Область техники, к которой относится изобретение
Настоящее изобретение относится, в общем, к разработке данных, а более конкретно к системам и способам, обеспечивающим автоматическое обнаружение аномалий данных в перспективных (то есть имеющих n измерений) представлениях данных.
Уровень техники
Преобразование информации в цифровую форму позволяет хранить огромные объемы данных в невероятно малых объемах пространства. Этот способ, например, позволяет осуществлять хранение содержимого библиотеки на одном единственном компьютерном накопителе на жестких магнитных дисках. Это возможно по той причине, что данные преобразованы в двоичные состояния, которые могут быть сохранены посредством цифровых кодирующих устройств на различных типах цифровых носителей информации, таких как накопители на жестких магнитных дисках, диски CD-ROM и гибкие диски. По мере того как развивается технология цифровых запоминающих устройств, плотность размещения информации в запоминающих устройствах позволяет хранить в некотором данном объеме пространства существенно больше данных, при этом плотность размещения данных ограничена главным образом физическими и производственными процессами.
При возрастающей емкости запоминающих устройств также растет и потребность в эффективном поиске данных, что делает легкость доступа к данным вопросам первостепенной важности. Например, тот факт, что библиотека имеет некоторую книгу, но не может определить ее местонахождение, не поможет читателю, которому хотелось бы прочитать книгу. Аналогичным образом, просто преобразование данных в цифровую форму не является шагом вперед, если к ним нельзя осуществить быстрый доступ. Это привело к созданию структур данных, которые способствуют эффективному поиску данных. Эти структуры обычно известны как «базы данных». Для обеспечения эффективного доступа к данным база данных содержит данные в структурированной форме. Структурирование хранения данных обеспечивает более высокие показатели эффективности при поиске данных, чем в случае неструктурированного хранения данных. Также могут применяться индексирование и другие технологии организации данных. Вместе с данными также могут быть сохранены и связи между данными, что увеличивает ценность данных.
На раннем этапе развития баз данных пользователь обычно должен был просматривать «необработанные данные» или данные, которые просматриваются точно в том же виде, в каком они были занесены в базу данных. В конечном счете, были разработаны технологии, которые позволяют форматировать данные, манипулировать ими и просматривать их более эффективным способом. Это позволило пользователю, например, применять к данным математические операторы и даже создавать отчеты. Коммерческие пользователи смогли получить доступ к такой информации, как «суммарный объем продаж», получаемой из данных в базе данных, которая содержала только сведения об индивидуальных продажах. Пользовательские интерфейсы продолжали развиваться в направлении дальнейшего содействия в поиске данных и отображении их в дружественной для пользователя форме. Пользователи, в конечном счете, поняли, что различные представления данных, такие как суммарный объем продаж, полученный из данных об индивидуальных продажах, позволяют им получать дополнительную информацию из необработанных данных, содержащихся в базе данных. Этот процесс тщательного извлечения дополнительных данных известен под названием «разработка данных», и он порождает «метаданные» (то есть данные о данных). Разработка данных предоставляет возможность извлекать из необработанных данных ценную дополнительную информацию. Это особенно полезно в бизнесе, где за рамками результатов, полученных только на основе необработанных входных данных базы данных, может быть найдена информация, объясняющая объем продаж предприятия и объем выпуска продукции.
Таким образом, манипуляция данными позволяет извлечь из необработанных данных критически важную информацию. Это манипулирование данными возможно по причине цифровой природы хранимых данных. Огромные объемы преобразованных в цифровую форму данных могут быть рассмотрены с различных сторон существенно быстрее, чем при попытке сделать это вручную. Каждое новое представление данных может позволить пользователю дополнительно расширить свое понимание этих данных. Это очень мощная концепция, которая способна привести предприятия к успеху в случае, если они ее используют, и к провалу в случае, если они ее не используют. Например, на основе необработанных данных, занесенных в базу данных, а именно их значений и временной характеристики, при условии наличия интуитивного, дружественного по отношению к пользователю доступа к преобразованной в цифровую форму информации, могут быть проведены анализ тенденций изменения, причинно-следственный анализ, исследование влияния факторов и прогнозирование.
В настоящий момент манипуляция данными, производимая для усиления возможностей разработки данных, требует от пользователя ввод данных в значительных объемах и значительных знаний, чтобы гарантировать, что ошибочные данные не будут включены в состав различных перспективных представлений данных. Это требует от пользователя, чтобы он имел глубокое знание данных и понимание того, какие типы ошибок могут встретиться в данных. Без этого предварительного знания пользователю приходится пытаться применять подход «проб и ошибок», рассчитывая уловить аномалии, скрытые в данном перспективном представлении данных. Этот подход обычно находится за пределами возможностей случайного пользователя и/или отнимает слишком много времени у квалифицированного пользователя. Объем хранимых данных обычно слишком велик и слишком сложен в том, что касается связи между данными, для того чтобы пользователь мог эффективно разработать пригодную для использования методологию, гарантирующую раскрытие всех аномалий данных.
Раскрытие изобретения
Нижеследующий раздел представляет упрощенное изложение сущности изобретения, приводимое с целью дать начальное понимание некоторых аспектов изобретения. Данное изложение сущности не является пространным обзором изобретения. Оно не предназначено для определения ключевых/критически важных элементов изобретения, равно как и для очерчивания объема изобретения. Его единственная цель заключается в том, чтобы в упрощенной форме представить некоторые концепции изобретения в качестве вступления к более подробному описанию, которое приводится позже.
Настоящее изобретение относится, в общем, к разработке данных, а более конкретно к системам и способам обеспечения автоматического обнаружения аномалий данных в перспективных представлениях данных. Способы подбора кривой данных задействованы таким образом, чтобы обеспечивать автоматическое обнаружение аномалий данных в «трубке данных», получаемой из перспективного представления данных, при этом трубка данных содержит данные, у которых только одно изменяющееся измерение данных. Это позволяет, например, обнаружить аномалии данных, такие как аномалии данных, присутствующие на экране, аномалии данных, выявляемые при нисходящем анализе, и аномалии данных, выявляемые при «поперечном» анализе (анализ данных в представлении, проводимый в направлении, поперечном к отображаемому измерению, т.е. вдоль неотображаемого измерения), например, в электронных сводных таблицах и/или кубах данных, созданных по технологии Оперативной аналитической обработки данных (OLAP) и т.п. Предлагая автоматический анализ перспективного представления данных, настоящее изобретение позволяет неопытным пользователям легко находить в базе данных информацию об ошибочных данных. Это достигается посредством определения того, существенно ли отклоняются данные от прогнозируемого значения, установленного процессом подбора кривой, такого как, например, применение кусочно-линейной функции к трубке данных. Также согласно данному изобретению может быть использовано пороговое значение, содействующее в определении степени отклонения, что необходимо, прежде чем значение данных будет признано аномальным. Пороговое значение может задаваться динамически и/или статически, например, системой и/или пользователем посредством пользовательского интерфейса и т.п. Кроме того, настоящее изобретение может оперативно указывать пользователю на перспективном представлении данных, относящемуся к верхнему уровню, тип и место расположения обнаруженной аномалии, без необходимости для пользователя рыскать в поисках аномалий данных по более низким уровням.
Для достижения вышеупомянутых и связанных с ними целей в данном документе приводятся некоторые иллюстративные аспекты изобретения в связи с нижеследующим описанием и прилагаемыми к нему чертежами. Эти аспекты, однако, указывают лишь на некоторые из различных способов, при помощи которых могут быть использованы принципы изобретения, при этом подразумевается, что настоящее изобретение охватывает все такие аспекты и их эквиваленты. Другие преимущества и признаки новизны изобретения могут стать очевидными из нижеследующего подробного описания изобретения при рассмотрении его совместно с прилагаемыми чертежами.
Краткое описание чертежей
Фиг. 1 - блок-схема системы автоматического обнаружения аномалий перспективных представлений данных, соответствующей аспекту настоящего изобретения.
Фиг. 2 - другая блок-схема системы автоматического обнаружения аномалий перспективных представлений данных, соответствующей аспекту настоящего изобретения.
Фиг. 3 - еще одна блок-схема компонента автоматического обнаружения аномалий перспективных представлений данных, соответствующего аспекту настоящего изобретения.
