ОБЛАСТЬ ЗНАНИЙ
Изобретение относится к упорядоченным массивам информации, логически организованным в базы данных, хранимых на физических носителях, например магнитных дисках, и к способам управления базами данных, реализуемым в виде программных средств, обрабатывающих информацию с помощью компьютеров.
База данных (далее - БД) характеризуется своей логической моделью данных и состоит из отдельных записей - данных, содержащих отличительные характеристики. Группы данных объединены в подмножества.
В состав информации БД входят собственно данные и метаданные, идентифицирующие данные в соответствии с систематикой предметной области. Информацию в БД также делят на структурированную - с записями однотипных данных в едином формате, и неструктурированную - с записями данных несовпадающих типов в различных форматах.
Способ управления БД основан на выполнении операций идентификации, записи, чтения, изменения и удаления информации из БД, сжатия информации в БД, контроля внутренней непротиворечивости информации в БД при совместной работе двух и более пользователей, восстановления внутренней непротиворечивости информации после аварийного завершения работы БД.
Известно несколько логических моделей данных БД, отличающихся своей внутренней структурой и способами управления:
- иерархическая (Hierarchical DB), основная особенность этой модели состоит в иерархической группировке отдельных данных внутри БД, такой, что каждое данное нижележащего уровня связано только с одним данным вышележащего уровня иерархии. Такая модель накладывает существенные ограничения на скорость чтения или записи данных в случае использования логики доступа, отличной от заданной иерархической структурой. Пример иерархической модели - IMS (компания IBM);
- сетевая (Network DB), является развитием иерархической модели. Каждое данное в БД может быть связано с одним или несколькими данными более высокого уровня. В сетевой модели отсутствуют ограничения на скорость чтения или записи данных при изменении логики доступа, при этом операции изменения или удаления данных требуют длительного времени на реорганизацию многочисленных связей данных. Пример сетевой модели - Adabas (компания SAP);
- реляционная (Relation DB), состоящая из множества двухмерных массивов - реляционных таблиц, содержащих однородные характеристики данных, объединенные в подмножества и связанные между собой логическими отношениями. Разнесение характеристик по реляционным таблицам обеспечивает независимость внешнего представления данных от организации внутренней структуры БД. При этом существенно увеличивается время чтения, записи, изменения или удаления данных из-за необходимости проведения массовых операций разделения/восстановления данных на/из отдельных характеристик. Пример реляционной модели - Oracle (компания Oracle);
- многомерная (Multidimensional DB), логически представляемая в виде многомерного пространства, определенного осями координат - измерениями (типами данных), гиперкубами - областями многомерного пространства (подмножествами данных) и векторами - ячейками многомерного пространства (данными). Организация доступа к информации в виде прямой адресации к ячейкам многомерного пространства обеспечивает высокую скорость выполнения всех видов операций с данными. Однако с увеличением количества измерений и их координат объем БД возрастает многократно (экспоненциально), при этом большинство ячеек многомерного пространства остаются незаполненными значимыми данными, скорость доступа к БД резко снижается. Пример многомерной модели - Analysis Services (компания Microsoft).
УРОВЕНЬ ТЕХНИКИ И ПРОТОТИП
Предмет изобретения относится к многомерным БД и способам управления ими. В качестве прототипа выбрано изобретение, описаное в патенте США №5359724 от 25 октября 1994 г.
Отличие логической модели данных прототипа от других многомерных БД основано на использовании в модели прототипа двух структурных уровней, предназначенных для хранения соответственно данных и координат многомерного пространства.
На нижнем структурном уровне содержится полный набор всех возможных комбинаций координат, представляющих собой ячейки многомерного пространства. В ячейках располагают адресные указатели на блоки данных, расположенные на верхнем структурном уровне. Каждый блок данных определен для ограниченного набора координат с целью агрегирования в блоках преимущественно значимых данных.
Количество ячеек многомерного пространства значительно превышает количество блоков данных. Ячейки, в которых располагают адресные указатели, могут индексироваться и объединяться в структуру типа бинарного дерева.
Структурированную и неструктурированную информацию хранят в БД в отдельных файлах, связанных между собой логическими ссылками.
Способ управления БД включает в себя выполнение следующих операций.
Идентификация информации производится путем сопоставления фактических значений координат данных с их унифицированными (типизированными по формату записи) значениями, предварительно записанными в базу данных. Полученный набор эталонных значений координат определяет выбор ячеек расположения адресных указателей и блоки записи идентифицированных данных.
Запись, чтение, изменение, удаление и сжатие информации осуществляют путем обращения к ячейке многомерного пространства и последующего перехода к блоку данных по адресному указателю. В случае применения индексной структуры обращение к ячейке многомерного пространства осуществляют путем обхода бинарного дерева индекса.
Запись информации производят в существующий блок данных или, в случае его отсутствия, в новый блок после его формирования совместно с адресным указателем, индексом ячейки многомерного пространства и ветвью бинарного дерева.
Чтение информации производят после нахождения искомого блока и перебора значений данных в блоке.
Изменение или удаление информации выполняют с помощью соответствующей корректировки данных в блоке, реорганизации структуры блоков и балансировки ветвей бинарного дерева в случае индексации ячеек многомерного пространства.
Сжатие информации в БД производят путем удаления блоков данных, для которых отсутствуют адресные указатели в ячейках многомерного пространства.
Контроль внутренней непротиворечивости информации в БД при совместной работе двух и более пользователей осуществляют поочередной блокировкой их доступа к используемым данным.
Восстановление внутренней непротиворечивости информации после аварийного завершения работы БД производят методом опережающей записи данных в дополнительный файл - журнал транзакций. Журнал транзакций имеет ограниченный объем и требует постоянного обновления путем замещения старых данных новыми. При запуске БД производят сопоставление последних по времени данных, записанных в файлах БД и журнала транзакций. В случае отсутствия в файле БД данных, сохраненных в файле журнала транзакций, их переносят в первый файл. В противном случае последние по времени записи данные исключают из файла БД.
Прототип изобретения позволяет сократить объем БД за счет организации хранения на втором структурном уровне преимущественно значимых данных. Однако наличие на первом структурном уровне полного набора ячеек многомерного пространства приводит к увеличению объема БД и времени доступа к ней.
Техническим результатом настоящего изобретения является уменьшение объема БД и времени доступа к ней.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Технический результат достигают формированием базы данных (БД), логическая модель которой включает:
- измерения, каждое из которых определяет тип данных и представлено унифицированными значениями координат и кодами их идентификаторов;
- гиперкубы, каждый из которых определяет подмножество данных и представлен идентификаторами координат, связанными адресными указателями с идентификаторами векторов данных с совпадающими кодами, записанными в файл последними;
- векторы данных, каждый из которых представлен идентификаторами координат, связанными адресными указателями с идентификаторами векторов данных с совпадающими кодами, ранее записанными в файл, при этом идентификаторы координат векторов данных, записанные в файл первыми, связаны адресными указателями с идентификаторами координат гиперкуба с совпадающими кодами.
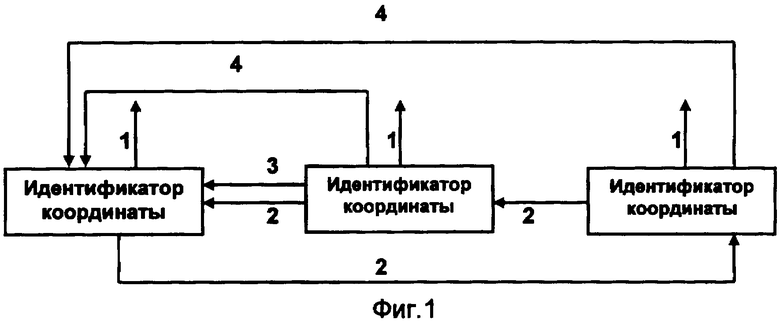
Идентификатор координаты состоит из следующего набора элементов:
- имя идентификатора, состоящее из величины его смещения относительно начала файла и порядкового номера записи в файл вектора данного;
- код идентификатора, состоящий из цифрового кода измерения и цифрового кода унифицированного значения координаты в этом измерении;
- комплект адресных указателей.
В комплект адресных указателей входят четыре типа указателей.
Адресный указатель первого типа состоит из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты с совпадающим кодом и порядкового номера данного идентификатора координаты в циклическом списке, образованном адресными указателями идентификаторов координат векторов данных и гиперкуба.
Адресный указатель второго типа состоит из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты и порядкового номера идентификатора координаты в циклическом списке, образованном адресными указателями идентификаторов координат, входящих в состав одного вектора данного, при этом первый по порядку записи идентификатор координаты связан с последним по порядку записи идентификатором координаты.
Адресный указатель третьего типа состоит из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты, находящегося на более высоком уровне иерархии, и порядкового номера уровня иерархии данного идентификатора координаты, при этом адресные указатели идентификаторов координат, входящие в состав одной и той же иерархической группы вектора данного, образуют конечный список.
Адресный указатель четвертого типа состоит из величины смещения относительно начала файла однотипного адресного указателя идентификатора координаты, входящего в одну вариантную группу, или, в случае завершения одной вариантной группы, входящей в состав другой вариантной группы, и порядкового номера вариантной группы, при этом адресные указатели идентификаторов координат, входящие в состав одного вектора данного, образуют конечный список.
Гиперкуб состоит из идентификаторов координат, каждый из которых представлен в виде вектора дескриптора. Адресный указатель первого типа вектора дескриптора содержит величину смещения относительно начала файла и порядковый номер адресного указателя первого типа идентификатора координаты вектора данного с совпадающим кодом идентификатора, записанного в файл последним.
