Предшествующий уровень техники
Планшетные персональные компьютеры обычно позволяют пользователю рисовать или писать непосредственно на экране. Этот рисунок или запись упоминаются, в общем случае, как «рукописный ввод». Рукописный ввод является типом пользовательского ввода и может включать в себя сенсорный экран и вариант, когда пользователь использует компьютерное перо и пишет на экране так, как будто он пишет традиционной ручкой на бумаге. Рукописный ввод используется в самых разнообразных приложениях. Например, рукописный ввод может использоваться в приложениях для рисования, приложениях для раскрашивания, приложениях обработки текстов, приложениях для подписи кредитной карточки и т.п.
Рукописный ввод может включать в себя больше, чем только визуальное представление штрихов, сделанных пером; он может включать в себя тип данных. В то время как известны структуры данных, размер структуры данных, используемой для хранения информации, может стать чрезмерно большим и громоздким. Также, совместимость структуры документа между программами увеличивает эффективность и общую применимость компьютера. Совместимость, однако, может быть проблемой, когда пользователь желает передать рукописные данные от одного приложения в другое приложение.
Сущность изобретения
В общем случае, аспекты данного изобретения относятся к системе и способу для генерации структуры документа и сохранения структуры документа в последовательном двоичном формате. Данное изобретение также относится к системе и способу для генерации структуры рукописного документа и сохранения структуры рукописного документа так, чтобы она была доступна другими приложениями. Данное изобретение дополнительно относится к системе и способу для модификации или изменения части рукописного ввода, не требуя вновь делать анализ всего рукописного ввода.
Аспекты изобретения касаются читаемого компьютером носителя информации, имеющего структуру данных для сохранения данных документа в последовательном двоичном формате так, чтобы данные документа были доступны для других приложений. Структура документа сгенерирована так, чтобы включать данные корневого узла. Документ сохраняется в последовательном двоичном формате данных. Последовательный двоичный формат включает сохранение данных размера, ассоциированных со структурой документа, в первом поле данных. Последовательный двоичный формат также включает сохранение данных дескриптора документа во втором поле данных, где данные дескриптора документа включают в себя, по меньшей мере, один флаг для указания ожидания данных. Последовательный двоичный формат дополнительно включает сохранение данных корневого узла в третьем поле данных, где корневые данные узла обозначены, по меньшей мере, одним из флагов.
Другие аспекты изобретения касаются осуществляемого компьютером способа сохранения структуры двоичного дерева в последовательном формате. Осуществляемый компьютером способ включает в себя сохранение данных размера структуры документа в первом поле данных. Осуществляемый компьютером способ также включает в себя сохранение данных дескриптора структуры документа во втором поле данных, где данные дескриптора структуры документа включают в себя по меньшей мере один флаг для указания ожидания данных. Осуществляемый компьютером способ дополнительно включает в себя сохранение данных корневого узла в третьем поле данных, где данные корневого узла обозначены, по меньшей мере, одним из флагов.
Еще один аспект изобретения касается читаемого компьютером носителя информации, имеющего исполняемые компьютером команды, сохраненные на нем. Команды включают в себя генерацию структуры рукописного документа, где структура рукописного документа включает в себя по меньшей мере один корневой узел. Команды также включают в себя сохранение структуры рукописного документа в последовательном двоичном формате. Последовательный двоичный формат включает сохранение данных размера, ассоциированных со структурой рукописного документа, в первом поле данных. Последовательный двоичный формат также включает сохранение данных дескриптора структуры рукописного документа во втором поле данных, где данные дескриптора структуры рукописного документа включают в себя по меньшей мере один флаг для указания ожидания данных. Последовательный двоичный формат может дополнительно включать в себя сохранение данных корневого узла в третьем поле данных, где данные корневого узла обозначены по меньшей мере одним из флагов.
Перечень чертежей
Фиг.1 - иллюстрация примерного вычислительного устройства, которое может использоваться в одном аспекте данного изобретения.
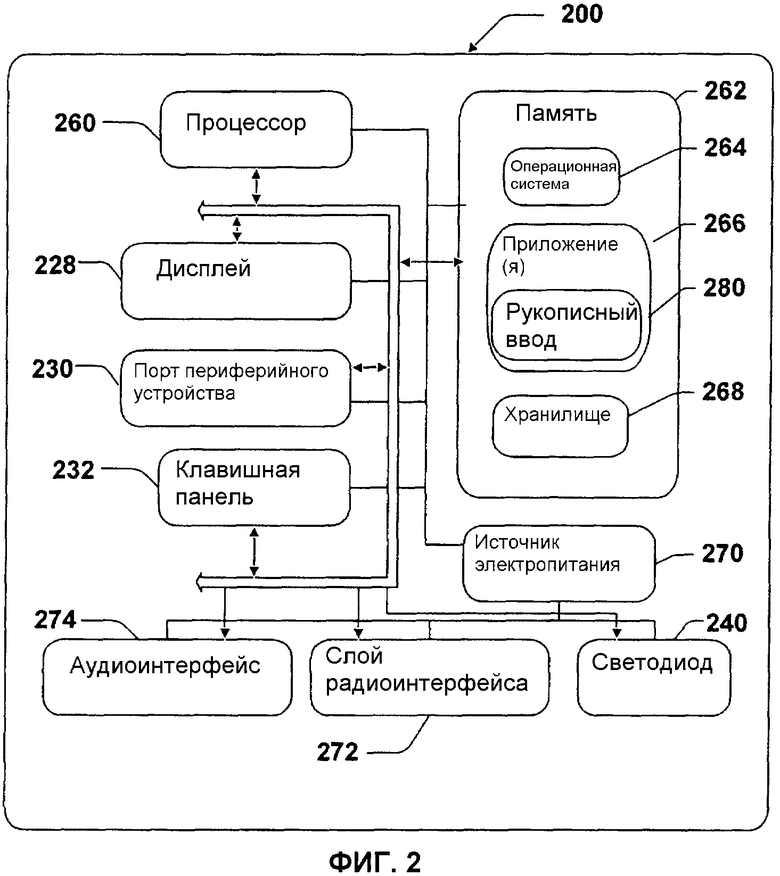
Фиг.2 - иллюстрация примерного мобильного устройства, которое может использоваться в одном аспекте данного изобретения.
Фиг.3 - иллюстрация одного примерного аспекта системы для сохранения данных рукописного документа в последовательном двоичном формате.
Фиг.4 - иллюстрация примерного рукописного ввода в соответствии с одним аспектом данного изобретения.
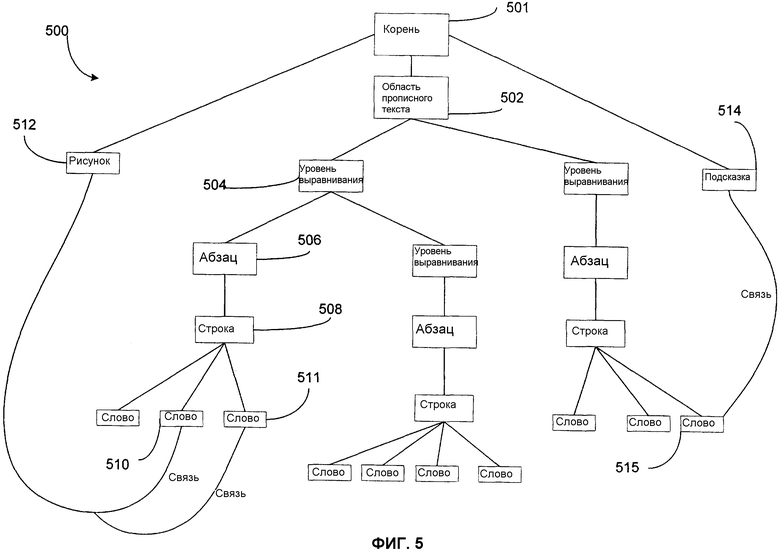
Фиг.5 - иллюстрация примерной структуры рукописного документа, которая представляет собой часть рукописного ввода, представленного на фиг.4.
Фиг.6 - иллюстрация структуры данных для сохранения блока последовательных двоичных данных в соответствии с аспектами данного изобретения.
Фиг.7 - иллюстрация структуры данных для сохранения данных контекстного узла в соответствии с аспектами данного изобретения.
Фиг.8 - иллюстрация блок-схемы последовательности операций, изображающей общие аспекты сохранения структуры рукописного документа в последовательном двоичном формате.