Фиг. 4 - блок-схема последовательности операций способа обеспечения автоматического обнаружения аномалий перспективных представлений данных, соответствующего аспекту настоящего изобретения.
Фиг. 5 - другая блок-схема последовательности операций способа обеспечения автоматического обнаружения аномалий перспективных представлений данных, соответствующего аспекту настоящего изобретения.
Фиг. 6 - иллюстрация приводимой в качестве примера операционной среды, в которой может функционировать настоящее изобретение.
Фиг. 7 - иллюстрация другой приводимой в качестве примера операционной среды, в которой может функционировать настоящее изобретение.
Осуществление изобретения
Настоящее изобретение описано ниже со ссылками на чертежи, где одинаковые ссылочные позиции используются для указания на одинаковые элементы на всех чертежах. В нижеследующем описании в целях его объяснения приводятся многочисленные конкретные подробности для того, чтобы обеспечить полное понимание настоящего изобретения. Представляется, однако, очевидным то, что данное изобретение может быть осуществлено без этих конкретных подробностей. В других случаях хорошо известные структуры и устройства показаны в форме блок-схем, что сделано с целью облегчения описания настоящего изобретения.
Термин «компонент» в том значении, в котором он использован в данной заявке, предназначен для обозначения некоторой связанной с компьютером сущности, будь то аппаратное обеспечение, сочетание аппаратного обеспечения и программного обеспечения, программное обеспечение и программное обеспечение в состоянии своего исполнения. Например, компонент может представлять собой, но не в ограничительном смысле: процесс, исполняемый процессором; процессор; объект; исполняемый модуль; поток исполнения; программу; и/или компьютер. В качестве иллюстрации отметим, что компьютерным компонентом может быть как приложение, исполняемое сервером, так и сервер. Внутри процесса и/или потока исполнения может находиться один или более компонентов, и компонент может быть локализован на одном компьютере и/или распределен между двумя или более компьютерами. «Поток» представляет собой сущность внутри процесса, чье исполнение планируется ядром операционной системы. Как хорошо известно в данной области техники, каждый поток имеет связанный с ним «контекст», который представляет собой изменяющиеся данные, связанные с исполнением потока. Контекст потока включает в себя содержимое системных регистров и виртуальный адрес, принадлежащий процессу этого потока. Таким образом, фактические данные, содержащие контекст потока, изменяются по мере его исполнения.
Настоящее изобретение обеспечивает анализ перспективных (то есть имеющих n измерений) представлений данных посредством автоматического обнаружения аномальных данных. Для подачи пользователю уведомления о том, что конкретное перспективное представление данных имеет на некотором уровне ошибочные данные, используются индикаторы. Этот уровень может представлять собой отображаемый на экране или верхний уровень и/или уровень, который на текущий момент не отображается и требует от пользователя для обнаружения ошибочных значений данных провести нисходящий анализ данных и/или «поперечный» анализ данных. Таким образом, пользователь может легко определить, что существуют аномалии данных, и определить то, сколько усилий и/или какое представление данных требуется для обнаружения ошибочных данных. Пользователь и/или система могут также статически и/или динамически установить пороговое значение, способствующее автоматическому обнаружению. Пользователь также может выбирать различные пороговые значения для различных типов аномалий данных. Пороговое значение определяет, насколько существенным должно быть отклонение значения данных, прежде чем оно будет признано аномальными. Отклонение определяется посредством сравнения значения данных с прогнозируемым значением данных, полученным при помощи процесса подбора кривой, примененного к трубке данных, имеющей только одно изменяющееся измерение данных. Функции, используемые в процессе подбора кривой, также могут выбираться пользователем. Таким образом, настоящее изобретение позволяет пользователю легко идентифицировать интересующие его характеристики данных, которые он просматривает.
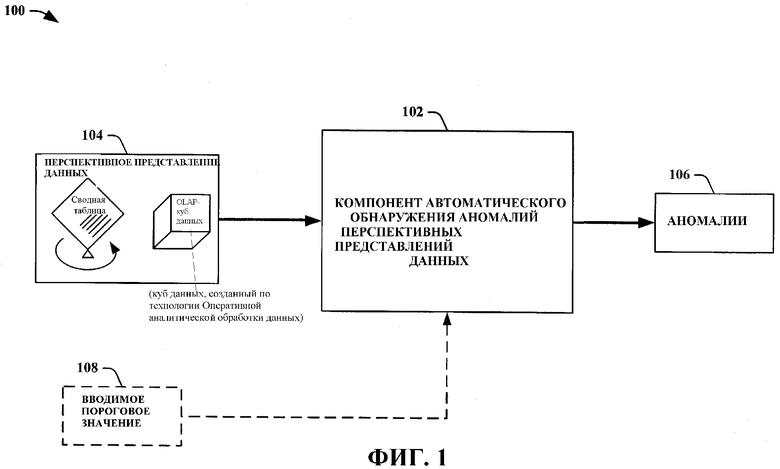
На Фиг. 1 показана блок-схема системы 100 автоматического обнаружения аномалий перспективных представлений данных, соответствующей аспекту настоящего изобретения. В состав системы 100 автоматического обнаружения аномалий перспективных представлений данных входит компонент 102 автоматического обнаружения аномалий перспективных представлений данных, который принимает перспективное представление 104 данных и автоматически определяет аномалии 106 данных. Перспективное представление может включать в себя, но не в качестве ограничения, электронные сводные таблицы и OLAP-кубы данных и т.п. Для обеспечения определения того, какие данные являются аномальными, компонентом 102 автоматического обнаружения аномалий перспективных представлений данных может использоваться необязательное внешнее вводимое пороговое значение 108. Пороговое значение также может быть определено как часть компонента 102 автоматического обнаружения аномалий перспективных представлений данных, как, например, в виде определенного системой значения и/или определенного системой процента отклонения и т.п. Также в настоящем изобретении может быть использовано множество установленных пользователем пороговых значений, которые предназначены для использования с различными типами аномалий данных. Для определения того, какие данные являются аномальными, компонент 102 автоматического обнаружения аномалий перспективных представлений данных использует процесс подбора кривой, применяемый к трубке данных из перспективного представления данных. Для обеспечения автоматического обнаружения аномалий данных процесс подбора кривой может также включать в себя заданные пользователем функции.
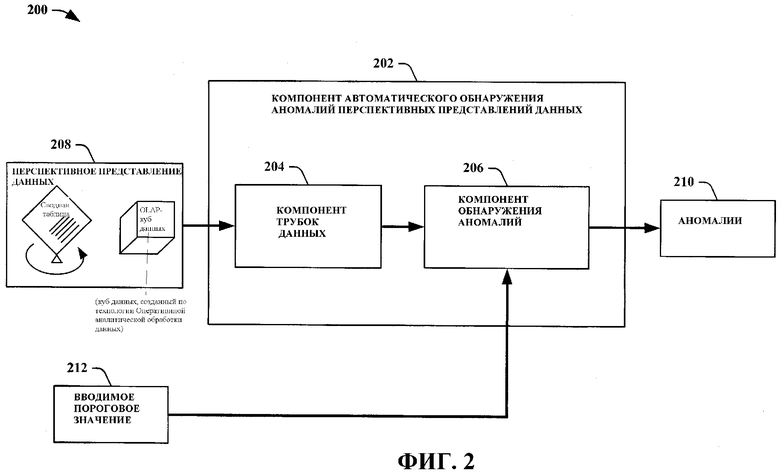
На Фиг. 2 изображена другая блок-схема системы 200 автоматического обнаружения аномалий перспективных представлений данных, соответствующей аспекту настоящего изобретения. В состав системы 200 автоматического обнаружения аномалий перспективных представлений данных входит компонент 202 автоматического обнаружения аномалий перспективных представлений данных, который состоит из компонента 204 трубок данных и компонента 206 обнаружения аномалий. Компонент 204 трубок данных принимает перспективное представление 208 данных и преобразует перспективное представление 208 данных в трубки данных. Трубки данных содержат срезы данных из перспективного представления 208 данных, имеющие только одно изменяющееся измерение данных. Компонент 206 обнаружения аномалий принимает трубки данных и обрабатывает их, используя для определения любых аномалий данных процесс подбора кривой. В состав процесса подбора кривой входит процесс, который пытается сгенерировать функцию, способную оценивать данные в трубке данных. Оцененные данные становятся «прогнозируемыми данными», которые используются для определения показателя отклонения для данных в этой трубке данных. Для определения того, какая величина отклонения является приемлемой, компонентом 206 обнаружения аномалий используется вводимое пороговое значение 212. Вводимое пороговое значение 212 может генерироваться системой и/или генерироваться пользователем. Любые данные, которые превышают вводимое пороговое значение 212, что определяется компонентом 206 обнаружения аномалий, затем выводятся как аномалии 210.
