (4)).
Даже при большом количестве технических документов в кластере, если оно не сильно отличается от количества технических документов в другом кластере, путем обработки данных для вычисления уравнения (8) можно предотвратить сильное влияние этого количества технических документов на результат вычисления подобия; однако в случае условия 4 с точки зрения восприятия результатов желательно, чтобы значение подобия было равно нескольким процентам.
Поскольку при условии 4 в результате обработки с использованием только одного поправочного члена 1 (1) могут появляться части, которые не согласуются с человеческим восприятием, то может оказаться полезным поправочный член 2, объяснение которого приведено ниже. Однако влияние кластеров 3, 1, 2 является значительным, так что влияние поправочного члена 1 (1) считается достаточным. Кроме того, если существуют кластеры с большим количеством технических документов, то путем обработки поправочного члена 1 (1) можно обеспечить воздействие количества технических документов, содержащихся в кластере, на подобие.
На Фиг.11 приведена таблица, в которой показаны примеры результатов вычисления подобия для тех случаев, в которых использован поправочный член 1 (1) (результаты вычислений при подстановке условий 1 - 4 в поправочный член 1 (1)).
Прикладная задача типа 2: Пример вычисления поправочного члена 2 (1)
Приведенное ниже уравнение (9) для поправочного члена 2 (1) обеспечивает введение поправки в соответствии с вероятностью смешивания технических документов в смешанном кластере.



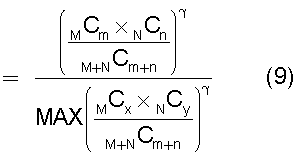
Здесь M - количество технических документов, содержащихся в первой группе технических документов (в группе A), N - количество технических документов, содержащихся во второй группе технических документов (в группе B), m - количество технических документов из первой группы технических документов (из группы A), содержащихся в заданном кластере, n - количество технических документов из второй группы технических документов (из группы B), содержащихся в заданном кластере, а γ - произвольная постоянная, причем γ>0.
Ниже показан пример вычисления подобия (уравнение (10)) с учетом вышеупомянутого поправочного члена 2 (1).



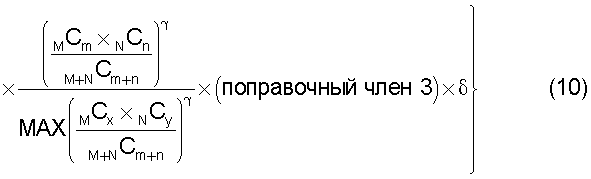
В поправочном члене 2 (1) из уравнения (10) в числителе находится значение вероятности того, что будет найдено m технических документов из первой группы технических документов (из группы A) и n технических документов из второй группы технических документов (из группы B) в степени γ (где 0<γ). Следовательно, может быть выполнено введение такой поправки, что подобие принимает большое значение в соответствии с вероятностью, связанной с количеством технических документов из первой группы технических документов (из группы A) и из второй группы технических документов (из группы B), которые содержатся в смешанном кластере.
Для обеспечения того, чтобы вычисленное значение подобия находилось в интервале 0≤ подобие ≤1, например, как указано в уравнении (10), в знаменателе в качестве нормировочного коэффициента находится максимальное значение вероятности того, что будет найдено m технических документов из первой группы технических документов (из группы A) и n технических документов из второй группы технических документов (из группы B) в степени γ (где 0<γ).
От нормировочного коэффициента требуется только лишь то, чтобы он представлял собой член, который может обеспечить выполнение следующего условия: 0≤ подобие ≤1, и он не ограничен нормировочным коэффициентом, показанным в уравнении (10).
Ниже приведено объяснение условий для задания значения экспоненты γ.
Если необходимо ввести в значение подобия поправку прямо пропорционально близости распределения технических документов из группы A и из группы B, содержащихся в смешанном кластере, к распределению, полученному при случайной выборке документов из групп А и B технических документов, то значение экспоненты γ следует установить равным единице (γ=1).
Если необходимо ввести в подобие поправку, чтобы оно имело большие значения, когда распределение технических документов из групп A и B, содержащихся в смешанном кластере, близко к распределению, полученному при случайной выборке документов из групп А и B технических документов, для увеличения важности, или если необходимо ввести в подобие поправку, чтобы оно имело меньшие значения, когда вышеупомянутое распределение является более далеким от распределения, полученного при случайной выборке документов из групп А и B технических документов, для уменьшения важности, то значение экспоненты γ следует установить большим, чем единица (γ>1).
Если необходимо ввести поправку, чтобы дополнительно увеличить значение подобия даже в том случае, когда распределение технических документов из групп A и B в смешанном кластере не является близким к распределению при случайной выборке из групп А и B технических документов, то значение экспоненты γ следует установить в интервале 0<γ<1.
Ниже показан пример вычисления, когда каждое из условий, показанных на Фиг.9, подставлено в уравнение (10) для прикладной задачи типа 2: поправочный член 2 (1). Результаты вычислений показаны на Фиг.12 в виде таблицы примеров результатов вычисления подобия с использованием поправочного члена 2 (1) (результатов вычислений при подстановке условий 1-4 в поправочный член 2 (1)).
В поправочном члене 2 (1) в числителе находится (количество комбинаций выборки m технических документов из группы A и n технических документов из группы B)/(количество комбинаций выборки m+n технических документов из смешанной группы, состоящей из группы A и группы B). Посредством этого в поправочном члене 2 (1) в подобие можно вести поправку для получения исправленного значения в соответствии с (искусственным) отклонением в количестве технических документов из групп A и B, содержащихся в смешанном кластере, что приводит к малому значению поправки, когда отклонение велико, и к большому значению поправки, когда отклонение мало. В этом варианте осуществления изобретения, когда отклонение велико, вычисление выполняется таким образом, что значение поправки уменьшается, и подобие будет малым. С другой стороны, когда отклонение велико, то значение поправки увеличивается, и подобие также будет большим.
В качестве нормировочного коэффициента в знаменателе находится (количество комбинаций выборки x технических документов из группы A и y технических документов из группы B) / (количество комбинаций выборки m+n технических документов из смешанной группы, состоящей из группы A и группы B). В результате, поскольку x и y представляет собой комбинацию, при которой значение знаменателя является максимальным, то может быть обеспечено то, что вычисленное значение подобия находится в интервале 0≤ подобие ≤1.
Кроме того, путем задания значения экспоненты γ в числителе равным единице (γ=1), в значение подобия может быть введена такая поправка, чтобы оно просто являлось пропорциональным близости распределения технических документов из групп A и B, содержащихся в смешанном кластере, к распределению, полученному при случайной выборке технических документов из групп А и B технических документов.
Путем задания значения экспоненты γ в числителе большим, чем единица (γ>1), может быть введена такая поправка, которая увеличивает значение подобия по мере того, как распределение технических документов из групп A и B, содержащихся в смешанном кластере, становится более близким к распределению, полученному при случайной выборке технических документов из групп А и B технических документов. И может быть введена такая поправка, которая уменьшает значение подобия по мере удаления распределения от распределения, полученного при случайной выборке технических документов из групп А и B технических документов.
Когда существует потребность введения такой поправки, которая дополнительно увеличит значение подобия даже в том случае, когда распределение технических документов из групп A и B, содержащихся в смешанном кластере, не является близким к распределению, полученному при случайной выборке технических документов из групп А и B технических документов, то значение экспоненты γ в числителе может быть установлено в интервале 0<γ<1.
Приведенное ниже уравнение (11) использовано для объяснения результатов вычислений для примера 10-1 вычисления (при подстановке условия 1 в уравнение (10)).
При учете только поправочного члена 2 (1) без учета влияния других поправочных членов (то есть когда поправочный член 1 = 1 и поправочный член 3 = 1) и при выполнении сравнений просто на основании вероятности смешения (то есть когда γ=1) получены следующие результаты пробных вычислений подобия, при которых в качестве условий для сравнения групп технических документов заданы условия 1-4.
Как указано в приведенном ниже уравнении (11), в случае наличия условия 1 вычисленная вероятность смешения технических документов, содержащихся в смешанном кластере 1, равна 0,409. Аналогичным образом, вычисленный коэффициент смешения технических документов, содержащихся в кластере 2, равен 0,409.
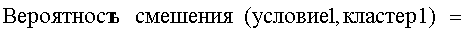

С другой стороны, нормировочный коэффициент в знаменателе равен максимальному значению вероятности смешения для смешанного кластера 1, поэтому, как показано ниже, вычисленный нормировочный коэффициент равен 0,409. В случае наличия условия 1 вычисленный нормировочный коэффициент для кластера 2 также равен 0,409.
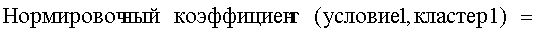
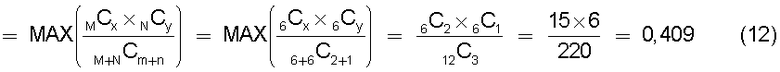
Следовательно, вычисленное значение поправочного члена 2 (1) при подстановке условия 1 в уравнение (12) равно: поправочный член 2 (1) = 1. Аналогичным образом, вычисленное значение поправочного члена 2 (1) для смешанного кластера 2 также равно 1.
Следовательно, как и в приведенном ниже уравнении (13), вычисленное значение поправочного члена 2 (1) равно 1, поэтому никакая особая поправка не введена, и вычисленное значение подобия равно 0,5.
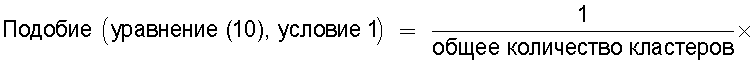
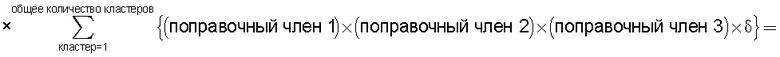

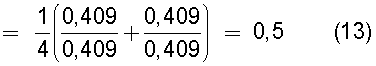
Значение подобия, равное 0,5, которое вычислено с использованием приведенного выше уравнения (13) (при подстановке условия 1 в уравнение (10)), согласуется с результатом вычисления подобия с использованием уравнения (1) без поправок. Количество технических документов, содержащихся в группах технических документов, равно соответственно шести и шести, а количество технических документов, содержащихся в смешанный кластерах, равно двум и одному, поэтому приведенный выше результат, по существу, согласуется со степенью подобия, оцененной с точки зрения здравого смысла. Следовательно, даже при введении поправочного члена 2 (1) может быть получен результат в пределах интервала допустимых значений.
Приведенное ниже уравнение (14) использовано для объяснения результатов вычислений для примера 10-2 вычислений (при подстановке условия 2 в уравнение (10)).
В случае условия 2 вероятность смешения технических документов, содержащихся в кластере 1, близка к отношению величин первой группы технических документов (группы A) и второй группы технических документов (группы B). Следовательно, понятно, что при вычислении подобия влияние коэффициента смешения технических документов, содержащихся в кластере 1, следует усилить, и подобие должно вычисляться для получения большего значения.
Приведенное ниже уравнение (14) иллюстрирует пример вычисления вероятности смешения в числителе поправочного члена 2 (1).
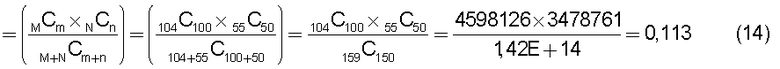
С другой стороны, нормировочный коэффициент в знаменателе представляет собой максимальное значение вероятности смешения для смешанного кластера 1, и, следовательно, как указано ниже, вычисленное значение нормировочного коэффициента равно 0,280. В случае условия 2 вычисленное значение нормировочного коэффициента для кластера 2 также равно 0,280.

