Данное изобретение относится, в целом, к области связи строк. В частности, данное изобретение относится к отысканию связей между короткими текстовыми строками.
Предшествующий уровень техники
Имеется ряд приложений, где короткие текстовые строки требуется концептуально привязывать к другим коротким текстовым строкам (или отображать на них). Например, при обучении классификатора необходимо связывать запросы из журнала запросов с задачами или предусмотренными описаниями. В случаях поиска может требоваться связывать дополнительные метаданные с термами поиска. Если строки, подлежащие сопоставлению, являются достаточно длинными, словарные перекрытия между строками можно использовать для определения, связаны ли они. Если же строки короткие, может быть очень трудно распознать возможные соотношения или связи, необходимые для создания отображения между строками. Это является результатом недостаточной информации, содержащейся в самих строках, посредством которой можно распознать связи и создать отображения.
Ранее для создания отображений между строками использовались люди-аннотаторы, опытные в соответствующей области техники. Этот процесс может быть медленным и трудоемким. Например, при обучении классификаторов люди-аннотаторы для каждой данной задачи вручную выбирают запросы, которые, по их мнению, связаны с задачей. С учетом того, что могут существовать сотни задач и тысячи запросов, аннотаторам трудно держать в уме все задачи и запросы и производить согласованную работу по аннотации. Кроме того, ввиду ограничений человеческого восприятия процесс может быть подверженным ошибкам и несогласованным. Для уменьшения ошибок над одним и тем же отображением запроса в задачу могут работать несколько аннотаторов. Однако с учетом сложности области и уровня знаний, необходимого аннотаторам, использование многочисленных людей-аннотаторов может быть очень дорогим.
Ввиду вышеизложенного, необходимы системы и способы, которые преодолевают ограничения и недостатки уровня техники.
Сущность изобретения
Полуавтоматическая система используется для генерации вариантов отображения между двумя наборами коротких строк, которые затем могут просматривать аннотаторы. Выбирают достаточно большой набор файлов, предпочтительно связанный с двумя наборами строк. В большом наборе файлов производят поиск каждой строки из двух наборов строк. Каждый файл, который совпадает со строкой, предполагается связанным с этой строкой и может обеспечивать дополнительную информацию и контекст о строке, которая используется для генерации возможных отображений между двумя наборами строк. В частности, любые две строки, для которых найдены совпадения в некотором количестве файлов, предполагаются связанными и отображаются друг на друга. Затем аннотаторы могут проверять эти возможные варианты отображения.
Аннотаторы, вместо того чтобы генерировать варианты отображения, как известно из уровня техники, могут действовать как обозреватели в сочетании с вариантами отображения настоящего изобретения. Им не нужно держать в уме все строки из каждого набора, они могут просто проверять, выглядят ли варианты отображения имеющими смысл (т.е. подходящими). Это менее подверженный ошибкам и значительно более быстрый процесс. Поскольку варианты отображения генерируются автоматически, они являются гораздо более согласованными. Таким образом, аннотирование данных в соответствии с настоящим изобретением значительно дешевле и обеспечивает значительно более высокое качество отображения в целом. Кроме того, этот способ применим к строкам на любом языке.
Дополнительные признаки и преимущества изобретения явствуют из нижеследующего подробного описания иллюстративных вариантов осуществления, приведенного со ссылкой на прилагаемые чертежи.
Краткое описание чертежей
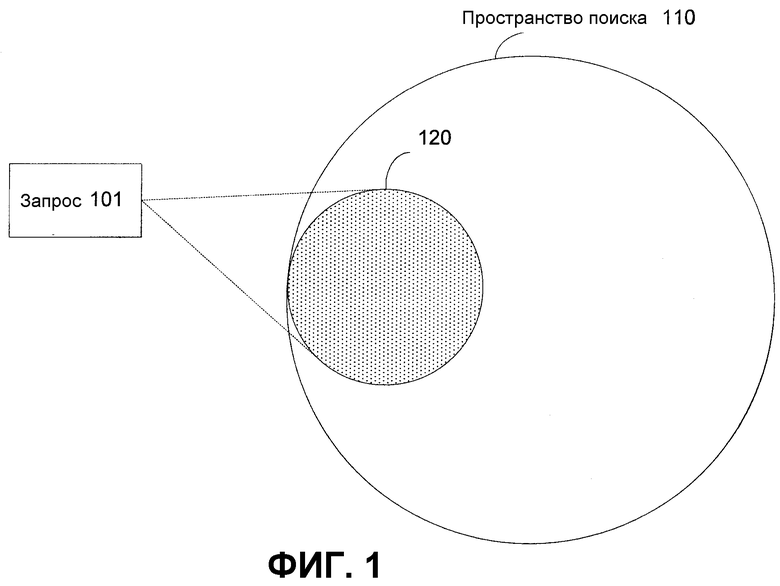
Фиг.1 - иллюстративное отображение запросов в набор файлов согласно настоящему изобретению.
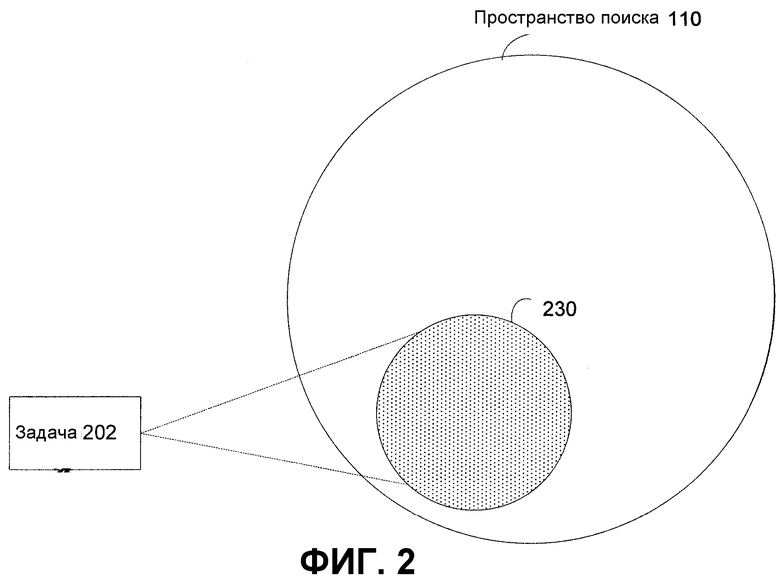
Фиг.2 - иллюстративное отображение задач в набор файлов согласно настоящему изобретению.
Фиг.3 - иллюстративное перекрытие между отображением запросов в набор файлов и отображением задач в набор файлов согласно настоящему изобретению.