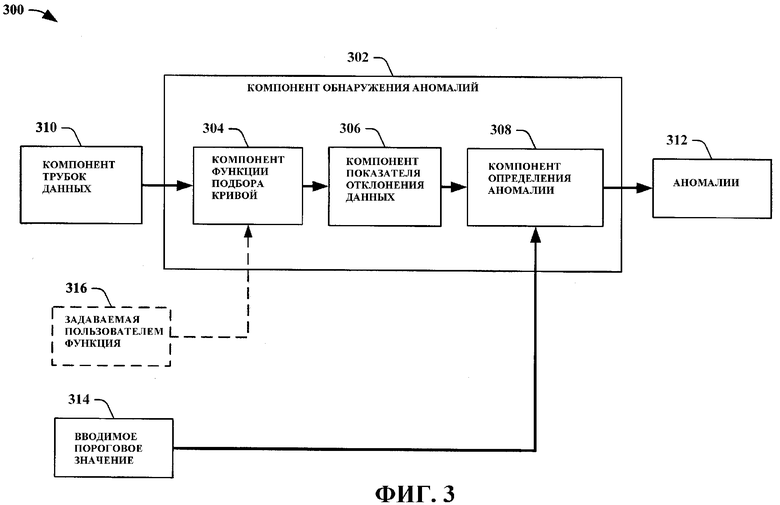
На Фиг. 3 проиллюстрирована еще одна блок-схема компонента 300 автоматического обнаружения аномалий перспективных представлений данных, соответствующего аспекту настоящего изобретения. В состав компонента 300 автоматического обнаружения аномалий перспективных представлений данных входят компонент 310 трубок данных и компонент 302 обнаружения аномалий. В состав компонента 302 обнаружения аномалий входят компонент 304 функции подбора кривой, компонент 306 показателя отклонения данных и компонент 308 определения аномалии. Компонент 304 функции подбора кривой принимает трубку данных от компонента 310 трубок данных и определяет подходящую функцию для представления данных из трубки данных. Это позволяет сгенерировать прогнозируемые данные для значений данных из трубки данных. Компонент 304 функции подбора кривой может также принимать не являющуюся обязательной, задаваемую пользователем функцию 316 для использования ее в качестве подходящей функции. Это позволяет пользователю приспосабливать процесс обнаружения к своим индивидуальным потребностям. Компонент 306 показателя отклонения данных принимает данные из трубки данных вместе с функцией подбора кривой, поступающей из компонента 304 функции подбора кривой. Компонент 306 показателя отклонения данных использует функцию подбора кривой для прогнозирования значений для данных. Эти значения затем сравниваются с фактически имеющимися значениями данных, и определяется показатель, основанный на величине отклонения от прогнозируемого значения. Компонент 308 определения аномалии принимает показатели отклонений и использует вводимое пороговое значение 314 для определения данных, которые превышают пороговое значение. Данные, по которым установлено, что они находятся за пределами порогового значения, признаются аномальными и выводятся как аномальные данные 312.
Для того чтобы лучше понять вышеописанные системы, полезно представить себе контекст и значение данных. Перспективные представления данных, такие как сводные таблицы и/или OLAP-кубы данных, являются для предприятий ключевыми инструментами. Они позволяют пользователю быстро и легко осуществлять навигацию по большим наборам данных, тем самым способствуя принятию связанных с бизнесом (и других) решений. По существу, перспективные представления данных, такие как сводные таблицы и/или OLAP-кубы данных, представляют собой n-мерные представления набора данных. Например, в Таблице 2 приводится иллюстрация сводной таблицы, соответствующей данным, частично показанным в Таблице 1.
Необработанные данные
Изделий
продаж
Формат перспективного представления данных
объемов продаж
итог
В этом перспективном представлении показаны средние объемы продаж как функция даты и «кат. изделий» (категории изделий); и объемы продаж усреднены по региону (региону продаж). В этом примере «объемы продаж» представляют собой целевые данные, в то время как «дата» и «кат. изделия» представляют собой отображаемые измерения, а «регион» представляет собой агрегированное измерение. В Таблице 2 агрегированное значение представляет собой среднее, но возможны и другие агрегированные значения (например, сумма, минимум и максимум). Возможны и другие перспективные представления того же самого набора данных - например, объемы продаж, как функция даты и региона, усредненные по категориям изделий. Количество отображаемых измерений может быть больше двух (см. Таблицу 4).
Каждое измерение может иметь иерархию. В данном примере иерархию даты составляют год, квартал, неделя; иерархию изделия составляют категория изделий, изделие; а иерархию местоположения составляют регион, штат. Важной частью перспективного представления данных, такого как сводная таблица, является уровень иерархии, который подлежит отображению. В Таблице 2 отображаемыми уровнями являются: год - для измерения «дата», категория изделий - для измерения «изделие» и регион - для измерения «местоположение». Пользователи могут осуществить нисходящий анализ внутрь (отображаемого) измерения. Это соответствует переходу к следующему более низкому уровню в иерархии этого измерения (см. Таблицу 5). Пользователи также могут осуществлять анализ в поперечном направлении по отношению к заданной оси, расширив ее в соответствии с измерением, не присутствующим на текущий момент в сводной таблице. Например, в Таблице 4 показан результат «поперечного» анализа, проводимого по региону, сводной таблицы, приведенной в Таблице 2.
Сводная таблица также имеет поле страницы, содержащее измерения (как некоторый уровень в их иерархии), которое выбирает данные, подлежащие показу. В Таблице 2 поле страницы содержит измерение «местоположение» на уровне «регион». Выбраны объемы продаж по всем регионам. В качестве альтернативы, пользователь мог бы выбрать объемы продаж для конкретного региона или штата. В общем, сводная таблица набора данных соответствует (1) целевым данным, (2) отображаемым измерениям на некотором уровне иерархии, (3) измерениям, указанным в поле страницы, на некотором уровне иерархии и (4) функции агрегирования.
Обычно одна или более ячеек в перспективном представлении данных, таком как, например, сводная таблица, могут быть аномальными. Настоящее изобретение обеспечивает автоматическое обнаружение и отображение, по меньшей мере, трех типов аномалий ячеек, таких как, например, (1) аномалии, присутствующие на экране, (2) аномалии, выявляемые при «поперечном» анализе, и (3) аномалии, выявляемые при нисходящем анализе, и т.п. Ячейка имеет аномалию, присутствующую на экране, если она аномальна в контексте других данных, отображаемых на экране. Ячейка имеет аномалию, выявляемую при «поперечном» анализе, если «поперечный» анализ этой ячейки выявляет аномалию. Ячейка имеет аномалию, выявляемую при нисходящем анализе, если анализ, направленный внутрь этой ячейки, выявляет аномалию. Эти типы аномалий показаны в Таблице 3 (идентичной Таблице 2 за исключением форматирования).
Аномалии перспективного представления данных
объемов продаж
итог
В Таблице 3 ячейка кат.2/1999 имеет аномалию, присутствующую на экране, поскольку ячейка имеет более высокие средние объемы продаж, чем любая другая ячейка в ее строке или столбцах. Ячейка кат.2/2001 в Таблице 3 имеет аномалию, выявляемую при «поперечном» анализе. Эта аномалия не очевидна до тех пор, пока пользователь не осуществит поперечный анализ перспективного представления данных по измерению «регион», что показано в Таблице 4, приводимой ниже.
