Область техники, к которой относится изобретение
Настоящее изобретение относится, в целом, к области сжатия данных и, в частности, к системе, серверу, способу и машиночитаемому носителю для сжатия данных.
Предшествующий уровень техники
Пользователи имеют доступ к постоянно возрастающим объемам данных все более разнообразными способами. Например, пользователь может осуществлять доступ к Web-сайту и принимать вещание концерта, т.е. пользоваться услугами Web-вещания. Кроме того, пользователь может осуществлять доступ к играм и другим приложениям по беспроводной сети с использованием беспроводного телефона. В порядке предоставления этих данных пользователю данные могут передаваться от сервера к клиенту в потоковом режиме с целью представления на клиенте. Далее, пользователь может взаимодействовать с представляемыми данными, например, смотря кино, слушая песню и т.д.
Потоковая передача данных обеспечивает пользователю повышенные функциональные возможности, так что пользователь может быстро принимать данные. Если бы не было потоковой передачи данных, то нужно было бы принять от сервера полный объем данных прежде, чем клиент их выведет, вследствие чего пользователь мог бы ощущать задержку представления данных на клиенте. Благодаря потоковой передаче данных, задержка, ощущаемая пользователем, может быть уменьшена. Потоковую передачу данных можно использовать для обеспечения представления данных в режиме реального времени.
При потоковой передаче данных данные передаются от сервера в потоковом или непрерывном режиме, обычно в виде пакетов, для представления на клиенте по мере поступления данных, в отличие от данных, которые невозможно представлять, пока на клиенте не будет всего файла, содержащего данные. Потоковый режим передачи можно использовать для различных типов данных, например, видеоданных, аудиоданных, мультимедийных данных и т.д. Поток видеоданных обеспечивает последовательность «движущихся изображений», которые передаются и визуализуются по мере поступления изображений. Аналогично, поток аудиоданных обеспечивает звуковые данные, которые воспроизводятся по мере поступления аудиоданных. Поток мультимедийных данных содержит аудио- и видеоданные.
Поток данных можно сжимать для эффективной передачи потока данных от сервера на клиент по сети для повышения полезности потоковых данных. Например, сеть, служащая средством связи между сервером и клиентом, может иметь ограниченную пропускную способность. Ограниченная пропускная способность может ограничивать объем данных, которые можно единомоментно передавать от сервера на клиент, и, следовательно, функциональные возможности, предоставляемые клиенту при потоковой передаче данных по сети. Например, видеоданные, передаваемые в потоковом режиме, могут быть ограничены более низким разрешением вследствие ограниченной пропускной способности по сравнению с разрешением, которое могло бы иметь место в случае использования сети с более высокой пропускной способностью. Поэтому пользователь, желающий получать потоковые видеоданные с более высоким разрешением, может быть вынужден тратиться на соединение с более высокой пропускной способностью. Благодаря сжатию потоковых данных, по сетям с низкой пропускной способностью можно единомоментно переносить больше данных и, таким образом, повышать полезность потоковых данных.
Однако при сжатии потоковых данных можно столкнуться с дополнительными сложностями в отличие от сжатия полного набора данных, например блочного сжатия. Например, чтобы сразу сжать целый фильм, процедура сжатия может проверить весь объем данных, который образует фильм, чтобы сжать данные. Процедура сжатия может обеспечить представления общих последовательностей, которые включены в данные, образующие фильм. Однако потоковая передача данных может обеспечиваться для представления данных в режиме реального времени. Поэтому клиент может располагать ограниченным временем для анализа потоковых данных при обеспечении представления данных в режиме реального времени. Кроме того, может иметься ограниченный объем данных, доступных для сравнения в любой отдельно взятый момент времени, для обеспечения представлений общих последовательностей.
Соответственно, имеется постоянная потребность в сжатии данных.
Сущность изобретения
Описано сжатие данных. В иллюстративной реализации модуль сжатия выполняется сервером для сжатия данных с целью потоковой передачи на клиент, например, данных, отправляемых в ответ на запрос удаленного доступа от клиента, данных в среде терминальных служб и т.д. Модуль сжатия использует буфер истории, который содержит данные, ранее переданные на клиент в потоковом режиме. При выполнении, модуль сжатия сравнивает последовательность данных, подлежащих потоковой передаче, с одной или несколькими последовательностями в буфере истории для нахождения совпадающей последовательности. Для отыскания последовательности в буфере истории используется поисковая таблица, имеющая совокупность ячеек, каждая из которых доступна по одному из совокупности индексов. Каждая из ячеек указывает, имеется ли соответствующий индекс в буфере истории, и, если да, дополнительно указывает одно или несколько положений соответствующего индекса в буфере истории. Поэтому модуль сжатия может использовать первоначальную последовательность в данных, подлежащих потоковой передаче, в качестве индекса в поисковой таблице для отыскания совпадающего индекса в буфере истории. Затем совпадающую последовательность в данных можно заменить представлением, которое описывает положение и длину совпадающей последовательности в буфере истории, чтобы сформировать сжатые данные для потоковой передачи на клиент.
В другой реализации, способ включает в себя прием обратной связи, которая указывает наличие ресурсов для передачи данных по сети от терминальной службы, предоставляемой сервером, на клиент, и настройку одного или нескольких параметров процедуры сжатия, используемой для сжатия данных в соответствии с обратной связью.
В еще одной реализации, способ включает в себя прием запроса на сервере от клиента для удаленного доступа к приложению или файлу, доступному через сервер. Определяют наличие ресурсов для передачи данных в ответ на запрос по сети. На основании определенного таким образом наличия настраивают один или несколько параметров процедуры сжатия, используемой для сжатия данных.
Перечень чертежей
Фиг.1 - схема иллюстративной реализации, где показана среда, в которой осуществляется потоковая передача данных от сервера на клиент по сети.
Фиг.2 - схема иллюстративной реализации, где более подробно показаны сервер и клиент, изображенные на фиг.1.
Фиг.3 - логическая блок-схема иллюстративной процедуры, в которой данные, подлежащие потоковой передаче, конфигурируются для сжатия.
Фиг.4 - логическая блок-схема иллюстративной процедуры, в которой поисковая таблица, показанная на фиг.3, сконфигурированная для включения в себя ссылок на пакет, подлежащий потоковой передаче, используется для сжатия пакета.
Фиг.5 - логическая блок-схема процедуры в иллюстративной реализации, в которой сжатый пакет, показанный на фиг.4, восстанавливается после сжатия на клиенте посредством выполнения модуля восстановления после сжатия.
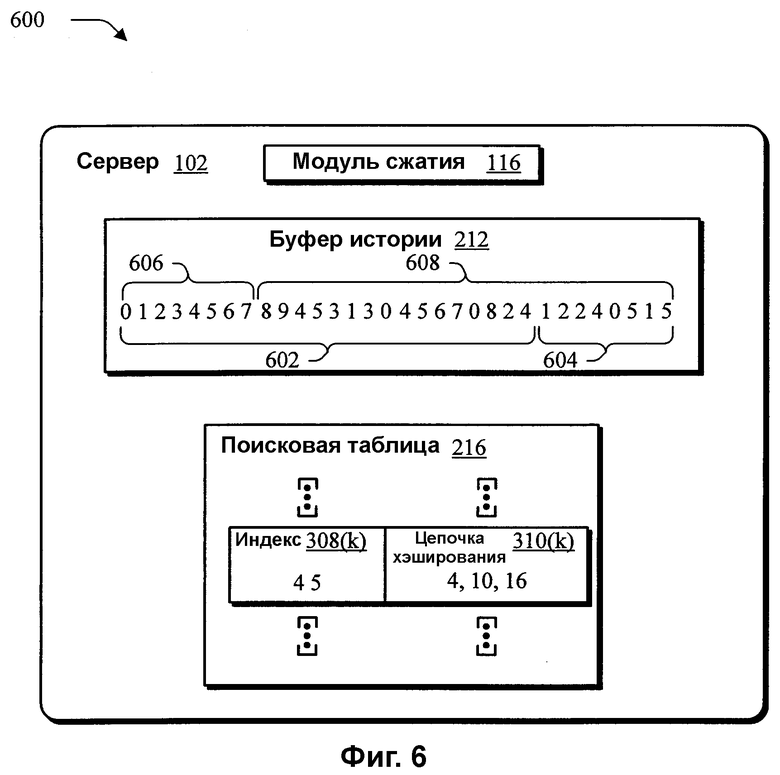
Фиг.6 - схема иллюстративной реализации, в которой скользящее окно используется в буфере истории для включения данных, подлежащих потоковой передаче.
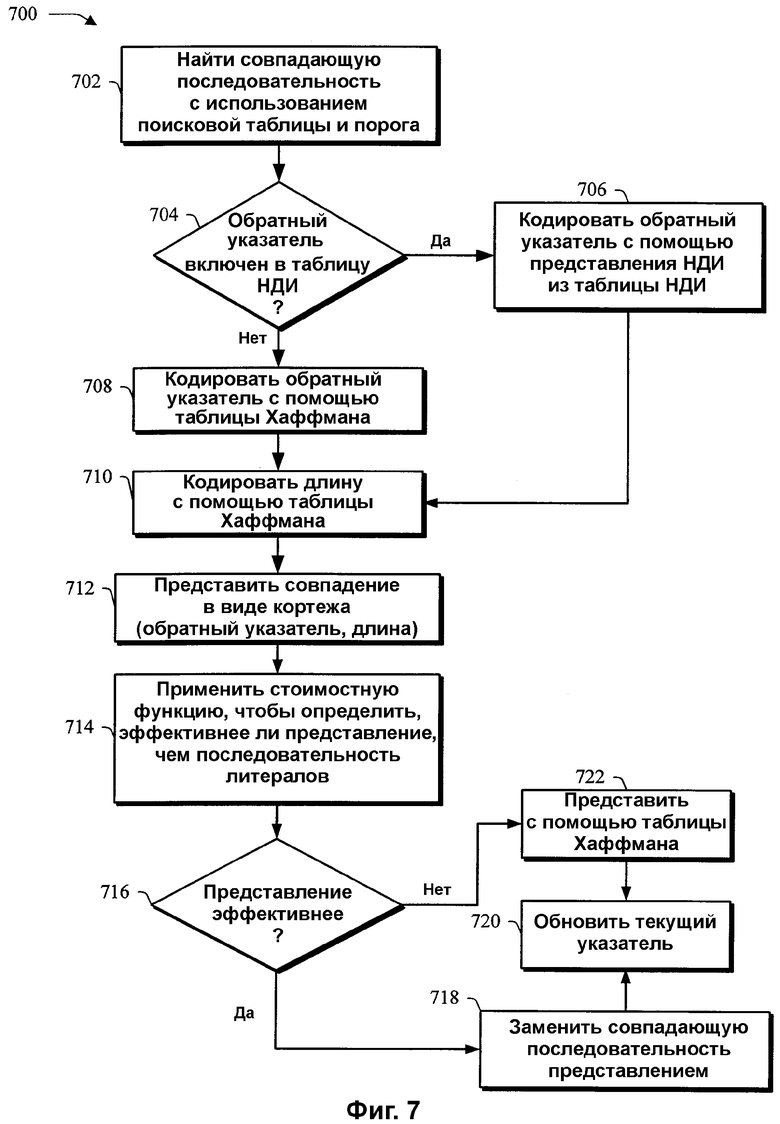
Фиг.7 - логическая блок-схема процедуры в иллюстративной реализации, в которой сжатие потоковых данных дополнительно оптимизируется.
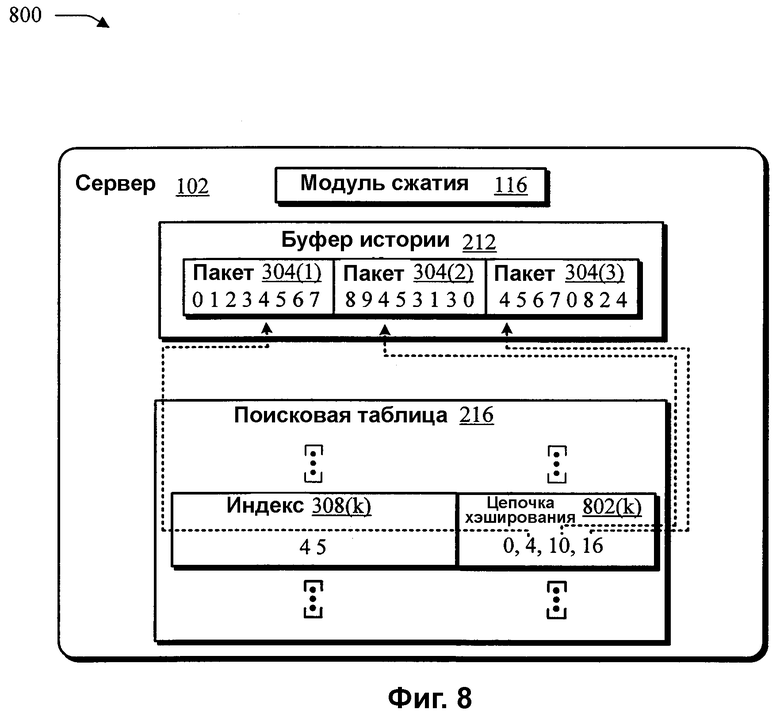
Фиг.8 - логическая блок-схема процедуры в иллюстративной реализации, в которой сравнение последовательностей оптимизируется для дополнительной оптимизации сжатия данных.
