ОБЛАСТЬ ТЕХНИКИ
[0001] Данное техническое решение относится к области вычислительной техники, в частности к способу хранения данных, и может быть использовано в системе управления базами данных (СУБД).
УРОВЕНЬ ТЕХНИКИ
[0002] Из уровня техники известен патент на изобретение US 8838593 В2 «Method and system for storing, organizing and processing data in a relational database», в котором предлагается с целью повышения компрессии хранимых данных и ускорения агрегатных операций, группировать записи по значениям атрибутов, при этом способ не обязывает располагать записи одной группы в физически смежных областях запоминающего устройства (ЗУ), а вводит дополнительные логические структуры совокупным размером до 1% от всех хранимых данных.
[0003] Известно о реализации специализированных кластерных объектов в СУБД Oracle Database, используемых для совместного хранения нескольких таблиц, которые часто соединяются вместе в SQL-запросах. Кластеризованные таблицы в СУБД Oracle Database замедляют операции добавления, обновления и удаления строк, требуют создания индекса кластера.
[0004] Наиболее близким является патент US 20090187591 A1 «Retrieving database records for aggregation without redundant database read operations», в котором с целью уменьшения операций ввода/вывода, и соответственно повышения производительности системы управления базами данных, предлагается хранить записи с идентичным значением одного из атрибутов в физически смежных областях запоминающего устройства. Описанное решение неэффективно для хранения данных в задачах, предполагающих высокую интенсивность изменения записей, поскольку модификация значения атрибута, по которому произведена группировка, приведет к обязательному перестроению групп и физическому переносу модифицированной записи в соответствующую область ЗУ. Кроме того, предлагаемый в US 20090187591 A1 способ не предполагает наличия в одной базе данных групп, сформированных по разным критериям.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям хранения связанных данных.
[0006] Заявляется способ организации хранения связанных данных, в котором объединяют записи в по крайней мере одну группу по схожему признаку; присваивают идентификатор каждой вышеуказанной группе и каждой записи, находящейся в данной группе; формируют связь идентификатора группы с адресом его расположения на запоминающем устройстве таким образом, что перемещение группы на запоминающем устройстве, а также между запоминающими устройствами не изменяет значение идентификатора группы; формируют связь идентификатора записи с адресом ее расположения внутри группы на запоминающем устройстве таким образом, что перемещение записи на запоминающем устройстве внутри группы не изменяет идентификатор записи; сохраняют записи одной группы на запоминающем устройстве в смежных областях.
[0007] Техническим результатом является повышение производительности системы управления базами данных.
[0008] Технический результат достигается путем сокращения операций ввода/вывода вследствие хранения в одной группе записей, связанных логикой предметной области и обладающих схожими признаками, а также относительной адресацией записи внутри группы, что снижает частоту изменений ссылающейся структуры данных.
[0009] В некоторых вариантах осуществления при объединении записей в группы схожим признаком является нахождение записей в реляционном отношении.
[00010] В некоторых вариантах осуществления при объединении записей в группы схожим признаком является хранение версий одних данных.
[00011] В некоторых вариантах осуществления при объединении записей в группы схожим признаком является принадлежность к одной горизонтальной секции.
[00012] В некоторых вариантах осуществления при объединении записей в группы схожим признаком является порядок добавления записей.
[00013] В некоторых вариантах осуществления при объединении записей в группы схожим признаком является идентичность одного или нескольких атрибутов.
[00014] В некоторых вариантах осуществления запоминающим устройством является ОЗУ, и/или ПЗУ, и/или магнитная память, и/или флэш-память, и/или магнитный диск, и/или оптический диск.
[00015] В некоторых вариантах осуществления идентификатор записи и группы не являются атрибутом отношения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[00016] Признаки и преимущества настоящего изобретения станут очевидными из приведенного ниже подробного описания изобретения и прилагаемых чертежей, на которых:
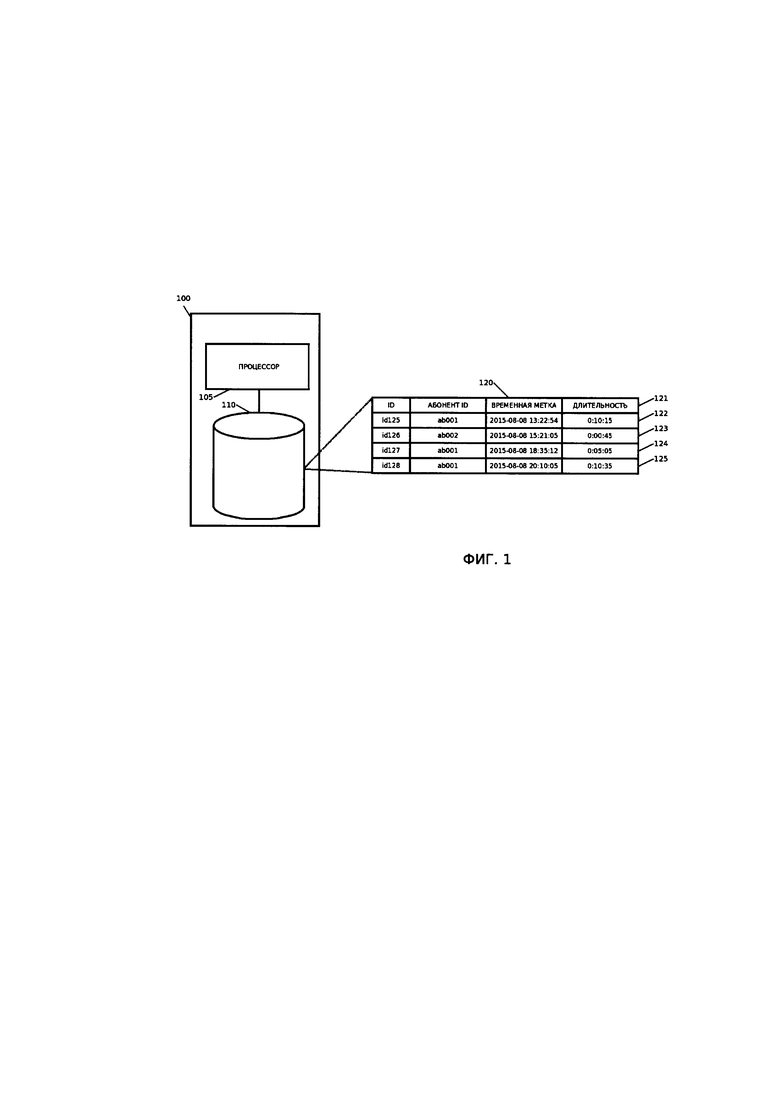
[00017] На Фиг. 1 изображен пример отношения (120) с атрибутами (121) и несколько записей (123-125), которые хранятся в ЗУ (ПО).
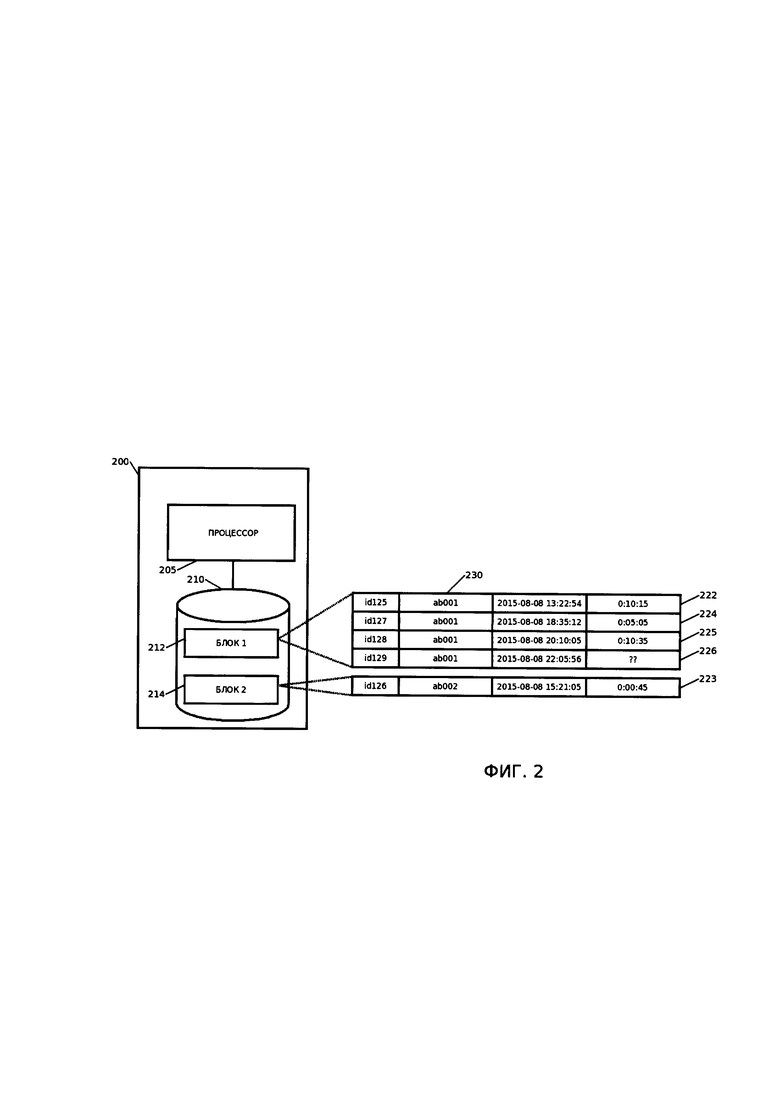
[00018] На Фиг. 2 приведена схема разбиения записей по группам. Записи (222-226) разделены на две группы, каждая из которых хранится в отдельном блоке (212, 214) запоминающего устройства (ЗУ) (210). Записи 222, 224-226 объедены в группу, поскольку имеют идентичный атрибут (230). Запись 226 иллюстрирует хранение в ЗУ (210) данных неоконченной транзакции.