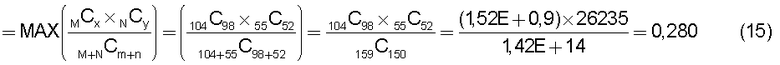
Следовательно, вычисленное значение поправочного члена 2 (1) для кластера 1 при условии 2 равно: поправочный член 2 (1) = 0,404. А вычисленное значение поправочного члена 2 (1) для кластера 2 при условии 2 равно "1", поэтому, как указано ниже уравнением (16), значение подобия, вычисленное на основании поправочного члена 2 (1), равно 0,351 (см. Фиг.12).
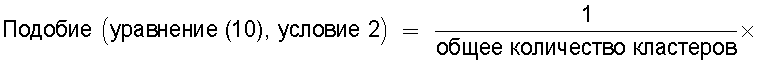


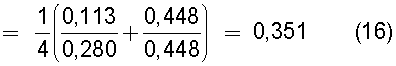
Значение 0,351, вычисленное с использованием уравнения (16) (при подстановке условия 2 в уравнение (10)), представляет собой значение, на которое оказала влияние вероятность смешения технических документов, содержащихся в кластере 1, и введена поправка, изменившая значение подобия от 0,962 (при подстановке условия 2 в уравнение (4)) до значения подобия, равного 0,351 (при подстановке условия 2 в уравнение (5)).
Приведенные ниже уравнения (17)-(19) использованы для объяснения результатов вычислений для примера 10-3 вычислений (при подстановке условия 3 в уравнение (10)). Уравнение (17) представляет собой пример вычисления вероятности смешения в числителе поправочного члена 2 (1).
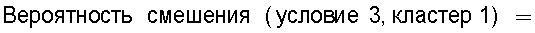
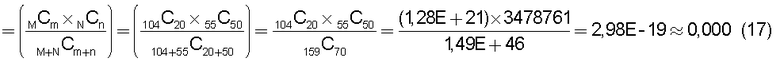 С другой стороны, нормировочный коэффициент в знаменателе равен максимальному значению вероятности смешения для смешанного кластера 1, и, следовательно, как показано ниже, вычисленное значение нормировочного коэффициента равно 0,133. В случае условия 3 вычисленное значение нормировочного коэффициента для кластера 2 равно 0,448.
С другой стороны, нормировочный коэффициент в знаменателе равен максимальному значению вероятности смешения для смешанного кластера 1, и, следовательно, как показано ниже, вычисленное значение нормировочного коэффициента равно 0,133. В случае условия 3 вычисленное значение нормировочного коэффициента для кластера 2 равно 0,448.
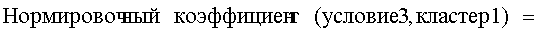
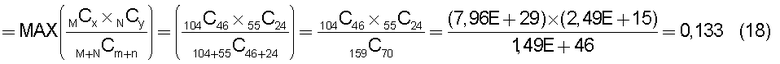
Следовательно, вычисленное значение поправочного члена 2 (1) для условия 3 равно: поправочный член 2 (1) = 0,000. Вычисленное значение поправочного члена 2 (1) для смешанного кластера 2, аналогично случаям условия 1 и условия 2, равно 1.
Таким образом, как показано ниже, вычисленное значение подобия равно 0,25.
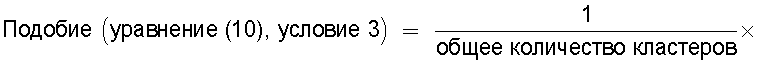
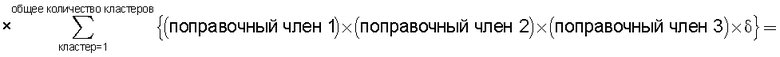

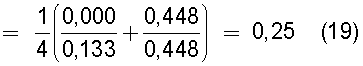
Значение подобия, вычисленное с использованием уравнения (19), которое равно 0,25 (при подстановке условия 3 в уравнение (10)), представляет собой значение, на которое оказала влияние вероятность смешения технических документов в кластере 1, при этом за счет введения поправки произошло изменение значения подобия от 0,459 (при подстановке условия 3 в уравнение (4)) до значения подобия, равного 0,25 (при подстановке условия 3 в уравнение (10)).
Приведенные ниже уравнения (20)-(24) использованы для объяснения результатов вычислений для примера 10-4 вычислений (при подстановке условия 4 в уравнение (10)).
В случае условия 4 сумма значений количества технических документов, содержащихся в кластерах, является той же самой, что и в случае условия 3, но доли группы А технических документов и группы B технических документов, содержащихся в кластере 1 и кластере 2, являются предельно неравными. Следовательно, несмотря на то, что в смешанных кластерах содержится большое количество технических документов, желательно, чтобы при вычислениях подобие не возрастало.
Вероятность смешения в числителе для смешанного кластера 1 из поправочного члена 2 (1) имеет следующее значение.

С другой стороны, нормировочный коэффициент в знаменателе равен максимальному значению вероятности смешения для смешанного кластера 1, и, следовательно, как показано ниже, вычисленное значение нормировочного коэффициента равно 0,141.

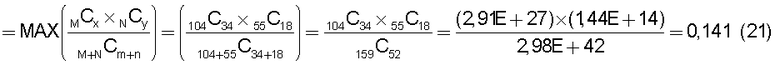 Следовательно, вычисленное значение поправочного члена 2 (1) для смешанного кластера 1 при условии 4 равно: поправочный член 2 (1) = 0,000.
Следовательно, вычисленное значение поправочного члена 2 (1) для смешанного кластера 1 при условии 4 равно: поправочный член 2 (1) = 0,000.
С другой стороны, как показано ниже, вычисленное значение поправочного члена 2 (1) для смешанного кластера 2 равно: поправочный член 2 (1) = 0,004.
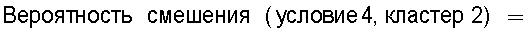
Нормировочный коэффициент в знаменателе для смешанного кластера 2 равен максимальному значению вероятности смешения для смешанного кластера 2, поэтому, как показано ниже, в случае условия 4 вычисленное значение нормировочного коэффициента равно 0,194.
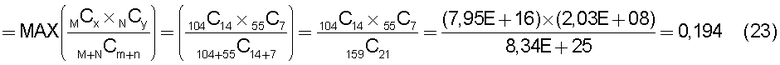
Следовательно, как показано ниже, вычисленное значение подобия равно 0,001.
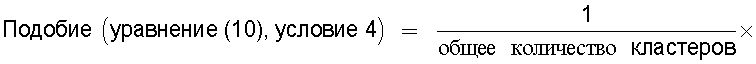


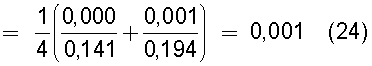
Посредством уравнения (24) в значение подобия введена поправка, изменившая его от значения подобия, равного 0,459 (при подстановке условия 4 в уравнение (4)), до значения подобия, равного 0,001 (при подстановке условия 4 в уравнение (10)). Это является результатом того факта, что вероятность смешения технических документов, содержащихся в кластере 1 и в кластере 2, намного меньше, чем максимальное значение вероятности смешения при случайной выборке технических документов из группы А технических документов и из группы B технических документов.
На Фиг.12 приведена таблица примеров результатов вычисления подобия для случая использования поправочного члена 2 (1) (результаты вычислений при подстановке условий 1-4 в поправочный член 2 (1)).
Как указано в таблице, значение поправочного члена 2 (1) больше для тех кластеров из смешанных кластеров, в которых технические документы являются хорошо смешанными (кластеров с условиями высокой вероятности смешения). Кроме того, в случае кластеров, в которых технические документы не являются хорошо смешанными (кластеров с условиями низкой вероятности смешения), значение поправочного члена 2 (1) является низким значением, по существу, равным "0", а вычисленное подобие также имеет малое значение.
На Фиг.13 приведена таблица примеров результатов вычисления подобия для случая использования поправочного члена 1 (1) и поправочного члена 2 (1) (результаты вычислений при подстановке условий 1-4 в поправочный член 1 (1) и в поправочный член 2 (1)).
Значение подобия 0,5, вычисленное для условия 1, по существу, согласуется со степенью подобия, оцененной с точки зрения здравого смысла.
В случае условия 2 количество технических документов, содержащихся в смешанном кластере 1, явно больше, чем количество технических документов, содержащихся в смешанных кластерах 2-4. Однако за счет введения поправки происходит изменение значения подобия от значения 0,5, которое получено при подстановке в вычисленное значение подобия (уравнение (1)) условия 2, до значения 0,4, которое получено при подстановке условия 2 с использованием поправочного члена 1 (1) и поправочного члена 2 (1). Вычисление подобия с использованием поправочного члена 1 (1) и поправочного члена 2 (1) полезно, когда требуется избежать умножения кластера 1 с большим количеством технических документов на большой весовой коэффициент.
В случае условия 3 сумма значений количества технических документов, содержащихся в кластерах, та же, что и в случае условия 2, но количество технических документов в смешанном кластере 1 не особенно велико, поэтому в вычисленное значение подобия введена поправка, уменьшающая его значение до 0,019. Такое вычисление подобия с использованием поправочного члена 1 (1) и поправочного члена 2 (1) полезно, когда имеется потребность предотвратить воздействие большого количества технических документов, содержащихся в кластере 1, на результат вычисления подобия.
В случае условия 4 сумма значений количества технических документов, содержащихся в кластерах, та же самая, что и в случае условия 2, но количество технических документов в смешанном кластере 1 и в смешанном кластере 2 не особенно велико, и, если состояние смешения технических документов по-прежнему является более близким к предельному, значение подобия корректируют до 0,0005. Если состояние смешения технических документов не одинаково, то за счет такого использования поправочного члена 1 (1) и поправочного члена 2 (1) для вычисления подобия можно ввести поправку, уменьшающую значение подобия, даже при большом количестве технических документов в каждом смешанном кластере.
То есть путем использования поправочного члена 1 (1) и поправочного члена 2 (1) для вычисления подобия в подобие может быть введена поправка, усиливающая влияние смешанных кластеров с большим количеством технических документов, а если состояние смешения технических документов не одинаково, то в подобие может быть введена поправка, уменьшающая его значение.
Как показано на чертеже, уравнение для поправочного члена 2 (1) проявляет тенденцию к чувствительной реакции значения поправочного члена на состояние смешения технических документов, поэтому в некоторых случаях может возникнуть необходимость в соответствующей корректировке значения γ. Как объяснено выше, введение поправки на основании количества технических документов, содержащихся в смешанном кластере, и введение поправки на основании состояния смешения технических документов, содержащихся в смешанном кластере, тесно связаны, и, следовательно, определение как надлежащего значения γ, так и надлежащего значения α, считается важным.
На Фиг.13 приведен пример результатов вычислений того случая, когда α=1 и γ=1. Однако если пробное вычисление выполняется со значением α, по-прежнему равным 1, но со значением γ, равным 0,25, то можно вычислить следующие значения подобия: для условия 1 подобие = 0,5 → 0,5; для условия 2 подобие = 0,4 → 0,769; для условия 3 подобие = 0,019 → 0,019; и для условия 4 подобие = 0,0005 → 0,033.
Прикладная задача типа 3: Пример вычисления поправочного члена 2 (2)
Поправочный член 2 (2) представляет собой поправочный член для введения в подобие поправки в соответствии с коэффициентом смешения технических документов в каждом смешанном кластере.
Если отношения количества технических документов, содержащихся в первой группе технических документов (в группе A) и во второй группе технических документов (в группе B), сильно отличаются, то, естественно, коэффициент смешения технических документов, содержащихся в каждом смешанном кластере, также должен различаться. Кроме того, справедливо предположить, что коэффициент смешения технических документов, содержащихся в кластерах, будет близким к отношению количества технических документов (к коэффициенту состава), содержащихся в первой группе технических документов (в группе A) и во второй группе технических документов (в группе B), настолько, насколько значения количества технических документов, содержащихся в этих двух группах, являются различными.
Следовательно, в настоящем изобретении в качестве поправочного члена для введения поправки в вычисленное значение подобия предложен поправочный член, пропорциональный отношению коэффициента состава и коэффициента смешения в степени ξ (где 0<ξ), для коэффициента N/M состава, равного отношению количества технических документов, содержащихся в первой группе технических документов (в группе A) и во второй группе технических документов (в группе B), и для коэффициента n/m смешения, равного отношению количества технических документов, содержащихся в каждом кластере.
То есть использована формула, устанавливающая более высокое значение подобия (приближающееся к единице), когда коэффициент N/M состава, равный отношению количества технических документов, содержащихся в первой группе технических документов (в группе A) и во второй группе технических документов (в группе B), близок к коэффициенту n/m смешения, равному отношению количества технических документов в каждом кластере.
Следовательно, значение поправочного члена 2 (2) принимает значения меньше единицы по мере возрастания различия между коэффициентом состава, равным отношению количества технических документов, содержащихся в первой группе технических документов (в группе A) и во второй группе технических документов (в группе B), и коэффициентом смешения технических документов в каждом кластере.
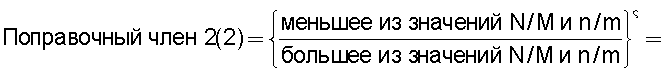
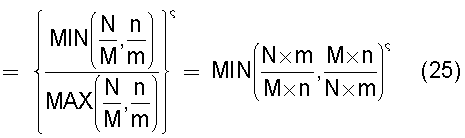
Приведенное ниже уравнение (26) представляет собой пример вычисления подобия с учетом поправочного члена 2 (2).
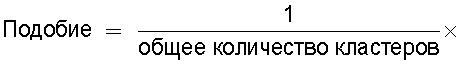


