Изобретение относится к технике передачи и хранения информации (в цифровом виде) и может использоваться в банках данных и в системах электросвязи, когда необходимо уменьшить время передачи данных по каналу или увеличить длительность элементарных посылок - носителей данных (с целью повышения помехоустойчивости передачи) при сохранении или увеличении скорости создания цифровой информации в источнике сообщений; когда необходимо сократить объём памяти некоторой базы данных или, наоборот, увеличить объём цифровой информации, предназначенной для хранения в существующем устройстве памяти; когда необходимо сжать ширину спектра передаваемых сигналов для уменьшения полосы частот проводного или радиоканала; когда требуется обеспечить скрытность передаваемой или хранящейся в устройстве памяти цифровой информации.
Известно много разных способов сжатия данных (СД). Наиболее близким техническим решением (прототипом) можно считать использование статического словаря в словарных методах СД /1, 2, 3/. Суть этого метода заключается в том, что некоторые последовательности символов - слова (создающие избыточность в сообщениях) - сохраняют в словаре и взаимно однозначно отображают метками (индексами, адресами и т.п.), которые состоят из меньшего числа символов, чем исходные последовательности, и наделены индивидуальными данными, позволяющими при необходимости восстановить конкретную последовательность символов в словаре. Каждое слово (последовательность символов) входного файла, объём (размер) которого предполагается уменьшить (сжать), ищется в словаре. Если этот поиск оказывается успешным, то в выходной файл вместо слова записывается соответствующая словарная метка (индекс, адрес). В противном случае в выходной файл записывается не индекс, а само слово без сжатия.
Статический словарь по составу обычно понимается как постоянный, хотя в него иногда добавляют новые последовательности, но из словаря последовательности никогда не удаляют /2, 3/ (в отличие от динамического (адаптивного) словаря, в котором разрешается и добавление, и удаление данных).
Недостатками разработанных словарных способов СД с применением статического словаря являются их сложная реализация, относительно невысокая эффективность (степень сжатия), привязанность каждого словаря к одному типу (характеру) текста, сравнительно низкая скорость кодирования и декодирования. Словарные методы с использованием динамических словарей обеспечивают несколько более высокую эффективность сжатия, но значительно сложнее в реализации и имеют другие недостатки.
Предлагаемый способ сжатия данных (В литературе о сжатии данных в настоящее время имеется множество терминов-«синонимов», вносящих некоторую неоднозначность в те или иные понятия, например: компрессор - кодер, символ - буква, слово - последовательность символов - кодовая комбинация, метки - индексы и т.д. Поэтому в рассматриваемом здесь процессе сжатия и восстановления данных для определённости примем следующее: поток (или некоторый объём) данных разделяется на блоки - входные кодовые комбинации (КК) - с числом разрядов n и основанием кода m, последовательно, один за другим поступающие в кодер (компрессор), в памяти (в статическом словаре) которого содержатся кодовые комбинации КК1, представляющие собой полный набор возможных (разных) КК (для современной техники это вполне реально даже при больших значениях n); каждая из входных КК идентифицируется с той или иной КК1, а все КК1 отображаются метками - кодовыми комбинациями КК2 с меньшим, чем в КК1, или таким же числом разрядов. При восстановлении данных в декодере (декомпрессоре) входные КК2 последовательно преобразуются в КК1, выходные КК - блоки, из которых далее формируется требуемый поток (или некоторый объём) данных.) (СД) прост в реализации; повышает скорость кодирования и декодирования; обеспечивает сжатие без потерь; имеет высокую эффективность даже на начальной стадии разработки (при любой реальной последовательности разных двоичных кодовых комбинаций (КК) длиной n, общее число которых равно двум в целой степени n (n=2, 3, 4,…), всегда только две из них оказываются несжатыми, и ими могут быть самые маловероятные последовательности из одних «0» или одних «1»; отношение средней длины ncp неравномерных кодов в выходном файле к одинаковой длине (n) равномерных кодов во входном файле ncp/n<1; после реализации любого известного способа СД или нескольких последовательно выполненных таких известных способов, если в результате будет получен поток (объём) данных, допускающий разделение на блоки одинаковой или разной длины, то предлагаемый способ СД всегда может обеспечить дополнительное СД.
Техническим результатом предлагаемого изобретения является: простота в реализации и повышение скорости кодирования и декодирования; уменьшение времени передачи данных по каналу связи при сохранении или увеличении скорости создания цифровой информации в источнике сообщений, что позволяет в том же канале или повысить скорость передачи данных, или увеличить длительность элементарных сигналов и тем самым получить выигрыш в помехоустойчивости передачи; сокращение необходимого объёма памяти некоторой базы данных или, наоборот, увеличение объёма цифровой информации, предназначенной для хранения в существующем устройстве памяти; сжатие ширины спектра передаваемых сигналов (без уменьшения скорости передачи информации) для уменьшения полосы частот проводного или радиоканала; обеспечение скрытности передаваемой или хранящейся в устройстве памяти цифровой информации.