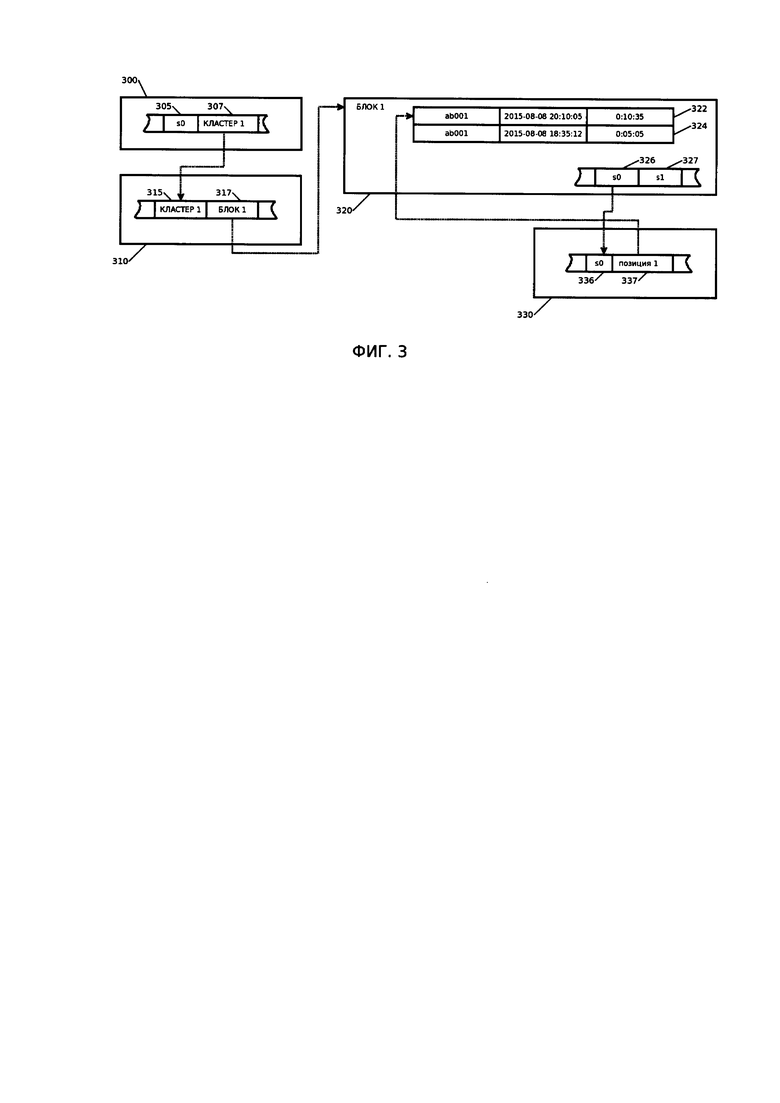
[00019] На Фиг. 3 приведена схема адресации записей и группы из ссылающейся структуры данных, где 300 - адресующая структура, 310 - адресный конвертер, 330 - слотовый конвертер, 320 - блок ЗУ, в котором хранится группы, а 324 и 322 - собственно записи.
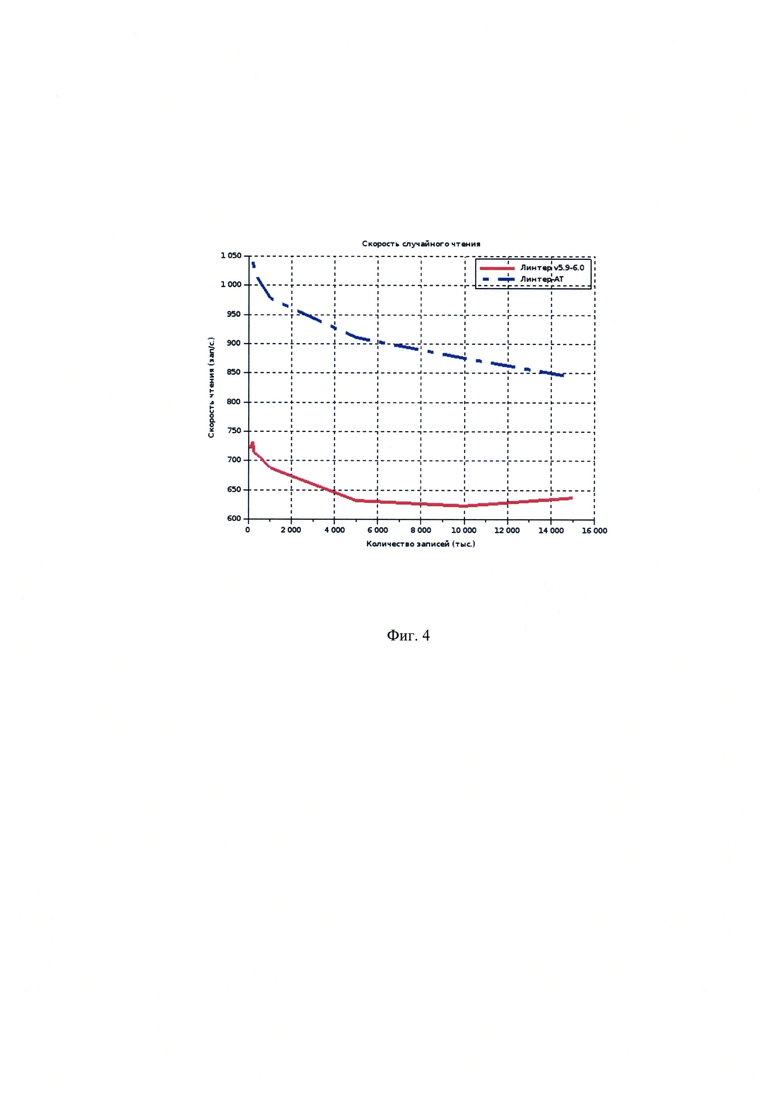
[00020] На Фиг. 4 показаны результаты замеров производительности случайного чтения страниц.
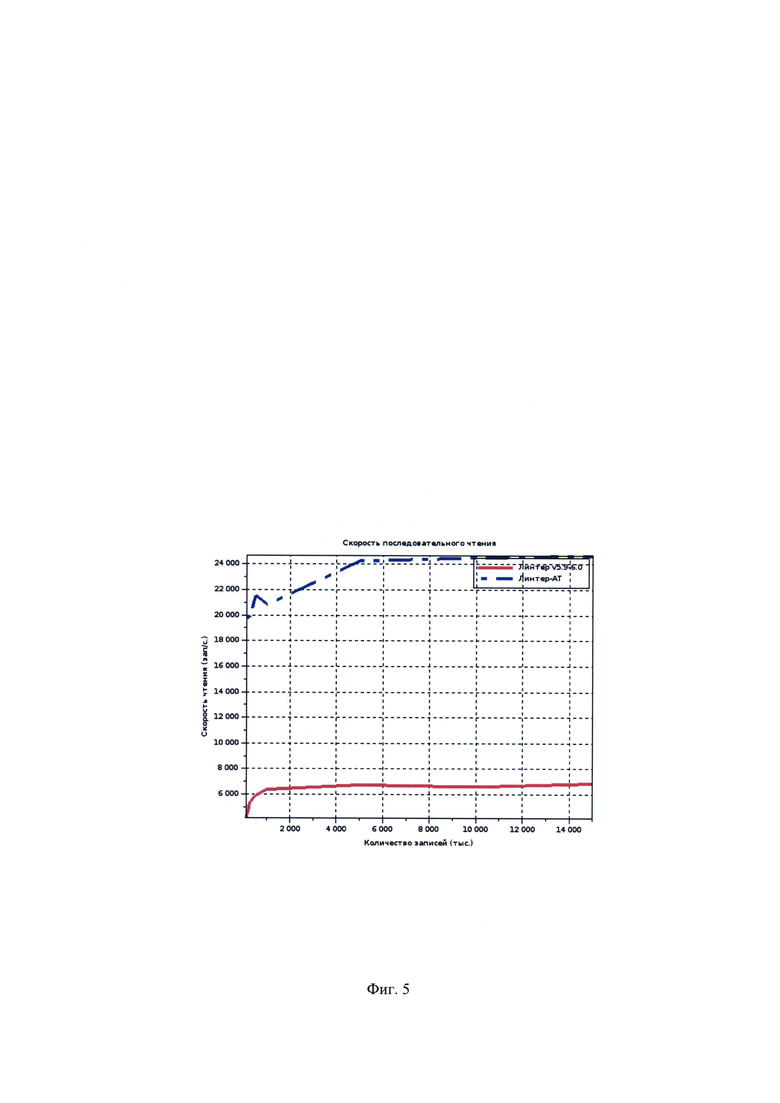
[00021] На Фиг. 5 показаны результаты замеров производительности последовательного чтения страниц.
[00022] На Фиг. 6 показан пример реализации таблицы «МАТЧИ».
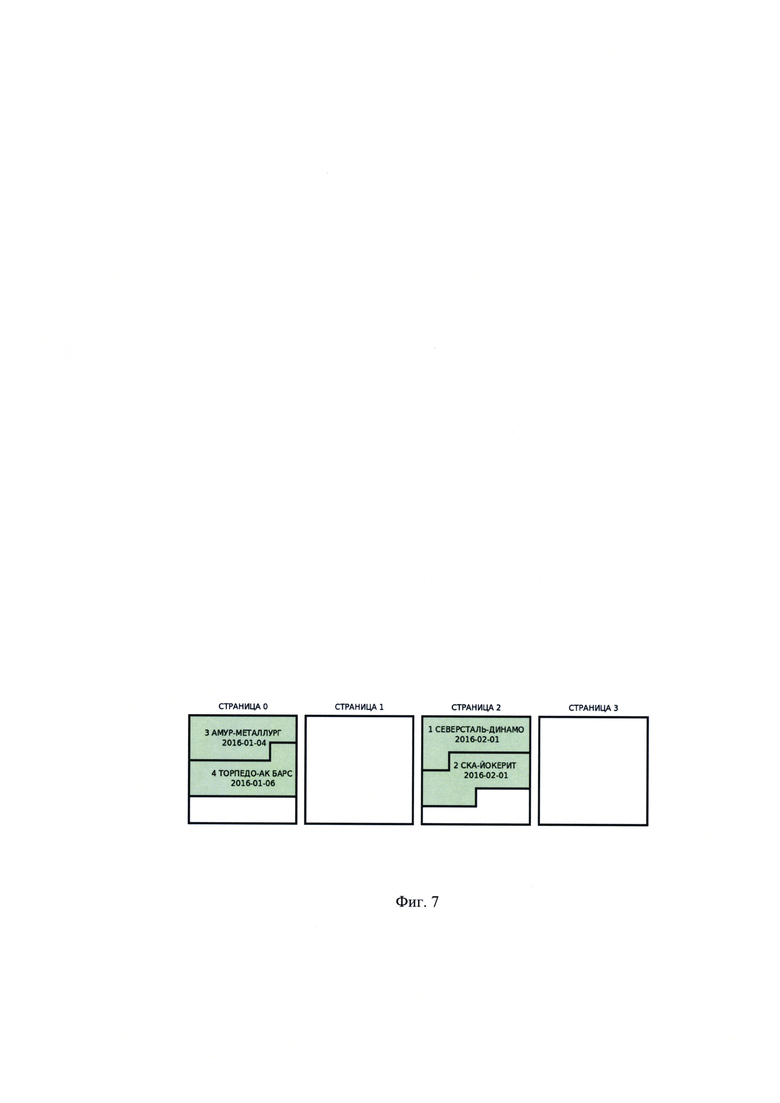
[00023] На Фиг. 7 показана схема хранения записей в страницах.