Аномалия, выявляемая при «поперечном» анализе
объемов продаж
изделий
итог
р.2
р.3
37,51
35,71
35,84
38,40
36,54
36,59
36,36
39,01
38,32
39,05
39,63
36,01
37,37
37,46
р.2
р.3
37,56
35,09
45,92
45,47
36,87
38,46
42,04
25,58
37,49
35,09
37,40
39,64
39,55
36,55
р.2
р.3
36,50
38,84
39,10
36,26
35,22
35,35
38,61
37,74
37,35
38,50
36,69
35,29
37,25
37,00
В Таблице 4 объемы продаж в регионе «р.3» показаны значительно более низкими, чем эти показатели в регионах «р.1» и «р.2». Кроме того, ячейка кат.3/2002 в Таблице 3 имеет аномалию, выявляемую при нисходящем анализе. Опять, аномалия не очевидна до тех пор, пока пользователь не проведет нисходящий анализ по иерархии изделия так, как это показано в Таблице 5, приведенной ниже.
Аномалия, выявляемая при нисходящем анализе
объемов продаж
итог
кат.2
кат.3
36,47
38,04
46,84
37,56
38,15
36,17
37,43
37,81
36,51
37,65
38,20
37,15
38,93
37,39
42,87
43,48
26,59
издел.2
издел.3
43,48
26,59
В Таблице 5 объемы продаж изделия 3 показаны значительно более низкими, чем эти показатели для изделия 1 и изделия 2. В этих примерах аномалии, видные на экране, были выделены, а аномалии, выявляемые при поперечном анализе, и аномалии, выявляемые при нисходящем анализе, были указаны рамкой. Однако специалист в данной области техники должен понимать, что возможно и много других вариантов.
Ниже приводится пример автоматического обнаружения аномалии согласно данному изобретению. Термин «трубка» используется для обозначения среза данного перспективного представления данных, в котором изменяется только одно измерение. В двухмерном перспективном представлении данных трубка просто соответствует строке и/или столбцу. Некоторые примеры трубок показаны в трехмерной сводной таблице, приведенной в Таблице 4, они соответствует (1) изменяющейся категории изделий при фиксированных дате и регионе, (2) изменяющемуся региону при фиксированных категории изделий и дате и (3) изменяющейся дате при фиксированных категории изделий и регионе.
Ячейка является аномальной по отношению к трубке, если она существенно отклоняется от ожидаемого значения для данной ячейки, рассчитанного при помощи функции подбора кривой. Вместо требования о том, чтобы значения в перспективном представлении данных были непрерывными, принимается, что перспективное представление данных является одномерным и имеет индекс, который упорядочен. Например, перспективное представление данных могло бы быть проиндексировано по времени, расстоянию или денежным суммам. Таким образом, значения перспективного представления данных могут быть непрерывными и/или дискретными. Тогда для обнаружения аномалии к этому перспективному представлению может быть применен некоторый метод подбора кривой, такой как, например, «авторегрессионный» метод подбора кривой. В одном примере по настоящему изобретению обнаружению аномалии может способствовать присвоение некоторого показателя отклонения за величину отклонения от ожидаемого значения. Этот показатель отклонения может затем сравниваться с заданным пороговым значением для определения того, существует ли аномалия. Например, в случае дискретных данных определяется вероятность наблюдаемых значений в перспективном представлении данных. Если вероятности в существенной мере низкие, то данные признаются аномальными.
В другом примере настоящего изобретения для имеющих непрерывное измерение данных, находящихся в трубке, подобрана кусочно-линейная функция (с использованием дерева регрессии и т.п.). Тогда ячейка имеет аномалию в том случае, если:
где левая сторона этого уравнения представляет собой показатель отклонения для ячейки.
В еще одном примере по настоящему изобретению для имеющих дискретное измерение данных, находящихся в трубке, подобрана авторегрессионная модель. Тогда ячейка имеет аномалию в том случае, если вероятность значения, содержащегося в ячейке, меньше, чем некоторое пороговое значение.
Как очевидно из вышесказанного, настоящее изобретение предусматривает для непрерывных данных и дискретных данных различные функции подбора кривой. Имеется, однако, множество способов определения того, является ли измерение дискретным или непрерывным. Например, пользователь может определить свой выбор (например, пометив это измерение как «число» посредством команды задания формата и т.п.). Или, в качестве дополнительного примера, этот выбор может быть сделан автоматически посредством исследования данных (например, используя для этого системы и способы, такие как те, что описаны в заявке на патент США, имеющей порядковый номер 09/298737, поданной Хекермэном и др. 23 апреля 1999 г. и озаглавленной «Определение того, является ли переменная численной или нечисленной»).
Три типа аномалий по данному примеру теперь будут определены для данного перспективного представления, такого как сводная таблица. Ячейка имеет присутствующую на экране аномалию, если она имеет аномалию по отношению к любой из отображаемых трубок. Другие определения могут включать в себя следующие определения (хотя и не ограничиваются ими): (1) ячейка имеет аномалию, присутствующую на экране, если она аномальна в отношении всех отображаемых трубок, и (2) ячейка имеет аномалию, присутствующую на экране, если усредненная степень отклонения по всем отображаемым на экране трубкам превышает пороговое значение. Ячейка имеет аномалию, выявляемую при «поперечном» анализе, если имеется аномальная трубка, которая изменяется по неотображаемому измерению (при фиксированных отображаемых измерениях). Ячейка имеет аномалию, выявляемую при нисходящем анализе, если имеется аномальная ячейка, которая изменяется по отображаемому в текущий момент измерению, подвергаемому нисходящему анализу с переходом на более глубокий уровень (при фиксированных всех других отображаемых измерениях).
Аномалии, выявляемые при «поперечном» анализе и при нисходящем анализе, по определению невидимы для пользователя. Способ продемонстрировать их заключается в том, чтобы предоставить пользователю возможность увидеть, какие измерения и/или иерархии должны быть расширены для наблюдения аномалий. В некоторых приложениях, использующих перспективные представления данных, это может быть сделано посредством «щелчка» правой клавишей указательного устройства (например, «мыши») по аномальной ячейке. Помимо индикации того, какие измерения и/или иерархии содержат аномалии, также может указываться и степень аномалии - например, посредством сортировки измерений и иерархий в соответствии с их соответствующим показателем отклонения.
Что же касается аномалий, присутствующих на экране, то пользователь может захотеть получить объяснения по поводу того, почему ячейка аномальна. Это достигается в настоящем изобретении посредством отображения (например, выделения) тех трубок, показатели отклонения которых превышают пороговое значение. Эта функция в некоторых приложениях также может задействоваться путем использования «щелчка» правой клавишей указательного устройства (например, «мыши»).
Что касается пороговых значений, то здесь следует рассмотреть два случая. Во-первых, рассматриваемая ячейка может быть подвергнута анализу, направленному внутрь ячейки, и/или «поперечному» анализу и/или в первоначальных данных может иметься множество элементов данных для одной и той же ячейки. В этом случае может быть использовано пороговое значение сσ, где с является устанавливаемой пользователем константой, а σ является стандартным отклонением данных, являющимся результатом одного или более расширений ячейки. Во-вторых, если ячейка не может быть расширена, или как альтернатива вышеописанному пороговому значению, в качестве порогового значения может быть использовано с<прогнозируемых значений> или просто с, где вновь с является устанавливаемой пользователем константой. В качестве альтернативы, могут быть показаны k наиболее значительных аномалий, где k выбирается пользователем. В качестве альтернативы, может быть выбрано, чтобы не помечалась никакая ячейка, которая не может быть расширена.
При рассмотрении иллюстративной системы, показанной и описанной выше, способы, которые могут быть осуществлены согласно настоящему изобретению, будут лучше поняты при ссылке на блок-схемы, приведенные на Фиг. 4-5. Хотя в целях простоты изложения способы показаны и описаны как последовательности этапов, следует понимать и иметь в виду, что настоящее изобретение не ограничено порядком следования этих этапов, поскольку некоторые этапы согласно настоящему изобретению имеют место в различных порядках следования и/или одновременно с другими этапами из числа показанных и описанных в данном документе. Кроме того, не все приведенные на иллюстрации этапы могут потребоваться для осуществления способов согласно настоящему изобретению.
Изобретение может быть описано в общем контексте машиноисполняемых команд, таких как программные модули, исполняемые одним или более компонентами. Обычно программные модули включают в себя процедуры, программы, объекты, структуры данных и т.д., выполняющие конкретные задачи или реализующие определенные абстрактные типы данных. Обычно функциональные возможности программных модулей могут быть объединены или распределены в зависимости от того, что требуется в различных вариантах осуществления изобретения.