Сущность предлагаемого изобретения заключается в том, что, как и в способе-прототипе /1, 2, 3/, последовательности символов (слова, кодовые комбинации КК1), предварительно записанные в статическом словаре (в первом блоке памяти кодера), заменяют специальными метками (кодовыми комбинациями КК2) из второго блока памяти кодера, но в отличие от указанного способа /1, 2, 3/ эти метки не содержат индивидуальных данных об отображаемых ими конкретных последовательностях символов (до процесса сжатия любой метке КК2 может быть поставлена в соответствие любая последовательность символов КК1, лишь бы в декодере была зафиксирована такая же связь метка - последовательность символов (КК2-КК1), как и в кодере); кроме того, число таких разных меток может быть столь большим и так мало отличаться от числа разных последовательностей символов, что теряется смысл различать в кодере две категории - метки и слова (КК) без сжатия; поэтому в первый блок памяти кодера предварительно записывают (под именем КК1) все (без исключения) возможные (разные) последовательности символов (КК), которые могут возникнуть на входе кодера, и все поступающие при СД в кодер последовательности символов (КК) идентифицируют с одной из КК1; в свою очередь каждой КК1 ставится в соответствие одна из меток - кодовая комбинация КК2, совокупность которых представляет собой последовательность групп с полным набором из mn m-ичных кодовых комбинаций одинаковой длины n в каждой группе (m - основание кода, m=2, 3, 4,…; число разрядов n=1, 2, 3, …; разрядность кода в группе выравнивается за счёт добавления незначащих символов «0» перед кодовыми комбинациями с числом разрядов меньше n, n=2, 3,…) за исключением последней группы (с выбранным максимальным значением n), которая может быть неполной и в КК2 которой число разрядов может быть таким же, как в КК1; кодовые комбинации КК2 в разных группах различаются числом разрядов, но могут отличаться или совпадать в численном выражении; в памяти и кодера, и декодера хранятся одинаковые наборы последовательностей символов (или КК1) и КК2.
Поскольку каждая КК2 характеризуется двумя параметрами - числом раз рядов и численным значением, процесс декодирования (декомпрессии, идентификации входной КК2 и КК2, а затем и КК1 в памяти декодера) может проводиться в два этапа: 1) выбор в памяти декодера группы из КК2 с числом разрядов, равным числу разрядов входной КК2, 2)определение внутри установленной группы кодовой комбинации КК2 с численным значением, таким же, как у входной КК2. Так как в этом случае отпадает необходимость идентификации входной КК2 с КК2 других групп, записанных в памяти декодера, скорость декодирования соответственно повышается.
Скорость кодирования по сравнению с аналогичной операцией в способе-прототипе тоже увеличивается, так как, во-первых, для каждой метки (в способе-прототипе в случае, например, радикального изменения характера текста метки приходится обновлять) не требуются выбор и анализ соответствующей последовательности символов (создающей избыточность в сообщениях), а также формирование индивидуальных данных; во-вторых, для ускорения процесса идентификации очередной КК с КК1 в памяти кодера цепь подачи КК в кодер можно разветвить на несколько цепей и соединить их с разными участками, на которые целесообразно разбить всю память КК1.
Если не раскрывать посторонним связи КК1-КК2 в кодере и декодере (а эти связи не сложно время от времени изменять), то можно обеспечить скрытность передаваемой или хранящейся в устройстве памяти цифровой информации.
В /4/ рассмотрен способ сжатия ширины спектра информационных электрических сигналов с ограниченной полосой частот, в основе которого лежит объединение нескольких отсчётов сигнала в один групповой отсчёт. При этом исходные отсчёты представляются двоичными кодовыми комбинациями, и если с помощью предлагаемого способа СД обеспечить сжатие последовательности указанных кодовых комбинаций, то можно объединить в один больше исходных отсчётов и увеличить тем самым сжатие ширины спектра передаваемых сигналов для уменьшения полосы частот проводного или радиоканала.
Если все кодовые комбинации (КК) на входе кодера, как и все КК1, имеют одинаковую длину k, то суммарное число кодовых комбинаций КК2 с меньшим, чем k, числом разрядов определяется алгоритмом
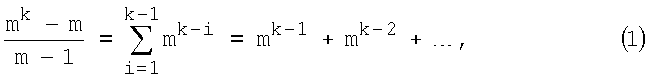
где основание кода m=2, 3, 4,…, число разрядов k=2, 3, 4… - неотрицательные целые значения, k>i. Если, например, m=2 и k=10, то (см. (1) и табл.1)
(210-2)/(2-1)=512+256+128+64+32+16+8+4+2=1022.
Это означает, например, что для 1024 последовательностей символов (КК1), записанных в словаре, существует 1022 метки с выигрышем в числе символов.
Каждое слагаемое в правой части (1) равно числу КК2 в соответствующей группе и, кроме последнего слагаемого (m), может быть представлено в форме (1).
Если все КК на входе кодера, как и все КК1, имеют одинаковую длину k, то суммарное число кодовых комбинаций КК2 с таким же числом разрядов k определяется алгоритмом

где основание кода m=2, 3, 4,…, число разрядов k=2, 3, 4… - неотрицательные целые значения. Если, например, m=2 и k=10, то (см. (1) и табл.1)
210-(210-2)/(2-1)=1024-1022=2.