[00024] На Фиг. 8 показана таблица «СОТРУДНИКИ».
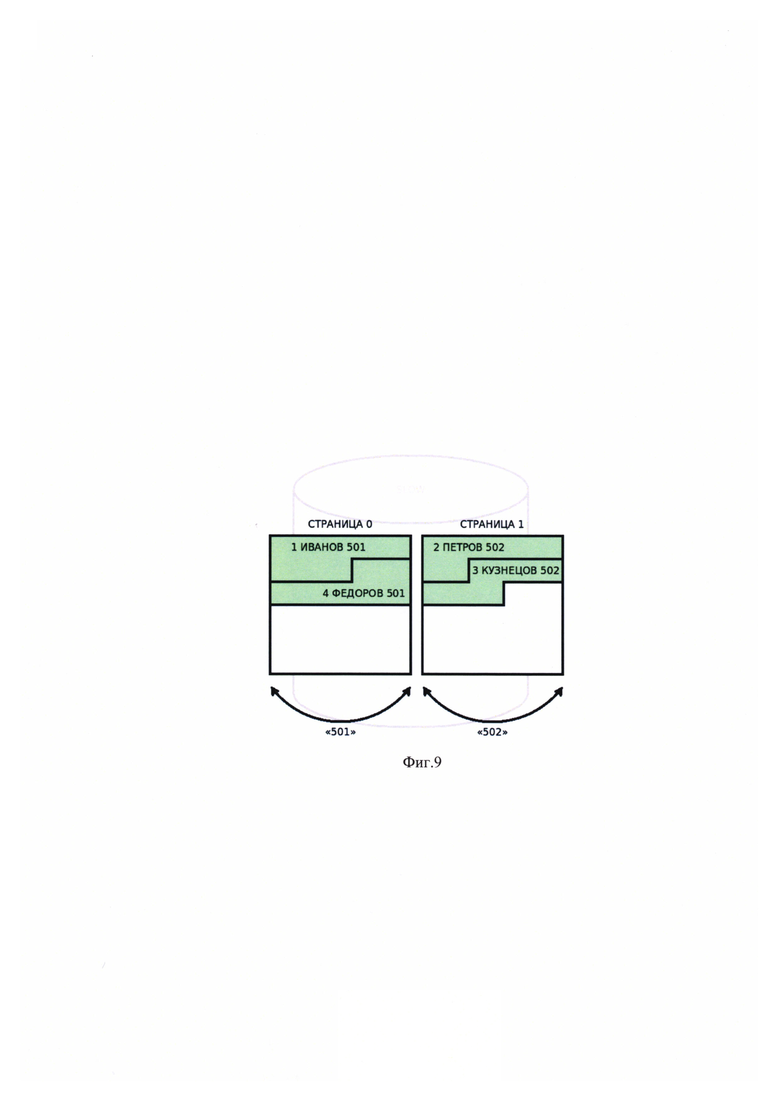
[00025] На Фиг. 9 показано разбиение записей на группы «501» и «502» и их расположение на страницах ЗУ с примерным наименованием «slow».
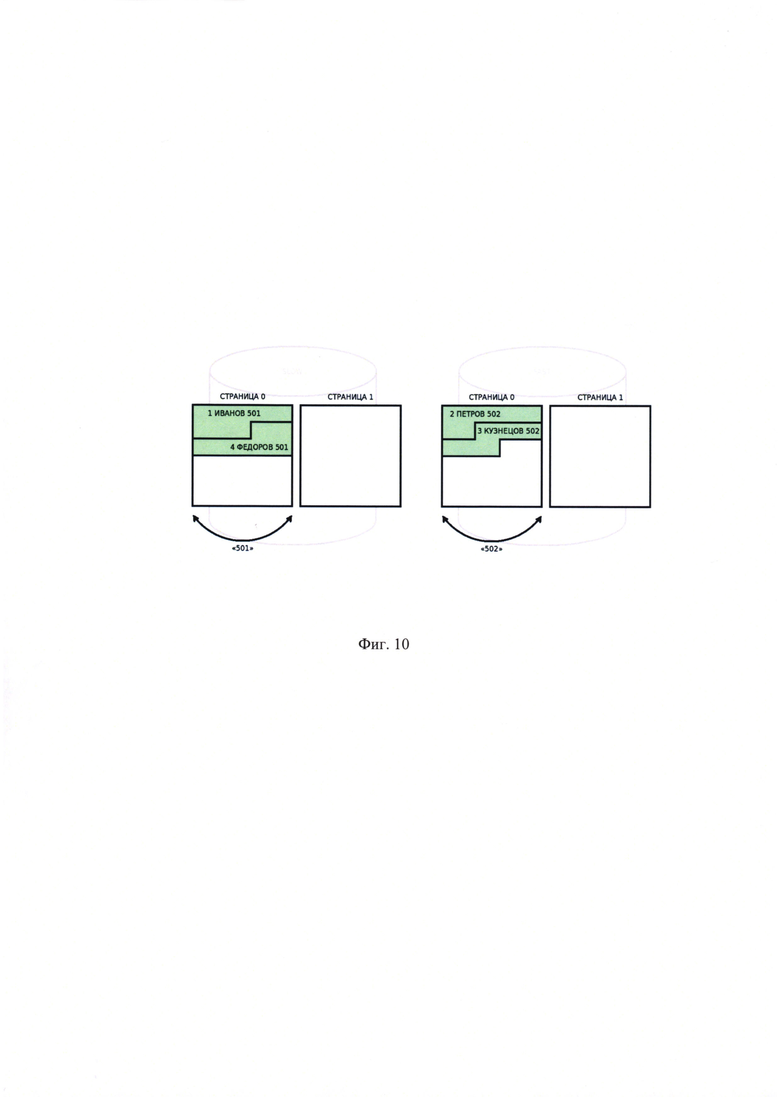
[00026] На Фиг. 10 показано размещение группы «501» на странице ЗУ «slow», а группы «502» на производительном ЗУ с примерным наименованием «fast».
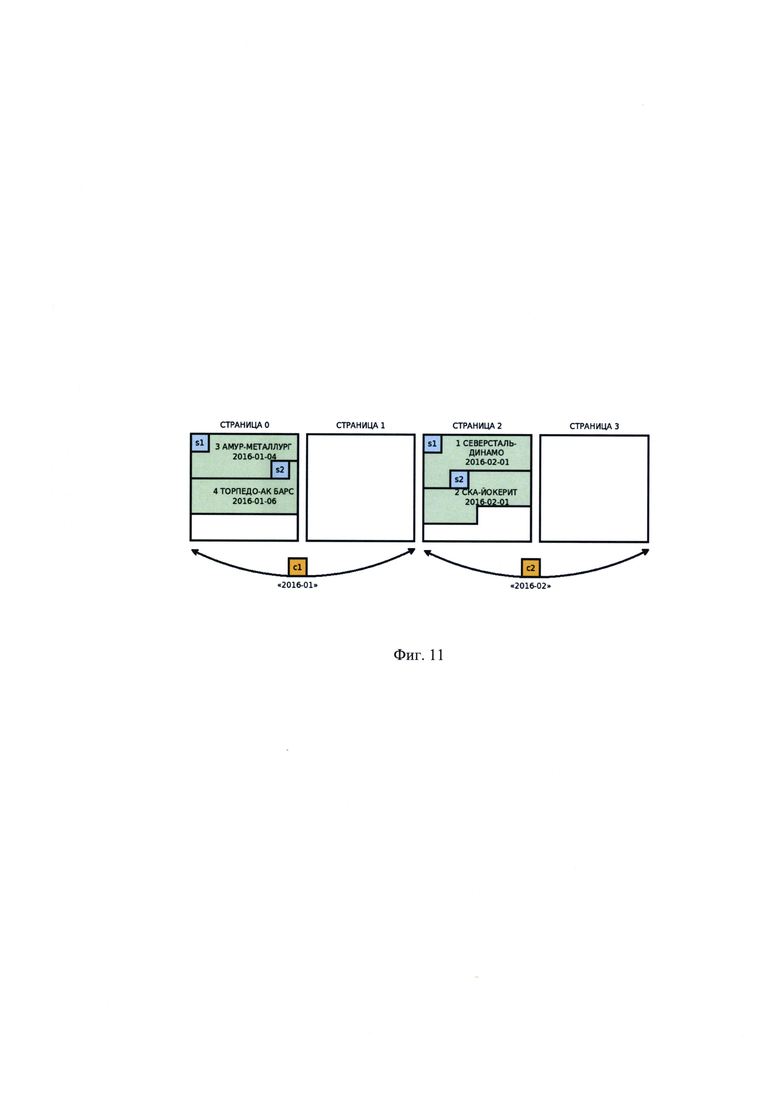
[00027] На Фиг. 11 показано разбиение записей на следующие группы: «2016-02» и «2016-01».
