Область техники
Настоящее изобретение относится к идентификации мультимедийной информации в общем и, в частности, к защищенной идентификационной системе и способу для выявления лиц, участвующих в незаконном изготовлении копий цифровых мультимедийных продуктов.
Уровень техники изобретения
Незаконное копирование цифровых данных мультимедийных продуктов (таких как фильмы и звукозаписи) является широкораспространенной проблемой. И, по-видимому, проблема только растет, несмотря на технические достижения в области защиты от копирования и попыток установки для осуществления прав на интеллектуальную собственность. Подобные нарушения прав на интеллектуальную собственность могут причинять большой финансовый ущерб их владельцу.
Растущая тенденция нелегального копирования связана, по-видимому, с расширением использования цифровых носителей и оборудования для хранения и распространения цифровых мультимедийных данных. Быстрое развитие Интернет-технологий и хранения данных в цифровом виде сделали возможным простое и недорогое изготовление идентичных высококачественных копий оригинала. Вдобавок, стало возможным делать указанные копии доступными всему Интернет-сообществу. Этот процесс становится все более легким с использованием Р2Р-сетей (сетей точка-точка). С увеличением доступности копирующих устройств и с увеличением их пропускной способности для цифровых данных необходимость ограничения нелегального распространения цифровых мультимедийных данных (таких как изображения, видео и музыка) становится важной проблемой.
Одним из путей сдерживания нелегального копирования является увеличение риска быть пойманным после того, как соучастие было обнаружено. Внедрение уникальной, невидимой метки в каждую копию (другими словами, секретное и надежное внедрение метки в воспринимаемое содержимое цифрового мультимедийного сигнала) является способом увеличения такого риска. Таким образом, если нелегальная копия была обнаружена где-либо, то становится возможным найти владельца копии и применить к нему действия, предусмотренные законодательством. Такой тип схемы обеспечения называется "использование отпечатков пальцев" или "использование идентификационной информации" (также известный в определенных кругах как "внедрение метки", используемой сотрудниками правоохранительных органов).
Идея идентификации состоит в том, чтобы уникально помечать каждую копию. Это делает каждую копию отличной от другой на уровне цифрового представления на носителе, но при этом воспринимаемое содержимое разных копий остается персептуально подобным. Таким образом, становится возможным различать между собой все легальные копии. Маркирование может быть использовано для идентифицирования копии и, следовательно, пользователя, если его идентификационные данные были каким-нибудь образом сопоставлены идентификационной информации. Например, если идентифицированные копии были переданы только персонам, которые идентифицировали себя, то становится возможным в случае определения нелегальной копии идентифицировать владельца легальной копии, с которой были сделаны нелегальные копии.
Допустим, владелец фильма на цифровом видеодиске (DVD) делает копии этого фильма для продажи. Каждая из копий содержит идентификационную информацию. Владелец продает копию пользователю, предварительно индивидуально и уникально помеченную каждую продаваемую копию идентификационной информацией, и ассоциирует каждую идентификационную информацию с конкретным покупателем. Позже, некоторые покупатели, именуемые пиратами, сговорившись, создают нелегальные копии, которые они распространяют (в данной ситуации, пираты также называются соучастниками). Владелец фильма может проанализировать нелегальную копию и попытаться выяснить, кто из покупателей принимал участие в создании нелегальных копий.
Техника идентификационной информации включает в себя внедрение идентификационной информации в каждую копию цифрового продукта с использованием схемы "водяного знака" (также известной как "внедрение метки"). Использование схемы "водяного знака" позволяет незаметно внедрить идентфикационную информацию в воспринимаемое содержимое таким образом, что эта идентификационная информация может быть восстановлена только с помощью секретного ключа. Следует заметить, что такой тип схемы полностью отличается от традиционной DRM-техники защиты содержимого (DRM - Цифровое Управление Правами). Имеются два важных отличия между водяными знаками (для экранирования содержимого для предотвращения нелегального копирования или записи) и идентификационной информацией (для отслеживания утечки сотрудниками правоохранительных органов). Во-первых, в то время, как в “водяных” знаках скрытое сообщение (метка) является одинаковым для всех покупателей (и эта метка часто идентифицирует владельца содержимого), в идентификационной информации метка поставлена в соответствие идентификационным данным покупателя. Во-вторых, сговор покупателей не может быть установлен на основе “водяного знака” (так как помеченные копии одного и того же содержимого являются одинаковыми для всех покупателей). Однако в идентификационной информации метка является различной для каждого покупателя, и для покупателей, вступивших в заговор, является возможным осуществить заговор путем сравнения имеющихся у них копий, локализации и удаления битов метки. Таким образом, при атаке на помеченные идентификационной информацией цифровые продукты, группа непорядочных пользователей сговаривается создавать нелегальные копии, которые скроют их идентификационные данные путем совмещения разных частей имеющихся у них копий. Атака расчитана на поиск и удаление из копии скрытой и внедренной в нее идентификационной информации.
Одна из проблем, связанная с текущими способами использования идентификационной информации, состоит в том, что все эти способы ограничены по числу соучастников, которые могут быть идентифицированы. Например, некоторые применяющиеся в настоящее время традиционные способы идентификации могут идентифицировать только от четырех до восьми соучастников. Некоторые более новые способы идентификации используют коды идентификационной информации для получения на порядок лучших результатов по сравнению с традиционными способами идентификации. Однако в производство нелегальных копий бывает вовлечено большое количество соучастников. Это означает, что используемые в данный момент способы идентификации не могут точно идентифицировать больше чем одну сотню лиц. Это часто ограничивает сдерживающий эффект идентификации с использованием идентификационной информации, поскольку соучастники знают, что все что им нужно сделать, это привлечь как можно больше владельцев других копий с тем, чтобы сделать идентификацию невозможной.
Другой проблемой, связанной с применяемыми способами идентификации, является чувствительность этих способов к оценочным атакам. Оценочная атака совершается, когда атакующие берут все кадры сцены и рассчитывают среднее число всех кадров, тем самым производя оценку оригинального немаркированного содержимого. В качестве альтернативы, разные способы могут также быть использованы для оценки идентификационной информации каждой копии на основе анализа неотъемлемой избыточности, которая имеется в сигнале носителя. Это позволяет значительно ослабить или исключить всю идентификационную информацию. Следовательно, требуются идентифицирующие системы и способы, которые способны точно идентифицировать хотя бы на порядок большее число лиц, чем используемые в настоящее время идентифицирующие способы. Также необходимо, чтобы системы и способы с использованием идентификационной информации были криптографически защищены и были бы устойчивы к оценочным атакам.
Сущность изобретения
Изобретение, раскрытое ниже, включает в себя систему и способ десинхронизированного использования идентификационной информации, устойчивые к атакам и которые могут идентифицировать большое число соучастников без использования кодов идентификационной информации. В частности, система и способ с использованием десинхронизированной идентификационной информации, раскрытые здесь, способны идентифицировать на порядок больше соучастников, чем используемые в настоящее время способы использования идентификационной информации.
Система и способ использования десинхронизированной идентификационной информации могут быть использованы для любого типа мультимедийных данных, в частности для звуко- и видеоприложений. В общем, для каждого пользователя назначаются разные ключи. Функция внедрения включает в себя применение псевдо-случайного преобразования выбранных зон. Ключ для псевдо-случайного преобразования является специфичным для каждого пользователя. Эти зоны выбираются с использованием защищенной хэш-функции мультимедийной информации. Функции обнаружения и извлечения включают в себя простой (грубый) поиск в области ключей пользователей. Если один из ключей является “вероятно” подходящим, то это означает, что этот пользователь был вовлечен в производство нелегальных копий.
Способ использования десинхронизированной идентификационной информации включает в себя процесс десинхронизированного внедрения и процессы обнаружения и извлечения. Процесс десинхронизированного внедрения включает в себя генерацию копий оригинального мультимедийного продукта (где каждая копия является псевдо-случайной десинхронизированной версией оригинала) и случайный выбор десинхронизирующей зоны и зоны внедрения, в которые нужно внедрить идентификационную информацию. Псевдо-случайная преднамеренная десинхронизация перед собственно внедрением метки гарантирует, что для соучастников будет трудно найти хорошую оценку непомеченного оригинального сигнала (например, атаки с использованием методов средних величин). Это происходит потому, что соучастники вынуждены "выравнивать" свои копии относительно друг друга для получения оценки, и это становится более трудным с увеличением количества участвующих (с учетом того, что общая вычислительная мощность ограничена). Процесс случайной десинхронизации включает в себя отображение (преобразование) ширины каждой зоны десинхронизации в псевдо-случайно опредленную величину, которая варьируется от копии к копии для разных клиентов. Мастер-ключ используется в процессе случайной десинхронизации. Аналогично, мастер-ключ и хэш-функция используются для случайного выбора зон для внедрения. Затем уникальная информация о копии и секретные ключи внедряются в зоны внедрения. В общем, нет необходимости в том, чтобы зоны внедрения и зоны десинхронизации были одними и теми же, поэтому они могут перекрываться.
Процессы обнаружения и извлечения включают в себя получение нелегальной копии оригинального цифрового мультимедийного продукта. Для этой нелегальной копии вычисляются хэш-значения, которые используются для определения зон внедрения путем сравнения их с хэш-значениями зон внедрения оригинального содержимого. В сущности, сложные (робастные) хэш-функции над воспринимаемым содержимым используются для закрытия зон внедрения на приемнике. Затем производится обнаружение “водяного” знака в каждой зоне внедрения с использованием для каждой своего секретного ключа. Определяется идентификационная информация и информация о соучастнике извлекается для построения списка соучастников. Этот список соучастников представляет лиц, которые участвовали в производстве нелегальных копий.
Краткое описание чертежей
Для лучшего понимания представленного изобретения приводятся следующие описания и сопроводительные чертежи, которые иллюстрируют аспекты изобретения. Другие признаки и преимущества станут очевидными из последующего подробного описания изобретения, приведенного со ссылками на сопроводительные чертежи, которые иллюстрируют, в качестве примера, принципы представленного изобретения.
На всех чертежах числа, в качестве ссылок, представляют соответствующие части:
ФИГ.1 является блок-схемой, иллюстрирующей пример реализации системы и способа использования десинхронизированной идентификационной информации здесь описанных.
ФИГ.2 является общей диаграммой процессов, иллюстрирующей общие операции системы использования десинхронизированной идентификационной информации, показанной на ФИГ.1.
ФИГ.3 является общей диаграммой процессов, иллюстрирующей операцию процесса десинхронизированного внедрения согласно способу использования десинхронизированной идентификационной информации, показанного на ФИГ.2.
ФИГ.4 является подробной диаграммой процессов, иллюстрирующей в подробностях операцию процесса десинхронизированного внедрения, показанного на ФИГ.3.
