ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Варианты выполнения настоящего изобретения относятся к взаимодействию между позиционно кодированным носителем и цифровой ручкой. Более конкретно, варианты выполнения настоящего изобретения относятся к нанесению метки на изображения документов, которые содержат позиционно кодированную информацию, причем метка основана на степени, в которой содержание документа закрывает информацию позиционного кодирования.
УРОВЕНЬ ТЕХНИКИ
Пользователи компьютеров привыкли к использованию мыши и клавиатуры, которые применяют в качестве средства взаимодействия с персональным компьютером. Хотя благодаря персональным компьютерам обеспечивается ряд преимуществ по сравнению с работой с написанными документами, большинство пользователей в некоторых случаях продолжают работать с текстом, отпечатанным на бумаге. Некоторые из этих работ включают чтение и внесение комментариев в письменные документы. В случае внесения комментариев, отпечатанный на бумаге документ приобретает большое значение, поскольку пользователь вносит в него комментарии. Однако при этом возникает трудность, связанная с дальнейшим использованием печатного документа с внесенными в него комментариями, поскольку при этом необходимо вводить внесенные в документ комментарии обратно в документ, выполненный в электронной форме. При этом первоначальный пользователь или другой человек должен разобраться с внесенными комментариями и ввести их в персональный компьютер. В некоторых случаях пользователь при этом вынужден внимательно сличать текст с внесенными в него комментариями с оригинальным текстом, создавая при этом новый документ. Указанное множество этапов затрудняет работу одновременно с печатным документом и электронной версией документа. Кроме того, отсканированное и внесенное в документ изображение часто невозможно модифицировать. При этом может отсутствовать возможность отделять комментарии от исходного текста. Это может привести к трудностям при использовании комментариев. В соответствии с этим необходим улучшенный способ обработки комментариев.
В одной из технологий ввода изображения записываемой от руки информации используется ручка, местоположение которой при письме может быть определено. В частности такая возможность обеспечивается с помощью ручки Anoto производства компании Anoto Inc. В этой ручке установлена камера, с помощью которой выполняют ввод изображения, записанного на бумаге, причем на бумагу нанесен код в виде определенной структуры. Пример такой структуры показан на фиг.15. Эта структура используется в ручке Anoto (производства компании Anoto Inc.) для определения местоположения ручки на листе бумаги. Однако неясно, насколько эффективно выполняется определение местоположения в системе, используемой в ручке Anoto. Для эффективного определения местоположения вводимого изображения необходимо использовать систему, которая обеспечивает эффективное декодирование вводимого изображения.
При записи комментария на документе пользователь наносит на документ метку, перемещая кончик ручки по отношению к документу. Путь кончика ручки может включать множество элементарных движений, при этом каждое элементарное движение соответствует набору вводимых изображений. Следовательно, для обработки комментария, записываемого на документе, необходимо обеспечить эффективную идентификацию пути ручки.
Участки позиционно кодированной информации такие, как лабиринтная структура в виде водяных знаков/ могут быть закрыты содержанием документа таким, как текст и/или графические изображения. Когда содержание документа закрывает относительно небольшое количество (или не закрывает) информации позиционного кодирования в области документа, тогда местоположение областей в документе может быть эффективно определено без необходимости выполнения объемных вычислений для определения местоположения. Однако, когда содержание документа закрывает относительно большое количество информации позиционного кодирования в области документа, может потребоваться применение технологий, в которых используется больший объем вычислений, для определения областей местоположения в этом документе. В соответствии с этим для повышения эффективности требуется разработать методику, предназначенную для различения случаев, в которых закрыто относительно небольшое количество информации позиционного кодирования, от случаев, в которых закрыто относительно большое количество информации позиционного кодирования, с помощью которой пользователи могут работать с документами, содержащими позиционно кодированную информацию.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Варианты выполнения настоящего изобретения относятся к анализу изображений документа, которые содержат позиционно кодированную информацию такую, как лабиринтные структуры, и нанесение меток на вводимые изображения. Результаты такого анализа документа можно использовать для эффективного определения местоположения изображения, вводимого камерой, в позиционно кодированном документе.
Система включает модуль ввода изображения и модуль анализа и нанесения метки. Модуль анализа и нанесения метки принимает в качестве входной информации, данные вводимого изображения, поступающие с выхода модуля ввода изображения и тренировочные данные, поступающие в автономном режиме/ выполняет обработку анализа и нанесения метки; и вырабатывает информацию метки изображения.
На печатные документы наносят водяные знаки в виде лабиринтной структуры. Такие лабиринтные структуры могут быть закрыты содержанием документа, таким как текст. В зависимости от степени такого закрытия может быть не возможно выделить достаточное количество битов позиционного кодирования из изображения, вводимого камерой, для определения местоположения на документе изображения, вводимого камерой.
Изображение документа с водяными знаками анализируют и наносят на него метки. Анализ и нанесение метки относится к возможности определения положения х-у в документе с водяными знаками на основе степени видимости лабиринтной структуры в конкретном местоположении на документе.
Дополнительные свойства и преимущества настоящего изобретения будут очевидны при чтении следующего подробного его описания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Приведенное выше краткое описание настоящего изобретения, так же как и следующее подробное описание предпочтительных вариантов его выполнения, следует рассматривать совместно с прилагаемыми чертежами, которые приведены в качестве примера, а не для ограничения заявленного изобретения.
На фиг.1 представлено общее описание компьютера, который можно использовать совместно с вариантами выполнения настоящего изобретения.
На фиг.2А и 2В показана система ввода изображения и соответствующее введенное изображение в соответствии с вариантами выполнения настоящего изобретения.
На фиг.3A-3F показаны различные последовательности и методики свертки в соответствии с вариантами выполнения настоящего изобретения.
На фиг.4А-4Е показаны различные системы кодирования в соответствии с вариантами выполнения настоящего изобретения.
На фиг.5A-5D показаны четыре получаемые в результате угла, которые могут быть ассоциированы с системой кодирования в соответствии с фиг.4А и 4В.
На фиг.6 показан поворот участка фиксированного изображения в соответствии с вариантами выполнения настоящего изобретения.
На фиг.7 представлены различные углы поворота, используемые совместно с системой кодирования, представленной на фиг.4А-4Е.
На фиг.8 представлен процесс определения местоположения введенной матрицы в соответствии с вариантами выполнения настоящего изобретения.
На фиг.9 представлен способ местоположения введенного изображения в соответствии с вариантами выполнения настоящего изобретения.
На фиг.10 представлен другой способ определения местоположения введенного изображения в соответствии с вариантами выполнения настоящего изобретения.
На фиг.11 представлен модуль ввода изображения и модуль анализа и нанесения метки в соответствии с различными вариантами выполнения настоящего изобретения.
На фиг.12 представлены этапы генерирования изображения документа серой шкалы с водяными знаками, которые можно анализировать и на которые можно ставить метки в соответствии с различными вариантами выполнения настоящего изобретения.
На фиг.13 представлены изображения участка содержания документа, участка позиционно кодированной лабиринтной структуры, комбинации содержания и лабиринтной структуры и увеличенный вид участка содержания и лабиринтной структуры.
На фиг.14 изображено подокно и центральный пиксель подокна комбинированного изображения документа и лабиринтной структуры, показанной на фиг.13.
На фиг.15 показан результат анализа примера документа в соответствии с различными вариантами выполнения настоящего изобретения.
На фиг.16 представлено изображение, вводимое камерой, имеющее ненулевой угол поворота и угол поворота 45 градусов.
На фиг 17 показаны два ядра свертки, которые формируют оператор Собеля (Sobel) выделения краев изображения.
На фиг.18 показана гистограмма градиентных изображений вводимого изображения, содержащего только лабиринтные структуры.
На фиг.19 показана гистограмма градиентных изображений вводимого изображения, содержащего содержание документа.
На фиг.20 показан пример результата тренировки в автономном режиме, включая пороговое значение, выбранное для разграничения между чистыми изображениями с лабиринтной структурой и изображениями, содержащими содержание документа.
На фиг.21 показано представление пространства кодирования в документе в соответствии с известным уровнем техники.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Аспекты настоящего изобретения относятся к определению местоположения вводимого изображения по отношению к более крупному изображению. Описанные здесь способ и система определения местоположения можно использовать совместно с многофункциональной ручкой.
Приведенное ниже описание разделено подзаголовками для удобства чтения. Подзаголовки включают: термины, компьютер общего назначения, ручка ввода изображения, кодирование матрицы, декодирование, коррекция ошибки, определение местоположения и анализ и постановка метки на изображения, вводимые камерой.
