Область техники, к которой относится изобретение
Настоящее изобретение относится к способу автоматической итеративной кластеризации электронных документов по семантической близости, способу поиска в совокупности кластеризованных по семантической близости документов, а также к машиночитаемым носителям с программами для реализации этих способов.
Уровень техники
Огромные объемы информации в сети Интернет приводят к тому, что количество объектов, выдаваемых по запросу пользователя, очень велико. Общей проблемой, снижающей эффективность работы пользователя с поисковой системой, является избыточность информации при выдаче результатов по запросу. Это затрудняет процесс обзора результатов и выбора наиболее подходящих материалов (статей, публикаций, отчетов и др.) из множества найденных.
В настоящее время известны различные способы кластеризации документов по их семантической близости, позволяющие в дальнейшем проводить поиск в совокупности таких документов.
Так, в патенте РФ №2268488 (опубл. 20.01.2006) раскрыт способ, в котором кодируют слова, фразы, идиомы, предложения и даже идеи для последующей числовой обработки, в том числе кластеризации. В патенте РФ №2273879 (опубл. 10.04.2006) приведен способ, в котором проводят морфологический и синтаксический анализ текста с последующей индексацией найденных единиц для отнесения текста к конкретному классу. В способе по патенту США №6871174 (опубл. 22.03.2005) определяют сходство текстов по текстовым фрагментам. В патенте ЕАПВ №002016 (опубл. 22.01.2001) описан способ, в котором во фрагментах текстового документа определяют уникальные блоки информации и используют их для последующей кластеризации и поиска. Недостаток всех этих способов состоит в том, что для их осуществления требуется очень большой объем памяти, т.к. при поступлении нового текста обработку приходится повторять для каждого уже обработанного текста.
В патенте США №6189002 (опубл. 13.02.2001) раскрыт способ, в котором текст разбивают на абзацы и слова, которые преобразуют в векторы упорядоченных элементов. Каждый элемент вектора соответствует абзацу, найденному применением заданной функции к числу появлений в этом абзаце слова, соответствующего этому элементу. Текстовый вектор рассматривается как семантический профиль документа, пригодный для сопоставления в случае кластеризации. Однако с учетом многообразия абзацев данный способ также требует огромного массива запомненных данных.
Раскрытие изобретения
Задачей настоящего изобретения является разработка такого способа итеративной кластеризации электронных документов по семантической близости, который бы обеспечивал упрощение и ускорение как соответствующей обработки электронных документов, так и последующего поиска в кластеризованной совокупности тех документов, которые релевантны поисковому запросу.
Для решения этой задачи и достижения указанного технического результата в первом объекте настоящего изобретения предложен способ автоматической итеративной кластеризации электронных документов по семантической близости, заключающийся в том, что: преобразуют каждый подлежащий обработке электронный документ в соответствующий многомерный вектор в многомерном пространстве, размерности которого определяются содержащимися в электронном документе термами; находят меру близости полученного многомерного вектора к каждому из многомерных векторов уже имеющихся кластеров, объединяющих семантически близкие электронные документы, обработанные ранее; дополняют подлежащим обработке электронным документом тот из кластеров, для которого найденная мера близости минимальна; определяют для дополненного кластера его новый многомерный вектор; принимают в качестве темы дополненного кластера название того из электронных документов в данном кластере, для которого мера близости его многомерного вектора к определенному новому многомерному вектору минимальна.
Особенность способа по первому объекту настоящего изобретения состоит в том, что могут накапливать совокупность подлежащих обработке электронных документов по мере их появления в течение заранее заданного интервала времени; после чего и осуществлять кластеризацию каждого из электронных документов в накопленной совокупности.
Еще одна особенность способа по первому объекту настоящего изобретения состоит в том, что преобразование электронного документа в многомерный вектор может включать в себя этапы, на которых: планаризируют текст электронного документа; формируют массивы термов для планаризованного текста каждого из электронных документов, для чего токенизируют планаризованный текст, получая в результате сегменты в виде слов, знаков препинания, пробелов, и стеммируют токенизированный текст, выделяя в результате основы слов с помощью по меньшей мере одного из эвристических алгоритмов, после чего находят вес каждого терма в каждом из электронных документов, и выражают каждый из электронных документов в виде вектора в многомерном пространстве, размерности которого определяются найденными весами термов в тексте данного электронного документа.
При этом вычисление веса каждого терма могут выполнять с использованием меры TF-IDF, представляющей собой произведение величины

на величину
 .
.
Еще одна особенность способа по первому объекту настоящего изобретения состоит в том, что нахождение меры близости многомерных векторов может включать в себя этапы, на которых: вычисляют косинусную меру близости между каждой парой многомерных векторов; разбивают все многомерные векторы на подмножества, в каждом из которых вычисленная косинусная мера близости между парой любых многомерных векторов меньше заранее заданного значения; рассчитывают вектор-центроид каждого из подмножеств как среднеарифметическое всех многомерных векторов данного подмножества; приписывают каждый многомерный вектор к подмножеству с ближайшим вектором-центроидом.
Еще одна особенность способа по первому объекту настоящего изобретения состоит в том, что дополнительно могут осуществлять этапы, на которых: находят меру взаимной близости многомерных векторов для каждой пары кластеров; объединяют в соответствующий топик те кластеры, для которых найденные меры взаимной близости их многомерных векторов не превышают заранее заданное пороговое значение; определяют для топика его многомерный вектор; принимают в качестве темы топика тему того из входящих в него кластеров, для которого мера близости его многомерного вектора к определенному многомерному вектору этого топика минимальна.
Еще одна особенность способа по первому объекту настоящего изобретения состоит в том, что дополнительно могут осуществлять этапы, на которых: находят меру взаимной близости многомерных векторов для каждой пары топиков; объединяют в соответствующий супертопик те топики, для которых найденные меры взаимной близости их многомерных векторов не превышают заранее заданный порог; определяют для супертопика его многомерный вектор; принимают в качестве темы супертопика тему того из входящих в него топиков, для которого мера близости его многомерного вектора к определенному многомерному вектору этого супертопика минимальна.
Еще одна особенность способа по первому объекту настоящего изобретения состоит в том, что могут строить граф, узлами которого являются супертопики, а каждое из ребер представляет собой отношение близости связываемых этим ребром супертопиков, топиков и документов.
При этом могут составлять глобальный словарь термов для обеспечения возможности последующего проведения поиска фрагментов графа, релевантных конкретному поисковому документу.
Для решения той же задачи и обеспечения того же технического результата во втором объекте настоящего изобретения предложен способ поиска в совокупности кластеризованных по семантической близости документов, заключающийся в том, что: осуществляют кластеризацию электронных документов согласно способу по первому объекту настоящего изобретения, после чего выполняют поиск релевантных поисковому запросу электронных документов как фрагментов построенного графа.
Для решения той же задачи и обеспечения того же технического результата в третьем объекте настоящего изобретения предложен машиночитаемый носитель, предназначенный для непосредственного участия в работе вычислительного средства и содержащий программу, которая при ее исполнении в вычислительном средстве обеспечивает выполнение способа по первому объекту настоящего изобретения.
Для решения той же задачи и обеспечения того же технического результата в четвертом объекте настоящего изобретения предложен машиночитаемый носитель, предназначенный для непосредственного участия в работе вычислительного средства и содержащий программу, которая при ее исполнении в вычислительном средстве обеспечивает выполнение способа по второму объекту настоящего изобретения.
Краткое описание чертежей
Настоящее изобретение иллюстрируется прилагаемыми чертежами.
На Фиг.1 показана блок-схема алгоритма семантической кластеризации электронных документов в соответствии с настоящим изобретением.
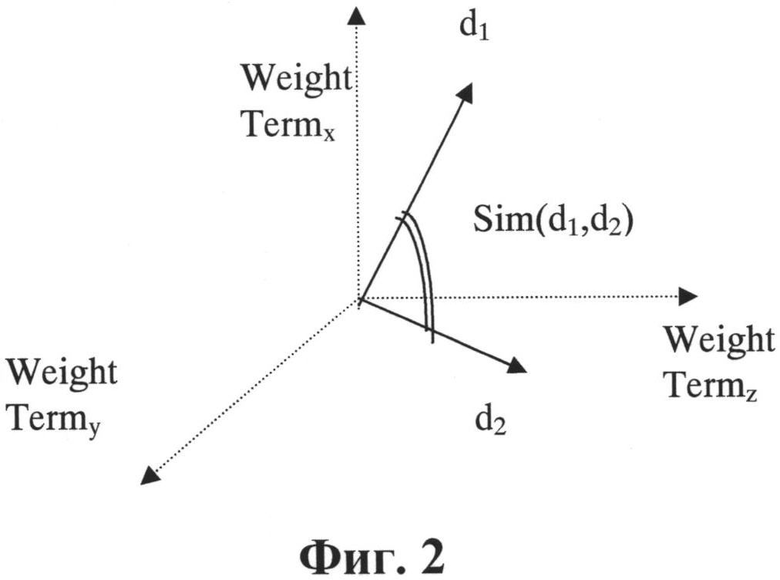
На Фиг.2 проиллюстрировано определение меры близости векторов.
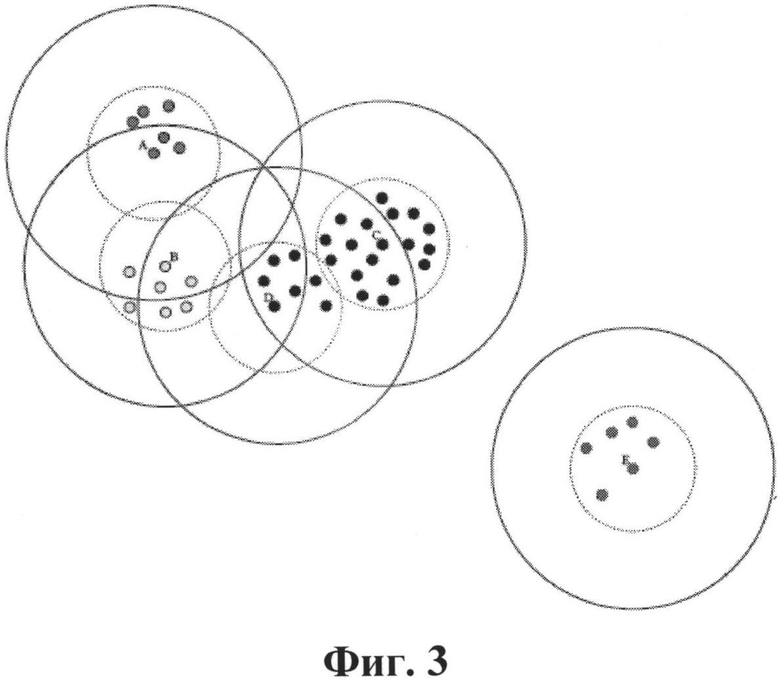
На Фиг.3 проиллюстрирован принцип кластеризации по методу Canopy.
На Фиг.4 показан граф, отображающий принцип, заложенный в способ по настоящему изобретению.
На Фиг.5 приведен скриншот части графа, возвращаемого на запрос «марс условия для жизни» в системе, использующей данное изобретение.
На Фиг.6 приведен пример отчета, формируемого системой по некоторым отборочным критериям.
Подробное описание вариантов осуществления
Задача уменьшения избыточности может решаться различными способами. В большинстве случаев огромные объемы информации можно сделать доступными для восприятия, если уметь разбивать источники информации, например web-страницы, на тематические группы. Тогда пользователь может сразу отбрасывать множество документов из групп с малой релевантностью. Такой процесс группировки текстовых данных осуществляется с помощью кластеризации.
Кластеризация выборки документов представляет собой эффективное средство повышения качества диалога пользователя с поисковой системой, позволяющее проводить разбиение полученной выборки по тематическим признакам. Целью кластеризации документов является автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества документов, когда никакие характеристики этих групп не задаются заранее.
Способ автоматической итеративной кластеризации электронных документов по семантической близости в соответствии с настоящим изобретением предназначен для повышения эффективности обработки информации, содержащейся в различных источниках, с целью обеспечения процессов управления данными, извлекаемыми из различных электронных источников научно-технической информации с использованием инновационных семантических технологий. Этот способ может осуществляться в системе, представляющей собой или включающей в себя вычислительное средство (сервер, персональный компьютер, и т.п.), запрограммированное для выполнения описываемых ниже действий.
Для выявления семантической близости электронных документов особую актуальность имеют методы интеллектуального анализа данных. Основная особенность этих методов заключается в установлении наличия и характера скрытых закономерностей в данных, тогда как традиционные статистические методы занимаются главным образом параметрической оценкой уже установленных закономерностей. Среди методов интеллектуального анализа данных особое место занимает кластеризация. Кластеризация, основываясь на отношении схожести элементов, устанавливает подмножества (кластеры), в которые группируются входные данные.
Обычно источниками обрабатываемых документов служат различные наборы документов сети Интернет. Определение значимых источников осуществляется пользователем с учетом его информационных и аналитических потребностей и возможностей, предоставляемых информационным пространством (наличие источников, наличие сведений о тех или иных объектах и т.п.), т.е. выясняется круг рассматриваемых источников информации, содержание предметной области.
При этом пользователь определяет тип информационной потребности и ее ограничения (по видам изданий, языкам публикаций, по географическим и хронологическим рамкам и т.п.).
Как правило, у пользователей существуют предпочтительные наборы ресурсов сети Интернет по тематике их деятельности. Список информационных ресурсов формируется таким образом, чтобы ресурсы, дополняя друг друга, максимально охватывали информацию по данной теме.
Исходными данными для реализации способов по настоящему изобретению является поток привязанных ко времени документов, который приходит в систему. Каждый документ рассматривается в качестве исходного информационного объекта, обладающего временем создания (появления) и уникальным идентификатором - унифицированным указателем ресурсов (УУР, URL - Uniform Resource Locator).
Задачей системы, реализующей способы по настоящему изобретению, является группировка входящего потока документов по темам и установление близости между темами. Система оперирует экземплярами объектов нескольких типов - документы, топики, супертопики, поясняемые далее. Каждый экземпляр любого из типов объектов имеет в системе свой уникальный номер.
Начальной операцией, выполняемой системой, является пополнение базы данных системы исходными информационными объектами. Специалистам понятно, что подлежащий кластеризации текст необходимо представить в электронной форме для последующей автоматизированной обработки. Этот этап на Фиг.1 условно обозначен ссылочной позицией 1 и может быть выполнен любым известным способом, например сканированием текста с последующим распознаванием с помощью общеизвестных средств типа ABBYY FineReader. Если же текст поступает на обработку из электронной сети, к примеру из Интернета, то этап его представления в электронной форме выполняется заранее, до размещения этого текста в сети. Поэтому на блок-схеме Фиг.1 этап представления документа в электронной форме показан пунктиром. Для каждого из таких объектов в базе данных системы сохраняется исходный вид документа в оригинальном формате (поз.2 на Фиг.1). На его основе получают текст документа, извлеченный из документа в оригинальном формате, именуемый планаризованным текстом (поз.3 на Фиг.1).
Далее формируют массивы термов для планаризованного текста каждого из сохраненных электронных документов. Для этого сначала планаризованный текст токенизируют, получая в результате сегменты в виде слов, знаков препинания, пробелов. Т.е. текст сегментируется на элементарные единицы, именуемые токенами (token). Токеном может быть любой объект из следующих: слова, состоящие каждое из последовательности букв и, возможно, дефисов; последовательность пробелов; знаки препинания; числа (к примеру, 2012, Тянь-Шань). Иногда сюда же относят такие последовательности символов, как А300, i150b и т.п. Выделение токенов всегда осуществляется по достаточно простым правилам, например, как в заявке на патент США №2007/0073533 (опубл. 29.03.2007). После этого токенизированный текст стеммируют, т.е. выделяют основы слов с помощью любого из известных эвристических алгоритмов - например, используя такие библиотеки как Snowball (см. http://snowball.tartarus.org/) и Ispell (см. http://www.gnu.org/software/ispell/). На Фиг.1 этот этап условно обозначен ссылочной позицией 4.
После этого находят вес каждого терма в сформированном массиве термов в каждом из электронных документов (поз.5 на Фиг.1). Это вычисление веса каждого терма можно выполнять, например, с использованием меры TF-IDF, представляющей собой произведение величины

на величину
 .
.
В принципе, веса термов можно находить и иначе, к примеру, так, как описано в вышеупомянутом патенте США №6189002.
После того, как найдены веса всех термов, входящих в текст конкретного электронного документа, этот электронный документ выражают в виде вектора в многомерном пространстве (поз.6 на Фиг.1). Например, если для данного документа выписать по порядку веса всех термов, включая те, которых нет в этом документе, получится вектор, который и будет представлением данного документа в векторном пространстве. Размерности этого пространства определяются найденными весами термов в тексте данного электронного документа. Т.е. вес терма в документе - это «важность» слова, исходного для этого терма, при идентификации данного текста. Если подсчитать количество употреблений терма в документе, так называемую частоту терма, то чем чаще слово встречается в документе, тем больший у него будет вес. Если терм не встречается в документе, то его вес в этом документе равен нулю.
В результате выполнения этапов, обозначенных ссылочными позициями 1-6 на Фиг.1, выполняется преобразование каждого подлежащего обработке электронного документа в соответствующий многомерный вектор в многомерном пространстве. Можно сказать, что сформированный многомерный вектор представляет собой упорядоченный набор чисел с длиной, равной числу записей в упорядоченном словаре термов, встречающихся в документах, где каждому терму соответствует величина TF-IDF. Термы представляют собой упоминаемые в документах слова, приведенные к нормальной форме.
Далее находят меру близости полученного многомерного вектора к каждому из многомерных векторов в уже имеющихся кластерах, объединяющих семантически близкие электронные документы, обработанные ранее (поз.7 на Фиг.1). Такую меру можно вычислять так же, как описано в уже упомянутом патенте США №6189002. Однако предпочтительно использовать косинусную меру близости векторов 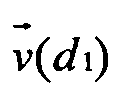 и
и 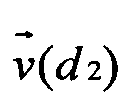 весов термов документов:
весов термов документов:
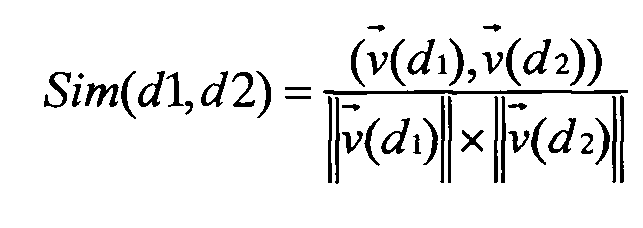 ,
,
где
-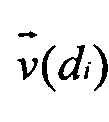 , i=1, 2 - вектор в пространстве термов
, i=1, 2 - вектор в пространстве термов 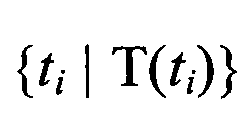 , извлекаемых из всего множества документов
, извлекаемых из всего множества документов 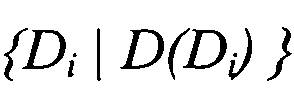 .
.
-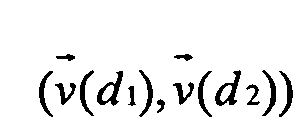 - скалярное произведение векторов весов, вычисляемое по формуле
- скалярное произведение векторов весов, вычисляемое по формуле
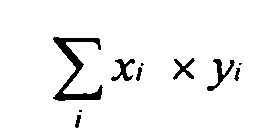 , где xi, yi, - i-e координаты векторов,
, где xi, yi, - i-e координаты векторов,
- 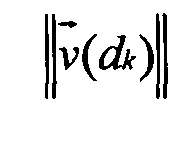 , k=1, 2 - евклидова норма вектора, вычисляемая по формуле
, k=1, 2 - евклидова норма вектора, вычисляемая по формуле
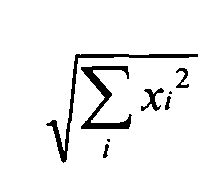 ,
,
а, xi - координата вектора (вес i-го терма), вычисляемая по формуле
 ,
,
в которой tft - частота (число упоминаний) терма t в данном документе, N - общее количество документов, а Nt - число документов, в которых встречается хотя бы один терм t. Отметим, что tft - это определенная выше величина TF для терма t.
На Фиг.2 проиллюстрировано определение меры близости векторов d1 и d2 в некотором пространстве.
После нахождения меры близости вектора в документе, подлежащем обработке, с векторами в уже имеющихся кластерах выполняют этап (поз.8 на Фиг.1), на котором дополняют этим подлежащим обработке электронным документом тот из уже имеющихся кластеров, для которого найденная на предыдущем этапе мера близости минимальна. Если же речь идет о начальной кластеризации нескольких документов (когда кластеры еще не определены) или о предварительной кластеризации совокупности еще не обработанных электронных документов (в случае их накопления в течение заранее заданного или произвольного интервала времени), то кластерный анализ может производиться следующим образом.
Вообще кластерный анализ - это способ группировки многомерных объектов, основанный на представлении результатов отдельных наблюдений точками подходящего геометрического пространства с последующим выделением групп как «сгустков» этих точек (кластеров). Кластерный анализ предполагает выделение компактных, удаленных друг от друга групп объектов, отыскивает «естественное» разбиение совокупности на области скопления объектов. Он используется, когда исходные данные представлены в виде матриц близости или расстояний между объектами либо в виде точек в многомерном пространстве. Наиболее распространены данные второго вида, для которых кластерный анализ ориентирован на выделение некоторых геометрически удаленных групп, внутри которых объекты близки. В настоящем изобретении точками в многомерном пространстве условно являются концы найденных многомерных векторов.
Таким образом, кластеризация - это разбиение множества документов на кластеры, т.е. подмножества, параметры которых заранее неизвестны. Количество кластеров может быть произвольным или фиксированным. Все методы кластеризации можно разделить на числовые и нечисловые. Числовые методы используют числовые характеристики о документах, а нечисловые методы используют для работы непосредственно слова и фразы, составляющие текст. Существуют статистические, иерархические и графовые алгоритмы кластеризации.
В настоящем изобретении кластеризация реализована как последовательный многоступенчатый процесс, на отдельных этапах которого выполняется «классическая» кластеризация некоторой порции данных посредством любого хорошо себя зарекомендовавшего алгоритма. Например, в практической реализации системы предпочтительно используется алгоритм кластеризации, именуемый методом Canopy (метод «навесов») (см. http://www.kamalnigam.com/papers/canopy-kdd00.pdf).
Основная идея этого метода заключается в выполнении кластеризации в два этапа, из которых первый этап является грубым и быстрым, он делит данные на пересекающиеся подмножества, называемые canopies («навесы»), а затем может применяться второй, более тщательный этап, на котором проводятся более затратные измерения расстояний только между точками, которые имеются под общим canopy («навесом»).
На первом этапе используется незатратное измерение расстояний для того, чтобы создать некоторое количество перекрывающихся подмножеств, называемых «навесами». «Навес» (canopy) - это просто подмножество элементов (т.е. точек данных или элементов), которые, в соответствии с приближенным измерением сходств, находятся на некотором расстоянии от центральной точки. Что особенно важно, элемент может оказаться под более чем одним «навесом», а каждый элемент должен находиться, по крайней мере, только под одним «навесом». «Навесы» создаются с тем намерением, что точки, которые не входят в какие-либо общие «навесы», находятся на достаточном удалении друг от друга, и, таким образом, не могут находиться в одном кластере. На Фиг.3 круги со сплошными линиями показывают пример перекрытия «навесов», которые охватывают наборы данных.
Таким образом, после нахождения многомерных векторов и вычисления меры их попарной близости (т.е. после этапа 8 на Фиг.1) все полученные многомерные векторы разбивают на подмножества, в каждом из которых вычисленная мера близости (например, косинусная мера близости) между парой любых многомерных векторов меньше заранее заданного значения. При этом рассчитывают вектор-центроид каждого из полученных подмножеств как среднеарифметическое всех многомерных векторов данного подмножества (поз.9 на Фиг.1).
На втором этапе метода «навесов» каждой точке приписывается только один кластер по принципу: каждая точка (т.е. каждый вектор) многомерного пространства приписывается к самому близкому центроиду. Классический алгоритм использует метрику расстояний и два порога расстояний Т1>Т2. Для каждой из множества точек, если расстояние от некоторой точки в конкретном кластере <Т1, эта точка добавляется в данный кластер (сплошные круги на Фиг.3). Далее, если это расстояние <Т2, то данная точка удаляется из дальнейшего рассмотрения и считается принадлежащей данному «навесу» (пунктирные круги на Фиг.3), что позволяет понизить вычислительную сложность алгоритма. Таким образом, объект (точка), очень близкий к центру будущего кластера, будет исключен (исключена) из дальнейшей обработки. Алгоритм повторяется до тех пор, пока начальный набор не станет пустым.
Затем выполняется формирование кластеров на основе полученных центроидов (среднеарифметическое всех точек, входящих в данный «навес»). Для каждой точки осуществляется поиск ближайшего центроида (центра данного «навеса», центра круга на Фиг.3). Каждая точка приписывается к самому близкому центроиду. При этом количество кластеров становится равным количеству «навесов».
После выполнения этапа дополнения кластера новым документом (поз.8 на Фиг.1) определяют для этого дополненного кластера его новый многомерный вектор (поз.10 на Фиг.1) как среднеарифметическое прежнего вектора этого кластера и вектора добавленного документа. Затем принимают в качестве темы упомянутого дополненного кластера название того из электронных документов в данном кластере, для которого мера близости его многомерного вектора к определенному новому многомерному вектору минимальна (поз.11 на Фиг.1).
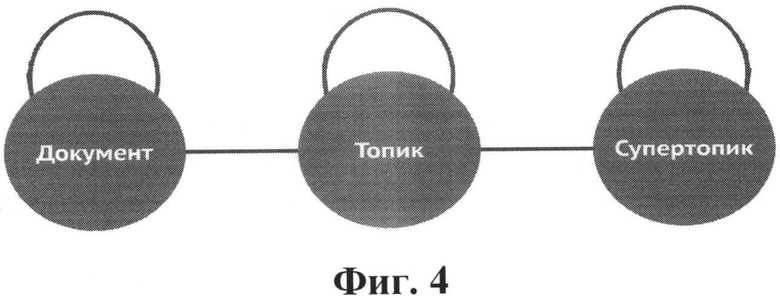
На Фиг.4 представлен шаблон графа, в который укладываются кластеры, полученные в результате вышеописанной кластеризации.
Горизонтальные ребра в этом графе есть иерархические обобщающие отношения между сущностями. Ребро документ-топик представляет тот факт, что документ является частью кластера, состоящего из близких по смыслу документов. Ребро топик-супертопик обобщает уже кластеры на более высоком уровне. Представленный шаблон в зависимости от природы или структуры исходных документов может быть продолжен вправо (гипертопики и т.д.) для достижения более высоких степеней обобщения.
Чем выше иерархия, тем меньше число сущностей на данном уровне. И чем выше иерархия, тем выше степень обобщения. Эти факты важны при использовании полученной структуры для ускорения информационного поиска и для представления огромных массивов информации в структурированном и обобщенном виде.
Ребра-дуги связывают сущности внутри каждого уровня иерархии. Эти связи полезны для расширения списка найденных документов близкими по смыслу документами.
Именно способ получения описанной выше структуры и является основным предметом данного изобретения.
Специфика способа по настоящему изобретению состоит в том, что уже имеющиеся кластеры обрабатывают как отдельные документы. Т.е. находят многомерный вектор каждого кластера (фактически он уже найден после дополнения кластера очередным электронным документом); находят меру взаимной близости многомерных векторов для каждой пары кластеров; объединяют в соответствующий топик (topic) те кластеры, для которых найденные меры взаимной близости их многомерных векторов не превышают заранее заданное пороговое значение; определяют многомерный вектор для топика; принимают в качестве темы топика тему того из входящих в него кластеров, для которого мера близости его многомерного вектора к определенному многомерному вектору этого топика минимальна.
Эту процедуру предпочтительно повторяют уже для топиков, т.е. находят меру взаимной близости многомерных векторов для каждой пары топиков; объединяют в соответствующий супертопик (сюжет) те топики, для которых найденные меры взаимной близости их многомерных векторов не превышают заранее заданный порог; определяют многомерный вектор для супертопика; принимают в качестве темы такого супертопика тему того из входящих в него топиков, для которого мера близости его многомерного вектора к определенному многомерному вектору этого супертопика минимальна.
Эту же процедуру можно повторять и для сюжетов, чтобы сформировать суперсюжеты, и т.д. К примеру, в случае определения тем для супертопиков в способе по настоящему изобретению строят граф, узлами которого являются супертопики, а каждое из ребер представляет собой отношение близости связываемых этим ребром супертопиков. После этого составляют глобальный словарь термов для обеспечения возможности последующего проведения поиска фрагментов построенного графа, релевантных конкретному поисковому документу.
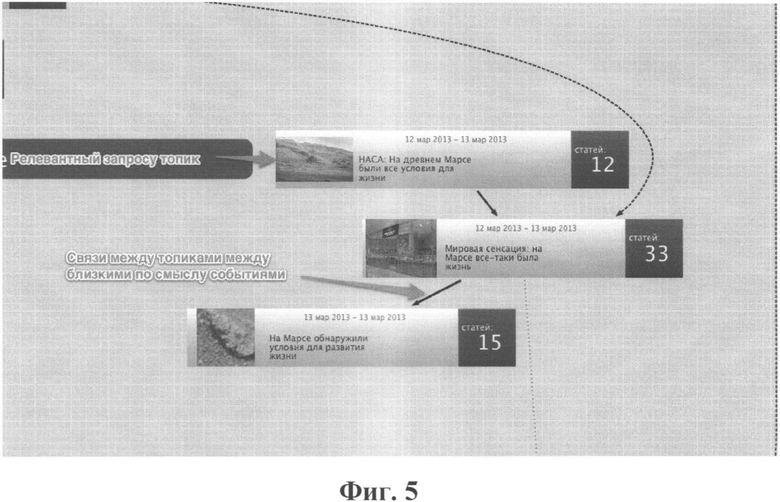
В качестве иллюстрации на Фиг.5 приведен скриншот графа, возвращаемого на запрос «марс условия для жизни» в системе, практически использующей данное изобретение. На этом изображении представлена часть описанной выше графовой структуры на уровне топиков, т.е. на уровне кластеров документов, между кластерами представлены связи-дуги (см. шаблон графа на Фиг.4). Система нашла, что вектор запроса «марс условия для жизни» при поиске на уровне топиков наиболее близок кластеру из 12 документов с заголовком, взятым из наиболее близкого к центроиду кластера документа «НАСА: На древнем Марсе были все условия для жизни».
Для иллюстрации иерархических связей на Фиг.6 приведен пример отчета, по типам дорожно-транспортных происшествий (ДТП) за некоторый период времени. Здесь сущности высокого уровня иерархии содержат в себе объекты более низких уровней. На Фиг.6 схематически показаны отчеты по ДТП трех типов: грузовик и автобус (общий круг слева внизу), грузовик и автомобиль (общий круг наверху), автомобиль и автомобиль (общий круг справа внизу). Здесь круги наименьшего диаметра (и наиболее темные) представляют документы (новостные сообщения), в которых упоминается факт ДТП. Далее, по иерархии, сообщения об одном и том же событии объединены в кластеры-топики, топики объединены в супертопики, супертопики объединены по типу описываемых в них событий (автомобиль-автомобиль, грузовик-автомобиль). При этом круг наибольшего диаметра (и наиболее светлый) несет чисто эстетическую нагрузку.
Для второго объекта настоящего изобретения - способа поиска в совокупности кластеризованных по семантической близости документов - сначала осуществляют кластеризацию электронных документов согласно способу по первому объекту настоящего изобретения с обязательным построением вышеупомянутого графа, а затем выполняют поиск релевантных поисковому запросу электронных документов как фрагментов построенного графа. Например, строится вектор запроса и на основании меры близости выполняется поиск самого близкого супертопика, затем топика, а далее - документа.
Специалистам понятно, что оба способа по настоящему изобретению выполняются в соответственно запрограммированной системе. Поэтому еще двумя объектами настоящего изобретения являются машиночитаемые носители, предназначенные каждый для непосредственного участия в работе вычислительного средства указанной системы и содержащие каждый программу, которая при ее исполнении в вычислительном средстве обеспечивает выполнение соответствующего способа. Такими машиночитаемыми носителями могут быть как жесткие диски, так и иные устройства, например флэш-память, диски DVD, магнитные ленты и т.д.
Таким образом, использование настоящего изобретения позволяет упростить и ускорить как кластеризацию электронных документов по семантической близости, так и последующий поиск в кластеризованной совокупности тех документов, которые релевантны поисковому запросу.

Изобретение относится к кластеризации документов по их семантической близости. Техническим результатом является упрощение и ускорение как обработки электронных документов, так и поиска в кластеризованной совокупности документов, релевантных поисковому запросу. В способе автоматической итеративной кластеризации электронных документов по семантической близости преобразуют каждый электронный документ в соответствующий многомерный вектор в многомерном пространстве, размерности которого определяются содержащимися в электронном документе термами. Находят меру близости полученного вектора к каждому из векторов уже имеющихся кластеров, объединяющих семантически близкие документы, обработанные ранее. Дополняют подлежащим обработке документом тот из кластеров, для которого найденная мера близости минимальна. Определяют для дополненного кластера его новый вектор. Принимают в качестве темы дополненного кластера название того из документов в данном кластере, для которого мера близости его вектора к определенному новому вектору минимальна. Таким образом, при поступлении новых электронных документов уже имеющиеся кластеры обрабатывают как отдельные документы, а не как множества документов. 4 н. и 8 з.п. ф-лы, 6 ил.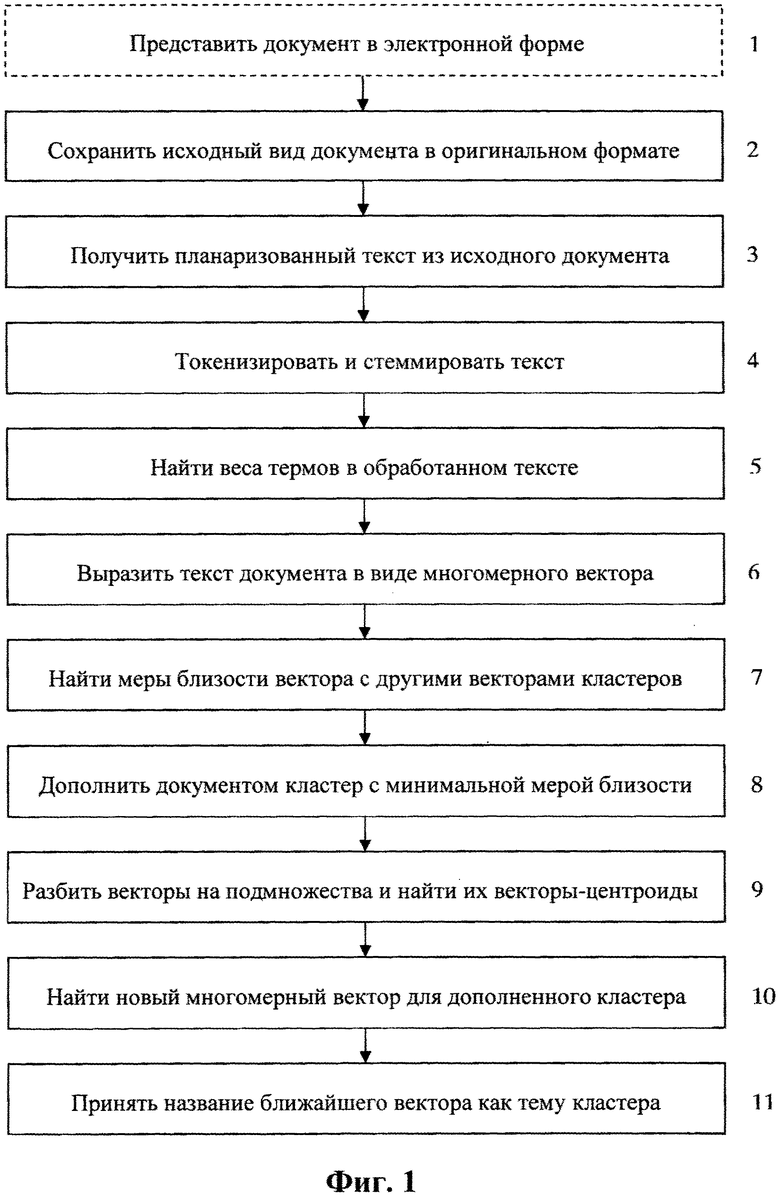
1. Способ автоматической итеративной кластеризации электронных документов по семантической близости, заключающийся в том, что:
- преобразуют каждый подлежащий обработке электронный документ в соответствующий многомерный вектор в многомерном пространстве, размерности которого определяются содержащимися в упомянутом электронном документе термами;
- находят меру близости полученного многомерного вектора к каждому из многомерных векторов уже имеющихся кластеров, объединяющих семантически близкие электронные документы, обработанные ранее;
- дополняют упомянутым подлежащим обработке электронным документом тот из упомянутых кластеров, для которого найденная мера близости минимальна;
- определяют для упомянутого дополненного кластера его новый многомерный вектор;
- принимают в качестве темы упомянутого дополненного кластера название того из электронных документов в данном кластере, для которого мера близости его многомерного вектора к определенному новому многомерному вектору минимальна.
2. Способ по п.1, в котором:
- накапливают совокупность подлежащих обработке электронных документов по мере их появления в течение заранее заданного интервала времени;
- после чего и осуществляют кластеризацию каждого из электронных документов в накопленной совокупности.
3. Способ по п.1, в котором упомянутое преобразование электронного документа в многомерный вектор включает в себя этапы, на которых:
- планаризируют текст упомянутого электронного документа;
- формируют массивы термов для планаризованного текста каждого из упомянутых электронных документов, для чего:
- токенизируют планаризованный текст, получая в результате сегменты в виде слов, знаков препинания, пробелов;
- стеммируют токенизированный текст, выделяя в результате основы слов с помощью, по меньшей мере, одного из эвристических алгоритмов; после чего:
- находят вес каждого терма в каждом из упомянутых электронных документов;
- выражают каждый из упомянутых электронных документов в виде вектора в многомерном пространстве, размерности которого определяются найденными весами термов в тексте данного электронного документа.
4. Способ по п.3, в котором упомянутое вычисление веса каждого терма выполняют с использованием меры TF-IDF, представляющей собой произведение величины

на величину
 .
.
5. Способ по п.1, в котором упомянутое нахождение меры близости многомерных векторов включает в себя этапы, на которых:
- вычисляют косинусную меру близости между каждой парой упомянутых многомерных векторов;
- разбивают все упомянутые многомерные векторы на подмножества, в каждом из которых вычисленная косинусная мера близости между парой любых многомерных векторов меньше заранее заданного значения;
- рассчитывают вектор-центроид каждого из упомянутых подмножеств как среднеарифметическое всех многомерных векторов данного подмножества;
- приписывают каждый многомерный вектор к подмножеству с ближайшим вектором-центроидом.
6. Способ по п.1, дополнительно содержащий этапы, на которых:
- находят меру взаимной близости многомерных векторов для каждой пары упомянутых кластеров;
- объединяют в соответствующий топик те кластеры, для которых найденные меры взаимной близости их многомерных векторов не превышают заранее заданное пороговое значение;
- определяют для упомянутого топика его многомерный вектор;
- принимают в качестве темы упомянутого топика тему того из входящих в него кластеров, для которого мера близости его многомерного вектора к определенному многомерному вектору этого топика минимальна.
7. Способ по п.6, дополнительно содержащий этапы, на которых:
- находят меру взаимной близости многомерных векторов для каждой пары упомянутых топиков;
- объединяют в соответствующий супертопик те топики, для которых найденные меры взаимной близости их многомерных векторов не превышают заранее заданный порог;
- определяют для упомянутого супертопика его многомерный вектор;
- принимают в качестве темы упомянутого супертопика тему того из входящих в него топиков, для которого мера близости его многомерного вектора к определенному многомерному вектору этого супертопика минимальна.
8. Способ по п.7, в котором строят граф, узлами которого являются упомянутые супертопики, топики и документы, а каждое из ребер этого графа представляет собой отношение близости связываемых этим ребром супертопиков, топиков и документов.
9. Способ по п.8, в котором составляют глобальный словарь термов для обеспечения возможности последующего проведения поиска фрагментов графа, релевантных конкретному поисковому документу.
10. Способ поиска в совокупности кластеризованных по семантической близости документов, заключающийся в том, что:
- осуществляют кластеризацию электронных документов согласно способу по п.9;
- выполняют поиск релевантных поисковому запросу электронных документов как фрагментов упомянутого графа.
11. Машиночитаемый носитель, предназначенный для непосредственного участия в работе вычислительного средства и содержащий программу, которая при ее исполнении в упомянутом вычислительном средстве обеспечивает выполнение способа по любому из пп.1-9.
12. Машиночитаемый носитель, предназначенный для непосредственного участия в работе вычислительного средства и содержащий программу, которая при ее исполнении в упомянутом вычислительном средстве обеспечивает выполнение способа по п.10.
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 6189002 B1, 13.02.2001 | |||
| US 6871174 B1, 22.03.2005 | |||
| US 8266077 B2, 11.09.2012 | |||
| СПОСОБ ПОСТРОЕНИЯ СЕМАНТИЧЕСКОЙ МОДЕЛИ ДОКУМЕНТА | 2011 |
|
RU2487403C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОРГАНИЗАЦИИ ДАННЫХ | 2000 |
|
RU2268488C2 |

