ПЕРЕКРЕСТНАЯ ССЫЛКА
[0001] По настоящей заявке испрашивается приоритет по российской заявке №20131452598, поданной 10 октября 2013 г. и озаглавленной «СПОСОБЫ И СИСТЕМЫ ИНДЕКСИРОВАНИЯ ССЫЛОК НА ДОКУМЕНТЫ В БАЗЕ ДАННЫХ В СООТВЕТСТВИИ С ПРОФИЛЯМИ ССЫЛОК И НАХОЖДЕНИЯ ДОКУМЕНТОВ В БАЗЕ ДАННЫХ С ПОМОЩЬЮ ПРОТОКОЛОВ ДЕКОДИРОВАНИЯ НА ОСНОВЕ ПРОФИЛЕЙ ССЫЛОК БАЗЫ ДАННЫХ» («METHODS AND SYSTEMS FOR INDEXING REFERENCES TO DOCUMENTS OF A DATABASE ACCORDING TO DATABASE REFERENCE PROFILES AND FOR LOCATING DOCUMENTS IN THE DATABASE USING DECODING PROTOCOLS BASED ON THE DATABASE REFERENCE PROFILES))), которая включена в настоящую заявку посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ТЕХНОЛОГИЯ
[0002] Настоящая технология относится к области использования больших баз данных и, в частности, к способам и системам индексирования ссылок на документы в базе данных в соответствии с профилями ссылок и нахождения документов в базе данных с помощью протоколов декодирования на основе профилей ссылок базы данных.
УРОВЕНЬ ТЕХНИКИ
[0003] На сегодняшний день в дата-центрах содержатся коллекции данных, которые включают в себя миллиарды элементов данных. Поиск конкретных элементов, удовлетворяющих конкретному поисковому запросу, в таких огромных коллекциях данных может занимать значительное количество времени и требовать значительных ресурсов. Время ответа на запрос может быть критичным во многих случаях, как из-за специфичных технических характеристик, так и из-за высоких ожиданий пользователей. Следовательно, существуют различные технологии для уменьшения времени выполнения поискового запроса.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[0004] Обычно для создания системы управления коллекциями данных, эффективной с точки зрения поиска, элементы данных индексируются в соответствии с некоторыми или всеми возможными поисковыми терминами. Так называемый инвертированный индекс коллекции данных поддерживается и обновляется системой, и используется при выполнении каждого поискового запроса. Инвертированный индекс включает в себя набор списков словопозиций, причем каждый список словопозиций соответствует поисковому термину и содержит ссылки на элементы данных, которые содержат этот термин, или которые удовлетворяют условию, выраженному в поисковом термине.
[0005] В качестве первого примера рассматривается сетевая поисковая система, элементы данных которой могут принимать форму текстовых документов, и поисковые термины могут представлять собой индивидуальные слова или некоторые наиболее часто используемые комбинации слов. Инвертированный индекс также содержит один список словопозиций для каждого слова, представленного по меньшей мере в некоторых документах. В качестве второго примера, коллекция данных может представлять собой базу данных, включающую в себя одну или несколько очень длинных таблиц, в которых элементы данных являются индивидуальными записями, например, строками в таблице, которая обладает несколькими признаками, представленными в виде некоторых значений в соответствующих столбцах. Во втором примере поисковые термины являются конкретными значениями признаков или другими условиями признаков и списков словопозиций для поискового термина в списке ссылок (индексы, порядковые числительные) на записи, которые удовлетворяют поисковому термину.
[0006] На Фиг. 1 представлено расширенное изображение инвертированного индекса в табличной форме. Таблица инвертированного индекса 2, показанная на Фиг. 1, значительно меньше, чем обычно, следовательно, инвертированный индекс 2 был значительно упрощен для целей иллюстрации. Табличный индекс 2 может быть применен к обоим примерам - сетевой поисковой системе и коллекции данных в базе данных. Таблица инвертированного индекса 2 соответствует 100 документам (не показано), которые хранятся в базе данных (не показана), документы пронумерованы от 1 до 100. Как показано, табличный инвертированный индекс 2 включает в себя строку 4 заголовка, который определяет элементы из различных столбцов 16, 18, 20, 22, 24 и 26. Строка 4 заголовка может не быть представлена в некоторых конкретных реализациях, и показана на Фиг. 1 только для целей иллюстрации. Другие строки 6, 8, 10, 12 и 14 включают в себя термин в столбце 16 и соответствующий список словопозиций в столбцах 18, 20, 22, 24 и 26. В конкретном примере, представленном на Фиг. 1, термины в строках 6, 8, 10, 12 и 14 являются названиями животных, которые упомянуты в некоторых из 100 документов в базе данных. Каждый список словопозиций содержит ссылку на первый документ в столбце 18 и может содержать дополнительные ссылки на документы в столбце 20-26. Например, в строке 6 термин «dog» (англ. «собака») находится в документах номер 25, 35, 47, 65 и 83 в базе данных. Первая ссылка на документ, расположенная в ряду 6, столбец 18, может быть абсолютным номером документа (25) или первой дельта-ссылкой, которая указывает на разницу между абсолютным номером документа номером нулевого документа, эта первая дельта-ссылка равна абсолютному номеру документа. Вторая ссылка документа расположена в ряду 6, столбец 20. Вторая ссылка документа может быть сохранена как абсолютный номер документа (35). Альтернативно, номер второго документа может быть сохранен как вторая дельта-ссылка, указывающая на разницу (10) между вторым номером документа (35) и номером первого документа (25); для того чтобы использовать дельта-ссылки, номера ссылок документов хранятся в списках словопозиций в порядке возрастания. Аналогично, номер третьего документа, содержащий термин «dog» может быть сохранен как абсолютный номер (47) документа или третья дельта (12) между номером (47) третьего документа и номером второго (35) документа.
[0007] Использование дельта-ссылок требует меньшего объема памяти для хранения табличного инвертированного индекса 2, поскольку в среднем элементы данных табличного инвертированного индекса 2 обладают меньшим размером и могут быть закодированы меньшим числом бит. Поскольку разница между двумя абсолютными номерами документов всегда будет по меньшей мере равной одному (1) или больше, может сохраняться дополнительное пространство путем пересчета дельта-ссылок в виде разницы между абсолютными номерами документов минус один (1). При таком способе вычисления дельта-ссылок все номера между круглыми скобками инвертированного индекса 2 будут уменьшены на единицу (1). Например, первая дельта-ссылка в ряду 8 для термина «horse» (англ. «лошадь») будет уменьшена с «8», которая требует четыре (4) бита для кодирования, до «7», которая может быть закодирована тремя (3) битами.
[0008] Представленный табличный инвертированный индекс 2 предоставляет ссылки на пять (5) различных названий животных, которые могут быть найдены среди 100 документов в базе данных. Следовательно, наибольший номер ссылки на документ не превышает 100. Можно заметить, что различные термины могут находиться в одном и том же документе, например, «dog» и «horse», оба могут находиться в документе номер 25, а термины, которые относятся к редким животным могут находиться в меньшем числе документов.
[0009] На Фиг. 2 представлено расширенное изображение инвертированного индекса в одновекторной форме. Информационные элементы табличного инвертированного индекса 2, показанного на Фиг. 1, перенесены в одновекторный инвертированный индекс 30, показанный на Фиг. 2; для целей иллюстрации были добавлены дополнительные элементы. Одновекторный инвертированный индекс 30 выполнен аналогично табличному инвертированному индексу 2, показанному на Фиг. 1, за исключением того, что термины и соответствующие списки словопозиций расположены на непрерывном векторе, второй термин («horse») следует за списком словопозиций для первого термина («dog»), таким образом пустых позиций не остается в отличие, например, от последних нескольких столбцов 10-14, показанных на Фиг. 1.
[00010] Запрос на документы, которые содержат конкретный элемент, может выполняться путем первичного нахождения конкретного термина в инвертированном индексе 2 или 30 и, далее, путем извлечения релевантных документов с помощью соответствующего списка словопозиций. Для увеличения скорости выполнения поисковых запросов инвертированный индекс обычно сохраняется в быстрой памяти, например, в ОЗУ одной или нескольких компьютерных систем. Документы и другие элементы данных могут быть сохранены на большем по объему, но более медленном носителе, например, магнитных или оптических дисках или других аналогичных устройствах большого объема. Таким образом, обработка поискового запроса включает в себя просмотр одного или нескольких списков словопозиций инвертированного индекса в более быстрой памяти, а не самих элементов данных.
[00011] Обычно документы или другие элементы данных в базе поисковой информации перечислены в инвертированном индексе в виде целочисленных номеров ссылок. Для некоторых приложений диапазон номеров документов может доходить до миллиарда и даже нескольких миллиардов. Некоторые слова, которые могут быть использованы как поисковые термины, могут находиться в огромном количестве документов, например, в миллионах документов. Следовательно, инвертированный индекс может включать в себя миллионы поисковых терминов, каждый из которых связан с потенциально длинным списком словопозиций. И, следовательно, существует необходимость в различных компьютерных приложениях, которые бы представляли длинные списки символов или кодовых слов, например, номера ссылок документов, в сжатой форме, и которые сохраняли бы длинные списки в быстрой памяти компьютера для эффективного доступа и обработки.
[00012] Во многих приложениях хранение документов в базе данных и обновление инвертированного индекса выполняется в фоновом приложении. Например, в случае так называемых приложений поисковых роботов, которые автоматически просматривают мировую паутину для сбора информации в базу данных сетевой поисковой системы. Для этих приложений скорость имеет второстепенное значение, в то время как более значимой является эффективность сжатия информации в инвертированном индексе. И напротив, скорость распаковки является более важной, поскольку пользователь сетевой поисковой системы или системы базы данных может требовать быстрого ответа на свои поисковые запросы.
[00013] На Фиг. 1 и 2 видно, что термины, которые могут находиться в большом числе документов, связаны с длинными списками словопозиций, которые, в свою очередь, содержат небольшие числа ссылок (небольшие целые числа) при использовании дельта-ссылок. Список словопозиций небольших целых чисел может быть разделен на короткие блоки, которые являются сжатыми для компактного хранения инвертированного индекса в памяти. В идеальном варианте, все элементы в коротком блоке будут обладать той же длиной в том смысле, что они будут закодированы одинаковым числом бит. Благодаря тому, что к элементами применяется однородное по длине кодирование в блоки, становится возможным использование компьютерных систем с низкими уровнями параллелизма, например, процессоров с одиночным потоком команд, множественным потоком данных (SIMD). Например, если процессор обладает подмножеством SIMD-инструкций, которые могут выполняться параллельно на восьми (8) различных элементах данных, желательно представлять длинный список символов в виде последовательности блоков, в котором каждый блок содержит или представляет ровно восемь (8) символов. По сути, некоторые процессоры способы выполнять SIMD-инструкции на 32 или даже на 128 элементах данных параллельно; блоки из 32 или 128 последовательных целых чисел, представляют номера ссылок (или номера дельта-ссылок) могут эффективно управляться такими процессорами, поскольку их 32 или 128 элементов обладают одинаковой длиной.
