Настоящее изобретение относится к организации иерархической памяти компьютерных файлов данных.
Объем данных, хранимых на жестких дисках персональных компьютеров, работающих в качестве устройств массовой памяти, быстро увеличивался в течение последнего десятилетия. Это особенно верно для данных, хранимых на сетевых файл-серверах, где в настоящее время обычными являются подсистемы на жестких дисках емкостью 1 Гб (гигабайт) или выше, содержащие многие тысячи файлов.
В типовом случае многие из файлов на сетевом файл-сервере не будут доступны в течение некоторого времени. Это объясняется несколькими причинами: файл может быть старой версией, резервной копией или может храниться до тех пор, пока однажды не потребуется. Файл может быть фактически вообще избыточным, однако только собственник файла может идентифицировать его таковым, и в результате файл хранится по причинам резервирования или надежности. В соответствии с общепринятой компьютерной практикой считается, что в случае сомнения файлы должны храниться неограниченно долго. Естественным следствием этого является то, что жесткий диск заполняется старыми файлами. Это случается фактически в каждой микропроцессорной персональной компьютерной системе от самой маленькой до самой большой.
Организация иерархической памяти (HSM) является известным способом решения этой проблемы. Большинство операционных систем поддерживают запись последних даты и времени обновления файла (т.е. записи). Многие также поддерживают запись последних даты и времени обращения к файлу (т.е. считывания). Система HSM периодически просматривает список файлов на жестком диске, проверяя последние дату/время каждого. Если файл не использовался в течение заранее определенного промежутка времени (обычно от 1 до 6 месяцев), то файл архивируется, т. е. он переносится на вторичное устройство памяти, например магнитную ленту, и удаляется с жесткого диска.
HSM обычно объединяется с резервированием. Рассмотрим систему резервирования на магнитную ленту с возможностью HSM, в которой порог пассивного состояния установлен равным 3 месяцам. Процесс резервирования запускается периодически (обычно, по меньшей мере, еженедельно) и отмечается, когда последняя дата обращения для данного файла будет соответствовать дате более 3 месяцев назад. Система резервного копирования убеждается, что имеется, например, три резервные копии файла на различных лентах (или ожидает случая, когда будут иметься три копии) и затем удаляет файл. Если даже файл потребуется, то пользователь просто восстанавливает его с одной из трех резервных магнитных лент. Система резервного копирования должна гарантировать, что ленты, содержащие архивные копии файла, не будут перезаписаны. Этот способ обеспечивает долговременное решение проблемы, так как магнитные ленты являются сменными, легко заменяемыми и недорогими.
Когда файл удален системой HSM, его больше нельзя найти на исходном диске. Это может быть невыгодным в случае, если пользователь или прикладная задача примут решение о необходимости доступа к файлу, так как никакого следа файла при поиске на диске не обнаружится. Пользователь или прикладная задача в этом случае не имеют средств, чтобы определить, может ли файл быть восстановлен из резервной копии, и прикладная задача, следовательно, может исходить из неправильной информации, что приведет к неисправимой ошибке.
В идеале вместо бесследного удаления файл должен продолжать оставаться в каталоге на диске (предпочтительно с некоторыми средствами идентификации, что он удален в резервную или вторичную память), но без реального присутствия данных файла и занятия ими дискового пространства. Фактически эта возможность предоставляется во многих HSM системах и известна как перемещение (миграция). Системы HSM обычно оставляют ссылку на файл в каталоге и удаляют данные файла с малым "остатком", содержащим указание на местоположение, где может быть найден перемещенный файл, или удаляют данные полностью, оставляя файл нулевой длины.
Дальнейшее усовершенствование систем HSM, известное как деперемещение (демиграция, обратное перемещение), вынуждает HSM-систему автоматически восстанавливать перемещенный файл на исходный диск в случае, когда пользователь или прикладная задача пытаются обратиться к нему. Очевидно, что это возможно, только если среда вторичной памяти, содержащая перемещенные файлы, постоянно подсоединена к системе. Когда перемещенные данные хранятся на таком устройстве, работающем "почти в линию", например на оптическом диске с автоматической сменой дисков, запрос на обращение к файлу может быть даже временно приостановлен до тех пор, пока файл не будет восстановлен, после чего продолжается работа, как если бы файл никогда не был перемещен.
Способы HSM, описанные выше, эффективны, когда применяются к большому количеству относительно малых файлов, используемых только одним пользователем одновременно. Однако рассмотрим систему базы данных, в которой множество пользователей обращаются к одному большому файлу базы данных, содержащему имена потребителей (пользователей) и адресные записи или аналогичные данные предыстории. Так как новые записи пользователей постоянно добавляются и записи текущих пользователей исправляются, то файл никогда не будет кандидатом на перемещение, так как он должен быть всегда доступен. Тем не менее, такой файл обычно будет иметь много записей для старых неактивных пользователей, чьи данные должны быть сохранены для возможных будущих ссылок, но чьи записи могут быть в противном случае оставлены без обращения в течение значительных периодов времени. Дисковое пространство, занимаемое такими неактивными записями, может быть часто представлено большей частью пространства, занимаемого целым файлом.
Уже известно, как можно организовать файл со случайным доступом, в котором малые количества данных могут быть записаны в любую часть файла или считаны с любой части файла с помощью случайного доступа. Когда создается новый файл со случайным доступом, файл имеет нулевую длину до тех пор, пока данные не будут в него записаны. Так как файл имеет организацию со случайным доступом, то первая часть записываемых данных необязательно должна иметь смещение 0 (т.е. быть началом файла), она может быть записана в любое место. Например, 10 байт данных могут быть записаны со смешением 1000. Файл поэтому будет иметь логическую длину 1010 байт, хотя в действительности записано только 10 байт. Некоторые операционные системы в такой ситуации автоматически заполняют "отсутствующие" 1000 байт пустыми или случайными символами, посредством этого размещая 1010 байт, хотя в действительности было записано только 10 байт.
Усовершенствованные операционные системы, такие как используемые в сетевых файл-серверах, поддерживают концепцию разбросанных файлов, в которых дисковое пространство назначается только тем областям файла, на которые данные реально записываются. Обычно, это достигается расширением таблицы распределения файлов (карты, содержащей сведения о том, как файлы хранятся на диске) так, что каждая запись, указывающая следующее положение, в котором хранятся данные конкретного файла, сопровождается значением, указывающим логическое смещение, с которого начинаются данные. Таким образом, в вышеприведенном примере первая запись будет указывать, что данные начинаются с позиции х на диске и что первый байт расположен в файле с логическим смещением 1000 (в "нормальном" файле логическое смещение должной быть равно "0"). Области разбросанного файла, в которые данные никогда не записываются, известны как дырки.
Сущность изобретения
Изобретение в своих различных аспектах определяется в независимых пунктах приведенной ниже формулы изобретения. Признаки, характеризующие предпочтительное осуществление изобретения, приведены в зависимых пунктах.