I. Термины
Ручка - любой пишущий инструмент, который может содержать или может не содержать запас чернил. В некоторых примерах в качестве ручки, в соответствии с вариантами выполнения настоящего изобретения, может использоваться пишущий узел (стайлус), в котором отсутствуют чернила.
Камера - система ввода изображения, которая позволяет вводить изображение с бумаги или любого другого носителя.
II. Компьютер общего назначения
На фиг.1 показан пример функциональной блок-схемы обычной цифровой вычислительной среды общего назначения, которую можно использовать для выполнения различных аспектов настоящего изобретения. На фиг.1 компьютер 100 включает блок 110 процессора, системное запоминающее устройство 120 и системную шину 130, с помощью которой различные компоненты системы, включая системное запоминающее устройство, соединены с блоком 110 процессора. Системная шина 130 может представлять собой любую из нескольких типов структуры шины, включая шину запоминающего устройства или контроллер запоминающего устройства, периферийную шину и локальную шину, построенные с использованием любой из множества архитектур шины. Системное запоминающее устройство 120 включает постоянное запоминающее устройство (ПЗУ) 140 и оперативное запоминающее устройство (ОЗУ) 150.
Базовая система 160 ввода/вывода (BIOS), содержащая основные процедуры, которые позволяют передавать информацию между элементами в компьютере 100, например, в ходе первоначальной загрузки, записана в ПЗУ 140. Компьютер 100 также включает привод 170 жесткого диска, предназначенный для считывания информации с жесткого диска (не показан) и записи на него, привод 180 магнитного диска, предназначенный для считывания информации со съемного магнитного диска 190 или записи на него, и привод 191 оптического диска, предназначенный для считывания информации со съемного оптического диска 192, такого как CD ROM или другого оптического носителя, или записи на него. Привод 170 жесткого диска, привод 180 магнитного диска и привод 191 оптического диска соединены с системной шиной 130 с помощью интерфейса 192 привода жесткого диска, интерфейса 193 привода магнитного диска и интерфейса 194 привода оптического диска соответственно. Приводы и ассоциированные с ними считываемые компьютером носители образуют энергонезависимое устройство накопления считываемых компьютером инструкций, структур данных, программных модулей и других данных для персонального компьютера 100. Для специалистов в данной области техники будет понятно, что другие типы считываемых компьютером носителей, на которых могут быть записаны данные, к которым может выполнять доступ компьютер, такие как магнитные кассеты, карты памяти типа флэш, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п., также можно использовать в примере операционной среды.
Множество программных модулей могут быть записаны через привод 170 жесткого диска, на магнитный диск 190, на оптический диск 192, в ПЗУ 140 или в ОЗУ 150, включая операционную систему 195, одну или больше прикладных программ 196, другие программные модули 197 и данные 198 для программ. Пользователь может вводить команды и информацию в компьютер 100 через устройства ввода данных, такие как клавиатура 101 и устройство 102 - указатель. Другие входные устройства (не показаны) могут включать микрофон, джойстик, игровую панель, спутниковую антенну, сканер или тому подобное. Эти и другие входные устройства часто соединены с блоком 110 процессора, через интерфейс 106 последовательного порта, который соединен с системной шиной, но могут быть подключены к другим интерфейсам, таким как параллельный порт, игровой порт или универсальная последовательная шина (УПШ, USB). Кроме того, эти устройства могут быть соединены непосредственно с системной шиной 130 через соответствующий интерфейс (не показан). Монитор 107 или устройство дисплея другого типа также соединен с системной шиной 130 через интерфейс, такой как видеоадаптер 108. Кроме монитора, персональные компьютеры обычно включают другие периферийные устройства вывода (не показаны), такие как громкоговорители и принтеры. В предпочтительном варианте выполнения ручку 165 с цифровым преобразователем и соответствующую ручку или пишущий узел 166 используют для цифрового ввода информации, записываемой от руки. Хотя на чертеже показано непосредственное соединение между ручкой 165 с цифровым преобразователем и последовательным портом, на практике ручка 165 с цифровым преобразователем может быть соединена с блоком 110 процессора непосредственно через параллельный порт или другой интерфейс и системную шину 130, как известно в данной области техники. Кроме того, хотя цифровой преобразователь 165 показан отдельно от монитора 107, предпочтительно, чтобы используемая область ввода цифрового преобразователя 165 имела те же размеры, что и область сопоставления монитора 107. Кроме того, цифровой преобразователь 165 может быть интегрирован в монитор 107, или может быть выполнен как отдельное устройство, наложенное на монитор 107 или присоединенное к нему другим способом.
Компьютер 100 может работать в сетевой среде с использованием логических соединений с одним или больше удаленным компьютером, таким как удаленный компьютер 109. Удаленный компьютер 109 может представлять собой сервер, маршрутизатор, сетевой ПК, одноранговое сетевое устройство или другой общий сетевой узел, и обычно включает множество или все элементы, описанные выше при описании компьютера 100, хотя на фиг.1 показано только одно запоминающее устройство 111. Логические связи, представленные на фиг.1, включают локальную вычислительную сеть (ЛВС, LAN) 112 и глобальную сеть (ГЛС, WAN) 113. Такие сетевые среды обычно используют в учреждениях, компьютерных сетях предприятий, сетях Интранет и Интернет.
При использовании в сетевой среды ЛВС компьютер 100 может быть подключен к локальной сети 112 через сетевой интерфейс или адаптер 114. При использовании в сетевой среде WAN персональный компьютер 100 обычно содержит модем 115 или другое средство установления связи через глобальную сеть 113, такую как Интернет. Модем 115, который может быть внутренним или внешним и может быть подключен к системной шине 130 через интерфейс 106 последовательного порта. В сетевой среде программные модули, представленные в персональном компьютере 100 или в его частях могут быть записаны в удаленном запоминающем устройстве.
Следует понимать, что показанные сетевые связи представлены только в качестве иллюстрации, и также можно использовать другие технологии установления линии связи между компьютерами. При этом предполагаются наличие любого из различных хорошо известных протоколов, таких как TCP/IP (межсетевой протокол управления передачей данных), Ethernet (передающая среда ЛВС с шинной архитектурой), FTP (протокол передачи файлов), HTTP (протокол передачи гипертекста), Bluetooth (спецификация технологии беспроводной ближней радиосвязи), IEEE 802.11x (спецификация беспроводных ЛВС) и т.п., при этом система может работать в конфигурации клиент-сервер, что позволяет пользователю получать сетевые страницы с сетевого сервера. Любые из различных, обычно используемых сетевых браузеров, можно использовать для сопоставления и обработки данных сетевых страниц.
III. Ручка ввода изображения
Аспекты настоящего изобретения включают размещение потока кодированных данных в отображаемой форме, которая представляет поток кодированных данных. (Например, как будет описано со ссылкой на фиг.4В, поток кодированных данных используют для создания графической структуры). Отображаемая форма может представлять собой печатный документ (или другой физический носитель) или может представлять собой отображение, на которое спроецирован поток кодированных данных, совместно с другим изображением или набором изображений. Например, поток кодированных данных может быть представлен как физическое графическое изображение на бумаге или графическое изображение, наложенное на отображаемое изображение (например, представляющее текст документа), или может представлять собой физическое (неизменяемое) графическое изображение на экране дисплея (так, что для любого участка изображения, введенного ручкой, может быть определено его положение на экране дисплея).
Такое определение местоположения введенного изображения можно использовать для определения местоположения воздействия пользователя на бумагу, носитель или экран дисплея. В некоторых аспектах настоящего изобретения ручка может представлять собой чернильную ручку, которой можно писать по бумаге. В других аспектах ручка может быть представлена пишущим узлом, которым пользователь пишет на поверхности компьютерного дисплея. Любое воздействие может быть передано обратно в систему с информацией кодированного изображения на документе или при поддержании документа на экране компьютера. Благодаря многократному вводу изображения с помощью камеры, установленной в ручке или в пишущем узле, по мере того, как ручка или пишущий узел перемещается по документу, система может отслеживать движение пишущего узла, управляемого пользователем. Отображаемое или напечатанное изображение может быть ассоциировано с помощью водяного знака с бланком или документом, содержащим содержание, или может быть ассоциировано с помощью водяного знака с изображаемым изображением или с фиксированной кодовой структурой, наложенной на экран или встроенной в экран.
На фиг.2А и 2В показан иллюстративный пример ручки 201 с камерой 203. Ручка 201 включает кончик 202, который может содержать резервуар для чернил или может быть без него. С помощью камеры 203 выполняют ввод изображения 204 с поверхности 207. Ручка 201 может дополнительно включать дополнительные датчики и/или процессоры, которые представлены прямоугольником 206, изображенным пунктирными линиями. Эти датчики и/или процессоры 206 также могут обеспечивать возможность передачи информации в другую ручку 201 и/или в персональный компьютер (например, с использованием протокола Bluetooth или других протоколов беспроводной связи).
