Область техники, к которой относится изобретение
Настоящее изобретение относится к кодированию/декодированию информационных величин и, в частности, к энтропийному кодированию с использованием компактных кодовых книг для генерации эффективного кода.
Описание предшествующего уровня техники
В последнее время методика многоканального аудиовоспроизведения становится все более важной. Это может быть вследствие того факта, что способы аудиосжатия/кодирования, такие как хорошо известный способ mp3, предоставили возможность распространения аудиозаписей через Интернет или другие каналы передачи с ограниченной полосой пропускания. Способ кодирования mp3 стал таким востребованным, потому что он предоставляет возможность распространения всех записей в стереоформате, то есть цифровое представление аудиозаписи включает в себя первый или левый стереоканал и второй или правый стереоканал.
Тем не менее, существуют базовые недостатки обычных двухканальных аудиосистем. Так, был разработан способ объемного звучания. В добавление к двум стереоканалам L и R рекомендованное многоканальное объемное представление включает в себя дополнительный центральный канал C и два объемных канала Ls, Rs. На этот формат звука также ссылаются, как на стерео три/два, что означает три фронтальных канала и два объемных канала. Обычно требуется пять каналов передачи. В условиях воспроизведения необходимы, по меньшей мере, пять динамиков в пяти подходящих местоположениях, чтобы получить оптимальную зону наилучшего восприятия на определенном расстоянии от пяти громкоговорителей, расположенных должным образом.
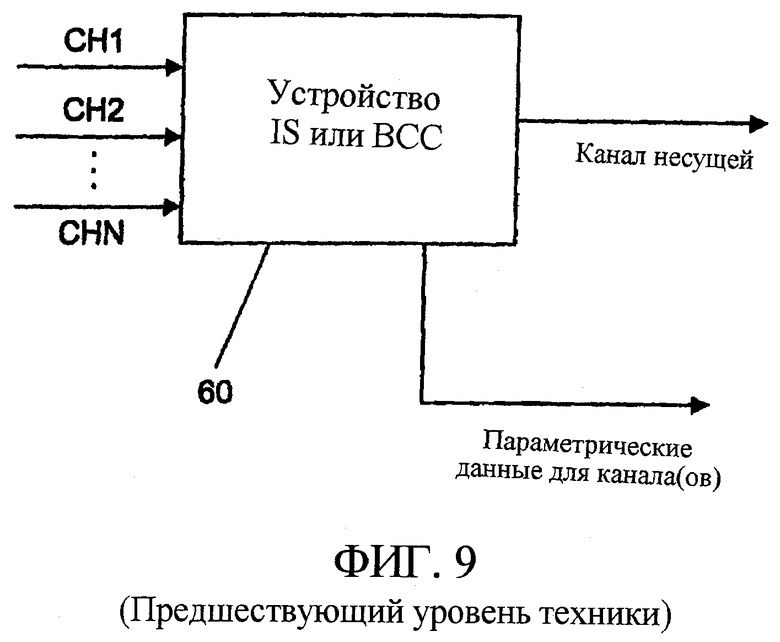
В данной области техники известны несколько методик для уменьшения объема данных, необходимых для передачи сигнала многоканального аудио. Такие методики называются методиками объединенного стерео. Для этого приведена ссылка на фиг.9, которая иллюстрирует устройство 60 объединенного стерео. Это устройство может быть устройством, реализующим, например, кодирование на основе интенсивности стерео (IS) или кодирование бинауральных характеристик (BCC). Такое устройство обычно в качестве ввода принимает, по меньшей мере, два канала (CH1, CH2,... CHn) и выводит, по меньшей мере, один канал несущей и параметрические данные. Параметрические данные задаются так, что в декодере может быть вычислена аппроксимация исходного канала (CH1, CH2,... CHn).
Как правило, канал несущей включает в себя выборки поддиапазонов, спектральные коэффициенты, выборки временной области и т.п., что обеспечивает относительно хорошее представление базового сигнала, тогда как параметрические данные не включают в себя такие выборки спектральных коэффициентов, а включают параметры управления для управления определенным алгоритмом восстановления, таким как взвешивание путем умножения, временная манипуляция, частотная манипуляция, фазовая манипуляция и т.п. Параметрические данные, следовательно, включают в себя только относительно грубое представление сигнала или ассоциированного канала. В количественном выражении объем данных, требуемых каналом несущей, будет в пределах 60-70 кбит/с, тогда как объем данных, требуемых параметрической дополнительной информацией для одного канала, будет в пределах 1,5-2,5 кбит/с. Примером параметрических данных являются хорошо известные масштабные коэффициенты, информация IS или параметры бинауральных характеристик, как описано ниже.
Способ BCC описан, например, в документе 5574 AES (Сообщества Инженеров-Звукотехников) «Binaural Cue Coding Applied to Stereo and Multi-Channel Audio Compression» ("Кодирование бинауральных характеристик, применяемое к сжатию стерео и многоканального аудио"), С.Фаллер, Ф.Бомгарт, май, 2002, Мюнхен, в документе IEEE WASPAA “Efficient representation of spatial audio using perceptual parametrization” ("Эффективное представление пространственного аудио, используя перцепционную параметризацию"), октябрь, 2001, Могонк, Нью-Йорк, в документе 113-го собрания AES препринт 5686 “Binaural cue coding applied to audio compression with flexible rendering” ("Кодирование бинауральных характеристик, применяемое к аудиокодированию с гибким рендерингом"), С.Фаллер и Ф.Бомгарт, Лос-Анджелес, октябрь, 2002, и в документе “Binaural cue coding - Part II: Schemes and applications” ("Кодирование бинауральных характеристик - Часть II: Схемы и приложения"), С. Фаллер и Ф. Бомгарт, Протоколы IEEE об обработке речи и аудио, том 11, № 6, ноябрь, 2003.
При кодировании BCC несколько входных аудиоканалов конвертируются в спектральное представление, используя преобразование, основанное на дискретном преобразовании Фурье (DFT), с перекрывающимися окнами. Результирующий однородный спектр разделяется на неперекрывающиеся разделы. Каждый раздел, примерно, имеет полосу частот, которая пропорциональна эквивалентной прямоугольной полосе частот (ERB). Параметры BCC, тогда, оцениваются между двумя каналами для каждого раздела. Эти параметры BCC, как правило, задаются для каждого канала относительно опорного канала и также квантуются. Передаваемые параметры в конечном итоге вычисляются согласно предписанным формулам (кодируются), что также может зависеть от особых разделов сигнала, который требуется обработать.
Существует ряд параметров BCC. Параметр ICLD, например, описывает разницу (отношение) между энергиями, содержащимися в двух сравниваемых каналах. Параметр ICC (межканальная когерентность/корреляция) описывает корреляцию между двумя каналами, которая может быть описана как схожесть форм волн двух каналов. Параметр ICTD (межканальная разность времени) описывает глобальный сдвиг во времени между 2 каналами, тогда как параметр IPD (межканальная разность фаз) описывает то же относительно фаз сигналов.
Известно, что при покадровой обработке аудиосигнала анализ BCC также выполняется покадровым образом, то есть меняющимся по времени образом, а также почастотным образом. Это означает, что для каждого спектрального диапазона параметры BCC получаются отдельно. Это означает, что в случае, когда блок аудиофильтров разлагает входной сигнал на, например, 32 сигнала полос пропускания, блок анализа BCC получает набор параметров BCC для каждой из 32 полос.
Относящаяся к этому методика, также известная как параметрическое стерео, описана в препринте 6072 “High-Quality Parametric Spatial Audio Coding at Low Bitrates” ("Высококачественное кодирование параметрического пространственного аудио при низких расходах битов"), Дж. Бриибаарт, С. Ван де Пар, А. Колрауш, Е.Шуйерс, 116-е собрание AES, Берлин, май, 2004, и в препринте 6073 “Low Complexity Parametric Stereo Coding” ("Кодирование параметрического стерео малой сложности"), 116-е собрание AES, Берлин, май, 2004.
Резюмируя, последние подходы для параметрического кодирования сигналов многоканального аудио ("Пространственное Аудиокодирование", "Кодирование бинауральных характеристик" (ВСС) и т.п.) представляют сигнал многоканального аудио посредством сигнала понижающего микширования (который может быть монофоническим или содержать несколько каналов) и параметрической дополнительной информации ("пространственных характеристик"), характеризующей воспринимаемый уровень пространственного звука. Желательно поддерживать расход битов (битрейт) для передачи дополнительной информации на наименьшем возможном уровне, чтобы минимизировать служебную информацию и оставить как можно больше доступной пропускной способности для кодирования сигналов понижающего микширования.
Один из вариантов удержания расхода битов дополнительной информации на низком уровне является кодирование без потерь дополнительной информации схемы пространственного аудио путем применения, например, алгоритмов энтропийного кодирования к дополнительной информации.
Кодирование без потерь широко применялось в обычном аудиокодировании, чтобы обеспечить оптимальное компактное представление квантованных спектральных коэффициентов и другой дополнительной информации. Примеры подходящих схем и способов кодирования даны в стандартах ISO/IEC: MPEG1 часть 3, MPEG2 часть 7 и MPEG4 часть 3.
Эти стандарты и, например, также документ IEEE “Noiseless Coding of Quantized Spectral Coefficients in MPEG-2 Advanced Audio Coding” ("Свободное от шумов кодирование квантованных спектральных коэффициентов в кодировании усовершенствованного аудио MPEG-2", С.Р.Куакенбуш, Дж.Д. Джонстон, IEEE WASPAA, Могонк, Нью-Йорк, Октябрь, 1997, описывают современные методики, которые включают в себя следующие меры для кодирования квантованных параметров без потерь.
