Область техники, к которой относится изобретение
Настоящее изобретение относится к определению того, какая часть документа соответствует захваченному изображению этой части. Различные аспекты настоящего изобретения применимы, в частности, для идентификации местоположения меток на документе путем захвата изображений документа.
Предшествующий уровень техники
Хотя электронные документы, хранящиеся в компьютерах, обеспечивают ряд преимуществ над письменными документами, многие пользователи продолжают решать некоторые задачи, пользуясь печатными версиями электронных документов. Эти задачи включают в себя, например, чтение и аннотирование документов. В связи с этими аннотациями следует отметить, что бумажная версия документа имеет вполне конкретное значение, потому пользователь, как правило, записывает аннотации непосредственно на отпечатанный документ. Вместе с тем одной из проблем, связанных с непосредственным аннотированием печатной версии документа, является затруднение при последующем преобразовании аннотаций в электронную форму. В идеальном случае аннотации, хранимые в электронной форме, должны соответствовать электронной версии документа таким же образом, как аннотации, написанные от руки, соответствуют бумажной версии документа.
Это соответствие обычно требует, чтобы первоначальный или другой пользователь разобрался в аннотациях и лично ввел их в компьютер. В некоторых случаях пользователь может провести электронное сканирование аннотаций, написанных на бумажном документе, и таким образом создать новый электронный документ. Эти несколько этапов требуют согласованности между печатной версией документа и электронной версией этого документа, причем эту согласованность трудно поддерживать при повторении упомянутых этапов. Кроме того, сканированные изображения зачастую не допускают редактирования. Таким образом, может оказаться невозможным отделить аннотации от первоначального текста документа. Это затрудняет использование аннотаций.
Для решения этой проблемы были разработаны перья, чтобы захватывать аннотации, записанные на печатные документы пером. Перо этого типа включает в себя камеру, которая захватывает изображения печатного документа, когда пользователь пишет аннотации. Однако при реализации некоторых примеров пера этого типа перо может использовать чернила, которые невидимы для камеры. Перо может использовать, например, неуглеродистые чернила и инфракрасное освещение для камеры, что не дает съемочной камере «увидеть» аннотацию, написанную этими чернилами. При наличии пера этого типа перо определяет движение кончика пера, формируя аннотации на документе из изображений, захватываемых пером во время написания аннотаций. Вместе с тем, чтобы связать изображения с первоначальным электронным документом, нужно определять положение изображений относительно документа. Соответственно, перо этого типа часто используют вместе с бумагой, которая включает в себя узор, однозначно идентифицирующий различные местоположения на бумаге. Анализируя этот узор, компьютер, принимающий изображение, может определить, какая часть бумаги (и, таким образом, какая часть печатного документа) была захвачена в изображении.
Хотя использование такой узорной бумаги или других носителей позволяет преобразовывать письменные аннотации на бумажном документе в электронную форму и надлежащим образом связывать с электронной версией документа, этот способ не всегда надежен. Например, документ, содержащий текст на бумаге, может скрывать области узора. Если перо захватывает изображение одной из этих областей, компьютер может оказаться неспособным использовать узор для точного определения местоположения части документа, захваченной с помощью изображения. Вместо этого компьютеру придется использовать другой способ идентификации местоположения части документа, захваченной в изображении. Например, компьютер может осуществлять попиксельное сравнение захваченного изображения с электронным документом.
Попиксельное сравнение будет обычно идентифицировать часть документа в захваченном изображении, но для этого способа характерны непроизводительные издержки при обработке. Чтобы осуществить этот способ, например, преобразование, такое как поворот и масштабирование, между захваченным изображением и изображением документа в типичном случае сначала должно быть оценено так, чтобы захваченное изображение можно было деформировать и согласовать с изображением документа на попиксельной основе. Если преобразование неизвестно, нужно рассматривать все возможные повороты и масштабы. Кроме того, в изображении выбирают опорный пиксел. Каждый пиксел в деформированном изображении затем сравнивают с соответствующим пикселом в электронном документе, так что опорный пиксел изображения, имеющийся в изображении, сравнивается с первым местоположением в электронном документе. Затем это сравнение нужно повторить так, чтобы в перспективе сравнить опорный пиксел с каждым местоположением в электронном документе. Сравнение, сопровождаемое наибольшим соответствием между пикселами изображения и электронного документа, идентифицирует положение опорного пиксела относительно электронного документа, а значит - и часть документа, захваченную в изображении. Поэтому было бы желательно разработать способ, который позволит компьютеру определять местоположение части документа в захваченном изображении без необходимости проведения попиксельного сравнения изображения со всем документом.
Краткое изложение сущности изобретения
В различных конкретных вариантах осуществления изобретения преимущественно предложен эффективный способ определения части документа, соответствующий захваченному изображению. В соответствии с различными конкретными вариантами осуществления изобретения идентифицируют области документа, в которых узор, по меньшей мере, частично скрыт. Выбирают опорный пиксел в изображении, оценивают поворот и масштаб захваченного изображения и определяют смещение между этим пикселом и узором. Затем осуществляют попиксельное сравнение деформированного изображения с документом таким образом, что только опорный пиксел сравнивается с местоположениями в документе, которые и находятся в пределах идентифицированных областей, и имеют определенное смещение от узора. Тогда сравнение, сопровождаемое наибольшим соответствием между пикселами изображения и электронного документа, идентифицирует положение опорного пиксела относительно электронного документа. Пользуясь этим способом, можно избежать сравнений опорного пиксела с другими местоположениями документа, тем самым уменьшая непроизводительные издержки при обработке, необходимые для определения местоположения части документа, захваченной в изображении.
Перечень фигур чертежей
Фиг. 1 - общее описание компьютера, который может быть использован совместно с вариантами осуществления настоящего изобретения.
Фиг. 2А - пример пера, соответствующего различным конкретным вариантам осуществления изобретения, а фиг. 2В - иллюстрация разрешения изображения, которое можно получить с помощью различных конкретных вариантов осуществления изобретения.
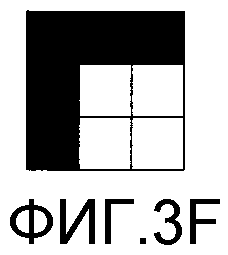
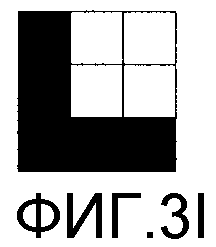
Фиг. 3А-3I - различные примеры кодовых систем в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 4 - графическая иллюстрация того, как можно использовать кодирующий узор для определения поворота изображения, захваченного из части документа.
Фиг. 5 - иллюстрация формулы, которую можно использовать для определения поворота изображения, захваченного из части документа.
Фиг. 6 - иллюстрация инструментального средства, которое можно использовать для согласования захваченного изображения с частью документа в соответствии с различными вариантами осуществления изобретения.
Фиг. 7А-7С - схема последовательности операций, описывающая способ согласования захваченного изображения с частью документа в соответствии с различными вариантами осуществления изобретения.
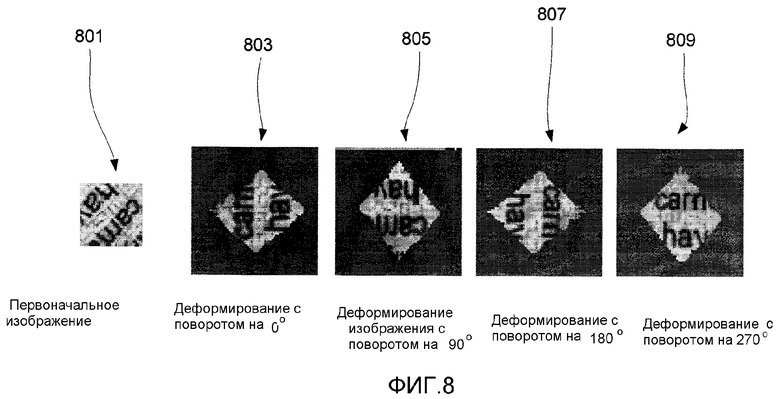
Фиг. 8 - пример того, как захваченное изображение деформируют, а затем поворачивают на углы, кратные 90°.
Подробное описание изобретения
На фиг. 1 показана функциональная блок-схема примера обычной цифровой вычислительной среды общего назначения, которую можно использовать для реализации различных аспектов настоящего изобретения. На фиг. 1 показано, что компьютер 100 включает в себя процессор 110, системную память 120 и системную шину 130, которая соединяет различные системные компоненты, включая системную память, с процессором 110. Системная шина 130 может представлять собой любую из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, с использованием множества архитектур шин. Системная память 120 включает в себя постоянную память (ROM) 140 и оперативную память (RAM) 150.
В ROM 140 хранится базовая система 160 ввода-вывода (BIOS), содержащая базовые процедуры, которые способствуют передаче информации между элементами внутри компьютера 100, например, во время запуска. Компьютер 100 также включает в себя накопитель 170 на жестких дисках для считывания с жесткого диска (не показан) и записи на него, магнитный дисковод 180 для считывания со сменного магнитного диска 190 и записи на него, и оптический дисковод 191 для считывания со сменного оптического диска 192, такого, как CD ROM или другой оптический носитель, и записи на него. Накопитель 170 на жестких дисках, магнитный дисковод 180 и оптический дисковод 191 подключены к системной шине 130 посредством интерфейса 189 накопителя на жестких дисках, интерфейса 193 магнитного дисковода и интерфейса 194 оптического дисковода, соответственно. Накопители и дисководы, связанные с ними машиночитаемые носители информации обеспечивают энергонезависимое хранение машиночитаемых команд, структур данных, программных модулей и других данных для персонального компьютера 100. Специалисты в данной области техники поймут, что в возможной операционной среде можно также использовать машиночитаемые носители информации других типов, выполненные с возможностью хранения данных, к которым может осуществить доступ компьютер, например, кассеты с магнитной лентой, платы флэш-памяти, цифровые видеодиски, картриджи Бернулли, блоки оперативной памяти (RAMs), блоки постоянной памяти (ROMs), и т.п.
В накопителе 170 на жестких дисках, на магнитном диске 190, оптическом диске 192, в ROM 140 или RAM 150 можно хранить некоторое количество программных модулей, включая операционную систему 195, одну или более прикладных программ 196, другие программные модули 197 и данные 198 программ. Пользователь может вводить команды и информацию в компьютер 100 посредством таких устройств ввода, как клавиатура 101 и указательное устройство 102. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую приставку, спутниковую тарелку, сканер и т.п. Эти и другие устройства ввода часто подключают к процессору 110 через интерфейс 106 последовательного порта, который подсоединен к системной шине, но их можно подключать через другие интерфейсы, например, параллельного порта, игрового порта или универсальной последовательной шины (USB). Кроме того, и эти устройства тоже можно подсоединять непосредственно к системной шине 130 через подходящий интерфейс (не показан). К системной шине 130 через такой интерфейс, как видеоадаптер 108, также подключен монитор 107 или отображающее устройство другого типа. Помимо монитора персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показаны), такие как громкоговорители и принтеры. В предпочтительном варианте осуществления предусматривается наличие цифрового преобразователя 165 перьевого вида и связанного с ним пера или пишущего элемента 166 для цифрового захвата рукописного ввода. Хотя показано непосредственное соединение между цифровым преобразователем 165 и последовательным портом, на практике цифровой преобразователь 165 может быть соединен с процессором непосредственно, через интерфейс параллельного порта или другой интерфейс и системную шину 130, как известно в данной области техники. Кроме того, хотя цифровой преобразователь 165 показан отдельно от монитора 107, предпочтительно, чтобы полезная область ввода цифрового преобразователя 165 была продолжением области отображения монитора 107. Помимо этого цифровой преобразователь 165 может быть встроен в монитор 107 или может существовать в качестве отдельного устройства, расположенного на мониторе 108 или подсоединенного к этому монитору иным образом.
Компьютер 100 может работать в сетевой среде с помощью логических соединений с одним или более удаленными компьютерами, такими как удаленный компьютер 109. Удаленный компьютер 109 может быть сервером, маршрутизатором, сетевым персональным компьютером, одноранговым устройством или другим обычным узлом сети, и в типичном случае включает в себя многие или все элементы, описанные выше применительно к компьютеру 100, хотя на фиг. 1 проиллюстрировано только запоминающее устройство 111. Логические соединения, изображенные на фиг. 1, включают в себя локальную сеть (LAN) 112 и глобальную сеть (WAN) 113. Такие сетевые среды широко распространены в офисах, компьютерных сетях масштаба предприятия, корпоративных локальных сетях и Internet.
При использовании в сетевой среде LAN компьютер 100 подключен к локальной сети 112 через сетевой интерфейс или адаптер 114. При использовании в сетевой среде WAN персональный компьютер 100 в типичном случае включает в себя модем 115 или другие средства для установления связи через глобальную сеть 113, такую как Internet. Модем 115, который может быть внутренним или внешним, может быть подключен к системной шине 113 через интерфейс 106 последовательного порта. В сетевой среде программные модули, предназначенные для персонального компьютера 100, или их части могут храниться в удаленном запоминающем устройстве.
Следует понять, что показанные сетевые соединения носят иллюстративный характер, и можно использовать другие методики установления линии связи между компьютерами. Предполагается наличие любых из многочисленных и широко известных протоколов, таких как TCP/IP (протокол управления передачей/межсетевой протокол), Ethernet, FTP (протокол передачи файлов), HTTP (протокол передачи гипертекста), Bluetooth, IEEE 802.11x и т.п., а система может работать в конфигурации «клиент-сервер», чтобы предоставить пользователю возможность извлекать web-страницы из сервера, работающего на основе web-технологии. Для отображения данных на web-страницах и манипулирования этими данными можно использовать любой из различных известных web-браузеров.
Устройство для захвата изображений
Различные варианты осуществления можно использовать для определения местоположений частей документа, захваченных в виде серии изображений. Как отмечалось выше, определение местоположения части документа, захваченной в изображении, можно использовать для выяснения местоположения взаимодействия пользователя с бумагой, экраном отображающего устройства или другим носителем, отображающим документ. В соответствии с некоторыми вариантами осуществления изобретения изображения можно получать с помощью чернильного пера, используемого для письма чернилами на бумаге. В соответствии с другими вариантами осуществления изобретения перо может быть пишущим элементом, используемым для «письма» электронными чернилами на поверхности цифрового преобразователя, отображающего документ.
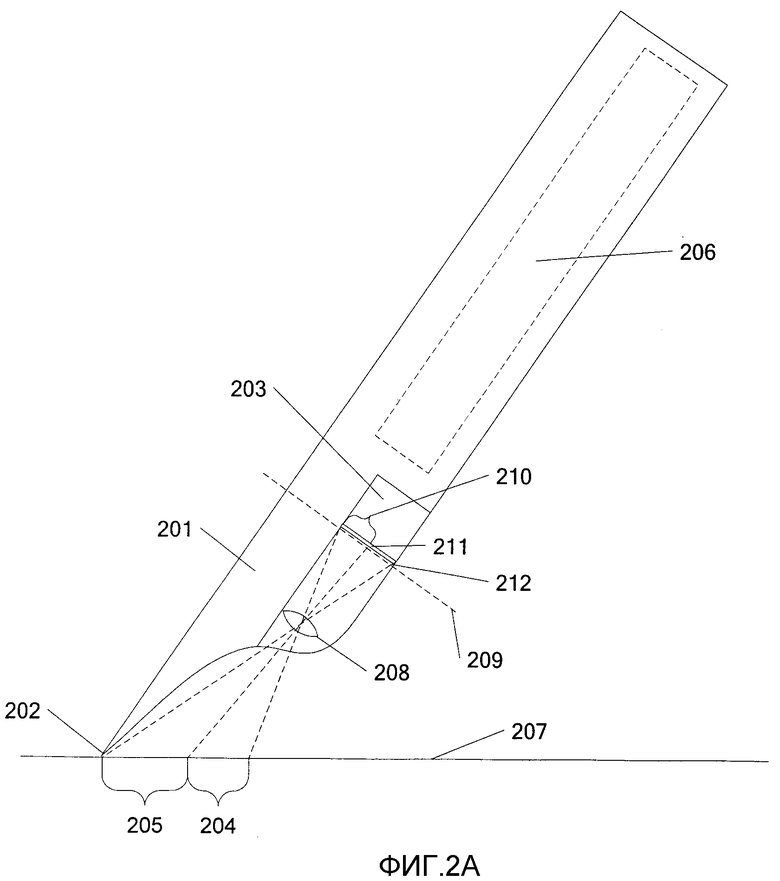
На фиг. 2А и 2В показан иллюстративный пример пера 201, которое можно применять в соответствии с различными вариантами осуществления изобретения. Перо 201 включает в себя кончик 202 и камеру 203. Кончик 202 может включать или не включать в себя резервуар с чернилами. Камера 203 захватывает изображение 204 с поверхности 207. Перо 201 может также включать в себя дополнительные датчики и/или процессоры, отображенные пунктирным прямоугольником 206. Эти датчики и/или процессоры 206 могут также предусматривать способность передавать информацию в еще одно перо 201 или в еще один персональный компьютер (например, посредством протокола Bluetooth или других протоколов беспроводной связи).
