Область техники, к которой относится изобретение
Настоящее изобретение относится к взаимодействию со средой, используя цифровое перо. В частности, настоящее изобретение относится к определению расположения цифрового пера во время взаимодействия с одной или несколькими поверхностями.
Уровень техники
Пользователи компьютеров привыкли к использованию мыши и клавиатуры в качестве средства взаимодействия с персональным компьютером. Хотя персональные компьютеры обеспечивают ряд преимуществ по сравнению с письменными документами, большинство пользователей продолжают выполнять некоторые функции, используя отпечатанную бумагу. Некоторые из таких функций включают в себя чтение и аннотирование письменных документов. В случае аннотаций отпечатанный документ приобретает большую важность из-за аннотаций, размещенных на нем пользователем. Одной из трудностей, однако, с отпечатанным документом с аннотациями является последующая необходимость ввода аннотаций обратно в электронную форму документа. Это создает необходимость для первоначального пользователя или другого пользователя разбираться в аннотациях и вводить их в персональный компьютер. В некоторых случаях пользователь сканирует аннотации и исходный текст, таким образом создавая новый документ. Эти многочисленные этапы делают взаимодействие между отпечатанным документом и электронной версией документа трудным для обработки на повторяющейся основе. Далее, отсканированные изображения часто являются немодифицируемыми. Возможны случаи, когда нельзя отделить аннотации от исходного текста. Это делает трудным использование аннотаций. Следовательно, требуется улучшенный способ обработки аннотаций.
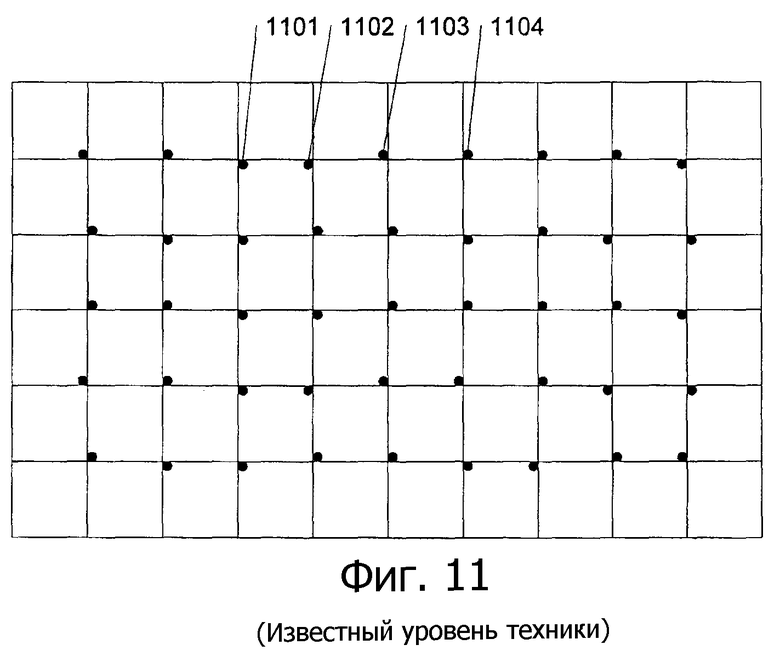
Одним методом захвата рукописной информации является использование пера, расположение которого может определяться во время записи. Одним пером, которое обеспечивает такую возможность, является перо Anoto компании Anoto Inc. Это перо действует с использованием камеры для захвата изображения бумаги, кодируемого по предопределенной структуре. Пример структуры изображения приведен на фиг.11. Данная структура используется пером Anoto (компании Anoto Inc.) для определения расположения пера на участке бумаги. Однако неясно, насколько эффективно определение расположения при помощи системы, используемой пером Anoto. Чтобы получить эффективное определение расположения захваченного изображения, необходима система, которая обеспечивает эффективное декодирование захваченного изображения.
При просмотре документа пользователь может аннотировать документ перемещением кончика пера относительно документа. Траектория кончика пера может содержать множество штрихов, где каждый штрих соответствует серии захваченных изображений. Следовательно, в промышленности существует реальная необходимость идентификации траектории пера для обработки аннотации на документе.
Раскрытие изобретения
Аспекты настоящего изобретения обеспечивают систему и способы, которые определяют траекторию кончика пера, когда кончик пера перемещается по документу. Согласно аспекту изобретения документ выполняется с водяным знаком и с лабиринтной структурой, из которой определяется кодированная информация о положении.
Согласно другому аспекту изобретения последовательность изображений захватывается камерой, которая расположена в пере. Траектория кончика пера определяется посредством декодирования связанной лабиринтной структуры (m-массива) и сравнения захваченных изображений с изображениями документа.
Согласно другому аспекту изобретения, если координаты положения любого кадра (соответствующего захваченному изображению), который связан со штрихом, не могут быть определены из декодирования m-массива, кадры преобразуются и затем сравниваются с областью изображения документа. После определения координат положения по меньшей мере одного кадра координаты положения других кадров могут определяться посредством сравнения кадров в соседней области.
Согласно другому аспекту изобретения траектория кончика пера (соответствующая штриху) отображается из центра кадра, используя перспективное преобразование и параметры калибровки. Перспективное преобразование получается из анализа лабиринтной структуры и в результате сравнения захваченных камерой изображений с изображениями документа.
Краткое описание чертежей
Вышеприведенный раздел Раскрытие изобретения, а также последующее подробное описание предпочтительных вариантов выполнения легче понять, читая их вместе с сопровождающими чертежами, которые включены в качестве примера и не в качестве ограничения в отношении заявленного изобретения.
Фиг.1 - общее описание компьютера, который может использоваться вместе с вариантами выполнения настоящего изобретения.
Фиг.2А и 2В - система захвата изображений и соответствующее захваченное изображение согласно вариантам выполнения настоящего изобретения.
Фиг.3А-3F - различные последовательности и методы свертки согласно вариантам выполнения настоящего изобретения.
Фиг.4А-4Е - различные системы кодирования согласно вариантам выполнения настоящего изобретения.
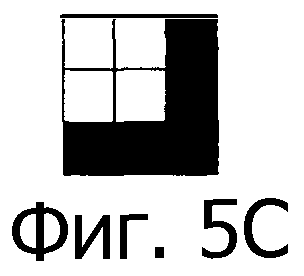
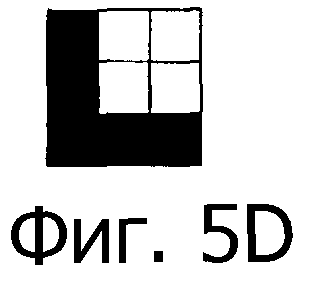
Фиг.5А-5D - четыре возможных результирующих уголка, связанных с системой кодирования по фиг.4А и 4В.
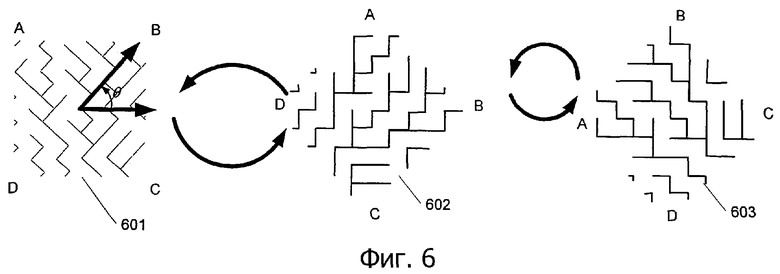
Фиг.6 - поворот части захваченного изображения согласно вариантам выполнения настоящего изобретения.
Фиг.7 - различные углы поворота, используемые вместе с системой кодирования по фиг.4А-4Е.
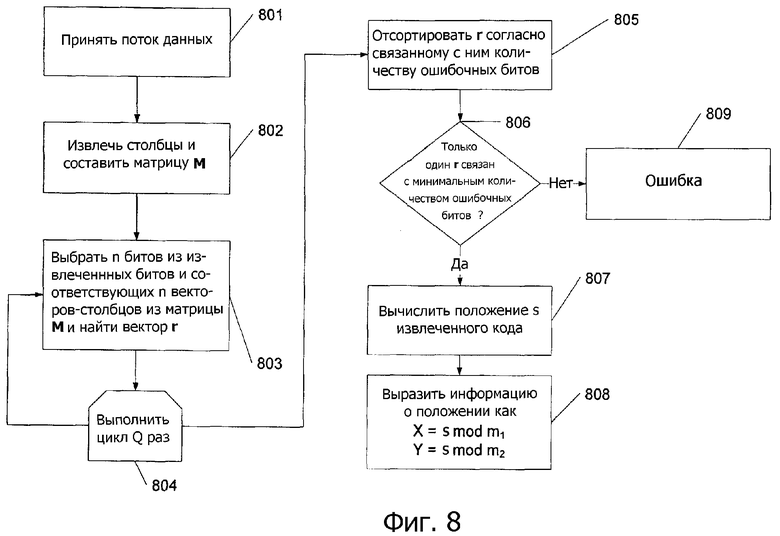
Фиг.8 - процесс определения расположения захваченного массива согласно вариантам выполнения настоящего изобретения.
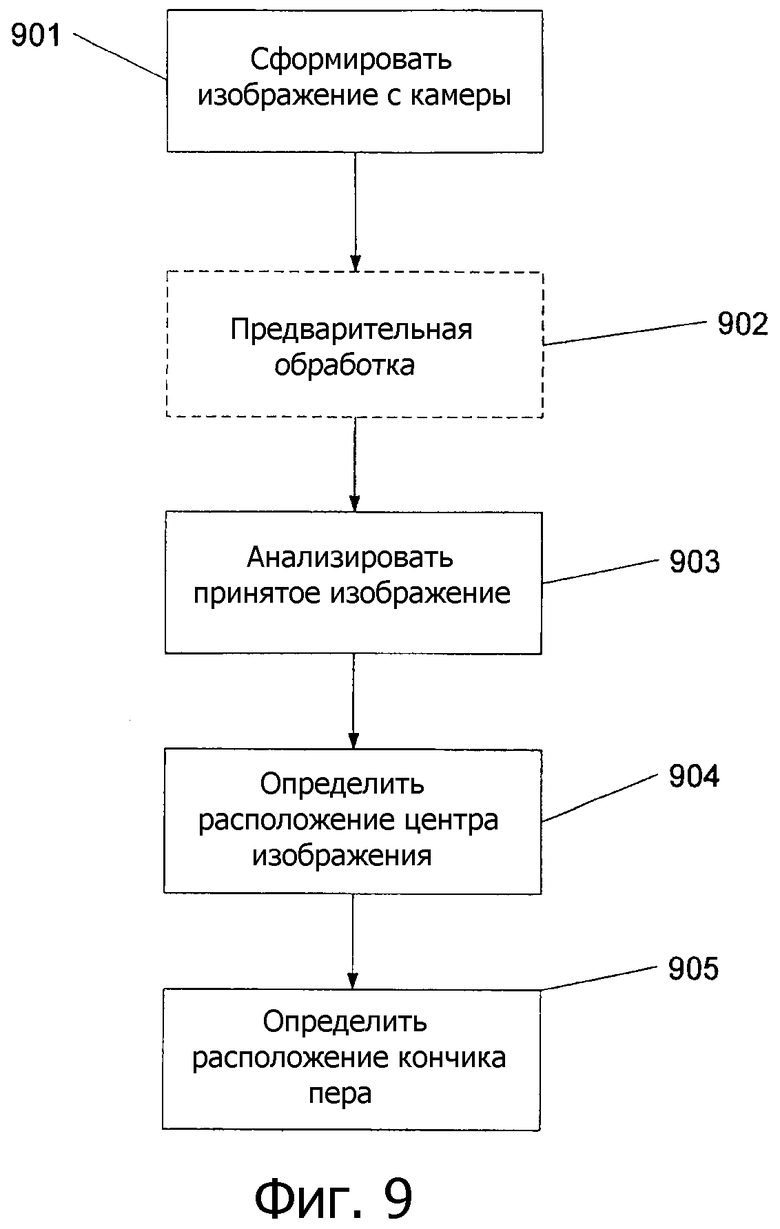
Фиг.9 - способ определения расположения захваченного изображения согласно вариантам выполнения настоящего изобретения.
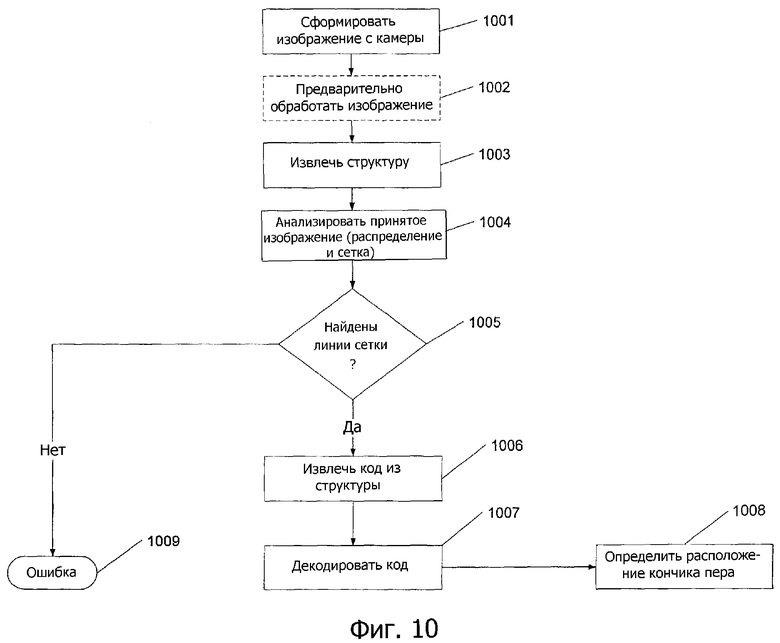
Фиг.10 - другой способ определения расположения захваченного изображения согласно вариантам выполнения настоящего изобретения.
Фиг.11 - представление пространства кодирования в документе согласно известному уровню техники.
Фиг.12 - блок-схема последовательности операций для декодирования извлеченных битов из захваченного изображения согласно вариантам выполнения настоящего изобретения.
Фиг.13 - выбор битов из извлеченных битов из захваченного изображения согласно вариантам выполнения настоящего изобретения.