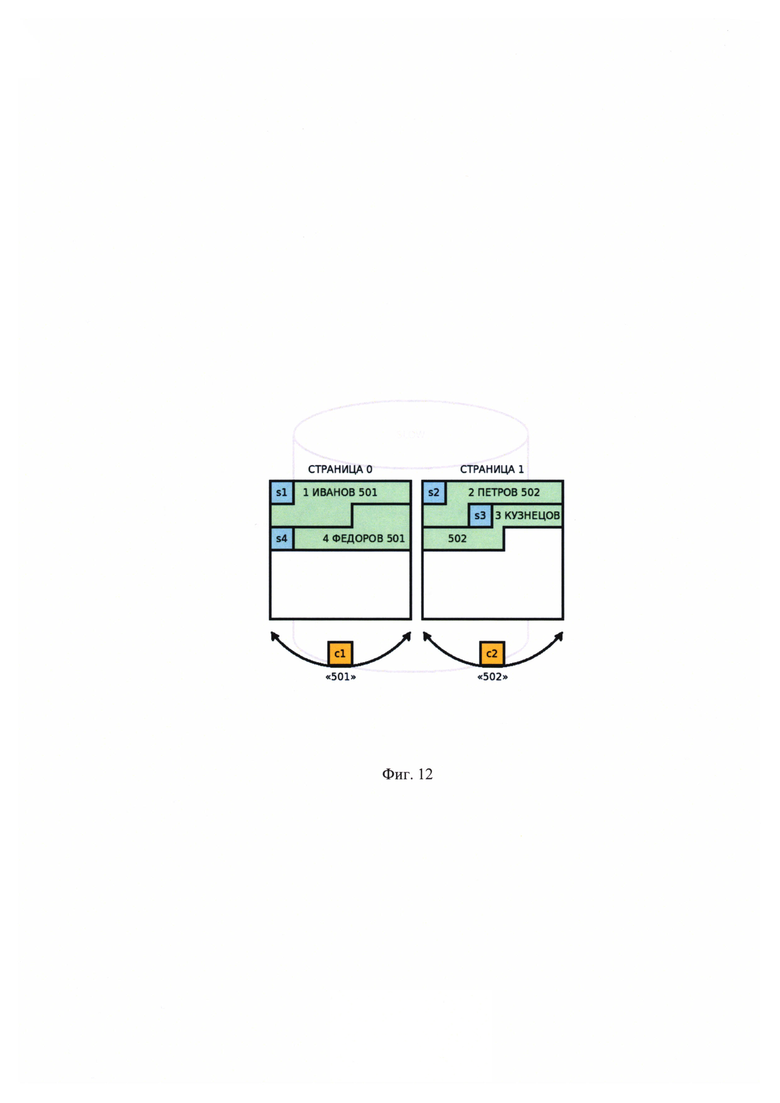
[00028] На Фиг. 12 показано содержимое страниц с данными в первоначальном состоянии (до переноса записей группы «502» на другое ЗУ).
[00029] На Фиг. 13 показано содержимое страниц с данными после переноса группы «502» в ЗУ «fast».
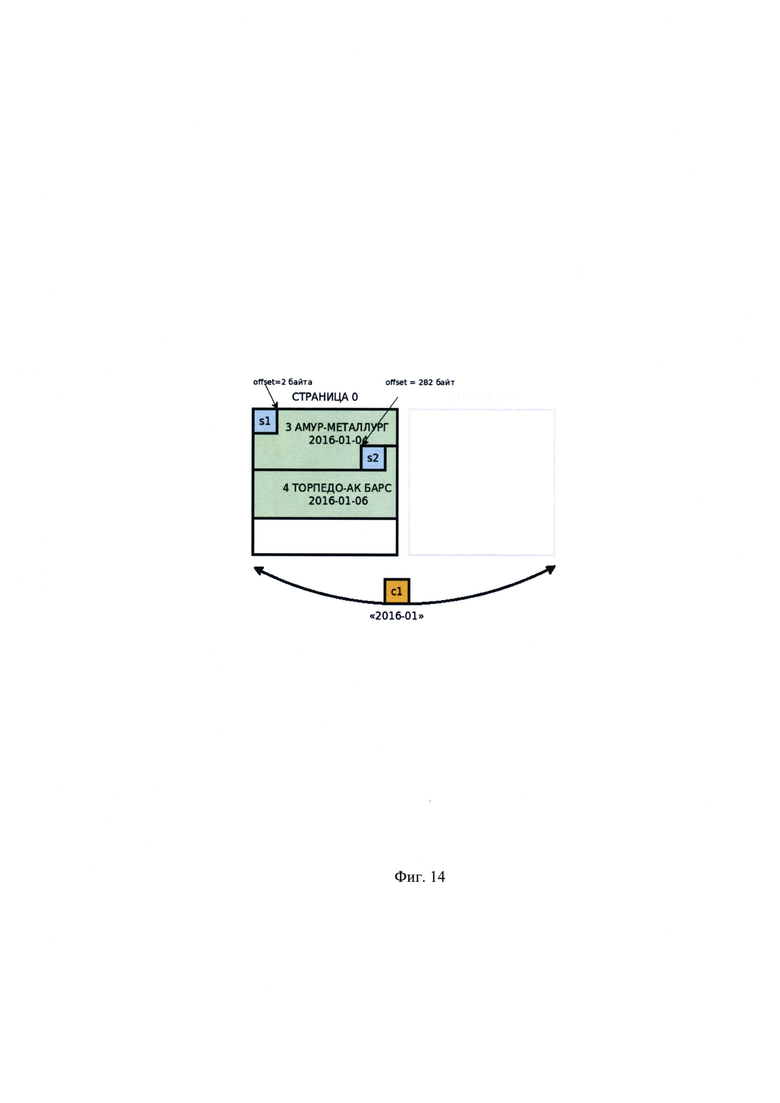
[00030] На Фиг. 14 показан примерный вариант осуществления группы c1.
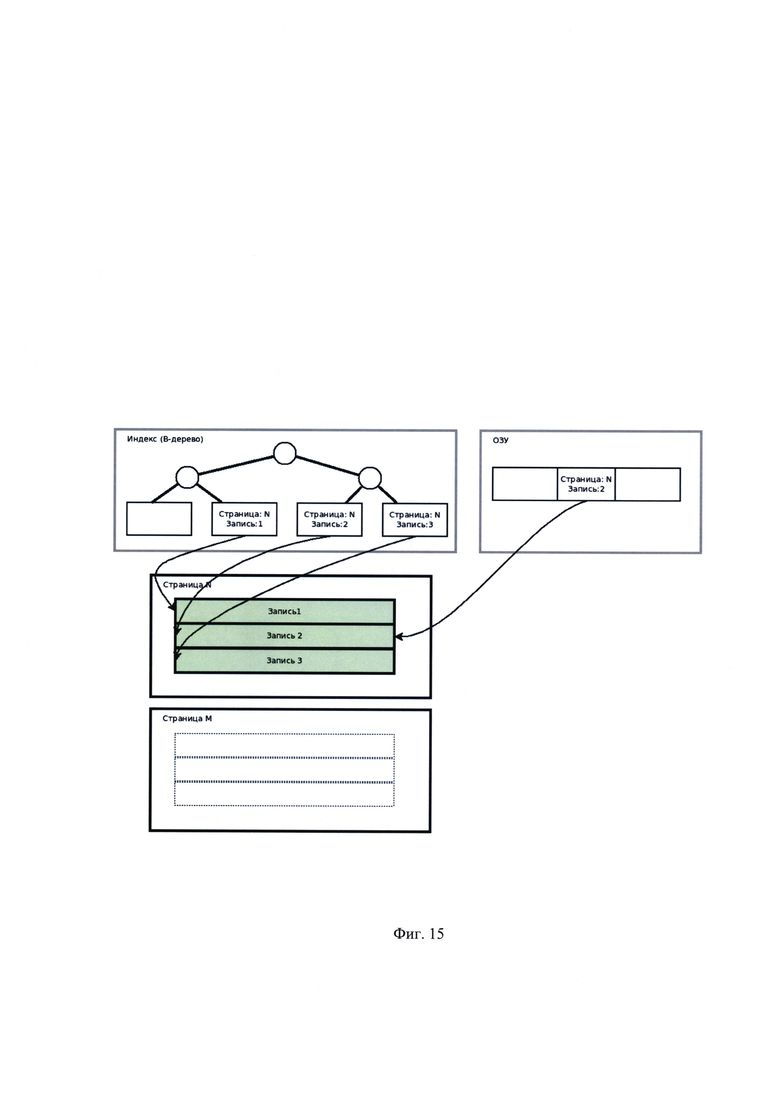
[00031] На Фиг. 15 показан вариант реализации адресации записей без адресного конвертера (до переноса записей);
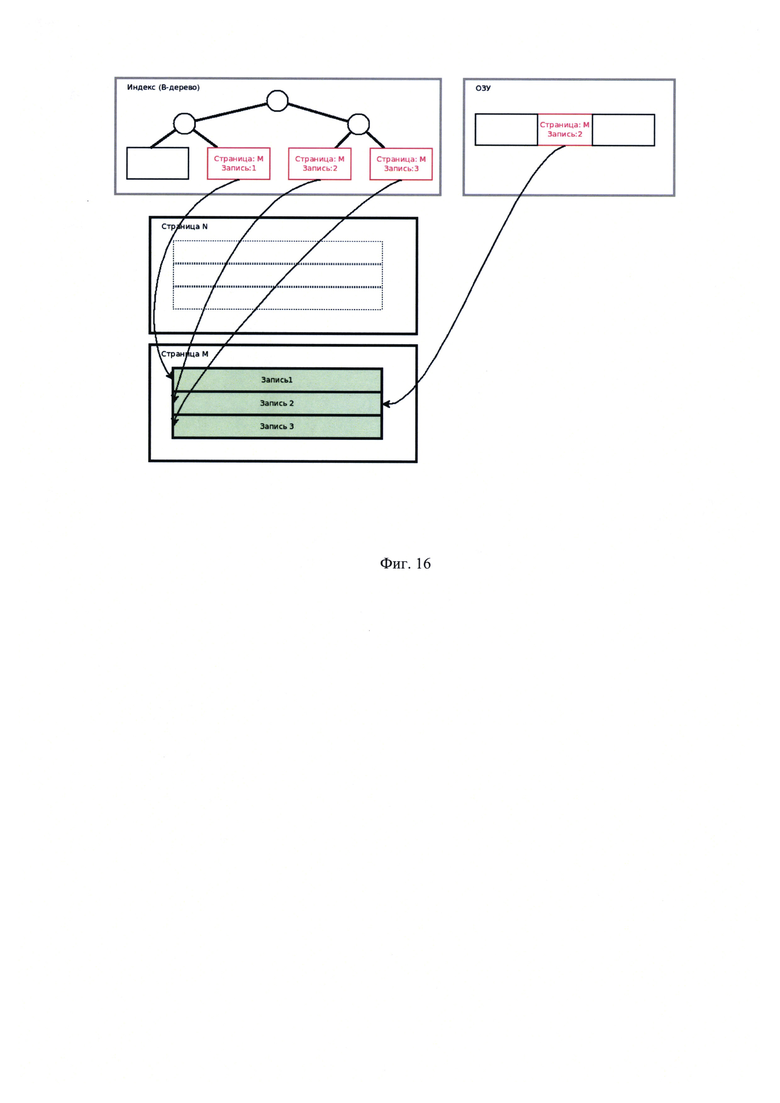
[00032] На Фиг. 16 показан вариант реализации адресации записей без адресного конвертера (после переноса записей);
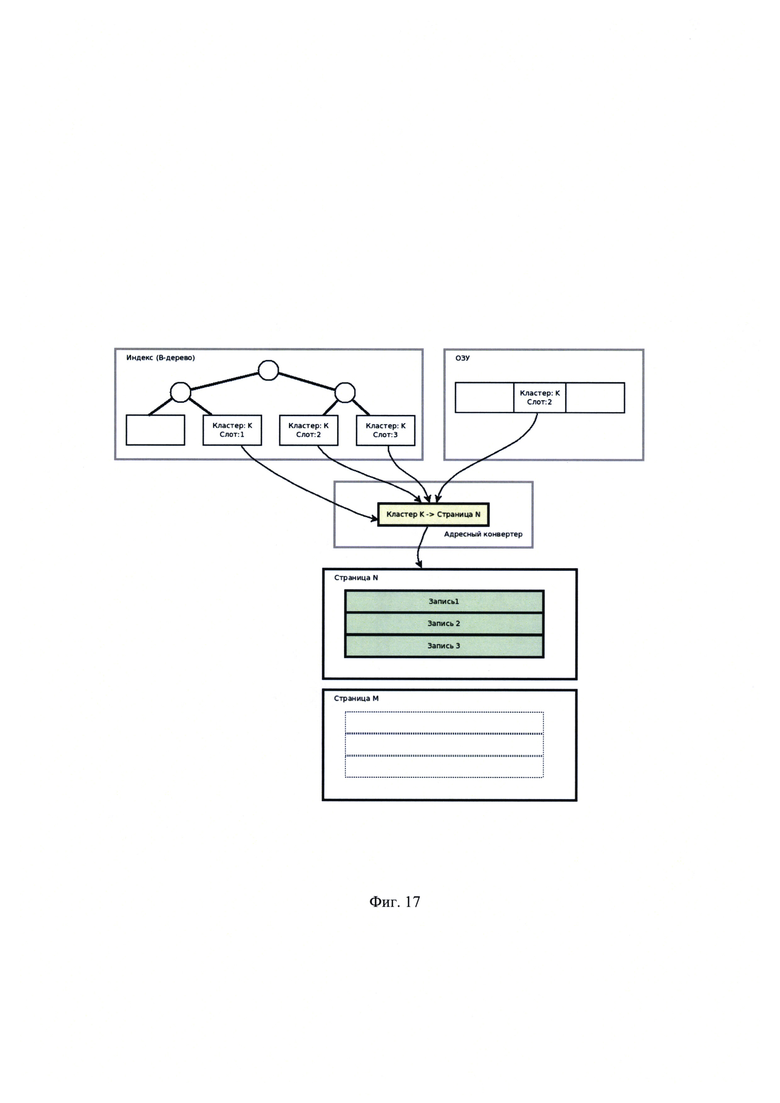