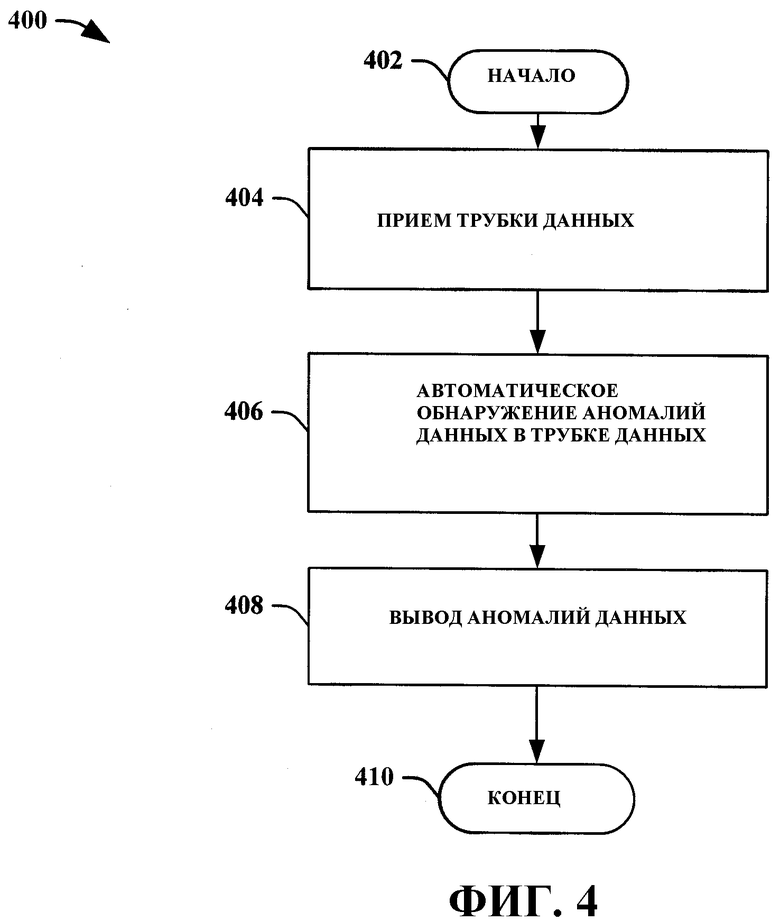
На Фиг. 4 показана блок-схема последовательности операций способа 400 обеспечения автоматического обнаружения аномалий перспективных представлений данных, соответствующего аспекту настоящего изобретения. Способ 400 начинается с этапа 402 приемом трубки данных, представляющей такой срез данных с перспективного представления данных, в котором изменяется только одно измерение (этап 404). После этого производится автоматическое обнаружение аномалий в данных, для чего используется функция подбора кривой, применяемая к этим данным (этап 406). Функция подбора кривой может быть выведена и/или задана пользователем. Далее обнаружению аномалии способствуют пороговые значения отклонения, предоставляемые системой и/или пользователем. Пороговые значения отклонения могут также варьироваться в зависимости от типа аномалии данных. Обнаруженные аномалии затем выводятся как аномалии данных (этап 408), после чего процесс заканчивается (этап 410).
На Фиг. 5 изображена другая блок-схема последовательности операций способа 500 обеспечения автоматического обнаружения аномалий перспективных представлений данных, соответствующего аспекту настоящего изобретения. Способ 500 начинается приемом трубки данных, представляющей такой срез данных с перспективного представления данных, в котором изменяется только одно измерение (этап 504). После этого производится определение того, какая функция наилучшим образом представляет данные в трубке данных (этап 506). Функция может быть получена при помощи авторегрессионного процесса, такого как кусочно-линейные процессы и процессы, использующие дерево регрессии, для непрерывных и дискретных данных. Функция также может быть получена как функция, задаваемая пользователем. После этого на основе прогнозируемого значения данных, выдаваемого функцией подбора кривой, и фактических значений данных определяются показатели отклонения (этап 508). После этого принимается пороговое значение, которое определяет величину отклонения, допускаемую прежде, чем значение данных признается ошибочным (этап 510). Пороговое значение может быть определено системой и/или предоставлено пользователем. Это может быть статическое значение и/или динамическое значение. Пороговое значение также может варьироваться в зависимости от типа аномалии данных. После этого путем определения того, какие значения данных имеют показатели отклонения, превышающие пороговое значение, производится обнаружение аномалий данных (этап 512), а этап 514 завершает процесс. Обычно аномалии данных транслируются пользователю посредством представленных на экране индикаторов, таких как выделение, оконтуривание и/или цветовое кодирование и т.п. Однако в равной степени могут использоваться пиктограммы и другие графические индикаторы. Индикаторы позволяют пользователям оценить, на каком уровне может быть найдена аномалия данных. Они также могут быть использованы для индикации типа аномалии данных и/или степени отклонения аномалии данных. Другие примеры по настоящему изобретению включают в себя дополнительные операции, которые автоматически отображают аномалию данных для пользователя, не требуя ввода пользователем дополнительных команд для просмотра фактических аномальных данных. Это значительно снижает количество выдаваемых пользователю данных, поскольку для этого не требуется, чтобы пользователь для нахождения и просмотра аномалии данных знал и понимал все индикаторы уровней данных.
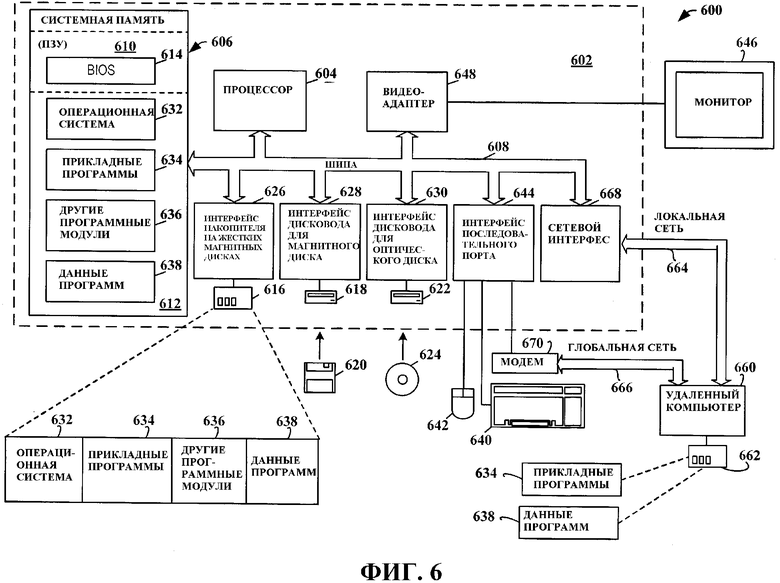
Фиг. 6 и нижеследующее обсуждение предназначены для того, чтобы в целях приведения дополнительного контекста для реализации различных аспектов настоящего изобретения дать краткое общего характера описание подходящей вычислительной среды 600, в которой могут быть осуществлены различные аспекты настоящего изобретения. Хотя изобретение было описано выше в общем контексте машиноисполняемых команд компьютерной программы, которая выполняется на локальном компьютере и/или удаленном компьютере, специалисты в данной области техники должны признать, что изобретение также может быть осуществлено в сочетании с другими программными модулями. Обычно программные модули включают в себя процедуры, программы, компоненты, структуры данных и т.д., которые выполняют конкретные задачи и/или реализуют определенные абстрактные типы данных. Кроме того, специалисты в данной области техники должны понимать, что предложенные в изобретении способы могут осуществляться и с другими конфигурациями компьютерных систем, включая однопроцессорные или многопроцессорные компьютерные системы, мини-компьютеры, универсальные компьютеры, равно как персональные компьютеры, переносные вычислительные устройства, основанные на микропроцессорах, и/или программируемые бытовые электронные приборы и т.п., каждый (каждая/каждое) из которых может в функциональном плане поддерживать связь с одним или более связанных с ним (с ней) устройств. Проиллюстрированные аспекты изобретения могут быть осуществлены в распределенных компьютерных средах, в которых определенные задания выполняются удаленными устройствами обработки данных, связанными через сеть связи. Однако некоторые, если не все, аспекты изобретения могут быть осуществлены на автономных компьютерах. В распределенной вычислительной среде программные модули могут быть размещены в локальных и/или удаленных запоминающих устройствах.
Термин «компонент» в том значении, в котором он использован в данной заявке, предназначен для обозначения некоторой связанной с компьютером сущности, будь то аппаратное обеспечение, сочетание аппаратного обеспечения и программного обеспечения, программное обеспечение и программное обеспечение в состоянии своего исполнения. Например, компонент может представлять собой, но не в ограничительном смысле, процесс, выполняемый процессором; процессор; объект; исполняемый модуль; поток исполнения; программу; и компьютер. В качестве иллюстрации отметим, что компонентом может быть приложение, исполняемое сервером, и/или сервер. Кроме того, компонент может включать в себя один или более подкомпонентов.
Согласно Фиг. 6 иллюстративная системная среда 600 для реализации различных аспектов изобретения включает в себя традиционный компьютер 602, включающий в себя процессор 604, системную память 606 и системную шину 608, которая соединяет различные компоненты системы, включая системную память, с процессором 604. Процессор 604 может представлять собой любой имеющийся в продаже или патентованный процессор. Кроме того, процессор может быть реализован в виде многопроцессорной системы, образованной из более чем одного процессора, такого, что может быть соединен параллельно.
Системная шина 608 может относиться к любому из нескольких типов структур шины, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующие любую из множества традиционных архитектур шины, таких как PCI (шина межсоединения периферийных компонентов), VESA (шина Ассоциации по стандартам в области видеоэлектроники), Microchannel (шина микроканальной архитектуры), ISA (шина архитектуры отраслевого стандарта), EISA (усовершенствованная шина архитектуры отраслевого стандарта), если упомянуть лишь некоторые из них. Системная память 606 включает в себя постоянное запоминающее устройство (ПЗУ) 610 и оперативное запоминающее устройство (ОЗУ) 612. Базовая система 614 ввода/вывода (BIOS), содержащая базовые процедуры, которые способствуют передаче информации между элементами внутри компьютера 602, например, при запуске, хранится в ПЗУ 610.
Компьютер 602 также может включать в себя, например, накопитель 616 на жестких магнитных дисках, дисковод 618 для магнитного диска, например, для считывания с несъемного диска 620 или записи на него и дисковод 622 для оптического диска, например, для считывания с диска 624 CD-ROM (ПЗУ на компакт-диске) или других оптических носителей информации и записи на них. Накопитель 616 на жестких магнитных дисках, дисковод 618 для магнитного диска и дисковод 622 для оптического диска подсоединены к системной шине 608 посредством интерфейса 626 накопителя на жестких магнитных дисках, интерфейса 628 дисковода для магнитного диска и интерфейса 630 дисковода для оптического диска соответственно. Дисководы 616 - 622 и соответствующие им машиночитаемые носители информации обеспечивают энергонезависимое хранение данных, структур данных, машиноисполняемых команд и т.п. для компьютера 602. Хотя приведенное выше описание машиночитаемых носителей информации относится к жесткому магнитному диску, съемному магнитному диску и компакт-диску, специалисты в данной области техники должны понимать, что в иллюстративной операционной среде 600 также могут быть использованы и другие типы носителей информации, которые могут быть считаны компьютером, такие как магнитные кассеты, карточки флэш-памяти, цифровые видеодиски, картриджи Бернулли и т.п., и, кроме того, что любые такие носители информации могут содержать машиноисполняемые команды для выполнения способов по настоящему изобретению.
На дисководах 616 - 622 и в ОЗУ 612 может храниться ряд программных модулей, включая операционную систему 632, одну или более прикладных программ 634, другие программные модули 636 и данные 638 программ. Операционная система 632 может представлять собой любую подходящую операционную систему или комбинацию операционных систем. В качестве примера, прикладные программы 634 могут включать в себя схему анализа перспективного представления данных, соответствующую аспекту настоящего изобретения.
Пользователь может вводить команды и информацию в компьютер 602 через одно или более пользовательских устройств ввода, таких как клавиатура 640 и указательное устройство (например, «мышь»). Другие устройства ввода (на чертеже не показаны) могут включать в себя микрофон, джойстик, игровую панель, спутниковую антенну, устройство удаленного беспроводного ввода, сканер или им подобные устройства. Часто эти и другие устройства ввода соединены с процессором 604 посредством интерфейса 644 последовательного порта, соединенного с системной шиной 608, но они могут быть соединены с процессором посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Также к системной шине 608 посредством интерфейса, такого как видеоадаптер 648, подсоединен монитор 646 или другой тип устройства отображения. В дополнение к монитору 646 компьютер 602 может включать в себя другие периферийные устройства вывода (на чертеже не показаны), такие как громкоговорители, принтеры и т.д.
Следует иметь в виду, что компьютер 602 может функционировать в сетевой среде, используя логические соединения с одним или более удаленных компьютеров 660. Удаленный компьютер 660 может представлять собой рабочую станцию, компьютер-сервер, маршрутизатор, одноранговое устройство или другой узел общей сети и обычно включает в себя многие или все элементы, описанные в отношении компьютера 602, хотя в целях краткости на Фиг. 6 изображено только запоминающее устройство 662. Логические соединения, изображенные на Фиг. 6, могут включать в себя локальную сеть (LAN) 664 и глобальную сеть (WAN) 666. Такие сетевые среды часто используются в офисах, компьютерных сетях масштаба предприятия, интрасетях и в сети Интернет.
При использовании в сетевой среде LAN, например, компьютер 602 соединен с локальной сетью 664 посредством сетевого интерфейса или адаптера 668. При использовании в сетевой среде WAN компьютер 602 обычно включает в себя модем (например, телефонный, использующий технологию DSL (Цифрового абонентского канала), кабельный и т.д.) 670 или соединен с сервером связи в сети LAN или имеет другое средство для установления связи через сеть WAN 666, такую как Интернет. Модем 670, который может быть внутренним или внешним по отношению к компьютеру 602, подсоединен к системной шине 608 посредством интерфейса 644 последовательного порта. В сетевой среде программные модули (включая прикладные программы 634) и/или данные 638 программ могут храниться в удаленном запоминающем устройстве 662. Следует иметь в виду, что показанные сетевые соединения являются иллюстративными и что при осуществлении аспекта настоящего изобретения могут быть использованы и другие средства (например, проводные или беспроводные) установления линии связи между компьютерами 602 и 660.
В соответствии с обыкновениями специалистов в области программирования для компьютеров и если не указано иное, настоящее изобретение описано со ссылкой на действия и символические представления операций, которые выполняются компьютером, таким как компьютер 602 или удаленный компьютер 660. Про такие действия и операции иногда говорят, что они являются машиноисполняемыми. Следует иметь в виду, что действия и представленные в символической форме операции включают в себя манипуляцию, осуществляемую процессором 604 над электрическими сигналами, представляющими биты данных, которая вызывает результирующую трансформацию или преобразование представления электрических сигналов, и сохранение битов данных в ячейках памяти запоминающей системы (включающей в себя системную память 606, накопитель 616 на жестких магнитных дисках, гибкие диски 620, CD-ROM 624 и удаленное запоминающее устройство 662), осуществляемые с целью реконфигурирования или иного изменения функционирования компьютерной системы, равно как и другую обработку сигналов. Ячейки памяти, в которых сохраняются такие биты данных, представляют собой физические места, которые имеют особые электрические, магнитные или оптические свойства, соответствующие битам данных.
