Область техники, к которой относится изобретение
Настоящее изобретение относится к обработке электронных чернил. Различные аспекты настоящего изобретения, в частности, применимы к анализу электронных чернил, включая анализ компоновки, классификацию и распознавание электронных чернил. Дополнительные аспекты изобретения относятся к использованию проанализированных по компоновке, классифицированных и распознанных электронных чернил, например, при создании гибких аннотаций с широкими возможностями в документе, выполненном электронными чернилами.
Предшествующий уровень техники
Так как в обществе распространилась роль компьютеров, то были разработаны всевозможные различные методики для ввода данных в компьютеры. Одной особенно применимой методикой представления данных является использование рукописного текста. В результате ввода пером или другим предметом на цифровом преобразователе для получения «электронных чернил» пользователь компьютера может отказаться от громоздких и неудобных клавиатур. Рукописный ввод может удобно использоваться, например, врачами, выполняющими обход, архитекторами на стройплощадке, курьерами, доставляющими посылки, рабочими складов, обходящими склад, и во многих ситуациях, когда использование клавиатуры было бы затруднительным или неудобным. Хотя рукописный ввод более удобен, чем ввод с клавиатуры во многих ситуациях, текст, записанный электронными чернилами, обычно не может быть непосредственно обработан большинством программных приложений. Вместо этого, текст, записанный электронными чернилами, должен быть проанализирован для преобразования его в другую форму, такую как знаки Американского стандартного кода обмена информацией (ASCII). Данный анализ включает в себя процесс распознавания рукописного текста, при котором распознают знаки, основываясь на различных зависимостях между отдельными штрихами электронных чернил, составляющими слово электронных чернил.
Алгоритмы распознавания рукописного текста в значительной степени улучшились в последние годы, но их точность может снижаться, когда электронные чернила записываются под углом. Аналогично, когда нельзя легко различить отдельные группы штрихов чернил, например, когда два слова написаны вплотную друг к другу, то многие алгоритмы распознавания не могут точно распознавать электронные чернила. Некоторые алгоритмы распознавания также могут неправильно распознавать электронные чернила в качестве текста, когда, фактически, электронные чернила, как предполагается, являются рисунком. Например, пользователь может аннотировать машинописный текст посредством написания штриха электронных чернил, который подчеркивает, выделяет, окружает или перечеркивает некоторую часть машинописного текста. Алгоритм распознавания рукописного текста может тогда неправильно распознавать данные штрихи аннотаций как тире, число нуль или букву «О».
Точность многих алгоритмов распознавания может быть в значительной степени повышена посредством «синтаксического разбора» (например, посредством анализа компоновки и/или «классификации») электронных чернил перед использованием алгоритма распознавания рукописного текста. Процесс классификации обычно определяет, является ли штрих электронных чернил частью рисунка (т.е. штрихом чернил рисунка) или частью рукописного текста (т.е. штрихом чернил текста). Также возможны алгоритмы классификации для идентификации других типов штрихов. Процесс анализа компоновки обычно группирует штрихи электронных чернил в значимые ассоциации, такие как слова, строки и абзацы. Процессы анализа компоновки и классификации могут быть использованы, таким образом, для идентификации того, какие штрихи в коллекции электронных чернил принадлежат одному слову, какие слова электронных чернил ассоциированы с одной строкой текста, записанного электронными чернилами, и какие строки текста, записанного электронными чернилами, ассоциированы с абзацем.
Хотя анализ компоновки и классификация могут в значительной степени улучшить распознавание электронных чернил, многие разработчики программных приложений не осознают важность данных действий перед распознаванием электронных чернил. До последнего времени алгоритмы анализа компоновки и классификации не были легкодоступными для использования с существующими программными приложениями. Например, операционная система Microsoft® Windows XP Tablet PC Edition Version 2002 обычно продавалась с программным приложением Microsoft® Windows Journal для хранения, отображения и управления электронными чернилами. Хотя программное приложение Microsoft® Windows Journal использует внутреннюю программу синтаксического разбора, до последнего времени данная программа синтаксического разбора не была доступна для других программных приложений, работающих под операционной системой.
Хотя процесс синтаксического разбора из программного приложения Windows Journal теперь отдельно доступен для других программных приложений, использование данной программы синтаксического разбора не является общеизвестным, и данная программа синтаксического разбора не может быть легко использована со многими программными приложениями, в которые пользователь может захотеть ввести рукописный текст. Кроме того, даже если разработчик программного приложения должен был создавать программу синтаксического разбора специально для использования с требуемым программным приложением (что само по себе может представлять собой трудный и трудоемкий процесс), выполнение процесса синтаксического разбора может быть очень трудоемким. Например, синтаксический разбор только нескольких штрихов электронных чернил, использующих относительно быстродействующий микропроцессор, может занимать у программы синтаксического разбора несколько секунд или даже нескольких минут. Если программное приложение должно останавливать свою работу до тех пор, пока не будет завершен процесс синтаксического разбора, то программное приложение становится слишком медленным для практического использования большинством пользователей.
Следовательно, существует потребность в методиках обработки электронных чернил, которые могут быть использованы различными программными приложениями, например, для анализа компоновки, классификации и/или распознавания электронных чернил. Далее, существует потребность в методиках обработки электронных чернил, которые могут обрабатывать электронные чернила, в то же самое время все же позволяя программному приложению применять методики для принятия нового ввода электронных чернил без признания недействительными результатов обработки чернил.
Краткое изложение сущности изобретения
Преимущественно различные примеры изобретения обеспечивают методики обработки электронных чернил, которые могут быть использованы различными программными приложениями для обработки электронных чернил. Далее, эти методики обработки электронных чернил позволяют производить обработку электронных чернил асинхронно относительно работы программного приложения, реализующего методики, так что электронные чернила могут быть обработаны без останова или существенной задержки работы программного приложения. Программное приложение даже может продолжать принимать новый ввод электронных чернил, в то время как обрабатывается предыдущий ввод электронных чернил.
В соответствии с различными примерами изобретения, элементы в файле или документе могут быть описаны, основываясь на их пространственном положении относительно друг друга. Например, как штрих электронных чернил, так и машинописный текст могут быть описаны на основе одной системы пространственных координат. Используя пространственную информацию для описания элементов документа, программное приложение, управляющее документом, может поддерживать структуру данных, описывающую зависимость между ее элементами документа. В частности, программное приложение может поддерживать структуру данных, как описывающую класс различных элементов документа, так и определяющую ассоциации между различными элементами документа. Эти ассоциации могут быть определены, например, как информация, используемая для связи данных штрихов электронных чернил или их коллекций с другими элементами в электронном документе (такими как слова, строки, абзацы, рисунки, ячейки таблицы и т.д.).
Посредством описания элементов документа в структуре данных файла или документа, основываясь на их пространственном положении, элементы документа для различных типов файлов могут использовать общие методики идентификации и управления своими элементами документа. Более конкретно, различные программные приложения могут описывать элементы документа в документе, основываясь на их пространственном положении, и применять данное пространственное положение, ссылаясь на использование общих способов анализа электронных чернил. Далее, посредством задания конкретной области документа для анализа каждое программное приложение может ограничить процесс анализа только требуемыми элементами в документе.
Для анализа нового ввода электронных чернил в документ в соответствии с различными примерами изобретения программное приложение, управляющее документом, модифицирует структуру данных, ассоциированную с документом, с целью включения новых чернил для анализа. Программное приложение затем подает эту структуру данных (или ее соответствующие части) на инструментальное средство анализа чернил, которое копирует некоторую часть или всю структуру данных для анализа (и работает над этой копией данных, которая является независимой от структуры данных документа программы приложения). Инструментальное средство анализа чернил передает копию процессу анализа, такому как процесс синтаксического разбора (например, процесс анализа компоновки и/или процесс классификации). Программное приложение может возобновить свою нормальную работу, включая прием нового ввода электронных чернил и/или других данных, в то время как выполняется процесс(ы) анализа чернил. В дополнение к приему новых электронных чернил программой приложения могут приниматься любые «другие данные», например, данные, модифицирующие размер, размещение или содержимое существующих чернил, текста, изображений, графиков, таблиц, блок-схем, диаграмм и т.п.; данные, добавляющие дополнительный текст, изображения, графики, таблицы, блок-схемы, диаграммы и т.п.; данные, удаляющие существующий текст, изображения, графики, таблицы, блок-схемы, диаграммы и т.п. После завершения всех требуемых процессов анализа, результаты анализа возвращаются инструментальному средству анализа чернил.
Таким образом, различные примеры систем и способов в соответствии с изобретением позволяют выполнять процессы анализа чернил асинхронно с работой программного приложения, использующего процесс анализа чернил. Данная асинхронная работа позволяет пользователю продолжать использовать программное приложение без задержки, вызываемой процессом анализа. Далее, это позволяет одновременно выполнять многочисленные процессы анализа.
В ответ на прием результатов анализа инструментальное средство анализа чернил получает текущую версию структуры данных электронного документа (которая может содержать новые и/или модифицированные данные, введенные во время выполнения процессов анализа) от программного приложения и согласовывает результаты анализа с текущей версией структуры данных. Посредством согласования результатов анализа с текущей версией структуры данных различные примеры изобретения могут исключить более сложные методики, такие как «блокировка», для асинхронного доступа к данным, используемым программным приложением. Вместо этого, согласование может быть вызвано любым программным приложением без необходимости в сложной внутренней блокировке.
После согласования результатов анализа с текущей версией структуры данных инструментальное средство анализа чернил затем может предоставить копию согласованных результатов анализа другому процессу анализа, такому как процесс распознавания рукописного текста. Опять же, программное приложение может возобновить свою нормальную работу, включая прием нового ввода электронных чернил и/или других данных, в то время как выполняется процесс(ы) второго анализа чернил. После того как будут завершены все требуемые процессы второго анализа, результаты процесса второго анализа возвращаются инструментальному средству анализа чернил. Инструментальное средство анализа чернил затем получает текущую версию структуры данных от программного приложения (которое снова может включать в себя новые и/или модифицированные данные) и согласовывает результаты второго анализа с текущей версией структуры данных. Инструментальное средство анализа чернил затем обновляет структуру данных, используя согласованные результаты процесса второго анализа. Конечно, может быть использовано любое количество процедур и/или этапов анализа чернил без отступления от изобретения.
Использование различных процессов анализа чернил, описанных выше, и пространственной информации, задающей соответствие или связывающей данные электронных чернил с другими признаками электронного документа, также может быть использовано для создания ценных, гибких и естественных аннотаций посредством чернил в электронном документе. Например, аспекты изобретения могут быть использованы для создания аннотаций посредством электронных чернил, которые динамически перемещаются и/или иным образом изменяются, основываясь на изменениях, выполненных в нижележащих аннотируемых элементах документа. Пользователи обычно аннотируют документы многими различными путями, например, они могут обводить, подчеркивать, выделять или зачеркивать слова; записывать примечания на полях; рисовать стрелки или другие указатели к аннотациям, расположенным на полях и т.д. Кроме того, пользователи делают аннотации на документах разнообразных отличающихся видов, включая, например, текст, электронные таблицы, рисунки, слайдовые презентации, таблицы, диаграммы, графики, блок-схемы и т.д.
Гладкое встраивание аннотаций электронных чернил в электронный документ требует того, чтобы аннотации изменялись соответствующим образом, когда по какой-либо причине изменяется базовый электронный документ. Например, если пользователь обводит слово в электронном документе (в качестве аннотации) и затем добавляет текст где-то в документе перед данным словом, то это может вызвать перемещение обведенного слова. В данном случае аннотация в виде обведения должна перемещаться и оставаться со словом. В качестве другого примера, если пользователь добавляет или удаляет знаки из обведенного слова или иным образом изменяет его размер любым образом, аннотация в виде обведения должна вытягиваться или сжиматься для адаптации к новому размеру слова. Предпочтительно, когда по любой причине происходит переформатирование текста нижележащего электронного документа и/или обновление положений его составляющих элементов (абзацев, рисунков, колонок и т.д.) относительно друг друга и/или страницы, то аннотации, выполненные посредством электронных чернил, также перемещаются и остаются правильно расположенными относительно базового текста или другой информации. Если аннотации не будут изменяться таким образом относительно текста базового электронного документа, то становится нецелесообразным редактирование или совместное использование активных электронных документов после аннотирования, и распечатка на бумаге будет все же самым простым и наиболее применимым методом аннотирования.
Определение того, как изменить соответствующим образом аннотацию, будет зависеть от различных факторов, относящихся к аннотации и электронному документу. Например, соответствующее изменение аннотации в случае переформатирования текста может зависеть, например, от возможностей вычислительной системы (например, средства синтаксического разбора) в отношении: (а) идентификации электронных чернил в качестве аннотации; (b) идентификации типа аннотации, выполненной посредством электронных чернил; и (с) идентификации зависимости электронных чернил от конкретного элемента в базовом электронном документе. Хотя можно запросить у пользователя некоторую или всю информацию данного типа, такие системы потребовали бы от пользователя значительно более обременительные действия, чем аннотирование на бумаге. Следовательно, в соответствии с различными аспектами изобретения вышеупомянутая информация может быть получена из: (1) самих электронных чернил и (2) содержимого базового документа, включая пространственное положение различных элементов в документе относительно электронных чернил.
Так как определение значения аннотаций, выполненных посредством чернил, может быть сложным и трудным, то крайне нецелесообразно ожидать, что каждая программа приложения, документ которой пользователь может захотеть аннотировать, будет индивидуальным образом реализовывать логику идентификации аннотации. Скорее, было бы предпочтительным создать многократно используемый компонент, обеспечивающий данную функцию аннотирования, который легко может быть интегрирован в любую программу приложения. Например, поскольку операционная система вычислительной системы на основе перьевого ввода обеспечивает компоненты для сбора и воспроизведения электронных чернил, было бы предпочтительным, чтобы эта операционная система могла обеспечить компонент, который определяет значение аннотаций, выполненных посредством чернил (также называемый «средством синтаксического разбора аннотаций»), который достаточно эффективно работать с рассматриваемыми чернилами.
Идентификация содержимого базового электронного документа, однако, ставит существенные трудности при обеспечении возможностей «интеллектуальной» аннотации. Например, всевозможные различные программы приложений имеют в значительной степени несопоставимые способы хранения, управления и переформатирования документов. Настоящее изобретение обеспечивает многократно используемое средство синтаксического разбора аннотаций, способное определять зависимость возможных аннотаций, выполненных посредством чернил, от всевозможных различных типов электронных документов. Более конкретно, в соответствии с некоторыми аспектами настоящего изобретения обеспечивается механизм со средством синтаксического разбора аннотаций, который выполняет обратный вызов к программе приложения для получения соответствующей информации, относящейся к чернилам, подвергаемым синтаксическому разбору, (например, информации, относящейся к электронному документу в пространственной области, соответствующей аннотации чернил, для получения «контекста» к аннотации чернил). Этот механизм достаточно прост для его практического интегрирования в любое основанное на документе приложение, и он достаточно эффективен для работы с очень большими документами (которые могут обрабатываться частями, такими как страницы и т.п.).
Методики обработки чернил в соответствии с различными примерами изобретения, таким образом, позволяют различным программным приложениям выполнять многочисленные процессы над электронными чернилами при помощи инструментального средства анализа чернил. Кроме того, программное приложение, использующее приведенные методики, может продолжать свою нормальную работу во время процесса анализа, включая прием нового ввода электронных чернил, без необходимости признания недействительными результатов процессов анализа.
Перечень фигур чертежей
Вышеупомянутые и другие задачи, признаки и преимущества настоящего изобретения очевидны и полностью понятны из последующего подробного описания, рассматриваемого совместно с прилагаемыми чертежами, на которых:
фиг.1 - схематическое представление цифровой вычислительной среды общего назначения, в которой могут быть реализованы некоторые аспекты настоящего изобретения;
фиг.2 - среда персонального компьютера (ПК) с перьевым вводом, в которой могут быть реализованы некоторые аспекты настоящего изобретения;
фиг.3 и 4 - разнообразные признаки примерных реализаций аспектов изобретения, относящихся к аннотированию электронных документов;
фиг.5 - общие признаки синтаксического разбора чернил электронного документа;
фиг.6А-6I - примерные структуры данных, применимые при осуществлении по меньшей мере некоторых аспектов настоящего изобретения;
фиг.7А-12В - примерные электронные документы и связанные с ними примерные структуры данных, применимые при обработке выполненных посредством электронных чернил аннотаций электронных документов;
фиг.13А-14В - примерные электронные документы и связанные с ними примерные структуры данных, применимые при обработке признаков электронных блок-схем в электронных документах;
фиг.15А-15С - примерные электронные документы и связанные с ними примерные структуры данных, применимые при обработке признаков электронных таблиц в электронных документах;
фиг.16А-16D - способ обработки электронных чернил в соответствии с различными примерами изобретения;
фиг.17, 19-21 и 23-26 - иллюстрации переноса объектов данных во время примерных процессов анализа чернил в соответствии с различными примерами изобретения;
фиг.18 и 22 - простые деревья данных, которыми можно манипулировать в соответствии с различными примерами изобретения;
фиг.27 - схема последовательности операций, изображающая способ согласования результатов анализа с текущим состоянием документа; и
фиг.28 - средство асинхронного анализа электронных чернил в соответствии с другими примерами изобретения.
Подробное описание чертежей
Термины
В настоящем описании изобретения используются следующие термины и, если не указано иначе или явно не следует из контекста, термины имеют значение, приведенное ниже:
«Воспроизводить», или «воспроизведенный», или «воспроизведение» - Процесс определения того, каким образом информация (включая текст, графики и/или электронные чернила) должна отображаться, например, на экране, печататься или выводиться некоторым другим образом.
«Машиночитаемый компьютером носитель» - любой доступный носитель, к которому пользователь на компьютерной системе может осуществить доступ. В качестве примера, а не ограничения, «машиночитаемый носитель» может включать в себя носитель данных компьютера и среду передачи данных. «Носитель данных компьютера» включает в себя энергозависимые и энергонезависимые, съемные и несъемные носители, выполненные любым способом или по любой технологии для хранения информации, такой как машиночитаемые компьютером инструкции, структуры данных, программные модули или другие данные. «Носитель данных компьютера» включает в себя, но не ограничительном смысле, оперативное запоминающее устройство (ОЗУ, RAM), постоянное запоминающее устройство (ПЗУ, ROM), электрически стираемое программируемое ПЗУ (EEPROM), флэш-память или память другой технологии; компакт диск, цифровой многофункциональный диск (DVD) или другие оптические запоминающие устройства; магнитные кассеты, магнитную ленту, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства; или любой другой носитель, который может быть использован для хранения требуемой информации и к которому компьютер может осуществить доступ. «Среда передачи данных» обычно воплощает машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном данными сигнале, таком как несущая волна или другой транспортный механизм, и включает в себя любую среду доставки информации. Термин «модулированный данными сигнал» означает сигнал, одна или несколько характеристик которого установлены или изменены так, что обеспечивается кодирование кодируют информации в этом сигнале. В качестве примера, а не ограничения, среда передачи данных включает в себя проводные среды, такие как проводную сеть или непосредственное проводное соединение, и беспроводные среды, такие как акустические, радиочастотные, инфракрасные и другие беспроводные среды. Комбинации любых из вышеперечисленных носителей данных и сред передачи также охватываются понятием «машиночитаемый носитель».
Обзор
В соответствии с различными примерами изобретения свойства элемента в документе (или файле другого типа) могут включать в себя информацию, относящуюся к пространственному положению данного элемента в документе. Таким образом, как штрих электронных чернил, так и машинописный текст могут быть описаны на основе одной системы пространственных координат для документа и/или на основе пространственной взаимосвязи или другой взаимосвязи с другими элементами в документе. Кроме того, связанные элементы в документе могут быть идентифицированы просто посредством идентификации пространственной области документа, содержащей эти элементы и/или посредством связывания этих элементов.
Используя упомянутую пространственную взаимосвязь между различными элементами документа, программное приложение может создавать и поддерживать структуру данных, которая описывает другие взаимосвязи между элементами документа. Например, программное приложение может поддерживать структуру данных, такую как дерево данных, которая определяет класс для различных элементов в документе. Таким образом, узел в структуре данных может соответствовать рукописному слову или рисунку, содержащему один или несколько штрихов чернил, и данные, хранимые в узле, могут дополнительно означать положение данного слова на странице. Любые другие подходящие или стандартные обычно хранимые данные, относящиеся к штриху чернил и/или слову электронных чернил, также могут храниться в узле слова.
Структура данных этого типа также может ассоциативно связывать элементы документа (такие как отдельные штрихи чернил или знаки машинописного текста) в значимые группы, такие как слова, строки слов, предложения, абзацы и т.п. Таким образом, если программное приложение поддерживает древовидную структуру документа, которая описывает абзац рукописных электронных чернил, концевые узлы структуры данных могут включать в себя данные, относящиеся к отдельным штрихам электронных чернил, и один или несколько штрихов могут быть ассоциативно связаны вместе в структуру данных в качестве узлов слова, соответствующих словам в абзаце (например, словам, определенным средство синтаксического разбора и/или средством распознавания). Древовидная структура затем может ассоциативно связывать узлы слова с узлами строки, соответствующими строкам в абзаце. Каждый узел строки дополнительно может быть ассоциативно связан с узлом, соответствующим абзацу. Далее, программное приложение может поддерживать дерево или другую структуру данных, которая ассоциативно связывает узел, соответствующий штриху электронных чернил и/или некоторой другой группировке электронных чернил, с другим узлом, соответствующим нечернильному элементу документа, такому как изображение; чернильный рисунок; машинописный знак, слово, строка, абзац или т.п. Приведенные структуры данных, таким образом, могут быть использованы для определения зависимостей между ассоциированными штрихами электронных чернил, чтобы отличать штрихи электронных чернил, образующих рукописный текст, от штрихов электронных чернил, аннотирующих нечернильные элементы документа, и/или связывать штрихи электронных чернил с другими элементами документа.
Как подробно описано ниже, эти структуры данных могут быть использованы с инструментальным средством анализа чернил в соответствии с различными примерами изобретения для анализа электронных чернил в документе. В соответствии с различными примерами изобретения программное приложение может провести анализ электронных чернил в документе посредством создания сначала структуры данных для документа. Эта структура данных описывает взаимосвязь между элементами документа, которые уже были проанализированы (если они есть), и, таким образом, обеспечивает контекст, в котором будут анализироваться любые новые электронные чернила. Упомянутая структура данных или «объект контекста анализа» также включает в себя любые новые электронные чернила, которые не были проанализированы. Т.е. объект контекста анализа также включает в себя электронные чернила, для которых еще не была установлена взаимосвязь с другими элементами документа. Для некоторых примеров изобретения программное приложение создает свой собственный объект контекста анализа. В соответствии с другими примерами изобретения, однако, программное приложение использует инструментальное средство анализа чернил или другое инструментальное средство для создания объекта контекста анализа.
После того, как программное приложение предоставило объект контекста анализа инструментальному средству анализа чернил (или инструментальное средство анализа чернил создало объект контекста анализа), инструментальное средство анализа чернил делает копию или извлекает информацию, относящуюся по меньшей мере к части объекта контекста анализа, содержащего непроанализированные электронные чернила. Посредством выполнения копии или приема информации, относящейся к требуемой части объекта контекста анализа, инструментальное средство анализа чернил создает структуру данных, которая, впоследствии, может быть проанализирована без изменения объекта контекста анализа, поддерживаемого программным приложением. Т.е. копия не зависит от фактического электронного документа, используемого в программном приложении, и, таким образом, может упоминаться ниже как «независимый от документа» объект контекста анализа.
Как только инструментальное средство анализа чернил создает независимый от документа объект контекста анализа, инструментальное средство анализа чернил предоставляет данный независимый от документа объект контекста анализа одному или нескольким процессам анализа. Например, если распознавание рукописного текста должно выполняться в отношении непроанализированных электронных чернил в документе, то тогда инструментальное средство анализа чернил может предоставить независимый от документа объект контекста анализа процессам классификации и/или анализа компоновки для классификации чернил на штрихи текста и рисунка (если необходимо, или если требуется) и затем группирования штрихов текста непроанализированных электронных чернил в ассоциированные группировки, на основе компоновки чернил. В то время, как процессы классификации и/или анализа компоновки анализируют независимый от документа объект контекста анализа, программное приложение может продолжать свою обычную работу. В частности, программное приложение может продолжать принимать новый ввод электронных чернил и/или любые другие данные в электронном документе, выполняемом программой приложения.
Когда процесс анализа, такой как процесс синтаксического разбора, завершает свой анализ независимого от документа объекта контекста анализа, он возвращает результаты анализа инструментальному средству анализа чернил. Более конкретно, процесс синтаксического разбора (который может включать в себя, в частности, процессы классификации и анализа компоновки, как описано выше) возвратит модифицированную версию независимого от документа объекта контекста анализа, изображающего новые взаимосвязи для ранее непроанализированных электронных чернил. Хотя программное приложение может свободно принимать новый ввод электронных чернил и/или любые другие данные для документа во время вышеописанной операции синтаксического разбора, однако, текущая версия объекта контекста анализа для документа (т.е. версия, поддерживаемая приложением) может отличаться как от независимого от документа объекта контекста анализа, первоначально предоставленного инструментальному средству анализа чернил, так и от результатов синтаксического разбора, предоставленных процессом синтаксического разбора.
Следовательно, в соответствии с некоторыми примерами изобретения инструментальное средство анализа чернил может получать текущую версию объекта контекста анализа от программного приложения и согласовывать результаты синтаксического разбора с текущей версией объекта контекста анализа. Во время данного процесса согласования инструментальное средство анализа чернил обновляет текущую версию объекта контекста анализа для отражения результатов процесса синтаксического разбора. Инструментальное средство анализа чернил затем передает согласованные данные от текущего объекта контекста анализа процессу распознавания рукописного текста для распознавания. В соответствии с другими примерами изобретения, однако, инструментальное средство анализа чернил может пропустить процесс согласования и, вместо этого, передать результаты синтаксического разбора непосредственно процессу распознавания рукописного текста.
Как только результаты синтаксического разбора согласованы с текущей версией объекта контекста анализа, программное приложение может снова возвратиться к своей обычной работе, и, таким образом, оно может продолжать принимать новый ввод электронных чернил и/или любые другие данные, относящиеся к документу. Тем временем, процесс распознавания анализирует согласованные данные от текущего объекта контекста анализа (или, альтернативно, результаты синтаксического разбора). После того, как процесс распознавания завершит свой анализ согласованных данных (или результатов синтаксического разбора), он возвращает свои результаты распознавания инструментальному средству анализа чернил. Опять же, так как программное приложение, может быть, приняло новый ввод электронных чернил и/или любые другие данные для документа во время работы процесса распознавания, инструментальное средство анализа чернил получает текущую версию объекта контекста анализа от программного приложения. Инструментальное средство анализа чернил затем согласовывает результаты процесса распознавания с текущей версией объекта контекста анализа для обновления текущей версии объекта контекста анализа результатами распознавания.
Примерное операционное окружение
На фиг.1 изображено схематическое представление цифровой вычислительной среды общего назначения, которая может быть использована для реализации различных аспектов настоящего изобретения. На фиг.1 компьютер 100 включает в себя блок 110 обработки данных, системную память 120 и системную шину 130, которая соединяет различные компоненты системы, включая системную память 120, с блоком 110 обработки данных. Системная шина 130 может быть любой из шинных структур нескольких видов, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, используя любую из разнообразных шинных архитектур. Системная память 120 может включать в себя постоянное запоминающее устройство (ПЗУ) 140 и оперативное запоминающее устройство (ОЗУ) 150.
Базовая система 160 ввода-вывода (BIOS), содержащая базовые процедуры, которые способствуют передаче информации между элементами в компьютере 100, например, во время запуска, хранится в ПЗУ 140. Компьютер 100 также может включать в себя накопитель 170 на жестких магнитных дисках для считывания и записи на жесткий диск (не показан), дисковод 180 для магнитного диска для считывания или записи на съемный магнитный диск 190 и дисковод 191 для оптического диска для считывания или записи на съемный оптический диск 192, такой как компакт-диск или другие оптические носители. Накопитель 170 на жестких магнитных дисках, дисковод 180 для магнитного диска и дисковод 191 для оптического диска подсоединены к системной шине 130 посредством интерфейса 192 накопителя на жестких магнитных дисках, интерфейса 193 дисковода для магнитного диска и интерфейса 194 дисковода для оптического диска, соответственно. Данные дисководы и накопители и связанные с ними машиночитаемые носители обеспечивают энергонезависимое хранение машиночитаемых инструкций, структур данных, программных модулей и других данных для персонального компьютера 100. Для специалиста в данной области техники очевидно, что в примерной операционной среде также могут быть использованы другие типы машиночитаемых носителей, которые могут хранить данные, к которым компьютер может осуществить доступ, такие как магнитные кассеты, карты флэш-памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Несколько программных модулей могут храниться на накопителе 170 на жестких магнитных дисках, магнитном диске 190, оптическом диске 192, в ПЗУ 140 или ОЗУ 150, включая операционную систему 195, одну или несколько программ 196 приложений, другие программные модули 197 и данные 198 программ. Пользователь может ввести команды и информацию в компьютер 100 при помощи устройств ввода, таких как клавиатура 101 и указательное устройство 102 (такое как мышь). Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровой планшет, антенну спутниковой связи, сканер и т.п. Приведенные и другие устройства ввода часто подключены к блоку 110 обработки данных через интерфейс 106 последовательного порта, который подсоединен к системной шине 130, но они также могут быть подсоединены при помощи других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB) и т.п. Далее, приведенные устройства могут быть подсоединены непосредственно к системной шине 130 через соответствующий интерфейс (не показан).
Монитор 107 или устройство отображения другого типа также может быть подсоединено к системной шине 130 через интерфейс, такой как видеоадаптер 108. В дополнение к монитору 107 персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показаны), такие как громкоговорители и принтеры. В одном примере предусмотрены цифровой преобразователь 165 перьевого ввода и сопровождающая его ручка или перо 166 для цифрового ввода данных от руки. Хотя на фиг.1 показано соединение между цифровым преобразователем 165 перьевого ввода и интерфейсом 106 последовательного порта, на практике цифровой преобразователь 165 перьевого ввода может быть непосредственно соединен с блоком 110 обработки данных, или он может быть подсоединен к блоку 110 обработки данных любым подходящим образом, например при помощи параллельного порта или другого интерфейса и системной шины 130, что известно из уровня техники. Кроме того, хотя цифровой преобразователь 165 показан отдельно от монитора 107 на фиг.1, используемая область ввода цифрового преобразователя 165 может иметь совместную пространственную протяженность с областью отображения монитора 107. Далее, цифровой преобразователь 165 может быть встроен в монитор 107, или он может существовать в виде отдельного устройства, наложенного или иным образом присоединенного к монитору 107.
Компьютер 100 может работать в сетевой среде, используя логические соединения с одним или несколькими удаленными компьютерами, такими как удаленный компьютер 109. Удаленным компьютером 109 может быть сервер, маршрутизатор, сетевой ПК, одноранговое устройство или другой общий узел сети, и он обычно включает в себя многие или все из элементов, описанных выше в отношении компьютера 100, хотя для простоты только устройство 111 хранения данных изображено на фиг.1. Логические соединения, изображенные на фиг.1, включают в себя локальную сеть (ЛС, LAN) 112 и глобальную сеть (ГС, WAN) 113. Такие сетевые среды являются общепринятыми в офисах, компьютерных сетях масштаба предприятия, интрасетях и Интернете, используя как проводные, так и беспроводные соединения.
При использовании в сетевой среде ЛС компьютер 100 подсоединен к локальной сети 112 посредством сетевого интерфейса или адаптера 114. При использовании в сетевом окружении ГС персональный компьютер 100 обычно включает в себя модем 115 или другое средство для установления линии связи по глобальной сети 113, такой как Интернет. Модем 115, который может быть внутренним или внешним для компьютера 100, может подключаться к системной шине 130 через интерфейс 106 последовательного порта. В сетевом окружении программные модули, описанные в отношении персонального компьютера 100, или его частей, могут храниться на удаленном устройстве хранения данных.
Следует понимать, что показанные сетевые соединения являются примерными, и могут быть использованы другие методики для установления линии связи между компьютерами. Предполагается существование любых из различных общеизвестных протоколов, таких как протокол управления передачей/протокол Интернет (TCP/IP), Ethernet, протокол передачи файлов (FTP), протокол передачи гипертекста (HTTP), протокол передачи дейтаграмм пользователя (UDP) и т.п., и система может работать в конфигурации “пользователь-сервер”, позволяя пользователю извлекать Web-страницы с Web-сервера. Могут быть использованы любые из различных обычных Web-браузеров для отображения и управления данными на Web-страницах.