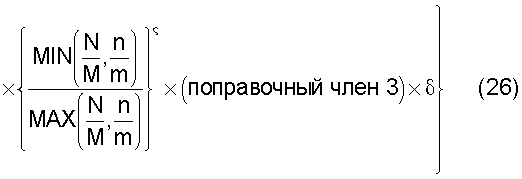
Как указано в уравнениях (25) и (26), в поправочном члене 2 (2) установлено настолько более высокое значение подобия (приближающееся к единице), насколько более высока степень близости коэффициента состава группы А технических документов и группы B технических документов к коэффициенту смешения технических документов в каждом кластере, поэтому в числитель помещено "меньшее из значений N/M и n/m", а в знаменатель помещено "большее из значений N/M и n/m".
В этом случае, когда необходимо предотвратить большое влияние смешанного кластера с малым коэффициентом смешения технических документов на результат вычисления подобия, то значение экспоненты ζ в поправочном члене должно устанавливаться большим, чем единица (ζ>1).
Кроме того, когда желательно просто увеличить или уменьшить значение подобия в соответствии с коэффициентом смешения технических документов в кластерах, то значение ζ должно устанавливаться равным единице (ζ=1).
Если необходимо предотвратить сильное влияние каждого смешанного кластера с большим коэффициентом смешения на результат вычисления подобия, то значение ζ должно устанавливаться в интервале 0<ζ<1.
Ниже приведено объяснение результата использования поправочного члена 2 (2) при вычислении подобия.
В поправочном члене 2 (2) в числителе находится меньший из коэффициента состава технических документов из группы A и группы B и коэффициента смешения технических документов в каждом кластере, а в знаменателе находится больший из коэффициента состава технических документов из группы A и группы B и коэффициента смешения технических документов в каждом кластере. В результате чем ближе коэффициент состава технических документов из группы A и группы B к коэффициенту смешения технических документов в каждом кластере, тем более высоким является вычисленное значение подобия (приближающееся к единице). А чем больше коэффициент состава технических документов из группы A и группы B отличается от коэффициента смешения технических документов в каждом кластере, тем более низким является вычисленное значение подобия.
Кроме того, отношение коэффициента состава технических документов из группы A и группы B и коэффициента смешения между техническими документами в каждом кластере вычисляются таким образом, чтобы вычисленное значение подобия гарантированно находилось в интервале 0 ≤ подобие ≤ 1.
Кроме того, путем задания значения экспоненты ζ большим, чем единица (ζ>1), может быть предотвращено сильное влияние на результат вычисления подобия смешанных кластеров, для которых отношение коэффициента состава технических документов из групп A и B и коэффициента смешения технических документов в кластере мало.
Путем задания значения экспоненты ζ равным единице (ζ=1) подобие может быть увеличено или уменьшено в соответствии с отношением коэффициента состава технических документов из групп A и B и коэффициента смешения технических документов в каждом кластере (простое сравнение коэффициента смешения).
Путем задания значения экспоненты в числителе в интервале 0<ζ<1 может быть уменьшено влияние отношения коэффициента состава технических документов из групп A и B и коэффициента смешения технических документов в каждом кластере на результат вычисления подобия.
Ниже описаны результаты пробного вычисления подобия в том случае, когда в качестве условий для сравнения групп технических документов учитывается только поправочный член 2 (2) без учета влияния других поправочных членов (то есть когда поправочный член 1 = 1 и поправочный член 3 = 1) для выполнения простого сравнения коэффициента смешения (то есть ζ=1), с использованием уравнения (26) при заданных условиях 1-4. Результаты вычисления показаны на Фиг.14 в виде таблицы примеров результатов вычисления подобия с использованием поправочного члена 2 (2) (результаты вычислений при подстановке в поправочный член 2 (2) условий 1-4).
В приведенном ниже уравнении (27) показаны результаты вычислений для примера 26-1 вычислений (при подстановке условия 1 в уравнение (26)).
При условии 1 количество технических документов в первой группе технических документов (в группе A) равно шести, а количество технических документов во второй группе технических документов (в группе B) также равно шести, поэтому коэффициент состава технических документов в группах A и B равен 1:1.
С другой стороны, при условии 1 количество технических документов, содержащихся в каждом смешанном кластере (в кластере 1 и в кластере 2), равно двум техническим документам из первой группы технических документов (группы A) и одному техническому документу из второй группы технических документов (группы B), поэтому коэффициент смешения равен 2:1.
Следовательно, ожидается, что имеет место, по меньшей мере, некоторое влияние коэффициента смешения технических документов, содержащихся в кластерах, на введенную в подобие поправку.
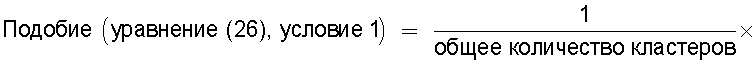
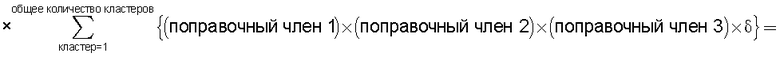

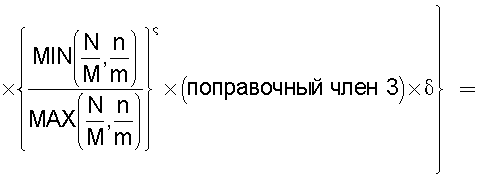
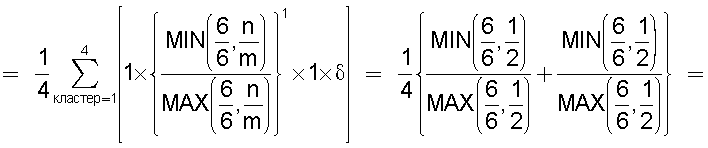
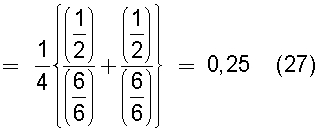
В приведенном ниже уравнении (28) показаны результаты вычислений для примера 26-2 вычислений (при подстановке условия 2 в уравнение (26)).
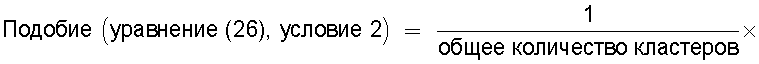

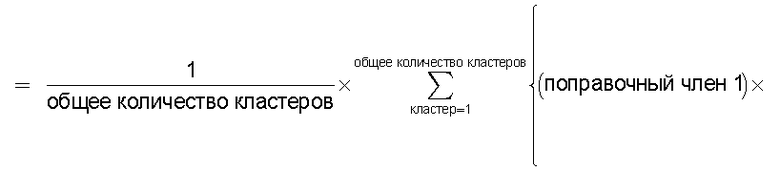
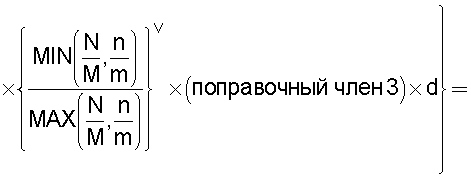
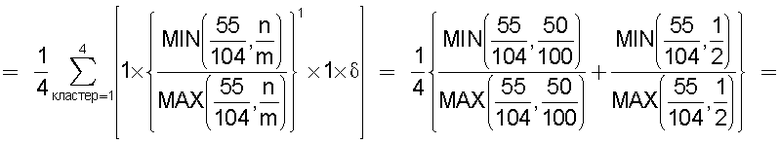
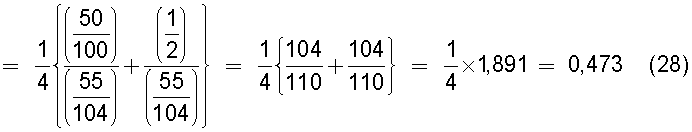
В приведенном ниже уравнении (29) показаны результаты вычислений для примера 26-3 вычислений (при подстановке условия 3 в уравнение (26)).
При условии 3 сумма значений количества технических документов, содержащихся в кластерах, та же, что и при условии 2, но коэффициент смешения технических документов, содержащихся в смешанном кластере 1, сильно отличается от коэффициента состава первой группы технических документов (группы A) и второй группы технических документов (группы B). Следовательно, при вычислении подобия желательно, чтобы влияние коэффициента смешения технических документов, содержащихся в смешанном кластере 1, не было столь же большим, как при условии 2.
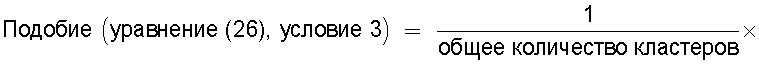

