Изобретение относится к области информационных технологий, в частности к способам поиска информации в больших документальных базах данных (БД).
Известен способ поиска информации путем анализа взаимной встречаемости терминов запроса и терминов в найденных документах, а также анализа мер сходства векторов документов, представленных на различных языках, так называемое семантическое векторное совпадение (US 6006221, G 06 F 17/30, опубл. 21.12.1999).
Недостатком данного способа является сложность операций по построению и преобразованию (суммирование, нормализация) векторов.
Известен способ автоматизированного поиска информации с расширением запроса путем построения статистического тезауруса (US 5926811, G 06 F 17/30, опубл. 20.07.1999).
Недостатком указанного способа является то, что тезаурусы требуют частого обновления.
Наиболее близким аналогом к заявляемому способу поиска информации является способ поиска информации (US 4839853, G 06 F 15/40, опубл. 13.01.1989) с использованием латентно-семантической структуры. Согласно этому способу из найденных в ответ на первоначальный запрос пользователя документов выделяются значимые для данной темы термины, затем этим терминам присваиваются веса значимости, после этого строится вектор запроса и все документы исходной БД ранжируются по степени сходства с этим вектором на основании соответствующей меры близости - косинус угла между вектором запроса и вектором найденного документа.
По своей сути описанный способ является рекурсивным, то есть потенциально позволяющим на основе статистического анализа последующих выдач документов строить все более развитые векторы запросов.
Недостатком этого способа является его низкая производительность вследствие того, что значения мер близости векторов запросов и документов (ранги документов) уменьшаются для каждой БД и каждого запроса слишком быстро, и следовательно, вместо "плавного" рекурсивного наращивания полноты поиска системам приходится выдавать пользователям только весьма небольшое множество документов самых высоких рангов, предварительно установив жесткое пороговое значение меры близости. Другими словами, настоящей рекурсии не получается из-за того, что все последующие (развитые) векторы запросов слишком зависят от лексического состава выдачи, полученной в ответ на первый, зачастую весьма неэффективный запрос пользователя. Это приводит к тому, что значительно увеличивается время, затрачиваемое на проведение поиска.
Решаемой изобретением задачей является устранение указанного недостатка и усовершенствование информационно-поисковой системы (ИПС). Достигаемый технический результат заключается в сокращении времени поиска нужной информации за счет сокращения количества рекурсий (повторений запросов).
Указанный технический результат достигается тем, что вводится новый критерий выдачи документов, позволяющий пользователю получать релевантные документы, наполненные новыми терминами, необходимыми для проведения дальнейших рекурсий (повторений запросов).
А именно, в способе поиска информации с использованием информационно-поисковой системы, в котором терминам вектора запроса присваивают порядковые номера, затем осуществляют поиск с занесением в память компьютера номеров найденных документов, в которых присутствует хотя бы один термин вектора запроса, затем заносят в память компьютера количество совпавших терминов с терминами запроса и порядковые номера совпавших терминов, затем сортируют в памяти компьютера документы по классам с равным количеством совпавших терминов, согласно данному изобретению осуществляют формирование внутри всех классов - подклассов индекса i классов индекса j, характеризующихся полным совпадением номеров терминов, затем определение количества документов (nij) в подклассах индекса i классов индекса j, затем определение количества документов (nj) класса j, затем определение вероятности принадлежности документа к подклассу i, при условии его принадлежности к классу j, как:
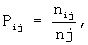
затем определение критерия выдачи для каждого класса как:
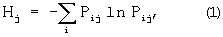
и далее расширение запроса, если в документах класса Hjmax, содержатся новые термины, которые относятся к тематике поиска. Hjmax - максимальное значение параметра характеризующего критерий выдачи классов документов.
Другой дополнительной особенностью данного способа может являться то, что в ИПС загружаются документы, представленные на естественном языке. При этом в ИПС для осуществления предлагаемого способа используется входной формат ASC11.
Еще одной дополнительной особенностью данного способа может являться то, что формирование классов и подклассов документов осуществляется автоматически.