На фиг.2В представлено изображение, получаемое с помощью камеры 203. В одном иллюстративном примере поле обзора камеры 203 (то есть разрешающая способность датчика изображения камеры) составляет 32х32 пикселя (где N=32). В варианте выполнения изображение, вводимое камерой 203 (32 пикселя на 32 пикселя) соответствует области поверхности плоскости размером приблизительно 5 мм на 5 мм. В соответствии с этим на фиг.2 В показано поле обзора длиной 32 пикселя и шириной 32 пикселя. Размер N можно регулировать так, что большее значение N будет соответствовать более высокой разрешающей способности изображения. Кроме того, хотя поле обзора камеры 203 показано здесь в качестве иллюстрации в виде квадрата, поле обзора может иметь другие формы, как известно в данной области техники.
Изображения, вводимые камерой 203, могут быть определены как последовательность кадров {Ii} изображения, где Ii представляет собой кадр, вводимый ручкой 201, в момент ti выборки. Частота выборки может быть высокой или низкой, в зависимости от конфигурации системы и требований к рабочим характеристикам. Размер кадра вводимого изображения может быть большим или малым, в зависимости от конфигурации системы и требований по рабочим характеристикам.
Изображение, вводимое камерой 203, может непосредственно использоваться системой обработки или может быть подвергнуто предварительной фильтрации. Такая предварительная фильтрация может быть проведена в ручке 201 или может быть выполнена за пределами ручки 201 (например, в персональном компьютере).
Размер изображения, показанного на фиг.2В, составляет 32×32 пикселя. Если размер каждого модуля кодирования составляет 3×3 пикселя, то количество вводимых кодированных модулей будет приблизительно составлять 100 модулей. Если размер модуля кодирования составляет 5×5 пикселей, то количество вводимых кодированных модулей будет приблизительно равно 36.
На фиг.2 также показана плоскость 209 изображения, на которой формируется изображение 210 структуры из местоположения 204. Свет, принятый от структуры на плоскости 207 объекта, фокусируется объективом 208. Объектив 208 может быть выполнен в виде однолинзовой или многолинзовой системы, но здесь для простоты представлен однолинзовый объектив. Датчик 211 ввода изображения выполняет ввод изображения 210.
Датчик 211 изображения может быть достаточно большим для ввода изображения 210. В качестве альтернативы, датчик 211 изображения может быть достаточно большим для ввода изображения кончика 202 ручки в местоположении 212. В качестве ссылки, изображение в местоположении 212 называется виртуальным кончиком ручки. Следует отметить, что местоположение виртуального кончика ручки на датчике 211 изображения фиксировано, поскольку существует постоянная взаимосвязь между кончиком ручки, объективом 208 и датчиком 211 изображения.
С помощью описанного ниже преобразования FS→P преобразуют координаты положения на изображении, введенном камерой, в координаты положения на реальном изображении на бумаге:
Lбумаги=FS→P (Lдатчика).
Когда ручкой пишут, датчик ручки и бумага находятся в одной плоскости. Соответственно, преобразование виртуального кончика ручки в реальный кончик ручки также может быть представлено как FS→P:
Lкончика ручки=FS→P (Lвиртуального кончика ручки).
Оценку преобразования FS→P можно провести как аффинное преобразование. Его можно упростить в следующем виде:
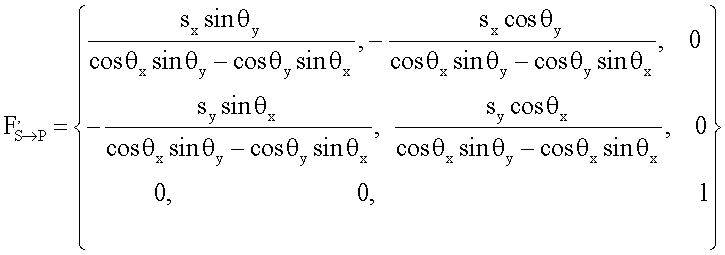
как оценку FS→P, в которой θх, θy, Sx и Sy представляют собой поворот и масштаб двух ориентаций структуры, введенной в местоположении 204. Кроме того, можно уточнить F′S→P путем сопоставления введенного изображения с соответствующим действительным изображением на бумаге. "Уточнить" означает получить более точную оценку преобразования FS→P с использованием определенного типа алгоритма оптимизации, который называется рекурсивным способом. В рекурсивном способе матрица F′S→P используется в качестве исходного значения. Уточненная оценка более точно описывает преобразование между S и Р.
Затем можно определить местоположение виртуального кончика ручки путем калибровки.
Кончик 22 ручки устанавливают в фиксированное местоположение 202 Lкончика ручки на бумаге. Затем ручку отклоняют, что позволяет с помощью камеры 203 вводить последовательность изображений в различных положениях ручки. Для каждого введенного изображения можно получить преобразование FS→P. По результату такого преобразования можно получить местоположение Lвиртуального кончика ручки виртуального кончика ручки:
Lвиртуального кончика ручки=FP→S (Lкончика ручки),
где Lкончика ручки инициализируют как (0, 0) и
FP→S=(FS→P)-1.
Путем усреднения значения Lвиртуального кончика ручки, полученного для каждого изображения, можно определить местоположение Lвиртуального кончика ручки виртуального кончика ручки. С помощью значения Lвиртуального кончика ручки можно получить более точную оценку Lкончика ручки. После нескольких итераций может быть определено точное местоположение Lвиртуального кончика ручки виртуального кончика ручки.
Местоположение Lвиртуального кончика ручки виртуального кончика ручки теперь известно. Можно также получить преобразование FS→P по вводимым изображениям. Наконец, можно использовать эту информацию для определения местоположения Lкончика ручки реального кончика ручки:
Lкончика ручки=FS→P (Lвиртуального кончика ручки).
IV. Кодирование Матрицы
Двумерная матрица может быть построена путем свертки одномерной последовательности. Любой участок двумерной матрицы, содержащий достаточное количество битов, можно использовать для определения его местоположения в полной двумерной матрице. Однако при этом может потребоваться определить местоположение по вводимому изображению или нескольким вводимым изображениям. При этом для минимизации вероятности того, что участок введенного изображения будет ассоциирован с двумя или больше местоположениями в двумерной матрице, для создания матрицы можно использовать неповторяющуюся последовательность. Одно из свойств создаваемой последовательности состоит в том, что последовательность не повторяется на длине (или в окне) n. Ниже описано построение одномерной последовательности с последующей сверткой последовательности в матрицу.
IV.А. Построение последовательности
Некоторая последовательность цифр может быть использована как начальная точка системы кодирования. Например, последовательность (также называемая m-последовательностью) может быть представлена, как q-элемент, установленный в поле Fq. Здесь, q=рn, где n≥1 и р - простое число. Последовательность или m-последовательность может быть сгенерирована с использованием множества различных методик, включая, без ограничения, деление многочлена. При использовании деления многочлена последовательность может быть определена следующим образом:
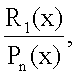
где Рn(x) представляет собой примитивный многочлен степени n в поле Fq[x] (содержащем qn элементов). R1(x) представляет собой ненулевой многочлен степени 1 (где 1<n) в поле Fg[x]. Последовательность может быть создана с использованием итеративной процедуры за два этапа: первый, деление двух многочленов (в результате чего получают элемент поля Fq), и второй, умножение остатка на х. Расчет прекращают, когда выходное значение начинает повторяться. Этот процесс может быть выполнен с помощью линейного сдвигового регистра с обратной связью, как описано в статье Douglas W. Clark и Lih-Jyh Weng, "Maximal and Near-Maximal Shift Register Sequences: Efficient Event Counters and Easy Discrete Logarithms", IEEE Transactions on Computers 43.5 (Май 1994 г., стр.560-568). В этой среде между циклическим сдвигом последовательности и многочленом R1(х) устанавливают взаимозависимость: при изменении R1(х) происходит только циклический сдвиг последовательности, и каждый циклический сдвиг соответствует многочлену R1(х). Одно из свойств получаемой в результате последовательности состоит в том, что последовательность имеет период qn-1 и, в пределах периода, по ширине (или длине) n, любой участок присутствует в последовательности один раз и только один раз. Это называется "свойством окна". Период qn-1 также называется длиной последовательности и n называется порядком последовательности.
Процесс, описанный выше, представляет собой один из множества процессов, которые можно использовать для построения последовательности со свойством окна.