[00033] На Фиг. 17 показан вариант реализации адресации записей с использованием адресного конвертера (до переноса записей);
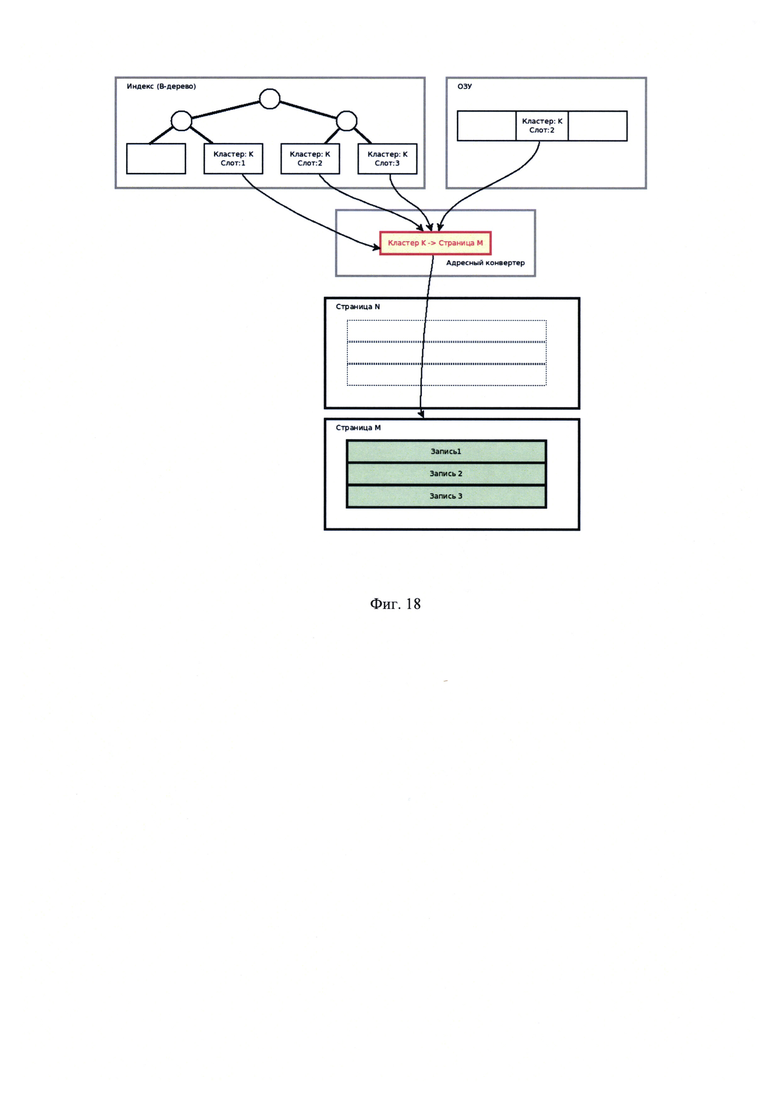
[00034] На Фиг. 18 показан вариант реализации адресации записей с использованием адресного конвертера (после переноса записей);
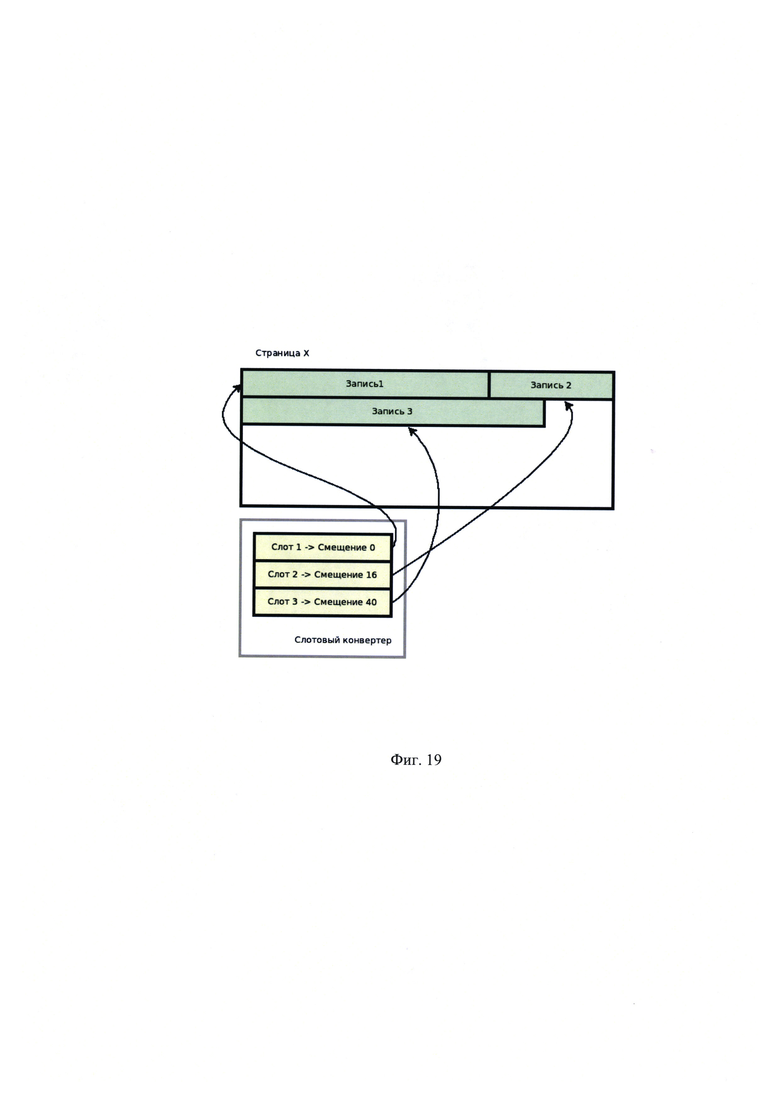
[00035] На Фиг. 19 показан вариант реализации, в котором в результате обновления данных запись №2 стала длиннее;
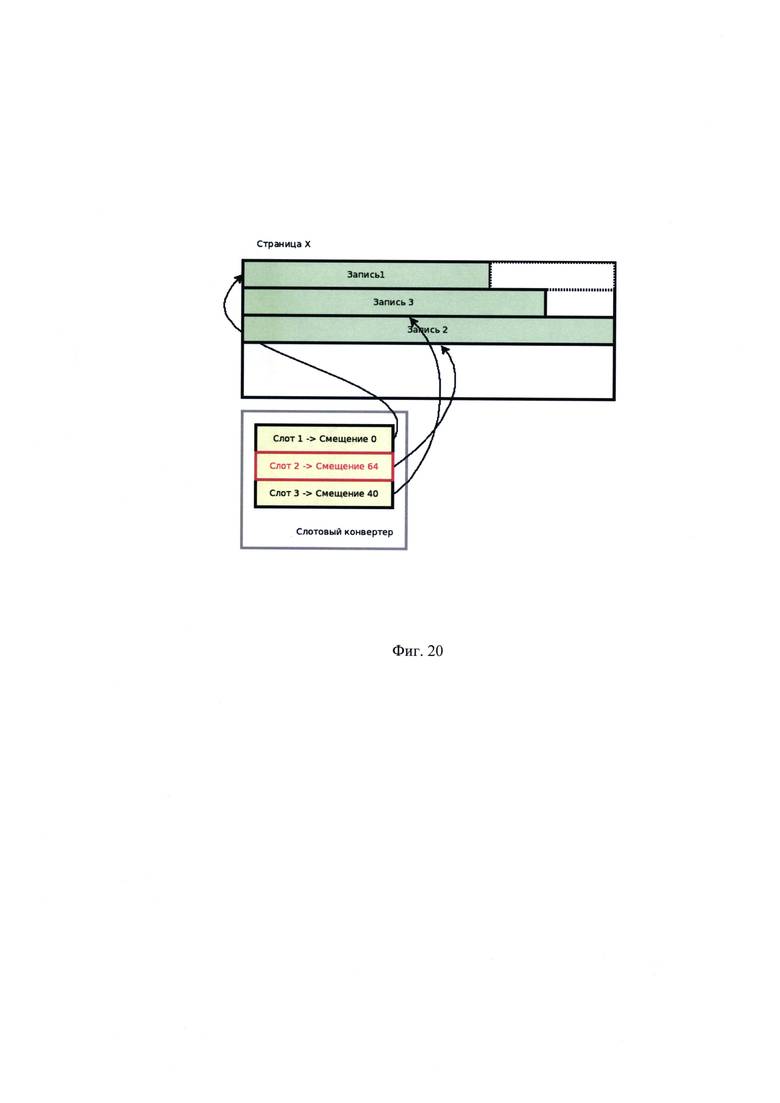
[00036] На Фиг. 20 показано фактическое перемещение записей внутри страниц не изменяющее номер адресующего слота.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[00037] Ниже будут описаны понятия и определения, необходимые для подробного раскрытия осуществляемого изобретения.