- Многомерное кодирование Хаффмана квантованных спектральных коэффициентов.
- Использование общей (многомерной) кодовой книги Хаффмана для наборов коэффициентов.
- Кодирование значения либо в целом, либо кодирование информации знака и информации величины по отдельности (то есть, имея в кодовой книге Хаффмана только записи для заданного абсолютного значения, что уменьшает необходимый размер кодовой книги "без учета знака" по сравнению с книгой "с учетом знака").
- Использование альтернативных кодовых книг различных наибольших абсолютных значений, то есть различных максимальных абсолютных значений среди параметров, которые требуется кодировать.
- Использование альтернативных кодовых книг различного статистического распределения для каждой наибольшей абсолютной величины.
- Передача в декодер выбора кодовой книги Хаффмана в качестве дополнительной информации.
- Использование "секций" для определения диапазона применения каждой выбранной кодовой книги Хаффмана.
- Дифференциальное кодирование масштабных коэффициентов по частоте и последующее кодирование результата по алгоритму Хаффмана.
Еще одна методика для кодирования без потерь грубо квантованных величин в единый код импульсно-кодовой манипуляции (ИКМ) предложена в стандарте MPEG 1 аудио (названная группой в рамках стандарта и используемая для уровня 2). Это более подробно описано в стандарте ISO/IEC 11172-3:93.
Публикация “Binaural cue coding - Part II: Schemes and applications” ("Кодирование бинауральных характеристик - Часть II: Схемы и приложения"), С. Фаллер и Ф. Бомгарт, Протоколы IEEE об обработке речи и аудио, том 11, № 6, ноябрь, 2003, дает некоторую информацию о кодировании параметров BCC. Предполагается, что квантованные параметры ICLD дифференциально кодируются:
- по частоте, и результат впоследствии кодируется согласно алгоритму Хаффмана (посредством одномерного кода Хаффмана),
- по времени, и результат впоследствии кодируется согласно алгоритму Хаффмана (посредством одномерного кода Хаффмана),
и что в конечном итоге наиболее эффективный вариант выбирается как представление исходного аудиосигнала.
Как упомянуто выше, было предложено оптимизировать эффективность сжатия путем применения дифференциального кодирования по частоте и, альтернативно, по времени и выбора наиболее эффективного варианта. Тогда, выбранный вариант сигнализируется в декодер посредством некоторой дополнительной информации.
Описанные выше способы полезны для уменьшения объема данных, которые, например, должны быть переданы в аудио- или видеопотоке. Использование вышеописанных способов кодирования без потерь, основанных на схемах энтропийного кодирования, обычно приводит к битовым потокам с переменной битовой скоростью.
В стандарте AAC (Усовершенствованного Аудиокодека) путем использования кодовых книг "без знаков" предлагается уменьшить как размер кодовых слов, так и размер базовой кодовой книги, причем это основывается на предположении, что распределение вероятностей информационных величин, которые требуется кодировать, зависит только от размера величин, а не от их знаков. Тогда, биты знака передаются отдельно, и они могут рассматриваться как постфиксный код, обратно отображающий кодированную информацию размера в действительную величину (знак x абсолютную величину).
Предполагая, например, что используется четырехмерная кодовая книга Хаффмана, этот подход приведет к сокращению размера кодовой книги на множитель 24=16 (при условии, что все величины имеют знаки).
Для уменьшения размера кода при энтропийном кодировании предпринималось достаточно много попыток. Несмотря на это все еще остаются некоторые значительные недостатки способов по предшествующему уровню техники. Например, при использовании многомерных кодовых книг Хаффмана можно достичь уменьшения расхода битов, необходимого для передачи некоторой кодированной информации. Это достигается за счет увеличения размера используемой кодовой книги Хаффмана, поскольку для каждого дополнительного измерения размер кодовой книги Хаффмана увеличивается в два раза. Это особенно неблагоприятно в приложениях, где кодовая книга Хаффмана передается вместе с кодированной информацией, как, например, имеет место в случае некоторых компьютерных программ сжатия. Даже если кодовая книга Хаффмана не должна передаваться вместе с данными, она должна быть сохранена в кодере и в декодере, что требует дорогостоящего объема памяти, который доступен только в ограниченных количествах, в особенности, в мобильных приложениях для потоковой передачи или воспроизведения видео или аудио.
Сущность изобретения
Целью настоящего изобретения является предоставление концепции для генерации и использования более эффективного кода для сжатия информационных величин и уменьшения размера базовой кодовой книги.
Согласно первому аспекту настоящего изобретения эта цель достигнута посредством кодера для кодирования информационных величин, причем кодер содержит: средство группирования (группирователь) для группирования двух или более информационных величин в кортеж согласно порядку кортежа;
средство генерации (генератор) информации кода для генерации информации порядка, указывающей порядок кортежа, и кодового слова для кортежа, используя правило кодирования, причем правило кодирования таково, что одинаковое кодовое слово назначается кортежам, имеющим идентичные информационные величины в различных порядках; и
интерфейс вывода для вывода кодового слова и ассоциированной с ним информации порядка.
Согласно второму аспекту настоящего изобретения эта цель достигнута посредством декодера для декодирования кодового слова, основанного на информационных величинах, причем декодер содержит:
интерфейс ввода, предоставляющий кодовое слово и ассоциированную с ним информацию порядка, указывающую порядок кортежа, причем порядок кортежа представляет собой порядок расположения двух или более информационных величин в кортеже информационных величин;
средство обработки (процессор) кода для получения кортежа, используя правило декодирования, зависящее он правила кодирования, использованного для создания кодового слова, причем правило декодирования таково, что различные кортежи получаются из одного и того же кодового слова, причем эти различные кортежи имеют одинаковые информационные величины, расположенные в различных порядках кортежа, как указывается различной информацией порядка; и
средство разгруппирования (разгруппирователь) для разгруппирования кортежей на две или более информационные величины.
Согласно третьему аспекту настоящего изобретения эта цель достигнута посредством способа кодирования информационных величин, причем способ содержит этапы, на которых:
группируют две или более информационные величины в кортеж согласно порядку кортежа;
генерируют информацию порядка, указывающую порядок кортежа;
генерируют кодовое слово для кортежа, используя правило кодирования, причем правило кодирования таково, что одинаковое кодовое слово назначается кортежам, имеющим идентичные информационные величины, расположенные в различных порядках; и
выводят кодовое слово и ассоциированную с ним информацию порядка.
Согласно четвертому аспекту настоящего изобретения эта цель достигнута посредством компьютерной программы, которая при исполнении на компьютере реализует вышеупомянутый способ.
Согласно пятому аспекту настоящего изобретения эта цель достигнута посредством способа декодирования кодовых слов, основанных на информационных величинах, причем способ содержит этапы, на которых:
предоставляют кодовое слово и ассоциированную с ним информацию порядка, указывающую порядок кортежа, причем порядок кортежа представляет собой порядок расположения двух или более информационных величин в кортеже информационных величин;
получают кортеж, используя правило декодирования, зависящее он правила кодирования, использованного для создания кодового слова, причем правило декодирования таково, что различные кортежи получаются из одного и того же кодового слова, причем эти различные кортежи имеют одинаковые информационные величины, расположенные в различных порядках кортежа, как указывается различной информацией порядка; и
разгруппировывают кортежи на две или более информационные величины.
Согласно шестому аспекту настоящего изобретения эта цель достигнута посредством компьютерной программы, которая при исполнении на компьютере реализует вышеупомянутый способ.
Согласно седьмому аспекту настоящего изобретения эта цель достигнута посредством кодированных данных, основанных на информационных величинах, причем кодированные данные содержат кодовое слово для кортежа из двух или более информационных величин, расположенных в кортеже согласно порядку кортежа, и информацию порядка, указывающую порядок кортежа.
Настоящее изобретение основано на том, что эффективный код для кодирования информационных величин может быть получен, когда две или более информационные величины группируются в кортеж согласно порядку кортежа и когда используется правило кодирования, согласно которому одно и то же кодовое слово назначается кортежам, имеющим одинаковые информационные величины, расположенные в различных порядках, и когда информация порядка, указывающая порядок кортежа, получается и связывается с кодовым словом.
Для энтропийного кодирования с использованием кодов Хаффмана вышеописанная изобретательская концепция может быть использована более эффективно. Размер кодовой книги Хаффмана зависит как от количества возможных величин, которые требуется кодировать, так и от количества совместно кодированных величин (размерность кодовой книги Хаффмана). Для того чтобы уменьшить требуемый объем памяти, необходимый для представления кодовой книги Хаффмана в конкретном приложении, полезно использовать симметрии в распределении вероятностей данных, которые должны быть кодированы так, чтобы одно кодовое слово Хаффмана представляло целый набор групп совместно кодированных величин с равной вероятностью. Тогда, фактическая группа совместно кодированных величин описывается посредством конкретного постфиксного кода.
Поскольку порядок двух или более величин в кортеже не зависит от содержимого, представляемого этими величинами, то, когда величины в некоторой степени некоррелированные, можно допустить, что вероятности различных порядков одних и тех же величин равны (поскольку величины некоррелированные). Предпочтительно, для кода с переменной длиной, то есть для кода, имеющего кодовые слова с различными длинами, эти равные вероятности могут в результате привести к меньшим кодовым книгам и эффективному коду, когда одно кодовое слово назначается кортежам с различными порядками одинаковых величин.
Следовательно, в предпочтительном варианте осуществления настоящего изобретения информационные величины, которые должны быть кодированы посредством двумерного кодера Хаффмана, сначала кодируются дифференциально, что приводит к дифференциальному представлению с определенными симметриями, как описано более подробно ниже. После этого к дифференциальному представлению применяется ряд операций симметрии, что уменьшает количество возможных кортежей, которые должны быть кодированы, таким образом уменьшая размер требуемой кодовой книги.