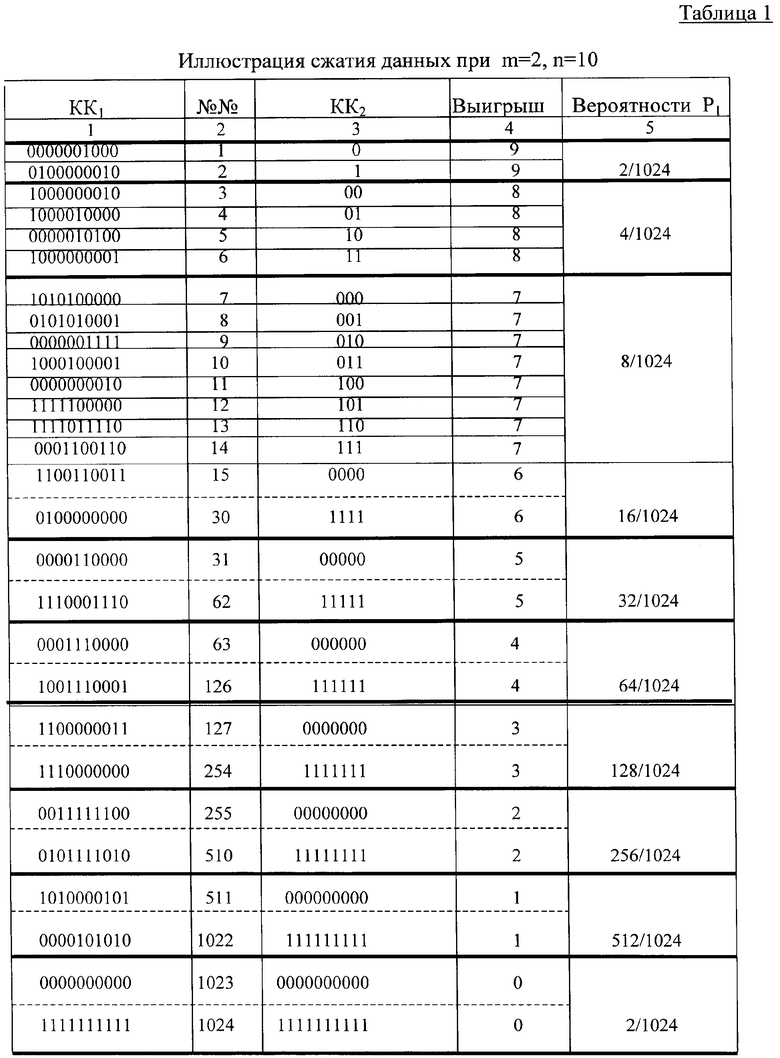
Пример 1. Все кодовые комбинации (КК) на входе кодера, как и КК1 в памяти кодера, имеют одинаковую длину и состоят из n=10 двоичных разрядов (m=2), т.е. общее число таких КК1 равно 210=1024; эти КК1 в произвольном порядке размещены в колонке 1 таблицы 1 (выбран один из [(210)!] возможных вариантов); в колонке 2 приведены десятичные номера КК1 от 1 до 210=1024; в колонке 3 содержатся двоичные кодовые комбинации КК2 (метки, индексы, адреса и т.п.) разной длины, взаимно однозначно отображающие соответствующие КК1 с назначенными им десятичными номерами (заметим, что в отличие от некоторых словарных методов СД роль этих номеров здесь весьма второстепенна: они лишь напоминают, что общее число как КК1, так и КК2 в рассматриваемом примере равно 1024, и ни коим образом не влияют на формирование КК2); в колонке 4 указан выигрыш в числе двоичных разрядов - как разность в длине соответствующих КК1 и КК2; в предположении, что все разные 10-разрядные блоки данных поступают на вход устройства СД (кодера) с одинаковой вероятностью Р=1/1024, в колонке 5 указаны суммарные вероятности P1 выбора КК2 одинаковой длины (эти же вероятности характеризуют и соответствующие значения выигрыша в числе двоичных разрядов).
Для примера 1, когда n=10, определим величину среднего выигрыша Vcp и отношение средней длины КК2 ncp к длине КК1 n. Используя приведённые в таблице 1 вероятности P1, а также соответствующие значения выигрыша и размеры (в числе двоичных разрядов - дв.р.) КК2 имеем
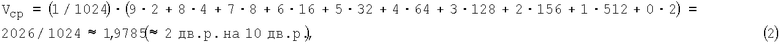
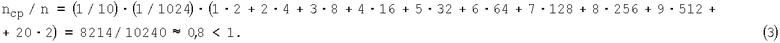
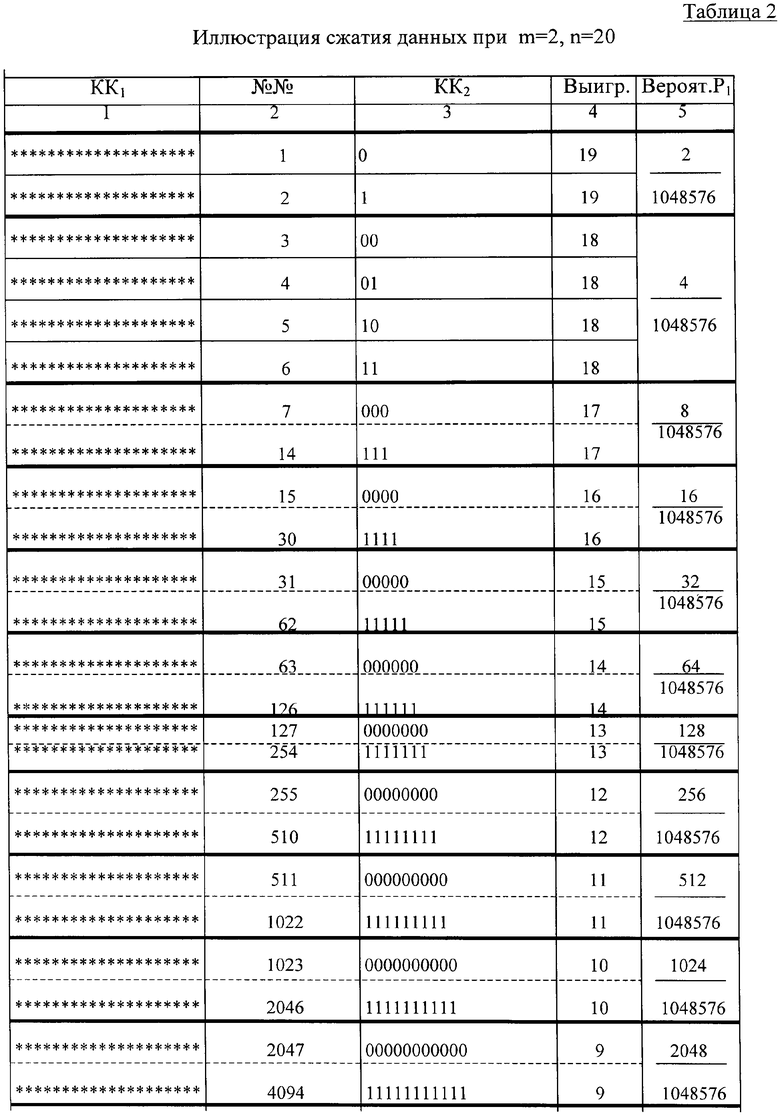
Пример 2. Все условия аналогичны соответствующим условиям примера 1, но n=20 и общее число КК1 равно 220=1048576; результаты - в таблице 2,
***…* в колонке 1 символизируют «1» и «0» в кодовых комбинациях КК1.
В этом примере, как и в предыдущем, когда длина входных КК и КК1 была вдвое меньше, лишь две комбинации из 1048576 не подверглись сжатию. Определим теперь для примера 2 средний выигрыш Vcp и отношение средней длины КК2 ncp к длине КК1 n. С учётом табл.2, по аналогии с (2) и (3) имеем
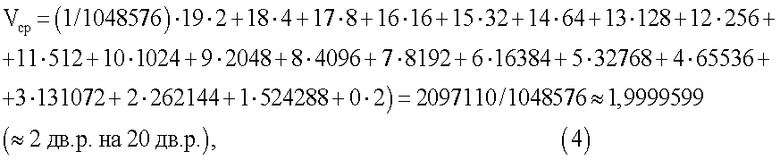

Даже если с целью более надёжного разделения комбинаций КК2 (на стороне декодера) каждую из них (в табл. 2) сопровождать специальной меткой, например паузой, равной длительности сигнала одного двоичного разряда, то ncp=19,00004, а (ncp/n)=0,950002<1. Хотя, очевидно, разделение комбинаций КК2 можно целиком построить на различии сигналов, отображающих следующие один за другим соседние КК2.
Из сравнения средних выигрышей Vcp в примерах 1 и 2 следует, что вариант, когда длина КК и КК1 n=10, предпочтительнее, т.к. в этом случае Vcp≈2 приходится на 10, а не на 20 двоичных разрядов.
В таблицах 1, 2 и в формулах (2)…(5) учтено, что все KK на входе каждого из кодеров равновероятны. В реальных ситуациях указанные КК поступают с разными вероятностями, и если эти вероятности известны или находятся и уточняются в процессе передачи данных, то размещение комбинаций КК1 относительно КК2 в табл. 1 и 2 надо изменить так, чтобы, следуя известному методу Хаффмана [1, 2, 3], наиболее вероятным входным КК и соответствующим комбинациям КК1 назначались самые короткие комбинации КК2, а наименее вероятным - самые длинные КК2.
Пример 3. В отличие от табл.1 и табл.2 в табл.3 принято, что n=4 (т.е. число разных 4-разрядных КК1 равно 24=16) и выбор (источником) таких комбинаций в одном случае производится с одинаковой вероятностью P1=1/16, а в другом случае (P2) - согласно методу Хаффмана.
