Изобретение относится к способу обнаружения ошибки при чтении элемента данных и способу защиты процессора безопасности. Настоящее изобретение также относится к носителю информации и процессору безопасности для реализации этих способов.
Известные способы обеспечивают обнаружение ошибки считывания выполнением следующих этапов:
a) сохранение первой копии элемента данных в первой области электронной памяти и сохранение второй копии элемента данных во второй области электронной памяти, в ответ на запрос считать элемент данных:
b) чтение значений первой и второй копий элемента данных в первой и второй областях соответственно,
c) сравнение считанных значений первой и второй копий элемента данных,
d) если считанные значения первой и второй копий одинаковы, то никакой ошибки при чтении данного элемента данных не обнаружено.
Область памяти или место в памяти представляет собой электронную память или часть электронной памяти, разделенную на несколько блоков памяти. Каждый блок памяти предназначен для хранения элемента данных. Как правило, блок памяти является страницей или однократной страницей. Страница представляет собой наименьшее число октетов, которые могут быть записаны в одной операции записи. Таким образом, даже если хранящийся элемент данных в странице имеет меньший размер, чем страница, вся страница считается занятой данным элементом данных, и это не позволяет хранить любые дополнительные данные на этой странице.
Предшествующий уровень техники, относящийся к известным способам, например, описан в следующих заявках на патент: GB 2404261, US 2006053308, WO 2008 23297, US 20070033417, US 20050160310, US 2008/140962 A1 и US 2009/113546 A1.
Известные способы направлены только на защиту от последствий неисправности блока памяти. Таким образом, если значения первой и второй копий различны, то сигнализируется ошибка и инициируются корректирующие меры. Одна из типовых корректирующих мер состоит в коррекции значения хранимого элемента данных. Однако эти способы также обеспечивают обнаружение ошибки при чтении элемента данных. В случае наличия ошибки в чтении данных, отсутствие равенства между значениями первой и второй копий элемента данных не следует из искажений данных, хранящихся в областях памяти, но из ошибки во время процесса чтения этих данных. Здесь, термин искажения или искаженные данные используется, когда физически хранящееся значение этого элемента данных является ошибочным из-за сбоя в блоке памяти. Таким образом, хотя хранящиеся значения первой и второй копий совершенно одинаковы, на этапе с), как описано выше, выявляется, что значения различны. Например, ошибка чтения может быть спровоцирована нарушением сигналов шины считывания или искажением скопированных данных в энергонезависимой памяти после чтения в энергозависимой области памяти.
Известные способы не обеспечивают установление различий между этими двумя типами ошибок и систематически инициируют выполнение мер для устранения ошибки после обнаружения. Как правило, мера по устранению ошибки состоит в исправлении ошибочного значения. Однако, в случае наличия ошибки чтения, такая коррекция не имеет смысла и приводит к нерациональному использованию компьютерных ресурсов, такого как время реализации данного способа микропроцессором.
Что касается процессоров безопасности, то существуют также еще одна веская причина для обеспечения выявления различий этих двух типов ошибок. Процессор безопасности представляет собой электронный процессор, который используется для усиления противостояния возможным действиям хакеров. Поэтому он, как правило, используется для размещения конфиденциальных данных. Теперь, обычная атака на процессор безопасности состоит в искажении хранимых данных для провоцирования непредсказуемого функционирования процессора безопасности, который может раскрыть часть или все конфиденциальные данные, которые он содержит. Тем не менее, для хакеров проще спровоцировать ошибку чтения, чем исказить хранимые данные. Когда хакер намеренно провоцирует возникновение ошибки чтения, используя скачки напряжения или лазерный луч или иное, считается, что процессор безопасности стал целью атаки чтения. Таким образом, в контексте процессоров безопасности, ошибка чтения позволяет однозначно обнаружить попытку выполнением криптоанализа, тогда как сбой в блоке памяти может быть случайным и ошибка вызвана, например, старением.
Целью изобретения является устранение этого недостатка. Предметом является способ обнаружения ошибки считывания в соответствии с п. 1 формулы изобретения.
Описанный выше способ позволяет отличить ошибку считывания от ошибки, вызванной искажением хранимых данных, и, таким образом, обнаружить ошибку считывания. В самом деле, на второй итерации описанных ранее этапов b) и с) значения первой и второй копий обязательно отличаются, если по меньшей мере одно из этих значений искажено. С другой стороны, идентичность этих значений на второй итерации этапов b) и с) однозначно определяет ошибку считывания элемента данных.
Таким образом, можно реализовать различные соответствующие меры реагирования на ошибки считывания или искажение сохраненных данных. Например, факт обнаружения ошибки считывания позволяет не допустить неэффективную реализацию мер, направленных на исправление сохраненных данных, когда последние не искажены. Кроме того, в случае с процессором безопасности, обнаружение ошибки считывания делает возможным вызвать выполнение контрмер для предупреждения криптоанализа.
Варианты осуществления этого способа обнаружения могут включать в себя один или более признаков зависимых пунктов формулы изобретения.
Варианты осуществления вышеописанного способа обнаружения, более того, имеют следующие преимущества:
- использование кода обнаружения ошибки позволяет восстановить функциональность способа обнаружения ошибки считывания даже после сбоя в блоке памяти,
- использование кода коррекции ошибки позволяет восстановить функциональность способа обнаружения ошибки считывания даже после того, как значения первой и второй копий элемента данных были искажены, при ограничении хранимого количества кодов коррекции ошибки,
- выбор блоков памяти, в которых хранится новый элемент данных, только среди блоков памяти, в которых сохраняют данные без сбоя, что позволяет избежать повторного использования неисправных блоков памяти для хранения данных,
- хранение преобразованного значения в первой области памяти, отличного от сохраненного значения во второй области памяти, что позволяет увеличить вероятность, того, что значения для чтения первой и второй копий отличаются в случае атаки чтения.
Другим объектом изобретения является способ защиты процессора от атаки считывания в соответствии с п. 6.
Другим объектом настоящего изобретения является носитель информации, включающий в себя команды для осуществления описанного способа обнаружения или защиты, когда эти команды выполняются электронным компьютером.
Наконец, еще одним объектом настоящего изобретения является процессор безопасности в соответствии с п. 8.
Варианты осуществления данного процессора безопасности могут включать в себя один или более признаков зависимых пунктов формулы изобретения.