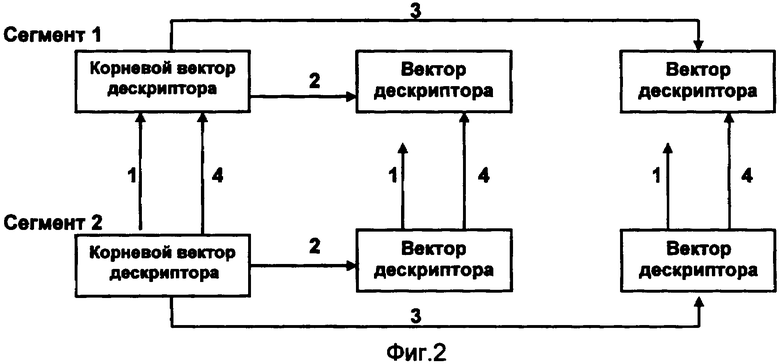
Для упорядоченности информации, например, в хронологическом порядке, векторы дескрипторов в составе гиперкуба могут быть логически объединены в два и более сегмента.
В состав каждого сегмента гиперкуба включают корневой вектор, состоящий из одного идентификатора координаты с системным кодом.
Корневой вектор и векторы дескрипторов, входящие в состав одного сегмента гиперкуба, связывают в индексную структуру типа бинарного дерева адресными указателями идентификаторов координат второго и третьего типов.
Корневые векторы и векторы дескрипторов с совпадающими кодами идентификаторов координат, входящие в разные сегменты одного гиперкуба, связывают в циклические списки адресными указателями идентификаторов координат четвертого типа.
Корневые векторы всех гиперкубов БД связаны в циклический список адресными указателями идентификаторов координат первого типа, порядковые номера которых принимают значение номеров гиперкубов в порядке записи их в файл.
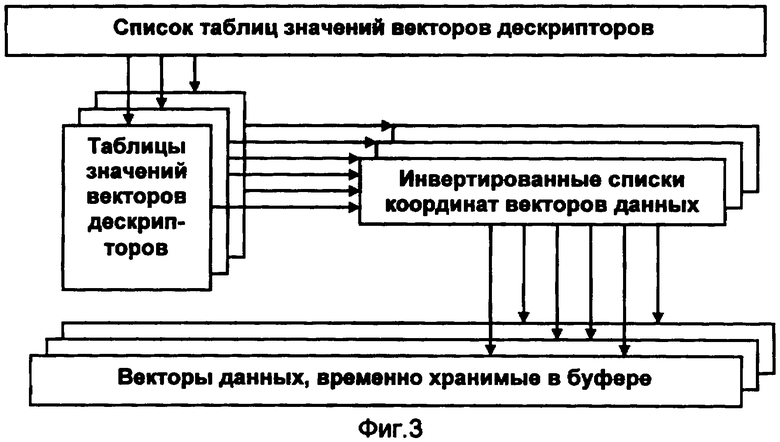
Для обеспечения доступа одновременно нескольких пользователей к файлу БД, записанному, например, на магнитном носителе, в оперативной памяти компьютера размещают постоянный информационный массив - буфер.
В состав буфера входят следующие элементы:
- таблицы значений векторов дескрипторов с наибольшими по величине порядковыми номерами адресных указателей координат четвертого типа;
- список таблиц значений векторов дескрипторов;
- инвертированные списки координат векторов данных;
- векторы данных, участвующих в операциях чтения и записи информации.
Список таблиц значений векторов дескрипторов содержит адреса расположения таблиц в буфере. Список таблиц формируют в порядке записи таблиц в файл.
Каждая таблица значений векторов дескрипторов соответствует одному из измерений логической модели данных БД.
Строки содержат наборы полей, каждый из которых соответствует одному из гиперкубов, образованному измерениями, соответствующими таблицам.
В состав одного набора входят по крайней мере следующие поля:
- поле величины смещения имени идентификатора вектора дескриптора относительно начала файла,
- поле порядкового номера адресного указателя четвертого типа идентификатора координаты вектора дескриптора,
- поле величины смещения относительно начала файла адресного указателя первого типа идентификатора координаты вектора данного с совпадающим кодом, записанного в файл последним, и
- поле порядкового номера адресного указателя первого типа идентификатора координаты этого вектора данного.
Кроме указанных наборов полей, строки таблиц дополнительно могут содержать поля унифицированных значений координат, поля индексов унифицированных значений координат и поля адресов инвертированных списков координат векторов данных в составе буфера.
Для хранения в общем файле структурированной (векторы данных, векторы дескрипторов, корневые векторы) и неструктурированной информации (значения координат, текстовые комментарии, графические изображения, аудио-, видео- и прочие записи) векторы данных при некоторых условиях могут содержать в себе фрагменты неструктурированной информации.
Технический результат в части способа ускорения доступа к данным и управления БД достигают следующими особенностями выполнения операций:
- идентификацию информации выполняют посредством цифрового кодирования унифицированных значений координат в составе измерений и замены фактических значений координат на цифровые коды в составе векторов данных;
- запись, чтение, изменение, удаление и сжатие информации обеспечивают посредством формирования логических сечений многомерного пространства, представленных циклическими списками идентификаторов координат векторов данных и гиперкубов с совпадающими кодами идентификаторов;
- контроль внутренней непротиворечивости информации при совместной работе двух и более пользователей обеспечивают посредством последовательной нумерации векторов данных в порядке записи их в файл;
- восстановление внутренней непротиворечивости информации после аварийного завершения работы многомерной базы данных обеспечивают посредством опережающей записи идентификаторов координат в состав векторов дескрипторов относительно момента их записи в состав векторов данных.
Идентификация информации в БД основана на сравнении фактических значений координат данного, поступившего из внешнего источника информации, с унифицированными значениями координат в составе измерений, ранее сохраненными в БД.
В случае несовпадения фактических и унифицированных значений координат, фактические значения включают в состав измерений в качестве новых унифицированных значений с присвоением им цифровых кодов идентификаторов.
Идентификацию данного завершают заменой значений координат на цифровые коды их идентификаторов.
Запись информации в БД осуществляют отдельными векторами данных после формирования связанного списка идентификаторов координат, включения фрагментов неструктурированной информации, записи в файл новых векторов дескрипторов или изменения значений векторов дескрипторов, ранее записанных в файл.
Чтение информации из БД осуществляется на основании ключа поиска, составленного пользователем из одного или нескольких идентификаторов координат с использованием пяти шаговой процедуры.
Изменение информации в БД осуществляют на логическом уровне путем записи нескольких версий вектора данного.
Удаление информации из БД осуществляют на логическом уровне путем записи нескольких версий вектора данного.
Последующее чтение удаленной информации осуществляют путем формирования консолидированной версии вектора данного, состоящей из идентификаторов координат с ненулевыми значениями кодов идентификаторов координат и заключенными между ними фрагментами неструктурированной информации.
Сжатие информации в БД осуществляют на физическом уровне путем сохранения в файле только консолидированных версий векторов данных. Для всего объема БД или для отдельных гиперкубов производят следующие действия.
Контроль внутренней непротиворечивости информации в БД при совместной работе двух и более пользователей с одними и тем же данными осуществляют путем выполнения операций изменения или удаления информации в последовательности выдачи пользователями команд на запись измененных (удаленных) версий векторов данных.
Восстановление внутренней непротиворечивости информации после аварийного завершения работы БД осуществляется путем сравнения между собой значений векторов дескрипторов и векторов данных, записанных в файл до момента аварийного завершения работы.
ОПИСАНИЕ ГРАФИЧЕСКОГО МАТЕРИАЛА
Фиг.1. Схема адресных связей вектора данного с одной иерархической и двумя вариантными группами идентификаторов координат в своем составе.
Фиг.2. Схема адресных связей векторов дескрипторов гиперкуба с двумя сегментами.
Фиг.3. Блок-схема буфера.
Фиг.4. Схема поиска информации в БД.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
ОПИСАНИЕ УСТРОЙСТВА
Техническим результатом настоящего изобретения является уменьшение объема БД и времени доступа к ней.
Технический результат в части устройства достигают формированием логической модели данных БД, включающей:
- измерения, каждое из которых определяет тип данных и представлено унифицированными значениями координат и кодами их идентификаторов;
- гиперкубы, каждый из которых определяет подмножество данных и представлен идентификаторами координат, связанными адресными указателями с идентификаторами векторов данных с совпадающими кодами, записанными в файл последними;
- векторы данных, каждый из которых представлен идентификаторами координат, связанными адресными указателями с идентификаторами векторов данных с совпадающими кодами, ранее записанными в файл, при этом идентификаторы координат векторов данных, записанные в файл первыми, связаны адресными указателями с идентификаторами координат гиперкуба с совпадающими кодами.
Структура БД представляет собой строчную развертку многомерного пространства, заполненного только значимыми данными. Их координаты могут входить в состав иерархических и вариантных групп в составе одного и того же вектора данного.
Идентификатор координаты состоит из следующего набора элементов:
- имя идентификатора, состоящее из величины его смещения относительно начала файла и порядкового номера записи в файл вектора данного;
- код идентификатора, состоящий из цифрового кода измерения и цифрового кода унифицированного значения координаты в этом измерении;
- комплект адресных указателей.
В комплект адресных указателей входят четыре типа указателей.
Адресный указатель первого типа состоит из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты с совпадающим кодом и порядкового номера данного идентификатора координаты в циклическом списке, образованном адресными указателями идентификаторов координат векторов данных и гиперкуба.
Адресный указатель второго типа состоит из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты и порядкового номера идентификатора координаты в циклическом списке, образованном адресными указателями идентификаторов координат, входящих в состав одного вектора данного, при этом первый по порядку записи идентификатор координаты связан с последним по порядку записи идентификатором координаты.
Адресный указатель третьего типа состоит из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты, находящегося на более высоком уровне иерархии, и порядкового номера уровня иерархии данного идентификатора координаты, при этом адресные указатели идентификаторов координат, входящие в состав одной и той же иерархической группы вектора данного, образуют конечный список.