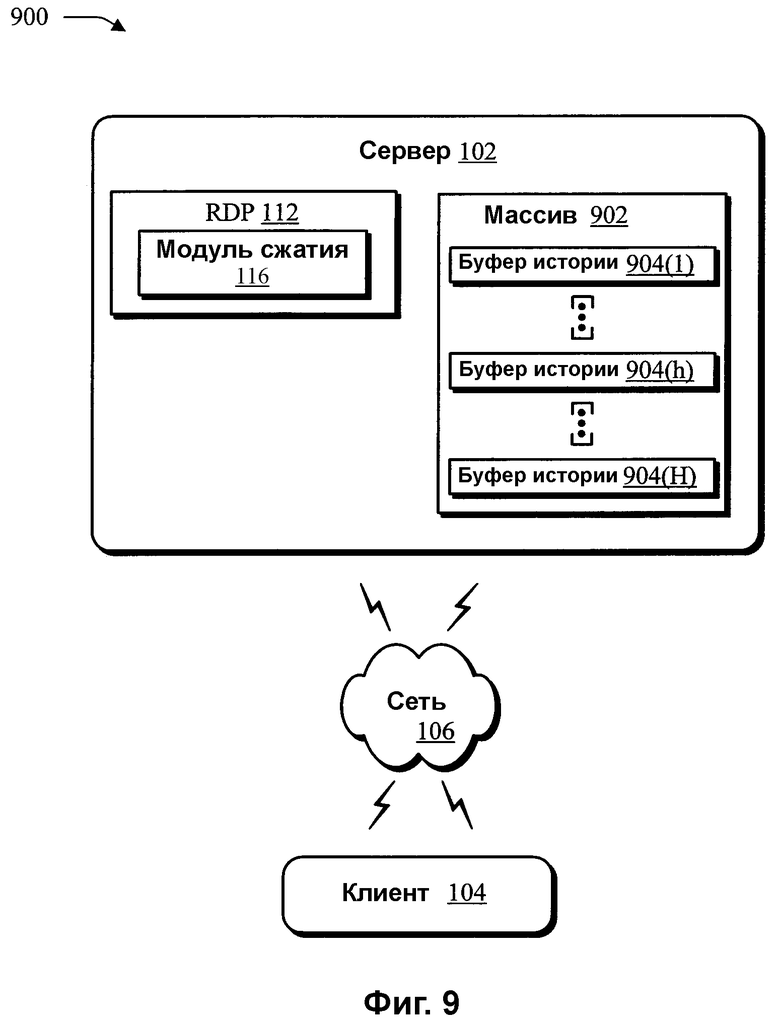
Фиг.9 - схема системы в иллюстративной реализации, в которой сжатие динамически настраивается в соответствии с обратной связью, полученной от системы.
Для обозначения сходных структур и компонентов в рассматриваемых примерах используются одни и те же ссылочные позиции.
Подробное описание изобретения
Обзор
Описано сжатие данных. В иллюстративной реализации модуль сжатия выполняется сервером для сжатия данных с целью потоковой передачи с сервера на клиент. Модуль сжатия использует буфер истории, который содержит данные, ранее переданные на клиент в потоковом режиме. При выполнении модуль сжатия сравнивает последовательность данных, подлежащих потоковой передаче, с одной или несколькими последовательностями в буфере истории для нахождения совпадающей последовательности. Для отыскания последовательности в буфере истории, используется поисковая таблица, имеющая совокупность ячеек. Каждая из ячеек доступна по одному из совокупности индексов. Каждая из ячеек указывает, имеется ли соответствующий индекс в буфере истории, и, если да, дополнительно указывает одно или несколько мест размещения соответствующего индекса в буфере истории. Поэтому модуль сжатия может использовать первоначальную последовательность в данных, подлежащих потоковой передаче, в качестве индекса в поисковой таблице для отыскания ячейки. Таким образом, модуль сжатия может быстро отыскивать каждое положение в буфере истории, имеющем первоначальную последовательность, без необходимости сравнивать каждую последовательность в буфере истории с каждой последовательностью в данных, подлежащих потоковой передаче.
Если соответствующая ячейка с совпадающим индексом указывает совокупность положений, то модуль сравнения может вывести совпадающую последовательность, сравнивая последовательность в каждом положении, имеющем совпадающий индекс, с последовательностью в данных, которые включают в себя первоначальную последовательность. Затем совпадающую последовательность в данных можно представить посредством представления, которое описывает положение и длину совпадающей последовательности буфера истории. Затем сжатые данные можно передавать на клиент в потоковом режиме. Клиент восстанавливает данные после сжатия с использованием буфера истории, который также содержит данные, которые были ранее переданы в потоковом режиме с сервера на клиент. Клиент, выполняя модуль восстановления после сжатия, находит совпадающую последовательность в буфере истории клиента, используя длину и положение, указанные в представлении, для восстановления данных. Таким образом, обеспечивается методика сжатия данных без потерь, которая позволяет сжимать данные и восстанавливать их после сжатия без потерь данных. Например, используя эту методику сжатия данных, можно сжимать и восстанавливать после сжатия видеоданные, не теряя фрагменты данных, и, таким образом, сохранять разрешение видеоданных.
Иллюстративная среда
На фиг.1 изображена схема иллюстративной реализации, где показана среда 100, в которой осуществляется потоковая передача данных от сервера 102 на клиент 104 по сети 106. Клиент 104 может иметь разнообразные конфигурации. Например, клиент 104 может иметь конфигурацию устройства, которое выполнено с возможностью осуществления связи по сети 106, например, настольного компьютера, который показан, мобильной станции, бытового прибора для развлечений, телевизионной приставки, беспроводного телефона и т.д. Под клиентом 104 также можно понимать лицо и/или сущность, которое/ая оперирует клиентом 104. Иными словами, клиент 104 может описывать логический клиент, который включает в себя пользователя и/или машину. Хотя проиллюстрирован один клиент 104, к сети 106 могут быть подключены с возможностью связи несколько клиентов. Сеть 106 проиллюстрирована как Интернет и может также включать в себя различные другие сети, например, интрасеть, проводную или беспроводную телефонную сеть и т.п.
Сервер 102 выполнен с возможностью передачи данных в потоковом режиме по сети 106 на клиент 104. Сервер 102 может обеспечивать разнообразные потоковые данные для представления на клиенте 104. В одной реализации, сервер 102 может обеспечивать Web-вещание концерта, который передается в потоковом режиме на клиент 104. При представлении на клиенте 104, пользователь может смотреть и слушать Web-вещание. В другой реализации, клиент 104 может принимать данные, включающие в себя песню, передаваемую в потоковом режиме с сервера 102 для вывода на клиенте 104.
В еще одной реализации, сервер 102 может также обеспечивать терминальные службы для удаленного выполнения приложения. Например, сервер 102 может включать в себя совокупность приложений 108(1),..., 108(n),..., 108(N), где «n» может быть любым приложением от 2 до «N». Каждое из приложений 108(1)-108(N) выполняется на сервере 102. Сервер 102 передает в потоковом режиме на клиент 104 по сети 106 экранную информацию, которая обеспечивается выполнением приложений 108(1)-108(N). Например, экранная информация может включать в себя изображение на дисплее настольного компьютера, обеспечиваемое операционной системой, и окно, отображающее информацию, относящуюся к выполнению текстового редактора, а также аудиоинформацию, обеспечиваемую операционной системой и/или текстовым редактором.
Экранная информация, передаваемая в потоковом режиме от сервера 102, представляется на клиенте 104 для наблюдения пользователю. Пользователь может взаимодействовать с клиентом 104 для обеспечения вводов с использованием устройств ввода клиента 104, например, мыши 108 и/или клавиатуры 110. Вводы могут соответствовать представляемой экранной информации, как, например, текстовый ввод для текстового редактора, который обеспечивается с использованием клавиатуры 110. Вводы передаются с клиента 104 на сервер 102 по сети 106. Вводы, принимаемые на сервере 102, могут использоваться при выполнении совокупности приложений 108(1)-108(N). Например, текстовый редактор может принимать текстовые вводы для включения в документ и передавать в потоковом режиме экранную информацию на клиент 104, чтобы иллюстрировать документ, в который включен упомянутый текст. Благодаря выполнению приложений 108(1)-108(N) на сервере 102 и передаче в потоковом режиме экранной информации на клиент 104, клиенту 104 могут быть доступны функции, которые, в противном случае, могли бы не присутствовать на самом клиенте 104.
Например, клиент 104 может иметь конфигурацию «тонкого» клиента, который располагает ограниченными ресурсами обработки данных и/или памяти. С другой стороны, сервер 102 может обладать большими возможностями, например, иметь более значительные ресурсы обработки данных и/или памяти, чем клиент 104. Поэтому сервер 102 может выполнять приложения, которые могут не выполняться на клиенте 104 и/или медленнее выполняться на клиенте 104. Сервер 102 выдает результаты выполнения одного или нескольких приложений 108(1)-108(N) на клиент 104, передавая экранную информацию на клиент 104, и принимает вводы от клиента 104 по сети 106. Таким образом, функциональные возможности, обеспечиваемые сервером 102, например, ресурсы обработки данных, ресурсы памяти и совокупность приложений 108(1)-108(N) могут быть предоставлены клиенту 104, который, в противном случае, не имел бы доступа к этим функциональным возможностям.
Для обеспечения связи между сервером 102 и клиентом 104 по сети, сервер 102 и клиент 104 могут реализовывать соответственно протокол удаленного рабочего стола (RDP) 112, 114. RDP 112, 114 предназначены для обеспечения возможностей удаленного отображения и ввода посредством сетевых соединений для приложений 108(1)-108(N) согласно описанному выше. Например, RDP можно использовать, чтобы разрешать отдельные виртуальные каналы, которые переносят информацию устройства и данные представления от сервера 102 на клиент 104, а также зашифрованные вводы, которые передаются от клиента 104 на сервер 102.
Протоколы RDP 112, 114 могут также обеспечивать снижение пропускной способности за счет включения модулей 116, 118 сжатия и восстановления после сжатия на сервере 102 и клиенте 104 соответственно. Модуль 116 сжатия может выполняться на сервере 102 посредством реализации RDP 112 для сжатия данных до их потоковой передачи по сети 106. Аналогично, модуль 118 восстановления после сжатия может выполняться на клиенте 104 посредством реализации RDP 114 для восстановления после сжатия данных, которые были переданы в потоковом режиме по сети 106 с сервера 102.
Модули 116 и 118 сжатия и восстановления после сжатия при выполнении соответственно сжимают и восстанавливают после сжатия данные, передаваемые в потоковом режиме по сети 106. Согласно вышесказанному, сжатие и восстановление после сжатия потоковых данных может приводить к особым трудностям, в отличие от сжатия и восстановления после сжатия сразу всего набора данных, т.е. блочного сжатия. Например, данные могут передаваться в потоковом режиме «в реальном времени», так что задержки, происходящие при потоковой передаче данных, могут уменьшать полезность данных. Модули 116, 118 сжатия и восстановления после сжатия позволяют устранять особые трудности потоковой передачи данных и, таким образом, обеспечивают потоковую передачу сжатых данных по сети 106, что более подробно описано со ссылкой на фиг.3-5.
Благодаря использованию терминальных служб (ТС, TS), клиент 104 может осуществлять доступ к одному или нескольким приложениям 108(1)-108(N), установленным на сервере 102, выполнять приложение на сервере 102 и отображать пользовательский интерфейс (ПИ, UI) приложения на клиенте 104. Поскольку приложения 108(1)-108(N) выполняются на сервере 102, ТС позволяют клиенту 104 пользоваться ресурсами корпоративной инфраструктуры независимо от того, имеет ли клиент 104 соответствующее аппаратное и программное обеспечение для локального выполнения ресурсов на самом клиенте 104.
Хотя клиент 104 описан в среде терминальных служб, в которой совокупность приложений 108(1)-108(N) выполняется на сервере 102, клиент 104 может также выполнять одно или несколько из совокупности приложений 120(1),..., 120(m),..., 120(M). Например, одно из приложений 120(1)-120(M) может обеспечивать интерфейс, используемый в сочетании с RDP 114 для представления данных для просмотра пользователем и для приема вводов от пользователя, например, с помощью мыши 108 и/или клавиатуры 110. Кроме того, хотя модули 116, 118 сжатия и восстановления после сжатия проиллюстрированы как часть соответствующих протоколов RDP 112, 114, модули 116, 118 сжатия и восстановления после сжатия могут действовать как автономные программные компоненты, которые выполняются для сжатия и восстановления после сжатия потоковых данных соответственно.