Хотя среда по фиг.1 изображает примерную среду, понятно, что также могут быть использованы другие вычислительные среды. Например, один или несколько примеров настоящего изобретения могут использовать среды, имеющие меньшее количество, чем все из различных аспектов, показанных на фиг.1 и описанных выше, и указанные аспекты могут проявляться в различных комбинациях и субкомбинациях, которые очевидны для специалиста в данной области техники.
На фиг.2 изображен персональный компьютер (ПК) 201 с перьевым вводом, который может использоваться в соответствии с различными аспектами настоящего изобретения. Любой или все признаки, подсистемы и функции в системе по фиг.1 могут быть включены в компьютер по фиг.2. Система 201 персонального компьютера с перьевым вводом включает в себя большую поверхность 202 отображения, например, преобразующий в цифровую форму дисплей с плоским экраном, такой как экран жидкокристаллического дисплея (ЖКД, LCD), на котором отображается множество окон 203. Используя перо 204, пользователь может выбрать, выделить и записать на преобразующей в цифровую форму области отображения. Примеры подходящих преобразующих в цифровую форму панелей отображения включают в себя электромагнитные цифровые преобразователи с перьевым вводом, таким образом цифровые преобразователи с перьевым вводом, поставляемые компанией Mutoh Co. (теперь известной как FinePoint Innovations Co.) или Wacom Technology Co. Также могут быть использованы другие типы цифровых преобразователей с перьевым вводом, например, оптические цифровые преобразователи и сенсорные цифровые преобразователи. Вычислительная система 201 с перьевым вводом интерпретирует жесты, сделанные с использованием пера 204, для манипуляции данными, ввода текста и выполнения обычных задач компьютерного приложения, таких как создание, редактирование и изменение электронных таблиц, программ обработки текстов и т.п.
Перо 204 может быть оснащено кнопками или другими признаками, чтобы дополнять его возможности. В одном примере перо 204 может быть выполнено в виде «карандаша» или «ручки», в которых один конец составляет пишущую часть, и другой конец составляет конец «ластика», и который при движении по дисплею указывает части электронных чернил на дисплее, которые должны быть стерты. Также могут быть использованы другие типы устройств ввода, такие как мышь, шаровой манипулятор, клавиатура или т.п. Дополнительно, собственный палец пользователя может использоваться для выбора или указания частей отображаемого изображения на сенсорном или бесконтактном дисплее. Следовательно, термин «устройство ввода пользователем», используемый в настоящей заявке, как предполагается, имеет широкое определение и охватывает многие варианты общеизвестных устройств ввода.
В различных примерах система обеспечивает платформу обработки чернил в виде комплекта служб модели компонентных объектов (COM) которые программа приложения может использовать для сбора, управления и хранения чернил. Платформа обработки чернил также может включать в себя язык разметки, включая язык, аналогичный расширяемому языку разметки (XML). Далее, система может использовать распределенную модель компонентных объектов (DCOM) в качестве другого варианта реализации. Могут быть использованы еще другие реализации, включающие в себя модель программирования Win32 и модель программирования.Net компании Microsoft Corporation. Упомянутые платформы имеются в продаже и известны в технике.
В дополнение к использованию перьевых вычислительных систем с полными рабочими характеристиками или «планшетных ПК» (например, трансформируемых переносных компьютеров или планшетных ПК типа «грифельной доски») аспекты настоящего изобретения могут использоваться совместно с другими типами перьевых вычислительных систем и/или других устройств, которые принимают данные в виде электронных чернил и/или принимают ввод электронной ручкой или пером, такие как: ручные или карманные вычислительные системы; персональные цифровые информационные устройства; карманные персональные компьютеры; мобильные и сотовые телефоны, пейджеры и другие устройства связи; часы; электроприборы; и любые другие приборы или системы, которые включают в себя монитор или другое устройство отображения и/или цифровой преобразователь дигитайзер, который представляет отпечатанную или графическую информацию пользователям и/или позволяет производить ввод с использованием электронной ручки или пера, или которые могут обрабатывать электронные чернила, собранные другим устройством (например, обычный настольный компьютер, который может обрабатывать электронные чернила, собранные планшетным ПК).
Изобретение ниже описывается в связи с остальными фигурами, на которых представлены различные примеры изобретения и информация, способствующая объяснению изобретения. Конкретные фигуры и информация, содержащаяся в настоящем подробном описании, не должны истолковываться как ограничивающие изобретение.
Обобщение пространственного вида документа
Как описано выше, некоторые аспекты настоящего изобретения относятся, в основном, к системам и способам предоставления более универсальных аннотаций с широкими возможностями, используя электронные чернила в электронных документах. Нижеследующее подробно описывает различные аспекты и примеры настоящего изобретения.
А. Общий обзор изобретения
На фиг.3 изображен, в общем виде, принцип действия систем и способов в соответствии по меньшей мере с некоторыми примерами настоящего изобретения. Конкретно, как изображено на фиг.3, пользователь может взаимодействовать некоторым образом с электронным документом 300 (документ «А» на фиг.3), например, посредством добавления электронных чернил к документу 300. В изображенном примере электронный документ 300 включает в себя электронный или машинописный текст 302 («Sample Text» (Образец текста) в изображенном примере) и рисунок 304 чернил (дом в изображенном примере). Конечно, электронный документ 300 может включать в себя любые данные или информацию, не выходя за рамки объема изобретения, такие как электронный текст, электронные чернила (рисунок или текст), изображения, графики, таблицы, диаграммы, другую графическую или электронную информацию и/или их комбинации. Для целей данного примера предположим, что исходный электронный документ 300 (также называемый «базовым документом» или «базовой частью» в настоящей заявке) включает в себя электронный машинописный текст 302 и рисунок 304 электронных чернил. Когда пользователь просматривает Документ А 300 в данном примере, он принимает решение включить аннотацию, выполненную посредством электронных чернил, в документ 300. Конкретно, в изображенном примере аннотация включает в себя обведение 306 вокруг некоторой части 308 электронного текста 302.
В данном примере, после того как пользователь введет аннотацию, программа приложения вызывает программу 310 синтаксического разбора и запрашивает проведение синтаксического разбора вновь введенных данных электронных чернил (как отмечено выше, «синтаксический разбор» может включать в себя, например, классификацию электронных чернил на различные типы чернил (например, рисунки, текст, блок-схемы, музыка и т.д.) и/или анализ компоновки чернил (например, уточнение пространственных и позиционных зависимостей среди штрихов чернил и группирование их в соответствующие группировки), а также другие процессы анализа). Конкретно, программа приложения посылает введенные данные электронных чернил (представляющие аннотацию 306 в данном примере) средству 310 синтаксического разбора в виде данных неклассифицированных чернил. Вышеописанное изображается на фиг.3 стрелкой 312 ввода.
В необязательном порядке, в этот же или примерно в этот момент времени программа приложения может послать некоторые или все данные, относящиеся к базовому электронному документу 300, средству 310 синтаксического разбора. Упомянутые данные могут включать в себя, например, данные, относящиеся к пространственной компоновке информации в документе 300, например, положению электронного текста 302, рисунка 304 и т.д. Дополнительно, программа приложения может послать данные, показывающие иерархическую структуру данных в документе, которая подробно описывается ниже. В качестве другой альтернативы, как также описано более подробно ниже, средство 310 синтаксического разбора может осуществить обратный вызов программы приложения, запрашивая некоторые данные, относящиеся к электронному документу 300, такие как информация, относящаяся к электронному документу 300 в пространственной области, ассоциированной с новыми неклассифицированными чернилами (в упомянутом примере данные, представляющие машинописный текст и информацию, расположенные пространственно около аннотации 306). Упомянутые данные, вводимые в средство 310 синтаксического разбора, изображены на фиг.3 посредством стрелки 314 ввода. Конечно, как неклассифицированные чернила, так и ранее проанализированные данные могут быть одновременно посланы программе синтаксического разбора и/или сделаны доступны для нее без отступления от изобретения.
Средство 310 синтаксического разбора принимает введенные данные 314 электронного документа и введенные данные 312 неклассифицированных чернил и использует упомянутую информацию для классификации новых данных электронных чернил на типы чернил. Чернила можно классифицировать на всевозможные различные типы чернил без отступления от изобретения, и ниже более подробно описываются различные примеры возможных типов чернил. Для настоящего примера, основываясь на введенных чернилах 306 и информации 302, содержащейся в базовом документе 300, программа 310 синтаксического разбора в соответствии с данным примером изобретения может определить и классифицировать введенные чернила 306 в качестве аннотации или даже более конкретно в качестве чернильного рисунка, соответствующего аннотации-контейнеру (например, обведению), который содержит определенный машинописный текст. Конечно, также возможны другие типы аннотаций, такие как аннотации выделением, аннотации с «указанием на», аннотации с «указанием от», аннотации с привязкой (например, без указания на или указания от), горизонтальный охват, вертикальный охват и т.п., и ниже подробно объяснены различные примеры.
После синтаксического разбора данные, ассоциированные с аннотацией 306, могут быть включены в иерархическую структуру данных «дерева документа», ассоциированную с электронным документом 300 (или любую другую подходящую или требуемую структуру данных), и упомянутая структура данных (или инструкции для модифицирования существующей структуры данных, поддерживаемой программой приложения) может быть послана обратно программе приложения, как показано на фиг.3 стрелкой 316. Если требуется, то другие данные также могут быть возвращены из средства 310 синтаксического разбора программе приложения без отступления от изобретения. Например, как показано на фиг.3, данные, ассоциированные с результатами процесса анализа распознавания (такого как средство распознавания рукописного текста или другое средство распознавания), могут быть возвращены программе приложения, если действия средства 310 синтаксического разбора включали вызовы одного или нескольких модулей, компонентов и/или программ средства распознавания.
На фиг.4 изображен пример реализации 400 различных признаков, используемых в некоторых примерах настоящего изобретения. Как изображено, электронный документ (такой как Документ А 300 на фиг.3) генерируется, запоминается и/или поддерживается программой 400а приложения в качестве структуры данных или модели 402 документа. Упомянутой структурой 402 данных может быть иерархическая структура данных или любая другая требуемая или подходящая структура данных без отступления от изобретения. Программа 400а приложения включает в себя объект 404 «Analysis Context» (контекст анализа), который содержит зеркальную копию, селективную копию или другую соответствующую информацию, относящуюся к структуре 402 данных (например, объектом 404 Analysis Context может быть уровень «преобразования», на котором запросы на объект 404 Analysis Context преобразуются в запросы на структуру собственных режимов документа - таким образом технология синтаксического разбора в соответствии с аспектами настоящего изобретения может быть преобразована для использования со всевозможными различными собственными программами приложения). «Платформа» 400b или сторона операционной системы данной примерной реализации 400 включает в себя метод 406 «Ink Analyzer» (анализатор чернил), который вызывается программой 400а приложения. Программа 400а приложения вызывает метод 406 Ink Analyzer и передает ему ссылку на объект 404 Analysis Context. Метод 406 Ink Analyzer вызывает средство 408 синтаксического разбора (также часть платформы 400b в данном примере), которая классифицирует и анализирует компоновку введенных данных, как вкратце описано выше. Принцип действия примерной реализации в соответствии с изобретением ниже описывается более подробно в разделе «Анализ чернил». Если средство 408 синтаксического разбора завершает свой анализ и обработку, то платформа 400b может послать данные обратно программе 400а приложения, позволяя модели 402 документа и/или объекту 404 Analysis Context перестроить свою структуру данных, основываясь на обработке и результатах средства синтаксического разбора, как вкратце изображено стрелкой 410 на фиг.4.
На фиг.5 в общем виде изображен пример структуры данных, который может быть использован для хранения данных электронного документа по меньшей мере в некоторых примерах настоящего изобретения, например, как часть объекта 404 «Analysis Context», как модель 402 документа или как структуры данных, сгенерированные и/или выводимые средством 408 синтаксического разбора. Конкретно, на фиг.5 изображен примерный электронный документ 500. При хранении в качестве объекта 502 Analysis Context или синтаксическом разборе структура данных может включать в себя различные элементы документа, классифицированные или размещенные в различных группировках или «узлах». Например, как изображено на фиг.5, электронный документ 500 включает в себя три абзаца 504, 506 и 508 электронного текста; один рисунок 510, выполненный посредством электронных чернил, и одну аннотацию 512, выполненную посредством электронных чернил. Примерная структура 502 данных Analysis Context для электронного документа 500 показана на фиг.5 в виде списка элементов верхнего уровня. Конкретно, элемент 504(а) узла соответствует абзацу 504 в электронном документе 500, элемент 506(а) узла соответствует абзацу 506 в электронном документе 500, элемент 508(а) узла соответствует абзацу 508 в электронном документе 500, элемент 510(а) узла соответствует чернильному рисунку 510 в электронном документе 500 и элемент 512(а) узла соответствует аннотации 512, выполненной посредством чернил, в электронном документе 500. Дополнительные узлы могут храниться в структуре данных (например, в виде иерархической схемы) как родительские узлы и/или дочерние узлы относительно узлов 504а, 506а, 508а, 510а и 512а верхнего уровня, изображенных на фиг.5, как подробно описано ниже.
В. Узлы контекста и иерархические структуры данных
На фиг.6А-6I изображены различные примеры узлов контекста и структур данных, которые могут быть использованы при построении, анализе и синтаксическом разборе данных электронного документа, таких как объект Analysis Context, в соответствии с некоторыми примерами настоящего изобретения. На фиг.6А изображена примерная структура 600 данных, которая может быть использована для хранения данных неклассифицированных электронных чернил (например, чернил, вновь введенных пользователем, которые ранее не подвергались синтаксическому разбору). Упомянутая примерная структура 600 данных включает в себя корневой узел 602 (который может соответствовать всему электронному документу в программе приложения, определенной странице документа или любой подходящей или требуемой группировке данных, такой как группировка, используемая программой приложения). Любые подходящие или требуемые данные могут быть включены в корневой узел 602, такие как номер страницы, указатели на предыдущую страницу и следующую страницу, расположение или размеры полей и т.д. Каждый корневой узел 602 может включать в себя любое количество узлов 604 неклассифицированных чернил в качестве дочерних узлов, и каждый узел 604 неклассифицированных чернил дополнительно может включать в себя любое количество узлов 606 отдельных штрихов (последний узел в иерархической структуре (узел 606 штриха в данном примере) также может называться «концевым узлом» в настоящем описании изобретения). (Буква «n» на различных фигурах может представлять любое число, включая нуль.) Различные узлы структуры 600 данных могут включать в себя любые требуемые или подходящие данные, соответствующие узлу. Например, узлы 606 штриха могут включать в себя данные, представляющие: точки цифрового преобразователя или другие данные, идентифицирующие штрих электронных чернил; данные о положении или ориентации штриха; данные о цвете штриха; данные о нажатии при выполнении штриха; данные о временных характеристиках ввода штриха; данные об идентификаторе штриха и/или любые другие стандартные или полезные данные, используемые при хранении информации о штрихе в системах и способах, способных принимать электронные чернила. Аналогично, узел(узлы) 604 неклассифицированных чернил может включать в себя любые требуемые или подходящие данные, ассоциированные с чернилами или узлом, такие как данные, представляющие: размеры ограничивающего прямоугольника всех штрихов, содержащихся в узле; расположение ограничивающего прямоугольника; информацию о временных характеристиках ввода; геометрическую информацию для чернил (такую как, например, информацию о выпуклой оболочке) и/или любые другие стандартные или полезные данные, относящиеся к штрихам неклассифицированных чернил, включенных в узел. Альтернативно, если требуется, данные о штрихе, в основном, могут быть сохранены в качестве свойства другого узла (например, узла слова, узла таблицы или т.п.), а не в виде отдельного узла в дереве документа.
Как только неклассифицированные чернила посланы на средство классифицирования, средство анализа компоновки, средство распознавания и/или другую систему синтаксического разбора, по меньшей мере некоторые части чернил могут быть ассоциативно связаны вместе и/или классифицированы на всевозможные различные типы, и структура данных, ассоциированная с чернилами, может быть изменена таким образом, чтобы соответствовать многочисленным ассоциациям и типам, на которые она была классифицирована. На фиг.6В изображена примерная структура 610 данных для электронных чернил, которая была классифицирована как текст, выполненный посредством чернил. Используя технологию синтаксического разбора, включающую обычные средства синтаксического разбора, известные и используемые в технике, может быть произведен синтаксический разбор и сохранение иерархическим образом введенных штрихов электронных чернил (например, данных электронных чернил, собранных между событием опускания пера и последующим во времени событием поднятия пера или некоторым другим образом), в которой связанные отдельные штрихи чернил могут быть сгруппированы вместе и сохранены как слова чернил, линейно размещенные чернильные слова могут быть сгруппированы вместе и сохранены как чернильные строки, связанные чернильные строки могут быть сгруппированы вместе и сохранены как чернильные абзацы, и связанные абзацы могут быть сохранены как электронные документы (например, в отдельных частях страницы, в качестве целых документов или в любых подходящих корневых группировках). Примерная иерархическая структура 610 данных, соответствующая данным электронных чернил, обрабатываемых синтаксическим разбором и сохраняемых таким образом, как изображено на фиг.6В, может включать в себя корневой узел 612, который может соответствовать целому электронному документу, странице или другой группировке, используемой программой приложения. Каждый корневой узел 612 может содержать любое количество узлов 614, соответствующих абзацам или подобным группировкам штрихов электронных чернил. Узлы 614 абзаца могут содержать любое количество узлов 616 отдельных строк, которые, в свою очередь, могут включать в себя любое количество узлов 618 отдельных чернильных слов, которые далее могут содержать любое количество узлов 620 отдельных штрихов, соответствующих отдельным штрихам введенных данных электронных чернил. В необязательном порядке, как отмечено выше, данные штриха могут быть запомнены в качестве «свойства» ассоциированного узла слова, если требуется. Различные узлы 612, 614, 616, 618 и 620 могут хранить любые подходящие данные, относящиеся к различным отдельным штрихам или коллекциям штрихов, содержащихся в узле, подобно данным о пространственной ориентации или расположении и/или другим данным, аналогичным тем, которые описаны выше.
Возможны другие типы данных и организации структур данных, соответствующие введенным штрихам электронных чернил, без отступления от изобретения. Например, технология классификации, анализа компоновки или средства распознавания может определить, что введенные электронные чернила образуют чернильный рисунок. На фиг.3 изображен примерный чернильный рисунок 304, который содержит несколько отдельных штрихов чернил. На фиг.6С и 6D изображены примерные иерархические структуры данных, которые могут быть использованы для группирования и хранения данных электронных чернил, определенных относящимися к чернильным рисункам. Как показано на фиг.6С, структура 630 данных включает в себя корневой узел 632 (который может соответствовать целому электронному документу, электронной странице или некоторой другой группировке данных, как описано выше). Каждый корневой узел 632 может включать в себя любое количество узлов 636 отдельных чернильных рисунков (например, так, что каждый отдельный рисунок имеет отдельный узел, хранящий данные, относящиеся, например, к ширине рисунка, высоте рисунка, положению рисунка, размеру ограничивающего прямоугольника и т.п.), и каждый узел 636 чернильного рисунка может включать в себя любое количество узлов 638 отдельных штрихов чернил (соответствующих отдельным штрихам чернил, составляющих рисунок). В необязательном порядке, данные штриха чернил могут храниться в качестве «свойства» их соответствующего узла чернильного рисунка (или другого узла).
На фиг.6D изображена альтернативная структура 630а данных для электронных документов, содержащих один или несколько чернильных рисунков. В данном примере электронный документ, или страница, или другая группировка данных (представленная корневым узлом 632а) может включать в себя одну или несколько групп (представленных узлом 634а) рисунков, выполненных посредством электронных чернил, причем их данные ассоциативно связывают вместе и сохраняют иерархическим образом, описанным в связи с фиг.6С, (например, целый электронный документ (представленный корневым узлом 632а) может включать в себя несколько отдельных страниц (каждая представлена узлом 634а группы), и каждая отдельная страница может иметь один или несколько отдельных чернильных рисунков (каждый представлен узлом 636а чернильного рисунка), и каждый отдельный чернильный рисунок может содержать один или несколько отдельных штрихов чернил (каждый представлен узлом 638а штриха или в свойстве узла чернильного рисунка)). Необходимо отметить, что как группы, так и чернильные рисунки могут быть дочерними узлами одного и того же корневого узла или любого узла группы. Кроме того, если требуется, узел группы может содержать дополнительные узлы группы. Конечно, могут быть использованы другие подходящие структуры данных для хранения рисунков электронных чернил без отступления от настоящего изобретения.
Иерархические структуры данных, однако, не ограничиваются использованием с введенными данными электронных чернил. Введенный машинописный текст (например, с клавиатуры) также может быть ассоциирован на различные группы и сохранен в иерархической структуре данных. На фиг.6Е изображен пример такой структуры 640 данных. Упомянутая структура 640 данных может включать в себя корневой узел 642 (например, аналогично корневым узлам, описанным выше). Каждый корневой узел 642 может включать в себя любое количество узлов 644 абзаца текста (соответствующих абзацам текста), причем каждый узел 644 абзаца может включать в себя любое количество узлов 646 строки текста (или, альтернативно, узлов предложений текста), и каждый узел 646 строки далее может включать в себя любое количество узлов 648 отдельных слов текста. Если требуется, то слова текста могут быть дополнительно разбиты на узлы отдельных знаков текста и еще дополнительно могут быть разбиты на узлы отдельных признаков знака (относящиеся, например, к признакам базовой линии, засечке, надстрочного элемента, подстрочного элемента каждого знака) без отступления от изобретения. Различные узлы могут хранить любые подходящие данные, относящиеся к тексту, такие как пространственное положение, содержимое, размер абзаца, строки или слова и т.п.; поля страницы, размеры или размещение полей; количество страниц и т.д.
Различные структуры данных, описанные выше в связи с фиг.6А-6Е, изображают структуры данных, которые содержат исключительно только данные электронных чернил или только данные электронного машинописного текста. Технология синтаксического разбора может быть использована для анализа, объединения, ассоциирования и группирования упомянутых различных типов данных в единую структуру данных без отступления от изобретения. На фиг.6F изображена примерная структура 650 данных, в которой электронный документ или его часть (представленные корневым узлом 652) содержат один или несколько отдельных абзацев (представленных узлом 654 абзаца) и одну или несколько отдельных строк (представленных узлом 656 строки). Строки, потенциально, могут содержать как машинописный текст (представленный узлом 658 слова текста), так и текст, выполненный посредством электронных чернил (представленный узлом 660 чернильного слова и узлом 662 штриха чернил). Каждый отдельный узел абзаца, строки и слова (как машинописного текста, так и чернильных слов) содержит соответствующие независимые данные, зависящие от содержимого абзаца, строки и слова. Дополнительно или альтернативно, отдельные слова могут далее включать в себя как знаки чернил, так и машинописные знаки без отступления от изобретения.
Другие электронные данные также могут быть включены в структуру данных электронного документа (включая иерархические структуры данных) без отступления от изобретения. Например, данные изображения (такие как цифровая фотография, графическая информация и т.п.) могут быть включены в структуру данных для электронного документа, например, как показано в структуре 664 данных по фиг.6G. Как изображено в данном примере, структура 664 данных включает в себя электронный документ или его часть (представленные корневым узлом 666), которая содержит одну или несколько отдельных группировок данных (представленных узлом 668 группы). Каждая группировка данных в данном примере дополнительно может включать в себя электронное изображение (представленное узлом 670 изображения), а также машинописный текст (представленный узлом 672 абзаца, узлом 674 строки и узлом 676 слова текста), как описано в общем виде выше в связи с фиг.6Е и 6F. Конечно, структура данных, аналогичная той, которая изображена на фиг.6G, также может содержать данные электронных чернил (например, аналогичные структурам данных, изображенным на фиг.6А-6D) или другие требуемые типы данных без отступления от изобретения.
На фиг.6H изображен пример другой потенциальной структуры 680 данных, которая может быть использована в соответствии по меньшей мере с некоторыми примерами настоящего изобретения. Более конкретно, структура 680 данных по фиг.6Н соответствует электронному документу или его части (представленных корневым узлом 682), содержащих один или несколько списков (представленных узлом 684 списка). Список в электронном документе может содержать любое количество отдельных элементов списка (представленных узлом 686 элемента списка), и каждый элемент списка может содержать всевозможные различные виды электронной информации. Например, некоторые элементы списка, в необязательном порядке, могут включать маркер списка, который может состоять из машинописного маркера или маркера электронных чернил (узел 688 маркера чернил, включающий один или несколько соответствующих узлов 690 штриха чернил, изображен в примере по фиг.6Н). Кроме того, каждый элемент списка, в необязательном порядке, может включать в себя один или несколько абзацев электронных чернил (представленных цепочкой 692 узлов), один или несколько рисунков чернил (представленных цепочкой 694 узлов) и/или один или несколько машинописных абзацев (представленных цепочкой 696 узлов). Дополнительно (или альтернативно), каждый элемент списка, в необязательном порядке, может включать в себя одно или несколько изображений (представленных узлом 698 изображения) и/или одну или несколько группировок данных, таких как группировки, описанные выше в связи с фиг.6D и 6G, (представленные цепочкой 700 узлов группы). Так как различные узлы и/или цепочки 692, 694, 696, 698, 700 узлов могут, в общем случае, соответствовать примерным структурам данных, изображенным на фиг.6А-6G, а также подмножествам и/или группировкам упомянутых структур данных, то дальнейшее объяснение опускается. Если требуется, то по меньшей мере в некоторых случаях узел 686 отдельного элемента списка также сам может содержать список, имеющий структуру данных, аналогичную той, которая изображена на фиг.6Н.
На фиг.6I изображена другая примерная структура 710 данных, которая может быть использована, по меньшей мере, в некоторых примерах настоящего изобретения. Упомянутая примерная структура 710 данных соответствует электронным данным, анализированным, ассоциативно связанным вместе, сгруппированным и сохраненным в виде таблицы. В данном изображенном примере каждый электронный документ или его часть (представленные корневым узлом 712) могут включать в себя одну или несколько таблиц (представленных узлом 714 таблицы). Таблица в данном примере может состоять из одной или нескольких строк информации (представленных узлом 716 строки таблицы), и каждая строка таблицы может состоять из одной или нескольких отдельных ячеек (представленных узлом 718 ячейки). Отдельные ячейки могут содержать одну или несколько структур данных, включающих, например, любую из всевозможных различных структур данных, описанных выше. В изображенном примере, отдельные ячейки таблицы показаны как потенциально содержащие любое количество изображений (представленных узлом 720 изображения), любое количество абзацев машинописного текста (представленных цепочкой 722 узлов), любое количество группировок (представленных цепочкой 724 узлов), любое количество чернильных рисунков (представленных цепочкой 726 узлов), любое количество дополнительных таблиц (представленных цепочкой 728 узлов) и любое количество списков (представленных цепочкой 730 узлов). Конечно, любые другие подходящие или требуемые структуры данных могут быть включены в таблицу без отступления от настоящего изобретения, включая различные конкретные структуры данных, описанные выше, и/или комбинации и подмножества структур данных, например, аналогичных тем, которые описаны выше.
Любые подходящие или требуемые данные могут храниться во всевозможных различных узлах, включая различные типы данных, описанных выше. Для использования с данными обработки, относящимися к аннотациям, может быть полезным по меньшей мере в некоторых примерах изобретения, чтобы различные узлы хранили данные, относящиеся к пространственному положению, ориентации или размещению узла в электронном документе, в необязательном порядке, так как упомянутая пространственная информация относится или связана с другими узлами в структуре данных электронного документа.
Также, могут быть использованы другие типы программ синтаксического разбора, средств классифицирования и/или средств распознавания и типы данных без отступления от изобретения. Например, средства распознавания могут быть использованы для анализа, распознавания, группирования и/или ассоциирования электрических или электронных символов (например, резисторов, источников напряжения, конденсаторов и т.д.); музыкальных символов; математических символов; элементов блок-схем; элементов круговой диаграммы и т.п. без отступления от изобретения.
Структуры данных, изображенные на фиг.6А-6I, являются просто примерами всевозможных структур данных, которые могут быть использованы в соответствии с аспектами настоящего изобретения. Для специалиста в данной области техники очевидно, что использованные конкретные структуры данных могут изменяться в широких пределах без отступления от изобретения. Например, могут быть использованы различные узлы, представляющие различные группировки компоновки, могут быть добавлены дополнительные типы узлов, или некоторые из описанных типов узлов могут быть исключены без отступления от изобретения (например, узлы столбца могут быть использованы вместо узлов строки таблицы в структуре данных таблицы). Дополнительно, вышеупомянутое описание оптимизировано для использования с языками и текстовыми представлениями, в которых знаки считываются слева направо и затем сверху вниз на странице. Могут быть использованы структуры данных, предназначенные для использования и соответствия другим языкам и размещению знаков, например, структур данных для обеспечения считывания и/или записи на языках справа налево, сверху вниз, снизу вверх и их комбинации без отступления от изобретения. Кроме того, если требуется (в частности, для некоторых языков, таких как азиатские языки), штрихи могут группироваться соответствующим образом в качестве знаков, которые затем могут группироваться в строки без использования промежуточного узла «слова», как описано выше. В качестве другого альтернативного варианта, может быть исключено использование узлов строки, и узлы слова могут группироваться вместе в качестве абзацев и/или в другие требуемые группировки. Могут быть использованы данные и другие разновидности в структуре данных, например, для согласования с характеристиками конкретного языка без отступления от изобретения.
С. Применение аспектов изобретения к аннотациям
Аспекты настоящего изобретения, включающие использование узлов контекста и иерархических структур данных, как описано выше, могут быть использованы для получения «интеллектуальных» аннотаций, выполненных посредством электронных чернил, в электронных документах. Как описано выше, одним желательным и выгодным использованием вычислительных систем с перьевым вводом является их использование при аннотировании электронных документов. Однако, для того чтобы они были особенно полезными и эффективными, аннотации, выполненные электронными чернилами в документах на вычислительной системе с перьевым вводом, должны быть достаточно гибкими, так что, если и когда характеристики, ассоциированные с различными элементами в базовом документе, по некоторым причинам изменяются (например, изменяются поля, изменяется размер отображения, изменяется шрифт, добавляется информация, удаляется информация и т.д.), то аннотации способны точно изменять положение и/или другие характеристики, основанные на изменениях аннотируемых элементов в базовом документе. Это может быть выполнено, например, связыванием по меньшей мере одного узла контекста, ассоциированного с аннотацией, с одним или несколькими узлами контекста, ассоциированными с базовым документом. По меньшей мере в некоторых случаях данные и/или характеристики, ассоциированные и хранящиеся относящимися к базовому документу, такие как данные, относящиеся к пространственным атрибутам, положению и/или размещению одного или нескольких элементов документа, могут быть использованы для управления размещением, видом и/или другими характеристиками аннотации.
На фиг.7А и 7В изображен один пример аннотации, которая может быть нанесена на электронный документ при помощи электронных чернил. Как изображено на фиг.7А, электронный документ 750 включает в себя предложение «Today the sky is green» (Сегодня небо зеленое). Пользователь вычислительной системы с перьевым вводом аннотировал упомянутый документ 750, используя электронные чернила, подчеркнув слово «green» (аннотация подчеркиванием показана позицией 752). На фиг.7В изображена примерная иерархическая структура 760 данных, соответствующая упомянутому составному электронному документу 750 (целый электронный документ 750 представлен в структуре 760 данных корневым узлом 762). При полном синтаксическом разборе структура 760 данных включает в себя узлы контекста, показывающие структуру полного документа. Более конкретно, информацию, относящуюся к машинописному тексту в электронном документе 750, анализируют и ассоциативно связывают вместе для указания того, что электронный документ 750 содержит один абзац (узел 764 абзаца), абзац содержит строку (узел 766 строки), и строка содержит пять слов (один узел 768а-768е слова текста для каждого из слов «Today», «the», «sky», «is» и «green», соответственно). Кроме того, средство синтаксического разбора отмечает присутствие данных в электронном документе 750, относящихся к аннотации 752, и она классифицирует упомянутые данные в качестве рисунка, выполненного посредством электронных чернил (узел 770 чернильного рисунка). Кроме того, основываясь на размещении и положении штриха (штрихов) рисунка чернил относительно машинописного текста в базовом документе 750, средство синтаксического разбора распознает и классифицирует аннотацию в качестве аннотации «подчеркиванием» и генерирует узел 772 подчеркивания. Кроме того, средство синтаксического разбора сохраняет данные всех штрихов, соответствующие фактическому штриху(ам) чернил аннотации подчеркиванием, в одном или нескольких концевых узлах 774 штриха (в необязательном порядке, данные штрихов могут быть сохранены в качестве свойства узла 772 подчеркивания или другого соответствующего узла).