Адресный указатель четвертого типа состоит из величины смещения относительно начала файла однотипного адресного указателя идентификатора координаты, входящего в одну вариантную группу, или, в случае завершения одной вариантной группы, входящей в состав другой вариантной группы, и порядкового номера вариантной группы, при этом адресные указатели идентификаторов координат, входящие в состав одного вектора данного, образуют конечный список.
Пример вектора данного, состоящего из трех идентификаторов координат, входящих в состав одной иерархической и двух вариантных групп изображен на фиг.1. Цифрами 1, 2, 3, 4 - обозначены адресные указатели соответствующих типов.
Гиперкуб состоит из идентификаторов координат, каждый из которых представлен в виде вектора дескриптора. Адресный указатель первого типа вектора дескриптора содержит величину смещения относительно начала файла и порядковый номер адресного указателя первого типа идентификатора координаты вектора данного с совпадающим кодом идентификатора, записанного в файл последним.
С целью упорядоченности информации, например, в хронологическом порядке, векторы дескрипторов в составе гиперкуба могут быть логически объединены в два и более сегмента.
В состав каждого сегмента гиперкуба включен корневой вектор, состоящий из одного идентификатора координаты с системным кодом.
Корневой вектор и векторы дескрипторов, входящие в состав одного сегмента гиперкуба, связаны в индексную структуру типа бинарного дерева адресными указателями идентификаторов координат второго и третьего типов.
Корневые векторы и векторы дескрипторов с совпадающими кодами идентификаторов координат, входящие в разные сегменты одного гиперкуба, связаны в циклические списки адресными указателями идентификаторов координат четвертого типа. При этом порядковым номерам адресных указателей идентификаторов координат присвоены значения номеров сегментов гиперкуба в порядке их записи в файл.
Корневые векторы всех гиперкубов БД связаны в циклический список адресными указателями идентификаторов координат первого типа, порядковым номерам которых присвоены значения номеров гиперкубов в порядке записи их в файл.
Схема адресных связей векторов дескрипторов гиперкуба с двумя сегментами изображена на фиг.2. Цифрами 1, 2, 3, 4 - обозначены адресные указатели соответствующих типов.
В целях обеспечения доступа пользователей к файлу БД, записанному, например, на магнитном диске, на дополнительной (или альтернативной) среде хранения, например, в оперативной памяти компьютера, размещен постоянный информационный массив (временный набор данных) - буфер.
В состав буфера входят следующие элементы:
- таблицы значений векторов дескрипторов с наибольшими по величине порядковыми номерами адресных указателей координат четвертого типа;
- список таблиц значений векторов дескрипторов;
- инвертированные списки координат векторов данных;
- векторы данных, участвующих в операциях чтения и записи информации.
Список таблиц значений векторов дескрипторов содержит адреса расположения таблиц в буфере. Список таблиц формируют в порядке записи таблиц в файл.
Каждая таблица значений векторов дескрипторов соответствует одному из измерений логической модели данных БД. Строки таблиц соответствуют координатам измерений и формируются в порядке записи унифицированных значений координат в файл.
Строки содержат наборы полей, каждый из которых соответствует одному из гиперкубов, образованному измерениями, соответствующими таблицам.
В состав одного набора входят:
- поле величины смещения имени идентификатора вектора дескриптора относительно начала файла,
- поле порядкового номера адресного указателя четвертого типа идентификатора координаты вектора дескриптора,
- поле величины смещения относительно начала файла адресного указателя первого типа идентификатора координаты вектора данного с совпадающим кодом, записанного в файл последним, и
- поле порядкового номера адресного указателя первого типа идентификатора координаты этого вектора данного.
Кроме указанных наборов полей, строки таблиц дополнительно могут содержать поля унифицированных значений координат, поля индексов унифицированных значений координат и поля адресов инвертированных списков координат векторов данных в составе буфера.
Инвертированные списки координат векторов данных содержат адреса векторов данных в составе буфера.
Каждому вектору данного в составе буфера присвоен порядковый номер, равный наибольшему порядковому номеру записи в файл одного из идентификаторов координат вектора данного. Порядковый номер вектора данного используют для обеспечения многопользовательского доступа к БД.
Блок-схема буфера представлена на фиг.3.
Для хранения в общем файле структурированной (векторы данных, векторы дескрипторов, корневые векторы) и неструктурированной информации (значения координат, текстовые комментарии, графические изображения, аудио-, видео- и прочие записи) векторы данных могут содержать в себе фрагменты неструктурированной информации при выполнении следующих условий:
- фрагмент неструктурированной информации в составе вектора данного начинается и заканчивается идентификаторами координат;
- идентификаторы координат отражают тип данных и формат записи фрагментов неструктурированной информации.
Технический результат в части устройства достигают также следующими особенностями выполнения операций:
- идентификация информации обеспечена посредством цифрового кодирования унифицированных значений координат в составе измерений и замены фактических значений координат на цифровые коды в составе векторов данных;
- запись, чтение, изменение, удаление и сжатие информации обеспечены посредством формирования логических сечений многомерного пространства, представленных циклическими списками идентификаторов координат векторов данных и гиперкубов с совпадающими кодами идентификаторов;
- контроль внутренней непротиворечивости информации при совместной работе двух и более пользователей обеспечен посредством последовательной нумерации векторов данных в порядке записи их в файл;
- восстановление внутренней непротиворечивости информации после аварийного завершения работы многомерной базы данных обеспечено посредством опережающей записи идентификаторов координат в состав векторов дескрипторов относительно момента их записи в состав векторов данных.
Идентификация информации в БД основана на сравнении фактических значений координат данного, поступившего из внешнего источника информации, с унифицированными значениями координат в составе измерений, ранее сохраненными в БД.
В случае несовпадения фактических и унифицированных значений координат, фактические значения помещены в состав измерений в качестве новых унифицированных значений с присвоением им цифровых кодов идентификаторов.
Запись информации в БД осуществлена порциями, равными отдельному вектору данных после формирования связанного списка идентификаторов координат, включения фрагментов неструктурированной информации, записи в файл новых векторов дескрипторов или изменения значений векторов дескрипторов, ранее записанных в файл.
Величину смещения в имени идентификатора координаты рассчитана как сумма величин ранее заполненного объема файла и смещения имени данного идентификатора координаты относительно начала вектора данного. Порядковый номер записи вектора данного в файл сгенерирован в виде уникального, возрастающего по значению целого числа.
Величина смещения адресного указателя первого типа идентификатора координаты вектора данного определен на основании текущего значения вектора дескриптора с совпадающим идентификатором. Первоначальные значения вектора дескриптора в момент записи первого идентификатора координаты вектора данного имеют ссылку на адрес расположения в файле вектора дескриптора в части величины смещения адресного указателя первого типа и единичное значение в части порядкового номера этого адресного указателя.
Величина смещения адресного указателя второго типа идентификатора координаты вектора данного задана как сумма величин ранее заполненного объема файла и смещения однотипного адресного указателя предыдущего идентификатора координаты относительно начала вектора данного. Для первого идентификатора в составе вектора данного вторым слагаемым является величина смещения адресного указателя последнего идентификатора относительно начала вектора данного. Порядковый номер адресного указателя задан позицией идентификатора координаты в составе вектора данного.
Величина смещения адресного указателя третьего типа идентификатора координаты вектора данного задана как сумма величин ранее заполненного объема файла и смещения относительно начала вектора однотипного адресного указателя предыдущего идентификатора координаты, находящегося на более высоком уровне иерархии. Для первого идентификатора координаты в составе вектора данного вторым слагаемым является величина смещения собственного адресного указателя. Порядковый номер адресного указателя задан уровнем иерархии идентификатора координаты.
Величина смещения адресного указателя четвертого типа идентификатора координаты вектора данного заданы как сумма величин ранее заполненного объема файла и смещения относительно начала вектора однотипного адресного указателя предыдущего идентификатора координаты, входящей в данную вариантную группу, или, в случае ее завершения, смещения относительно начала вектора однотипного адресного указателя предыдущей триады, входящей в состав другой вариантной группы. Для первого идентификатора координаты в составе вектора данного вторым слагаемым является величина смещения собственного адресного указателя. Порядковый номер адресного указателя задан с учетом принадлежности идентификатора координаты к данной вариантой группе.
В случае наличия в составе вектора данного одного или несколько фрагментов неструктурированной информации размер фрагмента учтен при расчете величин смещения следующих за ним идентификаторов координат.
В случае отсутствия в составе гиперкуба векторов дескрипторов с идентификаторами координат, совпадающем с идентификаторами координат вновь сформированного вектора данного, указанные векторы дескрипторов остаются записанными в файл.
Рассчитанные величины адресных указателей идентификаторов координат первого типа записаны в файл по месту расположения векторов дескрипторов. Вектор данного записан на новое место в конце файла (после завершения записи в векторы дескрипторов рассчитанных величин адресных указателей идентификаторов координат первого типа).
Для поиска и чтения информации из БД применен ключ поиска, составленный из одного или нескольких идентификаторов координат.
ОПИСАНИЕ СПОСОБА РАБОТЫ УСТРОЙСТВА
Технический результат в части способа ускорения доступа к данным достигают способом управления БД, который характеризуется выполнением следующих операций:
- предварительная идентификация информации посредством цифрового кодирования унифицированных значений координат в составе измерений и замены фактических значений координат на цифровые коды в составе векторов данных;
- запись, чтение, изменение, удаление и сжатие информации посредством формирования логических сечений многомерного пространства, представленных циклическими списками идентификаторов координат векторов данных и гиперкубов с совпадающими кодами идентификаторов;
- контроль внутренней непротиворечивости информации при совместной работе двух и более пользователей посредством последовательной нумерации векторов данных в порядке записи их в файл;
- восстановление внутренней непротиворечивости информации после аварийного завершения работы многомерной базы данных обеспечивают посредством опережающей записи идентификаторов координат в состав векторов дескрипторов относительно момента их записи в состав векторов данных.