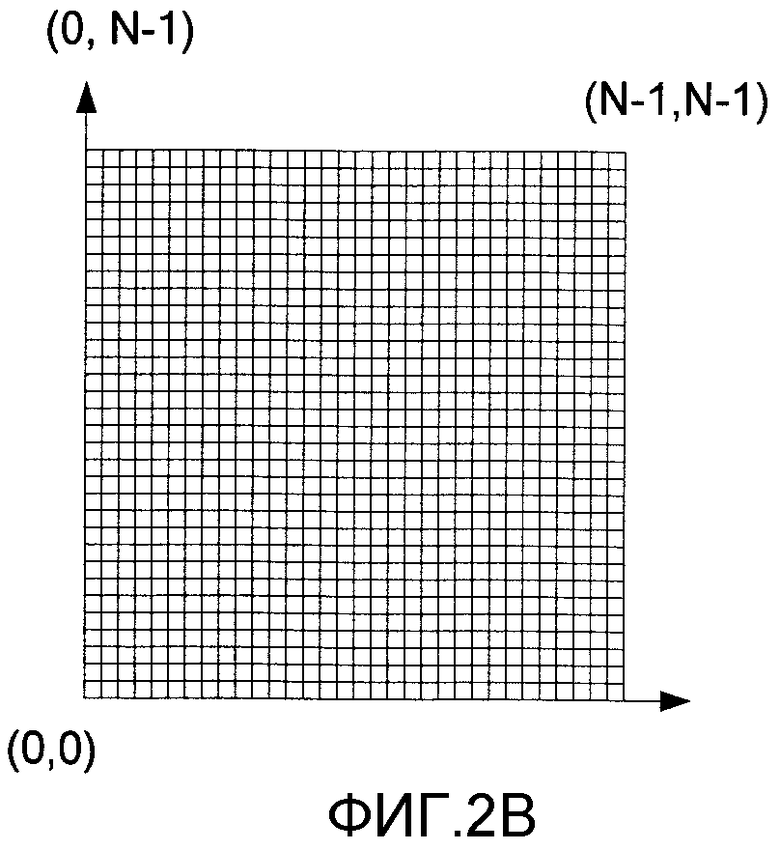
На фиг. 2В представлено изображение, как его «видит» камера 203. В одном иллюстративном примере разрешение изображения, захваченного камерой 203, составляет N×N пикселов (где N=32). Соответственно, на фиг. 2В показано возможное изображение, имеющее 32 пиксела в длину и 32 пиксела в ширину. Размер N является регулируемым, причем большее значение N будет обеспечивать большее разрешение изображения. Кроме того, хотя изображение, захваченное камерой 203, показано здесь в целях иллюстрации в виде квадрата, поле зрения съемочной камеры может предусматривать другие формы, как известно в данной области техники.
Изображения, захваченные камерой 203, можно охарактеризовать как последовательность кадров {Ii} изображения, где Ii захватывается пером 201 за время ti выборки. Частота выборки может быть большой или малой, в зависимости от конфигурации системы и требования эффективности. Размер кадра захваченного изображения может быть большим или малым, в зависимости от конфигурации системы и требования эффективности. Кроме того, должно быть ясно, что изображение, захваченное камерой 203, может прямо или косвенно использоваться обрабатывающей системой или может подвергаться предварительной фильтрации. Эта предварительная фильтрация может происходить в пере 201 или может происходить вне пера 201 (например, в персональном компьютере).
На фиг. 2А также показана плоскость 209 изображения, в которой сформировано изображение 210 узора из местоположения 204. Свет, получаемый от узора в предметной плоскости 207, фокусируется линзой 208. В соответствии с различными конкретными осуществлениями изобретения линза 208 может представлять собой одиночную линзу или многоэлементную линзовую систему, но в данном случае для простоты представлена в виде одиночной линзы. Датчик 211 захвата изображения захватывает изображение 210.
Датчик 211 изображения может быть достаточно большим, чтобы захватить изображение 210. В альтернативном варианте датчик 211 изображения может быть достаточно большим, чтобы захватить изображение кончика 202 пера в местоположении 212. Для справки отметим, что изображение в местоположении 212 будет считаться виртуальным кончиком пера. Следует заметить, что местоположение виртуального кончика пера относительно датчика 211 изображения является фиксированным ввиду неизменной взаимосвязи между кончиком пера, линзой 208 и датчиком 211 изображения.
Как отмечалось ранее, перо 201 в типичном случае будет использоваться совместно с носителем, таким как документ, отпечатанный на бумаге, с отображениями узора для идентификации положений на этом носителе. Этот узор преимущественно можно использовать для преобразования изображения 210, захваченного камерой 203, в форму, соответствующую внешнему виду носителя. Например, нижеследующее преобразование FS→P преобразует изображение 210, захваченное камерой 203, в реальное изображение на листе бумаги:
Lбумаги = FS→P(Lдатчика).
Во время письма кончик пера и бумага находятся в одной и той же плоскости. Соответственно, преобразование из виртуального кончика пера в реальный кончик пера также будет осуществлено преобразованием FS→P:
Lкончика пера = FS→P(Lвиртуального кончика пера).
Преобразование FS→P можно оценить как аффинное преобразование. Оно представляется в упрощенной форме как
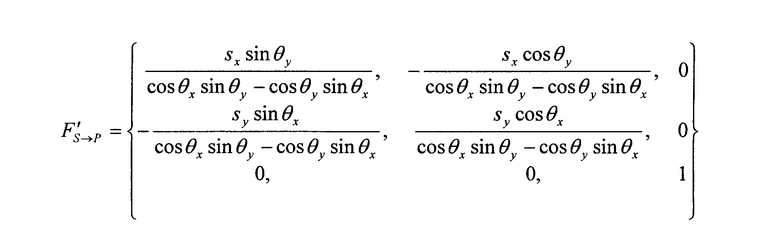
т.е. как оценка преобразования FS→P, где θx, θy, sx и sy представляют собой поворот и масштабирование двух ориентаций узора, захваченного в местоположении 204. Кроме того, можно получить уточнение F'S→P путем согласования захваченного изображения с соответствующим реальным изображением на бумаге. «Получить уточнение» означает получить более точную оценку преобразования FS→P с помощью некой разновидности алгоритма оптимизации, называемой рекурсивным методом. Рекурсивный метод рассматривает матрицу F'S→P как начальное значение. Уточненная оценка точнее описывает преобразование между S и P.
Местоположение виртуального кончика пера можно определить с еще большей точностью путем калибровки. Чтобы калибровать местоположение виртуального кончика пера, пользователь располагает кончик 202 пера в фиксированном местоположении Lкончика пера на бумаге. Затем пользователь наклоняет перо, давая камере 203 возможность захватить ряд изображений при разных положениях пера. Для каждого захваченного изображения получается преобразование FS→P. Из этого преобразования можно получить местоположение виртуального кончика пера, Lвиртуального кончика пера:
(Lвиртуального кончика пера) = FP→S(Lкончика пера),
где Lкончика пера инициализируется как (0, 0) и
FP→S = (FS→P)-1.
Усредняя Lвиртуального кончика пера, полученное из каждого изображения, можно определить местоположение виртуального кончика пера, Lвиртуального кончика пера. С помощью Lвиртуального кончика пера можно дать более точную оценку Lкончика пера. После нескольких итераций можно получить точное местоположение виртуального кончика пера, Lвиртуального кончика пера.
Узор для идентификации положений на носителе
Как отмечалось ранее, применяются различные варианты осуществления изобретения для определения части документа, соответствующей захваченному изображению, причем носитель, отображающий документ, также включает в себя узор для идентификации различных положений на носителе. Таким образом, узор можно считать кодированным потоком данных в отображенной форме. Носитель, отображающий узор, может быть отпечатанной бумагой (или другим физическим носителем) или, в альтернативном варианте, может быть дисплеем, проецирующим поток кодированных данных в связи с еще одним изображением или набором изображений. Например, кодированный поток данных может быть представлен в виде физического изображения на бумаге или изображения, накладываемого на отображенное изображение, или может быть физическим кодированным узором (т.е. неизменяемым узором), объединенным с экраном дисплея или накладываемым поверх него (так что любая часть изображения, захватываемая пером, размещается на экране дисплея).
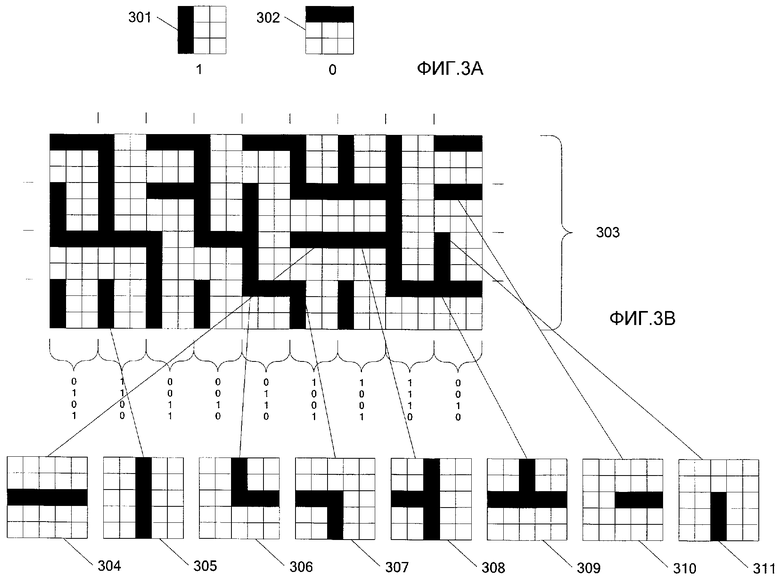
На фиг. 3А показан один пример способов кодирования, предназначенных для кодирования первого бита и второго бита с получением узора для идентификации положений на носителе. Первый бит 301 (например, со значением «1») представлен столбцом темных чернил. Второй бит 302 (например, со значением «0») представлен строкой темных чернил. Вместе с тем следует понять, что для представления различных битов можно использовать чернила любого цвета. Единственное требование к выбираемому цвету чернил состоит в том, чтобы он обеспечивал значительный контраст с фоном носителя, различаемый системой захвата изображений. В этом примере биты на фиг. 3А представлены имеющей размер 3×3 матрицей точек. Размер матрицы можно изменить с получением любого желаемого размера на основании размера и разрешения системы захвата изображения, используемой для захвата изображений носителя.