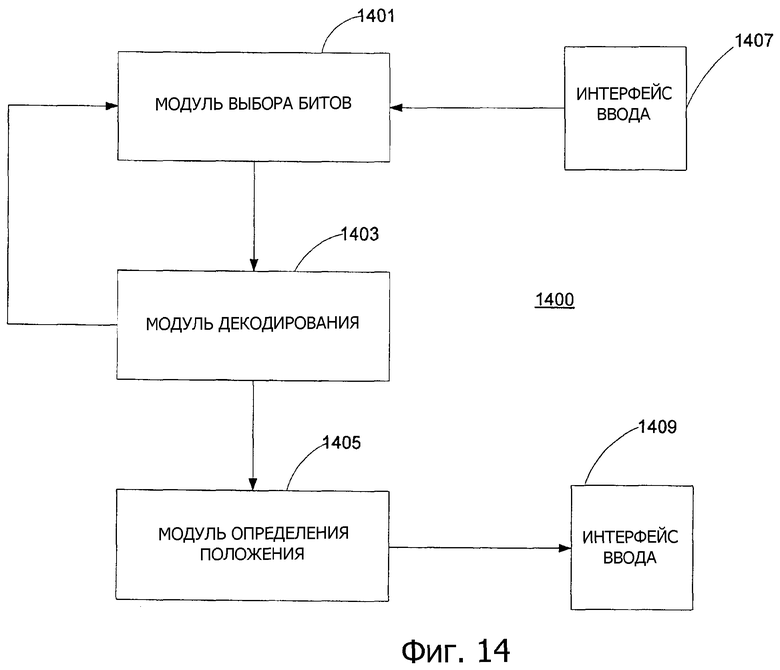
Фиг.14 - устройство для декодирования извлеченных битов из захваченного изображения согласно вариантам выполнения настоящего изобретения.
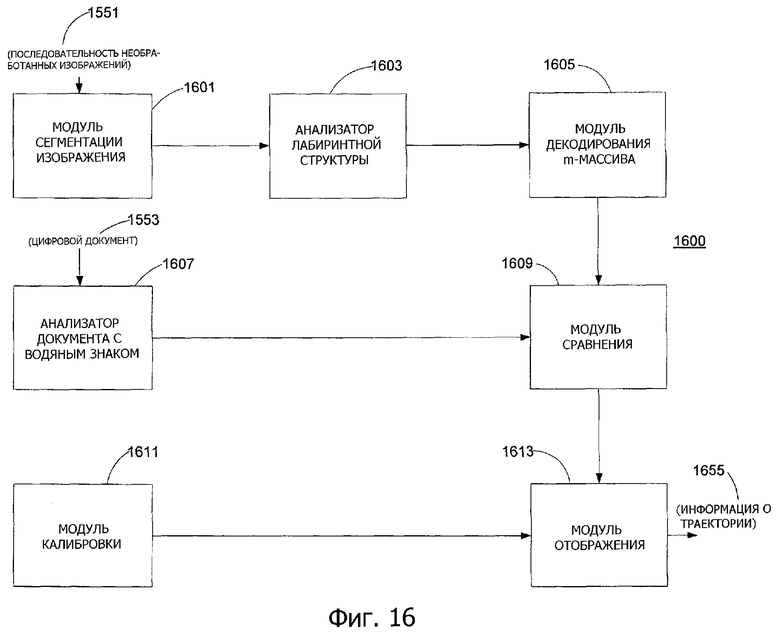
Фиг.15 - способ определения траектории кончика пера из последовательности захваченных кадров согласно варианту выполнения настоящего изобретения.
Фиг.16 - устройство для определения траектории кончика пера из последовательности захваченных кадров согласно варианту выполнения настоящего изобретения.
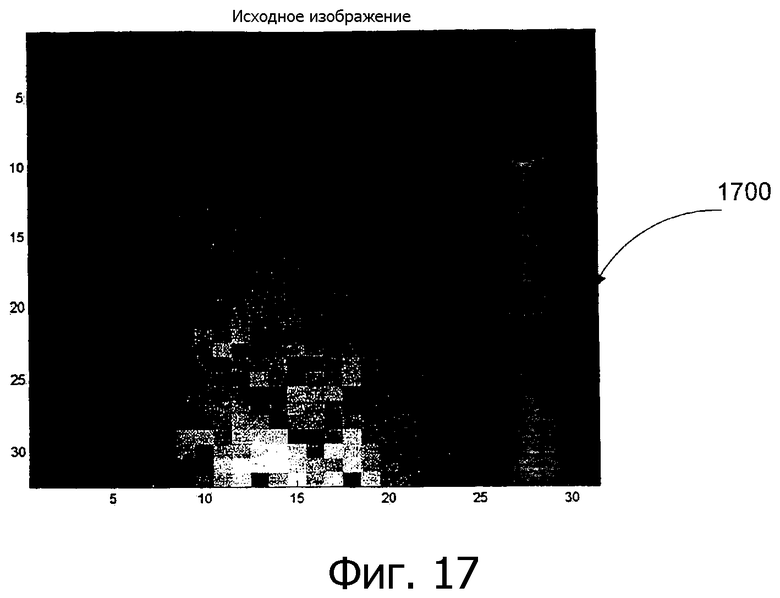
Фиг.17 - пример захваченного изображения согласно варианту выполнения изобретения.
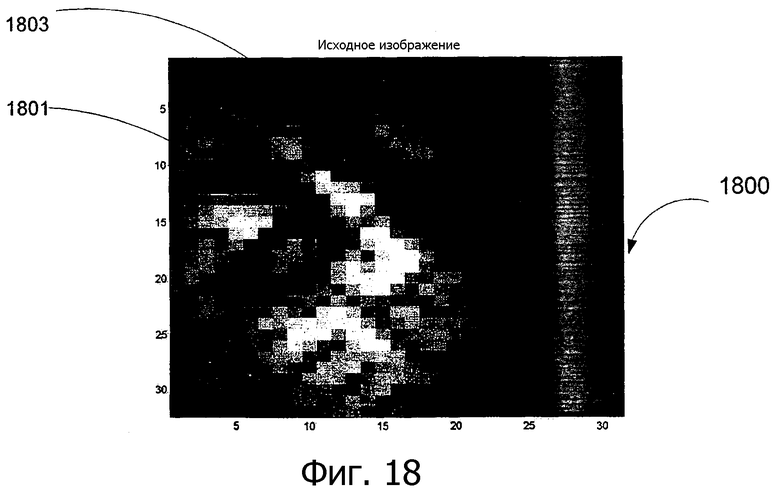
Фиг.18 - пример захваченного изображения, содержащего компонент текста, согласно варианту выполнения изобретения.
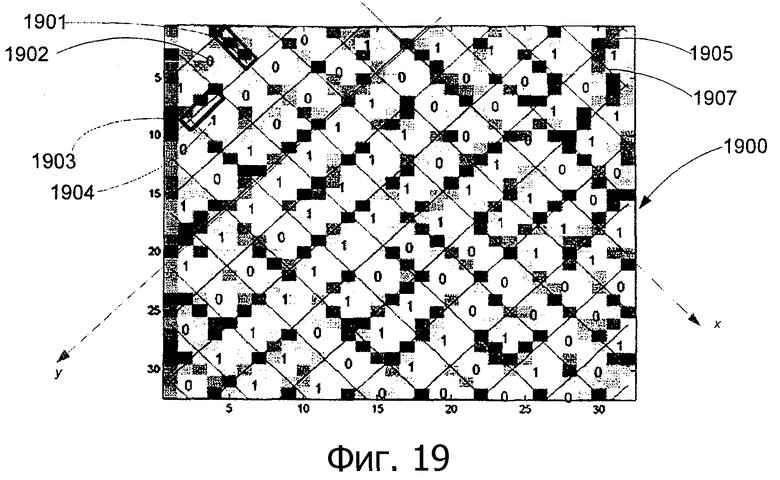
Фиг.19 - анализ лабиринтной структуры захваченного изображения согласно варианту выполнения изобретения.
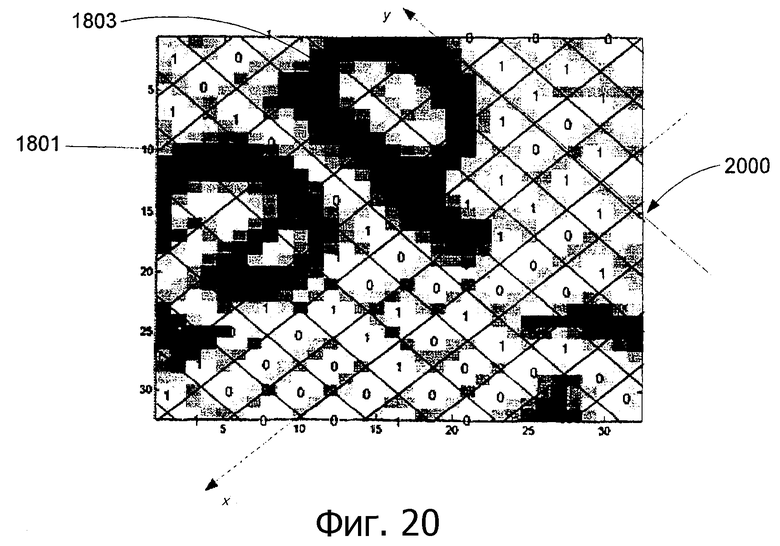
Фиг.20 - анализ лабиринтной структуры захваченного изображения, содержащего компонент текста, согласно варианту выполнения изобретения.
Фиг.21 - результат анализа изображения документа согласно варианту выполнения изобретения.
Фиг.22 - результат глобального определения расположения для примерного штриха согласно варианту выполнения изобретения.
Фиг.23 - результат локального определения расположения для примерного штриха согласно варианту выполнения изобретения.
Фиг.24 - восстановленный штрих кончика пера и траектория соответствующих центров захваченных изображений согласно варианту выполнения изобретения.
Фиг.25 - фактический штрих, который соответствует восстановленному штриху, как показано на фиг.24.
Осуществление изобретения
Аспекты настоящего изобретения относятся к определению расположения захваченного изображения в отношении большего изображения. Описанные в данной заявке способ и система определения расположения могут использоваться в комбинации с многофункциональным пером.
Нижеследующее разделяется подзаголовками для удобства читателя. Подзаголовки включают в себя: Термины, Компьютер общего назначения, Захватывающее изображение перо, Кодирование массива, Декодирование, Коррекция ошибок, Определение расположения, Декодирование m-массива и Архитектура для определения траектории пера.
Термины
Перо - любой пишущий инструмент, который может включать в себя или может не включать в себя возможность хранения чернил. В некоторых примерах стило без возможности использования чернил может использоваться в качестве пера согласно вариантам выполнения настоящего изобретения.
Камера - система захвата изображения, которая может захватывать изображение с бумаги или любой другой среды.
Компьютер общего назначения
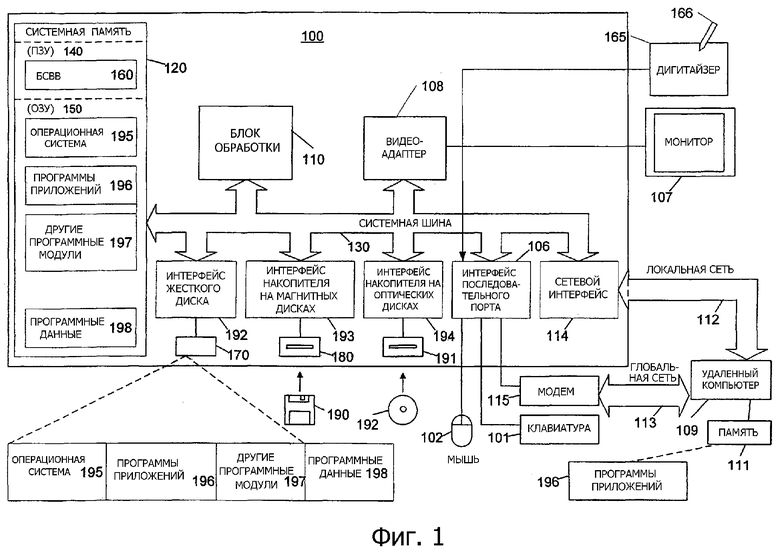
На фиг.1 представлена функциональная блок-схема примера обычной цифровой вычислительной среды общего назначения, которая может использоваться для осуществления различных аспектов настоящего изобретения. На фиг.1 компьютер 100 включает в себя блок 110 обработки, системную память 120 и системную шину 130, которая соединяет различные компоненты системы, включая системную память с блоком 110 обработки. Системная шина 130 может быть любой из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, используя любую из множества шинных архитектур. Системная память 120 включает в себя постоянное запоминающее устройство (ПЗУ) 140 и оперативное запоминающее устройство (ОЗУ) 150.
Базовая система 160 ввода-вывода (БСВВ), содержащая базовые подпрограммы, которые способствуют переносу информации между элементами внутри компьютера 100, например во время запуска, хранится в ПЗУ 140. Компьютер 100 также включает в себя накопитель 170 на жестких дисках для считывания и записи на жесткий диск (не показан), накопитель 180 на магнитных дисках для считывания или записи на съемный магнитный диск 190 и накопитель 191 на оптических дисках для считывания или записи на съемный оптический диск 192, такой как компакт-диск или другой оптический носитель. Накопитель 170 на жестких дисках, накопитель 180 на магнитных дисках и накопитель 191 на оптических дисках подсоединены к системной шине 130 при помощи интерфейса 192 накопителя на жестких дисках, интерфейса 193 накопителя на магнитных дисках и интерфейса 194 накопителя на оптических дисках, соответственно. Накопители и связанные с ними считываемые компьютером носители обеспечивают энергонезависимое хранение считываемых компьютером инструкций, структур данных, программных модулей и других данных для персонального компьютера 100. Для специалиста в данной области техники понятно, что в примерной операционной среде также могут использоваться другие типы считываемых компьютером носителей, которые могут хранить данные, к которым может обращаться компьютер, такие как магнитные кассеты, карты флэш-памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т. п.
Ряд программных модулей может храниться на накопителе 170 на жестких дисках, магнитном диске 190, оптическом диске 192, в ПЗУ 140 или ОЗУ 150, включая операционную систему 195, одну или несколько программ 196 приложений, другие программные модули 197 и программные данные 198. Пользователь может вводить команды и информацию в компьютер 100 при помощи устройств ввода, таких как клавиатура 101 и указательное устройство 102. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровой планшет, антенну спутниковой связи, сканер или т. п. Эти и другие устройства ввода часто подключаются к блоку 110 обработки через интерфейс 106 последовательного порта, который подключается к системной шине, но может подключаться при помощи других интерфейсов, таких как параллельный порт, игровой порт или универсальную последовательную шину (УПШ). Далее, эти устройства могут подключаться непосредственно к системной шине 130 через соответствующий интерфейс (не показан). Монитор 107 или устройство отображения другого типа также подключается к системной шине 130 через интерфейс, такой как видеоадаптер 108. В дополнение к монитору персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показаны), такие как громкоговорители и принтеры. В предпочтительном варианте выполнения предусмотрены перьевой дигитайзер 165 и сопровождающее перо или стило 166 для захвата изображения цифровым методом ввода, выполненного от руки. Хотя показано непосредственное соединение между перьевым дигитайзером 165 и последовательным портом, на практике перьевой дигитайзер 165 может подключаться к блоку 110 обработки непосредственно, через параллельный порт или другой интерфейс и системную шину 130, что известно в данной области техники. Кроме того, хотя дигитайзер 165 показан отдельно от монитора 107, предпочтительно, чтобы используемая область ввода дигитайзера 165 была совмещена с областью отображения монитора 107. Далее, дигитайзер 165 может быть встроен в монитор 107 или может существовать в качестве отдельного устройства, покрывающего или иным образом присоединенного к монитору 107.