Идентификацию информации в БД выполняют путем сравнения фактических значений координат данного, поступившего из внешнего источника информации, с унифицированными значениями координат в составе измерений, ранее сохраненными в БД.
В случае несовпадения фактических и унифицированных значений координат, фактические значения включают в состав измерений в качестве новых унифицированных значений с присвоением им цифровых кодов идентификаторов.
Идентификацию данного завершают заменой значений координат на цифровые коды их идентификаторов.
Запись информации в БД осуществляют порциями, равными отдельному вектору данных после формирования связанного списка идентификаторов координат, включения фрагментов неструктурированной информации, записи в файл новых векторов дескрипторов или изменения значений векторов дескрипторов, ранее записанных в файл.
Величину смещения в имени идентификатора координаты рассчитывают как сумму величин ранее заполненного объема файла и смещения имени данного идентификатора координаты относительно начала вектора данного. Порядковый номер записи вектора данного в файл генерируют в виде уникального, возрастающего по значению целого числа.
Величину смещения адресного указателя первого типа идентификатора координаты вектора данного определяют на основании текущего значения вектора дескриптора с совпадающим идентификатором. Первоначальные значения вектора дескриптора в момент записи первого идентификатора координаты вектора данного содержат ссылку на адрес расположения в файле вектора дескриптора в части величины смещения адресного указателя первого типа и единичное значение в части порядкового номера этого адресного указателя.
Величину смещения адресного указателя второго типа идентификатора координаты вектора данного определяют как сумму величин ранее заполненного объема файла и смещения однотипного адресного указателя предыдущего идентификатора координаты относительно начала вектора данного. Для первого идентификатора в составе вектора данного вторым слагаемым является величина смещения адресного указателя последнего идентификатора относительно начала вектора данного. Порядковый номер адресного указателя задают значением, соответствующим позиции идентификатора координаты в составе вектора данного.
Величину смещения адресного указателя третьего типа идентификатора координаты вектора данного определяют как сумму величин ранее заполненного объема файла и смещения относительно начала вектора однотипного адресного указателя предыдущего идентификатора координаты, находящегося на более высоком уровне иерархии. Для первого идентификатора координаты в составе вектора данного вторым слагаемым является смещения собственного адресного указателя. Порядковый номер адресного указателя задают значением уровня иерархии идентификатора координаты.
Величину смещения адресного указателя четвертого типа идентификатора координаты вектора данного определяют как сумму величин ранее заполненного объема файла и смещения относительно начала вектора однотипного адресного указателя предыдущего идентификатора координаты, входящей в данную вариантную группу, или, в случае ее завершения, смещения относительно начала вектора однотипного адресного указателя предыдущей триады, входящей в состав другой вариантной группы. Для первого идентификатора координаты в составе вектора данного вторым слагаемым является величина смещения собственного адресного указателя. Порядковый номер адресного указателя задают исходя из принадлежности идентификатора координаты к данной вариантой группе.
В случае включения в состав вектора данного одного или несколько фрагментов неструктурированной информации размер фрагмента учитывают при расчете величин смещения следующих за ним идентификаторов координат.
В случае отсутствия в составе гиперкуба векторов дескрипторов с идентификаторами координат, совпадающими с идентификаторами координат вновь сформированного вектора данного, указанные векторы дескрипторов записывают в файл.
Рассчитанные величины адресных указателей идентификаторов координат первого типа записывают в файл по месту расположения векторов дескрипторов. Вектор данного записывают на новое место в конце файла после завершения записи в векторы дескрипторов рассчитанных величин адресных указателей идентификаторов координат первого типа.
Чтение информации из БД осуществляют на основании ключа поиска, составленного пользователем из одного или нескольких идентификаторов координат.
На первом шаге в буфере, в списке адресов таблиц векторов дескрипторов производят поиск адресов таблиц, чьи позиции в списке соответствуют цифровым кодам измерений. После перехода к выбранным в результате поиска таблицам осуществляют поиск в их составе строк, позиции которых соответствуют цифровым кодам унифицированных значений координат.
В случае отсутствия значения хотя бы одного из искомых векторов дескрипторов чтение завершают формированием отрицательного отчета о поиске.
При наличии в буфере полного состава значений векторов дескрипторов производят сравнение порядковых номеров адресных указателей четвертого типа идентификаторов координат векторов дескрипторов. В случае их равенства порядковому номеру, соответствующему последнему сегменту гиперкуба, значения найденных векторов дескрипторов сравнивают между собой по величине порядковых номеров адресных указателей первого типа с последующим выбором вектора дескриптора с наименьшим номером. В противном случае осуществляют переход к сегменту гиперкуба, сохраненному в файле БД.
На втором шаге производят поиск векторов дескрипторов в сегменте гиперкуба путем обхода бинарного дерева индексной структуры. В случае равенства порядковых номеров адресных указателей четвертого типа векторы дескрипторов сравнивают между собой по величине порядковых номеров адресных указателей первого типа с последующим выбором вектора дескриптора с наименьшим номером. В противном случае осуществляют переход к следующему сегменту гиперкуба с повторением второго шага вплоть до совпадения порядковых номеров адресных указателей четвертого типа векторов дескрипторов.
На третьем шаге, на основании величины смещения адресного указателя первого типа вектора дескриптора осуществляют чтение идентификатора координаты вектора данного с наименьшим порядковым номером. В соответствии с адресными указателями второго типа осуществляют чтение остальных идентификаторов координат вектора данного и их сравнение с идентификаторами координат ключа поиска.
В случае их совпадения определяют один из совпадающих идентификаторов координат вектора данного с наибольшим порядковым номером адресного указателя второго типа. В противном случае переходят к выполнению пятого шага настоящей последовательности чтения информации.
На четвертом шаге производят обход иерархических и вариантных групп вектора данного, начиная с совпадающего идентификатора координаты с наибольшим порядковым номером адресного указателя второго типа. В случае вхождения идентификаторов координат ключа поиска в состав одних и тех же иерархических и вариантных групп вектора данного его включают в отчет о поиске.
На пятом шаге в составе прочитанного вектора данного производят сравнение между собой по величине порядковых номеров адресных указателей первого типа идентификаторов координат, соответствующих ключу поиска, выбор идентификатора координаты с наименьшим по величине порядковым номером, чтение идентификатора координаты предыдущего вектора данного по адресному указателю первого типа и чтение остальных идентификаторов координат предыдущего вектора данного по адресным указателям второго типа.
Четвертый и пятый шаги повторяют в порядке приближения к началу файла вплоть до чтения одного из идентификаторов координат вектора данного, соответствующих ключу поиска, с порядковым номером адресного указателя первого типа, равным единице.
Изменение информации в БД осуществляют на логическом уровне путем записи нескольких версий вектора данного в следующей последовательности.
На первом шаге производят чтение текущей версии вектора данного.
На втором шаге формируют измененную версию вектора данного в составе одного или нескольких идентификаторов координат и/или фрагментов неструктурированной информации, измененных относительно текущей версии, и одного неизменного идентификатора координаты.
На третьем шаге производят запись измененной версии вектора данного, с сохранением в именах идентификаторов координат величин смещения относительно начала файла, записанных в первой версии вектора данного.
Последующее чтение измененной информации осуществляют путем формирования консолидированной версии вектора данного, состоящей из одного идентификатора координаты с неизменным кодом идентификатора и одного или нескольких последних по порядку записи измененных идентификаторов координат и/или фрагментов неструктурированной информации.
Удаление информации из БД осуществляют на логическом уровне путем записи нескольких версий вектора данного в следующей последовательности:
на первом шаге производят чтение текущей версии вектора данного;
на втором шаге формируют удаленную версию вектора данного в составе одного или нескольких идентификаторов координат, удаленных из текущей версии вектора данного, и одного неизменного идентификатора координаты;
на третьем шаге производят запись удаленной версии вектора данного с заменой на нулевые значения кодов удаленных идентификаторов координат.
Последующее чтение удаленной информации осуществляют путем формирования консолидированной версии вектора данного, состоящей из идентификаторов координат с ненулевыми значениями кодов идентификаторов координат и заключенными между ними фрагментами неструктурированной информации.
Сжатие информации в БД осуществляют на физическом уровне путем сохранения в файле только консолидированных версий векторов данных. Для всего объема БД или для отдельных гиперкубов производят следующие действия.
На первом шаге создают второй экземпляр гиперкуба, связанный с первым экземпляром адресными указателями четвертого типа корневых векторов и векторов дескрипторов. Второй экземпляр гиперкуба используют для записи вновь поступающей информации из внешнего источника.
На втором шаге создают копию первого экземпляра гиперкуба, не связанную с первым экземпляром гиперкуба адресными указателями четвертого типа корневых векторов и векторов дескрипторов. Копия является приемником информации, ранее записанной в гиперкубе, первый экземпляр - источником информации.
На третьем шаге производят сжатие информации путем формирования консолидированных версий векторов данных, содержащихся в источнике информации, и их переноса в приемник информации.
На четвертом шаге источник информации замещают приемником информации путем связывания второго экземпляра и копии первого экземпляра гиперкуба адресными указателями четвертого типа корневых векторов и векторов дескрипторов. Первый экземпляр гиперкуба удаляют из файла.
Контроль внутренней непротиворечивости информации в БД при совместной работе двух и более пользователей с одними и тем же данными осуществляется путем выполнения операций изменения или удаления информации в последовательности выдачи пользователями команд на запись измененных (удаленных) версий векторов данных.
Для обеспечения указанной последовательности в буфере формируют информационный массив из консолидированных версий векторов данных, участвующих в операциях чтения или записи информации. Консолидированной версии вектора данного в буфере присваивают порядковый номер записи, равный наибольшему порядковому номеру записи в файл одного из идентификаторов координат вектора данного.