[00038] Запись - набор значений различных типов, предназначенный к хранению в ЗУ.
[00039] Группа - совокупность записей, которая рассматривается как самостоятельная единица в операциях чтения/записи, предполагающая физически объединенное хранение в ЗУ.
[00040] Физически смежные области - области ЗУ, предполагающие минимизацию вспомогательных операций позиционирования и адресации в операциях единовременного чтения/записи из этих областей. Зависит от реализации ЗУ, например: соседние секторы на дисковых носителях, смежные адреса виртуальной/физической памяти.
[00041] Идентификатор группы - набор данных (в частном случае - порядковый номер) однозначно идентифицирующий группу записей среди всего множества групп.
[00042] Идентификатор записи - набор данных (в частном случае - порядковый номер) однозначно идентифицирующий запись внутри группы (но не обязательно - среди всех записей всех групп).
[00043] Адресный конвертер - устройство, осуществляющее вычисление адреса блока в ЗУ, в котором хранится группа записей по идентификатору группы.
[00044] Слотовый конвертер - устройство, осуществляющее вычисление адреса начала записи в блоке данных по идентификатору записи.
[00045] Адресующая структура - структура, однозначно определяющая текущее физическое расположение записи в ЗУ, например: LBA адрес в дисковых накопителях или указатель на область виртуальной памяти.
[00046] Согласно техническому решению, способ организации хранения связанных данных, включает следующие шаги:
[00047] объединяют записи в по крайней мере одну группу по схожему признаку;
Признак, по которому происходит объединение записей в группы, не является ограничивающим, поскольку критерии могут быть разными и во многом определяются непосредственно данными и предметной областью. Например, данным критерием может быть нахождение записей в реляционном отношении или хранение версий одних данных или принадлежность к одной горизонтальной секции. Рассмотрим несколько вариантов осуществления технического решения, которые не являются ограничивающими.
Пример 1
Пусть имеется база данных, описывающая проведение чемпионата по хоккею и содержащая реляционное отношение «МАТЧИ» (Фиг. 6) с атрибутами ID, КОМАНДА ХОЗЯЕВ, КОМАНДА ГОСТЕЙ, ДАТА ПРОВЕДЕНИЯ и записями:
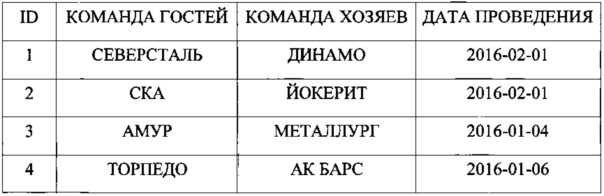
При создании данного отношения был определен признак управляемой группировки: «месяц и год проведения матча», что предопределило расположение записей соответствующих матчам в феврале 2016 г. (ID=1,2) к одной группе, а записей соответствующих матчам в январе того же года (ID=3,4) - к другой. Каждой группе выделен диапазон страниц в файле данных, пусть для группы «2016-01» выделены страницы с 0 по 1, а для группы «2016-02» - с 2 по 3, тогда схема хранения записей в страницах может быть представить таким образом, как это показано на Фиг. 7.
Страницы 1 и 3 не использованы, но зарезервированы для добавления новых записей в группу, к которому они назначены.
Пример 2
Пусть имеется база данных сотрудников предприятия, содержащая контактную информацию персонала в отношении «СОТРУДНИКИ» (Фиг. 8) со следующими атрибутами: ID, ФАМИЛИЯ, НОМЕР КАБИНЕТА.
При создании данного отношения был определен признак управляемой группировки: «Номер кабинета», кроме того, производится подсчет операций чтения групп, результаты которого определяют расположение группы в том или ином ЗУ. Таким образом, фактическое расположение группы с записями является адаптивным и формируется по мере эксплуатации способа автоматически.
Пусть в отношение добавлены следующие записи:
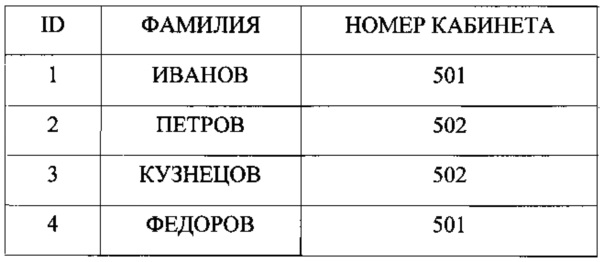
На момент добавления записи, не известна статистика чтения групп. Сформированные группы с наименованиями «502» и «501» изначально размещаются в страницах 0-1 хранилища «slow» (Фиг. 9).
Пусть по прошествии некоторого времени эксплуатации базы данных удалось собрать следующую статистику обращений к записям:


Поскольку группа является самостоятельной единицей в операциях чтения/записи, приведенная выше статистика означает, что к группе с условным наименованием «502» было 58 обращений (наибольшее количество из показателей по записям ID=2, ID=3), а к группе с условным наименованием «501» - 3 обращения. СУБД перемещает группу «502» на более производительное ЗУ «fast» (Фиг. 10).
[00048] присваивают идентификатор каждой вышеуказанной группе и каждой записи, находящейся в данной группе;
Каждая группа имеет уникальный (в рамках отношения) идентификатор, который необходим для адресации группы целиком, а каждая запись уникальный в рамках группы идентификатор для адресации уже непосредственно самой записи. Идентификаторы не являются атрибутом отношения.
Таким образом, для адресующей структуры (например В-дерева) для однозначной адресации каждой записи требуется пара значений: идентификатор группы и идентификатор записи. При этом пара значений не требует изменений в адресующей структуре в следующих случаях:
- группа переносится целиком в другое ЗУ;
- группа переносится целиком в другие блоки ЗУ;
- записи меняют порядок и положение внутри блока ЗУ, выделенного под соответствующую группу.
Соответствие между фактическим положением блока ЗУ и идентификатором группы определяет адресный конвертер, а положение записи внутри блока ЗУ - слотовый конвертер. Понятия адресный конвертер введены с целью упрощения описания настоящего технического решения. Специалисту в указанном уровне техники очевидно, что функции адресного и слотового конвертера может выполнять прикладной или графический процессор, не ограничиваясь.
Пример 1
Поскольку по условиям примера, группа была создана еще на этапе создания/наполнения отношения, то приведенные записи изначально разбиты на следующие группы: «2016-02» и «2016-01» (Фиг. 11). Пусть группе «2016-01» будет присвоен идентификатор c1, а группе «2016-01» - с2. Каждая же запись будет получать идентификатор в порядке заполнения страниц: s1 - для первой добавленной записи, s2 - для второй и т.д.
Пример 2
Пусть порядок назначения идентификаторов будет основан на порядке добавления записей и групп в БД, тогда в первоначальном состоянии (до переноса группы) содержимое страниц с данными можно будет условно представить таким образом, как показано на Фиг. 12, а после переноса - как показано на Фиг. 13.
В приведенной иллюстрации (Фиг. 13) представлен допустимый сценарий поведения: записи из групп c1 и с2 имеют сквозную нумерацию s1-s4, поскольку это не нарушает условие уникальности идентификаторов в рамках каждой группы.
[00049] формируют связь идентификатора группы с адресом его расположения на запоминающем устройстве таким образом, что перемещение группы на запоминающем устройстве, а также между запоминающими устройствами не изменяет значение идентификатора группы;
В примерном варианте осуществления функции адресного конвертера выполняет процессор.
Пример 1
Адресный конвертер получает на вход идентификатор группы и возвращает номер страницы с данными (допустим, что ЗУ в данном примере общее для всех групп):
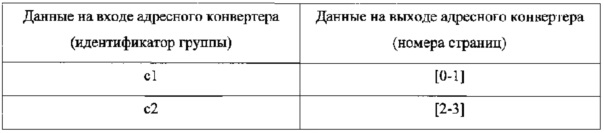
Пример 2.
Адресный конвертер получает на вход идентификатор группы и возвращает хранилище и номера страниц с данными.


Следует отметить, что пара идентификаторов записи (например c2:s2 - группа «502», запись №2) не меняется для адресующей структуры (например В-дерева) при переносе группы целиком, о чем упоминалось выше.
[00050] формируют связь идентификатора записи с адресом ее расположения внутри группы на запоминающем устройстве таким образом, что перемещение записи на запоминающем устройстве внутри группы не изменяет идентификатор записи;
В примерном варианте осуществления функции слотового конвертера могут выполняться с использованием процессора.