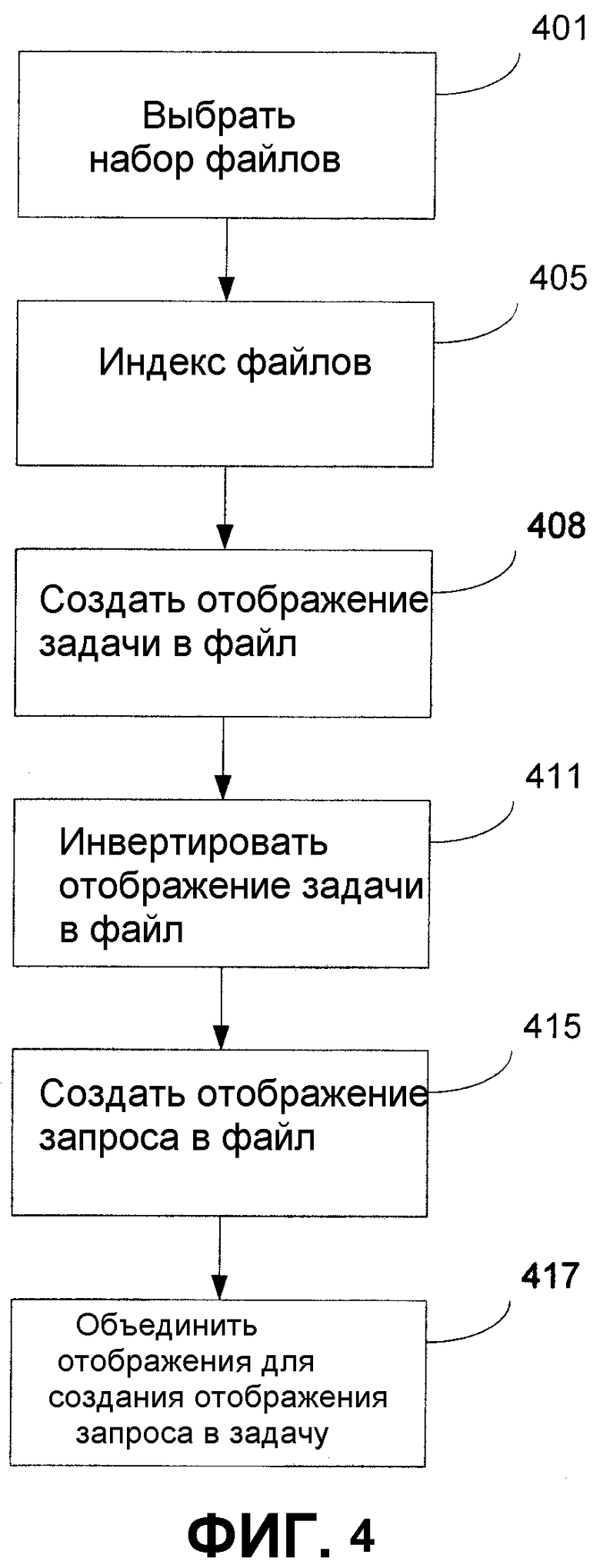
Фиг.4 - блок-схема операций иллюстративного способа отображения запроса в задачу согласно настоящему изобретению.
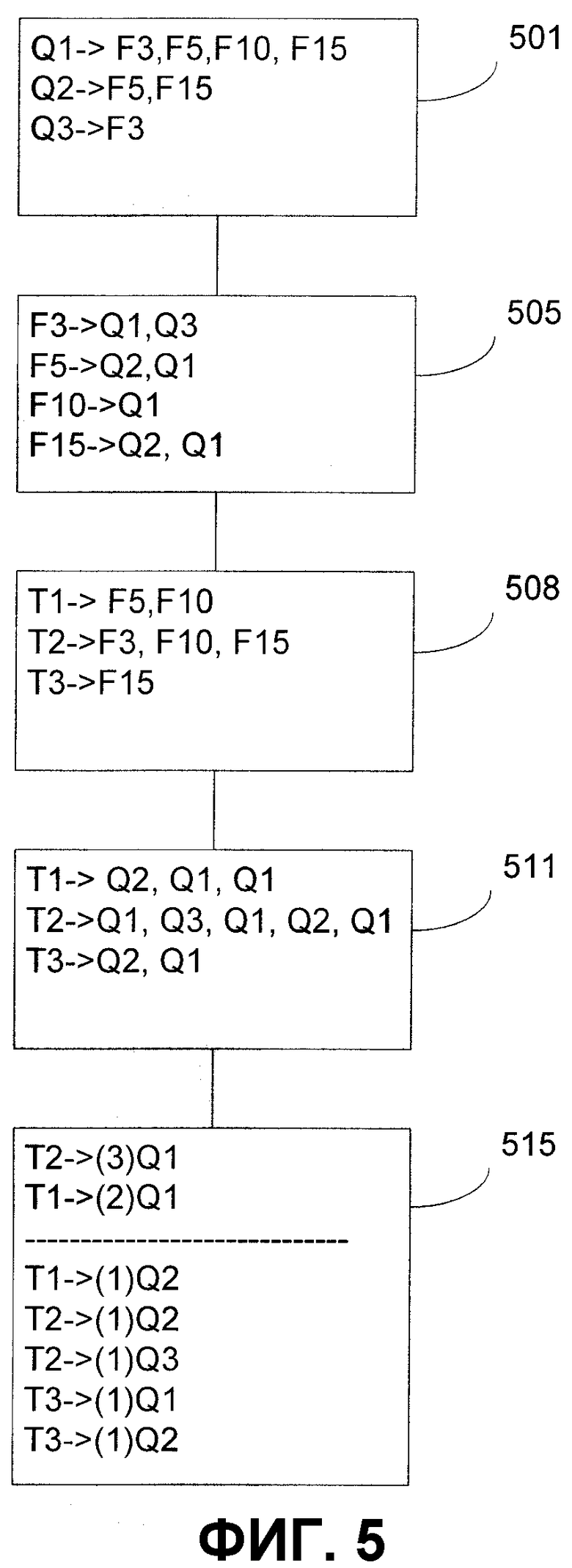
Фиг.5 - иллюстрация, полезная при описании иллюстративного способа для присвоения весовых коэффициентов генерированному отображению согласно настоящему изобретению.
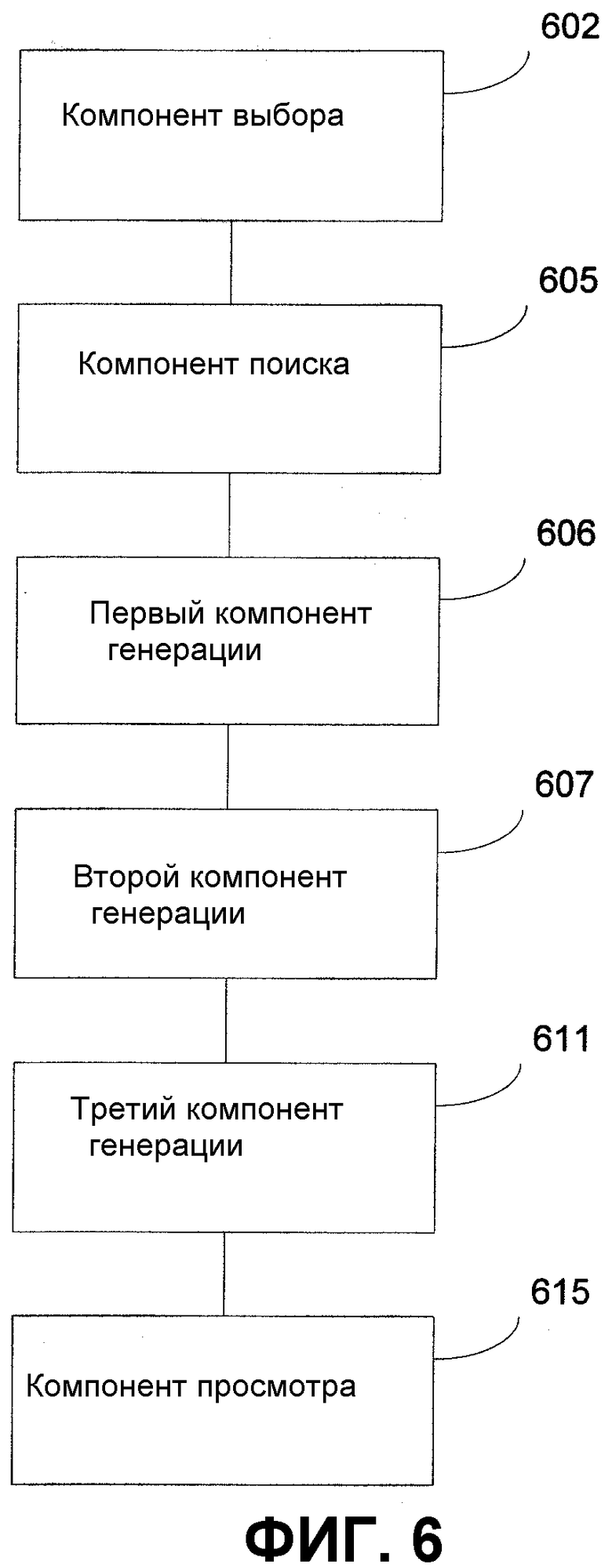
Фиг.6 - блок-схема компонентов иллюстративной системы согласно настоящему изобретению.
Фиг.7 - блок-схема иллюстративной вычислительной среды, в которой можно реализовать аспекты изобретения.
Подробное описание иллюстративных вариантов осуществления
На фиг.1 показано иллюстративное отображение запросов в набор файлов, на фиг.2 показано иллюстративное отображение задач в набор файлов, и на фиг.3 показано иллюстративное перекрытие между отображением запросов в набор файлов и отображением задач в набор файлов. Эти чертежи используются для представления иллюстративного способа для определения, существует ли взаимосвязь между запросом в виде короткой строки, показанным на фиг.1 как запрос 101, и задачей в виде короткой строки, показанной на фиг.2 как задача 202.
Задача 202 и запрос 101 отображаются в набор текстовых файлов, показанный на фиг.1-3 как пространство 110 поиска. Файлы, соответствующие задаче 202, показаны на фиг. 2 и 3 позицией 230. Файлы, соответствующие запросу 101, показаны на фиг. 1 и 3 позицией 120. Перекрытие между файлами, соответствующими запросу 101 и задаче 202, показаны на фиг.3 позицией 350. Чем больше перекрытие, тем более «связаны» задача и запрос. Хотя вариант осуществления описан со ссылкой на задачи и строки запроса, изобретение применимо к генерации отображений между любыми наборами коротких строк.
Более конкретно, на фиг.1 показано иллюстративное отображение запроса 101 в виде короткой строки в более богатый набор текстовых файлов в пространстве 110 поиска. Поскольку запрос 101 является короткой строкой, например одним словом, имеется очень мало содержимого для работы с ним при установлении возможной взаимосвязи между запросом 101 и задачей 202, показанными на фиг.2. Для нахождения возможных взаимосвязей между запросом 101 и задачей 202 необходимо отобразить запрос 101 и задачу 202 в пространство большей размерности (например, пространство поиска 110). Отображение в пространство большей размерности обеспечивает больше информации для сравнения задачи 202 и запроса 101 и определения, существует ли взаимосвязь между ними.
Как показано позицией 120, запрос 101 отображается в несколько файлов (представленных как пространство 120) в пространстве 110 поиска. Для определения (задания) отображения в каждом файле в пространстве 110 поиска предпочтительно производят поиск по тексту в соответствии с запросом 101. Для осуществления поиска по тексту в файле файл предпочтительно сканируют или подвергают поиску на предмет наличия слова или терма, представляемого запросом 101. Поиск по тексту можно производить с помощью любой/го системы, способа или техники, известной/го из уровня техники для поиска текстовых строк в файле. Любой файл, дающий совпадение, предположительно относится к запросу 101 и может обеспечить дополнительную информацию, касающуюся смысла запроса 101. Совпадение может быть точным совпадением; например, слово или терм обнаруживается полностью в тексте файла. Совпадение также может быть частичным совпадением, т.е. в файле обнаруживается только часть слова или терма. Кроме того, можно использовать более изощренные методы поиска для нахождения совпадений, например, учитывающие распространенные орфографические ошибки или морфологические варианты (например, 'run', 'ran', 'running' как альтернативы слова 'runs') для искомых термов. Можно использовать любую/ой систему, технику или метод, известную/ый из уровня техники, для согласования текстовых строк.
Затем эту информацию можно использовать для генерации варианта (кандидата) отображения. Набор файлов, для которых найдены совпадения, показан на фиг.1 позицией 120. Например, пусть пространство поиска 110 содержит два файла: файл 1 содержит слова "foo", "bar" и "banana"; и файл 2 содержит слова "apple", "pear" и "banana". Кроме того, допустим, что термом поиска является "foo". В этом примере после поиска по тексту в файле 1 и файле 2 на предмет "foo" для терма "foo" найдено совпадение в файле 1, но не в файле 2. Таким образом, терм "foo" отображается в файл 1, но не в файл 2. Аналогично, если термом поиска является "banana", то для терм "banana" найдено совпадение в файле 1 и в файле 2. Таким образом, терм "banana" отображается в файл 1 и файл 2.
Связан или нет конкретный файл, для которого найдено совпадение, с запросом 101 зависит как от размера пространства поиска 110, так и от соотношения пространства поиска 110 с запросом. Например, если выбрано большое пространство поиска, например Интернет, возможно, что между любыми двумя текстовыми строками нельзя будет найти никакого совпадения. Если выбрано слишком маленькое пространство поиска, может быть найдено слишком много совпадений. Поэтому важно тщательно выбирать пространство 110 поиска.
Один способ, позволяющий гарантировать, что данное совпадение имеет смысл, и сократить случайные совпадения, состоит в том, чтобы учитывать только совпадения, которые достигают ранга, превышающего некоторый заданный пользователем ранг. Ранг можно генерировать с использованием любой системы, способа или техники, известной/ого из уровня техники, для ранжирования возвращаемых совпадений для конкретного терма поиска. Например, ранг, заданный пользователем, предпочтительно представляет собой некоторое число, зависящее, связанное или иначе представляющее, сколько раз искомый терм должен появиться в файле, чтобы можно было считать, что для этого терма найдено совпадение в этом файле. Это количество можно определять экспериментально или регулировать в зависимости от количества файлов в пространстве 110 поиска, а также количества файлов, для которых найдено совпадение с любым данным термом поиска.
Например, запрос 101 может проявляться (давать совпадение) в конкретном файле только один раз, тогда как в другом файле он может проявляться сто раз. Интуитивно, запрос 101 с большей вероятностью связан с файлом, где он проявляется сто раз, чем с файлом, где он выполняется только один раз. Согласно варианту осуществления, можно учитывать только файлы, в которых запрос 101 дает совпадения с частотой, превышающей некоторую заданную пользователем частоту, или больше раз, чем некоторое заданное пользователем число раз. Хотя в этом примере рассматривается ранжирование результатов поиска на основании частоты появления терма поиска в конкретном файле, можно использовать другие способы ранжирования результатов поиска. Кроме того, ранжирование можно дополнительно использовать для ранжирования предложенных отображений запроса в задачу, что будет дополнительно рассмотрено со ссылкой на фиг.5.
Согласно фиг.2, задачу 202 предпочтительно отображают на несколько файлов в пространстве 110 поиска, что представлено позицией 230. Для определения отображения, каждый файл в пространстве 110 поиска предпочтительно подвергают поиску текста для задачи 202. Любой файл, дающий совпадение, предположительно связан с задачей 202 и может обеспечивать дополнительную информацию, касающуюся смысла задачи 202. Затем эту информацию можно использовать для генерации варианта отображения. Варианты отображения можно ранжировать аналогично описанному в отношении отображений запроса в файл, показанных на фиг.1.
На фиг.3 показано перекрытие между файлами в пространстве 110 поиска, отвечающих запросу 101, и файлами в пространстве 110 поиска, отвечающих задаче 202. Перекрытие файлов между 120 и 230 показано на фиг.3 позицией 350. Этот набор перекрытия образован файлами из пространства 110 поиска, которые содержат как запрос 101, так и задачу 202 где-то в тексте файлов. Чем больше эта область перекрытия, тем больше файлов содержат как запрос 101, так и задачу 202 и тем более вероятно, что между запросом 101 и задачей 202 имеется взаимосвязь. Кроме того, высокая вероятность взаимосвязи между запросом 101 и задачей 202 может быть обусловлена другими факторами, например, высокие весовые коэффициенты или ранги, связанные с нижележащими отображением запроса в файл и отображением задачи в файл, могут указывать высокую вероятность взаимосвязи, даже когда фактически отображаются немногие файлы.
Соотношение между размером перекрытия 350 и вероятностью существования взаимосвязи между запросом 101 и задачей 202 можно использовать для ранжирования или присвоения весовых коэффициентов предложенному отображению. Согласно описанному далее со ссылкой на фиг. 4 и 5, множественные термы запроса 101 и термы задачи 202 предпочтительно сравнивают наподобие описанного выше. Для некоторых термов запроса 101 и задачи 202 будет найдено совпадение в большем количестве файлов, чем для других термов запроса 101 и задачи 202. Интуитивно, это говорит о том, что термы связаны с большей степенью вероятности. Аналогично, некоторые термы запроса 101 и задачи 202, для которых найдено совпадение в конкретном файле, получат больший весовой коэффициент, или ранг, для файла, для которого найдено совпадение. Наличие терма запроса 101 и терма задачи 202, для которых найдено совпадение в одном и том же файле, причем каждый из них имеет высокий ранг, также указывает, что термы связаны друг с другом с высокой степью вероятности.