При равновероятных входных кодах средняя длина неравномерных кодов КК2 в выходном файле
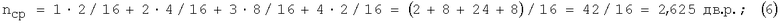
отношение 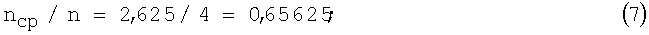
средний выигрыш 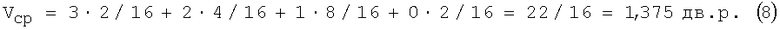
При разных вероятностях Р2:
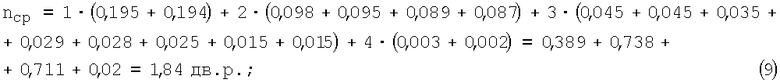

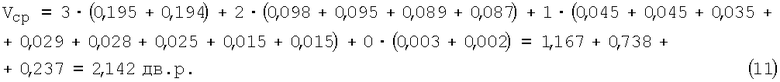
Таким образом, при учёте разных вероятностей поступления кодовых комбинаций на вход кодера все показатели сжатия данных улучшаются.
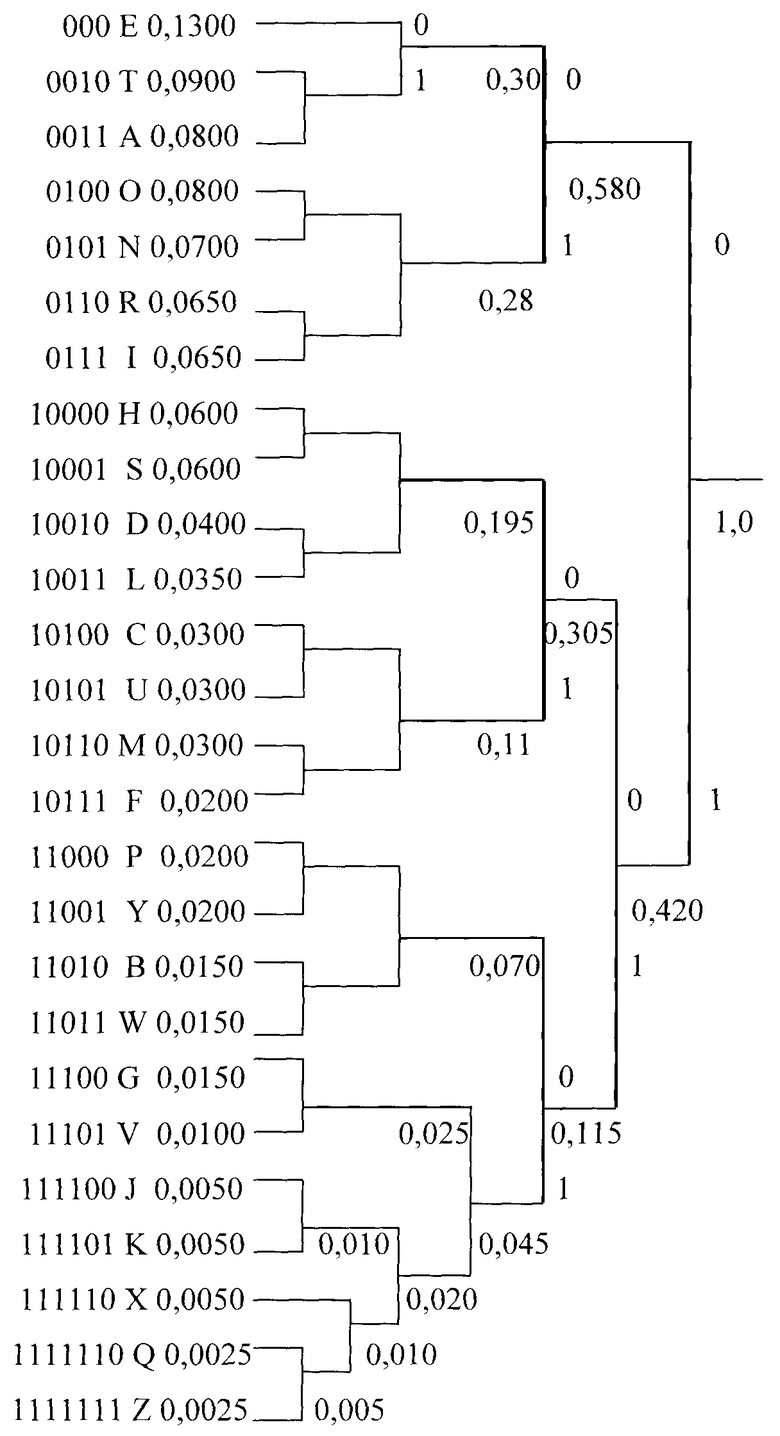
Пример 4. Рассмотрим алгоритм и код Хаффмана для английского алфавита /3/ - чертёж.
Средняя длина кода на чертеже (сумма произведений числа разрядов в i-й кодовой комбинации, отображающей соответствующую букву, на вероятность её появления; i = 1, 2, …, 26)
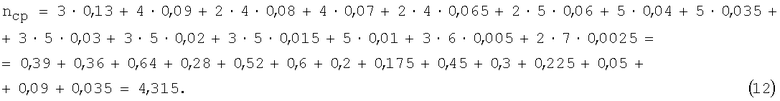
В табл.4 указаны те же 26 букв английского алфавита и длины кодов Хаффмана с соответствующими вероятностями их появления (как на чертеже). Но вместо кода Хаффмана использован способ СД с применением КК2 (см. табл.1, табл.2 и табл.3). Так как число 26 не является целой степенью числа 2 (4<n<5 и соответственно 24<26<25 ), правило (1) не применимо. Расчёт средней длины КК2 (ncp) по данным табл.4 выполняется аналогично (9).
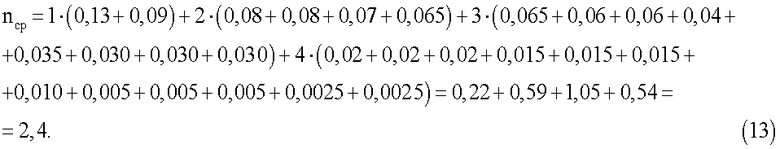
Это примерно в 1,8 раз меньше, чем при кодировании по Хаффману (см. (12)).
В колонке 5 таблицы 4 приведены значения выигрыша в числе двоичных разрядов (дв.р.) при переходе от кодовых комбинаций Хаффмана (чертёж) к соответствующим КК2. С учётом указанных вероятностей выбора букв средняя величина такого выигрыша
Vcp=1·(0,065+0,02+0,02+0,02+0,015+0,015+0,015+0,01)+2·(0,13+0,08++0,08+0,07+0,065+0,06+0,06+0,04+0,035+0,03+0,03+0,03+0,005+0,005+0,005)+3·(0,09+0,0025+0,0025)=0,18+1,51+0,285=1,975 дв.р.
Таким образом, выигрыш за счёт применения КК2 получается как при равномерных, так и при неравномерных входных кодах. При этом средние величины таких выигрышей в обоих случаях очень близки.
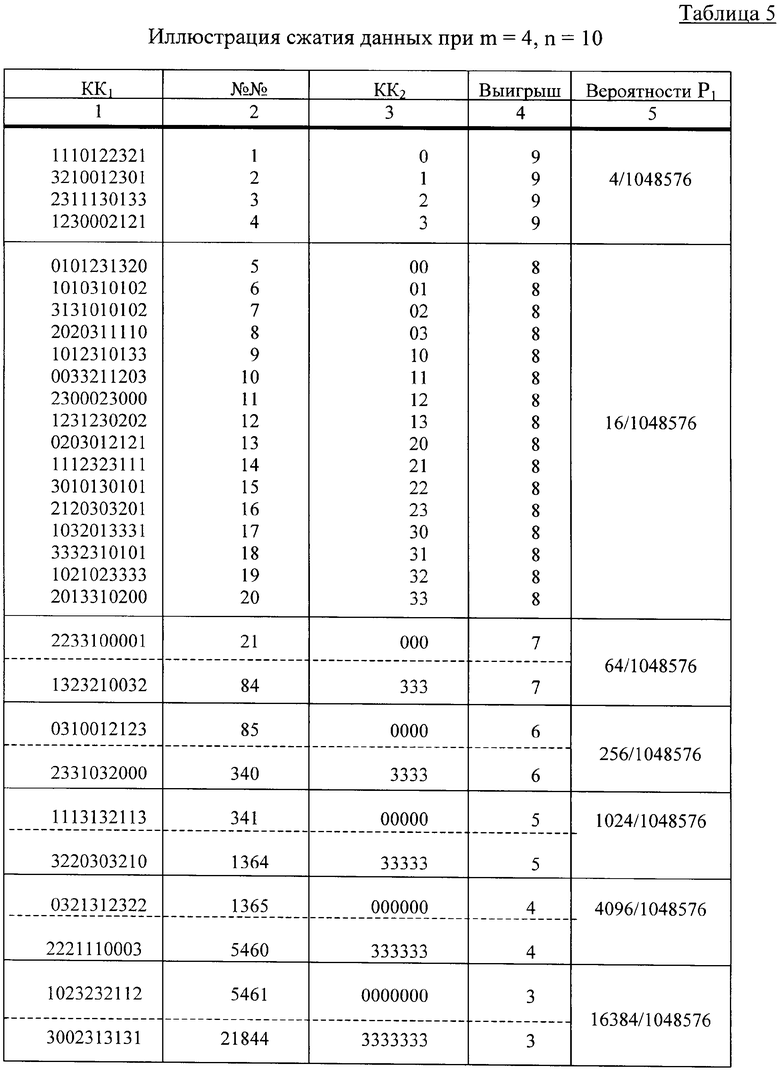
Пример 5. Выражения (1) и (1') допускают ситуации, когда m>2.