В предпочтительном варианте воплощения изобретения, описанном ниже со ссылками на чертежи, поддерживается вспомогательная база данных, указывающая, к каким блокам данных было обращение и в какие даты. Блоки, к которым не было обращения, могут быть затем заархивированы и удалены из файла на диске для снижения требований к памяти. Удаление может быть достигнуто корректировкой FAT (таблицы распределения файлов) для обращения с файлом, как с разбросанным файлом.
Если осуществляется запрос на считывание для части файла, которая заархивирована или перемещена, то система перемещает обратно требуемую часть файла перед тем, как запрос на считывание удовлетворяется.
Однако записи, обращение к которым имело место недавно, уже должны быть на жестком диске и доступ к ним может быть обеспечен немедленно в последующее время. Таким образом, доступ к часто требуемым записям будет обеспечен с высоким быстродействием без необходимости сохранения всего файла на жестком диске.
Способ может быть расширен, в сущности, с помощью увеличения порога пассивности для срока службы вспомогательной базы данных. Если из большого файла базы данных только к малому количеству записей было обращение, то все записи, к которым было обращение, могут быть сохранены на жестком диске, независимо от даты последнего обращения. Записи, к которым не было обращения, могут быть, однако, удалены для освобождения дискового пространства. В этом случае не требуется, чтобы вспомогательная база данных хранила дату или дату/время последнего обращения. Через продолжительные промежутки времени, например, каждый "месяц, все области, к которым было обращение, могут быть перемещены, а вспомогательная база данных очищена.
Более конкретно, указанный выше технический результат достигается тем, что в соответствии с изобретением способ обращения к данным, хранимым в компьютерной системе, содержащей память со случайным доступом, центральный процессор, средство массовой памяти, средство вторичной памяти для архивирования и устройство для архивирования данных, хранимых в компьютерной системе, включает этапы подачи команд, хранимых в памяти со случайным доступом, в центральный процессор для обеспечения им поиска данных обращения, хранимых в средстве массовой памяти, путем генерирования по меньшей мере запроса на считывание, идентификации файла, к которому требуется обращение, причем файл состоит из частей файла, идентификации частей файла в файле, к которым необходимо обращение, обращения к частям файла, причем этап обращения включает проверку таблицы распределения файлов, которая определяет местоположения частей файла в средстве массовой памяти, для определения того, находятся ли части файла в средстве массовой памяти, и если это так, то определение местоположений таких частей файла и формирования базы данных, которая идентифицирует местоположения частей файла, к которым должно осуществляться обращение, причем база данных не включает самой части файла.
Предпочтительно, части файла являются блоками, соответствующими элементарным блокам, идентифицированным в таблице распределения файлов, а база данных определяет, является ли обращение обращением для записи или обращением для считывания.
При этом на этапе формирования предпочтительно идентифицируют части файла, к которым должно быть осуществлено обращение, и дату или дату и время осуществления обращения, а на этапе формирования осуществляют консолидирование базы данных для удаления избыточной информации.
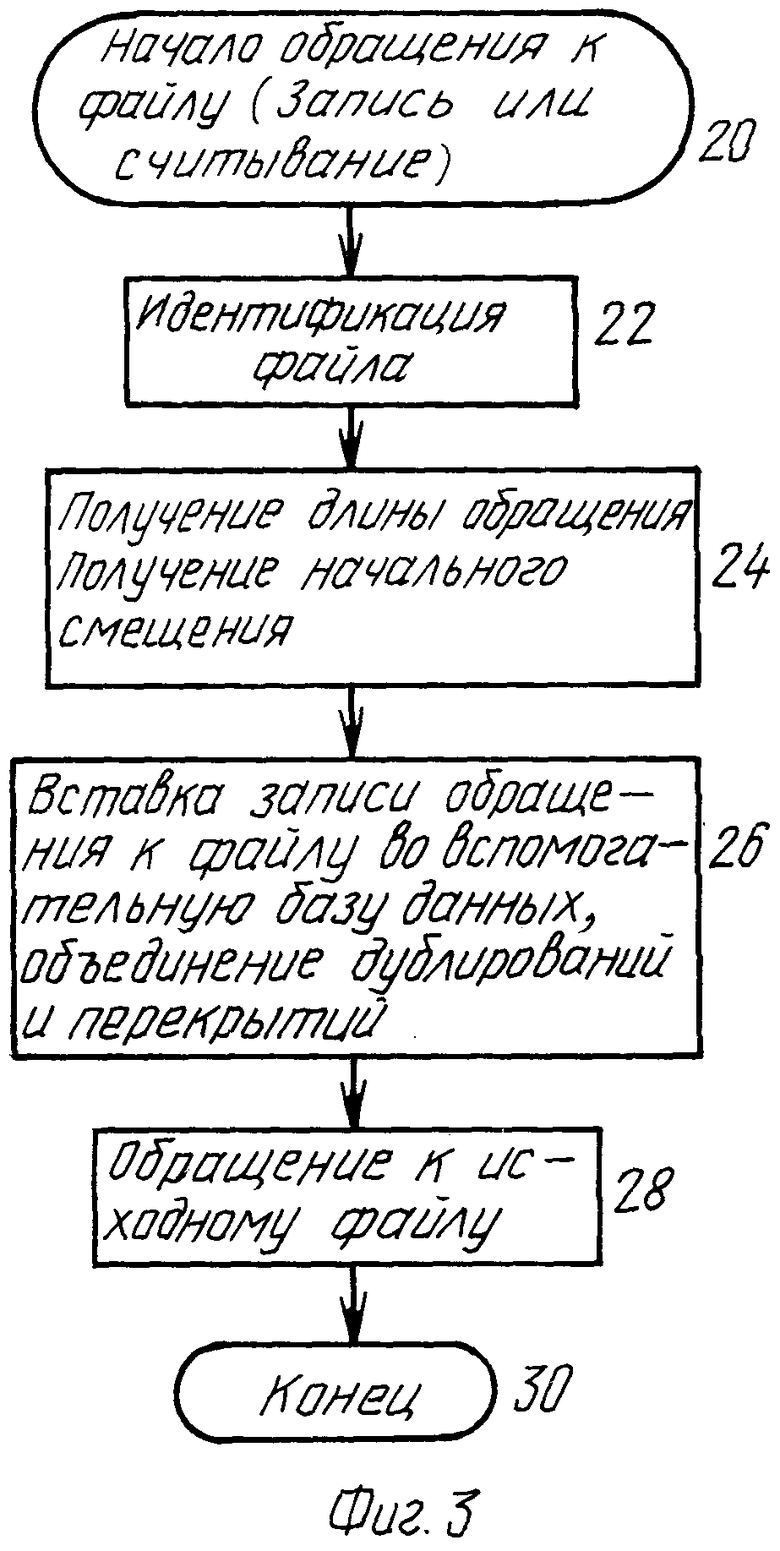
Указанный выше результат достигается также тем, что способ обращения к данным, хранимым в компьютерной системе, содержащей память со случайным доступом, центральный процессор, средство массовой памяти, средство вторичной памяти для архивирования и устройство для архивирования данных, хранимых в компьютерной системе, в соответствии с изобретением, включает этапы подачи команд, хранимых в памяти со случайным доступом, в центральный процессор для обеспечения им архивирования выбранных данных, хранимых в средстве массовой памяти, в средстве вторичной памяти для архивирования для освобождения пространства в средстве массовой памяти, идентификации из базы данных местоположений частей файла, к которым осуществлено обращение, архивирование из средства массовой памяти в средстве вторичной памяти для архивирования по меньшей мере некоторых частей файла, к которым не было обращения, и освобождение в средстве массовой памяти пространства, занимаемого теми частями файла, к которым не было обращения, но которые были архивированы средством архивирования при сохранении в средстве массовой памяти частей файла, к которым было обращение.