Дифференциальное кодирование распределения величин, появляющихся с заданным распределением вероятностей, в результате приведет к распределению величин разности, которая центрирована относительно нулевой точки, имея симметричное распределение вероятностей, то есть величины с одинаковой абсолютной величиной, но с различными знаками, появляются с одинаковой вероятностью.
Основной принцип энтропийного кодирования, как, например, кодирования по алгоритму Хаффмана, заключается в том, что используемая кодовая книга представляет заданное распределение вероятностей информационных величин наилучшим возможным образом ввиду назначения самых коротких возможных кодовых слов информационным величинам, появляющимся чаще всего. Многомерное кодирование Хаффмана следует тому же принципу, но в этом случае две или более информационные величины комбинируются в кортеж, причем целый кортеж впоследствии связывается с одним кодовым словом.
Следовательно, комбинирование дифференциального кодирования с двумерным кодированием Хаффмана приводит к двум симметриям, которые могут быть полезны.
Первая симметрия получается из наблюдения, заключающегося в том, что вероятность появления кортежа (a, b) примерно равна вероятности появления для кортежа (-a, -b). Это соответствует точечной симметрии относительно начала координатной системы, причем первая величина кортежа определяет ось X, а вторая величина кортежа определяет ось Y.
Вторая симметрия основана на предположении о том, что изменения порядка, в котором две величины появляются в кортеже, не изменит вероятность появления кортежа, то есть, что (a, b) и (b, a) вероятны в равной степени. В случае вышеописанной координатной системы это соответствует осевой симметрии относительно биссектрис координатной системы, проходящих через первый и третий квадранты.
Эти две симметрии можно использовать, чтобы размер кодовой книги Хаффмана уменьшился в четыре раза, что означает, что симметричным кортежам назначаются одинаковые кодовые слова. Информация симметрии, то есть порядок исходного кортежа и знак исходного кортежа, указывается информацией порядка и информацией знака, которые передаются вместе с кодовым словом, чтобы предоставить возможность декодирования и восстановления исходного кортежа, включая информацию знака и порядка.
Воспринимая вышеизложенное представление кортежей в двумерной координатной системе, обе симметрии совместно могут рассматриваться как двумерное распределение вероятностей с кривыми уровней (кривыми равных вероятностей), напоминающими овалы с главной осью, развернутой на 45 градусов относительно прямоугольной системы координат.
Если использовать эти две симметрии, кодами Хаффмана потребуется покрыть только примерно одну четверть (первый квадрант) возможных элементов в координатной системе. Двухбитный постфиксный код определяет однозначное соответствие между каждой парой величин в одном из четырех квадрантов и ее соответствующими парами величин в остальных трех квадрантах. Следует отметить, что для пар величин, расположенных на какой-либо граничной линии квадранта, постфиксный код состоит только из одного бита или даже может быть опущен в случае, когда пара величин расположена на обеих граничных линиях, то есть в центре распределения.
Изобретательская концепция уменьшит размер кодовой книги Хаффмана для данных, которые не показывают описанных выше симметрий. Если кодируются такие данные, то, с одной стороны, размер кодовой книги Хаффмана будет малым, но, с другой стороны, может оказаться, что кодированное представление не будет идеально сжатым, поскольку величины, появляющиеся с различными вероятностями, представляются одним и тем же кодовым словом, что приводит к неэффективному использованию расхода битов, поскольку кодовая книга Хаффмана не может быть подогнана так, чтобы соответствовать данным оптимальным образом.
Следовательно, предпочтительно, чтобы эти данные дифференциально кодировались до применения операций симметрии, поскольку дифференциальное кодирование автоматически приводит к полезным симметриям. Таким образом, изобретательская концепция может использоваться, обеспечивая компактное представление и малую кодовую книгу Хаффмана для базового набора информационных величин, поскольку недостаток удвоения количества возможных информационных величин, происходящего из-за дифференциального кодирования информационных величин, может быть компенсирован путем использования симметрий.
Перечень фигур чертежей
Предпочтительные варианты осуществления настоящего изобретения описаны ниже со ссылкой на прилагаемые чертежи, на которых:
фиг.1 - структурная схема отвечающего изобретению кодера;
фиг.2 - иллюстрация предпочтительного варианта осуществления отвечающего изобретению кодера;
фиг.3 - иллюстрация еще одного предпочтительного варианта осуществления отвечающего изобретению кодера;
фиг.4а - иллюстрация первой операции симметрии в отношении данных, которые должны быть кодированы;
фиг.4b - иллюстрация второй операции симметрии в отношении данных, которые должны быть кодированы;
фиг.5 - иллюстрация получения симметричного представления данных;
фиг.6 - структурная схема отвечающего изобретению декодера;
фиг.7 - иллюстрация предпочтительного варианта осуществления отвечающего изобретению декодера;
фиг.8 - иллюстрация еще одного предпочтительного варианта осуществления отвечающего изобретению декодера;
фиг.9 - иллюстрация многоканального кодера по предшествующему уровню техники.
Подробное описание предпочтительных вариантов осуществления
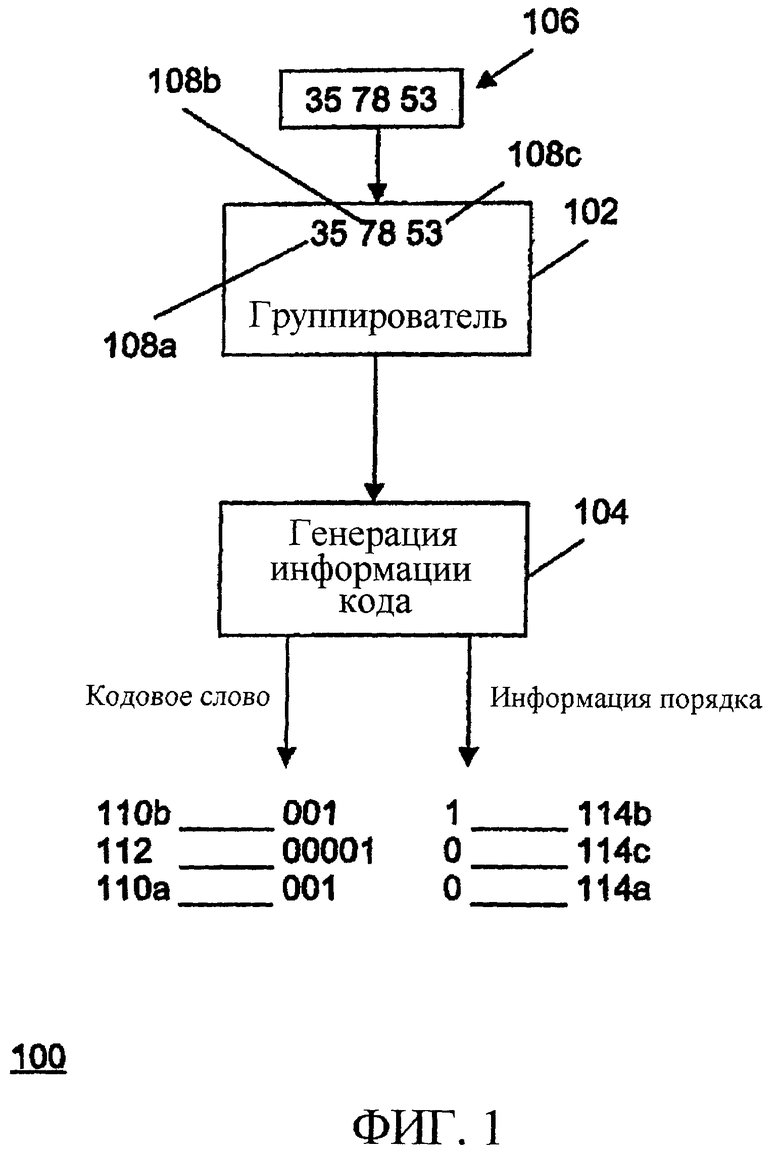
Фиг.1 иллюстрирует отвечающий изобретению кодер 100, содержащий группирователь 102 и генератор 104 информации кода, который включает в себя интерфейс вывода.
Информационные величины 106 группируются группирователем в кортежи 108a-108c информационных величин. В показанном на фиг.1 примере изобретательская концепция описана посредством построения кортежей, каждый из которых состоит из двух информационных величин, то есть путем использования двумерных кодов Хаффмана.
Кортежи 108a-108c передаются в генератор 104 информации кода, причем генератор информации кода реализует правило кодирования, согласно которому одно и то же кодовое слово назначается кортежам, имеющим идентичные информационные величины, расположенные в различных порядках. Следовательно, кортежи 108a и 108c кодируются в одинаковые кодовые слова 110a и 110b, тогда как кортеж 108b кодируется в другое кодовое слово 112. Согласно изобретательской концепции различные информации 114а и 114b порядка генерируются так, чтобы сохранить информацию о порядке, в котором информационные величины сгруппированы в кортежах 108а и 108c. Комбинация информации порядка и кодового слова, следовательно, может использоваться, чтобы восстанавливать исходные кортежи 108а и 108с, поэтому информация порядка доставляется интерфейсом вывода совместно с кодовым словом. Как правило, возможны различные схемы формирования порядков, которые приводят к различным битам информации порядка. В показанном на фиг.1 примере кортежи не подвергаются переупорядочению, когда величины в кортеже появляются в порядке возрастания, как имеет место в случае кортежей 108а и 108b. Кроме того, если принимается, что нулевая информация порядка назначается кортежам, которые не были переупорядочены, то это приведет к порядку информационных величин, в котором им были назначены кодовые слова на фиг.1.