IV. В. Построение матрицы
Матрица (или m-матрица), которую можно использовать для создания изображения (участок которого может быть введен камерой), представляет собой расширение одномерной последовательности или m-последовательности. Пусть А представляет собой матрицу с периодом (m1, m2), а именно A (k+m1, 1)=A (k, 1+m2)=А (k, 1). Когда окно n1 × n2 сдвигается через период А, все ненулевые матрицы n1 × n2 Fq появляются один раз и только один раз. Это свойство также называется "свойством окна", при котором каждое окно является уникальным. Окно затем может быть выражено как матрица с периодом (m1, m2) (причем m1 и m2 представляют собой количество битов по горизонтали и вертикали, присутствующих в матрице) и с порядком (n1, n2).
Двоичная матрица (или m-матрица) может быть построена путем свертки последовательности. Один из подходов состоит в получении последовательности, с последующим ее сверткой до размера m1 × m2, где длина матрицы составляет L=m1 × m2=2n-1. В качестве альтернативы, можно начать с заданного размера пространства, которое требуется перекрыть (например, один лист бумаги, 30 листов бумаги или размер монитора компьютера), затем определяют область (m1 × m2), после чего используют размер для обеспечения L≥m1 × m2, где L=2n-1.
Можно использовать множество различных методик свертки. Например, на фиг.3А-3С показаны три различные последовательности. Каждая из них может быть свернута в виде матрицы, показанной на фиг.3D. Три различных способа свертки показаны в виде наложения на фиг.3D и в виде пути растра на фиг.3Е и 3F. Здесь принят способ свертки, показанный на фиг.3D.
Для получения способа свертки, который показан на фиг.3D, создают последовательность {ai}, длиной L и с порядком n. Затем создают матрицу {bkl} размером m1 × m2, где наибольший общий делитель (m1, m2)=1 и L=m1 × m2 из последовательности {ai}, путем расчета каждого бита матрицы, как представлено уравнением 1;
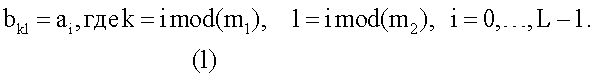
Такой подход при выполнении свертки в качестве альтернативы может быть выражен как укладывание последовательности на диагональ матрицы, с последующим продолжением от противоположной кромки, после достижения кромки.
На фиг.4А представлена методика кодирования выборки, которую можно использовать для кодирования матрицы по фиг.3D. При этом следует понимать, что можно использовать другие методики кодирования. Например, на фиг.11 показана альтернативная методика кодирования.
Как показано на фиг.4А, первый бит 401 (например, "1") представлен колонкой, начерченной черными чернилами. Второй бит 402 (например, "0") представлен строкой, начерченной черными чернилами. Следует понимать, что для представления различных битов можно использовать чернила любого цвета. Единственное требование состоит в том, что выбранный цвет чернил должен обеспечивать значительный контраст с фоном носителя, чтобы его можно было различать с помощью системы ввода изображения. Биты, показанные на фиг.4А, представлены матрицей ячеек размером 3×3.
Размер матрицы может быть изменен на любое значение, в зависимости от размера и разрешающей способности системы ввода изображения. Альтернативное представление битов 0 и 1 показано на фиг.4С-4Е. Следует понимать, что представление единицы или нуля при кодировании выборки, показанное на фиг.4А-4Е, можно переключать без какого-либо влияния. На фиг.4С показаны представления бита, которые занимают два ряда или две колонки с чередованием. На фиг.4D показана альтернативная компоновка пикселей в рядах и колонках в форме с разрывами. Наконец, на фиг.4Е показано представление пикселей в колонках и рядах с неравномерным расположением промежутка (например, после двух черных точек следует пустая точка).
Как показано на фиг.4А, если бит представлен матрицей размером 3×3, и система сопоставления детектирует в этой области размером 3×3 темный ряд и два белых ряда, обеспечивается возможность детектирования нуля (или единицы). Если детектируется изображение с темной колонкой и двумя белыми колонками, тогда детектируется единица (или ноль).
Здесь для представления бита используют более чем один пиксель или точку. Использование одного пикселя (или бита) для представления бита может быт ненадежным. Пыль, складки на бумаге, неплоское расположение структуры и т.п. создают трудности при считывании представлений одного бита модулей данных. Однако следует понимать, что можно использовать различные подходы для графического представления матрицы на поверхности. Некоторые такие подходы показаны на фиг.4С-4Е. При этом следует понимать, что также можно использовать другие подходы. Один из подходов показан на фиг.11 с использованием только точек со сдвигом положения.
Поток битов используется для создания графической структуры 403, показанной на фиг.4В. Графическая структура 403 включает 12 рядов и 18 колонок. Ряды и колонки сформированы на основе потока битов, который преобразован в графическое представление с использованием представлений 401 и 402. Фиг.4 В можно рассматривать как содержащую следующее представление битов:

V.Декодирование
Когда человек пишет ручкой, такой как показана на фиг.2А, или передвигает ручку рядом с закодированной структурой, камера вводит изображение. Например, в ручке 201 можно использовать датчик давления, который определяет, когда ручку 201 прижимают к бумаге, при этом ручку 201 перемещают поперек документа по бумаге. Изображение затем обрабатывают для определения ориентации введенного изображения по отношению к общему представлению кодированного изображения и выделяют биты, которые составляют введенное изображение.
При определении ориентации введенного изображения по отношению ко всей закодированной области, можно отметить, что не все четыре рассматриваемые угла, показанные на фиг.5A-5D, могут присутствовать в графической структуре 403. Фактически, при правильной ориентации, тип угла, показанный на фиг.5А, не может присутствовать в графической структуре 403. Поэтому ориентация, в которой отсутствует тип угла, показанный на фиг.5А, представляет собой правильную ориентацию.
Как показано на фиг.6, изображение, введенное камерой 601, может быть проанализировано, и его ориентация может быть определена так, что ее можно интерпретировать как положение, действительно представленное изображением 601. Вначале изображение 601 просматривают для определения угла θ, необходимого для поворота изображения, для выравнивания пикселей по горизонтали и вертикали. Следует отметить, что возможны альтернативные варианты расположения сетки, включая повернутое положение сетки с негоризонтальном и невертикальном ее расположением (например, под углом 45 градусов). При использовании негоризонтального и невертикального расположения, могут быть получены определенные преимущества, при которых исключается визуальное отвлечение пользователя, поскольку у пользователя может проявляться тенденция отмечать, прежде всего, горизонтальные и вертикальные структуры. Для упрощения ориентация сетки (горизонтальная и вертикальная и любой другой поворот основной сетки) совместно называется заданной ориентацией сетки.
Затем производится анализ изображения 601 для определения отсутствующего угла. Величина о поворота, необходимая для поворота изображения 601, для получения изображения 603, пригодного для декодирования, показана как о=(θ плюс величина поворота {определяемая по отсутствующему углу}). Величина поворота представлена уравнением на фиг.7. Как снова показано на фиг.6, вначале определяют угол θ по компоновке пикселей при их горизонтальном и вертикальном расположении (или с другой заданной ориентацией сетки), при этом компоновку пикселей и изображение поворачивают, как показано позицией 602. Затем выполняют анализ для определения отсутствующего угла, и изображение 602 поворачивают с получением изображения 603, для установки изображения для декодирования. Здесь изображение поворачивают на 90 градусов против часовой стрелки, в результате чего изображение 603 получает правильную ориентацию, и затем его используют для декодирования.
Следует понимать, что угол θ поворота может быть приложен до или после поворота изображения 601 для учета отсутствующего угла. Также предполагается, что в результате воздействия шумов на вводимом изображении могут присутствовать все четыре типа углов. При этом можно подсчитать количество углов каждого типа и выбрать тип, который имеет наименьшее количество, в качестве типа отсутствующего угла.
Наконец, код в изображении 603 считывают и коррелируют с исходным битовым потоком, который был использован для построения изображения 403. Корреляция может быть выполнена с использованием множества способов. Например, она может быть проведена с использованием рекурсивного подхода, в котором восстановленный битовый поток сравнивают со всеми другими фрагментами исходного битового потока. Во-вторых, между восстановленным битовым потоком и исходным битовым потоком может быть выполнен статистический анализ, например, при использовании расстояния Хемминга между двумя битовыми потоками. При этом предполагается, что можно использовать множество подходов для определения местоположения восстановленного битового потока в исходном битовом потоке.
После получения восстановленных битов необходимо определить местоположение введенного изображения в исходной матрице (например, такой как показана на фиг.4В). Процесс определения местоположения сегмента битов во всей матрице затруднен по ряду причин. Во-первых, вводимые биты могут быть закрыты (например, камера может вводить изображение во время письма от руки, когда исходный код закрыт). Во-вторых, пыль, складки, отражения и т.п. также могут создавать ошибки в вводимом изображении. Эти ошибки значительно затрудняют процесс определения местоположения. При этом система ввода изображения, возможно, должна обеспечивать возможность работы с непоследовательными битами, выделенными из изображения. Ниже представлен способ работы с непоследовательными битами, полученными из изображения.
