Изобретение используется для реализации контентно-ориентированного поиска Интернет-ресурсов. Использование комплексных запросов, определяющих требования как к текстовому содержимому, так и к мультимедийной информации, содержащейся на искомых web-страницах, позволяет существенно повысить эффективность поиска.
Поисковые сервисы, такие как Google и Yandex, обеспечивают поиск информации, доступной через Интернет. Пользователь формирует поисковый запрос, представляющий собой набор ключевых слов, которые должны содержаться в искомых ресурсах. Результат поиска представляется пользователю как список ссылок (url-адресов) на web-страницы, которые содержат запрашиваемые ключевые слова. При этом для большей эффективности обработки результатов поиска применяются различные алгоритмы расчета индекса соответствия (релевантности) результатов поиска предъявленному запросу (см., например, Патент US 7231399B1 «Ranking documents based on large data sets» от 12.07.2007). Индекс релевантности используется для сортировки результатов поиска по мере убывания их значимости. Подобные системы развиты уже довольно сильно и продолжают развиваться, в них реализуется сложный эвристический анализ индексируемой информации.
Помимо сервисов поиска текстовой информации интенсивно развиваются сервисы, направленные на поиск мультимедийной, в частности, графической информации. Запрос на поиск графической информации может быть сформулирован различными способами.
Базовым способом поиска изображений можно считать поиск по ключевым словам, описывающим изображения. Этот способ активно используется различными поисковыми системами.
Альтернативные способы поиска предполагают формирование запроса на поиск с использованием изображений-образцов. При этом использование изображений-образцов требует решения ряда задач: 1) определение степени сходства предъявленного образца с набором изображений, среди которых выполняется поиск; 2) формирование индексированного по степени сходства списка результатов поиска; 3) представления пользователю результатов поиска, отсортированных с учетом значений индекса.
Задачи определения степени сходства изображений могут решаться разными методами.
Известны способы определения сходства двух изображений с помощью методов, называемых Content Based Image Retrieval (CBIR) (см., например, Патент US 5751286A1 «Image query system and method» от 12.05.1998). Подобные методы судят о сходстве исходя исключительно из оценки совпадения цветов и яркостей соответствующих областей, сравниваемых изображений, в предельном случае - каждой пары точек изображений.
Более сложные алгоритмы определения сходства предполагают анализ степени сходства объектов, находящихся на изображении. Известны способы поиска и распознавания объектов на цифровом изображении с помощью выделения замкнутого контура, максимально совпадающего с границами объекта с последующим поочередным наложением шаблонов, хранящихся в памяти компьютера (см., например, патент RU 2250499 С1, 17.11.2003 «Способ компьютерного распознавания объектов»). Этот способ удовлетворительно работает лишь в том случае, когда на изображении расположен только один искомый объект. Наличие нескольких объектов на изображении, а также отсутствие искомых объектов вообще приводит к появлению некорректных результатов.
Известны способы поиска объектов на цифровом изображении, основанные на выделении замкнутых контуров (контуров одного цвета) на изображении с их последующим представлением в виде коэффициентов преобразования Фурье (см., например, US Patent № 6563959 B1, 13.05.2003, "Perceptual similarity image retrieval method"). В этом случае степень схожести двух объектов на разных изображениях определяется по ряду коэффициентов. Этот способ очень чувствителен к качеству изображения: при работе с зернистым изображением, а также при обработке изображения с большим числом мелких объектов метод затрачивает много времени на обработку изображения. Кроме того, зернистость изображения может свести на нет результаты поиска из-за усложнения характера границ и выделения зерен в качестве отдельных объектов.