На первом шаге каждый пользователь независимо от других осуществляет чтение информации, которое начинается с поиска в буфере консолидированной версии вектора данного, соответствующей ключу поиска. В случае отсутствия в буфере этой версии вектора данного чтение осуществляется из файла.
На втором шаге пользователи производят независимое формирование измененных (удаленных) версий вектора данного, которым временно присваивается порядковый номер записи ранее прочитанной консолидированной версии вектора данного.
На третьем шаге, по команде на запись пользователя, первым завершившего формирование измененной (удаленной) версии вектора данного, осуществляется повторное чтение в буфере или файле консолидированной версии вектора данного. Выполнение команд на запись остальных пользователей блокируется.
На четвертом шаге выполняют сравнение между собой порядковых номеров записи измененной (удаленной) версии и повторно прочитанной консолидированной версии вектора данного. В случае совпадения порядковых номеров записи в буфере формируют новую консолидированную версию вектора данного с актуальным порядковым номером записи, учитывающую изменение или удаление информации первым пользователем. В файл записывают измененную (удаленную) версию вектора данного с тем же актуальным порядковым номером записи.
В случае несовпадения порядковых номеров записи измененной (удаленной) версии и повторно прочитанной консолидированной версии вектора данного вновь выполняют формирование измененной (удаленной) и консолидированной версий с актуальным порядковым номером записи. Новой консолидированной версией замещают в буфере предыдущую консолидированную версию. Новую измененную (удаленную) версию записывают в файл. Выполнение команд на запись разблокируют с повторением третьего и четвертого шага для каждого следующего пользователя.
На пятом шаге выполняют удаление из буфера последней консолидированной версии вектора данного в случае отсутствия команд на чтение или запись в течение заданного промежутка времени.
Восстановление внутренней непротиворечивости информации после аварийного завершения работы БД осуществляют путем сравнения между собой значений векторов дескрипторов и векторов данных, записанных в файл до момента аварийного завершения работы.
На первом шаге, на основании сравнения значений векторов дескрипторов гиперкуба, осуществляют переход к идентификатору координаты последнего вектора данного, наиболее смещенного относительно начала файла, при этом по адресным указателям второго типа производят переход к другим идентификаторам координат последнего вектора данного.
В случае наличия в составе последнего вектора данного полного набора идентификаторов координат восстановление внутренней непротиворечивости информации после аварийного завершения работы заканчивают.
В противном случае осуществляют следующие действия.
На втором шаге значения векторов дескрипторов, коды идентификаторов которых соответствуют идентификаторам координат предыдущих векторов данных, заменяют на величины смещения относительно начала файла и порядковые номера адресных указателей первого типа идентификаторов координат вектора данного.
На третьем шаге осуществляют переход к последнему идентификатору координаты предпоследнего вектора данного, смещенного относительно первого идентификатора координаты последнего вектора данного на величину, заданную форматом идентификатора координаты. После этого по адресным указателям второго типа осуществляют переход к остальным идентификаторам координат, входящим в состав предпоследнего вектора данного.
На четвертом шаге коды идентификаторов координат предпоследнего вектора данного сравнивают с кодами идентификаторов координат векторов дескрипторов, соответствующих кодам идентификаторов координат, отсутствующим в составе последнего вектора данного.
При совпадении кодов значения векторов дескрипторов заменяют на величины смещения и порядковые номера адресных указателей первого типа идентификаторов координат предпоследнего вектора данного.
При несовпадении кодов осуществляют переход к следующим в порядке приближения к началу файла векторам данных вплоть до нахождения идентификаторов координат, коды которых совпадают с кодами идентификаторов координат, отсутствующих в составе последнего вектора данного, с последующей заменой значений векторов дескрипторов.
На пятом шаге последний вектор данного с неполным составом идентификаторов координат удаляют из файла. Восстановление внутренней непротиворечивости информации после аварийного завершения работы БД на этом заканчивают.
ПРИМЕР РЕАЛИЗАЦИИ
В качестве примера реализации настоящего изобретения рассматривают БД абонентов телефонных номеров.
Схема данных БД включает следующие измерения (в скобках указаны их цифровые коды):
- уникальные идентификационные номера (УИН) абонентов (1);
- фамилии абонентов (2);
- имена абонентов (3);
- наименования регионов (4);
- наименования городов (5);
- наименования улиц (6);
- номера домов (7);
- УИН телефонов (8);
- телефонные коды регионов (9);
- телефонные коды городов (10);
- абонентские номера телефонов (11);
- УИН телефонных кодов (12).
Многомерное пространство БД включает в себя гиперкуб абонентов, гиперкуб телефонов и гиперкуб телефонных кодов. Неизменной координатой первого гиперкуба является УИН абонента, второго гиперкуба - УИН телефона, третьего гиперкуба - УИН телефонного кода.
Данные гиперкуба абонентов состоят из следующих координат, объединенных в иерархии:
1 уровень иерархии - УИН абонента
2 уровень иерархии - фамилия абонента
3 уровень иерархии - имя абонента
2 уровень иерархии - регион
3 уровень иерархии - город
4 уровень иерархии - улица
5 уровень иерархии - номер дома
2 уровень иерархии - УИН телефона.
Данных гиперкуба телефонов состоят из следующих координат, объединенных в иерархию:
1 уровень иерархии - УИН телефона
2 уровень иерархии - телефонный код региона
3 уровень иерархии - телефонный код города
4 уровень иерархии - абонентский номер телефона.
Данных гиперкуба телефонных кодов состоят из следующих координат, объединенных в иерархии:
1 уровень иерархии - УИН телефонного кода
2 уровень иерархии - телефонный код региона
3 уровень иерархии - регион
3 уровень иерархии - телефонный код города
4 уровень иерархии - город.
Координаты вектора данного могут входить в несколько вариантных групп. Например, абонент может иметь разные адреса и более чем один телефонный номер.
Физическая запись информации в файле БД состоит из отдельных чисел, логически разделенных на векторы, идентификаторы координат и составляющие их элементы с помощью заданного формата записи.
В условной записи структуры консолидированных версий векторов данных строки соответствуют идентификаторам координат векторов. Первый знак «.» разделяет порядковые номера иерархической и вариантной групп компонент в составе вектора, второй знак «.» - цифровые коды измерения и унифицированного значения координаты, третий знак «.» - символьные наименования измерения и значения координаты, условно приведенные в примере. Знак «/» разделяет порядковые номера, цифровые коды и символьные наименования.
Условная запись векторов дескрипторов и неконсолидированных версий векторов данных в структуре БД состоит из отдельных абзацев - векторов, строк - идентификаторов координат и чисел - составляющих элементов, разделенных знаком «/». Каждый гиперкуб в примере состоит из одного сегмента.
СТРУКТУРА КОНСОЛИДИРОВАННЫХ ВЕРСИЙ ВЕКТОРОВ ДАННЫХ.
Гиперкуб абонентов
Консолидированная версия вектора
1.1 / 1.1 / УИН абонента. 1
2.1 / 2.1 / Фамилия. Смирнов
3.1 / 3.1 / Имя. Иван
2.1 / 4.1 / Регион. Татарстан
3.1 / 5.1 / Город. Казань
4.1 / 6.1 / Улица. Цветочная
5.1 / 7.1 / Номер дома. 128
2.1 / 8.1 / УИН телефона. 1
2.2 / 4.2 / Регион. Карелия
3.2 / 5.2 / Город. Петрозаводск
4.2 / 6.2 / Улица. Озерная
5.2 / 7.2 / Номер дома. 67
2.2 / 8.2 / УИН телефона. 2
Гиперкуб телефонов
Консолидированная версия первого вектора
1.1 / 8.1 / УИН телефона. 1 >
2.1 / 9.1 / Телефонный код региона. 560
3.1 / 10.1 / Телефонный код города. 39
4.1 / 11.1 / Абонентский номер телефона. 20847
Консолидированная версия второго вектора
1.1 / 8.2 / УИН телефона. 2
2.1 / 9.2 / Телефонный код региона. 315
3.1 / 10.2 / Телефонный код города. 76
4.1 / 11.2 / Абонентский номер телефона. 18428
Гиперкуб телефонных кодов
Консолидированная версия первого вектора
1.1 / 12.1 / УИН телефонного кода. 1
2.1 / 9.1 / Телефонный код региона. 560
3.1 / 4.1 / Регион. Татарстан
3.1 /10.1 / Телефонный код города. 39
4.1 / 5.1 / Город. Казань.
Консолидированная версия второго вектора
1.1 / 12.2 / УИН телефонного кода. 2
2.1 / 9.2 / Телефонный код региона. 315
3.1 / 4.2 / Регион. Карелия
3.1 / 10.2 / Телефонный код города. 76
4.1 / 5.2 / Город. Петрозаводск.
Структура корневого вектора сегмента гиперкуба (на примере корневого вектора гиперкуба абонентов).
Имя идентификатора
000 - величина смещения относительно начала файла идентификатора координаты корневого вектора дескриптора (в относительных или абсолютных выбранных условных единицах).
01 - порядковый номер записи корневого вектора дескриптора в файл.
Адресный указатель первого типа.
283 - величина смещения относительно начала файла адресного указателя первого типа идентификатора координаты последнего по порядку записи корневого вектора дескриптора в составе БД.
01 - порядковый номер гиперкуба в составе БД.
Адресный указатель второго типа
032 - величина смещения относительно начала файла адресного указателя второго типа пятого вектора дескриптора, расположенного на первом уровне узлов бинарного дерева
04 - уровень узлов бинарного дерева, на котором расположен корневой вектор дескриптора.
Адресный указатель третьего типа.
033 - величина смещения относительно начала файла адресного указателя третьего типа пятого вектора дескриптора, расположенного на первом уровне узлов бинарного дерева.
