Область изобретения
Настоящее изобретение относится к взаимодействию со средством, использующим цифровое перо. Более конкретно, настоящее изобретение относится к определению местоположения цифрового пера в процессе взаимодействия с одной или несколькими поверхностями.
Уровень техники
Пользователи компьютеров уже привыкли к использованию мыши и клавиатуры как способа осуществления взаимодействия с персональным компьютером. Хотя персональные компьютеры обеспечивают ряд преимуществ перед письменными документами, большинство пользователей продолжают выполнять некоторые функции, используя бумагу для печати. Некоторые из указанных функций включают считывание и аннотирование письменных документов. В случае аннотаций, печатный документ принимает большую значимость благодаря аннотациям, помещенным на нем пользователем. Однако одна из трудностей состоит в том, что в случае печатного документа с аннотациями позднее необходимо вводить аннотации обратно в электронную форму документа. Для этого требуется, чтобы первый пользователь или другой пользователь разобрался с аннотациями и ввел их в персональный компьютер. В некоторых случаях пользователь будет просматривать аннотации и исходный текст, создавая, тем самым, новый документ. Указанные многочисленные шаги приводят к затруднениям при осуществлении повторяющегося взаимодействия между печатным документом и электронной версией документа. Далее просмотренные изображения часто бывают не модифицируемыми. Может оказаться так, что невозможно отделить аннотации от исходного текста. Тем самым затрудняется использование аннотаций. Соответственно необходим усовершенствованный способ обращения с аннотациями.
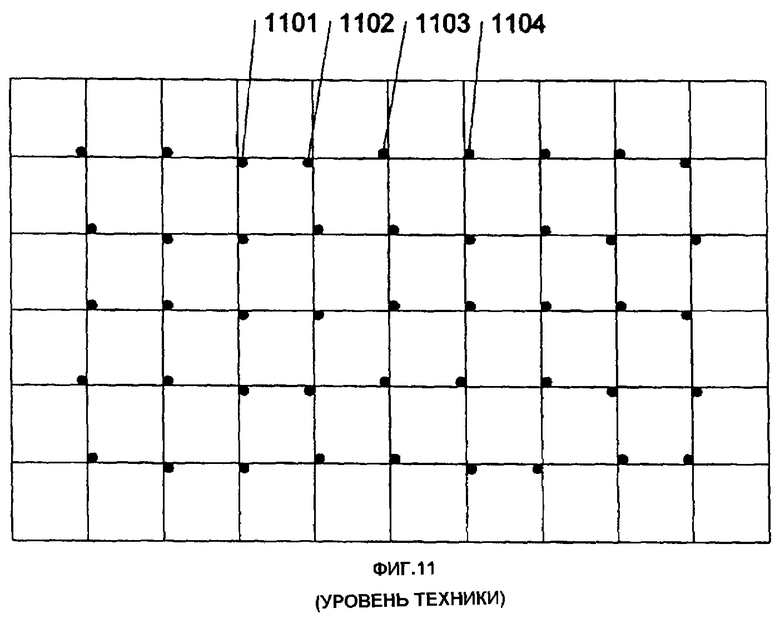
Способ “захвата” (ввода) рукописной информации состоит в использовании пера, местоположение которого можно определять во время записи. Одним из перьев, которое обеспечивает указанную способность, является перо Anoto, производимое компанией Anoto Inc. Упомянутое перо функционирует посредством использования камеры для захвата изображения бумаги, закодированного с заданным шаблоном. Пример шаблона изображения показан на фиг.11. Указанный шаблон используется пером Anoto (фирмы Anoto Inc.), для определения местоположения пера на участке бумаги. Однако непонятно, насколько эффективно определение местоположения для системы, использующей перо Anoto. Чтобы обеспечить эффективное определение местоположения захваченного изображения, нужна система, которая обеспечивает эффективное декодирование захваченного изображения.
Сущность изобретения
Аспекты настоящего изобретения обеспечивают решения, по меньшей мере, одного из вышеупомянутых пунктов, позволяя тем самым определять положение или положения захваченного изображения на просматриваемом документе с заданным шаблоном. Просматриваемый документ может быть размещен на бумаге, ЖКД экране или любой другой среде с заданным шаблоном. Аспекты настоящего изобретения включают процесс декодирования захваченного изображения, обеспечивающий возможность эффективного декодирования захваченного изображения, что обеспечивает эффективное определение местоположения изображения.
В одном аспекте настоящего изобретения, процесс декодирования тактично выбирает поднабор битов из битов, выделенных (извлеченных) из захваченного изображения. В другом аспекте настоящего изобретения процесс регулирует число итераций, которые выполняет процесс декодирования. В другом аспекте настоящего изобретения процесс определяет координаты X,Y местоположения выделенных (извлеченных) битов, так, чтобы X,Y координаты соответствовали локальному ограничению, например, области назначения. Эти и другие аспекты настоящего изобретения станут известными при рассмотрении следующих чертежей и соответствующего описания.
Краткое описание чертежей
В дальнейшем сущность изобретения поясняется описанием конкретных вариантов его воплощения со ссылками на сопровождающие чертежи, приложенные в качестве примера, но не ограничения, на которых:
фиг.1 изображает основные части компьютера, который может использоваться в вариантах воплощения настоящего изобретения,
фиг.2А и 2Б изображают систему захвата изображения и соответствующее захваченное изображение согласно вариантам воплощения настоящего изобретения,
фиг.3А-3Е изображают различные последовательности и способы свертывания согласно вариантам воплощения настоящего изобретения,
фиг.4А-4Д изображают различные системы кодирования согласно вариантам воплощения настоящего изобретения,
фиг.5А-5Г изображают четыре возможных результирующих угла, ассоциированных с системами кодирования согласно фиг.4А и 4Б,
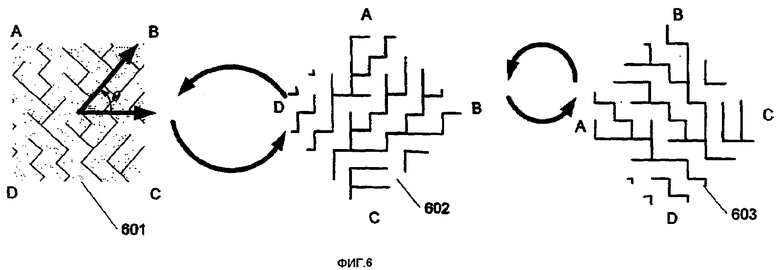
фиг.6 изображает вращение части захваченного изображения согласно вариантам воплощения настоящего изобретения,
фиг.7 изображает различные углы вращения, используемые в связи с системами кодирования фиг.4А-4Д,
фиг.8 изображает процесс определения местоположения захваченного массива согласно вариантам воплощения настоящего изобретения,
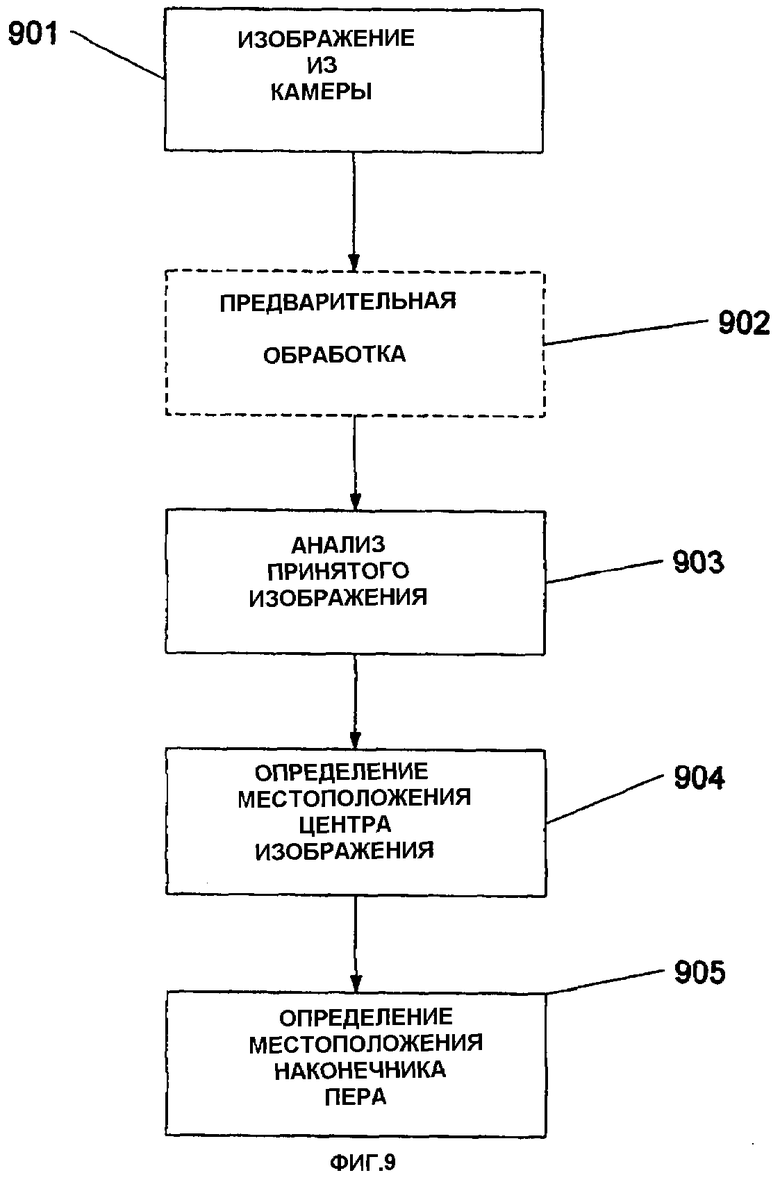
фиг.9 изображает способ определения местоположения захваченного изображения согласно вариантам воплощения настоящего изобретения,
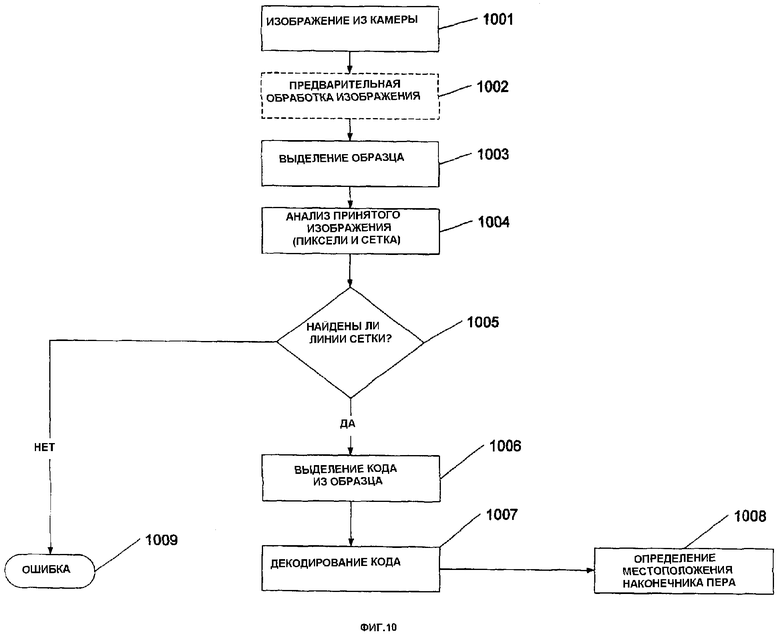
фиг.10 изображает другой способ определения местоположения захваченного изображения согласно вариантам воплощения настоящего изобретения,
фиг.11 изображает представление пространства кодирования в документе согласно уровню техники,
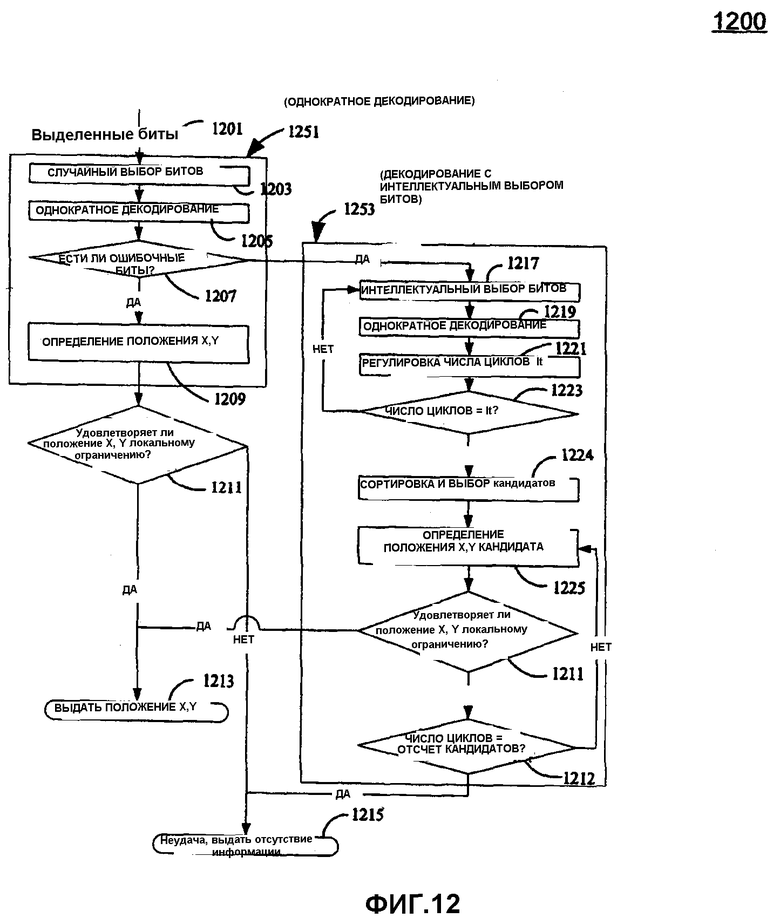
фиг.12 изображает блок схему процесса декодирования выделенных битов из захваченного изображения согласно вариантам воплощения настоящего изобретения,
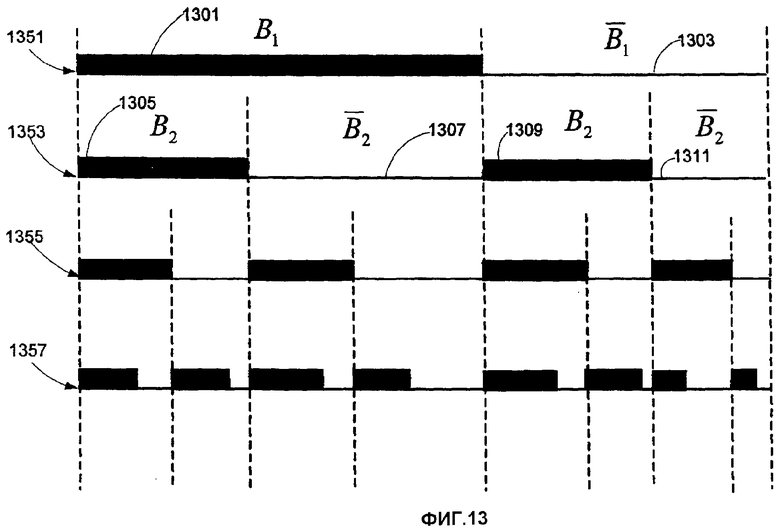
фиг.13 изображает битовый выбор извлеченных битов из захваченного изображения согласно вариантам воплощения настоящего изобретения,
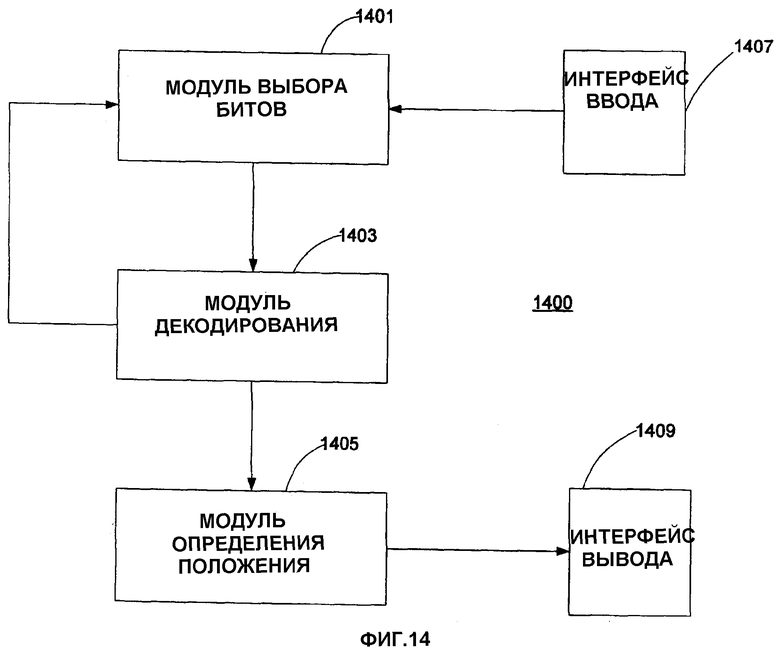
фиг.14 изображает устройство декодирования извлеченных битов из захваченного изображения согласно вариантам воплощения настоящего изобретения,
Подробное описание предпочтительных вариантов воплощения
Аспекты настоящего изобретения относятся к определению местоположения захваченного изображения относительно большего изображения. Способ и система определения местоположения, описанные здесь, могут использоваться в комбинации с многофункциональным пером.
Последующее описание разделено на подзаголовки для удобства читателем. Подзаголовки включают: термины, компьютер общего назначения, перо захвата изображения, кодирование массива, декодирование, исправление ошибок и определение местоположения.
Термины
Перо - любое средство записи, которое может иметь или не иметь способность хранить чернила. В некоторых примерах, согласно вариантам воплощения настоящего изобретения, может использоваться пишущий элемент без способности хранить чернила.
Камера - система захвата изображения, которая может захватывать изображение с бумаги или какой-либо другой среды.
Компьютер общего назначения
Фиг.1 изображает функциональную блок схему примера известной цифровой вычислительной среды общего назначения, которая может использоваться для осуществления различных аспектов настоящего изобретения. На фиг.1 изображено, что компьютер 100 содержит процессор 110, системную память 120 и системную шину 130, которая соединяет различные компоненты системы, включая системную память, к процессору 110. Системная шина 130 может быть любой из нескольких типов структур шин, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из множества архитектур шины. Системная память 120 содержит постоянное запоминающее устройство (ROM, ПЗУ) 140 и запоминающее устройство с произвольной выборкой (RAM, ЗУПВ) 150.
Базовая система ввода-вывода (BIOS) 160, содержащая базовые процедуры, которые помогают передавать информацию между элементами внутри компьютера 100, например, во время запуска, запоминается в ПЗУ 140. Компьютер 100 также содержит накопитель 170 на жестких дисках для считывания и записи на жесткий диск (не показан), дисковод 180 магнитных дисков для считывания и записи на сменный магнитный диск 190, дисковод 191 оптических дисков для считывания и записи на сменный оптический диск 192, такой, как например, компакт диск (CD ROM), или другие оптические носители. Накопитель 170 на жестких дисках, дисковод 180 магнитных дисков и дисковод 191 оптических дисков соединяются к системной шине 130 посредством интерфейса 192 накопителя на жестких дисках, интерфейса 193 дисковода магнитных дисков и интерфейса 194 дисковода оптических дисков соответственно. Накопители и их ассоциированные считываемые компьютером носители обеспечивают энергонезависимую память считываемых компьютером инструкций, структур данных, программных модулей и других данных для персонального компьютера 100. Специалистам должно быть понятно, что в иллюстративной операционной среде также можно использовать другие типы считываемых компьютером носителей, которые могут запоминать данные, которые доступны для компьютера, такие как, например, магнитные кассеты, карты флэш-памяти, цифровые видеодиски, картриджи Бернулли, запоминающие устройства с произвольной выборкой (ЗУПВ), постоянные запоминающие устройства (ПЗУ) и т.п.
Ряд программных модулей может запоминаться на накопителе 170 на жестких дисках, на магнитном диске 190, оптическом диске 192, ПЗУ 140 или ЗУПВ 150, включая операционную систему 195, одну или несколько прикладных программ 196, других программных модулей 197 и программных данных 198. Пользователь может вводить команды и информацию в компьютер 100 через устройства ввода, такие как клавиатура 101 и координатно-указательное устройство 102. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую клавиатуру, спутниковую антенну, сканер или т.п. Эти и другие устройства ввода часто подсоединяются к процессору 110 через интерфейс 106 последовательного порта, который соединяется к системной шине, но может соединяться другими интерфейсами, например, параллельным портом, игровым портом или универсальной последовательной шиной (USB). Кроме того, указанные устройства могут подсоединяться непосредственно к системной шине 130 через соответствующий интерфейс (не показан). Монитор 107 и другие типы устройств отображения также подсоединяются к системной шине 130 через интерфейс, например, видеоадаптер 108. В дополнение к монитору персональные компьютеры обычно содержат другие периферийные устройства вывода (не показаны), такие как, например, динамики и принтеры. В предпочтительном варианте воплощения для того, чтобы захватывать в цифровой форме ввод от руки, обеспечиваются цифровой преобразователь 165 пера и сопутствующее перо или пишущий элемент 166. Хотя показано непосредственное соединение между цифровым преобразователем 165 пера и последовательным портом, на практике, цифровой преобразователь 165 пера может соединяться непосредственно к процессору 110, либо через параллельный порт или другой интерфейс и системную шину, как известно в уровне технике. Кроме того, хотя цифровой преобразователь 165 показан отдельным от монитора 107, предпочтительно, чтобы используемая площадь ввода цифрового преобразователя 185 была общей с площадью отображения монитора 107. Более того, цифровой преобразователь 165 может быть интегрированным в мониторе 107 или может существовать в качестве отдельного устройства, совмещенного с монитором 107 или присоединенного к нему каким-либо другим способом.
Компьютер 100 может работать в сетевой среде, используя логические соединения к одному или нескольким удаленным компьютерам, например, удаленному компьютеру 109. Удаленный компьютер 109 может быть сервером, маршрутизатором, сетевым ПК, равноправным устройством или другим обычным сетевым узлом, и обычно содержит многие или все из элементов, описанных выше относительно компьютера 100, хотя на фиг.1 проиллюстрировано только запоминающее устройство 111. Логические соединения, изображенные на фиг.1, содержат локальную сеть (LAN) 112 и глобальную сеть (WAN) 113. Такие сетевые среды обычно имеют место в офисах, корпоративных компьютерных сетях, внутренних сетях и сети Интернет.