Компьютер 100 может работать в сетевой среде, используя логические подключения к одному или нескольким удаленным компьютерам, таким как удаленный компьютер 109. Удаленным компьютером 109 может быть сервер, маршрутизатор, сетевой персональный компьютер (ПК), одноранговое устройство или другой общий сетевой узел и обычно включает в себя многие или все элементы, описанные выше в отношении компьютера 100, хотя только устройство 111 хранения памяти изображено на фиг.1. Логические подключения, изображенные на фиг.1, включают в себя локальную сеть (ЛС) 112 и глобальную сеть (ГС) 113. Такие сетевые среды общеприняты в офисах, компьютерных сетях масштаба предприятия, интрасетях и Интернете.
При использовании в сетевой среде ЛС компьютер 100 подключается к локальной сети 112 при помощи сетевого интерфейса или адаптера 114. При использовании в сетевой среде ГС персональный компьютер 100 обычно включает в себя модем 115 или другое средство для установления связи по глобальной сети 113, такой как Интернет. Модем 115, который может быть внутренним или внешним, подключается к системной шине 130 при помощи интерфейса 106 последовательного порта. В сетевой среде программные модули, описанные в отношении персонального компьютера 100 или его частей, могут храниться на удаленном устройстве хранения.
Понятно, что показанные сетевые подключения являются иллюстративными, и могут использоваться другие методы для установления линии связи между компьютерами. Предполагается существование любых из множества общеизвестных протоколов, таких как TCP/IP (протокол управления передачей/протокол Интернета), Ethernet, FTP (протокол передачи файлов), TTP (протокол передачи гипертекста), Bluetooth, IEEE 802.11х и аналогичные, и система может работать в конфигурации клиент-сервер, позволяющей пользователю получать веб-страницы с веб-сервера. Можно использовать любые из многочисленных обычных веб-браузеров для отображения и манипулирования данными на веб-страницах.
Захватывающее изображение перо
Аспекты настоящего изобретения включают в себя размещение кодированного потока данных в отображаемой форме, которая представляет кодированный поток данных (Например, как описано в отношении фиг.4В, кодированный поток данных используется для создания графической структуры). Отображаемой формой может быть отпечатанная бумага (или другая физическая среда) или может быть дисплей, проецирующий кодированный поток данных вместе с другим изображением или группой изображений. Например, кодированный поток данных может представляться в виде физического графического изображения на бумаге, или графического изображения, перекрывающего отображаемое изображение (например, представляющее текст документа), или может быть физическим (немодифицируемым) графическим изображением на экране дисплея (таким образом любая часть изображения, захваченная пером, может располагаться на экране дисплея).
Это определение расположения захваченного изображения может использоваться для определения расположения участка взаимодействия пользователя с бумагой, средой или экраном дисплея. В некоторых аспектах настоящего изобретения пером может быть чернильное перо, пишущее на бумаге. В других аспектах пером может быть стило, при этом пользователь пишет на поверхности дисплея компьютера. Любое взаимодействие может быть передано обратно в систему со сведениями о кодированном изображении на документе или с поддержкой документа, отображаемого на экране компьютера. Посредством повторяющегося захвата изображений камерой в пере или стило, когда перо или стило пересекают документ, система может отслеживать перемещение стило, управляемого пользователем. Отображаемым или отпечатанным изображением может быть водяной знак, связанный с пустой бумагой или бумагой с информационным наполнением, или может быть водяной знак, связанный с отображаемым изображением или фиксированным кодированием, перекрывающим экран или встроенным в экран.
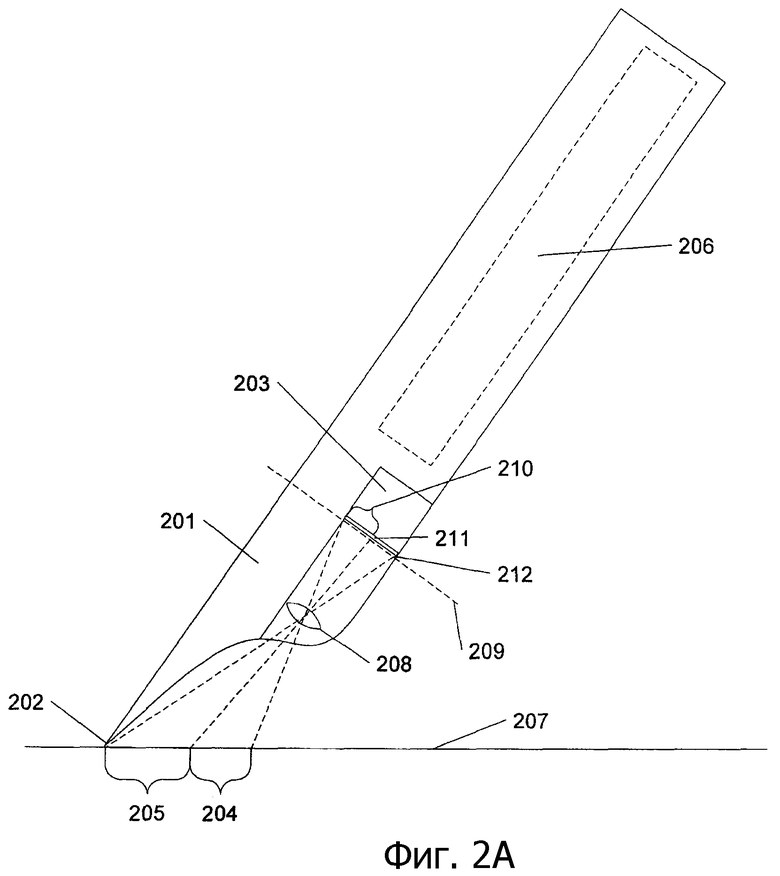
На фиг.2А и 2В приведен иллюстративный пример пера 201 с камерой 203. Перо 201 включает в себя кончик 202, который может включать в себя или может не включать в себя емкость с чернилами. Камера 203 захватывает изображение 204 с поверхности 207. Перо 201 может дополнительно включать в себя дополнительные датчики и/или процессоры, как представлено пунктирным прямоугольником 206. Эти датчики и/или процессоры 206 также могут включать в себя возможность передачи информации на другое перо 201 и/или персональный компьютер (например, по Bluetooth или другим беспроводным протоколам).
На фиг.2В представлено изображение, наблюдаемое камерой 203. В одном иллюстративном примере поле зрения камеры 203 (т.е. разрешение датчика изображения камеры) составляет 32х32 пиксела (где N=32). В одном варианте выполнения захваченное изображение (32 пиксела на 32 пиксела) соответствует области примерно 5 мм на 5 мм плоскости поверхности, захватываемой камерой 203. Следовательно, на фиг.2В показано поле зрения с длиной 32 пиксела и шириной 32 пиксела. Размер N является настраиваемым, так что большие N соответствуют более высокому разрешению изображения. Также, хотя поле зрения камеры 203 показано квадратным для целей иллюстрации в данном случае, поле зрения может включать в себя другие формы, что известно в данной области техники.
Изображения, захватываемые камерой 203, могут определяться как последовательность кадров {Ii} изображения, где Ii захватывается пером 201 в моменты ti времени выборки. Частота выборки может быть большой или малой в зависимости от конфигурации системы и требований к рабочим характеристикам. Размер кадра захваченного изображения может быть большим или маленьким в зависимости от конфигурации системы и требований к рабочим характеристикам.
Изображение, захватываемое камерой 203, может использоваться непосредственно системой обработки или может подвергаться префильтрации. Данная префильтрация может происходить в пере 201 или может происходить вне пера 201 (например, в персональном компьютере).
Размер изображения на фиг.2В составляет 32х32 пиксела. Если размер каждой единицы кодирования составляет 3х3 пиксела, то тогда количество захваченных кодированных единиц составит примерно 100 единиц. Если размер единицы кодирования составляет 5х5 пикселов, то тогда количество захваченных кодированных единиц составляет примерно 36.
На фиг.2А также показана плоскость 209 изображения, на которой формируется изображение 210 структуры с расположения 204. Свет, принимаемый от структуры на плоскости 207 объекта, фокусируется объективом 208. Объектив 208 может представлять собой единственную линзу или многоэлементную линзовую систему, но для простоты представлен в данной заявке в виде единственной линзы. Датчик 211 захвата изображения захватывает изображение 210.
Датчик 211 изображения может быть достаточно большим для захвата изображения 210. Альтернативно, датчик 211 изображения может быть достаточно большим для захвата изображения кончика 202 пера в расположении 212. Для ссылки, изображение в расположении 212 упоминается как виртуальный кончик пера. Отмечается, что расположение виртуального кончика пера относительно датчика 211 изображения является фиксированным из-за постоянного соотношения между кончиком пера, объективом 208 и датчиком 211 изображения.
Следующее преобразование FS→P преобразует координаты положения в изображении, захваченном камерой, в координаты положения в реальном изображении на бумаге:
Lбумага=FS→P(Lдатчик)
Во время записи кончик пера и бумага находятся в одной плоскости. Следовательно, преобразование из виртуального кончика пера в реальный кончик пера также представляет собой FS→P:
Lкончик пера=FS→P(Lвиртуальный-кончик пера)
Преобразование Fs→P может быть оценено как аффинное преобразование. Оно упрощается в:
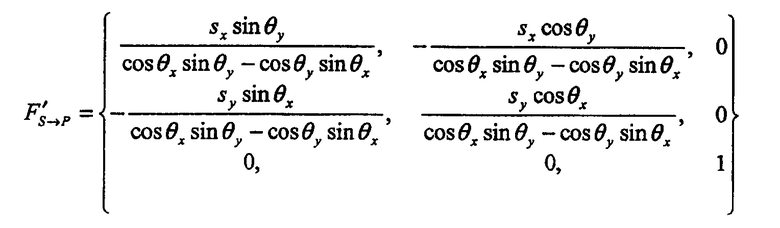
как оценка FS→P, в которой θx, θy, sx и sy представляют собой поворот и масштабирование двух ориентаций структуры, захваченной в расположении 204. Далее, можно уточнить F'S→P посредством сравнения захваченного изображения с соответствующим реальным изображением на бумаге. «Уточнение» означает получение более точной оценки преобразования FS→P посредством типа алгоритма оптимизации, упоминаемого как рекуррентный метод. Рекуррентный метод рассматривает матрицу F'S→P в качестве исходного значения. Уточненная оценка описывает более точно преобразование между S и P.
Затем можно определить расположение виртуального кончика пера посредством калибровки.
Размещают кончик 202 пера в фиксированном расположении Lкончик пера на бумаге. Затем наклоняют перо, давая возможность камере 203 захватить серию изображений с различными позициями пера. Для каждого захваченного изображения можно получить преобразование FS→P. Из этого преобразования можно получить расположение виртуального кончика пера Lвиртуальный-кончик пера:
Lвиртуальный-кончик пера=FP→S(Lкончик пера)
где Lкончик пера инициализируется как (0,0), и
FP→S=(FS→P)-1
Посредством усреднения Lвиртуальный-кончик пера, полученного из каждого изображения, можно определить расположение виртуального кончика пера Lвиртуальный-кончик пера. С Lвиртуальный-кончик пера можно получить более точную оценку Lкончик пера . После нескольких итераций можно определить точное расположение виртуального кончика пера Lвиртуальный-кончик пера.
Теперь известно расположение виртуального кончика пера Lвиртуальный-кончик пера. Также можно получить преобразование F S→P из захваченных изображений. Наконец, можно использовать эту информацию для определения расположения реального кончика пера Lкончик пера:
Lкончик пера=FS→P(Lвиртуальный-кончик пера)
Кодирование массива
Двумерный массив может быть составлен посредством свертки одномерной последовательности. Любая часть двумерного массива, содержащая достаточно большое количество битов, может использоваться для определения ее расположения в полном двумерном массиве. Однако может быть необходимым определить расположение из захваченного изображения или нескольких захваченных изображений. Чтобы минимизировать возможность сопоставления части захваченного изображения с двумя или более расположениями в двумерном массиве, может использоваться неповторяющаяся последовательность для создания массива. Одним свойством создаваемой последовательности является то, что последовательность не повторяется по длине (или окну) n. Нижеследующее описывает создание одномерной последовательности посредством свертки последовательности в массив.
Составление последовательности
Последовательность чисел может использоваться в качестве начальной точки системы кодирования. Например, последовательность (также упоминаемая как m-последовательность) может быть представлена как q-элемент, установленный в поле Fq. В данном случае q=pn, где n≥1 и p представляет собой простое число. Последовательность или m-последовательность может генерироваться посредством множества различных методов, включая, но не ограничиваясь им, деление многочленов. Используя деления многочленов, последовательность может определяться следующим образом:
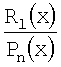
где Pn(x) представляет собой примитивный многочлен степени n в поле Fq[x] (имеющем qn элементов). Rl(x) представляет собой ненулевой многочлен степени l (где l<n) в поле Fq[x]. Последовательность может создаваться с использованием итерационной процедуры с двумя этапами: во-первых, деления двух многочленов (получая в результате элемент поля Fq) и, во-вторых, умножения остатка на x. Вычисление останавливается, когда выходной результат начинает повторяться. Этот процесс может быть реализован с использованием линейного регистра сдвига с обратными связями, как описано в статье Douglas W. Clark and Lih-Jyh Weng, "Maximal and Near-Maximal Shift Register Sequences: Efficient Event Counters and Easy Discrete Logarithms," IEEE Transactions on Computers 43.5 (May 1994, pp 560-568). В данном варианте выполнения устанавливается зависимость между циклическим сдвигом последовательности и многочленом Rl(x): изменение Rl(x) только циклически сдвигает последовательность, и каждый циклический сдвиг соответствует многочлену Rl(x). Одним из свойств результирующей последовательности является то, что последовательность имеет период qn-1, и внутри периода, по ширине (или длине) n, любая часть присутствует в последовательности один и только один раз. Это называется «свойством окна». Период qn-1 также упоминается как длина последовательности, и n - как порядок последовательности.
Описанный выше процесс является только одним из множества процессов, который может использоваться для создания последовательности со свойством окна.
Составление массива
Массив (или m-массив), который может использоваться для создания изображения (часть которого может захватываться камерой), представляет собой расширение одномерной последовательности или m-последовательности. Пусть А будет массив с периодом (m1, m2), а именно A(k+m1,l)=A(k,l+m2)=A(k,l). Когда окно n1 × n2 сдвигается на период A, все ненулевые матрицы n1 × n2 по Fq появляются один раз и только один раз. Это свойство также упоминается как «свойство окна» в том, что каждое окно является однозначным.
Двоичный массив (или m-массив) может быть составлен посредством свертки последовательности. Одним принципом является получение последовательности, затем свертка ее до размера m1 × m2, где длина массива составляет L = m1 × m2 = 2n - 1. Альтернативно, можно начать с предопределенного размера пространства, которое хотят охватить (например, один лист бумаги, 30 листов бумаги или размер монитора компьютера), определить область (m1 × m2), затем использовать размер, чтобы получить L ≥ m1 × m2, где L = 2n - 1.