04 - уровень узлов бинарного дерева, на котором расположен корневой вектор дескриптора.
Адресный указатель четвертого типа.
004 - величина смещения относительно начала файла адресного указателя четвертого типа идентификатора координаты корневого вектора дескриптора.
01 - порядковый номер сегмента.
Идентификатор.
000 - системный цифровой код сегмента гиперкуба.
01 - системный цифровой код корневого вектора дескриптора.
Структура вектора дескриптора гиперкуба (на примере первого вектора дескриптора гиперкуба абонентов).
Имя идентификатора.
006 - величина смещения относительно начала файла идентификатора координаты первого вектора дескриптора (в условных единицах).
02 - порядковый номер записи вектора дескриптора в файл.
Адресный указатель первого типа.
271 - величина смещения относительно начала файла адресного указателя первого типа идентификатора координаты последнего вектора данного с цифровым кодом идентификатора 001.01
04 - количество векторов данных с цифровым кодом идентификатора 001.01
Адресный указатель второго типа.
032 - величина смещения относительно начала файла адресного указателя второго типа пятого вектора дескриптора, расположенного на первом уровне узлов бинарного дерева
04 - уровень узлов бинарного дерева, на котором расположен первый вектор дескриптора.
Адресный указатель третьего типа.
033 - величина смещения относительно начала файла адресного указателя третьего типа пятого вектора дескриптора, расположенного на первом уровне узлов бинарного дерева.
04 - уровень узлов бинарного дерева, на котором расположен корневой вектор дескриптора.
Адресный указатель четвертого типа.
010 - величина смещения относительно начала файла вектора дескриптора гиперкуба с совпадающим идентификатором.
01 - порядковый номер сегмента гиперкуба. Идентификатор
001 - цифровой код измерения «УИН абонента».
01 - цифровой код унифицированного значения координаты.
Структура вектора данного (на примере первого идентификатора координаты первой версии первого вектора данного гиперкуба абонентов).
Имя идентификатора
048 - величина смещения относительно начала файла первого идентификатора координаты вектора данного (в условных единицах).
09 - порядковый номер записи вектора данного в файл.
Адресный указатель первого типа.
007 - величина смещения относительно начала файла адресного указателя первого типа идентификатора координаты вектора дескриптора гиперкуба абонентов.
01 - порядковый номер первого идентификатора первого вектора данного в циклическом списке идентификаторов координат с цифровым кодом 001.01
Адресный указатель второго типа.
086 - величина смещения относительно начала файла адресного указателя второго типа последнего идентификатора координаты вектора данного.
01 - порядковый номер первого идентификатора координаты в составе вектора данного.
Адресный указатель третьего типа.
051 - величина смещения относительно начала файла адресного указателя третьего типа последнего идентификатора координаты вектора данного.
01 - порядковый номер уровня иерархии координаты.
Адресный указатель четвертого типа
052 - величина смещения относительно начала файла адресного указателя четвертого типа первого идентификатора координаты вектора данного.
01 - порядковый номер вариантной группы координаты.
Идентификатор
001 - цифровой код измерения «УИН абонента».
01 - цифровой код унифицированного значения координаты «Смирнов».
Схема поиска информации представлена на фиг.4.
Поиск информации в БД осуществляют в соответствии с ключом поиска, сформированным из следующих унифицированных значений координат измерений:
измерение «УИН телефона» - значение неизвестной в начале поиска координаты «**»;
измерение «Фамилия» - значение искомой координаты «Смирнов»;
измерение «Город» - значение искомой координаты «Петрозаводск». В рассматриваемом примере буфер БД условно не используют. Поэтому процедуру поиска начинают с обращения непосредственно к векторам дескрипторов, записанным в файле БД, с целью сравнения между собой значений порядковых номеров записи координат «Смирнов» и «Петрозаводск».
В соответствии с идентификатором координаты «Смирнов» определяют вектор дескриптора гиперкуба абонентов и указанную в векторе дескриптора величину смещения адресного указателя первого типа идентификатора координаты первой версии вектора данного. Производят переход к этому идентификатору координаты, по адресным указателям второго типа осуществляют чтение всех идентификаторов координат, входящих в первую версию вектора данного. На основе сравнения порядковых номеров уровней иерархии определяют идентификатор координаты с порядковым номером уровня иерархии, равным 1 (неизменная координата из состава измерения «УИН абонента»). По адресному указателю первого типа этого идентификатора координаты первой версии вектора данного осуществляют переход к вектору дескриптора с совпадающим идентификатором.
По адресным указателям первого типа вектора дескриптора и промежуточных версий вектора данного осуществляют последовательный переход ко всем остальным версиям вектора данного гиперкуба абонентов. По адресным указателям второго типа осуществляют чтение всех идентификаторов координат версий вектора данного и сравнивают их с идентификатором ключа поиска по значению координаты «Петрозаводск», которая находится во второй измененной версии вектора данного.
В составе третьей измененной версии вектора данного находят идентификатор значения координаты измерения «УИН телефона» и по нему осуществляют переход к пятому вектору дескриптора гиперкуба телефонов. По адресному указателю первого типа вектора дескриптора осуществляют переход к первой версии второго вектора данного гиперкуба телефонов. В связи с тем, что адресный указатель первого типа идентификатора координаты указанной версии вектора данного имеет ссылку на вектор дескриптора, поиск версий векторов данных в гиперкубе телефонов завершают.
По адресным указателям второго типа осуществляют чтение идентификаторов координат первой версии второго вектора данного гиперкуба телефонов. Идентификаторы координат заменяют на унифицированные значения координат из состава измерения. Полный телефонный номер абонента помещают в отчет о поиске.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ.
Заявленные технические решения промышленно применимы, поскольку используют известные промышленно выпускаемые аппаратные средства, известные промышленно выпускаемые программные инструменты. Заявленные технические решения могут быть повторены в промышленности, используя приведенное описание и формулу.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОМЕРНАЯ БАЗА ДАННЫХ И СПОСОБ ДОСТУПА К МНОГОМЕРНОЙ БАЗЕ ДАННЫХ | 2006 |
|
RU2325690C1 |
| СПОСОБ ПРОВЕДЕНИЯ МИГРАЦИИ И РЕПЛИКАЦИИ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2020 |
|
RU2745679C1 |
| СПОСОБ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2019 |
|
RU2709288C1 |
| Система распределенной базы данных и способ ее реализации | 2022 |
|
RU2784208C1 |
| СПОСОБ ОРГАНИЗАЦИИ ХРАНЕНИЯ СВЯЗАННЫХ ДАННЫХ | 2016 |
|
RU2621628C1 |
| СПОСОБ ВОССТАНОВЛЕНИЯ ДАННЫХ В СИСТЕМЕ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ | 2013 |
|
RU2526753C1 |
| СПОСОБ ПЕРЕКЛЮЧЕНИЯ КОНТЕКСТА ЗАДАЧ И ПРОЦЕДУР В ПРОЦЕССОРЕ | 2006 |
|
RU2320002C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ТРАНЗАКЦИОННЫХ ФАЙЛОВЫХ ОПЕРАЦИЙ ПО СЕТИ | 2004 |
|
RU2380749C2 |
| СИСТЕМА ВЗАИМОДЕЙСТВИЯ БАЗ ДАННЫХ АВТОМАТИЗИРОВАННОЙ СИСТЕМЫ УПРАВЛЕНИЯ | 2006 |
|
RU2324974C1 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ РЕАЛИЗАЦИИ БАЗЫ ДАННЫХ, ПОДДЕРЖИВАЮЩЕЙ БЫСТРОЕ КОПИРОВАНИЕ | 2018 |
|
RU2740865C1 |
Изобретение относится к упорядоченным массивам информации, логически организованным в базы данных, хранимых на физических носителях, например магнитных дисках, и к способам управления базами данных, реализуемым в виде программных средств, обрабатывающих информацию с помощью компьютеров. Технический результат состоит в уменьшении объема базы данных и времени доступа к ней. Способ управления БД включает в себя выполнение следующих операций. Идентификация информации производится путем сопоставления фактических значений координат данных с их унифицированными (типизированными по формату записи) значениями, предварительно записанными в базу данных. Полученный набор эталонных значений координат определяет выбор ячеек расположения адресных указателей и блоки записи идентифицированных данных. Запись, чтение, изменение, удаление и сжатие информации осуществляют путем обращения к ячейке многомерного пространства и последующего перехода к блоку данных по адресному указателю. В случае применения индексной структуры обращение к ячейке многомерного пространства осуществляют путем обхода бинарного дерева индекса. 2 н. и 14 з.п. ф-лы, 4 ил.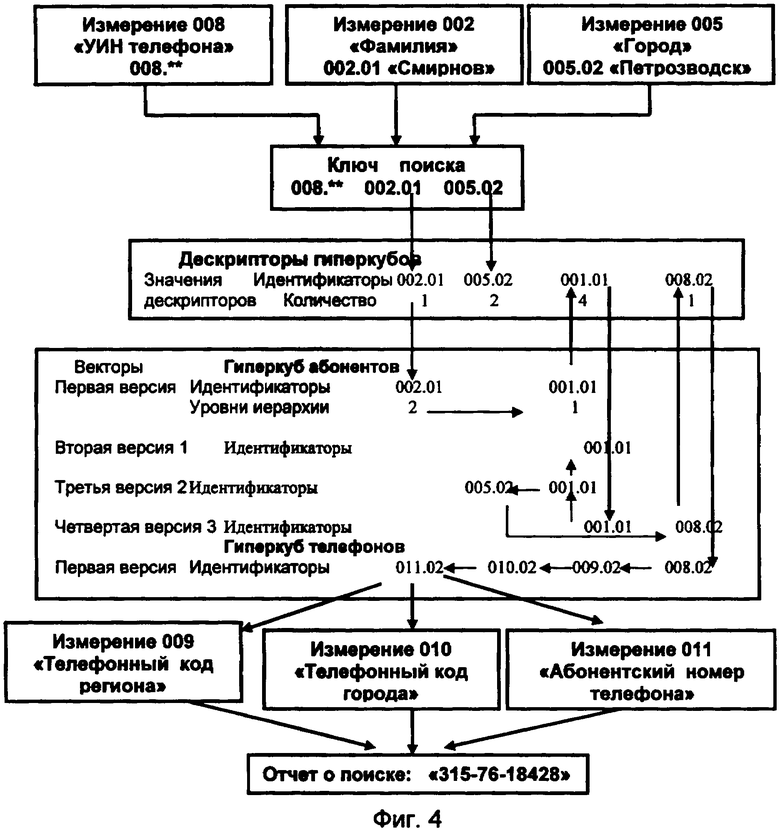
1. Многомерная база данных, логическая модель которой состоит из измерений, каждое из которых соответствует одному из типов данных, гиперкубов, каждый из которых соответствует одному из подмножества данных, и векторов, каждый из которых соответствует одному из данных, отличающаяся тем, что
измерение состоит из унифицированных значений координат и кодов их идентификаторов, гиперкуб состоит из идентификаторов координат, связанных адресными указателями с идентификаторами координат векторов данных с совпадающими кодами, записанных в файл последними;