Дополнительно, для того чтобы сохранять штрих 752 подчеркивания электронных чернил с данным отдельным словом «green», где бы оно не появилось в электронном документе 750 (например, если слово будет перемещено по какой-либо причине), данные сохраняются в структуре 760 данных упомянутого примера, означая то, что узел 772 контекста подчеркивания (например, узел контекста «источника» в данном примере связывания) связан с узлом 768е слова текста для слова «green» (узел «контекста назначения» в данном примере), как изображено на фиг.7В стрелкой 776, и данные сохраняются, означая то, что узел 768е слова текста связан посредством узла 772 подчеркивания, как указано стрелкой 778. Упомянутое связывание «жестко привязывает» узел 772 подчеркивания к узлу 768е слова текста (например, связь типа «жесткого связывания»). Следовательно, если по какой-либо причине данные, хранимые в узле 768е контекста слова текста, означают, что в электронном документе изменилось положение слова «green», то связи 776 и 778 позволяют программе приложения обнаружить, что, если возможно, она должна переместить воспроизводимое представление аннотации подчеркиванием в местоположение и/или пространственное положение узла 768е контекста слова текста в измененном электронном документе. В качестве другого примера, если данные «ограничивающего прямоугольника», данные ширины слова или другие данные, хранимые в узле 768е контекста, означают то, что по какой-либо причине изменился размер или положение слова (например, вследствие изменения размера шрифта, добавления знаков, удаления знаков, изменения в знаках и т.п.), то программа приложения тогда может изменить размер воспроизводимого подчеркивания (например, удлиняя или укорачивая), если возможно, чтобы оно соответствовало новому размеру, ассоциированному со словом текста, представленным узлом 768е контекста. Если применимо, системы и способы в соответствии по меньшей мере с некоторыми примерами изобретения могут разорвать штрих(и) аннотации, чтобы она присутствовала более чем на одной строке, если изменения в базовом документе вызывают присутствие аннотируемого элемента документа на нескольких строках (например, из-за добавляемых слов, знака переноса или т.п.). Также, может быть использована любая подходящая схема связывания между узлами или любые подходящие данные, представляющие связь, без отступления от изобретения.
На фиг.8А и 8В изображен другой пример аннотирования. В данном примере, как изображено на фиг.8А, электронный документ 800 снова включает в себя предложение «Today the sky is green», но в данном случае пользователь перьевой вычислительной системы аннотировал документ 800, используя электронные чернила, зачеркнув слово «green» (зачеркивание показано позицией 802). На фиг.8В изображена примерная иерархическая структура 810 данных, соответствующая упомянутому составному электронному документу 800, когда он полностью синтаксически разобран (так как конкретные узлы контекста для большей части фиг.8В соответствуют узлам контекста, присутствующим на фиг.7В, то эти же позиции, что и присутствующие на фиг.7В, используются на фиг.8В, и опущено дублирующее объяснение). В данном случае средство синтаксического разбора отмечает присутствие данных в электронном документе 800, относящихся к аннотации 802, и оно классифицирует упомянутые данные в качестве рисунка, выполненного посредством электронных чернил (узел 812 чернильного рисунка). Кроме того, основываясь на размещении и положении штриха(ов) рисунка чернил относительно содержимого базового машинописного текста в документе 800 (например, зачеркивание охватывает в горизонтальном направлении слово текста) средство синтаксического разбора распознает и классифицирует аннотацию как аннотацию «зачеркиванием» и генерирует узел 814 зачеркивания. Кроме того, программа синтаксического разбора сохраняет все данные штрихов, соответствующие фактическому штриху(ам) чернил аннотации зачеркиванием, в одном или нескольких концевых узлах 816 штриха (или альтернативно, в качестве свойства в узле 814 зачеркивания или другом соответствующем узле).
Как и в случае с аннотацией подчеркиванием, описанной в отношении фиг.7А и 7В, аннотация зачеркиванием может сохраняться с данным отдельным словом «green», если по какой-либо причине слово будет перемещено. Снова, это может быть выполнено, например, посредством сохранения данных в структуре 810 данных, означая то, что узел 814 контекста зачеркивания (в данном примере узел контекста «источника») связан с узлом 768е слова текста для слова «green» (в данном примере узлом контекста «назначения»), как изображено на фиг.8В стрелкой 818, и посредством сохранения данных в структуре данных, означая то, что узел 768е слова текста связан посредством узла 814 зачеркивания, что указано стрелкой 820. Тип связи в данном примере представляет собой тип связи «с горизонтальным охватом», который жестко привязывает узел 814 зачеркивания к узлу 768е слова текста. Следовательно, если по какой-либо причине данные, хранимые в узле 768е контекста слова текста, означают то, что в электронном документе 800 изменилось положение и/или размер слова «green» (или другого слова (слов), ассоциированного с узлом 768е), то связи 818 и 820 позволяют программе приложения обнаружить, что, если возможно, она должна скорректировать воспроизводимое представление зачеркивания и/или скорректировать его размер (если возможно) к размещению, пространственному положению и/или размеру слова, хранимого в узле 768е контекста в измененном электронном документе. Опять же, может быть использована любая подходящая схема связывания между узлами или любые подходящие данные, представляющие связь, без отступления от изобретения.
На фиг.9А и 9В изображен другой пример типа аннотации и дополнительно показаны ассоциирование или связывание аннотации с более, чем одним словом текста. В данном примере, изображенном на фиг.9А и 9В, электронный документ 900 снова включает в себя предложение «Today the sky is green», но в данном случае пользователь вычислительной системы с перьевым вводом аннотировал документ 900, используя электронные чернила, обведя слова «is green» (обведение или аннотация типа «контейнера» показана позицией 902 на фиг.9А). На фиг.9В изображена примерная иерархическая структура 910 данных, соответствующая упомянутому составному электронному документу 900, когда он полностью синтаксически разобран (так как конкретные узлы контекста для большей части фиг.9В соответствуют узлам контекста, присутствующим на фиг.7В, то эти же позиции, что и присутствующие на фиг.7В, используются на фиг.9В, и опущено дублирующее объяснение). В данном случае средство синтаксического разбора снова отмечает присутствие данных в электронном документе 900, относящихся к аннотации 902, и оно классифицирует приведенные данные в качестве рисунка, выполненного посредством электронных чернил (узел 912 чернильного рисунка). Кроме того, основываясь на местоположении и позиции штриха(ов) чернильного рисунка относительно содержимого базового машинописного текста в документе 900, средство синтаксического разбора распознает и классифицирует аннотацию как аннотацию-«контейнер» и генерирует узел 914 контейнера чернил в структуре 910 данных. Кроме того, средство синтаксического разбора сохраняет все данные штрихов, соответствующие фактическому штриху(ам) чернил аннотации-контейнера, в одном или нескольких концевых узлах 916 штриха (или альтернативно, в качестве свойства в узле контейнера чернил или другом соответствующем узле).
Как и в случае с аннотациями подчеркиванием и зачеркиванием, описанными в отношении фиг.7А-8В, аннотация-контейнер может сохраняться со словами «is green», если по какой-либо причине упомянутые слова будут перемещены. Опять же, это может быть выполнено, например, сохранением данных в структуре 910 данных, означая то, что узел 914 контекста контейнера чернил (в данном примере узел контекста «источника») связан с каждым из узлов 768d и 768е слова текста для слов «is green» (в данном примере узлами контекста «назначения»), как изображено на фиг.9В стрелками 918а и 918b. Кроме того, данные могут быть сохранены в структуре 910 данных, означая то, что узлы 768d и 768е слова текста связаны посредством узла 914 контейнера, что указано стрелками 920а и 920b на фиг.9В. Данная связь представляет собой связь типа «контейнера». Следовательно, если по какой-либо причине данные, хранимые в узлах 768d и 768е контекста слова текста, означают, что в электронном документе 900 изменилось положение и/или размер слов «is green» (или другого слова (слов), ассоциированного с данными узлами контекста), то связи 918а, 918b, 920а и 920b позволяют программе приложения обнаружить, что, если возможно, она должна скорректировать воспроизводимое представление аннотации-контейнера и/или ее размер к размещению, пространственному положению и/или размеру слов, хранимых в узлах 768d и 768е контекста в измененном электронном документе. Кроме того, если пользователь добавляет слова между словами «is» и «green», или если слова или знаки удалены или изменены любым образом, то программа приложения может изменить размер и/или размещение аннотации-контейнера для согласования с упомянутыми изменениями. Опять же, может быть сохранена другая схема связи или данные, означающие связь, без отступления от изобретения.
На фиг.10А и 10В изображен другой тип широко используемой аннотации, а именно, аннотации типа «комментарий на полях». В данном примере, как изображено на фиг.10А, пользователь аннотировал электронный документ 1000, содержащий предложение «Today the sky is green», комментарием 1002 на полях, выполненным посредством электронных чернил, утверждающим: «it's not green!» (оно не зеленое). В данном случае необходимо заметить, что, как показано на фиг.10В, была изменена структура 1010 данных, ассоциированная с машинописным текстом, так как упомянутый текст присутствует на двух строках в электронном документе 1000 (а не на одной строке, показанной на фиг.7А, 8А и 9А). Следовательно, структура 1010 данных имеет два узла 1012 и 1014 строки, и первый узел 1012 строки включает в себя узлы 768а и 768b слова текста (ассоциированные со словами «Today» и «the»), и второй узел 1014 строки включает в себя узлы 768с, 768d и 768е слова текста (ассоциированные со словами «sky», «is» и «green»).
Если составной электронный документ 1000 полностью синтаксически разобран, то средство синтаксического разбора распознает аннотацию 1002 как содержащую текст, выполненный посредством электронных чернил, и она классифицирует данную аннотацию (например, вследствие ее размещения на полях документа 1000) как аннотацию типа «комментарий на полях». Следовательно, программа синтаксического разбора генерирует соответствующий узел 1016 контекста для комментария на полях. Так как данный комментарий 1002 на полях содержит только текст электронных чернил, то программа синтаксического разбора далее генерирует узел 1018 абзаца, два узла 1020 и 1022 строки и соответствующие узлы 1024, 1026, 1028 чернильного слова и узлы 1030, 1032 и 1034 штриха, ассоциированные с иерархической структурой электронных чернил (как ранее отмечено, в необязательном порядке и в качестве альтернативы, данные штриха чернил могут сохраняться в качестве свойств узла(ов) чернильного слова, и/или узлы строки могут быть исключены из структуры 1010 данных).
Другое отношение связывания изображено в примере на фиг.10А и 10В. Конкретно, в данном примере, основываясь на размещении и ориентации комментария 1002 на полях относительно полей страницы и содержимого базового документа, средство синтаксического разбора сохраняет данные в структуре 1010 данных, означая то, что узел 1018 абзаца, ассоциированный с комментарием 1002 на полях (узел контекста «источника» в данном примере), связан с узлом 764 абзаца, ассоциированным с машинописным текстом (узлом контекста «назначения» в данном примере), как изображено на фиг.10В стрелкой 1036. Кроме того, средство синтаксического разбора сохраняет данные в структуре 1010 данных, означая то, что узел 764 абзаца, ассоциированный с машинописным текстом, связан посредством узла 1018 абзаца комментария 1002 на полях, как изображено стрелкой 1038. Вышеприведенное представляет собой схему связи типа “жесткого связывания”, при котором абзац чернил жестко привязывается к абзацу текста. Таким образом, куда бы ни перемещался абзац машинописного текста в электронном документе 1000, связи 1036 и 1038 позволяют программе приложения обнаруживать, что, если возможно, она должна переместить комментарий 1002 на полях, чтобы он оставался на полях рядом со связанным машинописным абзацем, даже если, в необязательном порядке, дополнительные строки и/или слова будут добавлены к абзацу, и/или если строки и/или слова будут удалены из абзаца, и/или если другие изменения будут выполнены в абзаце или электронном документе 1000. Конечно, могут быть сохранены другие схемы связывания или данные, ассоциированные со связями, без отступления от изобретения. Например, узел 1016 комментария на полях может быть связан с одним или несколькими узлами отдельных слов текста машинописного абзаца, таким как первый узел 768а слова текста.
На фиг.11А и 11В изображен в некоторой степени более сложный пример аннотации, распознаваемой системами и способами в соответствии по меньшей мере с некоторыми примерами настоящего изобретения. В изображенном примере электронный документ 1100 снова включает в себя фразу «Today the sky is green», но в данном случае пользователь аннотировал электронный документ 1100, используя комбинацию различных типов аннотации. Конкретно, пользователь нарисовал аннотацию 1102 типа контейнера, обводящую слово «green», аннотацию 1104 типа комментария на полях, содержащую слово электронных чернил «Blue!» (синее!), и аннотацию 1106 типа соединителя (например, стрелки в данном примере), направленную от аннотации 1102 типа контейнера на аннотацию 1104 типа комментария на полях.
Вследствие относительного положения и пространственной ориентации различных типов аннотации относительно базового документа, текста машинописного документа и полей документа, система синтаксического разбора в соответствии по меньшей мере с некоторыми примерами настоящего изобретения распознает различные типы аннотаций, их содержимое и их взаимосвязь друг с другом и с машинописным текстом электронного документа, как в общих чертах описано выше. На фиг.11В показана примерная иерархическая структура 1110 данных для электронного документа 1100, сгенерированная средством синтаксического разбора. Так как иерархическая структура для машинописного текста аналогична структуре, описанной выше на фиг.7В, одинаковые позиции используются для упомянутой структуры на фиг.11В, и опускается подробное объяснение. Также, как изображено на фиг.11В, цепочка 1112 узлов для аннотации 1102 типа контейнера чернил аналогична цепочке, изображенной на фиг.9В, и цепочка 1114 узлов для аннотации 1104 типа комментария на полях аналогична цепочке, изображенной на фиг.10В. Следовательно, не включается подробное описание приведенных цепочек узлов.
Для того, чтобы сохранить пространственное положение аннотаций с соответствующей частью и пространственным размещением базового текста, различные связи между узлами аннотаций и с соответствующим узлом текста обеспечиваются программой синтаксического разбора и сохраняются в структуре 1110 данных. В изображенном примере узел 1116 контейнера чернил (в данном случае узел контекста «источника») связан с узлом 768е слова текста для слова, которое он содержит (т.е. узлом «назначения», соответствующим слову «green» в данном примере), как изображено на фиг.11В стрелкой 1118. Аналогично, данные сохраняются в структуре 1110 данных, означая то, что узел 768е слова текста связан посредством узла 1116 контейнера чернил, как указано на фиг.11В стрелкой 1120. Вышеприведенное представляет собой схему связывания типа «контейнера».
Как отмечено выше, средство синтаксического разбора в соответствии с данным примером изобретения дополнительно распознает, что электронный документ 1100 включает в себя чернильный рисунок 1106, соответствующий чернильному соединителю (т.е. стрелке между аннотацией-контейнером 1102 и аннотацией 1104 типа комментария на полях в данном примере). Данная аннотация-соединитель 1106 сохраняется в структуре 1110 данных в качестве чернильного рисунка (представляемого узлом 1122 чернильного рисунка), который содержит узел, указывающий тип аннотации (узел 1124 чернильного соединителя в данном примере), который дополнительно включает в себя данные, означающие штрих или штрихи, составляющие соединитель (например, в узле(ах) 1126 штриха или в свойстве, ассоциированном с узлом 1124 чернильного соединителя (или другим подходящим узлом)). Кроме того, информация сохраняется в структуре 1110 данных, означая то, что узел 1124 чернильного соединителя (узел «назначения» в данном примере) указывает от узла 1116 контейнера чернил (узла «источника» в данном примере). Данная связь (связь типа «указания от») представлена на фиг.11В стрелкой 1128. Кроме того, структура 1110 данных дополнительно включает в себя данные, означающие то, что узел 1124 чернильного соединителя (узел контекста «источника» в данном примере) связан с узлом 1132 чернильного слова (узлом контекста «назначения» в данном примере). Упомянутая связь (связь типа «указания на») представлена на фиг.11В стрелкой 1134. Альтернативно, узел 1124 чернильного соединителя может быть связан с любым одним узлом из узла чернильной строки, узла чернильного абзаца или узла комментария на полях из состава цепочки 1114 узлов без отступления от изобретения. С конкретными связями, описанными выше, структура 1110 данных означает то, что чернильный соединитель 1106 указывает от рисунка 1102 обведением и указывает на чернильное слово, как изображено на фиг.11А. Упомянутые различные связи позволяют программе приложения обнаружить ассоциацию между базовым документом и различными компонентами аннотации. Затем, если возможно, программа приложения может переместить элементы аннотации так, чтобы они надлежащим образом соответствовали перемещениям в базовом документе. Может быть использована любая подходящая схема связывания или данные, ассоциированные со связью, без отступления от изобретения.
На фиг.12А и 12В изображен другой пример обычно используемого признака аннотации. В данном примере, как изображено на фиг.12А, электронный документ 1200 снова включает в себя предложение «Today the sky is green», но в данном случае пользователь вычислительной системы с перьевым вводом аннотировал документ 1200, используя электронные чернила для размещения звезды или звездочки около первого слова предложения (аннотация показана позицией 1202). На фиг.12В изображена примерная иерархическая структура 1210 данных, соответствующая упомянутому составному электронному документу 1200, когда он полностью синтаксически разобран (так как узлы контекста для большей части фиг.12В соответствуют узлам контекста, присутствующим на фиг.7В, то позиции, одинаковые с позициями, которые присутствуют на фиг.7В, используются на фиг.12В, и исключено дублирующее объяснение). В данном случае средство синтаксического разбора отмечает присутствие данных электронных чернил, относящихся к аннотации, и она классифицирует упомянутые данные как чернильный рисунок (узел 1212 рисунка чернил). Кроме того, основываясь на форме штриха чернил, а также размещении и положении штриха(ов) чернил аннотации 1202 относительно содержимого базового документа 1200 (например, вдоль строки машинописного текста), программа синтаксического разбора распознает аннотацию в качестве «звездочки», «маркера» или аннотации типа “жесткого связывания” и генерирует узел 1214 звездочки. Кроме того, программа синтаксического разбора сохраняет все данные штрихов, соответствующие фактическому штриху(ам) чернил звездочки в одном или нескольких концевых узлах 1216 штриха или в свойстве узла звездочки (или некоторого другого узла).
В данном примере аннотация 1202 типа звездочки может сохраняться со всей строкой машинописного текста, где бы ни появилась упомянутая строка в электронном документе 1200, если по какой-либо причине машинописный текст будет перемещен. Это может быть выполнено, например, сохранением данных в структуре 1210 данных, что означает то, что узел 1214 контекста звездочки (узел контекста «источника» в данном примере) связан с узлом 766 строки текста (узлом контекста «назначения» в данном примере), как изображено на фиг.12В стрелкой 1218, и сохранением данных, означая то, что узел 766 строки текста связан посредством узла 1214 звездочки, как указано стрелкой 1220. Следовательно, если по какой-либо причине данные, хранимые в узле 766 контекста строки текста, означают то, что в электронном документе 1200 изменилось положение или размещение строки, то связи 1218 и 1220 позволяют программе приложения обнаружить, что, если возможно, она должна скорректировать воспроизводимое представление звездочки к размещению и/или пространственному положению, соответствующему воспроизведению данных, ассоциированных с узлом 766 контекста, в измененном электронном документе. Альтернативно, если требуется, средство синтаксического разбора может связать узел 1214 звездочки (или любой подходящий узел, ассоциированный с аннотацией звездочкой) с узлом 764 абзаца или одним из узлов отдельных слов (например, узлом 768а слова) без отступления от изобретения. Также, если требуется, узел 1212 чернильного рисунка может быть узлом источника, привязанным к узлу 766 строки (или другому подходящему узлу, соответствующему машинописному тексту в данном примере). Может быть использована любая подходящая схема связывания или данные, представляющие связь, без отступления от изобретения.
Связанная аннотация типа «блок-схемы» изображена на фиг.13А и 13В. В данном примере электронный документ 1300 включает в себя блок-схему, которая, в необязательном порядке, может быть включена в качестве части аннотации в полном большем электронном документе. Как изображено на фиг.13А, аннотация или блок-схема включает в себя первый элемент 1302 чернил (буква «А» в данном примере), обведенный или охватываемый первой аннотацией-контейнером 1304, и второй элемент 1306 чернил, обведенный или охватываемый второй аннотацией-контейнером 1308. Кроме того, аннотация-соединитель 1310 (стрелка в данном примере) проходит от первой аннотации-контейнера 1304 до второй аннотации-контейнера 1308. Необходимо понять, однако, что взаимосвязи между элементами документа могут быть представлены альтернативным образом, отличным от связей. Например, упомянутые взаимосвязи могут быть представлены в структуре самого дерева данных при помощи, например, использования узлов контейнера, которые содержат ассоциированные элементы документа.
На фиг.13В изображена примерная структура 1320 данных, которая может быть ассоциирована с аннотацией типа блок-схемы электронного документа 1300 на фиг.13А, если произведен ее полный синтаксический разбор. В упомянутой примерной структуре 1320 данных корневой узел 1322, который может соответствовать всему электронному документу 1300 или его некоторой части, обеспечен в качестве родительского узла для узлов в аннотации типа блок-схемы. Первым узлом контекста, относящимся к конкретным структурам аннотации, является узел 1324 рисунка чернил, соответствующий контейнеру 1304 чернил. Узел 1326 контейнера чернил предусмотрен в качестве дочернего узла для узла 1324 рисунка чернил, и конкретный штрих(и), ассоциированный с аннотацией-контейнером 1304 чернил, сохраняется в концевом узле(ах) 1328 или в качестве свойств для узла 1326 контейнера чернил (или другого узла).
Как отмечено выше в отношении фиг.13А, аннотация дополнительно включает в себя текст, выполненный посредством электронных чернил, соответствующий букве «А» 1302. Подобно другому тексту, выполненному посредством электронных чернил, описанному выше, электронные чернила, ассоциированные с упомянутым текстом, выполненным посредством чернил, сохраняются в иерархической структуре 1320 данных в качестве узла 1330 абзаца, который содержит узел 1332 строки, который содержит узел 1334 чернильного слова, который, в необязательном порядке, содержит один или несколько концевых узлов 1336, соответствующих отдельным штрихам в аннотации текста, выполненного посредством чернил, или свойству, включающему данные штриха. Информация, хранимая в структуре 1320 данных, показывает, что узел 1326 контейнера чернил аннотации-контейнера 1304 (узел «источника») связан с узлом 1330 абзаца буквы «А» (узлом контекста «назначения»), как изображено на фиг.13В стрелкой 1338. Альтернативно, если требуется, узел 1334 чернильного слова или узел 1332 строки может служить в качестве узла назначения. Кроме того, информация, хранимая в структуре 1320 данных, также показывает, что узел 1330 абзаца связан посредством узла 1326 контейнера чернил, как обозначено на фиг.13В стрелкой 1340. Так как структура данных для контейнера 1308 чернил и буква «В» 1306 аннотации в данном примере совместно используют одну и ту же общую структуру, что и для контейнера 1304 чернил и буквы «А» 1302, включая эту же общую структуру связывания, то различные узлы в структуре 1320 данных для буквы «В» 1306 и ассоциированный с ней контейнер 1308 совместно используют эти же позиции, что и ассоциированные с буквой «А» и ее контейнером, но буква «b» повторяет ссылочные позиции для контейнера 1308 чернил и слова 1306 чернил на фиг.13В. Конечно, различные иерархические схемы и структуры связывания или данные связывания могут отличаться от тех, которые конкретно описаны выше, без отступления от изобретения.
Аннотация дополнительно включает в себя аннотацию-соединитель 1310, представленную в структуре 1320 данных посредством узла 1342 чернильного рисунка. Как описано выше в связи с фиг.11В, структура данных для рисунка чернил, представляющего аннотацию-контейнер чернил, дополнительно может включать в себя узел 1344 чернильного соединителя, который дополнительно может включать в себя одно или несколько свойств или концевой узел(ы) 1346, который включает в себя данные, ассоциированные с конкретным штрихом(ами), который составляет соединитель 1310. Для завершения структуры данных аннотации упомянутого примера данные, ассоциированные с аннотацией-контейнером 1310 чернил (узлом источника), связаны с данными, ассоциированными с двумя аннотациями-контейнерами 1304 и 1308 (узлами назначения). Конкретно, как показано в примере на фиг.13В, информация хранится в структуре 1320 данных, означая то, что узел 1326 контейнера чернил связан с узлом 1344 соединителя чернил (представленным стрелкой 1348) в качестве аннотации типа «указание от». Кроме того, информация хранится в структуре 1320 данных, означая то, что узел 1344 соединителя чернил связан с узлом 1326b контейнера чернил (представленным стрелкой 1352) в качестве аннотации типа «указание на». Таким образом хранимые данные, относящиеся к связям, означают то, что соединитель 1310 указывает от контейнера 1304 обведения на контейнер 1308 обведения, как изображено на фиг.13А. Таким образом, существование различных связей позволяет другим частям аннотации отслеживать перемещение одной части аннотации в электронном документе 1300, тем самым сохраняя аннотацию целой, даже если электронный документ 1300 некоторым образом изменяется. Конечно, эта вся структура также может быть связана с некоторым элементом базового документа, как описано выше, без отступления от изобретения.
Аналогично, аннотация может включать в себя два охватывателя, соединенные посредством соединителя с письменным комментарием, таким как, например, «поменять их!». Если одна часть аннотации перемещается, то может потребоваться независимое перемещение другой части аннотации, например, когда слова вводятся между двумя охватывателями. Связи между узлами контекста, представляющими аннотации электронных чернил, и узлами, представляющими нечернильное содержимое, могут быть использованы программным приложением для перемещения частей аннотаций и затем обратного их связывания вместе, когда будет завершена операция размещения.
На фиг.14А и 14В изображен другой пример электронного документа 1400, имеющего аннотацию или структуру чернил типа блок-схемы. В данном примере аннотация, выполненная посредством электронных чернил, для буквы «А» 1402 соединена с аннотациями, выполненными посредством электронных чернил, для букв «В» 1404 и «С» 1406, причем соединители 1408 и 1410, выполненных посредством электронных чернил, расположены между буквами «А» и «В», и «А» и «С» соответственно.
На фиг.14В изображена примерная структура 1420 данных для электронного документа 1400 после синтаксического разбора. Данные, относящиеся ко всему электронному документу или некоторой его части, могут быть сохранены в родительском корневом узле 1422. Данные, соответствующие словам «А», «В» и «С» электронных чернил, имеют одинаковую структуру узла (1424а, 1424b, 1424с) абзаца, узла (1426а, 1426b, 1426с) строки, узла (1428а, 1428b, 1428с) чернильного слова и узла(ов) (1430а, 1430b, 1430с) штриха, что и используемая на нескольких фигурах, описанных выше. Опускается повторное описание упомянутых узлов. Аналогично, чернильные соединители имеют структуру узла (1432а, 1432b) чернильного рисунка, узла (1434а, 1434b) контейнера чернил и узла(ов) (1436а, 1436b) штриха, используемую на вышеописанных фиг.11В и 13В, так что опускается повторное описание. Конечно, могут быть использованы разновидности в упомянутых конкретных структурах данных, включая возможные описанные выше разновидности, без отступления от изобретения.
Для того чтобы завершить структуру данных аннотации упомянутого примера, данные, ассоциированные с аннотацией-соединителем 1408 чернил, связаны с данными, ассоциированными с двумя аннотациями 1402 и 1404 в виде чернильных слов, которые она соединяет, и данные, ассоциированные с аннотацией-соединителем 1410 чернил, связаны с данными, ассоциированными с двумя аннотациями 1402 и 1406 в виде чернильных слов, которые она соединяет. Конкретно, как показано в примере на фиг.14В, информация хранится в структуре 1420 данных, означая то, что узел 1432а чернильного рисунка (узел «источника») «указывает на» узлы 1428а и 1428b чернильного слова (представленные стрелками 1438 и 1440, соответственно). Аналогично, информация хранится в структуре 1420 данных, означая то, что узел 1432b чернильного рисунка (узел «источника») «указывает на» узлы 1428а и 1428с чернильного слова (представленные стрелками 1442 и 1444, соответственно). Узлы 1428а, 1428b и 1428с чернильного слова служат в качестве узлов «назначения». Благодаря различным связям, перемещение одной части аннотации в электронном документе 1400 может отслеживаться другими частями аннотации, тем самым сохраняя аннотацию целой или связанной, даже если электронный документ 1400 некоторым образом будет изменен. Также, данная аннотация может быть связана с одним или несколькими другими элементами в электронном документе, такими как машинописный текст, рисунки, изображения и т.п., без отступления от изобретения.
На фиг.15А-15С изображены примеры электронного документа 1500 и примерные структуры данных, которые включают в себя, выполненную посредством электронных чернил аннотацию в виде таблицы, имеющей множество строк и столбцов. Конкретно, как изображено в примере на фиг.15А, электронный документ 1500 включает в себя таблицу 1502 с двумя строками и двумя столбцами (образуя в итоге четыре ячейки), и каждая ячейка таблицы составлена из границ, выполненных посредством электронных чернил, и содержит входные данные в виде текста, выполненного посредством электронных чернил.
На фиг.15В показана примерная структура 1510 данных для таблицы 1502, выполненной посредством электронных чернил, изображенной на фиг.15А, после полного синтаксического разбора. В данном примере структура 1510 данных включает в себя корневой узел 1512, который может соответствовать всему электронному документу 1500 или некоторой его части. Под корневым узлом 1512 в узле 1514 таблицы хранятся соответствующие данные, относящиеся к таблице. Они могут включать в себя, например, данные, определяющие размер таблицы, положение таблицы, количество строк таблицы, количество столбцов, размеры ограничивающего прямоугольника и т.п. Под узлом 1514 таблицы обеспечены узлы отдельных строк таблицы для каждой строки таблицы (в данном примере, как изображено на фиг.15В, обеспечены два узла 1516 и 1518 строки таблицы). Каждый узел строки таблицы приведенной примерной структуры данных дополнительно включает в себя один или несколько узлов ячейки (в изображенном примере узел 1516 строки таблицы включает два узла 1520 и 1522 ячейки, тогда как узел 1518 строки таблицы включает в себя два узла 1524 и 1526 ячейки). Так как каждая ячейка данного примера содержит данные текста, выполненного посредством электронных чернил, то остальная часть упомянутой примерной иерархической структуры 1510 данных имеет обычный узел абзаца, узел строки, узел чернильного слова и узел(ы) штриха, описанные подробно выше. Конечно, ячейки таблицы могут содержать данные одного или нескольких других типов в дополнение к и/или вместо данных электронных чернил, включая, например, данные машинописного текста и/или любые из различных типов данных, описанных подробно выше в отношении фиг.6I, без отступления от настоящего изобретения. В качестве другой альтернативы, вместо узлов 1516 и 1518 строки таблицы структура данных может включать в себя узлы столбца, которые тогда могут включать в себя узлы ячейки, узлы абзаца и т.д., как показано на фиг.15В. Штрихи чернил, которые составляют фактическую таблицу, могут быть сохранены например, в качестве части узла 1514 таблицы (например, в качестве свойств, ассоциированных с данным узлом), в качестве узла чернильного рисунка, который зависит от узла 1514 таблицы (с ассоциированными штрихами, сохраненными под ним) и/или в любом другом подходящем местоположении в структуре 1510 данных.