Предпочтительно этап идентификации частей файла, к которым осуществлено обращение, включает идентификацию из базы данных частей файла, к которым осуществлялось обращение с заданной даты, и частей файла, к которым не осуществлялось обращение с заданной даты, этап архивирования включает архивирование в средстве вторичной памяти для архивирования по меньшей мере некоторых частей файла, к которым не осуществлялось обращение с заданной даты, а этап освобождения включает освобождение в средстве массовой памяти пространства, занятого теми частями файла, к которым не осуществлялось обращение с заданной даты, но которые были архивированы средством архивирования при сохранении в средстве массовой памяти частей файла, к которым осуществлялось обращение с заданной даты.
При этом этап архивирования и этап освобождения предпочтительно включают архивирование и удаление тех частей файла, к которым не осуществлялось обращение с заданной даты и которые уже являются резервированными заданное количество раз, причем этап освобождения предпочтительно включает изменение таблицы распределения файлов.
Кроме того, способ может дополнительно включать этап извлечения требуемых частей файла из средства вторичной памяти для архивирования в средство массовой памяти для обращения.
Указанный выше технический результат достигается в соответствии с изобретением в компьютерной системе, содержащей память со случайным доступом, центральный процессор, средство массовой памяти, средство вторичной памяти для архивирования и устройство для архивирования данных, хранимых в компьютерной системе, содержащее средство для подачи команд, хранимых в памяти со случайным доступом, в центральный процессор для обеспечения центральным процессором поиска для обращения к данным, хранимым в средстве массовой памяти, путем генерирования по меньшей мере запроса на считывание, первое средство идентификации для идентификации файла, к которому требуется обращение, причем файл состоит из частей файла, второе средство идентификации для идентификации частей файла в файле, к которым необходимо обращение, средство обращения для обращения к частям файла, включающее в себя средство для проверки таблицы распределения файлов, которая определяет местоположения частей файла в средстве массовой памяти, для определения того, находятся ли части файла в средстве массовой памяти, и если это так, то для определения местоположений таких частей файла, и средство формирования для формирования базы данных, которая идентифицирует местоположения частей файла, к которым должно осуществляться обращение, причем база данных не включает самой части файла.
Предпочтительно части файла являются блоками, соответствующими элементарным блокам, идентифицированным в таблице распределения файлов, база данных определяет, является ли обращение обращением для записи или обращением для считывания.
Кроме того, средство формирования предпочтительно идентифицирует части файла, к которым должно быть осуществлено обращение и дату или дату и время осуществления обращения, а также осуществляет консолидирование базы данных для удаления избыточной информации.
Кроме того, вышеуказанный технический результат в соответствии с изобретением достигается в компьютерной системе, содержащей память со случайным доступом, центральный процессор, средство массовой памяти, средство вторичной памяти для архивирования и устройство для архивирования данных, хранимых в компьютерной системе, содержащее средство для подачи команд, хранимых в памяти со случайным доступом, в центральный процессор для обеспечения центральным процессором архивирования выбранных данных, хранимых в средстве массовой памяти, в средстве вторичной памяти для архивирования для освобождения пространства в средстве массовой памяти, средство идентификации для идентификации из базы данных, местоположений частей файла, к которым осуществлено обращение, средство архивирования для архивирования из средства массовой памяти в средстве вторичной памяти для архивирования по меньшей мере некоторых частей файла, к которым не было обращения, и средство удаления для освобождения в средстве массовой памяти пространства, занимаемого теми частями файла, к которым не было обращения, но которые были архивированы средством архивирования при сохранении в средстве массовой памяти частей файла, к которым было обращение.
Предпочтительно средство идентификации содержит средство для идентификации из базы данных частей файла, к которым осуществлялось обращение с заданной даты, и частей файла, к которым не осуществлялось обращение с заданной даты, средство архивирования содержит средство для архивирования в средстве вторичной памяти для архивирования по меньшей мере некоторых частей файла, к которым не осуществлялось обращение с заданной даты, а средство удаления содержит средство для освобождения в средстве массовой памяти пространства, занятого теми частями файла, к которым не осуществлялось обращение с заданной даты, но которые были архивированы средством архивирования при сохранении в средстве массовой памяти частей файла, к которым осуществлялось обращение с заданной даты.
Кроме того, предпочтительно, что средство архивирования и средство удаления содержат средство для архивирования и удаления тех частей файла, к которым не осуществлялось обращение с заданной даты и которые уже являются резервированными заданное количество раз, а средство удаления содержит средство для изменения таблицы распределения файлов.
При этом компьютерная система может дополнительно содержать средство для извлечения требуемых частей файла из средства вторичной памяти для архивирования в средство массовой памяти для обращения.
Способ может быть использован вместе со способом сохранения части файла вышеприведенной заявки. Вспомогательная база данных затем требуется для дополнительной записи, было ли к файлу обращение для записи, в этом случае данные могли быть модифицированы или было к файлу обращение только для считывания. Способ резервного копирования части файла вышеприведенной заявки не предусматривает освобождения дискового пространства на жестком диске, в то же время оставляя доступными те записи, к которым, вероятно, должно быть повторное обращение.
Краткое описание чертежей
Изобретение описывается ниже более подробно с помощью примера со ссылками на сопроводительные чертежи, на которых приведено следующее:
фиг. 1 - блок-схема персональной компьютерной системы с накопителем на магнитной ленте,
фиг.2 - диаграмма, иллюстрирующая обращение к файлу,
фиг.3 - блок-схема последовательности операций, иллюстрирующая обращение к файлу в соответствии с изобретением,
фиг.4 - диаграмма, аналогичная показанной на фиг.2, иллюстрирующая части файла, которые должны быть оставлены на жестком диске,
фиг.5 - блок-схема последовательности операций, иллюстрирующая процедуру резервирования в соответствии с изобретением, которая реализуется системой иерархической организации памяти.