Примем, что m=4, а n=10. Из (1) следует, что в этом случае суммарное число кодовых комбинаций КК2 с меньшим чем 10 числом разрядов равно
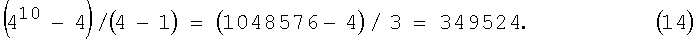
Из (1') находим суммарное число кодовых комбинаций КК2 с числом разрядов, равным 10 (без выигрыша):
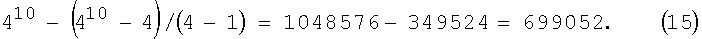
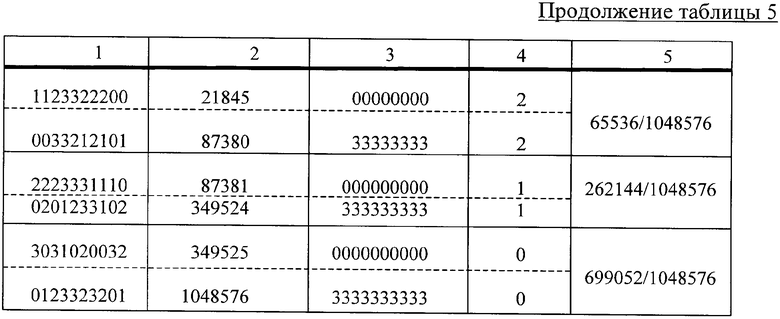
В таблице 5 приведены в произвольном порядке 10-разрядные 4-ичные числа - КК1 (колонка 1), порядковые номера, чтобы ориентироваться в этом множестве чисел (колонка 2), четверичные КК2 (колонка 3), выигрыш в числе четверичных разрядов при замене входных 10-разрядных КК на КК2 - эффект при СД (колонка 4) и суммарные вероятности P1 выбора одной из КК2 в соответствующей группе КК2 (колонка 5) при одинаковых (так принимаем) вероятностях Р появления разных КК на входе кодера.
Данные табл.5 подтверждают результаты, приведённые в (14) и (15). Если при m=2 (см. табл.1, 2 и 3) только две входные КК оказывались после кодера без выигрыша (без сжатия), то при m=4, n=10 (см. (15) и табл.5) число таких КК выросло до 699052, что составляет более 66% от всех КК (1048576). С учётом данных таблицы 5 по аналогии с (2) и (3) определим величину среднего выигрыша Vcp и отношение средней длины КК2 ncp к длине КК1 n:
Vcp=(1/1048576)·(9·4+8·16+7·64+6·256+5·1024+4·4096+3·16384+2·65536+1·262144+0·699052)=(1/1048576)·(36+128+448+1536+5120+16384+49152+131072+262144)=466020/1048576≈0,444 четверичного разряда,
ncp/n=(1/10)·(1/1048576)·(1·4+2·16+3·64+4·256+5·1024+6·4096+7·16384+8·65536+9·262144+10·699052)=(1/10485760)·(36+192+1024+5120+24576+114688+524288+2359296+6990520)=10019740/10485760≈0,955.
Если полученный средний выигрыш (Vcp>0!) перевести в двоичные разряды, он всё равно оказывается меньше, чем средний выигрыш при m=2 (см. примеры 1…3), но ncp/n<1 и при m>2.
Источники информации
1. Теория электрической связи: Учебник для вузов. / А.Г.Зюко, Д.Д.Кловский, В.И.Коржик, М.В.Назаров. / Под ред. Д.Д.Кловского. - М.: Радио и связь, 1998. - 432 с.: 204 ил.
2. Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. М.: Диалог - МИФИ, 2002.
3. Д.Сэломон. Сжатие данных, изображений и звука. Москва: Техносфера, 2004. - 368 с.
4. Патент на изобретение №2192708. Способ сжатия ширины спектра информационных электрических сигналов с ограниченной полосой частот. Автор: Дороднов Игорь Ливериевич. Москва, 10 ноября 2002 г.