На фиг.15С показана альтернативная примерная структура 1530 данных для электронного документа 1500, включающего таблицу 1502. В данном примере корневой узел 1512; узел 1514 таблицы; узлы 1516 и 1518 строки таблицы и узлы 1520, 1522, 1524 и 1526 ячейки являются теми же самыми, что и изображенные на фиг.15В. Однако, вместо того чтобы включать в себя данные текста, выполненного посредством электронных чернил, в качестве дочерних узлов под различными узлами 1520, 1522, 1524 и 1526 ячейки, узлы 1528а, 1528b, 1528с, 1528d абзаца данных текста, выполненного посредством электронных чернил, (или любой другой подходящей или требуемой структуры данных) связаны с их соответствующими узлами 1520, 1522, 1524 и 1526 ячейки, как показано на фиг.15С стрелками 1530а, 1530b, 1530с и 1530d, соответственно. Узлы ячейки в данном примере могут служить в качестве узлов «источника» типа контейнера для чернильных слов, содержащихся в них, и узлы абзаца, строки или чернильные слова служат в качестве узлов контекста «назначения». Благодаря различным связям, перемещение одной части аннотации-таблицы в электронном документе 1500 может отслеживаться другими частями аннотации, тем самым сохраняя аннотацию-таблицу целой или связанной, даже если электронный документ 1500 некоторым образом будет изменен. Таблица также может быть связана с некоторыми другими присутствующими узлами, основываясь на базовом электронном документе. Опять же, в качестве альтернативы, узлы 1516 и 1518 строки таблицы могут быть заменены узлами столбца, которые содержат различные узлы ячейки, без отступления от изобретения. Также, штрихи чернил, которые составляют фактическую таблицу, могут храниться в любом местоположении без отступления от изобретения, например, в качестве части узла 1514 таблицы (например, в качестве свойств, ассоциированных с данным узлом), в качестве узла чернильного рисунка, который зависит от узла 1514 таблицы (с ассоциированными штрихами, хранимыми под ним) и/или в любом другом подходящем местоположении в структуре 1510 данных.
Конечно, различные фигуры, относящиеся к различным примерным типам аннотации, описанным выше, описывают просто примеры возможных типов аннотации, использование аннотаций и информацию, которая может быть включена в аннотации. Для специалиста в данной области очевидно, что могут быть выполнены многочисленные модификации и изменения без отступления от изобретения. Например, аннотации могут содержать многочисленные различные типы данных (такие как выполненные посредством электронных чернил текст, рисунки, машинописный текст и изображения и т.д.) во многих различных комбинациях и перестановках без отступления от изобретения.
Кроме того, различные схемы связывания описаны в связи с различными описанными выше структурами данных. Такие схемы или методики связывания являются просто примерами того, как различные узлы данных могут быть связаны вместе. Любая подходящая схема связывания или данные, ассоциированные со связью, могут быть сохранены без отступления от изобретения. Например, возможно представление каждого узла отдельным идентификатором (таким как «глобальный уникальный идентификатор», или GUID) и представление связей с использованием двух (или более) GUID. В качестве другой альтернативы, единственная связь может быть использована для связывания узлов, а не двойная схема связывания, описанная в отношении некоторых вышеописанных примеров. В качестве другой возможной альтернативы, если необходимо или если требуется, узел может быть связан с самим собой (самосвязывание, например, когда узел источника и узел назначения представляют собой один и тот же узел). Для специалиста в данной области очевидно, что может быть использован любой подходящий способ связывания или ассоциирования различных наборов данных друг с другом без отступления от изобретения.
Анализ чернил
Ниже описываются различные примерные методики анализа электронных чернил в электронном документе в соответствии с примерами изобретения. В частности, на фиг.16А-16Е изображена блок-схема, показывающая шаги анализа документа в соответствии с различными примерами изобретения. На фиг.17-26 изображены взаимосвязи между различными компонентами, используемыми во время процесса анализа.
На фиг.17 изображено программное приложение 1701. Программное приложение 1701 поддерживает документ 1703, который может включать в себя как данные 1705 электронных чернил, так и нечернильные данные 1707, такие как машинописные знаки или изображения. Как подробно описано выше, свойства как данных 1705 электронных чернил, так и нечернильных данных 1707 могут быть описаны иерархической структурой данных, такой как дерево. Для того чтобы начать анализ электронных чернил, на шаге 1601 программное приложение 1701 создает такую структуру данных, идентифицированную как объект 1709 контекста анализа на фиг.17.
На фиг.18 изображено примерное дерево 1801 типа, который может быть включен в объект 1709 контекста анализа. Дерево 1801 включает в себя корневой узел 1803 и узел 1805 абзаца. Узел 1805 абзаца соответствует абзацу текста электронных чернил, который, например, возможно, ранее был идентифицирован в процессе более раннего анализа. Узел 1805 абзаца соединен с двумя узлами 1807 и 1809 строки, которые представляют две строки в абзаце текста электронных чернил. Узел 1807 строки, в свою очередь, ассоциирован с двумя узлами 1811 и 1813 слова. Каждый узел 1811 и 1813 слова соответствует слову в строке текста, выполненного посредством электронных чернил и представленного узлом 1807 строки. Узел 1811 слова содержит данные 1815 штриха чернил и данные 1817 штриха чернил. Таким образом, данные 1815 и 1817 штриха соответствуют штрихам текста, выполненного посредством электронных чернил, составляющим слово, представленное узлом 1811 слова. Аналогично, узел 1813 слова содержит данные 1819 штриха чернил и данные 1821 штриха чернил, которые соответствуют штрихам текста, выполненного посредством электронных чернил, составляющим слово, представленное узлом 1813 слова. Дерево 1801 также включает в себя данные 1823-1827 штриха, которые ассоциированы только с корневым узлом 1803. Упомянутые данные 1823-1827 чернил представляют новые штрихи чернил, которые не были классифицированы или ассоциированы с другим штрихом чернил или другим элементом документа.
Таким образом, вместо хранения штрихов в узлах отдельных штрихов различные узлы могут иметь ассоциированное свойство «штрихов», которое хранит данные, соответствующие штрихам, ассоциированным с узлом. Например: (а) узлы неклассифицированного контекста могут содержать одно или несколько свойств «штрихов», имеющих один или несколько штрихов, которые необходимо проанализировать; (b) узлы чернильного слова могут содержать одно или несколько свойств «штрихов», содержащих один или несколько штрихов, которые составляют чернильное слово; (с) узлы рисунка могут содержать одно или несколько свойств «штрихов», содержащих один или несколько штрихов, которые составляют рисунок и (d) узлы маркера могут содержать одно или несколько свойств «штрихов», содержащих один или несколько штрихов, которые составляют маркер в элементе списка. Конечно, в соответствии с альтернативными вариантами реализации изобретения могут быть использованы узлы отдельных штрихов в дереве данных для представления отдельных штрихов электронных чернил вместо ассоциирования штрихов чернил, например, с узлом слова или узлом рисунка.
Хотя дерево 1801, показанное на фиг.18, включает в себя штрихи чернил, которые уже организованы в слова, строки и абзацы, необходимо понять, что дерево 1801 может содержать только новые штрихи чернил, которые не были классифицированы или ассоциированы с другим штрихом чернил или элементом документа. Например, когда пользователь первоначально вводит электронные чернила в документ 1705, то упомянутые первоначальные штрихи чернил не проанализированы. Также необходимо понять, что дерево 1801 является только показательным, и оно упрощено для облегчения понимания различных аспектов изобретения. Например, узел строки обычно ассоциируется со множеством узлов слова, и каждый узел слова может содержать данные штриха для нескольких штрихов чернил. Также необходимо отметить, что, хотя дерево 1801 включает в себя только относящиеся к чернилам узлы, объект 1709 контекста анализа может включать в себя узлы, представляющие нечернильные элементы документа, такие как изображения и машинописный текст, как подробно описано выше.
Возвращаясь теперь к фиг.17, в соответствии с некоторыми примерами изобретения программное приложение 1701 создает и поддерживает свой собственный объект 1709 контекста анализа. Для упомянутых программных приложений 1701 программное приложение 1701 может просто обеспечить ссылку на объект 1709 анализа. Для упомянутых программных приложений 1701, однако, приложение 1701 должно включать в себя механизмы, необходимые для создания, заполнения и поддержания объекта анализа. Некоторые разработчики программного обеспечения, однако, не хотят брать на себя труд создавать такие механизмы в приложении 1701.
Следовательно, в соответствии с другими примерами изобретения программное приложение 1701 может реализовать другой объект для создания объекта 1709 контекста анализа. Например, программное приложение 1701 может использовать инструментальное средство анализа чернил или другой объект для создания и/или поддержания объекта 1709 контекста анализа. Например, программное приложение 1701 может идентифицировать или предоставить данные непроанализированных чернил инструментальному средству анализа чернил. В зависимости от инструкций от программного приложения 1701 инструментальное средство анализа чернил затем может создать объект 1709 контекста анализа, представляющий весь документ 1703, или, альтернативно, только конкретную область (или области) документа, которая содержит непроанализированные чернила, идентифицированные программным приложением 1701. В соответствии с некоторыми программными приложениями 1701, программное приложение 1701 может после этого поддерживать и обновлять объект 1709 контекста анализа либо само, либо используя службы, обеспеченные инструментальным средством анализа чернил или другим объектом. В соответствии с другими программными приложениями 1701, программное приложение 1701 может не поддерживать объект 1709 документа анализа, но вместо этого инструментальное средство анализа чернил или другой объект создает новый объект 1709 документа анализа, когда необходимо.
Обычно объект 1709 контекста анализа содержит информацию об элементах документа для всего документа 1703. Также необходимо заметить, однако, что в соответствии с некоторыми примерами изобретения объект 1709 контекста анализа может содержать информацию для элементов документа только в части документа 1703. Т.е. объект 1709 контекста анализа может представлять только элементы документа в пространственной зоне документа, содержащей новые или «невысохшие» чернила или другие данные. Если все элементы документа в зоне документа, включающей электронные чернила, были уже проанализированы, то тогда ранее проанализированные элементы документа не могут быть включены в объект 1709 контекста анализа. В качестве другой альтернативы, программа приложения может поддерживать отдельный объект 1709 контекста анализа для каждой страницы или другого поднабора данных, относящихся ко всему электронному документу 1703.
Если программное приложение 1701 создало объект 1709 контекста анализа, то на шаге 1603 инструментальное средство 1901 анализа чернил копирует по меньшей мере часть объекта 1709 контекста анализа, как показано на фиг.19. Более конкретно, если объект 1709 контекста анализа не ограничивается областями, содержащими новые чернила и/или другие данные, как описано выше, то тогда программное приложение 1701 обозначает области документа 1703, которые содержат новые чернила и/или другие данные, которые должны быть проанализированы. Программное приложение 1701 затем вызывает инструментальное средство 1901 анализа чернил для копирования части объекта 1709 контекста анализа, соответствующей обозначенной области документа 1703. (Конечно, если объект 1709 контекста анализа уже ограничен описанием областей, которые содержат новые чернила, то тогда инструментальное средство 1901 анализа чернил может копировать весь объект 1709 контекста анализа.)
Хотя программе 1701 приложения известно, какие чернила ранее не были проанализированы, ей может быть не известно, какая часть(и) упомянутого электронного документа 1703 (например, ранее проанализированные чернила, базовые данные в структуре документа и т.д.) оказывает влияние на новые чернила (и, следовательно, какая часть(и) подлежит представлению инструментальному средству 1901 анализа чернил). Поэтому, по меньшей мере в некоторых примерах изобретения программа 1701 приложения делает доступными большие разделы электронного документа 1703 для инструментального средства 1901 анализа чернил при помощи объекта 1709 контекста анализа. Программа 1701 приложения оставляет инструментального средства 1901 анализа чернил в рамках ответственности определение информации, фактически необходимой от программы 1701 приложения при помощи объекта 1709 контекста анализа.
В ответ на вызов для анализа новых данных инструментальное средство 1901 анализа чернил выполняет различные обратные вызовы объекта 1709 контекста анализа, если необходимо, для получения информации от объекта 1709 контекста анализа, необходимой для анализа новых чернил и/или других данных в области, обозначенной программным приложением 1701. Например, в дополнение к новым чернилам и/или другим данным инструментальное средство 1901 анализа чернил может запросить у объекта 1709 контекста анализа информацию, касающуюся чернил и/или других данных в обозначенной области, которые уже были проанализированы, или информацию, касающуюся нечернильных элементов документа в обозначенной области. «Обозначенная область» может, по меньшей мере в некоторых примерах изобретения, соответствовать данным в пространственной зоне и/или около зоны, содержащей новые чернила или другие данные, подлежащие анализу.
Как ранее проанализированные чернила, так и нечернильные элементы документа, в частности, те элементы, которые расположены около вновь введенных данных, подлежащих анализу, могут предоставить контекст, который улучшит анализ непроанализированных чернил иди других данных. Так как инструментальное средство 1901 анализа чернил получает требуемую информацию от объекта 1709 контекста анализа, то инструментальное средство 1901 анализа чернил создает независимый от документа объект 1903 контекста анализа с помощью полученной информации. Таким образом, независимый от документа объект 1903 контекста анализа содержит по меньшей мере поднабор информации, содержащейся в объекте 1709 контекста анализа, но он не зависит от документа 1703. Использование данного приема «обратного вызова» в основанном на запросе методе пространственной абстракции, описанном выше, делает возможным для инструментального средства 1901 анализа чернил эффективное получение и анализ необходимых данных, даже для больших документов. Необходимо заметить, однако, что приложение 1701 может все же ограничить содержимое в независимом от документа объекте 1903 контекста анализа, просто не открывая содержимое инструментальному средству анализа при запросе.
Также необходимо заметить, что, хотя инструментальное средство 1901 анализа чернил создает независимый от документа объект 1903 контекста анализа, программное приложение 1701 не должно изменять объект 1709 контекста анализа (и оно не может позволить другим потокам в программе приложения и/или другим программам изменить объект 1709 контекста анализа в течение данного периода времени). Т.е. программное приложение 1701 не должно вводить новых данных в документ 1703 в течение данного периода времени, и оно не должно разрешать делать это другим потокам и/или программам приложения. Процесс создания независимого от документа объекта 1903 контекста анализа относительно быстрый, однако и обычно, он не оказывает значительного влияния на работу программного приложения 1701. Если потребуется, однако, попытки ввода данных в документ 1703 могут быть кэшированы и введены в систему после создания независимого от документа объекта 1903 контекста анализа.
Как только создан независимый от документа объект 1903 контекста анализа, весь последующий анализ непроанализированных чернил и/или других данных может быть выполнен в отношении независимого от документа объекта 1903 контекста анализа, а не в отношении объекта 1709 контекста анализа, позволяя программному приложению 1701 продолжать свою нормальную работу без задержки или останова в результате анализа непроанализированных чернил и/или других данных. Программное приложение 1701 может даже вводить новые данные 1705 электронных чернил в документ 1703 (и в объект 1709 контекста анализа), не создавая помех анализу непроанализированных чернил в независимом от документа объекте 1903 контекста анализа.
Следовательно, после создания независимого от документа объекта 1903 контекста анализа на шаге 1605 инструментальное средство 1901 анализа чернил создает отдельный поток анализа для анализа чернил в независимом от документа объекте 1903 контекста анализа. Следовательно, на шаге 1607 программное приложение 1701 может возобновить управление основным потоком обработки и может продолжить свою нормальную работу. Затем на шаге 1609 инструментальное средство 1901 анализа чернил предоставляет независимый от документа объект 1903 контекста анализа процессу первого анализа для анализа. Например, как показано на фиг.20, инструментальное средство 1901 анализа чернил может передать независимый от документа объект 1903 контекста анализа процессу 2001 синтаксического разбора для синтаксического разбора с использованием потока анализа. Процесс синтаксического разбора дополнительно может включать в себя один или несколько процессов классификации без отступления от изобретения (например, для классификации чернил и/или других данных на всевозможные различные типы, такие как чернильный текст, чернильные рисунки, таблицы, диаграммы, графики, изображения, музыка, математика, рисунки, содержащие специальные символы (такие как электрические схемы с резисторами, конденсаторами и т.п.) и т.д.). Необходимо отметить, что в соответствии с некоторыми примерами изобретения инструментальное средство 1901 анализа чернил может выполнить копию независимого от документа объекта 1903 контекста анализа. Как подробно описано ниже, копия исходной формы независимого от документа объекта 1903 контекста анализа может быть использована для согласования результатов анализа процесса анализа с текущим состоянием документа 1703.
После того как процесс первого анализа проанализирует чернила и/или другие данные в независимом от документа объекте 1903 контекста анализа, процесс первого анализа возвращает результаты анализа инструментальному средству 1901 анализа чернил, которое, в свою очередь, информирует программное приложение 1701 на шаге 1611 о результатах анализа. Например, как показано на фиг.21, если процессом первого анализа является процесс 2001 синтаксического разбора, то процесс синтаксического разбора возвращает результаты 2101 синтаксического разбора инструментальному средству 1901 анализа чернил, которое затем может передать ссылку на результаты 2101 анализа программному приложению 1701 (например, посредством активизации события).
Как подробно описано ниже, с некоторыми примерами изобретения результатами 2101 анализа может быть независимый от документа объект 1903 контекста анализа, первоначально представленный процессу анализа, но модифицированный для включения новой информации, созданной процессом первого анализа (например, результатов синтаксического разбора в данном примере). В соответствии с другими примерами изобретения, однако, результатами 2101 анализа может быть модифицированная копия независимого от документа объекта 1903 контекста анализа. Посредством включения новой информации, созданной процессом первого анализа, в копию независимого от документа объекта 1903 контекста анализа, исходный независимый от документа объект 1903 контекста анализа может быть сохранен для использования, например, средством согласования и/или в других процессах анализа, как отмечено ранее.
На фиг.22 изображен пример того, как процесс синтаксического разбора, такой как процесс 2001 синтаксического разбора, может модифицировать дерево 1801 данных, чтобы показать изменения компоновки, созданные операцией синтаксического разбора. Как видно на данной фигуре, процесс 2001 синтаксического разбора определил, что штрих непроанализированных чернил, представленный данными 1823 штриха, является частью слова, представленного посредством узла 1813 слова. Следовательно, процесс синтаксического разбора разъединил данные 1823 штриха от корневого узла 1803 и вместо этого ассоциировал их с узлом 1813 слова.
Процесс синтаксического разбора также определил, что штрихи чернил, представленные данными 1825 и 1827 непроанализированных штрихов, являются частью нового слова в строке, представленной узлом 1809 строки, который ранее не был идентифицирован. Следовательно, процесс 2001 синтаксического разбора создал новый узел 2201 слова и ассоциировал данный узел 2201 слова с узлом 1809 строки. Процесс 2001 синтаксического разбора затем ассоциировал данные 1825 и 1827 штрихов с новым узлом 2201 слова. Таким образом, результаты 2101 синтаксического разбора описывают зависимости между штрихами ранее непроанализированных чернил и другими штрихами чернил (или другими элементами документа), идентифицированными процессом 2001 синтаксического разбора. Также, в дополнение к изображению изменений зависимостей, определенных процессом 2001 синтаксического разбора, результаты 2101 синтаксического разбора также могут включать в себя информацию о классификации, определенную процессом 2001 синтаксического разбора. Например, каждый экземпляр данных 1823-1827 штрихов чернил может быть модифицирован для классификации его соответствующего штриха чернил в качестве штриха чернил текста, а не штриха чернил рисунка. По меньшей мере в некоторых примерах изобретения, если потребуется, результаты 2101 синтаксического разбора могут быть представлены в независимом от документа объекте 1903 контекста анализа.
Как отмечено ранее, программное приложение 1701 может вводить в документ 1703 новые данные, включая как новые данные 1705 электронных чернил, так и новые нечернильные данные 1707, в то время как процесс первого анализа анализирует независимый от документа объект 1903 контекста анализа. Следовательно, результаты процесса первого анализа больше не могут быть применимы к текущему состоянию документа 1703. Например, в то время как процесс синтаксического разбора может определить, что штрих чернил ассоциирован со словом, пользователь может быть совсем удалить штрих чернил из документа 1703 (например, вместе со всем ассоциированным словом или в большем объеме). Следовательно, результаты 2101 анализа должны быть согласованы с текущим состоянием документа 1703 на шаге 1613. Примерный процесс согласования изображен в общем виде на фиг.23, и он подробно описывается ниже.
В соответствии с некоторыми примерами изобретения программное приложение 1701 может неавтоматизированным образом согласовать результаты 2101 анализа с текущим состоянием документа 1703. Т.е. программное приложение 1701 может выполнить сортировку при помощи результатов 2101 анализа для определения того, какие из результатов имеют отношение к элементам документа, находящимися в настоящее время в документе 1703. В соответствии с другими примерами изобретения, однако, инструментальное средство 1901 анализа чернил может обеспечивать функцию согласования для согласования результатов 2101 анализа с текущим объектом 1709 контекста анализа (т.е. объектом 1709 контекста анализа, отражающим текущее состояние документа 1703). Как подробно описано ниже, функция согласования различных примеров изобретения идентифицирует конфликты или «коллизии» между результатами 2101 анализа процесса первого анализа и объекта 1709 контекста анализа для текущего состояния документа 1703. Инструментальное средство 1901 анализа чернил затем обновляет объект 1709 контекста анализа, основываясь на результатах анализа, на шаге 1615 и создает новый независимый от документа объект 1903 контекста анализа из согласованных результатов анализа в объекте 1709 контекста анализа на шаге 1617.
Необходимо заметить, что, в то время как инструментальное средство 1901 анализа чернил согласовывает результаты 2101 анализа с текущим объектом 1709 контекста анализа, программное приложение 1701 не должно изменять объект 1709 контекста анализа (и оно не должно разрешать объекту 1709 контекста анализа изменяться посредством других потоков в программе приложения и/или любой другой программы приложения). Т.е. программное приложение 1701 не должно вводить новые данные в документ 1703, и/или оно не должно разрешать другим потокам и/или программе приложения вводить новые данные в документ 1703 до тех пор, пока не завершится согласование. Подобно процессу первоначального создания независимого от документа объекта 1903 контекста анализа процесс согласования относительно быстрый, и обычно не оказывает существенного влияния на работу программного приложения 1701. Если потребуется, однако, предпринимаемый пользователем ввод может быть кэширован и введен после завершения процесса согласования.
После того, как инструментальное средство 1901 анализа чернил согласует результаты 2101 анализа с объектом 1709 контекста анализа для текущего состояния документа 1703, инструментальное средство 1901 анализа чернил, в необязательном порядке, может предоставить согласованные результаты анализа процессу второго анализа для дополнительного анализа. Например, как показано на фиг.24, инструментальное средство 1901 анализа чернил может предоставить согласованные результаты 2401 синтаксического разбора процессу 2003 распознавания чернил для распознавания (например, для распознавания рукописного текста, музыки, математической информации или других типов специальных данных). В частности, инструментальное средство 1901 анализа чернил снова создает отдельный поток анализа для выполнения процесса второго анализа на шаге 1619. Так как инструментальное средство 1901 анализа чернил создает данный отдельный поток для выполнения процесса второго анализа, то программное приложение 1701 снова может возобновить свою нормальную работу на шаге 1621, и оно даже может принимать новые введенные данные, включая новые данные 1705 электронных чернил.
Затем на шаге 1623 инструментальное средство 1901 анализа чернил предоставляет согласованные результаты 2401 процесса первого анализа процессу второго анализа. После того, как начался процесс второго анализа, приложение 1701 может запустить другое выполнение процесса первого анализа в отношении новых непроанализированных чернил. Таким образом, одновременно могут выполняться многочисленные процессы анализа, так что, в то время как процесс второго анализа работает над результатами процесса первого анализа, приложение 1701 может повторно запустить процесс первого анализа для подготовки следующего набора результатов анализа.
Является выгодным то, что параллельное выполнение процессов анализа может улучшить работу программного приложения 1701. Например, процесс анализа синтаксического разбора обычно быстрый относительно процесса анализа распознавания, и результаты анализа синтаксического разбора могут быть использованы для реализации правильного поведения при выборе и поведения при вставлении промежутков без использования результатов анализа распознавания. Таким образом, так как различные процессы анализа могут выполняться параллельно, то новым чернилам, которые добавлены к документу 1703, не придется ожидать завершения процесса анализа распознавания в отношении данных более ранних чернил, до того как они могут быть правильно выбраны или правильно введены промежутки в них. Далее, различные примеры изобретения выполняют асинхронный анализ чернил, чтобы оградить разработчиков приложения, а также разработчиков алгоритмов для средств синтаксического разбора и распознавания от проблем многопоточной обработки, улучшая удобство сопровождения и упрощая процесс разработки для обеих групп, и допускают изменения во взаимодействии между процессами анализа без изменений в приложении.
Как отмечено выше, инструментальное средство 1901 анализа чернил может предоставить согласованные результаты анализа посредством создания нового независимого от документа объекта 1903 контекста анализа из объекта 1703 документа анализа, после того как он будет обновлен с целью включения соответствующих частей результатов 2101 анализа. В соответствии с другими примерами изобретения, однако, инструментальное средство 1901 анализа чернил может просто обновлять исходный независимый от документа объект 1903 контекста анализа результатами 2101 анализа, чтобы отражать текущее состояние документа 1703. Далее, инструментальное средство 1901 анализа чернил может просто предоставлять соответствующие данные чернил, подлежащие анализу, дополнительно процессу второго анализа.
Таким образом, различные примеры изобретения согласовывают результаты процесса предыдущего анализа с текущим состоянием документа 1703 перед выполнением процесса последующего анализа. Необходимо понять, однако, что упомянутый промежуточный шаг согласования может быть исключен в некоторых примерах изобретения. Более конкретно, в соответствии с некоторыми примерами изобретения результаты процесса более раннего анализа могут быть непосредственно предоставлены процессу последующего анализа без согласования упомянутых результатов с текущим состоянием документа 1703. Например, если процесс средства классифицирования чернил предусмотрен отдельно от процесса средства анализа компоновки чернил, то тогда чернила, классифицированные в качестве рукописного текста, могут быть предоставлены процессу средства анализа компоновки чернил без промежуточного шага согласования.
При любой схеме, после того как процесс 2003 второго анализа завершит анализ согласованных результатов 2401 процесса первого анализа, процесс 2003 второго анализа возвращает свои результаты 2501 инструментальному средству 1901 анализа чернил, как показано на фиг.25. Инструментальное средство 1901 анализа чернил затем информирует программное приложение 1701 о результатах 2501 второго анализа на шаге 1625.
Как ранее отмечено, программное приложение 1701 может вводить в документ 1703 новые данные, включая новые данные 1705 электронных чернил, в то время как процесс второго анализа анализирует согласованные результаты 2401 процесса первого анализа. Результаты 2501 процесса второго анализа, таким образом, больше не могут быть применимыми к текущему состоянию документа 1703. Следовательно, результаты 2501 процесса 2003 второго анализа также должны быть согласованы с текущим состоянием документа 1703 на шаге 1627. Примерный процесс согласования изображен, в основном, на фиг.26, и он подробно описывается ниже.
Опять же, в соответствии с некоторыми примерами изобретения программное приложение 1701 может неавтоматизированным образом согласовать результаты 2501 второго анализа с текущим состоянием документа 1703. Альтернативно, в соответствии с другими примерами изобретения инструментальное средство 1901 анализа чернил может предоставить функцию согласования для согласования результатов 2101 анализа с текущим объектом 1709 контекста анализа. Упомянутая функция согласования идентифицирует конфликты или «коллизии» между результатами 2501 анализа процесса второго анализа и объектом 1709 контекста анализа для текущего состояния документа 1703, и инструментальное средство 1901 анализа чернил затем обновляет объект 1709 контекста анализа, основываясь на результатах анализа на шаге 1629. Данный процесс затем может быть повторен по мере необходимости для анализа нового ввода чернил или чернил, которые были изменены во время процессов анализа.
Из вышеприведенного описания очевидно, что методики анализа чернил в соответствии с различными примерами изобретения позволяют проводить анализ электронных чернил асинхронно относительно программного приложения 1701, позволяя программному приложению 1701 во время процессов анализа продолжать принимать вводимые данные, включая новые электронные чернила. Необходимо отметить, что, хотя выше описаны только два процесса анализа, одновременно может выполняться любое количество параллельных процессов анализа. Например, различные варианты реализации изобретения могут использовать процесс первого синтаксического разбора, процесс второго синтаксического разбора и процесс распознавания. Таким образом, если завершается процесс каждого анализа, то его результаты могут быть переданы процессу следующего анализа, и процесс первого анализа может снова выполняться одновременно и параллельно в отношении вновь введенных чернил.
Далее, в соответствии с различными примерами изобретения один или несколько процессов анализа могут выполняться последовательно. Например, в соответствии с некоторыми программными приложениями пользователь может определить конкретный язык для штриха чернил или коллекции штрихов, такой как английский или японский. Данное определение языка затем может быть включено в объект 1709 контекста анализа и независимый от документа объект 1903 контекста анализа. Основываясь на определении языка, инструментальное средство 1901 анализа чернил может направить электронные чернила, определенные как первый язык, в процесс распознавания, разработанный для упомянутого первого языка, и впоследствии направить электронные чернила, определенные как второй язык, в другой процесс распознавания, разработанный для упомянутого второго языка. Таким же образом введенные данные, классифицированные и/или определенные как другие конкретные типы, могут посылаться на другие специализированные средства распознавания, такие как средства распознавания музыки, электрических символов, математических символов, признаков блок-схем, графических элементов и т.д.
Кроме того, так как процессы анализа необязательно должны быть частью программного приложения 1701, то любой требуемый процесс анализа может быть использован для анализа электронных чернил в программном приложении 1701. Например, разработчик программного приложения может разработать и использовать процесс синтаксического разбора или процесс распознавания, который специально подходит для анализа ввода электронных чернил, предполагаемого программным приложением 1701.
Еще другие разновидности этих методик могут быть использованы различными вариантами реализации изобретения. Например, в некоторых ситуациях может быть нежелательным, чтобы программное приложение 1701 поддерживало внутреннее дерево документа, отражающее взаимосвязи между различными элементами документа в документе 1703. Вместо этого, программное приложение 1701 может быть предназначено только для использования простой информации о состоянии, касающейся ввода электронных чернил. В соответствии с упомянутыми программными приложениями 1701, программное приложение 1701 может исключить создание объекта 1709 контекста анализа, который отражает текущее состояние всего документа 1703. Скорее, программное приложение 1701 может создать объект 1709 контекста анализа с конкретным назначением, который содержит информацию, соответствующую только конкретному вводу чернил, который программное приложение 1701 собирается проанализировать. Посредством использования объекта 1709 контекста анализа с конкретным назначением программное приложение 1701 может исключить сложность поддержки внутренней структуры данных, соответствующей состоянию документа 1703, в то же самое время имея возможность использовать требуемые процессы анализа для анализа чернил в документе.
Также, хотя выше приведено описание асинхронного анализа электронных чернил, необходимо заметить, что различные примеры изобретения могут дать возможность инструментальному средству 1901 анализа чернил проводить синхронный анализ чернил. Например, некоторые варианты реализации изобретения могут давать возможность программному приложению 1701 предписать инструментальному средству 1901 анализа чернил выполнение немедленного и синхронного анализа электронных чернил. Далее, синхронный анализ может выполняться только для чернил в конкретной области документа 1703 или для всего документа 1703.
Инструментальное средство анализа чернил
Как описано выше, инструментальное средство 1901 анализа чернил выполняет разнообразные функции, обеспечивающие обработку электронных чернил. Например, в соответствии с различными вариантами реализации изобретения инструментальное средство 1901 анализа чернил принимает информацию от программного приложения 1701, обозначающую одну или несколько областей в документе 1703 с данными чернил, подлежащими анализу, запрашивает программное приложение 1701 на получение информации, касающейся данных областей, и затем составляет независимый от документа объект 1903 контекста анализа, основываясь на упомянутой информации. Далее, инструментальное средство 1901 анализа чернил предоставляет независимый от документа объект 1903 контекста анализа одному или нескольким процессам анализа для анализа и затем согласовывает результаты процесса анализа с текущим состоянием документа 1703. Различные процессы могут выполняться с использованием отдельных потоков (как описано выше), при помощи пула потоков, в виде отдельных процессов, при помощи отдельных машин в кластере или любым другим подходящим или необходимым образом без отступления от изобретения.
В соответствии с различными примерами изобретения разнообразные программные объекты и инструментальные средства могут быть использованы для реализации инструментального средства 1901 анализа чернил и выполнения данных функций. В соответствии с некоторыми примерами изобретения, однако, инструментальное средство 1901 анализа чернил реализовано в качестве интерфейса прикладного программирования (API). Более конкретно, в соответствии с некоторыми примерами изобретения инструментальное средство 1901 анализа чернил может быть реализовано в виде группы процедур программных объектов и связанной с ними информации, которые могут быть, по необходимости, вызваны программным приложением 1701 для анализа чернил в документе 1703.