Поиск похожих изображений среди большого количества графических файлов делает неэффективным сравнение всех изображений с изображением образца, поэтому системы, ориентированные на обработку большого количества изображений, помимо алгоритмов оценки степени сходства изображений необходимо использовать алгоритмы классификации и индексирования обрабатываемых изображений для последующего использования индекса для организации поиска. В данном изобретении может использоваться, например, следующий алгоритм. На цифровом изображении локализуются изображения искомых объектов, которые затем нормализуются, приводятся к единому масштабу и предъявляются к распознаванию по базовому набору типовых изображений объектов. Каждое найденное изображение объекта поступает на вход искусственной нейронной сети, которая формирует ряд подобия, т.е. сортирует базовый набор изображений объектов по убыванию сходства. (Принципы функционирования нейронной сети описаны, например, в Ю.С.Корнев, Н.А.Филиппов, А.А.Юдашкин Адаптивный алгоритм локализации лиц на цветных фотографиях // Вестник Самарского гос. техн. ун-та, Серия "Технические науки", Вып. №32, 2005). Ряд подобия выступает в качестве индекса, который формируется для каждого из всех доступных алгоритму изображений объектов и для изображения объекта, предъявленного к поиску. Для определения степени сходства между двумя изображениями вводится понятие расстояния между их рядами подобия путем сложения разностей позиций каждого из базовых изображений в сопоставляемых рядах, что позволяет, в свою очередь, сортировать несколько изображений объектов по степени убывания сходства с предъявленным.
Формирование списка результатов поиска отсортированных по убыванию значений индекса релевантности искомых ресурсов может быть выполнено множеством способов. Один из способов описан, например, в патенте WO 2005033885A2 «Content oriented index and search method and system» от 14.04.2005. В нем предлагается решение для поиска мультимедийных файлов. Предлагается способ индексирования файлов, а также методы ранжирования результатов поиска, построенные на взвешенной оценке набора коэффициентов, рассчитываемых по их контентным сигнатурам. В целом любые способы ранжирования базируются на использовании понятия расстояния, разные методики расчета которого и отличают один способ от другого.
Известны способы формирования запроса на поиск изображений, состоящий из нескольких этапов: текстовый запрос на поиск изображений; использование результата запроса для нового поиска (см., например, Патент US2007174269A1 «Generating clusters of images for search results» от 26.07.2007). Фразы с web-страницы, на которой было найдено изображение, используются для поиска других изображений, ассоциированных с этими фразами. Недостаток способа - использование текстового описания изображения.
Известны способы поиска изображений по ключевым изображениям (см., например, Патент US 2007288453 A1 «System and Method for Searching Multimedia using Exemplar Images» от 13.12.2007). Пользователь формирует запрос с помощью графического интерфейса, комбинируя ключевые изображения. Запрос по ключевым изображениям может быть дополнен текстовым запросом. Результат поиска возвращается отранжированный по степени сходства найденных изображений с ключевыми изображениями.
Основным недостатком подобных систем является снижение эффективности формирования запроса при увеличении набора ключевых изображений.
Наиболее близким по технической сущности является способ формирования поискового запроса с помощью мультимодального (комбинированного) запроса, состоящего из текстового запроса и запроса по изображениям, при котором формируют комбинированный запрос, состоящий из текстового запроса и, по меньшей мере, одного запроса мультимедийных данных, вводят комбинированный запрос в поисковую систему и в процессе поиска выявляют мультимедийные данные, содержащие объекты, сходные с объектом, указанным в соответствующем запросе мультимедийных данных (Патент US 2007067345 A1 «Generating search requests from multimodal queries» от 22.03.2007). По текстовому запросу ищутся все изображения, которые ассоциированы с ключевыми словами запроса, а среди изображений-результатов текстового запроса выбираются изображения, которые визуально похожи на запрос-изображение. Для определения сходства изображений предлагается использовать один из методов поиска похожих изображений, известных как «CBIR» (content base information retrieval). Система может сформулировать запрос на поиск изображений по ключевым словам web-страницы, содержащей выбранные изображения, а затем обработать результаты как мультимодальный запрос.
Недостатком прототипа является использование примитивных методов оценки сходства изображений, ориентированных на анализ общего сходства изображений по совпадению яркостей соответствующих участков изображений. Кроме того, прототип ориентирован на поиск только графических изображений, никоим образом не анализируя прочие мультимедийные компоненты ресурса и сам информационный ресурс в целом.
Техническим результатом, на достижение которого направлено данное изобретение, является повышение качества поиска информационных ресурсов за счет предоставления пользователю эффективного инструмента для построения комбинированного запроса, включающего в себя текстовый запрос и любые мультимедийные данные (статические изображения, видео, музыку).