[00014] Тем не менее, кодирование всех элементов в блоке с одинаковым числом бит может быть неэффективно с учетом сжатия. Например, семь (7) элементов блока могут быть закодированы тремя (3) битами, а другому элементу блока может потребоваться пять (5) бит. Кодирование всех восьми (8) элементов блока пятью битами, таким образом, не позволит достичь оптимального уровня сжатия. Способ кодировки списка, называемый «модифицированная система координат» (PFor) предусматривает кодирование меньших элементов блока оптимальным числом бит (в настоящем примере, 3 бита), с одновременным перенесением больших элементов в отдельный список исключений, называемый «модификациями», которые кодируются большим числом бит. Позиция каждой модификации в «главном» блоке определяется номером позиции следующей модификации по отношению к данной, следовательно, создается цепной список переходов модификаций в блоке. Заголовок блока содержит номер позиции первой модификации по отношению к началу блока, а также число бит, которое было использовано для каждого меньшего элемента (в данном случае, 3 бита), расположенного на своей первоначальной позиции в блоке, и число бит (в данном случае, 2 бита) для каждой большей «модификации» элемента.
[00015] Считается, что модифицированная система координат (PFor) хорошо работает с блоком среднего размера, например, блоков величиной 128 элементов. Тем не менее, модифицированная система координат (PFor) не предоставляет достаточного параллелизма для декодирования списков, поскольку цепной список относительных переходов модификаций должен извлекаться последовательно и конвертироваться в абсолютные позиции модификаций в блоке. Также возможно, что относительный переход от одной позиции модификации к другой является слишком длинным и не может быть закодирован для «встраивания» таким количеством бит, которое было использовано для каждого встроенного элемента в блоке. В этих случаях необходимо вводить фиктивную позицию модификации для того, чтобы разделить переход на два более коротких.
[00016] В соответствии с измененным способом модифицированной системы (PFor), называемом "NewPForDelta" (NewPFD), менее значимые биты подходящего значения модификации (в представленном выше примере - 3 менее значимых бита) находятся на каждой позиции модификации, а оставшиеся биты кодируются отдельно (в представленном выше примере - 2 бита). Следовательно, представление блока целиком содержит три (3) списка, присоединенных друг к другу, включая (i) главный список, содержащий меньшие элементы и наименее значимые биты больших элементов в позициях модификаций; (ii) список остальных частей больших элементов, и (iii) цепной список переходов от одной позиции модификации до другой.
[00017] Способ NewPFD, тем не менее, все еще не предоставляет достаточного параллелизма для декодирования списков. Следовательно, дальнейшее изменение способа модифицированной системы координат PFor, называемое «Parallel PFor» (ParaPFor), заменяет цепной список относительных позиций их абсолютными номерами позиций в отношении начала блока. Например, в 32-элементном блоке каждая позиция модификации обладает номером от 0 до 31 и, следовательно, закодирована пятью (5) битами. Список позиций модификаций может быть распакован в нескольких параллельных SIMD-потоках одновременно с основным списком и списком оставшихся битов модификаций. Наконец, может выполняться операция параллельного поэлементного добавления, порождающая целый нераспакованный блок.
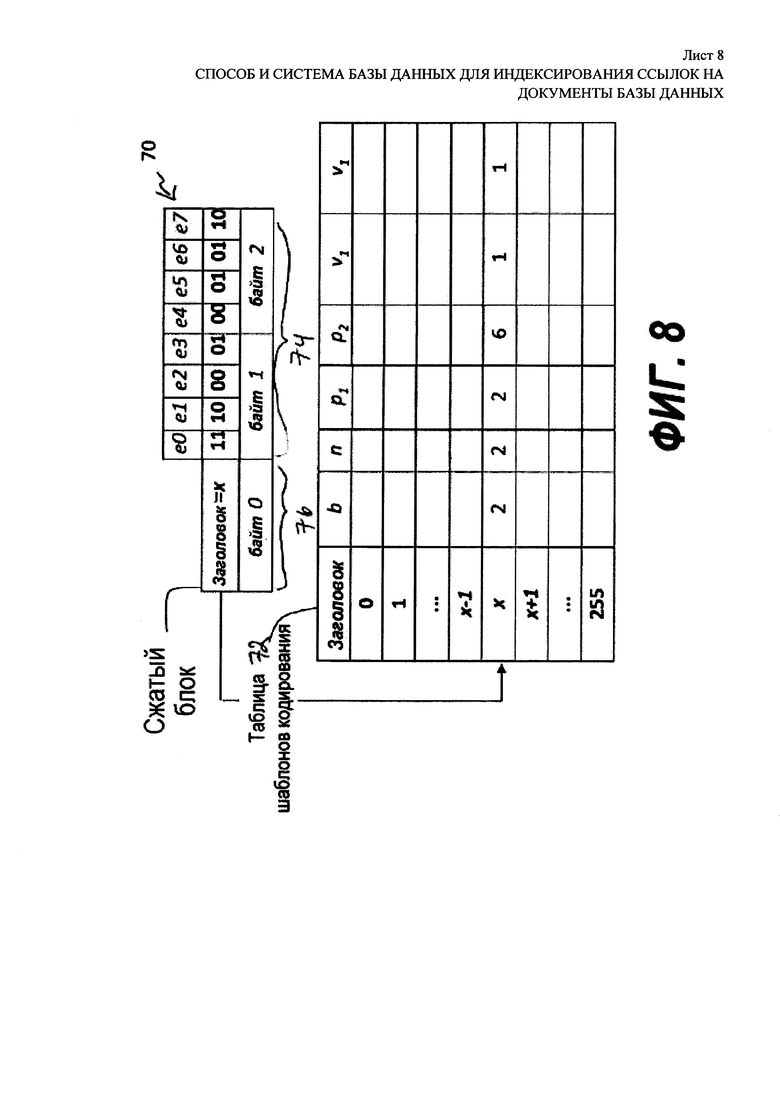
[00018] Способ ParaPFor может быть продемонстрирован на следующем примере: Предположим, что есть 8-элементный блок [3,2,4,1,0,1,5,2], каждый элемент которого представляет, например, дельта-ссылку в списке словопозиций. В бинарном представлении блок выглядит следующим образом: [11,10,100,1,0,1,101,10]. Элементы пронумерованы от е0 до е7, слева направо. Блок обладает тремя (3) элементами длиной 1 бит (элементы 3, 4, 5), тремя (3) элементами длиной 2 бита (элементы 0, 1, 7) и двумя элементами длиной 3 бита (элементы 2 и 6).
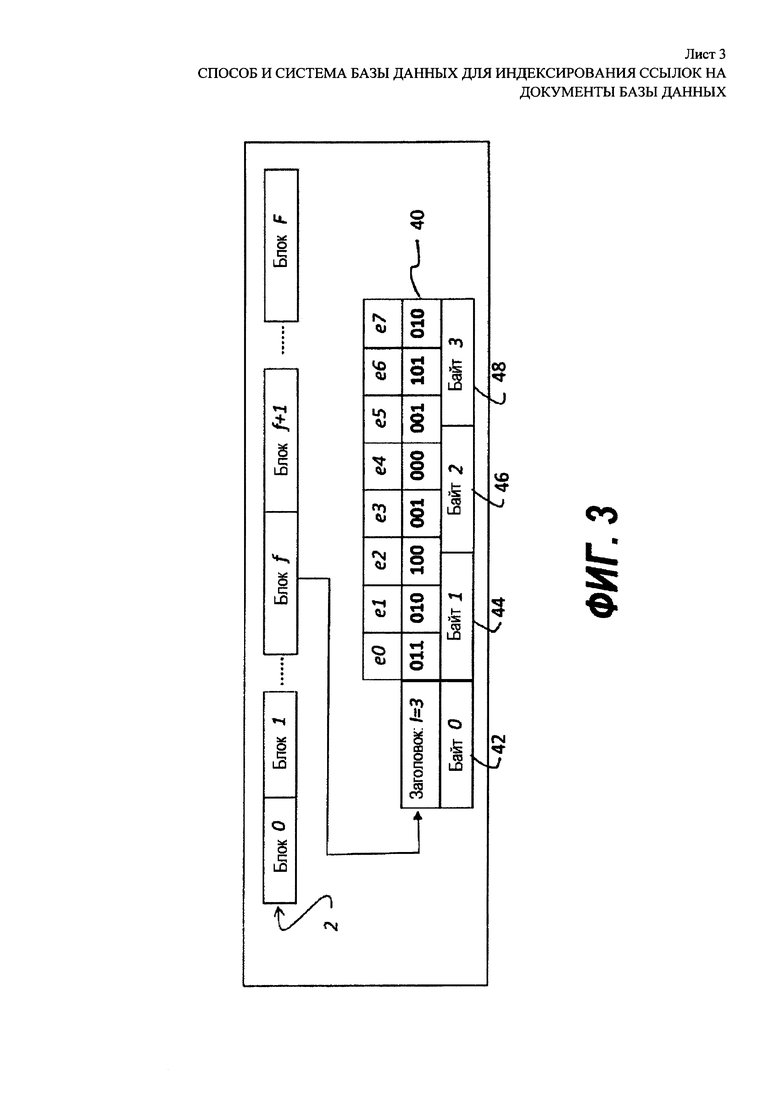
[00019] На Фиг. 3 представлена структура данных несжатого блока списка словопозиций. Блок состоит из блоков, в каждом из которых по восемь (8) элементов. Вышеупомянутый блок является блоком номер  в списке словопозиций; его содержимое схематично показано под номером 40. Длина элемента блока обозначает число бит, которое минимально необходимо для его бинарного представления; таким образом, наиболее короткое представление целого числа может быть названо «каноническим представлением». Когда целое число закодировано большим числом бит, чем необходимо для канонического представления, оно заполняется незначащими бинарными нулями (0) в верхних (левых) позициях. Блок включает в себя заглавный байт 42 и три (3) байта 44, 46, 48 данных. Заглавный байт 42 показывает, что все элементы блока/закодированы комбинацией длины
в списке словопозиций; его содержимое схематично показано под номером 40. Длина элемента блока обозначает число бит, которое минимально необходимо для его бинарного представления; таким образом, наиболее короткое представление целого числа может быть названо «каноническим представлением». Когда целое число закодировано большим числом бит, чем необходимо для канонического представления, оно заполняется незначащими бинарными нулями (0) в верхних (левых) позициях. Блок включает в себя заглавный байт 42 и три (3) байта 44, 46, 48 данных. Заглавный байт 42 показывает, что все элементы блока/закодированы комбинацией длины  , равной трем (3) битам. Этой длины достаточно для кодирования самых длинных элементов е2 и е6 блока , другие элементы блока обладают незначащими заполняющими битами. На Фиг. 3 представлена «немодифицированная» кодировка блока . Поскольку длина равна трем (3) битам и поскольку блок
, равной трем (3) битам. Этой длины достаточно для кодирования самых длинных элементов е2 и е6 блока , другие элементы блока обладают незначащими заполняющими битами. На Фиг. 3 представлена «немодифицированная» кодировка блока . Поскольку длина равна трем (3) битам и поскольку блок  содержит восемь (8) элементов, общая длина блока равна четырем (4) битам, т.е.
содержит восемь (8) элементов, общая длина блока равна четырем (4) битам, т.е. 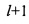 в байтах.
в байтах.
[00020] Способ ParaPFor определяет базовую длину b в количестве бит или, коротко, «встроенных» элементов. Элементы, которые не могут быть закодированы b битами, становятся усеченными значениями, которые также встраиваются в сжатый блок. Способ также определяет исключения, или модификации, для элементов блока, которые обладают длиной больше b бит. Измененный заголовок блока указывает на базовую длину b и позиции модификаций («позиции модификаций» р1, р2), каждая занимает три (3) бита. Более высокие значения каждого исключения («значения модификаций» v1, v2), представляющие разницу между фактическими значениями несжатых блоков и усеченных значений сжатых блоков, кодируются отдельно, до или после встроенных значений элементов.
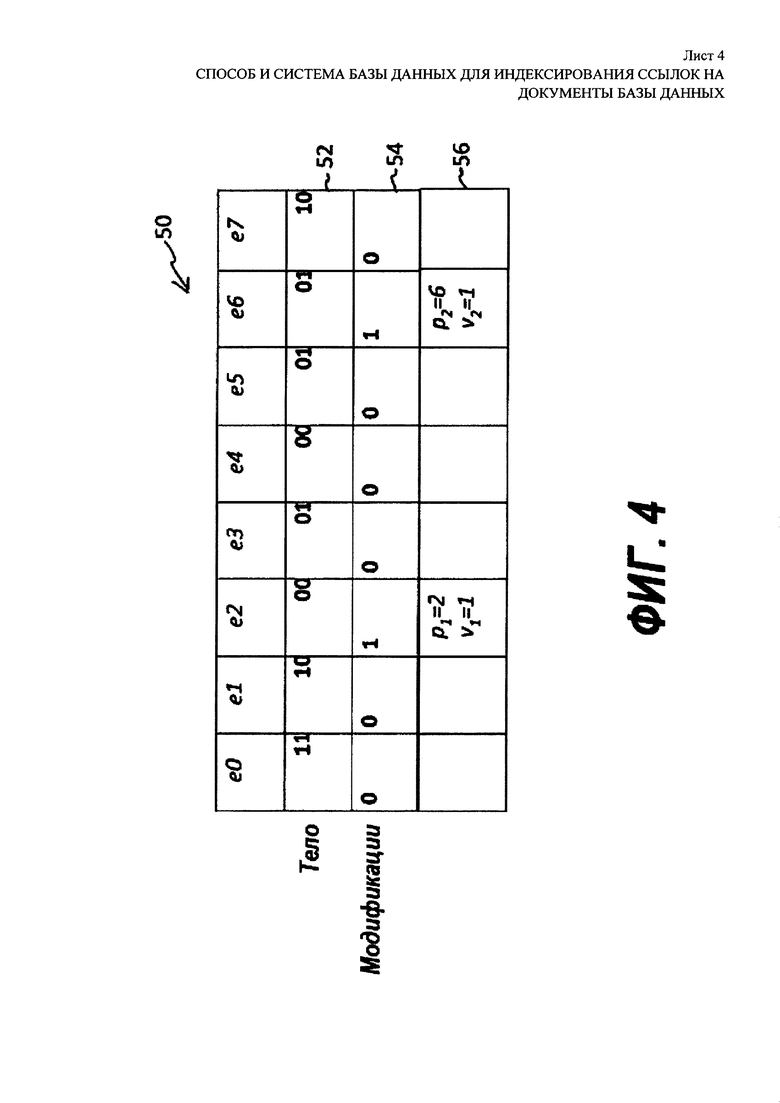
[00021] На Фиг. 4 показано определение модификации для блока списка словопозиций, представленного на Фиг. 3. Блок f, представленный на Фиг. 3, схематично представлен под номером 50, и содержит строку 52 тела, строку 54 значений модификаций и строку 56 признаков модификаций. Базовая длина b равна двум (2) битам, а тело блока состоит из двух (2) встроенных битов каждого элемента, причем элементы е2 и е6 были усечены. Значения модификации в ряду 52 равны либо «0» в позициях не-модификаций, либо «1» в позициях модификаций. Следует иметь в виду, что в конкретном примере, показанном здесь, значения модификаций ограничены максимально единицей (1), поскольку ни одно из значений не требует более трех (3) бит для кодировки, а базовая длина b равна двум (2) битам. Ряд 56 указывает на то, что есть две (2) модификации в позициях pi, которые равны 2 и 6, и что их значения vi оба равны единице (1).
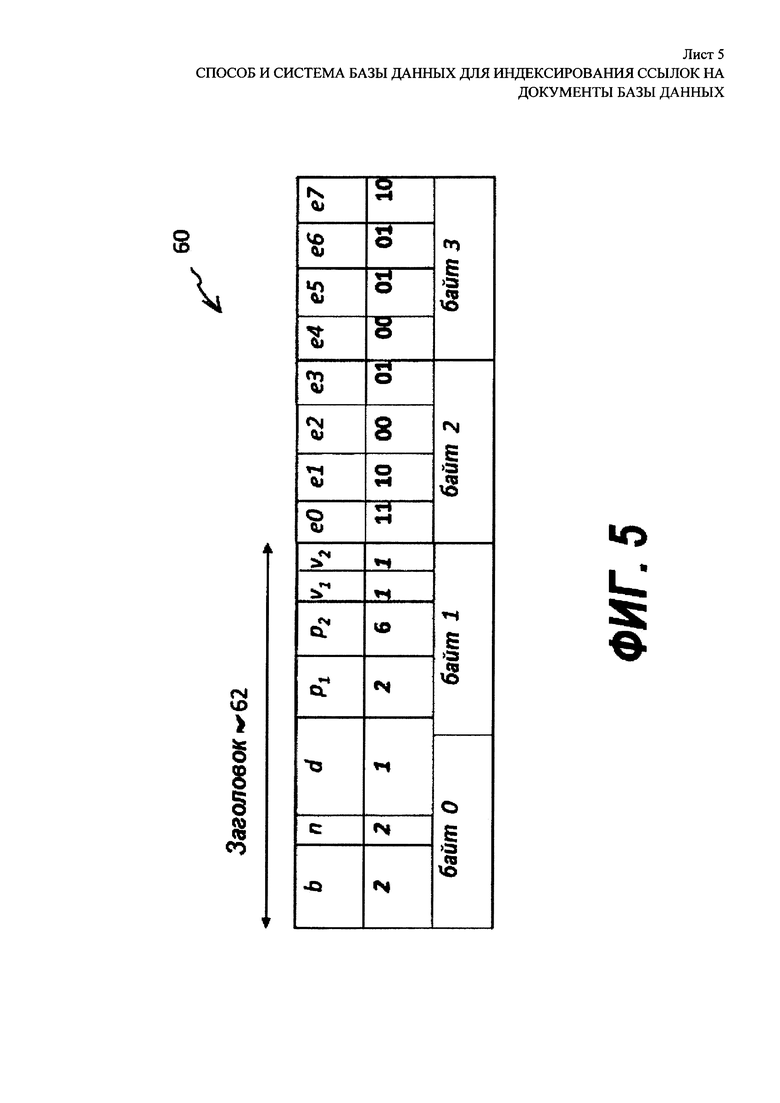
[00022] На Фиг. 5 показан обычный способ кодирования блока списка словопозиций, представленного на Фиг. 3, с определениями модификаций, показанными на Фиг. 4. Блок далее сжимается, как показано под номером 60. Используя кодирование ParaPFor, заголовок 62 блока задает общее число n модификаций, которое варьируется, например, от нуля (нет модификаций) до 2-3 модификаций. Заголовок 62 также содержит длину d каждого значения модификации в блоке; можно предположить, что все модификации обладают одинаковой длиной d, которая является длиной наиболее длинного значения модификации. Заголовок 62 далее содержит позиции p1, р2, … и значения модификаций v1, v2 … для всех n модификаций. Встроенные значения е0-е7, включая усеченные значения, если это возможно, добавляются в сжатый блок/60 после заголовка. Если какое-либо поле недостаточно велико, чтобы заполнить позицию сжатого блока f 60, то поле заполняется битами с незначащими нулями; это также применимо к значениям заголовков и встроенным значениям.
[00023] Способ ParaPFor обеспечивает чуть меньшее сжатие, чем обычный PFor или NewPFD, но обеспечивает большую скорость распаковки на специализированной архитектуре процессора с подходящим фактором SIMD-параллелизма, например, 32-потоковым параллелизмом, который может быть эффективно использован на графическом процессоре NVIDIATM GTX480. Способ ParaPFor, следовательно, может обеспечивать приемлемое соотношение коэффициента сжатия и скорости распаковки на подобных компьютерных системах. Тем не менее, существует большая семья процессоров общего назначения, обычно называемых «семья х86», которые содержат устройства от IntelTM, AMDTM, и некоторых других производителей, которые широко используются в компьютерных серверах с различной архитектурой, включая мощные мультипроцессорные серверы. Современные процессоры из семьи х86 снабжены наборами инструкций для так называемого «потокового SIMD-расширения» (SSE), которые обеспечивают параллельное выполнение одинаковых операций в банке из 8 16-битных регистров «короткого целого». Что позволяет достигать 8-потокового SIMD-параллелизма на каждом процессоре в сервере.
[00024] Для такой 8-потоковой SIMD-архитектуры, тем не менее, способ сжатия PFor или его известные модификации, включая ParaPFor, не обеспечивают оптимального баланса между плотностью сжатия и скоростью распаковки. Поскольку в коротком блоке из 8 элементов, конкретное указание на каждую позицию модификации становится неэффективным в отношении степени сжатия, по сравнению с простым перечислением комбинаций позиций модификаций. Также, повторяющиеся операции извлечения одного или нескольких номеров позиций и заголовка блока требуют времени и загружают процессор.
[00025] Следовательно, желательно обладать списком способов сжатия, которые предоставляют дальнейшие улучшения как в отношении плотности сжатия, так и скорости распаковки. Подобные улучшения будут особенно важны при использовании компьютерных архитектур с 8-потоковыми SIMD-расширениями или аналогичными конфигурациями.
[00026] В более общем случае, любой дальнейший прогресс в отношении плотности сжатия и скорости распаковки длинных списков, безусловно, желателен, и каждая новая технология сжатия списков, предоставляющая существенные преимущества по меньшей мере в одном из вышепредставленных параметров без существенных потерь в другом, является желательной. С учетом вышесказанного настоящая технология может быть описана, например, следующим образом: способ индексирования ссылок на документы базы данных, включающий: получение документа в базу данных с сервера; сохранение документа в базе данных; извлечение поискового термина из документа, в котором поисковый термин связан со списком словопозиций; разделение списка словопозиций на блоки, каждый из которых включает М ссылок базы данных; сжатие каждого блока в сжатый блок посредством: определения шаблона кодирования для каждого блока на основе значений всех М ссылок базы данных; кодирования содержимого блока посредством шаблона кодирования; нахождение записи таблицы шаблона кодирования, которая соответствует шаблону кодирования; ввода указателя, соответствующего найденной записи таблицы шаблона кодирования, в заголовок блока. В некоторых вариантах осуществления настоящей технологии список словопозиций включает в себя одну или несколько ссылок базы данных на документы, которые содержат поисковый термин. В некоторых вариантах осуществления в качестве М используют ненулевое положительное целое число кратное 8. В некоторых вариантах осуществления сохранение документа в базу данных включает в себя выбор из добавления документа в базу данных, обновления документа в базе данных, перезаписи документа в базе данных и модификации документа в базе данных. В некоторых вариантах осуществления документы сохраняют в базе данных независимо от поисковых терминов, которые они содержат. В некоторых вариантах осуществления настоящей технологии множество списков словопозиций соответствует множеству поисковых терминов, множество списков словопозиций формирует инвертированный индекс базы данных. В некоторых вариантах осуществления инвертированный индекс формирует двухмерную таблицу, в которой множество поисковых терминов является первым измерением, а списки словопозиций, соответствующие каждому из множества поисковых терминов, являются вторым измерением. В некоторых вариантах осуществления инвертированный индекс формирует непрерывный вектор, в котором за данным поисковым термином следует соответствующий список словопозиций, и в котором за списком словопозиций, который соответствует первому данному поисковому термину, идет следующий поисковый термин. В некоторых вариантах осуществления заголовок содержит один байт. В некоторых вариантах осуществления заголовок содержит один или несколько байт; заранее определенное значение первого байта заголовка указывает на наличие второго байта заголовка; два байта двухбайтового заголовка содержат заранее определенное значение и указатель, которые соответствуют найденной записи таблицы шаблонов кодирования. В некоторых вариантах осуществления заранее определенное значение включает в себя диапазон заранее определенных значений или флаг. В некоторых вариантах осуществления список словопозиций назначает монотонно возрастающие номера документов в базе данных. В некоторых вариантах осуществления первая ссылка базы данных в списке словопозиций представляет собой номер первого документа; а следующая ссылка базы данных в списке словопозиций является дельта-ссылкой на основе разницы между номером первого документа и номером следующего документа. В некоторых вариантах осуществления набор последовательных ссылок базы данных в списке словопозиций включает в себя набор дельта-ссылок. В некоторых вариантах осуществления данная дельта-ссылка равна номеру данного документа с вычетом номера предыдущего документа. В некоторых вариантах осуществления данная дельта-ссылка равна номеру данного документа с вычетом номера предыдущего документа минус один. В некоторых вариантах осуществления способ включает в себя ввод в блок последовательности М усеченных ссылок, каждая усеченная ссылка включает в себя по меньшей мере b значимых бит соответствующей одной из М ссылок базы данных. В некоторых вариантах осуществления определение шаблона кодирования включает в себя: определение числа n модификаций в соответствии с номером ссылок среди М ссылок базы данных, который больше или равен 2b; и если n>0: определение для каждой из n модификаций значения νk модификации путем удаления b наименее значимых битов из соответствующей одной из М ссылок базы данных, которые больше или равны 2b, причем k находится в пределах от 1 до n, и определение для каждой из n модификаций, позиции pk модификации, соответствующей позиции в диапазоне от 0 до М-1, из соответствующей одной из М ссылок базы данных, которая больше или равна 2b; причем шаблон кодирования включает в себя b, n, p1 … pn, v1 … vn. В некоторых вариантах осуществления если n=0, шаблон кодирования включает в себя b, n. В некоторых вариантах осуществления М равно 4 и n равно 0 или равно 1. В некоторых вариантах осуществления осуществляют: определение для каждого блока длины d модификации как длины, выраженной в битах, наиболее длинной из n модификаций; причем шаблон кодирования включает в себя b, n, d, p1 … pn, v1 … vn. В некоторых вариантах осуществления заголовок включает в себя явное значение по меньшей мере одного из b, n, p1 … pn, v1 … vn. В некоторых вариантах осуществления определение шаблона кодирования для данного блока включает в себя: определение трех наиболее длинных ссылок базы данных среди М ссылок базы данных данного блока; и выбор значения b, достаточного для кодирования третьей по длине из М ссылок базы данных; причем n не превышает 2. В некоторых вариантах осуществляют независимый выбор значения b для каждого блока. В некоторых вариантах осуществляют выбор значения b для каждого блока таким образом, чтобы и не превышало 2. В некоторых вариантах осуществляют независимый выбор значения b для данного блока в соответствии с наиболее длинной из М ссылок базы данных данного блока. В некоторых вариантах осуществления таблица шаблона включает в себя 256 записей таблицы шаблона кодирования для 256 соответствующих шаблонов кодирования. В некоторых вариантах осуществления первое подмножество 256 шаблонов кодирования включает в себя множество значений b; и каждый шаблон кодирования первого подмножества определяет n=0. В некоторых вариантах осуществления ссылки базы данных блока, которые соответствуют шаблону кодирования первого подмножества, не являются сжатыми. В некоторых вариантах осуществления второе подмножество 256 шаблонов кодирования включает в себя наиболее часто используемые шаблоны кодирования. В некоторых вариантах осуществления большая часть шаблонов кодирования второго подмножества обладает меньшими значениями b, чем шаблоны кодирования первого подмножества. В некоторых вариантах осуществления 256 шаблонов кодирования включают в себя: 24 шаблона кодирования для 24 отдельных значений b в сочетании с n=0; 120 шаблонов кодирования включаются в себя b, n=1, p1, v1, каждый из 120 шаблонов кодирования обладает одной модификацией, одно из 5 значений b, одно из 3 отдельных значений модификаций и одну из 8 отдельных позиций модификаций; и 112 шаблонов кодирования содержат дескрипторы b, n=2, p1, p2, 1,1, каждый из 112 шаблонов кодирования обладает двумя значениями модификации равными 1, одним из 4 различных значений b, причем p1 и р2 формируют 28 различных комбинаций из позиций модификации для двух модификаций. В некоторых вариантах осуществляют сортирование 256 шаблонов кодирования с позициями в порядке возрастания суммы b с длиной v; и для данной суммы, сортирование шаблонов кодирования с позициями с возрастанием значений b; и определение шаблона кодирования для данного блока включает в себя поиск шаблона кодирования путем просмотра отсортированных шаблонов кодирования, начиная с позиции, соответствующей длине наиболее длинной из М ссылок базы данных из данного блока. Также настоящая технология описывает систему базы данных для индексирования ссылок на документы базы данных, включающую: ввод для получения документа с сервера; базу данных для сохранения документа; память, содержащую инвертированный индекс, включающий множество списков словопозиций, и содержащий таблицу шаблонов кодирования; и процессор, функционально соединенный с вводом, с базой данных и памятью, и выполненный с возможностью: извлечения поискового термина из документа, причем поисковый термин связан в памяти со списком словопозиций; разделения в памяти списка словопозиций на блоки, каждый из которых включает М ссылок базы данных; для каждого блока осуществления сжатия в сжатый блок посредством: определения шаблона кодирования для блока на основе значений всех М ссылок базы данных; кодирования содержимого блока посредством шаблона кодирования; нахождения записи таблицы шаблона кодирования, соответствующей шаблону кодирования; сохранения в памяти, указателя, указывающего на найденную запись таблицы шаблонов кодирования в заголовке блока.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[00027] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[00028] На Фиг. 1 представлено расширенное изображение списка словопозиций в табличной форме;
[00029] На Фиг. 2 показано расширенное изображение списка словопозиций в одновекторной форме;
[00030] На Фиг. 3 показана структура данных несжатого блока списка словопозиций;
[00031] На Фиг. 4 показано определение модификаций для блока списка словопозиций, представленного на Фиг. 3;
[00032] На Фиг. 5 показан обычный способ кодирования блока списка словопозиций, представленного на Фиг. 3, с определениями модификаций, показанными на Фиг. 4.