Пример 1.
Рассмотрим группу c1 (Фиг. 14).

Пример 2
Рассмотрим группу c1 (Фиг. 12).

После перемещения группы (Фиг. 13) для группы c1:


Отсюда следует, что пара идентификаторов записи (например c1:s4 - группа «501», запись №4) не меняется для адресующей структуры (например В-дерева) при переносе группы, о чем упоминалось выше.
[00051] Записи могут быть подвержены изменению в ходе эксплуатации БД, причиной этому могут быть:
- модификация записи, после которой она уже не отвечает прежнему критерию группировки и должна быть перенесена в другую группу.
- расширение/усечение размера группы. В группе может закончиться свободное место для добавления новых записей или же свободного места было выделено слишком много и хранилище используется неэффективно. В таких случаях для оптимизации группы (а следовательно и записи в него входящие) могут перемещаться внутри хранилища.
[00052] Группы могут быть подвержены изменению в ходе эксплуатации БД, причиной этому могут быть:
- изменение критериев группировки, в результате которой все группы должны быть перестроены.
- перенос групп с одного хранилища в другое. Такая необходимость может возникнуть в случае переноса части отношения в архив или в случае размещения части записей на более производительный носитель, в случаях шардирования и т.п.
[00053] сохраняют записи одной группы на запоминающем устройстве в смежных областях.
Под смежными областями понимаются области ЗУ, предполагающие минимизацию вспомогательных операций позиционирования и адресации в операциях единовременного чтения/записи из этих областей. В обоих рассмотренных примерах в качестве ЗУ предполагается HDD, в таком случае под смежными областями предполагается секторы с соседними адресами, что позволяет в полной мере использовать реализованное в современных накопителях упреждающее чтение секторов. Замеры производительности прототипов (Фиг. 3-4) иллюстрируют это.
[00054] Запоминающее устройство может быть реализовано в виде любого типа энергозависимого запоминающего устройства, энергонезависимого запоминающего устройства или их комбинации, например, статического оперативного запоминающего устройства (СОЗУ), электрически-стираемого программируемого постоянного запоминающего устройства (ЭСППЗУ), стираемого программируемого постоянного запоминающего устройства (СППЗУ), программируемого постоянного запоминающего устройства (ППЗУ), постоянного запоминающего устройства (ПЗУ), магнитной памяти, флэш-памяти, магнитного диска или оптического диска.
[00055] Указанный технический результат достигается следующим образом. При оценке количества операций, порождаемых перемещением группы записей целиком, для случаев с адресным конвертером (или процессором) и без него получается: пусть группа из трех записей перемещается из страницы N в страницу М. Пусть на все три записи ссылается индекс таблицы, а на запись #2 еще и структура в ОЗУ (например, транзакция ожидает снятие блокировки). Без использования адресного конвертера все адресующие структуры ссылаются на запись, используя пару значений - номер страницы, номер слота на странице. Подобные решения используется в некоторых современных реляционных СУБД: Oracle, Firebierd. В рассмотренном примере на Фиг. 15 и Фиг. 16 даже в случае простого переноса страницы с тремя записями необходимо обновить три листа в В-дереве индекса и одну структуру в ОЗУ (изменения выделены красным на Фигуре 16). В случае использования адресного конвертера, как показано на Фиг. 17 и Фиг. 18, обновляются только служебные данные самого адресного конвертера, т.е. однократно в одном месте (изменения выделены красным на Фигуре 18). Рассмотрим слотовый конвертер на Фиг. 19. Пусть в результате обновления данных запись №2 стала длиннее, тогда она перемещается в хвост страницы. Как видно на Фиг. 20, фактическое перемещение записей внутри страниц не изменило номер адресующего слота, запись поменяла свое положение на странице, но не поменяла свой идентификатор.
[00056] Таким образом, совместное использование адресного и слотового конвертеров позволяют без изменения адресующих структур перемещать записи внутри хранилища. За свободу перемещения группы целиком отвечает адресный конвертер, за свободу перемещения одиночных записей в группе - слотовый конвертер. Эффект совместного использования адресного и слотового конвертеров используются для хранения записей одной группы «рядом» друг с другом в физически смежных областях.
[00057] Рассмотрим, чем заявленное техническое решение отличается от хеш-функций. Согласно Д. Кнуту (Искусство программирования, том 3, § 6.4) хеширование или метод рассеянной памяти предполагает наличие функции h(K)такой, что
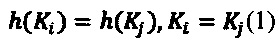
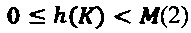
[00058] Кроме того, хорошая хеш-функция по Р. Флойду должна удовлетворять требованию минимизации коллизий. Т.е. в общем случае
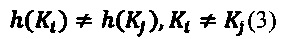
Адресный конвертер a() и слотовый конвертер s() не удовлетворяют условию (1). Пусть есть две идентичные записи
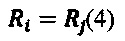
Согласно предлагаемому решению они относятся к одной группе (С-идентификатор группы):
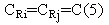
Внутри группы идентификатор слота I должен быть уникальным, т.е.
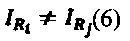
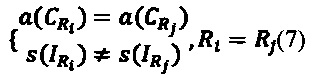
Поскольку для однозначной идентификации записи используется пара значений {CR,IR}, то, как видим, (7) нарушает требование (1). Т.е. а() и s() не обладают необходимыми свойствами хеш-функций.
Более того, (7) будет всегда верна только в том случае, когда вся группа расположена в одном блоке ЗУ, в противном случае в некоторых ситуациях одинаковые записи хоть и расположены в одной группе, но в разных блоках, и тогда первое равенство в (7) не будет для таких случаев.
Помимо этого, как указано в описании групп - они могут перемещаться внутри хранилища в ходе работы СУБД (например, для расширения, если группа переполнена), т.е. в разные моменты времени tn и tm выражение (5) может быть неверно даже для одной и той же записи:
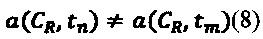
В свою очередь, в группе возможно освобождение слотов (например после удаления записи) и тогда слот может быть снова использован позднее для другой записи группы, т.е.:
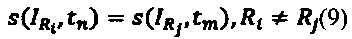
В заключении следует отметить, что назначение пары {С,I} для новых записей не является функцией в классическом ее понимании, а осуществляется механизмом, реализующим алгоритм принятия решения, который учитывает:
- признак группировки;
- наличие конфликтующих признаков группировки (запись попадает более чем под одно условие) и правила их разрешения (например, использовать приоритеты групп в случае конфликтов для определения целевой группы);
- заполненность блоков в которых размещены группы (не допускать полного заполнения блоков для возможности расширения записей);
- заполненность слотов внутри блока (повторно переиспользовать освобождающиеся идентификаторы);
- состояние СУБД (производить перестроение групп в фоновом режиме во время простоя, например).
[00059] Настоящее подробное описание составлено с приведением различных, не имеющих ограничительного и исчерпывающего характера вариантов осуществления. В то же время, специалистам, очевидно, что различные замены, модификации или сочетания любых раскрытых здесь вариантов осуществления (в том числе частично) могут быть воспроизведены в пределах объема настоящего технического решения. Таким образом, подразумевается и понимается, что настоящее описание включает дополнительные варианты осуществления, суть которых не изложена здесь в явно выраженной форме. Такие варианты осуществления могут быть получены путем, например, сочетания, модификации или преобразования каких-либо действий, компонентов, элементов, свойств, аспектов, характеристик, ограничений и пр., относящихся к приведенным здесь и не имеющим ограничительного характера вариантам осуществления.
ПРИМЕРЫ РЕАЛИЗАЦИИ
[00060] В рамках осуществления заявляемого технического решения был реализован вариант осуществления способа и проведены замеры скорости чтения страниц как в группах, так и без них. Производилось сравнение работы механизмов СУБД ЛИНТЕР v5.9-6.0 без описываемых в данном техническом решении существенных признаков с прототипом СУБД ЛИНТЕР AT, где организация хранения связанных данных была реализована.
[00061] Применялась следующая методика измерений:
1. В качестве эталонных значений скорости чтения/записи на тестовом аппаратном обеспечении приняты следующие значения, полученные утилитой hdparm:
1. чтение из страничного кеша ОС: 13225 Мб/с;
2. чтение с диска (последовательное): 147 Мб/с.
2. Испытания проводились сериями по 5 запусков с одинаковыми настройками, крайние значения отслеживаемых параметров отбрасывались, а от оставшихся трех бралось среднее арифметическое.
3. Каждая серия испытаний проводилась на двух типах формата: ЛИНТЕР v5.9-6.0 (без группировок связанных данных) и ЛИНТЕР AT (с группировками связанных данных) для следующих значений параметра n (количество генерируемых записей): 50 тыс., 100 тыс., 200 тыс., 250 тыс., 500 тыс., 1 млн, 5 млн, 10 млн, 15 млн.
4. Значение параметра m (размер выборки) во всех испытаниях принималось равным 50% от значения n.
5. Отслеживаемые значения: время генерации файлов, размер файлов, скорость чтения записей в последовательном и случайном режимах.
6. В каждом из испытаний размер тела генерируемой записи в байтах являлся случайным числом из диапазона [8…256], которое округлялось до наименьшего четного. С учетом заголовков среднее значение полного размера записи во всех замерах лежало в диапазоне [133…135] байт.
7. Инструментарий тестирования не использовал и не эмулировал кэш СУБД.
8. Во всех случаях записи размещались на страницах максимально плотно - место под расширение записей или для подселения новых не резервировалось.
9. Во всех случаях признаком группировки являлся порядок добавления записей.
[00062] Результаты сравнения ключевых показателей измерения для разных форматов приведены на Фиг. 4 и на Фиг. 5.
[00063] Реализация способа осуществляется изменением способа адресации записи из адресующей структуры (см. Фиг. 3) и введением адресного и слотового конвертеров.
[00064] В частном случае функции адресного и слотового конвертера могут выполняться с использованием прикладного или графического процессора.