Согласно рассмотренному выше, люди-обозреватели могут использоваться для проверки совпадений. Этот просмотр вручную дорого стоит и занимает много времени. Таким образом, желательно минимизировать время, затрачиваемое людьми при просмотре предложенных совпадений. Для этого предложенные совпадения можно ранжировать, и те совпадения, которые оказываются ниже предпочтительно некоторого заданного пользователем порога, можно исключать. Таким образом, совпадение(я) не будет(ут) направлено(ы) людям-аннотаторам для проверки совпадения. Определенный пользователем порог может быть задан администратором в зависимости от таких факторов, как количество предложенных совпадений и количества файлов в пространстве 110 поиска. Иллюстративный способ более подробно описан со ссылкой на фиг.5.
На фиг.4 изображена блок-схема последовательности операций иллюстративного способа генерирования отображения запроса в задачу согласно настоящему изобретению. Отображение между запросами и задачами генерируется посредством отображения запросов и задач в выбранные файлы или текстовые документы и объединения результатов. Выбирается набор выборочных файлов и генерируется индекс файлов. По генерированному индексу производится поиск в соответствии с набором запросов, и из выборочного набора файлов генерируется взвешенный список файлов, которые отвечают каждому из запросов, образующих набор запросов. По сгенерированному индексу производится поиск в соответствии с набором задач, и из выборочного набора файлов генерируется взвешенный список файлов, которые дают совпадения для каждой из задач, образующих набор задач.
Ранжированный список файлов из выборочного набора файлов, которые дают совпадения для каждой из задач, инвертируется для получения списка каждого файла и взвешенных списков задач, для которых найдено совпадение в этом файле. Список запросов и файлов, для которых найдено совпадение, можно объединять со списком файлов и задач, для которых найдено совпадение, для генерации взвешенного списка запросов и задач, для которых найдено совпадение. Хотя иллюстративный вариант осуществления рассматривается со ссылкой на задачи и запросы, способ применим для создания отображения между любыми наборами коротких строк.
Более конкретно, на этапе 401 создается набор файлов. Согласно рассмотренному выше со ссылкой на фиг.1 набор файлов предпочтительно связан с общей областью задач и запросов, подлежащих отображению. Кроме того, следует выбирать достаточно большой набор файлов. Если выбрать слишком много файлов, может не оказаться достаточно совпадений между задачами и файлами и между запросами и файлами, чтобы создать имеющее смысл отображение между запросами и задачами. Однако, если для списка файлов выбрать слишком мало файлов, имеется опасность генерирования слишком большого количества случайных совпадений (что может, например, создавать дополнительную работу для аннотаторов). В общем случае эта опасность мала, поскольку с любыми случайными совпадениями предпочтительно связан очень малый вес, что позволяет их исключить (например, перед любым последующим процессом аннотации).
На этапе 405 предпочтительно создают индекс с использованием выбранных файлов. Индексирование набора файлов позволяет быстро осуществлять поиск среди файлов. Элемент индекса для файла может содержать список всех слов, содержащихся в этом файле. Более сложный индекс может содержать число, указывающее, сколько раз каждое слово встречается в файле, что позволяет присваивать совпадению ранг или вероятность того, что совпадение имеет смысл. Чем больше раз совпадающее слово появляется в файле, тем выше вероятность того, что файл связан с совпадающим словом. Аналогично, индекс данного файла можно улучшить используя нормализацию текста, включая использование орфографии, морфологического анализа, пунктуации, словосочетаний и пр. Например, в индекс можно включить обычные орфографические ошибки слов, найденных в файлах. Согласно одному варианту осуществления для создания индекса файла можно использовать службу индексирования стандартной операционной системы, но также можно использовать любую/ой систему, способ или технику, известную/ый из уровня техники, для создания индекса или группы файлов.
На этапе 408 производится поиск задач по индексу файлов. Предпочтительно генерируется список, содержащий файлы, дающие совпадения для каждой из задач. Используя тот или иной тип индексирования можно ранжировать список файлов, дающих совпадение для каждой задачи, или определять уровень доверительности, указывающий качество совпадения или вероятность того, что совпадение является точным. Затем список файлов можно сократить исключив совпадения ниже (например, определенного пользователем) ранга или уровня согласования. Предполагается, что можно использовать любую/ой систему, способ или технику, известную/ый в области поиска по файлу.
На этапе 411 новый список, содержащий элемент для каждого файла в наборе файлов и соответствующие задачи, для которых найдены совпадения в элементе файла, предпочтительно генерируют из списка, содержащего элемент для каждой задачи и файлы, содержащие эту задачу. Список предпочтительно генерируют путем инвертирования или обращения списка, содержащего элемент для каждой задачи и файлы, содержащие эту задачу. Новый список содержит элемент для каждого файла в наборе файлов и соответствующие задачи, для которых найдены совпадения в элементе файла. В новом списке предпочтительно сохраняются любые ранги или уровень доверительности, связанные с каждым совпадением.
На этапе 415 производится поиск в соответствии с каждым из запросов по тому же индексу файлов, что и для задач. Предпочтительно генерируется список, содержащий файлы, дающие совпадения для каждого из запросов. Для каждого совпадения предпочтительно задают ранг или уровень доверительности. По аналогии с вышеуказанным сокращением задач, в зависимости от используемого типа индексирования, список файлов, дающих совпадения по каждому запросу, может быть сокращен путем устранения совпадений ниже определенного пользователем ранга или уровня доверительности. Можно использовать любую систему, способ или технику, используемую/ый в области поиска по файлу.
На этапе 417 генерированный список, содержащий отображение запроса в файлы, предпочтительно объединяют со списком, содержащим отображение файлов в задачу, создавая отображение запроса в задачу. Кроме того, согласно описанному ниже со ссылкой на фиг.5, каждое предложенное отображение запроса в задачу можно ранжировать или взвешивать на основании того, сколько раз для пары запрос-задача было найдено совпадение в файле, или на основании функции весов отображения задачи в файл и запроса в файл, возвращаемой используемой системой поиска. После генерации вариантов отображения их можно передавать людям-обозревателям (или другим автоматическим системам), которые могут удалять случайные или ложные отображения.
На фиг.5 показана иллюстрация, полезная при описании иллюстративного способа присвоения весовых коэффициентов генерированному отображению согласно настоящему изобретению. Согласно иллюстративному варианту осуществления отображение термов запроса в текстовые файлы создается путем поиска термов запроса в наборе текстовых файлов. Отображение термов задачи в текстовые файлы генерируется аналогичным образом. Отображение запросов в файлы инвертируется или обращается, при этом создается отображение файлов в термы запроса. Отображение задач в файлы объединяется с отображением файлов в запросы, при этом создается отображение задач в запросы. Число, указывающее, сколько раз конкретная задача отображается в конкретный запрос, можно использовать для ранжирования результатов. Аналогично ранги или уровни доверительности нижележащих отображений запроса в файл и задачи в файл можно использовать для генерации общего ранга или уровня доверительности для отображения запроса в задачу. Затем можно определить порог для исключения совпадений ниже заданного ранга, тем самым гарантируя точность генерированных совпадений. Хотя иллюстративный вариант осуществления рассматривается применительно к запросам и задачам, он в равной степени применим для генерации отображений между набором или наборами коротких строк и другим набором или наборами коротких строк.
На этапе 501 генерируется отображение запросов в файлы. Пусть в целях этого примера имеется три терма запроса 1-3 и пятнадцать текстовых файлов 1-15. Как показано, запрос 1 отображается в файлы 3, 5, 10 и 15; запрос 2 отображается в файлы 5 и 15; и запрос 3 отображается в файл 3. В этом примере обнаруживают, что конкретный запрос отображается в файл, когда терм запроса появляется в файле, по меньшей мере, один раз.