[00033] На Фиг. 6 представлена блок-схема этапов способа индексирования ссылок на документы в базе данных в соответствии с вариантом осуществления технологии;
[00034] На Фиг. 7 представлена блок-схема этапов определения шаблона кодирования блока в соответствии с вариантом осуществления технологии, показанном на Фиг. 6;
[00035] На Фиг. 8 представлено использование заголовка, связывающего блок с шаблоном кодировки записи в таблице в соответствии с профилем блока;
[00036] На Фиг. 9 представлена блок-схема этапов способа нахождения в базе данных документов, которые содержат поисковые термины в соответствии с вариантом осуществления технологии;
[00037] На Фиг. 10 представлена блок-схема этапов распаковки блока в соответствии с первым вариантом осуществления, представленном на Фиг. 9;
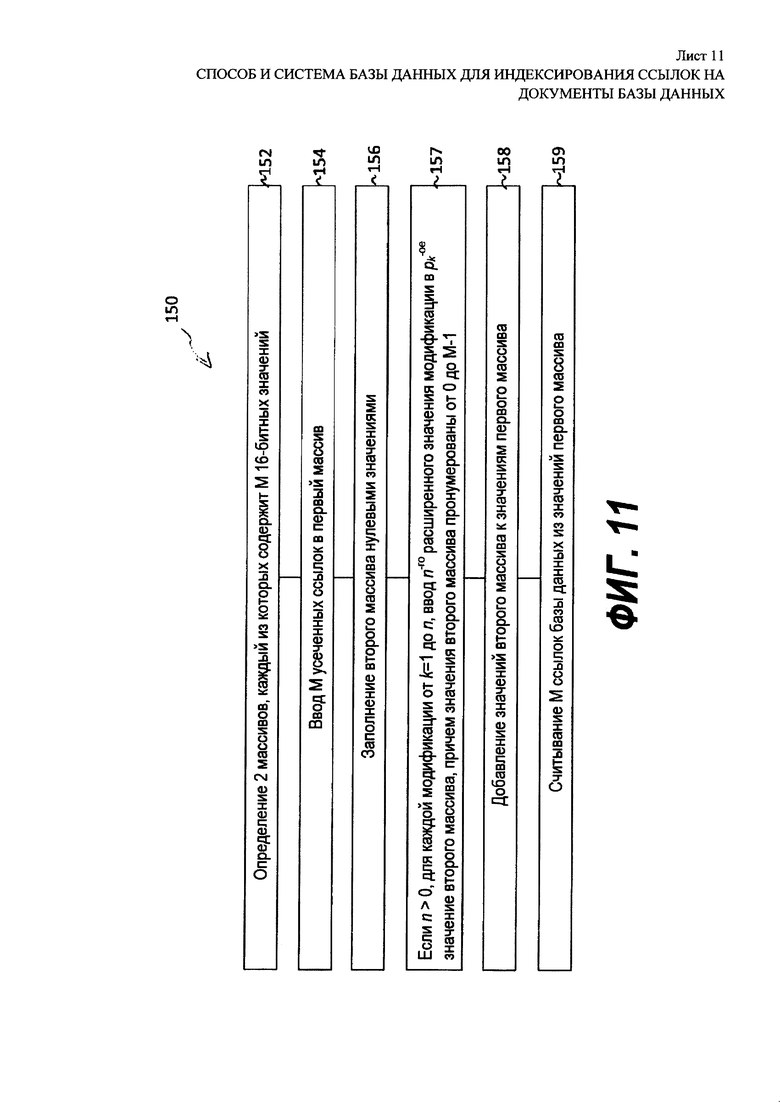
[00038] На Фиг. 11 представлена блок-схема этапов распаковки блока в соответствии со вторым вариантом осуществления технологии, показанном на Фиг. 9;
[00039] На Фиг. 12 представлен основанный на массиве вариант осуществления способа распаковки блока;
[00040] На Фиг. 13 представлено применение заголовка, который связывает сжатый блок с записью в таблице процедуры декодирования в соответствии с профилем блока;
[00041] На Фиг. 14 представлена последовательность выполнения декодирования блока;
[00042] На Фиг. 15 представлена процедура декодирования с помощью последовательности, показанной на Фиг. 14;
[00043] На Фиг. 16 представлена процедура пропуска, использованная последовательностью, показанной на Фиг. 14; и
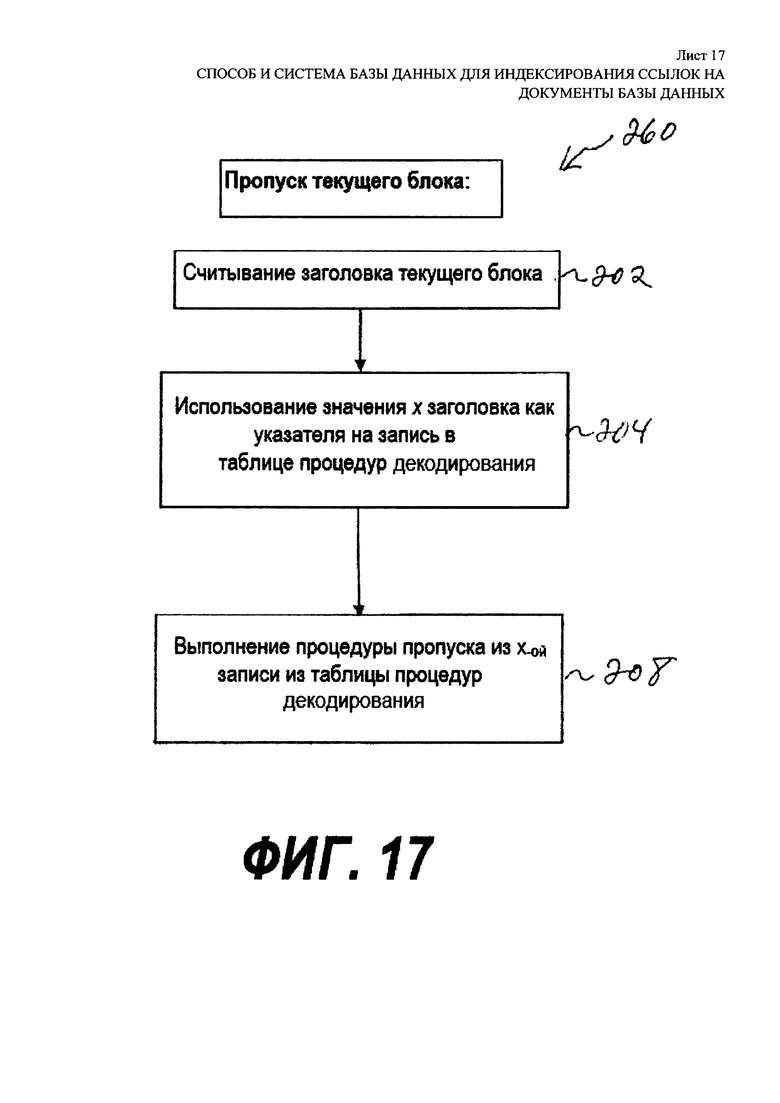
[00044] На Фиг. 17 представлена последовательность для пропуска текущего блока;
[00045] На Фиг. 18 представлена блок-схема системы базы данных, выполненная в соответствии с вариантом осуществления технологии.
ОСУЩЕСТВЛЕНИЕ ТЕХНОЛОГИИ
[00046] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов. Следует иметь в виду, что некоторые аспекты данной технологии, проистекающие из попыток достичь вышеупомянутой цели, могут удовлетворять другим целям, отдельно не указанным здесь.
[00047] Дополнительные и/или альтернативные характерные черты, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Сохранение и индексирование документов в базе данных
[00048] На Фиг. 6 представлена блок-схема этапов способа индексирования ссылок на документы в базе данных в соответствии с вариантом осуществления технологии; Последовательность 100 содержит множество этапов, некоторые из которых могут выполняться в вариативном порядке, а некоторые этапы могут выполняться одновременно. Последовательность 100 включает в себя определение профиля блока. Профиль блока основан на количестве бит, которые необходимы для кодирования элементов блока, включая число бит, которое достаточно для кодирования большинства элементов блока. Профиль блока включает в себя нумерацию исключений и способ кодировки исключений. Последовательность 100 определяет шаблон кодировки блока на основе его профиля. Последовательность 100 включает в себя этап 102 получения документа в базу данных с сервера. Документ сохраняется в базе данных на этапе 104. На этапе 106 поисковый термин, связанный со списком словопозиций, извлекается из документа. Список словопозиций, который включает в себя одну или несколько ссылок базы данных на документы, содержащие поисковый термин, разделяется на блоки на этапе 108, и каждый блок содержит М ссылок базы данных. Число М может представлять собой любое целочисленное значение, например, ненулевое положительное число, кратное восьми (8). Следующие три (3) этапа выполняются на каждом блоке. На этапе 110 шаблон кодирования определен на основе значений всех М ссылок базы данных. Запись в таблице шаблона кодирования, соответствующая шаблону кодирования, обнаруживается на этапе 112. На этапе 114 в заголовок блока добавляется указатель, соответствующий обнаруженной записи в таблице шаблона кодирования.
[00049] В последовательности 100 полученный документ может быть ранее сохранен в базе данных в том же варианте или в другом варианте. Следовательно, этап 104 сохранения документа в базе данных может включать в себя любое из: добавление документа в базу данных, обновления документа в базе данных, перезапись документа в базе данных или модификацию документа в базе данных. Сохранение документов в базе данных может выполняться любым известным способом и не обязательно зависит от поисковых терминов, которые могут содержаться в документах.
[00050] База данных может сохранять множество списков словопозиций, соответствующих множеству поисковых терминов, множество списков словопозиций формирует инвертированный индекс базы данных, как было описано в вышепредставленных описаниях Фиг. 1 и Фиг. 2. Инвертированный индекс, следовательно, может создавать двухмерную таблицу, в которой множество поисковых терминов является первым измерением, а списки словопозиций, соответствующие каждому из множества поисковых терминов, являются вторым измерением. Альтернативно, инвертированный индекс может создавать непрерывный вектор, в котором за первым данным поисковым термином следует соответствующий список словопозиций, а за списком словопозиций, соответствующем первому поисковому термину, следует следующий поисковый термин.
[00051] На этапе 114 указатель, соответствующий найденной записи таблицы шаблона кодирования, может быть добавлен в однобайтный заголовок блока. В одном варианте, заголовок может содержать один или несколько байт. Заранее определенное значение первого байта заголовка может указывать на наличие или отсутствие второго байта заголовка. Два байта двухбайтного заголовка далее включают в себя заранее определенное значение и указатель, соответствующий найденной записи таблицы шаблона кодирования. Это заранее определенное значение может, например, принимать форму флага, что указывает на наличие второго байта заголовка. Заранее определенное значение может быть значение с заранее определенным диапазоном для первого байта заголовка.
[00052] С учетом одновременно Фиг. 1, Фиг. 2 и Фиг. 6, один или несколько списков словопозиций может назначить монотонно возрастающие номера документов в базе данных, в которой первая ссылка базы данных ссылка в списке словопозиций представляет собой номер первого документа, а следующая ссылка базы данных в списке словопозиций представляет собой дельта-ссылку на основе разности между номером первого документа и номером следующего документа. Следовательно, набор последовательных ссылок базы данных в списке словопозиций может включать в себя набор дельта-ссылок. Данная дельта-ссылка может быть вычислена и быть равной номеру данного документа с вычетом номера предыдущего документа. Тем не менее, пока список словопозиций назначает монотонно возрастающие номера документов в базе данных, дельта-ссылка вычисляется как простая разница между номером данного документа и номером предыдущего документа, которая всегда будет составлять по меньшей мере единицу (1) или более. С учетом этого, в данном варианте можно рассчитать, что данная дельта-ссылка равна номеру данного документа с вычетом номера предыдущего документа минус один (1). Естественно, способ сжатия, использующий способ вычисления дельта-ссылки, будет связан со способом распаковки, который использует этот способ вычисления. Это решение сохраняет один (1) бит из каждый дельта-ссылки.
[00053] Определение шаблона кодирования на этапе 110 может выполняться различными способами. На Фиг. 7 представлена блок-схема этапов определения шаблона кодирования блока в соответствии с вариантом осуществления технологии, показанном на Фиг. 6. Последовательность 120 содержит множество этапов, некоторые из которых могут выполняться в вариативном порядке, и по меньшей мере некоторые этапы могут выполняться одновременно. В последовательности 120, последовательность М усеченных ссылок сначала добавляется в блок на этапе 122, каждая усеченная ссылка содержит по меньшей мере b значимых бит из соответствующей одной из М ссылок базы данных. Для того чтобы определить шаблон кодирования, число n модификаций определяется на этапе 124 в соответствии с номером ссылок среди М ссылок базы данных, который больше или равен 2b. Постоянное значение b, которое является общим для многих блоков, может быть использовано в некоторых приложениях. В других приложениях, значение b может быть выбрано независимо для каждого блока. В частности, значение b для каждого блока может быть выбрано таким образом, чтобы n не превышало желаемого значения, например, не превышало двух (2) модификаций. Выбор значения b в соответствии с наибольшей из М ссылок базы данных заданного блока обеспечивает то, что n остается равным нулю (0).
[00054] Если n>0, то значение vk модификации вычисляется на этапе 126 для каждого из n модификаций путем удаления b наименее значимых битов из соответствующей одной из М ссылок базы данных, которые больше или равны 2b, причем к находится в пределах от 1 до n. Если n>0, позиция pk модификации, которая соответствует позиции в пределах от 0 до М-1 соответствующей одной из М ссылок базы данных, которая больше или равна 2b, определяется на этапе 128 для каждой из n модификаций. Из значений, которые определяются на этапах 122, 124, 126 и 128, определяется шаблон 30 кодирования как комбинация дескрипторов, которая включает в себя b, n, p1 … pn, v1 … vn. Для данного блока, значение b может быть одинаковым для всех элементов, которые содержатся в блоке. В подобном случае, блок не содержит модификаций и n равно нулю (0). Шаблон кодирования для этого блока, следовательно, содержит b, n.
[00055] Следует отметить, что варианты шаблона кодирования могут содержать различные дескрипторы b, n, p1 … pn, v1 … vn, которые могут быть перечислены в любом порядке.