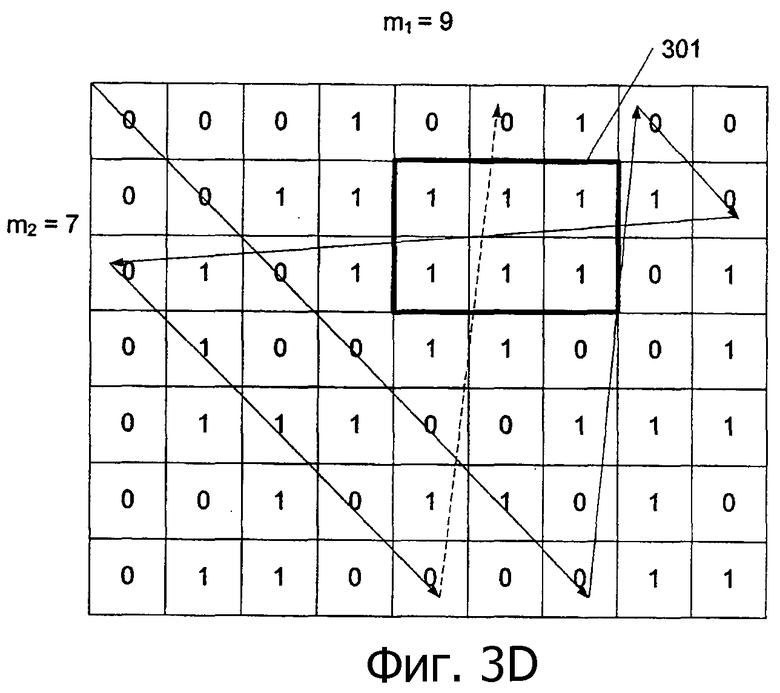
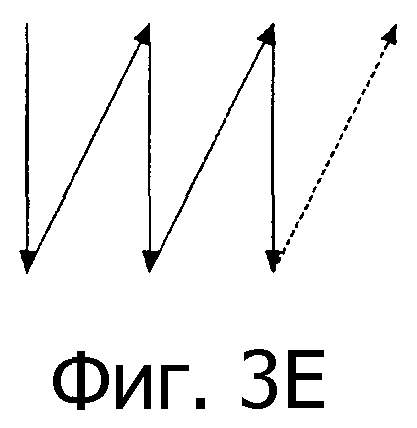
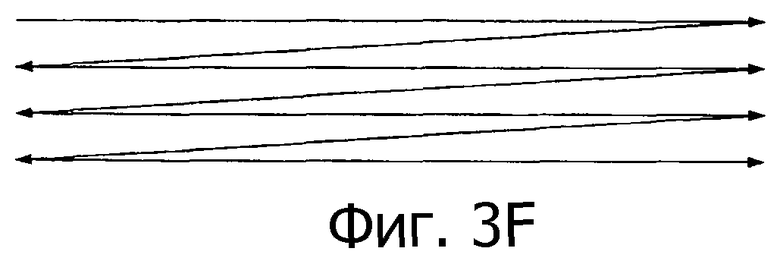
Можно использовать множество различных методов свертки. Например, на фиг.3А-3С показаны три различные последовательности. Каждая из них может быть свернута в массив, показанный на фиг.3D. Показаны три различных способа свертки, наложение на фиг.3D и траектории растра на фиг.3Е и 3F. Авторы принимают способ свертки, показанный на фиг.3D.
Для создания способа свертки, показанного на фиг.3D, создают последовательность {ai} длиной L и порядка n. Затем создается массив {bkl} размера m1 × m2, где наибольший общий делитель (m1,m2) = 1 и L = m1 × m2, из последовательности {ai}, вычисляя каждый бит массива так, как показано в уравнении 1:
bkl=ai, где k=i mod(m1), l=i mod(m2), i=0,..., L-1 (1)
(1)
Данный принцип свертки может быть альтернативно выражен как размещение последовательности по диагонали массива, затем продолжая с противоположного края при достижении края.
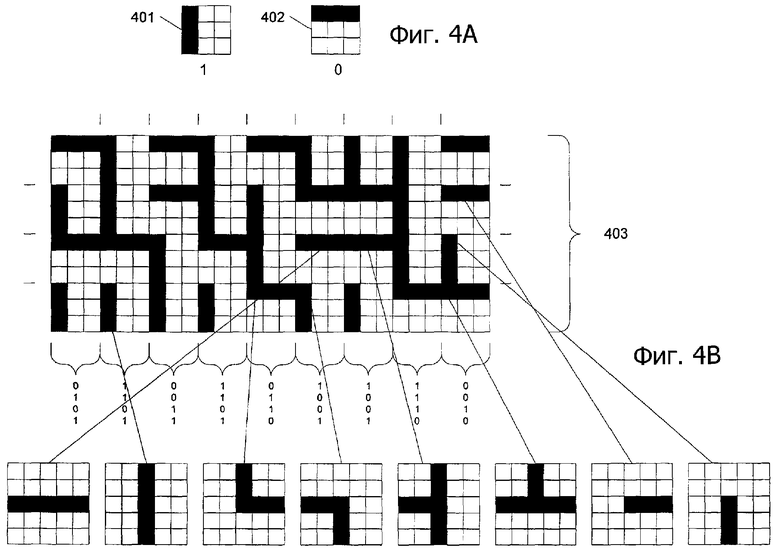
На фиг.4А показаны методы кодирования выборки, которые могут использоваться для кодирования массива по фиг.3D. Понятно, что могут использоваться другие методы кодирования. Например, альтернативный метод кодирования показан на фиг.11.
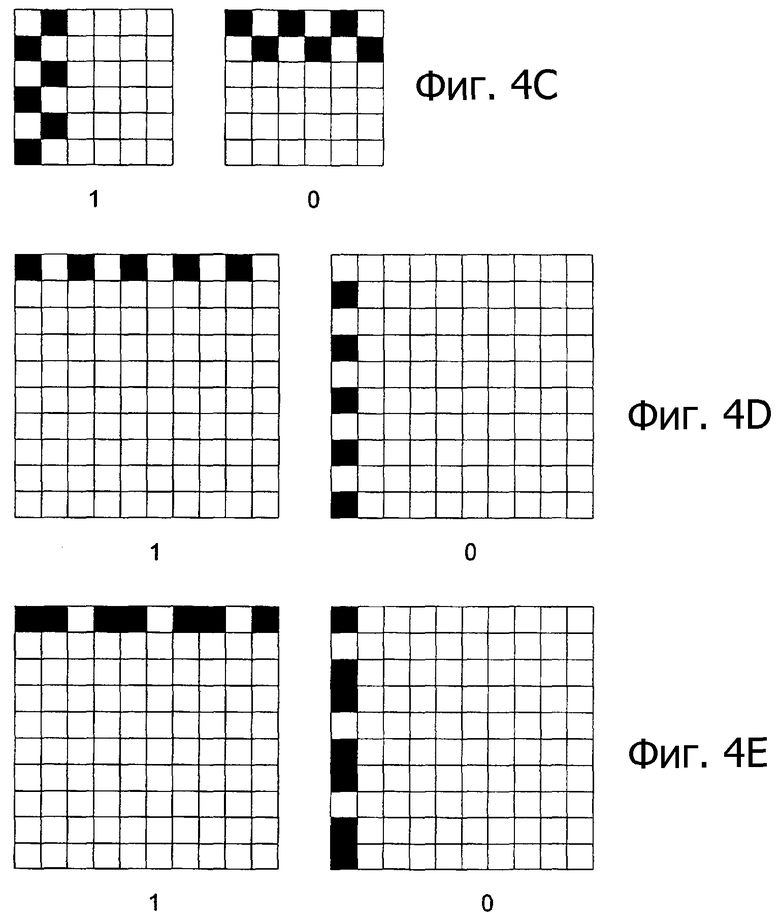
Ссылаясь на фиг.4А, первый бит 401 (например, «1») представляется столбцом темных чернил. Второй бит 402 (например, «0») представляется строкой темных чернил. Понятно, что могут использоваться чернила любого цвета, чтобы представлять различные биты. Единственным требованием к цвету выбираемых чернил является то, чтобы они обеспечивали существенный контраст по сравнению с фоном среды, чтобы быть различимыми системой захвата изображения. Биты на фиг.4А представлены матрицей 3х3 ячеек. Размер матрицы может модифицироваться, чтобы он равнялся любому размеру, основанному на размере и разрешении системы захвата изображения. Альтернативное представление битов 0 и 1 показано на фиг.4С-4Е. Понятно, что представление единицы или нуля для кодирования выборки по фиг.4А-4Е может переключаться безрезультатно. На фиг.4С показаны представления битов, занимающих две строки или столбца с чередованием. На фиг.4D показано альтернативное расположение пикселов строками и столбцами в виде пунктира. Наконец, на фиг.4Е показаны представления пикселов столбцами и строками в формате с неравномерными промежутками (например, две темные точки, за которыми следует пустая точка).
Ссылаясь обратно на фиг.4А, если бит представлен матрицей 3х3 и система формирования изображения обнаруживает темную строку и две белые строки в зоне 3х3, то тогда обнаруживается нуль (или единица). Если изображение обнаруживается с темным столбцом и двумя белыми столбцами, то тогда обнаруживается единица (или нуль).
В данном случае для представления бита используется более одного пиксела или точки. Использование одного пиксела (или бита) для представления бита является неустойчивым. Пыль, складки на бумаге, неплоские поверхности и т.п. создают трудности при считывании однобитовых представлений блоков данных. Однако понятно, что могут использоваться различные принципы для графического представления массива на поверхности. Такие принципы показаны на фиг.4С-4Е. Понятно, что также могут использоваться другие принципы. Один принцип изображен на фиг.11 с использованием только смещенных на интервал точек.
Поток битов используется для создания графической структуры 403 на фиг.4В. Графическая структура 403 включает в себя 12 строк и 18 столбцов. Строки и столбцы формируются потоком битов, который преобразуется в графическое представление с использованием представлений 401 и 402 битов. Фиг.4В может рассматриваться как имеющая следующее представление битов:

Декодирование
Когда человек пишет пером по фиг.2А или перемещает перо близко к кодированной структуре, камера захватывает изображение. Например, перо 201 может использовать датчик давления, когда перо 201 прижимается к бумаге, и перо 201 просматривает документ на бумаге. Изображение затем обрабатывается с целью определения ориентации захваченного изображения относительно полного представления кодированного изображения и извлекает биты, которые составляют захваченное изображение.
Для определения ориентации захваченного изображения относительно всей кодированной области можно заметить, что не все четыре возможные уголка, показанных на фиг.5А-5D, могут присутствовать в графической структуре 403. Фактически, при правильной ориентации тип уголка, показанный на фиг.5А, не может существовать в графической структуре 403. Поэтому ориентация, при которой отсутствует тип уголка, показанный на фиг.5А, является правильной ориентацией.
Продолжая на фиг.6 изображение, захваченное камерой 601, может анализироваться и может определяться его ориентация, чтобы оно было интерпретируемое в отношении положения, фактически представленного изображением 601. Во-первых, изображение 601 просматривается с целью определения угла θ, необходимого для поворота изображения, так чтобы пикселы были выровнены в горизонтальном и вертикальном направлении. Отмечается, что возможны альтернативные выравнивания сетки, включая поворот лежащей в основе сетки в негоризонтальное и невертикальное расположение (например, 45 градусов). Использование негоризонтального и невертикального размещения может обеспечивать возможное преимущество устранения у пользователя визуальной отвлекаемости, так как пользователи могут иметь тенденцию замечать горизонтальные и вертикальные структуры раньше других. С целью упрощения ориентация сетки (горизонтальная и вертикальная и любой другой поворот лежащей в основе сетки) упоминается вместе как предопределенная ориентация сетки.
Затем изображение 601 анализируется с целью определения, какой уголок отсутствует. Величина поворота о, необходимая для поворота изображения 601 в изображение, готовое для декодирования 603, показана как o = (θ плюс величина поворота {определенная тем, какой уголок отсутствует}). Величина поворота показана равенством на фиг.7. Ссылаясь обратно на фиг.6, угол θ сначала определяется раскладкой пикселов, что приводит к горизонтальному и вертикальному (или другой предопределенной ориентации сетки) размещению пикселов, и изображение поворачивается так, как показано в позиции 602. Затем проводится анализ с целью определения отсутствующего уголка, и изображение 602 поворачивается в изображение 603 для установки изображения для декодирования. В данном случае изображение поворачивается на 90 градусов против часовой стрелки, так что изображение 603 имеет правильную ориентацию и может использоваться для декодирования.
Понятно, что угол поворота θ может применяться до или после поворота изображения 601 с целью учета отсутствующего уголка. Также понятно, что, принимая во внимание шум в захваченном изображении, могут присутствовать все четыре типа уголков. Можно подсчитать количество уголков каждого типа и выбрать тип, который имеет наименьшее количество, в качестве типа уголка, который отсутствует.
Наконец, код в изображении 603 считывается и коррелируется с исходным потоков битов, используемым для создания изображения 403. Корреляция может быть выполнена несколькими способами. Например, она может быть выполнена посредством рекуррентного принципа, при котором восстановленный поток битов сравнивается со всеми другими фрагментами потока битов в исходном потоке битов. Во-вторых, может быть выполнен статистический анализ между восстановленным потоком битов и исходным потоком битов, например, посредством использования расстояния Хемминга между двумя потоками битов. Понятно, что может быть использовано множество принципов для определения расположения восстановленного потока битов в исходном потоке битов.
Если имеются восстановленные биты, то необходимо определить расположение захваченного изображения в исходном массиве (например, показанном на фиг.4В). Процесс определения расположения сегмента битов во всем массиве усложняется количеством элементов. Во-первых, фактические биты, подлежащие захвату, могут скрываться (например, камера может захватить изображение с содержимым документа, который скрывает код). Во-вторых, пыль, складки, отражения и т. п. также могут создавать ошибки в захваченном изображении. Эти ошибки делают более трудным процесс определения расположения. В этом отношении системе захвата изображения может потребоваться функционирование с непоследовательными битами, извлеченными из изображения. Нижеследующее представляет способ работы с непоследовательными битами из изображения.
Пусть последовательность (или m-последовательность) I соответствует степенному ряду I(x)=1/Pn(x), где n представляет собой порядок m-последовательности, и захваченное изображение содержит K битов из I b=(b0 b1 b2 … bK-1)t, где K≥n, и верхний индекс t представляет транспонированную матрицу или вектор. Расположение s из K битов представляет собой просто количество циклических сдвигов I, так что b 0 сдвигается в начало последовательности. Тогда эта сдвинутая последовательность R соответствует степенному ряду xs/Pn(x), или R=Ts(I), где T представляет собой оператор циклического сдвига. Авторы находят это s косвенно. Многочлены по модулю Pn(x) образуют поле. Гарантируется, что xs≡r0+r1x+…rn-1xn-1mod(Pn(x)). Поэтому можно найти (r0,r1,…,rn-1) и затем найти s.