Кроме того, хотя части нижеследующего рассмотрения описывают использование сжатия в среде терминальных служб, описанные здесь методики сжатия и восстановления после сжатия также можно использовать в различных других средах. Например, методики сжатия можно использовать для сжатия данных, используемых в среде удаленного доступа. Удаленный доступ описывает возможность доступа к компьютеру или сети из удаленного места. Например, удаленному офису корпорации может понадобиться доступ к сети корпорации и использование доступа к содержащимся там файлам и приложениям, например, через телефонную сеть, Интернет и т.п. Сервер 102 может иметь конфигурацию сервера удаленного доступа, имеющего соответствующее программное обеспечение, предназначенное для обслуживания клиентов, запрашивающих удаленный доступ. В одной реализации, сервер удаленного доступа включает в себя сервер брандмауэра (межсетевого средства защиты) для безопасности и маршрутизатор для пересылки запросов удаленного доступа в другие части сети. Сервер удаленного доступа также можно использовать как часть виртуальной частной сети (ВЧС, VPN).
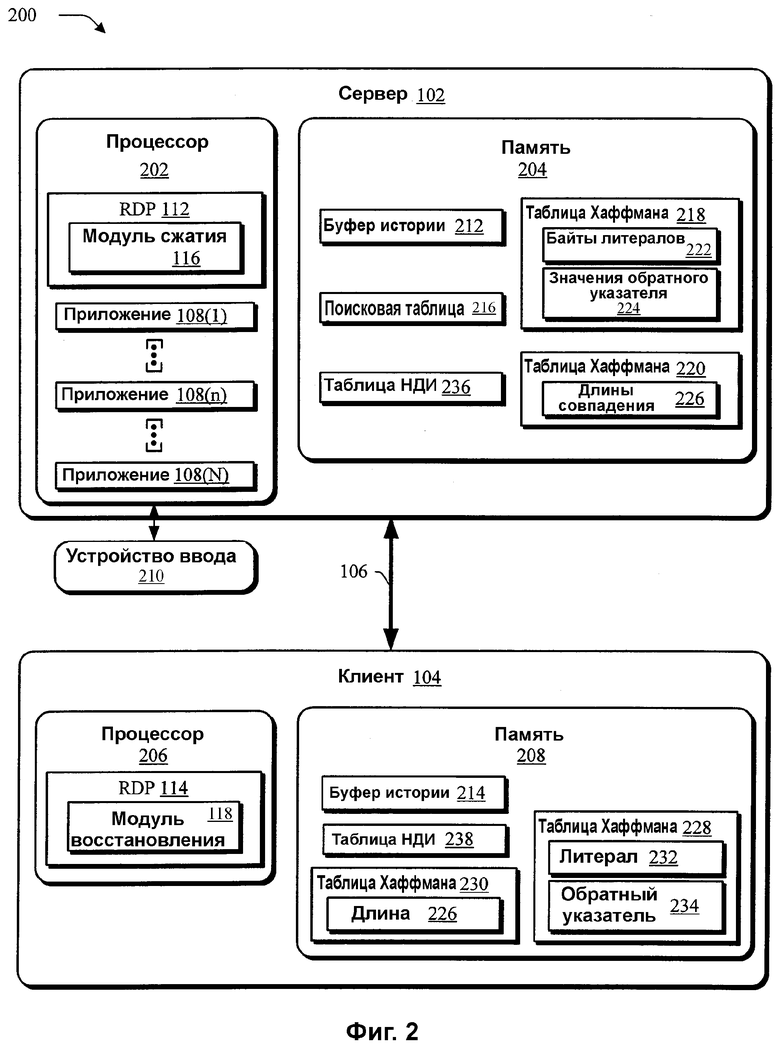
На фиг.2 изображена схема иллюстративной реализации 200, где более подробно показаны сервер 102 и клиент 104, изображенные на фиг.1. Сервер 102 содержит процессор 202 и память 204. Показано, что RDP 112 и его соответствующий модуль 116 сжатия выполняются на процессоре 202 и хранятся в памяти 204. Аналогично, клиент 104 содержит процессор 206 и память 208. Показано, что RDP 114 и его соответствующий модуль 118 сжатия выполняются на процессоре 206 и хранятся в памяти 208.
Данные, подлежащие потоковой передаче с сервера 102 на клиент 104, могут обеспечиваться из различных источников, например, путем выполнения одного или нескольких из приложений 108(1)-108(N), полученных от устройства 210 ввода, например, видеокамеры, микрофона и пр. Модуль 116 сжатия выполняется на процессоре 202 сервера 102 для сжатия данных с целью потоковой передачи на клиент 104. Данные могут передаваться в потоковом режиме с сервера 102 на клиент 104 в виде пакетов.
Например, модуль 116 сжатия может принимать данные, имеющие несжатую последовательность заданной длины, и пытаться сжать эту последовательность до меньшей (сжатой) длины, например, имеющей меньше байтов, битов и т.д. Модуль 116 сжатия может сжимать данные попакетно, заменяя последовательность представлением, для хранения которого используется меньше ресурсов памяти, например, меньше байтов, чем для заменяемой последовательности.
Если модуль 116 сжатия способен сжать последовательность, то сжатые данные передаются на концевую точку соединения RDP, т.е. RDP 114 клиента 104. Модуль 118 восстановления после сжатия выполняется на клиенте 104 для восстановления после сжатия сжатых данных, чтобы восстановить данные. В случае когда модуль 116 сжатия не способен сжать данные, данные могут передаваться на клиент 104 в потоковом режиме в несжатом виде, т.е. в виде последовательности литералов. Затем модуль 116 сжатия может выполняться на сервере 102 в попытке сжать следующую последовательность.
Основная операция, используемая для сжатия данных, предусматривает согласование по шаблону последовательностей в данных, подлежащих сжатию, с последовательностями, которые были переданы в потоковом режиме раньше. Для этого модуль 116 сжатия поддерживает буфер 212 истории, содержащий данные, которые ранее были переданы в потоковом режиме на клиент 104. Модуль 116 сжатия, при выполнении, согласует последовательность в данных, подлежащих потоковой передаче, с одной или несколькими последовательностями, которые входят в состав данных, которые уже переданы в потоковом режиме на клиент 104. Последовательности в данных, подлежащих потоковой передаче, которые совпадают с последовательностями в буфере истории, можно затем представить с использованием одного или нескольких представлений, которые указывают совпадающую последовательность в буфере 212 истории. Представления могут быть меньше, т.е. использовать меньше ресурсов памяти, чем используется для хранения фактической последовательности, подлежащей сжатию, т.е. совпадающей последовательности. Это эффективно уменьшает объем данных, включенных в потоковые данные.
Чтобы проиллюстрировать основной пример согласования по шаблону с использованием буфера 212 истории, предположим, что буфер 212 истории содержит следующую последовательность:
12745639451491
Модуль 116 сжатия выполняется на процессоре 202 сервера 102 и принимает следующую последовательность:
45974563945146
При выполнении, модуль 116 сжатия находит самую длинную последовательность в буфере истории, которая совпадает с последовательностью в данных, подлежащих сжатию, т.е. совпадающую последовательность. В этом случае совпадающая последовательность, которая появляется в буфере истории, показана ниже жирным шрифтом. Совпадающая последовательность имеет длину десять байтов и начинается с трех байтов от начала буфера 212 истории (начиная слева и продолжая с нуля).
45974563945146
Таким образом, модуль 116 сжатия, при выполнении, может формировать сжатые данные, представляя данные, подлежащие потоковой передаче, следующим образом:
4 5 9 (совпадение длины 10 байтов начиная с 3 байтов от начала буфера) 6.
Благодаря указанию совпадающей последовательности в буфере истории, серверу 102 не нужно повторно передавать последовательности, которые были переданы в потоковом режиме на клиент 104. Таким образом, модуль 116 сжатия сжимает данные, подлежащие потоковой передаче, отыскивая повторяющиеся шаблоны в данных, которые подлежат потоковой передаче, и заменяя повторяющиеся шаблоны, т.е. совпадающие последовательности, представлением, которое использует меньшие ресурсы памяти и полосу пропускания при передаче по сети 106.
Чтобы восстановить после сжатия сжатые данные, клиент 104 включает в себя модуль 118 восстановления после сжатия и буфер 214 истории. В буфере 214 истории клиента 104, как и в буфере 212 истории сервера 102, хранятся данные, переданные ранее в потоковом режиме. Поэтому модуль 118 восстановления после сжатия, при выполнении на клиенте 104, может восстанавливать после сжатия данные, которые были переданы в потоковом режиме на клиент 104, с использованием буфера 214 истории. Продолжая предыдущий пример, предположим, что клиент 104 принимает сжатые данные, которые показаны следующим образом:
4 5 9 (совпадение длины 10 байтов начиная с 3 байтов от начала буфера) 6.
На основании представления, включенного в сжатые данные, модуль 118 восстановления после сжатия, при выполнении, может извлекать сжатую последовательность из буфера 214 истории, которая показана жирным шрифтом следующим образом:
45974563945146
Таким образом, модуль 118 восстановления после сжатия может восстанавливать после сжатия сжатую строку с использованием буфера 214 истории.
Сервер 102 может также содержать поисковую таблицу 216 для отыскания совпадающих последовательностей в буфере 212 истории. Например, поисковая таблица 216 может содержать совокупность ячеек, доступных по одному из совокупности индексов. Каждая ячейка описывает каждое положение в буфере 212 истории, имеющее соответствующий индекс. Таким образом, модуль 116 сжатия, при выполнении на сервере 102, может использовать поисковую таблицу 216 для быстрого определения положения конкретной последовательности в буфере 212 истории. Дальнейшее рассмотрение поисковой таблицы 216 и буфера 212 истории приведено со ссылкой на фиг.3-4.
Сервер 102 может также использовать методы кодирования для дальнейшего сжатия данных для потоковой передачи, например, кодирование по Хаффману, арифметическое кодирование, префиксное кодирование и кодирование по Маркову. Например, данные, подлежащие потоковой передаче, могут включать в себя последовательности, которые не совпадают с последовательностями в буфере истории. Эти последовательности будем называть последовательностями «литералов». С использованием кодирования по Хаффману, некоторые или все последовательности литералов в данных можно сжимать для дополнительного сжатия данных. Например, кодирование по Хаффману может начинаться с таблицы частотности появлений, которая относится к частотности каждой последовательности литералов, которая должна быть дополнительно сжата. Таблицу частотности можно генерировать из самих данных и/или представительных (репрезентативных) данных. Например, частотность последовательности литералов можно получить путем обработки пакетов, ранее переданных в потоковом режиме, и затем использовать для обработки каждого последующего пакета.
Например, каждой последовательности литералов можно присвоить строку переменной длины, которая уникально представляет конкретную последовательность литералов, например, в качестве уникального префикса. Затем строки переменной длины организуются в дерево для кодирования и декодирования каждой(го) последовательности литералов и представления соответственно. Чтобы закодировать последовательность литералов, последовательность литералов, подлежащую кодированию, помещают в дерево. Ветви дерева, которые используются для определения положения листа (концевого узла), который содержит последовательность литералов, используются для кодирования последовательности литералов, т.е. обеспечивают представление последовательности литералов. Например, каждую ветвь дерева, используемого для кодирования по Хаффману, можно пометить символом выходного алфавита, например, битами 0 и 1, так что кодирование представляет собой перечисление меток ветвей на пути от корня дерева к кодируемой последовательности литералов. Декодирование каждого представления осуществляется обходом дерева от его корня вниз по ветвям до листа дерева на основании каждого последующего значения в строке переменной длины, пока не будет достигнут лист дерева, который содержит последовательность литералов.
Хотя было описано кодирование по Хаффману последовательностей литералов, кодирование по Хаффману можно использовать для дополнительного сжатия различных данных. Например, с помощью таблицы 218 Хаффмана можно кодировать как последовательности литералов 222, так и обратные указатели 224. Вышеописанные последовательности литералов включают в себя последовательности, не найденные в буфере 212 истории. Поэтому последовательности литералов 222 можно сжимать с использованием таблицы 218 Хаффмана. Обратный указатель 224 описывает положение конкретной последовательности в буфере 212 истории. Например, согласно описанному выше последовательность в данных, которая совпадает с последовательностью в буфере 212 истории, т.е. совпадающую последовательность, можно описывать как «совпадение длины Х байтов начиная с Y битов от начала буфера». Обратный указатель 224 описывает положение совпадающей последовательности в буфере 212 истории, т.е. 7 байтов. Таблицу 220 Хаффмана можно использовать для сжатия длины 226, т.е. Х байтов, совпадающей последовательности.