Изобретение будет лучше понятно из нижеследующего описания, приведенного только в качестве неограничивающего примера и со ссылкой на прилагаемые чертежи, на которых:
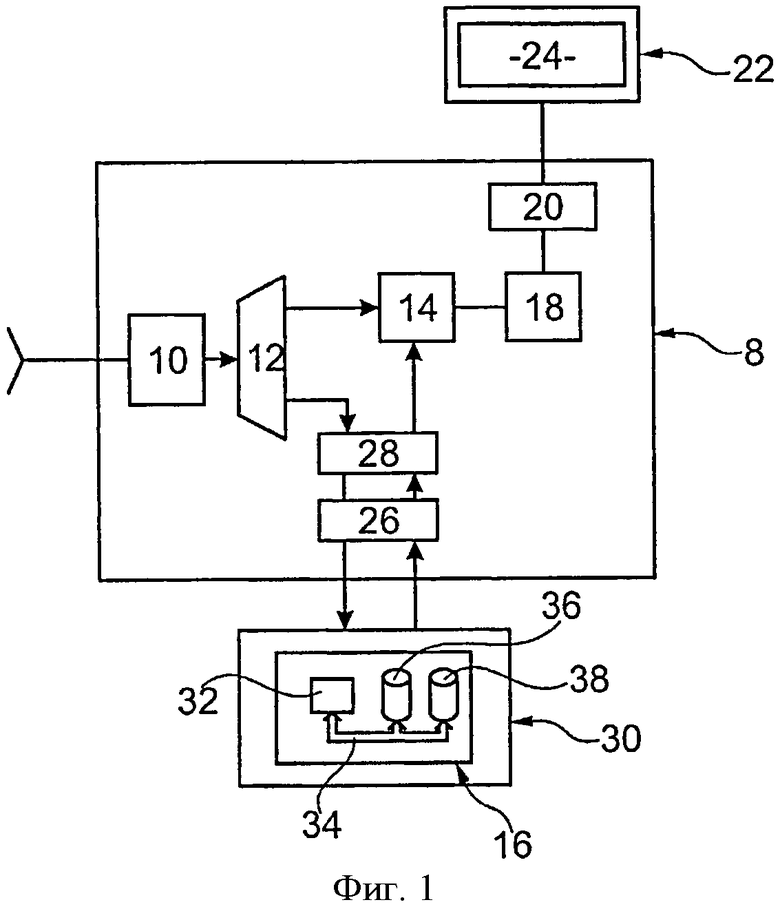
фиг. 1 представляет собой схематическое изображение приемного терминала скремблированного мультимедийного контента, ассоциированного с процессором безопасности,
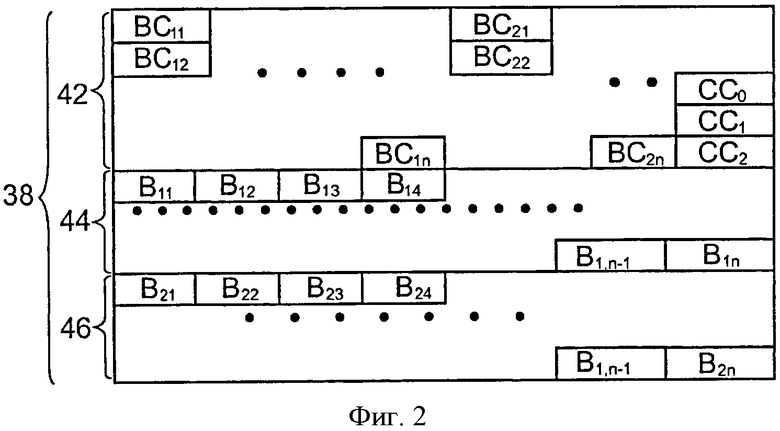
фиг. 2 представляет собой схематическое изображение организации памяти процессора безопасности, показанного на фиг. 1;
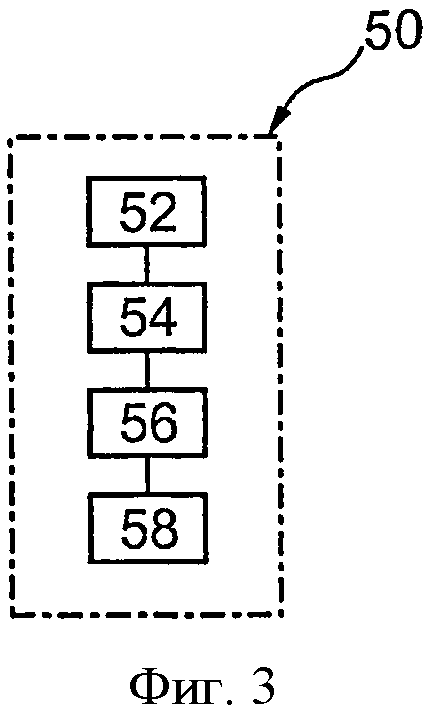
фиг. 3 представляет собой блок-схему алгоритма фазы записи данных в память, как показано на фиг. 2;
фиг. 4 представляет собой блок-схему алгоритма способа защиты процессора безопасности, показанного на фиг. 1; и
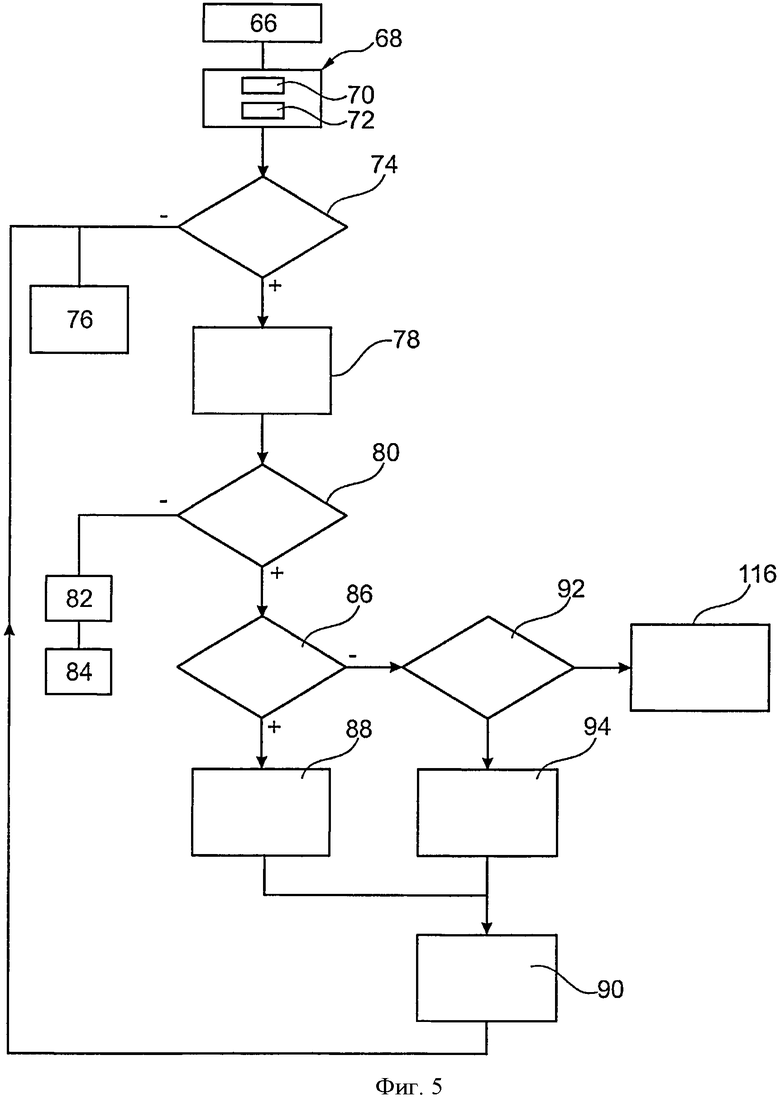
фиг. 5 представляет собой блок-схему алгоритма другого варианта осуществления способа защиты процессора безопасности, показанного на фиг. 1.
На этих чертежах одинаковые ссылочные позиции используются для обозначения одинаковых элементов.
В остальной части этого описания, признаки и функции, хорошо известные специалистам в данной области техники, не описаны подробно. Кроме того, используется терминология систем условного доступа для мультимедийного контента. Для получения дополнительной информации относительно терминологии читатель может обратиться к следующему документу:
"Функциональная модель системы условного доступа", EBU обзор. Технический европейский вещательный союз, Брюссель, BE, N° 266, 21-го декабря 1995 года ("Functional Model of Conditional Access System", EBU Review, Technical European Broadcasting Union, Brussels, BE, n° 266, 21st December 1995).
Изобретение относится, в частности, к области контроля доступа для предоставления оплачиваемого мультимедийного контента, такого как платного телевидения.
Как известно, осуществляется трансляция нескольких видов мультимедийного контента одновременно. Для этого каждый мультимедийный контент транслируется на своем канале. Канал обычно соответствует телевизионному каналу.
В этом описании "мультимедийный контент" более конкретно обозначает аудио и/или видео контент, предназначенный для восстановления в форме, которая непосредственно воспринимается и понятна для человека. Как правило, мультимедийный контент соответствует последовательности изображений, образующих фильм, телевизионную программу или какую-либо рекламу. Мультимедийный контент также может быть интерактивным контентом, таким как игра.
Для повышения безопасности и осуществления визуализации мультимедийного контента на определенных условиях, таких как подписка на оказание платных услуг, например, вещание мультимедийного контента в зашифрованном виде, а не в открытом виде.
Точнее, каждый мультимедийный контент разделен на периоды действия криптографического ключа. В течение всей продолжительности периода действия криптографического ключа, условия доступа к скремблированному мультимедийному контенту остаются неизменными. В частности, в течение всей продолжительности периода действия криптографического ключа мультимедийный контент скремблируется тем же контрольным словом. Как правило, контрольное слово изменяется от одного периода действия криптографического ключа к следующему.
Более того, контрольное слово, как правило, является специфичным для мультимедийного контента, причем последнее генерировано случайным или псевдослучайным образом.
Здесь термины "скремблирование" и "шифрование" считаются синонимами. То же самое касается терминов «дескремблирование» и «дешифрование».
Мультимедийный контент в ясной форме соответствует мультимедийному контенту до скремблирования последнего. Поэтому последний может быть представлен непосредственно в понятной форме для человека, не прибегая к операции дешифрования и без его визуализация при соблюдении определенных условий.
Необходимые контрольные слова для дешифрования мультимедийного контента передаются синхронно с мультимедийным контентом. Для этого контрольные слова мультиплексируются со скремблированным мультимедийным контентом, например.
Для повышения безопасности передачи контрольных слов последние передаются в терминалы в виде криптограмм, содержащихся в ECMs (сообщения контроля титрования). Здесь, "криптограмма" обозначает информационный элемент недостаточный сам по себе для получения контрольного слова в незашифрованном виде. Таким образом, если передача контрольного слова перехватывается, знание криптограммы только одного контрольного слова не позволяет извлечь контрольное слово, позволяющее расшифровать мультимедийный контент.
Для извлечения контрольного слова в незашифрованном виде, то есть контрольное слово, которое делает возможным напрямую расшифровывать мультимедийный контент, оно должно быть соединено с секретным элементом информации. Например, криптограмму контрольного слова получают посредством шифрования незашифрованного текса контрольного слова криптографическим ключом. В этом случае, секретный элемент информации представляет собой криптографический ключ, позволяющий расшифровать данную криптограмму. Криптограмма контрольного слова также может ссылаться на контрольное слово, хранимое в таблице, содержащей множество возможных контрольных слов. В этом случае, секретный элемент информации является таблицей, ассоциированной с незашифрованным текстом контрольного слова в каждой ссылке.
Секретный элемент информации должен храниться в безопасном месте. Чтобы сделать это, как было уже предложено, необходимо хранить секретный элемент информации в процессорах безопасности, таких как смарт-карты, непосредственно соединенные с каждым терминалом.
Фиг. 1 представляет терминал 8, предназначенный для использования в такой типовой системе управления доступом. Терминал 8 декодирует канал для отображения информации в ясной форме для зрителя.
Терминал 8 содержит приемник 10 широковещательного мультимедийного контента. Этот приемник 10 соединен с входом демультиплексора 12, который передает мультимедийный контент в дескремблер 14 и ECMs и EMMs (сообщения контроля титрования) в процессор 16 безопасности.
Дескремблер 14 расшифровывает зашифрованный мультимедийный контент на основании контрольного слова, передаваемого процессором 16. Расшифрованный мультимедийный контент передается в декодер 18, который декодирует его. Распакованный или декодированный мультимедийный контент передается в видеокарту 20, которая управляет отображением данного мультимедийного контента для просмотра на устройстве 22 отображения, оснащенным экраном 24. Устройство 22 отображения отображает мультимедийный контент в ясной форме на экране 24. Например, устройство 22 отображения представляет собой телевизор, компьютер или стационарный или мобильный телефон. В данном примере, устройство 22 отображения представляет собой телевизор.
Как правило, интерфейс между терминалом 8 и процессором 16 содержит считыватель 26, управляемый модулем 28 управления доступом. Здесь, считыватель 26 представляет собой считывающее устройство смарт-карт. Модуль 28, в частности, управляет:
- передачей демультиплексированных ECMs и EMMs в процессор 16, и
- приемом контрольных слов, расшифрованных процессором 16, и их передачей в дескремблер 14.
Процессор 16 обрабатывает конфиденциальную информацию, такую как криптографические ключи или данные авторизации доступа к мультимедийному контенту. Для обеспечения конфиденциальности этой информации необходимо обеспечить высокий уровень защищенности от атак хакеров. Поэтому необходимо обеспечить наиболее высокий уровень защиты от этих атак по сравнению с другими компонентами терминала 8. В частности, память, которая включает в себя только имеющие доступ и используется данным процессором 16. Здесь, процессор 16 является процессором безопасности смарт-карты 30.
Процессор 16, в частности, содержит программируемый электронный компьютер 32, подключенный посредством шины 34 передачи информации к энергонезависимой электронной памяти 36 и в энергозависимой электронной памяти 38.
Память 36, как правило, известна под аббревиатурой RAM (запоминающее устройство с произвольной выборкой). Память 38 хранит данные, которые хранятся даже в отсутствие других источников питания процессора 16. Кроме того, память 38 является перезаписываемой памятью. Как правило, это EEPROM (электрически стираемое программируемое постоянное запоминающее устройство) или флэш-память. Память 38 содержит конфиденциальную информацию, необходимую для расшифровки мультимедийного контента. Здесь, также содержатся команды, необходимые для выполнения способа, показанного на фиг. 4 или фиг. 5.
Фиг. 2 показывает различные области памяти 38 в деталях. Здесь, память 38 содержит следующие области памяти:
- область 42 управления,
- область 44 хранения первых данных, и
- область 46 хранения вторых данных.
Каждая область памяти определяется начальным адресом и конечным адресом. Здесь, каждая область занимает ряд последовательных адресов в памяти 38. Каждая область делится на несколько блоков памяти. Например, области 42, 44 и 46, каждая, содержат более 100 или 400 блоков памяти. Размер каждого блока памяти составляет несколько октетов. Здесь, блоки памяти данных областей все имеют тот же размер. Например, этот размер больше или равен 64о или 128о. Размеры областей 44 и 46 идентичны.
Область 44 разделяется на блоки B1j памяти Р одинакового размера, где индекс j идентифицирует начальную позицию блока B1j по отношению к начальному адресу области 44.
Область 46 также разделена на блоки B2j памяти Р такого же размера, что и блоки B1j. Индекс j определяет начальную позицию блока B2j по отношению к начальному адресу области 46. Здесь, для упрощения описания варианта осуществления, смещение между началом блока B2j и начальным адресом области 46 идентично смещению, которое существует между началом блока B1j и начальным адресом области 44. В этих условиях, блоки B1j и B2j называются "сдвоенными".
Область 42 содержит блоки CBij памяти 2Р одинакового размера. Каждый блок CBij, ассоциирован с блоком Bij области 44 или 46. Индекс i принимает значение "1" для идентифицирования области 44 и значение "2" для идентифицирования области 46.
Здесь, каждый блок CBij, в частности, содержит следующую информацию:
- указание того, является ли ассоциированный блок Bij свободным, т.е. он может быть использован для хранения нового элемента данных,
- где это применимо, указание следующего блока памяти, связанного с данным блоком Bij, или указание того, что этот блок Bij является последним блоком в цепочке связанных блоков,
- код CDij обнаружения ошибок,
- маску MRij и
- признак MDij, указывающий, является ли блок Bij нерабочим.
Код CDij создается исключительно из значения элемента данных, содержащегося в блоке Bij. Данный код CDij добавляет достаточную избыточность элементу данных, содержащегося в блоке Bij, для того, чтобы можно обнаружить один или несколько ошибочных битов в значении элемента данных, хранящегося в этом блоке.
Например, код CDij является кодом, которым осуществляется контроль при помощи циклического избыточного кода, более известного под аббревиатурой CRC. Например, код CDij является CRC 32.
Маска MRij является значением, используемым для обратного преобразования значения Dij элемента данных для сохранения в блоке Bij в трансформированном значении D'ij, которое хранится в этом блоке Bij. Это преобразование является обратимым, так что из значения маски MRij и преобразованного значения D'ij можно извлечь значение Dij элемента данных.
Признак MDij дает возможность запоминать, является или нет блок Bij в рабочем состоянии. Неисправный блок Bij является, например, блоком памяти, включающим в себя биты информации, чьи значения уже не могут быть переписаны или изменены, что приводит к появлению ошибок в хранимом значении в данном блоке памяти.
Область 42 также содержит коды коррекции ошибки СС0, CC1 и СС2. Код СС0 создается из контента областей 44 и 46. Он добавляет достаточную избыточность контенту, хранящемуся в областях 44 и 46, для того, чтобы можно не только обнаружить, но и исправить один или несколько ошибочных битов данных, хранящихся в этих областях 44 и 46. Аналогичным образом, коды CC1 и СС2 добавляют достаточную избыточность контенту областей 44 и 46 соответственно, чтобы сделать возможным корректировать ошибочные биты k в областях 44 и 46 соответственно, где k является натуральным целым числом, большим или равным единице и, предпочтительно, больше или равным пяти или десяти. В отличие от кода СС0, коды CC1 и СС2 позволяют только откорректировать ошибочные биты в областях 44 и 46 соответственно. Например, эти коды коррекции ошибок являются кодами Рида-Соломона.
Фиг. 3 представляет собой фазу 50 хранения элемента конфиденциальных данных в памяти 38. Элемент конфиденциальных данных, как правило, представляет собой криптографический ключ для расшифровки контрольного слова или данные авторизации доступа или отсутствия авторизации, доступа и расшифровки мультимедийного контента.
Если размер элемента данных больше, чем размер блока памяти, то элемент данных сначала делят на несколько частей, каждая из которых имеет меньший размер, чем размер блока памяти, с тем чтобы соответствовать элементу данных, имеющий размер, который меньше, чем размер блока памяти. В этом случае, различные части одного и того же элемента данных, например, соединены друг с другом с указанием в каждом блоке BCij адреса следующего блока памяти.
Прежде всего, на этапе 52, компьютер 32 выбирает из числа различных блоков памяти областей 44 и 46 пару блоков Bij памяти, удовлетворяющую следующим условиям:
- блоки B1j и B2j спарены,
- блоки B1j и B2j свободны, и
- блоки B1j и B2j не отмечены как неисправные.
Компьютер 32 проверяет факт того, что выбранные блоки B1j и B2j свободны и исправны на основании информации, содержащейся в блоках BC1j и BC2j области 42 управления.
В следующем тексте, значение элемента данных, хранящееся в блоках B1j и B2j, обозначается соответственно как D1j и D2j. Эти значения являются идентичными.
На этапе 54, компьютер 32 вычисляет новое значение кодов CD1j и CD2j, что позволяет обнаружить ошибку в значениях D1j и D2j соответственно. На этапе 54, компьютер 32 также вычисляет новые значения кодов CC0, CC1 и СС2 коррекции ошибок и сохраняет их в области 42.
Новые значения кодов CD1j и CD2j хранятся в блоках BC1j и BC2j соответственно.
Компьютер 32 также хранит в его блоков BC1j и BC2j сигнал индикации о том, что согласно которому блоки B1j и B2j памяти больше не свободны.
Далее, на этапе 56, значения D1j и D2j преобразуются соответственно в значения D'1j и D'2j как функция значения масок MR1j и MR2j соответственно. Значение масок MR1j и MR2j содержится в блоках BC1j и BC2j. Значения масок MR1j и MR2j различны, так что преобразованные значения D'1j и D2j различны.
Например, преобразование выполняется с использованием следующего соотношения: D'ij=Dij⊕MRij, где "⊕" является XOR операцией.
Далее, на этапе 58, значения D'1j и D'2j физически хранятся в блоках B1j и B2j памяти соответственно. На этом фаза 50 завершается.
При использовании, процессор 16 выполняет программу, например, для расшифровки контрольных слов. При выполнении этой программы, команды используются для чтения элемента данных, хранящегося в памяти 38, такого как криптографический ключ или данные авторизации доступа. Затем выполняется способ, показанный на фиг. 4.
Вначале на этапе 66 адрес блока памяти для чтения сохраняется в энергонезависимом считывающим адресном регистре. Например, этот регистр, содержится в памяти 38.
Далее, выполняется этап 68 чтения элемента данных в памяти 38 по указанному адресу. Точнее, в операции 70, значения D'1j и D'2j, содержащиеся в спаренных блоках B1j и B2j памяти, соответственно, считываются.
Далее, в ходе выполнения операции 72 компьютер 32 осуществляет обратное преобразование к тому выполнению способа, выполняемого на этапе 56, как показано на фиг. 3. Для реализации, используется значения масок MR1j и MR2j. Значения, полученные применением данного обратного преобразования значений D'1j и D'2j, впоследствии будет обозначаться как значения D1j и D2j соответственно. Отметим, что в случае ошибки чтения или искажения хранящихся данных, значения D1j и D2j не обязательно идентичны значениям D1j и D2j, хранящимся в фазе 50 записи.
На этапе 74, значения чтения D1j и D2j сравниваются. Если эти величины равны, то процесс переходит на этап 76, в течение которого программа выполняется процессором 16, обрабатывая значение D1j, и продолжается нормальное выполнение процесса. Например, компьютер 32 расшифровывает контрольное слово с помощью значения D1j. На этапе 76, ошибка чтения не обнаружена. Более того, на этапе 76, регистр адреса считывания стирается.
И наоборот, если значения считывания D1j и D2j не идентичны, то процесс выполнения программы прерывается и выполняется процедура проверки компьютером 32. Например, процессор безопасности перезапускается и во время перезагрузки процессора безопасности систематически выполняется процедура проверки, если адресный регистр чтения не является пустым. Процедура проверки также может быть запущена изменением маршрута события в случае ошибки при выполнении программы.
После запуска данной процедуры проверки на этапе 78 компьютер 32 вновь пытается считать элемент данных, хранящийся в памяти 38. Новая попытка чтения состоит в чтении элемента данных, соответствующих адресу, сохраненному в регистре адреса считывания. Этап 78, например, идентичен этапу 68.
Далее, на этапе 80 компьютер переходит к новому сравнению новых значений D1j и D2j, считанных на этапе 78.
Если на этот раз, значения D1j и D2j идентичны, то на этапе 82, обнаружена ошибка считывания. Действительно, разница между значениями D1j и D2j, считанными на этапе 68, не вытекает из искажения данных, хранящихся в памяти 38. В самом деле, обнаружение ошибки считывания указывает, в случае процессора безопасности, с очень высокой степенью вероятности, на то, что первая попытка чтения на этапе 68 была выполнена неудачно в связи с атакой считывания.
Таким образом, в ответ, на этапе 84, компьютер 32 инициирует реализацию контрмер, ограничивая расшифровку мультимедийного контента. Как результат, осуществляется временное или постоянное ограничение на расшифровку мультимедийного контента с помощью процессора 16. Как правило, расшифровка контрольных слов заблокирована.
Точнее, противодействие может представлять собой реализацию одним из следующих контрмер:
- стирание конфиденциальных данных, содержащихся в памяти 38, таких как криптографические ключи и данные авторизации доступа,
- срабатывание самоуничтожения процессора 16, с тем чтобы окончательно вывести из строя процессора, и
- временное или окончательное прекращение выполнения процесса расшифровки контрольных слов.
На этапе 84, если процессор 16 по-прежнему используется, несмотря на реализацию контрмер, то адресный регистр чтения стирается.
Если значения D1j и D2j, считанные на этапе 78, различны, то это означает, что сохраненные данные, безусловно, искажены. Поэтому отсутствует ошибка чтения.
В этом случае, на этапе 86 компьютер 32 проверяет, является ли значение D1j ошибочным, используя код CD1j.
Если значение D1j не ошибочно, то на этапе 88 осуществляется сохранение значения D1j в новых парных блоках памяти областей 44 и 46. Например, операции на этапе 88 выполняются аналогично фазе 50 записи. Следовательно, это сохраненное значение в этих новых блоках будет использовано во время следующего чтения того же элемента данных.
Далее, на этапе 90 обновляются признаки MD1j и MD2j, для индикации и сохранения в памяти информации того, что предыдущие блоки B1j и B2j неисправны. Здесь, блок B1j указывается как дефектный, в то время как значение, которое было сохранено, было корректным. Это позволяет продолжить управление процессом составления пар блоков памяти простым способом.
На этапе 90 также стирается адресный регистр чтения. Далее, значение D1j обрабатывается программой, которую продолжают выполнять на этапе 76.
Если на этапе 86 значение D1j является ошибочным, то далее выполняется операция на этапе 92 проверки, является ли значение D2j ошибочным или корректным, используя код CD2j.
Если элемент D2j данных корректен, то выполняется операция на этапе 94, идентично на этапе 88 исключением того, что используется значение D2j, которое используется вместо значения D1j. Выполнение операций на этапе 94 также продолжается посредством выполнения операций на этапе 90.
Если значения D1j и D2j являются ошибочными, то компьютер продолжает выполнение операций на этапе 98, в течение которого осуществляется первая попытка корректировки этих значений, используя код CC0. На этом этапе 98 компьютер 32 осуществляет коррекцию k ошибочных битов, распределенных в областях 44 и 46. Если существует менее, чем k ошибочных битов, то операция коррекции затем может рассматриваться как успешная. В этом случае получаются исправленные значения Dc1j и Dc2j для значений D1j и D2j соответственно.
В этом случае на этапе 100 компьютер 32 сравнивает значения Dc1j и Dc2j.
Если значения Dc1j и Dc2j идентичны на этапе 102, то значение Dc1j сохраняется в двух новых блоков памяти областей 44 и 46 соответственно. Операции на данном этапе, например, идентичны операции на этапе 88, за исключением того, что это значение Dc1j используется вместо значения D1j.
Далее выполняется операция на этапе 104, в течение которого блоки B1j и B2j помечаются как неисправные. Операция на этапе 104 идентична, например, операции, выполняемой на этапе 90. Последовательность выполнения способа далее возвращается на этап 76.
Если значения Dc1j и Dc2j различны или если исправление ошибок кодом CC0 не было выполнено, то компьютер 32 переходит на этап 108, в течение которого выполняется попытка исправления данных в области 44, используя код CC1. Если коррекция прошла успешно, то компьютер 32 получает скорректированное значение Dc1j для значения D1j. Далее выполняется операция на этапе 110, которая идентична этапу 102. Операция на этапе 110 выполняется после выполнения операции на этапе 104.
Если операция на этапе 108 не выполнена, т.е. не обеспечивается исправление значения D1j, то компьютер выполняет операцию на этапе 112, в течение которого осуществляется попытка исправить значение D2j, используя код СС2. Если операция на этапе 112 выполнена успешно, то компьютер 32 получает скорректированное значение Dc2j. Далее выполняется операция на этапе 114, которая идентична операции на этапе 94 за исключением того, что это значение Dc2j используется вместо значения D2j. Операция на этапе 114 выполняется после выполнения операции на этапе 104.
Если не удалось исправить либо значение D1j, или значение D2j, то на этапе 116 компьютер 32 устанавливает факт того, что элемент данных потерян, поскольку последний является ошибочным и не может быть исправлен. На этом этапе 116, компьютер 32 отмечает блоки B1j и B2j как неисправные. Эта операция выполняется по отношению к этапу 90. Затем, либо программа может управлять процессом, для которого отсутствует значение для этого элемента данных, и в этом случае выполнение программы продолжается. Если выполнение программы не может продолжаться без значения элемента данных, то выполнение программы останавливается, и процессор безопасности, например, перезапускается.
Фиг. 5 представляет способ защиты процессора 16, который идентичен способу, показанному на фиг. 4, исключением того, что коды коррекции ошибок не используются. Таким образом, в этом способе, этапы с 98 по 114 опускаются. Кроме того, в случае когда оба значения D1j и D2j обнаружены как ошибочные, то процесс переходит непосредственно на этап 116.
Возможны многие другие варианты осуществления. Например, операции преобразования хранимого значения могут быть опущены. В этом случае этапы 56 и 72 опускаются.
Распределение памяти может быть логическим или физическим распределением памяти.
Алгоритм, используемый для обнаружения ошибки в значении D1j, может отличаться от алгоритма, используемого для обнаружения ошибки в значении D2j. В этом случае, значения кодов CD1j и CD2j различны.
В одном варианте осуществления, код обнаружения ошибки также используется после коррекции сохраненного значения, с помощью кода коррекции ошибок. Это предоставляет возможность осуществить проверку, при необходимости, того, что скорректированное значение является правильным.
В другом варианте осуществления, код CC0 опущен или, наоборот, коды CC1 и CC2 опущены или не используется код коррекции ошибок.
В другом варианте осуществления, код коррекции ошибок используется только для одной из областей памяти.
Код коррекции ошибок не обязательно является общими для всей области памяти. В варианте, код коррекции ошибок построен на ограниченной группе нескольких блоков области памяти. Код коррекции ошибок также может быть использован для каждого блока памяти и только для этого блока памяти. В этом случае, код коррекции ошибок, предпочтительно, заменяет код обнаружения ошибок. В самом деле, почти все коды коррекции ошибок также обеспечивают обнаружение ошибки.
Код коррекции ошибок также может быть общим для значений D1j и D2j.
Код коррекции ошибок также может быть построен в соответствии с другими алгоритмами, такими как алгоритмы Хэмминга или турбокода.
Когда блок B1j памяти устанавливается как дефектный, то нет необходимости для блока B2j памяти, который запараллелен с ним, также должен систематически быть помечен как неисправен. В варианте, блок B2j помечается как неисправный, только если код CD2j, ассоциированный с этим блоком, подтверждает, что элемент данных также является ошибочным. В противном случае, таблица ассоциируется с адресом каждого блока B1j адресом спаренного блока B2j. В этом случае, данная таблица модифицируется для ассоциации по адресу блока B2j, новый блок B'1j используется для замены предыдущего блока B1j.
Область 42 управления может быть сохранена в блоках области 44. В этих условиях, как и все блоки этой области 44, дублируются в области 46. Таким образом, обеспечивается защита зоны управления против искажения данных или от появления ошибок чтения таким же способом, как любой другой блок этих областей 44 и 46.
Процесс преобразования значения Dij в значение D'ij может быть опущен или реализован лишь в одной из областей 44 или 46.
Порядок некоторых операций или этапов реализации способов, описанных здесь, могут быть изменены. Например, операция вычисления кода определения ошибок выполняется после операции преобразования значения Dij в трансформированное значение D'ij. В этом случае, во время чтения осуществляется проверка того, что элемент данных чтения корректен или ошибочен, на основании значения D'ij, а не значения Dij.
В варианте осуществления, перед обновлением признака MDij неисправного блока, компьютер проверяет, что блок Bij фактически неисправен. Например, он выполняет следующие операции:
α) запись значения Dij в блок Bij вызывающий сомнение, затем
β) чтение значения Dij хранимого в этом блоке Bij,
χ) сравнение записанного и прочитанного значений, и затем
δ) если эти значения равны, то операции с а) по с) повторяются, по меньшей мере, N раз.
В противном случае, признак MDij обновляется для индикации того, что блок Bij неисправен.
Как правило, число N больше чем два и, предпочтительно, больше десяти.
Если предыдущие операции с а) по d) часто выполняются для одного и того же блока Bij, но предшествующая проверка обеспечивает работоспособность блока Bij, конкретное значение может быть выделено для признака MDij о том, что этот блок Bij не защищен. В этих условиях, насколько это возможно, блок Bij затем не выбирается для хранения новых данных. С другой стороны, если отсутствуют любые другие доступные блоки памяти, которые являются более безопасными, то этот блок Bij будет использоваться для хранения элемента данных.
Каждый блок памяти, как описано здесь, может быть обеспечен в виде единого электронного компонента или объединения нескольких электронных компонентов, соединенных независимо друг от друга к компьютеру 32. Например, области 44 и 46 могут соответствовать двум отдельным физическим блокам памяти, каждый из которых связан собственной шиной считывания к компьютеру 32.
Более чем две резервные области памяти могут быть обеспечены. В этом случае, значение элемента данных, скопированного в этой памяти, копируется в каждую из этих областей памяти. Способы, описанные выше, могут быть легко адаптированы для случая W областей памяти, где W представляет собой целое число больше, чем два.
Предмет предшествующего описания также применим к энергонезависимой памяти.
Изобретение относится к способу обнаружения ошибки при считывании элемента данных, содержащему этапы, на которых: а) сохраняют первую копию элемента данных в первой области электронной памяти и сохраняют вторую копию элемента данных во второй области электронной памяти, b) считывают значения первой и второй копий элемента данных соответственно в первой и второй областях, с) сравнивают считанные значения первой и второй копий элемента данных, е) если считанные значения первой и второй копий не совпадают, то повторяют предыдущие этапы b) и с), и f) если считанные значения на этапе е) совпадают, обнаруживают ошибку считывания указанного элемента данных, а в противном случае не обнаруживают ошибки считывания указанного элемента данных. Заявленный способ позволяет отличить ошибку считывания от ошибки, вызванной искажением данных, таким образом позволяет избежать нерационального использования компьютерных ресурсов при проведении мер по устранению ошибок. 4 н. и 7 з.п. ф-лы, 5 ил.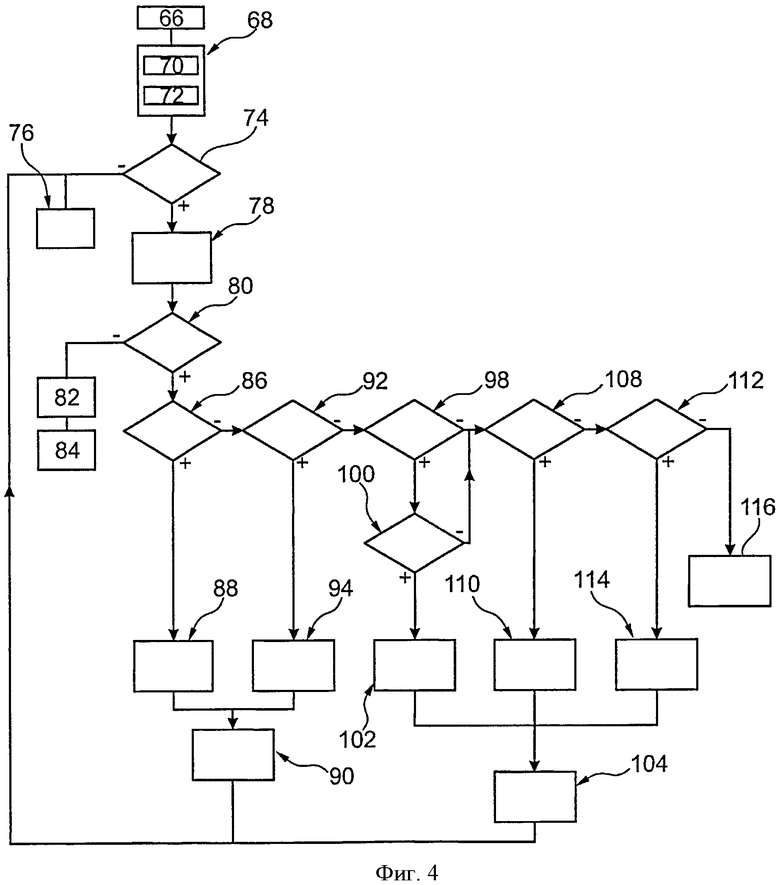
1. Способ обнаружения ошибки при считывании элемента данных, содержащий этапы, на которых:
a) сохраняют (50) первую копию элемента данных в первой области электронной памяти и сохраняют вторую копию элемента данных во второй области электронной памяти,
при этом в ответ на запрос считать элемент данных:
b) считывают (68) значения первой и второй копий элемента данных соответственно в первой и второй областях,
c) сравнивают (74) считанные значения первой и второй копий элемента данных,
d) если считанные значения первой и второй копий совпадают, то не обнаруживают ошибку считывания указанного элемента данных,
отличающийся тем, что:
e) если считанные значения первой и второй копий не совпадают, то повторяют (78, 80) этапы b) и с), и
f) если считанные значения на этапе е) совпадают, то обнаруживают (82) ошибку считывания указанного элемента данных, а в противном случае не обнаруживают ошибку считывания указанного элемента данных.
2. Способ по п. 1, дополнительно содержащий этапы, на которых:
связывают (54) со значением первой копии элемента данных код обнаружения ошибки, добавляющий избыточность элементу данных и позволяющий обнаружить ошибку в значении указанного элемента данных,
если на этапе f) считанные значения первой и второй копий не совпадают, то проверяют (86), является ли считанное значение первой копии ошибочным или верным с использованием кода обнаружения ошибки, связанного с указанным значением, и
если считанное значение первой копии верно, то сохраняют (88) значение первой копии в блоке памяти второй области памяти, отличном от блока памяти, где была обнаружена предыдущая вторая копия этого элемента данных, с тем чтобы сформировать новую вторую копию элемента данных, а затем
используют новую вторую копию вместо предыдущей второй копии элемента данных при новом повторении этапов b) и с).
3. Способ по п. 1, дополнительно содержащий этапы, на которых:
связывают (54) с первой и второй копиями элемента данных код коррекции ошибки, добавляющий достаточную избыточность значениям первой и второй копий и позволяющий скорректировать один или более ошибочных битов в значении каждой из указанных копий элемента данных,
если на этапе f) считанные значения первой и второй копий не совпадают, то:
корректируют (98) значения первой и второй копий элемента данных с использованием кода коррекции ошибки для получения скорректированных значений для первой и второй копий, а затем
сравнивают (100) скорректированные значения первой и второй копий, и
если скорректированные значения совпадают, сохраняют (102) скорректированные значения первой копии элемента данных в новых блоках памяти соответственно первой и второй областей памяти, отличных от блоков памяти, в которых были обнаружены предыдущие первые и вторые копии элемента данных, с тем чтобы сформировать новые первую и вторую копии элемента данных, а затем
используют новые первую и вторую копии вместо предыдущих первой и второй копий при новом повторении этапов b) и с).
4. Способ по п. 2, дополнительно содержащий этапы для каждого блока памяти, где была обнаружена предыдущая копия элемента данных, на которых:
запоминают (90, 104, 116) указанный блок памяти как неисправный, и
при выделении нового блока памяти в одной из областей памяти для сохранения информации, выбирают (52) блок памяти только среди блоков памяти области, который не запомнен как неисправный.
5. Способ по п. 3, дополнительно содержащий этапы для каждого блока памяти, где была обнаружена предыдущая копия элемента данных, на которых:
запоминают (90, 104, 116) указанный блок памяти как неисправный, и
при выделении нового блока памяти в одной из областей памяти для сохранения информации, выбирают (52) блок памяти только среди блоков памяти области, который не запомнен как неисправный.
6. Способ по п. 1, дополнительно содержащий этапы, на которых:
при сохранении первой копии элемента данных значение элемента данных сначала преобразуют (56) с использованием обратимой функции маскирования для получения преобразованного значения, отличного от непреобразованного значения и отличного от сохраненного значения второй копии, после чего сохраняют в первой области преобразованное значение, и
при чтении первой копии применяют (72) обратное преобразование к сохраненному преобразованному значению для получения считанного значения первой копии.
7. Способ защиты процессора безопасности от атаки считывания, причем процессор безопасности выполняет (76) процедуру шифрования или дешифрования элемента информации с использованием элемента конфиденциальных данных, хранящегося в первой и второй областях памяти процессора безопасности, отличающийся тем, что:
процессор безопасности обнаруживает (82) ошибку считывания элемента конфиденциальных данных с использованием способа по любому из пп. 1-6,
если ошибка считывания элемента конфиденциальных данных не обнаружена, процессор безопасности продолжает осуществлять шифрование или дешифрование (76) информационного элемента с использованием считанного элемента конфиденциальных данных, а в противном случае
в ответ на обнаружение ошибки считывания процессор безопасности автоматически инициирует (86) выполнение мер противодействия, ограничивая шифрование или дешифрование информационного элемента с использованием считанного элемента конфиденциальных данных по сравнению со случаем, когда ошибка считывания элемента конфиденциальных данных не обнаружена.
8. Носитель (38) информации, содержащий команды для осуществления способа по любому из пп. 1-6, при исполнении команд электронным компьютером.
9. Процессор безопасности, содержащий:
первую (44) и вторую (46) области электронной памяти,
электронный компьютер (32), запрограммированный для:
a) хранения первой копии элемента данных в первой области и хранения второй копии элемента данных во второй области, в ответ на запрос считать элемент данных:
b) считывания значений первой и второй копий элемента данных соответственно в первой и второй областях,
c) сравнения считанных значений первой и второй копий элемента данных, и
d) если считанные значения первой и второй копий совпадают, обнаружения отсутствия ошибки считывания указанного элемента данных,
отличающийся тем, что электронный компьютер также запрограммирован для:
e) повторения этапов b) и с), если считанные значения первой и второй копий не совпадают, и
f) если считанные значения на этапе е) совпадают, обнаружения ошибки считывания указанного элемента данных, а в противном случае указания на отсутствие ошибки считывания.
10. Процессор безопасности по п. 9, характеризующийся тем, что является процессором безопасности смарт-карты (30).
11. Процессор по п. 9 или 10, в котором электронная память (38), называемая первой памятью, является энергонезависимой памятью, причем процессор безопасности включает в себя вторую энергозависимую память (36), в которую систематически копируются считанные данные из первой памяти (38) для обработки электронным компьютером (32).
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ РЕМОНТНОГО ОБСЛУЖИВАНИЯ КОМПЬЮТЕРОВ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2000 |
|
RU2187835C1 |
| СПОСОБ ЗАГРУЗКИ ДАННЫХ В ПРИЕМНИК/ДЕКОДЕР МРЕG И СИСТЕМА ТРАНСЛЯЦИИ МРЕG ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2195086C2 |