вектор данного состоит из идентификаторов координат, связанных адресными указателями с идентификаторами координат векторов данных с совпадающими кодами, ранее записанными в файл, при этом идентификаторы координат векторов данных, записанные в файл первыми, связаны адресными указателями с идентификаторами координат гиперкуба с совпадающими кодами,
каждый из идентификаторов координат представлен набором, включающим
имя идентификатора, состоящее из величины его смещения относительно начала файла и порядкового номера записи в файл вектора данного;
код идентификатора, состоящий из цифрового кода измерения и цифрового кода унифицированного значения координаты в этом измерении;
комплект адресных указателей, причем в комплект адресных указателей входят
адресный указатель первого типа, состоящий из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты с совпадающим кодом и порядкового номера данного идентификатора координаты в циклическом списке, образованном адресными указателями идентификаторов координат векторов данных и гиперкуба;
адресный указатель второго типа, состоящий из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты и порядкового номера идентификатора координаты в циклическом списке, образованном адресными указателями идентификаторов координат, входящих в состав одного вектора данного, при этом первый по порядку записи идентификатор координаты связан с последним по порядку записи идентификатором координаты;
адресный указатель третьего типа, состоящий из величины смещения относительно начала файла однотипного адресного указателя предыдущего идентификатора координаты, находящегося на более высоком уровне иерархии, и порядкового номера уровня иерархии данного идентификатора координаты, при этом адресные указатели идентификаторов координат, входящие в состав одной и той же иерархической группы вектора данного, образуют конечный список;
адресный указатель четвертого типа, состоящий из величины смещения относительно начала файла однотипного адресного указателя идентификатора координаты, входящего в одну вариантную группу, или, в случае завершения одной вариантной группы, входящей в состав другой вариантной группы, и порядкового номера вариантной группы, при этом адресные указатели идентификаторов координат, входящие в состав одного вектора данного, образуют конечный список.
2. Многомерная база данных по п.1, отличающаяся тем, что каждый идентификатор координаты гиперкуба представлен в виде вектора дескриптора, при этом адресный указатель первого типа идентификатора координаты вектора дескриптора содержит величину смещения относительно начала файла и порядковый номер адресного указателя первого типа идентификатора координаты вектора данного с совпадающим кодом идентификатора, записанного в файл последним.
3. Многомерная база данных по п.2, отличающаяся тем, что;
векторы дескрипторов в составе гиперкуба логически объединены в два и более сегментов;
в состав каждого сегмента гиперкуба включается корневой вектор, состоящий из одного идентификатора координаты с системным кодом;
корневые векторы гиперкубов связаны в циклический список адресными указателями идентификаторов координат первого типа, порядковые номера которых принимают значения номеров гиперкубов в порядке их записи в файл;
корневой вектор и векторы дескрипторов, входящие в состав одного сегмента гиперкуба, связаны в индексную структуру типа бинарного дерева адресными указателями идентификаторов координат второго и третьего типов;
корневые векторы и векторы дескрипторов с совпадающими кодами идентификаторов координат, входящие в разные сегменты одного гиперкуба, связаны в циклические списки адресными указателями идентификаторов координат четвертого типа, при этом порядковые номера адресных указателей идентификаторов координат принимают значения номеров сегментов гиперкуба в порядке их записи в файл.
4. Многомерная база данных по п.3, отличающаяся тем, что в ее состав включен буфер, например, расположенный в оперативной памяти компьютера, состоящий из таблиц значений векторов дескрипторов с наибольшими по величине порядковыми номерами адресных указателей координат четвертого типа и списка таблиц значений векторов дескрипторов в составе буфера, при этом
список таблиц значений векторов дескрипторов содержит адреса таблиц в составе буфера и формируется в порядке записи таблиц в файл;
каждая таблица значений векторов дескрипторов соответствует одному из измерений;
строки таблиц значений векторов дескрипторов соответствуют координатам измерений, формируются в порядке записи унифицированных значений координат в файл и содержат наборы полей, каждый из которых соответствует одному из гиперкубов, образованному измерениями, соответствующими таблицам;
в состав одного набора полей строк таблиц значений векторов дескрипторов входят поле величины смещения имени идентификатора вектора дескриптора относительно начала файла, поле порядкового номера адресного указателя четвертого типа идентификатора координаты вектора дескриптора, поле величины смещения относительно начала файла адресного указателя первого типа идентификатора координаты вектора данного с совпадающим кодом, записанного в файл последним, и поле порядкового номера адресного указателя первого типа идентификатора координаты этого вектора данного.
5. Многомерная база данных по п.4, отличающаяся тем, что в буфере содержатся векторы данных, участвующих в операциях чтения и записи информации, и инвертированные списки координат этих векторов данных, при этом
инвертированные списки координат векторов данных содержат адреса векторов данных в составе буфера;
каждый вектор данного имеет порядковый номер, равный наибольшему порядковому номеру записи в файл одного из идентификаторов координат вектора данного.
6. Многомерная база данных по п.5, отличающаяся тем, что строки таблиц значений векторов дескрипторов дополнительно содержат поля унифицированных значений координат, поля индексов унифицированных значений координат и поля адресов инвертированных списков координат векторов данных в составе буфера.
7. Многомерная база данных по п.1, отличающаяся тем, что вектор данного может содержать в себе один или несколько фрагментов неструктурированной информации, каждый из которых ограничен с двух сторон идентификаторами координат, определяющими тип данных и формат записи фрагмента неструктурированной информации.
8. Способ управления многомерной базой данных по п.1, характеризующийся наличием операций идентификации, записи, чтения, изменения, удаления и сжатия информации, контроля внутренней непротиворечивости информации при совместной работе двух и более пользователей, восстановления внутренней непротиворечивости информации после аварийного завершения работы,
отличающийся тем, что
идентификацию информации обеспечивают посредством цифрового кодирования унифицированных значений координат в составе измерений и замены фактических значений координат на цифровые коды в составе векторов данных;
запись, чтение, изменение, удаление и сжатие информации обеспечивают посредством формирования логических сечений многомерного пространства, представленных циклическими списками идентификаторов координат векторов данных и гиперкубов с совпадающими кодами идентификаторов;
контроль внутренней непротиворечивости информации при совместной работе двух и более пользователей обеспечивают посредством последовательной нумерации векторов данных в порядке записи их в файл;
восстановление внутренней непротиворечивости информации после аварийного завершения работы многомерной базы данных обеспечивают посредством опережающей записи идентификаторов координат в состав векторов дескрипторов относительно момента их записи в состав векторов данных.
9. Способ управления многомерной базой данных по п.8, отличающийся тем, что идентификацию информации выполняют в следующей последовательности:
на первом шаге сравнивают фактические значения координат данного, поступившего из внешнего источника информации, с унифицированными значениями координат в составе измерений;
на втором шаге, в случае несовпадения фактических значений координат данного и унифицированных значений координат в составе измерений, фактические значения включают в состав измерений в качестве новых унифицированных значений с присвоением им цифровых кодов идентификаторов;
на третьем шаге производят замену фактических значений координат данного на цифровые коды идентификаторов унифицированных значений координат в составе измерений.
10. Способ управления многомерной базой данных по п.8, отличающийся тем, что сжатие информации осуществляют в следующей последовательности:
на первом шаге создают второй экземпляр гиперкуба, используемый для записи вновь поступающей информации и связанный с первым экземпляром адресными указателями четвертого типа корневых векторов и векторов дескрипторов;
на втором шаге создают копию первого экземпляра гиперкуба, не связанную с первым экземпляром адресными указателями четвертого типа корневых векторов и векторов дескрипторов, используемую как приемник информации, ранее записанной в первом экземпляре гиперкуба - источнике информации;
на третьем шаге производят сжатие информации путем формирования консолидированных версий векторов данных, содержащихся в источнике информации, и их переноса в приемник информации;
на четвертом шаге источник информации замещают приемником информации путем связывания второго экземпляра и копии первого экземпляра гиперкуба адресными указателями четвертого типа корневых векторов и векторов дескрипторов, первый экземпляр гиперкуба удаляют из файла.