Пусть последовательность (или m-последовательность) I соответствует степенному ряду I(х)=1/Рn(х), где n представляет собой порядок m-последовательности, и введенное изображение содержит К битов из I b=(b0, b1, b2 … bк-1)t, где К≥n и верхний индекс t представляет транспозицию матрицы или вектора. Местоположение s К битов представляет собой просто число циклических сдвигов I, при котором b0 сдвигается к началу последовательности. При этом такая последовательность R со сдвигом соответствует степенному ряду хs /Рn (х), или R=Ts(I), где Т представляет собой оператор циклического сдвига. При этом значение s определяют опосредованно. Модуль полинома Pn(х) формирует поле. При этом гарантируется, что хs=r0+r1x+…rn-1 xn-1mod(Pn(x)). Поэтому, можно найти (r0, r1 …, rn-1) и затем решение для s.
Взаимозависимость хs=r0+r1x+…rn-1, xn-1 хn-1mod(Pn(x)) предполагает, что R=r0+r1T(I)+…+rn-1 Tn-1 (I). При записи в виде бинарного линейного уравнения, она становится:

где r=(r0, r1 r2 … rn-1)t и А=(I T(I) … Tn-1(I))t, который состоит из циклических сдвигов I от 0 сдвига до (n-1)-го сдвига. Теперь, пусть только разреженные К битов доступны в R для вектора r. Пусть разности индекса между bi и b0 в R составляют ki, при этом i=1, 2, … , k-1, тогда 1-ый и (ki+1)-вый элементы R, i=1, 2, … , k-1 точно составляют b0, b1,…, bk-1. При выборе 1-ой и (ki+1)-ой колонок А, i=1, 2, … , k-1, формируется следующее бинарное линейное уравнение:
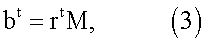
где М представляет собой подматрицу А размером n×К.
Если b не содержит ошибки, вектор r может быть выражен как:
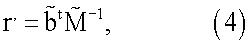
где 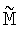 представляет собой любую невырожденную подматрицу М размером n×n и b представляет собой соответствующий подвектор b.
представляет собой любую невырожденную подматрицу М размером n×n и b представляет собой соответствующий подвектор b.
При известном r для определения s можно использовать алгоритм Полига-Геллмана-Силвера (Pohlig-Hellman-Silver), как указано в публикации Douglas W. Clark и Lih-Jyh Weng, "Maximal and Near-Maximal Shift register Sequences: Efficient Event Counters and Easy Discrete Logarithms", IEEE Transactions on Computers 43.5 (Май 1994 г., стр.560-568), так что хs=r0+r1x+…rn-1 xn-1mod(Pn(x)).
Поскольку матрица А (с размерами n на L, где L=2n-1) может быть очень большой, следует исключить необходимость записи всей матрицы А. Фактически, как видно из вышеприведенного процесса, в данных выделенных битах с разностью ki индекса для расчетов достаточно использовать только первую и (ki+1)-ую колонки А. Такой выбор ki в достаточной степени ограничен при заданном размере введенного изображения. При этом требуется сохранять только те колонки, которые используются для расчетов. Общее количество таких колонок намного меньше, чем L (где L=2n-1 представляют собой длину m-последовательности).
VI. Коррекция ошибки
Если в последовательности b существуют ошибки, тогда вектор r становится более сложным. При этом здесь нельзя непосредственно применять традиционные способы декодирования с коррекцией ошибки, поскольку матрица М, ассоциированная с вводимыми битами, может изменяться от одного введенного изображения к другому.
Для этого случая применяется стохастический подход. Если предположить, что количество ne битов с ошибками в последовательности b относительно невелико по сравнению с К, тогда высока вероятность выбора правильных n битов из К битов последовательности b и соответствующей подматрицы 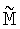 из матрицы М, которая является невырожденной.
из матрицы М, которая является невырожденной.
Если все n выбранных битов являются правильными, расстояние Хемминга между bt и rtМ, или количество битов с ошибкой, ассоциированных с r, должно быть минимальным, при этом r рассчитывают с использованием уравнения (4). При повторении процесса несколько раз, вполне вероятно, что можно будет идентифицировать правильный вектор r, в результате чего будет получено минимальное количество битов с ошибками.
Если существует только один вектор г, который ассоциирован с минимальным количеством битов с ошибками, тогда его рассматривают как правильное решение. В противном случае, если существует больше, чем один вектор r, который ассоциирован с минимальным количеством битов с ошибками, вероятность того, что ne превышает способность коррекции ошибок кода, генерируемого с помощью М, будет велика, и процесс декодирования не будет выполнен. В этом случае система может перейти к обработке следующего введенного изображения. В другом варианте выполнения можно учитывать информацию о предыдущих местах расположения ручки. То есть для каждого введенного изображения может быть идентифицирована область назначения, в которой, как можно ожидать, находится ручка. Например, если пользователь не поднял ручку между двумя изображения, вводимыми камерой, расположение ручки, определяемое по второму вводимому изображению, не должно находиться на слишком большом расстоянии от первого местоположения. Каждый вектор r, который ассоциирован с минимальным количеством битов ошибки, при этом можно проверить для определения, удовлетворяет ли местоположение s, рассчитанное на основе вектора r, ограничению по месту, то есть находятся ли это местоположение в пределах определенной области назначения.
Если местоположение s удовлетворяет местному ограничению, получают положения X, У выделенных битов в матрице. В противном случае процесс декодирования не может быть выполнен.
На фиг.8 представлен способ, который можно использовать для определения местоположения в последовательности (или m-последовательности) введенного изображения. Вначале, на этапе 801 принимают поток данных, относящихся к вводимому изображению. На этапе 802 выделяют соответствующие колонки из А и строят матрицу М.
На этапе 803 производят случайный выбор n независимых векторов колонок из матрицы М и определяют вектор r путем решения уравнения (4). Этот процесс выполняют Q раз (например, 100 раз) на этапе 804. Определение количества циклов описано в секции Вычисление количества циклов.
На этапе 805 r сортируют в соответствии с ассоциированным количеством битов с ошибками. Сортировка может быть выполнена с использованием различных алгоритмов сортировки, известных в данной области техники. Например, можно использовать алгоритм сортировки с выбором. Алгоритм сортировки с выбором является предпочтительным, когда число Q невелико. Однако, если Q становится большим, может более эффективно использовать другие алгоритмы сортировки (например, сортировка со слиянием), которые позволяют обрабатывать большие количества элементов.
Система затем определяет на этапе 806, успешно ли была выполнена коррекция ошибки, проверяя, ассоциировано ли множество векторов r с минимальным количеством битов с ошибками. Если результат положительный, на этапе 809 получают результат, свидетельствующий об ошибке, который указывает, что процесс декодирования не был проведен. В противном случае положение s выделенных битов в последовательности (или m-последовательности) рассчитывают на этапе 807, например, с использованием алгоритма Полига-Геллмана-Силвера.
Затем на этапе 808 рассчитывают положение (X, Y) в матрице как: х=s mod m1. и у=s mod m2 и результаты передают на выход.
VII. Определение местоположения
На фиг.9 представлен процесс определения местоположения кончика ручки. При этом в качестве входных данных используют изображение, введенное камерой, и в качестве выходных могут быть получены координаты положения кончика ручки. Кроме того, выходные данные могут включать (или нет) другую информацию, такую как угол поворота введенного изображения.
На этапе 901 получают изображение от камеры. Затем полученное изображение может быть, в случае необходимости, подвергнуто предварительной обработке, на этапе 902 (как показано пунктирным контуром, которым представлен этап 902), для регулировки контраста между светлыми и темными пикселями и т.п.
Затем на этапе 903 выполняют анализ изображения для определения потока битов, содержащегося в нем.
Затем на этапе 904 n битов выбирают случайным образом из потока битов множество раз и определяют местоположение принятого потока битов в исходной последовательности (или m-последовательности).
Наконец, после определения местоположения введенного изображения на этапе 904, на этапе 905 можно определить местоположение кончика ручки.
На фиг.10 более подробно представлены этапы 903 и 904 и показан подход, используемый для выделения битового потока во вводимом изображении. Вначале получают изображение от камеры на этапе 1001. Затем это изображение, в случае необходимости, может быть предварительно обработано на этапе 1002 (как показано пунктирным контуром, которым представлен этап 1002). Структуру выделяют на этапе 1003. Здесь могут быть выделены пиксели на различных линиях для определения ориентации структуры и угла θ.
