Область техники, к которой относится изобретение
Аспекты настоящего изобретения относятся к вычислительным системам. В частности, аспекты настоящего изобретения относятся к обработке альтернатив от систем распознавания.
Описание предшествующего уровня техники
В дополнение к работе с текстом компьютеры теперь имеют возможность записывать и модифицировать электронные чернила. Электронные чернила могут сохраняться в их исходной форме или могут распознаваться как текст. Распознавание электронных чернил не всегда идеально. Процесс распознавания может изменяться, основываясь на удобочитаемости почерка человека в дополнение к контексту, в котором человек пишет.
Вычислительные системы предоставляют альтернативы пользователям, так что пользователь может выбрать, какой результат распознавания является правильным для принятого рукописного текста. Однако обычные представления альтернатив не относятся к комплексным представлениям электронных чернил. Например, обычные представления альтернатив ограничиваются синтаксическим разбором единственной строки электронных чернил. Вычислительные системы не учитывают контекстуальную значимость электронных чернил вне любой заданной строки.
Существует потребность в улучшенной системе и процессе синтаксического разбора для представления альтернатив и связи их с общей древовидной структурой чернил.
Сущность изобретения
Аспекты настоящего изобретения относятся к одной или нескольким проблемам, описанным выше, предоставляя, таким образом, путь обработки альтернатив от систем распознавания.
Перечень чертежей
Настоящее изобретение иллюстрируется посредством примера и не ограничивается прилагаемыми фигурами, на которых одинаковые ссылочные позиции указывают аналогичные элементы и на которых:
Фиг.1А - схематическое представление цифровой вычислительной среды общего назначения, в которой могут быть реализованы определенные аспекты настоящего изобретения;
Фиг.1В-1М - среда компьютера общего назначения, поддерживающая один или несколько аспектов настоящего изобретения;
Фиг.2 - иллюстративный пример планшетного компьютера согласно аспектам настоящего изобретения;
Фиг.3 - пример электронных чернил согласно аспектам настоящего изобретения;
Фиг.4 - иллюстративный пример контекстного дерева согласно аспектам настоящего изобретения;
Фиг.5 - пример решетки согласно аспектам настоящего изобретения;
Фиг.6-7 - решетки выбора согласно аспектам настоящего изобретения;
Фиг.8-9 - решетки согласно аспектам настоящего изобретения;
Фиг.10 - зависимости объектов согласно аспектам настоящего изобретения;
Фиг.11 - иллюстративные процессы создания решетки согласно аспектам настоящего изобретения;
Фиг.12А-16 и 18 - контекстные деревья и альтернативы согласно аспектам настоящего изобретения;
Фиг.17 - электронные чернила согласно аспектам настоящего изобретения.
Подробное описание изобретения
Аспекты настоящего изобретения относятся к распознаванию и обработке представлений альтернатив электронных чернил. Аспекты включают в себя представление альтернативных результатов анализа в качестве части дерева.
Настоящий документ разделен на разделы, чтобы оказать помощь читателю. Данные разделы включают в себя: Обзор, Характеристики чернил, Термины, Вычислительную среду общего назначения, Представление альтернатив, Объекты и зависимости объектов, Интерфейсы прикладного программирования, Создание решетки и Примеры.
Отмечается, что в нижеследующем описании изложены разнообразные соединения между элементами. Отмечается, что эти соединения, вообще говоря, и, если не указано иначе, могут быть прямыми или косвенными, и, как предполагается, данное описание изобретения не является ограничивающим в этом отношении.
Обзор
В соответствии с различными примерами изобретения содержимое документа может упорядочиваться в древовидную структуру. Древовидная структура может включать в себя как электронные чернила, так и текстовые представления чернил. Дерево также может содержать нечернильное содержимое, включая, но не в ограничительном смысле, исходный текст, текст, распознанный из чернил, текст, распознанный из речи, рисунки, снимки, диаграммы, презентации, электронные таблицы, математические уравнения, музыкальные обозначения, аудиоклипы и/или видеоклипы и другую информацию. Так как текстовые представления могут изменяться, основываясь на контексте и удобочитаемости почерка человека, альтернативные представления текстовой информации также могут включаться в древовидную структуру. Аспекты настоящего изобретения включают в себя представления древовидной структуры посредством использования одной или нескольких решеток с альтернативными результатами распознавания.
Используя древовидную структуру, операционная система или приложение программного обеспечения легко может обходить древовидную структуру и получать альтернативы, когда это необходимо. Древовидная структура может определять различные элементы в документе. Например, узел в структуре данных может соответствовать штриху чернил и может дополнительно классифицировать, что штрихом чернил является или штрих чернил текста, или штрих чернил рисунка.
Этот тип структуры данных также может ассоциировать элементы документа в осмысленные группы, такие как слова, строки и абзацы. Таким образом, если приложение программного обеспечения поддерживает древовидную структуру, которая описывает абзац рукописных электронных чернил, концевые узлы могут ассоциировать отдельные штрихи электронных чернил с узлами слова, соответствующими словам в абзаце. Древовидная структура затем может ассоциировать узлы слова с узлами строки, соответствующими строкам в абзаце. Каждый узел строки затем может быть ассоциирован с узлом, соответствующим абзацу. Далее, операционная система или приложение программного обеспечения может поддерживать дерево или другую структуру данных, которая ассоциирует узел, соответствующий штриху электронных чернил, с результатом распознавания. Эти структуры данных, таким образом, могут использоваться как для определения зависимостей между ассоциированными штрихами электронных чернил, так и для улучшения обработки альтернативных результатов распознавания чернил.
Как описано ниже, эти структуры данных могут использоваться с инструментальным средством анализа чернил в соответствии с различными примерами изобретения для анализа электронных чернил в документе. В соответствии с различными примерами изобретения операционная система или приложение программного обеспечения может провести анализ электронных чернил в документе посредством создания сначала структуры данных для документа. Структура данных описывает зависимость между элементами документа, которые уже были проанализированы и, таким образом, обеспечивает контекст, в котором будут анализироваться новые электронные чернила. Эта структура данных или «объект анализатора чернил» также включает в себя новые электронные чернила, которые не были проанализированы. Т. е. объект анализатора чернил также включает в себя электронные чернила, для которых не была установлена зависимость с другими элементами документа.
По меньшей мере две операции могут выполняться над принятыми чернилами. Первой операцией является процесс синтаксического разбора, который анализирует принятые чернила и создает древовидную структуру. Второй операцией является процесс распознавания, который распознает электронные чернила и создает решетку из древовидной структуры, причем решетка включает в себя распознавание альтернатив электронных чернил. Другие операции также могут выполняться над принятыми чернилами и не ограничиваются процессами синтаксического разбора и распознавания, описанными выше. Например, синтаксический разбор определяет локальную группировку штрихов. Распознавание определяет, какие слова в языке (или формы, или другие типы данных) штрихи представляют.
Альтернативы распознавания могут ассоциироваться с решеткой и направляться вместе с родительскими документами или другими файлами. Альтернативно, решетка и альтернативные результаты распознавания могут создаваться заново на каждой вычислительной системе. Одним преимуществом предоставления возможности обмена решеткой и результатами распознавания между машинами является постоянство существования чернил и ранее полученной информации от одной машины к другой. Здесь второй машине нет необходимости запрашивать новые результаты у распознавателя, так как альтернативные результаты распознавания были ассоциированы с решеткой. Таким образом, решетка и альтернативы, если они существуют, могут использоваться на машинах с распознавателями и без них. Эта возможность дополнительно может поддерживать расширяемость результатов распознавания на все машины, независимо от того, имеют ли машины по направлению основного трафика возможность распознавания чернил или других вводов.
Элементами решетки могут быть объектные сущности внутри решетки, которая хранит (или, по меньшей мере, ссылается на) данные. Данные в элементах решетки не ограничиваются текстом. Элементы решетки могут включать в себя или ссылаться на любое количество распознаваемых объектных сущностей, включая, но не в ограничительном смысле, распознанные чернила, нераспознанные чернила, введенный с клавиатуры текст, математическое уравнение, музыкальное обозначение и т. п. Например, если использовался математический распознаватель, каждый из элементов может иметь математический расширяемый язык разметки (XML) (или подобный) в качестве значения каждого элемента. Различные элементы все же могут ссылаться на конкретные штрихи и следующий столбец, но данные не ограничиваются простым текстом.
Характеристики чернил
Как известно пользователям, которые используют чернильные ручки, физические чернила (вид, размещаемый на бумагу с использованием ручки с резервуаром чернил) могут передавать больше информации, чем последовательность координат, соединенных отрезками прямых линий. Например, физические чернила могут отражать давление пера (посредством толщины чернил), угол пера (посредством формы отрезков прямой линии или кривой и характера изменения чернил вокруг дискретных точек) и скорость кончика пера (посредством прямолинейности, ширины прямой линии, и ширина прямой линии изменяется по ходу прямой линии или кривой). Другие примеры включают в себя то, как чернила поглощаются волокнами бумаги или другой поверхностью, на которую они наносятся. Эти едва различимые характеристики также способствуют передаче вышеперечисленных свойств. Из-за этих дополнительных свойств, эмоция, индивидуальная особенность, выразительность и т. п. могут передаваться в большей степени немедленно, чем с равномерной шириной прямой линии между точками.
Электронные чернила (или чернила) относятся к захвату и отображению электронной информации, захваченной, когда пользователь использует основанное на стило устройство ввода. Электронные чернила относятся к последовательности или любой произвольной коллекции штрихов, где каждый штрих состоит из последовательности точек. Штрихи могут быть нарисованы или собраны одновременно или могут быть нарисованы или собраны в независимые моменты времени и позициях и по независимым причинам. Точки могут быть представлены с использованием множества известных методов, включая прямоугольную систему координат (X, Y), полярную систему координат (r, θ) и другие методы, известные в технике. Электронные чернила могут включать в себя представление свойств реальных чернил, включая давление, угол, скорость, цвет, размер стило и непрозрачность чернил. Электронные чернила дополнительно могут включать в себя другие свойства, включая порядок того, как чернила наносились на страницу (растровый шаблон слева направо, затем вниз для большинства западных языков), временную метку (указывающую, когда наносились чернила), указание автора чернил и создающее устройство (по меньшей мере одно из идентификатора машины, на которой были нарисованы чернила, или идентификатора пера, используемого для нанесения чернил) среди другой информации.
Среди вышеописанных характеристик используются, в основном, временной порядок штрихов и штрих, являющийся последовательностью координат. Все эти характеристики также могут использоваться.
Термины
Вычислительная среда общего назначения
На фиг.1 изображен пример подходящей среды 100 вычислительной системы, в которой может быть реализовано изобретение. Среда 100 вычислительной системы представляет собой только один пример подходящей вычислительной среды и не предназначена для того, чтобы предполагать какое-либо ограничение в отношении объема использования или функциональных возможностей изобретения. Вычислительная среда 100 также не должна интерпретироваться как имеющая какую-либо зависимость или требование, относящиеся к какому-либо одному или комбинации компонентов, изображенных в примерной операционной среде 100.
Изобретение может работать с многочисленными другими средами или конфигурациями вычислительных систем общего назначения или специального назначения. Примеры общеизвестных вычислительных систем, сред и/или конфигураций, которые могут быть подходящими для использования с изобретением, включают в себя, но не в ограничительном смысле, персональные компьютеры, серверные компьютеры, карманные или портативные устройства, мультипроцессорные системы, микропроцессорные системы, телевизионные приставки, программируемую бытовую электронику, сетевые персональные компьютеры (ПК), миникомпьютеры, мэйнфреймы, распределенные вычислительные среды, которые включают в себя любые из вышеупомянутых систем или устройств, и т. д.
Изобретение может быть описано в общем контексте исполняемых компьютером инструкций, таких как программные модули, исполняемые компьютером. В общих чертах, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т. п., которые выполняют конкретные задачи или реализуют определенные абстрактные типы данных. Изобретение также может применяться на практике в распределенных вычислительных средах, в которых задачи выполняются удаленными устройствами обработки данных, которые связаны через сеть связи. В распределенной вычислительной среде программные модули могут располагаться на носителях данных как локальных, так и удаленных компьютеров, включая запоминающие устройства.
С ссылкой на фиг.1, примерная система для реализации изобретения включает в себя вычислительное устройство общего назначения в виде компьютера 110. Компоненты компьютера 110 могут включать в себя, но не в ограничительном смысле, блок 120 обработки данных, системную память 130 и системную шину 121, которая соединяет различные компоненты системы, включая системную память, с блоком 120 обработки данных. Системная шина 121 может быть любой из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, используя любую из многочисленных шинных архитектур. В качестве примера, и не ограничения, такие архитектуры включают в себя шину архитектуры промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), шину расширенной ISA (EISA), локальную шину Ассоциации по стандартам в области видеоэлектроники (VESA) и шину межсоединений периферийных компонентов (PCI), также известную как шина расширения.
Компьютер 110 обычно включает в себя многочисленные считываемые компьютером носители. Считываемыми компьютером носителями могут быть любые доступные носители, к которым может обращаться компьютер 110, и они включают в себя как энергозависимые, так и энергонезависимые носители, как съемные, так и несъемные носители. В качестве примера, и не ограничения, считываемые компьютером носители могут содержать носители данных компьютера и среды передачи данных. Носители данных компьютера включают в себя как энергозависимые, так и энергонезависимые, как съемные, так и несъемные носители, выполненные по любому методу или технологии для хранения информации, такой как считываемые компьютером инструкции, структуры данных, программные модули или другие данные. Носители данных компьютера включают в себя, но не в ограничительном смысле, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или память другой технологии, компакт-диск, цифровые многофункциональные диски (DVD) или другое запоминающее устройство на оптических дисках, магнитные кассеты, магнитную ленту, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель, который может использоваться для хранения требуемой информации и к которому может обращаться компьютер 110. Среды передачи данных обычно воплощают считываемые компьютером инструкции, структуры данных, программные модули или другие данные в модулированном данными сигнале, таком как несущая волна или другой транспортный механизм, и включают в себя любые среды доставки информации. Термин «модулированный данными сигнал» означает сигнал, одна или несколько характеристик которого устанавливаются или изменяются так, что кодируют информацию в этом сигнале. В качестве примера, и не ограничения, среды передачи данных включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, РЧ, инфракрасные или другие беспроводные среды. Комбинации любых из вышеприведенных сред и носителей также охватываются понятием “считываемый компьютером носитель”.
Системная память 130 включает в себя носитель данных компьютера в виде энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ПЗУ) 131 и оперативное запоминающее устройство (ОЗУ) 132. Базовая система 133 ввода/вывода (BIOS), содержащая базовые процедуры, которые способствуют переносу информации между элементами в компьютере 110, например, во время запуска, обычно хранится в ПЗУ 131. ОЗУ 132 обычно содержит данные и/или программные модули, к которым осуществляется непосредственный доступ и/или которые в настоящий момент обрабатываются блоком 120 обработки данных. В качестве примера, и не ограничения, на фиг.1 изображена операционная система 134, программы 135 приложений, другие программные модули 136 и данные 137 программ.
Компьютер 110 также может включать в себя другие съемные/несъемные, энергозависимые/энергонезависимые носители данных компьютера. Только в качестве примера, на фиг.1 изображен накопитель 141 на жестких дисках, который считывает или записывает на несъемные энергонезависимые магнитные носители, магнитный дисковод 151, который считывает или записывает на съемный энергонезависимый магнитный диск 152, и оптический дисковод 155, который считывает или записывает на съемный энергонезависимый оптический диск 156, такой как компакт-диск или другой оптический носитель. Другие съемные/несъемные, энергозависимые/энергонезависимые носители данных компьютера, которые могут использоваться в примерной операционной среде, включают в себя, но не в ограничительном смысле, кассеты с магнитной лентой, карты флэш-памяти, цифровые многофункциональные диски, цифровую видеоленту, твердотельное ОЗУ, твердотельное ПЗУ и т. п. Накопитель 141 на жестких дисках обычно подсоединяется к системной шине 121 при помощи интерфейса несъемной памяти, такого как интерфейс 140, а магнитный дисковод 151 и оптический дисковод 155 обычно подсоединяются к системной шине 121 при помощи интерфейса съемной памяти, такого как интерфейс 150.
Накопители и дисководы и связанные с ними носители данных компьютера, описанные выше и изображенные на фиг.1, обеспечивают хранение считываемых компьютером инструкций, структур данных, программных модулей и других данных для компьютера 110. На фиг.1, например, накопитель 141 на жестких дисках изображен как хранящий операционную систему 144, программы 145 приложений, другие программные модули 146 и данные 147 программ. Отметьте, что эти компоненты могут быть или теми же самыми, или отличными от операционной системы 134, программ 135 приложений, других программных модулей 136 и данных 137 программ. Операционной системе 144, программам 145 приложений, другим программным модулям 146 и данным 147 программ присвоены другие ссылочные позиции в данном документе для иллюстрации того, что, как минимум, они представляют собой другие копии. Пользователь может вводить команды и информацию в компьютер 20 при помощи устройств ввода, таких как клавиатура 162 и указательное устройство 161, обычно упоминаемое как мышь, шаровой манипулятор или сенсорная панель. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровой планшет, антенну спутниковой связи, сканер и т. п. Эти и другие устройства ввода часто подключаются к блоку 120 обработки данных при помощи интерфейса 160 пользовательского ввода, который подсоединяется к системной шине, но могут подключаться при помощи других интерфейсов и шинных структур, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или устройство отображения другого типа также подключается к системной шине 121 при помощи интерфейса, такого как видеоинтерфейс 190. В дополнение к монитору, компьютеры также могут включать в себя другие периферийные устройства вывода, такие как громкоговорители 197 и принтер 196, которые могут подключаться при помощи периферийного интерфейса 195 вывода.
Компьютер 110 может работать в сетевой среде, используя логические соединения с одним или несколькими удаленными компьютерами, такими как удаленный компьютер 180. Удаленным компьютером 180 может быть персональный компьютер, сервер, маршрутизатор, сетевой ПК, одноранговое устройство или другой общий сетевой узел, и он обычно включает в себя многие или все из элементов, описанных выше в отношении компьютера 110, хотя только запоминающее устройство 181 изображено на фиг.1. Логические соединения, изображенные на фиг.1, включают в себя локальную сеть (ЛС) 171 и глобальную сеть (ГС) 173, но также могут включать в себя другие сети. Такие сетевые среды являются общепринятыми в офисах, компьютерных сетях масштаба предприятия, интрасетях и Интернете.
При использовании в сетевой среде ЛС компьютер 110 подключается к ЛС 171 при помощи сетевого интерфейса или адаптера 170. При использовании в сетевой среде ГС компьютер 110 обычно включает в себя модем 172 или другое средство для установления связи по ГС 173, такой как Интернет. Модем 172, который может быть внутренним или внешним, может подключаться к системной шине 121 при помощи интерфейса 160 пользовательского ввода или другого соответствующего механизма. В сетевой среде программные модули, описанные в отношении компьютера 110, или его частей, могут храниться на удаленном запоминающем устройстве. В качестве примера, и не ограничения, на фиг.1 изображены программы 185 удаленных приложений, постоянно находящиеся на устройстве 181 хранения. Понятно, что показанные сетевые соединения являются примерными, и могут использоваться другие средства установления линии связи между компьютерами.
В некоторых аспектах предусмотрен цифровой преобразователь 165 перьевого ввода и сопутствующее перо или стило 166 для цифрового захвата ввода от руки. Хотя показано непосредственное соединение между цифровым преобразователем 165 перьевого ввода и интерфейсом 160 пользовательского ввода, на практике цифровой преобразователь 165 перьевого ввода может быть соединен с блоком 110 обработки данных непосредственно, через параллельный порт или другой интерфейс или системную шину 130 посредством любого метода, включая беспроводным образом. Также, перо 166 может иметь камеру, связанную с ним, и приемопередатчик для беспроводной передачи информации с изображением, захваченной при помощи камеры, на интерфейс, взаимодействующий с шиной 130. Далее, перо может иметь другие считывающие системы в дополнение к камере или вместо нее для определения штрихов электронных чернил, включая акселерометры, магнитометры и гироскопы.
Понятно, что показанные сетевые соединения являются примерными, и могут использоваться другие средства установления линии связи между компьютерами. Предполагается существование любых из многочисленных общеизвестных протоколов, таких как протокол управления передачей/протокол Интернета (TCP/IP), Ethernet, протокол передачи файлов (FTP), протокол передачи гипертекста (HTTP) и т. п., и система может работать в конфигурации клиент-сервер, позволяющей пользователю извлекать web-страницы с web-сервера. Могут использоваться любые из многочисленных обычных web-браузеров для отображения и манипулирования данными на web-страницах.
Интерфейс программирования (или просто интерфейс) может рассматриваться как любой механизм, процесс, протокол, предоставляющий возможность одному или нескольким сегментам кода устанавливать связь или обращаться к функциональной возможности, обеспечиваемой одним или несколькими другими сегментами кода. Альтернативно, интерфейс программирования может рассматриваться как один или несколько механизмов, методов, вызовов функций, модулей, объектов и т. д. компонента системы, способных выполнять коммуникативное связывание с одним или несколькими механизмами, методами, вызовами функций, модулями и т. д. другого компонента (компонентов). Термин «сегмент кода» в предыдущем предложении, как предполагается, включает в себя одну или несколько инструкций или строк кода и включает в себя, например, модули кода, объекты, подпрограммы, функции и т. д. независимо от применяемой терминологии, или от того, отдельно ли компилируются сегменты кода, или от того, предусматриваются ли сегменты кода в виде исходного, промежуточного или объектного кода, от того, используются ли сегменты кода в системе или процессе времени выполнения, или от того, располагаются ли они на одной и той же или различных машинах, или от того, распределены ли по многочисленным машинам, или от того, реализуются ли функциональные возможности, представленные сегментами кода, полностью программными средствами, полностью аппаратными средствами или комбинацией аппаратных и программных средств.
Теоретически, интерфейс программирования может рассматриваться, в общем, как показано на фиг.1В или фиг.1С. На фиг.1В изображен интерфейс Interface1 в виде канала, по которому происходит передача первого и второго сегментов кода. На фиг.1С изображен интерфейс, содержащий объекты I1 и I2 интерфейса (которые могут быть или могут не быть частью первого и второго сегментов кода), которые дают возможность первому и второму сегментам кода системы передаваться при помощи носителя М. С учетом фиг.1С можно рассматривать объекты I1 и I2 интерфейса как отдельные интерфейсы одной и той же системы, и также можно считать, что объекты I1 и I2 плюс носитель М составляют интерфейс. Хотя на фиг.1В и 1С показан двунаправленный поток и интерфейсы на каждой стороне потока, определенные реализации могут иметь поток информации только в одном направлении (или отсутствие потока информации, как описано ниже) или могут иметь объект интерфейса только на одной стороне. В качестве примера, и не ограничения, термины, такие как интерфейс прикладного программирования (ИПП, API), точка входа, метод, функция, подпрограмма, удаленный вызов процедуры и интерфейс модели компонентных объектов (МКО, COM), охватываются определением интерфейса программирования.
Аспекты такого интерфейса программирования могут включать в себя метод, посредством которого первый сегмент кода передает информацию (где «информация» используется в ее самом широком смысле и включает в себя данные, команды, запросы и т. д.) второму сегменту кода; метод, посредством которого второй сегмент кода принимает информацию; и структуру, последовательность, синтаксис, организацию, схему, расчет по времени и содержимое информации. В этом отношении сама лежащая в основе передающая среда может не иметь значения для работы интерфейса, неважно, является ли среда проводной или беспроводной или их комбинацией, до тех пор, пока информация передается так, как определяется интерфейсом. В определенных ситуациях информация может не пропускаться в одном или обоих направлениях в обычном смысле, так как перенос информации может происходить при помощи или другого механизма (например, информации, размещенной в буфере, файле и т. д. отдельно от потока информации между сегментами кода), или быть несуществующим, например, когда один сегмент кода просто обращается к функциональной возможности, выполняемой вторым сегментом кода. Любой или все из этих аспектов могут быть важными в данной ситуации, например, в зависимости от того, являются ли сегменты кода частью системы в слабо связанной или сильно связанной конфигурации, и поэтому этот список должен рассматриваться иллюстративным и неограничивающим.
Это представление интерфейса программирования известно для специалистов в данной области техники и ясно из вышеприведенного подробного описания изобретения. Существуют, однако, другие пути реализации интерфейса программирования и, если только специально не исключено, они так же, как предполагается, охватываются формулой изобретения, изложенной в конце данного описания изобретения. Такие другие пути могут оказаться более сложными или комбинированными, чем упрощенный вид фиг.1В и 1С, но они, тем не менее, выполняют подобную функцию для достижения такого же общего результата. Ниже заявители кратко описывают некоторые иллюстративные альтернативные реализации интерфейса программирования.
А. Разложение на элементарные операции
Передача от одного сегмента кода к другому может осуществляться косвенно разбиением передачи на множество дискретных передач. Это схематически описывается на фиг.1D и 1Е. Как показано, некоторые интерфейсы могут описываться на языке делимых наборов функциональных возможностей. Таким образом, функциональные возможности интерфейса по фиг.1В и 1С могут быть разложены на элементарные операции для достижения такого же результата, точно так же, как можно математически получить 24, 2 умножив на 2, умножив на 3, умножив на 2. Следовательно, как изображено на фиг.1D, функция, представляемая интерфейсом Interface1, может быть разделена для преобразования передачи интерфейса на множества интерфейсов Interface1A, Interface1B, Interface1C и т. д., в то же время достигая такого же результата. Как изображено на фиг.1Е, функция, представляемая интерфейсом I1, может быть разделена на множество интерфейсов I1a, I1b, I1c и т. д., в то же время достигая такого же результата. Аналогично, интерфейс I2 второго сегмента кода, который принимает информацию от первого сегмента кода, может быть разложен на множество интерфейсов I2a, I2b, I2c и т. д. При разложении на элементарные операции количество интерфейсов, включенных в 1-й сегмент кода, необязательно совпадает с количеством интерфейсов, включенных во 2-й сегмент кода. В обоих случаях по фиг.1D и 1Е, функциональная сущность интерфейсов Interface1 и I1 остается такой же, что и на фиг.1В и 1С соответственно. Разложение на элементарные операции интерфейсов также может подчиняться ассоциативным, коммутативным и другим математическим свойствам, так что разложение на элементарные операции может быть трудным для распознавания. Например, порядок операций может не иметь значения, и, следовательно, функция, выполняемая интерфейсом, может выполняться задолго до достижения интерфейса, другой частью кода или интерфейса или выполняться отдельным компонентом системы. Кроме того, для специалиста в области программирования может быть понятно, что существует множество путей выполнения различных вызовов функции, которые достигают одинакового результата.
В. Переопределение
В некоторых случаях можно проигнорировать, добавить или переопределить некоторые аспекты (например, параметры) интерфейса программирования, в то же время все же достигая предполагаемого результата. Это изображено на фиг.1F и 1G. Например, предположим, что интерфейс Interface1 по фиг.1В включает в себя вызов функции возведения в квадрат Square(ввод, точность, вывод), вызов, который включает в себя три параметра - ввод, точность и вывод, и которая вызывается из 1-го сегмента кода для 2-го сегмента кода. Если средний параметр точности не имеет значения в данном сценарии, как показано на фиг.1F, он может быть просто проигнорирован или даже заменен на не имеющий смысла (в данной ситуации) параметр. Также можно добавить дополнительный, не имеющий смысла параметр. В любом случае, могут быть достигнуты функциональные возможности возведения в квадрат, поскольку возвращается вывод после возведения в квадрат ввода вторым сегментом кода. Точность вполне может быть значащим параметром для некоторой части по направлению трафика данных или другой части вычислительной системы; однако, если признано, что точность является необязательной для ограниченного назначения вычисления квадрата, она может быть заменена или проигнорирована. Например, вместо передачи действительного значения точности может быть передано не имеющее смысла значение, такое как день рождения, без неблагоприятного влияния на результат. Аналогично, как показано на фиг.1G, интерфейс I1 заменяется на интерфейс I1', переопределенный для игнорирования или добавления параметров к интерфейсу. Интерфейс I2 может быть аналогично переопределен как интерфейс I2', переопределенный для игнорирования необязательных параметров или параметров, которые могут быть обработаны где-то в другом месте. Вопрос в данном случае заключается в том, что в некоторых случаях интерфейс программирования может включать в себя аспекты, такие как параметры, которые не являются необходимыми для некоторых целей, и, поэтому, их можно проигнорировать или переопределить, или обработать где-то еще для других целей.
С. Встроенное кодирование
Также может быть возможным объединение некоторых или всех функциональных возможностей двух отдельных модулей кода, так что «интерфейс» между ними изменяет форму. Например, функциональные возможности фиг.1В и 1С могут быть преобразованы в функциональные возможности фиг.1Н и 1I соответственно. На фиг.1Н предыдущие 1-й и 2-й сегменты кода на фиг.1В объединяются в модуль, содержащий оба из них. В данном случае сегменты кода могут все же сообщаться друг с другом, но интерфейс может быть предназначен для формы, которая более подходит для единственного модуля. Таким образом, например, формальные операторы Call (Вызов) и Return (Возврат) больше могут не являться необходимыми, но аналогичная обработка или отклик(и), согласующийся с интерфейсом Interface1, все же может быть в действии. Аналогично, как показано на фиг.1I, часть интерфейса (или весь интерфейс) I2 с фиг.1С может быть переписан внутрь интерфейса I1, образуя интерфейс I1”. Как показано, интерфейс I2 делится на I2a и I2b, и часть I2a интерфейса закодирована внутрь интерфейса I1, образуя интерфейс I1”. Для конкретного примера рассмотрим, что интерфейс I1 с фиг.1С выполняет вызов функции square(ввод, вывод), которая принимается интерфейсом I2, который после обработки значения, переданного при помощи ввода (для вычисления квадрата ввода) посредством второго сегмента кода, передает обратно возведенный в квадрат результат с выводом. В таком случае обработка, выполняемая вторым сегментом кода (возведение в квадрат ввода), может быть выполнена первым сегментом кода без обращения к интерфейсу.
D. Разъединение
Передача от одного сегмента кода к другому может выполняться косвенно посредством разбиения передачи на множество дискретных передач. Это схематически изображается на фиг.1J и 1К. Как показано на фиг.1J, предусматриваются одна или несколько частей кода (Интерфейс(ы) разъединения, так как они отъединяют функциональные возможности и/или функции интерфейса от исходного интерфейса) для преобразования передач на первом интерфейсе Interface1, чтобы они соответствовали другому интерфейсу, в данном случае интерфейсам Interface2A, Interface2B и Interface2C. Это может быть выполнено, например, там, где имеется установленная база приложений, предназначенных для выполнения передач, например, с операционной системой по протоколу Interface1, но затем операционная система переходит на использование другого интерфейса, в данном случае интерфейсов Interface2A, Interface2B и Interface 2C. Вопрос заключается в том, что изменяется исходный интерфейс, используемый 2-м сегментом кода, так что он больше не является совместимым с интерфейсом, используемым 1-м сегментом кода, и, поэтому, используется промежуточный, чтобы сделать старый и новый интерфейсы совместимыми. Аналогично, как показано на фиг.1К, третий сегмент кода может быть введен при помощи интерфейса DI1 разъединения для приема передач от интерфейса I1 и при помощи интерфейса DI2 разъединения для передачи функциональных возможностей интерфейса, например, интерфейсам I2a и I2b, перестроенным для работы с DI2, но чтобы получать такой же функциональный результат. Аналогично, DI1 и DI2 могут работать вместе для конвертирования функциональных возможностей интерфейсов I1 и I2 по фиг.1С новой операционной системе, в то же время обеспечивая такой же или подобный функциональный результат.
Е. Перезапись
Еще другим возможным вариантом является динамическая перезапись кода для замены функциональных возможностей интерфейса на что-то еще, но которое достигает такого же общего результата. Например, им может быть система, в которой сегмент кода, представленный на промежуточном языке (например, промежуточный язык компании Microsoft, Java ByteCode и т. д.), подается на оперативный компилятор или интерпретатор в среде выполнения (такой как та, которая представлена инфраструктурой.NET, средой этапа выполнения языка Java или другими подобными средами типа этапа выполнения). Оперативный компилятор может записываться для того, чтобы динамически преобразовывать передачи от 1-го сегмента кода на 2-й сегмент кода, т. е. согласовывать их с другим интерфейсом, который может потребоваться для 2-го сегмента кода (или исходного, или другого 2-го сегмента кода). Это изображено на фиг.1L и 1М. Как можно видеть на фиг.1L, данный подход аналогичен сценарию разъединения, описанному выше. Это может быть сделано, например, там, где установленная база приложений предназначена для передачи данных операционной системой в соответствии с протоколом Interface1, но затем операционная система переходит на использование другого интерфейса. Оперативный компилятор может использоваться для согласования передач «на лету» от приложений с установленной базой на новый интерфейс операционной системы. Как изображено на фиг.1М, данный подход динамической перезаписи интерфейса(ов) может также применяться для динамического разложения на элементарные операции или изменения иным образом интерфейса(ов).
Также отмечается, что вышеописанные сценарии для достижения такого же или подобного результата в качестве интерфейса при помощи альтернативных вариантов осуществления также могут объединяться различными путями, последовательно и/или параллельно, или с другим промежуточным кодом. Таким образом, альтернативные варианты осуществления, представленные выше, не являются взаимно исключающими и могут соединяться, сопоставляться и объединяться для получения таких же или эквивалентных сценариев относительно общих сценариев, представленных на фиг.1В и 1С. Также отмечается, что, как и с большинством программных конструкций, существуют другие подобные пути достижения таких же или подобных функциональных возможностей интерфейса, которые могут не описываться в данном документе, но, тем не менее, представляются сущностью и объемом изобретения, т. е. отмечается, что именно, по меньшей мере частично, функциональные возможности, представленные интерфейсом, и полезные результаты, достигаемые им, лежат в основе ценности интерфейса.
На фиг.2 изображен иллюстративный планшетный ПК 201, который может использоваться согласно различным аспектам настоящего изобретения. Любые или все признаки, подсистемы и функции в системе по фиг.1 могут быть включены в компьютер по фиг.2. Планшетный ПК 201 включает в себя большую поверхность 202 дисплея, например, преобразующий в цифровую форму дисплей с плоским экраном, предпочтительно экран жидкокристаллического дисплея (ЖКД), на котором отображается множество окон 203. Используя стило 204, пользователь может выбирать, выделять и/или писать на преобразующей в цифровую форму поверхности 202 дисплея. Примеры подходящих преобразующих в цифровую форму поверхностей 202 дисплея включают в себя электромагнитные цифровые преобразователи перьевого ввода, такие как цифровые преобразователи перьевого ввода компаний Mutoh или Wacom. Также могут использоваться другие типы цифровых преобразователей перьевого ввода, например, оптические цифровые преобразователи. Планшетный ПК 201 интерпретирует жесты, сделанные с использованием стило 204, для манипулирования данными, ввода текста, создания рисунков и/или выполнения обычных задач приложения компьютера, таких как электронные таблицы, программы обработки текста и т. п.
Стило 204 может быть оснащено одной или несколькими кнопками или другими средствами, чтобы дополнять его возможности выбора. В одном варианте осуществления стило 204 может быть реализовано в виде «карандаша» или «ручки», в которых один конец составляет пишущую часть, и другой конец составляет конец «ластика», и который при движении по дисплею указывает части изображения на дисплее, которые должны быть стерты. Также могут быть использованы другие типы устройств ввода, такие как мышь, шаровой манипулятор или т. п. Дополнительно, собственный палец пользователя может представлять собой стило 204 и использоваться для выбора или указания частей отображаемого изображения на сенсорном или бесконтактном дисплее. Следовательно, термин «устройство пользовательского ввода», используемый в настоящем документе, как предполагается, имеет широкое определение и охватывает многие варианты общеизвестных устройств ввода, таких как стило 204. Область 205 показывает область обратной связи или область контакта, позволяющую пользователю определить, где стило 204 соприкасается с поверхностью 202 дисплея.
В различных вариантах осуществления система обеспечивает платформу обработки чернил в виде набора служб модели компонентных объектов (МКО), которые приложение может использовать для захвата, манипулирования и хранения чернил. Одна служба дает возможность приложению считывать и записывать чернила, используя описанные представления чернил. Платформа обработки чернил также может включать в себя язык разметки, включающий в себя язык, подобный расширяемому языку разметки (XML). Далее, система может использовать распределенную модель компонентных объектов (РМКО, DCOM) в качестве другой реализации. Могут использоваться еще другие реализации, включающие в себя модель программирования Win32 и модель программирования.Net компании Microsoft Corporation.
Представление альтернатив
На фиг.3 изображены электронные чернила, которые синтаксически разобраны и представлены в виде дерева на фиг.4. Электронными чернилами на фиг.3 является фраза “hello, this is a test”, при этом пять слов из фразы представлены метками А-Е. Слово “hello,” А включает в себя два штриха 301 и 311. Слово “this” В включает в себя три штриха 302-304. Слово “is” С включает в себя два штриха 305-306. Слово “a” D включает в себя один штрих 307. Слово “test” Е включает в себя штрихи 308-309. Фраза занимает две строки F (“hello, this is”) и G (“a test”). Эти строки вместе образуют абзац Н.
На фиг.4 представлен синтаксический разбор электронных чернил с фиг.3. Корневой узел 401 имеет узел Н абзаца, происходящий из него. Узел Н абзаца включает в себя узлы F и G строки. Узел F строки включает в себя узлы А-С слова. Узел G строки включает в себя узлы D и Е слова. Каждый узел слова включает в себя штрихи, как изображено на фиг.3. Каждый узел А-Н может упоминаться как узел контекста. Каждый узел контекста обеспечивает контекст для других узлов для анализа, распознавания или других целей. Например, распознавание штрихов в узле В может иметь одну коллекцию результатов, когда штрихи анализируются индивидуально или в отношении всех штрихов узла В. Однако результаты распознавания или упорядоченность результатов может быть другой, когда анализ штрихов в узле В включает в себя анализ (или результаты предыдущего анализа) штрихов из узлов А и С. Аналогично, результаты распознавания могут улучшаться с большим количеством узлов D-H контекста, которые включены в анализ узла В.
Понятно, что различные узлы могут использоваться дополнительно (или взамен вышеупомянутых узлов), включая узел предложения (который содержит все предложение), узел списка (который содержит список) и узел элемента списка (который содержит элемент списка).
На фиг.5 представлена решетка с альтернативами, полученными из дерева по фиг.4. Решетка представляет собой представление дерева с уровня узла. Например, решетка может представлять дерево с уровня узла строки, с уровня узла слова, с уровня узла абзаца и т. п. На фиг.5 решетка существует для каждого узла строки. Каждая решетка включает в себя столбцы (упоминаемые как столбцы решетки). Столбцы представляют слова, ассоциированные с каждым узлом строки (причем каждая альтернатива упоминается как элемент решетки в столбце решетки). Также, столбцы символа-заполнителя (также упоминаемые как столбцы символа-заполнителя или пустые столбцы) могут размещаться между словами, чтобы способствовать определению зависимостей между словами.
Решетка на F включает в себя пять столбцов. Каждый столбец включает в себя альтернативы, которые представляют альтернативные результаты распознавания от средства распознавания. Столбец F0 представляет слово “hello,”, находящееся на фиг.3. Здесь, “hello” может упоминаться как наилучшая альтернатива. Столбец решетки включает в себя ссылку на штрихи, которые составляют слово (здесь, штрихи S301 и S311). Столбец F0 решетки также включает в себя дополнительные альтернативы (здесь, “hellos” и “hello.”). Столбец F2 решетки ссылается на штрихи S302-S306 и включает в себя вводы для “this” и альтернативы “thesis” и “This”. Столбец F4 решетки ссылается на штрихи S305 и S306 и включает в себя вводы для “is” и альтернативу “i5”. Столбцы F1 и F3 решетки представляют собой столбцы разделительного знака (или разделителя). Решетка на G включает в себя три столбца. Столбец G0 решетки ссылается на штрихи S307-S310 и включает в себя “a” и альтернативы {an, or, aw, An, attest, detest}. Столбец G2 решетки ссылается на штрихи S308-S310 и включает в себя результат распознавания “test” и без альтернатив. Столбец G1 решетки представляет собой столбец разделительного знака.
Древовидная структура может содержать одну или несколько решеток. Что касается фиг.5, то решетка на F и решетка на G могут быть объединены вместе в большую решетку. Решетка в виде комбинации решетки на F и решетки на G может включать в себя в сумме девять столбцов, причем девятый столбец представляет собой столбец разделительного знака между решеткой на F и решеткой на G. Конкретно, этот новый столбец разделительного знака может добавляться в виде столбца F5 разделительного знака. Аналогично, можно разделить решетки на меньшие решетки. Отдельные решетки могут посылаться индивидуально или в группе на распознаватель или запрашиваться касательно информации. Если столбец разделительного знака начинает или завершает меньшую решетку, столбец разделительного знака может быть удален, так что остается столбец с содержимым. Конечно, столбцы разделительного знака могут оставаться в качестве альтернативного подхода.
Результаты распознавания и альтернативы, хранимые в каждом столбце решетки, могут упоминаться как элементы решетки. Каждый элемент решетки может включать в себя обозначение, сколько штрихов использовалось для получения результатов распознавания. Например, второй ввод в столбце F0 решетки “hellos” включает в себя обозначение (здесь, «2»), которое представляет, сколько штрихов использовалось для формирования результата распознавания. Для столбца F2 результат распознавания “this” использовал три штриха для формирования этого результата. Однако результат распознавания “thesis” использовал пять штрихов для формирования этого результата. Затем, каждый элемент решетки включает в себя указатель на следующий столбец. Здесь, элементы решетки столбца F0 указывают на столбец F1. Аналогично, элемент “this” решетки столбца F2 указывает на столбец F3 в качестве следующего столбца. Однако элемент “thesis” решетки столбца F2 указывает на несуществующий столбец (здесь, представленный как столбец 5). Конечно, указатель каждого элемента решетки на несуществующий столбец может быть вместо этого быть указателем на предопределенный столбец, который представляет конец решетки.
Обозначение элементов решетки среди столбцов может упоминаться как путь решетки. Путь решетки указывает конкретное альтернативное значение распознавания (например, хранение конкретной интерпретации чернил).
Упорядочение решетки поддерживает представление операций по выбору из многочисленных слов. На фиг.6 показан пример, где пользователь выбрал слова на строке F. Результирующий выбор может быть представлен как решетка выбора (а именно, коллекция выбранных узлов в решетке). Здесь, решетка выбора включает в себя столбцы F0-F4. На фиг.7 показан альтернативный выбор слов из двух строк. Здесь, выбор включает в себя {this is test}, и результирующая решетка выбора может включать в себя столбцы F2, F3, F4, G1 и G2. Столбец G1 разделительного знака может добавляться или может не добавляться автоматически для правильной расстановки пробелов между столбцами F4 и G2.
Решетки по фиг.5 были созданы, основываясь на узлах уровня строки по фиг.4. Решетки могут формироваться на любых уровнях по фиг.4. На фиг.8 показана решетка, соответствующая узлу Н абзаца. Здесь, девять столбцов показаны в итоге. Столбцы решетки представляют узлы слова по фиг.4 и их альтернативы. Решетка по фиг.9 изображает решетку, соответствующую узлу А слова.
Фиг.8 может включать или может не включать столбец H8 разделительного знака, который разделяет две строки. Это потому, что в некоторых языках не используется строка разделительных знаков между строками. Например, в основанных на знаках языках (например, китайский язык) могут не использоваться пробелы. В этих ситуациях может использоваться пустой знак вместо столбца разделительного знака. Распознаватель может обеспечивать столбец разделительного знака или пустой знак, что требуется. Например, в чернильном предложении с английскими словами, за которыми следуют японские знаки, за которыми следуют еще английские слова, можно проводить синтаксический разбор и направлять различные части на соответствующие распознаватели (например, посредством идентификации чернил по языку или распознавателем). Распознаватель английского языка может возвращать альтернативы, связанные разделительными пробелами. Распознаватель японского языка может возвращать альтернативы, связанные пустыми знаками. Выходные результаты могут объединяться для получения единственной решетки с комбинацией столбцов разделительного знака и пустых знаков, разделяющих результаты от разных распознавателей. Конечно, использование распознавателей, которые создают одинаковый тип разделительного пробела/пустого знака (например, распознаватели английского и французского языка) могут приводить к тому, что запоминается только один разделительный пробел/пустой знак, а не два, так как используется одинаковый тип лингвистической модели.
Далее, не требуются, чтобы разделительные пробелы/пустые знаки были направленными, как например, влево и вправо. Скорее, их расположение определяется направлением используемого языка (горизонтальная растеризация, вертикальная растеризация и другие направления).
Объекты и зависимости объектов
Этот раздел и последующий раздел (Интерфейсы прикладного программирования) описывают объекты, их зависимости между собой и интерфейсы для взаимодействия с различными моделями.
Различные зависимости существуют между объектами решетки, описанными выше. На фиг.10 изображены иллюстративные примеры этих зависимостей. Некоторая, вся или дополнительная информация может включаться в каждый объект, описанный ниже.
Решетка 1001 представляет собой объект, который может создаваться программой синтаксического разбора или распознавателем. Решетка может преобразовываться в последовательную форму для получения легкого доступа с одного узла. Можно обращаться ко всей решетке посредством запроса решетки с данного узла. Можно получать данные распознавания на различных уровнях внутри решетки посредством запроса информации с объекта решетки. Можно создавать решетку на любом узле посредством объединения или разделения существующих решеток. Решетка, возвращаемая для узла, может ссылаться только на штрихи, обнаруживаемые под этим узлом. Чтобы посмотреть все данные распознавания в дереве в одной решетке, можно запросить решетку, ассоциированную с корневым узлом дерева.
Решетка 1001 может включать в себя:
указание на то, присутствуют ли разделительные знаки и, в необязательном порядке, их идентификаторы (разделительные знаки могут использоваться при объединении одной решетки с другой решеткой. Объединение решеток с разделительными знаками может зависеть от языка, например, в английском языке слова разделяются пробелом, но в японском языке нет необходимости использовать пробелы);
список столбцов решетки (или указатель на первый столбец);
узел контекста (который указывает, где существует решетка 1001 документа);
коллекцию свойств;
наилучшую альтернативу пути решетки;
штрихи, содержащиеся в решетке, идентифицирующей штрих посредством его значения идентификации (или индексного значения штриха), или обоими; и
размер решетки.
Разделительные знаки (слева и справа, вверху и внизу и другие) могут запоминаться как часть столбца или как отсоединенные столбцы внутри решетки. Эти левые и правые разделительные знаки, в основном, имеют только единственный элемент со строковыми данными для разделительного знака. Эти левые и правые разделительные знаки обозначаются как наилучшая альтернатива для этих столбцов. Однако они не возвращаются в качестве альтернативы при запросе альтернатив у решетки. Это дает возможность выполнять более легкое объединение альтернатив в решетке. Альтернативно, эти столбцы разделительного знака могут возвращаться или удаляться, как потребуется.
Различные методы могут выполняться в отношении решетки. Они включают в себя:
запрос штрихов, ассоциированных с решеткой;
запрос, чтобы была обновлена сегментация дерева, основываясь на взаимодействии с решеткой (например, объединением слов);
запрос, чтобы решетка была преобразована в последовательную форму в сохраняемый формат;
запрос левых и правых разделительных знаков; и
запрос столбцов, ассоциированных с заданными штрихами.
Столбец 1004 решетки представляет собой столбец в решетке. Столбец решетки, в основном, соответствует сегментации в решетке. Ссылка на альтернативы выполняется посредством запоминания указателя на различные элементы решетки в каждом столбце. Если элементом решетки является наилучшая альтернатива, тогда столбец ссылается на элемент решетки в качестве наилучшей альтернативы.
Столбец решетки может включать в себя:
идентификацию штрихов в столбце решетки;
элементы решетки, содержащиеся в каждом столбце;
элемент наилучшей альтернативы из альтернатив в каждом столбце;
коллекцию свойств; и
ссылку на родительскую решетку.
Следующие методы могут выполняться над столбцом решетки:
запрос штрихов, ассоциированных со столбцом решетки;
запрос решетки, ассоциированной со столбцом решетки;
запрос элементов, ассоциированных со столбцом решетки; и
запрос или обозначение элемента наилучшей альтернативы для столбца решетки.
Элемент 1005 решетки может постоянно находиться в каждом столбце. Элемент решетки представляет собой часть пути решетки. Элемент решетки хранит строковые данные, ассоциированные со штрихом или словом. Штрихи, ассоциированные с элементом решетки, в основном, берутся из начала списка штрихов, ассоциированных со столбцом решетки. Это позволяет другому столбцу решетки содержать поднабор штрихов и иметь отдельные элементы решетки, ассоциированные с поднабором. Элемент решетки может обозначаться столбцом решетки в качестве наилучшей альтернативы для столбца.
Элемент решетки может включать в себя:
число штрихов;
данные или строку, ассоциированную с элементом решетки;
ссылку на столбец решетки, который содержит элемент решетки;
ссылку на предыдущий столбец решетки;
ссылку на следующий столбец решетки;
коллекцию свойств; и
доверительный уровень распознавания, указывающий, насколько доверительным является результат распознавания от средства распознавания.
Методы, воздействующие на элемент решетки, могут включать в себя:
запрос штрихов, ассоциированных с элементом решетки;
запрос столбца родительской решетки для столбца текущей решетки;
запрос доверительной оценки распознавания, ассоциированной с элементом решетки (а именно, насколько доверительным является распознаватель, который правильно распознал чернила);
запрос следующего столбца решетки;
запрос предыдущего столбца решетки; и
запрос распознанных строковых данных из элемента решетки.
Путь 1002 решетки представляет собой путь по столбцам решетки и включает в себя коллекцию элементов решетки по многочисленным решеткам. Путь решетки может включать в себя:
коллекцию элементов решетки, которые составляют путь решетки;
указание на то, распространяется ли путь по единственной решетке;
штрихи, ассоциированные с путем решетки;
данные или строку распознавания, ассоциированные с путем решетки; и
доверительный уровень распознавания, указывающий, насколько доверительным является результат распознавания от средства распознавания.
Нижеследующие методы могут выполняться с путем решетки:
определение того, распространяется ли путь решетки за пределы единственной решетки;
запрос коллекции элементов решетки;
запрос штрихов, ассоциированных с путем решетки;
запрос текста, основанного на коллекции штрихов;
запрос информации, подлежащей помещению в заданную строку;
запрос штрихов, соответствующих области текста;
запрос штрихов, соответствующих узлам;
запрос области текста, соответствующей штрихам; и
доверительный уровень распознавания, указывающий, насколько доверительным является результат распознавания от средства распознавания.
Решетка 1003 выбора представляет собой логическую объектную сущность, которая действует подобно решетке, но необязательно соответствует единственному узлу. Если объект решетки хранится на уровне строки, можно создать объект решетки выбора для некоторых слов на одной строке, некоторых штрихов на одной или нескольких строках, всех слов на одной строке или некоторых слов из многочисленных строк, и т. п. Решетка выбора хранит список столбцов решетки, которые не должны быть с одного и того же объекта решетки. Выбор штриха может распространяться и включать в себя чернильное слово или сегмент, ссылающийся на выбранные чернила. Когда два объекта решетки объединяются вместе в объект решетки выбора, могут вводиться, соответствующим образом, столбцы правого и левого разделительного знака в список столбцов. Объект решетки выбора может включать в себя:
столбец или столбцы решетки, которые содержат решетку выбора;
решетку или решетки, охватываемые решеткой выбора; и
наилучшую альтернативу для каждого столбца в решетке выбора.
Объект решетки выбора может поддерживать следующие методы:
запроса наилучшей альтернативы, основываясь на пути решетки; и
запроса столбцов решетки, ассоциированных с решеткой выбора.
Коллекция 1006 альтернатив представляет собой объект, который ссылается на решетку выбора. Коллекция альтернатив может включать в себя:
решетку выбора.
Нижеследующее предусматривает образец методов, которые могут использоваться с коллекцией альтернатив. Другие методы описываются ниже в следующих разделах:
запрос альтернатив из пути решетки; и
запрос альтернатив для узла контекста.
Различные объекты также могут иметь методы, ассоциированные с ними. Эти методы могут вызываться интерфейсом прикладного программирования (ИПП). Следующие классы могут использоваться для лучшей обработки информации в дереве.
Во-первых, может использоваться метод для получения альтернатив от средства анализа чернил. Первый метод объекта анализа чернил включает в себя метод «получить альтернативу», который возвращает коллекцию альтернативных объектов для всего дерева, заданных узлов или заданных штрихов. Здесь, данный метод запрашивает узлы контекста, ссылающиеся на подаваемые узлы. Поэтому, например, можно запросить альтернативы от данного узла строки. Система отвечает коллекцией альтернатив, или по меньшей мере альтернативой верхнего уровня для данного узла.
Может быть предусмотрен новый класс объектов (класс альтернатив анализа). Метод, который можно использовать в классе альтернатив анализа, может возвращать доверительный уровень распознавания текста. Здесь можно определить уровень доверительных данных в элементе решетки. Также, другой метод, который можно использовать в классе альтернатив анализа, включает в себя метод «получить распознанную строку». Здесь данный метод получает результат распознавания, ассоциированный с элементами решетки на этом пути решетки альтернативы.
Во-вторых, также может использоваться класс объектов коллекции альтернатив анализа. Данный класс включает в себя ряд методов, включая «получить эту альтернативу анализа», которой может быть результат возвращаемого значения в методе «получить альтернативы» в анализаторе чернил выше.
Следующие методы могут использоваться с контекстным деревом анализа. Во-первых, метод «получить альтернативы» может применяться к коллекции альтернатив анализа. Данный метод может включать в себя спецификацию узлов контекста, для которых ищутся альтернативы. Во-вторых, другой метод «получить альтернативы» может применяться к коллекции альтернатив анализа, но в данном случае также может задаваться максимальное количество альтернатив. Например, ссылаясь на столбец G0 решетки по фиг.5, можно запросить несколько альтернатив по сравнению со всей коллекцией альтернатив, ассоциированной со столбцом решетки.
Третий метод «получить альтернативы» может запрашивать альтернативы для заданных штрихов, которые есть, и альтернативы для заданных штрихов, которые возвращаются.
Другой метод может включать в себя метод «модифицировать наилучшую альтернативу», в котором можно модифицировать, какие альтернативы должны задаваться в качестве наилучшей альтернативы. Например, если пользователь выбрал одну альтернативу относительно другой, выбранная альтернатива может рассматриваться наилучшей альтернативой для будущих выборов. Еще другой метод может включать в себя метод «модифицировать наилучшую альтернативу», который автоматически подтверждает выбор альтернативы, так что она остается в качестве наилучшей альтернативы, в то время как вокруг нее происходят другие анализы чернил. Например, пользователь может выбрать новую наилучшую альтернативу. Новая наилучшая альтернатива может иметь другую сегментацию дерева. Эта новая сегментация берется как предпочтительная сегментация дерева, основываясь на выборе данной альтернативы. Предпочтительная сегментация изменяет форму дерева посредством изменения группировки штрихов и/или слов. В этом отношении каждый выбор новой альтернативы может приводить к совершенно новому дереву.
Альтернативы могут быть получены посредством передачи узлов или штрихов в контекст анализа. Нет необходимости, чтобы эти штрихи были из смежных частей контекстного дерева (смотрите, например, фиг.7 выше). Объект анализатора чернил может возвращать массив концевых узлов контекста, где штрихи в узлах соответствуют штрихам или узлам, переданным посредством метода GetAlternates(). С этих концевых узлов клиент может переместить свой фокус, так как он получает родительские или дочерние узлы или штрихи для исследования полной древовидной структуры, как если бы эти узлы были бы в наилучшей альтернативе.
Альтернатива решетки представляет собой коллекцию строковых данных для слов и штрихов, соответствующих этим словам, вместе со свойствами (доверительность распознавания и т. д.). Концевые узлы могут создаваться один на слово. Чтобы создать родительские узлы, можно рассмотреть многочисленные концевые узлы, которые могут происходить или могут не происходить из одной и той же коллекции штрихов. Неконцевые узлы могут дополнительно применяться в качестве альтернатив.
Интерфейсы прикладного программирования
Могут использоваться разнообразные интерфейсы прикладного программирования с аспектами изобретения. Нижеследующее перечисляет интерфейсы прикладного программирования и их функции.
Контекстом анализа может быть корневой узел в дереве. Может быть объявлен набор методов, направленных на анализ чернил в контексте анализа. Контекст анализа представляет собой корневой узел в контекстных деревьях, описанных в данном описании. Объект анализатора чернил, который относится к контексту анализа, может объявлять по меньшей мере два набора методов.
Во-первых, может быть объявлен набор методов «получить альтернативы». Здесь набор «получить альтернативы» может включать в себя множество определений, из которых четыре описаны здесь. GetAlternates(Context Node [] notes контекста) запрашивает альтернативы от узла или узлов контекста (например, узлов строки, слова, абзаца или других узлов) и задает узлы, для которых должны быть получены альтернативы. Например, применительно к фиг.5, GetAlternates, применимый к узлу А, возвращает коллекцию “hello,”, “hellos” и “hello”. GetAlternates также может применяться, основываясь на спецификации одного или нескольких штрихов. Например, GetAlternates, применимый к штрихам S302-S304, может возвращать коллекцию “this”, “thesis” и “This”. Возвращаемый текст может включать в себя или может не включать в себя дополнительные штрихи. В случае “thesis” также могут использоваться дополнительные штрихи S305-S306.
Метод GetAlternates может включать в себя или может не включать в себя указание на максимальное количество альтернатив, подлежащих возврату. Поэтому, если максимальное количество альтернатив было установлено на два, тогда GetAlternates(узел А) будет возвращать “hello,” и “hellos”, но не “hello.”.
Далее, если задается узел контекста или штрих, GetAlternates может возвращать альтернативы для всего контекста анализа.
Во-вторых, другой метод может включать в себя Модифицировать наилучшую альтернативу. Здесь, Модифицировать наилучшую альтернативу представляет то, как выглядит контекст анализа, если применяется выбранная альтернатива. В примере на фиг.5, если выбирается альтернатива “thesis”, тогда результат после модифицирования наилучшей альтернативы может включать в себя “hello, thesis a test”. Для каждой альтернативы, возвращаемой в GetAlternates выше, может просматриваться другое, тем не менее полностью законченное контекстное дерево анализа. Получить альтернативы и Модифицировать наилучшие альтернативы представляют собой представления решетки, описанной выше. Далее, Модифицировать наилучшие альтернативы также может модифицировать древовидную структуру так, чтобы она соответствовала сегментации вновь выбранной альтернативы.
Модифицирование альтернативы может включать в себя возможность задания того, должен ли выбор альтернативы предотвращать замену будущим анализом текущего выбора альтернативы. Этой спецификацией может быть, например, булев аргумент, заданный в вызове метода «Модифицировать наилучшую альтернативу» как подтверждение того, что наилучшая альтернатива должна быть заменена.
Каждый объект альтернативы, возвращаемый из «получить альтернативы», может ссылаться на массив концевых узлов контекста для набора штрихов или узлов, переданных в метод «получить альтернативы». Используя метод «получить альтернативы» и другие методы для получения штрихов или узлов, пользователь может получить родительские и дочерние узлы и штрихи и оценить, как дерево будет выглядеть, если будет применена альтернатива.
Деревья альтернатив могут создаваться заранее или могут создаваться динамически при запросе методом «получить альтернативы». Одним преимуществом ожидания до тех пор, пока не будет запроса на альтернативы, является то, что этот подход минимизирует необязательное создание нежелательных деревьев. При этом последнем подходе, если создан объект альтернативы, он может ссылаться только на имеющие отношение концевые ContextNodes. Если дерево дополнительно исследуется пользователем (запрашиванием родительского узла для концевого узла), каждый родительский узел может создаваться динамически по запросу.
Следующие методы могут использоваться с объектом анализатора чернил. Эти методы помогают находить узлы и способствуют преобразованию между узлами контекста и штрихами. StrokesToContextNodes принимает коллекцию штрихов и возвращает массив узлов контекста, которые ссылаются на штрих. В первом подходе на каждый штрих может ссылаться только один узел (в то время как родительский и прародительский узлы могут, в свою очередь, ссылаться на один узел). Здесь только наилучшая альтернатива ссылается на штрих. В альтернативном подходе комбинация альтернатив представляет собой ссылку на единственный штрих. В частности, более одного узла контекста могут ссылаться на штрих (например, на штрихи S305 и S306 могут ссылаться столбцы F2 и F4 решетки, соответствующие узлам В и С). В таких случаях StrokesToContextNodes может возвращать узлы контекста, которые ссылаются на штрих. При ответе на метод StrokesToContextNodes набор возвращаемых узлов контекста может включать в себя или может не включать в себя узлы, которые содержат штрихи кроме переданных штрихов.
Альтернативно и необязательно, в некоторых случаях многочисленные узлы могут включать в себя узлы более высокого порядка (включая узлы абзаца). Этот необязательный подход может выполняться для получения завершенной картины узлов контекста, которые ссылаются на подаваемые штрихи.
Например, на фиг.5 можно запросить узлы, ассоциированные со штрихами, затем все штрихи, ассоциированные с возвращаемыми узлами. При старте со штриха S301, результат может включать в себя штрихи S301 и S311. Аналогично, при старте со штрихов S301 и S306, результат может выдать штрихи S301, S311, S305 и S306.
Следующий метод ContextNodesToStrokes передает узлы контекста и возвращает коллекцию штрихов, содержащихся в ссылаемых узлах контекста. При помощи этого метода могут передаваться узлы слова, строки и абзаца, и корневые узлы. Другие типы узлов также могут включаться, включая узлы музыкальных обозначений, математические узлы, узлы рисунка, узлы снимка, узлы диаграммы и узлы, которые определяют область записи, уровень выравнивания и т. п.
Что касается класса альтернатив анализа, три метода могут ассоциироваться с классом. Во-первых, RecognitionConfidence позволяет извлекать доверительность распознавателя с результатом. Во-вторых, RecognizedString задает строковое значение альтернативы. Используя RecognizedString, можно запрашивать значения альтернатив, ассоциированных с узлами, без необходимости пошагового обхода узлов контекста, как описано выше. В-третьих, GetProperty позволяет получать любое свойство, установленное на объект решетки распознавателем объекта в классе альтернатив анализа (например, доверительность распознавания). Здесь можно задать глобально уникальный идентификатор (ГУИД, GUID) или другую идентифицирующую информацию и получить значение свойства.
Два метода могут использоваться для получения информации, относящейся к областям текста. Во-первых, GetNodesFromTextRange позволяет получать конкретные узлы контекста, основываясь на области текста. Областью текста могут быть позиции начала и окончания, информация о начале и продолжительности или другие представления областей текста. Используя чернила на фиг.3 и решетку на F на фиг.4, можно преобразовать область (7, 4) текста и получить штрихи 302, 303, 304, где 7 означает пропуск первых 6 знаков “hello,”, и 4 означает принятие следующих 4 знаков. (716) будет выдавать 302-306. Система может предотвратить разбиение слова распознавателем, поэтому (0, 1), (0, 2), (0, 3), (0, 4), (0, 5) и (0, 6) все будут выдавать s301, s311.
Второй метод GetTextRangeFromNodes позволяет получать конкретные области текста из подаваемых узлов контекста. Из подаваемых узлов контекста можно принять позиции начала и окончания, информацию о начале и продолжительности или другие представления областей текста. Этот метод может расширять набор штрихов, чтобы обеспечить, что включаются только полные слова.
Объекты узла контекста могут быть одинаковыми. Альтернативно, они могут быть различными, основываясь на том, на какой узел они ссылаются. Например, характерные для слова и строки узлы контекста могут иметь дополнительные свойства, включая значения, ассоциированные со штрихами (например, информацию, относящуюся к характеристикам надстрочного элемента, подстрочного элемента, средней линии и базовой линии чернил). Возвращаемые значения этих свойств могут включать в себя различные точки. Например, первая точка может описывать координаты x, y начала строки. Вторая точка может описывать координаты x, y конечной точки. Значения могут вычисляться на уровне строки посредством использования начальных и конечных значений содержащихся чернильных слов или могут быть средним значением для содержащихся чернильных слов. Это может применяться к узлам строки, узлам абзаца, узлам списка и узлам элементов списка наряду с другими.
Система может поддерживать дополнительные классы, которые относятся к состоянию анализа чернил. Например, система может включать в себя класс состояния анализа. Здесь, приложению могут потребоваться сведения, было ли успешным выполнение анализа, без каких-либо ошибок. Результаты операций анализа могут возвращать объект состояния анализа, который суммирует состояние выполнения. Объект может включать в себя информацию, касающуюся успешного выполнения анализа. Например, объект может включать в себя простое булево выражение, представляющее успешное выполнение анализа (например, «истина», если выполнение анализа не имело никаких предупреждений или ошибок). Если выполнение не было успешным, объект может включать в себя список предупреждений и влияние предупреждений. Объект может включать в себя список областей, измененных посредством анализа.
Создание решетки
На фиг.11 изображены различные процессы создания решетки. На этапе 1101 система принимает чернила. Чернила могут приниматься из запоминающего устройства (локального или удаленного) или из вводимой пользователем информации на цифровом преобразователе. Затем на этапе 1102 система может выполнять синтаксический разбор чернил. Результатом синтаксического разбора чернил является дерево 1103. В необязательном порядке, как показано при помощи пунктирной ветви к решетке 1104, система может создавать решетку, основываясь на информации из синтаксически разобранных чернил. После того как создано дерево 1103, система на этапе 1105 может распознавать чернила, используя механизм распознавания рукописного текста. Если решетка 1104 была создана ранее, система может обновить решетку при помощи альтернатив с этапа 1105 распознавания. Альтернативно, если она не создана ранее, решетка 1104 может создаваться после этапа 1105 распознавания чернил.
Примеры
Нижеследующее относится к примерам предоставления альтернатив для чернильной информации. На фиг.12А-19 показаны различные примеры того, как альтернативы могут применяться для контекстного дерева анализа. На фиг.12А показано контекстное дерево анализа с альтернативами. Информацией, обнаруживаемой в контекстном дереве анализа, является фраза “Today is Monday”. Контекстное дерево анализа имеет контекст А анализа верхнего узла, узел В абзаца, узел С строки и три узла D-F чернильных слов, соответствующих трем чернильным словам.
Здесь, пользователь выбрал слово “Monday”. Вызывая один из методов «получить альтернативы», описанных выше, система возвращает несколько альтернатив. Первой альтернативой, представленной посредством F', является “Monolog”. Второй альтернативой, представленной посредством F”, является “Monolay”. Если пользователь запрашивает просмотр узла строки, ассоциированного с чернильным словом “Monolog”, система генерирует узел C' строки, ассоциированный с F' “Monolog” на фиг.12В. Если пользователь затем запрашивает дочерний узел для узла C' строки, система дополнительно расширяет дерево альтернативы 1 и включает чернильные слова D' и E' и альтернативный узел C' строки (одинаковые значения, но части разных деревьев), как показано на фиг.12С. Кроме того, если пользователь запрашивает узел C' строки в отношении его родительского узла, то может динамически включаться узел B' абзаца. Если пользователь продолжает и запрашивает родительский узел для узла B' абзаца, может включаться корневой узел A', как показано на фиг.12D.
Как описано в отношении фиг.12А-12D, генерирование деревьев, основываясь на альтернативах, может выполняться только тогда, когда это запрашивается пользователем. Альтернативно, система может делать попытку сгенерировать все деревья альтернатив и запомнить их в решетке. Одно преимущество задержки генерирования деревьев альтернатив до фактического запроса пользователем включает в себя минимизирование времени обработки, расходуемого на создание не релевантных деревьев.
На фиг.13А и 13В показана фраза “the quick brown fox”, расположенная на двух строках. Здесь, фиг.13А включает в себя контекст А анализа, абзац В, строку С со словами Е и F и строку D со словами G и H. Выбор включает в себя слова “quick” F и “fox” Н. На фиг.13В показаны альтернативы 1 и 2 для выбранных слов. Здесь, альтернатива 1 включает в себя альтернативы “brick” F' для F и “box” H' для Н. Альтернатива 2 включает в себя альтернативы “brick” F” и “lox” H”.
На фиг.14 показана модификация альтернативной сегментации. Использование контекстного дерева анализа имеет контекст А анализа, абзац В, строку С и чернильные слова “the” D, “quick” E, “brown” F и “fox” G. Выбранными словами являются “brown” F и “fox” G. Альтернатива 1 показывает новую сегментацию для чернильных слов F и G. Здесь новое чернильное слово “Boonton” представлено как F'. Альтернатива 2 показывает исходную сегментацию с альтернативами “browne” F” и “for” G”.
На фиг.15 показан другой пример сегментации и альтернатив. Здесь контекстное дерево анализа включает в себя узел А контекста анализа, узел В абзаца, узел С строки и чернильное слово “together”. Альтернатива 1 изображает чернильное слово “together” D, разделенное на два слова “Tog” D' и “ether” E'. Альтернатива 2 изображает чернильные слова “To” D”, “get” E” и “her” F”. Из-за новых альтернатив узлы строки и абзаца в альтернативе 1 представлены как C' и B' соответственно, и в альтернативе 2 представлены как C” и B” соответственно.
На фиг.16 изображено контекстное дерево анализа, которое включает в себя альтернативы, которые включают в себя рисунки, а также чернильные слова. Выполняя синтаксический разбор фразы “O Canada”, контекстное дерево анализа на фиг.16 включает в себя контекст А анализа, абзац В, строку С, чернильное слово “O” D и “Canada” E. Альтернатива 1 включает в себя абзац В', строку С' и чернильное слово “OCanada” D'. Альтернатива 2 включает в себя другой анализ чернильного слова “O” D. Вместо рассмотрения его в качестве чернильного слова одна из альтернатив, созданных распознавателем, представляет собой вероятность того, что “O” представляет собой рисунок (распознанный, в частности, в данном случае как окружность) D”. Здесь альтернатива 2 включает в себя абзац B”, строку C” и чернильное слово “Canada” E”. Она также включает в себя группу F” рисунка с окружностью “O” D”.
В некоторых аспектах настоящего изобретения пользователь может модифицировать решетку, чтобы точно указать, какое должно быть распознавание слова. На фиг.17 изображены рукописные чернила, включающие в себя фразу “Hi. How are you?”. На фиг.18 изображен результирующий набор контекстных деревьев анализа, в которых чернильное слово “are” было указано пользователем в качестве правильно распознанного как слово “are”. Результирующий набор контекстных деревьев анализа может быть разделен на точно идентифицированное слово (в данном случае, “are”), имеющее свое собственное контекстное дерево, с другими контекстными деревьями анализа, охватывающими его.
На фиг.18 изображено три контекстных дерева анализа. В первом контекстном дереве анализа показаны пять узлов, включающие в себя контекст А анализа, абзац В, строку С, чернильное слово “Hi.” и чернильное слово “How” Е. Альтернатива показана как альтернатива 1, имеющая узел B' абзаца, строку C' и альтернативное распознавание всех штрихов, используемых для формирования чернильных слов D и Е в качестве “Hello” D'.
Затем, фиг.18 включает в себя второе контекстное дерево анализа, имеющее контекст F анализа, абзац G, строку Н и чернильное слово “are” I. Здесь, пользователь точно идентифицировал (или «закрепил») чернильное слово “are” I.
Наконец, фиг.18 включает в себя третье контекстное дерево анализа, имеющее контекст J анализа, абзац К, строку L и чернильное слово “you?” М. Альтернатива 1 из этого контекстного дерева анализа включает в себя абзац K', строку L' и чернильное слово “yon” M'.
Альтернативно, три дерева, показанные на фиг.18, могут быть объединены или оставаться в качестве единственного дерева. Например, если пользователь выбирает одну альтернативу, эта альтернатива может фиксироваться, тогда как другие альтернативы для других узлов могут все же модифицироваться, основываясь на последующем выборе альтернатив. Здесь узлы могут оставаться в качестве единственного дерева по сравнению с разделением узлов на отдельные деревья.
Настоящее изобретение было описано на языке его предпочтительных и примерных вариантов осуществления. Многочисленные другие варианты осуществления, модификации и изменения в рамках объема и сущности прилагаемой формулы изобретения могут быть выполнены специалистами в данной области техники при изучении данного описания.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2351982C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2358308C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2352981C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2008 |
|
RU2485579C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2326435C2 |
| РАЗДЕЛИТЕЛЬ ЧЕРНИЛ И ИНТЕРФЕЙС СООТВЕТСТВУЮЩЕЙ ПРИКЛАДНОЙ ПРОГРАММЫ | 2003 |
|
RU2358316C2 |
| ВВОД И ВОСПРОИЗВЕДЕНИЕ ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2365979C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
| СИСТЕМА И СПОСОБ ДЛЯ СОХРАНЕНИЯ ДОКУМЕНТА В ПОСЛЕДОВАТЕЛЬНОМ ДВОИЧНОМ ФОРМАТЕ | 2006 |
|
RU2406142C2 |
| ВЗАИМОДЕЙСТВИЕ ЦИФРОВОГО ПЕРСОНАЛЬНОГО ПОМОЩНИКА С ПОДРАЖАНИЯМИ И ПОЛНОФУНКЦИОНАЛЬНЫМИ МУЛЬТИМЕДИА В ОТВЕТАХ | 2015 |
|
RU2682023C1 |
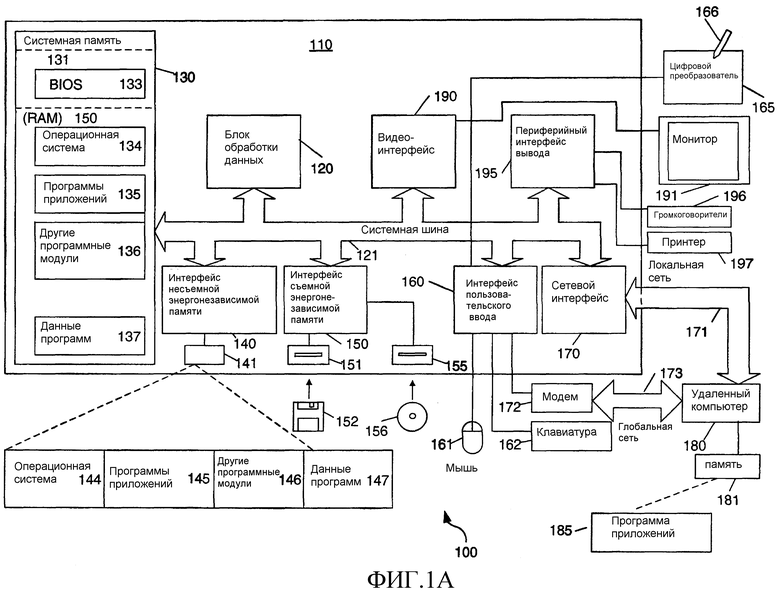
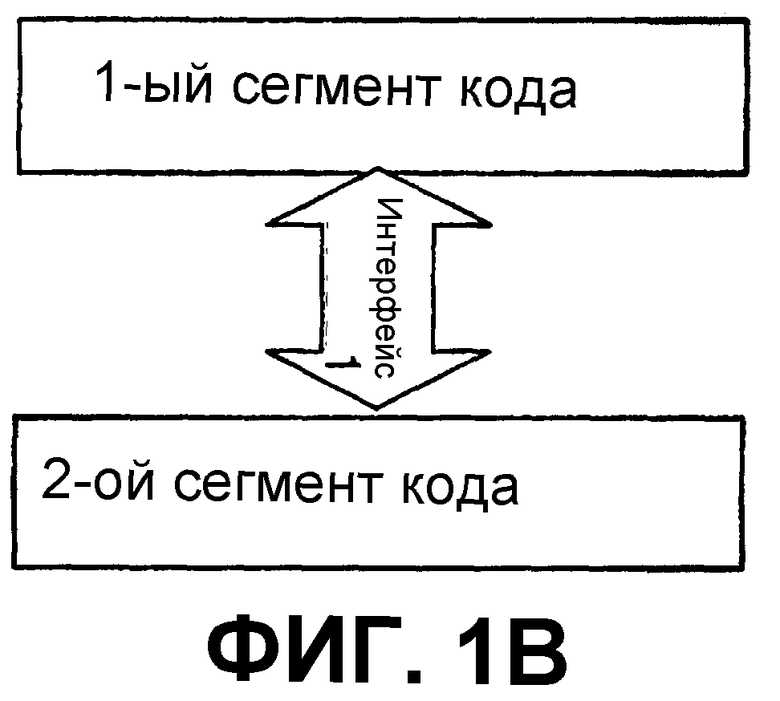
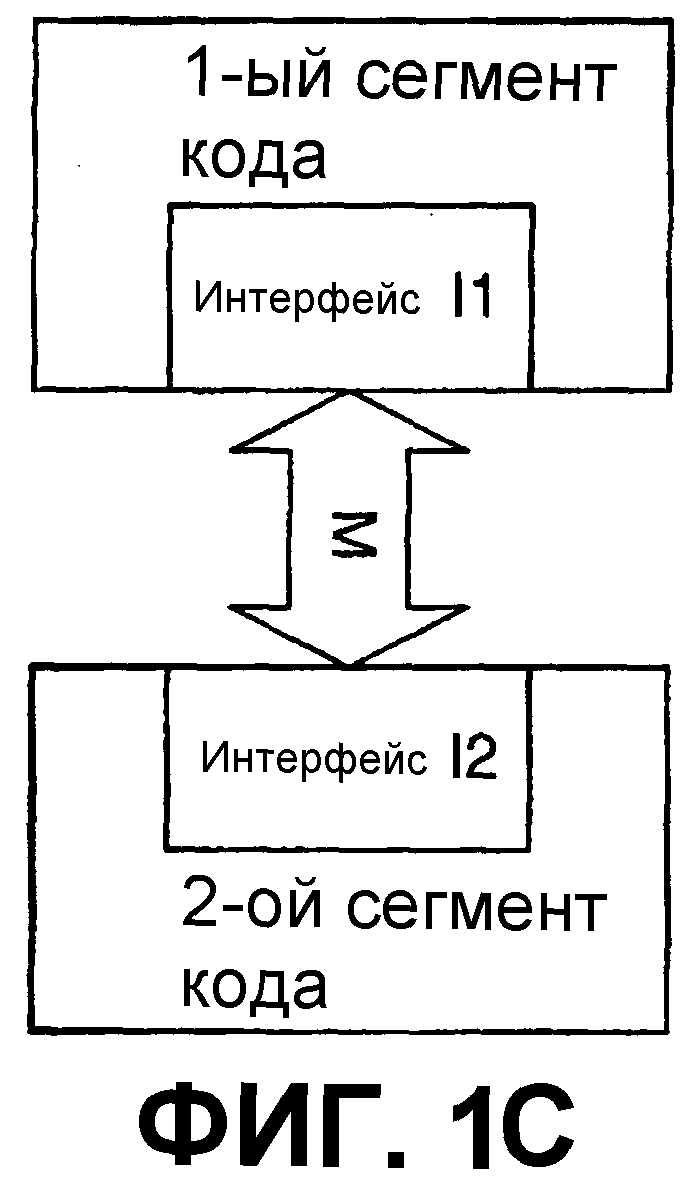
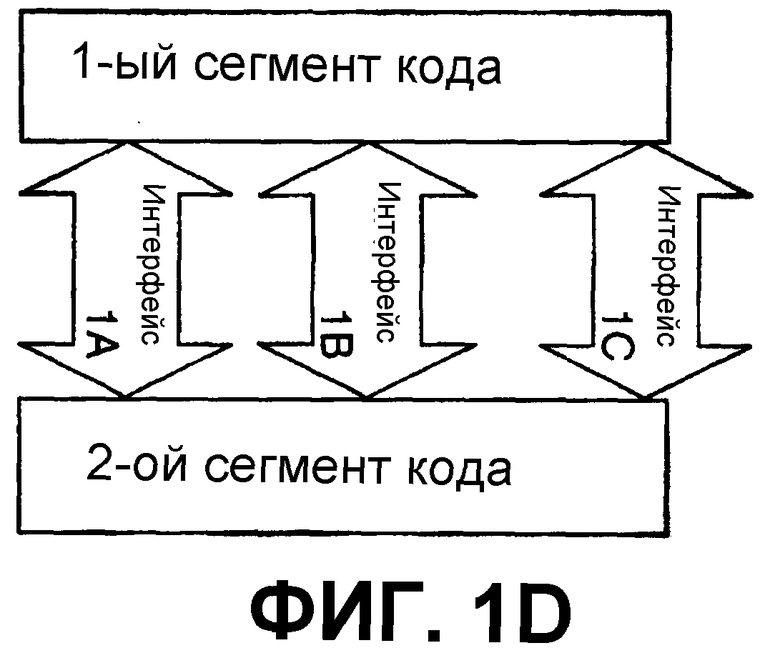
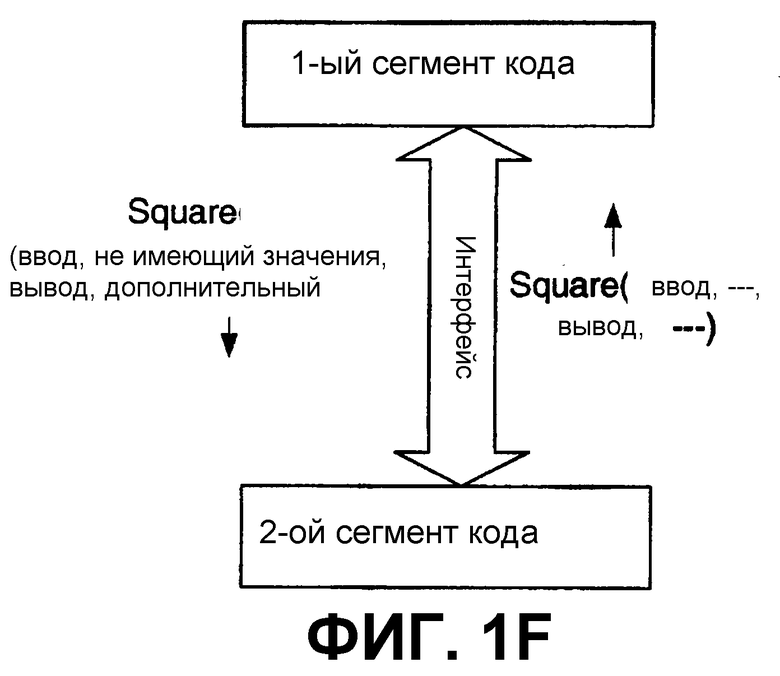
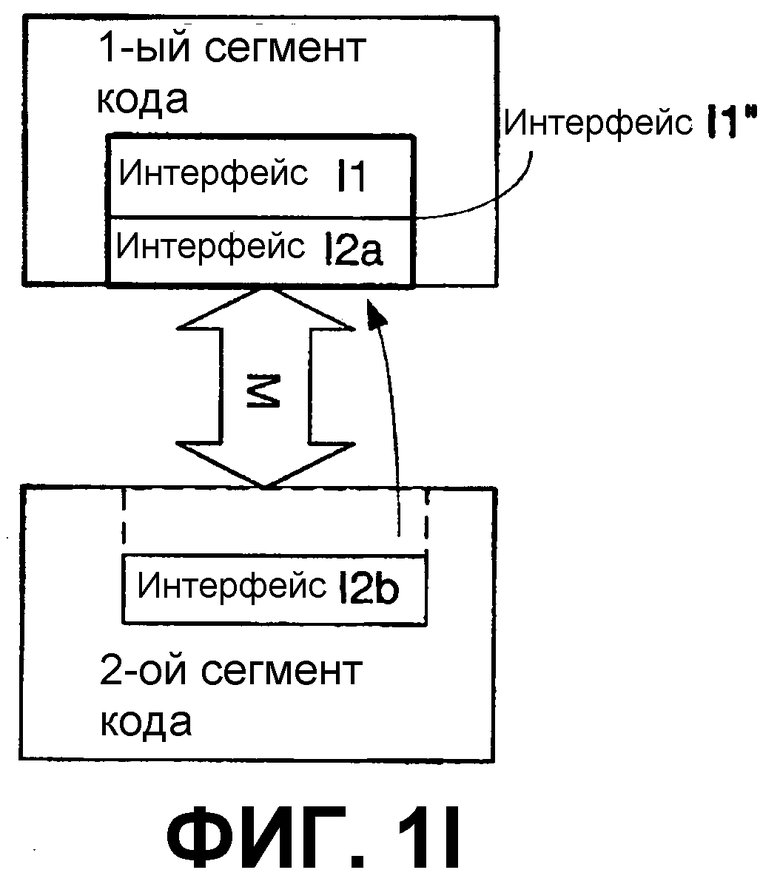
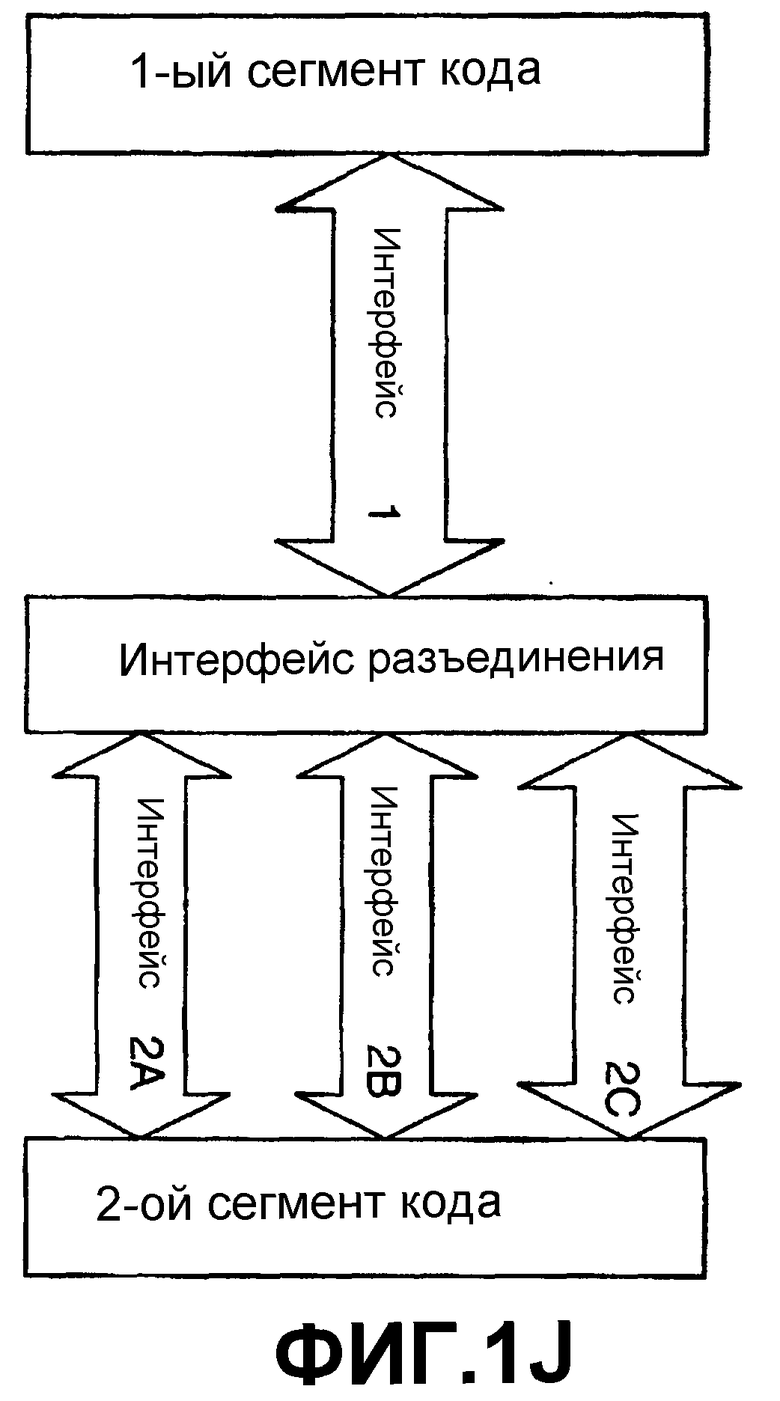
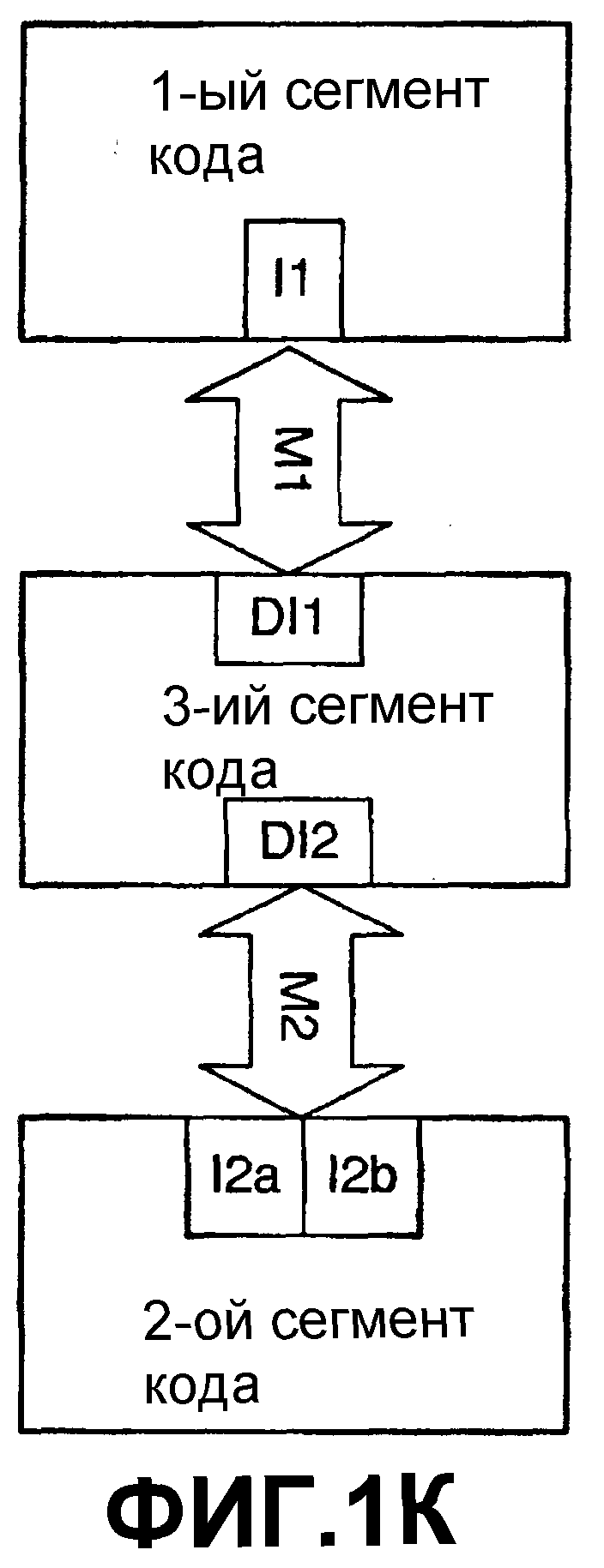
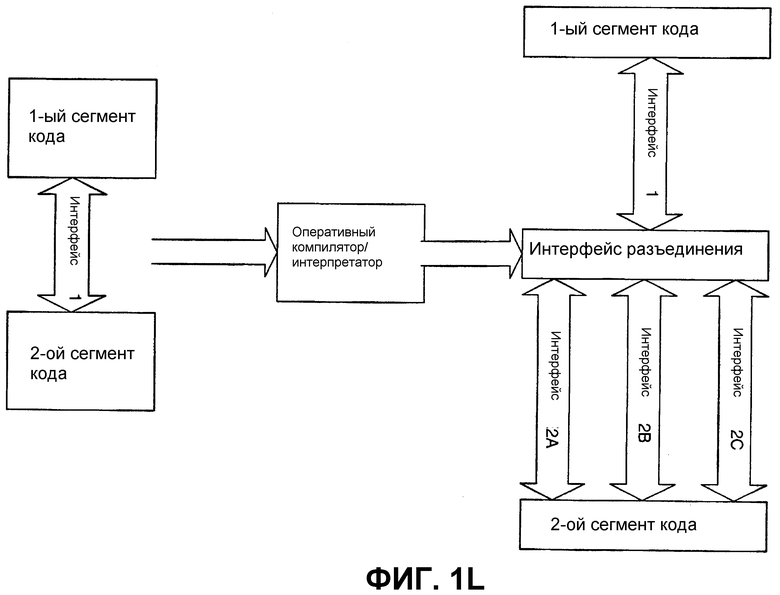
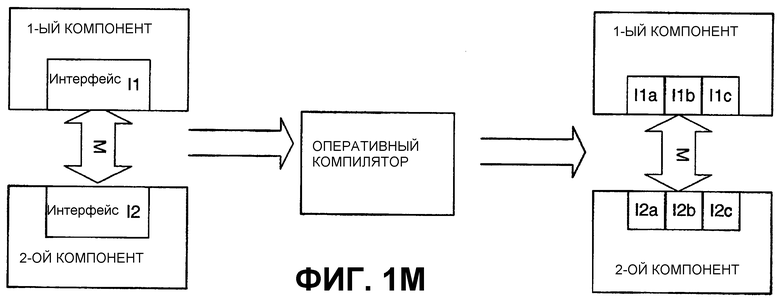
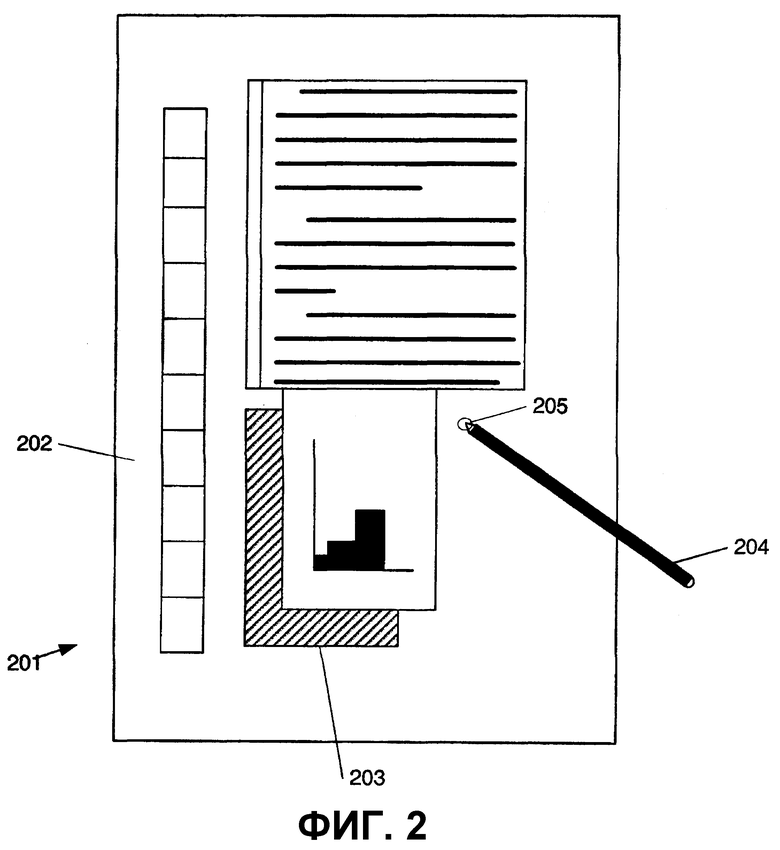

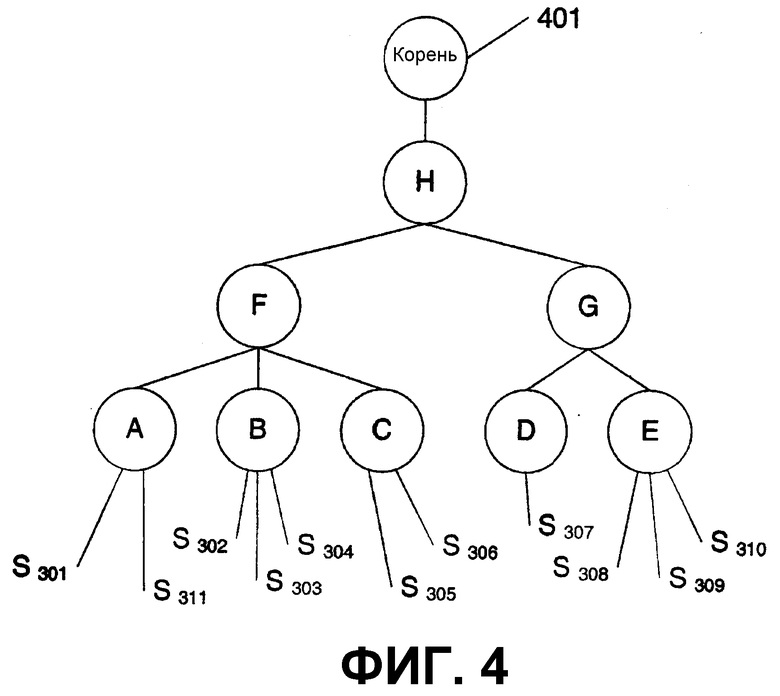
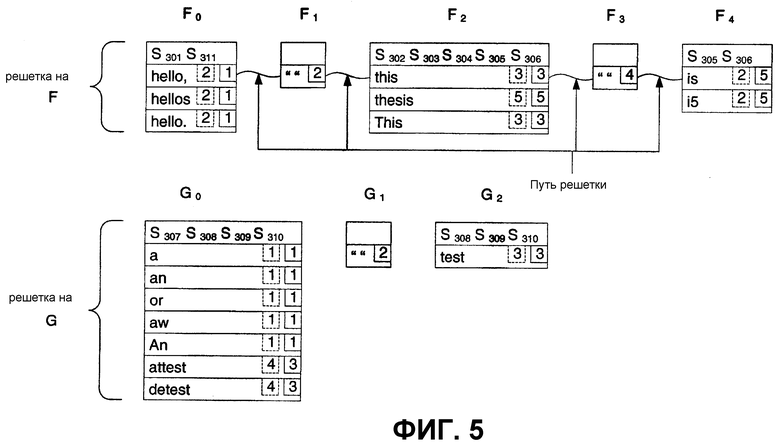


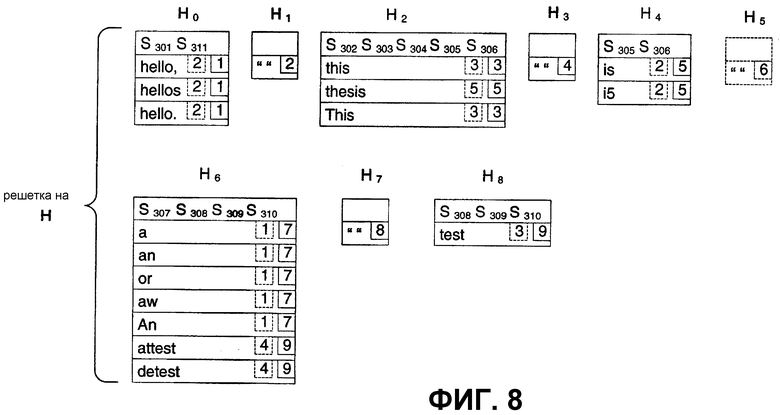
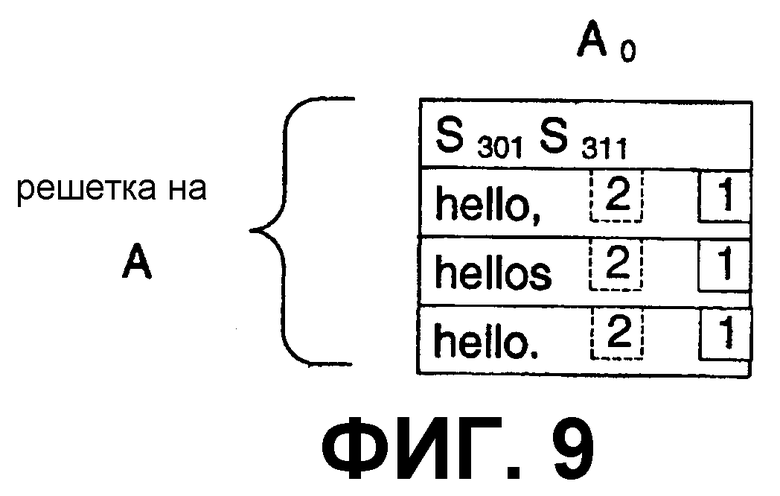
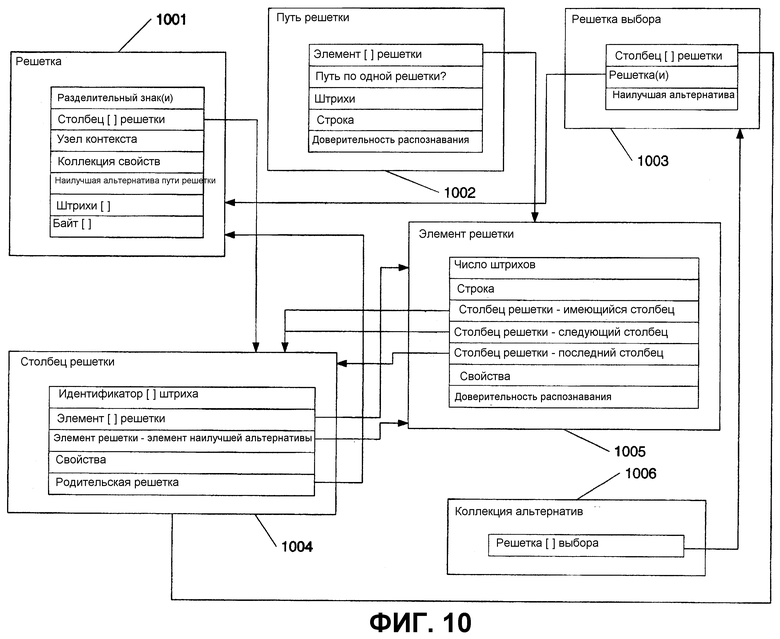
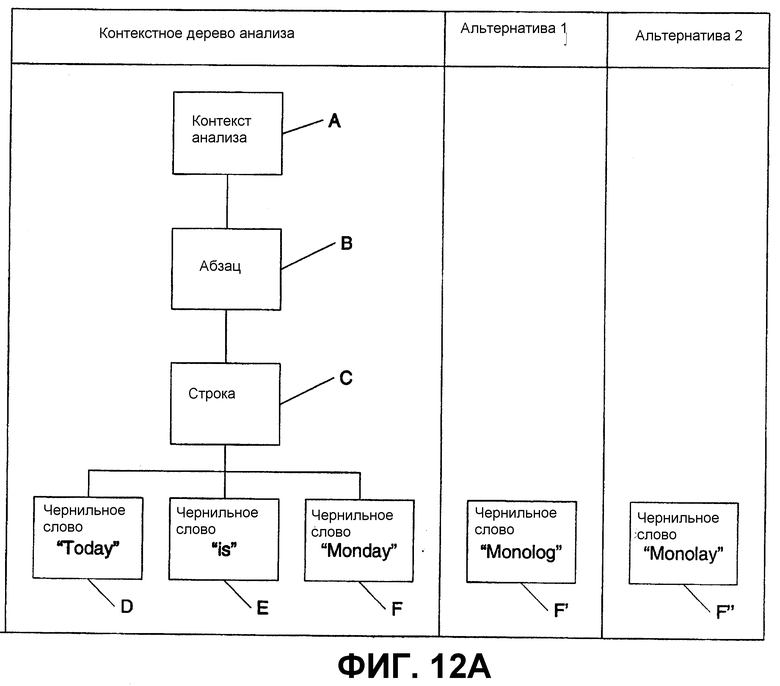
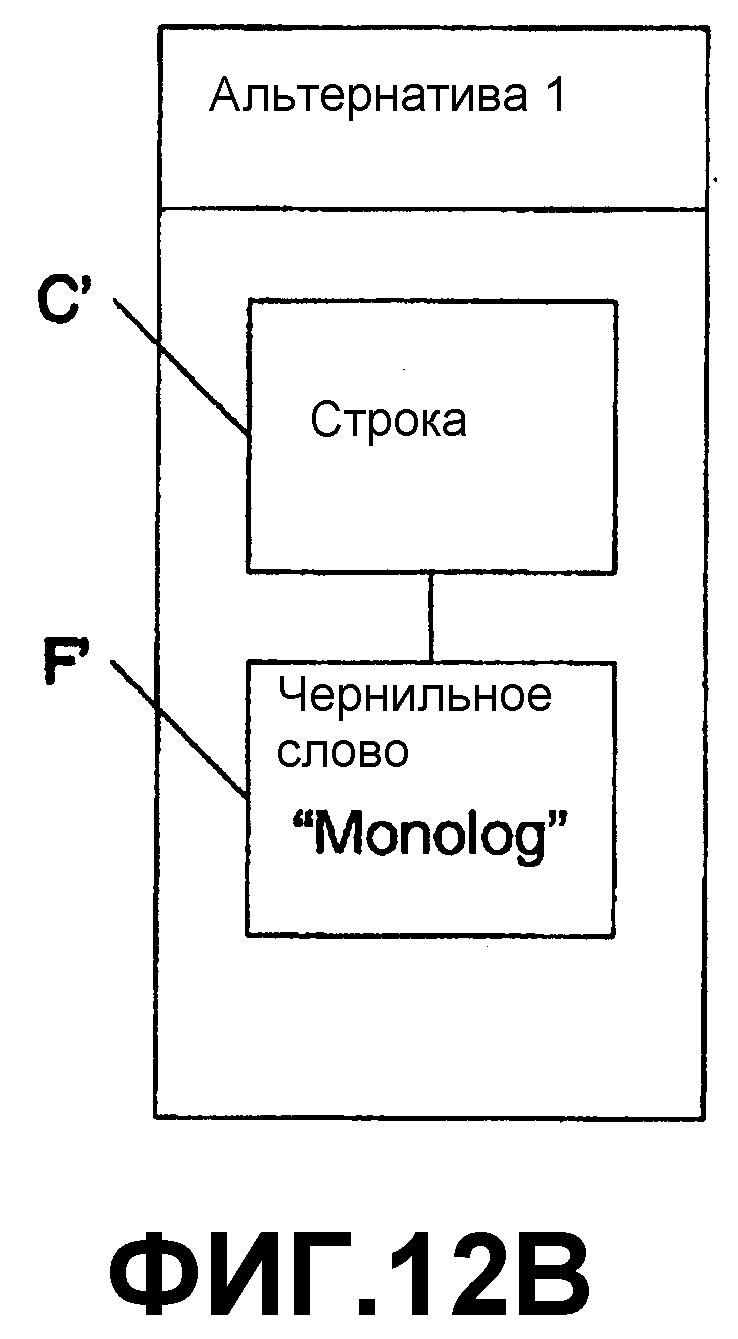
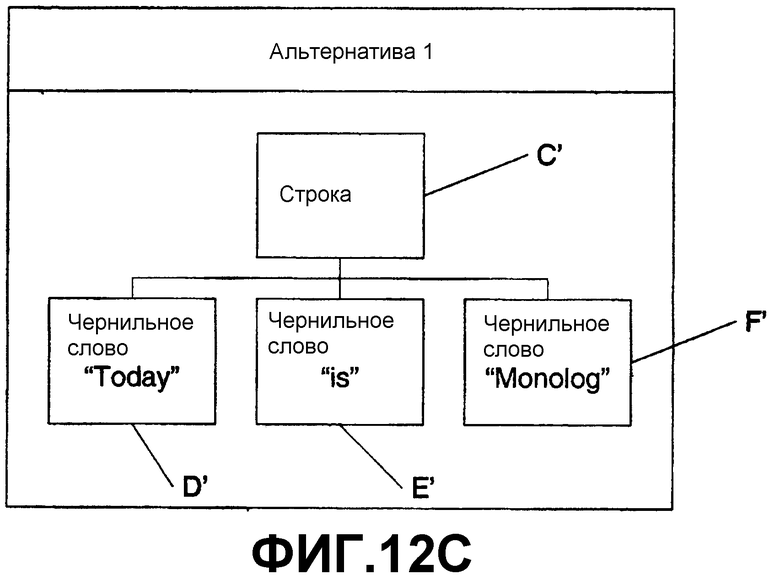
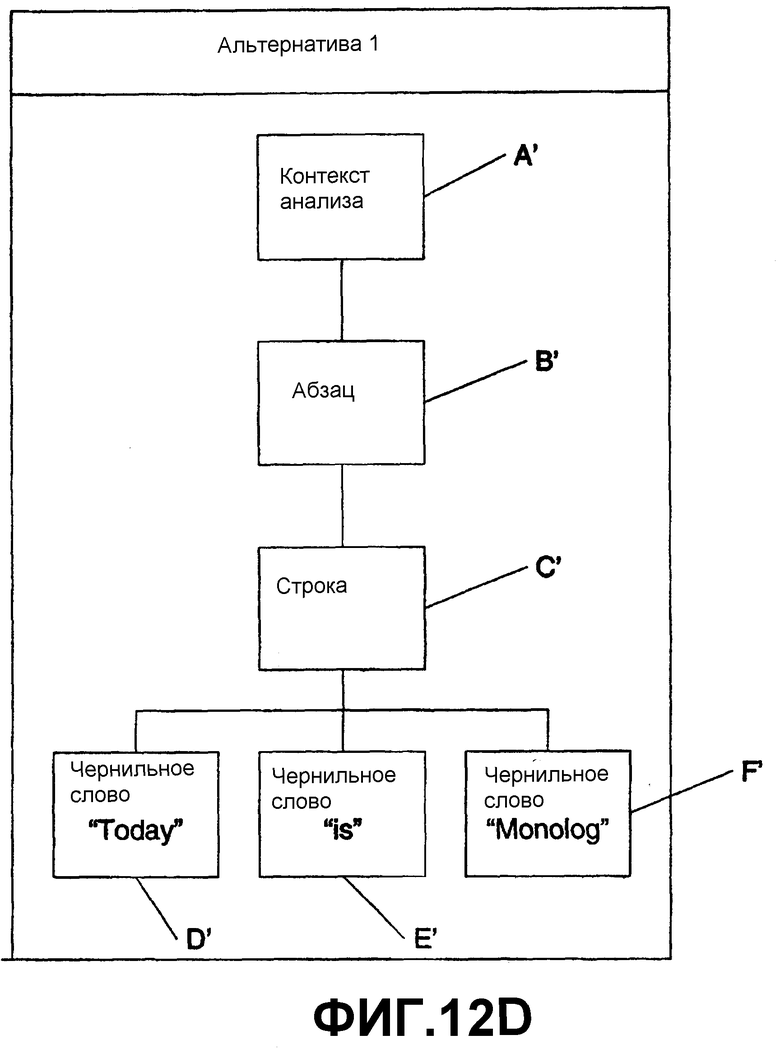
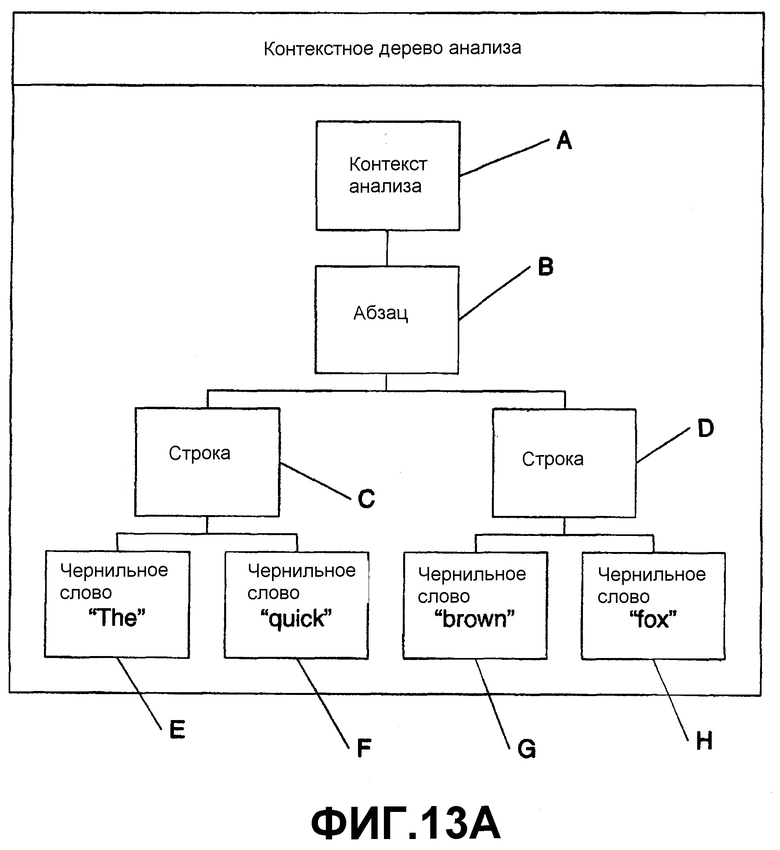
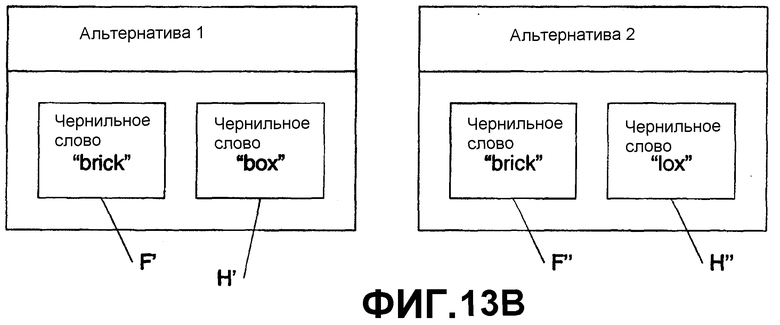
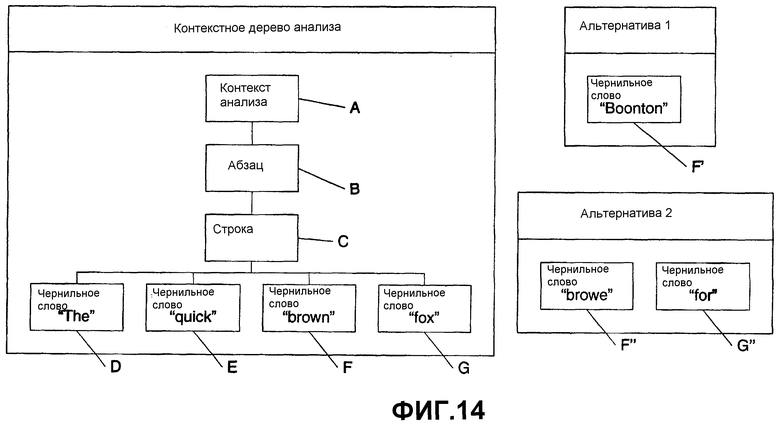
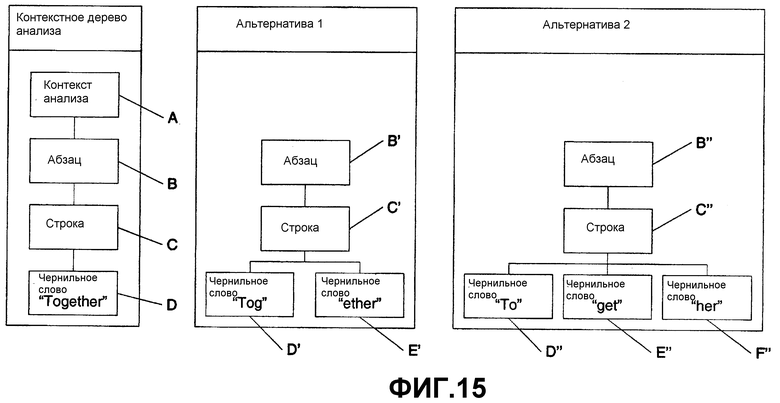
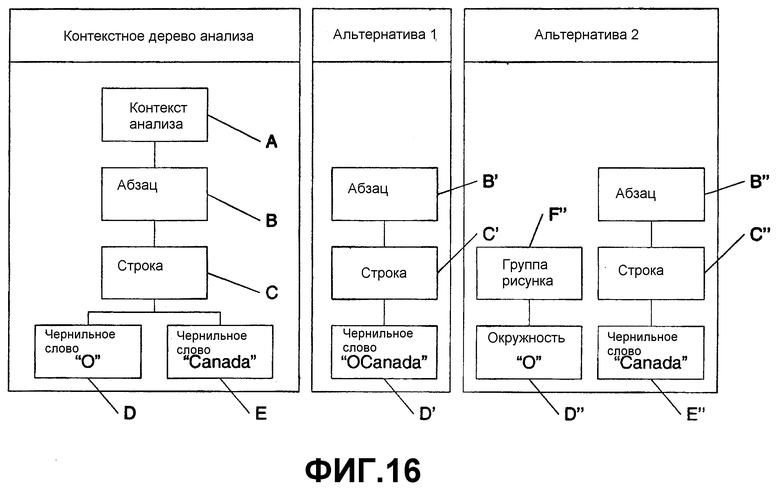
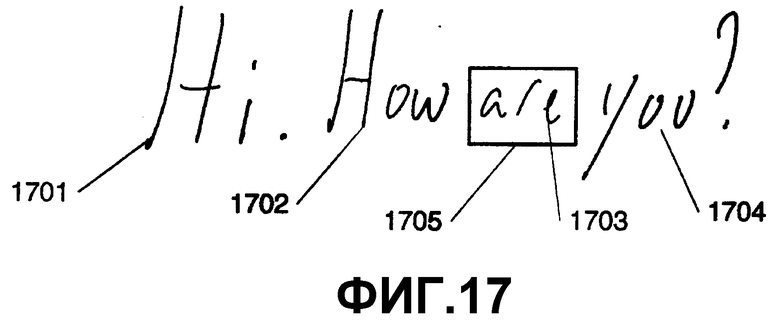
Изобретение относится к обработке альтернатив от систем распознавания. Изобретение позволяет предоставлять альтернативы, относящиеся к комплексным представлениям электронных чернил, не ограничиваясь единственной строкой электронных чернил. Создается древовидная структура, являющаяся результатом синтаксического разбора электронных чернил. Древовидная структура содержит одну или более решеток, представляющих эту древовидную структуру на уровне узла абзаца, узла строки, узла предложения и/или узла списка. Решетка включает в себя столбцы, и каждый столбец включает в себя альтернативы слов, ассоциированные с соответствующим узлом и представляющие альтернативные результаты распознавания. Посылают древовидной структуре запрос на получение альтернативных результатов распознавания, причем запрос задает один или более узлов в древовидной структуре. Принимают альтернативные результаты распознавания от узлов в древовидной структуре. 4 н. и 16 з.п. ф-лы, 34 ил.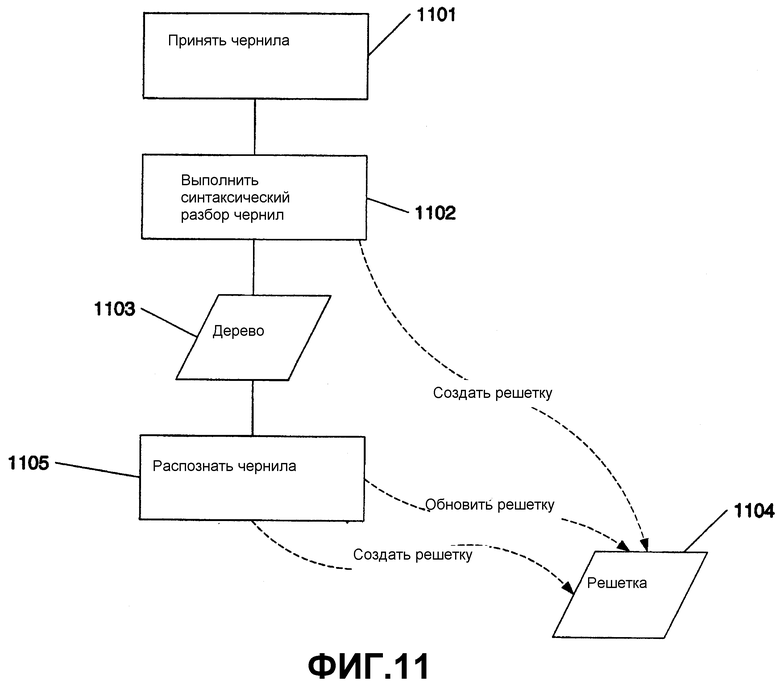
1. Способ взаимодействия с древовидной структурой, являющейся результатом синтаксического разбора электронных чернил, причем упомянутая древовидная структура включает в себя относящуюся к этим электронным чернилам информацию, содержащую по меньшей мере один из узла абзаца, узла строки, узла предложения, узла слова, узла списка и узла элемента списка, и также включает в себя альтернативные результаты распознавания, относящиеся к этим электронным чернилам, при этом данная древовидная структура содержит одну или более решеток, представляющих эту древовидную структуру на уровне узла абзаца, узла строки, узла предложения и/или узла списка, причем решетка включает в себя столбцы, и каждый столбец включает в себя альтернативы слов, ассоциированные с соответствующим узлом абзаца, узлом строки, узлом предложения и/или узлом списка и представляющие упомянутые альтернативные результаты распознавания, при этом упомянутый способ содержит этапы, на которых
посылают упомянутой древовидной структуре запрос на получение альтернативных результатов распознавания от упомянутой древовидной структуры, причем этот запрос задает один или более узлов в упомянутой древовидной структуре; и
принимают альтернативные результаты распознавания от упомянутых одного или более узлов в упомянутой древовидной структуре.
2. Способ по п.1, в котором при упомянутой посылке указывают максимальное количество альтернативных результатов распознавания, которые должны быть извлечены, при этом количество принятых альтернативных результатов распознавания равно или меньше, чем упомянутое количество указанных альтернативных результатов распознавания.
3. Способ по п.1, который дает пользователю возможность дополнительно просматривать упомянутую древовидную структуру посредством запроса альтернатив упомянутых узлов в упомянутой древовидной структуре.
4. Способ по п.1, в котором упомянутый запрос задает один или более штрихов в упомянутой древовидной структуре.
5. Способ по п.4, в котором при упомянутой посылке указывают максимальное количество альтернативных результатов распознавания, которые должны быть извлечены, при этом количество принятых альтернативных результатов распознавания равно или меньше, чем упомянутое количество указанных альтернативных результатов распознавания.
6. Способ по п.4, который дает пользователю возможность обходить вверх и вниз упомянутую древовидную структуру посредством запроса альтернатив узлов в упомянутой древовидной структуре.
7. Способ по любому из пп.1-6, дополнительно содержащий этапы, на которых
посылают упомянутой древовидной структуре запрос, в котором задан альтернативный результат распознавания; и
модифицируют упомянутую древовидную структуру, чтобы установить этот заданный альтернативный результат распознавания в качестве наилучшего альтернативного результата распознавания.
8. Способ по п.7, в котором при посылке упомянутого запроса дополнительно посылают упомянутой древовидной структуре указание для сохранения упомянутого заданного альтернативного результата распознавания в качестве упомянутого наилучшего альтернативного результата распознавания, несмотря на последующие модификации упомянутой древовидной структуры.
9. Способ по п.7, в котором при посылке упомянутого запроса дополнительно предотвращают последующую посылку упомянутого заданного альтернативного результата распознавания распознавателю.
10. Способ взаимодействия с древовидной структурой, являющейся результатом синтаксического разбора электронных чернил, причем упомянутая древовидная структура включает в себя относящуюся к этим электронным чернилам информацию, содержащую по меньшей мере один из узла абзаца, узла строки, узла предложения, узла слова, узла списка и узла элемента списка, и также включает в себя альтернативные результаты распознавания, относящиеся к этим электронным чернилам, при этом данная древовидная структура содержит одну или более решеток уровня узла абзаца, узла строки, узла предложения и/или узла списка, причем решетка включает в себя столбцы, и каждый из этих столбцов включает в себя альтернативы слов, ассоциированные с соответствующим узлом абзаца, узлом строки, узлом предложения и/или узлом списка и представляющие упомянутые альтернативные результаты распознавания, при этом упомянутый способ содержит этапы, на которых
посылают упомянутой древовидной структуре запрос на получение одного или более альтернативных результатов распознавания от упомянутой древовидной структуры, причем этот запрос задает один или более узлов в упомянутой древовидной структуре;
принимают эти один или более альтернативных результатов распознавания от упомянутых одного или более узлов в упомянутой древовидной структуре и
динамически создают древовидные структуры альтернатив при данном запросе для альтернативных результатов распознавания.
11. Система для взаимодействия с древовидной структурой, являющейся результатом синтаксического разбора электронных чернил, причем упомянутая древовидная структура включает в себя относящуюся к этим электронным чернилам информацию, содержащую по меньшей мере один из узла абзаца, узла строки, узла предложения, узла слова, узла списка и узла элемента списка, и также включает в себя альтернативные результаты распознавания, относящиеся к этим электронным чернилам, при этом данная древовидная структура содержит одну или более решеток, представляющих эту древовидную структуру на уровне узла абзаца, узла строки, узла предложения и/или узла списка, причем решетка включает в себя столбцы и каждый из этих столбцов включает в себя альтернативы слов, ассоциированные с соответствующим узлом абзаца, узлом строки, узлом предложения и/или узлом списка и представляющие упомянутые альтернативные результаты распознавания, при этом упомянутая система содержит
средство для посылки упомянутой древовидной структуре запроса на получение альтернативных результатов распознавания от упомянутой древовидной структуры, причем этот запрос задает один или более узлов в упомянутой древовидной структуре; и
средство для приема альтернативных результатов распознавания от упомянутых одного или более узлов в упомянутой древовидной структуре.
12. Система по п.11, в которой средство посылки указывает максимальное количество альтернативных результатов распознавания, которые должны быть извлечены, при этом количество принятых альтернативных результатов распознавания равно или меньше, чем упомянутое количество указанных альтернативных результатов распознавания.
13. Система по п.11, которая дает пользователю возможность дополнительно просматривать упомянутую древовидную структуру посредством запроса альтернатив упомянутых узлов в упомянутой древовидной структуре.
14. Система по п.11, в которой упомянутый запрос задает один или более штрихов в упомянутой древовидной структуре.
15. Система по п.14, в которой средство посылки указывает максимальное количество альтернативных результатов распознавания, которые должны быть извлечены, при этом количество принятых альтернативных результатов распознавания равно или меньше, чем упомянутое количество указанных альтернативных результатов распознавания.
16. Система по п.14, которая дает пользователю возможность обходить вверх и вниз упомянутую древовидную структуру посредством запроса альтернатив узлов в упомянутой древовидной структуре.
17. Система по любому из пп.11-16, дополнительно содержащая средство для посылки упомянутой древовидной структуре запроса, в котором задан альтернативный результат распознавания; и
средство для модифицирования упомянутой древовидной структуры, чтобы установить этот заданный альтернативный результат распознавания в качестве наилучшего альтернативного результата распознавания.
18. Система по п.17, в которой средство для посылки упомянутого запроса дополнительно содержит средство для посылки упомянутой древовидной структуре указания для сохранения упомянутого заданного альтернативного результата распознавания в качестве упомянутого наилучшего альтернативного результата распознавания, несмотря на последующие модификации упомянутой древовидной структуры.
19. Система по п.17, в которой средство для посылки упомянутого запроса дополнительно содержит средство для предотвращения последующей посылки упомянутого заданного альтернативного результата распознавания распознавателю.
20. Система для взаимодействия с древовидной структурой, являющейся результатом синтаксического разбора электронных чернил, причем упомянутая древовидная структура включает в себя относящуюся к этим электронным чернилам информацию, содержащую по меньшей мере один из узла абзаца, узла строки, узла предложения, узла слова, узла списка и узла элемента списка, и также включает в себя альтернативные результаты распознавания, относящиеся к этим электронным чернилам, при этом данная древовидная структура содержит одну или более решеток, представляющих эту древовидную структуру на уровне узла абзаца, узла строки, узла предложения и/или узла списка, причем решетка включает в себя столбцы и каждый столбец включает в себя альтернативы слов, ассоциированные с соответствующим узлом абзаца, узлом строки, узлом предложения и/или узлом списка и представляющие упомянутые альтернативные результаты распознавания, при этом упомянутая система содержит
средство для посылки упомянутой древовидной структуре запроса на получение одного или более альтернативных результатов распознавания от упомянутой древовидной структуры, причем этот запрос задает один или более узлов в упомянутой древовидной структуре;
средство для приема этих одного или более альтернативных результатов распознавания от упомянутых одного или более узлов в упомянутой древовидной структуре; и
средство для динамического создания древовидных структур альтернатив при данном запросе для альтернативных результатов распознавания.
| Peter Cruebaum, Using Recognition Alternatives, Microsoft Corporation, May 2004 (Найдено в Интернет: http://msdn.microsoft.com/en-us/library/ms812506.aspx) | |||
| РУЧКА ДЛЯ РУКОПИСНОГО ВВОДА ДАННЫХ В КОМПЬЮТЕР | 2001 |
|
RU2235362C2 |
| Сырьевая смесь для изготовления канализационных труб | 1987 |
|
SU1435568A1 |
| US 6771817 B1, 03.08.2004 | |||
| US 5416892 A, 16.05.1995 | |||
| Нерекурсивный цифровой фильтр | 1986 |
|
SU1365349A2 |
| Устройство для сопряжения двух ЭВМ | 1986 |
|
SU1363230A1 |