Еще одной дополнительной особенностью данного способа может являться то, что количество терминов вектора запроса находится в диапазоне от 10 до 1000.
В данном случае под вектором запроса понимается набор ключевых слов, классификационных индексов, фраз или просто слов без присвоения им весов значимости.
Наиболее сложной задачей информационного поиска является обнаружение информации, обозначение которой пользователю неизвестно. Поэтому, прежде чем получить нужный документ, необходимо найти дескрипторы - слова, классификационные индексы, имена и.т.п., по которым информация может быть найдена.
Это отнюдь не простая задача. Даже слова естественного языка не всегда легко подобрать для проведения эффективного сеанса поиска. Индексы различных классификаций и рубрикаторов, марки, названия фирм могут быть и вовсе не известны пользователю системы. Поэтому необходим механизм обнаружения таких терминов, по которым может быть найдена лексически удаленная, но необходимая пользователю информация.
Простейшим способом расширения запроса является отбор новых потенциально полезных терминов из документов, найденных в ответ на данный запрос.
Если пользователь выбрал набор терминов t1, t2, t3...tk, то необходимо установить правило, по которому ему будут выдаваться другие документы из исходного поискового массива, содержащие эти термины. Обычная логика подсказывает, что чем больше терминов из выбранных содержит документ, тем выше вероятность, что его содержание соответствует тематике первоначального запроса, и, следовательно, этот документ должен быть выдан в первую очередь. С другой стороны, такой документ лексически похож на те документы, из которых были выбраны термины t1, t2, t3...tk, и следовательно, слишком мала вероятность того, что в этом документе могут быть найдены дополнительные, полезные термины для дальнейшего расширения запроса и продолжений рекурсивного поиска.
Если произвести разбиение исходного поискового массива на классы документов с равным количеством терминов, совпавших с набором t1, t2, t3...tk и использовать в качестве критерия выдачи класса с индексом j количество совпавших терминов, то число отобранных новых полезных терминов на каждом шаге итерации будет в среднем в 2 раза меньше, чем при использовании критерия Hj(1), при одинаковом количестве просмотренных релевантных документов.
Изобретение поясняется чертежами.
Заявленный способ может быть реализован с помощью системы поиска информации
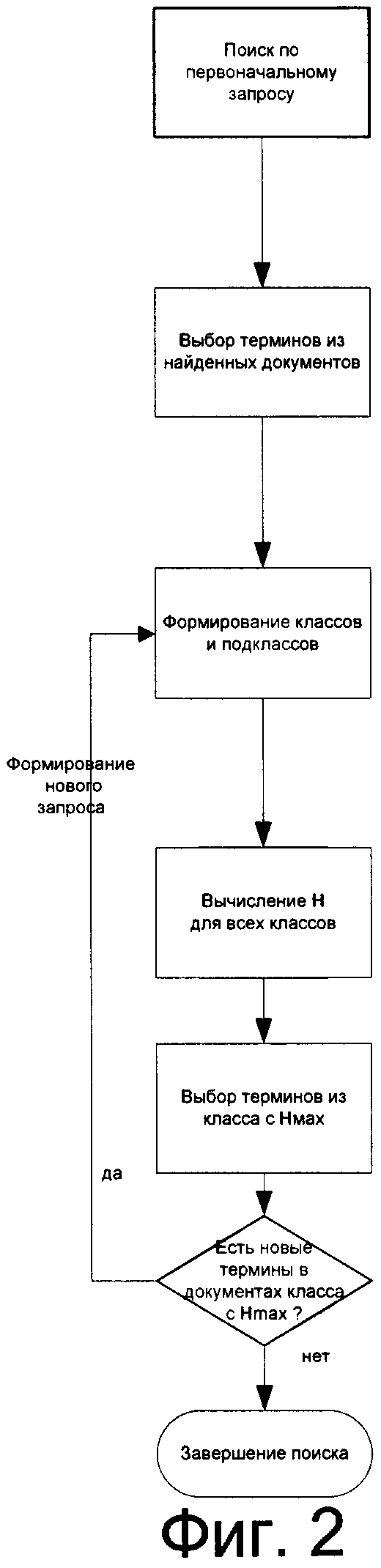
На фигуре 1 представлена функциональная схема системы поиска информации.
На фигуре 2 представлена блок схема алгоритма заявленного способа.
Система содержит блок формирования запроса 1, первый выход которого связан с входом блока памяти номеров документов 2, выход которого связан с первым входом блока поиска и сортировки 4, выход которого через соответствующие шины данных 9 и шины управления 10 связан с процессором 5, блоком воспроизведения 7, базой данных 6 и контроллером 8, причем второй вход блока поиска и сортировки 4 связан с выходом блока памяти номеров терминов 3, вход которого связан со вторым выходом блока формирования запроса 1.
Система для поиска информации согласно изобретению работает следующим образом.
Блок формирования запроса 1 может представлять собой стандартный блок ввода-вывода данных с клавиатурой и мышью, с возможностью отображения вводимой информации на экране блока воспроизведения 7, т.е. это может быть дисплей, экран монитора и.т.п. В то же время блок формирования запроса 1 может быть выполнен в виде формирователя сообщения о выборе базы данных для проведения поиска, которое передается в контроллер 8 для запуска программы поиска в выбранной базе данных.
Поиск осуществляется следующим образом.
При включении системы пользователю с помощью блока воспроизведения 7 предлагается меню, которое отображается на экране, на котором, в частности, представлен перечень названий имеющихся баз данных системы. Далее с помощью блока формирования запроса 1 пользователь формирует первоначальный запрос, сообщение об этом сразу попадает в контроллер 8.
Далее пользователю системы предлагаются документы, выданные на первоначальный запрос, которые отображаются на экране, в которых ему предлагается выбрать новые термины, которые по его мнению могут относиться к интересующей его тематической области, причем терминам запроса присваивают порядковые номера с занесением их в блок памяти номеров документов 2 и далее в блок поиска и сортировки 4, который через шину данных 9 отправляет запрос в базу данных 6.
С помощью блока воспроизведения 7 пользователь может ознакомиться с документами, найденными на запрос.
Далее номера документов, содержащие термины, совпавшие с терминами запроса, заносятся в блок памяти номеров документов 2, после чего в блоке поиска и сортировки 4 осуществляют сортировку документов по классам с равным количеством совпавших терминов.
Далее внутри классов формируют подклассы, характеризующиеся полным совпадением номеров совпавших терминов. Затем процессор 5 проводит расчет характеристики Нj для каждого класса документов.
Используя такую характеристику, пользователь системы может специальной командой с помощью блока формирования запроса 1 дополнить терминами (из документов класса с Hjmax) первоначальный запрос. Дальнейший поиск может быть также проведен с использованием сохраненных запросов в блоке памяти номеров терминов 3 и состоящих только из терминов, содержащихся в документах класса с Hjmax.
По дополненному запросу ИПС позволяет найти необходимую пользователю, но лексически удаленную от первоначального запроса информацию.
Указанная последовательность действий повторяется до тех пор, пока в найденных документах класса с Hjmax будут встречаться новые термины, относящиеся к исследуемой тематике.
Опыты показывают, что указанный технический результат может быть достигнут только взаимосвязанной совокупностью всех существенных признаков заявленного изобретения, отраженных в формуле изобретения. Указанные в ней отличия дают основание сделать вывод о новизне данного технического решения, а совокупность испрашиваемых притязаний в связи с их не очевидностью - об изобретательском уровне, что было показано выше. Соответствие критерию "промышленная применимость" предложенного способа доказывается как его реализацией, так и отсутствием в заявленных притязаниях каких-либо практически трудно реализуемых в промышленных масштабах признаков.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В ПОЛИТЕМАТИЧЕСКИХ МАССИВАХ НЕСТРУКТУРИРОВАННЫХ ТЕКСТОВ | 2008 |
|
RU2409849C2 |
| СПОСОБ ОЦЕНКИ СТЕПЕНИ РАСКРЫТИЯ ПОНЯТИЯ В ТЕКСТЕ, ОСНОВАННЫЙ НА КОНТЕКСТАХ, ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2007 |
|
RU2348072C1 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ | 2006 |
|
RU2320005C1 |
| СПОСОБ КЛАСТЕРИЗАЦИИ РЕЗУЛЬТАТОВ ПОИСКА В ЗАВИСИМОСТИ ОТ СЕМАНТИКИ | 2014 |
|
RU2564629C1 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| Способ интеллектуального информационного поиска и предоставления контекстуальной информации в распределенных хранилищах данных | 2019 |
|
RU2727076C1 |
| АВТОМАТИЧЕСКИЙ ПОИСК КОНТЕКСТНО-СВЯЗАННЫХ ЭЛЕМЕНТОВ ЗАДАЧИ | 2010 |
|
RU2573209C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОГО ПОИСКА ЭЛЕКТРОННЫХ ДОКУМЕНТОВ | 2011 |
|
RU2473119C1 |
Изобретение относится к области информационных технологий. Его использование при поиске информации в больших документальных базах данных обеспечивает технический результат в виде сокращения времени поиска нужной информации за счет сокращения количества рекурсий (повторений запросов). Способ заключается в том, что терминам вектора запроса присваивают порядковые номера, осуществляют поиск с занесением в память компьютера номеров документов хотя бы с одним термином вектора запроса, заносят в память компьютера количество терминов, совпавших с терминами запроса, и порядковые номера совпавших терминов, сортируют в памяти компьютера документы по классам с равным количеством совпавших терминов. Технический результат достигается тем, что вводится новый критерий выдачи документов, позволяющий пользователю получать релевантные документы, наполненные новыми терминами, необходимыми для проведения дальнейших рекурсий. Эффективность способа при этом не зависит от того, на каком естественном языке написаны тексты в базе данных. 3 з.п. ф-лы, 2 ил.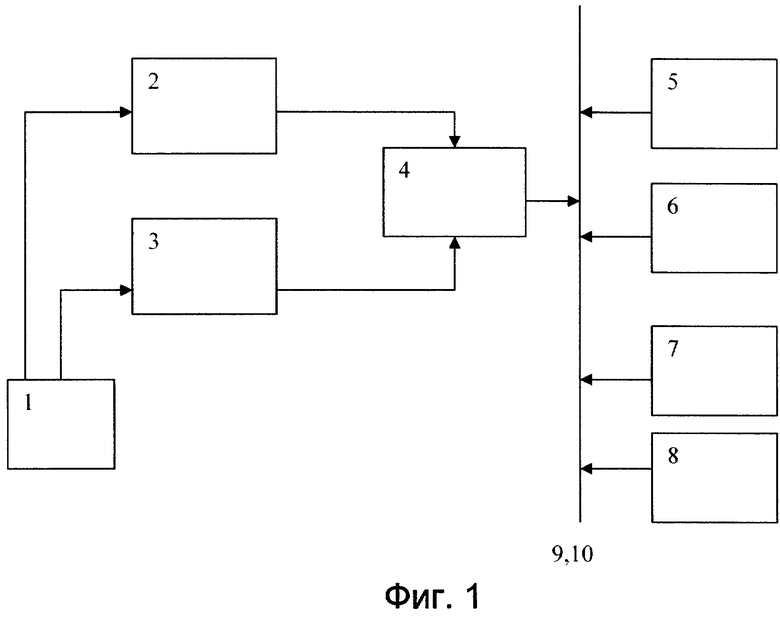
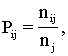
затем определяют критерий выдачи для каждого класса как
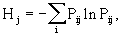
и далее расширяют запрос, если в документах класса с Hjmax содержатся новые термины, которые относятся к тематике поиска.
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ ПО ИХ ОПИСАНИЯМ | 1999 |
|
RU2167450C2 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |