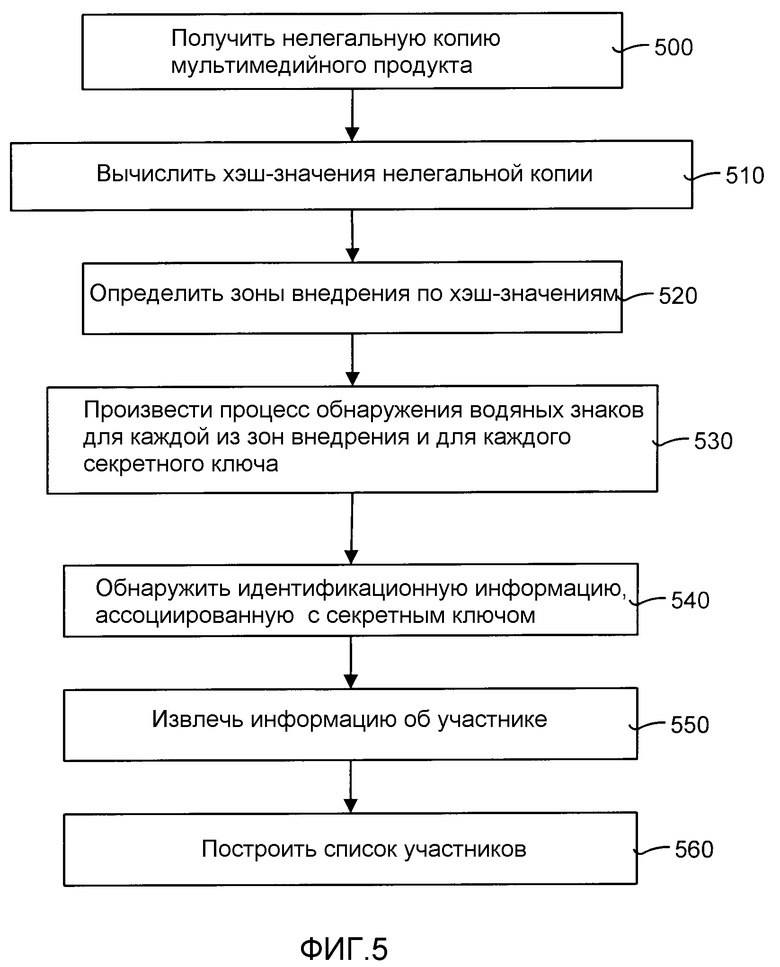
ФИГ.5 является общей диаграммой процессов, иллюстрирующей операцию процессов обнаружения и извлечения способа использования десинхронизированной идентификационной информации, показанного на ФИГ.2.
ФИГ.6 иллюстрирует пример подходящей среды вычислительных систем, в которых система и способ использования десинхронизированной идентификационной информации, показанные на ФИГ.1, могут быть реализованы.
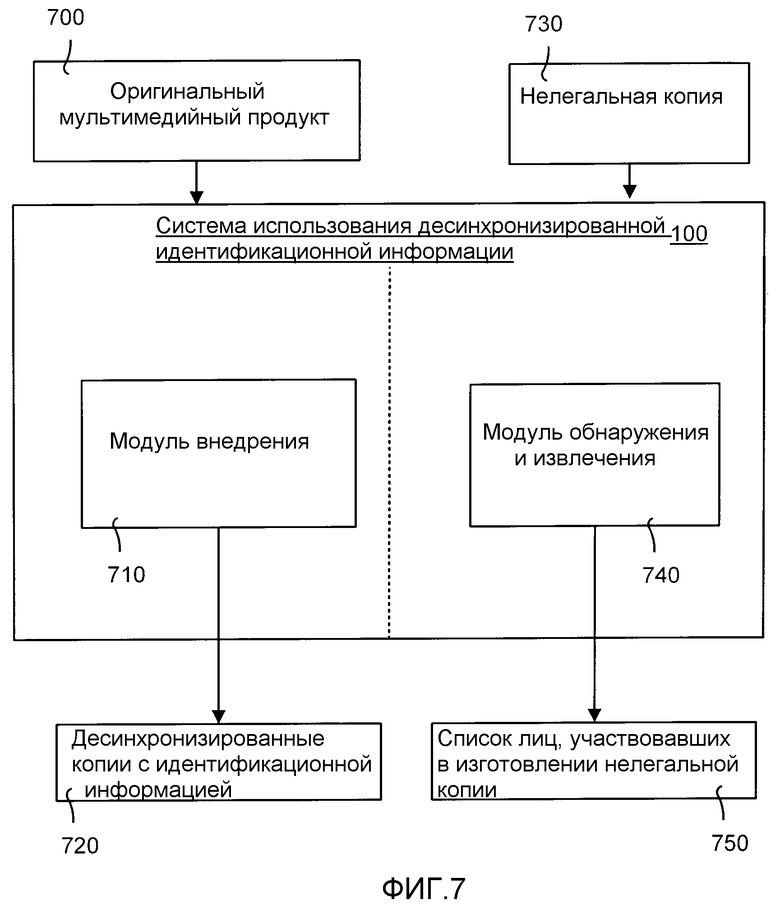
ФИГ.7 является блок-схемой, иллюстрирующей подробности системы использования десинхронизированной идентификационной информации, показанной на ФИГ.1.
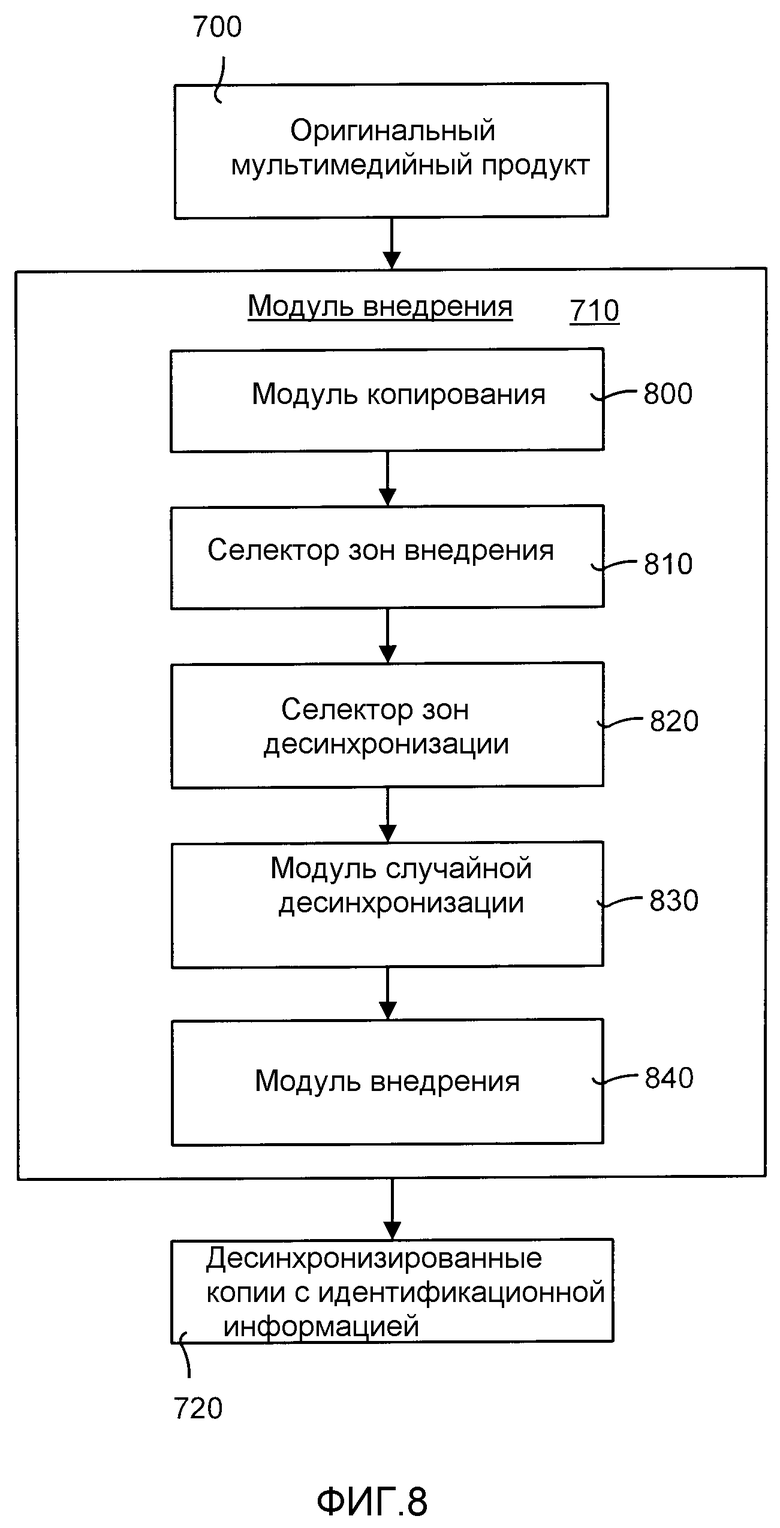
ФИГ.8 является блок-схемой, иллюстрирующей подробности модуля внедрения, показанного на ФИГ.7.
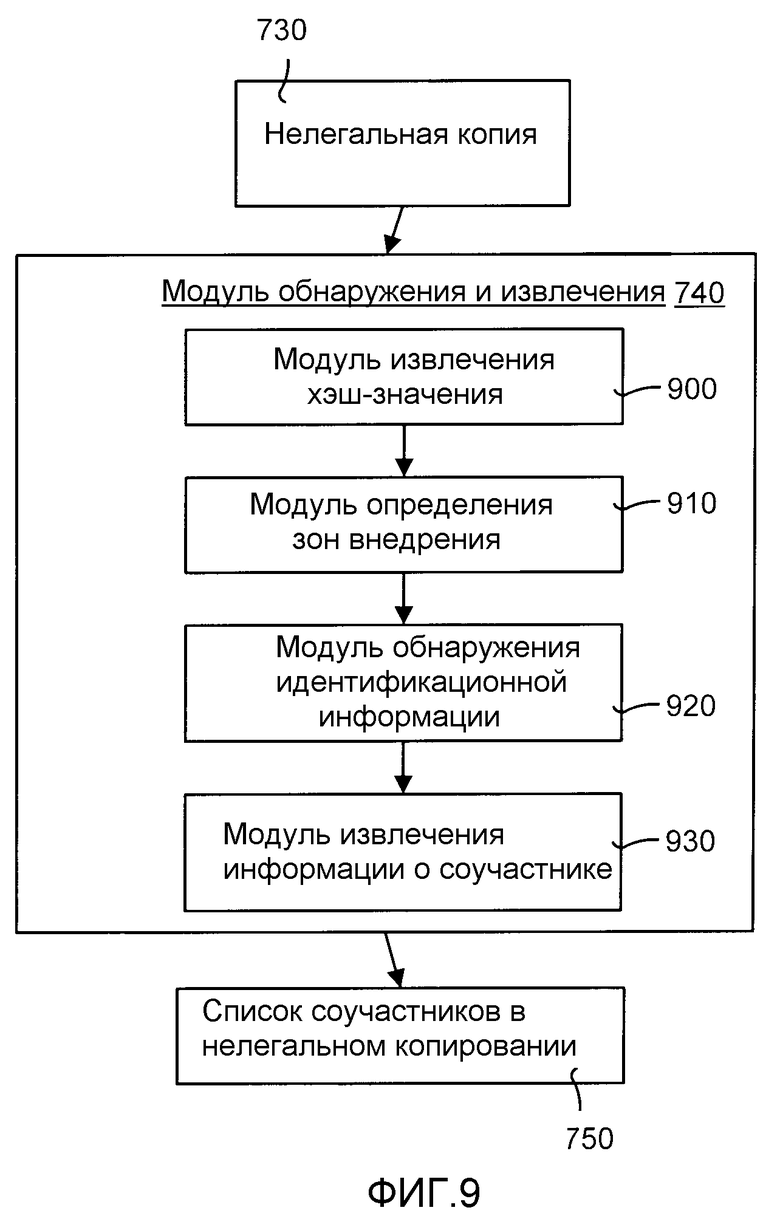
ФИГ.9 является блок-схемой, иллюстрирующей подробности модуля обнаружения и извлечения, показанного на ФИГ.7.
Подробное описание изобретения
В нижеприведенном описании изобретения сделаны ссылки на сопроводительные чертежи, которые являются частью описания и на которых показан, в качестве иллюстрации, конкретный пример, в соответствии с которым изобретение может быть применено. Понятно, что могут быть использованы и другие воплощения и что могут быть сделаны структурные изменения без выхода за рамки представленного изобретения.
I. Введение
Нелегальное копирование и распространение цифровых мультимедийных данных становится широкораспространенной проблемой, которая выражается в потере дохода для владельца интеллектуальной собственности. Одним из путей увеличения риска быть пойманным является применение способов с использованием идентификационной информации, которые уникально идентифицируют копию продукта, содержащего цифровые мультимедийные данные, с покупателем. Однако используемые в настоящее время способы идентификации весьма ограничены по числу соучастников, которые могут быть идентифицированы. К тому же, эти способы используют идентификационные коды, реализация которых может быть затруднена. Более того, используемые в настоящее время способы уязвимы для оценочных атак, которые могут фактически устранить идентификационную информацию.
Система и способ с использованием десинхронизированной идентификационной информации, описанные здесь, способны идентифицировать по меньшей мере на порядок больше соучастников, чем способы, используемые в настоящее время. Более того, система и способ достигают этого без применения кодов идентификационной информации. Хотя коды и могут быть использованы с системой и способом использования десинхронизированной идентификационной информации, но применение их необязательно. К тому же, система и способ использования десинхронизированной идентификационной информации сделаны устойчивыми к оценочным атакам путем использования нового процесса случайной десинхронизации, который произвольно изменяет ширину случайно выбранных зон десинхронизации. Затем, идентификационная информация встраивается в каждую копию цифровых мультимедийных данных в зоны внедрения, которые могут быть одинаковыми с зонами десинхронизации или быть отличными от них. Путем увеличения количества соучастников, которые могут быть идентифицированы, и путем создания способа более устойчивых против оценочных атак, система и способ использования десинхронизированной идентификационной информации служат надежным средством сдерживания нелегального копирования.
II. Общее описание
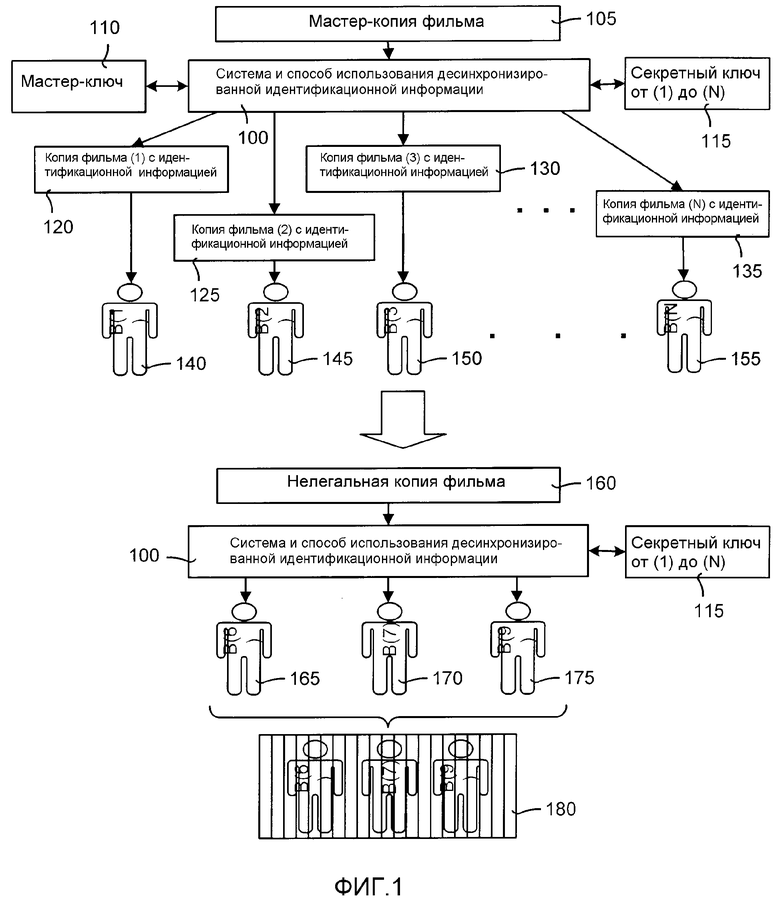
ФИГ.1 является блок-схемой, иллюстрирующей типичную реализацию системы и способа использования десинхронизированной идентификационной информации, здесь описанных. Необходимо заметить, что ФИГ.1 является просто одним из нескольких способов, которыми система и способ использования десинхронизированной идентификационной информации могут быть реализованы и использованы.
Система и способ использования десинхронизированной идентификационной информации оперируют с цифровыми мультимедийными данными (такими как изображения, видео и аудио). В общем, есть две части системы и способа использования десинхронизированной идентификационной информации. Первая часть состоит в использовании системы и способа использования десинхронизированной идентификационной информации для внедрения уникальной информации внутрь каждой копии цифрового мультимедийного продукта (таких как фильм или аудиозапись). Эта уникальная информация каталогизируется, так что копия продукта ассоциируется с конкретной персоной (такой как покупатель копии продукта). Вторая часть включает в себя анализ нелегальной копии продукта (такой как, например, анализ правоохранительными органами) для определения персон, участвовавших в изготовлении нелегальной копии.
В примерной реализации, показанной на ФИГ.1, цифровым мультимедийным продуктом является фильм. Более конкретно, как показано на ФИГ.1, система и способ 100 использования десинхронизированной идентификационной информации используются для изготовления мастер-копии фильма 105. Как подробно описано ниже, система и способ 100 использования десинхронизированной идентификационной информации используют мастер-ключ 110 и множество секретных ключей 115. В этой примерной реализации количество секретных ключей равно N. После обработки результатом применения системы и способа 100 использования десинхронизированной идентификационной информации является N копий фильма 105. В частности, система и способ 100 использования десинхронизированной идентификационной информации производят копию фильма (1) 120 с идентификационной информацией, копию фильма (2) 125 с идентификационной информацией, копию фильма (3) 130 с идентификационной информацией, и так далее до копии фильма (N) 135 с идентификационной информацией. Каждая копия фильма с идентификационной информацией имеет соответствующий один из секретных ключей 115. Секретный ключ, ассоциированный с копией фильма с идентификационной информацией, позволяет держателю ключа получить доступ к уникальной информации, содержащейся в копии фильма.
Каждая из копий фильма с идентификационной информацией затем распространяется каким-либо способом. Обычно, распространение включает предложение на продажу. Тем не менее, возможны и другие способы распространения, такие как распространения для каких-либо других целей клиента, таких как рецензирование, оценка, и так далее. В примере реализации, показанном на ФИГ.1, распространением является покупка кем-либо копии фильма с идентификационной информацией. В частности, первый покупатель (B(1)) 140 покупает копию фильма (1) 120 с идентификационной информацией, второй покупатель (B(2)) 145 покупает копию фильма (2) 125 с идентификационной информацией, третий покупатель (B(3)) 150 покупает копию фильма (3) 130 с идентификационной информацией, и так далее, что N-й покупатель (B(N)) 155 покупает копию фильма (N) 135 с идентификационной информацией. Делается запись о каждом покупателе и о номере копии фильма, которую они купили.
Нелегальная копия фильма 160 обычно изготавливается путем сотрудничества нескольких покупателей, как показано стрелкой 165 на ФИГ.1. Тем не менее, идентификационные данные покупателей, которые участвовали в изготовлении на данном этапе, не известны. Система и способ 100 использования десинхронизированной идентификационной информации используются для обработки нелегальной копии 160 и установления личности соучастников.
Нелегальная копия фильма 160 обрабатывается системой и способом 100 использования десинхронизированной идентификационной информации путем попытки применения каждого из секретных ключей 115. Если секретный ключ 115 открывает порцию информации, внедренную в нелегальную копию 160, то покупатель, ассоциированный с этим ключом, может быть заподозрен в участии в изготовлении нелегальной копии фильма 160. В этой примерной реализации, показанной на ФИГ.1, покупатели B(6) 165, В(7) 170 и В(9) 175 были идентифицированы как вовлеченные в изготовление нелегальной копии фильма 160. Затем могут быть применены соответствующие законные меры для удерживания других от участия в изготовлении нелегальных копий (такие как тюремное заключение виновников 180).
Следует заметить, что система и способ 100 использования десинхронизированной идентификационной информации могут идентифицировать гораздо большее количество соучастников, чем три показанные. По сути, одним из достоинств системы и способа 100 использования десинхронизированной идентификационной информации является их способность идентифицировать очень большое количество соучастников. Однако с целью упрощения в этом примере воплощения показаны только трое.
III. Обзор операций
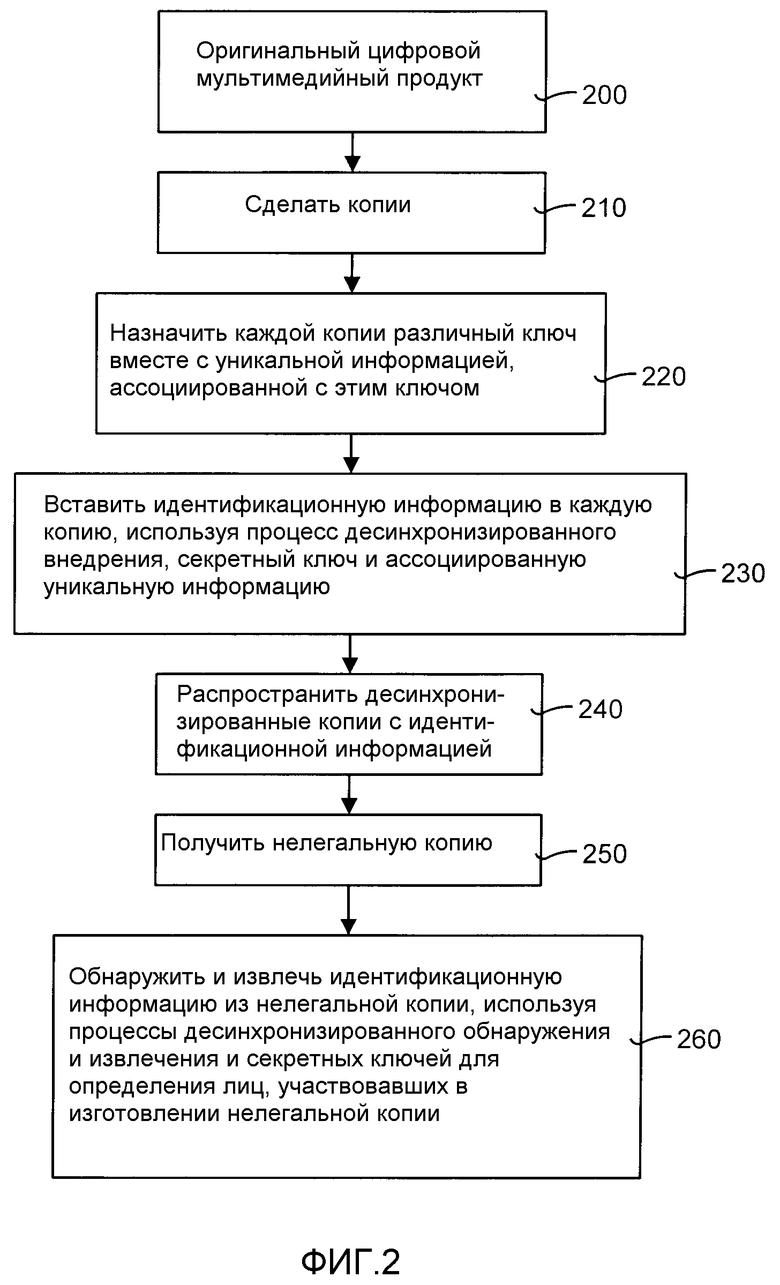
Далее приводится описание работы системы и способа 100 использования десинхронизированной идентификационной информации, показанных на ФИГ.1. ФИГ.2 является общей диаграммой процессов, иллюстрирующей общую работу системы использования десинхронизированной идентификационной информации, показанной на ФИГ.1. Способ использования десинхронизированной идентификационной информации начинается с получения оригинального цифрового мультимедийного продукта (этап 200) и изготовления копий (этап 210). Различный и уникальный секретный ключ присваивается каждой копии наряду с уникальной информацией, ассоциированной с этим ключом (блок 220). Например, уникальной информацией может быть номер копии.
Каждая копия идентифицируется внедрением секретного ключа и ассоциированной уникальной информации с использованием процесса десинхронизированного внедрения (этап 230). Затем, получившиеся в итоге десинхронизированные идентифицированные копии распространяются (этап 240). Например, копии могут поступить в продажу или могут быть предоставлены в аренду.
Некоторые держатели копий позже могут объединиться для изготовления нелегальной копии. Например, маленькая часть копий каждого участника может быть использована для производства единой нелегальной копии. Обычно, это требует вовлечения большого числа участников. В общем, идея в том, что увеличение участников не является выходом, потому что каждый из них все равно будет идентифицирован как соучастник.
Нелегальная копия получается (этап 250) и обрабатывается способом использования десинхронизированной идентификационной информации. Способ обнаруживает и извлекает внедренную в нелегальную копию идентификационную информацию (этап 260). Внедренная идентификационная информация обнаруживается и извлекается с помощью процесса обнаружения и извлечения десинхронизированной идентификационной информации и секретного ключа. Процесс обнаружения и извлечения десинхронизированной идентификационной информации определяет и идентифицирует соучастников, принимавших участие в изготовлении нелегальной копии.
IV. Детальное описание операций
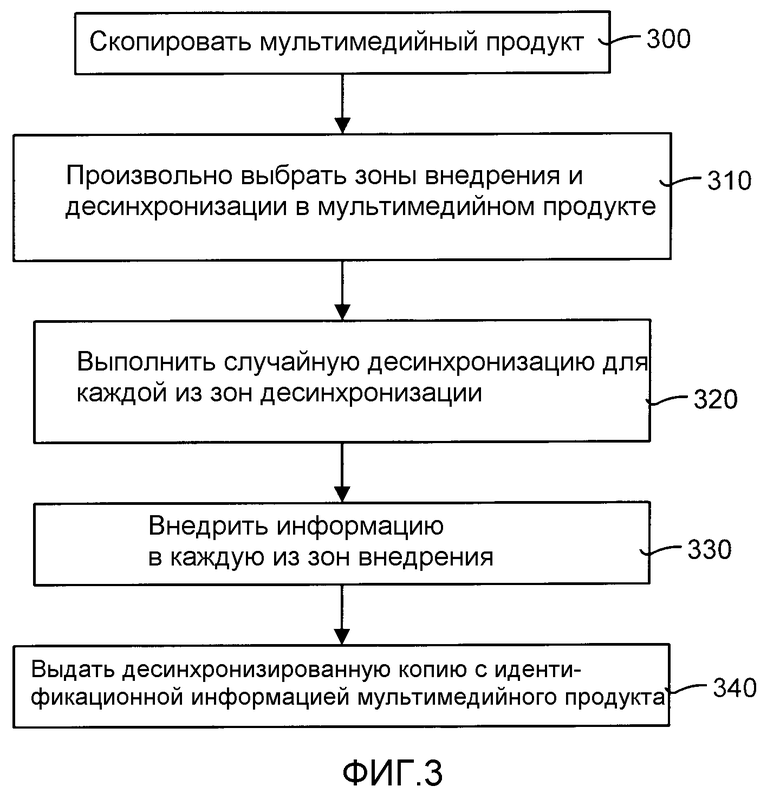
ФИГ.3 является общей диаграммой процессов, иллюстрирующей работу процесса десинхронизированного внедрения способа использования десинхронизированной идентификационной информации, показанного на ФИГ.2. В общем, процесс десинхронизированного внедрения выполняет две функции. Во-первых, процесс внедряет уникальную информацию в копию мультимедийного продукта в произвольные (случайные) зоны внедрения. Во-вторых, процесс произвольно десинхронизирует разные копии относительно друг друга (используя мастер-ключ) в разных зонах десинхронизации. В одном из вариантов воплощения зоны внедрения и зоны десинхронизации располагаются в одних и тех же местах. В качестве альтернативы, зоны внедрения могут располагаться в тех же местах, что и зоны десинхронизации.
Со ссылкой на ФИГ.3, процесс десинхронизированного внедрения перво-наперво получает копию мультимедийного продукта (этап 300). Далее, зоны внедрения и зоны десинхронизации копии мультимедийного продукта выбираются случайно (этап 310). Зона внедрения является местом в копии мультимедийного продукта, куда внедряется идентификационная информация. Зона десинхронизации является местом, где производятся изменения произвольной (случайной) ширины. Эти изменения произвольной ширины являются с высокой вероятностью различными для каждого пользователя. Если мультимедийный продукт является фильмом, то предпочтительно, чтобы зона внедрения была не одним кадром или сценой. В качестве альтернативы, зона внедрения может быть одной сценой, содержащей несколько кадров. Если мультимедийный продукт является звукозаписью, зона внедрения может быть клипом или фрагментом записи, содержащим часть аудиозаписи. Подобные требования предъявляются и к зонам десинхронизации. Обычно, аудиоклип, в который внедрена идентификационная информация, гораздо короче, чем вся запись.
Количество зон внедрения и десинхронизации могут выбираться случайно или могут быть указаны пользователем. Кроме того, воспринимаемые характеристики содержимого также важны при данном выборе. Обычно, не желательно внедрять метки в зоны с низкой активностью (зоны, имеющие маленькую энтропию) по причинам ухудшения восприятия и понижения уровня секретности. Естественно, это должно влиять на выбор количества зон. Даже если имеется большое количество высокоактивных зон (подходящих для внедрения меток в целях секретности и надежности), выбор количества зон внедрения является компромиссом между секретностью и затратами. Большее количество зон внедрения означает большее количество идентификационной информации и более высокую секретность и, как следствие, высокие затраты. С другой стороны, меньшее количество зон внедрения подразумевает меньшее количество идентификационной информации, и меньше секретности, и, следовательно, большее количество соучастников, которые могут быть упущены. Однако это также означает низкие затраты при обнаружении и извлечении идентификационной информации.
Случайная десинхронизация производится для каждой зоны десинхронизации (этап 320). Случайная десинхронизация является новым признаком способа использования десинхронизированной идентификационной информации, которая применяется для того, чтобы сделать способ использования десинхронизированной идентификационной информации более защищенным от оценочных атак. Одной из проблем использования идентификационной информации является класс организованных атак, которые возникают, если имеется большое количество копий продукта и если одна и та же сцена идентифицирована большим количеством ключей. Например, соучастник может взять все кадры этой сцены и посчитать среднюю величину для всех кадров (что известно как оценочная атака, когда соучастник формирует оценку оригинального немаркированного содержимого). В качестве альтернативы, соучастник может выбрать и совместить различные части сцены из различных копий, тем самым сформировав новую копию (что известно как атака copy&paste (скопировать-и-вставить). Эти типы атак (при условии правильного исполнения) обычно уничтожают всю идентификационную информацию.
В противовес этим типам атак (таких как оценочные атаки, copy&paste атаки, и тому подобные) способ использования десинхронизированной идентификационной информации использует случайную десинхронизацию для произвольного изменения количества кадров, которые содержит сцена. Необходимо отметить, что для осуществления организованных атак должно быть выполнено одно важное требование, состоящее в том, что все клиентские копии должны быть "выровнены". После применения псевдо-случайной десинхронизации каждая копия содержит различное количество кадров в одной и той же сцене. Эти количества выбираются псевдо-случайно для каждого пользователя и поэтому они с высокой вероятностью различны для каждого пользователя. Этот метод применяется к случайно выбранным зонам, называемым зонами десинхронизации. Метод десинхронизации, который является уникальным для способа использования десинхронизированной идентификационной информации, уменьшает вероятность того, что соучастники сотрут идентификационную информацию. Так, копия 1 в первой сцене фильма может содержать 28 кадров, тогда как копия 2 может содержать 32 кадра. Это сильно ограничивает возможность потенциального соучастника применить согласованные атаки. Это происходит потому, что способ делает трудным синхронизировать все копии и усреднить их. Более того, большее количество копий означает большие трудности при синхронизации копий и их совмещении для начала оценочной атаки.
Далее, информация внедряется в каждую из зон внедрения (этап 330). В общем, зоны десинхронизации и зоны внедрения не должны быть одними и теми же, но могут перекрываться. Внедренная информация, например, может быть номером копии мультимедийного продукта. И наконец, выдается копия мультимедийного продукта (этап 340) с десинхронизированной идентификационной информацией.