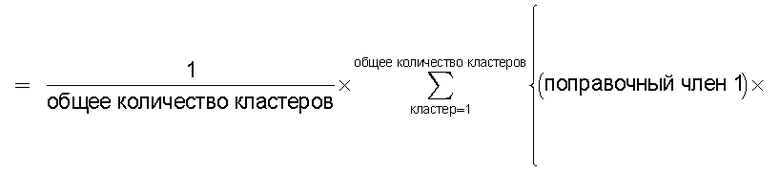
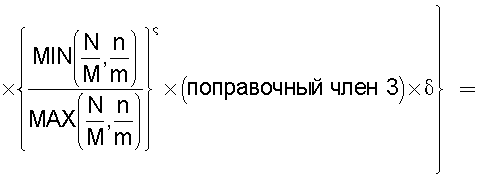
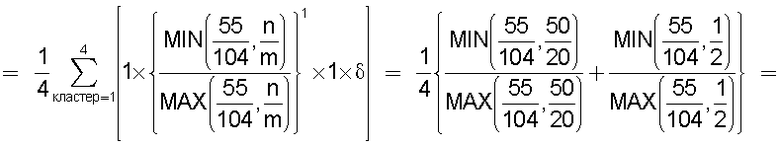
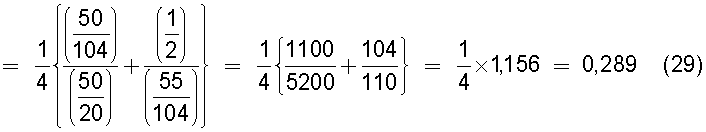
Значение подобия, равное 0,289, которое вычислено с использованием приведенного выше уравнения (29) (при подстановке условия 3 в уравнение (26)), представляет собой значение, которое за счет введения поправки было уменьшено до более низкого значения подобия, поскольку коэффициент смешения технических документов, содержащихся в смешанном кластере 1, отличается от коэффициента состава первой группы технических документов (группы A) и второй группы технических документов (группы B).
Следовательно, путем выполнения обработки данных для вычисления поправочного члена 2 (2) в подобие может быть введена поправка в соответствии с коэффициентами смешения технических документов даже в том случае, когда количество технических документов, содержащихся в каждом смешанном кластере, велико.
В приведенном ниже уравнении (30) показаны результаты вычислений для примера 26-4 вычислений (при подстановке условия 4 в уравнение (26)).
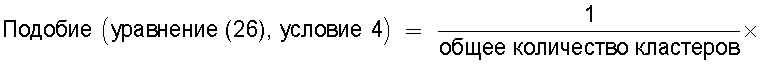

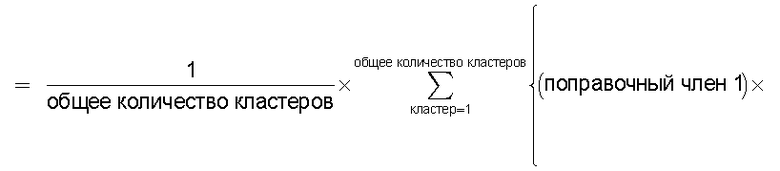
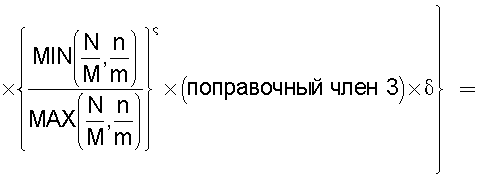
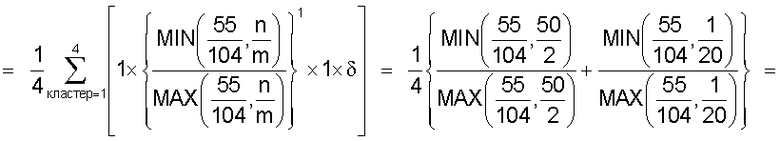

Значение подобия, равное 0,029, которое вычислено с использованием уравнения (30) (при подстановке условия 4 в уравнение (26)), представляет собой значение подобия, уменьшенное за счет введения поправки, поскольку коэффициент смешения технических документов, содержащихся в кластере 1 и в кластере 2, в высшей степени не одинаков, и, кроме того, коэффициент смешения в смешанном кластере 1 и в смешанном кластере 2 сильно отличается от коэффициента состава технических документов из первой группы технических документов (группы A) и второй группы технических документов (группы B).
На Фиг.14 приведена таблица, в которой показаны примеры результатов вычислений подобия в случае использования поправочного члена 2 (2) (результаты вычислений при подстановке условий 1-4 в поправочный член 2 (2)).
Смешанный кластер 1 и смешанный кластер 2 для условий 1 и 2, а также смешанный кластер 2 для условия 3, могут рассматриваться как примеры состояний, в которых технические документы хорошо смешаны, как указано на Фиг.9 (коэффициент смешения технических документов в каждом смешанном кластере близок к отношению значений количества технических документов, содержащихся в первой группе технических документов и во второй группе технических документов). В этом случае вычисленное значение поправочного члена довольно велико, что в результате приводит к увеличению значения подобия.
И, наоборот, можно сказать, что смешанный кластер 1 для условия 3 и каждый из смешанных кластеров для условия 4 находятся в состоянии плохого смешения технических документов (коэффициент смешения технических документов в смешанном кластере сильно отличается от отношения значений количества технических документов, содержащихся в первой группе технических документов и во второй группе технических документов), поэтому вычисленное значение поправочного члена является меньшим, так что в результате приводит к меньшему вычисленному значению подобия.
Следовательно, как указано в уравнении (4), путем вычисления подобия в совокупности с поправочным членом 1 (1) можно повысить точность вычисления подобия, указывающего степень технических связей между группами технических документов.
На Фиг.15 приведена таблица примеров результатов вычисления подобия в случае использования поправочного члена 1 (1) и поправочного члена 2 (2) (результаты вычислений при подстановке условий 1-4 в поправочный член 1 (1) и в поправочный член 2 (2)).
Как показано на чертеже, когда в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (2), подставлено условие 1, то подобие вычисляется в соответствии с коэффициентом смешения и с количеством технических документов, содержащихся в кластерах. Следовательно, значение подобия, равное 0,25, полученное при подстановке условия 1, меньше, чем значение подобия, равное 0,5, полученное при подстановке условия 1 в уравнение (1) (когда поправочные члены отсутствуют), но весьма близко к ожидаемому значению и может расцениваться как удовлетворительное представление технического подобия между техническими документами.
Когда в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (2), подставлено условие 2, то подобие вычисляется в соответствии с количеством технических документов и с коэффициентом смешения в кластерах. Следовательно, когда условие 2 подставлено в уравнение (1) (без введенных поправок), то подобие равно 0,5, но после использования поправочного члена 1 и поправочного члена 2 (2) при подстановке условия 2 значение подобия за счет введения поправки становится равным 0,909, которое значительно более близко к ожидаемому значению подобия, и представляет собой удовлетворительное представление технического подобия между техническими документами.
Путем подобного вычисления подобия с использованием поправочного члена 1 и поправочного члена 2 (2) кластеру 1 с большим количеством технических документов может быть присвоен весовой коэффициент.
Когда в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (2), подставлено условие 3, то подобие вычисляется в соответствии с количеством технических документов и с коэффициентом смешения в кластерах. Следовательно, по сравнению с условием 2, хотя суммарное количество технических документов, содержащихся в кластерах, то же, количество технических документов только лишь в одном смешанном кластере 1 не особенно велико, и, кроме того, когда коэффициент смешения технических документов в кластере 1 отличается от отношения между количеством технических документов из первой группы технических документов (группы A) и из второй группы технических документов (группы B), можно предотвратить особо сильное влияние существования кластера 1.
Здесь в вычисленное значение подобия введена поправка, изменившая его от значения подобия, равного 0,5, которое получено при подстановке условия 3 в уравнение (1) (без введения поправок), до значения подобия, равного 0,111, которое получено при подстановке условия 3 с использованием поправочного члена 1 и поправочного члена 2 (2); результат является весьма близким к ожидаемому значению, и можно сказать, что он отображает подобие между группами технических документов.
Если в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (2), подставлено условие 4, то подобие вычисляется в соответствии с количеством технических документов и с коэффициентом смешения в кластерах. Следовательно, по сравнению с условием 2 суммарное количество технических документов в кластерах является тем же самым, но их количество в смешанном кластере 1 и в смешанном кластере 2 не особенно велико, и когда состояние смешения технических документов по-прежнему является более близким к предельному, то коэффициент смешения технических документов в каждом смешанном кластере сильно отличается от отношения значений количества технических документов в группах A и B, поэтому влияние на подобие уменьшено.
Здесь в вычисленное значение подобия введена поправка, изменившая его от значения 0,5, полученного при подстановке условия 4 в уравнение (1) (без введения поправок), до значения 0,019, полученного при подстановке условия 4 с использованием поправочного члена 1 и поправочного член 2 (2); результат весьма близок к ожидаемому значению, и можно сказать, что он отображает подобие между группами технических документов.
Прикладная задача типа 4: Пример вычисления поправочного члена 2 (3)
Ниже приведено объяснение поправки, основанной на разности значений математического ожидания для технических документов в смешанных кластерах.
Естественно предположить, что чем более близким является количество m технических документов из первой группы технических документов (группы A) в каком-либо кластере к значению математического ожидания ((m+n)M/(M+N)) при случайной выборке технических документов из групп A и B, то тем более тщательно смешаны документы. (Это является определением третьего состояния смешения, аналогичного отношению вероятностей из приведенного выше уравнения (9) и коэффициенту смешения из уравнения (25).)
Следовательно, в настоящем изобретении значение математического ожидания нахождения технических документов из первой группы технических документов (группы A) вычисляется путем умножения количества технических документов, содержащихся в каждом смешанном кластере, (m+n) на вероятность (M/(M+N)) того, что в группе технических документов, в которой смешаны технические документы из первой группы технических документов (группы A) и из второй группы технических документов (группы B), будет найден технический документ из первой группы технических документов (из группы A). Затем вычисляется разность между значением математического ожидания и количеством m технических документов из первой группы технических документов (группы A), содержащихся в каждом смешанном кластере в виде разности значений математического ожидания (см. приведенное ниже уравнение (31)). Поправка вводится таким образом, что чем меньше эта разность (чем ближе она к 0), тем больше значение подобия.
Пример вычисления разности значений математического ожидания описан с использованием приведенного ниже уравнения (31).