| название | год | авторы | номер документа |
|---|---|---|---|
| Способ сжатия данных | 2016 |
|
RU2628199C1 |
| Компрессионный накопитель данных и устройство для его осуществления | 2019 |
|
RU2739705C1 |
| УСТРОЙСТВО ДЛЯ РАСПАКОВКИ ДАННЫХ | 2017 |
|
RU2658147C1 |
| СПОСОБ ПОВЫШЕНИЯ ПОМЕХОЗАЩИЩЕННОСТИ СИГНАЛОВ СИНХРОНИЗАЦИИ | 2019 |
|
RU2757975C2 |
| СПОСОБ СИНХРОНИЗАЦИИ ПЕРЕДАВАЕМЫХ СООБЩЕНИЙ | 2021 |
|
RU2792591C1 |
| СПОСОБ СИНХРОНИЗАЦИИ ПЕРЕДАВАЕМЫХ СООБЩЕНИЙ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2015 |
|
RU2591565C1 |
| УСТРОЙСТВО ДЛЯ СЖАТИЯ ДАННЫХ | 2016 |
|
RU2622878C1 |
| УСТРОЙСТВО ДЛЯ УПАКОВКИ ДАННЫХ | 2019 |
|
RU2701711C1 |
| УСТРОЙСТВО ДЛЯ КОМПРЕССИИ ДАННЫХ | 2017 |
|
RU2672625C1 |
| УСТРОЙСТВО ДЛЯ КОМПРЕССИИ ДАННЫХ | 2019 |
|
RU2710987C1 |
Изобретение относится к технике передачи и хранения информации и может быть использовано в банках данных и в системах электросвязи. Достигаемый технический результат - простота реализации, повышение скорости кодирования, уменьшение времени передачи данных по каналу связи, сжатие ширины спектра передаваемых сигналов, повышение помехоустойчивости передачи, обеспечение скрытности передаваемой или хранящейся информации. Способ сжатия данных осуществляется с помощью кодера. В первом блоке памяти кодера хранятся предварительно записанные кодовые комбинации (KK1) с числом разрядов n, где n=2, 3, 4…, представляющие собой полный набор возможных входных кодовых комбинаций (КК). Во втором блоке памяти кодера хранятся предварительно записанные кодовые комбинации КК2, однозначно соответствующие KK1, с числом разрядов, меньшим или таким же, как в КК1. Входной поток данных разделяют на КК с одинаковым числом разрядов n. KK последовательно вводят в кодер, идентифицируют путем сравнения с
КК1, отображают соответствующей выходной кодовой комбинацией КК2. КК2 представляют собой последовательность групп с одинаковым числом разрядов n в каждой. Совокупное число кодовых комбинации КК2-mn, где m=2, 3, 4…, n=1, 2, 3…. Число последовательных групп КК2 определяют как mn-1, mn-2… Разрядность КК2 в группе выравнивают за счет добавления незначащего нуля перед кодовой комбинацией. 1 з.п. ф-лы, 1 ил., 5 табл.
1. Способ сжатия данных, при котором кодовые комбинации КК1, предварительно записанные в первом блоке памяти кодера - статическом словаре, отображают кодовыми комбинациями КК2 - метками из второго блока памяти кодера, отличающийся тем, что входной поток или некоторый объем данных разделяют на равномерные кодовые комбинации КК с числом разрядов n=2, 3, 4…, которые последовательно вводят в кодер, кодовые комбинации КК1 в первом блоке памяти кодера представляют собой полный набор разных кодовых комбинаций КК; каждую из кодовых комбинаций КК идентифицируют с одной из кодовых комбинаций КК1, после чего последнюю отображают одной из хранящихся во втором блоке памяти кодера кодовых комбинаций КК2 с меньшим, чем в кодовых комбинациях КК1, или таким же числом разрядов; число кодовых комбинаций КК2 равно числу кодовых комбинаций КК1; кодовые комбинации КК2 не содержат индивидуальных данных об отображаемых ими кодовых комбинациях КК1; совокупность кодовых
комбинаций КК2 формируют как последовательность групп с полным набором из mn m-ичных кодовых комбинаций с одинаковым числом разрядов n в каждой группе, где основание кода m=2, 3, 4, …, а n=1, 2, 3, …; число разрядов в кодах группы выравнивают за счет добавления незначащих символов «0» перед кодовыми комбинациями с числом разрядов меньше n', n'=2, 3,…, за исключением группы с выбранным максимальным значением n, которая может быть неполной и в которой число разрядов может быть таким же, как в кодовых комбинациях КК1; в результате каждая кодовая комбинация
КК2 характеризуется двумя параметрами - числом разрядов и численным значением; при числе кодовых комбинаций КК1, равном mn, число кодовых комбинаций КК2 с таким же основанием m, но меньшим, чем n, числом разрядов определяют по формуле
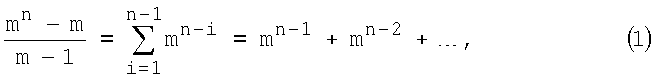
где основание кода m=2, 3, 4…, число разрядов n=2, 3, 4…, n>i; а число кодовых комбинаций КК2 с таким же, как у кодовых комбинаций КК1, числом разрядов n, определяют соответственно по формуле
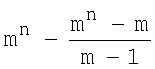 ,
,
где также основание кода m=2, 3, 4…, число разрядов n=2, 3, 4…, n>i; при этом каждое слагаемое в правой части (1) равно числу кодовых комбинаций в соответствующей группе и, кроме последнего слагаемого (m), может быть представлено в форме (1).
2. Способ по п.1, отличающийся тем, что если кодовыми комбинациями КК2 с учетом их длины заменить соответствующие кодовые комбинации в методе Хаффмана, то будет получен выигрыш в числе двоичных разрядов.
| JP 4145726, 19.05.1992 | |||
| СПОСОБ СЖАТИЯ ПОСЛЕДОВАТЕЛЬНОСТИ ИНФОРМАЦИОННЫХ СИГНАЛОВ | 1993 |
|
RU2080738C1 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ ТРЕХМЕРНЫХ ОБЪЕКТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2003 |
|
RU2267161C2 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| KR 100448289 B, 01.09.2004 | |||
| JP 3262331, 22.11.1991. | |||