[00065] Адресующая структура (300) содержит идентификатор группы CR(307) и идентификатор записи IR(305) внутри группы, которые (идентификаторы) являются логическими и никак не соотносятся с фактическим расположением записи в ЗУ. Пара значений (CR, IR) однозначно идентифицирует единичную запись R. Для получения адреса PR фактического расположения записи R в ЗУ используется адресный конвертер (310), производящий вычисление адреса Pc блока (320) в ЗУ, в котором (блоке) расположена группа CR. Непосредственно в самом блоке (320) хранятся соответствия (326, 327) идентификаторов записи и расположением тела записи (322) относительно начала блока. Вычисление этого смещения производит слотовый конвертер (330), производящий вычисление адреса начала записи относительно начала блока, ее содержащей. При такой адресации перемещение и модификация записи внутри одной группы, равно как и перемещение всей группы целиком на новый блок ЗУ, не приведет к изменению значений пары (CR,IR).
[00066] Рассмотрим пример реализации слотового конвертера в Линтер-AT.
[00067] Данные необходимые для определения адреса начала записи в блоке данных по идентификатору записи хранятся непосредственно в странице данных, приведем ее формат.
[00068] Страница данных содержит упакованные записи в соответствии с NSM (N-агу Storage Model) моделью хранения. Помимо заголовка в конце страницы расположен каталог слотов (slot directory) страницы, представляющий массив слотов. Размер каждой записи в слоте - 4 байта, при этом:
[00069] 8-19 биты - SLOT_LENGTH размер (фактический) записи;
[00070] 20-31 биты - OFFSET смещение на запись относительно начала страницы;
[00071] 7 бит - COLLECTION_FLAG признак того, что слот содержит коллекцию записей;
[00072] 3-6 бит - зарезервировано;
[00073] Типы слота могут быть следующими:
[00074] SLOT_FREE (0×0) слот свободен, OFFSET и SLOT LENGTH могут быть отличными от 0 и указывать свободную область;
[00075] SLOT_ADDRESS - слот содержит только адрес записи, но не саму запись;
[00076] SLOT_NORMAL - запись соответствует группе и полностью расположена в слоте;
[00077] SLOT_BIG - слот описывает «большую» запись;
[00078] SLOT_RELOCATED - запись содержит перенесенную;
[00079] SLOT_FRAGMENT - слот содержит фрагмент «длинной» записи без заголовков;
[00080] SLOT_DELETED - слот помечен к удалению.
[00081] Записи размещаются последовательно от заголовка к концу страницы, слоты - от конца страницы - к заголовку. Пространство между концом последней записи и первым слотом доступно для размещения новых записей. При удалении записи значение соответствующего слота выставляется в 0×00. При перемещении тела записи внутри одной страницы номер слота не меняется. Порядок записей на странице может не совпадать с порядком ссылающихся слотов.
[00082] Рассмотрим пример реализации адресного конвертера в Линтер-AT.
[00083] Данные, необходимые для вычисление адреса блока в ЗУ, в котором хранится группа записей по идентификатору группы, хранятся в файле данных в страницах данных адресного конвертера. Страницы адресного конвертера содержат упорядоченные записи, определяющие расположение групп в страницах файлов БД и фактическую занятость слотов в соответствующей группе. Формат записи не зависит от модели изоляции.
[00084] FREE_SPACE_FACTOR содержит оценочное значение свободного пространства для размещения новой записи, где 0×0 - свободна, 0×FF - занята полностью;
[00085] PAGENUM - номер страницы в файле данных, в котором расположена группа;
[00086] FNUM - номер файла;
[00087] BITMAP - битовая маска слотов в группе (необходима чтобы знать заранее о занятости слота).
[00088] Рассмотрим отличие идентификаторов группы и записи заявляемого технического решения от физического ROWID в СУБД Oracle.
[00089] Физические ROWID (https://docs.oracle.com/cd/B28359_01/server.111/b28318/datatype.htm#i6732) описывают текущее положение строки. Например

[00095] Любое перемещение записи в другой блок приведет к изменению физического ROWID.
[00096] В заявляемом техническом решении идентификаторы логические и группа может «переехать» вообще на другое ЗУ без изменения идентификатора.
[00097] Рассмотрим отличие идентификаторов группы и записи от логического ROWID в СУБД Oracle.
[00098] Во-первых, логические ROWID получаются на основе значения индексируемого атрибута, и его изменение приведет к изменению логического ROWID. В заявляемом техническом решении нет такой привязки идентификатора к значению записи или ее атрибута.
[00099] В-вторых, логический ROWID содержит неидентифицируемую составляющую, т.н. physical guess, которая фактически указывает последнее местоположение записи, но она может устареть при перемещении записи и операция чтения может потерпеть неудачу, в таком случае производится поиск записи.
[000100] В-третьих, ROWID никак не отображает «близость» расположения записей в ЗУ. В заявляемом решении идентификаторы двух записей одной группы будут иметь одинаковое значение CR, на основании сразу можно определить то, что эти записи гарантированно хранятся «рядом» на ЗУ.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОРГАНИЗАЦИИ ХРАНЕНИЯ ИСТОРИЧЕСКИХ ДЕЛЬТ ЗАПИСЕЙ | 2017 |
|
RU2647648C1 |
| СПОСОБ ОРГАНИЗАЦИИ ХРАНЕНИЯ ЧАСТИЧНО СОВПАДАЮЩИХ БОЛЬШИХ ОБЪЕКТОВ | 2017 |
|
RU2656721C1 |
| СПОСОБ И СИСТЕМА АДАПТИВНОГО УПРАВЛЕНИЯ СВОБОДНЫМ ПРОСТРАНСТВОМ ПАМЯТИ НА ЗАПОМИНАЮЩЕМ УСТРОЙСТВЕ ПРИ РАБОТЕ С БАЗАМИ ДАННЫХ | 2017 |
|
RU2672001C1 |
| Запоминающее устройство | 1984 |
|
SU1243033A1 |
| Устройство формирования видеоинформации | 1987 |
|
SU1483676A1 |
| СПОСОБ ПРОВЕДЕНИЯ РАЗДЕЛЕНИЯ ОБЪЕКТОВ БАЗЫ ДАННЫХ НА ОСНОВЕ МЕТОК КОНФИДЕНЦИАЛЬНОСТИ | 2017 |
|
RU2676223C1 |
| Способ обработки данных в гибридном хранилище | 2023 |
|
RU2831216C1 |
| ТАБЛИЦЫ ТЕНЕВЫХ СТРАНИЦ ДЛЯ УПРАВЛЕНИЯ ПРЕОБРАЗОВАНИЕМ АДРЕСОВ | 2004 |
|
RU2373566C2 |
| Устройство для сопряжения ЦВМ и накопителя информации | 1985 |
|
SU1265780A1 |
| Устройство для оперативного контроля в системах автоматизированного управления | 1984 |
|
SU1236505A1 |



Изобретение относится к области хранения данных. Техническим результатом является повышение производительности системы управления базами данных. Способ организации хранения связанных данных содержит этапы, на которых объединяют записи в по крайней мере одну группу по схожему признаку; присваивают идентификатор каждой вышеуказанной группе и каждой записи, находящейся в данной группе; формируют связь идентификатора группы с адресом его расположения на запоминающем устройстве таким образом, что перемещение группы на запоминающем устройстве, а также между запоминающими устройствами не изменяет значение идентификатора группы; формируют связь идентификатора записи с адресом ее расположения внутри группы на запоминающем устройстве таким образом, что перемещение записи на запоминающем устройстве внутри группы не изменяет идентификатор записи; сохраняют записи одной группы на запоминающем устройстве в смежных областях. 8 з.п. ф-лы, 20 ил.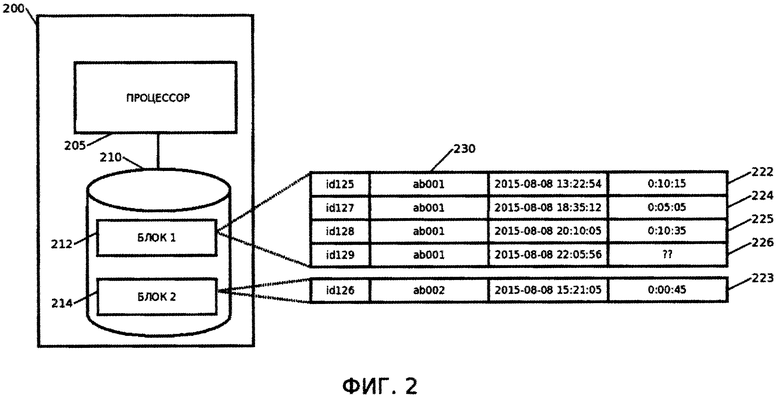
1. Способ организации хранения связанных данных, в котором:
- объединяют записи в по крайней мере одну группу по схожему признаку;
- присваивают идентификатор каждой вышеуказанной группе и каждой записи, находящейся в данной группе;
- формируют связь идентификатора группы с адресом его расположения на запоминающем устройстве таким образом, что перемещение группы на запоминающем устройстве, а также между запоминающими устройствами не изменяет значение идентификатора группы;
- формируют связь идентификатора записи с адресом ее расположения внутри группы на запоминающем устройстве таким образом, что перемещение записи на запоминающем устройстве внутри группы не изменяет идентификатор записи;
- сохраняют записи одной группы на запоминающем устройстве в смежных областях.
2. Способ по п. 1, в котором при объединении записей в группы схожим признаком является нахождение записей в реляционном отношении.
3. Способ по п. 1, в котором при объединении записей в группы схожим признаком является хранение версий одних данных.
4. Способ по п. 1, в котором при объединении записей в группы схожим признаком является принадлежность к одной горизонтальной секции.
5. Способ по п. 1, в котором при объединении записей в группы схожим признаком является порядок добавления записей.
6. Способ по п. 1, в котором при объединении записей в группы схожим признаком является идентичность одного или нескольких атрибутов.
7. Способ по п. 1, в котором запоминающим устройством является ОЗУ, и/или ПЗУ, и/или магнитная память, и/или флэш-память, и/или магнитный диск, и/или оптический диск.
8. Способ по п. 1, в котором идентификатор записи и группы не являются атрибутом отношения.
9. Способ по п. 1, в котором перемещают записи в случае в случае модификации записей или изменения критериев группировки.
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 8838593 B2, 16.09.2014 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 9003162 B2, 07.04.2015 | |||
| УПРАВЛЕНИЕ ДАННЫМИ В БАЗЕ ДАННЫХ КАТАЛОГА | 2010 |
|
RU2575987C2 |