При использовании в сетевой среде LAN компьютер 100 подсоединяется к локальной сети 112 через сетевой интерфейс или адаптер 114. При использовании в сетевой среде WAN персональный компьютер 100 обычно содержит модем 115 или другое средство для установления связи по глобальной сети 113, такой как сеть Интернет. Модем 115, который может быть внутренним или внешним, подсоединяется к системной шине 130 через интерфейс 106 последовательного порта. В сетевой среде программные модули, изображенные относительно персонального компьютера 100, или его частей, может сохраняться в удаленном запоминающем устройстве.
Должно быть понятно, что показанные сетевые соединения являются иллюстративными, и могут использоваться другие способы для установления линии связи между компьютерами. Допускается существование любого из различных хорошо известных сетевых протоколов, таких как TCP/IP, Ethernet, FTP, HTTP, Bluetooth, IEEE 802.11x и т.д., и система может работать в конфигурации клиент-сервер, чтобы позволить пользователю осуществлять поиск web страниц из www-сервера. Для отображения и управления данными на web страницах могут использоваться любые из различных известных web браузеров.
Перо захвата изображения
Аспекты настоящего изобретения содержат представление потока закодированных данных в отображаемой форме, представляющей поток закодированных данных. (Например, описано обсуждаться со ссылкой на фиг.4Б, поток закодированных данных используется для создания графического шаблона.) Отображаемая форма может быть отпечатанной бумагой (или другим физическим носителем) или может быть дисплеем, проектирующим поток закодированных данных в сочетании с другим изображением или набором изображений. Например, поток закодированных данных может быть представлен в качестве физического графического изображения на бумаге, или графического изображения, наложенного на отображаемое изображение (например, представление текста документа), или может быть физическим (не модифицируемым) графическим изображением на экране дисплея (так, любая часть изображения, захваченного пером, является локализуемой на экране дисплея).
Указанное определение местоположения захваченного изображения может использоваться для определения местоположения взаимодействия пользователя с бумагой, носителем или экраном дисплея. В некоторых аспектах настоящего изобретения перо может быть чернильным пером, записывающим на бумаге. В других аспектах перо может быть пишущим элементом, а пользователь пишет на поверхности дисплея компьютера. Любое взаимодействие может быть введено обратно в систему со знанием закодированного изображения на документе или поддержкой документа, отображаемого на экране компьютера. Посредством многократного захвата изображений камерой в пере или пишущем элементе, по мере того, как перо или пишущий элемент проходят через документ, система может отслеживать движение пишущего элемента, управляемого пользователем. Отображаемое или отпечатанное изображение может быть водяным знаком, ассоциированным с бланком или бумагой с заполненным содержанием, или может быть водяным знаком, ассоциированным с отображаемым изображением, или фиксированным кодированием, наложенным на экран или встроенным в экран.
Фиг.2а и 2Б показывают иллюстративный пример пера 201 с камерой 203. Перо 201 включает в себя наконечник 202, который может содержать или не включать в себя резервуар чернил. Камера 203 захватывает изображение 204 с поверхности 207. Далее перо 201 может содержать дополнительные датчики и/или процессоры, представленные в заштрихованной рамке 206. Указанные датчики и/или процессоры 206 также могут обладать способностью передавать информацию другому перу 201 и/или персональному компьютеру (например, через протокол Bluetooth или другие протоколы беспроводной связи).
Фиг.2Б представляет изображение так, как оно видно камерой 203. В одном иллюстративном примере поле зрения камеры 203 (то есть разрешение датчика изображения камеры) составляет 32x32 пикселя (где N=32). В одном из вариантов воплощения захваченное изображение (32 пикселя на 32 пикселя) соответствует площади приблизительно 5 мм на 5 мм плоскости поверхности, захваченной камерой 203. Соответственно фиг.2Б показывает поле зрения 32 пикселя в длину на 32 пикселя в ширину. Размер N может регулироваться, так что большее N соответствует более высокому разрешению изображения. Также, хотя для иллюстративных целей поле зрения камеры 203 показано как квадрат, поле зрения может иметь любые формы, известные в уровне техники.
Изображения, захваченные камерой 203, могут быть заданы как последовательность кадров изображения {Ii}, где Ii захватывается пером 201 в момент времени дискретизации ti. Частота дискретизации может быть большой или малой в зависимости от конфигурации системы или эксплуатационных требований. Размер кадра захваченного (считанного) изображения может быть большим или малым в зависимости от конфигурации системы или эксплуатационных требований.
Изображение, захваченное (введенное) камерой 203, может использоваться непосредственно системой обработки или может подвергаться предварительной фильтрации. Предварительная фильтрация может происходить в пере 201, или может происходить вне пера 203 (например, в персональном компьютере).
Размер изображения, показанный на фиг.2Б, составляет 32×32 пикселя. Если размер каждого блока кодирования составляет 3×3 пикселя, то число захваченных закодированных блоков может составлять приблизительно 100 блоков. Если размер блока кодирования составляет 5×5 пикселей, то число захваченных закодированных блоков может составлять приблизительно 36.
Фиг.2А также показывает плоскость 209 изображения, на которой формируется изображение 210 образца из местоположения 204. Свет, принятый от образца на предметной плоскости 207, фокусируется линзой 208. Линза 208 может быть одной линзой или же многолинзовой системой, но здесь она представлена для простоты одной линзой. Датчик 211 захвата изображения захватывает изображение 210.
Датчик 211 изображения может быть достаточно большим, чтобы захватывать изображение 210. Альтернативно, датчик 211 изображения может быть достаточно большим, чтобы захватывать изображение наконечника 202 пера в местоположении 212. Для ссылки, изображение в местоположении 212 упоминается как виртуальный наконечник пера. Следует заметить, что местоположение виртуального наконечника пера относительно датчика 211 изображения является фиксированным, вследствие постоянного соотношения между наконечником пера, линзой 208 и датчиком 211 изображения.
Следующее преобразование FS→P преобразует координаты положения в изображении, захваченном камерой, в координаты положения в реальном изображении на бумаге:
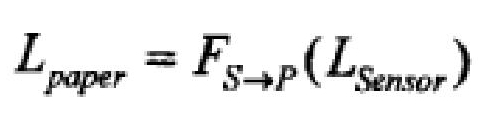
Во время записи наконечник пера и бумага находятся на одной плоскости. Соответственно преобразование из виртуального наконечника пера в реальный наконечник пера также является FS→P:
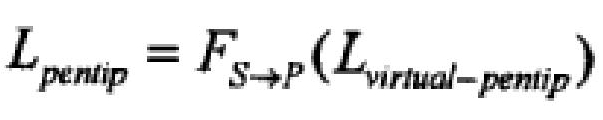
Преобразование FS→P может рассматриваться как аффинное преобразование. Оно упрощается как:
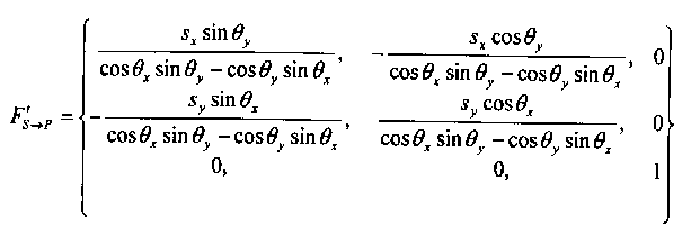
в качестве оценки FS→P, в которой θx, θy, sx и sy являются вращениями и масштабными множителями двух ориентаций образца, захваченного в местоположении 204. Далее, можно уточнить F'S→P путем согласования захваченного изображения с соответствующим реальным изображением на бумаге. 'Уточнить' означает получить более точную оценку преобразования FS→P посредством, например, алгоритма оптимизации, называемого как рекурсивный метод. Рекурсивный метод трактует матрицу F'S→P как исходное значение. Уточненная оценка описывает преобразование между S и P более точно.
Затем можно определить местоположение виртуального наконечника пера посредством калибровки.
Помещают наконечник 202 пера в фиксированное местоположение Lpentip на бумаге. Далее наклоняют перо, позволяя камере 203 захватить ряд изображений с различными положениями пера. Для каждого захваченного изображения можно получить преобразование FS→P. Из этого преобразования можно получить местоположение виртуального наконечника пера Lvirtual-pentip:
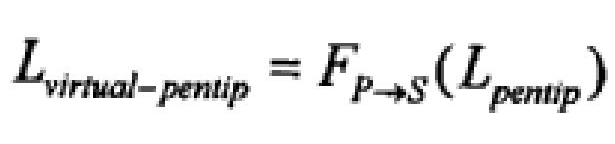
где Lpentip инициализируется как (0,0) и
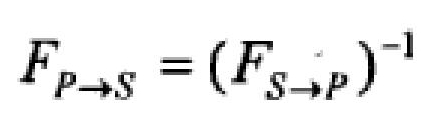
Усредняя Lvirtual-pentip, полученные из каждого изображения, можно определить местоположение виртуального наконечника пера Lvirtual-pentip. С известным Lvirtual-pentip можно получить более точную оценку Lpentip. После нескольких итераций можно определить точное местоположение виртуального наконечника пера Lvirtual-pentip.
Теперь известно местоположение виртуального наконечника пера Lvirtual-pentip. Можно также получить преобразование FS→P из захваченных изображений. Наконец, можно использовать эту информацию для определения местоположения реального наконечника пера Lpentip:
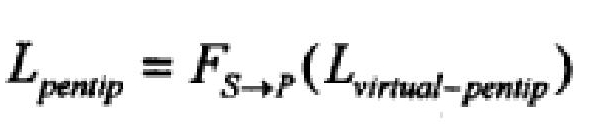
Кодирование массива
Двумерный массив можно сконструировать посредством свертывания одномерной последовательности. Любая часть двумерного массива, содержащая достаточно большое число битов, может быть использована для определения его местоположения в полном двумерном массиве. Однако может оказаться необходимым определять местоположение из захваченного изображения или нескольких захваченных изображений. Итак, чтобы минимизировать вероятность части захваченного изображения, ассоциированной с двумя или более местоположениями в двумерном массиве, для создания массива можно использовать не повторяющуюся последовательность. Одно свойство созданной последовательности состоит в том, что последовательность не повторяется на длине (или окне) n. Ниже описывается создание одномерной последовательности при свертывании последовательности в массив.
Построение последовательности
Последовательность чисел может использоваться в качестве начальной точки системы кодирования. Например, последовательность (также упоминаемая как m-последовательность) может быть представлена как q-элементный набор в поле Fq. Здесь q=pn, где n≥1 и p является простым числом. Последовательность или m-последовательность может генерироваться посредством множества различных методов, включая, но не ограничиваясь, полиномиальным делением. Используя полиномиальное деление, можно задать последовательность следующим образом.