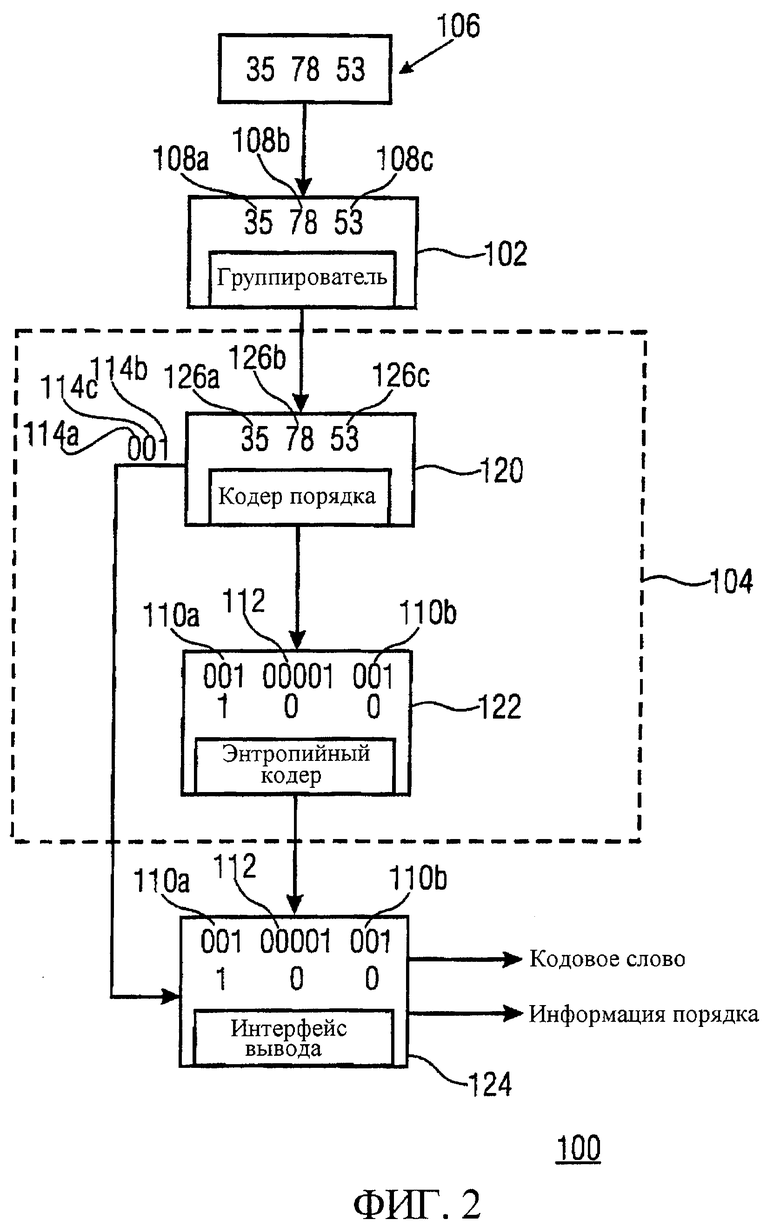
Фиг.2 иллюстрирует предпочтительный вариант осуществления настоящего изобретения, в котором генератор 104 информации кода содержит кодер 120 порядка и энтропийный кодер 122, причем кодер 100 содержит интерфейс 124 вывода.
Кодер 120 порядка генерирует информацию 114а-114с порядка кортежей (указывающую порядок кортежа) и передает эту информацию порядка в интерфейс 124 вывода. Одновременно с этим кодер 120 порядка переупорядочивает информационные величины в кортежах 108а-108с, чтобы получить кортежи 126а-126с, изменяя порядок кортежа на предопределенный порядок кортежа, причем предопределенный порядок кортежа определяет порядок кодирования информационных величин для групп кортежей, имеющих идентичные информационные величины.
Переупорядочивание, например, может быть выполнено также для кортежей, имеющих более чем две информационные величины, путем множества последовательных этапов изменения позиции двух информационных величин внутри кортежа. После каждого этапа выполняется проверка на предмет наличия в кодовой книге кодера порядка записи для данного порядка кортежа. Если это так, то переупорядочивание может быть остановлено, и может быть сгенерировано кодовое слово. Если нет, то вышеупомянутая процедура повторяется до тех пор, пока кодовое слово не будет найдено. Тогда, информация порядка может, например, быть получена из количества изменений, необходимых для получения кодового слова. Аналогично, корректный порядок кортежа может быть повторно сформирован на стороне декодера, используя информацию порядка.
Энтропийный кодер кодирует кортежи 126а-126с, чтобы получить кодовые слова 110а, 110b и 112, и передает эти кодовые слова в интерфейс 124 вывода.
Интерфейс вывода выводит кодовые слова 110а, 110b и 112 и ассоциированную с ними информацию 114а-114с порядка.
Фиг.3 иллюстрирует еще один предпочтительный вариант осуществления настоящего изобретения, в котором генератор информации кода, сверх того, содержит кодер 130 знака для получения информации знака, указывающей комбинацию знаков информационных величин в кортеже.
Показанный на фиг.3 отвечающий изобретению кодер также использует вторую симметрию, назначая одинаковые кодовые слова кортежам, имеющим информационные величины одинакового абсолютного значения, расположенные в одинаковом порядке относительно их абсолютных значений. Следовательно, кодер 130 знака получает информацию 132а-132с знака для каждого из кортежей 134а-134с, указывающую знак величин в кортеже. Кодер 130 знака одновременно изменяет знаки информационных величин в кортежах, чтобы получить предопределенную комбинацию знаков, определяющую комбинацию знака кодирования для каждого порядка абсолютных величин в кортеже, то есть для кортежей, отличающихся только знаками информационных величин.
Информация 132а-132с знака дополнительно передается в интерфейс 124 вывода, который также принимает информацию порядка от кодера 120 порядка и кодовые слова от статистического кодера 122. Интерфейс 124 вывода, тогда, предоставляет кодовые слова и ассоциированную с ними информацию порядка и информацию знака.
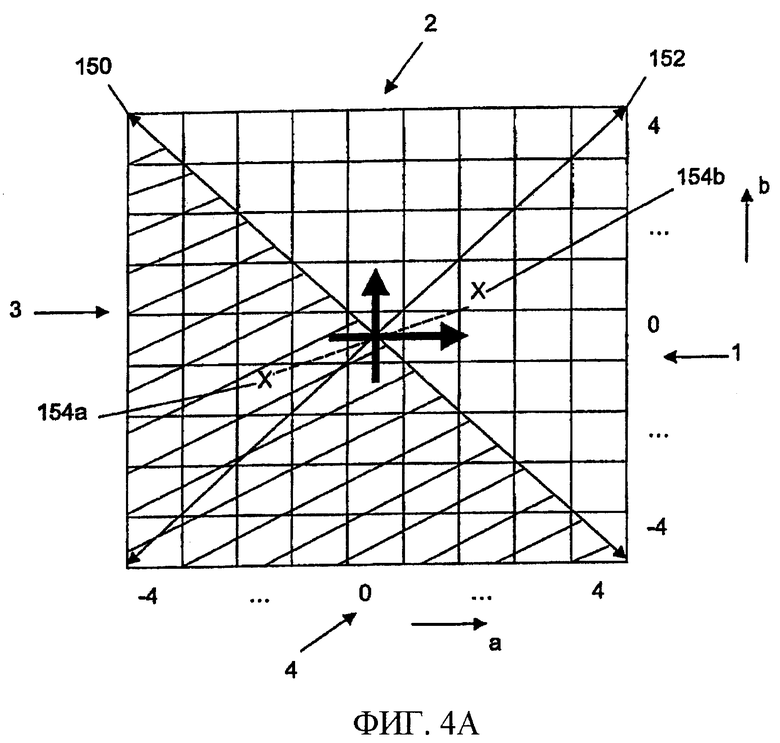
Фиг.4а иллюстрирует, как информация знака может быть получена посредством кодера 130 знака и как симметрия относительно знаков может быть использована, чтобы уменьшить размер требуемой кодовой книги Хаффмана.
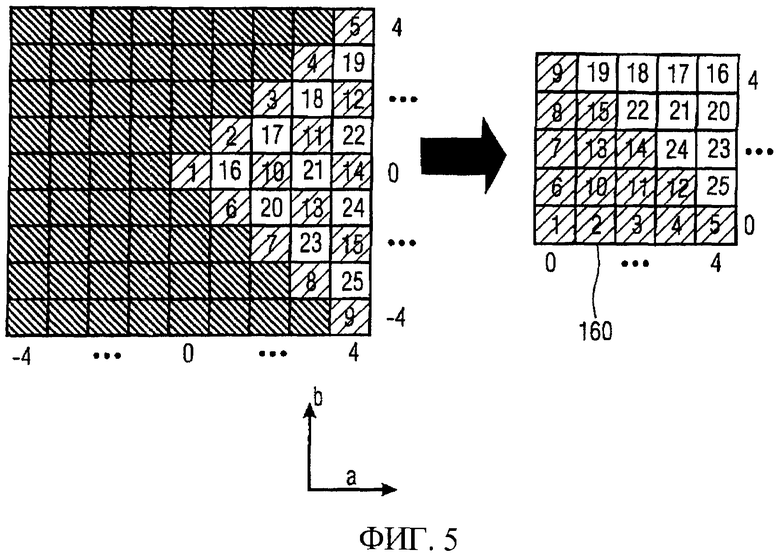
Изображены возможные величины кортежа (a, b), графически представленного матрицей, в которой величины для а показаны по оси X, а возможные величины для b показаны по оси Y. Величины для а и b симметричны относительно нулевой точки (например, вследствие предыдущего дифференциального кодирования), и каждая из них находится в диапазоне от -4 до 4.