Чтобы восстановить после сжатия сжатые данные, передаваемые в потоковом режиме от сервера 102 на клиент 104, модуль 116 восстановления после сжатия выполняется на клиенте 104 с использованием таблиц 228, 230 Хаффмана, которые соответствуют соответственно таблицам 218, 220 Хаффмана сервера 102. Например, таблицу 228 Хаффмана можно использовать для восстановления после сжатия последовательностей литералов 232 и обратного указателя 234, а таблицу 230 Хаффмана можно использовать для восстановления после сжатия длины 226 совпадающей последовательности. Дальнейшее рассмотрение таблиц Хаффмана приведено со ссылкой на фиг.7.
Сервер 102 и клиент 107 могут также включать в себя соответствующие таблицы 236, 238 наиболее давнего использования (НДИ, LRU). Каждую из таблиц 236, 238 НДИ можно использовать для дальнейшего кодирования обратных указателей в зависимости от того, является ли обратный указатель одним из «наиболее давно используемых» обратных указателей. Например, таблицу 236 НДИ можно использовать для обеспечения представления НДИ соответственно для каждого из последних четырех обратных указателей. Представление НДИ используется в качестве индекса для определения положения в таблице 236 НДИ. Таким образом, можно дополнительно сжимать повторяющиеся обратные указатели. Дополнительное рассмотрение таблиц НДИ приведено ниже со ссылкой на фиг.7.
Хотя описано сжатие данных, передаваемых в потоковом режиме от сервера 102 на клиент 104, клиент 104 также может сжимать данные и передавать их в потоковом режиме обратно на сервер 102. Кроме того, хотя в нижеследующем рассмотрении описано сжатие данных в отношении пакетов, передаваемых в потоковом режиме с сервера 102 на клиент 104, для сжатия данных можно использовать разнообразные совокупности данных, например, последовательности байтов подпакета, множественные пакеты и т.д. Кроме того, хотя в нижеследующем рассмотрении описаны последовательности байтов, можно также рассматривать другие последовательности данных, например, битов.
Иллюстративные процедуры
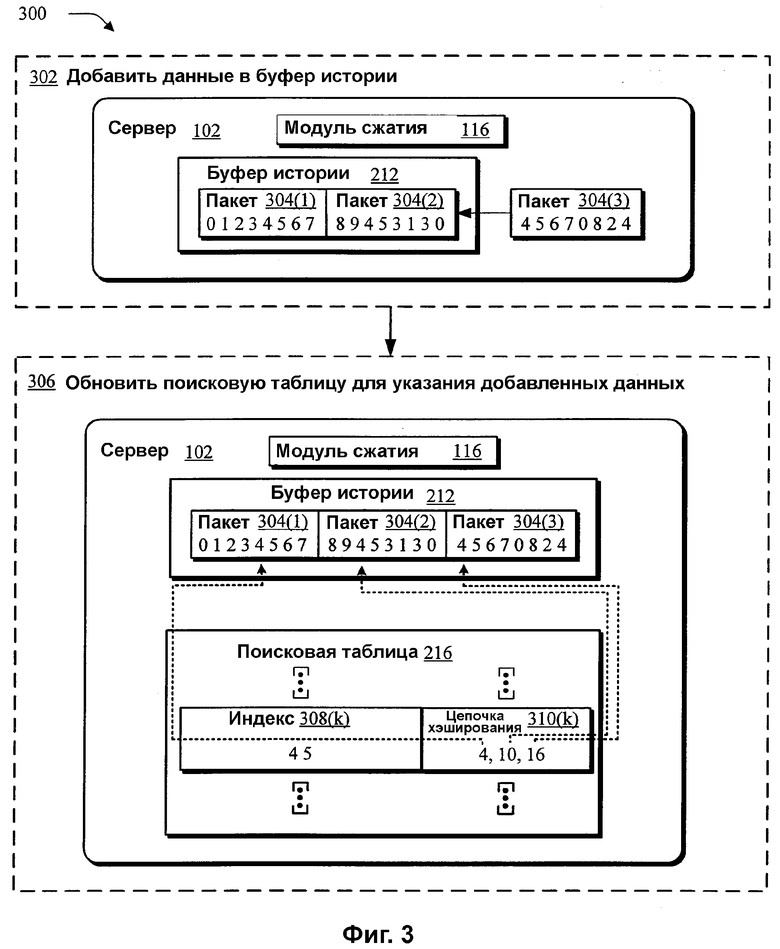
На фиг.3 изображена логическая блок-схема иллюстративной процедуры 300, в которой данные, подлежащие потоковой передаче, конфигурируют для сжатия. На этапе 302, данные добавляют в буфер 212 истории. Например, буфер 212 истории может содержать совокупность пакетов 304(1), 304(2), переданных в потоковом режиме, и/или готовых к потоковой передаче с сервера 102 на клиент 104, как показано на фиг.2, по сети 106. В одном варианте осуществления, пакеты 304(1), 304(2) могут соответствовать данным, которые раньше были обработаны посредством модуля 116 сжатия.
Сервер 102 принимает пакет 304(3), подлежащий потоковой передаче. Модуль 116 сжатия, при выполнении на сервере 102, добавляет пакет 304(3) в буфер 212 истории, так что буфер истории включают в себя пакеты 304(1), 304(2), которые были переданы в потоковом режиме, и пакет 304(3), подлежащий передаче.
На этапе 306 модуль 116 сжатия, при выполнении на сервере 102, обновляет поисковую таблицу 216 ссылкой на добавленные данные, т.е. пакет 304(3). Поисковая таблица 216 может включать в себя совокупность индексов 308(k), где «k» может быть любым индексом от «1» до «K». Каждый из индексов 308(k) используется для нахождения соответствующей одной из совокупности ячеек поисковой таблицы 216. Каждая ячейка указывает, находится ли соответствующий из совокупности индексов 308(k) в буфере 212 истории, и, если да, одно или несколько положений соответствующего индекса 308(k) в буфере 212 истории. Например, одна из совокупности ячеек может указывать совокупность положений в буфере 212 истории, которые имеют соответствующие индексы 308(k). Каждое из совокупности положений показано как описываемое с использованием соответствующей одной из совокупности цепочек 310(k) хэширования.
Например, показано, что индекс 308(k) имеет последовательность «4 5». Соответствующая ячейка для индекса 308(k), т.е. цепочка 310(k) хэширования в поисковой таблице 216, описывает каждое положение индекса 308(k) «4 5» в буфере 212 истории. Например, на фиг.3 показано, что пакет 304(1) имеет следующую последовательность:
01234567
На фиг.3 показано, что пакет 304(2) имеет следующую последовательность:
89453130
На фиг.3 показано, что пакет 304(3), подлежащий потоковой передаче на клиент 104, имеет следующую последовательность:
45670824
Пакеты 304(1)-304(3) можно последовательно организовать в буфере истории так, чтобы наблюдалась следующая последовательность:
012345678945313045670824
Цепочка 310(k) хэширования описывает каждое положение индекса 308(k) «4 5» в буфере 212 истории. Каждое положение можно описывать различными способами. Например, положения можно описывать как положение первого байта последовательности при отсчете от начала буфера 212 истории, начиная с номера нуль. Цепочка 310(k) хэширования описывает первое положение индекса 308(k) «4 5» в 16 байтах от начала последовательности в буфере 212 истории, что показано на фиг.3 пунктирной линией, идущей от «16» в цепочке 310(k) хэширования к началу пакета 304(3). Аналогично, цепочка 310(k) хэширования описывает второе положение индекса 308(k) «4 5» в десяти байтах от начала последовательности в буфере 212 истории, что показано на фиг.3 пунктирной линией, идущей от «10» в цепочке 310(k) хэширования к третьему байту пакета 304(3). Далее, цепочка 310(k) хэширования содержит третье и последнее положение индекса 308(k) «4 5» в 4 байтах в буфере 212 истории. Таким образом, поисковая таблица 216 содержит индекс 308(k), например, «4 5», имеющий соответствующую ячейку, которая указывает цепочку 310(k) хэширования, которая описывает каждое положение, например, 4, 10, 16 индекса 308(k) в буфере 212 истории. Обновляя поисковую таблицу 216, модуль 116 сжатия может, при выполнении, сжимать данные, подлежащие потоковой передаче, более эффективным образом, что будет более подробно описано со ссылкой на фиг.4.
Хотя на фиг.3 показано, что каждый индекс 308(k) имеет соответствующую одну из совокупности цепочек 310(k) хэширования, могут быть случаи, когда индекс 308(k) не имеет соответствующей цепочки хэширования. Например, в некоторых случаях буфер 212 истории может не содержать индекс. Поэтому ячейка поисковой таблицы 216, которая соответствует этому индексу, может не содержать цепочку хэширования. Иными словами, цепочка хэширования для этого индекса имеет значение нуль, т.е. в буфере 212 истории нет места, где располагается соответствующий индекс. Кроме того, хотя показано, что каждая из совокупности цепочек 310(k) хэширования включена в поисковую таблицу 216, одну или несколько цепочек 310(k) хэширования можно обеспечивать разными способами. Например, каждая ячейка поисковой таблицы 216 может содержать указатель на соответствующую цепочку хэширования, которая имеет конфигурацию массива, отдельного от поисковой таблицы 216.
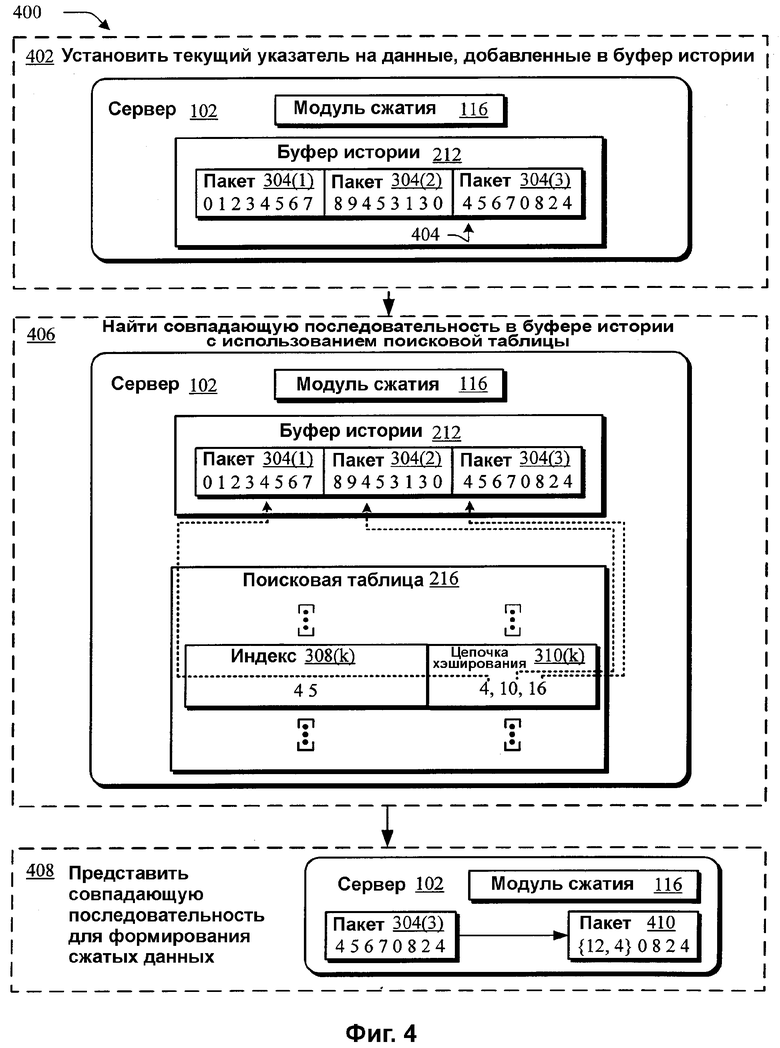
На фиг.4 показана логическая блок-схема иллюстративной процедуры 400, в которой показанная на фиг.3 поисковая таблица 216, сконфигурированная для включения ссылок на пакет 304(3), подлежащий потоковой передаче, используется для сжатия пакета 304(3). На этапе 402 модуль 116 сжатия, при выполнении, устанавливает текущий указатель 404 на данные, которые были добавлены, т.е. пакет 304(3), в буфер 212 истории на этапе 302 по фиг.3.
На этапе 406 модуль 116 сжатия выполняется на сервере 102 для отыскания индекса в поисковой таблице 216, который совпадает с первоначальной последовательностью по текущему указателю 404. Например, модуль 116 может использовать первоначальную последовательность, которая состоит из двух байтов, например, «4 5», по текущему указателю 404, чтобы найти один из совокупности индексов 308(k), которые совпадают с первоначальной последовательностью. В этом примере, индекс 308(k) «4 5» поисковой таблицы 216 совпадает с первоначальной последовательностью «4 5» по текущему указателю 404 в буфере 212 истории. Индекс 308(k) имеет соответствующую ячейку в поисковой таблице 216, которая указывает на цепочку 310(k) хэширования, которая описывает каждое положение индекса index «4 5» 308(k) в буфере 212 истории. Поэтому соответствующая ячейка описывает каждое положение первоначальной последовательности в буфере 212 истории.