[00056] Предусмотрено большое число вариантов для модификации последовательности 120 в соответствии с тем, что необходимо для конкретного приложения. Для некоторых приложений, например, для некоторых конфигураций процессора, число М может быть равно 4, и значение b может быть выбрано таким образом, чтобы n равнялось 0 или 1. В других приложениях, длина d модификации может быть вычислена для каждого блока как выраженная в битах длина наиболее длинной из n модификаций. В таких приложениях шаблон кодирования может быть определен как комбинация, включающая в себя b, n, d, p1 … pn, v1 … vn.
[00057] Как упоминалось ранее, запись таблицы шаблона кодирования, которая соответствует шаблону кодирования, обнаруживается на этапе 112, и указатель, соответствующий найденной записи таблицы шаблона кодирования, вводится в заголовок блока на этапе 114. Следовательно, заголовок может включать в себя простой указатель на таблицу шаблона кодирования. Тем не менее, в одном варианте, заголовок может дополнительно содержать явное значение по меньшей мере для одного из дескрипторов b, n, p1 … pn, v1 … vn. Без установления ограничений, подобное явное значение может быть введено во второй байт двухбайтного заголовка.
[00058] На Фиг. 8 представлено использование заголовка для связывания блока с шаблоном кодировки записи в таблице в соответствии с профилем блока. Блок f (см. 40 на Фиг. 3) был сжат в сжатый блок 70 с помощью способа индексирования ссылок на документы в базе данных, который описан здесь. Его значения [3,2,4,1,0,1,5,2], представленные как [11,10,100,1,0,1,101,10] в бинарной форме, были сжаты с помощью М=8 значений, усеченных до b=2 бит, которые распределяются в байтах 1 и 2, которые вместе показаны как тело 74 на Фиг. 8, причем n=2 модификации со значениями v1=v2=1, которые находятся в позициях p1=2 и р2=6, которые были пронумерованы от 0 до М-1=7. Число модификаций, значений модификаций и позиций модификаций никак явно не выражено в сжатом блоке 70. Вместо этого, таблица дескрипторов, содержащая набор значений b, n, p1 … pn, v1 … vn, которые определяют шаблон кодирования для сжатого блока 70, находится в строке x таблицы 72 шаблона кодирования. Указатель на ряд x находится в заголовке сжатого блока 70. Как показано, таблица 72 шаблона кодирования включает в себя 256 записей, пронумерованных от 0 до 255. Поскольку диапазон значений может быть закодирован с помощью восьми (8) бит, указатель на ряд x может сохраняться в заголовке 76 сжатого блока 8-битиого указателя, который занимает 0 байт сжатого блока 70. М=8 усеченных значений сжатого блока 70 занимает b=2 байт. Как будет показано далее, варианты таблицы шаблона кодирования могут включать в себя различные номера записей и могут относиться к заголовкам различной длины, например, двухбайтовым заголовкам.
[00059] Эффективность декодирования блока, закодированного с помощью последовательности 100 и 120, может зависеть от различных факторов, включая, например, тип процессора, который был использован системой базы данных. Одним из факторов, который может влиять на эффективность декодирования, является число модификаций в данном блоке. Для некоторых архитектур процессора может быть желательно ограничить число модификаций до двух (2) модификаций на каждый блок. Определение шаблона кодирования для данного блока может включать в себя идентификацию трех (3) наибольших ссылок базы данных среди М ссылок базы данных в данном блоке. Значение b, достаточное для кодирования третьей по величине из М ссылок базы данных далее выбирается таким образом, чтобы число n модификаций не превышало двух (2). Естественно, этот процесс может быть изменен таким образом, чтобы значение n не было ограничено каким-либо желаемым числом, путем идентификации in+1 наибольших ссылок базы данных среди М ссылок базы данных блока, и выбора значения b, достаточного для кодирования наименьшего среди наибольших из М ссылок базы данных.
[00060] Таблица 72 шаблона кодирования может включать в себя, например, 256 записей, соответствующих 256 шаблонам, и эти записи могут быть разделены на секции таким образом, чтобы блоки конкретного приложения были сжимаемыми.
[00061] Например, первое подмножество 256 шаблонов кодирования включает в себя множество значений b, каждый шаблон кодирования из первого подмножества определяет n=0, первое подмножество, следовательно, включает в себя один или несколько шаблонов плоского кодирования. Ссылки базы данных блока, которые соответствуют шаблону плоского кодирования, не являются сжатыми. Второе подмножество из 256 шаблонов кодирования может содержать наиболее часто используемые шаблоны кодирования. Большая часть шаблонов кодирования второго подмножества может обладать меньшими значениями b, чем шаблоны кодирования первого подмножества.
[00062] В другом варианте 256 шаблонов кодирования могут включать в себя подмножества из 24, 120 и 112 шаблонов кодирования. Первые 24 шаблона кодирования предназначены для 24 различных значений b в сочетании с n=0. Следующие 120 шаблонов кодировки содержат дескрипторы b, n=1, p1, v1, каждый из 120 шаблонов кодировки обладает одной модификацией, одним из 5 различных значений b, одним из 3 различных значений модификации и одной из 8 различных позиций модификации. Оставшиеся 112 шаблоны кодирования содержат дескрипторы b, n=2, p1, p2, 1, 1, каждый из 112 шаблонов кодирования обладает двумя значениями модификации равными 1, одним из 4 различных значений b, причем p1 и р2 формируют 28 различных комбинаций из позиций модификации для двух модификаций.
[00063] Специалисты в данной области техники смогут найти другие способы разделения на секции записей из таблицы 72 шаблонов кодирования в соответствии с нуждами конкретного приложения. Например, другой вариант может включать в себя сортирование 256 шаблонов кодирования с позициями в порядке увеличения суммы значений b с длиной v. Естественно, значение b выражено в количестве бит, и длина v также выражена в количестве бит. Для всех записей таблицы шаблонов кодирования, обладающих данной суммой, выраженной в количестве бит, шаблоны кодирования могут быть сортированы в порядке увеличения значений b - и убывания длины v. Далее, определение шаблона кодирования для данного блока может включать в себя поиск шаблона кодирования путем просмотра отсортированных шаблонов кодирования, начиная с позиции, которая соответствует длине наиболее длинной из М ссылок базы данных из данного блока. Этот способ поиска в таблице 72 шаблонов кодирования позволяет быстро находить подходящий шаблон кодирования для данного блока.
Поиск документов в базе данных
[00064] После того как документы были сохранены в базе данных, и после того как поисковые термины были извлечены из тех документов, которые были использованы для заполнения инвертированного индекса в соответствии с одним из различных вариантов осуществления способа индексирования ссылок на документы в базе данных, который был описан выше, пользователь может вводить в базу данных один или несколько поисковых запросов для того чтобы получить документы, содержащие один или несколько поисковых терминов. Поиск может выполняться независимо для каждого поискового термина, поэтому следующее описание дано для поискового запроса, содержащего один поисковый термин. В том случае, когда, например, пользователь вводит два поисковых термина, тот же процесс может быть выполнен дважды, т.е. по одному разу для каждого поискового термина. Ответ может содержать, например, список документов, которые содержат оба этих термина. Альтернативно, ответ может содержать список документов, которые содержат любой из поисковых терминов, представляя сначала наиболее релевантные документы, в которых содержатся оба этих поисковых термина.
[00065] На Фиг. 9 представлена блок-схема этапов способа нахождения документов в базе данных, которая содержит поисковые термины в соответствии с одним вариантом осуществления технологии. Последовательность 130 содержит множество этапов, некоторые из которых могут выполняться в вариативном порядке, а некоторые этапы могут выполняться одновременно. В последовательности 130 на этапе 132 база данных получает от клиента поисковый термин, связанный со списком словопозиций. Как было описано выше, список словопозиций разделен на блоки, и каждый блок содержит заголовок и М усеченных ссылок. Указатель из заголовка конкретного блока списка словопозиций на этапе 134. Указатель используется на этапе 136 для извлечения протокола декорирования из таблицы протоколов декодирования, причем протокол декодирования определяет шаблон кодирования для конкретного блока.
[00066] Различные практические осуществления способа нахождения документов в базе данных могут отражать соответствующие варианты осуществления способа индексирования ссылок на документы в базе данных. Соответственно, в одном или нескольких вариантах осуществления технологии список словопозиций, связанный с поисковым термином, может включать в себя одну или несколько ссылок базы данных на документы, которые содержат поисковый термин. Число М может представлять собой любое целочисленное значение, например, ненулевое положительное число, кратное восьми (8). База данных может сохранять множество списков словопозиций, соответствующих множеству поисковых терминов, множество списков словопозиций формирует инвертированный индекс базы данных, как было описано в вышепредставленных описаниях Фиг. 1 и Фиг. 2.
[00067] Сжатый список словопозиций формируется как набор блоков, содержащих первый заголовок, первый соответствующий набор М сжатых элементов, второй заголовок, второй соответствующий набор М сжатых элементов и так далее. Длина данного блока явно или неявно выражена в заголовке данного блока. Следовательно, данный блок необходимо по меньшей мере частично декодировать для определения его длины, если желательно знать позицию заголовка следующего блока. При просмотре списка словопозиций этап 134 считывания указания из заголовка текущего блока списка словопозиций может соответственно включать в себя, для первого блока, считывание начального заголовка списка словопозиций. Заголовок, из которого прочитывается указатель, может включать в себя один или несколько байт. Заранее определенное значение первого байта заголовка может указывать на наличие или отсутствие второго байта заголовка. Два байта двухбайтного заголовка далее включают в себя заранее определенное значение и указатель. Это заранее определенное значение может, например, принимать форму флага, что указывает на наличие второго байта заголовка. Заранее определенное значение может быть значение с заранее определенным диапазоном для первого байта заголовка.
[00068] Один или несколько вариантов списка словопозиций может назначать монотонно возрастающие номера документов в базе данных, причем ссылка первой базы данных в первом списке словопозиций является номером первого документа, а следующая ссылка базы данных в списке словопозиций является дельта-ссылкой на основе разницы между номером первого документа и номером следующего документа. Выражаясь иначе, первая ссылка базы данных в списке словопозиций может быть истолкована как дельта-ссылка в отношении 0-ой записи списка словопозиций, которая соответствует началу списка словопозиций. Следовательно, набор последовательных ссылок базы данных в списке словопозиций может включать в себя набор дельта-ссылок. Данная дельта-ссылка может быть вычислена и быть равной номеру данного документа с вычетом номера предыдущего документа. Тем не менее, пока список словопозиций назначает монотонно возрастающие номера документов в базе данных, дельта-ссылка вычисляется как простая разница между номером данного документа и номером предыдущего документа, которая всегда будет составлять по меньшей мере единицу (1) или более. С учетом этого, в одном варианте данная дельта-ссылка может быть вычислена и быть равной номеру данного документа с вычетом номера предыдущего документа минус один (1). Естественно, способ сжатия, использующий этот способ вычисления дельта-ссылки будет связан со способом распаковки, который также использует этот способ вычисления. Это решение сохраняет один (1) бит из каждый дельта-ссылки.
[00069] Как и в случае со способом индексирования ссылок на документы в базе данных, шаблон кодирования текущего блока может содержать базовую длину b из М усеченных ссылок из текущего блока, и число n модификаций в текущем блоке. Если n>0, профиль также включает в себя одно или несколько значений vk модификации текущего блока, в котором k находится в пределах от 1 до n. Если n>0, профиль также включает в себя одно или несколько позиций pk модификации в текущем блоке, в котором pk находится в диапазоне от 0 до М-1. Таблица протокола декодирования может включать в себя таблицу дескрипторов, определяющих b, n, p1 … pn, v1 … vn для множества шаблонов кодирования. В целом, длина текущего блока определяется длиной заголовка и шаблоном кодирования, что, в свою очередь, определяет длину сжатых элементов в блоке.
[00070] Протокол декодирования, который определяет шаблон кодирования для текущего блока, может быть определен различными способами. На Фиг. 10 представлена блок-схема этапов распаковки блока в соответствии со первым вариантом осуществления технологии, показанном на Фиг. 9; Последовательность 140 содержит множество этапов, некоторые из которых могут выполняться в вариативном порядке, и по меньшей мере некоторые этапы могут выполняться одновременно. В последовательности 140 текущий блок подвергается распаковке путем считывания в текущем блоке на этапе 142 b⋅M бит, которые содержат 1 усеченных ссылок, причем M-n из М усеченных ссылок являются ссылками базы данных. Эти M-n ссылок базы данных либо напрямую указывают на документы базы данных, либо, если они являются дельта-ссылками, могут напрямую быть использованы для вычисления ссылок на документы в базы данных. Если n>0, то текущий блок дополнительно распаковывается на этапе 144 путем вычисления для каждой модификации от k=1 до n расширенного значения модификации как vk⋅2b и путем добавления расширенного значения модификации к pk-ой из М усеченных ссылок, пронумерованных от 0 до М-1 для предоставления n дополнительных ссылок базы данных. После того как текущий блок был полностью сжат, становится известна общая длина текущего блока, следующий указатель может быть прочитан из следующего заголовка следующего текущего блока списка словопозиций, следующий заголовок следует непосредственно за М усеченных ссылок текущего блока. Следующий указатель далее может быть использован для извлечения следующего протокола декодирования для распаковки следующего текущего блока. Полный список ссылок базы данных на документы из базы данных, которые содержат поисковый термин, может быть получен путем считывания полного списка словопозиций.
[00071] На Фиг. 11 представлена блок-схема этапов распаковки блока в соответствии со вторым вариантом осуществления технологии, показанном на Фиг. 9; Последовательность 150 включает в себя множество этапов, некоторые из которых могут выполняться в вариативном порядке, и по меньшей мере некоторые этапы могу выполняться одновременно. Этапы последовательности 150 выполняются по кодовым инструкциям, назначенными указателем из заголовка текущего блока. На Фиг. 12 представлен основанный на массиве вариант осуществления способа распаковки блока. На Фиг. 12 показано два байта, которые содержат М=8 значений, усеченных до b=2 бит, два байта вместе представляют собой тело в вышепредставленном описании Фиг. 8. Опираясь одновременно на Фиг. 11 и Фиг. 12, последовательность 150 включает в себя этап 152 определения двух (2) массивов 160 и 162, каждый из которых содержит М полей данных одинакового размера. На этапе 154 М усеченных ссылок добавляются в М полей данных первого массива 160. На этапе 156 М полей данных второго массива 162 заполняются нулевыми значениями. На этапе 157, если n>0, для каждой в модификации от k=1 до n, расширенное значение n-ной модификаций добавляется в поле pk данных второго массива 162. Следует отметить, что для этого М полей данных второго массива 162 пронумеровано от 0 до М-1, этот диапазон соответствует диапазону значений pk. Значения второго массива 162 добавляются к значениям первого массива 160 на этапе 158, предоставляя декодированный блок 164. Естественно, значения первого массива 160 могут быть добавлены к значениям второго массива 162, предоставляя тот же результат.
[00072] Поля данных первого и второго массивов 160 и 162, каждое содержит L байт, причем L является ненулевым позитивным целым числом. Когда в данном блоке содержится ссылка базы данных, превышающая 2L⋅8-1, эта ссылка базы данных не может быть расположена в поле данных первого или второго массива 160, 162. В этом случае блок обладает шаблоном кодирования, содержащим b>L⋅8 и n=0. В качестве неограничивающего примера, где L равно двум (2) байтам, ссылка базы данных, превышающая 65535 не может быть введена в два массива, и блок, который содержит эту ссылку, обладает шаблоном кодирования с b>16 и n=0.
[00073] На Фиг. 13 представлено использование заголовка, связывающего блок с записью таблицы процедуры декодирования в соответствии с профилем блока. Сжатый блок 70, представленный в предшествующем описании Фиг. 8, содержит заголовок 76 и два байта, которые вместе показаны как тело 74, два байта содержат М=8 значений, усеченных до b=2 бит. Таблица 90 процедур декодирования включает в себя, в неограничивающем примере, 256 записей, пронумерованных от 0 до 255, и соответствующих 256 записям из таблицы 72 шаблона кодирования на Фиг. 8. Заголовок 76 включает в себя тот же 8-битный заголовок, обладающий значением, которое назначает ряд x таблицы 90 процедур декодирования. В первом варианте различные ряды таблицы 90 процедуры декодирования могут включать в себя ту же или эквивалентную таблицу дескрипторов b, n, p1 … pn, v1 … vn, что находится в таблице 72 шаблона кодирования, и сжатый блок 70 может быть распакован путем изменения М усеченных значением при добавлении значений vk от n модификаций к релевантным усеченным значениям, причем релевантные значения назначены позициями pk модификаций.
[00074] Вместо предоставления таблицы дескрипторов, определяющей b, n, p1 … pn, v1 … vn для множества шаблонов кодирования, протокол декодирования может использовать кодовые инструкции для распаковки текущего блока с помощью b, n, p1 … pn, v1 … vn. Таблица протокола декодирования может включать в себя кодовые инструкции или может содержать таблицу ссылок на кодовые инструкции. Отдельный набор кодовых инструкций может быть определен для каждого отдельного шаблона кодирования, но некоторые шаблоны кодирования могут обладать одинаковым набором кодовых инструкций. Альтернативно, большой набор кодовых инструкций может содержать ветви кода для распаковки любого блока с помощью значений дескрипторов b, n, p1 … pn, v1 … vn как параметры ветвей. В варианте осуществления технологии, показанном на Фиг. 13, каждый ряд таблицы 90 процедур декодирования включает в себя процедуру декодирования и процедуру пропуска. Этапы процедур декодирования и процедур пропуска будут описаны более подробно в описании Фиг. 14, 15, 16 и 17.
[00075] На Фиг. 14 представлена последовательность декодирования блока. Последовательность 200 включает в себя заголовок 76 текущего блока 70 списка словопозиций на этапе 202. На этапе 204 значение x из заголовка 76 используется как указатель на таблицу 90 процедур декодирования для получения процедуры x декодирования. На этапе 206 выполняется процедура декодирования из x-ой записи таблицы 90 процедур декодирования. На Фиг. 15 представлена процедура декодирования, которая используется последовательностью, представленной на Фиг. 14. Процедура 220 декодирования для ряда x таблицы 90 процедур декодирования включает в себя инструкции 222 для распаковки тела 74 текущего блока 70, состоящего из М=8 элементов от b бит на элемент до L байт на элемент, например, два (2) байта (16 бит) на элемент. Следует отметить, что значение b может отличаться в различных строках таблицы 90 процедур декодирования и, таким образом, кодовые инструкции 222 процедуры 220 декодирования для строки x могут отличаться от кодовых инструкций в процедурах декодирования для других строк таблицы 90 процедур декодирования. Процедура 220 декодирования также включает в себя инструкции 224 для добавления массива модификаций М=8 значений по L байт (например, 16-битовых значений) в распакованное тело. Инструкции 224 процедуры 220 декодирования для ряда x конкретно определяют массив модификаций для комбинации дескрипторов, включающей в себя b, n, p1 … pn, v1 … vn, отражающие значения для соответствующей строки x таблицы 72 шаблона кодирования, представленной на Фиг. 8. Таким образом, кодовые инструкции 224 процедуры 220 декодирования для строки x могут отличаться от кодовых инструкций в процедурах декодирования для других строк таблицы 90 процедур декодирования. Последовательность 200 продолжается на этапе 208 выполнения процедуры пропуска из x-ой записи таблицы 90 процедур декодирования. На Фиг. 16 представлена процедура пропуска, которая используется последовательностью, представленной на Фиг. 14. Процедура 240 пропуска для строки x таблицы 90 процедур декодирования включает в себя инструкции 242 вычисления позиции следующего блока списка словопозиций, следующего за текущим блоком 70. Длина заголовка 76 известна, и является равной одному (1) байту в примере, представленном на Фиг. 13, и длина тела 74 также известна, и является равной b байт, позиция нового блока 70 в списке словопозиций вычисляется с помощью кодовых инструкций 242, таким образом, последовательность 200 может далее распаковывать следующий блок 70.
[00076] На Фиг. 17 представлена последовательность пропуска текущего блока. Последовательность 260 может применяться в том случае, когда нет необходимости распаковывать текущий блок 70, и желательно перейти к следующему блоку 70, который необходимо распаковать с помощью последовательности 200. Последовательность 260 аналогична последовательности 200, показанной на Фиг. 14, и включает в себя те же этапы 202, 204 и 208, без необходимости выполнять декодирование, указанное на этапе 206. Последовательность 260 может быть частично полезной, когда список словопозиций является частью инвертированного индекса в одновекторной форме, как представлено на Фиг. 2. Последовательность 260 может выполняться столько раз, сколько необходимо для нахождения начала данного списка словопозиций в инвертированном индексе, показанном на Фиг. 2.
[00077] На Фиг. 18 представлена блок-схема системы базы данных, выполненная в соответствии с вариантом осуществления технологии. Система 80 базы данных включает в себя интерфейс, содержащий ввод 82, базу 84 данных, память 86 и процессор 88, причем процессор 88 функционально соединен с вводом 82, с базой 84 данных и памятью 86. В одном варианте осуществления системы 80 базы данных, ввод 82 получает документ с сервера. Процессор 88 получает документ от ввода 82 для сохранения его в базе 84 данных. Память 86 содержит инвертированный индекс, который включает в себя списки словопозиций и дополнительно включает в себя таблицу шаблонов кодирования. Процессор 88 извлекает поисковый термин из документа, в котором поисковый термин связан с памятью 86 в списке словопозиций. Процессор 88 структурирует в памяти 86 список словопозиций в блоки. В соответствии с этой структурой каждый блок включает в себя М ссылок базы данных. Для каждого блока процессор 88 определяет шаблон кодирования на основе значений М ссылок базы данных, находит в памяти 86 запись таблицы шаблонов кодирования, соответствующую шаблону кодирования, и сохраняет в памяти 86 указатель, соответствующий найденной записи таблицы шаблонов кодирования, в заголовке блока. Процессор 88 может повторять этот процесс для нескольких поисковых терминов или для всех поисковых терминов, полученных из документа.