Матрица иллюстрирует все 81 возможных комбинаций параметрических величин а и b. Также показана первая ось 150, указывающая те элементы матрицы, где сумма а и b (а+b) равна нулю. Фигура также иллюстрирует вторую ось 152, где разность а и b (a-b) равна нулю. Как можно видеть, две оси 150 и 152 разделяют матрицу на четыре квадранта, обозначенные номерами 1-4.
Предполагая, что комбинация (a, b) и комбинация (-a, -b) в равной степени вероятны, первая симметрия равна точечной симметрии относительно нулевой точки координат, которая явно показана для двух произвольных элементов 154а и 154b матрицы.
Отвечающий изобретению кодер может уменьшить размер требуемой кодовой книги Хаффмана на множитель, равный примерно двум, путем применения операции симметрии, зеркально отображая элементы третьего квадранта в первый квадрант и элементы четвертого квадранта во второй квадрант. Так можно сэкономить на элементах кодовой книги третьего и четвертого квадрантов, когда посредством информации знака кодер 130 знака дополнительно указывает, из какого квадранта выходит кортеж.
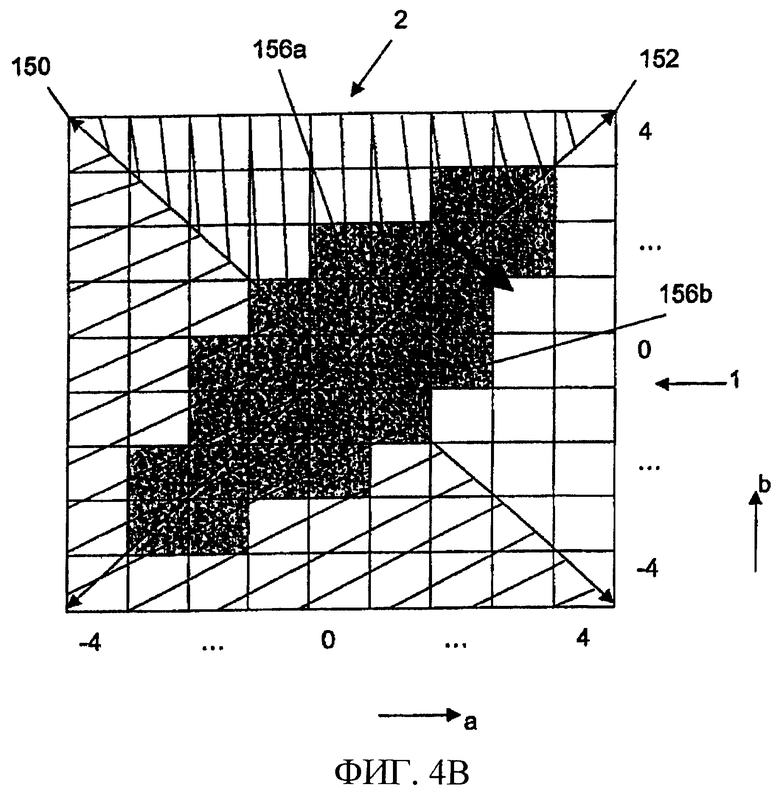
Фиг.4b иллюстрирует, как вторая симметрия может быть использована кодером 120 порядка, чтобы уменьшить размер кодовой книги Хаффмана на еще один множитель, примерно равный двум. Вторая симметрия, означающая, что кортежи (a, b) и (b, a) в равной степени вероятны, равна зеркальному отображению остальных элементов матрицы через ось 152. Это, например, показано для двух элементов 156а и 156b матрицы, показывающих зеркальное отображение кортежа (0, 2) к кортежу (2, 0). Следовательно, путем назначения соответствующим элементам второго и четвертого квадрантов одинаковых кодовых слов можно сэкономить в размере кодовой книги еще на один множитель, равный двум. Кодер 120 порядка получает информацию порядка, чтобы сохранить информацию о том, был ли исходный кортеж из первого квадранта или из второго квадранта.
Как проиллюстрировано фиг.4а и 4b, отвечающий изобретению кодер, включающий в себя кодер знака и кодер порядка, предоставляет возможность покрытия кодами Хаффмана только одного из четырех квадрантов. Двухбитный постфиксный код определяет однозначное соответствие между каждой парой величин в одном из четырех квадрантов и ее соответствующими парами величин в остальных трех квадрантах. Следует отметить, что для пар величин, расположенных на какой-либо граничной линии квадранта, постфиксный код состоит только из одного бита или даже может быть опущен в случае, когда пара величин расположена на обеих граничных линиях, то есть в центре матрицы.
С практической точки зрения, после выполнения операций симметрии, показанных на фиг.4а и 4b, может быть полезным переупорядочить (отобразить) пары величин в остающемся квадранте в квадратную матрицу, поскольку выполнение алгоритма в отношении квадратного представления гораздо более удобно.
Стратегия отображения, реализуемая одним вариантом осуществления настоящего изобретения, показана на фиг.5. В левой части показана исходная матрица с первым квадрантом, который должен быть отображен на квадратную матрицу 160. Квадратная матрица 160 также имеет параметрические величины для параметра а по оси X и параметрические величины для параметра b по оси Y. На чертеже показано переупорядочивание согласно алгоритму отображения, где каждый элемент матрицы обозначен уникальным номером. Следует отметить, что кортежи, в которых сумма информационных величин равна четному числу (сумма a+b представляет собой четное число, что верно для всех незаштрихованных элементов матрицы из первого квадранта), переупорядочиваются в нижнюю левую сторону квадратной матрицы 160, тогда как кортежи, в которых сумма информационных величин равна нечетному числу (заштрихованные элементы), переупорядочиваются в верхнюю правую сторону матрицы 160.
После выполнения вышеописанного процесса отображения кортежи, которые должны быть кодированы по алгоритму Хаффмана, задаются в квадратном представлении, и, следовательно, их легко обрабатывать.
Фиг.6 иллюстрирует структурную схему отвечающего изобретению декодера для декодирования кодовых слов, которые основаны на информационных величинах.
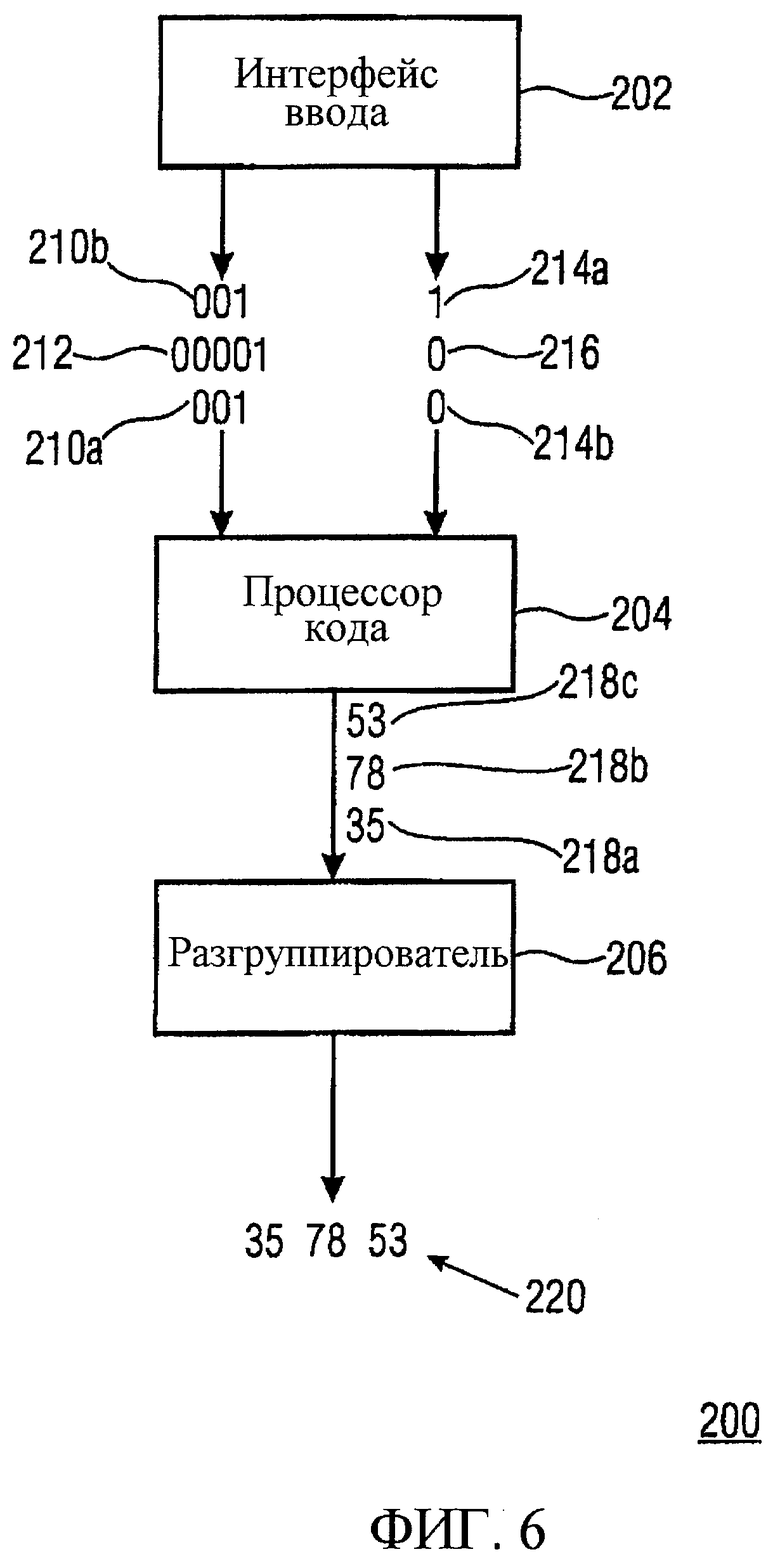
Декодер 200 содержит интерфейс 202 ввода, процессор 204 кода и разгруппирователь 206. Интерфейс 202 ввода предоставляет кодовые слова 210а, 210b и 212, а также ассоциированную с ними информацию 214а, 214b и 216 порядка в процессор 204 кода.