Если соответствующая ячейка совпадающего индекса 308(k) указывает совокупность положений, последовательность в каждом положении в буфере 212 истории, имеющую совпадающий индекс 308(k) «4 5», сравнивают с последовательностью в данных, имеющих первоначальную последовательность по текущему указателю 404. Например, первоначальная последовательность «4 5» по текущему указателю 404, т.е. положение «16» в буфере 212 истории, и последовательность в положении «10» в буфере 212 истории имеет длину «2», т.е. только первые два байта в последовательности байтов в каждом положении совпадают друг с другом. Согласно вышесказанному, положения в цепочке 310(k) хэширования в этом примере описываются отсчетом от начала буфера 212 истории, начиная с номера нуль. Первоначальная последовательность по текущему указателю 404 и последовательность в положении «4» в буфере 212 истории имеют длину «4». Иными словами, четыре байта в последовательности байтов в положении «4» совпадают с четырьмя байтами в последовательности в положении «4». Таким образом, из вычисленной длины выводится совпадающая последовательность «4 5 6 7». Чтобы найти оптимальную совпадающую последовательность, каждое положение в цепочке 310(k) хэширования можно сравнивать с последовательностью данных, подлежащей сжатию, т.е. пакетом 304(3), пока не будет вычислена максимальная длина и/или не будет достигнут порог, что описано более подробно ниже со ссылкой на фиг.7. Чтобы оптимизировать сравнение, следующий байт в последовательности, например, байт, который следует за первоначальной последовательностью или индексом в буфере 212 истории, можно сравнивать первым, поскольку из совпадения известно, что первые два байта совпадают. Дополнительное рассмотрение сравнения на основании «следующего» байта в последовательности приведено со ссылкой на фиг.8.
На этапе 408 совпадающую последовательность представляют с помощью представления, которое используется для формирования сжатых данных. Например, совпадающую последовательность «4 5 6 7» в пакете 304(3) можно представить с помощью представления, которое описывает длину совпадающей последовательности и положение совпадающей последовательности в буфере 212 истории. Представление может иметь формат кортежа, т.е. упорядоченного набора, в виде {обратный указатель, длина}. Обратный указатель может описывать относительное положение совпадающей последовательности как смещение в буфере 212 истории. Например, обратный указатель может описывать относительное положение как смещение между абсолютным положением совпадающей последовательности и абсолютным положением текущего указателя 404 в буфере 212 истории. В этом примере, абсолютным положением совпадающей последовательности является позиция 4 в буфере 212 истории, а абсолютным положением текущего указателя 404 является «16». Поэтому относительное положение совпадающей последовательности составляет 12 байтов от текущего указателя 404. Длина описывает длину совпадающей последовательности, например, «4». Таким образом, пакет 304(3) можно сжать, представляя совпадающую последовательность «4 5 6 7» с помощью представления «{12, 4}» для формирования сжатых данных, например, пакета 410. В другой реализации, положение совпадающей последовательности можно обеспечивать из абсолютного положения совпадающей последовательности в буфере истории, например, положения 4.
Таким образом, поисковая таблица 216 обеспечивает каждое положение каждого индекса 308(k) в буфере 212 истории. Поэтому, когда выполняется модуль 116 сжатия, каждое положение первоначальной последовательности можно найти в буфере 212 истории, не «просматривая» каждый отдельный бит или байт в буфере 212 истории для нахождения совпадающей последовательности. Таким образом, модуль 116 сжатия может эффективно сжимать данные, подлежащие потоковой передаче.
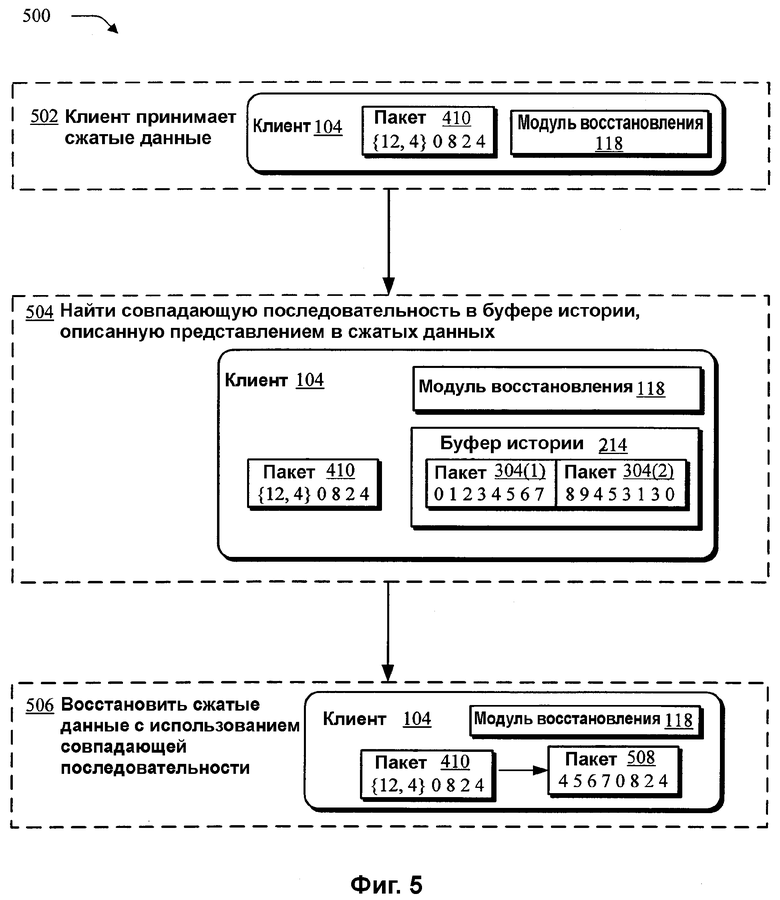
На фиг.5 изображена логическая блок-схема процедуры 500 в иллюстративной реализации, в которой сжатые данные, показанные на фиг.4, восстанавливаются после сжатия на клиенте 104 посредством выполнения модуля 128 восстановления после сжатия. На этапе 502 клиент 104 принимает сжатые данные, например, пакет 410, который был передан в потоковом режиме на клиент 104 с сервера 102, как показано на фиг.4.
На этапе 504 модуль 128 восстановления после сжатия, при выполнении, находит совпадающую последовательность в буфере 214 истории клиента 104. Буфер 214 истории клиента 104, как и буфер 212 истории сервера 102, может содержать данные, которые были переданы в потоковом режиме с сервера 102 на клиент 104. Таким образом, буфер 214 истории клиента 104 совпадает с буфером 212 истории сервера 102 до формирования сжатых данных, например, пакета 410. Поэтому модуль 118 восстановления после сжатия, при выполнении, может находить совпадающую последовательность в буфере 214 истории клиента 104 из представления, которое описывает длину и положение совпадающей последовательности в буфере 212 истории сервера. Продолжая вышеприведенный пример, совпадающую последовательность «4 5 6 7» находят в положении «12», которое является относительным положением, как описано выше.
На этапе 506 модуль 118 восстановления после сжатия, при выполнении, заменяет представление совпадающей последовательностью для восстановления данных. Например, представление «{12, 4}» заменяют совпадающей последовательностью байтов «4 5 6 7» для формирования пакета 508, который содержит последовательность «45670824», совпадающую с последовательностью пакета 304(3), который был сжат на этапе 408 по фиг.4. Например, сжатые данные могут быть сформированы из данных, подлежащих потоковой передаче, путем формирования нового набора данных, который включает в себя представление вместо совпадающей последовательности. Таким образом, как показано в этом примере, клиент 104 может восстанавливать после сжатия данные, не используя поисковую таблицу 216. Поэтому сжатые данные, передаваемые в потоковом режиме, можно восстанавливать после сжатия на клиенте 104, даже если клиент 104 имеет ограниченные аппаратные и/или программные ресурсы по сравнению с сервером 102.
В описанных иллюстративных процедурах 300, 400 соответственно со ссылкой на фиг.3, 4, поисковая таблица 216 имела такую конфигурацию, что каждый из совокупности индексов 308(k) содержит два байта. Поэтому поисковая таблица 216 может быть обеспечена 65536 соответствующими ячейками, которые описывают каждую двухбайтовую последовательность в буфере 212 истории. Это позволяет использовать первоначальную последовательность непосредственно в поисковой таблице 216. Иными словами, первоначальная последовательность не преобразуется для использования с поисковой таблицей 216 для нахождения соответствующей ячейки. Хотя были описаны индексы 308(k), имеющие два байта, можно использовать различные другие длины индекса, например, трехбайтовые последовательности, четырехбайтовые последовательности и т.д.
На фиг.6 показана схема иллюстративной реализации 600, в которой скользящее окно используется в буфере 212 истории для включения данных, подлежащих потоковой передаче. В реализации, описанной со ссылкой на фиг.3, пакет 304(3) был добавлен в буфер 212 истории. Затем поисковую таблицу 216 обновили указанием на пакет 304(3). Однако буфер 212 истории может иметь ограниченную емкость памяти. Поэтому для включения вновь добавленных данных в буфер 212 истории используется скользящее окно.
Например, буфер 212 истории может содержать последовательность 602 как результат добавления пакета 304(3) на этапе 302 по фиг.3. Буфер 212 истории в этом примере может хранить максимум 24 байта. Поэтому для добавления последовательности 604, имеющей восемь байтов, выполняется модуль 116 сжатия для удаления последовательности 606, имеющей восемь байтов, из начала буфера 212 истории и перемещения оставшейся последовательности в начало буфера 212 истории. Затем новая последовательность 604 добавляется в конец буфера 212 истории. За счет перемещения и добавления последовательностей, буфер 212 истории имеет последовательность 608, имеющую 24 байта, которая содержит вновь добавленную последовательность 604.
Чтобы обновить поисковую таблицу 216 для отражения последовательности 608, каждое положение в цепочках 310(k) хэширования в поисковой таблице 216 может иметь вычитаемое число, которое соответствует числу байтов, на которое каждый из байтов был сдвинут в буфере 212 истории. Например, в этом примере, каждый из байтов был сдвинут на восемь байтов для высвобождения места для новой последовательности 604. Поэтому каждое положение, описываемое совокупностью цепочек 310(1)-310(K) хэширования, имеет «8», вычитаемое из положения, для отражения нового положения соответствующего индекса 308(k) в буфере 212 истории. Для удаления положения из каждой из цепочек 310(k) хэширования, которые больше не включены в буфер 212 истории, любое положение, имеющее значение, меньшее нуля, удаляется из цепочек 310(k) хэширования.
На фиг.7 изображена логическая блок-схема процедуры 700 в иллюстративной реализации, в которой сжатие потоковых данных дополнительно оптимизируется. В предыдущих процедурах 300, 400, которые были рассмотрены со ссылкой на фиг.3,4, поисковая таблица 216 имела конфигурацию, позволяющую описывать каждое положение в буфере 212 истории соответствующего индекса 308(k), чтобы эффективно определять положение первоначальной последовательности в буфере 212 истории. Отыскание совпадающей последовательности в буфере 212 истории можно дополнительно оптимизировать, чтобы дополнительно повысить эффективность сжатия данных.
На этапе 702 совпадающую последовательность находят, например, с использованием поисковой таблицы и с применением порога. Можно применять различные пороги. Например, сравнение для нахождения совпадающей последовательности можно осуществлять на заранее определенном количестве положений в буфере истории, чтобы ограничивать количество производимых сравнений. Благодаря ограничению количества положений в буфере истории, которые сравниваются с данными, подлежащими потоковой передаче, можно ограничить размер (т.е. количество байтов) положения. Например, согласно описанному ранее, положение совпадающей последовательности в буфере 212 истории можно описать как относительное положение между началом и концом совпадающей последовательности до начала или конца текущего указателя, что можно описывать как обратный указатель. Поэтому, благодаря ограничению количества производимых сравнений, достигается большая вероятность того, что совпадающая последовательность будет расположена «ближе» к текущему указателю. Таким образом, положение будет иметь меньшее значение, например, использовать меньше байтов, в силу этой «близости». В другой реализации можно использовать порог, чтобы положения, имеющие значения выше заранее определенного порога, не рассматривались, что опять же может служить для ограничения размера значения положения. Таким образом, можно использовать различные пороги, например, количество положений, подлежащих поиску, размер значения, которое описывает каждое положение, размер значения, которое описывает длину каждой выявленной последовательности, и т.д.