[00078] В том же или другом варианте осуществления системы 80 базы данных, память 86 содержит таблицу протоколов декодирования и инвертированный индекс, который включает в себя множество списков словопозиций, и каждый список словопозиций разделен на блоки, каждый из которых содержит заголовок и М усеченных ссылок. Ввод 82 получает поисковый термин от клиента. Процессор 88 выбирает в памяти 86 список словопозиций, связанный с поисковым термином. Процессор 88 считывает указатель из заголовка текущего блока списка словопозиций. Процессор 88 далее использует указатель для извлечения протокола декодирования из таблицы протоколов декодирования, причем протокол декодирования определяет шаблон кодирования для конкретного блока.
[00079] Различные варианты осуществления системы 80 базы данных могут быть способны выполнять различные этапы способов, представленных на одной или нескольких из Фиг. 6. 7, 9, 10, и 11, и структуры данных, показанные на одной или нескольких из Фиг. 1, 2, 3, 4, 5, 8, 12 и 13, опционально используют последовательности и процедуры, показанные на одной или нескольких из Фиг. 14, 15, 16 и 17. Система 80 базы данных может быть выполнена как один аппаратный узел или может быть реализована как множество функционально связанных аппаратных узлов, которые могут быть размещены вместе или в различных помещениях, и связанные узлы работают в режиме разделения нагрузки, в режиме избыточности или в обоих этих режимах. Система 80 базы данных может содержать несколько аппаратных или программных компонентов, которые не показаны для простоты понимания, включая блоки питания, шины, интерфейсы связи, пользовательские интерфейсы и другие элементы, хорошо известные специалистам в данной области техники.
[00080] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.












Изобретение относится к области использования больших баз данных и, в частности, к способам и системам индексирования ссылок на документы в базе данных в соответствии с профилями ссылок и нахождения документов в базе данных с помощью протоколов декодирования на основе профилей ссылок базы данных. Техническим результатом является повышение плотности сжатия и скорости распаковки длинных списков словопозиций. В способе индексирования ссылок на документы базы данных документы могут быть найдены с помощью протоколов декодирования на основе профилей ссылок базы данных. С этой целью документы сохраняются в базе данных, и поисковые термины, которые из нее извлекаются, связаны со списками словопозиций. Каждый список разделен на блоки из М ссылок базы данных. Блоки закодированы в соответствии с шаблоном, который зависит от М ссылок базы данных. Соответствующий указатель на таблицу шаблонов кодирования добавляется к каждому блоку. При получении запроса на поисковый термин происходит извлечение блоков из соответствующих поисковому термину списков, и указатель для каждого блока используется для извлечения протокола декодирования, относящегося к шаблону кодирования блока. 2 н. и 32 з.п. ф-лы, 18 ил.
1. Способ индексирования ссылок на документы базы данных, включающий:
получение документа в базу данных с сервера;
сохранение документа в базе данных;
извлечение поискового термина из документа, в котором поисковый термин связан со списком словопозиций;
разделение списка словопозиций на блоки, каждый из которых включает М ссылок базы данных;
сжатие каждого блока в сжатый блок посредством:
определения шаблона кодирования для каждого блока на основе значений всех М ссылок базы данных;
кодирования содержимого блока посредством шаблона кодирования;
нахождение записи таблицы шаблона кодирования, которая соответствует шаблону кодирования;
ввода указателя, соответствующего найденной записи таблицы шаблона кодирования, в заголовок блока.
2. Способ по п. 1, в котором список словопозиций включает в себя одну или несколько ссылок базы данных на документы, которые содержат поисковый термин.
3. Способ по п. 1, в котором в качестве М используют ненулевое положительное целое число кратное 8.
4. Способ по п. 1, в котором сохранение документа в базу данных включает в себя выбор из добавления документа в базу данных, обновления документа в базе данных, перезаписи документа в базе данных и модификации документа в базе данных.
5. Способ по п. 1, в котором документы сохраняют в базе данных независимо от поисковых терминов, которые они содержат.
6. Способ по п. 1, в котором множество списков словопозиций соответствует множеству поисковых терминов, множество списков словопозиций формирует инвертированный индекс базы данных.
7. Способ по п. 6, в котором инвертированный индекс формирует двухмерную таблицу, в которой множество поисковых терминов является первым измерением, а списки словопозиций, соответствующие каждому из множества поисковых терминов, являются вторым измерением.
8. Способ по п. 6, в котором инвертированный индекс формирует непрерывный вектор, в котором за данным поисковым термином следует соответствующий список словопозиций и в котором за списком словопозиций, который соответствует первому данному поисковому термину, идет следующий поисковый термин.
9. Способ по п. 1, в котором заголовок содержит один байт.
10. Способ по п. 1, в котором:
заголовок содержит один или несколько байт;
заранее определенное значение первого байта заголовка указывает на наличие второго байта заголовка;
два байта двухбайтового заголовка содержат заранее определенное значение и указатель, которые соответствуют найденной записи таблицы шаблонов кодирования.
11. Способ по п. 10, в котором заранее определенное значение включает в себя диапазон заранее определенных значений или флаг.
12. Способ по п. 1, в котором список словопозиций назначает монотонно возрастающие номера документов в базе данных.
13. Способ по п. 12, в котором
первая ссылка базы данных в списке словопозиций представляет собой номер первого документа,
а следующая ссылка базы данных в списке словопозиций является дельта-ссылкой на основе разницы между номером первого документа и номером следующего документа.
14. Способ по п. 13, в котором набор последовательных ссылок базы данных в списке словопозиций включает в себя набор дельта-ссылок.
15. Способ по п. 14, в котором данная дельта-ссылка равна номеру данного документа с вычетом номера предыдущего документа.
16. Способ по п. 14, в котором данная дельта-ссылка равна номеру данного документа с вычетом номера предыдущего документа минус один.
17. Способ по п. 1, включающий в себя ввод в блок последовательности М усеченных ссылок, каждая усеченная ссылка включает в себя по меньшей мере b значимых бит соответствующей одной из М ссылок базы данных.
18. Способ по п. 17, в котором определение шаблона кодирования включает в себя:
определение числа n модификаций в соответствии с номером ссылок среди М ссылок базы данных, который больше или равен 2b; и
если n>0:
определение для каждой из n модификаций значения vk модификации путем удаления b наименее значимых битов из соответствующей одной из М ссылок базы данных, которые больше или равны 2b, причем k находится в пределах от 1 до n, и
определение для каждой из n модификаций позиции pk модификации, соответствующей позиции в диапазоне от 0 до М-1, из соответствующей одной из М ссылок базы данных, которая больше или равна 2b,
причем шаблон кодирования включает в себя b, n, p1 … pn, v1 … vn.
19. Способ по п. 18, в котором если n=0, шаблон кодирования включает в себя b, n.
20. Способ по п. 18, в котором М равно 4 и n равно 0 или равно 1.
21. Способ по п. 18, в котором осуществляют
определение для каждого блока длины d модификации как длины, выраженной в битах, наиболее длинной из n модификаций,
причем шаблон кодирования включает в себя b, n, d, p1 … pn, v1 … vn.
22. Способ по п. 18, в котором заголовок включает в себя явное значение по меньшей мере одного из b, n, p1 … pn, v1 … vn.
23. Способ по п. 18, в котором определение шаблона кодирования для данного блока включает в себя:
определение трех наиболее длинных ссылок базы данных среди М ссылок базы данных данного блока и
выбор значения b, достаточного для кодирования третьей по длине из М ссылок базы данных,
причем n не превышает 2.
24. Способ по п. 18, включающий в себя независимый выбор значения b для каждого блока.
25. Способ по п. 24, включающий в себя выбор значения b для каждого блока таким образом, чтобы n не превышало 2.
26. Способ по п. 24, включающий в себя независимый выбор значения b для данного блока в соответствии с наиболее длинной из М ссылок базы данных данного блока.
27. Способ по п. 18, в котором таблица шаблона включает в себя 256 записей таблицы шаблона кодирования для 256 соответствующих шаблонов кодирования.
28. Способ по п. 27, в котором:
первое подмножество 256 шаблонов кодирования включает в себя множество значений b; и
каждый шаблон кодирования первого подмножества определяет n=0.
29. Способ по п. 28, в котором ссылки базы данных блока, которые соответствуют шаблону кодирования первого подмножества, не являются сжатыми.
30. Способ по п. 28, в котором второе подмножество 256 шаблонов кодирования включает в себя наиболее часто используемые шаблоны кодирования.
31. Способ по п. 30, в котором большая часть шаблонов кодирования второго подмножества обладает меньшими значениями b, чем шаблоны кодирования первого подмножества.
32. Способ по п. 27, в котором 256 шаблонов кодирования включают в себя:
24 шаблона кодирования для 24 отдельных значений b в сочетании с n=0;
120 шаблонов кодирования включают в себя b, n=1, p1, v1, каждый из 120 шаблонов кодирования обладает одной модификацией, одно из 5 значений b, одно из 3 отдельных значений модификаций и одну из 8 отдельных позиций модификаций; и
112 шаблонов кодирования содержат дескрипторы b, n=2, p1, р2, 1, 1, каждый из 112 шаблонов кодирования обладает двумя значениями модификации равными 1, одним из 4 различных значений b, причем р1 и р2 формируют 28 различных комбинаций из позиций модификации для двух модификаций.
33. Способ по п. 32, включающий в себя:
сортирование 256 шаблонов кодирования с позициями в порядке возрастания суммы b с длиной v; и
для данной суммы сортирование шаблонов кодирования с позициями с возрастанием значений b;
и определение шаблона кодирования для данного блока включает в себя поиск шаблона кодирования путем просмотра отсортированных шаблонов кодирования, начиная с позиции, соответствующей длине наиболее длинной из М ссылок базы данных из данного блока.
34. Система базы данных для индексирования ссылок на документы базы данных, включающая:
устройство ввода данных для получения документа с сервера;
базу данных для сохранения документа;
память, содержащую инвертированный индекс, включающий множество списков словопозиций и содержащий таблицу шаблонов кодирования. и
процессор, функционально соединенный с устройством ввода данных, с базой данных и памятью и выполненный с возможностью:
извлечения поискового термина из документа, причем поисковый термин связан в памяти со списком словопозиций;
разделения в памяти списка словопозиций на блоки, каждый из которых включает М ссылок базы данных;
для каждого блока осуществления сжатия в сжатый блок посредством:
определения шаблона кодирования для блока на основе значений всех М ссылок базы данных;
кодирования содержимого блока посредством шаблона кодирования;
нахождения записи таблицы шаблона кодирования, соответствующей шаблону кодирования;
сохранения в памяти указателя, указывающего на найденную запись таблицы шаблонов кодирования в заголовке блока.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ИНТЕЛЛЕКТУАЛЬНОЕ ИНДЕКСИРОВАНИЕ КОНТЕЙНЕРА И ПОИСК В НЕМ | 2006 |
|
RU2417419C2 |