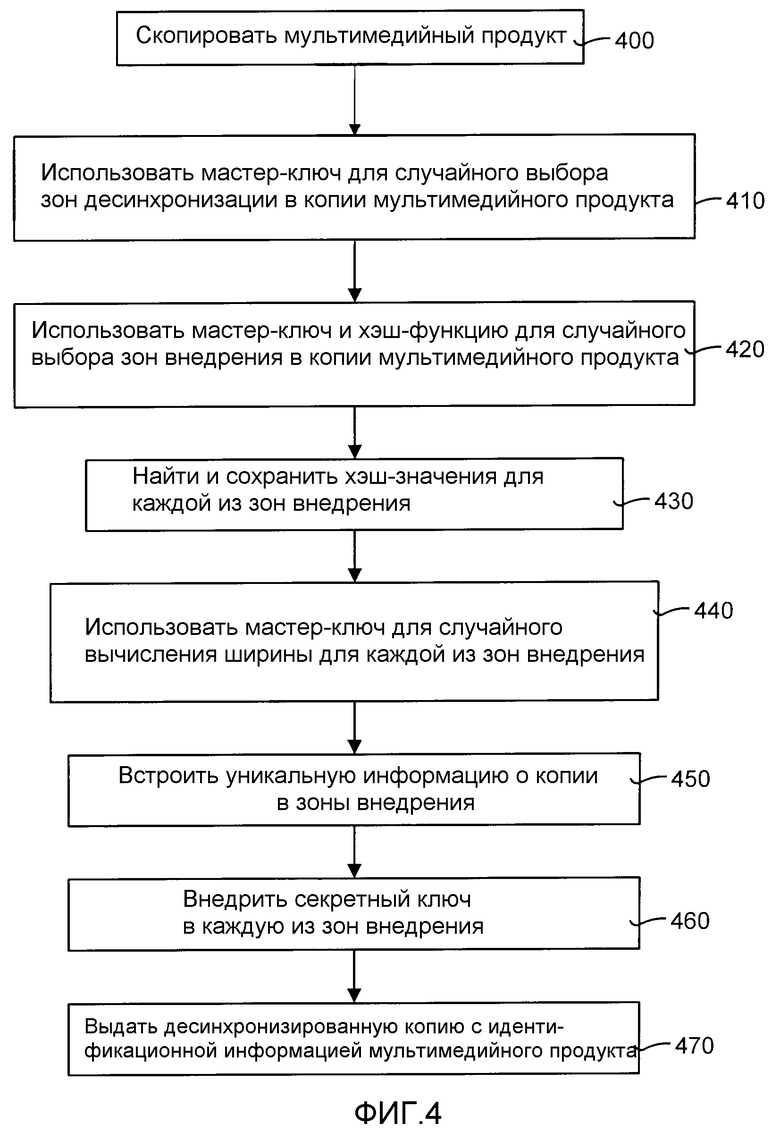
ФИГ.4 является подробной диаграммой процессов, иллюстрирующей более подробно работу процесса десинхронизированного внедрения, показанного на ФИГ.3. Создается копия мультимедийного продукта (этап 400). Затем, используется мастер ключ для произвольного выбора зон десинхронизации внутри копии мультимедийного продукта (этап 410). Также, мастер-ключ и хэш-функция используются для случайного выбора зон внедрения (этап 420). Хэш-значение вычисляется и внедряется в каждую зону внедрения (этап 430).
Процесс случайной десинхронизации включает в себя случайное изменение ширины зоны десинхронизации, так чтобы десинхронизировать копии продукта. Этот процесс случайной десинхронизации включает в себя использование мастер-ключа для случайного вычисления новой ширины для каждой зоны десинхронизации и соответствующего ее изменения (этап 440). Уникальная информация о копии внедряется в каждую зону внедрения (этап 450). В дополнение, секретный и уникальный ключ внедряются в каждую зону внедрения (этап 460). Наконец, выдается десинхронизированная копия продукта (этап 470) с идентификационной информацией.
ФИГ.5 является общей диаграммой процессов, иллюстрирующей работу процесса обнаружения и извлечения согласно способу использования десинхронизированной идентификационной информации, показанной на ФИГ.2. Процесс начинается с получения нелегальной копии оригинального мультимедийного продукта (этап 500). Затем, вычисляются хэш-значения нелегальной копии (этап 510). Затем на основе вычисленных хэш-значений обнаруживаются зоны внедрения (этап 520).
Затем для каждой зоны внедрения и для каждого секретного ключа выполняется процесс обнаружения водяного знака (этап 530). Так, для каждой зоны внедрения испытывается каждый секретный ключ. Это устраняет необходимость в кодах идентификационной информации или кодах других типов. При использовании данного процесса с увеличением затрат на вычисления может быть обнаружено соучастников больше, чем в данный момент доступно. В качестве альтернативы, может быть выбрано случайное количество ключей, которые могут быть применены к нелегальной копии. Это уменьшает затраты на вычисления, но увеличивает риск того, что некоторые соучастники могут быть упущены.
Затем происходит обнаружение идентификационной информации, ассоциированной с частным секретным ключом (этап 540). Эта информация может быть, например, именем и адресом покупателя копии продукта. Когда идентификационная информация обнаружена, она извлекается и ассоциируется с соучастником для получения информации о соучастнике (этап 550). Затем может быть составлен список соучастников (этап 560).
V. Типичная операционная среда
Система и способ 100 использования десинхронизированной идентификационной информации созданы для работы в вычислительной среде и на вычислительных устройствах. Ниже обсуждается вычислительная среда, в которой работают система и способ использования десинхронизированной идентификационной информации 100. Нижеследующее описание предназначено для предоставления краткого и общего описания подходящей вычислительной среды, в которой могут быть реализованы система и способ использования десинхронизированной идентификационной информации 100.
ФИГ.6 иллюстрирует пример подходящей вычислительной среды, в которой система и способ 100 использования десинхронизированной идентификационной информации, показанные на ФИГ.1, могут быть реализованы. Вычислительная среда 600 является только одним из примеров подходящей вычислительной среды и не предполагает наложения каких-либо ограничений для сферы использования или функциональности изобретения. Также не следует воспринимать вычислительную среду 600 как имеющую какие-либо зависимости или требования, относящиеся к одному или комбинации компонентов, показанных в типичной операционной среде 600.
Система и способ 100 использования десинхронизированной идентификационной информации работают в большом количестве других общего или специального назначения вычислительных системах, средах или конфигурациях. Примеры хорошо известных вычислительных систем, сред, и/или конфигураций, которые могут быть подходящими для использования с системой и способом 100 использования десинхронизированной идентификационной информации, включают в себя, но не ограничены ими, персональные компьютеры, серверы, ручные компьютеры, лэптопы, или мобильные компьютеры, или коммуникационные устройства, такие как сотовые телефоны и PDA (персональные цифровые ассистенты или карманные компьютеры), многопроцессорные системы, телевизионные приставки, программируемая потребительская электроника, сетевые персональные компьютеры, миникомпьютеры, большие вычислительные машины, распределенные вычислительные среды, которые могут включать в себя любые вышеперечисленные системы или устройства, и подобное.
Система и способ 100 использования десинхронизированной идентификационной информации могут быть описаны в общем контексте машиноисполняемых инструкций, таких как программные модули, выполняемые компьютером. Обычно, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и так далее, которые выполняют частные задачи или реализуют конкретные абстрактные типы данных. Система и способ 100 использования десинхронизированной идентификационной информации также могут быть опробованы в распределенных вычислительных средах, где задачи выполняются удаленными вычислительными устройствами, которые соединены через коммуникационную сеть. В распределенных вычислительных средах программные модули могут быть расположены и на локальных, и на удаленных компьютерных носителях, включая устройства памяти. Как показано на ФИГ.6, типичная система для реализации системы и способа 100 использования десинхронизированной идентификационной информации включает в себя вычислительное устройство общего назначения в виде компьютера 610.
Компоненты компьютера 610 могут включать в себя, но не ограничены ими, процессор 620, системную память 630 и системную шину 621, которая подсоединяет различные системные компоненты, в том числе системную память, к процессору 620. Системная шина 621 может быть любой из множества типов шинных структур, в том числе шина памяти или контроллер памяти, периферийная шина и локальная шина, использующих любую из множества шинных архитектур. В качестве примера, но не в качестве ограничения, такие архитектуры включают ISA (индустриальная стандартная архитектура), MCA (шина микроканальной архитектуры), EISA (расширенная ISA шина), VESA (локальная шина Ассоциации Стандартов Видео Электроники) и PCI (шина связи периферийных компонентов), также известную как шина расширения.
Компьютер 610 обычно включает в себя набор читаемых компьютером носителей. Читаемые компьютером носители могут быть любыми доступными носителями, к которым компьютер 610 может получить доступ, и включают в себя энергозависимые и энергонезависимые носители, съемные и несъемные носители. В качестве примера, но не в качестве ограничения, читаемые компьютером носители могут включать компьютерные запоминающие носители или среду связи. Компьютерные запоминающие носители включают в себя как энергозависимые запоминающие носители, так и энергонезависимые, съемные и несъемные носители, реализованные с использованием любого способа или технологии хранения информации, такой как читаемых компьютером инструкций, структур данных, программных модулей или других данных.
Компьютерные носители для хранения включают в себя, но не ограничены этим, RAM, ROM, EEPROM (электрически стираемая перепрограммируемая постоянная память), флэш-память или память по другой технологии хранения, (CD-ROM), цифровой универсальный диск (DVD) или другую память на оптическом диске, магнитные кассеты, магнитную ленту, память на магнитном диске или другое магнитное устройство хранения, или любой другой носитель, который может быть использован для хранения нужной информации и который может быть доступен компьютеру 610. Среда связи, как правило, включает читаемые компьютером инструкции, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, таких как сигнал несущей или другой транспортный механизм и включает в себя любой носитель доставки информации.
Термин "модулированный сигнал данных" означает сигнал, который имеет установленными или измененными одну или больше своих характеристик таким образом, чтобы закодировать информацию в этом сигнале. В качестве примера, но не в качестве ограничения, среда связи включает в себя проводные носители, такие как проводная сеть, или непосредственное проводное подключение, и беспроводные носители, такие как звук, радиосигнал, инфракрасное излучение и другие беспроводные носители. Комбинация из любых выше перечисленных также должна быть включена в понятие читаемых компьютером носителей.
Системная память 630 включает в себя компьютерные носители для хранения в форме энергозависимой и/или энергонезависимой памяти, таких как RAM 632 или ROM 631. BIOS 633 (базовая система ввода/вывода), содержащая основные процедуры, которые помогают передавать информацию между элементами внутри компьютера 610, таких как запуск, обычно записывается в ROM 631. RAM 632 обычно содержит данные и/или программные модули, которые доступны мгновенно и/или могут непосредственно быть обработанными процессором 620. В качестве примера, но не в качестве ограничения, ФИГ.6 изображает операционную систему 634, прикладные программы 635, другие программные модули 636 и программные данные 637.
Указанный компьютер 610 может также включать другие съемные/несъемные энергозависимые/энергонезависимые компьютерные носители для хранения. В качестве примера и только, ФИГ.6 изображает накопитель 641 на жестких дисках, который читает с или записывает на несъемный энергонезависимый магнитный носитель, накопитель 651 на магнитных дисках, который читает с или записывает на съемный энергонезависимый магнитный диск 652, и накопитель 655 на оптических дисках, который читает с или записывает на съемный энергонезависимый оптический диск 656, такой как CD-ROM или другой оптический носитель.
Другие съемные/несъемные, энергонезависимые/энергозависимые компьютерные носители для хранения, которые могут быть использованы в конкретной операционной среде, включают в себя, но не ограничены ими, кассеты с магнитной лентой, карты флэш-памяти, цифровые универсальные диски, цифровые видеоленты, твердотельные оперативные запоминающие устройства, твердотельные постоянные запоминающие устройства, и подобные. Накопитель на жестких дисках 641 обычно подсоединен к системной шине 621 через интерфейс к несъемной памяти, такой как интерфейс 640, накопитель на магнитных дисках 651 и накопитель на оптических дисках 655 обычно подсоединены к системной шине 621 с помощью съемного интерфейса памяти, такого как интерфейс 650.