На этапе 704 принятия решения проводится определение того, включен ли обратный указатель, который описывает положение совпадающей последовательности, в таблицу наиболее давнего использования (НДИ). Таблицу НДИ можно использовать для хранения обратных указателей наиболее давнего использования. Если обратный указатель для совпадающей последовательности включен в таблицу НДИ, то представление НДИ, соответствующее обратному указателю в таблице НДИ, используется для кодирования обратного указателя для совпадающей последовательности. Например, таблица НДИ может иметь глубину четыре, чтобы в таблице НДИ хранились последние четыре использованных обратных указателя. Каждый из обратных указателей в НДИ имеет соответствующее представление НДИ, которое отображается в таблицу НДИ. Поэтому, если обратный указатель включен в таблицу НДИ, то на этапе 706 обратный указатель можно кодировать с помощью представления НДИ из таблицы НДИ. Таким образом, модуль сжатия может адресовать дополнительные шаблоны, которые могут встретиться в потоковых данных, для дополнительного сжатия данных. Например, графические данные, передаваемые в потоковом режиме с сервера на клиент, могут содержать совпадающие последовательности, которые повторяются со сходными смещениями в буфере истории. Поэтому совпадающую последовательность можно сжать с использованием представления, которое включает в себя длину и положение совпадающей последовательности, причем положение можно дополнительно сжимать с использованием представления НДИ.
Если обратный указатель не включен в таблицу НДИ, то на этапе 708 обратный указатель можно закодировать с использованием таблицы 228 Хаффмана, показанной на фиг.2. Кодирование по Хаффману может начинаться с таблицы частотности, которая указывает частотность каждого обратного указателя, подлежащего дополнительному сжатию. Каждому обратному указателю присваивается строка переменой длины, которая уникально представляет этот обратный указатель. Например, каждая строка переменной длины может иметь уникальный префикс. Затем строки можно организовать в дерево для кодирования и декодирования каждого обратного указателя и представления соответственно. Чтобы закодировать обратный указатель, обратный указатель помещают в дерево. Ветви дерева, которые используются для определения положения листа, который содержит обратный указатель, используются для кодирования последовательности байтов, т.е. обеспечивают представление обратного указателя. Например, каждую ветвь дерева, используемого для кодирования по Хаффману, можно пометить символом выходного алфавита, например, битами 0 и 1, так что кодирование представляет собой перечисление меток ветвей на пути от корня дерева к кодируемому обратному указателю. Декодирование каждого представления осуществляется обходом дерева от его корня вниз по ветвям до листа дерева на основании каждого последующего значения в строке, пока не будет достигнут лист дерева, который содержит обратный указатель.
На этапе 710 длину совпадающей последовательности также кодируют с использованием таблицы Хаффмана. Например, таблицу Хаффмана, показанную на фиг.2, можно использовать для кодирования длины совпадающей последовательности в буфере истории для дополнительного сжатия данных. Длину можно кодировать так же, как было описано для обратного указателя.
На этапе 712 совпадающую последовательность представляют с помощью представления, имеющего конфигурацию кортежа, который содержит обратный указатель, описывающий положение совпадающей последовательности в буфере истории, и длину совпадающей последовательности. На этапе 714, применяют стоимостную функцию для определения того, является ли представление более эффективным, например, используется ли меньше ресурсов памяти при хранении и/или меньшая полоса пропускания при потоковой передаче этой совпадающей последовательности. Например, в некоторых случаях совпадающая последовательность может использовать меньше байтов, чем представление, которое описывает положение и длину совпадающей последовательности в буфере истории. Поэтому стоимостную функцию можно использовать для определения того, что эффективнее - представление или совпадающая последовательность, т.е. последовательность литералов в данных. Можно применять различные стоимостные функции. Например, стоимостная функция может использовать произведение размера обратного указателя и длины совпадающей последовательности.
Если на этапе 716 принятия решения выясняется, что представление более эффективно, то на этапе 718 сжатые данные формируют путем представления совпадающей последовательности с помощью представления. На этапе 720, текущий указатель обновляют и обрабатывают следующую первоначальную последовательность. Например, текущий указатель может быть увеличен на длину совпадающей последовательности, после чего процедура повторяется для следующей последовательности в данных. После увеличения текущего указателя в данных для потоковой передачи сжатые данные передают в потоковом режиме на клиент.
Если на этапе 716 принятия решения выясняется, что представление не эффективнее, то на этапе 722 совпадающую последовательность представляют с использованием таблицы Хаффмана согласно описанному выше. На этапе 720 текущий указатель увеличивают на количество байтов в совпадающей последовательности, и процедура переходит к следующей последовательности.
Согласно описанному выше, с помощью таблицы Хаффмана можно дополнительно сжимать данные, подлежащие потоковой передаче. Были описаны три таблицы Хаффмана для кодирования обратных указателей, длин и последовательностей литералов соответственно. Например, согласно фиг.2, таблицу 228 Хаффмана можно использовать для кодирования последовательностей байтов литералов 232 и обратных указателей 234. Чтобы различать обратные указатели и последовательности литералов внутри сжатого потока, обратные указатели и последовательности литералов можно снабдить соответствующими уникальными префиксами, например, каждый обратный указатель начинается с бита «0», и каждая последовательность литералов начинается с бита «1». В одном варианте осуществления, унифицированный индексный код можно использовать для кодирования как последовательностей литералов, так и обратных указателей путем объединения их в единый алфавит, так что обратные указатели и последовательности литералов имеют разные соответствующие символы.
Таблицы кодирования, например, вышеописанные таблицы Хаффмана, можно обеспечивать разными способами. Например, в одной реализации, таблицы кодирования предварительно конфигурируют для использования в модулях сжатия и восстановления после сжатия, так что таблицы кодирования не нужно вычислять для каждого пакета данных, подлежащего потоковой передаче. Это можно использовать для повышения скорости процесса шифрования. В другой реализации, таблицы кодирования динамически вычисляют с заранее заданными интервалами. Например, таблицы кодирования можно повторно вычислять каждый раз после приема заранее определенного количества пакетов для обновления таблиц кодирования.
На фиг.8 показана логическая блок-схема процедуры в иллюстративной реализации 800, в которой сравнение последовательностей оптимизируют для дополнительной оптимизации сжатия данных. Как и прежде, сервер 102 содержит буфер 212 истории и поисковую таблицу 216. Сервер 102 выполняет модуль 116 сжатия для сжатия пакета 304(3). Смещение от начала буфера 212 истории к началу самой правой последовательности, в которой первые два байта такие же, как можно представить в виде i1=HASH[HASH_SUM(s)]. В показанном примере, «s» равно «4 5», и i1=10 при отсчете от начала буфера 212 истории и начиная с нуля. Следующее смещение от начала буфера 212 истории до следующей самой правой последовательности можно представить как i2=NEXT[i1]. В приведенном примере, показанном на фиг.8, i2=NEXT[10]=4 в цепочке 802(k) хэширования. Аналогично, каждое последующее смещение от начала буфера 212 истории можно представить в цепочке 802(k) хэширования как i3=NEXT[i2]. В приведенном примере, i3=нуль, поскольку в буфере 212 истории больше нет последовательности, которая включает в себя «4 5».
Модуль 116 сжатия, при выполнении, может затем инициировать процедуру для сжатия пакета 304(3) начиная с «4 5» в позиции 16 в буфере 212 истории. Модуль 116 сжатия может сначала определять в буфере 212 истории положение последовательности, имеющей первоначальную последовательность «4 5» из положения i1=HASH[HASH_SUM ('4', '5')]=10 цепочки 802(k) хэширования. Положение сохраняют и NEXT[16] задают равным 10, и HASH[HASH_SUM ('4', '5')] задают равным 16. Последовательности сравнивают в текущем положении (16) и позиции i1 (10) друг с другом, сначала сравнивая следующий по счету байт в соответствующих последовательностях. В этом примере третий байт в пакете 304(3) сравнивают с пятым байтом в пакете 304(2) для нахождения совпадения. В приведенном примере, следующий по счету байт (т.е. третий байт в соответствующих последовательностях) отличаются, поскольку HISTORY[10+3]='3' и HISTORY[16+3]='6'. Поэтому длина ожидаемой совпадающей последовательности остается равной 2, и позиция ожидаемой совпадающей последовательности остается равной 10.
Модуль 116 сжатия может затем определить положение следующей последовательности в буфере 212 истории в положении i2=NEXT[i1]=4 из поисковой таблицы 216. Поскольку i2 не равен нулю, т.е. имеется совпадение, по меньшей мере, двух байтов. Следующие по счету байты, следующие после соответствующих байтов «4 5», сравниваются, как раньше, что приводит к совпадению 4 байтов. Поэтому, длину ожидаемой совпадающей последовательности задают равной 4, и позицию ожидаемой совпадающей последовательности задают равной 4. Модуль 116 сжатия может затем определять положение другой последовательности в буфере 212 истории в положении i3=NEXT[i2]=0 из цепочки 802(k) хэширования. Поскольку i3 равно нулю, это конец цепочки 802(k) хэширования, и никакие другие положения не сравниваются. Заметим, что модуль 116 сжатия, в одной реализации, не проверяет особо конец цепочки 802(k) хэширования. Вместо этого, последовательности в позиции «i0» (16 в примере, показанном на фиг.8), NEXT[0] задают равным i0. Поэтому по достижении конца цепочки 802(k) хэширования (iN=NEXT[i{N-1}]=0), это проверяется, и модуль 116 сжатия переходит к i{N+1}=NEXT[iN]=i0.
Сравнивая «следующие» по счету байты после ожидаемой длины совпадающей последовательности, можно повысить скорость сравнения. В предыдущем примере, например, HISTORY[i0+MatchLength] сравнивали с HISTORY[i0+MatchLength]. В отсутствие других последовательностей в буфере 212 истории для сравнения, осуществляется сравнение полной последовательности в каждом соответствующем положении. Иными словами, сравнивают каждый байт, один за другим, в соответствующих последовательностях в соответствующих положениях в буфере 212 истории. Если сравнение полной последовательности успешно, то извлекают совпадающую последовательность. Таким образом, можно получить ощутимое увеличение скорости сравнения последовательностей в буфере 212 истории.
На фиг.9 показана схема системы 900 в иллюстративной реализации, в которой сжатие динамически настраивается в соответствии с обратной связью, полученной от системы. Связь между сервером 102 и клиентом 104 по сети может варьироваться вследствие большого количества факторов. Например, клиент 104 может иметь ограниченные программные и/или аппаратные ресурсы, так что клиенту 104, для восстановления данных после сжатия приходится тратить больше времени, чем серверу 102 для их сжатия. В другом примере сервер 102 может выдавать данные на множество клиентов, и потому клиенты могут восстанавливать после сжатия данные быстрее, чем сервер 102 может сжимать данные для каждого из клиентов. Настраивая один или несколько параметров сжатия, которые были описаны выше, можно оптимизировать связь между сервером 102 и клиентом 104 с учетом аппаратных и/или программных ресурсов сервера 102 и клиента 104, а также ресурсов сети 106, которая служит средством связи между ними. Например, если сервер 102 «ожидает», чтобы отправить сжатые данные на клиент 104, то сервер 102 может осуществлять дополнительные вычисления сжатия для дальнейшего сжатия данных.
Для настройки параметров модуля 116 сжатия RDP 112 получают обратную связь. В качестве обратной связи для настройки параметров связи можно использовать различные факторы, например, общие характеристики сети. Например, информация от сетевого уровня, которая указывает наличие сетевого противодавления по причине медленной линии связи, может использоваться модулем 116 сжатия, чтобы указывать наличие дополнительного времени для дальнейшего сжатия данных. Поэтому модуль 116 сжатия можно динамически настраивать, чтобы тратить больше времени на сжатие данных, чтобы снижать окончательный выходной размер при наличии противодавления.
В другом примере RDP 112 может использовать фиксированный массив (пул) 902 буферов 904(1),..., 904(h),..., 904(H) истории. Верхние уровни, которые хотят отправить данные, действуют, запрашивая (выделяя) буфер (например, буфер 904(h)) из массива 902, заполняют буфер 904(h) данными (что включает в себя сжатие данных), а затем передавая сжатые данные на клиент 104. Буфер 904(h) только возвращается в массив 902, т.е. «освобождается», после передачи содержимого буфера. Эта методика позволяет RDP 112 и, в частности, модулю 116 сжатия получать обратную связь, т.е. информацию противодавления, как то, является ли сетевое соединение быстрым или медленным (например, величина пропускной способности), является ли клиент быстрым или медленным (например, время, необходимое клиенту для восстановления после сжатия данных) и т.д., на основании того, сколько требуется для «освобождения» буфера обратно в массив буферов.