11. Способ управления многомерной базой данных по п.9, отличающийся тем, что восстановление внутренней непротиворечивости информации после аварийного завершения работы производят в следующей последовательности:
на первом шаге, на основании сравнения значений векторов дескрипторов гиперкуба, осуществляют переход к идентификатору координаты последнего вектора данного, наиболее смещенного относительно начала файла, после этого по адресным указателям второго типа производят переход к другим идентификаторам координат последнего вектора данного;
причем в случае наличия в составе последнего вектора данного полного набора идентификаторов координат восстановление внутренней непротиворечивости информации после аварийного завершения работы на этом заканчивают, в случае отсутствия в составе последнего вектора данного хотя бы одного из идентификаторов координат, адрес расположения которого записан в векторе дескриптора, дополнительно осуществляют следующие шаги;
на втором шаге значения векторов дескрипторов, коды идентификаторов которых соответствуют идентификаторам координат предыдущих векторов данных, заменяют на величины смещения относительно начала файла и порядковые номера адресных указателей первого типа идентификаторов координат вектора данного;
на третьем шаге осуществляют переход к последнему идентификатору координаты предпоследнего вектора данного, смещенного относительно первого идентификатора координаты последнего вектора данного на величину, заданную форматом идентификатора координаты, после этого по адресным указателям второго типа осуществляют переход к остальным идентификаторам координат, входящим в состав предпоследнего вектора данного;
на четвертом шаге коды идентификаторов координат предпоследнего вектора данного сравнивают с кодами идентификаторов координат векторов дескрипторов, соответствующих кодам идентификаторов координат, отсутствующим в составе последнего вектора данного, причем при совпадении кодов значения векторов дескрипторов заменяют на величины смещения и порядковые номера адресных указателей первого типа идентификаторов координат предпоследнего вектора данного, при несовпадении кодов осуществляют переход к следующим в порядке приближения к началу файла векторам данных вплоть до нахождения идентификаторов координат, коды которых совпадают с кодами идентификаторов координат, отсутствующих в составе последнего вектора данного, с последующей заменой значений векторов дескрипторов;
на пятом шаге последний вектор данного с неполным составом идентификаторов координат удаляют из файла.
12. Способ управления многомерной базой данных по п.8, отличающийся тем, что чтение информации выполняют в следующей последовательности:
на первом шаге
пользователь формирует ключ поиска из одного или нескольких идентификаторов координат;
в составе буфера производят поиск значений векторов дескрипторов с соответствующими идентификаторами координат путем нахождения в списке адресов таблиц векторов дескрипторов, позиции которых соответствуют цифровым кодам измерений, перехода к указанным таблицам и поиска в их составе строк, позиции которых соответствуют цифровым кодам унифицированных значений координат;
в случае отсутствия в таблицах значений хотя бы одного из векторов дескрипторов с идентификаторами координат, соответствующими ключу поиска, чтение прекращают, в противном случае производят чтение значений векторов дескрипторов;
производят сравнение порядковых номеров адресных указателей четвертого типа идентификаторов координат векторов дескрипторов;
в случае их равенства порядковому номеру, соответствующему последнему сегменту гиперкуба, значения найденных векторов дескрипторов сравнивают между собой по величине порядковых номеров адресных указателей первого типа с последующим выбором вектора дескриптора с наименьшим номером, в противном случае по адресному указателю четвертого типа осуществляют переход к следующему сегменту гиперкуба;
на втором шаге
в составе сегмента гиперкуба производят поиск других векторов дескрипторов, идентификаторы координат которых совпадают с ключом поиска, путем обхода бинарного дерева индексной структуры;
в случае равенства порядковых номеров адресных указателей четвертого типа векторы дескрипторов сравнивают между собой по величине порядковых номеров адресных указателей первого типа с последующим выбором вектора дескриптора с наименьшим номером, в противном случае по адресному указателю четвертого типа осуществляют переход к следующему сегменту гиперкуба вплоть до совпадения порядковых номеров адресных указателей четвертого типа векторов дескрипторов;
на третьем шаге
на основании значения адресного указателя первого типа вектора дескриптора с наименьшим порядковым номером осуществляют чтение идентификатора координаты вектора данного;
в соответствии со значениями адресных указателей второго типа осуществляют чтение остальных идентификаторов координат вектора данного и их сравнение с идентификаторами координат ключа поиска;
в случае совпадения идентификаторов координат вектора данного с идентификаторами координат ключа поиска определяют один из совпадающих идентификаторов координат вектора данного с наибольшим порядковым номером адресного указателя второго типа;
в противном случае переходят к выполнению пятого шага настоящей последовательности чтения информации;
на четвертом шаге
производят обход иерархических и вариантных групп вектора данного, начиная с совпадающего идентификатора координаты с наибольшим порядковым номером адресного указателя второго типа, в случае вхождения идентификаторов координат ключа поиска в состав одних и тех же иерархических и вариантных групп вектора данного его включают в отчет о поиске;
на пятом шаге
в составе прочитанного вектора данного производят сравнение между собой по величине порядковых номеров адресных указателей первого типа идентификаторов координат, соответствующих ключу поиска, выбор идентификатора координаты с наименьшим по величине порядковым номером, чтение идентификатора координаты предыдущего вектора данного по адресному указателю первого типа и чтение остальных идентификаторов координат предыдущего вектора данного по адресным указателям второго типа;
причем четвертый и пятый шаги повторяют в порядке приближения к началу файла вплоть до чтения одного из идентификаторов координат вектора данного, соответствующих ключу поиска, с порядковым номером адресного указателя первого типа, равным единице.
13. Способ управления многомерной базой данных по п.12, отличающийся тем, что контроль внутренней непротиворечивости информации при совместной работе двух и более пользователей с одними и тем же данными осуществляют в следующей последовательности:
на первом шаге пользователи осуществляют независимое чтение информации, которое начинают с чтения в буфере консолидированной версии вектора данного, соответствующей ключу поиска, в случае отсутствия в буфере консолидированной версии вектора данного чтение осуществляют из файла;
на втором шаге пользователи производят независимое формирование измененных (удаленных) версий вектора данного, которым временно присваивают порядковый номер записи ранее прочитанной консолидированной версии вектора данного;
на третьем шаге, по команде на запись пользователя, первым завершившего формирование измененной (удаленной) версии вектора данного, осуществляют повторное чтение в буфере или файле консолидированной версии вектора данного, при этом выполнение команд на запись остальных пользователей блокируют;
на четвертом шаге производят сравнение между собой порядковых номеров записи измененной (удаленной) и повторно прочитанной консолидированной версий вектора данного;
причем в случае совпадения порядковых номеров записи в файл записывают измененную (удаленную) версию вектора данного, причем в случае несовпадения порядковых номеров записи производят повторное формирование измененной (удаленной) и новой консолидированной версий вектора данного с актуальным порядковым номером записи, новая консолидированная версия замещает в буфере предыдущую консолидированную версию, измененную (удаленную) версию записывают в файл, выполнение команд на запись разблокируют с повторением третьего и четвертого шагов для каждого следующего пользователя;
на пятом шаге производят удаление из буфера последней консолидированной версии вектора данного в случае отсутствия команд на чтение или запись в течение заданного промежутка времени.
14. Способ управления многомерной базой данных по п.8, отличающийся тем, что запись информации выполняют в следующей последовательности:
на первом шаге производят преобразование данного в векторную форму путем формирования идентификаторов координат, связывания их адресными указателями второго, третьего и четвертого типов, определения расчетным путем значений адресных указателей первого типа в случае отсутствия в составе гиперкуба векторов дескрипторов с совпадающими кодами идентификаторов или путем копирования значений адресных указателей первого типа векторов дескрипторов в случае наличия в составе гиперкуба векторов дескрипторов с совпадающими кодами идентификаторов;
на втором шаге в случае отсутствия в составе гиперкуба векторов дескрипторов с совпадающими идентификаторами производят запись в файл этих векторов дескрипторов, адресные указатели первого типа которых имеют расчетные значения однотипных адресных указателей вектора данного, или в случае наличия в составе блока координат этих векторов дескрипторов производят изменение на расчетные значений величин смещения относительно начала файла и порядкового номера записи однотипных адресных указателей векторов дескрипторов;
на третьем шаге производят запись вектора данного в конец файла.
15. Способ управления многомерной базой данных по п.14, отличающийся тем, что изменение информации осуществляют на логическом уровне путем записи нескольких версий вектора данного в следующей последовательности:
на первом шаге производят чтение текущей версии вектора данного;
на втором шаге формируют измененную версию вектора данного в составе одного или нескольких идентификаторов координат и/или фрагментов неструктурированной информации, измененных относительно текущей версии, и одного неизменного идентификатора координаты;
на третьем шаге производят запись измененной версии вектора данного с сохранением в именах идентификаторов координат величин смещения относительно начала файла, записанных в первой версии вектора данного;
причем последующее чтение измененной информации осуществляют путем формирования консолидированной версии вектора данного, состоящей из одного идентификатора координаты с неизменным кодом идентификатора и одного или нескольких последних по порядку записи измененных идентификаторов координат и/или фрагментов неструктурированной информации.
16. Способ управления многомерной базой данных по п.15, отличающийся тем, что удаление информации осуществляют на логическом уровне путем записи нескольких версий вектора данного в следующей последовательности:
на первом шаге производят чтение текущей версии вектора данного;
на втором шаге формируют удаленную версию вектора данного в составе одного или нескольких идентификаторов координат, удаленных из текущей версии вектора данного, и одного неизменного идентификатора координаты;
на третьем шаге производят запись удаленной версии вектора данного с заменой на нулевые значения кодов удаленных идентификаторов координат;
причем последующее чтение сохраненной информации осуществляют путем формирования консолидированной версии вектора данного, состоящей из идентификаторов координат с ненулевыми значениями кодов идентификаторов координат и заключенными между ними фрагментами неструктурированной информации.
| US 5359724 A, 25.10.1994 | |||
| МНОГОМЕРНАЯ БАЗА ДАННЫХ И СПОСОБ ДОСТУПА К МНОГОМЕРНОЙ БАЗЕ ДАННЫХ | 2006 |
|
RU2325690C1 |
| US 2007094236 A1, 26.04.2007 | |||
| US 2008133469 A1, 05.06.2008. | |||