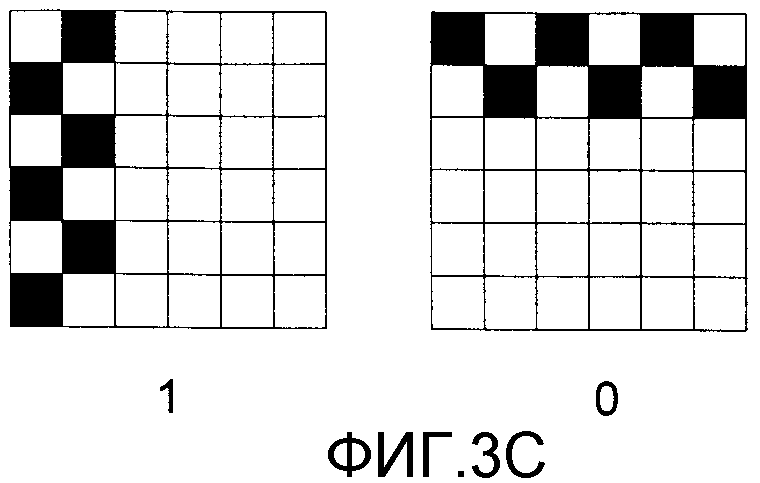
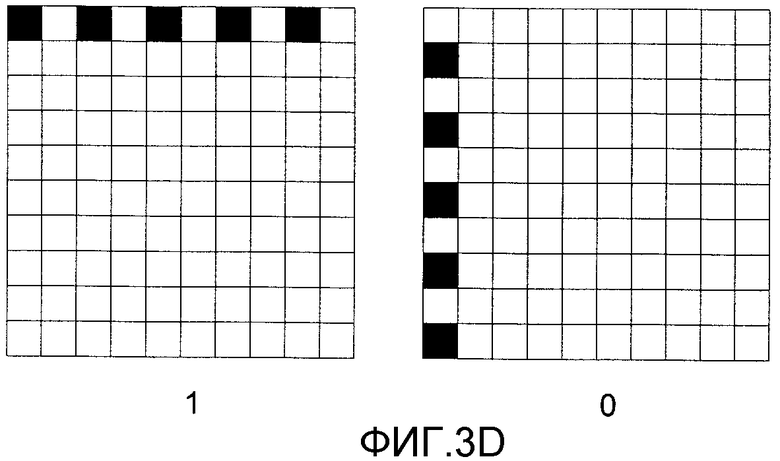
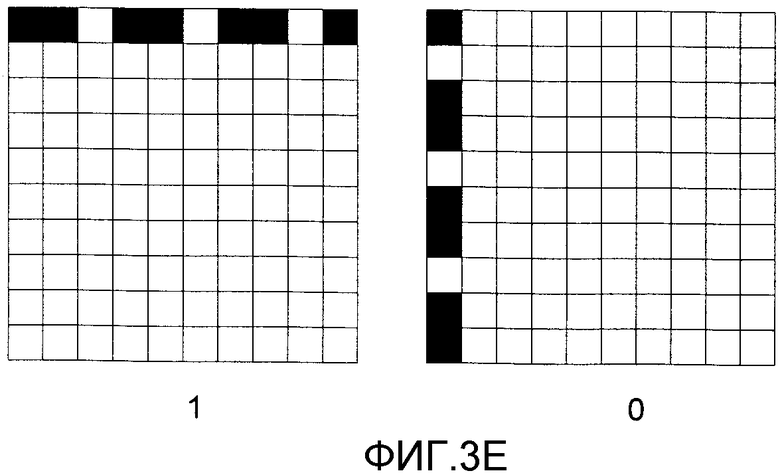
Альтернативные отображения битов со значениями 0 и 1 показаны на фиг. 3С-3Е. Следует понять, что представление нуля или единицы для кодирования выборок, показанное на фиг. 3А-3Е, можно изменять без эффекта. На фиг. 3С показаны представления битов, занимающие две строки или два столбца в перемежающемся расположении. На фиг. 3D показано альтернативное расположение пикселов в строках и столбцах в форме пунктирной линии. И, наконец, на фиг. 3Е показаны представления пикселов в столбцах и строках в формате с неодинаковыми промежутками (например, в виде двух темных точек с последующей неокрашенной точкой).
Следует отметить, что возможны альтернативные ориентации сетки, включая поворот нижележащей сетки в негоризонтальное и невертикальное расположение (например, когда правильная ориентация узора составляет 45 градусов). Используя негоризонтальное и невертикальное расположение, можно обеспечить вероятное преимущество, состоящее в исключении визуальных особенностей, отвлекающих внимание, создаваемых пользователем, поскольку пользователи могут быть склонны предпочитать горизонтальные и вертикальные узоры другим. Вместе с тем, в целях упрощения, ориентацию сетки (горизонтальную, вертикальную, а также соответствующую любому другому желаемому повороту нижележащей сетки) собирательно называют предварительно определенной ориентацией сетки.
Возвращаясь к фиг. 3А, отмечаем, что если некоторый бит представляется имеющей размер 3×3 матрицей элементов, а система обработки изображений обнаруживает темную строку и две светлых строки в области 3×3, то это означает, что обнаружена область со значением «нуль» (или, в альтернативном варианте, со значением «единица»). Если обнаружена область 3×3 с темным столбцом и двумя светлыми столбцами, то это означает, что обнаружена область со значением «единица» (или, в альтернативном варианте, со значением «нуль»). Соответственно, если размер изображения 210 на фиг. 2В составляет 32×32 пиксела, а размер каждого кодирующего блока составляет 3×3 пиксела, то количество захваченных кодированных блоков должно составлять приблизительно 100 блоков. Если размер кодированного блока составляет 5×5, то количество захваченных кодированных блоков должно составлять приблизительно 36.
Как показано на фиг. 3А, можно использовать более одного пиксела или одной точки для представления бита. Использование единственного пиксела (или единственной точки) для представления бита ненадежно. Пыль, сгибы на бумаге, неплоские поверхности и т.п. создают затруднения при чтении одноэлементных представлений блоков данных. Однако даже при использовании нескольких элементов для представления битов другой текст, отображаемый на носителе с узором, такой как отпечатанный текст в документе, может по-прежнему скрывать один или более битов в узоре.
Для создания графического узора 303, изображенного на фиг. 3В, используют поток битов. Графический узор 303 включает в себя 12 строк и 18 столбцов. Более конкретно, строки и столбцы сформированы потоком битов, преобразуемым в графический узор 303 с помощью представлений 301 и 302 битов. Таким образом, узор 303, изображенный на фиг. 3В, можно рассматривать как имеющий следующее представление битов:
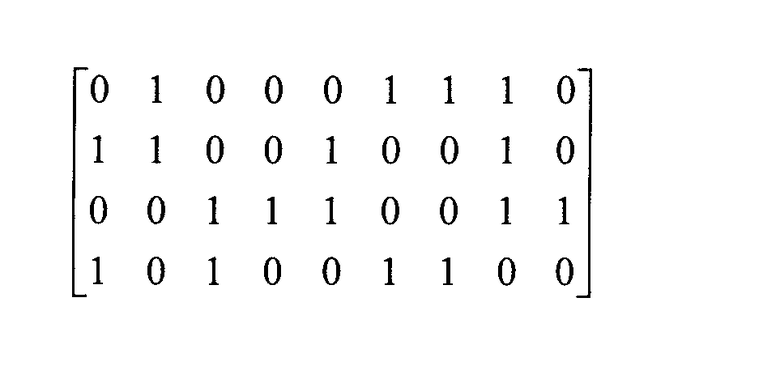
Для создания изображения 303, показанного на фиг. 3В, можно использовать различные потоки битов. Например, можно использовать случайную или псевдослучайную последовательность единиц и нулей. Последовательность битов можно располагать в строках, в столбцах, по диагоналям или с соблюдением любого другого стереотипного порядка. Например, вышеупомянутую матрицу можно сформировать с помощью следующего потока битов, если пробегать строки слева направо с последующим переходом к нижней строке:
0100 0111 0110 0100 1000 1110 0111 0100 1100.
Вышеупомянутую матрицу можно сформировать с помощью следующего потока битов, если пробегать столбцы сверху вниз с последующим переходом к правому столбцу:
0101 1100 0011 0010 0110 1001 1001 1110 0010.
Вышеупомянутую матрицу можно сформировать с помощью следующего потока битов, если пробегать матрицу по одной диагонали с последующим переходом на другую:
0110 0000 0101 0101 1000 0011 1111 1010 1010.
На фиг. 3В также показаны укрупненные виды блоков пикселов из изображения 303. Укрупненные виды 304-311 иллюстрируют имеющие размер 5×5 блоки пикселов. Блок 304 пикселов иллюстрирует темную строку между светлыми строками. Блок 305 пикселов иллюстрирует темный столбец между светлыми столбцами. Блок 306 пикселов иллюстрирует нижний левый угол. Блок 307 пикселов иллюстрирует верхний правый угол. Блок 308 пикселов иллюстрирует темный столбец с половиной темной строки слева. Блок 309 пикселов иллюстрирует темную строку с половиной темного столбца над этой строкой. Блок 310 пикселов иллюстрирует половину темной строки. Блок 311 пикселов иллюстрирует половину темного столбца. Анализируя комбинацию блоков пикселов, следует признать, что все комбинации пикселов можно сформировать с помощью сегментов изображения, обнаруживаемых в блоках 304-311 пикселов. Узор того типа, который показан на фиг. 3В, можно назвать «лабиринтным» узором, поскольку линейные сегменты явно образуют лабиринт при отсутствии области, со всех четырех сторон полностью окруженной этим лабиринтом.
Без преувеличения, следует ожидать, что каждую из четырех «угловых» комбинаций пикселов, показанных на фиг. 3F-3I, можно будет найти в лабиринтном узоре, показанном в изображении 303. Вместе с тем, как видно на фиг. 3В, в восьми блоках 304-311 пикселов, действительно, присутствуют только три типа углов. В этом примере нет угловой комбинации пикселов, показанной на фиг. 3F. Выбирая сегменты 301 и 302 изображения, чтобы исключить некоторый тип угла таким образом, можно определить ориентацию захваченного изображения на основании пропущенного типа угла.
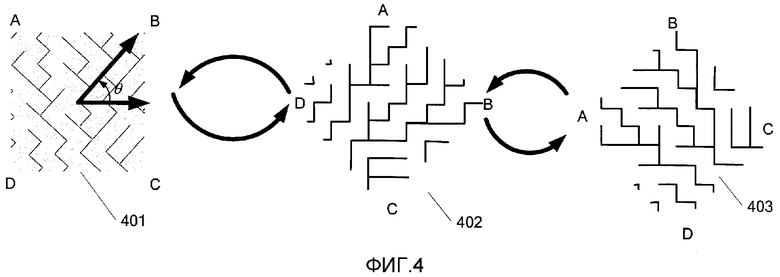
Например, как показано на фиг. 4, можно проанализировать изображение 401 в том виде, как оно захвачено камерой 203, и определить его ориентацию таким образом, чтобы обеспечить его интерпретацию применительно к положению, действительно, представляемому изображением 401. Во-первых, просматривают изображение 401, чтобы определить, какие пикселы изображения 401 образуют лабиринтный узор, и угол θ, необходимый для поворота изображения таким образом, чтобы пикселы узора оказались ориентированными горизонтально и вертикально. Следует отметить, что, как обсуждалось выше, возможны альтернативные ориентировки сетки с разными вариантами осуществления изобретения, включая поворот нижележащей сетки в негоризонтальное и невертикальное расположение (например, когда правильная ориентация узора составляет 45 градусов).
Далее изображение 401 анализируют, чтобы определить, какой угол пропущен. Величина «о» поворота, необходимая для поворота изображения 401 с тем, чтобы получить изображение 403, готовое к декодированию, показана как о = (θ плюс величина поворота {определяемая тем, какой угол пропущен}). Величина поворота показана уравнением на фиг. 5. Возвращаясь к фиг. 4, отмечаем, что сначала определяют угол θ по компоновке пикселов, необходимой для достижения вертикального и горизонтального (или обуславливающего другую предварительно определенную ориентацию сетки) расположения пикселов, и поворачивают изображение так, как обозначено позицией 402. Затем проводят анализ, чтобы определить пропущенный угол, и поворачивают изображение 402, получая изображение 403, чтобы задать изображение для декодирования. В данном случае изображение поворачивают на 90 градусов против часовой стрелки, так что изображение 403 имеет правильную ориентацию и может быть использовано для декодирования.
Следует понимать, что поворот на угол θ может быть осуществлен перед поворотом изображения 401, или после такого поворота, для учета пропущенного угла. Следует также понимать, что, принимая во внимание шум в захваченном изображении, могут присутствовать все четыре типа угла. Соответственно, при различных вариантах осуществления изобретения можно подсчитывать количество углов каждого типа, а тип, которому соответствует наименьшее количество углов, можно определить как тип угла, который пропущен.
И, наконец, считывают код в изображении 403 и выполняют корреляцию с первоначальным потоком битов, использованным для создания изображения 303. Корреляцию можно проводить многими способами. Например, ее можно проводить с помощью рекурсивного подхода, при котором восстановленный поток битов сравнивают со всеми остальными фрагментами потока битов в пределах первоначального потока битов. Во-вторых, можно провести статистический анализ для сопоставления восстановленного потока битов и первоначального потока битов, например, посредством использования расстояния Хэмминга между этими двумя потоками битов. Следует понимать, что можно применять множество подходов к определению местоположения восстановленного потока битов в пределах первоначального потока битов.
Из вышеизложенного будет ясно, что можно использовать вышеописанный лабиринтный узор, чтобы закодировать информацию на поверхности носителя, например на листе бумаги или дисплее цифрового преобразователя. Эту информацию затем можно захватывать в одном или более изображений с помощью камеры 203 пера 201 и декодировать. Одним исключительно полезным типом информации, которую можно кодировать на поверхности носителя, является информация о положении. Если части потока битов не повторяются на носителе, то компьютер 100 сможет определить часть документа, содержащую конкретный поток битов.
Если в изображении захватывается законченная часть узора, то компьютер 100 сможет определить часть документа, захваченную в изображении, как описано выше. Однако при некоторых обстоятельствах часть изображения может быть скрыта. Например, если носитель представляет собой документ, содержащий, например, отпечатанный текст, то этот текст может частично скрывать один или более битов в узоре. В вышеупомянутом примере (когда каждый бит построен на имеющей размер 3×3 матрице пикселов, а разрешение камеры 203 составляет 32×32 пиксела), компьютер 100 с очень большой вероятностью сможет определить часть документа, захваченную в изображении, если из этого изображения удастся идентифицировать 60 или более битов. Вместе с тем, если удастся идентифицировать лишь от 36-ти до 60-ти битов, то компьютер 100 по-прежнему окажется способным определить положение части документа, захваченной в изображении. А вот если удастся идентифицировать лишь 35 или менее битов из изображения, то компьютер 100 окажется неспособным определить положение части документа, захваченной в изображении.
Локализация путем быстрого согласования изображений
Как отмечалось выше, если из изображения идентифицируется недостаточное количество битов, то компьютер 100 не сможет определить, какая часть документа захвачена в изображении. Вместо этого компьютер 100 должен применить альтернативный способ, чтобы определить, какая часть документа захвачена в изображении. Прежде всего преобразование (например, поворот, масштабирование и т.д.) между захваченным изображением и изображением документа сначала следует оценить, чтобы можно было деформировать изображение так, чтобы оно имело такие же поворот и масштаб, как поворот и масштаб изображения электронного документа. Если преобразование неизвестно, нужно рассматривать все возможные повороты и масштабы. Затем, если документ хранится в электронной форме, то компьютер 100 сможет провести попиксельное сравнение каждого пиксела в деформированном изображении с каждым местоположением в электронном документе. Однако этот способ может потребовать большого количества процессов сравнения. Например, одна страница в электронном документе может содержать 1410×2019 пикселов, так что понадобятся 2889090 (1410×2019) сравнений. Кроме того, каждый процесс сравнения предусматривает сравнение большого количества пикселов. Например, захваченное изображение может содержать 1024 (32×32) пиксела. Этот способ также предусматривает большой объем непроизводительных затрат при обработке и требует больших затрат времени.
Вместо этого компьютер 100 может локализовать изображение, осуществляя быстрое согласование изображений в соответствии с различными вариантами осуществления изобретения. Те местоположения (т.е. пиксели) в электронном документе, которые не могут соответствовать опорному пикселу, исключаются. Потом компьютер 100 может провести попиксельное сравнение изображения с документом так, чтобы только опорный пиксел сравнивался с теми местоположениями в документе, которые не исключены. Таким путем можно идентифицировать местоположение в документе, захваченное с помощью изображения.