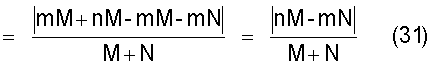
На Фиг.16 показаны примеры результатов вычисления разности значений математического ожидания при подстановке условий 1-4 в уравнение (31).
Как видно из результатов вычислений, полученных с использованием уравнения (31), когда в подобие введена такая поправка, что чем ближе количество технических документов из группы A и количество технических документов из группы B в определенном кластере к значениям математического ожидания при случайной выборке документов из групп A и B, тем больший вклад вносит этот кластер, то достаточно отрицательное значение математического ожидания, показанное на Фиг.16, использовать в качестве экспоненты.
Путем использования отрицательного значения разности значений математического ожидания в качестве экспоненты, когда в смешанном кластере существует ожидаемое количество технических документов, полученное исходя из значения математического ожидания, разность значений математического ожидания = 0, и когда экспонента = 0, то может быть выполнено вычисление, при котором значение поправочного члена установлено равным единице. Однако если использовано только лишь значение математического ожидания, то результат зависит не только от состояния смешения, но также и от размера заданного смешанного кластера; следовательно, разность значений математического ожидания делится на количество технических документов, содержащихся в кластере.
Ниже описан вариант осуществления определенного таким образом поправочного члена 2 (3).
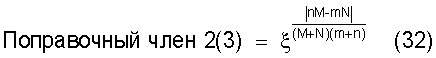
Здесь ξ представляет собой произвольную постоянную, при этом ξ>1.
Например, путем вычисления поправочного члена 2 так, как указано в приведенном выше уравнении (32), значение с введенной поправкой может быть сделано одинаковым в том случае, когда размер кластера равен 100, а разность значений математического ожидания равна 10, и в том случае, когда размер кластера равен 10, а разность значений математического ожидания равна 1.
Чем больше используемое значение ξ, тем более чувствительной является реакция на разность значений математического ожидания, поэтому в подобие может быть введена поправка, уменьшающая его значение.
На Фиг.17 приведена таблица примеров результатов вычисления подобия для случаев подстановки условий 1-4 в уравнение (32) при ξ=10.
На Фиг.18 приведена таблица примеров результатов вычисления подобия для случаев использования поправочного члена 1 (1) и поправочного члена 2 (3) (при подстановке условий 1-4 в поправочный член 1 (1) и в поправочный член 2 (3)).
Из чертежей понятно, что когда в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (3), подставлено условие 1, то подобие вычисляется в соответствии с количеством технических документов в кластерах и с разностями значений математического ожидания (чем более близким является количество технических документов из первой группы технических документов (группы A) и количество технических документов из второй группы технических документов (группы B) в заданном кластере к значениям математического ожидания, полученным в результате случайной выборки документов из групп A и B, тем большим является вычисленное значение подобия с введенной поправкой). При этом для случая подстановки условия 1 с использованием поправочного члена 1 и поправочного члена 2 (3) может быть вычислено значение подобия, равное 0,340, которое близко к значению 0,5, полученному при подстановке условия 1 в уравнение (1) (без введения поправки), поэтому может быть вычислено значение, близкое к ожидаемому значению.
В случае условия 2 количество технических документов, содержащихся в смешанном кластере 1, больше, чем их количество в кластерах 2-4, и разность значений математического ожидания мала, следовательно, необходимо придать особую важность составу технических документов, содержащихся в смешанном кластере 1.
Когда в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (3), подставлено условие 2, то подобие вычисляется в соответствии с количеством технических документов, содержащихся в кластерах, и с разностью значений математического ожидания (при этом вводится такая поправка, что чем более близким является количество технических документов из первой группы технических документов (группы A) и количество технических документов из второй группы технических документов (группы B), содержащихся в определенном кластере, к значению математического ожидания, полученному путем случайной выборки документов из групп A и B, тем больше вычисленное значение подобия). В результате за счет введения поправки получено значение подобия, равное 0,935, которое вычислено путем подстановки условия 2 с использованием поправочного члена 1 и поправочного члена 2 (3), являющееся большим, чем значение 0,5, полученное путем подстановки условия 1 в уравнение (1) (без введения поправки) и близкое к ожидаемому значению.
В случае условия 3 суммарное количество технических документов, содержащихся в кластерах, является тем же самым, что и для вышеупомянутого условия 2, но сам смешанный кластер 1 не особенно велик, поэтому кластеру 1 не следует придавать особую важность. Кроме того, технические документы, содержащиеся в смешанном кластере 1, имеют сильное отклонение от значений математического ожидания для документов, полученных путем случайной выборки из первой группы технических документов (группы A) и из второй группы технических документов (группы B), поэтому с учетом влияния большой разности значений математического ожидания для смешанного кластера 1 вычисленное значение подобия следует уменьшить.
Когда в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (3), подставлено условие 3, то подобие вычисляется в соответствии с количеством технических документов, содержащихся в кластерах, и с разностью значений математического ожидания (при этом вводится такая поправка, чтобы получить большое значение вычисленного подобия в том случае, когда количество технических документов из первой группы технических документов (группы A) и количество технических документов из второй группы технических документов (группы B) в определенном кластере близки к значениям математического ожидания, полученным при случайной выборке документов из групп A и B). При этом, когда произведена подстановка условия 3 и использованы поправочный член 1 и поправочный член 2 (3), вычисленное значение подобия равно 0,207. Это значение подобия также близко к ожидаемому значению.
В случае условия 4 суммарное количество технических документов, содержащихся в кластерах, то же самое, что и для вышеупомянутого условия 3, но количество технических документов, содержащихся в смешанном кластере 1 и в смешанном кластере 2, не особенно велико, и состояние смешения еще более близко к предельному, и, следовательно, желательно, чтобы весовой коэффициент смешанного кластера 1 не оказывал влияния на результат.
Когда в уравнение, в котором использованы поправочный член 1 (1) и поправочный член 2 (3), подставлено условие 4, то подобие вычисляется в соответствии с количеством технических документов, содержащихся в кластерах, и с разностями значений математического ожидания (при этом вводится такая поправка, чтобы получить настолько большее значение вычисленного подобия, насколько количество технических документов из первой группы технических документов (группы A) и количество технических документов из второй группы технических документов (группы B), содержащихся в определенном кластере, близки к значению математического ожидания, полученного при случайной выборке документов из групп A и B). В результате при подстановке условия 4 с использованием поправочного члена 1 и поправочного члена 2 (3) вычисленное значение подобия равно 0,146. Это значение подобия также является близким к ожидаемому значению.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
Согласно настоящему изобретению устройство вычисления подобия, которое вычисляет показатель, по которому судят о техническом подобии между первой группой технических документов и второй группой технических документов, каждая из которых содержит патентные документы, технические отчеты или иные технические документы, содержит
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации, например ключевых слов или индексов МПК;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для разложения найденных технических документов на кластеры для каждой технической информации;
средство вычисления подобия, предназначенное для вычисления в качестве подобия отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученных в результате кластерного анализа; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
Следовательно, показатель, указывающий подобие технического содержания, описанного в группах технических документов, может быть легко вычислен на основании отношения общего количества проанализированных кластеров к количеству смешанных кластеров.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы произведения значения первой поправки, которая принимает значение, соответствующее количеству технических документов, содержащихся в каждом смешанном кластере, и значения второй поправки, которая принимает значение, соответствующее состоянию смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов в каждом смешанном кластере, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, может быть выполнено введение поправки, которая вследствие существования поправочного члена 1 обеспечивает больший весовой коэффициент для смешанного кластера в соответствии с количеством содержащихся в нем технических документов и вследствие существования поправочного члена 2 обеспечивает такой весовой коэффициент кластера, чтобы он являлся более важным по мере того, как состав технических документов, содержащихся в смешанном кластере, становится более близким к заданному значению, для увеличения значения подобия таким образом, что в результат вычисления подобия может быть введена поправка для обеспечения его соответствия человеческому восприятию.
Следовательно, путем вычисления подобия с использованием поправочного члена 1 и поправочного члена 2 в подобие может быть введена поправка, увеличивающая вклад смешанных кластеров с большим количеством технических документов и уменьшающая значение подобия за счет введения поправки в том случае, когда состояние смешения технических документов является неустойчивым.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных количеству технических документов в каждом кластере в степени α (где 0<α), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, подобие может быть вычислено таким образом, что кластер приобретает большую важность тогда, когда в кластере имеется большее количество технических документов.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию деления количества технических документов в каждом кластере в степени α (где 0<α) на нормировочный коэффициент, например на общее количество кластеров, для вычисления подобия.
Следовательно, можно обеспечить, чтобы 0 ≤подобие ≤ 1.
В качестве нормировочного коэффициента используется среднее значение количества технических документов во всех кластерах, поэтому количество технических документов может быть вычислено с использованием в качестве опорной величины среднего значения количества технических документов во всех кластерах.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Другими словами, обеспечена функция, выполняющая вычисление с величиной (количество комбинаций того, что будет найдено m технических документов из группы A и n технических документов из группы B)/(количество комбинаций того, что будет найдено m+n технических документов из смешанной группы, состоящей из группы A и группы B), помещенной в числитель в средстве вычисления подобия. Следовательно, может быть введена поправка, обеспечивающая малое значение подобия для большого отклонения и большое значение подобия для малого отклонения, соответствующая (искусственному) отклонению в количестве технических документов из группы A и группы B, содержащихся в каждом смешанном кластере. Предусмотрен нормировочный коэффициент, равный максимальному значению вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), поэтому может быть обеспечено, что вычисленное значение подобия находится в следующем интервале: 0 ≤подобие ≤1.
Также согласно настоящему изобретению, средство вычисления подобия выполняет функцию вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных отношению коэффициента N/M состава и коэффициента n/m смешения в степени ζ (где 0<ζ), для коэффициента N/M состава, представляющего собой отношение количества N технических документов, содержащихся во второй группе технических документов, к количеству M технических документов, содержащихся в первой группе технических документов, и для коэффициента n/m смешения, представляющего собой отношение количества n технических документов из второй группы технических документов к количеству m технических документов из первой группы технических документов, которые содержатся в каждом смешанном кластере, полученном в результате кластерного анализа, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, подобие может быть вычислено таким образом, чтобы оно имело более высокое значение (приближающееся к единице) по мере того, как коэффициент состава, характеризующий количество технических документов из группы A и группы B, становится равным коэффициенту смешения технических документов в каждом кластере.
Путем задания экспоненты ζ для отношения коэффициента состава и коэффициента смешения таким образом, что ζ>1, может быть предотвращено сильное влияние смешанных кластеров с малым значением отношения коэффициента, равного отношению количества технических документов в группах A и B, и коэффициента смешения технических документов в каждом кластере, на результат вычисления подобия.
Путем задания экспоненты ζ таким образом, что ζ=1, может быть реализовано такое подобие, что оно просто увеличивается или уменьшается в соответствии с отношением коэффициента состава, равного отношению количества технических документов в группах A и B, и коэффициента смешения технических документов в каждом кластере.
Путем задания экспоненты в числителе таким образом, что 0<ζ<1, влияние результата вычисления подобия может быть уменьшено в том случае, когда отношение коэффициента состава, равного отношению количества технических документов в группах A и B, и коэффициента смешения технических документов в каждом кластере является большим.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем установления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, введение поправки может быть выполнено для обеспечения чувствительной реакции результата вычисления подобия на разность значений математического ожидания в соответствии с заданным значением параметра ξ.
Также согласно настоящему изобретению средство вычисления подобия выполняет функцию вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления разности значений математического ожидания на количество технических документов в каждом смешанном кластере, и установления результата деления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и последующего деления этой суммы на вычисленное общее количество кластеров для вычисления подобия.
Следовательно, введение поправки может быть выполнено для обеспечения чувствительной реакции результата вычисления подобия на разность значений математического ожидания в соответствии с заданным значением параметра ξ.