фиг.6 - блок-схема последовательности операций, иллюстрирующая процедуру обращения для считывания файла, который частично заархивирован,
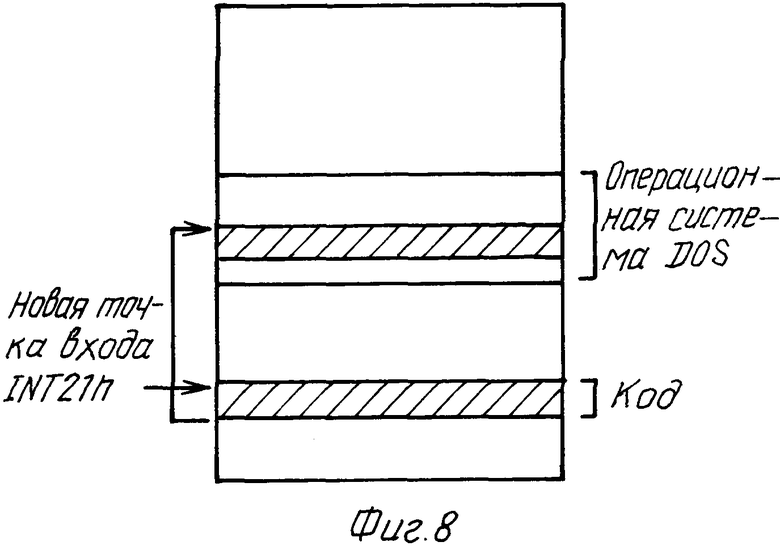
фиг. 7 - диаграмма, иллюстрирующая карту распределения памяти на уровне операционной системы обычного персонального компьютера,
фиг. 8 - диаграмма, иллюстрирующая соответствующую часть карты распределения памяти в способе по изобретению.
Подробное описание предпочтительного варианта воплощения
На фиг.1 представлен персональный компьютер (PC) 10, содержащий центральный процессор (ЦП) 12, память (RAM) 14 со случайным доступом и устройство массовой памяти в виде жесткого диска 16. Персональный компьютер снабжен также устройством 18 памяти на магнитной ленте, представляющим собой вторичную память для целей резервирования и архивирования.
В процессе функционирования память 14 со случайным доступом запоминает команды, которые подаются на центральный процессор 12 для управления его работой. Некоторые из этих команд могут быть направлены от операционной системы, а некоторые могут быть инициированы прикладными программами, выполняющимися в компьютере.
Операционные системы обычно поддерживают таблицу распределения памяти (FAT), в которой записано физическое местоположение на жестком диске каждого блока данных. К тому же операционная система записывает по отношению к каждому файлу флаг архивирования, который устанавливается (в "1"), когда файл модифицируется, и может быть очищен (установлен в "0"), когда файл резервируется. Существующие системы резервного копирования используют флаг архивирования для определения, был ли файл модифицирован и, таким образом, требуется ли его резервирование.
Может использоваться система организации иерархической памяти, которая автоматически резервирует на магнитную ленту любой файл, к которому не было обращения в течение определенного периода времени.
В предпочтительном варианте воплощения данного изобретения поддерживается вспомогательная база данных, которая указывает для каждого файла, к каким блокам данных было обращение и когда, так что система организации иерархической памяти может периодически архивировать или перемещать те блоки, к которым не было обращения. Эти блоки затем могут быть удалены и требования к объему памяти таким образом снижены.
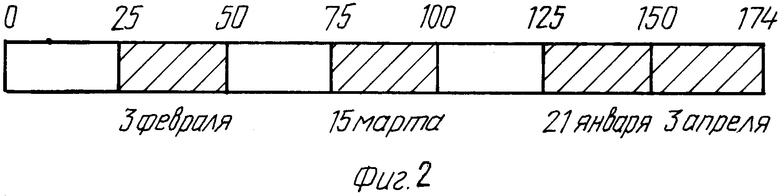
Рассмотрим файл с начальной длиной 125 байт, содержащий 5 записей длиной 25 байт каждая, от 1 января 1995 г, когда была открыта вспомогательная база данных для получения запросов на обращение к любой существующей записи в файле или добавления новой записи к файлу. Запросы в течение некоторого периода времени, например между 1 января и 10 апреля 1995 г, могут быть следующие:
21 января 1995 г добавлена новая запись, расположена со смещением 125, 25 байт длиной,
3 февраля 1995 г - обращение к старой записи (считывание), расположена со смещением 25, 25 байт длиной,
15 февраля 1995 г - обращение к старой записи (считывание), расположена со смещением 75, 25 байт длиной,
3 апреля 1995 г добавлена новая запись, расположена со смещением 150, 25 байт длиной.
Когда запрос получен, то дата, положение записи в файле и длина записи отмечаются во вспомогательной базе данных согласно табл.1 (см. в конце описания).
Конечно, должна обеспечиваться идентифицикация конкретного требуемого файла. Предполагается, что для каждого файла поддерживается отдельная вспомогательная база данных. На практике может быть предпочтительно поддерживать отдельную вспомогательную базу данных для каждого подкаталога, в этом случае файл также должен быть идентифицирован в базе данных. Это, однако, уменьшает количество вспомогательных баз данных и, таким образом, количество созданных дополнительных файлов. В принципе может быть создана единственная вспомогательная база данных для целого диска.
К некоторым областям файла, не включенным во вспомогательную базу данных, изображенную в таблице 1, не было обращения вообще. Порядковый номер дня является простым счетчиком, представляющим дни, которые прошли с произвольной начальной даты, в данном случае 1 января 1900 г. В более сложной системе могут быть включены дата и время (дата/время). Фиг.2 схематически изображает файл с затененными областями, представляющими собой данные файла, которые считываются или записываются, и не затененными областями, представляющими собой данные, к которым нет обращения.
Этапы, выполняемые при обращении, изображены на фиг.3. Этап 20 указывает, что требуется обращение. Это может быть обращение для считывания или обращение для записи. Сначала файл идентифицируется на этапе 22, а на этапе 24 идентифицируется начальное смещение и длина обращения. На этапе 26 эти данные сохраняются во вспомогательной базе данных вместе с датой, как изображено выше в таблице 1. Предпочтительно, этап 26 включает в себя операцию объединения, которая гарантирует, что вспомогательная база данных не содержит избыточной информации. Например, последовательные обращения могут дублироваться или перекрывать предыдущие обращения. Когда эти этапы завершены, то на этапе 28 осуществляется обращение к изначально требуемому файлу, после чего программа завершается на этапе 30.