Процессор кода получает кортежи информационных величин 218а, 218b и 218с, используя правило декодирования, причем правило декодирования таково, что различные кортежи получаются из одного и того же кодового слова, причем эти различные кортежи имеют одинаковые информационные величины, расположенные в различных порядках кортежа, как указывается различной информацией порядка.
Следовательно, упомянутые различные кортежи 218а и 218с получаются из одинаковых кодовых слов 210а и 210b, поскольку они ассоциированы с различной информацией 214а и 214b порядка. Кортежи информационных величин 218а-218с, тогда, разгруппировываются посредством разгруппирователя 206, чтобы получить информационные величины 220.
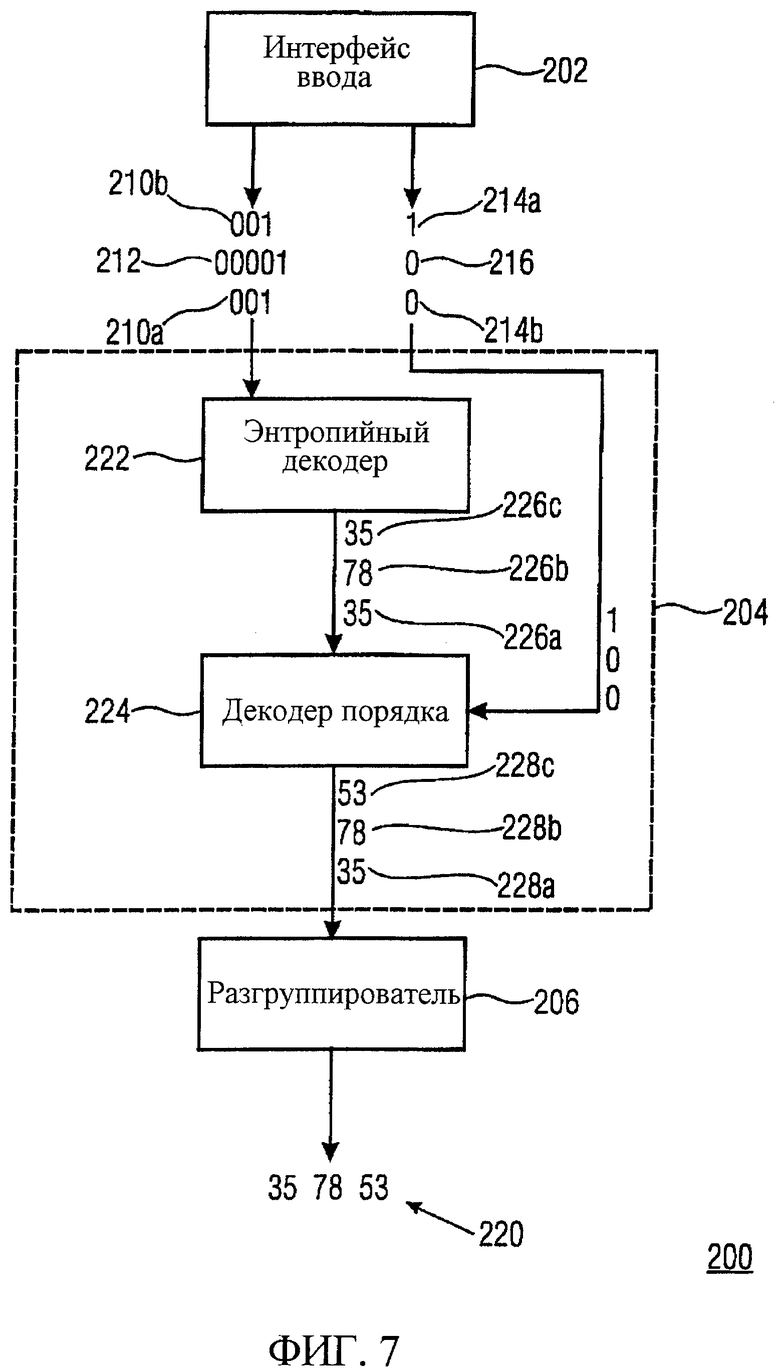
Фиг.7 иллюстрирует предпочтительный отвечающий изобретению декодер, в котором процессор 204 кода включает в себя энтропийный декодер 222 и декодер порядка 224.
Используя кодовую книгу Хаффмана, энтропийный декодер 222 назначает каждое из кодовых слов 210а, 210b и 212 одному кортежу 226а-226с. Кортежи 226а-226с передаются в декодер 224 порядка, который также принимает ассоциированную информацию порядка. Декодер 224 порядка получает информационные величины путем модификации кортежей 226а-226с согласно указанию информации порядка. Полученные окончательные кортежи 228а-228с, тогда, передаются в разгруппирователь 206, который разгруппировывает кортежи 228а-228с, чтобы получить информационные величины 220.
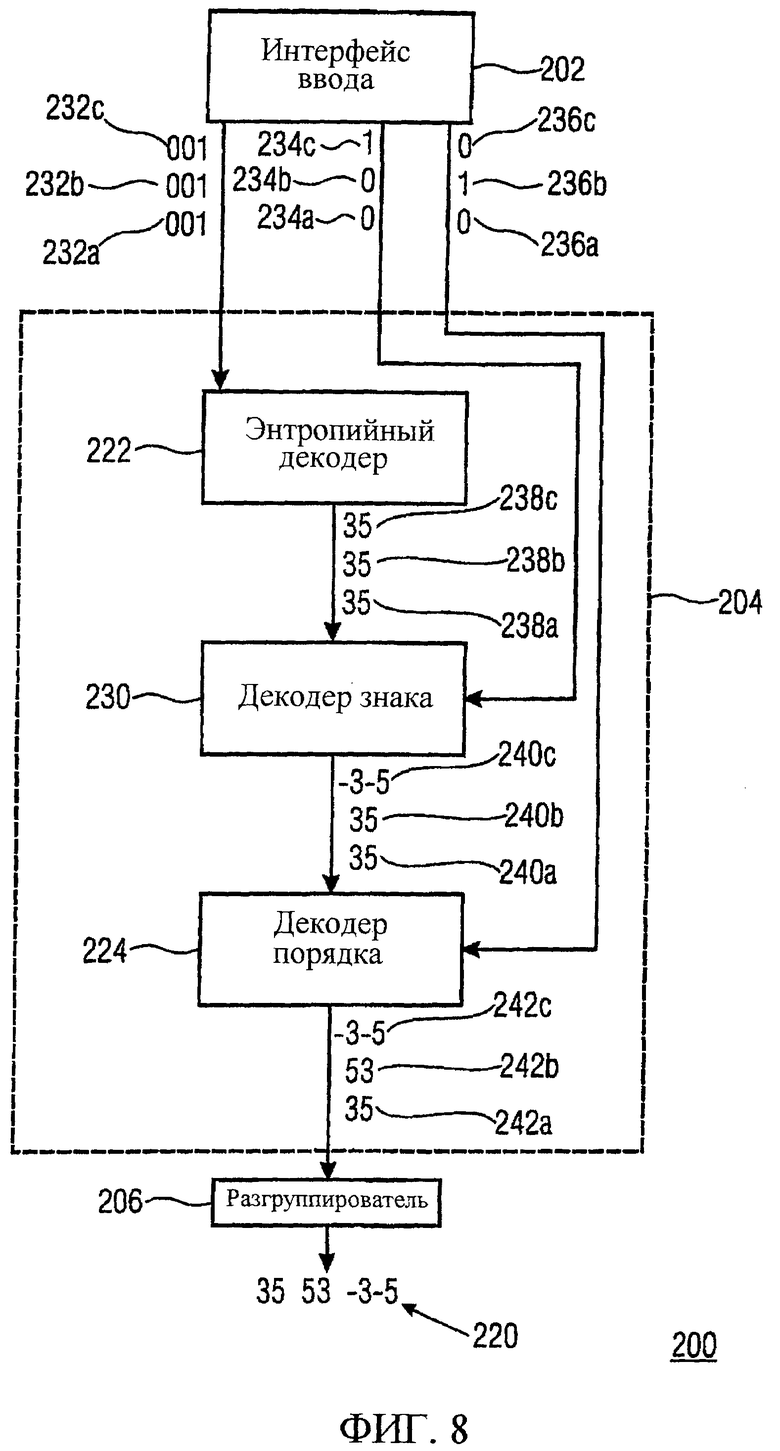
Фиг.8 иллюстрирует еще один предпочтительный вариант осуществления отвечающего изобретению декодера 200, в котором процессор 204 кода, сверх того, включает в себя декодер 230 знака.
Интерфейс ввода предоставляет три идентичных кодовых слова 232а-232с, биты 234а-234с информации знака и биты 236а-236с информации порядка.
Энтропийный декодер 222 декодирует три идентичных кодовых слова 232а-232с в три идентичных кортежа 238а-238с, которые после этого передаются в декодер 230 знака.
Декодер 230 знака дополнительно принимает информацию 234а-234с знака и модифицирует кортежи 238а-238с, как указывается информацией 234а-234с знака, чтобы получить кортежи 240а-240с, которые уже имеют информационные величины с правильными знаками.
Кортежи 240а-240с передаются в декодер 224 порядка, который дополнительно принимает информацию 236а-236с порядка и изменяет порядок информационных величин внутри кортежей 240а-240с, чтобы получить кортежи 242а-242с с правильным порядком информационных величин. Кортежи 242а-242с, тогда, передаются в разгруппирователь 206, который получает информационные величины 220 путем разгруппирования кортежей 242а-242с.
Несмотря на то что в предпочтительных вариантах осуществления отвечающих изобретению кодеров, показанных на фиг.2 и 3, предлагается, что кодер 120 порядка и кодер 130 знака извлекают информацию порядка или знака и одновременно изменяют кортеж, в альтернативном варианте представляется возможным, что кодер знака и кодер порядка извлекают информацию порядка и знака без изменения кортежа. Тогда, кодовая книга Хаффмана должна быть построена так, чтобы кортежам с различными информациями знака и порядка назначались одинаковые кодовые слова.
Несмотря на то что в показанных на фигурах предпочтительных вариантах осуществления концепция настоящего изобретения описывается с помощью двумерных кодовых книг Хаффмана, изобретательская идея использования сгруппированных величин и использования их симметрий может быть скомбинирована с другими способами кодирования без потерь, в особенности с кодовыми книгами Хаффмана больших размерностей, то есть путем построения кортежей, имеющих более чем две информационные величины.
Фиг.4а и 4b иллюстрируют способ получения информации симметрии, используемой, чтобы получить возможность использования меньших кодовых книг Хаффмана. На первом этапе третий и четвертый квадранты отображаются в первый и второй квадранты заданной матрицы. Альтернативно, также представляется возможным отображать другие комбинации двух соседних квадрантов в остальные два квадранта, при условии, что при этом сохраняется информация симметрии, так что это отображение может быть обращено. Указанное верно также для второй операции симметрии, показанной на фиг.4b.
Фиг.5 иллюстрирует один способ отображения одного квадранта матрицы в квадратную матрицу, что предоставляет удобство при использовании описания кодовой книги меньшего размера. Эта операция отображения является примером для множества возможных схем отображения, при которых отображения должны быть такими, чтобы они были уникальными и могли быть обращены.
В зависимости от требований конкретной реализации отвечающих изобретению способов, эти отвечающие изобретению способы могут быть реализованы посредством аппаратного обеспечения или программного обеспечения. Реализация может быть выполнена с использованием цифрового носителя информации, в частности диска, DVD или CD, имеющего сохраненные на нем читаемые электронным образом сигналы управления, которые взаимодействуют с программируемой компьютерной системой так, чтобы выполнялись упомянутые отвечающие изобретению способы. В целом, настоящее изобретение, следовательно, представляет собой компьютерный программный продукт с программным кодом, хранимым на машиночитаемом носителе, причем, когда компьютерный программный продукт исполняется на компьютере, программный код действует для выполнения отвечающих изобретению способов. Иначе говоря, отвечающие изобретению способы, следовательно, представляют собой компьютерную программу, имеющую программный код для выполнения, по меньшей мере, одного из отвечающих изобретению способов, когда компьютерная программа исполняется на компьютере.
Несмотря на то что настоящее изобретение было проиллюстрировано и описано со ссылкой на его конкретные варианты осуществления, специалистам в данной области техники будет очевидно, что могут быть выполнены различные изменения в форме и деталях в рамках объема и сущности настоящего изобретения. Следует понимать, что различные изменения могут быть выполнены при адаптации различных вариантов осуществления в рамках более широких концепций, раскрытых здесь и охватываемых нижеследующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ ИНФОРМАЦИИ БЕЗ ПОТЕРЬ С ГАРАНТИРОВАННОЙ МАКСИМАЛЬНОЙ БИТОВОЙ СКОРОСТЬЮ | 2006 |
|
RU2367087C2 |
| АДАПТИВНАЯ ГРУППИРОВКА ПАРАМЕТРОВ ДЛЯ УЛУЧШЕННОЙ ЭФФЕКТИВНОСТИ КОДИРОВАНИЯ | 2006 |
|
RU2368074C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2642373C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2018 |
|
RU2699677C2 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР, СПОСОБ ДЛЯ КОДИРОВАНИЯ АУДИОИНФОРМАЦИИ, СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ АУДИОИНФОРМАЦИИ И КОМПЬЮТЕРНАЯ ПРОГРАММА, ИСПОЛЬЗУЮЩИЕ ОПТИМИЗИРОВАННУЮ ХЭШ-ТАБЛИЦУ | 2011 |
|
RU2568381C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2595934C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2021 |
|
RU2779898C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2018 |
|
RU2758981C2 |
Изобретение относится к кодированию/декодированию информационных величин и, в частности, к энтропийному кодированию с использованием компактных кодовых книг для генерации эффективного кода. Технический результат - повышение точности кодирования/декодирования. Настоящее изобретение основано на том, что эффективный код для кодирования информационных величин может быть получен, когда две или более информационные величины группируются в кортеж согласно порядку кортежа и когда используется правило кодирования, согласно которому одинаковое кодовое слово назначается кортежам, имеющим одинаковые информационные величины, расположенные в различных порядках, и извлекается информация порядка, указывающая порядок кортежа, и когда кодовое слово выводится в связи с информацией порядка. 6 н. и 17 з.п. ф-лы, 9 ил.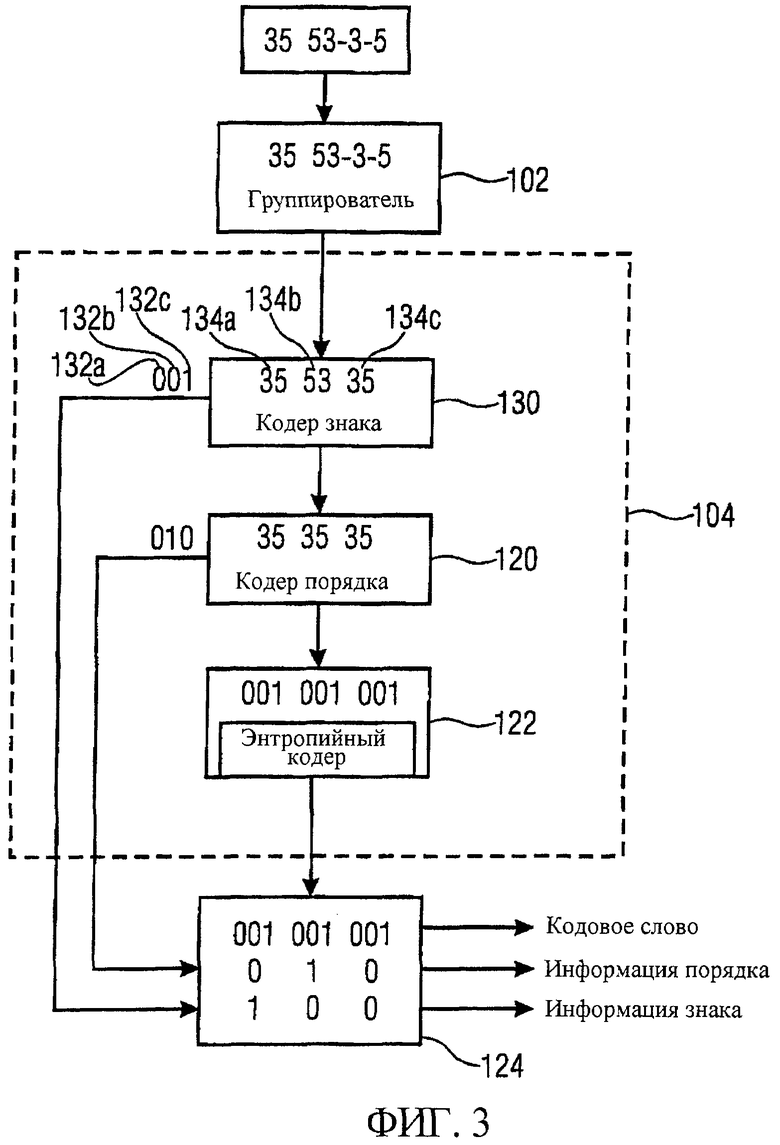
1. Кодер для кодирования информационных величин, содержащий:
дифференциальный кодер для дифференциального кодирования входных величин, чтобы получить дифференциально кодированное представление входных величин в качестве информационных величин;
средство группирования для группирования двух информационных величин в кортеж согласно порядку кортежа;
средство генерации информации кода для генерации информации порядка, указывающей порядок кортежа, и кодового слова для кортежа, используя правило кодирования, причем это правило кодирования таково, что одинаковое кодовое слово назначается разным кортежам, имеющим одинаковые информационные величины, расположенные в разных порядках, и, сверх того, данное правило кодирования таково, что одинаковое кодовое слово назначается только разным кортежам, имеющим информационные величины одинакового абсолютного значения, расположенные в одинаковом порядке и различающиеся знаком каждой информационной величины в кортеже;
кодер знака для получения информации знака, указывающей комбинацию знаков информационных величин в кортеже; и
интерфейс вывода для вывода кодового слова и ассоциированных с ним информации порядка и информации знака.
2. Кодер по п.1, в котором средство генерации информации кода включает в себя кодер порядка для получения информации порядка и энтропийный кодер для получения кодового слова, используя кодовую книгу, которая назначает кортежи, имеющие идентичные информационные величины, расположенные в различных порядках, одинаковому кодовому слову.
3. Кодер по п.2, в котором кодер порядка выполнен с возможностью переупорядочивать информационные величины в кортеже, чтобы изменить порядок кортежа на предопределенный порядок кортежа для этого кортежа, причем упомянутый предопределенный порядок кортежа определяет порядок кодирования информационных величин для групп кортежей, имеющих идентичные информационные величины, при этом кодер порядка выполнен с возможностью детектировать и кодировать отклонение порядка кортежа и порядка кодирования; и
причем энтропийный кодер имеет уменьшенную кодовую книгу, назначающую кодовое слово кортежам, имеющим информационные величины, упорядоченные согласно порядку кодирования.
4. Кодер по п.3, в котором кодер порядка выполнен с возможностью переупорядочивать информационные величины в кортеже путем перестановки первой информационной величины и второй информационной величины.
5. Кодер по п.4, в котором
кодер знака выполнен с возможностью изменять знаки информационных величин в кортеже, чтобы изменять комбинацию знаков на предопределенную комбинацию знаков, причем эта предопределенная комбинация знаков определяет комбинацию знаков кодирования для порядка информационных величин в кортеже, различающихся только отдельными знаками информационных величин;
и
средство генерации информации кода имеет энтропийный кодер, имеющий уменьшенную кодовую книгу, назначающую одинаковое кодовое слово каждому кортежу, имеющему одинаковый порядок абсолютных значений информационных величин.
6. Кодер по п.5, в котором кодер знака действует, чтобы изменять знак первой и второй информационных величин в кортеже.
7. Кодер по п.1, в котором дифференциально кодированное представление является представлением входных величин, дифференциально кодированных по времени или по частоте.
8. Кодер по п,1, в котором информационные величины содержат информационные величины, описывающие кадр видеосигнала или аудиосигнала.
9. Кодер по п.1, в котором информационные величины содержат параметры кодирования бинауральных характеристик (ВСС), описывающие пространственную корреляцию между первым и вторым аудио каналами, причем параметры ВСС выбраны из следующего перечня параметров ВСС:
межканальная когерентность/корреляция (ICC);
межканальная разность уровней (ICLD);
межканальная разность времен (ICTD);
межканальная разность фаз (IPD).
10. Кодер по п.1, в котором правило кодирования таково, что кодирование информационных величин дает в результате последовательность кодовых слов, имеющих различные длины.
11. Декодер для декодирования кодового слова, основанного на информационных величинах, содержащий:
интерфейс ввода для предоставления кодового слова и ассоциированной с ним информации порядка, указывающей порядок кортежа, который представляет собой порядок расположения двух информационных величин в кортеже информационных величин, и, сверх того, ассоциированной с ним информации знака, указывающей комбинацию знаков для информационных величин в этом кортеже;
средство обработки кода для получения кортежа, используя правило декодирования, зависящее от правила кодирования, использованного для создания кодового слова, причем правило декодирования таково, что разные кортежи, имеющие одинаковые информационные величины, расположенные в разных порядках, получаются из одинакового кодового слова, когда с ним ассоциирована различная информация порядка, и таково, что только разные кортежи, имеющие информационные величины одинакового абсолютного значения в одинаковом порядке и различающиеся знаком каждой информационной величины в кортеже, получаются из одинакового кодового слова, когда с ним ассоциирована различная информация знака, и
дифференциальный декодер для дифференциального декодирования информационных величин, чтобы получать дифференциально декодированное представление информационных величин.
12. Декодер по п.11, в котором средство обработки кода включает в себя
энтропийный декодер для получения предварительного кортежа, используя кодовую книгу, назначающую каждое кодовое слово предварительному кортежу; и
декодер порядка для получения кортежа путем переупорядочения информационных величин в предварительном кортеже, согласно указанию информации порядка.
13. Декодер по п.12, в котором декодер порядка выполнен с возможностью переупорядочивать информационные величины в предварительном кортеже путем перестановки первой информационной величины и второй информационной величины.
14. Декодер по п.13, в котором средство обработки кода дополнительно содержит декодер знака, чтобы получать кортеж из предварительного кортежа путем изменения знаков информационных величин в предварительном кортеже, как указывается информацией знака.
15. Декодер по п.14, в котором декодер знака выполнен с возможностью изменять знаки каждой информационной величины в предварительном кортеже.
16. Декодер по п.14, в котором декодер знака выполнен с возможностью изменять знак первой и второй информационных величин в предварительном кортеже.
17. Декодер по п.11, в котором дифференциально декодированное представление информационных величин является дифференциально декодированным по времени или по частоте.
18. Декодер по п.11, в котором информационные величины содержат информационные величины, описывающие кадр видеосигнала или аудиосигнала.
19. Декодер по п.11, в котором информационные величины содержат параметры кодирования бинауральных характеристик (ВСС), описывающие пространственную корреляцию между первым и вторым аудиоканалами, причем параметры ВСС выбраны из следующего перечня параметров ВСС:
межканальная когерентность/корреляция (ICC);
межканальная разность уровней (ICLD);
межканальная разность времен (ICTD);
межканальная разность фаз (IPD).
20. Способ кодирования информационных величин, содержащий этапы, на которых:
дифференциально кодируют входные величины, чтобы получать дифференциально кодированное представление входных величин в качестве информационных величин;
группируют две информационные величины в кортеж согласно порядку кортежа;
генерируют информацию порядка, указывающую порядок кортежа;
генерируют информацию знака, указывающую знак информационных величин в кортеже;
генерируют кодовое слово для кортежа, используя правило кодирования, причем правило кодирования таково, что одинаковое кодовое слово назначается разным кортежам, имеющим одинаковые информационные величины, расположенные в разных порядках, и, сверх того, правило кодирования таково, что одинаковое кодовое слово назначается только разным кортежам, имеющим информационные величины одинакового абсолютного значения, расположенные в одинаковом порядке и различающиеся знаком каждой информационной величины в кортеже; и
выводят кодовое слово и ассоциированные с ним информацию порядка и информацию знака.
21. Способ декодирования кодовых слов, основанных на информационных величинах, содержащий этапы, на которых:
предоставляют кодовое слово и ассоциированную с ним информацию порядка, указывающую порядок кортежа, который представляет собой порядок расположения двух информационных величин в кортеже информационных величин, и, сверх того, ассоциированную с ним информацию знака, указывающую комбинацию знаков для информационных величин в кортеже;
получают кортеж, используя правило декодирования, зависящее от правила кодирования, использованного для создания кодового слова, причем правило декодирования таково, что разные кортежи, имеющие одинаковые информационные величины, расположенные в разных порядках, получаются из одинакового кодового слова, когда с ним ассоциирована различная информация порядка, и таково, что только разные кортежи, имеющие информационные величины одинакового абсолютного значения, расположенные в одинаковом порядке и различающиеся знаком каждой информационной величины в кортеже, получаются из одинакового кодового слова, когда с ним ассоциирована различная информация знака;
разгруппировывают кортежи на две или более информационные величины; и
дифференциально декодируют эти информационные величины, чтобы получать дифференциально декодированное представление информационных величин.
22. Машиночитаемый носитель, на котором сохранена компьютерная программа, имеющая программный код для осуществления способа кодирования информационных величин при ее исполнении на компьютере, причем способ содержит этапы, на которых:
дифференциально кодируют входные величины, чтобы получать дифференциально кодированное представление входных величин в качестве информационных величин;
группируют две информационные величины в кортеж согласно порядку кортежа;
генерируют информацию порядка, указывающую порядок кортежа;
генерируют информацию знака, указывающую знак информационных величин в кортеже;
генерируют кодовое слово для кортежа, используя правило кодирования, причем правило кодирования таково, что одинаковое кодовое слово назначается разным кортежам, имеющим одинаковые информационные величины, расположенные в разных порядках, и, сверх того, правило кодирования таково, что одинаковое кодовое слово назначается только разным кортежам, имеющим информационные величины одинакового абсолютного значения, расположенные в одинаковом порядке и различающиеся знаком каждой информационной величины в кортеже; и
выводят кодовое слово и ассоциированные с ним информацию порядка и информацию знака.
23. Машиночитаемый носитель, на котором сохранена компьютерная программа, имеющая программный код для осуществления способа декодирования кодовых слов при ее исполнении на компьютере, причем способ содержит этапы, на которых:
предоставляют кодовое слово и ассоциированную с ним информацию порядка, указывающую порядок кортежа, который представляет собой порядок расположения двух информационных величин в кортеже информационных величин, и, сверх того, ассоциированную с ним информацию знака, указывающую комбинацию знаков для информационных величин в кортеже;
получают кортеж, используя правило декодирования, зависящее от правила кодирования, использованного для создания кодового слова, причем правило декодирования таково, что разные кортежи, имеющие одинаковые информационные величины, расположенные в разных порядках, получаются из одинакового кодового слова, когда с ним ассоциирована различная информация порядка, и таково, что только разные кортежи, имеющие информационные величины одинакового абсолютного значения, расположенные в одинаковом порядке и различающиеся знаком каждой информационной величины в кортеже, получаются из одинакового кодового слова, когда с ним ассоциирована различная информация знака;
разгруппировывают кортежи на две или более информационные величины; и
дифференциально декодируют эти информационные величины, чтобы получать дифференциально декодированное представление информационных величин.
| US 5550541 А, 27.08.1996 | |||
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ | 1995 |
|
RU2117388C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ МАСШТАБИРУЕМОГО КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ АУДИОСИГНАЛОВ | 1997 |
|
RU2214047C2 |
| US 5325091 А, 28.06.1994 | |||
| US 6166664 A1, 27.12.2000. | |||