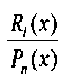
где Pn(x) является примитивным многочленом степени n в поле Fq[x] (имеющим qn элементов). Rl(x) является ненулевым многочленом степени l (где l<n) в поле Fq[x]. Последовательность может быть создана с использованием итеративной процедуры с двумя шагами: первый, деление двух полиномов (приводящее к элементу поля Fq), и второй, умножение остатка на x. Вычисление останавливается, когда выходное значение начинает повторяться. Данный процесс может быть выполнен, используя регистр сдвига с линейной обратной связью, описанный в статье Douglas W. Clark и Lih-Jyh Weng: "Maximal and Near-Maximal Shift Register Sequences: Efficient Event Counters and Easy Discrete Logarithms," IEEE Transactions on Computers 43.5 (May 1994, pp 560-568). В такой среде устанавливается соотношение между циклическим сдвигом последовательности и полинома Rl(x): изменение Rl(x) только циклически сдвигает последовательность, и каждый циклический сдвиг соответствует полиному Rl(x). Одно из свойств результирующей последовательности состоит в том, что последовательность имеет период qn-1, и в пределах периода, по ширине (или длине) n, любая часть встречается в последовательности один и только один раз. Это называется "свойством окна". Период qn-1 также называется длиной последовательности, а n порядком последовательности.
Вышеописанный процесс является одним из множества процессов, которые могут быть использованы для создания последовательности со свойством окна.
Построение массива
Массив (или m-массив), который может быть использован для создания изображения (часть которого может быть захвачена камерой), является расширением одномерной последовательности или m-последовательности. Пусть A является массивом с периодом (m1, m2), а именно  Когда окно n1×n2 сдвигается на период A, все ненулевые матрицы n1×n2 по Fq появляются только один раз. Указанное свойство также называется "свойством окна", при котором каждое окно является уникальным. Затем окно может быть выражено как массив с периодом (m1, m2) (где m1 и m2 являются горизонтальным и вертикальным числами битов, присутствующих в массиве) и порядком (n1, n2).
Когда окно n1×n2 сдвигается на период A, все ненулевые матрицы n1×n2 по Fq появляются только один раз. Указанное свойство также называется "свойством окна", при котором каждое окно является уникальным. Затем окно может быть выражено как массив с периодом (m1, m2) (где m1 и m2 являются горизонтальным и вертикальным числами битов, присутствующих в массиве) и порядком (n1, n2).
Двоичный массив (или m-массив) может быть построен посредством свертывания последовательности. Один подход состоит в том, чтобы получить последовательность при свертывании ее до размера m1×m2, где длина массива равна L=m1×m2=2n-1. Альтернативно, можно начать с заданного размера пространства, которое нужно охватить (например, один лист бумаги, 30 листов бумаги или размер монитора компьютера), определить площадь (m1×m2), затем использовать размер, допуская
L≥m1×m2, где L=2n-1.
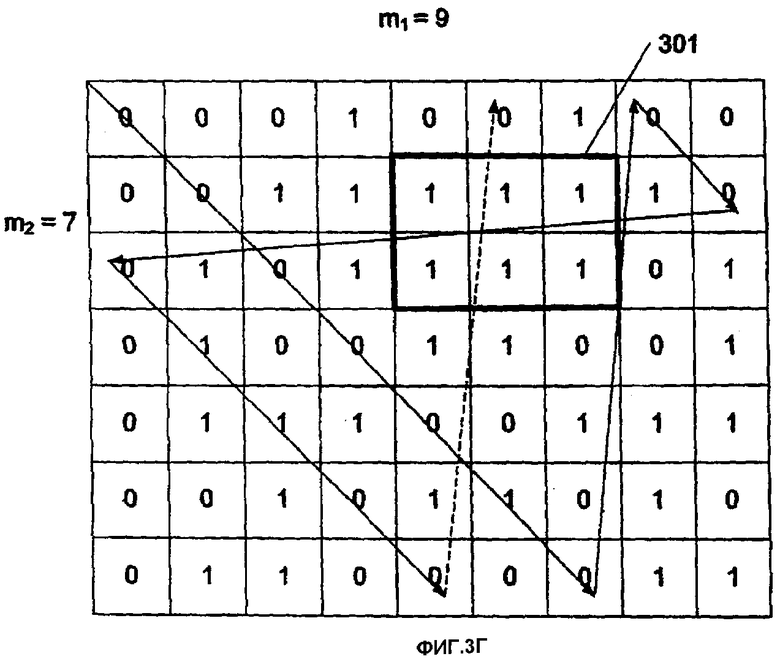
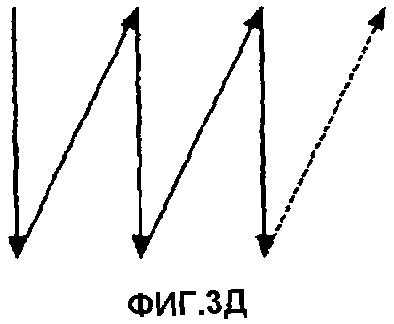
Можно использовать множество различных методов свертывания. Например, фиг.3А-3В изображают три различные последовательности. Каждая из них может быть свернута в массив, показанный фиг.3Г. Три различных способа свертывания показаны в виде рисунка на фиг.3Г и как траектории растра на фиг.3Д и 3Е. В настоящем изобретении принят метод свертывания, показанный на фиг.3Г.
Для создания способа свертывания, как показано на фиг.3Г, создают последовательность {ai} с длиной L и порядком n. Далее создается массив {bkl} размером m1×m2, где наибольший общий делитель gcd(m1, m2)=1 и L=m1×m2 создаются из последовательности {ai}, путем вычисления каждого бита этого массива как показано в уравнении 1:
b kl=a i, где k=i mod(m 1), l=i mod(m 2), i=0, …, L-1. (1).
Подход свертывания может быть альтернативно выражен как размещение последовательности на диагонали массива, затем продолжение от противоположного края, когда достигается край.
Фиг.4А показывает способы кодирования, которые могут быть использованы для кодирования массива фиг.3Г. Понятно, что можно использовать другие способы кодирования. Например, альтернативный способ кодирования показан на фиг.11.
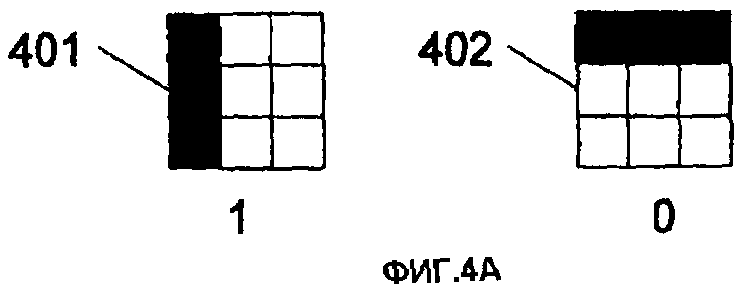
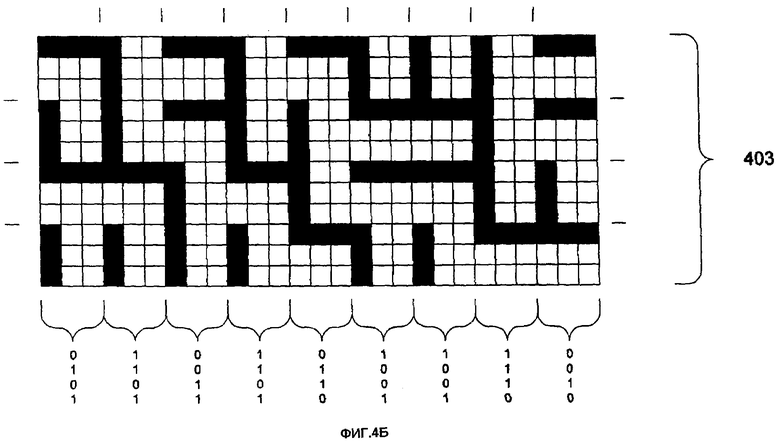
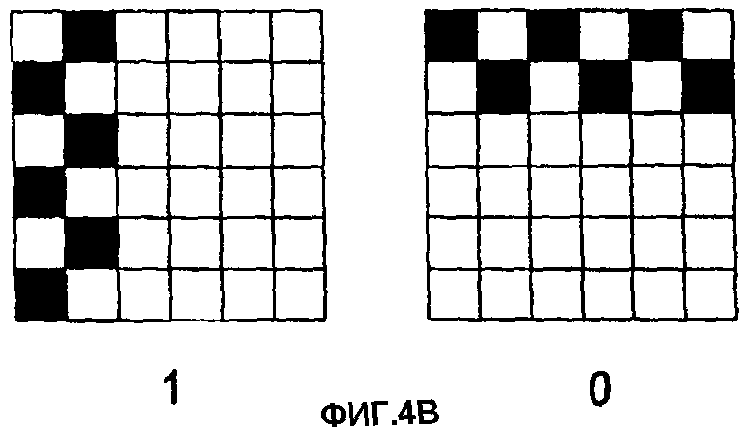
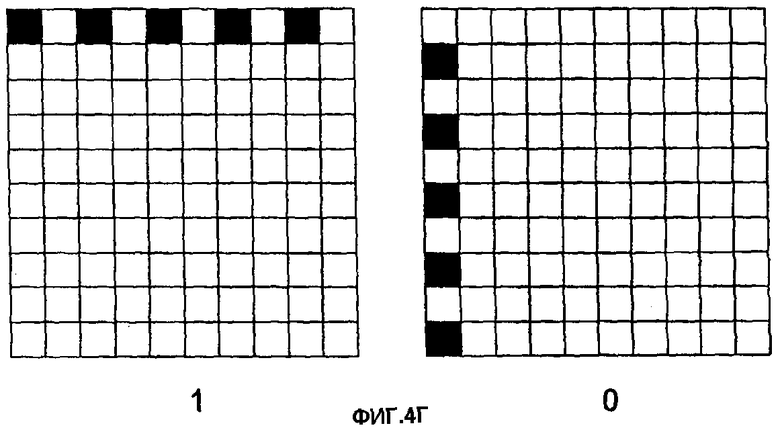
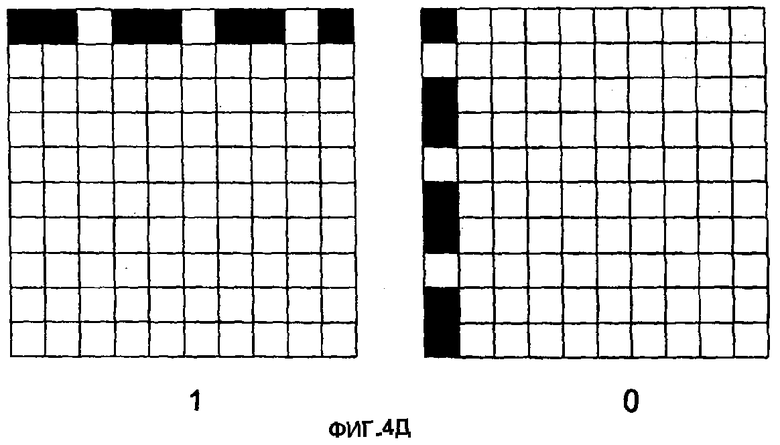
На фиг.4А, первый бит 401 (например, "1") представлен столбцом темных чернил (краски). Второй бит 402 (например, "0") представлен строкой темных чернил (краски). Понятно, что для представления различных битов можно использовать любые цветные чернила. Единственное требование к цвету чернил состоит в том, чтобы они обеспечивали значительный контраст с фоном носителя, чтобы различаться системой захвата изображения. Биты на фиг.4А представлены матрицей 3×3 клеток. Размер матрицы может быть модифицирован, чтобы иметь любой размер на основе размера и разрешения системы захвата изображения. Альтернативное представление битов 0 и 1 показано на фиг.4В-4Д. Понятно, что представление единицы или нуля для иллюстративного кодирования фиг.4А-4Д может переключаться без изменения результата. Фиг.4В показывает представления битов, занимающие две строки и два столбца в перемежающейся компоновке. Фиг.4Г показывает альтернативную компоновку пикселей в строках и столбцах в заштрихованной форме. Наконец, фиг.4Д показывает представления в строках и столбцах нерегулярного формата разнесения (например, две темные точки, за которыми следует белая точка).
На фиг.4А, если бит представлен матрицей 3×3 и система формирования изображения обнаруживает темную строку и две белых строки в области 3×3, то детектируется ноль (или единица). Если обнаруживается изображение с темным столбцом и двумя белыми столбцами, то детектируется единица (или ноль).
Здесь для представления бита используется больше одного пикселя или точки. Использование единственного пикселя (или бита) для представления бита является неудачным. Пыль, сгибы на бумаге, неплоских поверхностях и т.д. создают трудности считывания однобитовых представлений модулей данных. Однако понятно, что для графического представления массива на поверхности можно использовать различные подходы. Некоторые подходы показаны на фиг.4 В-4Д. Понятно, что также могут быть использованы другие подходы. На фиг.11 представлен подход, использующий только сдвинутые в пространстве точки.
Поток битов используется для создания графических образцов 403 фиг.4Б. Графический образец 403 содержит 12 строк и 18 столбцов. Строки и столбцы формируются потоком битов, который преобразуется в графическое представление, используя представления 401 и 402 битов. Фиг.4Б может рассматриваться в качестве имеющих следующее представление битов:
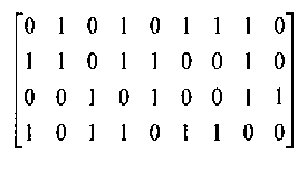
Декодирование
Когда человек пишет пером согласно фиг.2А или перемещает перо близко к закодированному образцу, камера захватывает изображение. Например, в пере 201 может использоваться датчик давления, когда перо 201 нажимает на бумагу и перо 201 пересекает документ на бумаге. Затем изображение обрабатывается для определения ориентации захваченного изображения относительно полного представления закодированного изображения и для выделения битов, которые составили захваченное изображение.
Что касается определения ориентации захваченного изображения относительно полной закодированной площади, следует отметить, что не все четыре возможных угла, показанных на фиг.5А-5Г, могут быть представлены на графическом образце 403. В действительности при правильной ориентации тип угла, показанного на фиг.5А, не может существовать на графическом образце 403. Следовательно, ориентация, в которой отсутствует тип угла, показанный на фиг.5А, является правильной ориентацией.
Как показано на фиг.6, изображение, захваченное камерой 601, может анализироваться, и его ориентация может определяться так, чтобы быть интерпретируемой в отношении положения, реально представленного изображением 601. Сначала изображение 601 просматривается, чтобы определить угол θ, необходимый для вращения изображения, так чтобы пиксели были выстроены горизонтально и вертикально. Следует отметить, что возможны альтернативные ориентации сетки, включая вращение нижележащей сетки в негоризонтальное и вертикальное расположение (например, 45 градусов). Использование негоризонтального и вертикального расположения может обеспечить вероятную выгоду устранения визуального отвлечения внимания пользователя, когда пользователи могут иметь тенденцию отмечать горизонтальные и вертикальные картины среди других. Для простоты, ориентация сетки (горизонтальная и вертикальная или любой другой поворот нижележащей сетки) в целом называется как заданная ориентация сетки.
Далее, изображение 601 анализируется для определения того, какой угол отсутствует. Величина о поворота, необходимая для вращения изображения 601 до изображения, готового для декодирования 603, показана как о=((плюс величина поворота {заданная тем, какой угол отсутствует}). Величина (значение) поворота показана уравнением на фиг.7. Возвращаясь к фиг.6, угол (сначала определяется расположением пикселей для достижения горизонтального и вертикального (или другой заранее заданной ориентации сетки) расположения пикселей, и изображение вращается, как показано позицией 602. Затем проводится анализ для определения отсутствующего угла, и изображение 602 вращается до изображения 603, чтобы установить изображение для декодирования. Здесь изображение поворачивается на 90 градусов против часовой стрелки так, чтобы изображение 603 имело правильную ориентацию и могло использоваться для декодирования.
Понятно, что угол θ поворота может применяться до или после вращения изображения 601, чтобы учесть отсутствующий угол. Также понятно, что посредством рассмотрения шума в захваченном изображении могут быть представлены все четыре типа углов. Можно посчитать число углов каждого типа и выбрать тип, который имеет наименьше число, в качестве отсутствующего угла.
Наконец, код в изображении 603 считывается и коррелируется с исходным битовым потоком, использованном для создания изображения 403. Корреляция может выполняться нескольким способами. Например, она может выполняться рекурсивным подходом, в котором восстановленный битовый поток сравнивается со всеми другими фрагментами битового потока в пределах исходного битового потока. Во-вторых, статистический анализ может выполняться между восстановленным битовым потоком и исходным битовым потоком, например, используя расстояние Хемминга между двумя битовыми потоками. Понятно, что для определения местоположения восстановленного битового потока в пределах исходного битового потока можно использовать множество разнообразных подходов.
Как только получены восстановленные биты, необходимо локализовать (определить местоположение) захваченное изображение в пределах исходного массива (например, как показано на Фиг.4Б). Процесс определения местоположения сегмента битов в переделах полного массива осложняется рядом факторов. Первое, действительные биты, которые должны быть захвачены, могут быть нечеткими (например, камера может захватывать изображение с рукописью, которое закрывает исходный код). Во-вторых, пыль, сгибы, отражения и т.п. также могут создавать ошибки в захваченном изображении. Указанные ошибки затрудняют процесс локализации. В этом отношении система захвата изображения должна функционировать с непоследовательными битами, выделенными из изображения. Далее представлен способ для работы с непоследовательными битами из изображения.
Допустим, последовательность (или m-последовательность) I соответствует степенному ряду I(x)=1/Pn(x), где n - порядок m-последовательности, и захваченное изображение содержит K битов последовательности I b=(b0 b1 b2 ••• bK-1)t, где K≥n, а показатель степени t представляет транспонирование матрицы или вектора. Местоположение s из K битов как раз является числом циклических сдвигов последовательности I, так что bо сдвигается к началу последовательности. Эта сдвинутая последовательность R соответствует степенному ряду xs/Pn(x), или R=Ts(I), где T представляет собой оператор циклического сдвига. Авторы нашли s косвенно. Полиномы по модулю Pn(x) формируют поле. Гарантируется, что x s ≡r 0 +r 1 x+…r n-1 x n-1 mod(P n (x)). Следовательно, находим (r0, r1, …, rn-1) и затем находим решение для s.
Соотношение x s ≡r 0 +r 1 x+…r n-1 x n-1 mod(P n (x)) подразумевает, что R=r 0 +r 1 T(I)+…+r n-1 T n-1(I). Записанное в виде бинарного линейного уравнения, выражение становится:
R=rtA (2)
где r=(r0, r1, …, rn-1)t, и A=(I T(I)…T n-1(I))t, которое состоит из циклических сдвигов последовательности I от 0-сдвига до (n-l)-сдвига. Теперь в последовательности R доступны только разбросанные K битов для решения r. Допустим, разность показателей между bt и b0 в последовательности R составляет ki, где i=1, 2, …, k-1, тогда 1-ый и (k i+1) элементы последовательности R, где i=1, 2, …, k-1, равны в точности b 0 , b 1 , …, b k-1. Выбирая 1-ый и (k i+1) столбцы матрицы A, где i=1, 2, …, k-1, получается следующее бинарное линейное уравнение:
bt=rtM (3)
где M является подматрицей размерностью n×K матрицы A.
Если b не содержит ошибок, то решение для r может быть записано в виде:
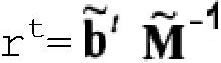
где 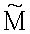 представляет собой невырожденную подматрицу матрицы М размерностью n×n, а
представляет собой невырожденную подматрицу матрицы М размерностью n×n, а 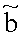 представляет собой соответствующий субвектор b.
представляет собой соответствующий субвектор b.
Зная r, можно использовать алгоритм Полига-Хеллмана-Сильвера (Pohlig-Hellman-Silver), как было отмечено Douglas W. Clark и Lih-Jyh Weng в работе: "Maximal and Near-Maximal Shift Register Sequences: Efficient Event Counters and Easy Discrete Logorithms", IEEE Transactions on Computers 43.5 (May 1994, pp.560-568), чтобы найти s, так что:
x s ≡r 0 +r 1 x+…r n-1 x n-1 mod(P n (x)).
Поскольку матрица A (размером n×L, где L=2n-1) может оказаться огромной, следует избегать хранения всей матрицы A. Действительно, как было видно в вышеприведенном процессе, принимая во внимание выделенные биты с разностью индексов ki, для расчетов нужны только первый и (ki+1)-й столбцы матрицы A. Такой выбор ki является достаточно ограниченным, принимая во внимание размер захваченного изображения. Таким образом, нужно сохранять только те столбцы, которые могут использоваться в расчетах. Общее число указанных столбцов оказывается намного меньше, чем L (где L=2n-1 - длина m-последовательности).
Исправление ошибок
Если в b имеются ошибки, то нахождение решения для r становится более сложным. Традиционные способы декодирования с исправлением ошибок не могут быть непосредственно использованы, поскольку матрица M, ассоциированная с захваченными битами, может изменяться от одного захваченного изображения к другому.
Авторы приняли стохастический подход. Полагая, что число ошибочных битов ne в b является относительно небольшим по сравнению с K, в этом случае вероятность выбора правильных n битов из K битов b и соответствующей подматрицы невырожденной матрицы M является высокой.
Если все выбранные n битов являются правильными, то расстояние Хэмминга между bt и rtM, или число ошибочных битов, ассоциированных с r, должно быть минимальным, где r вычисляется с помощью уравнения (4). Весьма вероятно, что, повторяя процесс несколько раз, может быть установлено правильное значение r, приводящее к минимальному числу ошибочных битов.
Если существует только одно r, ассоциированное с минимальным числом ошибочных битов, то оно рассматривается в качестве правильного решения. В противном случае, если существует более одного r, ассоциированного с минимальным числом ошибочных битов, то высока вероятность того, что ne превышает способность исправления ошибок кода, генерируемого посредством M, и процесс декодирования оказывается неудачным. Далее система может перейти к обработке следующего захваченного изображения. В другом варианте воплощения может быть принята во внимание информация о предыдущем местоположении пера. То есть для каждого захваченного изображения может быть идентифицирована область местонахождения (область назначения), в которой перо можно ожидать в будущем. Например, если пользователь не поднимает перо между двумя захватами камерой, местоположение пера, определенное посредством второго захвата изображения, не должно быть слишком далеко от первого местоположения. Каждое значение r, ассоциированное с минимальным числом ошибочных битов, может быть далее проверено, чтобы узнать, удовлетворяет ли местоположение s, вычисленное исходя из r, локальным ограничениям, т.е. находится ли местоположение в пределах заданной области назначения.
Если местоположение s удовлетворяет локальным ограничениям, то выдаются положения (позиции) X,Y выделенных (извлеченных) битов в массиве. Если нет, то процесс декодирования оказывается неудачным.
Фиг.8 изображает процесс, который может быть использован для того, чтобы определить местоположение захваченного изображения в последовательности (или m-последовательности). Сначала, на этапе 801, принимается поток данных, относящихся к захваченному изображению. На этапе 802 соответствующие столбцы выделяются (извлекаются) из матрицы A и строится матрица M.
На этапе 803 из матрицы M случайным образом выделяются n независимых столбцов векторов и, решая уравнение (4), определяют вектор r. Указанный процесс выполняется Q раз (например, 100 раз) на этапе 804. Определение числа циклов рассматривается в разделе “Вычисление числа циклов”.
На этапе 805 значение r сортируется в соответствии с ассоциированным числом ошибочных битов. Сортировка может быть проведена посредством использования множества разнообразных сортирующих алгоритмов, известных в уровне техники. Например, может быть использован алгоритм сортировки методом выбора. Алгоритм сортировки методом выбора является предпочтительным, когда число Q невелико. Однако, если Q становится большим, то могут быть использованы другие алгоритмы сортировки (например, сортировка слиянием), которые более эффективно обрабатывают большее число признаков.
Затем, на этапе 806 система определяет, было ли успешно выполнено исправление ошибок, посредством проверки того, ассоциированы ли многочисленные r с минимальным числом ошибочных битов. Если да, то ошибка выдается на этапе 809, показывая, что процесс декодирования потерпел неудачу. Если нет, то положение s выделенных битов в последовательности вычисляется на этапе 807, например, путем использования алгоритма Pohig-Hellman-Silver.
Далее вычисляется положение (X,Y) в массиве как x=s mod m1 и y=s mod m2, и результаты выдаются на этапе 808.
Определение местоположения
Фиг.9 изображает процесс определения местоположения наконечника пера. Входными данными являются изображение, захваченное камерой, а выходными значениями могут быть координаты положения наконечника пера. Также выходные значения могут содержать (или нет) другую информацию, такую как угол поворота захваченного изображения.
На этапе 901 изображение принимается из камеры. Далее, принятое изображение может быть дополнительно предварительно обработано на этапе 902 (как показано штрихованным контуром этапа 902) для регулировки контраста между светлыми и темными пикселями и т.п.
Далее, на этапе 903 изображение анализируется для определения битового потока в нем.
Далее, на этапе 904 из битового потока многократно случайным образом выбираются n битов, и определяется местоположение принятого битового потока в исходной последовательности (или m-последовательности).
Наконец, как только на этапе 904 определено местоположение захваченного изображения, может быть определено местоположение наконечника пера на этапе 905.
Фиг.10 дает детали этапов 903 и 904, и показывает подход для выделения (извлечения) битового потока в пределах захваченного изображения. Во-первых, на этапе 1001 изображение принимается из камеры. Затем изображение может быть дополнительно подвергнуто предварительной обработке на этапе 1002 (как показано штрихованным контуром этапа 1002). Образец выделяется на этапе 1003. Здесь могут быть выделены пиксели на различных линиях, чтобы найти ориентацию образца и угол θ.
Далее, принятое изображение анализируется на этапе 1004, чтобы определить нижележащие линии сетки. Если на этапе 1005 линии сетки найдены, то на этапе 1006 выделяется (извлекают) код из образца. Затем код декодируется на этапе 1007, и на этапе 1008 определяется местоположение наконечника пера. Если на этапе 1005 не были найдены линии сетки, то на этапе 1009 выдается ошибка.
Обзор улучшенного декодирования и алгоритма исправления ошибок
В случае варианта воплощения настоящего изобретения, изображенного на фиг.12, при наличии выделенных битов 1201 из захваченного (полученного) изображения (соответствующих захваченному массиву) и области назначения, вариация процесса декодирования массива исправления ошибок декодирует положение X,Y. Фиг.12 изображает блок схему алгоритма процесса 1200 данного улучшенного подхода. Процесс 1200 содержит два компонента 1251 и 1253.
Однократное декодирование
Компонент 1251 содержит три части:
- случайный выбор битов: случайно выбирает поднабор выделенных битов 1201 (этап 1203)
- декодирует поднабор (этап 1205)
- определяет положение X,Y с локальным ограничением (этап 1209).
Декодирование с логической (интеллектуальной) процедурой выбора битов
Компонент 1253 содержит четыре части:
- логическая процедура выбора битов: выбирает другой поднабор выделенных битов (этап 1217)
- декодирует поднабор (этап 1219)
- регулирует число итераций (число циклов) этапа 1217 и этапа 1219 (этап 1221)
- определяет положение X,Y с локальным ограничением (этап 1225).
Вариант воплощения настоящего изобретения использует дискретную стратегию к выбранным битам, регулирует число итераций цикла и определяет положение X,Y (координаты местоположения) согласно локальному ограничению, которое обеспечивается для процесса 1200. В обоих компонентах 1251 и 1253, этапы 1205 и 1219 ("Однократное декодирование") используют уравнение (4) для вычисления r.
Пусть 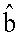 представляет собой декодированные биты, то есть:
представляет собой декодированные биты, то есть:
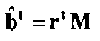 (5)
(5)
Разность между b и представляет собой ошибочные биты, ассоциированные с r.
Фиг.12 изображает блок схему алгоритма процесса 1200 декодирования выделенных битов 1201 из захваченного изображения в соответствии с вариантами воплощения настоящего изобретения. Процесс 1200 содержит компоненты 1251 и 1253. Компонент 1251 получает выделенные биты 1201 (содержащие K битом), ассоциированные с захваченным изображением (соответствующим захваченным массивом). На этапе 1203 n битов (где n - порядок m - массива) случайно выбираются из выделенных битов 1201. На этапе 1205 осуществляется процесс 1200 однократного декодирования и вычисляется r. На этапе 1207 процесс 1200 определяет, обнаружены ли ошибочные биты для b. Если этап 1207 определяет, что нет никаких ошибочных битов, то на этапе 1209 определяются координаты положения X,Y захваченного массива. На этапе 1211 если координаты X,Y удовлетворяют локальному ограничению, то есть координатам, расположенным в пределах области назначения, то процесс 1200 на этапе 1213 выдает местоположение X,Y (например, другому процессу или пользовательскому интерфейсу). В противном случае этап 1215 обеспечивает индикацию неудачи.
Если этап 1207 обнаруживает в b ошибочные биты, то выполняется компонент 1253 процесса, чтобы осуществить декодирование с ошибочными битами. Этап 1217 выбирает другой набор n битов (отличающийся, по меньшей мере, одним битом из n битов, выбранных на этапе 1203) из выделенных битов 1201. Этапы 1221 и 1223 определяют число итераций (число циклов), которые необходимы для декодирования выделенных битов. Этап 1225 определяет положение захваченного массива посредством проверки, какой из кандидатов, полученных на этапе 1219, удовлетворяет локальному ограничению. Этапы 1217-1225 будут обсуждаться более подробно.
Логическая (интеллектуальная) процедура выбора битов
На этапе 1203 случайным образом выбирается n битов из выделенных (извлеченных) битов 1201 (имеющих K битов), и находится решение для r1. Используя уравнение (5), могут быть рассчитаны декодированные биты. Пусть 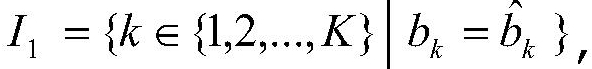
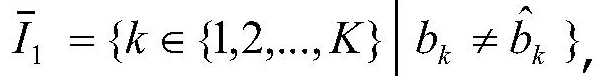
где 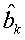 является k-ым битом ,
является k-ым битом , 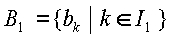 и
и 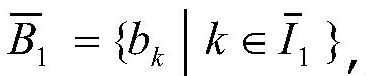
то есть B1 являются теми битами, у которых декодированные результаты те же самые, что и у исходных битов, а 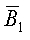 являются битами, для которых результаты декодирования отличаются от исходных битов, I1 и
являются битами, для которых результаты декодирования отличаются от исходных битов, I1 и 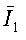 - соответствующие индексы указанных битов. Понятно, что если какие-либо n битов выбраны из B1, то будет получен один и тот же вектор r1. Поэтому, если следующие n битов не были тщательно выбраны, возможно, что выбранные биты являются поднабором B1, таким образом, давая в результате тот же самый r1.
- соответствующие индексы указанных битов. Понятно, что если какие-либо n битов выбраны из B1, то будет получен один и тот же вектор r1. Поэтому, если следующие n битов не были тщательно выбраны, возможно, что выбранные биты являются поднабором B1, таким образом, давая в результате тот же самый r1.
Чтобы избежать такой ситуации, на этапе 1217 выбирают следующие n битов согласно следующей процедуре.
1. Выбрать, по меньшей мере, один бит из 1303, а остальные биты - случайным образом из B1 1301 и 1303, как показано на фиг.13, соответствующей расположению 1351 битов. Затем процесс 1200 определяет решение r2 и находит B1 1305, 1309 и 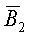 1307, 1311 посредством вычисления
1307, 1311 посредством вычисления 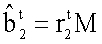 .
.
2. Повторить этап 1. При выборе следующих n битов, для каждого 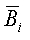 (i=1, 2, 3, …, x-1, где х - текущий номер цикла), имеется, по меньшей мере, один бит, выбранный из .
(i=1, 2, 3, …, x-1, где х - текущий номер цикла), имеется, по меньшей мере, один бит, выбранный из .
Итерации прекращаются, когда не может быть выбрано никакого поднабора битов, или когда достигнуто число циклов.
Вычисление числа циклов
В случае использования компонента 1253 исправления ошибок, число требуемых итераций (число циклов) регулируется после каждого цикла. Число циклов определяется исходя из ожидаемой частоты появления ошибок. Ожидаемая частота p e появления ошибок, в которой не все выбранные n битов являются правильными, выражается формулой
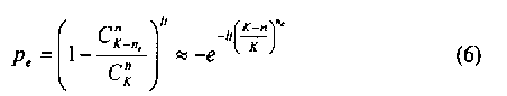
где lt представляет собой число циклов, которое устанавливается равным константе, K - число выделенных битов из захваченного массива, ne представляет минимальное число ошибочных битов, полученных в ходе итерации процесса 1200, n - порядок m-массива, а 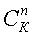 - число комбинаций, в которых n бит выбраны из К бит.
- число комбинаций, в которых n бит выбраны из К бит.
В варианте воплощения изобретения величина pe задается меньшей, чем е-5=0,0067. В комбинации с уравнением (6), имеем:
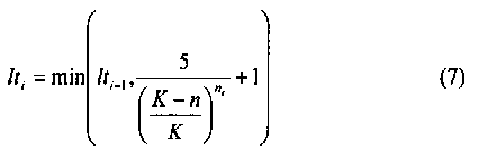
Регулирование числа циклов может существенно уменьшить число итераций процесса 1253, необходимых для исправления ошибок.
Определение X,Y положения с учетом локального ограничения
На этапах 1209 и 1225 декодированное положение должно находиться в области назначения. Область назначения является входными данными для алгоритма, и она может иметь различные размеры и участки или просто быть представлена всем m-массивом, в зависимости от различных приложений. Обычно она может быть спрогнозирована приложением. Например, если предыдущее положение определено, то с учетом скорости записи область назначения текущего положения наконечника пера должна быть близка к предыдущему положению. Однако, если перо поднято, то следующее его местоположение может быть в любом месте. Таким образом, в данном случае область назначения должна быть всем m-массивом. Правильное X,Y положение определяется посредством следующих этапов.
На этапе 1224 процесс 1200 выбирает такие ri, у которых соответствующее число ошибочных битов менее чем:
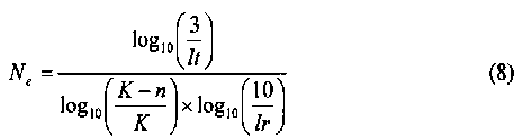
где lt - фактическое число циклов, а lr представляет частоту локального ограничения, вычисляемую посредством соотношения:
lr=(площадь области назначения)/L,
где L - длина m-массива.
На этапе 1224 сортируют ri в порядке возрастания числа ошибочных битов. Затем, на этапах 1225, 1211 и 1212 находится первый вектор ri, в котором соответствующее положение X,Y находится в пределах области назначения. Этапы 1225, 1211 и 1212 в конечном итоге выдают положение X,Y в качестве результата (этап 1213), или показывают, что процедура декодирования оказалась неудачной (этап 1215).
Иллюстративный пример улучшенного декодирования и процесса исправление ошибок
Иллюстративный пример демонстрирует процесс 1200, выполняемый компонентами 1251 и 1253. Предположим, n=3, K=5, I=(I0, I1, …, I6)t является m-последовательностью порядка n=3. Тогда
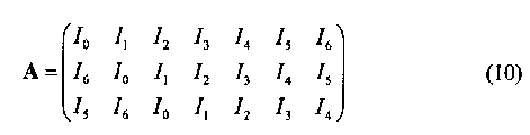
Также предположим, что выделенные биты b=(b0, b1, b2, b3, b4)t, где K=5, являются фактически s-ым, (s+1)-ым, (s+3)-ым, (s+4)-ым, и (s+6)-ым битами m-последовательности (указанные числа являются фактически модулями m-массива длиной L=2n-l=23-l=7). Таким образом,
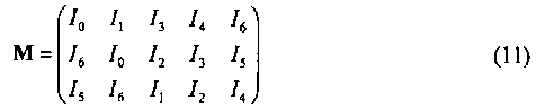
которая состоит из 0-го, 1-го, 3-го, 4-го, и 6-го столбцов матрицы А. Число s, которое уникально определяет положение X,Y b0 в m-массиве, может быть вычислено после нахождения решения r=(r0, r1, r2)t, которое, как ожидается, будет удовлетворять соотношению bt=rtM. Вследствие возможных ошибочных битов в b соотношение bt=rtM не может быть выполнено в точности.
Процесс 1200 использует следующую процедуру. Случайным образом выбираются n=3 битов, скажем,
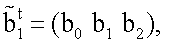 из b.
из b.
Решение для r1:

где 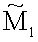 состоит из 0-го, 1-го и 2-го столбцов матрицы M. (Заметим, что - матрица nxn, а r1 t вектор является вектором 1xn, так, что
состоит из 0-го, 1-го и 2-го столбцов матрицы M. (Заметим, что - матрица nxn, а r1 t вектор является вектором 1xn, так, что 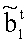 есть вектор 1xn из выбранных битов).
есть вектор 1xn из выбранных битов).
Затем вычисляются декодированные биты:

где М представляет собой матрицу nхK, а r1 t - вектор 1xn, так что 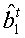 - вектор 1xK. Если
- вектор 1xK. Если 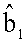 является идентичным b, т.е. не обнаружено ошибочных битов, то на этапе 1209 определяется положение X,Y, и на этапе 1211 определяется, находится ли декодированное положение внутри области назначения. Если да, то декодирование успешно, и выполняется этап 1213. В противном случае, декодирование оказывается неудачным, что показано этапом 1215. Если отличается от b, то в b обнаруживаются ошибочные биты, и выполняется компонент 1253. Этап 1217 определяет набор B1, скажем, {b0 b1 b2 b3}, в котором декодированные биты - те же, что и исходные биты. Таким образом,
является идентичным b, т.е. не обнаружено ошибочных битов, то на этапе 1209 определяется положение X,Y, и на этапе 1211 определяется, находится ли декодированное положение внутри области назначения. Если да, то декодирование успешно, и выполняется этап 1213. В противном случае, декодирование оказывается неудачным, что показано этапом 1215. Если отличается от b, то в b обнаруживаются ошибочные биты, и выполняется компонент 1253. Этап 1217 определяет набор B1, скажем, {b0 b1 b2 b3}, в котором декодированные биты - те же, что и исходные биты. Таким образом, 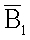 ={b4} (соответствуя расположению битов 1351 на фиг.13). Число циклов (lt) задается константой, например, 100, который может быть изменена в зависимости от приложения. Заметим, что число ошибочных битов, соответствующих r1, равно 1. Затем этап 1221 обновляет число циклов (lt) согласно уравнению (7), lt1=min(lt, 13)=13.
={b4} (соответствуя расположению битов 1351 на фиг.13). Число циклов (lt) задается константой, например, 100, который может быть изменена в зависимости от приложения. Заметим, что число ошибочных битов, соответствующих r1, равно 1. Затем этап 1221 обновляет число циклов (lt) согласно уравнению (7), lt1=min(lt, 13)=13.
Далее на этапе 1217 выбираются другие n=3 бита из b. Если все биты принадлежат B1, скажем, {b0 b2 b3}, то этап 1219 вновь определит r1. Чтобы избежать такого повторения, этап 1217 может выбрать, например, один бит {b4} из , а остальные два бита {b0 b1} из В1.
Три выбранных бита образуют вектор 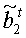 =(b0 b2 b4). На этапе 1219 ищется решение для r2:
=(b0 b2 b4). На этапе 1219 ищется решение для r2:

где 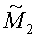 состоит из 0-ого, 1-ого и 4-ого столбцов матрицы М.
состоит из 0-ого, 1-ого и 4-ого столбцов матрицы М.
На этапе 1219 вычисляется 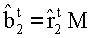 . Ищется набор B2, т.е. такой {b0 b1 b4}, что
. Ищется набор B2, т.е. такой {b0 b1 b4}, что 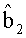 и b есть одно и то же. Тогда
и b есть одно и то же. Тогда 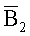 ={b2 b3} (что соответствует расположению 1353 битов на фиг.13). Этап 1221 обновляет число циклов в соответствии с уравнением (7). Заметим, что число ошибочных битов, ассоциированных с r2, равно 2. Подставляя в (7), lt2=min(lt1, 32)=13.
={b2 b3} (что соответствует расположению 1353 битов на фиг.13). Этап 1221 обновляет число циклов в соответствии с уравнением (7). Заметим, что число ошибочных битов, ассоциированных с r2, равно 2. Подставляя в (7), lt2=min(lt1, 32)=13.
Поскольку должна быть выполнена другая итерация, то на этапе 1217 выбираются другие n=3 битов из b. Выбранные биты не должны все принадлежать либо B1, либо B2. Таким образом, этап 1217 может выбрать, например, один бит из 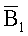 , один бит из
, один бит из 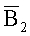 , а оставшийся один бит {b0}.
, а оставшийся один бит {b0}.
Решение для r, выбор битов и регулировка числа циклов продолжается до тех пор, пока не будут выбраны новые n=3 битов так, чтобы они все не принадлежали какому-либо предыдущему значению Bi, или же не будет достигнуто максимальное число циклов lt.
Предположим, что процесс 1200 вычисляет пять векторов ri (i=1, 2, 3, 4, 5), с числом ошибочных битов соответственно 1, 2, 4, 3, 2. (Действительно, для данного примера, число ошибочных битов не может превышать 2, однако иллюстративный пример показывает большее число ошибочных битов для того, чтобы проиллюстрировать алгоритм). Этап 1224 выбирает ri, например, r1, r2, r4, r5, чьи соответствующие номера ошибочных битов меньше, чем Ne, показанное в уравнении (8).
Этап 1224 осуществляет сортировку выбранных векторов r1, r2, r4, r5 по возрастанию их чисел ошибочных битов: r1, r2, r5, r4. Из отсортированного списка кандидатов, на этапах 1225, 1211 и 1212 находится первый вектор r, например, вектор r5, соответствующее положение которого находится в пределах области назначения. Затем этап 1213 выводит соответствующее положение. Если ни одно из местоположений не находится в пределах области назначения, то процесс декодирования оказывается неудачным, что указывается посредством этапа 1215.
Устройство
Фиг.14 изображает устройство 1400 декодирования выделенных битов 1201 из захваченного массива в соответствии с вариантами воплощения настоящего изобретения. Устройство 1400 содержит модуль 1401 выбора битов, модуль 1403 декодирования, модуль 1405 определения положения, интерфейс 1407 ввода, и интерфейс 1409 вывода. В одном из вариантов воплощения, интерфейс 1407 может принимать выделенные биты 1201 из различных источников, включая модуль, поддерживающий камеру 203 (как показано на фиг.2A). Модуль 1401 выбора битов выбирает n битов из выделенных битов 1201 в соответствии с этапами 1203 и 1217. Модуль 1403 декодирования декодирует выбранные биты (n битов, выбранных из K выделенных битов, которые выбраны модулем 1401 выбора битов), чтобы определить обнаруженные ошибки битов и соответствующие векторы ri согласно этапам 1205 и 1219. Модуль 1403 декодирования выдает определенные вектора ri в модуль 1405 определения положения. Модуль 1405 определения положения определяет координаты X,Y захваченного массива согласно этапам 1209 и 1225. Модуль 1405 определения положения выдает результаты, которые содержат координаты X,Y, в случае успеха, и индикацию ошибки, в случае неудачи, в интерфейс 1409 вывода. Интерфейс 1409 вывода может выдавать результаты в другой модуль, который может далее выполнять обработку, или в модуль, который может отображать результаты.
Устройство 1400 может принимать различные формы исполнения, включая модули, использующие и модули, использующие специализированные аппаратные средства, например, такие как интегральные схемы прикладной ориентации (ASIC).
Как должно быть понятно специалистам, компьютерная система с ассоциированным считываемым компьютером носителем, содержащим инструкции для управления компьютерной системой, может использоваться для осуществления иллюстративных вариантов воплощения, которые здесь раскрыты. Компьютерная система может содержать, по меньшей мере, один компьютер типа микропроцессора, цифровой сигнальный процессор и соответствующие периферийные электронные схемы.
Хотя изобретение было определено, используя приложенную формулу изобретения, указанные пункты формулы изобретения являются иллюстративными в том, что изобретение включает в себя элементы и этапы, описанные здесь, в произвольной комбинации или субкомбинации. Соответственно, имеется любое число альтернативных комбинаций для определения изобретения, которые охватывают один или несколько элементов из спецификации, включая описание, формулу изобретения и чертежи, в различных комбинациях или подкомбинациях. Специалистам должно быть понятно, что в свете представленной спецификации, те альтернативные комбинации аспектов изобретения, либо по одному, либо в комбинации с одним или несколькими элементами или этапами, определенными здесь, могут использоваться как модификации или изменения изобретения или как часть изобретения. Может быть так, что раскрытое здесь описание изобретения, охватывает все такие модификации и изменения.






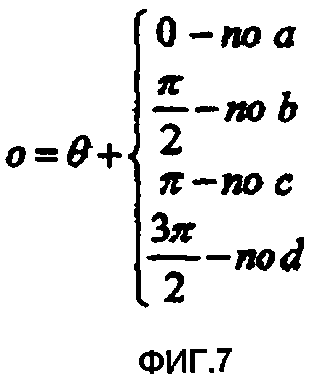
Изобретение относится к способу и устройству для определения местоположения захваченного массива из более крупного изображения. Техническим результатом является повышение точности декодирования захваченного массива. В способе неповторяющаяся последовательность может быть свернута в неповторяющийся массив, в котором массив является уникальным для каждого соседнего окна заданного размера. Может быть захвачена часть массива соседнего окна, и для того чтобы идентифицировать ошибочные биты, декодируется поднабор выделенных битов, соответствующий захваченному массиву. Местоположение захваченного массива определяется в пределах неповторяющегося массива посредством последующей обработки декодированных битов. Устройство реализует заявленный способ. 4 н. и 16 з.п. ф-лы, 27 ил.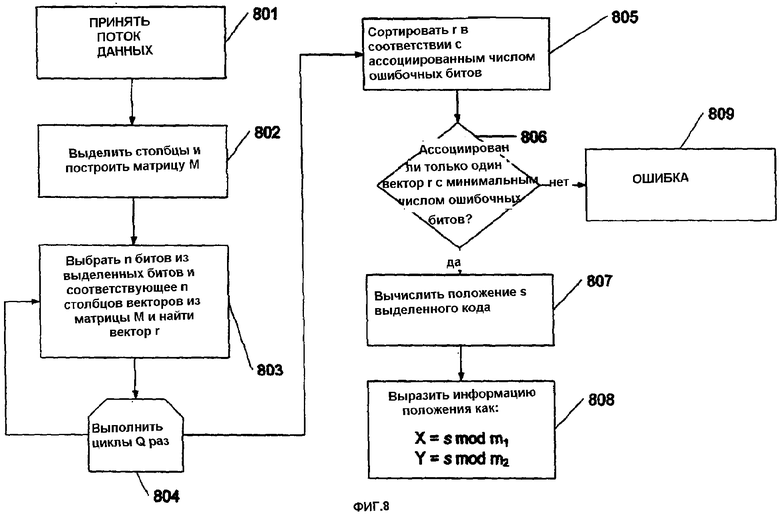
!. Способ определения местоположения захваченного изображения на просматриваемом документе с заданным шаблоном, причем способ осуществляется в цифровой вычислительной среде, при этом способ содержит этапы, на которых:
(A) получают выделенные биты, которые связаны с захваченным массивом битов, причем выделенные биты выделяются из захваченного изображения;
(Б) определяют координаты положения захваченного массива битов, если нет ошибочных битов, причем этап (Б) содержит этапы, на которых:
(i) выбирают первый поднабор из выделенных битов;
(ii) декодируют первый поднабор и
(iii) в ответ на (ii), если не обнаружены ошибочные биты, то определяют координаты положения захваченного массива битов; и
(B) если есть ошибочные биты, определяют координаты положения захваченного массива битов из части выделенных битов посредством выбора неповторяющихся битов, причем координаты положения соответствуют локальному ограничению, причем этап (В) содержит этапы, на которых:
(i) если детектируется ошибочный бит, выбирают отличающийся поднабор из выделенных битов, в котором, по меньшей мере, один бит отличающегося поднабора является битом из предыдущих поднаборов ошибочных битов;
(ii) декодируют отличающийся поднабор с соответствующими битами;
(iii) в ответ на этап (ii) определяют, должна ли выполняться другая итерация декодирования;
(iv) если другая итерация декодирования должна выполняться, то выбирают другой поднабор из выделенных битов и повторяют этап (ii); и (v) если другая итерация декодирования не должна выполняться, то определяют координаты положения захваченного массива битов.
2. Способ по п.1, в котором подэтап (ii) этапа (Б) использует первое матричное уравнение 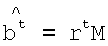 , в котором
, в котором 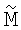 представляет собой подматрицу матрицы М, для определения вектора r.
представляет собой подматрицу матрицы М, для определения вектора r.
3. Способ по п.2, в котором подэтап (ii) этапа (Б) дополнительно использует второе матричное уравнение 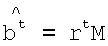 для определения декодированных битов.
для определения декодированных битов.
4. Способ по п.1, в котором подэтап (iii) этапа (Б) содержит этап, на котором (1) сравнивают декодированные биты с выделенными битами.
5. Способ по п.1, в котором вычисленные биты, заданные уравнением , отличаются от выделенных битов.
6. Способ по п.1, в котором этап (Б) дополнительно содержит этап, на котором (iv) проверяют, находятся ли координаты положения в пределах области назначения.
7. Способ по п.1, в котором этап (В) дополнительно содержит этап, на котором (vi) проверяют, находятся ли координаты положения в пределах области назначения.
8. Способ по п.1, в котором подэтап (i) этапа (Б) содержит этап, на котором (1) случайно выбирают составляющие биты первого поднабора из выделенных битов.
9. Способ по п.1, в котором подэтап (i) этапа (В) содержит этапы, на которых:
(1) выбирают соответствующие биты из отличающегося поднабора из выделенных битов, так чтобы декодированные биты удовлетворяли матричному уравнению bt=rtM в предыдущей итерации способа; и
(2) вычисляют, сколько различных битов находится между вычисленными битами, заданными уравнением 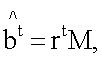 и выделенными битами.
и выделенными битами.
10. Способ по п.1, в котором подэтап (v) этапа (В) содержит этапы, на которых:
(1) выбирают определенный вектор ri, если этот определенный вектор соответствует числу ошибочных битов, которое меньше некоторого порога; и
(2) в ответ на этап (1) упорядочивают множество определенных векторов в порядке возрастания соответствующего числа ошибочных битов.
11. Способ по п.10, в котором подэтап (v) этапа (В) дополнительно содержит этап, на котором
(3) в ответ на этап (2) находят первое решение, которое соответствует координатам положения в пределах области назначения.
12. Способ по п.11, в котором подэтап (v) дополнительно содержит этап, на котором
(4) если нет решений, расположенных в пределах области назначения, то индицируют сбой декодирования.
13. Способ по п.1, в котором подэтап (iii) этапа (В) содержит этап, на котором
(1) регулируют требуемое число итераций способа на основе ожидаемой частоты появления ошибок ошибочных битов.
14. Способ по п.1, в котором подэтап (ii) этапа (В) содержит этапы, на которых:
(1) определяют вектор r, используя первое матричное уравнение bt=rtM;
(2) вычисляют декодированные биты, используя второе матричное уравнение , в котором вектор определяется на этапе (1); и
(3) сравнивают декодированные биты с выделенными битами для нахождения числа ошибочных битов.
15. Считываемый компьютером носитель, имеющий выполняемые компьютером инструкции для выполнения способа по п.1.
16. Устройство, которое определяет координаты положения захваченного изображения на просматриваемом документе с заданным шаблоном, содержащее:
(а) модуль выбора битов, применяющий интеллектуальную стратегию для выбора поднабора битов, который имеет, по меньшей мере, один бит из предыдущих наборов ошибочных битов, причем поднабор выбирается из выделенных битов, которые соответствуют захваченному массиву битов, причем выделенные биты выделяются из захваченного изображения;
(б) декодирующий модуль, обрабатывающий поднабор битов для определения информации об ошибках, относящейся к выделенным битам, и который определяет из этой информации об ошибках, нужна ли другая итерация декодирования;
(в) модуль определения положения захваченного массива битов, обрабатывающий информацию об ошибках для определения координат положения захваченного массива битов, в котором координаты положения захваченного массива битов находятся в пределах области назначения.
17. Устройство по п.16, дополнительно содержащее
интерфейс ввода, который принимает выделенные биты и передает выделенные биты в модуль выбора битов для обработки.
18. Устройство по п.16, в котором модуль декодирования вычисляет матрицу ri местоположения для i-й итерации и определяет ошибочные биты путем сравнения закодированных битов, определяемых из уравнения 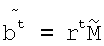 , с выделенными битами.
, с выделенными битами.
19. Устройство по п.16, дополнительно содержащее интерфейс вывода, который обеспечивает координаты положения захваченного массива, в котором координаты положения определяются модулем определения положения.
20. Способ определения координат местоположения захваченного изображения на просматриваемом документе с заданным шаблоном, причем способ осуществляется в цифровой вычислительной среде, при этом способ содержит этапы, на которых:
(A) принимают выделенные биты, которые связаны с захваченным массивом битов, причем выделенные биты выделяются из захваченного изображения;
(Б) выбирают первый поднабор битов из выделенных битов;
(B) декодируют первый поднабор битов;
(Г) если не обнаружены ошибочные биты, то определяют координаты местоположения захваченного массива битов, причем координаты местоположения находятся в пределах области назначения;
(Д) выбирают отличающийся поднабор из выделенных битов, в котором, по меньшей мере, один бит отличающегося поднабора не удовлетворяет матричному уравнению ;
(Е) декодируют выделенные биты отличающегося поднабора;
(Ж) регулируют число итераций для выполнения этапа (Е), причем это число регулируется согласно результатам этапа (Е);
(З) если должна выполняться другая итерация декодирования, повторяют этапы (Д)-(Ж); и
(И) если другая итерация декодирования не должна выполняться, то определяют координаты местоположения захваченного массива битов, причем координаты местоположения захваченного массива битов находятся в пределах области назначения.
| СПОСОБ ВВОДА ИНФОРМАЦИИ В МАЛОГАБАРИТНЫЙ ТЕРМИНАЛ, РАЗМЕЩАЮЩИЙСЯ В РУКЕ ПОЛЬЗОВАТЕЛЯ, В ЧАСТНОСТИ РАДИОТЕЛЕФОННУЮ ТРУБКУ, ПЕЙДЖЕР, ОРГАНАЙЗЕР | 2001 |
|
RU2201618C2 |
| ВИЗУАЛЬНОЕ УСТРОЙСТВО ОТОБРАЖЕНИЯ И СПОСОБ ФОРМИРОВАНИЯ ТРЕХМЕРНОГО ИЗОБРАЖЕНИЯ | 1995 |
|
RU2168192C2 |
| US 5454054 А, 26.09.1995 | |||
| US 6000614 А, 14.12.1999. | |||