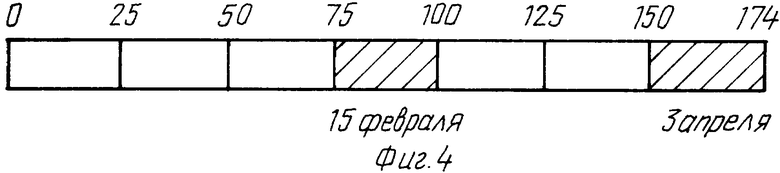
Эти этапы выполняются для каждого обращения и поэтому к 10 апреля файл имеет длину 175 байт и содержит семь записей, в то время как вспомогательная база данных выглядит так, как в таблице 1 выше. Во время периода текущего контроля (семьдесят девять дней) записи, к которым вообще не было обращения, очевидно, являются кандидатами на архивирование. Однако предположим, что решено, что все записи, к которым не было обращения в течение последних 60 дней, должны быть заархивированы. Записи сортируются, причем сначала предполагается, что весь файл должен быть перемещен во вторичную память, а затем просматривается вспомогательная база данных для всех записей с номером дня, равным 34739 или более (34739 является шестидесятым днем до 10 апреля, который имеет номер 34799). Любые записи с номером дня, удовлетворяющим этому критерию, идентифицируются, а части файла, содержащие их, помечаются соответствующим образом, указывающим, что они не являются объектом перемещения. Любые части файла, оставшиеся неотмеченными, предназначаются таким образом для перемещения.
Из четырех записей, к которым было обращение между 1 января и 10 апреля 1995 г, только последние две - 15 февраля и 3 апреля 1995 соответственно имеют номер дня, превышающий по меньшей мере 34739. Поэтому только две наиболее поздние записи должны остаться, оставляя остаток файла - части, определенные как байты от 0 до 74 и байты от 100 до 149 - для перемещения. Это схематически изображено на фиг.4, где записи, которые должны быть оставлены, изображены затененными, а записи, которые должны были перемещены, - незатемненными. Области данных файла, определенные для перемещения, далее копируются в устройство вторичной памяти с использованием обычной процедуры HSM. Детальные данные местоположения и длина каждой записи поддерживаются системой HSM для облегчения последующего поиска. К тому же вспомогательная база данных может быть отредактирована для удаления любых следов записей, имеющих номер дня, меньший чем 34739, посредством этого предотвращая беспрепятственное расширение размера вспомогательной базы данных.
Для обеспечения преимуществ от перемещения неиспользуемых записей на устройство вторичной памяти необходимо освободить пространство на диске, занятое одними и теми же записями. Эффективным образом это достигается преобразованием файла в разбросанный файл. Другими словами, записи, которые подвержены перемещению, заменяются дырками. Дисковое пространство, ранее занятое избыточными записями, таким образом восстанавливается, так как дырки не занимают дискового пространства. Предполагая, что запись с наибольшим значением смещения не заархивирована, логическая длина файла остается неизменной при этой операции, но количество байтов реальных данных уменьшается, освобождая место для новых данных файла.
Разбросанный файл может быть создан следующим образом.
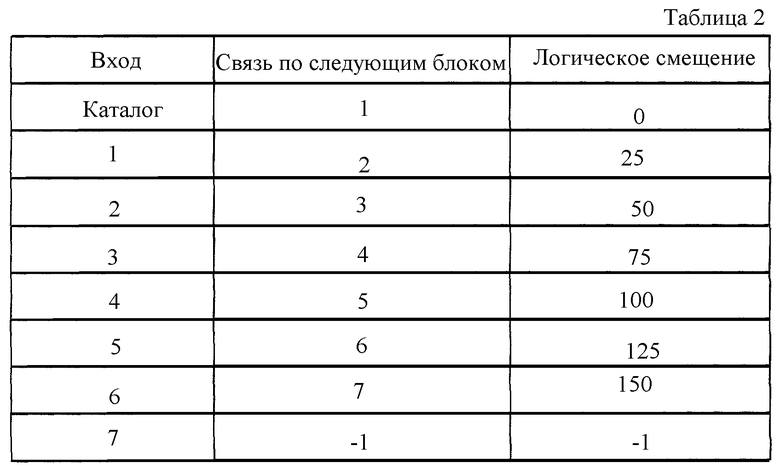
Предположим, что система имеет таблицу распределения файлов (FAT), в которой дисковое пространство последовательно распределено на блоки по 25 байтов. Поэтому требуется семь блоков для отсчета 175 байтов для файла, созданного 10 апреля 1995 г. Файл может быть распределен согласно табл.2 (см. в конце описания).
Отметим, что первая запись сохраняется в структуре каталога. Каждый блок на диске имеет запись в таблице, которая указывает блок, в котором может быть найдена следующая часть файла. Например, второй блок имеет запись, связывающую его с блоком 3, где может быть найдена часть файла со смещением 50 байт. Только седьмой блок имеет отрицательную запись (-1) для указания, что это последний блок, содержащий данные файла. В данном примере файл сохраняется удобным образом последовательно в блоках от 1 до 7, но на практике блоки с тем же успехом могут быть распределены случайным образом с промежутками между ними.
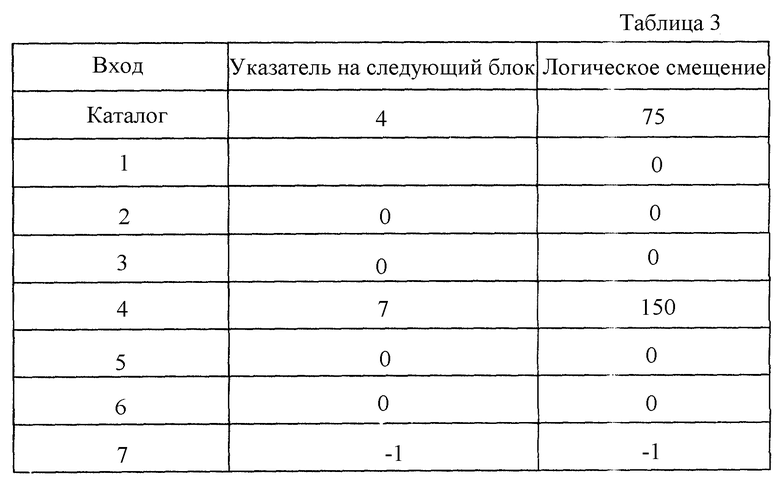
Таблица распределения должна быть откорректирована в соответствии со свободным дисковым пространством, используемым перемещенными данными, другими словами, чтобы байты с 0 до 74 и байты с 100 по 149 файла должны быть удалены. Первая область перекрывается блоками 1, 2 и 3, а вторая - блоками 5 и 6. Когда данные в этих блоках удалены, оставшиеся записи файла корректируются так, чтобы сохранялись цепочки записей. Модифицированная таблица распределения файла должна выглядеть согласно табл.3 (си. в конце описания).
Блоки 1, 2, 3, 5 и 6 каждый имеют нулевую запись (0) для указания на то, что они свободны от данных. Из модифицированной таблицы распределения файлов операционная система может легко определить, что первым распределенным блоком для файла является блок 4, который содержит данные, начинающиеся с блока с логическим смещением 75, и что следующий (и последний) блок данных файла хранится в блоке 7 и содержит данные, начинающиеся с логического смещения 150. Следует отметить, что некоторые операционные системы не сохраняют логического смещения для первого распределенного блока, который в таких системах поэтому не может быть освобожден.
Точный способ, каким осуществляется удаление, не имеет значения. Что важно, так это то, что пространство, занятое перемещенными блоками, делается доступным на жестком диске, т.е. нужно сказать, что они освобождаются для использования.
В приведенном выше примере для простоты объяснения предполагалось, что размер всех блоков и запросы на считывание/запись должны быть 25 байт, и поэтому предполагалось, что все запросы находятся точно в пределах одного блока. На практике размер распределенного блока кратен 512 байтам и положение и длина запросов на считывание/запись будут значительно меняться. Так как только целые блоки могут быть освобождены (удалены), то система должна быть организована так, чтобы только области данных, представляющие собой целое количество блоков, перемещались и удалялись. Так как большие файлы обычно занимают многие тысячи блоков, это уменьшение в действительности редко является значительным.
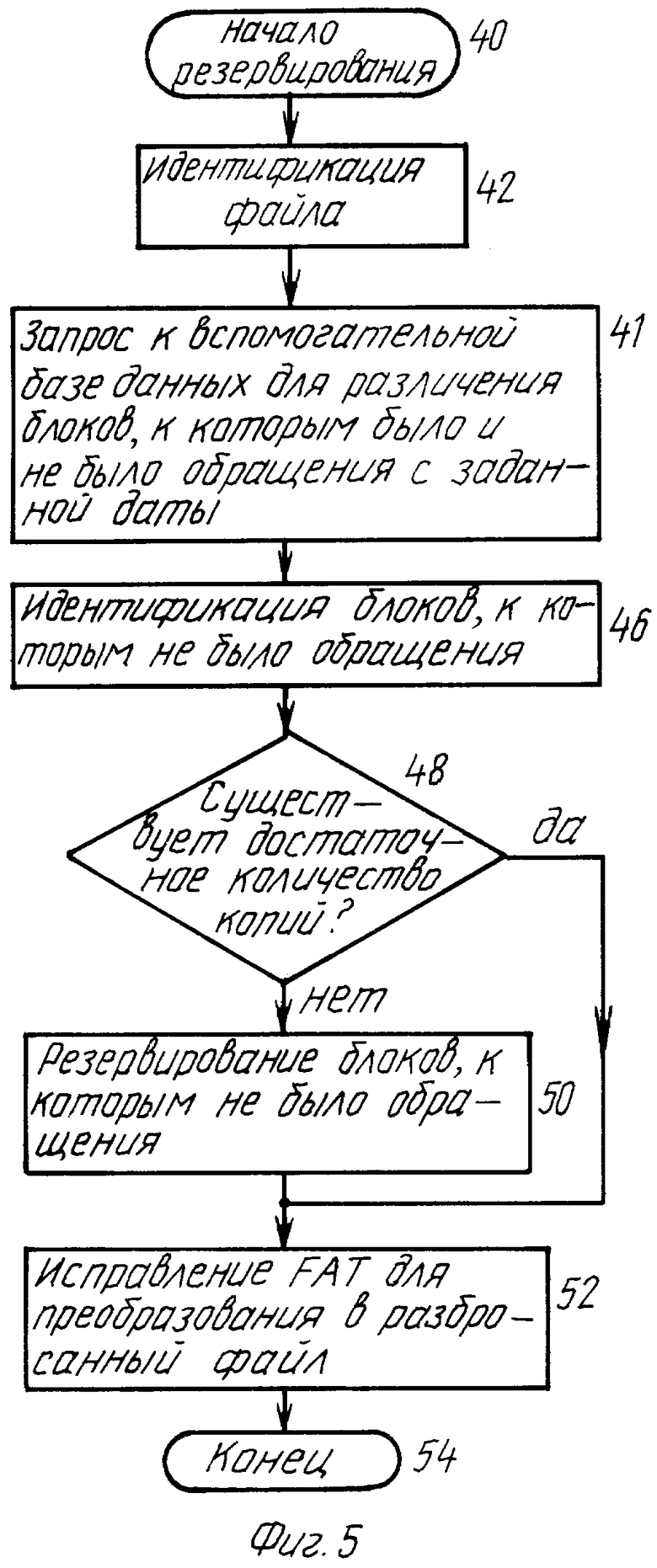
Указанные выше этапы изображены на блок-схеме на фиг.5. Этап 40 указывает начало операции резервирования. Сначала ни этапе 42 требуемый файл идентифицируется. Затем на этапе 44 вспомогательная база данных опрашивается для различения тех блоков, к которым было обращение с указанной даты, от тех, к которым обращения не было. На этапе 46 идентифицируются те блоки, к которым обращения не было с указанной даты. Теперь фактически может быть, что блоки, к которым обращения не было, уже резервированы как часть нормальной программной операции резервирования. Обычно они будут резервироваться более одного раза. Поэтому их не требуется перемещать или резервировать снова. Однако необходимо перемещать во вторичную память те блоки, для которых не существует достаточных резервных копий. Они могут быть идентифицированы посредством сопровождения тегом (признаком), независимо от того, являются ли блоки, которые должны быть перемещены, тэгированными или блоками, которые не являются несущественными, при условии, что они надлежащим образом различаются. Поэтому на этапе 48 принятия решения производится определение, существует ли достаточное количество (например, три) резервных копий. Если нет, то на этапе 50 тэгированные блоки резервируются или перемещаются. На этапе 52 пространство, занятое всеми блоками, к которым не было обращения, освобождается посредством исправления таблицы распределения файлов (FAT) для преобразования файла в разбросанный файл. Если файл уже является разбросанным, то добавляется большее количество дырок. Затем на этапе 54 программа завершается.
Последняя особенность заключается в получении последовательных запросов к файлу на считывание и определении того, направлен ли запрос на считывание перемещенных данных. Если не предусмотрена такая обработка получаемых запросов на считывание, то операционная система может возвратить пустые (неопределенные) данные или сообщить об ошибке, если была сделана попытка считать "дырку" разбросанного файла. При получении запроса на считывание перемещенных данных могут генерироваться соответствующие сигналы для автоматического обратного перемещения запрошенной информации. Если отдельные запросы на считывание малы, то время для обратного перемещения данных мало по сравнению с обратным перемещением целого файла, т.к. требуется восстановить только реально необходимые данные.