Технический результат, на достижение которого направлено создание данного изобретения, заключается в том, что в способе поиска web-страниц по комбинированному запросу, при котором формируют комбинированный запрос, состоящий из текстового запроса и, по меньшей мере, одного запроса мультимедийных данных, вводят комбинированный запрос в поисковую систему и в процессе поиска выявляют мультимедийные данные, содержащие объекты, сходные с объектом или объектами, указанными в соответствующем запросе мультимедийных данных, отличающийся тем, что при выявлении мультимедийных данных, содержащих объекты, сходные с объектом или объектами, указанными в соответствующем запросе мультимедийных данных, из предъявленных к поиску данных, содержащихся в запросе, выделяют характерные, в зависимости от типа анализируемых мультимедийных данных, объекты и осуществляют поиск мультимедийных данных, содержащих объекты, похожие на указанные выделенные объекты, при этом по каждому из запросов, составляющих комбинированный запрос, независимо формируют списки url-адресов, отвечающих текстовому запросу и запросам по мультимедийным данным, со значениями релевантности каждого url-адреса, формируют общий список url-адресов, выявляя одинаковые адреса из указанных списков - результатов текстового поиска и поисков по мультимедийным типам данных - и определяя итоговое значение релевантности, как взвешенную сумму значений релевантности результатов текстового поиска и поиска по каждому типу мультимедийных данных, и предоставляют пользователю указанный общий список url-адресов, отсортированный по убыванию итогового значения релевантности как результат комбинированного запроса.
При формировании списка url-адресов по запросу мультимедийных данных группируют выявленные в процессе поиска объекты с одинаковыми url-адресами и соответствующими им значениями релевантности, рассчитывают значение релевантности по каждой группе путем взвешенного суммирования максимального для каждой группы значения релевантности и значения нелинейной функции с насыщением от суммы значений релевантности всех объектов группы и формируют указанный список, содержащий url-адрес каждой группы и рассчитанное значение релевантности.
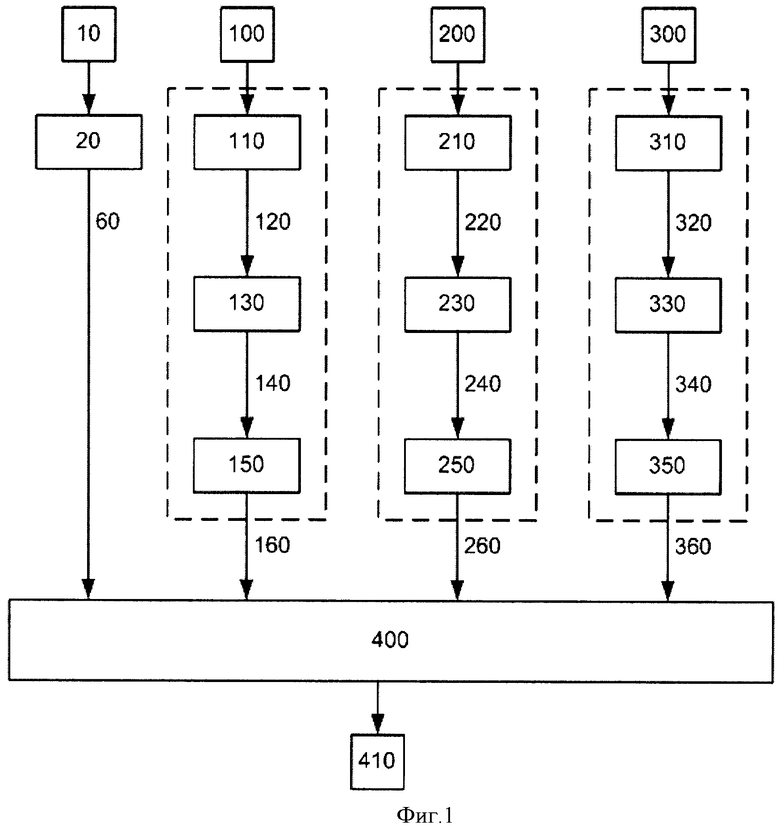
Предлагаемый способ иллюстрируется последовательностью операций, приведенных на фиг.1, где
10 - сформированный пользователем текстовый запрос;
20 - операция текстового поиска;
60 - список url-адресов, сформированный в результате текстового поиска;
100, 200, 300 - сформированные пользователем запросы по различным типам мультимедийных данных (изображения, видео, музыка);
110, 210, 310 - операции выделения характерных объектов из запросов по различным типам мультимедийных данных (изображения, видео, музыка) и формирования для каждого из найденных объектов сигнатур;
120, 220, 320 - списки сигнатур характерных объектов, выделенных из мультимедийных запросов различных типов (изображения, видео, музыка);
130, 230, 330 - операции поиска похожих объектов соответствующего типа мультимедийных данных;
140, 240, 340 - списки найденных объектов соответствующих типов мультимедийных данных, содержащие url-адрес, по которому расположен объект и значение релевантности;
150, 250, 350 - операции расчета значений релевантности для каждого url-адреса в зависимости от количества располагающихся по адресу объектов и значений релевантности объектов.