Согласно рассмотренному со ссылкой на фиг.4 конкретному отображению может быть назначен(а) доверительность или вес. Из уровня техники известны многочисленные способы присвоения веса или доверительности результату поиска, в том числе обращение частотности документа, насколько редким или частым является терм поиска и используемая в этом примере частотность терма. С использованием частотности терма конкретное совпадение ранжируется в зависимости от того, сколько раз запрос обнаружен в файле. Совпадения можно исключить или игнорировать, если они ниже определенного ранга. Например, если конкретный набор файлов и терм поиска дал большое количество совпадений, система или пользователь могут исключить любое совпадение, которое ниже некоторого ранга, чтобы увеличить вероятность того, что файлы, для которых найдены совпадения, связаны с искомым термом. Этот способ присвоения доверительности совпадениям можно использовать совместно со способом ранжирования предложенных взаимосвязей между задачами и запросами.
На этапе 505 отображение запросов в файлы предпочтительно инвертируют или обращают обеспечивая отображение файлов в запросы. Показано, что файл 3 отображается в запросы 1 и 3; файл 5 отображается в запросы 2 и 1; файл 10 отображается в запрос 1; и файл 15 отображается в запросы 2 и 1. Файлы 1, 2, 4, 6, 7, 8, 9, 11, 12, 13 и 14 опущены, поскольку они не дают совпадения ни по одному из запросов.
На этапе 508 генерируют отображение задач в файлы. В целях этого примера предположим, что имеются три терма задачи 1-3 и пятнадцать текстовых файлов 1-15. Показано, что задача 1 отображается в файлы 5 и 10; задача 2 отображается в файлы 3, 10 и 15; и задача 3 отображается в файл 15.
На этапе 511 отображение задач в файлы объединяют с отображением файлов в запросы создавая отображение задач в запросы. Каждый файл может отображаться в несколько разных запросов и несколько разных задач. В результате показано, что при объединении двух отображений некоторые задачи отображаются в один и тот же запрос несколько раз. Вместо того чтобы быть избыточными, число, указывающее, сколько раз для задачи найдено совпадение с конкретным запросом, может позволить оценить качество совпадения. Показано, что задача 1 отображается в запрос 2 один раз и в запрос 1 два раза; задача 2 отображается в запрос 1 три раза, в запрос 2 один раз и в запрос 1 один раз.
На этапе 515 генерируется ранг или уровень доверительности для каждого отображения. Как показано, каждое отображение задачи в запрос ранжируется количеством найденных повторных совпадений. Каждое повторное отображение представляет файл, содержащий как терм запроса, так и терм задачи. Чем выше ранг, тем больше вероятность того, что отображение между задачами и запросами имеет смысл.
Помимо ранжирования по количеству повторных совпадений, ранг или уровень доверительности для каждого отображения можно генерировать с использованием любой/го системы, способа или техники, известной/го из уровня техники, для присвоения весовых коэффициентов или уровней доверительности искомым термам. Например, если используются весовые коэффициенты, возвращаемые поисковой системой (степень совпадения), может случиться так, что в некоторых случаях может быть единичное перекрытие с большим весом, которое более значимо, чем найденный дубликат.
Для экономии времени и денег, затрачиваемых на просмотр вручную генерированных отображений, пользователь может фильтровать генерированные отображения на основании некоторого порога. Обозреватели проверяют каждое генерированное отображение с целью определения, существует ли реальная взаимосвязь между запросом и задачей или является ли совпадение простой случайностью или результатом бедного текстового файла в наборе файлов. Поскольку просмотр является дорогим процессом, производимым специалистом в данной области, желательно минимизировать количество просматриваемых отображений. Для этого пользователь предпочтительно определяет минимальный ранг, который можно найти между задачей и запросом до того, как отображение будет рассмотрено обозревателями. В примере, описанном со ссылкой на фиг.5, было определено, что количество повторных совпадений должно быть равно, по меньшей мере, двум. Как показано выше пунктирной линией в блоке 515, этому критерию отвечают только отображения между задачей 2 и запросом 1 и задачей 1 и запросом 1. На практике оптимальный ранг, необходимый для совпадения, в значительной степени зависит от размера пространства поиска, в которое отображаются запросы и задачи, а также от связанности файлов.
На фиг.6 показана блок-схема, иллюстрирующая компоненты иллюстративной системы согласно настоящему изобретению. Система содержит компонент 602 выбора; компонент 605 поиска; первый компонент 606 генерации; второй компонент 607 генерации; третий компонент 611 генерации; и компонент 615 просмотра.
Компонент 602 выбора предпочтительно используется для выбора набора файлов, который можно использовать для создания отображения между набором коротких строк запроса и набором коротких строк задачи. Поскольку запросы и задачи являются короткими строками, имеется мало информации, с помощью которой можно генерировать отображение. Как описано со ссылкой на фиг.1, предпочтительно выбирают набор файлов, связанных с областью строк запроса и задачи. Затем запросы и задачи предпочтительно отображают в набор файлов. Запросы и задачи, которые отображаются в один и тот же файл, предполагаются связанными и потому отображаются друг на друга. Таким образом, генерируется отображение между запросами и задачами. Для этого желательно, чтобы набор файлов, выбранный компонентом 602 выбора, был связан с общей областью запросов и задач и был достаточного размера, чтобы содержать достаточно файлов для создания отображения, и чтобы не каждый запрос отображался в каждую задачу. Компонент 602 выбора можно реализовать с использованием аппаратного обеспечения, программного обеспечения или комбинации того и другого. Хотя вариант осуществления рассматривается применительно к наборам запросов и задач, он применим к созданию отображения между любыми наборами коротких строк.
Компонент 605 поиска предпочтительно используется для поиска по выбранным текстовым файлам на предмет наличия строк из набора запросов и набора задач. Каждый запрос и каждая задача предпочтительно подвергаются текстовому поиску в наборе файлов. Согласно рассмотренному выше со ссылкой на фиг.1-3, выбранные файлы подвергаются текстовому поиску на предмет наличия каждого запроса и каждой задачи. Кроме того, компонент 605 поиска предпочтительно присваивает весовой коэффициент или уровень доверительности любым найденным совпадениям, указывающий, насколько конкретный файл связан с искомым термом. Можно использовать любую/ой систему, способ или технику, известную/ый из уровня техники, для поиска строки в наборе текстовых файлов и присвоения результатам весовых коэффициентов или уровней доверительности. Компонент 605 поиска можно реализовать с использованием аппаратного обеспечения, программного обеспечения или комбинации того и другого.
Первый компонент 606 генерации предпочтительно используется для генерации отображения между запросами и набором файлов. Генерированное отображение может содержать список, содержащий элемент для каждого терма запроса, совместно с каждым файлом из набора файлов, который содержит терм запроса. Первый компонент 606 генерации может также очищать генерированное отображение для данного терма, добавляя только файлы, которые достигли определенного ранга или уровня доверительности. Например, данный файл, в котором компонент 605 поиска обнаружил наличие совпадения с конкретным термом запроса, может получить низкий вес, а другой файл, имеющий совпадение с конкретным термом запроса, может получить очень высокий вес. По определению, файл с высоким весом с большей степенью вероятности связан с термом запроса, чем файл с низким весом. Первый компонент 606 генерации может добавлять элементы в список, где файл имеет совпадение с термом запроса, весовой коэффициент или уровень доверительности которого выше указанной пользователем величины. Первый генератор 606 можно реализовать с использованием аппаратного обеспечения, программного обеспечения или комбинации того и другого.
Второй компонент 607 генерации предпочтительно используется для генерации отображения между задачами и выбранными файлами. Генерированное отображение может содержать список, содержащий элемент для каждого терма задачи, совместно с каждым файлом из набора файлов, который содержит этот терм задачи. Второй компонент 607 генерации может дополнительно очищать генерированное отображение для данного терма, добавляя только файлы, которые содержат терм задачи, весовой коэффициент или уровень доверительности которого выше определенной заданной пользователем величины. Это более подробно описано со ссылкой на первый компонент 606 генерации. Второй компонент 607 генерации можно реализовать с использованием аппаратного обеспечения, программного обеспечения или комбинации того и другого.
Третий компонент 611 генерации предпочтительно используется для генерации отображения между набором коротких запросов и набором коротких задач. Отображение предпочтительно генерируется путем объединения отображения термов запроса в набор файлов и отображения термов задачи в набор файлов. Каждое отдельное отображение между запросом и задачей соответствует, по меньшей мере, одному файлу в наборе файлов, который содержит как терм запроса, так и терм задачи. Некоторые термы запроса и задачи имеют совпадения или содержатся вместе во множестве файлов из набора файлов. Третий компонент 611 генерации может дополнительно очищать отображение, исключая те отображения запроса и задачи, которые появляются вместе ниже некоторого определенного порога. Порог можно определять по отношению к общему числу предложенных отображений или размеру начального набора файлов.
Аналогично отображение между термами запроса и задачи можно очищать создавая ранг или уровень доверительности для каждого отображения на основании нижележащего ранга или уровня доверительности, связанного с отображением запроса в файл и отображением задачи в файл. С каждым термом запроса и задачи, для которого обнаружено совпадение, связан весовой коэффициент или уровень доверительности для нижележащих отображения запроса в файл и отображения задачи в файл, сгенерированный компонентом 605 поиска. Комбинируя два ранга, можно генерировать составной ранг для отображения запроса в задачу. Третий компонент 611 генерации может исключать те отображения запроса и задачи, которые получили ранг ниже определенного порога. Третий компонент 611 генерации можно реализовать с использованием аппаратного обеспечения, программного обеспечения или комбинации того и другого.
Компонент 615 просмотра предпочтительно определяет, какие из генерированных отображений между запросами и задачами имеют смысл, и предпочтительно исключает отображения, которые не имеют смысла. Люди-аннотаторы, действующие как обозреватели, предпочтительно имеющие опыт работы с термами запроса и задачи, могут проверять каждое отображение и исключать отображение, если термы запроса и задачи не выглядят связанными. Этот просмотр можно также автоматизировать или компьютеризировать. В таких случаях этот компонент 615 просмотра можно реализовать с использованием аппаратного обеспечения, программного обеспечения или комбинации того и другого.
Иллюстративная вычислительная среда
На фиг.7 показан пример подходящей среды 700 вычислительной системы, в которой можно реализовать изобретение. Среда 700 вычислительной системы является лишь одним примером подходящей вычислительной среды и не призвана накладывать каких-либо ограничений на объем использования или функциональные возможности изобретения. Кроме того, вычислительную среду 700 не следует рассматривать как имеющую какую-либо зависимость или какое-либо требование относительно любого из компонентов, проиллюстрированных в иллюстративной операционной среде 700, или их комбинации.
Изобретение применимо ко многим другим средам или конфигурациям вычислительной системы общего назначения или специального назначения. Примеры общеизвестных вычислительных систем, сред и/или конфигураций, которые могут быть пригодны для использования согласно изобретению, включают в себя, но без ограничения, персональные компьютеры, компьютеры-серверы, карманные или портативные устройства, многопроцессорные системы, системы на основе микропроцессора, телевизионные приставки, программируемую бытовую электронику, сетевые ПК, миникомпьютеры, универсальные компьютеры, распределенные вычислительные среды, которые включают в себя любые из вышеперечисленных систем или устройств и т.п.
Изобретение можно описать в общем контексте компьютерно-выполняемых команд, например программных модулей, выполняемых компьютером. В общем случае программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и пр., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Изобретение также можно осуществлять на практике в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, связанными посредством сети связи или другой среды передачи данных. В распределенной вычислительной среде программные модули и другие данные могут размещаться в локальных и удаленных компьютерных средах хранения данных, включающих в себя запоминающие устройства.
Согласно фиг.7, иллюстративная система для реализации изобретения включает в себя вычислительное устройство общего назначения в виде компьютера 710. Компоненты компьютера 710 могут включать в себя, но без ограничения, блок 720 обработки, системную память 730 и системную шину 721, которая подключает различные системные компоненты, в том числе системную память, к блоку 720 обработки. Системная шина 721 может относиться к любому из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую различные шинные архитектуры.
Компьютер 710 обычно включает в себя различные считываемые компьютером среды.
Считываемые компьютером среды могут быть любыми доступными средами, к которым может осуществлять доступ компьютер 710 и которые включают в себя энергозависимые и энергонезависимые носители, сменные и стационарные носители. В порядке примера, но не ограничения, считываемые компьютером среды могут содержать компьютерные среды хранения данных и среды передачи данных. Компьютерные среды хранения данных включают в себя энергозависимые и энергонезависимые, сменные и стационарные носители, реализованные посредством любого способа или технологии хранения информации, например считываемые компьютером команды, структуры данных, программные модули или другие данные. Компьютерные среды хранения данных включают в себя, но без ограничения, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другие оптические дисковые носители, магнитные кассеты, магнитную ленту, магнитный дисковый носитель или другие магнитные запоминающие устройства или любой другой носитель, который можно использовать для хранения полезной информации и к которому компьютер 710 может осуществлять доступ. Среды передачи данных обычно воплощают считываемые компьютером команды, структуры данных, программные модули или другие данные в сигнале, модулированном данными, например, несущей волне или другом транспортном механизме и включают в себя любые носители доставки информации. В порядке примера, но не ограничения, среды передачи данных включают в себя проводные носители, например проводную сеть или прямое проводное соединение, и беспроводные носители, например акустические, РЧ, инфракрасные или другие беспроводные носители. В объем считываемых компьютером сред также входят комбинации любых вышеперечисленных сред.
Системная память 730 включает в себя компьютерные среды хранения данных в виде энергозависимой и/или энергонезависимой памяти, например ПЗУ 731 и ОЗУ 732. Базовая система ввода/вывода 733 (BIOS), содержащая основные процедуры, которые помогают переносить информацию между элементами компьютера 710, например, при запуске, обычно хранится в ПЗУ 731. ОЗУ 732 обычно содержит данные и/или программные модули, которые непосредственно доступны блоку 720 обработки и/или которыми он в данный момент оперирует. В порядке примера, но не ограничения, на фиг.7 показаны операционная система 734, прикладные программы 735, другие программные модули 736 и программные данные 737.
Компьютер 710 также может включать в себя другие сменные/стационарные, энергозависимые/энергонезависимые компьютерные среды хранения данных. Исключительно в порядке примера на фиг.7 показан жесткий диск 740, который считывает со стационарного энергонезависимого магнитного носителя или записывает на него, привод 751 магнитного диска, который считывает со сменного энергонезависимого магнитного диска 752 или записывает на него, привод 755 оптического диска, который считывает со сменного энергонезависимого оптического диска 756, например CD-ROM или другого оптического носителя, или записывает на него. В иллюстративной операционной среде можно использовать другие сменные/стационарные, энергозависимые/энергонезависимые компьютерные среды хранения данных, например кассеты с магнитной лентой, карты флэш-памяти, цифровые универсальные диски, цифровую видеоленту, полупроводниковое ОЗУ, полупроводниковое ПЗУ и т.п. Жесткий диск 741 обычно подключен к системной шине 721 посредством интерфейса стационарной памяти, например интерфейса 740, и привод 751 магнитного диска и привод 755 оптического диска обычно подключены к системной шине 721 посредством интерфейса сменной памяти, например интерфейса 750.
Приводы и связанные с ними компьютерные среды хранения данных обеспечивают хранение считываемых компьютером команд, структур данных, программных модулей и других данных для компьютера 710. Например, на фиг.7 показано, что на жестком диске 741 хранятся операционная система 744, прикладные программы 745, другие программный модули 746 и программные данные 747. Заметим, что эти компоненты могут быть идентичными с или отличаться от операционной системы 734, прикладных программ 735, других программных модулей 736 и программных данных 737. Операционная система 744, прикладные программы 745, другие программные модули 746 и программные данные 747 обозначены здесь другими позициями для иллюстрации того, что они, как минимум, представляют собой разные копии. Пользователь может вводить команды и информацию в компьютер 710 посредством устройств ввода, например клавиатуры 762 и указательного устройства 761, под которым обычно понимают мышь, шаровой манипулятор или сенсорную панель. Эти и другие устройства ввода часто подключены к блоку 720 обработки посредством интерфейса 760 пользовательского ввода, который подключен к системной шине, но может быть подключен посредством других интерфейсных и шинных структур. Монитор 791 или устройство отображения другого типа также подключен к системной шине 721 посредством интерфейса, например видеоинтерфейса 790. Помимо монитора, компьютеры могут также включать в себя другие периферийные устройства вывода, например громкоговорители 797 и принтер 796, которые могут быть подключены через выходной периферийный интерфейс 795.
Компьютер 710 может работать в сетевой среде с использованием логических соединений с одним или несколькими удаленными компьютерами, например удаленным компьютером 780. Удаленный компьютер 780 может представлять собой персональный компьютер, сервер, маршрутизатор, сетевой ПК, равноправное устройство или общий сетевой узел и обычно включает в себя многие или все элементы, описанные выше применительно к компьютеру 710, хотя на фиг.7 показано только запоминающее устройство 781. Указанные логические соединения включают в себя ЛС 771 и ГС 773, но могут включать в себя и другие сети.
При использовании в сетевой среде ЛС компьютер 710 подключен к ЛС 771 посредством сетевого интерфейса или адаптера 770. При использовании в сетевой среде ГС компьютер 710 обычно включает в себя модем 772 или другое средство установления соединений по ГС 773, например Интернет. Модем 772, который может быть внутренним или внешним, может быть подключен к системной шине 721 через интерфейс 760 пользовательского ввода или иной подходящий механизм. В сетевой среде программные модули, описанные применительно к компьютеру 710, или их часть могут храниться в удаленном запоминающем устройстве. В порядке примера, но не ограничения, на фиг.7 показано, что удаленные прикладные программы 785 хранятся в запоминающем устройстве 781. Очевидно, что показанные сетевые соединения являются иллюстративными и что можно использовать другие средства установления канала связи между компьютерами.
Согласно вышеупомянутому, хотя иллюстративные варианты осуществления настоящего изобретения были описаны в связи с различными вычислительными устройствами, концепции, лежащие в их основе, можно применять к любому(й) вычислительному устройству или системе.
Различные описанные здесь реализации можно реализовать аппаратными или программными средствами или, если применимо, комбинированными средствами. Таким образом, способы и устройства, отвечающие настоящему изобретению, или их отдельные аспекты или части могут иметь вид программного кода (например, команд), воплощенного на материальных носителях, например на дискетах, компакт-дисках, жестких дисках или на любом машинно-считываемом носителе информации, причем, когда программный код загружается в машину, например компьютер, и выполняется на ней, машина становится устройством для практического применения изобретения. В случае выполнения программного кода на программируемых компьютерах вычислительное устройство в общем случае включает в себя процессор, носитель данных, считываемый процессором (включая энергозависимую и энергонезависимую память и/или элементы хранения), по меньшей мере, одно устройство ввода и, по меньшей мере, одно устройство вывода. Программа(ы) можно реализовать, при желании, на языке ассемблера или машинном языке. В любом случае язык может представлять собой компилируемый или интерпретируемый язык и может сочетаться с аппаратными реализациями.
Способы и устройства согласно настоящему изобретению можно также осуществлять на практике посредством связей, воплощенных в виде программного кода, который передается по некоторому носителю передачи, например электрическим проводам или кабелям, по оптическим волокнам или посредством любой другой формы передачи, в которой при приеме и загрузке программного кода в машину и его выполнении машиной, например ЭППЗУ, вентильной матрицей, программируемым логическим устройством (ПЛУ), компьютером-клиентом и т.п., машина становится устройством для практического осуществления изобретения. При реализации на процессоре общего назначения программный код объединяется с процессором для обеспечения уникального устройства, которое действует с использованием функциональных возможностей настоящего изобретения. Дополнительно любые средства хранения, используемые в связи с настоящим изобретением, могут неизменно представлять собой сочетание оборудования и программного обеспечения.
Хотя настоящее изобретение было описано в связи с предпочтительными вариантами осуществления различных фигур, очевидно, что можно использовать и другие сходные варианты осуществления, или в описанные варианты осуществления можно вносить изменения и дополнения для осуществления той же функции настоящего изобретения без отклонения от него. Поэтому настоящее изобретение не следует ограничивать никаким отдельным вариантом осуществления, но следует рассматривать в объеме, определяемом прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПОИСК ПРОИЗВОЛЬНОГО ТЕКСТА И ПОИСК ПО АТРИБУТАМ В ДАННЫХ ЭЛЕКТРОННОГО РУКОВОДСТВА ПО ПРОГРАММАМ | 2004 |
|
RU2365984C2 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ДИНАМИЧЕСКОГО ГЕНЕРИРОВАНИЯ РАСШИРЕНИЯ ДОПУСКАЮЩЕГО ВЫБОР ПОИСКА | 2004 |
|
RU2367013C2 |
| ЭФФЕКТИВНЫЕ ОПЕРАЦИИ ПРОСМОТРА БАЗЫ ДАННЫХ | 2007 |
|
RU2421801C2 |
| ПОИСКОВЫЕ РЕЗУЛЬТАТЫ ДЛЯ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2665888C2 |
| ПОИСКОВЫЕ РЕЗУЛЬТАТЫ ДЛЯ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2710293C2 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| ПОИСК В МЕНЮ ЗАПУСКА ПРОГРАММ ОПЕРАЦИОННОЙ СИСТЕМЫ | 2005 |
|
RU2405186C2 |
| СПОСОБ ПОИСКА WEB-СТРАНИЦ ПО КОМБИНИРОВАННОМУ ЗАПРОСУ | 2008 |
|
RU2393537C2 |
| Способ обработки поисковых запросов для нескольких реляционных баз данных произвольной структуры | 2019 |
|
RU2730241C1 |
Данное изобретение относится, в целом, к области связи строк. В частности, данное изобретение относится к отысканию связей между короткими текстовыми строками. Полуавтоматическая система используется для генерации вариантов отображения между двумя наборами коротких строк, которые затем могут просматривать аннотаторы. Генерируют варианты отображения между двумя наборами коротких строк. Выбирают набор файлов, связанный с двумя наборами строк. В наборе файлов осуществляют поиск каждой строки из двух наборов строк. Любые две строки, для которых найдено совпадение в одном и том же файле, предполагают связанными и отображают друг на друга. Затем аннотаторы/обозреватели могут проверять эти варианты отображения. 5 н. и 19 з.п. ф-лы, 7 ил.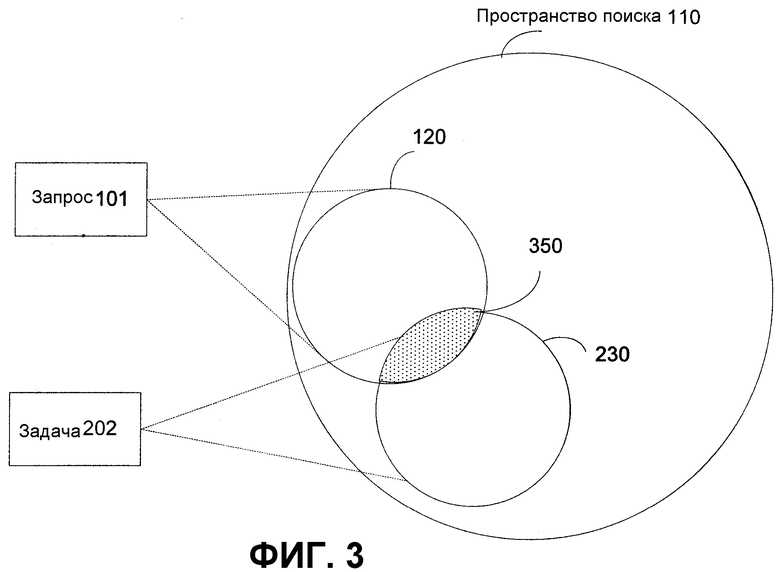
1. Способ определения взаимосвязей между первым набором строк и вторым набором строк, содержащий этапы, на которых
выбирают набор файлов,
создают индекс из набора файлов,
осуществляют поиск по индексу для отыскания файлов, которые связаны с первым набором строк,
создают первый список, содержащий элемент для каждой строки из первого набора строк и файлы из набора файлов, которые связаны с этой строкой,
осуществляют поиск по индексу для отыскания файлов, которые связаны со вторым набором строк,
создают второй список, содержащий элемент для каждой строки из второго набора строк и файлы из набора файлов, которые связаны с этой строкой,
генерируют из первого списка третий список, содержащий элемент для каждого файла из набора файлов и строки из первого набора строк, которые связаны с этим файлом, и
генерируют из второго списка и третьего списка четвертый список, содержащий элемент для каждой строки из второго набора строк и строки из первого набора строк, если таковые имеются, которые связаны с тем же файлом из набора файлов, что и строка из второго набора строк.