Подробное описание
Варианты воплощения данного изобретения далее будут описаны более полно со ссылкой на приложенные чертежи, которые составляют его часть и которые показывают, в качестве иллюстраций, определенные примерные варианты воплощения для осуществления изобретения на практике. Это изобретение может, однако, быть воплощено во многих различных формах и не должно рассматриваться как ограниченное вариантами воплощения, сформулированными здесь; скорее, эти варианты воплощения предоставлены для того, чтобы это раскрытие было полным и завершенным и полностью передавало объем изобретения специалистам в данной области техники. Среди прочего, данное изобретение может быть воплощено как способы или устройства. Соответственно данное изобретение может принять форму полностью аппаратного варианта воплощения, полностью программного варианта воплощения или варианта воплощения, объединяющего аспекты программного варианта и аппаратного варианта. Следующее подробное описание не должно поэтому быть взято в качестве ограничения.
Иллюстративные варианты воплощения способа и системы для сохранения данных в последовательном двоичном формате
В общем случае, данное изобретение относится к системам и способам для генерации структуры рукописного документа и сохранения этой структуры рукописного документа так, чтобы она была доступна другим приложениям. Более определенно, данное изобретение относится к системе и способу для сохранения данных в последовательном двоичном формате для увеличения эффективности хранения. Данное изобретение также относится к системе и способу для модификации или изменения части рукописного ввода, не требуя нового анализа всего рукописного ввода. Даже при том, что описание, сформулированное здесь, ссылается на сохранение и загрузку рукописного документа, последовательный двоичный формат, упоминаемый здесь, может использоваться для хранения других типов данных. Например, данное изобретение может включать в себя данные, ассоциированные с приложением обработки текстов, приложением для работы с электронными таблицами, приложением для рисования, приложением для работы с графикой, приложением для заметок, приложением для работы с картинками, или подобное этому. Кратко отметим, что последовательный двоичный формат может использоваться для хранения любого типа данных, который ассоциирован со структурой двоичного дерева.
1. Иллюстративные варианты воплощения приложения для рукописного ввода
Как общий контекст одного аспекта данного изобретения, приложение для рукописного ввода может обеспечить визуальную обратную связь в реальном времени, когда пользователь использует перо для ввода данных. Рукописный ввод, однако, может включать в себя намного больше, чем визуализация штрихов, сделанных пером; он может включать в себя тип данных. Пользователь может строить приложения для цифрового преобразователя, который поддерживает различные уровни функциональных возможностей для пера, рукописного ввода, разбора рукописного ввода и распознавания рукописного ввода. Такие приложения варьируются в диапазоне от распознавания простого текстового ввода до создания и редактирования сложных рукописных документов.
Приложения рукописного ввода могут также включать в себя преобразование рукописного ввода в текст. В некоторых ситуациях приложение не может принять прямой ввод рукописного ввода. В такой ситуации приложение для рукописного ввода может осуществлять распознавание прописного текста и преобразовывать рукописный ввод в текст так, чтобы он мог быть вырезан и вставлен в приложение, которое не принимает прямой ввод рукописного ввода. Приложения могут также распознавать объекты рукописного ввода и их контекст по отношению к другим объектам документа. Другие варианты воплощения позволяют пользователю управлять рукописным вводом и использовать рукописный ввод для создания богатых по возможностям документов, которые содержат текст, графику, векторные фигуры, мультимедийные объекты и т.п. Такие варианты воплощения обрабатывают рукописный ввод как тип данных, который имеет возможность переформатирования и перекрытия объектов рукописного ввода.
Рукописный ввод может быть ассоциирован с приложением в форме необработанных данных рукописного ввода. В одном варианте воплощения необработанные данные рукописного ввода можно послать анализатору рукописного ввода для обработки необработанных данных рукописного ввода и генерации структуры рукописного документа, которая может быть отдельной от необработанных данных рукописного ввода. Анализатор рукописного ввода может осуществлять процессы разбора и распознавания для разделения необработанных данных рукописного ввода на управляемые штриховые компоненты. Как более полно сформулировано ниже, в одном варианте воплощения анализатор рукописного ввода может генерировать структуру рукописного документа, имеющую двоичное дерево, где каждый узел дерева определяет отношение к частям необработанных данных рукописного ввода. Структура рукописного документа позволяет приложению рукописного ввода, ассоциированному с платформой, связывать необработанные данные рукописного ввода и структуру рукописного документа, чтобы загружать первоначальный рукописный ввод и ассоциированную структуру рукописного документа. Структура рукописного документа также позволяет пользователю загружать и изменять рукописный ввод, не требуя нового анализа всего рукописного документа. Также данное изобретение может позволить совместное использование рукописного ввода множеством приложений на платформе.
Фиг.3 представляет краткий обзор одного иллюстративного варианта воплощения системы для сохранения данных рукописного документа в последовательном двоичном формате. Как проиллюстрировано здесь, система 300 включает в себя цифровой преобразователь 302, приложение 304 и анализатор 306 рукописного ввода. Цифровой преобразователь 302 может включать в себя вычислительное устройство, описанное в связи с Фиг.1. Цифровой преобразователь 302 может также включать в себя мобильное вычислительное устройство, описанное в связи с Фиг.2. В одном варианте воплощения цифровой преобразователь включает в себя цифровой преобразователь планшетного персонального компьютера (Tablet PC), выполняющего WINDOWS XP TABLET PC EDITION от MICROSOFT CORPORATION, головной офис которой расположен в Редмонде, Вашингтон. Цифровой преобразователь 302, однако, может включать в себя любое устройство, которое обеспечивает функционирование приложения рукописного ввода.
Цифровой преобразователь 302 отцифровывает введенные пользователем штрихи (например, штрихи прописного текста и/или рисунка) и, в одном варианте воплощения, сохраняет данные в хранилище 308 необработанных данных. Хранилище 308 необработанных данных является любым типом хранилища, выполненного с возможностью поддержки данных от цифрового преобразователя 302. Хранилище 308 необработанных данных может быть ассоциировано с одним или более приложениями и/или одной или более платформами. В другом варианте воплощения цифровой преобразователь 302 минует хранилище 308 необработанных данных и передает оцифрованные данные приложению 304.
Приложение 304 может включать в себя любое приложение, ассоциированное с платформой. В одном варианте воплощения приложение 304 является приложением, которое обеспечивает рукописный ввод. Приложение 304 может включать в себя приложение обработки текстов, приложение для раскрашивания, приложение для черчения, приложение для рисования, приложение для подписи кредитной карточки или подобное этому. В одном варианте воплощения приложение 304 включает в себя InkEdit, InkPicture и/или OneNote от MICROSOFT CORPORATION. В другом варианте воплощения приложение 304 выполнено с возможностью осуществления операции сохранения и операции загрузки. Операция сохранения может включать в себя сохранение данных рукописного ввода и нерукописных данных. Приложение 304 может сохранять необработанные данные рукописного ввода в хранилище 308 необработанных данных, и приложение 304 может сохранять структуру рукописного документа для анализатора рукописного ввода, который ассоциирован с платформой. Во время операции загрузки приложение 304 может загрузить и интегрировать структуру рукописного документа и необработанные данные рукописного ввода, как будет сформулировано ниже.
Анализатор 306 рукописного ввода может быть сконфигурирован для получения необработанных данных рукописного ввода от приложения 304. Анализатор 306 рукописного ввода сконфигурирован для выполнения структурного анализа необработанных данных рукописного ввода для генерации структуры рукописного документа. Структурный анализ может включать в себя разбор необработанных данных и распознавание необработанных данных.
В одном варианте воплощения структурный анализ может обеспечить текстовое распознавание, классификацию прописного текста и рисунка и анализ компоновки. Анализатор 306 рукописного ввода может включать в себя компонент разбора и компонент распознавания, которые работают в координации для улучшения распознавания текста. Например, компонент разбора может выполнять операции в виде этапа предварительной обработки прежде, чем послать рукописный ввод компоненту распознавания. Предварительная обработка позволяет компоненту разбора выполнять разбор и «чистить» многострочный рукописный ввод и посылать его устройству распознавания одной посылкой за раз. Посылка может включать в себя часть рукописного документа. Компонент разбора может быть дополнительно сконфигурирован, чтобы исправлять некорректную информацию порядка ввода штрихов, чтобы гарантировать, что все штрихи будут распознаны независимо от порядка ввода. Также компонент разбора может генерировать информацию о соседних строках. Например, тот факт, что две соседних строки начинаются с маркера, может быть сильным индикатором того, что текущая строка начинается с маркера.
В другом варианте воплощения операция разбора, выполняемая анализатором 306 рукописного ввода, может также включать в себя классификацию рукописного ввода как рисунка или прописного текста. Прописной текст может включать в себя любой штрих рукописного ввода, который обеспечивает слово. Рисованный штрих может включать в себя все что угодно, что не является штрихом прописного текста. Например, обращаясь к фиг.4, штрих «H» может включать в себя штрих прописного текста, и «подчеркивание» может включать в себя рисованный штрих. Этим способом в соответствии с одним вариантом воплощения штрихи прописного текста могут быть единственными штрихами, посылаемыми компоненту распознавания.
В еще одном варианте воплощения анализатора 306 рукописного ввода анализ компоновки включает в себя разбиение прописных и рисованных штрихов по отношению друг к другу и данным нерукописного ввода. После того, как анализатор 306 рукописного ввода проанализирует штрихи рукописного ввода, может быть сгенерировано древовидное представление (то есть структура рукописного документа) этих штрихов. Кратко отметим, что анализатор 306 рукописного ввода может включать в себя любой тип анализатора, который выполнен с возможностью сохранять документ в виде двоичного дерева и обеспечивать доступность этого двоичного дерева для других приложений с помощью последовательного двоичного формата. Даже при том, что последовательный двоичный формат описан здесь со ссылкой на структуру рукописного документа, последовательный двоичный формат может использоваться для хранения любого типа информации, ассоциированной с древовидной структурой документа.
После того, как анализатор 306 рукописного ввода сгенерировал структуру рукописного документа на основе необработанных данных, структура рукописного документа делается доступной приложению 304. Структура рукописного документа может включать в себя динамическую структуру рукописного документа. Когда инициирована операция сохранения, приложение запрашивает анализатор рукописного ввода 306 сохранить структуру рукописного документа. Здесь анализатор 306 рукописного ввода является компонентом платформы, структура рукописного документа является доступной другим приложениям рукописного ввода. Например, если пользователь генерирует рукописный ввод в документе обработки текстов, этот рукописный ввод может быть вырезан и вставлен в приложение для рисования, без необходимости повторного анализа. В этом примере приложение для рисования понимает, как генерировать исходный рукописный ввод из структуры рукописного документа. Также, поскольку рукописный ввод разобран и сохранен в последовательном двоичном формате (обсуждаемом ниже), рукописный ввод может быть изменен и эффективно сохранен, не требуя повторного анализа всего рукописного ввода. Модифицированная часть может соответствовать единой посылке структуры рукописного документа и, поэтому, потребовать только повторного анализа измененной посылки.
Вообще, во время операции загрузки приложение 304 может загрузить необработанные данные рукописного ввода, данные нерукописного ввода и структуру рукописного документа. Необработанные данные рукописного ввода могут быть загружены из хранилища 308 необработанных данных. Данные нерукописного ввода могут также быть загружены из хранилища 308 необработанных данных. Это предполагает, однако, что данные нерукописного ввода могут быть загружены из любого хранилища, ассоциированного с приложением 304. Структура рукописного документа может быть загружена из анализатора 306 рукописного ввода, который может быть компонентом платформы. В одном варианте воплощения приложение 304 ассоциирует необработанные данные и структуру рукописного документа так, чтобы рукописный ввод загружался, не требуя повторного анализа.
Фиг.4 представляет примерный рукописный ввод 400 в соответствии с одним аспектом данного изобретения. Рукописный ввод 400 может быть ассоциирован или иметь взаимоотношения с текстом, рисунками, таблицами, диаграммами и т.п. Также рукописный ввод 400 может включать в себя различные типы записей, рисунков, форм, языков, символов и перекосов. Как более полно описано ниже, рукописный ввод 400 может включать в себя множество вводов, которые коррелируют с множеством узлов структуры рукописного документа. Например, ссылочный номер 402 указывает область прописного текста.
Как другой пример, ссылочный номер 404 указывает уровень выравнивания. Проиллюстрированные на фиг.4 первая и последняя строки рукописного ввода 400 намечены одном и том же уровне и, поэтому, указывают уровень 404 выравнивания. Средняя строка рукописного ввода 400 намечена с отступом внутрь и, поэтому, указывает другой уровень выравнивания.
В еще одном примере ссылочный номер 406 указывает абзац, а ссылочный номер 408 указывает строку. Рукописный ввод 400 также включает в себя слово 410, и, хотя это не показано, слово 410 может также включать в себя штрих. Штрих может включать в себя часть слова.
Фиг.5 представляет примерную структуру 500 рукописного документа. Примерная структура 500 рукописного документа относится к примерному рукописному вводу 400. Структура 500 рукописного документа является всего лишь одним примером структуры рукописного документа. Может быть реализован любой тип древовидной структуры для обеспечения представления структуры данных. Структура 500 рукописного документа включает в себя множество узлов, таких как корневой узел 501, узел 502 области прописного текста, узел 504 уровня выравнивания, узел 506 абзаца, узел 508 строки, узел 510 слова и/или узел штриха (не показанный). Структура 500 рукописного документа может также включать в себя узел 512 рисунка, узел 514 подсказки и одну или более связей.
На фиг.4 рисунок 412 является подчеркиванием имени «Mr. Bhattacharyay». Рисунок 412 представлен на фиг.5 с помощью узла 512 рисунка. Здесь рисунок 412 ассоциирован со словами «Mr.» и «Bhattacharyay», узел 512 рисунка и узлы 510 и 511 слова ассоциированы через связь, как изображено на фиг.5. Точно также ссылочный номер 414 представляет собой один тип подсказки. В одном варианте воплощения подсказка 414 включает в себя блок подсказки. Подсказка 414 может указать, что ввод будет числом, буквой, символом, структурой, кодом, порядком или подобным этому. Например, на фиг.4, подсказка может включать в себя подсказку, что ввод будет числом, которое состоит не более, чем из трех цифр. Соответственно анализатор рукописного ввода не будет путать «5» с «S». Здесь подсказка 414 ассоциирована с записью «35», узел подсказки 514 может быть ассоциирован с узлом слова 515 через связь, как изображено на фиг.5. Вышеупомянутый пример приведен только для целей иллюстрации и описания.
Этим способом рукописный ввод 400 может быть представлен через узлы в виде структуры 500 рукописного документа. Например, узлом штриха (не показанным здесь) может быть потомок узла 510 слова. Узел 510 слова может быть потомком узла 508 строки, и узел 508 выравнивания может быть потомком узла 506 абзаца. Аналогично, узел 506 абзаца может быть потомком узла 504 уровня выравнивания, и узел 504 уровня выравнивания может быть потомком узла 502 области прописного текста. Этим способом корневой узел 501 может содержать всю информацию своих дочерних узлов. В одном варианте воплощения полный рукописный ввод 400 может быть представлен по ссылке на корневой узел 501. Любое количество узлов может быть ассоциировано с любым типом документа, лишь бы обеспечивалось представление документа в древовидной структуре документа.
2. Преобразование рукописного документа в последовательную форму
Фиг.6 представляет один вариант примерного воплощения для внутреннего сохранения структуры документа в последовательном двоичном формате 600. Даже при том, что здесь ссылаются на структуру рукописного документа, последовательный двоичный формат 600 может использоваться для хранения любого типа древовидной структуры документа. Когда структура рукописного документа сгенерирована, будут существовать одна или более строк, которые относятся к структуре документа. В одном варианте воплощения сжатие включает в себя формат Lempel-Ziv Welch ("формат LZW") этих строк. Это предполагает, однако, что строки могут быть сжаты любым форматом сжатия, который уменьшает размер строк. Фиг.6 включает в себя расширенное представление хранения данных 604-618 (из которых некоторые данные, в необязательном порядке, сохранены). В одном варианте воплощения хранение включает в себя значения, закодированные мультибайтовым кодированием («MBE»), которые облегчают хранение целых чисел без знака для сохранения пространства памяти.
Блок 602 последовательных двоичных данных включает в себя преобразованные в последовательную форму двоичные данные для рукописного документа, и представлен блоками данных 604-618. Блоки данных 604-618 представляют расширенное представление всего блока 602 последовательных двоичных данных. Данные 604 размера могут быть первой информацией, которая сохранена в блоке 602 последовательных двоичных данных. Данные 604 размера включают в себя данные, ассоциированные с размером структуры рукописного документа.
Данные 606 дескриптора рукописного документа могут следовать за данными 604 размера. Данные 606 дескриптора рукописного документа могут включать в себя любой тип данных, который ассоциирует ожидание в отношении типа данных, включенных в блок 602 последовательных двоичных данных. Это ожидание может быть обозначено набором флагов, которые представляют ассоциированные данные, доступные в структуре рукописного документа. Флаги могут указать любые данные, которые являются доступными в блоке 602 последовательных двоичных данных. Блоки 604-618 данных являются только несколькими примерами данных, которые могут быть ассоциированы со структурой рукописного документа. В одном варианте воплощения данного изобретения данные 614 корневого узла (дополнительно описанные ниже) всегда ассоциированы с флагом в дескрипторе рукописного документа 606.
Данные 608 «черновой» области являются необязательными данными, которые могут не быть ассоциированы с каждой структурой рукописного документа. Данные 608 «черновой» области относятся к данным в структуре рукописного документа, которые полностью не проанализированы перед сохранением. Данные 608 «черновой» области могут относится и к данным рукописного ввода, и к данным нерукописного ввода типа TextWord, Image и т.п. Данные 608 «черновой» области могут быть обозначены флагом, ассоциированным с данными 606 дескриптора рукописного документа. Когда данные 606 дескриптора рукописного документа включают в себя флаг, который указывает на «черновую» область, этот флаг показывает, что структура рукописного документа имеет конечную, непустую «черновую» область. Если данные 608 «черновой» области существуют, эти данные могут быть представлены как ряд прямоугольников, которые сохранены в двоичном формате, чтобы облегчить восстановление «черновой» области. В ситуации, где документ рукописного ввода полностью проанализирован, данные 608 «черновой» области могут не присутствовать и не требовать флага в дескрипторе 606 рукописного документа. В одном варианте воплощения данные 608 «черновой» области (если представлены) следуют немедленно за данными 606 дескриптора рукописного документа.
В одном варианте воплощения данные 608 «черновой» области сохраняются в блоке 602 последовательных двоичных данных как данные области. Формат данных области может использоваться для того, чтобы сохранить данные 608 «черновой» области, данные местоположения для контекстных концевых узлов нерукописного ввода или местоположения для узлов подсказки. Данные области могут включать в себя массив отдельных прямоугольников, которые определяют всю область данных области. Чтобы должным образом восстановить объект данных области (например, данные 608 «черновой» области) из потока, данные области могут включать в себя количество прямоугольников. Для каждого прямоугольника данные области могут включать в себя информацию относительно данных верхней границы, данных левой границы, данных ширины и данных высоты. Отдельные значения, которые описывают данные прямоугольника, могут быть сохранены, используя MBE или MBE с подписью («SMBE»). Ниже дан один пример представления сохраненных данных области:
Данные прямоугольника могут быть представлены следующим образом:
SMBE [Прямоугольник. Левая Граница]
SMBE [Прямоугольник. Верхняя Граница]
SMBE [Прямоугольник. Ширина]
SMBE [Прямоугольник. Высота]
Данные 610 таблицы глобальных уникальных идентификаторов («GUID») являются необязательными данными, которые могут не быть ассоциированы не с каждой структурой рукописного документа. Данные 610 таблицы GUID могут включать в себя подсчет MBE GUID количества идентификаторов, которые ассоциированы с таблицей GUID и/или списком значений GUID. Список значений GUID может включать в себя 16-байтовое символьное значение без знака для каждого GUID. Структура рукописного документа или любой отдельный узел в древовидной структуре документа может содержать произвольные данные, которые идентифицированы GUID. Произвольные данные могут включать в себя известные типы данных и типы данных, которые ассоциированы с конкретным приложением. Для данных, которые ассоциированы с конкретным приложением (то есть данных настраиваемых свойств), данные сохранены для отдельного GUID. Данные 610 таблицы GUID задают значения любого GUID, используемого в отношении структуры рукописного документа, которые не являются известными дедуктивно. Данные 610 таблицы GUID соответствуют данным настраиваемых свойств на уровне рукописного документа или уровне контекстного узла, и на них можно впоследствии сослаться через MBE, отсчитываемые от нуля индексы в отношении данных таблицы 610 GUID. Как пример, не предопределенные GUID могут включать в себя специфические для конкретного приложения расширенные типы узлов и специфические для конкретного приложения расширенные свойства на узлах. В ситуации, где данные 610 таблицы GUID присутствуют по отношению к блоку 602 последовательных двоичных данных, это присутствие идентифицировано флагом, который относится к данным 606 дескриптора документа. Аналогично, если данные 610 таблицы GUID не присутствуют, флаг в данных 606 дескриптора рукописного документа не установлен. Ниже следует один пример представления сохраненных данных таблицы GUID:
Данные 612 таблицы строк являются необязательными данными, которые могут не быть ассоциированы с каждой структурой рукописного документа. Данные 612 таблицы строки могут включать в себя подсчет количества строк MBE в таблице строк, размер сжатых данных строк, и/или сжатые данные строк. Данные 612 таблицы строк могут быть ассоциированы с данными анализа суффикса подсказки, префиксными текстовыми данными, данными комментариев, данными имени подсказки, данными списка слов, данными настраиваемой связи узла, и данными распознанной строки. По отношению к одному аспекту изобретения данные 612 таблицы строк могут включать в себя дубликаты. В том, насколько структура рукописного документа загружена в конкретной последовательности, поддержка индекса для данных 612 таблицы строк позволяет загружать соответствующие данные строк из данных 612 таблицы строк.
Индекс может не быть записан каждый раз, когда строка ассоциирована с данными 612 таблицы строк. В такой ситуации сохранен по меньшей мере один байт на экземпляр. Кроме того, строки в данных 612 таблицы строк могут быть сжаты посредством LZW. С помощью невыполнения записи индекса для каждой строки в комбинации с LZW сжатием размер строки может быть существенно уменьшен. В ситуации, где данные 612 таблицы строки присутствуют по отношению к блоку 602 последовательных двоичных данных, это присутствие идентифицировано флагом, который относится к данным 606 дескриптора рукописного документа. Аналогично, если данные 612 таблицы строки не присутствуют, флаг в данных дескриптора рукописного документа 606 не установлен. Ниже приведен один пример представления сохраненных данных таблицы строк:
// Данные таблицы строк
MBE [Количество строк]
MBE [Размер сжатых данных строк]
[байты сжатых данных строк]
Данные 614 корневого узла включают в себя данные, относящиеся к размеру корневого узла и/или данные, ассоциированные с корневым узлом. Данные 614 корневого узла могут быть сохранены, как обсуждается для фиг.8 (более полно сформулировано ниже). В одном аспекте данные корневого узла являются обязательными данными, которые ассоциированы с каждой структурой рукописного документа, даже если данные 614 корневого узла пусты. Флаг, ассоциированный с данными 606 дескриптора рукописного документа, может указать присутствие данных 614 корневого узла.
Данные 616 связи являются необязательными данными, которые могут не быть ассоциированы с каждой структурой рукописного документа. Данные 616 связи включают в себя данные, которые указывают, связаны ли или нет какие-либо узлы структуры рукописного документа с другими узлами в той же самой структуре рукописного документа. Данные 616 связи могут быть поддержаны глобально в ассоциации со структурой рукописного документа. При сохранении данных 616 связи данные 616 связи могут включать в себя подсчет количества связей, ассоциированных со структурой рукописного документа. Отдельные данные 616 связи могут также включать в себя размер данных MBE. В одном аспекте данные размера MBE сопровождаются дескриптором связи, который идентифицирует тип связи и информацию источника. В другом аспекте данные дескриптора связи сопровождаются значением SMBE индекса исходного узла и значением SMBE индекса целевой узла. Индекс исходного узла и индекс целевого узла идентифицируют соответственно исходный узел и целевой узел. В еще одном аспекте, если данные дескриптора связи указывают, что данные 616 связи включают в себя настраиваемую связь, из глобальной таблицы строк читаются данные настраиваемой связи, которые идентифицированы индексом в глобальной таблице строк. В ситуации, где данные 616 связи присутствуют по отношению к блоку 602 последовательных двоичных данных, это присутствие идентифицировано флагом, который относится к данным 606 дескриптора рукописного документа. Аналогично, если данные 616 связи не присутствуют, флаг в данных 606 дескриптора рукописного документа не установлен. Ниже представлен один пример представления сохраненных данных связи:
[Дескриптор контекстной связи] // 1 байт
SMBE [Индекс исходного узла]
SMBE [Индекс целевого узла]
Данные 618 настраиваемых свойств являются необязательными данными, которые могут не быть ассоциированы с каждой структурой рукописного документа. Данные 618 настраиваемых свойств могут быть ассоциированы со структурой рукописного документа, и, в одном аспекте, сохранятся как данные настраиваемых свойств, ассоциированные с узлом. Данные настраиваемых свойств могут включать в себя любые произвольные данные, которые приложение ассоциирует с узлом. Данные настраиваемых свойств могут быть идентифицированы GUID и могут включать в себя известный или неизвестный GUID. В ситуации, где GUID неизвестен, GUID может быть сохранен как данные 610 таблицы GUID. При сохранении данных 618 настраиваемых свойств флаг может идентифицировать данные 618 настраиваемых свойств как известное значение. В другом аспекте сохранение данных 618 настраиваемых свойств включает в себя индекс для данных 610 таблицы GUID. Сохранение данных 618 настраиваемых свойств может также включать в себя значение MBE размера данных и массив байтов, которые представляют эти данные. В ситуации, где данные 618 настраиваемых свойств присутствуют относительно блока 602 последовательных двоичных данных, это присутствие идентифицируется флагом, который относится к данным 606 дескриптора рукописного документа. Аналогично, если данные 620 настраиваемых свойств не присутствуют, флаг в данных 606 дескриптора рукописного документа не установлен. Ниже следует один пример представления сохраненной структуры рукописного документа:
MBE [Размер]
<Дескриптор структуры рукописного ввода-1 байт>
// Данные «черновой» области
[Данные области анализа]
// Данные таблицы Guid
MBE [Количество идентификаторов Guid]
[GUID]}
...} Количество идентификаторов Guid
[GUID]}
// Данные таблицы строк
MBE [Количество строк]
MBE [Размер сжатых посредством LZ данных строк]
[сжатые посредством LZ данных строк]
// Данные корневого узла
MBE [Размер]
[Данные]
// Данные связи глобального контекста
MBE [Размер таблицы связей]
[Отдельные данные связи]
Фиг.7 представляет один примерный вариант воплощения для внутреннего сохранения данных 700 контекстного узла. В одном варианте воплощения данные 614 корневого узла являются контекстным узлом и сохраняются как данные 700 контекстного узла. Данные 700 контекстного узла могут быть включены в преобразованные в последовательную форму двоичные данные для рукописного документа и представлены блоками 704-716 данных. Блоки 704-716 данных представляют расширенное представление данных 702 контекстного узла.
Данные 704 дескриптора узла могут включать в себя данные, которые ассоциированы с каждым узлом структуры рукописного документа. Данные 704 дескриптора узла могут быть обозначены совокупностью флагов, которые определяют конфигурацию данных узлов, а также типы узлов, ассоциированных со структурой рукописного документа.
Данные 706 размера узла могут включать в себя возможные известные свойства, которые сохранены на конкретном узле (например, данные сетки, данные ограничивающих прямоугольников (невидимых прямоугольников, окружающих графический объект и определяющих его размер), и/или данные флагов прикрепления). Данные 706 размера узла могут также включать в себя неизвестные свойства (расширенные/настраиваемые свойства) наряду с данными местоположения, данными дочерних подузлов и данными штрихов. В одном аспекте данные 706 размера узла могут следовать непосредственно за данными 704 дескриптора узла. Кратко отметим, что данные 704 дескриптора узла могут указывать размер полного дерева контекстных узлов.
Данные 708 местоположения узла являются дополнительными данными, которые могут не быть ассоциированы с каждым типом узлов. В ситуации, где данные 708 местоположения узла присутствуют, это присутствие идентифицируется флагом, который относится к данным 704 дескриптора узла. Аналогично, если данные 708 местоположения узла не присутствуют, флаг в данных 704 дескриптора узла не установлен. В одном аспекте, если данные 704 дескриптора узла указывают концевой узел нерукописного ввода, данные 708 местоположения узла могут следовать. Концевой узел нерукописного ввода может включать в себя любой узел, который не имеет дочерних узлов и не включает в себя данные штрихов. Например, концевой узел нерукописного ввода может включать в себя узел изображения, текстовый узел или узел подсказки. В одном варианте воплощения данные 708 местоположения узла сохраняются как данные области. Данные области могут включать в себя массив отдельных прямоугольников, которые определяют всю зону данных области. Чтобы должным образом восстановить объект данных области (например, данные 708 местоположения узла) из потока, данные области могут включать в себя количество прямоугольников. Для каждого прямоугольника данные области могут включать в себя информацию относительно данных верхней границы, данных левой границы, данных ширины и данных высоты. Эти отдельные значения, которые описывают данные прямоугольника, могут быть сохранены, используя MBE или SMBE. Ниже представлен один пример представления сохраненных данных области:
MBE [Количество прямоугольников]
[Данные прямоугольника]}
[Данные Прямоугольника]}
Данные прямоугольника могут быть представлены следующим образом:
SMBE [Прямоугольник. Левая Граница]
SMBE [Прямоугольник. Верхняя Граница]
SMBE [Прямоугольник. Ширина]
SMBE [Прямоугольник. Высота]
Данные 710 штрихов являются необязательными данными, которые могут не быть ассоциированы с каждым типом узлов. Данные 710 штрихов могут включать в себя данные, ассоциированные с любым узлом, который включает в себя данные штрихов. Например, данные 710 штрихов могут быть ассоциированы с узлом неклассифицированного рукописного ввода, узлом слова или узлом рисунка. В ситуации, где данные 710 штрихов присутствуют, это присутствие может быть идентифицировано флагом, который относится к данным 704 дескриптора узла. Аналогично, если данные 710 штрихов не присутствуют, флаг в данных 704 дескриптора узла не установлен.
Когда данные 710 штрихов присутствуют, хранилище может включать в себя MBE значение количество штрихов, ассоциированных с узлом. В одном аспекте каждый штрих ассоциирован с однобайтовым дескриптором штриха, который включает в себя совокупность флагов дескриптора штриха. Эти флаги могут указать идентификацию штриха, которая показывает MBE данные, идентифицирующие штрих. В одном аспекте, если идентифицирующий флаг штриха не установлен, идентификация штриха может включать в себя последнюю найденную идентификацию штриха. Флаги могут также включать в себя запись флагов дескриптора штриха, которые идентифицируют тип штриха, ассоциированного с записью. В другом аспекте флаги могут включать в себя флаги дескриптора рисованного штриха, которые идентифицируют тип штриха, ассоциированного с рисунком. Флаги могут также включать в себя флаг дескриптора выделением, который идентифицирует тип штриха, ассоциированного с выделением. В еще одном варианте воплощения флаги могут включать в себя флаги дескриптора подтверждения предка, которые идентифицируют действительного подтвержденного предка для штриха. Значение MBE индекса преобразования в последовательную форму подтвержденного предка может быть сохранено в потоке. В еще одном варианте воплощения флаги могут включать в себя флаги идентификации языка штрихов, которые идентифицируют язык, ассоциированный со штрихом. Закодированное значение со знаком, соответствующее языку, может быть сохранено в потоке. В еще одном варианте воплощения значения, ассоциированные с флагами, сохранены в упомянутом выше порядке в зависимости от данных дескриптора штриха. Также подразумевается, что может быть установлен любой тип флага, который обеспечивает идентификацию штриха.
Данные 712 дочернего узла являются дополнительными данными, которые могут не быть ассоциированы с каждым типом узлов. В ситуации, где данные 712 дочернего узла присутствуют, это присутствие может быть идентифицировано флагом, который относится к данными 704 дескриптора узла. Аналогично, если данные 712 дочернего узла не присутствуют, флаг в данных 704 дескриптора узла не установлен. Данные 712 дочернего узла могут включать в себя узлы контейнерного типа (то есть узлы абзаца, узлы строки, узлы выравнивания, узлы области прописного текста и/или корневые узлы и т.д.). Контейнерные узлы могут включать в себя любой тип узла, который содержит дочерние узлы. Хранилище данных 712 дочерних узлов включает сохранение количества дочерних узлов и данных от каждого дочернего узла. Данные от каждого дочернего узла сохраняются тем же самым способом, что и данные 702 контекстных узлов.
Данные 714 известных свойств узла являются необязательными данными, которые могут не быть ассоциированы с каждым типом узлов. В ситуации, где присутствуют данные 714 известных свойств узла, это присутствие может быть идентифицировано флагом, который относится к данным 704 дескриптора узла. Аналогично, если данные 714 известных свойств узла не присутствуют, флаг в данных 704 дескриптора узла не установлен.
Данные 714 известных свойств узла включают в себя свойства, где тип данных и формат известны и обеспечивают оптимизацию для уменьшения размера данных. Данные 714 известных свойств узла могут включать в себя данные поворота ограничивающего прямоугольника (массив из восьми целых чисел), данные сетки распознавания (массив байтов, включая переменную длину), данные подтверждения данных аннотации (целочисленный тип) и/или данные подсказки (для узлов подсказки). В одном варианте воплощения эти данные сохраняются предопределенным способом для оптимизации двоичного представление данных. Например, массив целых чисел может быть сохранен в закодированном, со знаком, формате. Также сложные типы данных, типа данных структуры или класса, могут быть сохранены в двоичном формате, который эффективно определяет данные. Ниже представлен один пример представления сохраненных известных данных свойств:
[Дескриптор известных свойств] // 1 байт
[Данные поворота ограничивающего прямоугольника]
8*SMBE [целое число, представляющее координаты]
[Сетка распознавания]
MBE [Размер данных сетки]
[Данные сетки]
[Подтверждение]
SMBE [Подтверждение]
[Аннотация]
SMBE [Аннотация]
[Свойства подсказки для анализа]
[Данные подсказки для анализа]
Данные 716 настраиваемых свойств узла являются необязательными данными, которые могут не быть ассоциированы с каждым типом узлов. В ситуации, где присутствуют данные 716 настраиваемых свойств узла, это присутствие может быть идентифицировано флагом, который относится к данным дескриптора узла 704. Аналогично, если узел данных 716 настраиваемых свойств узла не присутствует, флаг в данных 704 дескриптора узла не установлен. Данные настраиваемых свойств узла могут включать в себя любые произвольные данные, которые приложение ассоциирует с узлом. Данные 716 настраиваемых свойств узла могут быть идентифицированы GUID и могут включать в себя известный или неизвестный GUID. В ситуации, где GUID неизвестен, GUID может быть сохранен как данные 610 таблицы GUID. При сохранении данных 716 настраиваемых свойств узла флаг может идентифицировать данные 716 настраиваемых свойств узла как известно значение. В другом аспекте сохранение данных 716 настраиваемых свойств узла включает в себя индекс для данных 610 таблицы GUID. Сохранение данных 716 настраиваемых свойств узла может также включать в себя значение размера данных MBE и массив байтов, которые представляют эти данные. Ниже следует один пример представления сохраненных данных контекстного узла:
MBE [Размер]
// Данные местоположения - Для концевых узлов нерукописного ввода
[Данные области анализа]
// Данные штрихов - Для концевых узлов нерукописного ввода
MBE [Количество штрихов]
[Данные штрихов]}
...} Количество штрихов
[Данные штрихов]}
Каждый большой двоичный объект данных штрихов представлен в потоке следующим образом:
<1 байт Флагов Дескриптора штриха>
MBE [Идентификатор штриха]
MBE [Индекс для подтвержденного узла предка]
MBE [Идентификатор языка штриха]
// Данные дочерних узлов - для контейнерного узла
<1-байтовый дескриптор узла>
MBE [Размер данных подузла]
[Данные подузла]
<1-байтовый дескриптор узла>
MBE [Размер данных подузла]
[Данные подузла]
[Данные для известных свойств]
[TagMaxKnownPropertyCount + Индекс в глобальной таблице Guid]
MBE [размер настраиваемых свойств]
[Данные настраиваемых свойств]
3. Иллюстративный процесс для сохранения документа в последовательном формате
Фиг.8 представляет один общий вариант воплощения системы для сохранения данных рукописного документа в последовательном двоичном формате. Система 800 начинается на этапе 802 начала и переходит к этапу 804, где генерируется рукописный документ. Этап 804 может включать в себя цифровой преобразователь для оцифровки штрихового ввода от пользователя. Цифровой преобразователь может включать в себя вычислительное устройство (например, Фиг.1), мобильное вычислительное устройство (например, Фиг.2), TABLET PC, выполняющий WINDOWS XP TABLET EDITION от MICROSOFT CORPORATION, или любое устройство, которое обеспечивает функционирование приложения рукописного ввода. Даже при том, что в описании даются ссылки на рукописный документ, система 800 может быть реализована по отношению к любому типу данных. Например, данное изобретение может также использоваться вместе с приложением обработки текстов, приложением для работы с электронными таблицами, приложением для рисования, приложением для работы с графикой, приложением для записи, приложением для раскрашивания или подобным приложениям. В одном варианте воплощения приложение включает в себя InkEdit, InkPicture и/или OneNote от MICROSOFT CORPORATION. С этапа 804 процесс 800 переходит к этапу 806.
Этап 806 указывает этап генерации необработанных данных рукописного ввода. В одном варианте воплощения генерация необработанных данных рукописного ввода включает в себя преобразование цифровым преобразователем, штрихового ввода в необработанные данные рукописного ввода и сохранение цифровым преобразователем необработанных данных рукописного ввода в хранилище необработанных данных. В другом варианте воплощения генерация необработанных данных рукописного ввода включает в себя преобразование цифровым преобразователем штрихового ввода в необработанные данные рукописного ввода и передачу цифровым преобразователем необработанных данных рукописного ввода приложению. Процесс 800 тогда переходит к этапу 808.
Этап 808 указывает этап генерации структуры рукописного документа. Этап 808 может включать в себя прием анализатором рукописного ввода необработанных данных рукописного ввода от приложения. Анализатор рукописного ввода может быть сконфигурирован для выполнения операций и распознавания, как более подробно сформулировано выше при описании Фиг.3. Этап 808 может дополнительно включать в себя генерацию структуры рукописного документа, как описано выше при описании фиг.4 и 5. В другом варианте воплощения структура рукописного документа включает в себя множество узлов, которые коррелируют с рукописным вводом. Например, структура рукописного документа может включать в себя узел области прописного текста, узел выравнивания, узел абзаца, узел строки, узел слова или узел штриха. Структура рукописного документа может также включать в себя узел рисунка и/или узел подсказки. Предусматривается, что структура рукописного документа может включать в себя любой тип узла, который обеспечивает представление рукописного ввода в виде двоичного дерева. В другом варианте воплощения узлы могут быть ассоциированы со связями, которые соотносят соответствующие узлы.
Перейдем к этапу 810, где структура рукописного документа может быть сохранена для глобальной доступности. В одном варианте воплощения структура рукописного документа сжимается и сохраняется, как сформулировано выше в связи с Фиг.6 и 7. В таком случае рукописный ввод может быть сгенерирован в отношении приложения, а затем сохранен с целью доступности других приложений. Говоря иначе, другие приложения, ассоциированные с платформой, могут использовать структуру рукописного документа и необработанный рукописный ввод для восстановления проанализированного рукописного ввода. Эта доступность облегчает операции вырезания и вставки между приложениями. Также рукописный ввод может быть модифицирован, не требуя повторного анализа всего рукописного документа, поскольку рукописный ввод был разобран, распознан и сохранен в последовательном формате.
4. Иллюстративная операционная среда
Что касается Фиг.1, примерная система для осуществления изобретения включает в себя вычислительное устройство, такое как вычислительное устройство 100. В основной конфигурации вычислительное устройство 100 обычно включает в себя по меньшей мере один процессор 102 и системную память 104. В зависимости от точной конфигурации и типа вычислительного устройства системная память 104 может быть энергозависима (типа ОЗУ), энергонезависима (типа ПЗУ, флэш-памяти и т.п.) или их некоторой комбинацией. Системная память 104 обычно включает в себя операционную систему 105, одно или более приложений 106 и может включать в себя данные 107 программ. В одном варианте воплощения приложения 106 дополнительно включают в себя приложение 120 для выполнения операций рукописного ввода. Эта основная конфигурация проиллюстрирована на фиг.1 компонентами в пределах пунктирной линии 108.
Вычислительное устройство 100 может также иметь дополнительные особенности или функциональные возможности. Например, вычислительное устройство 100 может также включать в себя дополнительные устройства хранения данных (сменные и/или несменные), такие как, например, магнитные диски, оптические диски или ленту. Такое дополнительное хранилище проиллюстрирована на фиг.1 с помощь сменного хранилища 109 и несменного хранилища 110. Компьютерные носители данных могут включать в себя энергозависимые и энергонезависимые, сменные и несменные носители, осуществленные любым способом или технологией для хранения информации, типа читаемых компьютером команд, структур данных, программных модулей или других данных. Системная память 104, сменная память 109 и несменная память 110 - все являются примерами компьютерных носителей данных. Компьютерные носители данных включают в себя, но не в ограничительном смысле, ОЗУ, ПЗУ, электрически стираемое программируемое ПЗУ, флэш-память или память другой технологии, CD-ROM, цифровые универсальные диски (DVD) или другую оптическую память, магнитные кассеты, магнитную ленту, магнитную память на диске или другие магнитные запоминающие устройства, или любые другие носители информации, которые могут использоваться для хранения желательной информации и к которым вычислительное устройство 100 может осуществить доступ. Любые такие компьютерные носители данных могут быть частью устройства 100. Вычислительное устройство 100 может также иметь устройство(а) 112 ввода данных типа клавиатуры, мыши, пера, устройства голосового ввода данных, сенсорного устройства ввода данных и т.д. Устройство(а) 114 вывода типа дисплея, динамиков, принтера и т.д. также могут быть включены. Все эти устройства известны в данной области техники и не должны подробно обсуждаться здесь.
Вычислительное устройство 100 также содержит коммуникационное соединение(я) 116, которое позволяет устройству связываться с другими компьютерными устройствами 118, например, по сети или беспроводной ячеистой сети. Коммуникационное соединение(я) 116 является примером коммуникационной среды. Коммуникационные среды обычно воплощают читаемые компьютерные команды, структуры данных, программные модули или другие данные в модулированном информационном сигнале, типа несущей или другого транспортного механизма, и включают в себя любые среды доставки информации. Термин «модулированный информационный сигнал» означает сигнал, одна или более характеристик которого установлены или изменены таким способом, чтобы кодировать информацию в этом сигнале. В качестве примера, но не ограничения, коммуникационные среды включают в себя проводные среды, типа проводной сети или прямого проводного соединения, и беспроводных сред, типа акустических, радиочастотных, инфракрасных и других беспроводных сред. Термин «читаемый компьютером носитель», как он используется здесь, включает в себя и носители данных, и коммуникационные среды.
Фиг.2 иллюстрирует мобильное вычислительное устройство, которое может использоваться в одном примерном варианте воплощения данного изобретения. Со ссылкой на фиг.2, одна примерная система для осуществления изобретения включает в себя мобильное вычислительное устройство, такое как мобильное вычислительное устройство 200. Мобильное вычислительное устройство 200 имеет процессор 260, память 262, дисплей 228 и клавишную панель 232. Память 262, в общем случае, включает в себя и энергозависимую память (например, ОЗУ), и энергонезависимую память (например, ПЗУ, флэш-память или т.п.). Мобильное вычислительное устройство 200 включает в себя операционную систему 264, которая постоянно находится в памяти 262 и выполняется на процессоре 260. Клавишная панель 232 может быть цифровой клавиатурой для набора номера (например, как на обычном телефоне), или многокнопочной клавиатурой (типа обычной клавиатуры). Дисплей 228 может быть жидкокристаллическим дисплеем или любым другим типом дисплея, обычно используемым в мобильном вычислительном устройстве. Дисплей 228 может быть сенсорным, и тогда он также может действовать как устройство ввода данных.
Одна или более прикладных программ 266 загружены в память 262 и выполняются на операционной системе 264. Примеры прикладных программ включают в себя программы для набора номера телефона, программы отправки электронной почты, программы расписания, программы PIM (управления личной информацией), программы обработки текстов, программы работы с электронными таблицами, программы обозревателя Интернет и т.д. Мобильное вычислительное устройство 200 также включает в себя энергонезависимую память 268 в пределах памяти 262. Энергонезависимая память 268 может использоваться для хранения постоянной информации, которая не должна быть потеряна, если мобильное вычислительное устройство 200 выключено. Приложения 266 могут использовать и хранить информацию в памяти 268, типа электронной почты или других сообщений, используемых почтовым приложением, контактную информацию, используемую PIM, информацию расписания, используемую в программе планирования, документы, используемые приложением обработки текстов, и т.п. В одном варианте воплощения приложения 266 дополнительно включают в себя приложение 280 для операций рукописного ввода.
Мобильное вычислительное устройство 200 имеет источник 270 электропитания, который может быть осуществлен как одна или более батарей. Источник 270 электропитания может дополнительно включать в себя внешний источник энергии, типа адаптера переменного тока или силового зарядного устройства, которые дополняют или перезаряжают батареи.
Мобильное вычислительное устройство 200 показано с двумя типами внешних механизмов уведомления: светодиод 240 и аудиоинтерфейс 274. Эти устройства могут быть непосредственно подсоединены к источнику 270 электропитания так, чтобы при активации они остались включенными на длительность, предписанную механизмом уведомления, даже при том, что процессор 260 и другие компоненты могут быть выключены, чтобы сохранить ресурс батареи питания. Светодиод 240 может быть запрограммирован так, чтобы оставаться включенным на неопределенное время, пока пользователь не примет меры, чтобы указать состояние включения устройства. Аудиоинтерфейс 274 используется, чтобы обеспечить звуковые сигналы и получить звуковые сигналы от пользователя. Например, аудиоинтерфейс 274 может быть соединен с динамиком для того, чтобы обеспечить звуковой вывод на микрофон для получения звукового ввода, например, для обеспечения сеанса телефонного разговора.
Мобильное вычислительное устройство 200 также включает в себя слой 272 радиоинтерфейса, который выполняет функцию передачи и приема при осуществлении связи, такой как радиочастотная связь. Слой 272 радиоинтерфейса обеспечивает беспроводную связь между мобильным вычислительным устройством 200 и внешним миром, через оператора связи или поставщика услуг. Передачи к и от слоя 272 радиоинтерфейса проводятся под управлением операционной системы 264. Другими словами, данные, принимаемые слоем 272 радиоинтерфейса, могут быть распространены на прикладные программы 266 через операционную систему 264, и наоборот.
Вышеупомянутое описание, примеры и данные обеспечивают законченное изложение изготовления и использования состава изобретения. Так как может быть сделано множество вариантов воплощения изобретения, не отступая от духа и объема изобретения, объем изобретения полностью определяется приложенной формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2351982C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2358308C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2352981C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2008 |
|
RU2485579C2 |
| ОБРАБОТКА ЭЛЕКТРОННЫХ ЧЕРНИЛ | 2003 |
|
RU2326435C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
| БЕЗОПАСНОСТЬ НА ОСНОВЕ ОБЛАСТИ | 2006 |
|
RU2413978C2 |
| СИНХРОНИЗАЦИЯ ДОКУМЕНТА ПО ПРОТОКОЛУ, НЕ ИСПОЛЬЗУЮЩЕМУ ИНФОРМАЦИЮ О СОСТОЯНИИ | 2009 |
|
RU2500023C2 |
| РАЗДЕЛИТЕЛЬ ЧЕРНИЛ И ИНТЕРФЕЙС СООТВЕТСТВУЮЩЕЙ ПРИКЛАДНОЙ ПРОГРАММЫ | 2003 |
|
RU2358316C2 |
| АЛЬТЕРНАТИВЫ АНАЛИЗА В КОНТЕКСТНЫХ ДЕРЕВЬЯХ | 2005 |
|
RU2398276C2 |





Изобретение относится к системе и способу для генерации структуры рукописного документа и сохранения структуры рукописного документа в последовательном двоичном формате. Технический результат заключается в избегании затратного в вычислительном плане повторного анализа рукописного ввода рукописного документа при использовании рукописного ввода среди множества приложений. Способ содержит этапы, на которых формируют рукописный документ в приложении, формируют структуру рукописного документа в виде двоичного дерева, сохраняют структуру рукописного документа в последовательном формате двоичных данных, причем при сохранении в последовательном формате двоичных данных сохраняют данные размера, ассоциированные со структурой документа, в первом поле данных, сохраняют данные дескриптора структуры документа во втором поле данных, сохраняют данные корневого узла в третьем поле данных, осуществляют доступ к сохраненной структуре рукописного документа из приложения, отличающегося от приложения, в котором рукописный документ был сформирован. 3 н. и 17 з.п. ф-лы, 8 ил.
1. Компьютерно-реализуемый способ сохранения данных рукописного документа, содержащий этапы, на которых
формируют рукописный документ в приложении;
формируют структуру рукописного документа на основе необработанных данных рукописного ввода, сгенерированных из рукописного документа, при этом структура рукописного документа представляет собой двоичное дерево, включающее в себя множество узлов, относящихся к рукописному вводу этого рукописного документа, причем это множество узлов включает в себя корневой узел;
сохраняют структуру рукописного документа в последовательном формате двоичных данных, причем при сохранении в последовательном формате двоичных данных:
сохраняют данные размера, ассоциированные со структурой рукописного документа, в первом поле данных последовательного формата двоичных данных,
сохраняют данные дескриптора структуры рукописного документа во втором поле данных последовательного формата двоичных данных, причем данные дескриптора структуры рукописного документа включают в себя один или более флагов для указания ассоциированных данных структуры рукописного документа, и
сохраняют данные корневого узла, ассоциированные с корневым узлом, в третьем поле данных последовательного формата двоичных данных, при этом данные корневого узла обозначаются флагом из упомянутых одного или более флагов из данных дескриптора структуры рукописного документа, находящихся во втором поле данных;
осуществляют доступ к сохраненной структуре рукописного документа, имеющей последовательный формат двоичных данных, из приложения, отличающегося от приложения, в котором рукописный документ был сформирован, для восстановления упомянутого рукописного ввода на основе структуры рукописного документа и упомянутых необработанных данных рукописного ввода.
2. Компьютерно-реализуемый способ по п.1, в котором при сохранении в последовательном формате двоичных данных дополнительно сохраняют данные «черновой» области в последующем поле данных последовательного формата двоичных данных, причем данные «черновой» области относятся к данным в структуре рукописного документа, которые полностью не проанализированы перед сохранением, при этом присутствие данных «черновой» области в преобразованных в последовательную форму данных обозначается одним из флагов, ассоциированных с данными дескриптора документа во втором поле данных последовательного формата двоичных данных.
3. Компьютерно-реализуемый способ по п.2, в котором данные «черновой» области включают в себя по меньшей мере одно из данных местоположения данных рукописного ввода, которые не были проанализированы анализатором рукописного ввода, и данных местоположения данных нерукописного ввода, которые не были проанализированы анализатором рукописного ввода.
4. Компьютерно-реализуемый способ по п.2, в котором данные «черновой» области включают в себя по меньшей мере одно из количества прямоугольников, ассоциированных с данными «черновой» области, данных верхней границы, данных левой границы, данных ширины и данных высоты.
5. Компьютерно-реализуемый способ по п.1, в котором при сохранении в последовательном формате двоичных данных дополнительно сохраняют данные глобальных уникальных идентификаторов в последующем поле данных последовательного формата двоичных данных, при этом присутствие данных глобальных уникальных идентификаторов в последовательном формате двоичных данных обозначается одним из флагов, ассоциированных с данными дескриптора документа во втором поле данных последовательного формата двоичных данных.
6. Компьютерно-реализуемый способ по п.5, в котором данные глобальных уникальных идентификаторов включают в себя по меньшей мере одно из специфических для конкретного приложения типов узлов и специфических для конкретного приложения расширенных свойств.
7. Компьютерно-реализуемый способ по п.1, в котором при сохранении в последовательном формате двоичных данных дополнительно сохраняют данные таблицы строк в последующем поле данных последовательного формата двоичных данных, при этом присутствие данных таблицы строк в последовательном формате двоичных данных обозначается одним из флагов, ассоциированных с данными дескриптора документа во втором поле данных последовательного формата двоичных данных.
8. Компьютерно-реализуемый способ по п.7, в котором данные таблицы строк ассоциированы с по меньшей мере одним из данных анализа суффикса подсказки, данных префикса текста, данных комментариев, данных узла подсказки, данных списка слов, данных настраиваемой связи узла и данных распознанной строки.
9. Компьютерно-реализуемый способ по п.1, в котором при сохранении в последовательном формате двоичных данных дополнительно сохраняют данные связи в последующем поле данных последовательного формата двоичных данных, при этом присутствие данных связи в преобразованных в последовательную форму данных обозначается одним из флагов, ассоциированных с данными дескриптора документа во втором поле данных последовательного формата двоичных данных.
10. Компьютерно-реализуемый способ по п.9, в котором данные связи включают в себя по меньшей мере одно из количества связей, ассоциированных со структурой документа, размера данных связи, дескриптора связи, данных индекса исходного узла и данных индекса целевого узла.
11. Компьютерно-реализуемый способ по п.1, в котором при сохранении в последовательном формате двоичных данных дополнительно сохраняют данные настраиваемых свойств в последующем поле данных последовательного формата двоичных данных, при этом присутствие данных настраиваемых свойств в последовательном формате двоичных данных обозначается одним из флагов, ассоциированных с данными дескриптора документа во втором поле данных последовательного формата двоичных данных.
12. Компьютерно-реализуемый способ по п.11, в котором данные настраиваемых свойств включают в себя по меньшей мере одно из данных размера и массива байтов, которые представляют данные настраиваемых свойств.
13. Компьютерно-реализуемый способ по п.1, в котором данные корневого узла в третьем поле данных последовательного формата двоичных данных включают в себя данные дескриптора, при этом присутствие данных дескриптора узла в последовательном формате двоичных данных включает в себя один или более флагов, которые указывают на данные, ассоциированные с данными корневого узла.
14. Компьютерно-реализуемый способ по п.13, в котором данные корневого узла включают в себя данные размера, которые указывают на размер данных корневого узла.
15. Компьютерно-реализуемый способ по п.13, в котором данные корневого узла включают в себя по меньшей мере одно из данных местоположения узла, данных штрихов, данных дочерних узлов, данных известных свойств узла и данных настраиваемых свойств узла.
16. Считываемый компьютером носитель, имеющий исполняемые компьютером команды для сохранения данных рукописного документа, при этом команды содержат:
формирование рукописного документа в приложении;
формирование структуры рукописного документа на основе необработанных данных рукописного ввода, сгенерированных из рукописного документа, при этом структура рукописного документа представляет собой двоичное дерево, включающее в себя множество узлов, относящихся к рукописному вводу этого рукописного документа, причем это множество узлов включает в себя корневой узел;
сохранение структуры рукописного документа в последовательном формате двоичных данных, включающее в себя:
сохранение данных размера, ассоциированных со структурой рукописного документа, в первом поле данных последовательного формата двоичных данных,
сохранение данных дескриптора структуры рукописного документа во втором поле данных последовательного формата двоичных данных, причем данные дескриптора структуры рукописного документа включают в себя один или более флагов для указания ассоциированных данных структуры рукописного документа, и
сохранение данных корневого узла, ассоциированных с корневым узлом, в третьем поле данных последовательного формата двоичных данных, при этом данные корневого узла обозначаются флагом из упомянутых одного или более флагов из данных дескриптора структуры рукописного документа, находящихся во втором поле данных;
доступ к сохраненной структуре рукописного документа, имеющей последовательный формат двоичных данных, из приложения, отличающегося от приложения, в котором структура рукописного документа была сформирована, для восстановления упомянутого рукописного ввода на основе структуры рукописного документа и упомянутых необработанных данных рукописного ввода.
17. Считываемый компьютером носитель по п.16, в котором данные корневого узла включают в себя по меньшей мере одно из данных ожидания, данных размера, данных местоположения узла, данных штрихов, данных дочерних узлов, данных известных свойств узла и данных настраиваемых свойств узла.
18. Компьютерная система для сохранения данных рукописного документа, содержащая процессор и память, в которой хранятся машиноисполняемые команды, предназначенные для:
формирования рукописного документа в приложении;
формирования структуры рукописного документа на основе необработанных данных рукописного ввода, сгенерированных из рукописного документа, при этом структура рукописного документа представляет собой двоичное дерево, включающее в себя множество узлов, относящихся к рукописному вводу этого рукописного документа, причем это множество узлов включает в себя корневой узел;
сохранения структуры рукописного документа в последовательном формате двоичных данных, причем данное сохранение включает в себя:
сохранение данных размера, ассоциированных со структурой рукописного документа, в первом поле данных последовательного формата двоичных данных,
сохранение данных дескриптора структуры рукописного документа во втором поле данных последовательного формата двоичных данных, причем данные дескриптора структуры рукописного документа включают в себя один или более флагов для указания ассоциированных данных структуры рукописного документа, и
сохранение данных корневого узла, ассоциированных с корневым узлом, в третьем поле данных последовательного формата двоичных данных, при этом данные корневого узла обозначаются флагом из упомянутых одного или более флагов из данных дескриптора структуры рукописного документа, находящихся во втором поле данных;
доступа к сохраненной структуре рукописного документа, имеющей последовательный формат двоичных данных, из приложения, отличающегося от приложения, в котором структура рукописного документа была сформирована, для восстановления упомянутого рукописного ввода на основе структуры рукописного документа и упомянутых необработанных данных рукописного ввода.
19. Система по п.18, в которой сохранение в последовательном формате двоичных данных дополнительно включает в себя сохранение в последующем поле данных последовательного формата двоичных данных по меньшей мере одного из данных глобальных уникальных идентификаторов, данных таблицы строк, данных связи, данных настраиваемых свойств и данных «черновой» области, относящихся к данным в структуре рукописного документа, которые полностью не проанализированы перед сохранением.
20. Система по п.18, в которой данные корневого узла включают в себя по меньшей мере одно из данных ожидания, данных размера, данных местоположения узла, данных штрихов, данных дочерних узлов, данных известных свойств узла и данных настраиваемых свойств узла.
| СРЕДСТВО ДЛЯ ВВОДА СИМВОЛОВ ИЛИ КОМАНД В КОМПЬЮТЕР | 1998 |
|
RU2236036C2 |
| RU 96103366 A, 20.05.1998 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 5553284 А, 03.09.1996 | |||
| Автомат для сортировки деталей | 1985 |
|
SU1331592A1 |