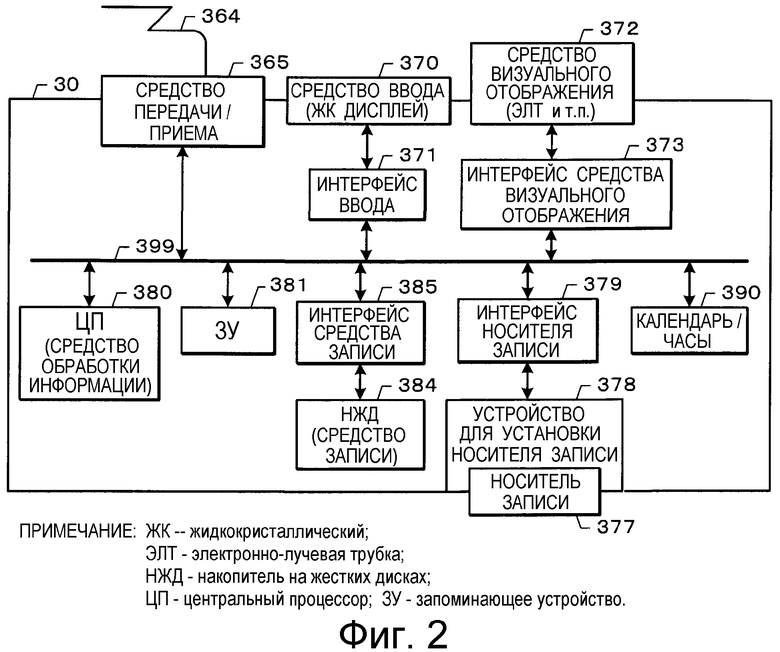
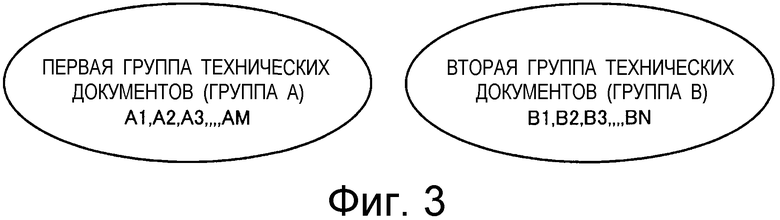