В еще одном примере, если не доступен ни один из буферов 904(1)-904(H) массива 902, модуль 116 сжатия можно адаптировать к «более тяжелой работе», настраивая различные пороги сжатия так, чтобы он тратил больше времени на сжатие. После улучшения условий сети, модуль 116 сжатия также можно настроить на осуществление меньшего числа операций сжатия, чтобы быстрее передавать данные. Например, если сеть 106 имеет значительную пропускную способность, то количество осуществляемых операций сжатия можно уменьшить, поскольку сжатие не требуется для сокращения времени, необходимого для передачи данных. Таким образом, можно использовать динамическую методику, позволяющую изменять параметры сжатия во время выполнения в зависимости от флуктуирующих условий сети. В другой реализации, первоначальное измерение скорости сети используется для настройки параметров, которые затем используются в ходе сеанса.
Согласно вышесказанному, факторы, используемые для настройки модуля 116 сжатия также могут учитывать аппаратные и программные ресурсы сервера 102. Например, можно учитывать нагрузку на сервер 102 (например, сколько активных сеансов обеспечивает сервер 102, нагрузку на процессор 202, показанный на фиг.2, и т.д.) и динамически настраивать степень сжатия, для компенсации за счет использования меньших ресурсов центрального процессора (ЦП) при сжатии. Примером параметра сжатия, который можно настраивать, является размер окна поиска. Например, размер окна поиска можно настраивать от 64К до 512К. Большее окно может обеспечить большее относительное сжатие, но оно может осуществляться медленнее. Поэтому может оказаться выгодным «переключаться» на большое окно, если сеть считается медленной.
Другим примером фактора, используемого для настройки модуля 116 сжатия, является количество связей в цепочке хэширования, пройденных для поиска совпадений, можно настраивать. Например, долгий обход связей цепочки может увеличить вероятность нахождения более длинных совпадений, но может стоить дополнительных аппаратных и/или программных ресурсов для осуществления согласования.
Еще одним примером фактора, используемого для настройки модуля 116 сжатия, является порог, указывающий наиболее длинное найденное совпадение для окончания поиска. Согласно описанному выше, порог можно использовать для ограничения объема поиска, осуществляемого для нахождения совпадения. Чем выше этот порог, тем больше вероятность нахождения более длинного совпадения и, таким образом, большего сжатия данных. Однако при осуществлении этого поиска также может быть использовано больше ресурсов обработки данных. Хотя были рассмотрены различные факторы и параметры, можно также использовать и другие описанные здесь факторы и параметры.
Хотя изобретение было описано применительно к структурным признакам и/или методологическим действиям, следует понимать, что изобретение, заданное прилагаемой формулой изобретения, не обязано ограничиваться конкретными описанными признаками или действиями. Напротив, конкретные признаки и действия раскрыты в иллюстративных формах реализации заявленного изобретения.
Изобретение относится к области сжатия данных. Техническим результатом является расширение функциональных возможностей. Сетевая система выполнена с возможностью настройки сжатия данных и содержит сеть, клиента и сервер, предоставляющий терминальную службу клиенту, при этом сервер выполнен с возможностью осуществлять процедуру сжатия данных и содержит, по меньшей мере, один буфер предыстории, при этом один или несколько параметров процедуры сжатия являются настраиваемыми в соответствии с информацией обратной связи, указывающей наличие ресурсов для передачи данных, помещенных в упомянутый буфер предыстории сжатых данных по сети от терминальной службы на клиент, и полученной на основе количества времени, затраченного на передачу всех данных из упомянутого буфера предыстории. Способы описывают работу указанной системы. 10 н. и 35 з.п. ф-лы, 9 ил.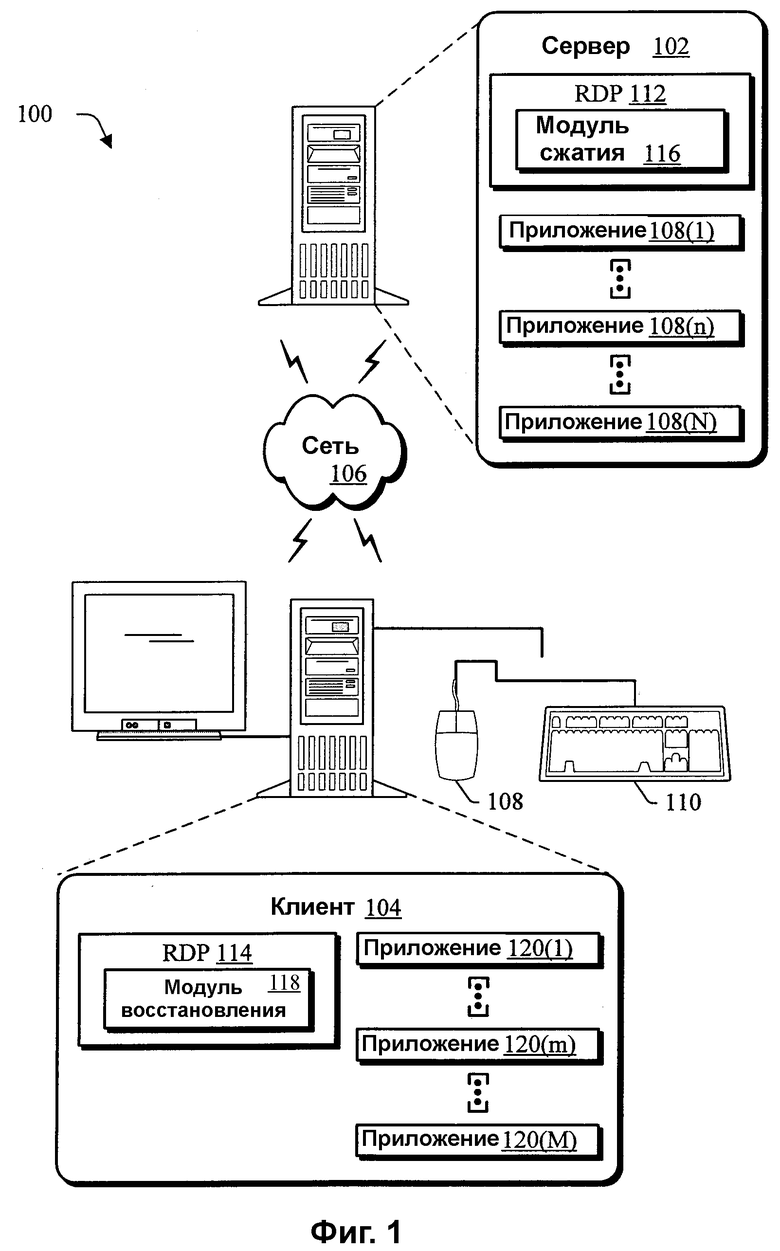
1. Способ сжатия данных для передачи в среде терминальных служб, содержащий этапы, на которых
находят индекс в поисковой таблице, который совпадает с первоначальной последовательностью в данных, при этом поисковая таблица содержит совокупность ячеек, причем каждая ячейка доступна с использованием конкретного одного из совокупности индексов, и каждая ячейка указывает, находится ли соответствующий индекс в буфере предыстории, и, если да, дополнительно указывает одно или несколько положений соответствующего индекса в буфере предыстории, и
если соответствующая ячейка совпадающего индекса указывает совокупность положений,
для каждого положения сравнивают последовательность в положении, имеющем совпадающий индекс, с последовательностью в данных, причем упомянутая последовательность содержит первоначальную последовательность,
получают совпадающую последовательность по результатам сравнения на основании по меньшей мере одного из длины и положения последовательности в каждом положении, и
представляют совпадающую последовательность с использованием представления, которое включает в себя длину и положение совпадающей последовательности в буфере предыстории.
2. Способ по п.1, дополнительно содержащий этапы, на которых
находят один индекс в поисковой таблице для каждой последовательности в данных,
формируют сжатые данные, которые содержат одно или несколько представлений, и
передают сжатые данные в потоковом режиме.
3. Способ по п.1, в котором соответствующая ячейка совпадающего индекса указывает цепочку хэширования, которая содержит каждое положение совпадающего индекса в буфере предыстории.
4. Способ по п.1, в котором и первоначальная последовательность, и индекс состоит из по меньшей мере двух байтов.
5. Способ по п.1, дополнительно содержащий этапы, на которых формируют сжатые данные, содержащие представление, и передают в потоковом режиме сжатые данные по сети, причем данные отформатированы в виде одного или нескольких пакетов.
6. Способ по п.1, дополнительно содержащий этап, на котором кодируют по меньшей мере одно из длины и положения представления с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
7. Способ по п.1, в котором
если соответствующая ячейка совпадающего индекса не указывает никакого положения, кодируют первоначальную последовательность путем кодирования по Хаффману,
если соответствующая ячейка совпадающего индекса указывает единственное положение,
сравнивают последовательность в этом единственном положении, имеющем совпадающий индекс, с последовательностью в данных,
получают совпадающую последовательность по результатам сравнения на основании по меньшей мере одного из длины и положения последовательности в упомянутом единственном положении, и
представляют совпадающую последовательность с использованием представления, содержащего длину и упомянутое единственное положение совпадающей последовательности, в буфере предыстории, и
когда каждая последовательность данных представлена или закодирована, передают в потоковом режиме данные, имеющие кодирование или представление.
8. Способ по п.1, в котором сравнение для получения совпадающей последовательности осуществляют с использованием одного или нескольких порогов, выбранных из группы, состоящей из
количества положений, имеющих совпадающий индекс, подлежащий сравнению,
размера значения, которое описывает каждое положение, имеющее совпадающий индекс, и
размера значения, которое описывает длину последовательности в каждом положении, которая совпадает с последовательностью в данных, которая содержит совпадающий индекс.
9. Способ по п.1, дополнительно содержащий этап, на котором применяют стоимостную функцию для определения того, использует ли представление меньше памяти при сохранении, чем совпадающая последовательность, и, если да, то формируют сжатые данные, содержащие представление.
10. Способ по п.1, дополнительно содержащий этап, на котором определяют, совпадает ли положение совпадающей последовательности с одним из совокупности положений в таблице наиболее давнего использования (НДИ), причем
каждое положение в таблице НДИ имеет соответствующее представление НДИ,
каждое положение в таблице НДИ описывает одно из совокупности наиболее давно использованных положений последовательностей в данных, ранее переданных в потоковом режиме, и
если положение совпадающей последовательности включено в таблицу НДИ, то положение совпадающей последовательности кодируют с помощью соответствующего представления НДИ из таблицы НДИ.
11. Машиночитаемый носитель, содержащий машиноисполняемые команды, которые при их исполнении осуществляют способ по п.1.
12. Способ сжатия данных для передачи в среде терминальных служб, содержащий этапы, на которых
добавляют данные в буфер предыстории,
обновляют поисковую таблицу, которая указывает на буфер предыстории, для включения добавленных данных, при этом поисковая таблица содержит совокупность ячеек, причем каждая ячейка доступна с использованием конкретного одного из совокупности индексов, и каждая ячейка указывает, находится ли соответствующий индекс в буфере предыстории, и, если да, дополнительно указывает одно или несколько положений соответствующего индекса в буфере предыстории,
устанавливают текущий указатель на добавленные данные в буфере предыстории,
находят один индекс в поисковой таблице, который совпадает с первоначальной последовательностью по текущему указателю,
если соответствующая ячейка совпадающего индекса указывает совокупность положений,
сравнивают последовательность в каждом положении, имеющем совпадающий индекс, с последовательностью в добавленных входных данных, которые содержат первоначальную последовательность,
получают совпадающую последовательность по результатам сравнения,
представляют совпадающую последовательность с помощью представления, которое включает в себя положение и длину совпадающей последовательности, в буфере предыстории,
применяют стоимостную функцию для определения того, использует ли представление меньший объем памяти при сохранении, чем совпадающая последовательность,
если да, конфигурируют данные так, чтобы они включали в себя упомянутое представление, и перемещают вперед текущий указатель на длину совпадающей последовательности,
в противном случае конфигурируют данные так, чтобы они включали в себя первоначальную последовательность, и перемещают вперед текущий указатель на длину первоначальной последовательности, и
когда текущий указатель передвинут через добавленные данные, пакетируют сконфигурированные данные для потоковой передачи.
13. Способ по п.12, дополнительно содержащий этап, на котором кодируют по меньшей мере одно из длины и положения представления с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
14. Способ по п.12, в котором, когда первоначальная последовательность по текущему указателю не совпадает ни с одной последовательностью в буфере предыстории, первоначальную последовательность байтов по текущему указателю кодируют для включения в конфигурированные данные для потоковой передачи с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
15. Способ по п.12, дополнительно содержащий этап, на котором определяют, совпадает ли положение совпадающей последовательности с одним из совокупности положений в таблице наиболее давнего использования (НДИ), причем
каждое положение в таблице НДИ имеет соответствующее представление НДИ,
каждое положение в таблице НДИ описывает одно из совокупности наиболее давно использованных положений последовательностей в данных, ранее переданных в потоковом режиме, и
если положение совпадающей последовательности включено в таблицу НДИ, то положение совпадающей последовательности кодируют с помощью соответствующего представления НДИ из таблицы НДИ.
16. Машиночитаемый носитель, содержащий машиноисполняемые команды, которые при их исполнении осуществляют способ по п.12.
17. Способ настройки сжатия данных, реализуемый в сетевой системе, содержащей сеть, клиент и сервер, предоставляющий терминальную службу клиенту, при этом сервер включает в себя процедуру сжатия для сжатия данных и по меньшей мере один буфер предыстории, при этом способ содержит этапы, на которых
заполняют упомянутый буфер предыстории данными, сжимают эти данные и передают сжатые данные через сеть на клиент;
получают информацию обратной связи, которая указывает наличие ресурсов для передачи упомянутых данных по сети от терминальной службы на клиент, на основе количества времени, затраченного на передачу всех данных из упомянутого буфера предыстории; и
настраивают один или несколько параметров процедуры сжатия в соответствии с упомянутой информацией обратной связи.
18. Способ по п.17, в котором ресурсы выбирают из группы, состоящей из
аппаратных ресурсов клиента,
программных ресурсов клиента,
сетевых ресурсов сети,
аппаратных ресурсов сервера,
программных ресурсов сервера и
любой их комбинации.
19. Машиночитаемый носитель, содержащий машиноисполняемые команды, которые при их исполнении осуществляют способ по п.17.
20. Сетевая система, выполненная с возможностью настройки сжатия данных и содержащая
сеть,
клиент и
сервер, предоставляющий терминальную службу клиенту, при этом сервер включает в себя процедуру сжатия для сжатия данных и по меньшей мере один буфер предыстории,
при этом один или несколько параметров процедуры сжатия являются настраиваемыми в соответствии с информацией обратной связи, указывающей наличие ресурсов для передачи помещенных в упомянутый буфер предыстории сжатых данных по сети от терминальной службы на клиент и полученной на основе количества времени, затраченного на передачу всех данных из упомянутого буфера предыстории.
21. Система по п.20, в которой ресурсы выбираются из группы, состоящей из
аппаратных ресурсов клиента,
программных ресурсов клиента,
сетевых ресурсов сети,
аппаратных ресурсов сервера,
программных ресурсов сервера и
любой их комбинации.
22. Сервер, содержащий
буфер предыстории, имеющий совокупность байтов,
поисковую таблицу, содержащую совокупность ячеек, причем каждая ячейка доступна с использованием конкретного одного из совокупности индексов и указывает, находится ли соответствующий индекс в буфере предыстории, и, если да, дополнительно указывает одно или несколько положений соответствующего индекса в буфере предыстории, и
модуль сжатия, который предназначен для выполнения, чтобы
находить одну последовательность индексов в поисковой таблице, которая совпадает с первоначальной последовательностью в данных, для передачи на клиент от терминальной службы,
если соответствующая ячейка совпадающего индекса указывает совокупность упомянутых положений,
для каждого положения сравнивать последовательность в положении, имеющем совпадающий индекс, с последовательностью в данных, причем упомянутая последовательность содержит первоначальную последовательность,
получать совпадающую последовательность по результатам сравнения на основании по меньшей мере одного из длины и положения последовательности в каждом положении, и
представлять совпадающую последовательность с использованием представления, которое включает в себя длину и положение совпадающей последовательности в буфере предыстории.
23. Сервер по п.22, в котором модуль сжатия дополнительно предназначен для выполнения, чтобы
находить один индекс в поисковой таблице для каждой последовательности в данных,
формировать сжатые данные, которые содержат одно или несколько представлений, и
передавать сжатые данные в потоковом режиме.
24. Сервер по п.22, в котором соответствующая ячейка совпадающего индекса указывает цепочку хэширования, которая содержит каждое положение совпадающего индекса в буфере предыстории.
25. Сервер по п.22, в котором и первоначальная последовательность, и индекс состоит из по меньшей мере двух байтов.
26. Сервер по п.22, в котором модуль сжатия дополнительно
предназначен для выполнения, чтобы
формировать сжатые данные, содержащие представление, и пакетировать сжатые данные для передачи в потоковом режиме по
сети, причем данные отформатированы в виде одного или нескольких
пакетов.
27. Сервер по п.22, в котором модуль сжатия дополнительно предназначен для выполнения, чтобы кодировать по меньшей мере одно из длины и положения представления с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
28. Сервер по п.22, в котором модуль сжатия дополнительно предназначен для выполнения, чтобы кодировать первоначальную последовательность, если соответствующая ячейка совпадающего индекса не указывает ни одного положения, с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
29. Сервер по п.22, в котором сравнение для получения совпадающей последовательности осуществляется с использованием одного или нескольких порогов, выбранных из группы, состоящей из
количества положений, имеющих совпадающий индекс, подлежащий сравнению,
размера значения, которое описывает каждое положение, имеющее совпадающий индекс, и
размера значения, которое описывает длину последовательности в каждом положении, которая совпадает с последовательностью в данных, которые содержат совпадающий индекс.
30. Сервер по п.22, в котором модуль сжатия дополнительно предназначен для выполнения, чтобы применять стоимостную функцию для определения того, использует ли представление меньше памяти при сохранении, чем совпадающая последовательность, и, если да, формирования сжатых данных, содержащих представление.
31. Сервер по п.22, в котором модуль сжатия дополнительно предназначен для выполнения, чтобы определять, совпадает ли положение совпадающей последовательности с одним из совокупности положений в таблице наиболее давнего использования (НДИ), причем
каждое положение в таблице НДИ имеет соответствующее представление НДИ,
каждое положение в таблице НДИ описывает одно из совокупности наиболее давно использованных положений последовательностей в данных, ранее переданных в потоковом режиме, и
если положение совпадающей последовательности включено в таблицу НДИ, положение совпадающей последовательности кодируется с помощью соответствующего представления НДИ из таблицы НДИ.
32. Сетевая система, выполненная с возможностью сжатия данных и содержащая
сеть,
сервер, содержащий
первый буфер предыстории, имеющий совокупность байтов,
поисковую таблицу, содержащую совокупность ячеек, причем каждая ячейка доступна с использованием конкретного одного из совокупности индексов, и каждая ячейка указывает, находится ли соответствующий индекс в буфере предыстории, и, если да, дополнительно указывает одно или несколько положений соответствующего индекса в буфере предыстории, и
модуль сжатия, который предназначен для выполнения, чтобы
находить один индекс в поисковой таблице, который совпадает с первоначальной последовательностью по текущему указателю, в данных, подлежащих потоковой передаче, в соответствии с запросом удаленного доступа,
если соответствующая ячейка совпадающего индекса указывает одно или несколько положений, сравнивать последовательность в каждом положении, имеющем совпадающий индекс, с последовательностью в данных по текущему указателю, получать совпадающую последовательность по результатам сравнения, конфигурировать данные так, чтобы они включали в себя положение и длину совпадающей последовательности в первом буфере предыстории, и перемещать вперед текущий указатель на длину совпадающей последовательности,
если соответствующая ячейка совпадающего индекса не указывает ни на какое положение, конфигурировать данные так, чтобы они включали в себя первоначальную последовательность, и перемещать вперед текущий указатель на длину первоначальной последовательности, и
когда текущий указатель передвинут через добавленные данные, выполнять потоковую передачу сконфигурированных данных по сети и
клиент, подключенный с возможностью связи к сети и содержащий второй буфер предыстории и модуль восстановления после сжатия, который предназначен для выполнения с целью восстановления после сжатия потоковых данных путем нахождения совпадающей последовательности во втором буфере предыстории на основании положения и длины, указанных в представлении.
33. Система по п.32, в которой модуль восстановления после сжатия дополнительно предназначен для выполнения клиентом с целью добавления данных, восстановленных после сжатия, во второй буфер предыстории.
34. Система по п.32, в которой модуль сжатия дополнительно предназначен для выполнения сервером с целью кодирования по меньшей мере одного из длины и положения представления с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
35. Система по п.32, в которой если соответствующая ячейка совпадающего индекса не указывает ни одного положения, модуль сжатия дополнительно предназначен для выполнения с целью кодирования первоначальной последовательности с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
36. Система по п.32, в которой модуль сжатия дополнительно предназначен для выполнения сервером с целью определения того, совпадает ли положение совпадающей последовательности с одним из совокупности положений, в таблице наиболее давнего использования (НДИ), причем
каждое положение в таблице НДИ имеет соответствующее представление НДИ,
каждое положение в таблице НДИ описывает одно из совокупности наиболее давно использованных положений последовательностей в данных, ранее переданных в потоковом режиме, и
если положение совпадающей последовательности включено в таблицу НДИ, положение совпадающей последовательности кодируется с помощью соответствующего представления НДИ из таблицы НДИ.
37. Машиночитаемый носитель, содержащий машиноисполняемые команды, которые при их исполнении компьютером предписывают компьютеру
находить индекс в поисковой таблице, который совпадает с первоначальной последовательностью в данных для потоковой передачи на клиент, причем эти данные предназначены для генерирования пользовательского интерфейса приложения, удаленно выполняемого с клиента, при этом поисковая таблица содержит совокупность ячеек, причем каждая ячейка доступна с использованием конкретного одного из совокупности индексов, и каждая ячейка указывает, находится ли соответствующий индекс в буфере предыстории, и, если да, дополнительно указывает одно или несколько положений соответствующего индекса в буфере предыстории,
если соответствующая ячейка совпадающего индекса указывает совокупность положений,
для каждого положения сравнивать последовательность в положении, имеющем совпадающий индекс, с последовательностью в данных, причем упомянутая последовательность содержит первоначальную последовательность, и
вычислять по результатам сравнения длину совпадающей последовательности.
38. Машиночитаемый носитель по п.37, в котором машиноисполняемые команды предписывают компьютеру представлять совпадающую последовательность с использованием представления, содержащего длину и положение.
39. Машиночитаемый носитель по п.37, в котором соответствующая ячейка совпадающего индекса указывает цепочку хэширования, которая содержит каждое положение совпадающего индекса в буфере предыстории.
40. Машиночитаемый носитель по п.37, в котором и первоначальная последовательность, и индекс состоит из по меньшей мере двух байтов.
41. Машиночитаемый носитель по п.37, в котором машиноисполняемые команды предписывают компьютеру кодировать по меньшей мере одно из длины и положения представления с использованием методику кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
42. Машиночитаемый носитель по п.37, в котором машиноисполняемые команды предписывают компьютеру кодировать первоначальную последовательность, если соответствующая ячейка совпадающего индекса не указывает ни одного положения, с использованием методики кодирования, выбранной из группы, состоящей из
кодирования по Хаффману,
арифметического кодирования,
префиксного кодирования и
кодирования по Маркову.
43. Машиночитаемый носитель по п.37, в котором сравнение осуществляется с использованием одного или нескольких порогов, выбранных из группы, состоящей из
количества положений, имеющих совпадающий индекс, подлежащий сравнению,
размера значения, которое описывает каждое положение, имеющее совпадающий индекс, и
размера значения, которое описывает длину последовательности в каждом положении, которая совпадает с последовательностью в данных, которые содержат совпадающий индекс.
44. Машиночитаемый носитель по п.37, в котором машиноисполняемые команды предписывают компьютеру применять стоимостную функцию для определения того, использует ли представление, которое содержит длину и положение совпадающей последовательности, меньше памяти при сохранении, чем совпадающая последовательность, и, если да, то формировать сжатые данные, содержащие представление.
45. Машиночитаемый носитель по п.37, в котором машиноисполняемые команды предписывают компьютеру определять, совпадает ли положение совпадающей последовательности с одним из совокупности положений в таблице наиболее давнего использования (НДИ), причем
каждое положение в таблице НДИ имеет соответствующее представление НДИ,
каждое положение в таблице НДИ описывает одно из совокупности наиболее давно использованных положений последовательностей в данных, ранее переданных в потоковом режиме, и
если положение совпадающей последовательности включено в таблицу НДИ, положение совпадающей последовательности кодируется с помощью соответствующего представления НДИ из таблицы НДИ.
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |
| СПОСОБ И СИСТЕМА ДЛЯ СКРЫТОГО КОНТРОЛЯ ВЫЗОВОВ, ПРОХОДЯЩИХ ЧЕРЕЗ СИСТЕМУ АВТОМАТИЧЕСКОГО РАСПРЕДЕЛЕНИЯ ВЫЗОВОВ В УСЛОВИЯХ СЕТИ С НАЛОЖЕНИЕМ РЕЧЕВЫХ СИГНАЛОВ НА СИГНАЛЫ ПЕРЕДАЧИ ДАННЫХ | 1999 |
|
RU2212112C2 |
| УСТРОЙСТВО ДЛЯ АДРЕСАЦИИ РЕКЛАМЫ, УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ДАННЫХ, ОТНОСЯЩИХСЯ К РЕКЛАМАМ В ПРОГРАММАХ, И СПОСОБ АДРЕСАЦИИ РЕКЛАМЫ | 1993 |
|
RU2192103C2 |