Зависимость xs≡r0+r1x+…rn-1xn-1mod(Pn(x)) означает, что R=r0+r1T(I)+…+rn-1Tn-1(I). Написанное в бинарном линейном уравнении, оно становится:
R=r
t
A
 (2)
(2)
где r=(r0 r1 r2 … rn-1)t, и A=(I T(I) … Tn-1(I))t, которое состоит из циклических сдвигов I с 0-сдвига до (n-1)-сдвига. Теперь только разреженные K биты доступны в R для нахождения r. Пусть разности индексов между bi и b0 в R равны k i, i=1,2,…,k-1, тогда
1ый и (ki+1)-ый элементы R, i=1,2,…,k-1 точно равны b0 , b1,…,bk-1. Выбрав 1ый и (ki+1)-ый столбцы А, i=1,2,…k-1, образуется следующее бинарное линейное уравнение:
b
t=r
t
М
(3)
где М представляет собой подматрицу n×K А.
Если b без ошибок, решение r может быть выражено как:
 (4)
(4)
где 
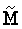 представляет собой любую невырожденную подматрицу n×n M,и
представляет собой любую невырожденную подматрицу n×n M,и 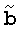 представляет собой соответствующий подвектор b.
представляет собой соответствующий подвектор b.
При известном r можно использовать алгоритм Полига-Хеллмана-Силвера, как отмечается в Douglas W. Clark and Lih-Jyh Weng, "Maximal and Near-Maximal Shift Register Sequences: Efficient Event Counters and Easy Discrete Logarithms", IEEE Transactions on Computers 43.5 (May 1994, pp 560-568), для определения s, так что xs≡r0+r1x+…rn-1xn-1mod(Pn(x)).
Так как матрица А (с размером n на L, где L=2n-1) может быть очень большой, необходимо избегать хранения всей матрицы А. Фактически, как видно в вышеупомянутом процессе, при данных извлеченных битах с разностью индексов ki только первый и (ki+1)-ый столбцы А имеют отношение к вычислению. Такой выбор ki довольно ограничен при данном размере захваченного изображения. Таким образом, необходимо сохранять только те столбцы, которые могут участвовать в вычислении. Общее количество таких столбцов значительно меньше L (где L=2n-1 представляет собой длину m-последовательности).
Коррекция ошибок
Если в b имеются ошибки, то тогда решение r становится более сложным. Нелегко можно применить традиционные способы декодирования с коррекцией ошибок, так как матрица М, связанная с захваченными битами, может изменяться от одного захваченного изображения к другому.
Авторы применяют стохастический принцип. Предполагая, что количество ошибочных битов в b, ne, относительно небольшое по сравнению с K, тогда существует высокая вероятность выбора правильных n битов из K битов b и того, что соответствующая подматрица 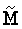 из М является невырожденной.
из М является невырожденной.
Когда выбранные n биты все являются правильными, должно быть минимальным расстояние Хемминга между b t и r t M, или количество ошибочных битов, связанных с r, где r вычисляется при помощи уравнения (4). Повторяя процесс несколько раз, вероятно, что может быть идентифицировано правильное r, которое является следствием минимального количества ошибочных битов.
Если существует только один r, который связан с минимальным количеством ошибочных битов, то тогда он рассматривается в качестве правильного решения. В противном случае, если существует более одного r, который связан с минимальным количеством ошибочных битов, вероятность того, что ne превышает способность коррекции ошибок кода, генерируемого при помощи М, является высокой, и процесс декодирования завершается неуспешно. Система тогда может перейти к обработке следующего захваченного изображения. При другой реализации может быть принята во внимание информация о предыдущих расположениях пера. То есть для каждого захваченного изображения может идентифицироваться область назначения, где перо может ожидаться в следующий раз. Например, если пользователь не поднял перо между двумя захватами изображения камерой, расположение пера, определенное посредством второго захвата изображения, не должно быть слишком далеко от первого расположения. Каждое r, которое связано с минимальным количеством ошибочных битов, затем может проверяться в отношении того, удовлетворяет ли расположение s, вычисленное из r, локальному ограничению, т.е. находится ли расположение внутри заданной области назначения.
Если расположение s удовлетворяет локальному ограничению, возвращаются положения X,Y извлеченных битов в массиве. Если нет, процесс декодирования завершается неуспешно.
На фиг.8 изображается процесс, который может использоваться для определения расположения в последовательности (или m-последовательности) захваченного изображения. Сначала, на этапе 801 принимается поток данных, относящийся к захваченному изображению. На этапе 802 соответствующие столбцы извлекаются из А, и составляется матрица М.
На этапе 803 n независимых векторов-столбцов случайно выбираются из матрицы М, и вектор r определяется посредством решения уравнения (4). Данный процесс выполняется Q раз (например, 100 раз) на этапе 804. Определение количества циклов описывается ниже в разделе Вычисление количества циклов.
На этапе 805 r сортируется по связанному с ним количеству ошибочных битов. Сортировка может выполняться с использованием множества алгоритмов сортировки, известных в данной области техники. Например, может использоваться алгоритм сортировки методом выбора. Алгоритм сортировки методом выбора выгоден тогда, когда количество Q небольшое. Однако, если Q становится большим, могут использоваться другие алгоритмы сортировки (например, сортировка слиянием), которая более эффективно обрабатывает большое количество элементов.
Система затем определяет на этапе 806, успешно ли была выполнена коррекция ошибок, посредством проверки, связаны ли многочисленные r с минимальным количеством ошибочных битов. Если да, возвращается ошибка на этапе 809, указывая, что процесс декодирования завершился неуспешно. Если нет, вычисляется положение s извлеченных битов в последовательности (или m-последовательности) на этапе 807, например, посредством использования алгоритма Похига-Хеллмана-Силвера.
Затем вычисляется положение (X,Y) в массиве как: x=s mod m1 и y=s mod m2, и результаты возвращаются на этапе 808.
Определение расположения
На фиг.9 показан процесс определения расположения кончика пера. Вводом является изображение, захваченное камерой, и выходным результатом могут быть координаты положения кончика пера. Также выходной результат может включать в себя (или не включать в себя) другую информацию, такую как угол поворота захваченного изображения.
На этапе 901 изображение принимается с камеры. Затем принятое изображение может дополнительно предварительно обрабатываться на этапе 902 (как показано пунктирным контуром этапа 902) для подстройки контраста между светлыми и темными пикселами и т.п.
Затем на этапе 903 изображение анализируется с целью определения потока битов в нем.
Затем на этапе 904 n битов случайно выбираются из потока битов для многочисленных моментов времени, и определяется расположение принимаемого потока битов в исходной последовательности (или m-последовательности).
Наконец, если на этапе 904 определено расположение захваченного изображения, на этапе 905 может быть определено расположение кончика пера.
На фиг.10 приведены подробности этапов 903 и 904, и показан принцип извлечения потока битов в захваченном изображении. Сначала принимается изображение с камеры на этапе 1001. Затем изображение может дополнительно проходить предварительную обработку изображения на этапе 1002 (как показано пунктирным контуром этапа 1002). Структура извлекается на этапе 1003. В данном случае могут идентифицироваться пикселы на различных линиях, и может быть оценена ориентация структуры (соответствующей углу θ), проходящей через пиксел.
Затем на этапе 1004 анализируется принятое изображение с целью определения линий, лежащей в основе сетки. Если линии сетки обнаруживаются на этапе 1005, тогда код извлекается из структуры на этапе 1006. Код затем декодируется на этапе 1007, и определяется расположение кончика пера на этапе 1008. Если на этапе 1005 не обнаружены линии сетки, тогда возвращается ошибка на этапе 1009.
Основы алгоритма улучшенного декодирования и коррекции ошибок.
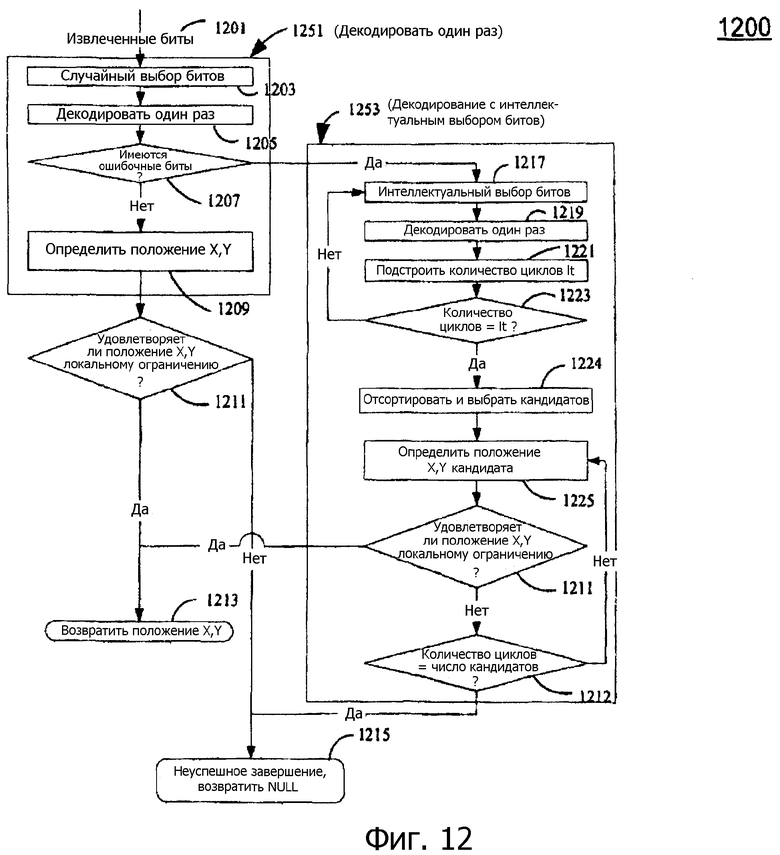
В варианте выполнения изобретения, как показано на фиг.12, при данных извлеченных битах 1201 из захваченного изображения (соответствующего захваченному массиву) и области назначения разновидность процесса декодирования m-массива и коррекции ошибок декодирует положение X,Y. На фиг.12 показана блок-схема последовательности операций процесса 1200 данного улучшенного принципа. Процесс 1200 содержит два компонента 1251 и 1253.
• Декодировать один раз. Компонент 1251 включает в себя три части.
- случайный выбор битов: случайно выбирает поднабор из извлеченных битов 1201 (этап 1203)
- декодирует поднабор (этап 1205)
- определяет положение X,Y с локальным ограничением (этап 1209)
• Декодирование с интеллектуальным выбором битов. Компонент 1253 включает в себя четыре части.
- интеллектуальный выбор битов: выбирает другой поднабор из извлеченных битов (этап 1217)
- декодирует поднабор (этап 1219)
- подстраивает количество итераций (количество циклов) этапа 1217 и этапа 1219 (этап 1221)
- определяет положение X,Y с локальным ограничением (этап 1225).
Вариант выполнения изобретения использует осторожную стратегию выбора битов, подстраивает количество итераций цикла и определяет положение X,Y (координаты расположения) согласно локальному ограничению, которое предоставляется процессу 1200. С обоими компонентами 1251 и 1253 этапы 1205 и 1219 («Декодировать один раз») используют уравнение (4) для вычисления r.
Пусть 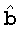 будет декодируемыми битами, т.е.:
будет декодируемыми битами, т.е.:
 (5)
(5)
Разность между b и 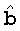 представляет собой ошибочные биты, сопоставленные с r.
представляет собой ошибочные биты, сопоставленные с r.
На фиг.12 показана блок-схема последовательности операций процесса 1200 для декодирования извлеченных битов 1201 из захваченного изображения согласно вариантам выполнения настоящего изобретения. Процесс 1200 содержит компоненты 1251 и 1253. Компонент 1251 получает извлеченные биты 1201 (содержащие K битов), связанные с захваченным изображением (соответствующим захваченному массиву). На этапе 1203 n битов (где n представляет собой порядок m-массива) случайно выбираются из извлеченных битов 1201. На этапе 1205 процесс 1200 декодирует один раз и вычисляет r. На этапе 1207 процесс 1200 определяет, обнаружены ли ошибочные биты для b. Если этап 1207 определяет, что нет ошибочных битов, определяются координаты X,Y положения захваченного массива на этапе 1209. На этапе 1211, если координаты X,Y удовлетворяют локальному ограничению, т.е. координатам, которые находятся внутри области назначения, процесс 1200 предоставляет положение X,Y (например, для другого процесса или пользовательского интерфейса) на этапе 1213. В противном случае, этап 1215 предоставляет указание на неуспешное завершение.
Если этап 1207 обнаруживает ошибочные биты в b, исполняется компонент 1253 для декодирования с ошибочными битами. Этап 1217 выбирает другой набор n битов (который отличается по меньшей мере одним битом от n битов, выбранных на этапе 1203) из извлеченных битов 1201. Этапы 1221 и 1223 определяют количество итераций (количество циклов), которые необходимы для декодирования извлеченных битов. Этап 1225 определяет положение захваченного массива посредством тестирования, какие кандидаты, полученные на этапе 1219, удовлетворяют локальному ограничению. Этапы 1217-1225 будут описаны более подробно.
Интеллектуальный выбор битов
На этапе 1203 случайно выбираются n битов из извлеченных битов 1201 (имеющих K битов), и находится r
1. Используя уравнение (5), можно вычислить декодируемые биты. Пусть  ,
,  , где
, где 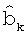 представляет собой k-ый бит в
представляет собой k-ый бит в 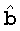 ,
, 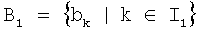 и
и 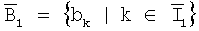 , т.е. B
1 представляет собой биты, когда декодированные результаты представляют собой одно и то же, что и исходные биты, и
, т.е. B
1 представляет собой биты, когда декодированные результаты представляют собой одно и то же, что и исходные биты, и 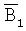 представляют собой биты, когда декодированные результаты отличаются от исходных битов, I1 и
представляют собой биты, когда декодированные результаты отличаются от исходных битов, I1 и 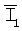 представляют собой соответствующие индексы этих битов. Понятно, что будут получены одинаковые r
1, когда любые n битов выбираются из B1. Поэтому, если не тщательно выбраны следующие n битов, то возможно, что выбранные биты являются поднабором B1, таким образом приводя к одинаковому получаемому r
1.
представляют собой соответствующие индексы этих битов. Понятно, что будут получены одинаковые r
1, когда любые n битов выбираются из B1. Поэтому, если не тщательно выбраны следующие n битов, то возможно, что выбранные биты являются поднабором B1, таким образом приводя к одинаковому получаемому r
1.