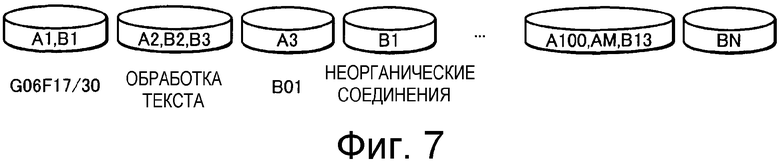
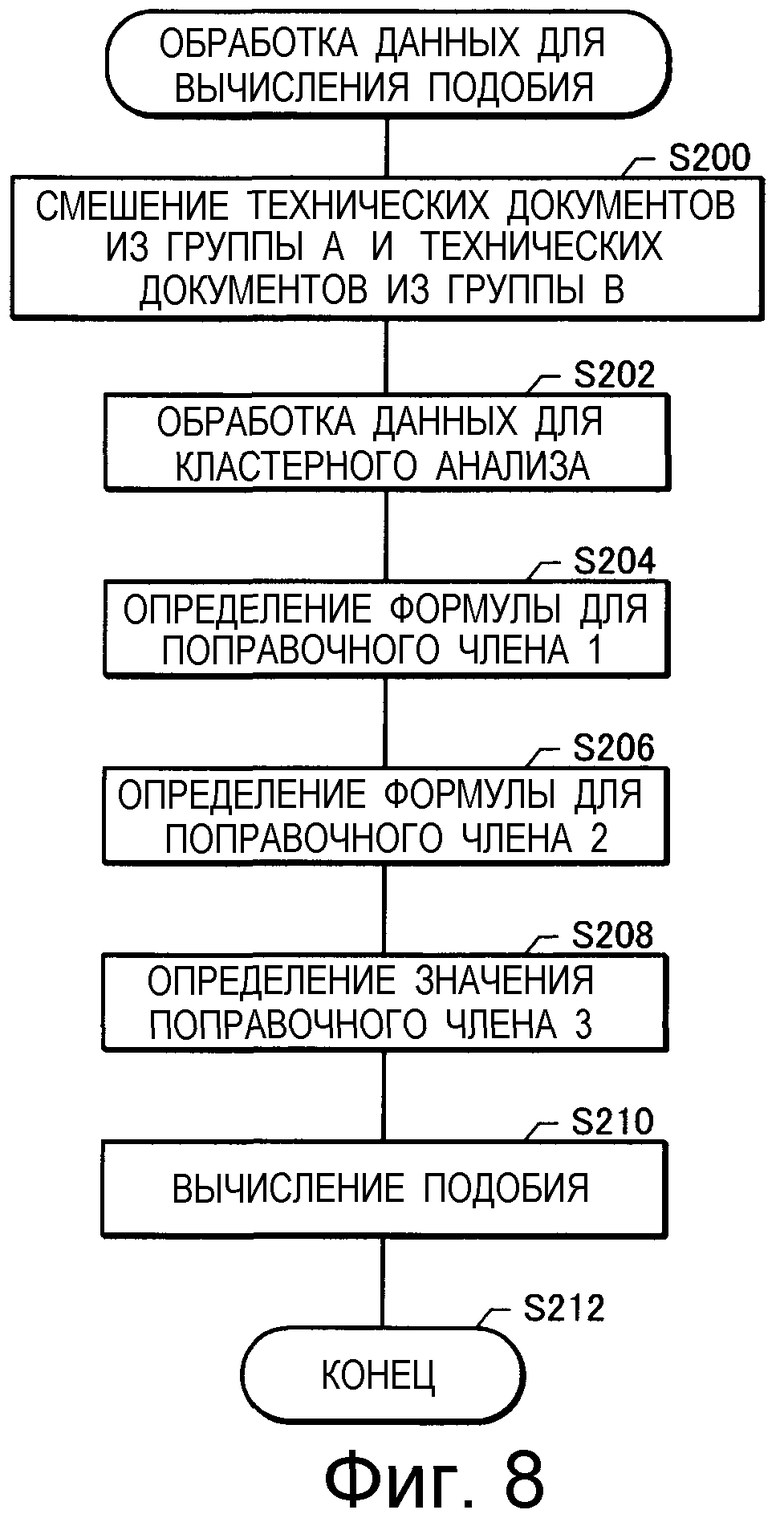
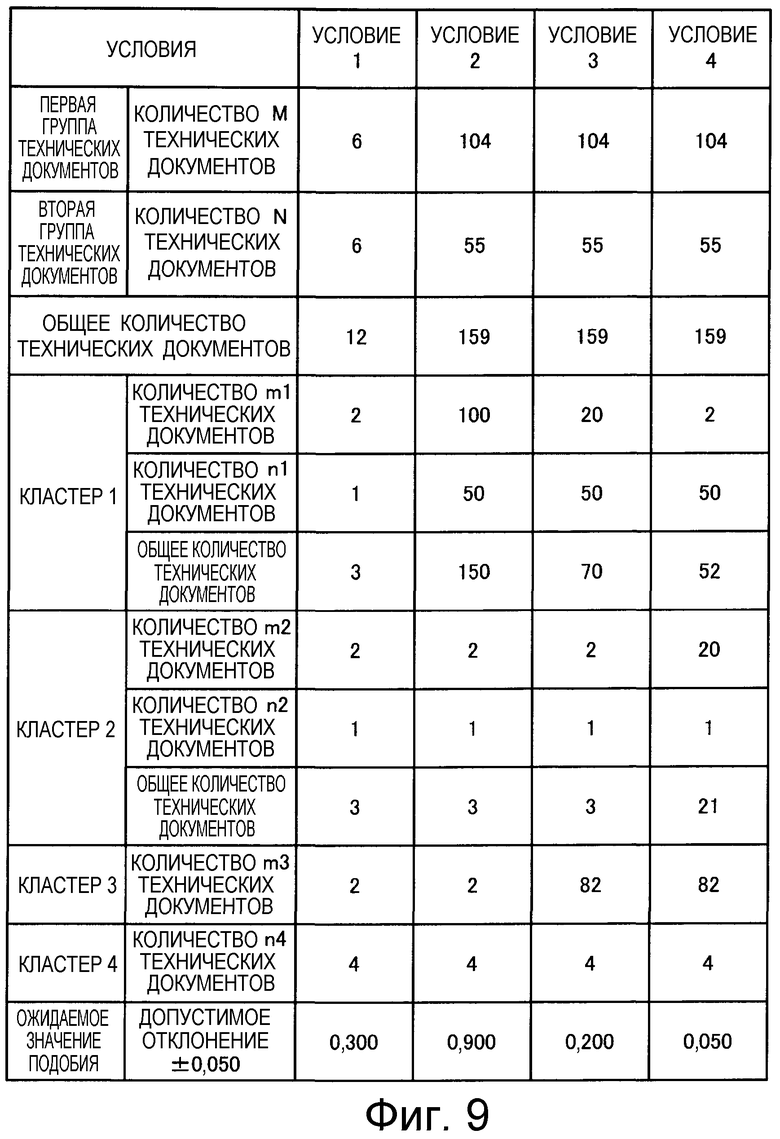
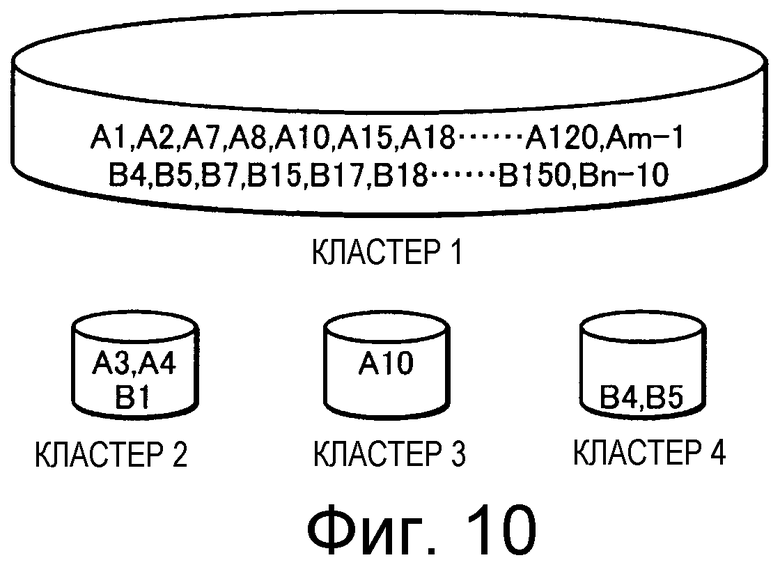
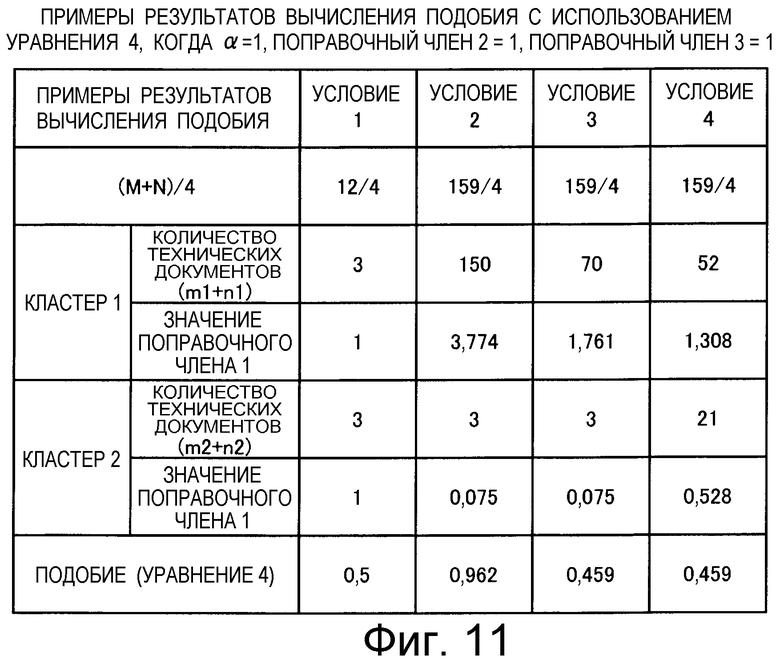
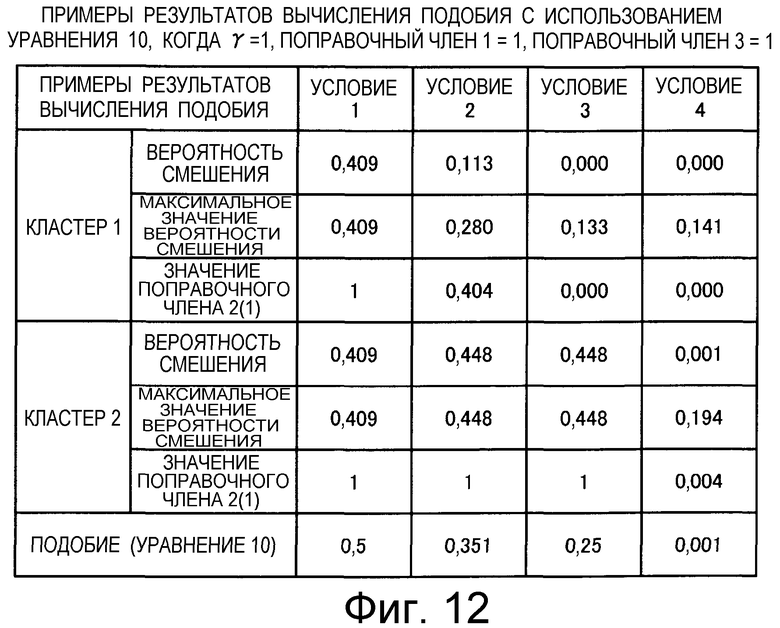
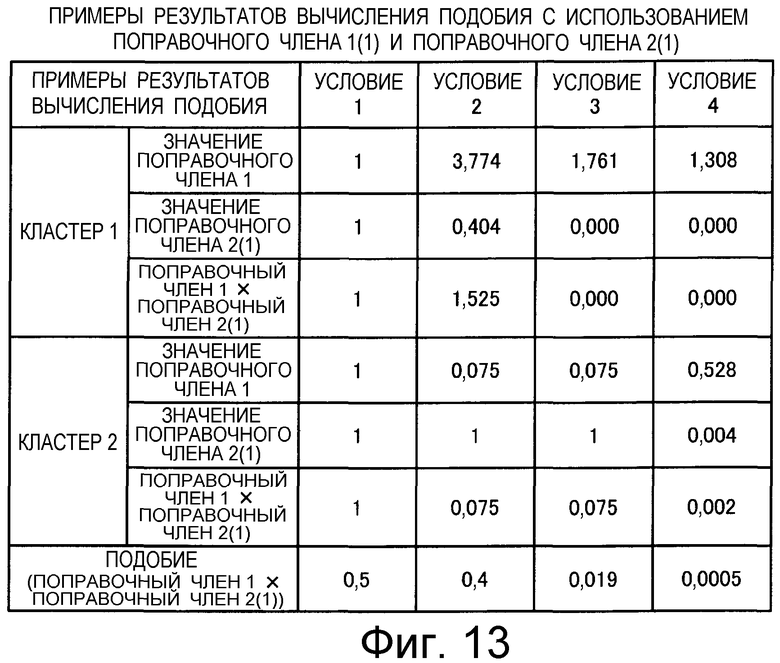
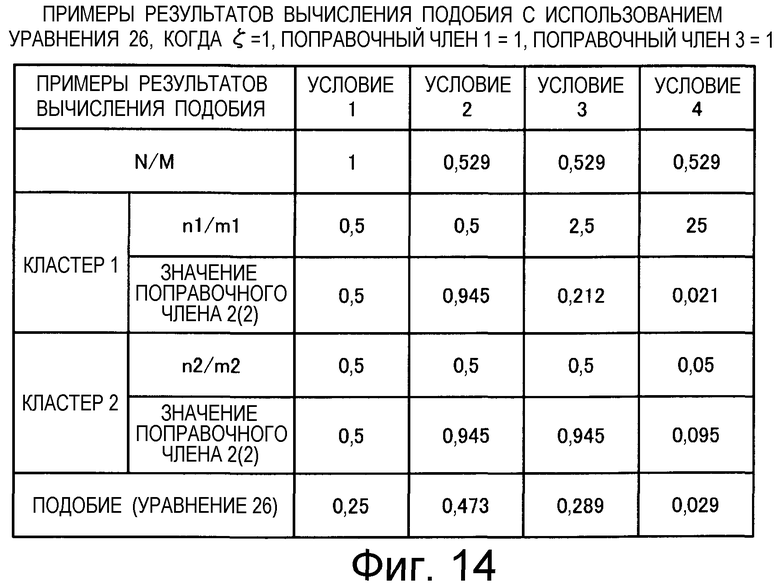
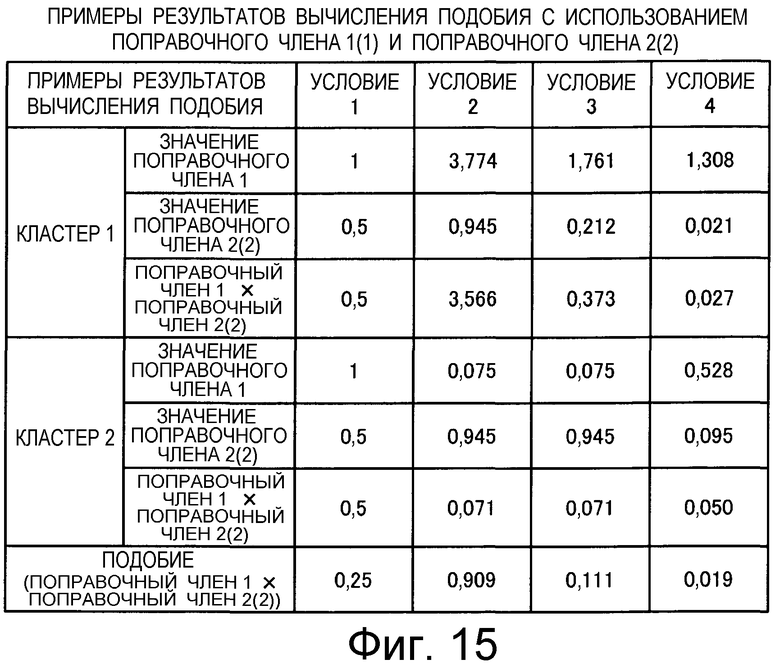
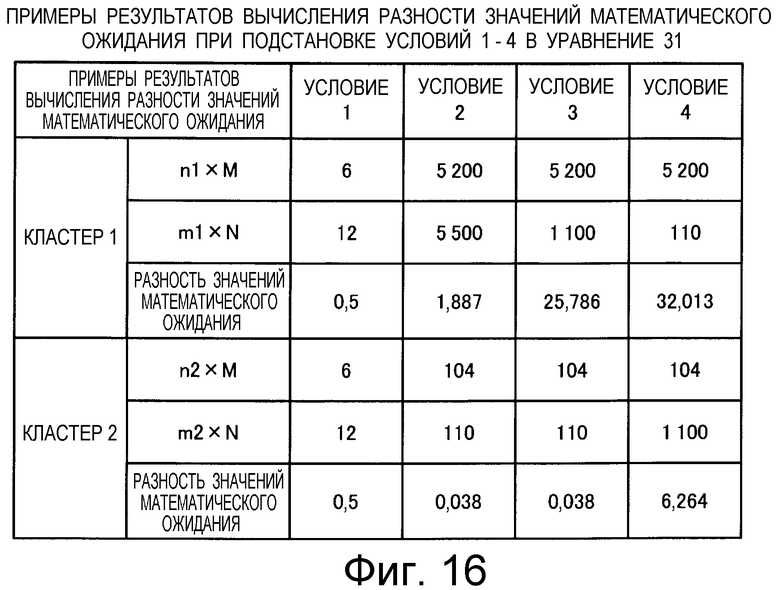
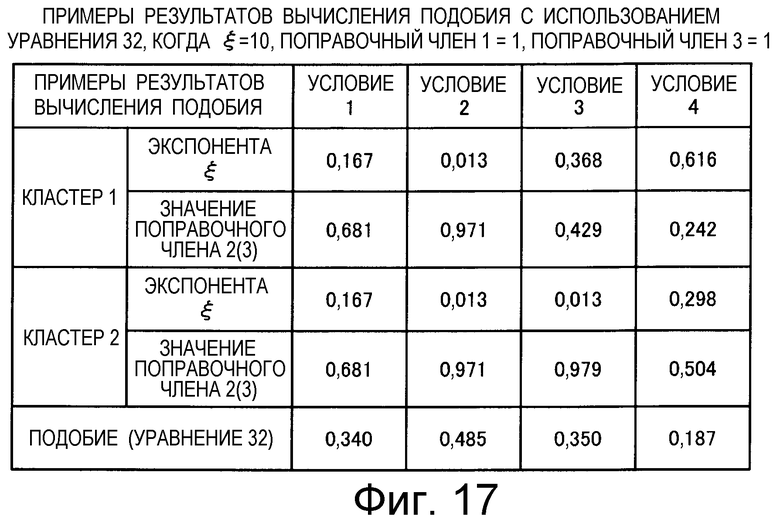