2. Способ по п.1, дополнительно содержащий этапы, на которых
определяют, представляет ли элемент четвертого списка достоверную взаимосвязь между строкой из второго набора строк и строкой из первого набора строк, и
удаляют из четвертого списка любой элемент, который не представляет достоверную взаимосвязь между строкой из второго набора строк и строкой из первого набора строк.
3. Способ по п.1, дополнительно содержащий этап, на котором формируют ранг для каждого элемента первого списка и второго списка и генерируют ранг для каждого элемента четвертого списка с использованием генерированных рангов из первого списка и второго списка.
4. Способ по п.3, дополнительно содержащий этап, на котором определяют минимальный ранг и удаляют из четвертого списка любой элемент, ранг которого ниже минимального ранга.
5. Способ по п.4, дополнительно содержащий этапы, на которых определяют, представляет ли элемент четвертого списка достоверную взаимосвязь между строкой из второго набора строк и строкой из первого набора строк, и удаляют из четвертого списка любой элемент, который не представляет достоверную взаимосвязь между строкой из второго набора строк и строкой из первого набора строк.
6. Способ по п.1, в котором при выборе набора файлов выбирают набор файлов в той же области, что и первый набор строк и второй набор строк.
7. Система для определения взаимосвязей между первым набором строк и вторым набором строк, содержащая
компонент выбора, который выбирает набор файлов, которые хранятся в запоминающем устройстве,
компонент поиска, который осуществляет поиск строк из первого набора строк и второго набора строк в наборе файлов,
первый компонент генерации, который генерирует первый список, содержащий, по меньшей мере, одну пару, причем пара содержит строку из первого набора строк и файл из набора файлов, который связан со строкой,
второй компонент генерации, который генерирует второй список, содержащий, по меньшей мере, одну пару, причем пара содержит строку из второго набора строк и файл из набора файлов, который связан со строкой, и
третий компонент генерации, который генерирует третий список с использованием первого списка и второго списка, содержащий по меньшей мере одну пару, причем пара содержит строку из первого набора строк и строку из второго набора строк, причем строка из первого набора строк и строка из второго набора строк совместно связаны с по меньшей мере одним файлом из набора файлов.
8. Система по п.7, дополнительно содержащая компонент просмотра, который проверяет пары в третьем списке и удаляет из третьего списка пары, которые не могут быть проверены.
9. Система по п.7, в которой первый список дополнительно содержит для каждой пары из первого списка указатель доверительности.
10. Система по п.9, в которой компонент поиска определяет указатель доверительности для пары на основании вероятности того, что строка из первого набора строк связана с файлом из набора файлов.
11. Система по п.10, в которой первый компонент генерации удаляет пару из первого списка, если указатель доверительности меньше заранее определенной величины.
12. Система по п.10, в которой первый компонент генерации удаляет пару из списка, если указатель доверительности ниже среднего указателя доверительности для первого списка.
13. Система по п.7, в которой второй список дополнительно содержит для каждой пары во втором списке указатель доверительности.
14. Система по п.13, в которой компонент поиска определяет указатель доверительности для пары на основании вероятности того, что строка из второго набора строк связана с файлом из набора файлов.
15. Система по п.13, в которой второй компонент генерации удаляет пару из второго списка, если указатель доверительности меньше заранее определенной величины.
16. Система по п.13, в которой второй компонент генерации удаляет пару из второго списка, если указатель доверительности ниже среднего указателя доверительности для второго списка.
17. Система по п.7, в которой компонент выбора выбирает набор файлов, который находится в той же области, что и первый набор строк и второй набор строк.
18. Способ создания отображения между первым набором строк и вторым набором строк, содержащий этапы, на которых
поддерживают индекс файлов,
создают первое отображение между первым набором строк и индексом файлов посредством поиска по индексу файлов для отыскания файлов, которые связаны с по меньшей мере одной из строк из первого набора строк, и - для каждой строки в первом наборе строк, которая связана с файлом из индекса файлов, - создания элемента в первом списке, причем этот элемент содержит строку из первого набора строк и каждый файл из индекса файлов, который связан со строкой из первого набора строк,
создают второе отображение между вторым набором строк и индексом файлов посредством поиска по индексу файлов для отыскания файлов, которые связаны с по меньшей мере одной из строк из второго набора строк, и - для каждой строки во втором наборе строк, которая связана с файлом из индекса файлов, - создания элемента во втором списке, причем этот элемент содержит строку из второго набора строк и каждый файл из индекса файлов, который связан со строкой из второго набора строк, и
создают отображение между первым набором строк и вторым набором строк на основании первого отображения и второго отображения, при котором
генерируют третий список из второго списка, причем третий список содержит элемент для каждого файла из индекса файлов, который связан со строкой из второго набора строк, совместно с каждой строкой из второго набора строк, которая связана с файлом,
генерируют четвертый список из третьего списка и первого списка, причем четвертый список содержит элемент для каждой строки из первого набора строк, которая связана с файлом из индекса файлов, и каждой строки из второго набора строк, которая связана с тем же файлом, что и строка из первого набора строк.
19. Способ по п.18, в котором при поддержании индекса файлов выбирают индекс файлов, который находится в той же области, что и первый набор строк и второй набор строк.
20. Способ по п.19, дополнительно содержащий этап, на котором генерируют ранг для каждого элемента четвертого списка.
21. Система для создания отображения между первым набором строк и вторым набором строк, содержащая
запоминающее устройство для поддержания индекса файлов и процессор для
создания первого отображения между первым набором строк и индексом файлов посредством поиска по индексу файлов для отыскания файлов, которые связаны с по меньшей, мере одной из строк из первого набора строк, и -для каждой строки в первом наборе строк, которая связана с файлом из индекса файлов, - создания элемента в первом списке, причем этот элемент содержит строку из первого набора строк и каждый файл из индекса файлов, который связан со строкой из первого набора строк,
создания второго отображения между вторым набором строк и индексом файлов посредством поиска по индексу файлов для отыскания файлов, которые связаны с по меньшей мере одной из строк из второго набора строк, и - для каждой строки во втором наборе строк, которая связана с файлом из индекса файлов, - создания элемента во втором списке, причем этот элемент содержит строку из второго набора строк и каждый файл из индекса файлов, который связан со строкой из второго набора строк и
создания отображения между первым набором строк и вторым набором строк на основании первого отображения и второго отображения посредством генерирования третьего списка из второго списка, причем третий список содержит элемент для каждого файла из индекса файлов, который связан со строкой из второго набора строк, совместно с каждой строкой из второго набора строк, которая связана с файлом, и генерирования четвертого списка из третьего списка и первого списка, причем четвертый список содержит элемент для каждой строки из первого набора строк, которая связана с файлом из индекса файлов, и каждой строки из второго набора строк, которая связана с тем же файлом, что и строка из первого набора строк,
22. Система по п.21, дополнительно содержащая устройство ввода для приема первого набора строк и второго набора строк.
23. Система по п.22, дополнительно содержащая генерацию, посредством процессора, ранга для каждого элемента четвертого списка.
24. Способ определения взаимосвязей между первым набором строк и вторым набором строк, содержащий этапы, на которых
принимают генерированное отображение между первым набором строк и вторым набором строк, причем отображение содержит множество элементов, каждый элемент содержит строку из первого набора строк и строку из второго набора строк, и создано любым одним из способа по п.1 или 18,
определяют, представляет ли элемент достоверную взаимосвязь между строкой из первого набора строк и строкой из второго набора строк, и
удаляют элемент, который не представляет достоверную взаимосвязь.
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Устройство для автоматизированного поиска информации | 1981 |
|
SU993274A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |