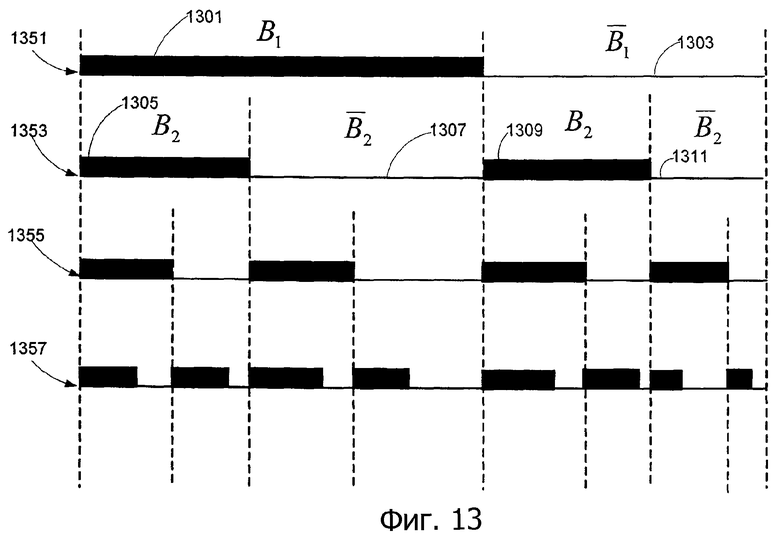
Чтобы исключить такую ситуацию, на этапе 1217 выбираются следующие n битов согласно следующей процедуре.
1. Выбрать по меньшей мере один бит из 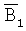 1303 и остальные биты случайно из B1 1301 и
1303 и остальные биты случайно из B1 1301 и 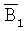 1303, как показано на фиг.13, соответствующие размещению 1351 битов. Процесс 1200 затем определяет r
2 и находит B2 1305, 1309 и
1303, как показано на фиг.13, соответствующие размещению 1351 битов. Процесс 1200 затем определяет r
2 и находит B2 1305, 1309 и 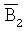 1307, 1311 посредством вычисления
1307, 1311 посредством вычисления 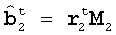 .
.
2. Повторить этап 1. При выборе следующих n битов для каждого  (i=1, 2, 3 …, x-1, где x представляет собой текущий номер цикла) существует по меньшей мере один бит, выбранный из
(i=1, 2, 3 …, x-1, где x представляет собой текущий номер цикла) существует по меньшей мере один бит, выбранный из  . Итерация завершается, когда не может быть выбран такой поднабор из битов, или когда достигается количество циклов.
. Итерация завершается, когда не может быть выбран такой поднабор из битов, или когда достигается количество циклов.
Вычисление количества циклов
С компонентом 1253 коррекции ошибок количество требуемых итераций (количество циклов) подстраивается после каждого цикла. Количество циклов определяется ожидаемой частотой ошибок. Ожидаемая частота ошибок pe, в которой не все выбранные n биты правильные, равняется:
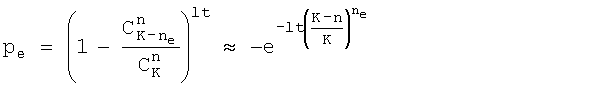 (6)
(6)
где lt представляет количество циклов и инициализируется при помощи постоянной, K представляет собой количество извлеченных битов из захваченного массива, ne представляет минимальное количество ошибочных битов, происходящих во время итерации процесса 1200, n представляет собой порядок m-массива, и 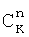 представляет собой количество комбинаций, в которых n битов выбираются из K битов.
представляет собой количество комбинаций, в которых n битов выбираются из K битов.
В варианте выполнения авторы хотят, чтобы pe было меньше e-5=0,0067. В комбинации с (6) авторы имеют:
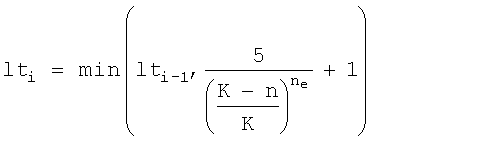 (7)
(7)
Подстройкой количества циклов можно значительно уменьшить количество итераций процесса 1253, которые требуются для коррекции ошибок.
Определение положения X,Y с локальным ограничением
На этапах 1209 и 1225 декодированное положение должно быть внутри области назначения. Область назначения является входом в алгоритм, и она может быть различных размеров и положений или просто всем m-массивом в зависимости от различных приложений. Обычно она может быть предсказана приложением. Например, если определено предыдущее положение, учитывая скорость письма, область назначения текущего кончика пера должна быть близко к предыдущему положению. Однако, если перо поднято, тогда его следующее положение может быть в любом месте. Поэтому в данном случае областью назначения должен быть весь m-массив. Правильное положение X,Y определяется следующими этапами.
На этапе 1224 процесс 1200 выбирает r i, соответствующее количество ошибочных битов которого меньше, чем:
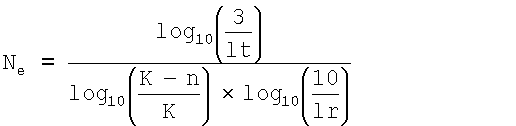 (8)
(8)
где lt представляет собой фактическое количество циклов, и lr представляет собой частоту локального ограничителя, вычисленную как:
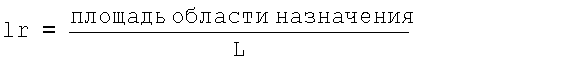 (9)
(9)
где L представляет собой длину m-массива.
Этап 1224 сортирует r i в возрастающем порядке количества ошибочных битов. Этапы 1225, 1211 и 1212 затем находят первые r i, в которых соответствующее положение X,Y находится внутри области назначения. Этапы 1225, 1211 и 1212, наконец, возвращают положение X,Y в качестве результата (посредством этапа 1213) или указания, что процедура декодирования завершилась неуспешно (посредством этапа 1215).
Архитектура для определения траектории штриха (определение расположения штрихов)
На фиг.15 показан способ определения траектории кончика пера из последовательности захваченных кадров 1551 согласно варианту выполнения настоящего изобретения. На этапе 1501 кадр обрабатывается, так что содержимое документа, такое как текст, отделяется от других областей, которые содержат только ячейки лабиринтной структуры. Также изображение (полутоновое) нормализуется для компенсации неравномерной освещенности. На этапе 1503 биты m-массива извлекаются из видимых черт лабиринтной структуры в кадре (захваченном изображении). На этапе 1505, если количество извлеченных битов (как определено на этапе 1503) превышает порядок внедренного m-массива, координаты однозначного положения (соответствующие положению x-y центра кадра) могут быть получены декодированием m-массива.
На этапе 1507 анализируется цифровой документ 1553 с целью определения областей документа 1553, в которых лабиринтная структура скрывается содержимым документа 1553. (С вариантом выполнения, где цифровой документ 1553 не включает в себя аннотации, созданные пользователем.) Если ячейки лабиринтной структуры скрываются содержимым документа 1553, то на этапе 1505 нельзя будет извлечь достаточно битов m-массива для определения положения x-y кадра. Посредством анализа всего документа 1553 с водяным знаком процесс 1500 может обнаружить области документа 1553, где положение x-y не может быть однозначно определено. Данный анализ может использоваться на этапе 1509, как будет описано.
На этапе 1511, если положение x-y любого кадра, который связан со штрихом, не может быть определено из декодирования m-массива (соответствующее этапу 1505), процесс 1500 не сможет определить положение кадра. В таких случаях этап 1509 выполняет глобальное определение расположения, при котором захваченные изображения могут деформироваться посредством аффинного преобразования, получаемого в результате анализа (этап 1503) лабиринтной структуры, и затем могут быть сравнены с областью изображения 1553 документа, где значительное количество ячеек лабиринтной структуры скрывается содержимым документа. Если один кадр успешно сравнен, локальное определение расположения (этап 1517, как будет описано) используется для определения расположения всего штриха (соответствующего серии кадров).
На этапе 1517 дополнительно обрабатываются кадры, положения x-y которых не декодируются на этапе 1505 или определяются посредством глобального определения расположения на этапе 1509. Расположение таких кадров должно быть около расположения кадров, положения x-y которых определяются посредством декодирования m-массива или глобального определения расположения. Расположение таких кадров определяется посредством сравнения кадров с соседней областью уже определенных положений x-y. Также получается перспективное преобразование FS→P (как описано ранее) между захваченными изображениями и изображениями документа.
Положения x-y, полученные из декодирования m-массива (соответствующего этапу 1505) и глобального/локального определения расположения (этапы 1509 и 1517 соответственно), представляют расположения (положения x-y) центров захваченных изображений. (Вариант выполнения изобретения может поддерживать одно, два или три измерения. В варианте выполнения поддерживаются два измерения, так что расположение положения соответствует положению x-y.) Чтобы получить положения x-y кончика пера, может потребоваться калибровка соотношения между кончиком пера (например, кончиком 202 пера, как показано на фиг.2) и связанной камерой (например, камерой 203, как показано на фиг.2). Этап 1513 поддерживает калибровку, что будет описано.
На этапе 1515 положения x-y кончика пера определяются посредством отображения положений x-y центров изображения, используя перспективное преобразование, полученное из локального определения расположения и параметров калибровки (Пример определения траектории 1555 кончика пера показан на фиг.26, что будет описано).
На фиг.16 показано устройство 1600 для определения траектории кончика пера из последовательности захваченных изображений (кадров) согласно варианту выполнения настоящего изобретения. В варианте выполнения изобретения модуль 1601 сегментации изображения выполняет этап 1501, анализатор 1603 лабиринтной структуры выполняет этап 1503, модуль 1605 декодирования m-массива выполняет этап 1505, модуль 1609 сравнения выполняет этапы 1511, 1509 и 1517, анализатор 1607 документа с водяным знаком выполняет этап 1507, модуль 1611 калибровки выполняет этап 1513, и модуль 1613 отображения выполняет этап 1515.
Анализ изображения документа и калибровка могут выполняться автономно или отдельно перед захватом изображения и обработкой в оперативном режиме. Другие компоненты (например, модуль 1601 сегментации изображения, анализатор 1603 лабиринтной структуры, модуль 1605 декодирования m-массива, модуль 1609 сравнения и модуль 1613 отображения) могут выполняться в оперативном режиме или автономно. Функциональные возможности компонентов подробно описаны ниже.
Сегментация изображения
Захваченные изображения могут содержать содержимое документа, такое как текст или рисунки, которые первоначально оцениваются при предварительной обработке. На фиг.17 показан пример захваченного изображения 1700 согласно варианту выполнения изобретения. На фиг.18 показан пример захваченного изображения, содержащего компонент текста (который включает в себя символы 1801 и 1803 текста) согласно варианту выполнения изобретения. Если изображение содержит область текста/рисунка, область текста/рисунка отделяется от другой области, которая содержит только лабиринтные структуры или пустые пикселы.
Кроме того, захваченные изображения (например, захваченные изображения 1700 и 1800) нормализуются для компенсации неравномерной освещенности. На фиг.19 показано обработанное изображение 1900, соответствующее нормализации освещенности захваченного изображения 1700 (как показано на фиг.17) согласно варианту выполнения изобретения. На фиг.20 показано обработанное изображение 2000, соответствующее нормализации освещенности захваченного изображения 1800 согласно варианту выполнения изобретения.
Анализ лабиринтной структуры
Задачей анализа лабиринтной структуры является извлечение битов m-массива из видимых черт лабиринтной структуры (например, черты 401 и 402, как показано на фиг.4А) в захваченном изображении. На фиг.19 показан анализ 1900 лабиринтной структуры захваченного изображения 1700 (как показано на фиг.17) согласно варианту выполнения изобретения. Бит 1901 (соответствующий значению 1902 бита «0») и бит 1903 (соответствующий значению бита 1904 «1») являются двумя элементами битов m-массива. Биты m-массива организованы в лабиринтную структуру в соответствии с линиями сетки лабиринтной структуры, например линиями 1905 и 1907 сетки. На фиг.20 показан анализ 2000 лабиринтной структуры захваченного изображения 1800 (как показано на фиг.18) согласно варианту выполнения изобретения (Следует отметить, что биты m-массива некоторых ячеек лабиринтной структуры вблизи символов 1801 и 1803 текста не могут быть определены в примере).
На фиг.19 и 20 показана иллюстрация ячеек лабиринтной структуры и черты лабиринтной структуры. Сначала вычисляются параметры линий сетки лабиринтной структуры (масштаб и поворот по каждому измерению, т.е. аффинное преобразование), и затем определяется исходное направление (или квадрант), в котором внедрена лабиринтная структура. В результате этого определяется информация о битах m-массива, основываясь на линиях сетки и направлении черт.
Декодирование m-массива
Если количество извлеченных битов, полученное на этапе 1505 (как показано на фиг.15), превышает порядок внедренного m-массива, может быть получено однозначное положение x-y посредством декодирования m-массива.
Анализ изображения документа с водяным знаком
Лабиринтные структуры, возможно, скрываются содержимым документа, что означает, что может быть недостаточно битов m-массива, которые могут быть извлечены для декодирования из захваченного изображения. Посредством анализа всего изображения документа с водяным знаком процесс 1500 или устройство 1600 могут определить, в какой области может быть однозначно определено положение x-y, и в какой области не может быть однозначно определено положение x-y. Результат анализа используется при глобальном определении расположения. На фиг.21 показан результат 2100 анализа изображения 1553 документа согласно варианту выполнения изобретения. В варианте выполнения пикселы на изображениях документа (например, документа 1553) обозначаются одним из четырех типов. Пикселы обозначаются в соответствии со следующим сопоставлением.
Тип I: соседнее окно 32 на 32 пиксела (при этом рассматриваемый пиксел в качестве центра) содержит только ячейки лабиринтной структуры.
Тип II: соседнее окно 32 на 32 пиксела содержит 60 или более ячеек лабиринтной структуры.
Тип III: соседнее окно 32 на 32 пиксела содержит 36-60 ячеек лабиринтной структуры.
Тип IV: соседнее окно 32 на 32 пиксела содержит 35 или менее ячеек лабиринтной структуры.
В варианте выполнения положение x-y захваченного изображения может определяться, если центр захваченного изображения располагается в областях типа I или типа II, и может определяться, если центр располагается в области типа III. На фиг.21 область 2101 соответствует области пикселов типа I, область 2103 соответствует области пикселов типа II, область 2107 соответствует области пикселов типа III, и область 2105 соответствует области пикселов типа IV (Весь документ анализируется и обозначается, но только часть показана на фиг.21).
В варианте выполнения процесс 1500 может получать цифровой документ 1553 посредством визуализации электронного документа в побитовое отображение или посредством сканирования бумажного документа и затем повторной выборки соответствующего побитового отображения с соответствующим разрешением. Определение разрешения основывается на следующих соображениях: (1) разрешение изображения документа не должно быть меньше, чем разрешение захваченного изображения, так как полутоновое изображение документа с водяным знаком будет сравниваться с захваченным камерой изображением, чтобы определить расположение захваченного изображения; (2) одна отпечатанная ячейка лабиринтной структуры должна отображаться в целое число пикселов изображения документа, так что алгоритм сравнения может работать более эффективно. Например, если разрешение камеры составляет 0,15 мм/пиксел, т.е. 0,15 мм в физическом «мире» отображается на один пиксел камеры, размер отпечатанной ячейки лабиринтной структуры составляет 0,45 мм * 0,45 мм, т.е. отпечатанная ячейка лабиринтной структуры отображается на 3*3 пиксела на датчике камеры, разрешение изображения документа также должно быть установлено на 0,15 мм/пиксел, так что отпечатанная ячейка лабиринтной структуры будет отображаться на область 3*3 пиксела в изображении документа.
Глобальное определение расположения посредством быстрого сравнения изображений
Если положения x-y захваченных изображений штриха не могут быть определены из декодирования m-массива, может быть предположено, что центры всех изображений располагаются в области, где не может быть однозначно определено положение x-y. В данном случае захваченные изображения деформируются посредством аффинного преобразования, получаемого посредством анализа лабиринтной структуры, и затем сравниваются с областью изображения документа, где не может быть однозначно определено положение x-y. Если один кадр успешно сравнен, используется алгоритм локального определения расположения для определения расположения всего штриха.
С документом 1553 (как показано на фиг.15) количество видимых ячеек лабиринтной структуры в подокне 32 на 32 пиксела обычно изменяется от 10 до 100. Пикселы в документе обозначаются одним из четырех типов посредством анализа документа с водяным знаком (этап 1507, как показано на фиг.15). Зона поиска устанавливается как совокупность областей типа III и типа IV.
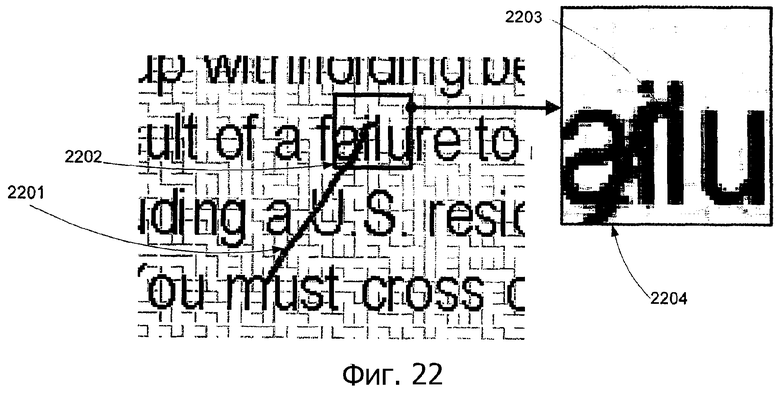
На фиг.22 показан результат глобального определения расположения для примерного штриха 2201 согласно варианту выполнения изобретения. Положение x-y точки 2203 на штрихе 2201 определяется посредством глобального определения расположения (соответствующего этапу 1509). Часть 2202 документа увеличена до увеличенной части 2204, чтобы лучше показать точку 2203 на штрихе (В варианте выполнения только одна точка на штрихе 2201 определяется посредством глобального определения расположения, и остальные точки определяются посредством локального определения расположения).
С глобальным определением расположения кадр сравнивается с изображением документа в выбранных точках зоны поиска. Исходный кадр может деформироваться (преобразовываться) посредством масштабирования и поворота (аффинное преобразование) из анализа лабиринтной структуры (соответствующего этапу 1503, как показано на фиг.15). Смещение может быть полезным для определения точек выбора при сравнении кадра.
В варианте выполнения успех сравнения кадра соответствует наибольшему значению взаимной корреляции между захваченным изображением и изображением документа (Значение взаимной корреляции изменяется от 0 до 1). Наибольшее значение взаимной корреляции должно быть значительно больше, чем другие значения взаимной корреляции, и порог, т.е. насколько больше, может определяться посредством автономного обучения. Например, глобальное определение расположения может потребовать, чтобы разность между наивысшим значением взаимной корреляции и вторым наивысшим значением взаимной корреляции была больше 0,1.
Локальное определение расположения посредством быстрого сравнения изображений
Для тех кадров, положения x-y которых не декодируются/определяются посредством декодирования m-массива/глобального определения расположения, расположения должны быть около расположений кадров, где определяются положения x-y. Следовательно, соответствующие расположения определяются посредством сравнения изображений с соседними областями уже определенных положений x-y. Также применяется перспективное преобразование между захваченными изображениями и изображениями документа.
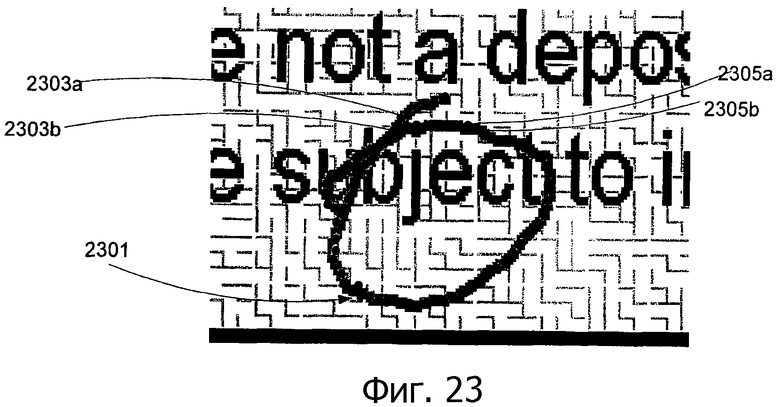
На фиг.23 показан результат локального определения расположения для примерного штриха 2301 согласно варианту выполнения изобретения. Положения расположения поднабора точек (например, точки 2305а и 2305b) на штрихе 2301 определяются посредством декодирования m-массива, и положения остальных точек (например, точек 2303а и 2303b) определяются посредством локального определения расположения.
В варианте выполнения локальное определение расположения использует начальные точки и начальные точки поворота. Начальные точки представляют собой расположение кадров, расположение которых успешно определяется посредством декодирования m-массива (соответствующего этапу 1505, как показано на фиг.15) или посредством глобального определения расположения (соответствующего этапу 1509, как показано на фиг.15). Последовательность кадров сегментируется на сегменты, в которых выполняется локальный поиск сегмент за сегментом. Сегмент может быть разбит на несколько сегментов во время локального определения расположения. В варианте выполнения локальный поиск ограничивается так, чтобы он происходил внутри зоны поиска, которая основывается на ограничениях перемещения кончика пера по скорости и ускорению.
Следующая процедура описывает вариант выполнения для локального определения расположения.
• Сегментация последовательность кадров
(а) Выбрать начальные точки поворота
Первая и последняя начальная точка в штрихе представляют собой начальные точки поворота.
Для начальных точек между двумя начальными точками поворота p1, p2 точка с максимальным расстоянием Dmax до линии L, которая проходит через p1, p2, и Dmax, который больше порога (обычно установленного на 0,5), представляет собой начальную точку поворота.
(b) Уточнить перспективное преобразование в начальных точках поворота
Получить более точное перспективное преобразование посредством сравнения захваченного камерой изображения с изображением документа.
(с) Сегментировать последовательность кадров при помощи начальных точек поворота
Каждый сегмент начинается с начальной точки поворота или первой точки штриха и заканчивается на начальной точке поворота или последней точке штриха.
• Определить законченный сегмент
Сегмент объявляется законченным сегментом, когда:
(а) Существует по меньшей мере одна начальная точка в данном сегменте, которая не является начальной точкой поворота, т.е. нельзя найти дополнительные начальные точки поворота для данного сегмента или, другими словами, сегмент очень похож на прямую линию. В данном случае все точки интерполируются, и сегмент объявляется законченным.
Или
(b) Для каждой точки в сегменте соответствующий кадр был обработан.
• Найти зону поиска для кадра незаконченного сегмента
(а) Первой точкой сегмента является начальная точка и не нуждается в обработке.
(b) Для второй точки сегмента центр зоны поиска устанавливается так, что является первой точкой, и размер зоны поиска ограничивается максимальной скоростью.
(с) Для других точек сегмента может быть оценена скорость в предыдущей точке, которая была обработана. Центр зоны поиска может быть вычислен из расположения и скорости предыдущей точки, и размер зоны поиска ограничивается максимальным ускорением.
• Сравнить с шаблоном в зоне поиска
Этот этап основывается на предположении, что существует только малое изменение позиции пера за короткий период времени, что означает, что существует только малая разность перспективного преобразования между соседними кадрами.
(а) Деформировать кадр посредством перспективной матрицы предыдущего обработанного кадра.
(b) Определить взаимную корреляцию в каждой точке зоны поиска посредством сравнения кадра с изображением документа с точкой в качестве центра.
(с) Точка с максимальной взаимной корреляцией должна быть правильным расположением данного кадра.
• Уточнить перспективное преобразование для точки
Уточнить перспективное преобразование посредством сравнения захваченного камерой изображения с изображением документа.
• Произвести отсечение результата поиска
Несколько факторов могут вызвать получение ошибочных результатов, такие как неправильные исходные параметры перспективного преобразования и размытость изображения из-за перемещения. Посредством ограничения перемещения по скорости и ускорению можно отсечь ошибочные результаты.
(а) Все начальные точки не должны отсекаться.
(b) Пройти весь штрих от первой точки до последней точки. Если точка не может удовлетворять ограничению перемещения предыдущих точек, тогда данная точка должна быть неправильной и должна быть отсечена.
(с) Пройти весь штрих от последней точки до первой точки. Если точка не может удовлетворять ограничению перемещения предыдущих точек, тогда данная точка должна быть неправильной и должна быть отсечена.
(d) После отсечения точки, сохраненные в штрихе, представляют собой правильные точки. Отсеченные точки заменяются точками, определенными при помощи интерполяции.
Калибровка камера-кончик пера
Положения x-y, полученные из декодирования m-массива и глобального/локального определения расположения, представляют расположения центров захваченных изображений. Чтобы получить положения x-y кончика 202 пера, необходимо калибровать соотношение между кончиком 202 пера и центром камеры 203. Важна быстрая и точная калибровка, так как чернильные картриджи могут часто меняться.
Посредством касания кончиком пера точки фиксированного контакта на поверхности записи в различных позициях захватываются несколько изображений. Определяются параметры калибровки посредством использования ограничения, что все положения x-y этих изображений должны отображаться в одну и ту же точку (точку фиксированного контакта) посредством правильных параметров калибровки.
В варианте выполнения используется следующая процедура для калибровки кончика пера. Процедура используется для оценки параметра калибровки Lвиртуальный-кончик пера.
а) Поместить реальный кончик пера в фиксированное расположение Lкончик пера на бумаге.
b) Поддерживать стоящим кончик пера в расположении Lкончик пера и захватить серию изображений при различных позициях пера.
с) Для каждого захваченного изображения преобразовать FS→P (которое преобразует координаты положения в изображении, захваченном камерой, в координаты положения в реальном изображении на бумаге), и вычисляется 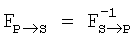 (обратное FS→P) посредством анализа лабиринтной структуры, декодирования m-массива и сравнения захваченного изображения с изображением документа, тогда
(обратное FS→P) посредством анализа лабиринтной структуры, декодирования m-массива и сравнения захваченного изображения с изображением документа, тогда
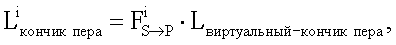 i=1,2,…,N
i=1,2,…,N
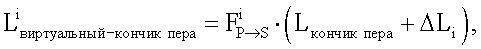 i=1,2,…,N
i=1,2,…,N
где N представляет собой количество захваченных изображений в эксперименте, и ΔPi представляет собой смещение между фактическим расположением кончика пера в i-ом кадре и Lкончик пера.
d) Инициализировать 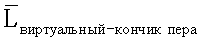 как (0,0), где
как (0,0), где 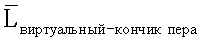 представляет собой оцененное значение Lвиртуальный-кончик пера.
представляет собой оцененное значение Lвиртуальный-кончик пера.
е) Используя первое уравнение в (с), установить Lвиртуальный-кончик пера как 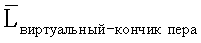 для получения
для получения  i=1,2,…,N. Посредством усреднения
i=1,2,…,N. Посредством усреднения  Lкончик пера оценивается как:
Lкончик пера оценивается как:
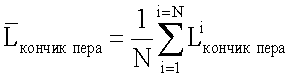
f) Используя второе уравнение в (с), установить Lкончик пера как  для получения
для получения 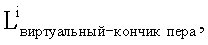 i=1,2,…,N. Посредством усреднения
i=1,2,…,N. Посредством усреднения 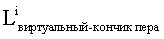 Lвиртуальный-кончик пера оценивается как:
Lвиртуальный-кончик пера оценивается как:
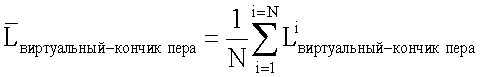
 g) Повторить этап е. После нескольких итераций Lвиртуальный-кончик пера и Lкончик пера сходятся, соответственно, к существенно более точным результатам, которые могут упоминаться как
g) Повторить этап е. После нескольких итераций Lвиртуальный-кончик пера и Lкончик пера сходятся, соответственно, к существенно более точным результатам, которые могут упоминаться как 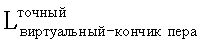 и
и 
Наконец, получают 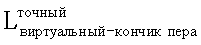 в качестве параметра калибровки
в качестве параметра калибровки
Lвиртуальный-кончик пера.
Отображение положения центра изображений на кончик пера
Положения x-y кончика 202 пера определяются посредством отображения положений x-y центров изображений с использованием перспективного преобразования, получаемого из локального определения расположения и параметров калибровки. На фиг.24 и 25 изображен результат калибровки кончика пера примера. На фиг.26 показан восстановленный штрих 2401 кончика 202 пера согласно варианту выполнения изобретения. На фиг.25 показан фактический штрих 2501, который связан с восстановленным штрихом, как показано на фиг.24. Штрих 2403 на фиг.24 изображает траекторию расположений центра захваченных изображений. То есть без калибровки штрих 2501 может быть неправильно восстановлен (восстановлен как штрих 2403), тогда как при правильной калибровке штрих 2501 восстанавливается правильно (восстанавливается как штрих 2401).
Для специалиста в данной области техники очевидно, что компьютерная система совместно со считываемой компьютером средой, содержащей инструкции для управления компьютерной системой, может использоваться для реализации примерных вариантов выполнения, которые описаны в данной заявке. Компьютерная система может включать в себя по меньшей мере один компьютер, такой как микропроцессор, цифровой процессор сигналов, и связанные с ним периферийные электронные схемы.