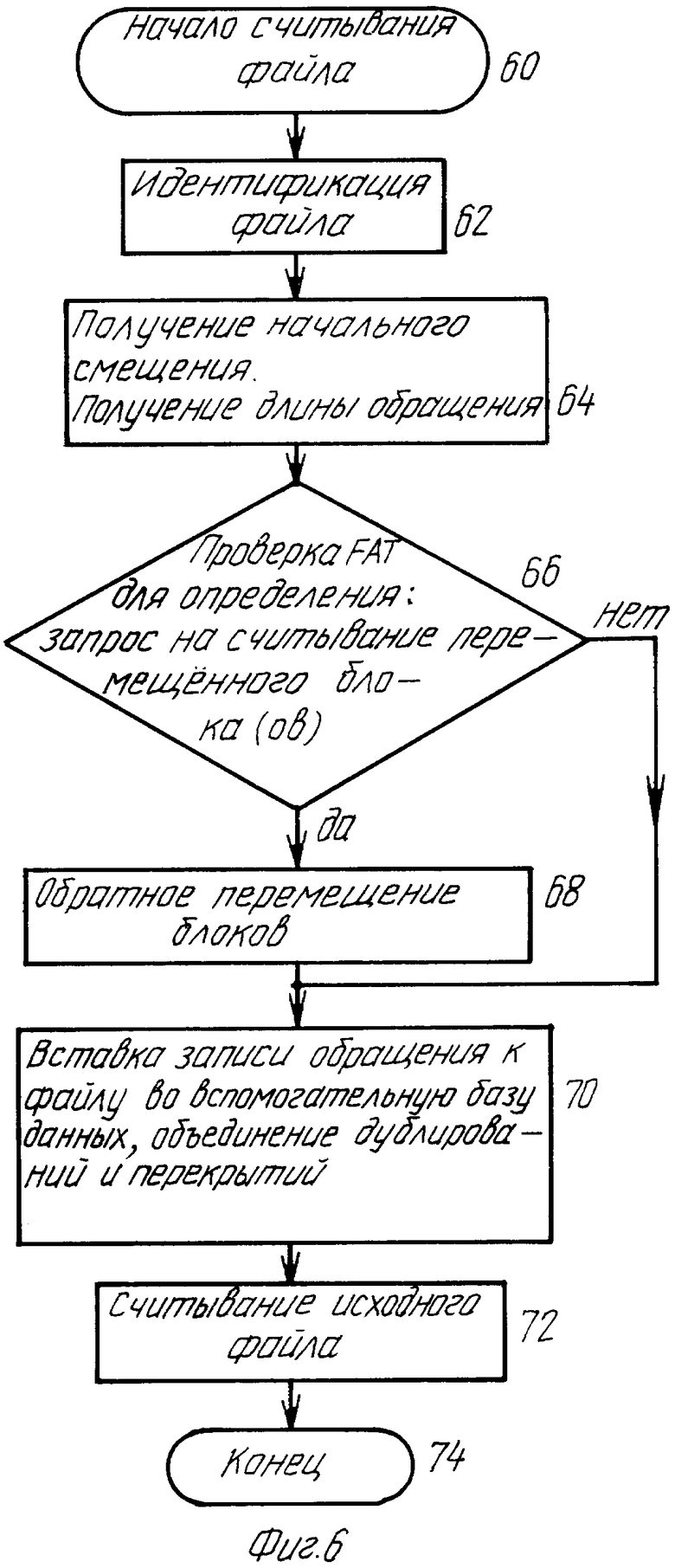
Эта операция изображена на фиг.6. Этап 60 указывает начало запроса на считывание файла. Файл идентифицируется на этапе 62 и выделяются на этапе 64 (как на фиг.3) начальное смещение и длина считывания. Далее работа продолжается на этапе 66 принятия решения, на котором проверяется таблица распределения файлов (FAT) для определения, является ли запрос на считывание запросом на считывание данных в каком-нибудь блоке или блоках, которые были перемешены с использованием программы, изображенной на фиг.5. Если ответ на этот вопрос "НЕТ", то работа продолжается в соответствии с этапами 70, 72 и 74, которые соответствуют этапам 26, 28 и 30 на фиг.3 соответственно. Однако, если ответ на этапе 66 на вопрос "ДА", то требуемые данные сначала на этапе 68 перемещаются обратно, прежде чем работа продолжится в соответствии с этапами 70, 72 и 74, как и раньше. Нет необходимости перемещать обратно целый блок, а вообще должны быть перемещены обратно только требуемая запись или записи. Они могут находиться в одном блоке или располагаться в двух или более блоках.
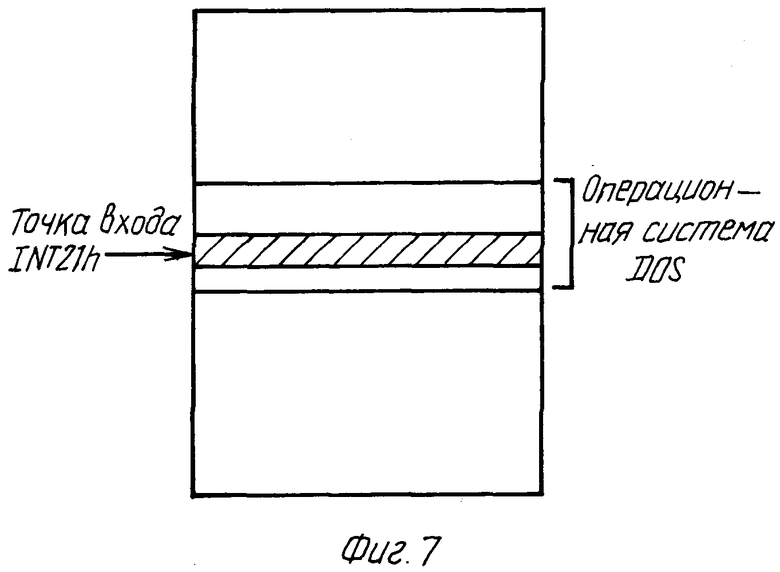
Процедуры, иллюстрируемые на фиг. 3 и 6, требуют приема обращений к диску. Каким образом это достигается, будет объяснено со ссылками на фиг.7 и 8. Когда программа желает обратиться к файлу, она вызывает стандартную программу, которая записывает данные на диск. Эта программа, которая в случае операционной системы DOS известна как программа обработки 21 прерывания (в шестнадцатеричной система счисления) (INT21h), является неотъемлемой частью операционной системы. Считывание с диска выполняется INT21h функцией 3Fh, а запись на диск выполняется INT21h функцией 40h. Действие, выполняемое программой, зависит от параметров, поступающих в программу через вход (обращение к ней). Эта программа изображена на фиг.7 как INT21h, образующая часть операционной системы в карте распределения памяти, точка входа INT21h изображена стрелкой. Для осуществления предпочтительного варианта способа согласно изобретению добавляется дополнительный программный код на уровне интерфейса операционной системы, как изображено на фиг.8. На практике в среде DOS он может быть загружен в компьютер как драйвер устройства с использованием файла CONFIG.SYS.
Добавленное программное обеспечение влияет на команды для записи данных посредством замены или подстановки альтернативного набора команд.
С другими операционными системами также необходимо прервать функцию записи файла аналогичным образом. Опытные программисты могут подготовить требуемые программы, следующие вышеуказанному описанию, касающемуся операционной системы DOS.
В более общем случае изобретение может быть реализовано многими модифицированными способами и иллюстрируются другие способы и системы, отличные от описанных.
В частности, способ и система могут быть объединены с системой резервирования части файла согласно вышеуказанной заявке 08/165 382 заявителя. Если это так, то может быть использована та же самая вспомогательная база данных для отметки модификаций данных, которая используется в соответствии с настоящим изобретением для отметки обращения к данным. Единственное различие заключается в том, что становится необходимым записывать во вспомогательную базу данных, было ли обращение по считыванию или обращение по записи. Система резервирования части файла согласно более ранней заявке заявителя затем реагирует на вводы данных, касающиеся обращений по записи к вспомогательной базе данных, в то время как система HSM резервирования части файла согласно настоящей заявке принимает во внимание обращения и по записи, и по считыванию.
В другой модификации система расширяется, в сущности, с помощью увеличения порога пассивности для срока службы вспомогательной базы данных. То есть на фиг.5 этап 44 модифицируется так, чтобы вместо различения блоков, к которым было или не было обращения с определенной даты, она различала блоки, к которым вообще не было обращения, т.е. с тех пор, когда вспомогательная база данных была изначально создана или заполнена. В этом случае вспомогательная база данных более не требует записывать дату или дату/время каждого обращения.
Могут иметься обстоятельства, при которых нежелательно перемещать некоторые части файла даже несмотря на то, что к ним не было обращения. Это может быть применимо, например, к первому и, возможно, к последнему блоку каждого файла.
Наконец, если изобретение должно быть воплощено в полностью новой операционной системе, то вспомогательная база данных может, в принципе, быть объединена с таблицей распределения файлов (FAT). Однако обычно предпочтительно сохранять их по отдельности.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОМПЬЮТЕРНАЯ ДУБЛИРУЮЩАЯ СИСТЕМА, ДЕЙСТВУЮЩАЯ С ОТКРЫТЫМИ ФАЙЛАМИ | 1996 |
|
RU2155373C2 |
| СПОСОБ РАБОТЫ КОМПЬЮТЕРНОЙ СИСТЕМЫ | 1995 |
|
RU2163726C2 |
| СПОСОБ ОБРАЩЕНИЯ К ДАННЫМ, ХРАНИМЫМ В ПАРАЛЛЕЛЬНОЙ ФАЙЛОВОЙ СИСТЕМЕ, С ИЕРАРХИЧЕСКОЙ ОРГАНИЗАЦИЕЙ ПАМЯТИ | 2011 |
|
RU2469388C1 |
| СИСТЕМА ПЕРЕМЕЩЕНИЯ ДАННЫХ В РЕАЛЬНОМ ВРЕМЕНИ И СПОСОБ ПРИМЕНЕНИЯ РАЗРЕЖЕННЫХ ФАЙЛОВ | 1996 |
|
RU2190248C2 |
| СПОСОБ ЗАЩИТЫ ДОСТУПНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ХРАНИМЫХ ДАННЫХ И СИСТЕМА НАСТРАИВАЕМОЙ ЗАЩИТЫ ХРАНИМЫХ ДАННЫХ | 2014 |
|
RU2584755C2 |
| ЭФФЕКТИВНОЕ ХРАНЕНИЕ ДАННЫХ РЕГИСТРАЦИИ С ПОДДЕРЖКОЙ ЗАПРОСА, СПОСОБСТВУЮЩЕЕ БЕЗОПАСНОСТИ КОМПЬЮТЕРНЫХ СЕТЕЙ | 2007 |
|
RU2424568C2 |
| СПОСОБ, СИСТЕМА И УСТРОЙСТВО ДЛЯ ОБМЕНА ДАННЫМИ МЕЖДУ УСТРОЙСТВАМИ-КЛИЕНТАМИ | 2013 |
|
RU2604423C2 |
| СВОБОДНАЯ ОТ БЛОКИРОВАНИЯ ПОТОКОВАЯ ПЕРЕДАЧА ДАННЫХ ИСПОЛНЯЕМОГО КОДА | 2013 |
|
RU2639235C2 |
| ИСПОЛНИТЕЛЬНАЯ ПРОГРАММА РЕГЕНЕРАЦИИ ДЛЯ ВСПОМОГАТЕЛЬНОЙ ПРОГРАММЫ РЕЗЕРВНОГО КОПИРОВАНИЯ | 1997 |
|
RU2192039C2 |
| РЕКОМЕНДАТЕЛЬНАЯ СИСТЕМА ДЛЯ ПОПОЛНЕНИЯ ДАННЫХ | 2012 |
|
RU2611966C2 |

Изобретение относится к организации иерархической памяти компьютерных файлов данных. Техническим результатом является автоматическое архивирование блоков данных, если к ним не было обращения в течение заданного промежутка времени. Система содержит память со случайным доступом, центральный процессор, средство массовой памяти, средство вторичной памяти, устройство для архивирования данных, средство для подачи команд, средство для идентификации частей файла в файле, средство для обращения к частям файла, средство для построения базы данных. Способы описывают функционирование указанной системы. 4 с. и 15 з.п. ф-лы, 8 ил., 3 табл.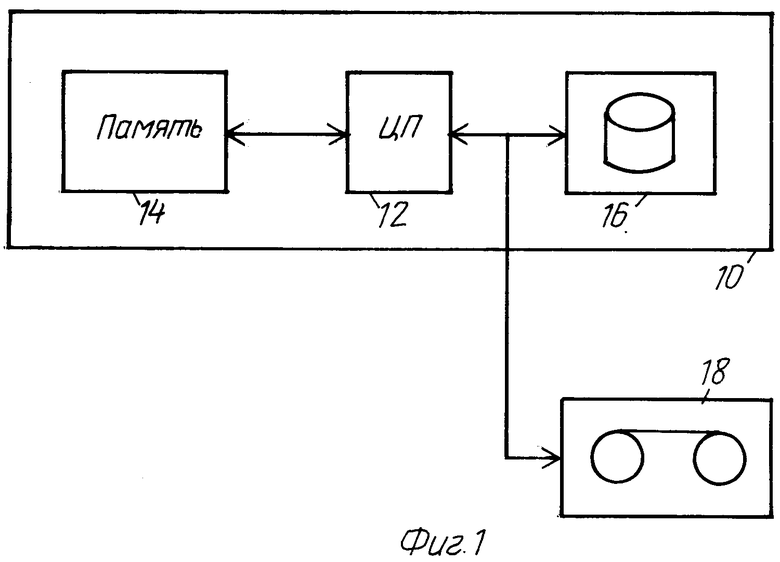
| СПОСОБ ОЦЕНКИ КАЧЕСТВА СУШЕНЫХ ДРОЖЖЕЙ-- В ПРОЦЕССЕ ИХ ПРОИЗВОДСТВА | 1972 |
|
SU426189A1 |
| Устройство для управления формированием массивов данных учета населения | 1989 |
|
SU1730642A1 |
| ЭЛЕКТРИЧЕСКАЯ МАШИНА | 2013 |
|
RU2624632C2 |
| DE 3736455 А1, 05.05.1988 | |||
| УСТРОЙСТВО ДЛЯ СЖИГАНИЯ ТОПЛИВА в ПУЛЬСИРУЮЩЕМ ПОТОКЕ | 0 |
|
SU237324A1 |
| Система сбора и обработки информации | 1987 |
|
SU1424024A1 |