160, 260, 360 - списки url-адресов, сформированные в результате поиска по каждому из типов мультимедийных данных;
400 - операция расчета обобщенного значения релевантности url-адреса;
410 - общий список url-адресов, отсортированных в порядке убывания значений обобщенной релевантности.
Для поиска по любому из типов мультимедийных данных в зависимости от типа анализируемых данных из предъявленных к поиску данных выделяются характерные объекты (например, лица - на изображениях или в видео, музыкальная тема - в музыке). Для каждого объекта с помощью искусственной нейронной сети формируется ряд подобия - отсортированный в порядке убывания сходства ряд объектов из базового набора (сигнатура).
Для выделенных объектов осуществляется поиск мультимедийных данных, содержащих похожие объекты и формирование списка url-адресов web-страниц с найденными мультимедийными данными.
Список url-адресов web-страниц формируется независимо, по каждому из типов мультимедийных данных. Индекс каждого объекта из базы данных системы рассчитывается по количеству совпадений объектов из базового набора в сигнатуре предъявленного на поиск объекта и в сигнатурах хранящихся в базе данных проиндексированных объектов. Таким образом, релевантность для каждого проиндексированного объекта может быть рассчитана как отношение количества совпадений объектов из базового набора к общему количеству объектов из базового набора в сигнатуре. На одной web-странице (по одному и тому же url-адресу) может располагаться несколько найденных объектов, поэтому релевантность каждого url-адреса из списка url-адресов рассчитывается путем взвешенного суммирования максимального значения релевантности находящихся на web-странице объектов и значения нелинейной функции с насыщением от суммы значений релевантности всех найденных на ней объектов.
Далее система формирует общий список url-адресов, группируя одинаковые адреса из списков-результатов текстового поиска и поисков по мультимедийным типам данных и рассчитывая итоговое значение релевантности как взвешенную сумму значений релевантности результатов текстового поиска и поиска по каждому типу мультимедийных данных. Общий список url-адресов, отсортированный по убыванию обобщенного значения релевантности, предоставляется пользователю как результат комбинированного запроса.
Пользователь инициирует поиск, формируя произвольную комбинацию запросов: текстовый запрос (10) и/или запрос на поиск по изображениям (100), и/или запрос на поиск по видео (200), и/или запрос на поиск по музыке (300).
Операция текстового поиска (20) обрабатывает сформированный пользователем текстовый запрос (10), формируя список url-адресов (60) со значениями релевантности каждого url-адреса текстовому запросу (10).
Операция выделения характерных объектов на предъявленных пользователем изображениях (110) формирует список сигнатур всех объектов (120), найденных на этих изображениях. Сигнатуры из списка (120) по очереди поступают на вход операции поиска похожих объектов (130), которая формирует список похожих объектов (140), находящихся в базе данных поисковой системы. Каждая строка списка содержит url-адрес, по которому располагается найденный объект и значение релевантности, рассчитанное для данного объекта по отношению к одному из объектов, находящихся в запросе пользователя (100). В итоге список (140) может содержать несколько строк с одинаковыми значениями url-адресов и соответствующими им значениями релевантности. Список (140) обрабатывается в результате операции расчета релевантности для каждого url-адреса (150). Одинаковые url-адреса группируются, затем рассчитывается значение релевантности для каждой группы путем взвешенного суммирования максимального для каждой группы значения релевантности и значения нелинейной функции с насыщением от суммы значений релевантности всех объектов группы. В результате операции (150) формируется список (160), содержащий url-адрес каждой группы и рассчитанное значение релевантности группы.
Аналогичные действия проводятся для запросов (200) и (300). Выделяются характерные объекты с помощью выполнения операций (210) и (310), по которым и будет выполняться поиск. Сигнатуры, сформированные для каждого из выделенных характерных объектов, заносятся в списки (220) и (320). В результате выполнения операций (230) и (330) соответственно и на базе списков найденных объектов (240), (340) путем выполнения операций (250), (350) формируются списки (260), (360), содержащие url-адреса каждой группы и рассчитанное значение релевантности группы для запроса по видео (200) и музыки (300) соответственно.
Сформированные списки (60), (160), (260), (360) подвергаются операции расчета обобщенного значения релевантности url-адреса (400). Из всех списков формируется единый список, который группируется по url-адресам. Обобщенное значение релевантности рассчитывается как сумма значений релевантности каждой группы, отнесенная к количеству типов компонентов комбинированного запроса. Список (410) url-адресов и обобщенных значений релевантности, отсортированный в порядке убывания значений, возвращается пользователю как результат комбинированного запроса.
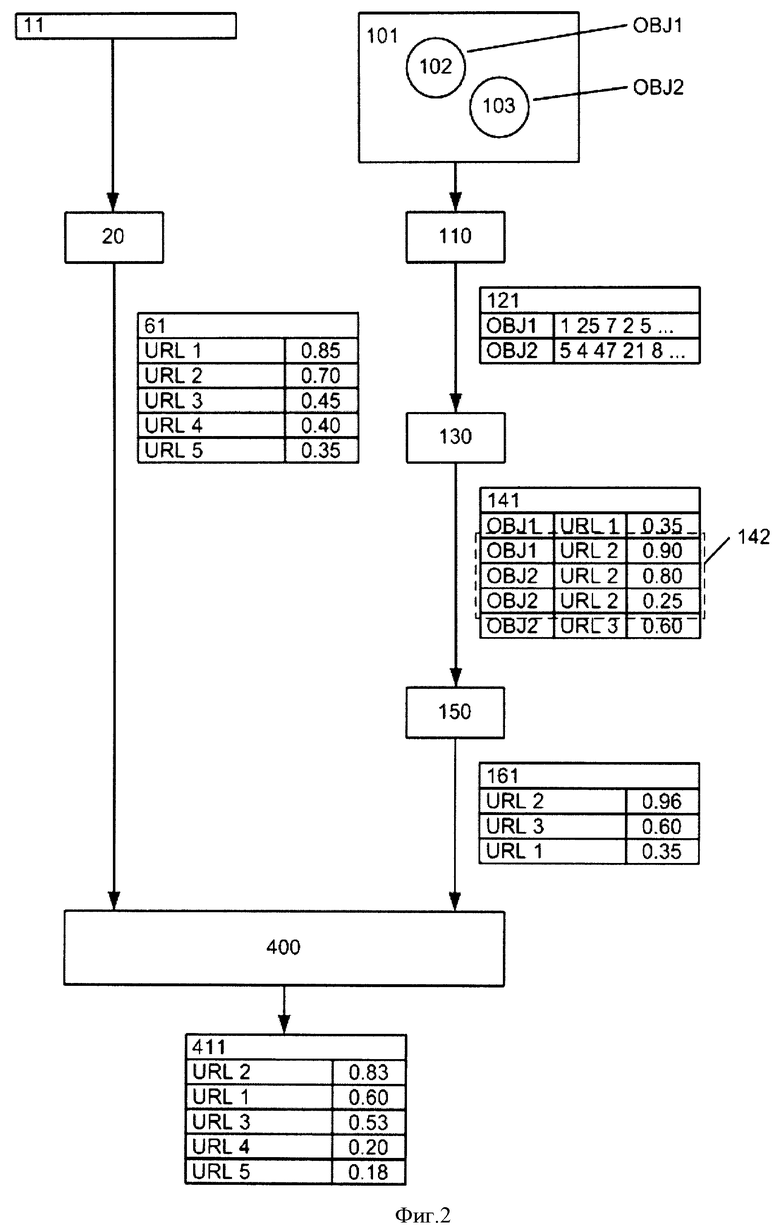
На фиг.2 приведен пример работы системы при обработке комбинированного запроса, здесь
11 - текстовый запрос;
61 - список url-адресов, сформированный в результате текстового поиска;
101 - изображение-запрос;
102, 103 - изображения объектов (ОВJ1 и OBJ2), которые найдены системой на изображении-запросе и используются для дальнейшего формирования запроса;
121 - список сигнатур для найденных на изображении-запросе объектов;
141 - список, в каждой строке которого указывается: искомый объект; url-адрес, по которому расположен объект, похожий на искомый; значение релевантности (степень сходства). Список сгруппирован по url-адресам;
142 - пример группы, с одним url-адресом;
161 - список url-адресов, сформированный после расчета значения релевантности для каждой группы;
411 - общий список url-адресов, отсортированных в порядке убывания значений обобщенной релевантности.
Операции (20), (110), (130), (400) выполняют те же действия, что и ранее.
В пример на фиг.2 пользователь формирует запрос, состоящий из текстового запроса (11) и изображения (101).
В результате обработки текстового запроса формируется список url-адресов (61).
Для обработки запроса по изображению (101) система находит на изображении-запросе изображения двух объектов (102) и (103), для которых формируется список сигнатур (121).
Далее, для каждого из объектов (102) и (103) находятся все похожие на него объекты в базе системы и формируется список (141), сгруппированный по одинаковым url-адресам (см. пример 142). Для каждой группы рассчитывается ее релевантность и формируется список url-адресов (161), отсортированный по убыванию релевантности.
Списки (61) и (161) используются для формирования окончательного результата поиска - списка (411), который возвращается пользователю в качестве результата запроса.
Изобретение относится к контентно-ориентированному поиску Интернет-ресурсов. Техническим результатом изобретения является повышение качества поиска информационных ресурсов. В способе поиска web-страниц из предъявленных к поиску данных, содержащихся в запросе, выделяют характерные, в зависимости от типа анализируемых мультимедийных данных, объекты и осуществляют поиск мультимедийных данных, содержащих объекты, похожие на указанные выделенные объекты. По каждому из запросов, составляющих комбинированный запрос, независимо формируют списки url-адресов. Сформированные списки подвергаются операции расчета обобщенного значения релевантности url-адреса. Из всех списков формируется единый список, который группируется по url-адресам. Обобщенное значение релевантности рассчитывается как сумма значений релевантности каждой группы, отнесенная к количеству типов компонентов комбинированного запроса. Список url-адресов и обобщенных значений релевантности, отсортированный в порядке убывания значений, возвращается пользователю как результат комбинированного запроса. 1 з.п. ф-лы, 2 ил.
1. Способ поиска web-страниц по комбинированному запросу, при котором формируют комбинированный запрос, состоящий из текстового запроса и, по меньшей мере, одного запроса мультимедийных данных, вводят комбинированный запрос в поисковую систему и в процессе поиска выявляют мультимедийные данные, содержащие объекты, сходные с объектом или объектами, указанными в соответствующем запросе мультимедийных данных, отличающийся тем, что при выявлении мультимедийных данных, содержащих объекты, сходные с объектом или объектами, указанными в соответствующем запросе мультимедийных данных, из предъявленных к поиску данных, содержащихся в запросе, выделяют характерные в зависимости от типа анализируемых мультимедийных данных объекты и осуществляют поиск мультимедийных данных, содержащих объекты, похожие на указанные выделенные объекты, при этом по каждому из запросов, составляющих комбинированный запрос, независимо формируют списки url-адресов, отвечающих текстовому запросу и запросам по мультимедийным данным, со значениями релевантности каждого url-адреса, формируют общий список url-адресов, выявляя одинаковые адреса из указанных списков-результатов текстового поиска и поисков по мультимедийным типам данных и определяя итоговое значение релевантности, как взвешенную сумму значений релевантности результатов текстового поиска и поиска по каждому типу мультимедийных данных, и предоставляют пользователю указанный общий список url-адресов отсортированный по убыванию итогового значения релевантности как результат комбинированного запроса.
2. Способ по п.1, отличающийся тем, что при формировании списка url-адресов по запросу мультимедийных данных группируют выявленные в процессе поиска объекты с одинаковыми url-адресами и соответствующими им значениями релевантности, определяют значение релевантности по каждой группе путем взвешенного суммирования максимального для каждой группы значения релевантности и значения нелинейной функции с насыщением от суммы значений релевантности всех объектов группы и формируют указанный список, содержащий url-адрес каждой группы и рассчитанное значение релевантности.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ КОМПЬЮТЕРНОГО РАСПОЗНАВАНИЯ ОБЪЕКТОВ | 2003 |
|
RU2250499C1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| CN 1851713 А, 25.10.2006 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |