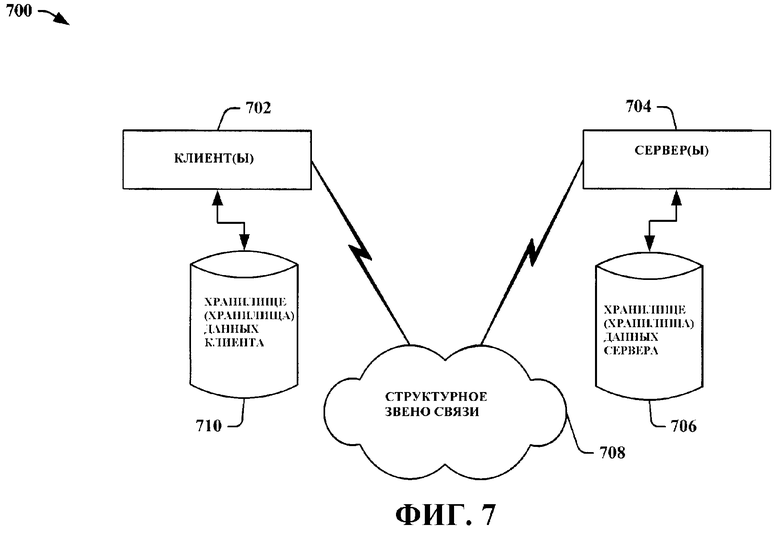
Фиг. 7 представляет собой другую блок-схему приводимой в качестве примера операционной среды 700, с которой может взаимодействовать настоящее изобретение. Система 700, кроме того, иллюстрирует систему, включающую в себя одного или более клиента (клиентов) 702. Клиент (клиенты) 702 может (могут) представлять собой аппаратуру и/или программное обеспечение (например, потоки, процессы, вычислительные устройства). Система 700 также включает в себя один или более сервер (серверов) 704. Сервер (серверы) 704 также может (могут) представлять собой аппаратуру и/или программное обеспечение (например, потоки, процессы, вычислительные устройства). Один возможный вариант коммуникации между клиентом 702 и сервером 704, может иметь форму пакета данных, приспособленного для передачи между двумя или более компьютерными процессами. Система 700 включает в себя структурное звено 708 связи, которое может быть использовано для обеспечения связи между клиентом (клиентами) 702 и сервером (серверами) 704. Клиент (клиенты) 702 функционально соединен (соединены) с одним или более хранилищем (хранилищами) 710 данных клиента, которое (которые) может (могут) использоваться для хранения информации, локальной по отношению к клиенту (клиентам) 702. Аналогичным образом, сервер (серверы) 704 функционально соединен (соединены) с одним или более хранилищем (хранилищами) 706 данных сервера, которое (которые) может (могут) использоваться для хранения информации, локальной по отношению к серверу 704.
В одном примере по настоящему изобретению пакет данных передается между двумя и более компьютерными компонентами, которые обеспечивают анализ перспективного представления данных, при этом пакет данных состоит, по меньшей мере, частично, из информации, относящейся к системе анализа перспективных представлений данных, которая использует, по меньше мере, частично, процесс подбора кривой, применяемый к данным из трубки данных; при этом трубка данных содержит срез данных, который включает в себя, по меньшей мере, одну ячейку данных из перспективного представления данных и в котором изменяется только одно измерение данных.
Следует иметь в виду, что системы и/или способы по настоящему изобретению могут быть использованы в схеме анализа перспективных представлений данных для обеспечения работы как компьютерных компонентов, так и связанных с ними некомпьютерных компонентов. Кроме того, специалисты в данной области техники должны признать, что системы и/или способы по настоящему изобретению могут быть использованы в широком спектре связанной с электроникой техники, включая, но не в качестве ограничения, компьютеры, серверы и/или переносные электронные устройства и т.п.
Приведенное выше описание включает в себя примеры по настоящему изобретению. Конечно, невозможно в целях описания настоящего изобретения описать каждое мыслимое сочетание компонентов или способов, но специалист, имеющий обычную квалификацию в данной области техники, может признать, что возможно и много других сочетаний и изменений по настоящему изобретению. Соответственно, подразумевается, что данное изобретение охватывает все такие изменения, модификации и разновидности, которые находятся в пределах сущности и объема, определяемые прилагаемой формулой изобретения. Кроме того, в той мере, в какой термин «включает в себя» используется как в подробном описании, так и формуле изобретения, подразумевается, что такой термин является включающим в себя таким же образом, как термин «содержащий» в том значении, в котором термин «содержащий» интерпретируется в качестве переходного слова в формуле изобретения.
Изобретение относится к области исследования данных. Техническим результатом является повышение эффективности обработки данных. Настоящее изобретение задействует способы обработки данных с использованием подбора кривой для обеспечения автоматического обнаружения аномалий данных в «трубке данных» из перспективного представления данных, что позволяет, например, производить обнаружение аномалий данных, таких как аномалии, представленные на экране, аномалии, выявляемые при нисходящем анализе, и аномалии, выявляемые при «поперечном» анализе, в, например, сводных таблицах и/или OLAP-кубах данных (кубах данных, созданных по технологии оперативной аналитической обработки данных). Согласно изобретению определяют, существенно ли отличаются данные от прогнозируемого значения, установленного процессом подбора кривой, таким как, например, кусочно-линейная функция, примененная к трубке данных. Также согласно настоящему изобретению может быть использовано пороговое значение, содействующее в определении степени отклонения, что необходимо, прежде чем значение данных будет признано аномальным. Кроме того, настоящее изобретение обеспечивает для пользователя индикацию типа и места расположения обнаруженной аномалии на перспективном представлении данных, относящемся к верхнему уровню. 4 н. и 32 з.п. ф-лы, 7 ил., 5 табл.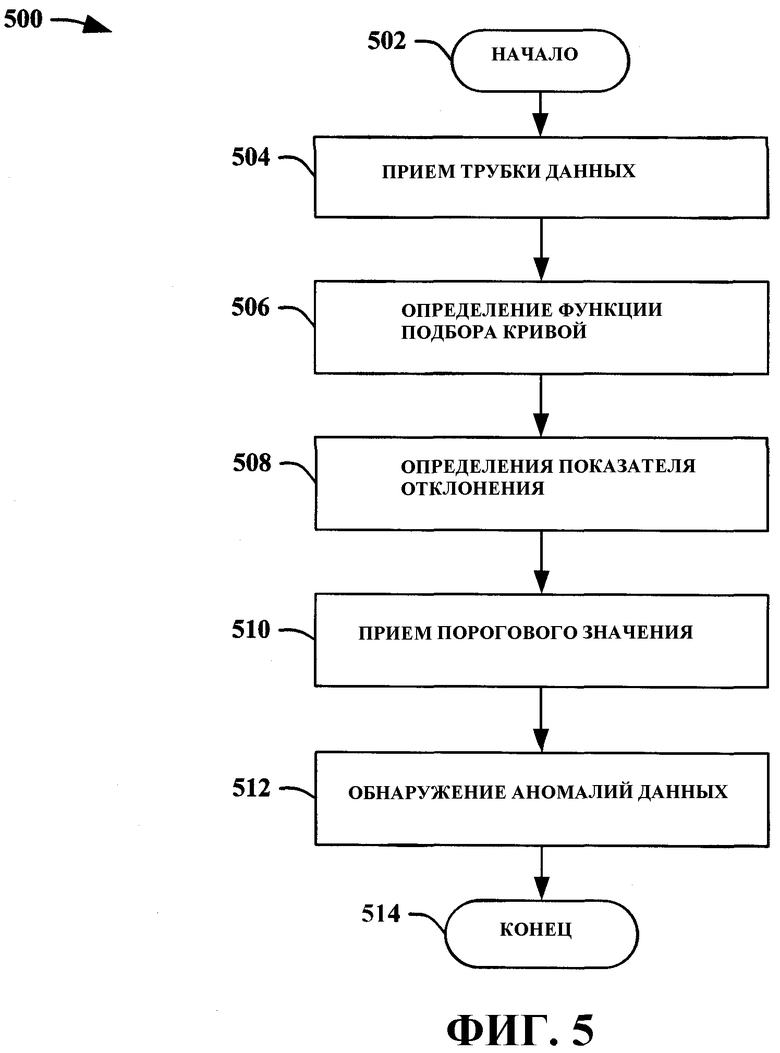
1. Система, обеспечивающая анализ перспективного представления данных и содержащая:
компонент, который принимает по меньшей мере одно перспективное представление данных; и
компонент обнаружения аномалии, который автоматически анализирует перспективное представление данных с целью обнаружить по меньшей мере одну аномалию данных посредством процесса подбора кривой, примененного к непрерывным и/или дискретным данным из трубки данных; при этом трубка данных содержит срез данных, который включает в себя по меньшей мере одну ячейку данных из перспективного представления данных и в котором изменяется только одно измерение данных.
2. Система по п.1, в которой процесс подбора кривой содержит процесс, который использует, по меньшей мере частично, кусочно-линейную функцию.
3. Система по п.2, в которой кусочно-линейная функция содержит функцию, которая использует, по меньшей мере частично, дерево регрессии.
4. Система по п.1, в которой процесс подбора кривой содержит процесс, который использует, по меньшей мере частично, вероятностную модель для прогнозирования значений в перспективном представлении данных, при этом вероятностная модель зависит нетривиальным образом от положения значения внутри перспективы данных.
5. Система по п.4, в которой вероятностная модель содержит авторегрессионную модель.
6. Система по п.1, в которой аномалия данных содержит аномалию, основанную на существенном отклонении значения данных от других значений данных, обнаруженных в трубке данных.
7. Система по п.6, в которой существенное отклонение основывается на по меньшей мере одном показателе отклонения, который превышает заданное пороговое значение.
8. Система по п.7, в которой показатель отклонения основывается, по меньшей мере частично, на значении ячейки данных, сравниваемом с прогнозируемым значением для этой ячейки данных, полученном на основе кусочно-линейной функции, представляющей трубку данных, которая содержит эту ячейку данных.
9. Система по п.7, в которой показатель отклонения основывается, по меньшей мере частично, на значении ячейки данных, сравниваемом с прогнозируемым значением для этой ячейки данных, полученном на основе вероятностной модели, предназначенной для прогнозирования дискретных значений в перспективном представлении данных, при этом вероятностная модель зависит нетривиальным образом от положения значения внутри перспективного представления данных.
10. Система по п.7, в которой заданное пороговое значение содержит по меньшей мере одно значение, выбранное из группы, состоящей из динамического порогового значения и статического порогового значения.
11. Система по п.10, в которой заданное пороговое значение содержит по меньшей мере одно значение, выбранное из группы, состоящей из порогового значения, определенного пользователем, и порогового значения, определенного системой.
12. Система по п.11, дополнительно содержащая компонент пользовательского интерфейса, который предоставляет множество выбираемых пороговых значений, определяемых пользователем, для использования с различными типами аномалий данных.
13. Система по п.1, в которой перспективное представление данных содержит по меньшей мере одно представление, выбранное из группы, состоящей из сводной таблицы и куба данных, созданного по технологии оперативной аналитической обработки данных (OLAP).
14. Система по п.1, дополнительно содержащая компонент пользовательского интерфейса, который осуществляет индикацию аномалии данных для по меньшей мере одного пользователя.
15. Система по п.14, в которой компонент пользовательского интерфейса осуществляет индикацию аномалии данных посредством по меньшей мере одного способа, выбранного из группы, состоящей из визуальной индикации и звуковой индикации.
16. Система по п.14, в которой компонент пользовательского интерфейса обеспечивает индикацию аномалии данных посредством использования по меньшей мере одного способа, выбранного из группы, состоящей из выделения по меньшей мере одной непосредственно наблюдаемой аномалии и оконтуривания по меньшей мере одной скрытой аномалии.
17. Система по п.14, в которой компонент пользовательского интерфейса содержит пользовательский интерфейс с управлением от ввода пользователя, регулирующий уровень индикации на основе степени по меньшей мере одной аномалии данных.
18. Система по п.14, в которой пользовательский интерфейс содержит компонент, который обеспечивает индикации аномалий данных посредством автоматического отображения на экране по меньшей мере одной аномалии данных.
19. Способ обеспечения анализа перспективного представления данных, включающий в себя этапы, на которых:
принимают по меньшей мере одно перспективное представление данных;
создают трубку данных из перспективного представления данных, при этом трубка данных содержит срез данных, который включает в себя по меньшей мере одну ячейку данных из перспективного представления данных и в котором изменяется только одно измерение данных;
определяют функцию подбора кривой, представляющую непрерывные и/или дискретные данные из трубки данных;
рассчитывают показатель отклонения, основываясь, по меньшей мере частично, на разнице фактического значения данных и прогнозируемого значения данных, заданного посредством функции подбора кривой; и
обнаруживают аномалии данных посредством оценки показателя отклонения и критерия обнаружения.
20. Способ по п.19, в котором функция подбора кривой содержит выбираемую пользователем функцию подбора кривой.
21. Способ по п.19, дополнительно включающий в себя этапы, на которых классифицируют аномалии данных в соответствии с их доступностью и отображают для пользователя аномалии данных, используя для этого набор индикаторов доступности аномалий.
22. Способ по п.21, дополнительно включающий в себя этап, на котором ограничивают количество отображаемых для пользователя аномалий данных, используя выбираемое пользователем число к аномалий данных, которое ограничивает количество аномалий данных к максимальными аномалиями, выбранными на основе их показателей отклонения.
23. Способ по п.21, дополнительно включающий в себя этап, на котором автоматически отображают для пользователя на экране по меньшей мере одну аномалию данных.
24. Способ по п.21, в котором индикаторы доступности аномалии содержат по меньшей мере один индикатор, выбранный из группы индикаторов, состоящей из индикатора аномалии, присутствующей на экране, индикатора аномалии, выявляемой при нисходящем анализе и индикатора аномалии, выявляемой при «поперечном» анализе.
25. Способ по п.19, в котором перспективное представление данных содержит по меньшей мере одно представление, выбранное из группы, состоящей из сводной таблицы и куба данных, созданного по технологии оперативной аналитической обработки данных (OLAP).
26. Способ по п.19, в котором критерий обнаружения содержит пороговое значение.
27. Способ по п.26, в котором этап, на котором оценивают показатель отклонения, включает в себя этап, на котором определяют, превосходит ли показатель отклонения пороговое значение.
28. Способ по п.26, в котором пороговое значение содержит по меньшей мере одно значение, выбранное из группы, состоящей из динамического порогового значения и статического порогового значения.
29. Способ по п.28, в котором пороговое значение содержит по меньшей мере одно значение, выбранное из группы, состоящей из порогового значения, определенного пользователем, и порогового значения, определенного системой.
30. Способ по п.29, дополнительно включающий в себя этап, на котором корректируют определенное пользователем пороговое значение в соответствии с типом аномалии данных.
31. Способ по п.26, в котором процесс подбора кривой содержит процесс, который использует, по меньшей мере частично, кусочно-линейную функцию.
32. Способ по п.31, в котором кусочно-линейная функция содержит функцию, которая использует, по меньшей мере частично, дерево регрессии.
33. Способ по п.26, в котором процесс подбора кривой содержит процесс, который использует, по меньшей мере частично, вероятностную модель для прогнозирования дискретных значений в перспективном представлении данных, при этом вероятностная модель зависит нетривиальным образом от положения значения внутри перспективы данных.
34. Способ по п.33, в котором вероятностная модель содержит функцию, которая использует, по меньшей мере частично, авторегрессионную модель.
35. Система, обеспечивающая анализ перспективного представления данных и содержащая:
средство для приема по меньшей мере одного перспективного представления данных; и
средство для автоматического анализа перспективного представления данных с целью обнаружить по меньшей мере одну аномалию данных посредством процесса подбора кривой, примененного к непрерывным и/или дискретным данным из трубки данных; при этом трубка данных содержит срез данных, который включает в себя по меньшей мере одну ячейку данных из перспективного представления данных и в котором изменяется только одно измерение данных.
36. Машиночитаемый носитель информации, на котором хранятся машиноисполняемые команды, которые при их исполнении компьютером предписывают компьютеру выполнять способ обеспечения анализа перспективного представления данных, включающий в себя прием по меньшей мере одного перспективного представления данных;
создание трубки данных из перспективного представления данных, при этом трубка данных содержит срез данных, который включает в себя по меньшей мере одну ячейку данных из перспективного представления данных и в котором изменяется только одно измерение данных;
определение функции подбора кривой, представляющей непрерывные и/или дискретные данные из трубки данных;
расчет показателя отклонения, основываясь, по меньшей мере частично, на разнице фактического значения данных и прогнозируемого значения данных, задаваемого посредством функции подбора кривой; и
обнаружение аномалии данных посредством оценки показателя отклонения и критерия обнаружения.
| СПОСОБ ВИЗУАЛЬНОГО ОТОБРАЖЕНИЯ И ДИНАМИЧЕСКОГО КОНТРОЛЯ КЛИНИЧЕСКИХ ДАННЫХ | 2001 |
|
RU2195017C1 |
| US 6094651 A, 25.07.2000 | |||
| US 5799300 A, 25.08.1998 | |||
| US 5825482 A, 20.10.1998. | |||