Для специалиста в данной области очевидно, что интерфейс прикладного программирования может быть организован в виде категорий или «классов», относящихся к программным объектам. «Объект» представляет собой коллекцию запоминаемых значений состояния и исполняемых поведений. Более конкретно, объект может поддерживать различные типы значений состояния, упоминаемых как «поля» и «свойства», которые могут быть ассоциированы с объектом или извлечены им. В отношении внешних программных приложений или другого программного объекта данные свойства могут быть только считаны (идентифицируются использованием терма «{get;}»), только записаны (идентифицируются использованием терма «{set;}») или считаны и записаны (идентифицируются как «{get; set}»). Объект также может исполнять задания или «методы», часто по запросу или «вызову» программного приложения или другого объекта. Таким образом, интерфейс прикладного программирования может включать в себя различные объекты, которые могут быть проинструктированы другим программным приложением на выполнение конкретных задач или предоставление конкретной информации по запросу.
Необходимо заметить, что различные примеры изобретения могут быть реализованы так, чтобы требовать от программного приложения 1701 предоставления только минимального объема информации, необходимой для завершения требуемого процесса анализа. По этой причине некоторые из свойств, описанных подробно ниже, могут быть описаны только как свойства только для чтения (т.е. «{get;}») или только для записи (т.е. «{set;}»), но могут быть как считываемыми, так и записываемыми для различных альтернативных вариантов реализации изобретения. Например, свойство, которое определяет «подсказки», которые должны использоваться процессом анализа для анализа электронных чернил, может быть идентифицировано как свойство только для чтения для ситуаций, когда программное приложение 1701 не предполагает использовать подсказки. Это позволяет объекту, созданному посредством Ink Analyzer, по меньшей мере считывать данное свойство и определять, что значением данного свойства является значение по умолчанию, равное нулю (т.е. «подсказки» не требуются программному приложению 1701). Если, однако, программное приложение 1701 собирается использовать подсказки для анализа чернил, то тогда данное свойство будет как считываемым, так и записываемым, позволяя программному приложению 1701 изменять значение данного свойства с нулевого значения, чтобы задавать требуемые подсказки.
В соответствии с различными примерами изобретения API, воплощающий реализацию инструментального средства 1901 анализа чернил, (упоминаемый ниже как API анализа чернил) может содержать два основных класса. Первый класс упоминается как класс «Analysis Context», и вторым классом является класс «Ink Analyzer». Компоненты класса «Analysis Context» используются для создания объекта 1709 контекста анализа. Следовательно, в соответствии с различными вариантами реализации изобретения, для которых программное приложение 1701 создает и поддерживает свой собственный объект 1701 контекста анализа, один или несколько компонентов в данном классе могут быть исключены из инструментального средства анализа чернил. Вместо этого, один или несколько из этих компонентов могут быть реализованы самим программным приложением 1701.
Компоненты класса «Ink Analyzer» тогда используются для создания и применения объекта, который предоставляет независимый от документа объект 1903 контекста анализа процессу анализа, определения того, когда были сгенерированы результаты анализа, и согласования результатов анализа с текущим состоянием документа 1703. Ниже подробно описываются эти и другие классы, которые могут быть включены в API анализа чернил, в соответствии с различными примерами изобретения.
Обращаясь сначала к классу Analysis Context, данный класс реализуется ведущим приложением 1701 для создания объекта 1703 контекста анализа, который служит в качестве вида-посредника на внутреннее дерево документа программного приложения 1701. Альтернативно, как отмечено ранее, если приложение реализует свой собственный объект контекста анализа, то тогда один или несколько компонентов в данном классе могут быть исключены из инструментального средства 1901 анализа чернил. Как описано ранее, объект 1703 контекста анализа содержит все данные непроанализированных чернил, и объект 1703 контекста анализа используется для идентификации того, какие данные непроанализированных чернил должны быть проанализированы. Объект 1703 контекста анализа также содержит информацию о ранее проанализированных чернилах. Упомянутые ранее проанализированные чернила могут быть использованы для принятия решения в отношении того, как должны анализироваться непроанализированные в настоящее время чернила, и сами могут быть модифицированы в ходе анализа непроанализированных чернил. Далее, объект 1703 содержимого анализа содержит информацию о нечернильном содержимом документа 1703, которая используется для правильной классификации чернил в качестве аннотаций для нечернильного содержимого.
В соответствии с различными примерами изобретения класс Analysis Context включает в себя конструктор, который, когда он вызывается программным приложением 1701, создает объект 1709 контекста анализа. Данный класс также может включать в себя разнообразные свойства для объекта 1709 контекста анализа, включая свойство с именем «Dirty Region {get;}». Свойство Dirty Region определяет часть документа (и, таким образом, часть объекта 1709 контекста анализа), которая содержит данные непроанализированных чернил. В соответствии с различными примерами изобретения Dirty Region может определять несовместную зону. Dirty Region задается как AnalysisRegion, которая подробно описывается ниже, но которая просто может быть коллекцией прямоугольных зон в документе. Если Dirty Region пустая, то анализа не происходит. Данный класс дополнительно может включать в себя свойство для объекта 1703 контекста анализа с именем «Margins {get;}», которое объявляет зоны страницы в документе 1703, которые считаются полями. Процесс анализа, который, например, анализирует компоновку и определяет классификацию электронных чернил, может использовать данное свойство, способствующее определению классификации электронных чернил, которые аннотируют нечернильное содержимое (например, чернила на полях).
Далее, класс Analysis Context может включать в себя свойство с именем «Rootnode {get;}», которое идентифицирует самый верхний или корневой узел контекста в объекте 1709 контекста анализа. Как подробно описано выше, данный корневой узел контекста содержит, в качестве дочерних узлов контекста, все другие объекты узлов контекста для данного объекта 1709 контекста анализа. Необходимо заметить, что в соответствии с различными примерами изобретения корневой узел контекста должен быть узлом контекста типа «Root». Также необходимо отметить, что в соответствии с примерами изобретения, где приложение 1701 реализует свой собственный объект 1709 контекста анализа, объект 1709 контекста анализа может иметь другие узлы контекста в качестве сестринских узлов корневого узла контекста, но компоненты класса Ink Analyzer могут ограничиваться рассмотрением узлов контекста, которые содержит корневой узел контекста.
Класс Analysis Context может дополнительно включать в себя свойство «Analysis Hints {get;}», которое возвращает массив объектов подсказок анализа, установленных программным приложением 1701. Как подробно описано ниже, объекты подсказок анализа могут содержать любой тип информации, которая может способствовать процессу анализа. Упомянутая информация может включать в себя, например, фактоиды, наставления или списки слов. Она также может включать в себя информацию, устанавливающую язык, который необходимо использовать для анализа, информацию, обозначающую непроанализированные чернила в качестве только рукописного текста или только рисунка, или предоставляющую любой вид наставления для процесса синтаксического разбора, такого как идентификация чернил в качестве списков, таблиц, форм, блок-схем, соединителей, контейнеров и т.п.
В дополнение к этим свойствам класс Analysis Context также может включать в себя разнообразные методы, которые могут быть вызваны, например, программным приложением 1701 для выполнения задачи объектом 1709 контекста анализа. Например, класс Analysis Context может включать в себя метод с именем «FindNode (Guid id)». Каждый узел в объекте 1709 контекста анализа имеет глобальный уникальный идентификатор (или GUID), и данный метод определяет местоположение узла, заданного в вызове, где угодно в объекте 1709 контекста анализа. Данный метод поиска должен быть реализован наиболее эффективным образом, так как данный метод может быть вызван из многих критических во времени операций.
Подобно классу Analysis Context класс Ink Analyzer также определяет открытый конструктор, который позволяет программному приложению 1701 создавать экземпляр класса (т.е. объект анализатора чернил) вместе с разнообразными свойствами. Например, он может содержать свойство с именем «User Interface Context {get; set;}», которое определяет поток обработки, к которому возвращаются результаты процесса анализа. Данное свойство позволяет результатам синхронизироваться с другим объектом. Например, если он установлен на основную форму, то результаты программы синтаксического разбора будут активизироваться по основному потоку приложения. Он также может содержать свойство «AnalysisOptions AnalysisOptions {get; set;}», которое задает различные критерии, которые могут быть использованы для процесса анализа. Данные критерии могут включать в себя, например, разрешение распознавания текста, разрешение использования таблиц, разрешение использования списков, разрешение использования аннотаций и разрешение использование соединителей и контейнеров.
Класс Ink Analyzer включает в себя различные методы. Например, данный класс может включать в себя метод с именем «AnalysisRegion Analyze ()». Этот метод запускает процесс синхронного анализа. Данные элементов документа передаются этому методу, который описывает текущее состояние документа 1703 и указывает, какие чернила в документе 1703 должны быть проанализированы. В соответствии с некоторыми вариантами реализации изобретения данные элементов документа могут быть представлены в качестве объекта 1709 контекста анализа (т.е. AnalysisRegion Analyze (Analysis Context)), как отмечено выше. Альтернативно, отдельные штрихи чернил могут быть переданы процессу анализа, либо используя ссылку на штрихи (т.е. AnalysisRegion Analyze (Strokes)), либо ссылаясь в качестве свойства объекта Ink Analyzer (например, InkAnalyzer.Strokes {get;set}) без передачи свойств методу Analyze.
После завершения процесса анализа данный метод возвращает ссылку на независимый от документа объект контекста анализа, который был модифицирован для того, чтобы содержать результаты процесса анализа. Метод также возвращает значение AnalysisRegion (подробно описанное ниже), описывающее зону в документе, где были рассчитаны результаты.
Класс Ink Analyzer также может включать в себя метод с именем «AnalysisRegion Analyze(AnalysisContext, waitRegion)». Данный метод аналогичен синхронному методу Analysis Region Analyze (), описанному выше, но он анализирует чернила только если требуются результаты в заданной зоне waitRegion. Более конкретно, вызов данного метода идентифицирует объект 1709 контекста анализа для документа 1703 и область объекта 1709 контекста анализа (упоминаемую как «waitRegion»), для которой процесс анализа должен выполнять анализ синхронно. В соответствии с различными примерами изобретения все другие области объекта 1709 контекста анализа будут игнорироваться, если только процессу анализа не потребуется провести анализ содержимого в упомянутых областях, чтобы завершить свой анализ waitRegion. Как описано выше, объект 1709 контекста анализа, переданный этому методу, содержит свойство с именем «DirtyRegion», которое описывает зоны документа 1703, которые требуют анализа. Посредством задания конкретной waitRegion программное приложение 1701 может получить результаты анализа быстрее для одной заданной области, представляющей интерес, а не анализировать все данные чернил в документе 1703.
Когда вызывается любой из этих методов Analyze, то будет выполняться каждый доступный процесс анализа. Также, так как эти методы Analyze представляют собой синхронные вызовы, то нет необходимости выполнять процесс согласования при их завершении и не будет активизироваться событие, если он завершен.
Класс Ink Analyzer также может включать в себя метод с именем «BackgroundAnalyze(AnalysisContext)». Данный метод запускает заданную операцию анализа, но делает это в отдельном фоновом потоке анализа. Таким образом, данный метод возвращает управление основному потоку обработки почти мгновенно, в то время как фактическая операция анализа завершается в фоновом потоке. В частности, данный метод возвращает значение «истина», если был успешно запущен процесс анализа. Опять же, значение AnalysisContext, переданное методу, идентифицирует объект 1709 контекста анализа для документа 1703 и указывает, какие чернила в документе 1703 требуют анализа. Как только операция анализа завершится в фоновом потоке, устанавливается событие Results, позволяющее программному приложению 1701 получить доступ к результатам. Событие содержит результаты и метод согласования, который используется для встраивания результатов обратно в объект 1709 контекста анализа для текущего состояния документа 1703, когда результаты возвращаются.
Необходимо отметить, что каждый из этих трех методов Analyze, в свою очередь, вызывает метод «Clone» в классе «Analysis Region», который подробно описывается ниже. Используя метод «Clone», эти методы Analyze создают независимый от документа объект контекста анализа, который впоследствии модифицируется процессом анализа, чтобы показать результаты анализа.
Класс Ink Analyzer также может включать в себя метод с именем «Reconcile (AnalysisContext current, AnalysisResultsEventArgs resultArgs)», который программное приложение 1701 вызывает после приема события результатов, которое было обусловлено вызовом метода BackgroundAnalyze(AnalysisContext). Метод Reconcile сравнивает результаты анализа, содержащиеся в независимом от документа объекте контекста анализа, с текущей версией объекта 1709 контекста анализа, поддерживаемого программным приложением 1701. Данный метод идентифицирует узлы, которые необходимо добавить и удалить из текущей версии объекта 1709 контекста анализа, и идентифицирует, изменились ли какие-нибудь из следующих свойств существующего узла: его результаты распознавания, его размещение, штрихи чернил, ассоциированные с узлом, или любые другие данные, ассоциированные с результатами операции анализа. Данный метод также записывает упомянутые идентифицированные изменения в текущую версию объекта 1709 контекста анализа. Данный метод чувствителен к порядку расположения узлов контекста, такому как порядок узлов контекста слов на узле контекста строк.
Результаты анализа (т.е. значение свойства AnalysisResultsEventArgs) передаются обратно с помощью этого метода, так как они содержат открытую структуру результатов и закрытую структуру результатов. Возвращается открытая структура, так что программное приложение 1701 может предварительно просмотреть изменения, которые будут иметь место на этапе согласования. Закрытая структура включена для того, чтобы предотвратить изменение программным приложением 1701 любого результата анализа перед процессом согласования.
Класс Ink Analyzer также может включать в себя методы с именами «Recognizers RecognizersPriority()» и «SetHighestPriorityRecognizer(recognizer)». Когда чернила необходимо распознать, то используется соответствующее средство распознавания, основываясь на языке и возможностях. Следовательно, метод Recognizers RecognizersPriority() возвращает процессы распознавания в порядке, в котором они оцениваются объектом Ink Analyzer. Порядок определяется согласно системе, в зависимости от доступных процессов распознавания, но может быть переопределен для программного приложения 1701 вызовом SetHighestPriorityRecognizer(recognizer) в отношении объекта Ink Analyzer. InkAnalyzer перечисляет данный упорядоченный список, пока не будет обнаружено соответствующее средство распознавания. Метод SetHighestPriorityRecognizer(recognizer) устанавливает приоритет процесса распознавания. Посредством установки приоритета конкретного процесса распознавания данный процесс распознавания будет использоваться, если он соответствует требуемому языку и возможностям текущей операции распознавания. По существу, SetHighestPriorityRecognizer(recognizer) проталкивает обозначенный процесс распознавания в верхнюю часть списка, возвращаемого методом RecognizersPriority.
Класс Ink Analyzer также может содержать метод с именем «AnalysisRegion Abort(), который может использовать объект контекста анализа в качестве параметра. Данный метод обеспечивает возможность раннего завершения операции высокоприоритетного или фонового анализа. Данный метод возвращает область анализа, которая описывает зону, которая анализировалась перед преждевременным прекращением. Таким образом, если программное приложение 1701 собирается позднее продолжить операцию анализа, то упомянутая область может быть объединена с DirtyRegion объекта 1709 контекста анализа для текущего состояния документа 1703. Далее, класс Ink Analyzer может включать в себя событие с именем «AnalysisResultsEventHandler», которое запускается для объекта InkAnalyzer настолько часто, насколько это целесообразно. Более конкретно, данное событие может запускаться между процессами анализа и по меньшей мере каждые 5 секунд. Данное событие может использоваться для предоставления приложению 1701 обновления в отношении состояния проходящего асинхронного процесса (или процессов) анализа.
API анализа чернил также может включать в себя классы в дополнение к классу Analysis Context и классу Ink Analyzer. Например, API анализа чернил в соответствии с различными примерами изобретения может включать в себя класс Context Node. Данный класс может включать в себя различные компоненты, относящиеся к узлам контекста, которые составляют объект 1709 контекста анализа и независимый от документа объект контекста анализа, такие как свойство с именем «ContextNodeType Type {get;}». Для специалиста в данной области техники очевидно, что каждый узел контекста имеет тип, и существует заданный набор правил, которых должен придерживаться каждый тип. Они включают в себя правила, такие как, например, какие типы дочерних узлов контекста разрешены и могут ли или нет штрихи непосредственно быть ассоциированы с узлом контекста или только через его дочерние узлы контекста.
Возможные типы узлов контекста могут быть определены в перечислении ContextNodeTypes и могут включать в себя (но не в ограничительном смысле), например, следующие типы: узел InkAnnotation, который представляет данные чернил, аннотирующие нетекстовые данные; узел InkDrawing, который представляет данные чернил, формирующие рисунок; узел InkWord, который представляет данные чернил, формирующие слово; узел Line, который содержит один или несколько узлов InkWord и/или узлов TextWord для слов, формирующих строку текста; узел ListItem, который может содержать узлы Paragraph, Image или подобные им, предполагаемые в списке; и узел List, который содержит один или несколько узлов ListItem, причем каждый описывает элемент в списке. Типы узлов также могут включать в себя узел NonInkDrawing, представляющий изображение нечернильного рисунка; узел Object, представляющий данные, не охватываемые другими значениями перечисления ContextNodeType; узел Paragraph, который содержит один или несколько узлов Line, соответствующих строкам, формирующим абзац; узел Picture или Image, представляющий изображение рисунка; узел Root, который служит в качестве самого верхнего узла в объекте контекста анализа; узел Table, который содержит узлы, представляющие элементы, составляющие таблицу; узел TextBox представляющий текстовое окно; узел TextWord и узел UnclassifiedInk, соответствующий данным чернил, которые еще не были классифицированы. Типы узлов также могут включать в себя узел Group для групп других узлов, узел InkBullet для элементов маркера, узел Row для элементов документа, представленных в строке таблицы, и узел Cell для элементов документа, представленных в ячейке таблицы.
Класс Context Node также может включать в себя свойство с именем «GUID Id {get;}», которое представляет собой глобальный уникальный идентификатор для текущего узла контекста. Для того, чтобы получить доступ к любому требуемому узлу контекста, каждый узел контекста в отдельном объекте контекста анализа всегда должен иметь уникальный идентификатор. Данный класс также может включать в себя свойство с именем «AnalysisRegion Location {get;}», которое определяет размещение в пространстве документа, где фактически расположен соответствующий узел контекста. Как отмечено ранее, AnalysisRegion представляет собой двухмерную структуру, группирующую вместе одну или несколько возможно непересекающихся структур подобных прямоугольнику. Данный класс также может включать в себя свойство с именем «StrokeCollection Strokes {get;}», которое идентифицирует штрихи чернил, ассоциированные с соответствующим узлом контекста. В соответствии с различными примерами изобретения только концевым узлам контекста (таким как узлы Word, Drawing и Bullet) разрешено API анализа чернил иметь штрихи. Программное приложение 1701 может использовать данное свойство для ссылки на штрихи на уровне концевых узлов всеми узлами-предками контекста (например, корневой узел содержит ссылку на штрихи на все штрихи в соответствующем объекте контекста анализа).
Далее, данный класс может включать в себя свойство с именем «ContextNode ParentNode {get;}», которое идентифицирует родительский узел контекста, содержащий соответствующий узел контекста. В соответствии с различными примерами изобретения узлы контекста всегда создаются с зависимостью от родительского узла контекста, причем узел контекста Root является статическим членом объекта контекста анализа. Данный класс также может включать в себя свойство «ContextNode[] SubNodes {get;}», которое идентифицирует все узлы контекста, которые являются непосредственными дочерними узлами соответствующего узла контекста. Т.е. данное свойство идентифицирует только те дочерние узлы контекста, которые находятся на один уровень ниже в объекте контекста анализа. Например, значение данного свойства для узла контекста Paragraph идентифицирует только узлы контекста строки, содержащиеся в узле Paragraph, а не узлы контекста слова, которые являются дочерними узлами узла контекста строки.
Данный класс также может включать в себя свойство с именем «RecognitionResult RecognitionResult {get;}», которое предоставляет результат распознавания, вычисленный соответствующим процессом или процессами анализа распознавания, так как RecognitionResult может представлять более одной строки текста с более чем одного языка. Recognition Result доступен для каждого узла контекста в независимом от документа объекте контекста анализа, даже если свойство RecognitionData (описанное подробно ниже), которое устанавливается процессом анализа распознавания и используется для создания объекта RecognitionResult, может устанавливаться только на одном уровне дерева узлов контекста, чтобы исключить дублирование данных. Если узел не имеет RecognitionData, ассоциированное с ним, то он либо объединяет результаты распознавания всех своих подузлов, либо извлекает результат распознавания из своего родительского узла. Данный класс также может включать в себя свойство с именем «Stream RecognitionData {get; set;}», которое представляет собой постоянную форму значения RecognitionResult. Опять же, процесс анализа распознавания создает значение Stream RecognitionData, которое устанавливается на соответствующем узле контекста. Объект RecognitionResult затем строится на основе упомянутого значения.
Класс Context Node дополнительно может включать в себя свойство с именем «ContextLink[] Links {get;}», которое обеспечивает массив объектов ContextLink. Объект ContextLink описывает альтернативную взаимосвязь между двумя узлами контекста. Хотя узлы контекста обычно имеют взаимосвязь вида “родительский узел - дочерний узел” с другими узлами контекста, ContextLink учитывает альтернативную зависимость между узлами контекста. Например, ContextLink может учитывать соединение между двумя узлами контекста, жесткую привязку одного узла контекста к другому узлу контекста, встраивание одного узла контекста в другой узел контекста или требуемый тип связи, определяемый программным приложением 1701. ContextLinks может быть добавлен к данному массиву посредством вызова метода AddLink, подробно описанного ниже. Аналогично, ContextLinks может быть удален из данного массива посредством вызова метода DeleteLink, который также подробно описан ниже.
Далее, данный класс может включать в себя свойства «IsContainer {get;}» и «IsInkLeaf {get;}». Свойство IsContainer {get;} имеет значение «истина», если соответствующий узел контекста не является концевым узлом контекста (т.е., если соответствующий узел контекста содержит дочерние узлы контекста и, таким образом, считается узлом контекста контейнера) и имеет значение «ложь» в противном случае. Свойство IsInkLeaf {get;} имеет значение «истина», если текущим узлом контекста не является узел контекста контейнера и имеет значение «ложь» в противном случае. Т.е., если текущий узел контекста не содержит никаких дочерних узлов контекста, то он считается концевым узлом контекста. Также необходимо заметить, что с различными примерами изобретения, как ожидается, узел контекста InkLeaf содержит ссылки на данные штрихов, тогда как узлы контекста контейнера не имеют упомянутого ограничения. Узлы контекста контейнера могут ссылаться на данные штрихов или могут не ссылаться на них, что определяется программным приложением 1701.
Класс Context Node также может содержать свойство «Rect RotatedBoundingBox {get; set;}». Значение данного свойства вычисляется процессом анализа компоновки и классификации. Если данные чернил, ассоциированные с соответствующим узлом контекста, записываются под углом, то тогда границы узла контекста все же будут выровнены горизонтально. Значение свойства RotatedBoundingBox, однако, будет выровнено с углом, под которым были записаны данные чернил, ассоциированные с соответствующим узлом контекста. Далее, данный класс может включать в себя свойство «ReClassifiable {get;}», которое информирует InkAnalyzer о том, разрешено ли ему модифицировать значения соответствующего узла контекста.
В дополнение к этим свойствам класс Context Node также может включать в себя различные методы. Например, данный класс может включать в себя метод с именем «ContextNode CreateSubNode(ContextNodeType type)». Данный метод позволяет создавать дочерний узел контекста конкретного типа. В соответствии с различными примерами изобретения данный метод может разрешать создание только допустимых типов дочерних узлов соответствующего узла контекста, тем самым предотвращая создание искаженных структур данных. Например, данный метод может разрешать узлу контекста Line создавать только дочерние узлы контекста InkWord и TextWord. Данный класс также может содержать метод с именем «void DeleteSubNode(ContextNode node)», который удаляет дочерний узел контекста, на который сделана ссылка, из соответствующего объекта контекста анализа. Необходимо заметить, однако, что в соответствии с различными примерами изобретения, если узел контекста, на который сделана ссылка, все еще содержит штрихи или дочерние узлы контекста, то тогда данный метод должен завершиться неуспешно. Также, если узел контекста, на который сделана ссылка, не является непосредственным дочерним узлом соответствующего узла контекста, то тогда данный метод должен завершиться неуспешно. Необходимо заметить, что если программное приложение 1701 реализует свой собственный объект 1709 контекста анализа и, в свою очередь, использует данный метод, он не удаляет непустые узлы контекста или узлы контекста, которые не являются непосредственными дочерними узлами соответствующего узла контекста, для предотвращения искаженных структур данных в объекте 1709 контекста анализа.
Далее, данный класс может включать в себя метод «ContextNode[] HitTestSubNodes(AnalysisRegion region)», который возвращает массив узлов контекста, которые расположены в заданной области. Необходимо заметить, однако, что возвращаются только непосредственные дочерние узлы данного элемента, а не все узлы-потомки. Область определяется объектом AnalysisRegion, который, как ранее отмечено, может быть коллекцией из одного или нескольких прямоугольников. В соответствии с различными примерами изобретения, если любая часть размещения узла контекста пересекает заданную область, то тогда данный узел контекста будет возвращен в массиве. Данный метод используется, например, для создания независимого от документа объекта контекста анализа и для согласования результатов анализа с объектом контекста анализа, соответствующим текущему состоянию документа 1703. Таким образом, данный метод часто вызывается и должен быть оптимизирован для быстрого многократного доступа со стороны объекта InkAnalyzer.
Класс Context Node также может содержать метод с именем «MoveStroke(Stroke stroke, ContextNode destination)». Данный метод перемещает ассоциацию штриха с одного концевого узла контекста на другой. В соответствии с различными примерами изобретения данный метод используется только между концевыми узлами контекста. Он также может включать в себя метод с именем «MoveSubNodeToPosition(int OldIndex, int NewIndex)», который переупорядочивает соответствующий узел контекста относительно его сестринских узлов контекста. Например, если документ 1703 имеет три слова в строке, например, слово 1, слово 2 и слово 3, то тогда их порядок является следствием массива подузлов, возвращаемых от родительского узла контекста. Данный метод позволяет изменить их порядок, так что относительно соответствующего родительского узла контекста слово 1 задается последним словом в строке посредством перемещения узла контекста для слова 1 из положения один в положение три.
Далее, данный класс может включать в себя метод с именем «AddLink(ContextLink link)», который добавляет новый объект ContextLink к текущему узлу контекста. В соответствии с различными примерами изобретения объект ContextLink должен содержать ссылку на соответствующий узел контекста, чтобы ContextLink был успешно добавлен к массиву ContextLinks, ассоциированному с соответствующим узлом контекста. Он также может содержать метод с именем «DeleteLink(ContextLink link)». Данный метод ликвидирует или удаляет заданный объект ContextLink из массива ContextLinks для соответствующего узла контекста. Необходимо заметить, что в соответствии с различными примерами изобретения данный вызов метода всегда завершается успешно, даже если ContextLink не существует в массиве ContextLinks, ассоциированном с соответствующим узлом контекста.
API анализа чернил также может включать в себя класс Analysis Hint. Как и в случае многих из ранее описанных классов класс Analysis Hint может включать в себя конструктор с именем «AnalysisHint()», который инициализирует объект Analysis Hint в пустое состояние. Данный класс также может включать в себя ряд свойств, включая свойство с именем «AnalysisRegion Location {get;}». Данное свойство задает местоположение в документе 1703 (в качестве AnalysisRegion), к которому применим AnalysisHint. Например, если документ 1703 представляет собой узел свободной формы с разделом заголовка в верхней части страницы, то тогда приложение 1701 может установить, что AnalysisHint для области заголовка задает, что горизонтальная чернильная строка предполагается в упомянутой области. Этот Analysis Hint будет способствовать повышению точности процесса анализа.
Данный класс также может включать в себя свойство с именем «string Factoid {get; set;}», который задает конкретный «фактоид», который должен использоваться для размещения в документе 1703, к которому применим AnalysisHint. Как известно специалисту в данной области техники, фактоиды обеспечивают подсказки процессу распознавания в отношении ожидаемого использования данных чернил (например, в качестве обыкновенного текста, цифр, почтовых кодов, имен файлов и унифицированных указателей ресурса (URL) «Всемирной паутины» (Web)). Данный класс также может включать в себя свойства с именами «RecognizerGuide Guide {get; set;}» и «OverrideLanguageId {get; set;}». Свойство RecognizerGuide Guide {get; set;} задает наставление записи, которое должно применяться к местоположению в документе 1703, к которому применимо AnalysisHint. Наставления записи, например, могут способствовать повышению точности процесса анализа средства распознавания посредством указания пользователю и информирования процесса анализа распознавателя о том, где пользователь будет записывать строки или знаки. Свойство OverrideLanguageId {get; set;} задает Language Hint для документа 1703, к которому применим AnalysisHint. Установка Language Hint вызывает использование объектом InkAnalyzer обозначенного языка вместо языка, заданного узлом контекста.
Данный класс также может включать в себя свойство с именем «PrefixText {get; set;}», которое задает текст, который записывается или печатается перед строкой чернил, которые должны быть распознаны. Далее, данный класс может включать в себя свойство с именем «RecognitionModes RecognitionFlags {get; set;}», которое задает конкретный тип режимов, которые процесс распознавания должен соблюдать в размещении в документе 1703, к которому применим AnalysisHint. Далее, данный класс может включать в себя свойство с именем «SuffixText {get; set;}», которое задает текст, который записывается или печатается после чернильной строки, которые должны быть распознаны, и свойство с именем «WordList WordList {get; set;}», которое задает конкретный набор слов, которые должны использоваться процессом анализа распознавания. Списки слов могут использоваться, когда известны ожидаемые результаты распознавания, до того как пользователь фактически запишет вводимые данные, такие как список медицинских терминов, которые, как ожидается, будут записываться в медицинской карте.
Далее, данный класс может включать в себя свойство с именем «WordMode {get; set;}». Если упомянутым значением является «истина», то тогда процесс анализа настраивает себя на возвращение одного слова для всей области анализа. Он также может включать в себя свойство с именем «Coerce {get; set;}», которое, если его значением является «истина», заставляет процесс анализа ограничить свой результат любым фактоидом или значением списка слов, установленным в соответствующей подсказке. Данный класс также может включать в себя свойство с именем «AllowPartialDictionaryTerms {get; set;}». Если значением данного свойства является «истина», то тогда процессу анализа распознавания разрешается возвратить части слова из его словаря распознавания.
В соответствии с различными примерами изобретения API анализа чернил может дополнительно включать в себя класс Analysis Region. Данный класс может включать в себя, например, множество конструкторов для построения объекта AnalysisRegion. Например, он может содержать первый конструктор для построения объекта AnalysisRegion, имеющего любую область, второй конструктор для построения объекта AnalysisRegion, основанного на параметрах для двухмерного прямоугольника, и третий конструктор для построения объекта AnalysisRegion, основанного на четырех пространственных координатах. Конструктор по умолчанию, например, может создавать пустую область. Данный класс также может включать в себя ряд свойств. Например, данный класс может включать в себя свойство с именем «Rectangle Bounds {get;}», которое извлекает ограничивающий прямоугольник для AnalysisRegion, свойство с именем «IsEmpty {get;}», которое указывает на то, имеет ли соответствующий объект AnalysisRegion пустую внутреннюю часть, и свойство с именем «IsInfinite {get;}», которое указывает, установлен ли AnalysisRegion на бесконечность или нет.
Данный класс также может включать в себя ряд методов, таких как метод с именем «AnalysisRegion Clone()», который клонирует соответствующий объект AnalysisRegion. Данный класс также может включать в себя метод с именем «Equals(AnalysisRegion otherRegion)», который проверяет, идентичен ли заданный объект AnalysisRegion (упоминаемый как otherRegion) соответствующему объекту AnalysisRegion. Данный метод возвращает значение «истина», если внутренняя часть заданного объекта Analysis Region идентична внутренней части соответствующего объекта Analysis Region, и, в противном случае, возвращает значение «ложь».