После этого выполняют анализ принятого изображения на этапе 1004 для определения лежащих в основе линий сетки. Если на этапе 1005 будут определено наличие линий сетки, на этапе 1006 выделяют код из структуры. Код затем декодируют на этапе 1007, и местоположение кончика ручки определяют на этапе 1008. Если на этапе 1005 не будут найдены линии сетки, на этапе 1009 формируется сообщение об ошибке.
VIII. Изображения документа с водяными знаками: генерирование, анализ и нанесение метки
Варианты выполнения настоящего изобретения относятся к анализу изображений документа, которые содержат позиционно кодированную информацию, такую как лабиринтные структуры, и нанесению метки на изображения. Результаты такого анализа документа можно использовать для эффективного определения местоположения изображения, вводимого камерой, на позиционно кодированном документе.
Как показано на фиг.11, система 1100, в соответствии с различными вариантами выполнения настоящего изобретения, включает модуль 1102 генерирования и ввода изображения и модуль 1106 анализа и нанесения метки. Соответствующие технологии ввода изображения для последующего анализа и нанесения метки описаны выше в секции III под названием Ручка для ввода изображения и ниже в разделе VIII.
А под названием Генерирование изображений документа серой шкалы с водяными знаками. В модуль 1106 анализа и нанесения метки поступают, в качестве входных данных, данные 1104 изображения с выхода модуля 1102 генерирования и ввода изображения и тренировочные данные 1110 в автономном режиме; этот модуль выполняет обработку анализа и нанесения метки, как более подробно описано ниже; и выводит информацию 1108 метки изображения.
В соответствии с различными вариантами выполнения настоящего изобретения размер вводимого изображения, получаемого с помощью камеры 203, составляет 32*32 пикселя. Порядок встроенной m-матрицы, которую используют для позиционного кодирования положения на поверхности 207, составляет 36, а именно, размер m-матрицы составляет (218+1) * (218-1). Поэтому для декодирования уникального положения х-у из подблока m-матрицы, количество битов подблока, используемого для определения положения на поверхности 207, должно составлять, по меньшей мере, 36.
В соответствии с различными вариантами выполнения настоящего изобретения на печатные документы наносят водяные знаки в виде лабиринтных структур. Такие лабиринтные структуры могут быть закрыты содержанием документа, таким как текст. В зависимости от степени такого закрытия может оказаться невозможным выделить достаточное количество битов m-матрицы из изображения, вводимого камерой, для определения местоположения в документе изображения, вводимого камерой.
В соответствии с различными вариантами выполнения настоящего изобретения изображения документа с водяными знаками анализируют и на них наносят метки. Анализ и нанесение метки относится к возможности определения положения х-у на документе с водяными знаками на основе степени видимости ячеек лабиринтной структуры в конкретном местоположении в документе.
VIII.А. Генерирование изображения документа серой шкалы с водяными знаками
На фиг.12 показаны этапы генерирования изображения документа серой шкалы с водяными знаками, которое можно анализировать и на которое можно наносить метки в соответствии с различными вариантами выполнения настоящего изобретения. Изображение документа получают, например, путем получения электронного растрового документа, соответствующему печатному документу, как показано на этапах 1200 и 1204, или путем сканирования документа на бумаге, как показано на этапах 1202 и 1206. Затем производят повторную выборку изображения в растровой форме для получения соответствующей разрешающей способности, как показано на этапе 1208. Определение разрешающей способности должно быть основано на следующих условиях: (1) разрешающая способность изображения документа не должна быть меньше, чем разрешающая способность вводимого изображения, поскольку, когда местоположение вводимого изображения нельзя будет определить путем декодирования m-матрицы, вводимое изображение будет сопоставлено для определения местоположения с изображением серой шкалы документа с водяными знаками; (2) одна ячейка напечатанной лабиринтной структуры должна быть сопоставлена с целым числом пикселей изображения документа, для обеспечения эффективной работы алгоритма сопоставления. Например, если разрешающая способность камеры составляет 0,15 мм/пиксель, то есть 0,15 мм, в физическом мире отображаются как один пиксель камеры, размер ячейки напечатанной лабиринтной структуры будет составлять 0,45 мм * 0,45 мм, то есть ячейка напечатанной лабиринтной структуры будет отображена на 3*3 пикселях, при этом на датчике камеры, разрешающая способность изображения документа также должна быть установлена равной 0,15 мм/пиксель, чтобы обеспечить отображение ячейки напечатанной лабиринтной структуры на область 3*3 пикселя в изображении документа.
На полученные изображения затем наносят водяные знаки. На фиг.13 показаны изображения участка содержания 1300 документа, участок позиционно кодированной лабиринтной структуры 1302, комбинация 1304 содержания и лабиринтной структуры, и увеличенный вид участка содержания и лабиринтной структуры 1306, представляющий: (1) местоположение 1308, в котором ячейка лабиринтной структуры не видна, поскольку она закрыта наложенным текстом, и (2) местоположение 1310, в котором ячейка лабиринтной структуры не закрыта содержанием документа и, поэтому, видна.
VI II.В. Анализ и нанесение метки на изображение документа
В соответствии с различными вариантами выполнения настоящего изобретения изображения документа анализируют путем разделения изображения на относительно небольшие блоки, имеющие, по существу, тот же размер, что и ячейки лабиринтной структуры/определения, закрыты ли эти небольшие блоки содержанием документа, таким как текст документа; и для каждого пикселя подсчета количества полностью видимых блоков в соседнем окне для пикселя, представляющего собой центр окна; и нанесение метки на пиксель на основе полученного количества. Соседнее окно может иметь, по существу, тот же размер, что и размер изображения, вводимого камерой 203, то есть 32 на 32 пикселя.
Следует отметить, что в вышеуказанном процессе не требуется наносит водяные знаки на изображение документа серой шкалы, то есть получать содержание в комбинации с лабиринтными структурами. Как только изображение документа будет разделено на относительно небольшие блоки, имеющие, по существу, такой же размер, что и ячейки лабиринтной структуры, закрытие ячеек лабиринтной структуры содержанием документа будет эквивалентно анализу закрытия блоков содержанием документа.
На фиг.14 показан пример такого соседнего окна 1400 размером 32 на 32 пикселя и его центральный пиксель 1402. В соответствии с различными вариантами выполнения настоящего изобретения пиксели изображений документа могут быть помечены, как один из четырех типов:
Тип I: соседнее окно размером 32 на 32 пикселя (с центром в рассматриваемом пикселе) содержит, по существу, только ячейки позиционно кодированной лабиринтной структуры.
Тип II: соседнее окно размером 32 на 32 пикселя содержит 60 или больше видимых ячеек лабиринтной структуры.
Тип III: 32 соседнее окно размером 32 на 32 пикселя содержит 36-60 видимых ячеек лабиринтной структуры.
Тип IV: соседнее окно размером 32 на 32 пикселя содержит 35 или меньше ячеек видимой лабиринтной структуры.
В соответствии с различными вариантами выполнения настоящего изобретения, когда центр вводимого изображения расположен в областях типа I или типа II, местоположение изображения в документе может быть уникально определено путем декодирования m-матрицы.
На фиг.15 показан результат анализа примера документа, в котором области документа по-разному раскрашены (или затушеваны) для представления типа (то есть типов I, II, III или IV), участка документа, которые были помечены на основе количества ячеек лабиринтной структуры, видимых в соседнем окне размером 32 на 32 пикселя.
Следует отметить, что при подсчете количества видимых ячеек лабиринтной структуры, соседнее окно размером 32 на 32 пикселя следует поворачивать на 360 градусов для учета того факта, что камера может фиксировать изображение документа под любым углом. Для простоты выполнения, однако, анализ приведен только для вида без наклона, и ошибка, связанная с углом наклона, учитывается с использованием порогового значения при определении типа пикселя. Например, на фиг.16 представлен случай, в котором изображение, вводимое камерой, повернуто на 45 градусов. Этот случай представляет собой сценарий наихудшего случая, когда максимально 17,2% видимых ячеек лабиринтной структуры могут быть потеряны.
Даже в этом случае пиксели типа II все еще будут содержать по меньшей мере 49 (=60*(1-17,2%)) видимых ячеек лабиринтной структуры, что позволяет определять уникальное положение х-у путем декодирования m-матрицы. Другими словами, если пиксель помечен как пиксель типа I или II, должно оставаться достаточное количество видимых ячеек лабиринтной структуры, независимо от того, под каким углом камера зафиксировала изображение для определения положения х-у путем декодирования m-матрицы. Следовательно, если вводимое изображение невозможно декодировать, наиболее вероятно, что оно расположено в областях типа III или IV.
Если положения х-у не могут быть декодированы из последовательности изображений, полученных при движении ручки, поскольку видно недостаточное количество ячеек лабиринтной структуры, можно использовать алгоритм поиска для определения на документе местоположения изображений, таких как области пикселей типа III и IV. Использование такого алгоритма поиска только в областях типа III и IV снижает объем вычислений для определения местоположения изображений, по сравнению со случаем использования алгоритма поиска, по существу, для всех частей документа. Например, в случае документа, показанного на фиг.15, только 13,7% области помечено как тип III (11,1%) или тип IV (2,6%). Объем расчетов, связанных с поиском по всему документу, значительно выше, чем объем, связанный с поиском только по областям типа III и типа IV. В одном варианте выполнения для поиска по всему документу требуется более 10 секунд, в то время, как для поиска только в областях типа III и типа IV требуется менее 1 секунды. Анализ изображения документа значительно снижает объем расчетов.
IX. Нанесение меток на изображения, вводимые камерой
Изображения, вводимые камерой, также могут быть помечены с использованием четырех типов, описанных выше, в разделе VIII.В. под названием Анализ и нанесение метки на изображения документа. При этом может быть выполнено определение, содержит ли изображение, вводимое камерой, по существу, только позиционно кодированные лабиринтные структуры. Другими словами, может быть выполнено определение, является ли изображение изображением типа I или нет. Такое исходное определение будет более подробно описано ниже.
Если изображение, вводимое камерой, не является изображением типа I, тогда можно провести анализ позиционно кодированной лабиринтной структуры изображения, вводимого камерой, для определения количества битов кодирования положения, которые могут быть выделены из изображения. Вначале рассчитывают параметры линий сетки лабиринтной структуры (масштаб и степень поворота каждого измерения, то есть аффинное преобразование) и затем определяют исходное положение (или квадрант), в который встроена лабиринтная структура. Затем определяют информацию битов m-матрицы на основе линий сетки и направлений полосок. Если количество выделенных битов больше, чем приблизительно 60, изображение помечают как тип II; если будет выделано от приблизительно 36 до 60 битов, изображение помечают как тип III; и, если будет выделено меньше, чем приблизительно 36 битов, изображение помечают как тип IV. Для назначения категории для изображений, вводимых таким образом с помощью камеры, можно использовать алгоритм порогового значения, который описан ниже в разделе IX.В. под названием Алгоритм порогового значения, предназначенный для разделения областей лабиринтной структуры от текстовых областей. Затем изображения могут быть помечены на основе количества выделенных битов. Биты, выделенные из областей типа I, II и III, можно использовать для определения положения х-у изображения, вводимого камерой, в большом документе. Обработка такого типа, связанная с определением положения, может быть исключена для изображений типа IV, поскольку они не содержат достаточное количество битов для декодирования положения х-у.
Для определения, содержит ли изображение, по существу, только позиционно кодированные лабиринтные структуры, в отличие от изображений одновременно содержащих содержание документа и лабиринтные структуры, можно использовать свойство, называемое интервалом поддержки гистограммы градиентного изображения (ИПГГИ, SIGIH) в соответствии с различными вариантами выполнения настоящего изобретения. SIGIH используют на основе знания того, что чистые изображения лабиринтной структуры обычно не содержат выделения краев, в то время как изображения с содержанием документа, таким как текст, обычно содержат выделения краев, поскольку содержание документа часто намного темнее, чем ячейки лабиринтной структуры или пустые области.
IX.А. Выделение свойства
В соответствии с различными вариантами выполнения настоящего изобретения первый этап выделения свойства представляет собой применение оператора градиента, такого как оператор выделения краев Собеля, или другого оператора градиента, который можно использовать для получения градиентного изображения. Как показано на фиг.17, два ядра свертки 1700 и 1702 формируют оператор выделения краев Собеля. Для использования оператора выделения краев Собеля каждый пиксель изображения сворачивают с обоими ядрами 1700 и 1702 свертки. Одно ядро в максимальной степени соответствует, в общем, вертикальной кромке, и другое ядро в максимальной степени соответствует горизонтальной кромке. Значение "векторной суммы" двух сверток получают как выходную величину для конкретного пикселя. В результате получают градиентное изображение.
Может быть рассчитана гистограмма градиентного изображения, получаемого в результате применения градиентного оператора градиента. Интервал поддержки гистограммы изображения (SIGIH) может быть затем получен по гистограмме градиентного изображения. Например, на фиг.18 показана гистограмма градиентного изображения вводимого изображения, содержащего только лабиринтные структуры. Свойство SIGIH равно 17, которое представляет собой наибольшее число вдоль оси X, имеющее ненулевую величину на гистограмме, показанной на фиг.17.
На фиг.19 показана гистограмма градиентного изображения вводимого изображения, содержащего содержание документа, такое как текст и/или один или больше рисунков. Свойство SIGIH для гистограммы, показанной на фиг.19, равно 44.
IX.В. Алгоритм порогового значения
Алгоритм порогового значения, предназначенный для определения, является ли изображение изображением типа I или нет, в соответствии с различными вариантами выполнения настоящего изобретения, может быть разделен на 2 сессии: (1) тренировка в автономном режиме; и (2) нанесение метки в рабочем режиме.
IX.B.I. Тренировка в автономном режиме
В ходе сессии тренировки в автономном режиме свойство SIGIH может быть рассчитано для относительно большого количества изображений с известными метками (то есть типы I, II, III или IV). Значение SIGIH изображений, содержащих чистую лабиринтную структуру, часто ниже, чем значение SIGIH для изображений других типов. Оптимальное пороговое значение η может быть выбрано на основе результатов обработки тренировочных данных. По существу, для всех изображений чистой лабиринтной структуры в тренировочном наборе значение SIGIH меньше, чем η, и, по существу, для всех изображений, не содержащих чистую лабиринтную структуру, значение SIGIH больше, чем η. На фиг.20 показан пример результата тренировки в автономном режиме, в котором η, оптимальное пороговое значение 2004, выбрано равным 32. Здесь также показаны полоски 2002 гистограммы, соответствующие изображениям с чистой лабиринтной структурой и полоски 2006 гистограммы, соответствующие изображениям, не содержащим чистую лабиринтную структуру (то есть изображениям, которые включают содержание документа).
IX.В.2. Нанесение метки в рабочем режиме
Во время нанесения метки в рабочем режиме рассчитывают значение SIGIH для каждого вводимого изображения. Если значение SIGIH меньше чем η, такое изображение помечают как изображение типа I. В противном случае, если значение SIGIH больше, чем η, такое изображение помечают как изображение другого типа, не являющееся изображением типа I (то есть типа II, III и IV).
В приведенном выше описании, которое относится к анализу документа и нанесению метки, предполагается, что контраст вводимых изображений остается относительно постоянным. Другими словами, предполагается, что усилитель датчика изображения и/или условия освещения камеры остаются относительно постоянными. Если эти условия резко изменяются, требуется выполнять новую тренировку для обновления параметров свойств.
X. Заключительные замечания
Выше описана только иллюстрация варианта применения принципов настоящего изобретения. Специалисты в данной области техники могут выполнить другие компоновки и способы без отхода от объема и сущности настоящего изобретения. Любой из способов, в соответствии с настоящим изобретением, может быть выполнен в форме программного обеспечения, которое может быть записано на компьютерные диски или другой машиносчитываемый носитель информации.
Предложенным изобретением является способ и устройство, осуществляющее способ, для нанесения метки на изображения. В способе анализируют изображение с позиционно кодированной информацией и наносят на него метку на основе степени перекрытия содержанием документа позиционно кодированной информации. В зависимости от степени такого закрытия может быть невозможно выделить достаточное количество битов позиционного кодирования из вводимого камерой изображения документа для определения местоположения вводимого камерой изображения на документе. Результаты обработки анализа и нанесения метки на документ можно использовать для эффективного определения местоположения вводимого камерой изображения на позиционно кодированном документе. 6 н. и 33 з.п. ф-лы, 21 ил.
1. Способ нанесения метки на изображение документа, содержащего позиционно кодированную информацию, для указания количества информации с кодированным положением, которая может быть выделена из изображения, содержащий:
получение изображения документа; и
нанесение метки на изображение, представляющей его как относящееся к типу, выбранному, по меньшей мере, из: первого типа, содержащего, по существу, только позиционно кодированную информацию, и, по существу, не содержащего содержание документа, и второго типа, содержащего содержание документа, которое закрывает, по меньшей мере, участок позиционно кодированной информации.
2. Способ по п.1, в котором получение изображения документа дополнительно содержит: получение электронного документа в форме растрового представления, соответствующего отпечатанному документу.
3. Способ по п.1, в котором получение изображения документа дополнительно содержит: обработку сканированного бумажного документа.
4. Способ по п.1, в котором второй тип подразделяют на множество подтипов, которые представляют различимые степени закрытия позиционно кодированной информации содержанием документа.
5. Способ нанесения меток на вводимое камерой изображение, содержащее позиционно кодированную информацию, для указания количества информации с кодированным положением, которая может быть выделена из изображения, содержащий:
получение вводимого камерой изображения; и
нанесение метки на изображение, представляющей его как относящееся к типу, выбранному, по меньшей мере, из: первого типа, содержащего, по существу, только позиционно кодированную информацию, и, по существу, не содержащего содержание документа, и второго типа, содержащего содержание документа, которое закрывает, по меньшей мере, участок позиционно кодированной информации.
6. Способ по п.5, в котором интервал поддержки гистограммы градиентного изображения используют для определения, является ли изображение изображением первого типа или изображением второго типа.
7. Способ по п.6, дополнительно содержащий: применение оператора градиента к изображению для получения градиентного изображения.
8. Способ по п.7, в котором оператор градиента представляет собой оператор выделения краев Собеля (Sobel).
9. Способ по п.8, дополнительно содержащий: генерирование гистограммы градиентного изображения.
10. Способ по п.9, дополнительно содержащий: использование наибольшего числа вдоль оси Х гистограммы, которое имеет ненулевое значение, в качестве интервала поддержки гистограммы градиентного изображения.
11. Способ по п.6, в котором сессию тренировки в автономном режиме и сессию нанесения метки в рабочем режиме используют для определения, является ли изображение изображением первого типа или изображением второго типа.
12. Способ по п.11, в котором пороговое значение, предназначенное для использования при различении изображений первого типа и изображений второго типа, выбирают на основе результатов сессии тренировки в автономном режиме, выполняемой на изображениях с тренировочными данными.
13. Способ по п.12, в котором во время сессии нанесения метки в рабочем режиме пороговое значение сравнивают с интервалом поддержки гистограммы градиентного изображения для определения, является ли изображение изображением первого типа или изображением второго типа.
14. Система, наносящая метки на изображение документа, содержащего позиционно кодированную информацию, для указания количества информации с кодированным положением, которая может быть выделена из изображения, содержащая:
модуль генерирования и ввода изображения, с помощью которого получают изображение документа; и
модуль анализа и нанесения метки, который наносит метки на изображение в соответствии с типом, выбранным из, по меньшей мере: первого типа, содержащего, по существу, только позиционно кодированную информацию и, по существу, не содержащего содержание документа, и второго типа, содержащего содержание документа, которое закрывает, по меньшей мере, участок позиционно кодированной информации.
15. Система по п.14, в которой с помощью модуля генерирования и ввода изображения получают электронный документ в форме растрового представления, соответствующего печатному документу.
16. Система по п.14, в которой модуль генерирования и ввода изображения обрабатывает сканированный бумажный документ.
17. Система по п.14, в которой второй тип подразделяют на множество подтипов, которые представляют различимые степени закрытия позиционно кодированной информации содержанием документа.
18. Система, которая обеспечивает нанесение меток на вводимое камерой изображение, содержащее позиционно кодированную информацию, для указания количества информации с кодированным положением, которая может быть выделена из изображения, содержащая:
модуль генерирования и ввода изображения, с помощью которого получают вводимое камерой изображение; и
модуль анализа и нанесения метки, который наносит метки на изображение в соответствии с типом, выбранным из, по меньшей мере: первого типа, содержащего, по существу, только позиционно кодированную информацию, и, по существу, не содержащего содержание документа, и второго типа, содержащего содержание документа, которое закрывает, по меньшей мере, участок позиционно кодированной информации.
19. Система по п.18, в которой интервал поддержки гистограммы градиентного изображения используют для определения, является ли изображение изображением первого типа или изображением второго типа.
20. Система по п.19, в которой модуль анализа и нанесения метки применяет оператор градиента к изображению для получения градиентного изображения.
21. Система по п.20, в которой оператор градиента представляет собой оператор выделения краев Собеля.
22. Система по п.19, в которой модуль анализа и нанесения метки генерирует гистограмму градиентного изображения.
23. Система по п.22, в которой в модуле анализа и нанесения метки используется наибольшее число вдоль оси Х гистограммы, которое имеет ненулевое значение, в качестве интервала поддержки гистограммы градиентного изображения.
24. Система по п.23, в которой модуль анализа и нанесения метки выполняет сессию тренировки в автономном режиме и сессию нанесения метки в рабочем режиме для определения, является ли изображение изображением первого типа или изображением второго типа.
25. Система по п.24, в которой пороговое значение, предназначенное для использования при различении изображений первого типа и изображений второго типа, выбирают на основе результатов сессии тренировки в автономном режиме, выполняемой на изображениях с тренировочными данными.
26. Система по п.25, в которой во время сессии в рабочем режиме модуль анализа и нанесения метки выполняет сравнение порогового значения с интервалом поддержки гистограммы градиентного изображения для определения, является ли изображение изображением первого типа или изображением второго типа.
27. Считываемый компьютером носитель информации, содержащий считываемые компьютером инструкции для нанесения метки на изображение документа, содержащее позиционно кодированную информацию, для указания количества информации с кодированным положением, которая может быть выделена из изображения, путем выполнения этапов, содержащих:
получение изображения документа; и
нанесение метки на изображение, представляющей его как относящееся к типу, выбранному, по меньшей мере, из: первого типа, содержащего, по существу, только позиционно кодированную информацию, и, по существу, не содержащего содержание документа, и второго типа, содержащего содержание документа, которое закрывает, по меньшей мере, участок позиционно кодированной информации.
28. Считываемый компьютером носитель информации по п.27, в котором получение изображения документа дополнительно содержит:
получение электронного документа в форме растрового представления, соответствующего отпечатанному документу.
29. Считываемый компьютером носитель информации по п.27, в котором получение изображения документа дополнительно содержит: обработку сканированного бумажного документа.
30. Считываемый компьютером носитель информации по п.27, в котором второй тип подразделяют на множество подтипов, которые представляют различимые степени закрытия позиционно кодированной информации содержанием документа.
31. Считываемый компьютером носитель информации, содержащий считываемые компьютером инструкции для нанесения метки на вводимое камерой изображение, содержащее позиционно кодированную информацию, для указания количества информации с кодированным положением, которая может быть выделена из изображения, путем выполнения этапов, содержащих:
получение вводимого камерой изображения; и
нанесение метки на изображение, представляющей его как относящееся к типу, выбранному, по меньшей мере, из: первого типа, содержащего, по существу, только позиционно кодированную информацию, и, по существу, не содержащего содержание документа, и второго типа, содержащего содержание документа, которое закрывает, по меньшей мере, участок позиционно кодированной информации.
32. Считываемый компьютером носитель информации по п.31, в котором интервал поддержки гистограммы градиентного изображения используют для определения, является ли изображение изображением первого типа или изображением второго типа.
33. Считываемый компьютером носитель информации по п.32, дополнительно содержащий выполняемые компьютером инструкции, предназначенные для выполнения этапов, содержащих: применение оператора градиента к изображению для получения градиентного изображения.
34. Считываемый компьютером носитель информации по п.33, в котором оператор градиента представляет собой оператор выделения краев Собеля.
35. Считываемый компьютером носитель информации по п.34, дополнительно содержащий выполняемые компьютером инструкции, предназначенные для выполнения этапов, содержащих: генерирование гистограммы градиентного изображения.
36. Считываемый компьютером носитель информации по п.35, дополнительно содержащий выполняемые компьютером инструкции, предназначенные для выполнения этапов, содержащие: использование наибольшего числа вдоль оси Х гистограммы, которое имеет ненулевое значение, в качестве интервала поддержки гистограммы градиентного изображения.
37. Считываемый компьютером носитель информации по п.32, в котором сессию тренировки в автономном режиме и сессию нанесения метки в рабочем режиме используют для определения, является ли изображение изображением первого типа или изображением второго типа.
38. Считываемый компьютером носитель информации по п.37, в котором пороговое значение, предназначенное для использования при различении изображений первого типа и изображений второго типа, выбирают на основе результатов сессии тренировки в автономном режиме, выполняемой на изображениях с тренировочными данными.
39. Считываемый компьютером носитель информации по п.38, в котором во время сессии нанесения метки в рабочем режиме пороговое значение сравнивают с интервалом поддержки гистограммы градиентного изображения для определения, является ли это изображение изображением первого типа или изображением второго типа.
| KR 20020080171 А, 23.10.2002 | |||
| US 2003107558 A1, 12.06.2003 | |||
| US 2003159010 A1, 21.08.2003 | |||
| KR 20030072988 A, 19.09.2003 | |||
| RU 2002101922 A, 10.08.2003. |