Накопители и связанные с ними компьютерные носители хранения, описанные выше и изображенные на ФИГ. 6, обеспечивают хранение читаемых компьютером инструкций, структур данных, программных модулей и других данных для компьютера 610. На Фиг. 6, например, накопитель 641 на жестких дисках изображен как хранящий операционную систему 644, прикладные программы 645, другие программные модули 646 и программные данные 647. Нужно отметить, что эти компоненты могут быть такими же или отличаться от операционной системы 634, прикладных программ 635, других программных модулей 636 и программных данных 637. Операционной системе 644, прикладным программам 645, другим программным модулям 646 и программным данным 647 присвоены здесь отличные номера для иллюстрации того, что они являются, как минимум, различными копиями. Пользователь может вводить команды и информацию в компьютер 610 через устройства ввода, такие как клавиатура 662, микрофон 661, указательное устройство, такое как мышь, шаровой манипулятор и сенсорный планшет.
Другие устройства ввода (не показаны) могут включать в себя джойстик, игровой планшет, спутниковую антенну, сканер и подобные. Эти и другие устройства обычно подключены к процессору 620 через пользовательский интерфейс 660 ввода, который подсоединен к системной шине 621, но может быть подключен к другому интерфейсу и шинным структурам, таким как параллельный порт, игровой порт, или через USB (универсальная серийная шина). Монитор 691 или устройства отображения других типов также подсоединены к системной шине 621 посредством такого интерфейса, как видеоинтерфейс 690. В дополнение к монитору, компьютеры могут также включать в себя другие периферийные устройства вывода, такие как громкоговорители 697 и принтер 696, которые могут быть подсоединены через периферийный интерфейс 695 вывода.
Компьютер 610 может работать в сетевой среде с использованием логических подсоединений к одному или более удаленным компьютерам, таким как удаленный компьютер 680. Этот удаленный компьютер 680 может быть персональным компьютером, ручным устройством, сервером, маршрутизатором, сетевым персональным компьютером, одноранговым устройством или другим общим сетевым узлом и, обычно, включает многие или все элементы, описанные выше в отношении компьютера 610. Логические подсоединения, изображенные на ФИГ. 6, включают в себя LAN (локальную сеть) 671 и WAN (глобальную сеть) 673, но могут также включать в себя и другие сети. Такие сетевые среды - обычное явление в офисах, компьютерных сетях предприятий, внутренних сетях и Интернет.
При использовании в локальных сетевых средах компьютер 610 подсоединен к LAN 671 через сетевой интерфейс или адаптер 670. При использовании в глобальных сетевых средах компьютер 610 обычно включает в себя модем 672, который может быть внутренним или внешним, может быть подсоединен к системной шине 621 через пользовательский интерфейс ввода 660, или другой подходящий механизм. В сетевых средах программные модули, изображенные относительно компьютера 610 или их комбинации, могут храниться на удаленных устройствах хранения. В качестве примера, но не как ограничение, ФИГ.6 изображает удаленные прикладные программы 685 размещенными на удаленном компьютере 681. Понятно, что эти сетевые соединения показаны в качестве примера и что могут использоваться и другие способы для установления канала связи между компьютерами.
VI. Компоненты системы
Система и способ 100 использования десинхронизированной идентификационной информации, показанные на ФИГ.1, включают в себя набор программных модулей, которые позволяют системе 100 уникально маркировать копии мультимедийного продукта и позже идентифицировать соучастников, вовлеченных в изготовление нелегальной копии продукта. В общем, система 100 включает в себя функцию внедрения и функцию обнаружения и извлечения. Далее будут описаны программные модули для каждой из этих функций.
ФИГ.7 является блок-схемой, иллюстрирующей подробности системы 100 использования десинхронизированной идентификационной информации, показанной на ФИГ.1. Система 100, по существу, имеет две функции, которые показаны прерывистой линией: (а) десинхронизированного внедрения; и (б) обнаружения и извлечения идентификационной информации. В частности, для функции внедрения оригинальный цифровой мультимедийный продукт 700 (такой как фильм или аудиозапись) поступает на вход в систему 100 использования десинхронизированной идентификационной информации. Модуль 710 внедрения, который расположен в системе 100 использования десинхронизированной идентификационной информации, используется для обработки продукта 700 таким образом, что создаются десинхронизированные копии 720 с идентификационной информацией продукта 700.
Что касается функций обнаружения и извлечения, то нелегальная копия 730 продукта 700 получается и анализируется системой 100 использования десинхронизированной идентификационной информации. Модуль 740 обнаружения и извлечения, который расположен в системе 100 использования десинхронизированной идентификационной информации, используется для обнаружения внедренной идентификационной информации и извлечения информации из идентификационной информации. Эта информация позволяет уникально идентифицировать соучастников, которые были вовлечены в изготовление нелегальной копии 730. Затем система 100 использования десинхронизированной идентификационной информации может создать список 750 соучастников.
ФИГ.8 является блок-схемой, иллюстрирующей подробности модуля 710 внедрения, показанного на ФИГ.7. В частности, модуль 710 внедрения включает в себя модуль 800 копирования, селектор 810 зон внедрения, селектор 820 зон десинхронизации, модуль 830 случайной десинхронизации и модуль 840 внедрения. Модуль 800 копирования используется для изготовления множества копий оригинального цифрового мультимедийного продукта 700. Каждая из этих копий обрабатывается модулем 840 внедрения. Селектор 810 зон внедрения случайным образом выбирает зоны в каждой из копии, в которые будет производиться внедрение идентификационной информации. Подобным образом, селектор 820 зон десинхронизации случайным образом выбирает зоны в каждой из копий, в которых будет применена произвольная десинхронизация с использованием изменения ширины зоны.
В некоторых вариантах воплощения, селектор 810 зон внедрения и селектор 820 зон десинхронизации также выбирают некоторое количество зон внедрения и десинхронизации.
Модуль 830 случайной десинхронизации случайным образом выбирает ширину каждой зоны десинхронизации. Это означает, что ширина зон десинхронизации будет немного отличаться от копии к копии продукта 700. Под шириной подразумевается количество кадров (если продукт 700 является фильмом) или длительность аудиосегмента (если продукт 700 является аудиозаписью). Модуль 840 внедрения внедряет идентификационную информацию в каждую зону внедрения для формирования десинхронизированной копии 720 с идентификационной информацией продукта 700.
ФИГ.9 является блок-схемой, иллюстрирующей подробности модуля 740 обнаружения и извлечения, показанного на ФИГ.7. Модуль 740 обнаружения и извлечения включает в себя модуль 900 извлечения хэш-значения, модуль 910 обнаружения зон внедрения, детектор 920 идентификационной информации и модуль 930 извлечения информации о соучастнике. Модуль 900 извлечения хэш-значения анализирует нелегальную копию 730 и извлекает хэш-значения. Модуль 910 обнаружения зон внедрения использует извлеченные хэш-значения для сравнения их с хэш-значениями зон внедрения оригинального сигнала для определения расположения зон внедрения в копии 730. Детектор 920 идентификационной информации ищет идентификационную информацию в каждой зоне внедрения. Каждый из секретных ключей используется для обнаружения идентификационной информации. Модуль 930 извлечения информации о соучастниках извлекает информацию о соучастниках на основании секретного ключа, использованного при обнаружении идентификационной информации. Если идентификационная информация обнаружена с помощью определенного ключа, то уникальная информация, ассоциированная с этим ключом, используется для идентификации соучастников, которые были вовлечены в производство нелегальной копии 730. Из-за того, что обычно имеется большое число соучастников, то генерируется список 750 соучастников, участвовавших в изготовлении нелегальной копии.
VII. Рабочий пример
Для лучшего понимания системы и способа использования десинхронизированной идентификационной информации, описанных здесь, приводятся подробности функционирования рабочего примера. Следует заметить, что этот рабочий пример является лишь одним из путей, которыми система и способ 100 использования десинхронизированной идентификационной информации могут быть реализованы. В этом рабочем примере система и способ использования десинхронизированной идентификационной информации применяются для объектов потоковой мультимедийной информации.
Система и способ использования десинхронизированной идентификационной информации могут быть использованы как для аудио-, так и для видеоприложений. В общем, различные ключи назначаются для каждого пользователя. Функция внедрения включает в себя применение псевдо-случайного преобразования выбранных зон. Ключ для псевдо-случайного преобразования является специфичным для пользователя. Эти зоны выбираются с помощью хэш-функции защищенной мультимедийной информации. Функция обнаружения и извлечения включает в себя поиск путем перебора множества ключей пользователей. Если один из ключей оказывается подходящим, то это означает, что пользователь был вовлечен в изготовление нелегальной копии.
Условные обозначения
Пусть данный мультимедийный сигнал состоит из отдельных "объектов" s1, s2, …, sM, где M является общим числом объектов. Например, в видеоприложении кадр может трактоваться как объект и M может означать общее количество кадров в видеозаписи. В качестве альтернативы, в аудиоприложениях блок фиксированной длительности может трактоваться как объект и М может означать общее число таких блоков фиксированной длительности. Пусть N будет общим числом клиентов (или покупателей). Соответственно, желательно произвести N различных копий мультимедийного сигнала. Пусть Ki будет секретным ключом для пользователя i, где 1≤i≤N. Пусть К будет секретным мастер-ключом, который отличается от
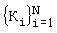 .
.
Хэш-функция
Пусть дана хэш-функция,
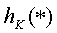
которая обрабатывает объекты,
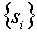
значение которой находится в диапазоне
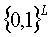 .
.
Хэш-функция является оператором формирования псевдо-случайного значения, который функционирует на основании секретного ключа K.
Пусть 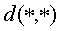 обозначает нормализованный интервал Хэмминга (нормализованный по L, длине выходного хэш-значения). Предположим, что
обозначает нормализованный интервал Хэмминга (нормализованный по L, длине выходного хэш-значения). Предположим, что
1. 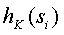 является почти равномерно распределенной в для каждого i.
является почти равномерно распределенной в для каждого i.
2. 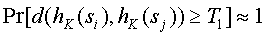 , где si и sj разные объекты.
, где si и sj разные объекты.
3. 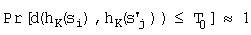 , где si и s'i персептуально подобные объекты. Заметим, что область вероятности определяется для разных ключей по вышеприведенным критериям. Для большинства практических целей, 0<T0<T1<0,5 и T0 и T1 отстоят друг от друга достаточно далеко.
, где si и s'i персептуально подобные объекты. Заметим, что область вероятности определяется для разных ключей по вышеприведенным критериям. Для большинства практических целей, 0<T0<T1<0,5 и T0 и T1 отстоят друг от друга достаточно далеко.
“Водяные знаки” для группы объектов
В данном рабочем примере используется псевдо-случайная функция внедрения водяных знаков,

которая работает на большинстве R объектов. Здесь Ki является ключом для генератора псевдо-случайных чисел, используемого для водяных знаков. Дано 1≤r≤R объектов, s1, ... sr-1, sr, функция внедрения “водяных знаков” производит r объектов
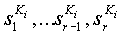
как функцию от ключа Ki. Объекты
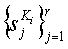
являются персептуально подобными объектам
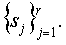
В данном контексте функция внедрения “водяных знаков” может быть рассмотрена как псевдо-случайное преобразование, индексированная секретным ключом. Далее, рабочий пример содержит соответствующую функцию обнаружения “водяного знака”
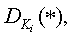
которая работает с тем же набором объектов, что и функция внедрения. Область значений функции определения является {0,1}, где 1 означает присутствие водяного знака с ключом Ki и 0 в противном случае. Допустим, что функция обнаружения работает надежно, т.е.
1. 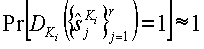 , где
, где 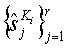 являются атакованными версиями
являются атакованными версиями 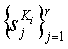 , так что они персептуально подобны.
, так что они персептуально подобны.
2. 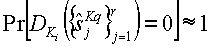 для
для 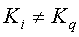 и
и 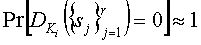 .
.
Внедрение метки в потоковые мультимедийные данные
Алгоритм внедрения метки для пользователя i(1≤i≤N) задается следующим образом.
1. Выбрать P различных мест, рандомизированные на основании мастер-ключа K. Пусть t1, t2, ..., tp означают эти места, где
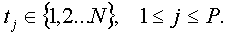
2. Найти и сохранить хэш-значения
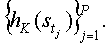
3. Для каждого места tj находится соседнее вокруг него в диапазоне
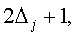
тем самым определяется зона
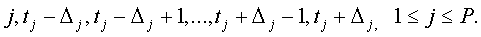
Затем, выбрать
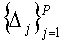
псевдо-случайным образом с использованием мастер-ключа K так, что для всех
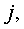
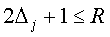
и зона j не пересекается с зоной k для всех
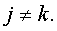
4. Для каждого 1≤j≤P заменить
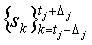 на
на 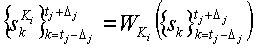 , где Ki является секретным ключом для пользователя i.
, где Ki является секретным ключом для пользователя i.
Декодирование потоковых мультимедийных данных
Пусть на вход декодера подается мультимедийный сигнал, который состоит из объектов x1, x2, ..., xM'. Отметим, что в общем возможно иметь
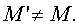
Процесс обнаружения и извлечения (или декодирования), использующийся в рабочем примере, включает в себя этапы:
1. Для каждого 1≤j≤M' вычисляется хэш-значение полученного сигнала hK(xj).
2. Для каждого 1≤j≤M' выполняется следующее:
а) если есть tk, 1≤k≤P, такой что
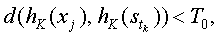
затем продолжить со следующего этапа.
б) Для всех Ki, 1≤i≤N запускается выполнение алгоритма обнаружения водяного знака на ширине 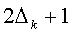 зоны вокруг tk: вычислить
зоны вокруг tk: вычислить
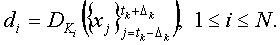
в) Для каждого 1≤i≤N если di=1, объявить, что метка пользователя i была обнаружена в полученных входных данных.
VIII. Улучшенный алгоритм временной синхронизации на основе хэш-функции изображения для цифрового видео.
В рабочем примере в предыдущем разделе было представлено описание общего алгоритма системы и способа использования десинхронизированной идентификационной информации. На этапе 2 алгоритма внедрения метки и этапе 2а алгоритма декодирования рабочего примера одно хэш-значение было использовано для определения мест внедрения метки. На практике, однако, этого бывает недостаточно. В частности, для цифрового видео, хэш-значения одного кадра часто не хватает для достаточно точного определения мест внедрения. Таким образом, в этом разделе представлен улучшенный вариант способа поиска зон на основе хэш-функций. Данный способ использует несколько хэш-значений вместо одного хэш-значения.
В этом разделе обсуждение ограничено цифровым видео и робастными хэш-функциями изображения, которые применяются для отдельных видеокадров (отдельных изображений). Тем не менее, следует заметить, что данная методология может быть распространена и на набор кадров или цифровых аудиосигналов. Как показано на ФИГ.9, улучшенный вариант способа поиска зон на основе хэш-функций, представленный в данном разделе, может быть применен в модуле 910 обнаружения зон внедрения.
Проблема в том, что видео с внедренными метками может подвергнуться изменениям, которые вызовут проблемы синхронизации времени при обнаружении или декодировании. Часто временные атаки являются атаками данного класса. В частности, любой тип злоумышленных атак, которые меняют порядок содержимого видео вдоль временной оси (таких как вставка сцен, изменения и перестановка местами, округление и интерполяция времени и сдвиги), могут создать потенциальные проблемы для декодера. Более того, даже в незлонамеренных случаях есть возможность вырезать и вставлять видео или вставлять рекламу в видео для различных целей в развлекательном бизнесе. Поэтому область с внедренной меткой в оригинальном видео может не быть в одном временном месте в получаемом видео. В таких случаях поиск мест внедрения метки на приемнике является нетривиальной проблемой. Для преодоления данной проблемы улучшенный вариант способа определения совпадения зон на основе хэш-функций, представленный в данном разделе, позволяет достичь синхронизации по времени в цифровом видео путем использования робастных хэш-функций изображений для определения мест внедрения меток.
Этот метод допускает, что результат робастных хэш-функций изображений является инвариантным относительно внедрения водяного знака, а также приемлемых атак (другими словами, сохраняет визуальное качество). Далее, для полноты, будут определены условные обозначения для этого раздела. Следует отметить, что условные обозначения в этом разделе отличаются от условных обозначений в разделе VII.
Условные обозначения
Жирные строчные буквы представляют кадры, буквы в нижнем регистре обозначают индексы элементов в наборах или векторах. Пусть N будет общим количеством кадров в интересующем нас оригинальном видео, и {s 1, s 2, ..., s N} и {x 1, x 2, ..., x N} обозначают оригинальные видеокадры и видеокадры с внедренными метками. Пусть NN обозначает общее количество кадров в атакованном видео (которое подается на вход декодеру) и {y 1, y 2, ..., y NN} обозначает атакованное видео. Следует отметить, что, в общем, N не равно NN. Другими словами, длина атакованного видео может отличаться от длины оригинального видео и видео с внедренными метками. Пусть M является общим количеством зон внедрения (т.е. зон, куда идентификационная информация была внедрена). Пусть h(.) и d(.,.) представляют робастную хэш-функцию изображения (которые подходят для использования в способе поиска зон на основе хэш-функций, описание которых дано в разделе VII) и интервал Хэмминга между двумя двоичными вводами соответственно. Пусть td(.,.) обозначает временной интервал (с информацией о направлении) между любыми двумя кадрами данного вида, например, td(s m,s n) = n-m.
Кодирование и декодирование
На стороне модуля внедрения для каждой зоны внедрения j (1<=j<=M), K кадров выбраны для представления временного места этой зоны. Эти представительные кадры известны как "веха" в терминологии, используемой в этом разделе и обозначаемые как {P jk}, где j (соотв. k) соответствуют зонам внедрения (в соответствии с индексом вехи внутри этой зоны), 1<=j<=M, 1<=k<=K. Очевидно, что множество (набор) {p jk} является подмножеством (поднабором) {s 1, s 2, ..., s N}. Как выбрать {p jk} для зоны j здесь не обсуждается. Тем не менее, в общем, в качестве практического способа, вехи должны быть выбраны приблизительно равномерно внутри зоны внедрения так, чтобы представить эту зону как можно точнее. Пусть {ajk} являются хэш-значениями {p jk}, т.е. для каждого j,k ajk=h(p jk). Хэш-значения {ajk} передаются приемнику в качестве дополнительной информации. Другими словами, предполагается, что приемник (или декодер) хорошо знает о {ajk}.
Хэш-значения {ajk} используются для блокирования приемника для корректировки позиции в атакованном видео {y i} для каждой зоны j внедрения. Для выполнения этой задачи следующий процесс должен быть принят во внимание, где ε и α являются параметрами, зависящими от пользователя:
1. Найти {b1, b2, ..., bNN}, где bi=h(y i), 1<=i<=NN.
2. Для каждой вехи p jk формируются персептуально подобные множества (наборы) Fjk из {y i}, где Fjk={yi|d(bi,ajk)< α, 1<=i<=N}.
3. Для каждой зоны j внедрения формируется множество (набор) Gj, которое состоит из всех "подходящих по времени" K-кортежей из подобных множеств (наборов) Fjk:
Gj={g j1, g j2, ..., g jK)| |td(g jk,g j,k+1)-td(p jk,pj,k+1)|< ε, g jk E Fjk, 1<=k<K}.
4. Найти оптимальный K-кортеж для зоны j внедрения с точки зрения подобия с помощью хэш-значений: (g j1 *, g j2 *, ..., g jK *) = argmin Σk=1 K d(h(g jk),ajk), где минимизация осуществляется над всеми элементами Gj.
5. K-кортеж (g j1 *, g j2 *, ..., g jK *) определяет j-ю зону внедрения в {y i}.
Замечание
Необходимо отметить, что при использовании этого прямого процесса, этапы 3 и 4 требуют O(K Пk=1 K|Fjk|) операций. Причина этого в том, что общее количество возможных K-кортежей составляет Пk=1 K|Fjk| (т.е. степень K) и для каждого K-кортежа требуется выполнить O(K) операций, чтобы найти оптимальное соответствие с учетом персептуального подобия (другими словами, интервал Хэмминга для оригинальных хэш-значений). Однако в этих операциях есть избыточность, потому что существуют K-кортежи, которые имеют общие элементы, для которых интервал Хэмминга между хэш-значениями не требует пересчета. Таким образом, с точки зрения вычислений будет более эффективным выполнять этапы 3 и 4 вместе, что может быть сделано с применением динамического программирования.
Псевдо-код
Нижеприведенный псевдо-код иллюстрирует основную идею использования динамического программирования. Это может заменить выше указанные этапы 3 и 4 для любого j. Более того, пусть Fjk = {g jkl}, где l является порядковым номером каждого элемента множества.
I. установить mindist равным очень большому числу и k=1, l=1.
II. Пока 1<=l<=F jk, делать:
II.I. Инициализировать K-кортеж path так, что path(m)=0 если m!=k и path(k)=g jkl, где path(k) является k-м элементом path.
II.II. Инициализировать dist=d(ajk, h(path(k))), VALIDITY=GOOD.
II.III. применить функцию FINDOPTPATH(path,dist,k+1,l, VALIDITY), которая определена ниже.
II.IV. Увеличить l на 1, перейти к этапу II.1.
function FINDOPTPATH(path,dist,k,l,VALIDITY)
I. инициализировать ll=1.
II. пока ll<=|Fjk| делать
II.I. вычислить
timedist=|td(path(k-1),g j,k,ll )-td(p j,k-1 , p jk )|.
II.II. Если (k<K) и (timedist > ε),
II.II.I. установить VALIDITY=BAD.
II.II.II. применить функцию
FINDOPTPATH(path,dist,K,ll, VALIDITY).
II.III. Иначе если (k<K) и (timedist <= ε),
II.III.I установить path(k) = g j,k,ll и увеличить dist на d(a jk ,h(path(k))).
II.III.II Применить функцию
FINDOPTPATH(path,dist,k+1,ll, VALIDITY).
II.IV. Иначе если (k=K) и (dist<mindist) и (VALIDITY=GOOD), установить mindist=dist и minpath=path.
II.V. увеличить l на 1, перейти к этапу II.I.
Предшествующее описание изобретения было представлено для иллюстрации и описания. Оно не является исчерпывающим или ограничивающим изобретение точно в изложенной форме. Возможно множество модификаций и вариаций в свете раскрытого выше. Это означает, что объем изобретения ограничен не этим подробным описанием изобретения, а скорее формулой изобретения, приложенной к нему.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТОЙЧИВАЯ К КОЛЛЕКТИВНЫМ АТАКАМ ДЕСИНХРОНИЗАЦИЯ ДЛЯ ЦИФРОВОГО ПОМЕЧАНИЯ ВИДЕО | 2006 |
|
RU2407215C2 |
| ПРЕДСТАВЛЕНИЕ ЦИФРОВЫХ МАТЕРИАЛОВ, ОСНОВАННОЕ НА ИНВАРИАНТНОСТЯХ МАТРИЦ | 2004 |
|
RU2387006C2 |
| УПРАВЛЕНИЕ ИМПОРТОМ КОНТЕНТА | 2004 |
|
RU2324301C2 |
| СПОСОБ ОБНАРУЖЕНИЯ ОШИБКИ ПРИ ЧТЕНИИ ЭЛЕМЕНТА ДАННЫХ | 2012 |
|
RU2573952C1 |
| СПОСОБ ЗАЩИТЫ МУЛЬТИМЕДИЙНЫХ ДАННЫХ | 2006 |
|
RU2449494C2 |
| ВСТАВКА ИДЕНТИФИКАЦИОННОЙ МЕТКИ В ДАННЫЕ | 2004 |
|
RU2339091C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УПРАВЛЕНИЯ РАСПРОСТРАНЕНИЕМ И ИСПОЛЬЗОВАНИЕМ ЦИФРОВЫХ РАБОТ | 2001 |
|
RU2279724C2 |
| КАРТА С ВОЗМОЖНОСТЬЮ АУТЕНТИФИКАЦИИ | 2006 |
|
RU2435218C2 |
| ПРОТОКОЛ ПРИВЯЗКИ УСТРОЙСТВА К СТАНЦИИ | 2009 |
|
RU2512118C2 |
| ЗАЩИТНАЯ ИНФРАСТРУКТУРА И СПОСОБ ДЛЯ ПРОТОКОЛА РАЗРЕШЕНИЯ РАВНОПРАВНЫХ ИМЕН (PNRP) | 2003 |
|
RU2320008C2 |
Изобретение относится к идентификации мультимедийной информации. Техническим результатом является расширение числа лиц, которые требуется идентифицировать, а также повышение криптографической защиты. Система и способ использования десинхронизированной идентификационной информации могут быть использованы как для аудиоприложений, так и для видеоприложений и включают в себя функции внедрения, и функции обнаружения, и извлечения. Различные и уникальные ключи ассоциированы с каждым покупателем копии цифровых данных. Функция внедрения включает применение псевдо-случайного преобразования выбранных зон внедрения. Ключ для псевдо-случайного преобразования является специфичным для пользователя. Зоны выбираются с использованием секретной хэш-функции мультимедийной информации. Функции обнаружения и извлечения включают грубый поиск во множестве ключей покупателей. Если один из ключей является достаточно вероятным, значит можно сказать, что этот пользователь был вовлечен в производство нелегальной копии. 6 н. и 22 з.п. ф-лы, 9 ил.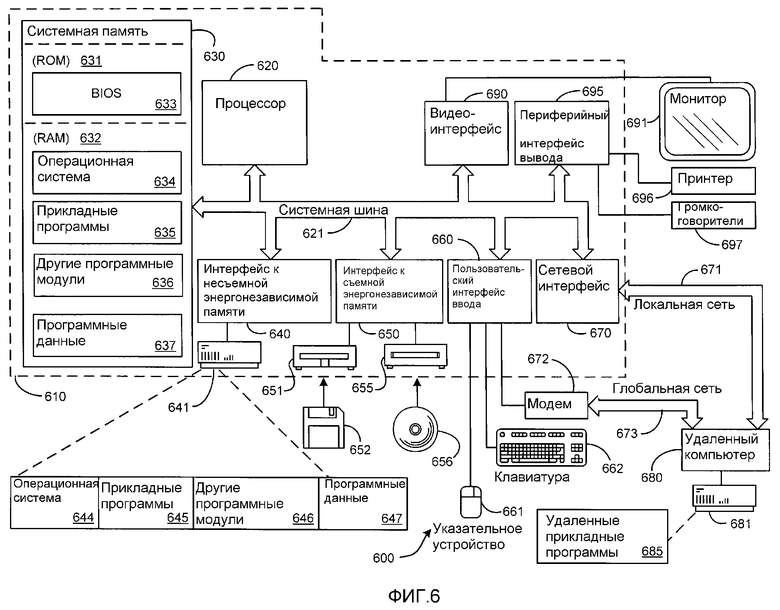
1. Выполняемый компьютером способ для десинхронизированной пометки идентификационной информацией цифровых данных, содержащий этапы:
выбирают зоны внедрения в цифровых данных для внедрения идентификационной информации;
выбирают зоны десинхронизации в цифровых данных для десинхронизации копий цифровых данных относительно друг друга;
выполняют случайную десинхронизацию для каждой из зон десинхронизации для случайного изменения ширины каждой зоны десинхронизации и внедряют идентификационную информацию в каждую из зон внедрения для формирования десинхронизированных помеченных идентификационной информацией цифровых данных.
2. Выполняемый компьютером способ по п.1, дополнительно содержащий этап случайного выбора зон внедрения и зон десинхронизации.
3. Выполняемый компьютером способ по п.1, дополнительно содержащий этап использования мастер-ключа и хэш-функции для случайного выбора зон внедрения.
4. Выполняемый компьютером способ по п.3, дополнительно содержащий нахождение и сохранение хэш-значений для каждой из зон внедрения.
5. Выполняемый компьютером способ по п.1, дополнительно содержащий использование мастер-ключа для случайного выбора зон десинхронизации.
6. Выполняемый компьютером способ по п.1, в котором этап выполнения случайной десинхронизации для каждой из зон десинхронизации дополнительно содержит использование мастер-ключа для случайного вычисления ширины каждой из зон десинхронизации таким образом, что эта ширина различается от копии к копии цифровых данных.
7. Выполняемый компьютером способ по п.1, дополнительно содержащий генерацию множества копий цифровых данных и пометку идентификационной информацией каждой копии.
8. Выполняемый компьютером способ по п.1, дополнительно содержащий внедрение уникального секретного ключа в каждую из зон внедрения.
9. Считываемый компьютером носитель, имеющий выполняемые компьютером инструкции для выполнения выполняемого компьютером способа, изложенного в п.1.
10. Считываемый компьютером носитель, имеющий выполняемые компьютером инструкции для десинхронизированной пометки идентификационной информацией цифровых мультимедийных данных, для выполнения этапов генерируют множество копий цифровых мультимедийных данных;
случайным образом выбирают зоны внедрения в каждой копии;
случайным образом выбирают зоны десинхронизации в каждой копии;
вычисляют случайную ширину для каждой из зон десинхронизации таким образом, что ширина каждой из зон десинхронизации различается от копии к копии; и
внедряют информацию в каждую зону внедрения для формирования десинхронизированным образом помеченных идентификационной информацией копий цифровых мультимедийных данных.
11. Считываемый компьютером носитель по п.10, в котором этап случайного выбора зон внедрения дополнительно содержит этап использования оператора вычисления псевдослучайного значения и мастер-ключа.
12. Считываемый компьютером носитель по п.11, в котором оператор вычисления псевдослучайного значения является хэш-функцией.
13. Считываемый компьютером носитель по п.10, дополнительно содержащий этапы нахождения и сохранения хэш-значений для каждой из зон внедрения.
14. Считываемый компьютером носитель по п.10, в котором случайный выбор зон десинхронизации дополнительно содержит этап использования мастер-ключа.
15. Считываемый компьютером носитель по п.10, в котором вычисление случайной ширины для каждой из зон десинхронизации дополнительно содержит этап использования мастер-ключа для вычисления случайного значения ширины и изменения этой ширины соответственно.
16. Считываемый компьютером носитель по п.10, в котором внедрение информации в каждую из зон внедрения дополнительно содержит внедрение уникальной информации о копии и уникального секретного ключа.
17. Считываемый компьютером носитель по п.16, который дополнительно содержит этап каталогизирования уникальной информации о копии таким образом, что каждая из множества копий является ассоциированной с конкретной личностью.
18. Считываемый компьютером носитель по п.16, дополнительно содержащий ассоциирование уникальной информации о копии с уникальным секретным ключом.
19. Считываемый компьютером носитель по п.18, в котором уникальная информация является номером конкретной копии из множества копий.
20. Считываемый компьютером носитель по п.17, дополнительно содержащий этапы:
извлечение уникальной информации о копии из нелегальной копии цифровых мультимедийных данных и
определение из уникальной информации о копии идентификационной информации о личностях, вовлеченных в изготовление нелегальной копии.
21. Способ обнаружения и извлечения идентификационной информации из цифровых данных, содержащий:
вычисление множества хэш-значений цифровых данных;
обнаружение зон внедрения в цифровых данных с использованием упомянутого множества хэш-значений;
использование множества секретных ключей для выполнения обнаружения идентификационной информации для каждой из зон внедрения и обнаружение идентификационной информации, ассоциированной с секретным ключом.
22. Способ по п.21, дополнительно содержащий извлечение информации о соучастнике из идентификационной информации.
23. Способ по п.22, дополнительно содержащий построение списка соучастников из информации о соучастнике, представляющий список персон, которые сотрудничали в формировании цифровых данных.
24. Считываемый компьютером носитель, имеющий считываемые компьютером инструкции, которые будучи выполненными одним или более процессорами вынуждают один или более процессоров выполнять способ по п.21.
25. Система пометки десинхронизированной идентификационной информацией для пометки десинхронизированной идентификационной информацией копий оригинального цифрового мулльтимедийного продукта и идентификации соучастников, участвовавших в производстве нелегальной копии оригинального цифрового мультимедийного продукта, содержащая:
модуль внедрения для внедрения идентификационной информации в каждую копию продукта посредством внедрения идентификационной информации в каждую из зон внедрения в цифровых данных, причем зоны внедрения выбраны и десинхронизированны относительно друг друга с целью формирования десинхронизированных помеченных идентификационной информацией цифровых данных в этих зонах внедрения; и
модуль обнаружения и извлечения для обнаружения внедренной идентификационной информации посредством определения зон внедрения в цифровых данных, извлечения из упомянутых зон внедрения внедренной идентификационной информации и извлечения информации о соучастнике из упомянутой идентификационной информации для идентификации соучастников, участвовавших в производстве нелегальной копии цифрового мультимедийного продукта.
26. Система пометки десинхронизированной идентификационной информацией по п.25, в которой модуль внедрения содержит селектор зоны внедрения для случайного выбора зон внедрения в каждой копии продукта, в которые нужно внедрить идентификационную информацию.
27. Система пометки десинхронизированной идентификационной информацией по п.25, в которой модуль внедрения дополнительно содержит селектор зоны десинхронизации для случайного выбора зон десинхронизации, в которых необходимо применить намеренную десинхронизацию.
28. Система пометки десинхронизированной идентификационной информацией по п.27, в которой модуль внедрения дополнительно содержит модуль случайной десинхронизации для случайного выбора и применения ширины зон десинхронизации таким образом, что ширина зоны десинхронизации различается от копии к копии продукта.
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| RU 2000131282 А, 20.11.2002 | |||
| JP 2003209816 A, 25.07.2003 | |||
| KR 20020066203 A, 14.08.2002 | |||
| KR 20040001213 A, 07.01.2004 | |||
| KR 20020034976 A, 09.05.2002 | |||
| KR 20010078531 A, 21.08.2001 | |||
| JP 2003058658 A, 28.02.2003. | |||