Данный класс может дополнительно включать в себя метод «Intersect(AnalysisRegion regionToIntersect)», который обрезает соответствующий объект AnalysisRegion до заданной области анализа. Таким образом, результирующий объект AnalysisRegion включает в себя только зоны, которые перекрывают или пересекают заданную область анализа. Данный класс также может включать в себя метод с именем «Intersect(Rectangle rectangle)», который обрезает соответствующий объект AnalysisRegion до заданного прямоугольника. Опять же, результирующий объект AnalysisRegion будет включать в себя только зоны, которые перекрывают или пересекают заданный прямоугольник. Он может также включать в себя метод с именем «MakeEmpty()», который инициализирует соответствующий объект AnalysisRegion до пустой внутренней части, и способ с именем «MakeInfinite()», который устанавливает зону, занимаемую соответствующим AnalysisRegion, равной бесконечности. Он дополнительно может включать в себя различные методы для объединения или разъединения различно определенных зон, такие как метод с именем «Union(AnalysisRegion regionToUnion)», который задает объединение или добавление объекта AnalysisRegion к соответствующему объекту AnalysisRegion, и метод с именем «Union(Rectangle rectangle)», который объединяет заданный прямоугольник с соответствующим объектом Analysis Region. С помощью данного метода прямоугольник может быть задан в значениях пространства координат для соответствующего объекта AnalysisRegion. Конечно, данный класс может включать в себя множество других методов для объединения зон или извлечения одной зоны из другой, основываясь на любом требуемом определении для зон.
API анализа чернил также может иметь класс Recognition Result. Как и в случае с многочисленными ранее описанными классами, класс Recognition Result может включать в себя один или несколько конструкторов. Например, данный класс может включать в себя конструктор с именем «RecognitionResult(Stream lattice)», который строит объект RecognitionResults из заданной решетки распознавания. В соответствии с различными примерами изобретения решетка распознавания представляет собой последовательную форму результатов процесса распознавания. Данный метод, например, может задавать решетку распознавания в качестве байтового массива, подлежащего использованию для построения соответствующего объекта RecognitionResult. Он также может включать в себя конструктор с именем «RecognitionResult(ContextNode node)», который строит объект RecognitionResults из заданного узла контекста. Он также может включать в себя конструктор с именем «RecognitionResult(string Text, int StrokeCount)», который строит объект RecognitionResults из заданного значения текста, которое, в свою очередь, ассоциировано с заданным количеством штрихов и может использоваться для коррекции, если процесс распознавания не выработает значение распознавания альтернативы, соответствующее фактическим данным рукописных чернил. Далее, данный класс может включать в себя конструктор с именем «RecognitionResult(RecognitionResult leftRecognitionResult, RecognitionResult rightRecognitionResult)», который строит объект RecognitionResults объединением вместе двух существующих объектов Recognition Results.
Класс Recognition Result также может включать в себя один или несколько свойств, таких как свойство с именем «StrokeCollection StrokeCollection {get;}», которое обеспечивает массив индексов штрихов, представляющих коллекцию штрихов, которые содержатся в отдельном объекте чернил, и свойство с именем «RecognitionAlternate TopAlternate {get;}», которое обеспечивает наилучшую альтернативу результата распознавания. Данный класс также может включать в себя свойство с именем «RecognitionConfidence RecognitionConfidence {get;}», которое обеспечивает уровень уверенности (например, сильная, промежуточная или слабая) в выбранной наилучшей альтернативе для текущих результатов процесса анализа распознавания, и свойства с именем «string TopString {get;}», которое возвращает строку наилучшего результата из результатов анализа процесса анализа распознавания.
Класс Recognition Results также может включать в себя ряд методов, таких как метод с именем «public RecognitionAlternateCollection GetAlternateCollectionFromSelection (selectionStart, selectionLength, maximumAlternates)», который задает коллекцию альтернатив из выбранного фрагмента внутри строки наилучшего результата из результатов анализа процесса анализа распознавания, где каждая альтернатива соответствует только одному сегменту чернил. Входные параметры для данного метода могут включать в себя, например, значение, которое задает начало выбранного фрагмента текста, из которого возвращается коллекция альтернатив, значение, которое задает длину выбранного фрагмента текста, из которого возвращается коллекция альтернатив, и значение, которое задает максимальное количество альтернатив для возврата. Данный метод может затем возвратить коллекцию RecognitionAlternateCollection альтернатив из выбранного фрагмента внутри строки наилучшего результата из результата распознавания.
Класс Recognition Results дополнительно может включать в себя метод с именем «RecognitionResult Merge(RecognitionResult left, string separator, RecognitionResult right)». Данный метод может использоваться для создания нового объекта RecognitionResult из одной строки, приводящей к плоской решетке, присоединения одной строки к началу или концу существующего объекта RecognitionResult или сцепления одной строки между двумя существующими объектами RecognitionResult. Данный класс также может включать в себя метод с именем «ModifyTopAlternate(RecognitionAlternate alternate), который задает модифицирование результата распознавания с помощью известной альтернативы. В соответствии с некоторыми вариантами выполнения изобретения, по умолчанию строка наилучшего результата из результатов процесса анализа распознавания соответствует наилучшей альтернативе. Однако данный метод может использоваться для задания того, что альтернативы, отличные от наилучшей альтернативы, используются в результатах процесса анализа распознавания. Если новая наилучшая альтернатива приводит к сегментации, отличной от предыдущей, то метод ModifyTopAlternate будет автоматически обновлять узлы контекста, чтобы отражать изменения. Необходимо отметить, что для того, чтобы извлечь альтернативы, которые могут быть использованы для модификации результата распознавания, данный метод вызывает метод GetAlternatesFromSelection, подробно описанный ниже. Данный класс также может иметь метод с именем «Stream Save()», который постоянно поддерживает соответствующий объект RecognitionResults в виде решетки распознавания. Решетка распознавания представляет собой сериализованный формат, используемый для выражения результатов процесса распознавания.
API анализа чернил также может иметь перечислимый тип Analysis Options. Упомянутый тип может содержать одно или несколько полей, которые задают то, как данные чернил будут анализироваться процессом анализа, такие как поле с именем «const AnalysisOptions Default», которое разрешает все доступные опции для процесса анализа. Упомянутое поле, например, может разрешить распознавание текста, использование таблиц, использование списков, использование аннотаций, использование соединителей и контейнеров и использование промежуточных результатов. Упомянутый тип также может включать в себя поле с именем «const AnalysisOptions EnableAnnotations», которое разрешает и запрещает обнаружение аннотаций, поле с именем «const AnalysisOptions EnableConnectorsAndContainers», которое разрешает и запрещает обнаружение соединителей и контейнеров, и поле с именем «const AnalysisOptions EnableIntermediateResults» разрешает и запрещает возврат результатов анализа программному приложению 1701 между использованием различных последовательных процессов анализа (например, между процессом синтаксического разбора и последующим процессом распознавания). Упомянутый тип также может иметь поле с именем «const AnalysisOptions EnableLists», которое разрешает и запрещает обнаружение списков, и поле с именем «const AnalysisOptions EnableTables», которое разрешает и запрещает обнаружение таблиц. Упомянутый перечислимый тип может дополнительно включать в себя поле с именем «const AnalysisOptions EnableTextRecognition», которое разрешает и запрещает процесс анализа распознавания текста. Необходимо заметить, однако, что если доступны дополнительные процессы анализа (или различные варианты одного и того же процесса анализа), то тогда данный тип может включать в себя, следовательно, дополнительный AnalysisOptions.
Далее, API анализа чернил может включать в себя класс AnalysisResultsEventArgs. Данный класс может иметь конструктор с именем «public AnalysisResultsEventArgs()», который создает структуру данных, которая содержит результаты анализа, и возвращает программному приложению 1701, когда устанавливается событие AnalysisResults. Данный класс также может включать в себя свойство с именем «InkAnalyzer InkAnalyzer {get;}», которое идентифицирует объект InkAnalyzer, который выполнял процесс анализа.
API также может иметь класс Line, который может применяться с некоторыми типами операционных систем, которые распознают использование объекта «Line», представляющего геометрическую линию. Данный класс может включать в себя конструктор, такой как конструктор с именем «public Line(Point beginPoint, Point endPoint)», который создает объект Line. Данный класс также может включать в себя различные свойства, такое как свойство с именем «public Point BeginPoint {get; set;}», которое представляет начальную точку объекта линии, и свойство с именем «public Point EndPoint {get; set;}», которое представляет конечную точку объекта линии.
В дополнение к данным классам API анализа чернил также может содержать класс Recognition Alternate. Данный класс может включать в себя элементы, представляющие возможные соответствия слов для сегментов чернил, которые сравниваются со словарем средства распознавания. Например, данный класс может включать в себя свойство с именем «Line Ascender {get;}», которое предоставляет линию надстрочного элемента объекта RecognitionAlternate, который существует на одной линии (причем линия представляется в виде двух точек), свойство с именем «public Line Baseline {get;}», которое предоставляет Baseline объекта RecognitionAlternate, который существует на одной линии, и свойство с именем «Line Descender {get;}», которое предоставляет линию подстрочного элемента объекта RecognitionAlternate, который существует на одной линии. Данный класс также может включать в себя свойство с именем «RecognitionResult Extract {get;}», которое предоставляет объект RecognitionResults для текущего объекта RecognitionAlternate. Данное свойство может быть использовано, например, для извлечения объекта RecognitionResult для слова из объекта RecognitionResult для строки, содержащей данное слово.
Он также может включать в себя свойство с именем «Line Midline {get;}», которое предоставляет среднюю линию для объекта RecognitionAlternate, который существует на одной линии, свойство с именем «StrokeCollection Stroke {get;}», которое предоставляет коллекцию штрихов, содержащихся в объекте чернил (т.е. оно предоставляет StrokeCollection, представляющую штрихи, которые ассоциированы с RecognitionResult), и свойство с именем «StrokeCollection[] StrokesArray {get;}», которое предоставляет коллекцию штрихов, содержащихся в одном или нескольких объектах чернил, представляющих штрихи, которые ассоциированы с RecognitionResult. Данный класс также может включать в себя свойство с именем «RecognitionConfidence RecognitionConfidence {get;}», которое предоставляет уровень уверенности (например, сильная, промежуточная или слабая), которую процесс анализа распознавания определил при распознавании объекта RecognitionAlternate или жеста. Для нестрочных узлов возвращается самая слабая RecognitionConfidence дочерних узлов соответствующих узлов контекста. Он также может содержать свойство с именем «string RecognizedString {get;}», которое задает строку результата альтернативы. Таким образом, для любого узла контекста над узлом контекста слова строка результатов сцепляется вместе посредством данного метода. Например, узел строки содержит строку результатов, которая, в свою очередь, содержит результаты всех ее дочерних узлов или узлов слова. Узел абзаца тогда содержит строку результатов, которая содержит результаты всех ее дочерних узлов или узлов строки.
Класс Recognition Alternate также может содержать один или несколько методов, включающих, например, метод с именем «StrokeCollection[] GetStrokesArrayFromTextRange(int selectionstart, selectionlength)», который задает StrokeCollection из каждого объекта чернил, который соответствует известной области текста. Данный класс также может содержать метод с именем «StrokeCollection[] GetStrokesFromStrokesArrayRanges(StrokeCollection[] strokesArray)», который задает наименьшую коллекцию штрихов, которая содержит известную введенную коллекцию штрихов и для которой средство распознавания может обеспечить альтернативы. Более конкретно, штрихи возвращаются посредством массива объектов чернил, причем каждый содержит массив индексов штрихов для коллекции. Необходимо заметить, что коллекция штрихов чернил, возвращаемая данным методом, может соответствовать введенной коллекции, или она может быть больше, если введенная коллекция соответствует только части наименьшего результата распознавания, который включает в себя все введенные штрихи. Данный класс может дополнительно включать в себя метод с именем «StrokeCollection GetStrokesFromStrokesRanges(StrokeCollection strokes)», который задает наименьшую коллекцию штрихов, которая содержит известную введенную коллекцию штрихов и для которой средство распознавания может обеспечить альтернативы, и метод с именем «StrokeCollection GetStrokesFromTextRange(int selectionstart, int selectionlength)», который задает StrokeCollection, который соответствует известной области текста.
Данный класс может дополнительно включать в себя метод с именем «void GetTextRangeFromStrokes(ref int selectionstart, ref int selectionend, StrokeCollection strokes)», который задает наименьшую область распознаваемого текста, для которой средство распознавания может возвратить альтернативу, которая содержит известный набор штрихов, и метод с именем «void GetTextRangeFromStrokesArray(ref int selectionstart, ref int selectionend, StrokeCollection[] strokesarray)», который задает наименьшую область распознаваемого текста, для которой средство распознавания может возвратить альтернативу, которая содержит известный набор штрихов. Он также может иметь метод с именем «RecognitionAlternateCollection SplitWithConstantPropertyValue(GUID propertyType)», который возвращает коллекцию альтернатив, которые представляют собой раздел альтернативы, для которой данный метод вызывается. Каждая альтернатива в коллекции содержит смежные сегменты распознавания, которые имеют такое же значение свойства для свойства, переданного методу. Например, данный метод может быть использован для получения альтернатив, которые делят исходную альтернативу уровнем границ уверенности (сильная, промежуточная или слабая) в результате распознавания, границ линии или границ сегмента. Он может дополнительно включать в себя метод с именем «byte[] GetPropertyValue(GUID propertyType)», который задает значение известного свойства альтернативы, такого как уверенность распознавателя в альтернативе. Не все процессы анализа распознавания, однако, предоставляют значение для всех типов свойств. Таким образом, данный метод предоставляет данные для типов, поддерживаемых соответствующим процессом анализа распознавания.
API анализа чернил также может включать в себя класс Recognition Alternate Collection. Подобно многим описанным выше классам данный класс может включать в себя конструктор с именем «RecognitionAlternateCollection()» для создания объекта RecognitionAlternateCollection. Данный класс также может включать в себя ряд свойств, таких как свойство с именем «Count {get;}», которое предоставляет количество объектов или коллекций, содержащихся в коллекции значений распознавания альтернатив, свойство с именем «IsSynchronized {get;}», которое предоставляет значение, указывающее, синхронизирован ли доступ к коллекции значений распознавания альтернатив с программным приложением 1701 (т.е. «надежность потока»), и свойство с именем «SyncRoot {get;}», которое предоставляет объект, который может использоваться для синхронизации доступа к коллекции значений распознавания альтернатив.
Данный класс также может содержать один или несколько методов, таких как метод с именем «virtual void CopyTo(Array array, int index)», который копирует все элементы текущей коллекции значений распознавания альтернатив в заданный одномерный массив, начинающийся с заданным индексом массива назначения, и метод с именем «IEnumerator IEnumerable.GetEnumerator()», который представляет собой стандартную реализацию IEnumerable, который разрешает вызывающей стороне использовать для каждого построения, чтобы перечислять каждый RecognitionAlternate в коллекции значений распознавания альтернатив. Данный класс также может включать в себя метод с именем «RecognitionAlternateCollectionEnumerator GetEnumerator()», который возвращает RecognitionAlternateCollectionEnumerator, который содержит все объекты внутри коллекции значений распознавания альтернатив. Данный метод может использоваться, например, для извлечения каждого объекта в коллекции значений распознавания альтернатив.
API анализа чернил может дополнительно включать в себя перечисление Recognition Confidence и перечисление Recognition Mode, каждое из которых может содержать одно или несколько полей, относящихся к процессу анализа распознавания. Например, класс Recognition Confidence может содержать множество полей, таких как поле с именем «Intermediate», указывающих, что процесс анализа распознавания уверен в том, что правильный результат находится в списке предоставленных значений распознавания альтернатив, поле с именем «Poor», которое указывает, что анализ распознавания не уверен в том, что результат находится в списке предоставленных значений распознавания альтернатив, и поле с именем «Strong», которое указывает, что процесс анализа распознавания уверен в том, что наилучшая альтернатива в значениях распознавания альтернатив является правильной.
Аналогично, класс Recognition Mode может включать в себя поля, которые задают то, как процесс анализа распознавания интерпретирует данные электронных чернил и, таким образом, определяет строку результатов распознавания. Например, данный класс может включать в себя поле с именем «Coerce», которое задает, что процесс анализа распознавания предписывает результату распознавания быть основанным на фактоиде, который был задан для контекста, и поле с именем «Line», которое задает, что процесс анализа распознавания рассматривает данные электронных чернил в виде одной строки. Данный класс также может включать в себя поле с именем «None», которое задает, что процесс анализа распознавания не применяет режим распознавания, и поле с именем «Segment», которое задает, что процесс анализа распознавания рассматривает данные электронных чернил как формирующие одно слово или знак. Далее, данный класс может включать в себя поле с именем «TopInkBreaksOnly», которое запрещает многократную сегментацию.
Далее, API анализа чернил может включать в себя класс Context Link, который определяет, как два узла контекста могут быть связаны вместе. Объект ContextLink сам по себе представляет то, какие два узла контекста связаны, направление связи и тип связи. Данный класс может включать в себя свойство с именем «ContextNode SourceNode{get;}», которое задает узел контекста источника, который связывается с другим узлом контекста, свойство с именем «ContextLinkType LinkType{get;}», которое задает тип отношения связи, которая существует между узлами контекста источника и назначения, и свойство с именем «CustomLinkType{get;}», которое задает, что используется нестандартная связь. Упомянутая ситуация может иметь место тогда, когда приложение принимает решение использовать систему связывания API анализатора чернил, чтобы представить связи, характерные для приложения, сверх того что API может распознать.
Данный класс также может включать в себя свойство с именем «ContextNode DestinationNode {get;}», которое задает узел контекста назначения, который связывается от другого узла контекста. Могут быть два конструктора, доступных для данного класса, которые создают взаимосвязь между существующими узлами контекста источника и назначения.
Данный класс также может включать в себя перечисление с именем «ContextLinkType enum», которое определяет тип взаимосвязи, совместно используемой двумя узлами контекста. Упомянутые различные типы связи могут включать в себя, например, тип «AnchorsTo», который описывает, что один узел жестко привязан к другому узлу. Оба узла могут использовать свойство SourceNode или DestinationNode, основываясь на ситуации с синтаксическим разбором. Типы связи также могут включать в себя тип «Contains», который описывает, что один узел содержит другой узел. В соответствии с упомянутой взаимосвязью узел контейнера может упоминаться как SourceNode, тогда как узел содержимого контейнера может упоминаться как DestinationNode. Типы связи дополнительно могут включать в себя тип «PointsTo», который описывает, что один узел указывает на другой узел. Для упомянутой взаимосвязи узел, выполняющий указывание, может упоминаться как SourceNode, тогда как узел, на который производится указывание, может упоминаться как DestinationNode. Далее, типы связи могут иметь тип «PointsFrom», который описывает, что один узел указывает от другого узла. При упомянутой взаимосвязи узел, указывающий от другого узла, может упоминаться как SourceNode, тогда как узел, на который указывают, может упоминаться как DestinationNode.
Типы связей дополнительно могут включать в себя тип «SpansHorizontally», который описывает, что один узел проходит по длине в горизонтальном направлении другого узла, и тип «SpansVertically», который описывает, что один узел проходит по длине в вертикальном направлении другого узла. Для данных типов узел, покрывающий (зачеркивание, подчеркивание, черта на полях) другой узел, обычно записанный последним, может упоминаться как SourceNode, тогда как узел, который является перекрываемым, может упоминаться как DestinationNode. Типы связей также могут включать в себя тип «Custom», который описывает, что используется тип нестандартной связи. Когда используется упомянутое значение, свойство «CustomLinkType» объекта ContextLink может предоставлять больше подробностей в отношении назначения упомянутой связи.
Следовательно, API анализатора чернил предоставляет разнообразные функции и службы для асинхронного анализа электронных чернил в документе и затем, впоследствии, согласования результатов процесса анализа с текущим состоянием документа, как подробно описано выше. Далее, необходимо понять, что различные классы, описанные выше, могут быть применены к разнообразным операционным системам и средам, таким как операционная среда Microsoft Windows, операционная среда Microsoft COM, операционная среда Unix или Linux или любая другая подходящая операционная среда компьютера. Кроме того, следует понимать, что интерфейс прикладного программирования в соответствии с различными вариантами реализации изобретения может исключать один или несколько компонентов класса, описанных выше, или может включать в себя дополнительные компоненты для получения требуемой службы или функциональных возможностей.
Согласование
Как подробно описано выше, различные примеры изобретения позволяют программному приложению 1701 продолжать свою работу, в то время как непроанализированные электронные чернила в документе 1703 анализируются посредством фонового процесса анализа. Вследствие этого, программное приложение 1701 может модифицировать документ 1703 различными путями, которые будут конфликтовать с результатами процесса анализа. Например, программное приложение 1701 может ввести новые данные 1705 электронных чернил в документ 1703 или удалить существующие данные 1705 электронных чернил из документа 1703. Далее, программное приложение 1701 может редактировать существующие данные 1705 электронных чернил, например, перемещением положения существующих данных 1705 электронных чернил или изменением свойств существующих данных 1705 электронных чернил. Далее, программное приложение 1701 может добавлять, удалять или модифицировать нечернильные элементы 1707 документа таким образом, который влияет на существующие данные 1705 электронных чернил. Например, программное приложение 1701 может удалить машинописный текст, который был аннотирован данными 1705 электронных чернил.
Программное приложение 1701 может дополнительно «закрепить» существующие данные 1705 электронных чернил, для того чтобы запретить их изменение процессом анализа. Например, если пользователь вручную задает компоновку или классификацию для группы штрихов чернил, то тогда программное приложение 1701 может обозначить, что данные штрихи чернил остаются в упомянутой конкретной компоновке или с упомянутой классификацией независимо от результатов, полученных процессом синтаксического разбора. Аналогично, пользователь может задать конкретный результат распознавания для группы штрихов чернил независимо от результатов, полученных процессом распознавания.
Различные типы закрепления могут быть использованы в соответствии с различными вариантами реализации изобретения. Например, инструментальное средство 1901 анализа чернил может разрешить программному приложению 1701 «жестко» закреплять чернила. В соответствии с упомянутой схемой штрихи чернил не могут быть добавлены ни к какому из концевых узлов под закрепленным узлом, штрихи не могут быть удалены из каких-либо концевых узлов под закрепленным узлом, не разрешено ни добавление, ни удаление дочерних узлов, и не разрешено повторное образование родительских узлов для любого узла под закрепленным узлом. Альтернативно или дополнительно, инструментальное средство 1901 анализа чернил может разрешить «жесткое» закрепление при помощи более поздних более штрихов, которое разрешает добавление более поздних штрихов при заданных условиях, запрещает удаление штрихов из любого концевого узла под закрепленным узлом, запрещает добавление или удаление дочерних узлов и запрещает повторное образование родительских узлов для любого узла под закрепленным узлом. Далее, инструментальное средство 1901 анализа чернил может разрешить программному приложению 1701, альтернативно или дополнительно, «мягко» закреплять чернила. В соответствии с упомянутой схемой штрихи не могут быть удалены из какого-либо концевого узла под закрепленным узлом, существуют заданные правила, разрешающие добавление штрихов (разрешается добавление поздних штрихов), и разрешены перегруппировка, добавление и удаление дочерних узлов. Необходимо заметить, что закрепление может быть удалено, и, если закрепление было удалено, то ранее закрепленные узлы и их дочерние узлы затем могут рассматриваться как «измененные» или требующие повторного анализа.
Далее, процесс обработки чернил в соответствие с различными примерами изобретения может использовать многочисленные процессы анализа, как подробно описано выше. Следовательно, результаты процесса более раннего анализа могут модифицировать данные 1705 электронных чернил, в то время как выполняется последующий процесс второго анализа. Следовательно, результаты процесса анализа должны быть согласованы с текущим состоянием документа 1703, так что только те результаты, которые являются действительными для текущего состояния документа 1703, применяются к его объекту 1709 контекста анализа. Т.е. модифицируется текущий объект 1709 контекста анализа (и, в некоторых случаях, результаты процесса анализа), чтобы исключить расхождения или «коллизии» между результатами процесса анализа и текущим состоянием документа 1703.
Необходимо заметить, что для того, чтобы результаты процесса согласования были действительными, состояние документа 1703 не должно изменяться во время процесса согласования. Процесс согласования, таким образом, может выполняться с использованием первичного потока, в котором выполняется программное приложение 1701, и выполнение процесса согласования может временно остановить работу программного приложения 1701. Альтернативно, другие методики, такие как блокирование структуры данных, могут быть использованы для обеспечения того, что состояние документа 1703 не меняется во время процесса согласования. Следовательно, желательно, чтобы процесс согласования выполнялся как можно быстрее, для того чтобы исключить неудовлетворенность пользователя рабочими характеристиками программного приложения 1701. Другим вопросом процесса согласования, требующим рассмотрения, является его влияние на рабочие характеристики процесса анализа, выполняемого в отдельном фоновом потоке анализа. Если расхождения между текущим объектом 1709 контекста анализа (т.е. объектом 1709 контекста анализа, отражающим текущее состояние документа 1703) и результатами анализа определены слишком широко, то тогда большие количества электронных чернил будут повторно анализироваться без необходимости. Конечно, могут быть использованы другие пути защиты целостности документа во время согласования без отступления от изобретения.
В соответствии с различными примерами изобретения процесс анализа и процесс согласования могут придерживаться одного или нескольких следующих соглашений, для того чтобы повысить эффективность и удобство процесса согласования. Во-первых, процесс анализа может, насколько возможно, повторно использовать узлы для элемента документа в независимом от документа объекте 1903 контекста анализа. Т.е. коллизии не должны аннулироваться посредством создания новых несвязанных узлов для элементов документа. Кроме того, процесс согласования должен соблюдать «закрепление», обозначенное программным приложением 1701. Хотя данный процесс анализа обычно соблюдает обозначения закрепления программного приложения 1701, программное приложение 1701 может закрепить данные 1705 электронных чернил во время выполнения процесса анализа. Далее, процесс согласования должен обеспечить, чтобы не оставалось пустых узлов в текущем объекте 1709 контекста анализа после завершения процесса согласования. Необходимо заметить, однако, что одно или несколько из упомянутых соглашений могут быть опущены и могут не выполняться согласно альтернативным варианты реализации изобретения. Например, некоторые вариантам реализации изобретения могут разрешить объекту 1709 анализа содержать пустые узлы.
В дополнение к этим соглашениям процесс согласования должен обычно соблюдать правила интерфейса, диктуемые объектом 1709 контекста анализа. Например, в соответствии с некоторыми вариантами реализации изобретения объект 1709 контекста анализа может не разрешать удаление узла для элемента документа за исключением того случая, когда он не имеет дочерних узлов.
Как ранее отмечено, коллизии имеют место тогда, когда процесс анализа выполняет изменение в независимом от документа объекте 1903 контекста анализа, который конфликтует некоторым образом с изменением в объекте 1709 контекста анализа, которое было сделано после инициирования процесса анализа. Коллизии могут быть разделены на два типа: обязательные коллизии и дискреционные коллизии.
Обязательные коллизии имеют место тогда, когда нельзя применить изменение, сделанное процессом анализа в независимом от документа объекте 1903 контекста анализа, к объекту 1709 контекста анализа для текущего состояния документа 1703. Обязательная коллизия имеет место тогда, когда, например, программное приложение 1701 «закрепило» или зафиксировало узел в объекте 1709 контекста анализа, и процесс анализа изменил соответствующий узел в независимом от документа объекте 1903 контекста анализа. Обязательная коллизия также имеет место тогда, когда процесс анализа сделал изменение любого вида узла в независимом от документа объекте 1903 контекста анализа, но программное приложение 1701 удалило соответствующий узел из объекта 1709 контекста анализа, и когда программное приложение 1701 добавило штрихи или дочерние узлы к узлу в объекте 1709 контекста анализа, когда процесс анализа удалил соответствующий узел в независимом от документа объекте 1903 контекста анализа. Далее, обязательная коллизия имеет место тогда, когда программное приложение 1701 удалило узел в объекте 1709 контекста анализа, когда процесс анализа переупорядочил или создал связь с соответствующим узлом в независимом от документа объекте 1903 контекста анализа.
Дискреционная коллизия имеет место тогда, когда программное приложение 1701 изменило значение в объекте 1709 контекста анализа, которое связано со значением, измененным процессом анализа в независимом от документа объекте 1903 контекста анализа, но ограничения закрепления, ограничения повторного использования элемента и присущие ограничения интерфейса для объекта 1709 контекста анализа все же могут разрешить применение изменения, сделанного процессом анализа в объекте 1709 контекста анализа. Дискреционная коллизия все же может быть применена в качестве изменения объекта 1709 контекста анализа или аннулирована. Далее, процесс согласования просто может совсем проигнорировать некоторые типы дискреционных коллизий.
Один графический пример дискреционной коллизии имеет место тогда, когда исходный узел как в объекте 1709 контекста анализа, так и в независимом от документа объекте 1903 контекста анализа имеет дочерние узлы А и В для штрихов А и В чернил. Программное приложение 1701 может тогда добавить третий дочерний узел С для штриха С чернил в объекте 1709 контекста анализа, в то время как процесс анализа добавляет третий дочерний узел D для штриха D чернил к независимому от документа объекту 1903 контекста анализа. В соответствии с различными вариантами выполнения изобретения процесс согласования может добавить дочерний узел D к родительскому узлу в объекте 1709 контекста анализа, основываясь на результатах анализа. Хотя данное изменение родительского узла в объекте 1709 контекста анализа не запрещено, однако, оно все же изменяет характеристики родительского узла таким образом, который может быть нежелательным для программного приложения 1701. Например, чернила, ассоциированные с родительским узлом, могут, впоследствии, считаться проанализированными и повторно могут не анализироваться, чтобы принять во внимание влияние чернил С на группу штрихов чернил. Далее, результаты распознавания для родительского узла теперь могут ссылаться на неправильные дочерние узлы или штрихи, и это также никогда не может быть снова скорректировано.
Следовательно, различные примеры изобретения не применяют изменения для дискреционной коллизии при обновлении объекта 1709 контекста анализа, основываясь на результатах процесса анализа. Хотя упомянутые критерии могут потребовать дополнительной обработки для идентификации и блокирования изменений, основываясь на дискреционных коллизиях, упомянутый критерий относительно просто реализовать и просто поддерживать. Конечно, другие примеры изобретения могут выполнять изменения, соответствующие дискреционным коллизиям согласно другим критериям. Более конкретно, данные альтернативные примеры могут осуществлять изменения из дискреционных коллизий, которые не создают постоянных логически несовместимых взаимосвязей в объекте 1709 контекста анализа.
Также необходимо заметить, что коллизии могут иметь транзитивный эффект, заключающийся в том, что одна коллизия может создавать другую. Например, процесс анализа может создать узел L для строки и затем создать узел W для слова в качестве дочернего узла для узла L. Если создание узла L не применялось к объекту 1709 контекста анализа вследствие коллизии любого вида, то тогда создание узла W будет представлять собой обязательную коллизию.
Различные примеры изобретения могут использовать основанный на протоколировании подход для согласования результатов процесса анализа с текущим состоянием документа 1703. В данном основанном на протоколировании подходе независимый от документа объект 1903 контекста анализа включает в себя протокол изменений в независимом от документа объекте 1903 контекста анализа, сделанных процессом анализа. Протокол может быть в виде, например, списка записей изменений. Каждая запись изменения, тогда, может включать в себя тип изменения, которое было сделано (посредством идентификации, например, метода, который был вызван для изменения независимого от документа объекта 1903 контекста анализа), элемент документа, в котором было сделано изменение (посредством идентификации, например, узла в независимом от документа объекте 1903 контекста анализа, для которого был вызван метод), и любую информацию, необходимую для повторного создания аргументов для вызова метода. Выгодно, так как независимый от документа объект 1903 контекста анализа осуществляется инструментальным средством 1901 анализа чернил и процессами анализа, чтобы протокол изменений мог быть невидимым для программного приложения 1701 (хотя протокол, альтернативно, может быть открыт приложению 1701, если потребуется).
Для того чтобы выполнить процесс согласования с использованием подхода протоколирования изменений, инструментальное средство 1901 анализа чернил исследует каждую запись изменения в хронологическом порядке изменений. Т.е. инструментальное средство 1901 анализа чернил идентифицирует каждое изменение, сделанное в независимом от документа объекте 1903 контекста анализа. Для каждого изменения инструментальное средство 1901 анализа чернил может выполнить процесс, изображенный на фиг.27. Сначала, на шаге 2701 инструментальное средство 1901 анализа чернил предпринимает попытку доступа к соответствующим узлам в текущем объекте 1709 контекста анализа, к которым необходимо применить изменение. Необходимо заметить, что данный шаг извлечения может завершиться неуспешно, если программное приложение 1701 удалило один или несколько необходимых узлов из объекта 1709 контекста анализа, приводя к обязательной коллизии.
Затем, на шаге 2703 инструментальное средство 1901 анализа чернил определяет, создает ли изменение обязательную или дискреционную коллизию. Процедура выполнения данного определения подробно объясняется ниже. На шаге 2705 инструментальное средство 1901 анализа чернил либо делает изменение, либо запрещает изменение, если оно создает обязательную коллизию или дискреционную коллизию, запрещенную критерием для процесса согласования. Например, если изменение создает обязательную коллизию или дискреционную коллизию, запрещенную критерием для процесса согласования, то тогда инструментальное средство 1901 анализа чернил может блокировать изменения узлов в объекте 1709 контекста анализа, представляющих соответствующую область документа 1703, в которой должно было быть сделано изменение. Если, с другой стороны, изменение применяется, то тогда инструментальное средство 1901 анализа чернил может вызвать соответствующий метод, чтобы сделать требуемое изменение необходимых узлов в объекте 1709 контекста анализа.
Если процесс анализа добавляет новый узел элемента к объекту 1709 контекста анализа, но затем не может переместить узлы штриха в новый узел, то тогда процесс анализа также не сделает попытку удалить узел элемента на том предположении, что узлы штриха были успешно перемещены в новые узлы. Таким образом, в независимом от документа объекте 1903 контекста анализа будет узел элемента, который соответствует пустому узлу в текущем объекте 1709 контекста анализа. Следовательно, если были обработаны все изменения в объекте 1709 контекста анализа, то на шаге 2707 инструментальное средство 1901 анализа чернил просматривает независимый от документа объект 1903 контекста анализа для удаления любых «пустых» узлов в объекте 1709 контекста анализа, которые соответствуют узлам в независимом от документа объекте 1903 контекста анализа. Данный шаг удаления пустых узлов является необязательным и может быть опущен без отступления от изобретения.
Необходимо заметить, что независимый от документа объект 1903 контекста анализа не должен содержать никаких пустых узлов, и процесс согласования должен запретить создание пустых узлов в независимом от документа объекте 1903 контекста анализа. Также необходимо заметить, что данный шаг, как исключение, не предпринимает попытку удалить корневой узел объекта 1709 контекста анализа, даже если он пустой. Наконец, на шаге 2709 инструментальное средство 1901 анализа чернил идентифицирует любые коллизии между результатами анализа в независимом от документа объекте 1903 контекста анализа и текущем объекте 1709 контекста анализа для программного приложения 1701, так что программное приложение 1701 может включать области документа 1703, затронутые коллизиями, в последующий процесс анализа.
Возвращаясь теперь к обнаружению коллизий на вышеупомянутом шаге 2703, если доступны все узлы в объекте 1709 контекста анализа, соответствующие изменениям в независимом от документа объекте 1903 контекста анализа, то все другие возможные обязательные коллизии для каждого узла в объекте 1709 контекста анализа могут быть обнаружены статически (или, альтернативно, отсутствие обязательной коллизии может быть обнаружено для каждого узла). Более конкретно, обязательные коллизии могут быть обнаружены, основываясь на правилах, обозначенных интерфейсом для объекта 1709 контекста анализа.
Дискреционные коллизии, однако, обычно не могут быть идентифицированы без дополнительной информации о состоянии в отношении документа 1703, так как данные изменения не уполномочены интерфейсом объекта 1709 контекста анализа, но, вместо этого, основываются на дискреционном выборе о разрешении изменений, сделанных программным приложением 1701, относительно изменений, сделанных процессом анализа, когда оба воздействовали на один и тот же узел в объекте 1709 контекста анализа. Эти коллизии, вместо этого, могут быть обнаружены сравнением текущего объекта 1709 контекста анализа с исходной версией независимого от документа объекта 1903 контекста анализа для определения того, какие узлы в объекте 1709 контекста анализа были изменены программным приложением 1701.
Например, критерий согласования может определять, что добавление или удаление дочернего узла штриха из родительского узла программным приложением 1701 представляет собой дискреционную коллизию для данного родительского узла. Для определения того, произошло ли такое изменение, инструментальное средство 1901 анализа чернил может просмотреть дочерние узлы штриха, зависящие от узла в текущем объекте 1709 контекста анализа, и сравнить их количество и GUID (или другой уникальный идентификатор) с дочерними узлами штриха, зависящими от соответствующего узла в исходной версии независимого от документа объекта 1903 контекста анализа. Если дочерние узлы штриха согласуются в данных аспектах (и в любых других требуемых аспектах), то тогда инструментальное средство 1901 анализа чернил может применить изменения, сделанные процессом анализа, к родительскому узлу в объекте 1709 контекста анализа.
Продолжая данный пример, следующее изменение в записи протокола может состоять из другого узла штриха, перемещаемого для зависимости от родительского узла в независимом от документа объекте 1903 контекста анализа. Если нет обязательных коллизий из-за данного изменения, то тогда инструментальному средству 1901 анализа чернил разрешается сделать соответствующее изменение в объекте 1709 контекста анализа. Когда инструментальное средство 1901 анализа чернил проверяет исходную версию независимого от документа объекта 1903 контекста анализа с целью определения того, существует ли дискреционная коллизия, однако, оно делает вывод о том, что родительский узел в текущем объекте 1709 контекста анализа имеет на один зависимый узел штриха больше, чем родительский узел в исходной версии независимого от документа объекта 1903 контекста анализа, так что оно ошибочно определит, что существует дискреционная коллизия (т.е. оно определит, что существует коллизия, основываясь на изменениях, которые оно сделало).
Следовательно, основанный на протоколировании процесс согласования должен исключать предыдущие изменения, сделанные в результате согласования, из сравнения между текущим объектом 1709 контекста анализа и исходной версией независимого от документа объекта 1903 контекста анализа. В соответствии с различными примерами изобретения данное исключение может быть сделано сравнением всех узлов в текущем объекте 1709 контекста анализа с их соответствующими узлами в исходной версии независимого от документа объекта 1903 контекста анализа перед исследованием любых элементов списка изменений и сохранением списка узлов, которые имеют коллизии.
Альтернативно или дополнительно, различные примеры изобретения могут поддерживать кэш элементов в текущем объекте 1709 контекста анализа, соответствующих элементам в независимом от документа объекте контекста анализа с результатами анализа, которые используются всякий раз, когда извлекаются соответствующие элементы. Нет предварительной передачи, но кэш заполняется первый раз, когда определено, что соответствующий элемент свободен от дискреционных коллизий. В необязательном порядке, кэш также может отслеживать то, какие элементы в результатах имели дискреционные коллизии. Данный подход имеет лучшие рабочие характеристики, чем подход с передачей нахождения дискреционных коллизий, когда протокол изменений короткий, но может иметь худшие рабочие характеристики, если независимый от документа объект 1903 контекста анализа с результатами анализа содержит много узлов. Он также не сложнее, чем другой подход.
Необходимо заметить, что родительские узлы контекста элементов в кэше также должны кэшироваться. Более конкретно, изменение дочернего узла контекста рассматривается как изменение свойств его родительского узла контекста. Таким образом, родительский узел контекста узла контекста, хранимого в кэше, также требует оценки в отношении изменений, сделанных программным приложением 1701 в данный момент. Кэширование родительских узлов для каждого узла контекста в кэше требует повторения вверх по дереву (например, от родительского узла к дедовскому узлу и к прадедовскому узлу), пока не будет пройден корневой узел или пока не будут обнаружены изменения. Во многих ситуациях, однако, такое повторение составляет только несколько узлов, так как дерево обычно не становится очень высоким.
Также необходимо заметить, что в соответствии с различными примерами изобретения исходная версия независимого от документа объекта 1903 контекста анализа используется только для обнаружения дискреционных коллизий. Если обнаружение дискреционных коллизий необязательно в соответствии с примером изобретения, то тогда может быть исключена как исходная версия независимого от документа объекта 1903 контекста анализа, так и кэш соответствующих элементов. Данный «основанный на протоколировании» подход может быть более легким для поддержки, чем «основанный на сравнении» подход, описанный ниже, так как он требует меньшего поиска для определения того, какие изменения были сделаны процессом анализа, и операции над независимым от документа объектом 1903 контекста анализа (такие как «удалить узел» или «создать узел») обрабатываются отдельно, так что добавление нового типа операции не имеет тенденции к оказанию влияния на другие операции.
Вместо «основанной на протоколировании» методики согласования результатов анализа с текущим состоянием документа 1703 различные примеры изобретения могут использовать для согласования «основанный на сравнении» подход. Основным отличительным признаком основанного на сравнении подхода является то, что не ведется протокол изменений, сделанных в независимом от документа объекте 1903 контекста анализа, так что упомянутая методика не собирает информацию о том, что процесс анализа делал иначе как посредством сравнения независимого от документа объекта 1903 контекста анализа, содержащего результаты анализа, с исходной версией независимого от документа объекта 1903 контекста анализа. Поэтому, в соответствии с упомянутым подходом всегда требуется исходная версия независимого от документа объекта 1903 контекста анализа независимо от любых оценок дискреционных коллизий.
Используя упомянутый подход инструментальное средство 1901 анализа чернил сначала строит карту штрихов. Т.е. для каждого концевого узла чернил в исходной версии независимого от документа объекта 1903 контекста анализа, если существует соответствующий узел в текущем объекте 1709 контекста анализа, то тогда концевой узел добавляется к хэш-таблице (или другой подходящей структуре данных). Таким образом, хэш-таблица отображает идентификаторы GUID (или другие уникальные идентификаторы узла) штриха в исходной версии независимого от документа объекта 1903 контекста анализа для ссылок на концевые узлы в текущем объекте 1709 контекста анализа.
Затем инструментальное средство 1901 анализа чернил идентифицирует все узлы, которые программное приложение 1701 изменило в объекте 1709 контекста анализа. Это может быть сделано с использованием методик для определения дискреционных коллизий, подробно описанных выше. Для каждого узла в исходной версии независимого от документа объекта 1903 контекста анализа, если существует соответствующий узел в текущем объекте 1709 контекста анализа, и он отличается в некоторой степени существенным образом от узла в исходной версии независимого от документа объекта 1903 контекста анализа, то тогда инструментальное средство 1901 анализа чернил определяет, что данный узел был изменен приложением и представляет собой потенциальную коллизию. Ссылки на такие узлы сохраняются в первом списке, соответствующем узлам результатов анализа, которые не должны добавляться к объекту 1709 контекста анализа (ниже упоминаемому как список resultsNodesNotToAdd), и во втором списке узлов, которые создают дискреционные коллизии.
Для каждого узла в исходной версии независимого от документа объекта 1903 контекста анализа инструментальное средство 1901 анализа чернил отыскивает соответствующие узлы как в независимом от документа объекте 1903 контекста анализа с результатами анализа, так и в текущем объекте 1709 контекста анализа. Для каждого узла в объекте 1709 контекста анализа инструментальное средство 1901 анализа чернил определяет, удалило ли программное приложение 1701 узел. Такие узлы существуют в исходной версии независимого от документа объекта 1903 контекста анализа, но не имеют соответствующего узла в объекте 1709 контекста анализа. Соответствующий узел в независимом от документа объекте 1903 контекста анализа с результатами анализа добавляется к списку resultsNodesNotToAdd, если он существует.
Затем инструментальное средство 1901 анализа чернил определяет, удалил ли процесс анализа узел из независимого от документа объекта 1903 контекста анализа. Это обнаруживается, когда существует соответствующий узел в текущем объекте 1709 контекста анализа, и он не изменился, но не существует соответствующего узла в независимом от документа объекте 1903 контекста анализа с результатами анализа. Узлы, удаленные процессом анализа, могут быть сохранены в списке удаленных узлов. Такой узел не добавляется к текущему объекту 1709 контекста анализа, но он не входит в список resultsNodesNotToAdd, потому что не существует соответствующего узла в независимом от документа объекте 1903 контекста анализа с результатами анализа.
Если программное приложение 1701 ни удалило, ни изменило узел, и процесс анализа не удалил узел, то тогда инструментальное средство 1901 анализа чернил может определить, изменил ли процесс анализа узел. Эти же методики, что и те, которые были описаны выше для использования при обнаружении изменений, сделанных программным приложением 1701, могут быть использованы для обнаружения изменений, сделанных процессом анализа. Узлы, которые были изменены процессом анализа, добавляются к списку resultsNodesNotToAdd, и изменения передаются посредством вызова соответствующих методов для узлов в объекте 1709 контекста анализа. Если ни программное приложение 1701, ни процесс анализа не изменили или не удалили узел, то тогда ничего не произошло с данным узлом, и инструментальное средство 1901 анализа чернил добавляет узел в список resultsNodesNotToAdd, так как узел существует в независимом от документа объекте 1903 контекста анализа с результатами анализа и не должен добавляться к объекту 1709 контекста анализа.
Затем для каждого узла в независимом от документа объекте 1903 контекста анализа с результатами анализа, если узел не находится в списке resultsNodesNotToAdd, то тогда инструментальное средство 1901 анализа чернил может передавать любые изменения узлу при помощи процесса анализа посредством создания соответствующего узла в объекте 1709 контекста анализа. Обход узлов в результатах анализа может выполняться с использованием обхода в прямом порядке сверху вниз, так что гарантируется, что родительские узлы создаются перед дочерними узлами.
При создании нового концевого узла в объекте 1709 контекста анализа любые штрихи чернил, ассоциированные с узлом, которые содержатся в результатах анализа, также могут быть перемещены в новый узел из других узлов в объекте 1709 контекста анализа. Описанная выше карта штрихов затем может быть использована для идентификации элементов источника для перемещения штрихов. Штрихи чернил не перемещаются, если элемент источника не существует (создавая обязательную коллизию), или если элемент источника содержится в списке дискреционных коллизий, также отмеченном выше. Сохраняя необязательные вызовы к объекту 1709 контекста анализа, данное инструментальное средство 1901 анализа чернил может избежать вызова метода для создания дочернего узла контекста, если не существует по меньшей мере один неконфликтующий узел источника штриха. Эта же проверка источника штриха также выполняется на нечернильных концевых узлах, так что узел для строки не создается до тех пор, пока по меньшей мере одно из составляющих строку слов, например, не собирается содержать по меньшей мере один успешно перемещенный штрих.
Затем другая информация также применяется к вновь созданному узлу, такая как решетка распознавания. Решетка распознавания все же применяется, даже если определенные штрихи не могут быть перемещены, создавая применяемую (т.е. неблокируемую) дискреционную коллизию, которая приводит к временной логической несовместимости. Однако, так как неуспешные перемещения штрихов отражаются в обозначении части объекта 1709 контекста анализа, соответствующей области документа, для которой изменения блокированы, несовместимость является временной, так как программное приложение 1701 уведомляется о повторном анализе блокированной области.
Для каждого узла, подлежащего удалению из объекта 1709 контекста анализа, список инструментального средства 1901 анализа чернил проверяет, может ли фактически быть удален узел теперь, когда были выполнены все другие редактирования и добавления к объекту 1709 контекста анализа. Узлы, которые должны быть удалены и которые фактически являются свободными от всех дочерних узлов и штрихов, удаляются из объекта 1709 контекста анализа. Если такой узел удален, то все узлы-предки (вплоть до, но не включая, корневого узла) удаляются последовательно до тех пор, пока не встретится узел-предок с другими оставшимися дочерними узлами.
Наконец, инструментальное средство 1901 анализа чернил выполняет глобальное сравнение упорядочения узлов между независимым от документа объектом 1903 контекста анализа с результатами анализа и объектом 1709 контекста анализа, чтобы обнаружить и передать изменения процессом анализа объекту 1709 контекста анализа. Необходимо заметить, однако, что данное сравнение игнорирует исходную версию независимого от документа объекта 1903 контекста анализа, поэтому у него нет возможности обнаружить изменения в упорядочении, сделанные программным приложением 1701. Затем для каждого узла контейнера в результатах анализа, который имеет соответствующий узел в объекте 1709 контекста анализа, сравнивается упорядочение дочерних узлов для узлов контейнера. Если оба узла контейнера имеют одинаковый набор дочерних узлов, то тогда упорядочение в результатах анализа передается объекту 1709 контекста анализа посредством организации циклов по списку дочерних узлов контейнера в результатах анализа до тех пор, пока не будет найден узел в этом же положении в списке контейнера в объекте 1709 контекста анализа, который не имеет такой же GUID (или другой тип идентификатора) что и дочерний узел в результатах анализа. Когда обнаруживается такое несоответствие, то соответствующий узел должен быть найден ниже в списке дочерних узлов в объекте 1709 контекста анализа. Инструментальное средство 1901 анализа чернил затем производит поиск узла в остальной части списка дочерних узлов в объекте 1709 контекста анализа и вызывает метод для перемещения дочернего узла для коррекции порядка для данного узла в объекте 1709 контекста узла. Затем инструментальное средство 1901 анализа чернил продолжает организацию циклов по узлам в результатах анализа.
Конечно, предположение об идентичных списках не является справедливым, так как либо список анализа, либо программное приложение 1701 может удалить или вставить узлы в любой список. Объект «средство отображения списка дочерних узлов» используется для имитирования предположения, являющегося справедливым, посредством представления «усеченных» списков, которые содержат только элементы, которые содержатся вместе. Описанная выше процедура затем выполняется над отображаемыми списками дочерних узлов, и перемещения преобразуются в реальные индексы и вызовы объектом - средством отображения списка.
Таким образом, методики согласования в соответствии с различными примерами изобретения, описанными выше, позволяют применять результаты процесса анализа к текущим элементам документа в документе, даже если содержимое документа изменилось с тех пор, как был инициирован процесс анализа. Данные методики согласования, поэтому, позволяют проводить анализ электронных чернил в документе асинхронно по отношению к работе программного приложения, являющегося ведущим по отношению к документу. Далее, данные методики согласования могут быть выгодно использованы разнообразными различными программными приложениями, включая существующие многопоточные программные приложения с существующей уникальной блокировкой или другими стратегиями синхронизации.
Управляемая событием система
Как описано выше, различные примеры изобретения создают «снимок» состояния документа посредством копирования независимого от документа объекта контекста анализа и затем асинхронно анализируют независимый от документа объект контекста анализа, в то время как программное приложение, являющееся ведущим по отношению к документу, продолжает свою работу. Альтернативно, различные примеры изобретения могут отказываться от использования независимого от документа объекта контекста анализа в пользу асинхронного анализа чернил. Вместо этого, данные примеры изобретения могут использовать изолированный компонент для хранения всех чернильных и семантических данных для документа. Более конкретно, данные примеры изобретения распознают два типа модификаций, которые могут быть сделаны в документе: чернильные события, такие как добавление, удаление или модифицирование штрихов; и структурные события, такие как группирование штрихов в слова, добавление семантических узлов или ассоциирование результатов распознавания текста со штрихами. Каждое событие содержит все данные, необходимые для полного описания события для внешнего слушателя. Например, событие «добавить штрих» включает в себя все данные штриха. С помощью данных событий с «широкими возможностями» слушатель может сохранять точный дубликат объекта чернил посредством применения событий в порядке, в котором они были приняты.
На фиг.28 изображен пример того, как может быть использована данная схема, в соответствии с различными примерами изобретения. Как видно на данной фигуре, приложение 2801 использует инструментальное средство 2803 анализа чернил. Инструментальное средство 2803 анализа чернил поддерживает данные 2805 чернил и структуру 2807 документа (например, такую как древовидная структура) для приложения 2801. Приложение также использует очередь 2809 событий, процесс 2811 синтаксического разбора и процесс 2817 распознавания. Процесс 2811 синтаксического разбора поддерживает клон 2813 данных 2805 чернил и клон 2815 структуры 2807 документа. Аналогично, процесс 2817 распознавания поддерживает клон 2819 данных 2805 чернил и клон 2821 структуры 2807 документа.
Когда приложение генерирует данные чернил, то оно предоставляет данные чернил инструментальному средству 2803 анализа чернил посредством метода 2823. В ответ инструментальное средство 2803 анализа чернил генерирует событие, соответствующее изменению в данных чернил, добавляет ярлык (тег) к каждому событию и определяет требуемый процесс или процессы анализа в качестве компонентов, которые прослушивают события с заданными ярлыками. Например, все изменения пользователя в чернилах могут быть помечены ярлыком «UserChange», и событие 2825 с данным тегом посылается синхронно в очередь 2809 событий в ответ на изменение. В некоторый момент в будущем процесс 2811 синтаксического разбора и процесс 2817 распознавания извлекают помеченное ярлыком событие из очереди 2809 событий.
Процесс первого анализа (например, процесс 2811 синтаксического разбора) затем прослушивает все события, выдаваемые инструментальным средством 2803 анализа чернил, и отвечает на те, которые помечены ярлыком UserChange. Процесс первого анализа затем применяет изменения, заданные событием, к его внутренней копии данных 2813 чернил и структуры 2815 документа, анализирует данные, описанные в событии, и затем создает и помечает события 2827, генерируемые их изменениями, ярлыком «Parser1Change». Эти события 2827 передаются инструментальным средством 2803 анализа чернил обратно в очередь 2809 событий. Процесс второго анализа (например, процесс 2817 распознавания рукописного текста) затем прослушивает события, помеченные тегом Parser1Change. В ответ он применяет изменения, заданные событием, к его внутренней копии данных 2819 чернил и структуре 2821 документа и в ответ анализирует данные, описанные в событиях. Второй анализатор затем создает и помечает событие 2829 с его результатами анализа тегом «HandwritingRecognitionChange». Так как инструментальное средство 2803 анализа чернил принимает события от процесса 2811 синтаксического разбора и процесса 2817 распознавания, то оно посылает события 2831 приложению 2801 для указания изменения в структуре 2807 документа.
Эти варианты выполнения изобретения также могут поддерживать каждый процесс анализа прослушиванием событий с более чем одним событием и помечать события на основании их изменений различными ярлыками, основываясь на внутренней обработке. Следовательно, эти альтернативные варианты реализации изобретения также могут предусматривать анализ электронных чернил в документе, который является асинхронным по отношению к работе программного приложения, являющегося ведущим по отношению к документу.
Заключение
Хотя изобретение было описано в отношении конкретных примеров, включающих предпочтительные в настоящее время варианты осуществления изобретения, для специалиста в данной области техники очевидно, что существуют многочисленные разновидности и изменения вышеописанных систем и методик, которые находятся в рамках сущности и объема изобретения, изложенного в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2351982C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2358308C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2352981C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2326435C2 |
| АЛЬТЕРНАТИВЫ АНАЛИЗА В КОНТЕКСТНЫХ ДЕРЕВЬЯХ | 2005 |
|
RU2398276C2 |
| РАЗДЕЛИТЕЛЬ ЧЕРНИЛ И ИНТЕРФЕЙС СООТВЕТСТВУЮЩЕЙ ПРИКЛАДНОЙ ПРОГРАММЫ | 2003 |
|
RU2358316C2 |
| СПОСОБ И СИСТЕМА ДЛЯ МАШИННОГО ИЗВЛЕЧЕНИЯ И ИНТЕРПРЕТАЦИИ ТЕКСТОВОЙ ИНФОРМАЦИИ | 2015 |
|
RU2592396C1 |
| СИСТЕМА И СПОСОБ ДЛЯ СОХРАНЕНИЯ ДОКУМЕНТА В ПОСЛЕДОВАТЕЛЬНОМ ДВОИЧНОМ ФОРМАТЕ | 2006 |
|
RU2406142C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ, ИЗВЛЕКАЕМОЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2015 |
|
RU2605077C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |



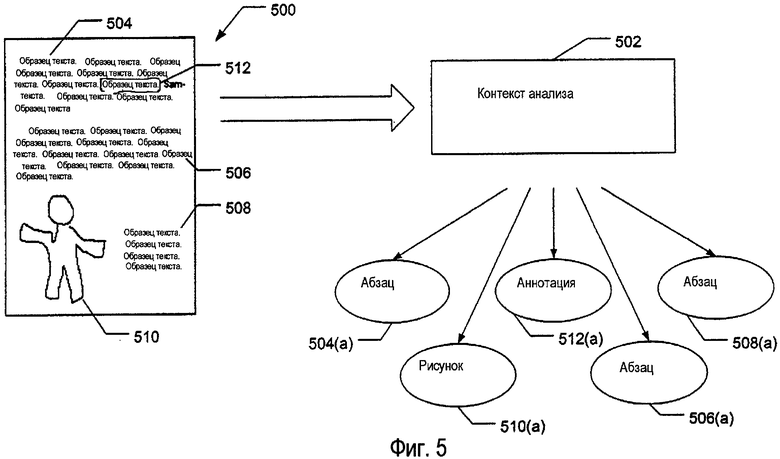
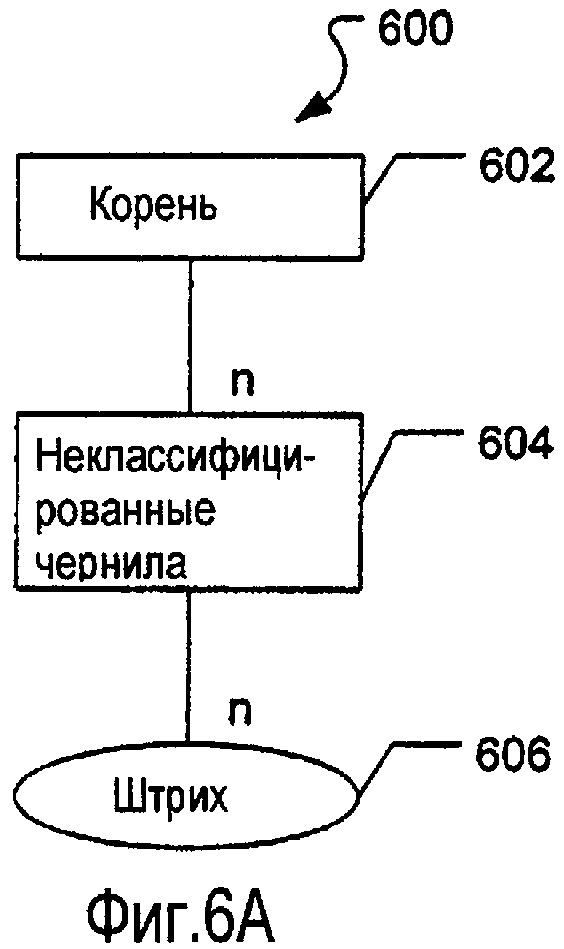


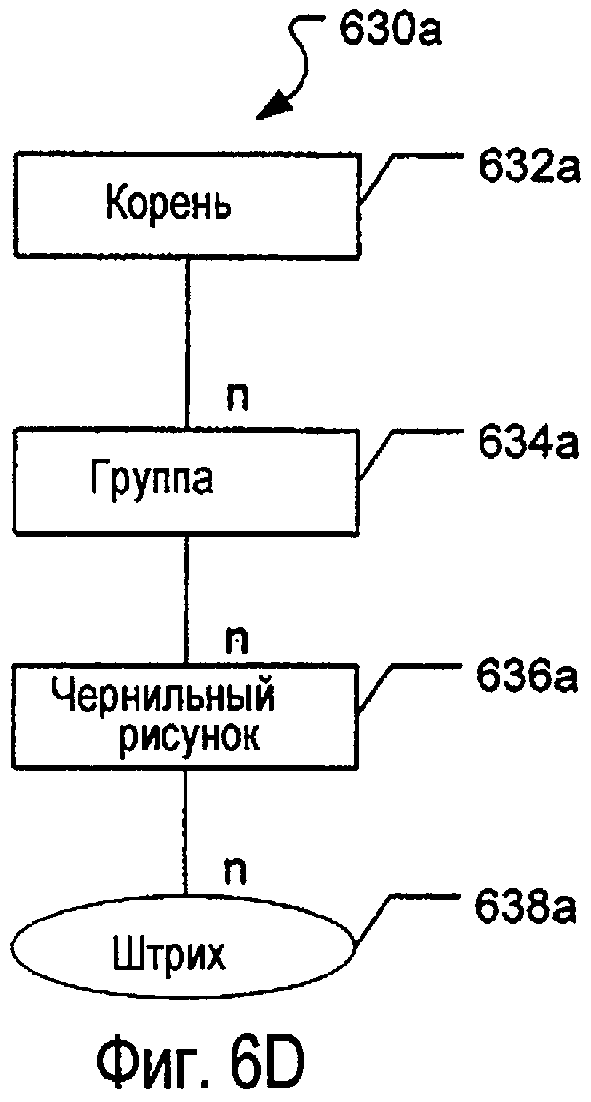
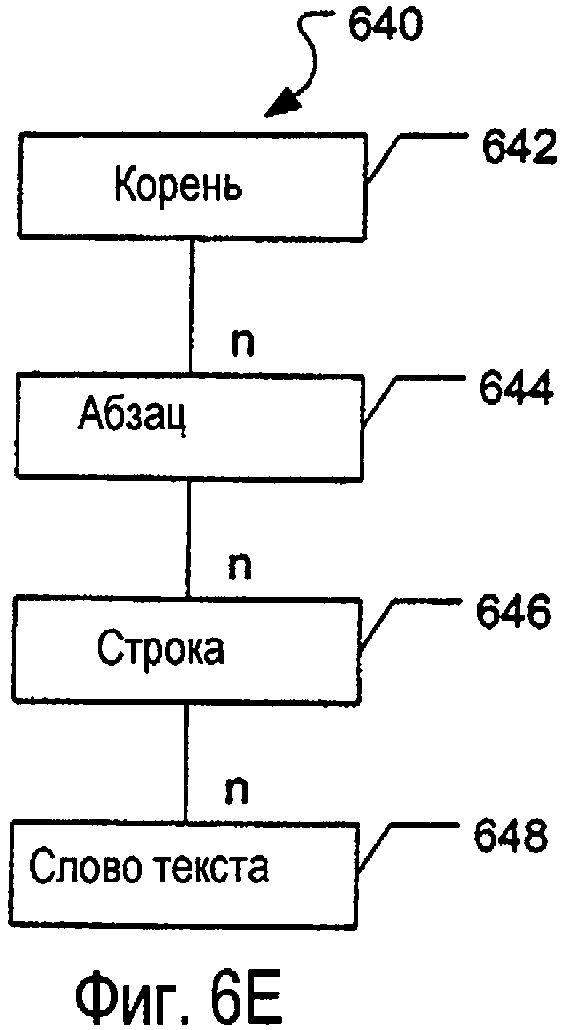



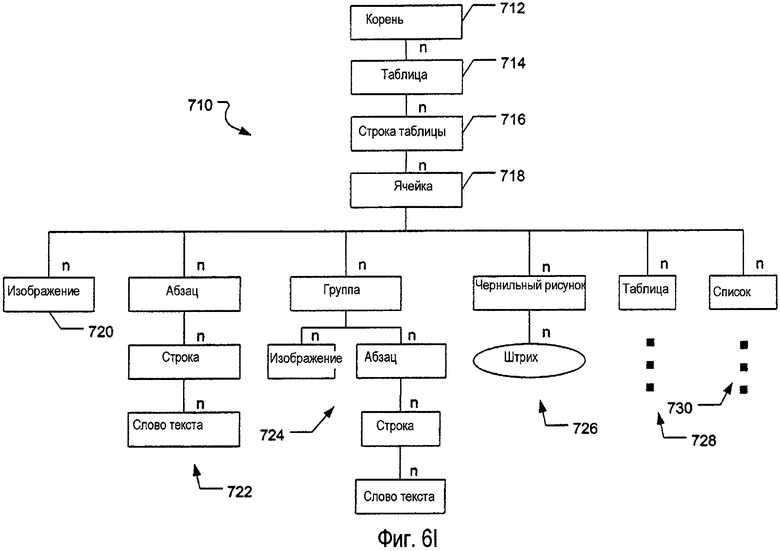


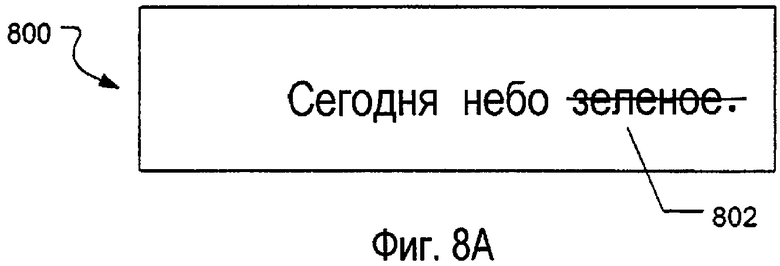
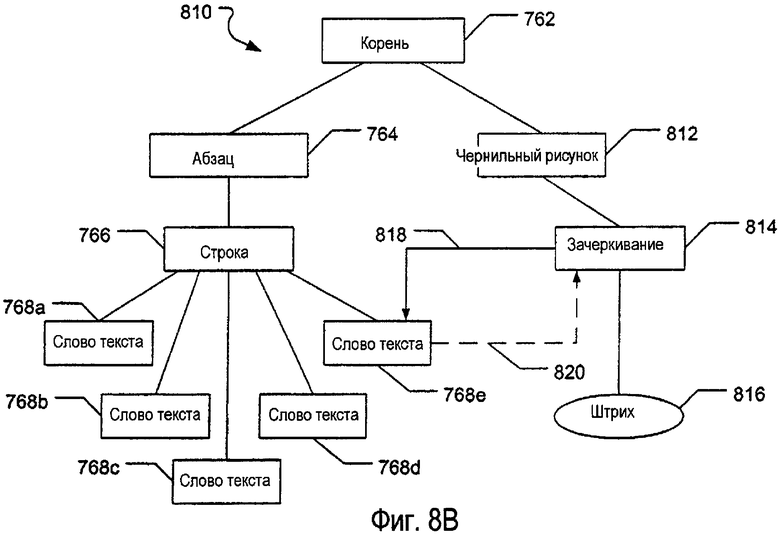


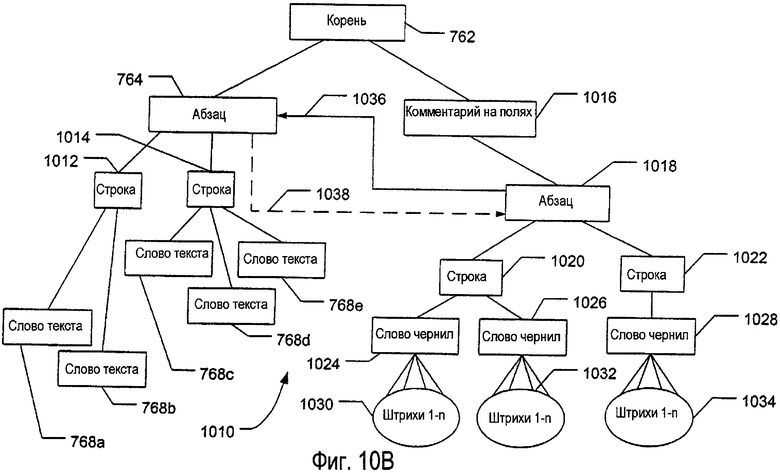
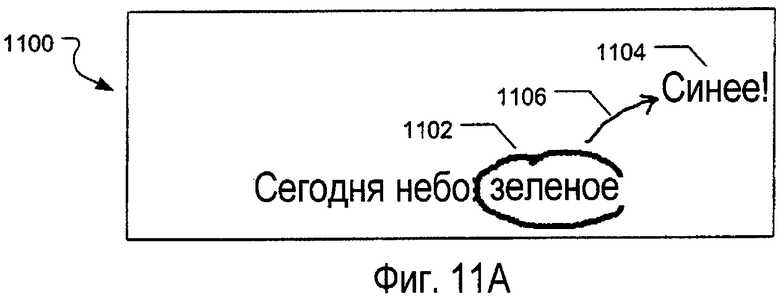
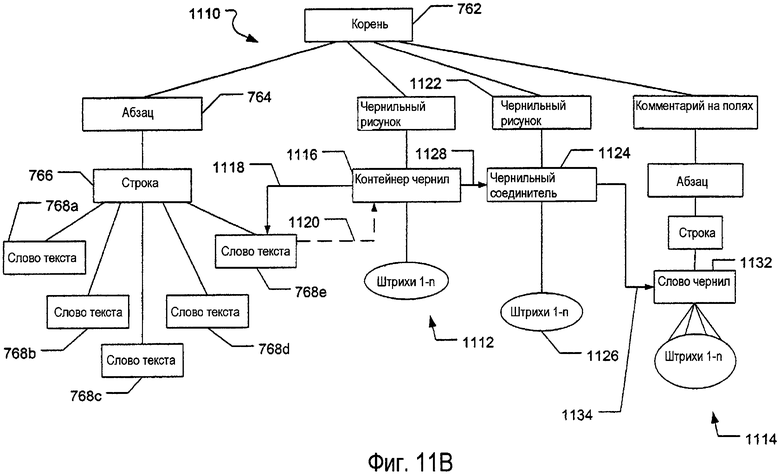

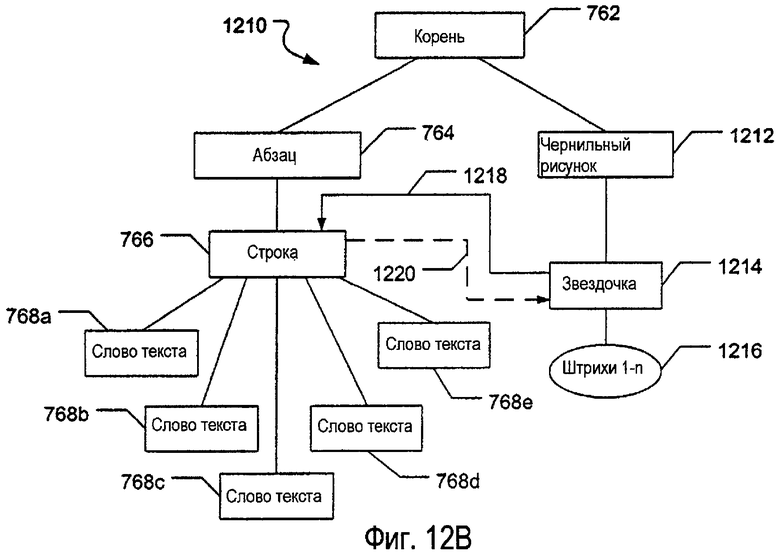
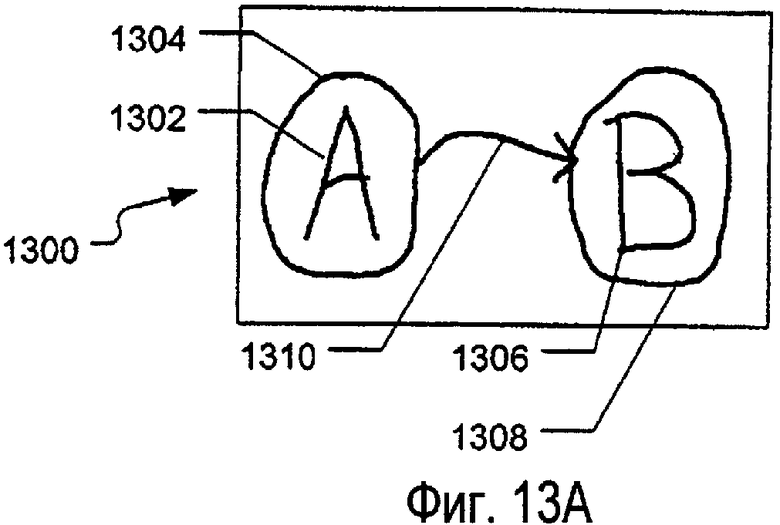


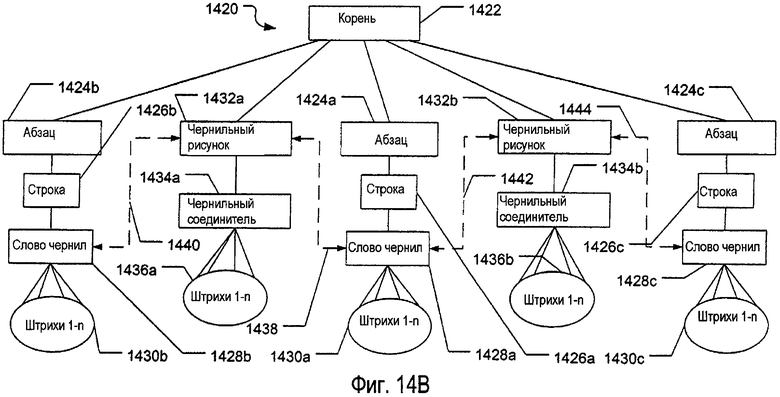


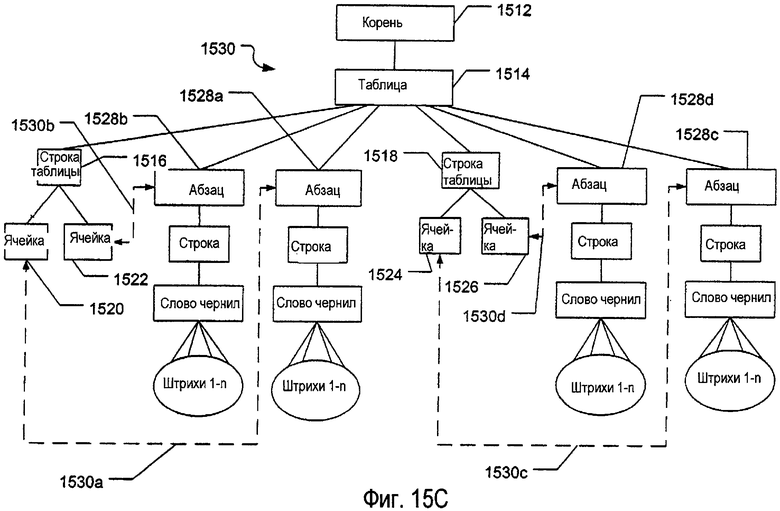
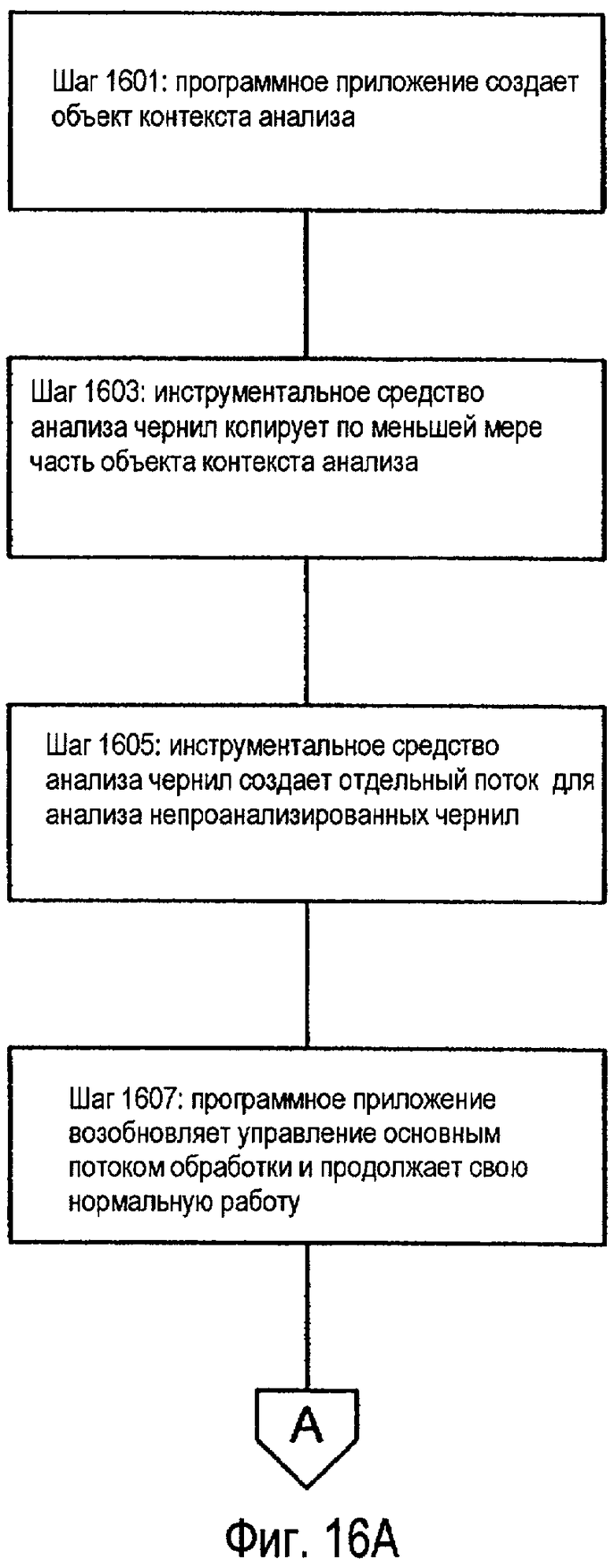


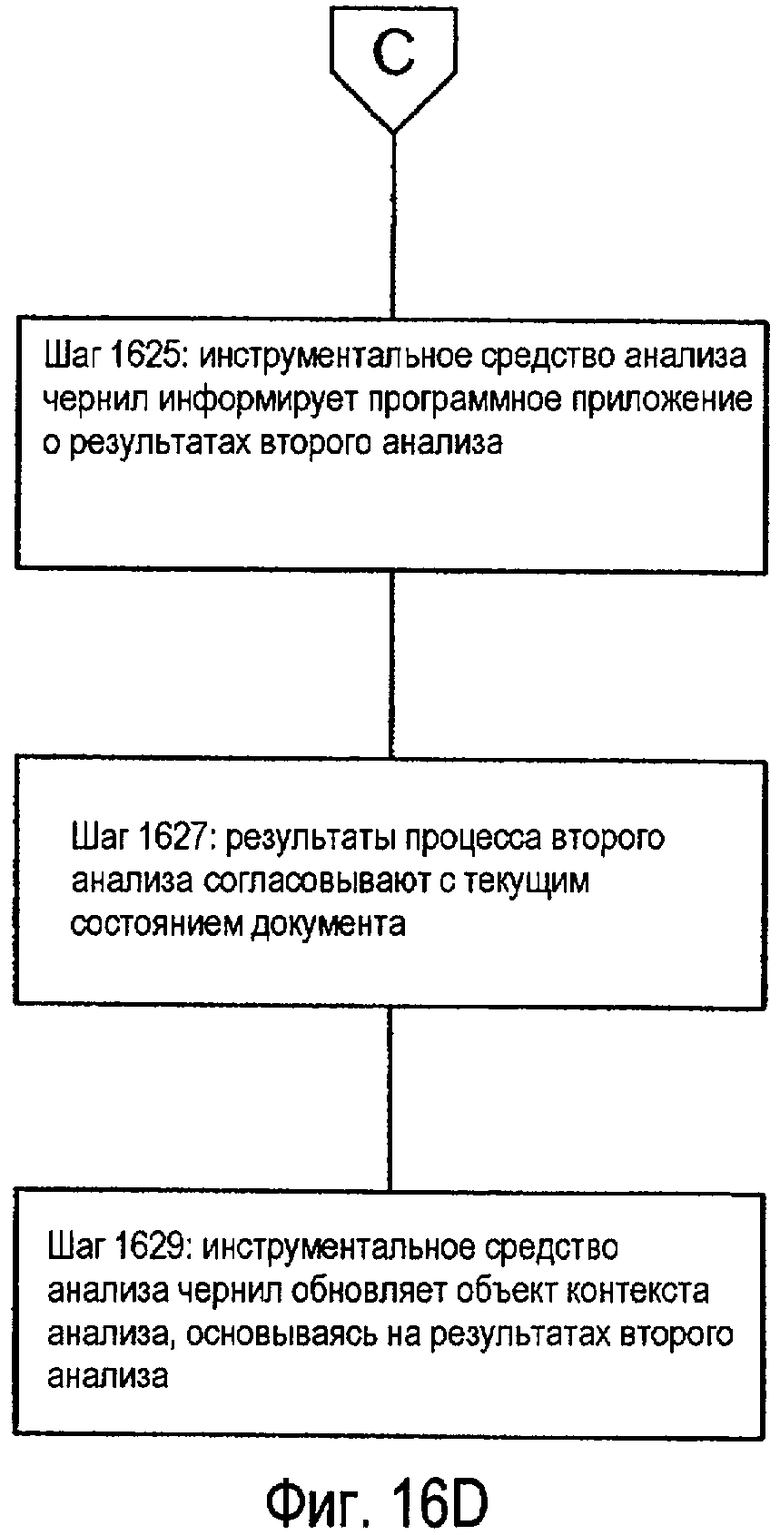
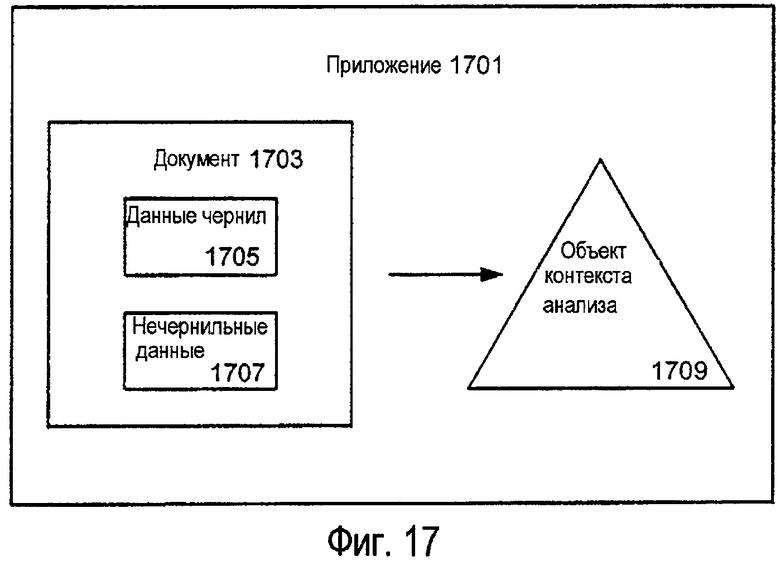
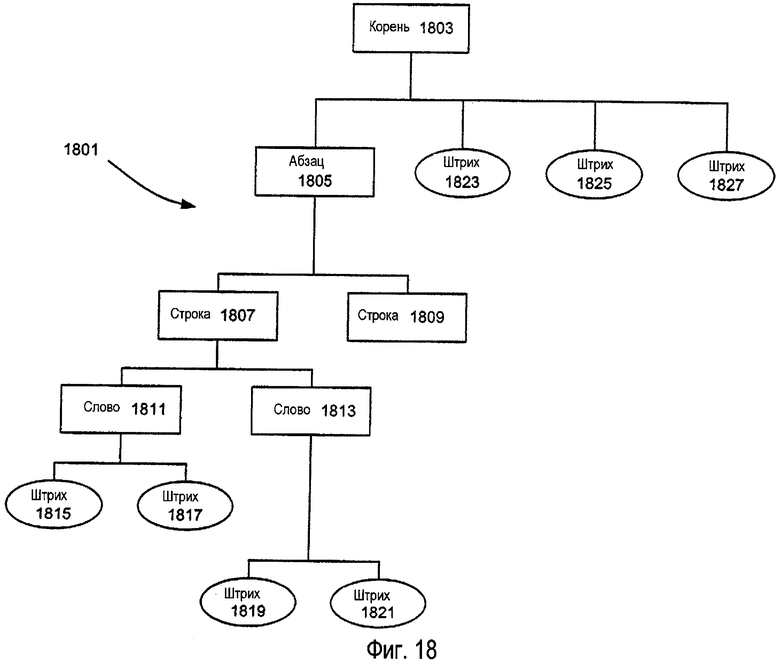


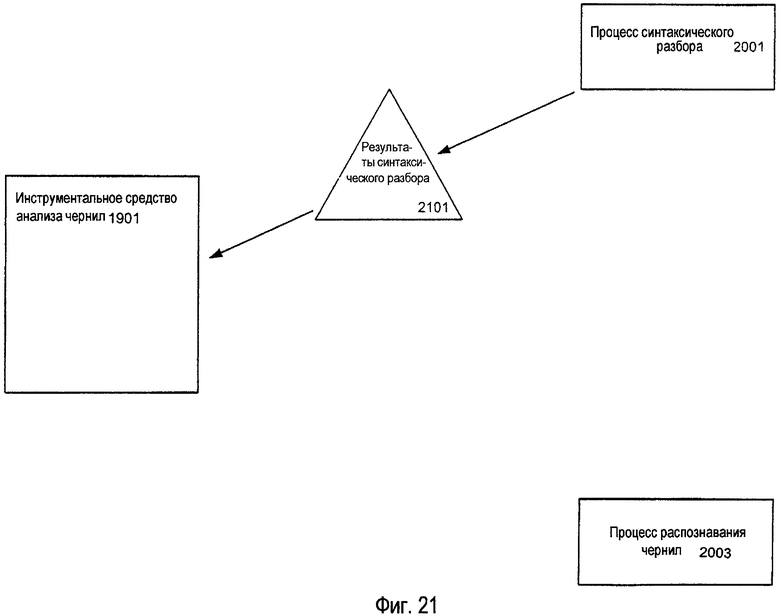


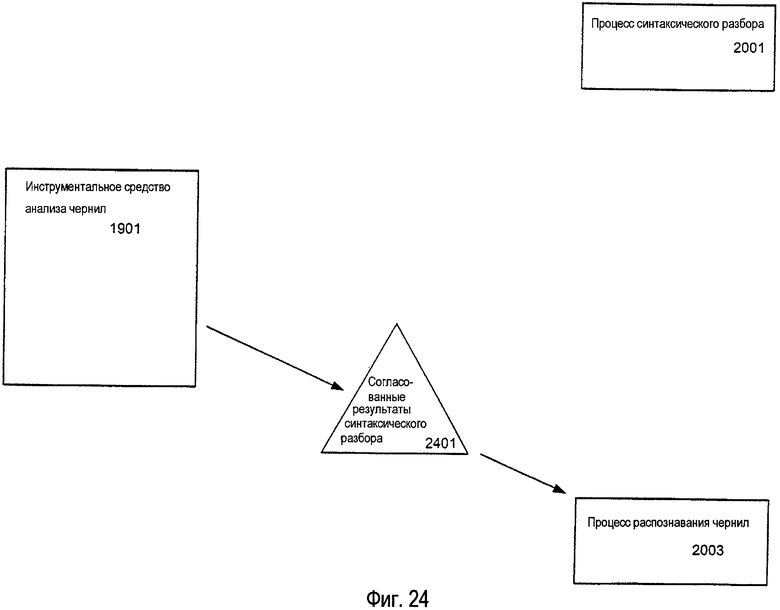

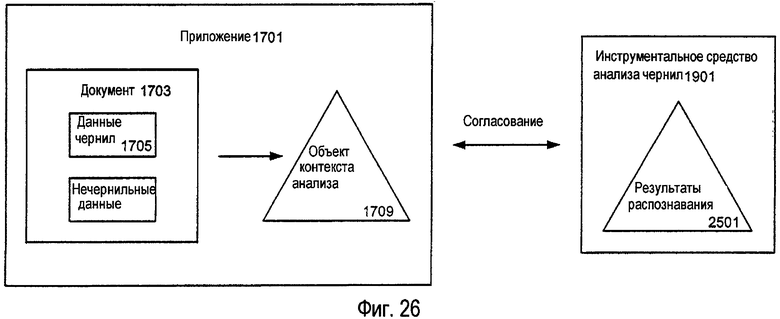
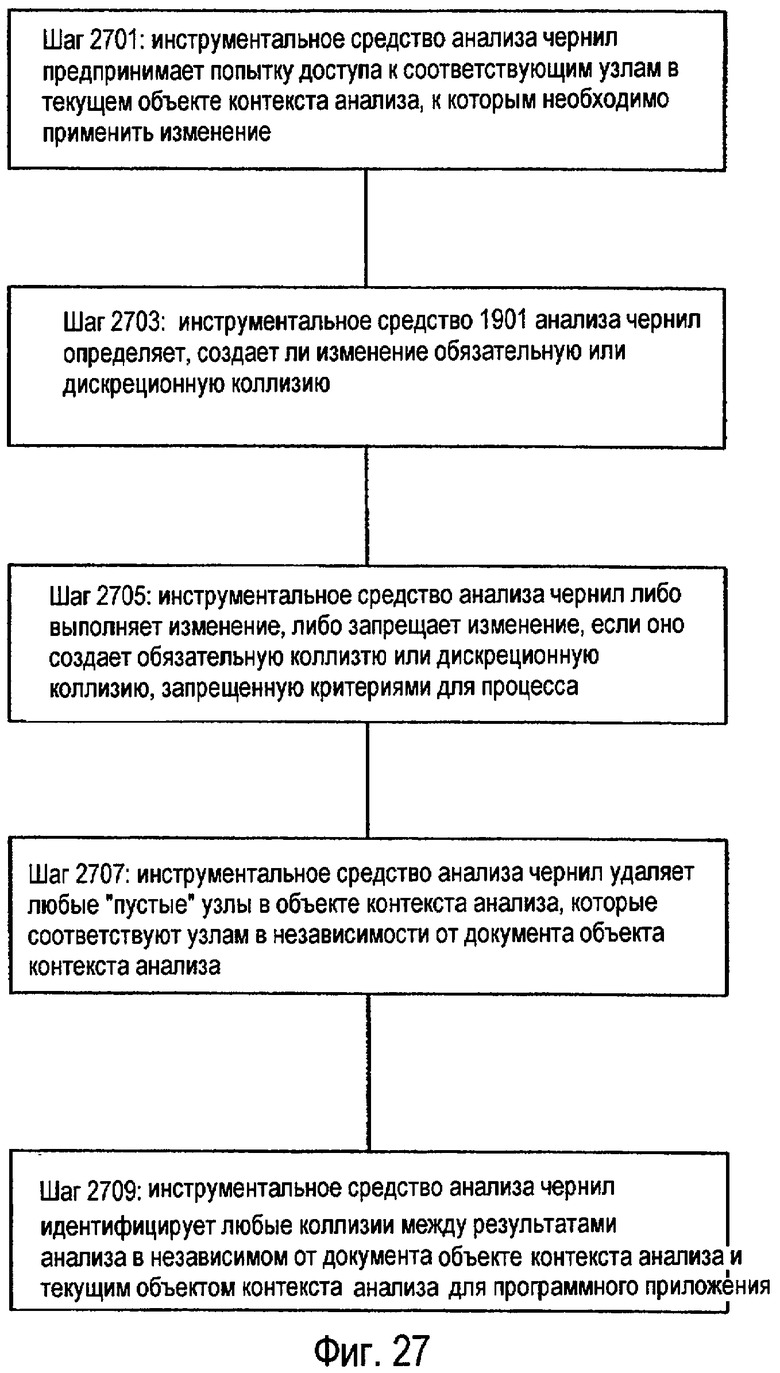
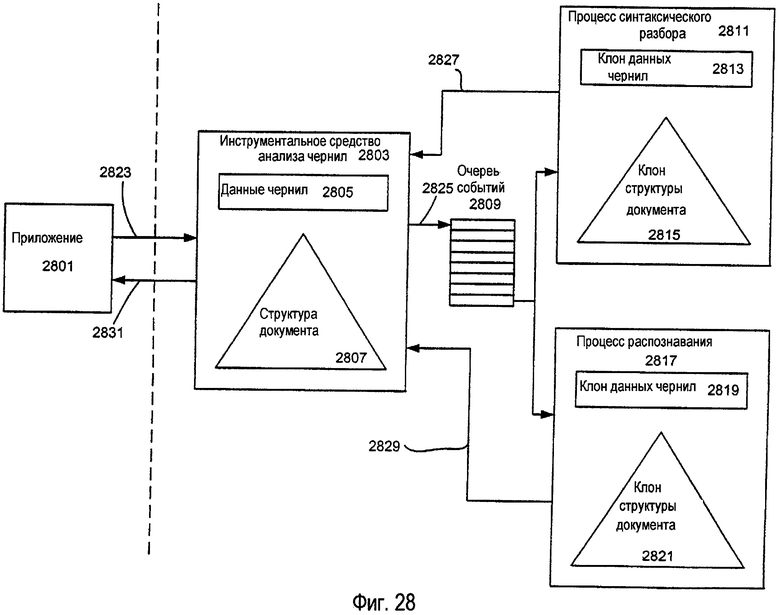
Изобретение относится к обработке электронных чернил. Техническим результатом является увеличение быстродействия обработки электронных чернил. Способ содержит этапы, на которых: создают независимый от документа объект контекста из текущего объекта контекста документа, создают копию независимого от документа объекта контекста, модифицируют указанную копию в процессе анализа документа для включения результатов анализа электронных чернил независимого от документа объекта контекста, принимают вторую версию текущего объекта контекста, для каждого узла чернил в независимом от документа объекте контекста, когда имеется соответствующий узел в текущем объекте контекста, добавляют этот узел в хэш-таблицу, в которой задается соответствие уникальных идентификаторов узлов в независимом от документа объекте контекста ссылкам на узлы в текущем объекте контекста, для каждого узла в независимом от документа объекте контекста определяют, отличается ли упомянутый соответствующий узел во второй версии текущего объекта контекста от упомянутого каждого узла, и добавляют этот узел в список узлов, для которых изменения не распространяются. 3 з.п. ф-лы, 49 ил.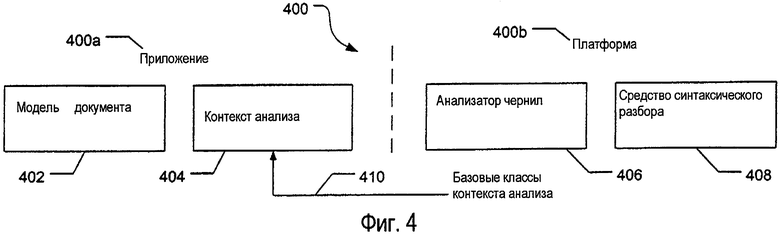
1. Способ согласования результатов анализа электронных чернил документа с текущей версией этого документа, содержащий этапы, на которых
создают независимый от документа объект контекста из текущего объекта контекста документа,
создают копию независимого от документа объекта контекста,
модифицируют копию независимого от документа объекта контекста в процессе анализа документа для включения результатов анализа электронных чернил независимого от документа объекта контекста, принимают вторую версию текущего объекта контекста,
для каждого узла чернил в независимом от документа объекте контекста, когда имеется соответствующий узел в текущем объекте контекста, добавляют этот узел в хэш-таблицу, в которой задается соответствие уникальных идентификаторов узлов в независимом от документа объекте контекста ссылкам на узлы в текущем объекте контекста,
для каждого узла в независимом от документа объекте контекста определяют, отличается ли упомянутый соответствующий узел во второй версии текущего объекта контекста от упомянутого каждого узла, и
для каждого узла в независимом от документа объекте контекста, когда узел в независимом от документа объекте контекста отличается от упомянутого соответствующего узла во второй версии текущего объекта контекста, добавляют этот узел в список узлов, для которых изменения не распространяются.
2. Способ по п.1, дополнительно содержащий этапы, на которых
для каждого узла в независимом от документа объекте контекста осуществляют поиск соответствующего узла в модифицированной копии независимого от документа объекта контекста и осуществляют поиск соответствующего узла во второй версии текущего объекта контекста,
определяют, удален ли этот соответствующий узел из модифицированной копии независимого от документа объекта контекста, и
когда упомянутый соответствующий узел удален из модифицированной копии независимого от документа объекта контекста, добавляют этот соответствующий узел в список узлов, для которых изменения не распространяются.
3. Способ по п.1, дополнительно содержащий этапы, на которых
анализируют каждый узел в копии независимого от документа объекта контекста, и
когда анализируемый узел не находится в списке узлов, для которых изменения не распространяются, распространяют изменения в анализируемом узле от соответствующего узла в копии независимого от документа объекта контекста на упомянутый соответствующий узел во второй версии текущего объекта контекста.
4. Способ по п.1, дополнительно содержащий этапы, на которых
для каждого узла в независимом от документа объекте контекста определяют, удален ли соответствующий узел из модифицированной копии независимого от документа объекта контекста, и
для каждого узла в независимом от документа объекте контекста, когда упомянутый соответствующий узел во второй версии текущего объекта контекста не отличается и когда упомянутый соответствующий узел удален из модифицированной копии независимого от документа объекта контекста, добавляют идентифицирующие узлы в список удаленных узлов, и
удаляют узлы в списке удаленных узлов после того, как все изменения распространены на вторую версию текущего объекта контекста.
| US 6535897 B1, 18.03.2003 | |||
| US 6377259 B2, 23.04.2002 | |||
| US 2002136462 A1, 26.09.2002 | |||
| СПОСОБ ИСПОЛЬЗОВАНИЯ ВСПОМОГАТЕЛЬНЫХ МАССИВОВ ДАННЫХ В ПРОЦЕССЕ ПРЕОБРАЗОВАНИЯ И/ИЛИ ВЕРИФИКАЦИИ КОМПЬЮТЕРНЫХ КОДОВ, ВЫПОЛНЕННЫХ В ВИДЕ СИМВОЛОВ, И СООТВЕТСТВУЮЩИХ ИМ ФРАГМЕНТОВ ИЗОБРАЖЕНИЯ | 1999 |
|
RU2166207C2 |