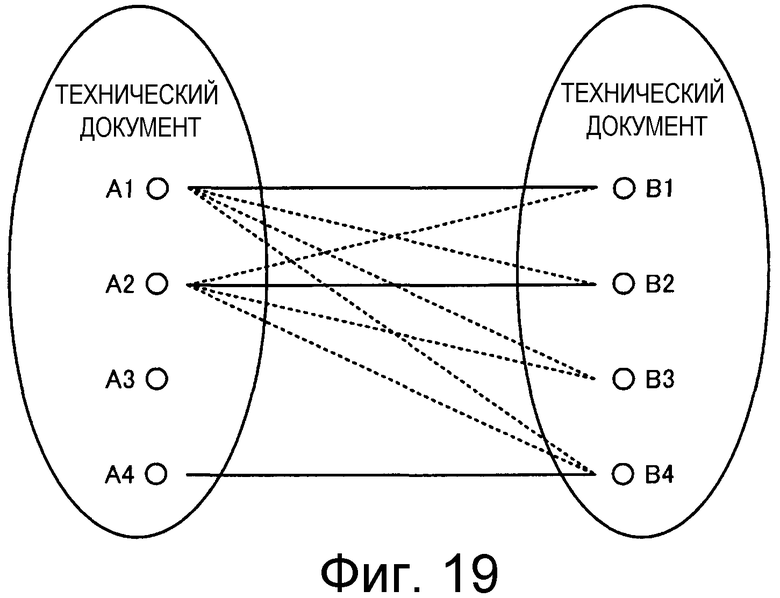
Изобретение относится к устройствам вычисления подобия, предназначенным для вычисления показателя, по которому судят о техническом подобии между группами технических документов. Техническим результатом является создание устройства и способа вычисления подобия, которые предоставляют возможность сравнения групп технических документов в широкой области, не ограниченной публикациями патентов или подобными документами. Устройство вычисления подобия содержит средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов, подлежащих сравнению; средство ввода технической информации, предназначенное для ввода технической информации; средство кластерного анализа, предназначенное для поиска технических документов, содержащихся в первой группе технических документов и во второй группе технических документов и содержащих введенную техническую информацию, и для разложения найденных технических документов на кластеры для каждой технической информации; средство вычисления подобия, предназначенное для вычисления отношения общего количества кластеров, полученных в результате кластерного разложения, к количеству смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов; и средство вывода, предназначенное для вывода вычисленного подобия. 27 н. и 6 з.п. ф-лы, 19 ил.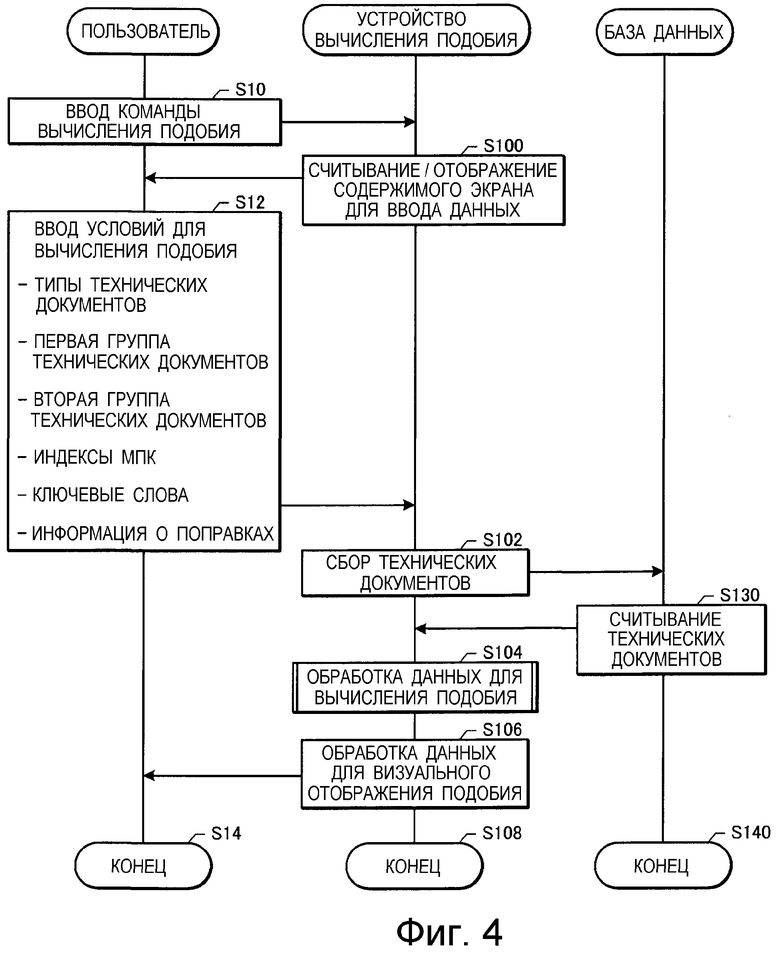
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления в качестве подобия отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученному в результате кластерного анализа; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы произведений значения первой поправки, которая принимает значение, соответствующее количеству технических документов, содержащихся в каждом смешанном кластере, и значения второй поправки, которая принимает значение, соответствующее состоянию смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов в каждом смешанном кластере, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных количеству технических документов в каждом кластере в степени α (где 0<α), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления количества технических документов в каждом кластере в степени α (где 0<α) на нормировочный коэффициент, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ) на нормировочный коэффициент, для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также для вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных отношению коэффициента N/M состава и коэффициента n/m смешения в степени ζ (где 0<ζ), для коэффициента N/M состава, равного отношению количества N технических документов, содержащихся во второй группе технических документов, к количеству М технических документов, содержащихся в первой группе технических документов, и для коэффициента n/m смешения, равного отношению количества n технических документов из второй группы технических документов к количеству m технических документов из первой группы технических документов, которые содержатся в каждом смешанном кластере, полученном в результате кластерного анализа, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и для вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем установления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
средство ввода групп технических документов, предназначенное для ввода первой группы технических документов и второй группы технических документов для их сравнения;
средство ввода технической информации, предназначенное для ввода технической информации;
средство кластерного анализа, предназначенное для поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и для кластеризации найденных технических документов по каждой технической информации;
средство вычисления подобия, предназначенное для вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и для вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также для вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления разности значений математического ожидания на количество технических документов в каждом смешанном кластере, и установления результата деления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и последующего деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
средство вывода, предназначенное для вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и вычисления в качестве подобия отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученному в результате кластерного анализа; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы произведений значения первой поправки, которая принимает значение, соответствующее количеству технических документов, содержащихся в каждом смешанном кластере, и значения второй поправки, которая принимает значение, соответствующее состоянию смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов в каждом смешанном кластере, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных количеству технических документов в каждом кластере в степени α (где 0<α), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления количества технических документов в каждом кластере в степени α (где 0<α) на нормировочный коэффициент, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ) на нормировочный коэффициент, для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных отношению коэффициента N/M состава и коэффициента n/m смешения в степени ζ (где 0<ζ), для коэффициента N/M состава, равного отношению количества N технических документов, содержащихся во второй группе технических документов, к количеству М технических документов, содержащихся в первой группе технических документов, и для коэффициента n/m смешения, равного отношению количества n технических документов из второй группы технических документов к количеству m технических документов из первой группы технических документов, которые содержатся в каждом смешанном кластере, полученном в результате кластерного анализа, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем установления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
при этом исполнение упомянутой программы обеспечивает осуществление средством обработки информации следующего:
выполняемой средством ввода групп технических документов функции ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемой средством ввода технической информации функции ввода технической информации;
выполняемой средством кластерного анализа функции поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемой средством вычисления подобия функции вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления разности значений математического ожидания на количество технических документов в каждом смешанном кластере, и установления результата деления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и последующего деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемой средством вывода функции вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и вычисления в качестве подобия отношения количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, к общему количеству кластеров, полученному в результате кластерного анализа; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы произведений значения первой поправки, которая принимает значение, соответствующее количеству технических документов, содержащихся в каждом смешанном кластере, и значения второй поправки, которая принимает значение, соответствующее состоянию смешения технических документов из первой группы технических документов и технических документов из второй группы технических документов в каждом смешанном кластере, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных количеству технических документов в каждом кластере в степени α (где 0<α), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления количества технических документов в каждом кластере в степени α (где 0<α) на нормировочный коэффициент, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ), для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления вероятности того, что будет найдено m технических документов из первой группы технических документов и n технических документов из второй группы технических документов, в степени γ (где 0<γ) на нормировочный коэффициент, для введения поправки в соответствии с вероятностью того, что в каждом смешанном кластере, полученном в результате кластерного анализа, содержится определенное количество технических документов из первой группы технических документов и из второй группы технических документов, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, а также вычисления по всем смешанным кластерам суммы значений поправки, пропорциональных отношению коэффициента N/M состава и коэффициента n/m смешения в степени ζ (где 0<ζ), для коэффициента N/M состава, равного отношению количества N технических документов, содержащихся во второй группе технических документов, к количеству М технических документов, содержащихся в первой группе технических документов, и для коэффициента n/m смешения, равного отношению количества n технических документов из второй группы технических документов к количеству m технических документов из первой группы технических документов, которые содержатся в каждом смешанном кластере, полученном в результате кластерного анализа, и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой труппы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем установления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
выполняемую средством ввода групп технических документов операцию ввода первой группы технических документов и второй группы технических документов для их сравнения;
выполняемую средством ввода технической информации операцию ввода технической информации;
выполняемую средством кластерного анализа операцию поиска среди технических документов, содержащихся в первой группе технических документов и во второй группе технических документов, тех технических документов, которые содержат введенную техническую информацию, и кластеризации найденных технических документов по каждой технической информации;
выполняемую средством вычисления подобия операцию вычисления общего количества кластеров, полученных в результате кластерного анализа, и количества смешанных кластеров, содержащих технические документы из первой группы технических документов и из второй группы технических документов, и вычисления значения математического ожидания того, что будет найден технический документ из первой группы технических документов, путем умножения вероятности того, что в группе технических документов, охватывающей первую группу технических документов и вторую группу технических документов, будет найден технический документ из первой группы технических документов, на количество технических документов, содержащихся в каждом смешанном кластере, и вычисления в качестве разности значений математического ожидания разности между значением математического ожидания и количеством технических документов из первой группы технических документов, содержащихся в каждом смешанном кластере, а также вычисления по всем смешанным кластерам суммы значений поправки, полученных путем деления разности значений математического ожидания на количество технических документов в каждом смешанном кластере, и установления результата деления разности значений математического ожидания в качестве отрицательной экспоненты для произвольной постоянной ξ (где 1<ξ), и последующего деления этой суммы на вычисленное общее количество кластеров для вычисления подобия; и
выполняемую средством вывода операцию вывода вычисленного подобия в средство записи, в средство визуального отображения или в средство связи.
| US 5787420 A, 28.07.1998 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 5317507 A, 31.05.1994 | |||
| US 6263314 B1, 17.07.2001 | |||
| СПОСОБ ПОИСКА ПАТЕНТНЫХ ДОКУМЕНТОВ ПРИ ПОМОЩИ ЦИФРОВЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ | 0 |
|
SU305479A1 |
| RU 216629 U1, 20.01.2001 | |||
| УСТРОЙСТВО ПОИСКА ИНФОРМАЦИИ | 2001 |
|
RU2199148C1 |
| Система для поиска и обработки научно-технической информации | 1981 |
|
SU993273A1 |