Хотя изобретение было определено с использованием прилагаемой формулы изобретения, данная формула изобретения является иллюстративной в том, что, как предполагается, изобретение включает в себя элементы и этапы, описанные в данной заявке, в любой комбинации или субкомбинации. Следовательно, существует любое количество альтернативных комбинаций для определения изобретения, которые включают один или несколько элементов из описания изобретения, включая описание, формулу изобретения и чертежи, в различных комбинациях или субкомбинациях. Для специалиста в соответствующей технологии понятно в свете настоящего описания изобретения, что альтернативные комбинации аспектов изобретения, или отдельно, или в комбинации с одним или несколькими элементами или этапами, определенными в данной заявке, могут использоваться в качестве модификаций или изменений изобретения или как часть изобретения. Может предполагаться, что письменное описание изобретения, содержащееся в данной заявке, охватывает все такие модификации и изменения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОТОБРАЖЕНИЕ МЕЖДУ КАМЕРОЙ И КОНЧИКОМ ПЕРА И КАЛИБРОВКА | 2004 |
|
RU2363032C2 |
| АНАЛИЗ ИЗОБРАЖЕНИЯ ПОЗИЦИОННО КОДИРОВАННОГО ДОКУМЕНТА И НАНЕСЕНИЕ МЕТКИ | 2004 |
|
RU2360303C2 |
| ГЛОБАЛЬНАЯ ЛОКАЛИЗАЦИЯ ПУТЕМ БЫСТРОГО СОГЛАСОВАНИЯ ИЗОБРАЖЕНИЙ | 2004 |
|
RU2347271C2 |
| МЕСТНАЯ ЛОКАЛИЗАЦИЯ С ИСПОЛЬЗОВАНИЕМ БЫСТРОГО СОГЛАСОВАНИЯ ИЗОБРАЖЕНИЙ | 2004 |
|
RU2369901C2 |
| УСОВЕРШЕНСТВОВАННЫЙ ПОДХОД К ДЕКОДИРОВАНИЮ m-МАССИВА И ИСПРАВЛЕНИЮ ОШИБОК | 2004 |
|
RU2380736C2 |
| УНИВЕРСАЛЬНОЕ КОМПЬЮТЕРНОЕ УСТРОЙСТВО | 2004 |
|
RU2392656C2 |
| ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ВОЛНОВЫХ ФРОНТОВ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2643652C2 |
| БУФЕРИЗАЦИЯ ВИДЕО С НИЗКОЙ ЗАДЕРЖКОЙ ПРИ КОДИРОВАНИИ ВИДЕО | 2013 |
|
RU2633165C2 |
| УРОВНИ ОГРАНИЧЕНИЯ ДЛЯ НЕЛИНЕЙНОГО АДАПТИВНОГО КОНТУРНОГО ФИЛЬТРА | 2020 |
|
RU2818228C2 |
| БУФЕРИЗАЦИЯ ВИДЕО С НИЗКОЙ ЗАДЕРЖКОЙ ПРИ КОДИРОВАНИИ ВИДЕО | 2013 |
|
RU2630176C2 |
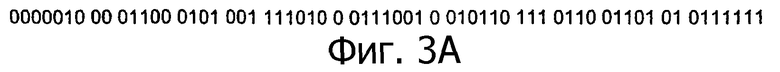

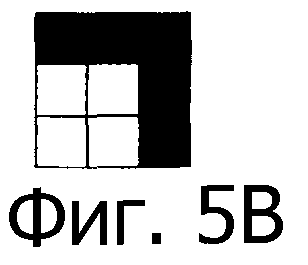
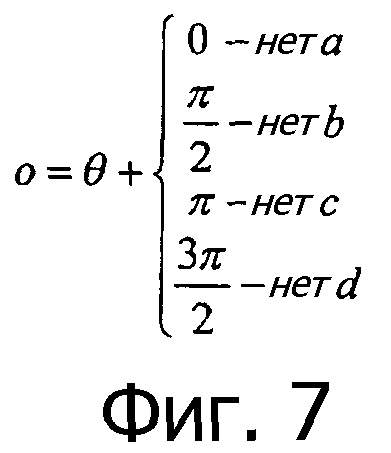



Изобретение относится к определению положения кончика пера, когда кончик пера перемещается по документу. Изобретение позволяет улучшить обработку рукописных аннотаций к документу. Документ имеет водяной знак с лабиринтной структурой, из которой определяется кодированная информация о положении. Последовательность изображений захватывается камерой, которая расположена в пере. Траектория кончика пера определяется посредством декодирования связанной лабиринтной структуры и посредством сравнения захваченных изображений с изображениями документа. Если координаты положения любого кадра, который связан со штрихом, не могут быть определены из декодирования m-массива, кадры преобразуются и затем сравниваются с областью изображения документа. Если определены координаты положения по меньшей мере одного кадра, координаты положения других кадров определяются посредством сравнения кадров в соседней области. 7 н. и 23 з.п. ф-лы, 25 ил.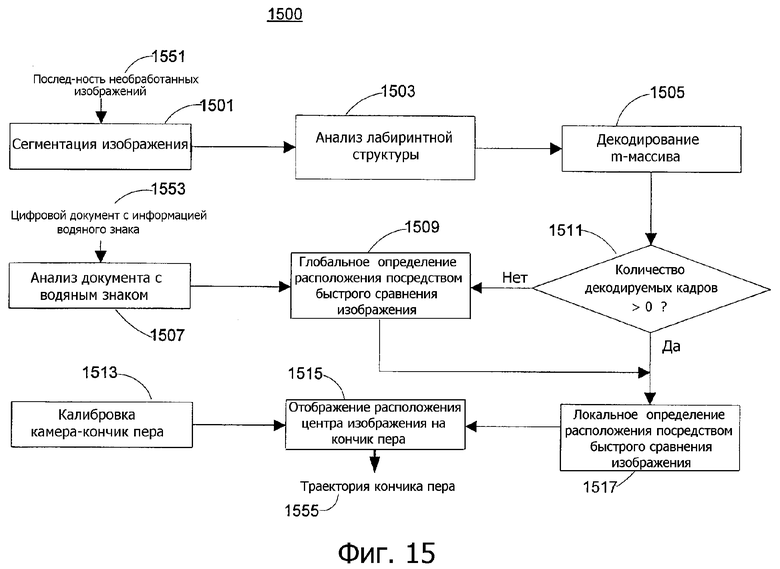
1. Способ определения траектории кончика пера в документе, причем способ содержит:
(A) декодирование извлеченных битов, связанных с захваченным изображением, с целью определения координат расположения захваченного изображения;
(B) в ответ на (А), если координаты расположения захваченного изображения не могут быть определены посредством декодирования, сравнение захваченного изображения с информацией об изображении документа, причем этап (В) содержит:
(i) сравнение захваченного изображения с областью изображения документа, причем область оценивается посредством анализа изображения документа или соответствующего расположения соседнего кадра изображения, и соответствующее расположение определяется посредством декодирования m-массива или глобального определения расположения;
(ii) в ответ на (i), если координаты расположения не могут быть определены, деформирование захваченного изображения; и
(iii) сравнение захваченного изображения с областью документа, причем положение х-у не может однозначно определяться посредством декодирования m-массива; и
(C) отображение траектории кончика пера из координат расположения захваченного изображения в координаты расположения кончика пера.
2. Способ по п.1, в котором информация об изображении выбирается из информации об изображении документа с водяным знаком или информации об изображении соседней области декодируемого положения, соответствующей захваченному изображению.
3. Способ по п.1, дополнительно содержащий:
(D) анализ лабиринтной структуры для извлечения битов из захваченного изображения, причем лабиринтная структура соответствует m-массиву.
4. Способ по п.3, дополнительно содержащий:
(Е) сегментацию лабиринтной структуры от препятствующего компонента захваченного изображения, причем препятствующий компонент скрывает лабиринтную структуру.
5. Способ по п.4, в котором (Е) содержит:
(i) нормализацию захваченного изображения для компенсации неравномерной освещенности.
6. Способ по п.1, в котором (В) дополнительно содержит:
(iv) в ответ на (iii) повторение (i).
7. Способ по п.1, дополнительно содержащий:
(D) определение области документа, причем область скрывается содержимым документа, и документ имеет водяной знак.
8. Способ по п.1, дополнительно содержащий:
(D) калибровку кончика пера для получения параметра калибровки, причем (С) содержит использование параметра калибровки и перспективного преобразования, полученного из локального определения расположения.
9. Способ по п.8, в котором (D) содержит:
(i) фиксирование кончика пера в точке контакта на документе;
(ii) изменение положения центра камеры пера и
(iii) отображение положения центра камеры пера на точку контакта.
10. Способ по п.8, в котором параметр калибровки служит указанием на положение виртуального кончика пера.
11. Способ по п.1, в котором (А) содержит:
(i) получение извлеченных битов, которые связаны с захваченным массивом;
(ii) обработку извлеченных битов с целью определения, содержат ли извлеченные биты по меньшей мере один ошибочный бит, и определения координат расположения, если не обнаруживаются ошибочные биты; и
(iii) если обнаруживается по меньшей мере один ошибочный бит, дополнительную обработку извлеченных битов с целью определения координат расположения из части извлеченных битов,
причем координаты расположения являются согласованными с локальным ограничением.
12. Способ по п.11, в котором (ii) содержит:
(1) выбор первого поднабора из извлеченных битов;
(2) декодирование первого поднабора; и
(3) в ответ на (2), если не обнаружены ошибочные биты, определение координат расположения захваченного массива.
13. Способ по п.12, в котором (iii) содержит:
(1) если обнаруживается ошибочный бит, выбор другого поднабора из извлеченных битов, причем по меньшей мере один бит из другого поднабора не является одним из ранее правильно декодированных битов;
(2) декодирование связанных битов другого поднабора;
(3) в ответ на (2) определение, должна ли выполняться другая итерация декодирования;
(4) если должна выполняться другая итерация декодирования, выбор другого поднабора из извлеченных битов, причем по меньшей мере один бит из другого поднабора выбирается из набора неправильно декодированных битов каждой предыдущей итерации и повторение (2); и
(5) если не должна выполняться другая итерация декодирования, определение координат расположения захваченного массива.
14. Способ по п.3, в котором (D) содержит:
(i) вычисление параметра структуры, причем параметр структуры характеризует линии сетки лабиринтной структуры.
15. Способ по п.1, в котором (ii) содержит:
(1) масштабирование и поворот захваченного изображения посредством применения аффинного преобразования, получаемого из анализа лабиринтной структуры; и
(2) выравнивание захваченной лабиринтной структуры для выбора точки зоны поиска.
16. Способ по п.15, в котором (ii) дополнительно содержит:
(3) сравнение деформированного кадра с изображением документа, причем деформированный кадр соответствует наибольшему значению взаимной корреляции.
17. Способ по п.1, в котором (С) содержит:
(i) вычисление координат расположения кончика пера из координат виртуального кончика пера с использованием перспективного преобразования.
18. Способ по п.7, в котором (D) содержит:
(i) получение изображения документа, причем изображение документа имеет водяной знак.
19. Способ по п.18, в котором (D) дополнительно содержит:
(ii) определение, содержит ли соседнее окно пиксела только ячейки лабиринтной структуры, причем изображение документа представляется множеством подокон; и
(iii) если подокно не содержит только лабиринтную структуру, различение меры видимых ячеек лабиринтной структуры.
20. Способ по п.19, в котором (iii) содержит:
(1) разделение изображения документа на множество блоков, имеющих, по существу, одинаковый размер, в качестве ячеек лабиринтной структуры;
(2) если соответствующие малые блоки скрываются содержимым документа, подсчет количества полностью видимых блоков в соседнем окне с пикселом в качестве центра окна; и
(3) обозначение пиксела указателем, который указывает на количество видимых блоков.
21. Машиночитаемый носитель, имеющий исполняемые компьютером инструкции для выполнения способа по п.1.
22. Машиночитаемый носитель, имеющий исполняемые компьютером инструкции для выполнения способа по п.3.
23. Машиночитаемый носитель, имеющий исполняемые компьютером инструкции для выполнения способа по п.7.
24. Машиночитаемый носитель, имеющий исполняемые компьютером инструкции для выполнения способа по п.8.
25. Устройство, которое определяет траекторию кончика пера в документе, содержащее:
модуль декодирования, который декодирует извлеченные биты, связанные с захваченным изображением;
модуль сравнения, который сравнивает захваченное изображение с информацией об изображении документа, если координаты расположения захваченного изображения не могут быть определены посредством модуля декодирования; и
модуль отображения, который отображает траекторию кончика пера из координат расположения захваченного изображения и который предоставляет информацию о траектории;
причем сравнение захваченного изображения с информацией об изображении документа заключается в том, что
(i) сравнивают захваченное изображение с областью изображения документа, причем область оценивается посредством анализа изображения документа или соответствующего расположения соседнего кадра изображения, и соответствующее расположение определяется посредством декодирования m-массива или глобального определения расположения;
(ii) в ответ на (i), если координаты расположения не могут быть определены, деформируют захваченное изображение; и
(iii) сравнивают захваченное изображение с областью документа, причем положение х-у не может однозначно определяться посредством декодирования m-массива.
26. Устройство по п.25, дополнительно содержащее:
модуль калибровки, который определяет параметр калибровки из информации о перемещении пера относительно кончика пера, причем модуль отображения использует преобразование и параметр калибровки вместе с координатами расположения захваченного изображения для отображения траектории кончика пера.
27. Устройство по п.25, дополнительно содержащее:
анализатор документа с водяным знаком, который определяет область документа и который предоставляет информацию об изображении, касающуюся области, причем область скрывается содержимым документа, и документ имеет водяной знак.
28. Устройство по п.25, дополнительно содержащее:
анализатор лабиринтной структуры, который извлекает извлекаемые биты, связанные с лабиринтной структурой захваченного изображения, и который предоставляет извлеченные биты модулю декодирования.
29. Устройство по п.25, дополнительно содержащее:
модуль сегментации изображения, который сегментирует лабиринтную структуру от препятствующего компонента захваченного изображения, причем препятствующий компонент содержит содержимое документа, которое скрывает лабиринтную структуру.
30. Способ определения траектории кончика пера в документе, причем способ содержит:
(А) калибровку пера для получения параметра калибровки;
(B) анализ изображения документа с водяным знаком для определения областей, где положения х-у не могут однозначно определяться посредством декодирования m-массива;
(C) сегментацию лабиринтной структуры от препятствующего компонента захваченного изображения, причем препятствующий компонент содержит содержимое документа, которое скрывает лабиринтную структуру;
(D) анализ лабиринтной структуры для извлечения битов из лабиринтной структуры захваченного изображения;
(Е) в ответ на (D) определение преобразования, которое преобразовывает координаты положения изображения в координаты фактического положения, причем координаты фактического положения идентифицируют расположение кончика пера относительно документа;
(F) декодирование извлеченных битов, связанных с захваченным изображением;
(G) в ответ на (F), если не могут быть определены координаты расположения изображения захваченного изображения, сравнение захваченного изображения с информацией об изображении, содержащее:
(i) деформирование захваченного изображения; и
(ii) сравнение деформированного изображения с областью документа, где соответствующее положение х-у не может однозначно определяться посредством декодирования m-массива;
(Н) определение координат расположения изображения других кадров изображения, которые связаны со штрихом пера, содержащее:
(i) сравнение соответствующего захваченного изображения с соседней областью координат расположения изображения ранее декодированного изображения и
(ii) повторение (i) до тех пор, пока не будут обработаны все кадры изображения штриха пера; и
(I) отображение траектории кончика пера из преобразования, параметра калибровки и координат расположения изображения.
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| РУЧКА ДЛЯ ВВОДА РУКОПИСНОЙ И ГРАФИЧЕСКОЙ ИНФОРМАЦИИ В КОМПЬЮТЕР "SHELPEN III" | 1998 |
|
RU2166796C2 |
| US 6181329 B1, 30.01.2001 | |||
| US 6259827 B1, 10.07.2001 | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |