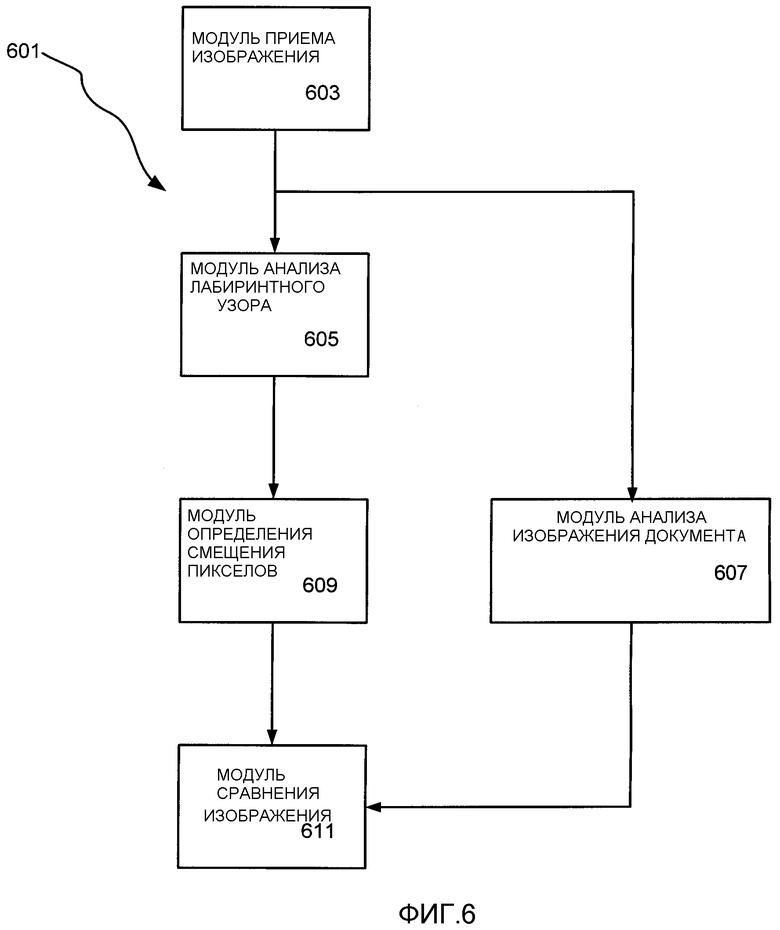
На фиг. 6 проиллюстрировано инструментальное средство 601, которое можно использовать для осуществления быстрого согласования захваченного изображения с частью документа в соответствии с различными вариантами осуществления изобретения. Инструментальное средство 601 включает в себя модуль 603 приема изображения, модуль 605 анализа лабиринтного узора, модуль 607 анализа изображения документа, модуль 609 определения смещения пикселов и модуль 611 сравнения изображения. Как будет подробнее описано ниже, модуль 603 приема изображения принимает изображение части документа, отображенной на физическом носителе, который включает в себя узор, такой как лабиринтный узор, подробно описанный выше. Затем модуль 605 анализа лабиринтного узора анализирует изображение, чтобы получить поворот и масштаб узора, такого как лабиринтный узор, подробно описанный выше, в изображении. Затем модуль 607 анализа изображения документа анализирует электронную версию документа, чтобы определить, где узор частично скрыт, например, текстами или чертежами в документе. Более конкретно в иллюстрируемых вариантах осуществления изобретения модуль 607 анализа изображения документа анализирует электронную версию документа для определения областей, в которых узор чересчур скрыт, чтобы обеспечить достоверную информацию о положении.
Затем модуль 609 определения смещения пикселов определяет смещение между опорным пикселом в захваченном изображении и узором в захваченном изображении, а модуль 611 сравнения сравнивает деформированное изображение (деформированное с помощью информации о повороте и масштабировании, полученной из модуля 605 анализа лабиринтного узора) с электронной версией документа. Более конкретно модуль 611 сравнения осуществляет попиксельное сравнение деформированного изображения с электронной версией документа на основании тех местоположений документа, которые идентифицированы как скрытые области и которые имеют определенное таким образом смещение. В одних иллюстрируемых вариантах осуществления можно реализовать один или более модулей 603-611 по средствам команд, исполняемых на компьютере, таком как компьютер 100. В других вариантах осуществления можно реализовать один или более модулей 603-611 с помощью компонентов аппаратных средств.
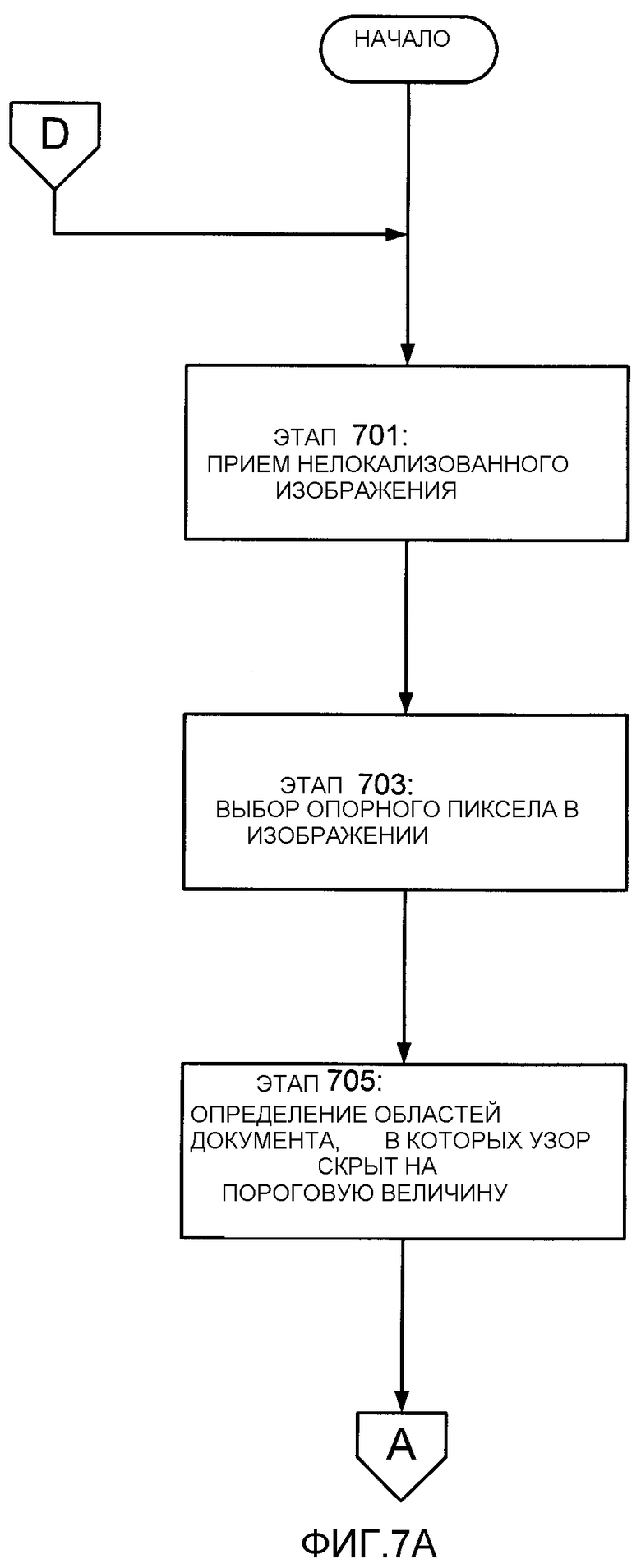
На фиг. 7А-7С проиллюстрирован способ быстрого согласования изображений, который может быть применен в соответствии с различными вариантами осуществления изобретения, например, с помощью такого инструментального средства, как инструментальное средство 601. На этапе 701 модуль 603 приема изображения принимает изображение части документа, отображенной на физическом носителе. Этот носитель может быть, например, листом бумаги, дисплеем цифрового преобразователя, могущим и отображать документ, и принимать входной сигнал из пера 201, или может быть физическим носителем любого другого типа. В иллюстрируемых вариантах осуществления принимаемое изображение является нелокализованным изображением, которое не может быть иным образом связано с конкретной частью документа посредством других способов.
Далее, на этапе 703, для изображения выбирают опорный пиксел. В различных вариантах осуществления опорным пикселом может быть центральный пиксел, имеющийся в изображении. Как станет ясно из нижеследующего описания, при использовании центрального пиксела в качестве опорного пиксела можно упростить некоторые расчеты, связанные с процессом определения. Однако в других вариантах осуществления опорным пикселом может быть любой желаемый пиксел. Например, опорным пикселом в альтернативном варианте может быть верхний левый пиксел изображения, нижний левый пиксел изображения, верхний правый пиксел изображения или нижний правый пиксел изображения.
Затем модуль 607 анализа изображения документа анализирует электронную версию документа, чтобы определить области, где узор частично скрыт (для удобства, такие области в нижеследующем тексте будут называться «скрытыми областями»). В соответствии с различными вариантами осуществления изобретения, модуль 607 анализа изображения документа специальным образом идентифицирует скрытые в документе области, в которых узор скрыт, с помощью некоторой пороговой величины. В частности, модуль 607 анализа изображения документа идентифицирует те области в документе, в которых скрыта чересчур большая часть узора, вследствие чего компьютер 100 может оказаться неспособным определить информацию о положении в этих областях.
Как подробно пояснялось выше, в различных примерах изобретения применяется узор, в котором каждый бит узора составлен из имеющей размер 3×3 матрицы пикселов. Кроме того, в некоторых вариантах осуществления изобретения разрешение камеры 203, используемой для захвата изображения части документа с узором, может составлять 32×32 пиксела. При такой организации компьютер 100, анализирующий изображение, сможет определить положение части документа, захваченной в изображении, если из этого изображения удастся идентифицировать 60 или более битов. Вместе с тем, если удастся идентифицировать лишь 59 битов или менее, то компьютер 100 может оказаться неспособным определить положение части документа, захваченной в изображении. Соответственно, если изображение части документа нельзя идентифицировать при этой организации, то изображение должно представлять собой область размером 32×32 пиксела в документе, в которой скрыты почти все биты узора за исключением 59 или менее битов узора. Путем идентификации этих областей размером 32×32 пиксела как имеющих 59 или менее нескрытых битов, модуль 607 анализа изображения документа может исключить другие области в документе (например, области, в которых отображены 60 или более битов) как источник изображения.
Следует отметить, что модуль 607 анализа изображения документа будет идентифицировать скрытые области документа по отношению к опорному пикселу, выбранному на этапе 703. Например, если в качестве опорного пиксела выбран центральный пиксел, то скрытые области будут состоять из пикселов, при этом окружающий массив пикселов размером 32×32 будет иметь 59 или менее нескрытых битов. Аналогично, если в качестве опорного пиксела выбран верхний правый пиксел в изображении, то скрытые области будут состоять из пикселов документа, при этом массив пикселов документа, имеющий размер 32×32 и расположенный ниже и слева от пикселов документа, имеет 59 или менее нескрытых битов. С другой стороны, если в качестве опорного пиксела выбран нижний правый пиксел в изображении, то скрытые области будут состоять из пикселов документа, при этом массив пикселов документа, имеющий размер 32×32 и расположенный выше и слева, имеет 59 или менее нескрытых битов.
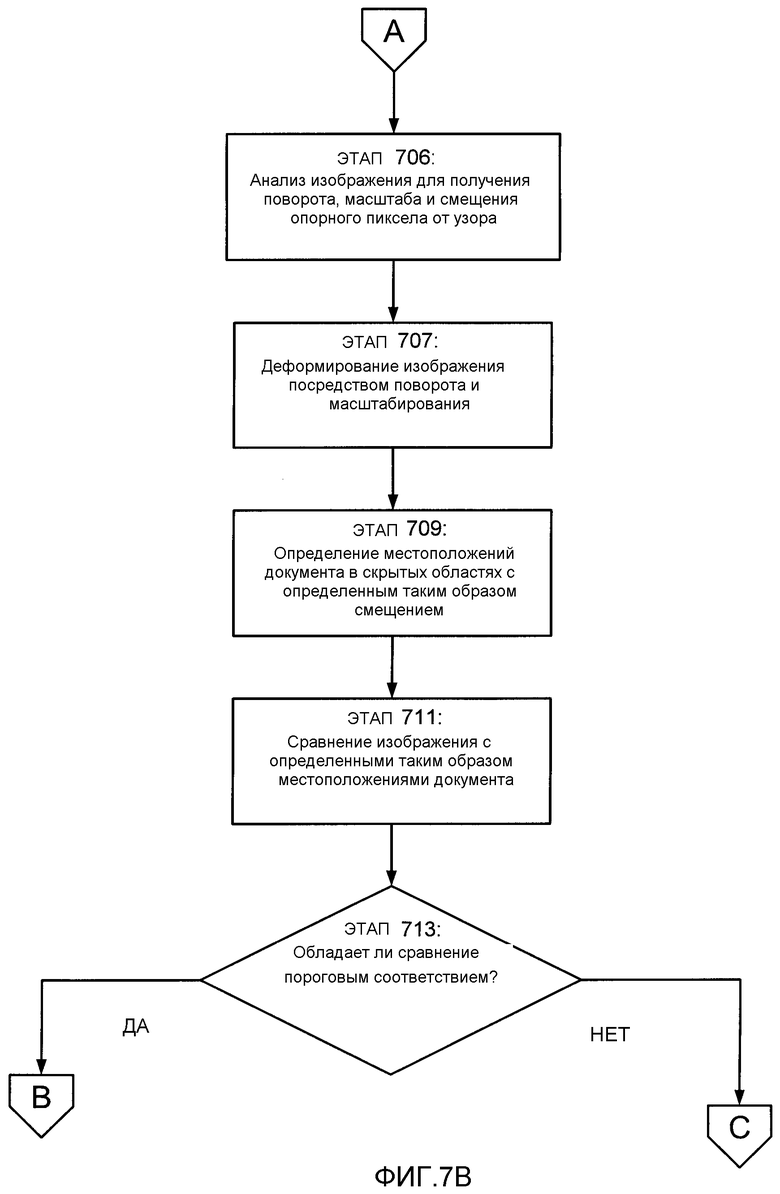
На этапе 706 модуль 605 анализа лабиринтного узора определяет поворот и масштаб принимаемого изображения относительно документа, а модуль 609 определения смещения пикселов определяет смещение опорного пиксела от узора. На этапе 707 принятое изображение деформируют с помощью информации о повороте и масштабе. Например, как подробно пояснялось выше, пользователь может и наклонять, и поворачивать перо 201, содержащее камеру 203, вызывая создание результирующего изображения неправильной формы относительно реального документа. Соответственно, правильное положение каждого пиксела, который имеется в захваченном изображении, должно быть переведено в значения координат, используемых для задания отдельных местоположений в документе. Если, например, изображение имеет 32×32 пиксела, то процесс деформирования обеспечит вычисление координат относительных положений всех 1024 пикселов в соответствии с системой координат документа. Таким образом, операция деформирования представляет собой аффинное преобразование и осуществляется с использованием матрицы преобразования. Это обусловит поворот и изменение масштаба изображения.
Изображение деформируют с использованием масштаба и поворота, определенных в результате анализа лабиринтного узора изображения, как подробно описано выше. Как отмечалось ранее, узор состоит из линий, которые перпендикулярны друг другу и расположены на одном и том же расстоянии друг от друга. Соответственно, путем идентификации узора в изображении модуль 605 анализа лабиринтного узора может определять разность углов между узором изображения и узором документа вдоль измерений по х и у. Модуль 605 анализа лабиринтного узора также может определять разность между промежутком в узоре изображения и промежутком в узоре документа. На основании этих разностей модуль 605 анализа лабиринтного узора может определять преобразование для деформирования изображения таким образом, чтобы оно соответствовало системе координат документа.
Ранее также отмечалось, что для идентификации абсолютной угловой ориентации изображения относительно документа можно использовать отличительные признаки узора, такие как типы форм углов. Вместе с тем, если места появления (или отсутствия) этих отличительных признаков скрыты в изображении, то модуль 605 анализа лабиринтного узора может оказаться неспособным определить абсолютную угловую ориентацию изображения относительно документа. При таких обстоятельствах, модуль 609 определения смещения пикселов повторит процесс деформирования четырежды через интервалы по 90°, чтобы гарантировать идентификацию деформирования с наилучшей ориентацией для координат документа. Например, на фиг. 8 показано первоначальное изображение 801. На этом чертеже также показано первое деформирование 803 изображения без дополнительного поворота (т.е. деформационный поворот на 0°) и второе деформирование 805 изображения с дополнительным поворотом на 90° (т.е. при деформационном повороте на 90°). На фиг. 8 также показаны третье деформирование 807 с дополнительным поворотом на 180° (т.е. при деформационном повороте на 180°) и четвертое деформирование 809 с дополнительным поворотом на 270° (т.е. при деформационном повороте на 270°). Как будет подробнее рассмотрено ниже, каждый из поворотов деформированного изображения будет сравниваться с документом.
Затем модуль 609 определения смещения пикселов определяет расстояние от опорного пиксела до ближайшего элемента узора. Кроме того, это расстояние вычисляется в двух направлениях - в направлении х и в направлении у (если местоположения в документе идентифицируются с использованием декартовых координат, как в проиллюстрированных примерах). Если смещение лабиринтного узора в первоначальном изображении определено как (dx, dy), а матрицей деформирования является матрица М, то смещение опорного пиксела от узора в деформированном изображении (обозначаемое как (dxi, dyi)) можно вычислить в виде
(dxi, dyi)T = М(dx, dy)T,
где символ «Т» обозначает матричный оператор транспонирования.
Сразу же после определения смещения относительно системы координат для электронной версии документа на этапе 709 модуль 609 определения смещения пикселов проверяет каждое местоположение в документе, чтобы определить, имеет ли это местоположение такое же смещение, как опорный пиксел. Более конкретно каждое местоположение (х, у) в ранее идентифицированных скрытых областях документа проверяется, чтобы увидеть, имеет ли это местоположение такое же смещение, как опорный пиксел. Если смещение некоторого местоположения в некоторой скрытой области от ближайшего элемента узора (как в направлении х, так и в направлении у) согласуется со смещением опорного пиксела в пределах некоторой пороговой величины, такой как 0,7 пиксела, то такое местоположение считается возможным совпадением с опорным пикселом в изображении. Таким образом, местоположение х, у в документе будет считаться возможным совпадением с опорным пикселом в изображении, если:
«Расстояние до элемента» (x+dx1, h)<0,7; и
«Расстояние до элемента» (у+dy1, h)<0,7,
где h - размер элемента лабиринтного узора, а «Расстояние до элемента» определяется как

где «mod(a,b)» означает «a mod b».
Следует отметить, что пороговое значение 0,7 выбрано для того, чтобы учесть возможные растровые погрешности и другие погрешности вычислений, которые могут возникать при деформировании изображения. В альтернативном варианте можно применять другие пороговые значения, если это желательно. Местоположения в документе, имеющие смещение, в достаточной степени согласующееся со смещением опорного пиксела, будут называться «согласующимися местоположениями» для удобства.
На этапе 711 модуль 611 сравнения сравнивает изображение с документом на основании согласующихся местоположений (т.е. тех местоположений в скрытых областях, которые согласуются со смещением опорного пиксела изображения). Более конкретно деформированное изображение сравнивается с разными частями документа таким образом, что опорный пиксел в деформированном изображении сравнивается с каждым согласующимся местоположением в документе (и сравнивается только с согласующимися местоположениями в документе). Как отмечалось ранее, этот процесс сравнения повторяется для каждого деформационного поворота изображения. Сравнение между деформированным изображением и частью документа может проводиться, например, для определения корреляции между значениями шкалы уровней серого для рассматриваемой части документа и значениями шкалы уровней серого для деформированного изображения. Конечно, можно применять любой подходящий способ сравнения деформированного изображения с частями документа.
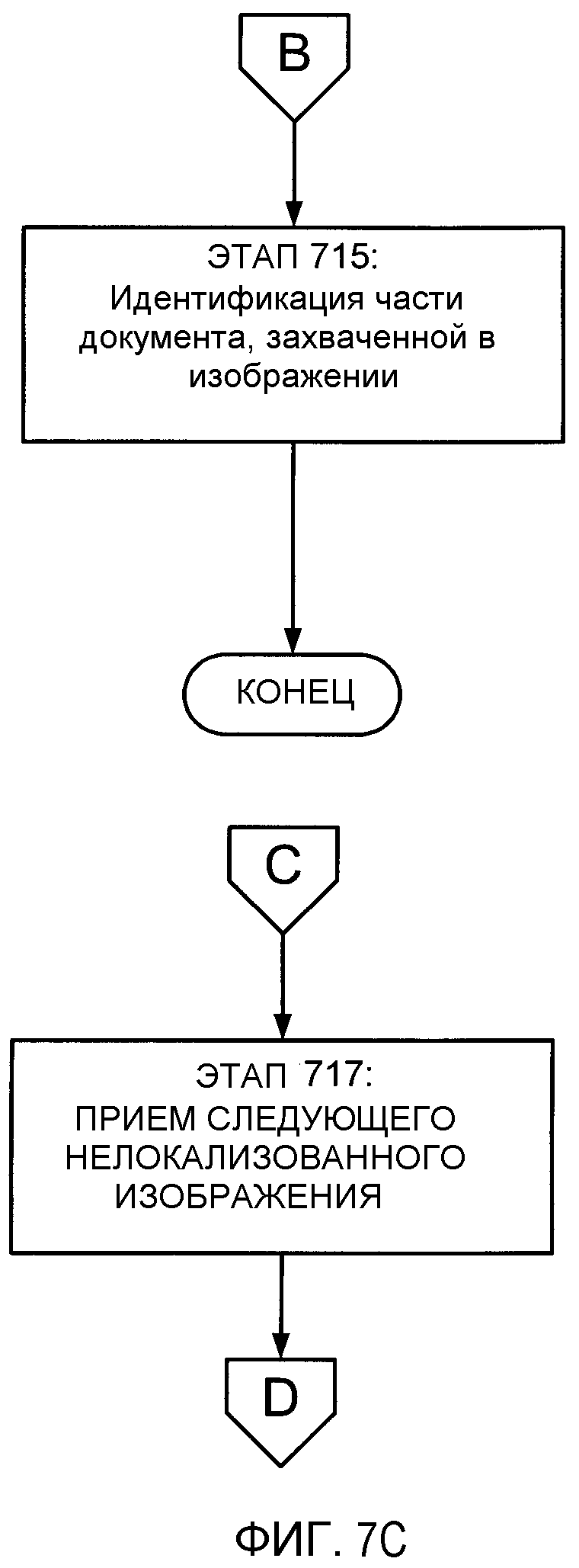
Если сравнение деформированного изображения с частью документа удовлетворяет одному или более желаемым пороговым требованиям, то модуль 611 сравнения изображения определит, что захваченное изображение является изображением части документа. Например, как отмечалось выше, каждое сравнение деформированного изображения с частью документа дает результат корреляции. В различных вариантах осуществления изобретения модуль 611 сравнения изображения будет идентифицировать те сравнения, которые дают корреляцию, например, величиной 0,5 (50%) или лучшую. Затем модуль 611 сравнения изображения будет идентифицировать первое сравнение с наибольшей корреляцией и второе сравнение со второй по величине корреляцией. Если значение корреляции для первого сравнения на 0,1 больше (т.е. на 10% больше), чем значение корреляции для второго сравнения, то модуль 611 сравнения изображения определит на этапе 711, что часть изображения, использованная в первом сравнении, является частью документа, захваченной в изображении.
Если ни одно из значений корреляции сравнения не удовлетворяет пороговой величине (например, 0,5), то изображение не будет согласованным с некоторой конкретной частью документа. Аналогично, если ни одно из значений корреляции сравнения не оказывается в достаточной степени превышающим другие значения корреляции сравнения, то изображение не будет согласованным с некоторой конкретной частью документа. Если изображение нельзя согласовать с некоторой конкретной частью документа, то на этапе 719 модуль 603 приема изображения принимает другое нелокализованное изображение, и вышеизложенная процедура повторяется.
Заключение
Хотя изобретение описано применительно к конкретным примерам, включая предпочтительные в настоящее время режимы осуществления изобретения, для специалистов в данной области техники будет очевидно, что возможны многочисленные изменения и перестановки вышеописанных систем и способов, находящиеся в рамках объема притязаний изобретения, охарактеризованного в прилагаемой формуле изобретения.


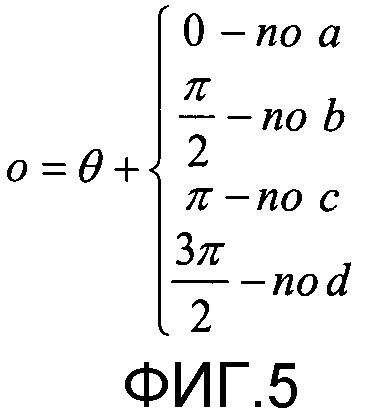
Изобретение относится к системам для идентификации местоположения меток на документе путем захвата изображения документа. Техническим результатом является повышение эффективности и скорости определения местоположения части документа в захваченном изображении без необходимости проведения попиксельного сравнения изображения со всем документом. Предложен способ определения части документа, соответствующей захваченному изображению, при котором идентифицируют области документа, в которых узор, по меньшей мере, частично скрыт. Выбирают в изображении опорный пиксел и определяют смещение между этим пикселом и узором, проводят попиксельное сравнение изображения с документом таким образом, что только опорный пиксел сравнивается с местоположениями в документе, которые и находятся в пределах идентифицированных областей, и имеют определенное таким образом смещение от узора, тогда сравнение, сопровождаемое наибольшим соответствием между пикселами изображения и электронного документа, обеспечивает идентификацию положения опорного пиксела относительно электронного документа. 9 з.п. ф-лы, 8 ил.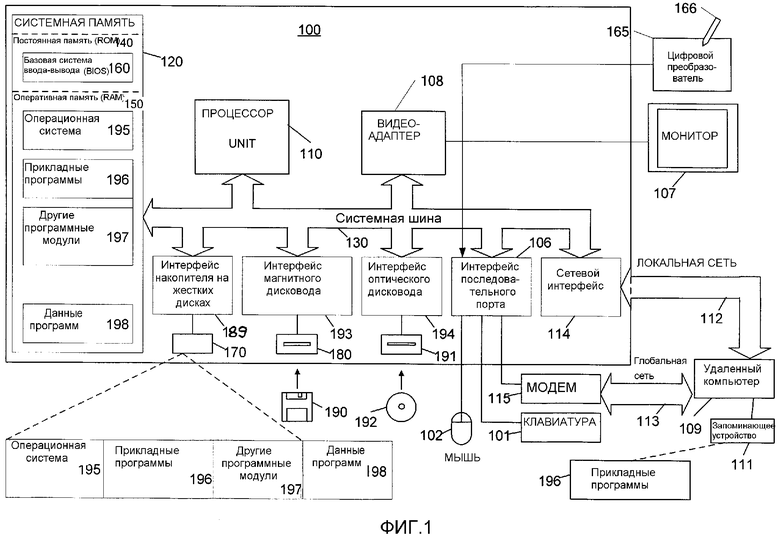
| US 6108612 А, 22.08.2000 | |||
| US 6408106 B1, 18.06.2002 | |||
| US 6219460 B1, 17.04.2001 | |||
| US 6302329 B1, 16.10.2001 | |||
| RU 2002111691 A, 27.12.2003 | |||
| ПРОГРАММНО-РЕАЛИЗУЕМЫЙ ЦИФРОВОЙ СПОСОБ ЗАЩИТЫ ОТ ПОДДЕЛОК И УСТРОЙСТВО ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 1996 |
|
RU2176823C2 |
| US 5946414 A, 31.08.1999 | |||
| Роликовый пресс для изготовления цилиндрических зубчаток | 1924 |
|
SU2934A1 |

